Showing preview only (2,058K chars total). Download the full file or copy to clipboard to get everything.
Repository: AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin
Branch: master
Commit: 6f6d4907adf0
Files: 149
Total size: 1.9 MB
Directory structure:
gitextract_gqg6c0_w/
├── .gitignore
├── .prettierignore
├── .prettierrc
├── LICENSE.md
├── README.md
├── build-script/
│ ├── pack-ccx.mjs
│ └── webpack.config.js
├── deprecated-do-not-use-start_server.bat
├── deprecated-do-not-use-start_server.sh
├── deprecated-do-not-use-start_server_MacOS.sh
├── deprecated-do-not-use-update_plugin.bat
├── deprecated-do-not-use-update_plugin.sh
├── dialog_box.js
├── docs/
│ └── Home.md
├── enum.js
├── helper.js
├── i18n/
│ └── zh_CN/
│ ├── ps-plugin.json
│ └── sd-official.json
├── index.html
├── index.js
├── install.py
├── manifest.json
├── package.json
├── presets/
│ ├── ctrlnet_inpaint.json
│ ├── ctrlnet_inpaint_tile.json
│ ├── ctrlnet_outpaint.json
│ ├── default.json
│ ├── img2img.json
│ ├── inpaint.json
│ └── outpaint.json
├── psapi.js
├── requirements.txt
├── scripts/
│ ├── main.py
│ └── test.py
├── sdapi_py_re.js
├── selection.js
├── server/
│ └── python_server/
│ ├── global_state.py
│ ├── img2imgapi.py
│ ├── init_images/
│ │ └── .gitignore
│ ├── metadata_to_json.py
│ ├── output/
│ │ └── .gitignore
│ ├── prompt_shortcut - Copy.json
│ ├── prompt_shortcut.py
│ ├── search.py
│ ├── serverHelper.py
│ └── serverMain.py
├── thumbnail.js
├── typescripts/
│ ├── @types/
│ │ ├── changedpi.d.ts
│ │ ├── custom.d.ts
│ │ ├── sdapi_py_re.d.ts
│ │ └── uxp.d.ts
│ ├── after_detailer/
│ │ ├── after_detailer.tsx
│ │ ├── config.ts
│ │ └── style/
│ │ └── after_detailer.css
│ ├── comfyui/
│ │ ├── comfyapi.ts
│ │ ├── comfyui.tsx
│ │ ├── img2img_api.json
│ │ ├── img2img_workflow.json
│ │ ├── inpaint_api.json
│ │ ├── inpaint_workflow.json
│ │ ├── main_ui.tsx
│ │ ├── native_workflows/
│ │ │ ├── IPAdapter_simple_api.json
│ │ │ ├── IPAdapter_weighted_api.json
│ │ │ ├── animatediff_lcm_api.json
│ │ │ ├── animatediff_simple_api.json
│ │ │ ├── real_time_lcm_img2img_api.json
│ │ │ ├── real_time_lcm_sketching_api.json
│ │ │ ├── real_time_lcm_txt2img_api.json
│ │ │ ├── sdxl_turbo_txt2img_api.json
│ │ │ └── zoom_out_api.json
│ │ ├── txt2img_api.json
│ │ ├── txt2img_workflow.json
│ │ └── util.ts
│ ├── controlnet/
│ │ ├── ControlNetTab.tsx
│ │ ├── ControlNetUnit.tsx
│ │ ├── entry.ts
│ │ ├── main.tsx
│ │ ├── store.ts
│ │ └── util.tsx
│ ├── entry.ts
│ ├── extra_page/
│ │ └── extra_page.tsx
│ ├── globalstore.ts
│ ├── history/
│ │ └── history.tsx
│ ├── image_search/
│ │ └── image_search.tsx
│ ├── lexical/
│ │ └── lexical.tsx
│ ├── locale/
│ │ ├── locale-for-old-html.ts
│ │ └── locale.ts
│ ├── main/
│ │ └── astore.ts
│ ├── multiTextarea.tsx
│ ├── one_button_prompt/
│ │ └── one_button_prompt.tsx
│ ├── preset/
│ │ ├── preset.tsx
│ │ └── shared_ui_preset.ts
│ ├── sam/
│ │ └── sam.tsx
│ ├── sd_tab/
│ │ ├── sd_tab.tsx
│ │ └── util.ts
│ ├── session/
│ │ ├── generate.tsx
│ │ ├── modes.ts
│ │ ├── progress.ts
│ │ ├── session.ts
│ │ ├── session_store.ts
│ │ └── style/
│ │ └── generate.css
│ ├── settings/
│ │ ├── settings.tsx
│ │ └── vae.tsx
│ ├── stores.ts
│ ├── tool_bar/
│ │ ├── style/
│ │ │ └── tool_bar.css
│ │ └── tool_bar.tsx
│ ├── tsconfig.json
│ ├── ultimate_sd_upscaler/
│ │ ├── config.ts
│ │ ├── scripts.tsx
│ │ └── ultimate_sd_upscaler.tsx
│ ├── util/
│ │ ├── collapsible.tsx
│ │ ├── elements.tsx
│ │ ├── errorBoundary.tsx
│ │ ├── grid.tsx
│ │ ├── logger.ts
│ │ ├── oldSystem.tsx
│ │ └── ts/
│ │ ├── api.ts
│ │ ├── document.ts
│ │ ├── enum.ts
│ │ ├── general.ts
│ │ ├── io.ts
│ │ ├── layer.ts
│ │ ├── sdapi.ts
│ │ ├── selection.ts
│ │ └── ui_ts.ts
│ └── viewer/
│ ├── preview.tsx
│ ├── style/
│ │ └── preview.css
│ ├── viewer.tsx
│ └── viewer_util.ts
└── utility/
├── api.js
├── dummy.js
├── general.js
├── html_manip.js
├── io.js
├── layer.js
├── notification.js
├── online_data.json
├── presets/
│ └── controlnet_preset.js
├── sampler.js
├── sd_scripts/
│ └── horde.js
├── sdapi/
│ ├── config.js
│ ├── horde_native.js
│ ├── options.js
│ ├── prompt_shortcut.js
│ └── python_replacement.js
├── session.js
├── tab/
│ ├── image_search_tab.js
│ └── settings.js
└── tips.js
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
**/__pycache__
env
/server_env
/tmp
/outputs
/log
/.idea
/.vscode
/.git
/.github
test.bat
server/python_server/output/*
server/python_server/init_images/*
node_modules/
server/python_server/prompt_shortcut.json
experimental/
start_server.sh
start_server.bat
*.ccx
*.zip
expanded_mask.png
original_mask.png
/config
/jimp/*
!/jimp/browser/
/jimp/browser/examples
/jimp/browser/*.md
/jimp/browser/*.editorconfig
/jimp/browser/lib/jimp.js
# comments when packaging (include in the package,uxp packager will use .gitignore to ignore files):
*/dist/*LICENSE.txt
*/dist/*.bundle.js
typescripts/dist
================================================
FILE: .prettierignore
================================================
server/python_server/output/*
*.md
manifest.json
jimp/**
server_env/**
.github\workflows\wiki-sync-action.yml
**/dist
.github\workflows\wiki-sync-action.yml
tsconfig.json
================================================
FILE: .prettierrc
================================================
{
"trailingComma": "es5",
"tabWidth": 4,
"semi": false,
"singleQuote": true
}
================================================
FILE: LICENSE.md
================================================
MIT License
Copyright (c) 2022 Abdullah Alfaraj
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# Auto-Photoshop-StableDiffusion-Plugin
[](https://www.patreon.com/AbdullahAlfaraj)
[![discord badge]][discord link]
[discord badge]: https://flat.badgen.net/discord/members/3mVEtrddXJ
[discord link]: https://discord.gg/3mVEtrddXJ
With Auto-Photoshop-StableDiffusion-Plugin, you can directly use the capabilities of Automatic1111 Stable Diffusion in Photoshop without switching between programs. This allows you to easily use Stable Diffusion AI in a familiar environment. You can edit your Stable Diffusion image with all your favorite tools and save it right in Photoshop.
# Table of Contents
- [Auto-Photoshop-StableDiffusion-Plugin](#auto-photoshop-stablediffusion-plugin)
- [Table of Contents](#table-of-contents)
- [Demo:](#demo)
- [Support Us On Patreon](#support-us-on-patreon)
- [How to Install](#how-to-install)
- [Method 1: One Click Installer](#method-1-one-click-installer)
- [Method 2: The Unzip Method](#method-2-the-unzip-method)
- [Method 3: The UXP Method (for Developers/Programmers Only)](#method-3-the-uxp-method-instruction-for-developers)
- [FAQ and Known Issues](#faq-and-known-issues)
- [What Photoshop version do I need to run the plugin?](#what-photoshop-version-do-i-need-to-run-the-plugin)
- [Path Doesn't Exist](#path-doesnt-exist)
- [Plugin Load Failed](#plugin-load-failed)
- [No application are connected to the service](#no-application-are-connected-to-the-service)
- [Load command failed in App with ID PS and Version X.X.X](#load-command-failed-in-app-with-id-ps-and-version-xxx)
- [Exception in ASGI application / Expecting value: line 1 column 1](#exception-in-asgi-application--expecting-value-line-1-column-1)
- [No Generations and Plugin Server doesn't send messages. (Remote setup)](#no-generations-and-plugin-server-doesnt-send-messages-remote-setup)
- [No GPU Options](#no-gpu-options)
- [Stable Horde](#stable-horde)
- [Colab](#colab)
# Support Us On Patreon:
By supporting us on [Patreon](https://www.patreon.com/AbdullahAlfaraj), you’ll help us continue to develop and improve the Auto-Photoshop-StableDiffusion-Plugin, making it even easier for you to use Stable Diffusion AI in a familiar environment. As a supporter, you’ll have the opportunity to provide feedback and suggestions for future development. Plus, you’ll get early access to new features and tutorials, as well as exclusive art tutorials and tips from a professional artist. We’re passionate about making AI approachable to artists and with your help, we can continue to do just that.
# Auto-Photoshop-SD Backers and Sponsors:
<h2>💎 Diamond</h2>
<table>
<tr>
<td><a href="https://ronnykhalil.com/"><img src="https://images.weserv.nl/?url=https://raw.githubusercontent.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin/206b56c911f67ede3ca3a934d0bce8c1d68a2113/docs/profile_image/A934E4F0-7778-47E9-A395-531BFF2E61F1_1_105_c.jpeg&h=80&w=80&fit=cover&mask=circle&maxage=7d" alt="Ronny Khalil"></a></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=zachary" alt="zachary"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Razvan+Matei" alt="Razvan Matei"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=MasterAI" alt="MasterAI"></td>
</tr>
<tr>
<td><a href="https://ronnykhalil.com/">Ronny Khalil</a></td>
<td>zachary</td>
<td>Razvan Matei</td>
<td>MasterAI</td>
</tr>
</table>
<h2>🥇 Gold</h2>
<table>
<tr>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Alex+" alt="Alex "></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Olivier+Lefebvre" alt="Olivier Lefebvre"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Arthur+Liu" alt="Arthur Liu"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Florin-Alexandru+Ilinescu" alt="Florin-Alexandru Ilinescu"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Zenko+" alt="Zenko "></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Juan+Pablo+Mendiola" alt="Juan Pablo Mendiola"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Robin+Edwards" alt="Robin Edwards"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Frederic+Dreuilhe" alt="Frederic Dreuilhe"></td>
</tr>
<tr>
<td>Alex </td>
<td>Olivier Lefebvre</td>
<td>Arthur Liu</td>
<td>Florin-Alexandru Ilinescu</td>
<td>Zenko </td>
<td>Juan Pablo Mendiola</td>
<td>Robin Edwards</td>
<td>Frederic Dreuilhe</td>
</tr>
<tr>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Danny+Sahagun" alt="Danny Sahagun"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=darius+coal" alt="darius coal"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Kerwin" alt="Kerwin"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=The+Dread+Vixen+Alinsa" alt="The Dread Vixen Alinsa"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Bruce+Hunter" alt="Bruce Hunter"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Chris+Canterbury" alt="Chris Canterbury"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Lawrence+L+Tran" alt="Lawrence L Tran"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Jake+Skokan" alt="Jake Skokan"></td>
</tr>
<tr>
<td>Danny Sahagun</td>
<td>darius coal</td>
<td>Kerwin</td>
<td>The Dread Vixen Alinsa</td>
<td>Bruce Hunter</td>
<td>Chris Canterbury</td>
<td>Lawrence L Tran</td>
<td>Jake Skokan</td>
</tr>
<tr>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=que0005" alt="que0005"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Xavier+Matia+Bernasconi" alt="Xavier Matia Bernasconi"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Mats+Oldin" alt="Mats Oldin"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Rodrigo+Terra" alt="Rodrigo Terra"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Nicolas+Meunier" alt="Nicolas Meunier"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Ihor+Pankin" alt="Ihor Pankin"></td>
</tr>
<tr>
<td>que0005</td>
<td>Xavier Matia Bernasconi</td>
<td>Mats Oldin</td>
<td>Rodrigo Terra</td>
<td>Nicolas Meunier</td>
<td>Ihor Pankin</td>
</tr>
</table>
<h2>🥈 Silver</h2>
<table>
<tr>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Amith+Thomas" alt="Amith Thomas"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=xiao+yuan" alt="xiao yuan"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Ezra+Blake" alt="Ezra Blake"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Kevin+Schofield" alt="Kevin Schofield"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Mvs+Srs" alt="Mvs Srs"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Felipe+Cortes" alt="Felipe Cortes"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Smith" alt="Smith"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Sanchez" alt="Sanchez"></td>
</tr>
<tr>
<td>Amith Thomas</td>
<td>xiao yuan</td>
<td>Ezra Blake</td>
<td>Kevin Schofield</td>
<td>Mvs Srs</td>
<td>Felipe Cortes</td>
<td>Smith</td>
<td>Sanchez</td>
</tr>
<tr>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Ziui+Witter" alt="Ziui Witter"></td>
</tr>
<tr>
<td>Ziui Witter</td>
</tr>
</table>
<h2>🥉 Copper</h2>
<table>
<tr>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Sebastian+Karbowniczek" alt="Sebastian Karbowniczek"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Petter+Lundh" alt="Petter Lundh"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=AWWalker" alt="AWWalker"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=cdmusic" alt="cdmusic"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=Jason+Bessonette" alt="Jason Bessonette"></td>
<td><img src="https://ui-avatars.com/api/?background=random&color=fff&rounded=true&name=22two+" alt="22two "></td>
</tr>
<tr>
<td>Sebastian Karbowniczek</td>
<td>Petter Lundh</td>
<td>AWWalker</td>
<td>cdmusic</td>
<td>Jason Bessonette</td>
<td>22two </td>
</tr>
</table>
<a href="https://www.patreon.com/AbdullahAlfaraj" rel="nofollow"><img src="docs/become_backer.svg" style="max-width: 100%;"></a>
# How To Install:
Use method 1 or 2 if you are an Artist
use method 3 if you are a Developer/Programmer
# Method 1: One Click Installer
1) Download the [.ccx](https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin/releases/latest) file
2) run the ccx file . that's all. you will be able to use all of stable diffusion modes (txt2img, img2img, inpainting and outpainting), check the [tutorials](https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin/wiki) section to master the tool.
3) (Don't skip) Install the `Auto-Photoshop-SD` Extension from Automatic1111 extension tab. The extension will allow you to use mask expansion and mask blur, which are necessary for achieving good results when outpainting and inpainting.
- a) Copy Auto-Photoshop plugin url
- b) Paste the url in auto1111's extension tab and click install
- c) Make sure the Auto-Photoshop plugin is listed, then click "Apply and Restart UI"
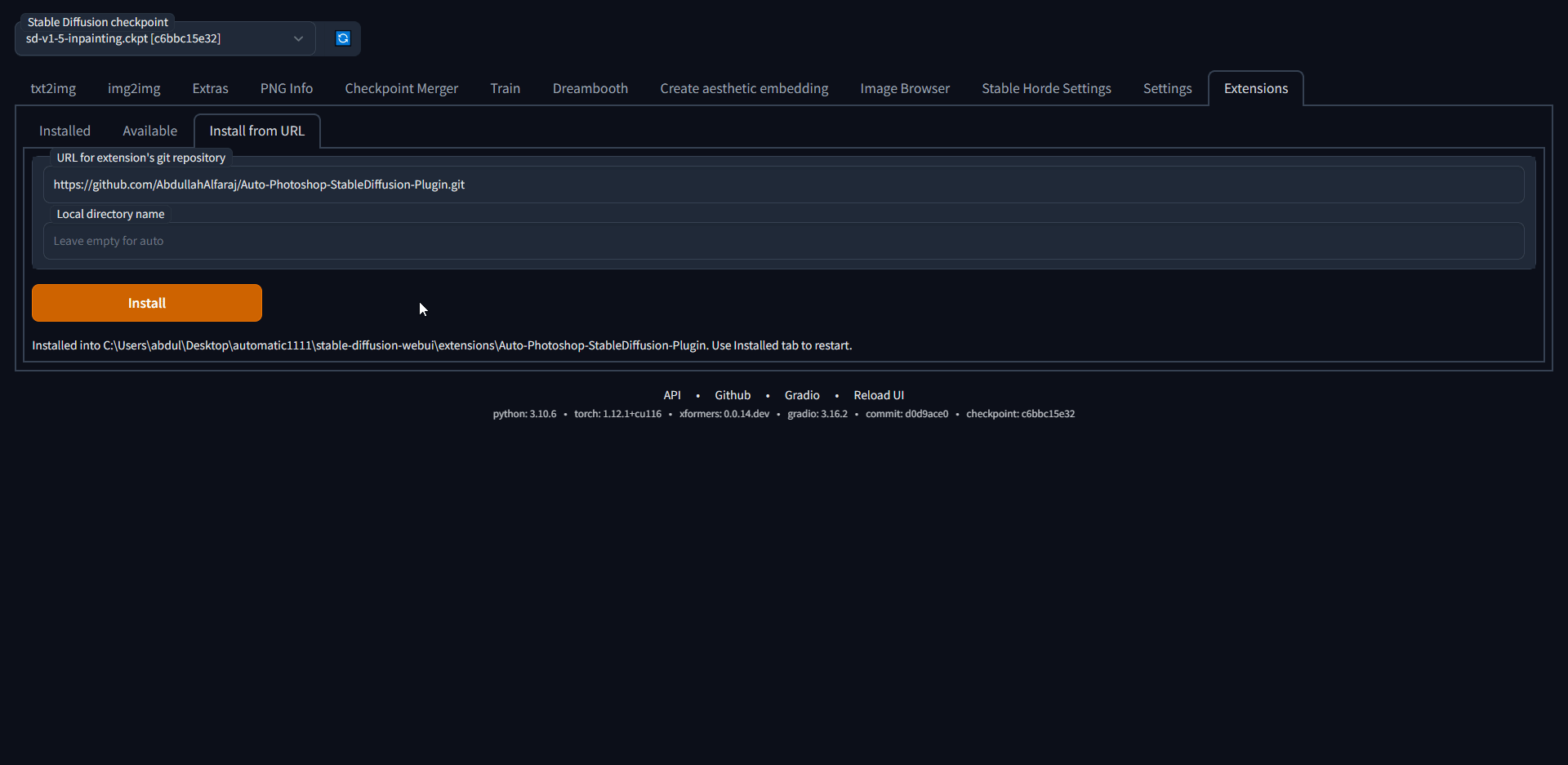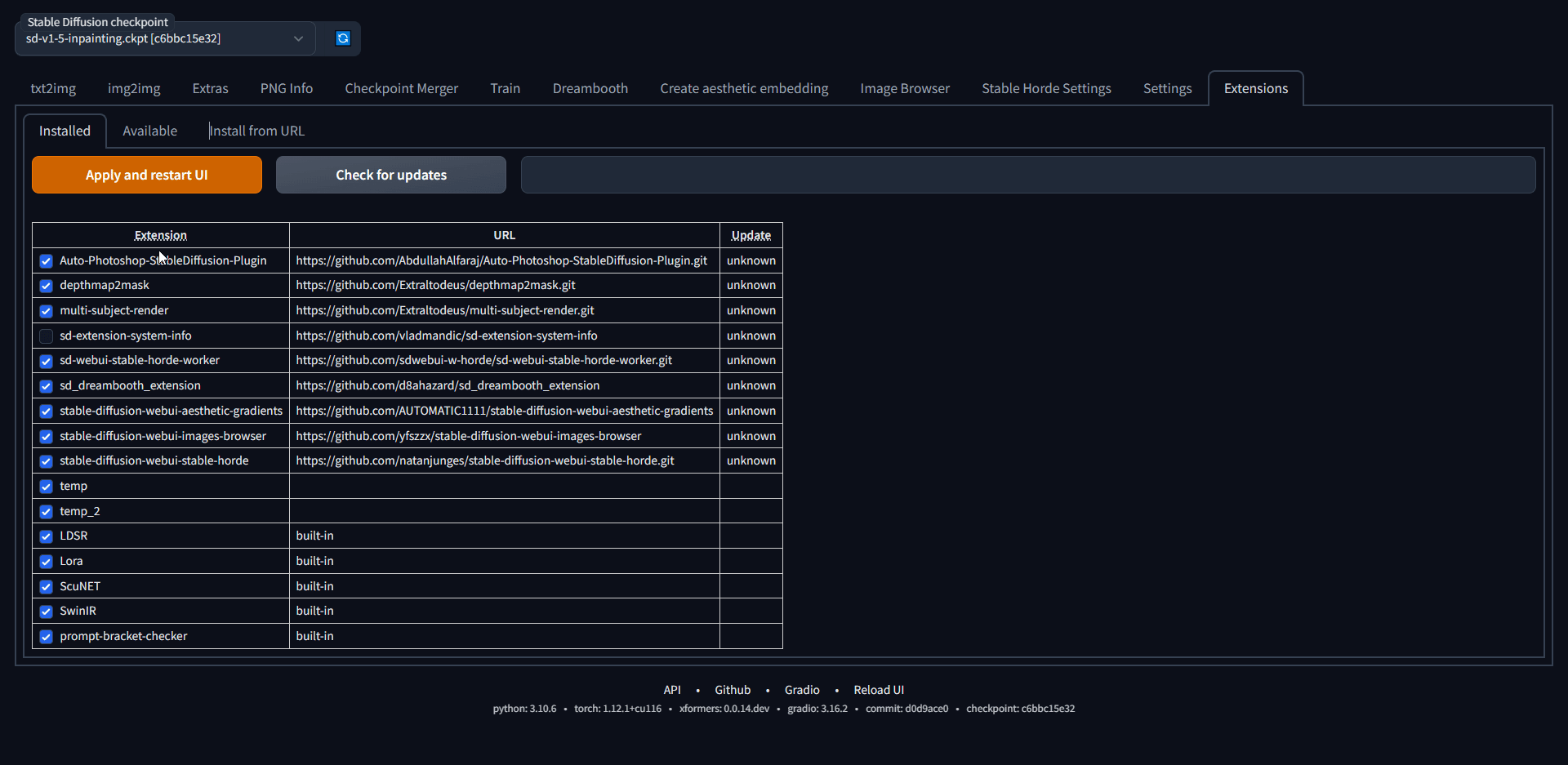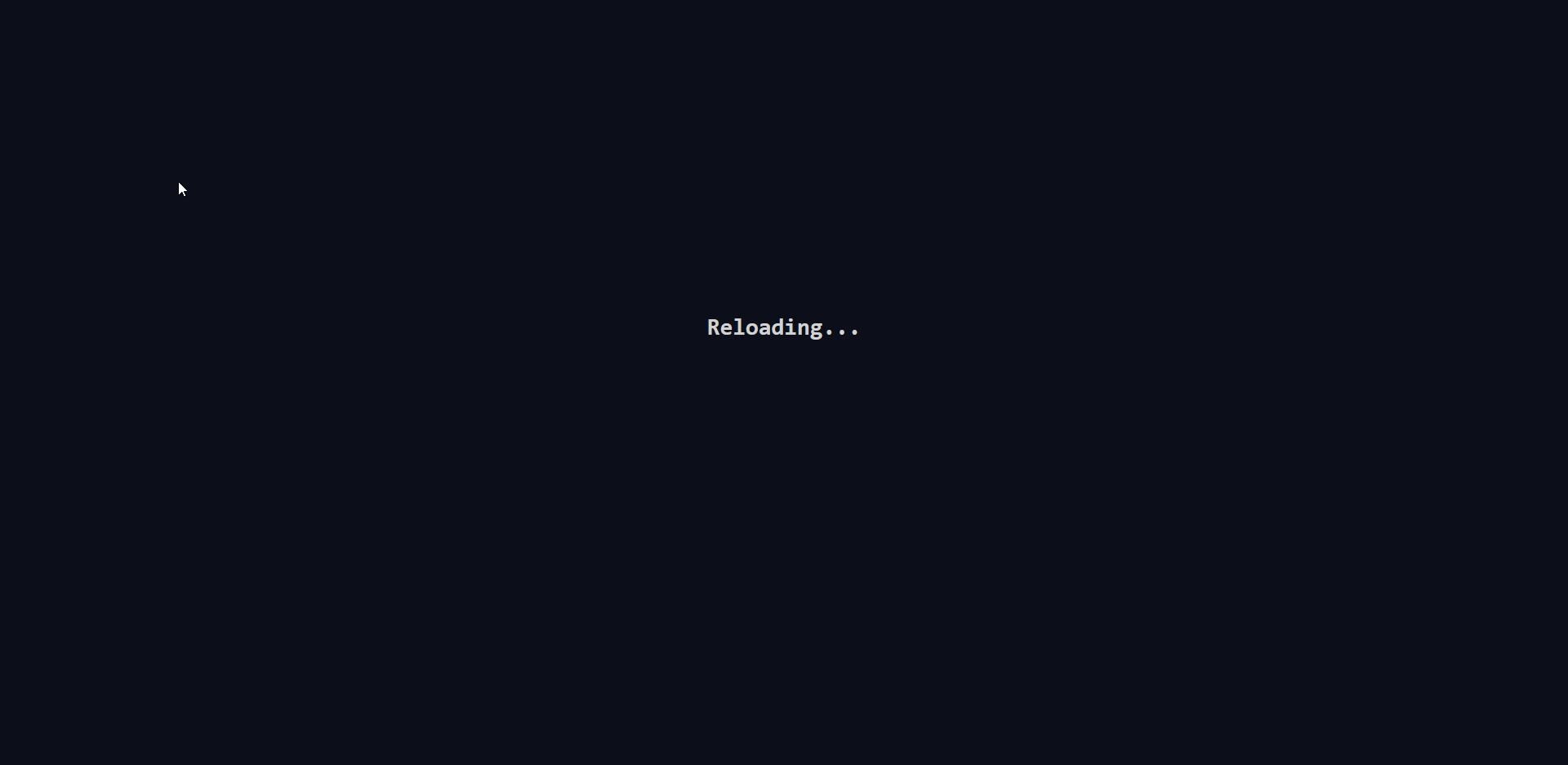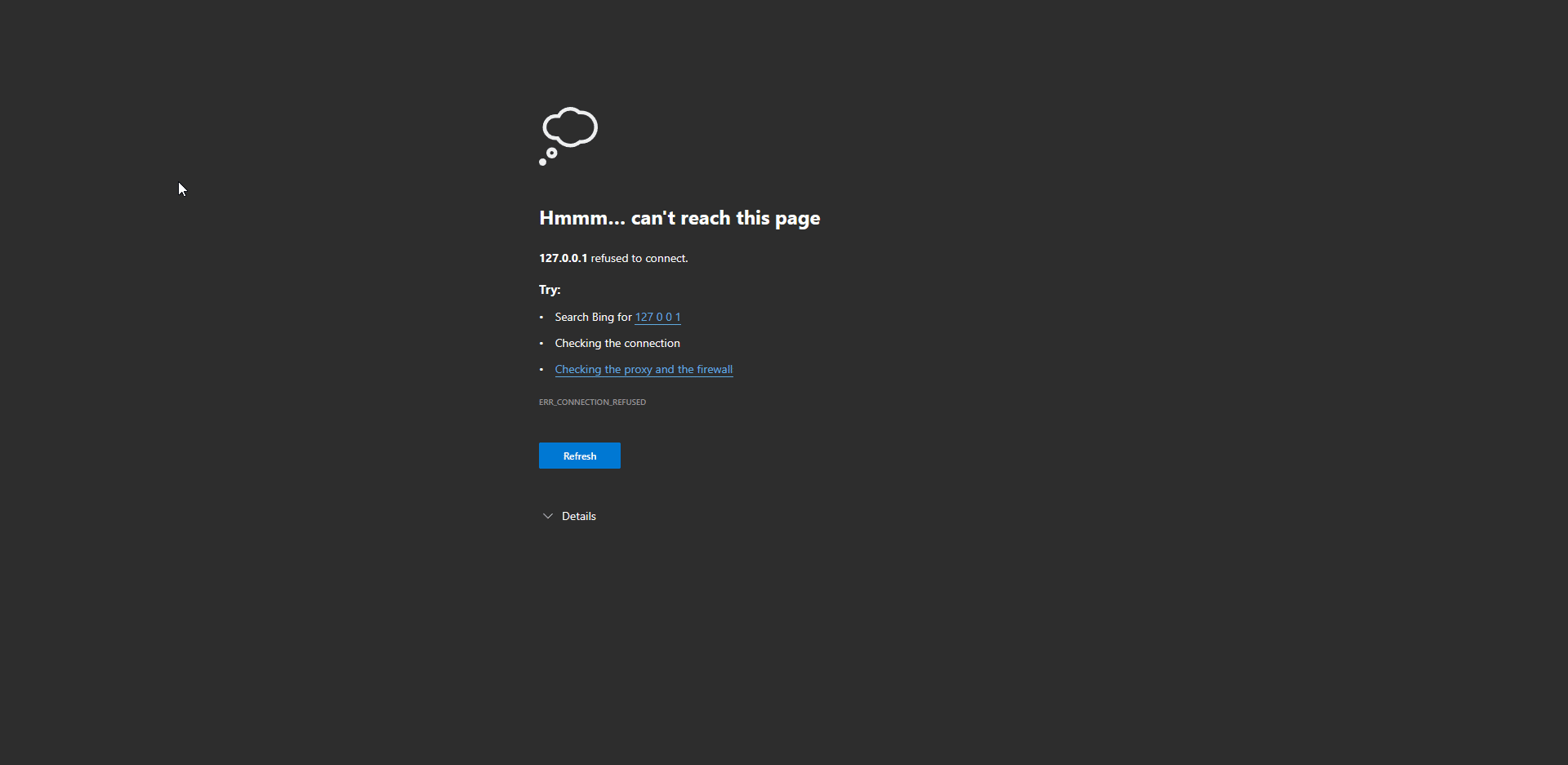
# Method 2: The Unzip Method
1) Download the [.zip](https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin/releases/latest) file
2) Unzip it in a folder with the same name
3) move the unzipped folder to the Photoshop Plugin folder
4) (Don't skip) Install the `Auto-Photoshop-SD` Extension from Automatic1111 extension tab. The extension will allow you to use mask expansion and mask blur, which are necessary for achieving good results when outpainting and inpainting.
- a) Copy Auto-Photoshop plugin url
# Method 3: The UXP method (Instruction for Developers):
For artists we recommend you use [the one click installer](#one-click-installer). If you are a developer Watch the any of these videos or follow the instruction bellow.
<a href="https://www.youtube.com/watch?v=BNzdhEpFHrg&ab_channel=Abdsart" title="How To Install Auto Photoshop Stable Diffusion Plugin by Abdullah Alfaraj" rel="Click Here to Watch How To Install Tutorial by Abdullah Alfaraj"><img src="https://user-images.githubusercontent.com/7842232/217941315-8d4a3b25-1a83-4dac-b921-79b3f82e0536.png" style="width:500px"></a>
<a href="https://www.youtube.com/watch?v=CJuTZw39Reg&t=145s&ab_channel=VladimirChopine%5BGeekatPlay%5D" title="How To Install Auto Photoshop Stable Diffusion Plugin by Vladimir Chopine" rel="Click Here to Watch How To Install Tutorial by Vladimir Chopine"><img src="https://i3.ytimg.com/vi/CJuTZw39Reg/maxresdefault.jpg" style="width:500px"></a>
For artists we recommend you use [the one click installer](#one-click-installer)
## First time running the plugin (local Automatic1111):
1) download the plugin:
```
git clone https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin.git
```
2) open cmd window in the "Auto-Photoshop-StableDiffusion-Plugin" directory and then install the dependencies by typing:
```
npm install
```
3) build the plugin by transpiling typescript to javascript:
```
npm run watch
```
4) run "start_server.bat" inside "Auto-Photoshop-StableDiffusion-Plugin" directory
5) go to where you have [automatic1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) installed.
Edit the "webui-user.bat" in automatic1111
change this line
```
set COMMANDLINE_ARGS=
```
to
```
set COMMANDLINE_ARGS= --api
```
that will allow the plugin to communicate with the automatic1111 project. After saving close the "webui-user.bat" file and run it normally.
6) run photoshop. go to edit -> prefrences -> plugins
1) make sure you check "Enable Developer Mode" checkbox
7) install "Adobe UXP Developer Tool" from here [Installation (adobe.com)](https://developer.adobe.com/photoshop/uxp/devtool/installation/)
this tool will add the plugin into photoshop
8) run Adobe UXP Developer Tool and click on "Add Plugin" button in the top right. Navigate to where you have "Auto-Photoshop-StableDiffusion-Plugin" folder and open "manifest.json"
9) select the plugin and click on Actions -> Load Selected
that's it.
## First time running the plugin (remote Automatic1111):
__The remote webui must also have `--api` set in `COMMANDLINE_ARGS`. You can check if api access is enabled by appending "/docs#" to the end of the url. If the documentation includes `/sdapi/v1/samplers` then api access is enabled.__
1) download the plugin:
```
git clone https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin.git
```
1) edit [start_server.bat](start_server.bat) (or start_server.sh if on linux) to point to the remote installation of Automatic1111
2) run "start_server.bat" inside "Auto-Photoshop-StableDiffusion-Plugin" directory
3) run photoshop. go to edit -> prefrences -> plugins
1) make sure you check "Enable Developer Mode" checkbox
4) install "Adobe UXP Developer Tool" from here [Installation (adobe.com)](https://developer.adobe.com/photoshop/uxp/devtool/installation/)
this tool will add the plugin into photoshop
5) run Adobe UXP Developer Tool and click on "Add Plugin" button in the top right. Navigate to where you have "Auto-Photoshop-StableDiffusion-Plugin" folder and open "manifest.json"
6) select the plugin and click on Actions -> Load Selected
that's it.
# Demo:
[](https://youtu.be/VL_gbQai79E "Stable diffusion AI Photoshop Plugin Free and Open Source")
# FAQ and Known Issues
## What Photoshop version do I need to run the plugin?
The minimum Photoshop version that the plugin supports is Photoshop v24
## Plugin Load Failed
There are a few issues that can result in this error, please follow the instructions for the corresponding error message in the UDT logs
### No application are connected to the service
This error occurs when Photoshop is not started before the plugin is attempted to be loaded. Simply start photoshop then restart UXP and load the plugin
## Exception in ASGI application / Expecting value: line 1 column 1
This error occurs due to mismatched expectations between the plugin and the Automatic1111 backend.
It can be solved by both updating the version of the Automatic111 backend to the latest verion, and making sure "Save text information about generation parameters as chunks to png files" setting is enabled within the UI.
## No Generations and Plugin Server doesn't send messages. (Remote setup)
This error occurs when the remote server does not have the api enabled. You can verify this by attempting to go to the URL you access the webui at and appending "/docs#" to the end of the url. If you have permissions, make relaunch the remote instance with the "--api" flag.
# No GPU Options:
we provide two options to use the auto-photoshp plugin without GPU.
## Stable Horde
This is an awesome free crowdsourced distributed cluster of Stable Diffusion workers. If you like this service, consider joining the horde yourself!
the horde is enabled completely by the generosity of volunteers so make sure you don't overwhelm the service and help join the cause if you can.
read more on their [GitHub page](https://github.com/db0/AI-Horde)
## Colab:
we link to this [Colab](https://colab.research.google.com/drive/1nbcx_WOneRmYv9idBO33pN5CbxXrqZHu?usp=sharing#scrollTo=Y4ebYsPqTrGb) directly inside plugin find it in the settings tab. you only need to run it. no need to change any of the settings. copy the gradio.live url the colab will generate and paste it into ```sd url``` field in the settings tab.
================================================
FILE: build-script/pack-ccx.mjs
================================================
import chalk from 'chalk'
import { program } from 'commander'
import { createWriteStream, readFileSync, statSync, writeFileSync } from 'fs'
import { globSync } from 'glob'
import { dirname, join, relative } from 'path'
import { fileURLToPath } from 'url'
import yazl from 'yazl'
const __dirname = dirname(fileURLToPath(import.meta.url))
const basePath = join(__dirname, '..')
program.requiredOption('--version <platform>', 'the target platform').parse()
const version = program.opts().version
if (!version.match(/\d+\.\d+\.\d+/))
throw new Error(`invalid version format: ${version}`)
console.log(chalk.cyan("rewriting manifest.json's version field to " + version))
const manifest = JSON.parse(readFileSync(`${basePath}/manifest.json`, 'utf-8'))
manifest.version = version
writeFileSync(`${basePath}/manifest.json`, JSON.stringify(manifest))
console.log(chalk.cyan("rewriting package.json's version field to " + version))
const packageJSON = JSON.parse(
readFileSync(`${basePath}/package.json`, 'utf-8')
)
packageJSON.version = version
writeFileSync(`${basePath}/package.json`, JSON.stringify(packageJSON))
console.log(chalk.cyan('packaging .ccx'))
const zipList = [
'./manifest.json',
'./i18n/**/*',
'./icon/**/*',
'./jimp/**/*',
'./scripts/**/*',
'./typescripts/dist/**/*',
'./utility/**/*',
'./server/**/*',
'./*.js',
'./package.json',
'./tsconfig.json',
'./*.html',
'./*.py',
'./*.txt',
'./*.md',
'./*.png',
'./presets/**/*',
'./typescripts/comfyui/**/*.json',
]
const zipfile = new yazl.ZipFile()
zipList.forEach((globber) => {
globSync(join(basePath, globber).replace(/\\/g, '/')).forEach(
(filepath) => {
if (statSync(filepath).isDirectory()) return
const rpath = relative(basePath, filepath)
zipfile.addFile(filepath, rpath)
}
)
})
zipfile.outputStream.pipe(
createWriteStream(
join(basePath, `Auto.Photoshop.SD.plugin_v${version}.ccx`)
)
)
zipfile.outputStream.pipe(
createWriteStream(
join(basePath, `Auto.Photoshop.SD.plugin_v${version}.zip`)
)
)
zipfile.end()
================================================
FILE: build-script/webpack.config.js
================================================
const path = require('path')
// const CleanWebpackPlugin = require('clean-webpack-plugin')
const CopyPlugin = require('copy-webpack-plugin')
module.exports = {
entry: {
bundle: path.resolve(__dirname, '../typescripts/entry.ts'),
},
output: {
path: path.resolve(__dirname, '../typescripts/dist'),
filename: '[name].js',
libraryTarget: 'commonjs2',
},
mode: 'development',
// mode: 'production',
devtool: false,
externals: {
uxp: 'commonjs2 uxp',
photoshop: 'commonjs2 photoshop',
os: 'commonjs2 os',
fs: 'commonjs2 fs',
},
resolve: {
extensions: ['.tsx', '.ts', '.js', '.jsx'],
fallback: {
util: require.resolve('util/'),
},
},
module: {
rules: [
{
test: /\.tsx?$/,
loader: 'ts-loader',
exclude: /node_modules/,
options: {
configFile: path.resolve(__dirname, '../typescripts/tsconfig.json'),
},
},
{
test: /\.jsx?$/,
exclude: /node_modules/,
loader: 'babel-loader',
options: {
plugins: [
'@babel/transform-react-jsx',
'@babel/proposal-object-rest-spread',
'@babel/plugin-syntax-class-properties',
],
},
},
{
test: /\.png$/,
exclude: /node_modules/,
loader: 'file-loader',
},
{
test: /\.css$/,
use: ['style-loader', 'css-loader'],
},
{
test: /\.svg$/,
use: ['@svgr/webpack', 'url-loader'],
},
],
},
plugins: [
//new CleanWebpackPlugin(),
// new CopyPlugin(['plugin'], {
// copyUnmodified: true,
// }),
],
}
================================================
FILE: deprecated-do-not-use-start_server.bat
================================================
@REM @echo off
git pull
set SD_URL=http://127.0.0.1:7860
echo does server_env\ exist
if exist server_env\ (
echo Yes
goto :activate_server_env
) else (
echo No
goto :create_server_env
)
:create_server_env
python -m venv server_env
@REM pause
:activate_server_env
::run a server
echo my_path: %~dp0
@REM set current_dir=
set VENV_DIR=%~dp0server_env
@REM cd ./server_env/Scripts/
set PYTHON="%VENV_DIR%\Scripts\Python.exe"
%PYTHON% -m pip install -r requirements.txt
cd ./server/python_server
echo python path: %PYTHON%
dir
echo %PYTHON% uvicorn serverMain:app --reload
%PYTHON% -m uvicorn serverMain:app --reload
pause
@REM exit /b
@REM %PYTHON% uvicorn serverMain:app --reload
pause
@REM %PYTHON% img2imgapi.py
@REM activate
@REM echo server_env %PYTHON%
@REM cd ./server/python_server
@REM %PYTHON% img2imgapi.py
@REM uvicorn serverMain:app --reload
@REM dir .
@REM call webui.bat
================================================
FILE: deprecated-do-not-use-start_server.sh
================================================
#!/bin/bash
git pull
# Set the desired remote host where the "<>" is
export SD_URL=http://127.0.0.1:7860
# Check python was installed
if ! hash python; then
echo "Python is not installed"
exit 1
fi
# Check the default python version
orig_ver=$(python -V 2>&1)
major_version=$(echo "$orig_ver" | sed 's/[^0-9]*\([0-9]*\)\..*/\1/')
minor_subversion=$(echo "$orig_ver" | sed -E 's/^[^.]*\.([^.]*).*$/\1/')
if [[ "$major_version" -ge "3" ]] && [[ "$minor_subversion" -ge "7" ]] # Because of uvicorn==0.20.0 in requirements
then
echo "You have valid version of $orig_ver"
else
echo "Your version $orig_ver not valid, should be >=3.7"
exit 1
fi
# Check if the desired environment exists
if [ ! -d "server_env" ]; then
# Create the environment if it doesn't exist
python -m venv server_env
source ./server_env/bin/activate
python -m pip install -r requirements.txt
else
source ./server_env/bin/activate
fi
cd ./server/python_server
python -m uvicorn serverMain:app --reload
================================================
FILE: deprecated-do-not-use-start_server_MacOS.sh
================================================
#!/bin/bash
git pull
# Set the desired remote host where the "<>" is
export SD_URL=http://127.0.0.1:7860
# Check if the desired environment exists
if [ ! -d "server_env" ]; then
# Create the environment if it doesn't exist
python3 -m venv server_env
source ./server_env/bin/activate
python3 -m pip install -r requirements.txt
else
source ./server_env/bin/activate
fi
cd ./server/python_server
python3 -m uvicorn serverMain:app --reload
================================================
FILE: deprecated-do-not-use-update_plugin.bat
================================================
git pull
================================================
FILE: deprecated-do-not-use-update_plugin.sh
================================================
#!/bin/bash
git pull
================================================
FILE: dialog_box.js
================================================
async function prompt(
heading,
body,
buttons = ['Cancel', 'Ok'],
options = { title: heading, size: { width: 360, height: 280 } }
) {
const [dlgEl, formEl, headingEl, dividerEl, bodyEl, footerEl] = [
'dialog',
'form',
'sp-heading',
'sp-divider',
'sp-body',
'footer',
].map((tag) => document.createElement(tag))
;[headingEl, dividerEl, bodyEl, footerEl].forEach((el) => {
el.style.margin = '6px'
el.style.width = 'calc(100% - 12px)'
})
formEl.setAttribute('method', 'dialog')
formEl.addEventListener('submit', () => dlgEl.close())
footerEl.style.marginTop = '26px'
dividerEl.setAttribute('size', 'large')
headingEl.textContent = heading
bodyEl.textContent = body
buttons.forEach((btnText, idx) => {
const btnEl = document.createElement('sp-button')
btnEl.setAttribute(
'variant',
idx === buttons.length - 1 ? btnText.variant || 'cta' : 'secondary'
)
if (idx === buttons.length - 1)
btnEl.setAttribute('autofocus', 'autofocus')
if (idx < buttons.length - 1) btnEl.setAttribute('quiet')
btnEl.textContent = btnText.text || btnText
btnEl.style.marginLeft = '12px'
btnEl.addEventListener('click', () =>
dlgEl.close(btnText.text || btnText)
)
footerEl.appendChild(btnEl)
})
;[headingEl, dividerEl, bodyEl, footerEl].forEach((el) =>
formEl.appendChild(el)
)
dlgEl.appendChild(formEl)
document.body.appendChild(dlgEl)
return dlgEl.uxpShowModal(options)
}
// const r1 = await prompt(
// 'Upload Large File',
// 'This is a large file (over 100MB) -- it may take a few moments to upload.',
// ['Skip', 'Upload']
// )
// if ((r1 || 'Upload') !== 'Upload') {
// /* cancelled or No */
// } else {
// /* Yes */
// }
// const r2 = await prompt(
// 'Delete File',
// 'Are you sure you wish to delete this file? This action cannot be undone.',
// ['Cancel', { variant: 'warning', text: 'Delete' }]
// )
// if (r2 !== 'Delete') {
// /* nope, don't do it! */
// } else {
// /* Do the delete */
// }
module.exports = { prompt }
================================================
FILE: docs/Home.md
================================================
*Version 1.1.0*
## Introduction
This guide explains the Auto Photoshop UI and its main features, it doesn't go into any detail of how Stable Diffusion works or the functionalities implemented by AUTOMATIC1111. For the latter you can read the manual [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features).
## Stable Diffusion UI Tab
![[Pasted image 20230131191554.png]]
- **Model Selection** - allows to select the .ckpt / .safetensors model to be used for image generation.
- **Refresh** - refreshes the models. *Note*: this will extract all loaded models in AUTOMATIC1111, if you want to add a new model, first refresh AUTOMATIC1111.
- **L2S (Layer to selection)** - convenience function to move the content of the currently selected layer into the photoshop selection.
