Repository: zhisheng17/flink-learning
Branch: master
Commit: d731cee76180
Files: 752
Total size: 1.8 MB
Directory structure:
gitextract_8nri6nxi/
├── .gitignore
├── Flink-Forward-2020/
│ └── README.md
├── Flink-Forward-Asia-2019-PPT/
│ └── README.md
├── Flink-Forward-Asia-2020-PPT/
│ └── README.md
├── Flink-Forward-Asia-2021-PPT/
│ └── README.md
├── LICENSE
├── README.md
├── books/
│ ├── README.md
│ ├── flink-in-action-1.1.md
│ ├── flink-in-action-1.2.md
│ ├── flink-in-action-1.3.md
│ ├── flink-in-action-10.1.md
│ ├── flink-in-action-10.2.md
│ ├── flink-in-action-11.1.md
│ ├── flink-in-action-11.2.md
│ ├── flink-in-action-11.3.md
│ ├── flink-in-action-11.4.md
│ ├── flink-in-action-11.5.md
│ ├── flink-in-action-12.1.md
│ ├── flink-in-action-12.2.md
│ ├── flink-in-action-12.3.md
│ ├── flink-in-action-2.1.md
│ ├── flink-in-action-2.2.md
│ ├── flink-in-action-2.3.md
│ ├── flink-in-action-2.4.md
│ ├── flink-in-action-3.1.md
│ ├── flink-in-action-3.10.md
│ ├── flink-in-action-3.11.md
│ ├── flink-in-action-3.12.md
│ ├── flink-in-action-3.2.md
│ ├── flink-in-action-3.3.md
│ ├── flink-in-action-3.4.md
│ ├── flink-in-action-3.5.md
│ ├── flink-in-action-3.6.md
│ ├── flink-in-action-3.7.md
│ ├── flink-in-action-3.8.md
│ ├── flink-in-action-3.9.md
│ ├── flink-in-action-4.1.md
│ ├── flink-in-action-4.2.md
│ ├── flink-in-action-4.3.md
│ ├── flink-in-action-5.1.md
│ ├── flink-in-action-5.2.md
│ ├── flink-in-action-6.1.md
│ ├── flink-in-action-6.2.md
│ ├── flink-in-action-6.3.md
│ ├── flink-in-action-6.4.md
│ ├── flink-in-action-6.5.md
│ ├── flink-in-action-7.1.md
│ ├── flink-in-action-7.2.md
│ ├── flink-in-action-8.1.md
│ ├── flink-in-action-8.2.md
│ ├── flink-in-action-9.1.md
│ ├── flink-in-action-9.2.md
│ ├── flink-in-action-9.3.md
│ ├── flink-in-action-9.4.md
│ ├── flink-in-action-9.5.md
│ └── flink-in-action-9.6.md
├── flink-learning-basic/
│ ├── README.md
│ ├── flink-learning-data-sinks/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── data/
│ │ │ └── sinks/
│ │ │ ├── Main.java
│ │ │ ├── Main2.java
│ │ │ ├── model/
│ │ │ │ └── Student.java
│ │ │ ├── sinks/
│ │ │ │ ├── MySink.java
│ │ │ │ └── SinkToMySQL.java
│ │ │ └── utils/
│ │ │ └── KafkaUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ ├── logback.xml
│ │ └── student.sql
│ ├── flink-learning-data-sources/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── data/
│ │ │ └── sources/
│ │ │ ├── Main.java
│ │ │ ├── Main2.java
│ │ │ ├── ScheduleMain.java
│ │ │ ├── model/
│ │ │ │ ├── Rule.java
│ │ │ │ └── Student.java
│ │ │ ├── sources/
│ │ │ │ └── SourceFromMySQL.java
│ │ │ └── utils/
│ │ │ ├── KafkaUtil.java
│ │ │ └── MySQLUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ ├── logback.xml
│ │ ├── rule.sql
│ │ └── student.sql
│ ├── flink-learning-libraries/
│ │ ├── README.md
│ │ ├── flink-learning-libraries-cep/
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── libraries/
│ │ │ │ └── cep/
│ │ │ │ ├── CEPMain.java
│ │ │ │ ├── CombinePatternMain.java
│ │ │ │ ├── IndividualPatternQuantifier.java
│ │ │ │ └── model/
│ │ │ │ ├── Alert.java
│ │ │ │ ├── Event.java
│ │ │ │ └── SubEvent.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ └── logback.xml
│ │ ├── flink-learning-libraries-state-processor-api/
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── libraries/
│ │ │ │ └── stateProcessApi/
│ │ │ │ ├── Main.java
│ │ │ │ └── StatefulFunctionWithTime.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ └── logback.xml
│ │ └── pom.xml
│ ├── flink-learning-metrics/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── metrics/
│ │ └── custom/
│ │ ├── CustomCounterMetrics.java
│ │ ├── CustomCounterMetrics2.java
│ │ ├── CustomCounterMetrics3.java
│ │ ├── CustomGaugeMetrics.java
│ │ ├── CustomHistogramMetrics.java
│ │ └── CustomMeterMetrics.java
│ ├── flink-learning-state/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── state/
│ │ │ ├── Main.java
│ │ │ ├── metadata/
│ │ │ │ └── MetadataSerializer.java
│ │ │ ├── operator/
│ │ │ │ └── state/
│ │ │ │ ├── UnionListStateExample.java
│ │ │ │ └── util/
│ │ │ │ └── UnionListStateUtil.java
│ │ │ └── queryablestate/
│ │ │ ├── ClimateLog.java
│ │ │ ├── QueryClient.java
│ │ │ └── QuerybleStateStream.java
│ │ └── resources/
│ │ └── _metadata
│ ├── flink-learning-window/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ ├── constant/
│ │ │ │ │ └── WindowConstant.java
│ │ │ │ ├── function/
│ │ │ │ │ ├── CustomSource.java
│ │ │ │ │ ├── CustomTrigger.java
│ │ │ │ │ └── LineSplitter.java
│ │ │ │ └── window/
│ │ │ │ ├── CustomTriggerMain.java
│ │ │ │ ├── Main.java
│ │ │ │ ├── Main2.java
│ │ │ │ ├── Main3.java
│ │ │ │ ├── Main4.java
│ │ │ │ ├── Main5.java
│ │ │ │ └── WindowAll.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ └── logback.xml
│ │ └── test/
│ │ └── java/
│ │ └── TestWindowSize.java
│ └── pom.xml
├── flink-learning-cdc/
│ ├── README.md
│ ├── flink-db2-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── db2/
│ │ └── Db2CDCExample.java
│ ├── flink-mongodb-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── mongodb/
│ │ └── MongoDBCDCExample.java
│ ├── flink-mysql-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── mysql/
│ │ └── MysqlCDCExample.java
│ ├── flink-oceanbase-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── oceanbase/
│ │ └── OceanBaseCDCExample.java
│ ├── flink-oracle-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── oracle/
│ │ └── OracleCDCExample.java
│ ├── flink-postgres-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── postgres/
│ │ └── PostgresCDCExample.java
│ ├── flink-sqlserver-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── sqlserver/
│ │ └── SqlServerCDCExample.java
│ ├── flink-tidb-cdc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── cdc/
│ │ └── tidb/
│ │ └── TidbCDCExample.java
│ └── pom.xml
├── flink-learning-common/
│ ├── README.md
│ ├── pom.xml
│ └── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── common/
│ │ │ ├── constant/
│ │ │ │ ├── MachineConstant.java
│ │ │ │ └── PropertiesConstants.java
│ │ │ ├── model/
│ │ │ │ ├── LogEvent.java
│ │ │ │ ├── MetricEvent.java
│ │ │ │ ├── OrderEvent.java
│ │ │ │ ├── OrderLineEvent.java
│ │ │ │ ├── ProductEvent.java
│ │ │ │ ├── ShopEvent.java
│ │ │ │ ├── UserEvent.java
│ │ │ │ └── WordEvent.java
│ │ │ ├── schemas/
│ │ │ │ ├── KafkaMetricSchema.java
│ │ │ │ ├── LogSchema.java
│ │ │ │ ├── MetricSchema.java
│ │ │ │ ├── OrderLineSchema.java
│ │ │ │ ├── OrderSchema.java
│ │ │ │ ├── ProductSchema.java
│ │ │ │ ├── ShopSchema.java
│ │ │ │ └── UserSchema.java
│ │ │ ├── utils/
│ │ │ │ ├── CheckPointUtil.java
│ │ │ │ ├── DateUtil.java
│ │ │ │ ├── ExecutionEnvUtil.java
│ │ │ │ ├── GsonUtil.java
│ │ │ │ ├── HttpUtil.java
│ │ │ │ └── KafkaConfigUtil.java
│ │ │ └── watermarks/
│ │ │ └── MetricWatermark.java
│ │ └── resources/
│ │ └── product.sql
│ └── test/
│ └── java/
│ └── com/
│ └── zhisheng/
│ └── common/
│ └── utils/
│ └── DateUtilTests.java
├── flink-learning-configuration-center/
│ ├── flink-learning-configuration-center-apollo/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── configuration/
│ │ │ └── apollo/
│ │ │ └── FlinkApolloTest.java
│ │ └── resources/
│ │ └── META-INF/
│ │ └── app.properties
│ ├── flink-learning-configuration-center-nacos/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── configuration/
│ │ └── nacos/
│ │ ├── FlinkNacosTest.java
│ │ └── FlinkNacosTest2.java
│ └── pom.xml
├── flink-learning-connectors/
│ ├── README.md
│ ├── flink-learning-connectors-activemq/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── activemq/
│ │ │ └── Main.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-cassandra/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── cassandra/
│ │ │ ├── batch/
│ │ │ │ ├── BatchExample.java
│ │ │ │ ├── BatchPojoExample.java
│ │ │ │ └── CustomCassandraAnnotatedPojo.java
│ │ │ └── streaming/
│ │ │ ├── CassandraPojoSinkExample.java
│ │ │ ├── CassandraTupleSinkExample.java
│ │ │ ├── CassandraTupleWriteAheadSinkExample.java
│ │ │ └── Message.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-clickhouse/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── clickhouse/
│ │ │ ├── ClickhouseSink.java
│ │ │ ├── applied/
│ │ │ │ ├── ClickhouseSinkBuffer.java
│ │ │ │ ├── ClickhouseSinkManager.java
│ │ │ │ ├── ClickhouseSinkScheduledChecker.java
│ │ │ │ └── ClickhouseWriter.java
│ │ │ ├── model/
│ │ │ │ ├── ClickhouseClusterSettings.java
│ │ │ │ ├── ClickhouseRequestBlank.java
│ │ │ │ ├── ClickhouseSinkCommonParams.java
│ │ │ │ └── ClickhouseSinkConsts.java
│ │ │ └── util/
│ │ │ ├── ConfigUtil.java
│ │ │ └── ThreadUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ ├── logback.xml
│ │ └── reference.conf
│ ├── flink-learning-connectors-es/
│ │ ├── flink-learning-connectors-es-common/
│ │ │ └── pom.xml
│ │ ├── flink-learning-connectors-es-universal/
│ │ │ ├── README.md
│ │ │ └── pom.xml
│ │ ├── flink-learning-connectors-es5/
│ │ │ ├── README.md
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── connectors/
│ │ │ │ └── es5/
│ │ │ │ └── Sink2ES5Main.java
│ │ │ └── resources/
│ │ │ └── logback.xml
│ │ ├── flink-learning-connectors-es6/
│ │ │ ├── README.md
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── connectors/
│ │ │ │ └── es6/
│ │ │ │ ├── Sink2ES6Main.java
│ │ │ │ └── utils/
│ │ │ │ ├── ESSinkUtil.java
│ │ │ │ └── RetryRequestFailureHandler.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ ├── es_index_template.json
│ │ │ └── logback.xml
│ │ ├── flink-learning-connectors-es7/
│ │ │ ├── README.md
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── connectors/
│ │ │ │ └── es7/
│ │ │ │ ├── Sink2ES7Main.java
│ │ │ │ └── util/
│ │ │ │ ├── ESSinkUtil.java
│ │ │ │ └── RetryRequestFailureHandler.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ ├── es_index_template.json
│ │ │ └── logback.xml
│ │ └── pom.xml
│ ├── flink-learning-connectors-flume/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── flume/
│ │ │ ├── FlumeEventBuilder.java
│ │ │ ├── FlumeSink.java
│ │ │ ├── Main.java
│ │ │ └── utils/
│ │ │ └── FlumeUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-gcp-pubsub/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── gcp/
│ │ │ └── pubsub/
│ │ │ ├── IntegerSerializer.java
│ │ │ ├── Main.java
│ │ │ └── PubSubPublisherUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-hbase/
│ │ ├── README.md
│ │ ├── flink-learning-connectors-hbase-1.4/
│ │ │ └── pom.xml
│ │ ├── flink-learning-connectors-hbase-2.2/
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── hbase/
│ │ │ │ ├── HBaseStreamWriteMain.java
│ │ │ │ ├── Main.java
│ │ │ │ └── constant/
│ │ │ │ └── HBaseConstant.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ └── logback.xml
│ │ └── pom.xml
│ ├── flink-learning-connectors-hdfs/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── hdfs/
│ │ │ └── Main.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-hive/
│ │ ├── README.md
│ │ ├── flink-learning-connectors-hive-1.2.2/
│ │ │ └── pom.xml
│ │ ├── flink-learning-connectors-hive-2.2.0/
│ │ │ └── pom.xml
│ │ ├── flink-learning-connectors-hive-2.3.6/
│ │ │ └── pom.xml
│ │ ├── flink-learning-connectors-hive-3.1.2/
│ │ │ └── pom.xml
│ │ └── pom.xml
│ ├── flink-learning-connectors-influxdb/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── influxdb/
│ │ │ ├── InfluxDBConfig.java
│ │ │ ├── InfluxDBSink.java
│ │ │ └── Main.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-jdbc/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── jdbc/
│ │ │ └── Main.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-kafka/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── kafka/
│ │ │ ├── FlinkKafkaConsumerTest1.java
│ │ │ ├── FlinkKafkaConsumerTest2.java
│ │ │ ├── FlinkKafkaProducerTest1.java
│ │ │ ├── FlinkKafkaSchemaTest1.java
│ │ │ ├── JSONKeyValueDeserializationSchemaTest.java
│ │ │ ├── KafkaDeserializationSchemaTest.java
│ │ │ └── Main.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-kudu/
│ │ ├── README.md
│ │ └── pom.xml
│ ├── flink-learning-connectors-mysql/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── mysql/
│ │ │ ├── Main.java
│ │ │ ├── model/
│ │ │ │ └── Student.java
│ │ │ ├── sinks/
│ │ │ │ └── SinkToMySQL.java
│ │ │ └── utils/
│ │ │ └── KafkaUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-netty/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── connectors/
│ │ └── netty/
│ │ └── Main.java
│ ├── flink-learning-connectors-nifi/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── nifi/
│ │ │ ├── NiFiSinkMain.java
│ │ │ └── NiFiSourceMain.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-pulsar/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── pulsar/
│ │ │ ├── PulsarSinkMain.java
│ │ │ └── PulsarSourceMain.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-rabbitmq/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── rabbitmq/
│ │ │ ├── Main.java
│ │ │ ├── Main1.java
│ │ │ ├── model/
│ │ │ │ └── EndPoint.java
│ │ │ └── utils/
│ │ │ └── RabbitMQProducerUtil.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ ├── flink-learning-connectors-redis/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── connectors/
│ │ │ │ └── redis/
│ │ │ │ ├── Main.java
│ │ │ │ └── utils/
│ │ │ │ └── ProductUtil.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ └── logback.xml
│ │ └── test/
│ │ └── java/
│ │ └── RedisTest.java
│ ├── flink-learning-connectors-rocketmq/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── connectors/
│ │ │ └── rocketmq/
│ │ │ ├── RocketMQConfig.java
│ │ │ ├── RocketMQSink.java
│ │ │ ├── RocketMQSource.java
│ │ │ ├── RocketMQUtils.java
│ │ │ ├── RunningChecker.java
│ │ │ ├── common/
│ │ │ │ ├── selector/
│ │ │ │ │ ├── DefaultTopicSelector.java
│ │ │ │ │ ├── SimpleTopicSelector.java
│ │ │ │ │ └── TopicSelector.java
│ │ │ │ └── serialization/
│ │ │ │ ├── KeyValueDeserializationSchema.java
│ │ │ │ ├── KeyValueSerializationSchema.java
│ │ │ │ ├── SimpleKeyValueDeserializationSchema.java
│ │ │ │ └── SimpleKeyValueSerializationSchema.java
│ │ │ └── example/
│ │ │ ├── RocketMQFlinkExample.java
│ │ │ ├── SimpleConsumer.java
│ │ │ └── SimpleProducer.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── logback.xml
│ └── pom.xml
├── flink-learning-core/
│ ├── pom.xml
│ └── src/
│ └── main/
│ └── java/
│ └── com/
│ └── zhisheng/
│ └── core/
│ ├── exception/
│ │ └── FlinkRuntimeException.java
│ ├── factory/
│ │ ├── DeserializerFactory.java
│ │ ├── SerializerFactory.java
│ │ ├── SinkFactory.java
│ │ └── SourceFactory.java
│ └── utils/
│ ├── ArrayUtils.java
│ ├── CollectionUtil.java
│ ├── ExecutorUtils.java
│ ├── StringUtils.java
│ └── TimeUtils.java
├── flink-learning-datalake/
│ ├── README.md
│ ├── flink-learning-datalake-deltalake/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── datalake/
│ │ └── delta/
│ │ └── DeltaLakeExample.java
│ ├── flink-learning-datalake-hudi/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── datalake/
│ │ └── hudi/
│ │ ├── HudiCDCSyncExample.java
│ │ ├── HudiDataLakeExample.java
│ │ └── HudiStreamingWriteExample.java
│ ├── flink-learning-datalake-iceberg/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── datalake/
│ │ └── iceberg/
│ │ ├── IcebergCDCSyncExample.java
│ │ ├── IcebergDataLakeExample.java
│ │ └── IcebergStreamingWriteExample.java
│ ├── flink-learning-paimon/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── datalake/
│ │ └── paimon/
│ │ ├── PaimonCDCSyncExample.java
│ │ ├── PaimonDataLakeExample.java
│ │ └── PaimonStreamingWriteExample.java
│ └── pom.xml
├── flink-learning-examples/
│ ├── README.md
│ ├── pom.xml
│ └── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── examples/
│ │ │ ├── batch/
│ │ │ │ ├── accumulator/
│ │ │ │ │ ├── Main.java
│ │ │ │ │ └── Main2.java
│ │ │ │ └── wordcount/
│ │ │ │ └── Main.java
│ │ │ ├── streaming/
│ │ │ │ ├── async/
│ │ │ │ │ └── AsyncIOExample.java
│ │ │ │ ├── broadcast/
│ │ │ │ │ ├── BroadcastAlertRule.java
│ │ │ │ │ ├── DataSetBrocastMain.java
│ │ │ │ │ ├── GetAlarmNotifyData.java
│ │ │ │ │ ├── Main.java
│ │ │ │ │ ├── Main2.java
│ │ │ │ │ └── MyBroadcastProcessFunction.java
│ │ │ │ ├── chain/
│ │ │ │ │ ├── DefaultChainMain.java
│ │ │ │ │ ├── DisableChainMain.java
│ │ │ │ │ ├── DisableChainMain1.java
│ │ │ │ │ ├── DisableChainMain3.java
│ │ │ │ │ ├── ExecutionPlanMain.java
│ │ │ │ │ ├── SharingGroupMain.java
│ │ │ │ │ └── StartNewChainMain.java
│ │ │ │ ├── checkpoint/
│ │ │ │ │ ├── Main.java
│ │ │ │ │ ├── PvStatExactlyOnce.java
│ │ │ │ │ ├── PvStatLocalKeyByExactlyOnce.java
│ │ │ │ │ └── util/
│ │ │ │ │ └── PvStatExactlyOnceKafkaUtil.java
│ │ │ │ ├── config/
│ │ │ │ │ ├── ConfigurationMain.java
│ │ │ │ │ ├── ConfigurationMain1.java
│ │ │ │ │ ├── ParameterToolGetArgsMain.java
│ │ │ │ │ ├── ParameterToolGetPropertiesMain.java
│ │ │ │ │ └── ParameterToolGetSystemMain.java
│ │ │ │ ├── file/
│ │ │ │ │ └── Main.java
│ │ │ │ ├── join/
│ │ │ │ │ ├── WindowJoin.java
│ │ │ │ │ └── WindowJoinSampleData.java
│ │ │ │ ├── ml/
│ │ │ │ │ ├── IncrementalLearningSkeleton.java
│ │ │ │ │ └── IncrementalLearningSkeletonData.java
│ │ │ │ ├── parallelism/
│ │ │ │ │ └── Main.java
│ │ │ │ ├── processFunction/
│ │ │ │ │ ├── KeyedProcessFunctionMain.java
│ │ │ │ │ └── ProcessFunctionMain.java
│ │ │ │ ├── remote/
│ │ │ │ │ └── Main.java
│ │ │ │ ├── restartStrategy/
│ │ │ │ │ ├── AEMain.java
│ │ │ │ │ ├── DefaultRestartStrategyMain.java
│ │ │ │ │ ├── EnableCheckpointMain.java
│ │ │ │ │ ├── FailureRateRestartStrategyMain.java
│ │ │ │ │ ├── FixedDelayRestartStrategyMain.java
│ │ │ │ │ └── NoRestartStrategyMain.java
│ │ │ │ ├── sideoutput/
│ │ │ │ │ ├── FilterEvent.java
│ │ │ │ │ ├── Main.java
│ │ │ │ │ └── SideOutputEvent.java
│ │ │ │ ├── socket/
│ │ │ │ │ ├── LambdaMain.java
│ │ │ │ │ └── Main.java
│ │ │ │ ├── state/
│ │ │ │ │ └── StateMain.java
│ │ │ │ ├── watermark/
│ │ │ │ │ ├── Main.java
│ │ │ │ │ ├── Main1.java
│ │ │ │ │ ├── Main2.java
│ │ │ │ │ ├── Main3.java
│ │ │ │ │ ├── Main4.java
│ │ │ │ │ ├── Word.java
│ │ │ │ │ ├── WordPeriodicWatermark.java
│ │ │ │ │ └── WordPunctuatedWatermark.java
│ │ │ │ └── wordcount/
│ │ │ │ └── Main.java
│ │ │ └── util/
│ │ │ ├── MySQLUtil.java
│ │ │ └── ThrottledIterator.java
│ │ └── resources/
│ │ ├── alarm-notify.sql
│ │ ├── application.properties
│ │ └── logback.xml
│ └── test/
│ └── java/
│ └── Test1.java
├── flink-learning-extends/
│ ├── FlinkLogKafkaAppender/
│ │ ├── KafkaAppenderCommon/
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ └── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── flink/
│ │ │ ├── model/
│ │ │ │ └── LogEvent.java
│ │ │ └── util/
│ │ │ ├── ExceptionUtil.java
│ │ │ └── JacksonUtil.java
│ │ ├── Log4j2KafkaAppender/
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ ├── main/
│ │ │ │ ├── java/
│ │ │ │ │ └── com/
│ │ │ │ │ └── zhisheng/
│ │ │ │ │ └── log/
│ │ │ │ │ └── appender/
│ │ │ │ │ └── KafkaLog4j2Appender.java
│ │ │ │ └── resources/
│ │ │ │ └── log4j2-example.properties
│ │ │ └── test/
│ │ │ └── java/
│ │ │ └── ExceptionUtilTest.java
│ │ ├── Log4jKafkaAppender/
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── log/
│ │ │ │ └── appender/
│ │ │ │ └── KafkaLog4jAppender.java
│ │ │ └── resources/
│ │ │ └── log4j-example.properties
│ │ ├── README.md
│ │ └── pom.xml
│ ├── README.md
│ ├── flink-metrics/
│ │ ├── flink-metrics-kafka/
│ │ │ ├── README.md
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ └── main/
│ │ │ ├── java/
│ │ │ │ └── org/
│ │ │ │ └── apache/
│ │ │ │ └── flink/
│ │ │ │ └── metrics/
│ │ │ │ └── kafka/
│ │ │ │ ├── KafkaReporter.java
│ │ │ │ ├── KafkaReporterFactory.java
│ │ │ │ ├── KafkaReporterOptions.java
│ │ │ │ ├── MetricEvent.java
│ │ │ │ └── util/
│ │ │ │ └── JacksonUtil.java
│ │ │ └── resources/
│ │ │ └── META-INF/
│ │ │ └── services/
│ │ │ └── org.apache.flink.metrics.reporter.MetricReporterFactory
│ │ ├── flink-metrics-prometheus/
│ │ │ ├── README.md
│ │ │ ├── pom.xml
│ │ │ └── src/
│ │ │ ├── main/
│ │ │ │ ├── java/
│ │ │ │ │ └── org/
│ │ │ │ │ └── apache/
│ │ │ │ │ └── flink/
│ │ │ │ │ └── metrics/
│ │ │ │ │ └── prometheus/
│ │ │ │ │ ├── AbstractPrometheusReporter.java
│ │ │ │ │ ├── ClusterMode.java
│ │ │ │ │ ├── PrometheusPushGatewayReporter.java
│ │ │ │ │ ├── PrometheusPushGatewayReporterFactory.java
│ │ │ │ │ ├── PrometheusPushGatewayReporterOptions.java
│ │ │ │ │ ├── PrometheusReporter.java
│ │ │ │ │ └── PrometheusReporterFactory.java
│ │ │ │ └── resources/
│ │ │ │ └── META-INF/
│ │ │ │ ├── NOTICE
│ │ │ │ └── services/
│ │ │ │ └── org.apache.flink.metrics.reporter.MetricReporterFactory
│ │ │ └── test/
│ │ │ └── resources/
│ │ │ └── log4j2-test.properties
│ │ └── pom.xml
│ └── pom.xml
├── flink-learning-k8s/
│ ├── README.md
│ ├── blogs/
│ │ ├── Flink HA 配置.md
│ │ ├── Flink K8s Pod 增加环境变量.md
│ │ ├── Kubernetes 入门之知识点梳理.md
│ │ ├── Pod 异常问题排查.md
│ │ └── 合理设置 Request 与 Limit.md
│ ├── dockerfile/
│ │ ├── Dockerfile-Hadoop-Hive
│ │ ├── Dockerfile-example-statemachine
│ │ ├── Dockerfile-flink-1.12.0-jar
│ │ ├── Dockerfile-flink-1.12.0-sql
│ │ ├── build_flink_docker_images.sh
│ │ ├── build_ingress.sh
│ │ ├── docker-entrypoint.sh
│ │ └── ingress_template.yaml
│ ├── flink-k8s/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── org/
│ │ │ └── apache/
│ │ │ └── flink/
│ │ │ └── kubernetes/
│ │ │ ├── KubernetesClusterClientFactory.java
│ │ │ ├── KubernetesClusterDescriptor.java
│ │ │ ├── KubernetesResourceManagerDriver.java
│ │ │ ├── KubernetesWorkerNode.java
│ │ │ ├── cli/
│ │ │ │ └── KubernetesSessionCli.java
│ │ │ ├── configuration/
│ │ │ │ ├── KubernetesConfigOptions.java
│ │ │ │ ├── KubernetesConfigOptionsInternal.java
│ │ │ │ ├── KubernetesDeploymentTarget.java
│ │ │ │ ├── KubernetesHighAvailabilityOptions.java
│ │ │ │ ├── KubernetesLeaderElectionConfiguration.java
│ │ │ │ └── KubernetesResourceManagerDriverConfiguration.java
│ │ │ ├── entrypoint/
│ │ │ │ ├── KubernetesApplicationClusterEntrypoint.java
│ │ │ │ ├── KubernetesEntrypointUtils.java
│ │ │ │ ├── KubernetesResourceManagerFactory.java
│ │ │ │ ├── KubernetesSessionClusterEntrypoint.java
│ │ │ │ └── KubernetesWorkerResourceSpecFactory.java
│ │ │ ├── executors/
│ │ │ │ ├── KubernetesSessionClusterExecutor.java
│ │ │ │ └── KubernetesSessionClusterExecutorFactory.java
│ │ │ ├── highavailability/
│ │ │ │ ├── KubernetesCheckpointIDCounter.java
│ │ │ │ ├── KubernetesCheckpointRecoveryFactory.java
│ │ │ │ ├── KubernetesCheckpointStoreUtil.java
│ │ │ │ ├── KubernetesHaServices.java
│ │ │ │ ├── KubernetesHaServicesFactory.java
│ │ │ │ ├── KubernetesJobGraphStoreUtil.java
│ │ │ │ ├── KubernetesLeaderElectionDriver.java
│ │ │ │ ├── KubernetesLeaderElectionDriverFactory.java
│ │ │ │ ├── KubernetesLeaderRetrievalDriver.java
│ │ │ │ ├── KubernetesLeaderRetrievalDriverFactory.java
│ │ │ │ ├── KubernetesRunningJobsRegistry.java
│ │ │ │ └── KubernetesStateHandleStore.java
│ │ │ ├── kubeclient/
│ │ │ │ ├── Endpoint.java
│ │ │ │ ├── Fabric8FlinkKubeClient.java
│ │ │ │ ├── FlinkKubeClient.java
│ │ │ │ ├── FlinkKubeClientFactory.java
│ │ │ │ ├── FlinkPod.java
│ │ │ │ ├── KubeClientFactory.java
│ │ │ │ ├── KubernetesJobManagerSpecification.java
│ │ │ │ ├── decorators/
│ │ │ │ │ ├── AbstractKubernetesStepDecorator.java
│ │ │ │ │ ├── EnvSecretsDecorator.java
│ │ │ │ │ ├── ExternalServiceDecorator.java
│ │ │ │ │ ├── FlinkConfMountDecorator.java
│ │ │ │ │ ├── HadoopConfMountDecorator.java
│ │ │ │ │ ├── HiveConfMountDecorator.java
│ │ │ │ │ ├── InitJobManagerDecorator.java
│ │ │ │ │ ├── InitTaskManagerDecorator.java
│ │ │ │ │ ├── InternalServiceDecorator.java
│ │ │ │ │ ├── JavaCmdJobManagerDecorator.java
│ │ │ │ │ ├── JavaCmdTaskManagerDecorator.java
│ │ │ │ │ ├── KerberosMountDecorator.java
│ │ │ │ │ ├── KubernetesStepDecorator.java
│ │ │ │ │ └── MountSecretsDecorator.java
│ │ │ │ ├── factory/
│ │ │ │ │ ├── KubernetesJobManagerFactory.java
│ │ │ │ │ └── KubernetesTaskManagerFactory.java
│ │ │ │ ├── parameters/
│ │ │ │ │ ├── AbstractKubernetesParameters.java
│ │ │ │ │ ├── KubernetesJobManagerParameters.java
│ │ │ │ │ ├── KubernetesParameters.java
│ │ │ │ │ └── KubernetesTaskManagerParameters.java
│ │ │ │ └── resources/
│ │ │ │ ├── AbstractKubernetesWatcher.java
│ │ │ │ ├── KubernetesConfigMap.java
│ │ │ │ ├── KubernetesConfigMapWatcher.java
│ │ │ │ ├── KubernetesException.java
│ │ │ │ ├── KubernetesLeaderElector.java
│ │ │ │ ├── KubernetesPod.java
│ │ │ │ ├── KubernetesPodsWatcher.java
│ │ │ │ ├── KubernetesResource.java
│ │ │ │ ├── KubernetesSecretEnvVar.java
│ │ │ │ ├── KubernetesService.java
│ │ │ │ ├── KubernetesToleration.java
│ │ │ │ ├── KubernetesTooOldResourceVersionException.java
│ │ │ │ └── KubernetesWatch.java
│ │ │ ├── taskmanager/
│ │ │ │ └── KubernetesTaskExecutorRunner.java
│ │ │ └── utils/
│ │ │ ├── Constants.java
│ │ │ └── KubernetesUtils.java
│ │ └── resources/
│ │ └── META-INF/
│ │ ├── NOTICE
│ │ └── services/
│ │ ├── org.apache.flink.client.deployment.ClusterClientFactory
│ │ └── org.apache.flink.core.execution.PipelineExecutorFactory
│ └── pom.xml
├── flink-learning-monitor/
│ ├── README.md
│ ├── flink-learning-monitor-alert/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── alert/
│ │ │ │ ├── alert/
│ │ │ │ │ ├── AsyncIOAlert.java
│ │ │ │ │ ├── BroadcastUpdateAlertRule.java
│ │ │ │ │ ├── LogEventAlert.java
│ │ │ │ │ └── OutageAlert.java
│ │ │ │ ├── function/
│ │ │ │ │ ├── AlertRuleAsyncIOFunction.java
│ │ │ │ │ ├── GetAlertRuleSourceFunction.java
│ │ │ │ │ └── OutageProcessFunction.java
│ │ │ │ ├── model/
│ │ │ │ │ ├── AlertEvent.java
│ │ │ │ │ ├── AlertRule.java
│ │ │ │ │ ├── AtMobiles.java
│ │ │ │ │ ├── BaseMessage.java
│ │ │ │ │ ├── Email.java
│ │ │ │ │ ├── LinkMessage.java
│ │ │ │ │ ├── MarkDownMessage.java
│ │ │ │ │ ├── MessageType.java
│ │ │ │ │ ├── OutageMetricEvent.java
│ │ │ │ │ ├── TextMessage.java
│ │ │ │ │ └── WorkNotify.java
│ │ │ │ ├── utils/
│ │ │ │ │ ├── DingDingAccessTokenUtil.java
│ │ │ │ │ ├── DingDingGroupMsgUtil.java
│ │ │ │ │ ├── DingDingWorkspaceNoticeUtil.java
│ │ │ │ │ ├── EmailNoticeUtil.java
│ │ │ │ │ ├── PhoneNoticeUtil.java
│ │ │ │ │ └── SMSNoticeUtil.java
│ │ │ │ └── watermark/
│ │ │ │ └── OutageMetricWaterMark.java
│ │ │ └── resources/
│ │ │ ├── LogEventDataExample.json
│ │ │ ├── application.properties
│ │ │ └── logback.xml
│ │ └── test/
│ │ └── java/
│ │ ├── BuildLogEventDataUtil.java
│ │ ├── BuildMachineMetricDataUtil.java
│ │ ├── DingDingMsgTest.java
│ │ └── LogEventDataExample.java
│ ├── flink-learning-monitor-collector/
│ │ ├── README.md
│ │ ├── flink_log_event.json
│ │ ├── flink_metrics_event.json
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── collector/
│ │ └── FlinkJobMetricCollect.java
│ ├── flink-learning-monitor-common/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── common/
│ │ ├── model/
│ │ │ ├── Job.java
│ │ │ ├── JobStatus.java
│ │ │ └── Task.java
│ │ └── utils/
│ │ └── PropertiesUtil.java
│ ├── flink-learning-monitor-dashboard/
│ │ ├── README.md
│ │ └── pom.xml
│ ├── flink-learning-monitor-log/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── zhisheng/
│ │ │ └── log/
│ │ │ ├── LogAlert.java
│ │ │ ├── LogMain.java
│ │ │ ├── LogSink2ES.java
│ │ │ ├── function/
│ │ │ │ └── OriLog2LogEventFlatMapFunction.java
│ │ │ ├── model/
│ │ │ │ └── OriginalLogEvent.java
│ │ │ ├── schema/
│ │ │ │ └── OriginalLogEventSchema.java
│ │ │ └── utils/
│ │ │ ├── ESSinkUtil.java
│ │ │ ├── GrokUtil.java
│ │ │ └── RetryRequestFailureHandler.java
│ │ └── resources/
│ │ ├── application.properties
│ │ └── patterns/
│ │ └── patterns
│ ├── flink-learning-monitor-pvuv/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── monitor/
│ │ └── pvuv/
│ │ ├── HyperLogLogUvExample.java
│ │ ├── MapStateUvExample.java
│ │ ├── RedisSetUvExample.java
│ │ ├── model/
│ │ │ └── UserVisitWebEvent.java
│ │ └── utils/
│ │ └── UvExampleUtil.java
│ ├── flink-learning-monitor-storage/
│ │ ├── README.md
│ │ ├── flink_log_2es.sql
│ │ ├── flink_metrics_2es.sql
│ │ └── pom.xml
│ ├── flink_monitor_measurements.md
│ └── pom.xml
├── flink-learning-project/
│ ├── README.md
│ ├── flink-learning-project-common/
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── common/
│ │ ├── constant/
│ │ │ └── ProjectConstants.java
│ │ ├── model/
│ │ │ ├── AlertEvent.java
│ │ │ ├── AlertRule.java
│ │ │ ├── PageAccessEvent.java
│ │ │ ├── ServerMetric.java
│ │ │ └── TransactionEvent.java
│ │ └── utils/
│ │ └── ProjectKafkaUtil.java
│ ├── flink-learning-project-deduplication/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── deduplication/
│ │ ├── KeyedStateDeduplication.java
│ │ ├── TuningKeyedStateDeduplication.java
│ │ ├── model/
│ │ │ └── UserVisitWebEvent.java
│ │ └── utils/
│ │ └── DeduplicationExampleUtil.java
│ ├── flink-learning-project-flink-job-scaffold/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── scaffold/
│ │ └── FlinkJobScaffold.java
│ ├── flink-learning-project-log/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── log/
│ │ ├── ErrorLogAlertJob.java
│ │ ├── LogAnalysisJob.java
│ │ └── model/
│ │ ├── AppLogEvent.java
│ │ └── LogStatistics.java
│ ├── flink-learning-project-monitor-alert/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── monitor/
│ │ └── alert/
│ │ ├── DynamicAlertRuleJob.java
│ │ └── MetricAggregateAlertJob.java
│ ├── flink-learning-project-monitor-dashboard/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── dashboard/
│ │ ├── RealTimeDashboardJob.java
│ │ ├── TopNHotPagesJob.java
│ │ └── model/
│ │ ├── PageViewStats.java
│ │ └── TopNResult.java
│ ├── flink-learning-project-real-time-computing-platform/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── platform/
│ │ ├── FlinkSqlPlatformJob.java
│ │ └── TableApiExampleJob.java
│ ├── flink-learning-project-real-time-data-warehouse/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── warehouse/
│ │ ├── DwsOrderStatsJob.java
│ │ ├── OdsToKafkaJob.java
│ │ └── model/
│ │ ├── OrderDetail.java
│ │ └── OrderStats.java
│ ├── flink-learning-project-risk-management/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ └── main/
│ │ └── java/
│ │ └── com/
│ │ └── zhisheng/
│ │ └── project/
│ │ └── risk/
│ │ ├── FraudDetectionCepJob.java
│ │ ├── RiskScoreJob.java
│ │ └── model/
│ │ └── RiskEvent.java
│ └── pom.xml
├── flink-learning-sql/
│ ├── README.md
│ ├── flink-learning-sql-blink/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── sql/
│ │ │ │ └── blink/
│ │ │ │ └── stream/
│ │ │ │ ├── catalog/
│ │ │ │ │ ├── CatalogAPI.java
│ │ │ │ │ └── CatalogTypes.java
│ │ │ │ └── example/
│ │ │ │ ├── FlinkSQLDistinctExample.java
│ │ │ │ ├── SQLExampleData2PG.java
│ │ │ │ ├── SQLExampleKafkaData2ES.java
│ │ │ │ ├── SQLExampleKafkaData2HBase.java
│ │ │ │ ├── SQLExampleKafkaData2Kafka.java
│ │ │ │ ├── SQLExampleKafkaRowData2ES.java
│ │ │ │ └── StreamWindowSQLExample.java
│ │ │ └── resources/
│ │ │ ├── application.properties
│ │ │ └── words.txt
│ │ └── test/
│ │ └── java/
│ │ └── test/
│ │ └── TableEnvironmentExample1.java
│ ├── flink-learning-sql-client/
│ │ ├── README.md
│ │ ├── pom.xml
│ │ └── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ └── com/
│ │ │ │ └── zhisheng/
│ │ │ │ └── sql/
│ │ │ │ ├── SqlSubmit.java
│ │ │ │ ├── cli/
│ │ │ │ │ ├── CliOptions.java
│ │ │ │ │ ├── CliOptionsParser.java
│ │ │ │ │ └── SqlCommandParser.java
│ │ │ │ ├── constant/
│ │ │ │ │ ├── Constant.java
│ │ │ │ │ └── UnitEnum.java
│ │ │ │ ├── exception/
│ │ │ │ │ └── SqlParserException.java
│ │ │ │ ├── planner/
│ │ │ │ │ ├── BatchPlanner.java
│ │ │ │ │ ├── Planner.java
│ │ │ │ │ └── StreamingPlanner.java
│ │ │ │ └── utils/
│ │ │ │ ├── CloseableRowIteratorWrapper.java
│ │ │ │ ├── Config.java
│ │ │ │ └── HttpClient.java
│ │ │ └── resources/
│ │ │ ├── dev/
│ │ │ │ ├── conf.properties
│ │ │ │ └── logback.xml
│ │ │ ├── pre/
│ │ │ │ ├── conf.properties
│ │ │ │ └── logback.xml
│ │ │ ├── prod/
│ │ │ │ ├── conf.properties
│ │ │ │ └── logback.xml
│ │ │ └── sql/
│ │ │ └── 124563.sql
│ │ └── test/
│ │ ├── java/
│ │ │ └── SqlSubmitTest.java
│ │ └── resources/
│ │ ├── dev/
│ │ │ ├── conf.properties
│ │ │ └── logback.xml
│ │ └── sql/
│ │ └── test.sql
│ ├── flink-learning-sql-common/
│ │ ├── README.md
│ │ └── pom.xml
│ └── pom.xml
├── paper/
│ └── paper.md
├── pom.xml
└── tree.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.DS_Store
.pampas/
**/.idea/*
**/target/*
.idea
*.iml
*.class
.project
**/.settings/*
**/*/dependency-reduced-pom.xml
# front dependencies
endpoints/**/node_modules
# production
endpoints/**/dist
endpoints/**/public/
endpoints/**/vendor/
endpoints/**/vendor_modules/
endpoints/**/components_vendor/
endpoints/**/components_eevee/
endpoints/**/app/components_vendor
endpoints/**/lib/server/
endpoints/**/npm-debug.log*
endpoints/**/yarn-error.log*
debug.properties
/dist/
.classpath
.factorypath
.vscode/
================================================
FILE: Flink-Forward-2020/README.md
================================================
Flink Forward 2020 是在线上举办的一次会议
1、《Keynote:Introducing Stateful Functions 2.0: Stream Processing meets Serverless Applications》
Stephan Ewen – Apache Flink PMC,Ververica Co-founder, CTO
讲解嘉宾:李钰(绝顶) – Apache Flink Committer,Apache Flink 1.10 Release Manager,阿里巴巴高级技术专家
2、《Keynote:Stream analytics made real with Pravega and Apache Flink》
Srikanth Satya – VP of Engineering at DellEMC
讲解嘉宾:滕昱 – DellEMC 技术总监
3、《Keynote:Apache Flink – Completing Cloudera’s End to End Streaming Platform》
Marton Balassi – Apache Flink PMC ,Senior Solutions Architect at Cloudera
Joe Witt – VP of Engineering at Cloudera
讲解嘉宾:杨克特(鲁尼) – Apache Member, Apache Flink PMC, 阿里巴巴高级技术专家
4、《Keynote:The Evolution of Data Infrastructure at Splunk》
Eric Sammer – Distinguished Engineer at Splunk
讲解嘉宾:王治江(淘江) – 阿里巴巴高级技术专家
5、《Flink SQL 之 2020:舍我其谁》
Fabian Hueske, & Timo Walther
讲解嘉宾:伍翀(云邪),Apache Flink PMC,阿里巴巴技术专家
6、《微博基于 Flink 的机器学习实践》
分享嘉宾:
于茜,微博机器学习研发中心高级算法工程师。多年来致力于使用 Flink 构建实时数据处理和在线机器学习框架,有丰富的社交媒体应用推荐系统的开发经验。
曹富强,微博机器学习研发中心系统工程师。现负责微博机器学习平台数据计算模块。主要涉及实时计算 Flink,Storm,Spark Streaming,离线计算 Hive,Spark 等。目前专注于 Flink 在微博机器学习场景的应用。
于翔,微博机器学习研发中心算法架构工程师。
7、《Flink’s application at Didi》
分享嘉宾:薛康 – 现任滴滴技术专家,实时计算负责人
8、《Alink:提升基于 Flink 的机器学习平台易用性》
分享嘉宾:杨旭(品数) – 阿里巴巴资深技术专家。
9、《Google: 机器学习工作流的分布式处理》
Ahmet Altay & Reza Rokni & Robert Crowe
讲解嘉宾:秦江杰 – Apache Flink PMC,阿里巴巴高级技术专家
10、《Flink + AI Flow:让 AI 易如反掌》
分享嘉宾:秦江杰 – Apache Flink PMC,阿里巴巴高级技术专家
11、《终于等到你:PyFlink + Zeppelin》
分享嘉宾:
孙金城(金竹) – Apache Member,Apache Flink PMC,阿里巴巴高级技术专家
章剑锋(简锋) – Apache Member,Apache Zeppelin PMC,阿里巴巴高级技术专家
12、《Uber :使用 Flink CEP 进行地理情形检测的实践》
Teng (Niel) Hu
讲解嘉宾:付典 – Apache Flink Committer,阿里巴巴技术专家
13、《AWS: 如何在全托管 Apache Flink 服务中提供应用高可用》
Ryan Nienhuis & Tirtha Chatterjee
讲解嘉宾:章剑锋(简锋) – Apache Member,Apache Zeppelin PMC,阿里巴巴高级技术专家
14、《Production-Ready Flink and Hive Integration – what story you can tell now?》
Bowen Li
讲解嘉宾:李锐(天离) – Apache Hive PMC,阿里巴巴技术专家
15、《Data Warehouse, Data Lakes, What’s Next?》
Xiaowei Jiang
讲解嘉宾:金晓军(仙隐) – 阿里巴巴高级技术专家
16、《Netflix 的 Flink 自动扩缩容》
Abhay Amin
讲解嘉宾:吕文龙(龙三),阿里巴巴技术专家
17、《Apache Flink 误用之痛》
Konstantin Knauf
讲解嘉宾:孙金城(金竹) – Apache Member,Apache Flink PMC,阿里巴巴高级技术专家
18、《A deep dive into Flink SQL》
分享嘉宾:伍翀(云邪),Apache Flink PMC,阿里巴巴技术专家
19、《Lyft: 基于Flink的准实时海量数据分析平台》
Ying Xu & Kailash Hassan Dayanand
讲解嘉宾:王阳(亦祺),阿里巴巴技术专家
### 如何获取上面这些 PPT?
上面的这些 PPT 本人已经整理好了,你可以扫描下面二维码,关注微信公众号:zhisheng,然后在里面回复关键字: **ff2020** 即可获取已放出的 PPT。

================================================
FILE: Flink-Forward-Asia-2019-PPT/README.md
================================================
Flink Forward Asia 2019 在北京召开的,有主会场和几个分会场(企业实践、Apache Flink 核心技术、开源大数据生态、实时数仓、人工智能),内容涉及很多,可以查看下面的 PPT。
### 主会场
1、《Stateful Functions: Building general-purpose Applications and Services on Apache Flink》
2、《Apache Flink Heading Towards A Unified Engine》
3、《Storage Reimagined for a Streaming World》
4、《Lyft 基于 Apache Flink 的大规模准实时数据分析平台》
### 企业实践
1、《Apache Flink 在字节跳动的实践与优化》
2、《Apache Flink在快手实时多维分析场景的应用》
3、《bilibili 实时平台的架构与实践》
4、《Apache Flink 资源动态调整及其实践》
5、《Apache Flink在滴滴的应用与实践》
6、《Apache Flink 在网易的实践》
7、《Apache Flink 在中国农业银行的探索和实践》
8、《基于 Apache Flink 的爱奇艺实时计算平台建设实践》
9、《实时计算在贝壳的实践》
10、《基于 Apache Flink 构建 CEP(Complex Event Process)引擎的挑战和实践》
### Apache Flink 核心技术
1、《Pluggable Shuffle Service and Unaligned Checkpoint》
2、《漂移计算 – 跨 DC 跨数据源的高性能 SQL 引擎》
3、《New Source API – Make it Easy! 》
4、《Stateful Functions: Unlocking the next wave of applications with Stream Processing》
5、《Apache Flink新场景——OLAP引擎》
6、《New Feature and Improvements on State Backends in Flink 1.10》
7、《阿里巴巴在 Apache Flink 大规模持久化存储的实践之道》
8、《Using Apache Flink as a Unified Data Processing Platform》
9、《深入探索 Apache Flink SQL 流批统一的查询引擎与最佳实践》
10、《Apache Flink 流批一体的资源管理与任务调度》
### 开源大数据生态
1、《YuniKorn 对 Apache Flink on K8s 的调度优化》
2、《流处理基准测试》
3、《Apache Flink and the Apache Way》
4、《Delivering stream data reliably with Pravega》
5、《Deep dive into Pyflink & integration with Zeppelin》
6、《Apache Flink 与 Apache Hive 的集成》
7、《趣头条基于 Apache Flink+ClickHouse 构建实时数据分析平台》
8、《基于 Apache Flink 的边缘流式计算》
9、《基于 Apache Pulsar 和 Apache Flink 进行批流一体的弹性数据处理》
10、《The integretion of Apache Flink SQL and Apache Calcite》
### 实时数仓
1、《美团点评基于 Apache Flink 的实时数仓平台实践》
2、《小米流式平台架构演进与实践》
3、《Netflix:Evolving Keystone to an Open Collaborative Real-time ETL Platform》
4、《菜鸟供应链实时数据技术架构的演进》
5、《OPPO 基于 Apache Flink 的实时数仓实践》
### 人工智能
1、《Deep Learning On Apache Flink》
2、《在 Apache Flink 上使用 Analytics-Zoo 进行大数据分析与深度学习模型推理的架构与实践》
3、《携程实时智能检测平台实践》
4、《基于Apache Flink的机器学习算法平台实践与开源》
5、《Apache Flink AI生态系统工作》
### 如何获取上面这些 PPT?
上面的这些 PPT 本人已经整理好了,你可以扫描下面二维码,关注微信公众号:zhisheng,然后在里面回复关键字: **ffa** 即可获取已放出的 PPT。

================================================
FILE: Flink-Forward-Asia-2020-PPT/README.md
================================================
Flink Forward Asia 2020 在北京召开的,有主会场和几个分会场(企业实践、Apache Flink 核心技术、开源大数据生态、实时数仓、人工智能),内容涉及很多,可以查看下面图片介绍。
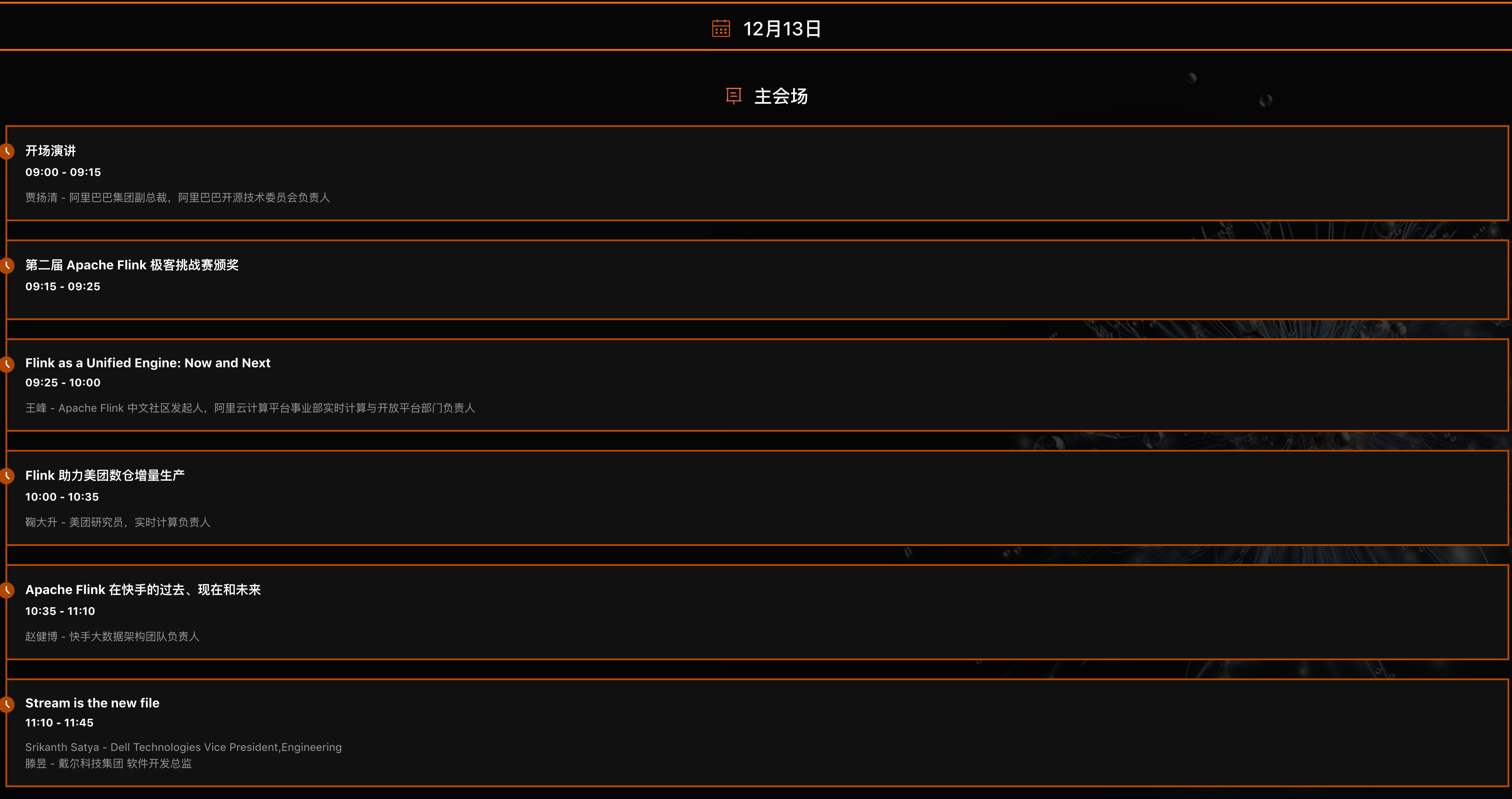
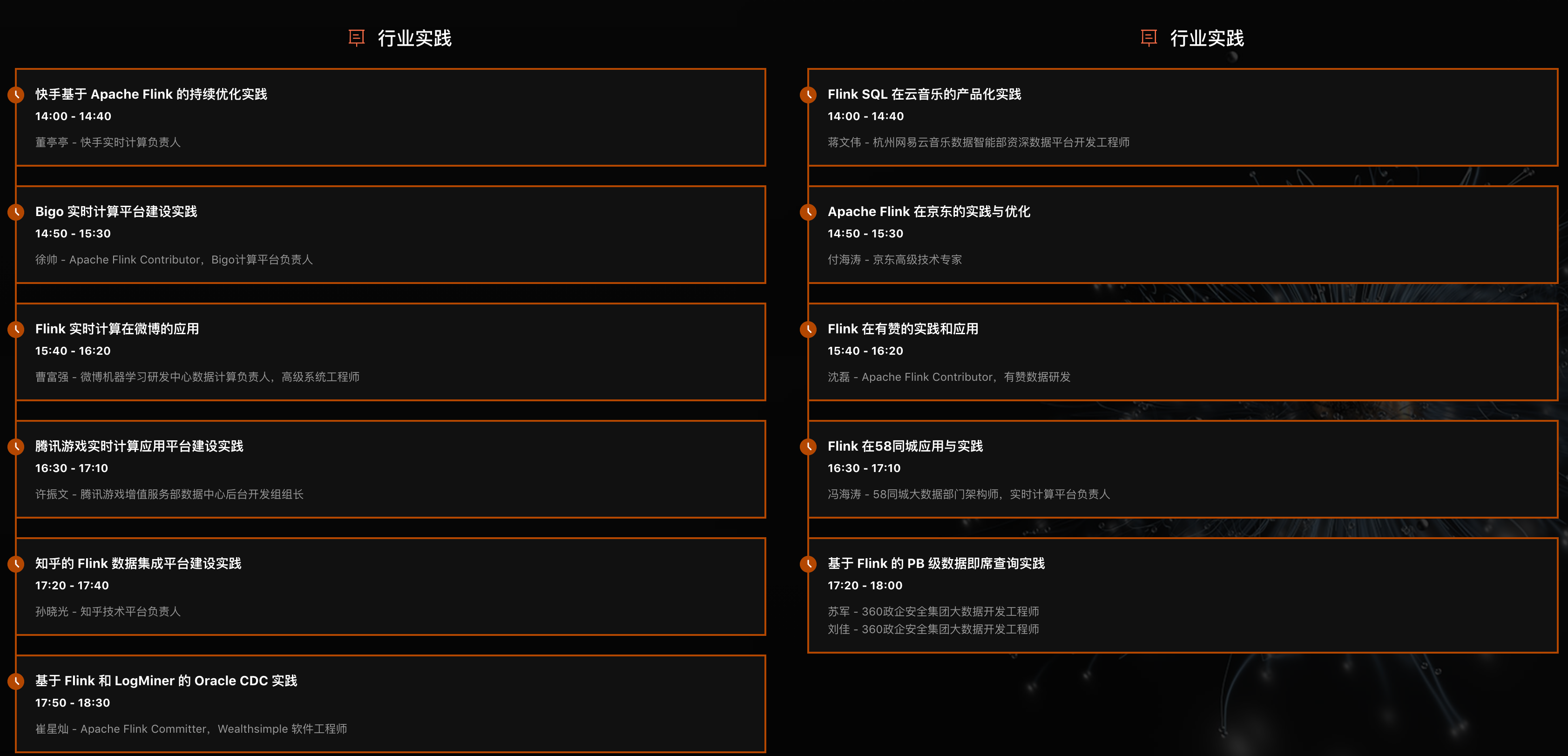
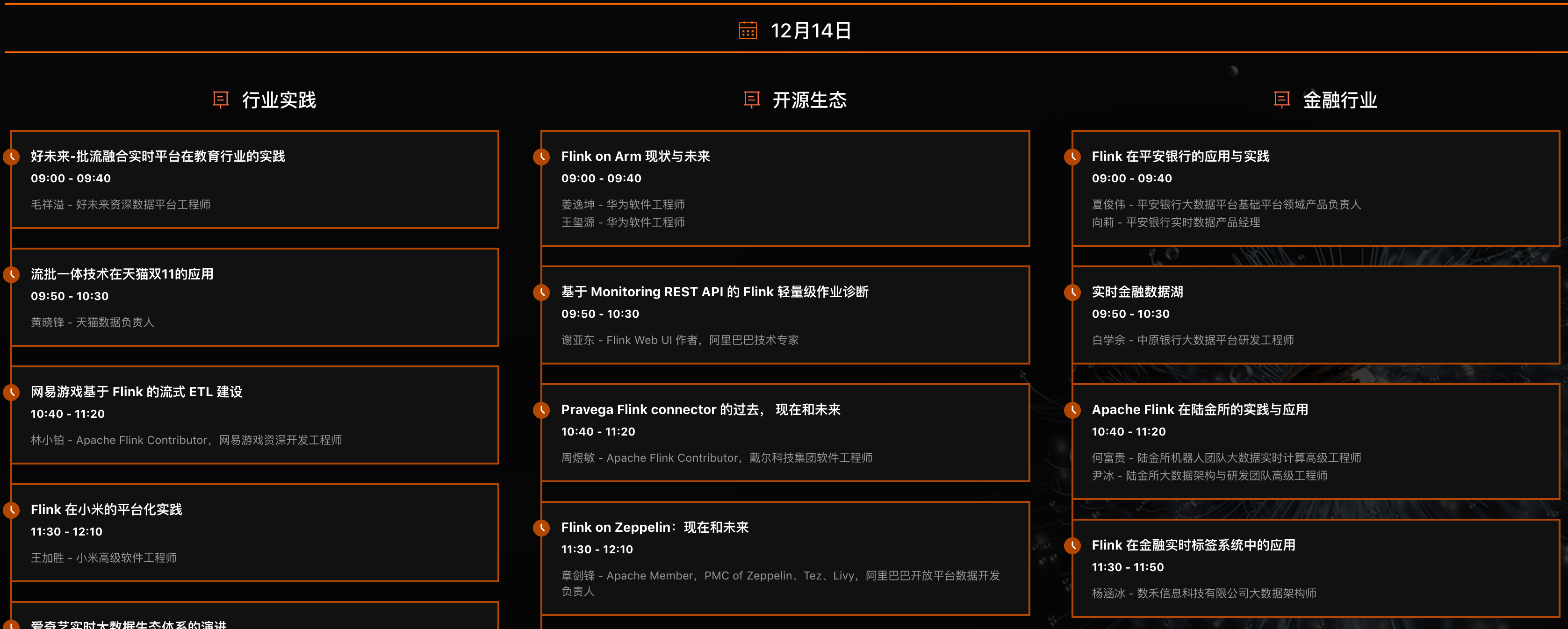
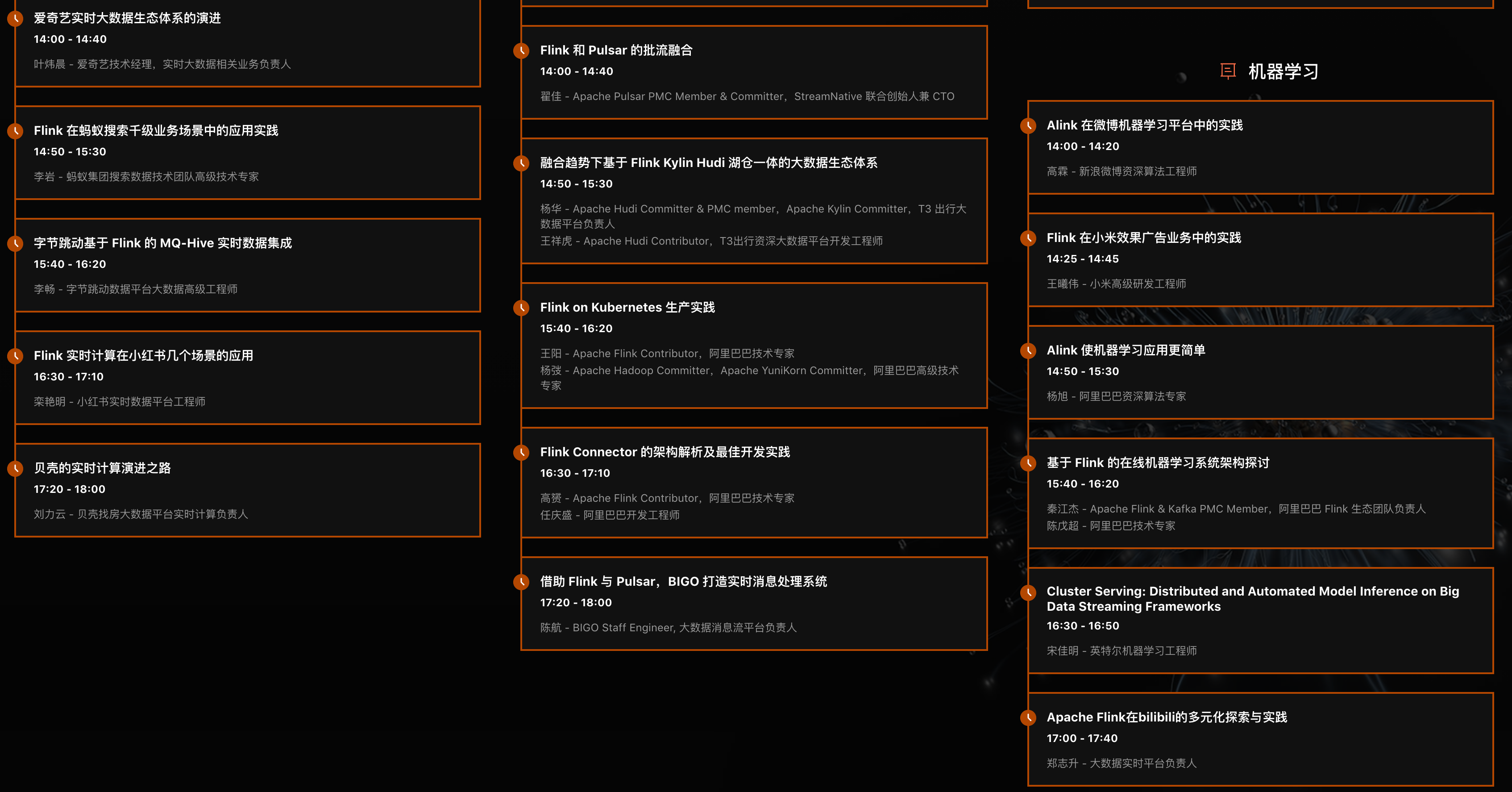

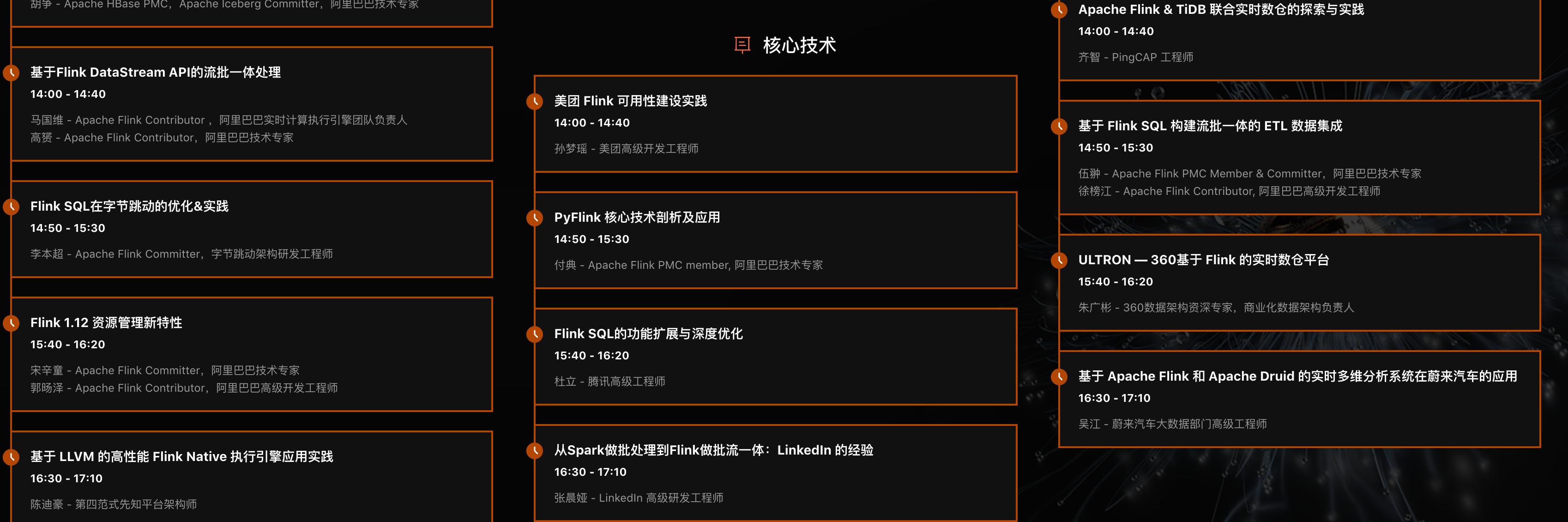
### 如何获取上面这些 PPT?
上面的这些 PPT 本人已经整理好了,你可以扫描下面二维码,关注微信公众号:zhisheng,然后在里面回复关键字: **ffa2020** 即可获取已放出的 PPT。

================================================
FILE: Flink-Forward-Asia-2021-PPT/README.md
================================================
Flink Forward Asia 2021 在线上召开的,有企业实践、Apache Flink 核心技术、开源大数据生态、实时数仓、人工智能、流批一体、数据湖等会场,内容涉及很多,可以查看下面图片介绍。







### 如何获取上面这些 PPT?
上面的这些 PPT 本人已经整理好了,你可以扫描下面二维码,关注微信公众号:zhisheng,然后在里面回复关键字: **ffa2021** 即可获取已放出的 PPT。

================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
# Flink 学习
麻烦路过的各位亲给这个项目点个 star,太不易了,写了这么多,算是对我坚持下来的一种鼓励吧!另外特别感谢 [JetBrains](https://jb.gg/OpenSourceSupport) 公司提供的免费全家桶工具,🙏🙏🙏!
## Stargazers over time

## 本项目结构

## How to build
Maybe your Maven conf file `settings.xml` mirrors can add aliyun central mirror :
```xml
alimaven
central
aliyun maven
https://maven.aliyun.com/repository/central
```
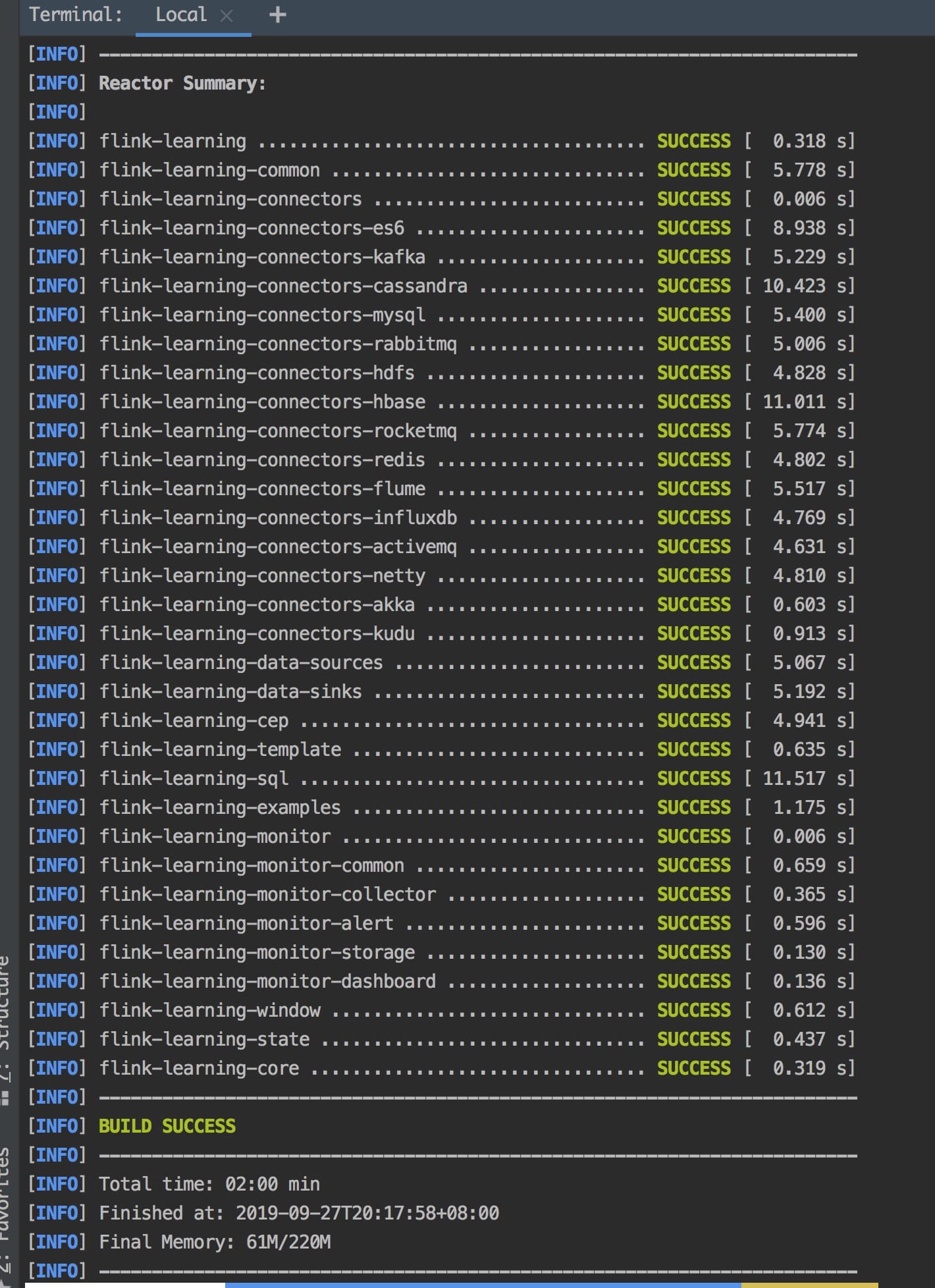
then you can run the following command :
```
mvn clean package -Dmaven.test.skip=true
```
you can see following result if build success.
## Flink 系统专栏
基于 Flink 1.9 讲解的专栏,涉及入门、概念、原理、实战、性能调优、系统案例的讲解。扫码下面专栏二维码可以订阅该专栏

首发地址:[http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/](http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/)
专栏地址:[https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f](https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f)
## Change
**2022/02/26** 将自己 《Flink 实战与性能优化》专栏放在 GitHub,参见 books 目录
**2021/12/18** 将该项目的 Flink 版本升级至 1.14.2,如果有需要可以去老的分支查看。
**2021/08/15** 将该项目的 Flink 版本升级至 1.13.2,API 发生重大改变,所以代码结构也做了相应的调整(部分代码在 master 分支已经删除,同时将之前的代码切到 [feature/flink-1.10.0](https://github.com/zhisheng17/flink-learning/tree/feature/flink-1.10.0) 上了,如果有需要可以去老的分支查看)。
**2020/02/16** 将该项目的 Flink 版本升级至 1.10,该版本代码都是经过测试成功运行的,尽量以该版本作为参考,如果代码在你们集群测试不成功,麻烦检查 Flink 版本是否一致,或者是否有包冲突问题。
**2019/09/06** 将该项目的 Flink 版本升级到 1.9.0,有一些变动,Flink 1.8.0 版本的代码经群里讨论保存在分支 [feature/flink-1.8.0](https://github.com/zhisheng17/flink-learning/tree/feature/flink-1.8.0) 以便部分同学需要。
**2019/06/08** 四本 Flink 书籍:
+ [Introduction_to_Apache_Flink_book.pdf]() 这本书比较薄,处于介绍阶段,国内有这本的翻译书籍
+ [Learning Apache Flink.pdf]() 这本书比较基础,初学的话可以多看看
+ [Stream Processing with Apache Flink.pdf]() 这本书是 Flink PMC 写的
+ [Streaming System.pdf]() 这本书评价不是一般的高
**2019/06/09** 新增流处理引擎相关的 Paper,在 paper 目录下:
+ [流处理引擎相关的 Paper](./paper/paper.md)
**【提示】**:关于书籍的下载,因版权问题,不方便提供,所以已经删除,需要的话可以切换到老分支去下载。
## 博客
1、[Flink 从0到1学习 —— Apache Flink 介绍](http://www.54tianzhisheng.cn/2018/10/13/flink-introduction/)
2、[Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门](http://www.54tianzhisheng.cn/2018/09/18/flink-install)
3、[Flink 从0到1学习 —— Flink 配置文件详解](http://www.54tianzhisheng.cn/2018/10/27/flink-config/)
4、[Flink 从0到1学习 —— Data Source 介绍](http://www.54tianzhisheng.cn/2018/10/28/flink-sources/)
5、[Flink 从0到1学习 —— 如何自定义 Data Source ?](http://www.54tianzhisheng.cn/2018/10/30/flink-create-source/)
6、[Flink 从0到1学习 —— Data Sink 介绍](http://www.54tianzhisheng.cn/2018/10/29/flink-sink/)
7、[Flink 从0到1学习 —— 如何自定义 Data Sink ?](http://www.54tianzhisheng.cn/2018/10/31/flink-create-sink/)
8、[Flink 从0到1学习 —— Flink Data transformation(转换)](http://www.54tianzhisheng.cn/2018/11/04/Flink-Data-transformation/)
9、[Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows](http://www.54tianzhisheng.cn/2018/12/08/Flink-Stream-Windows/)
10、[Flink 从0到1学习 —— Flink 中的几种 Time 详解](http://www.54tianzhisheng.cn/2018/12/11/Flink-time/)
11、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch](http://www.54tianzhisheng.cn/2018/12/30/Flink-ElasticSearch-Sink/)
12、[Flink 从0到1学习 —— Flink 项目如何运行?](http://www.54tianzhisheng.cn/2019/01/05/Flink-run/)
13、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka](http://www.54tianzhisheng.cn/2019/01/06/Flink-Kafka-sink/)
14、[Flink 从0到1学习 —— Flink JobManager 高可用性配置](http://www.54tianzhisheng.cn/2019/01/13/Flink-JobManager-High-availability/)
15、[Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍](http://www.54tianzhisheng.cn/2019/01/14/Flink-parallelism-slot/)
16、[Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL](http://www.54tianzhisheng.cn/2019/01/15/Flink-MySQL-sink/)
17、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ](https://t.zsxq.com/uVbi2nq)
18、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase](https://t.zsxq.com/zV7MnuJ)
19、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS](https://t.zsxq.com/zV7MnuJ)
20、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis](https://t.zsxq.com/zV7MnuJ)
21、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra](https://t.zsxq.com/uVbi2nq)
22、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume](https://t.zsxq.com/zV7MnuJ)
23、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB](https://t.zsxq.com/zV7MnuJ)
24、[Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ](https://t.zsxq.com/zV7MnuJ)
25、[Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了](https://t.zsxq.com/uniY7mm)
26、[Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了](https://t.zsxq.com/zV7MnuJ)
### Flink 源码项目结构

## 学习资料
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号了。
你可以加我的微信:**yuanblog_tzs**,然后回复关键字:**Flink** 即可无条件获取到,转载请联系本人获取授权,违者必究。

更多私密资料请加入知识星球!

