Showing preview only (783K chars total). Download the full file or copy to clipboard to get everything.
Repository: chubin/cheat.sh
Branch: master
Commit: 031a5d3887f0
Files: 112
Total size: 747.8 KB
Directory structure:
gitextract_e4plvajh/
├── .dockerignore
├── .github/
│ └── workflows/
│ ├── tests-macos.yml
│ └── tests-ubuntu.yml
├── .gitignore
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── README.md
├── bin/
│ ├── app.py
│ ├── clean_cache.py
│ ├── release.py
│ └── srv.py
├── doc/
│ ├── README-ja.md
│ └── standalone.md
├── docker-compose.debug.yml
├── docker-compose.yml
├── etc/
│ └── config.yaml
├── lib/
│ ├── adapter/
│ │ ├── __init__.py
│ │ ├── adapter.py
│ │ ├── cheat_cheat.py
│ │ ├── cheat_sheets.py
│ │ ├── cmd.py
│ │ ├── common.py
│ │ ├── git_adapter.py
│ │ ├── internal.py
│ │ ├── latenz.py
│ │ ├── learnxiny.py
│ │ ├── question.py
│ │ ├── rosetta.py
│ │ ├── tldr.py
│ │ └── upstream.py
│ ├── buttons.py
│ ├── cache.py
│ ├── cheat_wrapper.py
│ ├── cheat_wrapper_test.py
│ ├── config.py
│ ├── fetch.py
│ ├── fmt/
│ │ ├── __init__.py
│ │ ├── comments.py
│ │ ├── internal.py
│ │ └── markdown.py
│ ├── frontend/
│ │ ├── __init__.py
│ │ ├── ansi.py
│ │ └── html.py
│ ├── globals.py
│ ├── languages_data.py
│ ├── limits.py
│ ├── options.py
│ ├── panela/
│ │ ├── colors.json
│ │ ├── colors.py
│ │ └── panela_colors.py
│ ├── post.py
│ ├── postprocessing.py
│ ├── routing.py
│ ├── search.py
│ ├── standalone.py
│ └── stateful_queries.py
├── requirements.txt
├── share/
│ ├── adapters/
│ │ ├── chmod.grc
│ │ ├── chmod.sh
│ │ ├── oeis.sh
│ │ └── rfc.sh
│ ├── ansi2html.sh
│ ├── bash_completion.txt
│ ├── cht.sh.txt
│ ├── emacs-ivy.txt
│ ├── emacs.txt
│ ├── firstpage-v1.txt
│ ├── firstpage-v2.pnl
│ ├── firstpage-v2.txt
│ ├── fish.txt
│ ├── help.txt
│ ├── intro.txt
│ ├── post.txt
│ ├── scripts/
│ │ ├── cacheCleanup.go
│ │ └── remove-from-cache.sh
│ ├── static/
│ │ ├── 1.html
│ │ ├── malformed-response.html
│ │ ├── opensearch.xml
│ │ └── style.css
│ ├── styles-demo.txt
│ ├── vim/
│ │ └── .vimrc
│ ├── vim.txt
│ └── zsh.txt
└── tests/
├── README.md
├── results/
│ ├── 1
│ ├── 10
│ ├── 11
│ ├── 12
│ ├── 13
│ ├── 14
│ ├── 15
│ ├── 16
│ ├── 17
│ ├── 18
│ ├── 19
│ ├── 2
│ ├── 20
│ ├── 21
│ ├── 22
│ ├── 23
│ ├── 24
│ ├── 25
│ ├── 3
│ ├── 4
│ ├── 5
│ ├── 6
│ ├── 7
│ ├── 8
│ └── 9
├── run-tests.sh
└── tests.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
.git
.gitignore
docker-compose.yml
Dockerfile
================================================
FILE: .github/workflows/tests-macos.yml
================================================
name: MacOS Tests
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
build:
runs-on: macos-latest
steps:
- uses: actions/checkout@v4
- run: ./share/adapters/rfc.sh
================================================
FILE: .github/workflows/tests-ubuntu.yml
================================================
name: Ubuntu Tests
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
schedule:
- cron: '0 9 * * 4'
jobs:
build:
runs-on: ubuntu-24.04
steps:
- uses: actions/checkout@v4
- run: ./share/adapters/rfc.sh
- name: install dependencies
run: pip install --upgrade -r requirements.txt
- name: fetch upstream cheat sheets
run: python lib/fetch.py fetch-all
- name: run bash tests
run: bash tests/run-tests.sh
- name: run pytest
run: pytest lib/
docker:
runs-on: ubuntu-20.04
steps:
- uses: actions/checkout@v2
- run: docker-compose build
- run: docker images
- run: |
docker-compose -f docker-compose.yml up -d
# docker-compose -f docker-compose.yml -f docker-compose.debug.yml up -d
docker-compose ps
# wait until the web server is up
wget --timeout 3 --tries=5 --spider localhost:8002 2>&1 | grep -i http
docker-compose logs --no-color
- run: CHEATSH_TEST_STANDALONE=NO bash tests/run-tests.sh
================================================
FILE: .gitignore
================================================
*.pyc
*.swp
log/
ve/
share/vim/.vim/
share/vim/.viminfo
typescript
venv/
bin/upstream
upstream/
================================================
FILE: CONTRIBUTING.md
================================================
There are several ways how you can
contribute to cheat.sh and make it better and more useful:
1. Suggest a GitHub repository (or other information source) to be attached to cheat.sh. Just create an issue for it, where the name and the URL of the repository is specified. Please keep in mind, that the repository's license has to permit its usage by cheat.sh;
2. Create an adapter for some repository and add it to cheat.sh;
3. Create a Editor plugin for cheat.sh;
4. Create a new cheat sheet in one of its upstream repositories;
5. Go through the list of open issues, and try to fix some of them, or at least understand and share your opinion about them, if you have it.
================================================
FILE: Dockerfile
================================================
FROM alpine:3.14
# fetching cheat sheets
## installing dependencies
RUN apk add --update --no-cache git py3-six py3-pygments py3-yaml py3-gevent \
libstdc++ py3-colorama py3-requests py3-icu py3-redis sed
## copying
WORKDIR /app
COPY . /app
## building missing python packages
RUN apk add --no-cache --virtual build-deps py3-pip g++ python3-dev libffi-dev \
&& pip3 install --no-cache-dir --upgrade pygments \
&& pip3 install --no-cache-dir -r requirements.txt \
&& apk del build-deps
## fetching cheat sheets
RUN mkdir -p /root/.cheat.sh/log/ \
&& python3 lib/fetch.py fetch-all
# installing server dependencies
RUN apk add --update --no-cache py3-jinja2 py3-flask bash gawk
ENTRYPOINT ["python3", "-u", "bin/srv.py"]
CMD [""]
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2025 Igor Chubin
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
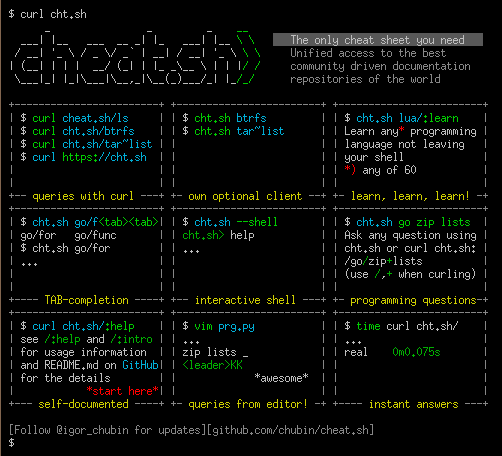
Unified access to the best community driven cheat sheets repositories of the world.
Let's imagine for a moment that there is such a thing as an ideal cheat sheet.
What should it look like?
What features should it have?
* **Concise** — It should only contain the things you need, and nothing else.
* **Fast** — It should be possible to use it instantly.
* **Comprehensive** — It should contain answers for every possible question.
* **Universal** — It should be available everywhere, anytime, without any preparations.
* **Unobtrusive** — It should not distract you from your main task.
* **Tutoring** — It should help you to learn the subject.
* **Inconspicuous** — It should be possible to use it completely unnoticed.
Such a thing exists! It's easy to [install](#installation) and there's even [auto-complete](#tab-completion).
## Features
**cheat.sh**
* Has a simple curl/browser/editor interface.
* Covers 56 programming languages, several DBMSes, and more than 1000 most important UNIX/Linux commands.
* Provides access to the best community driven cheat sheets repositories in the world, on par with StackOverflow.
* Available everywhere, no installation needed, but can be installed for offline usage.
* Ultrafast, returns answers within 100 ms, as a rule.
* Has a convenient command line client, `cht.sh`, that is very advantageous and helpful, though not mandatory.
* Can be used directly from code editors, without opening a browser and not switching your mental context.
* Supports a special stealth mode where it can be used fully invisibly without ever touching a key and making sounds.
<p align="center">
<img src='https://cheat.sh/files/demo-curl.gif'/>
</p>
## Contents
* [Features](#features)
* [Usage](#usage)
* [Command line client, cht.sh](#command-line-client-chtsh)
* [Installation](#installation)
* [Client usage](#client-usage)
* [Tab-completion](#tab-completion)
- [Bash Tab completion](#bash-tab-completion)
- [ZSH Tab completion](#zsh-tab-completion)
* [Stealth mode](#stealth-mode)
* [Windows command line client](#windows-command-line-client)
* [Self-Hosting](#self-hosting)
* [Docker](#docker)
* [Editors integration](#editors-integration)
* [Vim](#vim)
* [Emacs](#emacs)
* [Visual Studio Code](#visual-studio-code)
* [Sublime](#sublime)
* [IntelliJ IDEA](#intellij-idea)
* [QT Creator](#qtcreator)
* [Special pages](#special-pages)
* [Search](#search)
* [Programming languages cheat sheets](#programming-languages-cheat-sheets)
* [Cheat sheets sources](#cheat-sheets-sources)
* [How to contribute](#how-to-contribute)
* [How to edit a cheat sheet](#how-to-edit-a-cheat-sheet)
* [How to add a cheat sheet](#how-to-add-a-cheat-sheet)
* [How to add a cheat sheet repository](#how-to-add-a-cheat-sheet-repository)
## Usage
To get a cheat sheet for a UNIX/Linux command from a command line, query the service using `curl` or any other HTTP/HTTPS client
specifying the name of the command in the query:
```
curl cheat.sh/tar
curl cht.sh/curl
curl https://cheat.sh/rsync
curl https://cht.sh/tr
```
As you can see, you can use both HTTPS and HTTP to access the service, and both the long (cheat.sh) and the short (cht.sh) service names.
Here `tar`, `curl`, `rsync`, and `tr` are names of the UNIX/Linux commands you want to get cheat sheets for.
If you don't know the name of the command you need, you can search for it using the `~KEYWORD` notation.
For example, to see how you can make `snapshots` of a filesystem/volume/something else:
```
curl cht.sh/~snapshot
```
<p align="center">
<img src='https://cheat.sh/files/cht.sh-url-structure.png'/>
</p>
The programming language cheat sheets are located in special namespaces dedicated to them.
```
curl cht.sh/go/Pointers
curl cht.sh/scala/Functions
curl cht.sh/python/lambda
```
To get the list of available programming language cheat sheets, use the special query `:list`:
```
curl cht.sh/go/:list
```
Almost each programming language has a special page named `:learn`
that describes the language basics (that's a direct mapping from the *"Learn X in Y"* project).
It could be a good starting point if you've just started learning a language.
If there is no cheat sheet for a programming language query (and it is almost always the case),
it is generated on the fly, based on available cheat sheets and answers on StackOverflow.
Of course, there is no guarantee that the returned cheat sheet will be a 100% hit, but it is almost always exactly what you are looking for.
Try these (and your own) queries to get the impression of that, what the answers look like:
```
curl cht.sh/go/reverse+a+list
curl cht.sh/python/random+list+elements
curl cht.sh/js/parse+json
curl cht.sh/lua/merge+tables
curl cht.sh/clojure/variadic+function
```
If you don't like an answer for your queries, you can pick another one. For that, repeat the query with an additional parameter `/1`, `/2` etc. appended:
```
curl cht.sh/python/random+string
curl cht.sh/python/random+string/1
curl cht.sh/python/random+string/2
```
Cheat sheets are formatted as code of the queried programming language (at least we are trying our best to do so)
so they can be pasted into a program in this language directly. Text comments, if there are any, are formatted according to the language syntax.
```lua
$ curl cht.sh/lua/table+keys
-- lua: retrieve list of keys in a table
local keyset={}
local n=0
for k,v in pairs(tab) do
n=n+1
keyset[n]=k
end
--[[
[ Note that you cannot guarantee any order in keyset. If you want the
[ keys in sorted order, then sort keyset with table.sort(keyset).
[
[ [lhf] [so/q/12674345] [cc by-sa 3.0]
]]
```
If you don't need text comments in the answer, you can eliminate them
using a special option `\?Q`:
```lua
$ curl cht.sh/lua/table+keys\?Q
local keyset={}
local n=0
for k,v in pairs(tab) do
n=n+1
keyset[n]=k
end
```
And if you don't need syntax highlighting, switch it off using `\?T`.
You can combine the options together:
```
curl cht.sh/go/reverse+a+list\?Q
curl cht.sh/python/random+list+elements\?Q
curl cht.sh/js/parse+json\?Q
curl cht.sh/lua/merge+tables\?QT
curl cht.sh/clojure/variadic+function\?QT
```
Full list of all options described below and in `/:help`.
Try your own queries. Follow these rules:
1. Try to be more specific (`/python/append+file` is better than `/python/file` and `/python/append`).
2. Ask practical question if possible (yet theoretical question are possible too).
3. Ask programming language questions only; specify the name of the programming language as the section name.
4. Separate words with `+` instead of spaces.
5. Do not use special characters, they are ignored anyway.
6. If you want to eliminate cheat sheets containing some word, add it to the query with `+-`: `python/multiply+matrices+-numpy`
Read more about the programming languages queries below.
----
## Command line client, cht.sh
The cheat.sh service has its own command line client (`cht.sh`) that
has several useful features compared to querying the service directly with `curl`:
* Special shell mode with a persistent queries context and readline support.
* Queries history.
* Clipboard integration.
* Tab completion support for shells (bash, fish, zsh).
* Stealth mode.
### Installation
To install the client:
```bash
PATH_DIR="$HOME/bin" # or another directory on your $PATH
mkdir -p "$PATH_DIR"
curl https://cht.sh/:cht.sh > "$PATH_DIR/cht.sh"
chmod +x "$PATH_DIR/cht.sh"
```
or to install it globally (for all users):
```bash
curl -s https://cht.sh/:cht.sh | sudo tee /usr/local/bin/cht.sh && sudo chmod +x /usr/local/bin/cht.sh
```
Note: The package "rlwrap" is a required dependency to run in shell mode. Install this using `sudo apt install rlwrap`
### Client usage
Now, you can use `cht.sh` instead of `curl`, and write your queries in more natural way,
with spaces instead of `+`:
```
$ cht.sh go reverse a list
$ cht.sh python random list elements
$ cht.sh js parse json
```
It is even more convenient to start the client in a special shell mode:
```
$ cht.sh --shell
cht.sh> go reverse a list
```
If all your queries are about the same language, you can change the context
and spare repeating the programming language name:
```
$ cht.sh --shell
cht.sh> cd go
cht.sh/go> reverse a list
```
or even start the client in this context:
```
$ cht.sh --shell go
cht.sh/go> reverse a list
...
cht.sh/go> join a list
...
```
If you want to change the context, you can do it with the `cd` command,
or if you want do a single query for some other language, just prepend it with `/`:
```
$ cht.sh --shell go
...
cht.sh/go> /python dictionary comprehension
...
```
If you want to copy the last answer into the clipboard, you can
use the `c` (`copy`) command, or `C` (`ccopy`, without comments).
```
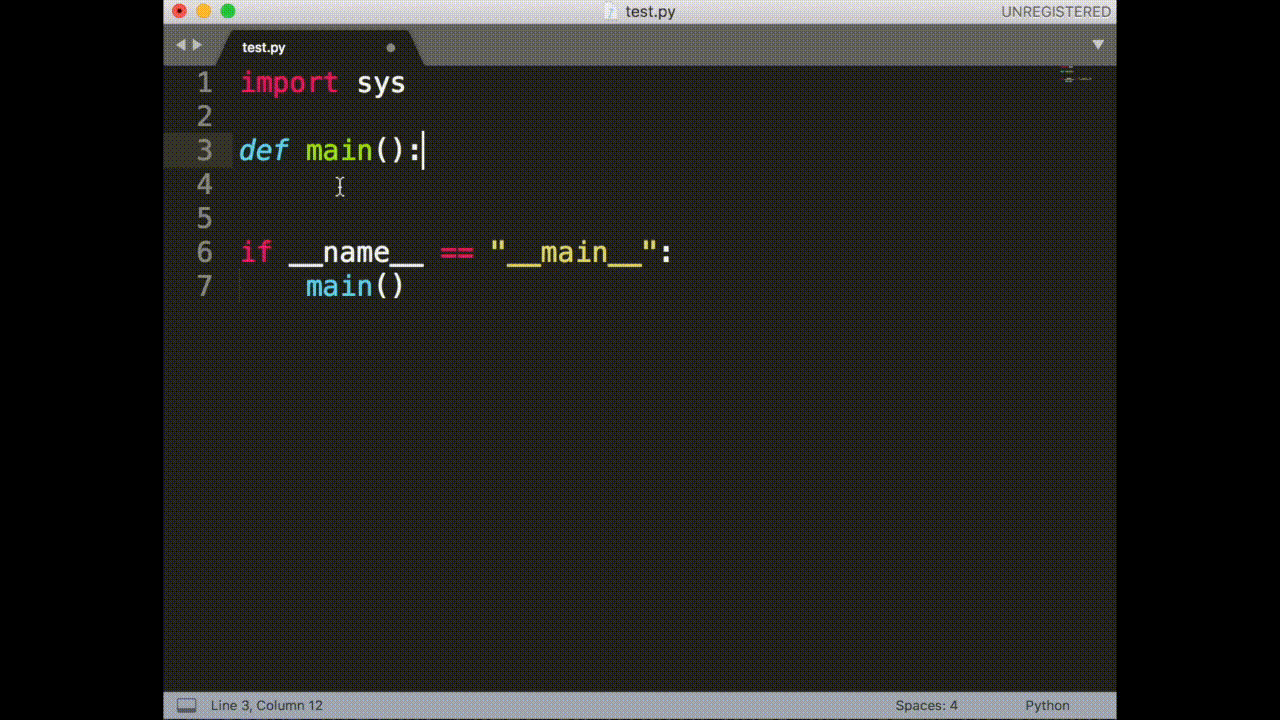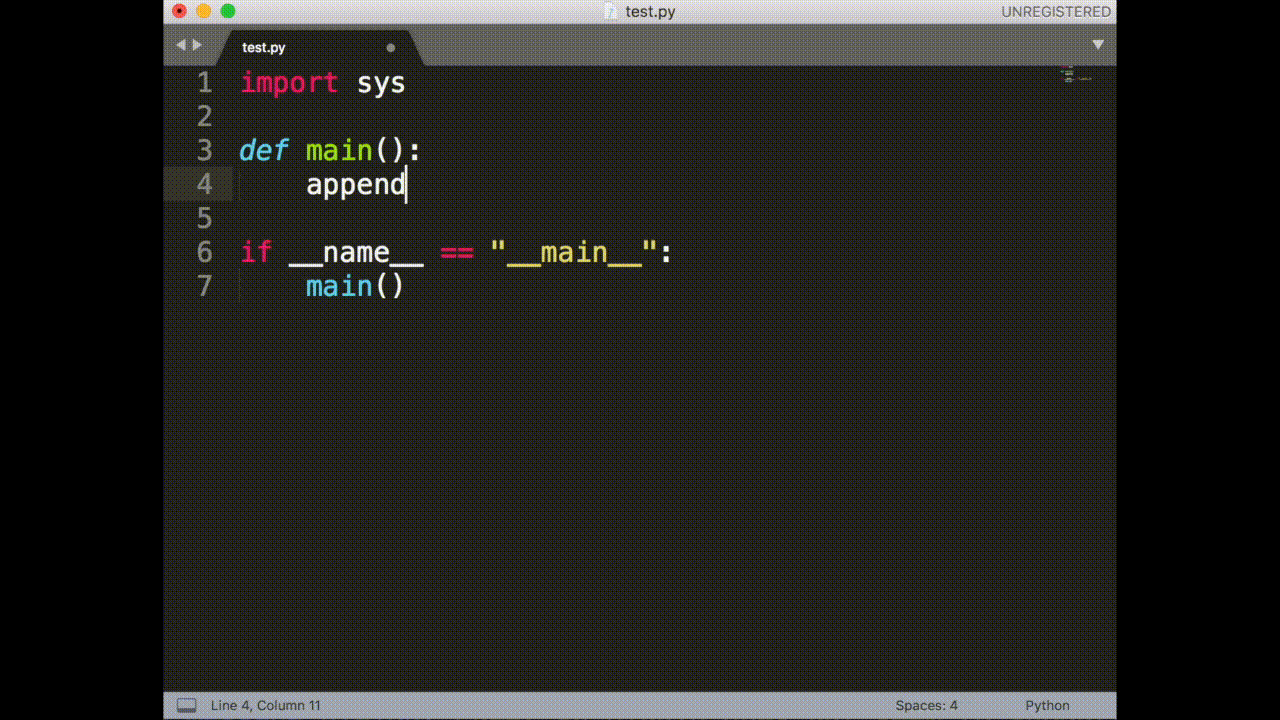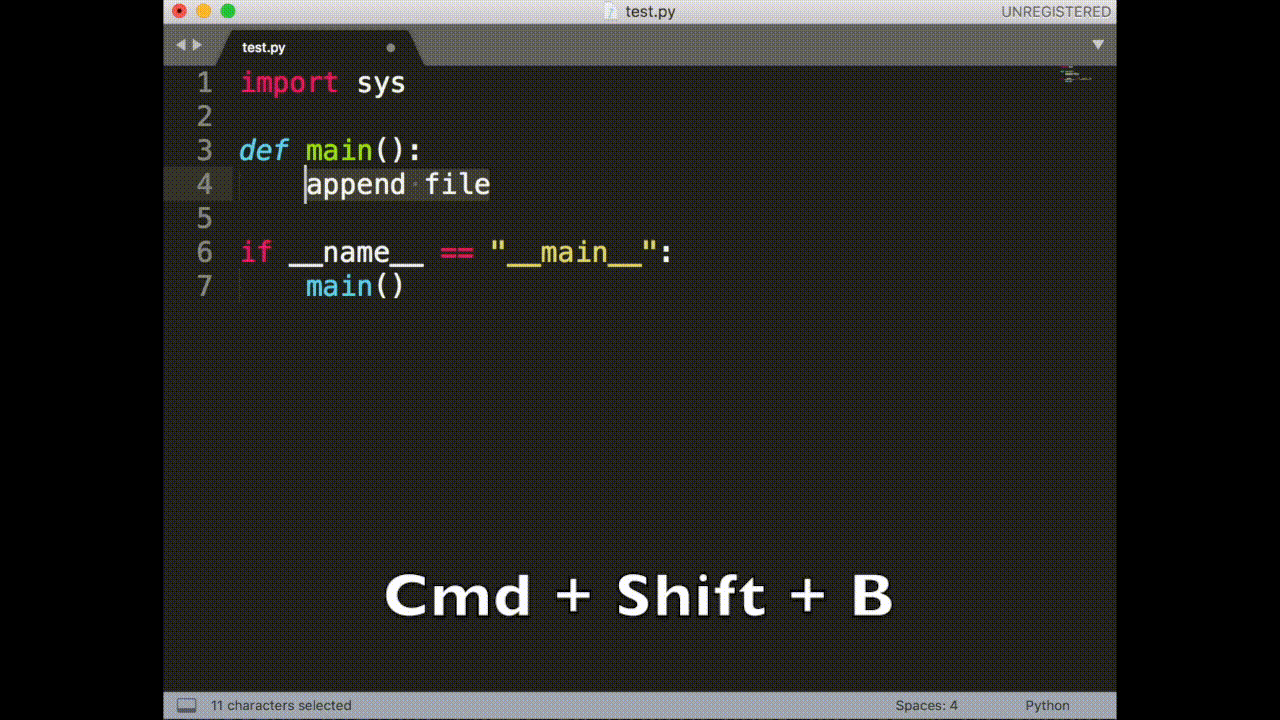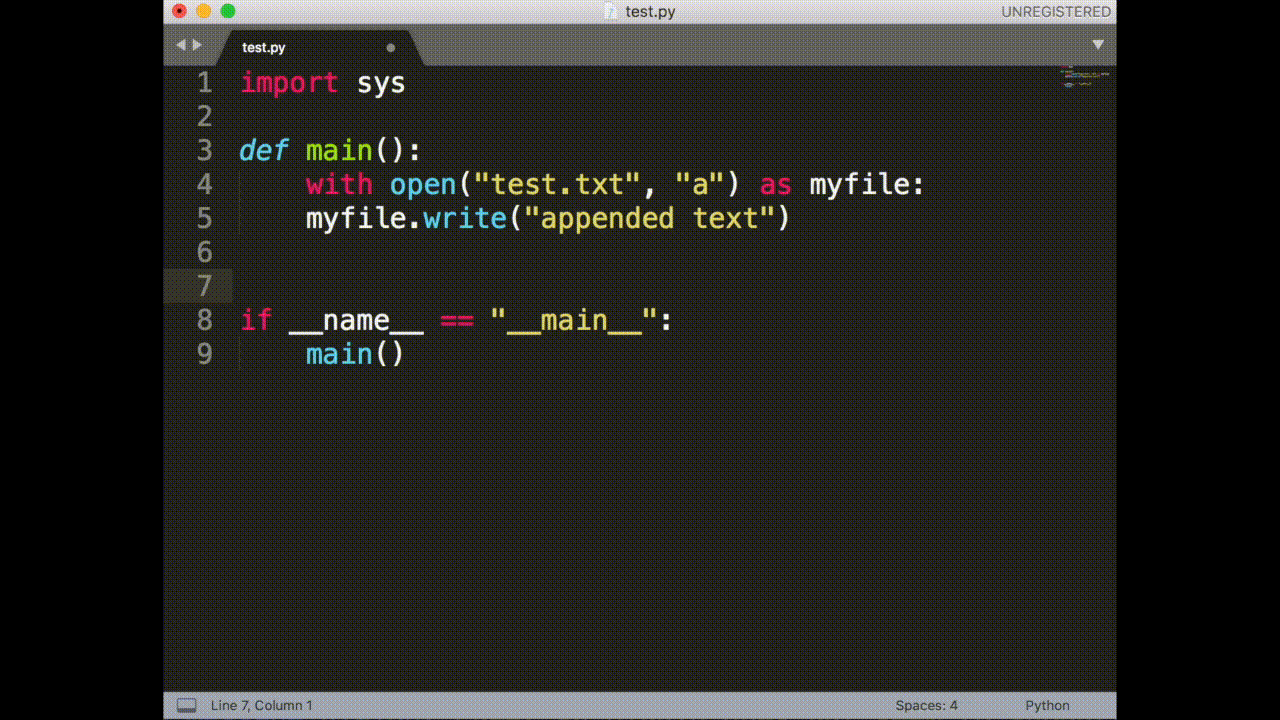
cht.sh/python> append file
# python - How do you append to a file?
with open("test.txt", "a") as myfile:
myfile.write("appended text")
cht.sh/python> C
copy: 2 lines copied to the selection
```
Type `help` for other internal `cht.sh` commands.
```
cht.sh> help
help - show this help
hush - do not show the 'help' string at start anymore
cd LANG - change the language context
copy - copy the last answer in the clipboard (aliases: yank, y, c)
ccopy - copy the last answer w/o comments (cut comments; aliases: cc, Y, C)
exit - exit the cheat shell (aliases: quit, ^D)
id [ID] - set/show an unique session id ("reset" to reset, "remove" to remove)
stealth - stealth mode (automatic queries for selected text)
update - self update (only if the scriptfile is writeable)
version - show current cht.sh version
/:help - service help
QUERY - space separated query staring (examples are below)
cht.sh> python zip list
cht.sh/python> zip list
cht.sh/go> /python zip list
```
The `cht.sh` client has its configuration file which is located at `~/.cht.sh/cht.sh.conf`
(location of the file can be overridden by the environment variable `CHTSH_CONF`).
Use it to specify query options that you would use with each query.
For example, to switch syntax highlighting off create the file with the following
content:
```bash
CHTSH_QUERY_OPTIONS="T"
```
Or if you want to use a special syntax highlighting theme:
```bash
CHTSH_QUERY_OPTIONS="style=native"
```
(`curl cht.sh/:styles-demo` to see all supported styles).
Other cht.sh configuration parameters:
```bash
CHTSH_CURL_OPTIONS="-A curl" # curl options used for cht.sh queries
CHTSH_URL=https://cht.sh # URL of the cheat.sh server
```
### Tab completion
#### Bash Tab completion
To activate tab completion support for `cht.sh`, add the `:bash_completion` script to your `~/.bashrc`:
```bash
curl https://cheat.sh/:bash_completion > ~/.bash.d/cht.sh
. ~/.bash.d/cht.sh
# and add . ~/.bash.d/cht.sh to ~/.bashrc
```
#### ZSH Tab completion
To activate tab completion support for `cht.sh`, add the `:zsh` script to the *fpath* in your `~/.zshrc`:
```zsh
curl https://cheat.sh/:zsh > ~/.zsh.d/_cht
echo 'fpath=(~/.zsh.d/ $fpath)' >> ~/.zshrc
# Open a new shell to load the plugin
```
----
### Stealth mode
Being used fully unnoticed is one of the most important property of any cheat sheet.
cheat.sh can be used completely unnoticed too. The cheat.sh client, `cht.sh`, has
a special mode, called **stealth mode**. Using that, you don't even need to touch your
keyboard to open a cheat sheet.
