Showing preview only (519K chars total). Download the full file or copy to clipboard to get everything.
Repository: GiggleLiu/NiLang.jl
Branch: master
Commit: 9f622819bfd6
Files: 114
Total size: 479.4 KB
Directory structure:
gitextract_mdwro7z3/
├── .github/
│ └── workflows/
│ ├── CompatHelper.yml
│ ├── TagBot.yml
│ └── ci.yml
├── .gitignore
├── LICENSE
├── Makefile
├── Project.toml
├── README.md
├── benchmark/
│ ├── besselj_gpu.jl
│ ├── besselj_irreversible.jl
│ ├── besselj_reversible.jl
│ ├── first_function.jl
│ └── stack.jl
├── docs/
│ ├── Project.toml
│ ├── make.jl
│ └── src/
│ ├── api.md
│ ├── extend.md
│ ├── faq.md
│ ├── grammar.md
│ ├── index.md
│ ├── instructions.md
│ ├── tutorial.md
│ └── why.md
├── examples/
│ ├── Adam.jl
│ ├── CUDA/
│ │ ├── README.md
│ │ ├── rotation_gate.jl
│ │ └── swap_gate.jl
│ ├── README.md
│ ├── Symbolics/
│ │ ├── print_jacobians.jl
│ │ ├── symbolic_utils.jl
│ │ └── symlib.jl
│ ├── _sharedwrite.jl
│ ├── batched_tr.jl
│ ├── besselj.jl
│ ├── boxmuller.jl
│ ├── fft.jl
│ ├── fib.jl
│ ├── fixedlog.jl
│ ├── lax_wendroff.jl
│ ├── lognumber.jl
│ ├── nice.jl
│ ├── nice_test.jl
│ ├── port_chainrules.jl
│ ├── port_zygote.jl
│ ├── pyramid.jl
│ ├── qr.jl
│ ├── realnvp.jl
│ ├── sparse.jl
│ └── unitary.jl
├── notebooks/
│ ├── README.md
│ ├── autodiff.jl
│ ├── basic.jl
│ ├── documentation.jl
│ ├── feynman.jl
│ ├── margolus.jl
│ └── reversibleprog.jl
├── src/
│ ├── NiLang.jl
│ ├── autobcast.jl
│ ├── autodiff/
│ │ ├── autodiff.jl
│ │ ├── checks.jl
│ │ ├── complex.jl
│ │ ├── gradfunc.jl
│ │ ├── hessian_backback.jl
│ │ ├── instructs.jl
│ │ ├── jacobian.jl
│ │ ├── stack.jl
│ │ ├── ulog.jl
│ │ └── vars.jl
│ ├── complex.jl
│ ├── deprecations.jl
│ ├── instructs.jl
│ ├── macros.jl
│ ├── stdlib/
│ │ ├── base.jl
│ │ ├── bennett.jl
│ │ ├── blas.jl
│ │ ├── linalg.jl
│ │ ├── mapreduce.jl
│ │ ├── nnlib.jl
│ │ ├── sorting.jl
│ │ ├── sparse.jl
│ │ ├── statistics.jl
│ │ └── stdlib.jl
│ ├── ulog.jl
│ ├── utils.jl
│ ├── vars.jl
│ └── wrappers.jl
└── test/
├── autobcast.jl
├── autodiff/
│ ├── autodiff.jl
│ ├── complex.jl
│ ├── gradfunc.jl
│ ├── hessian_backback.jl
│ ├── instructs.jl
│ ├── jacobian.jl
│ ├── manual.jl
│ ├── stack.jl
│ ├── ulog.jl
│ └── vars.jl
├── complex.jl
├── instructs.jl
├── macros.jl
├── runtests.jl
├── stdlib/
│ ├── base.jl
│ ├── bennett.jl
│ ├── blas.jl
│ ├── linalg.jl
│ ├── mapreduce.jl
│ ├── nnlib.jl
│ ├── sparse.jl
│ ├── statistics.jl
│ └── stdlib.jl
├── ulog.jl
├── utils.jl
├── vars.jl
└── wrappers.jl
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/CompatHelper.yml
================================================
name: CompatHelper
on:
schedule:
- cron: '00 * * * *'
issues:
types: [opened, reopened]
jobs:
build:
runs-on: ${{ matrix.os }}
strategy:
matrix:
julia-version: [1.5]
julia-arch: [x86]
os: [ubuntu-latest]
steps:
- uses: julia-actions/setup-julia@latest
with:
version: ${{ matrix.julia-version }}
- name: Pkg.add("CompatHelper")
run: julia -e 'using Pkg; Pkg.add("CompatHelper")'
- name: CompatHelper.main()
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: julia -e 'using CompatHelper; CompatHelper.main()'
================================================
FILE: .github/workflows/TagBot.yml
================================================
name: TagBot
on:
issue_comment:
types:
- created
workflow_dispatch:
jobs:
TagBot:
if: github.event_name == 'workflow_dispatch' || github.actor == 'JuliaTagBot'
runs-on: ubuntu-latest
steps:
- uses: JuliaRegistries/TagBot@v1
with:
token: ${{ secrets.GITHUB_TOKEN }}
ssh: ${{ secrets.DOCUMENTER_KEY }}
================================================
FILE: .github/workflows/ci.yml
================================================
name: CI
on:
- push
- pull_request
jobs:
test:
name: Julia ${{ matrix.version }} - ${{ matrix.os }} - ${{ matrix.arch }} - ${{ github.event_name }}
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
version:
- '1.5'
- 'nightly'
os:
- ubuntu-latest
- macOS-latest
- windows-latest
arch:
- x64
steps:
- uses: actions/checkout@v2
- uses: julia-actions/setup-julia@v1
with:
version: ${{ matrix.version }}
arch: ${{ matrix.arch }}
- uses: actions/cache@v1
env:
cache-name: cache-artifacts
with:
path: ~/.julia/artifacts
key: ${{ runner.os }}-test-${{ env.cache-name }}-${{ hashFiles('**/Project.toml') }}
restore-keys: |
${{ runner.os }}-test-${{ env.cache-name }}-
${{ runner.os }}-test-
${{ runner.os }}-
- uses: julia-actions/julia-buildpkg@v1
- uses: julia-actions/julia-runtest@v1
- uses: julia-actions/julia-processcoverage@v1
- uses: codecov/codecov-action@v1
with:
file: lcov.info
docs:
name: Documentation
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: julia-actions/setup-julia@v1
with:
version: '1'
- run: |
julia --project=docs -e '
using Pkg
Pkg.develop(PackageSpec(path=pwd()))
Pkg.instantiate()'
- run: |
julia --project=docs -e '
using Documenter: doctest
using NiLang
doctest(NiLang)'
- run: julia --project=docs docs/make.jl
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
DOCUMENTER_KEY: ${{ secrets.DOCUMENTER_KEY }}
================================================
FILE: .gitignore
================================================
*.jl.*.cov
*.jl.cov
*.jl.mem
.DS_Store
Manifest.toml
/dev/
/docs/build/
/docs/site/
/docs/src/examples/
_local/
*.swp
.vscode/
================================================
FILE: LICENSE
================================================
Copyright (c) 2019 JinGuo Liu, thautwarm
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "{}"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [year] [fullname]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: Makefile
================================================
JL = julia --project
default: init test
init:
$(JL) -e 'using Pkg; Pkg.precompile()'
init-docs:
$(JL) -e 'using Pkg; Pkg.activate("docs"); Pkg.develop(path="."), Pkg.precompile()'
update:
$(JL) -e 'using Pkg; Pkg.update(); Pkg.precompile()'
update-docs:
$(JL) -e 'using Pkg; Pkg.activate("docs"); Pkg.update(); Pkg.precompile()'
test:
$(JL) -e 'using Pkg; Pkg.test("GenericTensorNetworks")'
coverage:
$(JL) -e 'using Pkg; Pkg.test("GenericTensorNetworks"; coverage=true)'
serve:
$(JL) -e 'using Pkg; Pkg.activate("docs"); using LiveServer; servedocs(;skip_dirs=["docs/src/assets", "docs/src/generated"], literate_dir="examples")'
clean:
rm -rf docs/build
find . -name "*.cov" -type f -print0 | xargs -0 /bin/rm -f
.PHONY: init test coverage serve clean init-docs update update-docs
================================================
FILE: Project.toml
================================================
name = "NiLang"
uuid = "ab4ef3a6-0b42-11ea-31f6-e34652774712"
authors = ["JinGuo Liu", "thautwarm"]
version = "0.9.4"
[deps]
FixedPointNumbers = "53c48c17-4a7d-5ca2-90c5-79b7896eea93"
LinearAlgebra = "37e2e46d-f89d-539d-b4ee-838fcccc9c8e"
LogarithmicNumbers = "aa2f6b4e-9042-5d33-9679-40d3a6b85899"
MLStyle = "d8e11817-5142-5d16-987a-aa16d5891078"
NiLangCore = "575d3204-02a4-11ea-3f62-238caa8bf11e"
Reexport = "189a3867-3050-52da-a836-e630ba90ab69"
SparseArrays = "2f01184e-e22b-5df5-ae63-d93ebab69eaf"
TupleTools = "9d95972d-f1c8-5527-a6e0-b4b365fa01f6"
[compat]
FixedPointNumbers = "0.6, 0.7, 0.8"
LogarithmicNumbers = "0.4, 1.0"
MLStyle = "0.4"
NiLangCore = "0.10.1"
Reexport = "0.2, 1.0"
TupleTools = "1.2"
julia = "1.3"
[extras]
Distributions = "31c24e10-a181-5473-b8eb-7969acd0382f"
Random = "9a3f8284-a2c9-5f02-9a11-845980a1fd5c"
Statistics = "10745b16-79ce-11e8-11f9-7d13ad32a3b2"
FiniteDifferences = "26cc04aa-876d-5657-8c51-4c34ba976000"
Test = "8dfed614-e22c-5e08-85e1-65c5234f0b40"
[targets]
test = ["Test", "Random", "Statistics", "Distributions", "FiniteDifferences"]
================================================
FILE: README.md
================================================
<img src="docs/src/asset/logo3.png" width=500px/>
NiLang.jl (逆lang), is a reversible domain-specific language (DSL) that allow a program to go back to the past.
* Requires Julia version >= 1.3,
NiLang features:
* any program written in NiLang is differentiable,
* a reversible language with abstraction and arrays,
* complex values
* reversible logarithmic number system

[](https://codecov.io/gh/GiggleLiu/NiLang.jl)
The main docs can be found here:
[](https://giggleliu.github.io/NiLang.jl/stable/)
[](https://giggleliu.github.io/NiLang.jl/dev/)
There are also some Pluto-based notebooks:
* [tutorial](https://giggleliu.github.io/NiLang.jl/dev/notebooks/basic.html)
* [documentation](https://giggleliu.github.io/NiLang.jl/dev/notebooks/documentation.html)
* [Billiard ball model cellular automata](https://giggleliu.github.io/NiLang.jl/dev/notebooks/margolus.html)
> The strangeness of reversible computing is mainly due to
> our lack of experience with it.—Henry Baker, 1992
## To Start
```
pkg> add NiLang
```
## An example: Compute the norm of a vector
```julia
julia> using NiLang
julia> @i function f(res, y, x)
for i=1:length(x)
y += x[i] ^ 2
end
res += sqrt(y)
end
julia> res_out, y_out, x_out = f(0.0, 0.0, [1, 2, 3.0])
(3.7416573867739413, 14.0, [1.0, 2.0, 3.0])
julia> (~f)(res_out, y_out, x_out) # automatically generated inverse program.
(0.0, 0.0, [1.0, 2.0, 3.0])
julia> ∂res, ∂y, ∂x = NiLang.AD.gradient(Val(1), f, (0.0, 0.0, [1, 2, 3.0]))
# automatic differentiation, `Val(1)` means the first argument of `f` is the loss.
(1.0, 0.1336306209562122, [0.2672612419124244, 0.5345224838248488, 0.8017837257372732])
```
The performance of reversible programming automatic differentiation is much better than most traditional frameworks. Here is why, and how it works,

## Check our [paper](https://arxiv.org/abs/2003.04617)
```bibtex
@misc{Liu2020,
title={Differentiate Everything with a Reversible Programming Language},
author={Jin-Guo Liu and Taine Zhao},
year={2020},
eprint={2003.04617},
archivePrefix={arXiv},
primaryClass={cs.PL}
}
```
================================================
FILE: benchmark/besselj_gpu.jl
================================================
using NiLang, NiLang.AD
using CuArrays, CUDAnative, GPUArrays
using BenchmarkTools
@i @inline function :(-=)(CUDAnative.pow)(out!::GVar{T}, x::GVar{T}, n::GVar) where T
value(out!) -= CUDAnative.pow(value(x), value(n))
# grad x
@routine @invcheckoff begin
@zeros T anc1 anc2 anc3 jac1 jac2
DEC(value(n))
anc1 += CUDAnative.pow(value(x), value(n))
INC(value(n))
jac1 += anc1 * value(n)
# get grad of n
anc2 += log(value(x))
anc3 += CUDAnative.pow(value(x), value(n))
jac2 += anc3*anc2
end
grad(x) += grad(out!) * jac1
grad(n) += grad(out!) * jac2
~@routine
end
@i @inline function :(-=)(CUDAnative.pow)(out!::GVar{T}, x::GVar, n) where T
value(out!) -= CUDAnative.pow(value(x), n)
@routine @invcheckoff begin
anc1 ← zero(value(x))
jac ← zero(value(x))
DEC(value(n))
anc1 += CUDAnative.pow(value(x), n)
INC(value(n))
jac += anc1 * n
end
grad(x) += grad(out!) * jac
~@routine
end
@i @inline function :(-=)(CUDAnative.pow)(out!::GVar{T}, x, n::GVar) where T
value(out!) -= CUDAnative.pow(x, value(n))
# get jac of n
@routine @invcheckoff begin
anc1 ← zero(x)
anc2 ← zero(x)
jac ← zero(x)
anc1 += log(x)
anc2 += CUDAnative.pow(x, value(n))
jac += anc1*anc2
end
grad(n) += grad(out!) * jac
~@routine
end
# You need to replace all "^" operations in `ibessel` with `CUDAnative.pow`.
# Please remember to turn invertiblity check off, because error handling is not supported in a cuda thread.
# Function `i_dirtymul` and `i_factorial` are not changed.
@i function ibesselj(out!, ν, z; atol=1e-8)
@routine @invcheckoff begin
k ← 0
fact_nu ← zero(ν)
halfz ← zero(z)
halfz_power_nu ← zero(z)
halfz_power_2 ← zero(z)
out_anc ← zero(z)
anc1 ← zero(z)
anc2 ← zero(z)
anc3 ← zero(z)
anc4 ← zero(z)
anc5 ← zero(z)
halfz += z / 2
halfz_power_nu += CUDAnative.pow(halfz, ν)
halfz_power_2 += CUDAnative.pow(halfz, 2)
i_factorial(fact_nu, ν)
anc1 += halfz_power_nu/fact_nu
out_anc += anc1
@from k==0 while abs(unwrap(anc1)) > atol && abs(unwrap(anc4)) < atol
INC(k)
@routine begin
anc5 += k
anc5 += ν
anc2 -= k * anc5
anc3 += halfz_power_2 / anc2
end
i_dirtymul(anc1, anc3, anc4)
out_anc += anc1
~@routine
end
end
out! += out_anc
~@routine
end
# Define your reversible kernel function that calls the reversible bessel function
@i function ibesselj_kernel(out!, ν, z, atol)
i ← (blockIdx().x-1) * blockDim().x + threadIdx().x
@inbounds ibesselj(out![i], ν, z[i]; atol=atol)
@invcheckoff i → (blockIdx().x-1) * blockDim().x + threadIdx().x
end
# To launch this reversible kernel, you also need a reversible host function.
@i function ibesselj(out!::CuVector, ν, z::CuVector; atol=1e-8)
XY ← GPUArrays.thread_blocks_heuristic(length(out!))
@cuda threads=XY.:1 blocks=XY.:2 ibesselj_kernel(out!, ν, z, atol)
@invcheckoff XY → GPUArrays.thread_blocks_heuristic(length(out!))
end
# To test this function, we first define input parameters `a` and output `out!`
N = 4096
T = Float64
a = CuArray(ones(T, N))
out! = CuArray(zeros(T, N))
# We wrap the output with a randomly initialized gradient field, suppose we get the gradients from a virtual loss function.
# Also, we need to initialize an empty gradient field for elements in input cuda tensor `a`.
out! = ibesselj(out!, 2, GVar.(a))[1]
out_g! = GVar.(out!, CuArray(ones(T, N)))
a_g = GVar.(a)
# Call the inverse program, the multiple dispatch will drive you to the goal.
println("Benchmarking NiLang on CUDA, N = $N, T = $T")
display(@benchmark CuArrays.@sync (~ibesselj)($out_g!, 2, $a_g))
================================================
FILE: benchmark/besselj_irreversible.jl
================================================
using Zygote
using ForwardDiff
using BenchmarkTools
function besselj(ν, z; atol=1e-8)
k = 0
s = (z/2)^ν / factorial(ν)
out = s
while abs(s) > atol
k += 1
s *= (-1) / k / (k+ν) * (z/2)^2
out += s
end
out
end
function grad_besselj_manual(ν, z; atol=1e-8)
(besselj(ν-1, z; atol=atol) - besselj(ν+1, z); atol=atol)/2
end
println("Benchmarking Julia")
display(@benchmark besselj(2, 1.0))
println("Benchmarking Manual")
display(@benchmark grad_besselj_manual(2, 1.0))
println("Benchmarking Zygote")
display(@benchmark Zygote.gradient(besselj, 2, 1.0))
println("Benchmarking ForwardDiff")
display(@benchmark ForwardDiff.derivative(x->besselj(2, x), 1.0))
================================================
FILE: benchmark/besselj_reversible.jl
================================================
using NiLang, NiLang.AD
using BenchmarkTools
include("../exmamples/besselj.jl")
# To test this function, we first define input parameters `a` and output `out!`
a = 1.0
out! = 0.0
# We wrap the output with a randomly initialized gradient field, suppose we get the gradients from a virtual loss function.
# Also, we need to initialize an empty gradient field for elements in input cuda tensor `a`.
out! = ibesselj(out!, 2, a)[1]
out_g! = GVar(out!, 1.0)
a_g = GVar(a)
# Call the inverse program, the multiple dispatch will drive you to the goal.
println("Benchmarking NiLang")
display(@benchmark ibesselj($out!, 2, $a))
println("Benchmarking NiLang.AD")
display(@benchmark (~ibesselj)($out_g!, 2, $a_g))
================================================
FILE: benchmark/first_function.jl
================================================
t1 = time()
using NiLang
@i function dot(x, y, z)
for i=1:10
x += y[i]' * z[i]
end
end
t2 = time()
println("costs $(t2-t1)s")
================================================
FILE: benchmark/stack.jl
================================================
================================================
FILE: docs/Project.toml
================================================
[deps]
BenchmarkTools = "6e4b80f9-dd63-53aa-95a3-0cdb28fa8baf"
ChainRules = "082447d4-558c-5d27-93f4-14fc19e9eca2"
Compose = "a81c6b42-2e10-5240-aca2-a61377ecd94b"
DelimitedFiles = "8bb1440f-4735-579b-a4ab-409b98df4dab"
Documenter = "e30172f5-a6a5-5a46-863b-614d45cd2de4"
FixedPointNumbers = "53c48c17-4a7d-5ca2-90c5-79b7896eea93"
ForwardDiff = "f6369f11-7733-5829-9624-2563aa707210"
KernelAbstractions = "63c18a36-062a-441e-b654-da1e3ab1ce7c"
LinearAlgebra = "37e2e46d-f89d-539d-b4ee-838fcccc9c8e"
Literate = "98b081ad-f1c9-55d3-8b20-4c87d4299306"
LiveServer = "16fef848-5104-11e9-1b77-fb7a48bbb589"
LogarithmicNumbers = "aa2f6b4e-9042-5d33-9679-40d3a6b85899"
NiLang = "ab4ef3a6-0b42-11ea-31f6-e34652774712"
Plots = "91a5bcdd-55d7-5caf-9e0b-520d859cae80"
Random = "9a3f8284-a2c9-5f02-9a11-845980a1fd5c"
Reexport = "189a3867-3050-52da-a836-e630ba90ab69"
SparseArrays = "2f01184e-e22b-5df5-ae63-d93ebab69eaf"
Test = "8dfed614-e22c-5e08-85e1-65c5234f0b40"
Viznet = "52a3aca4-6234-47fd-b74a-806bdf78ede9"
Zygote = "e88e6eb3-aa80-5325-afca-941959d7151f"
================================================
FILE: docs/make.jl
================================================
using Documenter, NiLang
using SparseArrays
using Literate
tutorialpath = joinpath(@__DIR__, "src/examples")
sourcepath = joinpath(dirname(@__DIR__), "examples")
for jlfile in ["besselj.jl", "sparse.jl", "qr.jl", "port_zygote.jl", "port_chainrules.jl", "fib.jl", "unitary.jl", "nice.jl", "realnvp.jl", "boxmuller.jl", "lognumber.jl", "pyramid.jl"]
Literate.markdown(joinpath(sourcepath, jlfile), tutorialpath)
end
# # Pluto pages
# import Pkg
# Pkg.add([
# Pkg.PackageSpec(url="https://github.com/GiggleLiu/PlutoUtils.jl", rev="static-export"),
# Pkg.PackageSpec(url="https://github.com/fonsp/Pluto.jl", rev="05e5b68"),
# ]);
makedocs(;
modules=[NiLang],
format=Documenter.HTML(),
pages=[
"Home" => "index.md",
"What and Why" => "why.md",
"Tutorial" => Any[
"tutorial.md",
"examples/port_zygote.md",
"examples/port_chainrules.md"
],
"Examples" => Any[
"examples/fib.md",
"examples/pyramid.md",
"examples/besselj.md",
"examples/sparse.md",
"examples/lognumber.md",
"examples/unitary.md",
#"examples/nice.md",
#"examples/realnvp.md",
"examples/qr.md",
"examples/boxmuller.md",
],
"API & Manual" => Any[
"instructions.md",
"extend.md",
"api.md",
"faq.md",
]
],
repo="https://github.com/GiggleLiu/NiLang.jl/blob/{commit}{path}#L{line}",
sitename="NiLang.jl",
authors="JinGuo Liu, thautwarm",
)
# import PlutoUtils
# PlutoUtils.Export.github_action(; notebook_dir=NiLang.project_relative_path("notebooks"), offer_binder=false, export_dir=NiLang.project_relative_path("docs", "build", "notebooks"), generate_default_index=false, project=NiLang.project_relative_path("docs"))
deploydocs(;
repo="github.com/GiggleLiu/NiLang.jl.git",
)
================================================
FILE: docs/src/api.md
================================================
```@meta
DocTestSetup = quote
using NiLangCore, NiLang, NiLang.AD, Test
end
```
# API Manual
## Compiling Tools (Reexported from NiLangCore)
```@autodocs
Modules = [NiLangCore]
Order = [:macro, :function, :type]
```
## Instructions
```@autodocs
Modules = [NiLang]
Order = [:macro, :function, :type]
```
## Automatic Differentiation
```@autodocs
Modules = [NiLang.AD]
Order = [:macro, :function, :type]
```
================================================
FILE: docs/src/extend.md
================================================
# How to extend
## Extend `+=`, `-=` and `⊻=` for irreversible one-out functions
It directly works
```julia
julia> using SpecialFunctions, NiLang
julia> x, y = 2.1, 1.0
(2.1, 1.0)
julia> @instr y += besselj0(x)
2.1
julia> x, y
(2.1, 1.7492472503018073)
julia> @instr ~(y += besselj0(x))
2.1
julia> x, y
(2.1, 1.0)
```
Here the statement
```julia
@instr y += besselj0(x)
```
is mapped to
```julia
@instr y += besselj0(x)
```
However, doing this does not give you correct gradients.
For `y += scalar_out_function(x)`, one can bind the backward rules like
```julia
julia> using ChainRules, NiLang.AD
julia> besselj0_back(x) = ChainRules.rrule(besselj0, x)[2](1.0)[2]
besselj0_back (generic function with 1 method)
julia> primitive_grad(::typeof(besselj0), x::Real) = besselj0_back(x)
primitive_grad (generic function with 1 method)
julia> xg, yg = GVar(x), GVar(y, 1.0)
(GVar(2.1, 0.0), GVar(1.0, 1.0))
julia> @instr yg -= besselj0(xg)
GVar(2.1, -0.5682921357570385)
julia> xg, yg
(GVar(2.1, -0.5682921357570385), GVar(0.8333930196680097, 1.0))
julia> @instr yg += besselj0(xg)
GVar(2.1, 0.0)
julia> xg, yg
(GVar(2.1, 0.0), GVar(1.0, 1.0))
julia> NiLang.AD.check_grad(PlusEq(besselj0), (1.0, 2.1); iloss=1)
true
julia> using BenchmarkTools
julia> @benchmark PlusEq(besselj0)($yg, $xg)
BenchmarkTools.Trial:
memory estimate: 0 bytes
allocs estimate: 0
--------------
minimum time: 451.523 ns (0.00% GC)
median time: 459.431 ns (0.00% GC)
mean time: 477.419 ns (0.00% GC)
maximum time: 857.036 ns (0.00% GC)
--------------
samples: 10000
evals/sample: 197
```
Good!
## Reversible multi-in multi-out functions
It is easy to do, define two normal Julia functions reversible to each other,
using the macro `@dual` to tell the compiler they are reversible to each other.
For example, a pair of dual functions `ROT` (2D rotation) and `IROT` (inverse rotation) that already defined in NiLang.
```julia
"""
ROT(a!, b!, θ) -> a!', b!', θ
"""
@inline function ROT(i::Real, j::Real, θ::Real)
a, b = rot(i, j, θ)
a, b, θ
end
"""
IROT(a!, b!, θ) -> ROT(a!, b!, -θ)
"""
@inline function IROT(i::Real, j::Real, θ::Real)
i, j, _ = ROT(i, j, -θ)
i, j, θ
end
@dual ROT IROT
```
One can easily check the reversibility by typing
```julia
julia> check_inv(ROT, (1.0, 2.0, 3.0))
true
```
For self-reversible functions, one can declare the reversibility for it like this
```julia
"""
SWAP(a!, b!) -> b!, a!
"""
@inline function SWAP(a!::Real, b!::Real)
b!, a!
end
@selfdual SWAP
```
To bind gradients for this multi-in, multi-out function.
The general approach is *Binding the backward rule on its inverse*!
```julia
@i @inline function IROT(a!::GVar, b!::GVar, θ::GVar)
IROT(a!.x, b!.x, θ.x)
NEG(θ.x)
θ.x -= π/2
ROT(a!.g, b!.g, θ.x)
θ.g += a!.x * a!.g
θ.g += b!.x * b!.g
θ.x += π/2
NEG(θ.x)
ROT(a!.g, b!.g, π/2)
end
@i @inline function IROT(a!::GVar, b!::GVar, θ::Real)
IROT(a!.x, b!.x, θ)
NEG(θ)
θ -= π/2
ROT(a!.g, b!.g, θ)
θ += π/2
NEG(θ)
ROT(a!.g, b!.g, π/2)
end
@nograd IROT(a!::Real, b!::Real, θ::GVar)
```
When this inverse function is called, the backward rules are automatically applied.
Good! This method can also be extended to linear algebra functions, however, the memory allocation overhead is high because one need to wrap each element with `GVar`.
================================================
FILE: docs/src/faq.md
================================================
## Why reversibility check fails even though the program is reversible?
Due to the fact that floating pointing numbers are not exactly reversible, sometimes the invertibility check might fail due to the rounding error.
To fix this issue, you may want to make the check less restrictive
```julia
NiLangCore.GLOBAL_ATOL[] = 1e-6 # default is 1e-8
```
Or just turn off the check in the program (only if you are sure the program is correct)
```julia
@routine @invcheckoff begin
...
end
```
Turning off the check will make your program faster too!
## What makes the gradient check fails?
##### Finite difference error due to numeric instability
The `NiLang.AD.check_grad` function sometimes fail due to either the rounding error or the finite difference error, you may want to check the gradient manually with the `NiLang.AD.ng` function (numeric gradient).
```julia
julia> NiLang.AD.ng(jin, copy.((out,b,ma,jinzhi,spread,bili)), 6; iloss=1, δ=1e-4)
-5449.643843214744
julia> NiLang.AD.ng(jin, copy.((out,b,ma,jinzhi,spread,bili)), 5; iloss=1, δ=1e-4)
4503-element Array{Float64,1}:
-0.0023380584934784565
-0.0021096593627589755
-0.0019811886886600405
⋮
-0.009526640951662557
-0.006004695478623034
0.0
```
and
```julia
julia> NiLang.AD.gradient(Val(1), jin, copy.((out,b,ma,jinzhi,spread,bili)))[end]
-5449.643116967733
julia> NiLang.AD.gradient(Val(1), jin, copy.((out,b,ma,jinzhi,spread,bili)))[end-1]
4503-element Array{Float64,1}:
-0.0005285958114468947
-0.00030225263725219137
-0.00017545437275561654
⋮
-0.010422627668532736
-0.0069140339974312695
0.0
```
Here, we can see the `jin` function is numerically sensitive to perturbations, which makes the numeric gradient incorrect.
The above code is from https://github.com/HanLi123/NiLang/issues/3
##### Allocating a non-constant ancilla
Another possibility is, a non-constant ancilla is allocated.
```julia
julia> @i function f1(z, y)
x ← y # wrong!
z += x
x → y
end
julia> NiLang.AD.gradient(Val(1), f1, (0.0, 1.0))
(1.0, 0.0)
julia> @i function f2(z, y)
x ← zero(y)
x += y
z += x
x -= y
x → zero(y)
end
julia> NiLang.AD.gradient(Val(1), f2, (0.0, 1.0))
(1.0, 1.0)
```
`f1` will give incorrect gradient because when ancilla `x` is deallocated, its gradient field will also be discarded.
================================================
FILE: docs/src/grammar.md
================================================
# NiLang Grammar
To define a reversible function one can use macro **@i** plus a function definition like bellow
```julia
"""
docstring...
"""
@i function f(args..., kwargs...) where {...}
<stmts>
end
```
where the definition of **<stmts>** are shown in the grammar bellow.
The following is a list of terminologies used in the definition of grammar
* <ident>, symbols
* <num>, numbers
* 0, empty statement
* <JuliaExpr>, native Julia expression
* [ ], zero or one repetitions.
Here, all $JuliaExpr$ should be pure, otherwise the reversibility is not guaranteed.
Dataview is a view of a data, it can be a bijective mapping of an object, an item of an array or a field of an object.
```bnf
Stmts : 0
| Stmt
| Stmts Stmt
;
Stmt : BlockStmt
| IfStmt
| WhileStmt
| ForStmt
| InstrStmt
| RevStmt
| AncillaStmt
| TypecastStmt
| @routine Stmt
| @safe <JuliaExpr>
| CallStmt
;
BlockStmt : 'begin' Stmts 'end';
RevCond : '(' <JuliaExpr> ',' <JuliaExpr> ')';
IfStmt : 'if' RevCond Stmts ['else' Stmts] 'end';
WhileStmt : 'while' RevCond Stmts 'end';
Range : <JuliaExpr> ':' <JuliaExpr> [':' <JuliaExpr>];
ForStmt : 'for' <ident> '=' Range Stmts 'end';
KwArg : <ident> '=' <JuliaExpr>;
KwArgs : [KwArgs ','] KwArg ;
CallStmt : <JuliaExpr> '(' [DataViews] [';' KwArgs] ')';
Constant : <num> | 'π';
InstrBinOp : '+=' | '-=' | '⊻=';
InstrTrailer : ['.'] '(' [DataViews] ')';
InstrStmt : DataView InstrBinOp <ident> [InstrTrailer];
RevStmt : '~' Stmt;
AncillaStmt : <ident> '←' <JuliaExpr>
| <ident> '→' <JuliaExpr>
;
TypecastStmt : '(' <JuliaExpr> '=>' <JuliaExpr> ')' '(' <ident> ')';
@routine : '@routine' <ident> Stmt;
@safe : '@safe' <JuliaExpr>;
DataViews : 0
| DataView
| DataViews ',' DataView
| DataViews ',' DataView '...'
;
DataView : DataView '[' <JuliaExpr> ']'
| DataView '.' <ident>
| DataView '|>' <JuliaExpr>
| DataView '\''
| '-' DataView
| Constant
| <ident>
;
```
================================================
FILE: docs/src/index.md
================================================
# NiLang.jl
NiLang is a reversible eDSL that can run backwards. The motation is to support source to source AD.
Check [our paper](https://arxiv.org/abs/2003.04617)!
Welcome for discussion in [Julia slack](https://slackinvite.julialang.org/), **#autodiff** and **#reversible-commputing** channel.
