Showing preview only (1,097K chars total). Download the full file or copy to clipboard to get everything.
Repository: BitconFeng/Deep-Feature-video
Branch: master
Commit: fff73fbcd0e2
Files: 125
Total size: 1.0 MB
Directory structure:
gitextract_zxbt3wtx/
├── LICENSE
├── README.md
├── ThirdPartyNotices.txt
├── dff_rfcn/
│ ├── __init__.py
│ ├── _init_paths.py
│ ├── config/
│ │ ├── __init__.py
│ │ └── config.py
│ ├── core/
│ │ ├── DataParallelExecutorGroup.py
│ │ ├── __init__.py
│ │ ├── callback.py
│ │ ├── loader.py
│ │ ├── metric.py
│ │ ├── module.py
│ │ ├── rcnn.py
│ │ └── tester.py
│ ├── demo.py
│ ├── demo_batch.py
│ ├── function/
│ │ ├── __init__.py
│ │ ├── test_rcnn.py
│ │ ├── test_rpn.py
│ │ ├── train_rcnn.py
│ │ └── train_rpn.py
│ ├── operator_cxx/
│ │ ├── multi_proposal-inl.h
│ │ ├── multi_proposal.cc
│ │ ├── multi_proposal.cu
│ │ ├── psroi_pooling-inl.h
│ │ ├── psroi_pooling.cc
│ │ └── psroi_pooling.cu
│ ├── operator_py/
│ │ ├── __init__.py
│ │ ├── box_annotator_ohem.py
│ │ ├── proposal.py
│ │ ├── proposal_target.py
│ │ ├── rpn_inv_normalize.py
│ │ └── tile_as.py
│ ├── symbols/
│ │ ├── __init__.py
│ │ └── resnet_v1_101_flownet_rfcn.py
│ ├── test.py
│ └── train_end2end.py
├── experiments/
│ ├── dff_rfcn/
│ │ ├── cfgs/
│ │ │ ├── dff_rfcn_vid_demo.yaml
│ │ │ └── resnet_v1_101_flownet_imagenet_vid_rfcn_end2end_ohem.yaml
│ │ ├── dff_rfcn_end2end_train_test.py
│ │ └── dff_rfcn_test.py
│ └── rfcn/
│ ├── cfgs/
│ │ ├── resnet_v1_101_imagenet_vid_rfcn_end2end_ohem.yaml
│ │ └── rfcn_vid_demo.yaml
│ ├── rfcn_end2end_train_test.py
│ └── rfcn_test.py
├── green2.py
├── init.bat
├── init.sh
├── lib/
│ ├── Makefile
│ ├── __init__.py
│ ├── bbox/
│ │ ├── .gitignore
│ │ ├── __init__.py
│ │ ├── bbox.pyx
│ │ ├── bbox_regression.py
│ │ ├── bbox_transform.py
│ │ ├── setup_linux.py
│ │ └── setup_windows.py
│ ├── dataset/
│ │ ├── __init__.py
│ │ ├── ds_utils.py
│ │ ├── imagenet_vid.py
│ │ ├── imagenet_vid_eval.py
│ │ └── imdb.py
│ ├── nms/
│ │ ├── __init__.py
│ │ ├── cpu_nms.pyx
│ │ ├── gpu_nms.cu
│ │ ├── gpu_nms.hpp
│ │ ├── gpu_nms.pyx
│ │ ├── nms.py
│ │ ├── nms_kernel.cu
│ │ ├── setup_linux.py
│ │ ├── setup_windows.py
│ │ └── setup_windows_cuda.py
│ ├── rpn/
│ │ ├── __init__.py
│ │ ├── generate_anchor.py
│ │ └── rpn.py
│ └── utils/
│ ├── PrefetchingIter.py
│ ├── __init__.py
│ ├── combine_model.py
│ ├── create_logger.py
│ ├── image.py
│ ├── image_processing.py
│ ├── load_data.py
│ ├── load_model.py
│ ├── lr_scheduler.py
│ ├── roidb.py
│ ├── save_model.py
│ ├── show_boxes.py
│ ├── symbol.py
│ └── tictoc.py
├── rfcn/
│ ├── __init__.py
│ ├── _init_paths.py
│ ├── config/
│ │ ├── __init__.py
│ │ └── config.py
│ ├── core/
│ │ ├── DataParallelExecutorGroup.py
│ │ ├── __init__.py
│ │ ├── callback.py
│ │ ├── loader.py
│ │ ├── metric.py
│ │ ├── module.py
│ │ ├── rcnn.py
│ │ └── tester.py
│ ├── demo.py
│ ├── demo_batch.py
│ ├── function/
│ │ ├── __init__.py
│ │ ├── test_rcnn.py
│ │ ├── test_rpn.py
│ │ ├── train_rcnn.py
│ │ └── train_rpn.py
│ ├── operator_cxx/
│ │ ├── multi_proposal-inl.h
│ │ ├── multi_proposal.cc
│ │ ├── multi_proposal.cu
│ │ ├── psroi_pooling-inl.h
│ │ ├── psroi_pooling.cc
│ │ └── psroi_pooling.cu
│ ├── operator_py/
│ │ ├── __init__.py
│ │ ├── box_annotator_ohem.py
│ │ ├── proposal.py
│ │ ├── proposal_target.py
│ │ └── rpn_inv_normalize.py
│ ├── symbols/
│ │ ├── __init__.py
│ │ └── resnet_v1_101_rfcn.py
│ ├── test.py
│ └── train_end2end.py
└── zero.md
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
The MIT License (MIT)
Copyright (c) 2017 Microsoft Corporation
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# Deep Feature Flow for Video Recognition
## Introduction
**Deep Feature Flow** is initially described in a [CVPR 2017 paper]
It provides a simple, fast, accurate, and end-to-end framework for video recognition (e.g., object detection and semantic segmentation in videos). It is worth noting that:
* Deep Feature Flow significantly speeds up video recognition by applying the heavy-weight image recognition network (e.g., ResNet-101) on sparse key frames, and propagating the recognition outputs (feature maps) to the other frames by the light-weight flow network (e.g., [FlowNet].
* The entire system is end-to-end trained for the task of video recognition, which is vital for improving the recognition accuracy. Directly adopting state-of-the-art flow estimation methods without end-to-end training would deliver noticable worse results.
* Deep Feature Flow can easily make use of sparsely annotated video recognition datasets, where only a small portion of the frames are annotated with ground-truth labels.
***Click image to watch our demo video***
[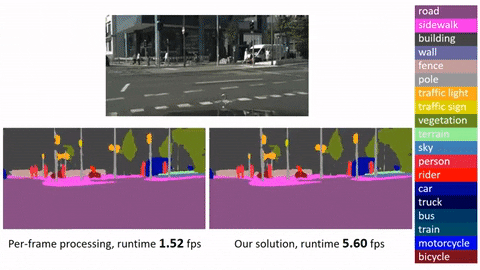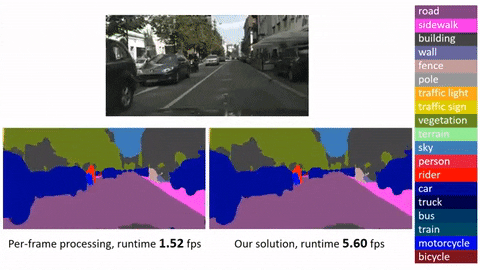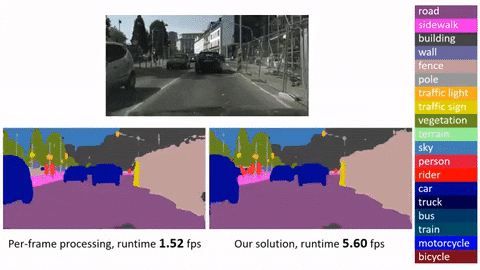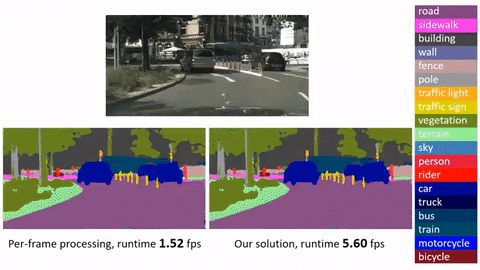]
[]
## Disclaimer
This is an official implementation for [Deep Feature Flow for Video Recognition](https://arxiv.org/abs/1611.07715) (DFF) based on MXNet. It is worth noticing that:
* The original implementation is based on our internal Caffe version on Windows. There are slight differences in the final accuracy and running time due to the plenty details in platform switch.
## License
© Microsoft, 2018. Licensed under the [MIT](LICENSE) License.
## Citing Deep Feature Flow
If you find Deep Feature Flow useful in your research, please consider citing:
```
@inproceedings{zhu17dff,
Author = {Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, Yichen Wei},
Title = {Deep Feature Flow for Video Recognition},
Conference = {CVPR},
Year = {2017}
}
@inproceedings{dai16rfcn,
Author = {Jifeng Dai, Yi Li, Kaiming He, Jian Sun},
Title = {{R-FCN}: Object Detection via Region-based Fully Convolutional Networks},
Conference = {NIPS},
Year = {2016}
}
```
## Main Results
| | <sub>training data</sub> | <sub>testing data</sub> | <sub>mAP@0.5</sub> | <sub>time/image</br> (Tesla K40)</sub> | <sub>time/image</br>(Maxwell Titan X)</sub> |
|---------------------------------|-------------------|--------------|---------|---------|--------|
| <sub>Frame baseline</br>(R-FCN, ResNet-v1-101)</sub> | <sub>ImageNet DET train + VID train</sub> | <sub>ImageNet VID validation</sub> | 74.1 | 0.271s | 0.133s |
| <sub>Deep Feature Flow</br>(R-FCN, ResNet-v1-101, FlowNet)</sub> | <sub>ImageNet DET train + VID train</sub> | <sub>ImageNet VID validation</sub> | 73.0 | 0.073s | 0.034s |
*Running time is counted on a single GPU (mini-batch size is 1 in inference, key-frame duration length for Deep Feature Flow is 10).*
*The runtime of the light-weight FlowNet seems to be a bit slower on MXNet than that on Caffe.*
## Requirements: Software
1. MXNet from
Due to the rapid development of MXNet, it is recommended to checkout this version if you encounter any issues. We may maintain this repository periodically if MXNet adds important feature in future release.
2. Python 2.7. We recommend using Anaconda2 as it already includes many common packages. We do not suppoort Python 3 yet, if you want to use Python 3 you need to modify the code to make it work.
3. Python packages might missing: cython, opencv-python >= 3.2.0, easydict. If `pip` is set up on your system, those packages should be able to be fetched and installed by running
```
pip install Cython
pip install opencv-python==3.2.0.6
pip install easydict==1.6
```
4. For Windows users, Visual Studio 2015 is needed to compile cython module.
## Requirements: Hardware
Any NVIDIA GPUs with at least 6GB memory should be OK
## Installation
1. Clone the Deep Feature Flow repository, and we'll call the directory that you cloned Deep-Feature-Flow as ${DFF_ROOT}.
~~~
git clone https://github.com/msracver/Deep-Feature-Flow.git
~~~
2. For Windows users, run ``cmd .\init.bat``. For Linux user, run `sh ./init.sh`. The scripts will build cython module automatically and create some folders.
3. Install MXNet:
3.1 Clone MXNet and checkout to [MXNet@(commit 62ecb60)] by
```
git clone --recursive https://github.com/dmlc/mxnet.git
git checkout 62ecb60
git submodule update
```
3.2 Copy operators in `$(DFF_ROOT)/dff_rfcn/operator_cxx` or `$(DFF_ROOT)/rfcn/operator_cxx` to `$(YOUR_MXNET_FOLDER)/src/operator/contrib` by
```
cp -r $(DFF_ROOT)/dff_rfcn/operator_cxx/* $(MXNET_ROOT)/src/operator/contrib/
```
3.3 Compile MXNet
```
cd ${MXNET_ROOT}
make -j4
```
3.4 Install the MXNet Python binding by
***Note: If you will actively switch between different versions of MXNet, please follow 3.5 instead of 3.4***
```
cd python
sudo python setup.py install
```
3.5 For advanced users, you may put your Python packge into `./external/mxnet/$(YOUR_MXNET_PACKAGE)`, and modify `MXNET_VERSION` in `./experiments/dff_rfcn/cfgs/*.yaml` to `$(YOUR_MXNET_PACKAGE)`. Thus you can switch among different versions of MXNet quickly.
## Demo
1. To run the demo with our trained model (on ImageNet DET + VID train), please download the model manually from [OneDrive](for users from Mainland China, please try [Baidu Yun]), and put it under folder `model/`.
Make sure it looks like this:
```
./model/rfcn_vid-0000.params
./model/rfcn_dff_flownet_vid-0000.params
```
2. Run (inference batch size = 1)
```
python ./rfcn/demo.py
python ./dff_rfcn/demo.py
```
or run (inference batch size = 10)
```
python ./rfcn/demo_batch.py
python ./dff_rfcn/demo_batch.py
```
## Preparation for Training & Testing
1. Please download ILSVRC2015 DET and ILSVRC2015 VID dataset, and make sure it looks like this:
```
./data/ILSVRC2015/
./data/ILSVRC2015/Annotations/DET
./data/ILSVRC2015/Annotations/VID
./data/ILSVRC2015/Data/DET
./data/ILSVRC2015/Data/VID
./data/ILSVRC2015/ImageSets
```
## FAQ
Q: It says `AttributeError: 'module' object has no attribute 'MultiProposal'`.
A: This is because either
- you forget to copy the operators to your MXNet folder
- or you copy to the wrong path
- or you forget to re-compile and install
- or you install the wrong MXNet
Please print `mxnet.__path__` to make sure you use correct MXNet
<br/><br/>
Q: I encounter `segment fault` at the beginning.
A: A compatibility issue has been identified between MXNet and opencv-python 3.0+. We suggest that you always `import cv2` first before `import mxnet` in the entry script.
<br/><br/>
Q: I find the training speed becomes slower when training for a long time.
A: It has been identified that MXNet on Windows has this problem. So we recommend to run this program on Linux. You could also stop it and resume the training process to regain the training speed if you encounter this problem.
<br/><br/>
Q: Can you share your caffe implementation?
A: Due to several reasons (code is based on a old, internal Caffe, port to public Caffe needs extra work, time limit, etc.). We do not plan to release our Caffe code. Since a warping layer is easy to implement, anyone who wish to do it is welcome to make a pull request.
================================================
FILE: ThirdPartyNotices.txt
================================================
Deep Feature Flow
THIRD-PARTY SOFTWARE NOTICES AND INFORMATION
This project incorporates components from the projects listed below. The original copyright notices and the licenses under which Microsoft received such components are set forth below. Microsoft reserves all rights not expressly granted herein, whether by implication, estoppel or otherwise.
1. MXNet (https://github.com/apache/incubator-mxnet)
2. Fast R-CNN (https://github.com/rbgirshick/fast-rcnn)
3. Faster R-CNN (https://github.com/rbgirshick/py-faster-rcnn)
4. MS COCO API (https://github.com/cocodataset/cocoapi)
MXNet
Copyright (c) 2015-2016 by Contributors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Fast R-CNN
Copyright (c) Microsoft Corporation
All rights reserved.
MIT License
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the "Software"),
to deal in the Software without restriction, including without limitation
the rights to use, copy, modify, merge, publish, distribute, sublicense,
and/or sell copies of the Software, and to permit persons to whom the
Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED *AS IS*, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
OTHER DEALINGS IN THE SOFTWARE.
Faster R-CNN
The MIT License (MIT)
Copyright (c) 2015 Microsoft Corporation
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
MS COCO API
Copyright (c) 2014, Piotr Dollar and Tsung-Yi Lin
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
The views and conclusions contained in the software and documentation are those
of the authors and should not be interpreted as representing official policies,
either expressed or implied, of the FreeBSD Project.
================================================
FILE: dff_rfcn/__init__.py
================================================
================================================
FILE: dff_rfcn/_init_paths.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Yuwen Xiong
# --------------------------------------------------------
import os.path as osp
import sys
def add_path(path):
if path not in sys.path:
sys.path.insert(0, path)
this_dir = osp.dirname(__file__)
lib_path = osp.join(this_dir, '..', 'lib')
add_path(lib_path)
================================================
FILE: dff_rfcn/config/__init__.py
================================================
================================================
FILE: dff_rfcn/config/config.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Xizhou Zhu, Yuwen Xiong, Bin Xiao
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import yaml
import numpy as np
from easydict import EasyDict as edict
config = edict()
config.MXNET_VERSION = ''
config.output_path = ''
config.symbol = ''
config.gpus = ''
config.CLASS_AGNOSTIC = True
config.SCALES = [(600, 1000)] # first is scale (the shorter side); second is max size
# default training
config.default = edict()
config.default.frequent = 20
config.default.kvstore = 'device'
# network related params
config.network = edict()
config.network.pretrained = ''
config.network.pretrained_flow = ''
config.network.pretrained_epoch = 0
config.network.PIXEL_MEANS = np.array([0, 0, 0])
config.network.IMAGE_STRIDE = 0
config.network.RPN_FEAT_STRIDE = 16
config.network.RCNN_FEAT_STRIDE = 16
config.network.FIXED_PARAMS = ['gamma', 'beta']
config.network.ANCHOR_SCALES = (8, 16, 32)
config.network.ANCHOR_RATIOS = (0.5, 1, 2)
config.network.NORMALIZE_RPN = True
config.network.ANCHOR_MEANS = (0.0, 0.0, 0.0, 0.0)
config.network.ANCHOR_STDS = (0.1, 0.1, 0.4, 0.4)
config.network.NUM_ANCHORS = len(config.network.ANCHOR_SCALES) * len(config.network.ANCHOR_RATIOS)
config.network.DFF_FEAT_DIM = 1024
# dataset related params
config.dataset = edict()
config.dataset.dataset = 'ImageNetVID'
config.dataset.image_set = 'DET_train_30classes+VID_train_15frames'
config.dataset.test_image_set = 'VID_val_videos'
config.dataset.root_path = './data'
config.dataset.dataset_path = './data/ILSVRC2015'
config.dataset.NUM_CLASSES = 31
config.TRAIN = edict()
config.TRAIN.lr = 0
config.TRAIN.lr_step = ''
config.TRAIN.lr_factor = 0.1
config.TRAIN.warmup = False
config.TRAIN.warmup_lr = 0
config.TRAIN.warmup_step = 0
config.TRAIN.momentum = 0.9
config.TRAIN.wd = 0.0005
config.TRAIN.begin_epoch = 0
config.TRAIN.end_epoch = 0
config.TRAIN.model_prefix = ''
# whether resume training
config.TRAIN.RESUME = False
# whether flip image
config.TRAIN.FLIP = True
# whether shuffle image
config.TRAIN.SHUFFLE = True
# whether use OHEM
config.TRAIN.ENABLE_OHEM = False
# size of images for each device, 2 for rcnn, 1 for rpn and e2e
config.TRAIN.BATCH_IMAGES = 2
# e2e changes behavior of anchor loader and metric
config.TRAIN.END2END = False
# group images with similar aspect ratio
config.TRAIN.ASPECT_GROUPING = True
# R-CNN
# rcnn rois batch size
config.TRAIN.BATCH_ROIS = 128
config.TRAIN.BATCH_ROIS_OHEM = 128
# rcnn rois sampling params
config.TRAIN.FG_FRACTION = 0.25
config.TRAIN.FG_THRESH = 0.5
config.TRAIN.BG_THRESH_HI = 0.5
config.TRAIN.BG_THRESH_LO = 0.0
# rcnn bounding box regression params
config.TRAIN.BBOX_REGRESSION_THRESH = 0.5
config.TRAIN.BBOX_WEIGHTS = np.array([1.0, 1.0, 1.0, 1.0])
# RPN anchor loader
# rpn anchors batch size
config.TRAIN.RPN_BATCH_SIZE = 256
# rpn anchors sampling params
config.TRAIN.RPN_FG_FRACTION = 0.5
config.TRAIN.RPN_POSITIVE_OVERLAP = 0.7
config.TRAIN.RPN_NEGATIVE_OVERLAP = 0.3
config.TRAIN.RPN_CLOBBER_POSITIVES = False
# rpn bounding box regression params
config.TRAIN.RPN_BBOX_WEIGHTS = (1.0, 1.0, 1.0, 1.0)
config.TRAIN.RPN_POSITIVE_WEIGHT = -1.0
# used for end2end training
# RPN proposal
config.TRAIN.CXX_PROPOSAL = True
config.TRAIN.RPN_NMS_THRESH = 0.7
config.TRAIN.RPN_PRE_NMS_TOP_N = 12000
config.TRAIN.RPN_POST_NMS_TOP_N = 2000
config.TRAIN.RPN_MIN_SIZE = config.network.RPN_FEAT_STRIDE
# approximate bounding box regression
config.TRAIN.BBOX_NORMALIZATION_PRECOMPUTED = True
config.TRAIN.BBOX_MEANS = (0.0, 0.0, 0.0, 0.0)
config.TRAIN.BBOX_STDS = (0.1, 0.1, 0.2, 0.2)
# DFF, trained image sampled from [min_offset, max_offset]
config.TRAIN.MIN_OFFSET = -9
config.TRAIN.MAX_OFFSET = 0
config.TEST = edict()
# R-CNN testing
# use rpn to generate proposal
config.TEST.HAS_RPN = False
# size of images for each device
config.TEST.BATCH_IMAGES = 1
# RPN proposal
config.TEST.CXX_PROPOSAL = True
config.TEST.RPN_NMS_THRESH = 0.7
config.TEST.RPN_PRE_NMS_TOP_N = 6000
config.TEST.RPN_POST_NMS_TOP_N = 300
config.TEST.RPN_MIN_SIZE = config.network.RPN_FEAT_STRIDE
# RCNN nms
config.TEST.NMS = 0.3
# DFF
config.TEST.KEY_FRAME_INTERVAL = 10
config.TEST.max_per_image = 300
# Test Model Epoch
config.TEST.test_epoch = 0
def update_config(config_file):
exp_config = None
with open(config_file) as f:
exp_config = edict(yaml.load(f))
for k, v in exp_config.items():
if k in config:
if isinstance(v, dict):
if k == 'TRAIN':
if 'BBOX_WEIGHTS' in v:
v['BBOX_WEIGHTS'] = np.array(v['BBOX_WEIGHTS'])
elif k == 'network':
if 'PIXEL_MEANS' in v:
v['PIXEL_MEANS'] = np.array(v['PIXEL_MEANS'])
for vk, vv in v.items():
config[k][vk] = vv
else:
if k == 'SCALES':
config[k][0] = (tuple(v))
else:
config[k] = v
else:
raise ValueError("key must exist in config.py")
================================================
FILE: dff_rfcn/core/DataParallelExecutorGroup.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import logging
import numpy as np
from mxnet import context as ctx
from mxnet import ndarray as nd
from mxnet.io import DataDesc
from mxnet.executor_manager import _split_input_slice
def _load_general(data, targets, major_axis):
"""Load a list of arrays into a list of arrays specified by slices"""
for d_src, d_targets in zip(data, targets):
if isinstance(d_targets, nd.NDArray):
d_src.copyto(d_targets)
elif isinstance(d_src, (list, tuple)):
for src, dst in zip(d_src, d_targets):
src.copyto(dst)
else:
raise NotImplementedError
def _load_data(batch, targets, major_axis):
"""Load data into sliced arrays"""
_load_general(batch.data, targets, major_axis)
def _load_label(batch, targets, major_axis):
"""Load label into sliced arrays"""
_load_general(batch.label, targets, major_axis)
def _merge_multi_context(outputs, major_axis):
"""Merge outputs that lives on multiple context into one, so that they look
like living on one context.
"""
rets = []
for tensors, axis in zip(outputs, major_axis):
if axis >= 0:
rets.append(nd.concatenate(tensors, axis=axis, always_copy=False))
else:
# negative axis means the there is no batch_size axis, and all the
# results should be the same on each device. We simply take the
# first one, without checking they are actually the same
rets.append(tensors[0])
return rets
class DataParallelExecutorGroup(object):
"""DataParallelExecutorGroup is a group of executors that lives on a group of devices.
This is a helper class used to implement data parallelization. Each mini-batch will
be split and run on the devices.
Parameters
----------
symbol : Symbol
The common symbolic computation graph for all executors.
contexts : list
A list of contexts.
workload : list
If not `None`, could be a list of numbers that specify the workload to be assigned
to different context. Larger number indicate heavier workload.
data_shapes : list
Should be a list of (name, shape) tuples, for the shapes of data. Note the order is
important and should be the same as the order that the `DataIter` provide the data.
label_shapes : list
Should be a list of (name, shape) tuples, for the shapes of label. Note the order is
important and should be the same as the order that the `DataIter` provide the label.
param_names : list
A list of strings, indicating the names of parameters (e.g. weights, filters, etc.)
in the computation graph.
for_training : bool
Indicate whether the executors should be bind for training. When not doing training,
the memory for gradients will not be allocated.
inputs_need_grad : bool
Indicate whether the gradients for the input data should be computed. This is currently
not used. It will be useful for implementing composition of modules.
shared_group : DataParallelExecutorGroup
Default is `None`. This is used in bucketing. When not `None`, it should be a executor
group corresponding to a different bucket. In other words, it will correspond to a different
symbol but with the same set of parameters (e.g. unrolled RNNs with different lengths).
In this case, many memory will be shared.
logger : Logger
Default is `logging`.
fixed_param_names: list of str
Indicate parameters to be fixed during training. Parameters in this list will not allocate
space for gradient, nor do gradient calculation.
grad_req : str, list of str, dict of str to str
Requirement for gradient accumulation. Can be 'write', 'add', or 'null'
(default to 'write').
Can be specified globally (str) or for each argument (list, dict).
"""
def __init__(self, symbol, contexts, workload, data_shapes, label_shapes, param_names,
for_training, inputs_need_grad, shared_group=None, logger=logging,
fixed_param_names=None, grad_req='write', state_names=None):
self.param_names = param_names
self.arg_names = symbol.list_arguments()
self.aux_names = symbol.list_auxiliary_states()
self.symbol = symbol
self.contexts = contexts
self.workload = workload
self.for_training = for_training
self.inputs_need_grad = inputs_need_grad
self.logger = logger
#In the future we should have a better way to profile memory per device (haibin)
# self._total_exec_bytes = 0
self.fixed_param_names = fixed_param_names
if self.fixed_param_names is None:
self.fixed_param_names = []
self.state_names = state_names
if self.state_names is None:
self.state_names = []
if not for_training:
grad_req = 'null'
# data_shapes = [x if isinstance(x, DataDesc) else DataDesc(*x) for x in data_shapes]
# if label_shapes is not None:
# label_shapes = [x if isinstance(x, DataDesc) else DataDesc(*x) for x in label_shapes]
data_names = [x.name for x in data_shapes[0]]
if isinstance(grad_req, str):
self.grad_req = {}
for k in self.arg_names:
if k in self.param_names:
self.grad_req[k] = 'null' if k in self.fixed_param_names else grad_req
elif k in data_names:
self.grad_req[k] = grad_req if self.inputs_need_grad else 'null'
else:
self.grad_req[k] = 'null'
elif isinstance(grad_req, (list, tuple)):
assert len(grad_req) == len(self.arg_names)
self.grad_req = dict(zip(self.arg_names, grad_req))
elif isinstance(grad_req, dict):
self.grad_req = {}
for k in self.arg_names:
if k in self.param_names:
self.grad_req[k] = 'null' if k in self.fixed_param_names else 'write'
elif k in data_names:
self.grad_req[k] = 'write' if self.inputs_need_grad else 'null'
else:
self.grad_req[k] = 'null'
self.grad_req.update(grad_req)
else:
raise ValueError("grad_req must be one of str, list, tuple, or dict.")
if shared_group is not None:
self.shared_data_arrays = shared_group.shared_data_arrays
else:
self.shared_data_arrays = [{} for _ in contexts]
# initialize some instance variables
self.batch_size = len(data_shapes)
self.slices = None
self.execs = []
self._default_execs = None
self.data_arrays = None
self.label_arrays = None
self.param_arrays = None
self.state_arrays = None
self.grad_arrays = None
self.aux_arrays = None
self.input_grad_arrays = None
self.data_shapes = None
self.label_shapes = None
self.data_layouts = None
self.label_layouts = None
self.output_layouts = [DataDesc.get_batch_axis(self.symbol[name].attr('__layout__'))
for name in self.symbol.list_outputs()]
self.bind_exec(data_shapes, label_shapes, shared_group)
def decide_slices(self, data_shapes):
"""Decide the slices for each context according to the workload.
Parameters
----------
data_shapes : list
list of (name, shape) specifying the shapes for the input data or label.
"""
assert len(data_shapes) > 0
major_axis = [DataDesc.get_batch_axis(x.layout) for x in data_shapes]
for (name, shape), axis in zip(data_shapes, major_axis):
if axis == -1:
continue
batch_size = shape[axis]
if self.batch_size is not None:
assert batch_size == self.batch_size, ("all data must have the same batch size: "
+ ("batch_size = %d, but " % self.batch_size)
+ ("%s has shape %s" % (name, shape)))
else:
self.batch_size = batch_size
self.slices = _split_input_slice(self.batch_size, self.workload)
return major_axis
def _collect_arrays(self):
"""Collect internal arrays from executors."""