In this mode, as soon as you select some text with the mouse (and thus adding it
into the selection buffer of X Window System or into the clipboard) it's used
as a query string for cheat.sh, and the correspondent cheat sheet is automatically shown.
Let's imagine, that you are having an online interview, where your interviewer asks you
some questions using a shared document (say Google Docs) and you are supposed
to write your coding answers there (it's possible too that you'll type in the questions
on your own, just to show to the interviewer that you've heard it right).
When using the stealth mode of `cht.sh`, the only thing you need to do in order to see
a cheat sheet for some question, is to select the question using the mouse.
If you don't want any text in the answers and the only thing you need is code,
use the `Q` option when starting the stealth mode.
<p align="center">
<img src='https://cheat.sh/files/stealth-mode.gif'/>
</p>
```
You: Hi! | $ cht.sh --shell python
She: Hi! | cht.sh/python> stealth Q
She: Are you ready for a small interview? | stealth: you are in the stealth mode; select any text
She: Just a couple of questions | stealth: selections longer than 5 words are ignored
She: We will talk about python | stealth: query arguments: ?Q
She: Let's start from something simple. | stealth: use ^C to leave this mode
She: Do you know how to reverse a list in python? |
You: Sure |
You: (selecting "reverse a list") | stealth: reverse a list
| reverse_lst = lst[::-1]
You: lst[::-1]? |
She: Good. |
She: Do you know how to chain a list of lists? |
You: (selecting "chain a list of lists") | stealth: chain a list of lists
| import itertools
| a = [["a","b"], ["c"]]
| print list(itertools.chain.from_iterable(a))
You: May I use external modules? |
She: What module do you want to use? |
You: itertools |
She: Yes, you may use it |
You: Ok, then: |
You: itertools.chain.from_iterable(a) |
She: Good. Let's try something harder. |
She: What about quicksort implementation? |
You: (selecting "quicksort implementation") | stealth: quicksort implementation
You: Let me think about it. | (some big and clumsy lowlevel implementation shown)
You: Well...(starting typing it in) | def sort(array=[12,4,5,6,7,3,1,15]):
| less = []
She: (seeing your ugly pascal style) | equal = []
She: Could you write it more concise? | greater = []
| if len(array) > 1:
You: What do you mean? | pivot = array[0]
| for x in array:
She: I mean, | if x < pivot: less.append(x)
She: do you really need all these ifs and fors? | if x == pivot: equal.append(x)
She: Could you maybe just use filter instead? | if x > pivot: greater.append(x)
| return sort(less)+equal+sort(greater)
You: quicksort with filter? | else:
| return array
She: Yes |
You: (selecting "quicksort with filter") | stealth: quicksort with filter
You: Ok, I will try. | return qsort(filter(lt, L[1:]))+[pivot] \
You: Something like this? | +qsort(filter(ge, L[1:]))
You: qsort(filter(lt, L[1:]))+[pivot] \ |
+ qsort(filter(ge, L[1:])) |
|
She: Yes! Perfect! Exactly what I wanted to see! |
|
```
Of course, this is just for fun, and you should never cheat in your coding interviews,
because you know what happens when you do.

### Windows command line client
You can access cheat.sh from Windows command line too.
Use cheat.sh command line client for that: [`cht.exe`](https://github.com/tpanj/cht.exe).
It supports:
* output colorization;
* command line options;
* its own configuration file.
You can also use [`scoop`](https://github.com/lukesampson/scoop) command-line installer for Windows to get it:
```batch
scoop install cht
```
----
## Self-Hosting
### Docker
Currently, the easiest way to get a self-hosted instance running is by using
the `docker-compose.yml` file.
docker-compose up
This builds and runs the image with baked in cheatsheets and starts the app
and a Redis instance to back it, making the service available at
http://localhost:8002 This is currently an early implementation and should
probably not be used for anything outside of internal/dev/personal use right
now.
## Editors integration
You can use *cheat.sh* directly from the editor
(*Emacs*, *Sublime*, *Vim*, and *Visual Studio Code* are currently supported;
not all features are supported by all plugins though; see below).
Instead of opening your browser, googling, browsing Stack Overflow
and eventually copying the code snippets you need into the clipboard
and later pasting them into the editor,
you can achieve the same instantly and without leaving the editor at all!
Here is what it looks like in Vim:
1. If you have a question while editing a program, you can just type
your question directly in the buffer and press `<leader>KK`. You will get
the answer to your question in pager. (with `<leader>KB` you'll get the answer
in a separate buffer).
2. If you like the answer, you can manually paste it from the buffer or
the pager, or if you are lazy you can use `<leader>KP` to paste it below/under
your question (or replace you question using `<leader>KR`). If you want the
answer without the comments, `<leader>KC` replays the last query
toggling them.
If you use some static analysis plugin such as *syntastic* (for Vim), you can use
its warning and error messages as cheat.sh queries: place the cursor on the problem line
and press `<leader>KE`: explanation for the warning will be opened in a new buffer.
Features supported by cheat.sh plugins for different editors:
|Feature |Emacs|Sublime|Vim|VSCode|IDEA|QtCreator|
|-------------------|-----|-------|---|------|----|---------|
|Command queries |✓ |✓ |✓ |✓ |✓ |✓ |
|Queries from buffer| | |✓ |✓ | |✓ |
|Toggle comments | | |✓ |✓ |✓ |✓ |
|Prev/next answer | | |✓ |✓ |✓ |✓ |
|Multiple answers | |✓ | | |✓ | |
|Warnings as queries| | |✓ | | | |
|Queries history | | |✓ |✓ | | |
|Session id | | |✓ | | | |
|Configurable server|✓ | |✓ |✓ | |✓ |
### Vim
* [cheat.sh-vim](https://github.com/dbeniamine/cheat.sh-vim) — Vim support
Here is Vim configuration example:
```vim
" some configuration above ...
let mapleader=" "
call vundle#begin()
Bundle 'gmarik/vundle'
Bundle 'scrooloose/syntastic'
Bundle 'dbeniamine/cheat.sh-vim'
call vundle#end()
let g:syntastic_javascript_checkers = [ 'jshint' ]
let g:syntastic_ocaml_checkers = ['merlin']
let g:syntastic_python_checkers = ['pylint']
let g:syntastic_shell_checkers = ['shellcheck']
" some configuration below ...
```
In this example, several Vim plugins are used:
* [gmarik/vundle](https://github.com/VundleVim/Vundle.vim) — Vim plugin manager
* [scrooloose/syntastic](https://github.com/vim-syntastic/syntastic) — Syntax checking plugin
* [cheat.sh-vim](https://github.com/dbeniamine/cheat.sh-vim) — Vim support
Syntastic shows warnings and errors (found by code analysis tools: `jshint`, `merlin`, `pylint`, `shellcheck` etc.),
and `cheat.sh-vim` shows you explanations for the errors and warnings
and answers on programming languages queries written in the editor.
Watch a demo, where the most important features of the cheat.sh Vim plugin are shown (5 Min):
<p align="center">
<img src='https://cheat.sh/files/vim-demo.gif'/>
</p>
Or, if you want to scroll and/or pause, the same on YouTube:
<p align="center">
<a href="http://www.youtube.com/watch?feature=player_embedded&v=xyf6MJ0y-z8
" target="_blank"><img src="http://img.youtube.com/vi/xyf6MJ0y-z8/0.jpg"
alt="cheat.sh-vim: Using cheat.sh from vim" width="700" height="490" border="10" /></a>
</p>
<!-- [](https://asciinema.org/a/c6QRIhus7np2OOQzmQ2RNXzRZ) -->
### Emacs
* [cheat-sh.el](https://github.com/davep/cheat-sh.el) — Emacs support (available also at cheat.sh/:emacs)
* cheat.sh/:emacs-ivy — Emacs support for ivy users
[](https://asciinema.org/a/3xvqwrsu9g4taj5w526sb2t35)
### Visual Studio Code
* [vscode-snippet](https://github.com/mre/vscode-snippet)
* Install it from [VSCode Marketplace](https://marketplace.visualstudio.com/items?itemName=vscode-snippet.Snippet)
Usage:
1. Hit <kbd>⌘ Command</kbd> + <kbd>⇧ Shift</kbd> + <kbd>p</kbd>
2. Run `Snippet: Find`.
3. Type your query and hit enter.
[](https://github.com/mre/vscode-snippet)
*(GIF courtesy: Matthias Endler, @mre)*
### Sublime
* [cheat.sh-sublime-plugin](https://github.com/gauravk-in/cheat.sh-sublime-plugin/)
Usage:
1. Write your query string.
2. Select the query string.
3. Press <kbd>Cmd</kbd> + <kbd>⇧ Shift</kbd> + <kbd>B</kbd> to replace the selected query string by the answer generated from `cht.sh`.
[](https://github.com/gauravk-in/cheat.sh-sublime-plugin)
*(GIF courtesy: Gaurav Kukreja, @gauravk-in)*
### IntelliJ IDEA
* [idea-cheatsh-plugin](https://github.com/szymonprz/idea-cheatsh-plugin)
* Install from [idea plugins marketplace](https://plugins.jetbrains.com/plugin/11942-cheat-sh-code-snippets)
Usage:
1. Write query string
2. Select the query string
3. Press keyboard shortcut <kbd>Alt</kbd> + <kbd>C</kbd> , <kbd>S</kbd> to replace the selected query string by the answer
[](https://github.com/szymonprz/idea-cheatsh-plugin)
*(GIF courtesy: Szymon Przebierowski, @szymonprz)*
### QtCreator
* [cheatsh-qtcreator](https://github.com/pozemka/cheatsh-qtcreator)
Current features:
* search word under cursor
* search selected
* query search
* disable comments
* paste answer (?TQ version)
* custom server URL
* custom search context (default is cpp)
* hotkeys and menu
[](https://github.com/pozemka/cheatsh-qtcreator)
*(GIF courtesy: Pozemka, @pozemka)*
## Special pages
There are several special pages that are not cheat sheets.
Their names start with colon and have special meaning.
Getting started:
```
:help description of all special pages and options
:intro cheat.sh introduction, covering the most important usage questions
:list list all cheat sheets (can be used in a subsection too: /go/:list)
```
Command line client `cht.sh` and shells support:
```
:cht.sh code of the cht.sh client
:bash_completion bash function for tab completion
:bash bash function and tab completion setup
:fish fish function and tab completion setup
:zsh zsh function and tab completion setup
```
Editors support:
```
:vim cheat.sh support for Vim
:emacs cheat.sh function for Emacs
:emacs-ivy cheat.sh function for Emacs (uses ivy)
```
Other pages:
```
:post how to post new cheat sheet
:styles list of color styles
:styles-demo show color styles usage examples
:random fetches a random page (can be used in a subsection too: /go/:random)
```
## Search
To search for a keyword, use the query:
```
/~keyword
```
In this case search is not recursive — it is conducted only in a page of the specified level.
For example:
```
/~snapshot look for snapshot in the first level cheat sheets
/scala/~currying look for currying in scala cheat sheets
```
For a recursive search in all cheat sheets, use double slash:
```
/~snapshot/r look for snapshot in all cheat sheets
```
You can use special search options after the closing slash:
```
/~shot/bi case insensitive (i), word boundaries (b)
```
List of search options:
```
i case insensitive search
b word boundaries
r recursive search
```
## Programming languages cheat sheets
Cheat sheets related to programming languages
are organized in namespaces (subdirectories), that are named according
to the programming language.
For each supported programming language
there are several special cheat sheets: its own sheet, `hello`, `:list` and `:learn`.
Say for lua it will look like:
```
lua
lua/hello
lua/:list
lua/:learn
```
Some languages has the one-liners-cheat sheet, `1line`:
```
perl/1line
```
* `hello` describes how you can start with the language — install it if needed, build and run its programs, and it shows the "Hello world" program written in the language;
* `:list` shows all topics related to the language
* `:learn` shows a learn-x-in-minutes language cheat sheet perfect for getting started with the language.
* `1line` is a collection of one-liners in this language
* `weirdness` is a collection of examples of weird things in this language

At the moment, cheat.sh covers the 58 following programming languages (alphabetically sorted):
|Prefix |Language |Basics|One-liners|Weirdness|StackOverflow|
|-----------|----------|------|----------|---------|-------------|
|`arduino/` |Arduino | | | |✓ |
|`assembly/`|Assembly | | | |✓ |
|`awk/` |AWK |✓ | | |✓ |
|`bash/` |Bash |✓ | | |✓ |
|`basic/` |BASIC | | | |✓ |
|`bf/` |Brainfuck |✓ | | |✓ |
|`c/` |C |✓ | | |✓ |
|`chapel/` |Chapel |✓ | | |✓ |
|`clean/` |Clean | | | |✓ |
|`clojure/` |Clojure |✓ | | |✓ |
|`coffee/` |CoffeeScript|✓ | | |✓ |
|`cpp/` |C++ |✓ | | |✓ |
|`csharp/` |C# |✓ | | |✓ |
|`d/` |D |✓ | | |✓ |
|`dart/` |Dart |✓ | | |✓ |
|`delphi/` |Dephi | | | |✓ |
|`dylan/` |Dylan |✓ | | |✓ |
|`eiffel/` |Eiffel | | | |✓ |
|`elixir/` |Elixir |✓ | | |✓ |
|`elisp/` |ELisp |✓ | | |✓ |
|`elm/` |Elm |✓ | | |✓ |
|`erlang/` |Erlang |✓ | | |✓ |
|`factor/` |Factor |✓ | | |✓ |
|`fortran/` |Fortran |✓ | | |✓ |
|`forth/` |Forth |✓ | | |✓ |
|`fsharp/` |F# |✓ | | |✓ |
|`go/` |Go |✓ | | |✓ |
|`groovy/` |Groovy |✓ | | |✓ |
|`haskell/` |Haskell |✓ | | |✓ |
|`java/` |Java |✓ | | |✓ |
|`js/` |JavaScript|✓ |✓ |✓ |✓ |
|`julia/` |Julia |✓ | | |✓ |
|`kotlin/` |Kotlin |✓ | | |✓ |
|`latex/` |LaTeX |✓ | | |✓ |
|`lisp/` |Lisp |✓ | | |✓ |
|`lua/` |Lua |✓ | | |✓ |
|`matlab/` |MATLAB |✓ | | |✓ |
|`nim/` |Nim |✓ | | |✓ |
|`ocaml/` |OCaml |✓ | | |✓ |
|`octave/` |Octave |✓ | | |✓ |
|`perl/` |Perl |✓ |✓ | |✓ |
|`perl6/` |Perl 6 |✓ |✓ | |✓ |
|`php/` |PHP |✓ | | |✓ |
|`pike/` |Pike | | | |✓ |
|`python/` |Python |✓ |✓ | |✓ |
|`python3/` |Python 3 |✓ | | |✓ |
|`r/` |R |✓ | | |✓ |
|`racket/` |Racket |✓ | | |✓ |
|`ruby/` |Ruby |✓ | | |✓ |
|`rust/` |Rust |✓ | | |✓ |
|`scala/` |Scala |✓ | | |✓ |
|`scheme/` |Scheme |✓ | | |✓ |
|`solidity/`|Solidity |✓ | | |✓ |
|`swift/` |Swift |✓ | | |✓ |
|`tcsh/` |Tcsh |✓ | | |✓ |
|`tcl/` |Tcl |✓ | | |✓ |
|`objective-c/`|Objective-C|✓ | | |✓ |
|`vb/` |VisualBasic|✓ | | |✓ |
|`vbnet/` |VB.Net |✓ | | |✓ |
And several other topics, that are though related to programming,
are not programming languages:
|Prefix |Topic |Basics|StackOverflow|
|-----------|----------|------|-------------|
|`cmake/` |CMake |✓ |✓ |
|`django/` |Django | |✓ |
|`flask/` |Flask | |✓ |
|`git/` |Git |✓ |✓ |
## Cheat sheets sources
Instead of creating yet another mediocre cheat sheet repository,
we are concentrating our efforts on creation of a unified
mechanism to access selected existing well developed and good maintained
cheat sheet repositories covering topics of our interest:
programming and operating systems usage.
*cheat.sh* uses selected community driven cheat sheet repositories
and information sources, maintained by thousands of users, developers and authors
all over the world
(in the *Users* column number of contributors/number of stars is shown):
| Cheat sheets | Repository | C/U* | Stars | Creation Date |
|-------------------------|-------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|---------------|
| UNIX/Linux, programming | [cheat.sheets](https://github.com/chubin/cheat.sheets) |  |  | May 1, 2017 |
| UNIX/Linux commands | [tldr-pages/tldr](https://github.com/tldr-pages/tldr) |  |  | Dec 8, 2013 |
| UNIX/Linux commands | [cheat/cheat](https://github.com/cheat/cheat) |  |  | Jul 28, 2013 |
| Programming languages | [adambard/learnxinyminutes-docs](https://github.com/adambard/learnxinyminutes-docs) |  |  | Jun 23, 2013 |
| Go | [a8m/go-lang-cheat-sheet](https://github.com/a8m/go-lang-cheat-sheet) |  |  | Feb 9, 2014 |
| Perl | [pkrumnis/perl1line.txt](https://github.com/pkrumins/perl1line.txt) |  |  | Nov 4, 2011 |
| Programming languages | [StackOverflow](https://stackoverflow.com) | [14M](https://stackexchange.com/leagues/1/alltime/stackoverflow) | N/A | Sep 15, 2008 |
<sup>(*) C/U — contributors for GitHub repositories, Users for Stackoverflow</sup>
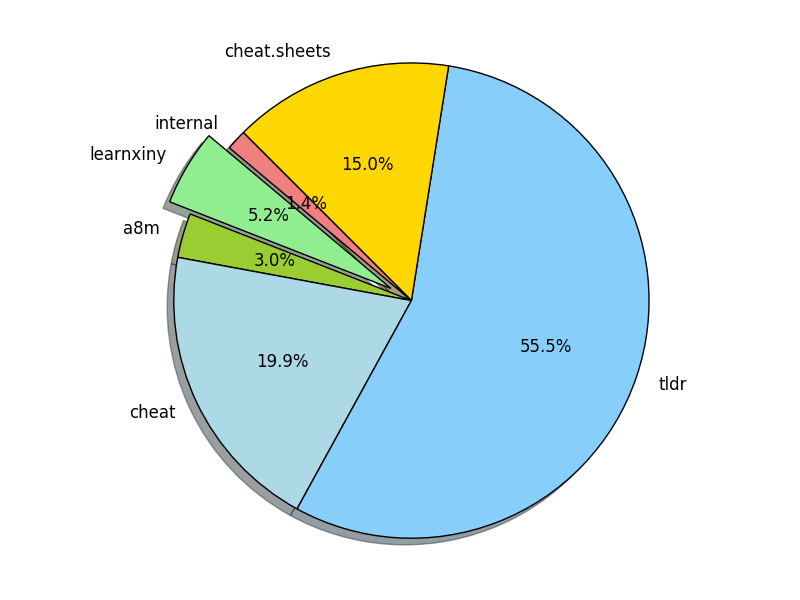
Pie diagram reflecting cheat sheets sources distribution (by number of cheat sheets on cheat.sh originating from a repository):
## How to contribute
### How to edit a cheat sheet
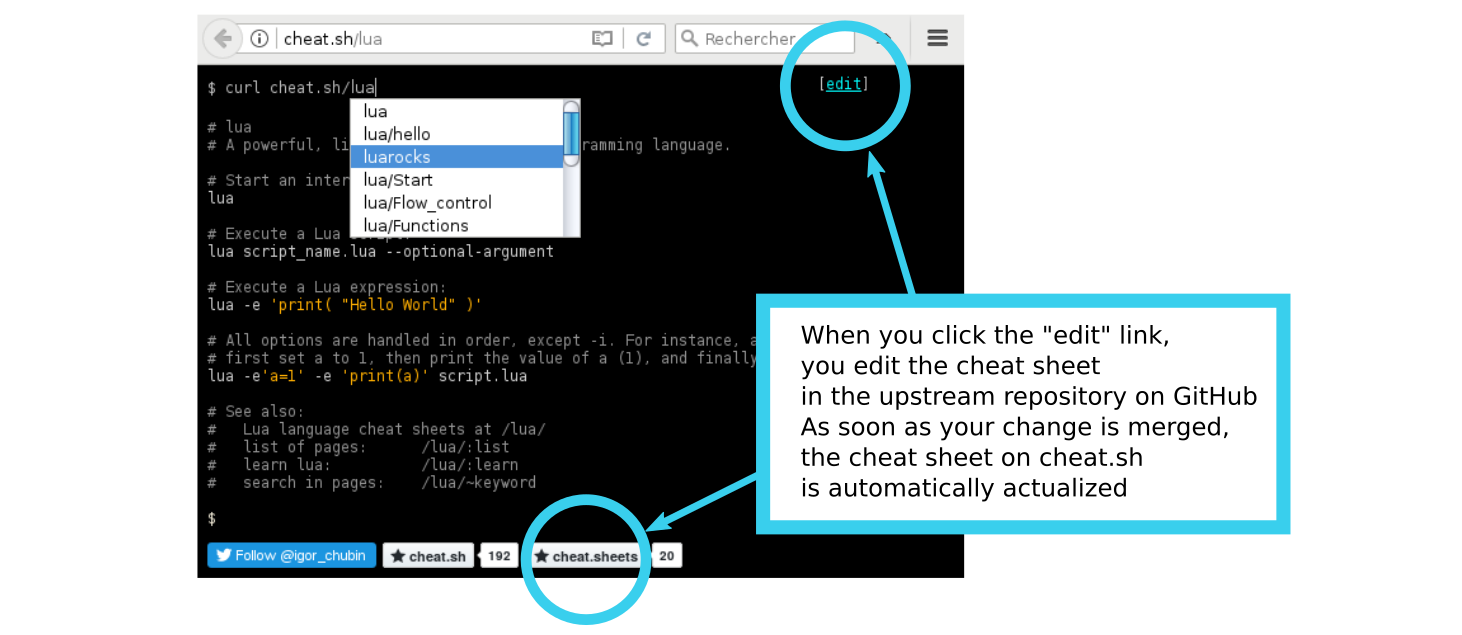
If you want to edit a cheat.sh cheat sheet, you should edit it in the upstream repository.
You will find the name of the source repository in a browser when you open a cheat sheet.
There are two github buttons at the bottom of the page: the second one is the button
of the repository, which belongs the current cheat sheet.
You can edit the cheat sheet directly in your browser (you need a github account for it).
There is an edit button in the top right corner. If you click on it, an editor will be open.
There you will change the cheat sheet (under the hood: the upstream repository is forked, your changes are
committed in the forked repository, a pull request to the upstream repository owner is sent).
### How to add a cheat sheet
If you want to add a cheat sheet, you have one of the following
ways:
* Add it to one of the external cheat sheets repositories; you should decide on your own what is the best repository for your cheat sheet;
* Add it to the local cheat.sh repository ([cheat.sheets](https://github.com/chubin/cheat.sheets)) on github (fork, commit, pull request);
* Post it on cheat.sh using curl or a web browser ([cheat.sh/:post](http://cheat.sh/:post)).
If you want to change an existing cheat sheet,
you have to find the original repository (when you open a cheat sheet in a browser,
you see the repository's github button in the bottom of the cheat sheet),
the cheat sheet is coming from, and change it there.
After some time the changes will be synchronized on cheat.sh.
### How to add a cheat sheet repository
If you want to add a cheat sheet repository to cheat.sh, please open an issue:
* [Add a new repository](https://github.com/chubin/cheat.sh/issues/new)
Please specify the name of the repository, and give its short description.
## Installation and standalone usage
You don't need to install anything, to start using *cheat.sh*.
There are two cases, when you want to install *cheat.sh* locally:
1. You plan to use it off-line, without Internet access;
2. You want to use your own cheat sheets (additionally, or as a replacement).
Installation process in described in details here: [cheat.sh standalone installation](doc/standalone.md)
================================================
FILE: bin/app.py
================================================
#!/usr/bin/env python
# vim: set encoding=utf-8
# pylint: disable=wrong-import-position,wrong-import-order
"""
Main server program.
Configuration parameters:
path.internal.malformed
path.internal.static
path.internal.templates
path.log.main
path.log.queries
"""
from __future__ import print_function
import sys
if sys.version_info[0] < 3:
reload(sys)
sys.setdefaultencoding("utf8")
import sys
import logging
import os
import requests
import jinja2
from flask import Flask, request, send_from_directory, redirect, Response
sys.path.append(os.path.abspath(os.path.join(__file__, "..", "..", "lib")))
from config import CONFIG
from limits import Limits
from cheat_wrapper import cheat_wrapper
from post import process_post_request
from options import parse_args
from stateful_queries import save_query, last_query
if not os.path.exists(os.path.dirname(CONFIG["path.log.main"])):
os.makedirs(os.path.dirname(CONFIG["path.log.main"]))
logging.basicConfig(
filename=CONFIG["path.log.main"],
level=logging.DEBUG,
format="%(asctime)s %(message)s",
)
# Fix Flask "exception and request logging" to `stderr`.
#
# When Flask's werkzeug detects that logging is already set, it
# doesn't add its own logger that prints exceptions.
stderr_handler = logging.StreamHandler()
logging.getLogger().addHandler(stderr_handler)
#
# Alter log format to disting log lines from everything else
stderr_handler.setFormatter(logging.Formatter("%(filename)s:%(lineno)s: %(message)s"))
#
# Sometimes werkzeug starts logging before an app is imported
# (https://github.com/pallets/werkzeug/issues/1969)
# resulting in duplicating lines. In that case we need root
# stderr handler to skip lines from werkzeug.
class SkipFlaskLogger(object):
def filter(self, record):
if record.name != "werkzeug":
return True
if logging.getLogger("werkzeug").handlers:
stderr_handler.addFilter(SkipFlaskLogger())
app = Flask(__name__) # pylint: disable=invalid-name
app.jinja_loader = jinja2.ChoiceLoader(
[app.jinja_loader, jinja2.FileSystemLoader(CONFIG["path.internal.templates"])]
)
LIMITS = Limits()
PLAIN_TEXT_AGENTS = [
"curl",
"httpie",
"lwp-request",
"wget",
"python-requests",
"openbsd ftp",
"powershell",
"fetch",
"aiohttp",
"xh",
]
def _is_html_needed(user_agent):
"""
Basing on `user_agent`, return whether it needs HTML or ANSI
"""
return all([x not in user_agent for x in PLAIN_TEXT_AGENTS])
def is_result_a_script(query):
return query in [":cht.sh"]
@app.route("/files/<path:path>")
def send_static(path):
"""
Return static file `path`.
Can be served by the HTTP frontend.
"""
return send_from_directory(CONFIG["path.internal.static"], path)
@app.route("/favicon.ico")
def send_favicon():
"""
Return static file `favicon.ico`.
Can be served by the HTTP frontend.
"""
return send_from_directory(CONFIG["path.internal.static"], "favicon.ico")
@app.route("/malformed-response.html")
def send_malformed():
"""
Return static file `malformed-response.html`.
Can be served by the HTTP frontend.
"""
dirname, filename = os.path.split(CONFIG["path.internal.malformed"])
return send_from_directory(dirname, filename)
def log_query(ip_addr, found, topic, user_agent):
"""
Log processed query and some internal data
"""
log_entry = "%s %s %s %s\n" % (ip_addr, found, topic, user_agent)
with open(CONFIG["path.log.queries"], "ab") as my_file:
my_file.write(log_entry.encode("utf-8"))
def get_request_ip(req):
"""
Extract IP address from `request`
"""
if req.headers.getlist("X-Forwarded-For"):
ip_addr = req.headers.getlist("X-Forwarded-For")[0]
if ip_addr.startswith("::ffff:"):
ip_addr = ip_addr[7:]
else:
ip_addr = req.remote_addr
if req.headers.getlist("X-Forwarded-For"):
ip_addr = req.headers.getlist("X-Forwarded-For")[0]
if ip_addr.startswith("::ffff:"):
ip_addr = ip_addr[7:]
else:
ip_addr = req.remote_addr
return ip_addr
def get_answer_language(request):
"""
Return preferred answer language based on
domain name, query arguments and headers
"""
def _parse_accept_language(accept_language):
languages = accept_language.split(",")
locale_q_pairs = []
for language in languages:
try:
if language.split(";")[0] == language:
# no q => q = 1
locale_q_pairs.append((language.strip(), "1"))
else:
locale = language.split(";")[0].strip()
weight = language.split(";")[1].split("=")[1]
locale_q_pairs.append((locale, weight))
except IndexError:
pass
return locale_q_pairs
def _find_supported_language(accepted_languages):
for lang_tuple in accepted_languages:
lang = lang_tuple[0]
if "-" in lang:
lang = lang.split("-", 1)[0]
return lang
return None
lang = None
hostname = request.headers["Host"]
if hostname.endswith(".cheat.sh"):
lang = hostname[:-9]
if "lang" in request.args:
lang = request.args.get("lang")
header_accept_language = request.headers.get("Accept-Language", "")
if lang is None and header_accept_language:
lang = _find_supported_language(_parse_accept_language(header_accept_language))
return lang
def _proxy(*args, **kwargs):
# print "method=", request.method,
# print "url=", request.url.replace('/:shell-x/', ':3000/')
# print "headers=", {key: value for (key, value) in request.headers if key != 'Host'}
# print "data=", request.get_data()
# print "cookies=", request.cookies
# print "allow_redirects=", False
url_before, url_after = request.url.split("/:shell-x/", 1)
url = url_before + ":3000/"
if "q" in request.args:
url_after = "?" + "&".join("arg=%s" % x for x in request.args["q"].split())
url += url_after
print(url)
print(request.get_data())
resp = requests.request(
method=request.method,
url=url,
headers={key: value for (key, value) in request.headers if key != "Host"},
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
)
excluded_headers = [
"content-encoding",
"content-length",
"transfer-encoding",
"connection",
]
headers = [
(name, value)
for (name, value) in resp.raw.headers.items()
if name.lower() not in excluded_headers
]
response = Response(resp.content, resp.status_code, headers)
return response
@app.route("/", methods=["GET", "POST"])
@app.route("/<path:topic>", methods=["GET", "POST"])
def answer(topic=None):
"""
Main rendering function, it processes incoming weather queries.
