Showing preview only (8,946K chars total). Download the full file or copy to clipboard to get everything.
Repository: NLP-LOVE/ML-NLP
Branch: master
Commit: 16733eb5e295
Files: 119
Total size: 32.9 MB
Directory structure:
gitextract_2bn0qfp0/
├── Deep Learning/
│ ├── 10. Neural Network/
│ │ ├── README.md
│ │ └── TensorFlow_LR.ipynb
│ ├── 11. CNN/
│ │ ├── CNN.ipynb
│ │ └── README.md
│ ├── 12. RNN/
│ │ ├── README.md
│ │ └── RNN.ipynb
│ ├── 12.1 GRU/
│ │ ├── GRU.ipynb
│ │ └── README.md
│ ├── 12.2 LSTM/
│ │ ├── LSTM.ipynb
│ │ └── README.md
│ ├── 13. Transfer Learning/
│ │ ├── README.md
│ │ └── Transfer Learning.ipynb
│ ├── 14. Reinforcement Learning/
│ │ └── README.md
│ ├── 15. DL Optimizer/
│ │ └── README.md
│ └── README.md
├── Machine Learning/
│ ├── 2.Logistics Regression/
│ │ ├── 2.Logistics Regression.md
│ │ ├── README.md
│ │ └── demo/
│ │ ├── CreditScoring.ipynb
│ │ └── README.md
│ ├── 3.1 Random Forest/
│ │ ├── 3.1 Random Forest.md
│ │ ├── README.md
│ │ └── RandomForestRegression.ipynb
│ ├── 3.2 GBDT/
│ │ ├── 3.2 GBDT.md
│ │ ├── GBDT_demo.ipynb
│ │ ├── README.md
│ │ ├── test_feat.txt
│ │ └── train_feat.txt
│ ├── 3.3 XGBoost/
│ │ ├── 3.3 XGBoost.ipynb
│ │ ├── 3.3 XGBoost.md
│ │ ├── README.md
│ │ ├── pima-indians-diabetes.csv
│ │ └── 数据说明.txt
│ ├── 3.4 LightGBM/
│ │ ├── 3.4 LightGBM.ipynb
│ │ ├── 3.4 LightGBM.md
│ │ └── README.md
│ ├── 3.Desition Tree/
│ │ ├── DecisionTree.csv
│ │ ├── DecisionTree.ipynb
│ │ ├── Desition Tree.md
│ │ └── README.md
│ ├── 4. SVM/
│ │ ├── 4. SVM.md
│ │ ├── README.md
│ │ └── news classification/
│ │ ├── README.md
│ │ └── svm_classification.ipynb
│ ├── 5.1 Bayes Network/
│ │ ├── 5.1 Bayes Network.md
│ │ ├── Naive Bayes Classifier.ipynb
│ │ └── README.md
│ ├── 5.2 Markov/
│ │ ├── 5.2 HMM.ipynb
│ │ ├── 5.2 Markov.md
│ │ └── README.md
│ ├── 5.3 Topic Model/
│ │ ├── HillaryEmail.ipynb
│ │ ├── HillaryEmails.csv
│ │ └── README.md
│ ├── 6. EM/
│ │ ├── README.md
│ │ └── gmm_em/
│ │ ├── README.md
│ │ ├── genSample.py
│ │ ├── gmm.data
│ │ ├── gmm.py
│ │ ├── main.py
│ │ └── sample.data
│ ├── 7. Clustering/
│ │ ├── GMM.ipynb
│ │ ├── K-Means.ipynb
│ │ ├── README.md
│ │ └── corpus_train.txt
│ ├── 8. ML特征工程和优化方法/
│ │ └── README.md
│ ├── 9. KNN/
│ │ ├── README.md
│ │ └── handwritingClass/
│ │ ├── README.md
│ │ └── handwritingClass.py
│ ├── Liner Regression/
│ │ ├── 1.Liner Regression.md
│ │ ├── README.md
│ │ └── demo/
│ │ ├── README.md
│ │ ├── housing_price.py
│ │ ├── kc_test.txt
│ │ └── kc_train.txt
│ └── README.md
├── NLP/
│ ├── 16. NLP/
│ │ └── README.md
│ ├── 16.1 Word Embedding/
│ │ ├── README.md
│ │ └── word2vec.ipynb
│ ├── 16.2 fastText/
│ │ ├── README.md
│ │ └── fastText.ipynb
│ ├── 16.3 GloVe/
│ │ ├── GloVe.ipynb
│ │ └── README.md
│ ├── 16.4 textRNN & textCNN/
│ │ ├── README.md
│ │ ├── cnews_loader.py
│ │ ├── cnn_model.py
│ │ ├── rnn_model.py
│ │ ├── textCNN.ipynb
│ │ └── textRNN.ipynb
│ ├── 16.5 seq2seq/
│ │ ├── README.md
│ │ └── seq2seq.ipynb
│ ├── 16.6 Attention/
│ │ ├── README.md
│ │ ├── datautil.py
│ │ ├── fanyichina/
│ │ │ ├── fromids/
│ │ │ │ └── README.md
│ │ │ ├── toids/
│ │ │ │ └── README.md
│ │ │ └── yuliao/
│ │ │ ├── from/
│ │ │ │ └── english1w.txt
│ │ │ └── to/
│ │ │ ├── README.md
│ │ │ └── chinese1w.txt
│ │ ├── myjiebadict.txt
│ │ ├── seq2seq_model.py
│ │ ├── test.py
│ │ └── train.ipynb
│ ├── 16.7 Transformer/
│ │ └── README.md
│ ├── 16.8 BERT/
│ │ ├── README.md
│ │ ├── bert-Chinese-classification-task.md
│ │ ├── data/
│ │ │ ├── dev.tsv
│ │ │ ├── test
│ │ │ └── train.tsv
│ │ ├── download_glue_data.py
│ │ ├── modeling.py
│ │ ├── optimization.py
│ │ ├── run.sh
│ │ ├── run_classifier_word.py
│ │ └── tokenization_word.py
│ ├── 16.9 XLNet/
│ │ └── README.md
│ └── README.md
├── Project/
│ ├── 17. Recommendation System/
│ │ └── README.md
│ ├── 18. Intelligent Customer Service/
│ │ └── README.md
│ └── README.md
├── README.md
└── images/
└── README.md
================================================
FILE CONTENTS
================================================
================================================
FILE: Deep Learning/10. Neural Network/README.md
================================================
## 目录
- [1. 深度学习有哪些应用](#1-深度学习有哪些应用)
- [2. 什么是神经网络](#2-什么是神经网络)
- [2.1 什么是感知器](#21-什么是感知器)
- [2.2 神经网络的结构](#22-神经网络的结构)
- [2.3 为什么神经网络具有非线性切分能力](#23-为什么神经网络具有非线性切分能力)
- [3. 神经网络的计算过程](#3-神经网络的计算过程)
- [3.1 计算过程](#31-计算过程)
- [3.2 随机初始化模型参数](#32-随机初始化模型参数)
- [3.3 激活函数](#33-激活函数)
- [3.4 正向传播](#34-正向传播)
- [3.5 反向传播(BP)](#35-反向传播bp)
- [3.6 随机梯度下降法(SGD)](#36-随机梯度下降法sgd)
- [4. 为什么说神经网络是端到端的网络?](#4-为什么说神经网络是端到端的网络)
- [5. 深度学习框架比较](#5-深度学习框架比较)
- [6. softmax分类器](#6-softmax分类器)
- [6.1 什么是softmax](#61-什么是softmax)
- [6.2 softmax的计算](#62-softmax的计算)
- [6.3 交叉熵损失函数](#63-交叉熵损失函数)
- [7. 神经网络实现](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/10.%20Neural%20Network/TensorFlow_LR.ipynb)
## 1. 深度学习有哪些应用
- 图像:图像识别、物体识别、图片美化、图片修复、目标检测。
- 自然语言处理:机器创作、个性化推荐、文本分类、翻译、自动纠错、情感分析。
- 数值预测、量化交易
## 2. 什么是神经网络
我们以房价预测的案例来说明一下,把房屋的面积作为神经网络的输入(我们称之为𝑥),通过一个节点(一个小圆圈),最终输出了价格(我们用𝑦表示)。其实这个小圆圈就是一个单独的神经元,就像人的大脑神经元一样。如果这是一个单神经元网络,不管规模大小,**它正是通过把这些单个神经元叠加在一起来形成。如果你把这些神经元想象成单独的乐高积木,你就通过搭积木来完成一个更大的神经网络。**
神经网络与大脑关联不大。这是一个过度简化的对比,把一个神经网络的逻辑单元和右边的生物神经元对比。至今为止其实连神经科学家们都很难解释,究竟一个神经元能做什么。
### 2.1 什么是感知器
这要从逻辑回归讲起,我们都知道逻辑回归的目标函数如下所示:


我们用网络来表示,这个网络就叫做感知器:

如果在这个感知器的基础上加上隐藏层,就会得到下面我们要说的神经网络结构了。
### 2.2 神经网络的结构
神经网络的一般结构是由**输入层、隐藏层(神经元)、输出层**构成的。隐藏层可以是1层或者多层叠加,层与层之间是相互连接的,如下图所示。

**一般说到神经网络的层数是这样计算的,输入层不算,从隐藏层开始一直到输出层,一共有几层就代表着这是一个几层的神经网络**,例如上图就是一个三层结构的神经网络。
**解释隐藏层的含义:**在一个神经网络中,当你使用监督学习训练它的时候,训练集包含了输入𝑥也包含了目标输出𝑦,所以术语隐藏层的含义是在训练集中,这些中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。
- 多隐藏层的神经网络比 单隐藏层的神经网络工程效果好很多。
- 提升隐层层数或者隐层神经元个数,神经网络“容量”会变大,空间表达力会变强。
- 过多的隐层和神经元节点,会带来过拟合问题。
- 不要试图通过降低神经网络参数量来减缓过拟合,用正则化或者dropout。
### 2.3 为什么神经网络具有非线性切分能力
假设对下图进行分类,圆圈为一类,红叉叉为另一类,如果用线性切分的话无论如何都不能把它们进行分开。

这时,引入神经网络(2层神经网络),包含一个隐藏层,在隐藏层中,分别得到了P1和P2的图形,P1这条线以上的部分都是红叉叉,P2这条线以下的部分都是红叉叉,两个神经元就有2条线性直线。从隐藏层到输出层要做的事情就是把这两条直线给合并起来,就会得到h(x)的图形,也就是说P1以上的空间交上P2以下的空间就是红叉叉的分类,其余空间分类为圆圈。这就使得原本不能够线性切分变成非线性切分了。

如果隐藏层更加复杂的话,就能够完美的实现复杂平面样本点分布的划分(类似于抠图),如下图所示:

## 3. 神经网络的计算过程
### 3.1 计算过程
如下图所示。用圆圈表示神经网络的计算单元,逻辑回归的计算有两个步骤,首先你按步骤计算出𝑧,然后在第二
步中你以 sigmoid 函数为激活函数计算𝑧(得出𝑎),一个神经网络只是这样子做了好多次重复计算。

其中的一个神经元计算如下图所示:

**向量化计算**,如果你执行神经网络的程序,用 for 循环来做这些看起来真的很低效。所以接下来我们要做的就是把这四个等式向量化。向量化的过程是将神经网络中的一层神经元参数纵向堆积起来,例如隐藏层中的𝑤纵向堆积起来变成一个(4,3)的矩阵,用符号𝑊[1]表示。另一个看待这个的方法是我们有四个逻辑回归单元,且每一个逻辑回归单元都有相对应的参数——向量𝑤,把这四个向量堆积在一起,你会得出这 4×3 的矩阵。

上面公式表示的是一个样本的向量化计算,那么**多样本向量化计算**其实就是在上面公式的基础上再增列数,每一列相当于一个样本。
### 3.2 随机初始化模型参数
在神经⽹络中,通常需要随机初始化模型参数。下⾯我们来解释这样做的原因。
假设输出层只保留⼀个输出单元*o*1(删去*o*2和*o*3以及指向它们的箭头),且隐藏层使⽤相同的激活函数。如果将每个隐藏单元的参数都初始化为相等的值,那么在正向传播时每个隐藏单元将根据相同的输⼊计算出相同的值, 并传递⾄输出层。在反向传播中,每个隐藏单元的参数梯度值相等。因此,这些参数在使⽤基于梯度的优化算法迭代后值依然相等。之后的迭代也是如此。
在这种情况下,⽆论隐藏单元有多少, 隐藏层本质上只有1个隐藏单元在发挥作⽤。因此,正如在前⾯的实验中所做的那样,我们通常将神经⽹络的模型参数,特别是权重参数,进⾏随机初始化。
**有两种初始化方法:**
1. 采用正态分布的随机初始化方法。
2. Xavier初始化方法:假设某全连接层的输入个数为a,输出个数为b,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布:

初始化后,**每层输出的方差不会受该层输入个数的影响,且每层梯度的方差也不受该层输出个数的影响。**
### 3.3 激活函数
#### 3.3.1 激活函数有哪些
在隐层接一个线性变换后 ,再接一个非线性变换(如sigmoid),这个非线性变换叫做**传递函数或者激活函数**。上面的例子用的都是逻辑回归的Sigmoid激活函数,如果还不明白激活函数在哪,可以看下面这幅图。

1. **sigmoid函数**

=\frac{1}{1+e^{-z}})
^{'}=\frac{d}{dz}g(z)=\alpha(1-\alpha))
2. **tanh(双曲正切)函数**
事实上,**tanh** 函数是 **sigmoid** 的向下平移和伸缩后的结果。对它进行了变形后,穿过了(0,0)点,并且值域介于+1 和-1 之间。但有一个例外:在二分类的问题中,对于输出层,因为𝑦的值是 0 或 1,所以想让𝑦^的数值介于0和1之间,而不是在-1和+1之间。所以需要使用**sigmoid**激活函数。


**sigmoid**函数和**tanh**函数两者共同的缺点是,在𝑧特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于 0,导致降低梯度下降的速度。
3. **ReLu(修正线性单元)函数**
只要𝑧是正值的情况下,导数恒等于 1,当𝑧是负 值的时候,导数恒等于 0。

)

这有一些选择激活函数的经验法则: 如果输出是 0、1 值(二分类问题),则输出层选择 **sigmoid** 函数,然后其它的所有单 元都选择 **Relu** 函数。
4. **softmax激活函数**
- 非线性变换之前计算:}=W^{(l)}a^{(l-1)}+b^{(l)})
- 经过非线性变换,临时变量:}})
- 归一化
- $a^l$表示的就是第几个类别的概率值,这些**概率值和为1**
之前,我们的激活函数都是接受单行数值输入,例如 **Sigmoid** 和 **ReLu** 激活函数,输入一个实数,输出一个实数。**Softmax** 激活函数的特殊之处在于,因为需要将所有可能的输出归一化,就需要输入一个向量,最后输出一个向量。
**hardmax** 函数会观察𝑧的元素,然后在𝑧中最大元素的位置放上 1,其它位置放上 0,**Softmax** 所做的从𝑧到这些概率的映射更为温和。
**Softmax** 回归将 **logistic** 回归推广到了两种分类以上。
#### 3.3.2 优缺点
- 在𝑧的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于0,在程序实现就是一个 **if-else** 语句,而 **sigmoid** 函数需要进行浮点四则运算,在实践中,使用 **ReLu** 激活函数神经网络通常会比使用 **sigmoid** 或者 **tanh** 激活函数学习的更快。
- **sigmoid** 和 **tanh** 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 **Relu** 和 **Leaky ReLu** 函数大于 0 部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,**Relu** 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 **Leaky ReLu** 不会有这问题) 𝑧在 **ReLu** 的梯度一半都是 0,但是,有足够的隐藏层使得 z 值大于 0,所以对大多数的 训练数据来说学习过程仍然可以很快。
#### 3.3.3 为什么使用激活函数
如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。在我们的简明案例中,事实证明如果你在隐藏层用线性激活函数,在输出层用 **sigmoid** 函数,那么这个模型的复杂度和没有任何隐藏层。的标准 **Logistic** 回归是一样的。
在这里线性隐层一点用也没有,因为这两个线性函数的组合本身就是线性函数,所以除非你引入非线性,否则你无法计算更有趣的函数,即使你的网络层数再多也不行。
#### 3.3.4 人工神经网络中为什么ReLu要好过于tanh和sigmoid function?
1. 采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
2. 对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
3. Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
#### 3.3.5 激活函数有哪些性质?
1. 非线性: 当激活函数是线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即 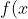=x),就不满足这个性质,而且如果 MLP 使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
2. 可微性: 当优化方法是基于梯度的时候,就体现了该性质;
3. 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数;
4. : 当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值;
5. 输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的 Learning Rate。
### 3.4 正向传播
正向传播(forward-propagation)是指对神经网络沿着从输入层到输出层的顺序,依次计算并存储模型的中间变量(包括输出)。
逻辑回归的计算步骤:所以回想当时我们讨论逻辑回归的时候,我们有这个正向传播步骤,其中我们计算𝑧,然后𝑎,然后损失函数𝐿。 正向传播类似,计算,再计算,最后得到**loss function**。

### 3.5 反向传播(BP)
反向传播(back-propagation)指的是计算神经网络参数梯度的方法。总的来说,反向传播依据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。
由正向传播经过所有的隐藏层到达输出层,会得到一个输出结果,然后根据这个带入**loss funcation**中,利用SGD算法进行最优化求解,其中每次梯度下降都会使用一次BP来更新各个网络层中的参数值,这就是BP回传误差的意思。

- 正向传播求损失,BP回传误差。
- 根据误差信号修正每层的权重。对各个w进行求导,然后更新各个w。
- **链式依赖损失函数**:)))
### 3.6 随机梯度下降法(SGD)
#### 3.6.1 mini-batch梯度下降
你可以把训练集分割为小一点的子集训练,这些子集被取名为 **mini-batch**,假设每一个子集中只有 1000 个样本,那么把其中的𝑥 (1)到𝑥 (1000)取出来,将其称为第一个子训练集,也叫做 **mini-batch**,然后你再取出接下来的 1000 个样本,从𝑥 (1001)到𝑥 (2000),然后再取 1000个样本,以此类推。
在训练集上运行 **mini-batch** 梯度下降法,你运行 for t=1……5000,因为我们有5000个各有 1000 个样本的组,在 **for** 循环里你要做得基本就是对𝑋 {𝑡}和𝑌 {𝑡}执行一步梯度下降法。
- batch_size=1,就是SGD。
- batch_size=n,就是mini-batch
- batch_size=m,就是batch
其中1<n<m,m表示整个训练集大小。
**优缺点:**
- batch:相对噪声低些,幅度也大一些,你可以继续找最小值。
- SGD:大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动。一次性只处理了一个训练样本,这样效率过于低下。
- mini-batch:实践中最好选择不大不小的 **mini-batch**,得到了大量向量化,效率高,收敛快。
首先,如果训练集较小,直接使用 **batch** 梯度下降法,这里的少是说小于 2000 个样本。一般的 **mini-batch** 大小为 64 到 512,考虑到电脑内存设置和使用的方式,如果 **mini-batch** 大小是 2 的𝑛次方,代码会运行地快一些。
#### 3.6.2 调节 Batch_Size 对训练效果影响到底如何?
1. Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
2. 随着 Batch_Size 增大,处理相同数据量的速度越快。
3. 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
4. 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5. 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
## 4. 为什么说神经网络是端到端的网络?
端到端学习(end-to-end)是一种解决问题的思路,与之对应的是多步骤解决问题,也就是将一个问题拆分为多个步骤分步解决,而端到端是由输入端的数据直接得到输出端的结果。
就是不要预处理和特征提取,直接把原始数据扔进去得到最终结果。
**特征提取包含在神经网络内部**,所以说神经网络是端到端的网络。
**优点**:
通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
**缺点**
- 它可能需要大量的数据。要直接学到这个𝑥到𝑦的映射,你可能需要大量(𝑥, 𝑦)数据。
- 它排除了可能有用的手工设计组件。
## 5. 深度学习框架比较
现有的深度学习开源平台主要有 Caffe, PyTorch, MXNet, CNTK, Theano, TensorFlow, Keras, fastai等。
| 平台 | 优点 | 缺点 |
| ---------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| TensorFlow | 1.功能很齐全,能够搭建的网络更丰富。<br/>2.支持多种编程语言。<br/>3.拥有强大的计算集群。<br/>4.谷歌支持<br/>5.社区活跃度高。<br/>6.支持多GPU。<br/>7.TensorBoard支持图形可视化。 | 1.编程入门难度较大。<br/>2.计算图是纯 Python 的,因此速度较慢<br/>3.图构造是静态的,意味着图必须先被「编译」再运行 |
| Keras | 1.Keras是TensorFlow高级集成APi<br/>2.Keras是一个简洁的API。 可以快速帮助您创建应用程序。<br/>3.代码更加可读和简洁。<br/>4.Keras处于高度集成框架。 <br/>5.社区活跃。 | 1.Keras框架环境配置比其他底层框架要复杂一些。<br/>2.虽然更容易创建模型,但是面对复杂的网络结构时可能不如TensorFlow。<br/>3.性能方面比较欠缺。 |
| Pytorch | 1.它可以在流程中更改体系结构。<br/>2.训练神经网络的过程简单明了。<br/>3.可以使用标准 Python 语法编写 for 循环语句。<br/>4.大量预训练模型 | 1.不够TensorFlow全面,不过未来会弥补。<br/>2.PyTorch部署移动端不是很好。 |
| MXNet | 1.支持多语言。<br/>2.文档齐全。<br/>3.支持多个GPU。<br/>4.清晰且易于维护的代码。<br/>5.命令式和符号式编程风格之间进行选择。 | 1.不被广泛使用。<br/>2.社区不够活跃。<br/>3.学习难度大一些。 |
目前从招聘来说,公司使用TensorFlow的占大多数,毕竟TensorFlow的社区、性能、部署方面都是很强的,所以之后写的实例代码都使用TensorFlow来完成。
## 6. softmax分类器
### 6.1 什么是softmax
在图像分类的情景中,softmax分类器输出可以是一个图像类别的离散值,和线性回归不同的是,**softmax输出单元从一个变成了多个。**
softmax回归和线性回归一样将输入特征与权重做线性叠加。与线性回归的一个主要不同在于,**softmax回归的输出值个数等于标签里的类别数。**下图是用神经网络描绘了softmax回归,也是一个单层神经网络,由于每个输出 的计算都要依赖于所有的输入 ,softmax回归的输出层也是一个全连接层。





### 6.2 softmax的计算
一个简单的办法是将输出值 当做预测类别是i的置信度,并将值最大的输出所对应的类别作为预测输出。例如,如果 分别为0.1 ; 10 ; 0.1,由于 最大,那么预测类别为2。
然而,直接使用输出层的输出会有两个问题:
- 由于输出层的输出值的范围不确定,我们难以直观上判断这些值得意义。
- 由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算解决了以上两个问题。它通过下面的公式将输出值变换成值为正且和为1的概率分布:
=\frac{exp(o_i)}{\sum_{i=1}^{n}exp(o_i)})
### 6.3 交叉熵损失函数
我们已经知道,softmax运算将输出变换成一个合法的类别预测分布。实际上,真实标签也可以用类别分布表达:
对于样本i,我们构造向量 }\in_{}R^q),使其第 })个元素为1,其余为0。这样我们的训练目标可以设为使预测概率分布 })尽可能接近真实的标签概率 })。
想要预测分类结果正确,**我们其实并不需要预测概率完全等于标签概率**,而平方损失则过于严格。改善这个问题的一个方法是使用更适合衡量两个概率分布差异的测量函数。其中,**交叉熵(cross entropy)是一个常用的衡量方法:**