# convenient data structures
self.data_arrays = [[e.arg_dict[name] for name, _ in self.data_shapes[0]] for e in self.execs]
self.state_arrays = [[e.arg_dict[name] for e in self.execs]
for name in self.state_names]
if self.label_shapes is not None:
self.label_arrays = [[e.arg_dict[name] for name, _ in self.label_shapes[0]] for e in self.execs]
else:
self.label_arrays = None
self.param_arrays = [[exec_.arg_arrays[i] for exec_ in self.execs]
for i, name in enumerate(self.arg_names)
if name in self.param_names]
if self.for_training:
self.grad_arrays = [[exec_.grad_arrays[i] for exec_ in self.execs]
for i, name in enumerate(self.arg_names)
if name in self.param_names]
else:
self.grad_arrays = None
data_names = [x[0] for x in self.data_shapes]
if self.inputs_need_grad:
self.input_grad_arrays = [[exec_.grad_arrays[i] for exec_ in self.execs]
for i, name in enumerate(self.arg_names)
if name in data_names]
else:
self.input_grad_arrays = None
self.aux_arrays = [[exec_.aux_arrays[i] for exec_ in self.execs]
for i in range(len(self.aux_names))]
def bind_exec(self, data_shapes, label_shapes, shared_group=None, reshape=False):
"""Bind executors on their respective devices.
Parameters
----------
data_shapes : list
label_shapes : list
shared_group : DataParallelExecutorGroup
reshape : bool
"""
assert reshape or not self.execs
for i in range(len(self.contexts)):
data_shapes_i = data_shapes[i]
if label_shapes is not None:
label_shapes_i = label_shapes[i]
else:
label_shapes_i = []
if reshape:
self.execs[i] = self._default_execs[i].reshape(
allow_up_sizing=True, **dict(data_shapes_i + label_shapes_i))
else:
self.execs.append(self._bind_ith_exec(i, data_shapes_i, label_shapes_i,
shared_group))
self.data_shapes = data_shapes
self.label_shapes = label_shapes
self._collect_arrays()
def reshape(self, data_shapes, label_shapes):
"""Reshape executors.
Parameters
----------
data_shapes : list
label_shapes : list
"""
if self._default_execs is None:
self._default_execs = [i for i in self.execs]
for i in range(len(self.contexts)):
self.execs[i] = self._default_execs[i].reshape(
allow_up_sizing=True, **dict(data_shapes[i] + (label_shapes[i] if label_shapes is not None else []))
)
self.data_shapes = data_shapes
self.label_shapes = label_shapes
self._collect_arrays()
def set_params(self, arg_params, aux_params):
"""Assign, i.e. copy parameters to all the executors.
Parameters
----------
arg_params : dict
A dictionary of name to `NDArray` parameter mapping.
aux_params : dict
A dictionary of name to `NDArray` auxiliary variable mapping.
"""
for exec_ in self.execs:
exec_.copy_params_from(arg_params, aux_params)
def get_params(self, arg_params, aux_params):
""" Copy data from each executor to `arg_params` and `aux_params`.
Parameters
----------
arg_params : list of NDArray
target parameter arrays
aux_params : list of NDArray
target aux arrays
Notes
-----
- This function will inplace update the NDArrays in arg_params and aux_params.
"""
for name, block in zip(self.param_names, self.param_arrays):
weight = sum(w.copyto(ctx.cpu()) for w in block) / len(block)
weight.astype(arg_params[name].dtype).copyto(arg_params[name])
for name, block in zip(self.aux_names, self.aux_arrays):
weight = sum(w.copyto(ctx.cpu()) for w in block) / len(block)
weight.astype(aux_params[name].dtype).copyto(aux_params[name])
def forward(self, data_batch, is_train=None):
"""Split `data_batch` according to workload and run forward on each devices.
Parameters
----------
data_batch : DataBatch
Or could be any object implementing similar interface.
is_train : bool
The hint for the backend, indicating whether we are during training phase.
Default is `None`, then the value `self.for_training` will be used.
Returns
-------
"""
_load_data(data_batch, self.data_arrays, self.data_layouts)
if is_train is None:
is_train = self.for_training
if self.label_arrays is not None:
assert not is_train or data_batch.label
if data_batch.label:
_load_label(data_batch, self.label_arrays, self.label_layouts)
for exec_ in self.execs:
exec_.forward(is_train=is_train)
def get_outputs(self, merge_multi_context=True):
"""Get outputs of the previous forward computation.
Parameters
----------
merge_multi_context : bool
Default is `True`. In the case when data-parallelism is used, the outputs
will be collected from multiple devices. A `True` value indicate that we
should merge the collected results so that they look like from a single
executor.
Returns
-------
If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it
is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output
elements are `NDArray`.
"""
outputs = [[exec_.outputs[i] for exec_ in self.execs]
for i in range(len(self.execs[0].outputs))]
if merge_multi_context:
outputs = _merge_multi_context(outputs, self.output_layouts)
return outputs
def get_states(self, merge_multi_context=True):
"""Get states from all devices
Parameters
----------
merge_multi_context : bool
Default is `True`. In the case when data-parallelism is used, the states
will be collected from multiple devices. A `True` value indicate that we
should merge the collected results so that they look like from a single
executor.
Returns
-------
If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it
is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output
elements are `NDArray`.
"""
assert not merge_multi_context, \
"merge_multi_context=True is not supported for get_states yet."
return self.state_arrays
def set_states(self, states=None, value=None):
"""Set value for states. Only one of states & value can be specified.
Parameters
----------
states : list of list of NDArrays
source states arrays formatted like [[state1_dev1, state1_dev2],
[state2_dev1, state2_dev2]].
value : number
a single scalar value for all state arrays.
"""
if states is not None:
assert value is None, "Only one of states & value can be specified."
_load_general(states, self.state_arrays, (0,)*len(states))
else:
assert value is not None, "At least one of states & value must be specified."
assert states is None, "Only one of states & value can be specified."
for d_dst in self.state_arrays:
for dst in d_dst:
dst[:] = value
def get_input_grads(self, merge_multi_context=True):
"""Get the gradients with respect to the inputs of the module.
Parameters
----------
merge_multi_context : bool
Default is `True`. In the case when data-parallelism is used, the outputs
will be collected from multiple devices. A `True` value indicate that we
should merge the collected results so that they look like from a single
executor.
Returns
-------
If `merge_multi_context` is `True`, it is like `[grad1, grad2]`. Otherwise, it
is like `[[grad1_dev1, grad1_dev2], [grad2_dev1, grad2_dev2]]`. All the output
elements are `NDArray`.
"""
assert self.inputs_need_grad
if merge_multi_context:
return _merge_multi_context(self.input_grad_arrays, self.data_layouts)
return self.input_grad_arrays
def backward(self, out_grads=None):
"""Run backward on all devices. A backward should be called after
a call to the forward function. Backward cannot be called unless
`self.for_training` is `True`.
Parameters
----------
out_grads : NDArray or list of NDArray, optional
Gradient on the outputs to be propagated back.
This parameter is only needed when bind is called
on outputs that are not a loss function.
"""
assert self.for_training, 're-bind with for_training=True to run backward'
if out_grads is None:
out_grads = []
for i, exec_ in enumerate(self.execs):
out_grads_slice = []
exec_.backward(out_grads=out_grads_slice)
def update_metric(self, eval_metric, labels):
"""Accumulate the performance according to `eval_metric` on all devices.
Parameters
----------
eval_metric : EvalMetric
The metric used for evaluation.
labels : list of NDArray
Typically comes from `label` of a `DataBatch`.
"""
for texec, labels in zip(self.execs, labels):
eval_metric.update(labels, texec.outputs)
def _bind_ith_exec(self, i, data_shapes, label_shapes, shared_group):
"""Internal utility function to bind the i-th executor.
"""
shared_exec = None if shared_group is None else shared_group.execs[i]
context = self.contexts[i]
shared_data_arrays = self.shared_data_arrays[i]
input_shapes = dict(data_shapes)
if label_shapes is not None:
input_shapes.update(dict(label_shapes))
arg_shapes, _, aux_shapes = self.symbol.infer_shape(**input_shapes)
assert arg_shapes is not None, "shape inference failed"
input_types = {x.name: x.dtype for x in data_shapes}
if label_shapes is not None:
input_types.update({x.name: x.dtype for x in label_shapes})
arg_types, _, aux_types = self.symbol.infer_type(**input_types)
assert arg_types is not None, "type inference failed"
arg_arrays = []
grad_arrays = {} if self.for_training else None
def _get_or_reshape(name, shared_data_arrays, arg_shape, arg_type, context, logger):
"""Internal helper to get a memory block or re-use by re-shaping"""
if name in shared_data_arrays:
arg_arr = shared_data_arrays[name]
if np.prod(arg_arr.shape) >= np.prod(arg_shape):
# nice, we can directly re-use this data blob
assert arg_arr.dtype == arg_type
arg_arr = arg_arr.reshape(arg_shape)
else:
logger.warning(('bucketing: data "%s" has a shape %s' % (name, arg_shape)) +
(', which is larger than already allocated ') +
('shape %s' % (arg_arr.shape,)) +
('. Need to re-allocate. Consider putting ') +
('default_bucket_key to') +
(' be the bucket taking the largest input for better ') +
('memory sharing.'))
arg_arr = nd.zeros(arg_shape, context, dtype=arg_type)
# replace existing shared array because the new one is bigger
shared_data_arrays[name] = arg_arr
else:
arg_arr = nd.zeros(arg_shape, context, dtype=arg_type)
shared_data_arrays[name] = arg_arr
return arg_arr
# create or borrow arguments and gradients
for j in range(len(self.arg_names)):
name = self.arg_names[j]
if name in self.param_names: # model parameters
if shared_exec is None:
arg_arr = nd.zeros(arg_shapes[j], context, dtype=arg_types[j])
if self.grad_req[name] != 'null':
grad_arr = nd.zeros(arg_shapes[j], context, dtype=arg_types[j])
grad_arrays[name] = grad_arr
else:
arg_arr = shared_exec.arg_dict[name]
assert arg_arr.shape == arg_shapes[j]
assert arg_arr.dtype == arg_types[j]
if self.grad_req[name] != 'null':
grad_arrays[name] = shared_exec.grad_dict[name]
else: # data, label, or states
arg_arr = _get_or_reshape(name, shared_data_arrays, arg_shapes[j], arg_types[j],
context, self.logger)
# data might also need grad if inputs_need_grad is True
if self.grad_req[name] != 'null':
grad_arrays[name] = _get_or_reshape('grad of ' + name, shared_data_arrays,
arg_shapes[j], arg_types[j], context,
self.logger)
arg_arrays.append(arg_arr)
# create or borrow aux variables
if shared_exec is None:
aux_arrays = [nd.zeros(s, context, dtype=t) for s, t in zip(aux_shapes, aux_types)]
else:
for j, arr in enumerate(shared_exec.aux_arrays):
assert aux_shapes[j] == arr.shape
assert aux_types[j] == arr.dtype
aux_arrays = shared_exec.aux_arrays[:]
executor = self.symbol.bind(ctx=context, args=arg_arrays,
args_grad=grad_arrays, aux_states=aux_arrays,
grad_req=self.grad_req, shared_exec=shared_exec)
# Get the total bytes allocated for this executor
return executor
def _sliced_shape(self, shapes, i, major_axis):
"""Get the sliced shapes for the i-th executor.
Parameters
----------
shapes : list of (str, tuple)
The original (name, shape) pairs.
i : int
Which executor we are dealing with.
"""
sliced_shapes = []
for desc, axis in zip(shapes, major_axis):
shape = list(desc.shape)
if axis >= 0:
shape[axis] = self.slices[i].stop - self.slices[i].start
sliced_shapes.append(DataDesc(desc.name, tuple(shape), desc.dtype, desc.layout))
return sliced_shapes
def install_monitor(self, mon):
"""Install monitor on all executors"""
for exe in self.execs:
mon.install(exe)
================================================
FILE: dff_rfcn/core/__init__.py
================================================
================================================
FILE: dff_rfcn/core/callback.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import time
import logging
import mxnet as mx
class Speedometer(object):
def __init__(self, batch_size, frequent=50):
self.batch_size = batch_size
self.frequent = frequent
self.init = False
self.tic = 0
self.last_count = 0
def __call__(self, param):
"""Callback to Show speed."""
count = param.nbatch
if self.last_count > count:
self.init = False
self.last_count = count
if self.init:
if count % self.frequent == 0:
speed = self.frequent * self.batch_size / (time.time() - self.tic)
s = ''
if param.eval_metric is not None:
name, value = param.eval_metric.get()
s = "Epoch[%d] Batch [%d]\tSpeed: %.2f samples/sec\tTrain-" % (param.epoch, count, speed)
for n, v in zip(name, value):
s += "%s=%f,\t" % (n, v)
else:
s = "Iter[%d] Batch [%d]\tSpeed: %.2f samples/sec" % (param.epoch, count, speed)
logging.info(s)
print(s)
self.tic = time.time()
else:
self.init = True
self.tic = time.time()
def do_checkpoint(prefix, means, stds):
def _callback(iter_no, sym, arg, aux):
weight = arg['rfcn_bbox_weight']
bias = arg['rfcn_bbox_bias']
repeat = bias.shape[0] / means.shape[0]
arg['rfcn_bbox_weight_test'] = weight * mx.nd.repeat(mx.nd.array(stds), repeats=repeat).reshape((bias.shape[0], 1, 1, 1))
arg['rfcn_bbox_bias_test'] = arg['rfcn_bbox_bias'] * mx.nd.repeat(mx.nd.array(stds), repeats=repeat) + mx.nd.repeat(mx.nd.array(means), repeats=repeat)
mx.model.save_checkpoint(prefix, iter_no + 1, sym, arg, aux)
arg.pop('rfcn_bbox_weight_test')
arg.pop('rfcn_bbox_bias_test')
return _callback
================================================
FILE: dff_rfcn/core/loader.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Xizhou Zhu, Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import numpy as np
import mxnet as mx
from mxnet.executor_manager import _split_input_slice
from config.config import config
from utils.image import tensor_vstack
from rpn.rpn import get_rpn_testbatch, get_rpn_pair_batch, assign_anchor
from rcnn import get_rcnn_testbatch, get_rcnn_batch
class TestLoader(mx.io.DataIter):
def __init__(self, roidb, config, batch_size=1, shuffle=False,
has_rpn=False):
super(TestLoader, self).__init__()
# save parameters as properties
self.cfg = config
self.roidb = roidb
self.batch_size = batch_size
self.shuffle = shuffle
self.has_rpn = has_rpn
# infer properties from roidb
self.size = np.sum([x['frame_seg_len'] for x in self.roidb])
self.index = np.arange(self.size)
# decide data and label names (only for training)
self.data_name = ['data', 'im_info', 'data_key', 'feat_key']
self.label_name = None
#
self.cur_roidb_index = 0
self.cur_frameid = 0
self.data_key = None
self.key_frameid = 0
self.cur_seg_len = 0
self.key_frame_flag = -1
# status variable for synchronization between get_data and get_label
self.cur = 0
self.data = None
self.label = []
self.im_info = None
# get first batch to fill in provide_data and provide_label
self.reset()
self.get_batch()
@property
def provide_data(self):
return [[(k, v.shape) for k, v in zip(self.data_name, idata)] for idata in self.data]
@property
def provide_label(self):
return [None for _ in range(len(self.data))]
@property
def provide_data_single(self):
return [(k, v.shape) for k, v in zip(self.data_name, self.data[0])]
@property
def provide_label_single(self):
return None
def reset(self):
self.cur = 0
if self.shuffle:
np.random.shuffle(self.index)
def iter_next(self):
return self.cur < self.size
def next(self):
if self.iter_next():
self.get_batch()
self.cur += self.batch_size
self.cur_frameid += 1
if self.cur_frameid == self.cur_seg_len:
self.cur_roidb_index += 1
self.cur_frameid = 0
self.key_frameid = 0
elif self.cur_frameid - self.key_frameid == self.cfg.TEST.KEY_FRAME_INTERVAL:
self.key_frameid = self.cur_frameid
return self.im_info, self.key_frame_flag, mx.io.DataBatch(data=self.data, label=self.label,
pad=self.getpad(), index=self.getindex(),
provide_data=self.provide_data, provide_label=self.provide_label)
else:
raise StopIteration
def getindex(self):
return self.cur / self.batch_size
def getpad(self):
if self.cur + self.batch_size > self.size:
return self.cur + self.batch_size - self.size
else:
return 0
def get_batch(self):
cur_roidb = self.roidb[self.cur_roidb_index].copy()
cur_roidb['image'] = cur_roidb['pattern'] % self.cur_frameid
self.cur_seg_len = cur_roidb['frame_seg_len']
data, label, im_info = get_rpn_testbatch([cur_roidb], self.cfg)
if self.key_frameid == self.cur_frameid: # key frame
self.data_key = data[0]['data'].copy()
if self.key_frameid == 0:
self.key_frame_flag = 0
else:
self.key_frame_flag = 1
else:
self.key_frame_flag = 2
extend_data = [{'data': data[0]['data'],
'im_info': data[0]['im_info'],
'data_key': self.data_key,
'feat_key': np.zeros((1,self.cfg.network.DFF_FEAT_DIM,1,1))}]
self.data = [[mx.nd.array(extend_data[i][name]) for name in self.data_name] for i in xrange(len(data))]
self.im_info = im_info
class AnchorLoader(mx.io.DataIter):
def __init__(self, feat_sym, roidb, cfg, batch_size=1, shuffle=False, ctx=None, work_load_list=None,
feat_stride=16, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2), allowed_border=0,
aspect_grouping=False, normalize_target=False, bbox_mean=(0.0, 0.0, 0.0, 0.0),
bbox_std=(0.1, 0.1, 0.4, 0.4)):
"""
This Iter will provide roi data to Fast R-CNN network
:param feat_sym: to infer shape of assign_output
:param roidb: must be preprocessed
:param batch_size: must divide BATCH_SIZE(128)
:param shuffle: bool
:param ctx: list of contexts
:param work_load_list: list of work load
:param aspect_grouping: group images with similar aspects
:param normalize_target: normalize rpn target
:param bbox_mean: anchor target mean
:param bbox_std: anchor target std
:return: AnchorLoader
"""
super(AnchorLoader, self).__init__()
# save parameters as properties
self.feat_sym = feat_sym
self.roidb = roidb
self.cfg = cfg
self.batch_size = batch_size
self.shuffle = shuffle
self.ctx = ctx
if self.ctx is None:
self.ctx = [mx.cpu()]
self.work_load_list = work_load_list
self.feat_stride = feat_stride
self.anchor_scales = anchor_scales
self.anchor_ratios = anchor_ratios
self.allowed_border = allowed_border
self.aspect_grouping = aspect_grouping
self.normalize_target = normalize_target
self.bbox_mean = bbox_mean
self.bbox_std = bbox_std
# infer properties from roidb
self.size = len(roidb)
self.index = np.arange(self.size)
# decide data and label names
if config.TRAIN.END2END:
self.data_name = ['data', 'data_ref', 'eq_flag', 'im_info', 'gt_boxes']
else:
self.data_name = ['data']
self.label_name = ['label', 'bbox_target', 'bbox_weight']
# status variable for synchronization between get_data and get_label
self.cur = 0
self.batch = None
self.data = None
self.label = None
# get first batch to fill in provide_data and provide_label
self.reset()
self.get_batch_individual()
@property
def provide_data(self):
return [[(k, v.shape) for k, v in zip(self.data_name, self.data[i])] for i in xrange(len(self.data))]
@property
def provide_label(self):
return [[(k, v.shape) for k, v in zip(self.label_name, self.label[i])] for i in xrange(len(self.data))]
@property
def provide_data_single(self):
return [(k, v.shape) for k, v in zip(self.data_name, self.data[0])]
@property
def provide_label_single(self):
return [(k, v.shape) for k, v in zip(self.label_name, self.label[0])]
def reset(self):
self.cur = 0
if self.shuffle:
if self.aspect_grouping:
widths = np.array([r['width'] for r in self.roidb])
heights = np.array([r['height'] for r in self.roidb])
horz = (widths >= heights)
vert = np.logical_not(horz)
horz_inds = np.where(horz)[0]
vert_inds = np.where(vert)[0]
inds = np.hstack((np.random.permutation(horz_inds), np.random.permutation(vert_inds)))
extra = inds.shape[0] % self.batch_size
inds_ = np.reshape(inds[:-extra], (-1, self.batch_size))
row_perm = np.random.permutation(np.arange(inds_.shape[0]))
inds[:-extra] = np.reshape(inds_[row_perm, :], (-1,))
self.index = inds
else:
np.random.shuffle(self.index)
def iter_next(self):
return self.cur + self.batch_size <= self.size
def next(self):
if self.iter_next():
self.get_batch_individual()
self.cur += self.batch_size
return mx.io.DataBatch(data=self.data, label=self.label,
pad=self.getpad(), index=self.getindex(),
provide_data=self.provide_data, provide_label=self.provide_label)
else:
raise StopIteration
def getindex(self):
return self.cur / self.batch_size
def getpad(self):
if self.cur + self.batch_size > self.size:
return self.cur + self.batch_size - self.size
else:
return 0
def infer_shape(self, max_data_shape=None, max_label_shape=None):
""" Return maximum data and label shape for single gpu """
if max_data_shape is None:
max_data_shape = []
if max_label_shape is None:
max_label_shape = []
max_shapes = dict(max_data_shape + max_label_shape)
input_batch_size = max_shapes['data'][0]
im_info = [[max_shapes['data'][2], max_shapes['data'][3], 1.0]]
_, feat_shape, _ = self.feat_sym.infer_shape(**max_shapes)
label = assign_anchor(feat_shape[0], np.zeros((0, 5)), im_info, self.cfg,
self.feat_stride, self.anchor_scales, self.anchor_ratios, self.allowed_border,
self.normalize_target, self.bbox_mean, self.bbox_std)
label = [label[k] for k in self.label_name]
label_shape = [(k, tuple([input_batch_size] + list(v.shape[1:]))) for k, v in zip(self.label_name, label)]
return max_data_shape, label_shape
def get_batch(self):
# slice roidb
cur_from = self.cur
cur_to = min(cur_from + self.batch_size, self.size)
roidb = [self.roidb[self.index[i]] for i in range(cur_from, cur_to)]
# decide multi device slice
work_load_list = self.work_load_list
ctx = self.ctx
if work_load_list is None:
work_load_list = [1] * len(ctx)
assert isinstance(work_load_list, list) and len(work_load_list) == len(ctx), \
"Invalid settings for work load. "
slices = _split_input_slice(self.batch_size, work_load_list)
# get testing data for multigpu
data_list = []
label_list = []
for islice in slices:
iroidb = [roidb[i] for i in range(islice.start, islice.stop)]
data, label = get_rpn_pair_batch(iroidb, self.cfg)
data_list.append(data)
label_list.append(label)
# pad data first and then assign anchor (read label)
data_tensor = tensor_vstack([batch['data'] for batch in data_list])
for data, data_pad in zip(data_list, data_tensor):
data['data'] = data_pad[np.newaxis, :]
new_label_list = []
for data, label in zip(data_list, label_list):
# infer label shape
data_shape = {k: v.shape for k, v in data.items()}
del data_shape['im_info']
_, feat_shape, _ = self.feat_sym.infer_shape(**data_shape)
feat_shape = [int(i) for i in feat_shape[0]]
# add gt_boxes to data for e2e
data['gt_boxes'] = label['gt_boxes'][np.newaxis, :, :]
# assign anchor for label
label = assign_anchor(feat_shape, label['gt_boxes'], data['im_info'], self.cfg,
self.feat_stride, self.anchor_scales,
self.anchor_ratios, self.allowed_border,
self.normalize_target, self.bbox_mean, self.bbox_std)
new_label_list.append(label)
all_data = dict()
for key in self.data_name:
all_data[key] = tensor_vstack([batch[key] for batch in data_list])
all_label = dict()
for key in self.label_name:
pad = -1 if key == 'label' else 0
all_label[key] = tensor_vstack([batch[key] for batch in new_label_list], pad=pad)
self.data = [mx.nd.array(all_data[key]) for key in self.data_name]
self.label = [mx.nd.array(all_label[key]) for key in self.label_name]
def get_batch_individual(self):
cur_from = self.cur
cur_to = min(cur_from + self.batch_size, self.size)
roidb = [self.roidb[self.index[i]] for i in range(cur_from, cur_to)]
# decide multi device slice
work_load_list = self.work_load_list
ctx = self.ctx
if work_load_list is None:
work_load_list = [1] * len(ctx)
assert isinstance(work_load_list, list) and len(work_load_list) == len(ctx), \
"Invalid settings for work load. "
slices = _split_input_slice(self.batch_size, work_load_list)
rst = []
for idx, islice in enumerate(slices):
iroidb = [roidb[i] for i in range(islice.start, islice.stop)]
rst.append(self.parfetch(iroidb))
all_data = [_['data'] for _ in rst]
all_label = [_['label'] for _ in rst]
self.data = [[mx.nd.array(data[key]) for key in self.data_name] for data in all_data]
self.label = [[mx.nd.array(label[key]) for key in self.label_name] for label in all_label]
def parfetch(self, iroidb):
# get testing data for multigpu
data, label = get_rpn_pair_batch(iroidb, self.cfg)
data_shape = {k: v.shape for k, v in data.items()}
del data_shape['im_info']
_, feat_shape, _ = self.feat_sym.infer_shape(**data_shape)
feat_shape = [int(i) for i in feat_shape[0]]
# add gt_boxes to data for e2e
data['gt_boxes'] = label['gt_boxes'][np.newaxis, :, :]
# assign anchor for label
label = assign_anchor(feat_shape, label['gt_boxes'], data['im_info'], self.cfg,
self.feat_stride, self.anchor_scales,
self.anchor_ratios, self.allowed_border,
self.normalize_target, self.bbox_mean, self.bbox_std)
return {'data': data, 'label': label}
================================================
FILE: dff_rfcn/core/metric.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import mxnet as mx
import numpy as np
def get_rpn_names():
pred = ['rpn_cls_prob', 'rpn_bbox_loss']
label = ['rpn_label', 'rpn_bbox_target', 'rpn_bbox_weight']
return pred, label
def get_rcnn_names(cfg):
pred = ['rcnn_cls_prob', 'rcnn_bbox_loss']
label = ['rcnn_label', 'rcnn_bbox_target', 'rcnn_bbox_weight']
if cfg.TRAIN.ENABLE_OHEM or cfg.TRAIN.END2END:
pred.append('rcnn_label')
if cfg.TRAIN.END2END:
rpn_pred, rpn_label = get_rpn_names()
pred = rpn_pred + pred
label = rpn_label
return pred, label
class RPNAccMetric(mx.metric.EvalMetric):
def __init__(self):
super(RPNAccMetric, self).__init__('RPNAcc')
self.pred, self.label = get_rpn_names()
def update(self, labels, preds):
pred = preds[self.pred.index('rpn_cls_prob')]
label = labels[self.label.index('rpn_label')]
# pred (b, c, p) or (b, c, h, w)
pred_label = mx.ndarray.argmax_channel(pred).asnumpy().astype('int32')
pred_label = pred_label.reshape((pred_label.shape[0], -1))
# label (b, p)
label = label.asnumpy().astype('int32')
# filter with keep_inds
keep_inds = np.where(label != -1)
pred_label = pred_label[keep_inds]
label = label[keep_inds]
self.sum_metric += np.sum(pred_label.flat == label.flat)
self.num_inst += len(pred_label.flat)
class RCNNAccMetric(mx.metric.EvalMetric):
def __init__(self, cfg):
super(RCNNAccMetric, self).__init__('RCNNAcc')
self.e2e = cfg.TRAIN.END2END
self.ohem = cfg.TRAIN.ENABLE_OHEM
self.pred, self.label = get_rcnn_names(cfg)
def update(self, labels, preds):
pred = preds[self.pred.index('rcnn_cls_prob')]
if self.ohem or self.e2e:
label = preds[self.pred.index('rcnn_label')]
else:
label = labels[self.label.index('rcnn_label')]
last_dim = pred.shape[-1]
pred_label = pred.asnumpy().reshape(-1, last_dim).argmax(axis=1).astype('int32')
label = label.asnumpy().reshape(-1,).astype('int32')
# filter with keep_inds
keep_inds = np.where(label != -1)
pred_label = pred_label[keep_inds]
label = label[keep_inds]
self.sum_metric += np.sum(pred_label.flat == label.flat)
self.num_inst += len(pred_label.flat)
class RPNLogLossMetric(mx.metric.EvalMetric):
def __init__(self):
super(RPNLogLossMetric, self).__init__('RPNLogLoss')
self.pred, self.label = get_rpn_names()
def update(self, labels, preds):
pred = preds[self.pred.index('rpn_cls_prob')]
label = labels[self.label.index('rpn_label')]
# label (b, p)
label = label.asnumpy().astype('int32').reshape((-1))
# pred (b, c, p) or (b, c, h, w) --> (b, p, c) --> (b*p, c)
pred = pred.asnumpy().reshape((pred.shape[0], pred.shape[1], -1)).transpose((0, 2, 1))
pred = pred.reshape((label.shape[0], -1))
# filter with keep_inds
keep_inds = np.where(label != -1)[0]
label = label[keep_inds]
cls = pred[keep_inds, label]
cls += 1e-14
cls_loss = -1 * np.log(cls)
cls_loss = np.sum(cls_loss)
self.sum_metric += cls_loss
self.num_inst += label.shape[0]
class RCNNLogLossMetric(mx.metric.EvalMetric):
def __init__(self, cfg):
super(RCNNLogLossMetric, self).__init__('RCNNLogLoss')
self.e2e = cfg.TRAIN.END2END
self.ohem = cfg.TRAIN.ENABLE_OHEM
self.pred, self.label = get_rcnn_names(cfg)
def update(self, labels, preds):
pred = preds[self.pred.index('rcnn_cls_prob')]
if self.ohem or self.e2e:
label = preds[self.pred.index('rcnn_label')]
else:
label = labels[self.label.index('rcnn_label')]
last_dim = pred.shape[-1]
pred = pred.asnumpy().reshape(-1, last_dim)
label = label.asnumpy().reshape(-1,).astype('int32')
# filter with keep_inds
keep_inds = np.where(label != -1)[0]
label = label[keep_inds]
cls = pred[keep_inds, label]
cls += 1e-14
cls_loss = -1 * np.log(cls)
cls_loss = np.sum(cls_loss)
self.sum_metric += cls_loss
self.num_inst += label.shape[0]
class RPNL1LossMetric(mx.metric.EvalMetric):
def __init__(self):
super(RPNL1LossMetric, self).__init__('RPNL1Loss')
self.pred, self.label = get_rpn_names()
def update(self, labels, preds):
bbox_loss = preds[self.pred.index('rpn_bbox_loss')].asnumpy()
# calculate num_inst (average on those kept anchors)
label = labels[self.label.index('rpn_label')].asnumpy()
num_inst = np.sum(label != -1)
self.sum_metric += np.sum(bbox_loss)
self.num_inst += num_inst
class RCNNL1LossMetric(mx.metric.EvalMetric):
def __init__(self, cfg):
super(RCNNL1LossMetric, self).__init__('RCNNL1Loss')
self.e2e = cfg.TRAIN.END2END
self.ohem = cfg.TRAIN.ENABLE_OHEM
self.pred, self.label = get_rcnn_names(cfg)
def update(self, labels, preds):
bbox_loss = preds[self.pred.index('rcnn_bbox_loss')].asnumpy()
if self.ohem:
label = preds[self.pred.index('rcnn_label')].asnumpy()
else:
if self.e2e:
label = preds[self.pred.index('rcnn_label')].asnumpy()
else:
label = labels[self.label.index('rcnn_label')].asnumpy()
# calculate num_inst (average on those kept anchors)
num_inst = np.sum(label != -1)
self.sum_metric += np.sum(bbox_loss)
self.num_inst += num_inst
================================================
FILE: dff_rfcn/core/module.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
"""A `MutableModule` implement the `BaseModule` API, and allows input shape
varying with training iterations. If shapes vary, executors will rebind,
using shared arrays from the initial module binded with maximum shape.