- **Snapshot** - convenience function equivalent to "ALT + Merge Visible Layers"
- **Reset** - reset UI to default values
- **Prompt Shortcut** - enables prompt shortcuts
- Prompt - text area for the image generation prompt
- Negative Prompt - text area for the image generation negative prompt
### txt2img
[[Pasted image 20230131192430.png]]
- **Images**: number of images to be generated in a single generation session
- **Steps**: number of steps
- **Selection Mode Ratio**: the generation dimension will be set automatically to match the proportion of the photoshop selection, using 512 as the base value.
- **Selection Mode Precise**: the generation dimension will be set to match exactly the photoshop selection.
- **Selection Mode Ignore**: the generation dimension are set by the user.
- **Width and Heigth**: the image generation dimensions
- **CFG Scale**: Influence strength of the prompt (for details please see the AUTOMATIC1111 wiki)
- **Restore Faces**: enables the restore faces function in AUTOMATIC1111
- **Hi Res Fix**: enables the Hi Res Fix function in AUTOMATIC1111 (see below)
- **Seed**: Displays and edit current seed (-1 = Random)
- **Random / Last**: sets seed to either random or last generation
- **Show Samplers**: allows to select the sampler used for image generation
**Hi Res Fix**
[[Pasted image 20230131195947.png]]
When Hi Res is checked, a number of parameters become avaiable including Upscaler model to be used, output dimensions and denoising strength. This is just an interface into the AUTOMATIC1111 functionality described [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#hires-fix).
### img2img
[[Pasted image 20230131200253.png]]
- **Image**: shows the current image used as img2img base.
- **Denoising Strength**: how much Stable Diffusion should be influenced by the image, 0 = output is same as image, 1 = completely different image.
- **Inpainting conditioning mask strength**; this field only works with inpainting special models (ending in "-inpainting."). Determines how much the process should stick to the image structure, check out [this post](https://www.reddit.com/r/StableDiffusion/comments/yi46px/new_hidden_img2img_feature_conditioning_mask/) for details.
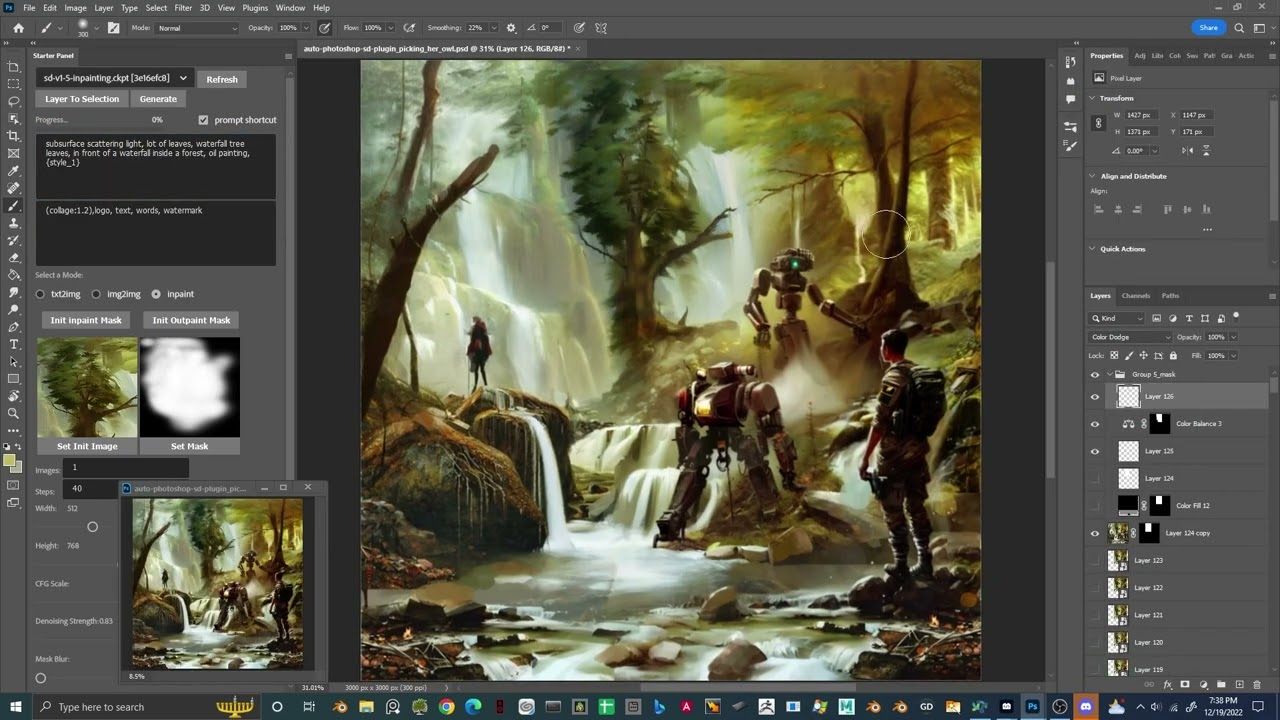
### inpaint
[[Pasted image 20230131201122.png]]
- **Image / Mask**: show image and mask used for the inpaint process
- **Denoising Strength**: similar to img2img however it behaves differently depending on Mask Content context.
- **Mask Blur**: how much to blur the mask before processing it in pixels
- **Mask Expansion**: how much the mask should expand to create a more blended output image
- Mask Content Fill: fill it with colors of the image
- Mask Content original: keep whatever was there originally
- Mask Content latent noise: fill it with latent space noise
- Mask Content latent nothing: fill it with latent space zeros
- **Inpaining at Full Res**: have a look [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4637) for an explanation of this feature.
- **Restore Faces**: same as img2img
### outpaint
UI and its functionality are same as inpaint.
## Viewer
Tab to manage the images generated in the current session.
[[Pasted image 20230131202255.png]]
- Set Mask: manually sets the currently selected mask
- Set Init Image: manually sets the currently selected image
- Generate More: adds more generated images to the current session
- Selection Area: selects the boundaries of the currently selected image in the viewer
- [[Pasted image 20230131202517.png]] Keep all images generated in the current session
- [[Pasted image 20230131202539.png]] Discard all images generated in the current session
- [[Pasted image 20230131202558.png]] Keep only the selected image in the viewer
- [[Pasted image 20230131202638.png]] Discard the selected image in the viewer
## History
[[Pasted image 20230201161508.png]]
- **Load Previous Generations**: loads the images generated within this Photoshop file.
- [[Pasted image 20230201161716.png]] hovering on the image loaded from history will allow bringing the image back into the Photoshop Layer stack
- Clicking on the image will load the pluging settings for the image generation (seed and image generation configuration)
- **Image Search**: loads a set of images from the internet, clicking on any of the images will load them into the layer stack.
## Prompts Library
[[Pasted image 20230201161938.png]]
- For this to work a file will need to be created in the following location: Auto-Photoshop-StableDiffusion-Plugin\\server\\python_server\\prompt_shortcut.json
- **Load / Save**: Once the file is present, values can be loaded and saved onto the file.
- **Key / Value / Add top Prompt Shortcut**: allows to change / add values to the existing json file.
- **Refresh Menu**: will load all values from the json, allowing the user to make changes to the value.
## Horde
Coming Soon
## Settings
[[Pasted image 20230201163236.png]]
# Tutorials
## Generate a txt2img
[[Generate txt2img.gif]]
1. Make a selection where you want the image to be generated
2. Press [[Pasted image 20230203191656.png]]
3. (optional) use the Viewer to select which images to keep in case of multiple image generation
## Using the Viewer
[[Viewer Tutorial.gif]]
1. Generate images as usual
2. Select the image in the viewer grid (shift + click for multiple selection)
3. Choose from: keep one, discard one, keep all, discard all.
4. Images are saved in the latest session layer folder.
## History Tab
[[History.gif]]
1. Load Previous Generations button
2. Single click on image to load its settings in the Stable Diffusion tab (seed, prompt, etc)
3. Click on edit button to load the image in Photoshop
## Generate an img2img
[[img2img.gif]]
1. Select the portion of the image to be used as a sample
2. Select img2img mode and adjust the parameters (denoising strenght especially)
3. Press Generate img2img
4. (optional) use the Viewer to select which images to keep in case of multiple image generation
## Prompts Shortcut
you can substitute a whole sequence of words with one word.
Instead of writing the following as a prompt :
```
Unreal Engine, Octane Render, arcane card game ui, hearthstone art style, epic fantasy style art
```
you could write:
```
{game_like}
```
as long as you have defined the relationship in the prompt library tab
```
{
"game_like": "Unreal Engine, Octane Render, arcane card game ui, hearthstone art style, epic fantasy style art"
}
```
[[prompt_shortcut_file.gif]]
### Editing and Using a Prompt File
[[prompt_shortcut.gif]]
1. Switch to the *Prompt Shortcut* tab.
2. Load the json file.
3. Input a keyword and its value
4. Press *Add to Prompt Shortcut*
5. Now the new Prompt Shortcut can be used in the Stable Diffusion tab
6. To reuse previously saved shortcuts, ensure you load the json file at the start of each session.
## Inpainting
[[inpainting.gif]]
1. Select inpainting mode in the Stable Diffusion tab
2. Select the target area where to produce the image using rectangular marquee tool
3. With a 100% opacity white brush paint the area that you wish to inpaint
4. Ensure that you have a -inpainting.ckpt model selected (this is as important as it is easy to forget)
5. Write a prompt describing the inpaining image
6. Select the desired Mask Content option and adjust the Denoising Strength accordingly.
7. Hit Generate
## Outpainting
[[outpainting.gif]]
1. Select outpainting mode in the Stable Diffusion tab
2. Select the target area where to produce the image using rectangular marquee tool, ensure that you have **some overlap** with the existing image (to provide Stable Diffusion with some context) and that the target area is **transparent**.
4. Ensure that you have a -inpainting.ckpt model selected (this also works for outpainting)
5. Write a prompt describing the outpaining image
6. Select the desired Mask Content option and adjust the Denoising Strength accordingly.
7. Hit Generate
## Heal Brush
[[heal_brush.gif]]
1. Select the "Heal Brush" from the Smart Preset dropdown menu in the Stable Diffusion tab
2. Select the target area where to produce the image using rectangular marquee tool
3. With a 100% opacity white brush paint the area that you wish to erase
4. Ensure that you have a -inpainting.ckpt model selected (this is as important as it is easy to forget)
5. Write a prompt describing what you would like to see in the erased area
6. Hit Generate
================================================
FILE: enum.js
================================================
const clickTypeEnum = {
Click: 'click',
ShiftClick: 'shift_click',
AltClick: 'alt_click',
SecondClick: 'second_click', //when we click a thumbnail that is active/ has orange border
}
const generationModeEnum = {
Txt2Img: 'txt2img',
Img2Img: 'img2img',
Inpaint: 'inpaint',
Outpaint: 'outpaint',
Upscale: 'upscale',
}
const AutomaticStatusEnum = {
NoApi: 'no_api',
Offline: 'offline',
RunningNoApi: 'running_no_api',
RunningWithApi: 'running_with_api',
AutoPhotoshopSDExtensionMissing: 'auto_photoshop_sd_missing',
}
const ViewerObjectTypeEnum = {
OutputImage: 'output_image',
InitImage: 'init_image',
MaskImage: 'mask_image',
}
const RequestStateEnum = {
Generating: 'generating', // in the generation process
Interrupted: 'interrupted', // canceled/ interrupted
Finished: 'finished', // finished generating
}
const BackgroundHistoryEnum = {
CorrectBackground: 'correct_background',
NoBackground: 'no_background',
}
module.exports = {
clickTypeEnum,
generationModeEnum,
AutomaticStatusEnum,
ViewerObjectTypeEnum,
RequestStateEnum,
BackgroundHistoryEnum,
}
================================================
FILE: helper.js
================================================
const { unselectActiveLayers } = require('./psapi')
const app = window.require('photoshop').app
function getActiveLayer() {
let activeLayers = app.activeDocument.activeLayers
// console.dir(getSize())
for (const layer of activeLayers) {
console.dir({ layer })
const name = layer.name
console.dir({ name })
let layer_size = getLayerSize(layer)
console.dir({ layer_size })
}
return activeLayers[0]
}
function getSize() {
let doc = app.activeDocument
return { height: doc.height, width: doc.width }
}
const { batchPlay } = require('photoshop').action
const { executeAsModal } = require('photoshop').core
async function reselectBatchPlay(selectionInfo) {
const result = await batchPlay(
[
{
_obj: 'set',
_target: [
{
_ref: 'channel',
_property: 'selection',
},
],
to: {
_obj: 'rectangle',
top: {
_unit: 'pixelsUnit',
_value: selectionInfo.top,
},
left: {
_unit: 'pixelsUnit',
_value: selectionInfo.left,
},
bottom: {
_unit: 'pixelsUnit',
_value: selectionInfo.bottom,
},
right: {
_unit: 'pixelsUnit',
_value: selectionInfo.right,
},
},
_options: {
dialogOptions: 'dontDisplay',
},
},
],
{
synchronousExecution: true,
modalBehavior: 'execute',
}
)
}
async function reselect(selectionInfo) {
await executeAsModal(
async () => {
reselectBatchPlay(selectionInfo)
},
{ commandName: 'reselect' }
)
}
//unselect the rectangular marquee selection area
async function unSelect() {
const batchPlay = require('photoshop').action.batchPlay
const result = await batchPlay(
[
{
_obj: 'set',
_target: [
{
_ref: 'channel',
_property: 'selection',
},
],
to: {
_enum: 'ordinal',
_value: 'none',
},
_options: {
dialogOptions: 'dontDisplay',
},
},
],
{
synchronousExecution: true,
modalBehavior: 'execute',
}
)
return result
}
/**
* Convert 1d index to 2d array
* @param {number} index sequential index
* @param {number} width width of 2d array
* @returns {number[]} [x,y]
*/
function indexToXY(index, width) {
return [index % width, Math.floor(index / width)]
}
module.exports = {}
================================================
FILE: i18n/zh_CN/ps-plugin.json
================================================
{
"Auto-Photoshop-SD": "SD插件(明空汉化)",
"'A' for Automatic1111 server (webui-user.bat), Green is connected. Red Means there is a problem with your Automatic1111. Run 'webui-user.bat' and hit 'Refresh' button ": "A代表SD服务器(webui-user.bat),绿色已连接。红色表示SD服务器有问题。运行“webui-user.bat”并点击刷新按钮",
"'P' for proxy server (start_server.bat), Green is connected. Red means you need to run 'start_server.bat' or hit Refresh button": "P为代理服务器(start_server.bat),绿色已连接。红色表示您需要运行'start_server.bat'或点击刷新按钮",
"Stable Diffusion": "稳定扩散",
"Stable Diffusion UI": "稳定扩散 UI",
"Refresh": "刷新",
"Refresh the plugin, only fixes minor issues.": "刷新插件,仅修复小问题。",
"Update": "更新",
"Update the plugin if you encounter bugs. Get the latest features": "如果遇到错误,请更新插件。 获取最新功能",
"Select Lora": "选择 Lora",
"use lora in your prompt": "在提示中使用 lora",
"Generate": "生成",
"Generate Txt2Img": "生成 Txt2Img",
"Generate Img2Img": "生成 Img2Img",
"Generate Inpaint": "生成 Inpaint",
"Generate Outpaint": "生成 Outpaint",
"outpaint": "outpaint",
"Progress...": "进度...",
"Toggle the visibility of the Preview Image on the canvas": "切换画布上预览图像的可见性",
"Move and reSize the highlighted layer to fit into the Selection Area": "移动和调整突出显示的图层以适合选择区域",
"create a snapshot of what you see on the canvas and place on a new layer": "创建画布上看到的快照并放置在新图层上",
"reset the ui settings to their default values": "将 UI 设置重置为默认值",
"Interrogate the selected area, convert Image to Prompt": "审问所选区域,将图像转换为提示",
"use this mode to generate images from text only": "使用此模式仅从文本生成图像",
"use this mode to generate variation of an image": "使用此模式生成图像的变体",
"use this mode to generate variation of a small area of an image, while keeping the rest of the image intact": "使用此模式生成图像的小区域的变体,同时保持图像的其余部分完好无损",
"use this mode to (1) fill any missing area of an image,(2) expand an image": "使用此模式来(1)填充图像的任何缺失区域,(2)扩展图像",
"Image": "图像",
"Mask": "蒙版",
"Batch Size:": "批量大小:",
"Batch Count:": "批量计数:",
"Steps:": "步数:",
"Selection Mode:": "选择模式:",
"ratio": "比率",
"precise": "精确",
"use the selection area width and height to fill the width and height sliders": "使用选择区域的宽度和高度来填充宽度和高度滑块",
"ignore": "忽略",
"fill the width and height sliders manually": "手动填充宽度和高度滑块",
"Smart Preset": "智能预设",
"auto fill the plugin with smart settings, to speed up your working process.": "自动填充智能设置的插件,以加快您的工作流程。",
"Width:": "宽度:",
"maintain the ratio between width and height slider": "保持宽度和高度滑块之间的比例",
"Height:": "高度:",
"CFG Scale:": "CFG 比例:",
"larger value will put more emphasis on the prompt": "较大的值将更加强调提示",
"Denoising Strength:": "降噪强度:",
"Image CFG Scale:": "图像 CFG 比例:",
"Pix2Pix CFG Scale (larger value will put more emphasis on the image)": "Pix2Pix CFG 比例(较大的值将更加强调图像)",
"Mask Blur:": "蒙版模糊:",
"Mask Expansion:": "蒙版扩展:",
"the larger the value the more the mask will expand, '0' means use precise masking, use in combination with the mask blur": "值越大,蒙版就会扩展得越多,“ 0”表示使用精确的蒙版,与蒙版模糊一起使用",
"Inpainting conditioning mask strength:": "修复条件蒙版强度:",
"0 will keep the composition; 1 will allow composition to change": "0将保持构图; 1将允许构图发生变化",
"Mask Content:": "蒙版内容:",
"fill": "填充",
"original": "原始",
"latent noise": "潜在噪声",
"latent nothing": "潜在无",
"Inpaint at Full Res": "在全分辨率下修复",
"Restore Faces": "面部修复",
"Hi Res Fix": "高分修复",
"Upscaler: ": "放大器:",
"Hi Res Steps:": "高分步数:",
"Hi Res Scale:": "高分比例:",
"Hi Res Denoising Strength:": "高分降噪强度:",
"Hi Res Output Width:": "高分输出宽度:",
"Hi Res Output Height:": "高分输出高度:",
"Inpaint Padding:": "修复填充:",
"Seed:": "种子:",
"Random": "随机",
"Last": "最后",
"Show Samplers": "显示采样器",
"Sampling Steps:": "Sampling Steps:",
"Select A Script": "选择脚本",
"Activate": "激活",
"Viewer": "查看器",
"Preview": "预览器",
"View your generated images on the canvas": "在画布上查看生成的图像",
"Set Mask": "设置蒙版",
"Set Init Image": "设置初始图像",
"Interrupt": "中断",
"Selection Area": "选择区域",
"Thumbnail Size": "缩略图大小",
"Square 1:1": "正方形 1:1",
"Prompts Library": "提示库",
"Prompt Shortcut: a single word that represent a prompt": "提示快捷方式:代表提示的单个单词",
"Key for new prompt shortcut": "新提示快捷方式的键",
"to be replaced": "要被替换的",
"Value for new prompt shortcut": "新提示快捷方式的值",
"to be replaced with": "要被替换为",
"Add to Prompt Shortcut": "添加到提示快捷方式",
"prompt shortcut": "提示快捷方式",
"Selection a prompt": "选择提示词",
"Refresh Menu": "刷新菜单",
"Load": "加载",
"Save": "保存",
"History": "历史记录",
"history of all the images you generated": "您生成的所有图像的历史记录",
"Load Previous Generations": "加载以前的生成",
"Clear Results": "清除结果",
"Lexica": "Lexica",
"Explore Lexica for prompts and inspiration": "探索提示词和灵感的词典",
"Search:": "搜索:",
"user prompt(text) to Search Lexica": "用户提示(文本)搜索词典",
"User the selected area (image) on canvas to Search Lexica": "用户在画布上选择的区域(图像)搜索词典",
"Image Search": "图像搜索",
"Image Search Engine": "图像搜索引擎",
"ControlNet": "ControlNet",
"The Controlnet Extension is missing from Automatic1111.Please install it to use it through the plugin.": "Automatic1111缺少ControlNet扩展。请安装它以通过插件使用它。",
"ControlNet Preset": "ControlNet预设",
"auto fill the ControlNet with smart settings, to speed up your working process.": "自动填充智能设置的ControlNet,以加快您的工作流程。",
"Set All CtrlNet Images": "设置所有 CtrlNet 图像",
"Disable ControlNet Tab": "禁用ControlNet选项卡",
"Control Net Settings Slot 0": "ControlNet设置插槽0",
"Set CtrlNet Img": "设置 CtrlNet 图像",
"Preview Annotator": "预览注释器",
"Enable": "启用",
"Low VRAM": "低显存",
"Guess Mode": "猜测模式",
"Weight:": "权重:",
"2 will keep the composition; 0 will allow composition to change": "2将保持构图; 0将允许构图发生变化",
"Guidance strength start:": "Guidance strength start:",
"Guidance strength end:": "Guidance strength end:",
"Horde": "Horde",
"Horde Key:": "Horde密钥:",
"Select Backend:": "选择后端:",
"Native Horde": "本机 Horde",
"use the horde with the plugin no need to install anything else": "使用插件的 Horde,无需安装其他任何内容",
"Auto1111 Horde Extension": "Auto1111 Horde 扩展",
"Use the horde extension from Automatic1111 Extension tab": "使用 Automatic1111 扩展选项卡中的 Horde 扩展",
"Auto1111 Only": "仅限 Auto1111",
"use Auto1111 disable the Horde": "使用 Auto1111 禁用 Horde",
"Refresh Models": "刷新模型",
"NSFW": "NSFW",
"Share with LION": "与 LION 共享",
"Extras": "额外",
"Resize": "调整大小",
"Resize scale of current selection size": "调整当前选择大小的比例",
"Generate upscale": "生成放大",
"No work in progress": "没有正在进行的工作",
"Upscaler 1:": "放大算法 1:",
"Upscaler 2:": "放大算法 2:",
"Upscaler 2 visibility:": "放大算法 2 可见性:",
"GFPGAN visibility:": "GFPGAN 可见性:",
"CodeFormer visibility:": "CodeFormer 可见性:",
"CodeFormer weight:": "CodeFormer 权重:",
"Settings": "设置",
"Custom Presets": "自定义预设",
"SD Url:": "SD Url:",
"Submit": "提交",
"use sharp mask": "使用锐化蒙版",
"Smart Object": "智能对象",
"Live Progress Image": "实时进度图像",
"Restore Original Prompt": "恢复原始提示",
"Image Cfg Scale Slider": "图像配置比例滑块",
"Use Silent Mode": "使用静默模式",
"Your PC Speed(optimization):": "电脑性能(优化):",
"Slow PC": "节能模式",
"Fast PC": "高性能模式",
"Use Colab": "使用 Colab",
"Select Extension:": "选择扩展:",
"Proxy Server": "代理服务器",
"use the proxy server, need to run 'start_server.bat' ": "使用代理服务器,需要运行“start_server.bat”",
"Auto111 Extension": "SD扩展",
"use Automatic1111 Photoshop SD Extension, need to install the extension in Auto1111": "使用Photoshop SD 扩展,需要在 Auto1111 中安装扩展",
"None": "无",
"Use the Plugin Only No Additional Component": "仅使用插件,无需其他组件",
"Folder Path (read only):": "文件夹路径(只读):",
"copy paste the address to access the folder where the images are stored": "复制粘贴地址以访问存储图像的文件夹",
"Get Path": "获取路径",
"Preset Name": "预设名称",
"New Preset": "新建预设",
"Preset Type:": "预设类型:",
"SD Preset": "SD 预设",
"Save Preset": "保存预设",
"Delete Preset": "删除预设",
"The Controlnet Extension is missing from Automatic1111.\nPlease install it to use it through the plugin.": "本地SD中缺少ControlNet扩展。\n请安装该插件后再使用。",
"Set CtrlImg": "设置原始图",
"ControlNet Tab": "ControlNet",
"ControlNet Unit": "ControlNet #",
"Select Filter": "选择过滤器",
"Select Module": "选择预处理器",
"Select Model": "选择模型",
"Keep all generated images on the canvas": "在画布上保留所有生成图像",
"Delete all generated images from the canvas": "在画布上删除所有生成图像",
"Keep only the highlighted images": "在画布上保留选中的图像",
"Generate More": "生成更多"
}
================================================
FILE: i18n/zh_CN/sd-official.json
================================================
{
"(0 = default (~0.03); minimum noise strength for k-diffusion noise scheduler)": "(0 = 默认 (~0.03); k-diffusion 噪声调度器的最小噪声强度)",
"(0 = default (~14.6); maximum noise strength for k-diffusion noise schedule)": "(0 = 默认 (~14.6); k-diffusion 噪声调度器的最大噪声强度)",
"(0 = default (7 for karras, 1 for polyexponential); higher values result in a more steep noise schedule (decreases faster))": "(0 = 默认 (karras 选择 7, polyexponential 选择 1); 值越高噪声调度曲线越陡峭 (递减更快速))",
"(0 = disable)": "(0 = 禁用)",
"(0=disable, higher=faster)": "(0 = 禁用, 数值越大 = 越快速)",
"(0 = maximum effect; 1 = minimum effect)": "(0 = 最大强度; 1 = 最小强度)",
"(0 = No limit)": "(0 = 无限制)",
"(0 = no tiling)": "(0 = 不分块)",
"180 Degree Rotation": "180 度旋转",
"1. Get Model Info by Civitai Url": "从 Civitai 链接拉取模型信息",
"-1 means that it is calculated automatically. If both are -1, the size will be the same as the source size.": "-1意味着自动计算。如果宽高都是-1,则将与源视频尺寸相同。",
"1st": "第一单元",
"1st and last digit must be 0 and values should be between 0 and 1. ex:'0, 0.01, 0'": "第一个和最后一个数字必须是 0,其他值应介于 0 和 1 之间。如:’0, 0.01, 0’",
"1st and last digit must be 1. ex:'1, 2, 1'": "第一个和最后一个数字必须是 1。例:'1, 2, 1'",
"2D operator that scales the canvas size, multiplicatively. [static = 1.0]": "缩放画布大小的2D操作符,以倍数缩放。[static=1.0]",
"2D operator to rotate canvas clockwise/anticlockwise in degrees per frame": "2D 操作器对每帧动画顺时针/逆时针旋转所指定的角度",
"2D or 3D animation_mode": " 2D 或 3D 动画模式中",
"2nd": "第二单元",
"360 Panorama to 3D": "360°全景图转 3D",
"3d glb": "3D (GLB 格式)",
"3D Mesh": "3D 网格",
"3D Openpose": "3D 骨架模型编辑 (3D Openpose)",
"3. Download Model": "下载模型",
"3rd": "第三单元",
"4th": "第四单元",
"5th": "第五单元",
"90 Degree Rotation": "90 度旋转",
"A, B or C": "A, B 或 C",
"About": "关于",
"Abs": "绝对值",
"abs. path or url to audio file": "音频文件的绝对路径或 URL",
"abstract": "abstract (抽象艺术)",
"Accent color": "强调色",
"Accent Generate Button": "强调生成按钮",
"Access results in ‘Open results’.": "点击“打开最终效果图”获取增强后的图片",
"According to Live preview subject setting": "实时预览主体设置",
"Accumulation steps": "累加步数",
"Action": "操作",
"Action on existing caption": "对已有标注的操作",
"Actions": "其他操作",
"Activate Selected Script": "激活选定脚本",
"Activation keywords, comma-separated": "该模型的触发词,以逗号分隔",
"Active": "启用",
"Active in img2img (Requires restart)": "在图生图中启用 (需重启)",
"Active in negative prompts (Requires restart)": "在反向提示词输入框中启用 (需重启)",
"Active in third party textboxes [Dataset Tag Editor] [Image Browser] [Tagger] [Multidiffusion Upscaler] (Requires restart)": "在第三方文本框中激活标签自动补全 [数据集标签编辑器 (Dataset Tag Editor)] [图库浏览器] [WD1.4标签器 (Tagger)] [Multidiffusion 超分辨率] (需重启)",
"Active in third party textboxes [Dataset Tag Editor] (Requires restart)": "在第三方输入框中启用 [数据集标签编辑器] (需重启)",
"Active in txt2img (Requires restart)": "在文生图中启用 (需重启)",
"Adaptive (Gaussian)": "自适应(高斯)",
"Adaptive (Mean)": "自适应(平均值)",
"➕ Add": "➕ 添加",
"Add": "添加",
"Add additional prompting to the prefix, suffix and negative prompt in this screen. The actual prompt fields are ignored.": "在此场景下添加附加提示词到前缀、后缀、反向提示词。实际的提示词段会被忽略。",
"Add additional prompts to the head": "在起始添加额外的提示词",
"Add ALL Displayed": "添加所有当前显示的图片",
"Add a prompt prefix, suffix and the negative prompt in the respective fields. They will be automatically added during processing.": "在相应的字段中添加提示词前缀、后缀和反向提示词。它们会在处理过程中被自动添加。",
"Add a second progress bar to the console that shows progress for an entire job.": "向控制台添加第二个进度条以显示作业的整体进度",
"add audio to video from file/url or init video": "从文件/链接或初始视频中提取音频以完成添加",
"Add background image": "添加背景图片",
"Add Background image": "添加背景图片",
"Add Background Image": "添加背景图片",
"Add Blur": "添加模糊",
"Add Custom Mappings": "添加自定义映射",
"Add Detail": "添加细节",
"Add difference": "差额叠加",
"Add difference:A+(B-C)*alpha": "差额叠加: A+(B-C)*α",
"Added": "已添加",
"Add extended info (seed, prompt) to filename when saving grid": "保存网格图时,将扩展信息(随机种子、提示词)添加到文件名",
"Add hypernetwork to prompt": "将 hypernetwork 添加到提示词",
"Add image number to grid": "在网格图上添加图像编号",
"Add inpaint batch mask directory to enable inpaint batch processing.": "添加重绘蒙版目录以启用重绘蒙版功能",
"Additional Generation Info": "附加生成信息",
"Additional Networks": "Additional Networks",
"Additional options": "附加选项",
"Additional tags (split by comma)": "附加标签 (逗号分隔)",
"Add last frame to keyframes": "设置最后一帧为关键帧",
"Add layer normalization": "启用网络层归一化处理",
"Add Lora hashes to infotext": "添加 Lora 的哈希值文本到图片信息中",
"Add Lora to prompt": "将 Lora 添加到提示词",
"Add LyCORIS to prompt": "将 LyCORIS 添加到提示词",
"Add model hash to generation information": "将模型哈希值添加到生成信息",
"Add model name to generation information": "将模型名称添加到生成信息",
"AddNet Model 1": "附加模型 1",
"AddNet Model 2": "附加模型 2",
"AddNet Model 3": "附加模型 3",
"AddNet Model 4": "附加模型 4",
"AddNet Model 5": "附加模型 5",
"AddNet TEnc Weight 1": "附加模型 1 Text Encoder 权重",
"AddNet TEnc Weight 2": "附加模型 2 Text Encoder 权重",
"AddNet TEnc Weight 3": "附加模型 3 Text Encoder 权重",
"AddNet TEnc Weight 4": "附加模型 4 Text Encoder 权重",
"AddNet TEnc Weight 5": "附加模型 5 Text Encoder 权重",
"AddNet UNet Weight 1": "附加模型 1 UNet 权重",
"AddNet UNet Weight 2": "附加模型 2 UNet 权重",
"AddNet UNet Weight 3": "附加模型 3 UNet 权重",
"AddNet UNet Weight 4": "附加模型 4 UNet 权重",
"AddNet UNet Weight 5": "附加模型 5 UNet 权重",
"AddNet Weight 1": "附加模型 1 权重",
"AddNet Weight 2": "附加模型 2 权重",
"AddNet Weight 3": "附加模型 3 权重",
"AddNet Weight 4": "附加模型 4 权重",
"AddNet Weight 5": "附加模型 5 权重",
"Add new prompts": "添加新提示词",
"Add N to seed when repeating": "重复时在种子数上加 N",
"Add number to filename when saving": "在文件名前添加序号",
"Add program version to generation information": "将项目版本添加到生成信息",
"Add/Remove...": "添加/删除...",
"Add Smart-Steps minimum step and ToMe merging ratio value to generation information.": "将优化迭代步数和TOME合并比率数值信息添加到图像生成信息中",
"Add soundtrack": "添加音轨",
"'add_soundtrack' and 'soundtrack_path' aren't being honoured in \"Interpolate an existing video\" mode. Original vid audio will be used instead with the same slow-mo rules above.": "‘添加音频’和‘音频路径’将不会在‘插入现有视频’模式中执行,原有视频的音频将会使用相同的慢动作规则设置",
"Add to Sequence X": "添加到 X 轴",
"Add to Sequence Y": "添加到 Y 轴",
"Add trigger words to prompt": "一键添加本模型的触发词到提示词输入框",
"Add weights to Sequence X": "将权重添加到 X 序列中",
"ADetailer CFG scale": "After Detailer 提示词引导系数 (CFG scale)",
"ADetailer CFG scale 2nd": "After Detailer 提示词引导系数 (CFG scale)",
"ADetailer CFG scale 3rd": "After Detailer 提示词引导系数 (CFG scale)",
"ADetailer CFG scale 4th": "After Detailer 提示词引导系数 (CFG scale)",
"ADetailer CFG scale 5th": "After Detailer 提示词引导系数 (CFG scale)",
"ADetailer confidence threshold %": "置信阈值 (单位: %)",
"ADetailer denoising strength": "重绘幅度",
"ADetailer erosion (-) / dilation (+)": "图像腐蚀 (-) / 图像膨胀 (+)",
"ADetailer mask blur": "重绘蒙版边缘模糊度",
"ADetailer model": "After Detailer 模型",
"ADetailer model 2nd": "After Detailer 模型",
"ADetailer model 3rd": "After Detailer 模型",
"ADetailer model 4th": "After Detailer 模型",
"ADetailer model 5th": "After Detailer 模型",
"ADetailer negative prompt": "After Detailer 反向提示词",
"ADetailer negative prompt 2nd": "After Detailer 反向提示词",
"ADetailer negative prompt 3rd": "After Detailer 反向提示词",
"ADetailer negative prompt 4th": "After Detailer 反向提示词",
"ADetailer negative prompt 5th": "After Detailer 反向提示词",
"ADetailer prompt": "After Detailer 正向提示词",
"ADetailer prompt 2nd": "After Detailer 正向提示词",
"ADetailer prompt 3rd": "After Detailer 正向提示词",
"ADetailer prompt 4th": "After Detailer 正向提示词",
"ADetailer prompt 5th": "After Detailer 正向提示词",
"ADetailer steps": "After Detailer 迭代步数",
"ADetailer steps 2nd": "After Detailer 迭代步数",
"ADetailer steps 3rd": "After Detailer 迭代步数",
"ADetailer steps 4th": "After Detailer 迭代步数",
"ADetailer steps 5th": "After Detailer 迭代步数",
"ADetailer x(→) offset": "X轴 (→) 偏移",
"ADetailer y(↑) offset": "Y轴 (↑) 偏移",
"A directory on the same machine where the server is running.": "服务器主机上某一目录",
"A directory or a file": "一个文件或文件夹",
"adjust denoise each img2img batch": "调整每个图生图批次的重绘幅度",
"adjusts the overall contrast per frame [default neutral at 1.0]": "调整每帧的整体对比度[默认值为1.0]",
"Adjusts the size of the image by multiplying the original width and height by the selected value. Ignored if either Resize width to or Resize height to are non-zero.": "通过将原宽度和高度乘以选定值来调整图像的大小。如果宽度调整为非零或高度调整为非零,则忽略。",
"Adjust strength": "调整强度",
"adjust the brightness of the mask. Should be a positive number, with 1.0 meaning no adjustment.": "调整蒙版的亮度。该值应该为正数,1.0 表示无调整",
"Admirable": "极好的",
"ads": "含广告",
"Advanced": "高级",
"Advanced options": "高级选项",
"Affine": "仿射",
"A file on the same machine where the server is running.": "服务器所在主机上的文件",
"Aggressive": "激进",
"Alias from file": "从文件读取别名",
"all": "全部",
"All": "全部",
"all - force multiple --> idea by redditor WestWordHoeDown, it forces to choose between 2 and 3 image types": "all -- 全部 - 强制混合 --> 来自于 redditor: WestWordHoeDown 的创意,强制选择 2-3 种图像类型。",
"All models in this directory will receive the selected model's metadata": "此目录下所有模型都将被粘贴与选中模型完全相同的元数据",
"all --> normally picks a image type as random. Can choose a ‘other’ more unique type.": "all -- 全部 --> 通常会随机选择一个图像类型。可以选择一个 \"其它\" 更独特的类型。",
"Allow detectmap auto saving": "允许自动保存检测图 (detected maps)",
"Allow img2img": "允许图生图",
"Allow NSFW": "允许成人内容",
"Allow other script to control this extension": "允许其他脚本控制此扩展",
"allow overwrite": "允许覆盖文件",
"Allow overwrite output-model": "允许输出时覆盖同名模型",
"Allow Preview": "允许预览",
"\uD83D\uDD04 All Reset": "\uD83D\uDD04 全部重置",
"alpha": "α",
"Alphabetical Order": "字母顺序",
"alpha threshold": "透明度阈值",
"Alpha threshold": "透明度阈值",
"also delete off-screen images": "允许同时删除屏幕外的图片",
"also enable wierd blocky upscale mode": "同时启用糟糕的分块放大模式",
"alternate": "交替",
"Alternatively, use": "或者, 使用 ",
"Alternatively, you can enable": "或者,您可以启用",
"Always": "保持",
"Always discard next-to-last sigma": "始终舍弃倒数第二个 sigma 值",
"Always Display Buttons": "总是显示按钮",
"Always print all generation info to standard output": "始终将所有生成信息输出到控制台",
"Always save all generated image grids": "始终保存所有生成的网格图",
"Always save all generated images": "始终保存所有生成的图像",
"A merger of the two checkpoints will be generated in your": "合并后的模型将保存在您的",
"Amount of images to generate": "图像生成数量",
"amount of presence of previous frame to influence next frame, also controls steps in the following formula [steps - (strength_schedule * steps)]": "前一帧影响下一帧的存在量,也控制下式中的步数:[steps - (strength_schedule * steps)]",
"Amount of tries": "尝试次数",
"Amount schedule": "数量表",
"Amount times to repeat upscaling with IMG2IMG (loopback)": "通过图生图放大的重复次数 (回送)",
"and": "与",
"and generate images according to random segmentation which preserve image layout.": " 来根据保存图像的布局随机分割生成图像。",
"and report your problem.": "反馈您遇到的问题。",
"and upscale to the size of the original video.": "放大图片到原始视频的尺寸。",
"A negative prompt to use when generating preview images.": "生成预览图像时使用的反向提示词",
"Angle": "角度",
"angular": "angular (棱角)",
"animal": "animal (动物)",
"animal - A random (fictional) animal. Has a chance to have human characteristics, such as clothing added.": "animal - 动物 - 一只随机的(虚构的)动物。可能会拥有人类的特征,如穿衣服。",
"animation": "动画",
"Animation mode": "动画模式",
"anime": "anime (动漫)",
"Anime": "动漫",
"Anime-inclined great guide (by FizzleDorf) with lots of examples:": "很不错的、带有许多示例的动画指南 (由 FizzleDorf 制作) : ",
"anime key visual": "anime key visual (动漫主视觉图/海报)",
"Anime Remove Background": "动漫移除背景模式",
"Annotator resolution": "预处理器分辨率",
"Anti Blur": "防模糊",
"API info may not be necessary for some boorus, but certain information or posts may fail to load without it. For example, Danbooru doesn't show certain posts in search results unless you auth as a Gold tier member.": "API 信息对于某些 booru 站点可能不是必需的,但如果没有它,某些信息或图帖可能无法加载。 例如,除非你的 API 验证属于黄金会员,否则 Danbooru 可能不会在搜索结果中显示某些图帖。",
"API Key": "API 密钥",
"API Keys": "API 密钥",
"append": "追加",
"Append": "追加至末尾",
"Append Caption to File Name": "将描述文本追加到文件名之后",
"Append comma on tag autocompletion": "自动添加逗号",
"Append commas": "追加逗号",
"Append DeepDanbooru to Caption": "把 DeepDanbooru 的结果追加到已有的描述文本之后",
"Append Hires prompts to the end of the original prompts instead of replacing it.": "将高分辨率修复提示词追加到原始提示词的末尾,而不是替换它们",
"Append interrogated prompt at each iteration": "在每次迭代时添加何种反推模型反推出的提示词",
"Append prompts, not replace": "追加提示词 (非替换)",
"Apply": "应用",
"Apply and quit": "应用更改并退出",
"Apply and restart UI": "应用更改并重载前端",
"Apply block weight from text": "从文本框应用分块权重值",
"Apply changes to ALL displayed images": "将更改应用于所有已显示的图像",
"Apply color correction to img2img results to match original colors.": "对图生图结果应用颜色校正以匹配原始颜色",
"Apply horizontal Flip": "应用水平翻转",
"Apply Horizontal Flip": "应用水平翻转",
"Apply if any": "应用 (如有)",
"Apply if any: remove style text from prompt; if any styles are found in prompt, put them into styles dropdown, otherwise keep it as it is.": "应用 (如有): 从提示词中删除对应预设样式文本; 将匹配到的预设样式加入下拉菜单",
"Apply inside mask only": "仅使用内部蒙版",
"Apply mask to original image": "应用蒙版到原始图",
"Apply mask to the Ref Image": "应用蒙版到参考图",
"Apply mask to the result": "应用蒙版到结果",
"Apply only selected scripts to ADetailer": "只将选定的脚本应用于 After Detailer",
"Apply Presets": "应用预设",
"Apply: remove style text from prompt, always replace styles dropdown value with found styles (even if none are found).": "应用: 从提示词中删除对应预设样式文本; 总是将下拉菜单内容替换为相应预设样式名 (即使不存在对应预设)",
"Apply scripts to faces": "使用脚本识别脸部",
"Apply selected styles to current prompt": "将所选预设样式插入到当前提示词之后",
"Apply settings": "保存设置",
"Apply to": "应用到",
"Apply transfer control when loading models": "加载模型时应用控制转移",
"a random seed will be used on each frame of the animation": "随机种子将被应用于每帧动画中",
"architecture": "architecture (建筑)",
"Architecture": "架构",
"Archive filename pattern": "压缩包文件名格式",
"Area": "区域",
"Area (large to small)": "面积 (从大到小)",
"Area lower bound": "图片最小面积(宽*高)",
"Area upper bound": "图片最大面积(宽*高)",
"Arguments are case-sensitive.": "参数区分大小写。",
"Arm Length": "手臂长度",
"art deco": "art deco (装饰艺术)",
"Artistic": "艺术",
"Artists have a major impact on the result. Automatically, it will select between 0-3 artists out of 3483 artists for your prompt.": "Artists (艺术家风格) 对图像结果有很大影响。它会自动从 3483 名艺术家中选择 0-3 名艺术家名作为你提示词的一部分。",
"art nouveau": "art nouveau (新艺术运动)",
"as a UI to define your animation schedules (see the Parseq section in the Init tab).": " 作为定义动画参数表的UI (请参见初始化选项卡中的参数定序器部分) .",
"Ascending": "升序",
"A setting of 1 will cause every frame to receive diffusion in the sequence of image outputs. A setting of 2 will only diffuse on every other frame, yet motion will still be in effect. The output of images during the cadence sequence will be automatically blended, additively and saved to the specified drive. This may improve the illusion of coherence in some workflows as the content and context of an image will not change or diffuse during frames that were skipped. Higher values of 4-8 cadence will skip over a larger amount of frames and only diffuse the “Nth” frame as set by the diffusion_cadence value. This may produce more continuity in an animation, at the cost of little opportunity to add more diffused content. In extreme examples, motion within a frame will fail to produce diverse prompt context, and the space will be filled with lines or approximations of content - resulting in unexpected animation patterns and artifacts. Video Input & Interpolation modes are not affected by diffusion_cadence.": "设置为 1 将使每个帧在图像输出序列中生成图像。设置为 2 将每隔一帧进行图像生成,但运动仍然有效。间隔序列期间的图像输出将自动混合、添加并保存到指定驱动器。这可能会改善某些工作流中的一致性错觉,因为图像的内容和上下文在跳过的帧期间不会改变或扩散。更高的间隔值,例如4-8,将跳过更多的帧,并仅生成由生成间隔值设置的“第N”帧。这可能会在动画中产生更多的连续性,但几乎没有机会添加更多的扩散内容。在极端的例子中,帧内的运动将无法产生不同的提示上下文,并且空间将充满线条或近似的内容,从而导致意外的动画模式和伪影。视频输入和插值模式不受生成间隔值的影响。",
"Aspect Ratio Helper": "纵横比助手",
"Attention Heatmap": "关键词热力图",
"Attention texts for visualization. (comma separated)": "待可视化关键词 (逗号分隔)",
"Audio (if provided) will *not* be transferred to the interpolated video if Slow-Mo is enabled.": "音频 (如果提供了) 在以下选项启用时将不会转码压制进帧插值后的视频内:慢动作",
"Author": "作者",
"Author of this model": "此模型的作者",
"auto": "自动",
"Auto": "自动",
"autocast": "自动转换",
"Autocomplete options": "自动补全选项",
"auto-delete imgs when video is ready": "视频完成时自动删除图片",
"Auto detect size from img2img": "从图生图自动检测图像尺寸",
"Auto focal point crop": "自动面部焦点剪裁",
"automatic": "自动",
"Automatic": "自动",
"“automatic” is entirely build around Latent Couple. It will pass artists and the amount of people/animals/objects to generate in the prompt automatically. Set the prompt compounder equal to the amount of areas defined in Laten Couple.": "\"自动\" 是完全围绕 Latent Couple 构建的。它将在提示词中自动传递艺术家和要生成的人/动物/物件的数量。将提示词混合值设置为等于 Latent Couple 中定义的分区数量。",
"Auto SAM": "自动 SAM",
"Auto SAM Config": "自动 SAM 配置",