其中带下标的 })是向量 })中非 0 即 1 的元素。也就是说,**交叉熵只关心对正确类别的预测概率**,因为只要其值足够大,就可以确保分类结果正确。**即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。**
## 7. 神经网络实现
[TensorFlow示例:线性回归](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/10.%20Neural%20Network/TensorFlow_LR.ipynb)
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/10. Neural Network/TensorFlow_LR.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAXIAAAD4CAYAAADxeG0DAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy8QZhcZAAAd5ElEQVR4nO3de3Ad1X0H8O/PikEWOICvHN6WDJiAH8QBJzT1TFNwAsRTMO+SSi4GGjW47cCUUkjkGZhmnKZ1poypMamTAfwaCJhhoK0zFAIZBiakyA3ExgxgsEVkKMhybeyR8Uu//nF2rdVqzz7u7r13997vZ+aOr/bu3XtYiZ+Ofud3zhFVBRERFdeYWjeAiIjSYSAnIio4BnIiooJjICciKjgGciKigvtcLT60tbVV29vba/HRRESFtWHDhh2qOtF/vCaBvL29HT09PbX4aCKiwhKR3qDjTK0QERUcAzkRUcExkBMRFVxNcuRBDh48iL6+Pnz22We1bgoBaG5uxmmnnYaxY8fWuilEFCE3gbyvrw/jx49He3s7RKTWzWloqoqBgQH09fVh8uTJtW4OEUXITWrls88+Q6lUYhDPARFBqVTiX0dEWVq7FmhvB8aMMf+uXZvZpXPTIwfAIJ4j/F4QZWjtWqCrCxgcNF/39pqvAaCjI/Xlc9MjJyKqW93dw0HcNThojmeAgdyjr68P8+bNw5QpU3DmmWfitttuw4EDBwLP/fDDD3HttddGXnPu3LnYtWtXWe2599578eMf/zjyvGOPPTb09V27dmH58uVltYGIyuRNpfQGzuMBPvggk48qbiDPON+kqrj66qtx5ZVX4t1338U777yDvXv3ojvgN+ahQ4dwyimnYN26dZHXXb9+PY4//vhUbUuLgZyoytxUSm8vELZ5z6RJmXxcMQO5/ya5+aYUwfyFF15Ac3MzbrrpJgBAU1MT7rvvPjz00EMYHBzEI488giuuuAIXX3wx5syZg23btmH69OkAgMHBQVx//fWYOnUqrrrqKlx44YVHliBob2/Hjh07sG3bNpx77rn4zne+g2nTpuGSSy7Bvn37AAA//elP8ZWvfAVf+tKXcM0112DQ/yeYz9atW/G1r30NM2bMwKJFi44c37t3L+bMmYPzzz8fM2bMwNNPPw0AuPvuu/Hee+9h5syZuPPOO63nEVFKbgezs3N0KsWvpQVYvDibz1XVqj8uuOAC9du8efOoY1ZtbaomhI98tLXFv4bP0qVL9fbbbx91fObMmfrGG2/oww8/rKeeeqoODAyoqurWrVt12rRpqqq6ZMkS7erqUlXVjRs3alNTk7722mtOU9u0v79ft27dqk1NTfrb3/5WVVWvu+46Xb16taqq7tix48jndXd36/3336+qqvfcc48uWbJkVJsuv/xyXblypaqqLlu2TI855hhVVT148KDu3r1bVVX7+/v1zDPP1KGhoRFtDTvPL9H3hKjRrVmj2tISHJu8DxETq9asSfwRAHo0IKbmqmolNlteKaN8k803v/lNTJgwYdTxl19+GbfddhsAYPr06TjvvPMC3z958mTMnDkTAHDBBRdg27ZtAIBNmzZh0aJF2LVrF/bu3YtLL700tB2vvPIKnnzySQDA/PnzcddddwEwv5S///3v46WXXsKYMWOwfft2fPzxx6PebzvvpJNOincjiGi0oAFNv7Y2wPn/PkvFTK3Y8kop8k1Tp07Fhg0bRhz79NNP8cEHH+Css84CABxzzDFlXx8Ajj766CPPm5qacOjQIQDAggULsGzZMmzcuBH33HNPrPrtoPLAtWvXor+/Hxs2bMDrr7+OE088MfBacc8jogSiOpJZplJ8ihnIFy82N8Ur5U2aM2cOBgcHsWrVKgDA4cOHcccdd2DBggVo8X+Wz+zZs/H4448DADZv3oyNGzcm+uw9e/bg5JNPxsGDB7E2Rp5/9uzZeOyxxwBgxPm7d+/GF77wBYwdOxYvvvgiep2R8vHjx2PPnj2R5xFRCmEdybY2YMWKTGrGgxQzkHd0mJvS1gaIZHKTRARPPfUUnnjiCUyZMgVnn302mpub8cMf/jDyvQsXLkR/fz+mTp2KRYsWYdq0aTjuuONif/YPfvADXHjhhZg9ezbOOeecyPOXLl2KBx54ADNmzMD27duPHO/o6EBPTw9mzJiBVatWHblWqVTC7NmzMX36dNx5553W84goRFSlnK2DuWaNSadUKIgDSD/YCeB0AC8C2AzgTQC3Rb0n9WBnzhw6dEj37dunqqpbtmzR9vZ23b9/f41blV6RvydEmQoayGxpGT1guWaNGchMMaAZBhUc7DwE4A5V/R8RGQ9gg4g8p6qbM7h2IQwODuKiiy7CwYMHoapYvnw5jjrqqFo3i4iyEjYz09vT7uiobM/bInUgV9WPAHzkPN8jIm8BOBWmh94Qxo8fz63riOpZjSrl4so0Ry4i7QC+DOA35bxfw2ZAUVXxe0HkUYFKuSxlFshF5FgATwK4XVU/DXi9S0R6RKSnv79/1Pubm5sxMDDAAJID6qxH3tzcXOumEOVD0ECmiJlVnvGStOWQLAKniIwF8B8AnlXVf4k6f9asWepPRXCHoHzhDkFEPmvXmpx4b68J4t7Y6X7d1maCfoXy5CKyQVVnjTqeNpCLmZmyEsBOVb09znuCAjkRUSG0t9tXMwRMz71CNeO2QJ5FamU2gPkALhaR153H3AyuS0SUP1EDnBmuMx5X6kCuqi+rqqjqeao603msz6JxRESZymL56zgDnFWuZinmzE4ioqSyWv46aODTr8rVLAzkRNQYytluLagH710iBDADnV4VXBzLhoGciOpPUAAOm9QTdH5YD76jw6yfogqsXp3puk/lyKT8MClWrRBRxfh3rAdML3ncOGBgYPT5pRKwb9/I8/3lhV4VWlM8jkpWrRAR5YcthQIET+oZGBh9flgHNyfT8r0YyImovtgC7c6do3Pb5WQkcjIt34uBnIjqS9i6KG5uu62tvCBeg4HMOBjIiag44tSBx9lBrJz0SI0GMuNgICeiYohbBx5nB7Gw9EhQOWE1dvlJgYGciPLN7YV3dobXgXt7693dpgc+NBQcgMO2ZctBOWFSWewQRERUGUGlhH69vUBrK7BnD3DgwPCxrq7hc7q7TTpl0qSRqxPajuc8cPuxjpyI8itqpcEoQTXiFVydsNJYR05ExZO2ZjuoRrwGqxNWGgM5EeWPm++uVMYgh5N60mAgJ6LaiVrjJEhLi0mZRAk7L4eTetLgYCcR1YZ/INMdoBw3zj646W6lBoweBB07Fvj8580MTnfwMui8nE7qSYOBnIhqw7Ymii2Ii4xerMpWdRL0WXHOKyhWrRBRbYwZkywHXsNVB/OCVStElC+2PHWpFD3FnkZgICei2rDNrly6NHqKPY3AHDkR1Uadza6sJfbIiagy4qxU6C4ra1sThWJhj5yIsmcrLQQYrCuAPXIiyl45O9ZT2RjIiSh7YTvW28RJxVAgBnIiyl7YdmtB4m4aQYEYyIkouajec1Bpocjw2uGtrSPfy1RMKhzsJKJk4gxkeksLe3tH7lg/MDB8Lfe9tmn5dbZKYaWwR05Eydh6z52dI3vncXesHxwEmpqCX6uzVQorhYGciJIJ6yUH5bbj9KoPH+a0/BQYyIkomahesj+3HadX7U7D57T8sjCQE9GwOCWAQQOZfr29w++POt/teXOWZ9kYyInIiFsC2NEx3HsO4x0E9fa2SyXzYM87M1yPnIgM2471TU2mlxy0KYO/giUI1xHPDNcjJ6JwtkHJw4ftPfQ4vXOWEFYcAzkRGXEGJYMm6XjLDMu9LqXCQE5ERpxBTMDew7ZtFMESwopjICciw5smEUk+Scf/fg5kVk0mgVxEHhKRT0RkUxbXI6Iq8pYcdnebHvTQELByZfIeNksIayKrtVYeAbAMwKqMrkdE1RBn3RTbVmyUG5n0yFX1JQA7s7gWEVVR1KqD3h724sXmONcLz52qrX4oIl0AugBgEkexifIh7gYQ3Lot16o22KmqK1R1lqrOmjhxYrU+lojCxN0AguuF5xqrVogaWdySwXK2bqOqYSAnamRxSwaTbt1GVZVV+eGjAH4N4Isi0icit2RxXSJKybaaoa3k0FYyyMk+uZbJYKeqfjuL6xBRhmwDlK+8YmrEkwxcshQx17j6IVG9ClvN8PDh0ce5SmHucfVDokYTtpphkvMp9xjIiYoqKv+d9K9tDlwWVtUmBBFRhuLmv+PiwGWhsUdOVES2CTorViQP4lylsPDYIycqoqT5bxsRDnDWAfbIifIizg72Lls+27aGeNK1xalQGMiJ8iDuDvYu2wSdrq5kx5kXrwsM5ER5kHRRKtvU+uXLkx1nXrwucEIQUR6MGRNcLihips5HWbuWsy4bACcEEeWBLQ+eZlGqpGkZqjsM5ETVEhZw4y5KFfSLgGuFNzymVoiqxbb2ibvGSVR6xD8JCDDB3lY3HjctQ4VhS62wjpyoWmy13729pocdldu29bxti2CxtLBhMLVClJWoOvCwwBqW23avG9SbB0wQZ2lhQ2MgJ8pCnAHHoDy4n5vbdoO3CDB/vj2IA8OlhCwtbFjMkRNlISr/7fLmwcP+3wvLffvPY9BuGCw/JKqkuJsTd3SYwD40ZIJ8kKameEGcPW9yMJATZaGcOnBbyWGcha/cnj6DOIGBnCgb5WxObJtmb+upx70uNRyWHxIl5c1zT5hgju3caZ6PG2eex50m39ERfI6/XlzE5NTb2jj9nkZhj5woCX91ysCAebjP9+0DVq82wba7O96StH5BPfXVq81nMJ1CAVi1QpREWD23q1QyAd0/A5MDk5QSq1aIshBnp/mBAa59QlXFQE6URJpp7729ydMsRDEwkBMlETU7s6XFpFZsuMQsVQADOVES/oHIUsk8vOWDS5eGB3umWShjDORE3sWuWlvNI6zaxDs7c8cO8xgaGq4o8QZ7mzi5dqKYGMipMQUtSuUvJ0yTBnGDvS2Yc4lZyhADOTUeby04EL541eAg0NlZ/iBlOTM+iRJiIKfGE7RBQ5Rye+e2afisJ6cMcUIQNR7bjvVxcZo81QgnBBG50uanWUJIOcNATo0nKG8tYv51ywmjsISQcoSBnBpP2KJUbjnhmjXR27KxhJBygsvYUmOyLR/rfR0wvW7bIlksIaScYI+cyMatBQ/qnbOEkHKEgZwah3cGZ5K6cJYQUs5lkloRkcsALAXQBOBnqvqjLK5LlBl3EpBbP+5WngDxAnJUKoaohlL3yEWkCcADAL4FYCqAb4vI1LTXJcpU0CQgVp5QncgitfJVAFtU9X1VPQDgMQDzMrguUTz+lMnChaNTKLYKE1aeUB3IIpCfCuD3nq/7nGMjiEiXiPSISE9/f38GH0sNJyjH7d9Ds7cXePDBkV93dQ1vkuzHyhOqA1UrP1TVFQBWAGaKfrU+lwrIu0u9uxs9EJzjHjcuet2UwUFzXkvL6H00WXlCdSCLQL4dwOmer09zjhElZxuUDArYg4PxF7/audNM+vH/guAAJtWBLAL5awCmiMhkmAB+A4A/y+C61Ihsg5JJVyv0UzXXZvCmOpQ6kKvqIRH5awDPwpQfPqSqb6ZuGTWmpIOPpRKwb1+8QJ+05JCoIDKZEKSq61X1bFU9U1WZdKTyJRl8bGkx+2P6J+vceqt9Zx6WHFId4lorlC+LF4/Mkdv41wQP6mHb1h1nySHVGU7Rp3yJs3GxG8S7u8On29t69yw5pDrDQE75E7VY1dy5o2vHgzZ64H6Z1CAYyCm/bItVrV8fb7o9F7uiBsE9O6l4bLlvEWBoqPrtIaoS7tlJ+WBbSjbJErPMfRONwEBO1RO0LkpXl1nkKk7O28XcN9EITK1Q9bS3B2+b1tQEHD48+nhbmxn0DBK0Hgtz31TnbKkVBnKqHltu24Y5b6IRmCOn2kuaw2bOmygWBnKqnqDctg1z3kSxMZBT9cSZtQmw3psoIa61QtXlbmIcVgtuG+AkokDskVNySWq+bVgLTpQZBnJKxlYLHhbMgwI/a8GJMsNATsnYdvCxrfFtC/wA10EhygjryCmZpOuc2CYBhU32IaJArCOnbCTNbds2ceDmDkSZYSCnZOLmtt28uO0vPg5qEmWGgZyS8a/xXSoB48YB8+cPD2R68+JBOKhJlCkGchoWt6zQ3cFn9Wqzg/3AwPBA5vz5QGenfc9NDmoSZY4Tgshwe9FuAPZWl9iCblAFS9jgOSf7EFUEe+RkJC0rBJIPWDIvTlQRDORklFNdkiQwMy9OVDEM5I0uTXVJ3NUMmRcnqigG8kYWVV0iYl5rbTUP/yCofzVDkZHvb2kB1qwxeXEGcaKKYSBvZEF5cZfIcC99YGBkZYp3bRW3gkXVVLFwyj1R1TGQ14NyVyMMy3+HVZ/YBkHdoD40xF44URUxkBddOasRutJUkXCKPVFuMJAXXTllgy7bdPtSKfq9LCUkyg0G8qKz9YzDBild/un2bl576dLwahSWEhLlCmd2Ft2kSfaqk4GB4efemZqA6bF/8IF5/+LFwfls95wJE8zXO3eGn09ENcH1yIvOP7U+Sqlk1kfxnt/SwgoTogLgeuT1Ku7O9K6BgfJz6kSUSwzk9cAt+4sbzIOwCoWosBjI60ncKfNBWIVCVFgM5Hlkm+ATNfEnaNOHOKWErEIhKjQOduZN0OBlSwtw443AypXlDVLaNkAGTNBnFQpRIVRksFNErhORN0VkSERGXZzKYJvg8+CDwcc7O6On5dsm/nBBK6K6kDa1sgnA1QBeyqAtBJQ36Bg1Ld828YcBnKgupArkqvqWqr6dVWMI5Q86RpUQckErorpVtcFOEekSkR4R6env76/WxxaHO5DZ2zt6Xe+4WEJI1JAiA7mIPC8imwIe85J8kKquUNVZqjpr4sSJ5be4XngrUFpbgZtvHh6QVC0vmLOEkKghRa61oqrfqEZDGoq/MsW7JopL1T6d3lbBwhJCoobEOvJqcnvhnZ3x1kbZuTN4kHL5cg5eEtERqerIReQqAP8KYCKAXQBeV9VLo97XkHXkSRe3AkyA3ratYk0iomKx1ZGnWsZWVZ8C8FSaazSMsP0xgzBVQkQxMbVSCUFT6aMqSsaONTlxpkqIKCFuLJE1fwrFnawzYULwoCbAafJElAp75FkJG8h0v+Y0eSKqAAbypILSJt6d7G1sFSgM4ESUElc/TMK2MuG4cfa0iYsVKESUUkWqVhqObWXCqGoUVqAQUQUxtZJEOWuZMIVCRBXGQB6HmxdPkobiQCYRVQkDeZQ4A5l+3l541PZsREQpMUceJemMTO+gpq2mHGAvnYgywx55lLC8eFBduHdQ0zY4GrYBBBFRQgzkUWxrfLvpk7C6cNsvAW4AQUQZYiCPYtu42J1SH7Z9mu2XADeAIKIMMZBHSbNxcdgvASKijDCQe/m3X2ttNc+7u03wTbpxMXevJ6Iq4BR9V9TGDy0tDMJEVFO2KfrskbuiygxZbUJEOcVA7opTScJqEyLKIQZyV5xKElabEFEOMZC7gipMvFhtQkQ5xUDu8leYlErcQ5OICqF+A7l/saqFC6MXr/JO8NmxwzySlhwSEVVZfQZy74qFqubfBx8c+XVX1/A2bVydkIgKrD5XP4yzYuHgoNkoWWR4nXGuTkhEBVTMHnlULzpJmaB/QhTrxYmoYIoXyIPSJm6axJW2TJD14kRUIMUL5LY1vjs7h3vnUaWEUVgvTkQFUrxAHtZb9ua4/YtV3Xqr+TcK68WJqGCKN9g5aVL4/plujttWMhi0OJY74NnWNrzOOBFRQRSvRx4nbRLWaw9aWnb1ahPIWS9ORAVUvEDuDcQ2quE14VE7+xARFUjxAjkwHIjXrLH3zoOqWYiI6lAxA7krqnfOmnAiagDFDuTAcO9cJPh11oQTUZ0rfiB3ccd6ImpQ9RPIuWM9ETWo+gnk3LGeiBpUcQJ5nOVmWVZIRA0o1cxOEVkC4HIABwC8B+AmVd2VRcNG8M/G5HKzRERHpO2RPwdguqqeB+AdAN9L36QAtoWyWFpIRJQukKvqf6nqIefLVwGclr5JAWwlhCwtJCLKNEd+M4Bf2F4UkS4R6RGRnv7+/mRXZmkhEZFVZCAXkedFZFPAY57nnG4AhwBY58Or6gpVnaWqsyZOnJislSwtJCKyihzsVNVvhL0uIgsA/AmAOar+fdMy4g5odnebdMqkSVxulojIkbZq5TIAfw/g66oasdtxSh0dDNxERAHS5siXARgP4DkReV1EfpJBm4iIKIFUPXJVPSurhhARUXmKM7OTiIgCMZATERUcAzkRUcFJpSoGQz9UpB9Ab5lvbwWwI8PmZIXtSobtSobtSiav7QLSta1NVUdNxKlJIE9DRHpUdVat2+HHdiXDdiXDdiWT13YBlWkbUytERAXHQE5EVHBFDOQrat0AC7YrGbYrGbYrmby2C6hA2wqXIyciopGK2CMnIiIPBnIiooLLZSAXketE5E0RGRIRa5mOiFwmIm+LyBYRudtzfLKI/MY5/nMROSqjdk0QkedE5F3n3xMCzrnIWUDMfXwmIlc6rz0iIls9r82sVruc8w57PvsZz/Fa3q+ZIvJr5/v9OxH5U89rmd4v28+L5/Wjnf/+Lc79aPe89j3n+NsicmmadpTRrr8Vkc3O/fmliLR5Xgv8nlapXQtEpN/z+X/hee1G5/v+rojcWOV23edp0zsissvzWiXv10Mi8omIbLK8LiJyv9Pu34nI+Z7X0t0vVc3dA8C5AL4I4FcAZlnOaYLZ8PkMAEcBeAPAVOe1xwHc4Dz/CYBbM2rXPwO423l+N4B/ijh/AoCdAFqcrx8BcG0F7lesdgHYazles/sF4GwAU5znpwD4CMDxWd+vsJ8XzzkLAfzEeX4DgJ87z6c65x8NYLJznaYqtusiz8/QrW67wr6nVWrXAgDLAt47AcD7zr8nOM9PqFa7fOf/DYCHKn2/nGv/EYDzAWyyvD4XZhc1AfAHAH6T1f3KZY9cVd9S1bcjTvsqgC2q+r6qHgDwGIB5IiIALgawzjlvJYArM2raPOd6ca97LYBfaKXXak/eriNqfb9U9R1Vfdd5/iGATwAk3EIqlsCfl5D2rgMwx7k/8wA8pqr7VXUrgC3O9arSLlV90fMzVLm9cRO2K8SlAJ5T1Z2q+n8wm7RfVqN2fRvAoxl9dihVfQmm42YzD8AqNV4FcLyInIwM7lcuA3lMpwL4vefrPudYCcAuHd4U2j2ehRNV9SPn+f8CODHi/Bsw+odosfNn1X0icnSV29UsZt/UV910D3J0v0TkqzC9rPc8h7O6X7afl8BznPuxG+b+xHlvJdvldQtG7o0b9D2tZruucb4/60Tk9ITvrWS74KSgJgN4wXO4UvcrDlvbU9+vVOuRpyEizwM4KeClblV9utrtcYW1y/uFqqqIWGs3nd+0MwA86zn8PZiAdhRMLeldAP6hiu1qU9XtInIGgBdEZCNMsCpbxvdrNYAbVXXIOVz2/apHItIJYBaAr3sOj/qequp7wVfI3L8DeFRV94vIX8L8NXNxlT47jhsArFPVw55jtbxfFVOzQK4Re4HGsB3A6Z6vT3OODcD8yfI5p1flHk/dLhH5WEROVtWPnMDzScilrgfwlKoe9Fzb7Z3uF5GHAfxdNdulqtudf98XkV8B+DKAJ1Hj+yUinwfwnzC/xF/1XLvs+xXA9vMSdE6fiHwOwHEwP09x3lvJdkFEvgHzy/HrqrrfPW75nmYRmCLbpaoDni9/BjMm4r73j33v/VUGbYrVLo8bAPyV90AF71cctranvl9FTq28BmCKmIqLo2C+ac+oGT14ESY/DQA3Asiqh/+Mc7041x2Vm3OCmZuXvhJA4Oh2JdolIie4qQkRaQUwG8DmWt8v53v3FEzucJ3vtSzvV+DPS0h7rwXwgnN/ngFwg5iqlskApgD47xRtSdQuEfkygH8DcIWqfuI5Hvg9rWK7TvZ8eQWAt5znzwK4xGnfCQAuwci/TCvaLqdt58AMHP7ac6yS9yuOZwD8uVO98gcAdjudlfT3q1IjuGkeAK6CyRPtB/AxgGed46cAWO85by6Ad2B+o3Z7jp8B8z/aFgBPADg6o3aVAPwSwLsAngcwwTk+C8DPPOe1w/yWHeN7/wsANsIEpDUAjq1WuwD8ofPZbzj/3pKH+wWgE8BBAK97HjMrcb+Cfl5gUjVXOM+bnf/+Lc79OMPz3m7nfW8D+FbGP+9R7Xre+f/AvT/PRH1Pq9SufwTwpvP5LwI4x/Pem537uAXATdVsl/P1vQB+5Htfpe/XozBVVwdh4tctAL4L4LvO6wLgAafdG+GpyEt7vzhFn4io4IqcWiEiIjCQExEVHgM5EVHBMZATERUcAzkRUcExkBMRFRwDORFRwf0/nH6AhvXqSi8AAAAASUVORK5CYII=\n",
"text/plain": [
"<Figure size 432x288 with 1 Axes>"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"train_X = np.linspace(-1, 1, 100)\n",
"train_Y = 2 * train_X + np.random.random(*train_X.shape) * 0.3\n",
"\n",
"## 显示模拟数据\n",
"plt.plot(train_X, train_Y, 'ro', label='Original data')\n",
"plt.legend()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 创建模型"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING: Logging before flag parsing goes to stderr.\n",
"W0804 13:33:33.643225 140261635254080 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n",
"\n"
]
}
],
"source": [
"## 占位符\n",
"X = tf.placeholder('float')\n",
"Y = tf.placeholder('float')\n",
"\n",
"## 模型参数初始化\n",
"## tf.random_normal()函数用于从服从指定正太分布的数值中取出指定个数的值。\n",
"## 初始化成[-1,1]的随机数\n",
"## Variable:定义变量\n",
"W =tf.Variable(tf.random_normal([1]), name=\"weight\")\n",
"b =tf.Variable(tf.zeros([1]), name=\"bias\")\n",
"\n",
"## 前向结构\n",
"## tf.multiply()两个矩阵中对应元素各自相乘\n",
"z = tf.multiply(X, W) + b"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 反向结构"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"W0804 13:33:33.736763 140261635254080 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.train.GradientDescentOptimizer is deprecated. Please use tf.compat.v1.train.GradientDescentOptimizer instead.\n",
"\n"
]
}
],
"source": [
"## reduce_mean计算张量的各个维度上的元素的平均值.\n",
"cost = tf.reduce_mean(tf.square(Y - z))\n",
"learning_rate = 0.01\n",
"\n",
"## 优化\n",
"optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 迭代训练模型\n",
"1.训练模型\n",
"\n",
"建立好模型后,可以通过迭代来训练模型了。TensorFlow中的任务是通过session来进行的。\n",
"\n",
"下面的代码中,先进行全局初始化,然后设置训练迭代的次数,启动session开始运行任务。"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Epoch: 1 cost= 1.1621948 W= [0.34350407] b= [0.628776]\n",
"Epoch: 3 cost= 0.103357114 W= [1.5536253] b= [0.3230953]\n",
"Epoch: 5 cost= 0.014590032 W= [1.8837897] b= [0.19906688]\n",
"Epoch: 7 cost= 0.00868373 W= [1.9694496] b= [0.16624025]\n",
"Epoch: 9 cost= 0.008319155 W= [1.9916037] b= [0.15773949]\n",
"Epoch: 11 cost= 0.0083027175 W= [1.9973322] b= [0.1555412]\n",
"Epoch: 13 cost= 0.008303675 W= [1.9988137] b= [0.1549727]\n",
"Epoch: 15 cost= 0.008304267 W= [1.999196] b= [0.15482597]\n",
"Epoch: 17 cost= 0.008304445 W= [1.9992955] b= [0.15478782]\n",
"Epoch: 19 cost= 0.008304496 W= [1.9993222] b= [0.15477769]\n",
" Finished!\n",
"cost= 0.008304502 W= [1.9993261] b= [0.1547761]\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAXIAAAD4CAYAAADxeG0DAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy8QZhcZAAAgAElEQVR4nO3dd1zV5R7A8c8DMkQ0FfdgOHIrjrQ0c+CeaVkqmt6Gq3uzXYrbzMqWZg5apmJDvaZ265q5GtqQrubeYLiFRBBBxnP/+B30AOccDnKAc+D7fr14Ab/zG0+/Q9/z+H2+v+dRWmuEEEK4LreiboAQQoj8kUAuhBAuTgK5EEK4OAnkQgjh4iSQCyGEiytVFBetVKmSDgwMLIpLCyGEy4qMjLysta6cfXuRBPLAwEB2795dFJcWQgiXpZSKtrRdUitCCOHiJJALIYSLk0AuhBAurkhy5JakpqYSExNDcnJyUTdFAN7e3tSqVQsPD4+ibooQIhdOE8hjYmIoW7YsgYGBKKWKujklmtaa2NhYYmJiCAoKKurmCCFy4TSpleTkZPz8/CSIOwGlFH5+fvKvIyEcKSICAgPBzc34HhHhsFM7TY8ckCDuROS9EMKBIiJgzBhISjJ+j442fgcIDc336Z2mRy6EEMVWWNitIJ4pKcnY7gASyM3ExMQwcOBA6tevT926dZk4cSI3btywuO/Zs2d58MEHcz1nnz59uHLlym21Z8aMGbz55pu57ufr62vz9StXrrBo0aLbaoMQ4jaZp1KiLT7HA6dPO+RSrhvIHZxv0lozePBg7r//fo4dO8bRo0dJTEwkzMInZlpaGjVq1GDNmjW5nvebb76hfPny+WpbfkkgF6KQZaZSoqPB1uI9/v4OuZxrBvLsNykz35SPYL5161a8vb35xz/+AYC7uzvvvPMOH3/8MUlJSSxbtowBAwbQtWtXQkJCiIqKomnTpgAkJSXx0EMP0bhxYwYNGkS7du1uTkEQGBjI5cuXiYqKolGjRjzxxBM0adKEHj16cP36dQA++OAD7rrrLlq0aMEDDzxAUvZ/gmVz6tQp7rnnHpo1a8aUKVNubk9MTCQkJIRWrVrRrFkz1q9fD8DLL7/MiRMnCA4O5oUXXrC6nxAinzI7mCNG5EylZOfjA3PmOOa6WutC/2rdurXO7uDBgzm2WRUQoLURwrN+BQTYf45s5s+fr59++ukc24ODg/XevXv1J598omvWrKljY2O11lqfOnVKN2nSRGut9bx58/SYMWO01lrv27dPu7u7699//93U1AB96dIlferUKe3u7q7/97//aa21HjJkiF6xYoXWWuvLly/fvF5YWJhesGCB1lrr6dOn63nz5uVoU//+/fWnn36qtdZ64cKFukyZMlprrVNTU3V8fLzWWutLly7punXr6oyMjCxttbVfdnl6T4Qo6Vau1NrHx3JsAp2q3PRnzXvoG+6ljFi1cmWeLwHs1hZiqlNVrdjNWl7JQfkma7p3707FihVzbP/pp5+YOHEiAE2bNqV58+YWjw8KCiI4OBiA1q1bExUVBcD+/fuZMmUKV65cITExkZ49e9psx88//8zatWsBGDlyJC+99BJgfChPnjyZH374ATc3N86cOcOFCxdyHG9tv2rVqtl3I4QQOVka0DSJrNGQsJ5PcrhKEL4rPqFf8xoOvbRrplas5ZXykW9q3LgxkZGRWbZdvXqV06dPU69ePQDKlClz2+cH8PLyuvmzu7s7aWlpAIwePZqFCxeyb98+pk+fblf9tqXywIiICC5dukRkZCR79uyhatWqFs9l735CiDyw0JG84u3LpJ7/5IGRbxJfuixL/K/Rt1l1h1/aNQP5nDlGfslcPvNNISEhJCUlsXz5cgDS09N57rnnGD16ND7Zr5VNhw4d+PLLLwE4ePAg+/bty9O1ExISqF69OqmpqUTYkefv0KEDn3/+OUCW/ePj46lSpQoeHh5s27aNaNNIedmyZUlISMh1PyFEPph1JDWwumkIXZ9YypfNuzPm0Pd8364UvSY8VCDPaLhmIA8NhfBwCAgApYzv4eH5KqxXSrFu3TpWr15N/fr1ufPOO/H29ubVV1/N9dgJEyZw6dIlGjduzJQpU2jSpAl33HGH3deePXs27dq1o0OHDjRs2DDX/efPn8/7779Ps2bNOHPmzM3toaGh7N69m2bNmrF8+fKb5/Lz86NDhw40bdqUF154wep+QggbcquUM3Uwj1by5+Hhr/FC32cIunKOr++8xuT171Dmkfw/+GON0rZKY+w5gVK1geVAVYwPonCt9Xxbx7Rp00ZnX1ji0KFDNGrUKF9tKSrp6emkpqbi7e3NiRMn6NatG0eOHMHT07Oom5YvrvyeCOFQ2Z/MBCMLYNaBTLqRxoL31vPhBQ98U64xad8GhjzaD7cRjgvgSqlIrXWb7NsdMdiZBjyntf5DKVUWiFRKbdZaH3TAuV1CUlISXbp0ITU1Fa01ixYtcvkgLoQwY+vJzNBQNh+8wIwNBzhzxZshd9ViUp9GVCwzrNCal+9ArrU+B5wz/ZyglDoE1ARKTCAvW7asLF0nRHFmpSLuzN/XmbF8N5sPXqB+FV++HHsPbYNyVrYVNIeWHyqlAoGWwK+OPK8QQhQpf/8sj9mnurnzcZuBvNsxFI5d5uXeDXns3iA83Itm2NFhV1VK+QJrgae11lctvD5GKbVbKbX70qVLjrqsEEIUPLNKud9rNqbf6PnM7fIoHU79j81rJzMu5pciC+LgoB65UsoDI4hHaK3/bWkfrXU4EA7GYKcjriuEEIUiNJS4NMVr/znAl3XaUzP+Ih+snUX3478Zr48caTyWHxBgBH0HTE2bF/kO5MooivwIOKS1fjv/TRJCCOeRkaFZHfkXr0VXIqFeB8Ye2MTEb5fik5pya6fM6j8HzzNuL0f8W6ADMBLoqpTaY/rq44DzFjp3d3eCg4NvfkVFRbF7926eeuopALZv387OnTtv7v/VV19x8GDex3Qzp501n3jL/DpCCOdw+PxVHlq6i5fW7qNeFV++mdiRSRvfyxrEs3PgPOP2ckTVyk9AsVhOpnTp0uzZsyfLtsDAQNq0Mco2t2/fjq+vL+3btweMQN6vXz8aN26c72u3adPm5nWEEAUkIsIIsqdPGwOYVtIg11LSmL/lGB/9dIpy3qV448HmPNiqFm5uKsfAp0UFPO9Tdq75ZGch2r59O/369SMqKoolS5bwzjvvEBwczI4dO9iwYQMvvPACwcHBnDhxghMnTtCrVy9at25Nx44dOXz4MGB92llL1wFjQYlHH32Uzp07U6dOHRYsWHBzv9mzZ9OgQQPuvfdehg0bZtfCE0II7Jr+WmvNpgPn6f72DsJ/OMmQ1rXY+lxnHmpT2wjiYHmKkOwcNM+4vZxy9sOZGw9w8GyOwpd8aVyjHNP7N7G5z/Xr12/OThgUFMS6detuvhYYGMi4cePw9fXl+eefB2DAgAH069fv5kpBISEhLFmyhPr16/Prr78yYcIEtm7dysSJExk/fjyPPPII77//vl3tPXz4MNu2bSMhIYEGDRowfvx49uzZw9q1a9m7dy+pqam0atWK1q1b387tEKLkyeWhnr/ikpix4QBbDl+kYbWyLBjWkjY/fwtNBljuwYeFGR8GSmVdPMKR84zbySkDeVGxlFqxV2JiIjt37mTIkCE3t6WkGHk0a9PO2tK3b1+8vLzw8vKiSpUqXLhwgZ9//pmBAwfi7e2Nt7c3/fv3v622ClHsWUqhWEl33Ig5y0fvrmF+jDtuGemEHfiW0SO74vHzX7YXTM4M6HamawqSUwby3HrOzigjI4Py5ctb/SDI64xn1qa8FULkwtqK9RUrQmxsll1/rdWEKX2e4tj50vQ8sZPpW8KpkXAZNn9ieYk2sx78TeZBvYhIjjwPsk8Ha/57uXLlCAoKYvXq1YCRa9u7dy9gfdrZvOrQoQMbN24kOTmZxMREvv7669s+lxDFlrUUCtzMbceWLsdzfZ7m4dDXSXIrxUdrZrL0q1eNIA6219ks5IFMe0ggz4P+/fuzbt06goOD+fHHHxk6dCjz5s2jZcuWnDhxgoiICD766CNatGhBkyZNbq6FaW3a2by66667GDBgAM2bN6d37940a9YsT9PlClEiWAu0cXFkLA3nsy7D6PrEUtY37sz4Xav5/sMJhJz43f7zF/JApj3yPY3t7Shu09gWpsTERHx9fUlKSuK+++4jPDycVq1aFci15D0RLikw0GJ54KHm9xA2dh5/nL5Cu4tHeWXDO9SP/Stv5842dW1hszaNrfTIXcyYMWMIDg6mVatWPPDAAwUWxIVwSrkt7gA5ygMTPUvzSo+x9Os9majYJN4c0oLPlz2X9yDugAVsCopTDnYK61atWlXUTRCiaFgbxIScg4+ADgvjv961mNljHOd9KjCsrT8v9WpAeR9P2w/1WCondNIAnsmpeuRFkeYRlsl7IZxGZi98xAjrdeDm+7m5cfrVt3n0iXcZf/8kKtQNYO349swd3MwI4mB93d+VK2HFCocuI1kYnKZH7u3tTWxsLH5+fgWyOKmwn9aa2NhYvL29i7opoqSztMRadtHRUKkSJCSQkp7BB3cP4b17HqZUbBpTAtIY7XeFUp1GWn+ox9J2Jw/c2TnNYGdqaioxMTEkJycXentETt7e3tSqVQsPD4+iboooyawMXFqyq3YzpvScwAm/2vQ+8jPTtoRT3RO4ft3mWpuuxNpgp9MEciGEyMHNzXZNN3DZ5w5e7fIY/27aldpXzjNr8xK6nMwlvgQEQFSU49pZSApy8WUhhHCszMfebQTxDBSrgnvxRqdRXPfw4p87P+fJXaspnWZjitlMTvhQT35IIBdCFB1L85SA7by4jw/7azUgrN0I9tZowN3Rf/LK5kXUi43JsR+lS+d4LB9wyod68kMCuRCiaFgrJyxd2moQT6x7J2+PfZVlsV5UTIrnnY1vcv/B7caCCB4eUK4cxMXZ/lAogtkJC5oEciFE0bA2J4qFIK6Bbxrey6yR07kYl8Lwdv68mLCPOzacMsoEc5t1sIhnJyxoMtgphCgadgxkAkSXr8a07uPYUacNTWqUY86gZgTXLl8IDXQ+MtgphHAu1p6u9POD69dJSblBeNsHWHjPQ3jodKZVT+KRJ3tTyt2pnmN0ChLIhRBFY84cy/nr+fPZmViKKXsTOVmuGn1PRzK1Rz2qjR5edG11chLIhRBFw8LTlRdnvMoc90asP3WWgKAqLBvQhM4N+hZtO12A/BtFCFEw7JmpMDQUoqJIT0tn+WfbCYny49t953kqpD6bnr6Pzg2qFHarXZL0yIUQjmfvTIXA/jPxTF63jz9j4ulQz4/ZA5tSp7JvITfYtUnVihDC8azNkWL2aPzV5FTe/u4oy3dFUbGMF1P7NWJAixoyaZ4NsrCEEKLwWHsE/vRptNZs3HuWbm/t4NNdUYy4O4Atz3Vi4IHtqKAg26kYYZGkVoQQjmeltPBU49ZM+/g3fjx2maY1y/HhqDY0r1U+T6kYkZP0yIUQeZfbQGa2hRuS3T14t8MwevaazJ4Dp5m5cwXrn+5C83uDb823YmvRCGGT9MiFEHljT+/ZrLTwR1WBad3Hc6piTfod+oFpWz6gyrW/sx5rbYKsYjZLYUGRwU4hRN7YWuwhIODmXCYXryYz+z+H2Lj3LEFxZ5i1eTEdo/ZYPs7dHdLTLZ/PBecNLyjyiL4QwjFs9ZKjo0kfO5aVlz15M64cKekZPP1TBON+WYN3eqr149LTjVRMMZ+lsKBIjlwIkTc25vL+s1o97n/gFaaf8yHYvzzfPX0fT8fstB3E4dYixy626LGzkEAuhLjFnqcxLaxAH+9VhmndxjHwkbe54FuR99a/zvLZDxO46SvLK9aby+x5m57yJCPD+C5B3G4SyIUQhsxBzOhoY3rZzIHI7ME8NPRm71kD6xt1IuTxJaxs2ZtRkV/z/Yfj6X/4R5T5IKh5b9vPz/iSnrfDyGCnEMJgbRDT3d3oJWdblOHEpUSmLfmen6950PzcUeZsep9mF07kPF4GLB1GBjuFELZZG8TMrCYx9bCTM2BR1TYs2XESL4/SzK5xleFfLMD9QlTeziscRgK5EMJgbaEHMzuqNmTaL6lElz3OwOAahPVtRJWy3vDUEOs9+mK20LEzkhy5EMJgY1DyvK8fTw58iVEPzcI9NYWIx9sxf2hLI4jbOl5KCAuF9MiFEIbsCz24uZGWoVneqh9vdxxBqps7z/2wgjHnd+MVPjb344vpQsfOyCGBXCn1MdAPuKi1buqIcwohCknmXCfZgu+eDz5n8i+XOVg5iE4ndzNr8xICblw1qkysCQ2VwF0EHNUjXwYsBJY76HxCiMJgYd6U+H89wxtnSrPq77JUqV6GRds/pPfO9Sh/f5gjpYLOyCE5cq31D0CcI84lhChEZrMOauDfTboQEvo2n1324B/tg9gytTd9flqHysgweuphYTJfuBMqtBy5UmoMMAbAX0axhXAOptLA4361mNJ9Ar8ENKfF2SMsWz2Dpm8cv7WfzBfu1Bz2QJBSKhD42p4cuTwQJIRzuF63Pgtr3kN4u8GUTk3hpe3LGLZ3E24B/lkf4rFj6TZR8OSBICFEFtsOX2Ta8Lf4K9Wdwfu2MHn7x1RKirdcMmhj6TZR9CSQC1HCnIu/zswNB/nvgfPUrVyOz3wvcM/n/4brV7PMJ56FtYeFJE3qFBwy2KmU+gzYBTRQSsUopR5zxHmFEPlkNpthWlAdPnx3Dd3e2sG2g+d4Ye96vn2pB/fMfckI3rZmHZSHfZyaQ3rkWuthjjiPEMKBzAYoI2s0ZErnCRw6X5ouqeeYtWomtc+betj2DFzKwz5OTWY/FKK4CgzkyoVYXu80ms+Ce1H96iWmbwmn54nfULKsmkuSwU4hShCtNWvL1uPVAa8S7+3L47+t45mfIiiTmmz9IBm4dFkyaZYQrsrKaj7HPvqMhx+bz/N9nyHw77N8vWwiU7Z9ZDuIgwxcujDpkQvhiiw8oHN9wj9ZsPsyH5QKxLdsVV77dgEP/bkZN+xIn8rApUuTQC6EKzJ7tB5gS927mNZ9HGe8qvLgvs1M2vYJftev2ncuayWHwmVIIBfCFZny2WfLVmJGt7F8d+c93Hkpmi8iXqJdzAH7z6OUDHAWA5IjF8JZ2LOCvUlqQCDhbQfR7fHF/BDUkpe2f8LXyybS7txhywe4u1veLnnxYkF65EI4gzxMSrU7Ko6wR97lSIo73Y79yvTvl1L76kUjzz1qFHz6aZa0i83tkhcvFqRHLoQzyJbzBozfw8Ju/hp37QYvrtnLg0t2keBdhvCARD6MXE7thEtGnjs8HBYtMr4HBBhpk9y2S168WJAHgoRwBm5uYOn/RaXISEtnTWQMc789REJyGo/dG8RTIfUp42X2D2orq/yI4sXaA0HSIxeiMFnLg1vJVR9p1o6Hw3fx4to/qVfFl/881ZFJfRrlDOJjxhjpGK1vpWVk4YcSQwK5EIXFVsDNNilVkocXc7s9Qd/eYRy/mMgbDzbnizH30GDLhpwfBHakZUTxJqkVIQpLboszmILyd57VmdlzAmfKVOShNrWY1LsRFcp45hwQBSP4Zw/imZQyZjQUxYbMtSJEUbM2l0l0NLi5EdMwmBlPvMv3CR40qFqWNYOa0iaw4q39rPW83d3B0iRYUlpYYkhqRQhHya0O3EpgveFWisVtB9O9Vxg/x6Uzqdp1vn7q3ltBPPO8lnrzYARxmSu8RJMeuRCOYE8d+Jw5OVIjv9ZqwpSeEzhWKYAeR3cx/ftwalb0gcopRg88OtpIkdhKgWY+Yi9VKyWW5MiFcAR7Fyc25cFjL11hbufRrGnWnZrxF5m5eQndTvx2az9buW9zPj5SD16CSI5ciIJk5+LEGcOG82X9jrz238MkJiYzftdq/rXrc3xSU27t5O5uXxCXya6EiQRyIRzBjsWJD527Sti6ffxx+gptAyvySs1Y7nx/NZgHcXt74rKajzAjg51COIKNxYmvpaQx5z8H6ffeT0TFJvHmkBZ8MfZu7nxsmOXH5gMCbF9LBjJFNtIjFyKvzB+Hr2iqLImLM34uXdr42d8f/cocNrUIYebbOzgXn8ywtrV5qVdDyvt43jpXaKjl1Ej2evHMAU9JpwgLJJALkRfZq1NiY2+9Fhtr9JZXrOCvG25M3xTN1v2RNPw7hoWt76D14Ob2XUNWrBd5JFUrQuSFrXpujJrwDzqH8l7wANx0Bs/8tIp/7F5PqdLeUl0i8k2qVoRwBBsrze+q3YypPcZzvJI/vY/8zLQt4VRPMPXYM+c+kUAuCoAMdgqRFxaezrzscwfP9nmGYcPnklLKk09Wz2DxV3NvBfFM0dG5rvwjxO2QHrkQeWH2dGYGis9b9OD1TqNJ8vTmyZ1f8M+9GyntYWVZNbC58o8Qt0sCuRB5YQq+B+ctIqzZYP5XsyF3nz3EK98soJ6vGyxaaOyXverEnKRZhINJIBfCWjmhhWqRxJQ03i7XkmW9J1PBx5O3+zZiUMs+KPV8zvNmzpViiY1cuxB5JYFclEyZwTv7pFTm5YRmaRA9fDjf7j/PrI0HuZCQzLC2/rzUsyF3+HhYPn9mfbi1KheZYlY4kARyUfJkrwW3VYKblET0P59n2qYz7KjRhMbVy7F4RCta+lew71oWZjyUJzOFo0nViih5LC3QYEGKeyneu+dhejz6Prv9gpj6wzI2+J22P4iD0SuX1etFAZMHgkTJY23FejM7/Zszpcd4TvrVpu/hH5m65UOqJZrSLvKYvCgi8kCQEJmszVQIXPIpz5yuj/FVky74/32OZV9Oo/OpP7LuJCWEwslIakWUPBZmKkx3c2dFcG+6jlnKfxp25F87P+e7j5/MGcQzySr1wolIj1yUPNkmpdrfvD1hg15g7/VStK/rx+z7m1L3u0SI/Dek3bB+HikhFE5CArkomUJDSXjgId767ijLd0VR0d2Tdx9uzMDgGiilsgZ7a7XgUkIonISkVkSJo7Vm496zhLy1g093RRHaLoAtz3Xm/pY1jSCeKTTUWIVn5UpZpV44NemRi5IjIoJTc99lWpMB/BjUiqbeaYRP6ERw7fK2j5P5wYWTc0ggV0r1AuYD7sCHWuvXHHFeIRwleUUESz7+jkW9JuOZnsaMzUsYeWQb7vWX2heQra3kI4QTyHdqRSnlDrwP9AYaA8OUUo3ze14hHOWnY5fpvSuFd9s9RI9jv7Dlw3GM/uNr3K9dk8oTUSw4IkfeFjiutT6ptb4BfA4MdMB5hbBPRIQxp4mbm/F9wgQIDORiWT/+NWwmIz76FZ2ezoovprBwwxtUTYy7daxUnohiwBGplZrAX2a/xwDtsu+klBoDjAHwl9F+cTvMZynMzFND1rlMoqNJX7KUiODezBv0CCnunkz8dTXjD27C++L5nOeUv0VRDBTaYKfWOhwIB+MR/cK6rnBBdgZsxowxVq03mzflz2r1COvxJPuq16fjqT+YtXkJQX+fBT8/o9JEJq8SxZAjAvkZoLbZ77VM24TIu+wzE1oJ2IDxu2lbvFcZ3uo4khWt+lDp2hUWbHiD/od+4GYxYVwcrFghlSeiWHJEIP8dqK+UCsII4EOB4Q44ryiJLM1MaBaws9PAhkb3MbvrE8T5lGNU5Nc8++NKyt3Itr/WxrkleItiKN+BXGudppT6J7AJo/zwY631gXy3TJRMeRh8PFmhBlP7TuTnmk1ocfYoy9bMoOmFE9YPkMmuRDHlkCc7tdbfaK3v1FrX1VpL0lHcPjsGH5PdPXj73uH0eux9/qzdmNk1kvj3jwtoevGkMcXs+PHGd0tksitRDMmTncK5WFpRx8wPgS2Z2mM80RVqMPCOG4T9sxtVynrDU0Ny7mxt3nEpORTFjMy1IpyL+Yo6Zi74VuTJAS/yyMOzcXd3JyIokflLn6HKHT5G7XhERM5zWevdS8mhKGYkkAvnYzZZVVoZXz5p3Z+Qx5ewuf7dPPvLF3zLH3R49lEj5631rdx39mBuYd5xKTkUxZEEcuG09tzXl4HPr2Rmt7G0OnOI7/77Kk890ROvb762XNmSPfct62WKEkLW7BROJz4plTc2HWbVb6epUtaLaf2a0KdZtVtTzFrLfSsFGRmF21ghCpG1NTulRy4KV/Z5UTLTIRER6MBA1jXtSsjkNXz2azSj2wfy/bOd6Nu8etZ5wiX3LUQWUrUiCo+1pzZ//pnjGzYzteMYdgW0IPjsYZbt+JimzSaDd5Oc57FU2SK5b1GCSWpFFJ7AwBzLpiWX8mRh+6EsbTuI0qkpvLjjU4bv+S9uaCOnHRVl+VyW5mOR3Lco5qylViSQi8KTLbe9rU5rpncbx+kK1Rm8fyuTtn1M5aQrt/aXnLcQWVgL5JJaEYXH3x+iozlX1o9ZIWP4tkEH6sT+xarPJtH+9D7L+wshciWBXBSatFfmsGzxet5pO4Q0N3ee/2E5T/z2b7zS03LuLDlvIewmgVwUij9O/01YrD+HOo6iy9n9zNzwDv7xFyzvHBAgOW8h8kACuShQV5Ju8Pp/j/D576epVs6bJSNa0bNJH5T7JMsHKGV9gFMIYZHUkYu8s1YLbkZrzdrIGELe2sGXu//isQ5BbH62E72ammrCpRZcCIeRQC7yJrMW3MY8J8cvJjA0/BeeW70Xfz8fNtaJZ8o/++Bb2vNW4Jd5UIRwGAnkIm+sreATFsb1G+m88d/D9J7/I4fPJzB3cDPWloui8cTHcwZ+kHlQhHAQqSMXeWNlnpMt9doy/fG5xPx9ncGtahLWpxF+vl4WHwICbD/sI4SwSOrIhWOYasEznS1biZkhY9jUoD31Pdz5YszdtKvjd2t/a4s4yOIOQjiMpFZE3phy26lu7oS3HUS3xxezo05rXqx6nf881fFWEM8cELX2Lz4Z1BTCYaRHLvImNJTIa+6E/XGVw+VrEnL6f8zYuZLap4/CfP9bg5U2lmuTQU0hHEt65OKWXMoK/752g5fX/skDJ8tyNaAuS/2v8eH6udSOPnJrIHPkSBgxwnoQl0FNIRxOeuTCYG2KWUAPH87qyBhe+/Yw8ddTGXtfHZ4KqU+ZBvVyBmxbg+fysI8QBUICuTBYKSs8+mi7V94AABHVSURBVPpCpiTU4beoOFoHVGDOoKY0rFbOeD2vA5aSFxeiQEggF4ZsQTnJw4sF7Yfy4V2D8L2YwOsPNGNI69q4uWVbqcdSaaElkhcXosBIjryks1BdsrleW7o/tpgldw9hUPTvbH2uMw/f5Z81iIPlpzMtkby4EAVKeuQlWba8eEy5yszoNpbv69/NnZeiWR3xEnfFHICtS4z94+KyrsaTGZjDwoyeuVJZc+Q+PhLAhSgE8mRnSWZ66jLVzZ2P2tzP/A7DAHj651U8GrkBD0vzhIP1AC3LrwlRoGSpt+LsdgOomxu/1WzMlB4TOFo5gO5HdzHj+3BqJlzK/Vh5xF6IQieP6BdXNsoGbQXzuGs3mPvgZFbXuYea8Rf5YO0suh//zf7ryiP2QjgN6ZG7ujxOSpWRoVkd+Rdzvz1MYtINHovcwMQdy/FJTTF28PGB0qUhNtb2daVHLkShkx55cWWtZxwdDZUqGT+bBikPT51L2I0AIqP/pm1gRWbf35QGW+Lh2HdZ0zIgj9gL4UIkkLs6W7Xcpl71NQ9v5gd15aMjZSjnEcu8Wsk8+NqTqAm55NQz8+4VKxq/Z69aEUI4BUmtuLrsOXIzGthU/x5mdXuCs+WqMHTvJl76cz0VrlzOur+UCQrhEiS1Ulxlr+U2+atcFWZ0H8eWem1pePEUCza8QJszhyyfw7TCjwRyIVyT9MiLk8BAbvx1hg/aDuK99g/jpjXP/LSK0ZEb8MhIt32sUpCRUTjtFELcFumRlwC/THqNKZHxHK9Yi55HdjJ9Szg1Ei7bd7BMaCWEy5K5VpyRtXnBrWyPTUzhuS/3MvRUWZKrVufjHYtYun4uNTw1+PlZuYgZqUIRwqVJasXZWBq89PGBUaPg00+zbM/wKcPnr33C63F3kHQjjSc61uFfXetT2tM96zmt1ZqDUQ8uVShCuARrqZV89ciVUkOUUgeUUhlKqRwnF7fByrzgLF6cZfuBKkE8MHgmk8/40DD6AN/WiefFXg1zBnGwPEuhjw+sXGk81CNBXAiXlt8c+X5gMLDUAW0RkOuj74mepXnn3lA+ad2fCtcTeOvrtxl8YCvqCx/wzrAclM0rW2RCKyGKHYekVpRS24HntdZ25UsktWKDlTSIBv57Z3tmdhvDBd+KDNuziRd/+JTyyYm3dpLH5oUo1oq8akUpNQYYA+AvFRI5Zc5gaGFe79N3VGVa9/Fsr9uGRhdOsuirubQ6eyTnOWQiKyFKpFwDuVLqe6CahZfCtNbr7b2Q1jocCAejR253C4sr86lnK1aEhAS4ccN4TWtQihQ3dz5oO5j37nmYUhnpTN0SzqjIrymlrdR7ywekECVSroFca92tMBpSomSvTLEw0+DO2k2Z0vtfnCxfgz6Hf2Lq1g+onhBrtYJFSgiFKLmkjrwwZdaBjxhhdWbBSz7leabvswwfNpc0rfgkMJFFez6jemLcrbUvFy0yvgcEGGkYWRNTiBItX4OdSqlBwHtAZeAKsEdr3TO340rkYKeNya0A0pUbq1r0ZF6nUVz38GLcr2t58swveJ84VsgNFUI4qwIZ7NRarwPW5eccJYal+nCT/VXqENbzSfbWaED7qL3M3ryIusl/G71sIYTIhaRWCoKlR+ktVJQkeJZmRsgYBox6hzN3VGX+tsVEfDmFumVLSapECGE3mTTL0aytoVmx4s1BTQ38p+G9zOr6BJd8KzDi+I88PzCYO977uujaLYRwWRLIHcW8Djy7pCRjHUwfH6I9yzG1+3h+qNOaphdPEh7sSfDrbxR+e4UQxYYE8rwyr/+2d41LICX+KkteX8X750rhmZbKjMgvGTmqB+4jhhZSw4UQxZUE8rywljYpXdpmEP8poAVT+zzFqYul6deyOlP7NaZquSGF1GghRHEngTwvrM1MaCWIXyxTnle6Ps6Gxp0J8Exn+Yi23Hdn5UJoqBCiJJFAnhd2zmWSrtyICO7NvE6PkFLKk4lVkhn/r/vx9rAwxawQQuSTBHJ7ZObF7Xh46s9q9ZjSYwJ/Vr+Te31TmTW2G3Uq+xZCI4UQJZXUkecmMy9ubYUdk6uePkzvNpaBj7zNufJVWVD7GivCBlLnu/WWl20TQggHkR55bmw8kQlGTfjGRvcxu+vjXC5TnkeO/cBzq16lnLeH9cFRkId9hBAOIz3y3NjIi5+qXodHHprFUwNepFpCLOu/nMzMB4KNIA7WB0fDwgqwwUKIkkZ65Lnx98+RVkl292Bxr8dZ3KwPXinJzNy8hBFx+3F/5ZWsPW1rHwKyAIQQwoEkkOdmzpws6ZEfA4OZ2vNJospXZ0DzGkzp24gq5R60fKyFD4Gb24UQwkEkkOfG1MO+MPsNZjfoxdeN7qOOZzorR7bj3vqVbB+b7UMAkAUghBAOJ4HcXPbl14D0v6+wvOsI3ho8hxtu7jzbpR5jO9XBq5QdNeGyer0QohBIIM9kYfm1vdXqEzZyKvur1aPjqT3M7l6HwJD6eTtvaKgEbiFEgZJAnsmswiTeqwxv3jeSlS37UDnxbxauf42+h39C7QqAR4cVcUOFECIrCeSZTp9GA+sbd+aVLo8R51OO0ZEbefbHlZS9cf3mPkII4WwkkJucaNKGqU3uZ2dgC1qcPcKy1dNpevFk1p2k2kQI4YRKfCBPTk3n/W3HWdpvGt7Xr/HKpvcZtncT7joj645SbSKEcFIlOpBvO3KR6esPcDouiUEtazH5+kEqf3UQ0ODnZ+wUFyfVJkIIp1Z8A3n2lXz69IFvvoHTpznfoBmzRs7gm6ue1KlchlWPt6N9vUpAMIweXtQtF0KIPCmec62Yz1iotfF98WLSTv/FR637E9JrClvi4Lmq1/m2yhnad2sjsxMKIVxW8eyRW5is6n/V7ySs55McrFqXzid2M2vzYvzjL4BSt+YZl9kJhRAuyDV75BERtuf4NisTjPcqw+QeTzJ45JvE+pRn8bpX+WTNDCOIQ87FImR2QiGEi3G9Hrk9c3z7+6Ojo1nXpAtzujzGldJleXT3Bp75KQLfzJpwW6ReXAjhQpS2Y/kyR2vTpo3evXv37R0cGGh9tZ6AAJgzh+PJbkzZdppfajWl5ZnDvPLd+zS5eMr+awQEQFTU7bVPCCEKiFIqUmvdJvt210ut2OgtXz9znnkfb6X38bIcCmjMq7+vYm3EizQpnQHjxxsBOjdSLy6EcDGul1qxMsf31jptmNZ9HDHlqzH45C9M/mgKlXz7A9ny59lTM3BrwNPUo5eBTiGEK3G9HvmcOUav2eRs2UqMu38Sjw6ZgXfaDT5f9TJvr55DJV8vy8eHhkJ4uBG0lTK+r1hhBPKoKAniQgiX43o9clOgTZ0ylWWVg3nn3uFkKMULOz7lid/W4ZmRZuwXGGi9dy1TywohihHXC+RA5L29CZtYm8PnE+h6KpKZmxZRO7OcMJPUhAshSgiXSq38fe0GL6/9kwcW7yL+eipLRrTmo/51qV3e2/IBUhMuhCgBXKpHPnPjATb+eY4x99VhYkh9yniVgqahMCLUeDjIUiml1IQLIYo5lwrkz/dswNhOdWlUvVzOF2XFeiFECeVSqZVaFXwsB3HIUc0CSE24EKJEcKlAbpOlssLwcBnoFEIUe64TyHObKAuMoB0VBRkZUhMuhCgx8pUjV0rNA/oDN4ATwD+01lcc0bAs7JkoSwghSqj89sg3A0211s2Bo8Ck/DfJAgvzi0tpoRBCGPIVyLXW32mtTY9S8gtQK/9NssBaCaGUFgohhENz5I8C31p7USk1Rim1Wym1+9KlS3k7s7USQiktFEKI3AO5Uup7pdR+C18DzfYJA9LIMdXgLVrrcK11G611m8qVK+etlVJaKIQQVuU62Km17mbrdaXUaKAfEKILapWKzAHNsDAjneLvL9PNCiGESX6rVnoBLwKdtNZJue2fLzJjoRBCWJTfHPlCoCywWSm1Rym1xAFtEkIIkQf56pFrres5qiFCCCFuj+s82SmEEMIiCeRCCOHiJJALIYSLUwVVMWjzokpdAixMHm6XSsBlBzbHUaRdeSPtyhtpV944a7sgf20L0FrneBCnSAJ5fiildmut2xR1O7KTduWNtCtvpF1546ztgoJpm6RWhBDCxUkgF0IIF+eKgTy8qBtghbQrb6RdeSPtyhtnbRcUQNtcLkcuhBAiK1fskQshhDAjgVwIIVycUwZypdQQpdQBpVSGUspqmY5SqpdS6ohS6rhS6mWz7UFKqV9N279QSnk6qF0VlVKblVLHTN8rWNini2kCscyvZKXU/abXlimlTpm9FlxY7TLtl2527Q1m24vyfgUrpXaZ3u8/lVIPm73m0Ptl7e/F7HUv03//cdP9CDR7bZJp+xGlVM/8tOM22vWsUuqg6f5sUUoFmL1m8T0tpHaNVkpdMrv+42avjTK978eUUqMKuV3vmLXpqFLqitlrBXm/PlZKXVRK7bfyulJKLTC1+0+lVCuz1/J3v7TWTvcFNAIaANuBNlb2ccdY8LkO4AnsBRqbXvsSGGr6eQkw3kHtegN42fTzy8DruexfEYgDfEy/LwMeLID7ZVe7gEQr24vsfgF3AvVNP9cAzgHlHX2/bP29mO0zAVhi+nko8IXp58am/b2AINN53AuxXV3M/obGZ7bL1ntaSO0aDSy0cGxF4KTpewXTzxUKq13Z9v8X8HFB3y/Tue8DWgH7rbzeB2MVNQXcDfzqqPvllD1yrfUhrfWRXHZrCxzXWp/UWt8APgcGKqUU0BVYY9rvU+B+BzVtoOl89p73QeBbXdBztee9XTcV9f3SWh/VWh8z/XwWuAjkcQkpu1j8e7HR3jVAiOn+DAQ+11qnaK1PAcdN5yuUdmmtt5n9DRXc2rh5bJcNPYHNWus4rfXfGIu09yqidg0DPnPQtW3SWv+A0XGzZiCwXBt+AcorparjgPvllIHcTjWBv8x+jzFt8wOu6FuLQmdud4SqWutzpp/PA1Vz2X8oOf+I5pj+WfWOUsqrkNvlrYx1U3/JTPfgRPdLKdUWo5d1wmyzo+6Xtb8Xi/uY7kc8xv2x59iCbJe5x8i6Nq6l97Qw2/WA6f1Zo5SqncdjC7JdmFJQQcBWs80Fdb/sYa3t+b5f+ZqPPD+UUt8D1Sy8FKa1Xl/Y7clkq13mv2ittVLKau2m6ZO2GbDJbPMkjIDmiVFL+hIwqxDbFaC1PqOUqgNsVUrtwwhWt83B92sFMEprnWHafNv3qzhSSo0A2gCdzDbneE+11icsn8HhNgKfaa1TlFJjMf4107WQrm2PocAarXW62baivF8FpsgCuc5lLVA7nAFqm/1ey7QtFuOfLKVMvarM7flul1LqglKqutb6nCnwXLRxqoeAdVrrVLNzZ/ZOU5RSnwDPF2a7tNZnTN9PKqW2Ay2BtRTx/VJKlQP+g/Eh/ovZuW/7fllg7e/F0j4xSqlSwB0Yf0/2HFuQ7UIp1Q3jw7GT1jolc7uV99QRgSnXdmmtY81+/RBjTCTz2M7Zjt3ugDbZ1S4zQ4EnzTcU4P2yh7W25/t+uXJq5XegvjIqLjwx3rQN2hg92IaRnwYYBTiqh7/BdD57zpsjN2cKZpl56fsBi6PbBdEupVSFzNSEUqoS0AE4WNT3y/TercPIHa7J9poj75fFvxcb7X0Q2Gq6PxuAocqoagkC6gO/5aMteWqXUqolsBQYoLW+aLbd4ntaiO2qbvbrAOCQ6edNQA9T+yoAPcj6L9MCbZepbQ0xBg53mW0ryPtljw3AI6bqlbuBeFNnJf/3q6BGcPPzBQzCyBOlABeATabtNYBvzPbrAxzF+EQNM9teB+N/tOPAasDLQe3yA7YAx4DvgYqm7W2AD832C8T4lHXLdvxWYB9GQFoJ+BZWu4D2pmvvNX1/zBnuFzACSAX2mH0FF8T9svT3gpGqGWD62dv033/cdD/qmB0bZjruCNDbwX/vubXre9P/B5n3Z0Nu72khtWsucMB0/W1AQ7NjHzXdx+PAPwqzXabfZwCvZTuuoO/XZxhVV6kY8esxYBwwzvS6At43tXsfZhV5+b1f8oi+EEK4OFdOrQghhEACuRBCuDwJ5EII4eIkkAshhIuTQC6EEC5OArkQQrg4CeRCCOHi/g8bMLAq3z5PZwAAAABJRU5ErkJggg==\n",