"""
import time
import logging
import warnings
from mxnet import context as ctx
from mxnet.initializer import Uniform, InitDesc
from mxnet.module.base_module import BaseModule, _check_input_names, _parse_data_desc, _as_list
from mxnet.model import _create_kvstore, _initialize_kvstore, _update_params, _update_params_on_kvstore, load_checkpoint, BatchEndParam
from mxnet import metric
from .DataParallelExecutorGroup import DataParallelExecutorGroup
from mxnet import ndarray as nd
from mxnet import optimizer as opt
class Module(BaseModule):
"""Module is a basic module that wrap a `Symbol`. It is functionally the same
as the `FeedForward` model, except under the module API.
Parameters
----------
symbol : Symbol
data_names : list of str
Default is `('data')` for a typical model used in image classification.
label_names : list of str
Default is `('softmax_label')` for a typical model used in image
classification.
logger : Logger
Default is `logging`.
context : Context or list of Context
Default is `cpu()`.
work_load_list : list of number
Default `None`, indicating uniform workload.
fixed_param_names: list of str
Default `None`, indicating no network parameters are fixed.
state_names : list of str
states are similar to data and label, but not provided by data iterator.
Instead they are initialized to 0 and can be set by set_states()
"""
def __init__(self, symbol, data_names=('data',), label_names=('softmax_label',),
logger=logging, context=ctx.cpu(), work_load_list=None,
fixed_param_names=None, state_names=None):
super(Module, self).__init__(logger=logger)
if isinstance(context, ctx.Context):
context = [context]
self._context = context
if work_load_list is None:
work_load_list = [1] * len(self._context)
assert len(work_load_list) == len(self._context)
self._work_load_list = work_load_list
self._symbol = symbol
data_names = list(data_names) if data_names is not None else []
label_names = list(label_names) if label_names is not None else []
state_names = list(state_names) if state_names is not None else []
fixed_param_names = list(fixed_param_names) if fixed_param_names is not None else []
_check_input_names(symbol, data_names, "data", True)
_check_input_names(symbol, label_names, "label", False)
_check_input_names(symbol, state_names, "state", True)
_check_input_names(symbol, fixed_param_names, "fixed_param", True)
arg_names = symbol.list_arguments()
input_names = data_names + label_names + state_names
self._param_names = [x for x in arg_names if x not in input_names]
self._fixed_param_names = fixed_param_names
self._aux_names = symbol.list_auxiliary_states()
self._data_names = data_names
self._label_names = label_names
self._state_names = state_names
self._output_names = symbol.list_outputs()
self._arg_params = None
self._aux_params = None
self._params_dirty = False
self._optimizer = None
self._kvstore = None
self._update_on_kvstore = None
self._updater = None
self._preload_opt_states = None
self._grad_req = None
self._exec_group = None
self._data_shapes = None
self._label_shapes = None
@staticmethod
def load(prefix, epoch, load_optimizer_states=False, **kwargs):
"""Create a model from previously saved checkpoint.
Parameters
----------
prefix : str
path prefix of saved model files. You should have
"prefix-symbol.json", "prefix-xxxx.params", and
optionally "prefix-xxxx.states", where xxxx is the
epoch number.
epoch : int
epoch to load.
load_optimizer_states : bool
whether to load optimizer states. Checkpoint needs
to have been made with save_optimizer_states=True.
data_names : list of str
Default is `('data')` for a typical model used in image classification.
label_names : list of str
Default is `('softmax_label')` for a typical model used in image
classification.
logger : Logger
Default is `logging`.
context : Context or list of Context
Default is `cpu()`.
work_load_list : list of number
Default `None`, indicating uniform workload.
fixed_param_names: list of str
Default `None`, indicating no network parameters are fixed.
"""
sym, args, auxs = load_checkpoint(prefix, epoch)
mod = Module(symbol=sym, **kwargs)
mod._arg_params = args
mod._aux_params = auxs
mod.params_initialized = True
if load_optimizer_states:
mod._preload_opt_states = '%s-%04d.states'%(prefix, epoch)
return mod
def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):
"""Save current progress to checkpoint.
Use mx.callback.module_checkpoint as epoch_end_callback to save during training.
Parameters
----------
prefix : str
The file prefix to checkpoint to
epoch : int
The current epoch number
save_optimizer_states : bool
Whether to save optimizer states for continue training
"""
self._symbol.save('%s-symbol.json'%prefix)
param_name = '%s-%04d.params' % (prefix, epoch)
self.save_params(param_name)
logging.info('Saved checkpoint to \"%s\"', param_name)
if save_optimizer_states:
state_name = '%s-%04d.states' % (prefix, epoch)
self.save_optimizer_states(state_name)
logging.info('Saved optimizer state to \"%s\"', state_name)
def _reset_bind(self):
"""Internal function to reset binded state."""
self.binded = False
self._exec_group = None
self._data_shapes = None
self._label_shapes = None
@property
def data_names(self):
"""A list of names for data required by this module."""
return self._data_names
@property
def label_names(self):
"""A list of names for labels required by this module."""
return self._label_names
@property
def output_names(self):
"""A list of names for the outputs of this module."""
return self._output_names
@property
def data_shapes(self):
"""Get data shapes.
Returns
-------
A list of `(name, shape)` pairs.
"""
assert self.binded
return self._data_shapes
@property
def label_shapes(self):
"""Get label shapes.
Returns
-------
A list of `(name, shape)` pairs. The return value could be `None` if
the module does not need labels, or if the module is not binded for
training (in this case, label information is not available).
"""
assert self.binded
return self._label_shapes
@property
def output_shapes(self):
"""Get output shapes.
Returns
-------
A list of `(name, shape)` pairs.
"""
assert self.binded
return self._exec_group.get_output_shapes()
def get_params(self):
"""Get current parameters.
Returns
-------
`(arg_params, aux_params)`, each a dictionary of name to parameters (in
`NDArray`) mapping.
"""
assert self.binded and self.params_initialized
if self._params_dirty:
self._sync_params_from_devices()
return (self._arg_params, self._aux_params)
def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_params=None,
allow_missing=False, force_init=False):
"""Initialize the parameters and auxiliary states.
Parameters
----------
initializer : Initializer
Called to initialize parameters if needed.
arg_params : dict
If not None, should be a dictionary of existing arg_params. Initialization
will be copied from that.
aux_params : dict
If not None, should be a dictionary of existing aux_params. Initialization
will be copied from that.
allow_missing : bool
If true, params could contain missing values, and the initializer will be
called to fill those missing params.
force_init : bool
If true, will force re-initialize even if already initialized.
"""
if self.params_initialized and not force_init:
warnings.warn("Parameters already initialized and force_init=False. "
"init_params call ignored.", stacklevel=2)
return
assert self.binded, 'call bind before initializing the parameters'
def _impl(name, arr, cache):
"""Internal helper for parameter initialization"""
if cache is not None:
if name in cache:
cache_arr = cache[name]
# just in case the cached array is just the target itself
if cache_arr is not arr:
cache_arr.copyto(arr)
else:
if not allow_missing:
raise RuntimeError("%s is not presented" % name)
if initializer != None:
initializer(name, arr)
else:
initializer(name, arr)
attrs = self._symbol.attr_dict()
for name, arr in self._arg_params.items():
desc = InitDesc(name, attrs.get(name, None))
_impl(desc, arr, arg_params)
for name, arr in self._aux_params.items():
desc = InitDesc(name, attrs.get(name, None))
_impl(desc, arr, aux_params)
self.params_initialized = True
self._params_dirty = False
# copy the initialized parameters to devices
self._exec_group.set_params(self._arg_params, self._aux_params)
def set_params(self, arg_params, aux_params, allow_missing=False, force_init=True):
"""Assign parameter and aux state values.
Parameters
----------
arg_params : dict
Dictionary of name to value (`NDArray`) mapping.
aux_params : dict
Dictionary of name to value (`NDArray`) mapping.
allow_missing : bool
If true, params could contain missing values, and the initializer will be
called to fill those missing params.
force_init : bool
If true, will force re-initialize even if already initialized.
Examples
--------
An example of setting module parameters::
>>> sym, arg_params, aux_params = \
>>> mx.model.load_checkpoint(model_prefix, n_epoch_load)
>>> mod.set_params(arg_params=arg_params, aux_params=aux_params)
"""
if not allow_missing:
self.init_params(initializer=None, arg_params=arg_params, aux_params=aux_params,
allow_missing=allow_missing, force_init=force_init)
return
if self.params_initialized and not force_init:
warnings.warn("Parameters already initialized and force_init=False. "
"set_params call ignored.", stacklevel=2)
return
self._exec_group.set_params(arg_params, aux_params)
# because we didn't update self._arg_params, they are dirty now.
self._params_dirty = True
self.params_initialized = True
def bind(self, data_shapes, label_shapes=None, for_training=True,
inputs_need_grad=False, force_rebind=False, shared_module=None,
grad_req='write'):
"""Bind the symbols to construct executors. This is necessary before one
can perform computation with the module.
Parameters
----------
data_shapes : list of (str, tuple)
Typically is `data_iter.provide_data`.
label_shapes : list of (str, tuple)
Typically is `data_iter.provide_label`.
for_training : bool
Default is `True`. Whether the executors should be bind for training.
inputs_need_grad : bool
Default is `False`. Whether the gradients to the input data need to be computed.
Typically this is not needed. But this might be needed when implementing composition
of modules.
force_rebind : bool
Default is `False`. This function does nothing if the executors are already
binded. But with this `True`, the executors will be forced to rebind.
shared_module : Module
Default is `None`. This is used in bucketing. When not `None`, the shared module
essentially corresponds to a different bucket -- a module with different symbol
but with the same sets of parameters (e.g. unrolled RNNs with different lengths).
"""
# force rebinding is typically used when one want to switch from
# training to prediction phase.
if force_rebind:
self._reset_bind()
if self.binded:
self.logger.warning('Already binded, ignoring bind()')
return
self.for_training = for_training
self.inputs_need_grad = inputs_need_grad
self.binded = True
self._grad_req = grad_req
if not for_training:
assert not inputs_need_grad
else:
pass
# this is not True, as some module might not contains a loss function
# that consumes the labels
# assert label_shapes is not None
# self._data_shapes, self._label_shapes = _parse_data_desc(
# self.data_names, self.label_names, data_shapes, label_shapes)
self._data_shapes, self._label_shapes = zip(*[_parse_data_desc(self.data_names, self.label_names, data_shape, label_shape)
for data_shape, label_shape in zip(data_shapes, label_shapes)])
if self._label_shapes.count(None) == len(self._label_shapes):
self._label_shapes = None
if shared_module is not None:
assert isinstance(shared_module, Module) and \
shared_module.binded and shared_module.params_initialized
shared_group = shared_module._exec_group
else:
shared_group = None
self._exec_group = DataParallelExecutorGroup(self._symbol, self._context,
self._work_load_list, self._data_shapes,
self._label_shapes, self._param_names,
for_training, inputs_need_grad,
shared_group, logger=self.logger,
fixed_param_names=self._fixed_param_names,
grad_req=grad_req,
state_names=self._state_names)
# self._total_exec_bytes = self._exec_group._total_exec_bytes
if shared_module is not None:
self.params_initialized = True
self._arg_params = shared_module._arg_params
self._aux_params = shared_module._aux_params
elif self.params_initialized:
# if the parameters are already initialized, we are re-binding
# so automatically copy the already initialized params
self._exec_group.set_params(self._arg_params, self._aux_params)
else:
assert self._arg_params is None and self._aux_params is None
param_arrays = [
nd.zeros(x[0].shape, dtype=x[0].dtype)
for x in self._exec_group.param_arrays
]
self._arg_params = {name:arr for name, arr in zip(self._param_names, param_arrays)}
aux_arrays = [
nd.zeros(x[0].shape, dtype=x[0].dtype)
for x in self._exec_group.aux_arrays
]
self._aux_params = {name:arr for name, arr in zip(self._aux_names, aux_arrays)}
if shared_module is not None and shared_module.optimizer_initialized:
self.borrow_optimizer(shared_module)
def reshape(self, data_shapes, label_shapes=None):
"""Reshape the module for new input shapes.
Parameters
----------
data_shapes : list of (str, tuple)
Typically is `data_iter.provide_data`.
label_shapes : list of (str, tuple)
Typically is `data_iter.provide_label`.
"""
assert self.binded
# self._data_shapes, self._label_shapes = _parse_data_desc(
# self.data_names, self.label_names, data_shapes, label_shapes)
self._data_shapes, self._label_shapes = zip(*[_parse_data_desc(self.data_names, self.label_names, data_shape, label_shape)
for data_shape, label_shape in zip(data_shapes, label_shapes)])
self._exec_group.reshape(self._data_shapes, self._label_shapes)
def init_optimizer(self, kvstore='local', optimizer='sgd',
optimizer_params=(('learning_rate', 0.01),), force_init=False):
"""Install and initialize optimizers.
Parameters
----------
kvstore : str or KVStore
Default `'local'`.
optimizer : str or Optimizer
Default `'sgd'`
optimizer_params : dict
Default `(('learning_rate', 0.01),)`. The default value is not a dictionary,
just to avoid pylint warning of dangerous default values.
force_init : bool
Default `False`, indicating whether we should force re-initializing the
optimizer in the case an optimizer is already installed.
"""
assert self.binded and self.params_initialized
if self.optimizer_initialized and not force_init:
self.logger.warning('optimizer already initialized, ignoring...')
return
(kvstore, update_on_kvstore) = \
_create_kvstore(kvstore, len(self._context), self._arg_params)
batch_size = self._exec_group.batch_size
if kvstore and 'dist' in kvstore.type and '_sync' in kvstore.type:
batch_size *= kvstore.num_workers
rescale_grad = 1.0/batch_size
if isinstance(optimizer, str):
idx2name = {}
if update_on_kvstore:
idx2name.update(enumerate(self._exec_group.param_names))
else:
for k in range(len(self._context)):
idx2name.update({i*len(self._context)+k: n
for i, n in enumerate(self._exec_group.param_names)})
optimizer_params = dict(optimizer_params)
if 'rescale_grad' not in optimizer_params:
optimizer_params['rescale_grad'] = rescale_grad
optimizer = opt.create(optimizer,
sym=self.symbol, param_idx2name=idx2name,
**optimizer_params)
else:
assert isinstance(optimizer, opt.Optimizer)
if optimizer.rescale_grad != rescale_grad:
#pylint: disable=no-member
warnings.warn(
"Optimizer created manually outside Module but rescale_grad " +
"is not normalized to 1.0/batch_size/num_workers (%s vs. %s). "%(
optimizer.rescale_grad, rescale_grad) +
"Is this intended?", stacklevel=2)
self._optimizer = optimizer
self._kvstore = kvstore
self._update_on_kvstore = update_on_kvstore
self._updater = None
if kvstore:
# copy initialized local parameters to kvstore
_initialize_kvstore(kvstore=kvstore,
param_arrays=self._exec_group.param_arrays,
arg_params=self._arg_params,
param_names=self._param_names,
update_on_kvstore=update_on_kvstore)
if update_on_kvstore:
kvstore.set_optimizer(self._optimizer)
else:
self._updater = opt.get_updater(optimizer)
self.optimizer_initialized = True
if self._preload_opt_states is not None:
self.load_optimizer_states(self._preload_opt_states)
self._preload_opt_states = None
def borrow_optimizer(self, shared_module):
"""Borrow optimizer from a shared module. Used in bucketing, where exactly the same
optimizer (esp. kvstore) is used.
Parameters
----------
shared_module : Module
"""
assert shared_module.optimizer_initialized
self._optimizer = shared_module._optimizer
self._kvstore = shared_module._kvstore
self._update_on_kvstore = shared_module._update_on_kvstore
self._updater = shared_module._updater
self.optimizer_initialized = True
def forward(self, data_batch, is_train=None):
"""Forward computation.
Parameters
----------
data_batch : DataBatch
Could be anything with similar API implemented.
is_train : bool
Default is `None`, which means `is_train` takes the value of `self.for_training`.
"""
assert self.binded and self.params_initialized
self._exec_group.forward(data_batch, is_train)
def backward(self, out_grads=None):
"""Backward computation.
Parameters
----------
out_grads : NDArray or list of NDArray, optional
Gradient on the outputs to be propagated back.
This parameter is only needed when bind is called
on outputs that are not a loss function.
"""
assert self.binded and self.params_initialized
self._exec_group.backward(out_grads=out_grads)
def update(self):
"""Update parameters according to the installed optimizer and the gradients computed
in the previous forward-backward batch.
"""
assert self.binded and self.params_initialized and self.optimizer_initialized
self._params_dirty = True
if self._update_on_kvstore:
_update_params_on_kvstore(self._exec_group.param_arrays,
self._exec_group.grad_arrays,
self._kvstore)
else:
_update_params(self._exec_group.param_arrays,
self._exec_group.grad_arrays,
updater=self._updater,
num_device=len(self._context),
kvstore=self._kvstore)
def get_outputs(self, merge_multi_context=True):
"""Get outputs of the previous forward computation.
Parameters
----------
merge_multi_context : bool
Default is `True`. In the case when data-parallelism is used, the outputs
will be collected from multiple devices. A `True` value indicate that we
should merge the collected results so that they look like from a single
executor.
Returns
-------
If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it
is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output
elements are `NDArray`.
"""
assert self.binded and self.params_initialized
return self._exec_group.get_outputs(merge_multi_context=merge_multi_context)
def get_input_grads(self, merge_multi_context=True):
"""Get the gradients with respect to the inputs of the module.
Parameters
----------
merge_multi_context : bool
Default is `True`. In the case when data-parallelism is used, the outputs
will be collected from multiple devices. A `True` value indicate that we
should merge the collected results so that they look like from a single
executor.
Returns
-------
If `merge_multi_context` is `True`, it is like `[grad1, grad2]`. Otherwise, it
is like `[[grad1_dev1, grad1_dev2], [grad2_dev1, grad2_dev2]]`. All the output
elements are `NDArray`.
"""
assert self.binded and self.params_initialized and self.inputs_need_grad
return self._exec_group.get_input_grads(merge_multi_context=merge_multi_context)
def get_states(self, merge_multi_context=True):
"""Get states from all devices
Parameters
----------
merge_multi_context : bool
Default is `True`. In the case when data-parallelism is used, the states
will be collected from multiple devices. A `True` value indicate that we
should merge the collected results so that they look like from a single
executor.
Returns
-------
If `merge_multi_context` is `True`, it is like `[out1, out2]`. Otherwise, it
is like `[[out1_dev1, out1_dev2], [out2_dev1, out2_dev2]]`. All the output
elements are `NDArray`.
"""
assert self.binded and self.params_initialized
return self._exec_group.get_states(merge_multi_context=merge_multi_context)
def set_states(self, states=None, value=None):
"""Set value for states. Only one of states & value can be specified.
Parameters
----------
states : list of list of NDArrays
source states arrays formatted like [[state1_dev1, state1_dev2],
[state2_dev1, state2_dev2]].
value : number
a single scalar value for all state arrays.
"""
assert self.binded and self.params_initialized
self._exec_group.set_states(states, value)
def update_metric(self, eval_metric, labels):
"""Evaluate and accumulate evaluation metric on outputs of the last forward computation.
Parameters
----------
eval_metric : EvalMetric
labels : list of NDArray
Typically `data_batch.label`.
"""
self._exec_group.update_metric(eval_metric, labels)
def _sync_params_from_devices(self):
"""Synchronize parameters from devices to CPU. This function should be called after
calling `update` that updates the parameters on the devices, before one can read the
latest parameters from `self._arg_params` and `self._aux_params`.
"""
self._exec_group.get_params(self._arg_params, self._aux_params)
self._params_dirty = False
def save_optimizer_states(self, fname):
"""Save optimizer (updater) state to file
Parameters
----------
fname : str
Path to output states file.
"""
assert self.optimizer_initialized
if self._update_on_kvstore:
self._kvstore.save_optimizer_states(fname)
else:
with open(fname, 'wb') as fout:
fout.write(self._updater.get_states())
def load_optimizer_states(self, fname):
"""Load optimizer (updater) state from file
Parameters
----------
fname : str
Path to input states file.
"""
assert self.optimizer_initialized
if self._update_on_kvstore:
self._kvstore.load_optimizer_states(fname)
else:
self._updater.set_states(open(fname, 'rb').read())
def install_monitor(self, mon):
""" Install monitor on all executors """
assert self.binded
self._exec_group.install_monitor(mon)
class MutableModule(BaseModule):
"""A mutable module is a module that supports variable input data.
Parameters
----------
symbol : Symbol
data_names : list of str
label_names : list of str
logger : Logger
context : Context or list of Context
work_load_list : list of number
max_data_shapes : list of (name, shape) tuple, designating inputs whose shape vary
max_label_shapes : list of (name, shape) tuple, designating inputs whose shape vary
fixed_param_prefix : list of str, indicating fixed parameters
"""
def __init__(self, symbol, data_names, label_names,
logger=logging, context=ctx.cpu(), work_load_list=None,
max_data_shapes=None, max_label_shapes=None, fixed_param_prefix=None):
super(MutableModule, self).__init__(logger=logger)
self._symbol = symbol
self._data_names = data_names
self._label_names = label_names
self._context = context
self._work_load_list = work_load_list
self._curr_module = None
self._max_data_shapes = max_data_shapes
self._max_label_shapes = max_label_shapes
self._fixed_param_prefix = fixed_param_prefix
fixed_param_names = list()
if fixed_param_prefix is not None:
for name in self._symbol.list_arguments():
for prefix in self._fixed_param_prefix:
if name.startswith(prefix):
fixed_param_names.append(name)
self._fixed_param_names = fixed_param_names
self._preload_opt_states = None
def _reset_bind(self):
self.binded = False
self._curr_module = None
@property
def data_names(self):
return self._data_names
@property
def output_names(self):
return self._symbol.list_outputs()
@property
def data_shapes(self):
assert self.binded
return self._curr_module.data_shapes
@property
def label_shapes(self):
assert self.binded
return self._curr_module.label_shapes
@property
def output_shapes(self):
assert self.binded
return self._curr_module.output_shapes
def get_params(self):
assert self.binded and self.params_initialized
return self._curr_module.get_params()
def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_params=None,
allow_missing=False, force_init=False):
if self.params_initialized and not force_init:
return
assert self.binded, 'call bind before initializing the parameters'
self._curr_module.init_params(initializer=initializer, arg_params=arg_params,
aux_params=aux_params, allow_missing=allow_missing,
force_init=force_init)
self.params_initialized = True
def bind(self, data_shapes, label_shapes=None, for_training=True,
inputs_need_grad=False, force_rebind=False, shared_module=None, grad_req='write'):
# in case we already initialized params, keep it
if self.params_initialized:
arg_params, aux_params = self.get_params()
# force rebinding is typically used when one want to switch from
# training to prediction phase.
if force_rebind:
self._reset_bind()
if self.binded:
self.logger.warning('Already binded, ignoring bind()')
return
assert shared_module is None, 'shared_module for MutableModule is not supported'
self.for_training = for_training
self.inputs_need_grad = inputs_need_grad
self.binded = True
max_shapes_dict = dict()
if self._max_data_shapes is not None:
max_shapes_dict.update(dict(self._max_data_shapes[0]))
if self._max_label_shapes is not None:
max_shapes_dict.update(dict(self._max_label_shapes[0]))
max_data_shapes = list()
for name, shape in data_shapes[0]:
if name in max_shapes_dict:
max_data_shapes.append((name, max_shapes_dict[name]))
else:
max_data_shapes.append((name, shape))
max_label_shapes = list()
if not label_shapes.count(None) == len(label_shapes):
for name, shape in label_shapes[0]:
if name in max_shapes_dict:
max_label_shapes.append((name, max_shapes_dict[name]))
else:
max_label_shapes.append((name, shape))
if len(max_label_shapes) == 0:
max_label_shapes = None
module = Module(self._symbol, self._data_names, self._label_names, logger=self.logger,
context=self._context, work_load_list=self._work_load_list,
fixed_param_names=self._fixed_param_names)
module.bind([max_data_shapes for _ in xrange(len(self._context))], [max_label_shapes for _ in xrange(len(self._context))],
for_training, inputs_need_grad, force_rebind=False, shared_module=None)
self._curr_module = module
# copy back saved params, if already initialized
if self.params_initialized:
self.set_params(arg_params, aux_params)
def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):
"""Save current progress to checkpoint.
Use mx.callback.module_checkpoint as epoch_end_callback to save during training.
Parameters
----------
prefix : str
The file prefix to checkpoint to
epoch : int
The current epoch number
save_optimizer_states : bool
Whether to save optimizer states for continue training
"""
self._curr_module.save_checkpoint(prefix, epoch, save_optimizer_states)
def init_optimizer(self, kvstore='local', optimizer='sgd',
optimizer_params=(('learning_rate', 0.01),), force_init=False):
assert self.binded and self.params_initialized
if self.optimizer_initialized and not force_init:
self.logger.warning('optimizer already initialized, ignoring.')
return
self._curr_module._preload_opt_states = self._preload_opt_states
self._curr_module.init_optimizer(kvstore, optimizer, optimizer_params,
force_init=force_init)
self.optimizer_initialized = True
def fit(self, train_data, eval_data=None, eval_metric='acc',
epoch_end_callback=None, batch_end_callback=None, kvstore='local',
optimizer='sgd', optimizer_params=(('learning_rate', 0.01),),
eval_end_callback=None,
eval_batch_end_callback=None, initializer=Uniform(0.01),
arg_params=None, aux_params=None, allow_missing=False,
force_rebind=False, force_init=False, begin_epoch=0, num_epoch=None,
validation_metric=None, monitor=None, prefix=None):
"""Train the module parameters.
Parameters
----------
train_data : DataIter
eval_data : DataIter
If not `None`, will be used as validation set and evaluate the performance
after each epoch.
eval_metric : str or EvalMetric
Default `'acc'`. The performance measure used to display during training.
epoch_end_callback : function or list of function
Each callback will be called with the current `epoch`, `symbol`, `arg_params`
and `aux_params`.
batch_end_callback : function or list of function
Each callback will be called with a `BatchEndParam`.
kvstore : str or KVStore
Default `'local'`.
optimizer : str or Optimizer
Default `'sgd'`
optimizer_params : dict
Default `(('learning_rate', 0.01),)`. The parameters for the optimizer constructor.
The default value is not a `dict`, just to avoid pylint warning on dangerous
default values.
eval_end_callback : function or list of function
These will be called at the end of each full evaluation, with the metrics over
the entire evaluation set.
eval_batch_end_callback : function or list of function
These will be called at the end of each minibatch during evaluation
initializer : Initializer
Will be called to initialize the module parameters if not already initialized.
arg_params : dict
Default `None`, if not `None`, should be existing parameters from a trained
model or loaded from a checkpoint (previously saved model). In this case,
the value here will be used to initialize the module parameters, unless they
are already initialized by the user via a call to `init_params` or `fit`.
`arg_params` has higher priority to `initializer`.
aux_params : dict
Default `None`. Similar to `arg_params`, except for auxiliary states.
allow_missing : bool
Default `False`. Indicate whether we allow missing parameters when `arg_params`
and `aux_params` are not `None`. If this is `True`, then the missing parameters
will be initialized via the `initializer`.
force_rebind : bool
Default `False`. Whether to force rebinding the executors if already binded.
force_init : bool
Default `False`. Indicate whether we should force initialization even if the
parameters are already initialized.
begin_epoch : int
Default `0`. Indicate the starting epoch. Usually, if we are resuming from a
checkpoint saved at a previous training phase at epoch N, then we should specify
this value as N+1.
num_epoch : int
Number of epochs to run training.