Depending on user agent it returns output in HTML or ANSI format.
Incoming data:
request.args
request.headers
request.remote_addr
request.referrer
request.query_string
"""
user_agent = request.headers.get("User-Agent", "").lower()
html_needed = _is_html_needed(user_agent)
options = parse_args(request.args)
if topic in [
"apple-touch-icon-precomposed.png",
"apple-touch-icon.png",
"apple-touch-icon-120x120-precomposed.png",
] or (topic is not None and any(topic.endswith("/" + x) for x in ["favicon.ico"])):
return ""
request_id = request.cookies.get("id")
if topic is not None and topic.lstrip("/") == ":last":
if request_id:
topic = last_query(request_id)
else:
return "ERROR: you have to set id for your requests to use /:last\n"
else:
if request_id:
save_query(request_id, topic)
if request.method == "POST":
process_post_request(request, html_needed)
if html_needed:
return redirect("/")
return "OK\n"
if "topic" in request.args:
return redirect("/%s" % request.args.get("topic"))
if topic is None:
topic = ":firstpage"
if topic.startswith(":shell-x/"):
return _proxy()
# return requests.get('http://127.0.0.1:3000'+topic[8:]).text
lang = get_answer_language(request)
if lang:
options["lang"] = lang
ip_address = get_request_ip(request)
if "+" in topic:
not_allowed = LIMITS.check_ip(ip_address)
if not_allowed:
return "429 %s\n" % not_allowed, 429
html_is_needed = _is_html_needed(user_agent) and not is_result_a_script(topic)
if html_is_needed:
output_format = "html"
else:
output_format = "ansi"
result, found = cheat_wrapper(
topic, request_options=options, output_format=output_format
)
if "Please come back in several hours" in result and html_is_needed:
malformed_response = open(
os.path.join(CONFIG["path.internal.malformed"])
).read()
return malformed_response
log_query(ip_address, found, topic, user_agent)
if html_is_needed:
return result
return Response(result, mimetype="text/plain")
================================================
FILE: bin/clean_cache.py
================================================
import sys
import redis
REDIS = redis.Redis(host="localhost", port=6379, db=0)
for key in sys.argv[1:]:
REDIS.delete(key)
================================================
FILE: bin/release.py
================================================
#!/usr/bin/env python
from __future__ import print_function
from datetime import datetime
import os
from os import path
import re
import shutil
import subprocess
from subprocess import Popen
import sys
SHARE_DIR = path.join(path.dirname(__file__), "../share/")
def run(args):
return Popen(args, stdout=sys.stdout, stderr=sys.stderr).wait()
status = subprocess.check_output(["git", "status", "--porcelain"])
if len(status) > 0:
print("Unclean working tree. Commit or stash changes first.", file=sys.stderr)
sys.exit(1)
timestamp = datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S +0000")
cht_curr = path.join(SHARE_DIR, "cht.sh.txt")
cht_new = path.join(SHARE_DIR, "cht.sh.txt.new")
re_version = re.compile(r"^__CHTSH_VERSION=(.*)$")
re_timestamp = re.compile(r"^__CHTSH_DATETIME=.*$")
with open(cht_curr, "rt") as fin:
with open(cht_new, "wt") as fout:
for line in fin:
match = re_version.match(line)
if match:
version = int(match.group(1)) + 1
fout.write("__CHTSH_VERSION=%s\n" % version)
continue
match = re_timestamp.match(line)
if match:
fout.write('__CHTSH_DATETIME="%s"\n' % timestamp)
continue
fout.write(line)
shutil.copymode(cht_curr, cht_new)
os.remove(cht_curr)
os.rename(cht_new, cht_curr)
message = "cht: v%s" % version
run(["git", "add", cht_curr])
run(["git", "commit", "-m", message])
run(["git", "tag", "cht@%s" % version, "-m", message])
================================================
FILE: bin/srv.py
================================================
#!/usr/bin/env python
#
# Serving cheat.sh with `gevent`
#
from gevent.monkey import patch_all
from gevent.pywsgi import WSGIServer
patch_all()
import os
import sys
from app import app, CONFIG
if "--debug" in sys.argv:
# Not all debug mode features are available under `gevent`
# https://github.com/pallets/flask/issues/3825
app.debug = True
if "CHEATSH_PORT" in os.environ:
port = int(os.environ.get("CHEATSH_PORT"))
else:
port = CONFIG["server.port"]
srv = WSGIServer((CONFIG["server.bind"], port), app)
print("Starting gevent server on {}:{}".format(srv.address[0], srv.address[1]))
srv.serve_forever()
================================================
FILE: doc/README-ja.md
================================================
唯一のチートシート https://cheat.sh/ が必要です
世界の最高のコミュニティ駆動チートシートリポジトリへの統一されたアクセス。
理想的なチートシートのようなものがあるとすぐに想像してみましょう。 どのように見える? どのような機能が必要ですか?
簡潔に – 簡潔にする必要があります。 それはあなたが必要とするものだけを含んでいなければなりません。
速く – それを即座に使用することが可能でなければなりません。
包括的 – あなたが持つ可能性があるすべての質問に対する回答を含める必要があります。
普遍的な – 準備ができていなくても、必要に応じてどこでもすぐに利用できるはずです。
邪魔になりません – あなたの主な仕事からあなたをそらすことはありません。
先入観 – それはあなたがその科目を学ぶのに役立ちます。
目立たない – 完全に気付かれないで使用することが可能でなければならない。
そんなことは存在しない。
特徴
チート.sh
単純なカール/ブラウザインターフェイスを備えています。
55のプログラミング言語、いくつかのDBMS、および1000以上の最も重要なUNIX / Linuxコマンドをカバーしています。
世界で最も優れたコミュニティ主導のチートシートリポジトリへのアクセスと、StackOverflowへのアクセスを提供します。
あらゆる場所で利用でき、インストールは必要ありません。
ultrafastは、原則として100ミリ秒以内に回答を返します。
便利で便利なコマンドラインクライアントcht.shがありますが、これは必須ではありません。
ブラウザを開いて精神的なコンテキストを切り替えることなく、コードエディタから直接使用することができます。
特殊モード(ステルスモード)をサポートしています。このモードでは、鍵に触れたり、音を出させたりすることなく、完全に目に見えない状態で使用できます。
使用法
コマンドラインからUNIX / Linuxコマンドのチートシートを取得するには、 curlまたは他のHTTP / HTTPSクライアントを使用して、クエリのコマンド名を指定してサービスをクエリします。
```
curl cheat.sh/tar
curl cht.sh/curl
curl https://cheat.sh/rsync
curl https://cht.sh/tr
```
ご覧のとおり、HTTPSとHTTPの両方を使用してサービスにアクセスし、長い(cheat.sh)サービス名と短い(cht.sh)サービス名の両方にアクセスできます。
ここで、 tar 、 curl 、 rsync 、 trはUNIX / Linuxコマンドの名前です。あなたはチートシートを入手したいと思っています。
必要なコマンドの名前がわからない場合は、 ~KEYWORD記法を使用して検索することができます。 たとえば、ファイルシステム/ボリューム/その他のsnapshotsを作成する方法を知るには:
```
curl cht.sh/~snapshot
```
プログラミング言語チートシートは、ルート名前空間には直接配置されず、専用の特別な名前空間に配置されます。
```
curl cht.sh/go/Pointers
curl cht.sh/scala/Functions
curl cht.sh/python/lambda
```
利用可能なプログラミング言語チートシートのリストを取得するには、特別なクエリを実行します。list:
```
curl cht.sh/go/:list
```
(ほぼ)それぞれのプログラミング言語には、 :learnという名前の特別なページがあります。これは、言語の基礎を説明しています( 「Learn X in Y」プロジェクトからの直接マッピングです)。 あなたが言語を学び始めたばかりの方は、良い出発点になるかもしれません。
いくつかのプログラミング言語のクエリ用のチートシートがない場合(ほとんどの場合そうです)、利用可能なチートシートとStackOverflowでの回答に基づいてオンザフライで生成されます。 もちろん、返されたチートシートが100%ヒットしたという保証はありませんが、ほとんど常にあなたが探しているものです。
これらの(そしてあなた自身の)クエリを試して、その印象をどのように見えるかを見てみましょう:
```
curl cht.sh/go/reverse+a+list
curl cht.sh/python/random+list+elements
curl cht.sh/js/parse+json
curl cht.sh/lua/merge+tables
curl cht.sh/clojure/variadic+function
```
いくつかのクエリの答えが気に入らない場合は、別のパラメータを選択することができます:追加のパラメータ/1 、 /2などをつけてクエリを繰り返します:
```
curl cht.sh/python/random+string
curl cht.sh/python/random+string/1
curl cht.sh/python/random+string/2
```
チートシートは照会されたプログラミング言語のコードとしてフォーマットされています(少なくともこれを行うために最善を尽くしています)。この言語のプログラムに直接貼り付けることができます。 テキストコメントがある場合は、言語構文に従って書式設定されます。
```
$ curl cht.sh/lua/table+keys
-- lua: retrieve list of keys in a table
local keyset={}
local n=0
for k,v in pairs(tab) do
n=n+1
keyset[n]=k
end
--[[
[ Note that you cannot guarantee any order in keyset. If you want the
[ keys in sorted order, then sort keyset with table.sort(keyset).
[
[ [lhf] [so/q/12674345] [cc by-sa 3.0]
]]
```
答えにテキストコメントが必要ない場合は、特別なオプションを使用してコメントを削除できます?Q :
```
$ curl cht.sh/lua/table+keys?Q
local keyset={}
local n=0
for k,v in pairs(tab) do
n=n+1
keyset[n]=k
end
```
構文強調表示が必要ない場合は、 ?Tを使ってスイッチをオフにし?T 。 オプションを一緒に組み合わせることができます:
```
curl cht.sh/go/reverse+a+list?Q
curl cht.sh/python/random+list+elements?Q
curl cht.sh/js/parse+json?Q
curl cht.sh/lua/merge+tables?QT
curl cht.sh/clojure/variadic+function?QT
```
下記および/:help記載されているすべてのオプションの完全なリスト
あなた自身の質問をお試しください。 次のルールに従ってください。
より具体的になるようにしてください( /python/append+fileは/python/fileや/python/appendよりも優れてい/python/append )。
可能であれば実践的な質問をする(しかし理論的な質問も可能である)。
プログラミング言語に関する質問のみを行います。 セクション名としてプログラミング言語の名前を指定します。
空白ではなく+区切ります。
とにかく無視される特殊文字は使用しないでください。
以下のプログラミング言語のクエリについての詳細を読む。
コマンドラインクライアント、cht.sh
cheat.shサービスには独自のコマンドラインクライアント( cht.sh )があり、 curlを使ってサービスを直接照会するのに比べ、いくつかの便利な機能があります。
永続的なクエリコンテキストとreadlineサポートを備えた特別なシェルモード。
クエリの履歴。
クリップボードの統合。
シェルのタブ補完のサポート(bash、fish、zsh);
ステルスモード。
クライアントをインストールするには:
```
curl https://cht.sh/:cht.sh > ~/bin/cht.sh
chmod +x ~/bin/cht.sh
```
さて、あなたはcurl代わりにcht.shを使い、より自然な方法であなたのクエリを+代わりにスペースで書くことができます:
```
$ cht.sh go reverse a list
$ cht.sh python random list elements
$ cht.sh js parse json
```
特別なシェルモードでクライアントを起動する方がさらに便利です:
```
$ cht.sh --shell
cht.sh> go reverse a list
```
すべてのクエリがほぼ同じ言語であると想定されている場合は、クエリのコンテキストを変更して、プログラミング言語の名前を繰り返すことができます。
```
$ cht.sh --shell
cht.sh> cd go
cht.sh/go> reverse a list
```
このコンテキストでクライアントを起動することさえできます:
```
$ cht.sh --shell go
cht.sh/go> reverse a list
...
cht.sh/go> join a list
...
```
コンテキストを変更したい場合は、 cdコマンドで行うことができます。あるいは、他の言語のクエリを1つだけ実行する場合は、 /ください:
```
$ cht.sh --shell go
...
cht.sh/go> /python dictionary comprehension
...
```
最後の回答をクリップボードにcopyする場合は、 c ( copy )コマンドまたはC (コメントなしのccopy )コマンドを使用できます。
```
cht.sh/python> append file
# python - How do you append to a file?
with open("test.txt", "a") as myfile:
myfile.write("appended text")
cht.sh/python> C
copy: 2 lines copied to the selection
```
他の内部cht.shコマンドのhelpを入力してください。
```
cht.sh> help
help - show this help
hush - do not show the 'help' string at start anymore
cd LANG - change the language context
copy - copy the last answer in the clipboard (aliases: yank, y, c)
ccopy - copy the last answer w/o comments (cut comments; aliases: cc, Y, C)
exit - exit the cheat shell (aliases: quit, ^D)
id [ID] - set/show an unique session id ("reset" to reset, "remove" to remove)
stealth - stealth mode (automatic queries for selected text)
update - self update (only if the scriptfile is writeable)
version - show current cht.sh version
/:help - service help
QUERY - space separated query staring (examples are below)
cht.sh> python zip list
cht.sh/python> zip list
cht.sh/go> /python zip list
```
cht.shクライアントの設定ファイルは~/.cht.sh/cht.sh.confます。 これを使用して、各クエリで使用するクエリオプションを指定します。 たとえば、構文の強調表示をオフに切り替えるには、次の内容のファイルを作成します。
```
QUERY_OPTIONS="T"
```
または、特殊な構文強調表示テーマを使用する場合は、次のようにします。
```
QUERY_OPTIONS="style=native"
```
( curl cht.sh/:styles-demoサポートされているすべてのスタイルが表示されます)。
タブ補完
cht.shタブ補完のサポートをcht.shにするには、 ~/.bashrc : :bash_completionスクリプトを追加してください:
$ curl https://cheat.sh/:bash_completion > ~/.bash.d/cht.sh
$ . ~/.bash.d/cht.sh
$ # and add . ~/.bash.d/cht.sh to ~/.bashrc
ステルスモード
実際のチートシートの重要な特性の1つは、それが完全に気付かれずに使用できるということです。
cheat.shはまったく気付かれずに使えます。 cheat.shクライアント、 cht.shには、 ステルスモードと呼ばれる特別なモードがあります。これは、キーボードに触れてチートシートを開く必要がないことを利用しています。
このモードでは、マウスでテキストを選択すると(そしてX Window Systemの選択バッファやクリップボードに追加されるとすぐに)、それはcheat.shのクエリ文字列として使用され、特派員のチートシートは自動的に表示されます。
インタビュー担当者が共有文書(Google Docsなど)を使っていくつかの質問をし、そこにコーディング回答を書くことになっているオンラインインタビューをしていることを想像してみましょう。面接官にあなたがそれを正しく聞いたことを示すために)
ステルスモードのcht.shを使用しているときは、何らかの質問のためにチートシートを見るために必要なのは、マウスを使って質問を選択することだけです。 答えにテキストを入れたくない場合は、コードだけが必要です。ステルスモードを開始するときには、 Qオプションを使用してください。
```
You: Hi! | $ cht.sh --shell python
She: Hi! | cht.sh/python> stealth Q
She: Are you ready for a small interview? | stealth: you are in the stealth mode; select any text
She: Just a couple of questions | stealth: selections longer than 5 words are ignored
She: We will talk about python | stealth: query arguments: ?Q
She: Let's start from something simple. | stealth: use ^C to leave this mode
She: Do you know how to reverse a list in python? |
You: Sure |
You: (selecting "reverse a list") | stealth: reverse a list
| reverse_lst = lst[::-1]
You: lst[::-1]? |
She: Good. |
She: Do you know how to chain a list of lists? |
You: (selecting "chain a list of lists") | stealth: chain a list of lists
| import itertools
| a = [["a","b"], ["c"]]
| print list(itertools.chain.from_iterable(a))
You: May I use external modules? |
She: What module do you want to use? |
You: itertools |
She: Yes, you may use it |
You: Ok, then: |
You: itertools.chain.from_iterable(a) |
She: Good. Let's try something harder. |
She: What about quicksort implementation? |
You: (selecting "quicksort implementation") | stealth: quicksort implementation
You: Let me think about it. | (some big and clumsy lowlevel implementation shown)
You: Well...(starting typing it in) | def sort(array=[12,4,5,6,7,3,1,15]):
| less = []
She: (seeing your ugly pascal style) | equal = []
She: Could you write it more concise? | greater = []
| if len(array) > 1:
You: What do you mean? | pivot = array[0]
| for x in array:
She: I mean, | if x < pivot: less.append(x)
She: do you really need all these ifs and fors? | if x == pivot: equal.append(x)
She: Could you may be just use filter instead? | if x > pivot: greater.append(x)
| return sort(less)+equal+sort(greater)
You: quicksort with filter? | else:
| return array
She: Yes |
You: (selecting "quicksort with filter") | stealth: quicksort with filter
You: Ok, I will try. | return qsort(filter(lt, L[1:]))+[pivot] \
You: Something like this? | +qsort(filter(ge, L[1:]))
You: qsort(filter(lt, L[1:]))+[pivot] \ |
+ qsort(filter(ge, L[1:])) |
|
She: Yes! Perfect! Exactly what I wanted to see! |
|
```
もちろん、それはちょうど楽しいことです。あなたが行ったときに何が起こるかを知っているので、コーディングのインタビューで決して欺くべきではありません。
エディターの統合
エディタから直接cheat.shを使うことができます( VimとEmacsは現在サポートされています)。 あなたのブラウザを開き、グーグルで、スタックオーバーフローをブラウズし、最終的に必要なコードスニペットをクリップボードにコピーして後でエディタに貼り付けるのではなく、エディタを離れずに同じことを達成することができます。
これはVimのように見えます:
プログラムの編集中に質問がある場合は、バッファに直接質問を入力して<leader>KKを押してください。 ポケットベルであなたの質問に対する答えが得られます。 ( <leader>KBすると、別のバッファで回答が得られます)。
答えが気に入ったらバッファやページャから手作業で貼り付けてください。怠け者の場合は<leader>KPを使って質問の下/下に貼り付けることができます。 コメントなしで回答が必要な場合は、 <leader>KCが最後のクエリを再生してそれらを切り替えます。
シンセシス (Vim用)などの静的解析プラグインを使用している場合は、警告とエラーメッセージをcheat.shクエリとして使用できます:カーソルを問題の行に置き、 <leader>KE :警告の説明を開きます新しいバッファに入れます。
ヴィム
cheat.sh-vim – Vimのサポート
ここにVimの設定例を示します:
```
" some configuration above ...
let mapleader=" "
call vundle#begin()
Bundle 'gmarik/vundle'
Bundle 'scrooloose/syntastic'
Bundle 'dbeniamine/cheat.sh-vim'
call vundle#end()
let g:syntastic_javascript_checkers = [ 'jshint' ]
let g:syntastic_ocaml_checkers = ['merlin']
let g:syntastic_python_checkers = ['pylint']
let g:syntastic_shell_checkers = ['shellcheck']
" some configuration below ...
```
この例では、いくつかのVimプラグインが使用されています:
gmarik / vundle – Vimプラグインマネージャ
scrooloose / syntastic – 構文チェックプラグイン
cheat.sh-vim – Vimのサポート
Syntasticは警告とエラー(code analysisツールで見つかった: jshint 、 jshint 、 pylint 、 shellcheckt etc.), and cheat.sh-vim`を表示すると、エディタに書き込まれたプログラミング言語のクエリに関するエラーと警告と回答の説明が表示されます。
cheat.sh Vimプラグインの最も重要な機能が表示されているデモをご覧ください(5分):
または、スクロールしたり一時停止したりする場合は、YouTubeでも同じです:
Emacs
cheat-sh.el – Emacsのサポート(cheat.sh/:emacsでも利用可能)
cheat.sh/:emacs-ivy – ivyユーザーのEmacsサポート
特別ページ
いくつかの特別なページがあり(その名前は常にコロンで始まります)、チートシートではなく特別な意味を持っています。
入門:
```
:help description of all special pages and options
:intro cheat.sh introduction, covering the most important usage questions
:list list all cheat sheets (can be used in a subsection too: /go/:list)
```
コマンドライン・クライアントcht.shとシェルは次のものをサポートしています。
```
:cht.sh code of the cht.sh client
:bash_completion bash function for tab completion
:bash bash function and tab completion setup
:fish fish function and tab completion setup
:zsh zsh function and tab completion setup
```
エディターのサポート:
:vim cheat.sh support for Vim
:emacs cheat.sh function for Emacs
:emacs-ivy cheat.sh function for Emacs (uses ivy)
その他のページ:
```
:post how to post new cheat sheet
:styles list of color styles
:styles-demo show color styles usage examples
```
サーチ
キーワードを検索するには、次のクエリを使用します。
```
/~keyword
```
この場合、検索は再帰的ではなく、指定されたレベルのページでのみ実行されます。 例えば:
```
/~snapshot look for snapshot in the first level cheat sheets
/scala/~currying look for currying in scala cheat sheets
```
すべてのチートシートで再帰的検索を行うには、二重スラッシュを使用します。
/~snapshot/r look for snapshot in all cheat sheets
スラッシュの後に特殊な検索オプションを使用することができます。
/~shot/bi case insensitive (i), word boundaries (b)
検索オプションのリスト:
```
i case insensitive search
b word boundaries
r recursive search
```
プログラミング言語チートシート
プログラミング言語に関連するチートシートは、プログラミング言語に従って名前が付けられた名前空間(サブディレクトリ)に編成されています。
サポートされているプログラミング言語ごとに、独自のsheet、 hello 、 :list 、 :learnいくつかの特別なチートシートがあり:learn 。 それはルアのように見えます:
```
lua
lua/hello
lua/:list
lua/:learn
```
いくつかの言語には、1行のチートシート、1 1line :
perl/1line
helloは、あなたがどのように言語を使い始めることができるかを記述します – 必要に応じてインストールし、プログラムをビルドして実行し、言語で書かれた “Hello world”プログラムを表示します。
:listには言語に関連するすべてのトピックが表示されます
:learnは、言語を使い始めるのに最適なx-in-minutes言語のチートシートを表示します。
1lineはこの言語の1ライナーの集合です
weirdnessなことはこの言語の奇妙なものの例の集まりです
現時点では、cheat.shは以下の55のプログラミング言語(アルファベット順にソートされています)をカバーしています:
接頭辞 言語 基本 ワンライナー 奇妙さ スタックオーバーフロー
arduino/ Arduino ✓
assembly/ アセンブリ ✓
awk/ AWK ✓ ✓
bash/ バッシュ ✓ ✓
basic/ ベーシック ✓
bf/ 頭痛 ✓ ✓
c/ C ✓ ✓
chapel/ チャペル ✓ ✓
clean/ クリーン ✓
clojure/ Clojure ✓ ✓
coffee/ CoffeeScript ✓ ✓
cpp/ C ++ ✓ ✓
csharp/ C# ✓ ✓
d/ D ✓ ✓
dart/ ダーツ ✓ ✓
delphi/ デフ ✓
dylan/ ディラン ✓ ✓
eiffel/ エッフェル ✓
elixir/ エリクシール ✓ ✓
elisp/ ELisp ✓ ✓
elm/ エルム ✓ ✓
erlang/ アーラン ✓ ✓
factor/ 因子 ✓ ✓
fortran/ Fortran ✓ ✓
forth/ 四方 ✓ ✓
fsharp/ F# ✓ ✓
go/ 行こう ✓ ✓
groovy/ Groovy ✓ ✓
haskell/ ハスケル ✓ ✓
java/ Java ✓ ✓
js/ JavaScript ✓ ✓ ✓ ✓
julia/ ジュリア ✓ ✓
kotlin/ コトリン ✓ ✓
lisp/ Lisp ✓ ✓
lua/ ルア ✓ ✓
matlab/ MATLAB ✓ ✓
ocaml/ OCaml ✓ ✓
perl/ Perl ✓ ✓ ✓
perl6/ Perl 6 ✓ ✓ ✓
php/ PHP ✓ ✓
pike/ パイク ✓
python/ Python ✓ ✓
python3/ Python 3 ✓ ✓
r/ R ✓ ✓
racket/ ラケット ✓ ✓
ruby/ ルビー ✓ ✓
rust/ 錆 ✓ ✓
scala/ スカラ ✓ ✓
scheme/ スキーム ✓ ✓
swift/ 迅速 ✓ ✓
tcsh/ Tcsh ✓ ✓
tcl/ Tcl ✓ ✓
objective-c/ 目標-C ✓ ✓
vb/ VisualBasic ✓ ✓
vbnet/ VB.Net ✓ ✓
チートシートのソース
さらに別の平凡なチートシートリポジトリを作成するのではなく、既存のよく開発されたよく管理されたチートシートリポジトリにアクセスする統一メカニズムの作成に力を注いでいます。
cheat.shは世界中の何千ものユーザー、開発者、作者によって管理されている選択されたコミュニティ駆動のチートシートリポジトリと情報ソースを使用します(貢献者のユーザー列数/星数が表示されます)。
カンニングペーパー リポジトリ ユーザー 作成日
UNIX / Linux、プログラミング カンニングペーパー 6/54 2017年5月1日
UNIX / Linuxコマンド tldr-pages / tldr 541/17360 2013年12月8日
UNIX / Linuxコマンド クリサンレン/チート 105/4193 2013年7月28日
プログラミング言語 adambard / learnxinyminutes-docs 1096/5285 2013年6月23日
行こう a8m / go-lang-cheat-sheet 29/3034 2014年2月9日
Perl pkrumnis / perl1line.txt 4/165 2011年11月4日
プログラミング言語 スタックオーバーフロー 9M 2008年9月15日
チートシートソースの分布を反映するパイダイアグラム(リポジトリから生成されたチート.shのチートシートの数による):
貢献する方法
チートシートの編集方法
cheat.shチートシートを編集する場合は、アップストリームレポジトリで編集する必要があります。 チートシートを開くと、ブラウザにソースリポジトリの名前が表示されます。 ページ下部に2つのgithubボタンがあります:2番目のボタンは、現在のチートシートに属するリポジトリのボタンです。
チートシートをブラウザで直接編集できます(githubアカウントが必要です)。 右上に編集ボタンがあります。 それをクリックすると、エディタが開きます。 そこではチートシートを変更します(ボンネットの下:アップストレームリポジトリはフォークされ、変更はフォークされたリポジトリでコミットされ、上流のリポジトリ所有者へのプルリクエストが送信されます)。
チートシートを追加する方法
チートシートを追加する場合は、次のいずれかの方法があります。
それを外部のチートシートレポジトリの1つに追加します。 自分のチートシートに最適なリポジトリが何であるかを決める必要があります。
github(fork、commit、pull request)のローカルcheat.shリポジトリ( cheat.sheets )に追加します。
curlやウェブブラウザ( cheat.sh/:post )を使ってcheat.shに投稿してください。
既存のチートシートを変更したい場合は、元のリポジトリを見つける必要があります(ブラウザでチートシートを開くと、チートシートの下部にリポジトリのgithubボタンが表示されます)、チートシートは、それを変更してください。 しばらくすると、変更はcheat.shで同期されます。
チートシートリポジトリを追加する方法
cheat.shにチートシートリポジトリを追加する場合は、問題を開いてください:
新しいリポジトリを追加する
リポジトリの名前を指定し、簡単な説明をしてください。
================================================
FILE: doc/standalone.md
================================================
You don't need to install anything, to start using *cheat.sh*.
The only tool that you need is *curl*, which is typically installed
in every system. In the rare cases when *curl* is not installed,
there should be one of its alternatives in the system: *wget*, *wget2*,
*httpie*, *ftp* (with HTTP support), *fetch*, etc.
There are two cases, when you want to install *cheat.sh* locally:
1. You plan to use it off-line, without Internet access;
2. You want to use your own cheat sheets (additionally, or as a replacement).
In this case you need to install cheat.sh locally.
## How to install cheat.sh locally
To use cheat.sh offline, you need to:
1. Install it,
2. Fetch its data sources.
If you already have the cht.sh cli client locally,
you can use it for the standalone installation.