## Tutorials
```@contents
Pages = [
"tutorial.md",
"examples/port_zygote.md",
]
Depth = 1
```
Also see blog posts
* [How to write a program differentiably](https://nextjournal.com/giggle/how-to-write-a-program-differentiably)
* [Simulate a reversible Turing machine in 50 lines of code](https://nextjournal.com/giggle/rtm50)
## Documentation
## Examples
```@contents
Pages = [
"examples/fib.md",
"examples/besselj.md",
"examples/sparse.md",
"examples/lognumber.md",
"examples/unitary.md",
"examples/qr.md",
"examples/nice.md",
"examples/realnvp.md",
"examples/boxmuller.md",
]
Depth = 1
```
## Manual
```@contents
Pages = [
"grammar.md",
"instructions.md",
"extend.md",
"examples/sharedwrite.md",
"api.md",
"faq.md",
]
Depth = 1
```
================================================
FILE: docs/src/instructions.md
================================================
# Instruction Reference
## Instruction definitions
The Julia functions and symbols for instructions
| instruction | translated | symbol |
| ----------- | ---------- | ---- |
| $y \mathrel{+}= f(args...)$ | PlusEq(f)(args...) | $\oplus$ |
| $y \mathrel{-}= f(args...)$ | MinusEq(f)(args...) | $\ominus$ |
| $y \mathrel{\veebar}= f(args...)$ | \texttt{XorEq(f)(args...) | $\odot$ |
The list of reversible instructions that implemented in NiLang
| instruction | output |
| ----------- | ---------- |
| ${\rm SWAP}(a, b)$ | $b, a$ |
| ${\rm ROT}(a, b, \theta)$ | $a \cos\theta - b\sin\theta, b \cos\theta + a\sin\theta, \theta$ |
| ${\rm IROT}(a, b, \theta)$ | $a \cos\theta + b\sin\theta, b \cos\theta - a\sin\theta, \theta$ |
| $y \mathrel{+}= a^\wedge b$ | $y+a^b, a, b$ |
| $y \mathrel{+}= \exp(x)$ | $y+e^x, x$ |
| $y \mathrel{+}= \log(x)$ | $y+\log x, x$ |
| $y \mathrel{+}= \sin(x)$ | $y+\sin x, x$ |
| $y \mathrel{+}= \cos(x)$ | $y+\cos x, x$ |
| $y \mathrel{+}= {\rm abs}(x)$ | $y+ |x|, x$ |
| $NEG(y)$ | $-y$ |
"." is the broadcasting operations in Julia.
## Jacobians and Hessians for Instructions
See my [blog post](https://giggleliu.github.io/2020/01/18/jacobians.html).
================================================
FILE: docs/src/tutorial.md
================================================
# My first NiLang program
## Basic Statements
| Statement | Meaning |
| :------------------------ | :----------------------------------------------------------- |
| x ← val | allocate a new variable `x`, with an initial value `val` (a constant). |
| x → val | deallocate variable `x` with content `val`. |
| x += f(y) | a reversible instruction. |
| x .+= f.(y) | instruction call with broadcasting. |
| f(y) | a reversible function. |
| f.(y) | function call with broadcasting. |
| if (pre, post) ... end | if statement. |
| @from post while pre ... end | while statement. |
| for x=1:3 ... end | for statement. |
| begin ... end | block statement. |
| @safe ... | insert an irreversible statement. |
| ~(...) | inverse a statement. |
| @routine ... | record a routine in the **routine stack**. |
| ~@routine | place the inverse of the routine on **routine stack** top. |
The condition expression in **if** and **while** statements are a bit hard to digest, please refer our paper [arXiv:2003.04617](https://arxiv.org/abs/2003.04617).
## A reversible program
Our first program is to compute a loss function defined as
```math
\mathcal{L} = {\vec z}^T(a\vec{x} + \vec{y}),
```
where $\vec x$, $\vec y$ and $\vec{z}$ are column vectors, $a$ is a scalar.
```julia
@i function r_axpy!(a::T, x::AbstractVector{T}, y!::AbstractVector{T}) where T
@safe @assert length(x) == length(y!)
for i=1:length(x)
y![i] += a * x[i]
end
end
@i function r_loss(out!, a, x, y!, z)
r_axpy!(a, x, y!)
for i=1:length(z)
out! += z[i] * y![i]
end
end
```
Functions do not have return statements, they return input arguments instead.
Hence `r_loss` defines a 5 variable to 5 variable bijection.
Let's check the reversibility
```julia
julia> out, a, x, y, z = 0.0, 2.0, randn(3), randn(3), randn(3)
(0.0, 2.0, [0.9265845776642722, 0.8532458027149912, 0.6201064385679095],
[1.1142808415540468, 0.5506163710455121, -1.9873779917908814],
[1.1603953198942412, 0.5562855137395296, 1.9650050430758796])
julia> out, a, x, y, z = r_loss(out, a, x, y, z)
(3.2308283403544342, 2.0, [0.9265845776642722, 0.8532458027149912, 0.6201064385679095],
[2.967449996882591, 2.2571079764754947, -0.7471651146550624],
[1.1603953198942412, 0.5562855137395296, 1.9650050430758796])
```
We find the contents in `out` and `y` are changed after calling the loss function.
Then we call the inverse loss function `~r_loss`.
```julia
julia> out, a, x, y, z = (~r_loss)(out, a, x, y, z)
(0.0, 2.0, [0.9265845776642722, 0.8532458027149912, 0.6201064385679095],
[1.1142808415540466, 0.5506163710455123, -1.9873779917908814],
[1.1603953198942412, 0.5562855137395296, 1.9650050430758796])
```
Values are restored. Here, instead of assigning variables one by one,
one can also use the macro `@instr`
```julia
@instr r_loss(out, a, x, y, z)
```
`@instr` macro is for executing a reversible statement.
## My first reversible AD program
```julia
julia> using NiLang.AD: Grad
julia> x, y, z = randn(3), randn(3), randn(3)
([2.2683181471139906, -0.7374245775047469, 0.9568936661385092],
[1.0275914704043452, 1.647972121962081, -0.8349079845797637],
[1.4272076815911372, 0.5317755971532034, 0.4412421572457776])
julia> Grad(r_loss)(0.0, 0.5, x, y, z; iloss=1)
(GVar(0.0, 1.0), GVar(0.5, 3.2674385142974036),
GVar{Float64,Float64}[GVar(2.2683181471139906, 0.7136038407955686), GVar(-0.7374245775047469, 0.2658877985766017), GVar(0.9568936661385092, 0.2206210786228888)],
GVar{Float64,Float64}[GVar(2.1617505439613405, 1.4272076815911372), GVar(1.2792598332097076, 0.5317755971532034), GVar(-0.35646115151050906, 0.4412421572457776)],
GVar{Float64,Float64}[GVar(1.4272076815911372, 3.295909617518336), GVar(0.5317755971532034, 0.9105475444573341), GVar(0.4412421572457776, 0.12198568155874556)])
julia> gout, ga, gx, gy, gz = Grad(r_loss)(0.0, 0.5, x, y, z; iloss=1)
(GVar(0.0, 1.0), GVar(0.5, 3.2674385142974036),
GVar{Float64,Float64}[GVar(2.2683181471139906, 0.7136038407955686), GVar(-0.7374245775047469, 0.2658877985766017), GVar(0.9568936661385092, 0.2206210786228888)],
GVar{Float64,Float64}[GVar(3.295909617518336, 1.4272076815911372), GVar(0.9105475444573341, 0.5317755971532034), GVar(0.12198568155874556, 0.4412421572457776)],
GVar{Float64,Float64}[GVar(1.4272076815911372, 4.4300686910753315), GVar(0.5317755971532034, 0.5418352557049606), GVar(0.4412421572457776, 0.6004325146280002)])
```
The results are a bit messy, since NiLang wraps each element with a gradient field automatically. We can take the gradient field using the `grad` function like
```julia
julia> grad(gout)
1.0
julia> grad(ga)
3.2674385142974036
julia> grad(gx)
3-element Array{Float64,1}:
0.7136038407955686
0.2658877985766017
0.2206210786228888
julia> grad(gy)
3-element Array{Float64,1}:
1.4272076815911372
0.5317755971532034
0.4412421572457776
julia> grad(gz)
3-element Array{Float64,1}:
4.4300686910753315
0.5418352557049606
0.6004325146280002
```
================================================
FILE: docs/src/why.md
================================================
# What is Reversible Computing and why do we need it
# What are reversible computing and reversible programming
Reversible computing is a computing paradigm that can deterministically undo a computational process, it requires a user not erasing any information during computations. It boomed during 1970-2005, however, but runs into a winter after that. It can do anything that a traditional computing device can do, with possible overheads in time and space. Reversible programing is often considered as the computing model designed for reversible computing, while it can also be executed on a irreversible device. The following book covers a lot about reversible programming.

## Why reversible computing is the future of computing: from a physicist's perspective
The driving force of studying reversible computing is improving the energy efficiency of our computing devices. Energy efficiency of computing devices affect the value of [bitcoins](https://www.investopedia.com/news/do-bitcoin-mining-energy-costs-influence-its-price/), the battery size of a [spacecraft](https://ieeexplore.ieee.org/document/7945170) and artificial intelligence (AI) industry as we will cover bellow.
As is well know, the fundamental laws of physics are reversible. Have you ever had such a confusion that why our computing model is irreversible while our world is governed by reversible laws? This discrepency is due to the fact that the irreversibility is an emergent phenomenon of statistic physics,
we need a ideal heat bath that having an "infinite size" to create irreversibility. This is why the energy efficiency of traditional devices is getting harder and harder to improve, although they are still several orders above the Landauer's limit. The [Landauer's principle](https://en.wikipedia.org/wiki/Landauer%27s_principle) states that irreversible computing has a lower bound of energy cost ~``\ln 2 k_b T``
> Landauer's principle is a physical principle pertaining to the lower theoretical limit of energy consumption of computation. It holds that "any logically irreversible manipulation of information, such as the erasure of a bit or the merging of two computation paths, must be accompanied by a corresponding entropy increase in non-information-bearing degrees of freedom of the information-processing apparatus or its environment".Another way of phrasing Landauer's principle is that if an observer loses information about a physical system, the observer loses the ability to extract work from that system.
Microscopic systems that can be used to build up a reversible computing device are ubiquitous, like [fluxon](https://ieeexplore.ieee.org/abstract/document/8990955), cold atoms, [DNA](https://www.amazon.com/Feynman-Lectures-Computation-Frontiers-Physics/dp/0738202967) and quantum dots. Even the adiabatic CMOS (a reversible computing device utilizing CMOS technology) can potentially be orders more energy efficient than traditional CMOS, and it is [already useful in spacecrafts](https://www.osti.gov/servlets/purl/1377599). The detailed analysis of the energy-speed trade off in adiabatic CMOS can be found [here](https://www3.nd.edu/~lent/pdf/nd/AdiabaticCMOS_HanninenSniderLent2014.pdf).
In reversible programming, [automatically differentiating any program is directly achievable](https://arxiv.org/abs/2003.04617). Automatic differentiation is a building block of artificial intelligence, crunching this problem can potentially lead to the next boom of AI. Programs are built on top of basic instructions like "+", "*", "/", "-". We can use these basic instructions to write Bessel functions, singular value decompositions et. al. [Traditional autodiff frameworks](https://epubs.siam.org/doi/book/10.1137/1.9780898717761) keep track of intermediate states in a global stack and use them for back-propagation. However, doing this brings space overheads that linear to time, which can easily explode the memory. Reversible programming reverse the tape directly for you, while having flexible yet efficient time-space tradeoff algorithms to control the memory usage.
I am optimistic about reversible computing also because we have so much room to improve in the energy perspective. Our computer computes one bit information at the energy cost ~``10^8 k_b T``, while in our body, DNA copy machine computes a bit information at an energy cost ~``10 k_b T``. To embrace the true artificial intelligence, we still have a long way to go.
================================================
FILE: examples/Adam.jl
================================================
export Adam
mutable struct Adam
lr::AbstractFloat
gclip::AbstractFloat
beta1::AbstractFloat
beta2::AbstractFloat
eps::AbstractFloat
t::Int
fstm
scndm
end
Adam(; lr=0.001, gclip=0, beta1=0.9, beta2=0.999, eps=1e-8)=Adam(lr, gclip, beta1, beta2, eps, 0, nothing, nothing)
function update!(w, g, p::Adam)
gclip!(g, p.gclip)
if p.fstm===nothing; p.fstm=zero(w); p.scndm=zero(w); end
p.t += 1
lmul!(p.beta1, p.fstm)
BLAS.axpy!(1-p.beta1, g, p.fstm)
lmul!(p.beta2, p.scndm)
BLAS.axpy!(1-p.beta2, g .* g, p.scndm)
fstm_corrected = p.fstm / (1 - p.beta1 ^ p.t)
scndm_corrected = p.scndm / (1 - p.beta2 ^ p.t)
BLAS.axpy!(-p.lr, @.(fstm_corrected / (sqrt(scndm_corrected) + p.eps)), w)
end
function gclip!(g, gclip)
if gclip == 0
g
else
gnorm = vecnorm(g)
if gnorm <= gclip
g
else
BLAS.scale!(gclip/gnorm, g)
end
end
end
================================================
FILE: examples/CUDA/README.md
================================================
# Reversible programming on GPU
Special Notes:
* please use `@invcheckoff` to close all reversibility check in a kernel.
* be careful about the race condition when automatic differentiating a CUDA program.
## Suggested reading order
1. `swap_gate.jl` simulates a quantum swap gate, its reversible counter part is here
http://tutorials.yaoquantum.org/dev/generated/developer-guide/2.cuda-acceleration/
2. `rotation_gate.jl` simulates a quantum rotation gate, obtaining the gradients on rotation angle would have race condition.
================================================
FILE: examples/CUDA/rotation_gate.jl
================================================
using CUDA, GPUArrays
using NiLang, NiLang.AD
const RotGates = Union{Val{:Rz}, Val{:Rx}, Val{:Ry}}
@i @inline function instruct!(state::CuVector, gate::RotGates, loc::Int, theta::Real)
mask ← 1<<(loc-1)
@cuda threads=256 blocks=ceil(Int, length(state)/256) rot_kernel(gate, state, mask, theta)
end
# @launchkernel CUDADevice() 256 length(out!) bessel_kernel(out!, v, z)
@i @inline function rot_kernel(gate::Val{:Rz}, state, mask, θ)
@invcheckoff b ← (blockIdx().x-1) * blockDim().x + threadIdx().x
@invcheckoff if (b < length(state) && b & mask == 0, ~)
ROT_INSTRUCT(gate, state[b+1], state[b⊻mask+1], θ)
end
end
@i @inline function ROT_INSTRUCT(gate::Val{:Rz}, a::T, b, θ) where T
# make sure `invcheck` is turned off!
@routine @invcheckoff begin
@zeros T anc1 anc2 anc3 anc4
anc1 += θ*(0.5im)
anc2 += CUDA.exp(anc1)
end
anc3 += a * anc2'
anc4 += b * anc2
NiLang.SWAP(a, anc3)
NiLang.SWAP(b, anc4)
anc3 -= a / anc2'
anc4 -= b / anc2
~@routine
end
v = randn(ComplexF64, 128) |> CuArray
v1 = instruct!(copy(v), Val(:Rz), 3, 0.5)[1]
# we can not obtain the gradient for the race condition.
# TODO: Rx and Ry gates, not finished!
@i @inline function ROT_INSTRUCT(gate::Val{:Rx}, a, b, θ)
ROT_INSTRUCT(Val(:Rz), a, b, π/2)
ROT_INSTRUCT(Val(:Ry), a, b, θ)
ROT_INSTRUCT(Val(:Rz), a, b, -π/2)
end
@i @inline function ROT_INSTRUCT(gate::Val{:Ry}, a, b, θ)
divint(θ, 2)
ROT(a, b, θ)
mulint(θ, 2)
end
================================================
FILE: examples/CUDA/swap_gate.jl
================================================
using CUDA, GPUArrays
using NiLang, NiLang.AD
"""
A reversible swap kernel for GPU for SWAP gate in quantum computing.
See the irreversible version for comparison
http://tutorials.yaoquantum.org/dev/generated/developer-guide/2.cuda-acceleration/
"""
@i @inline function swap_kernel(state::AbstractVector{T}, mask1, mask2) where T
@invcheckoff b ← (blockIdx().x-1) * blockDim().x + threadIdx().x
@invcheckoff if (b < length(state), ~)
if (b&mask1==0 && b&mask2==mask2, ~)
NiLang.SWAP(state[b+1], state[b ⊻ (mask1|mask2) + 1])
end
end
end
# TODO: support ::Type like argument.
"""
SWAP gate in quantum computing.
"""
@i function instruct!(state::CuVector, gate::Val{:SWAP}, locs::Tuple{Int,Int})
mask1 ← 1 << (locs[1]-1)
mask2 ← 1 << (locs[2]-1)
@cuda threads=256 blocks=ceil(Int,length(state)/256) swap_kernel(state, mask1, mask2)
end
using Test
@testset "swap gate" begin
v = cu(randn(128))
v1 = instruct!(copy(v), Val(:SWAP), (3,4))[1]
v2 = instruct!(copy(v1), Val(:SWAP), (3,4))[1]
v3 = (~instruct!)(copy(v1), Val(:SWAP), (3,4))[1]
@test !(v ≈ v1)
@test v ≈ v2
@test v ≈ v3
end
@i function loss(out!, state::CuVector)
instruct!(state, Val(:SWAP), (3,4))
out! += state[4]
end
loss(0.0, CuArray(randn(128)))
Grad(loss)(Val(1), 0.0, CuArray(randn(128)))
####################### A different loss ###############
@i function loss(out!, state::CuVector, target::CuVector)
instruct!(state, Val(:SWAP), (3,4))
out! += state' * target
end
# requires defining a new primitive, we don't how to parallelize a CUDA program automatically yet.
using LinearAlgebra: Adjoint
function (_::MinusEq{typeof(*)})(out!::GVar, x::Adjoint{<:Any, <:CuVector{<:GVar}}, y::CuVector{<:GVar})
chfield(out!, value, value(out!)-(value.(x) * value.(y))[]),
chfield.(parent(x), grad, grad.(parent(x)) .+ grad(out!)' .* conj.(value.(y)))',
chfield.(y, grad, grad.(y) .+ grad(out!) .* conj.(value.(x')))
end
function (_::PlusEq{typeof(*)})(out!::GVar, x::Adjoint{<:Any, <:CuVector{<:GVar}}, y::CuVector{<:GVar})
chfield(out!, value, value(out!)+(value.(x) * value.(y))[]),
chfield.(parent(x), grad, grad.(parent(x)) .- grad(out!)' .* conj.(value.(y)))',
chfield.(y, grad, grad.(y) .- grad(out!) .* conj.(value.(x')))
end
function (_::PlusEq{typeof(*)})(out!, x, y)
out! += x * y
out!, x, y
end
function (_::MinusEq{typeof(*)})(out!, x, y)
out! -= x * y
out!, x, y
end
loss(0.0, CuArray(randn(128)), CuArray(randn(128)))
Grad(loss)(Val(1), 0.0, CuArray(randn(128)), CuArray(randn(128)))
================================================
FILE: examples/README.md
================================================
# Examples
1. Reversible CUDA programming: [CUDA/](CUDA/)
2. Generate backward rules for Zygote: [port_zygote.jl](port_zygote.jl)
3. Obtaining symbolics gradients: [Symbolics/](Symbolics/)
4. Solving the graph embeding problem: [graph_embeding.jl](graph_embeding.jl) and [graph_embeding_zygote.jl](graph_embeding_zygote.jl)
5. NICE network: [nice.jl](nice.jl)
6. [Gaussian mixture model](https://github.com/JuliaReverse/NiGaussianMixture.jl)
7. [Bundle Adjustment](https://github.com/JuliaReverse/NiBundleAdjustment.jl)
================================================
FILE: examples/Symbolics/print_jacobians.jl
================================================
using NiLang, NiLang.AD
include("symlib.jl")
NiLang.AD.isvar(sym::Basic) = true
NiLang.AD.GVar(sym::Basic) = GVar(sym, zero(sym))
# a patch for symbolic IROT
@i @inline function NiLang.IROT(a!::GVar{<:Basic}, b!::GVar{<:Basic}, θ::GVar{<:Basic})
IROT(a!.x, b!.x, θ.x)
NEG(θ.x)
θ.x -= Basic(π)/2
ROT(a!.g, b!.g, θ.x)
θ.g += a!.x * a!.g
θ.g += b!.x * b!.g
θ.x += Basic(π)/2
NEG(θ.x)
ROT(a!.g, b!.g, Basic(π)/2)
end
NiLang.INC(x::Basic) = x + one(x)
NiLang.DEC(x::Basic) = x - one(x)
@inline function NiLang.ROT(i::Basic, j::Basic, θ::Basic)
a, b = rot(i, j, θ)
a, b, θ
end
@inline function NiLang.IROT(i::Basic, j::Basic, θ::Basic)
i, j, _ = ROT(i, j, -θ)
i, j, θ
end
Base.sincos(x::Basic) = (sin(x), cos(x))
function printall()
syms = [Basic(:a), Basic(:b), Basic(:c)]
for (subop, nargs) in [(identity, 2), (*, 3), (/, 3), (^, 3), (exp, 2), (log, 2), (sin, 2), (cos, 2)]
for opm in [PlusEq, MinusEq]
op = opm(subop)
@show op
printone(op, syms, nargs)
end
end
for (op, nargs) in [(-, 1), (ROT, 3), (IROT, 3)]
printone(op, syms, nargs)
end
# abs, conj
end
@i function jf1(op, x)
op(x[1])
end
@i function jf2(op, x)
op(x[1], x[2])
end
@i function jf3(op, x)
op(x[1], x[2], x[3])
end
"""print the jacobian of one operator"""
function printone(op, syms, n)
if n==1
jac = jacobian_repeat(jf1, op, syms[1:1]; iin=2, iout=2)
elseif n==2
jac = jacobian_repeat(jf2, op, syms[1:2]; iin=2, iout=2)
elseif n==3
jac = jacobian_repeat(jf3, op, syms[1:3]; iin=2, iout=2)
end
println("------ $op ------")
pretty_print_matrix(jac)
end
printall()
================================================
FILE: examples/Symbolics/symbolic_utils.jl
================================================
using NiLang, NiLang.AD
using SymbolicUtils
using SymbolicUtils: Term, Sym
using LinearAlgebra
const SymReal = Sym{Real}
const TermReal = Term{Real}
const SReals = Union{Term{Real}, Sym{Real}}
import NiLang: INC, DEC, ROT, IROT, FLIP
@inline FLIP(b::Sym{Bool}) = !b
@inline function INC(a!::SReals)
a! + one(a!)
end
@inline function DEC(a!::SReals)
a! - one(a!)
end
@inline function ROT(i::SReals, j::SReals, θ::SReals)
a, b = rot(i, j, θ)
a, b, θ
end
@inline function IROT(i::SReals, j::SReals, θ::SReals)
i, j, _ = ROT(i, j, -θ)
i, j, θ
end
NiLang.AD.GVar(x::SReals) = NiLang.AD.GVar(x, zero(x))
Base.convert(::Type{SymReal}, x::Integer) = SymReal(Symbol(x))
Base.convert(::Type{Term{Real}}, x::Integer) = TermReal(Symbol(x))
Base.zero(x::Sym{T}) where T = zero(Sym{T})
Base.one(x::Sym{T}) where T = one(Sym{T})
Base.zero(::Type{<:Sym{T}}) where T = Sym{T}(Symbol(0))
Base.zero(::Type{<:Term{T}}) where T = Term{T}(Symbol(0))
Base.one(::Type{<:Sym{T}}) where T = Sym{T}(Symbol(1))
Base.one(::Type{<:Term{T}}) where T = Term{T}(Symbol(1))
Base.iszero(x::Sym{T}) where T = x === zero(x)
Base.adjoint(x::SReals) = x
SymbolicUtils.Term{T}(x::Sym{T}) where T = Term{T}(x.name)
LinearAlgebra.dot(a::T, b::T) where T<:SReals = a * b
include("sparse.jl")
using BenchmarkTools, Random
syms = @syms a::Real b::Real c::Real d::Real e::Real f::Real g::Real
Base.rand(r::Random.AbstractRNG, ::Type{SymReal}, i::Integer) = rand(r, syms, i)
Base.rand(r::Random.AbstractRNG, ::Type{TermReal}, i::Integer) = rand(r, TermReal.(syms), i)
a = sprand(TermReal, 100, 100, 0.05);
b = sprand(TermReal, 100, 100, 0.05);
@benchmark SparseArrays.dot($a, $b)
@benchmark idot(TermReal(Symbol(0)), $a, $b)
@benchmark Grad(idot)(Val(1), TermReal(Symbol(0)), $a, $b)
GVar(a)
include("Symbolics/symlib.jl")
syms = @vars a b c d e f g
Base.rand(r::Random.AbstractRNG, ::Type{<:Basic}, i::Integer) = rand(r, syms, i)
a = sprand(Basic, 100, 100, 0.05);
b = sprand(Basic, 100, 100, 0.05);
@benchmark SparseArrays.dot($a, $b)
@benchmark idot(Basic(0), $a, $b)
@benchmark Grad(idot)(Val(1), Basic(0), $a, $b)
================================================
FILE: examples/Symbolics/symlib.jl
================================================
using SymEngine
using SymEngine: BasicType
sconj = SymFunction("conj")
Base.conj(x::Basic) = Basic(conj(SymEngine.BasicType(x)))
Base.conj(x::BasicType) = real(x) - im * imag(x)
Base.imag(x::BasicType{Val{:Constant}}) = Basic(0)
Base.imag(x::BasicType{Val{:Symbol}}) = Basic(0)
pretty_print_number(x; lengthonly=false) = pretty_print_number(stdout, x; lengthonly=lengthonly)
function pretty_print_number(io::IO, x; lengthonly=false)
sx = string(x)
lengthonly || print(io, sx)
return length(sx)
end
function pretty_print_number(io::IO, x::AbstractFloat; lengthonly=false)
closest_int = round(Int, x)
if isapprox(x, closest_int, atol=1e-12)
si = string(closest_int)
lengthonly || print(io, si)
return length(si)
else
sx = string(x)
lengthonly || print(io, sx)
return length(sx)
end
end
function pretty_print_number(io::IO, x::Complex; atol::Real = 1e-12, lengthonly=false)
l = 0
if !isapprox(real(x), 0, atol=atol)
l += pretty_print_number(io, real(x), lengthonly=lengthonly)
end
if !isapprox(imag(x), 0, atol=atol)
if !isapprox(real(x), 0, atol=atol)
lengthonly || print(imag(x) > 0 ? "+" : "")
l += 1
end
l += pretty_print_number(io, imag(x), lengthonly=lengthonly)
lengthonly || print(io, "I")
l += 1
else
if isapprox(real(x), 0, atol=atol)
lengthonly || print(io, "0")
l += 1
end
end
return l
end
pretty_print_matrix(m) = pretty_print_matrix(stdout, m)
function pretty_print_matrix(io::IO, m)
minlen = maximum(pretty_print_number.(m, lengthonly=true))+1
for i in 1:size(m,1)
print(io, "[")
for j in 1:size(m,2)
l = pretty_print_number(m[i,j])
print(" "^(minlen-l-(j==size(m,1))))
end
println(io, "]")
end
end
================================================
FILE: examples/_sharedwrite.jl
================================================
# # The shared write problem on GPU
# We will write a GPU version of `axpy!` function.
# ## The main program
using NiLang, NiLang.AD
using CUDA
using KernelAbstractions
CUDA.allowscalar(true)
# so far, this example requires patch: https://github.com/JuliaGPU/KernelAbstractions.jl/pull/52
@i @kernel function axpy_kernel(y!, α, x)
## invcheckoff to turn of `reversibility checker`
## GPU can not handle errors!
@invcheckoff begin
i ← @index(Global)
y![i] += x[i] * α
i → @index(Global)
end
end
@i function cu_axpy!(y!::AbstractVector, α, x::AbstractVector)
@launchkernel CUDADevice() 256 length(y!) axpy_kernel(y!, α, x)
end
@i function loss(out, y!, α, x)
cu_axpy!(y!, α, x)
## Note: the following code is stupid scalar operations on CuArray,
## They are only for testing.
for i=1:length(y!)
out += y![i]
end
end
y! = rand(100)
x = rand(100)
cuy! = y! |> CuArray
cux = x |> CuArray
α = 0.4
# ## Check the correctness of results
using Test
cu_axpy!(cuy!, α, cux)
@test Array(cuy!) ≈ y! .+ α .* x
(~cu_axpy!)(cuy!, α, cux)
@test Array(cuy!) ≈ y!
# Let's check the gradients
lsout = 0.0
@instr Grad(loss)(Val(1), lsout, cuy!, α, cux)
# you will see a correct vector `[0.4, 0.4, 0.4 ...]`
grad.(cux)
# you will see `0.0`.
grad(α)
# ## Why some gradients not correct?
# In the above example, `α` is a scalar, whereas a scalar is not allowed to change in a CUDA kernel.
# What if we change `α` to a CuArray?
# ## This one works: using a vector of `α`
@i @kernel function axpy_kernel(y!, α, x)
@invcheckoff begin
i ← @index(Global)
y![i] += x[i] * α[i]
i → @index(Global)
end
end
cuy! = y! |> CuArray
cux = x |> CuArray
cuβ = repeat([0.4], 100) |> CuArray
lsout = 0.0
@instr Grad(loss)(Val(1), lsout, cuy!, cuβ, cux)
# You will see correct answer
grad.(cuβ)
# ## This one has the shared write problem: using a vector of `α`, but shared read.
@i @kernel function axpy_kernel(y!, α, x)
@invcheckoff begin
i ← @index(Global)
y![i] += x[i] * α[i]
i → @index(Global)
end
end
cuy! = y! |> CuArray
cux = x |> CuArray
cuβ = repeat([0.4], 100) |> CuArray
lsout = 0.0
cuβ = [0.4] |> CuArray
# Run the following will give you a happy error
#
# > ERROR: a exception was thrown during kernel execution.
# > Run Julia on debug level 2 for device stack traces.
# ```julia
# @instr Grad(loss)(Val(1), lsout, cuy!, cuβ, cux)
# ```
# Because, shared write is not allowed. We need someone clever enough to solve this problem for us.
# ## Conclusion
# * Shared scalar: the gradient of a scalar will not be updated.
# * Expanded vector: works properly, but costs more memory.
# * Shared 1-element vector: error on shared write.
================================================
FILE: examples/batched_tr.jl
================================================
using NiLang, NiLang.AD
using KernelAbstractions, CUDA, CUDAKernels
@i @kernel function kernel_f(A, B::AbstractVector{TB}) where TB
# turng off reversibility check, since GPU can not handle errors
@invcheckoff begin
# allocate
batch ← @index(Global)
s ← zero(TB)
# computing
for i in axes(A, 1)
s += A[i, i, batch]
end
B[batch] += s
# deallocate safely
s → zero(TB)
batch → @index(Global)
end
end
@i function batched_tr!(A::CuArray{T, 3}, B::CuVector{T}) where T
@launchkernel CUDADevice() 256 length(B) kernel_f(A, B)
end
A = CuArray(randn(ComplexF32, 10, 10, 100))
B = CUDA.zeros(ComplexF32, 100)
A_out, B_out = batched_tr!(A, B)
# put random values in the gradient field of B
grad_B = CuArray(randn(ComplexF32, 100))
A_with_g, B_with_g = (~batched_tr!)(GVar(A_out), GVar(B_out, grad_B))
# will see nonzero gradients in complex diagonal parts of A
grad_A = grad(A_with_g |> Array)
================================================
FILE: examples/besselj.jl
================================================
# # Bessel function
# An Bessel function of the first kind of order ``\nu`` can be computed using Taylor expansion
# ```math
# J_\nu(z) = \sum\limits_{n=0}^{\infty} \frac{(z/2)^\nu}{\Gamma(k+1)\Gamma(k+\nu+1)} (-z^2/4)^{n}
# ```
# where ``\Gamma(n) = (n-1)!`` is the Gamma function. One can compute the accumulated item iteratively as ``s_n = -\frac{z^2}{4} s_{n-1}``.
using NiLang, NiLang.AD
using ForwardDiff: Dual
# Since we need to use logarithmic numbers to handle the sequential mutiplication.
# Let's first add patch about the conversion between `ULogarithmic` and `Dual` number.
function Base.convert(::Type{Dual{T,V,N}}, x::ULogarithmic) where {T,V,N}
Dual{T,V,N}(exp(x.log))
end
function Base.exp(::Type{ULogarithmic{Dual{T,V,N}}}, d::Dual) where {T,V,N}
invoke(Base.exp, Tuple{Type{ULogarithmic{T}}, T} where T<:Real, ULogarithmic{Dual{T,V,N}}, d)
end
@i function ibesselj(y!::T, ν, z::T; atol=1e-8) where T
if z == 0
if v == 0
out! += 1
end
else
@routine @invcheckoff begin
k ← 0
@ones ULogarithmic{T} lz halfz halfz_power_2 s
@zeros T out_anc
lz *= convert(z)
halfz *= lz / 2
halfz_power_2 *= halfz ^ 2
## s *= (z/2)^ν/ factorial(ν)
s *= halfz ^ ν
for i=1:ν
s /= i
end
out_anc += convert(s)
@from k==0 while s.log > -25 # upto precision e^-25
k += 1
## s *= 1 / k / (k+ν) * (z/2)^2
s *= halfz_power_2 / (@const k*(k+ν))
if k%2 == 0
out_anc += convert(s)
else
out_anc -= convert(s)
end
end
end
y! += out_anc
~@routine
end
end
# To obtain gradients, one call **Grad(ibesselj)**
y, x = 0.0, 1.0
Grad(ibesselj)(Val(1), y, 2, x)
# Here, **Grad(ibesselj)** is a callable instance of type **Grad{typeof(ibesselj)}}**.
# The first parameter `Val(1)` indicates the first argument is the loss.
# To obtain second order gradients, one can Feed dual numbers to this gradient function.
_, hxy, _, hxx = Grad(ibesselj)(Val(1), Dual(y, zero(y)), 2, Dual(x, one(x)))
println("The hessian dy^2/dx^2 is $(grad(hxx).partials[1])")
# Here, the gradient field is a Dual number, it has a field partials that stores the derivative with respect to `x`.
# This is the Hessian that we need.
# ## CUDA programming
# The AD in NiLang avoids most heap allocation, so that it is able to execute on a GPU device
# We suggest using [KernelAbstraction](https://github.com/JuliaGPU/KernelAbstractions.jl), it provides compatibility between CPU and GPU.