Examples
--------
An example of using fit for training::
>>> #Assume training dataIter and validation dataIter are ready
>>> mod.fit(train_data=train_dataiter, eval_data=val_dataiter,
optimizer_params={'learning_rate':0.01, 'momentum': 0.9},
num_epoch=10)
"""
assert num_epoch is not None, 'please specify number of epochs'
self.bind(data_shapes=train_data.provide_data, label_shapes=train_data.provide_label,
for_training=True, force_rebind=force_rebind)
if monitor is not None:
self.install_monitor(monitor)
self.init_params(initializer=initializer, arg_params=arg_params, aux_params=aux_params,
allow_missing=allow_missing, force_init=force_init)
self.init_optimizer(kvstore=kvstore, optimizer=optimizer,
optimizer_params=optimizer_params)
if validation_metric is None:
validation_metric = eval_metric
if not isinstance(eval_metric, metric.EvalMetric):
eval_metric = metric.create(eval_metric)
################################################################################
# training loop
################################################################################
for epoch in range(begin_epoch, num_epoch):
tic = time.time()
eval_metric.reset()
for nbatch, data_batch in enumerate(train_data):
if monitor is not None:
monitor.tic()
self.forward_backward(data_batch)
self.update()
self.update_metric(eval_metric, data_batch.label)
if monitor is not None:
monitor.toc_print()
if batch_end_callback is not None:
batch_end_params = BatchEndParam(epoch=epoch, nbatch=nbatch,
eval_metric=eval_metric,
locals=locals())
for callback in _as_list(batch_end_callback):
callback(batch_end_params)
# one epoch of training is finished
for name, val in eval_metric.get_name_value():
self.logger.info('Epoch[%d] Train-%s=%f', epoch, name, val)
toc = time.time()
self.logger.info('Epoch[%d] Time cost=%.3f', epoch, (toc-tic))
# sync aux params across devices
arg_params, aux_params = self.get_params()
self.set_params(arg_params, aux_params)
if epoch_end_callback is not None:
for callback in _as_list(epoch_end_callback):
callback(epoch, self.symbol, arg_params, aux_params)
#----------------------------------------
# evaluation on validation set
if eval_data:
res = self.score(eval_data, validation_metric,
score_end_callback=eval_end_callback,
batch_end_callback=eval_batch_end_callback, epoch=epoch)
#TODO: pull this into default
for name, val in res:
self.logger.info('Epoch[%d] Validation-%s=%f', epoch, name, val)
# end of 1 epoch, reset the data-iter for another epoch
train_data.reset()
def forward(self, data_batch, is_train=None):
assert self.binded and self.params_initialized
# get current_shapes
if self._curr_module.label_shapes is not None:
current_shapes = [dict(self._curr_module.data_shapes[i] + self._curr_module.label_shapes[i]) for i in xrange(len(self._context))]
else:
current_shapes = [dict(self._curr_module.data_shapes[i]) for i in xrange(len(self._context))]
# get input_shapes
if is_train:
input_shapes = [dict(data_batch.provide_data[i] + data_batch.provide_label[i]) for i in xrange(len(self._context))]
else:
input_shapes = [dict(data_batch.provide_data[i]) for i in xrange(len(data_batch.provide_data))]
# decide if shape changed
shape_changed = len(current_shapes) != len(input_shapes)
for pre, cur in zip(current_shapes, input_shapes):
for k, v in pre.items():
if v != cur[k]:
shape_changed = True
if shape_changed:
# self._curr_module.reshape(data_batch.provide_data, data_batch.provide_label)
module = Module(self._symbol, self._data_names, self._label_names,
logger=self.logger, context=[self._context[i] for i in xrange(len(data_batch.provide_data))],
work_load_list=self._work_load_list,
fixed_param_names=self._fixed_param_names)
module.bind(data_batch.provide_data, data_batch.provide_label, self._curr_module.for_training,
self._curr_module.inputs_need_grad, force_rebind=False,
shared_module=self._curr_module)
self._curr_module = module
self._curr_module.forward(data_batch, is_train=is_train)
def backward(self, out_grads=None):
assert self.binded and self.params_initialized
self._curr_module.backward(out_grads=out_grads)
def update(self):
assert self.binded and self.params_initialized and self.optimizer_initialized
self._curr_module.update()
def get_outputs(self, merge_multi_context=True):
assert self.binded and self.params_initialized
return self._curr_module.get_outputs(merge_multi_context=merge_multi_context)
def get_input_grads(self, merge_multi_context=True):
assert self.binded and self.params_initialized and self.inputs_need_grad
return self._curr_module.get_input_grads(merge_multi_context=merge_multi_context)
def update_metric(self, eval_metric, labels):
assert self.binded and self.params_initialized
self._curr_module.update_metric(eval_metric, labels)
def install_monitor(self, mon):
""" Install monitor on all executors """
assert self.binded
self._curr_module.install_monitor(mon)
================================================
FILE: dff_rfcn/core/rcnn.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
"""
Fast R-CNN:
data =
{'data': [num_images, c, h, w],
'rois': [num_rois, 5]}
label =
{'label': [num_rois],
'bbox_target': [num_rois, 4 * num_classes],
'bbox_weight': [num_rois, 4 * num_classes]}
roidb extended format [image_index]
['image', 'height', 'width', 'flipped',
'boxes', 'gt_classes', 'gt_overlaps', 'max_classes', 'max_overlaps', 'bbox_targets']
"""
import numpy as np
import numpy.random as npr
from utils.image import get_image, tensor_vstack
from bbox.bbox_transform import bbox_overlaps, bbox_transform
from bbox.bbox_regression import expand_bbox_regression_targets
def get_rcnn_testbatch(roidb, cfg):
"""
return a dict of testbatch
:param roidb: ['image', 'flipped'] + ['boxes']
:return: data, label, im_info
"""
# assert len(roidb) == 1, 'Single batch only'
imgs, roidb = get_image(roidb, cfg)
im_array = imgs
im_info = [np.array([roidb[i]['im_info']], dtype=np.float32) for i in range(len(roidb))]
im_rois = [roidb[i]['boxes'] for i in range(len(roidb))]
rois = im_rois
rois_array = [np.hstack((0 * np.ones((rois[i].shape[0], 1)), rois[i])) for i in range(len(rois))]
data = [{'data': im_array[i],
'rois': rois_array[i]} for i in range(len(roidb))]
label = {}
return data, label, im_info
def get_rcnn_batch(roidb, cfg):
"""
return a dict of multiple images
:param roidb: a list of dict, whose length controls batch size
['images', 'flipped'] + ['gt_boxes', 'boxes', 'gt_overlap'] => ['bbox_targets']
:return: data, label
"""
num_images = len(roidb)
imgs, roidb = get_image(roidb, cfg)
im_array = tensor_vstack(imgs)
assert cfg.TRAIN.BATCH_ROIS == -1 or cfg.TRAIN.BATCH_ROIS % cfg.TRAIN.BATCH_IMAGES == 0, \
'BATCHIMAGES {} must divide BATCH_ROIS {}'.format(cfg.TRAIN.BATCH_IMAGES, cfg.TRAIN.BATCH_ROIS)
if cfg.TRAIN.BATCH_ROIS == -1:
rois_per_image = np.sum([iroidb['boxes'].shape[0] for iroidb in roidb])
fg_rois_per_image = rois_per_image
else:
rois_per_image = cfg.TRAIN.BATCH_ROIS / cfg.TRAIN.BATCH_IMAGES
fg_rois_per_image = np.round(cfg.TRAIN.FG_FRACTION * rois_per_image).astype(int)
rois_array = list()
labels_array = list()
bbox_targets_array = list()
bbox_weights_array = list()
for im_i in range(num_images):
roi_rec = roidb[im_i]
# infer num_classes from gt_overlaps
num_classes = roi_rec['gt_overlaps'].shape[1]
# label = class RoI has max overlap with
rois = roi_rec['boxes']
labels = roi_rec['max_classes']
overlaps = roi_rec['max_overlaps']
bbox_targets = roi_rec['bbox_targets']
im_rois, labels, bbox_targets, bbox_weights = \
sample_rois(rois, fg_rois_per_image, rois_per_image, num_classes, cfg,
labels, overlaps, bbox_targets)
# project im_rois
# do not round roi
rois = im_rois
batch_index = im_i * np.ones((rois.shape[0], 1))
rois_array_this_image = np.hstack((batch_index, rois))
rois_array.append(rois_array_this_image)
# add labels
labels_array.append(labels)
bbox_targets_array.append(bbox_targets)
bbox_weights_array.append(bbox_weights)
rois_array = np.array(rois_array)
labels_array = np.array(labels_array)
bbox_targets_array = np.array(bbox_targets_array)
bbox_weights_array = np.array(bbox_weights_array)
data = {'data': im_array,
'rois': rois_array}
label = {'label': labels_array,
'bbox_target': bbox_targets_array,
'bbox_weight': bbox_weights_array}
return data, label
def sample_rois(rois, fg_rois_per_image, rois_per_image, num_classes, cfg,
labels=None, overlaps=None, bbox_targets=None, gt_boxes=None):
"""
generate random sample of ROIs comprising foreground and background examples
:param rois: all_rois [n, 4]; e2e: [n, 5] with batch_index
:param fg_rois_per_image: foreground roi number
:param rois_per_image: total roi number
:param num_classes: number of classes
:param labels: maybe precomputed
:param overlaps: maybe precomputed (max_overlaps)
:param bbox_targets: maybe precomputed
:param gt_boxes: optional for e2e [n, 5] (x1, y1, x2, y2, cls)
:return: (labels, rois, bbox_targets, bbox_weights)
"""
if labels is None:
overlaps = bbox_overlaps(rois[:, 1:].astype(np.float), gt_boxes[:, :4].astype(np.float))
gt_assignment = overlaps.argmax(axis=1)
overlaps = overlaps.max(axis=1)
labels = gt_boxes[gt_assignment, 4]
# foreground RoI with FG_THRESH overlap
fg_indexes = np.where(overlaps >= cfg.TRAIN.FG_THRESH)[0]
# guard against the case when an image has fewer than fg_rois_per_image foreground RoIs
fg_rois_per_this_image = np.minimum(fg_rois_per_image, fg_indexes.size)
# Sample foreground regions without replacement
if len(fg_indexes) > fg_rois_per_this_image:
fg_indexes = npr.choice(fg_indexes, size=fg_rois_per_this_image, replace=False)
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
bg_indexes = np.where((overlaps < cfg.TRAIN.BG_THRESH_HI) & (overlaps >= cfg.TRAIN.BG_THRESH_LO))[0]
# Compute number of background RoIs to take from this image (guarding against there being fewer than desired)
bg_rois_per_this_image = rois_per_image - fg_rois_per_this_image
bg_rois_per_this_image = np.minimum(bg_rois_per_this_image, bg_indexes.size)
# Sample foreground regions without replacement
if len(bg_indexes) > bg_rois_per_this_image:
bg_indexes = npr.choice(bg_indexes, size=bg_rois_per_this_image, replace=False)
# indexes selected
keep_indexes = np.append(fg_indexes, bg_indexes)
# pad more to ensure a fixed minibatch size
while keep_indexes.shape[0] < rois_per_image:
gap = np.minimum(len(rois), rois_per_image - keep_indexes.shape[0])
gap_indexes = npr.choice(range(len(rois)), size=gap, replace=False)
keep_indexes = np.append(keep_indexes, gap_indexes)
# select labels
labels = labels[keep_indexes]
# set labels of bg_rois to be 0
labels[fg_rois_per_this_image:] = 0
rois = rois[keep_indexes]
# load or compute bbox_target
if bbox_targets is not None:
bbox_target_data = bbox_targets[keep_indexes, :]
else:
targets = bbox_transform(rois[:, 1:], gt_boxes[gt_assignment[keep_indexes], :4])
if cfg.TRAIN.BBOX_NORMALIZATION_PRECOMPUTED:
targets = ((targets - np.array(cfg.TRAIN.BBOX_MEANS))
/ np.array(cfg.TRAIN.BBOX_STDS))
bbox_target_data = np.hstack((labels[:, np.newaxis], targets))
bbox_targets, bbox_weights = \
expand_bbox_regression_targets(bbox_target_data, num_classes, cfg)
return rois, labels, bbox_targets, bbox_weights
================================================
FILE: dff_rfcn/core/tester.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Xizhou Zhu, Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
from multiprocessing.pool import ThreadPool as Pool
import cPickle
import os
import time
import mxnet as mx
import numpy as np
from module import MutableModule
from utils import image
from bbox.bbox_transform import bbox_pred, clip_boxes
from nms.nms import py_nms_wrapper, cpu_nms_wrapper, gpu_nms_wrapper
from utils.PrefetchingIter import PrefetchingIter
class Predictor(object):
def __init__(self, symbol, data_names, label_names,
context=mx.cpu(), max_data_shapes=None,
provide_data=None, provide_label=None,
arg_params=None, aux_params=None):
self._mod = MutableModule(symbol, data_names, label_names,
context=context, max_data_shapes=max_data_shapes)
self._mod.bind(provide_data, provide_label, for_training=False)
self._mod.init_params(arg_params=arg_params, aux_params=aux_params)
def predict(self, data_batch):
self._mod.forward(data_batch)
# [dict(zip(self._mod.output_names, _)) for _ in zip(*self._mod.get_outputs(merge_multi_context=False))]
return [dict(zip(self._mod.output_names, _)) for _ in zip(*self._mod.get_outputs(merge_multi_context=False))]
def im_proposal(predictor, data_batch, data_names, scales):
output_all = predictor.predict(data_batch)
data_dict_all = [dict(zip(data_names, data_batch.data[i])) for i in xrange(len(data_batch.data))]
scores_all = []
boxes_all = []
for output, data_dict, scale in zip(output_all, data_dict_all, scales):
# drop the batch index
boxes = output['rois_output'].asnumpy()[:, 1:]
scores = output['rois_score'].asnumpy()
# transform to original scale
boxes = boxes / scale
scores_all.append(scores)
boxes_all.append(boxes)
return scores_all, boxes_all, data_dict_all
def generate_proposals(predictor, test_data, imdb, cfg, vis=False, thresh=0.):
"""
Generate detections results using RPN.
:param predictor: Predictor
:param test_data: data iterator, must be non-shuffled
:param imdb: image database
:param vis: controls visualization
:param thresh: thresh for valid detections
:return: list of detected boxes
"""
assert vis or not test_data.shuffle
data_names = [k[0] for k in test_data.provide_data[0]]
if not isinstance(test_data, PrefetchingIter):
test_data = PrefetchingIter(test_data)
idx = 0
t = time.time()
imdb_boxes = list()
original_boxes = list()
for im_info, data_batch in test_data:
t1 = time.time() - t
t = time.time()
scales = [iim_info[0, 2] for iim_info in im_info]
scores_all, boxes_all, data_dict_all = im_proposal(predictor, data_batch, data_names, scales)
t2 = time.time() - t
t = time.time()
for delta, (scores, boxes, data_dict, scale) in enumerate(zip(scores_all, boxes_all, data_dict_all, scales)):
# assemble proposals
dets = np.hstack((boxes, scores))
original_boxes.append(dets)
# filter proposals
keep = np.where(dets[:, 4:] > thresh)[0]
dets = dets[keep, :]
imdb_boxes.append(dets)
if vis:
vis_all_detection(data_dict['data'].asnumpy(), [dets], ['obj'], scale, cfg)
print 'generating %d/%d' % (idx + 1, imdb.num_images), 'proposal %d' % (dets.shape[0]), \
'data %.4fs net %.4fs' % (t1, t2 / test_data.batch_size)
idx += 1
assert len(imdb_boxes) == imdb.num_images, 'calculations not complete'
# save results
rpn_folder = os.path.join(imdb.result_path, 'rpn_data')
if not os.path.exists(rpn_folder):
os.mkdir(rpn_folder)
rpn_file = os.path.join(rpn_folder, imdb.name + '_rpn.pkl')
with open(rpn_file, 'wb') as f:
cPickle.dump(imdb_boxes, f, cPickle.HIGHEST_PROTOCOL)
if thresh > 0:
full_rpn_file = os.path.join(rpn_folder, imdb.name + '_full_rpn.pkl')
with open(full_rpn_file, 'wb') as f:
cPickle.dump(original_boxes, f, cPickle.HIGHEST_PROTOCOL)
print 'wrote rpn proposals to {}'.format(rpn_file)
return imdb_boxes
def im_detect(predictor, data_batch, data_names, scales, cfg):
output_all = predictor.predict(data_batch)
data_dict_all = [dict(zip(data_names, data_batch.data[i])) for i in xrange(len(data_batch.data))]
scores_all = []
pred_boxes_all = []
for output, data_dict, scale in zip(output_all, data_dict_all, scales):
if cfg.TEST.HAS_RPN:
rois = output['rois_output'].asnumpy()[:, 1:]
else:
rois = data_dict['rois'].asnumpy().reshape((-1, 5))[:, 1:]
im_shape = data_dict['data'].shape
# save output
scores = output['cls_prob_reshape_output'].asnumpy()[0]
bbox_deltas = output['bbox_pred_reshape_output'].asnumpy()[0]
# post processing
pred_boxes = bbox_pred(rois, bbox_deltas)
pred_boxes = clip_boxes(pred_boxes, im_shape[-2:])
# we used scaled image & roi to train, so it is necessary to transform them back
pred_boxes = pred_boxes / scale
scores_all.append(scores)
pred_boxes_all.append(pred_boxes)
if output_all[0].has_key('feat_conv_3x3_relu_output'):
feat = output_all[0]['feat_conv_3x3_relu_output']
else:
feat = None
return scores_all, pred_boxes_all, data_dict_all, feat
def im_batch_detect(predictor, data_batch, data_names, scales, cfg):
output_all = predictor.predict(data_batch)
data_dict_all = [dict(zip(data_names, data_batch.data[i])) for i in xrange(len(data_batch.data))]
scores_all = []
pred_boxes_all = []
for output, data_dict, scale in zip(output_all, data_dict_all, scales):
im_infos = data_dict['im_info'].asnumpy()
# save output
scores = output['cls_prob_reshape_output'].asnumpy()[0]
bbox_deltas = output['bbox_pred_reshape_output'].asnumpy()[0]
rois = output['rois_output'].asnumpy()
for im_idx in xrange(im_infos.shape[0]):
bb_idxs = np.where(rois[:,0] == im_idx)[0]
im_shape = im_infos[im_idx, :2].astype(np.int)
# post processing
pred_boxes = bbox_pred(rois[bb_idxs, 1:], bbox_deltas[bb_idxs, :])
pred_boxes = clip_boxes(pred_boxes, im_shape)
# we used scaled image & roi to train, so it is necessary to transform them back
pred_boxes = pred_boxes / scale[im_idx]
scores_all.append(scores[bb_idxs, :])
pred_boxes_all.append(pred_boxes)
return scores_all, pred_boxes_all, data_dict_all
def pred_eval(gpu_id, key_predictor, cur_predictor, test_data, imdb, cfg, vis=False, thresh=1e-4, logger=None, ignore_cache=True):
"""
wrapper for calculating offline validation for faster data analysis
in this example, all threshold are set by hand
:param predictor: Predictor
:param test_data: data iterator, must be non-shuffle
:param imdb: image database
:param vis: controls visualization
:param thresh: valid detection threshold
:return:
"""
det_file = os.path.join(imdb.result_path, imdb.name + '_'+ str(gpu_id) + '_detections.pkl')
if os.path.exists(det_file) and not ignore_cache:
with open(det_file, 'rb') as fid:
all_boxes, frame_ids = cPickle.load(fid)
return all_boxes, frame_ids
assert vis or not test_data.shuffle
data_names = [k[0] for k in test_data.provide_data[0]]
num_images = test_data.size
roidb_frame_ids = [x['frame_id'] for x in test_data.roidb]
if not isinstance(test_data, PrefetchingIter):
test_data = PrefetchingIter(test_data)
nms = py_nms_wrapper(cfg.TEST.NMS)
# limit detections to max_per_image over all classes
max_per_image = cfg.TEST.max_per_image
# all detections are collected into:
# all_boxes[cls][image] = N x 5 array of detections in
# (x1, y1, x2, y2, score)
all_boxes = [[[] for _ in range(num_images)]
for _ in range(imdb.num_classes)]
frame_ids = np.zeros(num_images, dtype=np.int)
roidb_idx = -1
roidb_offset = -1
idx = 0
data_time, net_time, post_time = 0.0, 0.0, 0.0
t = time.time()
for im_info, key_frame_flag, data_batch in test_data:
t1 = time.time() - t
t = time.time()
scales = [iim_info[0, 2] for iim_info in im_info]
if key_frame_flag != 2:
scores_all, boxes_all, data_dict_all, feat = im_detect(key_predictor, data_batch, data_names, scales, cfg)
else:
data_batch.data[0][-1] = feat
data_batch.provide_data[0][-1] = ('feat_key', feat.shape)
scores_all, boxes_all, data_dict_all, _ = im_detect(cur_predictor, data_batch, data_names, scales, cfg)
if key_frame_flag == 0:
roidb_idx += 1
roidb_offset = 0
else:
roidb_offset += 1
frame_ids[idx] = roidb_frame_ids[roidb_idx] + roidb_offset
t2 = time.time() - t
t = time.time()
for delta, (scores, boxes, data_dict) in enumerate(zip(scores_all, boxes_all, data_dict_all)):
for j in range(1, imdb.num_classes):
indexes = np.where(scores[:, j] > thresh)[0]
cls_scores = scores[indexes, j, np.newaxis]
cls_boxes = boxes[indexes, 4:8] if cfg.CLASS_AGNOSTIC else boxes[indexes, j * 4:(j + 1) * 4]
cls_dets = np.hstack((cls_boxes, cls_scores))
keep = nms(cls_dets)
all_boxes[j][idx+delta] = cls_dets[keep, :]
if max_per_image > 0:
image_scores = np.hstack([all_boxes[j][idx+delta][:, -1]
for j in range(1, imdb.num_classes)])
if len(image_scores) > max_per_image:
image_thresh = np.sort(image_scores)[-max_per_image]
for j in range(1, imdb.num_classes):
keep = np.where(all_boxes[j][idx+delta][:, -1] >= image_thresh)[0]
all_boxes[j][idx+delta] = all_boxes[j][idx+delta][keep, :]
if vis:
boxes_this_image = [[]] + [all_boxes[j][idx+delta] for j in range(1, imdb.num_classes)]
vis_all_detection(data_dict['data'].asnumpy(), boxes_this_image, imdb.classes, scales[delta], cfg)
idx += test_data.batch_size
t3 = time.time() - t
t = time.time()
data_time += t1
net_time += t2
post_time += t3
print 'testing {}/{} data {:.4f}s net {:.4f}s post {:.4f}s'.format(idx, num_images, data_time / idx * test_data.batch_size, net_time / idx * test_data.batch_size, post_time / idx * test_data.batch_size)
if logger:
logger.info('testing {}/{} data {:.4f}s net {:.4f}s post {:.4f}s'.format(idx, num_images, data_time / idx * test_data.batch_size, net_time / idx * test_data.batch_size, post_time / idx * test_data.batch_size))
with open(det_file, 'wb') as f:
cPickle.dump((all_boxes, frame_ids), f, protocol=cPickle.HIGHEST_PROTOCOL)
return all_boxes, frame_ids
def pred_eval_multiprocess(gpu_num, key_predictors, cur_predictors, test_datas, imdb, cfg, vis=False, thresh=1e-4, logger=None, ignore_cache=True):
if gpu_num == 1:
res = [pred_eval(0, key_predictors[0], cur_predictors[0], test_datas[0], imdb, cfg, vis, thresh, logger, ignore_cache),]
else:
pool = Pool(processes=gpu_num)
multiple_results = [pool.apply_async(pred_eval,args=(i, key_predictors[i], cur_predictors[i], test_datas[i], imdb, cfg, vis, thresh, logger, ignore_cache)) for i in range(gpu_num)]
pool.close()
pool.join()
res = [res.get() for res in multiple_results]
info_str = imdb.evaluate_detections_multiprocess(res)
if logger:
logger.info('evaluate detections: \n{}'.format(info_str))
def vis_all_detection(im_array, detections, class_names, scale, cfg, threshold=1e-4):
"""
visualize all detections in one image
:param im_array: [b=1 c h w] in rgb
:param detections: [ numpy.ndarray([[x1 y1 x2 y2 score]]) for j in classes ]
:param class_names: list of names in imdb
:param scale: visualize the scaled image
:return:
"""
import matplotlib.pyplot as plt
import random
im = image.transform_inverse(im_array, cfg.network.PIXEL_MEANS)
plt.imshow(im)
for j, name in enumerate(class_names):
if name == '__background__':
continue
color = (random.random(), random.random(), random.random()) # generate a random color
dets = detections[j]
for det in dets:
bbox = det[:4] * scale
score = det[-1]
if score < threshold:
continue
rect = plt.Rectangle((bbox[0], bbox[1]),
bbox[2] - bbox[0],
bbox[3] - bbox[1], fill=False,
edgecolor=color, linewidth=3.5)
plt.gca().add_patch(rect)
plt.gca().text(bbox[0], bbox[1] - 2,
'{:s} {:.3f}'.format(name, score),
bbox=dict(facecolor=color, alpha=0.5), fontsize=12, color='white')
plt.show()
def draw_all_detection(im_array, detections, class_names, scale, cfg, threshold=1e-1):
"""
visualize all detections in one image
:param im_array: [b=1 c h w] in rgb
:param detections: [ numpy.ndarray([[x1 y1 x2 y2 score]]) for j in classes ]
:param class_names: list of names in imdb
:param scale: visualize the scaled image
:return:
"""
import cv2
import random
color_white = (255, 255, 255)
im = image.transform_inverse(im_array, cfg.network.PIXEL_MEANS)
# change to bgr
im = cv2.cvtColor(im, cv2.COLOR_RGB2BGR)
for j, name in enumerate(class_names):
if name == '__background__':
continue
color = (random.randint(0, 256), random.randint(0, 256), random.randint(0, 256)) # generate a random color
dets = detections[j]
for det in dets:
bbox = det[:4] * scale
score = det[-1]
if score < threshold:
continue
bbox = map(int, bbox)
cv2.rectangle(im, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color=color, thickness=2)
cv2.putText(im, '%s %.3f' % (class_names[j], score), (bbox[0], bbox[1] + 10),
color=color_white, fontFace=cv2.FONT_HERSHEY_COMPLEX, fontScale=0.5)
return im
================================================
FILE: dff_rfcn/demo.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Xizhou Zhu, Yi Li, Haochen Zhang
# --------------------------------------------------------
import _init_paths
import argparse
import os
import glob
import sys
import logging
import pprint
import cv2
from config.config import config, update_config
from utils.image import resize, transform
import numpy as np
# get config
os.environ['PYTHONUNBUFFERED'] = '1'
os.environ['MXNET_CUDNN_AUTOTUNE_DEFAULT'] = '0'
os.environ['MXNET_ENABLE_GPU_P2P'] = '0'
cur_path = os.path.abspath(os.path.dirname(__file__))
update_config(cur_path + '/../experiments/dff_rfcn/cfgs/dff_rfcn_vid_demo.yaml')
sys.path.insert(0, os.path.join(cur_path, '../external/mxnet', config.MXNET_VERSION))
import mxnet as mx
from core.tester import im_detect, Predictor
from symbols import *
from utils.load_model import load_param
from utils.show_boxes import show_boxes, draw_boxes
from utils.tictoc import tic, toc
from nms.nms import py_nms_wrapper, cpu_nms_wrapper, gpu_nms_wrapper
def parse_args():
parser = argparse.ArgumentParser(description='Show Deep Feature Flow demo')
args = parser.parse_args()
return args
args = parse_args()
def main():
# get symbol
pprint.pprint(config)
config.symbol = 'resnet_v1_101_flownet_rfcn'
model = '/../model/rfcn_dff_flownet_vid'
sym_instance = eval(config.symbol + '.' + config.symbol)()
key_sym = sym_instance.get_key_test_symbol(config)
cur_sym = sym_instance.get_cur_test_symbol(config)
# set up class names
num_classes = 31
classes = ['airplane', 'antelope', 'bear', 'bicycle',
'bird', 'bus', 'car', 'cattle',
'dog', 'domestic_cat', 'elephant', 'fox',
'giant_panda', 'hamster', 'horse', 'lion',
'lizard', 'monkey', 'motorcycle', 'rabbit',
'red_panda', 'sheep', 'snake', 'squirrel',
'tiger', 'train', 'turtle', 'watercraft',
'whale', 'zebra']
# load demo data
image_names = glob.glob(cur_path + '/../demo/ILSVRC2015_val_00007010/*.JPEG')
output_dir = cur_path + '/../demo/rfcn_dff/'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