Otherwise it must be installed first.
```
curl https://cht.sh/:cht.sh > ~/bin/cht.sh
chmod +x ~/bin/cht.sh
```
Now you can install cheat.sh locally:
```
cht.sh --standalone-install
```
During the installation process, cheat.sh and its
data sources will be installed locally.
By default `~/.cheat.sh` is used as the installation
directory.

If you don't plan to use Redis for caching,
switch the caching off in the config file:
```
$ vim ~/.cheat.sh/etc/config.yaml
cache:
type: none
```
or with the environment variable `CHEATSH_CACHE_TYPE=none`.
## Update cheat sheets
Cheat sheets are fetched and installed to `~/.cheat.sh/upstream`.
To keep the cheat sheets up to date,
run the `cheat.sh` `update-all` command on regular basis.
Ideally, add it to *cron*:
```
0 5 0 0 0 $HOME/.cheat.sh/ve/bin/python $HOME/.cheat.sh/lib/fetch.py update-all
```
In this example, all information sources will be updated
each day at 5:00 local time, on regular basis.
## cheat.sh server mode
Your local cheat.sh installation is full-fledged, and it can
handle incoming HTTP/HTTPS queries.
To start cheat.sh in the server mode, run:
```
$HOME/.cheat.sh/ve/bin/python $HOME/.cheat.sh/bin/srv.py
```
You can also use `gunicorn` to start the cheat.sh server.
## Docker
You can deploy cheat.sh as a docker container.
Use `Dockerfile` in the source root directory, to build the Docker image:
```
docker build .
```
## Limitations
Some cheat sheets not available in the offline mode
for the moment. The reason for that is that to process some queries,
cheat.sh needs to access the Internet itself, because it does not have
the necessary data locally. We are working on that how to overcome
this limitation, but for the moment it still exists.
## Mac OS X Notes
### Installing Redis
To install Redis on Mac OS X (using `brew`):
```
$ brew install redis
$ ln -sfv /usr/local/opt/redis/*.plist ~/Library/LaunchAgents
$ launchctl load ~/Library/LaunchAgents/homebrew.mxcl.redis.plist
$ redis-cli ping
PONG
```
================================================
FILE: docker-compose.debug.yml
================================================
# Compose override, see https://docs.docker.com/compose/extends/
#
# - Run `flask` standalone server with more debug aids instead of `gevent`
# - Turn on Flask debug mode to print tracebacks and autoreload code
# - Mounts fresh sources from current dir as volume
#
# Usage:
# docker-compose -f docker-compose.yml -f docker-compose.debug.yml up
#
version: '2'
services:
app:
environment:
FLASK_ENV: development
#FLASK_RUN_RELOAD: False
FLASK_APP: "bin/app.py"
FLASK_RUN_HOST: 0.0.0.0
FLASK_RUN_PORT: 8002
entrypoint: ["/usr/bin/flask", "run"]
================================================
FILE: docker-compose.yml
================================================
version: '2'
services:
app:
build: .
image: cheat.sh
container_name: chtsh
depends_on:
- redis
environment:
- CHEATSH_CACHE_REDIS_HOST=redis
ports:
- "8002:8002"
volumes:
- .:/app:Z
redis:
image: redis:4-alpine
volumes:
- redis_data:/data
volumes:
redis_data:
================================================
FILE: etc/config.yaml
================================================
server:
address: "0.0.0.0"
cache:
type: redis
================================================
FILE: lib/adapter/__init__.py
================================================
"""
Import all adapters from the current directory
and make them available for import as
adapter_module.AdapterName
"""
# pylint: disable=wildcard-import,relative-import
from os.path import dirname, basename, isfile, join
import glob
__all__ = [
basename(f)[:-3]
for f in glob.glob(join(dirname(__file__), "*.py"))
if isfile(f) and not f.endswith("__init__.py")
]
from .adapter import all_adapters
from . import *
================================================
FILE: lib/adapter/adapter.py
================================================
"""
`Adapter`, base class of the adapters.
Configuration parameters:
path.repositories
"""
import abc
import os
from six import with_metaclass
from config import CONFIG
class AdapterMC(type):
"""
Adapter Metaclass.
Defines string representation of adapters
"""
def __repr__(cls):
if hasattr(cls, "_class_repr"):
return getattr(cls, "_class_repr")()
return super(AdapterMC, cls).__repr__()
class Adapter(with_metaclass(AdapterMC, object)):
"""
An abstract class, defines methods:
(cheat sheets retrieval)
* get_list
* is_found
* is_cache_needed
(repositories management)
" fetch
* update
and several properties that have to be set in each adapter subclass.
"""
_adapter_name = None
_output_format = "code"
_cache_needed = False
_repository_url = None
_local_repository_location = None
_cheatsheet_files_prefix = ""
_cheatsheet_files_extension = ""
_pages_list = []
@classmethod
def _class_repr(cls):
return "[Adapter: %s (%s)]" % (cls._adapter_name, cls.__name__)
def __init__(self):
self._list = {None: self._get_list()}
@classmethod
def name(cls):
"""
Return name of the adapter
"""
return cls._adapter_name
@abc.abstractmethod
def _get_list(self, prefix=None):
return self._pages_list
def get_list(self, prefix=None):
"""
Return available pages for `prefix`
"""
if prefix in self._list:
return self._list[prefix]
self._list[prefix] = set(self._get_list(prefix=prefix))
return self._list[prefix]
def is_found(self, topic):
"""
check if `topic` is available
CAUTION: only root is checked
"""
return topic in self._list[None]
def is_cache_needed(self):
"""
Return True if answers should be cached.
Return False if answers should not be cached.
"""
return self._cache_needed
@staticmethod
def _format_page(text):
"""
Preformatting page hook.
Converts `text` (as in the initial repository)
to text (as to be displayed).
"""
return text
@abc.abstractmethod
def _get_page(self, topic, request_options=None):
"""
Return page for `topic`
"""
pass
def _get_output_format(self, topic):
if "/" in topic:
subquery = topic.split("/")[-1]
else:
subquery = topic
if subquery in [":list"]:
return "text"
return self._output_format
# pylint: disable=unused-argument
@staticmethod
def _get_filetype(topic):
"""
Return language name (filetype) for `topic`
"""
return None
def get_page_dict(self, topic, request_options=None):
"""
Return page dict for `topic`
"""
#
# if _get_page() returns a dict, use the dictionary
# for the answer. It is possible to specify some
# useful properties as the part of the answer
# (e.g. "cache")
# answer by _get_page() always overrides all default properties
#
answer = self._get_page(topic, request_options=request_options)
if not isinstance(answer, dict):
answer = {"answer": answer}
answer_dict = {
"topic": topic,
"topic_type": self._adapter_name,
"format": self._get_output_format(topic),
"cache": self._cache_needed,
}
answer_dict.update(answer)
# pylint: disable=assignment-from-none
filetype = self._get_filetype(topic)
if filetype:
answer_dict["filetype"] = filetype
return answer_dict
@classmethod
def local_repository_location(cls, cheat_sheets_location=False):
"""
Return local repository location.
If name `self._repository_url` for the class is not specified, return None
It is possible that several adapters has the same repository_url,
in this case they should use the same local directory.
If for some reason the local repository location should be overridden
(e.g. if several different branches of the same repository are used)
if should set in `self._local_repository_location` of the adapter.
If `cheat_sheets_location` is specified, return path of the cheat sheets
directory instead of the repository directory.
"""
dirname = None
if cls._local_repository_location:
dirname = cls._local_repository_location
if not dirname and cls._repository_url:
dirname = cls._repository_url
if dirname.startswith("https://"):
dirname = dirname[8:]
elif dirname.startswith("http://"):
dirname = dirname[7:]
# if we did not manage to find out dirname up to this point,
# that means that neither repository url, not repository location
# is specified for the adapter, so it should be skipped
if not dirname:
return None
if dirname.startswith("/"):
return dirname
# it is possible that several repositories will
# be mapped to the same location name
# (because only the last part of the path is used)
# in this case provide the name in _local_repository_location
# (detected by fetch.py)
if "/" in dirname:
dirname = dirname.split("/")[-1]
path = os.path.join(CONFIG["path.repositories"], dirname)
if cheat_sheets_location:
path = os.path.join(path, cls._cheatsheet_files_prefix)
return path
@classmethod
def repository_url(cls):
"""
Return URL of the upstream repository
"""
return cls._repository_url
@classmethod
def fetch_command(cls):
"""
Initial fetch of the repository.
Return cmdline that has to be executed to fetch the repository.
Skipping if `self._repository_url` is not specified
"""
if not cls._repository_url:
return None
# in this case `fetch` has to be implemented
# in the distinct adapter subclass
raise RuntimeError(
"Do not known how to handle this repository: %s" % cls._repository_url
)
@classmethod
def update_command(cls):
"""
Update of the repository.
Return cmdline that has to be executed to update the repository
inside `local_repository_location()`.
"""
if not cls._repository_url:
return None
local_repository_dir = cls.local_repository_location()
if not local_repository_dir:
return None
# in this case `update` has to be implemented
# in the distinct adapter subclass
raise RuntimeError(
"Do not known how to handle this repository: %s" % cls._repository_url
)
@classmethod
def current_state_command(cls):
"""
Get current state of repository (current revision).
This is used to find what cache entries should be invalidated.
"""
if not cls._repository_url:
return None
local_repository_dir = cls.local_repository_location()
if not local_repository_dir:
return None
# in this case `update` has to be implemented
# in the distinct adapter subclass
raise RuntimeError(
"Do not known how to handle this repository: %s" % cls._repository_url
)
@classmethod
def save_state(cls, state):
"""
Save state `state` of the repository.
Must be called after the cache clean up.
"""
local_repository_dir = cls.local_repository_location()
state_filename = os.path.join(local_repository_dir, ".cached_revision")
open(state_filename, "w").write(state)
@classmethod
def get_state(cls):
"""
Return the saved `state` of the repository.
If state cannot be read, return None
"""
local_repository_dir = cls.local_repository_location()
state_filename = os.path.join(local_repository_dir, ".cached_revision")
state = None
if os.path.exists(state_filename):
state = open(state_filename, "r").read()
return state
@classmethod
def get_updates_list_command(cls):
"""
Return the command to get the list of updates
since the last update whose id is saved as the repository state (`cached_state`).
The list is used to invalidate the cache.
"""
return None
@classmethod
def get_updates_list(cls, updated_files_list):
"""
Return the pages that have to be invalidated if the files `updates_files_list`
were updated in the repository.
"""
if not cls._cheatsheet_files_prefix:
return updated_files_list
answer = []
cut_len = len(cls._cheatsheet_files_prefix)
for entry in updated_files_list:
if entry.startswith(cls._cheatsheet_files_prefix):
answer.append(entry[cut_len:])
else:
answer.append(entry)
return answer
def all_adapters(as_dict=False):
"""
Return list of all known adapters
If `as_dict` is True, return dict {'name': adapter} instead of a list.
"""
def _all_subclasses(cls):
return set(cls.__subclasses__()).union(
set([s for c in cls.__subclasses__() for s in _all_subclasses(c)])
)
if as_dict:
return {x.name(): x for x in _all_subclasses(Adapter)}
return list(_all_subclasses(Adapter))
def adapter_by_name(name):
"""
Return adapter having this name,
or None if nothing found
"""
return all_adapters(as_dict=True).get(name)
================================================
FILE: lib/adapter/cheat_cheat.py
================================================
"""
Adapter for https://github.com/cheat/cheat
Cheatsheets are located in `cheat/cheatsheets/`
Each cheat sheet is a separate file without extension
"""
# pylint: disable=relative-import,abstract-method
from .git_adapter import GitRepositoryAdapter
class Cheat(GitRepositoryAdapter):
"""
cheat/cheat adapter
"""
_adapter_name = "cheat"
_output_format = "code"
_cache_needed = True
_repository_url = "https://github.com/cheat/cheatsheets"
_cheatsheet_files_prefix = ""
_cheatsheet_file_mask = "*"
================================================
FILE: lib/adapter/cheat_sheets.py
================================================
"""
Implementation of the adapter for the native cheat.sh cheat sheets repository,
cheat.sheets. The cheat sheets repository is hierarchically structured: cheat
sheets covering programming languages are are located in subdirectories.
"""
# pylint: disable=relative-import
import os
import glob
from .git_adapter import GitRepositoryAdapter
def _remove_initial_underscore(filename):
if filename.startswith("_"):
filename = filename[1:]
return filename
def _sanitize_dirnames(filename, restore=False):
"""
Remove (or add) leading _ in the directories names in `filename`
The `restore` param means that the path name should be restored from the queryname,
i.e. conversion should be done in the opposite direction
"""
parts = filename.split("/")
newparts = []
for part in parts[:-1]:
if restore:
newparts.append("_" + part)
continue
if part.startswith("_"):
newparts.append(part[1:])
else:
newparts.append(part)
newparts.append(parts[-1])
return "/".join(newparts)
class CheatSheets(GitRepositoryAdapter):
"""
Adapter for the cheat.sheets cheat sheets.
"""
_adapter_name = "cheat.sheets"
_output_format = "code"
_repository_url = "https://github.com/chubin/cheat.sheets"
_cheatsheet_files_prefix = "sheets/"
def _get_list(self, prefix=None):
"""
Return all files on the first and the second level,
excluding directories and hidden files
"""
hidden_files = ["_info.yaml"]
answer = []
prefix = os.path.join(
self.local_repository_location(), self._cheatsheet_files_prefix
)
for mask in ["*", "*/*"]:
template = os.path.join(prefix, mask)
answer += [
_sanitize_dirnames(f_name[len(prefix) :])
for f_name in glob.glob(template)
if not os.path.isdir(f_name)
and os.path.basename(f_name) not in hidden_files
]
return sorted(answer)
def _get_page(self, topic, request_options=None):
filename = os.path.join(
self.local_repository_location(),
self._cheatsheet_files_prefix,
_sanitize_dirnames(topic, restore=True),
)
if os.path.exists(filename):
answer = self._format_page(open(filename, "r").read())
else:
# though it should not happen
answer = "%s:%s not found" % (str(self.__class__), topic)
return answer
class CheatSheetsDir(CheatSheets):
"""
Adapter for the cheat sheets directories.
Provides pages named according to subdirectories:
_dir => dir/
(currently only _get_list() is used; _get_page is shadowed
by the CheatSheets adapter)
"""
_adapter_name = "cheat.sheets dir"
_output_format = "text"
def _get_list(self, prefix=None):
template = os.path.join(
self.local_repository_location(), self._cheatsheet_files_prefix, "*"
)
answer = sorted(
[
_remove_initial_underscore(os.path.basename(f_name)) + "/"
for f_name in glob.glob(template)
if os.path.isdir(f_name)
]
)
return answer
def _get_page(self, topic, request_options=None):
"""
Content of the `topic` dir is the list of the pages in the dir
"""
template = os.path.join(
self.local_repository_location(),
self._cheatsheet_files_prefix,
topic.rstrip("/"),
"*",
)
answer = sorted([os.path.basename(f_name) for f_name in glob.glob(template)])
return "\n".join(answer) + "\n"
def is_found(self, topic):
return CheatSheets.is_found(self, topic.rstrip("/"))
================================================
FILE: lib/adapter/cmd.py
================================================
""" """
# pylint: disable=unused-argument,abstract-method
import os.path
import re
from subprocess import Popen, PIPE
from .adapter import Adapter
def _get_abspath(path):
"""Find absolute path of the specified `path`
according to its
"""
if path.startswith("/"):
return path
import __main__
return os.path.join(os.path.dirname(os.path.dirname(__main__.__file__)), path)
class CommandAdapter(Adapter):
""" """
_command = []
def _get_command(self, topic, request_options=None):
return self._command
def _get_page(self, topic, request_options=None):
cmd = self._get_command(topic, request_options=request_options)
if cmd:
try:
proc = Popen(cmd, stdout=PIPE, stderr=PIPE)
answer = proc.communicate()[0].decode("utf-8", "ignore")
except OSError:
return (
'ERROR of the "%s" adapter: please create an issue'
% self._adapter_name
)
return answer
return ""
class Fosdem(CommandAdapter):
"""
Show the output of the `current-fosdem-slide` command,
which shows the current slide open in some terminal.
This was used during the talk at FOSDEM 2019.
https://www.youtube.com/watch?v=PmiK0JCdh5A
`sudo` is used here because the session was running under
a different user; to be able to use the command via sudo,
the following `/etc/suders` entry was added:
srv ALL=(ALL:ALL) NOPASSWD: /usr/local/bin/current-fosdem-slide
Here `srv` is the user under which the cheat.sh server was running
"""
_adapter_name = "fosdem"
_output_format = "ansi"
_pages_list = [":fosdem"]
_command = ["sudo", "/usr/local/bin/current-fosdem-slide"]
class Translation(CommandAdapter):
""" """
_adapter_name = "translation"
_output_format = "text"
_cache_needed = True
def _get_page(self, topic, request_options=None):
from_, topic = topic.split("/", 1)
to_ = request_options.get("lang", "en")
if "-" in from_:
from_, to_ = from_.split("-", 1)
return [
"/home/igor/cheat.sh/bin/get_translation",
from_,
to_,
topic.replace("+", " "),
]
class AdapterRfc(CommandAdapter):
"""
Show RFC by its number.
Exported as: "/rfc/NUMBER"
"""
_adapter_name = "rfc"
_output_format = "text"
_cache_needed = True
_command = ["share/adapters/rfc.sh"]
def _get_command(self, topic, request_options=None):
cmd = self._command[:]
if not cmd[0].startswith("/"):
cmd[0] = _get_abspath(cmd[0])
# cut rfc/ off
if topic.startswith("rfc/"):
topic = topic[4:]
return cmd + [topic]
def _get_list(self, prefix=None):
return list("rfc/%s" % x for x in range(1, 8649))
def is_found(self, topic):
return True
class AdapterOeis(CommandAdapter):
"""
Show OEIS by its number.
Exported as: "/oeis/NUMBER"
"""
_adapter_name = "oeis"
_output_format = "text+code"
_cache_needed = True
_command = ["share/adapters/oeis.sh"]
@staticmethod
def _get_filetype(topic):
if "/" in topic:
language = topic.split("/")[-1].lower()
return language
return "bash"
def _get_command(self, topic, request_options=None):
cmd = self._command[:]
if not cmd[0].startswith("/"):
cmd[0] = _get_abspath(cmd[0])
# cut oeis/ off
# Replace all non (alphanumeric, '-', ':') chars with Spaces to delimit args to oeis.sh
if topic.startswith("oeis/"):
topic = topic[5:]
suffix = ""
if topic.endswith("/:list"):
suffix = " :list"
topic = topic[:-6]
topic = re.sub("[^a-zA-Z0-9-:]+", " ", topic) + suffix
return cmd + [topic]
def is_found(self, topic):
return True
class AdapterChmod(CommandAdapter):
"""
Show chmod numeric values and strings
Exported as: "/chmod/NUMBER"
"""
_adapter_name = "chmod"
_output_format = "text"
_cache_needed = True
_command = ["share/adapters/chmod.sh"]
def _get_command(self, topic, request_options=None):
cmd = self._command[:]
# cut chmod/ off
# remove all non (alphanumeric, '-') chars
if topic.startswith("chmod/"):
topic = topic[6:]
topic = re.sub("[^a-zA-Z0-9-]", "", topic)
return cmd + [topic]
def is_found(self, topic):
return True
================================================
FILE: lib/adapter/common.py
================================================
class Adapter(object):
pass
class cheatAdapter(Adapter):
pass
================================================
FILE: lib/adapter/git_adapter.py
================================================
"""
Implementation of `GitRepositoryAdapter`, adapter that is used to handle git repositories
"""
import glob
import os
from .adapter import Adapter # pylint: disable=relative-import
def _get_filenames(path):
return [os.path.split(topic)[1] for topic in glob.glob(path)]
class RepositoryAdapter(Adapter):
"""
Implements methods needed to handle standard
repository based adapters.
"""
def _get_list(self, prefix=None):
"""
List of files in the cheat sheets directory
with the extension removed
"""
answer = _get_filenames(
os.path.join(
self.local_repository_location(),
self._cheatsheet_files_prefix,
"*" + self._cheatsheet_files_extension,
)
)
ext = self._cheatsheet_files_extension
if ext:
answer = [
filename[: -len(ext)] for filename in answer if filename.endswith(ext)
]
return answer
def _get_page(self, topic, request_options=None):
filename = os.path.join(
self.local_repository_location(), self._cheatsheet_files_prefix, topic
)
if os.path.exists(filename) and not os.path.isdir(filename):
answer = self._format_page(open(filename, "r").read())
else:
# though it should not happen
answer = "%s:%s not found" % (str(self.__class__), topic)
return answer
class GitRepositoryAdapter(RepositoryAdapter): # pylint: disable=abstract-method
"""
Implements all methods needed to handle cache handling
for git-repository-based adapters
"""
@classmethod
def fetch_command(cls):
"""
Initial fetch of the repository.
Return cmdline that has to be executed to fetch the repository.
Skipping if `self._repository_url` is not specified
"""
if not cls._repository_url:
return None
if not cls._repository_url.startswith("https://github.com/"):
# in this case `fetch` has to be implemented
# in the distinct adapter subclass
raise RuntimeError(
"Do not known how to handle this repository: %s" % cls._repository_url
)
local_repository_dir = cls.local_repository_location()
if not local_repository_dir:
return None
return ["git", "clone", "--depth=1", cls._repository_url, local_repository_dir]
@classmethod
def update_command(cls):
"""
Update of the repository.
Return cmdline that has to be executed to update the repository
inside `local_repository_location()`.
"""
if not cls._repository_url:
return None
local_repository_dir = cls.local_repository_location()
if not local_repository_dir:
return None
if not cls._repository_url.startswith("https://github.com/"):
# in this case `update` has to be implemented
# in the distinct adapter subclass
raise RuntimeError(
"Do not known how to handle this repository: %s" % cls._repository_url
)
return ["git", "pull"]
@classmethod
def current_state_command(cls):
"""
Get current state of repository (current revision).
This is used to find what cache entries should be invalidated.
"""
if not cls._repository_url:
return None
local_repository_dir = cls.local_repository_location()
if not local_repository_dir:
return None
if not cls._repository_url.startswith("https://github.com/"):
# in this case `update` has to be implemented
# in the distinct adapter subclass
raise RuntimeError(
"Do not known how to handle this repository: %s" % cls._repository_url
)
return ["git", "rev-parse", "--short", "HEAD", "--"]
@classmethod
def save_state(cls, state):
"""
Save state `state` of the repository.
Must be called after the cache clean up.
"""
local_repository_dir = cls.local_repository_location()
state_filename = os.path.join(local_repository_dir, ".cached_revision")
open(state_filename, "wb").write(state)
@classmethod
def get_state(cls):
"""
Return the saved `state` of the repository.
If state cannot be read, return None
"""
local_repository_dir = cls.local_repository_location()
state_filename = os.path.join(local_repository_dir, ".cached_revision")
state = None
if os.path.exists(state_filename):
state = open(state_filename, "r").read()
return state
@classmethod
def get_updates_list_command(cls):
"""
Return list of updates since the last update whose id is saved as the repository state.
The list is used to invalidate the cache.
"""
current_state = cls.get_state()
if not current_state:
return ["git", "ls-tree", "--full-tree", "-r", "--name-only", "HEAD", "--"]
return ["git", "diff", "--name-only", current_state, "HEAD", "--"]
================================================
FILE: lib/adapter/internal.py
================================================
"""
Configuration parameters:
frontend.styles
path.internal.pages
"""
import sys
import os
import collections
try:
from rapidfuzz import process, fuzz
_USING_FUZZYWUZZY = False
except ImportError:
from fuzzywuzzy import process, fuzz
_USING_FUZZYWUZZY = True
from config import CONFIG
from .adapter import Adapter
from fmt.internal import colorize_internal
_INTERNAL_TOPICS = [
":cht.sh",
":bash_completion",
":emacs",
":emacs-ivy",
":firstpage",
":firstpage-v1",
":firstpage-v2",
":fish",
":help",
":intro",
":list",
":post",
":styles",
":styles-demo",
":vim",
":zsh",
]
_COLORIZED_INTERNAL_TOPICS = [
":intro",
]
class InternalPages(Adapter):
_adapter_name = "internal"
_output_format = "ansi"
def __init__(self, get_topic_type=None, get_topics_list=None):
Adapter.__init__(self)
self.get_topic_type = get_topic_type
self.get_topics_list = get_topics_list
def _get_stat(self):
stat = collections.Counter(
[self.get_topic_type(topic) for topic in self.get_topics_list()]
)
answer = ""
for key, val in stat.items():
answer += "%s %s\n" % (key, val)
return answer
@staticmethod
def get_list(prefix=None):
return _INTERNAL_TOPICS
def _get_list_answer(self, topic, request_options=None):
if "/" in topic:
topic_type, topic_name = topic.split("/", 1)
if topic_name == ":list":
topic_list = [
x[len(topic_type) + 1 :]
for x in self.get_topics_list()
if x.startswith(topic_type + "/")
]
return "\n".join(topic_list) + "\n"
answer = ""
if topic == ":list":
answer = "\n".join(x for x in self.get_topics_list()) + "\n"
return answer
def _get_page(self, topic, request_options=None):
if topic.endswith("/:list") or topic.lstrip("/") == ":list":
return self._get_list_answer(topic)
answer = ""
if topic == ":styles":
answer = "\n".join(CONFIG["frontend.styles"]) + "\n"
elif topic == ":stat":
answer = self._get_stat() + "\n"
elif topic in _INTERNAL_TOPICS:
answer = open(
os.path.join(CONFIG["path.internal.pages"], topic[1:] + ".txt"), "r"
).read()
if topic in _COLORIZED_INTERNAL_TOPICS:
answer = colorize_internal(answer)
return answer
def is_found(self, topic):
return topic in self.get_list() or topic.endswith("/:list")
class UnknownPages(InternalPages):
_adapter_name = "unknown"
_output_format = "text"
@staticmethod
def get_list(prefix=None):
return []
@staticmethod
def is_found(topic):
return True
def _get_page(self, topic, request_options=None):
topics_list = self.get_topics_list()
if topic.startswith(":"):
topics_list = [x for x in topics_list if x.startswith(":")]
else:
topics_list = [x for x in topics_list if not x.startswith(":")]
if _USING_FUZZYWUZZY:
possible_topics = process.extract(topic, topics_list, scorer=fuzz.ratio)[:3]
else:
possible_topics = process.extract(
topic, topics_list, limit=3, scorer=fuzz.ratio
)
possible_topics_text = "\n".join(
[(" * %s %s" % (x[0], int(x[1]))) for x in possible_topics]
)
return (
"""
Unknown topic.
Do you mean one of these topics maybe?
%s
"""
% possible_topics_text
)
class Search(Adapter):
_adapter_name = "search"
_output_format = "text"
_cache_needed = False
@staticmethod
def get_list(prefix=None):
return []
def is_found(self, topic):
return False
================================================
FILE: lib/adapter/latenz.py
================================================
"""
Adapter for the curlable latencies numbers (chubin/late.nz)
This module can be an example of a adapter for a python project.
The adapter exposes one page ("latencies") and several its aliases
("latencies", "late.nz", "latency")
"""
# pylint: disable=relative-import
import sys
import os
from .git_adapter import GitRepositoryAdapter
class Latenz(GitRepositoryAdapter):
"""
chubin/late.nz Adapter
"""
_adapter_name = "late.nz"
_output_format = "ansi"
_repository_url = "https://github.com/chubin/late.nz"
def _get_page(self, topic, request_options=None):
sys.path.append(os.path.join(self.local_repository_location(), "bin"))
import latencies
return latencies.render()
def _get_list(self, prefix=None):
return ["latencies"]
def is_found(self, topic):
return topic.lower() in ["latencies", "late.nz", "latency"]
================================================
FILE: lib/adapter/learnxiny.py
================================================
"""
Adapters for the cheat sheets from the Learn X in Y project
Configuration parameters:
log.level
"""
# pylint: disable=relative-import
from __future__ import print_function
import os
import re
from config import CONFIG
from .git_adapter import GitRepositoryAdapter
class LearnXinY(GitRepositoryAdapter):
"""
Adapter for the LearnXinY project
"""
_adapter_name = "learnxiny"
_output_format = "code"
_cache_needed = True
_repository_url = "https://github.com/adambard/learnxinyminutes-docs"
def __init__(self):
self.adapters = _ADAPTERS
GitRepositoryAdapter.__init__(self)
def _get_page(self, topic, request_options=None):
"""
Return cheat sheet for `topic`
or empty string if nothing found
"""
lang, topic = topic.split("/", 1)
if lang not in self.adapters:
return ""
return self.adapters[lang].get_page(topic)
def _get_list(self, prefix=None):
"""
Return list of all learnxiny topics
"""
answer = []
for language_adapter in self.adapters.values():
answer += language_adapter.get_list(prefix=True)
return answer
def is_found(self, topic):
"""
Return whether `topic` is a valid learnxiny topic
"""
if "/" not in topic:
return False
lang, topic = topic.split("/", 1)
if lang not in self.adapters:
return False
return self.adapters[lang].is_valid(topic)
class LearnXYAdapter(object):
"""
Parent class of all languages adapters
"""
_learn_xy_path = LearnXinY.local_repository_location()
_replace_with = {}
_filename = ""
prefix = ""
_replace_with = {}
_splitted = True
_block_cut_start = 2
_block_cut_end = 0
def __init__(self):
self._whole_cheatsheet = self._read_cheatsheet()
self._blocks = self._extract_blocks()
self._topics_list = [x for x, _ in self._blocks]
if "Comments" in self._topics_list:
self._topics_list = [x for x in self._topics_list if x != "Comments"] + [
"Comments"
]
self._topics_list += [":learn", ":list"]
if self._whole_cheatsheet and CONFIG.get("log.level") >= 5:
print(self.prefix, self._topics_list)
def _is_block_separator(self, before, now, after):
if (
re.match(r"////////*", before)
and re.match(r"// ", now)
and re.match(r"////////*", after)
):
block_name = re.sub(r"//\s*", "", now).replace("(", "").replace(")", "")
block_name = "_".join(block_name.strip(", ").split())
for character in "/,":
block_name = block_name.replace(character, "")
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
def _cut_block(self, block, start_block=False):
if not start_block:
answer = block[self._block_cut_start : -self._block_cut_end]
if answer == []:
return answer
if answer[0].strip() == "":
answer = answer[1:]
if answer[-1].strip() == "":
answer = answer[:1]
return answer
def _read_cheatsheet(self):
filename = os.path.join(self._learn_xy_path, self._filename)
# if cheat sheets are not there (e.g. were not yet fetched),
# just skip it
if not os.path.exists(filename):
return None
with open(filename) as f_cheat_sheet:
code_mode = False
answer = []
for line in f_cheat_sheet.readlines():
if line.startswith("```"):
if not code_mode:
code_mode = True
continue
else:
code_mode = False
if code_mode:
answer.append(line.rstrip("\n"))
return answer
def _extract_blocks(self):
if not self._splitted:
return []
lines = self._whole_cheatsheet
if lines is None:
return []
answer = []
block = []
block_name = "Comments"
for before, now, after in zip([""] + lines, lines, lines[1:]):
new_block_name = self._is_block_separator(before, now, after)
if new_block_name:
if block_name:
block_text = self._cut_block(block)
if block_text != []:
answer.append((block_name, block_text))
block_name = new_block_name
block = []
continue
else:
block.append(before)
answer.append((block_name, self._cut_block(block)))
return answer
def is_valid(self, name):
"""
Check whether topic `name` is valid.