有人要问知识星球里面更新什么内容?值得加入吗?
目前知识星球内已更新的系列文章:
### 大数据重磅炸弹
1、[《大数据重磅炸弹——实时计算引擎 Flink》开篇词](https://t.zsxq.com/fqfuVRR)
2、[你公司到底需不需要引入实时计算引擎?](https://t.zsxq.com/emMBaQN)
3、[一文让你彻底了解大数据实时计算框架 Flink](https://t.zsxq.com/eM3ZRf2)
4、[别再傻傻的分不清大数据框架Flink、Blink、Spark Streaming、Structured Streaming和Storm之间的区别了](https://t.zsxq.com/eAyRz7Y)
5、[Flink 环境准备看这一篇就够了](https://t.zsxq.com/iaMJAe6)
6、[一文讲解从 Flink 环境安装到源码编译运行](https://t.zsxq.com/iaMJAe6)
7、[通过 WordCount 程序教你快速入门上手 Flink](https://t.zsxq.com/eaIIiAm)
8、[Flink 如何处理 Socket 数据及分析实现过程](https://t.zsxq.com/Vnq72jY)
9、[Flink job 如何在 Standalone、YARN、Mesos、K8S 上部署运行?](https://t.zsxq.com/BiyvFUZ)
10、[Flink 数据转换必须熟悉的算子(Operator)](https://t.zsxq.com/fufUBiA)
11、[Flink 中 Processing Time、Event Time、Ingestion Time 对比及其使用场景分析](https://t.zsxq.com/r7aYB2V)
12、[如何使用 Flink Window 及 Window 基本概念与实现原理](https://t.zsxq.com/byZbyrb)
13、[如何使用 DataStream API 来处理数据?](https://t.zsxq.com/VzNBi2r)
14、[Flink WaterMark 详解及结合 WaterMark 处理延迟数据](https://t.zsxq.com/Iub6IQf)
15、[基于 Apache Flink 的监控告警系统](https://t.zsxq.com/MniUnqb)
16、[数据仓库、数据库的对比介绍与实时数仓案例分享](https://t.zsxq.com/v7QzNZ3)
17、[使用 Prometheus Grafana 监控 Flink](https://t.zsxq.com/uRN3VfA)
### 源码系列
1、[Flink 源码解析 —— 源码编译运行](https://t.zsxq.com/UZfaYfE)
2、[Flink 源码解析 —— 项目结构一览](https://t.zsxq.com/zZZjaYf)
3、[Flink 源码解析—— local 模式启动流程](https://t.zsxq.com/zV7MnuJ)
4、[Flink 源码解析 —— standalonesession 模式启动流程](https://t.zsxq.com/QZVRZJA)
5、[Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动](https://t.zsxq.com/u3fayvf)
6、[Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动](https://t.zsxq.com/MnQRByb)
7、[Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程](https://t.zsxq.com/YJ2Zrfi)
8、[Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程](https://t.zsxq.com/qnMFEUJ)
9、[Flink 源码解析 —— 如何获取 JobGraph?](https://t.zsxq.com/naaMf6y)
10、[Flink 源码解析 —— 如何获取 StreamGraph?](https://t.zsxq.com/qRFIm6I)
11、[Flink 源码解析 —— Flink JobManager 有什么作用?](https://t.zsxq.com/2VRrbuf)
12、[Flink 源码解析 —— Flink TaskManager 有什么作用?](https://t.zsxq.com/RZbu7yN)
13、[Flink 源码解析 —— JobManager 处理 SubmitJob 的过程](https://t.zsxq.com/zV7MnuJ)
14、[Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程](https://t.zsxq.com/zV7MnuJ)
15、[Flink 源码解析 —— 深度解析 Flink Checkpoint 机制](https://t.zsxq.com/ynQNbeM)
16、[Flink 源码解析 —— 深度解析 Flink 序列化机制](https://t.zsxq.com/JaQfeMf)
17、[Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?](https://t.zsxq.com/zjQvjeM)
18、[Flink Metrics 源码解析 —— Flink-metrics-core](https://t.zsxq.com/Mnm2nI6)
19、[Flink Metrics 源码解析 —— Flink-metrics-datadog](https://t.zsxq.com/Mnm2nI6)
20、[Flink Metrics 源码解析 —— Flink-metrics-dropwizard](https://t.zsxq.com/Mnm2nI6)
21、[Flink Metrics 源码解析 —— Flink-metrics-graphite](https://t.zsxq.com/Mnm2nI6)
22、[Flink Metrics 源码解析 —— Flink-metrics-influxdb](https://t.zsxq.com/Mnm2nI6)
23、[Flink Metrics 源码解析 —— Flink-metrics-jmx](https://t.zsxq.com/Mnm2nI6)
24、[Flink Metrics 源码解析 —— Flink-metrics-slf4j](https://t.zsxq.com/Mnm2nI6)
25、[Flink Metrics 源码解析 —— Flink-metrics-statsd](https://t.zsxq.com/Mnm2nI6)
26、[Flink Metrics 源码解析 —— Flink-metrics-prometheus](https://t.zsxq.com/Mnm2nI6)
26、[Flink Annotations 源码解析](https://t.zsxq.com/f6eAu3J)

除了《从1到100深入学习Flink》源码学习这个系列文章,《从0到1学习Flink》的案例文章也会优先在知识星球更新,让大家先通过一些 demo 学习 Flink,再去深入源码学习!
如果学习 Flink 的过程中,遇到什么问题,可以在里面提问,我会优先解答,这里做个抱歉,自己平时工作也挺忙,微信的问题不能做全部做一些解答,
但肯定会优先回复给知识星球的付费用户的,庆幸的是现在星球里的活跃氛围还是可以的,有不少问题通过提问和解答的方式沉淀了下来。
1、[为何我使用 ValueState 保存状态 Job 恢复是状态没恢复?](https://t.zsxq.com/62rZV7q)
2、[flink中watermark究竟是如何生成的,生成的规则是什么,怎么用来处理乱序数据](https://t.zsxq.com/yF2rjmY)
3、[消费kafka数据的时候,如果遇到了脏数据,或者是不符合规则的数据等等怎么处理呢?](https://t.zsxq.com/uzFIeiq)
4、[在Kafka 集群中怎么指定读取/写入数据到指定broker或从指定broker的offset开始消费?](https://t.zsxq.com/Nz7QZBY)
5、[Flink能通过oozie或者azkaban提交吗?](https://t.zsxq.com/7UVBeMj)
6、[jobmanager挂掉后,提交的job怎么不经过手动重新提交执行?](https://t.zsxq.com/mUzRbY7)
7、[使用flink-web-ui提交作业并执行 但是/opt/flink/log目录下没有日志文件 请问关于flink的日志(包括jobmanager、taskmanager、每个job自己的日志默认分别存在哪个目录 )需要怎么配置?](https://t.zsxq.com/Nju7EuV)
8、[通过flink 仪表盘提交的jar 是存储在哪个目录下?](https://t.zsxq.com/6muRz3j)
9、[从Kafka消费数据进行etl清洗,把结果写入hdfs映射成hive表,压缩格式、hive直接能够读取flink写出的文件、按照文件大小或者时间滚动生成文件](https://t.zsxq.com/uvFQvFu)
10、[flink jar包上传至集群上运行,挂掉后,挂掉期间kafka中未被消费的数据,在重新启动程序后,是自动从checkpoint获取挂掉之前的kafka offset位置,自动消费之前的数据进行处理,还是需要某些手动的操作呢?](https://t.zsxq.com/ubIY33f)
11、[flink 启动时不自动创建 上传jar的路径,能指定一个创建好的目录吗](https://t.zsxq.com/UfA2rBy)
12、[Flink sink to es 集群上报 slot 不够,单机跑是好的,为什么?](https://t.zsxq.com/zBMnIA6)
13、[Fllink to elasticsearch如何创建索引文档期时间戳?](https://t.zsxq.com/qrZBAQJ)
14、[blink有没有api文档或者demo,是否建议blink用于生产环境。](https://t.zsxq.com/J2JiIMv)
15、[flink的Python api怎样?bug多吗?](https://t.zsxq.com/ZVVrjuv)
16、[Flink VS Spark Streaming VS Storm VS Kafka Stream ](https://t.zsxq.com/zbybQNf)
17、[你们做实时大屏的技术架构是什么样子的?flume→kafka→flink→redis,然后后端去redis里面捞数据,酱紫可行吗?](https://t.zsxq.com/Zf6meAm)
18、[做一个统计指标的时候,需要在Flink的计算过程中多次读写redis,感觉好怪,星主有没有好的方案?](https://t.zsxq.com/YniI2JQ)
19、[Flink 使用场景大分析,列举了很多的常用场景,可以好好参考一下](https://t.zsxq.com/fYZZfYf)
20、[将kafka中数据sink到mysql时,metadata的数据为空,导入mysql数据不成功???](https://t.zsxq.com/I6eEqR7)
21、[使用了ValueState来保存中间状态,在运行时中间状态保存正常,但是在手动停止后,再重新运行,发现中间状态值没有了,之前出现的键值是从0开始计数的,这是为什么?是需要实现CheckpointedFunction吗?](https://t.zsxq.com/62rZV7q)
22、[flink on yarn jobmanager的HA需要怎么配置。还是说yarn给管理了](https://t.zsxq.com/mQ7YbQJ)
23、[有两个数据流就行connect,其中一个是实时数据流(kafka 读取),另一个是配置流。由于配置流是从关系型数据库中读取,速度较慢,导致实时数据流流入数据的时候,配置信息还未发送,这样会导致有些实时数据读取不到配置信息。目前采取的措施是在connect方法后的flatmap的实现的在open 方法中,提前加载一次配置信息,感觉这种实现方式不友好,请问还有其他的实现方式吗?](https://t.zsxq.com/q3VvB6U)
24、[Flink能通过oozie或者azkaban提交吗?](https://t.zsxq.com/7UVBeMj)
25、[不采用yarm部署flink,还有其他的方案吗? 主要想解决服务器重启后,flink服务怎么自动拉起? jobmanager挂掉后,提交的job怎么不经过手动重新提交执行?](https://t.zsxq.com/mUzRbY7)
26、[在一个 Job 里将同份数据昨晚清洗操作后,sink 到后端多个地方(看业务需求),如何保持一致性?(一个sink出错,另外的也保证不能插入)](https://t.zsxq.com/bYnimQv)
27、[flink sql任务在某个特定阶段会发生tm和jm丢失心跳,是不是由于gc时间过长呢,](https://t.zsxq.com/YvBAyrV)
28、[有这样一个需求,统计用户近两周进入产品详情页的来源(1首页大搜索,2产品频道搜索,3其他),为php后端提供数据支持,该信息在端上报事件中,php直接获取有点困难。 我现在的解决方案 通过flink滚动窗口(半小时),统计用户半小时内3个来源pv,然后按照日期序列化,直接写mysql。php从数据库中解析出来,再去统计近两周占比。 问题1,这个需求适合用flink去做吗? 问题2,我的方案总感觉怪怪的,有没有好的方案?](https://t.zsxq.com/fayf2Vv)
29、[一个task slot 只能同时运行一个任务还是多个任务呢?如果task slot运行的任务比较大,会出现OOM的情况吗?](https://t.zsxq.com/ZFiY3VZ)
30、[你们怎么对线上flink做监控的,如果整个程序失败了怎么自动重启等等](https://t.zsxq.com/Yn2JqB6)
31、[flink cep规则动态解析有接触吗?有没有成型的框架?](https://t.zsxq.com/YFMFeaA)
32、[每一个Window都有一个watermark吗?window是怎么根据watermark进行触发或者销毁的?](https://t.zsxq.com/VZvRrjm)
33、[ CheckPoint与SavePoint的区别是什么?](https://t.zsxq.com/R3ZZJUF)
34、[flink可以在算子中共享状态吗?或者大佬你有什么方法可以共享状态的呢?](https://t.zsxq.com/Aa62Bim)
35、[运行几分钟就报了,看taskmager日志,报的是 failed elasticsearch bulk request null,可是我代码里面已经做过空值判断了呀 而且也过滤掉了,flink版本1.7.2 es版本6.3.1](https://t.zsxq.com/ayFmmMF)
36、[这种情况,我们调并行度 还是配置参数好](https://t.zsxq.com/Yzzzb2b)
37、[大家都用jdbc写,各种数据库增删查改拼sql有没有觉得很累,ps.set代码一大堆,还要计算每个参数的位置](https://t.zsxq.com/AqBUR3f)
38、[关于datasource的配置,每个taskmanager对应一个datasource?还是每个slot? 实际运行下来,每个slot中datasorce线程池只要设置1就行了,多了也用不到?](https://t.zsxq.com/AqBUR3f)
39、[kafka现在每天出现数据丢失,现在小批量数据,一天200W左右, kafka版本为 1.0.0,集群总共7个节点,TOPIC有十六个分区,单条报文1.5k左右](https://t.zsxq.com/AqBUR3f)
40、[根据key.hash的绝对值 对并发度求模,进行分组,假设10各并发度,实际只有8个分区有处理数据,有2个始终不处理,还有一个分区处理的数据是其他的三倍,如截图](https://t.zsxq.com/AqBUR3f)
41、[flink每7小时不知道在处理什么, CPU 负载 每7小时,有一次高峰,5分钟内平均负载超过0.8,如截图](https://t.zsxq.com/AqBUR3f)
42、[有没有Flink写的项目推荐?我想看到用Flink写的整体项目是怎么组织的,不单单是一个单例子](https://t.zsxq.com/M3fIMbu)
43、[Flink 源码的结构图](https://t.zsxq.com/yv7EQFA)
44、[我想根据不同业务表(case when)进行不同的redis sink(hash ,set),我要如何操作?](https://t.zsxq.com/vBAYNJq)
45、[这个需要清理什么数据呀,我把hdfs里面的已经清理了 启动还是报这个](https://t.zsxq.com/b2zbUJa)
46、[ 在流处理系统,在机器发生故障恢复之后,什么情况消息最多会被处理一次?什么情况消息最少会被处理一次呢?](https://t.zsxq.com/QjQFmQr)
47、[我检查点都调到5分钟了,这是什么问题](https://t.zsxq.com/zbQNfuJ)
48、[reduce方法后 那个交易时间 怎么不是最新的,是第一次进入的那个时间,](https://t.zsxq.com/ZrjEauN)
49、[Flink on Yarn 模式,用yarn session脚本启动的时候,我在后台没有看到到Jobmanager,TaskManager,ApplicationMaster这几个进程,想请问一下这是什么原因呢?因为之前看官网的时候,说Jobmanager就是一个jvm进程,Taskmanage也是一个JVM进程](https://t.zsxq.com/VJyr3bM)
50、[Flink on Yarn的时候得指定 多少个TaskManager和每个TaskManager slot去运行任务,这样做感觉不太合理,因为用户也不知道需要多少个TaskManager适合,Flink 有动态启动TaskManager的机制吗。](https://t.zsxq.com/VJyr3bM)
51、[参考这个例子,Flink 零基础实战教程:如何计算实时热门商品 | Jark's Blog, 窗口聚合的时候,用keywindow,用的是timeWindowAll,然后在aggregate的时候用aggregate(new CustomAggregateFunction(), new CustomWindowFunction()),打印结果后,发现窗口中一直使用的重复的数据,统计的结果也不变,去掉CustomWindowFunction()就正常了 ? 非常奇怪](https://t.zsxq.com/UBmUJMv)
52、[用户进入产品预定页面(端埋点上报),并填写了一些信息(端埋点上报),但半小时内并没有产生任何订单,然后给该类用户发送一个push。 1. 这种需求适合用flink去做吗?2. 如果适合,说下大概的思路](https://t.zsxq.com/naQb6aI)
53、[业务场景是实时获取数据存redis,请问我要如何按天、按周、按月分别存入redis里?(比方说过了一天自动换一个位置存redis)](https://t.zsxq.com/AUf2VNz)
54、[有人 AggregatingState 的例子吗, 感觉官方的例子和 官网的不太一样?](https://t.zsxq.com/UJ6Y7m2)
55、[flink-jdbc这个jar有吗?怎么没找到啊?1.8.0的没找到,1.6.2的有](https://t.zsxq.com/r3BaAY3)
56、[现有个关于savepoint的问题,操作流程为,取消任务时设置保存点,更新任务,从保存点启动任务;现在遇到个问题,假设我中间某个算子重写,原先通过state编写,有用定时器,现在更改后,采用窗口,反正就是实现方式完全不一样;从保存点启动就会一直报错,重启,原先的保存点不能还原,此时就会有很多数据重复等各种问题,如何才能保证数据不丢失,不重复等,恢复到停止的时候,现在想到的是记下kafka的偏移量,再做处理,貌似也不是很好弄,有什么解决办法吗](https://t.zsxq.com/jiybIee)
57、[需要在flink计算app页面访问时长,消费Kafka计算后输出到Kafka。第一条log需要等待第二条log的时间戳计算访问时长。我想问的是,flink是分布式的,那么它能否保证执行的顺序性?后来的数据有没有可能先被执行?](https://t.zsxq.com/eMJmiQz)
58、[我公司想做实时大屏,现有技术是将业务所需指标实时用spark拉到redis里存着,然后再用一条spark streaming流计算简单乘除运算,指标包含了各月份的比较。请问我该如何用flink简化上述流程?](https://t.zsxq.com/Y7e6aIu)
59、[flink on yarn 方式,这样理解不知道对不对,yarn-session这个脚本其实就是准备yarn环境的,执行run任务的时候,根据yarn-session初始化的yarnDescription 把 flink 任务的jobGraph提交到yarn上去执行](https://t.zsxq.com/QbIayJ6)
60、[同样的代码逻辑写在单独的main函数中就可以成功的消费kafka ,写在一个spring boot的程序中,接受外部请求,然后执行相同的逻辑就不能消费kafka。你遇到过吗?能给一些查问题的建议,或者在哪里打个断点,能看到为什么消费不到kafka的消息呢?](https://t.zsxq.com/VFMRbYN)
61、[请问下flink可以实现一个流中同时存在订单表和订单商品表的数据 两者是一对多的关系 能实现得到 以订单表为主 一个订单多个商品 这种需求嘛](https://t.zsxq.com/QNvjI6Q)
62、[在用中间状态的时候,如果中间一些信息保存在state中,有没有必要在redis中再保存一份,来做第三方的存储。](https://t.zsxq.com/6ie66EE)
63、[能否出一期flink state的文章。什么场景下用什么样的state?如,最简单的,实时累加update到state。](https://t.zsxq.com/bm6mYjI)
64、[flink的双流join博主有使用的经验吗?会有什么常见的问题吗](https://t.zsxq.com/II6AEe2)
65、[窗口触发的条件问题](https://t.zsxq.com/V7EmUZR)
66、[flink 定时任务怎么做?有相关的demo么?](https://t.zsxq.com/JY3NJam)
67、[流式处理过程中数据的一致性如何保证或者如何检测](https://t.zsxq.com/7YZ3Fuz)
68、[重启flink单机集群,还报job not found 异常。](https://t.zsxq.com/nEEQvzR)
69、[kafka的数据是用 org.apache.kafka.common.serialization.ByteArraySerialize序列化的,flink这边消费的时候怎么通过FlinkKafkaConsumer创建DataStream?](https://t.zsxq.com/qJyvzNj)
70、[现在公司有一个需求,一些用户的支付日志,通过sls收集,要把这些日志处理后,结果写入到MySQL,关键这些日志可能连着来好几条才是一个用户的,因为发起请求,响应等每个环节都有相应的日志,这几条日志综合处理才能得到最终的结果,请问博主有什么好的方法没有?](https://t.zsxq.com/byvnaEi)
71、[flink 支持hadoop 主备么? hadoop主节点挂了 flink 会切换到hadoop 备用节点?](https://t.zsxq.com/qfie6qR)
72、[请教大家: 实际 flink 开发中用 scala 多还是 java多些? 刚入手 flink 大数据 scala 需要深入学习么?](https://t.zsxq.com/ZVZzZv7)
73、[我使用的是flink是1.7.2最近用了split的方式分流,但是底层的SplitStream上却标注为Deprecated,请问是官方不推荐使用分流的方式吗?](https://t.zsxq.com/Qzbi6yn)
74、[KeyBy 的正确理解,和数据倾斜问题的解释](https://t.zsxq.com/Auf2NVR)
75、[用flink时,遇到个问题 checkpoint大概有2G左右, 有背压时,flink会重启有遇到过这个问题吗](https://t.zsxq.com/3vnIm62)
76、[flink使用yarn-session方式部署,如何保证yarn-session的稳定性,如果yarn-session挂了,需要重新部署一个yarn-session,如何恢复之前yarn-session上的job呢,之前的checkpoint还能使用吗?](https://t.zsxq.com/URzVBIm)
77、[我想请教一下关于sink的问题。我现在的需求是从Kafka消费Json数据,这个Json数据字段可能会增加,然后将拿到的json数据以parquet的格式存入hdfs。现在我可以拿到json数据的schema,但是在保存parquet文件的时候不知道怎么处理。一是flink没有专门的format parquet,二是对于可变字段的Json怎么处理成parquet比较合适?](https://t.zsxq.com/MjyN7Uf)
78、[flink如何在较大的数据量中做去重计算。](https://t.zsxq.com/6qBqVvZ)
79、[flink能在没有数据的时候也定时执行算子吗?](https://t.zsxq.com/Eqjyju7)
80、[使用rocksdb状态后端,自定义pojo怎么实现序列化和反序列化的,有相关demo么?](https://t.zsxq.com/i2zVfIi)
81、[check point 老是失败,是不是自定义的pojo问题?到本地可以,到hdfs就不行,网上也有很多类似的问题 都没有一个很好的解释和解决方案](https://t.zsxq.com/vRJujAi)
82、[cep规则如图,当start事件进入时,时间00:00:15,而后进入end事件,时间00:00:40。我发现规则无法命中。请问within 是从start事件开始计时?还是跟window一样根据系统时间划分的?如果是后者,请问怎么配置才能从start开始计时?](https://t.zsxq.com/MVFmuB6)
83、[Flink聚合结果直接写Mysql的幂等性设计问题](https://t.zsxq.com/EybM3vR)
84、[Flink job打开了checkpoint,用的rocksdb,通过观察hdfs上checkpoint目录,为啥算副本总量会暴增爆减](https://t.zsxq.com/62VzNRF)
85、[Flink 提交任务的 jar包可以指定路径为 HDFS 上的吗]()
86、[在flink web Ui上提交的任务,设置的并行度为2,flink是stand alone部署的。两个任务都正常的运行了几天了,今天有个地方逻辑需要修改,于是将任务cancel掉(在命令行cancel也试了),结果taskmanger挂掉了一个节点。后来用其他任务试了,也同样会导致节点挂掉](https://t.zsxq.com/VfimieI)
87、[一个配置动态更新的问题折腾好久(配置用个静态的map变量存着,有个线程定时去数据库捞数据然后存在这个map里面更新一把),本地 idea 调试没问题,集群部署就一直报 空指针异常。下游的算子使用这个静态变量map去get key在集群模式下会出现这个空指针异常,估计就是拿不到 map](https://t.zsxq.com/nee6qRv)
88、[批量写入MySQL,完成HBase批量写入](https://t.zsxq.com/3bEUZfQ)
89、[用flink清洗数据,其中要访问redis,根据redis的结果来决定是否把数据传递到下流,这有可能实现吗?](https://t.zsxq.com/Zb6AM3V)
90、[监控页面流处理的时候这个发送和接收字节为0。](https://t.zsxq.com/RbeYZvb)
91、[sink到MySQL,如果直接用idea的话可以运行,并且成功,大大的代码上面用的FlinkKafkaConsumer010,而我的Flink版本为1.7,kafka版本为2.12,所以当我用FlinkKafkaConsumer010就有问题,于是改为
FlinkKafkaConsumer就可以直接在idea完成sink到MySQL,但是为何当我把该程序打成Jar包,去运行的时候,就是报FlinkKafkaConsumer找不到呢](https://t.zsxq.com/MN7iuZf)
92、[SocketTextStreamWordCount中输入中文统计不出来,请问这个怎么解决,我猜测应该是需要修改一下代码,应该是这个例子默认统计英文](https://t.zsxq.com/e2VNN7Y)
93、[ Flink 应用程序本地 ide 里面运行的时候并行度是怎么算的?](https://t.zsxq.com/RVRn6AE)
94、[ 请问下flink中对于窗口的全量聚合有apply和process两种 他们有啥区别呢](https://t.zsxq.com/rzbIQBi)
95、[不知道大大熟悉Hbase不,我想直接在Hbase中查询某一列数据,因为有重复数据,所以想使用distinct统计实际数据量,请问Hbase中有没有类似于sql的distinct关键字。如果没有,想实现这种可以不?](https://t.zsxq.com/UJIubub)
96、[ 来分析一下现在Flink,Kafka方面的就业形势,以及准备就业该如何准备的这方面内容呢?](https://t.zsxq.com/VFaQn2j)
97、[ 大佬知道flink的dataStream可以转换为dataSet吗?因为数据需要11分钟一个批次计算五六个指标,并且涉及好几步reduce,计算的指标之间有联系,用Stream卡住了。](https://t.zsxq.com/Zn2FEQZ)
98、[1.如何在同一窗口内实现多次的聚合,比如像spark中的这样2.多个实时流的jion可以用window来处理一批次的数据吗?](https://t.zsxq.com/aIqjmQN)
99、[写的批处理的功能,现在本机跑是没问题的,就是在linux集群上出现了问题,就是不知道如果通过本地调用远程jar包然后传参数和拿到结果参数返回本机](https://t.zsxq.com/ZNvb2FM)
100、[我用standalone开启一个flink集群,上传flink官方用例Socket Window WordCount做测试,开启两个parallelism能正常运行,但是开启4个parallelism后出现错误](https://t.zsxq.com/femmiqf)
101、[ 有使用AssignerWithPunctuatedWatermarks 的案例Demo吗?网上找了都是AssignerWithPeriodicWatermarks的,不知道具体怎么使用?](https://t.zsxq.com/YZ3vbY3)
102、[ 有一个datastream(从文件读取的),然后我用flink sql进行计算,这个sql是一个加总的运算,然后通过retractStreamTableSink可以把文件做sql的结果输出到文件吗?这个输出到文件的接口是用什么呢?](https://t.zsxq.com/uzFyVJe)
103、[ 为啥split这个流设置为过期的](https://t.zsxq.com/6QNNrZz)
104、[ 需要使用flink table的水印机制控制时间的乱序问题,这种场景下我就使用水印+窗口了,我现在写的demo遇到了问题,就是在把触发计算的窗口table(WindowedTable)转换成table进行sql操作时发现窗口中的数据还是乱序的,是不是flink table的WindowedTable不支持水印窗口转table-sql的功能](https://t.zsxq.com/Q7YNRBE)
105、[ Flink 对 SQL 的重视性](https://t.zsxq.com/Jmayrbi)
106、[ flink job打开了checkpoint,任务跑了几个小时后就出现下面的错,截图是打出来的日志,有个OOM,又遇到过的没?](https://t.zsxq.com/ZrZfa2Z)
107、[ 本地测试是有数据的,之前该任务放在集群也是有数据的,可能提交过多次,现在读不到数据了 group id 也换过了, 只能重启集群解决么?](https://t.zsxq.com/emaAeyj)
108、[使用flink清洗数据存到es中,直接在flatmap中对处理出来的数据用es自己的ClientInterface类直接将数据存入es当中,不走sink,这样的处理逻辑是不是会有问题。](https://t.zsxq.com/ayBa6am)
108、[ flink从kafka拿数据(即增量数据)与存量数据进行内存聚合的需求,现在有一个方案就是程序启动的时候先用flink table将存量数据加载到内存中创建table中,然后将stream的增量数据与table的数据进行关联聚合后输出结束,不知道这种方案可行么。目前个人认为有两个主要问题:1是增量数据stream转化成append table后不知道能与存量的table关联聚合不,2是聚合后输出的结果数据是否过于频繁造成网络传输压力过大](https://t.zsxq.com/QNvbE62)
109、[ 设置时间时间特性有什么区别呢, 分别在什么场景下使用呢?两种设置时间延迟有什么区别呢 , 分别在什么场景下使用](https://t.zsxq.com/yzjAQ7a)
110、[ flink从rabbitmq中读取数据,设置了rabbitmq的CorrelationDataId和checkpoint为EXACTLY_ONCE;如果flink完成一次checkpoint后,在这次checkpoint之前消费的数据都会从mq中删除。如果某次flink停机更新,那就会出现mq中的一些数据消费但是处于Unacked状态。在flink又重新开启后这批数据又会重新消费。那这样是不是就不能保证EXACTLY_ONCE了](https://t.zsxq.com/qRrJEaa)
111、[1. 在Flink checkpoint 中, 像 operator的状态信息 是在设置了checkpoint 之后自动的进行快照吗 ?2. 上面这个和我们手动存储的 Keyed State 进行快照(这个应该是增量快照)](https://t.zsxq.com/mAqn2RF)
112、[现在有个实时商品数,交易额这种统计需求,打算用 flink从kafka读取binglog日志进行计算,但binglog涉及到insert和update这种操作时 怎么处理才能统计准确,避免那种重复计算的问题?](https://t.zsxq.com/E2BeQ3f)
113、[我这边用flink做实时监控,功能很简单,就是每条消息做keyby然后三分钟窗口,然后做些去重操作,触发阈值则报警,现在问题是同一个时间窗口同一个人的告警会触发两次,集群是三台机器,standalone cluster,初步结果是三个算子里有两个收到了同样的数据](https://t.zsxq.com/vjIeyFI)
114、[在使用WaterMark的时候,默认是每200ms去设置一次watermark,那么每个taskmanager之间,由于得到的数据不同,所以往往产生的最大的watermark不同。 那么这个时候,是各个taskmanager广播这个watermark,得到全局的最大的watermark,还是说各个taskmanager都各自用自己的watermark。主要没看到广播watermark的源码。不知道是自己观察不仔细还是就是没有广播这个变量。](https://t.zsxq.com/unq3FIa)
115、[现在遇到一个需求,需要在job内部定时去读取redis的信息,想请教flink能实现像普通程序那样的定时任务吗?](https://t.zsxq.com/AeUnAyN)
116、[有个触发事件开始聚合,等到数量足够,或者超时则sink推mq 环境 flink 1.6 用了mapState 记录触发事件 1 数据足够这个OK 2 超时state ttl 1.6支持,但是问题来了,如何在超时时候增加自定义处理?](https://t.zsxq.com/z7uZbY3)
117、[请问impala这种mpp架构的sql引擎,为什么稳定性比较差呢?](https://t.zsxq.com/R7UjeUF)
118、[watermark跟并行度相关不是,过于全局了,期望是keyby之后再针对每个keyed stream 打watermark,这个有什么好的实践呢?](https://t.zsxq.com/q7myfAQ)
119、[请问如果把一个文件的内容读取成datastream和dataset,有什么区别吗??他们都是一条数据一条数据的被读取吗?](https://t.zsxq.com/rB6yfeA)
120、[有没有kylin相关的资料,或者调优的经验?](https://t.zsxq.com/j2j6EyJ)
121、[flink先从jdbc读取配置表到流中,另外从kafka中新增或者修改这个配置,这个场景怎么把两个流一份配置流?我用的connect,接着发不成广播变量,再和实体流合并,但在合并时报Exception in thread "main" java.lang.IllegalArgumentException](https://t.zsxq.com/iMjmQVV)
122、[Flink exactly-once,kafka版本为0.11.0 ,sink基于FlinkKafkaProducer 每五分钟一次checkpoint,但是checkpoint开始后系统直接卡死,at-lease-once 一分钟能完成的checkpoint, 现在十分钟无法完成没进度还是0, 不知道哪里卡住了](https://t.zsxq.com/RFQNFIa)
123、[flink的状态是默认存在于内存的(也可以设置为rocksdb或hdfs),而checkpoint里面是定时存放某个时刻的状态信息,可以设置hdfs或rocksdb是这样理解的吗?](https://t.zsxq.com/NJq3rj2)
124、[Flink异步IO中,下图这两种有什么区别?为啥要加 CompletableFuture.supplyAsync,不太明白?](https://t.zsxq.com/NJq3rj2)
125、[flink的状态是默认存在于内存的(也可以设置为rocksdb或hdfs),而checkpoint里面是定时存放某个时刻的状态信息,可以设置hdfs或rocksdb是这样理解的吗?](https://t.zsxq.com/NJq3rj2)
126、[有个计算场景,从kafka消费两个数据源,两个数据结构都有时间段概念,计算需要做的是匹配两个时间段,匹配到了,就生成一条新的记录。请问使用哪个工具更合适,flink table还是cep?请大神指点一下 我这边之前的做法,将两个数据流转为table.两个table over window后join成新的表。结果job跑一会就oom.](https://t.zsxq.com/rniUrjm)
127、[一个互联网公司,或者一个业务系统,如果想做一个全面的监控要怎么做?有什么成熟的方案可以参考交流吗?有什么有什么度量指标吗?](https://t.zsxq.com/vRZ7qJ2)
128、[怎么深入学习flink,或者其他大数据组件,能为未来秋招找一份大数据相关(计算方向)的工作增加自己的竞争力?](https://t.zsxq.com/3vfyJau)
129、[oppo的实时数仓,其中明细层和汇总层都在kafka中,他们的关系库的实时数据也抽取到kafka的ods,那么在构建数仓的,需要join 三四个大业务表,业务表会变化,那么是大的业务表是从kafka的ods读取吗?实时数仓,多个大表join可以吗](https://t.zsxq.com/VBIunun)
130、[Tuple类型有什么方法转换成json字符串吗?现在的场景是,结果在存储到sink中时希望存的是json字符串,这样应用程序获取数据比较好转换一点。如果Tuple不好转换json字符串,那么应该以什么数据格式存储到sink中](https://t.zsxq.com/vnaURzj)
140、[端到端的数据保证,是否意味着中间处理程序中断,也不会造成该批次处理失败的消息丢失,处理程序重新启动之后,会再次处理上次未处理的消息](https://t.zsxq.com/J6eAmYb)
141、[关于flink datastream window相关的。比如我现在使用滚动窗口,统计一周内去重用户指标,按照正常watermark触发计算,需要等到当前周的window到达window的endtime时,才会触发,这样指标一周后才能产出结果。我能不能实现一小时触发一次计算,每次统计截止到当前时间,window中所有到达元素的去重数量。](https://t.zsxq.com/7qBMrBe)
142、[FLIP-16 Loop Fault Tolerance 是讲现在的checkpoint机制无法在stream loop的时候容错吗?现在这个问题解决了没有呀?](https://t.zsxq.com/uJqzBIe)
143、[现在的需求是,统计各个key的今日累计值,一分钟输出一次。如,各个用户今日累计点击次数。这种需求用datastream还是table API方便点?](https://t.zsxq.com/uZnmQzv)
144、[本地idea可以跑的工程,放在standalone集群上,总报错,报错截图如下,大佬请问这是啥原因](https://t.zsxq.com/BqnYRN7)
145、[比如现在用k8s起了一个flink集群,这时候数据源kafka或者hdfs会在同一个集群上吗,还是会单独再起一个hdfs/kafka集群](https://t.zsxq.com/7MJujMb)
146、[flink kafka sink 的FlinkFixedPartitioner 分配策略,在并行度小于topic的partitions时,一个并行实例固定的写消息到固定的一个partition,那么就有一些partition没数据写进去?](https://t.zsxq.com/6U7QFMj)
147、[基于事件时间,每五分钟一个窗口,五秒钟滑动一次,同时watermark的时间同样是基于事件事件时间的,延迟设为1分钟,假如数据流从12:00开始,如果12:07-12:09期间没有产生任何一条数据,即在12:07-12:09这段间的数据流情况为···· (12:07:00,xxx),(12:09:00,xxx)······,那么窗口[12:02:05-12:07:05],[12:02:10-12:07:10]等几个窗口的计算是否意味着只有等到,12:09:00的数据到达之后才会触发](https://t.zsxq.com/fmq3fYF)
148、[使用flink1.7,当消费到某条消息(protobuf格式),报Caused by: org.apache.kafka.common.KafkaException: Record batch for partition Notify-18 at offset 1803009 is invalid, cause: Record is corrupt 这个异常。 如何设置跳过已损坏的消息继续消费下一条来保证业务不终断? 我看了官网kafka connectors那里,说在DeserializationSchema.deserialize(...)方法中返回null,flink就会跳过这条消息,然而依旧报这个异常](https://t.zsxq.com/MRvv3ZV)
149、[是否可以抽空总结一篇Flink 的 watermark 的原理案例?一直没搞明白基于事件时间处理时的数据乱序和数据迟到底咋回事](https://t.zsxq.com/MRJeAuj)
150、[flink中rpc通信的原理,与几个类的讲解,有没有系统详细的文章样,如有求分享,谢谢](https://t.zsxq.com/2rJyNrF)
151、[Flink中如何使用基于事件时间处理,但是又不使用Watermarks? 我在会话窗口中使用遇到一些问题,图一是基于处理时间的,测试结果session是基于keyby(用户)的,图二是基于事件时间的,不知道是我用法不对还是怎么的,测试结果发现并不是基于keyby(用户的),而是全局的session。不知道怎么修改?](https://t.zsxq.com/bM3ZZRf)
152、[flink实时计算平台,yarn模式日志收集怎么做,为什么会checkpoint失败,报警处理,后需要做什么吗?job监控怎么做](https://t.zsxq.com/BMVzzzB)
153、[有flink与jstorm的在不同应用场景下, 性能比较的数据吗? 从网络上能找大部分都是flink与storm的比较. 在jstorm官网上有一份比较的图表, 感觉参考意义不大, 应该是比较早的flink版本.](https://t.zsxq.com/237EAay)
154、[为什么使用SessionWindows.withGap窗口的话,State存不了东西呀,每次加1 ,拿出来都是null, 我换成 TimeWindow就没问题。](https://t.zsxq.com/J6eAmYb)
155、[请问一下,flink datastream流处理怎么统计去重指标? 官方文档中只看到批处理有distinct概念。](https://t.zsxq.com/y3nYZrf)
156、[好全的一篇文章,对比分析 Flink,Spark Streaming,Storm 框架](https://t.zsxq.com/qRjqFY3)
157、[关于 structured_streaming 的 paper](https://t.zsxq.com/Eau7qNB)
158、[zookeeper集群切换领导了,flink集群项目重启了就没有数据的输入和输出了,这个该从哪方面入手解决?](https://t.zsxq.com/rFYbEeq)
159、[我想请教下datastream怎么和静态数据join呢](https://t.zsxq.com/nEAaYNF)
160、[时钟问题导致收到了明天的数据,这时候有什么比较好的处理方法?看到有人设置一个最大的跳跃阈值,如果当前数据时间 - 历史最大时间 超过阈值就不更新。如何合理的设计水印,有没有一些经验呢?](https://t.zsxq.com/IAAeiA6)
161、[大佬们flink怎么定时查询数据库?](https://t.zsxq.com/EuJ2RRf)
162、[现在我们公司有个想法,就是提供一个页面,在页面上选择source sink 填写上sql语句,然后后台生成一个flink的作业,然后提交到集群。功能有点类似于华为的数据中台,就是页面傻瓜式操作。后台能自动根据相应配置得到结果。请问拘你的了解,可以实现吗?如何实现?有什么好的思路。现在我无从下手](https://t.zsxq.com/vzZBmYB)
163、[请教一下 flink on yarn 的 ha机制](https://t.zsxq.com/VRFIMfy)
164、[在一般的流处理以及cep, 都可以对于eventtime设置watermark, 有时可能需要设置相对大一点的值, 这内存压力就比较大, 有没有办法不应用jvm中的内存, 而用堆外内存, 或者其他缓存, 最好有cache机制, 这样可以应对大流量的峰值.](https://t.zsxq.com/FAiiEyr)
165、[请教一个flink sql的问题。我有两个聚合后的流表A和B,A和Bjoin得到C表。在设置state TTL 的时候是直接对C表设置还是,对A表和B表设置比较好?](https://t.zsxq.com/YnI2F66)
166、[spark改写为flink,会不会很复杂,还有这两者在SQL方面的支持差别大吗?](https://t.zsxq.com/unyneEU)
167、[请问flink allowedLateness导致窗口被多次fire,最终数据重复消费,这种问题怎么处理,数据是写到es中](https://t.zsxq.com/RfyZFUR)
168、[设置taskmanager.numberOfTaskSlots: 4的时候没有问题,但是cpu没有压上去,只用了30%左右,于是设置了taskmanager.numberOfTaskSlots: 8,但是就报错误找不到其中一个自定义的类,然后kafka数据就不消费了。为什么?cpu到多少合适?slot是不是和cpu数量一致是最佳配置?kafka分区数多少合适,是不是和slot,parallesim一致最佳?](https://t.zsxq.com/bIAEyFe)
169、[需求是根据每条日志切分出需要9个字段,有五个指标再根据9个字段的不同组合去做计算。 第一个方法是:我目前做法是切分的9个字段开5分钟大小1分钟计算一次的滑动窗口窗口,进行一次reduce去重,然后再map取出需要的字段,然后过滤再开5分钟大小1分钟计算一次的滑动窗口窗口进行计算保存结果,这个思路遇到的问题是上一个滑动窗口会每一分钟会计算5分钟数据,到第二个窗口划定的5分钟范围的数据会有好多重复,这个思路会造成数据重复。 第二个方法是:切分的9个字段开5分钟大小1分钟计算一次的滑动窗口窗口,再pross方法里完成所有的过滤,聚合计算,但是再高峰期每分钟400万条数据,这个思路担心在高峰期flink计算不过来](https://t.zsxq.com/BUNfYnY)
170、[a,b,c三个表,a和c有eventtime,a和c直接join可以,a和b join后再和c join 就会报错,这是怎么回事呢](https://t.zsxq.com/aAqBEY7)
171、[自定义的source是这样的(图一所示) 使用的时候是这样的(图二所示),为什么无论 sum.print().setParallelism(2)(图2所示)的并行度设置成几最后结果都是这样的](https://t.zsxq.com/zZNNRzr)
172、[刚接触flink,如有问的不合适的地方,请见谅。 1、为什么说flink是有状态的计算? 2、这个状态是什么?3、状态存在哪里](https://t.zsxq.com/i6Mz7Yj)
173、[这边用flink 1.8.1的版本,采用flink on yarn,hadoop版本2.6.0。代码是一个简单的滚动窗口统计函数,但启动的时候报错,如下图片。 (2)然后我把flink版本换成1.7.1,重新提交到2.6.0的yarn平台,就能正常运行了。 (3)我们测试集群hadoop版本是3.0,我用flink 1.8.1版本将这个程序再次打包,提交到3.0版本的yarn平台,也能正常运行。 貌似是flink 1.8.1版本与yarn 2.6.0版本不兼容造成的这个问题](https://t.zsxq.com/vNjAIMN)
174、[StateBackend我使用的是MemoryStateBackend, State是怎么释放内存的,例如我在函数中用ValueState存储了历史状态信息。但是历史状态数据我没有手动释放,那么程序会自动释放么?还是一直驻留在内存中](https://t.zsxq.com/2rVbm6Y)
175、[请问老师是否可以提供一些Apachebeam的学习资料 谢谢](https://t.zsxq.com/3bIEAyv)
176、[flink 的 DataSet或者DataStream支持索引查询以及删除吗,像spark rdd,如果不支持的话,该转换成什么](https://t.zsxq.com/yFEyZVB)
177、[关于flink的状态,能否把它当做数据库使用,类似于内存数据库,在处理过程中存业务数据。如果是数据库可以算是分布式数据库吗?是不是使用rocksdb这种存储方式才算是?支持的单库大小是不是只是跟本地机器的磁盘大小相关?如果使用硬盘存储会不会效率性能有影响](https://t.zsxq.com/VNrn6iI)
178、[我这边做了个http sink,想要批量发送数据,不过现在只能用数量控制发送,但最后的几个记录没法触发发送动作,想问下有没有什么办法](https://t.zsxq.com/yfmiUvf)
179、[请问下如何做定时去重计数,就是根据时间分窗口,窗口内根据id去重计数得出结果,多谢。试了不少办法,没有简单直接办法](https://t.zsxq.com/vNvrfmE)
180、[我有个job使用了elastic search sink. 设置了批量5000一写入,但是看es监控显示每秒只能插入500条。是不是bulkprocessor的currentrequest为0有关](https://t.zsxq.com/rzZbQFA)
181、[有docker部署flink的资料吗](https://t.zsxq.com/aIur7ai)
182、[在说明KeyBy的StreamGraph执行过程时,keyBy的ID为啥是6? 根据前面说,ID是一个静态变量,每取一次就递增1,我觉得应该是3啊,是我理解错了吗](https://t.zsxq.com/VjQjqF6)
183、[有没计划出Execution Graph的远码解析](https://t.zsxq.com/BEmAIQv)
184、[可以分享下物理执行图怎样划分task,以及task如何执行,还有他们之间数据如何传递这块代码嘛?](https://t.zsxq.com/vVjiYJQ)
185、[Flink源码和这个学习项目的结构图](https://t.zsxq.com/FyNJQbQ)
186、[请问flink1.8,如何做到动态加载外部udf-jar包呢?](https://t.zsxq.com/qrjmmaU)
187、[同一个Task Manager中不同的Slot是怎么交互的,比如:source处理完要传递给map的时候,如果在不同的Slot中,他们的内存是相互隔离,是怎么交互的呢? 我猜是通过序列化和反序列化对象,并且通过网络来进行交互的](https://t.zsxq.com/ZFQjQnm)
188、[你们有没有这种业务场景。flink从kafka里面取数据,每一条数据里面有mongdb表A的id,这时我会在map的时候采用flink的异步IO连接A表,然后查询出A表的字段1,再根据该字段1又需要异步IO去B表查询字段2,然后又根据字段2去C表查询字段3.....像这样的业务场景,如果多来几种逻辑,我应该用什么方案最好呢](https://t.zsxq.com/YBQFufi)
189、[今天本地运行flink程序,消费socket中的数据,连续只能消费两条,第三条flink就消费不了了](https://t.zsxq.com/vnufYFY)
190、[源数据经过过滤后分成了两条流,然后再分别提取事件时间和水印,做时间窗口,我测试时一条流没有数据,另一条的数据看日志到了窗口操作那边就没走下去,貌似窗口一直没有等到触发](https://t.zsxq.com/me6EmM3)
191、[有做flink cep的吗,有资料没?](https://t.zsxq.com/fubQrvj)
192、[麻烦问一下 BucketingSink跨集群写,如果任务运行在hadoop A集群,从kafka读取数据处理后写到Hadoo B集群,即使把core-site.xml和hdfs-site.xml拷贝到代码resources下,路径使用hdfs://hadoopB/xxx,会提示ava.lang.RuntimeException: Error while creating FileSystem when initializing the state of the BucketingSink.,跨集群写这个问题 flink不支持吗?](https://t.zsxq.com/fEQVjAe)
193、[想咨询下,如何对flink中的datastream和dataset进行数据采样](https://t.zsxq.com/fIMVJ2J)
194、[一个flink作业经常发生oom,可能是什么原因导致的。 处理流程只有15+字段的解析,redis数据读取等操作,TM配置10g。 业务会在夜间刷数据,qps能打到2500左右~](https://t.zsxq.com/7MVjyzz)
195、[我看到flink 1.8的状态过期仅支持Processing Time,那么如果我使用的是Event time那么状态就不会过期吗](https://t.zsxq.com/jA2NVnU)
196、[请问我想每隔一小时统计一个属性从当天零点到当前时间的平均值,这样的时间窗该如何定义?](https://t.zsxq.com/BQv33Rb)
197、[flink任务里面反序列化一个类,报ClassNotFoundException,可是包里面是有这个类的,有遇到这种情况吗?](https://t.zsxq.com/nEAiIea)
198、[在构造StreamGraph,类似PartitionTransformmation 这种类型的 transform,为什么要添加成一个虚拟节点,而不是一个实际的物理节点呢?](https://t.zsxq.com/RnayrVn)
199、[flink消费kafka的数据写入到hdfs中,我采用了BucketingSink 这个sink将operator出来的数据写入到hdfs文件上,并通过在hive中建外部表来查询这个。但现在有个问题,处于in-progress的文件,hive是无法识别出来该文件中的数据,可我想能在hive中实时查询进来的数据,且不想产生很多的小文件,这个该如何处理呢](https://t.zsxq.com/A2fYNFA)
200、[采用Flink单机集群模式一个jobmanager和两个taskmanager,机器是单机是24核,现在做个简单的功能从kafka的一个topic转满足条件的消息到另一个topic,topic的分区是30,我设置了程序默认并发为30,现在每秒消费2w多数据,不够快,请问可以怎么提高job的性能呢?](https://t.zsxq.com/7AurJU3)
201、[Flink Metric 源码分析](https://t.zsxq.com/Mnm2nI6)
202、[请问怎么理解官网的这段话?按官网的例子,难道只keyby之后才有keyed state,才能托管Flink存储状态么?source和map如果没有自定义operator state的话,状态是不会被保存的?](https://t.zsxq.com/iAi6QRb)
203、[想用Flink做业务监控告警,并要能够支持动态添加CEP规则,问下可以直接使用Flink CEP还是siddhi CEP? 有没有相关的资料学习下?谢谢!](https://t.zsxq.com/3rbeuju)
204、[请问一下,有没有关于水印,触发器的Java方面的demo啊](https://t.zsxq.com/eYJUbm6)
205、[老师,最近我们线上偶尔出现这种情况,就是40个并行度,其他有一个并行度CheckPoint一直失败,其他39个并行度都是毫秒级别就可以CheckPoint成功,这个怎么定位问题呢?还有个问题 CheckPoint的时间分为三部分 Checkpoint Duration (Async)和 Checkpoint Duration (Sync),还有个 end to end 减去同步和异步的时间,这三部分 分别指代哪块?如果发现这三者中的任意一个步骤时间长,该怎么去优化](https://t.zsxq.com/QvbAqVB)
206、[我这边有个场景很依赖消费出来的数据的顺序。在源头侧做了很多处理,将kafka修改成一个分区等等很多尝试,最后消费出来的还是乱序的。能不能在flink消费的时候做处理,来保证处理的数据的顺序。](https://t.zsxq.com/JaUZvbY)
207、[有一个类似于实时计算今天的pv,uv需求,采用source->keyby->window->trigger->process后,在process里采用ValueState计算uv ,问题是 这个window内一天的所有数据是都会缓存到flink嘛? 一天的数据量如果大点,这样实现就有问题了, 这个有其他的实现思路嘛?](https://t.zsxq.com/iQfaAeu)
208、[Flink 注解源码解析](https://t.zsxq.com/f6eAu3J)
209、[如何监控 Flink 的 TaskManager 和 JobManager](https://t.zsxq.com/IuRJYne)
210、[问下,在真实流计算过程中,并行度的设置,是与 kafka topic的partition数一样的吗?](https://t.zsxq.com/v7yfEIq)
211、[Flink的日志 如果自己做平台封装在自己的界面中 请问job Manger 和 taskManger 还有用户自己的程序日志 怎么获取呢 有api还是自己需要利用flume 采集到ELK?](https://t.zsxq.com/Zf2F6mM)
212、[我想问下一般用Flink统计pv uv是怎么做的?uv存到redis? 每个uv都存到redis,会不会撑爆?](https://t.zsxq.com/72VzBEy)
213、[Flink的Checkpoint 机制,在有多个source的时候,barrier n 的流将被暂时搁置,从其他流接收的记录将不会被处理,但是会放进一个输入缓存input buffer。如果被缓存的record大小超出了input buffer会怎么样?不可能一直缓存下去吧,如果其中某一条就一直没数据的话,整个过程岂不是卡死了?](https://t.zsxq.com/zBmm2fq)
214、[公司想实时展示订单数据,汇总金额,并需要和前端交互,实时生成数据需要告诉前端,展示成折线图,这种场景的技术选型是如何呢?包括数据的存储,临时汇总数据的存储,何种形式告诉前端](https://t.zsxq.com/ZnIAi2j)
215、[请问下checkpoint中存储了哪些东西?](https://t.zsxq.com/7EIeEyJ)
216、[我这边有个需求是实时计算当前车辆与前车距离,用经纬度求距离。大概6000台车,10秒一条经纬度数据。gps流与自己join的地方在进行checkpoint的时候特别缓,每次要好几分钟。checkpoint 状态后端是rocksDB。有什么比较好的方案吗?自己实现一个类似last_value的函数取车辆最新的经纬再join,或者弄个10秒的滑动窗口输出车辆最新的经纬度再进行join,这样可行吗?](https://t.zsxq.com/euvFaYz)
217、[flink在启动的时候能不能指定一个时间点从kafka里面恢复数据呢](https://t.zsxq.com/YRnEUFe)
218、[我们线上有个问题,很多业务都去读某个hive表,但是当这个hive表正在写数据的时候,偶尔出现过 读到表里数据为空的情况,这个问题怎么解决呢?](https://t.zsxq.com/7QJEEyr)
219、[使用 InfluxDB 和 Grafana 搭建监控 Flink 的平台](https://t.zsxq.com/yVnaYR7)
220、[flink消费kafka两个不同的topic,然后进行join操作,如果使用事件时间,两个topic都要设置watermaker吗,如果只设置了topic A的watermaker,topic B的不设置会有什么影响吗?](https://t.zsxq.com/uvFU7aY)
221、[请教一个问题,我的Flink程序运行一段时间就会报这个错误,定位好多天都没有定位到。checkpoint 时间是5秒,20秒都不行。Caused by: java.io.IOException: Could not flush and close the file system output stream to hdfs://HDFSaaaa/flink/PointWideTable_OffTest_Test2/1eb66edcfccce6124c3b2d6ae402ec39/chk-355/1005127c-cee3-4099-8b61-aef819d72404 in order to obtain the stream state handle](https://t.zsxq.com/NNFYJMn)
222、[Flink的反压机制相比于Storm的反压机制有什么优势呢?问题2: Flink的某一个节点发生故障,是否会影响其他节点的正常工作?还是会通过Checkpoint容错机制吗把任务转移到其他节点去运行呢?](https://t.zsxq.com/yvRNFEI)
223、[我在验证checkpoint的时候遇到给问题,不管是key state 还是operator state,默认和指定uid是可以的恢复state数据的,当指定uidHash时候无法恢复state数据,麻烦大家给解答一样。我操作state是实现了CheckpointedFunction接口,覆写snapshotState和initializeState,再这两个方法里操作的,然后让程序定时抛出异常,观察发现指定uidHash后snapshotState()方法里context.isRestored()为false,不太明白具体是什么原因](https://t.zsxq.com/ZJmiqZz)
224、[kafka 中的每条数据需要和 es 中的所有数据(动态增加)关联,关联之后会做一些额外的操作,这个有什么比较可行的方案?](https://t.zsxq.com/mYV37qF)
225、[flink消费kafka数据,设置1分钟checkpoint一次,假如第一次checkpoint完成以后,还没等到下一次checkpoint,程序就挂了,kafka offset还是第一次checkpoint记录的offset,那么下次重新启动程序,岂不是多消费数据了?那flink的 exactly one消费语义是怎么样的?](https://t.zsxq.com/buFeyZr)
226、[程序频繁发生Heartbeat of TaskManager with id container_e36_1564049750010_5829_01_000024 timed out. 心跳超时,一天大概10次左右。是内存没给够吗?还是网络波动引起的](https://t.zsxq.com/Znyja62)
227、[有没有性能优化方面的指导文章?](https://t.zsxq.com/AA6ma2Z)
228、[flink消费kafka是如何监控消费是否正常的,有啥好办法?](https://t.zsxq.com/a2N37a6)
229、[我按照官方的wordcount案例写了一个例子,然后在main函数中起了一个线程,原本是准备定时去更新某些配置,准备测试一下是否可行,所以直接在线程函数中打印一条语句测试是否可行。现在测试的结果是不可行,貌似这个线程根本就没有执行,请问这是什么原因呢? 按照理解,JobClient中不是反射类执行main函数吗, 执行main函数的时候为什么没有执行这个线程的打印函数呢?](https://t.zsxq.com/m2FeeMf)
230、[请问我想保留最近多个完成的checkpoint数据,是通过设置 state.checkpoints.num-retained 吗?要怎么使用?](https://t.zsxq.com/EyFUb6m)
231、[有没有etl实时数仓相关案例么?比如二十张事实表流join](https://t.zsxq.com/rFeIAeA)
232、[为什么我扔到flink 的stream job,立刻就finished](https://t.zsxq.com/n2RFmyN)
233、[有没有在flink上机器学习算法的一些例子啊,除了官网提供的flink exampke里的和flink ml里已有的](https://t.zsxq.com/iqJiyvN)
234、[如果我想扩展sql的关键词,比如添加一些数据支持,有什么思路,现在想的感觉都要改calcite(刚碰flink感觉难度太大了)](https://t.zsxq.com/uB6aUzZ)
235、[我想实现统计每5秒中每个类型的次数,这个现在不输出,问题出在哪儿啊](https://t.zsxq.com/2BEeu3Z)
236、[我用flink往hbase里写数据,有那种直接批量写hfile的方式的demo没](https://t.zsxq.com/VBA6IUR)
237、[请问怎么监控Kafka消费是否延迟,是否出现消息积压?你有demo吗?这种是用Springboot自己写一个监控,还是咋整啊?](https://t.zsxq.com/IieMFMB)
238、[请问有计算pv uv的例子吗](https://t.zsxq.com/j2fM3BM)
239、[通过控制流动态修改window算子窗口类型和长度要怎么写](https://t.zsxq.com/Rb2Z7uB)
240、[flink的远程调试能出一版么?网上资料坑的多](https://t.zsxq.com/UVbaQfM)
241、[企业里,Flink开发,java用得多,还是scala用得多?](https://t.zsxq.com/AYVjAuB)
242、[flink的任务运行在yarn的环境上,在yarn的resourcemanager在进行主备切换时,所有的flink任务都失败了,而MR的任务可以正常运行。报错信息如下:AM is not registered for known application attempt: appattempt_1565306391442_89321_000001 or RM had restarted after AM registered . AM should re-register
请问这是什么原因,该如何处理呢?](https://t.zsxq.com/j6QfMzf)
243、[请教一个分布式问题,比如在Flink的多个TaskManager上统计指标count,TM1有两条数据,TM2有一条数据,程序是怎么计算出来是3呢?原理是怎么样的](https://t.zsxq.com/IUVZjUv)
244、[现在公司部分sql查询oracle数据特别的慢,因为查询条件很多想问一下有什么方法,例如基于大数据组件可以加快查询速度的吗?](https://t.zsxq.com/7MFEQR3)
245、[想咨询下有没有做过flink同步配置做自定义计算的系统?或者有没有什么好的建议?业务诉求是希望业务用户可以自助配置计算规则做流式计算](https://t.zsxq.com/Mfa6aQB)
246、[我这边有个实时同步数据的任务,白天运行的时候一直是正常的,一到凌晨2点多之后就没有数据sink进mysql。晚上会有一些离线任务和一些dataX任务同步数据到mysql。但是任务一切都是正常的,ck也很快20ms,数据也是正常消费。看了yarn上的日志,没有任何error。自定义的sink里面也设置了日志打印,但是log里没有。这种如何快速定位问题。](https://t.zsxq.com/z3bunyN)
247、[有没有flink处理异常数据的案例资料](https://t.zsxq.com/Y3fe6Mn)
248、[flink中如何传递一个全局变量](https://t.zsxq.com/I2Z7Ybm)
249、[台4核16G的Flink taskmanager配一个单独的Yarn需要一台啥样的服务器?其他功能都不需要就一个调度的东西?](https://t.zsxq.com/iIUZrju)
250、[side-output 的分享](https://t.zsxq.com/m6I2BEE)
251、[使用 InfluxDB + Grafana 监控flink能否配置告警。是不是prometheus更强大点?](https://t.zsxq.com/amURFme)
252、[我们线上遇到一个问题,带状态的算子没有指定 uid,现在代码必须改,那个带状态的算子 不能正常恢复了,有解吗?通过某种方式能获取到系统之前自动生成的uid吗?](https://t.zsxq.com/rZfyZvn)
253、[tableEnv.registerDataStream("Orders", ds, "user, product, amount, proctime.proctime, rowtime.rowtime");请问像这样把流注册成表的时候,这两个rowtime分别是什么意思](https://t.zsxq.com/uZz3Z7Q)
254、[我想问一下 flink on yarn session 模式下提交任务官网给的例子是 flink run -c xxx.MainClass job.jar 这里是怎么知道 yarn 上的哪个是 flink 的 appid 呢?](https://t.zsxq.com/yBiEyf2)
255、[Flink Netty Connector 这个有详细的使用例子? 通过Netty建立的source能直接回复消息吗?还是只能被动接受消息?](https://t.zsxq.com/yBeyfqv)
256、[请问flink sqlclient 提交的作业可以用于生产环境吗?](https://t.zsxq.com/FIEia6M)
257、[flink批处理写回mysql是否没法用tableEnv.sqlUpdate("insert into t2 select * from t1")?作为sink表的t2要如何注册?查跟jdbc相关的就两个TableSink,JDBCAppendTableSink用于BatchTableSink,JDBCUpertTablSink用于StreamTableSink。前者只接受insert into values语法。所以我是先通过select from查询获取到DataSet再JDBCAppendTableSink.emitDataSet(ds)实现的,但这样达不到sql rule any目标](https://t.zsxq.com/ZBIaUvF)
258、[请问在stream模式下,flink的计算结果在不落库的情况下,可以通过什么restful api获取计算结果吗](https://t.zsxq.com/aq3BIU7)
259、[现在我有场景,需要把一定的消息发送给kafka topic指定的partition,该怎么搞?](https://t.zsxq.com/NbYnAYF)
260、[请问我的job作业在idea上运行正常 提交到生产集群里提示Caused by: java.lang.NoSuchMethodError: org.apache.flink.api.java.ClosureCleaner.clean(Ljava/lang/Object;Z)V请问如何解决](https://t.zsxq.com/YfmAMfm)
261、[遇到一个很奇怪的问题,在使用streamingSQL时,发现timestamp在datastream的时候还是正常的,在注册成表print出来的时候就少了八小时,大佬知道是什么原因么?](https://t.zsxq.com/72n6MVb)
262、[请问将flink的产生的一些记录日志异步到kafka中,需要如何配置,配置后必须要重启集群才会生效吗](https://t.zsxq.com/RjQFmIQ)
263、[星主你好,问下flink1.9对维表join的支持怎么样了?有文档吗](https://t.zsxq.com/Q7u3vzR)
264、[请问下 flink slq: SELECT city_name as city_name, count(1) as total, max(create_time) as create_time FROM * 。代码里面设置窗口为: retractStream.timeWindowAll(Time.minutes(5))一个global窗口,数据写入hdfs 结果数据重复 ,存在两条完全重复的数据如下 常州、2283、 1566230703):请问这是为什么](https://t.zsxq.com/aEEA66M)
265、[我用rocksdb存储checkpoint,线上运行一段时间发展checkpoint占用空间越来越大,我是直接存本地磁盘上的,怎么样能让它自动清理呢?](https://t.zsxq.com/YNrfyrj)
266、[flink应该在哪个用户下启动呢,是root的还是在其他的用户呢](https://t.zsxq.com/aAaqFYn)
267、[link可以读取lzo的文件吗](https://t.zsxq.com/2nUBIAI)
268、[怎么快速从es里面便利数据?我们公司现在所有的数据都存在Es里面的;我发现每次从里面scan数据的时候特别慢;你那有没有什么好的办法?](https://t.zsxq.com/beIY7mY)
269、[如果想让数据按照其中一个假如f0进行分区,然后每一个分区做处理的时候并行度都是1怎么设置呢](https://t.zsxq.com/fYnYrR7)
270、[近在写算子的过程中,使用scala语言写flink比较快,而且在process算子中实现ontime方式时,可以使用scala中的listbuff来输出一个top3的记录;那么到了java中,只能用ArrayList将flink中的ListState使用get()方法取出之后放在ArrayList吗?](https://t.zsxq.com/nQFYrBm)
271、[请问老师能否出一些1.9版本维表join的例子 包括async和维表缓存?](https://t.zsxq.com/eyRRv7q)
272、[flink kaka source设置为从组内消费,有个问题是第一次启动任务,我发现kafka中的历史数据不会被消费,而是从当前的数据开始消费,而第二次启动的时候才会从组的offset开始消费,有什么办法可以让第一次启动任务的时候可以消费kafka中的历史数据吗](https://t.zsxq.com/aMRzjMb)
273、[1.使用flink定时处理离线数据,有时间戳字段,如何求出每分钟的最大值,类似于流处理窗口那样,2如果想自己实现批流统一,有什么好的合并方向吗?比如想让流处理使用批处理的一个算子。](https://t.zsxq.com/3ZjiEMv)
274、[flink怎么实现流式数据批量对待?流的数据是自定义的source,读取的redis多个Hash表,需要控制批次的概念](https://t.zsxq.com/AIYnEQN)
275、[有人说不推荐在一个task中开多个线程,这个你怎么看?](https://t.zsxq.com/yJuFEYb)
276、[想做一个运行在hbase+es架构上的sql查询方案,flink sql能做吗,或者有没有其他的解决方案或者思路?](https://t.zsxq.com/3f6YBmu)
277、[正在紧急做第一个用到Flink的项目,咨询一下,Flink 1.8.1写入ES7就是用自带的Sink吗?有没有例子分享一下,我搜到的都是写ES6的。这种要求我知道不适合提,主要是急,自己试几下没成功。T T](https://t.zsxq.com/jIAqVnm)
278、[手动停止任务后,已经保存了最近一次保存点,任务重新启动后,如何使用上一次检查点?](https://t.zsxq.com/2fAiuzf)
279、[批处理使用流环境(为了使用窗口),那如何确定批处理结束,就是我的任务可以知道批文件读取完事,并且处理完数据后关闭任务,如果不能,那批处理如何实现窗口功能](https://t.zsxq.com/BIiImQN)
280、[如果限制只能在window 内进行去重,数据量还比较大,有什么好的方法吗?](https://t.zsxq.com/Mjyzj66)
281、[端到端exactly once有没有出文章](https://t.zsxq.com/yv7Ujme)
282、[流怎么动态加?,流怎么动态删除?,参数怎么动态修改 (广播](https://t.zsxq.com/IqNZFey)
283、[自定义的source数据源实现了有批次的概念,然后Flink将这个一个批次流注册为多个表join操作,有办法知道这个sql什么时候计算完成了?](https://t.zsxq.com/r7AqvBq)
284、[编译 Flink 报错,群主遇到过没,什么原因](https://t.zsxq.com/rvJiyf6)
285、[我现在是flink on yarn用zookeeper做HA现在在zk里查看检查点信息,为什么里面的文件是ip,而不是路径呢?我该如何拿到那个路径。
- 排除rest api 方式获取,因为任务关了restapi就没了
-排除history server,有点不好用](https://t.zsxq.com/nufIaey)
286、[在使用streamfilesink消费kafka之后进行hdfs写入的时候,当直接关闭flink程序的时候,下次再启动程序消费写入hdfs的时候,文件又是从part-0-0开始,这样就跟原来写入的冲突了,该文件就一直处于ingress状态。](https://t.zsxq.com/Fy3RfE6)
287、[现在有一个实时数据分析的需求,数据量不大,但要求sink到mysql,因为是实时更新的,我现在能想到的处理方法就是每次插入一条数据的时候,先从mysql读数据,如果有这条,就执行update,没有的话就insert,但是这样的话每写一条数据就有两次交互了。想问一下老师有没有更好的办法,或者flink有没有内置的api可以执行这种不确定是更新还是插入的操作](https://t.zsxq.com/myNF2zj)
288、[Flink设置了checkpoint,job manage会定期删除check point数据,但是task manage不删除,这个是什么原因](https://t.zsxq.com/ZFiMzrF)
289、[请教一下使用rocksdb作为statebackend ,在哪里可以监控rocksdb io 内存指标呢](https://t.zsxq.com/z3RzJUV)
290、[状态的使用场景,以及用法能出个文章不,这块不太了解](https://t.zsxq.com/AUjE2ZR)
291、[请问一下 Flink 1.9 SQL API中distinct count 是如何实现高效的流式去重的?](https://t.zsxq.com/aaynii6)
292、[在算子内如何获取当前算子并行度以及当前是第几个task](https://t.zsxq.com/mmEyVJA)
293、[有没有flink1.9结合hive的demo。kafka到hive](https://t.zsxq.com/fIqNF6y)
294、[能给讲讲apache calcite吗](https://t.zsxq.com/ne6UZrB)
295、[请问一下像这种窗口操作,怎么保证程序异常重启后保持数据的状态呢?](https://t.zsxq.com/VbUVFMr)
296、[请问一下,我在使用kafkasource的时候,把接过来的Jsonstr转化成自定义的一个类型,用的是gson. fromJson(jsonstr,classOf[Entity])报图片上的错误了,不知道怎么解决,在不转直接打印的情况下是没问题的](https://t.zsxq.com/EMZFyZz)
297、[DataStream读数据库的表,做多表join,能设置时间窗口么,一天去刷一次。流程序会一直拉数据,数据库扛不住了](https://t.zsxq.com/IEieI6a)
298、[请问一下flink支持多路径通配读取吗?例如路径:s3n://pekdc2-deeplink-01/Kinesis/firehose/2019/07/03/*/* ,通配读取找不到路径。是否需要特殊设置](https://t.zsxq.com/IemmiY7)
299、[flink yarn环境部署 但是把容器的url地址删除。就会跳转到的hadoop的首页。怎么屏蔽hadoop的yarn首页地址呢?要不暴露这个地址用户能看到所有任务很危险](https://t.zsxq.com/QvZFUNN)
300、[flink sql怎么写一个流,每秒输出当前时间呢](https://t.zsxq.com/2JiubeM)
301、[因为想通过sql弄一个数据流。哈哈 另外想问一个问题,我把全局设置为根据处理时间的时间窗口,那么我在processAllWindowFunction里面要怎么知道进来的每个元素的处理时间是多少呢?这个元素进入这个时间窗口的依据是什么](https://t.zsxq.com/bQ33BmM)
302、[如何实现一个设备上报的数据存储到同一个hdfs文件中?](https://t.zsxq.com/rB6ybYF)
303、[我自己写的kafka生产者测试,数据格式十分简单(key,i)key是一个固定的不变的字符串,i是自增的,flink consumer这边我开了checkpoint. 并且是exactly once,然后程序很简单,就是flink读取kafka的数据然后直接打印出来,我发现比如我看到打印到key,10的时候我直接关掉程序,然后重新启动程序,按理来说应当是从上次的offset继续消费,也就是key,11,但实际上我看到的可能是从key,9开始,然后依次递增,这是是不是说明是重复消费了,那exactly one需要怎么样去保障?](https://t.zsxq.com/MVfeeiu)
304、[假设有一个数据源在源源不断的产生数据,到Flink的反压来到source端的时候,由于Flink处理数据的速度跟不上数据源产生数据的速度,
问题1: 这个时候在Flink的source端会怎么处理呢?是将处理不完的数据丢弃还是进行缓存呢?
问题2: 如果是缓存,怎么进行缓存呢?](https://t.zsxq.com/meqzJme)
305、[一个stream 在sink多个时,这多个sink是串行 还是并行的。](https://t.zsxq.com/2fEeMny)
306、[我想在流上做一个窗口,触发窗口的条件是固定的时间间隔或者数据量达到预切值,两个条件只要有一个满足就触发,除了重写trigger在,还有什么别的方法吗?](https://t.zsxq.com/NJY76uf)
307、[使用rocksdb作为状态后端,对于使用sql方式对时间字段进行group by,以达到去窗口化,但是这样没办法对之前的数据清理,导致磁盘空间很大,对于这种非编码方式,有什么办法设置ttl,清理以前的数据吗](https://t.zsxq.com/A6UN7eE)
308、[请问什么时间窗为什么会有TimeWindow{start=362160000, end=362220000}
和 TimeWindow{start=1568025300000, end=1568025360000}这两种形式,我都用的是一分钟的TumblingEventTimeWindows,为什么会出现不同的情况?](https://t.zsxq.com/a2fUnEM)
309、[比如我统计一天的订单量。但是某个数据延迟一天才到达。比如2019.08.01这一天订单量应该是1000,但是有个100的单据迟到了,在2019.08.02才到达,那么导致2019.08.01这一天统计的是900.后面怎么纠正这个错误的结果呢](https://t.zsxq.com/Y3jqjuj)
310、[flink streaming 模式下只使用堆内内存么](https://t.zsxq.com/zJaMNne)
311、[如果考虑到集群的迁移,状态能迁移吗](https://t.zsxq.com/EmMrvVb)
312、[我们现在有一个业务场景,数据上报的值是这样的格式(时间,累加值),我们需要这样的格式数据(时间,当前值)。当前值=累加值-前一个数据的累加值。flink如何做到呢,有考虑过state机制,但是服务宕机后,state就被清空了](https://t.zsxq.com/6EUFeqr)
313、[Flink On k8s 与 Flink on Yarn相比的优缺点是什么?那个更适合在生产环境中使用呢](https://t.zsxq.com/y7U7Mzf)
314、[有没有datahub链接flink的 连接器呀](https://t.zsxq.com/zVNbaYn)
315、[单点resourcemanager 挂了,对任务会产生什么影响呢](https://t.zsxq.com/FQRNJ2j)
316、[flink监控binlog,跟另一张维表做join后,sink到MySQL的最终表。对于最终表的增删改操作,需要定义不同的sink么?](https://t.zsxq.com/rnemUN3)
317、[请问窗口是在什么时候合并的呢?例如:数据进入windowoperator的processElement,如果不是sessionwindow,是否会进行窗口合并呢?](https://t.zsxq.com/JaaQFqB)
318、[Flink中一条流能参与多路计算,并多处输出吗?他们之前会不会相互影响?](https://t.zsxq.com/AqNFM33)
319、[keyBy算子定义是将一个流拆分成不相交的分区,每个分区包含具有相同的key的元素。我不明白的地方是: keyBy怎么设置分区数,是给这个算子设置并行度吗? 分区数和slot数量是什么关系?](https://t.zsxq.com/nUzbiYj)
320、[动态cep-pattern,能否详细说下?滴滴方案未公布,您贴出来的几张图片是基于1.7的。或者有什么想法也可以讲解下,谢谢了](https://t.zsxq.com/66URfQb)
321、[问题1:使用常驻型session ./bin/yarn-session.sh -n 10 -s 3 -d启动,这个时候分配的资源是yarn 队列里面的, flink提交任务 flink run xx.jar, 其余机器是怎样获取到flink需要运行时的环境的,因为我只在集群的一台机器上有flink 安装包。](https://t.zsxq.com/maEQ3NR)
322、[flink task manager中slot间的内存隔离,cpu隔离是怎么实现的?flink 设计slot的概念有什么意义,为什么不像spark executor那样,内部没有做隔离?](https://t.zsxq.com/YjEYjQz)
323、[spark和kafka集成,direct模式,spark的一个分区对应kafka的一个主题的一个分区。那flink和kafka集成的时候,怎么消费kafka的数据,假设kafka某个主题5个partition](https://t.zsxq.com/nuzvVzZ)
324、[./bin/flink run -m yarn-cluster 执行的flink job ,作业自己打印的日志通过yarn application的log查看不了,只有集群自身的日志,程序中logger.info打印日志存放在哪,还是我打包的方式问题,打日志用的是slf4j。](https://t.zsxq.com/27u3ZZf)
325、[在物联网平台中,需要对每个key下的数据做越限判断,由于每个key的越限值是不同的,越限值配置在实时数据库中。
若将越限值加载到state中,由于key的量很大(大概3亿左右),会导致state太大,可能造成内存溢出。若在处理数据时从实时数据库中读取越限值,由于网络IO开销,可能造成实时性下降。请问该如何处理?谢谢](https://t.zsxq.com/miuzFY3)
326、[如果我一个flink程序有多个window操作,时间戳和watermark是不是每个window都需要分配,还有就是事件时间是不是一定要在数据源中就存在某个字段](https://t.zsxq.com/amURvZR)
327、[有没有flink1.9刚支持的用ddl链接kafka并写入hbase的资料,我们公司想把离线的数仓逐渐转成实时的,写sql对于我们来说上手更快一些,就想找一些这方面的资料学习一下。](https://t.zsxq.com/eqFuBYz)
328、[flink1.9 进行了数据类型的转化时发生了不匹配的问题, 目前使用的Type被弃用,推荐使用是datatypes 类型,但是之前使用的Type类型的方法 对应的schema typeinformation 目前跟datatypes的返回值不对应,请问下 该怎么去调整适配?](https://t.zsxq.com/yVvR3V3)
329、[link中处理数据其中一条出了异常都会导致整个job挂掉?有没有方法(除了异常捕获)让这条数据记录错误日志就行 下面的数据接着处理呢? 粗略看过一些容错处理,是关于程度挂了重启后从检查点拉取数据,但是如果这条数据本身就问提(特别生产上,这样就导致job直接挂了,影响有点大),那应该怎么过滤掉这条问题数据呢(异常捕获是最后的方法](https://t.zsxq.com/6AIQnEi)
330、[我在一个做日报的统计中使用rabbitmq做数据源,为什么rabbitmq中的数据一直处于unacked状态,每分钟触发一次窗口计算,并驱逐计算过的元素,我在测试环境数据都能ack,但是一到生产环境就不行了,也没有报错,有可能是哪里出了问题啊](https://t.zsxq.com/RBmi2vB)
331、[我们目前数据流向是这样的,kafka source ,etl,redis sink 。这样chk 是否可以保证端到端语义呢?](https://t.zsxq.com/fuNfuBi)
332、[1.在通过 yarn-session 提交 flink job 的时候。flink-core, flink-clients, flink-scala, flink-streaming-scala, scala-library, flink-connector-kafka-0.10 那些应该写 provided scope,那些应该写 compile scope,才是正确、避免依赖冲突的姿势?
2.flink-dist_2.11-1.8.0.jar 究竟包含了哪些依赖?(这个文件打包方式不同于 springboot,无法清楚看到有哪些 jar 依赖)](https://t.zsxq.com/mIeMzvf)
333、[Flink 中使用 count window 会有这样的问题就是,最后有部分数据一直没有达到 count 的值,然后窗口就一直不触发,这里看到个思路,可以将 time window + count window 组合起来](https://t.zsxq.com/AQzj6Qv)
334、[flink流处理时,注册一个流数据为Table后,该流的历史数据也会一直在Table里面么?为什么每次来新数据,历史处理过得数据会重新被执行?](https://t.zsxq.com/VvR3Bai)
335、[available是变化数据,除了最新的数据被插入数据库,之前处理过数据又重新执行了几次](https://t.zsxq.com/jMfyNZv)
336、[这里两天在研究flink的广播变量,发现一个问题,DataSet数据集中获取广播变量,获取的内存地址是一样的(一台机器维护一个广播数据集)。在DataStream中获取广播变量就成了一个task维护一个数据集。(可能是我使用方式有问题) 所以想请教下星主,DataStream中获取一个画面变量可以如DataSet中一台机器维护一个数据吗?](https://t.zsxq.com/m6Yrv7Q)
337、[Flink程序开启checkpoint 机制后,用yarn命令多次killed以后,ckeckpoint目录下有多个job id,再次开辟资源重新启动程序,程序如何找到上一次jobid目录下,而不是找到其他的jobid目录下?默认是最后一个还是需要制定特定的jobid?](https://t.zsxq.com/nqzZrbq)
338、[发展昨天的数据重复插入问题,是把kafka里进来的数据流registerDataStream注册为Table做join时,打印表的长度发现,数据会一直往表里追加,怎样才能来一条处理一条,不往上追加呀](https://t.zsxq.com/RNzfQ7e)
339、[flink1.9 sql 有没有类似分区表那样的处理方式呢?我们现在有一个业务是1个source,但是要分别计算5分钟,10分钟,15分钟的数据。](https://t.zsxq.com/AqRvNNj)
340、[我刚弄了个服务器,在启动基础的命令时候发现task没有启动起来,导致web页是三个0,我看了log也没有报错信息,请问您知道可能是什么问题吗?](https://t.zsxq.com/q3feIuv)
241、[我自定义了个 Sink extends RichSinkFunction,有了 field: private transient Object lock;
这个 lock 我直接初始化 private transient Object lock = new Object(); 就不行,在 invoke 里 使用lock时空指针,如果lock在 自定义 Sink 的 构造器初始化也不行。但是在 open 方法里初始化就可以,为什么?能解释一下 执行原理吗?如果一个slot 运行着5个 sink实例,那么 这个sink对象会new 5个还是1个?](https://t.zsxq.com/EIiyjeU)
342、[请问Kafka的broker 个数怎么估算?](https://t.zsxq.com/aMNnIy3)
343、[flink on yarn如何远程调试](https://t.zsxq.com/BU7iqbi)
344、[目前有个需求:就是源数据是dataA、dataB、DataC通过kafka三个topic获取,然后进行合并。
但是有有几个问题,目前不知道怎么解决:
dataA="id:10001,info:***,date:2019-08-01 12:23:33,entry1:1,entryInfo1:***"
dataB="id:10001,org:***,entry:1" dataC="id:10001,location:***"
(1) 如何将三个流合并? (1) 数据中dataA是有时间的,但是dataB和dataC中都没有时间戳,那么如何解决eventTime及迟到乱序的问题?帮忙看下,谢谢](https://t.zsxq.com/F6U7YbY)
345、[我flink从kafka读json数据,在反序列化后中文部分变成了一串问号,请问如何做才能使中文正常](https://t.zsxq.com/JmIqfaE)
346、[我有好几个Flink程序(独立jar),在线业务数据分析时都会用到同样的一批MySQL中的配置数据(5千多条),现在的实现方法是每一个程序都是独立把这些配置数据装到内存中,便于快速使用,但现在感觉有些浪费资源和结构不够美观,请问这类情况有什么其他的解决方案吗?谢谢](https://t.zsxq.com/3BMZfAM)
347、[Flink checkpoint 选 RocksDBStateBackend 还是 FsStatebackEnd ,我们目前是任务执行一段时间之后 任务就会被卡死。](https://t.zsxq.com/RFMjYZn)
348、[flink on k8s的高可用、扩缩容这块目前还有哪些问题?](https://t.zsxq.com/uVv7uJU)
349、[有个问题问一下,是这样的现在Kafka4个分区每秒钟生产4000多到5000条日志数据,但是在消费者FLINK这边接收我只开了4个solt接收,这边只是接收后做切分存储,现在出现了延迟现象,我不清楚是我这边处切分慢了还是Flink接收kafka的数据慢了?Flink UI界面显示这两个背压高](https://t.zsxq.com/zFq3fqb)
350、[想请问一下,在flink集群模式下,能不能指定某个节点来执行一个task?](https://t.zsxq.com/NbaMjem)
+ [请问一下aggrefunction 的merge方法什么时候会用到呢,google上有答案说合并相同的key, 但相同的key应该是被hash相同的task上了?这块不是很理解](https://t.zsxq.com/VnEim6m)
+ [请问flink遇到这种问题怎么解决?1. eventA发起事件,eventB响应事件,每分钟统计事件的响应的成功率。说明,eventA和eventB有相同的commitId关联,eventA到flink的时间早于eventB的时间,但eventB到达的时间也有可能早于eventA。要求是:eventA有A,B,C,D,E五条数据,如果eventB有A',B',C',X',Y'五条数据,成功率是3/5.2. 每分钟统计一次eventC成功率(状态0、1)。但该事件日志会重复报,只统计eventTime最早的一条。上一分钟统计到过的,下一分钟不再统计](https://t.zsxq.com/eMnMrRJ)
+ [Flink当前版本中Yarn,k8s,standalone的HA设计方案与源码解析请问可以系统性讲讲么](https://t.zsxq.com/EamqrFQ)
+ [怎么用javaAPI提交job以yarn-cluster模式运行](https://t.zsxq.com/vR76amq)
+ [有人遇到过流损坏的问题么?不知道怎么着手解决?](https://t.zsxq.com/6iMvjmq)
+ [从这个日志能看出什么异常的原因吗?我查看了kafka,yarn,zookeeper。这三个组件都没有任何异常](https://t.zsxq.com/uByFUrb)
+ [为啥flink内部维护两套通信框架,client与jobmanager和jobmanager与taskmanager是akka通信,然而takmanager之间是netty通信?](https://t.zsxq.com/yvBiImq)
+ [问各位球友一个小问题,flink 的 wordcount ,输出在控制台的时候,前面有个数字 > 是什么意思](https://t.zsxq.com/yzzBMji)
+ [从kafka的topicA读数据,转换后写入topicB,开启了checkpoint,任务启动后正常运行,新的topic也有数据写入,但是想监控一下消费topicA有没有延迟,使用kafka客户端提供的脚本查看groupid相关信息,提示没有该groupid](https://t.zsxq.com/MNFUVnE)
+ [将flink分流之后,再进行窗口计算,如何将多个窗口计算的结果汇总起来 作为一个sink,定时输出?
我想将多个流计算的不同实时统计指标,比如每1min对多个指标进行统计(多个指标分布在不同的流里面),然后将多个指标作为一条元组存入mysql中?](https://t.zsxq.com/mUfm2zF)
+ [Flink最终如何输出到数据大屏上去。](https://t.zsxq.com/nimeA66)
+ [为什么我keyby 之后,不同key的数据会进入同一个AggregateFunction中吗? 还是说不同key用的AggregateFunction实列是同一个呢?我在AggregateFunction中给一个对象赋值之后,发现其他key的数据会把之前的数据覆盖,这是怎么回事啊?](https://t.zsxq.com/IMzBUFA)
+ [flink窗口计算的结果怎么和之前的结果聚合在一起](https://t.zsxq.com/yFI2FYv)
+ [flink on yarn 的任务该如何监控呢,之前自带 influxdb metrics 好像无法采集到flink on yarn 的指标](https://t.zsxq.com/ZZ3FmqF)
+ [link1.9.0消费kafka0.10.1.1数据时,通过ui监控查看发现部分分区的current offset和commit offset一直显示为负数,随着程序运行也始终不变,麻烦问下这是怎么回事?](https://t.zsxq.com/QvRNjiU)
+ [flink 1.9 使用rank的时候报,org.apache.flink.table.api.TableException: RANK() on streaming table is not supported currently](https://t.zsxq.com/Y7MBaQb)
+ [Flink任务能不能动态的变更source源kafka的topic,但是又不用重启任务](https://t.zsxq.com/rzVjMjM)
+ [1、keyed state 和opeater state 区分点是啥(是否进行了shuffle流程?)
2、CheckpointedFunction 这个接口的作用是啥?
3、何时调用这个snapshotState这个方法?](https://t.zsxq.com/ZVnEyne)
+ [请教一下各位大佬,日志一般都怎么收集?task manager貌似把不同job的日志都打印在一起,有木有分开打印的办法?](https://t.zsxq.com/AayjeiM)
+ [最近接到一个需求,统计今天累计在线人数并且要去重,每5秒显示一次结果,请问如何做这个需求?](https://t.zsxq.com/IuJ2FYR)
+ [目前是flink消费kafka的一个问题。kafka使用的是阿里云的kafka,可以申请consumer。目前在同一个A-test的topic下,使用A1的consumer组进行消费,但是在两个程序里,source端得到的数据量差别很大,图一是目前消费kafka写入到另一个kafka的topic中,目前已知只有100条;图二是消费kafka,写入到hdfs中。两次消费起始偏移量一致(消费后,恢复偏移量到最初再消费)按照时间以及设置从头开始消费的策略也都还是只有100条;后面我把kafka的offset提交到checkpoint选项关掉了,也还是只有100条。很奇怪,所以想问一下,目前这个问题是要从state来出发解决](https://t.zsxq.com/eqBUZFm)
+ [问一下 grafana的dashboard 有没有推荐的,我们现在用是prometheus pushgateway reporter来收集metric。但是目前来说,到底哪些指标是要重点关注的还是不太清楚](https://t.zsxq.com/EYz7iMV)
+ [on yarn 1. session 模式提交是不是意味着 多个flink任务会由同一个 jobManager 管理 2. per-job 模式 会启动各自多个jobManager](https://t.zsxq.com/u3vVV3b)
+ [您在flink里面使用过lettuce连接redis cluster吗,我这里使用时报错,Cannot retrieve initial cluster partitions from initial URIs](https://t.zsxq.com/VNnEQJ6)
+ [zhisheng你好,我在使用flink滑动窗口时,每10分钟会向redis写入大量的内容,影响了线上性能,这个有什么办法可以控制写redis的速度吗?](https://t.zsxq.com/62ZZJmi)
+ [flink standalone模式,启动服务的命令为:flink run -c 类名 jar包 。对应的Slots怎么能均匀分布呢?目前遇到问题,一直使用一个机器的Slots,任务多了后直接会把taskjob挂掉。报错信息如二图](https://t.zsxq.com/2zjqVnE)
+ [zhisheng你好,像standalone与yarn集群,其master与workers相互通信都依赖于ssh协议,请问有哪种不依赖于ssh协议的搭建方式吗?](https://t.zsxq.com/qzrvbaQ)
+ [官网中,这两种周期性watermaker的产生分别适用什么场景呢?](https://t.zsxq.com/2fUjAQz)
+ [周期性的watermarke 设置定时产生, ExecutionConfig.setAutoWatermarkInterval(…),这个定时的时间一般怎样去评估呢?](https://t.zsxq.com/7IEAyV3)
+ [想问一下能否得到flink分配资源的时间?](https://t.zsxq.com/YjqRBq3)
+ [问下flink向kafka生产数据有时候报错:This server does not host this topic-partition](https://t.zsxq.com/vJyJiMJ)
+ [flink yarn 模式启动,log4j. properties配置信息见图片,yarn启动页面的taskmanager能看到日志输出到stdout,但是在指定的日志文件夹中就是没有日志文件生成。,本地运行有日志文件的](https://t.zsxq.com/N3ZrZbQ)
+ [教一个问题。flink2hbase 如何根据hbase中的日期字段,动态按天建表呢?我自定义了hbase sink,在invoke方法中根据数据的时间建表,但是带来了一个问题,每条数据都要去check表是否存在,这样会产生大量的rpc请求。请问星主大大,针对上述这种情况,有什么好的解决办法吗?](https://t.zsxq.com/3rNBubU)
+ [你好,有关于TM,slots,内存,线程数,进程数,cpu,调度相关的资料吗?比如一个slot起多少线程,为什么,如何起的,task是如何调度的之类的。网上没找到想要的,书上写的也不够细。源码的话刚开始看不太懂,所以想先找找资料看看](https://t.zsxq.com/buBIAMf)
+ [能否在flink中只新建一个FlinkKafkaConsumer读取多个kafka的topics ,这些topics的处理逻辑都是一样的 最终将数据写入每个topic对应的es表 请问这个实现逻辑是怎样的 ](https://t.zsxq.com/EY37aEm)
+ [能不能描述一下在窗口中,例如滚动窗口,多个事件进窗口后,事件在内存中保存的形式是怎么样的?会变成一个state?还是多个事件变成一个state?事件跟state的关系?事件时间过了在窗口是怎么清理事件的?如果state backends用的是RocksDBStateBackend,增量checkpoint,怎么清理已保存过期的事件咧?](https://t.zsxq.com/3vzzj62)
+ [请问一下 Flink的监控是如何做的?比如job挂了能告警通知。目前是想用Prometheus来做监控,但是发现上报的指标没有很符合的我需求。我这边用yarn-session启动的job,一个jobManger会管理多个job。Prometheus还是刚了解阶段可能遗漏了一些上报指标,球主大大有没有好的建议。](https://t.zsxq.com/vJyRnY7)
+ [ProcessTime和EventTime是否可以一起使用?当任务抛出异常失败的时候,如果配置了重启策略,重启时是不是从最近的checkpoint继续?遇到了一个数据库主键冲突的问题,查看kafka数据源发现该主键的消息只有一条,查看日志发现Redis连接池抛了异常(当时Redis在重启)导致任务失败重试,当时用的ProcessTime](https://t.zsxq.com/BuZJaUb)
+ [flink-kafka 自定义反序列化中如何更好的处理数据异常呢,有翻到前面一篇提问,如果使用 try-catch 捕获到异常,是抛出异常更好呢?还是return null 更好呢](https://t.zsxq.com/u3niYni)
+ [现在在用flink做上下游数据的比对,现在遇到了性能瓶颈,一个节点现在最多只能消费50条数据。观察taskmanager日志的gc日志发现最大堆内存有2.7g,但是新生代最大只有300m。能不能设置flink的jvm参数,flink on yarn启动模式](https://t.zsxq.com/rvJYBuB)
+ [请教一个原理性的问题,side out put和直接把一个流用两种方式处理有啥本质区别?我试了下,把一个流一边写缓存,一边入数据库,两边也都是全量数据](https://t.zsxq.com/Ee27i6a)
+ [如何定义一个flink window处理方式,1秒钟处理500条,1:kafka中有10000条数据时,仍旧1秒钟处理500条;2,kafka中有20条,每隔1秒处理一次。](https://t.zsxq.com/u7YbyFe)
+ [问一下大佬,网页UI可以进行savepoint的保存么?还是只能从savepoint启动?](https://t.zsxq.com/YfAqFUj)
+ [能否指定Kafka某些分区消费拉取消息,其他分区不拉取消息。现在有有很多场景,一个topic上百个分区,但是我只需要其中几个分区的数据](https://t.zsxq.com/AUfEAQB)
+ [我想过滤kafka 读到的某些数据,过滤条件从redis中拿到(与用户的配置相关,所以需要定时更新),总觉得怪怪的,请问有更好的方案吗?因为不提供redis的source,因此我是用jedis客户端来读取redis数据的,数据也获取不到,请问星主,flink代码在编写的时候,一般是如何调试的呢](https://t.zsxq.com/qr7UzjM)
+ [flink使用rocksdb状态检查点存在HDFS上,有的任务状态很小但是HDFS一个文件最小128M所以磁盘空间很快就满了,有没有啥配置可以自动清理检查点呢](https://t.zsxq.com/Ufqj2ZR)
+ [这是实时去重的问题。
举个例子,当发生订单交易的时候,业务中台会把该比订单消息发送到kafka,然后flink消费,统计总金额。如果因为业务中台误操作,发送了多次相同的订单过来(订单id相同),那么统计结果就会多次累加,造成统计的总金额比实际交易金额更多。我需要自定义在source里通过operate state去重,但是operate state是和每个source实例绑定,会造成重复的订单可能发送到不同的source实例,这样取出来的state里面就可能没有上一次已经记录的订单id,那么就会将这条重复的订单金额统计到最后结果中,](https://t.zsxq.com/RzB6E6A)
+ [双流join的时候,怎么能保证两边来的数据是对应的?举个例子,订单消息和库存消息,按逻辑来说,发生订单的时候,库存也会变,这两个topic都会同时各自发一条消息给我,我拿到这两条消息会根据订单id做join操作。问题是那如果库存消息延迟了5秒或者10秒,订单消息来的时候就join不到库存消息,这时候该怎么办?](https://t.zsxq.com/nunynmI)
+ [我这有一个比对程序用的是flink,数据源用的是flink-kafka,业务数据分为上下游,需要根据某个字段分组,相同的key上下游数据放一起比对。上下游数据进来的时间不一样,因此我用了一个可以迭代的窗口大小为5分钟window进行比对处理,最大迭代次数为3次。statebackend用的是fsstatebackend。通过监控发现当程序每分钟数据量超过2万条的时候,程序就不消费数据了,虽然webui上显示正常,而且jobmanager和taskmanager的stdout没有异常日志,但是程序就是不消费数据了。](https://t.zsxq.com/nmeE2Fm)
+ [异步io里面有个容量,是指同时多少个并发还是,假如我每个taskmanager核数设置10个,共10个taskmanager,那我这个数量只能设置100呢](https://t.zsxq.com/vjimeiI)
+ [有个性能问题想问下有没有相关的经验?一个job从kafka里读一个topic数据,然后进行分流,使用sideout分开之后直接处理,性能影响大吗?比如分开以后有一百多子任务。还有其他什么好的方案进行分流吗?](https://t.zsxq.com/mEeUrZB)
+ [线上有个作业抛出了一下异常,但是还能正常运行,这个怎么排查,能否提供一下思路](https://t.zsxq.com/Eayzr3R)
等等等,还有很多,复制粘贴的我手累啊 😂
另外里面还会及时分享 Flink 的一些最新的资料(包括数据、视频、PPT、优秀博客,持续更新,保证全网最全,因为我知道 Flink 目前的资料还不多)
[关于自己对 Flink 学习的一些想法和建议](https://t.zsxq.com/AybAimM)
[Flink 全网最全资料获取,持续更新,点击可以获取](https://t.zsxq.com/iaEiyB2)
再就是星球用户给我提的一点要求:不定期分享一些自己遇到的 Flink 项目的实战,生产项目遇到的问题,是如何解决的等经验之谈!
1、[如何查看自己的 Job 执行计划并获取执行计划图](https://t.zsxq.com/Zz3ny3V)
2、[当实时告警遇到 Kafka 千万数据量堆积该咋办?](https://t.zsxq.com/AIAQrnq)
3、[如何在流数据中比两个数据的大小?多种解决方法](https://t.zsxq.com/QnYjy7M)
4、[kafka 系列文章](https://t.zsxq.com/6Q3vN3b)
5、[Flink环境部署、应用配置及运行应用程序](https://t.zsxq.com/iiYfMBe)
6、[监控平台该有架构是长这样子的](https://t.zsxq.com/yfYrvFA)
7、[《大数据“重磅炸弹”——实时计算框架 Flink》专栏系列文章目录大纲](https://t.zsxq.com/beu7Mvj)
8、[《大数据“重磅炸弹”——实时计算框架 Flink》Chat 付费文章](https://t.zsxq.com/UvrRNJM)
9、[Apache Flink 是如何管理好内存的?](https://t.zsxq.com/zjQvjeM)
10、[Flink On K8s](https://t.zsxq.com/eYNBaAa)
11、[Flink-metrics-core](https://t.zsxq.com/Mnm2nI6)
12、[Flink-metrics-datadog](https://t.zsxq.com/Mnm2nI6)
13、[Flink-metrics-dropwizard](https://t.zsxq.com/Mnm2nI6)
14、[Flink-metrics-graphite](https://t.zsxq.com/Mnm2nI6)
15、[Flink-metrics-influxdb](https://t.zsxq.com/Mnm2nI6)
16、[Flink-metrics-jmx](https://t.zsxq.com/Mnm2nI6)
17、[Flink-metrics-slf4j](https://t.zsxq.com/Mnm2nI6)
18、[Flink-metrics-statsd](https://t.zsxq.com/Mnm2nI6)
19、[Flink-metrics-prometheus](https://t.zsxq.com/Mnm2nI6)
20、[Flink 注解源码解析](https://t.zsxq.com/f6eAu3J)
21、[使用 InfluxDB 和 Grafana 搭建监控 Flink 的平台](https://t.zsxq.com/yVnaYR7)
22、[一文搞懂Flink内部的Exactly Once和At Least Once](https://t.zsxq.com/UVfqfae)
23、[一文让你彻底了解大数据实时计算框架 Flink](https://t.zsxq.com/eM3ZRf2)
当然,除了更新 Flink 相关的东西外,我还会更新一些大数据相关的东西,因为我个人之前不是大数据开发,所以现在也要狂补些知识!总之,希望进来的童鞋们一起共同进步!
1、[Java 核心知识点整理.pdf](https://t.zsxq.com/7I6Iyrf)
2、[假如我是面试官,我会问你这些问题](https://t.zsxq.com/myJYZRF)
3、[Kafka 系列文章和学习视频](https://t.zsxq.com/iUZnamE)
4、[重新定义 Flink 第二期 pdf](https://t.zsxq.com/r7eIeyJ)
5、[GitChat Flink 文章答疑记录](https://t.zsxq.com/ZjiYrVr)
6、[Java 并发课程要掌握的知识点](https://t.zsxq.com/QZVJyz7)
7、[Lightweight Asynchronous Snapshots for Distributed Dataflows](https://t.zsxq.com/VVN7YB2)
8、[Apache Flink™- Stream and Batch Processing in a Single Engine](https://t.zsxq.com/VVN7YB2)
9、[Flink状态管理与容错机制](https://t.zsxq.com/NjAQFi2)
10、[Flink 流批一体的技术架构以及在阿里的实践](https://t.zsxq.com/MvfUvzN)
11、[Flink Checkpoint-��轻量级分布式快照](https://t.zsxq.com/QVFqjea)
12、[Flink 流批一体的技术架构以及在阿里的实践](https://t.zsxq.com/MvfUvzN)
13、[Stream Processing with Apache Flink pdf](https://t.zsxq.com/N37mUzB)
14、[Flink 结合机器学习算法的监控平台实践](https://t.zsxq.com/m6EAaQ3)
15、[《大数据重磅炸弹-实时计算Flink》预备篇——大数据实时计算介绍及其常用使用场景 pdf 和视频](https://t.zsxq.com/emMBaQN)
16、[《大数据重磅炸弹-实时计算Flink》开篇词 pdf 和视频](https://t.zsxq.com/fqfuVRR)
17、[四本 Flink 书](https://t.zsxq.com/rVBQFI6)
18、[流处理系统 的相关 paper](https://t.zsxq.com/rVBQFI6)
19、[Apache Flink 1.9 特性解读](https://t.zsxq.com/FyzvRne)
20、[打造基于Flink Table API的机器学习生态](https://t.zsxq.com/FyzvRne)
21、[基于Flink on Kubernetes的大数据平台](https://t.zsxq.com/FyzvRne)
22、[基于Apache Flink的高性能机器学习算法库](https://t.zsxq.com/FyzvRne)
23、[Apache Flink在快手的应用与实践](https://t.zsxq.com/FyzvRne)
24、[Apache Flink-1.9与Hive的兼容性](https://t.zsxq.com/FyzvRne)
25、[打造基于Flink Table API的机器学习生态](https://t.zsxq.com/FyzvRne)
26、[流处理系统的相关 paper](https://t.zsxq.com/rVBQFI6)
================================================
FILE: books/README.md
================================================
### 《大数据实时计算引擎 Flink 实战与性能优化》
2019 年著,基于 Flink 1.9 讲解的书籍目录大纲,含 Flink 入门、概念、原理、实战、性能调优、源码解析等内容。涉及 Flink Connector、Metrics、Library、DataStream API、Table API & SQL 等内容的学习案例,还有 Flink 落地应用的大型项目案例分享。
## 专栏介绍
首发地址:[http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/](http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/)
专栏地址:[https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f](https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f)
加入知识星球可以获取到专栏所有内容:

### 专栏亮点
+ 全网首个使用最新版本 **Flink 1.9** 进行内容讲解(该版本更新很大,架构功能都有更新),领跑于目前市面上常见的 Flink 1.7 版本的教学课程。
+ 包含大量的**实战案例和代码**去讲解原理,有助于读者一边学习一边敲代码,达到更快,更深刻的学习境界。目前市面上的书籍没有任何实战的内容,还只是讲解纯概念和翻译官网。
+ 在专栏高级篇中,根据 Flink 常见的项目问题提供了**排查和解决的思维方法**,并通过这些问题探究了为什么会出现这类问题。
+ 在实战和案例篇,围绕大厂公司的**经典需求**进行分析,包括架构设计、每个环节的操作、代码实现都有一一讲解。
### 为什么要学习 Flink?
随着大数据的不断发展,对数据的及时性要求越来越高,实时场景需求也变得越来越多,主要分下面几大类:

为了满足这些实时场景的需求,衍生出不少计算引擎框架。现有市面上的大数据计算引擎的对比如下图所示:

可以发现无论从 Flink 的架构设计上,还是从其功能完整性和易用性来讲都是领先的,再加上 Flink 是**阿里巴巴主推**的计算引擎框架,所以从去年开始就越来越火了!
目前,阿里巴巴、腾讯、美团、华为、滴滴出行、携程、饿了么、爱奇艺、有赞、唯品会等大厂都已经将 Flink 实践于公司大型项目中,带起了一波 Flink 风潮,**势必也会让 Flink 人才市场产生供不应求的招聘现象**。
### 专栏内容

#### 预备篇
介绍实时计算常见的使用场景,讲解 Flink 的特性,并且对比了 Spark Streaming、Structured Streaming 和 Storm 等大数据处理引擎,然后准备环境并通过两个 Flink 应用程序带大家上手 Flink。
### 基础篇
深入讲解 Flink 中 Time、Window、Watermark、Connector 原理,并有大量文章篇幅(含详细代码)讲解如何去使用这些 Connector(比如 Kafka、ElasticSearch、HBase、Redis、MySQL 等),并且会讲解使用过程中可能会遇到的坑,还教大家如何去自定义 Connector。
### 进阶篇
讲解 Flink 中 State、Checkpoint、Savepoint、内存管理机制、CEP、Table/SQL API、Machine Learning 、Gelly。在这篇中不仅只讲概念,还会讲解如何去使用 State、如何配置 Checkpoint、Checkpoint 的流程和如何利用 CEP 处理复杂事件。
### 高级篇
重点介绍 Flink 作业上线后的监控运维:如何保证高可用、如何定位和排查反压问题、如何合理的设置作业的并行度、如何保证 Exactly Once、如何处理数据倾斜问题、如何调优整个作业的执行效率、如何监控 Flink 及其作业?
### 实战篇
教大家如何分析实时计算场景的需求,并使用 Flink 里面的技术去实现这些需求,比如实时统计 PV/UV、实时统计商品销售额 TopK、应用 Error 日志实时告警、机器宕机告警。这些需求如何使用 Flink 实现的都会提供完整的代码供大家参考,通过这些需求你可以学到 ProcessFunction、Async I/O、广播变量等知识的使用方式。
### 系统案例篇
讲解大型流量下的真实案例:如何去实时处理海量日志(错误日志实时告警/日志实时 ETL/日志实时展示/日志实时搜索)、基于 Flink 的百亿数据实时去重实践(从去重的通用解决方案 --> 使用 BloomFilter 来实现去重 --> 使用 Flink 的 KeyedState 实现去重)。
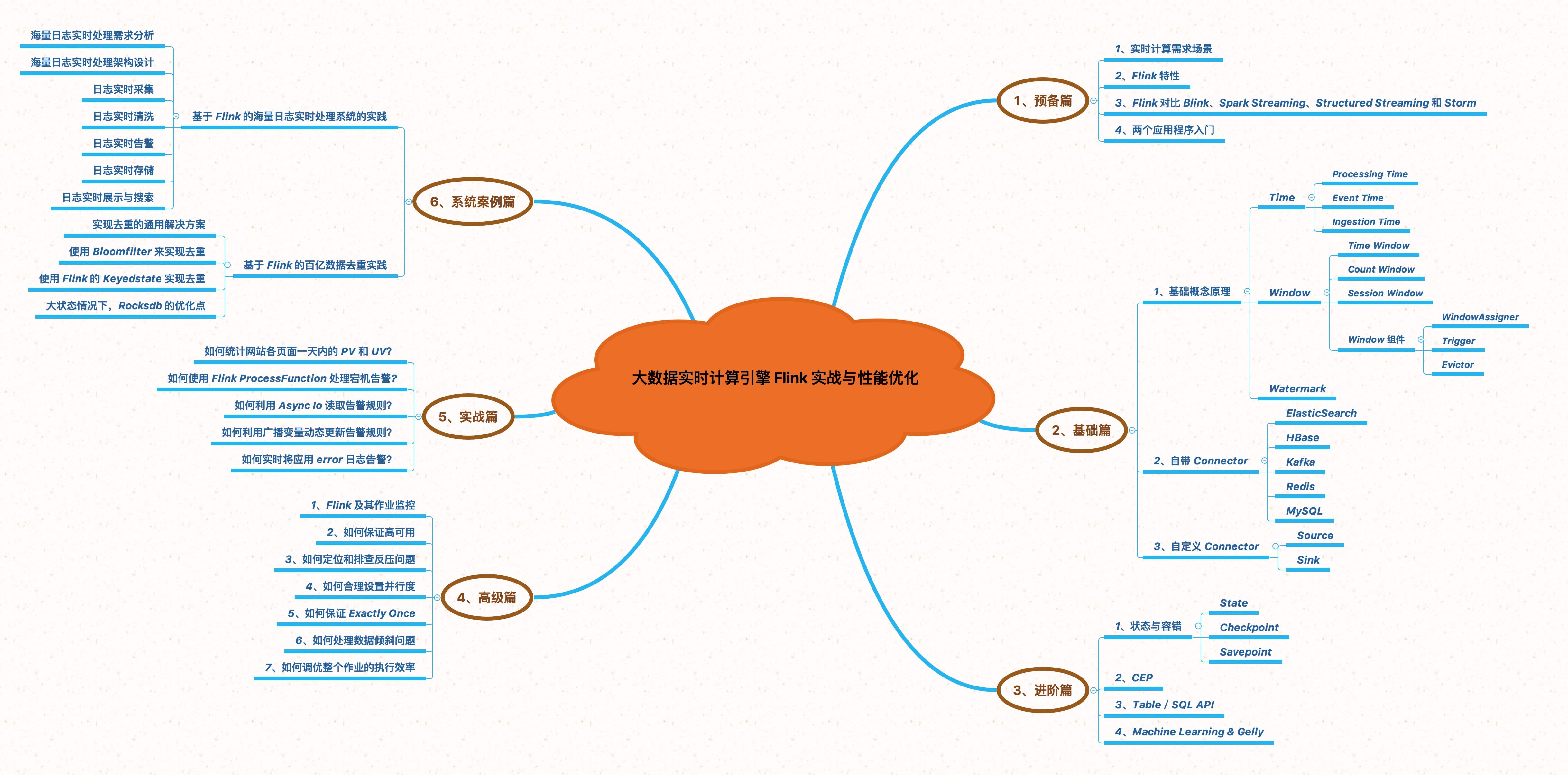
### 多图讲解 Flink 知识点
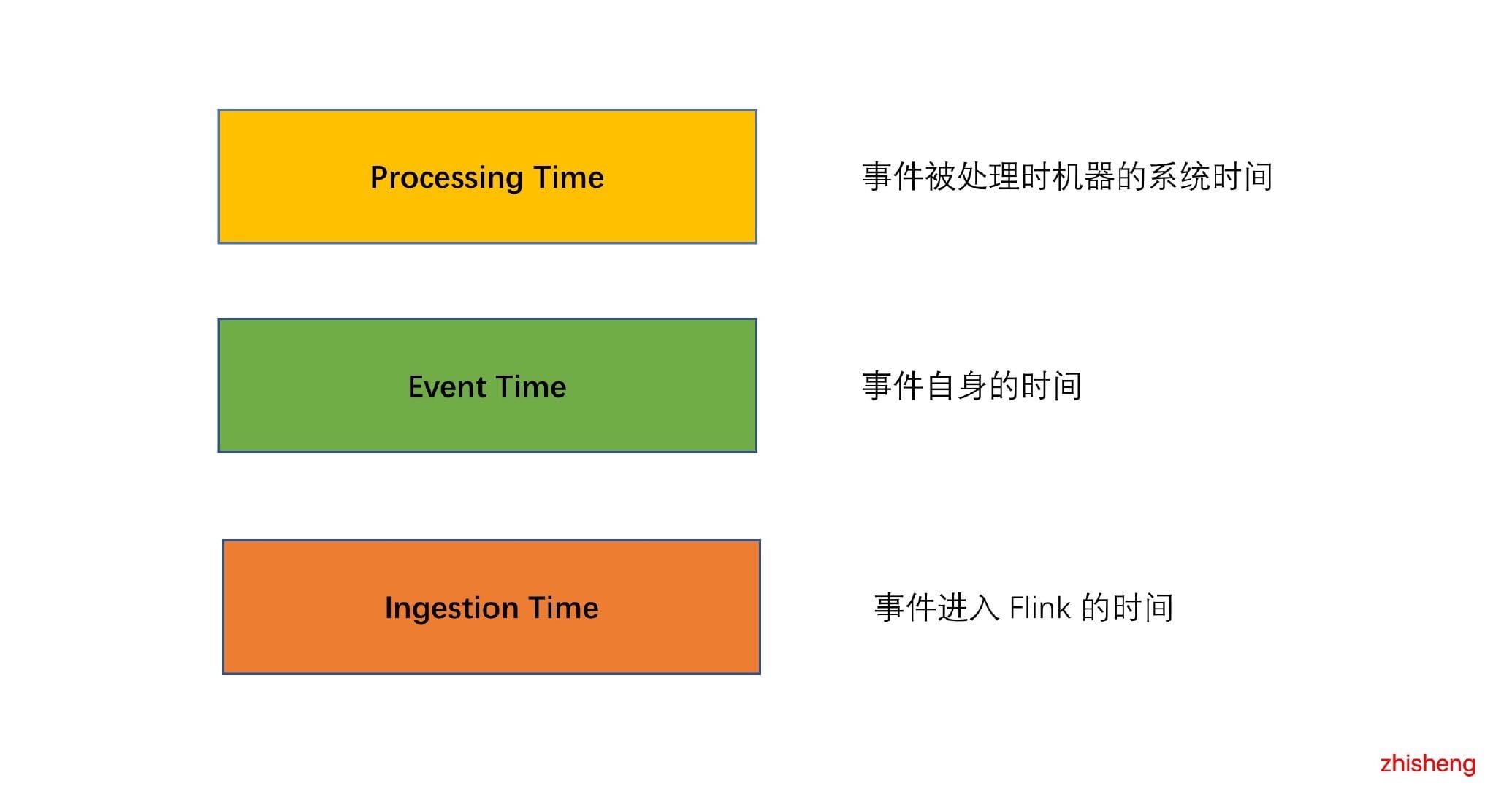
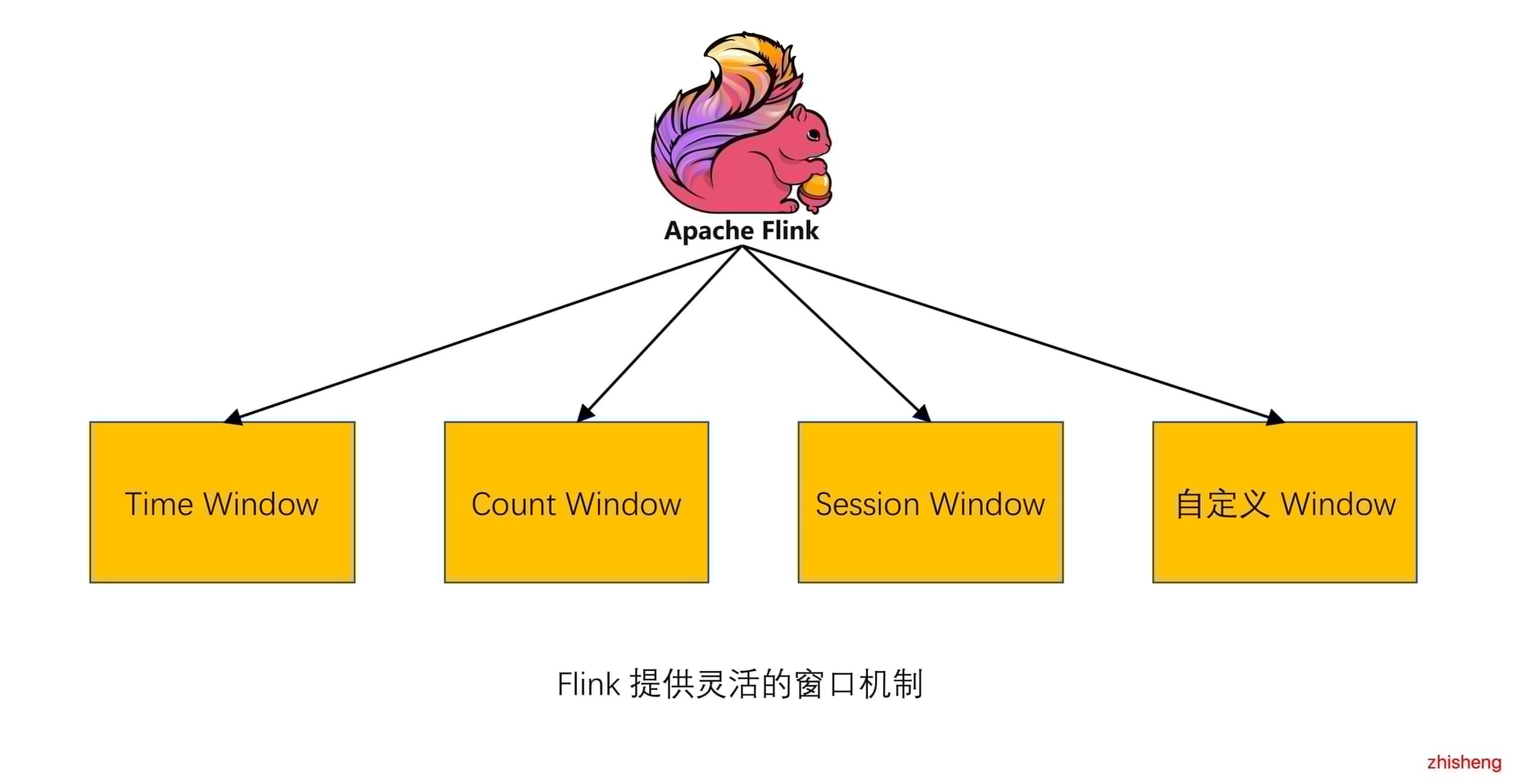
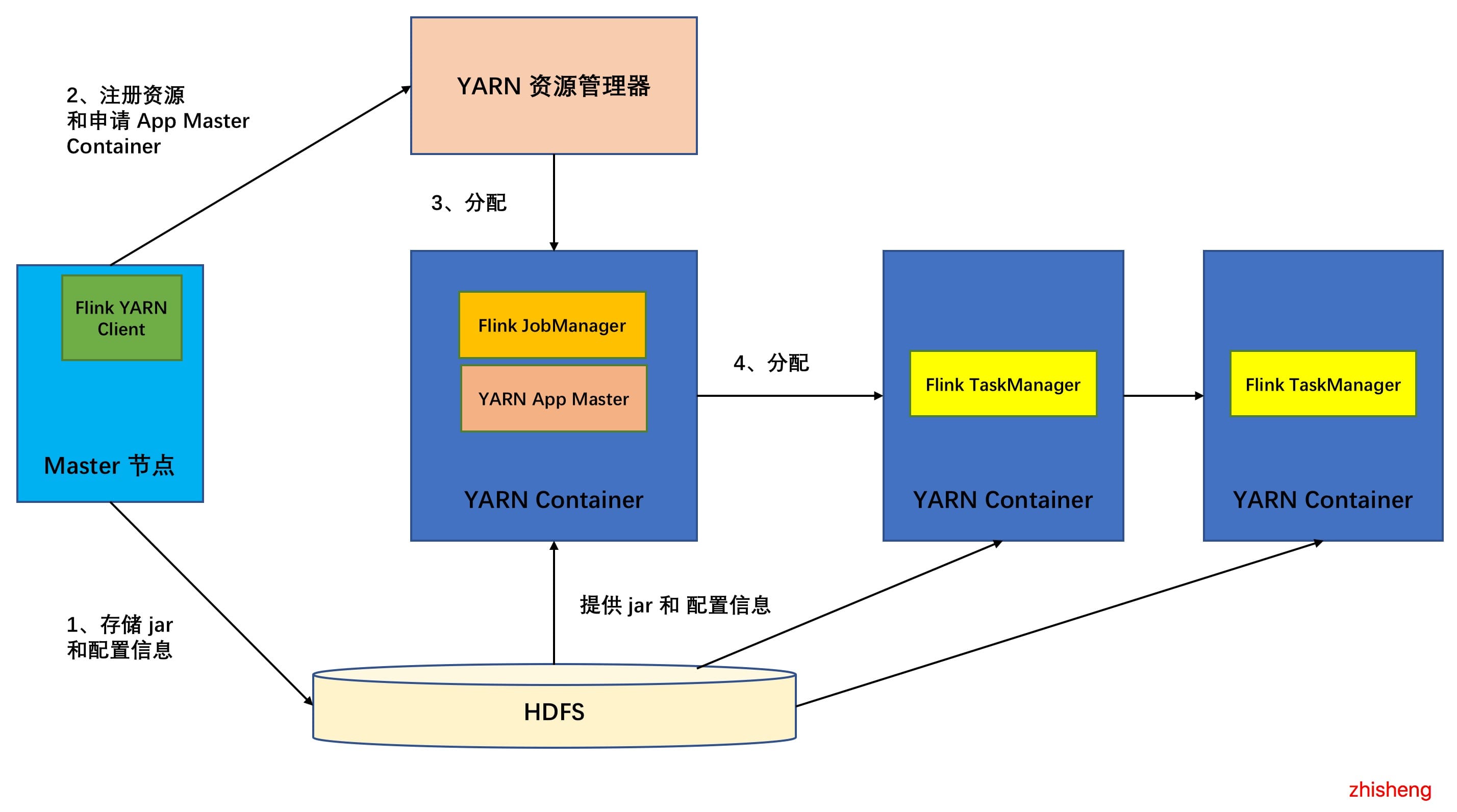
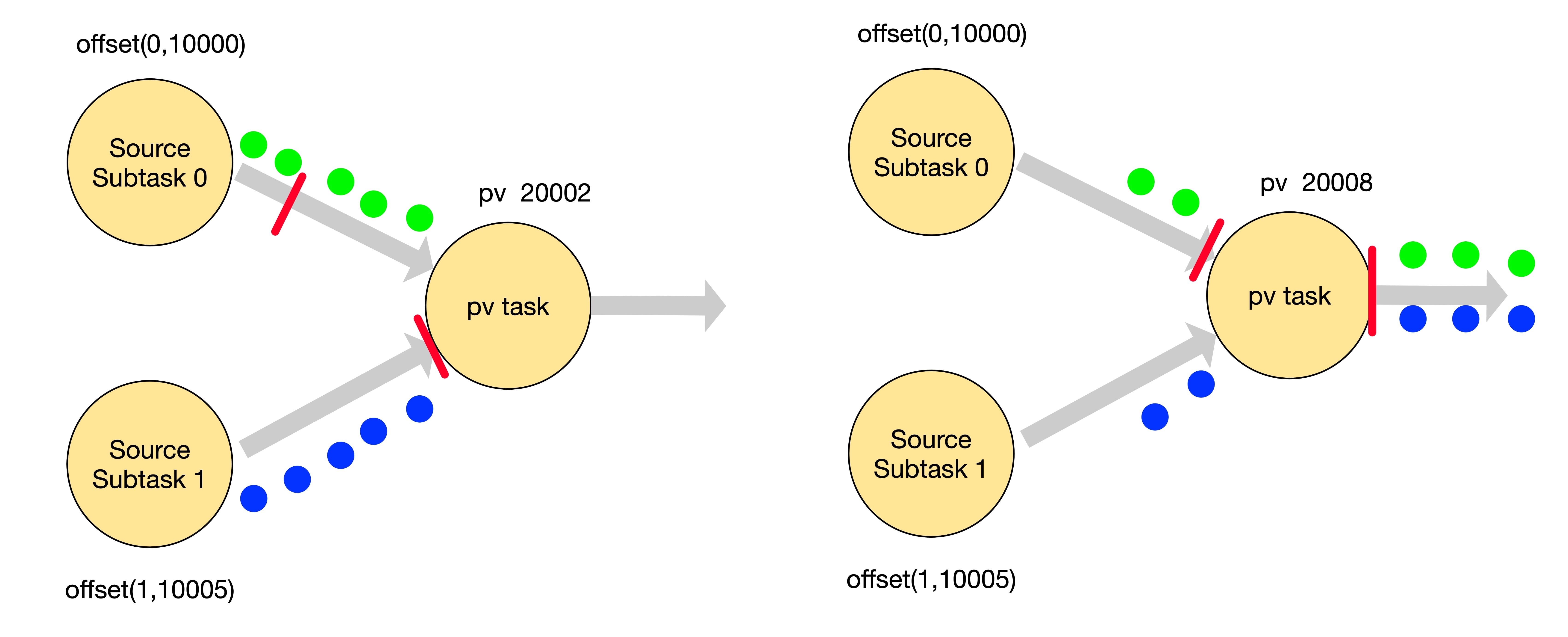
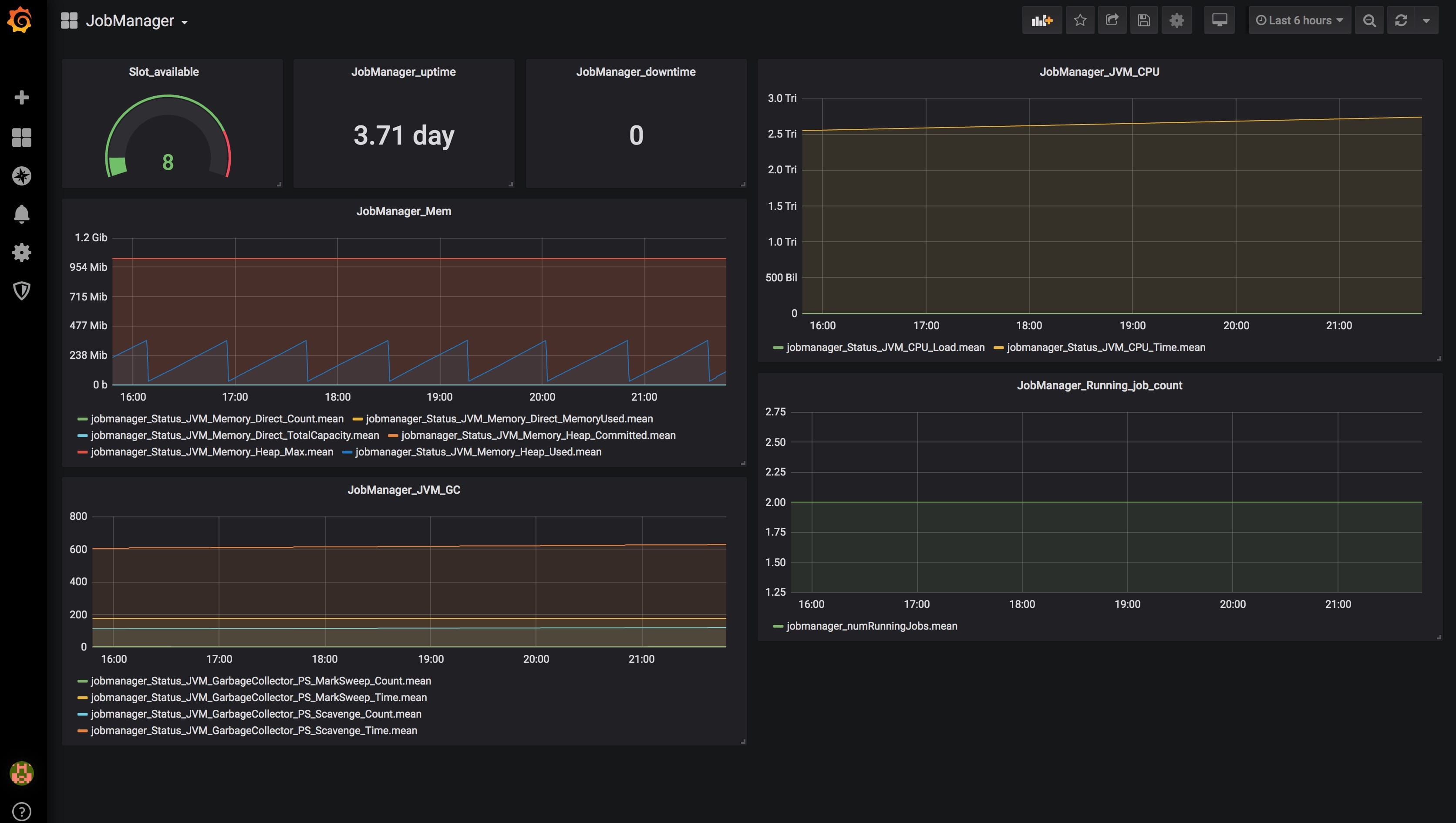
### 你将获得什么
+ 掌握 Flink 与其他计算框架的区别
+ 掌握 Flink Time/Window/Watermark/Connectors 概念和实现原理
+ 掌握 Flink State/Checkpoint/Savepoint 状态与容错
+ 熟练使用 DataStream/DataSet/Table/SQL API 开发 Flink 作业
+ 掌握 Flink 作业部署/运维/监控/性能调优
+ 学会如何分析并完成实时计算需求
+ 获得大型高并发流量系统案例实战项目经验
### 适宜人群
+ Flink 爱好者
+ 实时计算开发工程师
+ 大数据开发工程师
+ 计算机专业研究生
+ 有实时计算场景场景的 Java 开发工程师
## 目录大纲
```
1预备篇
第一章——实时计算引擎
1.1你的公司是否需要引入实时计算引擎
1.1.1 实时计算需求
1.1.2 数据实时采集
1.1.3 数据实时计算
1.1.4 数据实时下发
1.1.5 实时计算场景
1.1.6 离线计算 vs 实时计算
1.1.7 实时计算面临的挑战
1.1.8 小结与反思
1.2彻底了解大数据实时计算框架 Flink
1.2.1 Flink 简介
1.2.2 Flink 整体架构
1.2.3 Flink 的多种方式部署
1.2.4 Flink 分布式运行流程
1.2.5 Flink API
1.2.6 Flink 程序与数据流结构
1.2.7 丰富的 Connector
1.2.8 事件时间&处理时间语义
1.2.9 灵活的窗口机制
1.2.10 并行执行任务机制
1.2.11 状态存储和容错
1.2.12 自己的内存管理机制
1.2.13 多种扩展库
1.2.14 小结与反思
1.3大数据计算框架对比
1.3.1 Flink
1.3.2 Blink
1.3.3 Spark
1.3.4 Spark Streaming
1.3.5 Structured Streaming
1.3.6 Flink VS Spark
1.3.7 Storm
1.3.8 Flink VS Storm
1.3.9 全部对比结果
1.3.10 小结与反思
1.4总结
2第二章——Flink 入门
2.1Flink 环境准备
2.1.1 JDK 安装与配置
2.1.2 Maven 安装与配置
2.1.3 IDE 安装与配置
2.1.4 MySQL 安装与配置
2.1.5 Kafka 安装与配置
2.1.6 ElasticSearch 安装与配置
2.1.7 小结与反思
2.2Flink 环境搭建
2.2.1 Flink 下载与安装
2.2.2 Flink 启动与运行
2.2.3 Flink 目录配置文件解读
2.2.4 Flink 源码下载
2.2.5 Flink 源码编译
2.2.6 将 Flink 源码导入到 IDE
2.2.7 小结与反思
2.3案例1:WordCount 应用程序
2.3.1 使用 Maven 创建项目
2.3.2 使用 IDEA 创建项目
2.3.3 流计算 WordCount 应用程序代码实现
2.3.4 运行流计算 WordCount 应用程序
2.3.5 流计算 WordCount 应用程序代码分析
2.3.6 小结与反思
2.4案例2:实时处理 Socket 数据
2.4.1 使用 IDEA 创建项目
2.4.2 实时处理 Socket 数据应用程序代码实现
2.4.3 运行实时处理 Socket 数据应用程序
2.4.4 实时处理 Socket 数据应用程序代码分析
2.4.5 Flink 中使用 Lambda 表达式
2.4.5 小结与反思
2.5总结
2基础篇
3第三章——Flink 中的流计算处理
3.1Flink 多种时间语义对比
3.1.1 Processing Time
3.1.2 Event Time
3.1.3 Ingestion Time
3.1.4 三种 Time 的对比结果
3.1.5 使用场景分析
3.1.6 Time 策略设置
3.1.7 小结与反思
3.2Flink Window 基础概念与实现原理
3.2.1 Window 简介
3.2.2 Window 有什么作用?
3.2.3 Flink 自带的 Window
3.2.4 Time Window 的用法及源码分析
3.2.5 Count Window 的用法及源码分析
3.2.6 Session Window 的用法及源码分析
3.2.7 如何自定义 Window?
3.2.8 Window 源码分析
3.2.9 Window 组件之 WindowAssigner 的用法及源码分析
3.2.10 Window 组件之 Trigger 的用法及源码分析
3.2.11 Window 组件之 Evictor 的用法及源码分析
3.2.12 小结与反思
3.3必须熟悉的数据转换 Operator(算子)
3.3.1 DataStream Operator
3.3.2 DataSet Operator
3.3.3 流计算与批计算统一的思路
3.3.4 小结与反思
3.4使用 DataStream API 来处理数据
3.4.1 DataStream 的用法及分析
3.4.2 SingleOutputStreamOperator 的用法及分析
3.4.3 KeyedStream 的用法及分析
3.4.4 SplitStream 的用法及分析
3.4.5 WindowedStream 的用法及分析
3.4.6 AllWindowedStream 的用法及分析
3.4.7 ConnectedStreams 的用法及分析
3.4.8 BroadcastStream 的用法及分析
3.4.9 BroadcastConnectedStream 的用法及分析
3.4.10 QueryableStateStream 的用法及分析
3.4.11 小结与反思
3.5Watermark 的用法和结合 Window 处理延迟数据
3.5.1 Watermark 简介
3.5.2 Flink 中的 Watermark 的设置
3.5.3 Punctuated Watermark
3.5.4 Periodic Watermark
3.5.5 每个 Kafka 分区的时间戳
3.5.6 将 Watermark 与 Window 结合起来处理延迟数据
3.5.7 处理延迟数据的三种方法
3.5.8 小结与反思
3.6Flink 常用的 Source Connector 和 Sink Connector 介绍
3.6.1 Data Source 简介
3.6.2 常用的 Data Source
3.6.3 Data Sink 简介
3.6.4 常用的 Data Sink
3.6.5 小结与反思
3.7Flink Connector —— Kafka 的使用和源码分析
3.7.1 准备环境和依赖
3.7.2 将测试数据发送到 Kafka Topic
3.7.3 Flink 如何消费 Kafka 数据?
3.7.4 Flink 如何将计算后的数据发送到 Kafka?
3.7.5 FlinkKafkaConsumer 源码分析
3.7.6 FlinkKafkaProducer 源码分析
3.7.7 使用 Flink-connector-kafka 可能会遇到的问题
3.7.8 小结与反思
3.8自定义 Flink Connector
3.8.1 自定义 Source Connector
3.8.2 RichSourceFunction 的用法及源码分析
3.8.3 自定义 Sink Connector
3.8.4 RichSinkFunction 的用法及源码分析
3.8.5 小结与反思
3.9Flink Connector —— ElasticSearch 的用法和分析
3.9.1 准备环境和依赖
3.9.2 使用 Flink 将数据写入到 ElasticSearch 应用程序
3.9.3 验证数据是否写入 ElasticSearch?
3.9.4 如何保证在海量数据实时写入下 ElasticSearch 的稳定性?
3.9.5 使用 Flink-connector-elasticsearch 可能会遇到的问题
3.9.6 小结与反思
3.10Flink Connector —— HBase 的用法
3.10.1 准备环境和依赖
3.10.2 Flink 使用 TableInputFormat 读取 HBase 批量数据
3.10.3 Flink 使用 TableOutputFormat 向 HBase 写入数据
3.10.4 Flink 使用 HBaseOutputFormat 向 HBase 实时写入数据
3.10.5 项目运行及验证
3.10.6 小结与反思
3.11Flink Connector —— Redis 的用法
3.11.1 安装 Redis
3.11.2 将商品数据发送到 Kafka
3.11.3 Flink 消费 Kafka 中的商品数据
3.11.4 Redis Connector 简介
3.11.5 Flink 写入数据到 Redis
3.11.6 项目运行及验证
3.11.7 小结与反思
3.12使用 Side Output 分流
3.12.1 使用 Filter 分流
3.12.2 使用 Split 分流
3.12.3 使用 Side Output 分流
3.12.4 小结与反思
3.13总结
3进阶篇
4第四章——Flink 中的状态及容错机制
4.1深度讲解 Flink 中的状态
4.1.1 为什么需要 State?
4.1.2 State 的种类
4.1.3 Keyed State
4.1.4 Operator State
4.1.5 Raw and Managed State
4.1.6 如何使用托管的 Keyed State
4.1.7 State TTL(存活时间)
4.1.8 如何使用托管的 Operator State
4.1.9 Stateful Source Functions
4.1.10 Broadcast State
4.1.11 Queryable State
4.1.12 小结与反思
4.2Flink 状态后端存储
4.2.1 State Backends
4.2.2 MemoryStateBackend 的用法及分析
4.2.3 FsStateBackend 的用法及分析
4.2.4 RocksDBStateBackend 的用法及分析
4.2.5 如何选择状态后端存储?
4.2.6 小结与反思
4.3Flink Checkpoint 和 Savepoint 的区别及其配置使用
4.3.1 Checkpoint 简介及使用
4.3.2 Savepoint 简介及使用
4.3.3 Savepoint 与 Checkpoint 的区别
4.3.4 Checkpoint 流程
4.3.5 如何从 Checkpoint 中恢复状态
4.3.6 如何从 Savepoint 中恢复状态
4.3.6 小结与反思
4.4总结
5第五章——Table API & SQL
5.1Flink Table & SQL 概念与通用 API
5.1.1 新增 Blink SQL 查询处理器
5.1.2 为什么选择 Table API & SQL?
5.1.3 Flink Table 项目模块
5.1.4 两种 planner 之间的区别
5.1.5 添加项目依赖
5.1.6 创建一个 TableEnvironment
5.1.7 Table API & SQL 应用程序的结构
5.1.8 Catalog 中注册 Table
5.1.9 注册外部的 Catalog
5.1.10 查询 Table
5.1.11 提交 Table
5.1.12 翻译并执行查询
5.1.13 小结与反思
5.2Flink Table API & SQL 功能
5.2.1 Flink Table 和 SQL 与 DataStream 和 DataSet 集成
5.2.2 查询优化
5.2.3 数据类型
5.2.4 时间属性
5.2.5 SQL Connector
5.2.6 SQL Client
5.2.7 Hive
5.2.8 小结与反思
5.3总结
6第六章——扩展库
6.1Flink CEP 简介及其使用场景
6.1.1 CEP 简介
6.1.2 规则引擎对比
6.1.3 Flink CEP 简介
6.1.4 Flink CEP 动态更新规则
6.1.5 Flink CEP 使用场景分析
6.1.6 小结与反思
6.2使用 Flink CEP 处理复杂事件
6.2.1 准备依赖
6.2.2 Flink CEP 入门应用程序
6.2.3 Pattern API
6.2.4 检测 Pattern
6.2.5 CEP 时间属性
6.2.6 小结与反思
6.3Flink 扩展库——State Processor API
6.3.1 State Processor API 简介
6.3.2 在 Flink 1.9 之前是如何处理状态的?
6.3.3 使用 State Processor API 读写作业状态
6.3.4 使用 DataSet 读取作业状态
6.3.5 为什么要使用 DataSet API?
6.3.6 小结与反思
6.4Flink 扩展库——Machine Learning
6.4.1 Flink-ML 简介
6.4.2 使用 Flink-ML
6.4.3 使用 Flink-ML Pipeline
6.4.4 小结与反思
6.5Flink 扩展库——Gelly
6.5.1 Gelly 简介
6.5.2 使用 Gelly
6.5.3 Gelly API
6.5.4 小结与反思
6.6 总结
4高级篇
7第七章——Flink 作业环境部署
7.1Flink 配置详解及如何配置高可用?
7.1.1 Flink 配置详解
7.1.2 Log 的配置
7.1.3 如何配置 JobManager 高可用?
7.1.4 小结与反思
7.2Flink 作业如何在 Standalone、YARN、Mesos、K8S 上部署运行?
7.2.1 Standalone
7.2.2 YARN
7.2.3 Mesos
7.3.4 Kubernetes
7.2.5 小结与反思
7.3总结
8第八章——Flink 监控
8.1实时监控 Flink 及其作业
8.1.1 监控 JobManager
8.1.2 监控 TaskManager
8.1.3 监控 Flink 作业
8.1.4 最关心的性能指标
8.1.5 小结与反思
8.2搭建一套 Flink 监控系统
8.2.1 利用 API 获取监控数据
8.2.2 Metrics 类型简介
8.2.3 利用 JMXReporter 获取监控数据
8.2.4 利用 PrometheusReporter 获取监控数据
8.2.5 利用 PrometheusPushGatewayReporter 获取监控数据
8.2.6 利用 InfluxDBReporter 获取监控数据
8.2.7 安装 InfluxDB 和 Grafana
8.2.8 配置 Grafana 展示监控数据
8.2.9 小结与反思
8.3总结
9第九章——Flink 性能调优
9.1如何处理 Flink Job Backpressure (反压)问题?
9.1.1 Flink 流处理为什么需要网络流控
9.1.2 Flink 1.5 之前的网络流控机制
9.1.3 基于 Credit 的反压机制
9.1.4 定位产生反压的位置
9.1.5 分析和处理反压问题
9.1.6 小结与反思
9.2如何查看 Flink 作业执行计划?
9.2.1 如何获取执行计划 JSON?
9.2.2 生成执行计划图
9.2.3 深入探究 Flink 作业执行计划
9.2.4 Flink 中算子 chain 起来的条件
9.2.5 如何禁止 Operator chain?
9.2.6 小结与反思
9.3Flink Parallelism 和 Slot 深度理解
9.3.1 Parallelism 简介
9.3.2 如何设置 Parallelism?
9.3.3 Slot 简介
9.3.4 Slot 和 Parallelism 的关系
9.3.5 可能会遇到 Slot 和 Parallelism 的问题
9.3.6 小结与反思
9.4如何合理的设置 Flink 作业并行度?
9.4.1 Source 端并行度的配置
9.4.2 中间 Operator 并行度的配置
9.4.3 Sink 端并行度的配置
9.4.4 Operator Chain
9.4.5 小结与反思
9.5Flink 中如何保证 Exactly Once?
9.5.1 Flink 内部如何保证 Exactly Once?
9.5.2 端对端如何保证 Exactly Once?
9.5.3 分析 FlinkKafkaConsumer 的设计思想
9.5.4 小结与反思
9.6如何处理 Flink 中数据倾斜问题?
9.6.1 数据倾斜简介
9.6.2 判断是否存在数据倾斜
9.6.3 分析和解决数据倾斜问题
9.6.4 小结与反思
9.7总结
10第十章——Flink 最佳实践
10.1如何设置 Flink Job RestartStrategy(重启策略)?
10.1.1 常见错误导致 Flink 作业重启
10.1.2 RestartStrategy 简介
10.1.3 为什么需要 RestartStrategy?
10.1.4 如何配置 RestartStrategy?
10.1.5 RestartStrategy 源码分析
10.1.6 Failover Strategies(故障恢复策略)
10.1.7 小结与反思
10.2如何使用 Flink ParameterTool 读取配置?
10.2.1 Flink Job 配置
10.2.2 ParameterTool 管理配置
10.2.3 ParameterTool 源码分析
10.2.4 小结与反思
10.3总结
5实战篇
11第十一章——Flink 实战
11.1如何统计网站各页面一天内的 PV 和 UV?
11.1.1 统计网站各页面一天内的 PV
11.1.2 统计网站各页面一天内 UV 的三种方案
11.1.3 小结与反思
11.2如何使用 Flink ProcessFunction 处理宕机告警?
11.2.1 ProcessFunction 简介
11.2.2 CoProcessFunction 简介
11.2.3 Timer 简介
11.2.4 如果利用 ProcessFunction 处理宕机告警?
11.2.5 小结与反思
11.3如何利用 Async I/O 读取告警规则?
11.3.1 为什么需要 Async I/O?
11.3.2 Async I/O API
11.3.3 利用 Async I/O 读取告警规则需求分析
11.3.4 如何使用 Async I/O 读取告警规则数据
11.3.5 小结与反思
11.4如何利用广播变量动态更新告警规则?
11.4.1 BroadcastVariable 简介
11.4.2 如何使用 BroadcastVariable ?
11.4.3 利用广播变量动态更新告警规则数据需求分析
11.4.4 读取告警规则数据
11.4.5 监控数据连接规则数据
11.4.6 小结与反思
11.5如何实时将应用 Error 日志告警?
11.5.1 日志处理方案的演进
11.5.2 日志采集工具对比
11.5.3 日志结构设计
11.5.4 异常日志实时告警项目架构
11.5.5 日志数据发送到 Kafka
11.5.6 Flink 实时处理日志数据
11.5.7 处理应用异常日志
11.5.8 小结与反思
11.6总结
6案例篇
12第十二章——Flink 案例
12.1基于 Flink 实时处理海量日志
12.2.1 实时处理海量日志需求分析
12.2.2 实时处理海量日志架构设计
12.2.3 日志实时采集
12.2.4 日志格式统一
12.2.5 日志实时清洗
12.2.6 日志实时告警
12.2.7 日志实时存储
12.2.8 日志实时展示
12.2.9 小结与反思
12.2基于 Flink 的百亿数据实时去重
12.2.1 去重的通用解决方案
12.2.2 使用 BloomFilter 实现去重
12.2.3 使用 HBase 维护全局 Set 实现去重
12.2.4 使用 Flink 的 KeyedState 实现去重
12.2.5 使用 RocksDBStateBackend 的优化方法
12.2.6 小结与反思
12.3基于 Flink 的实时监控告警系统
12.3.1 监控系统的诉求
12.3.2 监控系统包含的内容
12.3.3 Metrics/Trace/Log 数据实时采集
12.3.4 消息队列如何撑住高峰流量
12.3.5 指标数据实时计算
12.3.6 提供及时且准确的根因分析告警
12.3.7 AIOps 智能运维道路探索
12.3.8 如何保障高峰流量实时写入存储系统的稳定性
12.3.9 监控数据使用可视化图表展示
12.3.10 小结与反思
12.4总结
```
================================================
FILE: books/flink-in-action-1.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》——你的公司是否需要引入实时计算引擎?
date: 2021-07-04
tags:
- Flink
- 大数据
- 流式计算
---
# 第一章 —— 实时计算引擎
本章会从公司常见的计算需求去分析该如何实现这些需求,接着会对比分析实时计算与离线计算之间的区别,从而帮大家分析公司是否需要引入实时计算引擎。接着将会详细的介绍目前最火的实时计算引擎 Flink 的特性,让大家知道其优点,最后会对比其他的计算框架,比如 Spark、Storm 等,希望可以从对比结果来分析这几种计算框架的各自优势,从而为你做技术选型提供一点帮助。
## 1.1 你的公司是否需要引入实时计算引擎
大数据发展至今,数据呈指数倍的增长,对实效性的要求也越来越高,所以你可能接触到的实时计算需求会越来越多。本章节将从实时计算需求开始讲起,然后阐述完成该需求需要做的工作,最后对比实时计算与离线计算。
### 1.1.1 实时计算需求
在公司里面,你可能会收到领导、产品经理或者运营等提出的如下需求:
```
小田,你看能不能做个监控大屏实时查看促销活动商品总销售额(GMV)?
小朱,搞促销活动的时候能不能实时统计下网站的 PV/UV 啊?
小鹏,我们现在搞促销活动能不能实时统计销量 Top5 商品啊?
小李,怎么回事啊?现在搞促销活动结果服务器宕机了都没告警,能不能加一个?
小刘,服务器这会好卡,是不是出了什么问题啊,你看能不能做个监控大屏实时查看机器的运行情况?
小赵,我们线上的应用频繁出现 Error 日志,但是只有靠人肉上机器查看才知道情况,能不能在出现错误的时候及时告警通知?
小夏,我们 1 元秒杀促销活动中有件商品被某个用户薅了 100 件,怎么都没有风控啊?
小宋,你看我们搞促销活动能不能根据每个顾客的浏览记录实时推荐不同的商品啊?
……
```
那上面这些需求分别对应着什么业务场景呢?我们来总结下,大概如下图所示:
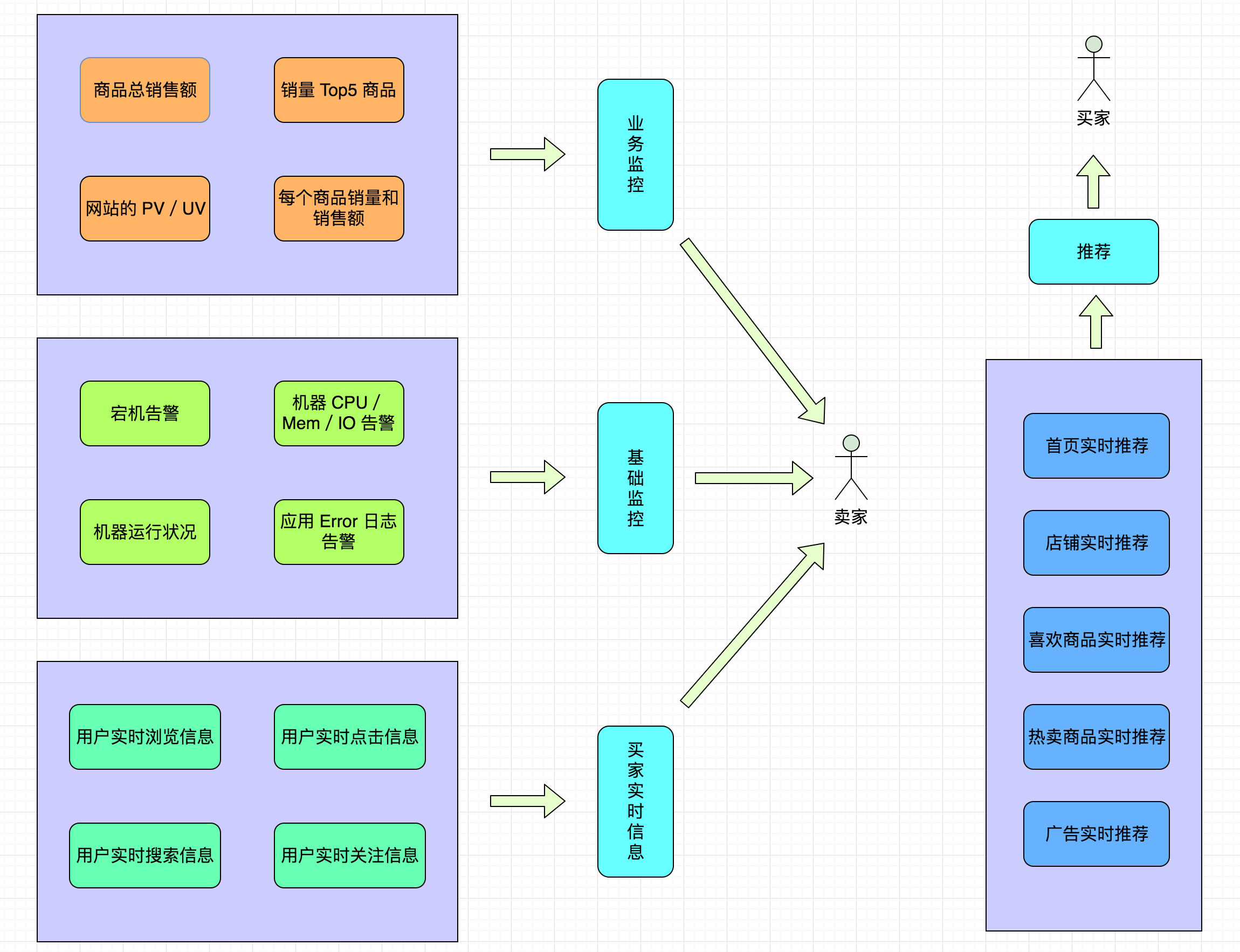
初看这些需求,你是不是感觉实现会比较难?那么接下来我们来分析一下该如何实现这些需求?从这些需求来看,最根本的业务都是需要**实时查看数据信息**,那么首先我们得想想如何实时去采集数据,然后将采集到的数据进行实时的计算,最后将计算后的结果下发到第三方。从采集到计算再到下发计算结果的整个过程,必须都得是实时的,这样我们看到的数据才是最接近实时的,这样才能够很完美的完成上面的这些实时计算需求。
### 1.1.2 数据实时采集
就上面这些需求,我们知道了需要实时去采集数据,但是针对这些需求,我们到底需要采集些什么数据呢?如下就是我们需要采集的数据:
+ 用户搜索信息
+ 用户浏览商品信息
+ 用户下单订单信息
+ 网站的所有浏览记录
+ 机器 CPU/Mem/IO 信息
+ 应用日志信息
### 1.1.3 数据实时计算
采集后的数据实时上报后,需要做实时的计算,那我们怎么实现计算呢?
+ 计算所有商品的总销售额
+ 统计单个商品的销量,最后求 Top5
+ 关联用户信息和浏览信息、下单信息
+ 统计网站所有的请求 IP 并统计每个 IP 的请求数量
+ 计算一分钟内机器 CPU/Mem/IO 的平均值、75 分位数值
+ 过滤出 Error 级别的日志信息
### 1.1.4 数据实时下发
实时计算后的数据,需要及时的下发到下游,这里说的下游代表可能是告警方式(邮件、短信、钉钉、微信)、存储(消息队列、DB、文件系统等)。
(1)告警方式(邮件、短信、钉钉、微信)
在计算层会将计算结果与阈值进行比较,超过阈值触发告警,让运维提前收到通知,告警消息如下图所示,这样运维可以及时做好应对措施,减少故障的损失大小。
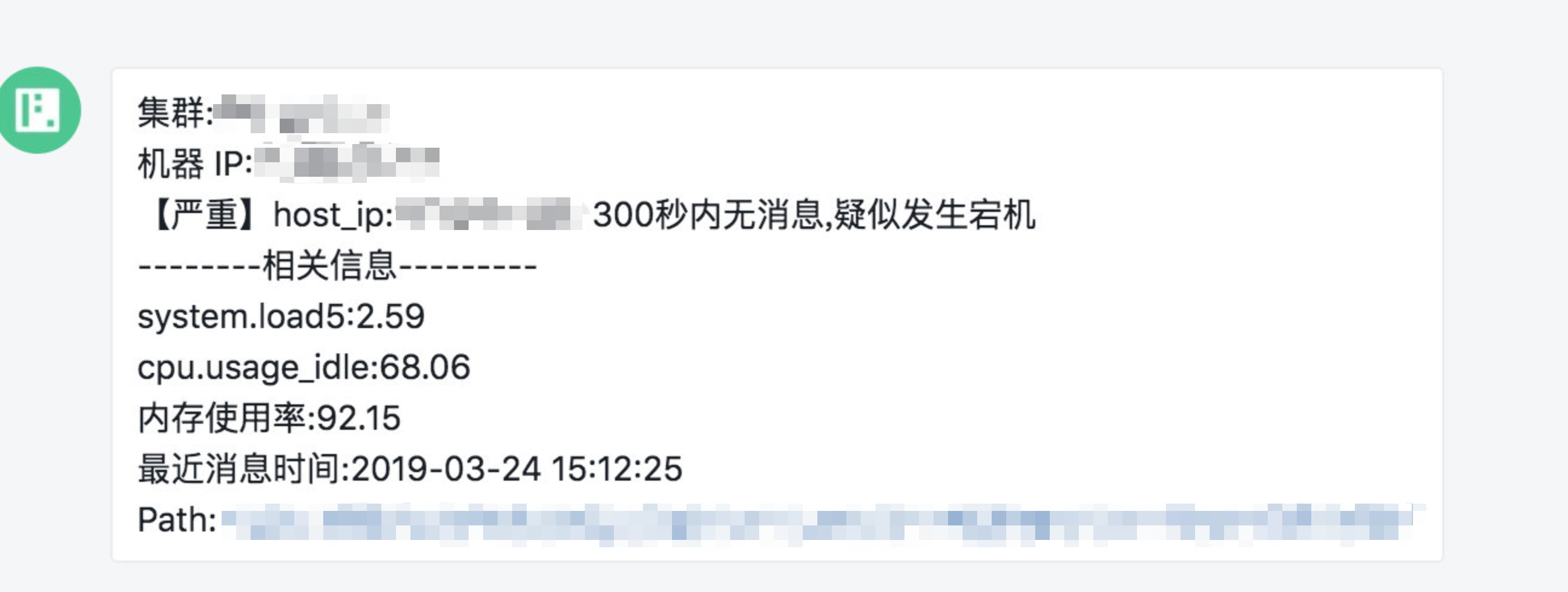
(2)存储(消息队列、DB、文件系统等)
数据存储后,监控大盘(Dashboard)从存储(ElasticSearch、HBase 等)里面查询对应指标的数据就可以查看实时的监控信息,做到对促销活动的商品销量、销售额,机器 CPU、Mem 等有实时监控,运营、运维、开发、领导都可以实时查看并作出对应的措施。
+ 让运营知道哪些商品是爆款,哪些店铺成交额最多,如下图所示,哪些商品成交额最高,哪些商品浏览量最多;

+ 让运维可以时刻了解机器的运行状况,如下图所示,出现宕机或者其他不稳定情况可以及时处理;
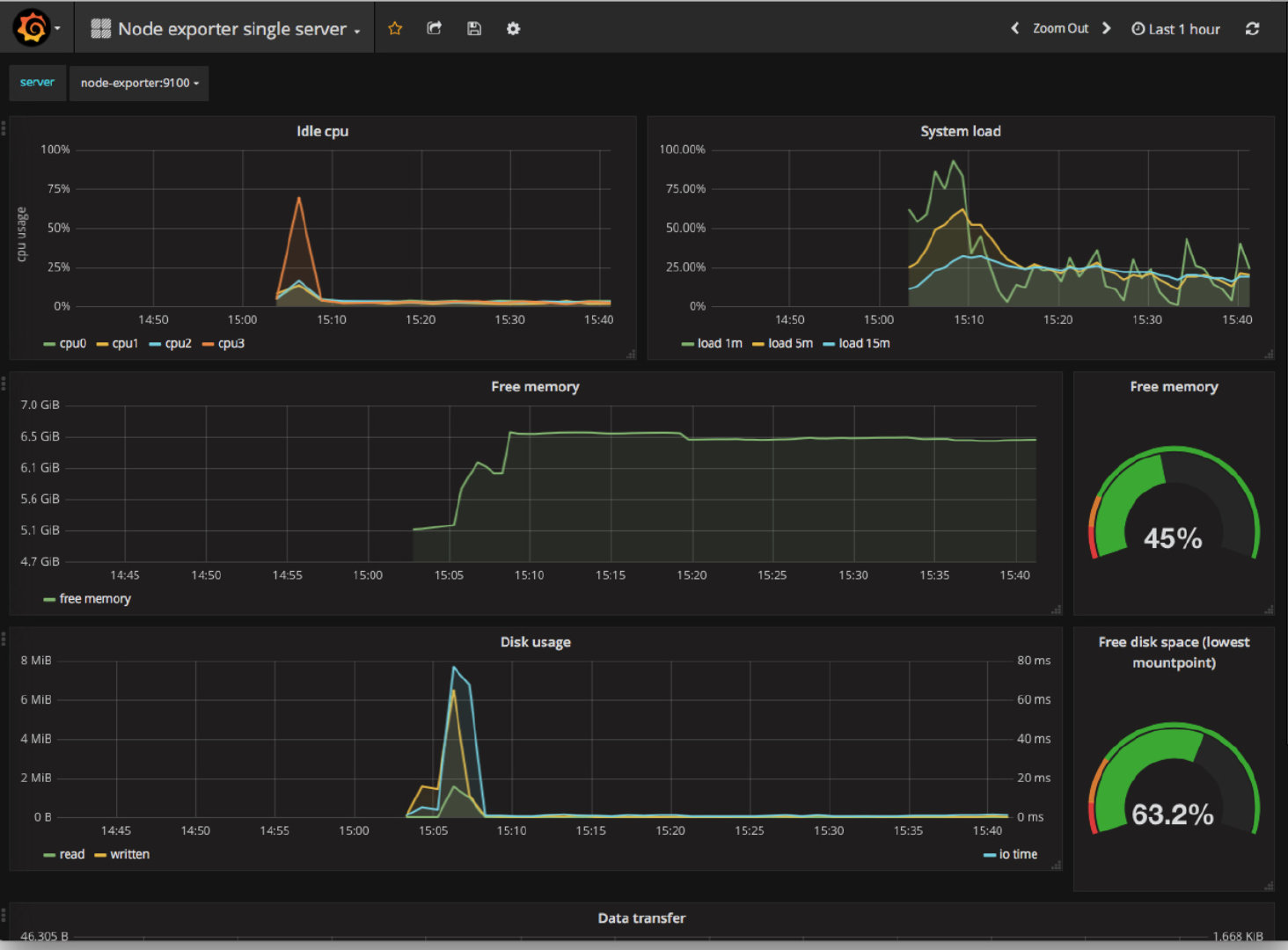
+ 让开发知道自己项目运行的情况,从 Error 日志知道出现了哪些 Bug,如下图所示;
+ 让领导知道这次促销赚了多少 money,如下图所示。

**从数据采集到数据计算再到数据下发,如下图所示,整个流程在上面的场景对实时性要求还是很高的,任何一个地方出现问题都将影响最后的效果!**
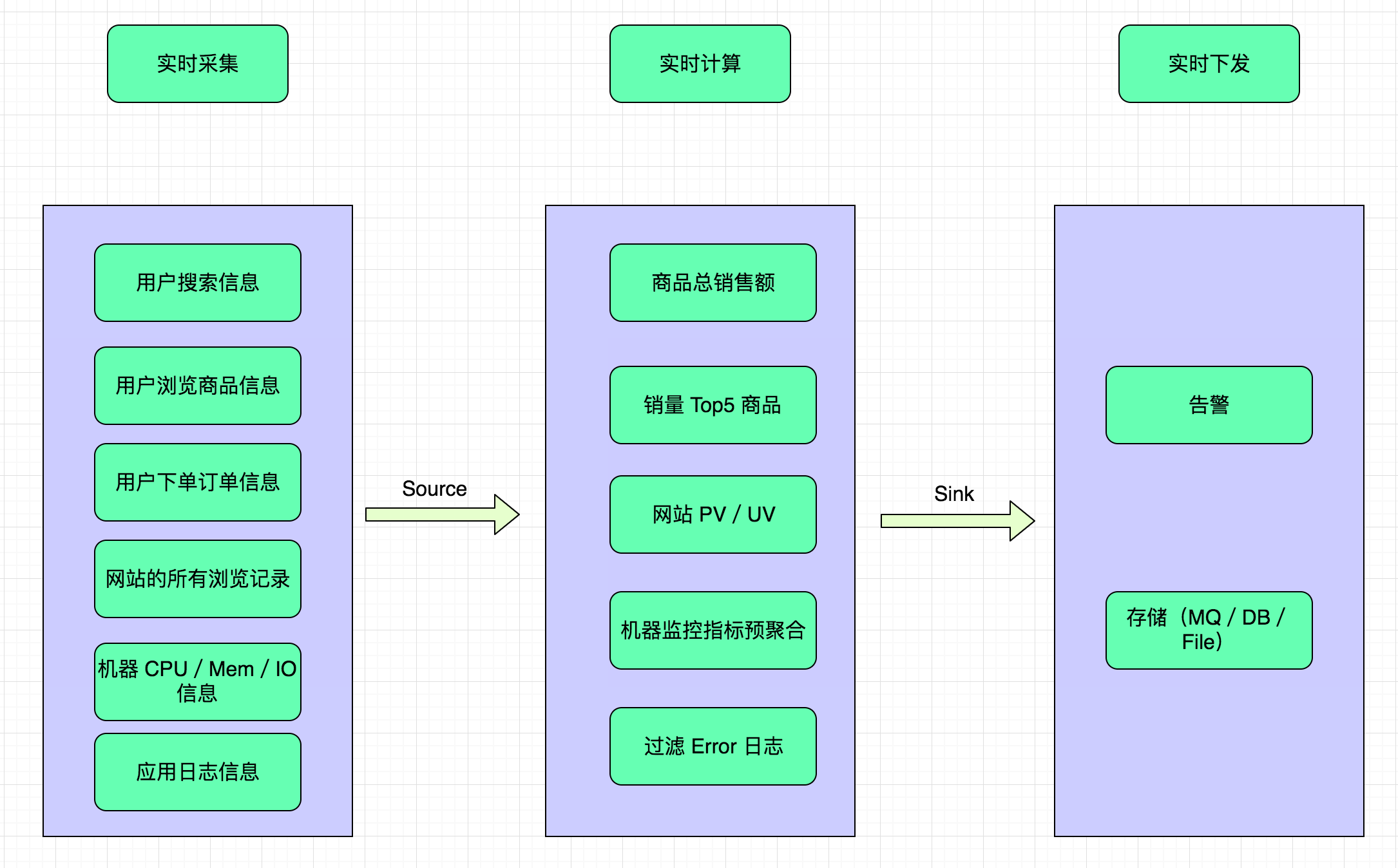
### 1.1.5 实时计算场景
前面说了这么多场景,这里我们总结一下实时计算常用的场景有哪些呢?比如:
+ 交通信号灯数据
+ 道路上车流量统计(拥堵状况)
+ 公安视频监控
+ 服务器运行状态监控
+ 金融证券公司实时跟踪股市波动,计算风险价值
+ 数据实时 ETL
+ 银行或者支付公司涉及金融盗窃的预警
……
另外自己还做过调研,实时计算框架的使用场景有如下这些:
+ 业务数据处理,聚合业务数据,统计之类
+ 流量日志
+ ETL
+ 安防这块,公安视频结构化数据,用 Flink 做图片搜索
+ 风控,主要处理结构化数据
+ 业务告警
+ 动态数据监控
总结一下大概有下面这四类,如下图所示:
这四类分别是:
+ **实时数据存储**:实时数据存储的时候做一些微聚合、过滤某些字段、数据脱敏,组建数据仓库,实时 ETL。
+ **实时数据分析**:实时数据接入机器学习框架(TensorFlow)或者一些算法进行数据建模、分析,然后动态的给出商品推荐、广告推荐
+ **实时监控告警**:金融相关涉及交易、实时风控、车流量预警、服务器监控告警、应用日志告警
+ **实时数据报表**:活动营销时销售额/销售量大屏,TopN 商品
说到实时计算,这里不得不讲一下它与传统的离线计算之间的区别!
### 1.1.6 离线计算 vs 实时计算
再讲离线计算和实时计算这两个区别之前,我们先来看看流处理和批处理。
#### 流处理与批处理
流处理是一种重要的大数据处理手段,其主要特点是其处理的数据是源源不断且实时到来的。批处理历史比较悠久,而且使用的场景比较多,其主要操作的是大容量的静态数据集,并在计算过程完成后返回结果。它们之间的区别如下图所示:
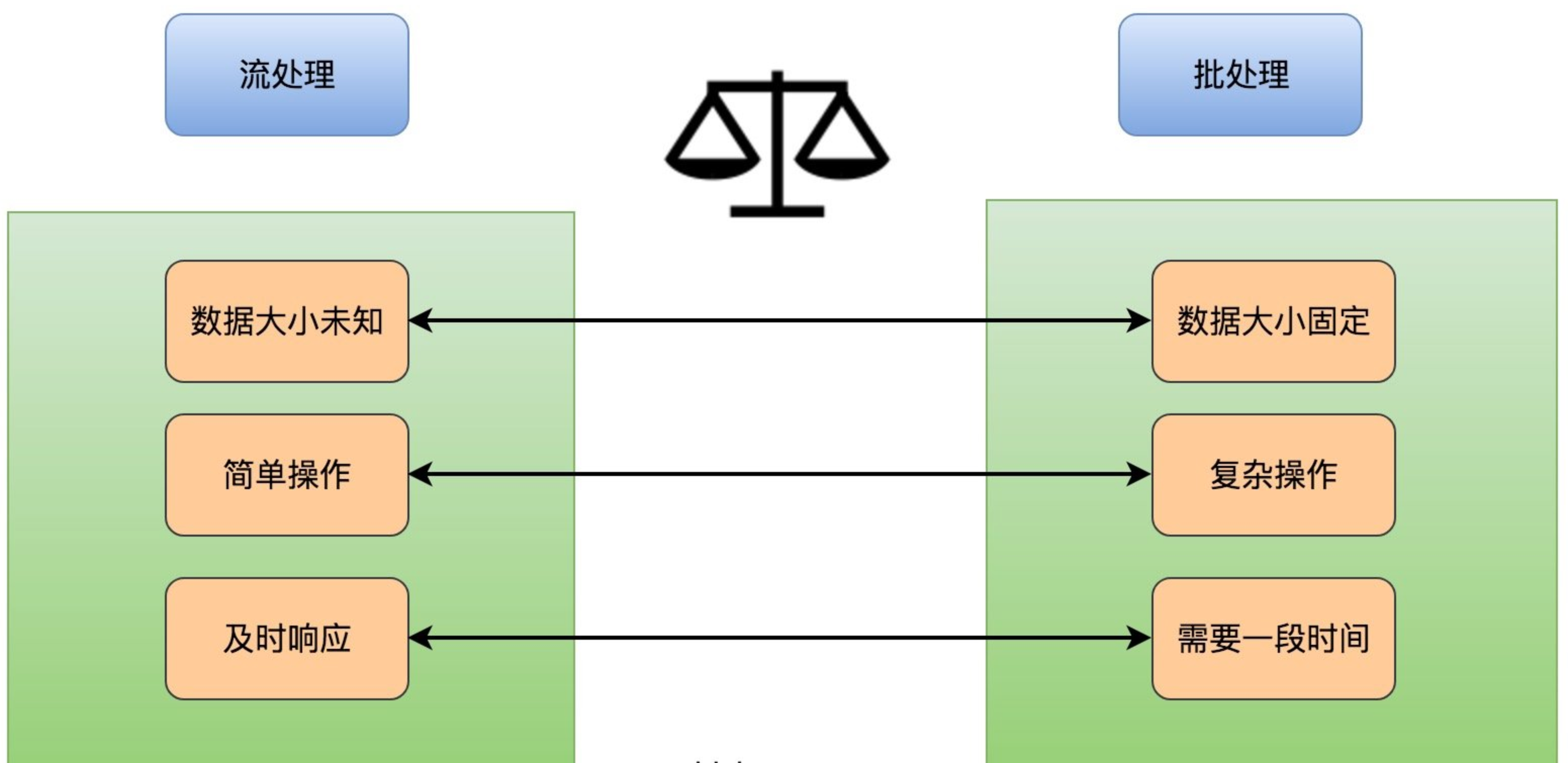
看完流处理与批处理这两者的区别之后,我们来抽象一下前面内容的场景需求计算流程(**实时计算**)如下图所示:
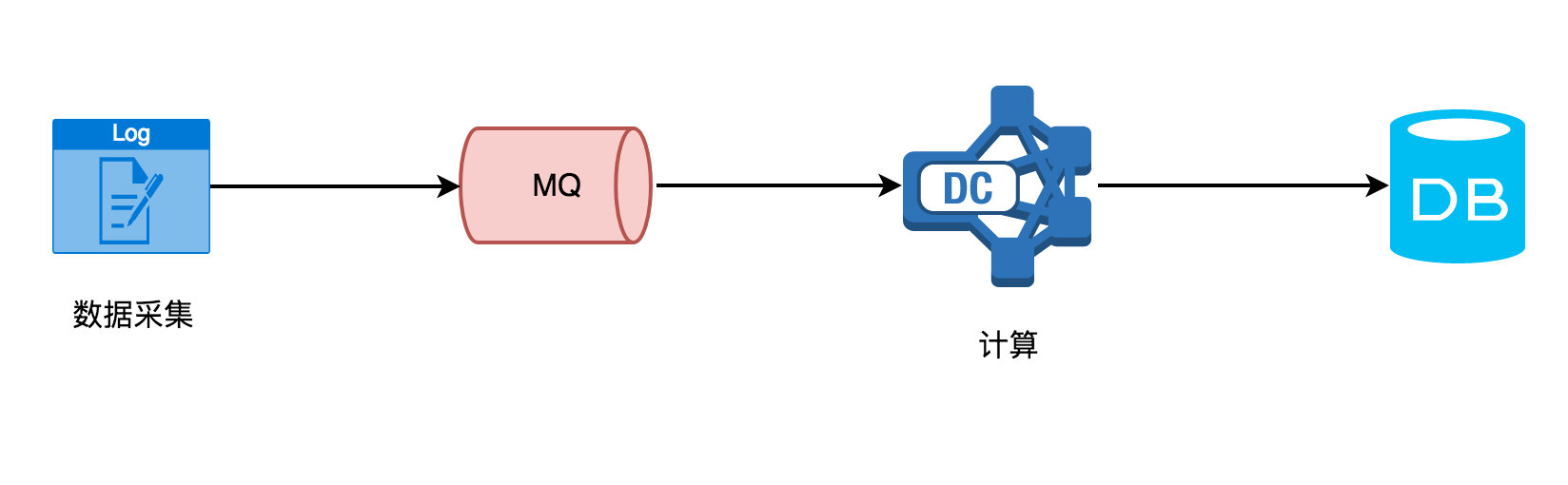
实时计算需要不断的从 MQ 中读取采集的数据,然后处理计算后往 DB 里存储,在计算这层你无法感知到会有多少数据量过来、要做一些简单的操作(过滤、聚合等)、及时将数据下发。然而传统的**离线计算**却如下图所示:
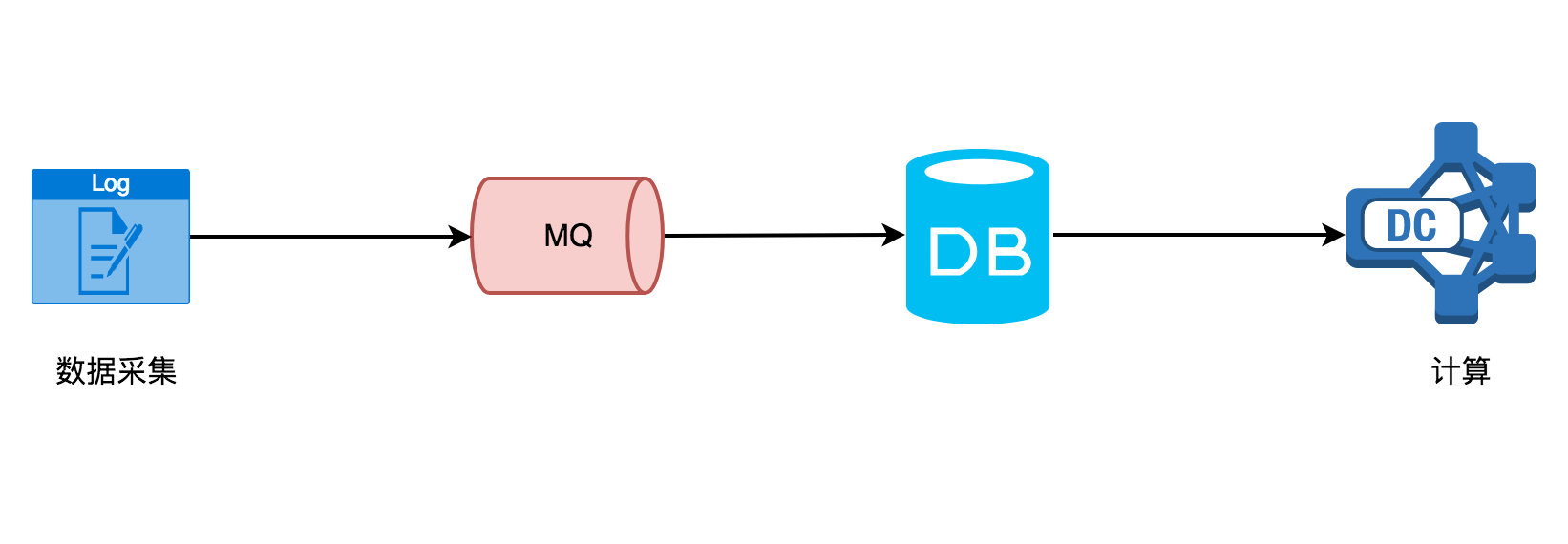
在计算这层,它从 DB(不限 MySQL,还有其他的存储介质)里面读取数据,该数据一般就是固定的(前一天、前一星期、前一个月),然后再做一些复杂的计算或者统计分析,最后生成可供直观查看的报表(dashboard)。
#### 离线计算的特点
离线计算一般有下面这些特点:
+ 数据量大且时间周期长(一天、一星期、一个月、半年、一年)
+ 在大量数据上进行复杂的批量计算操作
+ 数据在计算之前已经固定,不再会发生变化
+ 能够方便的查询批量计算的结果
#### 实时计算的特点
在大数据中与离线计算对应的则是实时计算,那么实时计算有什么特点呢?由于应用场景的各不相同,所以这两种计算引擎接收数据的方式也不太一样:离线计算的数据是固定的(不再会发生变化),通常离线计算的任务都是定时的,如:每天晚上 0 点的时候定时计算前一天的数据,生成报表;然而实时计算的数据源却是流式的。
这里我不得不讲讲什么是流式数据呢?我的理解是比如你在淘宝上下单了某个商品或者点击浏览了某件商品,你就会发现你的页面立马就会给你推荐这种商品的广告和类似商品的店铺,这种就是属于实时数据处理然后作出相关推荐,这类数据需要不断的从你在网页上的点击动作中获取数据,之后进行实时分析然后给出推荐。
#### 流式数据的特点
流式数据一般有下面这些特点:
+ 数据实时到达
+ 数据到达次序独立,不受应用系统所控制
+ 数据规模大且无法预知容量
+ 原始数据一经处理,除非特意保存,否则不能被再次取出处理,或者再次提取数据代价昂贵
通过上面的内容可以总结实时计算与离线计算的对比如下图所示:

#### 实时计算的优势
**实时计算一时爽,一直实时计算一直爽**,对于持续生成最新数据的场景,采用流数据处理是非常有利的。例如,再监控服务器的一些运行指标的时候,能根据采集上来的实时数据进行判断,当超出一定阈值的时候发出警报,进行提醒作用。再如通过处理流数据生成简单的报告,如五分钟的窗口聚合数据平均值。复杂的事情还有在流数据中进行数据多维度关联、聚合、筛选,从而找到复杂事件中的根因。更为复杂的是做一些复杂的数据分析操作,如应用机器学习算法,然后根据算法处理后的数据结果提取出有效的信息,作出、给出不一样的推荐内容,让不同的人可以看见不同的网页(千人千面)。
### 1.1.7 实时计算面临的挑战
虽然实时计算有这么多好处,但是要使用实时计算也会面临很多挑战,比如下面这些:
+ 数据处理唯一性(如何保证数据只处理一次?至少一次?最多一次?)
+ 数据处理的及时性(采集的实时数据量太大的话可能会导致短时间内处理不过来,如何保证数据能够及时的处理,不出现数据堆积?)
+ 数据处理层和存储层的可扩展性(如何根据采集的实时数据量的大小提供动态扩缩容?)
+ 数据处理层和存储层的容错性(如何保证数据处理层和存储层高可用,出现故障时数据处理层和存储层服务依旧可用?)
因为各种需求,也就造就了现在不断出现实时计算框架,在 1.2 节中将重磅介绍如今最火的实时计算框架 —— Flink,在 1.3 节中会对比介绍 Spark Streaming、Structured Streaming 和 Storm 之间的区别。
### 1.1.8 小结与反思
本节从实时计算的需求作为切入点,然后分析该如何去完成这种实时计算的需求,从而得知整个过程包括数据采集、数据计算、数据存储等,接着总结了实时计算场景的类型。最后开始介绍离线计算与实时计算的区别,并提出了实时计算可能带来的挑战。你们公司有文中所讲的类似需求吗?你是怎么解决的呢?
================================================
FILE: books/flink-in-action-1.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 彻底了解大数据实时计算框架 Flink
date: 2021-07-05
tags:
- Flink
- 大数据
- 流式计算
---
## 1.2 彻底了解大数据实时计算框架 Flink
在 1.1 节中讲解了日常开发常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算。随着这些年大数据的飞速发展,也出现了不少计算的框架(Hadoop、Storm、Spark、Flink)。在网上有人将大数据计算引擎的发展分为四个阶段。
+ 第一代:Hadoop 承载的 MapReduce
+ 第二代:支持 DAG(有向无环图)框架的计算引擎 Tez 和 Oozie,主要还是批处理任务
+ 第三代:支持 Job 内部的 DAG(有向无环图),以 Spark 为代表
+ 第四代:大数据统一计算引擎,包括流处理、批处理、AI、Machine Learning、图计算等,以 Flink 为代表
或许会有人不同意以上的分类,笔者觉得其实这并不重要的,重要的是体会各个框架的差异,以及更适合的场景。并进行理解,没有哪一个框架可以完美的支持所有的场景,也就不可能有任何一个框架能完全取代另一个。
本文将对 Flink 的整体架构和 Flink 的多种特性做个详细的介绍!在讲 Flink 之前的话,我们先来看看 **数据集类型** 和 **数据运算模型** 的种类。
#### 数据集类型
数据集类型有分无穷和有界数据集:
+ 无穷数据集:无穷的持续集成的数据集合
+ 有界数据集:有限不会改变的数据集合
那么那些常见的无穷数据集有哪些呢?
+ 用户与客户端的实时交互数据
+ 应用实时产生的日志
+ 金融市场的实时交易记录
+ …
#### 数据运算模型
数据运算模型有分流式处理和批处理:
+ 流式:只要数据一直在产生,计算就持续地进行
+ 批处理:在预先定义的时间内运行计算,当计算完成时释放计算机资源
那么我们再来看看 Flink 它是什么呢?
### 1.2.1 Flink 简介
Flink 是一个针对流数据和批数据的分布式处理引擎,代码主要是由 Java 实现,部分代码是 Scala。它可以处理有界的批量数据集、也可以处理无界的实时数据集,总结如下图所示。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已,所以 Flink 也是一款真正的流批统一的计算引擎。

如下图所示,Flink 提供了 State、Checkpoint、Time、Window 等,它们为 Flink 提供了基石,本篇文章下面会稍作讲解,具体深度分析后面会有专门的文章来讲解。
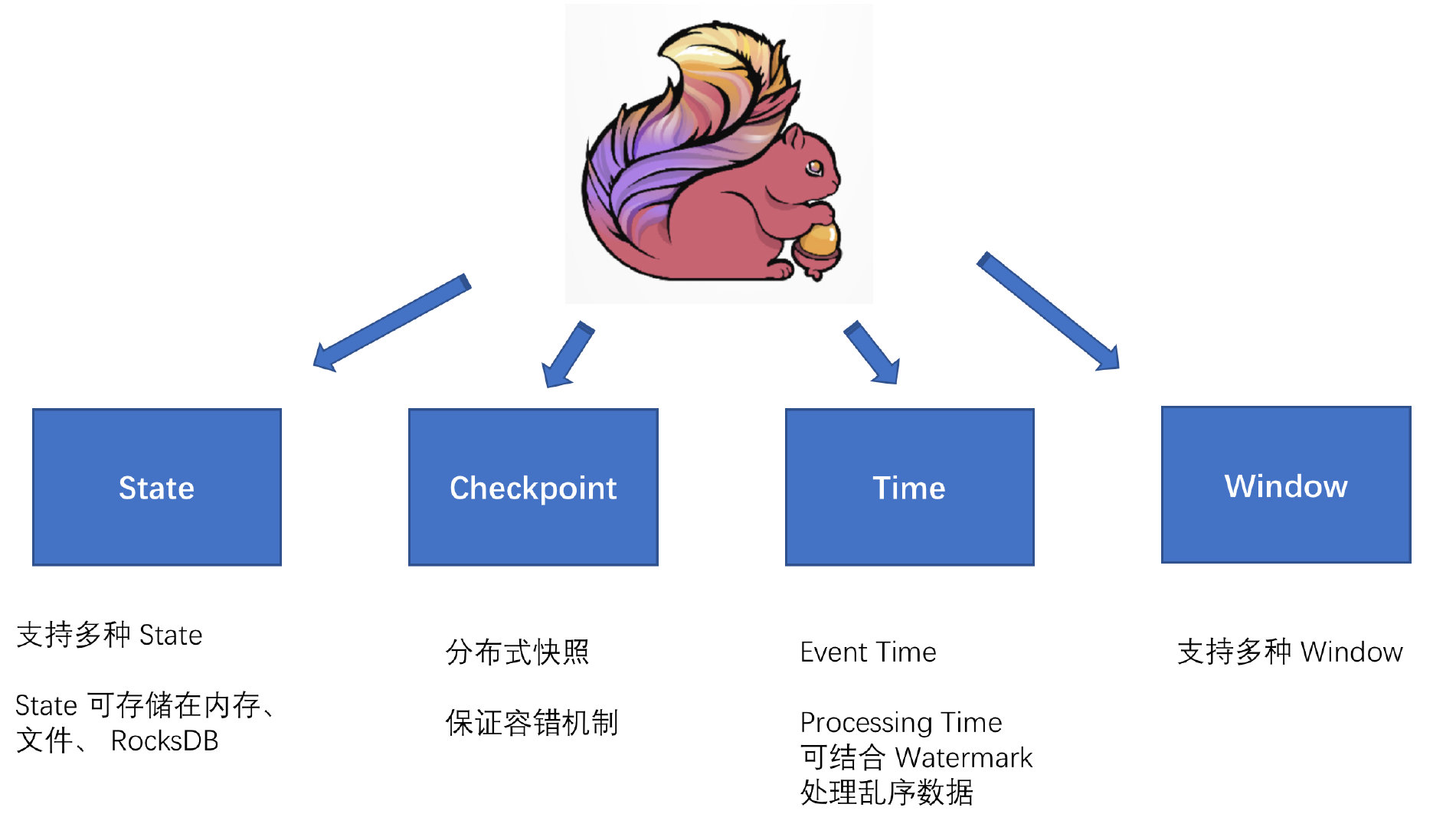
### 1.2.2 Flink 整体架构
Flink 整体架构从下至上分为:
1. 部署:Flink 支持本地运行(IDE 中直接运行程序)、能在独立集群(Standalone 模式)或者在被 YARN、Mesos、K8s 管理的集群上运行,也能部署在云上。
2. 运行:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。
3. API:DataStream、DataSet、Table API & SQL。
4. 扩展库:Flink 还包括用于 CEP(复杂事件处理)、机器学习、图形处理等场景。
整体架构如下图所示:
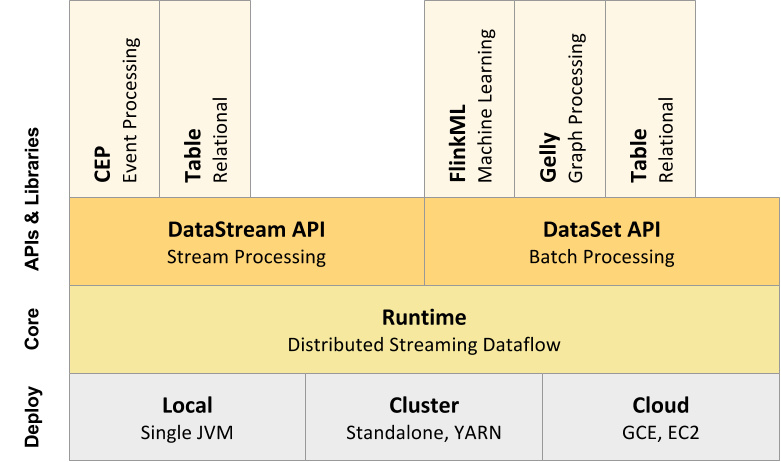
### 1.2.3 Flink 的多种方式部署
作为一个计算引擎,如果要做的足够完善,除了它自身的各种特点要包含,还得支持各种生态圈,比如部署的情况,Flink 是支持以 Standalone、YARN、Kubernetes、Mesos 等形式部署的,如下图所示。
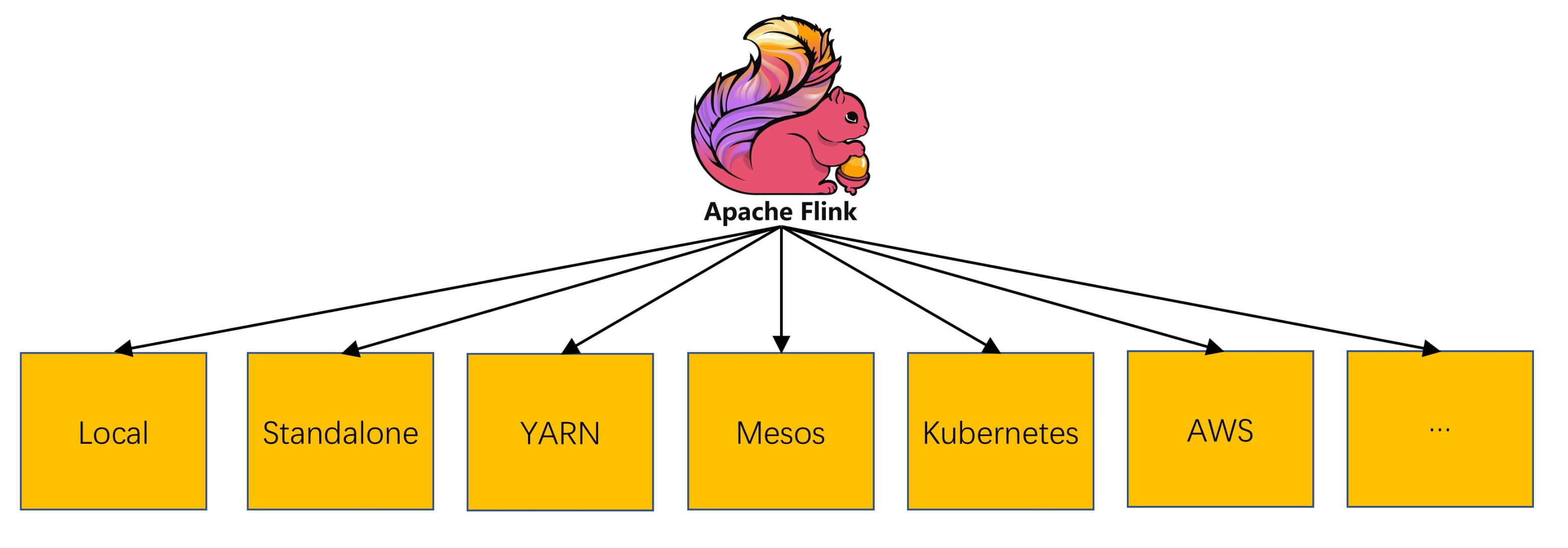
每种部署方式介绍如下:
+ Local:直接在 IDE 中运行 Flink Job 时则会在本地启动一个 mini Flink 集群。
+ Standalone:在 Flink 目录下执行 `bin/start-cluster.sh` 脚本则会启动一个 Standalone 模式的集群。
+ YARN:YARN 是 Hadoop 集群的资源管理系统,它可以在群集上运行各种分布式应用程序,Flink 可与其他应用并行于 YARN 中,Flink on YARN 的架构如下图所示。
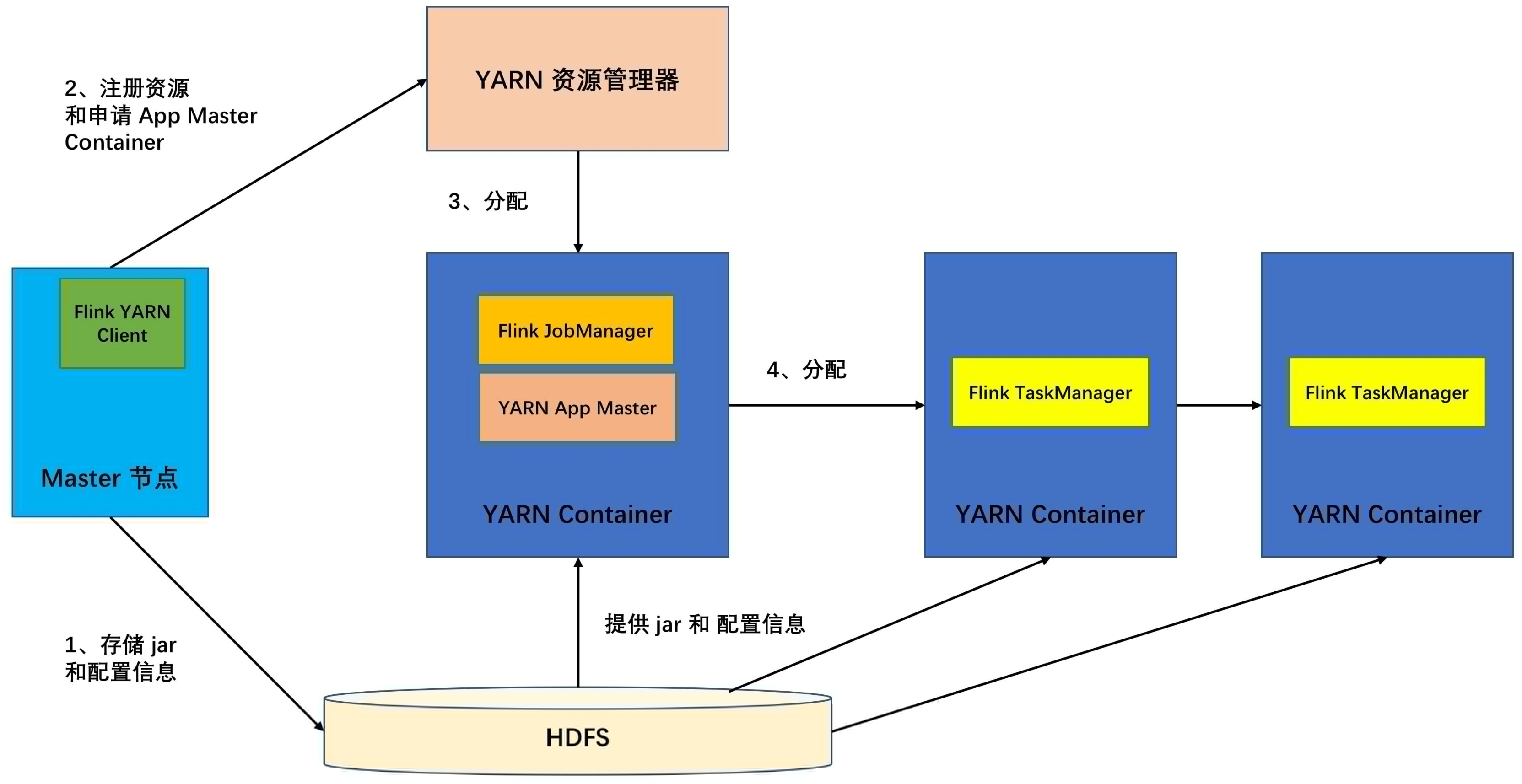
+ Kubernetes:Kubernetes 是 Google 开源的容器集群管理系统,在 Docker 技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性,Flink 也支持部署在 Kubernetes 上,在 [GitHub](https://github.com/Aleksandr-Filichkin/flink-k8s/blob/master/flow.jpg) 看到有下面这种运行架构的。

通常上面四种居多,另外还支持 AWS、MapR、Aliyun OSS 等。
### 1.2.4 Flink 分布式运行流程
Flink 作业提交架构流程如下图所示:
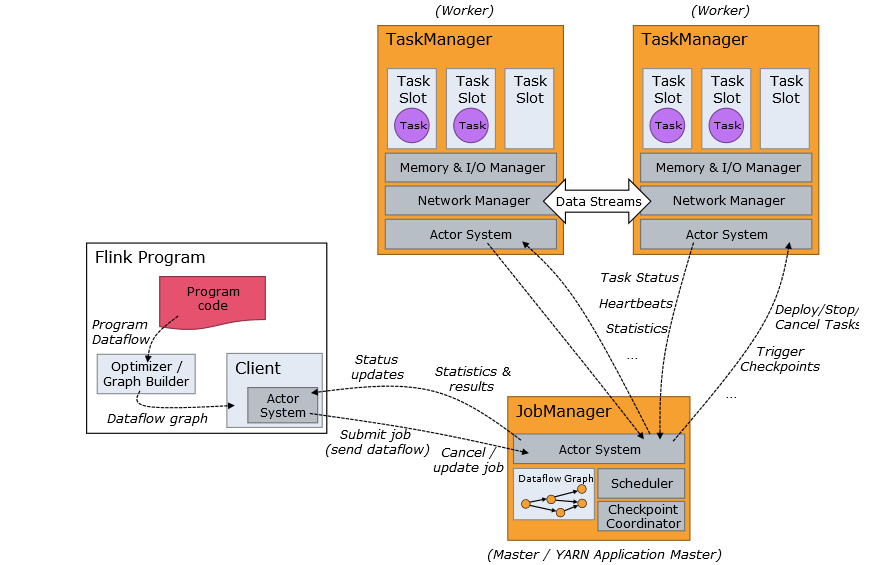
具体流程介绍如下:
1. Program Code:我们编写的 Flink 应用程序代码
2. Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 JobManager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户
3. JobManager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理 Checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 Checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; JobManager 包含 Actor system、Scheduler、Check pointing 三个重要的组件
4. TaskManager:从 JobManager 处接收需要部署的 Task。TaskManager 是在 JVM 中的一个或多个线程中执行任务的工作节点。 任务执行的并行性由每个 TaskManager 上可用的任务槽(Slot 个数)决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 TaskManager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。
同一 JVM 中的任务共享 TCP 连接和心跳消息。TaskManager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
### 1.2.5 Flink API
Flink 提供了不同的抽象级别的 API 以开发流式或批处理应用,如下图所示。
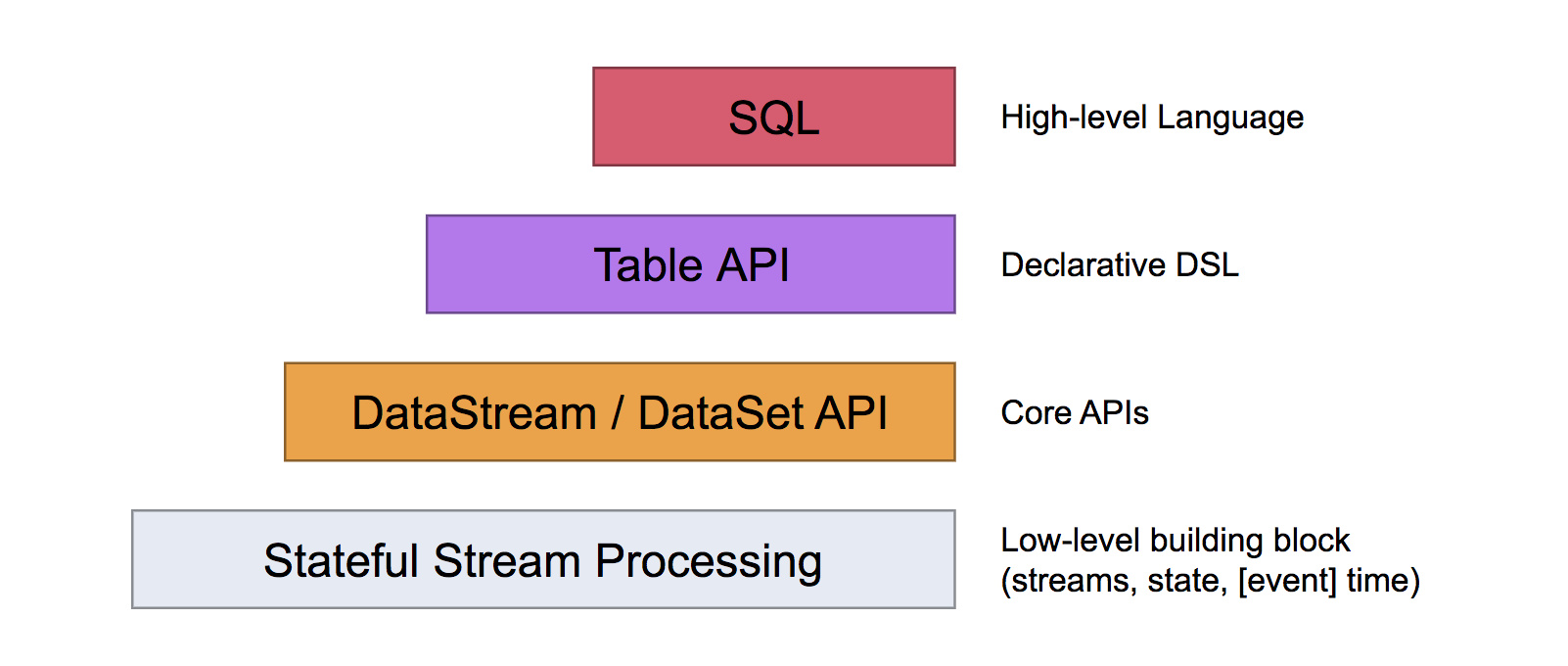
这四种 API 功能分别是:
+ 最底层提供了有状态流。它将通过 Process Function 嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致性、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
+ DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换或者计算。
+ Table API 是以表为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。
你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
+ Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
Flink 除了 DataStream 和 DataSet API,它还支持 Table API & SQL,Flink 也将通过 SQL 来构建统一的大数据流批处理引擎,因为在公司中通常会有那种每天定时生成报表的需求(批处理的场景,每晚定时跑一遍昨天的数据生成一个结果报表),但是也是会有流处理的场景(比如采用 Flink 来做实时性要求很高的需求),于是慢慢的整个公司的技术选型就变得越来越多了,这样开发人员也就要面临着学习两套不一样的技术框架,运维人员也需要对两种不一样的框架进行环境搭建和作业部署,平时还要维护作业的稳定性。当我们的系统变得越来越复杂了,作业越来越多了,这对于开发人员和运维来说简直就是噩梦,没准哪天凌晨晚上就被生产环境的告警电话给叫醒。所以 Flink 系统能通过 SQL API 来解决批流统一的痛点,这样不管是开发还是运维,他们只需要关注一个计算框架就行,从而减少企业的用人成本和后期开发运维成本。
### 1.2.6 Flink 程序与数据流结构
一个完整的 Flink 应用程序结构如下图所示:

它们的功能分别是:
+ Source:数据输入,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
+ Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
+ Sink:数据输出,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
代码结构如下图所示:
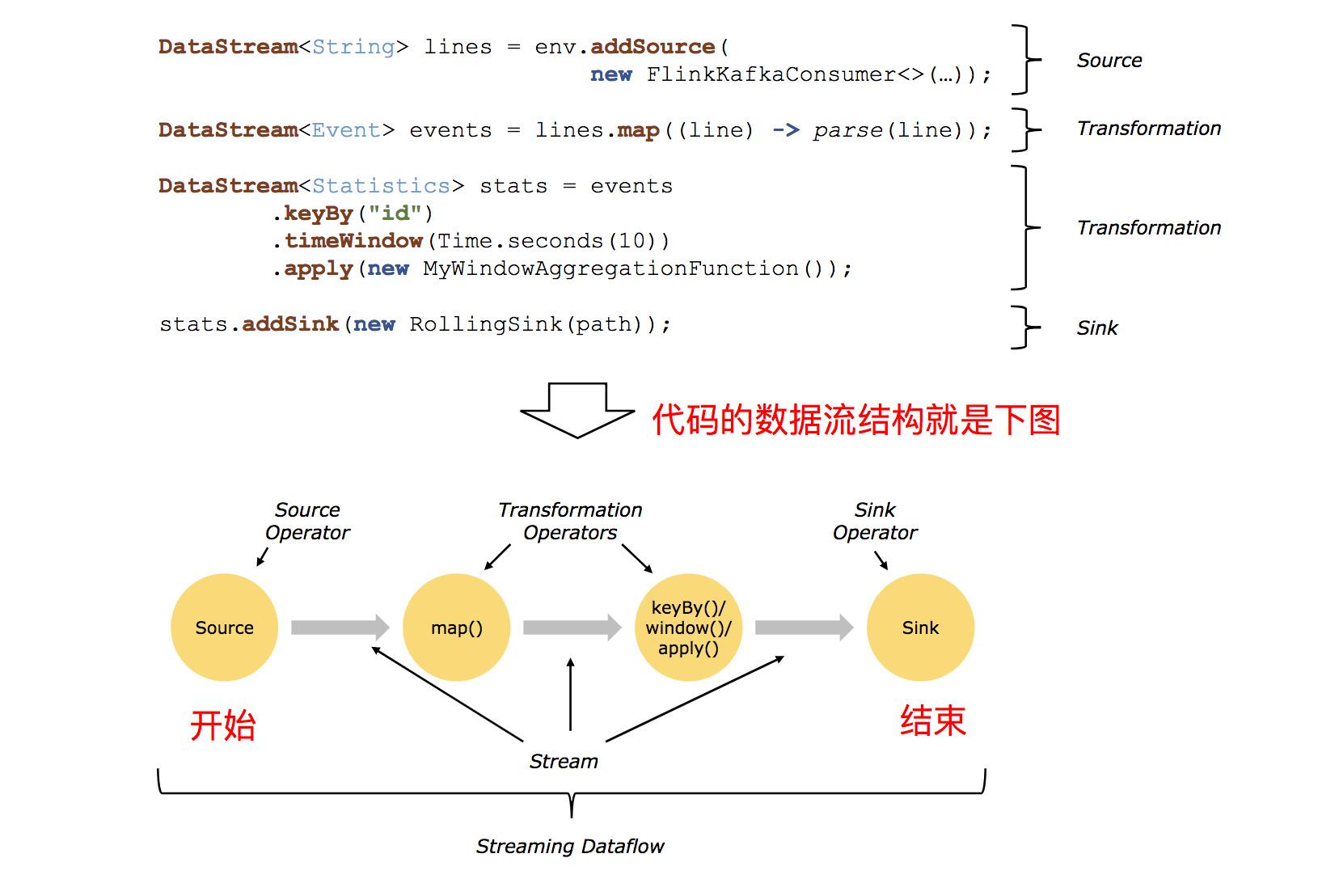
### 1.2.7 丰富的 Connector
通过源码可以发现不同版本的 Kafka、不同版本的 ElasticSearch、Cassandra、HBase、Hive、HDFS、RabbitMQ 都是支持的,除了流应用的 Connector 是支持的,另外还支持 SQL,如下图所示。
再就是要考虑计算的数据来源和数据最终存储,因为 Flink 在大数据领域的的定位就是实时计算,它不做存储(虽然 Flink 中也有 State 去存储状态数据,这里说的存储类似于 MySQL、ElasticSearch 等存储),所以在计算的时候其实你需要考虑的是数据源来自哪里,计算后的结果又存储到哪里去。庆幸的是 Flink 目前已经支持大部分常用的组件了,比如在 Flink 中已经支持了如下这些 Connector:
+ 不同版本的 Kafka
+ 不同版本的 ElasticSearch
+ Redis
+ MySQL
+ Cassandra
+ RabbitMQ
+ HBase
+ HDFS
+ ...
这些 Connector 除了支持流作业外,目前还有还有支持 SQL 作业的,除了这些自带的 Connector 外,还可以通过 Flink 提供的接口做自定义 Source 和 Sink(在 3.8 节中)。
### 1.2.8 事件时间&处理时间语义
Flink 支持多种 Time,比如 Event time、Ingestion Time、Processing Time,如下图所示,后面 3.1 节中会很详细的讲解 Flink 中 Time 的概念。

### 1.2.9 灵活的窗口机制
Flink 支持多种 Window,比如 Time Window、Count Window、Session Window,还支持自定义 Window,如下图所示。后面 3.2 节中会很详细的讲解 Flink 中 Window 的概念。
### 1.2.10 并行执行任务机制
Flink 的程序内在是并行和分布式的,数据流可以被分区成 stream partitions,operators 被划分为 operator subtasks; 这些 subtasks 在不同的机器或容器中分不同的线程独立运行;operator subtasks 的数量在具体的 operator 就是并行计算数,程序不同的 operator 阶段可能有不同的并行数;如下图所示,source operator 的并行数为 2,但最后的 sink operator 为 1:
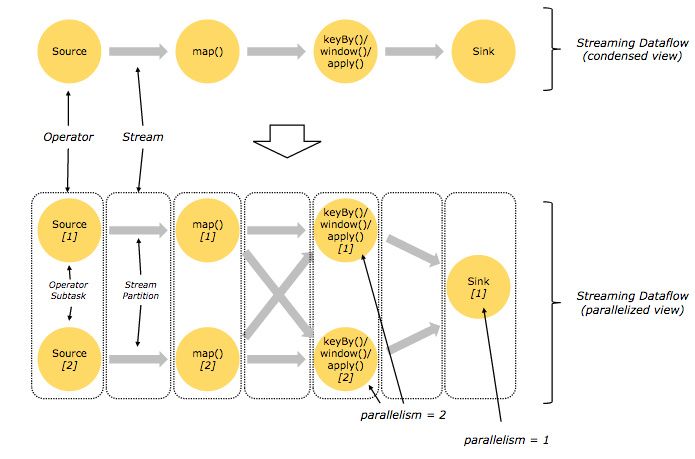
### 1.2.11 状态存储和容错
Flink 是一款有状态的流处理框架,它提供了丰富的状态访问接口,按照数据的划分方式,可以分为 Keyed State 和 Operator State,在 Keyed State 中又提供了多种数据结构:
+ ValueState
+ MapState
+ ListState
+ ReducingState
+ AggregatingState
另外状态存储也支持多种方式:
+ MemoryStateBackend:存储在内存中
+ FsStateBackend:存储在文件中
+ RocksDBStateBackend:存储在 RocksDB 中
Flink 中支持使用 Checkpoint 来提高程序的可靠性,开启了 Checkpoint 之后,Flink 会按照一定的时间间隔对程序的运行状态进行备份,当发生故障时,Flink 会将所有任务的状态恢复至最后一次发生 Checkpoint 中的状态,并从那里开始重新开始执行。另外 Flink 还支持根据 Savepoint 从已停止作业的运行状态进行恢复,这种方式需要通过命令进行触发。
### 1.2.12 自己的内存管理机制
Flink 并不是直接把对象存放在堆内存上,而是将对象序列化为固定数量的预先分配的内存段。它采用类似 DBMS 的排序和连接算法,可以直接操作二进制数据,以此将序列化和反序列化开销降到最低。如果需要处理的数据容量超过内存,那么 Flink 的运算符会将部分数据存储到磁盘。Flink 的主动内存管理和操作二进制数据有几个好处:
+ 保证内存可控,可以防止 OutOfMemoryError
+ 减少垃圾收集压力
+ 节省数据的存储空间
+ 高效的二进制操作
Flink 是如何分配内存、将对象进行序列化和反序列化以及对二进制数据进行操作的,可以参考文章 [Flink 是如何管理好内存的?](http://www.54tianzhisheng.cn/2019/03/24/Flink-code-memory-management/) ,该文中讲解了 Flink 的内存管理机制。
### 1.2.13 多种扩展库
Flink 扩展库中含有机器学习、Gelly 图形处理、CEP 复杂事件处理、State Processing API 等,这些扩展库在一些特殊场景下会比较适用,关于这块内容可以在第六章查看。
### 1.2.14 小结与反思
本节在开始介绍 Flink 之前先讲解了下数据集类型和数据运算模型,接着开始介绍 Flink 的各种特性,对于这些特性,你是否有和其他的计算框架做过对比?
================================================
FILE: books/flink-in-action-1.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 大数据计算框架对比
date: 2021-07-06
tags:
- Flink
- 大数据
- 流式计算
---
## 1.3 大数据计算框架对比
在 1.2 节中已经跟大家详细介绍了 Flink,那么在本节就主要 Blink、Spark Streaming、Structured Streaming 和 Storm 的区别。
### 1.3.1 Flink
Flink 是一个针对流数据和批数据分布式处理的引擎,在某些对实时性要求非常高的场景,基本上都是采用 Flink 来作为计算引擎,它不仅可以处理有界的批数据,还可以处理无界的流数据,在 Flink 的设计愿想就是将批处理当成是流处理的一种特例。
如下图所示,在 Flink 的母公司 [Data Artisans 被阿里收购](https://www.eu-startups.com/2019/01/alibaba-takes-over-berlin-based-streaming-analytics-startup-data-artisans/)之后,阿里也在开始逐步将内部的 Blink 代码开源出来并合并在 Flink 主分支上。
而 Blink 一个很强大的特点就是它的 Table API & SQL 很强大,社区也在 Flink 1.9 版本将 Blink 开源版本大部分代码合进了 Flink 主分支。
### 1.3.2 Blink
Blink 是早期阿里在 Flink 的基础上开始修改和完善后在内部创建的分支,然后 Blink 目前在阿里服务于阿里集团内部搜索、推荐、广告、菜鸟物流等大量核心实时业务,如下图所示。

Blink 在阿里内部错综复杂的业务场景中锻炼成长着,经历了内部这么多用户的反馈(各种性能、资源使用率、易用性等诸多方面的问题),Blink 都做了针对性的改进。在 Flink Forward China 峰会上,阿里巴巴集团副总裁周靖人宣布 Blink 在 2019 年 1 月正式开源,同时阿里也希望 Blink 开源后能进一步加深与 Flink 社区的联动,
Blink 开源地址:[https://github.com/apache/flink/tree/blink](https://github.com/apache/flink/tree/blink)
开源版本 Blink 的主要功能和优化点:
1、Runtime 层引入 Pluggable Shuffle Architecture,开发者可以根据不同的计算模型或者新硬件的需要实现不同的 shuffle 策略进行适配;为了性能优化,Blink 可以让算子更加灵活的 chain 在一起,避免了不必要的数据传输开销;在 BroadCast Shuffle 模式中,Blink 优化掉了大量的不必要的序列化和反序列化开销;Blink 提供了全新的 JM FailOver 机制,JM 发生错误之后,新的 JM 会重新接管整个 JOB 而不是重启 JOB,从而大大减少了 JM FailOver 对 JOB 的影响;Blink 支持运行在 Kubernetes 上。
2、SQL/Table API 架构上的重构和性能的优化是 Blink 开源版本的一个重大贡献。
3、Hive 的兼容性,可以直接用 Flink SQL 去查询 Hive 的数据,Blink 重构了 Flink catalog 的实现,并且增加了两种 catalog,一个是基于内存存储的 FlinkInMemoryCatalog,另外一个是能够桥接 Hive metaStore 的 HiveCatalog。
4、Zeppelin for Flink
5、Flink Web,更美观的 UI 界面,查看日志和监控 Job 都变得更加方便
对于开源那会看到一个对话让笔者感到很震撼:
> Blink 开源后,两个开源项目之间的关系会是怎样的?未来 Flink 和 Blink 也会由不同的团队各自维护吗?
> Blink 永远不会成为另外一个项目,如果后续进入 Apache 一定是成为 Flink 的一部分
对话详情如下图所示:

在 Blink 开源那会,笔者就将源码自己编译了一份,然后自己在本地一直运行着,感兴趣的可以看看文章 [阿里巴巴开源的 Blink 实时计算框架真香](http://www.54tianzhisheng.cn/2019/02/28/blink/) ,你会发现 Blink 的 UI 还是比较美观和实用的。
如果你还对 Blink 有什么疑问,可以看看下面两篇文章:
[阿里重磅开源 Blink:为什么我们等了这么久?](https://www.infoq.cn/article/wZ_b7Hw9polQWp3mTwVh)
[重磅!阿里巴巴 Blink 正式开源,重要优化点解读](https://www.infoq.cn/article/ZkOGAl6_vkZDTk8tfbbg)
### 1.3.3 Spark
Apache Spark 是一种包含流处理能力的下一代批处理框架。与 Hadoop 的 MapReduce 引擎基于各种相同原则开发而来的 Spark 主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运行速度。Spark 可作为独立集群部署(需要相应存储层的配合),或可与 Hadoop 集成并取代 MapReduce 引擎。
[Spark Streaming](https://spark.apache.org/docs/latest/streaming-programming-guide.html) 是 Spark API 核心的扩展,可实现实时数据的快速扩展,高吞吐量,容错处理。数据可以从很多来源(如 Kafka、Flume、Kinesis 等)中提取,并且可以通过很多函数来处理这些数据,处理完后的数据可以直接存入数据库或者 Dashboard 等,如下两图所示。
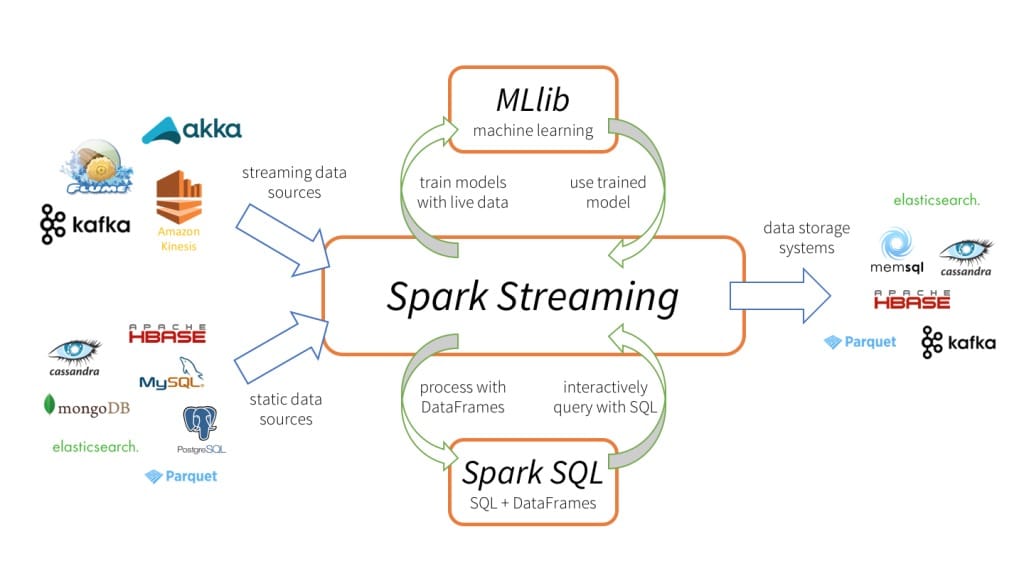
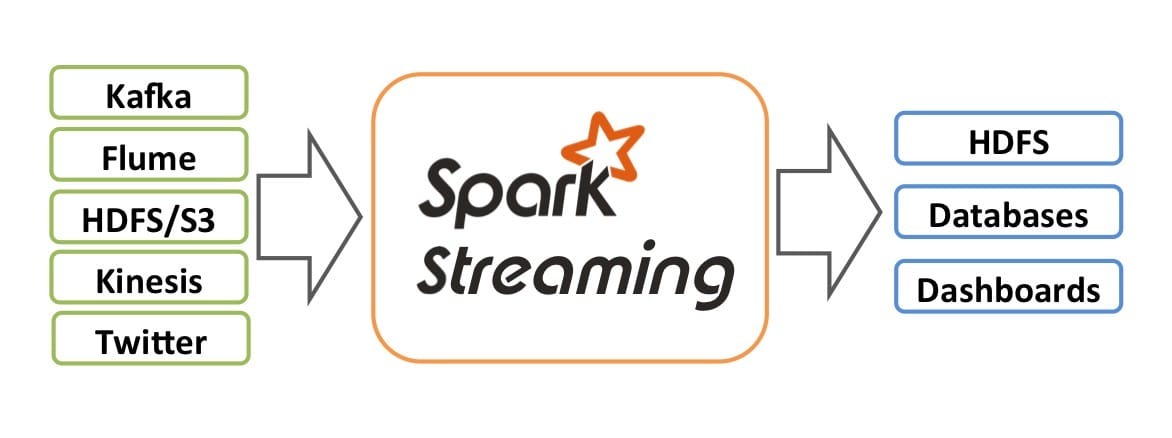
**Spark Streaming 的内部实现原理**是接收实时输入数据流并将数据分成批处理,然后由 Spark 引擎处理以批量生成最终结果流,也就是常说的 micro-batch 模式,如下图所示。

**Spark DStreams**
DStreams 是 Spark Streaming 提供的基本的抽象,它代表一个连续的数据流。它要么是从源中获取的输入流,要么是输入流通过转换算子生成的处理后的数据流。在内部实现上,DStream 由连续的序列化 RDD 来表示,每个 RDD 含有一段时间间隔内的数据,如下图所示:
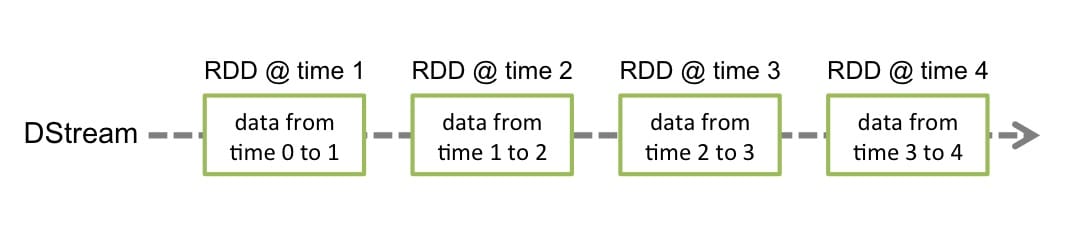
任何对 DStreams 的操作都转换成了对 DStreams 隐含的 RDD 的操作。例如 flatMap 操作应用于 lines 这个 DStreams 的每个 RDD,生成 words 这个 DStreams 的 RDD 过程如下图所示:
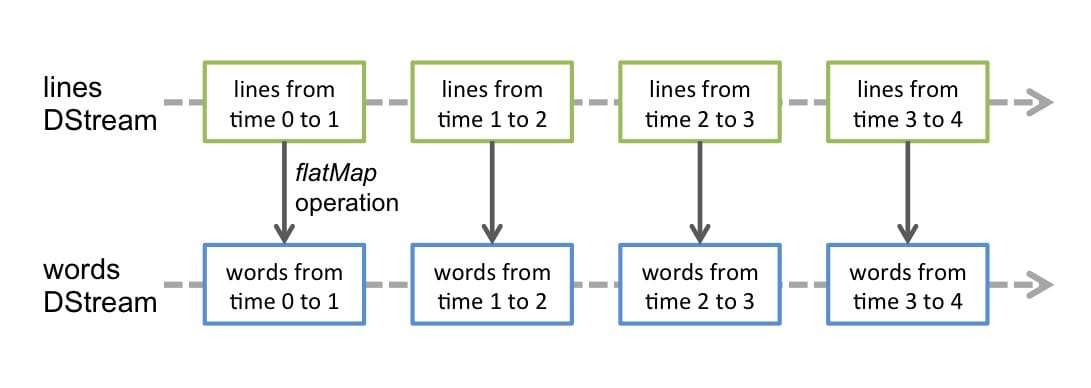
通过 Spark 引擎计算这些隐含 RDD 的转换算子。DStreams 操作隐藏了大部分的细节,并且为了更便捷,为开发者提供了更高层的 API。
**Spark 支持的滑动窗口**
它和 Flink 的滑动窗口类似,支持传入两个参数,一个代表窗口长度,一个代表滑动间隔,如下图所示。
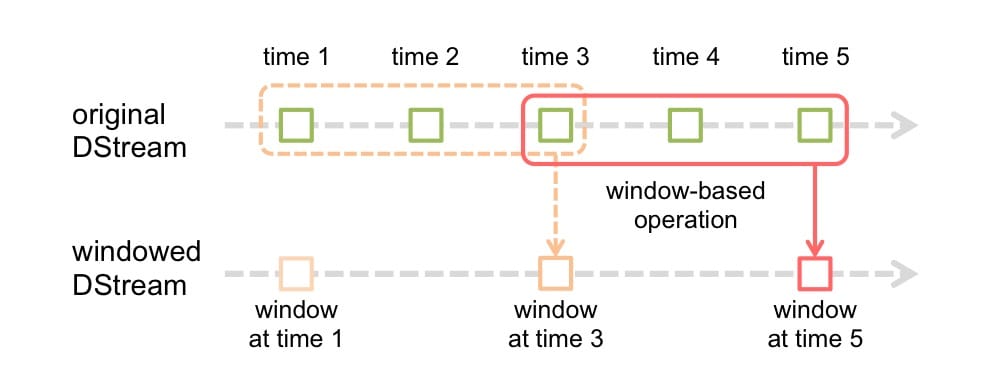
**Spark 支持更多的 API**
因为 Spark 是使用 Scala 开发的居多,所以从官方文档就可以看得到对 Scala 的 API 支持的很好,而 Flink 源码实现主要以 Java 为主,因此也对 Java API 更友好,从两者目前支持的 API 友好程度,应该是 Spark 更好,它目前也支持 Python API,但是 Flink 新版本也在不断的支持 Python API。
**Spark 支持更多的 Machine Learning Lib**
你可以很轻松的使用 Spark MLlib 提供的机器学习算法,然后将这些这些机器学习算法模型应用在流数据中,目前 Flink Machine Learning 这块的内容还较少,不过阿里宣称会开源些 Flink Machine Learning 算法,保持和 Spark 目前已有的算法一致,我自己在 GitHub 上看到一个阿里开源的仓库,感兴趣的可以看看 [flink-ai-extended](https://github.com/alibaba/flink-ai-extended)。
**Spark Checkpoint**
Spark 和 Flink 一样都支持 Checkpoint,但是 Flink 还支持 Savepoint,你可以在停止 Flink 作业的时候使用 Savepoint 将作业的状态保存下来,当作业重启的时候再从 Savepoint 中将停止作业那个时刻的状态恢复起来,保持作业的状态和之前一致。
**Spark SQL**
Spark 除了 DataFrames 和 Datasets 外,也还有 SQL API,这样你就可以通过 SQL 查询数据,另外 Spark SQL 还可以用于从 Hive 中读取数据。
从 Spark 官网也可以看到很多比较好的特性,这里就不一一介绍了,如果对 Spark 感兴趣的话也可以去[官网](https://spark.apache.org/docs/latest/index.html)了解一下具体的使用方法和实现原理。
**Spark Streaming 优缺点**
1、优点
+ Spark Streaming 内部的实现和调度方式高度依赖 Spark 的 DAG 调度器和 RDD,这就决定了 Spark Streaming 的设计初衷必须是粗粒度方式的,也就无法做到真正的实时处理
+ Spark Streaming 的粗粒度执行方式使其确保“处理且仅处理一次”的特性,同时也可以更方便地实现容错恢复机制。
+ 由于 Spark Streaming 的 DStream 本质是 RDD 在流式数据上的抽象,因此基于 RDD 的各种操作也有相应的基于 DStream 的版本,这样就大大降低了用户对于新框架的学习成本,在了解 Spark 的情况下用户将很容易使用 Spark Streaming。
2、缺点
+ Spark Streaming 的粗粒度处理方式也造成了不可避免的数据延迟。在细粒度处理方式下,理想情况下每一条记录都会被实时处理,而在 Spark Streaming 中,数据需要汇总到一定的量后再一次性处理,这就增加了数据处理的延迟,这种延迟是由框架的设计引入的,并不是由网络或其他情况造成的。
+ 使用的是 Processing Time 而不是 Event Time
### 1.3.4 Structured Streaming
### 1.3.5 Storm
#### Storm 核心组件
#### Storm 核心概念
#### Storm 数据处理流程图
### 1.3.6 计算框架对比
#### Flink VS Spark
#### Flink VS Storm
#### 全部对比结果
加入知识星球可以看到上面文章:https://t.zsxq.com/vVjeMBY

### 1.3.7 小结与反思
因在 1.2 节中已经对 Flink 的特性做了很详细的讲解,所以本节主要介绍其他几种计算框架(Blink、Spark、Spark Streaming、Structured Streaming、Storm),并对比分析了这几种框架的特点与不同。你对这几种计算框架中的哪个最熟悉呢?了解过它们之间的差异吗?你有压测过它们的处理数据的性能吗?
本章第一节从公司的日常实时计算需求出发,来分析该如何去实现这种实时需求,接着对比了实时计算与离线计算的区别,从而引出了实时计算的优势,接着就在第二节开始介绍本书的重点 —— 实时计算引擎 Flink,把 Flink 的架构、API、特点、优势等方面都做了讲解,在第三节中对比了市面上现有的计算框架,分别对这些框架做了异同点对比,最后还汇总了它们在各个方面的优势和劣势,以供大家公司内部的技术选型。
================================================
FILE: books/flink-in-action-10.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何设置 Flink Job RestartStrategy(重启策略)?
date: 2021-08-12
tags:
- Flink
- 大数据
- 流式计算
---
# 第十章 —— Flink 最佳实践
本章将介绍两个最佳实践,第一个是如何合理的配置重启策略,笔者通过自己的亲身经历来讲述配置重启策略的重要性,接着介绍了 Flink 中的重启策略和恢复策略的发展实现过程;第二个是如何去管理 Flink 作业的配置。两个实践大家可以参考,不一定要照搬运用在自己的公司,同时也希望你可以思考下自己是否有啥最佳实践可以分享。
## 10.1 如何设置 Flink Job RestartStrategy(重启策略)?
从使用 Flink 到至今,遇到的 Flink 有很多,解决的问题更多(含帮助微信好友解决问题),所以对于 Flink 可能遇到的问题及解决办法都比较清楚,那么在这章就给大家讲解下几个 Flink 中比较常遇到的问题的解决办法。
### 10.1.1 常见错误导致 Flink 作业重启
不知道大家是否有遇到过这样的问题:整个 Job 一直在重启,并且还会伴随着一些错误(可以通过 UI 查看 Exceptions 日志),以下三张图片中的错误信息是笔者曾经生产环境遇到过的一些问题。
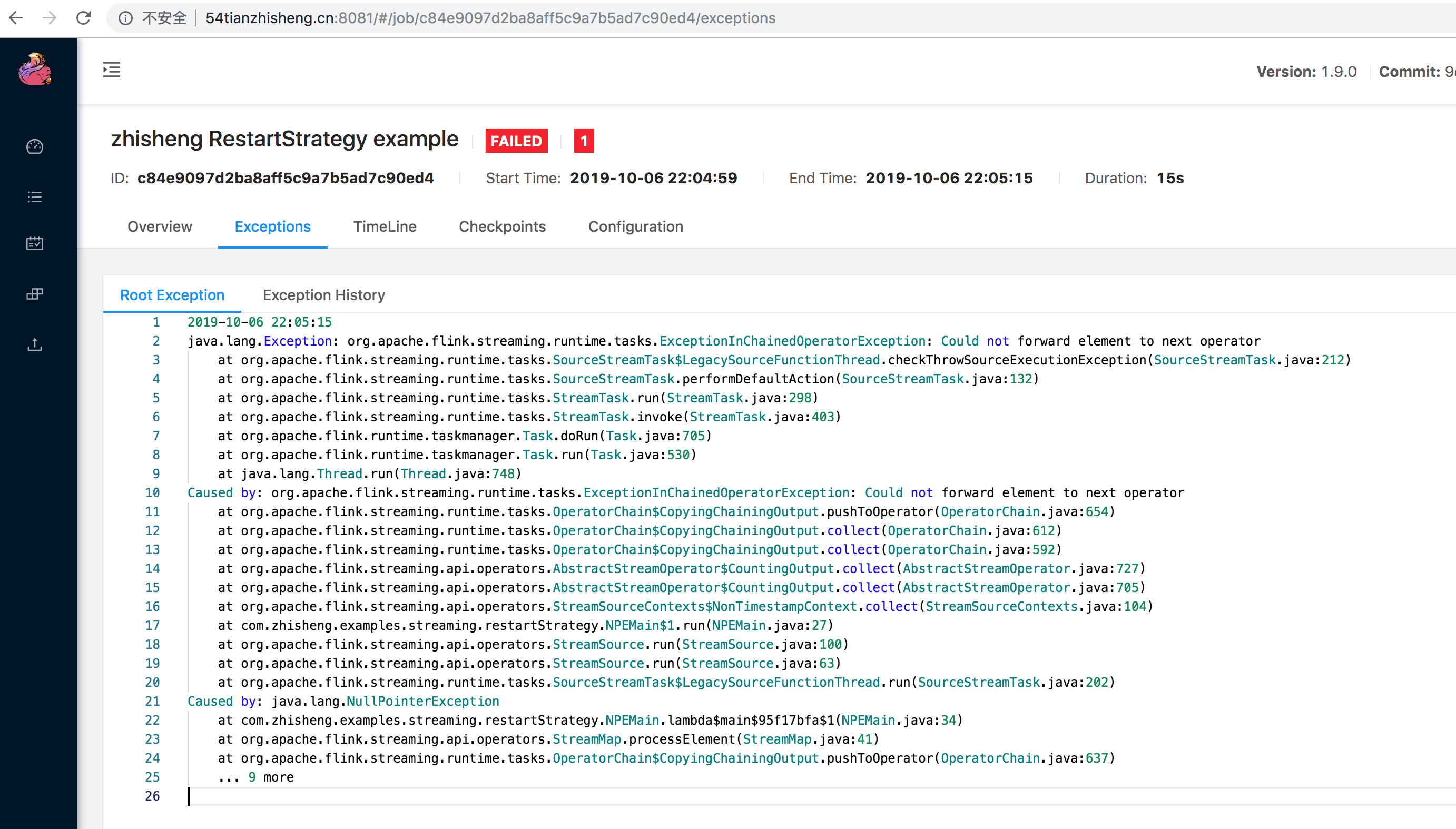
笔者就曾因为上图中的一个异常报错,作业一直重启,在深夜线上发版的时候,同事发现这个问题,凌晨两点的时候打电话把我叫醒起来修 BUG,真是惨的教训,哈哈哈,估计这辈子都忘不掉了!
其实遇到上面这种问题比较常见的,比如有时候因为数据的问题(不合规范、为 null 等),这时在处理这些脏数据的时候可能就会遇到各种各样的异常错误,比如空指针、数组越界、数据类型转换错误等。可能你会说只要过滤掉这种脏数据就行了,或者进行异常捕获就不会导致 Job 不断重启的问题了。
确实如此,如果做好了脏数据的过滤和异常的捕获,Job 的稳定性确实有保证,但是复杂的 Job 下每个算子可能都会产生出脏数据(包含源数据可能也会为空或者不合法的数据),你不可能在每个算子里面也用一个大的 try catch 做一个异常捕获,所以脏数据和异常简直就是防不胜防,不过我们还是要尽力的保证代码的健壮性,但是也要配置好 Flink Job 的 RestartStrategy(重启策略)。
### 10.1.2 RestartStrategy 简介
RestartStrategy,重启策略,在遇到机器或者代码等不可预知的问题时导致 Job 或者 Task 挂掉的时候,它会根据配置的重启策略将 Job 或者受影响的 Task 拉起来重新执行,以使得作业恢复到之前正常执行状态。Flink 中的重启策略决定了是否要重启 Job 或者 Task,以及重启的次数和每次重启的时间间隔。
### 10.1.3 为什么需要 RestartStrategy?
重启策略会让 Job 从上一次完整的 Checkpoint 处恢复状态,保证 Job 和挂之前的状态保持一致,另外还可以让 Job 继续处理数据,不会出现 Job 挂了导致消息出现大量堆积的问题,合理的设置重启策略可以减少 Job 不可用时间和避免人工介入处理故障的运维成本,因此重启策略对于 Flink Job 的稳定性来说有着举足轻重的作用。
### 10.1.4 如何配置 RestartStrategy?
既然 Flink 中的重启策略作用这么大,那么该如何配置呢?其实如果 Flink Job 没有单独设置重启重启策略的话,则会使用集群启动时加载的默认重启策略,如果 Flink Job 中单独设置了重启策略则会覆盖默认的集群重启策略。默认重启策略可以在 Flink 的配置文件 `flink-conf.yaml` 中设置,由 `restart-strategy` 参数控制,有 fixed-delay(固定延时重启策略)、failure-rate(故障率重启策略)、none(不重启策略)三种可以选择,如果选择的参数不同,对应的其他参数也不同。下面分别介绍这几种重启策略和如何配置。
#### FixedDelayRestartStrategy(固定延时重启策略)
FixedDelayRestartStrategy 是固定延迟重启策略,程序按照集群配置文件中或者程序中额外设置的重启次数尝试重启作业,如果尝试次数超过了给定的最大次数,程序还没有起来,则停止作业,另外还可以配置连续两次重启之间的等待时间,在 `flink-conf.yaml` 中可以像下面这样配置。
```yaml
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3 #表示作业重启的最大次数,启用 checkpoint 的话是 Integer.MAX_VALUE,否则是 1。
restart-strategy.fixed-delay.delay: 10 s #如果设置分钟可以类似 1 min,该参数表示两次重启之间的时间间隔,当程序与外部系统有连接交互时延迟重启可能会有帮助,启用 checkpoint 的话,延迟重启的时间是 10 秒,否则使用 akka.ask.timeout 的值。
```
在程序中设置固定延迟重启策略的话如下:
```java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
));
```
#### FailureRateRestartStrategy(故障率重启策略)
FailureRateRestartStrategy 是故障率重启策略,在发生故障之后重启作业,如果固定时间间隔之内发生故障的次数超过设置的值后,作业就会失败停止,该重启策略也支持设置连续两次重启之间的等待时间。
```yaml
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3 #固定时间间隔内允许的最大重启次数,默认 1
restart-strategy.failure-rate.failure-rate-interval: 5 min #固定时间间隔,默认 1 分钟
restart-strategy.failure-rate.delay: 10 s #连续两次重启尝试之间的延迟时间,默认是 akka.ask.timeout
```
可以在应用程序中这样设置来配置故障率重启策略:
```java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 固定时间间隔允许 Job 重启的最大次数
Time.of(5, TimeUnit.MINUTES), // 固定时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次重启的延迟时间
));
```
#### NoRestartStrategy(不重启策略)
NoRestartStrategy 作业不重启策略,直接失败停止,在 `flink-conf.yaml` 中配置如下:
```yaml
restart-strategy: none
```
在程序中如下设置即可配置不重启:
```java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
```
#### Fallback(备用重启策略)
如果程序没有启用 Checkpoint,则采用不重启策略,如果开启了 Checkpoint 且没有设置重启策略,那么采用固定延时重启策略,最大重启次数为 Integer.MAX_VALUE。
在应用程序中配置好了固定延时重启策略,可以测试一下代码异常后导致 Job 失败后重启的情况,然后观察日志,可以看到 Job 重启相关的日志:
```text
[flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Try to restart or fail the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) if no longer possible.
[flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) switched from state FAILING to RESTARTING.
[flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Restarting the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0).
```
最后重启次数达到配置的最大重启次数后 Job 还没有起来的话,则会停止 Job 并打印日志:
```text
[flink-akka.actor.default-dispatcher-2] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not restart the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) because the restart strategy prevented it.
```
Flink 中几种重启策略的设置如上,大家可以根据需要选择合适的重启策略,比如如果程序抛出了空指针异常,但是你配置的是一直无限重启,那么就会导致 Job 一直在重启,这样无非再浪费机器资源,这种情况下可以配置重试固定次数,每次隔多久重试的固定延时重启策略,这样在重试一定次数后 Job 就会停止,如果对 Job 的状态做了监控告警的话,那么你就会收到告警信息,这样也会提示你去查看 Job 的运行状况,能及时的去发现和修复 Job 的问题。
### 10.1.5 RestartStrategy 源码分析
再介绍重启策略应用程序代码配置的时候不知道你有没有看到设置重启策略都是使用 RestartStrategies 类,通过该类的方法就可以创建不同的重启策略,在 RestartStrategies 类中提供了五个方法用来创建四种不同的重启策略(有两个方法是创建 FixedDelay 重启策略的,只不过方法的参数不同),如下图所示。
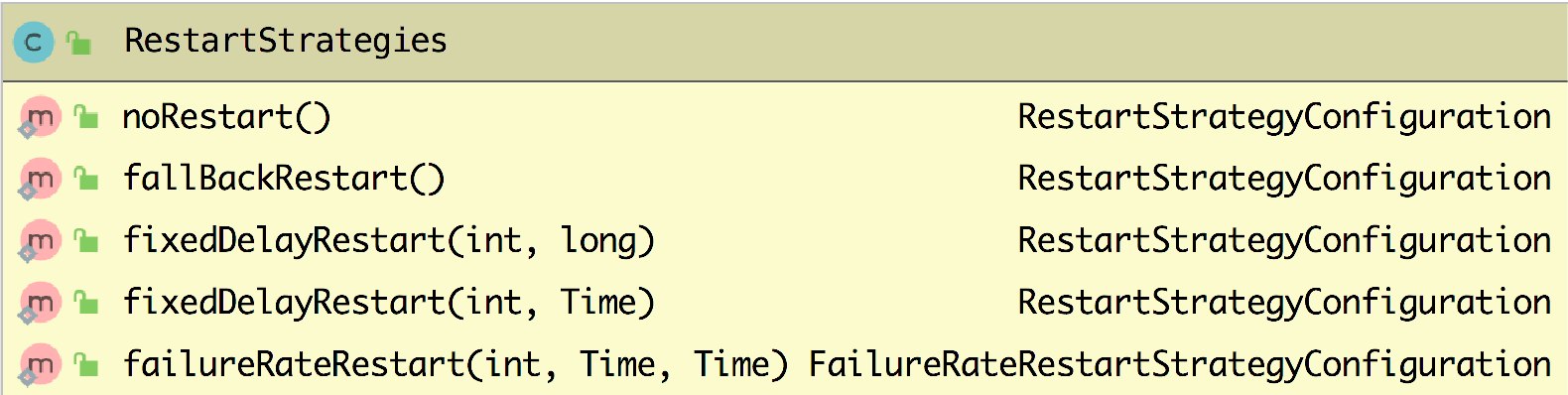
在每个方法内部其实调用的是 RestartStrategies 中的内部静态类,分别是 NoRestartStrategyConfiguration、FixedDelayRestartStrategyConfiguration、FailureRateRestartStrategyConfiguration、FallbackRestartStrategyConfiguration,这四个类都继承自 RestartStrategyConfiguration 抽象类,如下图所示。
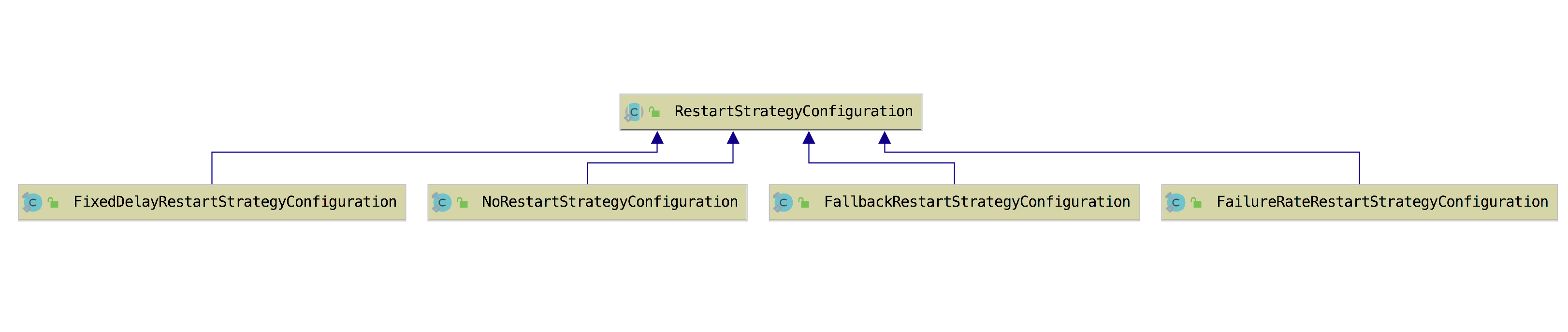
上面是定义的四种重启策略的配置类,在 Flink 中是靠 RestartStrategyResolving 类中的 resolve 方法来解析 RestartStrategies.RestartStrategyConfiguration,然后根据配置使用 RestartStrategyFactory 创建 RestartStrategy。RestartStrategy 是一个接口,它有 canRestart 和 restart 两个方法,它有四个实现类: FixedDelayRestartStrategy、FailureRateRestartStrategy、ThrowingRestartStrategy、NoRestartStrategy,如下图所示。
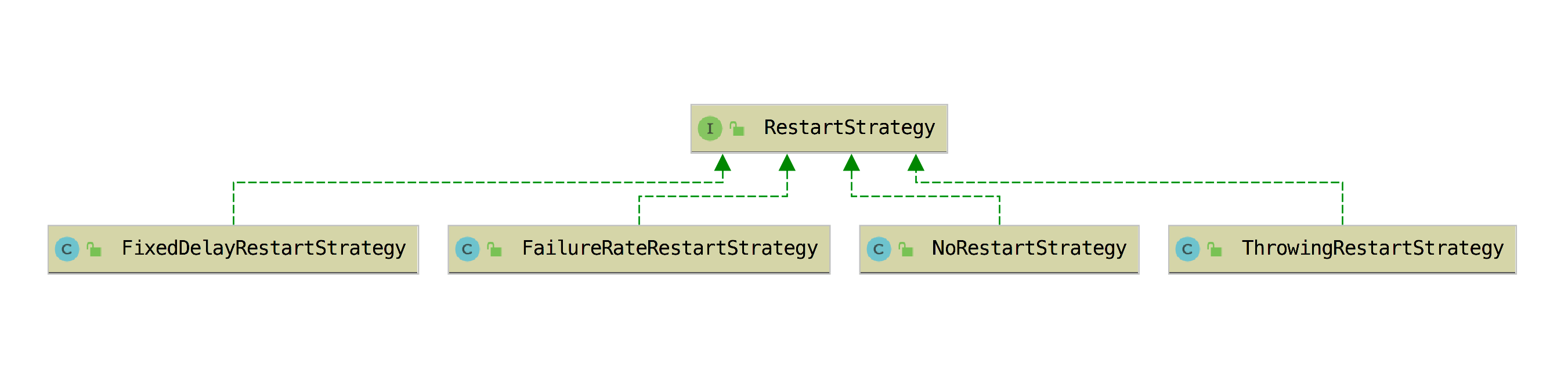
### 10.1.6 Failover Strategies(故障恢复策略)
#### 重启所有的任务
#### 基于 Region 的局部故障重启策略
### 10.1.7 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-10.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何设置 Flink Job RestartStrategy(重启策略)?
date: 2021-08-13
tags:
- Flink
- 大数据
- 流式计算
---
## 10.2 如何使用 Flink ParameterTool 读取配置?
在使用 Flink 中不知道你有没有觉得配置的管理很不方便,比如像算子的并行度配置、Kafka 数据源的配置(broker 地址、topic 名、group.id)、Checkpoint 是否开启、状态后端存储路径、数据库地址、用户名和密码等,反正各种各样的配置都杂乱在一起,当然你可能说我就在代码里面写死不就好了,但是你有没有想过你的作业是否可以不修改任何配置就直接在各种环境(开发、测试、预发、生产)运行呢?可能每个环境的这些配置对应的值都是不一样的,如果你是直接在代码里面写死的配置,那这下子就比较痛苦了,每次换个环境去运行测试你的作业,你都要重新去修改代码中的配置,然后编译打包,提交运行,这样你就要花费很多时间在这些重复的劳动力上了。有没有什么办法可以解决这种问题呢?
### 10.2.1 Flink Job 配置
在 Flink 中其实是有几种方法来管理配置,下面分别来讲解一下。
#### 使用 Configuration
Flink 提供了 withParameters 方法,它可以传递 Configuration 中的参数给,要使用它,需要实现那些 Rich 函数,比如实现 RichMapFunction,而不是 MapFunction,因为 Rich 函数中有 open 方法,然后可以重写 open 方法通过 Configuration 获取到传入的参数值。
```java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Configuration 类来存储参数
Configuration configuration = new Configuration();
configuration.setString("name", "zhisheng");
env.fromElements(WORDS)
.flatMap(new RichFlatMapFunction>() {
String name;
@Override
public void open(Configuration parameters) throws Exception {
//读取配置
name = parameters.getString("name", "");
}
@Override
public void flatMap(String value, Collector> out) throws Exception {
String[] splits = value.toLowerCase().split("\\W+");
for (String split : splits) {
if (split.length() > 0) {
out.collect(new Tuple2<>(split + name, 1));
}
}
}
}).withParameters(configuration) //将参数传递给函数
.print();
```
但是要注意这个 withParameters 只在批程序中支持,流程序中是没有该方法的,并且这个 withParameters 要在每个算子后面使用才行,并不是一次使用就所有都可以获取到,如果所有算子都要该配置,那么就重复设置多次就会比较繁琐。
### 10.2.2 ParameterTool 管理配置
上面通过 Configuration 的局限性很大,其实在 Flink 中还可以通过使用 ParameterTool 类读取配置,它可以读取环境变量、运行参数、配置文件,下面分别讲下每种如何使用。
#### 读取运行参数
我们知道 Flink UI 上是支持为每个 Job 单独传入 arguments(参数)的,它的格式要求是如下这种。
```
--brokers 127.0.0.1:9200
--username admin
--password 123456
```
或者这种
```
-brokers 127.0.0.1:9200
-username admin
-password 123456
```
然后在 Flink 程序中你可以直接使用 `ParameterTool.fromArgs(args)` 获取到所有的参数,然后如果你要获取某个参数对应的值的话,可以通过 `parameterTool.get("username")` 方法。那么在这个地方其实你就可以将配置放在一个第三方的接口,然后这个参数值中传入一个接口,拿到该接口后就能够通过请求去获取更多你想要的配置。
#### 读取系统属性
ParameterTool 还支持通过 `ParameterTool.fromSystemProperties()` 方法读取系统属性。
#### 读取配置文件
除了上面两种外,ParameterTool 还支持 `ParameterTool.fromPropertiesFile("/application.properties")` 读取 properties 配置文件。你可以将所有要配置的地方(比如并行度和一些 Kafka、MySQL 等配置)都写成可配置的,然后其对应的 key 和 value 值都写在配置文件中,最后通过 ParameterTool 去读取配置文件获取对应的值。
#### ParameterTool 获取值
ParameterTool 类提供了很多便捷方法去获取值,如下图所示。
你可以在应用程序的 main() 方法中直接使用这些方法返回的值,例如:你可以按如下方法来设置一个算子的并行度:
```java
ParameterTool parameters = ParameterTool.fromArgs(args);
int parallelism = parameters.get("mapParallelism", 2);
DataStream> counts = data.flatMap(new Tokenizer()).setParallelism(parallelism);
```
因为 ParameterTool 是可序列化的,所以你可以将它当作参数进行传递给自定义的函数。
```java
ParameterTool parameters = ParameterTool.fromArgs(args);
DataStream> counts = dara.flatMap(new Tokenizer(parameters));
```
然后在函数内部使用 ParameterTool 来获取命令行参数,这样就意味着你在作业任何地方都可以获取到参数,而不是像 withParameters 一样需要每次都设置。
#### 注册全局参数
在 ExecutionConfig 中可以将 ParameterTool 注册为全作业参数的参数,这样就可以被 JobManager 的 web 端以及用户自定义函数中以配置值的形式访问。
```java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(ParameterTool.fromArgs(args));
```
然后就可以在用户自定义的 Rich 函数中像如下这样获取到参数值了。
```java
env.addSource(new RichSourceFunction() {
@Override
public void run(SourceContext sourceContext) throws Exception {
while (true) {
ParameterTool parameterTool = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
sourceContext.collect(System.currentTimeMillis() + parameterTool.get("os.name") + parameterTool.get("user.home"));
}
}
@Override
public void cancel() {
}
})
```
在笔者公司内通常是以 Job 运行的环境变量为准,比如我们是运行在 K8s 上面,那么我们会为我们的这个 Flink Job 设置很多环境变量,设置的环境变量的值就得通过 ParameterTool 类去获取,我们是会优先根据环境变量的值为准,如果环境变量的值没有就会去读取应用运行参数,如果应用运行参数也没有才会去读取之前已经写好在配置文件中的配置。大概代码如下:
```java
public static ParameterTool createParameterTool(final String[] args) throws Exception {
return ParameterTool
.fromPropertiesFile(ExecutionEnv.class.getResourceAsStream("/application.properties"))
.mergeWith(ParameterTool.fromArgs(args))
.mergeWith(ParameterTool.fromSystemProperties())
.mergeWith(ParameterTool.fromMap(getenv()));// mergeWith 会使用最新的配置
}
//获取 Job 设置的环境变量
private static Map getenv() {
Map map = new HashMap<>();
for (Map.Entry entry : System.getenv().entrySet()) {
map.put(entry.getKey().toLowerCase().replace('_', '.'), entry.getValue());
}
return map;
}
```
这样如果 Job 要更改一些配置,直接在 Job 在 K8s 上面的环境变量进行配置就好了,修改配置后然后重启 Job 就可以运行起来了,整个过程都不需要再次将作业重新编译打包的。但是这样其实也有一定的坏处,重启一个作业的代价很大,因为在重启后你又要去保证状态要恢复到之前未重启时的状态,尽管 Flink 中的 Checkpoint 和 Savepoint 已经很强大了,但是对于复杂的它来说我们多一事不如少一事,所以其实更希望能够直接动态的获取配置,如果配置做了更改,作业能够感知到。在 Flink 中有的配置是不能够动态设置的,但是比如应用业务配置却是可以做到动态的配置,这时就需要使用比较强大的广播变量,广播变量在之前 3.4 节已经介绍过了,如果忘记可以再回去查看,另外在 11.4 节中会通过一个实际案例来教你如何使用广播变量去动态的更新配置数据。
### 10.2.3 ParameterTool 源码分析
### 10.2.4 自定义配置参数类
### 10.2.5 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

本章讲了两个实践相关的内容,一个是作业的重启策略,从分析真实线上故障来教大家如何去配置重启策略,以及介绍重启策略的种类,另一个是使用 ParameterTool 去管理配置。两个实践都是比较真实且有一定帮助作用的,希望你也可以应用在你的项目中去。
================================================
FILE: books/flink-in-action-11.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何统计网站各页面一天内的 PV 和 UV?
date: 2021-08-14
tags:
- Flink
- 大数据
- 流式计算
---
# 第十一章 —— Flink 实战
本章主要是 Flink 实战,介绍了一些常见的需求,比如实时统计网站页面的 PV/UV、宕机告警、动态更新配置、应用 Error 日志实时告警等,然后分别去分析这些需求的实现方式,明白该使用 Flink 中的哪些知识点才能够很好的完成这种需求,并提供完整的案例代码供大家参考。在实现完成这些需求之后,笔者还将会更深一步的去讲解下这些知识点背后的实现方式,希望可以加深你对这些知识点的印象,以便后面你可以灵活的处理类似的需求。
## 11.1 如何统计网站各页面一天内的 PV 和 UV?
大数据开发最常统计的需求可能就是 PV、UV。PV 全拼 PageView,即页面访问量,用户每次对网站的访问均被记录,按照访问量进行累计,假如用户对同一页面访问了 5 次,那该页面的 PV 就应该加 5。UV 全拼为 UniqueVisitor,即独立访问用户数,访问该页面的一台电脑客户端为一个访客,假如用户对同一页面访问了 5 次,那么该页面的 UV 只应该加 1,因为 UV 计算的是去重后的用户数而不是访问次数。当然如果是按天统计,那么当天 0 点到 24 点相同的客户端只被计算一次,如果过了今天 24 点,第二天该用户又访问了该页面,那么第二天该页面的 UV 应该加 1。 概念明白了那如何使用 Flink 来统计网站各页面的 PV 和 UV 呢?通过本节来详细描述。
### 11.1.1 统计网站各页面一天内的 PV
在 9.5.2 节端对端如何保证 Exactly Once 中的幂等性写入如何保证端对端 Exactly Once 部分已经用案例讲述了如何通过 Flink 的状态来计算 APP 的 PV,并能够保证 Exactly Once。如果在工作中需要计算网站各页面一天内的 PV,只需要将案例中的 APP 替换成各页面的 id 或者各页面的 url 进行统计即可,按照各页面 id 和日期组合做为 key 进行 keyBy,相同页面、相同日期的数据发送到相同的实例中进行 PV 值的累加,每个 key 对应一个 ValueState,将 PV 值维护在 ValueState 即可。如果一些页面属于爆款页面,例如首页或者活动页面访问特别频繁就可能出现某些 subtask 上的数据量特别大,导致各个 subtask 之前出现数据倾斜的问题,关于数据倾斜的解决方案请参考 9.6 节。
### 11.1.2 统计网站各页面一天内 UV 的三种方案
PV 统计相对来说比较简单,每来一条用户的访问日志只需要从日志中提取出相应的页面 id 和日期,将其对应的 PV 值加一即可。相对而言统计 UV 就有难度了,同一个用户一天内多次访问同一个页面,只能计数一次。所以每来一条日志,日志中对应页面的 UV 值是否需要加一呢?存在两种情况:如果该用户今天第一次访问该页面,那么 UV 应该加一。如果该用户今天不是第一次访问该页面,表示 UV 中已经记录了该用户,UV 要基于用户去重,所以此时 UV 值不应该加一。难点就在于如何判断该用户今天是不是第一次访问该页面呢?
把问题简单化,先不考虑日期,现在统计网站各页面的累积 UV,可以为每个页面维护一个 Set 集合,假如网站有 10 个页面,那么就维护 10 个 Set 集合,集合中存放着所有访问过该页面用户的 user_id。每来一条用户的访问日志,我们都需要从日志中解析出相应的页面 id 和用户 user_id,去该页面 id 对应的 Set 中查找该 user_id 之前有没有访问过该页面,如果 Set 中包含该 user_id 表示该用户之前访问过该页面,所以该页面的 UV 值不应该加一,如果 Set 中不包含该 user_id 表示该用户之前没有访问过该页面,所以该页面的 UV 值应该加一,并且将该 user_id 插入到该页面对应的 Set 中,表示该用户访问过该页面了。要按天去统计各页面 UV,只需要将日期和页面 id 看做一个整体 key,每个 key 对应一个 Set,其他流程与上述类似。具体的程序流程图如下图所示。