"Auto SAM is mainly for semantic segmentation and image layout generation, which is supported based on ControlNet. You must have ControlNet extension installed, and you should not change its directory name (sd-webui-controlnet).": "自动 SAM 基于 ControlNet 的支持,主要用于语义分割和图像分层。需安装 ControlNet 扩展,且不能修改其目录名 (sd-webui-controlnet)。",
"Auto search port": "自动检索端口",
"Auto segmentation output": "自动语义分割输出",
"Auto-sized crop": "自动按比例剪裁缩放",
"Auto Tagging": "自动标记",
"Auto Tagging option": "自动标记选项",
"Available": "可下载",
"A value that determines the output of random number generator - if you create an image with same parameters and seed as another image, you'll get the same result": "一个决定随机数生成器输出的值 - 以相同参数和相同种子进行多次生成,会得到相同的多张图像\n\uD83C\uDFB2 将随机种子设置为-1,则每次都会使用一个新的随机数\n♻️ 复用上一次使用的随机种子,对于固定输出结果有用",
"A weighted sum will be used for interpolation. Requires two models; A and B. The result is calculated as A * (1 - M) + B * M": "最终模型权重是前两个模型按比例相加的结果。需要 A、B 两个模型。计算公式为 A * (1 - M) + B * M",
"a-z": "按首字母正序",
"- Background": "- 背景",
"background color": "背景颜色",
"Background gradiant color": "背景渐变色",
"Background source(mp4 or directory containing images)": "背景源(mp4 或包含图像的目录)",
"Background type": "背景类型",
"Backup/Restore": "备份/恢复",
"Bake in VAE": "嵌入 VAE 模型",
"Balance between eyes": "双眼间距平衡",
"Balanced": "均衡",
"baroque": "baroque (巴洛克)",
"Base": "基层值",
"Base alpha": "α 基数",
"Base Depth": "基础深度",
"Base Sampler": "基础采样器",
"Basic": "基础",
"Basic info": "基本信息",
"Batch": "批量处理",
"Batch count": "总批次数",
"Batch from Dir": "批量处理文件夹",
"Batch from directory": "批量处理文件夹",
"Batch from Directory": "批量处理文件夹",
"Batch img2img": "批量图生图",
"Batch name": "批次名称",
"batch process": "批量处理",
"Batch Process": "批量处理",
"Batch Run": "批量处理",
"Batch Settings": "批量处理设置",
"batch size": "批量大小",
"Batch size": "单批数量",
"Batch Size": "单批数量",
"Batch-Warp": "批量修复",
"bauhaus": "bauhaus (包豪斯)",
"behind": "落后",
"Below here, you can generate a set of random prompts, and send them to the Workflow prompt field. The generation of the prompt uses the settings in the Main tab.": "在下方可以生成一组随机的提示词,并将它们发送到工作流提示词段。提示词的生成使用主菜单中的选项设置。",
"Benchmark Data": "基准测试数据",
"Benchmarks...": "基准测试...",
"beta": "β",
"Better": "更好的",
"Bicubic": "双三次",
"Bilinear": "双线性",
"Bilingual Localization": "双语对照本地化",
"Bitwise operation": "按位 (Bitwise) 运算",
"Blacklist": "黑名单",
"blend": "混合",
"Blend": "混合",
"Blend factor max": "最大混合系数",
"Blend factor slope": "混合斜率系数",
"Blend mode": "混合模式",
"BLIP: maximum description length": "BLIP: 最大描述长度",
"BLIP: minimum description length": "BLIP: 最小描述长度",
"BLIP: num_beams": "BLIP: 集束搜索候选项数目",
"Block ID": "区块 ID",
"Block size": "区块大小",
"blur": "模糊",
"Blur": "模糊",
"Blur amount:": "模糊度:",
"Blur edges of final overlay mask, if used. Minimum = 0 (no blur)": "模糊最终覆盖遮罩的边缘(如果使用)。最小值=0(无模糊)",
"- Body": "- 身体",
"(booru only)": "(仅 booru)",
"BOOST (multi-resolution merging)": "BOOST(分块生成后拼合)",
"border": "边框",
"Border": "边缘",
"border frames": "边界帧数",
"Border Frames": "边界帧数",
"Border Key Frames": "边界关键帧数",
"bottom-top": "下 - 上",
"box_nms_thresh": "箱体数量阈值",
"Branch": "分支",
"brightness": "亮度",
"Brightness:": "明亮度",
"Bring prompts and setting into one column left side": "将正反提示词输入框和设置移动到左侧",
"built-in": "内置",
"built with gradio": "基于 Gradio 构建",
"Built with Gradio": "基于 Gradio 构建",
"By comma": "逗号分组",
"By default and where supported, SVG-Edit can store your editor preferences and SVG content locally on your machine so you do not need to add these back each time you load SVG-Edit. If, for privacy reasons, you do not wish to store this information on your machine, you can change away from the default option below.": "默认情况下,SVG Edit 可以将设置和SVG图像保存在你的电脑上,因此你不需要在每次使用 SVG Edit 时重复设置。如果出于隐私因素,你不希望将信息保存在你的电脑上,你可以更改以下默认选项。",
"By default, the algorithm tends to like dark images too much, if you think the output is too dark or not dark enough, you can adjust this ratio. 1 = ‘Do not darken at all’, 0 = ‘A totally black image is ok’, default = 0.9.": "默认情况下,算法倾向于生成较黑的图像,如果你认为输出的图像太黑或不够黑,你可以调整最小照明比率。1=\"完全不变暗\",0=\"全黑的图像\",默认=0.9",
"By none": "不分组",
"By tokens": "词元分组",
"By vectors": "向量分组",
"By words": "单词分组",
"Cache LDSR model in memory": "将 LDSR 模型缓存在内存中",
"Cadence": "生成间隔",
"calculate dimension of LoRAs(It may take a few minutes if there are many LoRAs)": "计算 LoRA 维度 (取决于模型数量,可能需要数分钟)",
"Calculate hash": "计算哈希值",
"- Camera": "- 镜头",
"Camera Far": "镜头最远渲染距离",
"Camera Focal Length": "镜头焦距",
"Camera Near": "镜头最近渲染距离",
"Camera Parameters": "镜头参数",
"Can be empty,indicating no translation": "可以为空,表示无需翻译",
"Cancel": "取消",
"Cancel generate forever": "停止无限生成",
"Cancel training.": "取消训练",
"canny": "canny (硬边缘检测)",
"Canny": "Canny (硬边缘)",
"Canvas Height": "画布高度",
"Canvas Hotkeys": "画布热键",
"- Canvas Size": "- 画布尺寸",
"Canvas Width": "画布宽度",
"Card height for Extra Networks": "扩展模型卡牌高度",
"Card height for Extra Networks (px)": "扩展模型卡牌高度 (px)",
"Card width for Extra Networks": "扩展模型卡牌宽度",
"Card width for Extra Networks (px)": "扩展模型卡牌宽度 (px)",
"cartoon": "cartoon (卡通)",
"Cartoon": "卡通",
"cascadePSP": "CascadePSP",
"case sensitive": "区分大小写",
"Categorical mask status": "分类蒙版状态",
"⚠ Caution: You should only use these options if you know what you are doing. ⚠": "⚠ 警告: 你需要清楚知道自己在做什么才能使用这些选项. ⚠",
"centered": "居中",
"(CF10) Checkpoint format": "(CF10) 模型格式",
"(CF1) Checkpoint format": "(CF1) 模型格式",
"(CF2) Checkpoint format": "(CF2) 模型格式",
"(CF3) Checkpoint format": "(CF3) 模型格式",
"(CF4) Checkpoint format": "(CF4) 模型格式",
"(CF5) Checkpoint format": "(CF5) 模型格式",
"(CF6) Checkpoint format": "(CF6) 模型格式",
"(CF7) Checkpoint format": "(CF7) 模型格式",
"(CF8) Checkpoint format": "(CF8) 模型格式",
"(CF9) Checkpoint format": "(CF9) 模型格式",
"CFG scale": "提示词引导系数 (CFG Scale)",
"CFG Scale": "提示词引导系数 (CFG Scale)",
"Change brightness": "调节亮度",
"Change checkpoint": "更改模型",
"Change contrast": "调节对比度",
"Change CTRL keybindings to SHIFT": "将 CTRL 绑定更改为 SHIFT",
"Change gain": "调节增强强度",
"Change gamma": "调节伽马",
"Change saturation": "调节饱和度",
"(changes seeds drastically; use CPU to produce the same picture across different videocard vendors)": "(显著改变种子效果; 使用 CPU 选项可使不同型号显卡产生相同图像)",
"(changes seeds drastically; use CPU to produce the same picture across different vidocard vendors)": "(大幅改变种子效果, 使用 CPU 选项使不同型号显卡产生相同图像)",
"Change your brush width to make it thinner if you want to draw something.": "绘制内容前请先调整笔刷粗细。",
"Chant filename (Chants are longer prompt presets)": "Chant 文件名(Chant 指较长的提示词预设)",
"character": "character (角色)",
"Cheap neural network approximation. Very fast compared to VAE, but produces pictures with 4 times smaller horizontal/vertical resolution and lower quality.": "廉价的神经网络近似值。与VAE相比速度非常快,但生成的图片水平/垂直分辨率是VAE的四分之一,质量较低",
"Checkbox": "勾选框",
"Check Console log for Downloading Status": "检查控制台日志以查看下载信息",
"Check for updates": "检查更新",
"Check models' new version": "检查模型版本更新",
"Check models’ new version": "检索模型的新版本",
"Check New Version from Civitai": "从 Civitai 上检查版本更新",
"checkpoint": "模型",
"Checkpoint": "模型",
"Checkpoint A": "大模型 A",
"Checkpoint B": "大模型 B",
"Checkpoint Dropdown": "大模型下拉列表",
"Checkpoint format": "模型格式",
"Checkpoint Format": "模型格式",
"Checkpoint Merger": "模型融合",
"Checkpoint name": "模型名",
"Checkpoints": "模型",
"Checkpoint schedule": "模型表",
"Checkpoints to cache in RAM": "保留在内存中的 Stable Diffusion 模型数量",
"Check progress": "查看进度",
"Check system info for validity": "检测系统信息的有效性",
"Check tensors": "检测 tensors",
"check this box to enable guided images mode": "选中该项启用引导图像模式",
"* check your CLI for outputs": "检查 CLI 的输出",
"Chess": "分块",
"children's illustration": "children's illustration (儿童画作)",
"Choose latent sampling method": "选择潜变量采样方法",
"Choose mode:": "选择模式:",
"Choose preprocessor for semantic segmentation:": "选择语义分割的预处理器:",
"(choose Unet model: Automatic = use one with same filename as checkpoint; None = use Unet from checkpoint)": "(选择 Unet 模型: 自动 = 使用与大模型文件名相同的文件; 无 = 使用大模型中的 Unet)",
"Choose your favorite mask:": "请选择你喜欢的蒙版:",
"circle": "圆形",
"cityscape": "cityscape (城市景观)",
"Civitai Helper": "Civitai 助手",
"Civitai URL": "Civitai 链接",
"Civitai URL or Model ID": "Civitai 地址或模型 ID",
"ckpt": "ckpt",
"Class": "组件类别",
"Classifier Free Guidance Scale - how strongly the image should conform to prompt - lower values produce more creative results": "无分类器指导信息影响尺度(Classifier Free Guidance Scale) - 图像应在多大程度上服从提示词 - 较低的值会产生更有创意的结果",
"clean": "clean (绿色、清洁)",
"Cleanup non-default temporary directory when starting webui": "启动 WebUI 时清理非默认临时目录",
"Clear": "清除",
"Clear ALL filters": "清除所有过滤器",
"Clear prompt": "清空提示词内容",
"Clear selection": "清空选择",
"Clear tag filters": "标签清除过滤器",
"Clear values": "清空数值",
"Click Enhance.": "点击“增强”按钮",
"Click here after the generation to show the video": "生成完成后点这里显示视频",
"click here to gather relevant info": "点击此处以收集相关信息",
"Click to Upload": "点击上传",
"Clip and renormalize": "衰减与规格化",
"CLIP: maximum number of lines in text file": "CLIP: 文本文件的最大行数",
"CLiP model": "CLiP 模型",
"clipseg": "CLIP分割",
"clipseg options": "CLIPSeg 选项",
"Clip skip": "CLIP 终止层数",
"Clip Skip": "CLIP 终止层数",
"CLIP Skip": "CLIP 终止层数",
"CLIP: skip inquire categories": "CLIP: 跳过查询类别",
"CLIP skip schedule": "CLIP 终止层数计划表",
"CLIP tensors checker": "Clip tensors 检测",
"clip_threshold": "裁剪阈值",
"Close": "关闭",
"Closed": "关闭",
"Close Preview": "关闭预览",
"Closer is brighter": "越近越亮",
"Close the video": "关闭视频",
"cloudscape": "cloudscape (云景)",
"cluster num": "簇数",
"Codec": "编码器",
"CodeFormer vis.": "CodeFormer 可见程度",
"CodeFormer visibility": "CodeFormer 可见程度",
"CodeFormer weight": "CodeFormer 权重",
"CodeFormer Weight": "CodeFormer 权重",
"CodeFormer weight (0 = maximum effect, 1 = minimum effect)": "CodeFormer 权重 (为 0 时效果最大,为 1 时效果最小)",
"CodeFormer weight parameter; 0 = maximum effect; 1 = minimum effect": "CodeFormer 权重参数;为 0 时效果最大;为 1 时效果最小",
"Coherence": "一致性",
"collage": "collage (拼贴)",
"color_burn": "颜色加深",
"color_coherence": "颜色校正",
"Color coherence": "颜色一致性",
"Color correction factor": "颜色校正系数",
"color_dodge": "颜色减淡",
"Color force Grayscale": "强制颜色空间为灰度",
"colorful": "colorful (多彩)",
"[color-matcher]": "颜色匹配器",
"Color Matcher Ref Image": "颜色匹配器参考图",
"Color Matcher Ref Image Type": "颜色匹配器参考图类型",
"Color reduce algo": "色彩减弱算法",
"Color sketch inpainting": "彩色涂鸦重绘",
"Color Transfer Method": "颜色迁移算法",
"Color variation": "色彩变种",
"Combinations": "组合",
"Combine axis": "拼合方向",
"Combined": "兼有",
"Combine into one image": "拼合为一张图像",
"comics": "comics (美漫)",
"comma": "逗号",
"Comma separated face number(s)": "逗号分隔的面部编号",
"Comma-separated list of tab names; tabs listed here will appear in the extra networks UI first and in order lsited.": "以逗号分割的选项卡名称列表;这里列出的选项卡将首先按顺序出现在扩展模型面板中",
"Comma-separated list of tags (\"artist, style, character, 2d, 3d...\")": "以逗号分割的标签列表 (如 \"artist,style,character,2d,3d...\")",
"Commit": "提交",
"Comp alpha schedule": "混合透明度参数表",
"Compatibility": "兼容性",
"Comp mask type": "比较蒙版类型",
"Component": "模型组件",
"Composable Mask scheduling": "可组合的蒙版计划表",
"Composite audio files extracted from the original video onto the concatenated video.": "将原始视频中的音频整合到生成的视频中。",
"Composite video with previous frame init image in": "前一帧初始图像的合成视频在",
"Comp save extra frames": "保存合成过程所有额外帧",
"Compute Settings": "计算设置",
"Concatenate each frame while crossfading.": "在交叉融合运算时串联每一帧。",
"concept": "concept (概念)",
"concept art": "concept art (概念艺术)",
"concept - Can be a concept, such as “a X of Y”, or an historical event such as “The Trojan War”.": "concept - 概念 - 可以是一种概念:例如一个事物的某种特质;或者是一个历史事件,例如 “特洛伊战争“ 。",
"Config Backup: Config": "配置备份:配置",
"Config file for Adapter models": "Adapter 模型配置文件路径",
"Config file for Control Net models": "ControlNet 模型配置文件路径",
"Config Name": "配置名",
"Config Presets": "预设配置",
"Config-Presets": "预设配置",
"configuration": "插件设置",
"configuration for": "详细设置",
"Connecting": "连接中",
"Connection errored out.": "连接出错",
"Consider a donation on ko-fi! :3": "考虑在 ko-fi 上为本插件赞助! :3",
"Console logging": "控制台日志记录",
"Containing directory": "目标模型目录",
"contrast": "对比度",
"Contrast schedule": "对比度参数表",
"Control Mode": "控制模式",
"Control Mode (Guess Mode)": "控制类型 (猜测模式)",
"ControlNet guidance end": "ControlNet 引导结束时机",
"ControlNet guidance end 2nd": "ControlNet 引导结束时机",
"ControlNet guidance end 3rd": "ControlNet 引导结束时机",
"ControlNet guidance end 4th": "ControlNet 引导结束时机",
"ControlNet guidance end 5th": "ControlNet 引导结束时机",
"ControlNet guidance start": "ControlNet 引导介入时机",
"ControlNet guidance start 2nd": "ControlNet 引导介入时机",
"ControlNet guidance start 3rd": "ControlNet 引导介入时机",
"ControlNet guidance start 4th": "ControlNet 引导介入时机",
"ControlNet guidance start 5th": "ControlNet 引导介入时机",
"ControlNet Inpaint Index": "ControlNet 重绘 Unit 序号",
"ControlNet inpaint model index": "ControlNet 的 inpaint 模型启用单元页",
"ControlNet inpaint not masked": "ControlNet 重绘不使用蒙版",
"ControlNet Inpaint Number": "ControlNet 重绘序号",
"Controlnet input directory": "ControlNet 输入目录",
"ControlNet input directory": "ControlNet 的输入目录",
"ControlNet Input Video Path": "ControlNet 输入视频路径",
"ControlNet is more important": "更偏向 ControlNet",
"ControlNet Mask Video Path": "ControlNet 视频蒙版路径",
"ControlNet model": "ControlNet 模型",
"ControlNet model 2nd": "ControlNet 模型",
"ControlNet model 3rd": "ControlNet 模型",
"ControlNet model 4th": "ControlNet 模型",
"ControlNet model 5th": "ControlNet 模型",
"ControlNet number": "ControlNet 序号",
"ControlNet option": "ControlNet 选项",
"ControlNet Segmentation Index": "ControlNet 语义分割 Unit 序号",
"Controlnet tile model name": "Controlnet tile 模型名",
"ControlNet Video Input": "ControlNet 视频输入",
"ControlNet Video Mask Input": "ControlNet 视频蒙版输入",
"ControlNet weight": "ControlNet 权重",
"Control Net Weight": "ControlNet 权重",
"ControlNet weight 2nd": "ControlNet 权重",
"ControlNet weight 4th": "ControlNet 权重",
"ControlNet weight 5th": "ControlNet 权重",
"Control Net Weight For Face": "ControlNet 脸部权重",
"Controls the strength of the diffusion on the init image. 0 = disabled": "控制初始化图像生成器的强度。 0 = 禁用",
"Control Type": "控制类型",
"Control Weight": "控制权重",
"convert": "转换",
"Convert a 360 spherical panorama to a 3D mesh": "将单张 360° 球形全景图转换为 3D 网格",
"Convert a single 2D image to a 3D mesh": "将单张 3D 图像转换为 3D 网格",
"Convert currently loaded checkpoint into ONNX. The conversion will fail catastrophically if TensorRT was used at any point prior to conversion, so you might have to restart webui before doing the conversion.": "将当前加载的 checkpoint 转换为 ONNX 模型。如果在转换前的任意时间加载了 TensorRT, 转换会失败。推荐在转换前重启 webui",
"Converted checkpoints will be saved in your": "转换出的模型将会保存在你的",
"Convert ONNX to TensorRT": "将 ONNX 模型转换为 TensorRT 模型",
"Convert to ONNX": "转换为 ONNX 模型",
"Convert Unet to ONNX": "转换 Unet 为 ONNX 模型",
"copy": "复制",
"Copy": "复制",
"Copy config from": "复制配置文件",
"Copy image to:": "复制当前图像到: ",
"Copy Metadata": "开始复制元数据",
"Copy metadata to other models in directory": "将元数据复制到文件夹中的其他模型",
"\uD83D\uDCCB Copy to clipboard": "\uD83D\uDCCB 复制到剪切板",
"Copy to ControlNet Inpainting": "复制到 ControlNet 重绘",
"Copy to ControlNet Segmentation": "复制到 ControlNet 语义分割",
"Copy to favorites": "复制到收藏夹",
"Copy to Inpaint Upload & ControlNet Inpainting": "复制到局部重绘和 ControlNet 重绘",
"Copy to txt2img ControlNet Inpainting": "复制到文生图 ControlNet 重绘中",
"cosine": "余弦",
"cosine_with_restarts": "周期重启余弦",
"Cover image": "封面图像",
"Cozy Image Browser": "Cozy 图库浏览器",
"Cozy Nest Image Browser": "Cozy Nest 图库浏览器",
"Create": "创建",
"Create animation": "创建动画",
"Create a text file next to every image with generation parameters.": "同时为每个图片创建一个文本文件储存生成参数",
"Create blank canvas": "创建空白画布",
"Created at:": "创建时间:",
"Create debug image": "创建调试(debug)图像",
"Create embedding": "创建嵌入式模型",
"Create flipped copies": "创建水平翻转副本",
"Create From Hub": "从 Huggingface Hub 中创建",
"Create hypernetwork": "创建超网络 (Hypernetwork)",
"Create New Canvas": "创建新画布",
"Creates animation sequence from denoised intermediate steps with video frame interpolation to achieve desired animation duration": "利用视频插值从降噪过程的中间步骤图像中生成动画",
"Create txt2img canvas": "创建文生图画布",
"CRF": "固定码率因子 (CRF)",
"Crop and resize": "裁剪后缩放",
"Crop and Resize": "裁剪后缩放",
"Crop Images": "剪裁图像",
"crop_n_layers": "分层层数",
"crop_nms_thresh": "分层数量阈值",
"crop_n_points_downscale_factor": "分层采样点坍缩因子",
"crop_overlap_ratio": "分层重叠度",
"Cropping": "剪裁",
"Crop to fit": "裁剪以适应宽高比",
"Crop: top, left, bottom, right": "裁切:顶部,左侧,顶部,右侧",
"Cross-attention": "Cross-Attention 优化方案",
"Cross attention optimization": "Cross-Attention 优化方案",
"Crossfade blend rate": "交叉融合强度",
"Ctrl+up/down precision when editing (attention:1.1)": "使用 Ctrl + ↑/↓ 设置\"(tag:1.1)\"时的精度",
"Ctrl+up/down precision when editing <extra networks:0.9>": "使用 Ctrl + ↑/↓ 设置\"<extra networks:0.9>\"时的精度",
"Ctrl+up/down word delimiters": "可以使用 Ctrl + ↑/↓ 设置关注度的\"提示词分隔符类型\"",
"cubism": "cubism (立体主义)",
"Current": "Current (当前帧)",
"Current Cache": "当前缓存目录",
"currently selected model": "当前选择的模型",
"Current Model": "当前模型",
"Current version": "当前版本",
"Custom Config File": "自定义配置文件",
"Custom Name (Optional)": "自定义名称 (可选)",
"Custom settings file": "自定义设置文件",
"Custom size": "自定义尺寸",
"custum name": "自定义名称",
"Cutoff strongly.": "强效分隔",
"Cut white margin from input": "从输入中剪切空白区域",
"Daam script": "Daam 脚本",
"dark": "dark (暗黑)",
"darken": "变暗",
"Dataset directory": "数据集目录",
"Dataset Directory": "数据集目录",
"Dataset folder structure": "数据集文件夹结构",
"Dataset Images": "数据集图片",
"Dataset Load Settings": "数据集加载设置",
"date": "日期",
"Date": "日期",
"debug": "调试",
"Debug info": "调试信息",
"Debug level": "调试等级",
"Debug log": "调试日志",
"Decode CFG scale": "解码提示词引导系数(CFG scale)",
"Decoder Tile Size": "解码器分块大小",
"Decode steps": "解码迭代步数",
"deepbooru: escape (\\) brackets": "deepbooru: 转义 (\\) 括号",
"deepbooru: filter out those tags": "deepbooru: 过滤以下标签",
"deepbooru: score threshold": "deepbooru: 评分阈值",
"deepbooru: sort tags alphabetically": "deepbooru: 按字母顺序排序标签",
"deepbooru: use spaces in tags": "deepbooru: 在标签间使用空格",
"Default Image CFG": "默认图像引导系数 (CFG)",
"Defaults": "默认设置",
"Default scoring type": "默认评分类型",
"Default upscaler for image resize operations": "默认图像缩放算法",
"default variables: in \\{\\}, like \\{init_mask\\}, \\{video_mask\\}, \\{everywhere\\}": "默认变量:\\{\\},比如 \\{init_mask\\}, \\{video_mask\\}, \\{everywhere\\}",
"Default view for Extra Networks": "默认扩展模型视图",
"❌ Del": "❌ 删除",
"delete": "删除",
"❌Delete": "❌删除",
"Delete": "删除",
"Delete 0-entries from exif cache": "从 EXIF 缓存删除 0-entries",
"DELETE cannot be undone. The files will be deleted completely.": "删除操作无法撤销,文件会被完全删除。",
"DELETE File(s)": "删除文件",
"Delete Imgs": "删除图像",
"Delete intermediate": "删除临时文件",
"Delete intermediate frames after GIF generation": "生成 GIF 后删除临时帧图片",
"delete next": "删除后 N 张",
"delete or keep raw affected (interpolated/ upscaled depending on the UI section) png imgs": "删除或保留受影响的原始 (根据 UI 设置进行插值/放大) PNG 图像",
"Delete Selected Skeleton (D key)": "删除选中骨架 (D 键)",
"Denoise": "降噪",
"Denoise strength": "重绘幅度",
"Denoising": "重绘幅度",
"Denoising Diffusion Implicit Models - best at inpainting": "Denoising Diffusion Implicit models - (DDIM) - 最擅长局部重绘",
"Denoising strength": "重绘幅度",
"Denoising strength curve": "重绘幅度曲线",
"Denoising strength for face images": "脸部重绘幅度",
"Denoising strength for the entire image": "全图重绘幅度",
"Denoising strength (Inpaint)": "局部重绘幅度",
"Depth": "Depth (深度)",
"depth_leres": "depth_leres (LeReS 深度图估算)",
"depth_leres++": "depth_leres++ (LeReS 深度图估算++)",
"Depth Map": "深度图",
"Depth Maps": "深度图",
"depth_midas": "depth_midas (MiDaS 深度图估算)",
"Depth (Midas/Adabins)": "深度模式 (Midas / Adabins)",
"Depth Output": "深度图输出",
"Depth Prediction": "深度估计预处理",
"Depth Prediction demo": "深度估计预处理 Demo",
"depth_zoe": "depth_zoe (ZoE 深度图估算)",
"Descending": "降序",
"Description": "描述",
"description-based:": "基于描述:",
"Destination directory": "目标目录",
"Destination Directory": "目标文件夹",
"detailed": "detailed (细节)",
"Detailed": "详细设置",
"Detailed Save As": "详细保存为",
"Details": "详细设置",
"Detect from image": "从图像中提取",
"Detect from Image": "从图像中提取",
"Detection": "检测",
"Detection model confidence threshold": "检测模型置信阈值",
"Detection model confidence threshold %": "检测模型置信阈值 (单位: %)",
"Detection model confidence threshold % 2nd": "检测模型置信阈值 (单位: %)",
"Detection model confidence threshold 2nd": "检测模型置信阈值",
"Detection model confidence threshold % 3rd": "检测模型置信阈值 (单位: %)",
"Detection model confidence threshold 3rd": "检测模型置信阈值",
"Detection model confidence threshold % 4th": "检测模型置信阈值 (单位: %)",
"Detection model confidence threshold 4th": "检测模型置信阈值",
"Detection model confidence threshold % 5th": "检测模型置信阈值 (单位: %)",
"Detection model confidence threshold 5th": "检测模型置信阈值",
"Determines how little respect the algorithm should have for image's content. At 0, nothing will change, and at 1 you'll get an unrelated image. With values below 1.0, processing will take less steps than the Sampling Steps slider specifies.": "决定算法对图像内容的影响程度。设置 0 时,什么都不会改变,而在 1 时,你将获得不相关的图像。\n值低于 1.0 时,处理的迭代步数将少于“采样迭代步数”滑块指定的步数",
"deterministic": "可复现的",
"difference": "差值",
"Difference": "差分",
"Diffuse the first frame based on an image, similar to img2img.": "基于图像生成第一帧,类似于图生图",
"digital": "digital (数字)",
"digital art": "digital art (数字艺术)",
"Dilation factor (B)": "扩张因子 (B)",
"Dimension lower bound": "最小维度",
"Dimension upper bound": "最大维度",
"Directly Draw Scribbles": "直接绘制线稿",
"directory.": "目录。",
"Directory for detected maps auto saving": "检测图 (detected maps) 保存路径",
"Directory for saving images using the Save button": "“保存”按钮输出文件夹",
"Directory for saving init images when using img2img": "图生图初始图像的保存文件夹",
"Directory for temporary images; leave empty for default": "临时图像目录;默认为空",
"(directory is hidden if its name starts with \".\")": "(如果目录的名称以 \".\" 开头, 就会被隐藏)",
"(directory is hidden if its name starts with \".\".)": "(如果目录的名称以 \".\" 开头, 就会被隐藏)",
"Directory name pattern": "目录名称格式",
"Disable": "禁用",
"Disable all extensions": "停用所有扩展",
"Disable at the last loopback time": "最后一次回送时禁用",
"Disable built-in Lora handler": "停用内置 Lora 处理器",
"Disable control type selection": "禁用控制类型筛选",
"disable convert 'AND' to 'BREAK'": "不再将 \"AND \"转换为 \"BREAK\"",
"disabled": "禁用",
"Disabled": "已禁用",
"Disable during hires pass": "在高清修复过程中停用",
"Disable for Negative prompt.": "为反向提示词禁用本插件效果",
"Disable image browser (Reload UI required)": "禁用 Cozy 图库浏览器 (需重启UI)",
"Disable image browser (requires reload UI)": "禁用 Cozy 图库浏览器 (需要重启)",
"Disable openpose edit": "禁用 openpose 姿态编辑",
"Disable prompt token counters": "禁用提示词词元长度计数器",
"Disable waves and gradiant background": "禁用波纹和背景渐变效果",
"Disable waves and gradiant background animations": "禁用波纹和背景渐变动画",
"Discard": "丢弃",
"Discard: remove style text from prompt, keep styles dropdown as it is.": "丢弃: 从提示词中删除对应预设样式文本, 并保持预设样式下拉菜单不变",
"Discard weights with matching name": "删除匹配键名的表达式的权重",
"discord server": " Discord 服务器",
"display both english and target language": "同时显示英语和目标语言",
"Display information dialog on Cozy Nest error": "显示 Cozy Nest 的信息对话框",
"Display mode:": "显示模式:",
"Display name for this model": "此模型的显示名",
"Disregard checkpoint information from pasted infotext": "忽略粘贴的生成信息文本中的 Stable Diffusion 模型信息",
"Divergence (3D effect)": "发散性(3D 效果)",
"Divisions": "分区方式",
"Dolly": "希区柯克(推轨变焦)",
"Do not add watermark to images": "不在图像上添加水印",
"Do not append detectmap to output": "不输出检测图 (detected maps) (如深度估算图、动作检测图等)",
"Do not do anything special": "什么都不做",
"Do not fix prompt schedule for second order samplers.": "不为二阶采样方法修复提示词作用时间",
"Do not make DPM++ SDE deterministic across different batch sizes.": "保留 DPM++ SDE 采样器 在不同的批次大小之间的结果差异",
"Do not resize images": "不调整图像大小",
"Do not save grids consisting of one picture": "当仅有一张图时不保存网格图",
"Do not save heatmap images": "不保存热力图图像",
"Do not show any images in results for web": "不在浏览器输出结果中显示任何图像",
"Do not store my preferences or SVG content locally": "不在本地保存设置和SVG图像",
"Don't cache latents": "不要缓存潜空间图片",
"Don't Cache Latents": "不要缓存潜空间图片",
"Don't generate images": "不生成图像",
"Don't generate, only upscale": "不生成,仅放大",
"Don't outfill": "不进行填充",
"Don't Override": "不覆盖",
"Don’t use wierd blocky upscale mode. Or maybe do?": "不要用 \"糟糕的分块放大模式\" ,或者也许可以试试?",
"double-straight-line": "双直线",
"down": "下",
"Download": "下载",
"Download All files": "下载所有文件",
"\uD83D\uDCBE Download image": "\uD83D\uDCBE 下载图片",
"Download localization template": "导出 localization 模板",
"Download Max Size Preview": "下载最大尺寸预览图",
"Download missing models upon reading generation parameters from prompt": "从生成参数中的提示词读取并下载缺失的模型",
"Download missing preview images on startup": "启动时下载缺失的模型预览图",
"Download Model": "下载模型",
"Download NSFW (adult) preview images": "允许下载含成人内容的预览图",
"Download system info": "下载系统信息",
"Download the pose as .json file": "以 .json 格式保存姿态图",
"Downscaling": "缩小",
"Drag Me": "拖动页面",
"Drawing": "绘画",
"Drawing Canvas": "创建画布",
"Draw legend": "包含图例注释",
"Draw Legends": "包含图例注释",
"Draw mask": "绘制蒙版",
"dropdown": "下拉列表",
"Dropdown": "下拉列表",
"Drop File Here": "拖拽文件到此",
"Drop Image Here": "拖动图像至此",
"Drop out tags when creating prompts.": "创建提示词时丢弃标签(tags)",
"Drop tabs here to hide them": "把选项卡拖到此处隐藏它们",
"Drop Video Here": "拖动视频至此",
"Dry Run": "试运行",
"Due to ControlNet base extension's inner works it needs its models to be located at 'extensions/deforum-for-automatic1111-webui/models'. So copy, symlink or move them there until a more elegant solution is found. And, as of now, it requires use_init checked for the first run. The ControlNet extension version used in the dev process is a24089a62e70a7fae44b7bf35b51fd584dd55e25, if even with all the other options above used it still breaks, upgrade/downgrade your CN version to this one.": "因为 ControlNet 基层插件在内工作,所以需要将 ControlNet 模型置于 “extensions/deforum-for-automatic1111-webui/models”文件夹内。在更优雅的解决方法出现之前,请复制,软链接 symlink 或者移动模型。 \n同时目前为止,该插件需要在第一次运行时检查 use_init。\n用于开发进程的 ControlNet 插件版本为 a24089a62e70a7fae44b7bf35b51fd584dd55e25。如果全部按照上文使用还是损坏,请将 ControlNet 版本升级/降级到上述版本。",
"Due to the limitation of Segment Anything, when there are point prompts, at most 1 box prompt will be allowed; when there are multiple box prompts, no point prompts are allowed.": "由于Segment Anything的限制,当有标记点时,最多允许1个箱体标记;当有多个箱体提示时,不允许使用标记点。",
"duplicate": "重复的",
"Duplicate Skeleton (X-axis)": "复制骨架(X 轴)",
"Duplicate Skeleton (Z-axis)": "复制骨架(Z 轴)",
"Duration": "时长",
"during the run sequence, only frames specified by this value will be extracted, saved, and diffused upon. A value of 1 indicates that every frame is to be accounted for. Values of 2 will use every other frame for the sequence. Higher values will skip that number of frames respectively.": "在运行序列期间,只有由该值指定的帧才会被提取、保存和生成。1表示要考虑每个帧。2表示每隔一帧用于序列。较高的值将分别跳过该帧数。",
"Dynamic Prompts": "Dynamic Prompts (动态提示词)",
"Dynamic Prompts enabled": "启用动态提示词",
"Each image is center-cropped with an automatically chosen width and height.": "每张图片都会以自动选择好的宽和高进行中心裁剪",
"Early stopping parameter for CLIP model; 1 is stop at last layer as usual, 2 is stop at penultimate layer, etc.": "CLIP 模型的提前终止层参数;1是像往常一样停在最后一层,2是停在倒数第二层,以此类推",
"EBSynth Mode": "EBSynth 模式",
"EBSynth Settings": "Ebsynth 设置",
"edit": "编辑",
"Edit": "编辑",
"Edit common tags.": "编辑常见标签",
"editing": "后期编辑",
"Editing Enabled": "开启元数据编辑",
"Edit Openpose": "编辑 Openpose",
"Edit SVG": "编辑 SVG",
"Effect": "效果",
"Effective Block Analyzer": "高效区块分析器",
"EMA (nagetive)": "EMA (负)",
"ema-only": "仅保留 EMA 权重",
"EMA (positive)": "EMA (正)",
"Embedding": "嵌入式模型 (Embedding)",
"Embedding Learning rate": "嵌入式模型学习率",
"Emphasis: use (text) to make model pay more attention to text and [text] to make it pay less attention": "强调符:使用 (文字) 使模型更关注该文本,使用 [文字] 减少其关注度",
"empty cannot be saved": "留空时无法保存",
"empty strings cannot be translated": "无法翻译空的文本",
"Enable": "启用",
"Enable AA for Downscaling.": "缩小时使用抗锯齿",
"Enable AA for Upscaling.": "放大时使用抗锯齿",
"Enable ADetailer": "启用 After Detailer",
"Enable Anti Burn (and everything)": "启用 Anti Burn",
"Enable Autocomplete": "启用标签自动补全",
"Enable Autopruning": "启用自动修剪",
"Enable batch mode": "启用批处理模式",
"Enable Bilingual Localization": "启用双语对照翻译插件",
"Enable CFG-Based guidance": "启用基于 CFG 的引导 (CFG-Based guidance)",
"Enable checkpoint scheduling": "启用模型计划表",
"Enable clear gallery button in txt2img and img2img tabs": "在文生图和图生图标签页中启用清除图片输出栏按钮",
"Enable CLIP skip scheduling": "启用 CLIP 终止层数计划表",
"Enable color correction": "启用颜色校正",
"Enable Control": "启用控制",
"Enable controlnet tile resample": "启用 ControlNet 的 tile resample (分块 - 重采样)",
"enabled": "启用",
"Enabled": "启用",
"Enable Dynamic Thresholding (CFG Scale Fix)": "启用动态阈值 (CFG Scale 修复)",
"Enable emphasis": "启用强调符",
"Enable extra network tweaks": "启用扩展网络修改",
"Enable Face Prompt": "启用脸部提示词",
"Enable full page image viewer": "启用网页全屏图像查看器",
"Enable GroundingDINO": "启用 GroundingDINO",
"Enable guided images mode": "启用引导图像模式",
"Enable Hires. fix+": "启用高分修复PLUS",
"Enable JavaScript aspect ratio controls": "启用前端纵横比控制",
"Enable Jinja2 templates": "启用 Jinja2 模板",
"Enable Maintenance tab": "启用 \"维护\" 选项卡",
"Enable model compile (experimental)": "启用模型编译优化(实验性)",
"Enable MultiDiffusion": "启用 MultiDiffusion",
"Enable noise multiplier scheduling": "启用噪声乘法 (noise multiplier) 调度",
"Enable optimized monocular depth estimation": "启用单色深度估算优化 (optimized monocular depth estimation)",
"Enable overwrite": "允许覆盖",
"Enable perspective flip": "启用透视翻转",
"Enable pixelization": "启用像素化",
"Enable Pixel Perfect from lllyasviel. Configure your target width and height on txt2img/img2img default panel before preview if you wish to enable pixel perfect.": "启用 lllyasviel 的完美像素模式。在预览前,请在文生图/图生图界面配置好图像的目标宽度和高度。",
"Enable postprocessing operations in txt2img and img2img tabs": "在文生图/图生图选项卡中启用后处理操作",
"Enable quantization in K samplers for sharper and cleaner results": "对 K 采样器启用量化以获得更清晰、干净的结果",
"Enable quantization in K samplers for sharper and cleaner results. This may change existing seeds. Requires restart to apply.": "对 K 采样器启用量化以获得更清晰、干净的结果。这可能会改变现有的随机种子。需重启才能应用。",
"Enable Randomize extension": "启用随机化扩展",
"Enable Region 1": "启用区域 1",
"Enable Region 2": "启用区域 2",
"Enable Region 3": "启用区域 3",
"Enable Region 4": "启用区域 4",
"Enable Region 5": "启用区域 5",
"Enable Region 6": "启用区域 6",
"Enable Region 7": "启用区域 7",
"Enable Region 8": "启用区域 8",
"Enable sampler scheduling": "启用采样器计划表",
"Enable steps scheduling": "启用迭代步数计划表",
"Enable Subseed scheduling": "启用第二种子计划表",
"Enable Tag Autocompletion": "启用标签自动补全",
"Enable tensorboard logging": "启用 Tensorboard 日志记录",
"Enable tensorboard logging.": "启用 Tensorboard 日志记录",
"Enable this to save VRAM.": "启用此项以节省显存 (VRAM)。",
"Enable thumbnail tooltips": "启用缩略图工具提示",
"Enable Tiled Diffusion": "启用 Tiled Diffusion",
"Enable Tiled VAE": "启用 Tiled VAE",
"Enable tooltip on the canvas": "启用画布上的工具列提示框",
"Enable uploading manually created mask to SAM.": "启用手动上传蒙版到 SAM。",
"Enable upscale with extras": "启用后期处理放大",
"Enable Vectorizing": "启用矢量化",
"Enable webcam": "开启网络摄像头",
"Encoder Color Fix": "编码器颜色修复",
"Encoder Tile Size": "编码器分块大小",
"end at this step": "结束控制步数",
"End blur width": "结束模糊宽度",
"Ending Control Step": "引导终止时机",
"End Page": "尾页",
"end the animation at this frame number": "达成此帧数后停止生成",
"Engine": "引擎",
"Enhance": "增强",
"Enhanced img2img": "Enhanced img2img (图生图增强)",
"(ENSD; does not improve anything, just produces different results for ancestral samplers - only useful for reproducing images)": "(ENSD: 对图像质量无任何提升, 只为 ancestral 采样方法产生不同的结果 - 仅对复现图像有用)",
"Enter categody ids, separated by +. For example, if you want bed+person, your input should be 7+12 for ade20k and 59+0 for coco.": "在此输入类别 ID,用 + 分隔。例如,如果你想分割出 床 + 人,使用ade20k协议应该输入 7 + 12,使用coco协议应该输入 59 + 0。",
"Enter category IDs": "输入类别ID",
"Enter hypernetwork Dropout structure (or empty). Recommended : 0~0.35 incrementing sequence: 0, 0.05, 0.15": "输入 Hypernetwork Dropout 结构(或留空)\n推荐:0~0.35\n递增排序:0、0.05、0.15",
"Enter hypernetwork layer structure": "超网络层结构",
"Enter input path": "填写输入目录",
"Enter output path": "填写输出目录",
"Enter relative to webui folder or Full-Absolute path, and make sure it ends with something like this: '20230124234916_%09d.png', just replace 20230124234916 with your batch ID. The %05d is important, don't forget it!": "输入绝对路径或者以 webui 为根目录的相对路径,同时确认路径结尾类似“20230124234916_%09d.png”。只需要将 20230124234916 替换为你的 batch ID。“%05d”很重要,别忘了!",
"Equirectangular projection": "等距柱状投影图",
"Erase BG": "移除背景图",
"Error": "错误",
"Error threshold": "错误阈值 (%)",
"Escape brackets": "将结果中的括号进行转义处理",
"Escape parentheses on insertion": "插入时转义括号",
"Eta for ancestral samplers": "ancestral 采样方法的 Eta 系数",
"Eta for DDIM": "DDIM 采样方法的 Eta 系数",
"Eta noise seed delta": "Eta 噪声种子偏移量 (ENSD)",
"etc": "其他",
"Euler Ancestral - very creative, each can get a completely different picture depending on step count, setting steps higher than 30-40 does not help": "Euler Ancestral - 非常有创意,取决于迭代步数不同而生成完全不同的图像,这意味着将迭代步数设置为高于 30-40 不会有任何帮助",
"ex A.": "例 A:",
"Example: Default args should use 221 as total keyframes.": "示例:默认参数应使用 221 作为总关键帧数。",
"Example flow:": "工作流示例: ",
"Examples": "例子",
"Example: seed_schedule could use 0:(5), 1:(-1), 219:(-1), 220:(5)": "示例:种子数表可以使用 0:(5), 1:(-1), 219:(-1), 220:(5)",
"ex B.": "例 B:",
"ex C.": "例 C:",
"Exclude tags (split by comma)": "排除标签 (逗号分隔)",
"Exclude Target (e.g., finger, book)": "排除目标(如 finger, book)",
"exclusion": "排除",
"Excudes (split by comma)": "排除 (逗号分隔)",
"exif keyword": "EXIF 关键词",
"EXIF keyword search": "EXIF 关键词搜索",
"Existing Caption txt Action": "对已有标注的 txt 文件的操作",
"Expanded Mask": "扩展后蒙版",
"Expand Mask": "展开蒙版设置",
"(Experimental, keep cond caches across jobs, reduce overhead.)": "(实验性功能;在不同任务中保留缓存以减少开销)",
"Export": "导出",
"Exported Text": "输出文本",
"Export type": "输出类型",
"expressionism": "expressionism (表现主义)",
"Extension": "扩展",
"Extension index URL": "扩展列表地址",
"Extensions": "扩展",
"Extension State": "扩展状态",
"extension to be installed.": "插件",
"Extension version": "扩展版本",
"extra": "额外",
"Extra": "▼",
"Extra args": "额外参数",
"Extra arguments": "额外参数",
"Extra arguments for trtexec command in plain text form": "以纯文本形式填写用于 trtexec 命令的额外参数",
"Extract frames from the original video.": "从原始视频中提取帧。",
"Extract from frame": "提取开始帧",
"Extract nth frame": "提取间隔帧数",
"Extract to frame": "提取结束帧",
"Extract U-Net features": "提取 U-Net 特征值",
"Extra filename (for small sets of custom tags)": "额外文件名(用于小部分的自定义Tag)",
"Extra generation params": "附加生成参数",
"Extra network card height": "扩展模型卡牌高度",
"Extra network card width": "扩展模型卡牌宽度",
"Extra Networks": "扩展模型",
"Extra networks separator": "扩展模型分隔文本",
"Extra networks tab order": "扩展模型类型选项卡顺序",
"Extra paths to scan for LoRA models, comma-separated. Paths containing commas must be enclosed in double quotes. In the path, \" (one quote) must be replaced by \"\" (two quotes).": "扫描低秩微调模型 (LoRA) 的附加目录,以逗号分隔。包含逗号的路径必须用双引号括起来。 在路径中,\"(一个引号)必须替换为\"\"(两个引号)。",
"Extra path to scan for ControlNet models (e.g. training output directory)": "检索 ControlNet 模型的附加目录(如训练输出目录)",
"extras": "后期处理",
"Extras": "后期处理",
"(extra text to add before <...> when adding extra network to prompt)": "(添加扩展模型到提示词时, 在 <...> 之前添加的额外文本)",
"Extra text to add before <...> when adding extra network to prompt": "在向提示词中添加扩展模型标签时在 <…> 之前添加额外文本",
"Face Area Magnification": "脸部区域扩展",
"Face Crop option": "脸部修复选项",
"Face Crop Resolution": "脸部修复分辨率",
"Face Denoising Strength": "脸部去噪强度",
"Face detection confidence": "脸部识别强度",
"Face Detection Method": "人脸识别算法",
"Face Editor": "Face Editor (脸部修复)",
"Face margin": "脸部区域大小",
"Face restoration": "面部修复",
"Face restoration model": "面部修复模型",
"Face Restore Model": "面部修复模型",
"Fall-off exponent (lower=higher detail)": "衰减指数(越小 = 细节越多)",
"fantasy": "fantasy (魔幻)",
"Far clip": "远端衰减",
"fashion": "fashion (时尚)",
"fast": "快速模式",
"Fast Decoder": "使用快速解码器",
"Fast Encoder": "使用快速编码器",
"Fast Encoder Color Fix": "快速编码器颜色修复",
"Fast Encoder may change colors; Can fix it with more RAM and lower speed.": "快速编码器可能会导致颜色偏差;通过使用更大的内存和更慢的速度可以避免这个情况",
"fauvism": "fauvism (野兽派)",
"favorites": "收藏夹",
"Favorites": "收藏夹",
"Favorites path from settings: log/images": "从设置中获取收藏夹路径: log/images",
"Fetch output folder from a1111 settings (Reload needed to enable)": "从 webui 设置中获取输出文件夹 (需重载以启用)",
"FFmpeg CRF value": "FFmpeg CRF 值",
"FFmpeg path/ location": "FFmpeg 路径",
"FFmpeg settings": "FFmpeg 设置",
"figurativism": "figurativism (具象主义)",
"File": "文件",
"File format for grids": "网格图文件格式",
"File format for images": "图片文件后缀(格式)",
"filename": "文件名",
"Filename": "文件名",
"File Name": "文件名",
"Filename join string": "文件名连接用字符串",
"Filename keyword search": "文件名关键词搜索",
"filename(option)": "文件名 (可选)",
"Filename word regex": "文件名用词的正则表达式",
"Filepath:": "文件路径:",
"File size limit for the above option, MB": "上述选项的文件大小限制 (单位: MB)",
"Files to process": "要处理的文件",
"File type": "文件类型",
"fill": "填充",
"fill down": "向下扩展",
"fill it with colors of the image": "用图像颜色 (高强度模糊) 填充",
"fill it with latent space noise": "用潜空间噪声填充",
"fill it with latent space zeroes": "用空白潜空间填充",