"""
for topic_list in self._topics_list:
if topic_list == name:
return True
return False
def get_list(self, prefix=None):
"""
Get list of topics for `prefix`
"""
if prefix:
return ["%s/%s" % (self.prefix, x) for x in self._topics_list]
return self._topics_list
def get_page(self, name, partial=False):
"""
Return specified cheat sheet `name` for the language.
If `partial`, cheat sheet name may be shortened
"""
if name == ":list":
return "\n".join(self.get_list()) + "\n"
if name == ":learn":
if self._whole_cheatsheet:
return "\n".join(self._whole_cheatsheet) + "\n"
else:
return ""
if partial:
possible_names = []
for block_name, _ in self._blocks:
if block_name.startswith(name):
possible_names.append(block_name)
if possible_names == [] or len(possible_names) > 1:
return None
name = possible_names[0]
for block_name, block_contents in self._blocks:
if block_name == name:
return "\n".join(block_contents)
return None
#
# Specific programming languages LearnXY cheat sheets configurations
# Contains much code for the moment; should contain data only
# ideally should be replaced with YAML
#
class LearnAwkAdapter(LearnXYAdapter):
"Learn AWK in Y Minutes"
prefix = "awk"
_filename = "awk.html.markdown"
_splitted = False
class LearnBashAdapter(LearnXYAdapter):
"Learn Bash in Y Minutes"
prefix = "bash"
_filename = "bash.html.markdown"
_splitted = False
class LearnBfAdapter(LearnXYAdapter):
"Learn Brainfuck in Y Minutes"
prefix = "bf"
_filename = "bf.html.markdown"
_splitted = False
class LearnCAdapter(LearnXYAdapter):
"Learn C in Y Minutes"
prefix = "c"
_filename = "c.html.markdown"
_splitted = False
class LearnChapelAdapter(LearnXYAdapter):
"Learn Chapel in Y Minutes"
prefix = "chapel"
_filename = "chapel.html.markdown"
_splitted = False
class LearnClojureAdapter(LearnXYAdapter):
"""
Learn Clojure in Y Minutes
"""
prefix = "clojure"
_filename = "clojure.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match(r"\s*$", before)
and re.match(r";\s*", now)
and re.match(r";;;;;;+", after)
):
block_name = re.sub(r";\s*", "", now)
block_name = "_".join(
[x.strip(",&:") for x in block_name.strip(", ").split()]
)
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
if not start_block:
answer = block[2:]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnCoffeeScriptAdapter(LearnXYAdapter):
"Learn coffeescript in Y Minutes"
prefix = "coffee"
_filename = "coffeescript.html.markdown"
_splitted = False
class LearnCppAdapter(LearnXYAdapter):
"""
Learn C++ in Y Minutes
"""
prefix = "cpp"
_filename = "c++.html.markdown"
_replace_with = {
"More_about_Objects": "Prototypes",
}
def _is_block_separator(self, before, now, after):
if (
re.match(r"////////*", before)
and re.match(r"// ", now)
and re.match(r"////////*", after)
):
block_name = re.sub(r"//\s*", "", now).replace("(", "").replace(")", "")
block_name = "_".join(block_name.strip(", ").split())
for character in "/,":
block_name = block_name.replace(character, "")
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer == []:
return answer
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnCsharpAdapter(LearnXYAdapter):
"Learn C# in Y Minutes"
prefix = "csharp"
_filename = "csharp.html.markdown"
_splitted = False
class LearnDAdapter(LearnXYAdapter):
"Learn D in Y Minutes"
prefix = "d"
_filename = "d.html.markdown"
_splitted = False
class LearnDartAdapter(LearnXYAdapter):
"Learn Dart in Y Minutes"
prefix = "dart"
_filename = "dart.html.markdown"
_splitted = False
class LearnFactorAdapter(LearnXYAdapter):
"Learn Factor in Y Minutes"
prefix = "factor"
_filename = "factor.html.markdown"
_splitted = False
class LearnForthAdapter(LearnXYAdapter):
"Learn Forth in Y Minutes"
prefix = "forth"
_filename = "forth.html.markdown"
_splitted = False
class LearnFsharpAdapter(LearnXYAdapter):
"Learn F# in Y Minutes"
prefix = "fsharp"
_filename = "fsharp.html.markdown"
_splitted = False
class LearnElispAdapter(LearnXYAdapter):
"Learn Elisp in Y Minutes"
prefix = "elisp"
_filename = "elisp.html.markdown"
_splitted = False
class LearnElixirAdapter(LearnXYAdapter):
"""
Learn Elixir in Y Minutes
"""
prefix = "elixir"
_filename = "elixir.html.markdown"
_replace_with = {
"More_about_Objects": "Prototypes",
}
def _is_block_separator(self, before, now, after):
if (
re.match(r"## ---*", before)
and re.match(r"## --", now)
and re.match(r"## ---*", after)
):
block_name = re.sub(r"## --\s*", "", now)
block_name = "_".join(block_name.strip(", ").split())
for character in "/,":
block_name = block_name.replace(character, "")
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnElmAdapter(LearnXYAdapter):
"""
Learn Elm in Y Minutes
"""
prefix = "elm"
_filename = "elm.html.markdown"
_replace_with = {
"More_about_Objects": "Prototypes",
}
def _is_block_separator(self, before, now, after):
if (
re.match(r"\s*", before)
and re.match(r"\{--.*--\}", now)
and re.match(r"\s*", after)
):
block_name = re.sub(r"\{--+\s*", "", now)
block_name = re.sub(r"--\}", "", block_name)
block_name = "_".join(block_name.strip(", ").split())
for character in "/,":
block_name = block_name.replace(character, "")
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnErlangAdapter(LearnXYAdapter):
"""
Learn Erlang in Y Minutes
"""
prefix = "erlang"
_filename = "erlang.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match("%%%%%%+", before)
and re.match(r"%%\s+[0-9]+\.", now)
and re.match("%%%%%%+", after)
):
block_name = re.sub(r"%%+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip(".").strip().split())
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnFortranAdapter(LearnXYAdapter):
"Learn Fortran in Y Minutes"
prefix = "fortran"
_filename = "fortran95.html.markdown"
_splitted = False
class LearnGoAdapter(LearnXYAdapter):
"Learn Go in Y Minutes"
prefix = "go"
_filename = "go.html.markdown"
_splitted = False
class LearnGroovyAdapter(LearnXYAdapter):
"Learn Groovy in Y Minutes"
prefix = "groovy"
_filename = "groovy.html.markdown"
_splitted = False
class LearnJavaAdapter(LearnXYAdapter):
"Learn Java in Y Minutes"
prefix = "java"
_filename = "java.html.markdown"
_splitted = False
class LearnJavaScriptAdapter(LearnXYAdapter):
"""
Learn JavaScript in Y Minutes
"""
prefix = "js"
_filename = "javascript.html.markdown"
_replace_with = {
"More_about_Objects": "Prototypes",
}
def _is_block_separator(self, before, now, after):
if (
re.match("//////+", before)
and re.match(r"//+\s+[0-9]+\.", now)
and re.match(r"\s*", after)
):
block_name = re.sub(r"//+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip(", ").split())
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnJuliaAdapter(LearnXYAdapter):
"""
Learn Julia in Y Minutes
"""
prefix = "julia"
_filename = "julia.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match("####+", before)
and re.match(r"##\s*", now)
and re.match("####+", after)
):
block_name = re.sub(r"##\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip(", ").split())
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnHaskellAdapter(LearnXYAdapter):
"""
Learn Haskell in Y Minutes
"""
prefix = "haskell"
_filename = "haskell.html.markdown"
_replace_with = {
"More_about_Objects": "Prototypes",
}
def _is_block_separator(self, before, now, after):
if (
re.match("------+", before)
and re.match(r"--+\s+[0-9]+\.", now)
and re.match("------+", after)
):
block_name = re.sub(r"--+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip(", ").split())
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnLispAdapter(LearnXYAdapter):
"Learn Lisp in Y Minutes"
prefix = "lisp"
_filename = "common-lisp.html.markdown"
_splitted = False
class LearnLuaAdapter(LearnXYAdapter):
"""
Learn Lua in Y Minutes
"""
prefix = "lua"
_filename = "lua.html.markdown"
_replace_with = {
"1_Metatables_and_metamethods": "Metatables",
"2_Class-like_tables_and_inheritance": "Class-like_tables",
"Variables_and_flow_control": "Flow_control",
}
def _is_block_separator(self, before, now, after):
if (
re.match("-----+", before)
and re.match("-------+", after)
and re.match(r"--\s+[0-9]+\.", now)
):
block_name = re.sub(r"--+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip(".").strip().split())
if block_name in self._replace_with:
block_name = self._replace_with[block_name]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnMathematicaAdapter(LearnXYAdapter):
"Learn Mathematica in Y Minutes"
prefix = "mathematica"
_filename = "wolfram.html.markdown"
_splitted = False
class LearnMatlabAdapter(LearnXYAdapter):
"Learn Matlab in Y Minutes"
prefix = "matlab"
_filename = "matlab.html.markdown"
_splitted = False
class LearnOctaveAdapter(LearnXYAdapter):
"Learn Octave in Y Minutes"
prefix = "octave"
_filename = "matlab.html.markdown"
_splitted = False
class LearnKotlinAdapter(LearnXYAdapter):
"""
Learn Kotlin in Y Minutes
"""
prefix = "kotlin"
_filename = "kotlin.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match("#######+", before)
and re.match("#######+", after)
and re.match(r"#+\s+[0-9]+\.", now)
):
block_name = re.sub(r"#+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip().split())
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnObjectiveCAdapter(LearnXYAdapter):
"Learn Objective C in Y Minutes"
prefix = "objective-c"
_filename = "objective-c.html.markdown"
_splitted = False
class LearnOCamlAdapter(LearnXYAdapter):
"""
Learn OCaml in Y Minutes
"""
prefix = "ocaml"
_filename = "ocaml.html.markdown"
_replace_with = {
"More_about_Objects": "Prototypes",
}
def _is_block_separator(self, before, now, after):
if (
re.match(r"\s*", before)
and re.match(r"\(\*\*\*+", now)
and re.match(r"\s*", after)
):
block_name = re.sub(r"\(\*\*\*+\s*", "", now)
block_name = re.sub(r"\s*\*\*\*\)", "", block_name)
block_name = "_".join(block_name.strip(", ").split())
for k in self._replace_with:
if k in block_name:
block_name = self._replace_with[k]
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnPerlAdapter(LearnXYAdapter):
"""
Learn Perl in Y Minutes
"""
prefix = "perl"
_filename = "perl.html.markdown"
_replace_with = {
"Conditional_and_looping_constructs": "Control_Flow",
"Perl_variable_types": "Types",
"Files_and_I/O": "Files",
"Writing_subroutines": "Subroutines",
}
def _is_block_separator(self, before, now, after):
if re.match(r"####+\s+", now):
block_name = re.sub(r"#+\s", "", now)
block_name = "_".join(block_name.strip().split())
if block_name in self._replace_with:
block_name = self._replace_with[block_name]
return block_name
else:
return None
@staticmethod
def _cut_block(block, start_block=False):
if not start_block:
answer = block[2:]
if answer == []:
return answer
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnPerl6Adapter(LearnXYAdapter):
"Learn Perl 6 in Y Minutes"
prefix = "perl6"
_filename = "perl6.html.markdown"
_splitted = False
class LearnPHPAdapter(LearnXYAdapter):
"""
Learn PHP in Y Minutes
"""
prefix = "php"
_filename = "php.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match(r"/\*\*\*\*\*+", before)
and re.match(r"\s*\*/", after)
and re.match(r"\s*\*\s*", now)
):
block_name = re.sub(r"\s*\*\s*", "", now)
block_name = re.sub(r"&", "", block_name)
block_name = "_".join(block_name.strip().split())
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
return block[2:]
class LearnPythonAdapter(LearnXYAdapter):
"""
Learn Python in Y Minutes
"""
prefix = "python"
_filename = "python.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match("#######+", before)
and re.match("#######+", after)
and re.match(r"#+\s+[0-9]+\.", now)
):
block_name = re.sub(r"#+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip().split())
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnPython3Adapter(LearnXYAdapter):
"Learn Python 3 in Y Minutes"
prefix = "python3"
_filename = "python3.html.markdown"
_splitted = False
class LearnRAdapter(LearnXYAdapter):
"Learn R in Y Minutes"
prefix = "r"
_filename = "r.html.markdown"
_splitted = False
class LearnRacketAdapter(LearnXYAdapter):
"Learn Racket in Y Minutes"
prefix = "racket"
_filename = "racket.html.markdown"
_splitted = False
class LearnRubyAdapter(LearnXYAdapter):
"""
Learn Ruby in Y Minutes
Format of the file was changed, so we have to fix the function too.
This case is a good case for health check:
if number of extracted cheat sheets is suddenly became 1,
one should check the markup
"""
prefix = "ruby"
_filename = "ruby.html.markdown"
def _is_block_separator(self, before, now, after):
if (
re.match("#######+", before)
and re.match("#######+", after)
and re.match(r"#+\s+[0-9]+\.", now)
):
block_name = re.sub(r"#+\s+[0-9]+\.\s*", "", now)
block_name = "_".join(block_name.strip().split())
return block_name
return None
@staticmethod
def _cut_block(block, start_block=False):
answer = block[2:-1]
if answer[0].split() == "":
answer = answer[1:]
if answer[-1].split() == "":
answer = answer[:1]
return answer
class LearnRustAdapter(LearnXYAdapter):
"Learn Rust in Y Minutes"
prefix = "rust"
_filename = "rust.html.markdown"
_splitted = False
class LearnSolidityAdapter(LearnXYAdapter):
"Learn Solidity in Y Minutes"
prefix = "solidity"
_filename = "solidity.html.markdown"
_splitted = False
class LearnSwiftAdapter(LearnXYAdapter):
"Learn Swift in Y Minutes"
prefix = "swift"
_filename = "swift.html.markdown"
_splitted = False
class LearnTclAdapter(LearnXYAdapter):
"Learn Tcl in Y Minutes"
prefix = "tcl"
_filename = "tcl.html.markdown"
_splitted = False
class LearnTcshAdapter(LearnXYAdapter):
"Learn Tcsh in Y Minutes"
prefix = "tcsh"
_filename = "tcsh.html.markdown"
_splitted = False
class LearnVisualBasicAdapter(LearnXYAdapter):
"Learn Visual Basic in Y Minutes"
prefix = "vb"
_filename = "visualbasic.html.markdown"
_splitted = False
class LearnCMakeAdapter(LearnXYAdapter):
"Learn CMake in Y Minutes"
prefix = "cmake"
_filename = "cmake.html.markdown"
_splitted = False
class LearnNimAdapter(LearnXYAdapter):
"Learn Nim in Y Minutes"
prefix = "nim"
_filename = "nim.html.markdown"
_splitted = False
class LearnGitAdapter(LearnXYAdapter):
"Learn Git in Y Minutes"
prefix = "git"
_filename = "git.html.markdown"
_splitted = False
class LearnLatexAdapter(LearnXYAdapter):
"Learn Nim in Y Minutes"
prefix = "latex"
_filename = "latex.html.markdown"
_splitted = False
_ADAPTERS = {cls.prefix: cls() for cls in vars()["LearnXYAdapter"].__subclasses__()}
================================================
FILE: lib/adapter/question.py
================================================
"""
Configuration parameters:
path.internal.bin.upstream
"""
# pylint: disable=relative-import
from __future__ import print_function
import os
import re
from subprocess import Popen, PIPE
from polyglot.detect import Detector
from polyglot.detect.base import UnknownLanguage
from config import CONFIG
from languages_data import SO_NAME
from .upstream import UpstreamAdapter
NOT_FOUND_MESSAGE = """404 NOT FOUND
Unknown cheat sheet. Please try to reformulate your query.
Query format:
/LANG/QUESTION
Examples:
/python/read+json
/golang/run+external+program
/js/regex+search
See /:help for more info.
If the problem persists, file a GitHub issue at
github.com/chubin/cheat.sh or ping @igor_chubin
"""
class Question(UpstreamAdapter):
"""
Answer to a programming language question, using Stackoverflow
as the main data source. Heavy lifting is done by an external
program `CONFIG["path.internal.bin.upstream"]`.
If the program is not found, fallback to the superclass `UpstreamAdapter`,
which queries the upstream server (by default https://cheat.sh/)
for the answer
"""
_adapter_name = "question"
_output_format = "text+code"
_cache_needed = True
def _get_page(self, topic, request_options=None):
"""
Find answer for the `topic` question.
"""
if not os.path.exists(CONFIG["path.internal.bin.upstream"]):
# if the upstream program is not found, use normal upstream adapter
self._output_format = "ansi"
return UpstreamAdapter._get_page(
self, topic, request_options=request_options
)
topic = topic.replace("+", " ")
# if there is a language name in the section name,
# cut it off (de:python => python)
if "/" in topic:
section_name, topic = topic.split("/", 1)
if ":" in section_name:
_, section_name = section_name.split(":", 1)
section_name = SO_NAME.get(section_name, section_name)
topic = "%s/%s" % (section_name, topic)
# some clients send queries with - instead of + so we have to rewrite them to
topic = re.sub(r"(?<!-)-", " ", topic)
topic_words = topic.split()
topic = " ".join(topic_words)
lang = "en"
try:
query_text = topic # " ".join(topic)
query_text = re.sub("^[^/]*/+", "", query_text.rstrip("/"))
query_text = re.sub("/[0-9]+$", "", query_text)
query_text = re.sub("/[0-9]+$", "", query_text)
detector = Detector(query_text)
supposed_lang = detector.languages[0].code
if len(topic_words) > 2 or supposed_lang in [
"az",
"ru",
"uk",
"de",
"fr",
"es",
"it",
"nl",
]:
lang = supposed_lang
if supposed_lang.startswith("zh_") or supposed_lang == "zh":
lang = "zh"
elif supposed_lang.startswith("pt_"):
lang = "pt"
if supposed_lang in ["ja", "ko"]:
lang = supposed_lang
except UnknownLanguage:
print("Unknown language (%s)" % query_text)
if lang != "en":
topic = ["--human-language", lang, topic]
else:
topic = [topic]
cmd = [CONFIG["path.internal.bin.upstream"]] + topic
proc = Popen(cmd, stdin=open(os.devnull, "r"), stdout=PIPE, stderr=PIPE)
answer = proc.communicate()[0].decode("utf-8")
if not answer:
return NOT_FOUND_MESSAGE
return answer
def get_list(self, prefix=None):
return []
def is_found(self, topic):
return True
================================================
FILE: lib/adapter/rosetta.py
================================================
"""
Implementation of RosettaCode Adapter.
Exports:
Rosetta(GitRepositoryAdapter)
"""
# pylint: disable=relative-import
import os
import glob
import yaml
from .git_adapter import GitRepositoryAdapter
from .cheat_sheets import CheatSheets
class Rosetta(GitRepositoryAdapter):
"""
Adapter for RosettaCode
"""
_adapter_name = "rosetta"
_output_format = "code"
_local_repository_location = "RosettaCodeData"
_repository_url = "https://github.com/acmeism/RosettaCodeData"
__section_name = "rosetta"
def __init__(self):
GitRepositoryAdapter.__init__(self)
self._rosetta_code_name = self._load_rosetta_code_names()
@staticmethod
def _load_rosetta_code_names():
answer = {}
lang_files_location = CheatSheets.local_repository_location(
cheat_sheets_location=True
)
for filename in glob.glob(os.path.join(lang_files_location, "*/_info.yaml")):
text = open(filename, "r").read()
data = yaml.load(text, Loader=yaml.SafeLoader)
if data is None:
continue
lang = os.path.basename(os.path.dirname(filename))
if lang.startswith("_"):
lang = lang[1:]
if "rosetta" in data:
answer[lang] = data["rosetta"]
return answer
def _rosetta_get_list(self, query, task=None):
if query not in self._rosetta_code_name:
return []
lang = self._rosetta_code_name[query]
answer = []
if task:
glob_path = os.path.join(
self.local_repository_location(), "Lang", lang, task, "*"
)
else:
glob_path = os.path.join(
self.local_repository_location(), "Lang", lang, "*"
)
for filename in glob.glob(glob_path):
taskname = os.path.basename(filename)
answer.append(taskname)
answer = "".join("%s\n" % x for x in sorted(answer))
return answer
@staticmethod
def _parse_query(query):
if "/" in query:
task, subquery = query.split("/", 1)
else:
task, subquery = query, None
return task, subquery
def _get_task(self, lang, query):
if lang not in self._rosetta_code_name:
return ""
task, subquery = self._parse_query(query)
if task == ":list":
return self._rosetta_get_list(lang)
if subquery == ":list":
return self._rosetta_get_list(lang, task=task)
# if it is not a number or the number is too big, just ignore it
index = 1
if subquery:
try:
index = int(subquery)
except ValueError:
pass
lang_name = self._rosetta_code_name[lang]
tasks = sorted(
glob.glob(
os.path.join(
self.local_repository_location(), "Lang", lang_name, task, "*"
)
)
)
if not tasks:
return ""
if len(tasks) < index or index < 1:
index = 1
answer_filename = tasks[index - 1]
answer = open(answer_filename, "r").read()
return answer
def _starting_page(self, query):
number_of_pages = self._rosetta_get_list(query)
answer = ("# %s pages available\n" "# use /:list to list") % number_of_pages
return answer
def _get_page(self, topic, request_options=None):
if "/" not in topic:
return self._rosetta_get_list(topic)
lang, topic = topic.split("/", 1)
# this part should be generalized
# currently we just remove the name of the adapter from the path
if topic == self.__section_name:
return self._starting_page(topic)
if topic.startswith(self.__section_name + "/"):
topic = topic[len(self.__section_name + "/") :]
return self._get_task(lang, topic)
def _get_list(self, prefix=None):
return []
def get_list(self, prefix=None):
answer = [self.__section_name]
for i in self._rosetta_code_name:
answer.append("%s/%s/" % (i, self.__section_name))
return answer
def is_found(self, _):
return True
================================================
FILE: lib/adapter/tldr.py
================================================
"""
Adapter for https://github.com/cheat/cheat
Cheatsheets are located in `pages/*/`
Each cheat sheet is a separate file with extension .md
The pages are formatted with a markdown dialect
"""
# pylint: disable=relative-import,abstract-method
import re
import os
from .git_adapter import GitRepositoryAdapter
class Tldr(GitRepositoryAdapter):
"""
tldr-pages/tldr adapter
"""
_adapter_name = "tldr"
_output_format = "code"
_cache_needed = True
_repository_url = "https://github.com/tldr-pages/tldr"
_cheatsheet_files_prefix = "pages/*/"
_cheatsheet_files_extension = ".md"
@staticmethod
def _format_page(text):
"""
Trivial tldr Markdown implementation.
* Header goes until the first empty line after > prefixed lines.
* code surrounded with `` => code
* {{var}} => var
"""
answer = []
skip_empty = False
header = 2
for line in text.splitlines():
if line.strip() == "":
if skip_empty and not header:
continue
if header == 1:
header = 0
if header:
continue
else:
skip_empty = False
if line.startswith("-"):
line = "# " + line[2:]
skip_empty = True
elif line.startswith("> "):
if header == 2:
header = 1
line = "# " + line[2:]
skip_empty = True
elif line.startswith("`") and line.endswith("`"):
line = line[1:-1]
line = re.sub(r"{{(.*?)}}", r"\1", line)
answer.append(line)
return "\n".join(answer)
def _get_page(self, topic, request_options=None):
"""
Go through pages/{common,linux,osx,sunos,windows}/
and as soon as anything is found, format and return it.
"""
search_order = ["common", "linux", "osx", "sunos", "windows", "android"]
local_rep = self.local_repository_location()
ext = self._cheatsheet_files_extension
filename = None
for subdir in search_order:
_filename = os.path.join(local_rep, "pages", subdir, "%s%s" % (topic, ext))
if os.path.exists(_filename):
filename = _filename
break
if filename:
answer = self._format_page(open(filename, "r").read())
else:
# though it should not happen
answer = ""
return answer
@classmethod
def get_updates_list(cls, updated_files_list):
"""
If a .md file was updated, invalidate cache
entry with the name of this file
"""
answer = []
ext = cls._cheatsheet_files_extension
for entry in updated_files_list:
if entry.endswith(ext):
answer.append(entry.split("/")[-1][: -len(ext)])
return answer
================================================
FILE: lib/adapter/upstream.py
================================================
"""
Adapter for an external cheat sheets service (i.e. for cheat.sh)
Configuration parameters:
upstream.url
upstream.timeout
"""
# pylint: disable=relative-import
import textwrap
import requests
from config import CONFIG
from .adapter import Adapter
def _are_you_offline():
return textwrap.dedent(
"""
.
Are you offline?
_________________
| | ___________ |o| Though it could be theoretically possible
| | ___________ | | to use cheat.sh fully offline,
| | ___________ | | and for *the programming languages questions* too,
| | ___________ | | this very feature is not yet implemented.
| |_____________| |
| _______ | If you find it useful, please visit
| | | || https://github.com/chubin/issues/140
| DD | | V| and drop a couple of lines to encourage
|____|_______|____| the authors to develop it as soon as possible
.
"""
)
class UpstreamAdapter(Adapter):
"""
Connect to the upstream server `CONFIG["upstream.url"]` and fetch
response from it. The response is supposed to have the "ansi" format.
If the server does not respond within `CONFIG["upstream.timeout"]` seconds,
or if a connection error occurs, the "are you offline" banner is displayed.
Answers are by default cached; the failure answer is marked with the no-cache
property ("cache": False).
"""
_adapter_name = "upstream"
_output_format = "ansi"
_cache_needed = False
def _get_page(self, topic, request_options=None):
options_string = "&".join(
["%s=%s" % (x, y) for (x, y) in request_options.items()]
)
url = (
CONFIG["upstream.url"].rstrip("/")
+ "/"
+ topic.lstrip("/")
+ "?"
+ options_string
)
try:
response = requests.get(url, timeout=CONFIG["upstream.timeout"])
answer = {"cache": False, "answer": response.text}
except requests.exceptions.ConnectionError:
answer = {"cache": False, "answer": _are_you_offline()}
return answer
def _get_list(self, prefix=None):
return []
================================================
FILE: lib/buttons.py
================================================
TWITTER_BUTTON = """
<a href="https://twitter.com/igor_chubin" class="twitter-follow-button" data-show-count="false" data-button="grey">Follow @igor_chubin</a>
<script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs');</script>
"""
GITHUB_BUTTON = """
<!-- Place this tag where you want the button to render. -->
<a aria-label="Star chubin/wttr.in on GitHub" data-count-aria-label="# stargazers on GitHub" data-count-api="/repos/chubin/cheat.sh#stargazers_count" data-count-href="/chubin/cheat.sh/stargazers" data-icon="octicon-star" href="https://github.com/chubin/cheat.sh" class="github-button">cheat.sh</a>
"""
GITHUB_BUTTON_2 = """
<!-- Place this tag where you want the button to render. -->
<a aria-label="Star chubin/cheat.sheets on GitHub" data-count-aria-label="# stargazers on GitHub" data-count-api="/repos/chubin/cheat.sheets#stargazers_count" data-count-href="/chubin/cheat.sheets/stargazers" data-icon="octicon-star" href="https://github.com/chubin/cheat.sheets" class="github-button">cheat.sheets</a>
"""
GITHUB_BUTTON_FOOTER = """
<!-- Place this tag right after the last button or just before your close body tag. -->
<script async defer id="github-bjs" src="https://buttons.github.io/buttons.js"></script>
"""
================================================
FILE: lib/cache.py
================================================
"""
Cache implementation.