# To execute the above function on GPU, we need only 11 lines of code.
# ```julia
# using CUDA, GPUArrays, KernelAbstractions
#
# @i @kernel function bessel_kernel(out!, v, z)
# @invcheckoff i ← @index(Global)
# ibesselj(out![i], v, z[i])
# @invcheckoff i → @index(Global)
# end
# ```
# We have a macro support to KernelAbstraction in NiLang.
# So it is possible to launch directly like.
# ```julia
# @i function befunc(out!, v::Integer, z)
# @launchkernel CUDADevice() 256 length(out!) bessel_kernel(out!, v, z)
# end
# ```
# It is equivalent to call
# ```julia
# (~bessel_kernel)(CUDADevice(), 256)(out!, v, z; ndrange=length(out!))
# ```
# But it will execute the job eagerly for you.
# We will consider better support in the future.
# Except it is reversible
# ```julia repl
# julia> @code_reverse @launchkernel CUDA() 256 length(out!) bessel_kernel(out!, v, z)
# :(#= REPL[4]:1 =# @launchkernel CUDA() 256 length(out!) (~bessel_kernel)(out!, v, z))
# ```
# To test this function, we first define input parameters `a` and output `out!`
# ```julia
# a = CuArray(rand(128))
# out! = CuArray(zeros(128))
# ```
# We wrap the output with a randomly initialized gradient field, suppose we get the gradients from a virtual loss function.
# Also, we need to initialize an empty gradient field for elements in input cuda tensor `a`.
# ```julia
# out! = ibesselj(out!, 2, GVar.(a))[1]
# out_g! = GVar.(out!, CuArray(randn(128)))
# ```
# Call the inverse program, the multiple dispatch will drive you to the goal.
# ```julia
# (~ibesselj)(out_g!, 2, GVar.(a))
# ```
# You will get CUDA arrays with `GVar` elements as output, their gradient fields are what you want.
# Cheers! Now you have a adjoint mode differentiable CUDA kernel.
# ## Benchmark
# We have different source to souce automatic differention implementations of the first type Bessel function ``J_2(1.0)`` benchmarked and show the results below.
#
#
# | Package | Tangent/Adjoint | ``T_{\rm min}``/ns | Space/KB |
# | --------- | --------------- | ------------------- | --------- |
# | Julia | - | 22 | 0 |
# | NiLang | - | 59 | 0 |
# | ForwardDiff | Tangent | 35 | 0 |
# | Manual | Adjoint | 83 | 0 |
# | NiLang.AD | Adjoint | 213 | 0 |
# | NiLang.AD (GPU) | Adjoint | 1.4 | 0 |
# | Zygote | Adjoint | 31201 | 13.47 |
# | Tapenade | Adjoint | ? | ? |
# Julia is the CPU time used for running the irreversible forward program, is the baseline of benchmarking.
# NiLang is the reversible implementation, it is 2.7 times slower than its irreversible counterpart. Here, we have remove the reversibility check.
# ForwardDiff gives the best performance because it is designed for functions with single input.
# It is even faster than manually derived gradients
# ```math
# \frac{\partial J_{\nu}(z)}{\partial z} = \frac{J_{\nu-1} - J_{\nu+1}}{2}
# ```
# NiLang.AD is the reversible differential programming implementation, it considers only the backward pass.
# The benchmark of its GPU version is estimated on Nvidia Titan V by broadcasting the gradient function on CUDA array of size ``2^17`` and take average.
# The Zygote benchmark considers both forward pass and backward pass.
# Tapenade is not yet ready.
================================================
FILE: examples/boxmuller.jl
================================================
# # Box-Muller method to Generate normal distribution
using NiLang
# In this tutorial, we introduce using Box-Muller method to transform a uniform distribution to a normal distribution.
# The transformation and inverse transformation of `Box-Muller` method could be found in
# [this blog](https://mathworld.wolfram.com/Box-MullerTransformation.html)
@i function boxmuller(x::T, y::T) where T
@routine @invcheckoff begin
@zeros T θ logx _2logx
θ += 2π * y
logx += log(x)
_2logx += -2 * logx
end
## store results
z1 ← zero(T)
z2 ← zero(T)
z1 += _2logx ^ 0.5
ROT(z1, z2, θ)
~@routine
SWAP(x, z1)
SWAP(y, z2)
## arithmetic uncomputing: recomputing the original values of `x` and `y` to deallocate z1 and z2
@routine @invcheckoff begin
@zeros T at sq _halfsq
at += atan(y, x)
if (y < 0, ~)
at += T(2π)
end
sq += x ^ 2
sq += y ^ 2
_halfsq -= sq / 2
end
z1 -= exp(_halfsq)
z2 -= at / (2π)
@invcheckoff z1 → zero(T)
@invcheckoff z2 → zero(T)
~@routine
end
# One may wonder why this implementation is so long,
# should't NiLang generate the inverse for user?
# The fact is, although Box-Muller is arithmetically reversible.
# It is not finite precision reversible.
# Hence we need to "uncompute" it manually,
# this trick may introduce reversibility error.
using Plots
N = 5000
x = rand(2*N)
Plots.histogram(x, bins = -3:0.1:3, label="uniform",
legendfontsize=16, xtickfontsize=16, ytickfontsize=16)
# forward
@instr boxmuller.(x[1:N], x[N+1:end])
Plots.histogram(x, bins = -3:0.1:3, label="normal",
legendfontsize=16, xtickfontsize=16, ytickfontsize=16)
# backward
@instr (~boxmuller).(x[1:N], x[N+1:end])
Plots.histogram(x, bins = -3:0.1:3, label="uniform",
legendfontsize=16, xtickfontsize=16, ytickfontsize=16)
# ## Check the probability distribution function
using LinearAlgebra, Test
normalpdf(x) = sqrt(1/2π)*exp(-x^2/2)
# obtain `log(abs(det(jacobians)))`
@i function f(x::Vector)
boxmuller(x[1], x[2])
end
jac = NiLang.AD.jacobian(f, [0.5, 0.5], iin=1)
ladj = log(abs(det(jac)))
# check if it matches the `log(p/q)`.
z1, z2 = boxmuller(0.5, 0.5)
@test ladj ≈ log(1.0 / (normalpdf(z1) * normalpdf(z2)))
# ## To obtaining Jacobian - a simpler approach
# We can define a function that exactly reversible from the instruction level,
# but costs more space for storing output.
@i function boxmuller2(x1::T, x2::T, z1::T, z2::T) where T
@routine @invcheckoff begin
@zeros T θ logx _2logx
θ += 2π * x2
logx += log(x1)
_2logx += -2 * logx
end
## store results
z1 += _2logx ^ 0.5
ROT(z1, z2, θ)
~@routine
end
# However, this is not a bijector from that maps `x` to `z`,
# because computing the backward just erases the content in `z`.
# However, this function can be used to obtain `log(abs(det(jacobians)))`
@i function f2(x::Vector, z::Vector)
boxmuller2(x[1], x[2], z[1], z[2])
end
jac = NiLang.AD.jacobian(f2, [0.5, 0.5], [0.0, 0.0], iin=1, iout=2)
ladj = log(abs(det(jac)))
# check if it matches the `log(p/q)`.
_, _, z1, z2 = boxmuller2(0.5, 0.5, 0.0, 0.0)
@test ladj ≈ log(1.0 / (normalpdf(z1) * normalpdf(z2)))
================================================
FILE: examples/fft.jl
================================================
# https://rosettacode.org/wiki/Fast_Fourier_transform#Fortran
# In place Cooley-Tukey FFT
function fft!(x::AbstractVector{T}) where T
N = length(x)
@inbounds if N <= 1
return x
elseif N == 2
t = x[2]
oi = x[1]
x[1] = oi + t
x[2] = oi - t
return x
end
# divide
odd = x[1:2:N]
even = x[2:2:N]
# conquer
fft!(odd)
fft!(even)
# combine
@inbounds for i=1:N÷2
t = exp(T(-2im*π*(i-1)/N)) * even[i]
oi = odd[i]
x[i] = oi + t
x[i+N÷2] = oi - t
end
return x
end
using NiLang
@i function i_fft!(x::AbstractVector{T}) where T
@routine @invcheckoff N ← length(x)
@safe @assert N%2 == 0
@invcheckoff @inbounds if N <= 1
elseif N == 2
HADAMARD(x[1].re, x[2].re)
HADAMARD(x[1].im, x[2].im)
else
# devide and conquer
i_fft!(x[1:2:N])
i_fft!(x[2:2:N])
x2 ← zeros(T, N)
for i=1:N÷2
x2[i] += x[2i-1]
x2[i+N÷2] += x[2i]
end
for i=1:N
SWAP(x[i], x2[i])
end
for i=1:N÷2
x2[2i-1] -= x[i]
x2[2i] -= x[i+N÷2]
end
# combine
for i=1:N÷2
@routine θ ← -2*π*(i-1)/N
ROT(x[i+N÷2].re, x[i+N÷2].im, θ)
HADAMARD(x[i].re, x[i+N÷2].re)
HADAMARD(x[i].im, x[i+N÷2].im)
~@routine
end
x2 → zeros(T, N)
end
~@routine
end
using Test, FFTW
@testset "fft" begin
x = randn(ComplexF64, 64)
@test fft!(copy(x)) ≈ FFTW.fft(x)
@test i_fft!(copy(x)) .* sqrt(length(x)) ≈ FFTW.fft(x)
end
================================================
FILE: examples/fib.jl
================================================
# # Computing Fibonacci Numbers
# The following is an example that everyone likes, computing Fibonacci number recursively.
using NiLang
@i function rfib(out!, n::T) where T
@routine begin
n1 ← zero(T)
n2 ← zero(T)
n1 += n - 1
n2 += n - 2
end
if (value(n) <= 2, ~)
out! += 1
else
rfib(out!, n1)
rfib(out!, n2)
end
~@routine
end
# The time complexity of this recursive algorithm is exponential to input `n`. It is also possible to write a reversible linear time with for loops.
# A slightly non-trivial task is computing the first Fibonacci number that greater or equal to a certain number `z`, where a `while` statement is required.
@i function rfibn(n!, z)
@safe @assert n! == 0
out ← 0
rfib(out, n!)
@from n! == 0 while out < z
~rfib(out, n!)
n! += 1
rfib(out, n!)
end
~rfib(out, n!)
out → 0
end
# In this example, the postcondition `n!=0` in the `while` statement is false before entering the loop, and it becomes true in later iterations. In the reverse program, the `while` statement stops at `n==0`.
# If executed correctly, a user will see the following result.
rfib(0, 10)
# compute which the first Fibonacci number greater than 100.
rfibn(0, 100)
# and uncompute
(~rfibn)(rfibn(0, 100)...)
# This example shows how an addition postcondition provided by the user can help to reverse a control flow without caching controls.
================================================
FILE: examples/fixedlog.jl
================================================
using FixedPointNumbers, Test
"""
Reference
-------------------
[1] C. S. Turner, "A Fast Binary Logarithm Algorithm", IEEE Signal
Processing Mag., pp. 124,140, Sep. 2010.
"""
function log2fix(x::Fixed{T, P}) where {T, P}
PREC = UInt(P)
x.i == 0 && return typemin(T) # represents negative infinity
y = zero(T)
xi = x.i
while xi < 1 << PREC
xi <<= 1
y -= T(1) << PREC
end
while xi >= 2 << PREC
xi >>= 1
y += T(1) << PREC
end
z = xi
b = T(1) << (PREC - UInt(1))
for i = 1:P
temp = Base.widemul(z, z) >> PREC
z = T(temp)
if z >= T(2) << PREC
z >>= 1
y += b
end
b >>= 1
end
return Fixed{T,PREC}(y, nothing)
end
@test log2fix(Fixed{Int, 43}(2^1.24)) ≈ 1.24
================================================
FILE: examples/lax_wendroff.jl
================================================
"""
solve the 1D linear advection equation
```math
∂q/∂t=−u∂q/∂x
```
in a periodic domain, where ``q`` is the quantity being advected,
``t`` is time, ``x`` is the spatial coordinate and ``u`` is the velocity,
which is constant with ``x``.
"""
function lax_wendroff!(nt::Int, c, q_init::AbstractVector{T}, q::AbstractVector{T}) where T
nx = length(q)
flux = zeros(T, nx-1) # Fluxes between boxes
@inbounds for i=1:nx
q[i] = q_init[i] # Initialize q
end
@inbounds for j=1:nt # Main loop in time
for i=1:nx-1
flux[i] = 0.5*c*(q[i]+q[i+1]+c*(q[i]-q[i+1]))
end
for i=2:nx-1
q[i] += flux[i-1]-flux[i]
end
q[1] = q[nx-1]; q[nx] = q[2] # Treat boundary conditions
end
return q
end
using Random
Random.seed!(2)
q_init = randn(100)
q = zeros(100)
@show lax_wendroff!(2000, 1.0, q_init, zero(q_init))
using BenchmarkTools
@benchmark lax_wendroff!(2000, 1.0, $q_init, x) setup=(x=zero(q_init))
@time lax_wendroff!(2000, 1.0, q_init, q)
using NiLang
@i function i_lax_wendroff!(nt::Int, c, q_init::AbstractVector{T}, q::AbstractVector{T},
cache::AbstractMatrix{T}) where T
nx ← length(q)
@inbounds for i=1:nx
q[i] += q_init[i] # Initialize q
end
@inbounds for j=1:nt # Main loop in time
for i=1:nx-1
@routine begin
@zeros T anc1 anc2 anc3
anc1 += 0.5 * c
anc2 += q[i] - q[i+1]
anc3 += q[i] + q[i+1]
anc3 += c * anc2
end
cache[i,j] += anc1 * anc3
~@routine
end
for i=2:nx-1
q[i] += cache[i-1,j]-cache[i,j]
end
# Treat boundary conditions
cache[nx,j] += q[nx-1]
SWAP(q[1], cache[nx,j])
cache[nx+1,j] += q[2]
SWAP(q[nx], cache[nx+1,j])
end
nx → length(q)
end
nt = 2000
i_lax_wendroff!(nt, 1.0, q_init, zero(q_init), zeros(length(q_init)+1,nt))
================================================
FILE: examples/lognumber.jl
================================================
# # Logarithmic number system
# Computing basic functions like `power`, `exp` and `besselj` is not trivial for reversible programming.
# There is no efficient constant memory algorithm using pure fixed point numbers only.
# For example, to compute `x ^ n` reversiblly with fixed point numbers,
# we need to allocate a vector of size $O(n)$.
# With logarithmic numbers, the above computation is straight forward.
using LogarithmicNumbers
using NiLang, NiLang.AD
using FixedPointNumbers
@i function i_power(y::T, x::T, n::Int) where T
if !iszero(x)
@routine begin
lx ← one(ULogarithmic{T})
ly ← one(ULogarithmic{T})
## convert `x` to a logarithmic number
## Here, `*=` is reversible for log numbers
if x > 0
lx *= convert(x)
else
lx *= convert(-x)
end
for i=1:n
ly *= lx
end
end
## convert back to fixed point numbers
y += convert(ly)
if x < 0 && n%2 == 1
NEG(y)
end
~@routine
end
end
# To check the function
i_power(Fixed43(0.0), Fixed43(0.4), 3)
# ## `exp` function as an example
# The following example computes `exp(x)`.
@i function i_exp(y!::T, x::T) where T<:Union{Fixed, GVar{<:Fixed}}
@invcheckoff begin
@routine begin
s ← one(ULogarithmic{T})
lx ← one(ULogarithmic{T})
k ← 0
end
lx *= convert(x)
y! += convert(s)
@from k==0 while s.log > -20
k += 1
s *= lx / k
y! += convert(s)
end
~(@from k==0 while s.log > -20
k += 1
s *= x / k
end)
lx /= convert(x)
~@routine
end
end
x = Fixed43(3.5)
# We can check the reversibility
out, _ = i_exp(Fixed43(0.0), x)
@assert out ≈ exp(3.5)
# Computing the gradients
_, gx = NiLang.AD.gradient(Val(1), i_exp, (Fixed43(0.0), x))
@assert gx ≈ exp(3.5)
================================================
FILE: examples/nice.jl
================================================
# # NICE network
# For the definition of this network and concepts of normalizing flow,
# please refer this nice blog: https://lilianweng.github.io/lil-log/2018/10/13/flow-based-deep-generative-models.html,
# and the pytorch notebook: https://github.com/GiggleLiu/marburg/blob/master/notebooks/nice.ipynb
using NiLang, NiLang.AD
using LinearAlgebra
using DelimitedFiles
using Plots
# `include` the optimizer, you can find it under the `Adam.jl` file in the `examples/` folder.
include(NiLang.project_relative_path("examples", "Adam.jl"))
# ## Model definition
# First, define the single layer transformation and its behavior under `GVar` - the gradient wrapper.
struct NiceLayer{T}
W1::Matrix{T}
b1::Vector{T}
W2::Matrix{T}
b2::Vector{T}
y1::Vector{T}
y1a::Vector{T}
end
"""Apply a single NICE transformation."""
@i function nice_layer!(x::AbstractVector{T}, layer::NiceLayer{T},
y!::AbstractVector{T}) where T
@routine @invcheckoff begin
i_affine!(layer.y1, layer.W1, layer.b1, x)
@inbounds for i=1:length(layer.y1)
if (layer.y1[i] > 0, ~)
layer.y1a[i] += layer.y1[i]
end
end
end
i_affine!(y!, layer.W2, layer.b2, layer.y1a)
~@routine
## clean up accumulated rounding error, since this memory is reused.
@safe layer.y1 .= zero(T)
end
# Here, in each layer, we use the information in `x` to update `y!`.
# During computing, we use the `y1` and `y1a` fields of the network as ancilla space,
# both of them can be uncomputed at the end of the function.
# However, we need to erase small numbers to make sure the rounding error does not accumulate.
# A nice network always transforms inputs reversibly.
# We update one half of `x!` a time, so that input and output memory space do not clash.
const NiceNetwork{T} = Vector{NiceLayer{T}}
"""Apply a the whole NICE network."""
@i function nice_network!(x!::AbstractVector{T}, network::NiceNetwork{T}) where T
@invcheckoff for i=1:length(network)
np ← length(x!)
if (i%2==0, ~)
@inbounds nice_layer!(x! |> subarray(np÷2+1:np), network[i], x! |> subarray(1:np÷2))
else
@inbounds nice_layer!(x! |> subarray(1:np÷2), network[i], x! |> subarray(np÷2+1:np))
end
np → length(x!)
end
end
function random_nice_network(nparams::Int, nhidden::Int, nlayer::Int; scale=0.1)
random_nice_network(Float64, nparams, nhidden, nlayer; scale=scale)
end
function random_nice_network(::Type{T}, nparams::Int, nhidden::Int, nlayer::Int; scale=0.1) where T
nin = nparams÷2
scale = T(scale)
y1 = zeros(T, nhidden)
NiceLayer{T}[NiceLayer(randn(T, nhidden, nin)*scale, randn(T, nhidden)*scale,
randn(T, nin, nhidden)*scale, randn(T, nin)*scale, y1, zero(y1)) for _ = 1:nlayer]
end
# ## Parameter management
nparameters(n::NiceLayer) = length(n.W1) + length(n.b1) + length(n.W2) + length(n.b2)
nparameters(n::NiceNetwork) = sum(nparameters, n)
"""collect parameters in the `layer` into a vector `out`."""
function collect_params!(out, layer::NiceLayer)
a, b, c, d = length(layer.W1), length(layer.b1), length(layer.W2), length(layer.b2)
out[1:a] .= vec(layer.W1)
out[a+1:a+b] .= layer.b1
out[a+b+1:a+b+c] .= vec(layer.W2)
out[a+b+c+1:end] .= layer.b2
return out
end
"""dispatch vectorized parameters `out` into the `layer`."""
function dispatch_params!(layer::NiceLayer, out)
a, b, c, d = length(layer.W1), length(layer.b1), length(layer.W2), length(layer.b2)
vec(layer.W1) .= out[1:a]
layer.b1 .= out[a+1:a+b]
vec(layer.W2) .= out[a+b+1:a+b+c]
layer.b2 .= out[a+b+c+1:end]
return layer
end
function collect_params(n::NiceNetwork{T}) where T
out = zeros(T, nparameters(n))
k = 0
for layer in n
np = nparameters(layer)
collect_params!(view(out, k+1:k+np), layer)
k += np
end
return out
end
function dispatch_params!(network::NiceNetwork, out)
k = 0
for layer in network
np = nparameters(layer)
dispatch_params!(layer, view(out, k+1:k+np))
k += np
end
return network
end
# ## Loss function
# To obtain the log-probability of a data.
@i function logp!(out!::T, x!::AbstractVector{T}, network::NiceNetwork{T}) where T
(~nice_network!)(x!, network)
@invcheckoff for i = 1:length(x!)
@routine begin
xsq ← zero(T)
@inbounds xsq += x![i]^2
end
out! -= 0.5 * xsq
~@routine
end
end
# The negative-log-likelihood loss function
@i function nice_nll!(out!::T, cum!::T, xs!::Matrix{T}, network::NiceNetwork{T}) where T
@invcheckoff for i=1:size(xs!, 2)
@inbounds logp!(cum!, xs! |> subarray(:,i), network)
end
out! -= cum!/(@const size(xs!, 2))
end
# ## Training
function train(x_data, model; num_epochs = 800)
num_vars = size(x_data, 1)
params = collect_params(model)
optimizer = Adam(; lr=0.01)
for epoch = 1:num_epochs
loss, a, b, c = nice_nll!(0.0, 0.0, copy(x_data), model)
if epoch % 50 == 1
println("epoch = $epoch, loss = $loss")
display(showmodel(x_data, model))
end
_, _, _, gmodel = (~nice_nll!)(GVar(loss, 1.0), GVar(a), GVar(b), GVar(c))
g = grad.(collect_params(gmodel))
update!(params, grad.(collect_params(gmodel)), optimizer)
dispatch_params!(model, params)
end
return model
end
function showmodel(x_data, model; nsamples=2000)
scatter(x_data[1,1:nsamples], x_data[2,1:nsamples]; xlims=(-5,5), ylims=(-5,5))
zs = randn(2, nsamples)
for i=1:nsamples
nice_network!(view(zs, :, i), model)
end
scatter!(zs[1,:], zs[2,:])
end
# you can find the training data in `examples/` folder
x_data = Matrix(readdlm(NiLang.project_relative_path("examples", "train.dat"))')
import Random; Random.seed!(22)
model = random_nice_network(Float64, size(x_data, 1), 10, 4; scale=0.1)
# Before training, the distribution looks like
# 
model = train(x_data, model; num_epochs=800)
# After training, the distribution looks like
# 
================================================
FILE: examples/nice_test.jl
================================================
# bijectivity check
using Test
include("nice.jl")
@testset "nice" begin
num_vars = 4
model = random_nice_network(num_vars, 10, 3)
z = randn(num_vars)
x, _ = nice_network!(z, model)
z_infer, _ = (~nice_network!)(x, model)
@test z_infer ≈ z
newparams = randn(nparameters(model))
dispatch_params!(model, newparams)
@test collect_params(model) ≈ newparams
@test check_inv(logp!, (0.0, x, model))
end
@testset "nice logp" begin
z1 = [0.5, 0.2]
z2 = [-0.5, 1.2]
model = random_nice_network(2, 10, 4)
x1 = nice_network!(copy(z1), model)[1]
x2 = nice_network!(copy(z2), model)[1]
p1 = logp!(0.0, copy(x1), model)[1]
p2 = logp!(0.0, copy(x2), model)[1]
pz1 = exp(-sum(abs2, z1)/2)
pz2 = exp(-sum(abs2, z2)/2)
@test exp(p1 - p2) ≈ pz1/pz2
@test nice_nll!(0.0, 0.0, hcat(x1, x2), model)[1] ≈ -log(pz1 * pz2)/2
xs = hcat(x1, x2)
gmodel = Grad(nice_nll!)(Val(1), 0.0, 0.0, copy(xs), model)[end]
for i=1:10, j=1:4
model[j].W2[i] -= 1e-4
a = nice_nll!(0.0, 0.0, copy(xs), model)[1]
model[j].W2[i] += 2e-4
b = nice_nll!(0.0, 0.0, copy(xs), model)[1]
model[j].W2[i] -= 1e-4
ng = (b-a)/2e-4
@test gmodel[j].W2[i].g ≈ ng
end
for i=1:10, j=1:4
model[j].W1[i] -= 1e-4
a = nice_nll!(0.0, 0.0, copy(xs), model)[1]
model[j].W1[i] += 2e-4
b = nice_nll!(0.0, 0.0, copy(xs), model)[1]
model[j].W1[i] -= 1e-4
ng = (b-a)/2e-4
@test gmodel[j].W1[i].g ≈ ng
end
end
================================================
FILE: examples/port_chainrules.jl
================================================
# # [How to port NiLang to ChainRules](@id port_chainrules)
#
# In [How to port NiLang to Zygote](@ref port_zygote) we showed the way to insert Nilang-based
# gradient as Zygote's pullback/adjoint. Given that [ChainRules](https://github.com/JuliaDiff/ChainRules.jl)
# is now the core of many AD packages including Zygote, extending `ChainRules.rrule` with Nilang
# does the same job, except that it affects all ChainRules-based AD packages and not just Zygote.
#
# We'll use the same example as [How to port NiLang to Zygote](@ref port_zygote), so you might need
# to restart your Julia to get a fresh environment.
using NiLang, NiLang.AD, Zygote, ChainRules
# Let's start from the Julia native implementation of `norm2` function.
function norm2(x::AbstractArray{T}) where T
out = zero(T)
for i=1:length(x)
@inbounds out += x[i]^2
end
return out
end
# Zygote is able to generate correct dual function, i.e., gradients, but much slower than the primal
# function `norm2`
using BenchmarkTools
x = randn(1000);
original_grad = norm2'(x)
@benchmark norm2'($x) seconds=1
# The primal function is
@benchmark norm2($x) seconds=1
# Then we have the reversible implementation
@i function r_norm2(out::T, x::AbstractArray{T}) where T
for i=1:length(x)
@inbounds out += x[i]^2
end
end
# The gradient generated by NiLang is much faster, which is comparable to the forward program
@benchmark (~r_norm2)(GVar($(norm2(x)), 1.0), $(GVar(x))) seconds=1
# By defining our custom `rrule` using Nilang's gradient implementation, `Zygote` automaticallly
# gets boosted because it internally uses the available ChainRules ruleset.
# Here we need to create a new symbol here because otherwise Zygote will still use the
# previously generated slow implementation.
norm2_faster(x) = norm2(x)
function ChainRules.rrule(::typeof(norm2_faster), x::AbstractArray{T}) where T
out = norm2_faster(x)
function pullback(ȳ)
ChainRules.NoTangent(), grad((~r_norm2)(GVar(out, ȳ), GVar(x))[2])
end
out, pullback
end
@assert norm2_faster'(x) ≈ original_grad
# See, much faster
@benchmark norm2_faster'(x) seconds=1
================================================
FILE: examples/port_zygote.jl
================================================
# # [How to port NiLang to Zygote](@id port_zygote)
#
# In this demo we'll show how to insert NiLang's gradient implementation to boost Zygote's gradient.
# A similar demo for ChainRules can be found in [How to port NiLang to ChainRules](@ref port_chainrules).
using NiLang, NiLang.AD, Zygote
# Let's start from the Julia native implementation of `norm2` function.
function norm2(x::AbstractArray{T}) where T
out = zero(T)
for i=1:length(x)
@inbounds out += x[i]^2
end
return out
end
# Zygote is able to generate correct dual function, i.e., gradients, but much slower than the primal
# function `norm2`
using BenchmarkTools
x = randn(1000);
original_grad = norm2'(x)
@benchmark norm2'($x) seconds=1
# The primal function is
@benchmark norm2($x) seconds=1
# Then we have the reversible implementation
@i function r_norm2(out::T, x::AbstractArray{T}) where T
for i=1:length(x)
@inbounds out += x[i]^2
end
end
# The gradient generated by NiLang is much faster, which is comparable to the forward program
@benchmark (~r_norm2)(GVar($(norm2(x)), 1.0), $(GVar(x))) seconds=1
# to enjoy the speed of `NiLang` in `Zygote`, just bind the adjoint rule
Zygote.@adjoint function norm2(x::AbstractArray{T}) where T
out = norm2(x)
out, δy -> (grad((~r_norm2)(GVar(out, δy), GVar(x))[2]),)
end
@assert norm2'(x) ≈ original_grad
# See, much faster
@benchmark norm2'(x) seconds=1
================================================
FILE: examples/pyramid.jl
================================================
# # Pyramid example
#
# This is the Pyramid example in the book "Evaluate Derivatives", Sec. 3.5.
using NiLang, NiLang.AD
@i function pyramid!(y!, v!, x::AbstractVector{T}) where T
@safe @assert size(v!,2) == size(v!,1) == length(x)
@invcheckoff @inbounds for j=1:length(x)
v![1,j] += x[j]
end
@invcheckoff @inbounds for i=1:size(v!,1)-1
for j=1:size(v!,2)-i
@routine begin
@zeros T c s
c += cos(v![i,j+1])
s += sin(v![i,j])
end
v![i+1,j] += c * s
~@routine
end
end
y! += v![end,1]
end
x = randn(20)
pyramid!(0.0, zeros(20, 20), x)
# Let's benchmark the gradient of the pyramid function
using BenchmarkTools
@benchmark gradient(Val(1), pyramid!, (0.0, zeros(20, 20), $x))
================================================
FILE: examples/qr.jl
================================================
# # A simple QR decomposition
# ## Functions used in this example
using NiLang, NiLang.AD, Test
# ## The QR decomposition
# Let us consider a naive implementation of QR decomposition from scratch.
# This implementation is just a proof of principle which does not consider reorthogonalization and other practical issues.