"fill left": "向左扩展",
"fill right": "向右扩展",
"fill up": "向上扩展",
"Filter models by path name": "按路径名筛选模型",
"Filter NSFW content": "过滤成人内容 (NSFW)",
"Filter out following properties (comma seperated). Example film grain, purple, cat": "过滤以下提示词包含的属性 (逗号分隔). 例如: film grain, purple, cat",
"Filter values": "过滤值",
"Final denoising strength": "最终重绘幅度",
"find but bo translated:": "已找到但无翻译:",
"Find your cozy spot on Auto1111's webui": "探寻 Auto1111 webui 最舒适的使用方式",
"First": "First (第一生成帧)",
"First frame as init image": "第一帧作为初始化图像",
"first frame of img2img result": "图生图结果的第一帧",
"FirstGen": "FirstGen (处理后生成的第一帧)",
"First Page": "首页",
"Firstpass height": "首次生成高度",
"Firstpass width": "首次生成宽度",
"Fit video length": "适配视频长度",
"Fix broken CLIP position IDs": "修复损坏的 Clip position ID",
"fixed": "固定",
"Fixed seed": "固定种子",
"Focal point entropy weight": "焦点熵权重",
"Focal point face weight": "焦点面部权重",
"Font color": "字体颜色",
"Font for image grids that have text": "网格图文字字体",
"Font size": "字体大小",
"for ade20k and": "来获得 ade20k 类别, 查看",
"For advanced keyframing with Math functions, see": "对于想使用数学函数执行高级关键帧控制的用户,请参阅",
"For advanced users, you can create a permanent file in \\OneButtonPrompt\\userfiles\\ called antilist.csv": "对于专业用户,可以在 \\OneButtonPrompt\\userfiles\\ 中创建一个永久文件,命名为 antilist.csv",
"Force convert half to float on interpolation (for some platforms)": "在插值时强制将半精度浮点数转换为全精度 (适用于部分平台)",
"Force Reset": "强制重置",
"for coco to get category->id map. Note that coco jumps some numbers, so the actual ID is line_number - 21.": "来获得 coco 的类别 -> id 映射。需注意: coco 会跳过部分数字,所以实际 ID 应该是 “划定数字 - 21 (line_number - 21)”",
"for depth map.": "获取深度图更多信息",
"for detailed explanation.": "以了解详细信息。",
"Foreground Transparency": "前景透明度",
"for explanation of each parameter. If you still cannot understand, use default.": "以了解每个参数的含义。如果仍不理解,请保持默认。",
"FOR HELP CLICK HERE": "点击此处获取帮助",
"For hires fix, use width/height sliders to set final resolution rather than first pass (disables Upscale by, Resize width/height to).": "在高分辨率修复中,通过长宽滑块设定最终分辨率 (关闭放大倍率和自适应分辨率设置)",
"For image processing do exactly the amount of steps as specified": "在进行图片处理时,准确执行滑块所指定的迭代步数",
"For inpainting, include masked composite in results for web": "使用重绘时,在网页结果中包含复合蒙版",
"For inpainting, include the greyscale mask in results for web": "使用重绘时,在网页结果中包含灰度蒙版图",
"For inpainting, save a copy of the greyscale mask": "使用重绘时,保存一份灰度蒙版副本",
"For inpainting, save a masked composite": "使用重绘时,保存一份复合蒙版",
"Format": "格式",
"format: http://127.0.0.1:port": "格式: http://127.0.0.1:端口号",
"For negative prompts, please write your positive prompt, then --neg ugly, text, assymetric, or any other negative tokens of your choice. OR:": "对于反向提示词,请写出你的正向提示词,然后添加 --neg ugly,text,assymetric 等您选择的任何其他反向提示词。或者:",
"For SD upscale, how much overlap in pixels should there be between tiles. Tiles overlap so that when they are merged back into one picture, there is no clearly visible seam.": "使用 SD 放大 (SD upscale) 时,分块(Tiles)间的像素重叠宽度\n分块(Tiles)间重叠有助于使它们合并最终图像时避免过于明显的接缝",
"for your animation (leave blank to ignore).": "用于你的动画中(留空表示忽略)",
"Found a bug or want to ask for a feature ? Please": "发现了一个错误或想请求添加一个功能?请",
"Found a bug or want to ask for a feature ? Please use": "发现了一个错误或想请求添加一个功能?请使用",
"Found a bug or want to ask for a feature ? Please use ": "发现了 Bug 或者有个新的想法?请访问 ",
"Found tags": "匹配的标签",
"fp16": "fp16",
"fp32": "fp32",
"fps": "帧率",
"FPS": "帧率",
"Frame Height": "帧高度",
"Frame Interpolation": "帧插值",
"Frame Interpolation to smooth out, slow-mo (or both) any video.": " 进行帧插值来让任何视频获得顺滑的切换效果,慢动作 (或两者皆可)",
"Frame Interpolation will *not* run if any of the following are enabled: 'Store frames in ram' / 'Skip video for run all'.": "帧差值将不会在以下任一选项启用时启动:“保存帧图像到内存” / “跳过视频”",
"Framerate": "帧率",
"frames per keyframe": "每几帧提取1个关键帧",
"Frames to Video": "帧图片转视频",
"Frame Width": "帧宽度",
"Free GPU": "释放显存",
"Frequency": "频率",
"From (full path)": "从 (输入完整路径)",
"Full": "完整",
"Full res mask": "全分辨率蒙版",
"Full res mask padding": "全分辨率蒙版的填充尺寸",
"(Full = slow but pretty; Approx NN and TAESD = fast but low quality; Approx cheap = super fast but terrible otherwise)": "(完整 = 慢但显示效果好; Approx NN 和 TAESD = 快速但低质量; Approx cheap = 超级快但最糟糕)",
"Gallery height in _absolute_ percent of your screen (not remaining height)": "图像输出栏高度占屏幕的百分比 (非剩余高度)",
"Gamepad repeat period, in milliseconds": "游戏手柄回报率 (单位: 毫秒)",
"gamma": "伽马值",
"Gamma": "伽马值",
"Gap fill technique": "间隙填充技术",
"Gather": "生成",
"Gen": "生成",
"Generate": "生成",
"Generate 3D inpainted mesh. (Sloooow, required for generating videos)": "生成优化3D网格 (超慢,用于生成视频)",
"Generate 4 demo videos with 3D inpainted mesh.": "使用 3D 优化网格生成4个演示视频",
"Generate a checkpoint at the current training level.": "保存一个位于当前训练进度的模型文件。",
"Generate a checkpoint at the current training lvel.": "保存一个位于当前训练进度的模型文件。",
"Generate a .ckpt file when saving during training.": "训练中保存时生成一个 ckpt 文件。",
"Generate a mask image.": "生成一个蒙版图像。",
"Generate Batch": "批量处理",
"Generate Ckpt": "创建模型",
"Generate .ebs file.(ebsynth project file)": "生成 .ebs 文件。(Ebsynth 工程文件)",
"Generate forever": "无限生成",
"Generate human masks": "生成人工蒙版",
"Generate Info": "生成信息",
"Generate inputframes": "生成输入帧",
"Generate layout for batch process": "生成批量处理的图像分布",
"Generate layout for single image": "生成单张图像的图像分布",
"Generate me some prompts!": "生成一些提示词",
"Generate Movie Mode": "视频生成模式",
"Generate Preview": "生成预览",
"Generate preview images every N steps.": "每 N 步生成一次预览图像",
"Generate simple 3D mesh. (Fast, accurate only with ZoeDepth models and no boost, no custom maps)": "生成简单3D网格 (快速, 仅适用于 ZoeDepth 模型, 无 Boost, 无 Maps)",
"Generate stereoscopic image(s)": "生成立体图像",
"Generate video": "生成视频",
"Generate Video": "生成视频",
"Generate video from inpainted(!) mesh.": "从深度图生成视频。",
"Generation Info": "生成信息",
"Generation mode": "生成模式",
"Generation settings:": "生成设置:",
"Generation TEST!!(Ignore Project directory and use the image and mask specified in the main UI)": "生成测试!!(忽略工程目录,使用用户界面中指定的图像和蒙版)",
"Get Civitai Model Info by Model Page URL": "从 Civitai 模型页面链接拉取模型信息",
"*Get depth from uploaded video*": "*从上传的视频中获取深度*",
"Get javascript logs": "获取 javascript 日志",
"Get List": "获取列表",
"Get Model Info from Civitai": "从 Civitai 上获取模型信息",
"Get Model Info from Civitai by URL": "从 Civitai 链接获取模型信息",
"Get sub directories": "打开子目录文件夹",
"GFPGAN vis.": "GFPGAN 可见程度",
"GFPGAN visibility": "GFPGAN 可见程度",
"github": "GitHub",
"Glow": "辉光",
"Glow mode": "辉光模式",
"Gold Pendant": "装饰艺术",
"gore": "gore (血腥)",
"Gothic": "哥特",
"grad": "梯度",
"Gradient accumulation steps": "梯度累加步数",
"Gradient Clipping": "梯度 Clip 修剪",
"Gradient clip value": "梯度 Clip 值",
"Gradio theme": "Gradio 主题",
"Gradio theme (requires restart)": "Gradio 主题样式 (需重启)",
"graffiti": "graffiti (涂鸦)",
"graphic design": "graphic design (平面设计)",
"Great": "很好的",
"greg mode": "greg mode (Greg Mike: 美国艺术家)",
"Grid layout": "网格图布局",
"Grid margins (px)": "网格图边框 (单位: 像素)",
"Grid row count; use -1 for autodetect and 0 for it to be same as batch size": "网格图行数; 使用 -1 进行自动检测,使用 0 使其与单批数量相同",
"GroundingDINO batch progress status": "GroundingDINO 批量处理状态",
"GroundingDINO Box Threshold": "GroundingDINO 箱体阈值",
"GroundingDINO Detection Prompt": "GroundingDINO 检测提示词",
"GroundingDINO Model (Auto download from huggingface)": "GroundingDINO 模型 (自动从 huggingface 下载)",
"GroundingDINO + Segment Anything can achieve [text prompt]->[object detection]->[segmentation]": "GroundingDINO + Segment Anything 可以实现 [文本提示词]->[对象检测]->[语义分割]",
"Group/split table by: (when not started with single quote - so only for prompts, not for merge)": "提示词分组方式(非单引号开头时):",
"Guess Mode": "无提示词引导模式",
"Guidance End (T)": "引导终止时机",
"Guidance Start (T)": "引导介入时机",
"Guided Images": "引导图像",
"Guided images schedules": "引导图像参数表",
"haku_output": "Haku 输出",
"Half Model": "半精度模型",
"Hands": "手掌",
"Hand Size": "手掌尺寸",
"hard_light": "强光",
"has metadata": "有元数据",
"has user metadata": "内嵌用户元数据",
"Head Size": "头部尺寸",
"height": "高度",
"Height": "高度",
"Height Resolution": "高度分辨率",
"Help": "帮助",
"Help for Jinja2 templates": "Jinja2 模板帮助",
"[here]": "[这里]",
"here": "这里",
"Hidden UI tabs": "选择需要隐藏的 UI 标签栏",
"Hidden UI tabs (requires restart)": "需要隐藏的 UI 选项卡 (需要重启)",
"Hide annotator result": "隐藏预处理预览结果",
"Hide caption": "隐藏文本标注",
"Hide extensions with tags": "隐藏含有以下标签的扩展",
"Hide heatmap images": "隐藏热力图图像",
"Hide samplers in user interface": "隐藏用户界面中的采样方法",
"Hide samplers in user interface (requires restart)": "在用户界面中隐藏采样器 (需重启)",
"high contrast": "high contrast (高对比度)",
"Higher levels increases complexity and randomness of generated prompt": "随机等级越高, 生成的提示词越复杂和随机",
"Highres. fix": "高分辨率修复",
"Hires CFG": "高分修复提示词引导系数",
"hires. fix": "高分辨率修复",
"hiresfix": "高清修复",
"Hires. fix": "高分辨率修复 (Hires. fix)",
"Hires. fix+": "高分修复PLUS",
"Hires fix: show hires prompt and negative prompt": "高分辨率修复: 显示高分辨率修复的正反提示词输入框",
"Hires fix: show hires sampler selection": "高分辨率修复: 显示高分采样方法选择栏",
"Hires. fix+ to do steps optimization": "高分修复 PLUS 来优化迭代步数的话",
"Hires Negative prompt": "高分修复反向提示词",
"Hires Prompt": "高分修复正向提示词",
"Hires sampling method": "高分采样方法",
"Hires Sampling method": "高分辨率修复采样方法",
"Hires steps": "高分迭代步数",
"hires upscaler": "高分辨率修复放大算法",
"Historical": "Historical (当前帧前的倒数第二帧)",
"History": "历史记录",
"Horizontal": "水平",
"Horizontal Mirroring": "水平镜像",
"horizontal split num": "水平分割数",
"Horizontal+Vertical Mirroring": "水平+垂直镜像",
"horror": "horror (恐怖)",
"how closely the image should conform to the prompt. Lower values produce more creative results. (recommended range 5-15)": "图像应符合提示词的程度。较低的值会产生更具创造性的结果。(建议范围5-15)",
"how close to get to the colors of the input frame image/ the amount each frame during a tweening step to use the new images colors": "如何接近输入帧图像的颜色 / 在中间计算步骤中使用新图像颜色的每帧数量",
"How many batches of images to create": "创建多少批量次数的图像",
"How many results to load at once": "一次性加载Tag数",
"How many times to improve the generated image iteratively; higher values take longer; very low values can produce bad results": "迭代改进生成的图像的次数;较高的值需要更长的时间;非常低的值会产生不好的结果。",
"How many times to process an image. Each output is used as the input of the next loop. If set to 1, behavior will be as if this script were not used.": "单个图像的处理次数\n每次输出结果都被用作下一个处理的输入\n设置为 1 等同于不启用这个脚本",
"how much the image should look like the previou one and new image frame init. strength schedule might be better if this is higher, around .75 during the keyfames you want to switch on": "前一个图像和新的图像帧的初始化强度规划有多大的关系。在你想启用的关键帧中,如果这个数字高一点,大约0.75,可能会更好。",
"How much to blur the mask before processing, in pixels.": "处理前对蒙版进行模糊的强度 (单位: 像素)",
"How often, in seconds, to flush the pending tensorboard events and summaries to disk.": "刷新间隔,单位为秒;将待处理的 Tensorboard 事件和摘要刷新到硬盘",
"How strong of a variation to produce. At 0, there will be no effect. At 1, you will get the complete picture with variation seed (except for ancestral samplers, where you will just get something).": "变化强度。设为 0 时,将没有效果\n设为 1 时,你将获得完全产自差异随机种子的图像 (此功能对带有 a 后缀的采样器无效)",
"hue": "色度",
"HuggingFace Token": "HuggingFace 访问令牌",
"humanoid": "humanoid (人形)",
"humanoid - A random humanoid, males, females, fantasy types, fictional and non-fictional characters. Can add clothing, features and a bunch of other things.": "humanoid - 人形 - 一个随机的人形生物,男性、女性、幻想类型,虚构或非虚构的生物。可以添加服装,特征和其它东西。",
"Humans Masking": "人工蒙版",
"Hybrid composite": "混合合成模式",
"Hybrid motion": "混合模式",
"Hybrid Schedules": "混合参数表",
"Hybrid Settings": "合成设置",
"Hybrid Video": "视频合成",
"Hybrid Video Compositing in 2D/3D Mode": "2D/3D 模式下的混合视频合成",
"Hypernetwork": "超网络 (Hypernetwork)",
"Hypernetwork Learning rate": "超网络学习率",
"Hypernetworks": "超网络 (Hypernetworks)",
"Idea and inspiration by xKean.": "这个创意受 xKean 启发。",
"Idea by redditor jonesaid.": "这个创意来自于 redditor: jonesaid 。",
"If an image is specified below, it will be used with highest priority.": "如果在下面指定的一张图像,它将以最高优先级使用。",
"If an image is too large, crop it from the center.": "如果图像太大,则从中心裁剪掉边缘",
"If Deforum crashes due to CN updates, go": "如果 Deforum 由于 ControlNet 版本更新而崩溃,请前往",
"If enabled, only images will be saved": "启用时, 仅保存图片",
"if enabled, raw imgs will be deleted after a successful video/ videos (upsacling, interpolation, gif) creation": "如启用, 则在成功创建视频/其它项目 (放大,插值,gif) 后删除原始图像",
"If loading of the Yolov5_anime model fails, check": "如果 Yolov5_anime 模型加载失败,请查看",
"If multiple .ebs files are generated, run them all.": "如果生成了多个 .ebs 文件,则需要全部运行。",
"(if not: sort by score)": "(如不启用: 按评分排序标签)",
"(if not: use underscores)": "(如不启用: 使用下划线)",
"If out-* directory already exists in the Project directory, delete it manually before executing.": "如果out-*目录已经存在于工程目录中,请在执行前手动删除它。",
"If \"Save a copy of image before doing face restoration.\" is enabled, save every image during rolling generation": "如果 \"在进行面部修复前保存图像副本 \" 选项启用,则梯度放大倍数生成时保存每张图像",
"If setting2prompt width, which width-ratio between both columns (0: minimize setting, 1: 50/50, 6: minimize output gallery column)": "设置文生图, 图生图双栏宽度比 (0: 最小化左侧栏宽度, 1: 双侧栏各占50%宽度, 6: 最小化右侧图像输出栏)",
"If setting2prompt width, which width-ratio between both columns (0: minimize setting, 1: 50/50, 6: minimize output gallery column)": "设置文生图, 图生图双栏宽度比 (0: 最小化左侧栏宽度, 1: 双侧栏各占50%宽度, 6: 最小化右侧图像输出栏)",
"If Smart-Step is enabled, the number of iterations for Hires. fix will never be less than this:": "如果启用优化迭代步数,高分辨率修复的迭代步数将永远不会少于本选项设置的数值:",
"(if the file size is above the limit, or either width or height are above the limit)": "(如果图像文件大小超过限制, 或者其宽度或高度超过限制)",
"If the number of tokens is more than the number of vectors, some may be skipped.\nLeave the textbox empty to start with zeroed out vectors": "如果 Tokens 数量多于向量数量,一些 Tokens 可能会被跳过\n把输入文本框留空,就可以从清零的向量开始",
"If the saved image file size is above the limit, or its either width or height are above the limit, save a downscaled copy as JPG": "当图像文件大小或尺寸超过限制,另存一份缩小的副本为 JPG 格式",
"If this values is non-zero, it will be added to seed and used to initialize RNG for noises when using samplers with Eta. You can use this to produce even more variation of images, or you can use this to match images of other software if you know what you are doing.": "如果此值非零,它将被添加到种子中,并在使用Eta的采样器时用于初始化随机噪声。\n你可以用它来产生更多的图像变化,或者用它来模仿其他软件生成的图像,如果你确切知道本选项的功能和你在做什么的话。",
"If you have already created a background video in Invert Mask Mode([Ebsynth Utility]->[configuration]->[etc]->[Mask Mode]),": "如果你已经在反相蒙版模式下创建了一个背景视频([Ebsynth Utility]->[插件配置]->[其他]->[蒙版模式]),",
"If you have trouble entering the video path manually, you can also use drag and drop.For large videos, please enter the path manually.": "如果你手动输入视频路径嫌麻烦,也可以使用拖放。但是对于大型视频,还是烦请手动输入路径。",
"If you liked this extension, please": "如果你喜欢本插件,请",
"If you still cannot understand, use default.": "如果你仍然无法理解,请保持默认值。",
"If you want to use the same tagging results the next time you run img2img, rename the file to prompts.txt": "如果想在下次运行图生图时使用同样的标记结果,请将该文件重命名为 prompts.txt",
"If you want to use Width/Height which are not multiples of 64, please change noise_type to 'Uniform', in Keyframes --> Noise.": "如果你的宽 / 高参数不是 64 的倍数, 请设置 噪声_类型 选项为 'Uniform‘ , 该选项在关键帧 --> 噪声选项卡内",
"ignore": "无视",
"Ignore": "忽略",
"Ignore emphasis": "忽略强调符号",
"Ignore: keep prompt and styles dropdown as it is.": "忽略: 保持提示词和预设样式下拉菜单不变",
"Ignore selected VAE for stable diffusion checkpoints that have their own .vae.pt next to them": "对于拥有同名 .vae.pt 的模型,忽略外挂 VAE 设置",
"Ignores step count - uses a number of steps determined by the CFG and resolution": "忽略迭代步数 - 使用由 CFG 和分辨率确定的步数",
"I know what I am doing.": "高级选项",
"Illustration": "插画",
"image": "图像",
"Image": "图像",
"Image browser": "图库浏览器",
"Image Browser": "图库浏览器",
"Image Browser Settings": "Cozy 图库浏览器设置",
"Image CFG Scale": "图像引导系数 (CFG)",
"Image Count": "图片数量",
"Image creation progress preview mode": "图像生成过程预览模式",
"Image Directory": "图像目录",
"Image File": "图像文件",
"Image for Auto Segmentation": "用于语义分割的图像",
"Image for Image Layout": "用于图像分布的图像",
"Image for img2img": "图生图的图像",
"Image for inpainting with mask": "用于使用蒙版进行局部重绘的图像",
"Image for Recognition": "识别图像的分辨率",
"Image for Segment Anything": "用于分离的图像",
"Image height": "图像高度",
"Image Init": "图像初始化",
"Image Layout": "图像分布",
"Image layout status": "图像分布状态",
"Image Parameters": "图像参数",
"Image path": "图像路径",
"Image preview height": "预览图高度",
"Images directory": "图像目录",
"Images filename pattern": "图片文件名格式",
"Images path": "图像路径",
"Images to use for keyframe guidance": "用于关键帧引导的图像",
"Image strength schedule": "图像强度参数表",
"Image to 3D": "图转 3D",
"Image to 3D mesh": "图像转 3D 网格",
"Image to be masked": "需要叠加蒙版的图像",
"Image width": "图像宽度",
"I'm feeling lucky": "手气不错",
"img2img": "图生图",
"img2img alternative test": "图生图的替代性测试",
"img2img CFG": "图生图的提示词引导系数",
"img2img DDIM discretize": "图生图 DDIM 离散化",
"img2img denoise strength": "图生图的重绘幅度",
"img2img-grids": "图生图 (网格)",
"img2img: height of image editor": "图生图: 图像编辑器高度",
"img2img history": "图生图历史记录",
"img2img keyframes.": "将关键帧进行图生图。",
"img2img model to use": "图生图使用的模型",
"img2img padding": "图生图的重叠像素宽度",
"Img2Img Repeat Count (Loop Back)": "图生图重复次数(回送)",
"img2img sampler": "图生图的采样方法",
"img2img Sampling steps": "图生图的采样迭代步数",
"img2img scale": "图生图的放大倍数",
"Img2Img Settings:": "图生图设置:",
"IMG2IMG upscale": "图生图放大",
"img2img upscaler": "图生图的放大算法",
"Import": "导入",
"Import a model from Huggingface.co instead of using a local checkpoint.": "从 Huggingface.co 导入模型而非使用本地的模型文件。",
"Important notes:": "重要信息:",
"Important Notes:": "重要事项:",
"Important notes and Help": "重要信息与帮助",
"*Important* notes on Prompts": "对于提示词模式的重要笔记",
"Import Model from Huggingface Hub": "从 Huggingface Hub 载入模型",
"Import settings from file": "从文件导入设置",
"impressionism": "impressionism (印象派)",
"(improves performance when prompt and negative prompt have different lengths; changes seeds)": "(当正向提示词与反向提示词长度不同时可以提升性能; 影响随机性)",
"IN00": "输入层 00",
"IN01": "输入层 01",
"IN02": "输入层 02",
"IN03": "输入层 03",
"IN04": "输入层 04",
"IN05": "输入层 05",
"IN06": "输入层 06",
"IN07": "输入层 07",
"IN08": "输入层 08",
"IN09": "输入层 09",
"IN10": "输入层 10",
"IN11": "输入层 11",
"IN_A_00": "模型 A 输入层 00",
"IN_A_01": "模型 A 输入层 01",
"IN_A_02": "模型 A 输入层 02",
"IN_A_03": "模型 A 输入层 03",
"IN_A_04": "模型 A 输入层 04",
"IN_A_05": "模型 A 输入层 05",
"IN_A_06": "模型 A 输入层 06",
"IN_A_07": "模型 A 输入层 07",
"IN_A_08": "模型 A 输入层 08",
"IN_A_09": "模型 A 输入层 09",
"IN_A_10": "模型 A 输入层 10",
"IN_A_11": "模型 A 输入层 11",
"IN_B_00": "模型 B 输入层 00",
"IN_B_01": "模型 B 输入层 01",
"IN_B_02": "模型 B 输入层 02",
"IN_B_03": "模型 B 输入层 03",
"IN_B_04": "模型 B 输入层 04",
"IN_B_05": "模型 B 输入层 05",
"IN_B_06": "模型 B 输入层 06",
"IN_B_07": "模型 B 输入层 07",
"IN_B_08": "模型 B 输入层 08",
"IN_B_09": "模型 B 输入层 09",
"IN_B_11": "模型 B 输入层 11",
"Include confident of tags matches in results": "在结果中包含标签的匹配置信度",
"Include images in sub directories": "显示子目录中的图片",
"Include ranks of model tags matches in results.": "反推结果包含模型标签匹配等级",
"Include resource hashes in image metadata (for resource auto-detection on Civitai)": "在图像元数据中嵌入资源哈希值 (用于在 Civitai 上自动检测资源)",
"Include Sub Grids": "包含次级网格图",
"Include Sub Images": "包含次级图像",
"Increment seed after each controlnet batch iteration": "在每次 ControlNet 完成批量迭代后增加种子",
"Index": "索引",
"info": "info",
"Info": "信息",
"Info and links": "资讯和链接",
"Info & Help": "信息与帮助",
"Info, Links and Help": "基本信息与帮助链接",
"Information, comment and share @": "信息,评论和分享:",
"Infotext": "文本信息",
"In FPS": "输入帧率",
"In Frame Count": "输入帧数",
"In \"Interpolate existing pics\" mode, FPS is determined *only* by output FPS slider. Audio will be added if requested even with slow-mo \"enabled\", as it does *nothing* in this mode.": "在‘插入已有图像’模式中,帧率仅由帧率设置滑块决定。音频将会加入,即使在慢动作模式启用情况下,且在此模式下什么都不会做。",
"Init": "初始化",
"Initial denoising strength": "初始去噪强度",
"Initialization text": "初始化文本",
"Init image": "初始化图像",
"Init Video": "初始视频",
"In Keyframes tab, you can also set": "在关键帧选项卡, 可以设置",
"in <>, like <apple>, <hair>": "<>,比如 <apple>, <hair>",
"(in megapixels)": "(单位: 百万像素)",
"(in milliseconds)": "(单位: 毫秒)",
"inpaint": "局部重绘",
"Inpaint": "局部重绘",
"Inpaint area": "重绘区域",
"Inpaint Area(Override img2img Inpaint area)": "重绘区域(覆盖图生图的重绘区域)",
"Inpaint at full resolution 2nd": "全分辨率局部重绘",
"Inpaint at full resolution 3rd": "全分辨率局部重绘",
"Inpaint at full resolution 4th": "全分辨率局部重绘",
"Inpaint at full resolution 5th": "全分辨率局部重绘",
"Inpaint at full resolution padding, pixels 2nd": "预留像素",
"Inpaint at full resolution padding, pixels 3rd": "预留像素",
"Inpaint at full resolution padding, pixels 4th": "预留像素",
"Inpaint at full resolution padding, pixels 5th": "预留像素",
"Inpaint batch mask directory (required for inpaint batch processing only)": "批量重绘蒙版目录 (仅限批量重绘使用)",
"Inpaint denoising strength": "局部重绘幅度",
"Inpaint denoising strength 2nd": "局部重绘幅度",
"Inpaint denoising strength 3rd": "局部重绘幅度",
"Inpaint denoising strength 4th": "局部重绘幅度",
"Inpaint denoising strength 5th": "局部重绘幅度",
"inpaint_global_harmonious": "Inpaint_Global_Harmonious (重绘 - 全局融合算法)",
"inpaint height": "重绘高度",
"inpaint height 2nd": "重绘高度",
"inpaint height 3rd": "重绘高度",
"inpaint height 4th": "重绘高度",
"inpaint height 5th": "重绘高度",
"inpainting": "重绘",
"Inpainting": "重绘",
"Inpainting conditioning mask strength": "局部重绘时图像调节的蒙版屏蔽强度",
"Inpaint mask blur": "重绘蒙版边缘模糊度",
"Inpaint mask blur 2nd": "重绘蒙版边缘模糊度",
"Inpaint mask blur 3rd": "重绘蒙版边缘模糊度",
"Inpaint mask blur 4th": "重绘蒙版边缘模糊度",
"Inpaint mask blur 5th": "重绘蒙版边缘模糊度",
"Inpaint masked": "重绘蒙版内容",
"Inpaint not masked": "重绘非蒙版内容",
"inpaint_only": "inpaint_only (仅局部重绘)",
"inpaint_only+lama": "inpaint_only+lama (仅局部重绘 + 大型蒙版)",
"Inpaint only masked": "仅重绘蒙版内容",
"Inpaint only masked 2nd": "仅重绘蒙版内容",
"Inpaint only masked 3rd": "仅重绘蒙版内容",
"Inpaint only masked 4th": "仅重绘蒙版内容",
"Inpaint only masked 5th": "仅重绘蒙版内容",
"Inpaint only masked padding, pixels": "仅重绘蒙版区域边缘预留像素",
"Inpaint only masked padding, pixels 2nd": "仅重绘蒙版区域边缘预留像素",
"Inpaint only masked padding, pixels 3rd": "仅重绘蒙版区域边缘预留像素",
"Inpaint only masked padding, pixels 4th": "仅重绘蒙版区域边缘预留像素",
"Inpaint only masked padding, pixels 5th": "仅重绘蒙版区域边缘预留像素",
"inpaint sketch": "涂鸦重绘",
"Inpaint sketch": "涂鸦重绘",
"Inpaint upload": "上传重绘蒙版",
"inpaint width": "重绘宽度",
"inpaint width 2nd": "重绘宽度",
"inpaint width 3rd": "重绘宽度",
"inpaint width 4th": "重绘宽度",
"inpaint width 5th": "重绘宽度",
"(in pixels)": "(单位: 像素)",
"Input": "导入",
"Input directory": "输入目录",
"Input Directory": "输入目录",
"Input Folder": "输入文件夹",
"Input Image": "输入图像",
"Input images directory": "输入图像目录",
"Input Mesh (.ply | .obj)": "输入网格文件 (.ply | .obj)",
"Input <= Output": "输出图像 发送到 输入图像",
"Input path": "输入目录",
"Input Video": "输入视频",
"In queue...": "排队中……",
"In Res": "输入分辨率",
"(in sampling steps - show new live preview image every N sampling steps; -1 = only show after completion of batch)": "(每N个采样步骤更新一次实时预览图像; 设置为-1以在每批次完成后显示)",
"Insert after": "后插",
"Insert before": "前插",
"Inspect": "检查",
"install": "安装",
"Install": "安装",
"installation": "installation (装置艺术)",
"installed": "已安装",
"Installed": "已安装",
"Install from URL": "从网址安装",
"Installing...": "正在安装...",
"Instead it will pick up all files in the \\upscale_me\\ folder and upscale them with below settings.": "相对应的会用 \\upscale_me\\ 文件夹中的文件按照下列设置对它们进行放大。",
"instructs the run to start from a specified point": "指示运行从指定点开始",
"integrations": "集成功能",
"interactive splines and Bezier curves": "交互式样条曲线和贝赛尔曲线",
"Intermediate files path": "临时文件路径",
"Intermediate results may look better than the end results. /!\\ Intermediate results are cleaned after each run, save them elsewhere if you want to keep them.": "中间的结果可能比最终结果看起来更好。提示: 中间的结果在每次运行后都会被清理,如果你想保留它们,就把它们保存在其它地方",
"internal order": "内部排序",
"Interpolation": "插值",
"interpolation method": "插值模式",
"Interpolation method": "插值算法",
"Interpolation Method": "融合算法",
"Interrogate": "反推提示词",
"Interrogate\nCLIP": "CLIP\n反推",
"Interrogate\nDeepBooru": "DeepBooru\n反推",
"Interrogate: keep models in VRAM": "反推:将模型保留在显存中",
"Interrogate Options": "反推设置",
"Interrogate Result": "反推结果",
"Interrogate Selected Image": "反推所选图片",
"Interrogator": "反推模型",
"Interrogator Settings": "反推器设置",
"interrupt": "中止",
"Interrupt": "中止",
"In the main tab, set the subject to humanoids": "在主菜单标签页, 设置主题为 humanoids (人形)",
"In the prefix prompt field then add for example: Art by artistname, 2 people": "然后在前缀提示词段中添加示例: Art by artistname, 2 people",
"(in tokens - for texts shorter than specified, if they don't fit into 75 token limit, move them to the next 75 token chunk)": "(Token 中短于指定长度的提示词, 如果它们不符合 75 Tokens 的上限, 则将他们移至下一个 75 Tokens 组中)",
"Invert": "反相",
"Invert colors": "反转颜色",
"Invert colors if your image has white background.": "对于白色背景图片请开启颜色反转。",
"Invert DepthMap": "反转深度图",
"Invert DepthMap (black=near, white=far)": "反转深度图(黑色=近,白色=远)",
"invert (from white bg & black line)": "invert (白底黑线反色)",
"Invert Input Color": "反转输入颜色",
"Invert mask": "反转蒙版",
"Invert selection": "反向选择",
"is also a good option, it makes compact math formulae for Deforum keyframes by selecting various waveforms.": " 也是一个很好的选择,它可以通过选择各种波形来为 Deforum 关键帧生成严谨的数学公式.",
"is equivalent to": "等同于",
"is experimental functions and NO PROOF of effectiveness.": " 为实验性功能,不保证有效性。",
"is set,": "已经设置数值,",
"Iterate seed every line": "每行输入都换一个随机种子",
"It takes time, just wait. Check console log for detail": "检查需要一段时间,请耐心等待。检查控制台日志以查看详情。",
"It will then recognize the body type and not generate it. It also recognizes the keyword wearing, and will not generate an outfit.": "然后,它将识别体型来避免生成对应体型。它同样能识别关键词 \"穿着\",避免生成服装。",
"It will translate prompt from your native language into English. So, you can write prompt with your native language.": "这会将您输入的提示词翻译为英文。因此,您可以直接用母语输入提示词。",
"I want to preview GroundingDINO detection result and select the boxes I want.": "我想预览 GroundingDINO 的结果并选择我想要的箱体。",
"Javascript logs": "Javascript 日志",
"JavaScript selection method": "前端选择样式",
"Jitter step:": "抖动步数: ",
"Jitter the seeds of sub-generations when doing a rolling generation (Still deterministic)": "在进行梯度放大倍数生成时, 对子代生成的随机种子进行抖动 (图像依旧可复现)",
"Join the": "加入",
"- Joints and Limbs": "- 关节和四肢",
"json path": "json 路径",
"JSON Validator": "JSON 检查器中检查",
"Just resize": "仅调整大小",
"Just Resize": "仅调整大小",
"Just resize (latent upscale)": "调整大小 (潜空间放大)",
"Keep -1 for seeds": "保持种子随机",
"Keep at 1 for normal behavior.\nSet to different values to compound that many prompts together. My suggestion is to try 2 first.": "设置为 1 保持正常行为。\n设置其他数值来混合更多提示词。我的建议是先尝试设置为 2 。",
"Keep blank if you don't have mask": "如果没有遮罩, 请保持空白",
"Keep Imgs": "保留原图",
"Keep models in VRAM": "将模型保留在显存中",
"Keep occlusion edges": "保持边缘封闭",
"Keep original size": "保持原始尺寸",
"Keep temp images": "保留临时图像",
"Keep the Ratio": "保持图像比例",
"keep whatever was there originally": "保留原来的图像,不进行预处理",
"Kernel schedule": "Kernel 值表",
"Keyframes": "关键帧",
"Keyframes: animation settings (animation mode, max frames, border)": "关键帧:动画设置(动画模式,最大帧数,边界)",
"Keyframes: coherence (color coherence & cadence)": "关键帧:一致性(颜色一致性和间隔)",
"Keyframes: depth warping": "关键帧:深度扭曲",
"Keyframes: generation settings (noise, strength, contrast, scale).": "关键帧:通用设置(噪点,强度,对比度,缩放)",
"Keyframes: motion parameters for 2D and 3D (angle, zoom, translation, rotation, perspective flip).": "关键帧:2D 和 3D 的运动参数(角度,缩放,变换,旋转,透视翻转)",
"Keywords": "关键词",
"Label": "标记",
"LAB is a more linear approach to mimic human perception of color space - a good default setting for most users.": "LAB 是一种更为线性的方法,可以模拟人类对色彩空间的感知——这是大多数用户的一个很好的默认设置。",
"ladder": "阶梯式",
"Lanczos": "Lanczos",
"landscape": "landscape (景观)",
"landscape - A landscape or a landscape with a building.": "landscape - 景观 - 一般景观或有建筑的景观。",
"Last message": "最后输出信息",
"Latent Mirror mode": "潜空间镜像应用模式",
"Latent Mirror style": "潜空间镜像方式",
"latent noise": "潜空间噪声",
"latent nothing": "空白潜空间",
"Latent tile batch size": "潜空间分块单批数量",
"Latent tile height": "潜空间分块高度",
"Latent tile overlap": "潜空间分块重叠",
"Latent tile width": "潜空间分块宽度",
"latest": "最新",
"Layer1": "图层 1",
"Layer1 mask blur": "图层 1 蒙版模糊度",
"Layer1 mask strength": "图层 1 蒙版强度",
"Layer1 opacity": "图层 1 透明度",
"Layer2": "图层 2",
"Layer2 mask blur": "图层 2 蒙版模糊度",
"Layer2 mask strength": "图层 2 蒙版强度",
"Layer2 opacity": "图层 2 透明度",
"Layer3": "图层 3",
"Layer3 mask blur": "图层 3 蒙版模糊度",
"Layer3 mask strength": "图层 3 蒙版强度",
"Layer3 opacity": "图层 3 透明度",
"Layer4": "图层 4",
"Layer4 mask blur": "图层 4 蒙版模糊度",
"Layer4 mask strength": "图层 4 蒙版强度",
"Layer4 opacity": "图层 4 透明度",
"Layer5": "图层 5",
"Layer5 mask blur": "图层 5 蒙版模糊度",
"Layer5 mask strength": "图层 5 蒙版强度",
"Layer5 opacity": "图层 5 透明度",
"Layers": "图层",
"Lazy": "保守",
"LDSR processing steps. Lower = faster": "LDSR 处理步数。越少越快",
"Learning rate": "学习率",
"Learning Rate": "学习率",
"Learning Rate Scheduler": "学习率调度器",
"Learning Rate Warmup Steps": "学习率预热步数",
"Leave blank to save images to the default path.": "留空以将图像保存到默认路径",
"Leave blank to save images to the same path.": "留空以将图像保存到相同路径",
"Leave empty for auto": "留空时自动生成",
"Leave empty for default main branch": "留空以使用默认分支",
"Leave empty to use img2img batch controlnet input directory": "留空以使用图生图批量处理 ControlNet 输入目录",
"Leave empty to use input directory": "留空以使用普通输入目录",
"Leave empty to use the same name as model and put results into models/Unet-onnx directory": "留空以使用与 checkpoint 模型相同的名称, 并将转换出的模型放入 models/Unet-onnx 目录",
"Leave empty to use the same name as onnx and put results into models/Unet-trt directory": "留空以使用与 onnx 模型相同的名称, 并将转换出的模型放入 models/Unet-trt 目录",
"Leave the prompt field empty": "提示词段留空",
"Leave this alone unless you know what you are doing": "不明白这个选项的意思的话最好不要动",
"left": "左",
"Left click the image to add one positive point (black dot). Right click the image to add one negative point (red dot). Left click the point to remove it.": "左键点击图像添加一个黑色的正向标记点(想提取的部分)。右键点击图像添加一个红色的反向标记点(不想提取的部分)。左键再次点击可以删除标记点。",
"left-right": "左 - 右",
"Legacy hash": "旧哈希值",
"Leg Length": "腿部长度",
"Len": "长度",
"Lerp": "线性插值",
"Licenses": "许可协议",
"light": "light (照明艺术)",
"lighten": "变亮",
"like here": "链接",
"Linear": "线性",
"linear_burn": "线性加深",
"linear_dodge": "线性减淡",
"linear_light": "线性光",
"Lineart": "Lineart (线稿)",
"lineart_anime": "lineart_anime (动漫线稿提取)",
"lineart_anime_denoise": "lineart_anime_denoise (动漫线稿提取 - 去噪)",
"lineart_coarse": "lineart_coarse (粗略线稿提取)",
"lineart_realistic": "lineart_realistic (写实线稿提取)",
"lineart_standard (form white bg & black line)": "lineart_standard (标准线稿提取 - 白底黑线)",
"lineart_standard (from white bg & black line)": "lineart_standard (标准线稿提取 - 白底黑线反色)",
"line drawing": "line drawing (线描)",
"Link to DeepL": "Deepl 在线翻译链接",
"List loaded embeddings": "获取嵌入式模型列表",
"List of active tabs (separated by commas). Available options are txt2img, img2img, txt2img-grids, img2img-grids, Extras, Favorites, Others. Custom folders are also supported by specifying their path.": "激活的图像保存目录标签 (用逗号分隔). 可用的标签有, 文生图(txt2img),图生图(img2img), 文生图-网格(txt2img-grids), 图生图-网格(img2img-grids), 后期处理(Extras), 收藏夹(Favorites), 其它(Others). 也可以通过指定文件目录来自定义目录标签.",
"List of model names (with file extension) or their hashes to use as black/whitelist, separated by commas.": "用于黑/白名单的模型名称(带文件扩展名)或其哈希值的列表,用逗号分隔",
"List of prompt inputs": "提示词输入列表",
"List of setting names, separated by commas, for settings that should go to the quick access bar at the top, rather than the usual setting tab. See modules/shared.py for setting names. Requires restarting to apply.": "设置项名称的列表,以英文逗号分隔,该设置会移动到顶部的快速访问栏,而不是默认的设置选项卡。有关设置名称,请参阅 modules/shared.py。(需保存设置并重启)",
"Live preview display period": "实时预览显示周期",
"Live preview file format": "实时预览文件格式",
"Live preview method": "实时预览模式",
"Live previews": "实时过程预览",
"Live preview subject": "实时预览主体",
"⚙️ Load": "⚙️ 加载",
"Load": "加载",
"Load All Settings": "载入所有设置",
"Load an image.": "加载一张图片",
"Load BG": "加载背景图",
"Load from:": "加载扩展列表",
"Load from JSON": "加载 JSON",
"Load from subdirectories": "从子目录中加载",
"load_history": "加载历史记录",
"Loading...": "载入中...",
"Load models/files in hidden directories": "加载隐藏目录中的模型/文件",
"Load models using stream loading method": "使用流式模型加载方法",
"Load Params": "载入参数",
"Load Preset": "加载预设",
"Load results": "加载结果",
"Load Scene": "加载场景",
"Load Settings": "载入设定",
"Load Video Settings": "载入视频设置",
"Local directory name": "本地目录名",
"localization": "本地化",
"Localization": "本地化",
"Localization file (Please leave `User interface` - `Localization` as None)": "本地化文件 (请将\"用户界面\" - “本地化翻译”选项设置为“无”)",
"Localization (requires restart)": "本地化翻译(需要重启)",
"Location": "FFmpeg 所在位置",
"Log": "日志",
"Log directory": "日志目录",
"Logo": "图标",
"Loop": "循环",
"Loopback": "回送",
"[Loopback] Automatically send generated images to this ControlNet unit": "[回送] 自动将生成后的图像发送到此 ControlNet 单元",
"Loopback option": "回送选项",
"Loopback source": "回送源",
"Looping recommendations:": "循环设置建议:",
"Loops": "回送次数",
"LoRA Block Weight": "LoRA Block Weight (LoRA 区块权重配置)",
"LoRA directory (if not default)": "LoRA 模型文件目录 (如非默认)",
"LoRA model name filter": "按名称过滤低秩微调 (LoRA) 模型",
"Lora: use old method that takes longer when you have multiple Loras active and produces same results as kohya-ss/sd-webui-additional-networks extension": "Lora: 使用旧的加载方法,当多个 Lora 激活时需要更长的时间,并且可以生成与 kohya-ss/sd-webui-additional-networks 扩展相同的结果",
"low contrast": "low contrast (低对比度)",
"Low fps": "低帧率",
"(Low values = visible seam)": "(数值越低=接缝越明显)",
"Low VRAM": "低显存模式",
"Low VRAM (8GB or below)": "低显存 (8 GB 以下) 模式",
"luminism": "luminism (光色派)",
"M00": "中间层",
"M_A_00": "模型 A 中间层",
"Made by": "制作方: ",
"Made by deforum.github.io, port for AUTOMATIC1111's webui maintained by kabachuha": "由 deforum.github.io 制作,AUTOMATIC1111 的 webui 移植版本由 kabachuha 维护",
"magical realism": "magical realism (魔幻现实主义)",
"Main": "主菜单",
"Main menu position": "主菜单位置",
"Main Settings": "主设置",
"Maintenance": "维护",
"Make a backup copy of the model being edited when saving its metadata.": "保存元数据时,备份当前编辑的模型文件",
"Make an attempt to produce a picture similar to what would have been produced with same seed at specified resolution": "尝试生成与同一种子在特定分辨率下产生的图片相似的图片",
"Make GIF": "制作 GIF",
"Make Hires. fix+ run before any other extensions (will reload WebUI)": "使 高分辨率修复PLUS 在其它所有插件前执行 (勾选后会立刻重载WebUI)",
"Make Images": "制作图像",
"Make K-diffusion samplers produce same images in a batch as when making a single image": "使 K-diffusion 采样器在批量生成与生成单个图像时,产出相同的结果",
"Make LoRA (A-B)": "制作差分 LoRA (A-B)",
"Make LoRA (alpha * A - beta * B)": "制作差分 LoRA (α × A - β × B)",
"Make your changes, press 'View changes' to review the changed default values,": "修改后通过点击 '查看更改' 来复查修改后的默认设置数值。\n然后点击 \"应用\" 把更改后的数值写入到 webui 根目录中的 ui-config.json文件中。",
"Make your choices, adjust your settings, set a name, save. To edit a prior choice, select from dropdown and overwrite.": "做出选择,调整设置,设置名称,保存。要编辑先前的选择,请从下拉列表中选择并覆盖。",
"Make Zip when Save?": "保存时创建 zip 压缩文件?",
"Manage Extensions": "管理扩展",
"manga": "manga (日漫)",
"manipulations": "图片处理",
"Manual install": "手动安装",
"mask": "蒙版",
"Mask": "蒙版",
"Mask blur": "蒙版边缘模糊度",
"Mask Blur Kernel Size": "蒙版模糊内核大小",
"Mask Blur Kernel Size(GaussianBlur)": "蒙版模糊内核大小(高斯模糊)",
"Mask Blur Kernel Size(MedianBlur)": "蒙版模糊内核大小(中值模糊)",
"Mask brightness adjust": "蒙版亮度调整",
"Mask by Category": "按分类创建蒙版",
"mask content ratio": "蒙版内容比例",
"Mask contrast adjust": "蒙版对比度调整",
"Mask directory": "遮罩图像目录",
"Masked content": "蒙版区域内容处理",
"Mask erosion (-) / dilation (+)": "蒙版图像腐蚀 (-) / 蒙版图像膨胀 (+)",
"Mask erosion (-) / dilation (+) 2nd": "蒙版图像腐蚀 (-) / 蒙版图像膨胀 (+)",
"Mask erosion (-) / dilation (+) 3rd": "蒙版图像腐蚀 (-) / 蒙版图像膨胀 (+)",
"Mask erosion (-) / dilation (+) 4th": "蒙版图像腐蚀 (-) / 蒙版图像膨胀 (+)",
"Mask erosion (-) / dilation (+) 5th": "蒙版图像腐蚀 (-) / 蒙版图像膨胀 (+)",
"Mask file": "蒙版文件",
"Mask fill": "蒙版填充",
"Mask for ControlNet Inpaint": "用于 ControlNet 重绘的蒙版",
"mask image:": "蒙版图像:",
"Masking Method": "蒙版方式",
"Mask max area ratio": "蒙版区域最大比率",
"Mask max area ratio 2nd": "蒙版区域最大比率",
"Mask max area ratio 3rd": "蒙版区域最大比率",
"Mask max area ratio 4th": "蒙版区域最大比率",
"Mask max area ratio 5th": "蒙版区域最大比率",
"Mask merge mode": "蒙版合并模式",
"Mask merge mode 2nd": "蒙版合并模式",
"Mask merge mode 3rd": "蒙版合并模式",
"Mask merge mode 4th": "蒙版合并模式",
"Mask merge mode 5th": "蒙版合并模式",
"Mask min area ratio": "蒙版区域最小比率",
"Mask min area ratio 2nd": "蒙版区域最小比率",
"Mask min area ratio 3rd": "蒙版区域最小比率",
"Mask min area ratio 4th": "蒙版区域最小比率",
"Mask min area ratio 5th": "蒙版区域最小比率",
"Mask mode": "蒙版模式",
"Mask Mode": "蒙版模式",
"Mask Mode(Override img2img Mask mode)": "蒙版模式(覆盖图生图的蒙版模式)",
"Mask option": "蒙版选项",
"Mask overlay blur": "蒙版覆盖模糊度",
"Mask Preprocessing": "蒙版处理",
"Mask schedule": "蒙版参数表",
"Mask Setting": "蒙版设置",
"masks from files: in [], like [mask1.png]": "从文件中获取蒙版:[] ,比如 [mask1.png]",
"Mask size": "蒙版尺寸",
"Mask source": "蒙版来源",
"Mask Target (e.g., girl, cats)": "蒙版目标(如 girl, cats)",
"Mask Threshold": "蒙版阈值",
"Mask transparency": "蒙版透明度",
"Mask x(→) offset": "蒙版 X 轴 (→) 偏移",
"Mask x(→) offset 2nd": "蒙版 X 轴 (→) 偏移",