Currently only two types of cache are allowed:
* "none" cache switched off
* "redis" use redis for cache
Configuration parameters:
cache.type = redis | none
cache.redis.db
cache.redis.host
cache.redis.port
"""
import os
import json
from config import CONFIG
_REDIS = None
if CONFIG["cache.type"] == "redis":
import redis
_REDIS = redis.Redis(
host=CONFIG["cache.redis.host"],
port=CONFIG["cache.redis.port"],
db=CONFIG["cache.redis.db"],
)
_REDIS_PREFIX = ""
if CONFIG.get("cache.redis.prefix", ""):
_REDIS_PREFIX = CONFIG["cache.redis.prefix"] + ":"
def put(key, value):
"""
Save `value` with `key`, and serialize it if needed
"""
if _REDIS_PREFIX:
key = _REDIS_PREFIX + key
if CONFIG["cache.type"] == "redis" and _REDIS:
if isinstance(value, (dict, list)):
value = json.dumps(value)
_REDIS.set(key, value)
def get(key):
"""
Read `value` by `key`, and deserialize it if needed
"""
if _REDIS_PREFIX:
key = _REDIS_PREFIX + key
if CONFIG["cache.type"] == "redis" and _REDIS:
value = _REDIS.get(key)
try:
value = json.loads(value)
except (ValueError, TypeError):
pass
return value
return None
def delete(key):
"""
Remove `key` from the database
"""
if _REDIS:
if _REDIS_PREFIX:
key = _REDIS_PREFIX + key
_REDIS.delete(key)
return None
================================================
FILE: lib/cheat_wrapper.py
================================================
"""
Main cheat.sh wrapper.
Parse the query, get answers from getters (using get_answer),
visualize it using frontends and return the result.
Exports:
cheat_wrapper()
"""
import re
import json
from routing import get_answers, get_topics_list
from search import find_answers_by_keyword
from languages_data import LANGUAGE_ALIAS, rewrite_editor_section_name
import postprocessing
import frontend.html
import frontend.ansi
def _add_section_name(query):
# temporary solution before we don't find a fixed one
if " " not in query and "+" not in query:
return query
if "/" in query:
return query
if " " in query:
return re.sub(r" +", "/", query, count=1)
if "+" in query:
# replace only single + to avoid catching g++ and friends
return re.sub(r"([^\+])\+([^\+])", r"\1/\2", query, count=1)
def cheat_wrapper(query, request_options=None, output_format="ansi"):
"""
Function that delivers cheat sheet for `query`.
If `html` is True, the answer is formatted as HTML.
Additional request options specified in `request_options`.
"""
def _rewrite_aliases(word):
if word == ":bash.completion":
return ":bash_completion"
return word
def _rewrite_section_name(query):
"""
Rewriting special section names:
* EDITOR:NAME => emacs:go-mode
"""
if "/" not in query:
return query
section_name, rest = query.split("/", 1)
if ":" in section_name:
section_name = rewrite_editor_section_name(section_name)
section_name = LANGUAGE_ALIAS.get(section_name, section_name)
return "%s/%s" % (section_name, rest)
def _sanitize_query(query):
return re.sub('[<>"]', "", query)
def _strip_hyperlink(query):
return re.sub("(,[0-9]+)+$", "", query)
def _parse_query(query):
topic = query
keyword = None
search_options = ""
keyword = None
if "~" in query:
topic = query
pos = topic.index("~")
keyword = topic[pos + 1 :]
topic = topic[:pos]
if "/" in keyword:
search_options = keyword[::-1]
search_options = search_options[: search_options.index("/")]
keyword = keyword[: -len(search_options) - 1]
return topic, keyword, search_options
query = _sanitize_query(query)
query = _add_section_name(query)
query = _rewrite_aliases(query)
query = _rewrite_section_name(query)
# at the moment, we just remove trailing slashes
# so queries python/ and python are equal
# query = _strip_hyperlink(query.rstrip('/'))
topic, keyword, search_options = _parse_query(query)
if keyword:
answers = find_answers_by_keyword(
topic, keyword, options=search_options, request_options=request_options
)
else:
answers = get_answers(topic, request_options=request_options)
answers = [
postprocessing.postprocess(
answer, keyword, search_options, request_options=request_options
)
for answer in answers
]
answer_data = {
"query": query,
"keyword": keyword,
"answers": answers,
}
if output_format == "html":
answer_data["topics_list"] = get_topics_list()
return frontend.html.visualize(answer_data, request_options)
elif output_format == "json":
return json.dumps(answer_data, indent=4)
return frontend.ansi.visualize(answer_data, request_options)
================================================
FILE: lib/cheat_wrapper_test.py
================================================
from cheat_wrapper import _add_section_name
unchanged = """
python/:list
ls
+
g++
g/+
clang++
btrfs~volume
:intro
:cht.sh
python/copy+file
python/rosetta/:list
emacs:go-mode/:list
g++g++
"""
split = """
python copy file
python/copy file
python file
python/file
python+file
python/file
g++ -O1
g++/-O1
"""
def test_header_split():
for inp in unchanged.strip().splitlines():
assert inp == _add_section_name(inp)
for test in split.strip().split("\n\n"):
inp, outp = test.split("\n")
assert outp == _add_section_name(inp)
================================================
FILE: lib/config.py
================================================
"""
Global configuration of the project.
All configurable parameters are stored in the global variable CONFIG,
the only variable which is exported from the module.
Default values of all configuration parameters are specified
in the `_CONFIG` dictionary. Those parameters can be overridden
by three means:
* config file `etc/config.yaml` located in the work dir
* config file `etc/config.yaml` located in the project dir
(if the work dir and the project dir are not the same)
* environment variables prefixed with `CHEATSH_`
Configuration placement priorities, from high to low:
* environment variables;
* configuration file in the workdir
* configuration file in the project dir
* default values specified in the `_CONFIG` dictionary
If the work dir and the project dir are not the same, we do not
recommend that you use the config file located in the project dir,
except the cases when you use your own cheat.sh fork, and thus
configuration is a part of the project repository.
In all other cases `WORKDIR/etc/config.yaml` should be preferred.
Location of this config file can be overridden by the `CHEATSH_PATH_CONFIG`
environment variable.
Configuration parameters set by environment variables are mapped
in this way:
* CHEATSH_ prefix is trimmed
* _ replaced with .
* the string is lowercased
For instance, an environment variable named `CHEATSH_SERVER_PORT`
specifies the value for the `server.port` configuration parameter.
Only parameters that imply scalar values (integer or string)
can be set using environment variables, for the rest config files
should be used. If a parameter implies an integer, and the value
specified by an environment variable is not an integer, it is ignored.
"""
from __future__ import print_function
import os
from pygments.styles import get_all_styles
# def get_all_styles():
# return []
_ENV_VAR_PREFIX = "CHEATSH"
_MYDIR = os.path.abspath(os.path.join(__file__, "..", ".."))
def _config_locations():
"""
Return three possible config locations
where configuration can be found:
* `_WORKDIR`, `_CONF_FILE_WORKDIR`, `_CONF_FILE_MYDIR`
"""
var = _ENV_VAR_PREFIX + "_PATH_WORKDIR"
workdir = (
os.environ[var]
if var in os.environ
else os.path.join(os.environ["HOME"], ".cheat.sh")
)
var = _ENV_VAR_PREFIX + "_CONFIG"
conf_file_workdir = (
os.environ[var]
if var in os.environ
else os.path.join(workdir, "etc/config.yaml")
)
conf_file_mydir = os.path.join(_MYDIR, "etc/config.yaml")
return workdir, conf_file_workdir, conf_file_mydir
_WORKDIR, _CONF_FILE_WORKDIR, _CONF_FILE_MYDIR = _config_locations()
_CONFIG = {
"adapters.active": [
"tldr",
"cheat",
"fosdem",
"translation",
"rosetta",
"late.nz",
"question",
"cheat.sheets",
"cheat.sheets dir",
"learnxiny",
"rfc",
"oeis",
"chmod",
],
"adapters.mandatory": [
"search",
],
"cache.redis.db": 0,
"cache.redis.host": "localhost",
"cache.redis.port": 6379,
"cache.redis.prefix": "",
"cache.type": "redis",
"frontend.styles": sorted(list(get_all_styles())),
"log.level": 4,
"path.internal.ansi2html": os.path.join(_MYDIR, "share/ansi2html.sh"),
"path.internal.bin": os.path.join(_MYDIR, "bin"),
"path.internal.bin.upstream": os.path.join(_MYDIR, "bin", "upstream"),
"path.internal.malformed": os.path.join(
_MYDIR, "share/static/malformed-response.html"
),
"path.internal.pages": os.path.join(_MYDIR, "share"),
"path.internal.static": os.path.join(_MYDIR, "share/static"),
"path.internal.templates": os.path.join(_MYDIR, "share/templates"),
"path.internal.vim": os.path.join(_MYDIR, "share/vim"),
"path.log.main": "log/main.log",
"path.log.queries": "log/queries.log",
"path.log.fetch": "log/fetch.log",
"path.repositories": "upstream",
"path.spool": "spool",
"path.workdir": _WORKDIR,
"routing.pre": [
("^$", "search"),
("^[^/]*/rosetta(/|$)", "rosetta"),
("^rfc/", "rfc"),
("^oeis/", "oeis"),
("^chmod/", "chmod"),
("^:", "internal"),
("/:list$", "internal"),
("/$", "cheat.sheets dir"),
],
"routing.main": [
("", "cheat.sheets"),
("", "cheat"),
("", "tldr"),
("", "late.nz"),
("", "fosdem"),
("", "learnxiny"),
],
"routing.post": [
("^[^/ +]*$", "unknown"),
("^[a-z][a-z]-[a-z][a-z]$", "translation"),
],
"routing.default": "question",
"upstream.url": "https://cheat.sh",
"upstream.timeout": 5,
"search.limit": 20,
"server.bind": "0.0.0.0",
"server.port": 8002,
}
class Config(dict):
"""
configuration dictionary that handles relative
paths properly (making them relative to path.workdir)
"""
def _absolute_path(self, val):
if val.startswith("/"):
return val
return os.path.join(self["path.workdir"], val)
def __init__(self, *args, **kwargs):
dict.__init__(self)
self.update(*args, **kwargs)
def __setitem__(self, key, val):
if key.startswith("path.") and not val.startswith("/"):
val = self._absolute_path(val)
dict.__setitem__(self, key, val)
def update(self, *args, **kwargs):
"""
the built-in __init__ doesn't call update,
and the built-in update doesn't call __setitem__,
so `update` should be overridden
"""
newdict = dict(*args, **kwargs)
if "path.workdir" in newdict:
self["path.workdir"] = newdict["path.workdir"]
for key, val in newdict.items():
self[key] = val
def _load_config_from_environ(config):
update = {}
for key, val in config.items():
if not isinstance(val, str) or isinstance(val, int):
continue
env_var = _ENV_VAR_PREFIX + "_" + key.replace(".", "_").upper()
if not env_var in os.environ:
continue
env_val = os.environ[env_var]
if isinstance(val, int):
try:
env_val = int(env_val)
except (ValueError, TypeError):
continue
update[key] = env_val
return update
def _get_nested(data, key):
"""
Return value for a hierrachical key (like a.b.c).
Return None if nothing found.
If there is a key with . in the name, and a subdictionary,
the former is preferred:
>>> print(_get_nested({'a.b': 10, 'a':{'b': 20}}, 'a.b'))
10
>>> print(_get_nested({'a': {'b': 20}}, 'a.b'))
20
>>> print(_get_nested({'a': {'b': {'c': 30}}}, 'a.b.c'))
30
"""
if not data or not isinstance(data, dict):
return None
if "." not in key:
return data.get(key)
if key in data:
return data[key]
parts = key.split(".")
for i in range(len(parts))[::-1]:
prefix = ".".join(parts[:i])
if prefix in data:
return _get_nested(data[prefix], ".".join(parts[i:]))
return None
def _load_config_from_file(default_config, filename):
import yaml
update = {}
if not os.path.exists(filename):
return update
with open(filename) as f:
newconfig = yaml.load(f.read(), Loader=yaml.SafeLoader)
for key, val in default_config.items():
newval = _get_nested(newconfig, key)
if newval is None:
continue
if isinstance(val, int):
try:
newval = int(newval)
except (ValueError, TypeError):
continue
update[key] = newval
return update
CONFIG = Config()
CONFIG.update(_CONFIG)
CONFIG.update(_load_config_from_file(_CONFIG, _CONF_FILE_MYDIR))
if _CONF_FILE_WORKDIR != _CONF_FILE_MYDIR:
CONFIG.update(_load_config_from_file(_CONFIG, _CONF_FILE_WORKDIR))
CONFIG.update(_load_config_from_environ(_CONFIG))
if __name__ == "__main__":
import doctest
doctest.testmod()
================================================
FILE: lib/fetch.py
================================================
"""
Repositories fetch and update
This module makes real network and OS interaction,
and the adapters only say how exctly this interaction
should be done.
Configuration parameters:
* path.log.fetch
"""
from __future__ import print_function
import sys
import logging
import os
import subprocess
import textwrap
from globals import fatal
import adapter
import cache
from config import CONFIG
def _log(*message):
logging.info(*message)
if len(message) > 1:
message = message[0].rstrip("\n") % tuple(message[1:])
else:
message = message[0].rstrip("\n")
sys.stdout.write(message + "\n")
def _run_cmd(cmd):
shell = isinstance(cmd, str)
process = subprocess.Popen(
cmd, shell=shell, stdout=subprocess.PIPE, stderr=subprocess.STDOUT
)
output = process.communicate()[0]
return process.returncode, output
def fetch_all(skip_existing=True):
"""
Fetch all known repositories mentioned in the adapters
"""
def _fetch_locations(known_location):
for location, adptr in known_location.items():
if location in existing_locations:
continue
cmd = adptr.fetch_command()
if not cmd:
continue
sys.stdout.write("Fetching %s..." % (adptr))
sys.stdout.flush()
try:
process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
universal_newlines=True,
)
except OSError:
print("\nERROR: %s" % cmd)
raise
output = process.communicate()[0]
if process.returncode != 0:
sys.stdout.write("\nERROR:\n---\n" + output)
fatal("---\nCould not fetch %s" % adptr)
else:
print("Done")
# Searching for location duplicates for different repositories
known_location = {}
for adptr in adapter.adapter.all_adapters():
location = adptr.local_repository_location()
if not location:
continue
if (
location in known_location
and adptr.repository_url() != known_location[location].repository_url()
):
fatal(
"Duplicate location: %s for %s and %s"
% (location, adptr, known_location[location])
)
known_location[location] = adptr
# Parent directories creation
# target subdirectories will be create during the checkout process,
# but the parent directories should be created explicitly.
# Also we should make sure, that the target directory does not exist
existing_locations = []
for location in known_location:
if os.path.exists(location):
if skip_existing:
existing_locations.append(location)
print("Already exists %s" % (location))
else:
fatal("%s already exists" % location)
parent = os.path.dirname(location)
if os.path.exists(parent):
continue
os.makedirs(parent)
known_location = {
k: v for k, v in known_location.items() if k not in existing_locations
}
_fetch_locations(known_location)
def _update_adapter(adptr):
"""
Update implementation.
If `adptr` returns no update_command(), it is being ignored.
"""
os.chdir(adptr.local_repository_location())
cmd = adptr.update_command()
if not cmd:
return True
errorcode, output = _run_cmd(cmd)
if errorcode:
_log(
"\nERROR:\n---%s\n" % output.decode("utf-8")
+ "\n---\nCould not update %s" % adptr
)
return False
# Getting current repository state
# This state will be saved after the update procedure is finished
# (all cache entries invalidated)
cmd = adptr.current_state_command()
state = None
if cmd:
errorcode, state = _run_cmd(cmd)
if errorcode:
_log(
"\nERROR:\n---\n"
+ state
+ "\n---\nCould not get repository state: %s" % adptr
)
return False
state = state.strip()
# Getting list of files that were changed
# that will be later converted to the list of the pages to be invalidated
cmd = adptr.get_updates_list_command()
updates = []
if cmd:
errorcode, output = _run_cmd(cmd)
output = output.decode("utf-8")
if errorcode:
_log(
"\nERROR:\n---\n"
+ output
+ "\n---\nCould not get list of pages to be updated: %s" % adptr
)
return False
updates = output.splitlines()
entries = adptr.get_updates_list(updates)
if entries:
_log("%s Entries to be updated: %s", adptr, len(entries))
name = adptr.name()
for entry in entries:
cache_name = name + ":" + entry
_log("+ invalidating %s", cache_name)
cache.delete(cache_name)
if entries:
_log("Done")
adptr.save_state(state)
return True
def update_all():
"""
Update all known repositories, mentioned in the adapters
and fetched locally.
If repository is not fetched, it is skipped.
"""
for adptr in adapter.adapter.all_adapters():
location = adptr.local_repository_location()
if not location:
continue
if not os.path.exists(location):
continue
_update_adapter(adptr)
def update_by_name(name):
"""
Find adapter by its `name` and update only it.
"""
pass
def _show_usage():
sys.stdout.write(
textwrap.dedent(
"""
Usage:
python lib/fetch.py [command]
Commands:
update-all -- update all configured repositories
update [name] -- update repository of the adapter `name`
fetch-all -- fetch all configured repositories
"""
)
)
def main(args):
"""
function for the initial repositories fetch and manual repositories updates
"""
if not args:
_show_usage()
sys.exit(0)
logdir = os.path.dirname(CONFIG["path.log.fetch"])
if not os.path.exists(logdir):
os.makedirs(logdir)
logging.basicConfig(
filename=CONFIG["path.log.fetch"],
level=logging.DEBUG,
format="%(asctime)s %(message)s",
)
if args[0] == "fetch-all":
fetch_all()
elif args[0] == "update":
update_by_name(sys.argv[1])
elif args[0] == "update-all":
update_all()
else:
_show_usage()
sys.exit(0)
if __name__ == "__main__":
main(sys.argv[1:])
================================================
FILE: lib/fmt/__init__.py
================================================
================================================
FILE: lib/fmt/comments.py
================================================
"""
Extract text from the text-code stream and comment it.
Supports three modes of normalization and commenting:
1. Don't add any comments
2. Add comments
3. Remove text, leave code only
Since several operations are quite expensive,
it actively uses caching.
Exported functions:
beautify(text, lang, options)
code_blocks(text)
Configuration parameters:
"""
from __future__ import print_function
import sys
import os
import textwrap
import hashlib
import re
from itertools import groupby, chain
from subprocess import Popen
from tempfile import NamedTemporaryFile
from config import CONFIG
from languages_data import VIM_NAME
import cache
FNULL = open(os.devnull, "w")
TEXT = 0
CODE = 1
UNDEFINED = -1
CODE_WHITESPACE = -2
def _language_name(name):
return VIM_NAME.get(name, name)
def _remove_empty_lines_from_beginning(lines):
start = 0
while start < len(lines) and lines[start].strip() == "":
start += 1
lines = lines[start:]
return lines
def _remove_empty_lines_from_end(lines):
end = len(lines) - 1
while end >= 0 and lines[end].strip() == "":
end -= 1
lines = lines[: end + 1]
return lines
def _cleanup_lines(lines):
"""
Cleanup `lines` a little bit: remove empty lines at the beginning
and at the end; remove too many empty lines in between.
"""
lines = _remove_empty_lines_from_beginning(lines)
lines = _remove_empty_lines_from_end(lines)
if lines == []:
return lines
# remove repeating empty lines
lines = list(
chain.from_iterable(
[
(list(x[1]) if x[0] else [""])
for x in groupby(lines, key=lambda x: x.strip() != "")
]
)
)
return lines
def _line_type(line):
"""
Classify each line and say which of them
are text (0) and which of them are code (1).
A line is considered to be code,
if it starts with four spaces.
A line is considerer to be text if it is not
empty and is not code.
If line is empty, it is considered to be
code if it surrounded but two other code lines,
or if it is the first/last line and it has
code on the other side.
"""
if line.strip() == "":
return UNDEFINED
# some line may start with spaces but still be not code.
# we need some heuristics here, but for the moment just
# whitelist such cases:
if line.strip().startswith("* ") or re.match(r"[0-9]+\.", line.strip()):
return TEXT
if line.startswith(" "):
return CODE
return TEXT
def _classify_lines(lines):
line_types = [_line_type(line) for line in lines]
# pass 2:
# adding empty code lines to the code
for i in range(len(line_types) - 1):
if line_types[i] == CODE and line_types[i + 1] == UNDEFINED:
line_types[i + 1] = CODE_WHITESPACE
changed = True
for i in range(len(line_types) - 1)[::-1]:
if line_types[i] == UNDEFINED and line_types[i + 1] == CODE:
line_types[i] = CODE_WHITESPACE
changed = True
line_types = [CODE if x == CODE_WHITESPACE else x for x in line_types]
# pass 3:
# fixing undefined line types (-1)
changed = True
while changed:
changed = False
# changing all lines types that are near the text
for i in range(len(line_types) - 1):
if line_types[i] == TEXT and line_types[i + 1] == UNDEFINED:
line_types[i + 1] = TEXT
changed = True
for i in range(len(line_types) - 1)[::-1]:
if line_types[i] == UNDEFINED and line_types[i + 1] == TEXT:
line_types[i] = TEXT
changed = True
# everything what is still undefined, change to code type
line_types = [CODE if x == UNDEFINED else x for x in line_types]
return line_types
def _unindent_code(line, shift=0):
if shift == -1 and line != "":
return " " + line
if shift > 0 and line.startswith(" " * shift):
return line[shift:]
return line
def _wrap_lines(lines_classes, unindent_code=False):
"""
Wrap classified lines. Add the split lines to the stream.
If `unindent_code` is True, remove leading four spaces.
"""
result = []
for line_type, line_content in lines_classes:
if line_type == CODE:
shift = 3 if unindent_code else -1
result.append((line_type, _unindent_code(line_content, shift=shift)))
else:
if line_content.strip() == "":
result.append((line_type, ""))
for line in textwrap.fill(line_content).splitlines():
result.append((line_type, line))
return result
def _run_vim_script(script_lines, text_lines):
"""
Apply `script_lines` to `lines_classes`
and returns the result
"""
script_vim = NamedTemporaryFile(delete=True)
textfile = NamedTemporaryFile(delete=True)
open(script_vim.name, "w").write("\n".join(script_lines))
open(textfile.name, "w").write("\n".join(text_lines))
script_vim.file.close()
textfile.file.close()
my_env = os.environ.copy()
my_env["HOME"] = CONFIG["path.internal.vim"]
cmd = ["script", "-q", "-c", "vim -S %s %s" % (script_vim.name, textfile.name)]
Popen(
cmd,
shell=False,
stdin=open(os.devnull, "r"),
stdout=FNULL,
stderr=FNULL,
env=my_env,
).communicate()
return open(textfile.name, "r").read()
def _commenting_script(lines_blocks, filetype):
script_lines = []
block_start = 1
for block in lines_blocks:
lines = list(block[1])
block_end = block_start + len(lines) - 1
if block[0] == 0:
comment_type = "sexy"
if block_end - block_start < 1 or filetype == "ruby":
comment_type = "comment"
script_lines.insert(
0,
"%s,%s call NERDComment(1, '%s')"
% (block_start, block_end, comment_type),
)
script_lines.insert(
0, "%s,%s call NERDComment(1, 'uncomment')" % (block_start, block_end)
)
block_start = block_end + 1
script_lines.insert(0, "set ft=%s" % _language_name(filetype))
script_lines.append("wq")
return script_lines
def _beautify(text, filetype, add_comments=False, remove_text=False):
"""
Main function that actually does the whole beautification job.
"""
# We shift the code if and only if we either convert the text into comments
# or remove the text completely. Otherwise the code has to remain aligned
unindent_code = add_comments or remove_text
lines = [x.decode("utf-8").rstrip("\n") for x in text.splitlines()]
lines = _cleanup_lines(lines)
lines_classes = zip(_classify_lines(lines), lines)
lines_classes = _wrap_lines(lines_classes, unindent_code=unindent_code)
if remove_text:
lines = [line[1] for line in lines_classes if line[0] == 1]
lines = _cleanup_lines(lines)
output = "\n".join(lines)
if not output.endswith("\n"):
output += "\n"
elif not add_comments:
output = "\n".join(line[1] for line in lines_classes)
else:
lines_blocks = groupby(lines_classes, key=lambda x: x[0])
script_lines = _commenting_script(lines_blocks, filetype)
output = _run_vim_script(script_lines, [line for (_, line) in lines_classes])
return output
def code_blocks(text, wrap_lines=False, unindent_code=False):
"""
Split `text` into blocks of text and code.
Return list of tuples TYPE, TEXT
"""
text = text.encode("utf-8")
lines = [x.rstrip("\n") for x in text.splitlines()]
lines_classes = zip(_classify_lines(lines), lines)
if wrap_lines:
lines_classes = _wrap_lines(lines_classes, unindent_code=unindent_code)
lines_blocks = groupby(lines_classes, key=lambda x: x[0])
answer = [(x[0], "\n".join([y[1] for y in x[1]]) + "\n") for x in lines_blocks]
return answer
def beautify(text, lang, options):
"""
Process input `text` according to the specified `mode`.
Adds comments if needed, according to the `lang` rules.
Caches the results.
The whole work (except caching) is done by _beautify().
"""
options = options or {}
beauty_options = dict(
(k, v) for k, v in options.items() if k in ["add_comments", "remove_text"]
)
mode = ""
if beauty_options.get("add_comments"):
mode += "c"
if beauty_options.get("remove_text"):
mode += "q"
if beauty_options == {}:
# if mode is unknown, just don't transform the text at all
return text
if isinstance(text, str):
text = text.encode("utf-8")
digest = "t:%s:%s:%s" % (hashlib.md5(text).hexdigest(), lang, mode)
# temporary added line that removes invalid cache entries
# that used wrong commenting methods
if lang in ["git", "django", "flask", "cmake"]:
cache.delete(digest)
answer = cache.get(digest)
if answer:
return answer
answer = _beautify(text, lang, **beauty_options)
cache.put(digest, answer)
return answer
def __main__():
text = sys.stdin.read()
filetype = sys.argv[1]
options = {
"": {},
"c": dict(add_comments=True),
"C": dict(add_comments=False),
"q": dict(remove_text=True),
}[sys.argv[2]]
result = beautify(text, filetype, options)
sys.stdout.write(result)
if __name__ == "__main__":
__main__()
================================================
FILE: lib/fmt/internal.py
================================================
"""
Colorize internal cheat sheets.
Will be merged with panela later.
"""
import re
from colorama import Fore, Back, Style
import colored
PALETTES = {
0: {
1: Fore.WHITE,
2: Style.DIM,
},
1: {
1: Fore.CYAN,
2: Fore.GREEN,
3: colored.fg("orange_3"),
4: Style.DIM,
5: Style.DIM,
},
2: {
1: Fore.RED,
2: Style.DIM,
},
}
def _reverse_palette(code):
return {1: Fore.BLACK + _back_color(code), 2: Style.DIM}
def _back_color(code):
if code == 0 or (isinstance(code, str) and code.lower() == "white"):
return Back.WHITE
if code == 1 or (isinstance(code, str) and code.lower() == "cyan"):
return Back.CYAN
if code == 2 or (isinstance(code, str) and code.lower() == "red"):
return Back.RED
return Back.WHITE
def colorize_internal(text, palette_number=1):
"""
Colorize `text`, use `palette`
"""
palette = PALETTES[palette_number]
palette_reverse = _reverse_palette(palette_number)
def _process_text(text):
text = text.group()[1:-1]
factor = 1
if text.startswith("-"):
text = text[1:]
factor = -1
stripped = text.lstrip("0123456789")
return (text, stripped, factor)
def _extract_color_number(text, stripped, factor=1):
return int(text[: len(text) - len(stripped)]) * factor
def _colorize_curlies_block(text):
text, stripped, factor = _process_text(text)
color_number = _extract_color_number(text, stripped, factor)
if stripped.startswith("="):
stripped = stripped[1:]
reverse = color_number < 0
if reverse:
color_number = -color_number
if reverse:
stripped = palette_reverse[color_number] + stripped + Style.RESET_ALL
else:
stripped = palette[color_number] + stripped + Style.RESET_ALL
return stripped
def _colorize_headers(text):
if text.group(0).endswith("\n"):
newline = "\n"
else:
newline = ""
color_number = 3
return palette[color_number] + text.group(0).strip() + Style.RESET_ALL + newline
text = re.sub("{.*?}", _colorize_curlies_block, text)
text = re.sub("#(.*?)\n", _colorize_headers, text)
return text
def colorize_internal_firstpage_v1(answer):
"""
Colorize "/:firstpage-v1".
Legacy.