"text/plain": [
"<Figure size 432x288 with 1 Axes>"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYIAAACQCAYAAAAFk2ytAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy8QZhcZAAAWzElEQVR4nO3deZgU5bXH8e9hBhAQBIUgCjoqrrkRhBHhJlGjhCCJYiKK4hXRIGau3BiXJOQaE8198sTEm8QdMoobQeNCNCS4Ae5G1MEAOmIQFCJeEHABlEVgzv3jrXaa7p6ZBqa7uqd/n+epZ6rrVHedLoo6Xdv7mrsjIiKlq1XcCYiISLxUCERESpwKgYhIiVMhEBEpcSoEIiIlToVARKTElcedwI7q2rWrV1RUxJ2GiEhRmTt37hp375YpVnSFoKKigpqamrjTEBEpKma2rKGYTg2JiJQ4FQIRkRJXMoVg6VIYPRrefjvuTERECkvJFILycrjnHqiujjsTEZHCUjKFoGdPOPlkmDwZNm+OOxsRkcJRMoUAoKoK1qyBadPizkREpHCUVCEYPBgOOggmTow7ExGRwlF0zxHsilat4Ec/gkWLYOvWcN1ARKTUldyucNy4uDMQESksJXVqKKGuDmbOhPXr485ERCR+JVkI5s6FIUPC7aQiIqUuZ4XAzG43s1Vm9noDcTOzG8xssZktMLN+ucolVWUl9OkTLhqry2YRKXW5PCK4ExjaSPwk4OBoGAfk7V4es3Ar6fz5MGdOvpYqIlKYclYI3P1Z4MNGZhkO3O3BHKCzmfXIVT6pzj4bOnbUraQiInFeI9gXeDfp9fJoWl7svjuccw688AJs2ZKvpYqIFJ6iuFhsZuPMrMbMalavXt1sn/vLX8Kbb0Lr1s32kSIiRSfOQvAe0Cvpdc9oWhp3r3b3Snev7NYtYwc7O6Vz51AEtm4Nt5SKiJSiOAvBdGB0dPfQQGCtu6/IdxK1tVBRAbNm5XvJIiKFIWdPFpvZvcDxQFczWw78HGgN4O6TgEeAYcBiYANwXq5yaUzv3vDZZ+Gi8ZAhcWQgIhKvnBUCdz+ribgDF+Vq+dlq2xbOPx+uvRaWLw/NVYuIlJKiuFicaxdeGB4su/XWuDMREck/FQLggANg6NBQCHQrqYiUmpJrfbQhV10FH38MZWVxZyIikl8qBJEBA+LOQEQkHjo1lGTVKvjhD0PHNSIipUKFIEldHVx3HUyaFHcmIiL5o0KQZO+94TvfgTvvhA0b4s5GRCQ/VAhSVFXBRx/BfffFnYmISH6oEKQ47jg4/HA1Ty0ipUOFIIUZXHwxHHoobNoUdzYiIrmnQpDBhRfClCmw225xZyIiknsqBI2YPx/Wro07CxGR3FIhaMDChdC3L9x9d9yZiIjklgpBAw4/PDxtPHFiaJBORKSlUiFoRFVVODJ49tm4MxERyR0VgkaccUbozlK3kopIS6ZC0Ij27WHMGJg5U08ai0jLpULQhCuugKVLQ1EQEWmJ1Ax1E7p2DX8TF4zN4stFRCQXdESQhXfegT59YMaMuDMREWl+WRUCM7vYzDpZMNnMXjWzIblOrlD07Alr1uiisYi0TNkeEZzv7uuAIUAX4BzgmpxlVWBat4axY+HRR8PRgYhIS5JtIUicGR8GTHH32qRpJeGCC8L1gerquDMREWle2RaCuWb2BKEQPG5mHYG63KVVeHr1gpNPhttug82b485GRKT5ZHvX0HeBvsDb7r7BzPYEzstdWoVpwgRYvFh3DolIy5JtIRgEzHP3T83sP4B+wPW5S6swDRwYBhGRliTbU0MTgQ1m1ge4DFgClGS7nOvWwbXXhjaIRERagmwLwVZ3d2A4cJO73wx0zF1aheuzz+DKK+Gmm+LORESkeWRbCNab2U8It43OMLNWQOvcpVW4unaF008PPZh98knc2YiI7LpsC8FIYDPheYKVQE/g2pxlVeCqqmD9epg6Ne5MRER2XVaFINr5TwX2MLNvAZvcvclrBGY21Mz+aWaLzWxChvgYM1ttZvOiYewOf4MYDBoUmpxQpzUi0hJk28TEGcDLwOnAGcBLZjaiifeUATcDJwFHAGeZ2REZZr3P3ftGw207lH1MzOCii6B793BkICJSzLK9ffQK4Gh3XwVgZt2AWcCDjbxnALDY3d+O3vMnwsXmN3Y+3cIxdmx42lhEpNhle42gVaIIRD7I4r37Au8mvV4eTUt1mpktMLMHzaxXlvnELvFQ2fLlsHZtvLmIiOyKbAvBY2b2eHROfwwwA3ikGZb/V6DC3Y8EZgJ3ZZrJzMaZWY2Z1axevboZFts83n0XKipCsxMiIsUq24vFPwSqgSOjodrdf9zE294Dkn/h94ymJX/uB+6eaLnnNqB/A8uvdvdKd6/s1q1bNinnRa9e4cLxpElQV1ItL4lIS5J1xzTuPs3dL42Gh7J4yyvAwWZ2gJm1Ac4EpifPYGY9kl6eAhTd87pVVaH9odmz485ERGTnNFoIzGy9ma3LMKw3s3WNvdfdtwLjgccJO/j73b3WzH5hZqdEs33fzGrNbD7wfWDMrn+l/DrttPCQmTqtEZFiZV5kN8JXVlZ6TU1N3Gls58c/huuvhxUroEuXuLMREUlnZnPdvTJTTH0WN4PLLoMlS1QERKQ4ZfscgTTiC1+IOwMRkZ2nI4JmsnIlDB4MD2VzGV1EpICoEDSTbt1g0SK45Za4MxER2TEqBM2krAzGjYNZs+Ctt+LORkQkeyoEzWjsWCgvDw+YiYgUCxWCZrT33vDtb8Mdd8DGjXFnIyKSHd011MwuvRSOOUZNTohI8VAhaGYDB4ZBRKRY6NRQDmzaBHfdBbW1cWciItI0FYIc2LQpNEZ33XVxZyIi0jQVghzo3BnOOgvuuUed1ohI4VMhyJGqKtiwAe6+O+5MREQap0KQI5WVcPTRoXnqImvgVURKjApBDlVVQdu2UEC9a4qIpFEhyKFzz4VXX1XrpCJS2PQcQQ61isrsuqgvt06d4stFRKQhOiLIsTVrYN994eab485ERCQzFYIc69oVBgyAP/wBtm2LOxsRkXQqBHlQVQXLlsFjj8WdiYhIOhWCPBg+PLRMOnFi3JmIiKRTIciD1q1DXwWPPgorVsSdjYjI9lQI8mT8eJg3D3r0iDsTEZHt6fbRPOnePQwiIoVGRwR59PHHMGoUTJsWdyYiIvV0RJBHnTrBSy/Bs8/CU0/Vt0d0xBFgFnd2IlKqdESQR61aQXU19O4dOq457zwYNKi+UboHHghNVy9apK4uRSR/dESQZyeeGIa6urDDX7asvimK3/0O5swJ43vsAf37w7BhcNll8eUrIi2fCkFMWrWCww4LQ8Jzz8Ebb8Arr0BNTfg7f359vE+fcNfR0UeH00qVlaH5ChGRXWFeZI3lV1ZWek1NTdxp5I17uH7w2WfhCeWamtAXcqK5igkT4Fe/gi1bYNasUBy6dYs3ZxEpPGY2190rM8VyekRgZkOB64Ey4DZ3vyYl3ha4G+gPfACMdPelucyp2CQuIrdpA5Mnh/ENG8KRwiuvQL9+YVptbTiNBLD//vVHDGecAQcemP+8RaR45KwQmFkZcDPwdWA58IqZTXf3N5Jm+y7wkbv3NrMzgV8DI3OVU0vRvn24yDxoUP20Qw+Fp5+uP6VUUxNuU+3XLxSC55+HW26pLxD9+sHuu8f2FUSkgOTyiGAAsNjd3wYwsz8Bw4HkQjAcuCoafxC4yczMi+18VQFo1w6OOy4MCR9+GIoGhKYtnn8e7r03vDaDzp3DNYm994bf/x5uuAHKysJQXh7+vvgidOgQYvffXz898XfGjPBZ1dXw5JPbxzp0gBtvDMubMiUcxSRiZWVh+ZdeGuL33w9LltTnbgZ77QUXXBBeT50Ky5dv/5179IDRo8P4XXfBqlXbx/fbD0ZGPysmTw7PcSQ76CA49dQwPmlSONJKdthh9UdZN9wAW7duHz/ySBg8OJy+u+669H+T/v3h2GNh8+ZQhFMNGgQDB8Inn8Ctt6bHjz02fMaHH4bvl2rwYPjSl2Dlyvp/12TDhoUfCP/6V+ZnV4YPDz8SliyB6dPT46efDj17wsKFmRtMHDUqPCS5YAHMnp0eHzMGunQJP0qeey49Pm5c2Eb+/vdwW3Wq8eND8yzPPBM6eEp1ySXh78yZ8Prr28fatIGLLgrjM2aEGzOSdegQlg/w8MPwzjvbx7t0CflD2Dbfe2/7ePfu4ftD2DZTt71evWDEiDB+xx3p296BB4b1D6Fl4kzb3kknhfEbbwzb3iGHwDe/SW64e04GYAThdFDi9TnATSnzvA70THq9BOja2Of279/fZeetXOk+Y4b71Ve7jx/vvnZtmD5tmvvo0e6jRrmPHOl+2mnup57qvmlTiN9yi/sJJ7gfd5z7l7/sPnCg+4AB9Z/705+6H3KI+0EHuVdUuPfsGV4njB7t3r69e9u27mVl7uC+77718WHDwrTk4dBD6+Nf/Wp6vLKyPt63b3r8a1+rj/funR4/5ZT6ePfu6fFRo+rj7dunxy+8MMS2bUuPgfvll4f42rWZ41dfHeLLl2eO//a3Ib5wYeZ4dXWIv/xy5vi994b47NmZ43/7W4j/5S+Z4888E+J//GPm+Ny5IT5xYub4okUh/pvfZI6vWBHiV16ZOf7JJyF+ySXpsfBzMRg7Nj3esWN9fOTI9Pg++zTftnfUUTu+7Z188o5veyNH+i4BaryB/WrOLhab2QhgqLuPjV6fAxzj7uOT5nk9mmd59HpJNM+alM8aB4wD2G+//fovW7YsJzlLftXV1d86u2VL/bMTyZvkbruFv5s3pz9bYVYf37gxPd6qVThSgvCrO3VTLyurP2Javz49Xl5eH0/0Mpesdevw+e6Z423aNB5v2zbkX1cXlp9qt93CPNu2hfxTtWsXlrF1K3z66Y7H27cP32HLlvRfpBB+NZeXhxsVNm5Mj+++e1iHmzfDpk07Hu/YMfwbbdoU5knVqVP4N964MeSQao89wt8NG8J32JG4WX2PgZ9+mn6016pVyA/Cuk/tS6SsrP7U6vr16dteU/Hy8rB+IWwbqdte69b1297atenTdkZjF4tzWQgGAVe5+zei1z8BcPdfJc3zeDTPi2ZWDqwEunkjSZXaXUMiIs2hsUKQyyeLXwEONrMDzKwNcCaQeiZyOnBuND4CeLKxIiAiIs0vZxeL3X2rmY0HHifcPnq7u9ea2S8I56qmA5OBKWa2GPiQUCxERCSPiu6BMjNbDezsRYKuwJom5yoMxZKr8mxexZInFE+uyjPY390zPm5adIVgV5hZTUPnyApNseSqPJtXseQJxZOr8myaWh8VESlxKgQiIiWu1ApBddwJ7IBiyVV5Nq9iyROKJ1fl2YSSukYgIiLpSu2IQEREUrTIQmBmQ83sn2a22MwmZIi3NbP7ovhLZlYRQ469zOwpM3vDzGrN7OIM8xxvZmvNbF40/CzfeSblstTMXovySHu024IbonW6wMz6xZDjoUnrap6ZrTOzH6TME8s6NbPbzWxV1KxKYtqeZjbTzN6K/nZp4L3nRvO8ZWbnZponD7lea2ZvRv+2D5lZ5wbe2+h2koc8rzKz95L+fYc18N5G9xF5yPO+pByXmtm8Bt6bn/XZUCNExToQHl5bAhwItAHmA0ekzPOfwKRo/Ezgvhjy7AH0i8Y7Aosy5Hk88Le412mUy1IaaRAQGAY8ChgwEHipALaDlYR7p2Nfp8CxQD/g9aRpvwEmROMTgF9neN+ewNvR3y7ReJcYch0ClEfjv86UazbbSR7yvAq4PItto9F9RK7zTIn/FvhZnOuzJR4RfN78tbt/BiSav042HEg07PsgcKJZoguY/HD3Fe7+ajS+HlgIFHPHk8OBuz2YA3Q2sx4x5nMisMTdC6KFQnd/lvD0fLLk7fAu4NQMb/0GMNPdP3T3j4CZwNCcJUrmXN39CXdPNM02B+iZyxyy0cA6zUY2+4hm01ie0X7nDCBDQ+L50xILwb7Au0mvl5O+g/18nmjjXgvslZfsMohOTR0FZGiVnUFmNt/MHjWzL+Y1se058ISZzY1ag02VzXrPpzNp+D9XoazT7u6+IhpfCXTPME+hrVeA8wlHf5k0tZ3kw/joFNbtDZxuK6R1+lXgfXd/q4F4XtZnSywERcXMdgemAT9w99TGil8lnNroA9wIPJzv/JJ8xd37AScBF5nZsTHm0qiokcNTgAcyhAtpnX7Ow3mAgr+Fz8yuALYCUxuYJe7tZCJwENAXWEE47VLIzqLxo4G8rM+WWAjeA3olve4ZTcs4j4Xmr/cg9JmcV2bWmlAEprr7n1Pj7r7O3T+Jxh8BWptZ1zynmcjlvejvKuAhwuF1smzWe76cBLzq7u+nBgppnQLvJ06fRX9XZZinYNarmY0BvgWcHRWuNFlsJznl7u+7+zZ3rwNubWD5BbFOo33Pd4D7GponX+uzJRaComj+Ojo3OBlY6O6/a2CevRPXLsxsAOHfK46C1cHMOibGCRcOUzoHZDowOrp7aCCwNum0R741+CurUNZpJHk7PBf4S4Z5HgeGmFmX6DTHkGhaXpnZUOBHwCnunqEbm6y3k5xKuS717QaWn80+Ih8GA2961DFXqryuz1xfjY5jINzBsohwZ8AV0bRfEDZigN0Ipw0WAy8DB8aQ41cIpwIWAPOiYRjwPeB70TzjgVrCXQ1zgH+PaX0eGOUwP8onsU6TczXg5midvwZUxpRrB8KOfY+kabGvU0JhWgFsIZyT/i7hutRs4C1gFrBnNG8l23fzen60rS4Gzosp18WE8+qJbTVx190+wCONbSd5znNKtP0tIOzce6TmGb1O20fkM89o+p2J7TJp3ljWp54sFhEpcS3x1JCIiOwAFQIRkRKnQiAiUuJUCERESpwKgYhIiVMhkKJmZqc01Xqkme1jZg9G42PM7KYdXMZ/ZzHPnWY2Ykc+tzmZ2dNmVvD98kphUiGQoubu0939mibm+T9335WddJOFoJhFT7hKCVMhkIJkZhVR+/d3mtkiM5tqZoPN7IWoXf4B0Xyf/8KP5r3BzP5uZm8nfqFHn5X8RGav6Bf0W2b286RlPhw17lWbaODLzK4B2kXtwU+Npo2OGjWbb2ZTkj732NRlZ/hOC83s1mgZT5hZuyj2+S96M+tqZkuTvt/DFvorWGpm483sUjP7h5nNMbM9kxZxTpTn60nrp0PU+NrL0XuGJ33udDN7kvBQm5QwFQIpZL0JjYYdFg2jCE9kX07Dv9J7RPN8C2joSGEAcBpwJHB60imV8929P+HJ3u+b2V7uPgHY6O593f1sC62V/hQ4wUPDdckdCmWz7IOBm939i8DHUR5N+TdCmzRHA78ENrj7UcCLwOik+dq7e19Cfxu3R9OuIDShMgD4GnBt1FwBhDbyR7j7cVnkIC2YCoEUsnfc/TUPDYjVArM9PAr/GlDRwHsedvc6d3+DzM06Q2jf/wN33wj8mbDzhrDzTzQ90Yuw0051AvCAu68BcPfkduazWfY77p7ojWpuI98j2VPuvt7dVxOaTP9rND11Pdwb5fQs0MlCL2JDgAkWesB6mtC8yn7R/DNT8pcSpXODUsg2J43XJb2uo+FtN/k9DXU2lNquipvZ8YRGwAa5+wYze5qw09wR2Sw7eZ5tQLtofCv1P8xSl5vtekj7XlEep7n7P5MDZnYM8GkDOUqJ0RGBlKKvW+gvuB2hV7AXCE2RfxQVgcMI3W0mbLHQZDjAk4TTSXtB6He4mXJaCvSPxnf2wvZIADP7CqH117WElkr/K6nF1aN2MU9pgVQIpBS9TOgHYgEwzd1rgMeAcjNbSDi/Pydp/mpggZlNdfdawnn6Z6LTSBmbEN8J/wtUmdk/gJ3tH2FT9P5JhJY4Af4HaE3IvzZ6LbIdtT4qIlLidEQgIlLiVAhEREqcCoGISIlTIRARKXEqBCIiJU6FQESkxKkQiIiUOBUCEZES9/8ZUFKzJ4yN3AAAAABJRU5ErkJggg==\n",
"text/plain": [
"<Figure size 432x288 with 1 Axes>"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"#初始化所有变量\n",
"init = tf.global_variables_initializer()\n",
"#定义参数\n",
"training_epochs = 20\n",
"display_step = 2\n",
"\n",
"# 统计loss平均值\n",
"def moving_average(a, w=10):\n",
" if len(a) < w: \n",
" return a[:] \n",
" return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in \n",
" enumerate(a)]\n",
"\n",
"#启动session\n",
"with tf.Session() as sess:\n",
" sess.run(init)\n",
" plotdata={\"batchsize\":[],\"loss\":[]} #存放批次值和损失值\n",
" #向模型输入数据\n",
" for epoch in range(training_epochs):\n",
" for (x, y) in zip(train_X, train_Y):\n",
" sess.run(optimizer, feed_dict={X: x, Y: y})\n",
"\n",
" #显示训练中的详细信息\n",
" if epoch % display_step == 0:\n",
" loss = sess.run(cost,feed_dict={X:train_X,Y:train_Y})\n",
" print (\"Epoch:\", epoch+1,\"cost=\", loss,\"W=\",sess.run(W), \n",
" \"b=\", sess.run(b))\n",
" if not (loss == \"NA\" ):\n",
" plotdata[\"batchsize\"].append(epoch)\n",
" plotdata[\"loss\"].append(loss)\n",
"\n",
" print (\" Finished!\")\n",
" print (\"cost=\", sess.run(cost, feed_dict={X: train_X, Y: train_Y}), \n",
" \"W=\", sess.run(W), \"b=\", sess.run(b))\n",
" \n",
" ## 显示拟合曲线\n",
" plt.plot(train_X, train_Y, 'ro', label = 'Original data')\n",
" plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fittedling')\n",
" plt.legend()\n",
" plt.show()\n",
"\n",
" # 显示loss曲线\n",
" plotdata[\"avgloss\"] = moving_average(plotdata[\"loss\"])\n",
" plt.figure(1)\n",
" plt.subplot(211)\n",
" plt.plot(plotdata[\"batchsize\"], plotdata[\"avgloss\"],'b--')\n",
" plt.xlabel('minibatch number')\n",
" plt.ylabel('loss')\n",
" plt.title('')\n",
" plt.show()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: Deep Learning/11. CNN/CNN.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"import cifar10_input\n",
"import tensorflow as tf\n",
"import numpy as np\n",
"import urllib3\n",
"urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)\n",
"import pylab"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## cifar10数据集下载"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"begin\n",
"\u001b[1mDownloading and preparing dataset cifar10 (162.17 MiB) to /root/tensorflow_datasets/cifar10/1.0.2...\u001b[0m\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "6c5154fed7b64533a9a540ea8cb00084",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Dl Completed...', max=1, style=ProgressStyl…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "7e616ae764d44832aca0eae0a346bdff",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Dl Size...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "2260294e1cf648a99a5ebed0b87eb1ae",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Extraction completed...', max=1, style=Prog…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\n",
"\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "c5eb2a06f97941fcabf191b6812d6e7a",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', max=1), HTML(value='')))"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": []
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "5c48e97d8408436c9f16d9525515e57c",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Shuffling...', max=10, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING: Logging before flag parsing goes to stderr.\n",
"W0811 10:17:38.887802 139751066703680 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_datasets/core/file_format_adapter.py:209: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Use eager execution and: \n",
"`tf.data.TFRecordDataset(path)`\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "e9ed475ed3f14f6fb48e792da06eebd9",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "a1c59d88cd2b4ad4a112feece6c2257e",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "13ed5bec19244f13b6666659e40abce5",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "352dc0920486444f8cd7350d54cec32e",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "a89616d3e1c34a628daf935548b3d41b",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "189699b3e15047749ba9e4957219ed9d",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "5f52380c3f5b4eb2ad13e0592a0bd76d",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "3b7d9bb63b23414296826231c1d03ca6",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "d59f3fa8c5614b93be779f97f43743eb",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "25e55aa4f02e4e0c953da8bf6b3cab8e",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "64643f3cfb0a452389e549a6bfb02275",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "fb0f1f9ea0b045d280cca1f27fc0e472",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "868553576fc64349aa18acf2a8a4b7f9",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "f50523b0fe7546fd9ebdaea1d4c7fa98",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "f2a31be6698348ac8e59e8996c848dba",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "24caa746be154adda25ecf344f321d56",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "458cf00f911d41d3a53c68346c4a8565",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "f85d9280bc8f43038bf571e474b23894",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "9815f161223c459fa09b2dbc0421b2ae",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "bfe5d6c313f2415ea97c022a28324135",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=5000, style=ProgressStyle(description_width=…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": []
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "97efc88915694262809f54b6a65e8548",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', max=1), HTML(value='')))"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": []
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "ef6e0ca015ff4152a8fb871b013ecbc1",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Shuffling...', max=1, style=ProgressStyle(description_width='…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "1c944b8b6e224b66a0308dabc079d6c5",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=1, bar_style='info', description='Reading...', max=1, style=ProgressStyle(des…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "45f5b9cbecda4850aaab9a382e4001f8",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(IntProgress(value=0, description='Writing...', max=10000, style=ProgressStyle(description_width…"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"W0811 10:17:48.739059 139751066703680 dataset_builder.py:439] Warning: Setting shuffle_files=True because split=TRAIN and shuffle_files=None. This behavior will be deprecated on 2019-08-06, at which point shuffle_files=False will be the default for all splits.\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\u001b[1mDataset cifar10 downloaded and prepared to /root/tensorflow_datasets/cifar10/1.0.2. Subsequent calls will reuse this data.\u001b[0m\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"W0811 10:17:49.748125 139751066703680 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.estimator.inputs is deprecated. Please use tf.compat.v1.estimator.inputs instead.\n",
"\n",
"W0811 10:17:49.928486 139751066703680 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.random_crop is deprecated. Please use tf.image.random_crop instead.\n",
"\n",
"W0811 10:17:49.929857 139751066703680 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.image.resize_image_with_crop_or_pad is deprecated. Please use tf.image.resize_with_crop_or_pad instead.\n",
"\n",
"W0811 10:17:50.078672 139751066703680 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/image_ops_impl.py:1518: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Deprecated in favor of operator or tf.math.divide.\n",
"W0811 10:17:50.089546 139751066703680 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/cifar10_input.py:45: DatasetV1.make_one_shot_iterator (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Use `for ... in dataset:` to iterate over a dataset. If using `tf.estimator`, return the `Dataset` object directly from your input function. As a last resort, you can use `tf.compat.v1.data.make_one_shot_iterator(dataset)`.\n",
"W0811 10:17:50.109977 139751066703680 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.summary.image is deprecated. Please use tf.compat.v1.summary.image instead.\n",
"\n",
"W0811 10:17:50.114862 139751066703680 dataset_builder.py:439] Warning: Setting shuffle_files=True because split=TRAIN and shuffle_files=None. This behavior will be deprecated on 2019-08-06, at which point shuffle_files=False will be the default for all splits.\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"begin data\n"
]
}
],
"source": [
"batch_size = 128\n",
"print('begin')\n",
"\n",
"# 下载cifar10数据集\n",
"images_train, labels_train = cifar10_input.inputs(eval_data=False, batch_size=batch_size)\n",
"images_test, labels_test = cifar10_input.inputs(eval_data=True, batch_size=batch_size)\n",
"\n",
"print('begin data')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 定义网络结构"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"TensorFlow里使用tf.nn.conv2d函数来实现卷积,其格式如下。\n",
"\n",
"tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)\n",
"\n",
"除去参数name参数用以指定该操作的name,与方法有关的共有5个参数。\n",
"\n",
"- input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch,in_height,in_width,in_channels]这样的形状(shape),具体含义是“训练时一个batch的图片数量,图片高度,图片宽度,图像通道数”,注意这是一个四维的Tensor,要求类型为float32和float64其中之一。\n",
"- filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height,filter_width,in_channels,out_channels]这样的shape,具体含义是“卷积核的高度,滤波器的宽度,图像通道数,滤波器个数”,要求类型与参数input相同。有一个地方需要注意,第三维in_channels,就是参数input的第四维。\n",
"- strides:卷积时在图像每一维的步长,这是一个一维的向量,长度为4。\n",
"- padding:定义元素边框与元素内容之间的空间。string类型的量,只能是SAME和VALID其中之一,这个值决定了不同的卷积方式,padding的值为'VALID'时,表示边缘不填充,当其为'SAME'时,表示填充到滤波器可以到达图像边缘。\n",
"- use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true。\n",
"- 返回值:tf.nn.conr2d函数结果返回一个Tensor,这个输出就是常说的feature map。\n",
"\n",
"注意: 在卷积函数中,padding参数是最容易引起歧义的,该参数仅仅决定是否要补0,因此一定要清楚padding设为SAME的真正含义。在设为SAME的情况下,只有在步长为1时生成的feature map才会与输入值相等。"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [],
"source": [
"def weight_variable(shape):\n",
" # 对于权重w的定义,统一使用函数truncated_normal来生成标准差为0.1的随机数为其初始化。\n",
" initial = tf.truncated_normal(shape,stddev=0.1)\n",
" return tf.Variable(initial)\n",
"\n",
"def bias_variable(shape):\n",
" # 对于权重b的定义,统一初始化为0.1。\n",
" initial = tf.constant(0.1, shape=shape)\n",
" return tf.Variable(initial)\n",
"\n",
"def conv2d(x, W):\n",
" return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')\n",
"\n",
"def max_pool_2x2(x):\n",
" return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')\n",
"\n",
"def avg_pool_6x6(x):\n",
" return tf.nn.avg_pool(x, ksize=[1, 6, 6, 1], strides=[1, 6, 6, 1], padding='SAME')\n",
"\n",
"## 定义占位符\n",
"# cifar data的shape 24*24*3\n",
"x = tf.placeholder(tf.float32, [None, 24, 24, 3])\n",
"# 0~9 数字分类=> 10 classes\n",
"y = tf.placeholder(tf.float32, [None, 10])\n",
"\n",
"# 第一层卷积\n",
"W_conv1 = weight_variable([5, 5, 3, 64])\n",
"b_conv1 = bias_variable([64])\n",
"\n",
"x_image = tf.reshape(x, [-1, 24, 24, 3])\n",
"\n",
"h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)\n",
"h_pool1 = max_pool_2x2(h_conv1)\n",
"\n",
"# 第二层卷积\n",
"W_conv2 = weight_variable([5, 5, 64, 64])\n",
"b_conv2 = bias_variable([64])\n",
"\n",
"h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)\n",
"h_pool2 = max_pool_2x2(h_conv2)\n",
"\n",
"# 第三层卷积\n",
"W_conv3 = weight_variable([5, 5, 64, 10])\n",
"b_conv3 = bias_variable([10])\n",
"\n",
"h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)\n",
"nt_hpool3 = avg_pool_6x6(h_conv3)\n",
"nt_hpool3_flat = tf.reshape(nt_hpool3, [-1, 10])\n",
"\n",
"# 输出层\n",
"y_conv = tf.nn.softmax(nt_hpool3_flat)\n",
"\n",
"cross_entropy = -tf.reduce_sum(y * tf.log(y_conv))\n",
"\n",
"train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
"\n",
"correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y, 1))\n",
"accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 运行session进行训练"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"W0811 11:12:42.978402 139751066703680 queue_runner_impl.py:471] `tf.train.start_queue_runners()` was called when no queue runners were defined. You can safely remove the call to this deprecated function.\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"step 0, training accuracy 0.09375\n",
"step 200, training accuracy 0.273438\n",
"step 400, training accuracy 0.398438\n",
"step 600, training accuracy 0.414062\n",
"step 800, training accuracy 0.484375\n",
"step 1000, training accuracy 0.460938\n",
"step 1200, training accuracy 0.515625\n",
"step 1400, training accuracy 0.492188\n",
"step 1600, training accuracy 0.570312\n",
"step 1800, training accuracy 0.523438\n",
"step 2000, training accuracy 0.492188\n",
"step 2200, training accuracy 0.421875\n",
"step 2400, training accuracy 0.570312\n",
"step 2600, training accuracy 0.601562\n",
"step 2800, training accuracy 0.601562\n",
"step 3000, training accuracy 0.554688\n",
"step 3200, training accuracy 0.585938\n",
"step 3400, training accuracy 0.585938\n",
"step 3600, training accuracy 0.617188\n",
"step 3800, training accuracy 0.609375\n",
"step 4000, training accuracy 0.546875\n",
"step 4200, training accuracy 0.546875\n",
"step 4400, training accuracy 0.570312\n",
"step 4600, training accuracy 0.59375\n",
"step 4800, training accuracy 0.65625\n",
"step 5000, training accuracy 0.570312\n",
"step 5200, training accuracy 0.515625\n",
"step 5400, training accuracy 0.640625\n",
"step 5600, training accuracy 0.492188\n",
"step 5800, training accuracy 0.585938\n",
"step 6000, training accuracy 0.585938\n",
"step 6200, training accuracy 0.539062\n",
"step 6400, training accuracy 0.539062\n",
"step 6600, training accuracy 0.625\n",
"step 6800, training accuracy 0.65625\n",
"step 7000, training accuracy 0.703125\n",
"step 7200, training accuracy 0.570312\n",
"step 7400, training accuracy 0.679688\n",
"step 7600, training accuracy 0.65625\n",
"step 7800, training accuracy 0.664062\n",
"step 8000, training accuracy 0.609375\n",
"step 8200, training accuracy 0.570312\n",
"step 8400, training accuracy 0.617188\n",
"step 8600, training accuracy 0.617188\n",
"step 8800, training accuracy 0.609375\n",
"step 9000, training accuracy 0.648438\n",
"step 9200, training accuracy 0.625\n",
"step 9400, training accuracy 0.59375\n",
"step 9600, training accuracy 0.625\n",
"step 9800, training accuracy 0.609375\n",
"step 10000, training accuracy 0.6875\n",
"step 10200, training accuracy 0.601562\n",
"step 10400, training accuracy 0.664062\n",
"step 10600, training accuracy 0.734375\n",
"step 10800, training accuracy 0.585938\n",
"step 11000, training accuracy 0.640625\n",
"step 11200, training accuracy 0.671875\n",
"step 11400, training accuracy 0.625\n",
"step 11600, training accuracy 0.664062\n",
"step 11800, training accuracy 0.671875\n",
"step 12000, training accuracy 0.671875\n",
"step 12200, training accuracy 0.617188\n",
"step 12400, training accuracy 0.59375\n",
"step 12600, training accuracy 0.695312\n",
"step 12800, training accuracy 0.710938\n",
"step 13000, training accuracy 0.640625\n",
"step 13200, training accuracy 0.679688\n",
"step 13400, training accuracy 0.6875\n",
"step 13600, training accuracy 0.679688\n",
"step 13800, training accuracy 0.671875\n",
"step 14000, training accuracy 0.609375\n",
"step 14200, training accuracy 0.546875\n",
"step 14400, training accuracy 0.804688\n",
"step 14600, training accuracy 0.710938\n",
"step 14800, training accuracy 0.617188\n",
"finished! test accuracy 0.734375\n"
]
}
],
"source": [
"sess = tf.Session()\n",
"sess.run(tf.global_variables_initializer())\n",
"\n",
"# QueueRunner类用来启动tensor的入队线程,可以用来启动多个工作线程同时将多个tensor(训练数据)推送入文件名称队列中\n",
"tf.train.start_queue_runners(sess=sess)\n",
"for i in range(15000):\n",
" image_batch, label_batch = sess.run([images_train, labels_train])\n",
" \n",
" # one hot编码\n",
" # eye生成对角矩阵\n",
" label_b = np.eye(10, dtype=float)[label_batch]\n",
" \n",
" train_step.run(feed_dict={x: image_batch, y: label_b}, session=sess)\n",
" \n",
" if i % 200 == 0:\n",
" train_accuracy = accuracy.eval(feed_dict={x: image_batch, y: label_b}, session=sess)\n",
" print( \"step %d, training accuracy %g\"%(i, train_accuracy))\n",
" \n",
"\n",
"image_batch, label_batch = sess.run([images_test, labels_test])\n",
"label_b = np.eye(10,dtype=float)[label_batch] #one hot编码\n",
"print (\"finished! test accuracy %g\"%accuracy.eval(feed_dict={x:image_batch, y: label_b},session=sess))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: Deep Learning/11. CNN/README.md
================================================
## 目录
- [1. 什么是CNN](#1-什么是cnn)
- [1.1 输入层](#11-输入层)
- [1.2 卷积计算层(conv)](#12-卷积计算层conv)
- [1.3 激励层](#13-激励层)
- [1.4 池化层](#14-池化层)
- [1.5 全连接层](#15-全连接层)
- [1.6 层次结构小结](#16-层次结构小结)
- [1.7 CNN优缺点](#17-cnn优缺点)
- [2. 典型CNN发展历程](#2-典型cnn发展历程)
- [3. 图像相关任务](#3-图像相关任务)
- [3.1 图像识别与定位](#31-图像识别与定位)
- [3.2 物体检测(object detection)](#32-物体检测object-detection)
- [3.3 语义(图像)分割](#33-语义图像分割)
- [4. 代码实现CNN](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/11.%20CNN/CNN.ipynb)
- [5. 参考文献](#5-参考文献)
## 1. 什么是CNN
> 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含[卷积](https://baike.baidu.com/item/卷积/9411006)计算且具有深度结构的[前馈神经网络](https://baike.baidu.com/item/前馈神经网络/7580523)(Feedforward Neural Networks),是[深度学习](https://baike.baidu.com/item/深度学习/3729729)(deep learning)的代表算法之一。
我们先来看卷积神经网络各个层级结构图:

上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车。
- 最左边是数据**输入层**(input layer),对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
- CONV:卷积计算层(conv layer),线性乘积求和。
- RELU:激励层(activation layer),下文有提到:ReLU是激活函数的一种。
- POOL:池化层(pooling layer),简言之,即取区域平均或最大。
- FC:全连接层(FC layer)。
这几个部分中,卷积计算层是CNN的核心。
### 1.1 输入层
在做输入的时候,需要把图片处理成同样大小的图片才能够进行处理。
常见的处理数据的方式有:
1. 去均值(**常用**)
- **AlexNet**:训练集中100万张图片,对每个像素点求均值,得到均值图像,当训练时用原图减去均值图像。
- **VGG**:对所有输入在三个颜色通道R/G/B上取均值,只会得到3个值,当训练时减去对应的颜色通道均值。(**此种方法效率高**)
**TIPS:**在训练集和测试集上减去训练集的均值。
2. 归一化
幅度归一化到同样的范围。
3. PCA/白化(**很少用**)
- 用PCA降维
- 白化是对数据每个特征轴上的幅度归一化。
### 1.2 卷积计算层(conv)
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做**内积**(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
滤波器filter是什么呢!请看下图。图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。

不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。**相当于提取图像的不同特征,模型就能够学习到多种特征。**用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。如下图所示。

在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
- 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
- 步长stride:决定滑动多少步可以到边缘。
- 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。

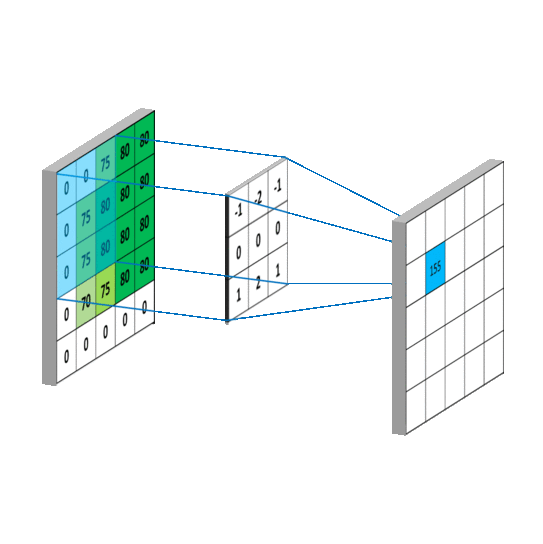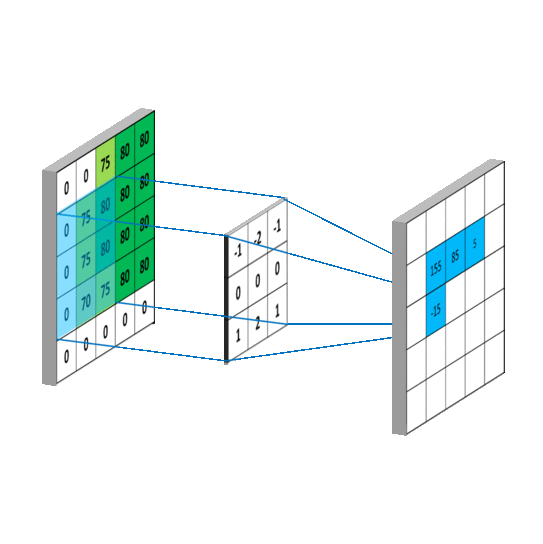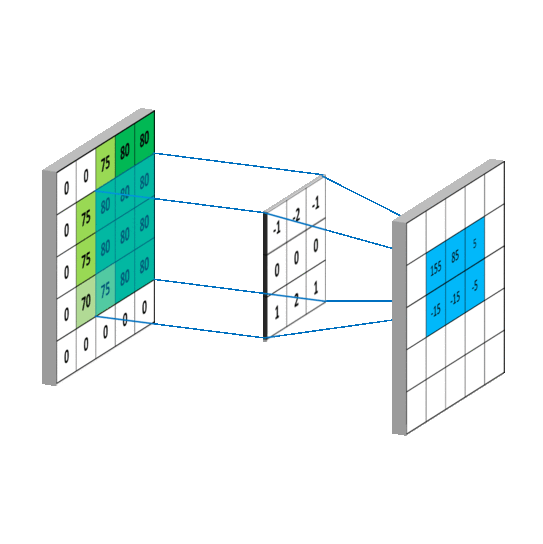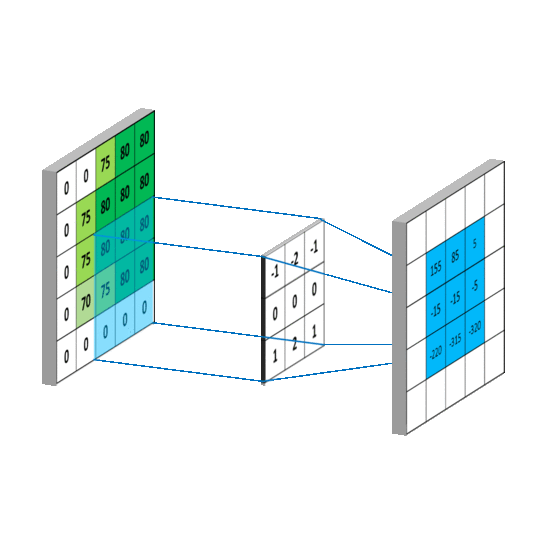
- **参数共享机制**
假设每个神经元连接数据窗的权重是固定对的。固定每个神经元连接权重,可以看做模板,每个神经元只关注**一个特性(模板)**,这使得需要估算的权重个数减少:一层中从1亿到3.5万。
- 一组固定的权重和不同窗口内数据做**内积**:卷积
- 作用在于捕捉某一种模式,具体表现为很大的值。
**卷积操作的本质特性包括稀疏交互和参数共享**。
### 1.3 激励层
把卷积层输出结果做非线性映射。
激活函数有:
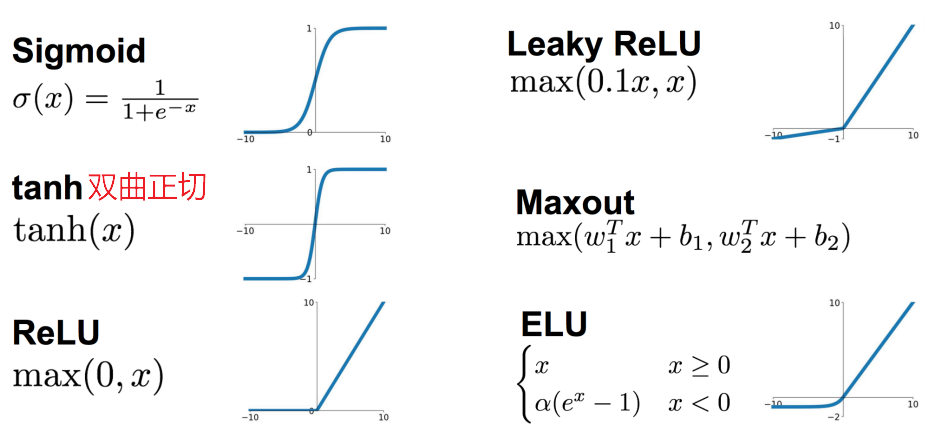
- sigmoid:在两端斜率接近于0,梯度消失。
- ReLu:修正线性单元,有可能出现斜率为0,但概率很小,因为mini-batch是一批样本损失求导之和。
**TIPS:**
- CNN慎用sigmoid!慎用sigmoid!慎用sigmoid!
- 首先试RELU,因为快,但要小心点。
- 如果RELU失效,请用 Leaky ReLU或者Maxout。
- 某些情况下tanh倒是有不错的结果,但是很少。
### 1.4 池化层
也叫**下采样层**,就算通过了卷积层,纬度还是很高 ,需要进行池化层操作。
- 夹在连续的卷积层中间。
- 压缩数据和参数的量,降低维度。
- 减小过拟合。
- 具有特征不变性。
方式有:**Max pooling、average pooling**

**Max pooling**
取出每个部分的最大值作为输出,例如上图左上角的4个黄色方块取最大值为3作为输出,以此类推。
**average pooling**
每个部分进行计算得到平均值作为输出,例如上图左上角的4个黄色方块取得平均值2作为输出,以此类推。
### 1.5 全连接层
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全连接的特性,一般全连接层的参数也是最多的。
- 两层之间所有神经元都有权重连接
- 通常全连接层在卷积神经网络尾部
### 1.6 层次结构小结
| CNN层次结构 | 作用 |
| ----------- | ---------------------------------------------------------- |
| 输入层 | 卷积网络的原始输入,可以是原始或预处理后的像素矩阵 |
| 卷积层 | 参数共享、局部连接,利用平移不变性从全局特征图提取局部特征 |
| 激活层 | 将卷积层的输出结果进行非线性映射 |
| 池化层 | 进一步筛选特征,可以有效减少后续网络层次所需的参数量 |
| 全连接层 | 用于把该层之前提取到的特征综合起来。 |
### 1.7 CNN优缺点
**优点:**
- 共享卷积核,优化计算量。
- 无需手动选取特征,训练好权重,即得特征。
- 深层次的网络抽取图像信息丰富,表达效果好。
- 保持了层级网络结构。
- 不同层次有不同形式与功能。
**缺点:**
- 需要调参,需要大样本量,GPU等硬件依赖。
- 物理含义不明确。
**与NLP/Speech共性:**
都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。
## 2. 典型CNN发展历程
- LeNet,这是最早用于数字识别的CNN
- AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比LeNet更深,用多层小卷积层叠加替换单大卷积层。
- ZF Net, 2013 ILSVRC比赛冠军
- GoogLeNet, 2014 ILSVRC比赛冠军
- VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如objectdetection)上效果很好
- ResNet(深度残差网络(Deep Residual Network,ResNet)), 2015ILSVRC比赛冠军,结构修正(残差学习)以适应深层次CNN训练。
- DenseNet, CVPR2017 best paper,把ResNet的add变成concat
## 3. 图像相关任务

### 3.1 图像识别与定位
1. **classification:**C个类别识别
- **input**:Image
- **Output**:类别标签
- **Evaluation metric**:准确率
2. **Localization定位)**
- **Input**:Image
- **Output**:物体边界框(x,y,w,h)
- **Evaluation metric**:交并准则(IOU) > 0.5 图中阴影部分所占面积

#### 3.1.1 思路1:识别+定位过程
1. **识别**可以看作多分类问题(**用softmax**),用别人训练好的CNN模型做fine-tune
2. **定位**的目标是(x,y,w,h)是连续值,当回归问题解决(**mse**)
在**1**的CNN尾部展开(例如把最后一层拿开),接上一个(x,y,w,h)的神经网络,成为**classification+regression的模型**。
更细致的识别可以提前规定好有k个组成部分,做成k个部分的回归,
**例如:**框出两只眼睛和两条腿,4元祖*4=16(个连续值)
3. Regression部分用欧氏距离损失,使用SGD训练。
#### 3.1.2 思路2:图窗+识别
- 类似刚才的classification+regression思路
- 咱们取不同大小的“框”
- 让框出现在不同的位置
- 判定得分
- 按照得分的高低对“结果框”做抽样和合并

### 3.2 物体检测(object detection)
#### 3.2.1 过程
当图像有很多物体怎么办的?难度可是一下暴增啊。
那任务就变成了:多物体识别+定位多个物体,那把这个任务看做分类问题?

看成分类问题有何不妥?
- 你需要找很多位置, 给很多个不同大小的框
- 你还需要对框内的图像分类
- 当然, 如果你的GPU很强大, 恩, 那加油做吧…
**边缘策略:**想办法先找到可能包含内容的图框(**候选框**),然后进行分类问题的识别。
**方法**:根据RGB值做区域融合。**fast-CNN**,共享图窗,从而加速候选框的形成。
- **R-CNN => fast-CNN => faster-RCNN** 速度对比

#### 3.2.2 R-CNN
R-CNN的简要步骤如下:
1. 输入测试图像。
2. 利用选择性搜索Selective Search算法在图像中从下到上提取2000个左右的可能包含物体的候选区域Region Proposal。
3. 因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征。
4. 将每个Region Proposal提取到的CNN特征输入到SVM进行分类。
#### 3.2.3 SPP-Net
SPP:Spatial Pyramid Pooling(空间金字塔池化),SPP-Net是出自2015年发表在IEEE上的论文。
众所周知,CNN一般都含有卷积部分和全连接部分,其中,卷积层不需要固定尺寸的图像,而全连接层是需要固定大小的输入。所以当全连接层面对各种尺寸的输入数据时,就需要对输入数据进行crop(crop就是从一个大图扣出网络输入大小的patch,比如227×227),或warp(把一个边界框bounding box(红框)的内容resize成227×227)等一系列操作以统一图片的尺寸大小,比如224*224(ImageNet)、32*32(LenNet)、96*96等。

所以才如你在上文中看到的,在R-CNN中,“因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN”。
但warp/crop这种预处理,导致的问题要么被拉伸变形、要么物体不全,限制了识别精确度。没太明白?说句人话就是,一张16:9比例的图片你硬是要Resize成1:1的图片,你说图片失真不?
SPP Net的作者Kaiming He等人逆向思考,既然由于全连接FC层的存在,普通的CNN需要通过固定输入图片的大小来使得全连接层的输入固定。那借鉴卷积层可以适应任何尺寸,为何不能在卷积层的最后加入某种结构,使得后面全连接层得到的输入变成固定的呢?
这个“化腐朽为神奇”的结构就是spatial pyramid pooling layer。
它的特点有两个:
1. **结合空间金字塔方法实现CNNs的多尺度输入。**
SPP Net的第一个贡献就是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。
换句话说,在普通的CNN机构中,输入图像的尺寸往往是固定的(比如224*224像素),输出则是一个固定维数的向量。SPP Net在普通的CNN结构中加入了ROI池化层(ROI Pooling),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。
简言之,CNN原本只能固定输入、固定输出,CNN加上SSP之后,便能任意输入、固定输出。神奇吧?
2. **只对原图提取一次卷积特征**
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。
而SPP Net根据这个缺点做了优化:只对原图进行一次卷积计算,便得到整张图的卷积特征feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层,完成特征提取工作。
如此这般,R-CNN要对每个区域计算卷积,而SPPNet只需要计算一次卷积,从而节省了大量的计算时间,比R-CNN有一百倍左右的提速。
#### 3.2.4 Fast R-CNN
SPP Net真是个好方法,R-CNN的进阶版Fast R-CNN就是在R-CNN的基础上采纳了SPP Net方法,对R-CNN作了改进,使得性能进一步提高。
R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。
**大缺点:**由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
**解决:**共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征。
原来的方法:许多候选框(比如两千个)-->CNN-->得到每个候选框的特征-->分类+回归
现在的方法:一张完整图片-->CNN-->得到每张候选框的特征-->分类+回归
所以容易看见,Fast R-CNN相对于R-CNN的提速原因就在于:不过不像R-CNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
**算法步骤:**
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)。
2. 对整张图片输进CNN,得到feature map。
3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类。
5. 对于属于某一类别的候选框,用回归器进一步调整其位置。
#### 3.2.5 Faster R-CNN
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
解决:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。
所以,rgbd在Fast R-CNN中引入Region Proposal Network(RPN)替代Selective Search,同时引入anchor box应对目标形状的变化问题(anchor就是位置和大小固定的box,可以理解成事先设置好的固定的proposal)。这就是Faster R-CNN。
**算法步骤:**
1. 对整张图片输进CNN,得到feature map。
2. 卷积特征输入到RPN,得到候选框的特征信息。
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类。
4. 对于属于某一类别的候选框,用回归器进一步调整其位置。
#### 3.2.6 YOLO
Faster R-CNN的方法目前是主流的目标检测方法,但是速度上并不能满足实时的要求。YOLO一类的方法慢慢显现出其重要性,这类方法使用了回归的思想,利用整张图作为网络的输入,直接在图像的多个位置上回归出这个位置的目标边框,以及目标所属的类别。
我们直接看上面YOLO的目标检测的流程图:
1. 给个一个输入图像,首先将图像划分成7\*7的网格。
2. 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)。
3. 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
**小结:**YOLO将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO可以每秒处理45张图像。而且由于每个网络预测目标窗口时使用的是全图信息,使得false positive比例大幅降低(充分的上下文信息)。
但是YOLO也存在问题:没有了Region Proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
#### 3.2.7 SSD
SSD: Single Shot MultiBox Detector。上面分析了YOLO存在的问题,使用整图特征在7*7的粗糙网格内回归对目标的定位并不是很精准。那是不是可以结合region proposal的思想实现精准一些的定位?SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制做到了这点。
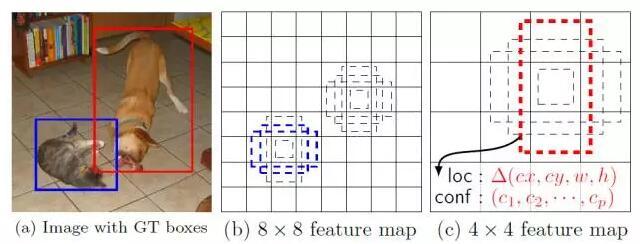
上图是SSD的一个框架图,首先SSD获取目标位置和类别的方法跟YOLO一样,都是使用回归,但是YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征(感觉更合理一些)。
那么如何建立某个位置和其特征的对应关系呢?可能你已经想到了,使用Faster R-CNN的anchor机制。如SSD的框架图所示,假如某一层特征图(图b)大小是8\*8,那么就使用3*3的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息(图c)。
不同于Faster R-CNN,这个anchor是在多个feature map上,这样可以利用多层的特征并且自然的达到多尺度(不同层的feature map 3*3滑窗感受野不同)。
小结:SSD结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。SSD在VOC2007上mAP可以达到72.1%,速度在GPU上达到58帧每秒。
### 3.3 语义(图像)分割
识别图上pixel的类别,用全卷积网络。

## 4. 代码实现CNN
[cifar10数据集分类--CNN](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/11.%20CNN/CNN.ipynb)
## 5. 参考文献
1. [基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD](https://www.julyedu.com/question/big/kp_id/32/ques_id/2103)
2. [通俗理解卷积神经网络](https://blog.csdn.net/v_july_v/article/details/51812459)
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/12. RNN/README.md
================================================
## 目录
- [1. 什么是RNN](#1-什么是rnn)
- [1.1 RNN的应用](#11-rnn的应用)
- [1.2 为什么有了CNN,还要RNN?](#12-为什么有了cnn还要rnn)
- [1.3 RNN的网络结构](#13-rnn的网络结构)
- [1.4 双向RNN](#14-双向rnn)
- [1.5 BPTT算法](#15-bptt算法)
- [2. 其它类型的RNN](#2-其它类型的rnn)
- [3. CNN与RNN的区别](#3-cnn与rnn的区别)
- [4. 为什么RNN 训练的时候Loss波动很大](#4-为什么rnn-训练的时候loss波动很大)
- [5. 实例代码](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/12.%20RNN/RNN.ipynb)
## 1. 什么是RNN
> 循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)
### 1.1 RNN的应用
- 文本生成(生成序列)
- 机器翻译
- 看图说话
- 文本(情感)分析
- 智能客服
- 聊天机器人
- 语音识别
- 搜索引擎
- 个性化推荐
### 1.2 为什么有了CNN,还要RNN?
- 传统神经网络(包括CNN),输入和输出都是互相独立的。图像上的猫和狗是分隔开的,但有些任务,后续的输出和之前的内容是相关的。例如:我是中国人,我的母语是____。这是一道填空题,需要依赖于之前的输入。
- 所以,RNN引入“记忆”的概念,也就是输出需要依赖于之前的输入序列,并把关键输入记住。循环2字来源于其每个元素都执行相同的任务。
- 它并⾮刚性地记忆所有固定⻓度的序列,而是通过隐藏状态来存储之前时间步的信息。
### 1.3 RNN的网络结构
首先先上图,然后再解释:

现在我们考虑输⼊数据存在时间相关性的情况。假设 是序列中时间步t的小批量输⼊, 是该时间步的隐藏变量。那么根据以上结构图当前的隐藏变量的公式如下:
)
从以上公式我们可以看出,这⾥我们保存上⼀时间步的隐藏变量 ,并引⼊⼀个新的权重参数,该参数⽤来描述在当前时间步如何使⽤上⼀时间步的隐藏变量。具体来说,**时间步 t 的隐藏变量的计算由当前时间步的输⼊和上⼀时间步的隐藏变量共同决定。** 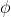**函数其实就是激活函数。**
我们在这⾥添加了 ⼀项。由上式中相邻时间步的隐藏变量 之间的关系可知,这⾥的隐藏变量能够捕捉截⾄当前时间步的序列的历史信息,就像是神经⽹络当前时间步的状态或记忆⼀样。因此,该隐藏变量也称为隐藏状态。**由于隐藏状态在当前时间步的定义使⽤了上⼀时间步的隐藏状态,上式的计算是循环的。使⽤循环计算的⽹络即循环神经⽹络(recurrent neural network)。**
在时间步t,输出层的输出和多层感知机中的计算类似:

### 1.4 双向RNN
之前介绍的循环神经⽹络模型都是假设当前时间步是由前⾯的较早时间步的序列决定的,因此它
们都将信息通过隐藏状态从前往后传递。有时候,当前时间步也可能由后⾯时间步决定。例如,
当我们写下⼀个句⼦时,可能会根据句⼦后⾯的词来修改句⼦前⾯的⽤词。**双向循环神经⽹络通过增加从后往前传递信息的隐藏层来更灵活地处理这类信息。**下图演⽰了⼀个含单隐藏层的双向循环神经⽹络的架构。

在双向循环神经⽹络的架构中,设该时间步正向隐藏状态为 (正向隐藏单元个数为h),反向隐藏状态为 (反向隐藏单元个数为h)。我们可以分别
计算正向隐藏状态和反向隐藏状态:
}+\overrightarrow{H}_{t-1}W_{hh}^{(f)}+b_h^{(f)}))
}+\overleftarrow{H}_{t-1}W_{hh}^{(b)}+b_h^{(b)}))
然后我们连结两个⽅向的隐藏状态 来得到隐藏状态 ,并将其输⼊到输出层。输出层计算输出 (输出个数为q):

双向循环神经⽹络在每个时间步的隐藏状态同时取决于该时间步之前和之后的⼦序列(包
括当前时间步的输⼊)。
### 1.5 BPTT算法

在之前你已经见过对于前向传播(上图蓝色箭头所指方向)怎样在神经网络中从左到右地计算这些激活项,直到输出所有地预测结果。而对于反向传播,我想你已经猜到了,反向传播地计算方向(上图红色箭头所指方向)与前向传播基本上是相反的。
我们先定义一个元素**损失函数:**

整个序列的损失函数:

在这个计算图中,通过 })可以计算对应的损失函数,于是计算出第一个时间步的损失函数,然后计算出第二个时间步的损失函数,然后是第三个时间步,一直到最后一个时间步,最后为了计算出总体损失函数,我们要把它们都加起来,通过等式计算出最后的𝐿,也就是把每个单独时间步的损失函数都加起来。然后你就可以通过导数相关的参数,用梯度下降法来更新参数。
在这个反向传播的过程中,最重要的信息传递或者说最重要的递归运算就是这个从右到左的运算,这也就是为什么这个算法有一个很别致的名字,叫做**“通过(穿越)时间反向传播(backpropagation through time)”。**取这个名字的原因是对于前向传播,你需要从左到右进行计算,在这个过程中,时刻𝑡不断增加。而对于反向传播,你需要从右到左进行计算,就像时间倒流。“通过时间反向传播”,就像穿越时光,这种说法听起来就像是你需要一台时光机来实现这个算法一样。
## 2. 其它类型的RNN
- **One to one:**这个可能没有那么重要,这就是一个小型的标准的神经网络,输入𝑥然后得到输出𝑦。
- **One to many:**音乐生成,你的目标是使用一个神经网络输出一些音符。对应于一段音乐,输入𝑥
可以是一个整数,表示你想要的音乐类型或者是你想要的音乐的第一个音符,并且如果你什么都不想输入,𝑥可以是空的输入,可设为 0 向量。
- **Many to one:**句子分类问题,输入文档,输出文档的类型。
- **Many to many():**命名实体识别。
- **Many to many():**机器翻译。