key_frame_interval = 10
#
data = []
key_im_tensor = None
for idx, im_name in enumerate(image_names):
assert os.path.exists(im_name), ('%s does not exist'.format(im_name))
im = cv2.imread(im_name, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
target_size = config.SCALES[0][0]
max_size = config.SCALES[0][1]
im, im_scale = resize(im, target_size, max_size, stride=config.network.IMAGE_STRIDE)
im_tensor = transform(im, config.network.PIXEL_MEANS)
im_info = np.array([[im_tensor.shape[2], im_tensor.shape[3], im_scale]], dtype=np.float32)
if idx % key_frame_interval == 0:
key_im_tensor = im_tensor
data.append({'data': im_tensor, 'im_info': im_info, 'data_key': key_im_tensor, 'feat_key': np.zeros((1,config.network.DFF_FEAT_DIM,1,1))})
# get predictor
data_names = ['data', 'im_info', 'data_key', 'feat_key']
label_names = []
data = [[mx.nd.array(data[i][name]) for name in data_names] for i in xrange(len(data))]
max_data_shape = [[('data', (1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),
('data_key', (1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),]]
provide_data = [[(k, v.shape) for k, v in zip(data_names, data[i])] for i in xrange(len(data))]
provide_label = [None for i in xrange(len(data))]
arg_params, aux_params = load_param(cur_path + model, 0, process=True)
key_predictor = Predictor(key_sym, data_names, label_names,
context=[mx.gpu(0)], max_data_shapes=max_data_shape,
provide_data=provide_data, provide_label=provide_label,
arg_params=arg_params, aux_params=aux_params)
cur_predictor = Predictor(cur_sym, data_names, label_names,
context=[mx.gpu(0)], max_data_shapes=max_data_shape,
provide_data=provide_data, provide_label=provide_label,
arg_params=arg_params, aux_params=aux_params)
nms = gpu_nms_wrapper(config.TEST.NMS, 0)
# warm up
for j in xrange(2):
data_batch = mx.io.DataBatch(data=[data[j]], label=[], pad=0, index=0,
provide_data=[[(k, v.shape) for k, v in zip(data_names, data[j])]],
provide_label=[None])
scales = [data_batch.data[i][1].asnumpy()[0, 2] for i in xrange(len(data_batch.data))]
if j % key_frame_interval == 0:
scores, boxes, data_dict, feat = im_detect(key_predictor, data_batch, data_names, scales, config)
else:
data_batch.data[0][-1] = feat
data_batch.provide_data[0][-1] = ('feat_key', feat.shape)
scores, boxes, data_dict, _ = im_detect(cur_predictor, data_batch, data_names, scales, config)
print "warmup done"
# test
time = 0
count = 0
for idx, im_name in enumerate(image_names):
data_batch = mx.io.DataBatch(data=[data[idx]], label=[], pad=0, index=idx,
provide_data=[[(k, v.shape) for k, v in zip(data_names, data[idx])]],
provide_label=[None])
scales = [data_batch.data[i][1].asnumpy()[0, 2] for i in xrange(len(data_batch.data))]
tic()
if idx % key_frame_interval == 0:
scores, boxes, data_dict, feat = im_detect(key_predictor, data_batch, data_names, scales, config)
else:
data_batch.data[0][-1] = feat
data_batch.provide_data[0][-1] = ('feat_key', feat.shape)
scores, boxes, data_dict, _ = im_detect(cur_predictor, data_batch, data_names, scales, config)
time += toc()
count += 1
print 'testing {} {:.4f}s'.format(im_name, time/count)
boxes = boxes[0].astype('f')
scores = scores[0].astype('f')
dets_nms = []
for j in range(1, scores.shape[1]):
cls_scores = scores[:, j, np.newaxis]
cls_boxes = boxes[:, 4:8] if config.CLASS_AGNOSTIC else boxes[:, j * 4:(j + 1) * 4]
cls_dets = np.hstack((cls_boxes, cls_scores))
keep = nms(cls_dets)
cls_dets = cls_dets[keep, :]
cls_dets = cls_dets[cls_dets[:, -1] > 0.7, :]
dets_nms.append(cls_dets)
# visualize
im = cv2.imread(im_name)
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
# show_boxes(im, dets_nms, classes, 1)
out_im = draw_boxes(im, dets_nms, classes, 1)
_, filename = os.path.split(im_name)
cv2.imwrite(output_dir + filename,out_im)
print 'done'
if __name__ == '__main__':
main()
================================================
FILE: dff_rfcn/demo_batch.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Xizhou Zhu, Yi Li, Haochen Zhang
# --------------------------------------------------------
import _init_paths
import argparse
import os
import glob
import sys
import logging
import pprint
import cv2
from config.config import config, update_config
from utils.image import resize, transform
import numpy as np
# get config
os.environ['PYTHONUNBUFFERED'] = '1'
os.environ['MXNET_CUDNN_AUTOTUNE_DEFAULT'] = '0'
os.environ['MXNET_ENABLE_GPU_P2P'] = '0'
cur_path = os.path.abspath(os.path.dirname(__file__))
update_config(cur_path + '/../experiments/dff_rfcn/cfgs/dff_rfcn_vid_demo.yaml')
sys.path.insert(0, os.path.join(cur_path, '../external/mxnet', config.MXNET_VERSION))
import mxnet as mx
from core.tester import im_batch_detect, Predictor
from symbols import *
from utils.load_model import load_param
from utils.show_boxes import show_boxes, draw_boxes
from utils.tictoc import tic, toc
from nms.nms import py_nms_wrapper, cpu_nms_wrapper, gpu_nms_wrapper
def parse_args():
parser = argparse.ArgumentParser(description='Show Deep Feature Flow demo')
args = parser.parse_args()
return args
args = parse_args()
def main():
# get symbol
pprint.pprint(config)
config.symbol = 'resnet_v1_101_flownet_rfcn'
model = '/../model/rfcn_dff_flownet_vid'
sym_instance = eval(config.symbol + '.' + config.symbol)()
sym = sym_instance.get_batch_test_symbol(config)
# set up class names
num_classes = 31
classes = ['airplane', 'antelope', 'bear', 'bicycle',
'bird', 'bus', 'car', 'cattle',
'dog', 'domestic_cat', 'elephant', 'fox',
'giant_panda', 'hamster', 'horse', 'lion',
'lizard', 'monkey', 'motorcycle', 'rabbit',
'red_panda', 'sheep', 'snake', 'squirrel',
'tiger', 'train', 'turtle', 'watercraft',
'whale', 'zebra']
# load demo data
image_names = glob.glob(cur_path + '/../demo/ILSVRC2015_val_00007010/*.JPEG')
output_dir = cur_path + '/../demo/rfcn_dff_batch/'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
key_frame_interval = 10
#
data = []
key_im_tensor = None
cur_im_tensor = []
im_info_tensor = []
image_names_list = []
image_names_batch = []
for idx, im_name in enumerate(image_names):
assert os.path.exists(im_name), ('%s does not exist'.format(im_name))
im = cv2.imread(im_name, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
target_size = config.SCALES[0][0]
max_size = config.SCALES[0][1]
im, im_scale = resize(im, target_size, max_size, stride=config.network.IMAGE_STRIDE)
im_tensor = transform(im, config.network.PIXEL_MEANS)
im_info = np.array([[im_tensor.shape[2], im_tensor.shape[3], im_scale]], dtype=np.float32)
if idx % key_frame_interval == 0:
key_im_tensor = im_tensor
else:
cur_im_tensor.append(im_tensor)
im_info_tensor.append(im_info)
image_names_batch.append(im_name)
if (idx+1) % key_frame_interval == 0 or idx == len(image_names) - 1:
data.append({'data_other': np.concatenate(cur_im_tensor), 'im_info': np.concatenate(im_info_tensor), 'data_key': key_im_tensor})
key_im_tensor = None
cur_im_tensor = []
im_info_tensor = []
image_names_list.append(image_names_batch)
image_names_batch = []
# get predictor
data_names = ['data_other', 'im_info', 'data_key']
label_names = []
data = [[mx.nd.array(data[i][name]) for name in data_names] for i in xrange(len(data))]
max_data_shape = [[('data_other', (key_frame_interval-1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),
('data_key', (1, 3, max([v[0] for v in config.SCALES]), max([v[1] for v in config.SCALES]))),]]
provide_data = [[(k, v.shape) for k, v in zip(data_names, data[i])] for i in xrange(len(data))]
provide_label = [None for i in xrange(len(data))]
arg_params, aux_params = load_param(cur_path + model, 0, process=True)
predictor = Predictor(sym, data_names, label_names,
context=[mx.gpu(0)], max_data_shapes=max_data_shape,
provide_data=provide_data, provide_label=provide_label,
arg_params=arg_params, aux_params=aux_params)
nms = gpu_nms_wrapper(config.TEST.NMS, 0)
# warm up
for j in xrange(1):
data_batch = mx.io.DataBatch(data=[data[j]], label=[], pad=0, index=0,
provide_data=[[(k, v.shape) for k, v in zip(data_names, data[j])]],
provide_label=[None])
scales = [data_batch.data[i][1].asnumpy()[:, 2] for i in xrange(len(data_batch.data))]
scores_all, boxes_all, data_dict = im_batch_detect(predictor, data_batch, data_names, scales, config)
print "warmup done"
# test
time = 0
count = 0
for idx, im_names in enumerate(image_names_list):
data_batch = mx.io.DataBatch(data=[data[idx]], label=[], pad=0, index=idx,
provide_data=[[(k, v.shape) for k, v in zip(data_names, data[idx])]],
provide_label=[None])
scales = [data_batch.data[i][1].asnumpy()[:, 2] for i in xrange(len(data_batch.data))]
tic()
scores_all, boxes_all, data_dict = im_batch_detect(predictor, data_batch, data_names, scales, config)
time += toc()
count += len(scores_all)
print 'testing {} {:.4f}s x {:d}'.format(im_names[0], time/count, len(scores_all))
for batch_idx in xrange(len(scores_all)):
boxes = boxes_all[batch_idx].astype('f')
scores = scores_all[batch_idx].astype('f')
dets_nms = []
for j in range(1, scores.shape[1]):
cls_scores = scores[:, j, np.newaxis]
cls_boxes = boxes[:, 4:8] if config.CLASS_AGNOSTIC else boxes[:, j * 4:(j + 1) * 4]
cls_dets = np.hstack((cls_boxes, cls_scores))
keep = nms(cls_dets)
cls_dets = cls_dets[keep, :]
cls_dets = cls_dets[cls_dets[:, -1] > 0.7, :]
dets_nms.append(cls_dets)
# visualize
im = cv2.imread(im_names[batch_idx])
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
# show_boxes(im, dets_nms, classes, 1)
out_im = draw_boxes(im, dets_nms, classes, 1)
_, filename = os.path.split(im_names[batch_idx])
cv2.imwrite(output_dir + filename,out_im)
print 'done'
if __name__ == '__main__':
main()
================================================
FILE: dff_rfcn/function/__init__.py
================================================
================================================
FILE: dff_rfcn/function/test_rcnn.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import argparse
import pprint
import logging
import time
import os
import numpy as np
import mxnet as mx
from symbols import *
from dataset import *
from core.loader import TestLoader
from core.tester import Predictor, pred_eval, pred_eval_multiprocess
from utils.load_model import load_param
def get_predictor(sym, sym_instance, cfg, arg_params, aux_params, test_data, ctx):
# infer shape
data_shape_dict = dict(test_data.provide_data_single)
sym_instance.infer_shape(data_shape_dict)
sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict, is_train=False)
# decide maximum shape
data_names = [k[0] for k in test_data.provide_data_single]
label_names = None
max_data_shape = [[('data', (1, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES]))),
('data_key', (1, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES]))),]]
# create predictor
predictor = Predictor(sym, data_names, label_names,
context=ctx, max_data_shapes=max_data_shape,
provide_data=test_data.provide_data, provide_label=test_data.provide_label,
arg_params=arg_params, aux_params=aux_params)
return predictor
def test_rcnn(cfg, dataset, image_set, root_path, dataset_path,
ctx, prefix, epoch,
vis, ignore_cache, shuffle, has_rpn, proposal, thresh, logger=None, output_path=None):
if not logger:
assert False, 'require a logger'
# print cfg
pprint.pprint(cfg)
logger.info('testing cfg:{}\n'.format(pprint.pformat(cfg)))
# load symbol and testing data
key_sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()
cur_sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()
key_sym = key_sym_instance.get_key_test_symbol(cfg)
cur_sym = cur_sym_instance.get_cur_test_symbol(cfg)
imdb = eval(dataset)(image_set, root_path, dataset_path, result_path=output_path)
roidb = imdb.gt_roidb()
# get test data iter
# split roidbs
gpu_num = len(ctx)
roidbs = [[] for x in range(gpu_num)]
roidbs_seg_lens = np.zeros(gpu_num, dtype=np.int)
for x in roidb:
gpu_id = np.argmin(roidbs_seg_lens)
roidbs[gpu_id].append(x)
roidbs_seg_lens[gpu_id] += x['frame_seg_len']
# get test data iter
test_datas = [TestLoader(x, cfg, batch_size=1, shuffle=shuffle, has_rpn=has_rpn) for x in roidbs]
# load model
arg_params, aux_params = load_param(prefix, epoch, process=True)
# create predictor
key_predictors = [get_predictor(key_sym, key_sym_instance, cfg, arg_params, aux_params, test_datas[i], [ctx[i]]) for i in range(gpu_num)]
cur_predictors = [get_predictor(cur_sym, cur_sym_instance, cfg, arg_params, aux_params, test_datas[i], [ctx[i]]) for i in range(gpu_num)]
# start detection
#pred_eval(0, key_predictors[0], cur_predictors[0], test_datas[0], imdb, cfg, vis=vis, ignore_cache=ignore_cache, thresh=thresh, logger=logger)
pred_eval_multiprocess(gpu_num, key_predictors, cur_predictors, test_datas, imdb, cfg, vis=vis, ignore_cache=ignore_cache, thresh=thresh, logger=logger)
================================================
FILE: dff_rfcn/function/test_rpn.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import argparse
import pprint
import logging
import mxnet as mx
from symbols import *
from dataset import *
from core.loader import TestLoader
from core.tester import Predictor, generate_proposals
from utils.load_model import load_param
def test_rpn(cfg, dataset, image_set, root_path, dataset_path,
ctx, prefix, epoch,
vis, shuffle, thresh, logger=None, output_path=None):
# set up logger
if not logger:
logging.basicConfig()
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# rpn generate proposal cfg
cfg.TEST.HAS_RPN = True
# print cfg
pprint.pprint(cfg)
logger.info('testing rpn cfg:{}\n'.format(pprint.pformat(cfg)))
# load symbol
sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()
sym = sym_instance.get_symbol_rpn(cfg, is_train=False)
# load dataset and prepare imdb for training
imdb = eval(dataset)(image_set, root_path, dataset_path, result_path=output_path)
roidb = imdb.gt_roidb()
test_data = TestLoader(roidb, cfg, batch_size=len(ctx), shuffle=shuffle, has_rpn=True)
# load model
arg_params, aux_params = load_param(prefix, epoch)
# infer shape
data_shape_dict = dict(test_data.provide_data_single)
sym_instance.infer_shape(data_shape_dict)
# check parameters
sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict, is_train=False)
# decide maximum shape
data_names = [k[0] for k in test_data.provide_data[0]]
label_names = None if test_data.provide_label[0] is None else [k[0] for k in test_data.provide_label[0]]
max_data_shape = [[('data', (1, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES])))]]
# create predictor
predictor = Predictor(sym, data_names, label_names,
context=ctx, max_data_shapes=max_data_shape,
provide_data=test_data.provide_data, provide_label=test_data.provide_label,
arg_params=arg_params, aux_params=aux_params)
# start testing
imdb_boxes = generate_proposals(predictor, test_data, imdb, cfg, vis=vis, thresh=thresh)
all_log_info = imdb.evaluate_recall(roidb, candidate_boxes=imdb_boxes)
logger.info(all_log_info)
================================================
FILE: dff_rfcn/function/train_rcnn.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import argparse
import logging
import pprint
import os
import mxnet as mx
from symbols import *
from core import callback, metric
from core.loader import ROIIter
from core.module import MutableModule
from bbox.bbox_regression import add_bbox_regression_targets
from utils.load_data import load_proposal_roidb, merge_roidb, filter_roidb
from utils.load_model import load_param
from utils.PrefetchingIter import PrefetchingIter
from utils.lr_scheduler import WarmupMultiFactorScheduler
def train_rcnn(cfg, dataset, image_set, root_path, dataset_path,
frequent, kvstore, flip, shuffle, resume,
ctx, pretrained, epoch, prefix, begin_epoch, end_epoch,
train_shared, lr, lr_step, proposal, logger=None, output_path=None):
# set up logger
if not logger:
logging.basicConfig()
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# load symbol
sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()
sym = sym_instance.get_symbol_rfcn(cfg, is_train=True)
# setup multi-gpu
batch_size = len(ctx)
input_batch_size = cfg.TRAIN.BATCH_IMAGES * batch_size
# print cfg
pprint.pprint(cfg)
logger.info('training rcnn cfg:{}\n'.format(pprint.pformat(cfg)))
# load dataset and prepare imdb for training
image_sets = [iset for iset in image_set.split('+')]
roidbs = [load_proposal_roidb(dataset, image_set, root_path, dataset_path,
proposal=proposal, append_gt=True, flip=flip, result_path=output_path)
for image_set in image_sets]
roidb = merge_roidb(roidbs)
roidb = filter_roidb(roidb, cfg)
means, stds = add_bbox_regression_targets(roidb, cfg)
# load training data
train_data = ROIIter(roidb, cfg, batch_size=input_batch_size, shuffle=shuffle,
ctx=ctx, aspect_grouping=cfg.TRAIN.ASPECT_GROUPING)
# infer max shape
max_data_shape = [('data', (cfg.TRAIN.BATCH_IMAGES, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES])))]
# infer shape
data_shape_dict = dict(train_data.provide_data_single + train_data.provide_label_single)
sym_instance.infer_shape(data_shape_dict)
# load and initialize params
if resume:
print('continue training from ', begin_epoch)
arg_params, aux_params = load_param(prefix, begin_epoch, convert=True)
else:
arg_params, aux_params = load_param(pretrained, epoch, convert=True)
sym_instance.init_weight_rfcn(cfg, arg_params, aux_params)
# check parameter shapes
sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict)
# prepare training
# create solver
data_names = [k[0] for k in train_data.provide_data_single]
label_names = [k[0] for k in train_data.provide_label_single]
if train_shared:
fixed_param_prefix = cfg.network.FIXED_PARAMS_SHARED
else:
fixed_param_prefix = cfg.network.FIXED_PARAMS
mod = MutableModule(sym, data_names=data_names, label_names=label_names,
logger=logger, context=ctx,
max_data_shapes=[max_data_shape for _ in range(batch_size)], fixed_param_prefix=fixed_param_prefix)
if cfg.TRAIN.RESUME:
mod._preload_opt_states = '%s-%04d.states'%(prefix, begin_epoch)
# decide training params
# metric
eval_metric = metric.RCNNAccMetric(cfg)
cls_metric = metric.RCNNLogLossMetric(cfg)
bbox_metric = metric.RCNNL1LossMetric(cfg)
eval_metrics = mx.metric.CompositeEvalMetric()
for child_metric in [eval_metric, cls_metric, bbox_metric]:
eval_metrics.add(child_metric)
# callback
batch_end_callback = callback.Speedometer(train_data.batch_size, frequent=frequent)
epoch_end_callback = [mx.callback.module_checkpoint(mod, prefix, period=1, save_optimizer_states=True),
callback.do_checkpoint(prefix, means, stds)]
# decide learning rate
base_lr = lr
lr_factor = cfg.TRAIN.lr_factor
lr_epoch = [float(epoch) for epoch in lr_step.split(',')]
lr_epoch_diff = [epoch - begin_epoch for epoch in lr_epoch if epoch > begin_epoch]
lr = base_lr * (lr_factor ** (len(lr_epoch) - len(lr_epoch_diff)))
lr_iters = [int(epoch * len(roidb) / batch_size) for epoch in lr_epoch_diff]
print('lr', lr, 'lr_epoch_diff', lr_epoch_diff, 'lr_iters', lr_iters)
lr_scheduler = WarmupMultiFactorScheduler(lr_iters, lr_factor, cfg.TRAIN.warmup, cfg.TRAIN.warmup_lr, cfg.TRAIN.warmup_step)
# optimizer
optimizer_params = {'momentum': cfg.TRAIN.momentum,
'wd': cfg.TRAIN.wd,
'learning_rate': lr,
'lr_scheduler': lr_scheduler,
'rescale_grad': 1.0,
'clip_gradient': None}
# train
if not isinstance(train_data, PrefetchingIter):
train_data = PrefetchingIter(train_data)
mod.fit(train_data, eval_metric=eval_metrics, epoch_end_callback=epoch_end_callback,
batch_end_callback=batch_end_callback, kvstore=kvstore,
optimizer='sgd', optimizer_params=optimizer_params,
arg_params=arg_params, aux_params=aux_params, begin_epoch=begin_epoch, num_epoch=end_epoch)
================================================
FILE: dff_rfcn/function/train_rpn.py
================================================
# --------------------------------------------------------
# Deep Feature Flow
# Copyright (c) 2017 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Modified by Yuwen Xiong
# --------------------------------------------------------
# Based on:
# MX-RCNN
# Copyright (c) 2016 by Contributors
# Licence under The Apache 2.0 License
# https://github.com/ijkguo/mx-rcnn/
# --------------------------------------------------------
import argparse
import logging
import pprint
import mxnet as mx
from symbols import *
from core import callback, metric
from core.loader import AnchorLoader
from core.module import MutableModule
from utils.load_data import load_gt_roidb, merge_roidb, filter_roidb
from utils.load_model import load_param
from utils.PrefetchingIter import PrefetchingIter
from utils.lr_scheduler import WarmupMultiFactorScheduler
def train_rpn(cfg, dataset, image_set, root_path, dataset_path,
frequent, kvstore, flip, shuffle, resume,
ctx, pretrained, epoch, prefix, begin_epoch, end_epoch,
train_shared, lr, lr_step, logger=None, output_path=None):
# set up logger
if not logger:
logging.basicConfig()
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# set up config
cfg.TRAIN.BATCH_IMAGES = cfg.TRAIN.ALTERNATE.RPN_BATCH_IMAGES
# load symbol
sym_instance = eval(cfg.symbol + '.' + cfg.symbol)()
sym = sym_instance.get_symbol_rpn(cfg, is_train=True)
feat_sym = sym.get_internals()['rpn_cls_score_output']
# setup multi-gpu
batch_size = len(ctx)
input_batch_size = cfg.TRAIN.BATCH_IMAGES * batch_size
# print cfg
pprint.pprint(cfg)
logger.info('training rpn cfg:{}\n'.format(pprint.pformat(cfg)))
# load dataset and prepare imdb for training
image_sets = [iset for iset in image_set.split('+')]
roidbs = [load_gt_roidb(dataset, image_set, root_path, dataset_path, result_path=output_path,
flip=flip)
for image_set in image_sets]
roidb = merge_roidb(roidbs)
roidb = filter_roidb(roidb, cfg)
# load training data
train_data = AnchorLoader(feat_sym, roidb, cfg, batch_size=input_batch_size, shuffle=shuffle,
ctx=ctx, feat_stride=cfg.network.RPN_FEAT_STRIDE, anchor_scales=cfg.network.ANCHOR_SCALES,
anchor_ratios=cfg.network.ANCHOR_RATIOS, aspect_grouping=cfg.TRAIN.ASPECT_GROUPING)
# infer max shape
max_data_shape = [('data', (cfg.TRAIN.BATCH_IMAGES, 3, max([v[0] for v in cfg.SCALES]), max([v[1] for v in cfg.SCALES])))]
max_data_shape, max_label_shape = train_data.infer_shape(max_data_shape)
print('providing maximum shape', max_data_shape, max_label_shape)
# infer shape
data_shape_dict = dict(train_data.provide_data_single + train_data.provide_label_single)
sym_instance.infer_shape(data_shape_dict)
# load and initialize params
if resume:
print('continue training from ', begin_epoch)
arg_params, aux_params = load_param(prefix, begin_epoch, convert=True)
else:
arg_params, aux_params = load_param(pretrained, epoch, convert=True)
sym_instance.init_weight_rpn(cfg, arg_params, aux_params)
# check parameter shapes
sym_instance.check_parameter_shapes(arg_params, aux_params, data_shape_dict)
# create solver
data_names = [k[0] for k in train_data.provide_data_single]
label_names = [k[0] for k in train_data.provide_label_single]
if train_shared:
fixed_param_prefix = cfg.network.FIXED_PARAMS_SHARED
else:
fixed_param_prefix = cfg.network.FIXED_PARAMS
mod = MutableModule(sym, data_names=data_names, label_names=label_names,
logger=logger, context=ctx, max_data_shapes=[max_data_shape for _ in xrange(batch_size)],
max_label_shapes=[max_label_shape for _ in xrange(batch_size)], fixed_param_prefix=fixed_param_prefix)
# decide training params
# metric
eval_metric = metric.RPNAccMetric()
cls_metric = metric.RPNLogLossMetric()
bbox_metric = metric.RPNL1LossMetric()
eval_metrics = mx.metric.CompositeEvalMetric()
for child_metric in [eval_metric, cls_metric, bbox_metric]:
eval_metrics.add(child_metric)
# callback
batch_end_callback = callback.Speedometer(train_data.batch_size, frequent=frequent)
# epoch_end_callback = mx.callback.do_checkpoint(prefix)
epoch_end_callback = mx.callback.module_checkpoint(mod, prefix, period=1, save_optimizer_states=True)
# decide learning rate
base_lr = lr
lr_factor = cfg.TRAIN.lr_factor
lr_epoch = [int(epoch) for epoch in lr_step.split(',')]
lr_epoch_diff = [epoch - begin_epoch for epoch in lr_epoch if epoch > begin_epoch]
lr = base_lr * (lr_factor ** (len(lr_epoch) - len(lr_epoch_diff)))
lr_iters = [int(epoch * len(roidb) / batch_size) for epoch in lr_epoch_diff]
print('lr', lr, 'lr_epoch_diff', lr_epoch_diff, 'lr_iters', lr_iters)
lr_scheduler = WarmupMultiFactorScheduler(lr_iters, lr_factor, cfg.TRAIN.warmup, cfg.TRAIN.warmup_lr, cfg.TRAIN.warmup_step)
# optimizer
optimizer_params = {'momentum': cfg.TRAIN.momentum,
'wd': cfg.TRAIN.wd,
'learning_rate': lr,
'lr_scheduler': lr_scheduler,
'rescale_grad': 1.0,
'clip_gradient': None}
if not isinstance(train_data, PrefetchingIter):
train_data = PrefetchingIter(train_data)
# train
mod.fit(train_data, eval_metric=eval_metrics, epoch_end_callback=epoch_end_callback,
batch_end_callback=batch_end_callback, kvstore=kvstore,
optimizer='sgd', optimizer_params=optimizer_params,
arg_params=arg_params, aux_params=aux_params, begin_epoch=begin_epoch, num_epoch=end_epoch)
================================================
FILE: dff_rfcn/operator_cxx/multi_proposal-inl.h
================================================
/*!
* Copyright (c) 2015 by Contributors
* Copyright (c) 2017 Microsoft
* Licensed under The MIT License [see LICENSE for details]
* \file multi_proposal-inl.h
* \brief MultiProposal Operator
* \author Piotr Teterwak, Bing Xu, Jian Guo, Xizhou Zhu
*/
#ifndef MXNET_OPERATOR_CONTRIB_PROPOSAL_INL_H_
#define MXNET_OPERATOR_CONTRIB_PROPOSAL_INL_H_
#include <dmlc/logging.h>
#include <dmlc/parameter.h>
#include <mxnet/operator.h>
#include <map>
#include <vector>
#include <string>
#include <utility>
#include <ctime>
#include <cstring>
#include <iostream>
#include "../operator_common.h"
#include "../mshadow_op.h"
// extend NumericalParam
namespace mxnet {
namespace op {
/*!