"Mask x(→) offset 3rd": "蒙版 X 轴 (→) 偏移",
"Mask x(→) offset 4th": "蒙版 X 轴 (→) 偏移",
"Mask x(→) offset 5th": "蒙版 X 轴 (→) 偏移",
"Mask y(↑) offset": "蒙版 Y 轴 (↑) 偏移",
"Mask y(↑) offset 2nd": "蒙版 Y 轴 (↑) 偏移",
"Mask y(↑) offset 3rd": "蒙版 Y 轴 (↑) 偏移",
"Mask y(↑) offset 4th": "蒙版 Y 轴 (↑) 偏移",
"Mask y(↑) offset 5th": "蒙版 Y 轴 (↑) 偏移",
"Match input size": "匹配输入图尺寸",
"Max": "最大值",
"Max Crop Size": "最大修复尺寸",
"max frames": "最大帧数",
"Max frames": "最大帧数",
"Max Image Size": "最大图像尺寸",
"Maximize area": "最大化面积",
"Maximum aesthetic_score": "最大美学评分",
"Maximum batch size": "最大单批数量",
"Maximum execution time (seconds)": "最大执行时间(以秒为单位)",
"Maximum height": "最大高度",
"Maximum Image Height:": "图片最大高度",
"Maximum image size": "最大图像尺寸",
"Maximum image size, in megapixels": "上述选项的最大图像尺寸,单位:百万像素",
"Maximum Image Width:": "图片最大宽度:",
"Maximum Image Width/Height:": "图片最大宽度/高度:",
"Maximum keyframe gap": "最大关键帧间隔",
"Maximum number of faces to detect": "检测的最大人脸数量",
"Maximum number of images in upscaling cache": "图像放大缓存中的最大图片数量",
"Maximum prompt token count": "最大提示词词元长度",
"Maximum ranking": "最高评分",
"Maximum results": "候选Tag最大数量",
"Maximum score": "最高评分",
"Maximum width": "最大宽度",
"Max key frames": "最大关键帧数",
"Max models": "最大模型数量",
"Max number of dataset folders to show": "要显示的最大数据集文件夹数",
"Max number of top tags to show": "要显示的最大常见标签数",
"Max prompt words for [prompt_words] pattern": "用于替代 [prompt_words] 占位符的最大提示词数量",
"Max resolution of temporary files": "临时文件最大分辨率",
"Max steps": "最大步数",
"Max Token Length": "最大词元长度",
"M_B_00": "模型 B 中间层",
"MBW": "分块设置权重(MBW)",
"MBW Each": "A/B 模型分别分块设置权重 (MBW Each)",
"mbw weights": "分块权重",
"mediapipe_face": "mediapipe_face (脸部边缘检测)",
"melanin": "melanin (黑色素/黑人)",
"Memory": "内存",
"Memory optimization": "显存优化选项",
"Memory usage": "内存使用量",
"Merge": "合并",
"Merge!": "融合",
"Merge and gen": "融合并生成",
"Merge And Gen": "融合并生成",
"Merge and Invert": "合并且反相",
"Merge Block Weighted": "模型分块合并",
"Merge&Gen": "融合并生成",
"Merge LoRAs": "合并 LoRA",
"Merge mode": "合并模式",
"Merge Mode": "融合算法",
"Merge models and load it for generation": "融合模型并生成图片",
"Merge to Checkpoint": "合并到大模型",
"Message": "信息",
"messy": "messy (混乱)",
"Metadata to show in XY-Grid label for Model axes, comma-separated (example: \"ss_learning_rate, ss_num_epochs\")": "显示在 X/Y 表标签下的元数据选项,以逗号分隔(示例:\"ss_learning_rate, ss_num_epochs\")",
"Method": "方案",
"MiDaS weight (vid2depth)": "MiDaS 权重 (vid2depth)",
"Min": "最小值",
"Minimize error": "最小错误阈值",
"minimum aesthetic_score": "按美学评分下限过滤",
"Minimum aesthetic_score": "最小美学评分",
"Minimum batch size": "最小单批数量",
"Minimum height": "最小高度",
"Minimum keyframe gap": "最小关键帧间隔",
"Minimum lighting ratio": "最小照明比率",
"Minimum number of pages per load": "每次加载的最小页数",
"Minimum prompt token count": "最小提示词词元长度",
"Minimum ranking": "最低评分",
"Minimum score": "最低评分",
"Minimum steps": "最小迭代步数",
"Minimum width": "最小宽度",
"min_mask_region_area": "最小蒙版面积",
"Min-max": "最低 - 最高",
"Mirror webcam": "镜像网络摄像头",
"missing metadata": " 无元数据",
"Mixed": "混合",
"Mixed Precision": "混合精度",
"MLDanbooru Tagger": "ML-Danbooru 标签器",
"mlsd": "mlsd (M-LSD 直线线条检测)",
"MLSD": "MLSD (直线)",
"mode": "模式",
"Mode": "模式",
"model": "模型",
"Model": "模型",
"Model 1": "模型 1",
"Model 2": "模型 2",
"Model 3": "模型 3",
"Model 4": "模型 4",
"Model 5": "模型 5",
"model A": "模型 A",
"model_A": "模型 A",
"Model A": "模型 A",
"Model_A": "模型A",
"model B": "模型 B",
"model_B": "模型 B",
"Model B": "模型 B",
"Model_B": "模型 B",
"model C": "模型 C",
"Model C": "模型 C",
"Model cache size (requires restart)": "模型缓存数量 (需重启)",
"Model compile mode (experimental)": "模型编译模式(实验性)",
"Model Converter": "模型转换",
"Model description/readme/notes/instructions": "模型的描述信息/说明/注释/指引",
"model hash": "模型哈希值",
"Model hash": "模型哈希值",
"Model Name": "模型名称",
"model of the upscaler to use. 'realesr-animevideov3' is much faster but yields smoother, less detailed results. the other models only do x4": "需要使用的超分模型。 'realesr-animevideov3' 速度更快但生成的结果更平滑、更详细。其他超分模型只支持 4 倍放大",
"Model path": "模型路径",
"Model Path": "模型路径",
"Model path filter": "按模型路径过滤",
"models": "模型相关",
"Models": "模型",
"Models...": "模型列表...",
"Model Toolkit": "模型工具箱",
"model to use": "使用的模型",
"Model Type": "模型种类",
"Model Types": "模型种类",
"Model Version": "模型版本",
"Mode to add the extra tags to the main tag list": "选择将额外标签添加到主要标签列表的模式",
"Mode to use for model list": "模型列表模式",
"Modules": "模块",
"monochromatic": "monochromatic (单色调)",
"More info about Anti Burn": "关于 Anti Burn 的更多信息",
"Motion": "运动参数",
"Mov2Mov output path for image": "Mov2Mov 图片输出路径",
"Mov2Mov output path for vedio": "Mov2Mov 视频输出路径",
"Mov2Mov output path for video": "Mov2Mov 视频输出路径",
"Move buttons copy instead of move": "将图库浏览器内所有 \"移动\" 按钮改为 \"复制\" 按钮",
"Move completion popup together with text cursor": "将弹出窗口与文本光标一起移动",
"Move ControlNet images to CPU (if applicable)": "将 ControlNet 图像移动到 CPU (如果适用)",
"Move ControlNet tensor to CPU (if applicable)": "将 ControlNet tensor 移至CPU (如果适用)",
"Move/Copy/Delete matching .txt files": "将图片的移动、复制、删除操作应用到与之同名的 txt 文件",
"Move face restoration model from VRAM into RAM after processing": "处理完成后,将面部修复模型从显存卸载到内存",
"Move File(s)": "移动文件",
"Move Mode (X key)": "移动模式(X 键)",
"Move or Delete": "移动或删除",
"Move quicksettings to image setting panel": "移动快速设置到左侧图像设置面板",
"Move to favorites": " 移动到收藏夹",
"Move VAE and CLIP to RAM when training hypernetwork. Saves VRAM.": "训练超网络时将 VAE 和 CLIP 模型移动到内存,可节省显存",
"Move VAE and CLIP to RAM when training if possible": "训练时尽可能将 VAE 与 CLIP 模型移动到内存",
"Move VAE and CLIP to RAM when training if possible. Saves VRAM.": "如果可行,训练时将 VAE 和 CLIP 模型从显存移动到内存,可节省显存",
"Move VAE to GPU": "将 VAE 移动到 GPU",
"Move VAE to GPU (if possible)": "将 VAE 移动到 GPU (如果允许)",
"Moving the canvas": "移动画布",
"Multi ControlNet: Max models amount (requires restart)": "ControlNet Unit 的最大数量 (需重启)",
"Multi-frame rendering": "多帧渲染",
"Multi Merge": "多重合并",
"Multi Model Merge": "多模型合并",
"Multiplication (2^N)": "倍率 (2^N)",
"multiplier": "倍率",
"Multiplier": "倍率",
"Multiplier for extra networks": "扩展模型默认权重",
"Multiplier (M) - set to 0 to get model A": "融合比例 (M) - 设为 0 等价于直接输出模型 A",
"multiply": "乘积",
"Multi Proc Cmd": "多进程命令",
"(must be < sampling steps)": "(需小于迭代步数)",
"My prompt is more important": "更偏向提示词",
"naive": "朴素卷积算法",
"naive_interpolating": "朴素插值算法",
"name": "名称",
"Name": "名称",
"Name 0": "名称 0",
"Name 1": "名称 1",
"Name 10": "名称 10",
"Name 11": "名称 11",
"Name 12": "名称 12",
"Name 13": "名称 13",
"Name 14": "名称 14",
"Name 15": "名称 15",
"Name 2": "名称 2",
"Name 3": "名称 3",
"Name 4": "名称 4",
"Name 5": "名称 5",
"Name 6": "名称 6",
"Name 7": "名称 7",
"Name 8": "名称 8",
"Name 9": "名称 9",
"nature": "nature (自然主义)",
"Navigate image viewer with gamepad": "使用游戏手柄导航图像查看器",
"Near clip": "近端衰减",
"need input your want to translate": "请输入你想翻译的内容",
"negative": "反向",
"Negative Guidance minimum sigma": "反向提示词引导最小 sigma",
"Negative prompt": "反向提示词",
"Negative Prompt": "反向提示词",
"Negative prompt for hires fix pass.\nLeave empty to use the same negative prompt as in first pass.": "用于高分修复层的反向提示词\n留空以使用与第一层相同的提示词",
"Negative prompt (press Ctrl+Enter or Alt+Enter to generate)": "反向提示词 (按 Ctrl+Enter 或 Alt+Enter 开始生成)\nNegative prompt",
"Negative Prompts": "反向提示词",
"negative prompt to be appended to *all* prompts. DON'T use --neg here!": "反向提示词会被添加到左右提示词内,请勿在此处使用 --neg 字段",
"Negative Prompt Weight": "反向提示词权重",
"Negative Prompt, will also be appended": "追加反向提示词",
"Net height": "深度图高度",
"Net width": "深度图宽度",
"Network module": "附加网络模块",
"Network module 1": "附加模型 1",
"Network module 2": "附加模型 2",
"Network module 3": "附加模型 3",
"Network module 4": "附加模型 4",
"Network module 5": "附加模型 5",
"Never": "从不",
"Nevysha Cozy Nest Settings": "Nevysha Cozy Nest 设置",
"Nevysha Cozy Nest Update Info": "Nevysha Cozy Nest 更新信息",
"New Canvas Height": "新画布高度",
"New Canvas Width": "新画布宽度",
"New defaults will apply after you restart the UI.": "新的默认设置将会在重启 UI 后应用。",
"newest first": "按发布日期倒序",
"New preset name ": "新预设名称",
"New Scribble Drawing Height": "新线稿画板高度",
"New Scribble Drawing Width": "新线稿画板宽度",
"Next batch": "下一批",
"Next Page": "下一页",
"no": "否",
"No": "否",
"no-ema": "删除 EMA 权重",
"no find:": "未找到:",
"no image selected": "没有图片被选中",
"No interpolation": "原样输出",
"No interpolation will be used. Requires one model; A. Allows for format conversion and VAE baking.": "直接输出主要模型。需要一个模型 A。可用于模型格式转换和嵌入 VAE。",
"Noise": "噪声",
"Noise Inversion": "噪声反转",
"Noise mask schedule": "噪点蒙版参数表",
"(noise multiplier; applies to Euler a and other samplers that have a in them)": "(噪声倍数: 适用于 Euler a 和其它具有 a 的采样方法)",
"Noise multiplier for img2img": "图生图噪声倍率",
"(noise multiplier; higher = more unperdictable results)": "(噪声倍数: 越高=结果越难以预测)",
"Noise multiplier schedule": "噪声乘法调度(Noise multiplier schedule)",
"Noise schedule": "噪点值表",
"Noise Tolerance": "噪声容忍度",
"Noise type": "噪声类型",
"No model has new version": "所有模型均是最新版本",
"none": "无",
"None": "无",
"NONE": "无",
"None (just grayscale)": "什么都不做(灰度模式)",
"None - prompt only": "无 - 仅提示词",
"normal": "正常",
"Normal": "常规",
"normal_bae": "normal_bae (Bae 法线贴图提取)",
"Normally, it creates a single random prompt. With prompt compounder, it will generate multiple prompts and compound them together.": "一般情况下只能创建一个单一的随机提示。但有了提示词混合,可以生成多个提示词并将它们复合在一起。",
"(normally you'd do less with less denoising)": "(正常情况下越小的重绘幅度需要的迭代步数更少)",
"normal_midas": "normal_midas (Midas 法线贴图提取)",
"Normal with batch": "正常(带批处理)",
"not": "不会",
"Note that parseq overrides:": "以下参数将会被参数定序器覆盖设置:",
"(not for Video Input mode)": " (不用于视频输入模式)",
"Nothing here. Add some content to the following directories:": "暂无内容。请添加模型到以下目录:",
"nudity": "nudity (裸体)",
"NUl Image Enhancer": "NUI 图像增强",
"Number of columns on the page": "每页列数",
"Number of frames": "总帧数",
"Number of iterations": "迭代次数",
"Number of negative vectors per token": "每个词元的反向向量数",
"Number of repeats for a single input image per epoch; used only for displaying epoch number": "每期 (epoch) 中单个输入图像的重复次数; 仅用于显示期数",
"Number of rows on the page": "每页行数",
"Number of samples to generate": "要生成的样本数量",
"Number of Samples to Generate": "要生成的样本数量",
"Number of sampling steps for upscaled picture. If 0, uses same as for original.": "高分辨率修复图片的迭代步数。如果为0,则使用与文生图设置相同的迭代步数。",
"number of the frames that we will blend between current imagined image and input frame image": "当前想象图像和输入帧图像之间混合的帧数",
"Number of vectors per token": "每个词元的向量数",
"(O10) Output ckpt Name": "(O10) 输出模型文件名",
"(O1) Output ckpt Name": "(O1) 输出模型文件名",
"(O2) Output ckpt Name": "(O2) 输出模型文件名",
"(O3) Output ckpt Name": "(O3) 输出模型文件名",
"(O4) Output ckpt Name": "(O4) 输出模型文件名",
"(O5) Output ckpt Name": "(O5) 输出模型文件名",
"(O6) Output ckpt Name": "(O6) 输出模型文件名",
"(O7) Output ckpt Name": "(O7) 输出模型文件名",
"(O8) Output ckpt Name": "(O8) 输出模型文件名",
"(O9) Output ckpt Name": "(O9) 输出模型文件名",
"object": "object (物件)",
"object - Can be a random object, a building or a vehicle.": "object - 物件 - 可以是一个随机的物体,也可以是一个建筑物或一辆车。",
"octane render": "octane render (OC渲染)",
"official Deforum Discord": " Deforum 官方 Discord 频道",
"Official Deforum Wiki:": "Deforum 官方 Wiki: ",
"# of threads to use for hash calculation (increase if using an SSD)": "用于哈希计算的线程数 (如果使用 SSD 可适当增加)",
"oldest first": "按发布日期正序",
"Once turned on, it will retry for n amount of times to get an image with the quality score. If not, it will take the best image so far and continue.": "一旦启用,它将持续生成 N 次以获得具有一定质量分数的图像。如果没有,它将保留评分最好的图像持续生成。",
"One Button Prompt": "One Button Prompt (一键生成提示词)",
"One Button Run and Upscale": "一键运行并放大",
"online": "线上服务",
"Online 3D Openpose Editor": "在线 3D Openpose 编辑器",
"(only applies if non-zero and overrides above)": "(仅在数值设置为非零时启用, 启用时覆盖原 Token 合并比率设置)",
"Only applies to inpainting models. Determines how strongly to mask off the original image for inpainting and img2img. 1.0 means fully masked, which is the default behaviour. 0.0 means a fully unmasked conditioning. Lower values will help preserve the overall composition of the image, but will struggle with large changes.": "仅适用于局部重绘专用的模型(模型后缀为 inpainting.ckpt 的模型)。决定了蒙版在局部重绘以及图生图中屏蔽原图内容的强度。 1.0 表示完全屏蔽原图,这是默认行为。0.0 表示完全不屏蔽让原图进行图像调节。较低的值将有助于保持原图的整体构图,但很难遇到较大的变化",
"Only copy to models with no metadata": "仅复制到不含元数据的模型",
"Only copy to models with same session ID": "仅复制到具有相同 Session ID 的模型",
"Only Hand": "仅显示手部(移除脚部)",
"*Only in use with pix2pix checkpoints!*": "*仅在加载 Pix2Pix 模型时生效!*",
"Only masked": "仅蒙版区域",
"Only masked padding, pixels": "仅蒙版区域下边缘预留像素",
"only other types --> Will pick only from the more unique types, such as stained glass window or a funko pop": "only other types -- 仅其它类型 --> 只从其它更独特的类型中挑选,如彩色玻璃窗或一只玩具人偶。",
"Only show alias": "仅展示别名",
"Only Show Models have no Info": "只显示缺少信息的模型",
"Only show models that have/don't have user-added metadata": "按是否有元数据过滤模型",
"Only show .safetensors format models": "只显示 .safetensors 格式的模型",
"Only store preferences locally": "仅在本地保存设置",
"Only upscale will not use txt2img to generate an image.": "仅放大时不会通过文生图功能生成图像",
"Only use mid-control when inference": "仅在生成图片时使用中间层控制 (mid-control)",
"Onnx model filename": "Onnx 模型文件名 (包含路径)",
"ONNX opset version": "ONNX 算子集版本",
"(O)Output Model Name": "输出模型文件名",
"Opacity": "不透明度",
"Open...": "打开...",
"Open images output directory": "打开图像输出目录",
"Open intermediate results": "立即打开当前效果图",
"Open new canvas": "打开新画布",
"Open New Canvas": "打开新画布",
"Open New Scribble Drawing Canvas": "创建新的线稿画板",
"Open output directory": "打开输出目录",
"openpose": "openpose (OpenPose 姿态)",
"OpenPose": "OpenPose (姿态)",
"OpenPose Editor": "OpenPose 编辑器",
"openpose_face": "openpose_face (OpenPose 姿态及脸部)",
"openpose_faceonly": "openpose_faceonly (OpenPose 仅脸部)",
"openpose_full": "openpose_full (OpenPose 姿态、手部及脸部)",
"openpose_hand": "openpose_hand (OpenPose 姿态及手部)",
"Open results": "打开最终效果图",
"Open TextEditor": "打开文本编辑器",
"Open the generated .ebs under project directory and press [Run All] button.": "打开工程目录下生成的 .ebs 文件,按[Run All]按钮。",
"Open this model's civitai url": "在新标签页打开本模型的 Civitai 页面",
"Open Url At Client Side": "在浏览器侧打开链接",
"Optical Flow": "光流法",
"Optical flow cadence": "生成间隔中启用光流法",
"Optimizations": "优化设置",
"Options are all options hardcoded, and additional you added in additional_components.py": "选项都是硬编码的选项,并且是您在 additional_components.py 中添加的附加选项",
"Options in main UI": "主界面额外选项",
"- or -": "- 或 -",
"or": "或",
"Order": "排序",
"original": "原图",
"Original:": "原项目:",
": Original extension": ": 原始扩展名",
": Original extension\nAvailable algorithms:": ": 原始扩展名\n可用算法: ",
": Original filename without extension": ": 没有扩展名的原始文件名",
"Original filename without extension": "没有扩展名的原始文件名",
"Original file’s hash (good for deleting duplication)": "原始文件哈希值 (有助于检测重复项)",
"Original First": "原文在上",
"Original Image": "原始图像",
"OriginalImg": "OriginalImg (原始输入的第一帧)",
"Original Movie Path": "原始视频路径",
"Original negative prompt": "原始反向提示词",
"Original prompt": "原始正向提示词",
"original video frame": "原始视频帧",
"Original Weights": "原始权重",
"or, manually enhance the image": "↓手动控制图像增强参数↓",
"(or open as text in a new page)": "(或在新的标签页查看)",
"or to CTRL+SHIFT": "将 CTRL 绑定更改为 CTRL+SHIFT",
"Other": "其他",
"Other prompt fields": "其它提示词段",
"others": "其它",
"- Others": "- 其它",
"Others": "其它",
"Other Setting": "其他设置",
"OUT00": "输出层 00",
"OUT01": "输出层 01",
"OUT02": "输出层 02",
"OUT03": "输出层 03",
"OUT04": "输出层 04",
"OUT05": "输出层 05",
"OUT06": "输出层 06",
"OUT07": "输出层 07",
"OUT08": "输出层 08",
"OUT09": "输出层 09",
"OUT10": "输出层 10",
"OUT11": "输出层 11",
"OUT_A_00": "模型 A 输出层 00",
"OUT_A_01": "模型 A 输出层 01",
"OUT_A_02": "模型 A 输出层 02",
"OUT_A_03": "模型 A 输出层 03",
"OUT_A_04": "模型 A 输出层 04",
"OUT_A_05": "模型 A 输出层 05",
"OUT_A_06": "模型 A 输出层 06",
"OUT_A_07": "模型 A 输出层 07",
"OUT_A_08": "模型 A 输出层 08",
"OUT_A_09": "模型 A 输出层 09",
"OUT_A_10": "模型 A 输出层 10",
"OUT_A_11": "模型 A 输出层 11",
"OUT_B_00": "模型 B 输出层 00",
"OUT_B_01": "模型 B 输出层 01",
"OUT_B_02": "模型 B 输出层 02",
"OUT_B_03": "模型 B 输出层 03",
"OUT_B_04": "模型 B 输出层 04",
"OUT_B_05": "模型 B 输出层 05",
"OUT_B_06": "模型 B 输出层 06",
"OUT_B_07": "模型 B 输出层 07",
"OUT_B_08": "模型 B 输出层 08",
"OUT_B_09": "模型 B 输出层 09",
"OUT_B_10": "模型 B 输出层 10",
"OUT_B_11": "模型 B 输出层 11",
"Outpainting direction": "向外绘制的方向",
"output": "输出",
"Output": "输出",
"Output animation path": "动画输出路径",
"Output directory": "输出目录",
"Output Directory": "输出目录",
"Output directory for grids": "网格图输出文件夹",
"Output directory for grids; if empty, defaults to two directories below": "网格图统一输出文件夹; 如果为空,则按以下两个文件夹分别输出",
"Output directory for images from extras tab": "后期处理输出文件夹",
"Output directory for images; if empty, defaults to three directories below": "统一输出文件夹; 如果为空,则按以下三个文件夹分别输出",
"Output directory for img2img grids": "图生图网格输出文件夹",
"Output directory for img2img images": "图生图输出文件夹",
"Output directory for txt2img grids": "文生图网格输出文件夹",
"Output directory for txt2img images": "文生图输出文件夹",
": Output extension (has no dot)": "输出扩展名 (没有 '.' 点)",
"Output filename": "输出文件名",
"Output filename format": "输出文件名格式",
"Output filename formats": "输出文件名格式",
"Output format": "输出格式",
"output height resolution": "输出高度分辨率",
"Output Image Width": "输出图像宽度",
"Output Model Name": "输出模型文件名",
"Output name": "输出名称",
"Output path": "输出路径",
"Output Paths": "输出路径",
"Output per image:": "单独输出每张图像:",
"output resolution": "输出分辨率",
"outputs": "输出",
"Output settings: all settings (including fps and max frames)": "输出设置:所有设置(包括帧率和最大帧数)",
"Output type": "输出类型",
"output video resolution": "输出视频的分辨率",
"Out Res": "输出分辨率",
"overlay": "叠加",
"Overlay mask": "覆盖蒙版",
"override:": "覆盖以下参数:",
"Override": "覆盖",
"Override `Denoising strength` to 1?": "覆写 `重绘幅度` 为 1?",
"Override options (choose the related subject type first for better results)": "覆盖选项 (首选相关的主题类型以获得更好的结果)",
"Override `prompt` to the same value as `original prompt`?(and `negative prompt`)": "覆写 `提示词` 为 `初始提示词`?` (反向提示词` 同理)",
"Override `Sampling method` to Euler?(this method is built for it)": "覆写 `采样方法` 为 Euler? (这个方法就是为它设计的)",
"Override `Sampling Steps` to the same value as `Decode steps`?": "覆写 `采样迭代步数` 为 `解码迭代步数`?",
"Override settings": "覆盖设置",
"overwrite": "允许覆盖",
"Overwrite": "覆写",
"Overwrite extracted frames": "覆盖已有帧",
"Overwrite image size": "覆盖图像尺寸",
"Overwrite input frames": "覆盖输入帧",
"Overwrite Old Embedding": "覆盖同名嵌入式模型文件",
"Overwrite Old Hypernetwork": "覆盖同名超网络文件",
"Overwrite subject": "覆盖主题",
"Overwrite subject:": "覆盖主题:",
"Overwrite type of image:": "覆盖图像类型",
"Padding token (ID or single token)": "填充提示词(完整ID或者单个提示词)",
"Pad prompt/negative prompt to be same length": "补齐正向/反向提示词到相同长度",
"Pad Tokens": "词元填充",
"Page Index": "页码",
"painting": "painting (画作)",
"Panorama to 3D mesh": "全景图转 3D 网格",
"Parse!": "解析",
"Parseq": "参数定序器 (parameter sequencer)",
"Parseq does": "参数定序器将",
"Parseq Manifest (JSON or URL)": "参数定序器配置文件(JSON 或者链接)",
"Passing ControlNet parameters with \"Send to img2img\"": "使用\"发送到图生图\"时传输 ControlNet 参数",
"Paste available values into the field": "将可用值粘贴到字段中",
"path name": "路径名",
"Path relative to the webui folder": "相对于 webui 文件夹的路径",
"Paths for saving": "保存路径",
"Path to directory containing annotator model directories (requires restart, overrides corresponding command line flag)": "预处理器模型 (annotator model) 的文件路径 (需重启,以覆盖相应的命令行标志)",
"Path to directory where to write outputs": "进行输出的目录路径",
"Path to directory with input images": "带有输入图像的目录路径",
"/path/to/images or /path/to/images/**/*": "/path/to/images 或 /path/to/images/**/*",
"Path to settings file you want to load. Path can be relative to webui folder OR full - absolute": "需要加载的设置文件路径。该路径可以相对于 SD-WebUI 根目录,也可以是完整的绝对路径",
"Pause": "暂停",
"PBRemTools": "精确背景去除工具",
"performance": "性能",
"Perform warmup": "进行预热",
"per side": "每边数量",
"persistent cond cache": "持久化调整缓存",
"Perspective": "透视",
"Perspective Flip": "透视翻转",
"Perspective flip gamma": "透视翻转伽马值",
"Perspective flip phi": "透视翻转角度(垂直)",
"Perspective flip theta": "透视翻转角度(水平)",
"photograph": "photograph (照片)",
"photography": "photography (摄影)",
"Pick Subfolder and Model Version": "选择子目录与模型版本",
"pin_light": "点光",
"Pixelize": "像素化",
"Pixel Perfect": "完美像素模式",
"Pixels to expand": "拓展的像素数",
"Place options in main UI into an accordion": "将选项置入主界面的一个手风琴式的容器中",
"Place this at back of generated prompt (suffix)": "此框填写的提示词放在生成提示词的后面 (后缀)",
"Place this in front of generated prompt (prefix)": "此框填写的提示词放在生成提示词的前面 (前缀)",
"Platform": "运行平台",
"Please add text prompts to generate masks": "请添加文本提示词以生成蒙版",
"Please always keep values in math functions above 0.": "请始终保持数学函数中的值大于 0。",
"Please enable the following settings to use controlnet from this script.": "请启用以下设置,以保证可以在此脚本中调用ControlNet。",
"Please use smaller tile size when got CUDA error: out of memory.": "当出现 CUDA error: out of memory 时,使用更小的分块尺寸",
"Please use smaller tile size when see CUDA error: out of memory.": "当出现 CUDA error: out of memory 时,使用更小的尺寸大小",
"PNG info": "PNG 图片信息",
"PNG Info": "PNG 图片信息",
"PNGs": "图片(PNG格式)",
"point1 x": "X 轴点 1",
"point1 y": "Y 轴点 1",
"point2 x": "X 轴点 2",
"point2 y": "Y 轴点 2",
"point3 y": "Y 轴点 3",
"points_per_batch": "每批采样点",
"points_per_side": "每边采样点",
"polylines_sharp": "多边形算法 - 锐利",
"polylines_soft": "多边形算法 - 柔和",
"Pooling Avg": "池化平均值",
"Pooling Max": "池化最大值",
"pop art": "pop art (波普艺术)",
"popular": "popular (流行艺术)",
", port for AUTOMATIC1111's webui maintained by": ", 是为 AUTOMATIC1111's webui 提供的插件项目,项目维护者: ",
"portrait": "portrait (肖像)",
"Pose": "姿势",
"Position (center to edge)": "位置 (中心到边缘)",
"Position (left to right)": "位置 (从左到右)",
"Positions": "分区位置",
"positive": "正向",
"Positive / Negative Prompts": "正向 / 反向提示词",
"positive prompt to be appended to *all* prompts": "正向提示词会被添加到所有提示词中",
"Postprocessing": "后期处理",
"Post Processing": "后期处理",
"Post-Processing": "后处理",
"Postprocessing operation order": "后处理操作顺序",
"Precision": "精度",
"predicted_iou_threshold": "预测交并比阈值",
"pred_iou_thresh": "预测滤波阈值",
"Prefix": "前缀",
"prefix AND prompt + suffix": "prefix AND prompt + suffix (前缀 AND 提示词 + 后缀)",
"prefix + prefix + prompt + suffix": "prefix + prefix + prompt + suffix (前缀 + 前缀 + 提示词 + 后缀)",
"Preload images at startup for first tab": "在启动时为第一个选项卡预载图像",
"prepare ebsynth": "预处理 Ebsynth",
"prepend": "前置",
"Prepend": "添加到开头",
"Prepend additional tags": "将额外标签前置",
"Preprocess": "预处理",
"Preprocess images": "图像预处理",
"Pre-Processing": "预处理",
"Preprocessor": "预处理器",
"Preprocessor Preview": "预处理结果预览",
"Preprocessor resolution": "预处理器分辨率",
"Preprocessor Resolution": "预处理器分辨率",
"Prerequisites and Important Info:": "前提条件和重要信息:",
"Preset": "预设",
"Preset Manager": "预设管理器",
"Presets": "预设",
"Preset Weights": "预设权重",
"Preset_Weights": "预设权重",
"Prev batch": "上一批",
"Prevent empty spots in grid (when set to autodetect)": "自动检测并消除网格图中的空位",
"Preview annotator result": "预览预处理结果",
"Preview as Input": "预处理结果作为输入",
"Preview automatically when add/remove points": "添加/删除标记点时自动预览",
"Preview image negative prompt": "预览图反向提示词",
"Preview image prompt": "预览图提示词",
"Preview mask": "预览蒙版",
"Preview Segmentation": "预览分离结果",
"Preview segmentation image": "预览语义分割图像",
"Previous": "Previous (上一生成帧)",
"Prev Page": "上一页",
"Primary model (A)": "模型 A",
"primitivism": "primitivism (原始主义画派)",
"Print": "输出",
"Print all deviations": "输出所有偏移量",
"print change": "打印变更",
"Print debug logs to the console": "将调试日志输出到控制台",
"Print extra hypernetwork information to console.": "将额外的超网络 (hypernetwork) 信息输出到控制台",
"Print image deletion messages to the console": "打印图像删除信息到控制台",
"Print warning logs to the console": "将警告信息输出到控制台",
"Process given file(s) under the input folder, seperate by comma": "指定在输入文件夹中要处理图像的文件名 (使用逗号隔开)",
"Process images in a directory on the same machine where the server is running.": "处理服务器主机上某一目录里的图像",
"processing |": "处理中 |",
"Process Stage": "过程步骤",
"Produce an image that can be tiled.": "生成可用于平铺(tiled)的图像",
"Progressbar and preview update period": "进度条/预览图更新周期",
"Progressbar/preview update period, in milliseconds": "进度条/预览图更新周期 (毫秒)",
"Project directory": "工程目录",
"project setting": "工程设置",
"Prompt": "提示词",
"prompt 1": "提示词①",
"prompt 2": "提示词②",
"prompt 4": "提示词④",
"prompt 5": "提示词⑤",
"Prompt attention parser": "提示词注意力解析器",
"Prompt compounder": "提示词混合",
"Prompt fields": "提示词段",
"Prompt for face": "针对脸部的提示词",
"Prompt for Face": "脸部提示词",
"Prompt for hires fix pass.\nLeave empty to use the same prompt as in first pass.": "用于高分修复层的正向提示词\n留空以使用与第一层相同的提示词",
"prompting": "提示词相关",
"Prompt matrix": "提示词矩阵",
"Prompt (press Ctrl+Enter or Alt+Enter to generate)": "正向提示词 (按 Ctrl+Enter 或 Alt+Enter 开始生成)\nPrompt",
"Prompts": "提示词",
"Prompts are stored in JSON format. If you've got an error, check it in a": "提示词以 JSON 格式存储。如果有错误,请在",
"Prompts are stored in JSON format. If you've got an error, check it in validator,": "提示词以 JSON 格式存储。如果您有错误,请在验证器中检查,",
"Prompt seperator": "提示词分隔符",
"Prompt seperator mode": "提示词分隔模式",
"prompts for your animation in a JSON format. Use --neg words to add 'words' as negative prompt": "动画的提示词以 JSON 格式储存。使用 --neg 字段去添加反向提示词",
"Prompts from file or textbox": "从文本框或文件载入提示词",
"Prompts negative": "反向提示词",
"Prompts positive": "正向提示词",
"Prompt template": "提示词模板",
"Prompt Translator": "提示词翻译器",
"Prompt, will append to your t2i prompt": "追加提示词",
"Prompt word wrap length limit": "提示词换组长度限制",
"Provider": "提供方",
"Proxy": "代理",
"Pruning Methods": "模型修剪",
"psychedelic": "psychedelic (迷幻艺术)",
"Put variable parts at start of prompt": "把可变部分放在提示词文本的开头",
"Put weight sets. float number x 25": "输入权重,共 25 个浮点数,逗号分隔",
"quad": "二阶",
"Quality": "质量",
"Quality for saved jpeg images": "保存 JPEG 图片的质量",
"Quality Gate": "质量把关",
"Quantize": "量化",
"query": "查询",
"queue:": "排队中: ",
"Quick": "快速设置",
"Quick batch": "快速批处理",
"Quick Guide": "快速指引",
"Quick Save": "快速保存",
"Quicksettings list": "快捷设置列表",
"Quicksettings position": "快速设置位置",
"random": "随机",
"Randomness": "随机度",
"Random number generator source.": "随机数生成来源",
"Random number generator source. Changes seeds drastically. Use CPU to produce the same picture across different vidocard vendors.": "随机数的生成来源。大幅度改变种子。使用CPU来在不同型号显卡间产生相同的图像",
"range": "范围",
"Range": "范围",
"ranking": "评分",
"ranking filter": "按图片评分过滤",
"Ranking filter": "评分过滤器",
"rating": "评分",
"Rating": "评分",
"Rating confidents": "评级置信度",
"Read generation parameters from prompt or last generation if prompt is empty into user interface.": "从提示词或上次生成的图片中读取生成参数",
"read_last_image": "载入上次图像",
"read_last_settings": "载入上次设置",
"*READ ME before you use this mode!*": "请在使用前认真阅读",
"Read parameters (prompt, etc...) from txt2img tab when making previews": "进行预览时,从文生图选项卡中读取参数(提示词等)",
"Read tabular commands": "读取 tabular 命令",
"Read tags from text files": "从文本文件中读取提示词",
"realism": "realism (现实主义)",
"Reapply ranking after moving files": "移动文件后重新评分",
"Rebuild exif cache": "重建 EXIF 缓存",
"Recipe": "配方",
"recombine ebsynth": "重组 Ebsynth",
"Recommended settings: Sampling Steps: 80-100, Sampler: Euler a, Denoising strength: 0.8": "推荐设置: 采样迭代步数: 80-100, 采样器: Euler a, 重绘幅度: 0.8",
"Recommended to set tile sizes as large as possible before got CUDA error: out of memory.": "建议在得到 CUDA error: out of memory 报错前尽可能大的设置编码器分块大小",
"Recommend enabling the following settings.": "建议启用以下设置:",
"Reconstruct prompt from existing image and put it into the prompt field.": "从现有的图像中重构出提示词,并将其放入提示词的输入文本框",
"Rectangular": "矩形",
"red-cyan-anaglyph": "红蓝浮雕效果",
"Reference": "Reference (参考)",
"reference_adain": "reference_adain (仅参考输入图 - 自适应实例规范)",
"reference_adain+attn": "reference_adain+attn (仅参考输入图 - 自适应实例规范 + Attention链接)",
"reference_only": "reference_only (仅参考输入图)",
"Ref image (for conviently locate regions)": "参考图(用于方便定位区域)",
"refresh": "刷新",
"Refresh": "刷新",
"Refresh Civitai Helper": "刷新 Civitai 助手",
"Refresh Civitai Helper's additional buttons": "刷新 Civitai 助手的附加按钮",
"Refresh Civitai Helper's model card buttons": "刷新 Civitai 助手 的模型卡片按钮",
"Refresh data": "刷新数据",
"Refresh extension list": "刷新扩展列表",
"Refresh models": "刷新模型列表",
"Refresh openOutpaint": "刷新 openOutpaint",
"Refresh page": "刷新页面",
"Refresh TAC temp files": "刷新 TAC 缓存文件",
"regex - e.g. ^(?!.*Hires).*$": "正则表达式 - 如 ^(?!.*Hires).*$",
"Region 1": "区域 1",
"Region 2": "区域 2",
"Region 3": "区域 3",
"Region 4": "区域 4",
"Region 5": "区域 5",
"Region 6": "区域 6",
"Region 7": "区域 7",
"Region 8": "区域 8",
"Region Prompt Control": "分区提示词控制",
"Regions": "分区",
"Regular expression; if weights's name matches it, the weights is not written to the resulting checkpoint. Use ^model_ema to discard EMA weights.": "输入正则表达式。键名匹配该表达式的权重将从最终合并模型中剔除。使用 ^model_ema 可剔除 EMA 权重。",
"Related to original file": "与原始文件相关",
"Related to output file": "与输出文件相关",
"Reload Cache List": "重载缓存列表",
"Reload checkpoint": "刷新模型列表",
"Reload Checkpoints": "重新加载模型",
"Reload custom script bodies (No ui updates, No restart)": "重新加载自定义脚本主体(不进行界面更新及重启)",
"Reloading...": "正在重新加载...",
"Reload Presets": "重载预设",
"Reload/Save Settings (config.json)": "重新载入/保存设置 (config.json)",
"Reload scripts": "重载脚本",
"Reload settings": "重新载入设置",
"Reload Tags": "重载标签",
"Reload the last SD checkpoint back into VRAM": "重新将上次使用的 Stable Diffusion 模型加载到显存中",
"Reload UI": "重载前端",
"Reload UI needed to apply": "需重启前端",
"Reloat List": "重新加载列表",
"remake dimension": "重制维度",
"Remember this choice?": "记住这个选择?",
"➖ Remove": "➖ 移除",
"Remove": "移除",
"Remove all point prompts": "移除所有标记点",
"Remove Auto Trans": "移除自动翻译",
"Remove background": "移除背景",
"Remove background image": "移除背景图片",
"Remove duplicated tag": "删除重复标签",
"Remove occluded edges": "移除遮挡边缘",
"Remove selected": "移除已选择的图片",
"renaissance": "renaissance (文艺复兴)",
"Rename keyframes.": "重命名关键帧。",
"Renoise kernel size": "重铺噪声大小",
"Renoise strength": "重铺噪声强度",
"Replace or save the selected component.": "替换或保存所选组件",
"replace preview image with currently selected in gallery": "用当前网页输出中选中的图像替换预览图像",
"Replace underscores with spaces on insertion": "插入时用空格替换下划线",
"Replace '_' with ' '(Does not affect the function to add tokens using add_token.txt.)": "用空格替换下划线(不影响使用 add_token.txt 添加 Token 的功能)",
"replicate": "复制",
"Request browser notifications": "请求浏览器通知权限",
"(requires restart)": "(需要重启)",
"Requires the": "需要安装",
"reroll": "回滚",
"Reroll blank frames": "回滚空白帧",
"reset": "重置",
"↻ Reset": "↻ 重置",
"Reset": "重置",
"\uD83C\uDFA5 Reset Camera": "\uD83C\uDFA5 重置镜头",
"Reset default (Reload UI needed to apply)": "重置为默认值(需重载UI)",
"Reset mixer": "重置合并设置",
"\uD83E\uDDCD Reset Pose": "\uD83E\uDDCD 重置姿态",
"Reset Tile Size": "重置区块大小",
"resizable": "可缩放",
"Resize": "缩放比例",
"Resize and fill": "缩放后填充空白",
"Resize and Fill": "缩放后填充空白",
"Resize by": "重绘尺寸倍数",
"Resize height to": "将高度调整为",
"Resize image to target resolution. Unless height and width match, you will get incorrect aspect ratio.": "将图像大小调整为目标分辨率。除非高度和宽度匹配,否则你将获得不正确的纵横比",
"Resize mode": "缩放模式",
"Resize Mode": "缩放模式",
"Resize seed from height": "从高度中调整种子",
"Resize seed from width": "从宽度中调整种子",
"Resizes image to this height. If 0, height is inferred from either of two nearby sliders.": "将图像调整到此高度。如果为0,则从附近的两个滑块中的任意一个推断其高度。",
"Resizes image to this width. If 0, width is inferred from either of two nearby sliders.": "将图像调整到此宽度。如果为0,则从附近的两个滑块中的任意一个推断其宽度。",
"Resize the image so that entirety of image is inside target resolution. Fill empty space with image's colors.": "调整图像大小,使整个图像位于目标分辨率内\n用图像的颜色填充空白区域",
"Resize the image so that entirety of target resolution is filled with the image. Crop parts that stick out.": "调整图像大小,使整个目标分辨率都被图像填充\n裁剪多余部分",
"Resize to": "重绘尺寸",
"Resize width to": "将宽度调整为",
"Resizing objective": "缩放设置",
"Resolution": "分辨率",
"Restart": "重启",
"Restart debug": "重启调试",
"Restart server": "重启服务器",
"Restart UI": "重载前端",
"Restore defaults": "恢复默认",
"Restore Face": "面部修复",
"Restore faces": "面部修复",
"Restore Faces": "面部修复",
"Restore faces after ADetailer": "在 After Detailer 之后修复面部",
"Restore faces after ADetailer 2nd": "在 After Detailer 之后修复面部",
"Restore faces after ADetailer 3rd": "在 After Detailer 之后修复面部",
"Restore faces after ADetailer 4th": "在 After Detailer 之后修复面部",
"Restore faces after ADetailer 5th": "在 After Detailer 之后修复面部",
"Restore Faces, Tiling & more": "面部修复,平铺图等更多选项",
"Restore Last Scene": "恢复上次场景",
"Restore low quality faces using GFPGAN neural network": "使用 GFPGAN 神经网络修复低质量面部",
"Restore progress": "恢复进程",
"Restore Selected Config": "恢复所选配置",
"Result = A": "结果 = A",
"Result = A * (1 - M) + B * M": "结果 = A * (1 - M) + B * M",
"Result = A + (B - C) * M": "结果 = A + (B - C) * M",
"Results": "结果",
"Resume Animation": "恢复制作动画过程",
"Resume & Run from file": "恢复动画与加载设置",
"Retouch": "修复程度",
"Reuse original image": "复用原图",
"Reuse seed from last generation, mostly useful if it was randomed": "使用上一次生成的随机数种子,用于重现结果",
"Reverse model sort order": "逆序排序",
"RGB to BGR": "RGB 转 BGR",
"RIFE v4.6 and FILM.": "RIFE v4.6 和 FILM.",
"right": "右",
"right-left": "右 - 左",
"Roll Channels": "色彩通道轮替",
"Rolling factor": "梯度放大倍数",
"romanticism": "romanticism (浪漫主义)",
"Rotate images (clockwise)": "旋转图像 (顺时针)",
"run": "运行",
"Run": "运行参数",
"Run benchmark": "运行基准测试",
"Run from Settings file": "加载配置文件",
"Run Merge": "开始合并",
"Running ebsynth.(on your self)": "运行 Ebsynth。(自行操作)",
"Run on incomplete": "中断后仍然运行",
"Run preprocessor": "运行预处理",
"Run: Sampler, Width, Height, tiling, resize seed.": "运行参数: 采样器,宽度,高度,平铺图,种子大小调整",
"Run: seed, subseed, subseed strength.": "运行参数:第二种子,第二种子强度",
"safetensors": "safetensors",
"SAG Mask Threshold": "SAG 蒙版阈值",
"same to Strength": "与强度相同",
"SAM Model": "SAM 模型",
"sampler": "采样器",
"Sampler": "采样方法",
"Sampler parameters": "采样器参数",
"Sampler schedule": "采样器参数表",
"Sampler Settings": "采样器设置",
"Sampling method": "采样方法 (Sampler)",
"Sampling settings": "采样器设置",
"Sampling steps": "迭代步数 (Steps)",
"Sampling Steps": "迭代步数 (Steps)",
"SAM requires an input image. Please upload an image first.": "SAM 需要你先上传一张图片。",
"saturation": "饱和度",
"save": "保存",
"\uD83D\uDCBE Save": "\uD83D\uDCBE 保存",
"Save": "保存",
"Save a copy of embedding to log directory every N steps, 0 to disable": "每 N 步将 Embedding 的副本保存到日志目录,0 表示禁用",
"Save a copy of image before applying color correction to img2img results": "在对图生图结果应用颜色校正之前保存图像副本",
"Save a copy of image before applying highres fix.": "在进行高分辨率修复前保存初始图像副本",
"Save a copy of image before doing face restoration.": "在进行面部修复前保存图像副本",
"Save all changes": "保存所有更改",
"Save an csv containing the loss to log directory every N steps, 0 to disable": "每 N 步保存一个包含 loss 的 csv 表格到日志目录,0 表示禁用",
"Save an image to log directory every N steps, 0 to disable": "每 N 步保存一张图像到日志目录,0 表示禁用",
"Save as float16": "储存半精度 (float16) 模型",
"Save as half": "保存半精度模型",
"Save as safetensors": "存为 SafeTensors 格式",
"Save background instead of foreground": "保存背景而不是前景",
"Save changes": "保存更改",
"Save copy of large images as JPG": "将超过大小限制的图像保存JPG副本",
"Save Current Config": "保存当前配置",
"Save current settings": "保存当前设置",
"Save current settings as default": "将当前设置保存为默认值",
"Save depth map": "保存深度图",
"Save DepthMap": "保存深度图",
"Save depth maps": "保存深度图",
"Save generated images within tensorboard.": "在 tensorboard 中保存所生成的图像",
"Save grids to a subdirectory": "将网格图保存到子目录",
"Save images before ADetailer": "在进行后期细节修复前保存原始生成图片",
"Save images to a subdirectory": "将图像保存到子目录",
"Save images with embedding in PNG chunks": "保存嵌入 Embedding 模型的 PNG 图片",
"Save init images when using img2img": "使用图生图时保存初始图像",
"Save JSON": "保存为 JSON 格式",
"Save mask": "保存蒙版",
"Save masked image": "保存蒙版后图像",
"Save mask previews": "保存蒙版预览",
"Save Metadata": "保存元数据",
"Save metadata (.safetensors only)": "保存元数据 (仅限 .safetensors)",
"save model": "保存模型",
"Save original image": "保存原始图像",
"Save original image with mask and bounding box": "保存带有蒙版和箱体的原始图像",
"Save PNG": "保存为 PNG 格式",
"\uD83D\uDCBE\uD83E\uDDCD Save Pose": "\uD83D\uDCBE\uD83E\uDDCD 保存姿态",
"Save preprocessed": "保存预处理",
"Save Preset": "保存预设",
"Save Presets": "保存预设",
"Save preview": "保存预览",
"Save Preview(s) Frequency": "保存预览图的频率",
"Save ranking in image's pnginfo": "在PNG图片信息中保存评分",
"Save & Restart": "保存并重启",
"Save Scene": "保存场景",
"save setting": "保存设置",
"Save Setting": "保存设置",
"save settings": "储存设置",
"Save Settings": "保存设置",
"Saves Optimizer state as separate *.optim file. Training of embedding or HN can be resumed with the matching optim file.": "将优化器状态保存为单独的 optim 文件。在训练嵌入式模型或者超网格化模型时可以根据匹配上的 optim 文件恢复训练进度",
"Save style": "将当前提示词储存为预设样式",
"save successful": "保存成功",
"Save text information about generation parameters as chunks to png files": "将图片生成参数保存到 PNG 文件中",
"Save textual inversion and hypernet settings to a text file whenever training starts.": "每次训练开始时保存 TI 和 Hypernetwork 设置到文本文件中",
"Save to Presets": "保存到预设",
"Save vector to text file": "将向量保存到文本文件",
"Save with JSON": "保存为 JSON 格式",
"Saving images/grids": "图片保存设置",
"Saving to a directory": "保存到文件夹",
"Scale": "尺度",
"Scale by": "缩放倍数",
"Scale Factor": "放大倍数",
"Scale to": "缩放到",
"Scan": "扫描",