## 3. CNN与RNN的区别
| 类别 | 特点描述 |
| ------ | ------------------------------------------------------------ |
| 相同点 | 1、传统神经网络的扩展。<br/>2、前向计算产生结果,反向计算模型更新。<br/>3、每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。 |
| 不同点 | 1、CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算<br/>2、RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出 |
## 4. 为什么RNN 训练的时候Loss波动很大
由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss会震荡起伏,为了解决RNN的这个问题,在训练的时候,可以设置临界值,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止大幅震荡。
## 5. 实例代码
[TensorFlow实现RNN](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/12.%20RNN/RNN.ipynb)
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/12. RNN/RNN.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"def gen_data(size=100000):\n",
" \"\"\"\n",
" 生成数据:\n",
" 输入数据X:在时间t,Xt的值有50%的概率为1,50%的概率为0;\n",
" 输出数据Y:在实践t,Yt的值有50%的概率为1,50%的概率为0,除此之外,如果`Xt-3 == 1`,Yt为1的概率增加50%, 如果`Xt-8 == 1`,则Yt为1的概率减少25%, 如果上述两个条件同时满足,则Yt为1的概率为75%。\n",
" \"\"\"\n",
" X = np.random.choice(2,(size,))\n",
" Y = []\n",
" for i in range(size):\n",
" threshold = 0.5\n",
" # 判断X[i-3]和X[i-8]是否为1,修改阈值\n",
" if X[i-3] == 1:\n",
" threshold += 0.5\n",
" if X[i-8] == 1:\n",
" threshold -= 0.25\n",
" # 生成随机数,以threshold为阈值给Yi赋值\n",
" if np.random.rand() > threshold:\n",
" Y.append(0)\n",
" else:\n",
" Y.append(1)\n",
" return X,np.array(Y)"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"def gen_batch(raw_data, batch_size, num_steps):\n",
" # raw_data是使用gen_data()函数生成的数据,分别是X和Y\n",
" raw_x, raw_y = raw_data\n",
" data_length = len(raw_x)\n",
" \n",
" # 首先将数据切分成batch_size份,0-batch_size,batch_size-2*batch_size。。。\n",
" batch_partition_length = data_length // batch_size\n",
" data_x = np.zeros([batch_size, batch_partition_length], dtype=np.int32)\n",
" data_y = np.zeros([batch_size, batch_partition_length], dtype=np.int32)\n",
" \n",
" # 因为RNN模型一次只处理num_steps个数据,所以将每个batch_size在进行切分成epoch_size份,每份num_steps个数据。注意这里的epoch_size和模型训练过程中的epoch不同。\n",
" for i in range(batch_size):\n",
" data_x[i] = raw_x[i * batch_partition_length:(i + 1) * batch_partition_length]\n",
" data_y[i] = raw_x[i * batch_partition_length:(i + 1) * batch_partition_length]\n",
" \n",
" # x是0-num_steps, batch_partition_length -batch_partition_length +num_steps。。。共batch_size个\n",
" epoch_size = batch_partition_length // num_steps\n",
" for i in range(epoch_size):\n",
" x = data_x[:, i * num_steps:(i + 1) * num_steps]\n",
" y = data_x[:, i * num_steps:(i + 1) * num_steps]\n",
" yield (x, y)"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"def gen_epochs(n, num_steps):\n",
" '''这里的n就是训练过程中用的epoch,即在样本规模上循环的次数'''\n",
" for i in range(n):\n",
" yield gen_batch(gen_data(), batch_size, num_steps=num_steps)\n"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"W0815 13:59:50.105675 139691886995264 deprecation.py:323] From <ipython-input-6-938f039f2ac0>:20: BasicRNNCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"This class is equivalent as tf.keras.layers.SimpleRNNCell, and will be replaced by that in Tensorflow 2.0.\n",
"W0815 13:59:50.107444 139691886995264 deprecation.py:323] From <ipython-input-6-938f039f2ac0>:21: static_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `keras.layers.RNN(cell, unroll=True)`, which is equivalent to this API\n",
"W0815 13:59:50.110475 139691886995264 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:455: Layer.add_variable (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `layer.add_weight` method instead.\n",
"W0815 13:59:50.120152 139691886995264 deprecation.py:506] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:459: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Call initializer instance with the dtype argument instead of passing it to the constructor\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\\EPOCH 0\n",
"Average loss at step 100 for last 100 steps: 0.45625598669052125\n",
"Average loss at step 200 for last 100 steps: 0.33522686779499056\n",
"Average loss at step 300 for last 100 steps: 0.32363319605588914\n",
"Average loss at step 400 for last 100 steps: 0.3198443701863289\n",
"Average loss at step 500 for last 100 steps: 0.31799371004104615\n",
"Average loss at step 600 for last 100 steps: 0.316926654279232\n",
"Average loss at step 700 for last 100 steps: 0.3162370014190674\n",
"Average loss at step 800 for last 100 steps: 0.3157545381784439\n",
"Average loss at step 900 for last 100 steps: 0.31540178656578066\n",
"Average loss at step 1000 for last 100 steps: 0.3151378232240677\n",
"Average loss at step 1100 for last 100 steps: 0.31492061764001844\n",
"Average loss at step 1200 for last 100 steps: 0.314748175740242\n",
"Average loss at step 1300 for last 100 steps: 0.3146084254980087\n",
"Average loss at step 1400 for last 100 steps: 0.3144863533973694\n",
"Average loss at step 1500 for last 100 steps: 0.3143901726603508\n",
"Average loss at step 1600 for last 100 steps: 0.3143030619621277\n",
"Average loss at step 1700 for last 100 steps: 0.31422749906778336\n",
"Average loss at step 1800 for last 100 steps: 0.3141659554839134\n",
"Average loss at step 1900 for last 100 steps: 0.31411062598228456\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAXoAAAD4CAYAAADiry33AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy8QZhcZAAAfcUlEQVR4nO3dfZAcd33n8fdnZnZn9DBjG2l3BZKMbCMgsp0Q3Z5tckAcHhQ5JLZ5SmRz4At3Ma5YFacODkyFcjmGVGGSOHdcdIACTrgAEZCDO9VZxCZHOBLONlobP0Q2imTZjqUYaSULS6unffreH9Oz21rvw0j73P15VW1N969/PfPd0ejTvT3961ZEYGZm2VWY7QLMzGx6OejNzDLOQW9mlnEOejOzjHPQm5llXGm2Cxhp6dKlsWrVqtkuw8xsXnnooYcORkTbaMvmXNCvWrWKrq6u2S7DzGxekfTsWMuaOnQjab2knZJ2S7p1nH7vkhSSOlNtPyvpfkk7JD0uqXJm5ZuZ2WRMuEcvqQhsAt4G7AW2S9oaEU+M6FcFbgEeTLWVgC8D74uIRyUtAfqmsH4zM5tAM3v0lwG7I2JPRPQCW4BrRun3CeBO4GSqbR3wWEQ8ChARhyJiYJI1m5nZGWgm6JcDz6Xm9yZtQyStBVZGxD0j1n01EJLulfSwpI+M9gKSbpTUJamru7v7DMo3M7OJTPr0SkkF4C7gQ6MsLgFvAN6bPL5D0ltGdoqIzRHRGRGdbW2jfmlsZmZnqZmg3wesTM2vSNoaqsAlwPckPQNcAWxNvpDdC3w/Ig5GxHFgG7B2Kgo3M7PmNBP024HVki6Q1ApsALY2FkbEixGxNCJWRcQq4AHg6ojoAu4FLpW0MPli9heBJ176EmZmNl0mDPqI6Ac2Ug/tJ4GvR8QOSXdIunqCdQ9TP6yzHXgEeHiU4/hTYt9PT3DXfTt55uCx6Xh6M7N5q6kBUxGxjfphl3TbbWP0vXLE/Jepn2I5rX56vJfPfHc3a15RY9XSRdP9cmZm80ZmrnXTUauPw9p/5NQsV2JmNrdkJuhftrCVUkHsP3Jy4s5mZjmSmaAvFERbtew9ejOzETIT9ADttQoHjnqP3swsLVNB31Etc8B79GZmp8lU0LfXyuz3Hr2Z2WkyFfQd1Qo/Pd7HqX5fN83MrCFbQZ+cYunDN2ZmwzIV9O21MoC/kDUzS8lW0Fc9aMrMbKRMBX1HY4/eg6bMzIZkKujPW9hKS1HsP+o9ejOzhkwFfaEg2qsVXwbBzCwlU0EP0FYt0+09ejOzIZkL+o5a2Xv0ZmYpGQz6is+6MTNLyVzQt1fLvHiij5N9Hh1rZgZZDPpkdKyP05uZ1WUu6IfvNOXj9GZm0GTQS1ovaaek3ZJuHaffuySFpM4R7edL6pH04ckWPJHGoCkfpzczq5sw6CUVgU3AVcAa4DpJa0bpVwVuAR4c5WnuAr49uVKb07gMgq93Y2ZW18we/WXA7ojYExG9wBbgmlH6fQK4EzgtYSVdCzwN7JhkrU05b2FLfXSs9+jNzIDmgn458Fxqfm/SNkTSWmBlRNwzon0x8FHg98d7AUk3SuqS1NXd3d1U4eM8F+3Viq93Y2aWmPSXsZIK1A/NfGiUxbcDfxIRPeM9R0RsjojOiOhsa2ubbEm+05SZWUqpiT77gJWp+RVJW0MVuAT4niSAZcBWSVcDlwPvlvRp4FxgUNLJiPjTqSh+LB3VCk91j7ttMTPLjWaCfjuwWtIF1AN+A3B9Y2FEvAgsbcxL+h7w4YjoAt6Yar8d6JnukIf6mTf/76mD0/0yZmbzwoSHbiKiH9gI3As8CXw9InZIuiPZa59z2msVjpzs50SvR8eamTWzR09EbAO2jWi7bYy+V47RfvsZ1nbW2qvDtxR85ZJFM/WyZmZzUuZGxkLqJuG+DIKZWbaD3pdBMDPLaNA3Dt140JSZWUaD/tyFLbQWC74MgpkZGQ16SbTXyhzwHr2ZWTaDHhp3mvIevZlZZoO+vep7x5qZQYaDvqNW8emVZmZkOOjba2WOnuzneG//bJdiZjarMhv0HY0bkPgLWTPLucwGfXutcRkEB72Z5Vtmg96jY83M6rIb9FUHvZkZZDjoawtKtJYKPnRjZrmX2aCXREet7HvHmlnuZTbooX74xhc2M7O8y3bQ1yq+SbiZ5V6mg76t6gubmZllOug7ahV6TvVz7JRHx5pZfjUV9JLWS9opabekW8fp9y5JIakzmX+bpIckPZ48vnmqCm9GhwdNmZlNHPSSisAm4CpgDXCdpDWj9KsCtwAPppoPAr8WEZcCNwB/ORVFN6vd59KbmTW1R38ZsDsi9kREL7AFuGaUfp8A7gSGUjUifhQR/5LM7gAWSCpPsuameY/ezKy5oF8OPJea35u0DZG0FlgZEfeM8zzvAh6OiJekrqQbJXVJ6uru7m6ipOa01xoXNvMevZnl16S/jJVUAO4CPjROn4up7+1/cLTlEbE5IjojorOtrW2yJQ2pVUpUWgo+dGNmudZM0O8DVqbmVyRtDVXgEuB7kp4BrgC2pr6QXQF8C3h/RDw1FUU3SxLtHjRlZjnXTNBvB1ZLukBSK7AB2NpYGBEvRsTSiFgVEauAB4CrI6JL0rnAPcCtEfGDaah/Qh21Mgc8aMrMcmzCoI+IfmAjcC/wJPD1iNgh6Q5JV0+w+kbgVcBtkh5JftonXfUZaK9VPGjKzHKt1EyniNgGbBvRdtsYfa9MTX8S+OQk6pu09mqZ7/kYvZnlWKZHxkJ9dOyx3gF6PDrWzHIqB0GfnEvvvXozy6nsB/3Q6FgfpzezfMp80A/fJNx79GaWTzkI+sboWO/Rm1k+ZT7oq+USC1qKHh1rZrmV+aBv3Dt2vy9sZmY5lfmgh/rlin3WjZnlVT6Cvlb2pYrNLLdyEfQdtQr7j5wkIma7FDOzGZeLoG+vljnu0bFmllO5CPqOximWPnxjZjmUi6BvDJryKZZmlke5CPoOD5oysxzLRdC3V71Hb2b5lYugX1wusbC16GP0ZpZLuQj6+ujYivfozSyXchH0AG3Vso/Rm1kuNRX0ktZL2ilpt6Rbx+n3LkkhqTPV9rFkvZ2Sfnkqij4bHbWKL1VsZrk0YdBLKgKbgKuANcB1ktaM0q8K3AI8mGpbA2wALgbWA/8teb4Z11Ets//IKY+ONbPcaWaP/jJgd0TsiYheYAtwzSj9PgHcCaR3m68BtkTEqYh4GtidPN+M66hVONE3wFGPjjWznGkm6JcDz6Xm9yZtQyStBVZGxD1num6y/o2SuiR1dXd3N1X4mWr3vWPNLKcm/WWspAJwF/Chs32OiNgcEZ0R0dnW1jbZkkbVXvWgKTPLp1ITffYBK1PzK5K2hipwCfA9SQDLgK2Srm5i3RnT0bgMgr+QNbOcaWaPfjuwWtIFklqpf7m6tbEwIl6MiKURsSoiVgEPAFdHRFfSb4OksqQLgNXAD6f8t2hC496x+71Hb2Y5M+EefUT0S9oI3AsUgbsjYoekO4CuiNg6zro7JH0deALoB26OiIEpqv2MLC6XWNRa9KEbM8udZg7dEBHbgG0j2m4bo++VI+b/APiDs6xvSnXUKj50Y2a5k5uRsZDcUtBn3ZhZzuQr6KsVH6M3s9zJVdB31MocOOp7x5pZvuQs6Cuc7BvkyEmPjjWz/MhV0LcP3WnKx+nNLD/yFfTJnaZ8AxIzy5NcBX3H0KAp79GbWX7kKuiH7x3rPXozy49cBf2iconF5ZL36M0sV3IV9FAfNNXtY/RmliO5C/qOqm8Sbmb5kr+gr5V9vRszy5XcBX17reJ7x5pZruQv6KtlevsHOXLCo2PNLB9yF/RD59L78I2Z5UTugn74XHoHvZnlQ+6CvqPmm4SbWb7kLujbfZNwM8uZ3AX9wtYS1UrJe/RmlhtNBb2k9ZJ2Stot6dZRlt8k6XFJj0j6B0lrkvYWSV9Klj0p6WNT/QucjfZq2cfozSw3Jgx6SUVgE3AVsAa4rhHkKV+NiEsj4nXAp4G7kvb3AOWIuBT4V8AHJa2aotrPWket4ksVm1luNLNHfxmwOyL2REQvsAW4Jt0hIo6kZhcBjdFIASySVAIWAL1Auu+s6Kj5Mghmlh/NBP1y4LnU/N6k7TSSbpb0FPU9+t9Jmv8aOAY8D/wz8EcR8cIo694oqUtSV3d39xn+CmeuvVrmgEfHmllOTNmXsRGxKSIuAj4KfDxpvgwYAF4BXAB8SNKFo6y7OSI6I6Kzra1tqkoaU3utQu/AIC+e6Jv21zIzm23NBP0+YGVqfkXSNpYtwLXJ9PXA30REX0QcAH4AdJ5NoVOpo+YbkJhZfjQT9NuB1ZIukNQKbAC2pjtIWp2afTuwK5n+Z+DNSZ9FwBXAjydb9GT5loJmlieliTpERL+kjcC9QBG4OyJ2SLoD6IqIrcBGSW8F+oDDwA3J6puAP5e0AxDw5xHx2HT8ImfCl0EwszyZMOgBImIbsG1E222p6VvGWK+H+imWc0p7NbkMgk+xNLMcyN3IWIAFrUVqlRIHvEdvZjmQy6CHxrn03qM3s+zLbdC318oc8IXNzCwHchv09ZuEe4/ezLIvt0HfXqtw4OhJj441s8zLb9BXy/QNBIePe3SsmWVbboN+6E5TPk5vZhmX46D3ZRDMLB9yHPS+DIKZ5UNug74tuQyCB02ZWdblNugrLUXOWdDiyyCYWeblNuihfpzeh27MLOtyHfTtHjRlZjmQ76Cvlen2oRszy7hcB31HMjp2cNCjY80su/Id9EOjY3tnuxQzs2mT66BvHzqX3odvzCy7ch30jdGxvgyCmWVZroN+6JaC3qM3swxrKuglrZe0U9JuSbeOsvwmSY9LekTSP0hak1r2s5Lul7Qj6VOZyl9gMtprvkm4mWXfhEEvqQhsAq4C1gDXpYM88dWIuDQiXgd8GrgrWbcEfBm4KSIuBq4E5sx1gculIucu9OhYM8u2ZvboLwN2R8SeiOgFtgDXpDtExJHU7CKgcb7iOuCxiHg06XcoIgYmX/bUqd9pynv0ZpZdzQT9cuC51PzepO00km6W9BT1PfrfSZpfDYSkeyU9LOkjo72ApBsldUnq6u7uPrPfYJLaa2X2e4/ezDJsyr6MjYhNEXER8FHg40lzCXgD8N7k8R2S3jLKupsjojMiOtva2qaqpKa0Vyu+gqWZZVozQb8PWJmaX5G0jWULcG0yvRf4fkQcjIjjwDZg7dkUOl06kssgeHSsmWVVM0G/HVgt6QJJrcAGYGu6g6TVqdm3A7uS6XuBSyUtTL6Y/UXgicmXPXU6ahX6B4MXPDrWzDKqNFGHiOiXtJF6aBeBuyNih6Q7gK6I2ApslPRW6mfUHAZuSNY9LOku6huLALZFxD3T9LuclY7UKZZLF5dnuRozs6k3YdADRMQ26odd0m23paZvGWfdL1M/xXJOamsMmjp6iotnuRYzs+mQ65GxkLoMgr+QNbOMyn3QN+4d6wubmVlW5T7oy6Ui5y1s8aApM8us3Ac9NG5A4j16M8smBz3169L7GL2ZZZWDnvqdpnyM3syyykFPcpPwnlMMeHSsmWWQg576MfqBweCFYx4da2bZ46Bn+E5TPvPGzLLIQc/wnaZ871gzyyIHPfVDN+B7x5pZNjnogbbFHh1rZtnloAdaSwWWLGplvw/dmFkGOegTbdWyB02ZWSY56BO+DIKZZZWDPtFRK/v0SjPLJAd9oqNWofuoR8eaWfY46BPt1TKDAYeO+fCNmWWLgz7R7nPpzSyjmgp6Sesl7ZS0W9Ktoyy/SdLjkh6R9A+S1oxYfr6kHkkfnqrCp1pj0JSP05tZ1kwY9JKKwCbgKmANcN3IIAe+GhGXRsTrgE8Dd41Yfhfw7Smod9q0+5aCZpZRzezRXwbsjog9EdELbAGuSXeIiCOp2UXA0Deakq4FngZ2TL7c6dO4d6yvd2NmWdNM0C8HnkvN703aTiPpZklPUd+j/52kbTHwUeD3x3sBSTdK6pLU1d3d3WztU6qlWGDp4lbv0ZtZ5kzZl7ERsSkiLqIe7B9Pmm8H/iQieiZYd3NEdEZEZ1tb21SVdMbaq76loJllT6mJPvuAlan5FUnbWLYAn02mLwfeLenTwLnAoKSTEfGnZ1PsdGuvlT061swyp5mg3w6slnQB9YDfAFyf7iBpdUTsSmbfDuwCiIg3pvrcDvTM1ZAH6KhWeOJfjkzc0cxsHpkw6COiX9JG4F6gCNwdETsk3QF0RcRWYKOktwJ9wGHghukserp01Moc7DlF/8AgpaKHGJhZNjSzR09EbAO2jWi7LTV9SxPPcfuZFjfT2mqVZHRs79B59WZm8513W1NWnrcAgK888CwRvuaNmWWDgz7ljavbeOfa5Xzmu7v51N/82GFvZpnQ1KGbvCgWxB+9++dY0FLk8/93Dyd6B7j91y6mUNBsl2ZmdtYc9CMUCuKT117ConKJzd/fw/HeAT71zkv95ayZzVsO+lFI4mNXvZaFrUX+89/u4kTvAH/yG6+jteSwN7P5x0E/Bkn87ltfzaLWEn+w7UlO9g2w6b1rqbQUZ7s0M7Mz4l3UCfzWmy7kk9dewnd3HuADf7GdY6f6Z7skM7Mz4qBvwr+94pX88Xt+jgf2HOL9d/+QF0/0zXZJZmZNc9A36Z1rV7Dp+rU8tvenvPcLD/DCsd7ZLsnMrCkO+jNw1aUvZ/P7Otm1v4ff+Pz9vtKlmc0LDvoz9EuvbefPf/Nfs++nJ3jP5+9n7+Hjs12Smdm4HPRn4RcuWsqX/8PlvHCsl1//3P08ffDYbJdkZjYmB/1ZWnv+efzVb13Byf5B3vO5+9n5k6OzXZKZ2agc9JNwyfJz+PoHr6Ag2LD5fh7f++Jsl2Rm9hIO+kl6VXuVb9z0eha2lrj+zx6g65kXZrskM7PTOOinwCuXLOIbN72etmqZ933xh/xg98HZLsnMbIiDfoq84twFfO2Dr+eVSxbyvi8+yK9/7n6+8Pd7ePaQv6g1s9mluXbN9c7Ozujq6prtMs7ai8f7uPsHT3PfE/t58vn6/Wdf01Fl3cUdrFuzjEuW15B82WMzm1qSHoqIzlGXOeinz3MvHOe+J/Zz346fsP2ZFxgMePk5Fdat6eBta5Zx+YUvo8WXPzazKTDpoJe0Hvgv1G8O/oWI+NSI5TcBNwMDQA9wY0Q8IeltwKeAVqAX+E8R8d3xXitLQZ/2wrFevvvjA9y34yd8f1c3J/sGqVVKvPm17ay7eBlvenUbi8u+mKiZnZ1JBb2kIvBPwNuAvcB24LqIeCLVpxYRR5Lpq4Hfjoj1kn4e2B8R/yLpEuDeiFg+3utlNejTTvQO8Pe7uvnOE/v52yf3c/h4H63FAv/mVUtYd/Ey3vIz7bRXfXNyM2veeEHfzC7kZcDuiNiTPNkW4BpgKOgbIZ9YBETS/qNU+w5ggaRyRJw6s18hWxa0Fll38TLWXbyM/oFBHnr2cP0QzxM/4e+++TgSXPKKc1jdvpgL2xZxYVv9cdWSRb4evpmdsWaCfjnwXGp+L3D5yE6Sbgb+I/XDNG8e5XneBTw8WshLuhG4EeD8889voqTsKBULXH7hEi6/cAkff/vPsHP/Ue7bsZ8Hnz7E/XsO8c0f7RvqK8HycxfUg3/pIi5KbQSW1Sr+ktfMRjVlB4UjYhOwSdL1wMeBGxrLJF0M3AmsG2PdzcBmqB+6maqa5htJvHZZjdcuqwGrATh2qp+nDx5jz8Fj7OnuYU/3MfYc7KHrmRc43jswtO6CliIXLF009BfARW2LOP9lC1m6uExbtey/BMxyrJmg3wesTM2vSNrGsgX4bGNG0grgW8D7I+KpsykyzxaVS1yy/BwuWX7Oae0Rwf4jp9jT3cNTqY3Ao3t/yj2PP8/Ir14WtRZZWi2zZFErSxeXWbK4TNviVpYsLifz9fali1s5Z0GL/zowy5Bmgn47sFrSBdQDfgNwfbqDpNURsSuZfTuwK2k/F7gHuDUifjBlVRuSWHZOhWXnVPiFVy09bdnJvgGePXScvYePc6inl+6eUxzq6eVgzykOHTvFs4eO8/A/H+bQsd6XbBAASgUNBf95C1upVkosLpeoVlpYXClRGzFfrZSoJvPVSomFrUVvKMzmkAmDPiL6JW0E7qV+euXdEbFD0h1AV0RsBTZKeivQBxxm+LDNRuBVwG2Sbkva1kXEgan+RWxYpaXIa5ZVec2y6rj9BgaDw8eTDUCyITjY2CAk04eP97L/yEl6TvVz9GQ/PU3cM7cghjYEjeBf0FpkQUuRBa0lFrQUWNBSpNJoa6kvryTTC5P29PJyS4FyqUhrqUC5VKBUkDcmZk3ygCk7I4ODQU9vPz0nG8Hfx5GTp88fTabrP32c6BvgRO/A6Y/J9Kn+wbOqQ4JyqUBrsUC5pZg8JvOl0zcKjceWYoGWUoGWgmgpFigVC7QWRamYLCsqeSxQKorW5DG9rFSot5UKOn26WEgek/b0dNLHGyabTpM9vdJsSKEgapUWapWWKXm+wcHgZP8Ax3vrwX+yb+AlG4bjvQP0Dgxyqq/xOFh/7B+kt3+QU/0DqenhtuO9/Rw+PtzeNzBI30DQNzBIfzLdO3B2G5qzUSzUA7+Y/Jw+XaBQgFKhUG9T0l4UBZ3ed+hHolAQBdWfu6DT24ceC1BUfUPTWLfe9/T2ghheb5TnbqwjDdcnMbSsoPqyQqOt0Jgfbhurv8boU59+6fMAQ/UVJMRLn0sIFYaXN55PGq0t2xthB73NqkJBLGwtsbB1dj6KEcHAYNQ3AIOD9PUP0j8Y9CaP9Y1DegMR9A/Wl/UPBP0DyfRgY1nyMzA49Lwj+wwkfQaj/jgwEAxEqj3pOzA43NaYbtQ1GMNtETAQ9fUazzM8zVDfwVSfwcFknYhRv6fJI4nTw596w9BGI7WBQOl+w9Mw3KYR6w29Rqq9sYFqTP/Sa9r5+K+umfLfzUFvuSYlh1iKsIB8noIaEQwGwxuDoQ0DwxuGZOOQ3mgMDAaRWj/dJxrzybLT+qSWn/Ycg/WRlvXl6f715ZGab/RpbOQiSD1PJM9z+nrDzz1cT6SfC5LnGV4W1J94MPUa6Y3j4Ijnr7c3XqO+fno9UnUOv95wnS8/d8G0/Bs76M1yrn4opn6IxrLJl040M8s4B72ZWcY56M3MMs5Bb2aWcQ56M7OMc9CbmWWcg97MLOMc9GZmGTfnLmomqRt4dhJPsRQ4OEXlTCfXObXmS50wf2p1nVNruut8ZUS0jbZgzgX9ZEnqGusKbnOJ65xa86VOmD+1us6pNZt1+tCNmVnGOejNzDIui0G/ebYLaJLrnFrzpU6YP7W6zqk1a3Vm7hi9mZmdLot79GZmluKgNzPLuHkZ9JLWS9opabekW0dZXpb0tWT5g5JWzXyVIGmlpL+T9ISkHZJuGaXPlZJelPRI8nPbLNX6jKTHkxpecnd21X0meU8fk7R2Fmp8Tep9ekTSEUm/O6LPrL2fku6WdEDSP6baXibpO5J2JY/njbHuDUmfXZJumIU6/1DSj5N/229JOneMdcf9nMxAnbdL2pf69/2VMdYdNyNmoM6vpWp8RtIjY6w7M+9nDN2Sa378AEXgKeBCoBV4FFgzos9vA59LpjcAX5ulWl8OrE2mq8A/jVLrlcD/ngPv6zPA0nGW/wrwbeq3trwCeHAOfA5+Qn2QyJx4P4E3AWuBf0y1fRq4NZm+FbhzlPVeBuxJHs9Lps+b4TrXAaVk+s7R6mzmczIDdd4OfLiJz8a4GTHddY5Y/sfAbbP5fs7HPfrLgN0RsScieoEtwDUj+lwDfCmZ/mvgLZqF27xHxPMR8XAyfRR4Elg+03VMkWuA/x51DwDnSnr5LNbzFuCpiJjMKOopFRHfB14Y0Zz+LH4JuHaUVX8Z+E5EvBARh4HvAOtnss6IuC8i+pPZB4AV0/X6zRrj/WxGMxkxZcarM8mdXwf+arpevxnzMeiXA8+l5vfy0vAc6pN8eF8ElsxIdWNIDh/9PPDgKItfL+lRSd+WdPGMFjYsgPskPSTpxlGWN/O+z6QNjP2fZy68nw0dEfF8Mv0ToGOUPnPtvf0A9b/eRjPR52QmbEwOMd09xqGwufR+vhHYHxG7xlg+I+/nfAz6eUfSYuB/AL8bEUdGLH6Y+uGHnwP+K/A/Z7q+xBsiYi1wFXCzpDfNUh0TktQKXA18Y5TFc+X9fImo/60+p89nlvR7QD/wlTG6zPbn5LPARcDrgOepHxaZy65j/L35GXk/52PQ7wNWpuZXJG2j9pFUAs4BDs1IdSNIaqEe8l+JiG+OXB4RRyKiJ5neBrRIWjrDZRIR+5LHA8C3qP/5m9bM+z5TrgIejoj9IxfMlfczZX/jEFfyeGCUPnPivZX074BfBd6bbJReoonPybSKiP0RMRARg8CfjfH6c+X9LAHvBL42Vp+Zej/nY9BvB1ZLuiDZs9sAbB3RZyvQOHPh3cB3x/rgTqfk+NwXgScj4q4x+ixrfH8g6TLq/yYzulGStEhStTFN/Yu5fxzRbSvw/uTsmyuAF1OHJGbamHtJc+H9HCH9WbwB+F+j9LkXWCfpvORQxLqkbcZIWg98BLg6Io6P0aeZz8m0GvG90DvGeP1mMmImvBX4cUTsHW3hjL6f0/1t73T8UD8D5J+of7P+e0nbHdQ/pAAV6n/W7wZ+CFw4S3W+gfqf6o8BjyQ/vwLcBNyU9NkI7KB+ZsADwC/MQp0XJq//aFJL4z1N1ylgU/KePw50ztJ7uoh6cJ+TapsT7yf1jc/zQB/148L/nvp3Q/8H2AX8LfCypG8n8IXUuh9IPq+7gd+chTp3Uz+u3ficNs5aewWwbbzPyQzX+ZfJ5+8x6uH98pF1JvMvyYiZrDNp/4vG5zLVd1beT18Cwcws4+bjoRszMzsDDnozs4xz0JuZZZyD3sws4xz0ZmYZ56A3M8s4B72ZWcb9f8W/GShI3/AYAAAAAElFTkSuQmCC\n",
"text/plain": [
"<Figure size 432x288 with 1 Axes>"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"batch_size = 5\n",
"num_steps = 10\n",
"state_size = 10\n",
"n_classes = 2\n",
"learning_rate = 0.1\n",
"\n",
"x = tf.placeholder(tf.int32, [batch_size, num_steps])\n",
"y = tf.placeholder(tf.int32, [batch_size, num_steps])\n",
"\n",
"#RNN的初始化状态,全设为零。注意state是与input保持一致,接下来会有concat操作,所以这里要有batch的维度。即每个样本都要有隐层状态\n",
"init_state = tf.zeros([batch_size, state_size])\n",
"\n",
"#将输入转化为one-hot编码,两个类别。[batch_size, num_steps, num_classes]\n",
"x_one_hot = tf.one_hot(x, n_classes)\n",
"\n",
"#将输入unstack,即在num_steps上解绑,方便给每个循环单元输入。这里可以看出RNN每个cell都处理一个batch的输入(即batch个二进制样本输入)\n",
"rnn_inputs = tf.unstack(x_one_hot, axis=1)\n",
"\n",
"#定义rnn_cell的权重参数,\n",
"cell = tf.contrib.rnn.BasicRNNCell(state_size)\n",
"rnn_outputs, final_state = tf.contrib.rnn.static_rnn(cell, rnn_inputs, initial_state=init_state)\n",
"\n",
"# 定义softmax层\n",
"with tf.variable_scope('softmax'):\n",
" W = tf.get_variable('W', [state_size, n_classes])\n",
" b = tf.get_variable('b', [n_classes])\n",
"\n",
"#注意,这里要将num_steps个输出全部分别进行计算其输出,然后使用softmax预测\n",
"logits = [tf.matmul(rnn_output, W) + b for rnn_output in rnn_outputs]\n",
"predictions = [tf.nn.softmax(logit) for logit in logits]\n",
"\n",
"# tf.stack()这是一个矩阵拼接的函数,tf.unstack()则是一个矩阵分解的函数\n",
"y_as_lists = tf.unstack(y, num=num_steps, axis=1)\n",
"\n",
"losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(labels=label, logits=logit) for label, logit in zip(y_as_lists, predictions)]\n",
"total_loss = tf.reduce_mean(losses)\n",
"train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)\n",
"\n",
"def train_network(num_epochs, num_steps, state_size, verbose=True):\n",
" with tf.Session() as sess:\n",
" sess.run(tf.global_variables_initializer())\n",
" training_losses = []\n",
" \n",
" for idx, epoch in enumerate(gen_epochs(num_epochs, num_steps)):\n",
" training_loss = 0\n",
" # 保存每次执行后的最后状态,然后赋给下一次执行\n",
" training_state = np.zeros((batch_size, state_size))\n",
" if verbose:\n",
" print('\\EPOCH', idx)\n",
" \n",
" # 这是具体获得数据的部分\n",
" for step, (X, Y) in enumerate(epoch):\n",
" tr_losses, training_loss_, training_state, _ = sess.run([losses, total_loss, final_state, train_step], \n",
" feed_dict={x:X, y:Y, init_state: training_state})\n",
" \n",
" training_loss += training_loss_\n",
" if step % 100 == 0 and step > 0:\n",
" if verbose:\n",
" print(\"Average loss at step\", step,\"for last 100 steps:\", training_loss / 100)\n",
" \n",
" training_losses.append(training_loss / 100)\n",
" training_loss = 0\n",
" \n",
" return training_losses\n",
"\n",
"training_losses = train_network(1, num_steps, state_size)\n",
"plt.plot(training_losses)\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: Deep Learning/12.1 GRU/GRU.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Extracting data/train-images-idx3-ubyte.gz\n",
"Extracting data/train-labels-idx1-ubyte.gz\n",
"Extracting data/t10k-images-idx3-ubyte.gz\n",
"Extracting data/t10k-labels-idx1-ubyte.gz\n"
]
}
],
"source": [
"import tensorflow as tf\n",
"from tensorflow.contrib import rnn\n",
"old_v = tf.compat.v1.logging.get_verbosity()\n",
"tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)\n",
"# 导入 MINST 数据集\n",
"from tensorflow.examples.tutorials.mnist import input_data\n",
"mnist = input_data.read_data_sets(\"data/\", one_hot=True)\n",
"tf.compat.v1.logging.set_verbosity(old_v)"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"batch_size = 100\n",
"time_step =28 # 时间步(每个时间步处理图像的一行)\n",
"data_length = 28 # 每个时间步输入数据的长度(这里就是图像的宽度)\n",
"learning_rate = 0.01"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING: Logging before flag parsing goes to stderr.\n",
"W0816 15:02:08.115901 140215968261952 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n",
"\n",
"W0816 15:02:08.121917 140215968261952 deprecation.py:323] From <ipython-input-3-b0516593e217>:14: GRUCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"This class is equivalent as tf.keras.layers.GRUCell, and will be replaced by that in Tensorflow 2.0.\n",
"W0816 15:02:08.123775 140215968261952 deprecation.py:323] From <ipython-input-3-b0516593e217>:14: MultiRNNCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"This class is equivalent as tf.keras.layers.StackedRNNCells, and will be replaced by that in Tensorflow 2.0.\n",
"W0816 15:02:08.124845 140215968261952 deprecation.py:323] From <ipython-input-3-b0516593e217>:16: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `keras.layers.RNN(cell)`, which is equivalent to this API\n",
"W0816 15:02:08.186853 140215968261952 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:558: Layer.add_variable (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `layer.add_weight` method instead.\n",
"W0816 15:02:08.196528 140215968261952 deprecation.py:506] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:564: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Call initializer instance with the dtype argument instead of passing it to the constructor\n",
"W0816 15:02:08.282342 140215968261952 deprecation.py:506] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:574: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Call initializer instance with the dtype argument instead of passing it to the constructor\n",
"W0816 15:02:08.359511 140215968261952 deprecation.py:323] From <ipython-input-3-b0516593e217>:17: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Use keras.layers.Dense instead.\n",
"W0816 15:02:08.360661 140215968261952 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/layers/core.py:187: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `layer.__call__` method instead.\n",
"W0816 15:02:08.374940 140215968261952 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.losses.softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.softmax_cross_entropy instead.\n",
"\n",
"W0816 15:02:08.402209 140215968261952 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/losses/losses_impl.py:121: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Use tf.where in 2.0, which has the same broadcast rule as np.where\n",
"W0816 15:02:08.411217 140215968261952 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.train.AdamOptimizer is deprecated. Please use tf.compat.v1.train.AdamOptimizer instead.\n",
"\n",
"W0816 15:02:08.920478 140215968261952 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.metrics.accuracy is deprecated. Please use tf.compat.v1.metrics.accuracy instead.\n",
"\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"step: 0 train loss: 2.3052 | val accuracy: 0.13\n",
"step: 100 train loss: 0.1519 | val accuracy: 0.53\n",
"step: 200 train loss: 0.1007 | val accuracy: 0.68\n",
"step: 300 train loss: 0.0438 | val accuracy: 0.75\n",
"step: 400 train loss: 0.0623 | val accuracy: 0.80\n",
"step: 500 train loss: 0.1239 | val accuracy: 0.83\n",
"step: 600 train loss: 0.0623 | val accuracy: 0.85\n",
"step: 700 train loss: 0.0691 | val accuracy: 0.86\n",
"step: 800 train loss: 0.0951 | val accuracy: 0.88\n",
"step: 900 train loss: 0.0745 | val accuracy: 0.89\n",
"step: 1000 train loss: 0.1131 | val accuracy: 0.89\n",
"step: 1100 train loss: 0.1958 | val accuracy: 0.90\n",
"step: 1200 train loss: 0.0453 | val accuracy: 0.91\n",
"step: 1300 train loss: 0.0631 | val accuracy: 0.91\n",
"step: 1400 train loss: 0.0495 | val accuracy: 0.92\n",
"step: 1500 train loss: 0.0844 | val accuracy: 0.92\n",
"step: 1600 train loss: 0.0420 | val accuracy: 0.92\n",
"step: 1700 train loss: 0.0085 | val accuracy: 0.93\n",
"step: 1800 train loss: 0.0670 | val accuracy: 0.93\n",
"step: 1900 train loss: 0.2119 | val accuracy: 0.93\n",
"step: 2000 train loss: 0.0291 | val accuracy: 0.93\n",
"step: 2100 train loss: 0.0566 | val accuracy: 0.94\n",
"step: 2200 train loss: 0.0220 | val accuracy: 0.94\n",
"step: 2300 train loss: 0.0533 | val accuracy: 0.94\n",
"step: 2400 train loss: 0.0464 | val accuracy: 0.94\n",
"step: 2500 train loss: 0.1071 | val accuracy: 0.94\n",
"step: 2600 train loss: 0.0377 | val accuracy: 0.94\n",
"step: 2700 train loss: 0.1267 | val accuracy: 0.94\n",
"step: 2800 train loss: 0.1242 | val accuracy: 0.94\n",
"step: 2900 train loss: 0.2198 | val accuracy: 0.94\n",
"test loss: 0.9424\n"
]
}
],
"source": [
"# 定义占位符\n",
"X_ = tf.placeholder(tf.float32, [None, 784])\n",
"Y_ = tf.placeholder(tf.int32, [None, 10])\n",
"\n",
"# dynamic_rnn的输入数据(batch_size, max_time, ...)\n",
"inputs = tf.reshape(X_, [-1, time_step, data_length])\n",
"\n",
"# 验证集\n",
"validate_data = {X_: mnist.validation.images, Y_: mnist.validation.labels}\n",
"# 测试集\n",
"test_data = {X_: mnist.test.images, Y_: mnist.test.labels}\n",
"\n",
"# 定义一个两层的GRU模型\n",
"gru_layers = rnn.MultiRNNCell([rnn.GRUCell(num_units=num) for num in [100, 100]], state_is_tuple=True)\n",
"\n",
"outputs, h_ = tf.nn.dynamic_rnn(gru_layers, inputs, dtype=tf.float32)\n",
"output = tf.layers.dense(outputs[:, -1, :], 10) #获取GRU网络的最后输出状态\n",
"\n",
"# 定义交叉熵损失函数和优化器\n",
"loss = tf.losses.softmax_cross_entropy(onehot_labels=Y_, logits=output)\n",
"train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)\n",
"\n",
"# 计算准确率\n",
"accuracy = tf.metrics.accuracy(labels=tf.argmax(Y_, axis=1), predictions=tf.argmax(output, axis=1))[1]\n",
"\n",
"## 初始化变量\n",
"sess = tf.Session()\n",
"init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())\n",
"sess.run(init)\n",
"\n",
"for step in range(3000):\n",
" # 获取一个batch的训练数据\n",
" train_x, train_y = mnist.train.next_batch(batch_size)\n",
" _, loss_ = sess.run([train_op, loss], {X_: train_x, Y_: train_y})\n",
" \n",
" # 在验证集上计算准确率\n",
" if step % 100 == 0:\n",
" val_acc = sess.run(accuracy, feed_dict=validate_data)\n",
" print('step:', step,'train loss: %.4f' % loss_, '| val accuracy: %.2f' % val_acc)\n",
" \n",
"## 计算测试集史上的准确率\n",
"test_acc = sess.run(accuracy, feed_dict=test_data)\n",
"print('test loss: %.4f' % test_acc)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: Deep Learning/12.1 GRU/README.md
================================================
## 目录
- [1. 什么是GRU](#1-什么是gru)
- [2. ⻔控循环单元](#2-⻔控循环单元)
- [2.1 重置门和更新门](#21-重置门和更新门)
- [2.2 候选隐藏状态](#22-候选隐藏状态)
- [2.3 隐藏状态](#23-隐藏状态)
- [3. 代码实现GRU](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/12.1%20GRU/GRU.ipynb)
- [4. 参考文献](#4-参考文献)
## 1. 什么是GRU
在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较小时,**循环神经⽹络的梯度较容易出现衰减或爆炸。虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题。**通常由于这个原因,循环神经⽹络在实际中较难捕捉时间序列中时间步距离较⼤的依赖关系。
**门控循环神经⽹络(gated recurrent neural network)的提出,正是为了更好地捕捉时间序列中时间步距离较⼤的依赖关系。**它通过可以学习的⻔来控制信息的流动。其中,门控循环单元(gatedrecurrent unit,GRU)是⼀种常⽤的门控循环神经⽹络。
## 2. ⻔控循环单元
### 2.1 重置门和更新门
GRU它引⼊了**重置⻔(reset gate)和更新⻔(update gate)**的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。
门控循环单元中的重置⻔和更新⻔的输⼊均为当前时间步输⼊ 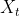与上⼀时间步隐藏状态,输出由激活函数为sigmoid函数的全连接层计算得到。 如下图所示:

具体来说,假设隐藏单元个数为 h,给定时间步 t 的小批量输⼊ (样本数为n,输⼊个数为d)和上⼀时间步隐藏状态 。重置⻔ 和更新⻔ 的计算如下:
)
)
sigmoid函数可以将元素的值变换到0和1之间。因此,重置⻔ 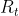和更新⻔ 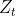中每个元素的值域都是[0*,* 1]。
### 2.2 候选隐藏状态
接下来,⻔控循环单元将计算候选隐藏状态来辅助稍后的隐藏状态计算。我们将当前时间步重置⻔的输出与上⼀时间步隐藏状态做按元素乘法(符号为*⊙*)。如果重置⻔中元素值接近0,那么意味着重置对应隐藏状态元素为0,即丢弃上⼀时间步的隐藏状态。如果元素值接近1,那么表⽰保留上⼀时间步的隐藏状态。然后,将按元素乘法的结果与当前时间步的输⼊连结,再通过含激活函数tanh的全连接层计算出候选隐藏状态,其所有元素的值域为[-1,1]。

具体来说,时间步 t 的候选隐藏状态 的计算为:
W_{hh}+b_h))
从上⾯这个公式可以看出,重置⻔控制了上⼀时间步的隐藏状态如何流⼊当前时间步的候选隐藏状态。而上⼀时间步的隐藏状态可能包含了时间序列截⾄上⼀时间步的全部历史信息。因此,重置⻔可以⽤来丢弃与预测⽆关的历史信息。
### 2.3 隐藏状态
最后,时间步*t*的隐藏状态 的计算使⽤当前时间步的更新⻔ 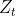来对上⼀时间步的隐藏状态 和当前时间步的候选隐藏状态 做组合:

值得注意的是,**更新⻔可以控制隐藏状态应该如何被包含当前时间步信息的候选隐藏状态所更新,**如上图所⽰。假设更新⻔在时间步之间⼀直近似1。那么,在时间步间的输⼊信息⼏乎没有流⼊时间步 t 的隐藏状态 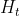实际上,这可以看作是较早时刻的隐藏状态 直通过时间保存并传递⾄当前时间步 t。这个设计可以应对循环神经⽹络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较⼤的依赖关系。
我们对⻔控循环单元的设计稍作总结:
- 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
- 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。
## 3. 代码实现GRU
[MNIST--GRU实现](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/12.1%20GRU/GRU.ipynb)
## 4. 参考文献
[《动手学--深度学习》](http://zh.gluon.ai)
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/12.2 LSTM/LSTM.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 构建单层LSTM网络对MNIST数据集分类"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这里的输入x当成28个时间段,每段内容为28个值,使用unstack将原始的输入28×28调整成具有28个元素的list\n",
"\n",
"每个元素为1×28的数组。这28个时序一次送入RNN中,如图下图所示:\n",
"\n",
"\n",
"由于是批次操作,所以每次都取该批次中所有图片的一行作为一个时间序列输入。\n",
"\n",
"理解了这个转换之后,构建网络就变得很容易了,先建立一个包含128个cell的类lstm_cell,然后将变形后的x1放进去生成节点outputs,最后通过全连接生成pred,最后使用softmax进行分类。"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Extracting data/train-images-idx3-ubyte.gz\n",
"Extracting data/train-labels-idx1-ubyte.gz\n",
"Extracting data/t10k-images-idx3-ubyte.gz\n",
"Extracting data/t10k-labels-idx1-ubyte.gz\n"
]
}
],
"source": [
"import tensorflow as tf\n",
"old_v = tf.compat.v1.logging.get_verbosity()\n",
"tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)\n",
"# 导入 MINST 数据集\n",
"from tensorflow.examples.tutorials.mnist import input_data\n",
"mnist = input_data.read_data_sets(\"data/\", one_hot=True)\n",
"tf.compat.v1.logging.set_verbosity(old_v)"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING: Logging before flag parsing goes to stderr.\n",
"W0817 18:06:34.657757 140362178049856 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n",
"\n",
"W0817 18:06:34.662876 140362178049856 lazy_loader.py:50] \n",
"The TensorFlow contrib module will not be included in TensorFlow 2.0.\n",
"For more information, please see:\n",
" * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n",
" * https://github.com/tensorflow/addons\n",
" * https://github.com/tensorflow/io (for I/O related ops)\n",
"If you depend on functionality not listed there, please file an issue.\n",
"\n",
"W0817 18:06:34.663518 140362178049856 deprecation.py:323] From <ipython-input-2-94e8e97bcb25>:12: BasicLSTMCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"This class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.\n",
"W0817 18:06:34.665515 140362178049856 deprecation.py:323] From <ipython-input-2-94e8e97bcb25>:13: static_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `keras.layers.RNN(cell, unroll=True)`, which is equivalent to this API\n",
"W0817 18:06:34.685794 140362178049856 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:734: Layer.add_variable (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `layer.add_weight` method instead.\n",
"W0817 18:06:34.695257 140362178049856 deprecation.py:506] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/ops/rnn_cell_impl.py:738: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Call initializer instance with the dtype argument instead of passing it to the constructor\n",
"W0817 18:06:35.048599 140362178049856 deprecation.py:323] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/contrib/layers/python/layers/layers.py:1866: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Please use `layer.__call__` method instead.\n",
"W0817 18:06:35.065407 140362178049856 deprecation.py:323] From <ipython-input-2-94e8e97bcb25>:23: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"\n",
"Future major versions of TensorFlow will allow gradients to flow\n",
"into the labels input on backprop by default.\n",
"\n",
"See `tf.nn.softmax_cross_entropy_with_logits_v2`.\n",
"\n",
"W0817 18:06:35.085622 140362178049856 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.train.AdamOptimizer is deprecated. Please use tf.compat.v1.train.AdamOptimizer instead.\n",
"\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Iter 1280, Minibatch Loss= 2.123669, Training Accuracy= 0.32031\n",
"Iter 2560, Minibatch Loss= 1.880366, Training Accuracy= 0.36719\n",
"Iter 3840, Minibatch Loss= 1.604660, Training Accuracy= 0.41406\n",
"Iter 5120, Minibatch Loss= 1.290977, Training Accuracy= 0.53906\n",
"Iter 6400, Minibatch Loss= 1.121061, Training Accuracy= 0.59375\n",
"Iter 7680, Minibatch Loss= 0.952852, Training Accuracy= 0.71875\n",
"Iter 8960, Minibatch Loss= 0.892485, Training Accuracy= 0.73438\n",
"Iter 10240, Minibatch Loss= 0.698507, Training Accuracy= 0.75000\n",
"Iter 11520, Minibatch Loss= 0.692774, Training Accuracy= 0.79688\n",
"Iter 12800, Minibatch Loss= 0.712652, Training Accuracy= 0.75781\n",
"Iter 14080, Minibatch Loss= 0.628787, Training Accuracy= 0.77344\n",
"Iter 15360, Minibatch Loss= 0.480412, Training Accuracy= 0.85938\n",
"Iter 16640, Minibatch Loss= 0.431347, Training Accuracy= 0.87500\n",
"Iter 17920, Minibatch Loss= 0.464947, Training Accuracy= 0.87500\n",
"Iter 19200, Minibatch Loss= 0.450698, Training Accuracy= 0.87500\n",
"Iter 20480, Minibatch Loss= 0.382798, Training Accuracy= 0.88281\n",
"Iter 21760, Minibatch Loss= 0.506578, Training Accuracy= 0.85938\n",
"Iter 23040, Minibatch Loss= 0.380739, Training Accuracy= 0.89062\n",
"Iter 24320, Minibatch Loss= 0.345643, Training Accuracy= 0.87500\n",
"Iter 25600, Minibatch Loss= 0.422373, Training Accuracy= 0.85938\n",
"Iter 26880, Minibatch Loss= 0.332909, Training Accuracy= 0.89062\n",
"Iter 28160, Minibatch Loss= 0.269029, Training Accuracy= 0.93750\n",
"Iter 29440, Minibatch Loss= 0.421532, Training Accuracy= 0.87500\n",
"Iter 30720, Minibatch Loss= 0.232879, Training Accuracy= 0.92188\n",
"Iter 32000, Minibatch Loss= 0.412540, Training Accuracy= 0.85156\n",
"Iter 33280, Minibatch Loss= 0.303702, Training Accuracy= 0.90625\n",
"Iter 34560, Minibatch Loss= 0.260348, Training Accuracy= 0.92969\n",
"Iter 35840, Minibatch Loss= 0.181875, Training Accuracy= 0.95312\n",
"Iter 37120, Minibatch Loss= 0.296286, Training Accuracy= 0.89062\n",
"Iter 38400, Minibatch Loss= 0.123771, Training Accuracy= 0.96094\n",
"Iter 39680, Minibatch Loss= 0.184759, Training Accuracy= 0.96094\n",
"Iter 40960, Minibatch Loss= 0.222321, Training Accuracy= 0.96875\n",
"Iter 42240, Minibatch Loss= 0.251163, Training Accuracy= 0.92188\n",
"Iter 43520, Minibatch Loss= 0.264645, Training Accuracy= 0.91406\n",
"Iter 44800, Minibatch Loss= 0.301121, Training Accuracy= 0.91406\n",
"Iter 46080, Minibatch Loss= 0.218629, Training Accuracy= 0.91406\n",
"Iter 47360, Minibatch Loss= 0.150714, Training Accuracy= 0.96094\n",
"Iter 48640, Minibatch Loss= 0.185175, Training Accuracy= 0.95312\n",
"Iter 49920, Minibatch Loss= 0.201719, Training Accuracy= 0.92969\n",
"Iter 51200, Minibatch Loss= 0.299931, Training Accuracy= 0.91406\n",
"Iter 52480, Minibatch Loss= 0.149284, Training Accuracy= 0.96094\n",
"Iter 53760, Minibatch Loss= 0.168152, Training Accuracy= 0.94531\n",
"Iter 55040, Minibatch Loss= 0.166098, Training Accuracy= 0.95312\n",
"Iter 56320, Minibatch Loss= 0.127440, Training Accuracy= 0.96875\n",
"Iter 57600, Minibatch Loss= 0.229024, Training Accuracy= 0.92969\n",
"Iter 58880, Minibatch Loss= 0.204111, Training Accuracy= 0.93750\n",
"Iter 60160, Minibatch Loss= 0.132831, Training Accuracy= 0.95312\n",
"Iter 61440, Minibatch Loss= 0.247493, Training Accuracy= 0.91406\n",
"Iter 62720, Minibatch Loss= 0.170920, Training Accuracy= 0.94531\n",
"Iter 64000, Minibatch Loss= 0.250919, Training Accuracy= 0.94531\n",
"Iter 65280, Minibatch Loss= 0.256693, Training Accuracy= 0.93750\n",
"Iter 66560, Minibatch Loss= 0.258490, Training Accuracy= 0.92969\n",
"Iter 67840, Minibatch Loss= 0.145542, Training Accuracy= 0.96094\n",
"Iter 69120, Minibatch Loss= 0.080276, Training Accuracy= 0.98438\n",
"Iter 70400, Minibatch Loss= 0.186373, Training Accuracy= 0.93750\n",
"Iter 71680, Minibatch Loss= 0.149742, Training Accuracy= 0.97656\n",
"Iter 72960, Minibatch Loss= 0.123503, Training Accuracy= 0.96094\n",
"Iter 74240, Minibatch Loss= 0.109718, Training Accuracy= 0.96875\n",
"Iter 75520, Minibatch Loss= 0.187299, Training Accuracy= 0.93750\n",
"Iter 76800, Minibatch Loss= 0.116320, Training Accuracy= 0.95312\n",
"Iter 78080, Minibatch Loss= 0.200649, Training Accuracy= 0.94531\n",
"Iter 79360, Minibatch Loss= 0.127103, Training Accuracy= 0.96875\n",
"Iter 80640, Minibatch Loss= 0.106132, Training Accuracy= 0.97656\n",
"Iter 81920, Minibatch Loss= 0.122763, Training Accuracy= 0.96875\n",
"Iter 83200, Minibatch Loss= 0.160990, Training Accuracy= 0.94531\n",
"Iter 84480, Minibatch Loss= 0.173910, Training Accuracy= 0.95312\n",
"Iter 85760, Minibatch Loss= 0.147762, Training Accuracy= 0.96094\n",
"Iter 87040, Minibatch Loss= 0.173037, Training Accuracy= 0.93750\n",
"Iter 88320, Minibatch Loss= 0.061748, Training Accuracy= 0.99219\n",
"Iter 89600, Minibatch Loss= 0.132250, Training Accuracy= 0.96094\n",
"Iter 90880, Minibatch Loss= 0.315201, Training Accuracy= 0.91406\n",
"Iter 92160, Minibatch Loss= 0.115778, Training Accuracy= 0.94531\n",
"Iter 93440, Minibatch Loss= 0.120537, Training Accuracy= 0.95312\n",
"Iter 94720, Minibatch Loss= 0.121461, Training Accuracy= 0.96094\n",
"Iter 96000, Minibatch Loss= 0.122786, Training Accuracy= 0.96094\n",
"Iter 97280, Minibatch Loss= 0.115688, Training Accuracy= 0.96875\n",
"Iter 98560, Minibatch Loss= 0.186289, Training Accuracy= 0.93750\n",
"Iter 99840, Minibatch Loss= 0.182592, Training Accuracy= 0.94531\n",
" Finished!\n",
"Testing Accuracy: 0.984375\n"
]
}
],
"source": [
"n_input = 28 #MNIST data 输入(img shape: 28*28)\n",
"n_steps = 28 #序列个数\n",
"n_hidden = 128 #隐藏层个数\n",
"n_classes = 10 #MNIST 分类个数 (0~9 digits)\n",
"\n",
"# 定义占位符\n",
"x = tf.placeholder('float', [None, n_steps, n_input])\n",
"y = tf.placeholder('float', [None, n_classes])\n",
"\n",
"# 对矩阵进行分解\n",
"x1 = tf.unstack(x, n_steps, 1)\n",
"lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)\n",
"outputs, states = tf.contrib.rnn.static_rnn(lstm_cell, x1, dtype=tf.float32)\n",
"\n",
"pred = tf.contrib.layers.fully_connected(outputs[-1], n_classes, activation_fn=None)\n",
"\n",
"learning_rate = 0.001\n",
"training_iters = 100000\n",
"batch_size = 128\n",
"display_step = 10\n",
"\n",
"# 平均交叉熵损失\n",
"cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))\n",
"optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)\n",
"\n",
"## 评估模型\n",
"# tf.argmax(input,axis)根据axis取值的不同返回每行或者每列最大值的索引。\n",
"# axis = 1: 行\n",
"# equal,相等的意思。顾名思义,就是判断,x, y 是不是相等\n",
"# tf.cast 数据类型转换\n",
"correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))\n",
"accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))\n",
"\n",
"# 启动session\n",
"with tf.Session() as sess:\n",
" sess.run(tf.global_variables_initializer())\n",
" step = 1\n",
" \n",
" while step * batch_size < training_iters:\n",
" batch_x, batch_y = mnist.train.next_batch(batch_size)\n",
" \n",
" # Reshape data to get 28 seq of 28 elements\n",
" batch_x = batch_x.reshape((batch_size, n_steps, n_input))\n",
" \n",
" sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})\n",
" if step % display_step == 0:\n",
" # 计算批次数据的准确率\n",
" acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})\n",
" loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})\n",
" \n",
" print(\"Iter \" + str(step*batch_size) + \", Minibatch Loss= \" + \\\n",
" \"{:.6f}\".format(loss) + \", Training Accuracy= \" + \\\n",
" \"{:.5f}\".format(acc))\n",
" \n",
" step += 1\n",
" print (\" Finished!\")\n",
" \n",
" # 计算准确率 for 128 mnist test images\n",
" test_len = 128\n",
" test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))\n",
" test_label = mnist.test.labels[:test_len]\n",
" print (\"Testing Accuracy:\", \\\n",
" sess.run(accuracy, feed_dict={x: test_data, y: test_label}))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: Deep Learning/12.2 LSTM/README.md
================================================
## 目录
- [1. 什么是LSTM](#1-什么是lstm)
- [2. 输⼊⻔、遗忘⻔和输出⻔](#2-输遗忘和输出)
- [3. 候选记忆细胞](#3-候选记忆细胞)
- [4. 记忆细胞](#4-记忆细胞)
- [5. 隐藏状态](#5-隐藏状态)
- [6. LSTM与GRU的区别](#6-lstm与gru的区别)
- [7. LSTM可以使用别的激活函数吗?](#7-lstm可以使用别的激活函数吗)
- [8. 代码实现](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/12.2%20LSTM/LSTM.ipynb)
- [9. 参考文献](#9-参考文献)
## 1. 什么是LSTM
在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义。我们不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。我们的思想拥有持久性。LSTM就是具备了这一特性。
这篇将介绍另⼀种常⽤的⻔控循环神经⽹络:**⻓短期记忆(long short-term memory,LSTM)[1]。**它⽐⻔控循环单元的结构稍微复杂⼀点,也是为了解决在RNN网络中梯度衰减的问题,是GRU的一种扩展。
可以先理解GRU的过程,在来理解LSTM会容易许多,链接地址:[三步理解--门控循环单元(GRU)](https://blog.csdn.net/weixin_41510260/article/details/99679481)
LSTM 中引⼊了3个⻔,即输⼊⻔(input gate)、遗忘⻔(forget gate)和输出⻔(output gate),以及与隐藏状态形状相同的记忆细胞(某些⽂献把记忆细胞当成⼀种特殊的隐藏状态),从而记录额外的信息。
## 2. 输⼊⻔、遗忘⻔和输出⻔
与⻔控循环单元中的重置⻔和更新⻔⼀样,⻓短期记忆的⻔的输⼊均为当前时间步输⼊Xt与上⼀时间步隐藏状态Ht−1,输出由激活函数为sigmoid函数的全连接层计算得到。如此⼀来,这3个⻔元素的值域均为[0, 1]。如下图所示:

具体来说,假设隐藏单元个数为 h,给定时间步 t 的小批量输⼊ (样本数为n,输⼊个数为d)和上⼀时间步隐藏状态 。三个门的公式如下:
**输入门:** )
**遗忘问:** )
**输出门:** )
## 3. 候选记忆细胞
接下来,⻓短期记忆需要计算候选记忆细胞 。它的计算与上⾯介绍的3个⻔类似,但使⽤了值域在[−1, 1]的tanh函数作为激活函数,如下图所示:

具体来说,时间步t的候选记忆细胞计算如下:
)
## 4. 记忆细胞
我们可以通过元素值域在[0, 1]的输⼊⻔、遗忘⻔和输出⻔来控制隐藏状态中信息的流动,这⼀般也是通过使⽤按元素乘法(符号为⊙)来实现的。当前时间步记忆细胞的计算组合了上⼀时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘⻔和输⼊⻔来控制信息的流动:

如下图所⽰,遗忘⻔控制上⼀时间步的记忆细胞Ct−1中的信息是否传递到当前时间步,而输⼊⻔则控制当前时间步的输⼊Xt通过候选记忆细胞C˜t如何流⼊当前时间步的记忆细胞。如果遗忘⻔⼀直近似1且输⼊⻔⼀直近似0,过去的记忆细胞将⼀直通过时间保存并传递⾄当前时间步。这个设计可以应对循环神经⽹络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较⼤的依赖关系。

## 5. 隐藏状态
有了记忆细胞以后,接下来我们还可以通过输出⻔来控制从记忆细胞到隐藏状态Ht的信
息的流动:
)
这⾥的tanh函数确保隐藏状态元素值在-1到1之间。需要注意的是,当输出⻔近似1时,记忆细胞信息将传递到隐藏状态供输出层使⽤;当输出⻔近似0时,记忆细胞信息只⾃⼰保留。**下图展⽰了⻓短期记忆中隐藏状态的全部计算:**

## 6. LSTM与GRU的区别
LSTM与GRU二者结构十分相似,**不同在于**:
1. 新的记忆都是根据之前状态及输入进行计算,但是GRU中有一个重置门控制之前状态的进入量,而在LSTM里没有类似门;
2. 产生新的状态方式不同,LSTM有两个不同的门,分别是遗忘门(forget gate)和输入门(input gate),而GRU只有一种更新门(update gate);
3. LSTM对新产生的状态可以通过输出门(output gate)进行调节,而GRU对输出无任何调节。
4. GRU的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。
5. LSTM更加强大和灵活,因为它有三个门而不是两个。
## 7. LSTM可以使用别的激活函数吗?
关于激活函数的选取,在LSTM中,遗忘门、输入门和输出门使用Sigmoid函数作为激活函数;在生成候选记忆时,使用双曲正切函数Tanh作为激活函数。
值得注意的是,这两个激活函数都是饱和的,也就是说在输入达到一定值的情况下,输出就不会发生明显变化了。如果是用非饱和的激活函数,例如ReLU,那么将难以实现门控的效果。
Sigmoid函数的输出在0~1之间,符合门控的物理定义。且当输入较大或较小时,其输出会非常接近1或0,从而保证该门开或关。在生成候选记忆时,使用Tanh函数,是因为其输出在−1~1之间,这与大多数场景下特征分布是0中心的吻合。此外,Tanh函数在输入为0附近相比Sigmoid函数有更大的梯度,通常使模型收敛更快。
激活函数的选择也不是一成不变的,但要选择合理的激活函数。
## 8. 代码实现
[MIST数据分类--TensorFlow实现LSTM](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/12.2%20LSTM/LSTM.ipynb)
## 9. 参考文献
[《动手学--深度学习》](http://zh.gluon.ai)
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/13. Transfer Learning/README.md
================================================
## 目录
- [1. 什么是迁移学习](#1-什么是迁移学习)
- [2. 为什么需要迁移学习?](#2-为什么需要迁移学习)
- [3. 迁移学习的基本问题有哪些?](#3-迁移学习的基本问题有哪些)
- [4. 迁移学习有哪些常用概念?](#4-迁移学习有哪些常用概念)
- [5. 迁移学习与传统机器学习有什么区别?](#5-迁移学习与传统机器学习有什么区别)
- [6. 迁移学习的核心及度量准则?](#6-迁移学习的核心及度量准则)
- [7. 迁移学习与其他概念的区别?](#7-迁移学习与其他概念的区别)
- [8. 什么情况下可以使用迁移学习?](#8-什么情况下可以使用迁移学习)
- [9. 什么是finetune?](#9-什么是finetune)
- [10. 什么是深度网络自适应?](#10-什么是深度网络自适应)
- [11. GAN在迁移学习中的应用](#11-gan在迁移学习中的应用)
- [12. 代码实现](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/13.%20Transfer%20Learning/Transfer%20Learning.ipynb)
- [13. 参考文献](#13-参考文献)
## 1. 什么是迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。 迁移学习对人类来说很常见,例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。
找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域(domain)学习过的模型应用在新领域上。
## 2. 为什么需要迁移学习?
1. **大数据与少标注的矛盾**:虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型。人工进行数据标定太耗时。
2. **大数据与弱计算的矛盾**:普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移。
3. **普适化模型与个性化需求的矛盾**:即使是在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在不同人之间做模型的适配。
4. **特定应用(如冷启动)的需求**。
## 3. 迁移学习的基本问题有哪些?
基本问题主要有3个:
- **How to transfer**: 如何进行迁移学习?(设计迁移方法)
- **What to transfer**: 给定一个目标领域,如何找到相对应的源领域,然后进行迁移?(源领域选择)
- **When to transfer**: 什么时候可以进行迁移,什么时候不可以?(避免负迁移)
## 4. 迁移学习有哪些常用概念?
- 基本定义
- 域(Domain):数据特征和特征分布组成,是学习的主体
- **源域 (Source domain)**:已有知识的域
- **目标域 (Target domain)**:要进行学习的域
- **任务 (Task)**:由目标函数和学习结果组成,是学习的结果
- 按特征空间分类
- **同构迁移学习(Homogeneous TL)**: 源域和目标域的特征空间相同,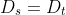
- **异构迁移学习(Heterogeneous TL)**:源域和目标域的特征空间不同,
- 按迁移情景分类
- **归纳式迁移学习(Inductive TL)**:源域和目标域的学习任务不同
- **直推式迁移学习(Transductive TL)**:源域和目标域不同,学习任务相同
- **无监督迁移学习(Unsupervised TL)**:源域和目标域均没有标签
- 按迁移方法分类
- **基于样本的迁移 (Instance based TL)**:通过权重重用源域和目标域的样例进行迁移
基于样本的迁移学习方法 (Instance based Transfer Learning) 根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。下图形象地表示了基于样本迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重。

- **基于特征的迁移 (Feature based TL)**:将源域和目标域的特征变换到相同空间
基于特征的迁移方法 (Feature based Transfer Learning) 是指将通过特征变换的方式互相迁移,来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。下图很形象地表示了两种基于特 征的迁移学习方法。

- **基于模型的迁移 (Parameter based TL)**:利用源域和目标域的参数共享模型
基于模型的迁移方法 (Parameter/Model based Transfer Learning) 是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是: 源域中的数据与目标域中的数据可以共享一些模型的参数。下图形象地表示了基于模型的迁移学习方法的基本思想。

- **基于关系的迁移 (Relation based TL)**:利用源域中的逻辑网络关系进行迁移
基于关系的迁移学习方法 (Relation Based Transfer Learning) 与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。下图形象地表示了不 同领域之间相似的关系。


## 5. 迁移学习与传统机器学习有什么区别?
| | 迁移学习 | 传统机器学习 |
| -------- | -------------------------- | -------------------- |
| 数据分布 | 训练和测试数据不需要同分布 | 训练和测试数据同分布 |
| 数据标签 | 不需要足够的数据标注 | 足够的数据标注 |
| 建模 | 可以重用之前的模型 | 每个任务分别建模 |
## 6. 迁移学习的核心及度量准则?
**迁移学习的总体思路可以概括为**:开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习。
**迁移学习的核心是**:找到源领域和目标领域之间的相似性,并加以合理利用。这种相似性非常普遍。比如,不同人的身体构造是相似的;自行车和摩托车的骑行方式是相似的;国际象棋和中国象棋是相似的;羽毛球和网球的打球方式是相似的。这种相似性也可以理解为不变量。以不变应万变,才能立于不败之地。
**有了这种相似性后,下一步工作就是, 如何度量和利用这种相似性。**度量工作的目标有两点:一是很好地度量两个领域的相似性,不仅定性地告诉我们它们是否相似,更定量地给出相似程度。二是以度量为准则,通过我们所要采用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
**一句话总结: 相似性是核心,度量准则是重要手段。**
## 7. 迁移学习与其他概念的区别?
1. 迁移学习与多任务学习关系:
- **多任务学习**:多个相关任务一起协同学习;
- **迁移学习**:强调信息复用,从一个领域(domain)迁移到另一个领域。
2. 迁移学习与领域自适应:**领域自适应**:使两个特征分布不一致的domain一致。
3. 迁移学习与协方差漂移:**协方差漂移**:数据的条件概率分布发生变化。
## 8. 什么情况下可以使用迁移学习?
迁移学习**最有用的场合**是,如果你尝试优化任务B的性能,通常这个任务数据相对较少。 例如,在放射科中你知道很难收集很多射线扫描图来搭建一个性能良好的放射科诊断系统,所以在这种情况下,你可能会找一个相关但不同的任务,如图像识别,其中你可能用 1 百万张图片训练过了,并从中学到很多低层次特征,所以那也许能帮助网络在任务在放射科任务上做得更好,尽管任务没有这么多数据。
假如两个领域之间的区别特别的大,**不可以直接采用迁移学习**,因为在这种情况下效果不是很好。在这种情况下,推荐以上的方法,在两个相似度很低的domain之间一步步迁移过去(踩着石头过河)。
## 9. 什么是finetune?
度网络的finetune也许是最简单的深度网络迁移方法。**Finetune**,也叫微调、fine-tuning, 是深度学习中的一个重要概念。简而言之,finetune就是利用别人己经训练好的网络,针对自己的任务再进行调整。从这个意思上看,我们不难理解finetune是迁移学习的一部分。
**为什么需要已经训练好的网络?**
在实际的应用中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像ImageNet那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。
**为什么需要 finetune?**
因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的训练数据和我们的数据之间不服从同一个分布;可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。
## 10. 什么是深度网络自适应?
深度网络的 finetune 可以帮助我们节省训练时间,提高学习精度。但是 finetune 有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为 finetune 的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
以我们之前介绍过的数据分布自适应方法为参考,许多深度学习方法都开发出了自适应层(AdaptationLayer)来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。
## 11. GAN在迁移学习中的应用
生成对抗网络 GAN(Generative Adversarial Nets) 受到自博弈论中的二人零和博弈 (two-player game) 思想的启发而提出。它一共包括两个部分:
- 一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被成为生成器(Generator);
- 另一部分为判别网络(Discriminative Network), 此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器(Discriminator) 生成器和判别器的互相博弈,就完成了对抗训练。
GAN 的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器 (Feature Extractor)。
## 12. 代码实现
[Transfer Learning例子](https://github.com/NLP-LOVE/ML-NLP/blob/master/Deep%20Learning/13.%20Transfer%20Learning/Transfer%20Learning.ipynb)
**数据集下载:**
- Inception-v3模型:[点击下载](https://www.lanzous.com/i5mxw5c)
- flower_photos数据集:[点击下载](http://download.tensorflow.org/example_images/flower_photos.tgz)
## 13. 参考文献
[[https://github.com/scutan90/DeepLearning-500-questions/tree/master/ch11_%E8%BF%81%E7%A7%BB%E5%AD%A6%E4%B9%A0](https://github.com/scutan90/DeepLearning-500-questions/tree/master/ch11_迁移学习)]([https://github.com/scutan90/DeepLearning-500-questions/tree/master/ch11_%E8%BF%81%E7%A7%BB%E5%AD%A6%E4%B9%A0](https://github.com/scutan90/DeepLearning-500-questions/tree/master/ch11_迁移学习))
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/13. Transfer Learning/Transfer Learning.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 数据下载\n",
"\n",
"Inception-v3模型:[点击下载](https://www.lanzous.com/i5mxw5c)\n",
"\n",
"flower_photos数据集:[点击下载](http://download.tensorflow.org/example_images/flower_photos.tgz)\n",
"\n",
"解压放到images目录下面,路径参考下面程序。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import glob\n",
"import os.path\n",
"import random\n",
"import numpy as np\n",
"import tensorflow as tf\n",
"from tensorflow.python.platform import gfile"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"# Inception-v3模型瓶颈层的节点个数\n",
"BOTTLENECK_TENSOR_SIZE = 2048\n",
"\n",
"# Inception-v3模型中代表瓶颈层结果的张量名称。\n",
"# 在谷歌提出的Inception-v3模型中,这个张量名称就是'pool_3/_reshape:0'。\n",
"# 在训练模型时,可以通过tensor.name来获取张量的名称。\n",
"BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'\n",
"\n",
"# 图像输入张量所对应的名称。\n",
"JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'\n",
"\n",
"# 下载的谷歌训练好的Inception-v3模型文件目录\n",
"MODEL_DIR = './images/model/'\n",
"\n",
"# 下载的谷歌训练好的Inception-v3模型文件名\n",
"MODEL_FILE = 'tensorflow_inception_graph.pb'\n",
"\n",
"# 因为一个训练数据会被使用多次,所以可以将原始图像通过Inception-v3模型计算得到的特征向量保存在文件中,免去重复的计算。\n",
"# 下面的变量定义了这些文件的存放地址。\n",
"CACHE_DIR = './images/tmp/bottleneck/'\n",
"\n",
"# 图片数据文件夹。\n",
"# 在这个文件夹中每一个子文件夹代表一个需要区分的类别,每个子文件夹中存放了对应类别的图片。\n",
"INPUT_DATA = './images/flower_photos/'\n",
"\n",
"# 验证的数据百分比\n",
"VALIDATION_PERCENTAGE = 10\n",
"# 测试的数据百分比\n",
"TEST_PERCENTAGE = 10\n",
"\n",
"# 定义神经网络的设置\n",
"LEARNING_RATE = 0.01\n",
"STEPS = 4000\n",
"BATCH = 100"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数从数据文件夹中读取所有的图片列表并按训练、验证、测试数据分开。\n",
"# testing_percentage和validation_percentage参数指定了测试数据集和验证数据集的大小。\n",
"def create_image_lists(testing_percentage, validation_percentage):\n",
" # 得到的所有图片都存在result这个字典(dictionary)里。\n",
" # 这个字典的key为类别的名称,value也是一个字典,字典里存储了所有的图片名称。\n",
" result = {}\n",
" # 获取当前目录下所有的子目录\n",
" sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]\n",
" # 得到的第一个目录是当前目录,不需要考虑\n",
" is_root_dir = True\n",
" for sub_dir in sub_dirs:\n",
" if is_root_dir:\n",
" is_root_dir = False\n",
" continue\n",
"\n",
" # 获取当前目录下所有的有效图片文件。\n",
" extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']\n",
" file_list = []\n",
" dir_name = os.path.basename(sub_dir)\n",
" for extension in extensions:\n",
" file_glob = os.path.join(INPUT_DATA, dir_name, '*.'+extension)\n",
" file_list.extend(glob.glob(file_glob))\n",
" if not file_list:\n",
" continue\n",
"\n",
" # 通过目录名获取类别的名称。\n",
" label_name = dir_name.lower()\n",
" # 初始化当前类别的训练数据集、测试数据集和验证数据集\n",
" training_images = []\n",
" testing_images = []\n",
" validation_images = []\n",
" for file_name in file_list:\n",
" base_name = os.path.basename(file_name)\n",
" # 随机将数据分到训练数据集、测试数据集和验证数据集。\n",
" chance = np.random.randint(100)\n",
" if chance < validation_percentage:\n",
" validation_images.append(base_name)\n",
" elif chance < (testing_percentage + validation_percentage):\n",
" testing_images.append(base_name)\n",
" else:\n",
" training_images.append(base_name)\n",
"\n",
" # 将当前类别的数据放入结果字典。\n",
" result[label_name] = {\n",
" 'dir': dir_name,\n",
" 'training': training_images,\n",
" 'testing': testing_images,\n",
" 'validation': validation_images\n",
" }\n",
" # 返回整理好的所有数据\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数通过类别名称、所属数据集和图片编号获取一张图片的地址。\n",
"# image_lists参数给出了所有图片信息。\n",
"# image_dir参数给出了根目录。存放图片数据的根目录和存放图片特征向量的根目录地址不同。\n",
"# label_name参数给定了类别的名称。\n",
"# index参数给定了需要获取的图片的编号。\n",
"# category参数指定了需要获取的图片是在训练数据集、测试数据集还是验证数据集。\n",
"def get_image_path(image_lists, image_dir, label_name, index, category):\n",
" # 获取给定类别中所有图片的信息。\n",
" label_lists = image_lists[label_name]\n",
" # 根据所属数据集的名称获取集合中的全部图片信息。\n",
" category_list = label_lists[category]\n",
" mod_index = index % len(category_list)\n",
" # 获取图片的文件名。\n",
" base_name = category_list[mod_index]\n",
" sub_dir = label_lists['dir']\n",
" # 最终的地址为数据根目录的地址 + 类别的文件夹 + 图片的名称\n",
" full_path = os.path.join(image_dir, sub_dir, base_name)\n",
" return full_path"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数通过类别名称、所属数据集和图片编号获取经过Inception-v3模型处理之后的特征向量文件地址。\n",
"def get_bottlenect_path(image_lists, label_name, index, category):\n",
" return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + '.txt';"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数使用加载的训练好的Inception-v3模型处理一张图片,得到这个图片的特征向量。\n",
"def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):\n",
" # 这个过程实际上就是将当前图片作为输入计算瓶颈张量的值。这个瓶颈张量的值就是这张图片的新的特征向量。\n",
" bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})\n",
" # 经过卷积神经网络处理的结果是一个四维数组,需要将这个结果压缩成一个特征向量(一维数组)\n",
" bottleneck_values = np.squeeze(bottleneck_values)\n",
" return bottleneck_values"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数获取一张图片经过Inception-v3模型处理之后的特征向量。\n",
"# 这个函数会先试图寻找已经计算且保存下来的特征向量,如果找不到则先计算这个特征向量,然后保存到文件。\n",
"def get_or_create_bottleneck(sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):\n",
" # 获取一张图片对应的特征向量文件的路径。\n",
" label_lists = image_lists[label_name]\n",
" sub_dir = label_lists['dir']\n",
" sub_dir_path = os.path.join(CACHE_DIR, sub_dir)\n",
" if not os.path.exists(sub_dir_path):\n",
" os.makedirs(sub_dir_path)\n",
" bottleneck_path = get_bottlenect_path(image_lists, label_name, index, category)\n",
" # 如果这个特征向量文件不存在,则通过Inception-v3模型来计算特征向量,并将计算的结果存入文件。\n",
" if not os.path.exists(bottleneck_path):\n",
" # 获取原始的图片路径\n",
" image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)\n",
" # 获取图片内容。\n",
" image_data = gfile.FastGFile(image_path, 'rb').read()\n",
" # print(len(image_data))\n",
" # 由于输入的图片大小不一致,此处得到的image_data大小也不一致(已验证),但却都能通过加载的inception-v3模型生成一个2048的特征向量。具体原理不详。\n",
" # 通过Inception-v3模型计算特征向量\n",
" bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor, bottleneck_tensor)\n",
" # 将计算得到的特征向量存入文件\n",
" bottleneck_string = ','.join(str(x) for x in bottleneck_values)\n",
" with open(bottleneck_path, 'w') as bottleneck_file:\n",
" bottleneck_file.write(bottleneck_string)\n",
" else:\n",
" # 直接从文件中获取图片相应的特征向量。\n",
" with open(bottleneck_path, 'r') as bottleneck_file:\n",
" bottleneck_string = bottleneck_file.read()\n",
" bottleneck_values = [float(x) for x in bottleneck_string.split(',')]\n",
" # 返回得到的特征向量\n",
" return bottleneck_values"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数随机获取一个batch的图片作为训练数据。\n",
"def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many, category,\n",
" jpeg_data_tensor, bottleneck_tensor):\n",
" bottlenecks = []\n",
" ground_truths = []\n",
" for _ in range(how_many):\n",
" # 随机一个类别和图片的编号加入当前的训练数据。\n",
" label_index = random.randrange(n_classes)\n",
" label_name = list(image_lists.keys())[label_index]\n",
" image_index = random.randrange(65536)\n",
" bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index, category,\n",
" jpeg_data_tensor, bottleneck_tensor)\n",
" ground_truth = np.zeros(n_classes, dtype=np.float32)\n",
" ground_truth[label_index] = 1.0\n",
" bottlenecks.append(bottleneck)\n",
" ground_truths.append(ground_truth)\n",
" return bottlenecks, ground_truths"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"# 这个函数获取全部的测试数据。在最终测试的时候需要在所有的测试数据上计算正确率。\n",
"def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):\n",
" bottlenecks = []\n",
" ground_truths = []\n",
" label_name_list = list(image_lists.keys())\n",
" # 枚举所有的类别和每个类别中的测试图片。\n",
" for label_index, label_name in enumerate(label_name_list):\n",
" category = 'testing'\n",
" for index, unused_base_name in enumerate(image_lists[label_name][category]):\n",
" # 通过Inception-v3模型计算图片对应的特征向量,并将其加入最终数据的列表。\n",
" bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, index, category,\n",
" jpeg_data_tensor, bottleneck_tensor)\n",
" ground_truth = np.zeros(n_classes, dtype = np.float32)\n",
" ground_truth[label_index] = 1.0\n",
" bottlenecks.append(bottleneck)\n",
" ground_truths.append(ground_truth)\n",
" return bottlenecks, ground_truths"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"def main(_):\n",
" # 读取所有图片。\n",
" image_lists = create_image_lists(TEST_PERCENTAGE, VALIDATION_PERCENTAGE)\n",
" n_classes = len(image_lists.keys())\n",
" # 读取已经训练好的Inception-v3模型。\n",
" # 谷歌训练好的模型保存在了GraphDef Protocol Buffer中,里面保存了每一个节点取值的计算方法以及变量的取值。\n",
" # TensorFlow模型持久化的问题在第5章中有详细的介绍。\n",
" with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:\n",
" graph_def = tf.GraphDef()\n",
" graph_def.ParseFromString(f.read())\n",
" # 加载读取的Inception-v3模型,并返回数据输入所对应的张量以及计算瓶颈层结果所对应的张量。\n",
" bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def, return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME])\n",
" # 定义新的神经网络输入,这个输入就是新的图片经过Inception-v3模型前向传播到达瓶颈层时的结点取值。\n",
" # 可以将这个过程类似的理解为一种特征提取。\n",
" bottleneck_input = tf.placeholder(tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder')\n",
" # 定义新的标准答案输入\n",
" ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')\n",
" # 定义一层全连接层来解决新的图片分类问题。\n",
" # 因为训练好的Inception-v3模型已经将原始的图片抽象为了更加容易分类的特征向量了,所以不需要再训练那么复杂的神经网络来完成这个新的分类任务。\n",
" with tf.name_scope('final_training_ops'):\n",
" weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.001))\n",
" biases = tf.Variable(tf.zeros([n_classes]))\n",
" logits = tf.matmul(bottleneck_input, weights) + biases\n",
" final_tensor = tf.nn.softmax(logits)\n",
" # 定义交叉熵损失函数\n",
" cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)\n",
" cross_entropy_mean = tf.reduce_mean(cross_entropy)\n",
" train_step = tf.compat.v1.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)\n",
" # 计算正确率\n",
" with tf.name_scope('evaluation'):\n",
" correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))\n",
" evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n",
"\n",
" with tf.Session() as sess:\n",
" tf.global_variables_initializer().run()\n",
" # 训练过程\n",
" for i in range(STEPS):\n",
" # 每次获取一个batch的训练数据\n",
" train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(\n",
" sess, n_classes, image_lists, BATCH, 'training', jpeg_data_tensor, bottleneck_tensor)\n",
" sess.run(train_step, feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})\n",
" # 在验证集上测试正确率。\n",
" if i%100 == 0 or i+1 == STEPS:\n",
" validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(\n",
" sess, n_classes, image_lists, BATCH, 'validation', jpeg_data_tensor, bottleneck_tensor)\n",
" validation_accuracy = sess.run(evaluation_step, feed_dict={\n",
" bottleneck_input:validation_bottlenecks, ground_truth_input: validation_ground_truth})\n",
" print('Step %d: Validation accuracy on random sampled %d examples = %.1f%%'\n",
" % (i, BATCH, validation_accuracy*100))\n",
" # 在最后的测试数据上测试正确率\n",
" test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess, image_lists, n_classes,\n",
" jpeg_data_tensor, bottleneck_tensor)\n",
" test_accuracy = sess.run(evaluation_step, feed_dict={bottleneck_input: test_bottlenecks,\n",
" ground_truth_input: test_ground_truth})\n",
" print('Final test accuracy = %.1f%%' % (test_accuracy * 100))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 开始运行"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING: Logging before flag parsing goes to stderr.\n",
"W0818 10:06:49.402768 140018601760576 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.\n",
"\n",
"W0818 10:06:49.440685 140018601760576 deprecation.py:323] From <ipython-input-10-6359a469440b>:8: FastGFile.__init__ (from tensorflow.python.platform.gfile) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"Use tf.gfile.GFile.\n",
"W0818 10:06:49.441340 140018601760576 module_wrapper.py:136] From /usr/local/python3/lib/python3.6/site-packages/tensorflow_core/python/util/module_wrapper.py:163: The name tf.GraphDef is deprecated. Please use tf.compat.v1.GraphDef instead.\n",
"\n",
"W0818 10:06:49.918245 140018601760576 deprecation.py:323] From <ipython-input-10-6359a469440b>:26: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\n",
"Instructions for updating:\n",
"\n",
"Future major versions of TensorFlow will allow gradients to flow\n",
"into the labels input on backprop by default.\n",
"\n",
"See `tf.nn.softmax_cross_entropy_with_logits_v2`.\n",
"\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Step 0: Validation accuracy on random sampled 100 examples = 48.0%\n",
"Step 100: Validation accuracy on random sampled 100 examples = 76.0%\n",
"Step 200: Validation accuracy on random sampled 100 examples = 85.0%\n",
"Step 300: Validation accuracy on random sampled 100 examples = 88.0%\n",
"Step 400: Validation accuracy on random sampled 100 examples = 86.0%\n",
"Step 500: Validation accuracy on random sampled 100 examples = 88.0%\n",
"Step 600: Validation accuracy on random sampled 100 examples = 86.0%\n",
"Step 700: Validation accuracy on random sampled 100 examples = 89.0%\n",
"Step 800: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 900: Validation accuracy on random sampled 100 examples = 88.0%\n",
"Step 1000: Validation accuracy on random sampled 100 examples = 92.0%\n",
"Step 1100: Validation accuracy on random sampled 100 examples = 88.0%\n",
"Step 1200: Validation accuracy on random sampled 100 examples = 88.0%\n",
"Step 1300: Validation accuracy on random sampled 100 examples = 89.0%\n",
"Step 1400: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 1500: Validation accuracy on random sampled 100 examples = 89.0%\n",
"Step 1600: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 1700: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 1800: Validation accuracy on random sampled 100 examples = 88.0%\n",
"Step 1900: Validation accuracy on random sampled 100 examples = 91.0%\n",
"Step 2000: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 2100: Validation accuracy on random sampled 100 examples = 91.0%\n",
"Step 2200: Validation accuracy on random sampled 100 examples = 91.0%\n",
"Step 2300: Validation accuracy on random sampled 100 examples = 92.0%\n",
"Step 2400: Validation accuracy on random sampled 100 examples = 93.0%\n",
"Step 2500: Validation accuracy on random sampled 100 examples = 86.0%\n",
"Step 2600: Validation accuracy on random sampled 100 examples = 96.0%\n",
"Step 2700: Validation accuracy on random sampled 100 examples = 94.0%\n",
"Step 2800: Validation accuracy on random sampled 100 examples = 81.0%\n",
"Step 2900: Validation accuracy on random sampled 100 examples = 91.0%\n",
"Step 3000: Validation accuracy on random sampled 100 examples = 87.0%\n",
"Step 3100: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 3200: Validation accuracy on random sampled 100 examples = 92.0%\n",
"Step 3300: Validation accuracy on random sampled 100 examples = 86.0%\n",
"Step 3400: Validation accuracy on random sampled 100 examples = 87.0%\n",
"Step 3500: Validation accuracy on random sampled 100 examples = 94.0%\n",
"Step 3600: Validation accuracy on random sampled 100 examples = 91.0%\n",
"Step 3700: Validation accuracy on random sampled 100 examples = 95.0%\n",
"Step 3800: Validation accuracy on random sampled 100 examples = 90.0%\n",
"Step 3900: Validation accuracy on random sampled 100 examples = 91.0%\n",
"Step 3999: Validation accuracy on random sampled 100 examples = 85.0%\n",
"Final test accuracy = 91.2%\n"
]
},
{
"ename": "SystemExit",
"evalue": "",
"output_type": "error",
"traceback": [
"An exception has occurred, use %tb to see the full traceback.\n",
"\u001b[0;31mSystemExit\u001b[0m\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"/usr/local/python3/lib/python3.6/site-packages/IPython/core/interactiveshell.py:3333: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.\n",
" warn(\"To exit: use 'exit', 'quit', or Ctrl-D.\", stacklevel=1)\n"
]
}
],
"source": [
"tf.app.run()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: Deep Learning/14. Reinforcement Learning/README.md
================================================
## 目录
- [1. 什么是强化学习](#1-什么是强化学习)
- [2. 强化学习模型](#2-强化学习模型)
- [2.1 打折的未来奖励](#21-打折的未来奖励)
- [2.2 Q-Learning算法](#22-q-learning算法)
- [2.3 Deep Q Learning(DQN)](#23-deep-q-learningdqn)
- [3. 强化学习和监督学习、无监督学习的区别](#3-强化学习和监督学习无监督学习的区别)
- [4. 什么是多任务学习](#4-什么是多任务学习)
- [5. 参考文献](#5-参考文献)
## 1. 什么是强化学习
其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报。在很多场景中,当前的行动不仅会影响当前的rewards,还会影响之后的状态和一系列的rewards。RL最重要的3个特定在于:
1. 基本是以一种闭环的形式;
2. 不会直接指示选择哪种行动(actions);
3. 一系列的actions和奖励信号(reward signals)都会影响之后较长的时间。
> 强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是[机器学习](https://baike.baidu.com/item/机器学习/217599)的范式和[方法论](https://baike.baidu.com/item/方法论/82748)之一,用于描述和解决[智能体](https://baike.baidu.com/item/智能体/9446647)(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 [1] 。