* \brief structure for numerical tuple input
* \tparam VType data type of param
*/
template<typename VType>
struct NumericalParam {
NumericalParam() {}
explicit NumericalParam(VType *begin, VType *end) {
int32_t size = static_cast<int32_t>(end - begin);
info.resize(size);
for (int i = 0; i < size; ++i) {
info[i] = *(begin + i);
}
}
inline size_t ndim() const {
return info.size();
}
std::vector<VType> info;
};
template<typename VType>
inline std::istream &operator>>(std::istream &is, NumericalParam<VType> ¶m) {
while (true) {
char ch = is.get();
if (ch == '(') break;
if (!isspace(ch)) {
is.setstate(std::ios::failbit);
return is;
}
}
VType idx;
std::vector<VType> tmp;
// deal with empty case
size_t pos = is.tellg();
char ch = is.get();
if (ch == ')') {
param.info = tmp;
return is;
}
is.seekg(pos);
// finish deal
while (is >> idx) {
tmp.push_back(idx);
char ch;
do {
ch = is.get();
} while (isspace(ch));
if (ch == ',') {
while (true) {
ch = is.peek();
if (isspace(ch)) {
is.get(); continue;
}
if (ch == ')') {
is.get(); break;
}
break;
}
if (ch == ')') break;
} else if (ch == ')') {
break;
} else {
is.setstate(std::ios::failbit);
return is;
}
}
param.info = tmp;
return is;
}
template<typename VType>
inline std::ostream &operator<<(std::ostream &os, const NumericalParam<VType> ¶m) {
os << '(';
for (index_t i = 0; i < param.info.size(); ++i) {
if (i != 0) os << ',';
os << param.info[i];
}
// python style tuple
if (param.info.size() == 1) os << ',';
os << ')';
return os;
}
} // namespace op
} // namespace mxnet
namespace mxnet {
namespace op {
namespace proposal {
enum MultiProposalOpInputs {kClsProb, kBBoxPred, kImInfo};
enum MultiProposalOpOutputs {kOut, kScore};
enum MultiProposalForwardResource {kTempResource};
} // proposal
struct MultiProposalParam : public dmlc::Parameter<MultiProposalParam> {
int rpn_pre_nms_top_n;
int rpn_post_nms_top_n;
float threshold;
int rpn_min_size;
NumericalParam<float> scales;
NumericalParam<float> ratios;
int feature_stride;
bool output_score;
bool iou_loss;
DMLC_DECLARE_PARAMETER(MultiProposalParam) {
float tmp[] = {0, 0, 0, 0};
DMLC_DECLARE_FIELD(rpn_pre_nms_top_n).set_default(6000)
.describe("Number of top scoring boxes to keep after applying NMS to RPN proposals");
DMLC_DECLARE_FIELD(rpn_post_nms_top_n).set_default(300)
.describe("Overlap threshold used for non-maximum"
"suppresion(suppress boxes with IoU >= this threshold");
DMLC_DECLARE_FIELD(threshold).set_default(0.7)
.describe("NMS value, below which to suppress.");
DMLC_DECLARE_FIELD(rpn_min_size).set_default(16)
.describe("Minimum height or width in proposal");
tmp[0] = 4.0f; tmp[1] = 8.0f; tmp[2] = 16.0f; tmp[3] = 32.0f;
DMLC_DECLARE_FIELD(scales).set_default(NumericalParam<float>(tmp, tmp + 4))
.describe("Used to generate anchor windows by enumerating scales");
tmp[0] = 0.5f; tmp[1] = 1.0f; tmp[2] = 2.0f;
DMLC_DECLARE_FIELD(ratios).set_default(NumericalParam<float>(tmp, tmp + 3))
.describe("Used to generate anchor windows by enumerating ratios");
DMLC_DECLARE_FIELD(feature_stride).set_default(16)
.describe("The size of the receptive field each unit in the convolution layer of the rpn,"
"for example the product of all stride's prior to this layer.");
DMLC_DECLARE_FIELD(output_score).set_default(false)
.describe("Add score to outputs");
DMLC_DECLARE_FIELD(iou_loss).set_default(false)
.describe("Usage of IoU Loss");
}
};
template<typename xpu>
Operator *CreateOp(MultiProposalParam param);
#if DMLC_USE_CXX11
class MultiProposalProp : public OperatorProperty {
public:
void Init(const std::vector<std::pair<std::string, std::string> >& kwargs) override {
param_.Init(kwargs);
}
std::map<std::string, std::string> GetParams() const override {
return param_.__DICT__();
}
bool InferShape(std::vector<TShape> *in_shape,
std::vector<TShape> *out_shape,
std::vector<TShape> *aux_shape) const override {
using namespace mshadow;
CHECK_EQ(in_shape->size(), 3) << "Input:[cls_prob, bbox_pred, im_info]";
const TShape &dshape = in_shape->at(proposal::kClsProb);
if (dshape.ndim() == 0) return false;
Shape<4> bbox_pred_shape;
bbox_pred_shape = Shape4(dshape[0], dshape[1] * 2, dshape[2], dshape[3]);
SHAPE_ASSIGN_CHECK(*in_shape, proposal::kBBoxPred,
bbox_pred_shape);
Shape<2> im_info_shape;
im_info_shape = Shape2(dshape[0], 3);
SHAPE_ASSIGN_CHECK(*in_shape, proposal::kImInfo, im_info_shape);
out_shape->clear();
// output
out_shape->push_back(Shape2(dshape[0] * param_.rpn_post_nms_top_n, 5));
// score
out_shape->push_back(Shape2(dshape[0] * param_.rpn_post_nms_top_n, 1));
return true;
}
OperatorProperty* Copy() const override {
auto ptr = new MultiProposalProp();
ptr->param_ = param_;
return ptr;
}
std::string TypeString() const override {
return "_contrib_MultiProposal";
}
std::vector<ResourceRequest> ForwardResource(
const std::vector<TShape> &in_shape) const override {
return {ResourceRequest::kTempSpace};
}
std::vector<int> DeclareBackwardDependency(
const std::vector<int> &out_grad,
const std::vector<int> &in_data,
const std::vector<int> &out_data) const override {
return {};
}
int NumVisibleOutputs() const override {
if (param_.output_score) {
return 2;
} else {
return 1;
}
}
int NumOutputs() const override {
return 2;
}
std::vector<std::string> ListArguments() const override {
return {"cls_prob", "bbox_pred", "im_info"};
}
std::vector<std::string> ListOutputs() const override {
return {"output", "score"};
}
Operator* CreateOperator(Context ctx) const override;
private:
MultiProposalParam param_;
}; // class MultiProposalProp
#endif // DMLC_USE_CXX11
} // namespace op
} // namespace mxnet
//========================
// Anchor Generation Utils
//========================
namespace mxnet {
namespace op {
namespace utils {
inline void _MakeAnchor(float w,
float h,
float x_ctr,
float y_ctr,
std::vector<float> *out_anchors) {
out_anchors->push_back(x_ctr - 0.5f * (w - 1.0f));
out_anchors->push_back(y_ctr - 0.5f * (h - 1.0f));
out_anchors->push_back(x_ctr + 0.5f * (w - 1.0f));
out_anchors->push_back(y_ctr + 0.5f * (h - 1.0f));
out_anchors->push_back(0.0f);
}
inline void _Transform(float scale,
float ratio,
const std::vector<float>& base_anchor,
std::vector<float> *out_anchors) {
float w = base_anchor[2] - base_anchor[1] + 1.0f;
float h = base_anchor[3] - base_anchor[1] + 1.0f;
float x_ctr = base_anchor[0] + 0.5 * (w - 1.0f);
float y_ctr = base_anchor[1] + 0.5 * (h - 1.0f);
float size = w * h;
float size_ratios = std::floor(size / ratio);
float new_w = std::floor(std::sqrt(size_ratios) + 0.5f) * scale;
float new_h = std::floor((new_w / scale * ratio) + 0.5f) * scale;
_MakeAnchor(new_w, new_h, x_ctr,
y_ctr, out_anchors);
}
// out_anchors must have shape (n, 5), where n is ratios.size() * scales.size()
inline void GenerateAnchors(const std::vector<float>& base_anchor,
const std::vector<float>& ratios,
const std::vector<float>& scales,
std::vector<float> *out_anchors) {
for (size_t j = 0; j < ratios.size(); ++j) {
for (size_t k = 0; k < scales.size(); ++k) {
_Transform(scales[k], ratios[j], base_anchor, out_anchors);
}
}
}
} // namespace utils
} // namespace op
} // namespace mxnet
#endif // MXNET_OPERATOR_CONTRIB_PROPOSAL_INL_H_
================================================
FILE: dff_rfcn/operator_cxx/multi_proposal.cc
================================================
/*!
* Copyright (c) 2017 Microsoft
* Licensed under The MIT License [see LICENSE for details]
* \file multi_proposal.cc
* \brief
* \author Xizhou Zhu
*/
#include "./multi_proposal-inl.h"
namespace mxnet {
namespace op {
template<typename xpu>
class MultiProposalOp : public Operator{
public:
explicit MultiProposalOp(MultiProposalParam param) {
this->param_ = param;
}
virtual void Forward(const OpContext &ctx,
const std::vector<TBlob> &in_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) {
LOG(FATAL) << "not implemented";
}
virtual void Backward(const OpContext &ctx,
const std::vector<TBlob> &out_grad,
const std::vector<TBlob> &in_data,
const std::vector<TBlob> &out_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &in_grad,
const std::vector<TBlob> &aux_states) {
LOG(FATAL) << "not implemented";
}
private:
MultiProposalParam param_;
}; // class MultiProposalOp
template<>
Operator *CreateOp<cpu>(MultiProposalParam param) {
return new MultiProposalOp<cpu>(param);
}
Operator* MultiProposalProp::CreateOperator(Context ctx) const {
DO_BIND_DISPATCH(CreateOp, param_);
}
DMLC_REGISTER_PARAMETER(MultiProposalParam);
MXNET_REGISTER_OP_PROPERTY(_contrib_MultiProposal, MultiProposalProp)
.describe("Generate region proposals via RPN")
.add_argument("cls_score", "NDArray-or-Symbol", "Score of how likely proposal is object.")
.add_argument("bbox_pred", "NDArray-or-Symbol", "BBox Predicted deltas from anchors for proposals")
.add_argument("im_info", "NDArray-or-Symbol", "Image size and scale.")
.add_arguments(MultiProposalParam::__FIELDS__());
} // namespace op
} // namespace mxnet
================================================
FILE: dff_rfcn/operator_cxx/multi_proposal.cu
================================================
/*!
* Copyright (c) 2015 by Contributors
* Copyright (c) 2017 Microsoft
* Licensed under The MIT License [see LICENSE for details]
* \file multi_proposal.cu
* \brief MultiProposal Operator
* \author Shaoqing Ren, Xizhou Zhu, Jian Guo
*/
#include <dmlc/logging.h>
#include <dmlc/parameter.h>
#include <mxnet/operator.h>
#include <mshadow/tensor.h>
#include <mshadow/cuda/reduce.cuh>
#include <thrust/sort.h>
#include <thrust/execution_policy.h>
#include <thrust/functional.h>
#include <map>
#include <vector>
#include <string>
#include <utility>
#include <ctime>
#include <iostream>
#include "../operator_common.h"
#include "../mshadow_op.h"
#include "./multi_proposal-inl.h"
#define DIVUP(m, n) ((m) / (n) + ((m) % (n) > 0))
#define FRCNN_CUDA_CHECK(condition) \
/* Code block avoids redefinition of cudaError_t error */ \
do { \
cudaError_t error = condition; \
CHECK_EQ(error, cudaSuccess) << " " << cudaGetErrorString(error); \
} while (0)
namespace mshadow {
namespace cuda {
namespace multi_proposal {
// scores are (b, 2 * anchor, h, w)
// workspace_proposals are (b, h * w * anchor, 5)
// w defines "x" and h defines "y"
// count should be total anchors numbers, h * w * anchors
template<typename Dtype>
__global__ void ProposalGridKernel(const int count,
const int num_anchors,
const int height,
const int width,
const int feature_stride,
const Dtype* scores,
Dtype* workspace_proposals) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
int a = index % num_anchors;
int w = (index / num_anchors) % width;
int h = (index / num_anchors / width) % height;
int b = index / num_anchors / width / height;
workspace_proposals[index * 5 + 0] = workspace_proposals[a * 5 + 0] + w * feature_stride;
workspace_proposals[index * 5 + 1] = workspace_proposals[a * 5 + 1] + h * feature_stride;
workspace_proposals[index * 5 + 2] = workspace_proposals[a * 5 + 2] + w * feature_stride;
workspace_proposals[index * 5 + 3] = workspace_proposals[a * 5 + 3] + h * feature_stride;
workspace_proposals[index * 5 + 4] =
scores[((b * (2 * num_anchors) + a + num_anchors) * height + h) * width + w];
//workspace_proposals[index * 5 + 4] = scores[(a * height + h) * width + w];
}
}
// boxes are (b, h * w * anchor, 5)
// deltas are (b, 4 * anchor, h, w)
// out_pred_boxes are (b, h * w * anchor, 5)
// count should be total anchors numbers, b * h * w * anchors
// in-place write: boxes and out_pred_boxes are the same location
template<typename Dtype>
__global__ void BBoxPredKernel(const int count,
const int num_anchors,
const int feat_height,
const int feat_width,
const int feature_stride,
const Dtype* im_infos,
const Dtype* boxes,
const Dtype* deltas,
Dtype* out_pred_boxes) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
int a = index % num_anchors;
int w = (index / num_anchors) % feat_width;
int h = (index / num_anchors / feat_width) % feat_height;
int b = index / num_anchors / feat_width / feat_height;
float im_height = im_infos[b * 3];
float im_width = im_infos[b * 3 + 1];
int real_height = static_cast<int>(im_height / feature_stride);
int real_width = static_cast<int>(im_width / feature_stride);
float width = boxes[index * 5 + 2] - boxes[index * 5 + 0] + 1.0f;
float height = boxes[index * 5 + 3] - boxes[index * 5 + 1] + 1.0f;
float ctr_x = boxes[index * 5 + 0] + 0.5f * (width - 1.0f);
float ctr_y = boxes[index * 5 + 1] + 0.5f * (height - 1.0f);
int ba = (b * num_anchors + a);
float dx = deltas[((ba * 4) * feat_height + h) * feat_width + w];
float dy = deltas[((ba * 4 + 1) * feat_height + h) * feat_width + w];
float dw = deltas[((ba * 4 + 2) * feat_height + h) * feat_width + w];
float dh = deltas[((ba * 4 + 3) * feat_height + h) * feat_width + w];
float pred_ctr_x = dx * width + ctr_x;
float pred_ctr_y = dy * height + ctr_y;
float pred_w = exp(dw) * width;
float pred_h = exp(dh) * height;
float pred_x1 = pred_ctr_x - 0.5f * (pred_w - 1.0f);
float pred_y1 = pred_ctr_y - 0.5f * (pred_h - 1.0f);
float pred_x2 = pred_ctr_x + 0.5f * (pred_w - 1.0f);
float pred_y2 = pred_ctr_y + 0.5f * (pred_h - 1.0f);
pred_x1 = max(min(pred_x1, im_width - 1.0f), 0.0f);
pred_y1 = max(min(pred_y1, im_height - 1.0f), 0.0f);
pred_x2 = max(min(pred_x2, im_width - 1.0f), 0.0f);
pred_y2 = max(min(pred_y2, im_height - 1.0f), 0.0f);
out_pred_boxes[index * 5 + 0] = pred_x1;
out_pred_boxes[index * 5 + 1] = pred_y1;
out_pred_boxes[index * 5 + 2] = pred_x2;
out_pred_boxes[index * 5 + 3] = pred_y2;
if (h >= real_height || w >= real_width) {
out_pred_boxes[index * 5 + 4] = -1.0f;
}
}
}
// boxes are (b, h * w * anchor, 5)
// deltas are (b, 4 * anchor, h, w)
// out_pred_boxes are (b, h * w * anchor, 5)
// count should be total anchors numbers, b * h * w * anchors
// in-place write: boxes and out_pred_boxes are the same location
template<typename Dtype>
__global__ void IoUPredKernel(const int count,
const int num_anchors,
const int feat_height,
const int feat_width,
const int feature_stride,
const Dtype* im_infos,
const Dtype* boxes,
const Dtype* deltas,
Dtype* out_pred_boxes) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
int a = index % num_anchors;
int w = (index / num_anchors) % feat_width;
int h = (index / num_anchors / feat_width) % feat_height;
int b = index / num_anchors / feat_width / feat_height;
float im_height = im_infos[b * 3];
float im_width = im_infos[b * 3 + 1];
int real_height = static_cast<int>(im_height / feature_stride);
int real_width = static_cast<int>(im_width / feature_stride);
float x1 = boxes[index * 5 + 0];
float y1 = boxes[index * 5 + 1];
float x2 = boxes[index * 5 + 2];
float y2 = boxes[index * 5 + 3];
int ba = (b * num_anchors + a);
float dx1 = deltas[((ba * 4) * feat_height + h) * feat_width + w];
float dy1 = deltas[((ba * 4 + 1) * feat_height + h) * feat_width + w];
float dx2 = deltas[((ba * 4 + 2) * feat_height + h) * feat_width + w];
float dy2 = deltas[((ba * 4 + 3) * feat_height + h) * feat_width + w];
float pred_x1 = max(min(x1 + dx1, im_width - 1.0f), 0.0f);
float pred_y1 = max(min(y1 + dy1, im_height - 1.0f), 0.0f);
float pred_x2 = max(min(x2 + dx2, im_width - 1.0f), 0.0f);
float pred_y2 = max(min(y2 + dy2, im_height - 1.0f), 0.0f);
out_pred_boxes[index * 5 + 0] = pred_x1;
out_pred_boxes[index * 5 + 1] = pred_y1;
out_pred_boxes[index * 5 + 2] = pred_x2;
out_pred_boxes[index * 5 + 3] = pred_y2;
if (h >= real_height || w >= real_width) {
out_pred_boxes[index * 5 + 4] = -1.0f;
}
}
}
// filter box with stride less than rpn_min_size
// filter: set score to zero
// dets (b, n, 5)
template<typename Dtype>
__global__ void FilterBoxKernel(const int count,
const int count_anchors,
const float original_min_size,
const Dtype* im_infos,
Dtype* dets) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
int b = index / count_anchors;
float iw = dets[index * 5 + 2] - dets[index * 5 + 0] + 1.0f;
float ih = dets[index * 5 + 3] - dets[index * 5 + 1] + 1.0f;
float min_size = original_min_size * im_infos[b * 3 + 2];
if (iw < min_size || ih < min_size) {
dets[index * 5 + 0] -= min_size / 2;
dets[index * 5 + 1] -= min_size / 2;
dets[index * 5 + 2] += min_size / 2;
dets[index * 5 + 3] += min_size / 2;
dets[index * 5 + 4] = -1.0f;
}
}
}
// copy score and init order
// dets (n, 5); score (n, ); order (n, )
// count should be n (total anchors or proposals)
template<typename Dtype>
__global__ void CopyScoreKernel(const int count,
const Dtype* dets,
Dtype* score,
int* order) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
score[index] = dets[index * 5 + 4];
order[index] = index;
}
}
// reorder proposals according to order and keep the top_n proposals
// prev_dets (n, 5); order (n, ); dets (n, 5)
// count should be output anchor numbers (top_n)
template<typename Dtype>
__global__ void ReorderProposalsKernel(const int count,
const Dtype* prev_dets,
const int* order,
Dtype* dets) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
const int order_i = order[index];
for (int j = 0; j < 5; j ++) {
dets[index * 5 + j] = prev_dets[order_i * 5 + j];
}
}
}
__device__ inline float devIoU(float const * const a, float const * const b) {
float left = max(a[0], b[0]), right = min(a[2], b[2]);
float top = max(a[1], b[1]), bottom = min(a[3], b[3]);
float width = max(right - left + 1, 0.f), height = max(bottom - top + 1, 0.f);
float interS = width * height;
float Sa = (a[2] - a[0] + 1) * (a[3] - a[1] + 1);
float Sb = (b[2] - b[0] + 1) * (b[3] - b[1] + 1);
return interS / (Sa + Sb - interS);
}
__global__ void nms_kernel(const int n_boxes, const float nms_overlap_thresh,
const float *dev_boxes, uint64_t *dev_mask) {
const int threadsPerBlock = sizeof(uint64_t) * 8;
const int row_start = blockIdx.y;
const int col_start = blockIdx.x;
// if (row_start > col_start) return;
const int row_size =
min(n_boxes - row_start * threadsPerBlock, threadsPerBlock);
const int col_size =
min(n_boxes - col_start * threadsPerBlock, threadsPerBlock);
__shared__ float block_boxes[threadsPerBlock * 5];
if (threadIdx.x < col_size) {
block_boxes[threadIdx.x * 5 + 0] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 5 + 0];
block_boxes[threadIdx.x * 5 + 1] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 5 + 1];
block_boxes[threadIdx.x * 5 + 2] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 5 + 2];
block_boxes[threadIdx.x * 5 + 3] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 5 + 3];
block_boxes[threadIdx.x * 5 + 4] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 5 + 4];
}
__syncthreads();
if (threadIdx.x < row_size) {
const int cur_box_idx = threadsPerBlock * row_start + threadIdx.x;
const float *cur_box = dev_boxes + cur_box_idx * 5;
int i = 0;
uint64_t t = 0;
int start = 0;
if (row_start == col_start) {
start = threadIdx.x + 1;
}
for (i = start; i < col_size; i++) {
if (devIoU(cur_box, block_boxes + i * 5) > nms_overlap_thresh) {
t |= 1ULL << i;
}
}
const int col_blocks = DIVUP(n_boxes, threadsPerBlock);
dev_mask[cur_box_idx * col_blocks + col_start] = t;
}
}
void _nms(const mshadow::Tensor<gpu, 2>& boxes,
const float nms_overlap_thresh,
int *keep,
int *num_out) {
const int threadsPerBlock = sizeof(uint64_t) * 8;
const int boxes_num = boxes.size(0);
const int boxes_dim = boxes.size(1);
float* boxes_dev = boxes.dptr_;
uint64_t* mask_dev = NULL;
const int col_blocks = DIVUP(boxes_num, threadsPerBlock);
FRCNN_CUDA_CHECK(cudaMalloc(&mask_dev,
boxes_num * col_blocks * sizeof(uint64_t)));
dim3 blocks(DIVUP(boxes_num, threadsPerBlock),
DIVUP(boxes_num, threadsPerBlock));
dim3 threads(threadsPerBlock);
nms_kernel<<<blocks, threads>>>(boxes_num,
nms_overlap_thresh,
boxes_dev,
mask_dev);
FRCNN_CUDA_CHECK(cudaPeekAtLastError());
std::vector<uint64_t> mask_host(boxes_num * col_blocks);
FRCNN_CUDA_CHECK(cudaMemcpy(&mask_host[0],
mask_dev,
sizeof(uint64_t) * boxes_num * col_blocks,
cudaMemcpyDeviceToHost));
std::vector<uint64_t> remv(col_blocks);
memset(&remv[0], 0, sizeof(uint64_t) * col_blocks);
int num_to_keep = 0;
for (int i = 0; i < boxes_num; i++) {
int nblock = i / threadsPerBlock;
int inblock = i % threadsPerBlock;
if (!(remv[nblock] & (1ULL << inblock))) {
keep[num_to_keep++] = i;
uint64_t *p = &mask_host[0] + i * col_blocks;
for (int j = nblock; j < col_blocks; j++) {
remv[j] |= p[j];
}
}
}
*num_out = num_to_keep;
FRCNN_CUDA_CHECK(cudaFree(mask_dev));
}
// copy proposals to output
// dets (top_n, 5); keep (top_n, ); out (top_n, )
// count should be top_n (total anchors or proposals)
template<typename Dtype>
__global__ void PrepareOutput(const int count,
const Dtype* dets,
const int* keep,
const int out_size,
const int image_index,
Dtype* out,
Dtype* score) {
for (int index = blockIdx.x * blockDim.x + threadIdx.x;
index < count;
index += blockDim.x * gridDim.x) {
out[index * 5] = image_index;
if (index < out_size) {
int keep_i = keep[index];
for (int j = 0; j < 4; ++j) {
out[index * 5 + j + 1] = dets[keep_i * 5 + j];
}
score[index] = dets[keep_i * 5 + 4];
} else {
int keep_i = keep[index % out_size];
for (int j = 0; j < 4; ++j) {
out[index * 5 + j + 1] = dets[keep_i * 5 + j];
}
score[index] = dets[keep_i * 5 + 4];
}
}
}
} // namespace multi_proposal
} // namespace cuda
} // namespace mshadow
namespace mxnet {
namespace op {
template<typename xpu>
class MultiProposalGPUOp : public Operator{
public:
explicit MultiProposalGPUOp(MultiProposalParam param) {
this->param_ = param;
}
virtual void Forward(const OpContext &ctx,
const std::vector<TBlob> &in_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) {
using namespace mshadow;
using namespace mshadow::expr;
using namespace mshadow::cuda;
using namespace mshadow::cuda::multi_proposal;
CHECK_EQ(in_data.size(), 3);
CHECK_EQ(out_data.size(), 2);
CHECK_GT(req.size(), 1);
CHECK_EQ(req[proposal::kOut], kWriteTo);
/*CHECK_EQ(in_data[proposal::kClsProb].shape_[0], 1)
<< "Sorry, multiple images each device is not implemented.";*/
Stream<xpu> *s = ctx.get_stream<xpu>();
Tensor<xpu, 4> scores = in_data[proposal::kClsProb].get<xpu, 4, real_t>(s);
Tensor<xpu, 4> bbox_deltas = in_data[proposal::kBBoxPred].get<xpu, 4, real_t>(s);
Tensor<xpu, 2> im_info = in_data[proposal::kImInfo].get<xpu, 2, real_t>(s);
Tensor<xpu, 2> out = out_data[proposal::kOut].get<xpu, 2, real_t>(s);
Tensor<xpu, 2> out_score = out_data[proposal::kScore].get<xpu, 2, real_t>(s);
int num_images = scores.size(0);
int num_anchors = scores.size(1) / 2;
int height = scores.size(2);
int width = scores.size(3);
int count_anchors = num_anchors * height * width; // count of total anchors
int count = num_images * count_anchors;
// set to -1 for max
int rpn_pre_nms_top_n = (param_.rpn_pre_nms_top_n > 0) ? param_.rpn_pre_nms_top_n : count_anchors;
rpn_pre_nms_top_n = std::min(rpn_pre_nms_top_n, count_anchors);
int rpn_post_nms_top_n = std::min(param_.rpn_post_nms_top_n, rpn_pre_nms_top_n);
// Generate first anchors based on base anchor
std::vector<float> base_anchor(4);
base_anchor[0] = 0.0;
base_anchor[1] = 0.0;
base_anchor[2] = param_.feature_stride - 1.0;
base_anchor[3] = param_.feature_stride - 1.0;
CHECK_EQ(num_anchors, param_.ratios.info.size() * param_.scales.info.size());
std::vector<float> anchors;
utils::GenerateAnchors(base_anchor,
param_.ratios.info,
param_.scales.info,
&anchors);
// Copy generated anchors to GPU
float* workspace_proposals_ptr = NULL;
FRCNN_CUDA_CHECK(cudaMalloc(&workspace_proposals_ptr, sizeof(float) * num_images * count_anchors * 5));
Tensor<xpu, 3> workspace_proposals(workspace_proposals_ptr, Shape3(num_images, count_anchors, 5));
FRCNN_CUDA_CHECK(cudaMemcpy(workspace_proposals.dptr_,
&anchors[0], sizeof(float) * anchors.size(),
cudaMemcpyHostToDevice));
// Copy proposals to a mesh grid
dim3 dimGrid((count + kMaxThreadsPerBlock - 1) / kMaxThreadsPerBlock);
dim3 dimBlock(kMaxThreadsPerBlock);
CheckLaunchParam(dimGrid, dimBlock, "ProposalGrid");
ProposalGridKernel<<<dimGrid, dimBlock>>>(
count, num_anchors, height, width, param_.feature_stride,
scores.dptr_, workspace_proposals.dptr_);
FRCNN_CUDA_CHECK(cudaPeekAtLastError());
// Transform anchors and bbox_deltas into bboxes
CheckLaunchParam(dimGrid, dimBlock, "BBoxPred");
if (param_.iou_loss) {
IoUPredKernel<<<dimGrid, dimBlock>>>(
count, num_anchors, height, width, param_.feature_stride, im_info.dptr_,
workspace_proposals.dptr_, bbox_deltas.dptr_, workspace_proposals.dptr_);
} else {
BBoxPredKernel<<<dimGrid, dimBlock>>>(
count, num_anchors, height, width, param_.feature_stride, im_info.dptr_,
workspace_proposals.dptr_, bbox_deltas.dptr_, workspace_proposals.dptr_);
}
FRCNN_CUDA_CHECK(cudaPeekAtLastError());
// filter boxes with less than rpn_min_size
CheckLaunchParam(dimGrid, dimBlock, "FilterBox");
FilterBoxKernel<<<dimGrid, dimBlock>>>(
count, count_anchors, param_.rpn_min_size, im_info.dptr_, workspace_proposals.dptr_);
FRCNN_CUDA_CHECK(cudaPeekAtLastError());
dimGrid = dim3((count_anchors + kMaxThreadsPerBlock - 1) / kMaxThreadsPerBlock);
dimBlock = dim3(kMaxThreadsPerBlock);
// Copy score to a continuous memory
float* score_ptr = NULL;
FRCNN_CUDA_CHECK(cudaMalloc(&score_ptr, sizeof(float) * count_anchors));
Tensor<xpu, 1> score(score_ptr, Shape1(count_anchors));
int* order_ptr = NULL;
FRCNN_CUDA_CHECK(cudaMalloc(&order_ptr, sizeof(int) * count_anchors));
gitextract_zxbt3wtx/ ├── LICENSE ├── README.md ├── ThirdPartyNotices.txt ├── dff_rfcn/ │ ├── __init__.py │ ├── _init_paths.py │ ├── config/ │ │ ├── __init__.py │ │ └── config.py │ ├── core/ │ │ ├── DataParallelExecutorGroup.py │ │ ├── __init__.py │ │ ├── callback.py │ │ ├── loader.py │ │ ├── metric.py │ │ ├── module.py │ │ ├── rcnn.py │ │ └── tester.py │ ├── demo.py │ ├── demo_batch.py │ ├── function/ │ │ ├── __init__.py │ │ ├── test_rcnn.py │ │ ├── test_rpn.py │ │ ├── train_rcnn.py │ │ └── train_rpn.py │ ├── operator_cxx/ │ │ ├── multi_proposal-inl.h │ │ ├── multi_proposal.cc │ │ ├── multi_proposal.cu │ │ ├── psroi_pooling-inl.h │ │ ├── psroi_pooling.cc │ │ └── psroi_pooling.cu │ ├── operator_py/ │ │ ├── __init__.py │ │ ├── box_annotator_ohem.py │ │ ├── proposal.py │ │ ├── proposal_target.py │ │ ├── rpn_inv_normalize.py │ │ └── tile_as.py │ ├── symbols/ │ │ ├── __init__.py │ │ └── resnet_v1_101_flownet_rfcn.py │ ├── test.py │ └── train_end2end.py ├── experiments/ │ ├── dff_rfcn/ │ │ ├── cfgs/ │ │ │ ├── dff_rfcn_vid_demo.yaml │ │ │ └── resnet_v1_101_flownet_imagenet_vid_rfcn_end2end_ohem.yaml │ │ ├── dff_rfcn_end2end_train_test.py │ │ └── dff_rfcn_test.py │ └── rfcn/ │ ├── cfgs/ │ │ ├── resnet_v1_101_imagenet_vid_rfcn_end2end_ohem.yaml │ │ └── rfcn_vid_demo.yaml │ ├── rfcn_end2end_train_test.py │ └── rfcn_test.py ├── green2.py ├── init.bat ├── init.sh ├── lib/ │ ├── Makefile │ ├── __init__.py │ ├── bbox/ │ │ ├── .gitignore │ │ ├── __init__.py │ │ ├── bbox.pyx │ │ ├── bbox_regression.py │ │ ├── bbox_transform.py │ │ ├── setup_linux.py │ │ └── setup_windows.py │ ├── dataset/ │ │ ├── __init__.py │ │ ├── ds_utils.py │ │ ├── imagenet_vid.py │ │ ├── imagenet_vid_eval.py │ │ └── imdb.py │ ├── nms/ │ │ ├── __init__.py │ │ ├── cpu_nms.pyx │ │ ├── gpu_nms.cu │ │ ├── gpu_nms.hpp │ │ ├── gpu_nms.pyx │ │ ├── nms.py │ │ ├── nms_kernel.cu │ │ ├── setup_linux.py │ │ ├── setup_windows.py │ │ └── setup_windows_cuda.py │ ├── rpn/ │ │ ├── __init__.py │ │ ├── generate_anchor.py │ │ └── rpn.py │ └── utils/ │ ├── PrefetchingIter.py │ ├── __init__.py │ ├── combine_model.py │ ├── create_logger.py │ ├── image.py │ ├── image_processing.py │ ├── load_data.py │ ├── load_model.py │ ├── lr_scheduler.py │ ├── roidb.py │ ├── save_model.py │ ├── show_boxes.py │ ├── symbol.py │ └── tictoc.py ├── rfcn/ │ ├── __init__.py │ ├── _init_paths.py │ ├── config/ │ │ ├── __init__.py │ │ └── config.py │ ├── core/ │ │ ├── DataParallelExecutorGroup.py │ │ ├── __init__.py │ │ ├── callback.py │ │ ├── loader.py │ │ ├── metric.py │ │ ├── module.py │ │ ├── rcnn.py │ │ └── tester.py │ ├── demo.py │ ├── demo_batch.py │ ├── function/ │ │ ├── __init__.py │ │ ├── test_rcnn.py │ │ ├── test_rpn.py │ │ ├── train_rcnn.py │ │ └── train_rpn.py │ ├── operator_cxx/ │ │ ├── multi_proposal-inl.h │ │ ├── multi_proposal.cc │ │ ├── multi_proposal.cu │ │ ├── psroi_pooling-inl.h │ │ ├── psroi_pooling.cc │ │ └── psroi_pooling.cu │ ├── operator_py/ │ │ ├── __init__.py │ │ ├── box_annotator_ohem.py │ │ ├── proposal.py │ │ ├── proposal_target.py │ │ └── rpn_inv_normalize.py │ ├── symbols/ │ │ ├── __init__.py │ │ └── resnet_v1_101_rfcn.py │ ├── test.py │ └── train_end2end.py └── zero.md
SYMBOL INDEX (596 symbols across 80 files)
FILE: dff_rfcn/_init_paths.py
function add_path (line 11) | def add_path(path):
FILE: dff_rfcn/config/config.py
function update_config (line 157) | def update_config(config_file):
FILE: dff_rfcn/core/DataParallelExecutorGroup.py
function _load_general (line 24) | def _load_general(data, targets, major_axis):
function _load_data (line 37) | def _load_data(batch, targets, major_axis):
function _load_label (line 42) | def _load_label(batch, targets, major_axis):
function _merge_multi_context (line 47) | def _merge_multi_context(outputs, major_axis):
class DataParallelExecutorGroup (line 64) | class DataParallelExecutorGroup(object):
method __init__ (line 108) | def __init__(self, symbol, contexts, workload, data_shapes, label_shap...