"Scan Exif-/.txt-data (initially slower, but required for many features to work)": "扫描图片的 Exif 信息与同名 txt 数据文件(初始读取速度较慢,许多功能都需要需要本选项启用)",
"Scan Models for Civitai": "扫描并匹配 Civitai 模型记录",
"Scanning takes time, just wait. Check console log for detail": "扫描需要一段时间,请耐心等待。检查控制台日志以查看详情。",
"scene": "scene (情景)",
"schedule": "参数表",
"scheduler type": "调度器类型",
"sci-fi": "sci-fi (科幻电影)",
"Scoring type": "评分类型",
"screen": "屏幕",
"Scribble": "Scribble (涂鸦)",
"scribble_hed": "scribble_hed (涂鸦 - 合成)",
"scribble_pidinet": "scribble_pidinet (涂鸦 - 手绘)",
"scribble_xdog": "scribble_xdog (涂鸦 - 强化边缘)",
"script": "脚本",
"Script": "脚本",
"Script Enabled": "启用脚本",
"Script names to apply to ADetailer (separated by comma)": "应用于 After Detailer 的脚本名称 (用逗号分隔)",
"scroll": "滚动",
"sculpture": "sculpture (雕塑)",
"sd-parseq manifest": "sd-parseq 配置文件",
"SD VAE": "外挂 VAE 模型",
"Seams denoise strenght": "接缝重绘幅度",
"Seams fix": "接缝修复",
"Seams Mask blur (offset pass only)": "接缝蒙版边缘模糊程度 (仅偏移层)",
"Seams padding": "接缝填充度",
"Seams Width": "接缝宽度",
"search": "搜索",
"Search": "搜索",
"Search...": "检索...",
"Search and Replace": "搜索与替换",
"Search anything : Prompt, Size, Model, ...": "检索任意内容: 提示词, 尺寸, 模型, ...",
"Search by alias": "按别名检索",
"Search by translation": "按照译文检索",
"Search for embeddings": "检索嵌入式模型 (Embeddings)",
"Search for hypernetworks": "检索超网络",
"Search for Loras": "检索 Lora 模型",
"Search for LyCORIS/LoHa": "检索 LyCORIS/LoHa 模型",
"Search for wildcards": "检索通配符",
"Search Mode": "搜索模式",
"Search negative prompt": "检索反向提示词",
"Search Text": "搜索文本",
"seascape": "seascape (海景)",
"Secondary model (B)": "模型 B",
"See": "查看",
"seed": "随机数种子 (seed)",
"Seed": "随机数种子 (Seed)",
"Seed behavior": "种子生成方式",
"Seed iter N": "种子迭代量 N",
"Seed of a different picture to be mixed into the generation.": "将要参与生成的另一张图的随机种子",
"Seed schedule": "种子数表",
"seed_schedule should start and end on the same seed.": "种子数表应该在同一种子上开始和结束。",
"See here for explanation of each parameter.": "有关每个参数的说明,请点击 这里 查看。",
"See the progress.": "查看图像增强的实时预览进程",
"Seg": "Seg (语义分割)",
"Segment Anything": "Segment Anything (分离图像元素)",
"Segment Anything Output": "分离元素结果",
"Segment Anything status": "Segment Anything 状态",
"segmentation prompt": "图像切分提示词",
"Segmentation status": "语义分割状态",
"seg_ofade20k": "seg_ofade20k (语义分割 - OneFormer 算法 - ADE20k 协议)",
"seg_ofcoco": "seg_ofcoco (语义分割 - OneFormer 算法 - COCO 协议)",
"seg_ufade20k": "seg_ufade20k (语义分割 - UniFormer 算法 - ADE20k 协议)",
"Select a component class or specific component.": "选择一个组件类或特定组件",
"Select activation function of hypernetwork. Recommended : Swish / Linear(none)": "超网络的激活函数。推荐 Swish / Linear (线性)",
"Select components to hide": "选择要隐藏的组件",
"(select Disco output format).": " (选择 Disco 输出格式) .",
"Selected": "选择",
"(selected items appear first)": "(选中组件优先显示)",
"Select joining char": "选择分隔符",
"Select keyframes to be given to ebsynth.": "选择关键帧提交到 Ebsynth。",
"Select Layer weights initialization. Recommended: Kaiming for relu-like, Xavier for sigmoid-like, Normal otherwise": "选择初始化层权重的方案。建议:类relu 用 Kaiming; 类sigmoid 用 Xavier;其它就用正态",
"Select prompt": "选择提示词",
"Select Translater": "选择翻译引擎",
"Select which Real-ESRGAN models to show in the web UI.": "选择在 web UI 显示的 Real-ESRGAN 模型",
"Select which Real-ESRGAN models to show in the web UI. (Requires restart)": "选择在网页界面显示哪些 Real-ESRGAN 模型。(需重启)",
"Send dimensions to stable diffusion": "将当前图片尺寸信息发送到生成设置",
"Send image to tag selection": "发送到 标签 (Tag) 选择",
"Send pose to /openpose_editor_index for edit.": "发送姿态图到 openpose editor 页面编辑",
"Send prompt up": "发送提示词到上方",
"Send seed when sending prompt or image to other interface": "将提示词或者图像发送到其他界面时,同时传送种子数值",
"Send size when sending prompt or image to another interface": "将提示词或者图像发送到其他界面时,同时传送图像尺寸",
"Send this image to ControlNet.": "将图片发送至 ControlNet",
"Send to": "发送到",
"Send to Blend": "发送到 混合",
"Send to Canvas Editor": "发送到 Canvas Editor",
"Send to ControlNet": "发送到 ControlNet",
"Send to Effect": "发送到 效果",
"Send to extras": "发送到 后期处理",
"Send to img2img": "发送到 图生图",
"Send to img2img:": "发送到 图生图:",
"Send to img2img ControlNet": "发送到 图生图 ControlNet",
"Send to inpaint": "发送到 重绘",
"Send to inpaint upload": "发送到 重绘蒙版",
"Send to ip2p": "发送到 图生图 pix2pix",
"Send to Layer1": "发送到图层 1",
"Send to Layer2": "发送到图层 2",
"Send to Layer3": "发送到图层 3",
"Send to Layer4": "发送到图层 4",
"Send to Layer5": "发送到图层 5",
"Send to Multi-Merge": "发送到 多重合并",
"Send to openOutpaint": "发送到 openOutpaint",
"Send to txt2img": "发送到 文生图",
"Send to txt2img:": "发送到 文生图:",
"Send to txt2img and img2img": "发送到 文生图和图生图",
"Send to txt2img ControlNet": "发送到 文生图 ControlNet",
"(separate by comma)": "(用逗号分隔)",
"Separate UNet/Text Encoder weights": "单独设置 UNet/Text Encoder 权重",
"Separate values for X axis using commas.": "使用逗号分隔 X 轴的值",
"Separate values for Y axis using commas.": "使用逗号分隔 Y 轴的值",
"Sequential Merge Parameters": "合并参数序列",
"Sequential XY Merge and Generation": "顺序合并并生成 XY 图",
"Server start time": "服务器启动时间",
"\uD83D\uDDBC Set": "\uD83D\uDDBC 设置",
"Set \"Hires steps\" to [0], if you need": "设置 \"高分迭代步数\" 为 [0], 如果你需要",
"Set Init tab's strength slider greater than 0. Recommended value (.65 - .80).": "将Init选项卡的强度滑块设置为大于0。建议值(.65-.80)。",
"Set Random Pose": "设置随机姿势",
"Set 'seed_behavior' to 'schedule' under the Seed Scheduling section below.": "在下面的“种子调度”部分下,将 “seed_behavior” 设置为 “schedule” 。",
"Set the Latent Couple extension to 2 area’s (standard setting)": "设置 Latent Couple 插件为 2 分区域 (标准设置)",
"Set the preprocessor to [invert] If your image has white background and black lines.": "如果使用白底黑线图片,请使用 \"invert\" 预处理器。",
"Set the prompt compounder to: 2": "设置提示词混合为: 2",
"Set the Prompt Seperator mode to: automatic": "设置提示词分隔模式为: 自动",
"Set the Prompt Seperator mode to: prefix AND prompt + suffix": "设置提示词分隔模式为: prefix AND prompt + suffix (前缀 AND 提示词 + 后缀)",
"Set the Prompt seperator to: AND": "设置提示词分隔符为: AND",
"Set the strength to 0 automatically when no init image is used": "当无初始化图像在再被使用时,强度值将自动设置为 0",
" Setting": "设置",
"(setting entries that appear at the top of page rather than in settings tab)": "(添加位于网页界面顶部的选项, 而不是在设置标签栏中)",
"settings": "设置",
"Settings": "设置",
"Settings->ControlNet->Allow other script to control this extension": "设置->ControlNet->允许其他脚本控制此插件",
"Settings File": "设置文件",
"Settings file Path can be relative to webui folder OR full - absolute": "设置文件路径可以相对于 SD-WebUI 根目录,也可以是完整的绝对路径",
"settings for": "设置。包括: ",
"Settings->Interrogate Option->Interrogate: include ranks of model tags matches in results": "设置->反推设置->反推结果包含模型标签匹配等级",
"Settings stack. If it's not checked, it wont overwrite. Apply one, then another. Reset is old, update how you need.": "设置堆栈。如果未选中,则不会覆盖。应用一个,再应用另一个。重置已过时,请根据需要进行更新。",
"Set your total number of keyframes to be 21 more than the last inserted keyframe image.": "将关键帧总数设置为比上次插入的关键帧图像多21个。",
"SFW mode \uD83D\uDC40 (blur all images)": "健全模式 \uD83D\uDC40 (模糊所有图像)",
"Shapes": "形状",
"Sharpness:": "锐化度",
"should be 2 or lower.": "应小于等于2",
"Show all pages": "显示所有设置页",
"Show all results": "展示所有候选标签",
"Show batch images in gradio gallerie output": "在 Gradio Gallerie 输出中批量显示图像",
"Show batch images in gradio gallery output": "在 Gradio Gallery 输出中批量显示图像",
"Show Button On Thumb Mode": "在缩略图模式下显示按钮",
"Show cards for models in hidden directories": "显示隐藏目录中的模型卡片",
"Show Civitai Link events in the console": "在控制台输出 Civitai Link 事件",
"Show command for conversion": "显示转换命令行",
"Show console debug": "在控制台显示调试信息",
"Show DepthMap": "展示深度图",
"Show extra networks": "显示扩展模型面板",
"Show extra options": "显示额外选项",
"Show generation progress in window title.": "在窗口标题中显示生成进度",
"Show grid in results for web": "在网页输出结果中显示网格图",
"Show HeatMap": "展示热力图",
"Show hidden directories": "显示隐藏目录",
"Show/hide extra networks": "显示/隐藏扩展模型",
"Show/Hide Generation Info": "显示/隐藏生成信息",
"Show images zoomed in by default in full page image viewer": "在网页全屏图像查看器中,默认放大显示图像",
"Show intermediate steps": "显示中间步骤",
"Show live previews of the created image": "显示当前生成图像的实时预览",
"Show live tag translation below prompt (WIP, expect some bugs)": "在提示词下方显示实时标签翻译 (未完成,预计会有一些bug)",
"Show more info": "显示更多信息",
"Show '?' next to tags, linking to its Danbooru or e621 wiki page (Warning: This is an external site and very likely contains NSFW examples!)": "在 Tag 旁边显示 '?' , 链接到其 Danbooru 或 e621 维基页面(警告:外部网站可能包含 NSFW 内容!)",
"Show Preview": "显示预览",
"Show previews of all images generated in a batch as a grid": "通过网格图预览单个批次的所有图像",
"Show progressbar": "显示进度条",
"Show progress indicator": "显示进度指示器",
"Show result images": "显示输出图像",
"Show verbose debug info at console": "在控制台中输出详尽的调试信息",
"Show warnings in console.": "在控制台中显示警告",
"Show Width/Height and Batch sliders in same row": "将批次与批量设置整合到长宽设置的右侧",
"shuffle": "shuffle (随机洗牌)",
"Shuffle": "Shuffle (随机洗牌)",
"Shuffleing tags by ',' when create texts.": "创建文本时打乱以 ',' 分割的标签",
"Shuffle tags by ',' when creating prompts.": "创建提示词时按 ',' 打乱标签(tags)",
"Shutdown server": "关闭服务器",
"Sidebar": "侧边栏",
"Sides": "每边张数",
"Sigma adjustment for finding noise for image": "为寻找图中噪点的 Sigma 调整",
"sigma churn": "sigma churn (流失率)",
"sigma max": "最大 Sigma",
"sigma min": "最小 Sigma",
"sigma noise": "sigma noise (噪声标准差)",
"Sigma noise": "Sigma 噪声",
"Sigma Noise": "Sigma 噪声",
"Sigma schedule": "Sigma 值表",
"sigma tmin": "sigma tmin (最小时间步长)",
"Simple": "单一值",
"Simple (Auto-value)": "单一值(自动取值)",
"Single": "单次处理",
"single image": "单张图片",
"Single Image": "单张图片",
"Single process": "单次处理",
"Size of the face when recreating": "重建脸部的尺寸",
"Size of the thumbnails (px)": "缩略图大小 (单位: 像素)",
"Size to generate": "生成规格",
"sketch": "涂鸦",
"Sketch": "涂鸦",
"Skip": "跳过",
"Skip generation and use (edited/custom) depthmaps in output directory when a file exists.": "当文件已存在时, 跳过生成并在输出目录中使用 (编辑后/自定义) 的深度图",
"Skip img2img processing when using img2img initial image": "使用图生图初始图像时跳过图生图处理",
"(skip negative prompt for some steps when the image is almost ready; 0=disable, higher=faster)": "(当图像接近生成完成时, 跳过部分步数的负面提示词影响; 0=禁用, 数值越大=越快速)",
"Skip negative prompt for steps where image is already mostly denoised; the higher this value, the more skips there will be; provides increased performance in exchange for minor quality reduction.": "对图像已经完成大部分去噪的采样步数, 跳过反向提示词; 这个值越高, 跳过的步数就越多; 以轻微的质量降低换取更高的性能",
"Skip NSFW Preview Images": "下载预览图时跳过含成人内容的图像",
"SKip NSFW Preview images": "下载预览图时跳过含成人内容的图像",
"SKip NSFW Preview Images": "下载预览图时跳过含成人内容的图像",
"Skip/Reset CLIP position_ids": "跳过或重置 CLIP position_ids 键值",
"Skip video creation": "跳过视频生成",
"Smart subject": "智能主题",
"Smart subject tries to determine what to and not to generate based on your subject. Example, if your Overwrite subject is formed like this: Obese man wearing a kimono": "智能主题会尝试根据你的主题决定要生成什么和避免生成什么。\n比如说,如果你的覆盖主题是这样的格式:穿着和服的肥胖男子",
"Socket port for image browser": "Cozy 图库浏览器的 Socket 端口",
"SoftEdge": "SoftEdge (软边缘)",
"softedge_hed": "softedge_hed (HED 软边缘检测)",
"softedge_hedsafe": "SoftEdge_HEDSafe (软边缘检测 - 保守 HED 算法)",
"softedge_pidinet": "SoftEdge_PiDiNet (软边缘检测 - PiDiNet 算法)",
"softedge_pidisafe": "SoftEdge_PiDiNetSafe (软边缘检测 - 保守 PiDiNet 算法)",
"soft_light": "柔光",
"solution.":
gitextract_gqg6c0_w/
├── .gitignore
├── .prettierignore
├── .prettierrc
├── LICENSE.md
├── README.md
├── build-script/
│ ├── pack-ccx.mjs
│ └── webpack.config.js
├── deprecated-do-not-use-start_server.bat
├── deprecated-do-not-use-start_server.sh
├── deprecated-do-not-use-start_server_MacOS.sh
├── deprecated-do-not-use-update_plugin.bat
├── deprecated-do-not-use-update_plugin.sh
├── dialog_box.js
├── docs/
│ └── Home.md
├── enum.js
├── helper.js
├── i18n/
│ └── zh_CN/
│ ├── ps-plugin.json
│ └── sd-official.json
├── index.html
├── index.js
├── install.py
├── manifest.json
├── package.json
├── presets/
│ ├── ctrlnet_inpaint.json
│ ├── ctrlnet_inpaint_tile.json
│ ├── ctrlnet_outpaint.json
│ ├── default.json
│ ├── img2img.json
│ ├── inpaint.json
│ └── outpaint.json
├── psapi.js
├── requirements.txt
├── scripts/
│ ├── main.py
│ └── test.py
├── sdapi_py_re.js
├── selection.js
├── server/
│ └── python_server/
│ ├── global_state.py
│ ├── img2imgapi.py
│ ├── init_images/
│ │ └── .gitignore
│ ├── metadata_to_json.py
│ ├── output/
│ │ └── .gitignore
│ ├── prompt_shortcut - Copy.json
│ ├── prompt_shortcut.py
│ ├── search.py
│ ├── serverHelper.py
│ └── serverMain.py
├── thumbnail.js
├── typescripts/
│ ├── @types/
│ │ ├── changedpi.d.ts
│ │ ├── custom.d.ts
│ │ ├── sdapi_py_re.d.ts
│ │ └── uxp.d.ts
│ ├── after_detailer/
│ │ ├── after_detailer.tsx
│ │ ├── config.ts
│ │ └── style/
│ │ └── after_detailer.css
│ ├── comfyui/
│ │ ├── comfyapi.ts
│ │ ├── comfyui.tsx
│ │ ├── img2img_api.json
│ │ ├── img2img_workflow.json
│ │ ├── inpaint_api.json
│ │ ├── inpaint_workflow.json
│ │ ├── main_ui.tsx
│ │ ├── native_workflows/
│ │ │ ├── IPAdapter_simple_api.json
│ │ │ ├── IPAdapter_weighted_api.json
│ │ │ ├── animatediff_lcm_api.json
│ │ │ ├── animatediff_simple_api.json
│ │ │ ├── real_time_lcm_img2img_api.json
│ │ │ ├── real_time_lcm_sketching_api.json
│ │ │ ├── real_time_lcm_txt2img_api.json
│ │ │ ├── sdxl_turbo_txt2img_api.json
│ │ │ └── zoom_out_api.json
│ │ ├── txt2img_api.json
│ │ ├── txt2img_workflow.json
│ │ └── util.ts
│ ├── controlnet/
│ │ ├── ControlNetTab.tsx
│ │ ├── ControlNetUnit.tsx
│ │ ├── entry.ts
│ │ ├── main.tsx
│ │ ├── store.ts
│ │ └── util.tsx
│ ├── entry.ts
│ ├── extra_page/
│ │ └── extra_page.tsx
│ ├── globalstore.ts
│ ├── history/
│ │ └── history.tsx
│ ├── image_search/
│ │ └── image_search.tsx
│ ├── lexical/
│ │ └── lexical.tsx
│ ├── locale/
│ │ ├── locale-for-old-html.ts
│ │ └── locale.ts
│ ├── main/
│ │ └── astore.ts
│ ├── multiTextarea.tsx
│ ├── one_button_prompt/
│ │ └── one_button_prompt.tsx
│ ├── preset/
│ │ ├── preset.tsx
│ │ └── shared_ui_preset.ts
│ ├── sam/
│ │ └── sam.tsx
│ ├── sd_tab/
│ │ ├── sd_tab.tsx
│ │ └── util.ts
│ ├── session/
│ │ ├── generate.tsx
│ │ ├── modes.ts
│ │ ├── progress.ts
│ │ ├── session.ts
│ │ ├── session_store.ts
│ │ └── style/
│ │ └── generate.css
│ ├── settings/
│ │ ├── settings.tsx
│ │ └── vae.tsx
│ ├── stores.ts
│ ├── tool_bar/
│ │ ├── style/
│ │ │ └── tool_bar.css
│ │ └── tool_bar.tsx
│ ├── tsconfig.json
│ ├── ultimate_sd_upscaler/
│ │ ├── config.ts
│ │ ├── scripts.tsx
│ │ └── ultimate_sd_upscaler.tsx
│ ├── util/
│ │ ├── collapsible.tsx
│ │ ├── elements.tsx
│ │ ├── errorBoundary.tsx
│ │ ├── grid.tsx
│ │ ├── logger.ts
│ │ ├── oldSystem.tsx
│ │ └── ts/
│ │ ├── api.ts
│ │ ├── document.ts
│ │ ├── enum.ts
│ │ ├── general.ts
│ │ ├── io.ts
│ │ ├── layer.ts
│ │ ├── sdapi.ts
│ │ ├── selection.ts
│ │ └── ui_ts.ts
│ └── viewer/
│ ├── preview.tsx
│ ├── style/
│ │ └── preview.css
│ ├── viewer.tsx
│ └── viewer_util.ts
└── utility/
├── api.js
├── dummy.js
├── general.js
├── html_manip.js
├── io.js
├── layer.js
├── notification.js
├── online_data.json
├── presets/
│ └── controlnet_preset.js
├── sampler.js
├── sd_scripts/
│ └── horde.js
├── sdapi/
│ ├── config.js
│ ├── horde_native.js
│ ├── options.js
│ ├── prompt_shortcut.js
│ └── python_replacement.js
├── session.js
├── tab/
│ ├── image_search_tab.js
│ └── settings.js
└── tips.js
SYMBOL INDEX (1030 symbols across 83 files)
FILE: dialog_box.js
function prompt (line 1) | async function prompt(
FILE: helper.js
function getActiveLayer (line 5) | function getActiveLayer() {
function getSize (line 19) | function getSize() {
function reselectBatchPlay (line 27) | async function reselectBatchPlay(selectionInfo) {
function reselect (line 69) | async function reselect(selectionInfo) {
function unSelect (line 79) | async function unSelect() {
function indexToXY (line 116) | function indexToXY(index, width) {
FILE: index.js
function setLogMethod (line 106) | function setLogMethod(should_log_to_file = true) {
function hasSessionSelectionChanged (line 181) | async function hasSessionSelectionChanged() {
function calcWidthHeightFromSelection (line 205) | async function calcWidthHeightFromSelection(selectionInfo) {
function getCurrentGenerationModeByValue (line 252) | function getCurrentGenerationModeByValue(value) {
function getUniqueDocumentId (line 269) | async function getUniqueDocumentId() {
function getSelectedText (line 352) | function getSelectedText() {
function getCommentedString (line 373) | function getCommentedString() {
function displayNotification (line 407) | async function displayNotification(automatic_status) {
function checkAutoStatus (line 419) | async function checkAutoStatus() {
function promptShortcutExample (line 464) | function promptShortcutExample() {
function createTempInpaintMaskLayer (line 597) | async function createTempInpaintMaskLayer() {
function deleteTempInpaintMaskLayer (line 620) | async function deleteTempInpaintMaskLayer() {
function postModeSelection (line 640) | async function postModeSelection() {
function selectTool (line 702) | function selectTool() {
function fillImage (line 726) | async function fillImage() {
function pastImage2Layer (line 742) | function pastImage2Layer() {
function sliderToResolution (line 777) | function sliderToResolution(sliderValue) {
function storeActiveLayers (line 783) | async function storeActiveLayers() {
function restoreActiveLayers (line 802) | async function restoreActiveLayers() {
function storeActiveSelection (line 819) | async function storeActiveSelection() {
function restoreActiveSelection (line 836) | async function restoreActiveSelection() {
function updateMetadata (line 854) | function updateMetadata(new_metadata) {
function hasSelectionChanged (line 869) | async function hasSelectionChanged(new_selection, old_selection) {
function updateProgressBarsHtml (line 883) | function updateProgressBarsHtml(new_value) {
function _base64ToArrayBuffer (line 898) | function _base64ToArrayBuffer(base64) {
function _arrayBufferToBase64 (line 908) | function _arrayBufferToBase64(buffer) {
function getDocFolder (line 919) | async function getDocFolder(doc_uuid) {
function getCurrentDocFolder (line 939) | async function getCurrentDocFolder() {
function getInitImagesDir (line 947) | async function getInitImagesDir() {
function base64ToFile (line 963) | async function base64ToFile(b64Image, image_name = 'output_image.png') {
function placeImageB64ToLayer (line 1029) | async function placeImageB64ToLayer(image_path, entery) {
function openImageAction (line 1103) | async function openImageAction() {
function openImageExe (line 1122) | async function openImageExe() {
function convertToSmartObjectAction (line 1128) | async function convertToSmartObjectAction() {
function convertToSmartObjectExe (line 1144) | async function convertToSmartObjectExe() {
function silentImagesToLayersExe_old (line 1149) | async function silentImagesToLayersExe_old(images_info) {
function silentImagesToLayersExe (line 1235) | async function silentImagesToLayersExe(images_info) {
function stackLayers (line 1315) | async function stackLayers() {
function removeInitImageFromViewer (line 1351) | function removeInitImageFromViewer() {}
function removeMaskFromViewer (line 1352) | function removeMaskFromViewer() {}
function viewerThumbnailclickHandler (line 1354) | async function viewerThumbnailclickHandler(e, viewer_obj_owner) {
function createViewerImgHtml (line 1390) | function createViewerImgHtml(output_dir_relative, image_path, base64_ima...
function toggleLayerVisibility (line 1402) | function toggleLayerVisibility(layer, b_on) {
function turnMaskVisible (line 1410) | async function turnMaskVisible(
function loadPromptShortcut (line 1493) | async function loadPromptShortcut() {
function refreshPromptMenu (line 1503) | async function refreshPromptMenu() {
function changePromptShortcutKey (line 1544) | function changePromptShortcutKey(new_key) {
function changePromptShortcutValue (line 1548) | function changePromptShortcutValue(new_value) {
function downloadIt (line 1553) | async function downloadIt(link, writeable_entry, image_file_name) {
function downloadItExe (line 1593) | async function downloadItExe(link, writeable_entry, image_file_name) {
function base64ToSrc (line 1606) | function base64ToSrc(base64_image) {
function getDimensions (line 1613) | function getDimensions(image) {
function switchMenu (line 1633) | function switchMenu(rb) {
function switchMenu_new (line 1736) | function switchMenu_new(rb) {
function openFileFromUrl (line 1791) | async function openFileFromUrl(url, format = 'gif') {
function openFileFromUrlExe (line 1819) | async function openFileFromUrlExe(url, format = 'gif') {
FILE: install.py
function install_or_update_package (line 54) | def install_or_update_package(package_name, package_version):
FILE: psapi.js
function createSolidLayer (line 13) | async function createSolidLayer(r, g, b) {
function makeGroupCommand (line 50) | async function makeGroupCommand() {
function createEmptyGroup (line 78) | async function createEmptyGroup(name = 'New Group') {
function moveToGroupCommand (line 89) | async function moveToGroupCommand(to_index, layerIDs) {
function MoveToGroupExe (line 123) | function MoveToGroupExe(toIndex, layerIDs) {
function getIndexCommand (line 133) | async function getIndexCommand(layer_id) {
function getLayerIndex (line 159) | async function getLayerIndex(layer_id) {
function unselectActiveLayers (line 173) | async function unselectActiveLayers() {
function unselectActiveLayersExe (line 179) | async function unselectActiveLayersExe() {
function selectLayers (line 184) | async function selectLayers(layers) {
function setVisibleExe (line 199) | async function setVisibleExe(layer, is_visible) {
function selectLayersExe (line 208) | async function selectLayersExe(layers) {
function selectGroup (line 213) | async function selectGroup(layer) {
function collapseGroup (line 217) | async function collapseGroup(layer) {
function createMaskCommand (line 222) | async function createMaskCommand() {
function createMaskExe (line 253) | async function createMaskExe() {
function unSelectMarqueeCommand (line 259) | async function unSelectMarqueeCommand() {
function unSelectMarqueeExe (line 289) | async function unSelectMarqueeExe() {
function selectMarqueeRectangularToolExe (line 298) | async function selectMarqueeRectangularToolExe() {
function promptForMarqueeTool (line 326) | async function promptForMarqueeTool() {
function selectLayerChannelCommand (line 345) | async function selectLayerChannelCommand() {
function getSelectionInfoCommand (line 408) | async function getSelectionInfoCommand() {
function isSelectionValid (line 437) | function isSelectionValid(selection) {
function getSelectionInfoExe (line 454) | async function getSelectionInfoExe() {
function reSelectMarqueeCommand (line 480) | async function reSelectMarqueeCommand(selectionInfo) {
function reSelectMarqueeExe (line 521) | async function reSelectMarqueeExe(selectionInfo) {
function snapshot_layer (line 534) | async function snapshot_layer() {
function snapshot_layer_new (line 580) | async function snapshot_layer_new() {
function snapshot_layerExe (line 641) | async function snapshot_layerExe() {
function snapshot_layer_no_slide (line 656) | async function snapshot_layer_no_slide() {
function snapshot_layer_no_slide_Exe (line 703) | async function snapshot_layer_no_slide_Exe() {
function fillAndGroup (line 720) | async function fillAndGroup() {
function fillAndGroupExe (line 771) | async function fillAndGroupExe() {
function fastSnapshot (line 776) | async function fastSnapshot() {
function layerToFileName (line 781) | function layerToFileName(layer, session_id) {
function layerNameToFileName (line 785) | function layerNameToFileName(layer_name, layer_id, session_id) {
function cleanLayers (line 790) | async function cleanLayers(layers) {
function createClippingMaskExe (line 844) | async function createClippingMaskExe() {
function checkIfSelectionAreaIsActive (line 881) | async function checkIfSelectionAreaIsActive() {
function saveUniqueDocumentIdExe (line 889) | async function saveUniqueDocumentIdExe(new_id) {
function readUniqueDocumentIdExe (line 932) | async function readUniqueDocumentIdExe() {
function selectCanvasCommand (line 1031) | async function selectCanvasCommand() {
function selectCanvasExe (line 1078) | async function selectCanvasExe() {
function newExportPng (line 1086) | async function newExportPng(layer, image_name, width, height) {
function tempExportPng (line 1143) | async function tempExportPng(layer, image_name, width, height) {
function mergeVisibleCommand (line 1197) | async function mergeVisibleCommand() {
function mergeVisibleExe (line 1218) | async function mergeVisibleExe() {
function layerToSelection (line 1224) | async function layerToSelection(selection_info) {
function executeCommandExe (line 1302) | function executeCommandExe(commandFunc) {
function executeDescExe (line 1313) | async function executeDescExe(Desc) {
FILE: scripts/main.py
function searchImage (line 38) | async def searchImage(request:Request):
function maskExpansionHandler (line 59) | async def maskExpansionHandler(request:Request):
function on_app_started (line 92) | def on_app_started(demo: gr.Blocks, app: FastAPI):
FILE: sdapi_py_re.js
function requestSavePng (line 11) | async function requestSavePng(base64_image, image_name) {
function requestTxt2Img (line 25) | async function requestTxt2Img(payload) {
function requestImg2Img (line 40) | async function requestImg2Img(payload) {
function requestProgress (line 55) | async function requestProgress() {
function requestInterrupt (line 72) | async function requestInterrupt() {
function changeSdUrl (line 97) | async function changeSdUrl(new_sd_url) {
function loadHistory (line 129) | async function loadHistory(uniqueDocumentId) {
function loadPromptShortcut (line 142) | async function loadPromptShortcut() {
function savePromptShortcut (line 156) | async function savePromptShortcut(prompt_shortcut) {
function requestGetConfig (line 169) | async function requestGetConfig() {
function requestGetOptions (line 183) | async function requestGetOptions() {
function imageSearch (line 201) | async function imageSearch(keywords) {
function requestExtraSingleImage (line 345) | async function requestExtraSingleImage(payload) {
function isWebuiRunning (line 359) | async function isWebuiRunning() {
FILE: selection.js
function finalWidthHeight (line 4) | function finalWidthHeight(
function selectionToFinalWidthHeight (line 34) | async function selectionToFinalWidthHeight(
function selectBoundingBox (line 60) | async function selectBoundingBox() {
function convertSelectionObjectToSelectionInfo (line 67) | function convertSelectionObjectToSelectionInfo(selection_obj) {
function createChannelIfNotExists (line 95) | async function createChannelIfNotExists(channelName) {
function makeMaskChannelExe (line 162) | async function makeMaskChannelExe(channel_name = 'mask') {
function multiGetExe (line 199) | async function multiGetExe() {
function applyMaskChannelExe (line 218) | async function applyMaskChannelExe(channel_name = 'mask') {
function selectionToChannel (line 250) | async function selectionToChannel(channel_name) {
function createLayerFromMaskChannel (line 273) | async function createLayerFromMaskChannel(channel_name = 'mask') {
function channelToSelectionExe (line 309) | async function channelToSelectionExe(channel_name = 'mask') {
function keepRatio (line 327) | function keepRatio(selectionInfo, offset) {
function makeSquare (line 345) | function makeSquare(selectionInfo, offset) {
function inpaintLassoInitImageAndMask (line 370) | async function inpaintLassoInitImageAndMask(
function fillSelectionWhiteOutsideBlack (line 450) | async function fillSelectionWhiteOutsideBlack(selectionInfo) {
function inpaintLasoInitImage (line 587) | async function inpaintLasoInitImage() {
class Selection (line 780) | class Selection {
method getSelectionInfoExe (line 781) | static async getSelectionInfoExe() {
method isSelectionValid (line 810) | static isSelectionValid(selection) {
method reselectArea (line 826) | static reselectArea(selection_info) {}
method isSameSelection (line 827) | static isSameSelection(selection_info_1, selection_info_2) {}
method getImageToSelectionDifference (line 828) | static async getImageToSelectionDifference() {
function moveToTopLayerStackExe (line 844) | async function moveToTopLayerStackExe() {
function colorRange (line 868) | async function colorRange() {
function colorRangeExe (line 909) | async function colorRangeExe() {
function base64ToLassoSelection (line 924) | async function base64ToLassoSelection(base64, selection_info) {
function base64ToChannel (line 951) | async function base64ToChannel(base64, selection_info, channel_name) {
function black_white_layer_to_mask (line 1004) | async function black_white_layer_to_mask(mask_id, target_layer_id, mask_...
function black_white_layer_to_mask_multi_batchplay (line 1068) | async function black_white_layer_to_mask_multi_batchplay(
FILE: server/python_server/global_state.py
function filter_selected_helper (line 90) | def filter_selected_helper(k,preprocessor_list,model_list):
FILE: server/python_server/img2imgapi.py
function img_2_b64 (line 15) | def img_2_b64(image):
function b64_2_img (line 26) | def b64_2_img(base64_image):
function reserveBorderPixels (line 30) | def reserveBorderPixels(img,dilation_img):
function maskExpansion (line 47) | def maskExpansion(mask_img,mask_expansion,blur =10):
function base64ToPng (line 60) | async def base64ToPng(base64_image,image_path):
function applyDilation (line 70) | def applyDilation(img,iteration=20,max_filter=3):
function img2ImgRequest (line 81) | async def img2ImgRequest(sd_url,payload):
FILE: server/python_server/metadata_to_json.py
function convertMetadataToJson (line 8) | def convertMetadataToJson(metadata_str):
function getMetadataFromPng (line 36) | def getMetadataFromPng(image_path):
function createMetadataJsonFileIfNotExist (line 50) | def createMetadataJsonFileIfNotExist(image_path):
FILE: server/python_server/prompt_shortcut.py
function readToJson (line 6) | def readToJson():
function writeToJson (line 9) | def writeToJson(file_name,data_dict):
function load (line 14) | def load():
function find_words_inside_braces (line 24) | def find_words_inside_braces(string):
function replaceShortcut (line 40) | def replaceShortcut(text,prompt_shortcut_dict):
FILE: server/python_server/search.py
function imageSearch (line 11) | async def imageSearch(keywords="cute cats"):
function main (line 18) | async def main():
FILE: server/python_server/serverHelper.py
function writeJson (line 8) | def writeJson(file_name,data_dict):
function readJson (line 16) | def readJson(file_name):
function createFolder (line 27) | def createFolder(fullpath):
function makeDirPathName (line 33) | def makeDirPathName():
function getUniqueDocumentDirPathName (line 44) | def getUniqueDocumentDirPathName(uniqueDocumentId):
function makeUniqueID (line 52) | def makeUniqueID():
FILE: server/python_server/serverMain.py
function txt2ImgRequest (line 24) | async def txt2ImgRequest(payload):
function img_2_b64 (line 85) | def img_2_b64(image):
function read_root (line 104) | def read_root():
function getVersion (line 109) | def getVersion():
function changeSdUrl (line 144) | async def changeSdUrl(request:Request):
function txt2ImgHandle (line 167) | async def txt2ImgHandle(request:Request):
function img2ImgHandle (line 175) | async def img2ImgHandle(request:Request):
function getInitImageHandle (line 188) | async def getInitImageHandle(request:Request):
function sdapi (line 218) | async def sdapi(request: Request, response: Response):
function sdapi (line 230) | async def sdapi(path: str, request: Request, response: Response):
function sdapi (line 242) | async def sdapi(path: str, request: Request, response: Response):
function savePng (line 273) | async def savePng(request:Request):
function searchImage (line 297) | async def searchImage(request:Request):
function maskExpansionHandler (line 317) | async def maskExpansionHandler(request:Request):
function loadHistory (line 350) | async def loadHistory(request: Request):
function loadPromptShortcut (line 396) | async def loadPromptShortcut(request: Request):
function loadPromptShortcut (line 415) | async def loadPromptShortcut(request: Request):
function swapModel (line 437) | async def swapModel(request:Request):
function openUrl (line 452) | async def openUrl(request:Request):
function list_available_loras (line 471) | async def list_available_loras():
function list_available_vae (line 498) | async def list_available_vae():
function filter (line 510) | async def filter(keyword:str = Body('All',title="keyword to filter by"),
function heartbeat (line 536) | async def heartbeat():
function readPngMetadata (line 542) | async def readPngMetadata(request: Request):
FILE: thumbnail.js
class Thumbnail (line 1) | class Thumbnail {
method wrapImgInContainer (line 2) | static wrapImgInContainer(img, container_style_class) {
method addSPButtonToContainer (line 9) | static addSPButtonToContainer(
FILE: typescripts/after_detailer/after_detailer.tsx
class AfterDetailerComponent (line 64) | class AfterDetailerComponent extends React.Component<{
method componentDidMount (line 74) | async componentDidMount(): Promise<void> {
method componentDidUpdate (line 87) | async componentDidUpdate(
method isInstalled (line 96) | async isInstalled() {
method getInpaintModels (line 113) | async getInpaintModels() {
method render (line 128) | render() {
FILE: typescripts/after_detailer/config.ts
constant MASK_MERGE_INVERT (line 1) | let MASK_MERGE_INVERT = ['None', 'Merge', 'Merge and Invert']
FILE: typescripts/comfyui/comfyapi.ts
type ComfyError (line 5) | interface ComfyError {
type NodeError (line 12) | interface NodeError {
type ComfyResult (line 17) | interface ComfyResult {
class ComfyAPI (line 21) | class ComfyAPI {
method constructor (line 26) | constructor(comfy_url: string) {
method init (line 29) | async init(display_error = false) {
method setUrl (line 42) | setUrl(comfy_url: string) {
method refresh (line 45) | async refresh() {
method queue (line 48) | async queue() {
method prompt (line 54) | async prompt(prompt: any) {
method getHistory (line 67) | async getHistory(prompt_id: string = '') {
method view (line 78) | async view(
method initializeObjectInfo (line 89) | async initializeObjectInfo(comfy_url: string) {
method getObjectInfo (line 101) | getObjectInfo() {
method getReadableError (line 109) | getReadableError(result: ComfyResult): string {
method getData (line 129) | private getData(path: string[]): any[] {
method getModels (line 145) | getModels(): any[] {
method getVAEs (line 154) | getVAEs(): any[] {
method getSamplerNames (line 157) | getSamplerNames(): string[] {
method getHiResUpscalers (line 160) | getHiResUpscalers(): string[] {
method getLoras (line 168) | getLoras(): string[] {
method interrupt (line 171) | async interrupt() {
FILE: typescripts/comfyui/comfyui.tsx
type Error (line 46) | interface Error {
type NodeError (line 53) | interface NodeError {
type Result (line 59) | interface Result {
function logError (line 64) | function logError(result: Result) {
function workflowEntries (line 100) | async function workflowEntries() {
function postPrompt (line 119) | async function postPrompt(prompt: any) {
function generateRequest (line 135) | async function generateRequest(prompt: any) {
function generateImage (line 160) | async function generateImage(prompt: any) {
function getConfig (line 204) | async function getConfig() {
function getWorkflowApi (line 229) | async function getWorkflowApi(image_path: string) {
function filterObjectProperties (line 253) | function filterObjectProperties(node_inputs: any, valid_keys: string[]) {
function parseUIFromNode (line 258) | function parseUIFromNode(node: ComfyUINode, node_id: string) {
function storeToPrompt (line 298) | function storeToPrompt(store: any, basePrompt: any) {
function createMenu (line 317) | function createMenu(input: ValidInput) {
function createTextField (line 343) | function createTextField(input: ValidInput) {
function createTextArea (line 361) | function createTextArea(input: ValidInput) {
function createImageBase64 (line 376) | function createImageBase64(input: ValidInput) {
function nodeInputToHtmlElement (line 411) | function nodeInputToHtmlElement(input: ValidInput) {
function loadWorkflow (line 429) | async function loadWorkflow(workflow_path: string) {
function setSliderValue (line 478) | function setSliderValue(store: any, node_id: string, name: string, value...