上图中agent代表自身,如果是自动驾驶,agent就是车;如果你玩游戏它就是你当前控制的游戏角色,如马里奥,马里奥往前走时环境就一直在发生变化,有小怪物或者障碍物出现,它需要通过跳跃来进行躲避,就是要做action(如向前走和跳起的动作);无人驾驶的action就是车左转、右转或刹车等等,它无时无刻都在与环境产生交互,action会反馈给环境,进而改变环境,如果自动驾驶的车行驶目标是100米,它向前开了10米,那环境就发生了变化,所以每次产生action都会导致环境改变,环境的改变会反馈给自身(agent),就是这样的一个循环;反馈又两种方式:
1. 做的好(reward)即正反馈,
2. 做得不好(punishment惩罚)即负反馈。
**Agent可能做得好,也可能做的不好,环境始终都会给它反馈,agent会尽量去做对自身有利的决策,通过反反复复这样的一个循环,agent会越来越做的好,就像孩子在成长过程中会逐渐明辨是非,这就是强化学习。**
## 2. 强化学习模型

如上图左边所示,一个agent(例如:玩家/智能体等)做出了一个action,对environment造成了影响,也就是改变了state,而environment为了反馈给agent,agent就得到了一个奖励(例如:积分/分数),不断的进行这样的循环,直到结束为止。
上述过程就相当于一个**马尔可夫决策过程**,为什么这样叫呢?因为符合**马儿可夫假设**:
- 当前状态 St 只由上一个状态 St-1 和行为所决定,而和前序的更多的状态是没有关系的。
上图右边所示,S0 状态经过了 a0 的行为后,获得了奖励 r1 ,变成了状态S1,后又经过了 a0 行为得到奖励 r2,变成了状态 S2 ,如此往复循环,直到结束为止。
### 2.1 打折的未来奖励
通过以上的描述,大家都已经确定了一个概念,也就是agent(智能体)在当下做出的决定肯定使得未来收益最大化,那么,一个马儿可夫决策过程对应的奖励总和为:
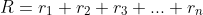
t 时刻(当下)的未来奖励,只考虑后面的奖励,前面的改变不了:

接下来,**当前的情况下做出的动作是能够得到结果的,但对于未来的影响是一个不确定的,**这也符合我们的真实世界,比如谁都不知道一只蝴蝶只是煽动了一次翅膀会造成飓风式的影响(蝴蝶效应)。所以,当前的行为对于未来是不确定性的,要打一个折扣,也就是加入一个系数gamma,是一个 0 到 1 的值:

离当前越远的时间,gamma的惩罚系数就会越大,也就是越不确定。为的就是在当前和未来的决策中取得一个平衡。gamma取 0 ,相当于不考虑未来,只考虑当下,是一种很短视的做法;而gamma取 1 ,则完全考虑了未来,又有点过虑了。所以一般gamma会取 0 到 1 之间的一个值。
Rt 可以用 Rt+1 来表示,写成递推式:
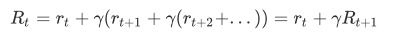
### 2.2 Q-Learning算法
**Q(s, a)函数(Quality),**质量函数用来表示智能体在s状态下采用a动作并在**之后采取最优动作条件下**的打折的未来奖励(先不管未来的动作如何选择):
=maxR_{t+1})
假设有了这个Q函数,那么我们就能够求得在当前 t 时刻当中,做出各个决策的最大收益值,通过对比这些收益值,就能够**得到 t 时刻某个决策是这些决策当中收益最高。**
=argmax_aQ(s,a))
于是乎,根据Q函数的递推公式可以得到:
=r+\gamma_{}max_aQ(s_{t+1},a_{t+1}))
**这就是注明的贝尔曼公式。**贝尔曼公式实际非常合理。对于某个状态来讲,最大化未来奖励相当于
最大化即刻奖励与下一状态最大未来奖励之和。
**Q-learning的核心思想是:**我们能够通过贝尔曼公式迭代地近似Q-函数。
### 2.3 Deep Q Learning(DQN)
Deep Q Learning(DQN)是一种融合了神经网络和的Q-Learning方法。
#### 2.3.1 神经网络的作用
使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事. 不过, 在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络.
我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值.
还有一种形式的是这样, 我们也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作.
我们可以想象, 神经网络接受外部的信息, 相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作.
#### 2.3.2 神经网络计算Q值
这一部分就跟监督学习的神经网络一样了我,输入状态值,输出为Q值,根据大量的数据去训练神经网络的参数,最终得到Q-Learning的计算模型,这时候我们就可以利用这个模型来进行强化学习了。
## 3. 强化学习和监督学习、无监督学习的区别
1. 监督式学习就好比你在学习的时候,有一个导师在旁边指点,他知道怎么是对的怎么是错的。
强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
2. 监督式学习出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出。监督学习做了比较坏的选择会立刻反馈给算法。
强化学习出的是给机器的反馈 reward function,即用来判断这个行为是好是坏。 另外强化学习的结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏。
3. 监督学习的输入是独立同分布的。
强化学习面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入。
4. 监督学习算法不考虑这种平衡,就只是 exploitative。
强化学习,一个 agent 可以在探索和开发(exploration and exploitation)之间做权衡,并且选择一个最大的回报。
5. 非监督式不是学习输入到输出的映射,而是模式(自动映射)。
对强化学习来说,它通过对没有概念标记、但与一个延迟奖赏或效用(可视为延迟的概念标记)相关联的训练例进行学习,以获得某种从状态到行动的映射。
**强化学习和前二者的本质区别**:没有前两者具有的明确数据概念,它不知道结果,只有目标。数据概念就是大量的数据,有监督学习、无监督学习需要大量数据去训练优化你建立的模型。
| | 监督学习 | 非监督学习 | 强化学习 |
| ---- | ---------------- | -------------- | ------------------------------------------------------------ |
| 标签 | 正确且严格的标签 | 没有标签 | 没有标签,通过结果反馈调整 |
| 输入 | 独立同分布 | 独立同分布 | 输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入。 |
| 输出 | 输入对应输出 | 自学习映射关系 | reward function,即结果用来判断这个行为是好是坏 |
## 4. 什么是多任务学习
在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI。为了达到这个目标,我们训练单一模型或多个模型集合来完成指定得任务。然后,我们通过精细调参,来改进模型直至性能不再提升。尽管这样做可以针对一个任务得到一个可接受得性能,但是我们可能忽略了一些信息,这些信息有助于在我们关心的指标上做得更好。具体来说,这些信息就是相关任务的监督数据。**通过在相关任务间共享表示信息,我们的模型在原始任务上泛化性能更好。这种方法称为多任务学习(Multi-Task Learning)**
在不同的任务中都会有一些共性,而这些共性就构成了多任务学习的一个连接点,也就是任务都需要通过这个共性能得出结果来的。比如电商场景中的点击率和转化率,都要依赖于同一份数据的输入和神经网络层次。多语种语音识别等。

## 5. 参考文献
- [GitHub]([https://github.com/scutan90/DeepLearning-500-questions/blob/master/ch10_%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0/%E7%AC%AC%E5%8D%81%E7%AB%A0_%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0.md](https://github.com/scutan90/DeepLearning-500-questions/blob/master/ch10_强化学习/第十章_强化学习.md))
- [强化学习](https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/)
------
> 作者:[@mantchs](https://github.com/NLP-LOVE/ML-NLP)
>
> GitHub:[https://github.com/NLP-LOVE/ML-NLP](https://github.com/NLP-LOVE/ML-NLP)
>
> 欢迎大家加入讨论!共同完善此项目!群号:【541954936】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=863f915b9178560bd32ca07cd090a7d9e6f5f90fcff5667489697b1621cecdb3"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="NLP面试学习群" title="NLP面试学习群"></a>
================================================
FILE: Deep Learning/15. DL Optimizer/README.md
================================================
## 目录
- [1. 训练误差和泛化误差](#1-训练误差和泛化误差)
- [2. 该如何选择模型](#2-该如何选择模型)
- [2.1 验证数据集](#21-验证数据集)
- [2.2 K 折交叉验证](#22-k-折交叉验证)
- [3. ⽋拟合和过拟合](#3-⽋拟合和过拟合)
- [4. 丢弃法(Dropout)](#4-丢弃法dropout)
- [5. 梯度消失/梯度爆炸(Vanishing / Exploding gradients)](#5-梯度消失梯度爆炸vanishing--exploding-gradients)
- [6. 随机梯度下降法(SGD)](#6-随机梯度下降法sgd)
- [6.1 mini-batch梯度下降](#61-mini-batch梯度下降)
- [6.2 调节 Batch_Size 对训练效果影响到底如何?](#62-调节-batch_size-对训练效果影响到底如何)
- [7. 优化算法](#7-优化算法)
- [7.1 动量法](#71-动量法)
- [7.2 AdaGrad算法](#72-adagrad算法)
- [7.3 RMSProp算法](#73-rmsprop算法)
- [7.4 AdaDelta算法](#74-adadelta算法)
- [7.5 Adam算法](#75-adam算法)
- [7.6 局部最优--鞍点问题](#76-局部最优--鞍点问题)
- [8. 如何解决训练样本少的问题](#8-如何解决训练样本少的问题)
- [9. 如何提升模型的稳定性?](#9-如何提升模型的稳定性)
- [10. 有哪些改善模型的思路](#10-有哪些改善模型的思路)
- [11. 如何提高深度学习系统的性能](#11-如何提高深度学习系统的性能)
- [12. 参考文献](#12-参考文献)
## 1. 训练误差和泛化误差
机器学习模型在训练数据集和测试数据集上的表现。如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确。这是为什么呢?
因为存在着训练误差和泛化误差:
- **训练误差:**模型在训练数据集上表现出的误差。
- **泛化误差:**模型在任意⼀个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。
训练误差的期望小于或等于泛化误差。也就是说,⼀般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。**由于⽆法从训练误差估计泛化误差,⼀味地降低训练误差并不意味着泛化误差⼀定会降低。**
**机器学习模型应关注降低泛化误差。**
## 2. 该如何选择模型
在机器学习中,通常需要评估若⼲候选模型的表现并从中选择模型。这⼀过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。以多层感知机为例,我们可以选择隐藏层的个数,以及每个隐藏层中隐藏单元个数和激活函数。为了得到有效的模型,我们通常要在模型选择上下⼀番功夫。
### 2.1 验证数据集
从严格意义上讲,测试集只能在所有超参数和模型参数选定后使⽤⼀次。不可以使⽤测试数据选择模型,如调参。由于⽆法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留⼀部分在训练数据集和测试数据集以外的数据来进⾏模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取⼀小部分作为验证集,而将剩余部分作为真正的训练集。
可以通过预留这样的验证集来进行模型选择,判断验证集在模型中的表现能力。
### 2.2 K 折交叉验证
由于验证数据集不参与模型训练,当训练数据不够⽤时,预留⼤量的验证数据显得太奢侈。⼀种改善的⽅法是K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的⼦数据集,然后我们做K次模型训练和验证。每⼀次,我们使⽤⼀个⼦数据集验证模型,并使⽤其他K − 1个⼦数据集来训练模型。在这K次训练和验证中,每次⽤来验证模型的⼦数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
## 3. ⽋拟合和过拟合
- **欠拟合:**模型⽆法得到较低的训练误差。
- **过拟合:**是模型的训练误差远小于它在测试数据集上的误差。
给定训练数据集,
- 如果模型的复杂度过低,很容易出现⽋拟合;
- 如果模型复杂度过⾼,很容易出现过拟合。
应对⽋拟合和过拟合的⼀个办法是针对数据集选择合适复杂度的模型。

**训练数据集⼤⼩**
影响⽋拟合和过拟合的另⼀个重要因素是训练数据集的⼤小。⼀般来说,如果训练数据集中样本数过少,特别是⽐模型参数数量(按元素计)更少时,过拟合更容易发⽣。此外,泛化误差不会随训练数据集⾥样本数量增加而增⼤。因此,在计算资源允许的范围之内,我们通常希望训练数据集⼤⼀些,特别是在模型复杂度较⾼时,例如层数较多的深度学习模型。
**正则化**
应对过拟合问题的常⽤⽅法:权重衰减(weight decay),权重衰减等价于L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常⽤⼿段。
## 4. 丢弃法(Dropout)
除了上面提到的权重衰减以外,深度学习模型常常使⽤丢弃法(dropout)来应对过拟合问题。丢弃法有⼀些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。
回忆⼀下,“多层感知机”描述了⼀个单隐藏层的多层感知机。其中输⼊个数为4,隐藏单元个数为5,且隐藏单元hi(i = 1, . . . , 5)的计算表达式为:
)
这⾥ϕ是激活函数,x1, . . . , x4是输⼊,隐藏单元i的权重参数为w1i, . . . , w4i,偏差参数为bi。当对该隐藏层使⽤丢弃法时,该层的隐藏单元将有⼀定概率被丢弃掉。设丢弃概率为p,那么有p的概率hi会被清零,有1 − p的概率hi会除以1 − p做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量ξi为0和1的概率分别为p和1 − p。使⽤丢弃法时我们计算新的隐藏单元 。

由于E(ξi) = 1 − p,因此:

**即丢弃法不改变其输⼊的期望值。**让我们对隐藏层使⽤丢弃法,⼀种可能的结果如下图所⽰,其中h2和h5被清零。这时输出值的计算不再依赖h2和h5,在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即h1, . . . , h5都有可能被清零,输出层的计算⽆法过度依赖h1, . . . , h5中的任⼀个,从而在训练模型时起到正则化的作⽤,并可以⽤来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,⼀般不使⽤丢弃法。

## 5. 梯度消失/梯度爆炸(Vanishing / Exploding gradients)
训练神经网络,尤其是深度神经所面临的一个问题就是梯度消失或梯度爆炸,也就是你训练神经网络的时候,导数或坡度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度。
本质上,梯度消失和爆炸是一种情况。在深层网络中,由于网络过深,如果初始得到的梯度过小,或者传播途中在某一层上过小,则在之后的层上得到的梯度会越来越小,即产生了梯度消失。梯度爆炸也是同样的。一般地,不合理的初始化以及激活函数,如sigmoid等,都会导致梯度过大或者过小,从而引起消失/爆炸。
**解决方案**
1. **预训练加微调**
其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。
此方法有一定的好处,但是目前应用的不是很多了。
2. **梯度剪切、正则**
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)比较常见的是L1和L2正则。
3. **ReLu、leakReLu等激活函数**
ReLu:其函数的导数在正数部分是恒等于1,这样在深层网络中,在激活函数部分就不存在导致梯度过大或者过小的问题,缓解了梯度消失或者爆炸。同时也方便计算。当然,其也存在存在一些缺点,例如过滤到了负数部分,导致部分信息的丢失,输出的数据分布不在以0为中心,改变了数据分布。
leakrelu:就是为了解决relu的0区间带来的影响,其数学表达为:leakrelu=max(k*x,0)其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来。
4. **Batch Normalization**
Batch Normalization是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batch Normalization本质上是解决反向传播过程中的梯度问题。Batch Normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。
- 有一些从 0 到 1 而不是从 1 到 1000 的特征值,通过归一化所有的输入特征值𝑥,以获得类似范围的值,可以加速学习。所以 Batch 归一化起的作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值。
- 它可以使权重比你的网络更滞后或更深层,比如,第 10 层的权重更能经受得住变化。
5. **残差结构**
残差的方式,能使得深层的网络梯度通过跳级连接路径直接返回到浅层部分,使得网络无论多深都能将梯度进行有效的回传。
6. **LSTM**
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates)。在计算时,将过程中的梯度进行了抵消。
## 6. 随机梯度下降法(SGD)
### 6.1 mini-batch梯度下降
你可以把训练集分割为小一点的子集训练,这些子集被取名为 **mini-batch**,假设每一个子集中只有 1000 个样本,那么把其中的𝑥 (1)到𝑥 (1000)取出来,将其称为第一个子训练集,也叫做 **mini-batch**,然后你再取出接下来的 1000 个样本,从𝑥 (1001)到𝑥 (2000),然后再取 1000个样本,以此类推。
在训练集上运行 **mini-batch** 梯度下降法,你运行 for t=1……5000,因为我们有5000个各有 1000 个样本的组,在 **for** 循环里你要做得基本就是对𝑋 {𝑡}和𝑌 {𝑡}执行一步梯度下降法。
- batch_size=1,就是SGD。
- batch_size=n,就是mini-batch
- batch_size=m,就是batch
其中1<n<m,m表示整个训练集大小。
**优缺点:**
- batch:相对噪声低些,幅度也大一些,你可以继续找最小值。
- SGD:大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动。一次性只处理了一个训练样本,这样效率过于低下。
- mini-batch:实践中最好选择不大不小的 **mini-batch**,得到了大量向量化,效率高,收敛快。
首先,如果训练集较小,直接使用 **batch** 梯度下降法,这里的少是说小于 2000 个样本。一般的 **mini-batch** 大小为 64 到 512,考虑到电脑内存设置和使用的方式,如果 **mini-batch** 大小是 2 的𝑛次方,代码会运行地快一些。
### 6.2 调节 Batch_Size 对训练效果影响到底如何?
1. Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
2. 随着 Batch_Size 增大,处理相同数据量的速度越快。
3. 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
4. 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5. 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
## 7. 优化算法
### 7.1 动量法
在每次迭代中,梯度下降根据⾃变量当前位置,沿着当前位置的梯度更新⾃变量。然而,如果⾃变量的
迭代⽅向仅仅取决于⾃变量当前位置,这可能会带来⼀些问题。
让我们考虑⼀个输⼊和输出分别为⼆维向量x = [x1, x2]⊤和标量的⽬标函数 =0.1x_1^2+2x_2^2)。,这⾥将系数从1减小到了0.1。下⾯实现基于这个⽬标函数的梯度下降,并演⽰使⽤学习率为0.4时⾃变量的迭代轨迹。

可以看到,同⼀位置上,⽬标函数在竖直⽅向(x2轴⽅向)⽐在⽔平⽅向(x1轴⽅向)的斜率的绝对值更⼤。**因此,给定学习率,梯度下降迭代⾃变量时会使⾃变量在竖直⽅向⽐在⽔平⽅向移动幅度更⼤。**那么,我们需要⼀个较小的学习率从而避免⾃变量在竖直⽅向上越过⽬标函数最优解。然而,这会造成⾃变量在⽔平⽅向上朝最优解移动变慢。
**动量法的提出是为了解决梯度下降的上述问题。**由于小批量随机梯度下降⽐梯度下降更为⼴义,本章后续讨论将沿⽤“小批量随机梯度下降”⼀节中时间步t的小批量随机梯度gt的定义。设时间步t的⾃变量为xt,学习率为ηt。在时间步0,动量法创建速度变量v0,并将其元素初始化成0。在时间步t > 0,动量法对每次迭代的步骤做如下修改:

其中,动量超参数γ满⾜0 ≤ γ < 1。当γ = 0时,动量法等价于小批量随机梯度下降。在梯度下降时候使用动量法后的迭代轨迹:

可以看到使⽤较小的学习率η = 0.4和动量超参数γ = 0.5时,动量法在竖直⽅向上的移动更加平滑,且在⽔平⽅向上更快逼近最优解。
所以,在动量法中,⾃变量在各个⽅向上的移动幅度不仅取决当前梯度,还取决于过去的各个梯度在各个⽅向上是否⼀致。在本节之前⽰例的优化问题中,所有梯度在⽔平⽅向上为正(向右),而在竖直⽅向上时正(向上)时负(向下)。这样,我们就可以使⽤较⼤的学习率,从而使⾃变量向最优解更快移动。
### 7.2 AdaGrad算法
优化算法中,⽬标函数⾃变量的每⼀个元素在相同时间步都使⽤同⼀个学习率来⾃我迭代。在“动量法”⾥我们看到当x1和x2的梯度值有较⼤差别时,需要选择⾜够小的学习率使得⾃变量在梯度值较⼤的维度上不发散。但这样会导致⾃变量在梯度值较小的维度上迭代过慢。动量法依赖指数加权移动平均使得⾃变量的更新⽅向更加⼀致,从而降低发散的可能。**本节我们介绍AdaGrad算法,它根据⾃变量在每个维度的梯度值的⼤小来调整各个维度上的学习率,从而避免统⼀的学习率难以适应所有维度的问题。**
AdaGrad算法会使⽤⼀个小批量随机梯度gt按元素平⽅的累加变量st。在时间步0,AdaGrad将s0中每个元素初始化为0。在时间步t,⾸先将小批量随机梯度gt按元素平⽅后累加到变量st:

其中⊙是按元素相乘。接着,我们将⽬标函数⾃变量中每个元素的学习率通过按元素运算重新调整⼀下:

其中η是学习率,ϵ是为了维持数值稳定性而添加的常数,如10的-6次方。这⾥开⽅、除法和乘法的运算都是按元素运算的。这些按元素运算使得⽬标函数⾃变量中每个元素都分别拥有⾃⼰的学习率。
需要强调的是,小批量随机梯度按元素平⽅的累加变量st出现在学习率的分⺟项中。因此,
- 如果⽬标函数有关⾃变量中某个元素的偏导数⼀直都较⼤,那么该元素的学习率将下降较快;
- 反之,如果⽬标函数有关⾃变量中某个元素的偏导数⼀直都较小,那么该元素的学习率将下降较慢。
然而,由于st⼀直在累加按元素平⽅的梯度,⾃变量中每个元素的学习率在迭代过程中⼀直在降低(或不变)。**所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。**

### 7.3 RMSProp算法
当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。为了解决这⼀问题,RMSProp算法对AdaGrad算法做了⼀点小小的修改。
不同于AdaGrad算法⾥状态变量st是截⾄时间步t所有小批量随机梯度gt按元素平⽅和,RMSProp算法将这些梯度按元素平⽅做指数加权移动平均。具体来说,给定超参数0 ≤ γ < 1,RMSProp算法在时间步t > 0计算:

和AdaGrad算法⼀样,RMSProp算法将⽬标函数⾃变量中每个元素的学习率通过按元素运算重新调整,然后更新⾃变量:

其中η是学习率,ϵ是为了维持数值稳定性而添加的常数,如10的-6次方。因为RMSProp算法的状态变量st是对平⽅项gt ⊙ gt的指数加权移动平均,**所以可以看作是最近1/(1 − γ)个时间步的小批量随机梯度平⽅项的加权平均。如此⼀来,⾃变量每个元素的学习率在迭代过程中就不再⼀直降低(或不变)。**

### 7.4 AdaDelta算法
除了RMSProp算法以外,另⼀个常⽤优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有⽤解的问题做了改进。有意思的是,AdaDelta算法没有学习率这⼀超参数。
AdaDelta算法也像RMSProp算法⼀样,使⽤了小批量随机梯度gt按元素平⽅的指数加权移动平均变量st。在时间步0,它的所有元素被初始化为0。给定超参数0 ≤ ρ < 1(对应RMSProp算法中的γ),在时间步t > 0,同RMSProp算法⼀样计算:

与RMSProp算法不同的是,AdaDelta算法还维护⼀个额外的状态变量∆xt,其元素同样在时间步0时被初始化为0。我们使⽤∆xt−1来计算⾃变量的变化量:

最后,我们使⽤∆xt来记录⾃变量变化量 按元素平⽅的指数加权移动平均:

可以看到,如不考虑ϵ的影响,AdaDelta算法与RMSProp算法的不同之处在于使⽤ 来替代超参数η。
### 7.5 Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。
Adam算法使⽤了动量变量vt和RMSProp算法中小批量随机梯度按元素平⽅的指数加权移动平均变量st,并在时间步0将它们中每个元素初始化为0。给定超参数0 ≤ β1 < 1(算法作者建议设为0.9),时间步t的动量变量vt即小批量随机梯度gt的指数加权移动平均:
g_t)
和RMSProp算法中⼀样,给定超参数0 ≤ β2 < 1(算法作者建议设为0.999),将小批量随机梯度按元素平⽅后的项gt ⊙ gt做指数加权移动平均得到st:

由于我们将 v0 和 s0 中的元素都初始化为 0,在时间步 t 我们得到 \sum_{i=1}^t\beta_1^{t-i}g_i)。将过去各时间步小批量随机梯度的权值相加,得到 \sum_{i=1}^t\beta_1^{t-i}=1-\beta_1^t)。需要注意的是,当 t 较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当β1 = 0.9时,v1 = 0.1g1。为了消除这样的影响,对于任意时间步 t,我们可以将 vt 再除以 ,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量 vt 和 st 均作偏差修正:


接下来,Adam算法使⽤以上偏差修正后的变量***v***ˆ*t*和***s***ˆ*t*,将模型参数中每个元素的学习率通过按元素运算重新调整:

其中*η*是学习率,*ϵ*是为了维持数值稳定性而添加的常数,如10的-8次方。和AdaGrad算法、RMSProp算法以及AdaDelta算法⼀样,⽬标函数⾃变量中每个元素都分别拥有⾃⼰的学习率。最后,使⽤迭代⾃变量:

### 7.6 局部最优--鞍点问题
一个具有高维度空间的函数,如果梯度为 0,那么在每个方向,它可能是凸函数,也可能是凹函数。如果你在 2 万维空间中,那么想要得到局部最优,所有的 2 万个方向都需要是这样,但发生的机率也许很小,也许是2的-20000次方,你更有可能遇到有些方向的曲线会这样向上弯曲,另一些方向曲线向下弯,而不是所有的都向上弯曲,因此在高维度空间,你更可能碰到鞍点。