#### 使用 Redis 的 set 来维护用户集合
每个 key 都需要维护一个 Set,这个 Set 存放在哪里呢?这里每条日志都需要访问一次 Set,对 Set 访问比较频繁,对存储介质的延迟要求比较高,所以可以使用 Redis 的 set 数据结构,Redis 的 set 数据结构也会对数据进行去重。可以将页面 id 和日期拼接做为 Redis 的 key,通过 Redis 的 sadd 命令将 user_id 放到 key 对应的 set 中即可。Redis 的 set 中存放着今天访问过该页面所有用户的 user_id。
在真实的工作中,Flink 任务可能不需要维护一个 UV 值,Flink 任务承担的角色是实时计算,而查询 UV 可能是一个 Java Web 项目。Web 项目只需要去 Redis 查询相应 key 对应的 set 中元素的个数即可,Redis 的 set 数据结构有 scard 命令可以查询 set 中元素个数,这里的元素个数就是我们所要统计的网站各页面每天的 UV 值。所以使用 Redis set 数据结构的方案 Flink 任务的代码很简单,只需要从日志中解析出相应的日期、页面id 和 user_id,将日期和页面 id 组合做为 Redis 的 key,最后将 user_id 通过 sadd 命令添加到 set 中,Flink 任务的工作就结束了,之后 Web 项目就能从 Redis 中查询到实时增加的 UV 了。下面来看详细的代码实现。
用户访问网站页面的日志实体类:
```java
public class UserVisitWebEvent {
// 日志的唯一 id
private String id;
// 日期,如:20191025
private String date;
// 页面 id
private Integer pageId;
// 用户的唯一标识,用户 id
private String userId;
// 页面的 url
private String url;
}
```
生成测试数据的核心代码如下:
```java
String yyyyMMdd = new DateTime(System.currentTimeMillis()).toString("yyyyMMdd");
int pageId = random.nextInt(10); // 随机生成页面 id
int userId = random.nextInt(100); // 随机生成用户 id
UserVisitWebEvent userVisitWebEvent = UserVisitWebEvent.builder()
.id(UUID.randomUUID().toString()) // 日志的唯一 id
.date(yyyyMMdd) // 日期
.pageId(pageId) // 页面 id
.userId(Integer.toString(userId)) // 用户 id
.url("url/" + pageId) // 页面的 url
.build();
// 对象序列化为 JSON 发送到 Kafka
ProducerRecord record = new ProducerRecord(topic,
null, null, GsonUtil.toJson(userVisitWebEvent));
producer.send(record);
```
统计 UV 的核心代码如下,对 Redis Connector 不熟悉的请参阅 3.11 节如何使用 Flink Connectors —— Redis:
```java
public class RedisSetUvExample {
public static void main(String[] args) throws Exception {
// 省略了 env初始化及 Checkpoint 相关配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, UvExampleUtil.broker_list);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app-uv-stat");
FlinkKafkaConsumerBase kafkaConsumer = new FlinkKafkaConsumer011<>(
UvExampleUtil.topic, new SimpleStringSchema(), props)
.setStartFromLatest();
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig
.Builder().setHost("192.168.30.244").build();
env.addSource(kafkaConsumer)
.map(string -> {
// 反序列化 JSON
UserVisitWebEvent userVisitWebEvent = GsonUtil.fromJson(
string, UserVisitWebEvent.class);
// 生成 Redis key,格式为 日期_pageId,如: 20191026_0
String redisKey = userVisitWebEvent.getDate() + "_"
+ userVisitWebEvent.getPageId();
return Tuple2.of(redisKey, userVisitWebEvent.getUserId());
})
.returns(new TypeHint>(){})
.addSink(new RedisSink<>(conf, new RedisSaddSinkMapper()));
env.execute("Redis Set UV Stat");
}
// 数据与 Redis key 的映射关系
public static class RedisSaddSinkMapper
implements RedisMapper> {
@Override
public RedisCommandDescription getCommandDescription() {
// 这里必须是 sadd 操作
return new RedisCommandDescription(RedisCommand.SADD);
}
@Override
public String getKeyFromData(Tuple2 data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2 data) {
return data.f1;
}
}
}
```
Redis 中统计结果如下图所示,左侧展示的 Redis key,20191026_1 表示 2019年10月26日浏览过 pageId 为 1 的页面对应的 key,右侧展示 key 对应的 set 集合,表示 userId 为 [0,6,27,30,66,67,79,88] 的用户在 2019年10月26日浏览过 pageId 为 1 的页面。
 要想获取 20191026_1 对应的 UV 值,可通过 scard 命令获取 set 中 user_id 的数量,具体操作如下所示:
```shell
redis> scard 20191026_1
8
```
通过上述代码即可通过 Redis 的 set 数据结构来统计网站各页面的 UV。
#### 使用 Flink 的 KeyedState 来维护用户集合
#### 使用 Redis 的 HyperLogLog 来统计 UV
### 11.1.3 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何使用 Flink ProcessFunction 处理宕机告警?
date: 2021-08-15
tags:
- Flink
- 大数据
- 流式计算
---
## 11.2 如何使用 Flink ProcessFunction 处理宕机告警?
在 3.3 节中讲解了 Process 算子的概念,本节中将更详细的讲解 Flink ProcessFunction,然后教大家如何使用 ProcessFunction 来解决公司中常见的问题 —— 宕机,这个宕机不仅仅包括机器宕机,还包含应用宕机,通常出现宕机带来的影响是会很大的,所以能及时收到告警会减少损失。
### 11.2.1 ProcessFunction 简介
在 1.2.5 节中讲了 Flink 的 API 分层,其中可以看见 Flink 的底层 API 就是 ProcessFunction,它是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:Event、State、Timer。ProcessFunction 可以被认为是一种提供了对 KeyedState 和定时器访问的 FlatMapFunction。每当数据源中接收到一个事件,就会调用来此函数来处理。对于容错的状态,ProcessFunction 可以通过 RuntimeContext 访问 KeyedState。
定时器可以对处理时间和事件时间的变化做一些处理。每次调用 processElement() 都可以获得一个 Context 对象,通过该对象可以访问元素的事件时间戳以及 TimerService。TimerService 可以为尚未发生的事件时间/处理时间实例注册回调。当定时器到达某个时刻时,会调用 onTimer() 方法。在调用期间,所有状态再次限定为定时器创建的 key,允许定时器操作 KeyedState。如果要访问 KeyedState 和定时器,那必须在 KeyedStream 上使用 KeyedProcessFunction,比如在 keyBy 算子之后使用:
```java
dataStream.keyBy(...).process(new KeyedProcessFunction<>(){
})
```
KeyedProcessFunction 是 ProcessFunction 函数的一个扩展,它可以在 onTimer 和 processElement 方法中获取到分区的 Key 值,这对于数据传递是很有帮助的,因为经常有这样的需求,经过 keyBy 算子之后可能还需要这个 key 字段,那么在这里直接构建成一个新的对象(新增一个 key 字段),然后下游的算子直接使用这个新对象中的 key 就好了,而不在需要重复的拼一个唯一的 key。
```java
public void processElement(String value, Context ctx, Collector out) throws Exception {
System.out.println(ctx.getCurrentKey());
out.collect(value);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
System.out.println(ctx.getCurrentKey());
super.onTimer(timestamp, ctx, out);
}
```
### 11.2.2 CoProcessFunction 简介
如果要在两个输入流上进行操作,可以使用 CoProcessFunction,这个函数可以传入两个不同的数据流输入,并为来自两个不同数据源的事件分别调用 processElement1() 和 processElement2() 方法。可以按照下面的步骤来实现一个典型的 Join 操作:
+ 为一个数据源的数据建立一个状态对象
+ 从数据源处有新数据流过来的时候更新这个状态对象
+ 在另一个数据源接收到元素时,关联状态对象并对其产生出连接的结果
比如,将监控的 metric 数据和告警规则数据进行一个连接,在流数据的状态中存储了告警规则数据,当有监控数据过来时,根据监控数据的 metric 名称和一些 tag 去找对应告警规则计算表达式,然后通过规则的表达式对数据进行加工处理,判断是否要告警,如果是要告警则会关联构造成一个新的对象,新对象中不仅有初始的监控 metric 数据,还有含有对应的告警规则数据以及通知策略数据,组装成这样一条数据后,下游就可以根据这个数据进行通知,通知还会在状态中存储这个告警状态,表示它在什么时间告过警了,下次有新数据过来的时候,判断新数据是否是恢复的,如果属于恢复则把该状态清除。
### 11.2.3 Timer 简介
Timer 提供了一种定时触发器的功能,通过 TimerService 接口注册 timer。TimerService 在内部维护两种类型的定时器(处理时间和事件时间定时器)并排队执行。处理时间定时器的触发依赖于 ProcessingTimeService,它负责管理所有基于处理时间的触发器,内部使用 ScheduledThreadPoolExecutor 调度定时任务;事件时间定时器的触发依赖于系统当前的 Watermark。需要注意的一点就是:**Timer 只能在 KeyedStream 中使用**。
TimerService 会删除每个 Key 和时间戳重复的定时器,即每个 Key 在同一个时间戳上最多有一个定时器。如果为同一时间戳注册了多个定时器,则只会调用一次 onTimer() 方法。Flink 会同步调用 onTimer() 和 processElement() 方法,因此不必担心状态的并发修改问题。TimerService 不仅提供了注册和删除 Timer 的功能,还可以通过它来获取当前的系统时间和 Watermark 的值。TimerService 类中的方法如下图所示。
#### 容错
定时器具有容错能力,并且会与应用程序的状态一起进行 Checkpoint,如果发生故障重启会从 Checkpoint/Savepoint 中恢复定时器的状态。如果有处理时间定时器原本是要在恢复起来的那个时间之前触发的,那么在恢复的那一刻会立即触发该定时器。定时器始终是异步的进行 Checkpoint(除 RocksDB 状态后端存储、增量的 Checkpoint、基于堆的定时器外)。因为定时器实际上也是一种特殊状态的状态,在 Checkpoint 时会写入快照中,所以如果有大量的定时器,则无非会增加一次 Checkpoint 所需要的时间,必要的话得根据实际情况合并定时器。
#### 合并定时器
由于 Flink 仅为每个 Key 和时间戳维护一个定时器,因此可以通过降低定时器的频率来进行合并以减少定时器的数量。对于频率为 1 秒的定时器(基于事件时间或处理时间),可以将目标时间向下舍入为整秒数,则定时器最多提前 1 秒触发,但不会迟于我们的要求,精确到毫秒。因此,每个键每秒最多有一个定时器。
```java
long coalescedTime = ((ctx.timestamp() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);
```
由于事件时间计时器仅在 Watermark 到达时才触发,因此可以将当前 Watermark 与下一个 Watermark 的定时器一起调度和合并:
```java
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);
```
定时器也可以类似下面这样移除:
```java
//删除处理时间定时器
long timestampOfTimerToStop = ...
ctx.timerService().deleteProcessingTimeTimer(timestampOfTimerToStop);
//删除事件时间定时器
long timestampOfTimerToStop = ...
ctx.timerService().deleteEventTimeTimer(timestampOfTimerToStop);
```
如果没有该时间戳的定时器,则删除定时器无效。
### 11.2.4 如果利用 ProcessFunction 处理宕机告警?
#### 宕机告警需求分析
#### 宕机告警代码实现
### 11.2.5 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何利用 Async I/O 读取告警规则?
date: 2021-08-16
tags:
- Flink
- 大数据
- 流式计算
---
## 11.3 如何利用 Async I/O 读取告警规则?
Async 中文是异步的意思,在流计算中,使用异步 I/O 能够提升作业整体的计算能力,本节中不仅会讲解异步 I/O 的 API 原理,还会通过一个实战需求(读取告警规则)来讲解异步 I/O 的使用。
### 11.3.1 为什么需要 Async I/O?
在大多数情况下,IO 操作都是一个耗时的过程,尤其在流计算中,如果在具体的算子里面还有和第三方外部系统(比如数据库、Redis、HBase 等存储系统)做交互,比如在一个 MapFunction 中每来一条数据就要去查找 MySQL 中某张表的数据,然后跟查询出来的数据做关联(同步交互)。查询请求到数据库,再到数据库响应返回数据的整个流程的时间对于流作业来说是比较长的。那么该 Map 算子处理数据的速度就会降下来,在大数据量的情况下很可能会导致整个流作业出现反压问题(在 9.1 节中讲过),那么整个作业的消费延迟就会增加,影响作业整体吞吐量和实时性,从而导致最终该作业处于不可用的状态。
这种同步(Sync)的与数据库做交互操作,会因耗时太久导致整个作业延迟,如果换成异步的话,就可以同时处理很多请求并同时可以接收响应,这样的话,等待数据库响应的时间就会与其他发送请求和接收响应的时间重叠,相同的等待时间内会处理多个请求,从而比同步的访问要提高不少流处理的吞吐量。虽然也可以通过增大该算子的并行度去执行查数据库,但是这种解决办法需要消耗更多的资源(并行度增加意味着消费的 slot 个数也会增加),这种方法和使用异步处理的方法对比一下,还是使用异步的查询数据库这种方法值得使用。同步操作(Sync I/O)和异步操作(Async I/O)的处理流程如下图所示。
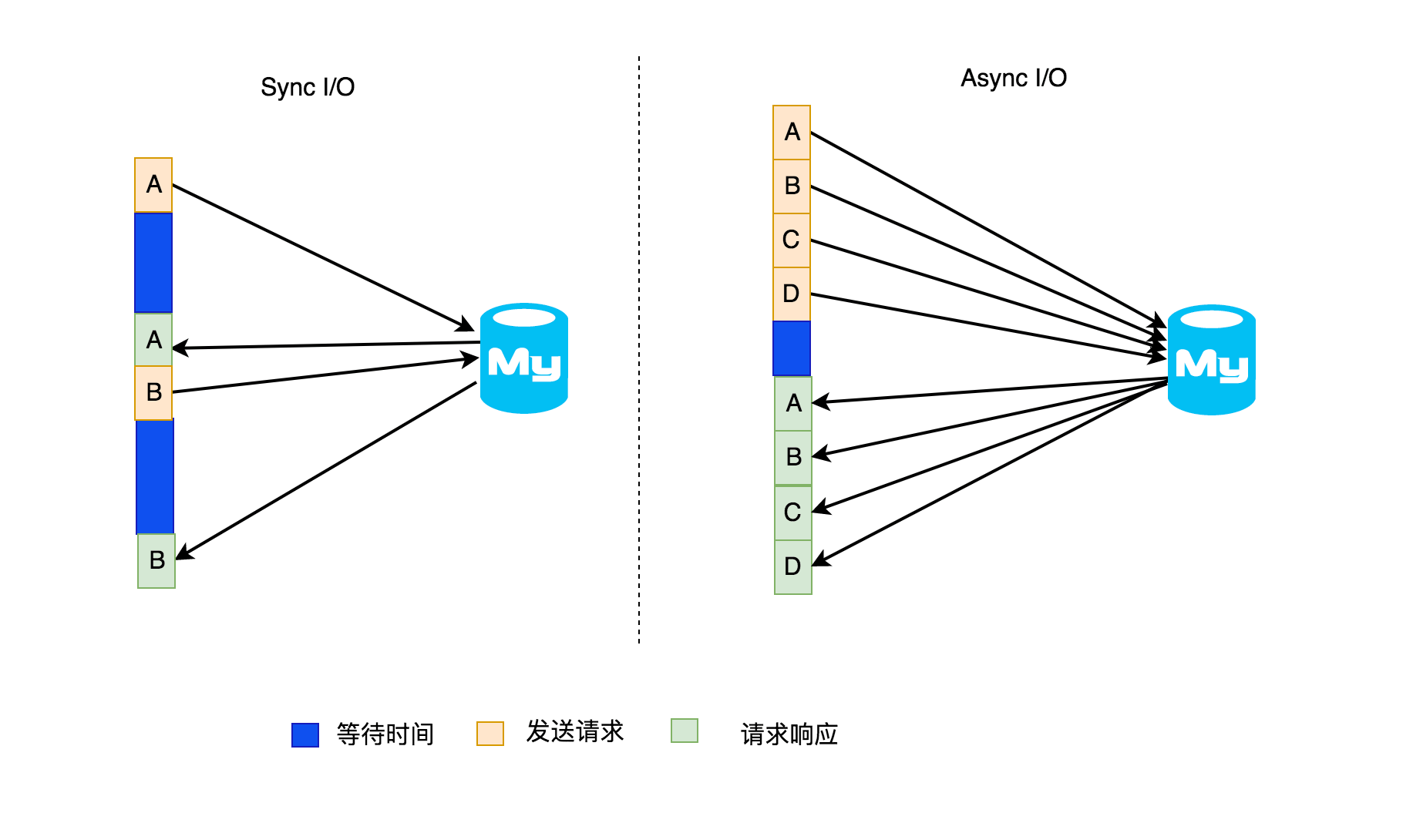
左侧表示的是在流处理中同步的数据库请求,右侧是异步的数据库请求。假设左侧是数据流中 A 数据来了发送一个查询数据库的请求看是否之前存在 A,然后等待查询结果返回,只有等 A 整个查询请求响应后才会继续开始 B 数据的查询请求,依此继续;而右侧是连续的去数据库查询是否存在 A、B、C、D,后面哪个请求先响应就先处理哪个,不需要和左侧的一样要等待上一个请求全部完成才可以开始下一个请求,所以异步的话吞吐量自然就高起来了。但是得注意的是:使用异步这种方法前提是要数据库客户端支持异步的请求,否则可能需要借助线程池来实现异步请求,但是现在主流的数据库通常都支持异步的操作,所以不用太担心。
### 11.3.2 Async I/O API
Flink 的 Async I/O API 允许用户在数据流处理中使用异步请求,并且还支持超时处理、处理顺序、事件时间、容错。在 Flink 中,如果要使用 Async I/O API,是非常简单的,需要通过下面三个步骤来执行对数据库的异步操作。
+ 继承 RichAsyncFunction 抽象类或者实现用来分发请求的 AsyncFunction 接口
+ 返回异步请求的结果的 Future
+ 在 DataStream 上使用异步操作
官网也给出案例如下:
```java
class AsyncDatabaseRequest extends RichAsyncFunction> {
//数据库的客户端,它可以发出带有 callback 的并发请求
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture> resultFuture) throws Exception{
//发出异步请求,接收 future 的结果
final Future result = client.query(key);
//设置客户端请求完成后执行的 callback,callback 只是将结果转发给 ResultFuture
CompletableFuture.supplyAsync(new Supplier() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
//原始数据
DataStream stream = ...;
//应用异步 I/O 转换
DataStream> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
```
注意:ResultFuture 在第一次调用 resultFuture.complete 时就已经完成了,后面所有 resultFuture.complete 的调用都会被忽略。
下面两个参数控制了异步操作:
+ Timeout:timeout 定义了异步操作过了多长时间后会被丢弃,这个参数是防止了死的或者失败的请求
+ Capacity:这个参数定义可以同时处理多少个异步请求。虽然异步请求会带来更好的吞吐量,但是该操作仍然可能成为流作业的性能瓶颈。限制并发请求的数量可确保操作不会不断累积处理请求,一旦超过 Capacity 值,它将触发反压。
#### 超时处理
#### 结果顺序
#### 事件时间
#### 容错性保证
#### 实践技巧
#### 注意点
### 11.3.3 利用 Async I/O 读取告警规则需求分析
#### 监控数据样例
#### 告警规则表设计
#### 告警规则实体类
### 11.3.4 如何使用 Async I/O 读取告警规则数据
### 11.3.5 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.4.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何利用广播变量动态更新告警规则?
date: 2021-08-17
tags:
- Flink
- 大数据
- 流式计算
---
## 11.4 如何利用广播变量动态更新告警规则?
一个在生产环境运行的流作业有时候会想变更一些作业的配置或者数据流的配置,然后作业可以读取并使用新的配置,而不是通过修改配置然后重启作业来读取配置,毕竟重启一个有状态的流作业代价挺大,本节将带你熟悉 Broadcast,并通过一个案例来教会你如何去动态的更新作业的配置。
### 11.4.1 BroadcastVariable 简介
BroadcastVariable 中文意思是广播变量,其实可以理解是一个公共的共享变量(可能是固定不变的数据集合,也可能是动态变化的数据集合),在作业中将该共享变量广播出去,然后下游的所有任务都可以获取到该共享变量,这样就可以不用将这个变量拷贝到下游的每个任务中。之所以设计这个广播变量的原因主要是因为在 Flink 中多并行度的情况下,每个算子或者不同算子运行所在的 Slot 不一致,这就导致它们不会共享同一个内存,也就不可以通过静态变量的方式去获取这些共享变量值。对于这个问题,有不少读者在问过我为啥我设置的静态变量值在本地运行是可以获取到的,在集群环境运行作业就出现空指针啊,该问题其实笔者自己也在生产环境遇到过,所以接下来好好教大家使用!
### 11.4.2 如何使用 BroadcastVariable ?
在 3.4 节中讲过如何 broadcast 算子和 BroadcastStream 如何使用,在 4.1 节中讲解了 Broadcast State 如何使用以及需要注意的地方,注意 BroadcastVariable 只能应用在批作业中,如果要应用在流作业中则需要要使用 BroadcastStream。
在批作业中通过使用 `withBroadcastSet(DataSet, String)` 来广播一个 DataSet 数据集合,并可以给这份数据起个名字,如果要获取数据的时候,可以通过 `getRuntimeContext().getBroadcastVariable(String)` 获取广播出去的变量数据。下面演示一下广播一个 DataSet 变量和获取变量的样例。
```java
final ParameterTool params = ParameterTool.fromArgs(args);
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//1. 待广播的数据
DataSet toBroadcast = env.fromElements(1, 2, 3);
env.fromElements("a", "b")
.map(new RichMapFunction() {
List broadcastData;
@Override
public void open(Configuration parameters) throws Exception {
// 3. 获取广播的 DataSet 数据 作为一个 Collection
broadcastData = getRuntimeContext().getBroadcastVariable("zhisheng");
}
@Override
public String map(String value) throws Exception {
return broadcastData.get(1) + value;
}
}).withBroadcastSet(toBroadcast, "zhisheng")// 2. 广播 DataSet
.print();
```
注意广播的时候设置的名称和获取的名称要一致,然后运行的结果如下图所示。
流作业中通常使用 BroadcastStream 的方式将变量集合在数据流中传递,可能数据集合会做修改更新,但是修改后其实并不想重启作业去读取这些新修改的配置,因为对于一个流作业来说重启带来的代价很高(需要考虑数据堆积和如何恢复至重启前的状态等问题),那么这种情况下就可以在广播数据流处定时查询数据,这样就能够获取更改后的数据,通常在这种广播数据处获取数据只需要设置一个并行度就好,时间根据需求来判断及时性,一般 1 分钟内的数据变更延迟都是在容忍范围之内。广播流中的元素保证流所有的元素最终都会发到下游的所有并行实例,但是元素到达下游的并行实例的顺序可能不相同。因此,对广播状态的修改不能依赖于输入数据的顺序。在进行 Checkpoint 时,所有的任务都会 Checkpoint 下它们的广播状态。
另外需要注意的是:广播出去的变量存在于每个节点的内存中,所以这个数据集不能太大,因为广播出去的数据,会一致在内存中存在,除非程序执行结束。个人建议:如果数据集在几十兆或者百兆的时候,可以选择进行广播,如果数据集的大小上 G 的话,就不建议进行广播了。
上面介绍了下广播变量的在批作业的使用方式,下面通过一个案例来教大家如何在流作业中使用广播变量。
### 11.4.3 利用广播变量动态更新告警规则数据需求分析
在 11.3.3 节中有设计一张简单的告警规则表,通常告警规则是会对外提供接口进行增删改查的,那么随着业务应用上线,开发人员会对其应用服务新增或者修改告警规则(更改之前规则中的阈值),那么更改之后就需要让告警的作业能够去感知到之前的规则发生了变动,所以就需要在作业中想个什么办法去获取到更改后的数据。有两种方式可以让作业知道规则的变更: push 和 pull 模式。
push 模式则需要在更新、删除、新增接口中不仅操作数据库,还需要额外的发送更新、删除、新增规则的事件到消息队列中,然后作业消费消息队列的数据再去做更新、删除、新增规则,这种及时性有保证,但是可能会有数据不统一的风险(如果消息队列的数据丢了,但是在接口中还是将规则的数据变更存储到数据库);pull 模式下就需要作业定时去查找一遍所有的告警规则数据,然后存在作业内存中,这个时间可以设置的比较短,比如 1 分钟,这样就能既保证数据的一致性,时间延迟也是在容忍范围之内。
对于这种动态变化的规则数据,在 Flink 中通常是使用广播流来处理的。那么接下来就演示下如何利用广播变量动态更新告警规则数据,假设我们在数据库中新增告警规则或者修改告警规则指标的阈值,然后看作业中是否会出现相应的变化。
### 11.4.4 读取告警规则数据
### 11.4.5 监控数据连接规则数据
### 11.4.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.5.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何实时将应用 Error 日志告警?
date: 2021-08-18
tags:
- Flink
- 大数据
- 流式计算
---
## 11.5 如何实时将应用 Error 日志告警?
大数据时代,随着公司业务不断的增长,数据量自然也会跟着不断的增长,那么业务应用和集群服务器的的规模也会逐渐扩大,几百台服务器在一般的公司已经是很常见的了。那么将应用服务部署在如此多的服务器上,对开发和运维人员来说都是一个挑战。一个优秀的系统运维平台是需要将部署在这么多服务器上的应用监控信息汇总成一个统一的数据展示平台,方便运维人员做日常的监测、提升运维效率,还可以及时反馈应用的运行状态给应用开发人员。举个例子,应用的运行日志需要按照时间排序做一个展示,并且提供日志下载和日志搜索等服务,这样如果应用出现问题开发人员首先可以根据应用日志的错误信息进行问题的排查。那么该如何实时的将应用的 Error 日志推送给应用开发人员呢,接下来我们将讲解日志的处理方案。
### 11.5.1 日志处理方案的演进
日志处理的方案也是有一个演进的过程,要想弄清楚整个过程,我们先来看下日志的介绍。
#### 什么是日志?
日志是带时间戳的基于时间序列的数据,它可以反映系统的运行状态,包括了一些标识信息(应用所在服务器集群名、集群机器 IP、机器设备系统信息、应用名、应用 ID、应用所属项目等)
#### 日志处理方案演进
日志处理方案的演进过程:
+ 日志处理 v1.0: 应用日志分布在很多机器上,需要人肉手动去机器查看日志信息。
+ 日志处理 v2.0: 利用离线计算引擎统一的将日志收集,形成一个日志搜索分析平台,提供搜索让用户根据关键字进行搜索和分析,缺点就是及时性比较差。
+ 日志处理 v3.0: 利用 Agent 实时的采集部署在每台机器上的日志,然后统一发到日志收集平台做汇总,并提供实时日志分析和搜索的功能,这样从日志产生到搜索分析出结果只有简短的延迟(在用户容忍时间范围之内),优点是快,但是日志数据量大的情况下带来的挑战也大。
### 11.5.2 日志采集工具对比
上面提到的日志采集,其实现在已经有很多开源的组件支持去采集日志,比如 Logstash、Filebeat、Fluentd、Logagent 等,这里简单做个对比。
#### Logstash
Logstash 是一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。如下图所示,Logstash 将采集到的数据用作分析、监控、告警等。
**优势**:Logstash 主要的优点就是它的灵活性,它提供很多插件,详细的文档以及直白的配置格式让它可以在多种场景下应用。而且现在 ELK 整个技术栈在很多公司应用的比较多,所以基本上可以在往上找到很多相关的学习资源。
**劣势**:Logstash 致命的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的,它在大数据量的情况下会是个问题。另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池:
#### Filebeat
作为 Beats 家族的一员,Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点,Filebeat 作为一个轻量级的日志传输工具可以将日志推送到 Kafka、Logstash、ElasticSearch、Redis。它的处理流程如下图所示:
**优势**:Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性还是很高的。它也为我们提供了很多可以调节的点,例如:它以何种方式搜索新的文件,以及当文件有一段时间没有发生变化时,何时选择关闭文件句柄。
**劣势**:Filebeat 的应用范围十分有限,所以在某些场景下我们会碰到问题。例如,如果使用 Logstash 作为下游管道,我们同样会遇到性能问题。正因为如此,Filebeat 的范围在扩大。开始时,它只能将日志发送到 Logstash 和 Elasticsearch,而现在它可以将日志发送给 Kafka 和 Redis,在 5.x 版本中,它还具备过滤的能力。
#### Fluentd
Fluentd 创建的初衷主要是尽可能的使用 JSON 作为日志输出,所以传输工具及其下游的传输线不需要猜测子字符串里面各个字段的类型。这样它为几乎所有的语言都提供库,这也意味着可以将它插入到自定义的程序中。它的处理流程如下图所示:

**优势**:和多数 Logstash 插件一样,Fluentd 插件是用 Ruby 语言开发的非常易于编写维护。所以它数量很多,几乎所有的源和目标存储都有插件(各个插件的成熟度也不太一样)。这也意味这可以用 Fluentd 来串联所有的东西。
**劣势**:因为在多数应用场景下得到 Fluentd 结构化的数据,它的灵活性并不好。但是仍然可以通过正则表达式来解析非结构化的数据。尽管性能在大多数场景下都很好,但它并不是最好的,它的缓冲只存在与输出端,单线程核心以及 Ruby GIL 实现的插件意味着它大的节点下性能是受限的。
#### Logagent
Logagent 是 Sematext 提供的传输工具,它用来将日志传输到 Logsene(一个基于 SaaS 平台的 Elasticsearch API),因为 Logsene 会暴露 Elasticsearch API,所以 Logagent 可以很容易将数据推送到 Elasticsearch 。
**优势**:可以获取 /var/log 下的所有信息,解析各种格式的日志,可以掩盖敏感的数据信息。它还可以基于 IP 做 GeoIP 丰富地理位置信息。同样,它轻量又快速,可以将其置入任何日志块中。Logagent 有本地缓冲,所以在数据传输目的地不可用时不会丢失日志。
**劣势**:没有 Logstash 灵活。
### 11.5.3 日志结构设计
前面介绍了日志和对比了常用日志采集工具的优势和劣势,通常在不同环境,不同机器上都会部署日志采集工具,然后采集工具会实时的将新的日志采集发送到下游,因为日志数据量毕竟大,所以建议发到 MQ 中,比如 Kafka,这样再想怎么处理这些日志就会比较灵活。假设我们忽略底层采集具体是哪种,但是规定采集好的日志结构化数据如下:
```java
public class LogEvent {
private String type;//日志的类型(应用、容器、...)
private Long timestamp;//日志的时间戳
private String level;//日志的级别(debug/info/warn/error)
private String message;//日志内容
//日志的标识(应用 ID、应用名、容器 ID、机器 IP、集群名、...)
private Map tags = new HashMap<>();
}
```
然后上面这种 LogEvent 的数据(假设采集发上来的是这种结构数据的 JSON 串,所以需要在 Flink 中做一个反序列化解析)就会往 Kafka 不断的发送数据,样例数据如下:
```json
{
"type": "app",
"timestamp": 1570941591229,
"level": "error",
"message": "Exception in thread \"main\" java.lang.NoClassDefFoundError: org/apache/flink/api/common/ExecutionConfig$GlobalJobParameters",
"tags": {
"cluster_name": "zhisheng",
"app_name": "zhisheng",
"host_ip": "127.0.0.1",
"app_id": "21"
}
}
```
那么在 Flink 中如何将应用异常或者错误的日志做实时告警呢?
### 11.5.4 异常日志实时告警项目架构
整个异常日志实时告警项目的架构如下图所示。
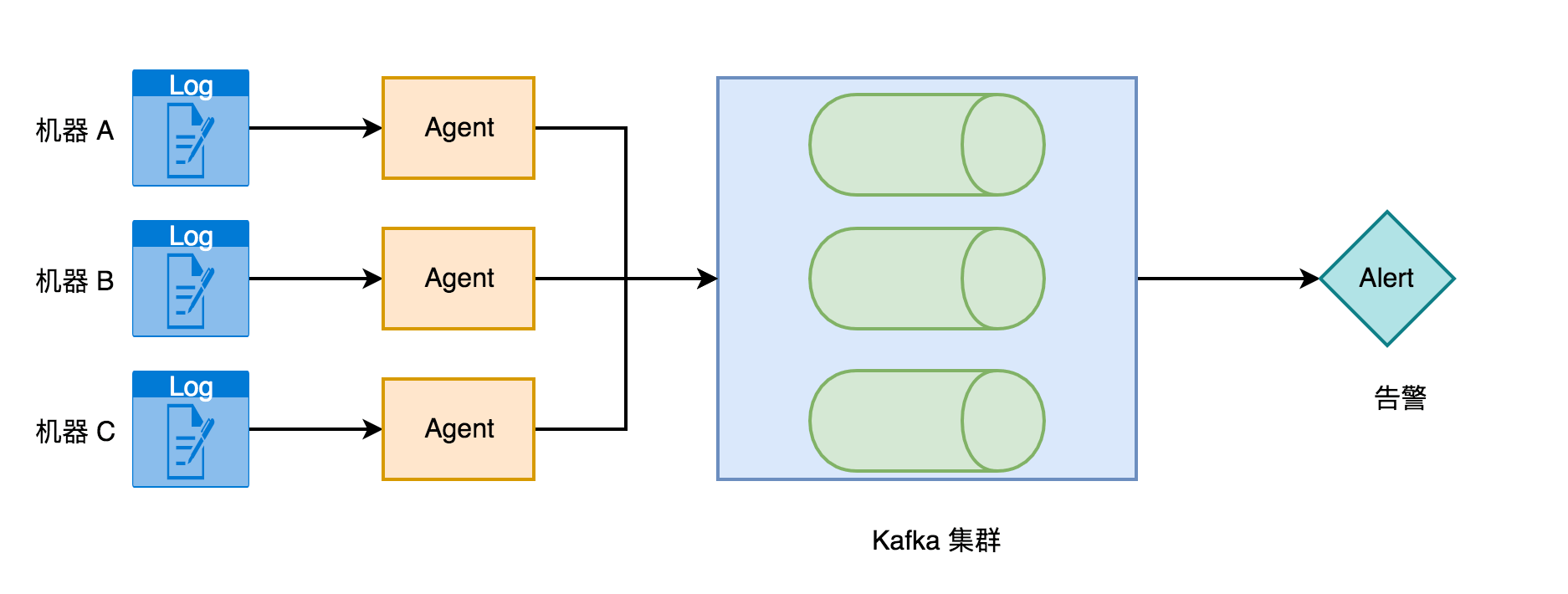
应用日志散列在不同的机器,然后每台机器都有部署采集日志的 Agent(可以是上面的 Filebeat、Logstash 等),这些 Agent 会实时的将分散在不同机器、不同环境的应用日志统一的采集发到 Kafka 集群中,然后告警这边是有一个 Flink 作业去实时的消费 Kafka 数据做一个异常告警计算处理。如果还想做日志的搜索分析,可以起另外一个作业去实时的将 Kafka 的日志数据写入进 ElasticSearch,再通过 Kibana 页面做搜索和分析。
### 11.5.5 日志数据发送到 Kafka
上面已经讲了日志数据 LogEvent 的结构和样例数据,因为要在服务器部署采集工具去采集应用日志数据对于本地测试来说可能稍微复杂,所以在这里就只通过代码模拟构造数据发到 Kafka 去,然后在 Flink 作业中去实时消费 Kafka 中的数据,下面演示构造日志数据发到 Kafka 的工具类,这个工具类主要分两块,构造 LogEvent 数据和发送到 Kafka。
```java
@Slf4j
public class BuildLogEventDataUtil {
//Kafka broker 和 topic 信息
public static final String BROKER_LIST = "localhost:9092";
public static final String LOG_TOPIC = "zhisheng_log";
public static void writeDataToKafka() {
Properties props = new Properties();
props.put("bootstrap.servers", BROKER_LIST);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
for (int i = 0; i < 10000; i++) {
//模拟构造 LogEvent 对象
LogEvent logEvent = new LogEvent().builder()
.type("app")
.timestamp(System.currentTimeMillis())
.level(logLevel())
.message(message(i + 1))
.tags(mapData())
.build();
// System.out.println(logEvent);
ProducerRecord record = new ProducerRecord(LOG_TOPIC, null, null, GsonUtil.toJson(logEvent));
producer.send(record);
}
producer.flush();
}
public static void main(String[] args) {
writeDataToKafka();
}
public static String message(int i) {
return "这是第 " + i + " 行日志!";
}
public static String logLevel() {
Random random = new Random();
int number = random.nextInt(4);
switch (number) {
case 0:
return "debug";
case 1:
return "info";
case 2:
return "warn";
case 3:
return "error";
default:
return "info";
}
}
public static String hostIp() {
Random random = new Random();
int number = random.nextInt(4);
switch (number) {
case 0:
return "121.12.17.10";
case 1:
return "121.12.17.11";
case 2:
return "121.12.17.12";
case 3:
return "121.12.17.13";
default:
return "121.12.17.10";
}
}
public static Map mapData() {
Map map = new HashMap<>();
map.put("app_id", "11");
map.put("app_name", "zhisheng");
map.put("cluster_name", "zhisheng");
map.put("host_ip", hostIp());
map.put("class", "BuildLogEventDataUtil");
map.put("method", "main");
map.put("line", String.valueOf(new Random().nextInt(100)));
//add more tag
return map;
}
}
```
如果之前 Kafka 中没有 zhisheng_log 这个 topic,运行这个工具类之后也会自动创建这个 topic 了。
### 11.5.6 Flink 实时处理日志数据
### 11.5.7 处理应用异常日志
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

本章属于 Flink 实战篇,前面章节讲了很多 Flink 相关的技术知识点,这章主要是通过技术点来教大家如何去完成一些真实的需求,比如通过 State 去实时统计网站各页面一天的 PV 和 UV、通过 ProcessFunction 去做定时器处理一些延迟的事件(宕机告警)、通过 Async IO 读取告警规则、通过广播变量动态的更新告警规则、如何实时的做到日志告警。
虽然这些需求换到你们公司去可能不一样,但是这些技术知识点是可以运用到你的项目需求中去的,这里介绍的这些需求,你要学会去分析,然后去判断这些需求到底该使用什么技术来实现会更好,这样才可以做到活学活用。
================================================
FILE: books/flink-in-action-12.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 基于 Flink 实时处理海量日志
date: 2021-08-19
tags:
- Flink
- 大数据
- 流式计算
---
# 第十二章 —— Flink 案例
本章将介绍 Flink 在多个场景下落地实现的大型案例,第一个是实时处理海量的日志,将从日志的收集、日志的传输、日志的实时清洗和异常检测、日志存储、日志展示等方面去介绍 Flink 在其中起的作用,希望整个日志处理的架构大家可以灵活的运用在自己的公司;第二个是百亿数据量的情况下如何使用 Flink 实时去重,在这个案例中将对比介绍其他几种常见的去重实现方案;第三个是 Flink 在监控告警系统中的落地实现,在这个案例中同样很详细的介绍了一个监控告警系统的全链路,每一个关节都不可或缺,并且还介绍了 Flink 在未来结合机器学习算法做一些 AIOps 的事情。三个案例都比较典型,如果你也在做类似的项目,希望对你们的技术选型有一定的帮助。
## 12.1 基于 Flink 实时处理海量日志
在 11.5 节中讲解了 Flink 如何实时处理异常的日志,并且对比分析了几种常用的日志采集工具。我们也知道通常在排查线上异常故障的时候,日志是必不可缺的一部分,通过异常日志我们可以快速的定位到问题的根因。那么通常在公司对于日志处理有哪些需求呢?
### 12.1.1 实时处理海量日志需求分析
现在公司都在流行构建分布式、微服务、云原生的架构,在这类架构下,项目应用的日志都被分散到不同的机器上,日志查询就会比较困难,所以统一的日志收集几乎也是每家公司必不可少的。据笔者调研,不少公司现在是有日志统一的收集,也会去做日志的实时 ETL,利用一些主流的技术比如 ELK 去做日志的展示、搜索和分析,但是却缺少了日志的实时告警。总结来说,大部分公司对于日志这块的现状是:
+ **日志分布零散**:分布式应用导致日志分布在不同的机器上,人肉登录到机器上操作复杂,需要统一的日志收集工具。
+ **异常日志无告警**:出错时无异常日志告警,导致错过最佳定位问题的时机,需要异常错误日志的告警。
+ **日志查看不友好**:登录服务器上在终端查看日志不太方便,需要一个操作友好的页面去查看日志。
+ **无日志搜索分析**:历史日志文件太多,想找某种日志找不到了,需要一个可以搜索日志的功能。
在本节中,笔者将为大家讲解日志的全链路,包含了日志的实时采集、日志的 ETL、日志的实时监控告警、日志的存储、日志的可视化图表展示与搜索分析等。
### 12.1.2 实时处理海量日志架构设计
分析完我们这个案例的需求后,接下来对整个项目的架构做一个合理的设计。
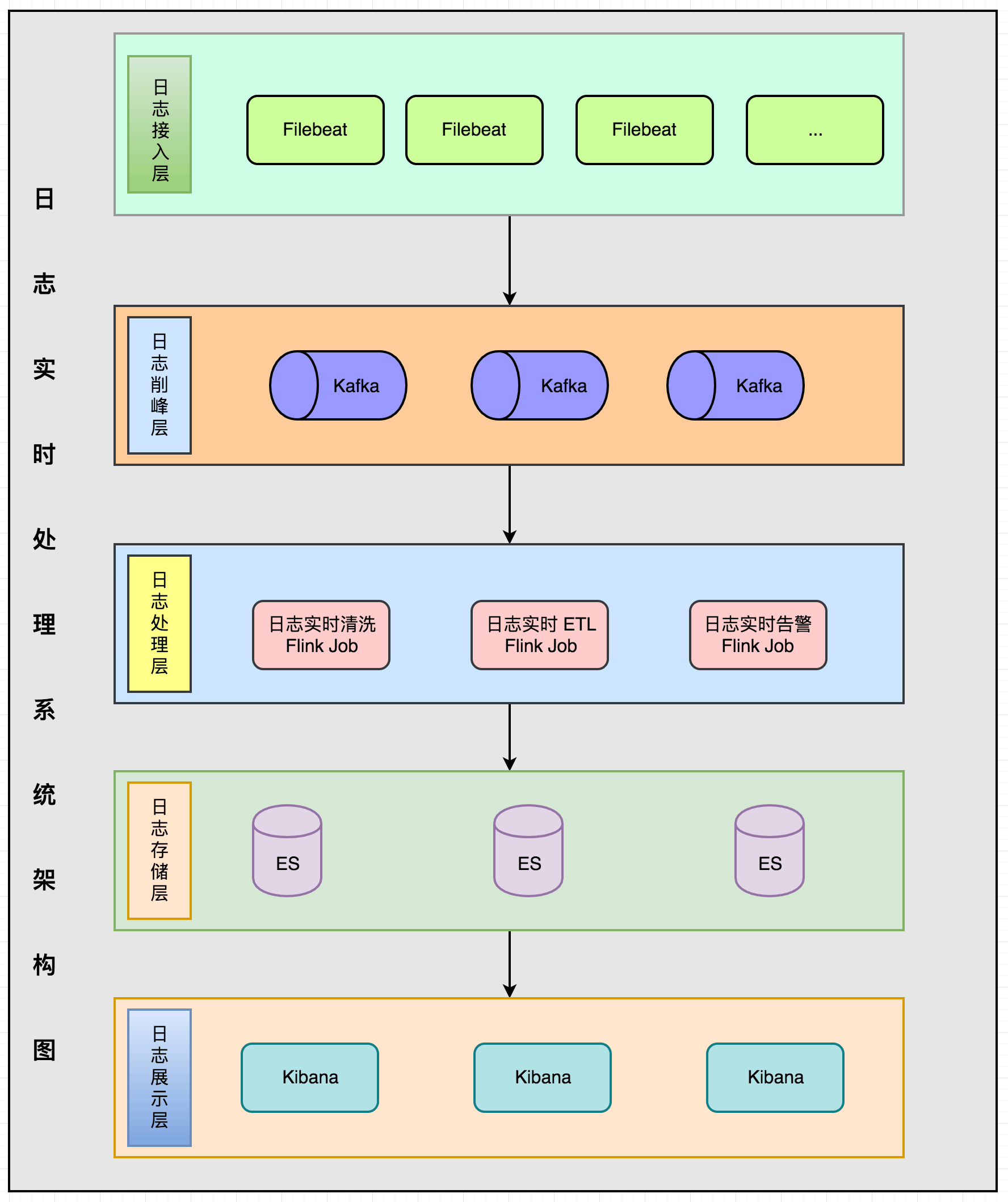
整个架构分为五层:日志接入层、日志削峰层、日志处理层、日志存储层、日志展示层。
+ 日志接入层:日志采集的话使用的是 Filebeat 组件,需要在每台机器上部署一个 Filebeat。
+ 日志削峰层:防止日志流量高峰,使用 Kafka 消息队列做削峰。
+ 日志处理层:Flink 作业同时消费 Kafka 数据做日志清洗、ETL、实时告警。
+ 日志存储层:使用 ElasticSearch 做日志的存储。
+ 日志展示层:使用 Kibana 做日志的展示与搜索查询界面。
### 12.1.3 日志实时采集
在 11.5.1 中对比了这几种比较流行的日志采集工具(Logstash、Filebeat、Fluentd、Logagent),从功能完整性、性能、成本、使用难度等方面综合考虑后,这里演示使用的是 Filebeat。
#### 安装 Filebeat
在服务器上下载 [Fliebeat 6.3.2](https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-linux-x86_64.tar.gz) 安装包(请根据自己服务器和所需要的版本进行下载),下载后进行解压。
```
tar xzf filebeat-6.3.2-linux-x86_64.tar.gz
```
#### 配置 Filebeat
配置 Filebeat 需要编辑 Filebeat 的配置文件 `filebeat.yml`,不同安装方式配置文件的存放路径有一些不同,对于解压包安装的方式,配置文件存在解压目录下面;对于 rpm 和 deb 的方式, 配置文件路径的是 `/etc/filebeat/filebeat.yml` 下。
因为 Filebeat 是要实时采集日志的,所以得让 Filebeat 知道日志的路径是在哪里,下面在配置文件中定义一下日志文件的路径。通常建议在服务器上固定存放日志的路径,然后应用的日志都打在这个固定的路径中,这样 Filebeat 的日志路径配置只需要填写一次,其他机器上可以拷贝同样的配置就能将 Filebeat 运行起来,配置如下。
```
- type: log
# 配置为 true 表示开启
enabled: true
# 日志的路径
paths:
- /var/logs/*.log
```
上面的配置表示将对 /var/logs 目录下所有以 .log 结尾的文件进行采集,接下来配置日志输出的方式,这里使用的是 Kafka,配置如下。
```
output.kafka:
# 填写 Kafka 地址信息
hosts: ["localhost:9092"]
# 数据发到哪个 topic
topic: zhisheng-log
partition.round_robin:
reachable_only: false
required_acks: 1
```
上面讲解的两个配置,笔者这里将它们写在一个新建的配置文件中 kafka.yml,然后启动 Filebeat 的时候使用该配置。
```yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/logs/*.log
output.kafka:
hosts: ["localhost:9092"]
topic: zhisheng_log
partition.round_robin:
reachable_only: false
required_acks: 1
```
#### 启动 Filebeat
日志路径的配置和 Kafka 的配置都写好后,则接下来通过下面命令将 Filebeat 启动:
```
bin/filebeat -e -c kafka.yml
```
执行完命令后出现的日志如下则表示启动成功了,另外还可以看得到会在终端打印出 metrics 数据出来。
#### 验证 Filebeat 是否将日志数据发到 Kafka
那么此时就得去查看是否真正就将这些日志数据发到 Kafka 了呢,你可以通过 Kafka 的自带命令去消费这个 Topic 看是否不断有数据发出来,命令如下:
```
bin/kafka-console-consumer.sh --zookeeper 106.54.248.27:2181 --topic zhisheng_log --from-beginning
```
如果出现数据则代表是已经有数据发到 Kafka 了,如果你不喜欢使用这种方式验证,可以自己写个 Flink Job 去读取 Kafka 该 Topic 的数据,比如写了个作业运行结果如下就代表着日志数据已经成功发送到 Kafka。

#### 发到 Kafka 的日志结构
既然数据都已经发到 Kafka 了,通过消费 Kafka 该 Topic 的数据我们可以发现这些数据的格式否是 JSON,结构如下:
```json
{
"@timestamp": "2019-10-26T08:18:18.087Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.8.4",
"topic": "zhisheng_log"
},
"prospector": {
"type": "log"
},
"input": {
"type": "log"
},
"beat": {
"name": "VM_0_2_centos",
"hostname": "VM_0_2_centos",
"version": "6.8.4"
},
"host": {
"name": "VM_0_2_centos"
},
"source": "/var/logs/middleware/kafka.log",
"offset": 9460,
"log": {
"file": {
"path": "/var/logs/middleware/kafka.log"
}
},
"message": "2019-10-26 16:18:11 TRACE [Controller id=0] Leader imbalance ratio for broker 0 is 0.0 (kafka.controller.KafkaController)"
}
```
这个日志结构里面包含了很多字段,比如 timestamp、metadata、host、source、message 等,但是其中某些字段我们其实根本不需要的,你可以根据公司的需求丢弃一些字段,把要丢弃的字段也配置在 kafka.yml 中,如下所示。
```
processors:
- drop_fields:
fields: ["prospector","input","beat","log","offset","@metadata"]
```
然后再次启动 Filebeat ,发现上面配置的字段在新的数据中没有了(除 @metadata 之外),另外经笔者验证:不仅 @metadata 字段不能丢弃,如果 @timestamp 这个字段在 drop_fields 中配置了,也是不起作用的,它们两不允许丢弃。通常来说一行日志已经够长了,再加上这么多我们不需要的字段,就会增加数据的大小,对于生产环境的话,日志数据量非常大,那无疑会对后面所有的链路都会造成一定的影响,所以一定要在底层数据源头做好精简。另外还可以在发送 Kafka 的时候对数据进行压缩,可以在配置文件中配置一个 `compression: gzip`。精简后的日志数据结构如下:
```json
{
"@timestamp": "2019-10-26T09:23:16.848Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.8.4",
"topic": "zhisheng_log"
},
"host": {
"name": "VM_0_2_centos"
},
"source": "/var/logs/middleware/kafka.log",
"message": "2019-10-26 17:23:11 TRACE [Controller id=0] Leader imbalance ratio for broker 0 is 0.0 (kafka.controller.KafkaController)"
}
```
### 12.1.4 日志格式统一
因为 Filebeat 是在机器上采集的日志,这些日志的种类比较多,常见的有应用程序的运行日志、作业构建编译打包的日志、中间件服务运行的日志等。通常在公司是可以给开发约定日志打印的规则,但是像中间件这类服务的日志是不固定的,如果将 Kafka 中的消息直接存储到 ElasticSearch 的话,后面如果要做区分筛选的话可能会有问题。为了避免这个问题,我们得在日志存入 ElasticSearch 之前做一个数据格式化和清洗的工作,因为 Flink 处理数据的速度比较好,而且可以做到实时,所以选择在 Flink Job 中完成该工作。
在该作业中的要将 message 解析,一般该行日志信息会包含很多信息,比如日志打印时间、日志级别、应用名、唯一性 ID(用来关联各个请求)、请求上下文。那么我们就需要一个新的日志结构对象来统一日志的格式,定义如下:
### 12.1.5 日志实时清洗
### 12.1.6 日志实时告警
### 12.1.7 日志实时存储
### 12.1.8 日志实时展示
### 12.1.9 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy

================================================
FILE: books/flink-in-action-12.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 基于 Flink 的百亿数据去重实践
date: 2021-08-20
tags:
- Flink
- 大数据
- 流式计算
---
## 12.2 基于 Flink 的百亿数据去重实践
在工作中经常会遇到去重的场景,例如基于 APP 的用户行为日志分析系统:用户的行为日志从手机 APP 端上报到 Nginx 服务端,然后通过 Logstash、Flume 或其他工具将日志从 Nginx 写入到 Kafka 中。由于用户手机客户端的网络可能出现不稳定,所以手机 APP 端上传日志的策略是:宁可重复上报,也不能漏报日志,所以导致 Kafka 中可能会出现日志重复的情况,即:同一条日志出现了 2 条或 2 条以上。通常情况下,Flink 任务的数据源都是 Kafka,若 Kafka 中数据出现了重复,在实时 ETL 或者流计算时都需要考虑基于日志主键对日志进行去重,否则会导致流计算结果偏高或结果不准确的问题,例如用户 a 在某个页面只点击了一次,但由于日志重复上报,所以用户 a 在该页面的点击日志在 Kafka 中出现了 2 次,最后统计该页面的点击数时,结果就会偏高。这里只阐述了一种可能造成 Kafka 中数据重复的情况,在生产环境中很多情况都可能造成 Kafka 中数据重复,这里不一一列举,本节主要讲述出现了数据重复后,该如何处理。
### 12.2.1 去重的通用解决方案
Kafka 中数据出现重复后,各种解决方案都比较类似,一般需要一个全局 Set 集合来维护历史所有数据的主键。当处理新日志时,需要拿到当前日志的主键与历史数据的 Set 集合按照规则进行比较,若 Set 集合中已经包含了当前日志的主键,说明当前日志在之前已经被处理过了,则当前日志应该被过滤掉,否则认为当前日志不应该被过滤应该被处理,而且处理完成后需要将新日志的主键加入到 Set 集合中,Set 集合永远存放着所有已经被处理过的数据。这种去重的通用解决方案的流程图如下图所示。
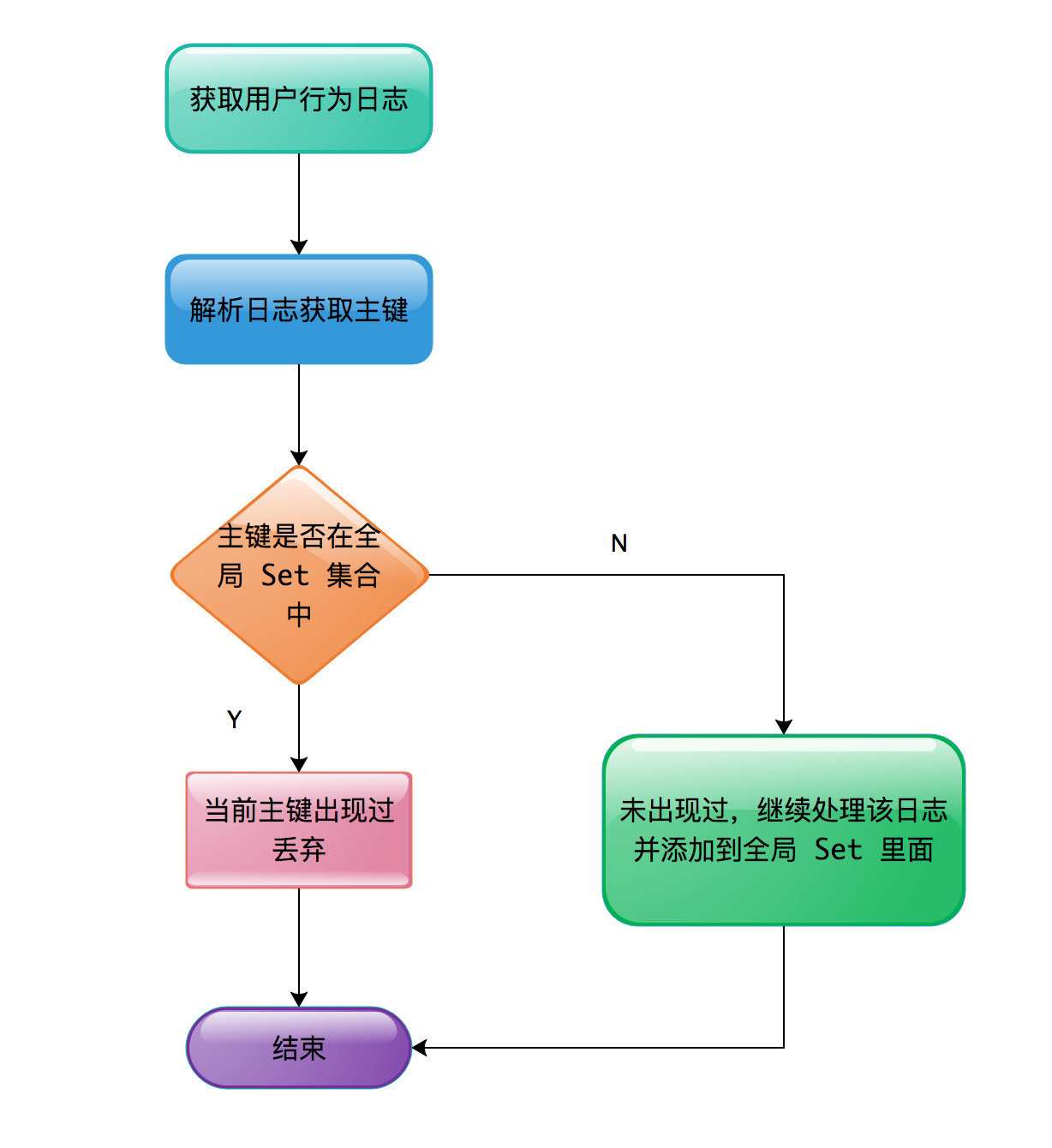
处理流程很简单,关键在于如何维护这个 Set 集合,可以简单估算一下这个 Set 集合需要占用多大空间。本小节要解决的问题是百亿数据去重,所以就按照每天 1 百亿的数据量来计算。由于每天数据量巨大,因此主键占用空间通常会比较大,如果主键占用空间小意味着表示的数据范围就比较小,就可能导致主键冲突,例如:4 个字节的 int 类型表示数据范围是为 -2147483648 ~ 2147483647,总共可以表示 42 亿个数,如果这里每天百亿的数据量选用 int 类型做为主键的话,很明显会有大量的主键发生冲突,会将不重复的数据认为是发生了重复。用户的行为日志是在手机客户端生成的,没有全局发号器,一般会选取 UUID 做为日志的主键,UUID 会生成 36 位的字符串,例如:"f106c4a1-4c6f-41c1-9d30-bbb2b271284a"。每个主键占用 36 字节,每天 1 百亿数据,36字节 * 100亿 ≈ 360 GB。这仅仅是一天的数据量,所以该 Set 集合要想存储空间不发生持续地爆炸式增长,必须增加一个功能,那就是给所有的主键增加 TTL(过期时间)。如果不增加 TTL,10 天数据量的主键占用空间就 3.6T,100 天数据量的主键占用空间 36T,所以在设计之初必须考虑为主键设定 TTL。如果要求按天进行去重或者认为日志发生重复上报的时间间隔不可能大于 24 小时,那么为了系统的可靠性 TTL 可以设置为 36 小时。每天数据量 1 百亿,且 Set 集合中存放着 36 小时的数据量,即 100 亿 * 1.5 = 150 亿,所以 Set 集合中需要维护 150 亿的数据量,且 Set 集合中每条数据都增加了 TTL,意味着 Set 集合需要为每条数据再附带保存一个时间戳,来确定该数据什么时候过期。例如 Redis 中为一个 key 设置了 TTL,如果没有为这个 key 附带时间戳,那么根本无法判断该 key 什么时候应该被清理。所以在考虑每条数据占用空间时,不仅要考虑数据本身,还需要考虑是否需要其他附带的存储。主键本身占用 36 字节加上 long 类型的时间戳 8 字节,所以每条数据至少需要占用 44 字节,150 亿 * 44 字节 = 660 GB。所以每天百亿的数据量,如果我们使用 Set 集合的方案来实现,至少需要占用 660 GB 以上的存储空间。
### 12.2.2 使用 BloomFilter 实现去重
有些流计算的场景对准确性要求并不是很高,例如传统的 Lambda 架构中,都会有离线去矫正实时计算的结果,所以根据业务场景,当业务要求可以接受结果有小量误差时,可以选择使用一些低成本的数据结构。BloomFilter 和 HyperLogLog 都是相对低成本的数据结构,分别有自己的应用场景,且两种数据结构都有一定误差。HyperLogLog 可以估算出 HyperLogLog 中插入了多少个不重复的元素,而不能告诉我们之前是否插入了哪些元素。BloomFilter 则恰好相反,相对而言 BloomFilter 更像是一个 Set 集合,BloomFilter 可以告诉你 BloomFilter 中**肯定不包含**元素 a,或者告诉你 BloomFilter 中**可能包含**元素 b,但 BloomFilter 不能告诉你 BloomFilter 中插入了多少个元素。接下来了解一下 BloomFilter 的实现原理。
#### bitmap 位图
了解 BloomFilter,从 bitmap(位图)开始说起。现在有 1 千万个整数,数据范围在 0 到 2 千万之间。如何快速查找某个整数是否在这 1 千万个整数中呢?可以将这 1 千万个数保存在 HashMap 中,不考虑对象头及其他空间,1000 万个 int 类型数据需要占用大约 1000万 * 4 字节 ≈ 40 MB 存储空间。有没有其他方案呢?因为数据范围是 0 到 2 千万,所以可以申请一个长度为 2000 万、boolean 类型的数组,将这 2 千万个整数作为数组下标,将其对应的数组默认值设置成 false,如下图所示,数组下标为 2、666、999 的位置存储的数据为 true,表示 1 千万个数中包含了 2、666、999 等。当查询某个整数 K 是否在这 1 千万个整数中时,只需要将对应的数组值 `array[K]` 取出来,看是否等于 true。如果等于 true,说明 1 千万整数中包含这个整数 K,否则表示不包含这个整数 K。

Java 的 boolean 基本类型占用一个字节(8bit)的内存空间,所以上述方案需要申请 2000 万字节。如下图所示,可以通过编程语言用二进制位来模拟布尔类型,二进制的 1 表示true、二进制的 0 表示false。通过二进制模拟布尔类型的方案,只需要申请 2000 万 bit 即可,相比 boolean 类型而言,存储空间占用仅为原来的 1/8。2000 万 bit ≈ 2.4 MB,相比存储原始数据的方案 40 MB 而言,占用的存储空间少了很多。

假如这 1 千万个整数的数据范围是 0 到 100 亿,那么就需要申请 100 亿个 bit 约等于 1200 MB,比存储原始数据方案的 40MB 还要大很多。该情况下,直接使用位图使用的存储空间更多了,怎么解决呢?可以只申请 1 亿 bit 的存储空间,对 1000 万个数求hash,映射到 1 亿的二进制位上,最后大约占用 12 MB 的存储空间,但是可能存在 hash 冲突的情况。例如 3 和 100000003(一亿零三)这两个数对一亿求余都为 3,所以映射到长度为 1 亿的位图上,这两个数会占用同一个 bit,就会导致一个问题:1 千万个整数中包含了一亿零三,所以位图中下标为 3 的位置存储着二进制 1。当查询 1 千万个整数中是否包含数字 3 时,同样也是去位图中下标 3 的位置去查找,发现下标为 3 的位置存储着二进制 1,所以误以为 1 千万个整数中包含数字 3。为了减少 hash 冲突,于是诞生了 BloomFilter。
#### BloomFilter 原理介绍
hash 存在 hash 冲突(碰撞)的问题,两个不同的 key 通过同一个 hash 函数得到的值有可能相同。为了减少冲突,可以引入多个 hash 函数,如果通过其中的一个 hash 函数发现某元素不在集合中,那么该元素肯定不在集合中。当所有的 hash 函数告诉我们该元素在集合中时,才能确定该元素存在于集合中,这便是BloomFilter的基本思想。
如下图所示,是往 BloomFilter 中插入元素 a、b 的过程,有 3 个 hash 函数,元素 a 经过 3 个 hash 函数后对应的 2、8、10 这三个二进制位,所以将这三个二进制位置为 1,元素 b 经过 3 个 hash 函数后,对应的 5、10、14 这三个二进制位,将这三个二进制位也置为 1,其中下标为 10 的二进制位被 a、b 元素都涉及到。
要想获取 20191026_1 对应的 UV 值,可通过 scard 命令获取 set 中 user_id 的数量,具体操作如下所示:
```shell
redis> scard 20191026_1
8
```
通过上述代码即可通过 Redis 的 set 数据结构来统计网站各页面的 UV。
#### 使用 Flink 的 KeyedState 来维护用户集合
#### 使用 Redis 的 HyperLogLog 来统计 UV
### 11.1.3 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何使用 Flink ProcessFunction 处理宕机告警?
date: 2021-08-15
tags:
- Flink
- 大数据
- 流式计算
---
## 11.2 如何使用 Flink ProcessFunction 处理宕机告警?
在 3.3 节中讲解了 Process 算子的概念,本节中将更详细的讲解 Flink ProcessFunction,然后教大家如何使用 ProcessFunction 来解决公司中常见的问题 —— 宕机,这个宕机不仅仅包括机器宕机,还包含应用宕机,通常出现宕机带来的影响是会很大的,所以能及时收到告警会减少损失。
### 11.2.1 ProcessFunction 简介
在 1.2.5 节中讲了 Flink 的 API 分层,其中可以看见 Flink 的底层 API 就是 ProcessFunction,它是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:Event、State、Timer。ProcessFunction 可以被认为是一种提供了对 KeyedState 和定时器访问的 FlatMapFunction。每当数据源中接收到一个事件,就会调用来此函数来处理。对于容错的状态,ProcessFunction 可以通过 RuntimeContext 访问 KeyedState。
定时器可以对处理时间和事件时间的变化做一些处理。每次调用 processElement() 都可以获得一个 Context 对象,通过该对象可以访问元素的事件时间戳以及 TimerService。TimerService 可以为尚未发生的事件时间/处理时间实例注册回调。当定时器到达某个时刻时,会调用 onTimer() 方法。在调用期间,所有状态再次限定为定时器创建的 key,允许定时器操作 KeyedState。如果要访问 KeyedState 和定时器,那必须在 KeyedStream 上使用 KeyedProcessFunction,比如在 keyBy 算子之后使用:
```java
dataStream.keyBy(...).process(new KeyedProcessFunction<>(){
})
```
KeyedProcessFunction 是 ProcessFunction 函数的一个扩展,它可以在 onTimer 和 processElement 方法中获取到分区的 Key 值,这对于数据传递是很有帮助的,因为经常有这样的需求,经过 keyBy 算子之后可能还需要这个 key 字段,那么在这里直接构建成一个新的对象(新增一个 key 字段),然后下游的算子直接使用这个新对象中的 key 就好了,而不在需要重复的拼一个唯一的 key。
```java
public void processElement(String value, Context ctx, Collector out) throws Exception {
System.out.println(ctx.getCurrentKey());
out.collect(value);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
System.out.println(ctx.getCurrentKey());
super.onTimer(timestamp, ctx, out);
}
```
### 11.2.2 CoProcessFunction 简介
如果要在两个输入流上进行操作,可以使用 CoProcessFunction,这个函数可以传入两个不同的数据流输入,并为来自两个不同数据源的事件分别调用 processElement1() 和 processElement2() 方法。可以按照下面的步骤来实现一个典型的 Join 操作:
+ 为一个数据源的数据建立一个状态对象
+ 从数据源处有新数据流过来的时候更新这个状态对象
+ 在另一个数据源接收到元素时,关联状态对象并对其产生出连接的结果
比如,将监控的 metric 数据和告警规则数据进行一个连接,在流数据的状态中存储了告警规则数据,当有监控数据过来时,根据监控数据的 metric 名称和一些 tag 去找对应告警规则计算表达式,然后通过规则的表达式对数据进行加工处理,判断是否要告警,如果是要告警则会关联构造成一个新的对象,新对象中不仅有初始的监控 metric 数据,还有含有对应的告警规则数据以及通知策略数据,组装成这样一条数据后,下游就可以根据这个数据进行通知,通知还会在状态中存储这个告警状态,表示它在什么时间告过警了,下次有新数据过来的时候,判断新数据是否是恢复的,如果属于恢复则把该状态清除。
### 11.2.3 Timer 简介
Timer 提供了一种定时触发器的功能,通过 TimerService 接口注册 timer。TimerService 在内部维护两种类型的定时器(处理时间和事件时间定时器)并排队执行。处理时间定时器的触发依赖于 ProcessingTimeService,它负责管理所有基于处理时间的触发器,内部使用 ScheduledThreadPoolExecutor 调度定时任务;事件时间定时器的触发依赖于系统当前的 Watermark。需要注意的一点就是:**Timer 只能在 KeyedStream 中使用**。
TimerService 会删除每个 Key 和时间戳重复的定时器,即每个 Key 在同一个时间戳上最多有一个定时器。如果为同一时间戳注册了多个定时器,则只会调用一次 onTimer() 方法。Flink 会同步调用 onTimer() 和 processElement() 方法,因此不必担心状态的并发修改问题。TimerService 不仅提供了注册和删除 Timer 的功能,还可以通过它来获取当前的系统时间和 Watermark 的值。TimerService 类中的方法如下图所示。

#### 容错
定时器具有容错能力,并且会与应用程序的状态一起进行 Checkpoint,如果发生故障重启会从 Checkpoint/Savepoint 中恢复定时器的状态。如果有处理时间定时器原本是要在恢复起来的那个时间之前触发的,那么在恢复的那一刻会立即触发该定时器。定时器始终是异步的进行 Checkpoint(除 RocksDB 状态后端存储、增量的 Checkpoint、基于堆的定时器外)。因为定时器实际上也是一种特殊状态的状态,在 Checkpoint 时会写入快照中,所以如果有大量的定时器,则无非会增加一次 Checkpoint 所需要的时间,必要的话得根据实际情况合并定时器。
#### 合并定时器
由于 Flink 仅为每个 Key 和时间戳维护一个定时器,因此可以通过降低定时器的频率来进行合并以减少定时器的数量。对于频率为 1 秒的定时器(基于事件时间或处理时间),可以将目标时间向下舍入为整秒数,则定时器最多提前 1 秒触发,但不会迟于我们的要求,精确到毫秒。因此,每个键每秒最多有一个定时器。
```java
long coalescedTime = ((ctx.timestamp() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);
```
由于事件时间计时器仅在 Watermark 到达时才触发,因此可以将当前 Watermark 与下一个 Watermark 的定时器一起调度和合并:
```java
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);
```
定时器也可以类似下面这样移除:
```java
//删除处理时间定时器
long timestampOfTimerToStop = ...
ctx.timerService().deleteProcessingTimeTimer(timestampOfTimerToStop);
//删除事件时间定时器
long timestampOfTimerToStop = ...
ctx.timerService().deleteEventTimeTimer(timestampOfTimerToStop);
```
如果没有该时间戳的定时器,则删除定时器无效。
### 11.2.4 如果利用 ProcessFunction 处理宕机告警?
#### 宕机告警需求分析
#### 宕机告警代码实现
### 11.2.5 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何利用 Async I/O 读取告警规则?
date: 2021-08-16
tags:
- Flink
- 大数据
- 流式计算
---
## 11.3 如何利用 Async I/O 读取告警规则?
Async 中文是异步的意思,在流计算中,使用异步 I/O 能够提升作业整体的计算能力,本节中不仅会讲解异步 I/O 的 API 原理,还会通过一个实战需求(读取告警规则)来讲解异步 I/O 的使用。
### 11.3.1 为什么需要 Async I/O?
在大多数情况下,IO 操作都是一个耗时的过程,尤其在流计算中,如果在具体的算子里面还有和第三方外部系统(比如数据库、Redis、HBase 等存储系统)做交互,比如在一个 MapFunction 中每来一条数据就要去查找 MySQL 中某张表的数据,然后跟查询出来的数据做关联(同步交互)。查询请求到数据库,再到数据库响应返回数据的整个流程的时间对于流作业来说是比较长的。那么该 Map 算子处理数据的速度就会降下来,在大数据量的情况下很可能会导致整个流作业出现反压问题(在 9.1 节中讲过),那么整个作业的消费延迟就会增加,影响作业整体吞吐量和实时性,从而导致最终该作业处于不可用的状态。
这种同步(Sync)的与数据库做交互操作,会因耗时太久导致整个作业延迟,如果换成异步的话,就可以同时处理很多请求并同时可以接收响应,这样的话,等待数据库响应的时间就会与其他发送请求和接收响应的时间重叠,相同的等待时间内会处理多个请求,从而比同步的访问要提高不少流处理的吞吐量。虽然也可以通过增大该算子的并行度去执行查数据库,但是这种解决办法需要消耗更多的资源(并行度增加意味着消费的 slot 个数也会增加),这种方法和使用异步处理的方法对比一下,还是使用异步的查询数据库这种方法值得使用。同步操作(Sync I/O)和异步操作(Async I/O)的处理流程如下图所示。

左侧表示的是在流处理中同步的数据库请求,右侧是异步的数据库请求。假设左侧是数据流中 A 数据来了发送一个查询数据库的请求看是否之前存在 A,然后等待查询结果返回,只有等 A 整个查询请求响应后才会继续开始 B 数据的查询请求,依此继续;而右侧是连续的去数据库查询是否存在 A、B、C、D,后面哪个请求先响应就先处理哪个,不需要和左侧的一样要等待上一个请求全部完成才可以开始下一个请求,所以异步的话吞吐量自然就高起来了。但是得注意的是:使用异步这种方法前提是要数据库客户端支持异步的请求,否则可能需要借助线程池来实现异步请求,但是现在主流的数据库通常都支持异步的操作,所以不用太担心。
### 11.3.2 Async I/O API
Flink 的 Async I/O API 允许用户在数据流处理中使用异步请求,并且还支持超时处理、处理顺序、事件时间、容错。在 Flink 中,如果要使用 Async I/O API,是非常简单的,需要通过下面三个步骤来执行对数据库的异步操作。
+ 继承 RichAsyncFunction 抽象类或者实现用来分发请求的 AsyncFunction 接口
+ 返回异步请求的结果的 Future
+ 在 DataStream 上使用异步操作
官网也给出案例如下:
```java
class AsyncDatabaseRequest extends RichAsyncFunction> {
//数据库的客户端,它可以发出带有 callback 的并发请求
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture> resultFuture) throws Exception{
//发出异步请求,接收 future 的结果
final Future result = client.query(key);
//设置客户端请求完成后执行的 callback,callback 只是将结果转发给 ResultFuture
CompletableFuture.supplyAsync(new Supplier() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
//原始数据
DataStream stream = ...;
//应用异步 I/O 转换
DataStream> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
```
注意:ResultFuture 在第一次调用 resultFuture.complete 时就已经完成了,后面所有 resultFuture.complete 的调用都会被忽略。
下面两个参数控制了异步操作:
+ Timeout:timeout 定义了异步操作过了多长时间后会被丢弃,这个参数是防止了死的或者失败的请求
+ Capacity:这个参数定义可以同时处理多少个异步请求。虽然异步请求会带来更好的吞吐量,但是该操作仍然可能成为流作业的性能瓶颈。限制并发请求的数量可确保操作不会不断累积处理请求,一旦超过 Capacity 值,它将触发反压。
#### 超时处理
#### 结果顺序
#### 事件时间
#### 容错性保证
#### 实践技巧
#### 注意点
### 11.3.3 利用 Async I/O 读取告警规则需求分析
#### 监控数据样例
#### 告警规则表设计
#### 告警规则实体类
### 11.3.4 如何使用 Async I/O 读取告警规则数据
### 11.3.5 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.4.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何利用广播变量动态更新告警规则?
date: 2021-08-17
tags:
- Flink
- 大数据
- 流式计算
---
## 11.4 如何利用广播变量动态更新告警规则?
一个在生产环境运行的流作业有时候会想变更一些作业的配置或者数据流的配置,然后作业可以读取并使用新的配置,而不是通过修改配置然后重启作业来读取配置,毕竟重启一个有状态的流作业代价挺大,本节将带你熟悉 Broadcast,并通过一个案例来教会你如何去动态的更新作业的配置。
### 11.4.1 BroadcastVariable 简介
BroadcastVariable 中文意思是广播变量,其实可以理解是一个公共的共享变量(可能是固定不变的数据集合,也可能是动态变化的数据集合),在作业中将该共享变量广播出去,然后下游的所有任务都可以获取到该共享变量,这样就可以不用将这个变量拷贝到下游的每个任务中。之所以设计这个广播变量的原因主要是因为在 Flink 中多并行度的情况下,每个算子或者不同算子运行所在的 Slot 不一致,这就导致它们不会共享同一个内存,也就不可以通过静态变量的方式去获取这些共享变量值。对于这个问题,有不少读者在问过我为啥我设置的静态变量值在本地运行是可以获取到的,在集群环境运行作业就出现空指针啊,该问题其实笔者自己也在生产环境遇到过,所以接下来好好教大家使用!
### 11.4.2 如何使用 BroadcastVariable ?
在 3.4 节中讲过如何 broadcast 算子和 BroadcastStream 如何使用,在 4.1 节中讲解了 Broadcast State 如何使用以及需要注意的地方,注意 BroadcastVariable 只能应用在批作业中,如果要应用在流作业中则需要要使用 BroadcastStream。
在批作业中通过使用 `withBroadcastSet(DataSet, String)` 来广播一个 DataSet 数据集合,并可以给这份数据起个名字,如果要获取数据的时候,可以通过 `getRuntimeContext().getBroadcastVariable(String)` 获取广播出去的变量数据。下面演示一下广播一个 DataSet 变量和获取变量的样例。
```java
final ParameterTool params = ParameterTool.fromArgs(args);
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//1. 待广播的数据
DataSet toBroadcast = env.fromElements(1, 2, 3);
env.fromElements("a", "b")
.map(new RichMapFunction() {
List broadcastData;
@Override
public void open(Configuration parameters) throws Exception {
// 3. 获取广播的 DataSet 数据 作为一个 Collection
broadcastData = getRuntimeContext().getBroadcastVariable("zhisheng");
}
@Override
public String map(String value) throws Exception {
return broadcastData.get(1) + value;
}
}).withBroadcastSet(toBroadcast, "zhisheng")// 2. 广播 DataSet
.print();
```
注意广播的时候设置的名称和获取的名称要一致,然后运行的结果如下图所示。

流作业中通常使用 BroadcastStream 的方式将变量集合在数据流中传递,可能数据集合会做修改更新,但是修改后其实并不想重启作业去读取这些新修改的配置,因为对于一个流作业来说重启带来的代价很高(需要考虑数据堆积和如何恢复至重启前的状态等问题),那么这种情况下就可以在广播数据流处定时查询数据,这样就能够获取更改后的数据,通常在这种广播数据处获取数据只需要设置一个并行度就好,时间根据需求来判断及时性,一般 1 分钟内的数据变更延迟都是在容忍范围之内。广播流中的元素保证流所有的元素最终都会发到下游的所有并行实例,但是元素到达下游的并行实例的顺序可能不相同。因此,对广播状态的修改不能依赖于输入数据的顺序。在进行 Checkpoint 时,所有的任务都会 Checkpoint 下它们的广播状态。
另外需要注意的是:广播出去的变量存在于每个节点的内存中,所以这个数据集不能太大,因为广播出去的数据,会一致在内存中存在,除非程序执行结束。个人建议:如果数据集在几十兆或者百兆的时候,可以选择进行广播,如果数据集的大小上 G 的话,就不建议进行广播了。
上面介绍了下广播变量的在批作业的使用方式,下面通过一个案例来教大家如何在流作业中使用广播变量。
### 11.4.3 利用广播变量动态更新告警规则数据需求分析
在 11.3.3 节中有设计一张简单的告警规则表,通常告警规则是会对外提供接口进行增删改查的,那么随着业务应用上线,开发人员会对其应用服务新增或者修改告警规则(更改之前规则中的阈值),那么更改之后就需要让告警的作业能够去感知到之前的规则发生了变动,所以就需要在作业中想个什么办法去获取到更改后的数据。有两种方式可以让作业知道规则的变更: push 和 pull 模式。
push 模式则需要在更新、删除、新增接口中不仅操作数据库,还需要额外的发送更新、删除、新增规则的事件到消息队列中,然后作业消费消息队列的数据再去做更新、删除、新增规则,这种及时性有保证,但是可能会有数据不统一的风险(如果消息队列的数据丢了,但是在接口中还是将规则的数据变更存储到数据库);pull 模式下就需要作业定时去查找一遍所有的告警规则数据,然后存在作业内存中,这个时间可以设置的比较短,比如 1 分钟,这样就能既保证数据的一致性,时间延迟也是在容忍范围之内。
对于这种动态变化的规则数据,在 Flink 中通常是使用广播流来处理的。那么接下来就演示下如何利用广播变量动态更新告警规则数据,假设我们在数据库中新增告警规则或者修改告警规则指标的阈值,然后看作业中是否会出现相应的变化。
### 11.4.4 读取告警规则数据
### 11.4.5 监控数据连接规则数据
### 11.4.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

================================================
FILE: books/flink-in-action-11.5.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何实时将应用 Error 日志告警?
date: 2021-08-18
tags:
- Flink
- 大数据
- 流式计算
---
## 11.5 如何实时将应用 Error 日志告警?
大数据时代,随着公司业务不断的增长,数据量自然也会跟着不断的增长,那么业务应用和集群服务器的的规模也会逐渐扩大,几百台服务器在一般的公司已经是很常见的了。那么将应用服务部署在如此多的服务器上,对开发和运维人员来说都是一个挑战。一个优秀的系统运维平台是需要将部署在这么多服务器上的应用监控信息汇总成一个统一的数据展示平台,方便运维人员做日常的监测、提升运维效率,还可以及时反馈应用的运行状态给应用开发人员。举个例子,应用的运行日志需要按照时间排序做一个展示,并且提供日志下载和日志搜索等服务,这样如果应用出现问题开发人员首先可以根据应用日志的错误信息进行问题的排查。那么该如何实时的将应用的 Error 日志推送给应用开发人员呢,接下来我们将讲解日志的处理方案。
### 11.5.1 日志处理方案的演进
日志处理的方案也是有一个演进的过程,要想弄清楚整个过程,我们先来看下日志的介绍。
#### 什么是日志?
日志是带时间戳的基于时间序列的数据,它可以反映系统的运行状态,包括了一些标识信息(应用所在服务器集群名、集群机器 IP、机器设备系统信息、应用名、应用 ID、应用所属项目等)
#### 日志处理方案演进
日志处理方案的演进过程:
+ 日志处理 v1.0: 应用日志分布在很多机器上,需要人肉手动去机器查看日志信息。
+ 日志处理 v2.0: 利用离线计算引擎统一的将日志收集,形成一个日志搜索分析平台,提供搜索让用户根据关键字进行搜索和分析,缺点就是及时性比较差。
+ 日志处理 v3.0: 利用 Agent 实时的采集部署在每台机器上的日志,然后统一发到日志收集平台做汇总,并提供实时日志分析和搜索的功能,这样从日志产生到搜索分析出结果只有简短的延迟(在用户容忍时间范围之内),优点是快,但是日志数据量大的情况下带来的挑战也大。
### 11.5.2 日志采集工具对比
上面提到的日志采集,其实现在已经有很多开源的组件支持去采集日志,比如 Logstash、Filebeat、Fluentd、Logagent 等,这里简单做个对比。
#### Logstash
Logstash 是一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。如下图所示,Logstash 将采集到的数据用作分析、监控、告警等。

**优势**:Logstash 主要的优点就是它的灵活性,它提供很多插件,详细的文档以及直白的配置格式让它可以在多种场景下应用。而且现在 ELK 整个技术栈在很多公司应用的比较多,所以基本上可以在往上找到很多相关的学习资源。
**劣势**:Logstash 致命的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的,它在大数据量的情况下会是个问题。另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池:
#### Filebeat
作为 Beats 家族的一员,Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点,Filebeat 作为一个轻量级的日志传输工具可以将日志推送到 Kafka、Logstash、ElasticSearch、Redis。它的处理流程如下图所示:

**优势**:Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性还是很高的。它也为我们提供了很多可以调节的点,例如:它以何种方式搜索新的文件,以及当文件有一段时间没有发生变化时,何时选择关闭文件句柄。
**劣势**:Filebeat 的应用范围十分有限,所以在某些场景下我们会碰到问题。例如,如果使用 Logstash 作为下游管道,我们同样会遇到性能问题。正因为如此,Filebeat 的范围在扩大。开始时,它只能将日志发送到 Logstash 和 Elasticsearch,而现在它可以将日志发送给 Kafka 和 Redis,在 5.x 版本中,它还具备过滤的能力。
#### Fluentd
Fluentd 创建的初衷主要是尽可能的使用 JSON 作为日志输出,所以传输工具及其下游的传输线不需要猜测子字符串里面各个字段的类型。这样它为几乎所有的语言都提供库,这也意味着可以将它插入到自定义的程序中。它的处理流程如下图所示:

**优势**:和多数 Logstash 插件一样,Fluentd 插件是用 Ruby 语言开发的非常易于编写维护。所以它数量很多,几乎所有的源和目标存储都有插件(各个插件的成熟度也不太一样)。这也意味这可以用 Fluentd 来串联所有的东西。
**劣势**:因为在多数应用场景下得到 Fluentd 结构化的数据,它的灵活性并不好。但是仍然可以通过正则表达式来解析非结构化的数据。尽管性能在大多数场景下都很好,但它并不是最好的,它的缓冲只存在与输出端,单线程核心以及 Ruby GIL 实现的插件意味着它大的节点下性能是受限的。
#### Logagent
Logagent 是 Sematext 提供的传输工具,它用来将日志传输到 Logsene(一个基于 SaaS 平台的 Elasticsearch API),因为 Logsene 会暴露 Elasticsearch API,所以 Logagent 可以很容易将数据推送到 Elasticsearch 。
**优势**:可以获取 /var/log 下的所有信息,解析各种格式的日志,可以掩盖敏感的数据信息。它还可以基于 IP 做 GeoIP 丰富地理位置信息。同样,它轻量又快速,可以将其置入任何日志块中。Logagent 有本地缓冲,所以在数据传输目的地不可用时不会丢失日志。
**劣势**:没有 Logstash 灵活。
### 11.5.3 日志结构设计
前面介绍了日志和对比了常用日志采集工具的优势和劣势,通常在不同环境,不同机器上都会部署日志采集工具,然后采集工具会实时的将新的日志采集发送到下游,因为日志数据量毕竟大,所以建议发到 MQ 中,比如 Kafka,这样再想怎么处理这些日志就会比较灵活。假设我们忽略底层采集具体是哪种,但是规定采集好的日志结构化数据如下:
```java
public class LogEvent {
private String type;//日志的类型(应用、容器、...)
private Long timestamp;//日志的时间戳
private String level;//日志的级别(debug/info/warn/error)
private String message;//日志内容
//日志的标识(应用 ID、应用名、容器 ID、机器 IP、集群名、...)
private Map tags = new HashMap<>();
}
```
然后上面这种 LogEvent 的数据(假设采集发上来的是这种结构数据的 JSON 串,所以需要在 Flink 中做一个反序列化解析)就会往 Kafka 不断的发送数据,样例数据如下:
```json
{
"type": "app",
"timestamp": 1570941591229,
"level": "error",
"message": "Exception in thread \"main\" java.lang.NoClassDefFoundError: org/apache/flink/api/common/ExecutionConfig$GlobalJobParameters",
"tags": {
"cluster_name": "zhisheng",
"app_name": "zhisheng",
"host_ip": "127.0.0.1",
"app_id": "21"
}
}
```
那么在 Flink 中如何将应用异常或者错误的日志做实时告警呢?
### 11.5.4 异常日志实时告警项目架构
整个异常日志实时告警项目的架构如下图所示。