function onChangeLoadImage (line 483) | async function onChangeLoadImage(
function onChangeLoadVideo (line 500) | async function onChangeLoadVideo(
function renderNode (line 517) | function renderNode(node_id: string, node: any, is_output: boolean) {
function renderInput (line 1007) | function renderInput(
function swap (line 1232) | function swap(index1: number, index2: number) {
function moveToTop (line 1242) | function moveToTop(index: number) {
function moveToBottom (line 1252) | function moveToBottom(index: number) {
function saveWorkflowData (line 1263) | function saveWorkflowData(
function loadWorkflowData (line 1272) | function loadWorkflowData(workflow_name: string): WorkflowData {
type WorkflowData (line 1278) | interface WorkflowData {
function resetWorkflowData (line 1284) | function resetWorkflowData(workflow_name: string) {
function loadWorkflow2 (line 1298) | function loadWorkflow2(workflow: any) {
function getUploadedImages (line 1424) | async function getUploadedImages(images_list: string[]) {
function getBorderColor (line 1455) | function getBorderColor(is_output: boolean, last_moved: boolean) {
class ComfyWorkflowComponent (line 1472) | @observer
method componentDidMount (line 1474) | async componentDidMount(): Promise<void> {
method render (line 1491) | render(): React.ReactNode {
FILE: typescripts/comfyui/main_ui.tsx
function parseMetadata (line 22) | function parseMetadata(title: string) {
function getInput (line 53) | function getInput(node: any, name: string) {
function getNode (line 59) | function getNode(nodes: any[], node_id: string) {
function getNodeByNameId (line 65) | function getNodeByNameId(nodes: any[], node_name_id: string) {
function getPromptNodeByNameId (line 73) | function getPromptNodeByNameId(
function setInputValue (line 83) | function setInputValue(
function getLink (line 103) | function getLink(links: any[], link_id: number) {
function getNodesFromLink (line 109) | function getNodesFromLink(link: any) {
function mutePromptNode (line 115) | function mutePromptNode(nodes: any[], prompt: any, node_name_id: string) {
function reuseOrUploadComfyImage (line 231) | async function reuseOrUploadComfyImage(
function addMissingSettings (line 255) | async function addMissingSettings(plugin_settings: Record<string, any>) {
function addMissingControlnetSettings (line 298) | async function addMissingControlnetSettings(
function mapPluginSettingsToComfyuiPrompt (line 346) | async function mapPluginSettingsToComfyuiPrompt(
function generateComfyMode (line 417) | async function generateComfyMode(
function generateComfyTxt2Img (line 501) | async function generateComfyTxt2Img(
function generateComfyImg2Img (line 511) | async function generateComfyImg2Img(
function generateComfyInpaint (line 521) | async function generateComfyInpaint(
FILE: typescripts/comfyui/util.ts
type InputTypeEnum (line 11) | enum InputTypeEnum {
type ValidInput (line 18) | interface ValidInput {
type PhotoshopNode (line 26) | interface PhotoshopNode {
type ComfyUIConfig (line 31) | interface ComfyUIConfig {
type ComfyUINode (line 38) | interface ComfyUINode {
type ImageLoadingMethod (line 99) | interface ImageLoadingMethod {
type Workflow (line 103) | interface Workflow {}
function getNodes (line 104) | function getNodes(workflow: Workflow) {
type ComfyInputType (line 111) | enum ComfyInputType {
type ComfyNodeType (line 123) | enum ComfyNodeType {
type ComfyOutputImage (line 130) | interface ComfyOutputImage {
function getNodeType (line 136) | function getNodeType(node_name: any) {
function parseComfyInput (line 151) | function parseComfyInput(
function makeHtmlInput (line 218) | function makeHtmlInput() {}
function getHistory (line 220) | async function getHistory(prompt_id: string) {
function postPromptAndGetBase64JsonResult (line 233) | async function postPromptAndGetBase64JsonResult(
function base64UrlFromComfy (line 283) | async function base64UrlFromComfy({
function base64UrlFromFileName (line 291) | function base64UrlFromFileName(base64: string, filename: string) {
function base64Url (line 294) | function base64Url(base64: string, format: string = 'png') {
function generatePrompt (line 297) | function generatePrompt(prompt: Record<string, any>) {
function updateOutput (line 300) | function updateOutput(output: any, output_store_obj: any) {
function mapComfyOutputToStoreOutput (line 305) | async function mapComfyOutputToStoreOutput(
type LooseObject (line 347) | interface LooseObject {
function isSameStructure (line 351) | function isSameStructure(obj1: LooseObject, obj2: LooseObject): boolean {
function extractFormat (line 387) | function extractFormat(input: string) {
function uploadImagePost (line 401) | async function uploadImagePost(
function uploadImage (line 439) | async function uploadImage(
function readFile (line 473) | async function readFile() {
function getRandomBigIntApprox (line 482) | function getRandomBigIntApprox(min: bigint, max: bigint): bigint {
function runRandomSeedScript (line 489) | function runRandomSeedScript() {
function maskExpansion (line 510) | async function maskExpansion(
FILE: typescripts/controlnet/ControlNetTab.tsx
class ControlNetTab (line 21) | @observer
method updatePresetMenuChildren (line 78) | updatePresetMenuChildren(newChildren: any) {
method updatePresetMenuEvent (line 81) | async updatePresetMenuEvent() {
method onSetAllControlImage (line 115) | async onSetAllControlImage() {
method componentDidMount (line 130) | componentDidMount(): void {
method unitBackgroundColor (line 134) | unitBackgroundColor(is_enabled: boolean, is_tab_enabled: boolean) {
method render (line 147) | render() {
FILE: typescripts/controlnet/ControlNetUnit.tsx
class ControlNetUnit (line 35) | class ControlNetUnit extends React.Component<
method onEnableChange (line 39) | onEnableChange(event: any) {
method onLowVRamChange (line 45) | onLowVRamChange(event: any) {
method onGuessModeChange (line 51) | onGuessModeChange(event: any) {
method onPixelPerfectChange (line 57) | onPixelPerfectChange(event: any) {
method onAutoImageChange (line 64) | onAutoImageChange(event: any) {
method onWeightMove (line 71) | onWeightMove(event: any) {
method onGuidanceStartMove (line 85) | onGuidanceStartMove(event: any) {
method onGuidanceEndMove (line 99) | onGuidanceEndMove(event: any) {
method onFilterChange (line 113) | async onFilterChange(
method onPreprocsesorChange (line 139) | onPreprocsesorChange(item: string) {
method onModelChange (line 144) | onModelChange(item: string) {
method onResolutionMove (line 149) | onResolutionMove(event: any) {
method onThresholdAMove (line 161) | onThresholdAMove(event: any) {
method onThresholdBMove (line 171) | onThresholdBMove(event: any) {
method onSetImageButtonClick (line 181) | async onSetImageButtonClick() {
method onMaskButtonClick (line 195) | async onMaskButtonClick() {
method requestControlNetDetectMap (line 214) | async requestControlNetDetectMap(
method previewAnnotator (line 243) | async previewAnnotator() {
method setMask (line 283) | async setMask() {
method resetMask (line 298) | async resetMask() {
method toCanvas (line 301) | async toCanvas() {
method toControlNetInitImage (line 320) | async toControlNetInitImage() {
method previewAnnotatorFromCanvas (line 326) | async previewAnnotatorFromCanvas() {
method render (line 375) | render() {
FILE: typescripts/controlnet/entry.ts
function convertComfyModuleDetailsToPluginModuleDetails (line 18) | function convertComfyModuleDetailsToPluginModuleDetails(
function requestControlNetPreprocessors (line 52) | async function requestControlNetPreprocessors() {
function requestControlNetModelList (line 59) | async function requestControlNetModelList(): Promise<any> {
function requestControlNetApiVersion (line 67) | async function requestControlNetApiVersion() {
function requestControlNetMaxUnits (line 74) | async function requestControlNetMaxUnits() {
function requestControlNetFiltersKeywords (line 83) | async function requestControlNetFiltersKeywords(
function initializeControlNetTab (line 107) | async function initializeControlNetTab(controlnet_max_models: number) {
function initializeControlNetTabComfyUI (line 149) | async function initializeControlNetTabComfyUI(
function getEnableControlNet (line 182) | function getEnableControlNet(index: number) {
function mapPluginSettingsToControlNet (line 189) | async function mapPluginSettingsToControlNet(plugin_settings: any) {
function getControlNetMaxModelsNumber (line 303) | function getControlNetMaxModelsNumber() {
function getUnitsData (line 306) | function getUnitsData() {
function setUnitData (line 310) | function setUnitData(unitData: controlNetUnitData, index: number) {
function setControlDetectMapSrc (line 327) | function setControlDetectMapSrc(base64: string, index: number) {
function setControlInputImageSrc (line 331) | function setControlInputImageSrc(base64: string, index: number) {
function isControlNetModeEnable (line 334) | function isControlNetModeEnable() {
function getModuleDetail (line 351) | function getModuleDetail() {
FILE: typescripts/controlnet/main.tsx
function scrollToEnabledControlNetUnit (line 49) | function scrollToEnabledControlNetUnit() {}
FILE: typescripts/controlnet/store.ts
type ResizeMode (line 3) | type ResizeMode = 'Just Resize' | 'Crop and Resize' | 'Resize and Fill'
type ControlnetMode (line 9) | type ControlnetMode = (typeof controlnetModes)[number]
type controlNetUnitData (line 60) | interface controlNetUnitData {
type ControlNetMobxStore (line 86) | interface ControlNetMobxStore {
FILE: typescripts/controlnet/util.tsx
function mapRange (line 1) | function mapRange(
function versionCompare (line 18) | function versionCompare(to: string, from: string) {
FILE: typescripts/extra_page/extra_page.tsx
function refreshExtraUpscalers (line 29) | async function refreshExtraUpscalers() {
class ExtraPage (line 42) | class ExtraPage extends React.Component {
method componentDidMount (line 43) | componentDidMount(): void {}
method render (line 45) | render(): React.ReactNode {
FILE: typescripts/globalstore.ts
type GlobalStore (line 4) | interface GlobalStore {
FILE: typescripts/history/history.tsx
function getMetaDataForOutputEntry (line 31) | async function getMetaDataForOutputEntry(doc_entry: any, output_entry: a...
function getOutputImagesEntries (line 52) | async function getOutputImagesEntries(doc_entry: any) {
function loadHistory (line 62) | async function loadHistory(payload: any) {
function moveHistoryImageToLayer (line 124) | async function moveHistoryImageToLayer(
function historyMetadataToPreset (line 154) | function historyMetadataToPreset(metadata: any) {}
function getHistoryMetadata (line 155) | function getHistoryMetadata(metadata_json: any) {
type Auto111Metadata (line 188) | interface Auto111Metadata {
function ChangeSettingsFromAuto1111Metadata (line 202) | function ChangeSettingsFromAuto1111Metadata(metadata: Auto111Metadata) {
type CombinedElement (line 224) | interface CombinedElement {
function combineAndSortArrays (line 230) | function combineAndSortArrays(
function segmentCombinedArray (line 261) | function segmentCombinedArray(combinedArray: CombinedElement[]) {
class History (line 283) | @observer
method componentDidMount (line 285) | componentDidMount(): void {
method componentWillUnmount (line 297) | componentWillUnmount(): void {
method onClearHistoryCache (line 309) | onClearHistoryCache() {
method onLoadHistory (line 314) | async onLoadHistory() {
method createGrids (line 327) | createGrids(
method createGrid (line 373) | createGrid(thumbnails: string[], images: string[], metadata_jsons: any...
method render (line 414) | render(): React.ReactNode {
FILE: typescripts/lexical/lexical.tsx
type LexicaItem (line 21) | interface LexicaItem {
function requestLexica (line 49) | async function requestLexica(search_query: string) {
function loadSettingsToUI (line 57) | async function loadSettingsToUI(lexica_item: LexicaItem) {
function onThumbnailClick (line 84) | function onThumbnailClick(lexical_item: LexicaItem) {
function searchForSimilarImage (line 99) | async function searchForSimilarImage(lexica_item: LexicaItem) {
class Lexical (line 113) | class Lexical extends React.Component {
method componentDidMount (line 114) | componentDidMount(): void {}
method componentWillUnmount (line 115) | componentWillUnmount(): void {}
method render (line 117) | render() {
FILE: typescripts/locale/locale-for-old-html.ts
function renderLocale (line 87) | function renderLocale(locale: string) {
FILE: typescripts/locale/locale.ts
function isExists (line 8) | function isExists(path: string): boolean {
function Locale (line 19) | function Locale(
FILE: typescripts/main/astore.ts
type AStoreData (line 4) | interface AStoreData {
class AStore (line 7) | class AStore<T extends AStoreData> {
method constructor (line 10) | constructor(data: T) {
method updateProperty (line 16) | updateProperty(key: keyof T, value: any) {
method updatePropertyArray (line 19) | updatePropertyArray(key: keyof T, value: any) {
method updatePropertyArrayRemove (line 22) | updatePropertyArrayRemove(key: keyof T, valueToRemove: any) {
method toJsFunc (line 28) | toJsFunc() {
FILE: typescripts/multiTextarea.tsx
type AStoreData (line 9) | interface AStoreData {
function getPrompt (line 23) | function getPrompt(): { positive: string; negative: string } {
function setPrompt (line 30) | function setPrompt({
class MultiTextArea (line 44) | class MultiTextArea extends React.Component {
method componentDidMount (line 45) | componentDidMount(): void {
method componentWillUnmount (line 51) | componentWillUnmount(): void {
method switchTextArea (line 64) | switchTextArea(index: number) {
method handleInput (line 68) | handleInput(event: any) {
method changePositivePrompt (line 71) | changePositivePrompt(text: string, index: number) {
method changeNegativePrompt (line 78) | changeNegativePrompt(text: string, index: number) {
method render (line 86) | render() {
FILE: typescripts/one_button_prompt/one_button_prompt.tsx
function requestRandomPrompts (line 33) | async function requestRandomPrompts(
function handleInput (line 69) | function handleInput(event: any) {
function requestConfig (line 78) | async function requestConfig() {
class OneButtonPrompt (line 96) | @observer
method initScript (line 98) | async initScript() {
method componentDidMount (line 103) | async componentDidMount() {
method renderContainer (line 108) | renderContainer() {
method render (line 243) | render() {
FILE: typescripts/preset/preset.tsx
function getPresetSettingsHtml (line 47) | function getPresetSettingsHtml() {
function updateTextAreaHeight (line 54) | function updateTextAreaHeight(textarea_element: any) {
function deletePreset (line 73) | async function deletePreset() {
function filterControlnetUnitData (line 90) | function filterControlnetUnitData(controlnet_units_data: controlNetUnitD...
function onNewPreset (line 105) | function onNewPreset() {
function onSavePreset (line 132) | async function onSavePreset() {
class PresetTab (line 154) | @observer
method componentDidMount (line 156) | async componentDidMount() {
method renderTab (line 168) | renderTab() {
method render (line 264) | render(): React.ReactNode {
FILE: typescripts/preset/shared_ui_preset.ts
function getLoadedPresets (line 6) | async function getLoadedPresets(ui_settings_obj: any) {
function getCustomPresetEntries (line 35) | async function getCustomPresetEntries(preset_folder_name: string) {
function loadPresetSettingsFromFile (line 46) | async function loadPresetSettingsFromFile(preset_file_name: string) {
function getAllCustomPresetsSettings (line 62) | async function getAllCustomPresetsSettings() {
function loadPreset (line 81) | function loadPreset(ui_settings: any, preset: any) {
function loadCustomPreset (line 85) | function loadCustomPreset(
function mapCustomPresetsToLoaders (line 91) | async function mapCustomPresetsToLoaders(ui_settings_obj: any) {
function getCustomPresetsNames (line 104) | function getCustomPresetsNames(custom_presets: any) {
function onLoadControlnetPreset (line 112) | function onLoadControlnetPreset() {}
function onLoadSDPreset (line 113) | function onLoadSDPreset() {}
FILE: typescripts/sam/sam.tsx
function getSamMap (line 23) | async function getSamMap(base64: string, prompt: string) {
class Sam (line 59) | class Sam extends React.Component<{
method initScript (line 62) | async initScript() {
method componentDidMount (line 66) | async componentDidMount(): Promise<void> {
method renderScript (line 70) | renderScript() {
method render (line 194) | render() {
FILE: typescripts/sd_tab/sd_tab.tsx
class SDTab (line 171) | @observer
method componentDidMount (line 173) | async componentDidMount() {
method render (line 207) | render() {
FILE: typescripts/sd_tab/util.ts
type SelectionModeEnum (line 98) | enum SelectionModeEnum {
function refreshModels (line 211) | async function refreshModels() {
function promptForUpdate (line 242) | async function promptForUpdate(header_message: any, long_message: any) {
function updateClickEventHandler (line 279) | async function updateClickEventHandler(current_version: string) {
function tempDisableElement (line 300) | function tempDisableElement(element: any, time: number) {
function updateVersionUI (line 313) | async function updateVersionUI() {
function initSamplers (line 330) | async function initSamplers() {
function loadNativePreset (line 346) | function loadNativePreset() {
function refreshUI (line 361) | async function refreshUI(display_error = false) {
function requestGetHiResUpscalers (line 458) | async function requestGetHiResUpscalers(): Promise<string[]> {
function requestLoraModels (line 484) | async function requestLoraModels() {
function requestEmbeddings (line 495) | async function requestEmbeddings() {
function getLoraModelPrompt (line 507) | function getLoraModelPrompt(lora_model_name: string) {
function onModeChange (line 511) | async function onModeChange(new_mode: ScriptMode) {
function viewMaskExpansion (line 524) | function viewMaskExpansion() {
function viewDrawnMask (line 536) | function viewDrawnMask() {
function initInitMaskElement (line 545) | function initInitMaskElement() {
function scaleToRatio (line 574) | function scaleToRatio(
function widthSliderOnChangeEventHandler (line 594) | function widthSliderOnChangeEventHandler(
function heightSliderOnChangeEventHandler (line 624) | function heightSliderOnChangeEventHandler(
function calcLinkedValue (line 654) | function calcLinkedValue(new_value: number) {}
function initPlugin (line 655) | async function initPlugin() {
function scaleFromToLabel (line 676) | function scaleFromToLabel(width: number, height: number, scale: number) {
function onWidthSliderInput (line 682) | function onWidthSliderInput(new_value: number) {
function onHeightSliderInput (line 696) | function onHeightSliderInput(new_value: number) {
function calcRatio (line 709) | function calcRatio(
function loadPresetSettings (line 722) | function loadPresetSettings(preset: any) {
function isHiResMode (line 742) | function isHiResMode() {
FILE: typescripts/session/modes.ts
type SessionData (line 37) | interface SessionData {
type ImageInfo (line 42) | interface ImageInfo {
function saveOutputImagesToDrive (line 48) | async function saveOutputImagesToDrive(
function saveOutputImagesToDriveComfy (line 76) | async function saveOutputImagesToDriveComfy(
class Mode (line 96) | class Mode {
method constructor (line 97) | constructor() {}
method initializeSession (line 99) | async initializeSession(): Promise<SessionData> {
method generate (line 102) | static async generate(settings: any): Promise<{
method getSettings (line 109) | static async getSettings(session_data: any) {
method processOutput (line 115) | static async processOutput(images_info: any, settings: any): Promise<a...
method interrupt (line 122) | static async interrupt() {
method requestInterrupt (line 132) | static async requestInterrupt() {
class Txt2ImgMode (line 153) | class Txt2ImgMode extends Mode {
method initializeSession (line 157) | static async initializeSession(): Promise<SessionData> {
method requestTxt2Img (line 173) | static async requestTxt2Img(payload) {
method requestControlNetTxt2Img (line 188) | static async requestControlNetTxt2Img(plugin_settings: any) {
method generate (line 290) | static async generate(
method processOutput (line 340) | static async processOutput(images_info: any, settings: any): Promise<a...
class Img2ImgMode (line 349) | class Img2ImgMode extends Mode {
method constructor (line 350) | constructor() {
method requestControlNetImg2Img (line 355) | static async requestControlNetImg2Img(plugin_settings: any) {
method requestImg2Img (line 464) | static async requestImg2Img(payload: any) {
method initializeSession (line 480) | static async initializeSession(): Promise<SessionData> {
method generate (line 486) | static async generate(
class InpaintMode (line 539) | class InpaintMode extends Img2ImgMode {
method constructor (line 540) | constructor() {
method initializeSession (line 544) | static async initializeSession() {
class LassoInpaintMode (line 570) | class LassoInpaintMode extends Img2ImgMode {
method constructor (line 571) | constructor() {
method initializeSession (line 575) | static async initializeSession() {
class OutpaintMode (line 601) | class OutpaintMode extends Img2ImgMode {
method constructor (line 602) | constructor() {
method initializeSession (line 606) | static async initializeSession() {
class UpscaleMode (line 622) | class UpscaleMode extends Img2ImgMode {
method requestExtraSingleImage (line 623) | static async requestExtraSingleImage(payload: any) {
method getSettings (line 637) | static async getSettings(session_data: any) {
method generate (line 679) | static async generate(settings: any): Promise<{
FILE: typescripts/session/progress.ts
function updateProgressImage (line 25) | async function updateProgressImage(progress_base64: string) {
function requestProgress (line 90) | async function requestProgress() {
class Progress (line 107) | class Progress {
method deleteProgressImage (line 109) | static async deleteProgressImage() {
method deleteProgressLayer (line 115) | static async deleteProgressLayer() {
method startTimer (line 123) | static startTimer(callback: any, interval: number = 1500) {
method endTimer (line 139) | static async endTimer(callback: any) {
class ProgressAutomatic (line 158) | class ProgressAutomatic extends Progress {}
class ProgressHordeNative (line 160) | class ProgressHordeNative {}
FILE: typescripts/session/session.ts
function hasSelectionChanged (line 63) | function hasSelectionChanged(new_selection: any, old_selection: any) {
type ModeToClassMap (line 117) | interface ModeToClassMap {
function getExpandedMask (line 136) | async function getExpandedMask(
class Session (line 177) | class Session {
method constructor (line 178) | constructor() {}
method initializeSession (line 179) | static async initializeSession(mode: GenerationModeEnum): Promise<any> {
method getSettings (line 252) | static async getSettings(session_data: any) {
method processOutput (line 260) | static processOutput() {}
method validate (line 261) | static validate() {
method initializeGeneration (line 269) | static async initializeGeneration() {
method generate (line 275) | static async generate(mode: GenerationModeEnum): Promise<{
method generateMore (line 345) | static async generateMore(): Promise<{
method interrupt (line 396) | static async interrupt(): Promise<any> {
method getProgress (line 408) | static async getProgress() {
method endProgress (line 448) | static async endProgress() {
method endSession (line 456) | static endSession() {
method getOutput (line 468) | static async getOutput() {}
FILE: typescripts/session/session_store.ts
type AStoreUISettings (line 8) | interface AStoreUISettings {
type AStoreData (line 13) | interface AStoreData {
FILE: typescripts/settings/settings.tsx
type InterpolationMethod (line 22) | type InterpolationMethod = {
type ExtensionTypeEnum (line 44) | enum ExtensionTypeEnum {
function extensionTypeName (line 67) | function extensionTypeName(extension_type: ExtensionTypeEnum) {
type AStoreData (line 73) | interface AStoreData {
function onShouldLogToFileChange (line 110) | function onShouldLogToFileChange(event: any) {
function setDeleteLogTimer (line 138) | function setDeleteLogTimer() {
function postOptions (line 145) | async function postOptions(options: Object) {
type Options (line 154) | interface Options {
function getOptions (line 159) | async function getOptions(): Promise<Options | null> {
class Settings (line 172) | class Settings extends React.Component<{}> {
method componentDidMount (line 173) | async componentDidMount(): Promise<void> {
method render (line 183) | render() {
FILE: typescripts/settings/vae.tsx
class VAEComponent (line 20) | class VAEComponent extends React.Component<{
method componentDidMount (line 23) | componentDidMount(): void {}
method changeVAEModel (line 24) | changeVAEModel(vae_model: string) {
method handleRefresh (line 32) | handleRefresh() {
method render (line 35) | render(): React.ReactNode {
function requestGetVAE (line 65) | async function requestGetVAE() {
function populateVAE (line 71) | async function populateVAE() {
FILE: typescripts/tool_bar/tool_bar.tsx
function clipInterrogate (line 25) | async function clipInterrogate() {
function onInterrogate (line 52) | async function onInterrogate(evt: any) {
function scrollToPreview (line 71) | function scrollToPreview() {
function scrollToHistory (line 81) | function scrollToHistory() {
function scrollToLexica (line 90) | function scrollToLexica() {
class ToolBar (line 100) | @observer
method componentDidMount (line 102) | componentDidMount(): void {
method render (line 105) | render() {
FILE: typescripts/ultimate_sd_upscaler/scripts.tsx
function toJsFunc (line 12) | function toJsFunc(store: any) {
class ScriptStore (line 16) | class ScriptStore {
method constructor (line 35) | constructor() {
method setSelectedScript (line 47) | setSelectedScript(name: string) {
method setIsActive (line 53) | setIsActive(new_value: boolean) {
method updateProperty (line 56) | updateProperty(id: any, value: any) {}
method orderedValues (line 58) | orderedValues() {
method setDisabled (line 68) | setDisabled(newDisabled: boolean[]) {
method setMode (line 74) | setMode(newMode: ScriptMode) {
method isInstalled (line 99) | isInstalled() {
class ScriptComponent (line 106) | @observer
method render (line 108) | render(): React.ReactNode {
FILE: typescripts/ultimate_sd_upscaler/ultimate_sd_upscaler.tsx
type ScriptMode (line 16) | enum ScriptMode {
type UltimateSDUpscalerData (line 28) | interface UltimateSDUpscalerData {
function requestGetUpscalers (line 72) | async function requestGetUpscalers() {
class UltimateSDUpscalerStore (line 87) | class UltimateSDUpscalerStore {
method constructor (line 91) | constructor(data: UltimateSDUpscalerData) {
method setIsActive (line 97) | setIsActive(b_value: boolean) {
method updateProperty (line 101) | updateProperty(key: keyof UltimateSDUpscalerData, value: any) {
method isInstalled (line 105) | isInstalled() {
method toJsFunc (line 108) | toJsFunc() {
class UltimateSDUpscalerForm (line 127) | class UltimateSDUpscalerForm extends React.Component<{
method componentDidMount (line 136) | async componentDidMount(): Promise<void> {
method getUpscalers (line 161) | async getUpscalers() {
method isInstalled (line 179) | async isInstalled() {
method renderScaleSlider (line 192) | renderScaleSlider() {
method render (line 239) | render() {
FILE: typescripts/util/collapsible.tsx
type CollapsibleProps (line 6) | interface CollapsibleProps {
function Collapsible (line 16) | function Collapsible({
FILE: typescripts/util/elements.tsx
type IntrinsicElements (line 14) | interface IntrinsicElements {
function mapRange (line 34) | function mapRange(
type SliderType (line 45) | enum SliderType {
class SpSliderWithLabel (line 50) | class SpSliderWithLabel extends React.Component<{
method constructor (line 76) | constructor(props: any) {
method componentDidMount (line 89) | componentDidMount(): void {
method stepToOutputValue (line 93) | stepToOutputValue(slider_step: number) {
method outputValueToStep (line 106) | outputValueToStep(output_value: number) {
method setSliderValue (line 118) | setSliderValue(newValue: any) {
method onSliderValueInputHandler (line 133) | onSliderValueInputHandler(event: React.ChangeEvent<HTMLInputElement>) {
method onSliderValueChangeHandler (line 144) | onSliderValueChangeHandler(event: React.ChangeEvent<HTMLInputElement>) {
method render (line 158) | render() {
class SpMenu (line 196) | class SpMenu extends React.Component<{
method componentDidUpdate (line 213) | componentDidUpdate(prevProps: any) {
method render (line 238) | render() {
class PhotoshopElem (line 286) | class PhotoshopElem extends React.Component<{ [key: string]: any }, {}> {
method componentDidMount (line 291) | componentDidMount(): void {
method updateEventListener (line 299) | updateEventListener() {
method componentWillUnmount (line 314) | componentWillUnmount(): void {
method splitProps (line 319) | splitProps(props: any): [any, any] {
class SpPicker (line 333) | class SpPicker extends PhotoshopElem {
method render (line 334) | render() {
class SpMenuComponent (line 344) | class SpMenuComponent extends PhotoshopElem {
method render (line 345) | render() {
class SpMenuItem (line 355) | class SpMenuItem extends PhotoshopElem {
method render (line 356) | render() {
class SpLabel (line 366) | class SpLabel extends PhotoshopElem {
method render (line 367) | render() {
class SpCheckBox (line 377) | class SpCheckBox extends PhotoshopElem {
method render (line 378) | render() {
class SpSlider (line 389) | class SpSlider extends PhotoshopElem {
method render (line 390) | render() {
class SpTextfield (line 400) | class SpTextfield extends PhotoshopElem {
method render (line 401) | render() {
class SpRadioGroup (line 411) | class SpRadioGroup extends PhotoshopElem {
method render (line 412) | render() {
class SpRadio (line 422) | class SpRadio extends PhotoshopElem {
method render (line 423) | render() {
class SpDivider (line 433) | class SpDivider extends PhotoshopElem {
method render (line 434) | render() {
class Thumbnail (line 445) | class Thumbnail extends React.Component<{
method render (line 449) | render() {
class ActionButtonSVG (line 458) | class ActionButtonSVG extends React.Component<{
method render (line 463) | render() {
type ScriptInstallComponentProps (line 487) | interface ScriptInstallComponentProps {
class SearchableMenu (line 509) | class SearchableMenu extends React.Component<{
method selectItem (line 525) | selectItem(selected_item: string) {
method componentDidMount (line 532) | componentDidMount(): void {
method componentDidUpdate (line 538) | componentDidUpdate(prevProps: any, prevState: { searchQuery: string }) {
method render (line 574) | render() {
FILE: typescripts/util/errorBoundary.tsx
type Props (line 4) | interface Props {
type State (line 8) | interface State {
type State (line 12) | interface State {
class ErrorBoundary (line 17) | class ErrorBoundary extends Component<Props, State> {
method getDerivedStateFromError (line 23) | public static getDerivedStateFromError(_: Error): Partial<State> {
method componentDidCatch (line 28) | public componentDidCatch(error: Error, errorInfo: ErrorInfo) {
method render (line 40) | public render() {
FILE: typescripts/util/grid.tsx
class Grid (line 4) | class Grid extends React.Component<{
method componentDidMount (line 27) | componentDidMount() {
method componentDidUpdate (line 33) | componentDidUpdate(prevProps: any) {
method render (line 45) | render() {
FILE: typescripts/util/logger.ts
function formateLog (line 2) | function formateLog(data: any, ...optional_param: any[]) {
FILE: typescripts/util/oldSystem.tsx
type _Jimp (line 26) | interface _Jimp extends Jimp {}
FILE: typescripts/util/ts/api.ts
function requestGet (line 4) | async function requestGet(url: string) {
function requestPost (line 39) | async function requestPost(url: string, payload: any) {
function requestFormDataPost (line 65) | async function requestFormDataPost(url: string, payload: any) {
function isScriptInstalled (line 98) | async function isScriptInstalled(script_name: string): Promise<boolean> {
function postArrayBuffer (line 113) | async function postArrayBuffer(url: string, data: Uint8Array) {
function postPng (line 129) | async function postPng() {
FILE: typescripts/util/ts/document.ts
type DocumentTypeEnum (line 10) | enum DocumentTypeEnum {
function isCorrectBackground (line 17) | async function isCorrectBackground() {
function getColor (line 26) | async function getColor(X: any, Y: any) {
function findDocumentType (line 59) | async function findDocumentType() {
function correctDocumentType (line 139) | async function correctDocumentType(documentType: any) {
function initializeBackground (line 167) | async function initializeBackground() {
function base64ToFileAndGetLayer (line 205) | async function base64ToFileAndGetLayer(
FILE: typescripts/util/ts/enum.ts
type GenerationModeEnum (line 1) | enum GenerationModeEnum {
type ScriptMode (line 11) | enum ScriptMode {
type MaskModeEnum (line 18) | enum MaskModeEnum {
type SelectionInfoType (line 24) | interface SelectionInfoType {
type PresetTypeEnum (line 33) | enum PresetTypeEnum {
FILE: typescripts/util/ts/general.ts
function autoResize (line 5) | function autoResize(textarea: any, text_content: string, delay = 300) {
function urlToCanvas (line 51) | async function urlToCanvas(url: string, image_name = 'image.png') {
function base64ToBase64Url (line 58) | function base64ToBase64Url(base64_image: string) {
function base64UrlToBase64 (line 61) | function base64UrlToBase64(base64_url: string) {
function newOutputImageName (line 66) | function newOutputImageName(format = 'png') {
function isValidVersion (line 73) | function isValidVersion(minMajorVersion: number) {
function getImageFromLayer (line 82) | async function getImageFromLayer(
function imageObjectToBase64 (line 105) | async function imageObjectToBase64(imgObj: any) {
function imageObjectToBase64Url (line 119) | async function imageObjectToBase64Url(imgObj: any) {
function getImageFromCanvas_new (line 127) | async function getImageFromCanvas_new(layer_id?: number) {
function deleteKeys (line 150) | function deleteKeys(obj: Record<string, any>, keys: string[]) {
FILE: typescripts/util/ts/io.ts
type KeyValuePair (line 12) | type KeyValuePair = { [key: string]: any }
function _arrayBufferToBase64 (line 15) | function _arrayBufferToBase64(buffer: any) {
function moveImageToLayer_old (line 25) | async function moveImageToLayer_old(
function moveImageToLayer (line 50) | async function moveImageToLayer(
function convertGrayscaleToWhiteAndTransparent (line 104) | async function convertGrayscaleToWhiteAndTransparent(
function getBase64FromJimp (line 153) | async function getBase64FromJimp(jimp_image: Jimp) {
function readPreset (line 159) | function readPreset(path: string) {
function writePreset (line 168) | function writePreset(path: string, preset: KeyValuePair) {
function storeToPreset (line 176) | function storeToPreset(store: any) {
function presetToStore (line 180) | function presetToStore(preset: KeyValuePair, store: any) {
FILE: typescripts/util/ts/layer.ts
type RectArea (line 8) | interface RectArea {
function transformBatchPlay (line 15) | async function transformBatchPlay(
function transformCurrentLayerTo (line 100) | async function transformCurrentLayerTo(
function SetLayerColor (line 136) | async function SetLayerColor() {
FILE: typescripts/util/ts/sdapi.ts
function getVersionRequest (line 4) | async function getVersionRequest() {
function requestGetSamplers (line 10) | async function requestGetSamplers() {
function requestGetUpscalers (line 25) | async function requestGetUpscalers() {
function setInpaintMaskWeight (line 40) | async function setInpaintMaskWeight(value: number) {
function requestGetModels (line 59) | async function requestGetModels() {
function requestSwapModel (line 76) | async function requestSwapModel(model_title: string) {
FILE: typescripts/util/ts/selection.ts
function applyMaskFromBlackAndWhiteImage (line 10) | async function applyMaskFromBlackAndWhiteImage(
function selectionFromBlackAndWhiteImage (line 102) | async function selectionFromBlackAndWhiteImage(
function activateSessionSelectionArea (line 161) | async function activateSessionSelectionArea() {
FILE: typescripts/util/ts/ui_ts.ts
class UI (line 106) | class UI {
method constructor (line 107) | constructor() {}
type UIElements (line 109) | interface UIElements {
class UIElement (line 130) | class UIElement {
method constructor (line 134) | constructor() {
method setValue (line 139) | setValue(new_value: any) {}
method getValue (line 140) | getValue(): any {}
function createUIElement (line 142) | function createUIElement(getter: any, setter: any) {
class UISettings (line 148) | class UISettings {
method constructor (line 166) | constructor() {
method autoFillInSettings (line 281) | autoFillInSettings(settings: any) {
method getSettings (line 297) | getSettings() {
method saveAsJson (line 308) | saveAsJson(json_file_name: string, settings: any) {
function loadLatentNoiseSettings (line 327) | function loadLatentNoiseSettings(ui_settings: any) {
function loadFillSettings (line 331) | function loadFillSettings(ui_settings: any) {
function loadOriginalSettings (line 334) | function loadOriginalSettings(ui_settings: any) {
function loadHealBrushSettings (line 337) | async function loadHealBrushSettings(ui_settings: any) {
function loadCustomPresetsSettings (line 343) | function loadCustomPresetsSettings() {}
function mapCustomPresetsToLoaders (line 344) | async function mapCustomPresetsToLoaders(ui_settings_obj: any) {
function getNativeSDPresets (line 363) | function getNativeSDPresets() {
function getUISettingsObject (line 367) | function getUISettingsObject() {
function addPresetMenuItem (line 372) | function addPresetMenuItem(preset_title: string) {
FILE: typescripts/viewer/viewer.tsx
function findClickType (line 50) | function findClickType(event: any) {
FILE: typescripts/viewer/viewer_util.ts
type ClickTypeEnum (line 4) | enum ClickTypeEnum {
type OutputImageStateEnum (line 11) | enum OutputImageStateEnum {
type ClassNameEnum (line 15) | enum ClassNameEnum {
type AStoreData (line 20) | interface AStoreData {
type AStoreDataWithImagesAndThumbnails (line 99) | interface AStoreDataWithImagesAndThumbnails {
function updateViewerStoreImageAndThumbnail (line 104) | async function updateViewerStoreImageAndThumbnail<
FILE: utility/api.js
function requestGet (line 5) | async function requestGet(url) {
function requestPost (line 23) | async function requestPost(url, payload) {
function requestFormDataPost (line 49) | async function requestFormDataPost(url, payload) {
FILE: utility/dummy.js
function getDummyBase64 (line 1) | function getDummyBase64() {
function getDummyBase64_2 (line 6) | function getDummyBase64_2() {
function getDummyWebpBase64 (line 11) | function getDummyWebpBase64() {
FILE: utility/general.js
function newOutputImageName (line 3) | function newOutputImageName(format = 'png') {
function makeImagePath (line 10) | function makeImagePath(format = 'png') {
function convertImageNameToPng (line 15) | function convertImageNameToPng(image_name) {
function fixNativePath (line 19) | function fixNativePath(native_path) {
function base64ToBase64Url (line 24) | function base64ToBase64Url(base64_image) {
function base64UrlToBase64 (line 27) | function base64UrlToBase64(base64_url) {
function mapRange (line 33) | function mapRange(x, in_min, in_max, out_min, out_max) {
function compareVersions (line 37) | function compareVersions(version_1, version_2) {
function requestOnlineData (line 54) | async function requestOnlineData() {
function nearestMultiple (line 59) | function nearestMultiple(input, multiple) {
function sudoTimer (line 66) | function sudoTimer(progress_text = 'Loading ControlNet...') {
function countNewLines (line 86) | function countNewLines(string) {
FILE: utility/html_manip.js
function autoFillInPrompt (line 3) | function autoFillInPrompt(prompt_value) {
function autoFillInNegativePrompt (line 12) | function autoFillInNegativePrompt(negative_prompt_value) {
function getWidth (line 21) | function getWidth() {
function getHrWidth (line 25) | function getHrWidth() {
function getHrHeight (line 31) | function getHrHeight() {
function autoFillInWidth (line 36) | async function autoFillInWidth(width_value) {
function getHeight (line 47) | function getHeight() {
function autoFillInHeight (line 53) | async function autoFillInHeight(height_value) {
function autoFillInHRHeight (line 61) | function autoFillInHRHeight(height_value) {
function autoFillInHRWidth (line 65) | function autoFillInHRWidth(width_value) {
function getSliderSdValue_Old (line 71) | function getSliderSdValue_Old(slider_id, multiplier) {
function autoFillInSliderUi (line 80) | function autoFillInSliderUi(sd_value, slider_id, label_id, multiplier) {
function getSliderSdValue (line 90) | function getSliderSdValue(
function setSliderSdValue (line 109) | function setSliderSdValue(
function getSliderSdValueByElement (line 128) | function getSliderSdValueByElement(
function setSliderSdValueByElements (line 147) | function setSliderSdValueByElements(
function autoFillInHiResFixs (line 167) | function autoFillInHiResFixs(firstphase_width, firstphase_height) {
function autoFillInInpaintMaskWeight (line 176) | function autoFillInInpaintMaskWeight(sd_value) {
function unCheckAllSamplers (line 188) | function unCheckAllSamplers() {
function getSelectedRadioButtonElement (line 195) | function getSelectedRadioButtonElement(rbClass) {
function getSamplerElementByName (line 205) | function getSamplerElementByName(sampler_name) {
function getBackendType (line 219) | function getBackendType() {
function getHordeApiKey (line 225) | function getHordeApiKey() {
function setHordeApiKey (line 231) | function setHordeApiKey(key) {
function checkSampler (line 234) | function checkSampler(sampler_name) {
function autoFillInSampler (line 238) | function autoFillInSampler(sampler_name) {
function getModelElementByHash (line 246) | function getModelElementByHash(model_hash) {
function getModelHashByTitle (line 258) | function getModelHashByTitle(model_title) {
function getSelectedModelHash (line 269) | function getSelectedModelHash() {
function selectModelUi (line 280) | function selectModelUi(model_hash) {
function getInitImageElement (line 289) | function getInitImageElement() {
function setInitImageSrc (line 293) | function setInitImageSrc(image_src) {
function setControlImageSrc (line 297) | function setControlImageSrc(image_src, element_index = 0) {
function setProgressImageSrc (line 307) | function setProgressImageSrc(image_src) {
function getInitImageMaskElement (line 321) | function getInitImageMaskElement() {
function setInitImageMaskSrc (line 325) | function setInitImageMaskSrc(image_src) {
function setAutomaticStatus (line 337) | function setAutomaticStatus(newStatusClass, oldStatusClass) {
function setProxyServerStatus (line 341) | function setProxyServerStatus(newStatusClass, oldStatusClass) {
function getBatchNumber (line 351) | function getBatchNumber() {
function autoFillInBatchNumber (line 355) | function autoFillInBatchNumber(batch_number) {
function setCFG (line 360) | function setCFG(cfg_value) {
function getCFG (line 363) | function getCFG() {
function autoFillSettings (line 367) | function autoFillSettings(settings) {
function setMaskBlur (line 399) | function setMaskBlur(mask_blur) {
function getPromptShortcut (line 403) | function getPromptShortcut() {
function setPromptShortcut (line 411) | function setPromptShortcut(prompt_shortcut) {
function getMaskContent (line 418) | function getMaskContent() {
function setMaskContent (line 423) | function setMaskContent(value) {
function addHistoryButtonsHtml (line 438) | function addHistoryButtonsHtml(img_html) {
function updateProgressBarsHtml (line 475) | function updateProgressBarsHtml(new_value, progress_text = 'Progress...') {
function isSquareThumbnail (line 496) | function isSquareThumbnail() {
function populateMenu (line 500) | async function populateMenu(
function populateMenuByElement (line 536) | async function populateMenuByElement(
function getSelectedMenuItem (line 571) | function getSelectedMenuItem(menu_id) {
function getSelectedMenuItemByElement (line 579) | function getSelectedMenuItemByElement(menu_element) {
function selectMenuItem (line 587) | function selectMenuItem(menu_id, item) {
function selectMenuItemByElement (line 599) | function selectMenuItemByElement(menu_element, item) {
function getSelectedMenuItemTextContent (line 613) | function getSelectedMenuItemTextContent(menu_id) {
function getSelectedMenuItemTextContentByElement (line 624) | function getSelectedMenuItemTextContentByElement(menu_element) {
function unselectMenuItem (line 634) | function unselectMenuItem(menu_id) {
function unselectMenuItemByElement (line 641) | function unselectMenuItemByElement(menu_element) {
function getUseNsfw (line 649) | function getUseNsfw() {
function getUseSilentMode_Old (line 654) | function getUseSilentMode_Old() {
function getUseSilentMode (line 658) | function getUseSilentMode() {
FILE: utility/io.js
function isBlackAndWhiteImage (line 12) | async function isBlackAndWhiteImage(base64EncodedImage) {
function convertBlackAndWhiteImageToRGBChannels (line 31) | async function convertBlackAndWhiteImageToRGBChannels(base64EncodedImage) {
function convertBlackAndWhiteImageToRGBChannels2 (line 49) | async function convertBlackAndWhiteImageToRGBChannels2(base64EncodedImag...