"""
def _colorize_line(line):
if line.startswith("T"):
line = colored.fg("grey_62") + line + colored.attr("reset")
line = re.sub(
r"\{(.*?)\}",
colored.fg("orange_3") + r"\1" + colored.fg("grey_35"),
line,
)
return line
line = re.sub(
r"\[(F.*?)\]",
colored.bg("black") + colored.fg("cyan") + r"[\1]" + colored.attr("reset"),
line,
)
line = re.sub(
r"\[(g.*?)\]",
colored.bg("dark_gray")
+ colored.fg("grey_0")
+ r"[\1]"
+ colored.attr("reset"),
line,
)
line = re.sub(
r"\{(.*?)\}", colored.fg("orange_3") + r"\1" + colored.attr("reset"), line
)
line = re.sub(
r"<(.*?)>", colored.fg("cyan") + r"\1" + colored.attr("reset"), line
)
return line
lines = answer.splitlines()
answer_lines = lines[:9]
answer_lines.append(colored.fg("grey_35") + lines[9] + colored.attr("reset"))
for line in lines[10:]:
answer_lines.append(_colorize_line(line))
answer = "\n".join(answer_lines) + "\n"
return answer
================================================
FILE: lib/fmt/markdown.py
================================================
"""
Markdown support.
Exports:
format_text(text, config=None, highlighter=None):
Uses external pygments formatters for highlighting (passed as an argument).
"""
import re
import ansiwrap
import colored
def format_text(text, config=None, highlighter=None):
"""
Renders `text` according to markdown rules.
Uses `highlighter` for syntax highlighting.
Returns a dictionary with "output" and "links".
"""
return _format_section(text, config=config, highlighter=highlighter)
def _split_into_paragraphs(text):
return re.split("\n\n+", text)
def _colorize(text):
return re.sub(
r"`(.*?)`",
colored.bg("dark_gray")
+ colored.fg("white")
+ " "
+ r"\1"
+ " "
+ colored.attr("reset"),
re.sub(
r"\*\*(.*?)\*\*",
colored.attr("bold") + colored.fg("white") + r"\1" + colored.attr("reset"),
text,
),
)
def _format_section(section_text, config=None, highlighter=None):
answer = ""
# cut code blocks
block_number = 0
while True:
section_text, replacements = re.subn(
"^```.*?^```",
"MULTILINE_BLOCK_%s" % block_number,
section_text,
1,
flags=re.S | re.MULTILINE,
)
block_number += 1
if not replacements:
break
# cut links
links = []
while True:
regexp = re.compile(r"\[(.*?)\]\((.*?)\)")
match = regexp.search(section_text)
if match:
links.append(match.group(0))
text = match.group(1)
# links are not yet supported
#
text = "\x1b]8;;%s\x1b\\\\%s\x1b]8;;\x1b\\\\" % (
match.group(2),
match.group(1),
)
else:
break
section_text, replacements = regexp.subn(
text, section_text, 1 # 'LINK_%s' % len(links),
)
block_number += 1
if not replacements:
break
for paragraph in _split_into_paragraphs(section_text):
answer += (
"\n".join(
ansiwrap.fill(_colorize(line)) + "\n" for line in paragraph.splitlines()
)
+ "\n"
)
return {"ansi": answer, "links": links}
================================================
FILE: lib/frontend/__init__.py
================================================
================================================
FILE: lib/frontend/ansi.py
================================================
"""
ANSI frontend.
Exports:
visualize(answer_data, request_options)
Format:
answer_data = {
'answers': '...',}
answers = [answer,...]
answer = {
'topic': '...',
'topic_type': '...',
'answer': '...',
'format': 'ansi|code|markdown|text...',
}
Configuration parameters:
frontend.styles
"""
import os
import sys
import re
import colored
from pygments import highlight as pygments_highlight
from pygments.formatters import (
Terminal256Formatter,
) # pylint: disable=no-name-in-module
# pylint: disable=wrong-import-position
sys.path.append(os.path.abspath(os.path.join(__file__, "..")))
from config import CONFIG
import languages_data # pylint: enable=wrong-import-position
import fmt.internal
import fmt.comments
def visualize(answer_data, request_options):
"""
Renders `answer_data` as ANSI output.
"""
answers = answer_data["answers"]
return _visualize(
answers, request_options, search_mode=bool(answer_data["keyword"])
)
ANSI_ESCAPE = re.compile(r"(\x9B|\x1B\[)[0-?]*[ -\/]*[@-~]")
def remove_ansi(sometext):
"""
Remove ANSI sequences from `sometext` and convert it into plaintext.
"""
return ANSI_ESCAPE.sub("", sometext)
def _limited_answer(answer):
return (
colored.bg("dark_goldenrod")
+ colored.fg("yellow_1")
+ " "
+ answer
+ " "
+ colored.attr("reset")
+ "\n"
)
def _colorize_ansi_answer(
topic,
answer,
color_style, # pylint: disable=too-many-arguments
highlight_all=True,
highlight_code=False,
unindent_code=False,
language=None,
):
color_style = color_style or "native"
lexer_class = languages_data.LEXER["bash"]
if "/" in topic:
if language is None:
section_name = topic.split("/", 1)[0].lower()
else:
section_name = language
section_name = languages_data.get_lexer_name(section_name)
lexer_class = languages_data.LEXER.get(section_name, lexer_class)
if section_name == "php":
answer = "<?\n%s?>\n" % answer
if highlight_all:
highlight = (
lambda answer: pygments_highlight(
answer, lexer_class(), Terminal256Formatter(style=color_style)
).strip("\n")
+ "\n"
)
else:
highlight = lambda x: x
if highlight_code:
blocks = fmt.comments.code_blocks(
answer, wrap_lines=True, unindent_code=(4 if unindent_code else False)
)
highlighted_blocks = []
for block in blocks:
if block[0] == 1:
this_block = highlight(block[1])
else:
this_block = block[1].strip("\n") + "\n"
highlighted_blocks.append(this_block)
result = "\n".join(highlighted_blocks)
else:
result = highlight(answer).lstrip("\n")
return result
def _visualize(answers, request_options, search_mode=False):
highlight = not bool(request_options and request_options.get("no-terminal"))
color_style = (request_options or {}).get("style", "")
if color_style not in CONFIG["frontend.styles"]:
color_style = ""
# if there is more than one answer,
# show the source of the answer
multiple_answers = len(answers) > 1
found = True
result = ""
for answer_dict in answers:
topic = answer_dict["topic"]
topic_type = answer_dict["topic_type"]
answer = answer_dict["answer"]
found = found and not topic_type == "unknown"
if multiple_answers and topic != "LIMITED":
section_name = f"{topic_type}:{topic}"
if not highlight:
result += f"#[{section_name}]\n"
else:
result += "".join(
[
"\n",
colored.bg("dark_gray"),
colored.attr("res_underlined"),
f" {section_name} ",
colored.attr("res_underlined"),
colored.attr("reset"),
"\n",
]
)
if answer_dict["format"] in ["ansi", "text"]:
result += answer
elif topic == ":firstpage-v1":
result += fmt.internal.colorize_internal_firstpage_v1(answer)
elif topic == "LIMITED":
result += _limited_answer(topic)
else:
result += _colorize_ansi_answer(
topic,
answer,
color_style,
highlight_all=highlight,
highlight_code=(
topic_type == "question"
and not request_options.get("add_comments")
and not request_options.get("remove_text")
),
language=answer_dict.get("filetype"),
)
if request_options.get("no-terminal"):
result = remove_ansi(result)
result = result.strip("\n") + "\n"
return result, found
================================================
FILE: lib/frontend/html.py
================================================
"""
Configuration parameters:
path.internal.ansi2html
"""
import sys
import os
import re
from subprocess import Popen, PIPE
MYDIR = os.path.abspath(os.path.join(__file__, "..", ".."))
sys.path.append("%s/lib/" % MYDIR)
# pylint: disable=wrong-import-position
from config import CONFIG
from globals import error
from buttons import TWITTER_BUTTON, GITHUB_BUTTON, GITHUB_BUTTON_FOOTER
import frontend.ansi
# temporary having it here, but actually we have the same data
# in the adapter module
GITHUB_REPOSITORY = {
"late.nz": "chubin/late.nz",
"cheat.sheets": "chubin/cheat.sheets",
"cheat.sheets dir": "chubin/cheat.sheets",
"tldr": "tldr-pages/tldr",
"cheat": "chrisallenlane/cheat",
"learnxiny": "adambard/learnxinyminutes-docs",
"internal": "",
"search": "",
"unknown": "",
}
def visualize(answer_data, request_options):
query = answer_data["query"]
answers = answer_data["answers"]
topics_list = answer_data["topics_list"]
editable = len(answers) == 1 and answers[0]["topic_type"] == "cheat.sheets"
repository_button = ""
if len(answers) == 1:
repository_button = _github_button(answers[0]["topic_type"])
result, found = frontend.ansi.visualize(answer_data, request_options)
return (
_render_html(
query, result, editable, repository_button, topics_list, request_options
),
found,
)
def _github_button(topic_type):
full_name = GITHUB_REPOSITORY.get(topic_type, "")
if not full_name:
return ""
short_name = full_name.split("/", 1)[1] # pylint: disable=unused-variable
button = (
"<!-- Place this tag where you want the button to render. -->"
'<a aria-label="Star %(full_name)s on GitHub"'
' data-count-aria-label="# stargazers on GitHub"'
' data-count-api="/repos/%(full_name)s#stargazers_count"'
' data-count-href="/%(full_name)s/stargazers"'
' data-icon="octicon-star"'
' href="https://github.com/%(full_name)s"'
' class="github-button">%(short_name)s</a>'
) % locals()
return button
def _render_html(
query, result, editable, repository_button, topics_list, request_options
):
def _html_wrapper(data):
"""
Convert ANSI text `data` to HTML
"""
cmd = [
"bash",
CONFIG["path.internal.ansi2html"],
"--palette=solarized",
"--bg=dark",
]
try:
proc = Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=PIPE)
except FileNotFoundError:
print("ERROR: %s" % cmd)
raise
data = data.encode("utf-8")
stdout, stderr = proc.communicate(data)
if proc.returncode != 0:
error((stdout + stderr).decode("utf-8"))
return stdout.decode("utf-8")
result = result + "\n$"
result = _html_wrapper(result)
title = "<title>cheat.sh/%s</title>" % query
submit_button = (
'<input type="submit" style="position: absolute;'
' left: -9999px; width: 1px; height: 1px;" tabindex="-1" />'
)
topic_list = '<datalist id="topics">%s</datalist>' % (
"\n".join("<option value='%s'></option>" % x for x in topics_list)
)
curl_line = "<span class='pre'>$ curl cheat.sh/</span>"
if query == ":firstpage":
query = ""
form_html = (
'<form action="/" method="GET">'
"%s%s"
"<input"
' type="text" value="%s" name="topic"'
' list="topics" autofocus autocomplete="off"/>'
"%s"
"</form>"
) % (submit_button, curl_line, query, topic_list)
edit_button = ""
if editable:
# It's possible that topic directory starts with omitted underscore
if "/" in query:
query = "_" + query
edit_page_link = (
"https://github.com/chubin/cheat.sheets/edit/master/sheets/" + query
)
edit_button = (
'<pre style="position:absolute;padding-left:40em;overflow:visible;height:0;">'
'[<a href="%s" style="color:cyan">edit</a>]'
"</pre>"
) % edit_page_link
result = re.sub("<pre>", edit_button + form_html + "<pre>", result)
result = re.sub("<head>", "<head>" + title, result)
if not request_options.get("quiet"):
result = result.replace(
"</body>",
TWITTER_BUTTON
+ GITHUB_BUTTON
+ repository_button
+ GITHUB_BUTTON_FOOTER
+ "</body>",
)
return result
================================================
FILE: lib/globals.py
================================================
"""
Global functions that our used everywhere in the project.
Please, no global variables here.
For the configuration related things see `config.py`
"""
from __future__ import print_function
import sys
import logging
def fatal(text):
"""
Fatal error function.
The function is being used in the standalone mode only
"""
sys.stderr.write("ERROR: %s\n" % text)
sys.exit(1)
def error(text):
"""
Log error `text` and produce a RuntimeError exception
"""
if not text.startswith("Too many queries"):
print(text)
logging.error("ERROR %s", text)
raise RuntimeError(text)
def log(text):
"""
Log error `text` (if it does not start with 'Too many queries')
"""
if not text.startswith("Too many queries"):
print(text)
logging.info(text)
================================================
FILE: lib/languages_data.py
================================================
"""
Programming languages information.
Will be (probably) moved to a separate file/directory
from the project tree.
"""
import pygments.lexers
LEXER = {
"assembly": pygments.lexers.NasmLexer,
"awk": pygments.lexers.AwkLexer,
"bash": pygments.lexers.BashLexer,
"basic": pygments.lexers.QBasicLexer,
"bf": pygments.lexers.BrainfuckLexer,
"chapel": pygments.lexers.ChapelLexer,
"clojure": pygments.lexers.ClojureLexer,
"coffee": pygments.lexers.CoffeeScriptLexer,
"cpp": pygments.lexers.CppLexer,
"c": pygments.lexers.CLexer,
"csharp": pygments.lexers.CSharpLexer,
"d": pygments.lexers.DLexer,
"dart": pygments.lexers.DartLexer,
"delphi": pygments.lexers.DelphiLexer,
"elisp": pygments.lexers.EmacsLispLexer,
"elixir": pygments.lexers.ElixirLexer,
"elm": pygments.lexers.ElmLexer,
"erlang": pygments.lexers.ErlangLexer,
"factor": pygments.lexers.FactorLexer,
"forth": pygments.lexers.ForthLexer,
"fortran": pygments.lexers.FortranLexer,
"fsharp": pygments.lexers.FSharpLexer,
"git": pygments.lexers.BashLexer,
"go": pygments.lexers.GoLexer,
"groovy": pygments.lexers.GroovyLexer,
"haskell": pygments.lexers.HaskellLexer,
"java": pygments.lexers.JavaLexer,
"js": pygments.lexers.JavascriptLexer,
"julia": pygments.lexers.JuliaLexer,
"kotlin": pygments.lexers.KotlinLexer,
"latex": pygments.lexers.TexLexer,
"lisp": pygments.lexers.CommonLispLexer,
"lua": pygments.lexers.LuaLexer,
"mathematica": pygments.lexers.MathematicaLexer,
"matlab": pygments.lexers.MatlabLexer,
"mongo": pygments.lexers.JavascriptLexer,
"nim": pygments.lexers.NimrodLexer,
"objective-c": pygments.lexers.ObjectiveCppLexer,
"ocaml": pygments.lexers.OcamlLexer,
"octave": pygments.lexers.OctaveLexer,
"perl": pygments.lexers.PerlLexer,
"perl6": pygments.lexers.Perl6Lexer,
"php": pygments.lexers.PhpLexer,
"psql": pygments.lexers.PostgresLexer,
"python": pygments.lexers.PythonLexer,
"python3": pygments.lexers.Python3Lexer,
"r": pygments.lexers.SLexer,
"racket": pygments.lexers.RacketLexer,
"ruby": pygments.lexers.RubyLexer,
"rust": pygments.lexers.RustLexer,
"so
gitextract_e4plvajh/
├── .dockerignore
├── .github/
│ └── workflows/
│ ├── tests-macos.yml
│ └── tests-ubuntu.yml
├── .gitignore
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── README.md
├── bin/
│ ├── app.py
│ ├── clean_cache.py
│ ├── release.py
│ └── srv.py
├── doc/
│ ├── README-ja.md
│ └── standalone.md
├── docker-compose.debug.yml
├── docker-compose.yml
├── etc/
│ └── config.yaml
├── lib/
│ ├── adapter/
│ │ ├── __init__.py
│ │ ├── adapter.py
│ │ ├── cheat_cheat.py
│ │ ├── cheat_sheets.py
│ │ ├── cmd.py
│ │ ├── common.py
│ │ ├── git_adapter.py
│ │ ├── internal.py
│ │ ├── latenz.py
│ │ ├── learnxiny.py
│ │ ├── question.py
│ │ ├── rosetta.py
│ │ ├── tldr.py
│ │ └── upstream.py
│ ├── buttons.py
│ ├── cache.py
│ ├── cheat_wrapper.py
│ ├── cheat_wrapper_test.py
│ ├── config.py
│ ├── fetch.py
│ ├── fmt/
│ │ ├── __init__.py
│ │ ├── comments.py
│ │ ├── internal.py
│ │ └── markdown.py
│ ├── frontend/
│ │ ├── __init__.py
│ │ ├── ansi.py
│ │ └── html.py
│ ├── globals.py
│ ├── languages_data.py
│ ├── limits.py
│ ├── options.py
│ ├── panela/
│ │ ├── colors.json
│ │ ├── colors.py
│ │ └── panela_colors.py
│ ├── post.py
│ ├── postprocessing.py
│ ├── routing.py
│ ├── search.py
│ ├── standalone.py
│ └── stateful_queries.py
├── requirements.txt
├── share/
│ ├── adapters/
│ │ ├── chmod.grc
│ │ ├── chmod.sh
│ │ ├── oeis.sh
│ │ └── rfc.sh
│ ├── ansi2html.sh
│ ├── bash_completion.txt
│ ├── cht.sh.txt
│ ├── emacs-ivy.txt
│ ├── emacs.txt
│ ├── firstpage-v1.txt
│ ├── firstpage-v2.pnl
│ ├── firstpage-v2.txt
│ ├── fish.txt
│ ├── help.txt
│ ├── intro.txt
│ ├── post.txt
│ ├── scripts/
│ │ ├── cacheCleanup.go
│ │ └── remove-from-cache.sh
│ ├── static/
│ │ ├── 1.html
│ │ ├── malformed-response.html
│ │ ├── opensearch.xml
│ │ └── style.css
│ ├── styles-demo.txt
│ ├── vim/
│ │ └── .vimrc
│ ├── vim.txt
│ └── zsh.txt
└── tests/
├── README.md
├── results/
│ ├── 1
│ ├── 10
│ ├── 11
│ ├── 12
│ ├── 13
│ ├── 14
│ ├── 15
│ ├── 16
│ ├── 17
│ ├── 18
│ ├── 19
│ ├── 2
│ ├── 20
│ ├── 21
│ ├── 22
│ ├── 23
│ ├── 24
│ ├── 25
│ ├── 3
│ ├── 4
│ ├── 5
│ ├── 6
│ ├── 7
│ ├── 8
│ └── 9
├── run-tests.sh
└── tests.txt
SYMBOL INDEX (338 symbols across 38 files)
FILE: bin/app.py
class SkipFlaskLogger (line 65) | class SkipFlaskLogger(object):
method filter (line 66) | def filter(self, record):
function _is_html_needed (line 96) | def _is_html_needed(user_agent):
function is_result_a_script (line 103) | def is_result_a_script(query):
function send_static (line 108) | def send_static(path):
function send_favicon (line 117) | def send_favicon():
function send_malformed (line 126) | def send_malformed():
function log_query (line 135) | def log_query(ip_addr, found, topic, user_agent):
function get_request_ip (line 144) | def get_request_ip(req):
function get_answer_language (line 165) | def get_answer_language(request):
function _proxy (line 212) | def _proxy(*args, **kwargs):
function answer (line 256) | def answer(topic=None):
FILE: bin/release.py
function run (line 17) | def run(args):
FILE: lib/adapter/adapter.py
class AdapterMC (line 15) | class AdapterMC(type):
method __repr__ (line 21) | def __repr__(cls):
class Adapter (line 27) | class Adapter(with_metaclass(AdapterMC, object)):
method _class_repr (line 54) | def _class_repr(cls):
method __init__ (line 57) | def __init__(self):
method name (line 61) | def name(cls):
method _get_list (line 68) | def _get_list(self, prefix=None):
method get_list (line 71) | def get_list(self, prefix=None):
method is_found (line 82) | def is_found(self, topic):
method is_cache_needed (line 89) | def is_cache_needed(self):
method _format_page (line 97) | def _format_page(text):
method _get_page (line 107) | def _get_page(self, topic, request_options=None):
method _get_output_format (line 113) | def _get_output_format(self, topic):
method _get_filetype (line 125) | def _get_filetype(topic):
method get_page_dict (line 131) | def get_page_dict(self, topic, request_options=None):
method local_repository_location (line 162) | def local_repository_location(cls, cheat_sheets_location=False):
method repository_url (line 212) | def repository_url(cls):
method fetch_command (line 219) | def fetch_command(cls):
method update_command (line 235) | def update_command(cls):
method current_state_command (line 256) | def current_state_command(cls):
method save_state (line 276) | def save_state(cls, state):
method get_state (line 286) | def get_state(cls):
method get_updates_list_command (line 300) | def get_updates_list_command(cls):
method get_updates_list (line 309) | def get_updates_list(cls, updated_files_list):
function all_adapters (line 327) | def all_adapters(as_dict=False):
function adapter_by_name (line 343) | def adapter_by_name(name):
FILE: lib/adapter/cheat_cheat.py
class Cheat (line 13) | class Cheat(GitRepositoryAdapter):
FILE: lib/adapter/cheat_sheets.py
function _remove_initial_underscore (line 15) | def _remove_initial_underscore(filename):
function _sanitize_dirnames (line 21) | def _sanitize_dirnames(filename, restore=False):
class CheatSheets (line 42) | class CheatSheets(GitRepositoryAdapter):
method _get_list (line 52) | def _get_list(self, prefix=None):
method _get_page (line 75) | def _get_page(self, topic, request_options=None):
class CheatSheetsDir (line 92) | class CheatSheetsDir(CheatSheets):
method _get_list (line 105) | def _get_list(self, prefix=None):
method _get_page (line 121) | def _get_page(self, topic, request_options=None):
method is_found (line 136) | def is_found(self, topic):
FILE: lib/adapter/cmd.py
function _get_abspath (line 12) | def _get_abspath(path):
class CommandAdapter (line 25) | class CommandAdapter(Adapter):
method _get_command (line 30) | def _get_command(self, topic, request_options=None):
method _get_page (line 33) | def _get_page(self, topic, request_options=None):
class Fosdem (line 48) | class Fosdem(CommandAdapter):
class Translation (line 71) | class Translation(CommandAdapter):
method _get_page (line 78) | def _get_page(self, topic, request_options=None):
class AdapterRfc (line 92) | class AdapterRfc(CommandAdapter):
method _get_command (line 103) | def _get_command(self, topic, request_options=None):
method _get_list (line 114) | def _get_list(self, prefix=None):
method is_found (line 117) | def is_found(self, topic):
class AdapterOeis (line 121) | class AdapterOeis(CommandAdapter):
method _get_filetype (line 133) | def _get_filetype(topic):
method _get_command (line 139) | def _get_command(self, topic, request_options=None):
method is_found (line 158) | def is_found(self, topic):
class AdapterChmod (line 162) | class AdapterChmod(CommandAdapter):
method _get_command (line 173) | def _get_command(self, topic, request_options=None):
method is_found (line 184) | def is_found(self, topic):
FILE: lib/adapter/common.py
class Adapter (line 1) | class Adapter(object):
class cheatAdapter (line 5) | class cheatAdapter(Adapter):
FILE: lib/adapter/git_adapter.py
function _get_filenames (line 11) | def _get_filenames(path):
class RepositoryAdapter (line 15) | class RepositoryAdapter(Adapter):
method _get_list (line 21) | def _get_list(self, prefix=None):
method _get_page (line 43) | def _get_page(self, topic, request_options=None):
class GitRepositoryAdapter (line 58) | class GitRepositoryAdapter(RepositoryAdapter): # pylint: disable=abstra...