method decide_slices (line 193) | def decide_slices(self, data_shapes):
method _collect_arrays (line 219) | def _collect_arrays(self):
method bind_exec (line 253) | def bind_exec(self, data_shapes, label_shapes, shared_group=None, resh...
method reshape (line 283) | def reshape(self, data_shapes, label_shapes):
method set_params (line 302) | def set_params(self, arg_params, aux_params):
method get_params (line 315) | def get_params(self, arg_params, aux_params):
method forward (line 336) | def forward(self, data_batch, is_train=None):
method get_outputs (line 363) | def get_outputs(self, merge_multi_context=True):
method get_states (line 386) | def get_states(self, merge_multi_context=True):
method set_states (line 407) | def set_states(self, states=None, value=None):
method get_input_grads (line 428) | def get_input_grads(self, merge_multi_context=True):
method backward (line 450) | def backward(self, out_grads=None):
method update_metric (line 470) | def update_metric(self, eval_metric, labels):
method _bind_ith_exec (line 483) | def _bind_ith_exec(self, i, data_shapes, label_shapes, shared_group):
method _sliced_shape (line 575) | def _sliced_shape(self, shapes, i, major_axis):
method install_monitor (line 593) | def install_monitor(self, mon):
FILE: dff_rfcn/core/callback.py
class Speedometer (line 19) | class Speedometer(object):
method __init__ (line 20) | def __init__(self, batch_size, frequent=50):
method __call__ (line 27) | def __call__(self, param):
function do_checkpoint (line 54) | def do_checkpoint(prefix, means, stds):
FILE: dff_rfcn/core/loader.py
class TestLoader (line 23) | class TestLoader(mx.io.DataIter):
method __init__ (line 24) | def __init__(self, roidb, config, batch_size=1, shuffle=False,
method provide_data (line 62) | def provide_data(self):
method provide_label (line 66) | def provide_label(self):
method provide_data_single (line 70) | def provide_data_single(self):
method provide_label_single (line 74) | def provide_label_single(self):
method reset (line 77) | def reset(self):
method iter_next (line 82) | def iter_next(self):
method next (line 85) | def next(self):
method getindex (line 102) | def getindex(self):
method getpad (line 105) | def getpad(self):
method get_batch (line 111) | def get_batch(self):
class AnchorLoader (line 131) | class AnchorLoader(mx.io.DataIter):
method __init__ (line 133) | def __init__(self, feat_sym, roidb, cfg, batch_size=1, shuffle=False, ...
method provide_data (line 194) | def provide_data(self):
method provide_label (line 198) | def provide_label(self):
method provide_data_single (line 202) | def provide_data_single(self):
method provide_label_single (line 206) | def provide_label_single(self):
method reset (line 209) | def reset(self):
method iter_next (line 228) | def iter_next(self):
method next (line 231) | def next(self):
method getindex (line 241) | def getindex(self):
method getpad (line 244) | def getpad(self):
method infer_shape (line 250) | def infer_shape(self, max_data_shape=None, max_label_shape=None):
method get_batch (line 267) | def get_batch(self):
method get_batch_individual (line 326) | def get_batch_individual(self):
method parfetch (line 347) | def parfetch(self, iroidb):
FILE: dff_rfcn/core/metric.py
function get_rpn_names (line 18) | def get_rpn_names():
function get_rcnn_names (line 24) | def get_rcnn_names(cfg):
class RPNAccMetric (line 36) | class RPNAccMetric(mx.metric.EvalMetric):
method __init__ (line 37) | def __init__(self):
method update (line 41) | def update(self, labels, preds):
class RCNNAccMetric (line 60) | class RCNNAccMetric(mx.metric.EvalMetric):
method __init__ (line 61) | def __init__(self, cfg):
method update (line 67) | def update(self, labels, preds):
class RPNLogLossMetric (line 87) | class RPNLogLossMetric(mx.metric.EvalMetric):
method __init__ (line 88) | def __init__(self):
method update (line 92) | def update(self, labels, preds):
class RCNNLogLossMetric (line 114) | class RCNNLogLossMetric(mx.metric.EvalMetric):
method __init__ (line 115) | def __init__(self, cfg):
method update (line 121) | def update(self, labels, preds):
class RPNL1LossMetric (line 144) | class RPNL1LossMetric(mx.metric.EvalMetric):
method __init__ (line 145) | def __init__(self):
method update (line 149) | def update(self, labels, preds):
class RCNNL1LossMetric (line 160) | class RCNNL1LossMetric(mx.metric.EvalMetric):
method __init__ (line 161) | def __init__(self, cfg):
method update (line 167) | def update(self, labels, preds):
FILE: dff_rfcn/core/module.py
class Module (line 35) | class Module(BaseModule):
method __init__ (line 59) | def __init__(self, symbol, data_names=('data',), label_names=('softmax...
method load (line 110) | def load(prefix, epoch, load_optimizer_states=False, **kwargs):
method save_checkpoint (line 148) | def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):
method _reset_bind (line 170) | def _reset_bind(self):
method data_names (line 178) | def data_names(self):
method label_names (line 183) | def label_names(self):
method output_names (line 188) | def output_names(self):
method data_shapes (line 193) | def data_shapes(self):
method label_shapes (line 203) | def label_shapes(self):
method output_shapes (line 215) | def output_shapes(self):
method get_params (line 224) | def get_params(self):
method init_params (line 237) | def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_...
method set_params (line 295) | def set_params(self, arg_params, aux_params, allow_missing=False, forc...
method bind (line 333) | def bind(self, data_shapes, label_shapes=None, for_training=True,
method reshape (line 430) | def reshape(self, data_shapes, label_shapes=None):
method init_optimizer (line 449) | def init_optimizer(self, kvstore='local', optimizer='sgd',
method borrow_optimizer (line 527) | def borrow_optimizer(self, shared_module):
method forward (line 542) | def forward(self, data_batch, is_train=None):
method backward (line 555) | def backward(self, out_grads=None):
method update (line 568) | def update(self):
method get_outputs (line 586) | def get_outputs(self, merge_multi_context=True):
method get_input_grads (line 606) | def get_input_grads(self, merge_multi_context=True):
method get_states (line 626) | def get_states(self, merge_multi_context=True):
method set_states (line 646) | def set_states(self, states=None, value=None):
method update_metric (line 660) | def update_metric(self, eval_metric, labels):
method _sync_params_from_devices (line 671) | def _sync_params_from_devices(self):
method save_optimizer_states (line 679) | def save_optimizer_states(self, fname):
method load_optimizer_states (line 695) | def load_optimizer_states(self, fname):
method install_monitor (line 710) | def install_monitor(self, mon):
class MutableModule (line 716) | class MutableModule(BaseModule):
method __init__ (line 731) | def __init__(self, symbol, data_names, label_names,
method _reset_bind (line 755) | def _reset_bind(self):
method data_names (line 760) | def data_names(self):
method output_names (line 764) | def output_names(self):
method data_shapes (line 768) | def data_shapes(self):
method label_shapes (line 773) | def label_shapes(self):
method output_shapes (line 778) | def output_shapes(self):
method get_params (line 782) | def get_params(self):
method init_params (line 786) | def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_...
method bind (line 796) | def bind(self, data_shapes, label_shapes=None, for_training=True,
method save_checkpoint (line 852) | def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):
method init_optimizer (line 867) | def init_optimizer(self, kvstore='local', optimizer='sgd',
method fit (line 879) | def fit(self, train_data, eval_data=None, eval_metric='acc',
method forward (line 1016) | def forward(self, data_batch, is_train=None):
method backward (line 1051) | def backward(self, out_grads=None):
method update (line 1055) | def update(self):
method get_outputs (line 1059) | def get_outputs(self, merge_multi_context=True):
method get_input_grads (line 1062) | def get_input_grads(self, merge_multi_context=True):
method update_metric (line 1066) | def update_metric(self, eval_metric, labels):
method install_monitor (line 1070) | def install_monitor(self, mon):
FILE: dff_rfcn/core/rcnn.py
function get_rcnn_testbatch (line 36) | def get_rcnn_testbatch(roidb, cfg):
function get_rcnn_batch (line 58) | def get_rcnn_batch(roidb, cfg):
function sample_rois (line 126) | def sample_rois(rois, fg_rois_per_image, rois_per_image, num_classes, cfg,
FILE: dff_rfcn/core/tester.py
class Predictor (line 28) | class Predictor(object):
method __init__ (line 29) | def __init__(self, symbol, data_names, label_names,
method predict (line 38) | def predict(self, data_batch):
function im_proposal (line 44) | def im_proposal(predictor, data_batch, data_names, scales):
function generate_proposals (line 64) | def generate_proposals(predictor, test_data, imdb, cfg, vis=False, thres...
function im_detect (line 130) | def im_detect(predictor, data_batch, data_names, scales, cfg):
function im_batch_detect (line 164) | def im_batch_detect(predictor, data_batch, data_names, scales, cfg):
function pred_eval (line 193) | def pred_eval(gpu_id, key_predictor, cur_predictor, test_data, imdb, cfg...
function pred_eval_multiprocess (line 295) | def pred_eval_multiprocess(gpu_num, key_predictors, cur_predictors, test...
function vis_all_detection (line 308) | def vis_all_detection(im_array, detections, class_names, scale, cfg, thr...
function draw_all_detection (line 342) | def draw_all_detection(im_array, detections, class_names, scale, cfg, th...
FILE: dff_rfcn/demo.py
function parse_args (line 36) | def parse_args():
function main (line 43) | def main():
FILE: dff_rfcn/demo_batch.py
function parse_args (line 36) | def parse_args():
function main (line 43) | def main():
FILE: dff_rfcn/function/test_rcnn.py
function get_predictor (line 28) | def get_predictor(sym, sym_instance, cfg, arg_params, aux_params, test_d...
function test_rcnn (line 47) | def test_rcnn(cfg, dataset, image_set, root_path, dataset_path,
FILE: dff_rfcn/function/test_rpn.py
function test_rpn (line 26) | def test_rpn(cfg, dataset, image_set, root_path, dataset_path,
FILE: dff_rfcn/function/train_rcnn.py
function train_rcnn (line 31) | def train_rcnn(cfg, dataset, image_set, root_path, dataset_path,
FILE: dff_rfcn/function/train_rpn.py
function train_rpn (line 29) | def train_rpn(cfg, dataset, image_set, root_path, dataset_path,
FILE: dff_rfcn/operator_cxx/multi_proposal-inl.h
function namespace (line 26) | namespace mxnet {
function namespace (line 115) | namespace mxnet {
function namespace (line 252) | namespace mxnet {
FILE: dff_rfcn/operator_cxx/multi_proposal.cc
type mxnet (line 12) | namespace mxnet {
type op (line 13) | namespace op {
class MultiProposalOp (line 16) | class MultiProposalOp : public Operator{
method MultiProposalOp (line 18) | explicit MultiProposalOp(MultiProposalParam param) {
method Forward (line 22) | virtual void Forward(const OpContext &ctx,
method Backward (line 30) | virtual void Backward(const OpContext &ctx,
function Operator (line 45) | Operator *CreateOp<cpu>(MultiProposalParam param) {
function Operator (line 49) | Operator* MultiProposalProp::CreateOperator(Context ctx) const {
FILE: dff_rfcn/operator_cxx/psroi_pooling-inl.h
function namespace (line 23) | namespace mxnet {
FILE: dff_rfcn/operator_cxx/psroi_pooling.cc
type mshadow (line 21) | namespace mshadow {
function PSROIPoolForward (line 23) | inline void PSROIPoolForward(const Tensor<cpu, 4, DType> &out,
function PSROIPoolBackwardAcc (line 35) | inline void PSROIPoolBackwardAcc(const Tensor<cpu, 4, DType> &in_grad,
type mxnet (line 46) | namespace mxnet {
type op (line 47) | namespace op {
function Operator (line 50) | Operator *CreateOp<cpu>(PSROIPoolingParam param, int dtype) {
function Operator (line 58) | Operator *PSROIPoolingProp::CreateOperatorEx(Context ctx, std::vecto...
FILE: dff_rfcn/operator_py/box_annotator_ohem.py
class BoxAnnotatorOHEMOperator (line 19) | class BoxAnnotatorOHEMOperator(mx.operator.CustomOp):
method __init__ (line 20) | def __init__(self, num_classes, num_reg_classes, roi_per_img):
method forward (line 26) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 56) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class BoxAnnotatorOHEMProp (line 62) | class BoxAnnotatorOHEMProp(mx.operator.CustomOpProp):
method __init__ (line 63) | def __init__(self, num_classes, num_reg_classes, roi_per_img):
method list_arguments (line 69) | def list_arguments(self):
method list_outputs (line 72) | def list_outputs(self):
method infer_shape (line 75) | def infer_shape(self, in_shape):
method create_operator (line 82) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 85) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: dff_rfcn/operator_py/proposal.py
class ProposalOperator (line 31) | class ProposalOperator(mx.operator.CustomOp):
method __init__ (line 32) | def __init__(self, feat_stride, scales, ratios, output_score,
method forward (line 51) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 170) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
method _filter_boxes (line 176) | def _filter_boxes(boxes, min_size):
method _clip_pad (line 184) | def _clip_pad(tensor, pad_shape):
class ProposalProp (line 201) | class ProposalProp(mx.operator.CustomOpProp):
method __init__ (line 202) | def __init__(self, feat_stride='16', scales='(8, 16, 32)', ratios='(0....
method list_arguments (line 214) | def list_arguments(self):
method list_outputs (line 217) | def list_outputs(self):
method infer_shape (line 223) | def infer_shape(self, in_shape):
method create_operator (line 238) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 242) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: dff_rfcn/operator_py/proposal_target.py
class ProposalTargetOperator (line 30) | class ProposalTargetOperator(mx.operator.CustomOp):
method __init__ (line 31) | def __init__(self, num_classes, batch_images, batch_rois, cfg, fg_frac...
method forward (line 44) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 82) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class ProposalTargetProp (line 88) | class ProposalTargetProp(mx.operator.CustomOpProp):
method __init__ (line 89) | def __init__(self, num_classes, batch_images, batch_rois, cfg, fg_frac...
method list_arguments (line 97) | def list_arguments(self):
method list_outputs (line 100) | def list_outputs(self):
method infer_shape (line 103) | def infer_shape(self, in_shape):
method create_operator (line 117) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 120) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: dff_rfcn/operator_py/rpn_inv_normalize.py
class RPNInvNormalizeOperator (line 12) | class RPNInvNormalizeOperator(mx.operator.CustomOp):
method __init__ (line 13) | def __init__(self, num_anchors, bbox_mean, bbox_std):
method forward (line 19) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 28) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class RPNInvNormalizeProp (line 32) | class RPNInvNormalizeProp(mx.operator.CustomOpProp):
method __init__ (line 33) | def __init__(self, num_anchors, bbox_mean='(0.0, 0.0, 0.0, 0.0)', bbox...
method list_arguments (line 39) | def list_arguments(self):
method list_outputs (line 42) | def list_outputs(self):
method infer_shape (line 45) | def infer_shape(self, in_shape):
method create_operator (line 50) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 53) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: dff_rfcn/operator_py/tile_as.py
class TileAsOperator (line 12) | class TileAsOperator(mx.operator.CustomOp):
method __init__ (line 13) | def __init__(self):
method forward (line 16) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 21) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class TileAsProp (line 27) | class TileAsProp(mx.operator.CustomOpProp):
method __init__ (line 28) | def __init__(self):
method list_arguments (line 31) | def list_arguments(self):
method list_outputs (line 34) | def list_outputs(self):
method infer_shape (line 37) | def infer_shape(self, in_shape):
method create_operator (line 46) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 49) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: dff_rfcn/symbols/resnet_v1_101_flownet_rfcn.py
class resnet_v1_101_flownet_rfcn (line 17) | class resnet_v1_101_flownet_rfcn(Symbol):
method __init__ (line 19) | def __init__(self):
method get_resnet_v1 (line 29) | def get_resnet_v1(self, data):
method get_flownet (line 482) | def get_flownet(self, img_cur, img_ref):
method get_train_symbol (line 541) | def get_train_symbol(self, cfg):
method get_key_test_symbol (line 661) | def get_key_test_symbol(self, cfg):
method get_cur_test_symbol (line 737) | def get_cur_test_symbol(self, cfg):
method get_batch_test_symbol (line 816) | def get_batch_test_symbol(self, cfg):
method init_weight (line 896) | def init_weight(self, cfg, arg_params, aux_params):
FILE: dff_rfcn/test.py
function parse_args (line 24) | def parse_args():
function main (line 49) | def main():
FILE: dff_rfcn/train_end2end.py
function parse_args (line 25) | def parse_args():
function train_net (line 58) | def train_net(args, ctx, pretrained, pretrained_flow, epoch, prefix, beg...
function main (line 172) | def main():
FILE: green2.py
function modify (line 66) | def modify():
function commit (line 78) | def commit():
function set_sys_time (line 84) | def set_sys_time(day, month, year):
function trick_commit (line 88) | def trick_commit(year, month, day):
function daily_commit (line 94) | def daily_commit(start_date, end_date):
FILE: lib/bbox/bbox_regression.py
function compute_bbox_regression_targets (line 23) | def compute_bbox_regression_targets(rois, overlaps, labels, cfg):
function add_bbox_regression_targets (line 60) | def add_bbox_regression_targets(roidb, cfg):
function expand_bbox_regression_targets (line 120) | def expand_bbox_regression_targets(bbox_targets_data, num_classes, cfg):
FILE: lib/bbox/bbox_transform.py
function bbox_overlaps (line 18) | def bbox_overlaps(boxes, query_boxes):
function bbox_overlaps_py (line 22) | def bbox_overlaps_py(boxes, query_boxes):
function clip_boxes (line 45) | def clip_boxes(boxes, im_shape):
function filter_boxes (line 62) | def filter_boxes(boxes, min_size):
function nonlinear_transform (line 74) | def nonlinear_transform(ex_rois, gt_rois):
function nonlinear_pred (line 103) | def nonlinear_pred(boxes, box_deltas):
function iou_transform (line 143) | def iou_transform(ex_rois, gt_rois):
function iou_pred (line 149) | def iou_pred(boxes, box_deltas):
FILE: lib/bbox/setup_linux.py
function customize_compiler_for_nvcc (line 29) | def customize_compiler_for_nvcc(self):
class custom_build_ext (line 67) | class custom_build_ext(build_ext):
method build_extensions (line 68) | def build_extensions(self):
FILE: lib/dataset/ds_utils.py
function unique_boxes (line 11) | def unique_boxes(boxes, scale=1.0):
function filter_small_boxes (line 19) | def filter_small_boxes(boxes, min_size):
FILE: lib/dataset/imagenet_vid.py
class ImageNetVID (line 26) | class ImageNetVID(IMDB):
method __init__ (line 27) | def __init__(self, image_set, root_path, dataset_path, result_path=None):
method load_image_set_index (line 62) | def load_image_set_index(self):
method image_path_from_index (line 82) | def image_path_from_index(self, index):
method gt_roidb (line 96) | def gt_roidb(self):
method load_vid_annotation (line 115) | def load_vid_annotation(self, iindex):
method evaluate_detections (line 184) | def evaluate_detections(self, detections):
method evaluate_detections_multiprocess (line 199) | def evaluate_detections_multiprocess(self, detections):
method get_result_file_template (line 214) | def get_result_file_template(self):
method write_vid_results (line 223) | def write_vid_results(self, all_boxes):
method write_vid_results_multiprocess (line 245) | def write_vid_results_multiprocess(self, detections):
method do_python_eval (line 270) | def do_python_eval(self):
method do_python_eval_gen (line 291) | def do_python_eval_gen(self):
FILE: lib/dataset/imagenet_vid_eval.py
function parse_vid_rec (line 17) | def parse_vid_rec(filename, classhash, img_ids, defaultIOUthr=0.5, pixel...
function vid_ap (line 45) | def vid_ap(rec, prec):
function vid_eval (line 70) | def vid_eval(detpath, annopath, imageset_file, classname_map, annocache,...
FILE: lib/dataset/imdb.py
function get_flipped_entry_outclass_wrapper (line 26) | def get_flipped_entry_outclass_wrapper(IMDB_instance, seg_rec):
class IMDB (line 29) | class IMDB(object):
method __init__ (line 30) | def __init__(self, name, image_set, root_path, dataset_path, result_pa...
method image_path_from_index (line 51) | def image_path_from_index(self, index):
method gt_roidb (line 54) | def gt_roidb(self):
method evaluate_detections (line 57) | def evaluate_detections(self, detections):
method evaluate_segmentations (line 60) | def evaluate_segmentations(self, segmentations):
method cache_path (line 64) | def cache_path(self):
method result_path (line 75) | def result_path(self):
method image_path_at (line 81) | def image_path_at(self, index):
method load_rpn_data (line 89) | def load_rpn_data(self, full=False):
method load_rpn_roidb (line 100) | def load_rpn_roidb(self, gt_roidb):
method rpn_roidb (line 109) | def rpn_roidb(self, gt_roidb, append_gt=False):
method create_roidb_from_box_list (line 124) | def create_roidb_from_box_list(self, box_list, gt_roidb):
method get_flipped_entry (line 173) | def get_flipped_entry(self, seg_rec):
method append_flipped_images_for_segmentation (line 180) | def append_flipped_images_for_segmentation(self, segdb):
method append_flipped_images (line 202) | def append_flipped_images(self, roidb):
method flip_and_save (line 233) | def flip_and_save(self, image_path):
method evaluate_recall (line 250) | def evaluate_recall(self, roidb, candidate_boxes=None, thresholds=None):
method merge_roidbs (line 358) | def merge_roidbs(a, b):
FILE: lib/nms/nms.py
function py_nms_wrapper (line 19) | def py_nms_wrapper(thresh):
function cpu_nms_wrapper (line 25) | def cpu_nms_wrapper(thresh):
function gpu_nms_wrapper (line 31) | def gpu_nms_wrapper(thresh, device_id):
function nms (line 37) | def nms(dets, thresh):
FILE: lib/nms/setup_linux.py
function find_in_path (line 22) | def find_in_path(name, path):
function locate_cuda (line 33) | def locate_cuda():
function customize_compiler_for_nvcc (line 72) | def customize_compiler_for_nvcc(self):
class custom_build_ext (line 110) | class custom_build_ext(build_ext):
method build_extensions (line 111) | def build_extensions(self):
FILE: lib/nms/setup_windows.py
function find_in_path (line 31) | def find_in_path(name, path):
function locate_cuda (line 42) | def locate_cuda():
function customize_compiler_for_nvcc (line 86) | def customize_compiler_for_nvcc(self):
class custom_build_ext (line 130) | class custom_build_ext(build_ext):
method build_extensions (line 131) | def build_extensions(self):
FILE: lib/nms/setup_windows_cuda.py
class CUDA_build_ext (line 48) | class CUDA_build_ext(build_ext):
method build_extensions (line 53) | def build_extensions(self):
method spawn (line 62) | def spawn(self, cmd, search_path=1, verbose=0, dry_run=0):
FILE: lib/rpn/generate_anchor.py
function generate_anchors (line 21) | def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
function _whctrs (line 35) | def _whctrs(anchor):
function _mkanchors (line 47) | def _mkanchors(ws, hs, x_ctr, y_ctr):
function _ratio_enum (line 62) | def _ratio_enum(anchor, ratios):
function _scale_enum (line 76) | def _scale_enum(anchor, scales):
FILE: lib/rpn/rpn.py
function get_rpn_testbatch (line 34) | def get_rpn_testbatch(roidb, cfg):
function get_rpn_batch (line 52) | def get_rpn_batch(roidb, cfg):
function get_rpn_pair_batch (line 78) | def get_rpn_pair_batch(roidb, cfg):
function assign_anchor (line 108) | def assign_anchor(feat_shape, gt_boxes, im_info, cfg, feat_stride=16,
FILE: lib/utils/PrefetchingIter.py
class PrefetchingIter (line 19) | class PrefetchingIter(mx.io.DataIter):
method __init__ (line 40) | def __init__(self, iters, rename_data=None, rename_label=None):
method __del__ (line 75) | def __del__(self):
method provide_data (line 83) | def provide_data(self):
method provide_label (line 95) | def provide_label(self):
method reset (line 106) | def reset(self):
method iter_next (line 116) | def iter_next(self):
method next (line 129) | def next(self):
method getdata (line 135) | def getdata(self):
method getlabel (line 138) | def getlabel(self):
method getindex (line 141) | def getindex(self):
method getpad (line 144) | def getpad(self):
FILE: lib/utils/combine_model.py
function combine_model (line 12) | def combine_model(prefix1, epoch1, prefix2, epoch2, prefix_out, epoch_out):
FILE: lib/utils/create_logger.py
function create_logger (line 12) | def create_logger(root_output_path, cfg, image_set):
FILE: lib/utils/image.py
function get_image (line 17) | def get_image(roidb, config):
function get_pair_image (line 49) | def get_pair_image(roidb, config):
function resize (line 104) | def resize(im, target_size, max_size, stride=0, interpolation = cv2.INTE...
function transform (line 134) | def transform(im, pixel_means):
function transform_seg_gt (line 147) | def transform_seg_gt(gt):
function transform_inverse (line 158) | def transform_inverse(im_tensor, pixel_means):
function tensor_vstack (line 177) | def tensor_vstack(tensor_list, pad=0):
FILE: lib/utils/image_processing.py
function resize (line 12) | def resize(im, target_size, max_size):
function transform (line 31) | def transform(im, pixel_means, need_mean=False):
function transform_inverse (line 52) | def transform_inverse(im_tensor, pixel_means):
function tensor_vstack (line 72) | def tensor_vstack(tensor_list, pad=0):
FILE: lib/utils/load_data.py
function load_gt_roidb (line 12) | def load_gt_roidb(dataset_name, image_set_name, root_path, dataset_path,...
function load_proposal_roidb (line 22) | def load_proposal_roidb(dataset_name, image_set_name, root_path, dataset...
function merge_roidb (line 34) | def merge_roidb(roidbs):
function filter_roidb (line 42) | def filter_roidb(roidb, config):
function load_gt_segdb (line 61) | def load_gt_segdb(dataset_name, image_set_name, root_path, dataset_path,...
function merge_segdb (line 71) | def merge_segdb(segdbs):
FILE: lib/utils/load_model.py
function load_checkpoint (line 11) | def load_checkpoint(prefix, epoch):
function convert_context (line 34) | def convert_context(params, ctx):
function load_param (line 46) | def load_param(prefix, epoch, convert=False, ctx=None, process=False):
FILE: lib/utils/lr_scheduler.py
class WarmupMultiFactorScheduler (line 12) | class WarmupMultiFactorScheduler(LRScheduler):
method __init__ (line 27) | def __init__(self, step, factor=1, warmup=False, warmup_lr=0, warmup_s...
method __call__ (line 45) | def __call__(self, num_update):
FILE: lib/utils/roidb.py
function prepare_roidb (line 20) | def prepare_roidb(imdb, roidb, cfg):
FILE: lib/utils/save_model.py
function save_checkpoint (line 11) | def save_checkpoint(prefix, epoch, arg_params, aux_params):
FILE: lib/utils/show_boxes.py
function show_boxes (line 12) | def show_boxes(im, dets, classes, scale = 1.0):
function draw_boxes (line 36) | def draw_boxes(im, dets, classes, scale = 1.0):
FILE: lib/utils/symbol.py
class Symbol (line 9) | class Symbol:
method __init__ (line 10) | def __init__(self):
method symbol (line 17) | def symbol(self):
method get_symbol (line 20) | def get_symbol(self, cfg, is_train=True):
method init_weights (line 26) | def init_weights(self, cfg, arg_params, aux_params):
method get_msra_std (line 29) | def get_msra_std(self, shape):
method infer_shape (line 36) | def infer_shape(self, data_shape_dict):
method check_parameter_shapes (line 43) | def check_parameter_shapes(self, arg_params, aux_params, data_shape_di...