应用日志散列在不同的机器,然后每台机器都有部署采集日志的 Agent(可以是上面的 Filebeat、Logstash 等),这些 Agent 会实时的将分散在不同机器、不同环境的应用日志统一的采集发到 Kafka 集群中,然后告警这边是有一个 Flink 作业去实时的消费 Kafka 数据做一个异常告警计算处理。如果还想做日志的搜索分析,可以起另外一个作业去实时的将 Kafka 的日志数据写入进 ElasticSearch,再通过 Kibana 页面做搜索和分析。
### 11.5.5 日志数据发送到 Kafka
上面已经讲了日志数据 LogEvent 的结构和样例数据,因为要在服务器部署采集工具去采集应用日志数据对于本地测试来说可能稍微复杂,所以在这里就只通过代码模拟构造数据发到 Kafka 去,然后在 Flink 作业中去实时消费 Kafka 中的数据,下面演示构造日志数据发到 Kafka 的工具类,这个工具类主要分两块,构造 LogEvent 数据和发送到 Kafka。
```java
@Slf4j
public class BuildLogEventDataUtil {
//Kafka broker 和 topic 信息
public static final String BROKER_LIST = "localhost:9092";
public static final String LOG_TOPIC = "zhisheng_log";
public static void writeDataToKafka() {
Properties props = new Properties();
props.put("bootstrap.servers", BROKER_LIST);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
for (int i = 0; i < 10000; i++) {
//模拟构造 LogEvent 对象
LogEvent logEvent = new LogEvent().builder()
.type("app")
.timestamp(System.currentTimeMillis())
.level(logLevel())
.message(message(i + 1))
.tags(mapData())
.build();
// System.out.println(logEvent);
ProducerRecord record = new ProducerRecord(LOG_TOPIC, null, null, GsonUtil.toJson(logEvent));
producer.send(record);
}
producer.flush();
}
public static void main(String[] args) {
writeDataToKafka();
}
public static String message(int i) {
return "这是第 " + i + " 行日志!";
}
public static String logLevel() {
Random random = new Random();
int number = random.nextInt(4);
switch (number) {
case 0:
return "debug";
case 1:
return "info";
case 2:
return "warn";
case 3:
return "error";
default:
return "info";
}
}
public static String hostIp() {
Random random = new Random();
int number = random.nextInt(4);
switch (number) {
case 0:
return "121.12.17.10";
case 1:
return "121.12.17.11";
case 2:
return "121.12.17.12";
case 3:
return "121.12.17.13";
default:
return "121.12.17.10";
}
}
public static Map mapData() {
Map map = new HashMap<>();
map.put("app_id", "11");
map.put("app_name", "zhisheng");
map.put("cluster_name", "zhisheng");
map.put("host_ip", hostIp());
map.put("class", "BuildLogEventDataUtil");
map.put("method", "main");
map.put("line", String.valueOf(new Random().nextInt(100)));
//add more tag
return map;
}
}
```
如果之前 Kafka 中没有 zhisheng_log 这个 topic,运行这个工具类之后也会自动创建这个 topic 了。
### 11.5.6 Flink 实时处理日志数据
### 11.5.7 处理应用异常日志
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M

本章属于 Flink 实战篇,前面章节讲了很多 Flink 相关的技术知识点,这章主要是通过技术点来教大家如何去完成一些真实的需求,比如通过 State 去实时统计网站各页面一天的 PV 和 UV、通过 ProcessFunction 去做定时器处理一些延迟的事件(宕机告警)、通过 Async IO 读取告警规则、通过广播变量动态的更新告警规则、如何实时的做到日志告警。
虽然这些需求换到你们公司去可能不一样,但是这些技术知识点是可以运用到你的项目需求中去的,这里介绍的这些需求,你要学会去分析,然后去判断这些需求到底该使用什么技术来实现会更好,这样才可以做到活学活用。
================================================
FILE: books/flink-in-action-12.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 基于 Flink 实时处理海量日志
date: 2021-08-19
tags:
- Flink
- 大数据
- 流式计算
---
# 第十二章 —— Flink 案例
本章将介绍 Flink 在多个场景下落地实现的大型案例,第一个是实时处理海量的日志,将从日志的收集、日志的传输、日志的实时清洗和异常检测、日志存储、日志展示等方面去介绍 Flink 在其中起的作用,希望整个日志处理的架构大家可以灵活的运用在自己的公司;第二个是百亿数据量的情况下如何使用 Flink 实时去重,在这个案例中将对比介绍其他几种常见的去重实现方案;第三个是 Flink 在监控告警系统中的落地实现,在这个案例中同样很详细的介绍了一个监控告警系统的全链路,每一个关节都不可或缺,并且还介绍了 Flink 在未来结合机器学习算法做一些 AIOps 的事情。三个案例都比较典型,如果你也在做类似的项目,希望对你们的技术选型有一定的帮助。
## 12.1 基于 Flink 实时处理海量日志
在 11.5 节中讲解了 Flink 如何实时处理异常的日志,并且对比分析了几种常用的日志采集工具。我们也知道通常在排查线上异常故障的时候,日志是必不可缺的一部分,通过异常日志我们可以快速的定位到问题的根因。那么通常在公司对于日志处理有哪些需求呢?
### 12.1.1 实时处理海量日志需求分析
现在公司都在流行构建分布式、微服务、云原生的架构,在这类架构下,项目应用的日志都被分散到不同的机器上,日志查询就会比较困难,所以统一的日志收集几乎也是每家公司必不可少的。据笔者调研,不少公司现在是有日志统一的收集,也会去做日志的实时 ETL,利用一些主流的技术比如 ELK 去做日志的展示、搜索和分析,但是却缺少了日志的实时告警。总结来说,大部分公司对于日志这块的现状是:
+ **日志分布零散**:分布式应用导致日志分布在不同的机器上,人肉登录到机器上操作复杂,需要统一的日志收集工具。
+ **异常日志无告警**:出错时无异常日志告警,导致错过最佳定位问题的时机,需要异常错误日志的告警。
+ **日志查看不友好**:登录服务器上在终端查看日志不太方便,需要一个操作友好的页面去查看日志。
+ **无日志搜索分析**:历史日志文件太多,想找某种日志找不到了,需要一个可以搜索日志的功能。
在本节中,笔者将为大家讲解日志的全链路,包含了日志的实时采集、日志的 ETL、日志的实时监控告警、日志的存储、日志的可视化图表展示与搜索分析等。
### 12.1.2 实时处理海量日志架构设计
分析完我们这个案例的需求后,接下来对整个项目的架构做一个合理的设计。

整个架构分为五层:日志接入层、日志削峰层、日志处理层、日志存储层、日志展示层。
+ 日志接入层:日志采集的话使用的是 Filebeat 组件,需要在每台机器上部署一个 Filebeat。
+ 日志削峰层:防止日志流量高峰,使用 Kafka 消息队列做削峰。
+ 日志处理层:Flink 作业同时消费 Kafka 数据做日志清洗、ETL、实时告警。
+ 日志存储层:使用 ElasticSearch 做日志的存储。
+ 日志展示层:使用 Kibana 做日志的展示与搜索查询界面。
### 12.1.3 日志实时采集
在 11.5.1 中对比了这几种比较流行的日志采集工具(Logstash、Filebeat、Fluentd、Logagent),从功能完整性、性能、成本、使用难度等方面综合考虑后,这里演示使用的是 Filebeat。
#### 安装 Filebeat
在服务器上下载 [Fliebeat 6.3.2](https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-linux-x86_64.tar.gz) 安装包(请根据自己服务器和所需要的版本进行下载),下载后进行解压。
```
tar xzf filebeat-6.3.2-linux-x86_64.tar.gz
```
#### 配置 Filebeat
配置 Filebeat 需要编辑 Filebeat 的配置文件 `filebeat.yml`,不同安装方式配置文件的存放路径有一些不同,对于解压包安装的方式,配置文件存在解压目录下面;对于 rpm 和 deb 的方式, 配置文件路径的是 `/etc/filebeat/filebeat.yml` 下。
因为 Filebeat 是要实时采集日志的,所以得让 Filebeat 知道日志的路径是在哪里,下面在配置文件中定义一下日志文件的路径。通常建议在服务器上固定存放日志的路径,然后应用的日志都打在这个固定的路径中,这样 Filebeat 的日志路径配置只需要填写一次,其他机器上可以拷贝同样的配置就能将 Filebeat 运行起来,配置如下。
```
- type: log
# 配置为 true 表示开启
enabled: true
# 日志的路径
paths:
- /var/logs/*.log
```
上面的配置表示将对 /var/logs 目录下所有以 .log 结尾的文件进行采集,接下来配置日志输出的方式,这里使用的是 Kafka,配置如下。
```
output.kafka:
# 填写 Kafka 地址信息
hosts: ["localhost:9092"]
# 数据发到哪个 topic
topic: zhisheng-log
partition.round_robin:
reachable_only: false
required_acks: 1
```
上面讲解的两个配置,笔者这里将它们写在一个新建的配置文件中 kafka.yml,然后启动 Filebeat 的时候使用该配置。
```yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/logs/*.log
output.kafka:
hosts: ["localhost:9092"]
topic: zhisheng_log
partition.round_robin:
reachable_only: false
required_acks: 1
```
#### 启动 Filebeat
日志路径的配置和 Kafka 的配置都写好后,则接下来通过下面命令将 Filebeat 启动:
```
bin/filebeat -e -c kafka.yml
```
执行完命令后出现的日志如下则表示启动成功了,另外还可以看得到会在终端打印出 metrics 数据出来。

#### 验证 Filebeat 是否将日志数据发到 Kafka
那么此时就得去查看是否真正就将这些日志数据发到 Kafka 了呢,你可以通过 Kafka 的自带命令去消费这个 Topic 看是否不断有数据发出来,命令如下:
```
bin/kafka-console-consumer.sh --zookeeper 106.54.248.27:2181 --topic zhisheng_log --from-beginning
```
如果出现数据则代表是已经有数据发到 Kafka 了,如果你不喜欢使用这种方式验证,可以自己写个 Flink Job 去读取 Kafka 该 Topic 的数据,比如写了个作业运行结果如下就代表着日志数据已经成功发送到 Kafka。

#### 发到 Kafka 的日志结构
既然数据都已经发到 Kafka 了,通过消费 Kafka 该 Topic 的数据我们可以发现这些数据的格式否是 JSON,结构如下:
```json
{
"@timestamp": "2019-10-26T08:18:18.087Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.8.4",
"topic": "zhisheng_log"
},
"prospector": {
"type": "log"
},
"input": {
"type": "log"
},
"beat": {
"name": "VM_0_2_centos",
"hostname": "VM_0_2_centos",
"version": "6.8.4"
},
"host": {
"name": "VM_0_2_centos"
},
"source": "/var/logs/middleware/kafka.log",
"offset": 9460,
"log": {
"file": {
"path": "/var/logs/middleware/kafka.log"
}
},
"message": "2019-10-26 16:18:11 TRACE [Controller id=0] Leader imbalance ratio for broker 0 is 0.0 (kafka.controller.KafkaController)"
}
```
这个日志结构里面包含了很多字段,比如 timestamp、metadata、host、source、message 等,但是其中某些字段我们其实根本不需要的,你可以根据公司的需求丢弃一些字段,把要丢弃的字段也配置在 kafka.yml 中,如下所示。
```
processors:
- drop_fields:
fields: ["prospector","input","beat","log","offset","@metadata"]
```
然后再次启动 Filebeat ,发现上面配置的字段在新的数据中没有了(除 @metadata 之外),另外经笔者验证:不仅 @metadata 字段不能丢弃,如果 @timestamp 这个字段在 drop_fields 中配置了,也是不起作用的,它们两不允许丢弃。通常来说一行日志已经够长了,再加上这么多我们不需要的字段,就会增加数据的大小,对于生产环境的话,日志数据量非常大,那无疑会对后面所有的链路都会造成一定的影响,所以一定要在底层数据源头做好精简。另外还可以在发送 Kafka 的时候对数据进行压缩,可以在配置文件中配置一个 `compression: gzip`。精简后的日志数据结构如下:
```json
{
"@timestamp": "2019-10-26T09:23:16.848Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.8.4",
"topic": "zhisheng_log"
},
"host": {
"name": "VM_0_2_centos"
},
"source": "/var/logs/middleware/kafka.log",
"message": "2019-10-26 17:23:11 TRACE [Controller id=0] Leader imbalance ratio for broker 0 is 0.0 (kafka.controller.KafkaController)"
}
```
### 12.1.4 日志格式统一
因为 Filebeat 是在机器上采集的日志,这些日志的种类比较多,常见的有应用程序的运行日志、作业构建编译打包的日志、中间件服务运行的日志等。通常在公司是可以给开发约定日志打印的规则,但是像中间件这类服务的日志是不固定的,如果将 Kafka 中的消息直接存储到 ElasticSearch 的话,后面如果要做区分筛选的话可能会有问题。为了避免这个问题,我们得在日志存入 ElasticSearch 之前做一个数据格式化和清洗的工作,因为 Flink 处理数据的速度比较好,而且可以做到实时,所以选择在 Flink Job 中完成该工作。
在该作业中的要将 message 解析,一般该行日志信息会包含很多信息,比如日志打印时间、日志级别、应用名、唯一性 ID(用来关联各个请求)、请求上下文。那么我们就需要一个新的日志结构对象来统一日志的格式,定义如下:
### 12.1.5 日志实时清洗
### 12.1.6 日志实时告警
### 12.1.7 日志实时存储
### 12.1.8 日志实时展示
### 12.1.9 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy

================================================
FILE: books/flink-in-action-12.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 基于 Flink 的百亿数据去重实践
date: 2021-08-20
tags:
- Flink
- 大数据
- 流式计算
---
## 12.2 基于 Flink 的百亿数据去重实践
在工作中经常会遇到去重的场景,例如基于 APP 的用户行为日志分析系统:用户的行为日志从手机 APP 端上报到 Nginx 服务端,然后通过 Logstash、Flume 或其他工具将日志从 Nginx 写入到 Kafka 中。由于用户手机客户端的网络可能出现不稳定,所以手机 APP 端上传日志的策略是:宁可重复上报,也不能漏报日志,所以导致 Kafka 中可能会出现日志重复的情况,即:同一条日志出现了 2 条或 2 条以上。通常情况下,Flink 任务的数据源都是 Kafka,若 Kafka 中数据出现了重复,在实时 ETL 或者流计算时都需要考虑基于日志主键对日志进行去重,否则会导致流计算结果偏高或结果不准确的问题,例如用户 a 在某个页面只点击了一次,但由于日志重复上报,所以用户 a 在该页面的点击日志在 Kafka 中出现了 2 次,最后统计该页面的点击数时,结果就会偏高。这里只阐述了一种可能造成 Kafka 中数据重复的情况,在生产环境中很多情况都可能造成 Kafka 中数据重复,这里不一一列举,本节主要讲述出现了数据重复后,该如何处理。
### 12.2.1 去重的通用解决方案
Kafka 中数据出现重复后,各种解决方案都比较类似,一般需要一个全局 Set 集合来维护历史所有数据的主键。当处理新日志时,需要拿到当前日志的主键与历史数据的 Set 集合按照规则进行比较,若 Set 集合中已经包含了当前日志的主键,说明当前日志在之前已经被处理过了,则当前日志应该被过滤掉,否则认为当前日志不应该被过滤应该被处理,而且处理完成后需要将新日志的主键加入到 Set 集合中,Set 集合永远存放着所有已经被处理过的数据。这种去重的通用解决方案的流程图如下图所示。

处理流程很简单,关键在于如何维护这个 Set 集合,可以简单估算一下这个 Set 集合需要占用多大空间。本小节要解决的问题是百亿数据去重,所以就按照每天 1 百亿的数据量来计算。由于每天数据量巨大,因此主键占用空间通常会比较大,如果主键占用空间小意味着表示的数据范围就比较小,就可能导致主键冲突,例如:4 个字节的 int 类型表示数据范围是为 -2147483648 ~ 2147483647,总共可以表示 42 亿个数,如果这里每天百亿的数据量选用 int 类型做为主键的话,很明显会有大量的主键发生冲突,会将不重复的数据认为是发生了重复。用户的行为日志是在手机客户端生成的,没有全局发号器,一般会选取 UUID 做为日志的主键,UUID 会生成 36 位的字符串,例如:"f106c4a1-4c6f-41c1-9d30-bbb2b271284a"。每个主键占用 36 字节,每天 1 百亿数据,36字节 * 100亿 ≈ 360 GB。这仅仅是一天的数据量,所以该 Set 集合要想存储空间不发生持续地爆炸式增长,必须增加一个功能,那就是给所有的主键增加 TTL(过期时间)。如果不增加 TTL,10 天数据量的主键占用空间就 3.6T,100 天数据量的主键占用空间 36T,所以在设计之初必须考虑为主键设定 TTL。如果要求按天进行去重或者认为日志发生重复上报的时间间隔不可能大于 24 小时,那么为了系统的可靠性 TTL 可以设置为 36 小时。每天数据量 1 百亿,且 Set 集合中存放着 36 小时的数据量,即 100 亿 * 1.5 = 150 亿,所以 Set 集合中需要维护 150 亿的数据量,且 Set 集合中每条数据都增加了 TTL,意味着 Set 集合需要为每条数据再附带保存一个时间戳,来确定该数据什么时候过期。例如 Redis 中为一个 key 设置了 TTL,如果没有为这个 key 附带时间戳,那么根本无法判断该 key 什么时候应该被清理。所以在考虑每条数据占用空间时,不仅要考虑数据本身,还需要考虑是否需要其他附带的存储。主键本身占用 36 字节加上 long 类型的时间戳 8 字节,所以每条数据至少需要占用 44 字节,150 亿 * 44 字节 = 660 GB。所以每天百亿的数据量,如果我们使用 Set 集合的方案来实现,至少需要占用 660 GB 以上的存储空间。
### 12.2.2 使用 BloomFilter 实现去重
有些流计算的场景对准确性要求并不是很高,例如传统的 Lambda 架构中,都会有离线去矫正实时计算的结果,所以根据业务场景,当业务要求可以接受结果有小量误差时,可以选择使用一些低成本的数据结构。BloomFilter 和 HyperLogLog 都是相对低成本的数据结构,分别有自己的应用场景,且两种数据结构都有一定误差。HyperLogLog 可以估算出 HyperLogLog 中插入了多少个不重复的元素,而不能告诉我们之前是否插入了哪些元素。BloomFilter 则恰好相反,相对而言 BloomFilter 更像是一个 Set 集合,BloomFilter 可以告诉你 BloomFilter 中**肯定不包含**元素 a,或者告诉你 BloomFilter 中**可能包含**元素 b,但 BloomFilter 不能告诉你 BloomFilter 中插入了多少个元素。接下来了解一下 BloomFilter 的实现原理。
#### bitmap 位图
了解 BloomFilter,从 bitmap(位图)开始说起。现在有 1 千万个整数,数据范围在 0 到 2 千万之间。如何快速查找某个整数是否在这 1 千万个整数中呢?可以将这 1 千万个数保存在 HashMap 中,不考虑对象头及其他空间,1000 万个 int 类型数据需要占用大约 1000万 * 4 字节 ≈ 40 MB 存储空间。有没有其他方案呢?因为数据范围是 0 到 2 千万,所以可以申请一个长度为 2000 万、boolean 类型的数组,将这 2 千万个整数作为数组下标,将其对应的数组默认值设置成 false,如下图所示,数组下标为 2、666、999 的位置存储的数据为 true,表示 1 千万个数中包含了 2、666、999 等。当查询某个整数 K 是否在这 1 千万个整数中时,只需要将对应的数组值 `array[K]` 取出来,看是否等于 true。如果等于 true,说明 1 千万整数中包含这个整数 K,否则表示不包含这个整数 K。

Java 的 boolean 基本类型占用一个字节(8bit)的内存空间,所以上述方案需要申请 2000 万字节。如下图所示,可以通过编程语言用二进制位来模拟布尔类型,二进制的 1 表示true、二进制的 0 表示false。通过二进制模拟布尔类型的方案,只需要申请 2000 万 bit 即可,相比 boolean 类型而言,存储空间占用仅为原来的 1/8。2000 万 bit ≈ 2.4 MB,相比存储原始数据的方案 40 MB 而言,占用的存储空间少了很多。

假如这 1 千万个整数的数据范围是 0 到 100 亿,那么就需要申请 100 亿个 bit 约等于 1200 MB,比存储原始数据方案的 40MB 还要大很多。该情况下,直接使用位图使用的存储空间更多了,怎么解决呢?可以只申请 1 亿 bit 的存储空间,对 1000 万个数求hash,映射到 1 亿的二进制位上,最后大约占用 12 MB 的存储空间,但是可能存在 hash 冲突的情况。例如 3 和 100000003(一亿零三)这两个数对一亿求余都为 3,所以映射到长度为 1 亿的位图上,这两个数会占用同一个 bit,就会导致一个问题:1 千万个整数中包含了一亿零三,所以位图中下标为 3 的位置存储着二进制 1。当查询 1 千万个整数中是否包含数字 3 时,同样也是去位图中下标 3 的位置去查找,发现下标为 3 的位置存储着二进制 1,所以误以为 1 千万个整数中包含数字 3。为了减少 hash 冲突,于是诞生了 BloomFilter。
#### BloomFilter 原理介绍
hash 存在 hash 冲突(碰撞)的问题,两个不同的 key 通过同一个 hash 函数得到的值有可能相同。为了减少冲突,可以引入多个 hash 函数,如果通过其中的一个 hash 函数发现某元素不在集合中,那么该元素肯定不在集合中。当所有的 hash 函数告诉我们该元素在集合中时,才能确定该元素存在于集合中,这便是BloomFilter的基本思想。
如下图所示,是往 BloomFilter 中插入元素 a、b 的过程,有 3 个 hash 函数,元素 a 经过 3 个 hash 函数后对应的 2、8、10 这三个二进制位,所以将这三个二进制位置为 1,元素 b 经过 3 个 hash 函数后,对应的 5、10、14 这三个二进制位,将这三个二进制位也置为 1,其中下标为 10 的二进制位被 a、b 元素都涉及到。
 如下图所示,是从 BloomFilter 中查找元素 c、d 的过程,同样包含了 3 个 hash 函数,元素 c 经过 3 个 hash 函数后对应的 2、6、9 这三个二进制位,其中下标 6 和 9 对应的二进制位为 0,所以会认为 BloomFilter 中不存在元素 c。元素 d 经过 3 个 hash 函数后对应的 5、8、14 这三个二进制位,这三个位对应的二进制位都为 1,所以会认为 BloomFilter 中存在元素 d,但其实 BloomFilter 中并不存在元素 d,是因为元素 a 和元素 b 也对应到了 5、8、14 这三个二进制位上,所以 BloomFilter 会有误判。但是从实现原理来看,当 BloomFilter 告诉你不包含元素 c 时,BloomFilter 中**肯定不包含**元素 c,当 BloomFilter 告诉你 BloomFilter 中包含元素 d 时,它只是**可能包含**,也有可能不包含。
如下图所示,是从 BloomFilter 中查找元素 c、d 的过程,同样包含了 3 个 hash 函数,元素 c 经过 3 个 hash 函数后对应的 2、6、9 这三个二进制位,其中下标 6 和 9 对应的二进制位为 0,所以会认为 BloomFilter 中不存在元素 c。元素 d 经过 3 个 hash 函数后对应的 5、8、14 这三个二进制位,这三个位对应的二进制位都为 1,所以会认为 BloomFilter 中存在元素 d,但其实 BloomFilter 中并不存在元素 d,是因为元素 a 和元素 b 也对应到了 5、8、14 这三个二进制位上,所以 BloomFilter 会有误判。但是从实现原理来看,当 BloomFilter 告诉你不包含元素 c 时,BloomFilter 中**肯定不包含**元素 c,当 BloomFilter 告诉你 BloomFilter 中包含元素 d 时,它只是**可能包含**,也有可能不包含。
 #### 使用 BloomFilter 实现数据去重
Redis 4.0 之后 BloomFilter 以插件的形式加入到 Redis 中,关于 api 的具体使用这里不多赘述。BloomFilter 在创建时支持设定一个预期容量和误判率,预期容量即预计插入的数据量,误判率即:当 BloomFilter 中插入的数据达到预期容量时,误判的概率,如果 BloomFilter 中插入数据较少的话,误判率会更低。
经笔者测试,申请一个预期容量为 10 亿,误判率为千分之一的 BloomFilter,BloomFilter 会申请约 143 亿个 bit,即:14G左右,相比之前 660G 的存储空间小太多了。但是在使用过程中,需要记录 BloomFilter 中插入元素的个数,当插入元素个数达到 10 亿时,为了保障误差率,可以将当前 BloomFilter 清除,重新申请一个新的 BloomFilter。
通过使用 Redis 的 BloomFilter,我们可以通过相对较小的内存实现百亿数据的去重,但是 BloomFilter 有误差,所以只能使用在那些对结果能承受一定误差的应用场景,对于广告计费等对数据精度要求非常高的场景,极力推荐大家使用精准去重的方案来实现。
### 12.2.3 使用 HBase 维护全局 Set 实现去重
通过之前分析,我们知道要想实现百亿数据量的精准去重,需要维护 150 亿数据量的 Set 集合,每条数据占用 44 KB,总共需要 660 GB 的存储空间。注意这里说的是存储空间而不是内存空间,为什么呢?因为 660 G 的内存实在是太贵了,660G 的 Redis 云服务一个月至少要 2 万 RMB 以上,俗话说设计架构不考虑成本等于耍流氓。这里使用 Redis 确实可以解决问题,但是成本较高。HBase 基于 RowKey Get 的效率比较高,所以这里可以考虑将这个大的 Set 集合以 HBase RowKey 的形式存放到 HBase 中。HBase 表设置 TTL 为 36 小时,最近 36 小时的 150 亿条日志的主键都存放到 HBase 中,每来一条数据,先拿到主键去 HBase 中查询,如果 HBase 表中存在该主键,说明当前日志已经被处理过了,当前日志应该被过滤。如果 HBase 表中不存在该主键,说明当前日志之前没有被处理过,此时应该被处理,且处理完成后将当前主键 Put 到 HBase 表中。由于数据量比较大,所以一定要提前对 HBase 表进行预分区,将压力分散到各个 RegionServer 上。
#### 使用 HBase RowKey 去重带来的问题
### 12.2.4 使用 Flink 的 KeyedState 实现去重
下面就教大家如何使用 Flink 的 KeyedState 实现去重。
#### 使用 Flink 状态来维护 Set 集合的优势
#### 如何使用 KeyedState 维护 Set 集合
#### 优化主键来减少状态大小,且提高吞吐量
### 12.2.5 使用 RocksDBStateBackend 的优化方法
在使用上述方案的过程中,可能会出现吞吐量时高时低,或者吞吐量比笔者的测试性能要低一些,当出现这类问题的时候,可以尝试从以下几个方面进行优化。
#### 设置本地 RocksDB 的数据目录
#### Checkpoint 参数相关配置
#### RocksDB 参数相关配置
### 12.2.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy

================================================
FILE: books/flink-in-action-12.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 基于 Flink 的实时监控告警系统
date: 2021-08-21
tags:
- Flink
- 大数据
- 流式计算
---
## 12.3 基于 Flink 的实时监控告警系统
在如今微服务、云原生等技术盛行的时代,当谈到说要从 0 开始构建一个监控系统,大家无非就首先想到三个词:Metrics、Tracing、Logging。
### 12.3.1 监控系统的诉求
国外一篇比较火的文章 [Metrics, Tracing, and Logging](http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html) 内有个图很好的总结了一个监控系统的诉求,分别是 Metrics、Logging、Tracing,如下图所示。
Metrics 的特点:它自己提供了五种基本的度量类型 Gauge、Counter、Histogram、Timer、Meter。
Tracing 的特点:提供了一个请求从接收到处理完毕整个生命周期的跟踪路径,通常请求都是在分布式的系统中处理,所以也叫做分布式链路追踪。
Logging 的特点:提供项目应用运行的详细信息,例如方法的入参、运行的异常记录等。
这三者在监控系统中缺一不可,它们之间的关系是:基于 Metrics 的异常告警事件,然后通过 Tracing 定位问题可疑模块,根据模块详细的日志定位到错误根源,最后再返回来调整 Metrics 的告警规则,以便下次更早的预警,提前预防出现此类问题。
### 12.3.2 监控系统包含的内容
针对提到的三个点,笔者找到国内外的开源监控系统做了对比,发现真正拥有全部功能的比较少,有的系统比较专注于 Logging、有的系统比较专注于 Tracing,而大部分其他的监控系统无非是只是监控系统的一部分,比如是作为一款数据库存储监控数据、作为一个可视化图表的系统去展示各种各样的监控数据信息。
拿 Logging 来说,开源用的最多最火的技术栈是 ELK,Tracing 这块有 Skywalking、Pinpoint 等技术,它们的对比如 [APM 巅峰对决:Skywalking PK Pinpoint](https://mp.weixin.qq.com/s/_XE-gCJnDY3-yEK4xmWiMg) 一文介绍。而存储监控数据的时序数据库那就比较多了,常见的比如 InfluxDB、Prometheus、OpenTSDB 等,它们之间的对比介绍如下图所示。
监控可视化图表的开源系统个人觉得最好看的就是 Grafana,在 8.2 节中搭建 Flink 监控系统的数据展示也是用的 Grafana,当然还可以利用 ECharts、BizCharts 等数据图表库做二次开发来适配公司的数据展示图表。
上面说了这么多,这里笔者根据自己的工作经验先谈谈几点自己对监控系统的心得:
1. **告警是监控系统第一入口,图表展示体现监控的价值**:告警是唯一可以第一时间反映运行状态,它承担着系统与人之间的沟通桥梁,通常告警消息又会携带链接跳转到图表展示,它作为第一入口并衔接上了整个监控系统。
2. **数据采集是监控的源泉**:数据采集是监控系统的源泉,如果采集的数据是错误的,将导致后面的链路(告警、数据展示)全处于无效状态,所以千万千万要保证数据采集的准确性和完整性。
3. **数据存储是监控最大挑战**:当机器、系统应用和监控指标等变得越多来多时,采集上来的数据是爆炸性增长的,将海量的监控数据实时存储到任何一个数据库,挑战都是不小的。
说完心得再来讲解到底一个监控系统真正该包含哪些东西呢?笔者觉得首先分 6 层:数据采集层、数据传输层、数据计算层、告警、数据存储、数据展示,如下图所示。
监控系统这六层的主要功能分别是:
+ 数据采集层:该层主要功能就是去采集各种各样的数据,比如 Metrics、Logging、Tracing 数据。
+ 数据传输层:该层主要功能就是传输采集到的监控数据,一般使用消息队列居多,比如 Kafka、RocketMQ 等。
+ 数据计算层:该层的主要功能是将采集到的数据进行数据清洗和计算,一般采用 Flink、Spark 等计算引擎来处理。
+ 告警:该层其实也属于数据计算层,但是因为告警涉及的内容太多,比如告警规则、告警计算、告警通知等,所以可以单独作为一个重要点来讲。
+ 数据存储层:该层的主要功能是存储所有的监控数据,为后面的数据可视化提供数据源。
+ 数据展示层:该层的主要功能是将监控数据通过可视化图表来展示出来,通过图表可以知道服务器、应用的运行状态。
### 12.3.3 Metrics/Tracing/Logging 数据实时采集
在 12.1 节中讲解了日志数据如何采集,那么对于 Metrics 和 Tracing 数据该怎么采集呢?
#### Metrics
#### Tracing
### 12.3.4 消息队列如何撑住高峰流量
#### RabbitMQ
#### Kafka
#### RocketMQ
### 12.3.5 指标数据实时计算
### 12.3.6 提供及时且准确的根因分析告警
#### 告警本质
#### 告警通知对象
#### 告警通知方式
#### 告警规则的设计
#### 根因分析告警
#### 告警事件解耦
#### 告警工单记录告警解决过程
### 12.3.7 AIOps 智能运维道路探索
### 12.3.8 如何保障高峰流量实时写入存储系统的稳定性
### 12.3.9 监控数据使用可视化图表展示
#### Grafana 介绍
### 12.3.10 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy

### 本章总结
本章讲了三个公司常见场景案例:日志处理、去重、监控告警。在日志处理案例中讲解了日志的采集的需求,以及分析了整个日志采集案例的架构设计分层,关于日志采集工具的选型在 11.5 节中有讲过,所以该案例中就直接讲述采集工具的使用和安装,并将采集到的数据发送到 Kafka,然后使用 Flink 清洗日志数据并将异常日志告警通知到相应负责人,接着将数据写入到 ElasticSearch,最后通过 Kibana 可以展示和搜索日志数据。
在百亿数据实时去重案例中通过对比通用解决方法、使用 BloomFilter、使用 HBase 和使用 Flink KeyedState 几种方案来分析实时去重的解决方案,并在该案例中还提及到如何去优化去重的效果。
在实时监控告警案例中讲述了公司通用的监控告警需求,包括 Metrics、Logging、Tracing,然后设计出整个监控告警系统的架构分层和技术选型,其中分层包含数据采集层、数据传输层、数据计算层、数据存储层、数据展示层。关于数据采集工具、消息队列、数据存储中间件、数据展示的技术选型,笔者也分别做了对比介绍,以便大家可以根据自己公司的情况做架构选型。另外针对实时告警这块,笔者也详述了很多,包括告警规则的设计、告警通知对象、告警通知方式、告警消息收敛、告警消息根因分析等,最后还讲了对监控告警的展望,希望能够在 AIOps 做更多的探索,对于这块的内容,笔者在社区钉钉群做过视频直播,大家可以去笔者的博客查看录播的视频。
================================================
FILE: books/flink-in-action-2.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 环境准备
date: 2021-07-07
tags:
- Flink
- 大数据
- 流式计算
---
# 第二章 —— Flink 入门
通过第一章对 Flink 的介绍,相信你对 Flink 的概念和特性有了一定的了解,接下来本章将开始正式进入 Flink 的学习之旅,笔者将带你搭建 Flink 的环境和编写两个案例(WordCount 程序、读取 Socket 数据)来入门 Flink。
## 2.1 Flink 环境准备
通过前面的章节内容,相信你已经对 Flink 的基础概念等知识已经有一定了解,现在是不是迫切的想把 Flink 给用起来?先别急,我们先把电脑的准备环境给安装好,这样后面才能更愉快地玩耍。
废话不多说了,直奔主题。因为本书后面章节内容会使用 Kafka、MySQL、ElasticSearch 等组件,并且运行 Flink 程序是需要依赖 Java 的,另外就是我们需要使用 IDE 来开发 Flink 应用程序以及使用 Maven 来管理 Flink 应用程序的依赖,所以本节我们提前安装这个几个组件,搭建好本地的环境,后面如果还要安装其他的组件笔者会在对应的章节中补充,如果你的操作系统已经中已经安装过 JDK、Maven、MySQL、IDEA 等,那么你可以跳过对应的内容,直接看你未安装过的。
这里笔者再说下自己电脑的系统环境:macOS High Sierra 10.13.5,后面文章的演示环境不作特别说明的话就是都在这个系统环境中。
### 2.1.1 JDK 安装与配置
虽然现在 JDK 已经更新到 12 了,但是为了稳定我们还是安装 JDK 8,如果没有安装过的话,可以去[官网](https://www.oracle.com/technetwork/java/javase/downloads/index.html) 的[下载页面](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)下载对应自己操作系统的最新 JDK8 就行。
Mac 系统的是 `jdk-8u211-macosx-x64.dmg` 格式、Linux 系统的是 `jdk-8u211-linux-x64.tar.gz` 格式。Mac 系统安装的话直接双击然后一直按照提示就行了,最后 JDK 的安装目录在 `/Library/Java/JavaVirtualMachines/` ,然后在 `/etc/hosts` 中配置好环境变量(注意:替换你自己电脑本地的路径)。
```
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:
export PATH=$PATH:$JAVA_HOME/bin
```
Linux 系统的话就是在某个目录下直接解压就行了,然后在 `/etc/profile` 添加一下上面的环境变量(注意:替换你自己电脑的路径)。然后执行 `java -version` 命令可以查看是否安装成功!
```
zhisheng@zhisheng ~ java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
```
### 2.1.2 Maven 安装与配置
安装好 JDK 后我们就可以安装 Maven 了,我们在[官网](http://maven.apache.org/download.cgi)下载二进制包就行,然后在自己本地软件安装目录解压压缩包就行。接下来你需要配置一下环境变量:
```
export M2_HOME=/Users/zhisheng/Documents/maven-3.5.2
export PATH=$PATH:$M2_HOME/bin
```
然后执行命令 `mvn -v` 可以验证是否安装成功,结果如下:
```
zhisheng@zhisheng ~ /Users mvn -v
Apache Maven 3.5.2 (138edd61fd100ec658bfa2d307c43b76940a5d7d; 2017-10-18T15:58:13+08:00)
Maven home: /Users/zhisheng/Documents/maven-3.5.2
Java version: 1.8.0_152, vendor: Oracle Corporation
Java home: /Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "mac os x", version: "10.13.5", arch: "x86_64", family: "mac"
```
### 2.1.3 IDE 安装与配置
安装完 JDK 和 Maven 后,就可以安装 IDE 了,大家可以选择你熟练的 IDE 就行,笔者后面演示的代码都是在 IDEA 中运行的,如果想为了后面不出其他的问题的话,建议尽量和笔者的环境保持一致。
IDEA 官网下载地址:[下载页面的地址](https://www.jetbrains.com/idea/download/#section=mac),下载后可以双击后然后按照提示一步步安装,安装完成后需要在 IDEA 中配置 JDK 路径和 Maven 的路径,后面我们开发也都是靠 Maven 来管理项目的依赖。
### 2.1.4 MySQL 安装与配置
### 2.1.5 Kafka 安装与配置
### 2.1.6 ElasticSearch 安装与配置
加入知识星球可以看到上面文章:https://t.zsxq.com/JyRzVnU

### 2.1.7 小结与反思
本节讲解了下 JDK、Maven、IDE、MySQL、Kafka、ElasticSearch 的安装与配置,因为这些都是后面要用的,所以这里单独抽一篇文章来讲解环境准备的安装步骤,当然这里还并不涉及全,因为后面我们还可能会涉及到 HBase、HDFS 等知识,后面我们用到再看,本书的内容主要讲解 Flink,所以更多的环境准备还是得靠大家自己独立完成。
这里笔者说下笔者自己一般安装环境的选择:
xxx
下面章节我们就正式进入 Flink 专题了!
================================================
FILE: books/flink-in-action-2.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 环境搭建
date: 2021-07-08
tags:
- Flink
- 大数据
- 流式计算
---
## 2.2 Flink 环境搭建
在 2.1 节中已经将 Flink 的准备环境已经讲完了,本章节将带大家正式开始接触 Flink,那么我们得先安装一下 Flink。Flink 是可以在多个平台(Windows、Linux、Mac)上安装的。在开始写本书的时候最新版本是 1.8 版本,但是写到一半后更新到 1.9 了(合并了大量 Blink 的新特性),所以笔者又全部更新版本到 1.9,书籍后面也都是基于最新的版本讲解与演示。
Flink 的官网地址是:[https://flink.apache.org/](https://flink.apache.org/)
### 2.2.1 Flink 下载与安装
Flink 在 Mac、Linux、Window 平台上的安装方式如下。
#### 在 Mac 和 Linux 下安装
你可以通过该地址 [https://flink.apache.org/downloads.html](https://flink.apache.org/downloads.html) 下载到最新版本的 Flink。这里我们选择 `Apache Flink 1.9.0 for Scala 2.11` 版本,点击跳转到了一个镜像下载选择的地址,如下图所示,随便选择哪个就行,只是下载速度不一致而已。

下载完后,你就可以直接解压下载的 Flink 压缩包了。接下来我们可以启动一下 Flink,我们进入到 Flink 的安装目录下执行命令 `./bin/start-cluster.sh` 即可,产生的日志如下:
```
zhisheng@zhisheng /usr/local/flink-1.9.0 ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host zhisheng.
Starting taskexecutor daemon on host zhisheng.
```
如果你的电脑是 Mac 的话,那么你也可以通过 Homebrew 命令进行安装。先通过命令 `brew search flink` 查找一下包:
```
zhisheng@zhisheng ~ brew search flink
==> Formulae
apache-flink ✔ homebrew/linuxbrew-core/apache-flink
```
可以发现找得到 Flink 的安装包,但是这样安装的版本可能不是最新的,如果你要安装的话,则使用命令:
```
brew install apache-flink
```
那么它就会开始进行下载并安装好,安装后的目录应该是在 `/usr/local/Cellar/apache-flink` 下,如下图所示:

你可以通过下面命令检查安装的 Flink 到底是什么版本的:
```
flink --version
```
结果如下:
```
Version: 1.9.0, Commit ID: ff472b4
```
这种的话运行是得进入 `/usr/local/Cellar/apache-flink/1.9.0/libexec/bin` 目录下执行命令 `./start-cluster.sh` 才可以启动 Flink 的。执行命令后的启动日志如下所示:
```
Starting cluster.
Starting standalonesession daemon on host zhisheng.
Starting taskexecutor daemon on host zhisheng.
```
#### 在 Windows 下安装
如果你的电脑系统是 Windows 的话,那么你就直接双击 Flink 安装目录下面 bin 文件夹里面的 `start-cluster.bat` 就行,同样可以将 Flink 起动成功。
### 2.2.2 Flink 启动与运行
启动成功后的话,我们可以通过访问地址`http://localhost:8081/` 查看 UI 长啥样了,如下图所示:
### 2.2.3 Flink 目录配置文件解读
### 2.2.4 Flink 源码下载
### 2.2.5 Flink 源码编译
### 2.2.6 将 Flink 源码导入到 IDE
加入知识星球可以看到上面文章:https://t.zsxq.com/JyRzVnU

### 2.2.7 小结与反思
本节主要讲了 FLink 在不同系统下的安装和运行方法,然后讲了下怎么去下载源码和将源码导入到 IDE 中。不知道你在将源码导入到 IDE 中是否有遇到什么问题呢?
================================================
FILE: books/flink-in-action-2.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 案例1:WordCount 应用程序
date: 2021-07-09
tags:
- Flink
- 大数据
- 流式计算
---
## 2.3 案例1:WordCount 应用程序
在 2.2 节中带大家讲解了下 Flink 的环境安装,这篇文章就开始我们的第一个 Flink 案例实战,也方便大家快速开始自己的第一个 Flink 应用。大数据里学习一门技术一般都是从 WordCount 开始入门的,那么笔者还是不打破常规了,所以这篇文章笔者也将带大家通过 WordCount 程序来初步了解 Flink。
### 2.3.1 使用 Maven 创建项目
Flink 支持 Maven 直接构建模版项目,你在终端使用该命令:
```
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.0
```
在执行的过程中它会提示你输入 groupId、artifactId、和 package 名,你按照要求输入就行,最后就可以成功创建一个项目,如下图所示。
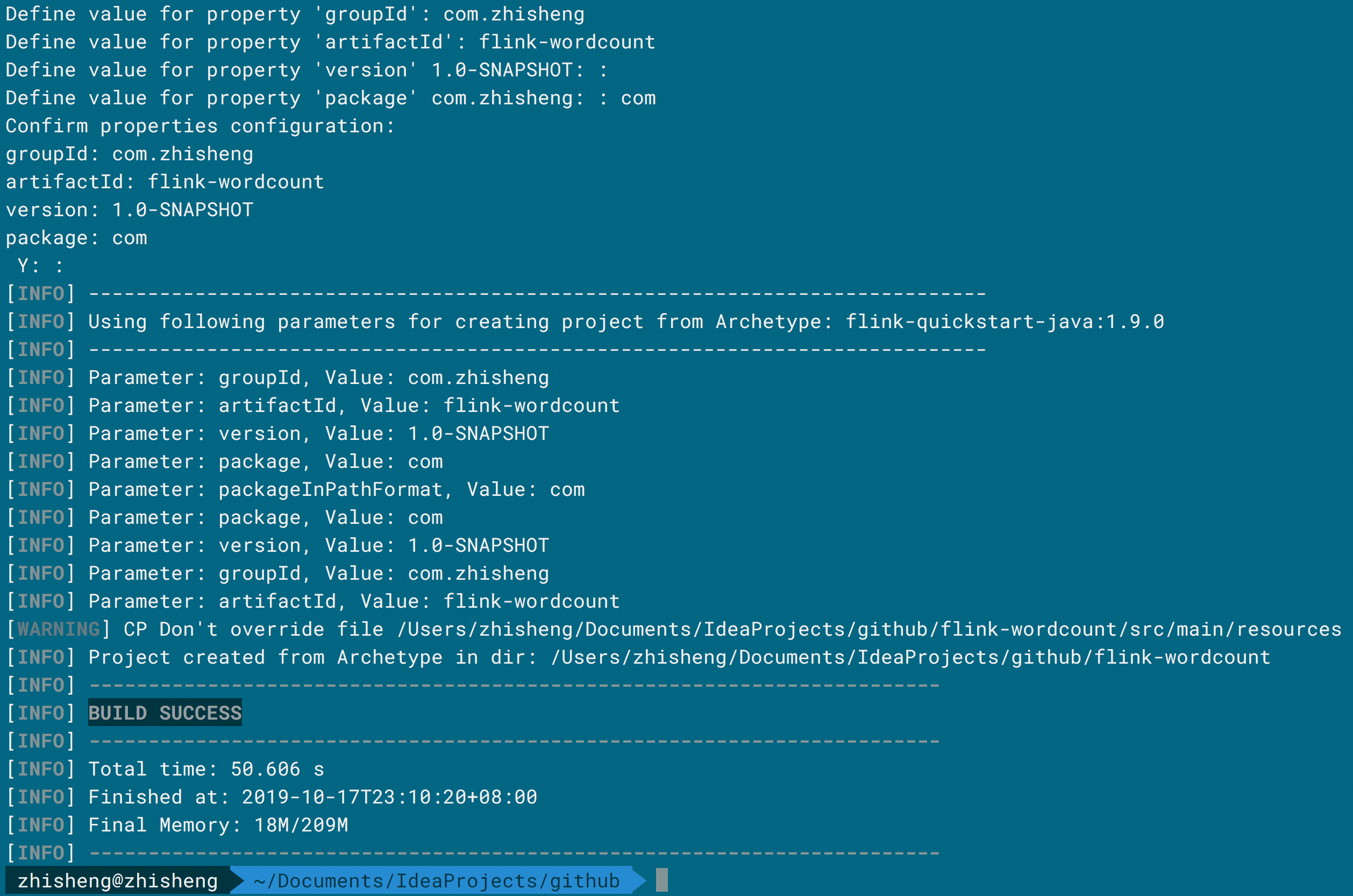
进入到目录你就可以看到已经创建了项目,里面结构如下:
```
zhisheng@zhisheng ~/IdeaProjects/github/Flink-WordCount tree
.
├── pom.xml
└── src
└── main
├── java
│ └── com
│ └── zhisheng
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
6 directories, 4 files
```
该项目中包含了两个类 BatchJob 和 StreamingJob,另外还有一个 log4j.properties 配置文件,然后你就可以将该项目导入到 IDEA 了。你可以在该目录下执行 `mvn clean package` 就可以编译该项目,编译成功后在 target 目录下会生成一个 Job 的 Jar 包,但是这个 Job 还不能执行,因为 StreamingJob 这个类中的 main 方法里面只是简单的创建了 StreamExecutionEnvironment 环境,然后就执行 execute 方法,这在 Flink 中是不算一个可执行的 Job 的,因此如果你提交到 Flink UI 上也是会报错的。
如下图所示,上传作业程序打包编译的 Jar 包:
运行报错结果如下图所示:
```
Server Response Message:
Internal server error.
```
我们查看 Flink JobManager 的日志,可以看见错误信息如下图所示:
```
2019-04-26 17:27:33,706 ERROR org.apache.flink.runtime.webmonitor.handlers.JarRunHandler - Unhandled exception.
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No operators defined in streaming topology. Cannot execute.
```
因为 execute 方法之前我们是需要补充我们 Job 的一些算子操作的,所以报错还是很正常的,本节下面将会提供完整代码。
### 2.3.2 使用 IDEA 创建项目
一般我们项目可能是由多个 Job 组成,并且代码也都是在同一个工程下面进行管理,上面那种创建方式适合单个 Job 执行,但如果在公司多人合作的时候还是得在同一个工程下面创建项目,每个 Flink Job 对应着一个 module,该 module 负责独立的业务逻辑,比如笔者在 GitHub 的 [https://github.com/zhisheng17/flink-learning](https://github.com/zhisheng17/flink-learning) 项目,它的项目结构如下图所示:
接下来我们需要在父工程的 pom.xml 中加入如下属性(含编码、Flink 版本、JDK 版本、Scala 版本、Maven 编译版本):
```xml
UTF-8
1.9.0
1.8
2.11
${java.version}
${java.version}
```
然后加入依赖:
```xml
org.apache.flink
flink-java
${flink.version}
provided
org.apache.flink
flink-streaming-java_${scala.binary.version}
${flink.version}
provided
org.slf4j
slf4j-log4j12
1.7.7
runtime
log4j
log4j
1.2.17
runtime
```
上面依赖中 flink-java 和 flink-streaming-java 是我们 Flink 必备的核心依赖,为什么设置 scope 为 provided 呢(默认是 compile)?是因为 Flink 其实在自己的安装目录中 lib 文件夹里的 `lib/flink-dist_2.11-1.9.0.jar` 已经包含了这些必备的 Jar 了,所以我们在给自己的 Flink Job 添加依赖的时候最后打成的 Jar 包可不希望又将这些重复的依赖打进去。有两个好处:
+ 减小了我们打的 Flink Job Jar 包容量大小
+ 不会因为打入不同版本的 Flink 核心依赖而导致类加载冲突等问题
但是问题又来了,我们需要在 IDEA 中调试运行我们的 Job,如果将 scope 设置为 provided 的话,是会报错的:
```
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/ExecutionConfig$GlobalJobParameters
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.common.ExecutionConfig$GlobalJobParameters
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
```
默认 scope 为 compile 的话,本地调试的话就不会出错了。另外测试到底能够减小多少 Jar 包的大小呢?我这里先写了个 Job 测试。当 scope 为 compile 时,编译后的 target 目录:
```
zhisheng@zhisheng ~/Flink-WordCount/target master ●✚ ll
total 94384
-rw-r--r-- 1 zhisheng staff 45M 4 26 21:23 Flink-WordCount-1.0-SNAPSHOT.jar
drwxr-xr-x 4 zhisheng staff 128B 4 26 21:23 classes
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 generated-sources
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 maven-archiver
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 maven-status
-rw-r--r-- 1 zhisheng staff 7.2K 4 26 21:23 original-Flink-WordCount-1.0-SNAPSHOT.jar
```
当 scope 为 provided 时,编译后的 target 目录:
```
zhisheng@zhisheng ~/Flink-WordCount/target master ●✚ ll
total 32
-rw-r--r-- 1 zhisheng staff 7.5K 4 26 21:27 Flink-WordCount-1.0-SNAPSHOT.jar
drwxr-xr-x 4 zhisheng staff 128B 4 26 21:27 classes
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 generated-sources
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 maven-archiver
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 maven-status
-rw-r--r-- 1 zhisheng staff 7.2K 4 26 21:27 original-Flink-WordCount-1.0-SNAPSHOT.jar
```
。。。
### 2.3.3 流计算 WordCount 应用程序代码实现
### 2.3.4 运行流计算 WordCount 应用程序
#### 本地 IDE 运行
#### UI 运行 Job
### 2.3.5 流计算 WordCount 应用程序代码分析
### 2.3.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/Z7EAmq3

================================================
FILE: books/flink-in-action-2.4.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 案例2:实时处理 Socket 数据
date: 2021-07-10
tags:
- Flink
- 大数据
- 流式计算
---
## 2.4 案例2:实时处理 Socket 数据
在 2.3 节中讲解了 Flink 最简单的 WordCount 程序的创建、运行结果查看和代码分析,本节将继续带大家来看一个入门上手的程序:Flink 处理 Socket 数据。
### 2.4.1 使用 IDEA 创建项目
使用 IDEA 创建新的 module,结构如下:
```
├── pom.xml
└── src
├── main
│ ├── java
│ │ └── com
│ │ └── zhisheng
│ │ └── socket
│ │ └── Main.java
│ └── resources
│ └── log4j.properties
└── test
└── java
```
项目创建好了后,我们下一步开始编写 Flink Socket Job 的代码。
### 2.4.2 实时处理 Socket 数据应用程序代码实现
程序代码如下所示:
```java
public class Main {
public static void main(String[] args) throws Exception {
//参数检查
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount ");
return;
}
String hostname = args[0];
Integer port = Integer.parseInt(args[1]);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据
DataStreamSource stream = env.socketTextStream(hostname, port);
//计数
SingleOutputStreamOperator> sum = stream.flatMap(new LineSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketText");
}
public static final class LineSplitter implements FlatMapFunction> {
@Override
public void flatMap(String s, Collector> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token: tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2(token, 1));
}
}
}
}
}
```
**pom.xml** 添加 build:
```xml
org.apache.maven.plugins
maven-compiler-plugin
3.1
${java.version}
${java.version}
org.apache.maven.plugins
maven-shade-plugin
3.0.0
package
shade
org.apache.flink:force-shading
com.google.code.findbugs:jsr305
org.slf4j:*
log4j:*
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.zhisheng.socket.Main
```
### 2.4.3 运行实时处理 Socket 数据应用程序
下面分别讲解在 IDE 和 Flink UI 上运行作业。
#### 本地 IDE 运行
#### UI 运行 Job
### 2.4.4 实时处理 Socket 数据应用程序代码分析
加入知识星球可以看到上面文章:https://t.zsxq.com/VBEQv3F

### 2.4.5 Flink 中使用 Lambda 表达式
因为 Lambda 表达式看起来简洁,所以有时候也是希望在这些 Flink 作业中也可以使用上它,虽然 Flink 中是支持 Lambda,但是个人感觉不太友好。比如上面的应用程序如果将 LineSplitter 该类之间用 Lambda 表达式完成的话则要像下面这样写:
```java
stream.flatMap((s, collector) -> {
for (String token : s.toLowerCase().split("\\W+")) {
if (token.length() > 0) {
collector.collect(new Tuple2(token, 1));
}
}
})
.keyBy(0)
.sum(1)
.print();
```
但是这样写完后,运行作业报错如下:
```
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(LambdaMain.java:34)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
at org.apache.flink.api.dag.Transformation.getOutputType(Transformation.java:417)
at org.apache.flink.streaming.api.datastream.DataStream.getType(DataStream.java:175)
at org.apache.flink.streaming.api.datastream.DataStream.keyBy(DataStream.java:318)
at com.zhisheng.examples.streaming.socket.LambdaMain.main(LambdaMain.java:41)
Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Collector' are missing. In many cases lambda methods don't provide enough information for automatic type extraction when Java generics are involved. An easy workaround is to use an (anonymous) class instead that implements the 'org.apache.flink.api.common.functions.FlatMapFunction' interface. Otherwise the type has to be specified explicitly using type information.
at org.apache.flink.api.java.typeutils.TypeExtractionUtils.validateLambdaType(TypeExtractionUtils.java:350)
at org.apache.flink.api.java.typeutils.TypeExtractionUtils.extractTypeFromLambda(TypeExtractionUtils.java:176)
at org.apache.flink.api.java.typeutils.TypeExtractor.getUnaryOperatorReturnType(TypeExtractor.java:571)
at org.apache.flink.api.java.typeutils.TypeExtractor.getFlatMapReturnTypes(TypeExtractor.java:196)
at org.apache.flink.streaming.api.datastream.DataStream.flatMap(DataStream.java:611)
at com.zhisheng.examples.streaming.socket.LambdaMain.main(LambdaMain.java:34)
```
根据上面的报错信息其实可以知道要怎么解决了,该错误是因为 Flink 在用户自定义的函数中会使用泛型来创建 serializer,当使用匿名函数时,类型信息会被保留。但 Lambda 表达式并不是匿名函数,所以 javac 编译的时候并不会把泛型保存到 class 文件里。解决方法:使用 Flink 提供的 returns 方法来指定 flatMap 的返回类型
```java
//使用 TupleTypeInfo 来指定 Tuple 的参数类型
.returns((TypeInformation) TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class))
```
在 flatMap 后面加上上面这个 returns 就行了,但是如果算子多了的话,每个都去加一个 returns,其实会很痛苦的,所以通常使用匿名函数或者自定义函数居多。
### 2.4.5 小结与反思
在第一章中介绍了 Flink 的特性,本章主要是让大家能够快速入门,所以在第一节和第二节中分别讲解了 Flink 的环境准备和搭建,在第三节和第四节中通过两个入门的应用程序(WordCount 应用程序和读取 Socket 数据应用程序)让大家可以快速入门 Flink,两个程序都是需要自己动手实操,所以更能加深大家的印象。
================================================
FILE: books/flink-in-action-3.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 中 Processing Time、Event Time、Ingestion Time 对比及其使用场景分析
date: 2021-07-11
tags:
- Flink
- 大数据
- 流式计算
---
# 第三章 —— Flink 中的流计算处理
通过第二章的入门案例讲解,相信你已经知道了 Flink 程序的开发过程,本章将带你熟悉 Flink 中的各种特性,比如多种时间语义、丰富的窗口机制、流计算中常见的运算操作符、Watermark 机制、丰富的 Connectors(Kafka、ElasticSearch、Redis、HBase 等) 的使用方式。除了介绍这些知识点的原理之外,笔者还将通过案例来教会大家如何去实战使用,最后还会讲解这些原理的源码实现,希望你可以更深刻的理解这些特性。
## 3.1 Flink 多种时间语义对比
Flink 在流应用程序中支持不同的 **Time** 概念,就比如有 Processing Time、Event Time 和 Ingestion Time。下面我们一起来看看这三个 Time。
### 3.1.1 Processing Time
Processing Time 是指事件被处理时机器的系统时间。
如果我们 Flink Job 设置的时间策略是 Processing Time 的话,那么后面所有基于时间的操作(如时间窗口)都将会使用当时机器的系统时间。每小时 Processing Time 窗口将包括在系统时钟指示整个小时之间到达特定操作的所有事件。
例如,如果应用程序在上午 9:15 开始运行,则第一个每小时 Processing Time 窗口将包括在上午 9:15 到上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 到 11:00 之间处理的事件。
Processing Time 是最简单的 "Time" 概念,不需要流和机器之间的协调,它提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,Processing Time 不能提供确定性,因为它容易受到事件到达系统的速度(例如从消息队列)、事件在系统内操作流动的速度以及中断的影响。
### 3.1.2 Event Time
Event Time 是指事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。在 Event Time 中,时间取决于数据,而跟其他没什么关系。Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制。
完美的说,无论事件什么时候到达或者其怎么排序,最后处理 Event Time 将产生完全一致和确定的结果。但是,除非事件按照已知顺序(事件产生的时间顺序)到达,否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
假设所有数据都已到达,Event Time 操作将按照预期运行,即使在处理无序事件、延迟事件、重新处理历史数据时也会产生正确且一致的结果。 例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,不管它们到达的顺序如何(是否按照事件产生的时间)。
### 3.1.3 Ingestion Time
Ingestion Time 是事件进入 Flink 的时间。 在数据源操作处(进入 Flink source 时),每个事件将进入 Flink 时当时的时间作为时间戳,并且基于时间的操作(如时间窗口)会利用这个时间戳。
Ingestion Time 在概念上位于 Event Time 和 Processing Time 之间。 与 Processing Time 相比,成本可能会高一点,但结果更可预测。因为 Ingestion Time 使用稳定的时间戳(只在进入 Flink 的时候分配一次),所以对事件的不同窗口操作将使用相同的时间戳(第一次分配的时间戳),而在 Processing Time 中,每个窗口操作符可以将事件分配给不同的窗口(基于机器系统时间和到达延迟)。
与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序中不必指定如何生成水印。
在 Flink 中,Ingestion Time 与 Event Time 非常相似,唯一区别就是 Ingestion Time 具有自动分配时间戳和自动生成水印功能。
### 3.1.4 三种 Time 的对比结果
### 3.1.5 使用场景分析
### 3.1.6 Time 策略设置
### 3.1.7 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/znqnMNB

================================================
FILE: books/flink-in-action-3.10.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink Connector —— HBase 的用法
date: 2021-07-21
tags:
- Flink
- 大数据
- 流式计算
---
## 3.10 Flink Connector —— HBase 的用法
HBase 是一个分布式的、面向列的开源数据库,同样,很多公司也有使用该技术存储数据的,本节将对 HBase 做些简单的介绍,以及利用 Flink HBase Connector 读取 HBase 中的数据和写入数据到 HBase 中。
### 3.10.1 准备环境和依赖
下面分别讲解 HBase 的环境安装、配置、常用的命令操作以及添加项目需要的依赖。
#### HBase 安装
如果是苹果系统,可以使用 HomeBrew 命令安装:
```
brew install hbase
```
HBase 最终会安装在路径 `/usr/local/Cellar/hbase/` 下面,安装版本不同,文件名也不同。
#### 配置 HBase
打开 `libexec/conf/hbase-env.sh` 修改里面的 JAVA_HOME:
```
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home"
```
根据你自己的 JAVA_HOME 来配置这个变量。
打开 `libexec/conf/hbase-site.xml` 配置 HBase 文件存储目录:
```xml
hbase.rootdir
file:///usr/local/var/hbase
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.property.dataDir
/usr/local/var/zookeeper
hbase.zookeeper.dns.interface
lo0
hbase.regionserver.dns.interface
lo0
hbase.master.dns.interface
lo0
```
#### 运行 HBase
执行启动的命令:
```
./bin/start-hbase.sh
```
执行后打印出来的日志如:
```
starting master, logging to /usr/local/var/log/hbase/hbase-zhisheng-master-zhisheng.out
```
#### 验证是否安装成功
使用 jps 命令:
```
zhisheng@zhisheng /usr/local/Cellar/hbase/1.2.9/libexec jps
91302 HMaster
62535 RemoteMavenServer
1100
91471 Jps
```
出现 HMaster 说明安装运行成功。
#### 启动 HBase Shell
执行下面命令:
```
./bin/hbase shell
```
运行结果如下图所示:

#### 停止 HBase
执行下面的命令:
```
./bin/stop-hbase.sh
```
运行结果如下图所示:

#### HBase 常用命令
HBase 中常用的命令有:list(列出已存在的表)、create(创建表)、put(写数据)、get(读数据)、scan(读数据,读全表)、describe(显示表详情),如下图所示。

简单使用上诉命令的结果如下:
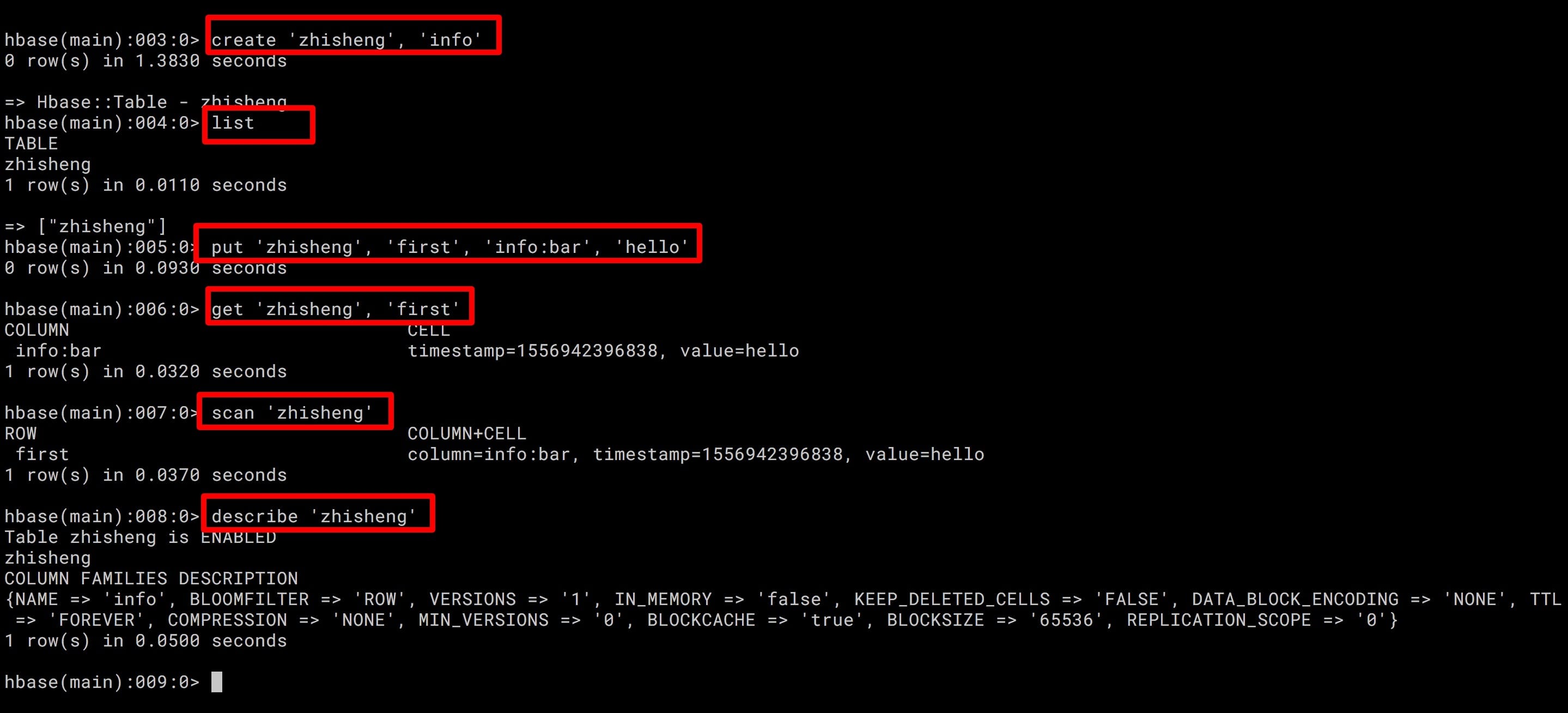
#### 添加依赖
在 pom.xml 中添加 HBase 相关的依赖:
```xml
org.apache.flink
flink-hbase_${scala.binary.version}
${flink.version}
org.apache.hadoop
hadoop-common
2.7.4
```
Flink HBase Connector 中,HBase 不仅可以作为数据源,也还可以写入数据到 HBase 中去,我们先来看看如何从 HBase 中读取数据。
### 3.10.2 Flink 使用 TableInputFormat 读取 HBase 批量数据
这里我们使用 TableInputFormat 来读取 HBase 中的数据,首先准备数据。
#### 准备数据
先往 HBase 中插入五条数据如下:
```jshelllanguage
put 'zhisheng', 'first', 'info:bar', 'hello'
put 'zhisheng', 'second', 'info:bar', 'zhisheng001'
put 'zhisheng', 'third', 'info:bar', 'zhisheng002'
put 'zhisheng', 'four', 'info:bar', 'zhisheng003'
put 'zhisheng', 'five', 'info:bar', 'zhisheng004'
```
scan 整个 `zhisheng` 表的话,有五条数据,运行结果如下图所示:
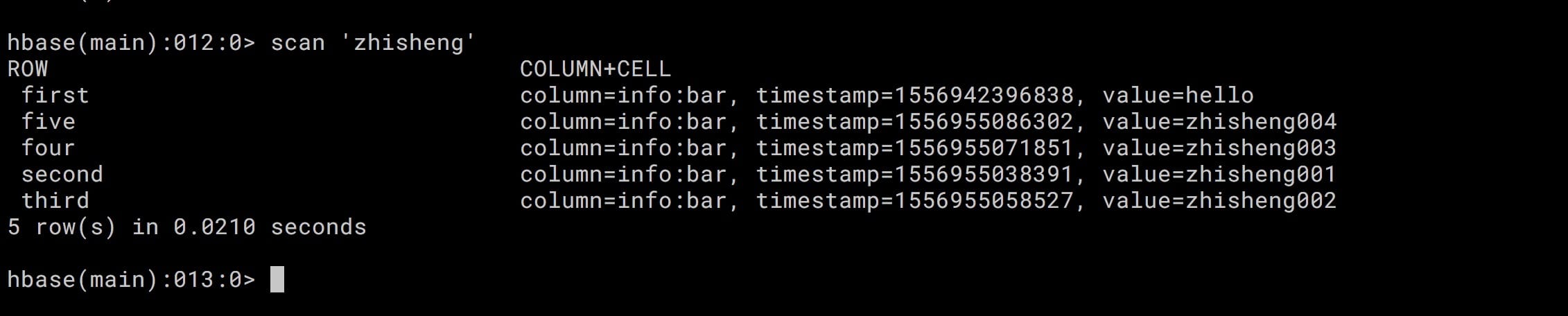
#### Flink Job 代码
Flink 读取 HBase 数据的程序代码如下所示:
```java
/**
* Desc: 读取 HBase 数据
*/
public class HBaseReadMain {
//表名
public static final String HBASE_TABLE_NAME = "zhisheng";
// 列族
static final byte[] INFO = "info".getBytes(ConfigConstants.DEFAULT_CHARSET);
//列名
static final byte[] BAR = "bar".getBytes(ConfigConstants.DEFAULT_CHARSET);
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.createInput(new TableInputFormat>() {
private Tuple2 reuse = new Tuple2();
@Override
protected Scan getScanner() {
Scan scan = new Scan();
scan.addColumn(INFO, BAR);
return scan;
}
@Override
protected String getTableName() {
return HBASE_TABLE_NAME;
}
@Override
protected Tuple2 mapResultToTuple(Result result) {
String key = Bytes.toString(result.getRow());
String val = Bytes.toString(result.getValue(INFO, BAR));
reuse.setField(key, 0);
reuse.setField(val, 1);
return reuse;
}
}).filter(new FilterFunction>() {
@Override
public boolean filter(Tuple2 value) throws Exception {
return value.f1.startsWith("zhisheng");
}
}).print();
}
}
```
上面代码中将 HBase 中的读取全部读取出来后然后过滤以 `zhisheng` 开头的 value 数据。读取结果如下图所示:
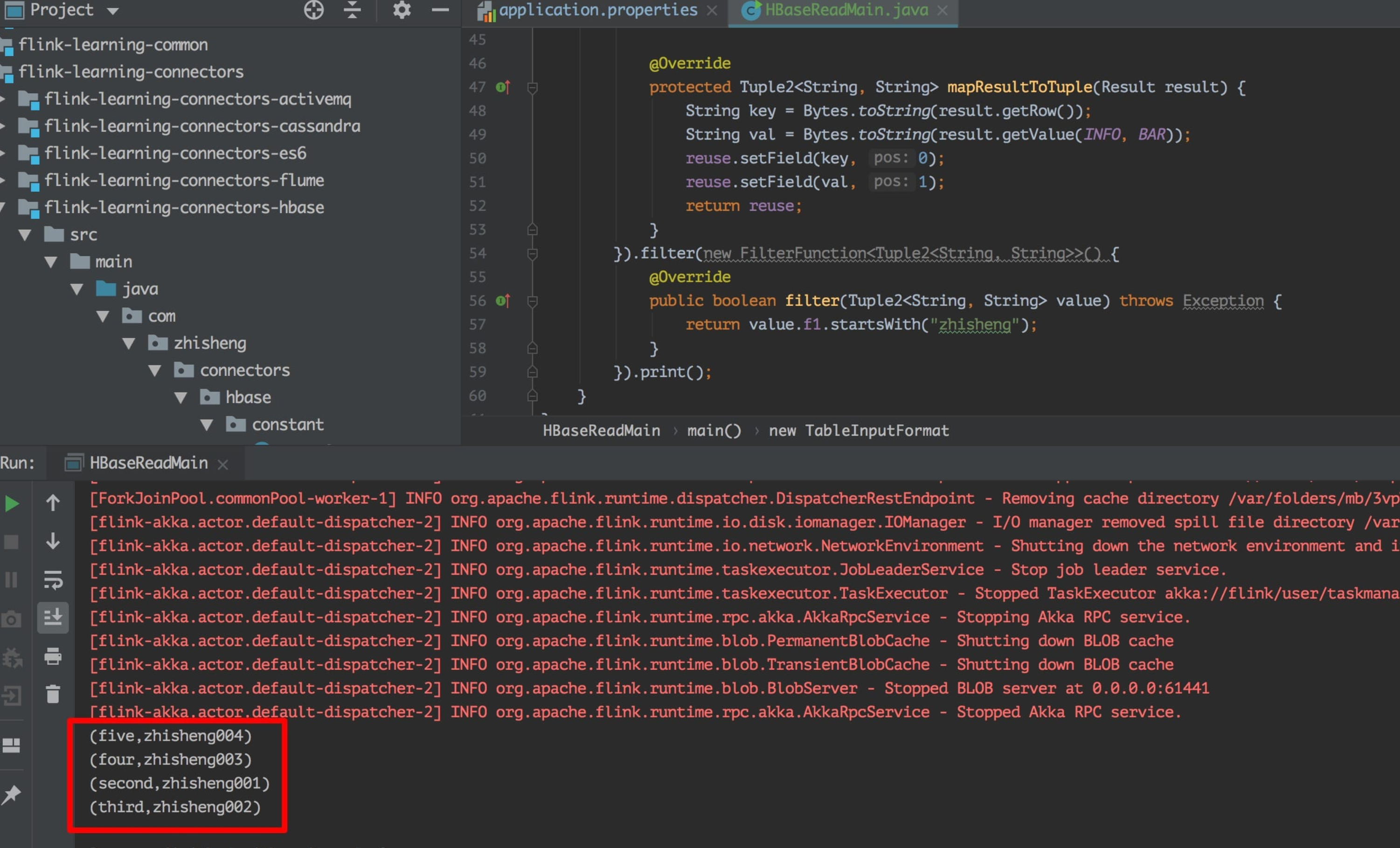
可以看到输出的结果中已经将以 `zhisheng` 开头的四条数据都打印出来了。
### 3.10.3 Flink 使用 TableOutputFormat 向 HBase 写入数据
#### 添加依赖
#### Flink Job 代码
### 3.10.4 Flink 使用 HBaseOutputFormat 向 HBase 实时写入数据
#### 读取数据
#### 写入数据
#### 配置文件
### 3.10.5 项目运行及验证
### 3.10.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/3bimqBM

================================================
FILE: books/flink-in-action-3.11.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink Connector —— Redis 的用法
date: 2021-07-22
tags:
- Flink
- 大数据
- 流式计算
---
## 3.11 Flink Connector —— Redis 的用法
在生产环境中,通常会将一些计算后的数据存储在 Redis 中,以供第三方的应用去 Redis 查找对应的数据,至于 Redis 的特性笔者不会在本节做过多的讲解。
### 3.11.1 安装 Redis
首先介绍下 Redis 的的安装和启动运行。
#### 下载安装
先从 [官网](https://redis.io/download) 下载 Redis,然后解压。
```
wget http://download.redis.io/releases/redis-5.0.4.tar.gz
tar xzf redis-5.0.4.tar.gz
cd redis-5.0.4
make
```
#### 通过 HomeBrew 安装
```
brew install redis
```
如果需要后台运行 Redis 服务,使用命令:
```
brew services start redis
```
要运行命令,可以直接到 /usr/local/bin 目录下,有:
```
redis-server
redis-cli
```
两个命令,执行 `redis-server` 可以打开服务端,启动后结果如下图所示:
然后另外开一个终端,运行 `redis-cli` 命令可以运行客户端,执行后效果如下图所示:

### 3.11.2 将商品数据发送到 Kafka
这里我打算将从 Kafka 读取到所有到商品的信息,然后将商品信息中的 **商品ID** 和 **商品价格** 提取出来,然后写入到 Redis 中,供第三方服务根据商品 ID 查询到其对应的商品价格。
首先定义我们的商品类 (其中 id 和 price 字段是我们最后要提取的)为:
ProductEvent.java
```java
/**
* Desc: 商品
* blog:http://www.54tianzhisheng.cn/
* 微信公众号:zhisheng
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ProductEvent {
/**
* Product Id
*/
private Long id;
/**
* Product 类目 Id
*/
private Long categoryId;
/**
* Product 编码
*/
private String code;
/**
* Product 店铺 Id
*/
private Long shopId;
/**
* Product 店铺 name
*/
private String shopName;
/**
* Product 品牌 Id
*/
private Long brandId;
/**
* Product 品牌 name
*/
private String brandName;
/**
* Product name
*/
private String name;
/**
* Product 图片地址
*/
private String imageUrl;
/**
* Product 状态(1(上架),-1(下架),-2(冻结),-3(删除))
*/
private int status;
/**
* Product 类型
*/
private int type;
/**
* Product 标签
*/
private List tags;
/**
* Product 价格(以分为单位)
*/
private Long price;
}
```
然后写个工具类不断的模拟商品数据发往 Kafka,工具类 `ProductUtil.java` 的代码如下:
```java
public class ProductUtil {
public static final String broker_list = "localhost:9092";
public static final String topic = "zhisheng"; //kafka topic 需要和 flink 程序用同一个 topic
public static final Random random = new Random();
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
for (int i = 1; i <= 10000; i++) {
ProductEvent product = ProductEvent.builder().id((long) i) //商品的 id
.name("product" + i) //商品 name
.price(random.nextLong() / 10000000000000L) //商品价格(以分为单位)
.code("code" + i).build(); //商品编码
ProducerRecord record = new ProducerRecord(topic, null, null, GsonUtil.toJson(product));
producer.send(record);
System.out.println("发送数据: " + GsonUtil.toJson(product));
}
producer.flush();
}
}
```
### 3.11.3 Flink 消费 Kafka 中的商品数据
我们需要在 Flink 中消费 Kafka 数据,然后将商品中的两个数据(商品 id 和 price)取出来。先来看下这段 Flink Job 代码:
```java
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool parameterTool = ExecutionEnvUtil.PARAMETER_TOOL;
Properties props = KafkaConfigUtil.buildKafkaProps(parameterTool);
SingleOutputStreamOperator> product = env.addSource(new FlinkKafkaConsumer011<>(
parameterTool.get(METRICS_TOPIC), //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props))
.map(string -> GsonUtil.fromJson(string, ProductEvent.class)) //反序列化 JSON
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(ProductEvent value, Collector> out) throws Exception {
//收集商品 id 和 price 两个属性
out.collect(new Tuple2<>(value.getId().toString(), value.getPrice().toString()));
}
});
product.print();
env.execute("flink redis connector");
}
}
```
然后 IDEA 中启动运行 Job,再运行上面的 ProductUtil 发送 Kafka 数据的工具类(注意:也得提前启动 Kafka),运行结果如下图所示。
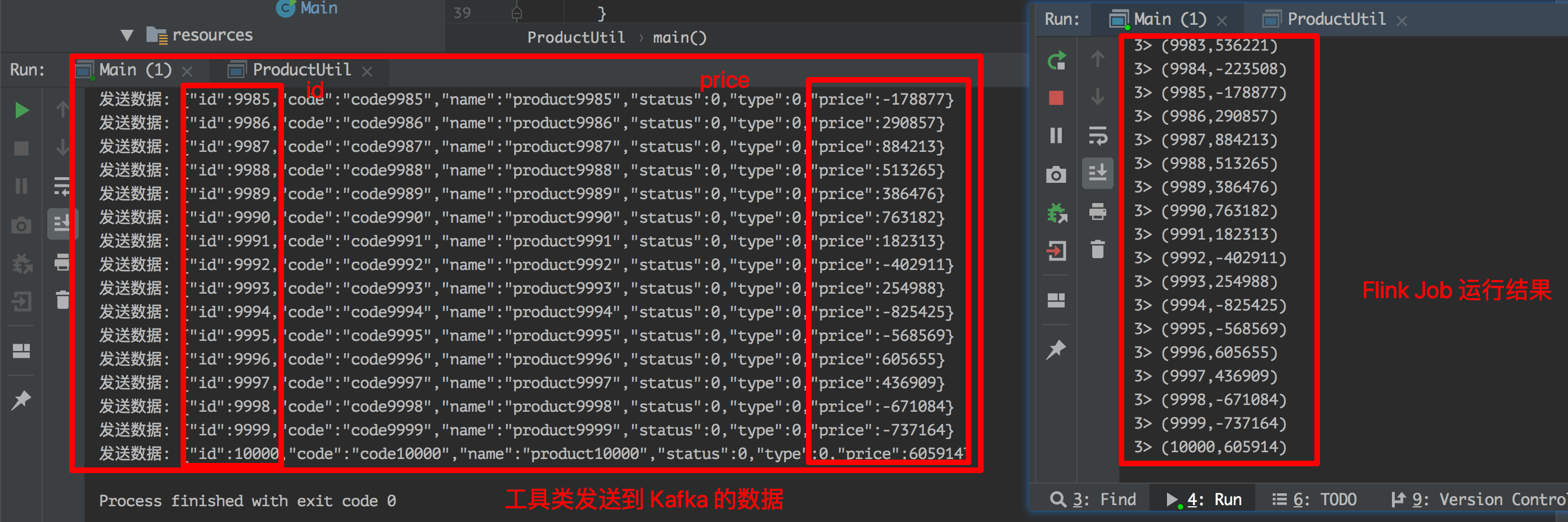
上图左半部分是工具类发送数据到 Kafka 打印的日志,右半部分是 Job 执行的结果,可以看到它已经将商品的 id 和 price 数据获取到了。
那么接下来我们需要的就是将这种 `Tuple2` 格式的 KV 数据写入到 Redis 中去。要将数据写入到 Redis 的话是需要先添加依赖的。
### 3.11.4 Redis Connector 简介
Redis Connector 提供用于向 Redis 发送数据的接口的类。接收器可以使用三种不同的方法与不同类型的 Redis 环境进行通信:
+ 单 Redis 服务器
+ Redis 集群
+ Redis Sentinel
### 添加依赖
需要添加 Flink Redis Sink 的 Connector,这个 Redis Connector 官方只有老的版本,后面也一直没有更新,所以可以看到网上有些文章都是添加老的版本的依赖。
```xml
org.apache.flink
flink-connector-redis_2.10
1.1.5
```
包括该部分的文档都是很早之前的啦,可以查看 [flink-docs-release-1.1 redis](https://ci.apache.org/projects/flink/flink-docs-release-1.1/apis/streaming/connectors/redis.html)。
另外在 [flink-streaming-redis](https://bahir.apache.org/docs/flink/current/flink-streaming-redis/) 也看到一个 Flink Redis Connector 的依赖。
```xml
org.apache.bahir
flink-connector-redis_2.11
1.0
```
两个依赖功能都是一样的,我们还是就用官方的那个 Maven 依赖来进行演示。
### 3.11.5 Flink 写入数据到 Redis
### 3.11.6 项目运行及验证
### 3.11.7 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/zr76I66