而不会碰到局部最优。**至于为什么会把一个曲面叫做鞍点,**你想象一下,就像是放在马背上的马鞍一样,如果这是马,这是马的头,这就是马的眼睛,画得不好请多包涵,然后你就是骑马的人,要坐在马鞍上,因此这里的这个点,导数为 0 的点,这个点叫做鞍点。我想那确实是你坐在马鞍上的那个点,而这里导数为 0。
鞍点中的平稳段是一个问题,这样使得学习十分缓慢,**这也是像 Momentum 或是RMSprop,Adam 这样的算法,能够加速学习算法的地方。**在这些情况下,更成熟的优化算法,如 Adam 算法,能够加快速度,让你尽早往下走出平稳段。
## 8. 如何解决训练样本少的问题
1. **利用预训练模型进行迁移微调(fine-tuning),**预训练模型通常在特征上拥有很好的语义表达。此时,只需将模型在小数据集上进行微调就能取得不错的效果。CV有ImageNet,NLP有BERT等。
2. **数据集进行下采样操作,**使得符合数据同分布。
3. 数据集增强、正则或者半监督学习等方式来解决小样本数据集的训练问题。
## 9. 如何提升模型的稳定性?
1. 正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。
2. 前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。
3. 扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。
4. 特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。
## 10. 有哪些改善模型的思路
1. **数据角度 **
增强数据集。无论是有监督还是无监督学习,数据永远是最重要的驱动力。更多的类型数据对良好的模型能带来更好的稳定性和对未知数据的可预见性。对模型来说,“看到过的总比没看到的更具有判别的信心”。
2. **模型角度**
模型的容限能力决定着模型可优化的空间。在数据量充足的前提下,对同类型的模型,增大模型规模来提升容限无疑是最直接和有效的手段。
3. **调参优化角度**
如果你知道模型的性能为什么不再提高了,那已经向提升性能跨出了一大步。 超参数调整本身是一个比较大的问题。一般可以包含模型初始化的配置,优化算法的选取、学习率的策略以及如何配置正则和损失函数等等。
4. **训练角度**
在越大规模的数据集或者模型上,诚然一个好的优化算法总能加速收敛。但你在未探索到模型的上限之前,永远不知道训练多久算训练完成。所以在改善模型上充分训练永远是最必要的过程。充分训练的含义不仅仅只是增大训练轮数。有效的学习率衰减和正则同样是充分训练中非常必要的手段。
## 11. 如何提高深度学习系统的性能
1. 提高模型的结构。
2. 改进模型的初始化方式,保证早期梯度具有某些有益的性质,或者具备大量的稀疏性,或者利用线性代数原理的优势。
3. 择更强大的学习算法。
## 12. 参考文献
- [动手学--深度学习](http://zh.gluon.ai/)
- [吴恩达--深度学习笔记](https://github.com/fengdu78/deeplearning_ai_books)
- [G
gitextract_2bn0qfp0/
├── Deep Learning/
│ ├── 10. Neural Network/
│ │ ├── README.md
│ │ └── TensorFlow_LR.ipynb
│ ├── 11. CNN/
│ │ ├── CNN.ipynb
│ │ └── README.md
│ ├── 12. RNN/
│ │ ├── README.md
│ │ └── RNN.ipynb
│ ├── 12.1 GRU/
│ │ ├── GRU.ipynb
│ │ └── README.md
│ ├── 12.2 LSTM/
│ │ ├── LSTM.ipynb
│ │ └── README.md
│ ├── 13. Transfer Learning/
│ │ ├── README.md
│ │ └── Transfer Learning.ipynb
│ ├── 14. Reinforcement Learning/
│ │ └── README.md
│ ├── 15. DL Optimizer/
│ │ └── README.md
│ └── README.md
├── Machine Learning/
│ ├── 2.Logistics Regression/
│ │ ├── 2.Logistics Regression.md
│ │ ├── README.md
│ │ └── demo/
│ │ ├── CreditScoring.ipynb
│ │ └── README.md
│ ├── 3.1 Random Forest/
│ │ ├── 3.1 Random Forest.md
│ │ ├── README.md
│ │ └── RandomForestRegression.ipynb
│ ├── 3.2 GBDT/
│ │ ├── 3.2 GBDT.md
│ │ ├── GBDT_demo.ipynb
│ │ ├── README.md
│ │ ├── test_feat.txt
│ │ └── train_feat.txt
│ ├── 3.3 XGBoost/
│ │ ├── 3.3 XGBoost.ipynb
│ │ ├── 3.3 XGBoost.md
│ │ ├── README.md
│ │ ├── pima-indians-diabetes.csv
│ │ └── 数据说明.txt
│ ├── 3.4 LightGBM/
│ │ ├── 3.4 LightGBM.ipynb
│ │ ├── 3.4 LightGBM.md
│ │ └── README.md
│ ├── 3.Desition Tree/
│ │ ├── DecisionTree.csv
│ │ ├── DecisionTree.ipynb
│ │ ├── Desition Tree.md
│ │ └── README.md
│ ├── 4. SVM/
│ │ ├── 4. SVM.md
│ │ ├── README.md
│ │ └── news classification/
│ │ ├── README.md
│ │ └── svm_classification.ipynb
│ ├── 5.1 Bayes Network/
│ │ ├── 5.1 Bayes Network.md
│ │ ├── Naive Bayes Classifier.ipynb
│ │ └── README.md
│ ├── 5.2 Markov/
│ │ ├── 5.2 HMM.ipynb
│ │ ├── 5.2 Markov.md
│ │ └── README.md
│ ├── 5.3 Topic Model/
│ │ ├── HillaryEmail.ipynb
│ │ ├── HillaryEmails.csv
│ │ └── README.md
│ ├── 6. EM/
│ │ ├── README.md
│ │ └── gmm_em/
│ │ ├── README.md
│ │ ├── genSample.py
│ │ ├── gmm.data
│ │ ├── gmm.py
│ │ ├── main.py
│ │ └── sample.data
│ ├── 7. Clustering/
│ │ ├── GMM.ipynb
│ │ ├── K-Means.ipynb
│ │ ├── README.md
│ │ └── corpus_train.txt
│ ├── 8. ML特征工程和优化方法/
│ │ └── README.md
│ ├── 9. KNN/
│ │ ├── README.md
│ │ └── handwritingClass/
│ │ ├── README.md
│ │ └── handwritingClass.py
│ ├── Liner Regression/
│ │ ├── 1.Liner Regression.md
│ │ ├── README.md
│ │ └── demo/
│ │ ├── README.md
│ │ ├── housing_price.py
│ │ ├── kc_test.txt
│ │ └── kc_train.txt
│ └── README.md
├── NLP/
│ ├── 16. NLP/
│ │ └── README.md
│ ├── 16.1 Word Embedding/
│ │ ├── README.md
│ │ └── word2vec.ipynb
│ ├── 16.2 fastText/
│ │ ├── README.md
│ │ └── fastText.ipynb
│ ├── 16.3 GloVe/
│ │ ├── GloVe.ipynb
│ │ └── README.md
│ ├── 16.4 textRNN & textCNN/
│ │ ├── README.md
│ │ ├── cnews_loader.py
│ │ ├── cnn_model.py
│ │ ├── rnn_model.py
│ │ ├── textCNN.ipynb
│ │ └── textRNN.ipynb
│ ├── 16.5 seq2seq/
│ │ ├── README.md
│ │ └── seq2seq.ipynb
│ ├── 16.6 Attention/
│ │ ├── README.md
│ │ ├── datautil.py
│ │ ├── fanyichina/
│ │ │ ├── fromids/
│ │ │ │ └── README.md
│ │ │ ├── toids/
│ │ │ │ └── README.md
│ │ │ └── yuliao/
│ │ │ ├── from/
│ │ │ │ └── english1w.txt
│ │ │ └── to/
│ │ │ ├── README.md
│ │ │ └── chinese1w.txt
│ │ ├── myjiebadict.txt
│ │ ├── seq2seq_model.py
│ │ ├── test.py
│ │ └── train.ipynb
│ ├── 16.7 Transformer/
│ │ └── README.md
│ ├── 16.8 BERT/
│ │ ├── README.md
│ │ ├── bert-Chinese-classification-task.md
│ │ ├── data/
│ │ │ ├── dev.tsv
│ │ │ ├── test
│ │ │ └── train.tsv
│ │ ├── download_glue_data.py
│ │ ├── modeling.py
│ │ ├── optimization.py
│ │ ├── run.sh
│ │ ├── run_classifier_word.py
│ │ └── tokenization_word.py
│ ├── 16.9 XLNet/
│ │ └── README.md
│ └── README.md
├── Project/
│ ├── 17. Recommendation System/
│ │ └── README.md
│ ├── 18. Intelligent Customer Service/
│ │ └── README.md
│ └── README.md
├── README.md
└── images/
└── README.md
SYMBOL INDEX (178 symbols across 13 files)
FILE: Machine Learning/6. EM/gmm_em/gmm.py
function debug (line 17) | def debug(*args, **kwargs):
function phi (line 28) | def phi(Y, mu_k, cov_k):
function getExpectation (line 39) | def getExpectation(Y, mu, cov, alpha):
function maximize (line 71) | def maximize(Y, gamma):
function scale_data (line 105) | def scale_data(Y):
function init_params (line 120) | def init_params(shape, K):
function GMM_EM (line 136) | def GMM_EM(Y, K, times):
FILE: Machine Learning/9. KNN/handwritingClass/handwritingClass.py
function createDataSet (line 9) | def createDataSet():
function classify0 (line 21) | def classify0(inX, dataSet, labels, k):
function test1 (line 138) | def test1():
function file2matrix (line 149) | def file2matrix(filename):
function autoNorm (line 178) | def autoNorm(dataSet):
function datingClassTest (line 207) | def datingClassTest():
function img2vector (line 233) | def img2vector(filename):
function handwritingClassTest (line 250) | def handwritingClassTest():
FILE: NLP/16.4 textRNN & textCNN/cnews_loader.py
function native_word (line 17) | def native_word(word, encoding='utf-8'):
function native_content (line 25) | def native_content(content):
function open_file (line 32) | def open_file(filename, mode='r'):
function read_file (line 43) | def read_file(filename):
function build_vocab (line 58) | def build_vocab(train_dir, vocab_dir, vocab_size=5000):
function read_vocab (line 74) | def read_vocab(vocab_dir):
function read_category (line 84) | def read_category():
function to_words (line 95) | def to_words(content, words):
function process_file (line 100) | def process_file(filename, word_to_id, cat_to_id, max_length=600):
function batch_iter (line 116) | def batch_iter(x, y, batch_size=64):
FILE: NLP/16.4 textRNN & textCNN/cnn_model.py
class TCNNConfig (line 6) | class TCNNConfig(object):
class TextCNN (line 28) | class TextCNN(object):
method __init__ (line 31) | def __init__(self, config):
method cnn (line 41) | def cnn(self):
FILE: NLP/16.4 textRNN & textCNN/rnn_model.py
class TRNNConfig (line 6) | class TRNNConfig(object):
class TextRNN (line 29) | class TextRNN(object):
method __init__ (line 31) | def __init__(self, config):
method rnn (line 41) | def rnn(self):
FILE: NLP/16.6 Attention/datautil.py
function getRawFileList (line 26) | def getRawFileList( path):
function get_ch_lable (line 35) | def get_ch_lable(txt_file,Isch=True,normalize_digits=False):
function get_ch_path_text (line 58) | def get_ch_path_text(raw_data_dir,Isch=True,normalize_digits=False):
function basic_tokenizer (line 85) | def basic_tokenizer(sentence):
function fenci (line 99) | def fenci(training_data):
function create_vocabulary (line 126) | def create_vocabulary(vocabulary_file, raw_data_dir, max_vocabulary_size...
function build_dataset (line 153) | def build_dataset(words, n_words):
function create_seq2seqfile (line 174) | def create_seq2seqfile(data ,sorcefile,targetfile,textssz):
function plot_scatter_lengths (line 186) | def plot_scatter_lengths(title, x_title, y_title, x_lengths, y_lengths):
function plot_histo_lengths (line 195) | def plot_histo_lengths(title, lengths):
function splitFileOneline (line 212) | def splitFileOneline(training_data ,textssz):
function analysisfile (line 219) | def analysisfile(source_file,target_file):
function initialize_vocabulary (line 248) | def initialize_vocabulary(vocabulary_path):
function sentence_to_ids (line 261) | def sentence_to_ids(sentence, vocabulary,
function textfile_to_idsfile (line 278) | def textfile_to_idsfile(data_file_name, target_file_name, vocab,
function textdir_to_idsdir (line 295) | def textdir_to_idsdir(textdir,idsdir,vocab, normalize_digits=True,Isch=T...
function ids2texts (line 308) | def ids2texts( indices,rev_vocab):
function main (line 334) | def main():
FILE: NLP/16.6 Attention/seq2seq_model.py
class Seq2SeqModel (line 31) | class Seq2SeqModel(object):
method __init__ (line 41) | def __init__(self,
method step (line 196) | def step(self, session, encoder_inputs, decoder_inputs, target_weights,
method get_batch (line 254) | def get_batch(self, data, bucket_id):
FILE: NLP/16.6 Attention/test.py
function getfanyiInfo (line 49) | def getfanyiInfo():
function main (line 64) | def main():
function createModel (line 111) | def createModel(session, forward_only,from_vocab_size,to_vocab_size):
FILE: NLP/16.8 BERT/download_glue_data.py
function download_and_extract (line 41) | def download_and_extract(task, data_dir):
function format_mrpc (line 50) | def format_mrpc(data_dir, path_to_data):
function download_diagnostic (line 94) | def download_diagnostic(data_dir):
function get_tasks (line 103) | def get_tasks(task_names):
function main (line 114) | def main(arguments):
FILE: NLP/16.8 BERT/modeling.py
function gelu (line 29) | def gelu(x):
class BertConfig (line 37) | class BertConfig(object):
method __init__ (line 40) | def __init__(self,
method from_dict (line 89) | def from_dict(cls, json_object):
method from_json_file (line 97) | def from_json_file(cls, json_file):
method to_dict (line 103) | def to_dict(self):
method to_json_string (line 108) | def to_json_string(self):
class BERTLayerNorm (line 113) | class BERTLayerNorm(nn.Module):
method __init__ (line 114) | def __init__(self, config, variance_epsilon=1e-12):
method forward (line 122) | def forward(self, x):
class BERTEmbeddings (line 128) | class BERTEmbeddings(nn.Module):
method __init__ (line 129) | def __init__(self, config):
method forward (line 142) | def forward(self, input_ids, token_type_ids=None):
class BERTSelfAttention (line 159) | class BERTSelfAttention(nn.Module):
method __init__ (line 160) | def __init__(self, config):
method transpose_for_scores (line 176) | def transpose_for_scores(self, x):
method forward (line 181) | def forward(self, hidden_states, attention_mask):
class BERTSelfOutput (line 210) | class BERTSelfOutput(nn.Module):
method __init__ (line 211) | def __init__(self, config):
method forward (line 217) | def forward(self, hidden_states, input_tensor):
class BERTAttention (line 224) | class BERTAttention(nn.Module):
method __init__ (line 225) | def __init__(self, config):
method forward (line 230) | def forward(self, input_tensor, attention_mask):
class BERTIntermediate (line 236) | class BERTIntermediate(nn.Module):
method __init__ (line 237) | def __init__(self, config):
method forward (line 242) | def forward(self, hidden_states):
class BERTOutput (line 248) | class BERTOutput(nn.Module):
method __init__ (line 249) | def __init__(self, config):
method forward (line 255) | def forward(self, hidden_states, input_tensor):
class BERTLayer (line 262) | class BERTLayer(nn.Module):
method __init__ (line 263) | def __init__(self, config):
method forward (line 269) | def forward(self, hidden_states, attention_mask):
class BERTEncoder (line 276) | class BERTEncoder(nn.Module):
method __init__ (line 277) | def __init__(self, config):
method forward (line 282) | def forward(self, hidden_states, attention_mask):
class BERTPooler (line 290) | class BERTPooler(nn.Module):
method __init__ (line 291) | def __init__(self, config):
method forward (line 296) | def forward(self, hidden_states):
class BertModel (line 305) | class BertModel(nn.Module):
method __init__ (line 322) | def __init__(self, config: BertConfig):
method forward (line 333) | def forward(self, input_ids, token_type_ids=None, attention_mask=None):
class BertForSequenceClassification (line 360) | class BertForSequenceClassification(nn.Module):
method __init__ (line 381) | def __init__(self, config, num_labels):
method forward (line 399) | def forward(self, input_ids, token_type_ids, attention_mask, labels=No...
class BertForQuestionAnswering (line 411) | class BertForQuestionAnswering(nn.Module):
method __init__ (line 430) | def __init__(self, config):
method forward (line 449) | def forward(self, input_ids, token_type_ids, attention_mask, start_pos...
FILE: NLP/16.8 BERT/optimization.py
function warmup_cosine (line 22) | def warmup_cosine(x, warmup=0.002):
function warmup_constant (line 27) | def warmup_constant(x, warmup=0.002):
function warmup_linear (line 32) | def warmup_linear(x, warmup=0.002):
class BERTAdam (line 44) | class BERTAdam(Optimizer):
method __init__ (line 58) | def __init__(self, params, lr, warmup=-1, t_total=-1, schedule='warmup...
method get_lr (line 78) | def get_lr(self):
method to (line 93) | def to(self, device):
method initialize_step (line 99) | def initialize_step(self, initial_step):
method step (line 114) | def step(self, closure=None):
FILE: NLP/16.8 BERT/run_classifier_word.py
class InputExample (line 44) | class InputExample(object):
method __init__ (line 47) | def __init__(self, guid, text_a, text_b=None, label=None):
class InputFeatures (line 65) | class InputFeatures(object):
method __init__ (line 68) | def __init__(self, input_ids, input_mask, segment_ids, label_id):
class DataProcessor (line 75) | class DataProcessor(object):
method get_train_examples (line 78) | def get_train_examples(self, data_dir):
method get_dev_examples (line 82) | def get_dev_examples(self, data_dir):
method get_labels (line 86) | def get_labels(self):
method _read_tsv (line 91) | def _read_tsv(cls, input_file, quotechar=None):
class NewsProcessor (line 99) | class NewsProcessor(DataProcessor):
method __init__ (line 102) | def __init__(self):
method get_train_examples (line 105) | def get_train_examples(self, data_dir):
method get_dev_examples (line 111) | def get_dev_examples(self, data_dir):
method get_labels (line 116) | def get_labels(self):
method _create_examples (line 120) | def _create_examples(self, lines, set_type):
class MrpcProcessor (line 134) | class MrpcProcessor(DataProcessor):
method get_train_examples (line 137) | def get_train_examples(self, data_dir):
method get_dev_examples (line 143) | def get_dev_examples(self, data_dir):
method get_labels (line 148) | def get_labels(self):
method _create_examples (line 152) | def _create_examples(self, lines, set_type):
class MnliProcessor (line 166) | class MnliProcessor(DataProcessor):
method get_train_examples (line 169) | def get_train_examples(self, data_dir):
method get_dev_examples (line 174) | def get_dev_examples(self, data_dir):
method get_labels (line 180) | def get_labels(self):
method _create_examples (line 184) | def _create_examples(self, lines, set_type):
class ColaProcessor (line 199) | class ColaProcessor(DataProcessor):
method get_train_examples (line 202) | def get_train_examples(self, data_dir):
method get_dev_examples (line 207) | def get_dev_examples(self, data_dir):
method get_labels (line 212) | def get_labels(self):
method _create_examples (line 216) | def _create_examples(self, lines, set_type):
function convert_examples_to_features (line 228) | def convert_examples_to_features(examples, label_list, max_seq_length, t...
function _truncate_seq_pair (line 324) | def _truncate_seq_pair(tokens_a, tokens_b, max_length):
function accuracy (line 340) | def accuracy(out, labels):
function copy_optimizer_params_to_model (line 344) | def copy_optimizer_params_to_model(named_params_model, named_params_opti...
function set_optimizer_params_grad (line 354) | def set_optimizer_params_grad(named_params_optimizer, named_params_model...
function main (line 370) | def main():
FILE: NLP/16.8 BERT/tokenization_word.py
function convert_to_unicode (line 25) | def convert_to_unicode(text):
function printable_text (line 45) | def printable_text(text):
function load_vocab (line 68) | def load_vocab(vocab_file):
function convert_tokens_to_ids (line 93) | def convert_tokens_to_ids(vocab, tokens):
function whitespace_tokenize (line 101) | def whitespace_tokenize(text):
class FullTokenizer (line 110) | class FullTokenizer(object):
method __init__ (line 113) | def __init__(self, vocab_file, do_lower_case=True):
method tokenize (line 118) | def tokenize(self, text):
method convert_tokens_to_ids (line 126) | def convert_tokens_to_ids(self, tokens):
class BasicTokenizer (line 130) | class BasicTokenizer(object):
method __init__ (line 133) | def __init__(self, do_lower_case=True):
method tokenize (line 141) | def tokenize(self, text):
method _run_strip_accents (line 163) | def _run_strip_accents(self, text):
method _run_split_on_punc (line 174) | def _run_split_on_punc(self, text):
method _tokenize_chinese_chars (line 194) | def _tokenize_chinese_chars(self, text):
method _is_chinese_char (line 207) | def _is_chinese_char(self, cp):
method _clean_text (line 229) | def _clean_text(self, text):
class WordpieceTokenizer (line 243) | class WordpieceTokenizer(object):
method __init__ (line 246) | def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=...
method tokenize (line 251) | def tokenize(self, text):
function _is_whitespace (line 305) | def _is_whitespace(char):
function _is_control (line 317) | def _is_control(char):
function _is_punctuation (line 329) | def _is_punctuation(char):
Condensed preview — 119 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (9,092K chars).
[
{
"path": "Deep Learning/10. Neural Network/README.md",
"chars": 13244,
"preview": "## 目录\n- [1. 深度学习有哪些应用](#1-深度学习有哪些应用)\n- [2. 什么是神经网络](#2-什么是神经网络)\n - [2.1 什么是感知器](#21-什么是感知器)\n - [2.2 神经网络的结构](#22-神经网络的"
},
{
"path": "Deep Learning/10. Neural Network/TensorFlow_LR.ipynb",
"chars": 42474,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "Deep Learning/11. CNN/CNN.ipynb",
"chars": 26430,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "Deep Learning/11. CNN/README.md",
"chars": 10871,
"preview": "## 目录\n- [1. 什么是CNN](#1-什么是cnn)\n - [1.1 输入层](#11-输入层)\n - [1.2 卷积计算层(conv)](#12-卷积计算层conv)\n - [1.3 激励层](#13-激励层)\n - [1"
},
{
"path": "Deep Learning/12. RNN/README.md",
"chars": 5320,
"preview": "## 目录\n- [1. 什么是RNN](#1-什么是rnn)\n - [1.1 RNN的应用](#11-rnn的应用)\n - [1.2 为什么有了CNN,还要RNN?](#12-为什么有了cnn还要rnn)\n - [1.3 RNN的网络"
},
{
"path": "Deep Learning/12. RNN/RNN.ipynb",
"chars": 21162,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "Deep Learning/12.1 GRU/GRU.ipynb",
"chars": 10285,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\":"
},
{
"path": "Deep Learning/12.1 GRU/README.md",
"chars": 3612,
"preview": "## 目录\n- [1. 什么是GRU](#1-什么是gru)\n- [2. ⻔控循环单元](#2-⻔控循环单元)\n - [2.1 重置门和更新门](#21-重置门和更新门)\n - [2.2 候选隐藏状态](#22-候选隐藏状态)\n - "
},
{
"path": "Deep Learning/12.2 LSTM/LSTM.ipynb",
"chars": 14518,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# 构建单层LSTM网络对MNIST数据集分类\"\n ]\n },\n"
},
{
"path": "Deep Learning/12.2 LSTM/README.md",
"chars": 3960,
"preview": "## 目录\n- [1. 什么是LSTM](#1-什么是lstm)\n- [2. 输⼊⻔、遗忘⻔和输出⻔](#2-输遗忘和输出)\n- [3. 候选记忆细胞](#3-候选记忆细胞)\n- [4. 记忆细胞](#4-记忆细胞)\n- [5. 隐藏状态]"
},
{
"path": "Deep Learning/13. Transfer Learning/README.md",
"chars": 6624,
"preview": "## 目录\n\n- [1. 什么是迁移学习](#1-什么是迁移学习)\n- [2. 为什么需要迁移学习?](#2-为什么需要迁移学习)\n- [3. 迁移学习的基本问题有哪些?](#3-迁移学习的基本问题有哪些)\n- [4. 迁移学习有哪些常用概"
},
{
"path": "Deep Learning/13. Transfer Learning/Transfer Learning.ipynb",
"chars": 20548,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 数据下载\\n\",\n \"\\n\",\n \"Inceptio"
},
{
"path": "Deep Learning/14. Reinforcement Learning/README.md",
"chars": 6190,
"preview": "## 目录\n- [1. 什么是强化学习](#1-什么是强化学习)\n- [2. 强化学习模型](#2-强化学习模型)\n - [2.1 打折的未来奖励](#21-打折的未来奖励)\n - [2.2 Q-Learning算法](#22-q-le"
},
{
"path": "Deep Learning/15. DL Optimizer/README.md",
"chars": 13236,
"preview": "## 目录\n- [1. 训练误差和泛化误差](#1-训练误差和泛化误差)\n- [2. 该如何选择模型](#2-该如何选择模型)\n - [2.1 验证数据集](#21-验证数据集)\n - [2.2 K 折交叉验证](#22-k-折交叉验证"
},
{
"path": "Deep Learning/README.md",
"chars": 1881,
"preview": "------\n\n\n\n## 目录\n\n| 模块 | 章节 | 负责人(GitHub) "
},
{
"path": "Machine Learning/2.Logistics Regression/2.Logistics Regression.md",
"chars": 5012,
"preview": "## 目录\n- [1. 什么是逻辑回归](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/2.Logistics%20Regression#1-什么是逻辑回"
},
{
"path": "Machine Learning/2.Logistics Regression/README.md",
"chars": 5012,
"preview": "## 目录\n- [1. 什么是逻辑回归](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/2.Logistics%20Regression#1-什么是逻辑回"
},
{
"path": "Machine Learning/2.Logistics Regression/demo/CreditScoring.ipynb",
"chars": 14925,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## machine learning for credit scor"
},
{
"path": "Machine Learning/2.Logistics Regression/demo/README.md",
"chars": 174,
"preview": "## Kaggle上简单的金融信用分类,代码都有注释,此处不再赘述!\n[CreditScoring.ipynb](https://github.com/NLP-LOVE/ML-NLP/blob/master/Machine%20Learni"
},
{
"path": "Machine Learning/3.1 Random Forest/3.1 Random Forest.md",
"chars": 4361,
"preview": "## 目录\n- [1.什么是随机森林](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.1%20Random%20Forest#1什么是随机森林)\n "
},
{
"path": "Machine Learning/3.1 Random Forest/README.md",
"chars": 4361,
"preview": "## 目录\n- [1.什么是随机森林](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.1%20Random%20Forest#1什么是随机森林)\n "
},
{
"path": "Machine Learning/3.1 Random Forest/RandomForestRegression.ipynb",
"chars": 49973,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"### 构建随机森林回归模型\"\n ]\n },\n {\n \"c"
},
{
"path": "Machine Learning/3.2 GBDT/3.2 GBDT.md",
"chars": 4642,
"preview": "## 目录\n- [1. 解释一下GBDT算法的过程](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.2%20GBDT#1-解释一下gbdt算法的过程)"
},
{
"path": "Machine Learning/3.2 GBDT/GBDT_demo.ipynb",
"chars": 11264,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 53,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n"
},
{
"path": "Machine Learning/3.2 GBDT/README.md",
"chars": 4667,
"preview": "## 目录\n- [1. 解释一下GBDT算法的过程](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.2%20GBDT#1-解释一下gbdt算法的过程)"
},
{
"path": "Machine Learning/3.2 GBDT/test_feat.txt",
"chars": 445,
"preview": "0.00598802 0.569231 0.647059 0.95122 -0.225434 0.837989 0.357258 -0.0030581 -0.383475 320\r\n0.161677 0.743195 0.682353 0."
},
{
"path": "Machine Learning/3.2 GBDT/train_feat.txt",
"chars": 445,
"preview": "0.00598802 0.569231 0.647059 0.95122 -0.225434 0.837989 0.357258 -0.0030581 -0.383475 320\r\n0.161677 0.743195 0.682353 0."
},
{
"path": "Machine Learning/3.3 XGBoost/3.3 XGBoost.ipynb",
"chars": 1945,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "Machine Learning/3.3 XGBoost/3.3 XGBoost.md",
"chars": 5888,
"preview": "## 目录\n- [1. 什么是XGBoost](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.3%20XGBoost#1-什么是xgboost)\n "
},
{
"path": "Machine Learning/3.3 XGBoost/README.md",
"chars": 5888,
"preview": "## 目录\n- [1. 什么是XGBoost](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.3%20XGBoost#1-什么是xgboost)\n "
},
{
"path": "Machine Learning/3.3 XGBoost/pima-indians-diabetes.csv",
"chars": 24045,
"preview": "6,148,72,35,0,33.6,0.627,50,1\r\n1,85,66,29,0,26.6,0.351,31,0\r\n8,183,64,0,0,23.3,0.672,32,1\r\n1,89,66,23,94,28.1,0.167,21,0"
},
{
"path": "Machine Learning/3.3 XGBoost/数据说明.txt",
"chars": 357,
"preview": "# 1. Number of times pregnant\r\n# 2. Plasma glucose concentration a 2 hours in an oral glucose tolerance test\r\n# 3. Diast"
},
{
"path": "Machine Learning/3.4 LightGBM/3.4 LightGBM.ipynb",
"chars": 3962,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"为了演示LightGBM在蟒蛇中的用法,本代码以sklearn包中自带"
},
{
"path": "Machine Learning/3.4 LightGBM/3.4 LightGBM.md",
"chars": 4318,
"preview": "## 目录\n- [1. LightGBM是什么东东](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.4%20LightGBM#1-lightgbm是什"
},
{
"path": "Machine Learning/3.4 LightGBM/README.md",
"chars": 4318,
"preview": "## 目录\n- [1. LightGBM是什么东东](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.4%20LightGBM#1-lightgbm是什"
},
{
"path": "Machine Learning/3.Desition Tree/DecisionTree.csv",
"chars": 3167869,
"preview": "workclass,education,marital-status,occupation,relationship,race,gender,native-country,income\n State-gov, Bachelors, Neve"
},
{
"path": "Machine Learning/3.Desition Tree/DecisionTree.ipynb",
"chars": 753890,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 用决策树模型完成分类问题\"\n ]\n },\n {\n \""
},
{
"path": "Machine Learning/3.Desition Tree/Desition Tree.md",
"chars": 6665,
"preview": "## 目录\n- [1. 什么是决策树](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.Desition%20Tree#1-什么是决策树)\n - [1"
},
{
"path": "Machine Learning/3.Desition Tree/README.md",
"chars": 6665,
"preview": "## 目录\n- [1. 什么是决策树](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/3.Desition%20Tree#1-什么是决策树)\n - [1"
},
{
"path": "Machine Learning/4. SVM/4. SVM.md",
"chars": 8872,
"preview": "## 目录\n- [1. 讲讲SVM](#1-讲讲svm)\n - [1.1 一个关于SVM的童话故事](#11-一个关于svm的童话故事)\n - [1.2 理解SVM:第一层](#12-理解svm第一层)\n - [1.3 深入SVM:第"
},
{
"path": "Machine Learning/4. SVM/README.md",
"chars": 8872,
"preview": "## 目录\n- [1. 讲讲SVM](#1-讲讲svm)\n - [1.1 一个关于SVM的童话故事](#11-一个关于svm的童话故事)\n - [1.2 理解SVM:第一层](#12-理解svm第一层)\n - [1.3 深入SVM:第"
},
{
"path": "Machine Learning/4. SVM/news classification/README.md",
"chars": 1901,
"preview": "## 目录\n- [1.新闻分类案例](#1新闻分类案例)\n - [1.1介绍](#11介绍)\n - [1.2数据集下载](#12数据集下载)\n - [1.3libsvm库安装](#13libsvm库安装)\n - [1.4实现步骤]("
},
{
"path": "Machine Learning/4. SVM/news classification/svm_classification.ipynb",
"chars": 14155,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n"
},
{
"path": "Machine Learning/5.1 Bayes Network/5.1 Bayes Network.md",
"chars": 9292,
"preview": "## 目录\n- [1. 对概率图模型的理解](#1-对概率图模型的理解)\n- [2. 细数贝叶斯网络](#2-细数贝叶斯网络)\n - [2.1 频率派观点](#21-频率派观点)\n - [2.2 贝叶斯学派](#22-贝叶斯学派)\n "
},
{
"path": "Machine Learning/5.1 Bayes Network/Naive Bayes Classifier.ipynb",
"chars": 4440,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "Machine Learning/5.1 Bayes Network/README.md",
"chars": 9292,
"preview": "## 目录\n- [1. 对概率图模型的理解](#1-对概率图模型的理解)\n- [2. 细数贝叶斯网络](#2-细数贝叶斯网络)\n - [2.1 频率派观点](#21-频率派观点)\n - [2.2 贝叶斯学派](#22-贝叶斯学派)\n "
},
{
"path": "Machine Learning/5.2 Markov/5.2 HMM.ipynb",
"chars": 15075,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 使用HMM进行词性标注\\n\",\n \"这里我们用NLTK自带"
},
{
"path": "Machine Learning/5.2 Markov/5.2 Markov.md",
"chars": 10749,
"preview": "## 目录\n\n- [1. 马尔可夫网络、马尔可夫模型、马尔可夫过程、贝叶斯网络的区别](#1-马尔可夫网络马尔可夫模型马尔可夫过程贝叶斯网络的区别)\n- [2. 马尔可夫模型](#2-马尔可夫模型)\n - [2.1 马尔可夫过程](#21"
},
{
"path": "Machine Learning/5.2 Markov/README.md",
"chars": 10749,
"preview": "## 目录\n\n- [1. 马尔可夫网络、马尔可夫模型、马尔可夫过程、贝叶斯网络的区别](#1-马尔可夫网络马尔可夫模型马尔可夫过程贝叶斯网络的区别)\n- [2. 马尔可夫模型](#2-马尔可夫模型)\n - [2.1 马尔可夫过程](#21"
},
{
"path": "Machine Learning/5.3 Topic Model/HillaryEmail.ipynb",
"chars": 15088,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# LDA模型应用:一眼看穿希拉里的邮件\\n\",\n \"\\n\",\n"
},
{
"path": "Machine Learning/5.3 Topic Model/README.md",
"chars": 11495,
"preview": "## 目录\n- [1. LDA模型是什么](#1-lda模型是什么)\n - [1.1 5个分布的理解](#11-5个分布的理解)\n - [1.2 3个基础模型的理解](#12-3个基础模型的理解)\n - [1.3 LDA模型](#13"
},
{
"path": "Machine Learning/6. EM/README.md",
"chars": 4796,
"preview": "## 目录\n- [1. 什么是EM算法](#1-什么是em算法)\n - [1.1 似然函数](#11-似然函数)\n - [1.3 极大似然函数的求解步骤](#13-极大似然函数的求解步骤)\n - [1.4 EM算法](#14-em算法"
},
{
"path": "Machine Learning/6. EM/gmm_em/README.md",
"chars": 371,
"preview": "# gmm-em-clustering\n高斯混合模型(GMM 聚类)的 EM 算法实现。\n\n在给出代码前,先作一些说明。\n\n- 在对样本应用高斯混合模型的 EM 算法前,需要先进行数据预处理,即把所有样本值都缩放到 0 和 1 之间。\n- "
},
{
"path": "Machine Learning/6. EM/gmm_em/genSample.py",
"chars": 493,
"preview": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\ncov1 = np.mat(\"0.3 0;0 0.1\")\r\ncov2 = np.mat(\"0.2 0;0 0.3\")\r\nmu1 ="
},
{
"path": "Machine Learning/6. EM/gmm_em/gmm.data",
"chars": 5440,
"preview": "3.600000 79.000000\r\n1.800000 54.000000\r\n3.333000 74.000000\r\n2.283000 62.000000\r\n4.533000 85.000000\r\n2.883000 55.000000\r\n"
},
{
"path": "Machine Learning/6. EM/gmm_em/gmm.py",
"chars": 4010,
"preview": "# -*- coding: utf-8 -*-\r\n# ----------------------------------------------------\r\n# Copyright (c) 2017, Wray Zheng. All R"
},
{
"path": "Machine Learning/6. EM/gmm_em/main.py",
"chars": 1032,
"preview": "# -*- coding: utf-8 -*-\r\n# ----------------------------------------------------\r\n# Copyright (c) 2017, Wray Zheng. All R"
},
{
"path": "Machine Learning/6. EM/gmm_em/sample.data",
"chars": 5020,
"preview": "-7.068508871962037032e-01 8.704213984933941717e-01\n-7.051058525701757451e-02 8.753081466186661830e-01\n1.1979108012639055"
},
{
"path": "Machine Learning/7. Clustering/GMM.ipynb",
"chars": 11862,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 模拟两个正态分布的参数\"\n ]\n },\n {\n \"c"
},
{
"path": "Machine Learning/7. Clustering/K-Means.ipynb",
"chars": 28207,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "Machine Learning/7. Clustering/README.md",
"chars": 7081,
"preview": "## 目录\n- [1. 聚类算法都是无监督学习吗?](#1-聚类算法都是无监督学习吗)\n- [2. k-means(k均值)算法](#2-k-meansk均值算法)\n - [2.1 算法过程](#21-算法过程)\n - [2.2 损失函"
},
{
"path": "Machine Learning/7. Clustering/corpus_train.txt",
"chars": 235276,
"preview": "1\titv episode paris sunday scene kill show jekyll hyde terrorist gameshow pull drama pm face news postponed bang factor "
},
{
"path": "Machine Learning/8. ML特征工程和优化方法/README.md",
"chars": 18075,
"preview": "## 目录\n- [1. 特征工程有哪些?](#1-特征工程有哪些)\n - [1.1 特征归一化](#11-特征归一化)\n - [1.2 类别型特征](#12-类别型特征)\n - [1.3 高维组合特征的处理](#13-高维组合特征的处"
},
{
"path": "Machine Learning/9. KNN/README.md",
"chars": 13481,
"preview": "## 目录\n- [1. 什么是KNN](#1-什么是knn)\n - [1.1 KNN的通俗解释](#11-knn的通俗解释)\n - [1.2 近邻的距离度量](#12-近邻的距离度量)\n - [1.3 K值选择](#13-k值选择)\n"
},
{
"path": "Machine Learning/9. KNN/handwritingClass/README.md",
"chars": 3468,
"preview": "### 项目案例: 手写数字识别系统\n\n[完整代码地址](https://github.com/NLP-LOVE/ML-NLP/blob/master/Machine%20Learning/9.%20KNN/handwritingClass"
},
{
"path": "Machine Learning/9. KNN/handwritingClass/handwritingClass.py",
"chars": 8918,
"preview": "from __future__ import print_function\r\nfrom numpy import *\r\n# ѧnumpyģoperator\r\nimport operator\r\nfrom os import listdir\r\n"
},
{
"path": "Machine Learning/Liner Regression/1.Liner Regression.md",
"chars": 4563,
"preview": "## 目录\n- [1.什么是线性回归](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/Liner%20Regression#1什么是线性回归)\n- [2."
},
{
"path": "Machine Learning/Liner Regression/README.md",
"chars": 4563,
"preview": "## 目录\n- [1.什么是线性回归](https://github.com/NLP-LOVE/ML-NLP/tree/master/Machine%20Learning/Liner%20Regression#1什么是线性回归)\n- [2."
},
{
"path": "Machine Learning/Liner Regression/demo/README.md",
"chars": 3778,
"preview": "## 目录\n- [1.题目](#1题目)\n- [2.步骤](#2步骤)\n- [3.模型选择](#3模型选择)\n- [4.环境配置](#4环境配置)\n- [5.csv数据处理](#5csv数据处理)\n- [6.数据处理](#6数据处理)\n- "
},
{
"path": "Machine Learning/Liner Regression/demo/housing_price.py",
"chars": 1465,
"preview": "# 兼容 pythone2,3\nfrom __future__ import print_function\n\n# 导入相关python库\nimport os\nimport numpy as np\nimport pandas as pd\n\n#"
},
{
"path": "Machine Learning/Liner Regression/demo/kc_test.txt",
"chars": 182453,
"preview": "20140502,2,1,880,6380,1,7,880,0,1938,1994,47.6924,-122.322\r20150213,4,2.5,2880,8833,2,7,2880,0,2006,0,47.5388,-121.89\r20"
},
{
"path": "Machine Learning/Liner Regression/demo/kc_train.txt",
"chars": 679399,
"preview": "20150302,545000,3,2.25,1670,6240,1,8,1240,430,1974,0,47.6413,-122.113\r20150211,785000,4,2.5,3300,10514,2,10,3300,0,1984,"
},
{
"path": "Machine Learning/README.md",
"chars": 3388,
"preview": "------\n\n\n\n## 目录\n\n| 模块 | 章节 | 负责人(GitHub) "
},
{
"path": "NLP/16. NLP/README.md",
"chars": 3129,
"preview": "## 目录\n- [1. 什么是NLP](#1-什么是nlp)\n- [2. NLP主要研究方向](#2-nlp主要研究方向)\n- [3. NLP的发展](#3-nlp的发展)\n- [4. NLP任务的一般步骤](#4-nlp任务的一般步骤)\n"
},
{
"path": "NLP/16.1 Word Embedding/README.md",
"chars": 7339,
"preview": "## 目录\n- [1. 什么是词嵌入(Word Embedding)](#1-什么是词嵌入word-embedding)\n- [2.离散表示](#2离散表示)\n - [2.1 One-hot表示](#21-one-hot表示)\n - ["
},
{
"path": "NLP/16.1 Word Embedding/word2vec.ipynb",
"chars": 13977,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## word2vec训练中文模型\\n\",\n \"------\\n"
},
{
"path": "NLP/16.2 fastText/README.md",
"chars": 4338,
"preview": "## 目录\n- [1. 什么是fastText](#1-什么是fasttext)\n- [2. n-gram表示单词](#2-n-gram表示单词)\n- [3. fastText模型架构](#3-fasttext模型架构)\n- [4. fas"
},
{
"path": "NLP/16.2 fastText/fastText.ipynb",
"chars": 8032,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 使用fastText对文本进行分类\\n\",\n \"\\n\",\n"
},
{
"path": "NLP/16.3 GloVe/GloVe.ipynb",
"chars": 5310,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 1.生成词向量\\n\",\n \"\\n\",\n \"下载Git"
},
{
"path": "NLP/16.3 GloVe/README.md",
"chars": 4681,
"preview": "## 目录\n- [1. 说说GloVe](#1-说说glove)\n- [2. GloVe的实现步骤](#2-glove的实现步骤)\n - [2.1 构建共现矩阵](#21-构建共现矩阵)\n - [2.2 词向量和共现矩阵的近似关系](#"
},
{
"path": "NLP/16.4 textRNN & textCNN/README.md",
"chars": 5452,
"preview": "## 目录\n- [1. 什么是textRNN](#1-什么是textrnn)\n - [1.1 textRNN的原理](#11-textrnn的原理)\n- [2. textRNN网络结构](#2-textrnn网络结构)\n - [2.1 "
},
{
"path": "NLP/16.4 textRNN & textCNN/cnews_loader.py",
"chars": 3386,
"preview": "# coding: utf-8\n\nimport sys\nfrom collections import Counter\n\nimport numpy as np\nimport tensorflow.keras as kr\n\nif sys.ve"
},
{
"path": "NLP/16.4 textRNN & textCNN/cnn_model.py",
"chars": 2492,
"preview": "# coding: utf-8\n\nimport tensorflow as tf\n\n\nclass TCNNConfig(object):\n \"\"\"CNN配置参数\"\"\"\n\n embedding_dim = 64 # 词向量维度\n"
},
{
"path": "NLP/16.4 textRNN & textCNN/rnn_model.py",
"chars": 3167,
"preview": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport tensorflow as tf\n\nclass TRNNConfig(object):\n \"\"\"RNN配置参数\"\"\"\n\n # 模"
},
{
"path": "NLP/16.4 textRNN & textCNN/textCNN.ipynb",
"chars": 20866,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 数据集下载\\n\",\n \"\\n\",\n \"使用THUCN"
},
{
"path": "NLP/16.4 textRNN & textCNN/textRNN.ipynb",
"chars": 20726,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 数据集下载\\n\",\n \"\\n\",\n \"使用THUCN"
},
{
"path": "NLP/16.5 seq2seq/README.md",
"chars": 7120,
"preview": "## 目录\n- [1. 什么是seq2seq](#1-什么是seq2seq)\n- [2. 编码器](#2-编码器)\n- [3. 解码器](#3-解码器)\n- [4. 训练模型](#4-训练模型)\n- [5. seq2seq模型预测](#5-"
},
{
"path": "NLP/16.5 seq2seq/seq2seq.ipynb",
"chars": 248941,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"### 通过sin与con进行叠加变形生成无规律的模拟曲线,使用Seq"
},
{
"path": "NLP/16.6 Attention/README.md",
"chars": 7811,
"preview": "## 目录\n- [1. 什么是Attention机制](#1-什么是attention机制)\n- [2. 编解码器中的Attention](#2-编解码器中的attention)\n - [2.1 计算背景变量](#21-计算背景变量)\n "
},
{
"path": "NLP/16.6 Attention/datautil.py",
"chars": 12555,
"preview": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jul 11 16:11:18 2017\r\n\r\n@author: 代码医生 qq群:40016981,公众号:xiangyuejiqiren\r\n@bl"
},
{
"path": "NLP/16.6 Attention/fanyichina/fromids/README.md",
"chars": 1,
"preview": "\n"
},
{
"path": "NLP/16.6 Attention/fanyichina/toids/README.md",
"chars": 1,
"preview": "\n"
},
{
"path": "NLP/16.6 Attention/fanyichina/yuliao/from/english1w.txt",
"chars": 1891167,
"preview": "in 1998 , the yili autonomous prefecture cpc committee and the yili prefecture cpc committee made unified arrangements a"
},
{
"path": "NLP/16.6 Attention/fanyichina/yuliao/to/README.md",
"chars": 1,
"preview": "\n"
},
{
"path": "NLP/16.6 Attention/fanyichina/yuliao/to/chinese1w.txt",
"chars": 671428,
"preview": "1998年 , 经过 统一 部署 , 伊犁州 , 地 两 级 党委 开始 尝试 以 宣讲 团 的 形式 , 深入 学校 , 村民 院落 , 田间 地头 , 向 各族 群众 进行 面对面 宣讲 .\r\n在 不少 乡村 , 群众 在 草地 , 球"
},
{
"path": "NLP/16.6 Attention/myjiebadict.txt",
"chars": 42,
"preview": "_NUM nz\r\n_PAD nz\r\n_GO nz\r\n_EOS nz\r\n_UNK nz"
},
{
"path": "NLP/16.6 Attention/seq2seq_model.py",
"chars": 12505,
"preview": "# Copyright 2015 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"L"
},
{
"path": "NLP/16.6 Attention/test.py",
"chars": 4307,
"preview": "\nimport tensorflow as tf\nimport numpy as np\nimport os\nfrom six.moves import xrange\n\n\n_buckets = []\nconvo_hist_limit = 1\n"
},
{
"path": "NLP/16.6 Attention/train.ipynb",
"chars": 18869,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## 注意力模型实现中英文机器翻译\\n\",\n \"\\n\",\n "
},
{
"path": "NLP/16.7 Transformer/README.md",
"chars": 9105,
"preview": "## 目录\n- [1. 什么是Transformer](#1-什么是transformer)\n- [2. Transformer结构](#2-transformer结构)\n - [2.1 总体结构](#21-总体结构)\n - [2.2 "
},
{
"path": "NLP/16.8 BERT/README.md",
"chars": 11487,
"preview": "## 目录\n- [1. 什么是BERT](#1-什么是bert)\n- [2. 从Word Embedding到Bert模型的发展](#2-从word-embedding到bert模型的发展)\n - [2.1 图像的预训练](#21-图像的"
},
{
"path": "NLP/16.8 BERT/bert-Chinese-classification-task.md",
"chars": 1282,
"preview": "# bert-Chinese-classification-task\nbert中文分类实践\n\n在run_classifier_word.py中添加NewsProcessor,即新闻的预处理读入部分 \\\n在main方法中添加news类型数据处"
},
{
"path": "NLP/16.8 BERT/data/dev.tsv",
"chars": 16121,
"preview": "game\tEDGϣʦʾ̭ ϷԭֹվõȡΥ߱ؾFnaticʦɹʾһƱȫĽǿŶACD0-3ս˵ǴǵʿΪ0-3Ŀ֣Ϊֻ۳ߵĿܣ֮ǰʵߵķʽк֣ܶ١ֻҪһĶս֡Fnaticʦ조ʱ˺͡Ĵ˵ҲǡС6-02-4·ߡFnatic״̬ãһ4-0ʵת˫ɱI"
},
{
"path": "NLP/16.8 BERT/data/test",
"chars": 1,
"preview": "\n"
},
{
"path": "NLP/16.8 BERT/data/train.tsv",
"chars": 149433,
"preview": "game\t5000,ͶϷж!Ϸǿÿα Ϣ,һлĶ Ϸǿÿα!/ԣС5µһܿν߳𡱡رǿտպ˺ǻԵ¼(ͬѧտպؼ)µĽչ,˵Ůҵ߸迪5Wн,LV,չͶ5000,Ųù˾ʽҽƱաµĽչ,С57ٴη,ǻԵָ,Ͷ5000ǷϤˡݡɹԭί9Ӧڴ¼,С,ǡ"
},
{
"path": "NLP/16.8 BERT/download_glue_data.py",
"chars": 7775,
"preview": "''' Script for downloading all GLUE data.\n\nNote: for legal reasons, we are unable to host MRPC.\nYou can either use the v"
},
{
"path": "NLP/16.8 BERT/modeling.py",
"chars": 20865,
"preview": "# coding=utf-8\n# Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.\n#\n# Licensed under the"
},
{
"path": "NLP/16.8 BERT/optimization.py",
"chars": 7623,
"preview": "# coding=utf-8\n# Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.\n#\n# Licensed under the"
},
{
"path": "NLP/16.8 BERT/run.sh",
"chars": 1516,
"preview": "\n\nexport GLUE_DIR=/search/odin/wuyonggang/bert/extract_code/glue_data\nexport BERT_BASE_DIR=/search/odin/wuyonggang/bert/"
},
{
"path": "NLP/16.8 BERT/run_classifier_word.py",
"chars": 29804,
"preview": "# coding=utf-8\n# Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.\n#\n# Licensed under the"
},
{
"path": "NLP/16.8 BERT/tokenization_word.py",
"chars": 11596,
"preview": "# coding=utf-8\n# Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.\n#\n# Licensed under the"
},
{
"path": "NLP/16.9 XLNet/README.md",
"chars": 8558,
"preview": "## 目录\n- [1. 什么是XLNet](#1-什么是xlnet)\n- [2. 自回归语言模型(Autoregressive LM)](#2-自回归语言模型autoregressive-lm)\n- [3. 自编码语言模型(Autoenco"
},
{
"path": "NLP/README.md",
"chars": 2086,
"preview": "------\n\n\n\n## 目录\n\n| 模块 | 章节 | 负责人(GitHub) "
},
{
"path": "Project/17. Recommendation System/README.md",
"chars": 14172,
"preview": "## 目录\n- [1. 什么是推荐系统](#1-什么是推荐系统)\n- [2. 总体架构](#2-总体架构)\n - [2.1 离线推荐](#21-离线推荐)\n - [2.2 在线训练](#22-在线训练)\n- [3. 特征数据](#3-特"
},
{
"path": "Project/18. Intelligent Customer Service/README.md",
"chars": 8234,
"preview": "## 目录\n- [1. 智能客服系统](#1-智能客服系统)\n - [1.1 智能客服的目标](#11-智能客服的目标)\n - [1.2 细分领域](#12-细分领域)\n - [1.3 智能客服常见功能](#13-智能客服常见功能)\n"
},
{
"path": "Project/README.md",
"chars": 1030,
"preview": "------\n\n\n\n## 目录\n\n| 模块 | 章节 | 负责人(GitHub) "
},
{
"path": "README.md",
"chars": 7191,
"preview": "## 项目介绍\n\n- 此项目是**机器学习、NLP面试**中常考到的**知识点和代码实现**,也是作为一个算法工程师必会的理论基础知识。\n- 既然是以面试为主要目的,亦不可以篇概全,请谅解,有问题可提出。\n- 此项目以各个模块为切入点,让大"
},
{
"path": "images/README.md",
"chars": 1,
"preview": "\n"
}
]
// ... and 1 more files (download for full content)
About this extraction
This page contains the full source code of the NLP-LOVE/ML-NLP GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 119 files (32.9 MB), approximately 2.2M tokens, and a symbol index with 178 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.