FILE: lib/utils/tictoc.py
function tic (line 10) | def tic():
function toc (line 16) | def toc():
FILE: rfcn/_init_paths.py
function add_path (line 11) | def add_path(path):
FILE: rfcn/config/config.py
function update_config (line 148) | def update_config(config_file):
FILE: rfcn/core/DataParallelExecutorGroup.py
function _load_general (line 24) | def _load_general(data, targets, major_axis):
function _load_data (line 37) | def _load_data(batch, targets, major_axis):
function _load_label (line 42) | def _load_label(batch, targets, major_axis):
function _merge_multi_context (line 47) | def _merge_multi_context(outputs, major_axis):
class DataParallelExecutorGroup (line 64) | class DataParallelExecutorGroup(object):
method __init__ (line 108) | def __init__(self, symbol, contexts, workload, data_shapes, label_shap...
method decide_slices (line 193) | def decide_slices(self, data_shapes):
method _collect_arrays (line 219) | def _collect_arrays(self):
method bind_exec (line 253) | def bind_exec(self, data_shapes, label_shapes, shared_group=None, resh...
method reshape (line 283) | def reshape(self, data_shapes, label_shapes):
method set_params (line 302) | def set_params(self, arg_params, aux_params):
method get_params (line 315) | def get_params(self, arg_params, aux_params):
method forward (line 336) | def forward(self, data_batch, is_train=None):
method get_outputs (line 363) | def get_outputs(self, merge_multi_context=True):
method get_states (line 386) | def get_states(self, merge_multi_context=True):
method set_states (line 407) | def set_states(self, states=None, value=None):
method get_input_grads (line 428) | def get_input_grads(self, merge_multi_context=True):
method backward (line 450) | def backward(self, out_grads=None):
method update_metric (line 470) | def update_metric(self, eval_metric, labels):
method _bind_ith_exec (line 483) | def _bind_ith_exec(self, i, data_shapes, label_shapes, shared_group):
method _sliced_shape (line 575) | def _sliced_shape(self, shapes, i, major_axis):
method install_monitor (line 593) | def install_monitor(self, mon):
FILE: rfcn/core/callback.py
class Speedometer (line 19) | class Speedometer(object):
method __init__ (line 20) | def __init__(self, batch_size, frequent=50):
method __call__ (line 27) | def __call__(self, param):
function do_checkpoint (line 54) | def do_checkpoint(prefix, means, stds):
FILE: rfcn/core/loader.py
class TestLoader (line 23) | class TestLoader(mx.io.DataIter):
method __init__ (line 24) | def __init__(self, roidb, config, batch_size=1, shuffle=False,
method provide_data (line 57) | def provide_data(self):
method provide_label (line 61) | def provide_label(self):
method provide_data_single (line 65) | def provide_data_single(self):
method provide_label_single (line 69) | def provide_label_single(self):
method reset (line 72) | def reset(self):
method iter_next (line 77) | def iter_next(self):
method next (line 80) | def next(self):
method getindex (line 90) | def getindex(self):
method getpad (line 93) | def getpad(self):
method get_batch (line 99) | def get_batch(self):
class AnchorLoader (line 110) | class AnchorLoader(mx.io.DataIter):
method __init__ (line 112) | def __init__(self, feat_sym, roidb, cfg, batch_size=1, shuffle=False, ...
method provide_data (line 173) | def provide_data(self):
method provide_label (line 177) | def provide_label(self):
method provide_data_single (line 181) | def provide_data_single(self):
method provide_label_single (line 185) | def provide_label_single(self):
method reset (line 188) | def reset(self):
method iter_next (line 207) | def iter_next(self):
method next (line 210) | def next(self):
method getindex (line 220) | def getindex(self):
method getpad (line 223) | def getpad(self):
method infer_shape (line 229) | def infer_shape(self, max_data_shape=None, max_label_shape=None):
method get_batch (line 246) | def get_batch(self):
method get_batch_individual (line 305) | def get_batch_individual(self):
method parfetch (line 326) | def parfetch(self, iroidb):
FILE: rfcn/core/metric.py
function get_rpn_names (line 18) | def get_rpn_names():
function get_rcnn_names (line 24) | def get_rcnn_names(cfg):
class RPNAccMetric (line 36) | class RPNAccMetric(mx.metric.EvalMetric):
method __init__ (line 37) | def __init__(self):
method update (line 41) | def update(self, labels, preds):
class RCNNAccMetric (line 60) | class RCNNAccMetric(mx.metric.EvalMetric):
method __init__ (line 61) | def __init__(self, cfg):
method update (line 67) | def update(self, labels, preds):
class RPNLogLossMetric (line 87) | class RPNLogLossMetric(mx.metric.EvalMetric):
method __init__ (line 88) | def __init__(self):
method update (line 92) | def update(self, labels, preds):
class RCNNLogLossMetric (line 114) | class RCNNLogLossMetric(mx.metric.EvalMetric):
method __init__ (line 115) | def __init__(self, cfg):
method update (line 121) | def update(self, labels, preds):
class RPNL1LossMetric (line 144) | class RPNL1LossMetric(mx.metric.EvalMetric):
method __init__ (line 145) | def __init__(self):
method update (line 149) | def update(self, labels, preds):
class RCNNL1LossMetric (line 160) | class RCNNL1LossMetric(mx.metric.EvalMetric):
method __init__ (line 161) | def __init__(self, cfg):
method update (line 167) | def update(self, labels, preds):
FILE: rfcn/core/module.py
class Module (line 34) | class Module(BaseModule):
method __init__ (line 58) | def __init__(self, symbol, data_names=('data',), label_names=('softmax...
method load (line 109) | def load(prefix, epoch, load_optimizer_states=False, **kwargs):
method save_checkpoint (line 147) | def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):
method _reset_bind (line 169) | def _reset_bind(self):
method data_names (line 177) | def data_names(self):
method label_names (line 182) | def label_names(self):
method output_names (line 187) | def output_names(self):
method data_shapes (line 192) | def data_shapes(self):
method label_shapes (line 202) | def label_shapes(self):
method output_shapes (line 214) | def output_shapes(self):
method get_params (line 223) | def get_params(self):
method init_params (line 236) | def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_...
method set_params (line 294) | def set_params(self, arg_params, aux_params, allow_missing=False, forc...
method bind (line 332) | def bind(self, data_shapes, label_shapes=None, for_training=True,
method reshape (line 429) | def reshape(self, data_shapes, label_shapes=None):
method init_optimizer (line 448) | def init_optimizer(self, kvstore='local', optimizer='sgd',
method borrow_optimizer (line 526) | def borrow_optimizer(self, shared_module):
method forward (line 541) | def forward(self, data_batch, is_train=None):
method backward (line 554) | def backward(self, out_grads=None):
method update (line 567) | def update(self):
method get_outputs (line 585) | def get_outputs(self, merge_multi_context=True):
method get_input_grads (line 605) | def get_input_grads(self, merge_multi_context=True):
method get_states (line 625) | def get_states(self, merge_multi_context=True):
method set_states (line 645) | def set_states(self, states=None, value=None):
method update_metric (line 659) | def update_metric(self, eval_metric, labels):
method _sync_params_from_devices (line 670) | def _sync_params_from_devices(self):
method save_optimizer_states (line 678) | def save_optimizer_states(self, fname):
method load_optimizer_states (line 694) | def load_optimizer_states(self, fname):
method install_monitor (line 709) | def install_monitor(self, mon):
class MutableModule (line 715) | class MutableModule(BaseModule):
method __init__ (line 730) | def __init__(self, symbol, data_names, label_names,
method _reset_bind (line 754) | def _reset_bind(self):
method data_names (line 759) | def data_names(self):
method output_names (line 763) | def output_names(self):
method data_shapes (line 767) | def data_shapes(self):
method label_shapes (line 772) | def label_shapes(self):
method output_shapes (line 777) | def output_shapes(self):
method get_params (line 781) | def get_params(self):
method init_params (line 785) | def init_params(self, initializer=Uniform(0.01), arg_params=None, aux_...
method bind (line 795) | def bind(self, data_shapes, label_shapes=None, for_training=True,
method save_checkpoint (line 851) | def save_checkpoint(self, prefix, epoch, save_optimizer_states=False):
method init_optimizer (line 866) | def init_optimizer(self, kvstore='local', optimizer='sgd',
method fit (line 878) | def fit(self, train_data, eval_data=None, eval_metric='acc',
method forward (line 1015) | def forward(self, data_batch, is_train=None):
method backward (line 1050) | def backward(self, out_grads=None):
method update (line 1054) | def update(self):
method get_outputs (line 1058) | def get_outputs(self, merge_multi_context=True):
method get_input_grads (line 1061) | def get_input_grads(self, merge_multi_context=True):
method update_metric (line 1065) | def update_metric(self, eval_metric, labels):
method install_monitor (line 1069) | def install_monitor(self, mon):
FILE: rfcn/core/rcnn.py
function get_rcnn_testbatch (line 36) | def get_rcnn_testbatch(roidb, cfg):
function get_rcnn_batch (line 58) | def get_rcnn_batch(roidb, cfg):
function sample_rois (line 126) | def sample_rois(rois, fg_rois_per_image, rois_per_image, num_classes, cfg,
FILE: rfcn/core/tester.py
class Predictor (line 27) | class Predictor(object):
method __init__ (line 28) | def __init__(self, symbol, data_names, label_names,
method predict (line 37) | def predict(self, data_batch):
function im_proposal (line 43) | def im_proposal(predictor, data_batch, data_names, scales):
function generate_proposals (line 63) | def generate_proposals(predictor, test_data, imdb, cfg, vis=False, thres...
function im_detect (line 129) | def im_detect(predictor, data_batch, data_names, scales, cfg):
function im_batch_detect (line 157) | def im_batch_detect(predictor, data_batch, data_names, scales, cfg):
function pred_eval (line 185) | def pred_eval(predictor, test_data, imdb, cfg, vis=False, thresh=1e-3, l...
function vis_all_detection (line 276) | def vis_all_detection(im_array, detections, class_names, scale, cfg, thr...
function draw_all_detection (line 310) | def draw_all_detection(im_array, detections, class_names, scale, cfg, th...
FILE: rfcn/demo.py
function parse_args (line 36) | def parse_args():
function main (line 43) | def main():
FILE: rfcn/demo_batch.py
function parse_args (line 36) | def parse_args():
function main (line 43) | def main():
FILE: rfcn/function/test_rcnn.py
function test_rcnn (line 28) | def test_rcnn(cfg, dataset, image_set, root_path, dataset_path,
FILE: rfcn/function/test_rpn.py
function test_rpn (line 26) | def test_rpn(cfg, dataset, image_set, root_path, dataset_path,
FILE: rfcn/function/train_rcnn.py
function train_rcnn (line 31) | def train_rcnn(cfg, dataset, image_set, root_path, dataset_path,
FILE: rfcn/function/train_rpn.py
function train_rpn (line 29) | def train_rpn(cfg, dataset, image_set, root_path, dataset_path,
FILE: rfcn/operator_cxx/multi_proposal-inl.h
function namespace (line 26) | namespace mxnet {
function namespace (line 115) | namespace mxnet {
function namespace (line 252) | namespace mxnet {
FILE: rfcn/operator_cxx/multi_proposal.cc
type mxnet (line 12) | namespace mxnet {
type op (line 13) | namespace op {
class MultiProposalOp (line 16) | class MultiProposalOp : public Operator{
method MultiProposalOp (line 18) | explicit MultiProposalOp(MultiProposalParam param) {
method Forward (line 22) | virtual void Forward(const OpContext &ctx,
method Backward (line 30) | virtual void Backward(const OpContext &ctx,
function Operator (line 45) | Operator *CreateOp<cpu>(MultiProposalParam param) {
function Operator (line 49) | Operator* MultiProposalProp::CreateOperator(Context ctx) const {
FILE: rfcn/operator_cxx/psroi_pooling-inl.h
function namespace (line 23) | namespace mxnet {
FILE: rfcn/operator_cxx/psroi_pooling.cc
type mshadow (line 21) | namespace mshadow {
function PSROIPoolForward (line 23) | inline void PSROIPoolForward(const Tensor<cpu, 4, DType> &out,
function PSROIPoolBackwardAcc (line 35) | inline void PSROIPoolBackwardAcc(const Tensor<cpu, 4, DType> &in_grad,
type mxnet (line 46) | namespace mxnet {
type op (line 47) | namespace op {
function Operator (line 50) | Operator *CreateOp<cpu>(PSROIPoolingParam param, int dtype) {
function Operator (line 58) | Operator *PSROIPoolingProp::CreateOperatorEx(Context ctx, std::vecto...
FILE: rfcn/operator_py/box_annotator_ohem.py
class BoxAnnotatorOHEMOperator (line 19) | class BoxAnnotatorOHEMOperator(mx.operator.CustomOp):
method __init__ (line 20) | def __init__(self, num_classes, num_reg_classes, roi_per_img):
method forward (line 26) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 56) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class BoxAnnotatorOHEMProp (line 62) | class BoxAnnotatorOHEMProp(mx.operator.CustomOpProp):
method __init__ (line 63) | def __init__(self, num_classes, num_reg_classes, roi_per_img):
method list_arguments (line 69) | def list_arguments(self):
method list_outputs (line 72) | def list_outputs(self):
method infer_shape (line 75) | def infer_shape(self, in_shape):
method create_operator (line 82) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 85) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: rfcn/operator_py/proposal.py
class ProposalOperator (line 31) | class ProposalOperator(mx.operator.CustomOp):
method __init__ (line 32) | def __init__(self, feat_stride, scales, ratios, output_score,
method forward (line 51) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 170) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
method _filter_boxes (line 176) | def _filter_boxes(boxes, min_size):
method _clip_pad (line 184) | def _clip_pad(tensor, pad_shape):
class ProposalProp (line 201) | class ProposalProp(mx.operator.CustomOpProp):
method __init__ (line 202) | def __init__(self, feat_stride='16', scales='(8, 16, 32)', ratios='(0....
method list_arguments (line 214) | def list_arguments(self):
method list_outputs (line 217) | def list_outputs(self):
method infer_shape (line 223) | def infer_shape(self, in_shape):
method create_operator (line 238) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 242) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: rfcn/operator_py/proposal_target.py
class ProposalTargetOperator (line 30) | class ProposalTargetOperator(mx.operator.CustomOp):
method __init__ (line 31) | def __init__(self, num_classes, batch_images, batch_rois, cfg, fg_frac...
method forward (line 44) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 82) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class ProposalTargetProp (line 88) | class ProposalTargetProp(mx.operator.CustomOpProp):
method __init__ (line 89) | def __init__(self, num_classes, batch_images, batch_rois, cfg, fg_frac...
method list_arguments (line 97) | def list_arguments(self):
method list_outputs (line 100) | def list_outputs(self):
method infer_shape (line 103) | def infer_shape(self, in_shape):
method create_operator (line 117) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 120) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: rfcn/operator_py/rpn_inv_normalize.py
class RPNInvNormalizeOperator (line 12) | class RPNInvNormalizeOperator(mx.operator.CustomOp):
method __init__ (line 13) | def __init__(self, num_anchors, bbox_mean, bbox_std):
method forward (line 19) | def forward(self, is_train, req, in_data, out_data, aux):
method backward (line 28) | def backward(self, req, out_grad, in_data, out_data, in_grad, aux):
class RPNInvNormalizeProp (line 32) | class RPNInvNormalizeProp(mx.operator.CustomOpProp):
method __init__ (line 33) | def __init__(self, num_anchors, bbox_mean='(0.0, 0.0, 0.0, 0.0)', bbox...
method list_arguments (line 39) | def list_arguments(self):
method list_outputs (line 42) | def list_outputs(self):
method infer_shape (line 45) | def infer_shape(self, in_shape):
method create_operator (line 50) | def create_operator(self, ctx, shapes, dtypes):
method declare_backward_dependency (line 53) | def declare_backward_dependency(self, out_grad, in_data, out_data):
FILE: rfcn/symbols/resnet_v1_101_rfcn.py
class resnet_v1_101_rfcn (line 16) | class resnet_v1_101_rfcn(Symbol):
method __init__ (line 18) | def __init__(self):
method get_resnet_v1 (line 28) | def get_resnet_v1(self, data):
method get_train_symbol (line 481) | def get_train_symbol(self, cfg):
method get_test_symbol (line 593) | def get_test_symbol(self, cfg):
method init_weight (line 662) | def init_weight(self, cfg, arg_params, aux_params):
FILE: rfcn/test.py
function parse_args (line 24) | def parse_args():
function main (line 49) | def main():
FILE: rfcn/train_end2end.py
function parse_args (line 25) | def parse_args():
function train_net (line 58) | def train_net(args, ctx, pretrained, epoch, prefix, begin_epoch, end_epo...
function main (line 167) | def main():
Condensed preview — 125 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,111K chars).
[
{
"path": "LICENSE",
"chars": 1092,
"preview": "The MIT License (MIT)\n\n\nCopyright (c) 2017 Microsoft Corporation\n\n\nPermission is hereby granted, free of charge, to any "
},
{
"path": "README.md",
"chars": 7437,
"preview": "# Deep Feature Flow for Video Recognition\n\n\n## Introduction\n\n\n**Deep Feature Flow** is initially described in a [CVPR 20"
},
{
"path": "ThirdPartyNotices.txt",
"chars": 4920,
"preview": "Deep Feature Flow\n\nTHIRD-PARTY SOFTWARE NOTICES AND INFORMATION\n\nThis project incorporates components from the projects "
},
{
"path": "dff_rfcn/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "dff_rfcn/_init_paths.py",
"chars": 467,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/config/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "dff_rfcn/config/config.py",
"chars": 5459,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/DataParallelExecutorGroup.py",
"chars": 24651,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "dff_rfcn/core/callback.py",
"chars": 2373,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/loader.py",
"chars": 14522,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/metric.py",
"chars": 6141,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/module.py",
"chars": 45123,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/rcnn.py",
"chars": 7401,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/core/tester.py",
"chars": 15121,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/demo.py",
"chars": 7058,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/demo_batch.py",
"chars": 6893,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/function/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "dff_rfcn/function/test_rcnn.py",
"chars": 3640,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/function/test_rpn.py",
"chars": 2721,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/function/train_rcnn.py",
"chars": 5735,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/function/train_rpn.py",
"chars": 5922,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/operator_cxx/multi_proposal-inl.h",
"chars": 8821,
"preview": "/*!\n * Copyright (c) 2015 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "dff_rfcn/operator_cxx/multi_proposal.cc",
"chars": 1962,
"preview": "/*!\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE for details]\n * \\file multi_proposal."
},
{
"path": "dff_rfcn/operator_cxx/multi_proposal.cu",
"chars": 22742,
"preview": "/*!\n * Copyright (c) 2015 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "dff_rfcn/operator_cxx/psroi_pooling-inl.h",
"chars": 8395,
"preview": "/*!\n * Copyright (c) 2017 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "dff_rfcn/operator_cxx/psroi_pooling.cc",
"chars": 3031,
"preview": "/*!\n * Copyright (c) 2017 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "dff_rfcn/operator_cxx/psroi_pooling.cu",
"chars": 10275,
"preview": "/*!\n * Copyright (c) 2017 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "dff_rfcn/operator_py/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "dff_rfcn/operator_py/box_annotator_ohem.py",
"chars": 3253,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/operator_py/proposal.py",
"chars": 9898,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/operator_py/proposal_target.py",
"chars": 4696,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/operator_py/rpn_inv_normalize.py",
"chars": 2256,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/operator_py/tile_as.py",
"chars": 1653,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/symbols/__init__.py",
"chars": 33,
"preview": "import resnet_v1_101_flownet_rfcn"
},
{
"path": "dff_rfcn/symbols/resnet_v1_101_flownet_rfcn.py",
"chars": 84399,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/test.py",
"chars": 2276,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "dff_rfcn/train_end2end.py",
"chars": 8311,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "experiments/dff_rfcn/cfgs/dff_rfcn_vid_demo.yaml",
"chars": 2503,
"preview": "---\nMXNET_VERSION: \"mxnet\"\noutput_path: \"./output/dff_rfcn/imagenet_vid\"\ngpus: '0'\nCLASS_AGNOSTIC: true\nSCALES:\n- 600\n- "
},
{
"path": "experiments/dff_rfcn/cfgs/resnet_v1_101_flownet_imagenet_vid_rfcn_end2end_ohem.yaml",
"chars": 2675,
"preview": "---\nMXNET_VERSION: \"mxnet\"\noutput_path: \"./output/dff_rfcn/imagenet_vid\"\nsymbol: resnet_v1_101_flownet_rfcn\ngpus: '0,1,2"
},
{
"path": "experiments/dff_rfcn/dff_rfcn_end2end_train_test.py",
"chars": 613,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "experiments/dff_rfcn/dff_rfcn_test.py",
"chars": 563,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "experiments/rfcn/cfgs/resnet_v1_101_imagenet_vid_rfcn_end2end_ohem.yaml",
"chars": 2605,
"preview": "---\nMXNET_VERSION: \"mxnet\"\noutput_path: \"./output/rfcn/imagenet_vid\"\nsymbol: resnet_v1_101_rfcn\ngpus: '0,1,2,3'\nCLASS_AG"
},
{
"path": "experiments/rfcn/cfgs/rfcn_vid_demo.yaml",
"chars": 2495,
"preview": "---\nMXNET_VERSION: \"mxnet\"\noutput_path: \"./output/rfcn/imagenet_vid\"\ngpus: '0'\nCLASS_AGNOSTIC: true\nSCALES:\n- 600\n- 1000"
},
{
"path": "experiments/rfcn/rfcn_end2end_train_test.py",
"chars": 609,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "experiments/rfcn/rfcn_test.py",
"chars": 559,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "green2.py",
"chars": 3168,
"preview": "# _*_ coding: utf-8 _*_\n\nimport datetime\nimport os\nimport random\nfrom random import choice\n\ncomments = [\n 'Update Rea"
},
{
"path": "init.bat",
"chars": 261,
"preview": "cd /d %~dp0\nmkdir .\\output\nmkdir .\\external\\mxnet\nmkdir .\\model\\pretrained_model\npause\ncd lib\\bbox\npython setup_windows."
},
{
"path": "init.sh",
"chars": 207,
"preview": "#!/bin/bash\n\nmkdir -p ./output\nmkdir -p ./external/mxnet\nmkdir -p ./model/pretrained_model\n\ncd lib/bbox\npython setup_lin"
},
{
"path": "lib/Makefile",
"chars": 366,
"preview": "all:\n\tcd nms/; python setup.py build_ext --inplace; rm -rf build; cd ../../\n\tcd bbox/; python setup.py build_ext --inpla"
},
{
"path": "lib/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/bbox/.gitignore",
"chars": 9,
"preview": "*.c\n*.cpp"
},
{
"path": "lib/bbox/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/bbox/bbox.pyx",
"chars": 1994,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/bbox/bbox_regression.py",
"chars": 5550,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/bbox/bbox_transform.py",
"chars": 6080,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/bbox/setup_linux.py",
"chars": 2922,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/bbox/setup_windows.py",
"chars": 1366,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/dataset/__init__.py",
"chars": 59,
"preview": "from imdb import IMDB\nfrom imagenet_vid import ImageNetVID\n"
},
{
"path": "lib/dataset/ds_utils.py",
"chars": 696,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/dataset/imagenet_vid.py",
"chars": 13772,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/dataset/imagenet_vid_eval.py",
"chars": 7956,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/dataset/imdb.py",
"chars": 16034,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/nms/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/nms/cpu_nms.pyx",
"chars": 2456,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/nms/gpu_nms.cu",
"chars": 287659,
"preview": "// ------------------------------------------------------------------\n// Deep Feature Flow\n// Copyright (c) 2017 Microso"
},
{
"path": "lib/nms/gpu_nms.hpp",
"chars": 667,
"preview": "// ------------------------------------------------------------------\n// Deep Feature Flow\n// Copyright (c) 2017 Microso"
},
{
"path": "lib/nms/gpu_nms.pyx",
"chars": 1341,
"preview": "# ------------------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2015 Microsoft\n"
},
{
"path": "lib/nms/nms.py",
"chars": 1894,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/nms/nms_kernel.cu",
"chars": 5243,
"preview": "// ------------------------------------------------------------------\n// Deep Feature Flow\n// Copyright (c) 2015 Microso"
},
{
"path": "lib/nms/setup_linux.py",
"chars": 5358,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/nms/setup_windows.py",
"chars": 5083,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/nms/setup_windows_cuda.py",
"chars": 6285,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/rpn/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/rpn/generate_anchor.py",
"chars": 2365,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/rpn/rpn.py",
"chars": 11177,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/PrefetchingIter.py",
"chars": 5040,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/utils/combine_model.py",
"chars": 985,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/create_logger.py",
"chars": 1301,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/image.py",
"chars": 8279,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/image_processing.py",
"chars": 3030,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/load_data.py",
"chars": 2536,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/load_model.py",
"chars": 2253,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/lr_scheduler.py",
"chars": 2425,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/roidb.py",
"chars": 1584,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/save_model.py",
"chars": 1016,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/show_boxes.py",
"chars": 1974,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/symbol.py",
"chars": 2227,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "lib/utils/tictoc.py",
"chars": 559,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "rfcn/_init_paths.py",
"chars": 466,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/config/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "rfcn/config/config.py",
"chars": 5228,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/DataParallelExecutorGroup.py",
"chars": 24651,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "rfcn/core/callback.py",
"chars": 2373,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/loader.py",
"chars": 13473,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/metric.py",
"chars": 6141,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/module.py",
"chars": 45122,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/rcnn.py",
"chars": 7401,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/core/tester.py",
"chars": 13625,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/demo.py",
"chars": 5682,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/demo_batch.py",
"chars": 6499,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/function/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "rfcn/function/test_rcnn.py",
"chars": 2532,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/function/test_rpn.py",
"chars": 2721,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/function/train_rcnn.py",
"chars": 5735,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/function/train_rpn.py",
"chars": 5922,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/operator_cxx/multi_proposal-inl.h",
"chars": 8821,
"preview": "/*!\n * Copyright (c) 2015 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "rfcn/operator_cxx/multi_proposal.cc",
"chars": 1962,
"preview": "/*!\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE for details]\n * \\file multi_proposal."
},
{
"path": "rfcn/operator_cxx/multi_proposal.cu",
"chars": 22742,
"preview": "/*!\n * Copyright (c) 2015 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "rfcn/operator_cxx/psroi_pooling-inl.h",
"chars": 8395,
"preview": "/*!\n * Copyright (c) 2017 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "rfcn/operator_cxx/psroi_pooling.cc",
"chars": 3031,
"preview": "/*!\n * Copyright (c) 2017 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "rfcn/operator_cxx/psroi_pooling.cu",
"chars": 10275,
"preview": "/*!\n * Copyright (c) 2017 by Contributors\n * Copyright (c) 2017 Microsoft\n * Licensed under The MIT License [see LICENSE"
},
{
"path": "rfcn/operator_py/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "rfcn/operator_py/box_annotator_ohem.py",
"chars": 3253,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/operator_py/proposal.py",
"chars": 9898,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/operator_py/proposal_target.py",
"chars": 4696,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/operator_py/rpn_inv_normalize.py",
"chars": 2256,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/symbols/__init__.py",
"chars": 26,
"preview": "import resnet_v1_101_rfcn\n"
},
{
"path": "rfcn/symbols/resnet_v1_101_rfcn.py",
"chars": 66964,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/test.py",
"chars": 2276,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "rfcn/train_end2end.py",
"chars": 7904,
"preview": "# --------------------------------------------------------\n# Deep Feature Flow\n# Copyright (c) 2017 Microsoft\n# Licensed"
},
{
"path": "zero.md",
"chars": 1,
"preview": "0"
}
]
About this extraction
This page contains the full source code of the BitconFeng/Deep-Feature-video GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 125 files (1.0 MB), approximately 300.2k tokens, and a symbol index with 596 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.