================================================
FILE: books/flink-in-action-3.12.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 使用 Side Output 分流
date: 2021-07-23
tags:
- Flink
- 大数据
- 流式计算
---
## 3.12 使用 Side Output 分流
通常,在 Kafka 的 topic 中会有很多数据,这些数据虽然结构是一致的,但是类型可能不一致,举个例子:Kafka 中的监控数据有很多种:机器、容器、应用、中间件等,如果要对这些数据分别处理,就需要对这些数据流进行一个拆分,那么在 Flink 中该怎么完成这需求呢,有如下这些方法。
### 3.12.1 使用 Filter 分流
使用 filter 算子根据数据的字段进行过滤分成机器、容器、应用、中间件等。伪代码如下:
```java
DataStreamSource data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator machineData = data.filter(m -> "machine".equals(m.getTags().get("type"))); //过滤出机器的数据
SingleOutputStreamOperator dockerData = data.filter(m -> "docker".equals(m.getTags().get("type"))); //过滤出容器的数据
SingleOutputStreamOperator applicationData = data.filter(m -> "application".equals(m.getTags().get("type"))); //过滤出应用的数据
SingleOutputStreamOperator middlewareData = data.filter(m -> "middleware".equals(m.getTags().get("type"))); //过滤出中间件的数据
```
### 3.12.2 使用 Split 分流
先在 split 算子里面定义 OutputSelector 的匿名内部构造类,然后重写 select 方法,根据数据的类型将不同的数据放到不同的 tag 里面,这样返回后的数据格式是 SplitStream,然后要使用这些数据的时候,可以通过 select 去选择对应的数据类型,伪代码如下:
```java
DataStreamSource data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SplitStream splitData = data.split(new OutputSelector() {
@Override
public Iterable select(MetricEvent metricEvent) {
List tags = new ArrayList<>();
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
tags.add("machine");
break;
case "docker":
tags.add("docker");
break;
case "application":
tags.add("application");
break;
case "middleware":
tags.add("middleware");
break;
default:
break;
}
return tags;
}
});
DataStream machine = splitData.select("machine");
DataStream docker = splitData.select("docker");
DataStream application = splitData.select("application");
DataStream middleware = splitData.select("middleware");
```
上面这种只分流一次是没有问题的,注意如果要使用它来做连续的分流,那是有问题的,笔者曾经就遇到过这个问题,当时记录了博客 —— [Flink 从0到1学习—— Flink 不可以连续 Split(分流)?](http://www.54tianzhisheng.cn/2019/06/12/flink-split/) ,当时排查这个问题还查到两个相关的 Flink Issue。
+ [FLINK-5031 Issue](https://issues.apache.org/jira/browse/FLINK-5031)
+ [FLINK-11084 Issue](https://issues.apache.org/jira/browse/FLINK-11084)
这两个 Issue 反映的就是连续 split 不起作用,在第二个 Issue 下面的评论就有回复说 Side Output 的功能比 split 更强大, split 会在后面的版本移除(其实在 1.7.x 版本就已经设置为过期),那么下面就来学习一下 Side Output。
### 3.12.3 使用 Side Output 分流
要使用 Side Output 的话,你首先需要做的是定义一个 OutputTag 来标识 Side Output,代表这个 Tag 是要收集哪种类型的数据,如果是要收集多种不一样类型的数据,那么你就需要定义多种 OutputTag。要完成本节前面的需求,需要定义 4 个 OutputTag,如下:
```java
//创建 output tag
private static final OutputTag machineTag = new OutputTag("machine") {
};
private static final OutputTag dockerTag = new OutputTag("docker") {
};
private static final OutputTag applicationTag = new OutputTag("application") {
};
private static final OutputTag middlewareTag = new OutputTag("middleware") {
};
```
定义好 OutputTag 后,可以使用下面几种函数来处理数据:
+ ProcessFunction
+ KeyedProcessFunction
+ CoProcessFunction
+ ProcessWindowFunction
+ ProcessAllWindowFunction
在利用上面的函数处理数据的过程中,需要对数据进行判断,将不同种类型的数据存到不同的 OutputTag 中去,如下代码所示:
```java
DataStreamSource data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator sideOutputData = data.process(new ProcessFunction() {
@Override
public void processElement(MetricEvent metricEvent, Context context, Collector collector) throws Exception {
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
context.output(machineTag, metricEvent);
case "docker":
context.output(dockerTag, metricEvent);
case "application":
context.output(applicationTag, metricEvent);
case "middleware":
context.output(middlewareTag, metricEvent);
default:
collector.collect(metricEvent);
}
}
});
```
好了,既然上面已经将不同类型的数据放到不同的 OutputTag 里面了,那么该如何去获取呢?可以使用 getSideOutput 方法来获取不同 OutputTag 的数据,比如:
```java
DataStream machine = sideOutputData.getSideOutput(machineTag);
DataStream docker = sideOutputData.getSideOutput(dockerTag);
DataStream application = sideOutputData.getSideOutput(applicationTag);
DataStream middleware = sideOutputData.getSideOutput(middlewareTag);
```
这样你就可以获取到 Side Output 数据了,其实在 3.4 和 3.5 节就讲了 Side Output 在 Flink 中的应用(处理窗口的延迟数据),大家如果没有印象了可以再返回去复习一下。
### 3.12.4 小结与反思
本节讲了下 Flink 中将数据分流的三种方式,完整代码的 GitHub 地址:[sideoutput](https://github.com/zhisheng17/flink-learning/tree/master/flink-learning-examples/src/main/java/com/zhisheng/examples/streaming/sideoutput)
本章全部在介绍 Flink 的技术点,比如多种时间语义的对比分析和应用场景分析、多种灵活的窗口的使用方式及其原理实现、平时开发使用较多的一些算子、深入讲解了 DataStream 中的流类型及其对应的方法实现、如何将 Watermark 与 Window 结合来处理延迟数据、Flink Connector 的使用方式。
因为 Flink 的 Connector 比较多,所以本书只挑选了些平时工作用的比较多的 Connector,比如 Kafka、ElasticSearch、HBase、Redis 等,并教会了大家如何去自定义 Source 和 Sink,这样就算 Flink 中的 Connector 没有你需要的,那么也可以通过这种自定义的方法来实现读取和写入数据。
本章讲解的内容更侧重于在 Flink DataStream 和 Connector 的使用技巧和优化,在讲解这些时还提供了详细的代码实现,目的除了大家可以参考外,其实更期望大家能够自己跟着多动手去实现和优化,这样才可以提高自己的编程水平。另外本章还介绍了自己在使用这些 Connector 时遇到的一些问题,是怎么解决的,也希望大家在工作的时候遇到问题可以静下来自己独立的思考下出现问题的原因是啥,该如何解决,多独立思考后,相信遇到问题后你也能够从容的分析和解决问题。
加入知识星球可以看到更多文章

================================================
FILE: books/flink-in-action-3.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何使用 Flink Window 及 Window 基本概念与实现原理?
date: 2021-07-12
tags:
- Flink
- 大数据
- 流式计算
---
## 3.2 Flink Window 基础概念与实现原理
目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语,例如,“windowing(窗口化)”、“at-least-once(至少一次)”、“exactly-once(只有一次)” 。
对于刚刚接触流处理的人来说,这种转变和新术语可能会非常混乱。 Apache Flink 是一个为生产环境而生的流处理器,具有易于使用的 API,可以用于定义高级流分析程序。Flink 的 API 在数据流上具有非常灵活的窗口定义,使其在其他开源流处理框架中脱颖而出。
在本节将讨论用于流处理的窗口的概念,介绍 Flink 的内置窗口,并解释它对自定义窗口语义的支持。
### 3.2.1 Window 简介
下面我们结合一个现实的例子来说明。
就拿交通传感器的示例:统计经过某红绿灯的汽车数量之和?
假设在一个红绿灯处,我们每隔 15 秒统计一次通过此红绿灯的汽车数量,如下图所示:

可以把汽车的经过看成一个流,无穷的流,不断有汽车经过此红绿灯,因此无法统计总共的汽车数量。但是,我们可以换一种思路,每隔 15 秒,我们都将与上一次的结果进行 sum 操作(滑动聚合),如下图所示:
这个结果似乎还是无法回答我们的问题,根本原因在于流是无界的,我们不能限制流,但可以在有一个有界的范围内处理无界的流数据。因此,我们需要换一个问题的提法:每分钟经过某红绿灯的汽车数量之和?
这个问题,就相当于一个定义了一个 Window(窗口),Window 的界限是 1 分钟,且每分钟内的数据互不干扰,因此也可以称为翻滚(不重合)窗口,如下图所示:
第一分钟的数量为 18,第二分钟是 28,第三分钟是 24……这样,1 个小时内会有 60 个 Window。
再考虑一种情况,每 30 秒统计一次过去 1 分钟的汽车数量之和,如下图所示:
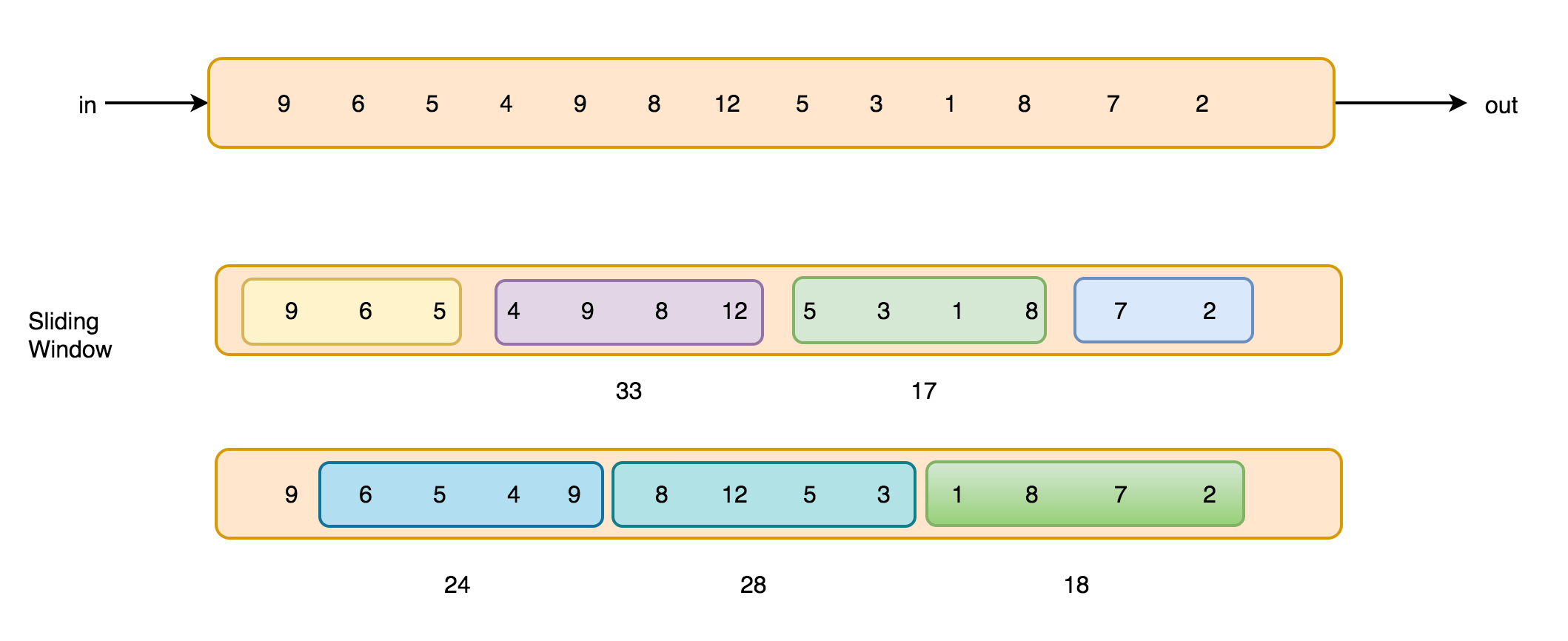
此时,Window 出现了重合。这样,1 个小时内会有 120 个 Window。
### 3.2.2 Window 有什么作用?
通常来讲,Window 就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。Window 又可以分为基于时间(Time-based)的 Window 以及基于数量(Count-based)的 window。
### 3.2.3 Flink 自带的 Window
Flink 在 KeyedStream(DataStream 的继承类) 中提供了下面几种 Window:
+ 以时间驱动的 Time Window
+ 以事件数量驱动的 Count Window
+ 以会话间隔驱动的 Session Window
提供上面三种 Window 机制后,由于某些特殊的需要,DataStream API 也提供了定制化的 Window 操作,供用户自定义 Window。
下面将先围绕上面说的三种 Window 来进行分析并教大家如何使用,然后对其原理分析,最后在解析其源码实现。
### 3.2.4 Time Window 的用法及源码分析
### 3.2.5 Count Window 的用法及源码分析
### 3.2.6 Session Window 的用法及源码分析
### 3.2.7 如何自定义 Window?
### 3.2.8 Window 源码分析
### 3.2.9 Window 组件之 WindowAssigner 的用法及源码分析
### 3.2.10 Window 组件之 Trigger 的用法及源码分析
### 3.2.11 Window 组件之 Evictor 的用法及源码分析
加入知识星球可以看到上面文章:https://t.zsxq.com/qnQRvrf

### 3.2.12 小结与反思
本节从生活案例来分享关于 Window 方面的需求,进而开始介绍 Window 相关的知识,并把 Flink 中常使用的三种窗口都一一做了介绍,并告诉大家如何使用,还分析了其实现原理。最后还对 Window 的内部组件做了详细的分析,为自定义 Window 提供了方法。
不知道你看完本节后对 Window 还有什么疑问吗?你们是根据什么条件来选择使用哪种 Window 的?在使用的过程中有遇到什么问题吗?
================================================
FILE: books/flink-in-action-3.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 数据转换必须熟悉的算子(Operator)
date: 2021-07-13
tags:
- Flink
- 大数据
- 流式计算
---
## 3.3 必须熟悉的数据转换 Operator(算子)
在 Flink 应用程序中,无论你的应用程序是批程序,还是流程序,都是上图这种模型,有数据源(source),有数据下游(sink),我们写的应用程序多是对数据源过来的数据做一系列操作,总结如下。

1、**Source**: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
2、**Transformation**: 数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
3、**Sink**: 接收器,Sink 是指 Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来。Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 Socket 、自定义的 Sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
那么本文将给大家介绍的就是 Flink 中的批和流程序常用的算子(Operator)。
### 3.3.1 DataStream Operator
我们先来看看流程序中常用的算子。
#### Map
Map 算子的输入流是 DataStream,经过 Map 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成一个元素,举个例子:
```java
SingleOutputStreamOperator map = employeeStream.map(new MapFunction() {
@Override
public Employee map(Employee employee) throws Exception {
employee.salary = employee.salary + 5000;
return employee;
}
});
map.print();
```
新的一年给每个员工的工资加 5000。
#### FlatMap
FlatMap 算子的输入流是 DataStream,经过 FlatMap 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成零个、一个或多个元素,举个例子:
```java
SingleOutputStreamOperator flatMap = employeeStream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(Employee employee, Collector out) throws Exception {
if (employee.salary >= 40000) {
out.collect(employee);
}
}
});
flatMap.print();
```
将工资大于 40000 的找出来。
#### Filter
#### KeyBy
#### Reduce
#### Aggregations
#### Window
#### WindowAll
#### Union
#### Window Join
#### Split
#### Select
### 3.3.2 DataSet Operator
#### First-n
### 3.3.3 流计算与批计算统一的思路
加入知识星球可以看到上面文章:https://t.zsxq.com/iYFMZFA

### 3.3.4 小结与反思
本节介绍了在开发 Flink 作业中数据转换常使用的算子(包含流作业和批作业),DataStream API 和 DataSet API 中部分算子名字是一致的,也有不同的地方,最后讲解了下 Flink 社区后面流批统一的思路。
你们公司使用 Flink 是流作业居多还是批作业居多?
================================================
FILE: books/flink-in-action-3.4.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 使用 DataStream API 来处理数据
date: 2021-07-14
tags:
- Flink
- 大数据
- 流式计算
---
## 3.4 使用 DataStream API 来处理数据
在 3.3 节中讲了数据转换常用的 Operators(算子),然后在 3.2 节中也讲了 Flink 中窗口的概念和原理,那么我们这篇文章再来细讲一下 Flink 中的各种 DataStream API。
我们先来看下源码里面的 DataStream 大概有哪些类呢?如下图所示,展示了 1.9 版本中的 DataStream 类。
可以发现其实还是有很多的类,只有熟练掌握了这些 API,我们才能在做数据转换和计算的时候足够灵活的运用开来(知道何时该选用哪种 DataStream?选用哪个 Function?)。那么我们先从 DataStream 开始吧!
### 3.4.1 DataStream 的用法及分析
首先我们来看下 DataStream 这个类的定义吧:
```text
A DataStream represents a stream of elements of the same type. A DataStreamcan be transformed into another DataStream by applying a transformation as
DataStream#map or DataStream#filter}
```
大概意思是:DataStream 表示相同类型的元素组成的数据流,一个数据流可以通过 map/filter 等算子转换成另一个数据流。
然后 DataStream 的类结构图如下图所示:
它的继承类有 KeyedStream、SingleOutputStreamOperator 和 SplitStream。这几个类本文后面都会一一给大家讲清楚。下面我们来看看 DataStream 这个类中的属性和方法吧。
它的属性就只有两个:
```java
protected final StreamExecutionEnvironment environment;
protected final StreamTransformation transformation;
```
但是它的方法却有很多,并且我们平时写的 Flink Job 几乎离不开这些方法,这也注定了这个类的重要性,所以得好好看下这些方法该如何使用,以及是如何实现的。
#### union
通过合并相同数据类型的数据流,然后创建一个新的数据流,union 方法代码实现如下:
```java
public final DataStream union(DataStream... streams) {
List> unionedTransforms = new ArrayList<>();
unionedTransforms.add(this.transformation);
for (DataStream newStream : streams) {
if (!getType().equals(newStream.getType())) { //判断数据类型是否一致
throw new IllegalArgumentException("Cannot union streams of different types: " + getType() + " and " + newStream.getType());
}
unionedTransforms.add(newStream.getTransformation());
}
//构建新的数据流
return new DataStream<>(this.environment, new UnionTransformation<>(unionedTransforms));//通过使用 UnionTransformation 将多个 StreamTransformation 合并起来
}
```
那么我们该如何去使用 union 呢(不止连接一个数据流,也可以连接多个数据流)?
```java
//数据流 1 和 2
final DataStream stream1 = env.addSource(...);
final DataStream stream2 = env.addSource(...);
//union
stream1.union(stream2)
```
#### split
该方法可以将两个数据流进行拆分,拆分后的数据流变成了 SplitStream(在下文会详细介绍这个类的内部实现),该 split 方法通过传入一个 OutputSelector 参数进行数据选择,方法内部实现就是构造一个 SplitStream 对象然后返回:
```java
public SplitStream split(OutputSelector outputSelector) {
return new SplitStream<>(this, clean(outputSelector));
}
```
然后我们该如何使用这个方法呢?
```java
dataStream.split(new OutputSelector() {
private static final long serialVersionUID = 8354166915727490130L;
@Override
public Iterable select(Integer value) {
List s = new ArrayList();
if (value > 4) { //大于 4 的数据放到 > 这个 tag 里面去
s.add(">");
} else { //小于等于 4 的数据放到 < 这个 tag 里面去
s.add("<");
}
return s;
}
});
```
注意:该方法已经不推荐使用了!在 1.7 版本以后建议使用 Side Output 来实现分流操作。
#### connect
通过连接不同或相同数据类型的数据流,然后创建一个新的连接数据流,如果连接的数据流也是一个 DataStream 的话,那么连接后的数据流为 ConnectedStreams(会在下文介绍这个类的具体实现),它的具体实现如下:
```java
public ConnectedStreams connect(DataStream dataStream) {
return new ConnectedStreams<>(environment, this, dataStream);
}
```
如果连接的数据流是一个 BroadcastStream(广播数据流),那么连接后的数据流是一个 BroadcastConnectedStream(会在下文详细介绍该类的内部实现),它的具体实现如下:
```java
public BroadcastConnectedStream connect(BroadcastStream broadcastStream) {
return new BroadcastConnectedStream<>(
environment, this, Preconditions.checkNotNull(broadcastStream),
broadcastStream.getBroadcastStateDescriptor());
}
```
使用如下:
```java
//1、连接 DataStream
DataStream> src1 = env.fromElements(new Tuple2<>(0L, 0L));
DataStream> src2 = env.fromElements(new Tuple2<>(0L, 0L));
ConnectedStreams, Tuple2> connected = src1.connect(src2);
//2、连接 BroadcastStream
DataStream> src1 = env.fromElements(new Tuple2<>(0L, 0L));
final BroadcastStream broadcast = srcTwo.broadcast(utterDescriptor);
BroadcastConnectedStream, String> connect = src1.connect(broadcast);
```
#### keyBy
keyBy 方法是用来将数据进行分组的,通过该方法可以将具有相同 key 的数据划分在一起组成新的数据流,该方法有四种(它们的参数各不一样):
```java
//1、参数是 KeySelector 对象
public KeyedStream keyBy(KeySelector key) {
...
return new KeyedStream<>(this, clean(key));//构造 KeyedStream 对象
}
//2、参数是 KeySelector 对象和 TypeInformation 对象
public KeyedStream keyBy(KeySelector key, TypeInformation keyType) {
...
return new KeyedStream<>(this, clean(key), keyType);//构造 KeyedStream 对象
}
//3、参数是 1 至多个字段(用 0、1、2... 表示)
public KeyedStream keyBy(int... fields) {
if (getType() instanceof BasicArrayTypeInfo || getType() instanceof PrimitiveArrayTypeInfo) {
return keyBy(KeySelectorUtil.getSelectorForArray(fields, getType()));
} else {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));//调用 private 的 keyBy 方法
}
}
//4、参数是 1 至多个字符串
public KeyedStream keyBy(String... fields) {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));//调用 private 的 keyBy 方法
}
//真正调用的方法
private KeyedStream keyBy(Keys keys) {
return new KeyedStream<>(this, clean(KeySelectorUtil.getSelectorForKeys(keys,
getType(), getExecutionConfig())));
}
```
如何使用呢:
```java
DataStream dataStream = env.fromElements(
new Event(1, "zhisheng01", 1.0),
new Event(2, "zhisheng02", 2.0),
new Event(3, "zhisheng03", 2.1),
new Event(3, "zhisheng04", 3.0),
new SubEvent(4, "zhisheng05", 4.0, 1.0),
);
//第1种
dataStream.keyBy(new KeySelector() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
});
//第2种
dataStream.keyBy(new KeySelector() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
}, Types.STRING);
//第3种
dataStream.keyBy(0);
//第4种
dataStream.keyBy("zhisheng01", "zhisheng02");
```
#### partitionCustom
使用自定义分区器在指定的 key 字段上将 DataStream 分区,这个 partitionCustom 有 3 个不同参数的方法,分别要传入的参数有自定义分区 Partitioner 对象、位置、字符和 KeySelector。它们内部也都是调用了私有的 partitionCustom 方法。
#### broadcast
broadcast 是将数据流进行广播,然后让下游的每个并行 Task 中都可以获取到这份数据流,通常这些数据是一些配置,一般这些配置数据的数据量不能太大,否则资源消耗会比较大。这个 broadcast 方法也有两个,一个是无参数,它返回的数据是 DataStream;另一种的参数是 MapStateDescriptor,它返回的参数是 BroadcastStream(这个也会在下文详细介绍)。
使用方法:
```java
//1、第一种
DataStream> source = env.addSource(...).broadcast();
//2、第二种
final MapStateDescriptor utterDescriptor = new MapStateDescriptor<>(
"broadcast-state", BasicTypeInfo.LONG_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO
);
final DataStream srcTwo = env.fromCollection(expected.values());
final BroadcastStream broadcast = srcTwo.broadcast(utterDescriptor);
```
#### map
map 方法需要传入的参数是一个 MapFunction,当然传入 RichMapFunction 也是可以的,它返回的是 SingleOutputStreamOperator(这个类在会在下文详细介绍),该 map 方法里面的实现如下:
```java
public SingleOutputStreamOperator map(MapFunction mapper) {
TypeInformation outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
//调用 transform 方法
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
```
该方法平时使用的非常频繁,然后我们该如何使用这个方法呢:
```java
dataStream.map(new MapFunction() {
private static final long serialVersionUID = 1L;
@Override
public String map(Integer value) throws Exception {
return value.toString();
}
})
```
#### flatMap
flatMap 方法需要传入一个 FlatMapFunction 参数,当然传入 RichFlatMapFunction 也是可以的,如果你的 Flink Job 里面有连续的 filter 和 map 算子在一起,可以考虑使用 flatMap 一个算子来完成两个算子的工作,它返回的是 SingleOutputStreamOperator,该 flatMap 方法里面的实现如下:
```java
public SingleOutputStreamOperator flatMap(FlatMapFunction flatMapper) {
TypeInformation outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper),
getType(), Utils.getCallLocationName(), true);
//调用 transform 方法
return transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
}
```
该方法平时使用的非常频繁,使用方式如下:
```java
dataStream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(Integer value, Collector out) throws Exception {
out.collect(value);
}
})
```
#### process
在输入流上应用给定的 ProcessFunction,从而创建转换后的输出流,通过该方法返回的是 SingleOutputStreamOperator,具体代码实现如下:
```java
public SingleOutputStreamOperator process(ProcessFunction processFunction) {
TypeInformation outType = TypeExtractor.getUnaryOperatorReturnType(
processFunction, ProcessFunction.class, 0, 1,
TypeExtractor.NO_INDEX, getType(), Utils.getCallLocationName(), true);
//调用下面的 process 方法
return process(processFunction, outType);
}
public SingleOutputStreamOperator process(
ProcessFunction processFunction,
TypeInformation outputType) {
ProcessOperator operator = new ProcessOperator<>(clean(processFunction));
//调用 transform 方法
return transform("Process", outputType, operator);
}
```
使用方法:
```java
DataStreamSource data = env.generateSequence(0, 0);
//定义的 ProcessFunction
ProcessFunction processFunction = new ProcessFunction() {
private static final long serialVersionUID = 1L;
@Override
public void processElement(Long value, Context ctx,
Collector out) throws Exception {
//具体逻辑
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx,
Collector out) throws Exception {
//具体逻辑
}
};
DataStream processed = data.keyBy(new IdentityKeySelector()).process(processFunction);
```
#### filter
filter 用来过滤数据的,它需要传入一个 FilterFunction,然后返回的数据也是 SingleOutputStreamOperator,该方法的实现是:
```java
public SingleOutputStreamOperator filter(FilterFunction filter) {
return transform("Filter", getType(), new StreamFilter<>(clean(filter)));
}
```
该方法平时使用非常多:
```java
DataStream filter1 = src
.filter(new FilterFunction() {
@Override
public boolean filter(String value) throws Exception {
return "zhisheng".equals(value);
}
})
```
上面这些方法是平时写代码时用的非常多的方法,我们这里讲解了它们的实现原理和使用方式,当然还有其他方法,比如 assignTimestampsAndWatermarks、join、shuffle、forward、addSink、rebalance、iterate、coGroup、project、timeWindowAll、countWindowAll、windowAll、print 等,这里由于篇幅的问题就不一一展开来讲了。
### 3.4.2 SingleOutputStreamOperator 的用法及分析
SingleOutputStreamOperator 这个类继承自 DataStream,所以 DataStream 中有的方法在这里也都有,那么这里就讲解下额外的方法的作用,如下。
+ name():该方法可以设置当前数据流的名称,如果设置了该值,则可以在 Flink UI 上看到该值;uid() 方法可以为算子设置一个指定的 ID,该 ID 有个作用就是如果想从 savepoint 恢复 Job 时是可以根据这个算子的 ID 来恢复到它之前的运行状态;
+ setParallelism() :该方法是为每个算子单独设置并行度的,这个设置优先于你通过 env 设置的全局并行度;
+ setMaxParallelism() :该为算子设置最大的并行度;
+ setResources():该方法有两个(参数不同),设置算子的资源,但是这两个方法对外还没开放(是私有的,暂时功能性还不全);
+ forceNonParallel():该方法强行将并行度和最大并行度都设置为 1;
+ setChainingStrategy():该方法对给定的算子设置 ChainingStrategy;
+ disableChaining():该这个方法设置后将禁止该算子与其他的算子 chain 在一起;
+ getSideOutput():该方法通过给定的 OutputTag 参数从 side output 中来筛选出对应的数据流。
### 3.4.3 KeyedStream 的用法及分析
KeyedStream 是 DataStream 在根据 KeySelector 分区后的数据流,DataStream 中常用的方法在 KeyedStream 后也可以用(除了 shuffle、forward 和 keyBy 等分区方法),在该类中的属性分别是 KeySelector 和 TypeInformation。
DataStream 中的窗口方法只有 timeWindowAll、countWindowAll 和 windowAll 这三种全局窗口方法,但是在 KeyedStream 类中的种类就稍微多了些,新增了 timeWindow、countWindow 方法,并且是还支持滑动窗口。
除了窗口方法的新增外,还支持大量的聚合操作方法,比如 reduce、fold、sum、min、max、minBy、maxBy、aggregate 等方法(列举的这几个方法都支持多种参数的)。
最后就是它还有 asQueryableState() 方法,能够将 KeyedStream 发布为可查询的 ValueState 实例。
### 3.4.4 SplitStream 的用法及分析
SplitStream 这个类比较简单,它代表着数据分流后的数据流了,它有一个 select 方法可以选择分流后的哪种数据流了,通常它是结合 split 使用的,对于单次分流来说还挺方便的。但是它是一个被废弃的类(Flink 1.7 后被废弃的,可以看下笔者之前写的一篇文章 [Flink 从0到1学习—— Flink 不可以连续 Split(分流)?](http://www.54tianzhisheng.cn/2019/06/12/flink-split/) ),其实可以用 side output 来代替这种 split,后面文章中我们也会讲通过简单的案例来讲解一下该如何使用 side output 做数据分流操作。
因为这个类的源码比较少,我们可以看下这个类的实现:
```java
public class SplitStream extends DataStream {
//构造方法
protected SplitStream(DataStream dataStream, OutputSelector outputSelector) {
super(dataStream.getExecutionEnvironment(), new SplitTransformation(dataStream.getTransformation(), outputSelector));
}
//选择要输出哪种数据流
public DataStream select(String... outputNames) {
return selectOutput(outputNames);
}
//上面那个 public 方法内部调用的就是这个方法,该方法是个 private 方法,对外隐藏了它是如何去找到特定的数据流。
private DataStream selectOutput(String[] outputNames) {
for (String outName : outputNames) {
if (outName == null) {
throw new RuntimeException("Selected names must not be null");
}
}
//构造了一个 SelectTransformation 对象
SelectTransformation selectTransform = new SelectTransformation(this.getTransformation(), Lists.newArrayList(outputNames));
//构造了一个 DataStream 对象
return new DataStream(this.getExecutionEnvironment(), selectTransform);
}
}
```
### 3.4.5 WindowedStream 的用法及分析
虽然 WindowedStream 不是继承自 DataStream,并且我们在 3.1 节中也做了一定的讲解,但是当时没讲里面的 Function,所以在这里刚好一起做一个补充。
在 WindowedStream 类中定义的属性有 KeyedStream、WindowAssigner、Trigger、Evictor、allowedLateness 和 lateDataOutputTag。
+ KeyedStream:代表着数据流,数据分组后再开 Window
+ WindowAssigner:Window 的组件之一
+ Trigger:Window 的组件之一
+ Evictor:Window 的组件之一(可选)
+ allowedLateness:用户指定的允许迟到时间长
+ lateDataOutputTag:数据延迟到达的 Side output,如果延迟数据没有设置任何标记,则会被丢弃
在 3.1 节中我们讲了上面的三个窗口组件 WindowAssigner、Trigger、Evictor,并教大家该如何使用,那么在这篇文章我就不再重复,那么接下来就来分析下其他几个的使用方式和其实现原理。
先来看下 allowedLateness 这个它可以在窗口后指定允许迟到的时间长,使用如下:
```java
dataStream.keyBy(0)
.timeWindow(Time.milliseconds(20))
.allowedLateness(Time.milliseconds(2))
```
lateDataOutputTag 这个它将延迟到达的数据发送到由给定 OutputTag 标识的 side output(侧输出),当水印经过窗口末尾(并加上了允许的延迟后),数据就被认为是延迟了。
对于 keyed windows 有五个不同参数的 reduce 方法可以使用,如下:
```java
//1、参数为 ReduceFunction
public SingleOutputStreamOperator reduce(ReduceFunction function) {
...
return reduce(function, new PassThroughWindowFunction());
}
//2、参数为 ReduceFunction 和 WindowFunction
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, WindowFunction function) {
...
return reduce(reduceFunction, function, resultType);
}
//3、参数为 ReduceFunction、WindowFunction 和 TypeInformation
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, WindowFunction function, TypeInformation resultType) {
...
return input.transform(opName, resultType, operator);
}
//4、参数为 ReduceFunction 和 ProcessWindowFunction
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, ProcessWindowFunction function) {
...
return reduce(reduceFunction, function, resultType);
}
//5、参数为 ReduceFunction、ProcessWindowFunction 和 TypeInformation
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, ProcessWindowFunction function, TypeInformation resultType) {
...
return input.transform(opName, resultType, operator);
}
```
除了 reduce 方法,还有六个不同参数的 fold 方法、aggregate 方法;两个不同参数的 apply 方法、process 方法(其中你会发现这两个 apply 方法和 process 方法内部其实都隐式的调用了一个私有的 apply 方法);其实除了前面说的两个不同参数的 apply 方法外,还有四个其他的 apply 方法,这四个方法也是参数不同,但是其实最终的是利用了 transform 方法;还有的就是一些预定义的聚合方法比如 sum、min、minBy、max、maxBy,它们的方法参数的个数不一致,这些预聚合的方法内部调用的其实都是私有的 aggregate 方法,该方法允许你传入一个 AggregationFunction 参数。我们来看一个具体的实现:
```java
//max
public SingleOutputStreamOperator max(String field) {
//内部调用私有的的 aggregate 方法
return aggregate(new ComparableAggregator<>(field, input.getType(), AggregationFunction.AggregationType.MAX, false, input.getExecutionConfig()));
}
//私有的 aggregate 方法
private SingleOutputStreamOperator aggregate(AggregationFunction aggregator) {
//继续调用的是 reduce 方法
return reduce(aggregator);
}
//该 reduce 方法内部其实又是调用了其他多个参数的 reduce 方法
public SingleOutputStreamOperator reduce(ReduceFunction function) {
...
function = input.getExecutionEnvironment().clean(function);
return reduce(function, new PassThroughWindowFunction());
}
```
从上面的方法调用过程,你会发现代码封装的很深,得需要你自己好好跟一下源码才可以了解更深些。
上面讲了这么多方法,你会发现 reduce 方法其实是用的蛮多的之一,那么就来看看该如何使用:
```java
dataStream.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction>() {
@Override
public Tuple2 reduce(Tuple2 value1, Tuple2 value2) {
return value1;
}
})
.print();
```
### 3.4.6 AllWindowedStream 的用法及分析
前面讲完了 WindowedStream,再来看看这个 AllWindowedStream 你会发现它的实现其实无太大区别,该类中的属性和方法都和前面 WindowedStream 是一样的,然后我们就不再做过多的介绍,直接来看看该如何使用呢?
AllWindowedStream 这种场景下是不需要让数据流做 keyBy 分组操作,直接就进行 windowAll 操作,然后在 windowAll 方法中传入 WindowAssigner 参数对象即可,然后返回的数据结果就是 AllWindowedStream 了,下面使用方式继续执行了 AllWindowedStream 中的 reduce 方法来返回数据:
```java
dataStream.windowAll(SlidingEventTimeWindows.of(Time.of(1, TimeUnit.SECONDS), Time.of(100, TimeUnit.MILLISECONDS)))
.reduce(new RichReduceFunction>() {
private static final long serialVersionUID = -6448847205314995812L;
@Override
public Tuple2 reduce(Tuple2 value1,
Tuple2 value2) throws Exception {
return value1;
}
});
```
### 3.4.7 ConnectedStreams 的用法及分析
ConnectedStreams 这个类定义是表示(可能)两个不同数据类型的数据连接流,该场景如果对一个数据流进行操作会直接影响另一个数据流,因此可以通过流连接来共享状态。比较常见的一个例子就是一个数据流(随时间变化的规则数据流)通过连接其他的数据流,这样另一个数据流就可以利用这些连接的规则数据流。
ConnectedStreams 在概念上可以认为和 Union 数据流是一样的。
在 ConnectedStreams 类中有三个属性:environment、inputStream1 和 inputStream2,该类中的方法如下图所示:
在 ConnectedStreams 中可以通过 getFirstInput 获取连接的第一个流、通过 getSecondInput 获取连接的第二个流,同时它还含有六个 keyBy 方法来将连接后的数据流进行分组,这六个 keyBy 方法的参数各有不同。另外它还含有 map、flatMap、process 方法来处理数据(其中 map 和 flatMap 方法的参数分别使用的是 CoMapFunction 和 CoFlatMapFunction),其实如果你细看其方法里面的实现就会发现都是调用的 transform 方法。
上面讲完了 ConnectedStreams 类的基础定义,接下来我们来看下该类如何使用呢?
```java
DataStream> src1 = env.fromElements(new Tuple2<>(0L, 0L)); //流 1
DataStream> src2 = env.fromElements(new Tuple2<>(0L, 0L)); //流 2
ConnectedStreams, Tuple2> connected = src1.connect(src2); //连接流 1 和流 2
//使用连接流的六种 keyBy 方法
ConnectedStreams, Tuple2> connectedGroup1 = connected.keyBy(0, 0);
ConnectedStreams, Tuple2> connectedGroup2 = connected.keyBy(new int[]{0}, new int[]{0});
ConnectedStreams, Tuple2> connectedGroup3 = connected.keyBy("f0", "f0");
ConnectedStreams, Tuple2> connectedGroup4 = connected.keyBy(new String[]{"f0"}, new String[]{"f0"});
ConnectedStreams, Tuple2> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector());
ConnectedStreams, Tuple2> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector(), Types.STRING);
//使用连接流的 map 方法
connected.map(new CoMapFunction, Tuple2, Object>() {
private static final long serialVersionUID = 1L;
@Override
public Object map1(Tuple2 value) {
return null;
}
@Override
public Object map2(Tuple2 value) {
return null;
}
});
//使用连接流的 flatMap 方法
connected.flatMap(new CoFlatMapFunction, Tuple2, Tuple2>() {
@Override
public void flatMap1(Tuple2 value, Collector> out) throws Exception {}
@Override
public void flatMap2(Tuple2 value, Collector> out) throws Exception {}
}).name("testCoFlatMap")
//使用连接流的 process 方法
connected.process(new CoProcessFunction, Tuple2, Tuple2>() {
@Override
public void processElement1(Tuple2 value, Context ctx, Collector> out) throws Exception {
if (value.f0 < 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout1-" + String.valueOf(value));
}
}
@Override
public void processElement2(Tuple2 value, Context ctx, Collector> out) throws Exception {
if (value.f0 >= 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout2-" + String.valueOf(value));
}
}
});
```
### 3.4.8 BroadcastStream 的用法及分析
### 3.4.9 BroadcastConnectedStream 的用法及分析
### 3.4.10 QueryableStateStream 的用法及分析
### 3.4.11 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/fy3RnMv

================================================
FILE: books/flink-in-action-3.5.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Watermark 的用法和结合 Window 处理延迟数据
date: 2021-07-15
tags:
- Flink
- 大数据
- 流式计算
---
## 3.5 Watermark 的用法和结合 Window 处理延迟数据
在 3.1 节中讲解了 Flink 中的三种 Time 和其对应的使用场景,然后在 3.2 节中深入的讲解了 Flink 中窗口的机制以及 Flink 中自带的 Window 的实现原理和使用方法。如果在进行 Window 计算操作的时候,如果使用的时间是 Processing Time,那么在 Flink 消费数据的时候,它完全不需要关心的数据本身的时间,意思也就是说不需要关心数据到底是延迟数据还是乱序数据。因为 Processing Time 只是代表数据在 Flink 被处理时的时间,这个时间是顺序的。但是如果你使用的是 Event Time 的话,那么你就不得不面临着这么个问题:事件乱序 & 事件延迟。
选择 Event Time 与 Process Time 的实际效果如下图所示:
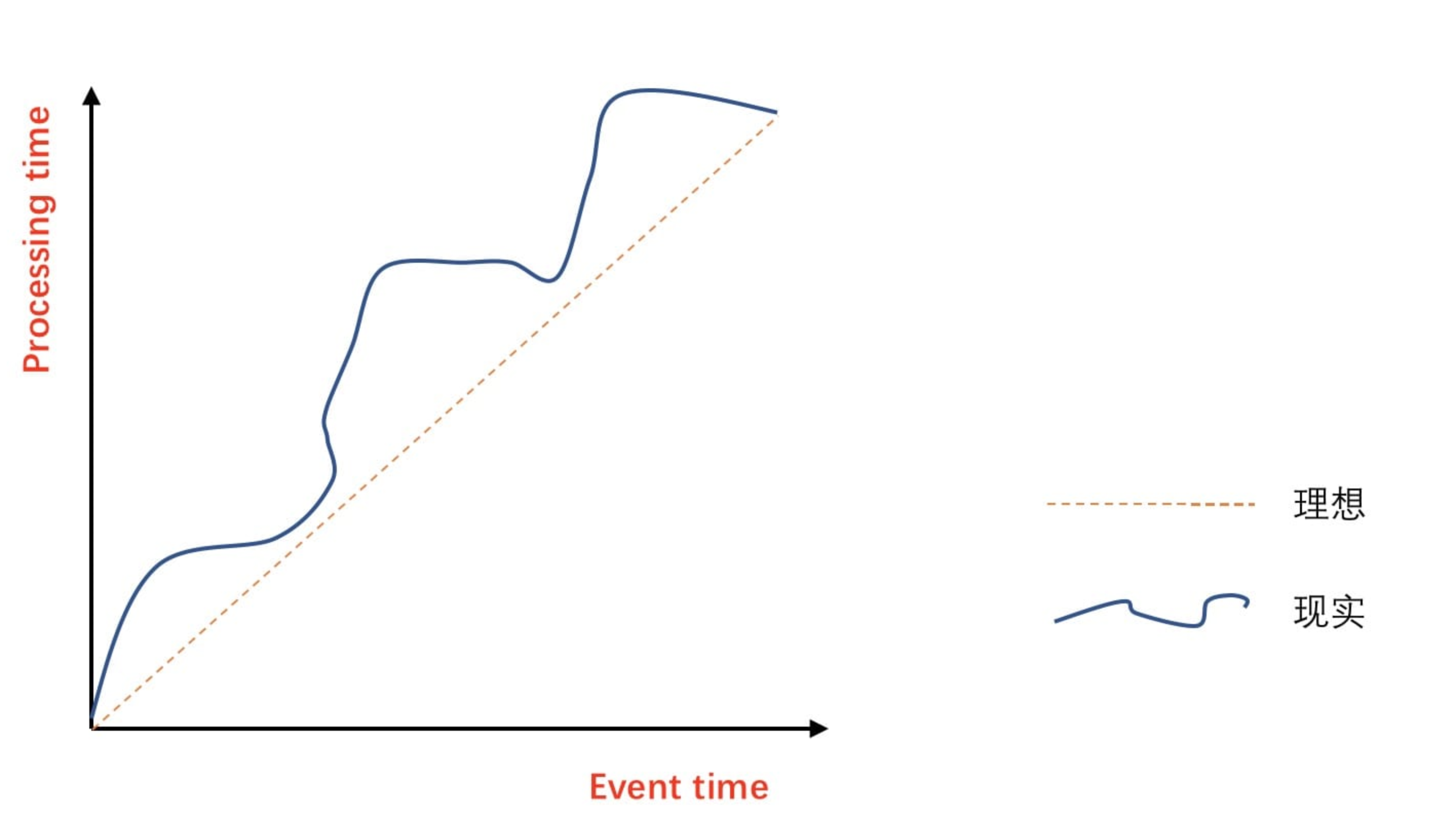
在理想的情况下,Event Time 和 Process Time 是相等的,数据发生的时间与数据处理的时间没有延迟,但是现实却仍然这么骨感,会因为各种各样的问题(网络的抖动、设备的故障、应用的异常等原因)从而导致如图中曲线一样,Process Time 总是会与 Event Time 有一些延迟。所谓乱序,其实是指 Flink 接收到的事件的先后顺序并不是严格的按照事件的 Event Time 顺序排列的。如下图所示:
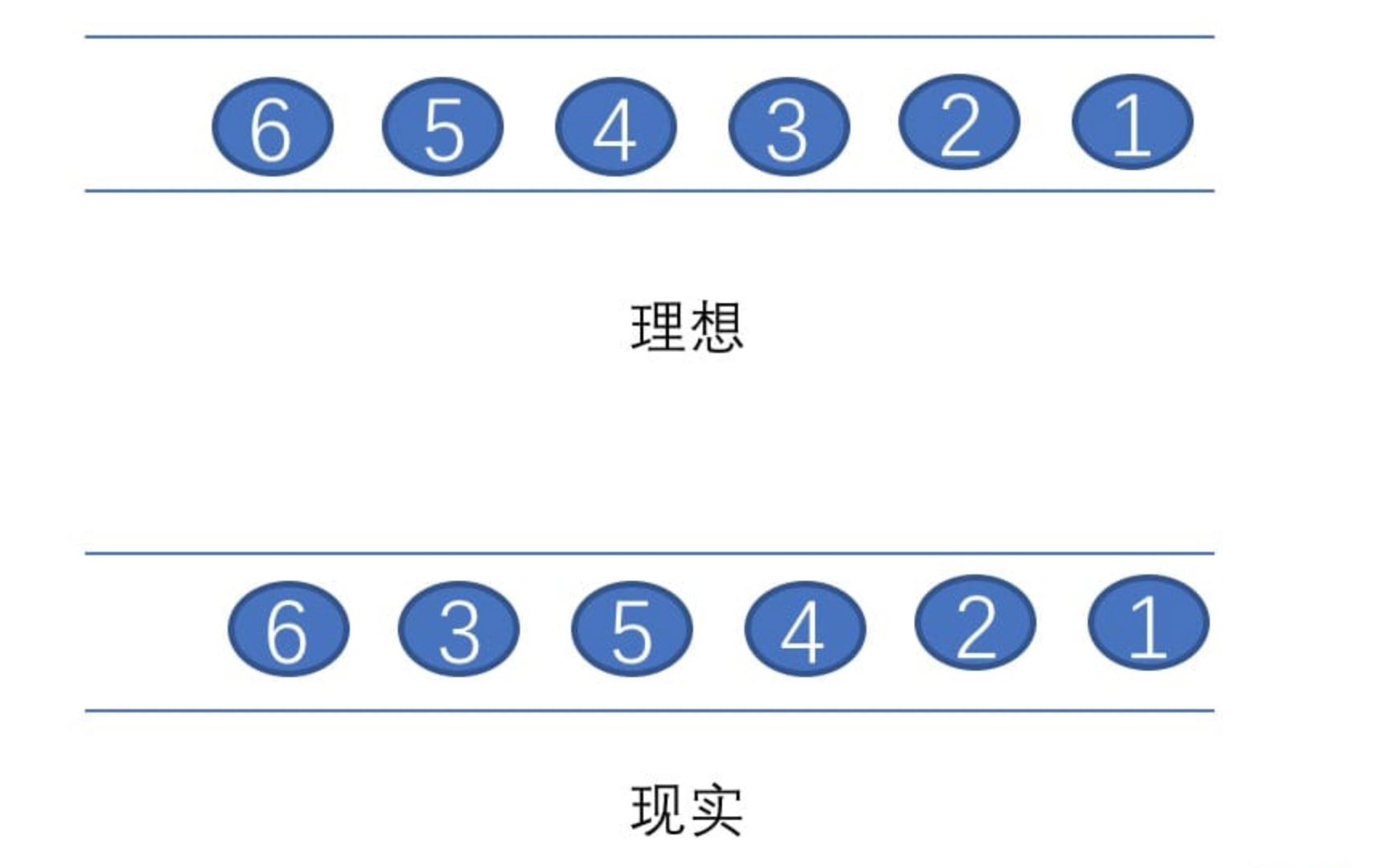
然而在有些场景下,其实是特别依赖于事件时间而不是处理时间,比如:
+ 错误日志的时间戳,代表着发生的错误的具体时间,开发们只有知道了这个时间戳,才能去还原那个时间点系统到底发生了什么问题,或者根据那个时间戳去关联其他的事件,找出导致问题触发的罪魁祸首
+ 设备传感器或者监控系统实时上传对应时间点的设备周围的监控情况,通过监控大屏可以实时查看,不错漏重要或者可疑的事件
这种情况下,最有意义的事件发生的顺序,而不是事件到达 Flink 后被处理的顺序。庆幸的是 Flink 支持用户以事件时间来定义窗口(也支持以处理时间来定义窗口),那么这样就要去解决上面所说的两个问题。针对上面的问题(事件乱序 & 事件延迟),Flink 引入了 Watermark 机制来解决。
### 3.5.1 Watermark 简介
举个例子:
统计 8:00 ~ 9:00 这个时间段打开淘宝 App 的用户数量,Flink 这边可以开个窗口做聚合操作,但是由于网络的抖动或者应用采集数据发送延迟等问题,于是无法保证在窗口时间结束的那一刻窗口中是否已经收集好了在 8:00 ~ 9:00 中用户打开 App 的事件数据,但又不能无限期的等下去?当基于事件时间的数据流进行窗口计算时,最为困难的一点也就是如何确定对应当前窗口的事件已经全部到达。然而实际上并不能百分百的准确判断,因此业界常用的方法就是基于已经收集的消息来估算是否还有消息未到达,这就是 Watermark 的思想。
Watermark 是一种衡量 Event Time 进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的 Watermark。Watermark 本质来说就是一个时间戳,代表着比这时间戳早的事件已经全部到达窗口,即假设不会再有比这时间戳还小的事件到达,这个假设是触发窗口计算的基础,只有 Watermark 大于窗口对应的结束时间,窗口才会关闭和进行计算。按照这个标准去处理数据,那么如果后面还有比这时间戳更小的数据,那么就视为迟到的数据,对于这部分迟到的数据,Flink 也有相应的机制(下文会讲)去处理。
下面通过几个图来了解一下 Watermark 是如何工作的!如下图所示,数据是 Flink 从消息队列中消费的,然后在 Flink 中有个 4s 的时间窗口(根据事件时间定义的窗口),消息队列中的数据是乱序过来的,数据上的数字代表着数据本身的 timestamp,`W(4)` 和 `W(9)` 是水印。
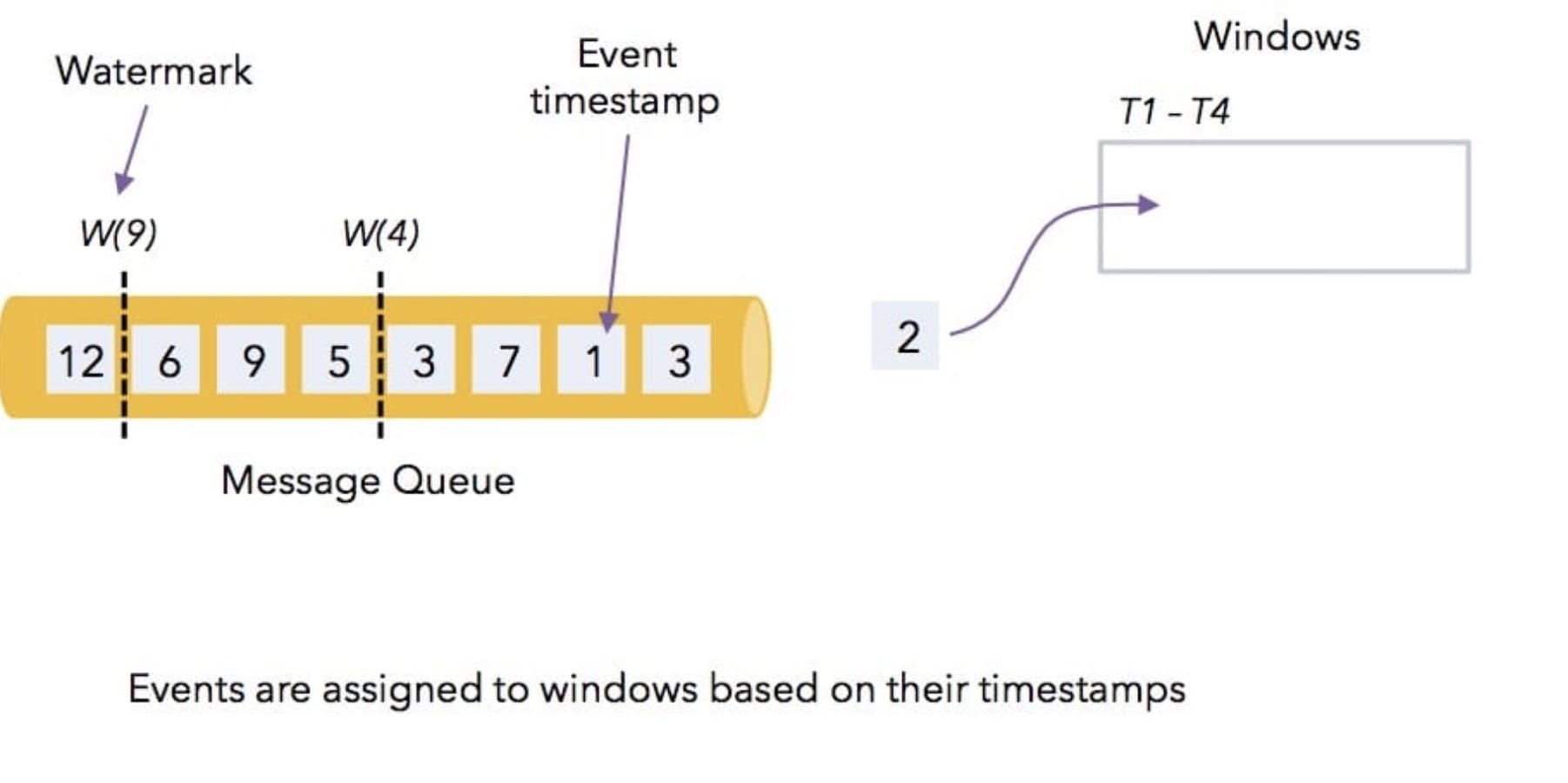
经过 Flink 的消费,数据 `1`、`3`、`2` 进入了第一个窗口,然后 `7` 会进入第二个窗口,接着 `3` 依旧会进入第一个窗口,然后就有水印了,此时水印过来了,就会发现水印的 timestamp 和第一个窗口结束时间是一致的,那么它就表示在后面不会有比 `4` 还小的数据过来了,接着就会触发第一个窗口的计算操作,如下图所示。
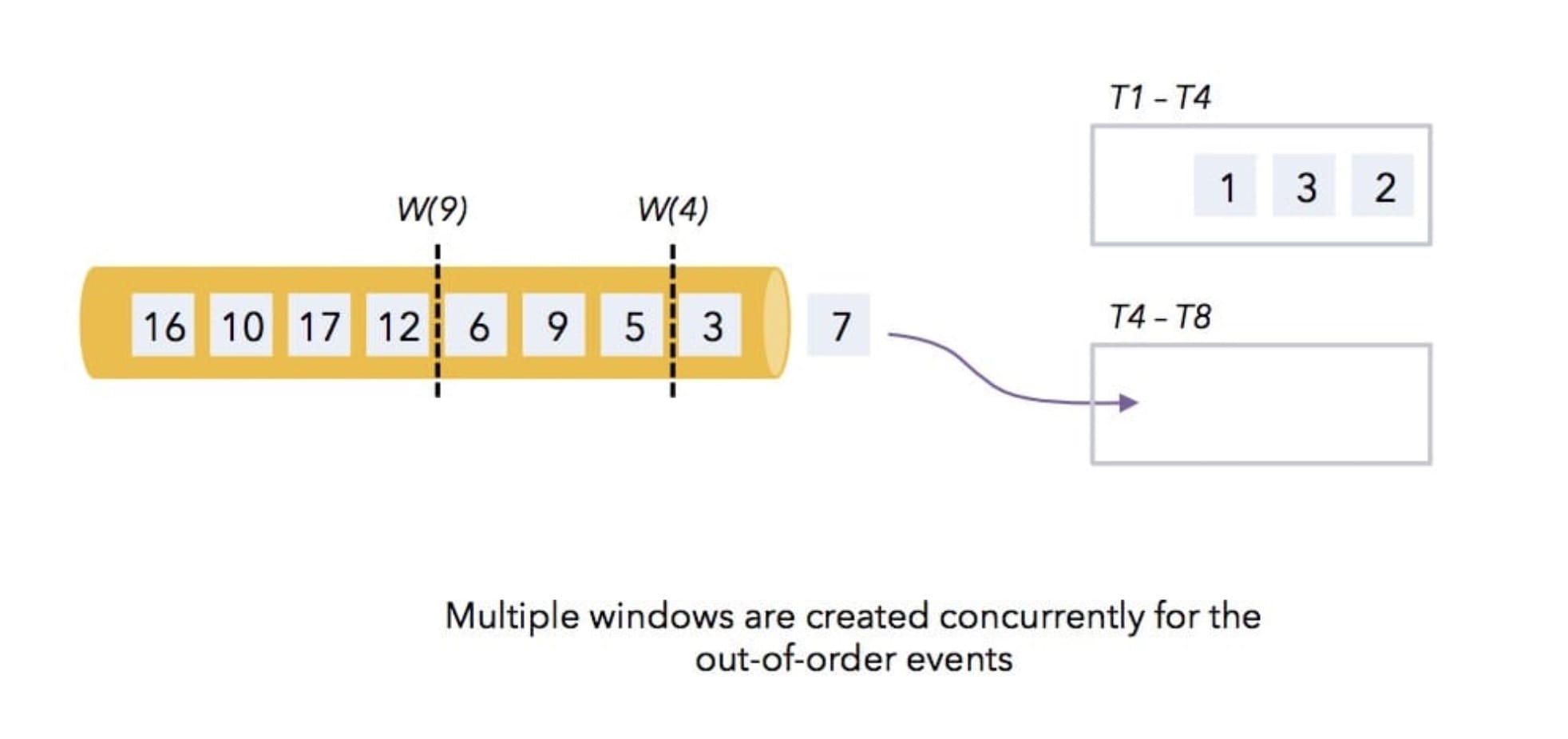
那么接着后面的数据 `5` 和 `6` 会进入到第二个窗口里面,数据 `9` 会进入在第三个窗口里面,如下图所示。
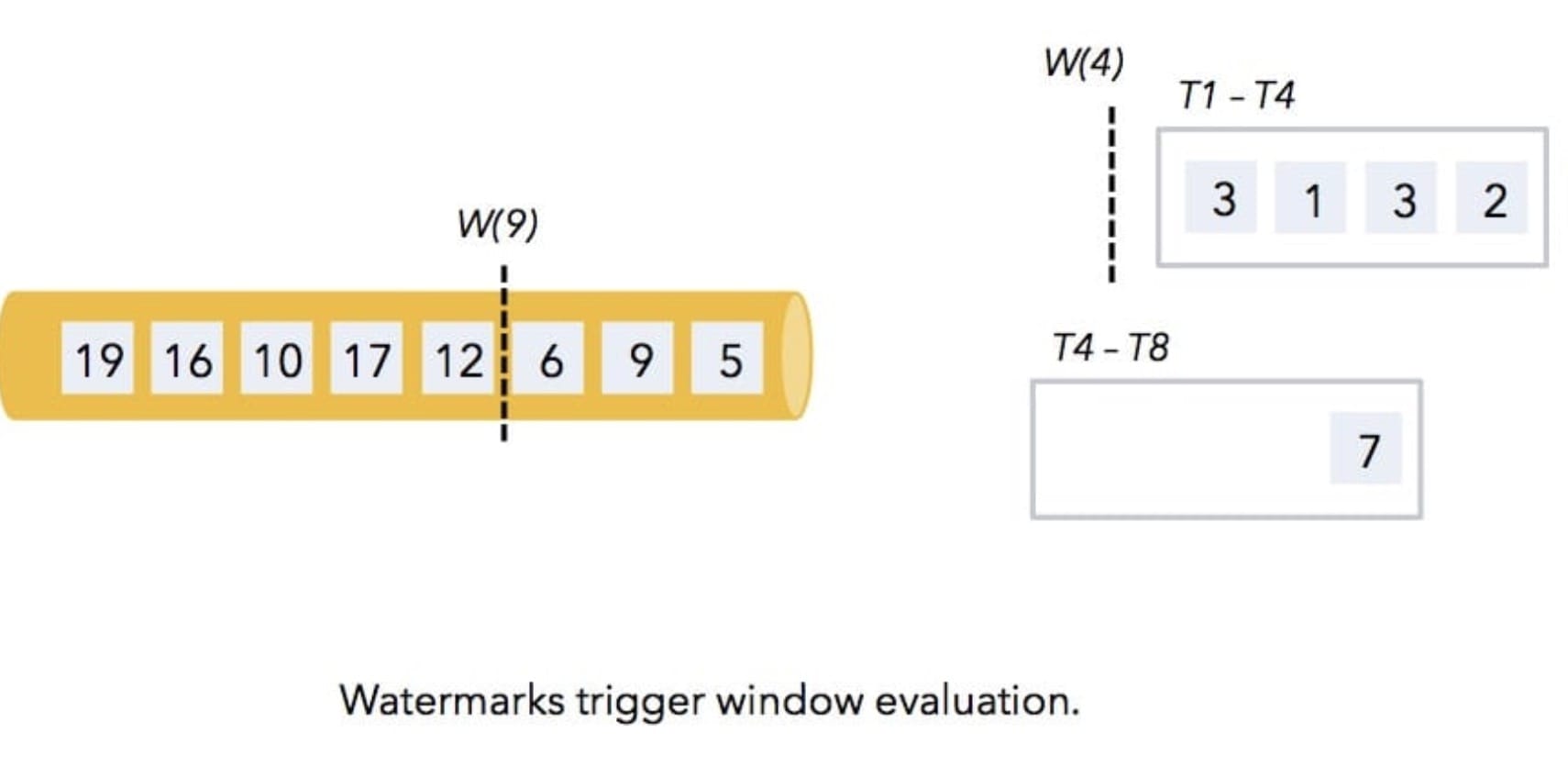
那么当遇到水印 `9` 时,发现水印比第二个窗口的结束时间 `8` 还大,所以第二个窗口也会触发进行计算,然后以此继续类推下去,如下图所示。
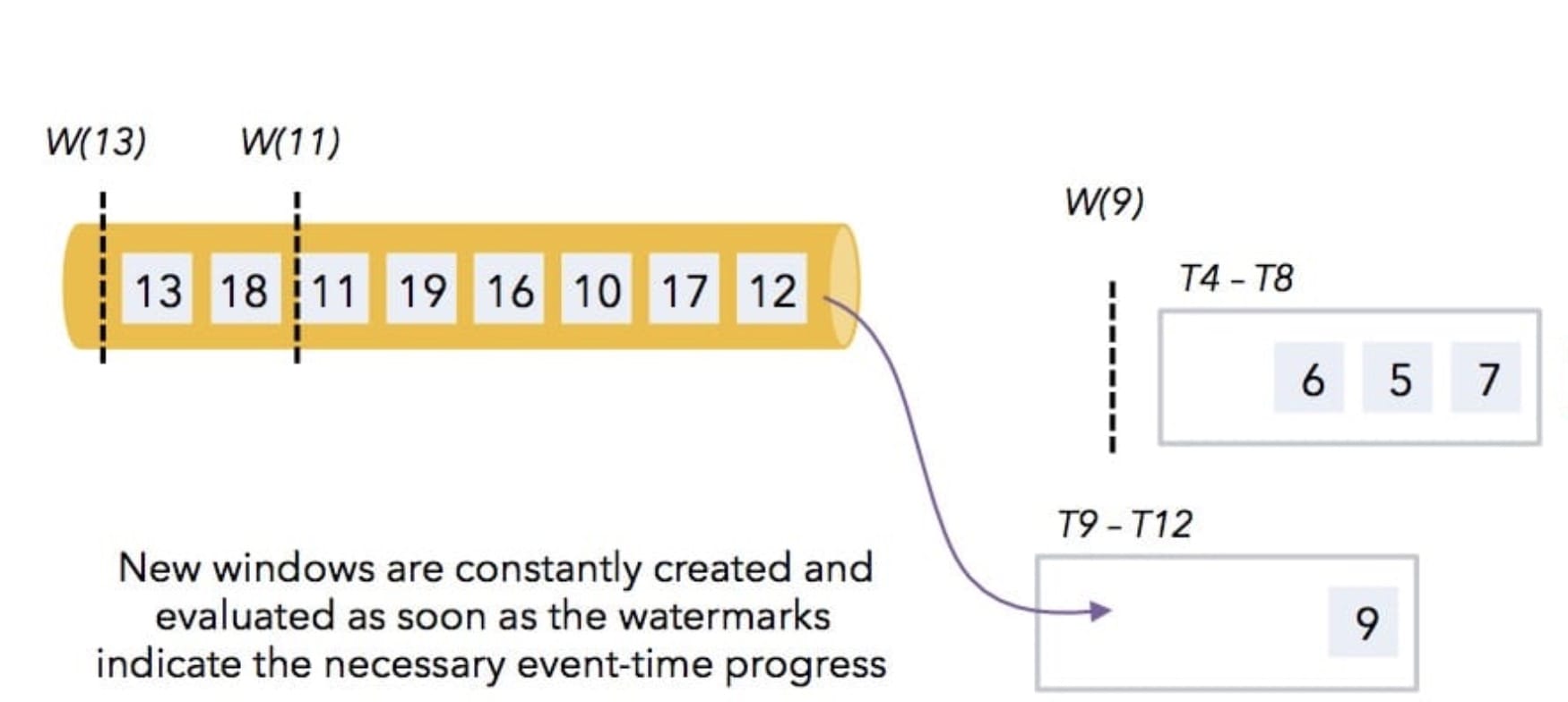
相信看完上面几个图的讲解,你已经知道了 Watermark 的工作原理是啥了,那么在 Flink 中该如何去配置水印呢,下面一起来看看。
### 3.5.2 Flink 中的 Watermark 的设置
在 Flink 中,数据处理中需要通过调用 DataStream 中的 assignTimestampsAndWatermarks 方法来分配时间和水印,该方法可以传入两种参数,一个是 AssignerWithPeriodicWatermarks,另一个是 AssignerWithPunctuatedWatermarks。
```java
public SingleOutputStreamOperator assignTimestampsAndWatermarks(AssignerWithPeriodicWatermarks timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPeriodicWatermarks cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPeriodicWatermarksOperator operator = new TimestampsAndPeriodicWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
public SingleOutputStreamOperator assignTimestampsAndWatermarks(AssignerWithPunctuatedWatermarks timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPunctuatedWatermarks cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPunctuatedWatermarksOperator operator = new TimestampsAndPunctuatedWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
```
所以设置 Watermark 是有如下两种方式:
+ AssignerWithPunctuatedWatermarks:数据流中每一个递增的 EventTime 都会产生一个 Watermark。
在实际的生产环境中,在 TPS 很高的情况下会产生大量的 Watermark,可能在一定程度上会对下游算子造成一定的压力,所以只有在实时性要求非常高的场景才会选择这种方式来进行水印的生成。
+ AssignerWithPeriodicWatermarks:周期性的(一定时间间隔或者达到一定的记录条数)产生一个 Watermark。
在实际的生产环境中,通常这种使用较多,它会周期性产生 Watermark 的方式,但是必须结合时间或者积累条数两个维度,否则在极端情况下会有很大的延时,所以 Watermark 的生成方式需要根据业务场景的不同进行不同的选择。
下面再分别详细讲下这两种的实现方式。
### 3.5.3 Punctuated Watermark
AssignerWithPunctuatedWatermarks 接口中包含了 checkAndGetNextWatermark 方法,这个方法会在每次 extractTimestamp() 方法被调用后调用,它可以决定是否要生成一个新的水印,返回的水印只有在不为 null 并且时间戳要大于先前返回的水印时间戳的时候才会发送出去,如果返回的水印是 null 或者返回的水印时间戳比之前的小则不会生成新的水印。
那么该怎么利用这个来定义水印生成器呢?
```java
public class WordPunctuatedWatermark implements AssignerWithPunctuatedWatermarks {
@Nullable
@Override
public Watermark checkAndGetNextWatermark(Word lastElement, long extractedTimestamp) {
return extractedTimestamp % 3 == 0 ? new Watermark(extractedTimestamp) : null;
}
@Override
public long extractTimestamp(Word element, long previousElementTimestamp) {
return element.getTimestamp();
}
}
```
需要注意的是这种情况下可以为每个事件都生成一个水印,但是因为水印是要在下游参与计算的,所以过多的话会导致整体计算性能下降。
### 3.5.4 Periodic Watermark
通常在生产环境中使用 AssignerWithPeriodicWatermarks 来定期分配时间戳并生成水印比较多,那么先来讲下这个该如何使用。
```java
public class WordPeriodicWatermark implements AssignerWithPeriodicWatermarks {
private long currentTimestamp = Long.MIN_VALUE;
@Override
public long extractTimestamp(Word word, long previousElementTimestamp) {
long timestamp = word.getTimestamp();
currentTimestamp = Math.max(timestamp, currentTimestamp);
return word.getTimestamp();
}
@Nullable
@Override
public Watermark getCurrentWatermark() {
long maxTimeLag = 5000;
return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - maxTimeLag);
}
}
```
上面的是我根据 Word 数据自定义的水印周期性生成器,在这个类中,有两个方法 extractTimestamp() 和 getCurrentWatermark()。extractTimestamp() 方法是从数据本身中提取 Event Time,然后将当前时间戳与事件时间进行比较,取最大值后赋值给当前时间戳 currentTimestamp,然后返回事件时间。getCurrentWatermark() 方法是获取当前的水位线,通过 `currentTimestamp - maxTimeLag` 得到水印的值,这里有个 maxTimeLag 参数代表数据能够延迟的时间,上面代码中定义的 `long maxTimeLag = 5000;` 表示最大允许数据延迟时间为 5s,超过 5s 的话如果还来了之前早的数据,那么 Flink 就会丢弃了,因为 Flink 的窗口中的数据是要触发的,不可能一直在等着这些迟到的数据(由于网络的问题数据可能一直没发上来)而不让窗口触发结束进行计算操作。
通过定义这个时间,可以避免部分数据因为网络或者其他的问题导致不能够及时上传从而不把这些事件数据作为计算的,那么如果在这延迟之后还有更早的数据到来的话,那么 Flink 就会丢弃了,所以合理的设置这个允许延迟的时间也是一门细活,得观察生产环境数据的采集到消息队列再到 Flink 整个流程是否会出现延迟,统计平均延迟大概会在什么范围内波动。这也就是说明了一个事实那就是 Flink 中设计这个水印的根本目的是来解决部分数据乱序或者数据延迟的问题,而不能真正做到彻底解决这个问题,不过这一特性在相比于其他的流处理框架已经算是非常给力了。
AssignerWithPeriodicWatermarks 这个接口有四个实现类,如下图所示:
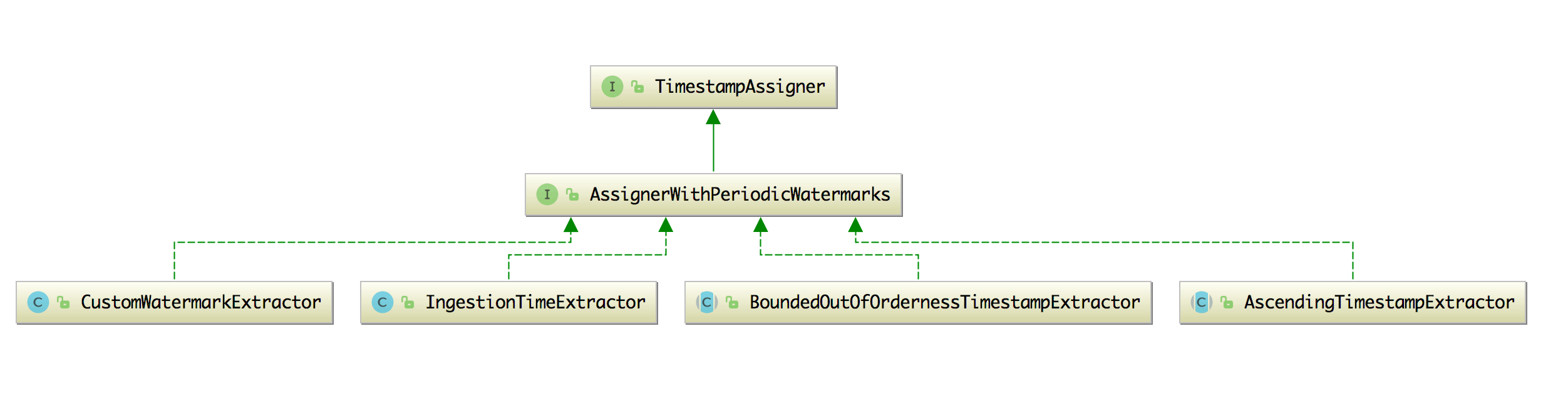
这四个实现类的功能和使用方式如下:
+ BoundedOutOfOrdernessTimestampExtractor:该类用来发出滞后于数据时间的水印,它的目的其实就是和我们上面定义的那个类作用是类似的,你可以传入一个时间代表着可以允许数据延迟到来的时间是多长。该类内部实现如下图所示:
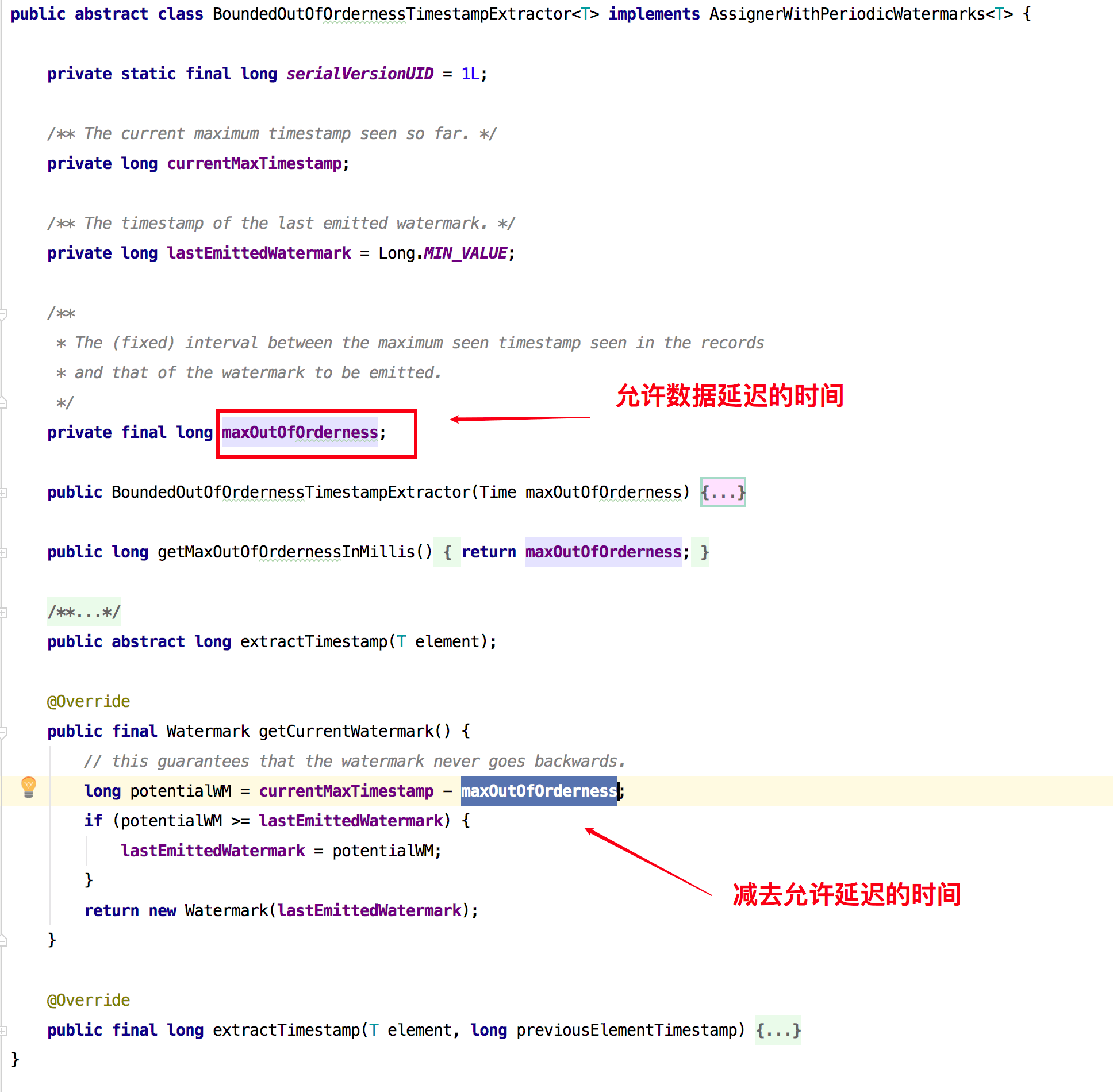
你可以像下面一样使用该类来分配时间和生成水印:
```java
//Time.seconds(10) 代表允许延迟的时间大小
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(10)) {
//重写 BoundedOutOfOrdernessTimestampExtractor 中的 extractTimestamp()抽象方法
@Override
public long extractTimestamp(Event event) {
return event.getTimestamp();
}
})
```
+ CustomWatermarkExtractor:这是一个自定义的周期性生成水印的类,在这个类里面的数据是 KafkaEvent。
+ AscendingTimestampExtractor:时间戳分配器和水印生成器,用于时间戳单调递增的数据流,如果数据流的时间戳不是单调递增,那么会有专门的处理方法,代码如下:
```java
public final long extractTimestamp(T element, long elementPrevTimestamp) {
final long newTimestamp = extractAscendingTimestamp(element);
if (newTimestamp >= this.currentTimestamp) {
this.currentTimestamp = ne∏wTimestamp;
return newTimestamp;
} else {
violationHandler.handleViolation(newTimestamp, this.currentTimestamp);
return newTimestamp;
}
}
```
+ IngestionTimeExtractor:依赖于机器系统时间,它在 extractTimestamp 和 getCurrentWatermark 方法中是根据 `System.currentTimeMillis()` 来获取时间的,而不是根据事件的时间,如果这个时间分配器是在数据源进 Flink 后分配的,那么这个时间就和 Ingestion Time 一致了,所以命名也取的就是叫 IngestionTimeExtractor。
**注意**:
1、使用这种方式周期性生成水印的话,你可以通过 `env.getConfig().setAutoWatermarkInterval(...);` 来设置生成水印的间隔(每隔 n 毫秒)。
2、通常建议在数据源(source)之后就进行生成水印,或者做些简单操作比如 filter/map/flatMap 之后再生成水印,越早生成水印的效果会更好,也可以直接在数据源头就做生成水印。比如你可以在 source 源头类中的 run() 方法里面这样定义
```java
@Override
public void run(SourceContext
#### 使用 BloomFilter 实现数据去重
Redis 4.0 之后 BloomFilter 以插件的形式加入到 Redis 中,关于 api 的具体使用这里不多赘述。BloomFilter 在创建时支持设定一个预期容量和误判率,预期容量即预计插入的数据量,误判率即:当 BloomFilter 中插入的数据达到预期容量时,误判的概率,如果 BloomFilter 中插入数据较少的话,误判率会更低。
经笔者测试,申请一个预期容量为 10 亿,误判率为千分之一的 BloomFilter,BloomFilter 会申请约 143 亿个 bit,即:14G左右,相比之前 660G 的存储空间小太多了。但是在使用过程中,需要记录 BloomFilter 中插入元素的个数,当插入元素个数达到 10 亿时,为了保障误差率,可以将当前 BloomFilter 清除,重新申请一个新的 BloomFilter。
通过使用 Redis 的 BloomFilter,我们可以通过相对较小的内存实现百亿数据的去重,但是 BloomFilter 有误差,所以只能使用在那些对结果能承受一定误差的应用场景,对于广告计费等对数据精度要求非常高的场景,极力推荐大家使用精准去重的方案来实现。
### 12.2.3 使用 HBase 维护全局 Set 实现去重
通过之前分析,我们知道要想实现百亿数据量的精准去重,需要维护 150 亿数据量的 Set 集合,每条数据占用 44 KB,总共需要 660 GB 的存储空间。注意这里说的是存储空间而不是内存空间,为什么呢?因为 660 G 的内存实在是太贵了,660G 的 Redis 云服务一个月至少要 2 万 RMB 以上,俗话说设计架构不考虑成本等于耍流氓。这里使用 Redis 确实可以解决问题,但是成本较高。HBase 基于 RowKey Get 的效率比较高,所以这里可以考虑将这个大的 Set 集合以 HBase RowKey 的形式存放到 HBase 中。HBase 表设置 TTL 为 36 小时,最近 36 小时的 150 亿条日志的主键都存放到 HBase 中,每来一条数据,先拿到主键去 HBase 中查询,如果 HBase 表中存在该主键,说明当前日志已经被处理过了,当前日志应该被过滤。如果 HBase 表中不存在该主键,说明当前日志之前没有被处理过,此时应该被处理,且处理完成后将当前主键 Put 到 HBase 表中。由于数据量比较大,所以一定要提前对 HBase 表进行预分区,将压力分散到各个 RegionServer 上。
#### 使用 HBase RowKey 去重带来的问题
### 12.2.4 使用 Flink 的 KeyedState 实现去重
下面就教大家如何使用 Flink 的 KeyedState 实现去重。
#### 使用 Flink 状态来维护 Set 集合的优势
#### 如何使用 KeyedState 维护 Set 集合
#### 优化主键来减少状态大小,且提高吞吐量
### 12.2.5 使用 RocksDBStateBackend 的优化方法
在使用上述方案的过程中,可能会出现吞吐量时高时低,或者吞吐量比笔者的测试性能要低一些,当出现这类问题的时候,可以尝试从以下几个方面进行优化。
#### 设置本地 RocksDB 的数据目录
#### Checkpoint 参数相关配置
#### RocksDB 参数相关配置
### 12.2.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy

================================================
FILE: books/flink-in-action-12.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 基于 Flink 的实时监控告警系统
date: 2021-08-21
tags:
- Flink
- 大数据
- 流式计算
---
## 12.3 基于 Flink 的实时监控告警系统
在如今微服务、云原生等技术盛行的时代,当谈到说要从 0 开始构建一个监控系统,大家无非就首先想到三个词:Metrics、Tracing、Logging。
### 12.3.1 监控系统的诉求
国外一篇比较火的文章 [Metrics, Tracing, and Logging](http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html) 内有个图很好的总结了一个监控系统的诉求,分别是 Metrics、Logging、Tracing,如下图所示。

Metrics 的特点:它自己提供了五种基本的度量类型 Gauge、Counter、Histogram、Timer、Meter。
Tracing 的特点:提供了一个请求从接收到处理完毕整个生命周期的跟踪路径,通常请求都是在分布式的系统中处理,所以也叫做分布式链路追踪。
Logging 的特点:提供项目应用运行的详细信息,例如方法的入参、运行的异常记录等。
这三者在监控系统中缺一不可,它们之间的关系是:基于 Metrics 的异常告警事件,然后通过 Tracing 定位问题可疑模块,根据模块详细的日志定位到错误根源,最后再返回来调整 Metrics 的告警规则,以便下次更早的预警,提前预防出现此类问题。
### 12.3.2 监控系统包含的内容
针对提到的三个点,笔者找到国内外的开源监控系统做了对比,发现真正拥有全部功能的比较少,有的系统比较专注于 Logging、有的系统比较专注于 Tracing,而大部分其他的监控系统无非是只是监控系统的一部分,比如是作为一款数据库存储监控数据、作为一个可视化图表的系统去展示各种各样的监控数据信息。
拿 Logging 来说,开源用的最多最火的技术栈是 ELK,Tracing 这块有 Skywalking、Pinpoint 等技术,它们的对比如 [APM 巅峰对决:Skywalking PK Pinpoint](https://mp.weixin.qq.com/s/_XE-gCJnDY3-yEK4xmWiMg) 一文介绍。而存储监控数据的时序数据库那就比较多了,常见的比如 InfluxDB、Prometheus、OpenTSDB 等,它们之间的对比介绍如下图所示。

监控可视化图表的开源系统个人觉得最好看的就是 Grafana,在 8.2 节中搭建 Flink 监控系统的数据展示也是用的 Grafana,当然还可以利用 ECharts、BizCharts 等数据图表库做二次开发来适配公司的数据展示图表。
上面说了这么多,这里笔者根据自己的工作经验先谈谈几点自己对监控系统的心得:
1. **告警是监控系统第一入口,图表展示体现监控的价值**:告警是唯一可以第一时间反映运行状态,它承担着系统与人之间的沟通桥梁,通常告警消息又会携带链接跳转到图表展示,它作为第一入口并衔接上了整个监控系统。
2. **数据采集是监控的源泉**:数据采集是监控系统的源泉,如果采集的数据是错误的,将导致后面的链路(告警、数据展示)全处于无效状态,所以千万千万要保证数据采集的准确性和完整性。
3. **数据存储是监控最大挑战**:当机器、系统应用和监控指标等变得越多来多时,采集上来的数据是爆炸性增长的,将海量的监控数据实时存储到任何一个数据库,挑战都是不小的。
说完心得再来讲解到底一个监控系统真正该包含哪些东西呢?笔者觉得首先分 6 层:数据采集层、数据传输层、数据计算层、告警、数据存储、数据展示,如下图所示。

监控系统这六层的主要功能分别是:
+ 数据采集层:该层主要功能就是去采集各种各样的数据,比如 Metrics、Logging、Tracing 数据。
+ 数据传输层:该层主要功能就是传输采集到的监控数据,一般使用消息队列居多,比如 Kafka、RocketMQ 等。
+ 数据计算层:该层的主要功能是将采集到的数据进行数据清洗和计算,一般采用 Flink、Spark 等计算引擎来处理。
+ 告警:该层其实也属于数据计算层,但是因为告警涉及的内容太多,比如告警规则、告警计算、告警通知等,所以可以单独作为一个重要点来讲。
+ 数据存储层:该层的主要功能是存储所有的监控数据,为后面的数据可视化提供数据源。
+ 数据展示层:该层的主要功能是将监控数据通过可视化图表来展示出来,通过图表可以知道服务器、应用的运行状态。
### 12.3.3 Metrics/Tracing/Logging 数据实时采集
在 12.1 节中讲解了日志数据如何采集,那么对于 Metrics 和 Tracing 数据该怎么采集呢?
#### Metrics
#### Tracing
### 12.3.4 消息队列如何撑住高峰流量
#### RabbitMQ
#### Kafka
#### RocketMQ
### 12.3.5 指标数据实时计算
### 12.3.6 提供及时且准确的根因分析告警
#### 告警本质
#### 告警通知对象
#### 告警通知方式
#### 告警规则的设计
#### 根因分析告警
#### 告警事件解耦
#### 告警工单记录告警解决过程
### 12.3.7 AIOps 智能运维道路探索
### 12.3.8 如何保障高峰流量实时写入存储系统的稳定性
### 12.3.9 监控数据使用可视化图表展示
#### Grafana 介绍
### 12.3.10 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy

### 本章总结
本章讲了三个公司常见场景案例:日志处理、去重、监控告警。在日志处理案例中讲解了日志的采集的需求,以及分析了整个日志采集案例的架构设计分层,关于日志采集工具的选型在 11.5 节中有讲过,所以该案例中就直接讲述采集工具的使用和安装,并将采集到的数据发送到 Kafka,然后使用 Flink 清洗日志数据并将异常日志告警通知到相应负责人,接着将数据写入到 ElasticSearch,最后通过 Kibana 可以展示和搜索日志数据。
在百亿数据实时去重案例中通过对比通用解决方法、使用 BloomFilter、使用 HBase 和使用 Flink KeyedState 几种方案来分析实时去重的解决方案,并在该案例中还提及到如何去优化去重的效果。
在实时监控告警案例中讲述了公司通用的监控告警需求,包括 Metrics、Logging、Tracing,然后设计出整个监控告警系统的架构分层和技术选型,其中分层包含数据采集层、数据传输层、数据计算层、数据存储层、数据展示层。关于数据采集工具、消息队列、数据存储中间件、数据展示的技术选型,笔者也分别做了对比介绍,以便大家可以根据自己公司的情况做架构选型。另外针对实时告警这块,笔者也详述了很多,包括告警规则的设计、告警通知对象、告警通知方式、告警消息收敛、告警消息根因分析等,最后还讲了对监控告警的展望,希望能够在 AIOps 做更多的探索,对于这块的内容,笔者在社区钉钉群做过视频直播,大家可以去笔者的博客查看录播的视频。
================================================
FILE: books/flink-in-action-2.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 环境准备
date: 2021-07-07
tags:
- Flink
- 大数据
- 流式计算
---
# 第二章 —— Flink 入门
通过第一章对 Flink 的介绍,相信你对 Flink 的概念和特性有了一定的了解,接下来本章将开始正式进入 Flink 的学习之旅,笔者将带你搭建 Flink 的环境和编写两个案例(WordCount 程序、读取 Socket 数据)来入门 Flink。
## 2.1 Flink 环境准备
通过前面的章节内容,相信你已经对 Flink 的基础概念等知识已经有一定了解,现在是不是迫切的想把 Flink 给用起来?先别急,我们先把电脑的准备环境给安装好,这样后面才能更愉快地玩耍。
废话不多说了,直奔主题。因为本书后面章节内容会使用 Kafka、MySQL、ElasticSearch 等组件,并且运行 Flink 程序是需要依赖 Java 的,另外就是我们需要使用 IDE 来开发 Flink 应用程序以及使用 Maven 来管理 Flink 应用程序的依赖,所以本节我们提前安装这个几个组件,搭建好本地的环境,后面如果还要安装其他的组件笔者会在对应的章节中补充,如果你的操作系统已经中已经安装过 JDK、Maven、MySQL、IDEA 等,那么你可以跳过对应的内容,直接看你未安装过的。
这里笔者再说下自己电脑的系统环境:macOS High Sierra 10.13.5,后面文章的演示环境不作特别说明的话就是都在这个系统环境中。
### 2.1.1 JDK 安装与配置
虽然现在 JDK 已经更新到 12 了,但是为了稳定我们还是安装 JDK 8,如果没有安装过的话,可以去[官网](https://www.oracle.com/technetwork/java/javase/downloads/index.html) 的[下载页面](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)下载对应自己操作系统的最新 JDK8 就行。
Mac 系统的是 `jdk-8u211-macosx-x64.dmg` 格式、Linux 系统的是 `jdk-8u211-linux-x64.tar.gz` 格式。Mac 系统安装的话直接双击然后一直按照提示就行了,最后 JDK 的安装目录在 `/Library/Java/JavaVirtualMachines/` ,然后在 `/etc/hosts` 中配置好环境变量(注意:替换你自己电脑本地的路径)。
```
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:
export PATH=$PATH:$JAVA_HOME/bin
```
Linux 系统的话就是在某个目录下直接解压就行了,然后在 `/etc/profile` 添加一下上面的环境变量(注意:替换你自己电脑的路径)。然后执行 `java -version` 命令可以查看是否安装成功!
```
zhisheng@zhisheng ~ java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
```
### 2.1.2 Maven 安装与配置
安装好 JDK 后我们就可以安装 Maven 了,我们在[官网](http://maven.apache.org/download.cgi)下载二进制包就行,然后在自己本地软件安装目录解压压缩包就行。接下来你需要配置一下环境变量:
```
export M2_HOME=/Users/zhisheng/Documents/maven-3.5.2
export PATH=$PATH:$M2_HOME/bin
```
然后执行命令 `mvn -v` 可以验证是否安装成功,结果如下:
```
zhisheng@zhisheng ~ /Users mvn -v
Apache Maven 3.5.2 (138edd61fd100ec658bfa2d307c43b76940a5d7d; 2017-10-18T15:58:13+08:00)
Maven home: /Users/zhisheng/Documents/maven-3.5.2
Java version: 1.8.0_152, vendor: Oracle Corporation
Java home: /Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "mac os x", version: "10.13.5", arch: "x86_64", family: "mac"
```
### 2.1.3 IDE 安装与配置
安装完 JDK 和 Maven 后,就可以安装 IDE 了,大家可以选择你熟练的 IDE 就行,笔者后面演示的代码都是在 IDEA 中运行的,如果想为了后面不出其他的问题的话,建议尽量和笔者的环境保持一致。
IDEA 官网下载地址:[下载页面的地址](https://www.jetbrains.com/idea/download/#section=mac),下载后可以双击后然后按照提示一步步安装,安装完成后需要在 IDEA 中配置 JDK 路径和 Maven 的路径,后面我们开发也都是靠 Maven 来管理项目的依赖。
### 2.1.4 MySQL 安装与配置
### 2.1.5 Kafka 安装与配置
### 2.1.6 ElasticSearch 安装与配置
加入知识星球可以看到上面文章:https://t.zsxq.com/JyRzVnU

### 2.1.7 小结与反思
本节讲解了下 JDK、Maven、IDE、MySQL、Kafka、ElasticSearch 的安装与配置,因为这些都是后面要用的,所以这里单独抽一篇文章来讲解环境准备的安装步骤,当然这里还并不涉及全,因为后面我们还可能会涉及到 HBase、HDFS 等知识,后面我们用到再看,本书的内容主要讲解 Flink,所以更多的环境准备还是得靠大家自己独立完成。
这里笔者说下笔者自己一般安装环境的选择:
xxx
下面章节我们就正式进入 Flink 专题了!
================================================
FILE: books/flink-in-action-2.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 环境搭建
date: 2021-07-08
tags:
- Flink
- 大数据
- 流式计算
---
## 2.2 Flink 环境搭建
在 2.1 节中已经将 Flink 的准备环境已经讲完了,本章节将带大家正式开始接触 Flink,那么我们得先安装一下 Flink。Flink 是可以在多个平台(Windows、Linux、Mac)上安装的。在开始写本书的时候最新版本是 1.8 版本,但是写到一半后更新到 1.9 了(合并了大量 Blink 的新特性),所以笔者又全部更新版本到 1.9,书籍后面也都是基于最新的版本讲解与演示。
Flink 的官网地址是:[https://flink.apache.org/](https://flink.apache.org/)
### 2.2.1 Flink 下载与安装
Flink 在 Mac、Linux、Window 平台上的安装方式如下。
#### 在 Mac 和 Linux 下安装
你可以通过该地址 [https://flink.apache.org/downloads.html](https://flink.apache.org/downloads.html) 下载到最新版本的 Flink。这里我们选择 `Apache Flink 1.9.0 for Scala 2.11` 版本,点击跳转到了一个镜像下载选择的地址,如下图所示,随便选择哪个就行,只是下载速度不一致而已。

下载完后,你就可以直接解压下载的 Flink 压缩包了。接下来我们可以启动一下 Flink,我们进入到 Flink 的安装目录下执行命令 `./bin/start-cluster.sh` 即可,产生的日志如下:
```
zhisheng@zhisheng /usr/local/flink-1.9.0 ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host zhisheng.
Starting taskexecutor daemon on host zhisheng.
```
如果你的电脑是 Mac 的话,那么你也可以通过 Homebrew 命令进行安装。先通过命令 `brew search flink` 查找一下包:
```
zhisheng@zhisheng ~ brew search flink
==> Formulae
apache-flink ✔ homebrew/linuxbrew-core/apache-flink
```
可以发现找得到 Flink 的安装包,但是这样安装的版本可能不是最新的,如果你要安装的话,则使用命令:
```
brew install apache-flink
```
那么它就会开始进行下载并安装好,安装后的目录应该是在 `/usr/local/Cellar/apache-flink` 下,如下图所示:

你可以通过下面命令检查安装的 Flink 到底是什么版本的:
```
flink --version
```
结果如下:
```
Version: 1.9.0, Commit ID: ff472b4
```
这种的话运行是得进入 `/usr/local/Cellar/apache-flink/1.9.0/libexec/bin` 目录下执行命令 `./start-cluster.sh` 才可以启动 Flink 的。执行命令后的启动日志如下所示:
```
Starting cluster.
Starting standalonesession daemon on host zhisheng.
Starting taskexecutor daemon on host zhisheng.
```
#### 在 Windows 下安装
如果你的电脑系统是 Windows 的话,那么你就直接双击 Flink 安装目录下面 bin 文件夹里面的 `start-cluster.bat` 就行,同样可以将 Flink 起动成功。
### 2.2.2 Flink 启动与运行
启动成功后的话,我们可以通过访问地址`http://localhost:8081/` 查看 UI 长啥样了,如下图所示:
### 2.2.3 Flink 目录配置文件解读
### 2.2.4 Flink 源码下载
### 2.2.5 Flink 源码编译
### 2.2.6 将 Flink 源码导入到 IDE
加入知识星球可以看到上面文章:https://t.zsxq.com/JyRzVnU

### 2.2.7 小结与反思
本节主要讲了 FLink 在不同系统下的安装和运行方法,然后讲了下怎么去下载源码和将源码导入到 IDE 中。不知道你在将源码导入到 IDE 中是否有遇到什么问题呢?
================================================
FILE: books/flink-in-action-2.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 案例1:WordCount 应用程序
date: 2021-07-09
tags:
- Flink
- 大数据
- 流式计算
---
## 2.3 案例1:WordCount 应用程序
在 2.2 节中带大家讲解了下 Flink 的环境安装,这篇文章就开始我们的第一个 Flink 案例实战,也方便大家快速开始自己的第一个 Flink 应用。大数据里学习一门技术一般都是从 WordCount 开始入门的,那么笔者还是不打破常规了,所以这篇文章笔者也将带大家通过 WordCount 程序来初步了解 Flink。
### 2.3.1 使用 Maven 创建项目
Flink 支持 Maven 直接构建模版项目,你在终端使用该命令:
```
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.0
```
在执行的过程中它会提示你输入 groupId、artifactId、和 package 名,你按照要求输入就行,最后就可以成功创建一个项目,如下图所示。

进入到目录你就可以看到已经创建了项目,里面结构如下:
```
zhisheng@zhisheng ~/IdeaProjects/github/Flink-WordCount tree
.
├── pom.xml
└── src
└── main
├── java
│ └── com
│ └── zhisheng
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
6 directories, 4 files
```
该项目中包含了两个类 BatchJob 和 StreamingJob,另外还有一个 log4j.properties 配置文件,然后你就可以将该项目导入到 IDEA 了。你可以在该目录下执行 `mvn clean package` 就可以编译该项目,编译成功后在 target 目录下会生成一个 Job 的 Jar 包,但是这个 Job 还不能执行,因为 StreamingJob 这个类中的 main 方法里面只是简单的创建了 StreamExecutionEnvironment 环境,然后就执行 execute 方法,这在 Flink 中是不算一个可执行的 Job 的,因此如果你提交到 Flink UI 上也是会报错的。
如下图所示,上传作业程序打包编译的 Jar 包:

运行报错结果如下图所示:

```
Server Response Message:
Internal server error.
```
我们查看 Flink JobManager 的日志,可以看见错误信息如下图所示:

```
2019-04-26 17:27:33,706 ERROR org.apache.flink.runtime.webmonitor.handlers.JarRunHandler - Unhandled exception.
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No operators defined in streaming topology. Cannot execute.
```
因为 execute 方法之前我们是需要补充我们 Job 的一些算子操作的,所以报错还是很正常的,本节下面将会提供完整代码。
### 2.3.2 使用 IDEA 创建项目
一般我们项目可能是由多个 Job 组成,并且代码也都是在同一个工程下面进行管理,上面那种创建方式适合单个 Job 执行,但如果在公司多人合作的时候还是得在同一个工程下面创建项目,每个 Flink Job 对应着一个 module,该 module 负责独立的业务逻辑,比如笔者在 GitHub 的 [https://github.com/zhisheng17/flink-learning](https://github.com/zhisheng17/flink-learning) 项目,它的项目结构如下图所示:

接下来我们需要在父工程的 pom.xml 中加入如下属性(含编码、Flink 版本、JDK 版本、Scala 版本、Maven 编译版本):
```xml
UTF-8
1.9.0
1.8
2.11
${java.version}
${java.version}
```
然后加入依赖:
```xml
org.apache.flink
flink-java
${flink.version}
provided
org.apache.flink
flink-streaming-java_${scala.binary.version}
${flink.version}
provided
org.slf4j
slf4j-log4j12
1.7.7
runtime
log4j
log4j
1.2.17
runtime
```
上面依赖中 flink-java 和 flink-streaming-java 是我们 Flink 必备的核心依赖,为什么设置 scope 为 provided 呢(默认是 compile)?是因为 Flink 其实在自己的安装目录中 lib 文件夹里的 `lib/flink-dist_2.11-1.9.0.jar` 已经包含了这些必备的 Jar 了,所以我们在给自己的 Flink Job 添加依赖的时候最后打成的 Jar 包可不希望又将这些重复的依赖打进去。有两个好处:
+ 减小了我们打的 Flink Job Jar 包容量大小
+ 不会因为打入不同版本的 Flink 核心依赖而导致类加载冲突等问题
但是问题又来了,我们需要在 IDEA 中调试运行我们的 Job,如果将 scope 设置为 provided 的话,是会报错的:
```
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/ExecutionConfig$GlobalJobParameters
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.common.ExecutionConfig$GlobalJobParameters
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
```
默认 scope 为 compile 的话,本地调试的话就不会出错了。另外测试到底能够减小多少 Jar 包的大小呢?我这里先写了个 Job 测试。当 scope 为 compile 时,编译后的 target 目录:
```
zhisheng@zhisheng ~/Flink-WordCount/target master ●✚ ll
total 94384
-rw-r--r-- 1 zhisheng staff 45M 4 26 21:23 Flink-WordCount-1.0-SNAPSHOT.jar
drwxr-xr-x 4 zhisheng staff 128B 4 26 21:23 classes
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 generated-sources
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 maven-archiver
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 maven-status
-rw-r--r-- 1 zhisheng staff 7.2K 4 26 21:23 original-Flink-WordCount-1.0-SNAPSHOT.jar
```
当 scope 为 provided 时,编译后的 target 目录:
```
zhisheng@zhisheng ~/Flink-WordCount/target master ●✚ ll
total 32
-rw-r--r-- 1 zhisheng staff 7.5K 4 26 21:27 Flink-WordCount-1.0-SNAPSHOT.jar
drwxr-xr-x 4 zhisheng staff 128B 4 26 21:27 classes
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 generated-sources
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 maven-archiver
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 maven-status
-rw-r--r-- 1 zhisheng staff 7.2K 4 26 21:27 original-Flink-WordCount-1.0-SNAPSHOT.jar
```
。。。
### 2.3.3 流计算 WordCount 应用程序代码实现
### 2.3.4 运行流计算 WordCount 应用程序
#### 本地 IDE 运行
#### UI 运行 Job
### 2.3.5 流计算 WordCount 应用程序代码分析
### 2.3.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/Z7EAmq3

================================================
FILE: books/flink-in-action-2.4.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 案例2:实时处理 Socket 数据
date: 2021-07-10
tags:
- Flink
- 大数据
- 流式计算
---
## 2.4 案例2:实时处理 Socket 数据
在 2.3 节中讲解了 Flink 最简单的 WordCount 程序的创建、运行结果查看和代码分析,本节将继续带大家来看一个入门上手的程序:Flink 处理 Socket 数据。
### 2.4.1 使用 IDEA 创建项目
使用 IDEA 创建新的 module,结构如下:
```
├── pom.xml
└── src
├── main
│ ├── java
│ │ └── com
│ │ └── zhisheng
│ │ └── socket
│ │ └── Main.java
│ └── resources
│ └── log4j.properties
└── test
└── java
```
项目创建好了后,我们下一步开始编写 Flink Socket Job 的代码。
### 2.4.2 实时处理 Socket 数据应用程序代码实现
程序代码如下所示:
```java
public class Main {
public static void main(String[] args) throws Exception {
//参数检查
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount ");
return;
}
String hostname = args[0];
Integer port = Integer.parseInt(args[1]);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据
DataStreamSource stream = env.socketTextStream(hostname, port);
//计数
SingleOutputStreamOperator> sum = stream.flatMap(new LineSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketText");
}
public static final class LineSplitter implements FlatMapFunction> {
@Override
public void flatMap(String s, Collector> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token: tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2(token, 1));
}
}
}
}
}
```
**pom.xml** 添加 build:
```xml
org.apache.maven.plugins
maven-compiler-plugin
3.1
${java.version}
${java.version}
org.apache.maven.plugins
maven-shade-plugin
3.0.0
package
shade
org.apache.flink:force-shading
com.google.code.findbugs:jsr305
org.slf4j:*
log4j:*
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.zhisheng.socket.Main
```
### 2.4.3 运行实时处理 Socket 数据应用程序
下面分别讲解在 IDE 和 Flink UI 上运行作业。
#### 本地 IDE 运行
#### UI 运行 Job
### 2.4.4 实时处理 Socket 数据应用程序代码分析
加入知识星球可以看到上面文章:https://t.zsxq.com/VBEQv3F

### 2.4.5 Flink 中使用 Lambda 表达式
因为 Lambda 表达式看起来简洁,所以有时候也是希望在这些 Flink 作业中也可以使用上它,虽然 Flink 中是支持 Lambda,但是个人感觉不太友好。比如上面的应用程序如果将 LineSplitter 该类之间用 Lambda 表达式完成的话则要像下面这样写:
```java
stream.flatMap((s, collector) -> {
for (String token : s.toLowerCase().split("\\W+")) {
if (token.length() > 0) {
collector.collect(new Tuple2(token, 1));
}
}
})
.keyBy(0)
.sum(1)
.print();
```
但是这样写完后,运行作业报错如下:
```
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(LambdaMain.java:34)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
at org.apache.flink.api.dag.Transformation.getOutputType(Transformation.java:417)
at org.apache.flink.streaming.api.datastream.DataStream.getType(DataStream.java:175)
at org.apache.flink.streaming.api.datastream.DataStream.keyBy(DataStream.java:318)
at com.zhisheng.examples.streaming.socket.LambdaMain.main(LambdaMain.java:41)
Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Collector' are missing. In many cases lambda methods don't provide enough information for automatic type extraction when Java generics are involved. An easy workaround is to use an (anonymous) class instead that implements the 'org.apache.flink.api.common.functions.FlatMapFunction' interface. Otherwise the type has to be specified explicitly using type information.
at org.apache.flink.api.java.typeutils.TypeExtractionUtils.validateLambdaType(TypeExtractionUtils.java:350)
at org.apache.flink.api.java.typeutils.TypeExtractionUtils.extractTypeFromLambda(TypeExtractionUtils.java:176)
at org.apache.flink.api.java.typeutils.TypeExtractor.getUnaryOperatorReturnType(TypeExtractor.java:571)
at org.apache.flink.api.java.typeutils.TypeExtractor.getFlatMapReturnTypes(TypeExtractor.java:196)
at org.apache.flink.streaming.api.datastream.DataStream.flatMap(DataStream.java:611)
at com.zhisheng.examples.streaming.socket.LambdaMain.main(LambdaMain.java:34)
```
根据上面的报错信息其实可以知道要怎么解决了,该错误是因为 Flink 在用户自定义的函数中会使用泛型来创建 serializer,当使用匿名函数时,类型信息会被保留。但 Lambda 表达式并不是匿名函数,所以 javac 编译的时候并不会把泛型保存到 class 文件里。解决方法:使用 Flink 提供的 returns 方法来指定 flatMap 的返回类型
```java
//使用 TupleTypeInfo 来指定 Tuple 的参数类型
.returns((TypeInformation) TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class))
```
在 flatMap 后面加上上面这个 returns 就行了,但是如果算子多了的话,每个都去加一个 returns,其实会很痛苦的,所以通常使用匿名函数或者自定义函数居多。
### 2.4.5 小结与反思
在第一章中介绍了 Flink 的特性,本章主要是让大家能够快速入门,所以在第一节和第二节中分别讲解了 Flink 的环境准备和搭建,在第三节和第四节中通过两个入门的应用程序(WordCount 应用程序和读取 Socket 数据应用程序)让大家可以快速入门 Flink,两个程序都是需要自己动手实操,所以更能加深大家的印象。
================================================
FILE: books/flink-in-action-3.1.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 中 Processing Time、Event Time、Ingestion Time 对比及其使用场景分析
date: 2021-07-11
tags:
- Flink
- 大数据
- 流式计算
---
# 第三章 —— Flink 中的流计算处理
通过第二章的入门案例讲解,相信你已经知道了 Flink 程序的开发过程,本章将带你熟悉 Flink 中的各种特性,比如多种时间语义、丰富的窗口机制、流计算中常见的运算操作符、Watermark 机制、丰富的 Connectors(Kafka、ElasticSearch、Redis、HBase 等) 的使用方式。除了介绍这些知识点的原理之外,笔者还将通过案例来教会大家如何去实战使用,最后还会讲解这些原理的源码实现,希望你可以更深刻的理解这些特性。
## 3.1 Flink 多种时间语义对比
Flink 在流应用程序中支持不同的 **Time** 概念,就比如有 Processing Time、Event Time 和 Ingestion Time。下面我们一起来看看这三个 Time。
### 3.1.1 Processing Time
Processing Time 是指事件被处理时机器的系统时间。
如果我们 Flink Job 设置的时间策略是 Processing Time 的话,那么后面所有基于时间的操作(如时间窗口)都将会使用当时机器的系统时间。每小时 Processing Time 窗口将包括在系统时钟指示整个小时之间到达特定操作的所有事件。
例如,如果应用程序在上午 9:15 开始运行,则第一个每小时 Processing Time 窗口将包括在上午 9:15 到上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 到 11:00 之间处理的事件。
Processing Time 是最简单的 "Time" 概念,不需要流和机器之间的协调,它提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,Processing Time 不能提供确定性,因为它容易受到事件到达系统的速度(例如从消息队列)、事件在系统内操作流动的速度以及中断的影响。
### 3.1.2 Event Time
Event Time 是指事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。在 Event Time 中,时间取决于数据,而跟其他没什么关系。Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制。
完美的说,无论事件什么时候到达或者其怎么排序,最后处理 Event Time 将产生完全一致和确定的结果。但是,除非事件按照已知顺序(事件产生的时间顺序)到达,否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
假设所有数据都已到达,Event Time 操作将按照预期运行,即使在处理无序事件、延迟事件、重新处理历史数据时也会产生正确且一致的结果。 例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,不管它们到达的顺序如何(是否按照事件产生的时间)。
### 3.1.3 Ingestion Time
Ingestion Time 是事件进入 Flink 的时间。 在数据源操作处(进入 Flink source 时),每个事件将进入 Flink 时当时的时间作为时间戳,并且基于时间的操作(如时间窗口)会利用这个时间戳。
Ingestion Time 在概念上位于 Event Time 和 Processing Time 之间。 与 Processing Time 相比,成本可能会高一点,但结果更可预测。因为 Ingestion Time 使用稳定的时间戳(只在进入 Flink 的时候分配一次),所以对事件的不同窗口操作将使用相同的时间戳(第一次分配的时间戳),而在 Processing Time 中,每个窗口操作符可以将事件分配给不同的窗口(基于机器系统时间和到达延迟)。
与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序中不必指定如何生成水印。
在 Flink 中,Ingestion Time 与 Event Time 非常相似,唯一区别就是 Ingestion Time 具有自动分配时间戳和自动生成水印功能。
### 3.1.4 三种 Time 的对比结果
### 3.1.5 使用场景分析
### 3.1.6 Time 策略设置
### 3.1.7 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/znqnMNB

================================================
FILE: books/flink-in-action-3.10.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink Connector —— HBase 的用法
date: 2021-07-21
tags:
- Flink
- 大数据
- 流式计算
---
## 3.10 Flink Connector —— HBase 的用法
HBase 是一个分布式的、面向列的开源数据库,同样,很多公司也有使用该技术存储数据的,本节将对 HBase 做些简单的介绍,以及利用 Flink HBase Connector 读取 HBase 中的数据和写入数据到 HBase 中。
### 3.10.1 准备环境和依赖
下面分别讲解 HBase 的环境安装、配置、常用的命令操作以及添加项目需要的依赖。
#### HBase 安装
如果是苹果系统,可以使用 HomeBrew 命令安装:
```
brew install hbase
```
HBase 最终会安装在路径 `/usr/local/Cellar/hbase/` 下面,安装版本不同,文件名也不同。
#### 配置 HBase
打开 `libexec/conf/hbase-env.sh` 修改里面的 JAVA_HOME:
```
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home"
```
根据你自己的 JAVA_HOME 来配置这个变量。
打开 `libexec/conf/hbase-site.xml` 配置 HBase 文件存储目录:
```xml
hbase.rootdir
file:///usr/local/var/hbase
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.property.dataDir
/usr/local/var/zookeeper
hbase.zookeeper.dns.interface
lo0
hbase.regionserver.dns.interface
lo0
hbase.master.dns.interface
lo0
```
#### 运行 HBase
执行启动的命令:
```
./bin/start-hbase.sh
```
执行后打印出来的日志如:
```
starting master, logging to /usr/local/var/log/hbase/hbase-zhisheng-master-zhisheng.out
```
#### 验证是否安装成功
使用 jps 命令:
```
zhisheng@zhisheng /usr/local/Cellar/hbase/1.2.9/libexec jps
91302 HMaster
62535 RemoteMavenServer
1100
91471 Jps
```
出现 HMaster 说明安装运行成功。
#### 启动 HBase Shell
执行下面命令:
```
./bin/hbase shell
```
运行结果如下图所示:

#### 停止 HBase
执行下面的命令:
```
./bin/stop-hbase.sh
```
运行结果如下图所示:

#### HBase 常用命令
HBase 中常用的命令有:list(列出已存在的表)、create(创建表)、put(写数据)、get(读数据)、scan(读数据,读全表)、describe(显示表详情),如下图所示。

简单使用上诉命令的结果如下:

#### 添加依赖
在 pom.xml 中添加 HBase 相关的依赖:
```xml
org.apache.flink
flink-hbase_${scala.binary.version}
${flink.version}
org.apache.hadoop
hadoop-common
2.7.4
```
Flink HBase Connector 中,HBase 不仅可以作为数据源,也还可以写入数据到 HBase 中去,我们先来看看如何从 HBase 中读取数据。
### 3.10.2 Flink 使用 TableInputFormat 读取 HBase 批量数据
这里我们使用 TableInputFormat 来读取 HBase 中的数据,首先准备数据。
#### 准备数据
先往 HBase 中插入五条数据如下:
```jshelllanguage
put 'zhisheng', 'first', 'info:bar', 'hello'
put 'zhisheng', 'second', 'info:bar', 'zhisheng001'
put 'zhisheng', 'third', 'info:bar', 'zhisheng002'
put 'zhisheng', 'four', 'info:bar', 'zhisheng003'
put 'zhisheng', 'five', 'info:bar', 'zhisheng004'
```
scan 整个 `zhisheng` 表的话,有五条数据,运行结果如下图所示:

#### Flink Job 代码
Flink 读取 HBase 数据的程序代码如下所示:
```java
/**
* Desc: 读取 HBase 数据
*/
public class HBaseReadMain {
//表名
public static final String HBASE_TABLE_NAME = "zhisheng";
// 列族
static final byte[] INFO = "info".getBytes(ConfigConstants.DEFAULT_CHARSET);
//列名
static final byte[] BAR = "bar".getBytes(ConfigConstants.DEFAULT_CHARSET);
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.createInput(new TableInputFormat>() {
private Tuple2 reuse = new Tuple2();
@Override
protected Scan getScanner() {
Scan scan = new Scan();
scan.addColumn(INFO, BAR);
return scan;
}
@Override
protected String getTableName() {
return HBASE_TABLE_NAME;
}
@Override
protected Tuple2 mapResultToTuple(Result result) {
String key = Bytes.toString(result.getRow());
String val = Bytes.toString(result.getValue(INFO, BAR));
reuse.setField(key, 0);
reuse.setField(val, 1);
return reuse;
}
}).filter(new FilterFunction>() {
@Override
public boolean filter(Tuple2 value) throws Exception {
return value.f1.startsWith("zhisheng");
}
}).print();
}
}
```
上面代码中将 HBase 中的读取全部读取出来后然后过滤以 `zhisheng` 开头的 value 数据。读取结果如下图所示:

可以看到输出的结果中已经将以 `zhisheng` 开头的四条数据都打印出来了。
### 3.10.3 Flink 使用 TableOutputFormat 向 HBase 写入数据
#### 添加依赖
#### Flink Job 代码
### 3.10.4 Flink 使用 HBaseOutputFormat 向 HBase 实时写入数据
#### 读取数据
#### 写入数据
#### 配置文件
### 3.10.5 项目运行及验证
### 3.10.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/3bimqBM

================================================
FILE: books/flink-in-action-3.11.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink Connector —— Redis 的用法
date: 2021-07-22
tags:
- Flink
- 大数据
- 流式计算
---
## 3.11 Flink Connector —— Redis 的用法
在生产环境中,通常会将一些计算后的数据存储在 Redis 中,以供第三方的应用去 Redis 查找对应的数据,至于 Redis 的特性笔者不会在本节做过多的讲解。
### 3.11.1 安装 Redis
首先介绍下 Redis 的的安装和启动运行。
#### 下载安装
先从 [官网](https://redis.io/download) 下载 Redis,然后解压。
```
wget http://download.redis.io/releases/redis-5.0.4.tar.gz
tar xzf redis-5.0.4.tar.gz
cd redis-5.0.4
make
```
#### 通过 HomeBrew 安装
```
brew install redis
```
如果需要后台运行 Redis 服务,使用命令:
```
brew services start redis
```
要运行命令,可以直接到 /usr/local/bin 目录下,有:
```
redis-server
redis-cli
```
两个命令,执行 `redis-server` 可以打开服务端,启动后结果如下图所示:

然后另外开一个终端,运行 `redis-cli` 命令可以运行客户端,执行后效果如下图所示:

### 3.11.2 将商品数据发送到 Kafka
这里我打算将从 Kafka 读取到所有到商品的信息,然后将商品信息中的 **商品ID** 和 **商品价格** 提取出来,然后写入到 Redis 中,供第三方服务根据商品 ID 查询到其对应的商品价格。
首先定义我们的商品类 (其中 id 和 price 字段是我们最后要提取的)为:
ProductEvent.java
```java
/**
* Desc: 商品
* blog:http://www.54tianzhisheng.cn/
* 微信公众号:zhisheng
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ProductEvent {
/**
* Product Id
*/
private Long id;
/**
* Product 类目 Id
*/
private Long categoryId;
/**
* Product 编码
*/
private String code;
/**
* Product 店铺 Id
*/
private Long shopId;
/**
* Product 店铺 name
*/
private String shopName;
/**
* Product 品牌 Id
*/
private Long brandId;
/**
* Product 品牌 name
*/
private String brandName;
/**
* Product name
*/
private String name;
/**
* Product 图片地址
*/
private String imageUrl;
/**
* Product 状态(1(上架),-1(下架),-2(冻结),-3(删除))
*/
private int status;
/**
* Product 类型
*/
private int type;
/**
* Product 标签
*/
private List tags;
/**
* Product 价格(以分为单位)
*/
private Long price;
}
```
然后写个工具类不断的模拟商品数据发往 Kafka,工具类 `ProductUtil.java` 的代码如下:
```java
public class ProductUtil {
public static final String broker_list = "localhost:9092";
public static final String topic = "zhisheng"; //kafka topic 需要和 flink 程序用同一个 topic
public static final Random random = new Random();
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
for (int i = 1; i <= 10000; i++) {
ProductEvent product = ProductEvent.builder().id((long) i) //商品的 id
.name("product" + i) //商品 name
.price(random.nextLong() / 10000000000000L) //商品价格(以分为单位)
.code("code" + i).build(); //商品编码
ProducerRecord record = new ProducerRecord(topic, null, null, GsonUtil.toJson(product));
producer.send(record);
System.out.println("发送数据: " + GsonUtil.toJson(product));
}
producer.flush();
}
}
```
### 3.11.3 Flink 消费 Kafka 中的商品数据
我们需要在 Flink 中消费 Kafka 数据,然后将商品中的两个数据(商品 id 和 price)取出来。先来看下这段 Flink Job 代码:
```java
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool parameterTool = ExecutionEnvUtil.PARAMETER_TOOL;
Properties props = KafkaConfigUtil.buildKafkaProps(parameterTool);
SingleOutputStreamOperator> product = env.addSource(new FlinkKafkaConsumer011<>(
parameterTool.get(METRICS_TOPIC), //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props))
.map(string -> GsonUtil.fromJson(string, ProductEvent.class)) //反序列化 JSON
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(ProductEvent value, Collector> out) throws Exception {
//收集商品 id 和 price 两个属性
out.collect(new Tuple2<>(value.getId().toString(), value.getPrice().toString()));
}
});
product.print();
env.execute("flink redis connector");
}
}
```
然后 IDEA 中启动运行 Job,再运行上面的 ProductUtil 发送 Kafka 数据的工具类(注意:也得提前启动 Kafka),运行结果如下图所示。

上图左半部分是工具类发送数据到 Kafka 打印的日志,右半部分是 Job 执行的结果,可以看到它已经将商品的 id 和 price 数据获取到了。
那么接下来我们需要的就是将这种 `Tuple2` 格式的 KV 数据写入到 Redis 中去。要将数据写入到 Redis 的话是需要先添加依赖的。
### 3.11.4 Redis Connector 简介
Redis Connector 提供用于向 Redis 发送数据的接口的类。接收器可以使用三种不同的方法与不同类型的 Redis 环境进行通信:
+ 单 Redis 服务器
+ Redis 集群
+ Redis Sentinel
### 添加依赖
需要添加 Flink Redis Sink 的 Connector,这个 Redis Connector 官方只有老的版本,后面也一直没有更新,所以可以看到网上有些文章都是添加老的版本的依赖。
```xml
org.apache.flink
flink-connector-redis_2.10
1.1.5
```
包括该部分的文档都是很早之前的啦,可以查看 [flink-docs-release-1.1 redis](https://ci.apache.org/projects/flink/flink-docs-release-1.1/apis/streaming/connectors/redis.html)。
另外在 [flink-streaming-redis](https://bahir.apache.org/docs/flink/current/flink-streaming-redis/) 也看到一个 Flink Redis Connector 的依赖。
```xml
org.apache.bahir
flink-connector-redis_2.11
1.0
```
两个依赖功能都是一样的,我们还是就用官方的那个 Maven 依赖来进行演示。
### 3.11.5 Flink 写入数据到 Redis
### 3.11.6 项目运行及验证
### 3.11.7 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/zr76I66

================================================
FILE: books/flink-in-action-3.12.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 使用 Side Output 分流
date: 2021-07-23
tags:
- Flink
- 大数据
- 流式计算
---
## 3.12 使用 Side Output 分流
通常,在 Kafka 的 topic 中会有很多数据,这些数据虽然结构是一致的,但是类型可能不一致,举个例子:Kafka 中的监控数据有很多种:机器、容器、应用、中间件等,如果要对这些数据分别处理,就需要对这些数据流进行一个拆分,那么在 Flink 中该怎么完成这需求呢,有如下这些方法。
### 3.12.1 使用 Filter 分流
使用 filter 算子根据数据的字段进行过滤分成机器、容器、应用、中间件等。伪代码如下:
```java
DataStreamSource data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator machineData = data.filter(m -> "machine".equals(m.getTags().get("type"))); //过滤出机器的数据
SingleOutputStreamOperator dockerData = data.filter(m -> "docker".equals(m.getTags().get("type"))); //过滤出容器的数据
SingleOutputStreamOperator applicationData = data.filter(m -> "application".equals(m.getTags().get("type"))); //过滤出应用的数据
SingleOutputStreamOperator middlewareData = data.filter(m -> "middleware".equals(m.getTags().get("type"))); //过滤出中间件的数据
```
### 3.12.2 使用 Split 分流
先在 split 算子里面定义 OutputSelector 的匿名内部构造类,然后重写 select 方法,根据数据的类型将不同的数据放到不同的 tag 里面,这样返回后的数据格式是 SplitStream,然后要使用这些数据的时候,可以通过 select 去选择对应的数据类型,伪代码如下:
```java
DataStreamSource data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SplitStream splitData = data.split(new OutputSelector() {
@Override
public Iterable select(MetricEvent metricEvent) {
List tags = new ArrayList<>();
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
tags.add("machine");
break;
case "docker":
tags.add("docker");
break;
case "application":
tags.add("application");
break;
case "middleware":
tags.add("middleware");
break;
default:
break;
}
return tags;
}
});
DataStream machine = splitData.select("machine");
DataStream docker = splitData.select("docker");
DataStream application = splitData.select("application");
DataStream middleware = splitData.select("middleware");
```
上面这种只分流一次是没有问题的,注意如果要使用它来做连续的分流,那是有问题的,笔者曾经就遇到过这个问题,当时记录了博客 —— [Flink 从0到1学习—— Flink 不可以连续 Split(分流)?](http://www.54tianzhisheng.cn/2019/06/12/flink-split/) ,当时排查这个问题还查到两个相关的 Flink Issue。
+ [FLINK-5031 Issue](https://issues.apache.org/jira/browse/FLINK-5031)
+ [FLINK-11084 Issue](https://issues.apache.org/jira/browse/FLINK-11084)
这两个 Issue 反映的就是连续 split 不起作用,在第二个 Issue 下面的评论就有回复说 Side Output 的功能比 split 更强大, split 会在后面的版本移除(其实在 1.7.x 版本就已经设置为过期),那么下面就来学习一下 Side Output。
### 3.12.3 使用 Side Output 分流
要使用 Side Output 的话,你首先需要做的是定义一个 OutputTag 来标识 Side Output,代表这个 Tag 是要收集哪种类型的数据,如果是要收集多种不一样类型的数据,那么你就需要定义多种 OutputTag。要完成本节前面的需求,需要定义 4 个 OutputTag,如下:
```java
//创建 output tag
private static final OutputTag machineTag = new OutputTag("machine") {
};
private static final OutputTag dockerTag = new OutputTag("docker") {
};
private static final OutputTag applicationTag = new OutputTag("application") {
};
private static final OutputTag middlewareTag = new OutputTag("middleware") {
};
```
定义好 OutputTag 后,可以使用下面几种函数来处理数据:
+ ProcessFunction
+ KeyedProcessFunction
+ CoProcessFunction
+ ProcessWindowFunction
+ ProcessAllWindowFunction
在利用上面的函数处理数据的过程中,需要对数据进行判断,将不同种类型的数据存到不同的 OutputTag 中去,如下代码所示:
```java
DataStreamSource data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator sideOutputData = data.process(new ProcessFunction() {
@Override
public void processElement(MetricEvent metricEvent, Context context, Collector collector) throws Exception {
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
context.output(machineTag, metricEvent);
case "docker":
context.output(dockerTag, metricEvent);
case "application":
context.output(applicationTag, metricEvent);
case "middleware":
context.output(middlewareTag, metricEvent);
default:
collector.collect(metricEvent);
}
}
});
```
好了,既然上面已经将不同类型的数据放到不同的 OutputTag 里面了,那么该如何去获取呢?可以使用 getSideOutput 方法来获取不同 OutputTag 的数据,比如:
```java
DataStream machine = sideOutputData.getSideOutput(machineTag);
DataStream docker = sideOutputData.getSideOutput(dockerTag);
DataStream application = sideOutputData.getSideOutput(applicationTag);
DataStream middleware = sideOutputData.getSideOutput(middlewareTag);
```
这样你就可以获取到 Side Output 数据了,其实在 3.4 和 3.5 节就讲了 Side Output 在 Flink 中的应用(处理窗口的延迟数据),大家如果没有印象了可以再返回去复习一下。
### 3.12.4 小结与反思
本节讲了下 Flink 中将数据分流的三种方式,完整代码的 GitHub 地址:[sideoutput](https://github.com/zhisheng17/flink-learning/tree/master/flink-learning-examples/src/main/java/com/zhisheng/examples/streaming/sideoutput)
本章全部在介绍 Flink 的技术点,比如多种时间语义的对比分析和应用场景分析、多种灵活的窗口的使用方式及其原理实现、平时开发使用较多的一些算子、深入讲解了 DataStream 中的流类型及其对应的方法实现、如何将 Watermark 与 Window 结合来处理延迟数据、Flink Connector 的使用方式。
因为 Flink 的 Connector 比较多,所以本书只挑选了些平时工作用的比较多的 Connector,比如 Kafka、ElasticSearch、HBase、Redis 等,并教会了大家如何去自定义 Source 和 Sink,这样就算 Flink 中的 Connector 没有你需要的,那么也可以通过这种自定义的方法来实现读取和写入数据。
本章讲解的内容更侧重于在 Flink DataStream 和 Connector 的使用技巧和优化,在讲解这些时还提供了详细的代码实现,目的除了大家可以参考外,其实更期望大家能够自己跟着多动手去实现和优化,这样才可以提高自己的编程水平。另外本章还介绍了自己在使用这些 Connector 时遇到的一些问题,是怎么解决的,也希望大家在工作的时候遇到问题可以静下来自己独立的思考下出现问题的原因是啥,该如何解决,多独立思考后,相信遇到问题后你也能够从容的分析和解决问题。
加入知识星球可以看到更多文章

================================================
FILE: books/flink-in-action-3.2.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 如何使用 Flink Window 及 Window 基本概念与实现原理?
date: 2021-07-12
tags:
- Flink
- 大数据
- 流式计算
---
## 3.2 Flink Window 基础概念与实现原理
目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语,例如,“windowing(窗口化)”、“at-least-once(至少一次)”、“exactly-once(只有一次)” 。
对于刚刚接触流处理的人来说,这种转变和新术语可能会非常混乱。 Apache Flink 是一个为生产环境而生的流处理器,具有易于使用的 API,可以用于定义高级流分析程序。Flink 的 API 在数据流上具有非常灵活的窗口定义,使其在其他开源流处理框架中脱颖而出。
在本节将讨论用于流处理的窗口的概念,介绍 Flink 的内置窗口,并解释它对自定义窗口语义的支持。
### 3.2.1 Window 简介
下面我们结合一个现实的例子来说明。
就拿交通传感器的示例:统计经过某红绿灯的汽车数量之和?
假设在一个红绿灯处,我们每隔 15 秒统计一次通过此红绿灯的汽车数量,如下图所示:

可以把汽车的经过看成一个流,无穷的流,不断有汽车经过此红绿灯,因此无法统计总共的汽车数量。但是,我们可以换一种思路,每隔 15 秒,我们都将与上一次的结果进行 sum 操作(滑动聚合),如下图所示:

这个结果似乎还是无法回答我们的问题,根本原因在于流是无界的,我们不能限制流,但可以在有一个有界的范围内处理无界的流数据。因此,我们需要换一个问题的提法:每分钟经过某红绿灯的汽车数量之和?
这个问题,就相当于一个定义了一个 Window(窗口),Window 的界限是 1 分钟,且每分钟内的数据互不干扰,因此也可以称为翻滚(不重合)窗口,如下图所示:

第一分钟的数量为 18,第二分钟是 28,第三分钟是 24……这样,1 个小时内会有 60 个 Window。
再考虑一种情况,每 30 秒统计一次过去 1 分钟的汽车数量之和,如下图所示:

此时,Window 出现了重合。这样,1 个小时内会有 120 个 Window。
### 3.2.2 Window 有什么作用?
通常来讲,Window 就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。Window 又可以分为基于时间(Time-based)的 Window 以及基于数量(Count-based)的 window。
### 3.2.3 Flink 自带的 Window
Flink 在 KeyedStream(DataStream 的继承类) 中提供了下面几种 Window:
+ 以时间驱动的 Time Window
+ 以事件数量驱动的 Count Window
+ 以会话间隔驱动的 Session Window
提供上面三种 Window 机制后,由于某些特殊的需要,DataStream API 也提供了定制化的 Window 操作,供用户自定义 Window。
下面将先围绕上面说的三种 Window 来进行分析并教大家如何使用,然后对其原理分析,最后在解析其源码实现。
### 3.2.4 Time Window 的用法及源码分析
### 3.2.5 Count Window 的用法及源码分析
### 3.2.6 Session Window 的用法及源码分析
### 3.2.7 如何自定义 Window?
### 3.2.8 Window 源码分析
### 3.2.9 Window 组件之 WindowAssigner 的用法及源码分析
### 3.2.10 Window 组件之 Trigger 的用法及源码分析
### 3.2.11 Window 组件之 Evictor 的用法及源码分析
加入知识星球可以看到上面文章:https://t.zsxq.com/qnQRvrf

### 3.2.12 小结与反思
本节从生活案例来分享关于 Window 方面的需求,进而开始介绍 Window 相关的知识,并把 Flink 中常使用的三种窗口都一一做了介绍,并告诉大家如何使用,还分析了其实现原理。最后还对 Window 的内部组件做了详细的分析,为自定义 Window 提供了方法。
不知道你看完本节后对 Window 还有什么疑问吗?你们是根据什么条件来选择使用哪种 Window 的?在使用的过程中有遇到什么问题吗?
================================================
FILE: books/flink-in-action-3.3.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Flink 数据转换必须熟悉的算子(Operator)
date: 2021-07-13
tags:
- Flink
- 大数据
- 流式计算
---
## 3.3 必须熟悉的数据转换 Operator(算子)
在 Flink 应用程序中,无论你的应用程序是批程序,还是流程序,都是上图这种模型,有数据源(source),有数据下游(sink),我们写的应用程序多是对数据源过来的数据做一系列操作,总结如下。

1、**Source**: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
2、**Transformation**: 数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
3、**Sink**: 接收器,Sink 是指 Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来。Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 Socket 、自定义的 Sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
那么本文将给大家介绍的就是 Flink 中的批和流程序常用的算子(Operator)。
### 3.3.1 DataStream Operator
我们先来看看流程序中常用的算子。
#### Map
Map 算子的输入流是 DataStream,经过 Map 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成一个元素,举个例子:
```java
SingleOutputStreamOperator map = employeeStream.map(new MapFunction() {
@Override
public Employee map(Employee employee) throws Exception {
employee.salary = employee.salary + 5000;
return employee;
}
});
map.print();
```
新的一年给每个员工的工资加 5000。
#### FlatMap
FlatMap 算子的输入流是 DataStream,经过 FlatMap 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成零个、一个或多个元素,举个例子:
```java
SingleOutputStreamOperator flatMap = employeeStream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(Employee employee, Collector out) throws Exception {
if (employee.salary >= 40000) {
out.collect(employee);
}
}
});
flatMap.print();
```
将工资大于 40000 的找出来。
#### Filter
#### KeyBy
#### Reduce
#### Aggregations
#### Window
#### WindowAll
#### Union
#### Window Join
#### Split
#### Select
### 3.3.2 DataSet Operator
#### First-n
### 3.3.3 流计算与批计算统一的思路
加入知识星球可以看到上面文章:https://t.zsxq.com/iYFMZFA

### 3.3.4 小结与反思
本节介绍了在开发 Flink 作业中数据转换常使用的算子(包含流作业和批作业),DataStream API 和 DataSet API 中部分算子名字是一致的,也有不同的地方,最后讲解了下 Flink 社区后面流批统一的思路。
你们公司使用 Flink 是流作业居多还是批作业居多?
================================================
FILE: books/flink-in-action-3.4.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— 使用 DataStream API 来处理数据
date: 2021-07-14
tags:
- Flink
- 大数据
- 流式计算
---
## 3.4 使用 DataStream API 来处理数据
在 3.3 节中讲了数据转换常用的 Operators(算子),然后在 3.2 节中也讲了 Flink 中窗口的概念和原理,那么我们这篇文章再来细讲一下 Flink 中的各种 DataStream API。
我们先来看下源码里面的 DataStream 大概有哪些类呢?如下图所示,展示了 1.9 版本中的 DataStream 类。

可以发现其实还是有很多的类,只有熟练掌握了这些 API,我们才能在做数据转换和计算的时候足够灵活的运用开来(知道何时该选用哪种 DataStream?选用哪个 Function?)。那么我们先从 DataStream 开始吧!
### 3.4.1 DataStream 的用法及分析
首先我们来看下 DataStream 这个类的定义吧:
```text
A DataStream represents a stream of elements of the same type. A DataStreamcan be transformed into another DataStream by applying a transformation as
DataStream#map or DataStream#filter}
```
大概意思是:DataStream 表示相同类型的元素组成的数据流,一个数据流可以通过 map/filter 等算子转换成另一个数据流。
然后 DataStream 的类结构图如下图所示:

它的继承类有 KeyedStream、SingleOutputStreamOperator 和 SplitStream。这几个类本文后面都会一一给大家讲清楚。下面我们来看看 DataStream 这个类中的属性和方法吧。
它的属性就只有两个:
```java
protected final StreamExecutionEnvironment environment;
protected final StreamTransformation transformation;
```
但是它的方法却有很多,并且我们平时写的 Flink Job 几乎离不开这些方法,这也注定了这个类的重要性,所以得好好看下这些方法该如何使用,以及是如何实现的。
#### union
通过合并相同数据类型的数据流,然后创建一个新的数据流,union 方法代码实现如下:
```java
public final DataStream union(DataStream... streams) {
List> unionedTransforms = new ArrayList<>();
unionedTransforms.add(this.transformation);
for (DataStream newStream : streams) {
if (!getType().equals(newStream.getType())) { //判断数据类型是否一致
throw new IllegalArgumentException("Cannot union streams of different types: " + getType() + " and " + newStream.getType());
}
unionedTransforms.add(newStream.getTransformation());
}
//构建新的数据流
return new DataStream<>(this.environment, new UnionTransformation<>(unionedTransforms));//通过使用 UnionTransformation 将多个 StreamTransformation 合并起来
}
```
那么我们该如何去使用 union 呢(不止连接一个数据流,也可以连接多个数据流)?
```java
//数据流 1 和 2
final DataStream stream1 = env.addSource(...);
final DataStream stream2 = env.addSource(...);
//union
stream1.union(stream2)
```
#### split
该方法可以将两个数据流进行拆分,拆分后的数据流变成了 SplitStream(在下文会详细介绍这个类的内部实现),该 split 方法通过传入一个 OutputSelector 参数进行数据选择,方法内部实现就是构造一个 SplitStream 对象然后返回:
```java
public SplitStream split(OutputSelector outputSelector) {
return new SplitStream<>(this, clean(outputSelector));
}
```
然后我们该如何使用这个方法呢?
```java
dataStream.split(new OutputSelector() {
private static final long serialVersionUID = 8354166915727490130L;
@Override
public Iterable select(Integer value) {
List s = new ArrayList();
if (value > 4) { //大于 4 的数据放到 > 这个 tag 里面去
s.add(">");
} else { //小于等于 4 的数据放到 < 这个 tag 里面去
s.add("<");
}
return s;
}
});
```
注意:该方法已经不推荐使用了!在 1.7 版本以后建议使用 Side Output 来实现分流操作。
#### connect
通过连接不同或相同数据类型的数据流,然后创建一个新的连接数据流,如果连接的数据流也是一个 DataStream 的话,那么连接后的数据流为 ConnectedStreams(会在下文介绍这个类的具体实现),它的具体实现如下:
```java
public ConnectedStreams connect(DataStream dataStream) {
return new ConnectedStreams<>(environment, this, dataStream);
}
```
如果连接的数据流是一个 BroadcastStream(广播数据流),那么连接后的数据流是一个 BroadcastConnectedStream(会在下文详细介绍该类的内部实现),它的具体实现如下:
```java
public BroadcastConnectedStream connect(BroadcastStream broadcastStream) {
return new BroadcastConnectedStream<>(
environment, this, Preconditions.checkNotNull(broadcastStream),
broadcastStream.getBroadcastStateDescriptor());
}
```
使用如下:
```java
//1、连接 DataStream
DataStream> src1 = env.fromElements(new Tuple2<>(0L, 0L));
DataStream> src2 = env.fromElements(new Tuple2<>(0L, 0L));
ConnectedStreams, Tuple2> connected = src1.connect(src2);
//2、连接 BroadcastStream
DataStream> src1 = env.fromElements(new Tuple2<>(0L, 0L));
final BroadcastStream broadcast = srcTwo.broadcast(utterDescriptor);
BroadcastConnectedStream, String> connect = src1.connect(broadcast);
```
#### keyBy
keyBy 方法是用来将数据进行分组的,通过该方法可以将具有相同 key 的数据划分在一起组成新的数据流,该方法有四种(它们的参数各不一样):
```java
//1、参数是 KeySelector 对象
public KeyedStream keyBy(KeySelector key) {
...
return new KeyedStream<>(this, clean(key));//构造 KeyedStream 对象
}
//2、参数是 KeySelector 对象和 TypeInformation 对象
public KeyedStream keyBy(KeySelector key, TypeInformation keyType) {
...
return new KeyedStream<>(this, clean(key), keyType);//构造 KeyedStream 对象
}
//3、参数是 1 至多个字段(用 0、1、2... 表示)
public KeyedStream keyBy(int... fields) {
if (getType() instanceof BasicArrayTypeInfo || getType() instanceof PrimitiveArrayTypeInfo) {
return keyBy(KeySelectorUtil.getSelectorForArray(fields, getType()));
} else {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));//调用 private 的 keyBy 方法
}
}
//4、参数是 1 至多个字符串
public KeyedStream keyBy(String... fields) {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));//调用 private 的 keyBy 方法
}
//真正调用的方法
private KeyedStream keyBy(Keys keys) {
return new KeyedStream<>(this, clean(KeySelectorUtil.getSelectorForKeys(keys,
getType(), getExecutionConfig())));
}
```
如何使用呢:
```java
DataStream dataStream = env.fromElements(
new Event(1, "zhisheng01", 1.0),
new Event(2, "zhisheng02", 2.0),
new Event(3, "zhisheng03", 2.1),
new Event(3, "zhisheng04", 3.0),
new SubEvent(4, "zhisheng05", 4.0, 1.0),
);
//第1种
dataStream.keyBy(new KeySelector() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
});
//第2种
dataStream.keyBy(new KeySelector() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
}, Types.STRING);
//第3种
dataStream.keyBy(0);
//第4种
dataStream.keyBy("zhisheng01", "zhisheng02");
```
#### partitionCustom
使用自定义分区器在指定的 key 字段上将 DataStream 分区,这个 partitionCustom 有 3 个不同参数的方法,分别要传入的参数有自定义分区 Partitioner 对象、位置、字符和 KeySelector。它们内部也都是调用了私有的 partitionCustom 方法。
#### broadcast
broadcast 是将数据流进行广播,然后让下游的每个并行 Task 中都可以获取到这份数据流,通常这些数据是一些配置,一般这些配置数据的数据量不能太大,否则资源消耗会比较大。这个 broadcast 方法也有两个,一个是无参数,它返回的数据是 DataStream;另一种的参数是 MapStateDescriptor,它返回的参数是 BroadcastStream(这个也会在下文详细介绍)。
使用方法:
```java
//1、第一种
DataStream> source = env.addSource(...).broadcast();
//2、第二种
final MapStateDescriptor utterDescriptor = new MapStateDescriptor<>(
"broadcast-state", BasicTypeInfo.LONG_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO
);
final DataStream srcTwo = env.fromCollection(expected.values());
final BroadcastStream broadcast = srcTwo.broadcast(utterDescriptor);
```
#### map
map 方法需要传入的参数是一个 MapFunction,当然传入 RichMapFunction 也是可以的,它返回的是 SingleOutputStreamOperator(这个类在会在下文详细介绍),该 map 方法里面的实现如下:
```java
public SingleOutputStreamOperator map(MapFunction mapper) {
TypeInformation outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
//调用 transform 方法
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
```
该方法平时使用的非常频繁,然后我们该如何使用这个方法呢:
```java
dataStream.map(new MapFunction() {
private static final long serialVersionUID = 1L;
@Override
public String map(Integer value) throws Exception {
return value.toString();
}
})
```
#### flatMap
flatMap 方法需要传入一个 FlatMapFunction 参数,当然传入 RichFlatMapFunction 也是可以的,如果你的 Flink Job 里面有连续的 filter 和 map 算子在一起,可以考虑使用 flatMap 一个算子来完成两个算子的工作,它返回的是 SingleOutputStreamOperator,该 flatMap 方法里面的实现如下:
```java
public SingleOutputStreamOperator flatMap(FlatMapFunction flatMapper) {
TypeInformation outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper),
getType(), Utils.getCallLocationName(), true);
//调用 transform 方法
return transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
}
```
该方法平时使用的非常频繁,使用方式如下:
```java
dataStream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(Integer value, Collector out) throws Exception {
out.collect(value);
}
})
```
#### process
在输入流上应用给定的 ProcessFunction,从而创建转换后的输出流,通过该方法返回的是 SingleOutputStreamOperator,具体代码实现如下:
```java
public SingleOutputStreamOperator process(ProcessFunction processFunction) {
TypeInformation outType = TypeExtractor.getUnaryOperatorReturnType(
processFunction, ProcessFunction.class, 0, 1,
TypeExtractor.NO_INDEX, getType(), Utils.getCallLocationName(), true);
//调用下面的 process 方法
return process(processFunction, outType);
}
public SingleOutputStreamOperator process(
ProcessFunction processFunction,
TypeInformation outputType) {
ProcessOperator operator = new ProcessOperator<>(clean(processFunction));
//调用 transform 方法
return transform("Process", outputType, operator);
}
```
使用方法:
```java
DataStreamSource data = env.generateSequence(0, 0);
//定义的 ProcessFunction
ProcessFunction processFunction = new ProcessFunction() {
private static final long serialVersionUID = 1L;
@Override
public void processElement(Long value, Context ctx,
Collector out) throws Exception {
//具体逻辑
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx,
Collector out) throws Exception {
//具体逻辑
}
};
DataStream processed = data.keyBy(new IdentityKeySelector()).process(processFunction);
```
#### filter
filter 用来过滤数据的,它需要传入一个 FilterFunction,然后返回的数据也是 SingleOutputStreamOperator,该方法的实现是:
```java
public SingleOutputStreamOperator filter(FilterFunction filter) {
return transform("Filter", getType(), new StreamFilter<>(clean(filter)));
}
```
该方法平时使用非常多:
```java
DataStream filter1 = src
.filter(new FilterFunction() {
@Override
public boolean filter(String value) throws Exception {
return "zhisheng".equals(value);
}
})
```
上面这些方法是平时写代码时用的非常多的方法,我们这里讲解了它们的实现原理和使用方式,当然还有其他方法,比如 assignTimestampsAndWatermarks、join、shuffle、forward、addSink、rebalance、iterate、coGroup、project、timeWindowAll、countWindowAll、windowAll、print 等,这里由于篇幅的问题就不一一展开来讲了。
### 3.4.2 SingleOutputStreamOperator 的用法及分析
SingleOutputStreamOperator 这个类继承自 DataStream,所以 DataStream 中有的方法在这里也都有,那么这里就讲解下额外的方法的作用,如下。
+ name():该方法可以设置当前数据流的名称,如果设置了该值,则可以在 Flink UI 上看到该值;uid() 方法可以为算子设置一个指定的 ID,该 ID 有个作用就是如果想从 savepoint 恢复 Job 时是可以根据这个算子的 ID 来恢复到它之前的运行状态;
+ setParallelism() :该方法是为每个算子单独设置并行度的,这个设置优先于你通过 env 设置的全局并行度;
+ setMaxParallelism() :该为算子设置最大的并行度;
+ setResources():该方法有两个(参数不同),设置算子的资源,但是这两个方法对外还没开放(是私有的,暂时功能性还不全);
+ forceNonParallel():该方法强行将并行度和最大并行度都设置为 1;
+ setChainingStrategy():该方法对给定的算子设置 ChainingStrategy;
+ disableChaining():该这个方法设置后将禁止该算子与其他的算子 chain 在一起;
+ getSideOutput():该方法通过给定的 OutputTag 参数从 side output 中来筛选出对应的数据流。
### 3.4.3 KeyedStream 的用法及分析
KeyedStream 是 DataStream 在根据 KeySelector 分区后的数据流,DataStream 中常用的方法在 KeyedStream 后也可以用(除了 shuffle、forward 和 keyBy 等分区方法),在该类中的属性分别是 KeySelector 和 TypeInformation。
DataStream 中的窗口方法只有 timeWindowAll、countWindowAll 和 windowAll 这三种全局窗口方法,但是在 KeyedStream 类中的种类就稍微多了些,新增了 timeWindow、countWindow 方法,并且是还支持滑动窗口。
除了窗口方法的新增外,还支持大量的聚合操作方法,比如 reduce、fold、sum、min、max、minBy、maxBy、aggregate 等方法(列举的这几个方法都支持多种参数的)。
最后就是它还有 asQueryableState() 方法,能够将 KeyedStream 发布为可查询的 ValueState 实例。
### 3.4.4 SplitStream 的用法及分析
SplitStream 这个类比较简单,它代表着数据分流后的数据流了,它有一个 select 方法可以选择分流后的哪种数据流了,通常它是结合 split 使用的,对于单次分流来说还挺方便的。但是它是一个被废弃的类(Flink 1.7 后被废弃的,可以看下笔者之前写的一篇文章 [Flink 从0到1学习—— Flink 不可以连续 Split(分流)?](http://www.54tianzhisheng.cn/2019/06/12/flink-split/) ),其实可以用 side output 来代替这种 split,后面文章中我们也会讲通过简单的案例来讲解一下该如何使用 side output 做数据分流操作。
因为这个类的源码比较少,我们可以看下这个类的实现:
```java
public class SplitStream extends DataStream {
//构造方法
protected SplitStream(DataStream dataStream, OutputSelector outputSelector) {
super(dataStream.getExecutionEnvironment(), new SplitTransformation(dataStream.getTransformation(), outputSelector));
}
//选择要输出哪种数据流
public DataStream select(String... outputNames) {
return selectOutput(outputNames);
}
//上面那个 public 方法内部调用的就是这个方法,该方法是个 private 方法,对外隐藏了它是如何去找到特定的数据流。
private DataStream selectOutput(String[] outputNames) {
for (String outName : outputNames) {
if (outName == null) {
throw new RuntimeException("Selected names must not be null");
}
}
//构造了一个 SelectTransformation 对象
SelectTransformation selectTransform = new SelectTransformation(this.getTransformation(), Lists.newArrayList(outputNames));
//构造了一个 DataStream 对象
return new DataStream(this.getExecutionEnvironment(), selectTransform);
}
}
```
### 3.4.5 WindowedStream 的用法及分析
虽然 WindowedStream 不是继承自 DataStream,并且我们在 3.1 节中也做了一定的讲解,但是当时没讲里面的 Function,所以在这里刚好一起做一个补充。
在 WindowedStream 类中定义的属性有 KeyedStream、WindowAssigner、Trigger、Evictor、allowedLateness 和 lateDataOutputTag。
+ KeyedStream:代表着数据流,数据分组后再开 Window
+ WindowAssigner:Window 的组件之一
+ Trigger:Window 的组件之一
+ Evictor:Window 的组件之一(可选)
+ allowedLateness:用户指定的允许迟到时间长
+ lateDataOutputTag:数据延迟到达的 Side output,如果延迟数据没有设置任何标记,则会被丢弃
在 3.1 节中我们讲了上面的三个窗口组件 WindowAssigner、Trigger、Evictor,并教大家该如何使用,那么在这篇文章我就不再重复,那么接下来就来分析下其他几个的使用方式和其实现原理。
先来看下 allowedLateness 这个它可以在窗口后指定允许迟到的时间长,使用如下:
```java
dataStream.keyBy(0)
.timeWindow(Time.milliseconds(20))
.allowedLateness(Time.milliseconds(2))
```
lateDataOutputTag 这个它将延迟到达的数据发送到由给定 OutputTag 标识的 side output(侧输出),当水印经过窗口末尾(并加上了允许的延迟后),数据就被认为是延迟了。
对于 keyed windows 有五个不同参数的 reduce 方法可以使用,如下:
```java
//1、参数为 ReduceFunction
public SingleOutputStreamOperator reduce(ReduceFunction function) {
...
return reduce(function, new PassThroughWindowFunction());
}
//2、参数为 ReduceFunction 和 WindowFunction
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, WindowFunction function) {
...
return reduce(reduceFunction, function, resultType);
}
//3、参数为 ReduceFunction、WindowFunction 和 TypeInformation
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, WindowFunction function, TypeInformation resultType) {
...
return input.transform(opName, resultType, operator);
}
//4、参数为 ReduceFunction 和 ProcessWindowFunction
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, ProcessWindowFunction function) {
...
return reduce(reduceFunction, function, resultType);
}
//5、参数为 ReduceFunction、ProcessWindowFunction 和 TypeInformation
public SingleOutputStreamOperator reduce(ReduceFunction reduceFunction, ProcessWindowFunction function, TypeInformation resultType) {
...
return input.transform(opName, resultType, operator);
}
```
除了 reduce 方法,还有六个不同参数的 fold 方法、aggregate 方法;两个不同参数的 apply 方法、process 方法(其中你会发现这两个 apply 方法和 process 方法内部其实都隐式的调用了一个私有的 apply 方法);其实除了前面说的两个不同参数的 apply 方法外,还有四个其他的 apply 方法,这四个方法也是参数不同,但是其实最终的是利用了 transform 方法;还有的就是一些预定义的聚合方法比如 sum、min、minBy、max、maxBy,它们的方法参数的个数不一致,这些预聚合的方法内部调用的其实都是私有的 aggregate 方法,该方法允许你传入一个 AggregationFunction 参数。我们来看一个具体的实现:
```java
//max
public SingleOutputStreamOperator max(String field) {
//内部调用私有的的 aggregate 方法
return aggregate(new ComparableAggregator<>(field, input.getType(), AggregationFunction.AggregationType.MAX, false, input.getExecutionConfig()));
}
//私有的 aggregate 方法
private SingleOutputStreamOperator aggregate(AggregationFunction aggregator) {
//继续调用的是 reduce 方法
return reduce(aggregator);
}
//该 reduce 方法内部其实又是调用了其他多个参数的 reduce 方法
public SingleOutputStreamOperator reduce(ReduceFunction function) {
...
function = input.getExecutionEnvironment().clean(function);
return reduce(function, new PassThroughWindowFunction());
}
```
从上面的方法调用过程,你会发现代码封装的很深,得需要你自己好好跟一下源码才可以了解更深些。
上面讲了这么多方法,你会发现 reduce 方法其实是用的蛮多的之一,那么就来看看该如何使用:
```java
dataStream.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction>() {
@Override
public Tuple2 reduce(Tuple2 value1, Tuple2 value2) {
return value1;
}
})
.print();
```
### 3.4.6 AllWindowedStream 的用法及分析
前面讲完了 WindowedStream,再来看看这个 AllWindowedStream 你会发现它的实现其实无太大区别,该类中的属性和方法都和前面 WindowedStream 是一样的,然后我们就不再做过多的介绍,直接来看看该如何使用呢?
AllWindowedStream 这种场景下是不需要让数据流做 keyBy 分组操作,直接就进行 windowAll 操作,然后在 windowAll 方法中传入 WindowAssigner 参数对象即可,然后返回的数据结果就是 AllWindowedStream 了,下面使用方式继续执行了 AllWindowedStream 中的 reduce 方法来返回数据:
```java
dataStream.windowAll(SlidingEventTimeWindows.of(Time.of(1, TimeUnit.SECONDS), Time.of(100, TimeUnit.MILLISECONDS)))
.reduce(new RichReduceFunction>() {
private static final long serialVersionUID = -6448847205314995812L;
@Override
public Tuple2 reduce(Tuple2 value1,
Tuple2 value2) throws Exception {
return value1;
}
});
```
### 3.4.7 ConnectedStreams 的用法及分析
ConnectedStreams 这个类定义是表示(可能)两个不同数据类型的数据连接流,该场景如果对一个数据流进行操作会直接影响另一个数据流,因此可以通过流连接来共享状态。比较常见的一个例子就是一个数据流(随时间变化的规则数据流)通过连接其他的数据流,这样另一个数据流就可以利用这些连接的规则数据流。
ConnectedStreams 在概念上可以认为和 Union 数据流是一样的。
在 ConnectedStreams 类中有三个属性:environment、inputStream1 和 inputStream2,该类中的方法如下图所示:

在 ConnectedStreams 中可以通过 getFirstInput 获取连接的第一个流、通过 getSecondInput 获取连接的第二个流,同时它还含有六个 keyBy 方法来将连接后的数据流进行分组,这六个 keyBy 方法的参数各有不同。另外它还含有 map、flatMap、process 方法来处理数据(其中 map 和 flatMap 方法的参数分别使用的是 CoMapFunction 和 CoFlatMapFunction),其实如果你细看其方法里面的实现就会发现都是调用的 transform 方法。
上面讲完了 ConnectedStreams 类的基础定义,接下来我们来看下该类如何使用呢?
```java
DataStream> src1 = env.fromElements(new Tuple2<>(0L, 0L)); //流 1
DataStream> src2 = env.fromElements(new Tuple2<>(0L, 0L)); //流 2
ConnectedStreams, Tuple2> connected = src1.connect(src2); //连接流 1 和流 2
//使用连接流的六种 keyBy 方法
ConnectedStreams, Tuple2> connectedGroup1 = connected.keyBy(0, 0);
ConnectedStreams, Tuple2> connectedGroup2 = connected.keyBy(new int[]{0}, new int[]{0});
ConnectedStreams, Tuple2> connectedGroup3 = connected.keyBy("f0", "f0");
ConnectedStreams, Tuple2> connectedGroup4 = connected.keyBy(new String[]{"f0"}, new String[]{"f0"});
ConnectedStreams, Tuple2> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector());
ConnectedStreams, Tuple2> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector(), Types.STRING);
//使用连接流的 map 方法
connected.map(new CoMapFunction, Tuple2, Object>() {
private static final long serialVersionUID = 1L;
@Override
public Object map1(Tuple2 value) {
return null;
}
@Override
public Object map2(Tuple2 value) {
return null;
}
});
//使用连接流的 flatMap 方法
connected.flatMap(new CoFlatMapFunction, Tuple2, Tuple2>() {
@Override
public void flatMap1(Tuple2 value, Collector> out) throws Exception {}
@Override
public void flatMap2(Tuple2 value, Collector> out) throws Exception {}
}).name("testCoFlatMap")
//使用连接流的 process 方法
connected.process(new CoProcessFunction, Tuple2, Tuple2>() {
@Override
public void processElement1(Tuple2 value, Context ctx, Collector> out) throws Exception {
if (value.f0 < 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout1-" + String.valueOf(value));
}
}
@Override
public void processElement2(Tuple2 value, Context ctx, Collector> out) throws Exception {
if (value.f0 >= 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout2-" + String.valueOf(value));
}
}
});
```
### 3.4.8 BroadcastStream 的用法及分析
### 3.4.9 BroadcastConnectedStream 的用法及分析
### 3.4.10 QueryableStateStream 的用法及分析
### 3.4.11 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/fy3RnMv

================================================
FILE: books/flink-in-action-3.5.md
================================================
---
toc: true
title: 《Flink 实战与性能优化》—— Watermark 的用法和结合 Window 处理延迟数据
date: 2021-07-15
tags:
- Flink
- 大数据
- 流式计算
---
## 3.5 Watermark 的用法和结合 Window 处理延迟数据
在 3.1 节中讲解了 Flink 中的三种 Time 和其对应的使用场景,然后在 3.2 节中深入的讲解了 Flink 中窗口的机制以及 Flink 中自带的 Window 的实现原理和使用方法。如果在进行 Window 计算操作的时候,如果使用的时间是 Processing Time,那么在 Flink 消费数据的时候,它完全不需要关心的数据本身的时间,意思也就是说不需要关心数据到底是延迟数据还是乱序数据。因为 Processing Time 只是代表数据在 Flink 被处理时的时间,这个时间是顺序的。但是如果你使用的是 Event Time 的话,那么你就不得不面临着这么个问题:事件乱序 & 事件延迟。
选择 Event Time 与 Process Time 的实际效果如下图所示:

在理想的情况下,Event Time 和 Process Time 是相等的,数据发生的时间与数据处理的时间没有延迟,但是现实却仍然这么骨感,会因为各种各样的问题(网络的抖动、设备的故障、应用的异常等原因)从而导致如图中曲线一样,Process Time 总是会与 Event Time 有一些延迟。所谓乱序,其实是指 Flink 接收到的事件的先后顺序并不是严格的按照事件的 Event Time 顺序排列的。如下图所示:

然而在有些场景下,其实是特别依赖于事件时间而不是处理时间,比如:
+ 错误日志的时间戳,代表着发生的错误的具体时间,开发们只有知道了这个时间戳,才能去还原那个时间点系统到底发生了什么问题,或者根据那个时间戳去关联其他的事件,找出导致问题触发的罪魁祸首
+ 设备传感器或者监控系统实时上传对应时间点的设备周围的监控情况,通过监控大屏可以实时查看,不错漏重要或者可疑的事件
这种情况下,最有意义的事件发生的顺序,而不是事件到达 Flink 后被处理的顺序。庆幸的是 Flink 支持用户以事件时间来定义窗口(也支持以处理时间来定义窗口),那么这样就要去解决上面所说的两个问题。针对上面的问题(事件乱序 & 事件延迟),Flink 引入了 Watermark 机制来解决。
### 3.5.1 Watermark 简介
举个例子:
统计 8:00 ~ 9:00 这个时间段打开淘宝 App 的用户数量,Flink 这边可以开个窗口做聚合操作,但是由于网络的抖动或者应用采集数据发送延迟等问题,于是无法保证在窗口时间结束的那一刻窗口中是否已经收集好了在 8:00 ~ 9:00 中用户打开 App 的事件数据,但又不能无限期的等下去?当基于事件时间的数据流进行窗口计算时,最为困难的一点也就是如何确定对应当前窗口的事件已经全部到达。然而实际上并不能百分百的准确判断,因此业界常用的方法就是基于已经收集的消息来估算是否还有消息未到达,这就是 Watermark 的思想。
Watermark 是一种衡量 Event Time 进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的 Watermark。Watermark 本质来说就是一个时间戳,代表着比这时间戳早的事件已经全部到达窗口,即假设不会再有比这时间戳还小的事件到达,这个假设是触发窗口计算的基础,只有 Watermark 大于窗口对应的结束时间,窗口才会关闭和进行计算。按照这个标准去处理数据,那么如果后面还有比这时间戳更小的数据,那么就视为迟到的数据,对于这部分迟到的数据,Flink 也有相应的机制(下文会讲)去处理。
下面通过几个图来了解一下 Watermark 是如何工作的!如下图所示,数据是 Flink 从消息队列中消费的,然后在 Flink 中有个 4s 的时间窗口(根据事件时间定义的窗口),消息队列中的数据是乱序过来的,数据上的数字代表着数据本身的 timestamp,`W(4)` 和 `W(9)` 是水印。

经过 Flink 的消费,数据 `1`、`3`、`2` 进入了第一个窗口,然后 `7` 会进入第二个窗口,接着 `3` 依旧会进入第一个窗口,然后就有水印了,此时水印过来了,就会发现水印的 timestamp 和第一个窗口结束时间是一致的,那么它就表示在后面不会有比 `4` 还小的数据过来了,接着就会触发第一个窗口的计算操作,如下图所示。

那么接着后面的数据 `5` 和 `6` 会进入到第二个窗口里面,数据 `9` 会进入在第三个窗口里面,如下图所示。

那么当遇到水印 `9` 时,发现水印比第二个窗口的结束时间 `8` 还大,所以第二个窗口也会触发进行计算,然后以此继续类推下去,如下图所示。

相信看完上面几个图的讲解,你已经知道了 Watermark 的工作原理是啥了,那么在 Flink 中该如何去配置水印呢,下面一起来看看。
### 3.5.2 Flink 中的 Watermark 的设置
在 Flink 中,数据处理中需要通过调用 DataStream 中的 assignTimestampsAndWatermarks 方法来分配时间和水印,该方法可以传入两种参数,一个是 AssignerWithPeriodicWatermarks,另一个是 AssignerWithPunctuatedWatermarks。
```java
public SingleOutputStreamOperator assignTimestampsAndWatermarks(AssignerWithPeriodicWatermarks timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPeriodicWatermarks cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPeriodicWatermarksOperator operator = new TimestampsAndPeriodicWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
public SingleOutputStreamOperator assignTimestampsAndWatermarks(AssignerWithPunctuatedWatermarks timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPunctuatedWatermarks cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPunctuatedWatermarksOperator operator = new TimestampsAndPunctuatedWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
```
所以设置 Watermark 是有如下两种方式:
+ AssignerWithPunctuatedWatermarks:数据流中每一个递增的 EventTime 都会产生一个 Watermark。
在实际的生产环境中,在 TPS 很高的情况下会产生大量的 Watermark,可能在一定程度上会对下游算子造成一定的压力,所以只有在实时性要求非常高的场景才会选择这种方式来进行水印的生成。
+ AssignerWithPeriodicWatermarks:周期性的(一定时间间隔或者达到一定的记录条数)产生一个 Watermark。
在实际的生产环境中,通常这种使用较多,它会周期性产生 Watermark 的方式,但是必须结合时间或者积累条数两个维度,否则在极端情况下会有很大的延时,所以 Watermark 的生成方式需要根据业务场景的不同进行不同的选择。
下面再分别详细讲下这两种的实现方式。
### 3.5.3 Punctuated Watermark
AssignerWithPunctuatedWatermarks 接口中包含了 checkAndGetNextWatermark 方法,这个方法会在每次 extractTimestamp() 方法被调用后调用,它可以决定是否要生成一个新的水印,返回的水印只有在不为 null 并且时间戳要大于先前返回的水印时间戳的时候才会发送出去,如果返回的水印是 null 或者返回的水印时间戳比之前的小则不会生成新的水印。
那么该怎么利用这个来定义水印生成器呢?
```java
public class WordPunctuatedWatermark implements AssignerWithPunctuatedWatermarks {
@Nullable
@Override
public Watermark checkAndGetNextWatermark(Word lastElement, long extractedTimestamp) {
return extractedTimestamp % 3 == 0 ? new Watermark(extractedTimestamp) : null;
}
@Override
public long extractTimestamp(Word element, long previousElementTimestamp) {
return element.getTimestamp();
}
}
```
需要注意的是这种情况下可以为每个事件都生成一个水印,但是因为水印是要在下游参与计算的,所以过多的话会导致整体计算性能下降。
### 3.5.4 Periodic Watermark
通常在生产环境中使用 AssignerWithPeriodicWatermarks 来定期分配时间戳并生成水印比较多,那么先来讲下这个该如何使用。
```java
public class WordPeriodicWatermark implements AssignerWithPeriodicWatermarks {
private long currentTimestamp = Long.MIN_VALUE;
@Override
public long extractTimestamp(Word word, long previousElementTimestamp) {
long timestamp = word.getTimestamp();
currentTimestamp = Math.max(timestamp, currentTimestamp);
return word.getTimestamp();
}
@Nullable
@Override
public Watermark getCurrentWatermark() {
long maxTimeLag = 5000;
return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - maxTimeLag);
}
}
```
上面的是我根据 Word 数据自定义的水印周期性生成器,在这个类中,有两个方法 extractTimestamp() 和 getCurrentWatermark()。extractTimestamp() 方法是从数据本身中提取 Event Time,然后将当前时间戳与事件时间进行比较,取最大值后赋值给当前时间戳 currentTimestamp,然后返回事件时间。getCurrentWatermark() 方法是获取当前的水位线,通过 `currentTimestamp - maxTimeLag` 得到水印的值,这里有个 maxTimeLag 参数代表数据能够延迟的时间,上面代码中定义的 `long maxTimeLag = 5000;` 表示最大允许数据延迟时间为 5s,超过 5s 的话如果还来了之前早的数据,那么 Flink 就会丢弃了,因为 Flink 的窗口中的数据是要触发的,不可能一直在等着这些迟到的数据(由于网络的问题数据可能一直没发上来)而不让窗口触发结束进行计算操作。
通过定义这个时间,可以避免部分数据因为网络或者其他的问题导致不能够及时上传从而不把这些事件数据作为计算的,那么如果在这延迟之后还有更早的数据到来的话,那么 Flink 就会丢弃了,所以合理的设置这个允许延迟的时间也是一门细活,得观察生产环境数据的采集到消息队列再到 Flink 整个流程是否会出现延迟,统计平均延迟大概会在什么范围内波动。这也就是说明了一个事实那就是 Flink 中设计这个水印的根本目的是来解决部分数据乱序或者数据延迟的问题,而不能真正做到彻底解决这个问题,不过这一特性在相比于其他的流处理框架已经算是非常给力了。
AssignerWithPeriodicWatermarks 这个接口有四个实现类,如下图所示:

这四个实现类的功能和使用方式如下:
+ BoundedOutOfOrdernessTimestampExtractor:该类用来发出滞后于数据时间的水印,它的目的其实就是和我们上面定义的那个类作用是类似的,你可以传入一个时间代表着可以允许数据延迟到来的时间是多长。该类内部实现如下图所示:

你可以像下面一样使用该类来分配时间和生成水印:
```java
//Time.seconds(10) 代表允许延迟的时间大小
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(10)) {
//重写 BoundedOutOfOrdernessTimestampExtractor 中的 extractTimestamp()抽象方法
@Override
public long extractTimestamp(Event event) {
return event.getTimestamp();
}
})
```
+ CustomWatermarkExtractor:这是一个自定义的周期性生成水印的类,在这个类里面的数据是 KafkaEvent。
+ AscendingTimestampExtractor:时间戳分配器和水印生成器,用于时间戳单调递增的数据流,如果数据流的时间戳不是单调递增,那么会有专门的处理方法,代码如下:
```java
public final long extractTimestamp(T element, long elementPrevTimestamp) {
final long newTimestamp = extractAscendingTimestamp(element);
if (newTimestamp >= this.currentTimestamp) {
this.currentTimestamp = ne∏wTimestamp;
return newTimestamp;
} else {
violationHandler.handleViolation(newTimestamp, this.currentTimestamp);
return newTimestamp;
}
}
```
+ IngestionTimeExtractor:依赖于机器系统时间,它在 extractTimestamp 和 getCurrentWatermark 方法中是根据 `System.currentTimeMillis()` 来获取时间的,而不是根据事件的时间,如果这个时间分配器是在数据源进 Flink 后分配的,那么这个时间就和 Ingestion Time 一致了,所以命名也取的就是叫 IngestionTimeExtractor。
**注意**:
1、使用这种方式周期性生成水印的话,你可以通过 `env.getConfig().setAutoWatermarkInterval(...);` 来设置生成水印的间隔(每隔 n 毫秒)。
2、通常建议在数据源(source)之后就进行生成水印,或者做些简单操作比如 filter/map/flatMap 之后再生成水印,越早生成水印的效果会更好,也可以直接在数据源头就做生成水印。比如你可以在 source 源头类中的 run() 方法里面这样定义
```java
@Override
public void run(SourceContext