@i function qr(Q, R, A::Matrix{T}) where T
@routine begin
anc_norm ← zero(T)
anc_dot ← zeros(T, size(A,2))
ri ← zeros(T, size(A,1))
end
for col = 1:size(A, 1)
ri .+= A[:,col]
for precol = 1:col-1
i_dot(anc_dot[precol], Q[:,precol], ri)
R[precol,col] += anc_dot[precol]
for row = 1:size(Q,1)
ri[row] -=
anc_dot[precol] * Q[row, precol]
end
end
i_norm2(anc_norm, ri)
R[col, col] += anc_norm^0.5
for row = 1:size(Q,1)
Q[row,col] += ri[row] / R[col, col]
end
~begin
ri .+= A[:,col]
for precol = 1:col-1
i_dot(anc_dot[precol], Q[:,precol], ri)
for row = 1:size(Q,1)
ri[row] -= anc_dot[precol] *
Q[row, precol]
end
end
i_norm2(anc_norm, ri)
end
end
~@routine
end
# Here, in order to avoid frequent uncomputing, we allocate ancillas `ri` and `anc_dot` as vectors.
# The expression in `~` is used to uncompute `ri`, `anc_dot` and `anc_norm`.
# `i_dot` and `i_norm2` are reversible functions to compute dot product and vector norm.
# One can quickly check the correctness of the gradient function
A = randn(4,4)
q, r = zero(A), zero(A)
@i function test1(out, q, r, A)
qr(q, r, A)
i_sum(out, q)
end
@test check_grad(test1, (0.0, q, r, A); iloss=1)
# Here, the loss function `test1` is defined as the sum of the output unitary matrix `q`.
# The `check_grad` function is a gradient checker function defined in module `NiLang.AD`.
================================================
FILE: examples/realnvp.jl
================================================
# # RealNVP network
# For the definition of this network and concepts of normalizing flow,
# please refer this realnvp blog: https://lilianweng.github.io/lil-log/2018/10/13/flow-based-deep-generative-models.html,
# and the pytorch notebook: https://github.com/GiggleLiu/marburg/blob/master/solutions/realnvp.ipynb
using NiLang, NiLang.AD
using LinearAlgebra
using DelimitedFiles
using Plots
# `include` the optimizer, you can find it under the `Adam.jl` file in the `examples/` folder.
include(NiLang.project_relative_path("examples", "Adam.jl"))
# ## Model definition
# First, define the single layer transformation and its behavior under `GVar` - the gradient wrapper.
struct RealNVPLayer{T}
## transform network
W1::Matrix{T}
b1::Vector{T}
W2::Matrix{T}
b2::Vector{T}
y1::Vector{T}
y1a::Vector{T}
## scaling network
sW1::Matrix{T}
sb1::Vector{T}
sW2::Matrix{T}
sb2::Vector{T}
sy1::Vector{T}
sy1a::Vector{T}
end
"""collect parameters in the `layer` into a vector `out`."""
function collect_params!(out, layer::RealNVPLayer)
k=0
for field in [:W1, :b1, :W2, :b2, :sW1, :sb1, :sW2, :sb2]
v = getfield(layer, field)
nv = length(v)
out[k+1:k+nv] .= vec(v)
k += nv
end
return out
end
"""dispatch vectorized parameters `out` into the `layer`."""
function dispatch_params!(layer::RealNVPLayer, out)
k=0
for field in [:W1, :b1, :W2, :b2, :sW1, :sb1, :sW2, :sb2]
v = getfield(layer, field)
nv = length(v)
vec(v) .= out[k+1:k+nv]
k += nv
end
return out
end
function nparameters(n::RealNVPLayer)
sum(x->length(getfield(n, x)), [:W1, :b1, :W2, :b2, :sW1, :sb1, :sW2, :sb2])
end
# Then, we define `network` and how to access the parameters.
const RealNVP{T} = Vector{RealNVPLayer{T}}
nparameters(n::RealNVP) = sum(nparameters, n)
function collect_params(n::RealNVP{T}) where T
out = zeros(T, nparameters(n))
k = 0
for layer in n
np = nparameters(layer)
collect_params!(view(out, k+1:k+np), layer)
k += np
end
return out
end
function dispatch_params!(network::RealNVP, out)
k = 0
for layer in network
np = nparameters(layer)
dispatch_params!(layer, view(out, k+1:k+np))
k += np
end
return network
end
function random_realnvp(nparams::Int, nhidden::Int, nhidden_s::Int, nlayer::Int; scale=0.1)
random_realnvp(Float64, nparams, nhidden, nhidden_s::Int, nlayer; scale=scale)
end
function random_realnvp(::Type{T}, nparams::Int, nhidden::Int, nhidden_s::Int, nlayer::Int; scale=0.1) where T
nin = nparams÷2
scale = T(scale)
y1 = zeros(T, nhidden)
sy1 = zeros(T, nhidden_s)
RealNVPLayer{T}[RealNVPLayer(
randn(T, nhidden, nin)*scale, randn(T, nhidden)*scale,
randn(T, nin, nhidden)*scale, randn(T, nin)*scale, y1, zero(y1),
randn(T, nhidden_s, nin)*scale, randn(T, nhidden_s)*scale,
randn(T, nin, nhidden_s)*scale, randn(T, nin)*scale, sy1, zero(sy1),
) for _ = 1:nlayer]
end
# ## Loss function
#
# In each layer, we use the information in `x` to update `y!`.
# During computing, we use to vector type ancillas `y1` and `y1a`,
# both of them can be uncomputed at the end of the function.
@i function onelayer!(x::AbstractVector{T}, layer::RealNVPLayer{T},
y!::AbstractVector{T}, logjacobian!::T; islast) where T
@routine @invcheckoff begin
## scale network
scale ← zero(y!)
ytemp2 ← zero(y!)
i_affine!(layer.sy1, layer.sW1, layer.sb1, x)
@inbounds for i=1:length(layer.sy1)
if (layer.sy1[i] > 0, ~)
layer.sy1a[i] += layer.sy1[i]
end
end
i_affine!(scale, layer.sW2, layer.sb2, layer.sy1a)
## transform network
i_affine!(layer.y1, layer.W1, layer.b1, x)
## relu
@inbounds for i=1:length(layer.y1)
if (layer.y1[i] > 0, ~)
layer.y1a[i] += layer.y1[i]
end
end
end
## inplace multiply exp of scale! -- dangerous
@inbounds @invcheckoff for i=1:length(scale)
@routine begin
expscale ← zero(T)
tanhscale ← zero(T)
if (islast, ~)
tanhscale += tanh(scale[i])
else
tanhscale += scale[i]
end
expscale += exp(tanhscale)
end
logjacobian! += tanhscale
## inplace multiply!!!
temp ← zero(T)
temp += y![i] * expscale
SWAP(temp, y![i])
temp -= y![i] / expscale
temp → zero(T)
~@routine
end
## affine the transform layer
i_affine!(y!, layer.W2, layer.b2, layer.y1a)
~@routine
## clean up accumulated rounding error, since this memory is reused.
@safe layer.y1 .= zero(T)
@safe layer.sy1 .= zero(T)
end
# A realnvp network always transforms inputs reversibly.
# We update one half of `x!` a time, so that input and output memory space do not clash.
@i function realnvp!(x!::AbstractVector{T}, network::RealNVP{T}, logjacobian!) where T
@invcheckoff for i=1:length(network)
np ← length(x!)
if (i%2==0, ~)
@inbounds onelayer!(x! |> subarray(np÷2+1:np), network[i], x! |> subarray(1:np÷2), logjacobian!; islast=i==length(network))
else
@inbounds onelayer!(x! |> subarray(1:np÷2), network[i], x! |> subarray(np÷2+1:np), logjacobian!; islast=i==length(network))
end
np → length(x!)
end
end
# How to obtain the log-probability of a data.
@i function logp!(out!::T, x!::AbstractVector{T}, network::RealNVP{T}) where T
(~realnvp!)(x!, network, out!)
@invcheckoff for i = 1:length(x!)
@routine begin
xsq ← zero(T)
@inbounds xsq += x![i]^2
end
out! -= 0.5 * xsq
~@routine
end
end
# The negative-log-likelihood loss function
@i function nll_loss!(out!::T, cum!::T, xs!::Matrix{T}, network::RealNVP{T}) where T
@invcheckoff for i=1:size(xs!, 2)
@inbounds logp!(cum!, xs! |> subarray(:,i), network)
end
out! -= cum!/(@const size(xs!, 2))
end
# ## Training
function train(x_data, model; num_epochs = 800)
num_vars = size(x_data, 1)
params = collect_params(model)
optimizer = Adam(; lr=0.01)
for epoch = 1:num_epochs
loss, a, b, c = nll_loss!(0.0, 0.0, copy(x_data), model)
if epoch % 50 == 1
println("epoch = $epoch, loss = $loss")
display(showmodel(x_data, model))
end
_, _, _, gmodel = (~nll_loss!)(GVar(loss, 1.0), GVar(a), GVar(b), GVar(c))
g = grad.(collect_params(gmodel))
update!(params, grad.(collect_params(gmodel)), optimizer)
dispatch_params!(model, params)
end
return model
end
function showmodel(x_data, model; nsamples=2000)
scatter(x_data[1,1:nsamples], x_data[2,1:nsamples]; xlims=(-5,5), ylims=(-5,5))
zs = randn(2, nsamples)
for i=1:nsamples
realnvp!(view(zs, :, i), model, 0.0)
end
scatter!(zs[1,:], zs[2,:])
end
# you can find the training data in `examples/` folder
x_data = Matrix(readdlm(NiLang.project_relative_path("examples", "train.dat"))')
import Random; Random.seed!(22)
model = random_realnvp(Float64, size(x_data, 1), 10, 10, 4; scale=0.1)
# Before training, the distribution looks like
# 
model = train(x_data, model; num_epochs=800)
# After training, the distribution looks like
# 
================================================
FILE: examples/sparse.jl
================================================
# # Sparse matrices
#
# Source to source automatic differentiation is useful in differentiating sparse matrices. It is a well-known problem that sparse matrix operations can not benefit directly from generic backward rules for dense matrices because general rules do not keep the sparse structure.
# In the following, we will show that reversible AD can differentiate the Frobenius dot product between two sparse matrices with the state-of-the-art performance. Here, the Frobenius dot product is defined as \texttt{trace(A'B)}.
# Its native Julia (irreversible) implementation is `SparseArrays.dot`.
#
# The following is a reversible counterpart
using NiLang, NiLang.AD
using SparseArrays
@i function idot(r::T, A::SparseMatrixCSC{T},B::SparseMatrixCSC{T}) where {T}
@routine begin
m, n ← size(A)
branch_keeper ← zeros(Bool, 2*m)
end
@safe size(B) == (m,n) || throw(DimensionMismatch("matrices must have the same dimensions"))
@invcheckoff @inbounds for j = 1:n
@routine begin
ia1 ← A.colptr[j]
ib1 ← B.colptr[j]
ia2 ← A.colptr[j+1]
ib2 ← B.colptr[j+1]
ia ← ia1
ib ← ib1
end
@inbounds for i=1:ia2-ia1+ib2-ib1-1
ra ← A.rowval[ia]
rb ← B.rowval[ib]
if (ra == rb, ~)
r += A.nzval[ia]' * B.nzval[ib]
end
## b move -> true, a move -> false
branch_keeper[i] ⊻= @const ia == ia2-1 || ra > rb
ra → A.rowval[ia]
rb → B.rowval[ib]
if (branch_keeper[i], ~)
INC(ib)
else
INC(ia)
end
end
~@inbounds for i=1:ia2-ia1+ib2-ib1-1
## b move -> true, a move -> false
branch_keeper[i] ⊻= @const ia == ia2-1 || A.rowval[ia] > B.rowval[ib]
if (branch_keeper[i], ~)
INC(ib)
else
INC(ia)
end
end
~@routine
end
~@routine
end
# Here, the key point is using a \texttt{branch\_keeper} vector to cache branch decisions.
# The time used for a native implementation is
using BenchmarkTools
a = sprand(1000, 1000, 0.01);
b = sprand(1000, 1000, 0.01);
@benchmark SparseArrays.dot($a, $b)
# To compute the gradients, we wrap each matrix element with `GVar`, and send them to the reversible backward pass
out! = SparseArrays.dot(a, b)
@benchmark (~idot)($(GVar(out!, 1.0)),
$(GVar.(a)), $(GVar.(b)))
# The time used for computing backward pass is approximately 1.6 times Julia's native forward pass.
# Here, we have turned off the reversibility check off to achieve better performance.
# By writing sparse matrix multiplication and other sparse matrix operations reversibly,
# we will have a differentiable sparse matrix library with proper performance.
# See my another blog post for [reversible sparse matrix multiplication](https://nextjournal.com/giggle/how-to-write-a-program-differentiably).
================================================
FILE: examples/unitary.jl
================================================
# # Unitary matrix operations without allocation
# A unitary matrix features uniform eigenvalues and reversibility. It is widely used as an approach to ease the gradient exploding and vanishing problem and the memory wall problem.
# One of the simplest ways to parametrize a unitary matrix is representing a unitary matrix as a product of two-level unitary operations. A real unitary matrix of size $N$ can be parametrized compactly by $N(N-1)/2$ rotation operations
#
# ```math
# {\rm ROT}(a!, b!, \theta) = \left(\begin{matrix}
# \cos(\theta) & - \sin(\theta)\\
# \sin(\theta) & \cos(\theta)
# \end{matrix}\right)
# \left(\begin{matrix}
# a!\\
# b!
# \end{matrix}\right),
# ```
#
# where $\theta$ is the rotation angle, `a!` and `b!` are target registers.
using NiLang, NiLang.AD
@i function umm!(x!, θ)
@safe @assert length(θ) ==
length(x!)*(length(x!)-1)/2
k ← 0
for j=1:length(x!)
for i=length(x!)-1:-1:j
k += 1
ROT(x![i], x![i+1], θ[k])
end
end
k → length(θ)
end
# Here, the ancilla `k` is deallocated manually by specifying its value, because we know the loop size is $N(N-1)/2$.
# We define the test functions in order to check gradients.
@i function isum(out!, x::AbstractArray)
for i=1:length(x)
out! += x[i]
end
end
@i function test!(out!, x!::Vector, θ::Vector)
umm!(x!, θ)
isum(out!, x!)
end
# Let's print the program output
out, x, θ = 0.0, randn(4), randn(6);
@instr Grad(test!)(Val(1), out, x, θ)
x
# We can erease the gradient field by uncomputing the gradient function.
# If you want, you can differentiate it twice to obtain Hessians.
# However, we suggest using ForwardDifferentiation over our NiLang program, this is more efficient.
@instr (~Grad(test!))(Val(1), out, x, θ)
x
# In the above testing code, `Grad(test)` attaches a gradient field to each element of `x`. `~Grad(test)` is the inverse program that erase the gradient fields.
# Notably, this reversible implementation costs zero memory allocation, although it changes the target variables inplace.
================================================
FILE: notebooks/README.md
================================================
# How to use notebooks
1. Install Pluto notebook from [here](https://github.com/fonsp/Pluto.jl),
2. Open this file in a Pluto notebook.
================================================
FILE: notebooks/autodiff.jl
================================================
### A Pluto.jl notebook ###
# v0.14.5
using Markdown
using InteractiveUtils
# ╔═╡ f11023e5-8f7b-4f40-86d3-3407b61863d9
begin
using PlutoUI, Viznet, Compose, Plots
function shrink(a, b, da, db)
d = b .- a
r = sqrt(sum(abs2, d))
unitd = d ./ r
a .+ unitd .* da, b .- unitd .* db
end
end;
# ╔═╡ ce44f8bd-692e-4eab-9ba4-055b25e40c81
using ForwardDiff: Dual
# ╔═╡ 9a46597c-b1ee-4e3b-aed1-fd2874b6e77a
using BenchmarkTools
# ╔═╡ ccd38f52-104d-434a-aea3-dd94e571374f
using NiLang
# ╔═╡ f4230251-ba54-434a-b86b-f972c7389217
using MacroTools
# ╔═╡ 69dc2685-b70f-4a81-af30-f02e0054bd52
using NiLang.AD
# ╔═╡ 200f1848-0980-4185-919a-93ab2e7f788f
using SparseArrays
# ╔═╡ 30c191c5-642b-4062-98f3-643d314a054d
using LinearAlgebra
# ╔═╡ 864dbde7-b689-4165-a08e-6bbbd72190de
using Test
# ╔═╡ a1ef579e-4b66-4042-944e-7e27c660095e
md"""
```math
\newcommand{\comment}[1]{{\bf \color{blue}{\text{◂~ #1}}}}
```
"""
# ╔═╡ 100b4293-fd1e-4b9c-a831-5b79bc2a5ebe
begin
# left right layout
function leftright(a, b; width=600)
HTML("""
<style>
table.nohover tr:hover td {
background-color: white !important;
}</style>
<table width=$(width)px class="nohover" style="border:none">
<tr>
<td>$(html(a))</td>
<td>$(html(b))</td>
</tr></table>
""")
end
# up down layout
function updown(a, b; width=nothing)
HTML("""<table class="nohover" style="border:none" $(width === nothing ? "" : "width=$(width)px")>
<tr>
<td>$(html(a))</td>
</tr>
<tr>
<td>$(html(b))</td>
</tr></table>
""")
end
function highlight(str)
HTML("""<span style="background-color:yellow">$(str)</span>""")
end
end;
# ╔═╡ 9d11e058-a7d0-11eb-1d78-6592ff7a1b43
md"# An introduction to automatic differentiation
-- GiggleLiu"
# ╔═╡ b73157bf-1a77-47b8-8a06-8d6ec2045023
html"<button onclick='present()'>present</button>"
# ╔═╡ ec13e0a9-64ff-4f66-a5a6-5fef53428fa1
md"""
* What is automatic differentiation (AD)?
* A true history of AD
* Forward mode AD
* Reverse mode AD
* primitves on tensors (including Jax, pytorch et al.)
* primitves on elementary instructions (usually source code transformation based)
* defined on a reversible program
* Some applications in **scientific computing**
* solving the graph embedding problem
* inverse engineering a hamiltonian
* obtaining maximum independent set (MIS) configurations
* towards differentiating `expmv` ``\comment{will be used in our emulator}``
"""
# ╔═╡ f8b0d1ce-99f7-4729-b46e-126da540cbbe
md"""
## The true history of automatic differentiation
"""
# ╔═╡ 435ac19e-1c0c-4ee5-942d-f2a97c8c4d80
md"""
* 1964 ~ Robert Edwin Wengert, A simple automatic derivative evaluation program. ``\comment{first forward mode AD}``
* 1970 ~ Seppo Linnainmaa, Taylor expansion of the accumulated rounding error. ``\comment{first backward mode AD}``
* 1986 ~ Rumelhart, D. E., Hinton, G. E., and Williams, R. J., Learning representations by back-propagating errors.
* 1992 ~ Andreas Griewank, Achieving logarithmic growth of temporal and spatial complexity in reverse automatic differentiation. ``\comment{foundation of source code transformation based AD.}``
* 2000s ~ The boom of tensor based AD frameworks for machine learning.
* 2018 ~ People re-invented AD as differential programming ([wiki](https://en.wikipedia.org/wiki/Differentiable_programming) and this [quora answer](https://www.quora.com/What-is-Differentiable-Programming).)

* 2020 ~ Me, Differentiate everything with a reversible embeded domain-specific language ``\comment{AD based on reversible programming}``.
"""
# ╔═╡ 48ecd619-d01d-43ff-8b52-7c2566c3fa2b
md"## Forward mode automatic differentiation"
# ╔═╡ 4878ce45-40ff-4fae-98e7-1be41e930e4d
md"""
Forward mode AD attaches a infitesimal number $\epsilon$ to a variable, when applying a function $f$, it does the following transformation
```math
\begin{align}
f(x+g \epsilon) = f(x) + f'(x) g\epsilon + \mathcal{O}(\epsilon^2)
\end{align}
```
The higher order infinitesimal is ignored.
**In the program**, we can define a *dual number* with two fields, just like a complex number
```
f((x, g)) = (f(x), f'(x)*g)
```
"""
# ╔═╡ b2c1936c-2c27-4fbb-8183-e38c5e858483
res = sin(Dual(π/4, 2.0))
# ╔═╡ 8be1b812-fcac-404f-98aa-0571cb990f34
res === Dual(sin(π/4), cos(π/4)*2.0)
# ╔═╡ 33e0c762-c75e-44aa-bfe2-bff92dd1ace8
md"
We can apply this transformation consecutively, it reflects the chain rule.
```math
\begin{align}
\frac{\partial \vec y_{i+1}}{\partial x} &= \boxed{\frac{\partial \vec y_{i+1}}{\partial \vec y_i}}\frac{\partial \vec y_i}{\partial x}\\
&\text{local Jacobian}
\end{align}
```
"
# ╔═╡ c59c35ee-1907-4736-9893-e22c052150ca
let
lb = textstyle(:math, fontsize(8), width=0.5, height=0.5)
tb = textstyle(:default, fontsize(10), Compose.font("monospace"))
tb_big = textstyle(:default, fontsize(3.5), fill("white"), Compose.font("monospace"))
nb = nodestyle(:circle, fill("white"), Compose.stroke("black"); r=0.08)
tri = nodestyle(:triangle, Compose.stroke("transparent"), fill("black"); r=0.02)
eb = bondstyle(:default, linewidth(0.5mm))
ebr = bondstyle(:default, Compose.stroke("red"), linewidth(0.5mm))
ebd = bondstyle(:default, linewidth(0.5mm), dashed=true)
eba = bondstyle(:default, linewidth(0.5mm), Compose.arrow(), Compose.stroke("red"), Compose.fill("red"))
function arrow(x, y)
mid = (x .+ y) ./ 2
t = nodestyle(:triangle, fill("red"), θ=π/2-atan((y .- x)...)-1π/6)
ebr >> (x, y)
t >> mid
end
Compose.set_default_graphic_size(15cm, 5cm)
x = (0.1, 0.5)
fi0 = (0.35, 0.5)
fi1 = (0.7, 0.5)
fi2 = (1.0, 0.5)
img = canvas() do
nb >> fi0
nb >> fi1
lb >> (fi0 .- (0.05, 0.1), "f_{i-1}")
lb >> (fi1 .- (0.02, 0.1), "f_{i}")
lb >> (x, "x")
lb >> ((fi1 .+ fi0) ./ 2 .- (0.02, 0.0), raw"\vec{y}_{i}")
lb >> ((fi1 .+ fi2) ./ 2 .- (0.05, 0.0), raw"\vec{y}_{i+1}")
lb >> ((fi1 .+ fi2) ./ 2 .- (0.05, 0.0), "\\vec{y}_{i+1}")
lb >> (x .- (0.00, 0.25), raw"\color{red}{1}")
lb >> ((fi1 .+ fi0) ./ 2 .- (0.05, 0.45), raw"\color{red}{\frac{\partial \vec{y}_{i}}{\partial x}}")
lb >> ((fi1 .+ fi2) ./ 2 .- (0.08, 0.45), raw"\color{red}{\frac{\partial \vec{y}_{i+1}}{\partial x}}")
ebd >> (x, fi0)
eb >> (fi0, fi1)
eb >> (fi1, fi2)
#arrow((fi1 .+ fi0) ./ 2 .+ (0.08, -0.3), (fi1 .+ fi2) ./ 2 .+ (-0.08, -0.3))
arrow((fi1 .+ fi0) ./ 2 .+ (0.08, -0.3), (fi1 .+ fi2) ./ 2 .+ (-0.08, -0.3))
end
img
end
# ╔═╡ 0ae13734-b826-4dbf-93d1-11044ce88bd4
x_ = Dual(π/4, 1.0)
# ╔═╡ 99187515-c8be-49c2-8d70-9c2998d9993c
sin(x_)
# ╔═╡ 78ca6b08-84c4-4e4d-8412-ae6c28bfafce
md"when automatic comes in"
# ╔═╡ f12b25d8-7c78-4686-b46d-00b34e565605
let
x = Dual(π/4, 1.0)
z = Dual(1.1)
for i=1:10
x = sin(x) * z
end
x
end
# ╔═╡ d90c3cc9-084d-4cf7-9db7-42cea043030b
md"""
**Example:** Computing two gradients $\frac{\partial z\sin x}{\partial x}$ and $\frac{\partial \sin^2x}{\partial x}$ at one sweep
"""
# ╔═╡ 93c98cb2-18af-47df-afb3-8c5a34b4723c
let
lb = textstyle(:math, fontsize(8), width=1.0, height=0.5)
tb = textstyle(:default, fontsize(3.5), Compose.font("monospace"))
tb_big = textstyle(:default, fontsize(4.5), fill("white"), Compose.font("monospace"))
nb = nodestyle(:circle, fill("black"), Compose.stroke("transparent"); r=0.05)
tri = nodestyle(:triangle, Compose.stroke("transparent"), fill("black"); r=0.02)
eb = bondstyle(:default, linewidth(0.5mm))
x_x = (0.1, 0.25)
x_y = (0.9, 0.5)
x_y2 = (0.9, 0.25)
x_z = (0.3, 0.5)
x_sin = (0.3, 0.25)
x_mul = (0.5, 0.5)
x_square = (0.5, 0.25)
function arrow(x, y)
mid = (x .+ y) ./ 2
t = nodestyle(:triangle, θ=π/2-atan((y .- x)...)-1π/6)
eb >> (x, y)
t >> mid
end
img = canvas() do
nb >> x_sin
nb >> x_mul
nb >> x_square
tb_big >> (x_sin, "sin")
tb_big >> (x_mul .+ (0, 0.01), "*")
tb_big >> (x_square, "^2")
arrow(x_sin, x_mul)
arrow(x_x, x_sin)
arrow(x_mul, x_y)
arrow(x_square, x_y2)
arrow(x_z, x_mul)
arrow(x_sin, x_square)
tb >> ((x_x .+ x_sin) ./ 2 .- (0.02, 0.04), "x+ϵˣ")
tb >> ((x_sin .+ x_mul) ./ 2 .- (0.08, 0.04), "sin(x)+cos(x)*ϵˣ")
tb >> ((x_y .+ x_mul) ./ 2 .- (-0.04, 0.055), "z*sin(x)\n+z*cos(x)*ϵˣ")
tb >> ((x_y2 .+ x_square) ./ 2 .- (-0.04, 0.055), "sin(x)^2\n+2*sin(x)*cos(x)*ϵˣ")
tb >> ((x_z .+ x_mul) ./ 2 .- (0.05, 0.02), "z")
end
Compose.set_default_graphic_size(100mm, 100mm/2)
Compose.compose(context(0, -0.15, 1, 2), img)
end
# ╔═╡ 2dc74e15-e2ea-4961-b43f-0ada1a73d80a
md"so the gradients are $z\cos x$ and $2\sin x\cos x$"
# ╔═╡ 7ee75a15-eaea-462a-92b6-293813d2d4d7
md"""
**What if we want to compute gradients for multiple inputs?**
The computing time grows **linearly** as the number of variables that we want to differentiate. But does not grow significantly with the number of outputs.
"""
# ╔═╡ 02a25b73-7353-43b1-8738-e7ca472d0cc7
md"""
## Reverse mode automatic differentiation
"""
# ╔═╡ 2afb984f-624e-4381-903f-ccc1d8a66a17
md"On the other side, the back-propagation can differentiate **many inputs** with respect to a **single output** efficiently"
# ╔═╡ 7e5d5e69-90f2-4106-8edf-223c150a8168
md"""
```math
\begin{align}
\frac{\partial \mathcal{L}}{\partial \vec y_i} = \frac{\partial \mathcal{L}}{\partial \vec y_{i+1}}&\boxed{\frac{\partial \vec y_{i+1}}{\partial \vec y_i}}\\
&\text{local jacobian?}
\end{align}
```
"""
# ╔═╡ 92d7a938-9463-4eee-8839-0b8c5f762c79
let
lb = textstyle(:math, fontsize(8), width=0.5, height=0.5)
tb = textstyle(:default, fontsize(10), Compose.font("monospace"))
tb_big = textstyle(:default, fontsize(3.5), fill("white"), Compose.font("monospace"))
nb = nodestyle(:circle, fill("white"), Compose.stroke("black"); r=0.08)
tri = nodestyle(:triangle, Compose.stroke("transparent"), fill("black"); r=0.02)
eb = bondstyle(:default, linewidth(0.5mm))
ebr = bondstyle(:default, Compose.stroke("red"), linewidth(0.5mm))
ebd = bondstyle(:default, linewidth(0.5mm), dashed=true)
eba = bondstyle(:default, linewidth(0.5mm), Compose.arrow(), Compose.stroke("red"), Compose.fill("red"))
function arrow(x, y)
mid = (x .+ y) ./ 2
t = nodestyle(:triangle, fill("red"), θ=π/2-atan((y .- x)...)-1π/6)
ebr >> (x, y)
t >> mid
end
Compose.set_default_graphic_size(15cm, 5cm)
x = (0.1, 0.5)
fi0 = (0.35, 0.5)
fi1 = (0.7, 0.5)
fi2 = (0.9, 0.5)
img = canvas() do
nb >> fi0
nb >> fi1
lb >> (fi0 .- (0.02, 0.1), "f_{i}")
lb >> (fi1 .- (0.05, 0.1), "f_{i+1}")
lb >> (fi2 .- (0.05, 0.0), raw"\mathcal{L}")
lb >> ((fi0 .+ x) ./ 2 .- (0.05, 0.0), raw"\vec{y}_{i}")
lb >> ((fi0 .+ fi1) ./ 2 .- (0.05, 0.0), raw"\vec{y}_{i+1}")
lb >> ((fi0 .+ fi1) ./ 2 .- (0.05, 0.0), "\\vec{y}_{i+1}")
lb >> (fi2 .- (0.05, 0.25), raw"\color{red}{1}")
lb >> ((fi0 .+ x) ./ 2 .- (0.08, 0.45), raw"\color{red}{\frac{\partial \mathcal{L}}{\partial \vec{y}_{i}}}")
lb >> ((fi0 .+ fi1) ./ 2 .- (0.08, 0.45), raw"\color{red}{\frac{\partial \mathcal{L}}{\partial \vec{y}_{i+1}}}")
ebd >> (fi1, fi2)
eb >> (fi0, fi1)
eb >> (x, fi0)
#arrow((fi1 .+ fi0) ./ 2 .+ (0.08, -0.3), (fi1 .+ fi2) ./ 2 .+ (-0.08, -0.3))
arrow( (fi0 .+ fi1) ./ 2 .+ (-0.08, -0.3), (fi0 .+ x) ./ 2 .+ (0.05, -0.3),)
end
img
end
# ╔═╡ 4b1a0b59-ddc6-4b2d-b5f5-d92084c31e46
md"### How to visit local Jacobians in the reversed order? "
# ╔═╡ 81f16b8b-2f0b-4ba3-8c26-6669eabf48aa
md"The naive approach is to store everything."
# ╔═╡ fb6c3a48-550a-4d2e-a00b-a1e40d86b535
md"""
**Example:** Computing the gradient $\frac{\partial z\sin x}{\partial x}$ and $\frac{\partial z\sin x}{\partial z}$ by back propagating cached local information.
"""
# ╔═╡ ab6fa4ac-29ed-4722-88ed-fa1caf2072f3
let
lb = textstyle(:math, fontsize(10), width=1.0, height=0.5)
tb = textstyle(:default, fontsize(3.5), Compose.font("monospace"))
tbc = textstyle(:default, fontsize(3.5), fill("red"), Compose.font("monospace"))
tb_big = textstyle(:default, fontsize(4), fill("white"), Compose.font("monospace"))
nb = nodestyle(:circle, fill("black"), Compose.stroke("transparent"); r=0.05)
tri = nodestyle(:triangle, Compose.stroke("transparent"), fill("black"); r=0.02)
eb = bondstyle(:default, linewidth(0.5mm))
x_x = (0.1, 0.2)
x_y = (0.9, 0.5)
x_z = (0.1, 0.7)
x_sin = (0.3, 0.3)
x_mul = (0.5, 0.5)
function arrow(x, y)
mid = (x .+ y) ./ 2
t = nodestyle(:triangle, θ=π/2-atan((y .- x)...)-1π/6)
eb >> (x, y)
t >> mid
end
img1 = canvas() do
nb >> x_sin
nb >> x_mul
tb_big >> (x_sin, "sin")
tb_big >> (x_mul .+ (0, 0.01), "*")
arrow(x_sin, x_mul)
arrow(x_x, x_sin)
arrow(x_mul, x_y)
arrow(x_z, x_mul)
tb >> ((x_x .+ x_sin) ./ 2 .- (0.0, 0.1), "x \n push(Σ,x)")
tb >> ((x_sin .+ x_mul) ./ 2 .- (-0.15, 0.04), "s = sin(x) \n push(Σ,s)")
tb >> ((x_y .+ x_mul) ./ 2 .- (-0.05, 0.04), "y = z*sin(x)")
tb >> ((x_z .+ x_mul) ./ 2 .- (0.05, 0.07), "z\n push(Σ,z)")
end
img2 = canvas() do
nb >> x_sin
nb >> x_mul
tb_big >> (x_sin, "sin")
tb_big >> (x_mul .+ (0, 0.01), "*")
arrow(x_mul, x_sin)
arrow(x_sin, x_x)
arrow(x_y, x_mul)
arrow(x_mul, x_z)
tb >> ((x_x .+ x_sin) ./ 2 .- (0.0, 0.1), "x = pop(Σ)\nx̄ = cos(x)*s̄")
tb >> ((x_sin .+ x_mul) ./ 2 .- (-0.12, 0.04), "z = pop(Σ)\ns̄ = z*ȳ")
tb >> ((x_y .+ x_mul) ./ 2 .- (-0.05, 0.06), "y\nȳ=1")
tb >> ((x_z .+ x_mul) ./ 2 .- (0.05, 0.07), "s = pop(Σ)\nz̄ = s*ȳ")
end
Compose.set_default_graphic_size(150mm, 75mm/1.4)
Compose.compose(context(),
(context(0, -0.1, 0.5, 1.4), img1),
(context(0.5, -0.1, 0.5, 1.4), img2)
)
end
# ╔═╡ 8e72d934-e307-4505-ac82-c06734415df6
md"Here, we use $\overline y$ for $\frac{\partial \mathcal{L}}{\partial y}$, which is also called the adjoint."