function convertBlackAndWhiteImageToRGBChannels3 (line 67) | async function convertBlackAndWhiteImageToRGBChannels3(base64EncodedImag...
function snapShotLayer (line 86) | async function snapShotLayer() {
function snapShotLayerExe (line 158) | async function snapShotLayerExe() {
class IO (line 195) | class IO {
method exportWebp (line 197) | static async exportWebp(layer, export_width, export_height) {
method exportPng (line 225) | static async exportPng() {}
method exportDoc (line 226) | static async exportDoc() {}
method exportLayer (line 227) | static async exportLayer() {}
method base64PngToPngFile (line 229) | static async base64PngToPngFile(
method openImageFileAsDocument (line 243) | static async openImageFileAsDocument(file_entry) {
method base64PngToBase64Webp (line 247) | static async base64PngToBase64Webp(base64_png) {
method base64WebpFromFile (line 284) | static async base64WebpFromFile(file_entry) {
method base64ToLayer (line 304) | static async base64ToLayer(
method getSelectionFromCanvasAsBase64Silent (line 350) | static async getSelectionFromCanvasAsBase64Silent(
method getSelectionFromCanvasAsBase64NonSilent (line 399) | static async getSelectionFromCanvasAsBase64NonSilent(
method getSelectionFromCanvasAsBase64Interface (line 425) | static async getSelectionFromCanvasAsBase64Interface(
method getSelectionFromCanvasAsBase64Interface_New (line 452) | static async getSelectionFromCanvasAsBase64Interface_New(
method urlToLayer (line 487) | static async urlToLayer(image_url, image_file_name = 'image_from_url.p...
class IOHelper (line 498) | class IOHelper {
method saveAsWebp (line 499) | static async saveAsWebp(doc_entry) {
method saveAsWebpExe (line 549) | static async saveAsWebpExe(doc_entry) {
method createDocumentExe (line 557) | static async createDocumentExe(width, height) {
method cropPng (line 574) | static async cropPng(
class IOBase64ToLayer (line 629) | class IOBase64ToLayer {
method base64PngToLayer (line 631) | static async base64PngToLayer(base64_png, image_name) {
class IOFolder (line 640) | class IOFolder {
method createSettingsFolder (line 642) | static async createSettingsFolder() {
method findOrCreateFolderExe (line 650) | static async findOrCreateFolderExe(folder_name) {
method doesFolderExist (line 659) | static async doesFolderExist(folder_name) {
method createFolderSafe (line 674) | static async createFolderSafe(folder_name) {
method getDocumentFolderNativePath (line 695) | static async getDocumentFolderNativePath() {
method getDocFolder (line 708) | static async getDocFolder(doc_uuid) {
method getSettingsFolder (line 713) | static async getSettingsFolder() {
method getPresetFolder (line 718) | static async getPresetFolder() {
method getCustomPresetFolder (line 723) | static async getCustomPresetFolder(
method createFolderIfDoesNotExist (line 732) | static async createFolderIfDoesNotExist(folder_name) {
class IOLog (line 748) | class IOLog {
method saveLogToFile (line 750) | static async saveLogToFile(json, file_name) {
class IOJson (line 768) | class IOJson {
method saveJsonToFile (line 770) | static async saveJsonToFile(json, folder_entry, file_name) {
method saveJsonToFileExe (line 787) | static async saveJsonToFileExe(json, folder_entry, file_name) {
method loadJsonFromFile (line 792) | static async loadJsonFromFile(folder_entry, file_name) {
method saveSettingsToFile (line 810) | static async saveSettingsToFile(settings_json, settings_file_name) {
method loadSettingsFromFile (line 820) | static async loadSettingsFromFile(settings_file_name) {
method loadSessionIDFromFile (line 828) | static async loadSessionIDFromFile(uuid) {
method saveSessionID (line 841) | static async saveSessionID(session_id, uuid) {
method saveHordeSettingsToFile (line 853) | static async saveHordeSettingsToFile(settings_json) {
method loadHordeSettingsFromFile (line 857) | static async loadHordeSettingsFromFile() {
method getJsonEntries (line 865) | static async getJsonEntries(doc_entry) {
method deleteFile (line 874) | static async deleteFile(doc_entry, file_name) {
function createThumbnail (line 882) | async function createThumbnail(base64Image, width = 100) {
function getImageFromCanvas (line 893) | async function getImageFromCanvas(scale_to_sliders = true) {
function getBase64FromJimp (line 912) | async function getBase64FromJimp(jimp_image) {
function transparentToMask (line 918) | function transparentToMask(x, y, idx) {
function inpaintTransparentToMask (line 930) | function inpaintTransparentToMask(x, y, idx) {
function transparentToWhiteBackground (line 948) | function transparentToWhiteBackground(x, y, idx) {
function getMask (line 963) | async function getMask() {
function getImg2ImgInitImage (line 988) | async function getImg2ImgInitImage() {
function getOutpaintInitImageAndMask (line 1006) | async function getOutpaintInitImageAndMask() {
function getMaskFromCanvas (line 1053) | async function getMaskFromCanvas() {
function getInpaintInitImageAndMask (line 1075) | async function getInpaintInitImageAndMask() {
function saveFileInSubFolder (line 1111) | async function saveFileInSubFolder(b64Image, sub_folder_name, file_name) {
function saveJsonFileInSubFolder (line 1138) | async function saveJsonFileInSubFolder(json, sub_folder_name, file_name) {
function fixTransparentEdges (line 1171) | async function fixTransparentEdges(base64) {
function maskFromInitImage (line 1196) | async function maskFromInitImage(base64) {
function fixMaskEdges (line 1230) | async function fixMaskEdges(base64) {
function getUniqueDocumentId (line 1260) | async function getUniqueDocumentId() {
function getImageSize (line 1289) | async function getImageSize(base64) {
function convertGrayscaleToMonochrome (line 1295) | async function convertGrayscaleToMonochrome(base64) {
function convertBlackToTransparentKeepBorders (line 1337) | async function convertBlackToTransparentKeepBorders(
function deleteFileIfLargerThan (line 1389) | async function deleteFileIfLargerThan(file_name, size_mb = 200) {
FILE: utility/layer.js
function createNewLayerExe (line 18) | async function createNewLayerExe(layerName, opacity = 100) {
function createNewLayerCommand (line 26) | async function createNewLayerCommand(layerName, opacity = 100) {
function deleteLayers (line 34) | async function deleteLayers(layers) {
function getIndexCommand (line 42) | async function getIndexCommand() {
function getIndexExe (line 64) | async function getIndexExe() {
function collapseFolderExe (line 103) | async function collapseFolderExe(layers, expand = false, recursive = fal...
class Layer (line 118) | class Layer {
method doesLayerExist (line 119) | static doesLayerExist(layer) {
method getLayerInfo (line 134) | static async getLayerInfo(layer) {
method scaleTo (line 149) | static async scaleTo(layer, new_width, new_height) {
method resizeImage (line 178) | static async resizeImage(percent_width, percent_height) {
method resizeImageExe (line 276) | static async resizeImageExe(percent_width, percent_height) {
method moveTo (line 286) | static async moveTo(layer, to_x, to_y) {
method resizeTo (line 309) | static resizeTo() {}
method fitSelection (line 310) | static fitSelection() {}
method duplicateToDoc (line 311) | static async duplicateToDoc(layer, to_doc) {
method duplicateLayerExe (line 317) | static async duplicateLayerExe(layer) {
function hasBackgroundLayer (line 343) | async function hasBackgroundLayer() {
function toggleActiveLayer (line 398) | async function toggleActiveLayer() {
function toggleBackgroundLayerExe (line 433) | async function toggleBackgroundLayerExe() {
function createBackgroundLayer (line 447) | async function createBackgroundLayer(r = 255, g = 255, b = 255) {
function fixImageBackgroundLayer (line 480) | async function fixImageBackgroundLayer() {
FILE: utility/notification.js
class Notification (line 4) | class Notification {
method webuiIsOffline (line 6) | static async webuiIsOffline() {
method webuiAPIMissing (line 24) | static async webuiAPIMissing() {
method backgroundLayerIsMissing (line 42) | static async backgroundLayerIsMissing() {
method inactiveSelectionArea (line 74) | static async inactiveSelectionArea(
FILE: utility/sd_scripts/horde.js
function requestModelsHorde (line 1) | async function requestModelsHorde() {
function addHordeModelMenuItem (line 16) | function addHordeModelMenuItem(model_title, model_name) {
function refreshModelsHorde (line 26) | async function refreshModelsHorde() {
function getModelHorde (line 64) | function getModelHorde() {
function getScriptArgs (line 70) | function getScriptArgs() {
FILE: utility/sdapi/config.js
class SdConfig (line 1) | class SdConfig {
method constructor (line 2) | constructor() {
method getConfig (line 6) | async getConfig() {
method getUpscalerModels (line 14) | getUpscalerModels() {
method getControlNetMaxModelsNum (line 38) | getControlNetMaxModelsNum() {
method getControlNetPreprocessors (line 62) | getControlNetPreprocessors() {
FILE: utility/sdapi/horde_native.js
class HordeSettings (line 7) | class HordeSettings {
method saveSettings (line 9) | static async saveSettings() {
method loadSettings (line 21) | static async loadSettings() {
class hordeGenerator (line 31) | class hordeGenerator {
method constructor (line 46) | constructor() {
method getSettings (line 59) | async getSettings() {
method generateRequest (line 80) | async generateRequest(settings) {
method generate (line 105) | async generate() {
method isValidGeneration (line 118) | isValidGeneration() {
method preGenerate (line 125) | preGenerate() {}
method layerToBase64Webp (line 129) | async layerToBase64Webp(layer, document_name, image_name) {
method layerToBase64ToFile (line 146) | async layerToBase64ToFile(layer, document_name, image_name) {
method toGenerationFormat (line 163) | async toGenerationFormat(images_info) {
method toSession (line 229) | async toSession(images_info) {
method interruptRequest (line 275) | async interruptRequest(horde_id) {
method interrupt (line 302) | async interrupt() {
method processHordeResult (line 316) | async processHordeResult() {
method updateHordeProgressBar (line 369) | updateHordeProgressBar(check_horde_status) {
method startCheckingProgress (line 399) | async startCheckingProgress() {
function mapPluginSettingsToHorde (line 482) | async function mapPluginSettingsToHorde(plugin_settings) {
function getWorkerID (line 570) | function getWorkerID(workers_json) {
function getWorkers (line 579) | async function getWorkers() {
function requestHorde (line 596) | async function requestHorde(payload) {
function requestHordeCheck (line 661) | async function requestHordeCheck(id) {
function requestHordeStatus (line 690) | async function requestHordeStatus(id) {
function cancelRequestClientSide (line 720) | function cancelRequestClientSide() {
FILE: utility/sdapi/options.js
class SdOptions (line 1) | class SdOptions {
method constructor (line 2) | constructor() {
method getOptions (line 7) | async getOptions() {
method getCurrentModel (line 23) | getCurrentModel() {
method getInpaintingMaskWeight (line 27) | getInpaintingMaskWeight() {
FILE: utility/sdapi/prompt_shortcut.js
function find_words_inside_braces (line 1) | function find_words_inside_braces(string) {
function replaceShortcut (line 12) | function replaceShortcut(text, prompt_shortcut_json) {
FILE: utility/sdapi/python_replacement.js
function convertMetadataToJson (line 12) | function convertMetadataToJson(metadata_str) {
function getAuto1111Metadata (line 46) | async function getAuto1111Metadata(base64_image) {
function convertToStandardResponse (line 74) | async function convertToStandardResponse(settings, images, uuid) {
function replacePromptsWithShortcuts (line 119) | function replacePromptsWithShortcuts(
function txt2ImgRequest (line 134) | async function txt2ImgRequest(payload) {
function getExtensionUrl (line 204) | function getExtensionUrl() {
function openUrlRequest (line 219) | async function openUrlRequest(url) {
function maskExpansionRequest (line 245) | async function maskExpansionRequest(original_mask, mask_expansion_value,...
function img2ImgRequest (line 276) | async function img2ImgRequest(sd_url, payload) {
function savePromptShortcut (line 354) | async function savePromptShortcut(json, file_name) {
function loadPromptShortcut (line 378) | async function loadPromptShortcut(file_name) {
function extraSingleImageRequest (line 407) | async function extraSingleImageRequest(sd_url, payload) {
FILE: utility/session.js
class GenerationSession (line 21) | class GenerationSession {
method constructor (line 22) | constructor() {
method isActive (line 48) | isActive() {
method isInactive (line 51) | isInactive() {
method activate (line 54) | activate() {
method deactivate (line 57) | deactivate() {
method name (line 60) | name() {
method deleteInitImageLayers (line 64) | deleteInitImageLayers() {}
method closePreviousOutputGroup (line 65) | async closePreviousOutputGroup() {
method isSameMode (line 83) | isSameMode(selected_mode) {
method loadLastSession (line 89) | loadLastSession() {
method saveCurrentSession (line 92) | saveCurrentSession() {
method moveToTopOfOutputGroup (line 95) | async moveToTopOfOutputGroup(layer) {
method deleteProgressLayer (line 105) | async deleteProgressLayer() {
method deleteProgressImageHtml (line 112) | deleteProgressImageHtml() {
method deleteProgressImage (line 125) | async deleteProgressImage() {
method setControlNetImageHelper (line 130) | async setControlNetImageHelper() {
method setControlNetImage (line 165) | async setControlNetImage(control_net_index = 0, base64_image) {
function getSettings (line 181) | async function getSettings(session_data) {
FILE: utility/tab/settings.js
function setUseSharpMask (line 3) | function setUseSharpMask() {
function getSdUrlHtml (line 23) | function getSdUrlHtml() {
function setSdUrlHtml (line 27) | function setSdUrlHtml(sd_url) {
function changeSdUrl (line 30) | async function changeSdUrl(sd_url) {
function saveSettings (line 48) | async function saveSettings() {
function loadSettings (line 62) | async function loadSettings() {
function getUseOriginalPrompt (line 76) | function getUseOriginalPrompt() {
Condensed preview — 149 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (2,118K chars).
[
{
"path": ".gitignore",
"chars": 595,
"preview": "**/__pycache__\nenv\n/server_env\n/tmp\n/outputs\n/log\n/.idea\n/.vscode\n/.git\n/.github\ntest.bat\nserver/python_server/output/*\n"
},
{
"path": ".prettierignore",
"chars": 170,
"preview": "server/python_server/output/*\n*.md\nmanifest.json\njimp/**\nserver_env/**\n.github\\workflows\\wiki-sync-action.yml\n**/dist\n.g"
},
{
"path": ".prettierrc",
"chars": 94,
"preview": "{\n \"trailingComma\": \"es5\",\n \"tabWidth\": 4,\n \"semi\": false,\n \"singleQuote\": true\n}\n"
},
{
"path": "LICENSE.md",
"chars": 1073,
"preview": "MIT License\n\nCopyright (c) 2022 Abdullah Alfaraj\n\nPermission is hereby granted, free of charge, to any person obtaining "
},
{
"path": "README.md",
"chars": 17462,
"preview": "\n\n# Auto-Photoshop-StableDiffusion-Plugin\n[\n// const CleanWebpackPlugin = require('clean-webpack-plugin')\nconst CopyPlugin = require('c"
},
{
"path": "deprecated-do-not-use-start_server.bat",
"chars": 904,
"preview": "@REM @echo off\ngit pull\n\nset SD_URL=http://127.0.0.1:7860\n\necho does server_env\\ exist\nif exist server_env\\ (\n echo Yes"
},
{
"path": "deprecated-do-not-use-start_server.sh",
"chars": 1002,
"preview": "#!/bin/bash\ngit pull\n# Set the desired remote host where the \"<>\" is\nexport SD_URL=http://127.0.0.1:7860\n\n# Check python"
},
{
"path": "deprecated-do-not-use-start_server_MacOS.sh",
"chars": 448,
"preview": "#!/bin/bash\ngit pull\n# Set the desired remote host where the \"<>\" is\nexport SD_URL=http://127.0.0.1:7860\n\n# Check if the"
},
{
"path": "deprecated-do-not-use-update_plugin.bat",
"chars": 8,
"preview": "git pull"
},
{
"path": "deprecated-do-not-use-update_plugin.sh",
"chars": 20,
"preview": "#!/bin/bash\ngit pull"
},
{
"path": "dialog_box.js",
"chars": 2221,
"preview": "async function prompt(\n heading,\n body,\n buttons = ['Cancel', 'Ok'],\n options = { title: heading, size: { wi"
},
{
"path": "docs/Home.md",
"chars": 9278,
"preview": "\n*Version 1.1.0*\n\n## Introduction\n\nThis guide explains the Auto Photoshop UI and its main features, it doesn't go into a"
},
{
"path": "enum.js",
"chars": 1173,
"preview": "const clickTypeEnum = {\n Click: 'click',\n ShiftClick: 'shift_click',\n AltClick: 'alt_click',\n SecondClick: '"
},
{
"path": "helper.js",
"chars": 3128,
"preview": "const { unselectActiveLayers } = require('./psapi')\n\nconst app = window.require('photoshop').app\n\nfunction getActiveLaye"
},
{
"path": "i18n/zh_CN/ps-plugin.json",
"chars": 8646,
"preview": "{\n \"Auto-Photoshop-SD\": \"SD插件(明空汉化)\",\n \"'A' for Automatic1111 server (webui-user.bat), Green is connected. Red Mea"
},
{
"path": "i18n/zh_CN/sd-official.json",
"chars": 186906,
"preview": "{\n \"(0 = default (~0.03); minimum noise strength for k-diffusion noise scheduler)\": \"(0 = 默认 (~0.03); k-diffusion 噪声调"
},
{
"path": "index.html",
"chars": 52989,
"preview": "<!DOCTYPE html>\n<html>\n <head>\n <script src=\"index.js\"></script>\n </head>\n <style>\n sp-textarea,\n"
},
{
"path": "index.js",
"chars": 62781,
"preview": "// import {helloHelper} from 'helper.js'\n// helloHelper2 = require('./helper.js')\n// for organizational proposes\n// let "
},
{
"path": "install.py",
"chars": 2463,
"preview": "import os\nfrom pathlib import Path\nfrom launch import git, run\nimport launch\nimport sys\n\n# launch.run(f'git pull', f\"upd"
},
{
"path": "manifest.json",
"chars": 5765,
"preview": "{\n \"id\": \"auto.photoshop.stable.diffusion.plugin\",\n \"name\": \"Auto Photoshop Stable Diffusion Plugin\",\n \"version"
},
{
"path": "package.json",
"chars": 2465,
"preview": "{\n \"name\": \"auto-photoshop-stable-diffusion-plugin\",\n \"version\": \"1.3.3\",\n \"description\": \"A user-friendly plug"
},
{
"path": "presets/ctrlnet_inpaint.json",
"chars": 1479,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"inpaint\",\n \"rb_mode\": \"inpaint\",\n "
},
{
"path": "presets/ctrlnet_inpaint_tile.json",
"chars": 2043,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"inpaint\",\n \"rb_mode\": \"inpaint\",\n "
},
{
"path": "presets/ctrlnet_outpaint.json",
"chars": 1482,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"outpaint\",\n \"rb_mode\": \"outpaint\",\n "
},
{
"path": "presets/default.json",
"chars": 988,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"txt2img\",\n \"rb_mode\": \"txt2img\",\n "
},
{
"path": "presets/img2img.json",
"chars": 827,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"img2img\",\n \"rb_mode\": \"img2img\",\n "
},
{
"path": "presets/inpaint.json",
"chars": 825,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"inpaint\",\n \"rb_mode\": \"inpaint\",\n "
},
{
"path": "presets/outpaint.json",
"chars": 802,
"preview": "{\n \"sd_tab_preset\": {\n \"is_lasso_mode\": false,\n \"mode\": \"outpaint\",\n \"rb_mode\": \"outpaint\",\n "
},
{
"path": "psapi.js",
"chars": 40848,
"preview": "const app = window.require('photoshop').app\nconst batchPlay = require('photoshop').action.batchPlay\nconst { executeAsMod"
},
{
"path": "requirements.txt",
"chars": 438,
"preview": "anyio==3.6.2\nasyncio==3.4.3\ncertifi==2022.12.7\ncharset-normalizer==2.1.1\nclick==8.1.7\nfastapi==0.88.0\nh11==0.14.0\nhttpco"
},
{
"path": "scripts/main.py",
"chars": 3251,
"preview": "from modules import scripts, processing, shared, images, devices, ui, lowvram\nimport gradio\nimport requests\nimport time\n"
},
{
"path": "scripts/test.py",
"chars": 101,
"preview": "# import sys\n# sys.path.insert(0, 'server/python_server')\n# import search\n\n# print(\"hello test.py\") "
},
{
"path": "sdapi_py_re.js",
"chars": 11113,
"preview": "const { getDummyBase64, getDummyBase64_2 } = require('./utility/dummy')\nconst { base64ToBase64Url } = require('./utility"
},
{
"path": "selection.js",
"chars": 36338,
"preview": "const psapi = require('./psapi')\n\nconst html_manip = require('./utility/html_manip')\nfunction finalWidthHeight(\n sele"
},
{
"path": "server/python_server/global_state.py",
"chars": 4414,
"preview": "#code copied from controlnet repo global_state.py \n\n\npreprocessor_filters = {\n \"All\": \"none\",\n \"Canny\": \"canny\",\n"
},
{
"path": "server/python_server/img2imgapi.py",
"chars": 6030,
"preview": "import json\nimport requests\nimport io\nimport base64\nfrom PIL import Image, PngImagePlugin\n# from serverMain import sd_ur"
},
{
"path": "server/python_server/init_images/.gitignore",
"chars": 70,
"preview": "# Ignore everything in this directory\n*\n# Except this file\n!.gitignore"
},
{
"path": "server/python_server/metadata_to_json.py",
"chars": 3016,
"preview": "import os\nfrom pathlib import Path\nfrom PIL import Image\nimport json\n\nimport serverHelper\n# metadata_str = 'cute cat\\nSt"
},
{
"path": "server/python_server/output/.gitignore",
"chars": 70,
"preview": "# Ignore everything in this directory\n*\n# Except this file\n!.gitignore"
},
{
"path": "server/python_server/prompt_shortcut - Copy.json",
"chars": 1970,
"preview": "{\n \"painterly_style_1\": \"A full portrait of a beautiful post apocalyptic offworld arctic explorer, intricate, elegant"
},
{
"path": "server/python_server/prompt_shortcut.py",
"chars": 1903,
"preview": "import re\nimport json\nprompt_shortcut_dict ={}\n\n\ndef readToJson():\n return load()\n\ndef writeToJson(file_name,data_dic"
},
{
"path": "server/python_server/search.py",
"chars": 624,
"preview": "import asyncio\n\ntry:\n from duckduckgo_search import AsyncDDGS\nexcept ImportError:\n raise ImportError(\n \"duc"
},
{
"path": "server/python_server/serverHelper.py",
"chars": 1855,
"preview": "import time\nimport os\nimport datetime\nimport uuid\nimport json\n\n# this function should be used whenever we need to write "
},
{
"path": "server/python_server/serverMain.py",
"chars": 16850,
"preview": "\nimport json\nimport requests\nimport io\nimport base64\nfrom PIL import Image, PngImagePlugin\nimport asyncio\nimport httpx\nf"
},
{
"path": "thumbnail.js",
"chars": 1113,
"preview": "class Thumbnail {\n static wrapImgInContainer(img, container_style_class) {\n const container = document.createE"
},
{
"path": "typescripts/@types/changedpi.d.ts",
"chars": 27,
"preview": "declare module 'changedpi'\n"
},
{
"path": "typescripts/@types/custom.d.ts",
"chars": 210,
"preview": "declare module '*.svg' {\n import React = require('react')\n export const ReactComponent: React.FunctionComponent<\n "
},
{
"path": "typescripts/@types/sdapi_py_re.d.ts",
"chars": 77,
"preview": "declare module 'sdapi_py_re' {\n const exports: any\n export = exports\n}\n"
},
{
"path": "typescripts/@types/uxp.d.ts",
"chars": 166,
"preview": "declare module 'uxp' {\n // Add type declarations for the uxp module here\n export const storage: any\n export con"
},
{
"path": "typescripts/after_detailer/after_detailer.tsx",
"chars": 9546,
"preview": "import React, { ReactPropTypes } from 'react'\nimport ReactDOM from 'react-dom/client'\n\n// import { action, makeAutoObser"
},
{
"path": "typescripts/after_detailer/config.ts",
"chars": 6038,
"preview": "let MASK_MERGE_INVERT = ['None', 'Merge', 'Merge and Invert']\n\nexport const model_list = [\n 'face_yolov8n.pt',\n 'f"
},
{
"path": "typescripts/after_detailer/style/after_detailer.css",
"chars": 791,
"preview": "/* Style the button that is used to open and close the collapsible content */\n.collapsible {\n background-color: #2d2d"
},
{
"path": "typescripts/comfyui/comfyapi.ts",
"chars": 4996,
"preview": "import { app } from 'photoshop'\nimport settings_tab from '../settings/settings'\nimport { requestGet, requestPost } from "
},
{
"path": "typescripts/comfyui/comfyui.tsx",
"chars": 89968,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { requestGet, requestPost } from '../util/ts/ap"
},
{
"path": "typescripts/comfyui/img2img_api.json",
"chars": 5041,
"preview": "{\n \"3\": {\n \"inputs\": {\n \"seed\": 532429388244110,\n \"steps\": 20,\n \"cfg\": 8,\n \"sampler_name\": \"dpmp"
},
{
"path": "typescripts/comfyui/img2img_workflow.json",
"chars": 36316,
"preview": "{\n \"last_node_id\": 109,\n \"last_link_id\": 204,\n \"nodes\": [\n {\n \"id\": 8,\n \"type\": \"VAEDecode\",\n \"pos\""
},
{
"path": "typescripts/comfyui/inpaint_api.json",
"chars": 5816,
"preview": "{\n \"3\": {\n \"inputs\": {\n \"seed\": [\n \"141\",\n 0\n ],\n \"steps\": 20,\n \"cfg\": 7,\n \"s"
},
{
"path": "typescripts/comfyui/inpaint_workflow.json",
"chars": 34769,
"preview": "{\n \"last_node_id\": 162,\n \"last_link_id\": 313,\n \"nodes\": [\n {\n \"id\": 13,\n \"type\": \"VAEDecode\",\n \"pos"
},
{
"path": "typescripts/comfyui/main_ui.tsx",
"chars": 20377,
"preview": "import txt2img from './txt2img_workflow.json'\nimport txt2img_api from './txt2img_api.json'\n\nimport img2img from './img2i"
},
{
"path": "typescripts/comfyui/native_workflows/IPAdapter_simple_api.json",
"chars": 2916,
"preview": "{\n \"8\": {\n \"inputs\": {\n \"samples\": [\n \"50\",\n 0\n ],\n \"vae\": [\n \"32\",\n 0\n "
},
{
"path": "typescripts/comfyui/native_workflows/IPAdapter_weighted_api.json",
"chars": 2948,
"preview": "{\n \"1\": {\n \"inputs\": {\n \"ckpt_name\": \"dreamshaper_8.safetensors\"\n },\n \"class_type\": \"CheckpointLoaderSimp"
},
{
"path": "typescripts/comfyui/native_workflows/animatediff_lcm_api.json",
"chars": 3624,
"preview": "{\n \"2\": {\n \"inputs\": {\n \"vae_name\": \"vae-ft-mse-840000-ema-pruned.safetensors\"\n },\n \"class_type\": \"VAELoa"
},
{
"path": "typescripts/comfyui/native_workflows/animatediff_simple_api.json",
"chars": 2475,
"preview": "{\n \"2\": {\n \"inputs\": {\n \"vae_name\": \"vae-ft-mse-840000-ema-pruned.safetensors\"\n },\n \"class_type\": \"VAELoa"
},
{
"path": "typescripts/comfyui/native_workflows/real_time_lcm_img2img_api.json",
"chars": 1946,
"preview": "{\n \"6\": {\n \"inputs\": {\n \"text\": \"cute girl\",\n \"clip\": [\n \"38\",\n 1\n ]\n },\n \"class_"
},
{
"path": "typescripts/comfyui/native_workflows/real_time_lcm_sketching_api.json",
"chars": 4044,
"preview": "{\n \"6\": {\n \"inputs\": {\n \"text\": \"\",\n \"clip\": [\n \"38\",\n 1\n ]\n },\n \"class_type\": \"C"
},
{
"path": "typescripts/comfyui/native_workflows/real_time_lcm_txt2img_api.json",
"chars": 1540,
"preview": "{\n \"6\": {\n \"inputs\": {\n \"text\": \"cute girl\",\n \"clip\": [\n \"38\",\n 1\n ]\n },\n \"class_"
},
{
"path": "typescripts/comfyui/native_workflows/sdxl_turbo_txt2img_api.json",
"chars": 1647,
"preview": "{\n \"5\": {\n \"inputs\": {\n \"width\": 512,\n \"height\": 512,\n \"batch_size\": 1\n },\n \"class_type\": \"Empt"
},
{
"path": "typescripts/comfyui/native_workflows/zoom_out_api.json",
"chars": 4917,
"preview": "{\n \"1\": {\n \"inputs\": {\n \"image\": \"000662ed61a84c86fc8a3fe69d38a6e2 (1).jpg\",\n \"choose file to upload\": \"im"
},
{
"path": "typescripts/comfyui/txt2img_api.json",
"chars": 4678,
"preview": "{\n \"3\": {\n \"inputs\": {\n \"seed\": 945794611996037,\n \"steps\": 12,\n \"cfg\": 8,\n \"sampler_name\": \"dpmp"
},
{
"path": "typescripts/comfyui/txt2img_workflow.json",
"chars": 28345,
"preview": "{\n \"last_node_id\": 98,\n \"last_link_id\": 156,\n \"nodes\": [\n {\n \"id\": 8,\n \"type\": \"VAEDecode\",\n \"pos\":"
},
{
"path": "typescripts/comfyui/util.ts",
"chars": 18585,
"preview": "import { readdirSync, readFileSync } from 'fs'\nimport { requestPost } from '../util/ts/api'\n\nimport { storage } from 'ux"
},
{
"path": "typescripts/controlnet/ControlNetTab.tsx",
"chars": 11021,
"preview": "import { observer } from 'mobx-react'\nimport React from 'react'\nimport ControlNetUnit from './ControlNetUnit'\n\nimport Co"
},
{
"path": "typescripts/controlnet/ControlNetUnit.tsx",
"chars": 38298,
"preview": "import { observer } from 'mobx-react'\nimport React from 'react'\nimport {\n MoveToCanvasSvg,\n ActionButtonSVG,\n S"
},
{
"path": "typescripts/controlnet/entry.ts",
"chars": 12349,
"preview": "import { toJS } from 'mobx'\nimport { setControlImageSrc } from '../../utility/html_manip'\n// import { session_ts } from "
},
{
"path": "typescripts/controlnet/main.tsx",
"chars": 1672,
"preview": "import ReactDOM from 'react-dom/client'\nimport React from 'react'\nimport ControlNetTab from './ControlNetTab'\nimport sto"
},
{
"path": "typescripts/controlnet/store.ts",
"chars": 4007,
"preview": "import { observable, reaction } from 'mobx'\nimport { SelectionInfoType } from '../util/ts/enum'\ntype ResizeMode = 'Just "
},
{
"path": "typescripts/controlnet/util.tsx",
"chars": 851,
"preview": "export function mapRange(\n x: number,\n in_min: number,\n in_max: number,\n out_min: number,\n out_max: numbe"
},
{
"path": "typescripts/entry.ts",
"chars": 2083,
"preview": "import { configure } from 'mobx'\nconfigure({\n enforceActions: 'never', // disable mobx warning temporarily\n})\nexport "
},
{
"path": "typescripts/extra_page/extra_page.tsx",
"chars": 10441,
"preview": "import { observer } from 'mobx-react'\nimport React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { ErrorBo"
},
{
"path": "typescripts/globalstore.ts",
"chars": 346,
"preview": "import { observable } from 'mobx'\nimport { host } from 'uxp'\n\ninterface GlobalStore {\n Locale: 'zh_CN' | 'en_US'\n}\n\nc"
},
{
"path": "typescripts/history/history.tsx",
"chars": 18243,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { observer } from 'mobx-react'\nimport { AStore,"
},
{
"path": "typescripts/image_search/image_search.tsx",
"chars": 2153,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { observer } from 'mobx-react'\nimport { AStore "
},
{
"path": "typescripts/lexical/lexical.tsx",
"chars": 9251,
"preview": "//TODO: delete lexical_tab.js and lexica tab from html\nimport { observer } from 'mobx-react'\nimport React, { TextareaHTM"
},
{
"path": "typescripts/locale/locale-for-old-html.ts",
"chars": 3851,
"preview": "import { reaction } from 'mobx'\nimport globalStore from '../globalstore'\nimport Locale from './locale'\n\nconst elemSelect"
},
{
"path": "typescripts/locale/locale.ts",
"chars": 1725,
"preview": "import globalStore from '../globalstore'\nimport type zhHans from '../../i18n/zh_CN/sd-official.json'\nimport type zhHansF"
},
{
"path": "typescripts/main/astore.ts",
"chars": 771,
"preview": "import { makeAutoObservable, reaction, toJS } from 'mobx'\nexport { toJS } from 'mobx'\n// import { Provider, inject, obse"
},
{
"path": "typescripts/multiTextarea.tsx",
"chars": 7487,
"preview": "import { observer } from 'mobx-react'\nimport React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { AStore "
},
{
"path": "typescripts/one_button_prompt/one_button_prompt.tsx",
"chars": 10128,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { Collapsible } from '../util/collapsible'\nimp"
},
{
"path": "typescripts/preset/preset.tsx",
"chars": 9717,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { observer } from 'mobx-react'\nimport { ErrorBo"
},
{
"path": "typescripts/preset/shared_ui_preset.ts",
"chars": 3696,
"preview": "import { AStore } from '../main/astore'\nimport { html_manip, io } from '../util/oldSystem'\nimport { PresetTypeEnum } fro"
},
{
"path": "typescripts/sam/sam.tsx",
"chars": 9197,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { Collapsible } from '../util/collapsible'\nimpo"
},
{
"path": "typescripts/sd_tab/sd_tab.tsx",
"chars": 71521,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { observer } from 'mobx-react'\n\nimport { Gener"
},
{
"path": "typescripts/sd_tab/util.ts",
"chars": 23193,
"preview": "import { control_net } from '../entry'\nimport vae_settings from '../settings/vae'\nimport { AStore } from '../main/astore"
},
{
"path": "typescripts/session/generate.tsx",
"chars": 11928,
"preview": "import { app } from 'photoshop'\nimport React from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { observer } f"
},
{
"path": "typescripts/session/modes.ts",
"chars": 24384,
"preview": "// import { control_net, scripts, session_ts } from '../entry'\n// import * as session_ts from '../session/session'\nimpor"
},
{
"path": "typescripts/session/progress.ts",
"chars": 5286,
"preview": "import { reaction } from 'mobx'\nimport { AStore } from '../main/astore'\nimport { io, layer_util } from '../util/oldSyste"
},
{
"path": "typescripts/session/session.ts",
"chars": 15408,
"preview": "import { app } from 'photoshop'\n// import { control_net, preview, viewer, progress } from '../entry'\nimport * as progres"
},
{
"path": "typescripts/session/session_store.ts",
"chars": 2793,
"preview": "import { AStore } from '../main/astore'\nimport {\n GenerationModeEnum,\n ScriptMode,\n SelectionInfoType,\n} from '"
},
{
"path": "typescripts/session/style/generate.css",
"chars": 204,
"preview": ".generateButtonMargin {\n margin-top: 1px;\n margin-bottom: 3px;\n display: inline-block;\n}\n\n.generateColor {\n "
},
{
"path": "typescripts/settings/settings.tsx",
"chars": 18791,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { observer } from 'mobx-react'\nimport { AStore "
},
{
"path": "typescripts/settings/vae.tsx",
"chars": 3102,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\nimport { observer } from 'mobx-react'\nimport { AStore "
},
{
"path": "typescripts/stores.ts",
"chars": 169,
"preview": "export { store as session_store } from './session/session_store'\nexport { store as sd_tab_store } from './sd_tab/util'\ne"
},
{
"path": "typescripts/tool_bar/style/tool_bar.css",
"chars": 90,
"preview": "/* styles.css */\n#_tool_bar_container button:not(:last-child) {\n margin-bottom: 3px;\n}\n"
},
{
"path": "typescripts/tool_bar/tool_bar.tsx",
"chars": 9276,
"preview": "import { observer } from 'mobx-react'\nimport React from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { genera"
},
{
"path": "typescripts/tsconfig.json",
"chars": 12412,
"preview": "{\n \"compilerOptions\": {\n /* Visit https://aka.ms/tsconfig to read more about this file */\n\n /* Projects */\n //"
},
{
"path": "typescripts/ultimate_sd_upscaler/config.ts",
"chars": 2746,
"preview": "export let ui_config = {\n tile_width: {\n minimum: 0,\n maximum: 2048,\n step: 64,\n label: '"
},
{
"path": "typescripts/ultimate_sd_upscaler/scripts.tsx",
"chars": 6070,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { makeAutoObservable, toJS } from 'mobx'\nimpor"
},
{
"path": "typescripts/ultimate_sd_upscaler/ultimate_sd_upscaler.tsx",
"chars": 12553,
"preview": "import React, { ReactEventHandler } from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { action, makeAutoObser"
},
{
"path": "typescripts/util/collapsible.tsx",
"chars": 2089,
"preview": "import React, { CSSProperties, ComponentType } from 'react'\n// import ReactDOM from 'react-dom'\n\nimport { useState, Reac"
},
{
"path": "typescripts/util/elements.tsx",
"chars": 23220,
"preview": "import React, { CSSProperties, ComponentType } from 'react'\n// import ReactDOM from 'react-dom'\nimport ReactDOM from 're"
},
{
"path": "typescripts/util/errorBoundary.tsx",
"chars": 1413,
"preview": "import React, { Component, ErrorInfo, ReactNode } from 'react'\nimport { refreshUI } from '../sd_tab/util'\n\ninterface Pro"
},
{
"path": "typescripts/util/grid.tsx",
"chars": 5046,
"preview": "import React from 'react'\nimport { ActionButtonSVG, Thumbnail } from './elements'\n\nexport class Grid extends React.Compo"
},
{
"path": "typescripts/util/logger.ts",
"chars": 185,
"preview": "import { format } from 'util'\nexport function formateLog(data: any, ...optional_param: any[]) {\n const formattedOutpu"
},
{
"path": "typescripts/util/oldSystem.tsx",
"chars": 1260,
"preview": "import type Jimp from 'jimp'\n\n//@ts-ignore\nconst req = window['require']\n\n// because we use window['require'], so the ba"
},
{
"path": "typescripts/util/ts/api.ts",
"chars": 5309,
"preview": "import { storage } from 'uxp'\n\ndeclare let g_sd_url: string\nexport async function requestGet(url: string) {\n let data"
},
{
"path": "typescripts/util/ts/document.ts",
"chars": 11814,
"preview": "import { app, core, action } from 'photoshop'\nimport { Jimp, layer_util, psapi } from '../oldSystem'\nimport { storage } "
},
{
"path": "typescripts/util/ts/enum.ts",
"chars": 728,
"preview": "export enum GenerationModeEnum {\n Txt2Img = 'txt2img',\n Img2Img = 'img2img',\n Inpaint = 'inpaint',\n Outpaint"
},
{
"path": "typescripts/util/ts/general.ts",
"chars": 5269,
"preview": "import { app, core, imaging } from 'photoshop'\nimport { io, psapi } from '../oldSystem'\nimport { host } from 'uxp'\n\nexpo"
},
{
"path": "typescripts/util/ts/io.ts",
"chars": 4902,
"preview": "import { app, core, action } from 'photoshop'\nimport { Jimp, io, psapi } from '../oldSystem'\nimport { base64ToFileAndGet"
},
{
"path": "typescripts/util/ts/layer.ts",
"chars": 4035,
"preview": "import { app, core, action } from 'photoshop'\nimport { layer_util, psapi } from '../oldSystem'\n// import { settings_tab_"
},
{
"path": "typescripts/util/ts/sdapi.ts",
"chars": 2509,
"preview": "declare let g_version: any\ndeclare let g_sd_url: any\n\nexport async function getVersionRequest() {\n console.log('reque"
},
{
"path": "typescripts/util/ts/selection.ts",
"chars": 4907,
"preview": "import { moveImageToLayer, moveImageToLayer_old } from './io'\nimport { io, layer_util, psapi } from '../oldSystem'\n\nimpo"
},
{
"path": "typescripts/util/ts/ui_ts.ts",
"chars": 12531,
"preview": "import { multiPrompts } from '../../entry'\nimport {\n getAllCustomPresetsSettings,\n loadCustomPreset,\n loadPrese"
},
{
"path": "typescripts/viewer/preview.tsx",
"chars": 2903,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\n\nimport { Collapsible } from '../util/collapsible'\nimp"
},
{
"path": "typescripts/viewer/style/preview.css",
"chars": 131,
"preview": ".preview_progress_bar {\n border-left: 2px solid #3e3e3e;\n border-right: 2px solid #3e3e3e;\n margin: 0;\n widt"
},
{
"path": "typescripts/viewer/viewer.tsx",
"chars": 24120,
"preview": "import React from 'react'\nimport ReactDOM from 'react-dom/client'\n// import ReactDOM from 'react-dom'\nimport { observer "
},
{
"path": "typescripts/viewer/viewer_util.ts",
"chars": 3083,
"preview": "import { AStore } from '../main/astore'\nimport { io } from '../util/oldSystem'\n\nexport enum ClickTypeEnum {\n Click = "
},
{
"path": "utility/api.js",
"chars": 3283,
"preview": "//deprecated file don't use\n\nconsole.warn('api.js is deprecated, use typescript/util/ts/api.ts')\n\nasync function request"
},
{
"path": "utility/dummy.js",
"chars": 570541,
"preview": "function getDummyBase64() {\n const b64Image =\n 'iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAIAAADTED8xAAADMElEQVR4nOzVwQ"
},
{
"path": "utility/general.js",
"chars": 3390,
"preview": "const { requestGet } = require('./api')\n\nfunction newOutputImageName(format = 'png') {\n const random_id = Math.floor("
},
{
"path": "utility/html_manip.js",
"chars": 22157,
"preview": "////// Start Prompt//////////\n\nfunction autoFillInPrompt(prompt_value) {\n // document.getElementById('taPrompt').valu"
},
{
"path": "utility/io.js",
"chars": 49540,
"preview": "const psapi = require('../psapi')\n\nconst layer_util = require('../utility/layer')\nconst general = require('./general')\n\n"
},
{
"path": "utility/layer.js",
"chars": 14579,
"preview": "const { batchPlay } = require('photoshop').action\nconst { executeAsModal } = require('photoshop').core\nconst {\n clean"
},
{
"path": "utility/notification.js",
"chars": 3501,
"preview": "const dialog_box = require('../dialog_box')\nconst psapi = require('../psapi')\nconst { createBackgroundLayer } = require("
},
{
"path": "utility/online_data.json",
"chars": 272,
"preview": "{\n \"new_version\": \"v1.4.1\",\n \"update_message\": \"Your version is outdated.Please visit our Github page and download"
},
{
"path": "utility/presets/controlnet_preset.js",
"chars": 4686,
"preview": "const MaintainPositionSettings = {\n 0: {\n module: 'openpose',\n model: 'control_sd15_openpose [fef5e48e]"
},
{
"path": "utility/sampler.js",
"chars": 2282,
"preview": "samplers = [\n {\n name: 'Euler a',\n aliases: ['k_euler_a', 'k_euler_ancestral'],\n options: {},\n "
},
{
"path": "utility/sd_scripts/horde.js",
"chars": 3472,
"preview": "async function requestModelsHorde() {\n //get the models list from url\n // https://stablehorde.net/api/v2/status/mo"
},
{
"path": "utility/sdapi/config.js",
"chars": 2542,
"preview": "class SdConfig {\n constructor() {\n this.config //store sd options\n }\n\n async getConfig() {\n try {"
},
{
"path": "utility/sdapi/horde_native.js",
"chars": 26431,
"preview": "const general = require('../general')\nconst psapi = require('../../psapi')\nconst html_manip = require('../html_manip')\nc"
},
{
"path": "utility/sdapi/options.js",
"chars": 1039,
"preview": "class SdOptions {\n constructor() {\n // this.status = false // true if we have a valid copy of sd options, fals"
},
{
"path": "utility/sdapi/prompt_shortcut.js",
"chars": 1047,
"preview": "function find_words_inside_braces(string) {\n const re = /\\{(.*?)\\}/g\n let keywords = string.match(re)\n // conso"
},
{
"path": "utility/sdapi/python_replacement.js",
"chars": 14327,
"preview": "//how to get environment variable in javascript\nconst settings_tab = require('../tab/settings')\nconst { getPromptShortcu"
},
{
"path": "utility/session.js",
"chars": 17688,
"preview": "const { cleanLayers } = require('../psapi')\nconst psapi = require('../psapi')\nconst io = require('./io')\nconst Enum = re"
},
{
"path": "utility/tab/image_search_tab.js",
"chars": 858,
"preview": "const sdapi = require('../../sdapi_py_re')\nconst { image_search } = require('../../typescripts/dist/bundle')\n\nconst stor"
},
{
"path": "utility/tab/settings.js",
"chars": 2660,
"preview": "const io = require('../io')\n\nfunction setUseSharpMask() {\n console.warn('setUseSharpMask is not setup')\n}\n\ndocument.g"
},
{
"path": "utility/tips.js",
"chars": 2094,
"preview": "//tips that will display when you hover over a html element\nconst tips_json = {\n snapshot: '',\n txt2img: 'use this"
}
]
About this extraction
This page contains the full source code of the AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 149 files (1.9 MB), approximately 733.3k tokens, and a symbol index with 1030 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.