# ╔═╡ e6ff86a9-9f54-474b-8111-a59a25eda506
md"### Primitives on different scales"
# ╔═╡ 9c1d9607-a634-4350-aacd-2d40984d647d
md"We call the leaf nodes defining AD rules \"**primitives**\""
# ╔═╡ 63db2fa2-50b2-4940-b8ee-0dc6e3966a57
md"
**Design Decision**
* A: If we define primitives on **arrays**, we need tons of manually defined backward rules. (Jax, Pytorch, Zygote.jl, ReverseDiff.jl et al.)
* B: If we define primitives on **scalar instructions**, we will have worse tensor performance. (Tapenade, Adept, NiLang et al.)
*Note*: Here, implementing AD on scalars means specifically the **optimal checkpointing** approach, rather than a package like Jax, Zygote and ReverseDiff that having scalar support.
"
# ╔═╡ 693167e7-e80c-401d-af89-55b5fae30848
let
w, h = 0.22, 0.1
lb = Compose.compose(context(), polygon([(-w, -h), (-w, h), (w, h), (w, -h)]), Compose.stroke("transparent"))
lb2 = Compose.compose(context(), polygon([(-w, -h), (-w, h), (w, h), (w, -h)]), Compose.stroke("transparent"), fill("red"))
tb = Compose.compose(context(), Compose.text(0.0, 0.0, ""), fontsize(3), Compose.font("monospace"))
tb_big = textstyle(:default, fontsize(3), fill("white"), Compose.font("monospace"))
eb = bondstyle(:default, linewidth(0.5mm))
ar = bondstyle(:default, linewidth(0.3mm), Compose.arrow())
xprog = (0.25, 0.15)
xtensors = (0.25, 0.5)
t1 = (0.5, 0.15)
t2 = (0.5, 0.5)
t3 = (0.5, 0.85)
xscalars2 = (0.25, 0.85)
function box(loc, text; color="black")
(color=="black" ? lb : lb2) >> loc
tb_big >> (loc, text)
end
Compose.set_default_graphic_size(10cm, 5cm)
canvas() do
box(xprog, "Program")
ar >> (xprog, xtensors .+ (0, -h-0.03))
#ar >> (xprog, xscalars .+ (-w/2, -h-0.03))
ar >> (xtensors, xscalars2 .+ (0, -h-0.05))
box(xtensors, "Functions on arrays")
#box(xscalars, "Functions on Scalars")
box(xscalars2, "Finite instructions"; color="red")
tb >> (t1, "Neural networks")
tb >> (t2, "matrix multiplication")
tb >> (t3, "+, -, *")
end
end
# ╔═╡ 4cd70901-2142-4868-9a33-c46ca0d064ec
html"""
<table>
<tr>
<th width=200></th>
<th width=300>on tensors</th>
<th width=300>on finite instructions</th>
</tr>
<tr style="vertical-align:top">
<td>meaning</td>
<td>defining backward rules manully for functions on tensors</td>
<td>defining backward rules on a limited set of basic scalar operations, and generate gradient code using source code transformation</td>
</tr>
<tr style="vertical-align:top">
<td>pros and cons</td>
<td>
<ol>
<li style="color:green">Good tensor performance</li>
<li style="color:green">Mature machine learning ecosystem</li>
<li style="color:red">Need to define backward rules manually</li>
</ol>
</td>
<td>
<ol>
<li style="color:green">Reasonalbe scalar performance</li>
<li style="color:red">hard to utilize GPU kernels (except NiLang.jl) and BLAS</li>
</ol>
</td>
<td>
</td>
</tr>
<tr style="vertical-align:top">
<td>packages</td>
<td>Jax<br>PyTorch</td>
<td><a href="http://tapenade.inria.fr:8080/tapenade/">Tapenade</a><br>
<a href="http://www.met.reading.ac.uk/clouds/adept/">Adept</a><br>
<a href="https://github.com/GiggleLiu/NiLang.jl">NiLang.jl</a>
</td>
</tr>
</table>
"""
# ╔═╡ 89018a35-76f4-4f23-b15a-a600db046d6f
md"## A book"
# ╔═╡ 1d219222-0778-4c37-9182-ed5ccbb3ef32
leftright(html"""
<img src="https://images-na.ssl-images-amazon.com/images/I/51+dn97bfKL._SY344_BO1,204,203,200_.jpg"/>
""", md"**Evaluating derivatives: principles and techniques of algorithmic differentiation**
By: Griewank, Andreas, and Andrea Walther
(2008)")
# ╔═╡ 4ff09f7c-aeac-48bd-9d58-8446137c3acd
md"""
## The AD ecosystem in Julia
Please check JuliaDiff: [https://juliadiff.org/](https://juliadiff.org/)
A short list:
* Forward mode AD: ForwardDiff.jl
* Reverse mode AD (tensor): ReverseDiff.jl/Zygote.jl
* Reverse mode AD (scalar): NiLang.jl
Warnings
* The main authors of `Tracker`, `ReverseDiff` and `Zygote` are not maintaining them anymore.
"""
#=
| | Rules | Favors Tensor? | Type |
| ---- | ---- | --- | --- |
| Zygote | C | ✓ | R |
| ReverseDiff | D | ✓ | R |
| Nabla | D→C | ✓ | R |
| Tracker | D | ✓ | R |
| Yota | C | ✓ | R |
| NiLang | - | × | R |
| Enzyme | - | × | R |
| ForwardDiff | - | × | F |
| Diffractor | ? | ? | ? |
* R: reverse mode
* F: forward mode
* C: ChainRules
* D: DiffRules
"""
=#
# ╔═╡ ea44037b-9359-4fbd-990f-529d88d54351
md"# Quick summary
1. The history of AD is longer than many people have thought. People are most familar with *reverse mode AD with primitives implemented on tensors* that brings the boom of machine learning. There are also AD frameworks that can differentiate a general program directly, which does not require users defining AD rules manually.
2. **Forward mode AD** propagate gradients forward, it has a computational overhead propotional to the number of input parameters.
2. **Backward mode AD** propagate gradients backward, it has a computational overhead propotional to the number of output parameters.
* primitives on **tensors** v.s. **scalars**
* it is very expensive to reverse the program
4. Julia has one of the most active AD community!
#### Forward v.s. Backward
when is forward mode AD more useful?
* It is often combined with backward mode AD for obtaining Hessians (forward over backward).
* Having <20 input parameters.
when is backward mode AD more useful?
* In most variational optimizations, especially when we are training a neural network with ~ 100M parameters.
"
# ╔═╡ e731a8e3-6462-4a60-83e9-6ab7ddfff50e
md"# How do AD libraries work?"
# ╔═╡ 685c2b28-b071-452c-a881-801128dcb6c3
md"`ForwardDiff` is operator overloading based, many of its overheads can be optimized by Julia's JIT compiler."
# ╔═╡ 177ddfc2-2cbe-4dba-9d05-2857633dd1ae
md"# [Tapenade](http://tapenade.inria.fr:8080/tapenade/index.jsp)
"
# ╔═╡ 6c2a3a93-385f-4758-9b6e-4cb594a8e856
md"## Example 1: Bessel Example"
# ╔═╡ fb8168c2-8489-418b-909b-cede57b5ae64
md"bessel.f90"
# ╔═╡ fdb39284-dbb1-49fa-9a1c-f360f9e6b765
md"""
```fortran
subroutine besselj(res, v, z, atol)
implicit none
integer, intent(in) :: v
real*8, intent(in) :: z, atol
real*8, intent(out) :: res
real*8 :: s
integer :: k, i, factv
k = 0
factv = 1
do i = 2,v
factv = factv * i
enddo
s = (z/2.0)**v / factv
res = s
do while(abs(s) > atol)
k = k + 1
s = -s / k / (k+v) * ((z/2) ** 2)
res = res + s
enddo
endsubroutine besselj
```
"""
# ╔═╡ 60214f22-c8bb-4a32-a882-4e6c727b29a9
md"""
besselj_d.f90 (forward mode)
```fortran
! Generated by TAPENADE (INRIA, Ecuador team)
! Tapenade 3.15 (master) - 15 Apr 2020 11:54
!
! Differentiation of besselj in forward (tangent) mode:
! variations of useful results: res
! with respect to varying inputs: z
! RW status of diff variables: res:out z:in
SUBROUTINE BESSELJ_D(res, resd, v, z, zd, atol)
IMPLICIT NONE
INTEGER, INTENT(IN) :: v
REAL*8, INTENT(IN) :: z, atol
REAL*8, INTENT(IN) :: zd
REAL*8, INTENT(OUT) :: res
REAL*8, INTENT(OUT) :: resd
REAL*8 :: s
REAL*8 :: sd
INTEGER :: k, i, factv
INTRINSIC ABS
REAL*8 :: abs0
REAL*8 :: pwx1
REAL*8 :: pwx1d
REAL*8 :: pwr1
REAL*8 :: pwr1d
INTEGER :: temp
k = 0
factv = 1
DO i=2,v
factv = factv*i
END DO
pwx1d = zd/2.0
pwx1 = z/2.0
IF (pwx1 .LE. 0.0 .AND. (v .EQ. 0.0 .OR. v .NE. INT(v))) THEN
pwr1d = 0.0_8
ELSE
pwr1d = v*pwx1**(v-1)*pwx1d
END IF
pwr1 = pwx1**v
sd = pwr1d/factv
s = pwr1/factv
resd = sd
res = s
DO WHILE (.true.)
IF (s .GE. 0.) THEN
abs0 = s
ELSE
abs0 = -s
END IF
IF (abs0 .GT. atol) THEN
k = k + 1
temp = k*(k+v)*(2*2)
sd = -((z**2*sd+s*2*z*zd)/temp)
s = -(s*(z*z)/temp)
resd = resd + sd
res = res + s
ELSE
EXIT
END IF
END DO
END SUBROUTINE BESSELJ_D
```
besselj_b.f90 (backward mode)
```fortran
! Generated by TAPENADE (INRIA, Ecuador team)
! Tapenade 3.15 (master) - 15 Apr 2020 11:54
!
! Differentiation of besselj in reverse (adjoint) mode:
! gradient of useful results: res z
! with respect to varying inputs: res z
! RW status of diff variables: res:in-zero z:incr
SUBROUTINE BESSELJ_B(res, resb, v, z, zb, atol)
IMPLICIT NONE
INTEGER, INTENT(IN) :: v
REAL*8, INTENT(IN) :: z, atol
REAL*8 :: zb
REAL*8 :: res
REAL*8 :: resb
REAL*8 :: s
REAL*8 :: sb
INTEGER :: k, i, factv
INTRINSIC ABS
REAL*8 :: abs0
REAL*8 :: tempb
INTEGER :: ad_count
INTEGER :: i0
INTEGER :: branch
k = 0
factv = 1
DO i=2,v
factv = factv*i
END DO
s = (z/2.0)**v/factv
ad_count = 1
DO WHILE (.true.)
IF (s .GE. 0.) THEN
abs0 = s
ELSE
abs0 = -s
END IF
IF (abs0 .GT. atol) THEN
CALL PUSHINTEGER4(k)
k = k + 1
CALL PUSHREAL8(s)
s = -(s/k/(k+v)*(z/2)**2)
ad_count = ad_count + 1
ELSE
GOTO 100
END IF
END DO
CALL PUSHCONTROL1B(0)
GOTO 110
100 CALL PUSHCONTROL1B(1)
110 DO i0=1,ad_count
IF (i0 .EQ. 1) THEN
CALL POPCONTROL1B(branch)
IF (branch .EQ. 0) THEN
sb = 0.0_8
ELSE
sb = 0.0_8
END IF
ELSE
sb = sb + resb
CALL POPREAL8(s)
tempb = -(sb/(k*(k+v)*2**2))
sb = z**2*tempb
zb = zb + 2*z*s*tempb
CALL POPINTEGER4(k)
END IF
END DO
sb = sb + resb
IF (.NOT.(z/2.0 .LE. 0.0 .AND. (v .EQ. 0.0 .OR. v .NE. INT(v)))) zb = &
& zb + v*(z/2.0)**(v-1)*sb/(2.0*factv)
resb = 0.0_8
END SUBROUTINE BESSELJ_B
```
"""
# ╔═╡ 7a6dbe09-cb7f-405f-b9b5-b350ca170e5f
md"## Example 2: Matrix multiplication"
# ╔═╡ 5dc4a849-76dd-4c4f-8828-755671839e5e
md"""
matmul_b.f90
```fortran
! Generated by TAPENADE (INRIA, Ecuador team)
! Tapenade 3.16 (develop) - 9 Apr 2021 17:40
!
! Differentiation of mymatmul in reverse (adjoint) mode:
! gradient of useful results: x y z
! with respect to varying inputs: x y z
! RW status of diff variables: x:incr y:incr z:in-out
SUBROUTINE MYMATMUL_B(z, zb, x, xb, y, yb, m, n, o)
IMPLICIT NONE
INTEGER, INTENT(IN) :: m, n, o
REAL*8, DIMENSION(:, :) :: z(m, n)
REAL*8 :: zb(m, n)
REAL*8, DIMENSION(:, :), INTENT(IN) :: x(m, o), y(o, n)
REAL*8 :: xb(m, o), yb(o, n)
REAL*8 :: temp
REAL*8 :: tempb
INTEGER :: i, j, k
DO j=n,1,-1
DO i=m,1,-1
tempb = zb(i, j)
zb(i, j) = 0.0_8
DO k=o,1,-1
xb(i, k) = xb(i, k) + y(k, j)*tempb
yb(k, j) = yb(k, j) + x(i, k)*tempb
END DO
END DO
END DO
END SUBROUTINE MYMATMUL_B
```
"""
# ╔═╡ b053f11b-9ed7-47ff-ab32-0c70b87e71ed
md"## Example 3: Pyramid"
# ╔═╡ 7b1aa6dd-647f-44cb-b580-b58e23e8b5a6
html"""
<img src="https://user-images.githubusercontent.com/6257240/117090732-228e1a00-ad27-11eb-8231-09c462a17dc7.png" width=500/>
"""
# ╔═╡ b96bac75-b4ad-45f7-aeec-cb6a387eebf0
md"You will see a lot allocation"
# ╔═╡ 5fe022eb-6a17-466e-a6d0-d67e82af23cd
md"pyramid.f90"
# ╔═╡ 92047e95-7eba-4021-9668-9bb4b92261d7
md"""
```fortran
! Differentiation of pyramid in reverse (adjoint) mode:
! gradient of useful results: v x
! with respect to varying inputs: v x
! RW status of diff variables: v:in-out x:incr
SUBROUTINE PYRAMID_B(v, vb, x, xb, n)
IMPLICIT NONE
INTEGER, INTENT(IN) :: n
REAL*8 :: v(n, n)
REAL*8 :: vb(n, n)
REAL*8, INTENT(IN) :: x(n)
REAL*8 :: xb(n)
INTEGER :: i, j
INTRINSIC SIN
INTRINSIC COS
INTEGER :: ad_to
DO j=1,n
v(1, j) = x(j)
END DO
DO i=1,n-1
DO j=1,n-i
CALL PUSHREAL8(v(i+1, j))
v(i+1, j) = SIN(v(i, j))*COS(v(i, j+1))
END DO
CALL PUSHINTEGER4(j - 1)
END DO
DO i=n-1,1,-1
CALL POPINTEGER4(ad_to)
DO j=ad_to,1,-1
CALL POPREAL8(v(i+1, j))
vb(i, j) = vb(i, j) + COS(v(i, j))*COS(v(i, j+1))*vb(i+1, j)
vb(i, j+1) = vb(i, j+1) - SIN(v(i, j+1))*SIN(v(i, j))*vb(i+1, j)
vb(i+1, j) = 0.0_8
END DO
END DO
DO j=n,1,-1
xb(j) = xb(j) + vb(1, j)
vb(1, j) = 0.0_8
END DO
END SUBROUTINE PYRAMID_B
```
"""
# ╔═╡ e2ae1084-8759-4f27-8ad1-43a88e434a3d
md"## How does NiLang avoid too many allocation?"
# ╔═╡ edd3aea8-abdb-4e12-9ef9-12ac0fff835b
@i function pyramid!(y!, v!, x::AbstractVector{T}) where T
@safe @assert size(v!,2) == size(v!,1) == length(x)
@inbounds for j=1:length(x)
v![1,j] += x[j]
end
@invcheckoff @inbounds for i=1:size(v!,1)-1
for j=1:size(v!,2)-i
@routine begin
@zeros T c s
c += cos(v![i,j+1])
s += sin(v![i,j])
end
v![i+1,j] += c * s
~@routine
end
end
y! += v![end,1]
end
# ╔═╡ a2904efb-186c-449d-b1aa-caf530f88e91
@i function power(x3, x)
@routine begin
x2 ← zero(x)
x2 += x^2
end
x3 += x2 * x
~@routine
end
# ╔═╡ 14faaf82-ad3e-4192-8d48-84adfa30442d
ex = NiLangCore.precom_ex(NiLang, :(for j=1:size(v!,2)-i
@routine begin
@zeros T c s
c += cos(v![i,j+1])
s += sin(v![i,j])
end
v![i+1,j] += c * s
~@routine
end)) |> NiLangCore.rmlines
# ╔═╡ 5d141b88-ec07-4a02-8eb3-37405e5c9f5d
NiLangCore.dual_ex(NiLang, ex)
# ╔═╡ 0907e683-f216-4cf6-a210-ae5181fdc487
function pyramid0!(v!, x::AbstractVector{T}) where T
@assert size(v!,2) == size(v!,1) == length(x)
for j=1:length(x)
v![1,j] = x[j]
end
@inbounds for i=1:size(v!,1)-1
for j=1:size(v!,2)-i
v![i+1,j] = cos(v![i,j+1]) * sin(v![i,j])
end
end
end
# ╔═╡ 0bbfa106-f465-4a7b-80a7-7732ba435822
x = randn(20);
# ╔═╡ 805c7072-98fa-4086-a69d-2e126c55af36
let
@benchmark pyramid0!(v, x) seconds=1 setup=(x=randn(1000); v=zeros(1000, 1000))
end
# ╔═╡ 7e527024-c294-4c16-8626-9953588d9b6a
let
@benchmark pyramid!(0.0, v, x) seconds=1 setup=(x=10*randn(1000); v=zeros(1000, 1000))
end
# ╔═╡ 3e59c65a-ceed-42ed-be64-a6964db016e7
pyramid!(0.0, zeros(20, 20), x)
# ╔═╡ 29f85d05-99fd-4843-9be0-5663e681dad7
html"""<img src="https://github.com/GiggleLiu/NiLang.jl/blob/master/examples/pyramid-benchmark.png?raw=true" width=500/>
"""
# ╔═╡ e7830e55-bd9e-4a8a-9239-4191a5f0b1d1
let
@benchmark NiLang.AD.gradient(Val(1), pyramid!, (0.0, v, x)) seconds=1 setup=(x=randn(1000); v=zeros(1000, 1000))
end
# ╔═╡ de2cd247-ba68-4ba4-9784-27a743478635
md"## NiLang's implementation"
# ╔═╡ dc929c23-7434-4848-847a-9fa696e84776
md"""
```math
\begin{align}
&v_{−1} &= & x_1 &=&1.5000\\
&v_0 &= & x_2 &=&0.5000\\
&v_1 &= & v_{−1}/v_0 &=&1.5000/0.5000 &= 3.0000\\
&v_2 &= & \sin(v1)&=& \sin(3.0000) &= 0.1411\\
&v_3 &= & \exp(v0)&=& \exp(0.5000) &= 1.6487\\
&v_4 &= & v_1 − v_3 &=&3.0000 − 1.6487 &= 1.3513\\
&v_5 &= & v_2 + v_4 &=&0.1411 + 1.3513 &= 1.4924\\
&v_6 &= & v_5 ∗ v_4 &=&1.4924 ∗ 1.3513 &= 2.0167\\
&y &= & v_6 &=&2.0167
\end{align}
```
"""
# ╔═╡ 4f1df03f-c315-47b1-b181-749e1231594c
html"""
<img src="https://user-images.githubusercontent.com/6257240/117074233-168f6180-ad01-11eb-8b16-7ae9836cfdcd.png" width=400/>
"""
# ╔═╡ 7eccba6a-3ad5-440b-9c5d-392dc8dc7aba
@i function example_linear(y::T, x1::T, x2::T) where T
@routine begin
@zeros T v1 v2 v3 v4 v5
v1 += x1 / x2
v2 += sin(v1)
v3 += exp(x2)
v4 += v1 - v3
v5 += v2 + v4
end
y += v5 * v4
~@routine
end
# ╔═╡ 4a858a3e-ce28-4642-b061-3975a3ed99ff
md"NOTES:
* a statement changes values inplace directly,
* no return statement, returns the input arguments directly
* `@routine <compute>; <copy statements>; ~@routine` is the Bennett's compute copy uncompute design pattern
"
# ╔═╡ 674bb3bb-637b-44f2-bf6d-d1678da03fbd
PlusEq(identity)(2, 3)
# ╔═╡ 5a59d96f-b2f1-4564-82c7-7f0fe181afb8
prettify(@macroexpand @i function f(y::T, x::T) where T
y.re += x.re
end)
# ╔═╡ 55d2f8ee-4f77-4d44-b704-30643dbbab84
@i function f3(y::T, x::T) where T
y.re += x.re
end
# ╔═╡ 14951168-97c2-43ae-8d5e-5506408a2bb2
f3(1+2im, 2+3im)
# ╔═╡ 4f564581-6032-449c-8b15-3c741f44237a
x5 = GVar(3+4.0im)
# ╔═╡ a36516e8-76c1-4bff-8a12-3e1e621b857d
~example_linear
# ╔═╡ 402b861c-d363-4d23-b9e9-eb088f57b5c4
expre = NiLangCore.precom_ex(@__MODULE__, :(begin
@routine begin
@zeros T v1 v2 v3 v4 v5
v1 += x1 / x2
v2 += sin(v1)
v3 += exp(x2)
v4 += v1 - v3
v5 += v2 + v4
end
y += v5 * v4
~@routine
end), NiLangCore.PreInfo(Symbol[])) |> NiLangCore.rmlines
# ╔═╡ 63975a80-1b41-4f55-91a1-4a316ad7bf26
example_linear(0.0, 1.5, 0.5)
# ╔═╡ 6f688f88-432a-42b2-a2db-19d6bb282e0a
NiLangCore.dual_ex(@__MODULE__, expre)
# ╔═╡ fb46db14-f7e0-4f01-9096-02334c62942d
(~example_linear)(example_linear(0.0, 1.5, 0.5)...)
# ╔═╡ b2c3db3d-c250-4daa-8453-3c9a2734aede
md"**How to get gradients?**"
# ╔═╡ 9a986264-5ba7-4697-a00d-711f8efe29f0
let
y, x1, x2 = 0.0, 1.5, 0.5
# compute
(y_out, x1_out, x2_out) = example_linear(y, x1, x2)
# wrap elements with GVar
y_out_with_g = GVar(y_out, 1.0)
x1_out_with_g = GVar(x1_out, 0.0)
x2_out_with_g = GVar(x2_out, 0.0)
# uncompute
(y_with_g, x1_with_g, x2_with_g) = (~example_linear)(y_out_with_g, x1_out_with_g, x2_out_with_g)
# get gradients
grad(y_with_g), grad(x1_with_g), grad(x2_with_g)
end
# ╔═╡ 560cf3e9-0c14-4497-85b9-f07045eea32a
with_terminal() do
dump(GVar)
end
# ╔═╡ 8ab79efc-e8d0-4c6f-81df-a89008142bb7
gvar1 = GVar(1.5, 0.0)
# ╔═╡ 0eec318c-2c09-4dd6-9187-9c0273d29915
grad(gvar1)
# ╔═╡ 1f0ef29c-0ad5-4d97-aeed-5ff44e86577a
gvar2 = GVar(1.0, 2.0)
# ╔═╡ 603d8fc2-5e7b-4d55-92b6-208b25ea6569
grad(gvar2)
# ╔═╡ 2b3c765e-b505-4f07-9bcb-3c8cc47364ad
md"To differentiate operation `y += exp(x)`, we bind the backward rule on its inverse `y -= exp(x)`, i.e. `MinusEq(exp)` in the program."
# ╔═╡ e0f266da-7e65-4398-bfd4-a6c0b54e626b
MinusEq(exp)(gvar2, gvar1)
# ╔═╡ e1d35886-79d0-40a5-bd33-1c4e5f4a0a9a
md"""
```math
\left(\begin{matrix}\overline y& \overline x\end{matrix}\right) \rightarrow \left(\begin{matrix}\overline y& \overline x\end{matrix}\right)\left(\begin{matrix}
1 & \exp(x) \\
0 & 1
\end{matrix}\right) = \left(\begin{matrix}\overline y& \overline x + \exp(x) \overline y\end{matrix}\right)
```
"""
# ╔═╡ b63a30b0-c75b-4998-a2b2-0b79574cab81
exp(1.5) * 2
# ╔═╡ 139bf020-c4a8-45c8-96fa-aeebc7ddaedc
md"*one line version*"
# ╔═╡ 8967c0f0-89f8-4893-b11b-253333d1a823
NiLang.AD.gradient(example_linear, (0.0, 1.5, 0.5); iloss=1)
# ╔═╡ f2540450-5a07-4fb8-93fb-a6d48dd36a56
md"## Control Flows"
# ╔═╡ 3acb2cfd-fa29-4a2b-8f23-f5aaf474edd0
(@code_julia for i=1:10
x += y
end) |> NiLangCore.rmlines
# ╔═╡ aa1547f2-5edd-4b7e-b93e-bdfc4e4fc6d5
md"""# Memory Management"""
# ╔═╡ 6e76a107-4f51-4e32-b133-7b6e04d7d107
md"The true reverse mode autodiff has to handle the memory wall problem."
# ╔═╡ 999f7a8f-d72e-4ccd-8cbf-b5bbb7db1842
md"""
## Checkpointing
"""
# ╔═╡ 32772c2a-6b80-4779-963c-06974ff0d832
html"""
<img src="https://raw.githubusercontent.com/GiggleLiu/WuLiXueBao/master/paper/tikzimg-1.svg" style="clip-path: inset(0px 300px 40px 0px); margin-left:40px;" width=600/>
"""
# ╔═╡ 41642bd5-1321-490a-95ad-4c1d6363456f
md"
* red arrow: back propagation
* black dot: cached
* white dot: not cached
"
# ╔═╡ 2a553e32-05ef-4c2d-aba7-41185c6035d4
md"Most time efficient (checkpoint every step)"
# ╔═╡ ab8345ce-e038-4d6b-9e1f-57e4f33bb67b
html"""
<img src="https://raw.githubusercontent.com/GiggleLiu/WuLiXueBao/master/paper/tikzimg3-1.svg" style="clip-path: inset(0px 0px 0px 0px); margin-left:40px;" width=300/>
"""
# ╔═╡ bb9c9a4c-601a-4708-9b2d-04d1583938f2
md"Most space efficient (only checkpoint the first step)"
# ╔═╡ b9917e94-c33d-423f-a478-3252bacc2494
html"""
<img src="https://raw.githubusercontent.com/GiggleLiu/WuLiXueBao/master/paper/tikzimg4-1.svg" style="clip-path: inset(0px 0px 0px 0px); margin-left:40px;" width=300/>
"""
# ╔═╡ 4978f404-11ff-41b8-a673-f2d051b1f526
md"Restricting the number of checkpoints, is evenly checkpointed program optimal?"
# ╔═╡ 73bd2e3b-902f-461b-860f-246257608ecd
html"""
<img src="https://raw.githubusercontent.com/GiggleLiu/WuLiXueBao/master/paper/tikzimg2-1.svg" style="clip-path: inset(0px 0px 0px 0px); margin-left:40px;" width=500/>
"""
# ╔═╡ 4dd47dc8-6dfa-47a4-a088-689b4b870762
md"## Optimal checkpointing"
# ╔═╡ ecd975d2-9374-4f40-80ac-2cceda11e7fb
md"""
1992 ~ Andreas Griewank, Achieving logarithmic growth of temporal and spatial complexity in reverse automatic differentiation.
Julia implementation: [TreeverseAlgorithm.jl](https://github.com/GiggleLiu/TreeverseAlgorithm.jl)
"""
# ╔═╡ 832cc81d-a49d-46e7-9d2b-d8bde9bb1273
html"""
<img src="https://user-images.githubusercontent.com/6257240/116494309-91263000-a86e-11eb-8054-9b91646be0e5.png" style="clip-path: inset(74px 350px 0px 0px);"/>
"""
# ╔═╡ 2192a1de-1042-4b13-a313-b67de489124c
md"""
1. Devide the program into ``\delta`` segments, each segment having size $\eta(\delta, \tau) = \frac{(\delta+\tau)!}{\delta! \tau!}$, where ``\delta=1,...,d`` and ``\tau=t-1``.
2. Cache the first state of each segment,
3. Compute gradients in the last segment,
4. Deallocate last checkpoint,
5. Devide the second last segments into two parts.
6. Recursively apply treeverse (Step 2-5).
"""
# ╔═╡ 01c709c7-806c-4389-bbb2-4081e64426d9
md"total number of steps ``T = \eta(d, t)``, both ``t`` and ``d`` can be logarithmic"
# ╔═╡ b1e0cf83-4337-4044-a7d1-5fca8ae79268
md"## An example"
# ╔═╡ 71f4b476-027d-4c8f-b561-1ee418bc9e61
html"""
<img src="https://raw.githubusercontent.com/GiggleLiu/WuLiXueBao/master/paper/bennett_treeverse_pebbles.svg" style="clip-path: inset(50px 350px 0px 0px);"/>
"""
# ╔═╡ 042013cf-9cd2-409d-827f-a311a2f8ce62
md"""
* black dot: current step,
* gray dot: checkpointed state,
* empty dot: state deallocated in current step,
* red square: gradient computed.
"""
# ╔═╡ 82593cd0-1403-4597-8370-919c80494479
md"# Program is not always linear!"
# ╔═╡ f58720b5-2bcb-4950-b453-bd59f648c66a
md"You think your program is like"
# ╔═╡ 4576d791-6af7-4ba5-9b80-fe99c0bb2e88
let
Compose.set_default_graphic_size(15cm, 3cm)
nb = nodestyle(:circle, r=0.01)
eb = compose(context(), bondstyle(:default, r=0.1), Compose.arrow(), linewidth(0.2mm))
loc(i) = (i/11, 0.5)
eloc(i) = (loc(i-1) .- (-0.02, 0.0), loc(i) .- (0.025, 0.0))
canvas() do
for i=1:10
nb >> loc(i)
i == 1 || eb >> eloc(i)
end
end
end
# ╔═╡ 6e9d17f1-b17d-4e8d-82a3-921558a20c0f
md"or a DAG (directed acyclic graph)"
# ╔═╡ f18d89f5-1129-43e0-8b4a-5c1fcd618eab
let
Compose.set_default_graphic_size(15cm, 3cm)
nb = nodestyle(:circle, r=0.01)
eb = compose(context(), bondstyle(:default, r=0.1), Compose.arrow(), linewidth(0.2mm))
loc(i) = (i/11, 0.2)
loc2(i) = (i/11, 0.7)
eloc(i, j) = shrink(loc(i), loc(j), 0.02, 0.025)
eloc2(i, j) = shrink(loc2(i), loc2(j), 0.02, 0.025)
eloc12(i, j) = shrink(loc(i), loc2(j), 0.1, 0.15)
eloc21(i, j) = shrink(loc2(i), loc(j), 0.05, 0.1)
canvas() do
for i=1:10
nb >> loc(i)
i == 1 || eb >> eloc(i-1,i)
end
for i=2:5
nb >> loc2(i)
i == 2 || eb >> eloc2(i-1, i)
end
eb >> eloc12(2,2)
eb >> eloc12(4,5)
eb >> eloc21(5,7)
end
end
# ╔═╡ 2912c7ed-75e3-4dfd-9c40-92115cc08194
md"The truth is"
# ╔═╡ 5d1517c0-562b-40db-bec2-32b5494de1b8
let
Compose.set_default_graphic_size(15cm, 3cm)
nb = nodestyle(:circle, r=0.01)
tb = textstyle(:default)
eb = compose(context(), bondstyle(:default, r=0.1), Compose.arrow(), linewidth(0.2mm))
eb2 = compose(context(), bondstyle(:dcurve, r=0.8), Compose.arrow(), linewidth(0.2mm))
loc(i) = (i/11, 0.2)
loc2(i) = (i/11, 0.7)
eloc(i, j) = shrink(loc(i), loc(j), 0.02, 0.025)
eloc2(i, j) = shrink(loc2(j), loc2(i), 0.02, 0.025)
eloc12(i, j) = shrink(loc2(j), loc(i), 0.1, 0.15)
eloc21(i, j) = shrink(loc(j), loc2(i), 0.05, 0.1)
canvas() do
for i=1:10
nb >> loc(i)
i == 1 || eb >> eloc(i-1,i)
end
for i=2:5
nb >> loc2(i)
i == 2 || eb >> eloc2(i-1, i)
end
eb >> eloc12(2,2)
eb >> eloc12(4,5)
tb >> ((0.3, 0.45), "× n")
for i=7:8
nb >> loc2(i)
i == 7 || eb >> eloc2(i-1, i)
end
eb >> eloc12(7,7)
eb >> eloc12(8,8)
tb >> ((0.68, 0.45), "× ∞")
eb2 >> (loc(6) .+ (0.0, 0.1), loc(9) .+ (0, 0.15))
end
end
# ╔═╡ ae096ad2-3ae9-4440-a959-0d7d9a174f1d
md"## Example 3: Sparse matrix multiplication"
# ╔═╡ 8148bc1f-ef99-40a4-a5ce-0a42643f703d
md"original implementation: [https://github.com/JuliaLang/julia/blob/master/stdlib/SparseArrays/src/linalg.jl](https://github.com/JuliaLang/julia/blob/master/stdlib/SparseArrays/src/linalg.jl)
"
# ╔═╡ bd86c5c2-16be-4cfd-ba7a-a0e2544d82d1
@i function mul!(C::StridedVecOrMat{T}, A::SparseMatrixCSC{T}, B::StridedVecOrMat{T}, α::Number) where T
@safe A.n == size(B, 1) || throw(DimensionMismatch())
@safe A.m == size(C, 1) || throw(DimensionMismatch())
@safe size(B, 2) == size(C, 2) || throw(DimensionMismatch())
@invcheckoff for k = 1:size(C, 2)
@inbounds for col = 1:A.n
@routine begin
αxj ← zero(T)
αxj += α*B[col,k]
end
for j = A.colptr[col]:(A.colptr[col + 1] - 1)
C[A.rowval[j], k] += A.nzval[j]*αxj
end
~@routine
end
end
end
# ╔═╡ 11557d6b-3a1e-416d-874f-b8d217976f76
md"## Example 4: How to differentiate QR"
# ╔═╡ 48a10ea2-5d32-4a55-b8c0-f6a5e82eace9
md"original implementation: [https://github.com/JuliaLang/julia/blob/master/stdlib/LinearAlgebra/src/qr.jl](https://github.com/JuliaLang/julia/blob/master/stdlib/LinearAlgebra/src/qr.jl)
"
# ╔═╡ fafc1b0f-6469-4b6c-a00d-5272a45fc69b
md"See also"
# ╔═╡ ad6cff7b-5cbf-4ab1-94f7-d21cbc171000
leftright(html"<img src='https://images-na.ssl-images-amazon.com/images/I/41JjpllrDrL._SX364_BO1,204,203,200_.jpg' width=150/>", md"**Matrix computations**
Golub, Gene H., and Charles F. Van Loan (2013)")
# ╔═╡ 4d373cf6-9b39-44bc-8f13-220933fc8f5c
function qrfactPivotedUnblocked!(A::AbstractMatrix)
m, n = size(A)
piv = Vector(UnitRange{BlasInt}(1,n))
τ = Vector{eltype(A)}(undef, min(m,n))
for j = 1:min(m,n)
# Find column with maximum norm in trailing submatrix
jm = indmaxcolumn(view(A, j:m, j:n)) + j - 1
if jm != j
# Flip elements in pivoting vector
tmpp = piv[jm]
piv[jm] = piv[j]
piv[j] = tmpp
# Update matrix with
for i = 1:m
tmp = A[i,jm]
A[i,jm] = A[i,j]
A[i,j] = tmp
end
end
# Compute reflector of columns j
x = view(A, j:m, j)
τj = LinearAlgebra.reflector!(x)
τ[j] = τj
# Update trailing submatrix with reflector
LinearAlgebra.reflectorApply!(x, τj, view(A, j:m, j+1:n))
end
return LinearAlgebra.QRPivoted{eltype(A), typeof(A)}(A, τ, piv)
end
# ╔═╡ 293a68ca-e02f-47b3-85ed-aeeb8995f3ec
struct Reflector{T,RT,VT<:AbstractVector{T}}
ξ::T
normu::RT
sqnormu::RT
r::T
y::VT
end
# ╔═╡ fa5716f9-8bff-4295-812b-691ccdc12832
struct QRPivotedRes{T,RT,VT}
factors::Matrix{T}
τ::Vector{T}
jpvt::Vector{Int}
reflectors::Vector{Reflector{T,RT,VT}}
vAs::Vector{Vector{T}}
jms::Vector{Int}
end
# ╔═╡ 8324f365-fd12-4ca3-8ca6-657e5917f946
# Elementary reflection similar to LAPACK. The reflector is not Hermitian but
# ensures that tridiagonalization of Hermitian matrices become real. See lawn72
@i function reflector!(R::Reflector{T,RT}, x::AbstractVector{T}) where {T,RT}
n ← length(x)
@inbounds @invcheckoff if n != 0
@zeros T ξ1
@zeros RT normu sqnormu
ξ1 += x[1]
sqnormu += abs2(ξ1)
for i = 2:n
sqnormu += abs2(x[i])
end
if !iszero(sqnormu)
normu += sqrt(sqnormu)
if real(ξ1) < 0
NEG(normu)
end
ξ1 += normu
R.y[1] -= normu
for i = 2:n
R.y[i] += x[i] / ξ1
end
R.r += ξ1/normu
end
SWAP(R.ξ, ξ1)
SWAP(R.normu, normu)
SWAP(R.sqnormu, sqnormu)
end
end
# ╔═╡ 70fb10ea-9229-46ef-8ba3-b1d3874b7929
# apply reflector from left
@i function reflectorApply!(vA::AbstractVector{T}, x::AbstractVector, τ::Number, A::StridedMatrix{T}) where T
(m, n) ← size(A)
if length(x) != m || length(vA) != n
@safe throw(DimensionMismatch("reflector has length ($(length(x)), $(length(vA))), which must match the first dimension of matrix A, ($m, $n)"))
end
@inbounds @invcheckoff if m != 0
for j = 1:n
# dot
@zeros T vAj vAj_τ
vAj += A[1, j]
for i = 2:m
vAj += x[i]'*A[i, j]
end
vAj_τ += τ' * vAj
# ger
A[1, j] -= vAj_τ
for i = 2:m
A[i, j] -= x[i]*vAj_τ
end
vAj_τ -= τ' * vAj
SWAP(vA[j], vAj)
end
end
end
# ╔═╡ 51504ba4-4711-48b7-aab9-d4f26c009659
function alloc(::typeof(reflector!), x::AbstractVector{T}) where T
RT = real(T)
Reflector(zero(T), zero(RT), zero(RT), zero(T), zero(x))
end
# ╔═╡ f267e315-3c19-4345-8fba-641bb0ea515b
@i function qr_pivoted!(res::QRPivotedRes, A::StridedMatrix{T}) where T
m, n ← size(A)
@invcheckoff @inbounds for j = 1:min(m,n)
# Find column with maximum norm in trailing submatrix
jm ← LinearAlgebra.indmaxcolumn(NiLang.value.(view(A, j:m, j:n))) + j - 1
if jm != j
# Flip elements in pivoting vector
SWAP(res.jpvt[jm], res.jpvt[j])
# Update matrix with
for i = 1:m
SWAP(A[i, jm], A[i, j])
end
end
# Compute reflector of columns j
R ← alloc(reflector!, A |> subarray(j:m, j))
vA ← zeros(T, n-j)
reflector!(R, A |> subarray(j:m, j))
# Update trailing submatrix with reflector
reflectorApply!(vA, R.y, R.r, A |> subarray(j:m, j+1:n))
for i=1:length(R.y)
SWAP(R.y[i], A[j+i-1, j])
end
PUSH!(res.reflectors, R)
PUSH!(res.vAs, vA)
PUSH!(res.jms, jm)
R → _zero(Reflector{T,real(T),Vector{T}})
vA → zeros(T, 0)
jm → 0
end
@inbounds for i=1:length(res.reflectors)
res.τ[i] += res.reflectors[i].r
end
res.factors += A
end
# ╔═╡ a07b93b1-742b-41d4-bd0f-bc899de55338
function alloc_qr(A::AbstractMatrix{T}) where T
(m, n) = size(A)
τ = zeros(T, min(m,n))
jpvt = collect(1:n)
reflectors = Reflector{T,real(T),Vector{T}}[]
vAs = Vector{T}[]
jms = Int[]
QRPivotedRes(zero(A), τ, jpvt, reflectors, vAs, jms)
end
# ╔═╡ 5f207f59-b9f4-477f-b79f-0aee743bdb8e
A = randn(ComplexF64, 20, 20);
# ╔═╡ f88517d6-b87d-45ba-bf3f-67074fa51fca
@test qr_pivoted!(alloc_qr(A), copy(A))[1].factors ≈ LinearAlgebra.qrfactPivotedUnblocked!(copy(A)).factors
# ╔═╡ 45aef837-9b2c-49b2-b815-e4d60f103f58
let
@testset "qr pivoted gradient" begin
# rank deficient initial matrix
n = 50
U = LinearAlgebra.qr(randn(n, n)).Q
Σ = Diagonal((x=randn(n); x[n÷2+1:end] .= 0; x))
A = U*Σ*U'
res = alloc_qr(A)
@test rank(A) == n ÷ 2
qrres = qr_pivoted!(deepcopy(res), copy(A))[1]
@test count(x->(x>1e-12), sum(abs2, QRPivoted(qrres.factors, qrres.τ, qrres.jpvt).R, dims=2)) == n ÷ 2
@i function loss(y, qrres, A)
qr_pivoted!(qrres, A)
y += abs(qrres.factors[1])
end
nrloss(A) = loss(0.0, deepcopy(res), A)[1]
ngA = zero(A)
δ = 1e-5
for j=1:size(A, 2)
for i=1:size(A, 1)
A_ = copy(A)
A_[i,j] -= δ/2
l1 = nrloss(copy(A_))
A_[i,j] += δ
l2 = nrloss(A_)
ngA[i,j] = (l2-l1)/δ
end
end
gA = NiLang.AD.gradient(loss, (0.0, res, A); iloss=1)[3]
@test real.(gA) ≈ ngA
end
end
# ╔═╡ Cell order:
# ╟─a1ef579e-4b66-4042-944e-7e27c660095e
# ╟─100b4293-fd1e-4b9c-a831-5b79bc2a5ebe
# ╟─f11023e5-8f7b-4f40-86d3-3407b61863d9
# ╟─9d11e058-a7d0-11eb-1d78-6592ff7a1b43
# ╟─b73157bf-1a77-47b8-8a06-8d6ec2045023
# ╟─ec13e0a9-64ff-4f66-a5a6-5fef53428fa1
# ╟─f8b0d1ce-99f7-4729-b46e-126da540cbbe
# ╟─435ac19e-1c0c-4ee5-942d-f2a97c8c4d80
# ╟─48ecd619-d01d-43ff-8b52-7c2566c3fa2b
# ╟─4878ce45-40ff-4fae-98e7-1be41e930e4d
# ╠═ce44f8bd-692e-4eab-9ba4-055b25e40c81
# ╠═b2c1936c-2c27-4fbb-8183-e38c5e858483
# ╠═8be1b812-fcac-404f-98aa-0571cb990f34
# ╟─33e0c762-c75e-44aa-bfe2-bff92dd1ace8
# ╟─c59c35ee-1907-4736-9893-e22c052150ca
# ╠═0ae13734-b826-4dbf-93d1-11044ce88bd4
# ╠═99187515-c8be-49c2-8d70-9c2998d9993c
# ╟─78ca6b08-84c4-4e4d-8412-ae6c28bfafce
# ╠═f12b25d8-7c78-4686-b46d-00b34e565605
# ╟─d90c3cc9-084d-4cf7-9db7-42cea043030b
# ╟─93c98cb2-18af-47df-afb3-8c5a34b4723c
# ╟─2dc74e15-e2ea-4961-b43f-0ada1a73d80a
# ╟─7ee75a15-eaea-462a-92b6-293813d2d4d7
# ╟─02a25b73-7353-43b1-8738-e7ca472d0cc7
# ╟─2afb984f-624e-4381-903f-ccc1d8a66a17
# ╟─7e5d5e69-90f2-4106-8edf-223c150a8168
# ╟─92d7a938-9463-4eee-8839-0b8c5f762c79
# ╟─4b1a0b59-ddc6-4b2d-b5f5-d92084c31e46
# ╟─81f16b8b-2f0b-4ba3-8c26-6669eabf48aa
# ╟─fb6c3a48-550a-4d2e-a00b-a1e40d86b535
# ╟─ab6fa4ac-29ed-4722-88ed-fa1caf2072f3
# ╟─8e72d934-e307-4505-ac82-c06734415df6
# ╟─e6ff86a9-9f54-474b-8111-a59a25eda506
# ╟─9c1d9607-a634-4350-aacd-2d40984d647d
# ╟─63db2fa2-50b2-4940-b8ee-0dc6e3966a57
# ╟─693167e7-e80c-401d-af89-55b5fae30848
# ╟─4cd70901-2142-4868-9a33-c46ca0d064ec
# ╟─89018a35-76f4-4f23-b15a-a600db046d6f
# ╟─1d219222-0778-4c37-9182-ed5ccbb3ef32
# ╟─4ff09f7c-aeac-48bd-9d58-8446137c3acd
# ╟─ea44037b-9359-4fbd-990f-529d88d54351
# ╟─e731a8e3-6462-4a60-83e9-6ab7ddfff50e
# ╟─685c2b28-b071-452c-a881-801128dcb6c3
# ╟─177ddfc2-2cbe-4dba-9d05-2857633dd1ae
# ╟─6c2a3a93-385f-4758-9b6e-4cb594a8e856
# ╟─fb8168c2-8489-418b-909b-cede57b5ae64
# ╟─fdb39284-dbb1-49fa-9a1c-f360f9e6b765
# ╟─60214f22-c8bb-4a32-a882-4e6c727b29a9
# ╟─7a6dbe09-cb7f-405f-b9b5-b350ca170e5f
# ╟─5dc4a849-76dd-4c4f-8828-755671839e5e
# ╟─b053f11b-9ed7-47ff-ab32-0c70b87e71ed
# ╟─7b1aa6dd-647f-44cb-b580-b58e23e8b5a6
# ╟─b96bac75-b4ad-45f7-aeec-cb6a387eebf0
# ╟─5fe022eb-6a17-466e-a6d0-d67e82af23cd
# ╟─92047e95-7eba-4021-9668-9bb4b92261d7
# ╟─e2ae1084-8759-4f27-8ad1-43a88e434a3d
# ╠═edd3aea8-abdb-4e12-9ef9-12ac0fff835b
# ╠═a2904efb-186c-449d-b1aa-caf530f88e91
# ╠═14faaf82-ad3e-4192-8d48-84adfa30442d
# ╠═5d141b88-ec07-4a02-8eb3-37405e5c9f5d
# ╠═0907e683-f216-4cf6-a210-ae5181fdc487
# ╠═805c7072-98fa-4086-a69d-2e126c55af36
# ╠═7e527024-c294-4c16-8626-9953588d9b6a
# ╠═0bbfa106-f465-4a7b-80a7-7732ba435822
# ╠═3e59c65a-ceed-42ed-be64-a6964db016e7
# ╟─29f85d05-99fd-4843-9be0-5663e681dad7
# ╠═9a46597c-b1ee-4e3b-aed1-fd2874b6e77a
# ╠═e7830e55-bd9e-4a8a-9239-4191a5f0b1d1
# ╟─de2cd247-ba68-4ba4-9784-27a743478635
# ╟─dc929c23-7434-4848-847a-9fa696e84776
# ╟─4f1df03f-c315-47b1-b181-749e1231594c
# ╠═ccd38f52-104d-434a-aea3-dd94e571374f
# ╠═7eccba6a-3ad5-440b-9c5d-392dc8dc7aba
# ╠═f4230251-ba54-434a-b86b-f972c7389217
# ╟─4a858a3e-ce28-4642-b061-3975a3ed99ff
# ╠═674bb3bb-637b-44f2-bf6d-d1678da03fbd
# ╠═5a59d96f-b2f1-4564-82c7-7f0fe181afb8
# ╠═55d2f8ee-4f77-4d44-b704-30643dbbab84
# ╠═14951168-97c2-43ae-8d5e-5506408a2bb2
# ╠═4f564581-6032-449c-8b15-3c741f44237a
# ╠═a36516e8-76c1-4bff-8a12-3e1e621b857d
# ╠═402b861c-d363-4d23-b9e9-eb088f57b5c4
# ╠═63975a80-1b41-4f55-91a1-4a316ad7bf26
# ╠═6f688f88-432a-42b2-a2db-19d6bb282e0a
# ╠═fb46db14-f7e0-4f01-9096-02334c62942d
# ╟─b2c3db3d-c250-4daa-8453-3c9a2734aede
# ╠═69dc2685-b70f-4a81-af30-f02e0054bd52
# ╠═9a986264-5ba7-4697-a00d-711f8efe29f0
# ╠═560cf3e9-0c14-4497-85b9-f07045eea32a
# ╠═8ab79efc-e8d0-4c6f-81df-a89008142bb7
# ╠═0eec318c-2c09-4dd6-9187-9c0273d29915
# ╠═1f0ef29c-0ad5-4d97-aeed-5ff44e86577a
# ╠═603d8fc2-5e7b-4d55-92b6-208b25ea6569
# ╟─2b3c765e-b505-4f07-9bcb-3c8cc47364ad
# ╠═e0f266da-7e65-4398-bfd4-a6c0b54e626b
# ╟─e1d35886-79d0-40a5-bd33-1c4e5f4a0a9a
# ╠═b63a30b0-c75b-4998-a2b2-0b79574cab81
# ╟─139bf020-c4a8-45c8-96fa-aeebc7ddaedc
# ╠═8967c0f0-89f8-4893-b11b-253333d1a823
# ╟─f2540450-5a07-4fb8-93fb-a6d48dd36a56
# ╠═3acb2cfd-fa29-4a2b-8f23-f5aaf474edd0
# ╟─aa1547f2-5edd-4b7e-b93e-bdfc4e4fc6d5
# ╟─6e76a107-4f51-4e32-b133-7b6e04d7d107
# ╟─999f7a8f-d72e-4ccd-8cbf-b5bbb7db1842
# ╟─32772c2a-6b80-4779-963c-06974ff0d832
# ╟─41642bd5-1321-490a-95ad-4c1d6363456f
# ╟─2a553e32-05ef-4c2d-aba7-41185c6035d4
# ╟─ab8345ce-e038-4d6b-9e1f-57e4f33bb67b
# ╟─bb9c9a4c-601a-4708-9b2d-04d1583938f2
# ╟─b9917e94-c33d-423f-a478-3252bacc2494
# ╟─4978f404-11ff-41b8-a673-f2d051b1f526
# ╟─73bd2e3b-902f-461b-860f-246257608ecd
# ╟─4dd47dc8-6dfa-47a4-a088-689b4b870762
# ╟─ecd975d2-9374-4f40-80ac-2cceda11e7fb
# ╟─832cc81d-a49d-46e7-9d2b-d8bde9bb1273
# ╟─2192a1de-1042-4b13-a313-b67de489124c
# ╟─01c709c7-806c-4389-bbb2-4081e64426d9
# ╟─b1e0cf83-4337-4044-a7d1-5fca8ae79268
# ╟─71f4b476-027d-4c8f-b561-1ee418bc9e61
# ╟─042013cf-9cd2-409d-827f-a311a2f8ce62
# ╟─82593cd0-1403-4597-8370-919c80494479
# ╟─f58720b5-2bcb-4950-b453-bd59f648c66a
# ╟─4576d791-6af7-4ba5-9b80-fe99c0bb2e88
# ╟─6e9d17f1-b17d-4e8d-82a3-921558a20c0f
# ╟─f18d89f5-1129-43e0-8b4a-5c1fcd618eab
# ╟─2912c7ed-75e3-4dfd-9c40-92115cc08194
# ╟─5d1517c0-562b-40db-bec2-32b5494de1b8
# ╟─ae096ad2-3ae9-4440-a959-0d7d9a174f1d
# ╟─8148bc1f-ef99-40a4-a5ce-0a42643f703d
# ╠═200f1848-0980-4185-919a-93ab2e7f788f
# ╠═bd86c5c2-16be-4cfd-ba7a-a0e2544d82d1
# ╟─11557d6b-3a1e-416d-874f-b8d217976f76
# ╟─48a10ea2-5d32-4a55-b8c0-f6a5e82eace9
# ╟─fafc1b0f-6469-4b6c-a00d-5272a45fc69b
# ╟─ad6cff7b-5cbf-4ab1-94f7-d21cbc171000
# ╠═30c191c5-642b-4062-98f3-643d314a054d
# ╠═fa5716f9-8bff-4295-812b-691ccdc12832
# ╠═f267e315-3c19-4345-8fba-641bb0ea515b
# ╠═4d373cf6-9b39-44bc-8f13-220933fc8f5c
# ╠═293a68ca-e02f-47b3-85ed-aeeb8995f3ec
# ╠═8324f365-fd12-4ca3-8ca6-657e5917f946
# ╠═70fb10ea-9229-46ef-8ba3-b1d3874b7929
# ╠═51504ba4-4711-48b7-aab9-d4f26c009659
# ╠═a07b93b1-742b-41d4-bd0f-bc899de55338
# ╠═864dbde7-b689-4165-a08e-6bbbd72190de
# ╠═5f207f59-b9f4-477f-b79f-0aee743bdb8e
# ╠═f88517d6-b87d-45ba-bf3f-67074fa51fca
# ╠═45aef837-9b2c-49b2-b815-e4d60f103f58
================================================
FILE: notebooks/basic.jl
================================================
### A Pluto.jl notebook ###
# v0.14.5
using Markdown
using InteractiveUtils
# This Pluto notebook uses @bind for interactivity. When running this notebook outside of Pluto, the following 'mock version' of @bind gives bound variables a default value (instead of an error).
macro bind(def, element)
quote
local el = $(esc(element))
global $(esc(def)) = Core.applicable(Base.get, el) ? Base.get(el) : missing
el
end
end
# ╔═╡ 1ef174fa-16f0-11eb-328a-afc201effd2f
using Pkg, Printf
# ╔═╡ 55cfdab8-d792-11ea-271f-e7383e19997c
using PlutoUI;
# ╔═╡ 9e509f80-d485-11ea-0044-c5b7e750aacb
using NiLang
# ╔═╡ 37ed073a-d492-11ea-156f-1fb155128d0f
using Zygote, BenchmarkTools
# ╔═╡ 4d75f302-d492-11ea-31b9-bbbdb43f344e
using NiLang.AD
# ╔═╡ 627ea2fb-6530-4ea0-98ee-66be3db54411
html"""
<div align="center">
<a class="Header-link " href="https://github.com/GiggleLiu/NiLang.jl" data-hotkey="g d" aria-label="Homepage " data-ga-click="Header, go to dashboard, icon:logo">
<svg class="octicon octicon-mark-github v-align-middle" height="32" viewBox="0 0 16 16" version="1.1" width="32" aria-hidden="true"><path fill-rule="evenodd" d="M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.36.09 2 .27 1.53-1.04 2.2-.82 2.2-.82.44 1.1.16 1.92.08 2.12.51.56.82 1.27.82 2.15 0 3.07-1.87 3.75-3.65 3.95.29.25.54.73.54 1.48 0 1.07-.01 1.93-.01 2.2 0 .21.15.46.55.38A8.013 8.013 0 0016 8c0-4.42-3.58-8-8-8z"></path></svg>
</a>
<br>
<a href="https://raw.githubusercontent.com/GiggleLiu/NiLang.jl/master/notebooks/basic.jl" target="_blank" download>Download this notebook</a>
</div>
"""
# ╔═╡ 94b2b962-e02a-11ea-09a5-81b3226891ed
md"""# 连猩猩都能懂的可逆编程
### (Reversible programming made simple)
[https://github.com/JuliaReverse/NiLangTutorial/](https://github.com/JuliaReverse/NiLangTutorial/)
$(html"<br>")
**Jinguo Liu** (github: [GiggleLiu](https://github.com/GiggleLiu/))
*Postdoc, Institute of physics, Chinese academy of sciences* (when doing this project)
*Consultant, QuEra Computing* (current)
*Postdoc, Havard* (soon)
"""
# ╔═╡ a5ee60c8-e02a-11ea-3512-7f481e499f23
md"""
# Table of Contents
1. Reversible programming basics
2. Differentiate everything with a reversible programming language
4. Real world applications and benchmarks
"""
# ╔═╡ a11c4b60-d77d-11ea-1afe-1f2ab9621f42
md"""
## In this talk,
We use the reversible eDSL [NiLang](https://github.com/GiggleLiu/NiLang.jl) is a [Julia](https://julialang.org/) as our reversible programming tool.
A package that can differentiate everything.

Authors:
[GiggleLiu](https://github.com/GiggleLiu), [Taine Zhao](https://github.com/thautwarm)
"""
# ╔═╡ e54a1be6-d485-11ea-0262-034c56e0fda8
md"""
## Sec I. Reversible programming basic
### Reversible function definition
A reversible function `f` is defined as
```julia
(~f)(f(x, y, z...)...) == (x, y, z...)
```
"""
# ╔═╡ d1628f08-ddfb-11ea-241a-c7e6c1a22212
md"""
## Example 1: reversible adder
```math
\begin{align}
f &: x, y → x+y, y\\
{\small \mathrel{\sim}}f &: x, y → x-y, y
\end{align}
```
"""
# ╔═╡ 278ac6b6-e02c-11ea-1354-cd7ecd1099be
md"The reversible macro `@i` defines two functions, the function itself and its inverse."
# ╔═╡ a28d38be-d486-11ea-2c40-a377b74a05c1
@i function reversible_plus(x, y)
x += y
end
# ╔═╡ e93f0bf6-d487-11ea-1baa-21d51ddb4a20
reversible_plus(2.0, 3.0)
# ╔═╡ fc932606-d487-11ea-303e-75ca8b7a02f6
(~reversible_plus)(5.0, 3.0)
# ╔═╡ e3d2b23a-ddfb-11ea-0f5e-e72ed299bb45
md"## The difference to a regular programming language"
# ╔═╡ a961e048-ddf2-11ea-0262-6d19eb82b36b
md"**Comment 1**: The return statement is not allowed, a reversible function returns input arguments directly."
# ╔═╡ 2d22f504-ddf1-11ea-28ec-5de6f4ee79bb
md"**Comment 2**: Every operation is reversible. `+=` is considered as reversible for integers and floating point numbers in NiLang, although for floating point numbers, there are *rounding errors*."
# ╔═╡ 7d08ac24-e143-11ea-2085-539fd9e35889
md"### A case where `+=` is not reversible"
# ╔═╡ 9fcdd77c-e0df-11ea-09e6-49a2861137e5
let
x, y = 1e-20, 1e20
x += y
x -= y
(x, y)
end
# ╔═╡ 0a1a8594-ddfc-11ea-119a-1997c86cd91b
md"""
## Use this function
"""
# ╔═╡ 0b4edb1a-ddf0-11ea-220c-91f2df7452e7
@i function reversible_plus2(x, y)
reversible_plus(x, y) # equivalent to `reversible_plus(x, y)`
reversible_plus(x, y)
end
# ╔═╡ f875ecd6-ddef-11ea-22a1-619809d15b37
md"**Comment**: Inside a reversible function definition, a statement changes a variable *inplace*"
# ╔═╡ e7557bee-e0cc-11ea-1788-411e759b4766
reversible_plus2(2.0, 3.0)
# ╔═╡ cd7b2a2e-ddf5-11ea-04c4-f7583bbb5a53
md"A statement can be **uncalled** with `~`"
# ╔═╡ bc98a824-ddf5-11ea-1a6a-1f795452d3d0
@i function do_nothing(x, y)
reversible_plus(x, y)
~reversible_plus(x, y) # uncall the expression
end
# ╔═╡ 05f8b91c-e0cd-11ea-09e3-f3c5c0e07e63
do_nothing(2.0, 3.0)
# ╔═╡ ac302844-e07b-11ea-35dd-e3e06054401b
md"## Example 2: Compute $x^5$"
# ╔═╡ b722e098-e07b-11ea-3483-01360fb6954e
@i function naive_power5(y, x::T) where T
y = one(T) # error 1: `=` is not reversible
for i=1:5
y *= x # error 2: `*=` is not reversible
end
end
# ╔═╡ bf8b722c-dfa4-11ea-196a-719802bc23c5
md"""
## Compute $x^5$ reversibly
"""
# ╔═╡ 330edc28-dfac-11ea-35a5-3144c4afbfcf
md"note: `*=` is not reversible for usual number systems"
# ╔═╡ 0a679e04-dfa7-11ea-0288-a1fa490c4387
@i function power5(x5, x4, x3, x2, x1, x)
x1 += x
x2 += x1 * x
x3 += x2 * x
x4 += x3 * x
x5 += x4 * x
end
# ╔═╡ cc32cae8-dfab-11ea-0d0b-c70ea8de720a
power5(0.0, 0.0, 0.0, 0.0, 0.0, 2.0)
# ╔═╡ b4240c16-dfac-11ea-3a40-33c54436e3a3
md"# Don't make me so many input arguments!"
# ╔═╡ ade52358-dfac-11ea-2dd3-d3a691e7a8a2
@i function power5_twoinputs(x5, x::T) where T
x1 ← zero(T)
x2 ← zero(T)
x3 ← zero(T)
x4 ← zero(T)
x1 += x
x2 += x1 * x
x3 += x2 * x
x4 += x3 * x
x5 += x4 * x
x4 -= x3 * x
x3 -= x2 * x
x2 -= x1 * x
x1 -= x
x4 → zero(T)
x3 → zero(T)
x2 → zero(T)
x1 → zero(T)
end
# ╔═╡ d86e2e5e-dfab-11ea-0053-6d52f1164bc5
power5_twoinputs(0.0, 2.0)
# ╔═╡ 7951b9ec-e030-11ea-32ee-b1de49378186
md"""
**Comment**:
`n ← zero(T)` is the variable allocation operation. It means
```
if n is defined
error
else
n = zero(T)
end
```
Its inverse is `n → zero(T)`. It means
```
@assert n == zero(T)
deallocate(n)
```
"""
# ╔═╡ 6bc97f5e-dfad-11ea-0c43-e30b6620e6e8
md"# Shorter: compute-copy-uncompute"
# ╔═╡ 80d24e9e-dfad-11ea-1dae-49568d534f10
@i function power5_twoinputs_shorter(x5, x::T) where T
@routine begin # compute
@zeros T x1 x2 x3 x4
x1 += x
x2 += x1 * x
x3 += x2 * x
x4 += x3 * x
end
x5 += x4 * x # copy
~@routine # uncompute
end
# ╔═╡ a8092b18-dfad-11ea-0989-474f37d05f73
power5_twoinputs_shorter(0.0, 2.0)
# ╔═╡ 43f0c2fc-e030-11ea-25d9-b323e6496a35
md"""**Comment**:
```
@routine statement
~@routine
```
is equivalent to
```
statement
~(statement)
```
This is the famous `compute-copy-uncompute` design pattern in reversible computing. Check this [reference](https://epubs.siam.org/doi/10.1137/0219046).
"""
# ╔═╡ b4ad5830-dfad-11ea-0057-055dda8cc9be
md"# How to compute x^1000?"
# ╔═╡ cf576d38-dfad-11ea-2682-7bd540db44a5
@i function power1000(x1000, x::T) where T
@routine begin
xs ← zeros(T, 1000)
xs[1] += 1
for i=2:1000
xs[i] += xs[i-1] * x
end
end
x1000 += xs[1000] * x
~@routine
end
# ╔═╡ 35fff53c-dfae-11ea-3602-918a17d5a5fa
power1000(0.0, 1.001)
# ╔═╡ 9b9b5328-e030-11ea-1d00-f3341572734a
html"""
<h5>For loop</h5>
<div style="-webkit-column-count: 2; -moz-column-count: 2; column-count: 2; -webkit-column-rule: 1px dotted #e0e0e0; -moz-column-rule: 1px dotted #e0e0e0; column-rule: 1px dotted #e0e0e0; margin-top:30px">
<div style="display: inline-float">
<center><strong>Forward</strong></center>
<pre><code class="language-julia">
for i=start:step:stop
# do something
end
</code></pre>
</div>
<div style="display: inline-block;">
<center><strong>Reverse</strong></center>
<pre><code class="language-julia">
for i=stop:-step:start
# undo something
end
</code>
</pre>
</div>
</div>
"""
# ╔═╡ f3b87892-e080-11ea-353d-8d81c52cf9ac
md"### Sometimes, a for loop can break down"
# ╔═╡ b27a3974-e030-11ea-0bcd-7f7035d55165
@i function power1000_bad(x1000, x::T) where T
@routine begin
xs ← zeros(T, 1000)
xs[1] += 1
for i=2:length(xs)
xs[i] += xs[i-1] * x
PUSH!(xs, @const zero(T))
end
end
x1000 += xs[1000] * x
~@routine
end
# ╔═╡ e5d47096-e030-11ea-1e87-5b9b1dbecfe0
power1000_bad(0.0, 1.001)
# ╔═╡ 9c62289a-dfae-11ea-0fe0-b1cb80a87704
md"# Don't allocate for me!"
# ╔═╡ 88838bce-dfaf-11ea-1a72-7d15629cfcb0
md"""
Multipling two unsigned logarithmic numbers `x = exp(lx)` and `y = exp(ly)`
```
x * y = exp(lx) * exp(ly) = exp(lx + ly)
```
"""
# ╔═╡ a593f970-dfae-11ea-2d79-876030850dee
@i function power1000_noalloc(x1000, x::T) where T
if x!= 0
@routine begin
absx ← zero(T)
lx ← one(ULogarithmic{T})
lx1000 ← one(ULogarithmic{T})
absx += abs(x)
lx *= convert(absx)
for i=1:1000
lx1000 *= lx
end
end
x1000 += convert(lx1000)
~@routine
end
end
# ╔═╡ f448548e-dfaf-11ea-05c0-d5d177683445
power1000_noalloc(0.0, 1.001)
# ╔═╡ 65cd13ca-e031-11ea-3fc6-977792eb5f8c
html"""
<h5>If statement</h5>
<div style="-webkit-column-count: 2; -moz-column-count: 2; column-count: 2; -webkit-column-rule: 1px dotted #e0e0e0; -moz-column-rule: 1px dotted #e0e0e0; column-rule: 1px dotted #e0e0e0; margin-top:30px">
<div style="display: inline-float">
<center><strong>Forward</strong></center>
<pre><code class="language-julia">
if (precondition, postcondition)
# do A
else
# do B
end
</code></pre>
</div>
<div style="display: inline-block;">
<center><strong>Reverse</strong></center>
<pre><code class="language-julia">
if (postcondition, precondition)
# undo A
else
# undo B
end
</code>
</pre>
</div>
</div>
"""
# ╔═╡ 53c02100-e08f-11ea-1f5d-8b2311b095d2
md"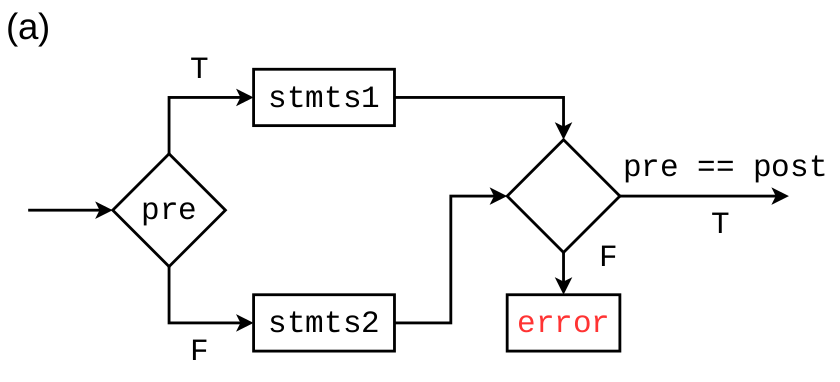"
# ╔═╡ 75751b24-e0b8-11ea-2b37-9d138121345c
md"### You should not do"
# ╔═╡ 76b84de4-e031-11ea-0bcf-39b86a6b4552
@i function break_if(x)
if x%2 == 1
x += 1
else
x -= 1
end
end
# ╔═╡ b1984d24-e031-11ea-3b13-3bd0119a2bcb
break_if(3)
# ╔═╡ 7f163d82-e0b8-11ea-2fe7-332bb4dee586
md"### You should do"
# ╔═╡ ddc6329e-e031-11ea-0e6e-e7332fa26e22
@i function happy_if(x)
if (x%2 == 1, x%2 == 0)
x += 1
else
x -= 1
end
end
# ╔═╡ f3d5e1b0-e031-11ea-1a90-7bed88e28bad
happy_if(3)
# ╔═╡ ab67419a-dfae-11ea-27ba-09321303ad62
md"""# Wrap up
1. reversible arithmetic instructions `+=` and `-=`, besides, we have `SWAP`, `NEG`, `INC` and `ROT` et. al.
2. inverse statement `~`
3. there is no "`=`" operation in reversible computing, use "`←`" to allocate a new variable, and use "`→`" to deallocate an pre-emptied variable.
4. compute-uncompute macro `@routine` and `~@routine`
5. reversible control flow: `for` loop and `if` statement, the `while` statement is also available.
6. logarithmic number is reversible under `*=` and `/=`
"""
# ╔═╡ d5c2efbc-d779-11ea-11ad-1f5873b95628
md"""

"""
# 
# ╔═╡ 30af9642-e084-11ea-1f92-b52abfddcf06
md"# Sec II. Automatic differentiation in NiLang
### References
* Nextjournal [https://nextjournal.com/giggle/reverse-checkpointing](https://nextjournal.com/giggle/reverse-checkpointing)
* arXiv: 2003.04617
"
# ╔═╡ db1fab1c-e084-11ea-0bf0-b1fbe9e74b3f
html"""<h1><del>Auto</del>matic differentiation?</h1>"""
# ╔═╡ e1370f80-e0bc-11ea-2a90-d50cc762cbcb
md"When we start learning AD, we start by learning the backward rules of the matrix multiplication"
# ╔═╡ 3098411c-e0bc-11ea-2754-eb0afbd663de
function mymul!(out::AbstractMatrix, A::AbstractMatrix, B::AbstractMatrix)
@assert size(A, 2) == size(B, 1) && size(out) == (size(A, 1), size(B, 2))
for k=1:size(B, 2)
for j=1:size(B, 1)
for i=size(A, 1)
@inbounds out[i, k] += A[i, j] * B[j, k]
end
end
end
return out
end
# ╔═╡ 3d0150ee-e0bd-11ea-0a5a-339465b496dc
md"Then, we learning how to use chain rule to chain different utilities."
# ╔═╡ 8016ff94-e0bc-11ea-3b9e-4f0676587edf
md"##### But wait! Why don't we start from the backward rules of `+` and `*`, then use the chain rule to derive the backward rule for matrix multiplication?"
# ╔═╡ 99108ace-e0bc-11ea-2744-d1b18db50ae1
md"# They are different"
# ╔═╡ b2337f26-e0bb-11ea-3da0-9507c35101ae
md"""
### Domain-specific autodiff (DS-AD)
* **Tensor**Flow
* **PyTorch**
* **Jax**
* **Flux (Zygote backended)**
### General Purposed autodiff (GP-AD)
* **Tapenade**
* **NiLang**
"""
# ╔═╡ 48db515c-e084-11ea-2eec-018b8545fa34
md"## Traditional AD uses checkpointing
Checkpoint every 100 steps. Blue and yellow objects are computing and re-computing. Here states 1 and state 101 are cached. Blue objects are computing, and yellow ones are re-computing. The state 100 is the desired state.
"
# ╔═╡ f531f556-e083-11ea-2f7e-77e110d6c53a
md""
# ╔═╡ 62643fbc-e084-11ea-1b1f-39b87ff32b9e
md"## Reverse Computing
Reversible computing approach to free up memories (a) when no operations are reversible. (b) when all operations are reversible. Blue and yellow diamonds are reversible operations executed in forward and backward directions, red cubics are garbage variables.
"
# ╔═╡ 0bf54b08-e084-11ea-3d11-7be65f3ec022
md""
# ╔═╡ 15f7c60a-e08e-11ea-31ea-a5cd055644db
md"## Difference Explained"
# ╔═╡ 55a3a260-d48e-11ea-06e2-1b7bd7bba6f5
md"""

"""
# ╔═╡ 38014ad0-e08e-11ea-1905-198038ab7e5f
md"# Obtaining the gradient of norm in Zygote"
# ╔═╡ 2e6fe4da-d79d-11ea-1e90-f5215190395c
md"**Obtaining the gradient of the norm function**"
# ╔═╡ 6560c28c-e08e-11ea-1094-d333b88071ce
function regular_norm(x::AbstractArray{T}) where T
res = zero(T)
for i=1:length(x)
@inbounds res += x[i]^2
end
return sqrt(res)
end
# ╔═╡ 744dd3c6-d492-11ea-0ed5-0fe02f99db1f
@benchmark Zygote.gradient($regular_norm, $(randn(1000))) seconds=1
# ╔═╡ f72246f8-e08e-11ea-3aa0-53f47a64f3e9
md"## The reversible counterpart"
# ╔═╡ f025e454-e08e-11ea-20d6-d139b9a6b301
@i function reversible_norm(res, y, x::AbstractArray{T}) where {T}
for i=1:length(x)
@inbounds y += x[i]^2
end
res += sqrt(y)
end
# ╔═╡ 8fedd65a-e08e-11ea-27f4-03bf9ed65875
let x = randn(1000)
@assert Zygote.gradient(regular_norm, x)[1] ≈ NiLang.AD.gradient(reversible_norm, (0.0, 0.0, x), iloss=1)[3]
end
# ╔═╡ 8ad60dc0-d492-11ea-2cb3-1750b39ddf86
@benchmark NiLang.AD.gradient($reversible_norm, (0.0, 0.0, $(randn(1000))), iloss=1)
# ╔═╡ 7bab4614-d77e-11ea-037c-8d1f432fc3b8
md"""

"""
# 
# ╔═╡ fcca27ba-d4a4-11ea-213a-c3e2305869f1
#**1. The bundle adjustment jacobian benchmark**
#$(LocalResource("ba-origin.png"))
#
#**2. The Gaussian mixture model benchmark**
#$(LocalResource("gmm-origin.png"))
#
md"""
# Sec III. Applications in real world and benchmarks
"""
# ╔═╡ 519dc834-e092-11ea-2151-57ef23810b84
md"""
## 1. Bundle Adjustment (Jacobian)

*Srajer, Filip, Zuzana Kukelova, and Andrew Fitzgibbon. "A benchmark of selected algorithmic differentiation tools on some problems in computer vision and machine learning." Optimization Methods and Software 33.4-6 (2018): 889-906.*
### Benchmarks
**Devices**
* CPU: Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz
* GPU: Nvidia Titan V.
**Github Repos**
* [https://github.com/microsoft/ADBench](https://github.com/microsoft/ADBench)
* [https://github.com/JuliaReverse/NiBundleAdjustment.jl](https://github.com/JuliaReverse/NiBundleAdjustment.jl)
"""
# ╔═╡ c89108f0-e092-11ea-0fe2-efad85008b28
html"""
<div style="float: left"><img src="https://adbenchresults.blob.core.windows.net/plots/2020-03-29_15-46-08_70e2e936bea81eebf0de78ce18d4d196daf1204e/static/jacobian/BA%20[Jacobian]%20-%20Release%20Graph.png" width=500/></div>
"""
# ╔═╡ 2ec4c700-e093-11ea-06ff-47d2c21a068f
md"""##### NiLang.AD and Tapenade
"""
# ╔═╡ 474aa228-e092-11ea-042b-bdfaeb99f16f
md"""
## 2. Gaussian Mixture Model (Gradient)

"""
# ╔═╡ 2baaff10-d56c-11ea-2a23-bfa3a7ae2e4b
md"""
### Benchmarks
*Srajer, Filip, Zuzana Kukelova, and Andrew Fitzgibbon. "A benchmark of selected algorithmic differentiation tools on some problems in computer vision and machine learning." Optimization Methods and Software 33.4-6 (2018): 889-906.*
**Devices**
* CPU: Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz
**Github Repos**
* [https://github.com/microsoft/ADBench](https://github.com/microsoft/ADBench)
* [https://github.com/JuliaReverse/NiGaussianMixture.jl](https://github.com/JuliaReverse/NiGaussianMixture.jl)
"""
# ╔═╡ 102fbf2e-d56b-11ea-189d-c78d56c0a924
html"""
<h5>Results from the original benchmark<h5>
<img src="https://adbenchresults.blob.core.windows.net/plots/2020-03-29_15-46-08_70e2e936bea81eebf0de78ce18d4d196daf1204e/static/jacobian/GMM%20(10k)%20[Jacobian]%20-%20Release%20Graph.png" width=5000/>
"""
# ╔═╡ cc0d5622-d788-11ea-19cd-3bf6864d9263
md"""##### Including NiLang.AD
"""
# ╔═╡ a1646ef0-e091-11ea-00f1-e7c246e191ff
md"## 3. Solve the memory wall problem in machine learning"
# ╔═╡ b18b3ae8-e091-11ea-24a1-e968b70b217c
html"""
Learning a ring distribution with NICE network, before and after training
<img style="float:left" src="https://giggleliu.github.io/NiLang.jl/dev/asset/nice_before.png" width=340/>
<img src="https://giggleliu.github.io/NiLang.jl/dev/asset/nice_after.png" width=340/>
<h5>References</h5>
<ul>
<li><a href="https://arxiv.org/abs/1410.8516">arXiv: 1410.8516</li>
<li><a href="https://giggleliu.github.io/NiLang.jl/dev/examples/nice/#NICE-network-1">NiLang's documentation</a></li>
</ul>
"""
# ╔═╡ bf3774de-e091-11ea-3372-ef56452158e6
md"""
## 4. Solve the spinglass ground state configuration
Obtaining the optimal configuration of a spinglass problem on a $28 \times 28$ square lattice.

##### References
Jin-Guo Liu, Lei Wang, Pan Zhang, **arXiv 2008.06888**
"""
# ╔═╡ c8e4f7a6-e091-11ea-24a3-4399635a41a5
md"""
## 5. Optimizing problems in finance
Gradient based optimization of Sharpe rate.
600x acceleration comparing with using pure Zygote.
##### References
* Han Li's Github repo: [https://github.com/HanLi123/NiLang](https://github.com/HanLi123/NiLang) and his Zhihu blog [猴子掷骰子](https://zhuanlan.zhihu.com/c_1092471228488634368).
"""
# ╔═╡ bc872296-e09f-11ea-143b-9bfd5e52b14f
md"""## 6. Accelerate the performance critical part of variational mean field
[https://github.com/quantumlang/NiLangTest/pull/1](https://github.com/quantumlang/NiLangTest/pull/1)
600x acceleration comparing with using pure Zygote.
"""
# ╔═╡ e7b21fce-e091-11ea-180c-7b42e00598a9
md"""# Thank you!
Special thanks to my collaborator **Taine Zhao** and (ex-)advisor **Lei Wang**.
QuEra computing (a quantum computing company located in Boston) is hiring people.
"""
# ╔═╡ 7c79975c-d789-11ea-30b1-67ff05418cdb
md"""

"""
# 
# ╔═╡ 5f1c3f6c-d48b-11ea-3eb0-357fd3ece4fc
md"""
## Sec IV. More about number systems
* Integers are reversible under (`+=`, `-=`).
* Floating point number system is **irreversible** under (`+=`, `-=`) and (`*=`, `/=`).
* [Fixedpoint number system](https://github.com/JuliaMath/FixedPointNumbers.jl) are reversible under (`+=`, `-=`)
* [Logarithmic number system](https://github.com/cjdoris/LogarithmicNumbers.jl) is reversible under (`*=`, `/=`)
"""
# ╔═╡ 11ddebfe-d488-11ea-223a-e9403f6ec8de
md"""
##### Example 1: Affine transformation with rounding error
```julia
y = A * x + b
```
"""
# ╔═╡ 030e592e-d488-11ea-060d-97a3bb6353b7
@i function reversible_affine!(y!::AbstractVector{T}, W::AbstractMatrix{T}, b::AbstractVector{T}, x::AbstractVector{T}) where T
@safe @assert size(W) == (length(y!), length(x)) && length(b) == length(y!)
for j=1:size(W, 2)
for i=1:size(W, 1)
@inbounds y![i] += W[i,j]*x[j]
end
end
for i=1:size(W, 1)
@inbounds y![i] += b[i]
end
end
# ╔═╡ c8d26856-d48a-11ea-3cd3-1124cd172f3a
begin
W = randn(10, 10)
b = randn(10)
x = randn(10)
end;
# ╔═╡ 37c4394e-d489-11ea-174c-b13bdddbe741
yout, Wout, bout, xout = reversible_affine!(zeros(10), W, b, x)
# ╔═╡ fef54688-d48a-11ea-340b-295b88d21382
# should be restored to 0, but not!
yin, Win, bin, xin = (~reversible_affine!)(yout, Wout, bout, xout)
# ╔═╡ 259a2852-d48c-11ea-0f01-b9634850e09d
md"""
### Reversible arithmetic functions
Computing basic functions like `power`, `exp` and `besselj` is not trivial for reversible programming.
There is no efficient constant memory algorithm using pure fixed point numbers only.
"""
# ╔═╡ f06fb004-d79f-11ea-0d60-8151019bf8c7
md"""
##### Example 2: Computing power function
To compute `x ^ n` reversiblly with fixed point numbers,
we need to either allocate a vector of size $O(n)$ or suffer from polynomial time overhead. It does not show the advantage to checkpointing.
"""
# ╔═╡ 26a8a42c-d7a1-11ea-24a3-45bc6e0674ea
@i function i_power_cache(y!::T, x::T, n::Int) where T
@routine @invcheckoff begin
cache ← zeros(T, n) # allocate a buffer of size n
cache[1] += x
for i=2:n
cache[i] += cache[i-1] * x
end
end
y! += cache[n]
~@routine # uncompute cache
end
# ╔═╡ 399552c4-d7a1-11ea-36bb-ad5ca42043cb
# To check the function
i_power_cache(Fixed43(0.0), Fixed43(0.99), 100)
# ╔═╡ 4bb19760-d7bf-11ea-12ed-4d9e4efb3482
md"""
##### Example 3: reversible thinker, the logarithmic number approach
With **logarithmic numbers**, we can still utilize reversibility. Fixed point numbers and logarithmic numbers can be converted via "a fast binary logarithm algorithm".
##### References
* [1] C. S. Turner, "A Fast Binary Logarithm Algorithm", IEEE Signal Processing Mag., pp. 124,140, Sep. 2010.
"""
# ╔═╡ 5a8ba8f4-d493-11ea-1839-8ba81f86799d
@i function i_power_lognumber(y::T, x::T, n::Int) where T
@routine @invcheckoff begin
lx ← one(ULogarithmic{T})
ly ← one(ULogarithmic{T})
## convert `x` to a logarithmic number
## Here, `*=` is reversible for log numbers
lx *= convert(x)
for i=1:n
ly *= lx
end
end
## convert back to fixed point numbers
y += convert(ly)
~@routine
end
# ╔═╡ a625a922-d493-11ea-1fe9-bdd4a694cde0
# To check the function
i_power_lognumber(Fixed43(0.0), Fixed43(0.99), 100)
# ╔═╡ 4fd20ed2-d7a2-11ea-206e-13799234913f
md"**Less allocation, better speed**"
# ╔═╡ 692dfb44-d7a1-11ea-00da-af6550bc0622
@benchmark i_power_cache(Fixed43(0.0), Fixed43(0.99), 100)
# ╔═╡ 7e4ee09c-d7a1-11ea-0e56-c1921012bc30
@benchmark i_power_lognumber(Fixed43(0.0), Fixed43(0.99), 100)
# ╔═╡ 4c209bbe-d7b1-11ea-0628-33eb8d664f5b
md"""##### Example 4: The first kind Bessel function computed with Taylor expansion
```math
J_\nu(z) = \sum\limits_{n=0}^{\infty} \frac{(z/2)^\nu}{\Gamma(k+1)\Gamma(k+\nu+1)} (-z^2/4)^{n}
```
"""
# ╔═╡ fd44a3d4-d7a4-11ea-24ea-09456ff2c53d
@i function ibesselj(y!::T, ν, z::T; atol=1e-8) where T
if z == 0
if ν == 0
out! += 1
end
else
@routine @invcheckoff begin
k ← 0
@ones ULogarithmic{T} lz halfz halfz_power_2 s
@zeros T out_anc
lz *= convert(z)
halfz *= lz / 2
halfz_power_2 *= halfz ^ 2
# s *= (z/2)^ν/ factorial(ν)
s *= halfz ^ ν
for i=1:ν
s /= i
end
out_anc += convert(s)
while (s.log > -25, k!=0) # upto precision e^-25
k += 1
# s *= 1 / k / (k+ν) * (z/2)^2
@routine begin
@zeros Int kkv kv
kv += k+ ν
kkv += kv*k
end
s *= halfz_power_2 / kkv
if k%2 == 0
out_anc += convert(s)
else
out_anc -= convert(s)
end
~@routine
end
end
y! += out_anc
~@routine
end
end
# ╔═╡ 84272664-d7b7-11ea-2e37-dffd2023d8d6
md"z = $(@bind z Slider(0:0.01:10; default=1.0))"
# ╔═╡ 900e2ea4-d7b8-11ea-3511-6f12d95e638a
begin
y = ibesselj(Fixed43(0.0), 2, Fixed43(z))[1]
gz = NiLang.AD.gradient(Val(1), ibesselj, (Fixed43(0.0), 2, Fixed43(z)))[3]
end;
# ╔═╡ d76be888-d7b4-11ea-2989-2174682ead76
let
md"""
| ``z`` | ``y`` | ``\partial y/\partial z`` |
| ---- | ----- | -------- |
| $(@sprintf "%.5f" z) | $(@sprintf "%.5f" y) | $(@sprintf "%.5f" gz) |
"""
end
# ╔═╡ 85c9edcc-d789-11ea-14c8-71697cd6a047
md"""

"""
# 
# ╔═╡ Cell order:
# ╟─1ef174fa-16f0-11eb-328a-afc201effd2f
# ╟─627ea2fb-6530-4ea0-98ee-66be3db54411
# ╟─94b2b962-e02a-11ea-09a5-81b3226891ed
# ╟─a5ee60c8-e02a-11ea-3512-7f481e499f23
# ╟─a11c4b60-d77d-11ea-1afe-1f2ab9621f42
# ╟─e54a1be6-d485-11ea-0262-034c56e0fda8
# ╟─55cfdab8-d792-11ea-271f-e7383e19997c
# ╟─d1628f08-ddfb-11ea-241a-c7e6c1a22212
# ╠═9e509f80-d485-11ea-0044-c5b7e750aacb
# ╟─278ac6b6-e02c-11ea-1354-cd7ecd1099be
# ╠═a28d38be-d486-11ea-2c40-a377b74a05c1
# ╠═e93f0bf6-d487-11ea-1baa-21d51ddb4a20
# ╠═fc932606-d487-11ea-303e-75ca8b7a02f6
# ╟─e3d2b23a-ddfb-11ea-0f5e-e72ed299bb45
# ╟─a961e048-ddf2-11ea-0262-6d19eb82b36b
# ╟─2d22f504-ddf1-11ea-28ec-5de6f4ee79bb
# ╟─7d08ac24-e143-11ea-2085-539fd9e35889
# ╠═9fcdd77c-e0df-11ea-09e6-49a2861137e5
# ╟─0a1a8594-ddfc-11ea-119a-1997c86cd91b
# ╠═0b4edb1a-ddf0-11ea-220c-91f2df7452e7
# ╟─f875ecd6-ddef-11ea-22a1-619809d15b37
# ╠═e7557bee-e0cc-11ea-1788-411e759b4766
# ╟─cd7b2a2e-ddf5-11ea-04c4-f7583bbb5a53
# ╠═bc98a824-ddf5-11ea-1a6a-1f795452d3d0
# ╠═05f8b91c-e0cd-11ea-09e3-f3c5c0e07e63
# ╟─ac302844-e07b-11ea-35dd-e3e06054401b
# ╠═b722e098-e07b-11ea-3483-01360fb6954e
# ╟─bf8b722c-dfa4-11ea-196a-719802bc23c5
# ╟─330edc28-dfac-11ea-35a5-3144c4afbfcf
# ╠═0a679e04-dfa7-11ea-0288-a1fa490c4387
# ╠═cc32cae8-dfab-11ea-0d0b-c70ea8de720a
# ╟─b4240c16-dfac-11ea-3a40-33c54436e3a3
# ╠═ade52358-dfac-11ea-2dd3-d3a691e7a8a2
# ╠═d86e2e5e-dfab-11ea-0053-6d52f1164bc5
# ╟─7951b9ec-e030-11ea-32ee-b1de49378186
# ╟─6bc97f5e-dfad-11ea-0c43-e30b6620e6e8
# ╠═80d24e9e-dfad-11ea-1dae-49568d534f10
# ╠═a8092b18-dfad-11ea-0989-474f37d05f73
# ╟─43f0c2fc-e030-11ea-25d9-b323e6496a35
# ╟─b4ad5830-dfad-11ea-0057-055dda8cc9be
# ╠═cf576d38-dfad-11ea-2682-7bd540db44a5
# ╠═35fff53c-dfae-11ea-3602-918a17d5a5fa
# ╟─9b9b5328-e030-11ea-1d00-f3341572734a
# ╟─f3b87892-e080-11ea-353d-8d81c52cf9ac
# ╠═b27a3974-e030-11ea-0bcd-7f7035d55165
# ╠═e5d47096-e030-11ea-1e87-5b9b1dbecfe0
# ╟─9c62289a-dfae-11ea-0fe0-b1cb80a87704
# ╟─88838bce-dfaf-11ea-1a72-7d15629cfcb0
# ╠═a593f970-dfae-11ea-2d79-876030850dee
# ╠═f448548e-dfaf-11ea-05c0-d5d177683445
# ╟─65cd13ca-e031-11ea-3fc6-977792eb5f8c
# ╟─53c02100-e08f-11ea-1f5d-8b2311b095d2
# ╟─75751b24-e0b8-11ea-2b37-9d138121345c
# ╠═76b84de4-e031-11ea-0bcf-39b86a6b4552
# ╠═b1984d24-e031-11ea-3b13-3bd0119a2bcb
# ╟─7f163d82-e0b8-11ea-2fe7-332bb4dee586
# ╠═ddc6329e-e031-11ea-0e6e-e7332fa26e22
# ╠═f3d5e1b0-e031-11ea-1a90-7bed88e28bad
# ╟─ab67419a-dfae-11ea-27ba-09321303ad62
# ╟─d5c2efbc-d779-11ea-11ad-1f5873b95628
# ╟─30af9642-e084-11ea-1f92-b52abfddcf06
# ╟─db1fab1c-e084-11ea-0bf0-b1fbe9e74b3f
# ╟─e1370f80-e0bc-11ea-2a90-d50cc762cbcb
# ╠═3098411c-e0bc-11ea-2754-eb0afbd663de
# ╟─3d0150ee-e0bd-11ea-0a5a-339465b496dc
# ╟─8016ff94-e0bc-11ea-3b9e-4f0676587edf
# ╟─99108ace-e0bc-11ea-2744-d1b18db50ae1
# ╟─b2337f26-e0bb-11ea-3da0-9507c35101ae
# ╟─48db515c-e084-11ea-2eec-018b8545fa34
# ╟─f531f556-e083-11ea-2f7e-77e110d6c53a
# ╟─62643fbc-e084-11ea-1b1f-39b87ff32b9e
# ╟─0bf54b08-e084-11ea-3d11-7be65f3ec022
# ╟─15f7c60a-e08e-11ea-31ea-a5cd055644db
# ╟─55a3a260-d48e-11ea-06e2-1b7bd7bba6f5
# ╟─38014ad0-e08e-11ea-1905-198038ab7e5f
# ╟─2e6fe4da-d79d-11ea-1e90-f5215190395c
# ╠═6560c28c-e08e-11ea-1094-d333b88071ce
# ╠═37ed073a-d492-11ea-156f-1fb155128d0f
# ╠═744dd3c6-d492-11ea-0ed5-0fe02f99db1f
# ╟─f72246f8-e08e-11ea-3aa0-53f47a64f3e9
# ╠═f025e454-e08e-11ea-20d6-d139b9a6b301
# ╠═4d75f302-d492-11ea-31b9-bbbdb43f344e
# ╠═8fedd65a-e08e-11ea-27f4-03bf9ed65875
# ╠═8ad60dc0-d492-11ea-2cb3-1750b39ddf86
# ╟─7bab4614-d77e-11ea-037c-8d1f432fc3b8
# ╟─fcca27ba-d4a4-11ea-213a-c3e2305869f1
# ╟─519dc834-e092-11ea-2151-57ef23810b84
# ╟─c89108f0-e092-11ea-0fe2-efad85008b28
# ╟─2ec4c700-e093-11ea-06ff-47d2c21a068f
# ╟─474aa228-e092-11ea-042b-bdfaeb99f16f
# ╟─2baaff10-d56c-11ea-2a23-bfa3a7ae2e4b
# ╟─102fbf2e-d56b-11ea-189d-c78d56c0a924
# ╟─cc0d5622-d788-11ea-19cd-3bf6864d9263
# ╟─a1646ef0-e091-11ea-00f1-e7c246e191ff
# ╟─b18b3ae8-e091-11ea-24a1-e968b70b217c
# ╟─bf3774de-e091-11ea-3372-ef56452158e6
# ╟─c8e4f7a6-e091-11ea-24a3-4399635a41a5
# ╟─bc872296-e09f-11ea-143b-9bfd5e52b14f
# ╟─e7b21fce-e091-11ea-180c-7b42e00598a9
# ╟─7c79975c-d789-11ea-30b1-67ff05418cdb
# ╟─5f1c3f6c-d48b-11ea-3eb0-357fd3ece4fc
# ╟─11ddebfe-d488-11ea-223a-e9403f6ec8de
# ╠═030e592e-d488-11ea-060d-97a3bb6353b7
# ╠═c8d26856-d48a-11ea-3cd3-1124cd172f3a
# ╠═37c4394e-d489-11ea-174c-b13bdddbe741
# ╠═fef54688-d48a-11ea-340b-295b88d21382
# ╟─259a2852-d48c-11ea-0f01-b9634850e09d
# ╟─f06fb004-d79f-11ea-0d60-8151019bf8c7
# ╠═26a8a42c-d7a1-11ea-24a3-45bc6e0674ea
# ╠═399552c4-d7a1-11ea-36bb-ad5ca42043cb
# ╟─4bb19760-d7bf-11ea-12ed-4d9e4efb3482
# ╠═5a8ba8f4-d493-11ea-1839-8ba81f86799d
# ╠═a625a922-d493-11ea-1fe9-bdd4a694cde0
# ╟─4fd20ed2-d7a2-11ea-206e-13799234913f
# ╠═692dfb44-d7a1-11ea-00da-af6550bc0622
# ╠═7e4ee09c-d7a1-11ea-0e56-c1921012bc30
# ╟─4c209bbe-d7b1-11ea-0628-33eb8d664f5b
# ╠═fd44a3d4-d7a4-11ea-24ea-09456ff2c53d
# ╟─84272664-d7b7-11ea-2e37-dffd2023d8d6
# ╠═900e2ea4-d7b8-11ea-3511-6f12d95e638a
# ╟─d76be888-d7b4-11ea-2989-2174682ead76
# ╟─85c9edcc-d789-11ea-14c8-71697cd6a047
================================================
FILE: notebooks/documentation.jl
================================================
### A Pluto.jl notebook ###
# v0.14.5
using Markdown
using InteractiveUtils
# ╔═╡ d941d6c2-55bf-11eb-0002-35c7474e4050
using NiLang, Test
# ╔═╡ 2061b434-0ad1-46eb-a0c7-1a5f432bfa62
begin
twocol(left, right; llabel="forward", rlabel="backward") = HTML("
<table style=\"border:0px\" class=\"normal-table\" width=80%>
<tr>
<td align='center' style='font-family:verdana; background-color: white;'>$llabel</td>
<td align='center' style='font-family:verdana; background-color: white;'>$rlabel</td>
</tr>
<tr style=\"background-color: white;\">
<td>
$(html(left))
</td>
<td>
$(html(right))
</td>
</tr>
</table>
")
example(str) = HTML("""<h6 class="example">$str</h6>""")
title1(str) = HTML("""<div class="root"><h2 id=$(replace(str, ' '=>'_'))>$str</h2></div>""")
title2(str) = HTML("""<h4 id=$(replace(str, ' '=>'_'))>$str</h4>""")
titleref(str) = HTML("""<a href="#$(replace(str, ' '=>'_'))">$str</a>""")
using PlutoUI: TableOfContents
using Pkg
pkgversion(m::Module) = Pkg.TOML.parsefile(NiLang.project_relative_path("Project.toml"))["version"]
hightlight(str) = HTML("<span style='background-color:yellow'>$str</span>")
end;
# ╔═╡ 8c2c4fa6-172f-4dde-a279-5d0aecfdbe46
module M
using NiLang
# define two functions
function new_forward(x)
if x > 0
return x * 2
elseif x < 0
return x / 2
end
end
function new_backward(x)
if x > 0
return x / 2
elseif x < 0
return x * 2
end
end
# declare them as reversible to each other
@dual new_forward new_backward
# The following is need only when your function is differentiable
using NiLang.AD: GVar
function new_backward(x::GVar)
if x.x > 0
GVar(new_backward(x.x), x.g * 2)
elseif x.x < 0
GVar(new_backward(x.x), x.g / 2)
end
end
function new_forward(x::GVar)
if x.x > 0
GVar(new_forward(x.x), x.g / 2)
elseif x.x < 0
GVar(new_forward(x.x), x.g * 2)
end
end
end
# ╔═╡ 3199a048-7b39-40f8-8183-6a54cccd91b6
using BenchmarkTools
# ╔═╡ 0e1ba158-a6bc-401c-9ba7-ed78020ad068
using Base.Threads
# ╔═╡ a4e76427-f051-4b29-915a-fdfce3a299bb
html"""
<div align="center">
<a class="Header-link " href="https://github.com/GiggleLiu/NiLang.jl" data-hotkey="g d" aria-label="Homepage " data-ga-click="Header, go to dashboard, icon:logo">
<svg class="octicon octicon-mark-github v-align-middle" height="32" viewBox="0 0 16 16" version="1.1" width="32" aria-hidden="true"><path fill-rule="evenodd" d="M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.3
gitextract_mdwro7z3/
├── .github/
│ └── workflows/
│ ├── CompatHelper.yml
│ ├── TagBot.yml
│ └── ci.yml
├── .gitignore
├── LICENSE
├── Makefile
├── Project.toml
├── README.md
├── benchmark/
│ ├── besselj_gpu.jl
│ ├── besselj_irreversible.jl
│ ├── besselj_reversible.jl
│ ├── first_function.jl
│ └── stack.jl
├── docs/
│ ├── Project.toml
│ ├── make.jl
│ └── src/
│ ├── api.md
│ ├── extend.md
│ ├── faq.md
│ ├── grammar.md
│ ├── index.md
│ ├── instructions.md
│ ├── tutorial.md
│ └── why.md
├── examples/
│ ├── Adam.jl
│ ├── CUDA/
│ │ ├── README.md
│ │ ├── rotation_gate.jl
│ │ └── swap_gate.jl
│ ├── README.md
│ ├── Symbolics/
│ │ ├── print_jacobians.jl
│ │ ├── symbolic_utils.jl
│ │ └── symlib.jl
│ ├── _sharedwrite.jl
│ ├── batched_tr.jl
│ ├── besselj.jl
│ ├── boxmuller.jl
│ ├── fft.jl
│ ├── fib.jl
│ ├── fixedlog.jl
│ ├── lax_wendroff.jl
│ ├── lognumber.jl
│ ├── nice.jl
│ ├── nice_test.jl
│ ├── port_chainrules.jl
│ ├── port_zygote.jl
│ ├── pyramid.jl
│ ├── qr.jl
│ ├── realnvp.jl
│ ├── sparse.jl
│ └── unitary.jl
├── notebooks/
│ ├── README.md
│ ├── autodiff.jl
│ ├── basic.jl
│ ├── documentation.jl
│ ├── feynman.jl
│ ├── margolus.jl
│ └── reversibleprog.jl
├── src/
│ ├── NiLang.jl
│ ├── autobcast.jl
│ ├── autodiff/
│ │ ├── autodiff.jl
│ │ ├── checks.jl
│ │ ├── complex.jl
│ │ ├── gradfunc.jl
│ │ ├── hessian_backback.jl
│ │ ├── instructs.jl
│ │ ├── jacobian.jl
│ │ ├── stack.jl
│ │ ├── ulog.jl
│ │ └── vars.jl
│ ├── complex.jl
│ ├── deprecations.jl
│ ├── instructs.jl
│ ├── macros.jl
│ ├── stdlib/
│ │ ├── base.jl
│ │ ├── bennett.jl
│ │ ├── blas.jl
│ │ ├── linalg.jl
│ │ ├── mapreduce.jl
│ │ ├── nnlib.jl
│ │ ├── sorting.jl
│ │ ├── sparse.jl
│ │ ├── statistics.jl
│ │ └── stdlib.jl
│ ├── ulog.jl
│ ├── utils.jl
│ ├── vars.jl
│ └── wrappers.jl
└── test/
├── autobcast.jl
├── autodiff/
│ ├── autodiff.jl
│ ├── complex.jl
│ ├── gradfunc.jl
│ ├── hessian_backback.jl
│ ├── instructs.jl
│ ├── jacobian.jl
│ ├── manual.jl
│ ├── stack.jl
│ ├── ulog.jl
│ └── vars.jl
├── complex.jl
├── instructs.jl
├── macros.jl
├── runtests.jl
├── stdlib/
│ ├── base.jl
│ ├── bennett.jl
│ ├── blas.jl
│ ├── linalg.jl
│ ├── mapreduce.jl
│ ├── nnlib.jl
│ ├── sparse.jl
│ ├── statistics.jl
│ └── stdlib.jl
├── ulog.jl
├── utils.jl
├── vars.jl
└── wrappers.jl
Condensed preview — 114 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (533K chars).
[
{
"path": ".github/workflows/CompatHelper.yml",
"chars": 637,
"preview": "name: CompatHelper\n\non:\n schedule:\n - cron: '00 * * * *'\n issues:\n types: [opened, reopened]\n\njobs:\n build:\n "
},
{
"path": ".github/workflows/TagBot.yml",
"chars": 362,
"preview": "name: TagBot\non:\n issue_comment:\n types:\n - created\n workflow_dispatch:\njobs:\n TagBot:\n if: github.event_n"
},
{
"path": ".github/workflows/ci.yml",
"chars": 1840,
"preview": "name: CI\non:\n - push\n - pull_request\njobs:\n test:\n name: Julia ${{ matrix.version }} - ${{ matrix.os }} - ${{ matr"
},
{
"path": ".gitignore",
"chars": 126,
"preview": "*.jl.*.cov\n*.jl.cov\n*.jl.mem\n.DS_Store\nManifest.toml\n/dev/\n/docs/build/\n/docs/site/\n/docs/src/examples/\n_local/\n*.swp\n.v"
},
{
"path": "LICENSE",
"chars": 11384,
"preview": "Copyright (c) 2019 JinGuo Liu, thautwarm\n\n Apache License\n Ver"
},
{
"path": "Makefile",
"chars": 798,
"preview": "JL = julia --project\n\ndefault: init test\n\ninit:\n\t$(JL) -e 'using Pkg; Pkg.precompile()'\ninit-docs:\n\t$(JL) -e 'using Pkg;"
},
{
"path": "Project.toml",
"chars": 1087,
"preview": "name = \"NiLang\"\nuuid = \"ab4ef3a6-0b42-11ea-31f6-e34652774712\"\nauthors = [\"JinGuo Liu\", \"thautwarm\"]\nversion = \"0.9.4\"\n\n["
},
{
"path": "README.md",
"chars": 2481,
"preview": "<img src=\"docs/src/asset/logo3.png\" width=500px/>\n\nNiLang.jl (逆lang), is a reversible domain-specific language (DSL) tha"
},
{
"path": "benchmark/besselj_gpu.jl",
"chars": 4000,
"preview": "using NiLang, NiLang.AD\nusing CuArrays, CUDAnative, GPUArrays\nusing BenchmarkTools\n\n@i @inline function :(-=)(CUDAnative"
},
{
"path": "benchmark/besselj_irreversible.jl",
"chars": 703,
"preview": "using Zygote\nusing ForwardDiff\nusing BenchmarkTools\n\nfunction besselj(ν, z; atol=1e-8)\n k = 0\n s = (z/2)^ν / facto"
},
{
"path": "benchmark/besselj_reversible.jl",
"chars": 706,
"preview": "using NiLang, NiLang.AD\nusing BenchmarkTools\n\ninclude(\"../exmamples/besselj.jl\")\n\n# To test this function, we first defi"
},
{
"path": "benchmark/first_function.jl",
"chars": 143,
"preview": "t1 = time()\nusing NiLang\n\n@i function dot(x, y, z)\n for i=1:10\n x += y[i]' * z[i]\n end\nend\nt2 = time()\nprin"
},
{
"path": "benchmark/stack.jl",
"chars": 0,
"preview": ""
},
{
"path": "docs/Project.toml",
"chars": 1050,
"preview": "[deps]\nBenchmarkTools = \"6e4b80f9-dd63-53aa-95a3-0cdb28fa8baf\"\nChainRules = \"082447d4-558c-5d27-93f4-14fc19e9eca2\"\nCompo"
},
{
"path": "docs/make.jl",
"chars": 1948,
"preview": "using Documenter, NiLang\nusing SparseArrays\n\nusing Literate\ntutorialpath = joinpath(@__DIR__, \"src/examples\")\nsourcepath"
},
{
"path": "docs/src/api.md",
"chars": 419,
"preview": "```@meta\nDocTestSetup = quote\n using NiLangCore, NiLang, NiLang.AD, Test\nend\n```\n\n# API Manual\n## Compiling Tools (Re"
},
{
"path": "docs/src/extend.md",
"chars": 3424,
"preview": "# How to extend\n\n## Extend `+=`, `-=` and `⊻=` for irreversible one-out functions\n\nIt directly works\n```julia\njulia> usi"
},
{
"path": "docs/src/faq.md",
"chars": 2377,
"preview": "## Why reversibility check fails even though the program is reversible?\nDue to the fact that floating pointing numbers a"
},
{
"path": "docs/src/grammar.md",
"chars": 2104,
"preview": "# NiLang Grammar\n\nTo define a reversible function one can use macro **@i** plus a function definition like bellow\n\n```ju"
},
{
"path": "docs/src/index.md",
"chars": 1106,
"preview": "# NiLang.jl\n\nNiLang is a reversible eDSL that can run backwards. The motation is to support source to source AD.\n\nCheck "
},
{
"path": "docs/src/instructions.md",
"chars": 1194,
"preview": "# Instruction Reference\n\n## Instruction definitions\n\nThe Julia functions and symbols for instructions\n\n| instruction | t"
},
{
"path": "docs/src/tutorial.md",
"chars": 5625,
"preview": "# My first NiLang program\n\n## Basic Statements\n\n| Statement | Meaning "
},
{
"path": "docs/src/why.md",
"chars": 4511,
"preview": "# What is Reversible Computing and why do we need it\n\n# What are reversible computing and reversible programming\nReversi"
},
{
"path": "examples/Adam.jl",
"chars": 963,
"preview": "export Adam\n\nmutable struct Adam\n lr::AbstractFloat\n gclip::AbstractFloat\n beta1::AbstractFloat\n beta2::Abst"
},
{
"path": "examples/CUDA/README.md",
"chars": 529,
"preview": "# Reversible programming on GPU\n\nSpecial Notes:\n* please use `@invcheckoff` to close all reversibility check in a kernel"
},
{
"path": "examples/CUDA/rotation_gate.jl",
"chars": 1519,
"preview": "using CUDA, GPUArrays\nusing NiLang, NiLang.AD\n\nconst RotGates = Union{Val{:Rz}, Val{:Rx}, Val{:Ry}}\n\n@i @inline function"
},
{
"path": "examples/CUDA/swap_gate.jl",
"chars": 2599,
"preview": "using CUDA, GPUArrays\nusing NiLang, NiLang.AD\n\n\"\"\"\nA reversible swap kernel for GPU for SWAP gate in quantum computing.\n"
},
{
"path": "examples/README.md",
"chars": 521,
"preview": "# Examples\n\n1. Reversible CUDA programming: [CUDA/](CUDA/)\n2. Generate backward rules for Zygote: [port_zygote.jl](port_"
},
{
"path": "examples/Symbolics/print_jacobians.jl",
"chars": 1733,
"preview": "using NiLang, NiLang.AD\n\ninclude(\"symlib.jl\")\nNiLang.AD.isvar(sym::Basic) = true\nNiLang.AD.GVar(sym::Basic) = GVar(sym, "
},
{
"path": "examples/Symbolics/symbolic_utils.jl",
"chars": 2108,
"preview": "using NiLang, NiLang.AD\nusing SymbolicUtils\nusing SymbolicUtils: Term, Sym\nusing LinearAlgebra\n\nconst SymReal = Sym{Real"
},
{
"path": "examples/Symbolics/symlib.jl",
"chars": 1900,
"preview": "using SymEngine\nusing SymEngine: BasicType\n\nsconj = SymFunction(\"conj\")\nBase.conj(x::Basic) = Basic(conj(SymEngine.Basic"
},
{
"path": "examples/_sharedwrite.jl",
"chars": 2767,
"preview": "# # The shared write problem on GPU\n\n# We will write a GPU version of `axpy!` function.\n\n# ## The main program\n\nusing Ni"
},
{
"path": "examples/batched_tr.jl",
"chars": 994,
"preview": "using NiLang, NiLang.AD\nusing KernelAbstractions, CUDA, CUDAKernels\n\n@i @kernel function kernel_f(A, B::AbstractVector{T"
},
{
"path": "examples/besselj.jl",
"chars": 5915,
"preview": "# # Bessel function\n# An Bessel function of the first kind of order ``\\nu`` can be computed using Taylor expansion\n\n# ``"
},
{
"path": "examples/boxmuller.jl",
"chars": 3276,
"preview": "# # Box-Muller method to Generate normal distribution\nusing NiLang\n\n# In this tutorial, we introduce using Box-Muller me"
},
{
"path": "examples/fft.jl",
"chars": 1678,
"preview": "# https://rosettacode.org/wiki/Fast_Fourier_transform#Fortran\n# In place Cooley-Tukey FFT\nfunction fft!(x::AbstractVecto"
},
{
"path": "examples/fib.jl",
"chars": 1473,
"preview": "# # Computing Fibonacci Numbers\n# The following is an example that everyone likes, computing Fibonacci number recursivel"
},
{
"path": "examples/fixedlog.jl",
"chars": 813,
"preview": "using FixedPointNumbers, Test\n\n\"\"\"\nReference\n-------------------\n\n[1] C. S. Turner, \"A Fast Binary Logarithm Algorithm\""
},
{
"path": "examples/lax_wendroff.jl",
"chars": 1987,
"preview": "\"\"\"\nsolve the 1D linear advection equation\n```math\n∂q/∂t=−u∂q/∂x\n```\nin a periodic domain, where ``q`` is the quantity b"
},
{
"path": "examples/lognumber.jl",
"chars": 2019,
"preview": "# # Logarithmic number system\n\n# Computing basic functions like `power`, `exp` and `besselj` is not trivial for reversib"
},
{
"path": "examples/nice.jl",
"chars": 6205,
"preview": "# # NICE network\n# For the definition of this network and concepts of normalizing flow,\n# please refer this nice blog: h"
},
{
"path": "examples/nice_test.jl",
"chars": 1561,
"preview": "# bijectivity check\nusing Test\ninclude(\"nice.jl\")\n\n@testset \"nice\" begin\n num_vars = 4\n model = random_nice_networ"
},
{
"path": "examples/port_chainrules.jl",
"chars": 2150,
"preview": "# # [How to port NiLang to ChainRules](@id port_chainrules)\n#\n# In [How to port NiLang to Zygote](@ref port_zygote) we s"
},
{
"path": "examples/port_zygote.jl",
"chars": 1420,
"preview": "# # [How to port NiLang to Zygote](@id port_zygote)\n#\n# In this demo we'll show how to insert NiLang's gradient implemen"
},
{
"path": "examples/pyramid.jl",
"chars": 820,
"preview": "# # Pyramid example\n#\n# This is the Pyramid example in the book \"Evaluate Derivatives\", Sec. 3.5.\n\nusing NiLang, NiLang."
},
{
"path": "examples/qr.jl",
"chars": 2009,
"preview": "# # A simple QR decomposition\n\n# ## Functions used in this example\n\nusing NiLang, NiLang.AD, Test\n\n# ## The QR decomposi"
},
{
"path": "examples/realnvp.jl",
"chars": 7602,
"preview": "# # RealNVP network\n# For the definition of this network and concepts of normalizing flow,\n# please refer this realnvp b"
},
{
"path": "examples/sparse.jl",
"chars": 3019,
"preview": "# # Sparse matrices\n#\n# Source to source automatic differentiation is useful in differentiating sparse matrices. It is a"
},
{
"path": "examples/unitary.jl",
"chars": 2127,
"preview": "# # Unitary matrix operations without allocation\n# A unitary matrix features uniform eigenvalues and reversibility. It i"
},
{
"path": "notebooks/README.md",
"chars": 137,
"preview": "# How to use notebooks\n\n1. Install Pluto notebook from [here](https://github.com/fonsp/Pluto.jl),\n2. Open this file in a"
},
{
"path": "notebooks/autodiff.jl",
"chars": 51355,
"preview": "### A Pluto.jl notebook ###\n# v0.14.5\n\nusing Markdown\nusing InteractiveUtils\n\n# ╔═╡ f11023e5-8f7b-4f40-86d3-3407b61863d9"
},
{
"path": "notebooks/basic.jl",
"chars": 31283,
"preview": "### A Pluto.jl notebook ###\n# v0.14.5\n\nusing Markdown\nusing InteractiveUtils\n\n# This Pluto notebook uses @bind for inter"
},
{
"path": "notebooks/documentation.jl",
"chars": 45545,
"preview": "### A Pluto.jl notebook ###\n# v0.14.5\n\nusing Markdown\nusing InteractiveUtils\n\n# ╔═╡ d941d6c2-55bf-11eb-0002-35c7474e4050"
},
{
"path": "notebooks/feynman.jl",
"chars": 67391,
"preview": "### A Pluto.jl notebook ###\n# v0.15.0\n\nusing Markdown\nusing InteractiveUtils\n\n# This Pluto notebook uses @bind for inter"
},
{
"path": "notebooks/margolus.jl",
"chars": 4339,
"preview": "### A Pluto.jl notebook ###\n# v0.12.21\n\nusing Markdown\nusing InteractiveUtils\n\n# This Pluto notebook uses @bind for inte"
},
{
"path": "notebooks/reversibleprog.jl",
"chars": 70954,
"preview": "### A Pluto.jl notebook ###\n# v0.15.0\n\nusing Markdown\nusing InteractiveUtils\n\n# This Pluto notebook uses @bind for inter"
},
{
"path": "src/NiLang.jl",
"chars": 597,
"preview": "module NiLang\n\nusing Reexport\n@reexport using NiLangCore\nimport NiLangCore: invtype\n\nusing FixedPointNumbers: Q20f43, Fi"
},
{
"path": "src/autobcast.jl",
"chars": 2335,
"preview": "export AutoBcast\n\n\"\"\"\n AutoBcast{T,N} <: IWrapper{T}\n\nA vectorized variable.\n\"\"\"\nstruct AutoBcast{T,N} <: IWrapper{T}"
},
{
"path": "src/autodiff/autodiff.jl",
"chars": 474,
"preview": "module AD\n\nusing ..NiLang\nusing NiLangCore\nusing MLStyle, TupleTools\n\nimport ..NiLang: ROT, IROT, SWAP,\n chfield, val"
},
{
"path": "src/autodiff/checks.jl",
"chars": 3531,
"preview": "export check_grad, nparams\nexport gradient_numeric\n\nusing FixedPointNumbers: Fixed\n\n@nospecialize\nisvar(x) = nparams(x) "
},
{
"path": "src/autodiff/complex.jl",
"chars": 671,
"preview": "@i @inline function :(+=)(angle)(r!::T, x::Complex{T}) where T<:GVar\n r! += atan(x.im, x.re)\nend\n\n@i @inline function"
},
{
"path": "src/autodiff/gradfunc.jl",
"chars": 1885,
"preview": "export Grad, NGrad, Hessian, gradient\n\n\"\"\"\n NGrad{N,FT} <: Function\n\nObtain gradients `Grad(f)(Val(i), args..., kwarg"
},
{
"path": "src/autodiff/hessian_backback.jl",
"chars": 1750,
"preview": "export hessian_backback\n\n@i function backback(f, args...; index::Int, iloss::Int, kwargs...)\n # forward\n Grad(f)(a"
},
{
"path": "src/autodiff/instructs.jl",
"chars": 11141,
"preview": "# unary\n@i @inline function NEG(a!::GVar)\n NEG(a!.x)\n NEG(a!.g)\nend\n\nfunction INV(x!::GVar{T}) where T\n x2 = x!"
},
{
"path": "src/autodiff/jacobian.jl",
"chars": 2806,
"preview": "export jacobian, jacobian_repeat\n\nwrap_tuple(x, args) = length(args) == 1 ? (x,) : x\n\n\"\"\"\n jacobian_repeat(f, args..."
},
{
"path": "src/autodiff/stack.jl",
"chars": 557,
"preview": "# This is a patch for loading a data to GVar correctly.\nimport NiLangCore\n\nNiLangCore.loaddata(::Type{GT}, x::T) where {"
},
{
"path": "src/autodiff/ulog.jl",
"chars": 569,
"preview": "@i function (:-=)(gaussian_log)(y!::GVar{T}, x::GVar{T}) where T\n\ty!.x -= gaussian_log(x.x)\n\t@routine @invcheckoff begin"
},
{
"path": "src/autodiff/vars.jl",
"chars": 8655,
"preview": "######## GVar, a bundle that records gradient\n\"\"\"\n GVar{T,GT} <: IWrapper{T}\n GVar(x)\n\nAdd gradient information to"
},
{
"path": "src/complex.jl",
"chars": 3927,
"preview": "export CONJ\nNiLangCore.chfield(x::Complex, ::typeof(real), r) = chfield(x, Val{:re}(), r)\nNiLangCore.chfield(x::Complex,"
},
{
"path": "src/deprecations.jl",
"chars": 229,
"preview": "@deprecate simple_hessian hessian_backback\n@deprecate hessian_repeat hessian_backback\n@deprecate ngradient gradient_nume"
},
{
"path": "src/instructs.jl",
"chars": 6509,
"preview": "export SWAP, FLIP\nexport ROT, IROT\nexport INC, DEC, NEG, INV, AddConst, SubConst\nexport HADAMARD\nexport PUSH!, POP!, COP"
},
{
"path": "src/macros.jl",
"chars": 2701,
"preview": "using MLStyle, NiLang\nexport alloc, @auto_alloc, @auto_expand\n\n\"\"\"\n alloc(f, args...)\n\nallocate function output space"
},
{
"path": "src/stdlib/base.jl",
"chars": 972,
"preview": "export i_sqdistance, i_dirtymul, i_factorial\n\n\"\"\"\n i_sqdistance(dist!, x1, x2)\n\nSquared distance between two points `"
},
{
"path": "src/stdlib/bennett.jl",
"chars": 3898,
"preview": "export bennett, bennett!\n\nfunction direct_emulate(step, x0::T, args...; N::Int, kwargs...) where T\n xpre = copy(x0)\n "
},
{
"path": "src/stdlib/blas.jl",
"chars": 2164,
"preview": "export i_sum, i_mul!, i_dot, i_axpy!, i_umm!, i_norm2\n\n\"\"\"\n i_sum(out!, x)\n\nget the sum of `x`.\n\"\"\"\n@i function i_sum"
},
{
"path": "src/stdlib/linalg.jl",
"chars": 1742,
"preview": "export i_inv!, i_affine!\n\n\"\"\"\n i_inv!(out!, A)\n\nGet the inverse of `A`.\n\n```note!!!\nthis function is implemented as a"
},
{
"path": "src/stdlib/mapreduce.jl",
"chars": 691,
"preview": "export i_mapfoldl, i_filter!, i_map!\n\n\"\"\"\n i_mapfoldl(map, fold, out!, iter)\n\nReversible `mapfoldl` function, `map` c"
},
{
"path": "src/stdlib/nnlib.jl",
"chars": 1716,
"preview": "export i_softmax_crossentropy, i_relu, i_logsumexp\n\nfunction (_::PlusEq{typeof(argmax)})(out!, x::AbstractArray)\n out"
},
{
"path": "src/stdlib/sorting.jl",
"chars": 619,
"preview": "export i_ascending!\n\n\"\"\"\n\ti_ascending!(xs!, inds!, arr)\n\nFind the ascending sequence in `arr` and store the results into"
},
{
"path": "src/stdlib/sparse.jl",
"chars": 2381,
"preview": "using SparseArrays\n\n@i function i_mul!(C::StridedVecOrMat, A::AbstractSparseMatrix, B::StridedVector{T}, α::Number, β::N"
},
{
"path": "src/stdlib/statistics.jl",
"chars": 2674,
"preview": "export i_mean_sum, i_var_mean_sum, i_normal_logpdf, i_cor_cov\nexport VarianceInfo\n\n\"\"\"\n i_mean_sum(out!, sum!, x)\n\nge"
},
{
"path": "src/stdlib/stdlib.jl",
"chars": 230,
"preview": "using .NiLang.AD\nusing LinearAlgebra\ninclude(\"base.jl\")\ninclude(\"blas.jl\")\ninclude(\"linalg.jl\")\ninclude(\"statistics.jl\")"
},
{
"path": "src/ulog.jl",
"chars": 2355,
"preview": "using LogarithmicNumbers\nexport gaussian_log, gaussian_nlog\nexport ULogarithmic\n\n@i @inline function (:*=(identity))(x::"
},
{
"path": "src/utils.jl",
"chars": 504,
"preview": "export rot, plshift, prshift, arshift\n\n\"\"\"\n rot(a, b, θ)\n\nrotate variables `a` and `b` by an angle `θ`\n\"\"\"\nfunction r"
},
{
"path": "src/vars.jl",
"chars": 460,
"preview": "# variable manipulation\nexport @zeros, @ones\n\n\"\"\"\nCreate zeros of specific type.\n\n```julia\njulia> @i function f(x)\n "
},
{
"path": "src/wrappers.jl",
"chars": 2223,
"preview": "export IWrapper, Partial, unwrap, value\n\n\"\"\"\n value(x)\n\nGet the `value` from a wrapper instance.\n\"\"\"\nvalue(x) = x\nNiL"
},
{
"path": "test/autobcast.jl",
"chars": 1476,
"preview": "using NiLang\nusing Test\n\n@testset \"auto bcast\" begin\n a = AutoBcast([1.0, 2.0, 3.0])\n @instr NEG(a)\n @test a.x "
},
{
"path": "test/autodiff/autodiff.jl",
"chars": 234,
"preview": "using Test, NiLang, NiLang.AD\n\ninclude(\"vars.jl\")\ninclude(\"stack.jl\")\ninclude(\"gradfunc.jl\")\n\ninclude(\"instructs.jl\")\nin"
},
{
"path": "test/autodiff/complex.jl",
"chars": 2116,
"preview": "using Test, NiLang, NiLang.AD\n\n@testset \"complex GVar\" begin\n a = 1.0+ 2im\n @test GVar(a) == Complex(GVar(1.0), GV"
},
{
"path": "test/autodiff/gradfunc.jl",
"chars": 2944,
"preview": "using Test, NiLang, NiLang.AD\n\nconst add = PlusEq(identity)\n\n@testset \"NGrad\" begin\n @test NGrad{3}(exp) isa NGrad{3,"
},
{
"path": "test/autodiff/hessian_backback.jl",
"chars": 561,
"preview": "using NiLang, NiLang.AD, Test\nusing NiLang.AD: hessian_numeric\n\n@testset \"hessian\" begin\n h1 = hessian_backback(PlusE"
},
{
"path": "test/autodiff/instructs.jl",
"chars": 6477,
"preview": "using NiLang, NiLang.AD\nusing Test\n\n@testset \"check grad\" begin\n for opm in [PlusEq, MinusEq]\n @test check_gra"
},
{
"path": "test/autodiff/jacobian.jl",
"chars": 1813,
"preview": "using NiLang, NiLang.AD\nusing Test\nusing NiLang.AD: wrap_bcastgrad\n\n@i function asarrayfunc(params; f, kwargs...)\n if"
},
{
"path": "test/autodiff/manual.jl",
"chars": 406,
"preview": "using NiLang, Test\nusing NiLang.AD\n\ntest_func(x) = exp(x)\nNiLang.AD.primitive_grad(::typeof(test_func), x) = exp(x)\n\ntes"
},
{
"path": "test/autodiff/stack.jl",
"chars": 2447,
"preview": "using NiLang, Test, NiLang.AD\n\n@testset \"loaddata\" begin\n @test NiLang.loaddata(GVar(0.1), 0.3) == GVar(0.3)\n @tes"
},
{
"path": "test/autodiff/ulog.jl",
"chars": 2116,
"preview": "using NiLang, NiLang.AD\nusing Test, Random\nusing FixedPointNumbers\nusing NiLangCore: default_constructor\nusing FiniteDif"
},
{
"path": "test/autodiff/vars.jl",
"chars": 3146,
"preview": "using NiLang, NiLang.AD\nusing Test\n\n@testset \"gvar\" begin\n g1 = GVar(0.0)\n @test (~GVar)(g1) === 0.0\n @assign ("
},
{
"path": "test/complex.jl",
"chars": 1279,
"preview": "using Test, NiLang\n\n@testset \"complex\" begin\n a = 1.0+ 2im\n @instr (a |> real) += 2\n @instr (a |> imag) += 2\n "
},
{
"path": "test/instructs.jl",
"chars": 2795,
"preview": "using NiLang\nusing Test\n\n@testset \"identity\" begin\n x, y = 0.2, 0.5\n @instr x += identity(y)\n @test x == 0.7 &&"
},
{
"path": "test/macros.jl",
"chars": 1070,
"preview": "using Test, NiLang\nusing NiLang: auto_alloc, auto_expand\n\nNiLang.alloc(::typeof(NiLang.i_sum), x::AbstractArray{T}) wher"
},
{
"path": "test/runtests.jl",
"chars": 616,
"preview": "using NiLang\nusing Test\n\n@testset \"vars.jl\" begin\n include(\"vars.jl\")\nend\n\n@testset \"utils.jl\" begin\n include(\"uti"
},
{
"path": "test/stdlib/base.jl",
"chars": 130,
"preview": "using NiLang, NiLang.AD\nusing Test\n\n@testset \"sqdistance\" begin\n @test i_sqdistance(0.0, [1.0, 0.0], [0.0, 1.0])[1] ="
},
{
"path": "test/stdlib/bennett.jl",
"chars": 2205,
"preview": "using Test\nusing NiLang, NiLang.AD\n\n@testset \"integrate\" begin\n FT = Float64\n n = 100\n h = FT(π/n)\n dt = FT("
},
{
"path": "test/stdlib/blas.jl",
"chars": 2111,
"preview": "using Test\nusing LinearAlgebra\nusing NiLang, NiLang.AD\n\n@testset \"i_norm2, dot\" begin\n out = 0.0im\n vec = [1.0im, "
},
{
"path": "test/stdlib/linalg.jl",
"chars": 774,
"preview": "using Test\nusing NiLang, NiLang.AD\nusing LinearAlgebra\nusing Random\n\n@testset \"inv\" begin\n Random.seed!(2)\n\n id = "
},
{
"path": "test/stdlib/mapreduce.jl",
"chars": 276,
"preview": "using NiLang, Test\n\n@testset \"filter and mapfoldl\" begin\n @i function f(z, y, x)\n i_filter!((@skip! x -> x < 0"
},
{
"path": "test/stdlib/nnlib.jl",
"chars": 1248,
"preview": "using Test, Random\nusing NiLang, NiLang.AD\n\nfunction _sce(x::AbstractArray{T,N}, p) where {T,N}\n x = x .- maximum(x; "
},
{
"path": "test/stdlib/sparse.jl",
"chars": 424,
"preview": "using NiLang\nusing SparseArrays\nusing Test, Random\n\n@testset \"dot\" begin\n Random.seed!(2)\n sp1 = sprand(10, 10,0.3"
},
{
"path": "test/stdlib/statistics.jl",
"chars": 928,
"preview": "import Statistics\nusing Test, Random\nusing NiLang, NiLang.AD\nusing Distributions\n\n@testset \"statistics\" begin\n x = ra"
},
{
"path": "test/stdlib/stdlib.jl",
"chars": 171,
"preview": "include(\"base.jl\")\ninclude(\"blas.jl\")\ninclude(\"linalg.jl\")\ninclude(\"statistics.jl\")\ninclude(\"nnlib.jl\")\ninclude(\"sparse."
},
{
"path": "test/ulog.jl",
"chars": 1626,
"preview": "using NiLang, NiLang.AD\nusing Test, Random\nusing NiLangCore: default_constructor\n\n@testset \"basic instructions, ULogarit"
},
{
"path": "test/utils.jl",
"chars": 279,
"preview": "using NiLang\nusing Test\n\n@testset \"vec dataview\" begin\n @i function f(x::AbstractVector, y::AbstractMatrix)\n x"
},
{
"path": "test/vars.jl",
"chars": 389,
"preview": "using Test, NiLang, NiLangCore\n\n@testset \"@zeros\" begin\n @test (@macroexpand @zeros Float64 a b c) == :(begin\n "
},
{
"path": "test/wrappers.jl",
"chars": 1172,
"preview": "using NiLang, Test\n\n@testset \"partial\" begin\n x = Partial{:im}(3+2im)\n println(x)\n @test x === Partial{:im,Comp"
}
]
About this extraction
This page contains the full source code of the GiggleLiu/NiLang.jl GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 114 files (479.4 KB), approximately 200.6k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.