method fetch_command (line 65) | def fetch_command(cls):
method update_command (line 89) | def update_command(cls):
method current_state_command (line 113) | def current_state_command(cls):
method save_state (line 136) | def save_state(cls, state):
method get_state (line 146) | def get_state(cls):
method get_updates_list_command (line 160) | def get_updates_list_command(cls):
FILE: lib/adapter/internal.py
class InternalPages (line 49) | class InternalPages(Adapter):
method __init__ (line 54) | def __init__(self, get_topic_type=None, get_topics_list=None):
method _get_stat (line 59) | def _get_stat(self):
method get_list (line 70) | def get_list(prefix=None):
method _get_list_answer (line 73) | def _get_list_answer(self, topic, request_options=None):
method _get_page (line 90) | def _get_page(self, topic, request_options=None):
method is_found (line 108) | def is_found(self, topic):
class UnknownPages (line 112) | class UnknownPages(InternalPages):
method get_list (line 118) | def get_list(prefix=None):
method is_found (line 122) | def is_found(topic):
method _get_page (line 125) | def _get_page(self, topic, request_options=None):
class Search (line 152) | class Search(Adapter):
method get_list (line 159) | def get_list(prefix=None):
method is_found (line 162) | def is_found(self, topic):
FILE: lib/adapter/latenz.py
class Latenz (line 16) | class Latenz(GitRepositoryAdapter):
method _get_page (line 25) | def _get_page(self, topic, request_options=None):
method _get_list (line 31) | def _get_list(self, prefix=None):
method is_found (line 34) | def is_found(self, topic):
FILE: lib/adapter/learnxiny.py
class LearnXinY (line 18) | class LearnXinY(GitRepositoryAdapter):
method __init__ (line 28) | def __init__(self):
method _get_page (line 32) | def _get_page(self, topic, request_options=None):
method _get_list (line 42) | def _get_list(self, prefix=None):
method is_found (line 51) | def is_found(self, topic):
class LearnXYAdapter (line 66) | class LearnXYAdapter(object):
method __init__ (line 80) | def __init__(self):
method _is_block_separator (line 93) | def _is_block_separator(self, before, now, after):
method _cut_block (line 109) | def _cut_block(self, block, start_block=False):
method _read_cheatsheet (line 120) | def _read_cheatsheet(self):
method _extract_blocks (line 142) | def _extract_blocks(self):
method is_valid (line 171) | def is_valid(self, name):
method get_list (line 181) | def get_list(self, prefix=None):
method get_page (line 189) | def get_page(self, name, partial=False):
class LearnAwkAdapter (line 227) | class LearnAwkAdapter(LearnXYAdapter):
class LearnBashAdapter (line 235) | class LearnBashAdapter(LearnXYAdapter):
class LearnBfAdapter (line 243) | class LearnBfAdapter(LearnXYAdapter):
class LearnCAdapter (line 251) | class LearnCAdapter(LearnXYAdapter):
class LearnChapelAdapter (line 259) | class LearnChapelAdapter(LearnXYAdapter):
class LearnClojureAdapter (line 267) | class LearnClojureAdapter(LearnXYAdapter):
method _is_block_separator (line 275) | def _is_block_separator(self, before, now, after):
method _cut_block (line 289) | def _cut_block(block, start_block=False):
class LearnCoffeeScriptAdapter (line 299) | class LearnCoffeeScriptAdapter(LearnXYAdapter):
class LearnCppAdapter (line 307) | class LearnCppAdapter(LearnXYAdapter):
method _is_block_separator (line 318) | def _is_block_separator(self, before, now, after):
method _cut_block (line 335) | def _cut_block(block, start_block=False):
class LearnCsharpAdapter (line 346) | class LearnCsharpAdapter(LearnXYAdapter):
class LearnDAdapter (line 354) | class LearnDAdapter(LearnXYAdapter):
class LearnDartAdapter (line 362) | class LearnDartAdapter(LearnXYAdapter):
class LearnFactorAdapter (line 370) | class LearnFactorAdapter(LearnXYAdapter):
class LearnForthAdapter (line 378) | class LearnForthAdapter(LearnXYAdapter):
class LearnFsharpAdapter (line 386) | class LearnFsharpAdapter(LearnXYAdapter):
class LearnElispAdapter (line 394) | class LearnElispAdapter(LearnXYAdapter):
class LearnElixirAdapter (line 402) | class LearnElixirAdapter(LearnXYAdapter):
method _is_block_separator (line 413) | def _is_block_separator(self, before, now, after):
method _cut_block (line 430) | def _cut_block(block, start_block=False):
class LearnElmAdapter (line 439) | class LearnElmAdapter(LearnXYAdapter):
method _is_block_separator (line 450) | def _is_block_separator(self, before, now, after):
method _cut_block (line 468) | def _cut_block(block, start_block=False):
class LearnErlangAdapter (line 477) | class LearnErlangAdapter(LearnXYAdapter):
method _is_block_separator (line 485) | def _is_block_separator(self, before, now, after):
method _cut_block (line 497) | def _cut_block(block, start_block=False):
class LearnFortranAdapter (line 506) | class LearnFortranAdapter(LearnXYAdapter):
class LearnGoAdapter (line 514) | class LearnGoAdapter(LearnXYAdapter):
class LearnGroovyAdapter (line 522) | class LearnGroovyAdapter(LearnXYAdapter):
class LearnJavaAdapter (line 530) | class LearnJavaAdapter(LearnXYAdapter):
class LearnJavaScriptAdapter (line 538) | class LearnJavaScriptAdapter(LearnXYAdapter):
method _is_block_separator (line 549) | def _is_block_separator(self, before, now, after):
method _cut_block (line 564) | def _cut_block(block, start_block=False):
class LearnJuliaAdapter (line 573) | class LearnJuliaAdapter(LearnXYAdapter):
method _is_block_separator (line 581) | def _is_block_separator(self, before, now, after):
method _cut_block (line 593) | def _cut_block(block, start_block=False):
class LearnHaskellAdapter (line 602) | class LearnHaskellAdapter(LearnXYAdapter):
method _is_block_separator (line 613) | def _is_block_separator(self, before, now, after):
method _cut_block (line 628) | def _cut_block(block, start_block=False):
class LearnLispAdapter (line 637) | class LearnLispAdapter(LearnXYAdapter):
class LearnLuaAdapter (line 645) | class LearnLuaAdapter(LearnXYAdapter):
method _is_block_separator (line 658) | def _is_block_separator(self, before, now, after):
method _cut_block (line 672) | def _cut_block(block, start_block=False):
class LearnMathematicaAdapter (line 681) | class LearnMathematicaAdapter(LearnXYAdapter):
class LearnMatlabAdapter (line 689) | class LearnMatlabAdapter(LearnXYAdapter):
class LearnOctaveAdapter (line 697) | class LearnOctaveAdapter(LearnXYAdapter):
class LearnKotlinAdapter (line 705) | class LearnKotlinAdapter(LearnXYAdapter):
method _is_block_separator (line 713) | def _is_block_separator(self, before, now, after):
method _cut_block (line 725) | def _cut_block(block, start_block=False):
class LearnObjectiveCAdapter (line 734) | class LearnObjectiveCAdapter(LearnXYAdapter):
class LearnOCamlAdapter (line 742) | class LearnOCamlAdapter(LearnXYAdapter):
method _is_block_separator (line 753) | def _is_block_separator(self, before, now, after):
method _cut_block (line 769) | def _cut_block(block, start_block=False):
class LearnPerlAdapter (line 778) | class LearnPerlAdapter(LearnXYAdapter):
method _is_block_separator (line 792) | def _is_block_separator(self, before, now, after):
method _cut_block (line 803) | def _cut_block(block, start_block=False):
class LearnPerl6Adapter (line 815) | class LearnPerl6Adapter(LearnXYAdapter):
class LearnPHPAdapter (line 823) | class LearnPHPAdapter(LearnXYAdapter):
method _is_block_separator (line 831) | def _is_block_separator(self, before, now, after):
method _cut_block (line 844) | def _cut_block(block, start_block=False):
class LearnPythonAdapter (line 848) | class LearnPythonAdapter(LearnXYAdapter):
method _is_block_separator (line 856) | def _is_block_separator(self, before, now, after):
method _cut_block (line 868) | def _cut_block(block, start_block=False):
class LearnPython3Adapter (line 877) | class LearnPython3Adapter(LearnXYAdapter):
class LearnRAdapter (line 885) | class LearnRAdapter(LearnXYAdapter):
class LearnRacketAdapter (line 893) | class LearnRacketAdapter(LearnXYAdapter):
class LearnRubyAdapter (line 901) | class LearnRubyAdapter(LearnXYAdapter):
method _is_block_separator (line 914) | def _is_block_separator(self, before, now, after):
method _cut_block (line 926) | def _cut_block(block, start_block=False):
class LearnRustAdapter (line 935) | class LearnRustAdapter(LearnXYAdapter):
class LearnSolidityAdapter (line 943) | class LearnSolidityAdapter(LearnXYAdapter):
class LearnSwiftAdapter (line 951) | class LearnSwiftAdapter(LearnXYAdapter):
class LearnTclAdapter (line 959) | class LearnTclAdapter(LearnXYAdapter):
class LearnTcshAdapter (line 967) | class LearnTcshAdapter(LearnXYAdapter):
class LearnVisualBasicAdapter (line 975) | class LearnVisualBasicAdapter(LearnXYAdapter):
class LearnCMakeAdapter (line 983) | class LearnCMakeAdapter(LearnXYAdapter):
class LearnNimAdapter (line 991) | class LearnNimAdapter(LearnXYAdapter):
class LearnGitAdapter (line 999) | class LearnGitAdapter(LearnXYAdapter):
class LearnLatexAdapter (line 1007) | class LearnLatexAdapter(LearnXYAdapter):
FILE: lib/adapter/question.py
class Question (line 42) | class Question(UpstreamAdapter):
method _get_page (line 57) | def _get_page(self, topic, request_options=None):
method get_list (line 130) | def get_list(self, prefix=None):
method is_found (line 133) | def is_found(self, topic):
FILE: lib/adapter/rosetta.py
class Rosetta (line 19) | class Rosetta(GitRepositoryAdapter):
method __init__ (line 31) | def __init__(self):
method _load_rosetta_code_names (line 36) | def _load_rosetta_code_names():
method _rosetta_get_list (line 54) | def _rosetta_get_list(self, query, task=None):
method _parse_query (line 76) | def _parse_query(query):
method _get_task (line 83) | def _get_task(self, lang, query):
method _starting_page (line 122) | def _starting_page(self, query):
method _get_page (line 127) | def _get_page(self, topic, request_options=None):
method _get_list (line 144) | def _get_list(self, prefix=None):
method get_list (line 147) | def get_list(self, prefix=None):
method is_found (line 153) | def is_found(self, _):
FILE: lib/adapter/tldr.py
class Tldr (line 18) | class Tldr(GitRepositoryAdapter):
method _format_page (line 31) | def _format_page(text):
method _get_page (line 70) | def _get_page(self, topic, request_options=None):
method get_updates_list (line 96) | def get_updates_list(cls, updated_files_list):
FILE: lib/adapter/upstream.py
function _are_you_offline (line 19) | def _are_you_offline():
class UpstreamAdapter (line 40) | class UpstreamAdapter(Adapter):
method _get_page (line 55) | def _get_page(self, topic, request_options=None):
method _get_list (line 74) | def _get_list(self, prefix=None):
FILE: lib/cache.py
function put (line 34) | def put(key, value):
function get (line 49) | def get(key):
function delete (line 67) | def delete(key):
FILE: lib/cheat_wrapper.py
function _add_section_name (line 23) | def _add_section_name(query):
function cheat_wrapper (line 36) | def cheat_wrapper(query, request_options=None, output_format="ansi"):
FILE: lib/cheat_wrapper_test.py
function test_header_split (line 34) | def test_header_split():
FILE: lib/config.py
function _config_locations (line 57) | def _config_locations():
class Config (line 157) | class Config(dict):
method _absolute_path (line 163) | def _absolute_path(self, val):
method __init__ (line 168) | def __init__(self, *args, **kwargs):
method __setitem__ (line 172) | def __setitem__(self, key, val):
method update (line 177) | def update(self, *args, **kwargs):
function _load_config_from_environ (line 192) | def _load_config_from_environ(config):
function _get_nested (line 215) | def _get_nested(data, key):
function _load_config_from_file (line 246) | def _load_config_from_file(default_config, filename):
FILE: lib/fetch.py
function _log (line 28) | def _log(*message):
function _run_cmd (line 38) | def _run_cmd(cmd):
function fetch_all (line 47) | def fetch_all(skip_existing=True):
function _update_adapter (line 121) | def _update_adapter(adptr):
function update_all (line 190) | def update_all():
function update_by_name (line 207) | def update_by_name(name):
function _show_usage (line 214) | def _show_usage():
function main (line 233) | def main(args):
FILE: lib/fmt/comments.py
function _language_name (line 43) | def _language_name(name):
function _remove_empty_lines_from_beginning (line 47) | def _remove_empty_lines_from_beginning(lines):
function _remove_empty_lines_from_end (line 55) | def _remove_empty_lines_from_end(lines):
function _cleanup_lines (line 63) | def _cleanup_lines(lines):
function _line_type (line 85) | def _line_type(line):
function _classify_lines (line 115) | def _classify_lines(lines):
function _unindent_code (line 154) | def _unindent_code(line, shift=0):
function _wrap_lines (line 164) | def _wrap_lines(lines_classes, unindent_code=False):
function _run_vim_script (line 185) | def _run_vim_script(script_lines, text_lines):
function _commenting_script (line 217) | def _commenting_script(lines_blocks, filetype):
function _beautify (line 247) | def _beautify(text, filetype, add_comments=False, remove_text=False):
function code_blocks (line 277) | def code_blocks(text, wrap_lines=False, unindent_code=False):
function beautify (line 295) | def beautify(text, lang, options):
function __main__ (line 336) | def __main__():
FILE: lib/fmt/internal.py
function _reverse_palette (line 30) | def _reverse_palette(code):
function _back_color (line 34) | def _back_color(code):
function colorize_internal (line 45) | def colorize_internal(text, palette_number=1):
function colorize_internal_firstpage_v1 (line 97) | def colorize_internal_firstpage_v1(answer):
FILE: lib/fmt/markdown.py
function format_text (line 15) | def format_text(text, config=None, highlighter=None):
function _split_into_paragraphs (line 24) | def _split_into_paragraphs(text):
function _colorize (line 28) | def _colorize(text):
function _format_section (line 45) | def _format_section(section_text, config=None, highlighter=None):
FILE: lib/frontend/ansi.py
function visualize (line 44) | def visualize(answer_data, request_options):
function remove_ansi (line 57) | def remove_ansi(sometext):
function _limited_answer (line 64) | def _limited_answer(answer):
function _colorize_ansi_answer (line 76) | def _colorize_ansi_answer(
function _visualize (line 126) | def _visualize(answers, request_options, search_mode=False):
FILE: lib/frontend/html.py
function visualize (line 37) | def visualize(answer_data, request_options):
function _github_button (line 56) | def _github_button(topic_type):
function _render_html (line 77) | def _render_html(
FILE: lib/globals.py
function fatal (line 13) | def fatal(text):
function error (line 23) | def error(text):
function log (line 33) | def log(text):
FILE: lib/languages_data.py
function rewrite_editor_section_name (line 227) | def rewrite_editor_section_name(section_name):
function get_lexer_name (line 262) | def get_lexer_name(section_name):
FILE: lib/limits.py
function _time_caps (line 25) | def _time_caps(minutes, hours, days):
class Limits (line 33) | class Limits(object):
method __init__ (line 42) | def __init__(self):
method _log_visit (line 57) | def _log_visit(self, interval, ip_address):
method _limit_exceeded (line 62) | def _limit_exceeded(self, interval, ip_address):
method _get_limit (line 67) | def _get_limit(self, interval):
method _report_excessive_visits (line 70) | def _report_excessive_visits(self, interval, ip_address):
method check_ip (line 75) | def check_ip(self, ip_address):
method reset (line 93) | def reset(self):
method _clear_counters_if_needed (line 100) | def _clear_counters_if_needed(self):
FILE: lib/options.py
function parse_args (line 6) | def parse_args(args):
FILE: lib/panela/colors.py
function rgb_from_str (line 10) | def rgb_from_str(s):
function find_nearest_color (line 16) | def find_nearest_color(hex_color):
FILE: lib/panela/panela_colors.py
function color_mapping (line 33) | def color_mapping(clr):
class Point (line 39) | class Point(object):
method __init__ (line 44) | def __init__(self, char=None, foreground=None, background=None):
class Panela (line 50) | class Panela:
method __init__ (line 86) | def __init__(self, x=80, y=25, panela=None, field=None):
method in_field (line 104) | def in_field(self, col, row):
method copy (line 119) | def copy(self, x1, y1, x2, y2):
method cut (line 140) | def cut(self, x1, y1, x2, y2):
method extend (line 164) | def extend(self, cols=None, rows=None):
method crop (line 179) | def crop(self, left=None, right=None, top=None, bottom=None):
method paste (line 210) | def paste(self, panela, x1, y1, extend=False, transparence=False):
method strip (line 249) | def strip(self):
method put_point (line 291) | def put_point(self, col, row, char=None, color=None, background=None):
method put_string (line 311) | def put_string(self, col, row, s=None, color=None, background=None):
method put_line (line 319) | def put_line(self, x1, y1, x2, y2, char=None, color=None, background=N...
method paint (line 406) | def paint(
method put_rectangle (line 471) | def put_rectangle(
method put_circle (line 501) | def put_circle(self, x0, y0, radius, char=None, color=None, background...
method read_ansi (line 558) | def read_ansi(self, seq, x=0, y=0, transparence=True):
method __str__ (line 578) | def __str__(self):
class Template (line 612) | class Template(object):
method __init__ (line 613) | def __init__(self):
method _process_line (line 637) | def _process_line(self, line):
method read (line 643) | def read(self, filename):
method apply_mask (line 662) | def apply_mask(self):
method show (line 678) | def show(self):
function main (line 686) | def main():
FILE: lib/post.py
function _save_cheatsheet (line 16) | def _save_cheatsheet(topic_name, cheatsheet):
function process_post_request (line 31) | def process_post_request(req, topic):
FILE: lib/postprocessing.py
function postprocess (line 5) | def postprocess(answer, keyword, options, request_options=None):
function _answer_add_comments (line 13) | def _answer_add_comments(answer, request_options=None):
function _answer_filter_by_keyword (line 36) | def _answer_filter_by_keyword(answer, keyword, options, request_options=...
function _filter_by_keyword (line 41) | def _filter_by_keyword(answer, keyword, options):
FILE: lib/routing.py
class Router (line 25) | class Router(object):
method __init__ (line 34) | def __init__(self):
method get_topics_list (line 63) | def get_topics_list(self, skip_dirs=False, skip_internal=False):
method get_topic_type (line 86) | def get_topic_type(self, topic: str) -> List[str]:
method _get_page_dict (line 113) | def _get_page_dict(self, query, topic_type, request_options=None):
method handle_if_random_request (line 121) | def handle_if_random_request(self, topic):
method get_answers (line 168) | def get_answers(
FILE: lib/search.py
function _limited_entry (line 28) | def _limited_entry():
function _parse_options (line 37) | def _parse_options(options):
function match (line 51) | def match(paragraph, keyword, options=None, options_dict=None):
function find_answers_by_keyword (line 88) | def find_answers_by_keyword(directory, keyword, options="", request_opti...
FILE: lib/standalone.py
function show_usage (line 23) | def show_usage():
function parse_cmdline (line 41) | def parse_cmdline(args):
function main (line 64) | def main(args):
FILE: lib/stateful_queries.py
function save_query (line 8) | def save_query(client_id, query):
function last_query (line 15) | def last_query(client_id):
FILE: share/scripts/cacheCleanup.go
function removeInvalidEntries (line 16) | func removeInvalidEntries() error {
function main (line 47) | func main() {
Condensed preview — 112 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (947K chars).
[
{
"path": ".dockerignore",
"chars": 46,
"preview": ".git\n.gitignore\ndocker-compose.yml\nDockerfile\n"
},
{
"path": ".github/workflows/tests-macos.yml",
"chars": 217,
"preview": "name: MacOS Tests\n\non:\n push:\n branches: [ master ]\n pull_request:\n branches: [ master ]\n\njobs:\n build:\n run"
},
{
"path": ".github/workflows/tests-ubuntu.yml",
"chars": 1066,
"preview": "name: Ubuntu Tests\n\non:\n push:\n branches: [ master ]\n pull_request:\n branches: [ master ]\n schedule:\n - cron"
},
{
"path": ".gitignore",
"chars": 96,
"preview": "*.pyc\n*.swp\nlog/\nve/\nshare/vim/.vim/\nshare/vim/.viminfo\ntypescript\nvenv/\nbin/upstream\nupstream/\n"
},
{
"path": "CONTRIBUTING.md",
"chars": 673,
"preview": "There are several ways how you can \ncontribute to cheat.sh and make it better and more useful:\n\n1. Suggest a GitHub repo"
},
{
"path": "Dockerfile",
"chars": 751,
"preview": "FROM alpine:3.14\n# fetching cheat sheets\n## installing dependencies\nRUN apk add --update --no-cache git py3-six py3-pygm"
},
{
"path": "LICENSE",
"chars": 1068,
"preview": "MIT License\n\nCopyright (c) 2025 Igor Chubin\n\nPermission is hereby granted, free of charge, to any person obtaining a cop"
},
{
"path": "README.md",
"chars": 37438,
"preview": "\n\n\n\nUnified access to the best community driven cheat sheet"
},
{
"path": "bin/app.py",
"chars": 9377,
"preview": "#!/usr/bin/env python\n# vim: set encoding=utf-8\n# pylint: disable=wrong-import-position,wrong-import-order\n\n\"\"\"\nMain ser"
},
{
"path": "bin/clean_cache.py",
"chars": 128,
"preview": "import sys\nimport redis\n\nREDIS = redis.Redis(host=\"localhost\", port=6379, db=0)\n\nfor key in sys.argv[1:]:\n REDIS.dele"
},
{
"path": "bin/release.py",
"chars": 1532,
"preview": "#!/usr/bin/env python\n\nfrom __future__ import print_function\n\nfrom datetime import datetime\nimport os\nfrom os import pat"
},
{
"path": "bin/srv.py",
"chars": 634,
"preview": "#!/usr/bin/env python\n#\n# Serving cheat.sh with `gevent`\n#\n\nfrom gevent.monkey import patch_all\nfrom gevent.pywsgi impor"
},
{
"path": "doc/README-ja.md",
"chars": 16953,
"preview": " 唯一のチートシート https://cheat.sh/ が必要です\n\n世界の最高のコミュニティ駆動チートシートリポジトリへの統一されたアクセス。\n\n理想的なチートシートのようなものがあるとすぐに想像してみましょう。 どのように見える? ど"
},
{
"path": "doc/standalone.md",
"chars": 2966,
"preview": "\nYou don't need to install anything, to start using *cheat.sh*.\nThe only tool that you need is *curl*, which is typicall"
},
{
"path": "docker-compose.debug.yml",
"chars": 584,
"preview": "# Compose override, see https://docs.docker.com/compose/extends/\n#\n# - Run `flask` standalone server with more debug aid"
},
{
"path": "docker-compose.yml",
"chars": 332,
"preview": "version: '2'\nservices:\n app:\n build: .\n image: cheat.sh\n container_name: chtsh\n depends_on:\n - redis\n "
},
{
"path": "etc/config.yaml",
"chars": 56,
"preview": "server:\n address: \"0.0.0.0\"\ncache:\n type: redis\n"
},
{
"path": "lib/adapter/__init__.py",
"chars": 434,
"preview": "\"\"\"\nImport all adapters from the current directory\nand make them available for import as\n adapter_module.AdapterName\n"
},
{
"path": "lib/adapter/adapter.py",
"chars": 10048,
"preview": "\"\"\"\n`Adapter`, base class of the adapters.\n\nConfiguration parameters:\n\n path.repositories\n\"\"\"\n\nimport abc\nimport os\nf"
},
{
"path": "lib/adapter/cheat_cheat.py",
"chars": 538,
"preview": "\"\"\"\nAdapter for https://github.com/cheat/cheat\n\nCheatsheets are located in `cheat/cheatsheets/`\nEach cheat sheet is a se"
},
{
"path": "lib/adapter/cheat_sheets.py",
"chars": 3891,
"preview": "\"\"\"\nImplementation of the adapter for the native cheat.sh cheat sheets repository,\ncheat.sheets. The cheat sheets repos"
},
{
"path": "lib/adapter/cmd.py",
"chars": 4683,
"preview": "\"\"\" \"\"\"\n\n# pylint: disable=unused-argument,abstract-method\n\nimport os.path\nimport re\nfrom subprocess import Popen, PIPE\n"
},
{
"path": "lib/adapter/common.py",
"chars": 72,
"preview": "class Adapter(object):\n pass\n\n\nclass cheatAdapter(Adapter):\n pass\n"
},
{
"path": "lib/adapter/git_adapter.py",
"chars": 5282,
"preview": "\"\"\"\nImplementation of `GitRepositoryAdapter`, adapter that is used to handle git repositories\n\"\"\"\n\nimport glob\nimport os"
},
{
"path": "lib/adapter/internal.py",
"chars": 3982,
"preview": "\"\"\"\nConfiguration parameters:\n\n frontend.styles\n path.internal.pages\n\"\"\"\n\nimport sys\nimport os\nimport collections\n"
},
{
"path": "lib/adapter/latenz.py",
"chars": 900,
"preview": "\"\"\"\nAdapter for the curlable latencies numbers (chubin/late.nz)\nThis module can be an example of a adapter for a python "
},
{
"path": "lib/adapter/learnxiny.py",
"chars": 26532,
"preview": "\"\"\"\nAdapters for the cheat sheets from the Learn X in Y project\n\nConfiguration parameters:\n\n log.level\n\"\"\"\n\n# pylint:"
},
{
"path": "lib/adapter/question.py",
"chars": 3835,
"preview": "\"\"\"\nConfiguration parameters:\n\n path.internal.bin.upstream\n\"\"\"\n\n# pylint: disable=relative-import\n\nfrom __future__ im"
},
{
"path": "lib/adapter/rosetta.py",
"chars": 4320,
"preview": "\"\"\"\nImplementation of RosettaCode Adapter.\n\nExports:\n\n Rosetta(GitRepositoryAdapter)\n\"\"\"\n\n# pylint: disable=relative-"
},
{
"path": "lib/adapter/tldr.py",
"chars": 3011,
"preview": "\"\"\"\nAdapter for https://github.com/cheat/cheat\n\nCheatsheets are located in `pages/*/`\nEach cheat sheet is a separate fil"
},
{
"path": "lib/adapter/upstream.py",
"chars": 2312,
"preview": "\"\"\"\nAdapter for an external cheat sheets service (i.e. for cheat.sh)\n\nConfiguration parameters:\n\n upstream.url\n up"
},
{
"path": "lib/buttons.py",
"chars": 1460,
"preview": "TWITTER_BUTTON = \"\"\"\n<a href=\"https://twitter.com/igor_chubin\" class=\"twitter-follow-button\" data-show-count=\"false\" dat"
},
{
"path": "lib/cache.py",
"chars": 1539,
"preview": "\"\"\"\nCache implementation.\nCurrently only two types of cache are allowed:\n * \"none\" cache switched off\n * \"redis"
},
{
"path": "lib/cheat_wrapper.py",
"chars": 3595,
"preview": "\"\"\"\nMain cheat.sh wrapper.\nParse the query, get answers from getters (using get_answer),\nvisualize it using frontends an"
},
{
"path": "lib/cheat_wrapper_test.py",
"chars": 559,
"preview": "from cheat_wrapper import _add_section_name\n\nunchanged = \"\"\"\npython/:list\nls\n+\ng++\ng/+\nclang++\nbtrfs~volume\n:intro\n:cht."
},
{
"path": "lib/config.py",
"chars": 8107,
"preview": "\"\"\"\nGlobal configuration of the project.\n\nAll configurable parameters are stored in the global variable CONFIG,\nthe only"
},
{
"path": "lib/fetch.py",
"chars": 6842,
"preview": "\"\"\"\nRepositories fetch and update\n\nThis module makes real network and OS interaction,\nand the adapters only say how exct"
},
{
"path": "lib/fmt/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/fmt/comments.py",
"chars": 9615,
"preview": "\"\"\"\nExtract text from the text-code stream and comment it.\n\nSupports three modes of normalization and commenting:\n\n 1"
},
{
"path": "lib/fmt/internal.py",
"chars": 3694,
"preview": "\"\"\"\nColorize internal cheat sheets.\nWill be merged with panela later.\n\"\"\"\n\nimport re\n\nfrom colorama import Fore, Back, S"
},
{
"path": "lib/fmt/markdown.py",
"chars": 2312,
"preview": "\"\"\"\nMarkdown support.\n\nExports:\n format_text(text, config=None, highlighter=None):\n\nUses external pygments formatters"
},
{
"path": "lib/frontend/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/frontend/ansi.py",
"chars": 5121,
"preview": "\"\"\"\nANSI frontend.\n\nExports:\n visualize(answer_data, request_options)\n\nFormat:\n answer_data = {\n 'answers':"
},
{
"path": "lib/frontend/html.py",
"chars": 4554,
"preview": "\"\"\"\n\nConfiguration parameters:\n\n path.internal.ansi2html\n\"\"\"\n\nimport sys\nimport os\nimport re\nfrom subprocess import P"
},
{
"path": "lib/globals.py",
"chars": 821,
"preview": "\"\"\"\nGlobal functions that our used everywhere in the project.\nPlease, no global variables here.\nFor the configuration re"
},
{
"path": "lib/languages_data.py",
"chars": 7371,
"preview": "\"\"\"\n\nProgramming languages information.\nWill be (probably) moved to a separate file/directory\nfrom the project tree.\n\n\"\""
},
{
"path": "lib/limits.py",
"chars": 2973,
"preview": "\"\"\"\nConnection limitation.\n\nNumber of connections from one IP is limited.\nWe have nothing against scripting and automate"
},
{
"path": "lib/options.py",
"chars": 917,
"preview": "\"\"\"\nParse query arguments.\n\"\"\"\n\n\ndef parse_args(args):\n \"\"\"\n Parse arguments and options.\n Replace short option"
},
{
"path": "lib/panela/colors.json",
"chars": 30762,
"preview": "[{\"colorId\":0,\"hexString\":\"#000000\",\"rgb\":{\"r\":0,\"g\":0,\"b\":0},\"hsl\":{\"h\":0,\"s\":0,\"l\":0},\"name\":\"Black\"},{\"colorId\":1,\"he"
},
{
"path": "lib/panela/colors.py",
"chars": 766,
"preview": "import os\nimport json\n\nCOLORS_JSON = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"colors.json\")\nCOLOR_TABLE"
},
{
"path": "lib/panela/panela_colors.py",
"chars": 21123,
"preview": "# vim: encoding=utf-8\n\nimport os\nimport sys\nimport colored\nimport itertools\nfrom globals import MYDIR\n\n\"\"\"\n\nAfter panela"
},
{
"path": "lib/post.py",
"chars": 1258,
"preview": "\"\"\"\nPOST requests processing.\nCurrently used only for new cheat sheets submission.\n\nConfiguration parameters:\n\n path."
},
{
"path": "lib/postprocessing.py",
"chars": 1847,
"preview": "import search\nimport fmt.comments\n\n\ndef postprocess(answer, keyword, options, request_options=None):\n answer = _answe"
},
{
"path": "lib/routing.py",
"chars": 8371,
"preview": "\"\"\"\nQueries routing and caching.\n\nExports:\n\n get_topics_list()\n get_answers()\n\"\"\"\n\nimport random\nimport re\nfrom ty"
},
{
"path": "lib/search.py",
"chars": 3136,
"preview": "\"\"\"\nVery naive search implementation. Just a placeholder.\n\nExports:\n\n find_answer_by_keyword()\n\nIt should be implemen"
},
{
"path": "lib/standalone.py",
"chars": 1368,
"preview": "\"\"\"\nStandalone wrapper for the cheat.sh server.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport sys\nimport textwrap\n\n"
},
{
"path": "lib/stateful_queries.py",
"chars": 346,
"preview": "\"\"\"\nSupport for the stateful queries\n\"\"\"\n\nimport cache\n\n\ndef save_query(client_id, query):\n \"\"\"\n Save the last que"
},
{
"path": "requirements.txt",
"chars": 164,
"preview": "wheel\ngevent\nflask\nrequests\npygments\ndateutils\nfuzzywuzzy\nredis\ncolored<1.4.3\nlangdetect\ncffi\npolyglot\nPyICU\npycld2\ncolo"
},
{
"path": "share/adapters/chmod.grc",
"chars": 790,
"preview": "# with option -sI\n# e.g. grc curl -sI mysite.com\n# http\nregexp=^(HTTP).*\ncolours=yellow\n======\n# server\nregexp=^(Server)"
},
{
"path": "share/adapters/chmod.sh",
"chars": 4911,
"preview": "#!/usr/bin/env bash\n\n# Contributed by Erez Binyamin (github.com/ErezBinyamin)\n\nGRC_STYLESHEET=\"${BASH_SOURCE[0]}\"; GRC_S"
},
{
"path": "share/adapters/oeis.sh",
"chars": 6091,
"preview": "#!/usr/bin/env bash\n\n# Written by Erez Binyamin (github.com/ErezBinyamin)\n\n# Search for an integer sequence\n# USAGE:\n#\to"
},
{
"path": "share/adapters/rfc.sh",
"chars": 3791,
"preview": "#!/usr/bin/env bash\n\n# Contributed by Erez Binyamin (github.com/ErezBinyamin)\n\n# Search for an RFC\n# Contrib to chubin -"
},
{
"path": "share/ansi2html.sh",
"chars": 16188,
"preview": "#!/bin/sh\n\n# Convert ANSI (terminal) colours and attributes to HTML\n\n# Licence: LGPLv2\n# Author:\n# http://www.pixelbe"
},
{
"path": "share/bash_completion.txt",
"chars": 386,
"preview": "_cht_complete()\n{\n local cur prev opts\n _get_comp_words_by_ref -n : cur\n\n COMPREPLY=()\n cur=\"${COMP_WORDS[CO"
},
{
"path": "share/cht.sh.txt",
"chars": 22941,
"preview": "#!/bin/bash\n# shellcheck disable=SC1117,SC2001\n#\n# [X] open section\n# [X] one shot mode\n# [X] usage info\n# [X] dependenc"
},
{
"path": "share/emacs-ivy.txt",
"chars": 645,
"preview": ";;\n;; Written by RenJMR\n;; https://www.reddit.com/r/emacs/comments/6ddr7p/snippet_search_cheatsh_using_ivy/ \n;; \n;;;\n;;;"
},
{
"path": "share/emacs.txt",
"chars": 5525,
"preview": ";;; cheat-sh.el --- Interact with cheat.sh -*- lexical-binding: t -*-\n;; Copyright 2017 by Dave Pearson <davep@davep.or"
},
{
"path": "share/firstpage-v1.txt",
"chars": 1545,
"preview": "\n oooo . oooo \n `888 "
},
{
"path": "share/firstpage-v2.pnl",
"chars": 5062,
"preview": " _ _ _ __ \n ___| |__ ___ __ _| |_ ___| |__ \\ \\ The only cheat sheet you need\n"
},
{
"path": "share/firstpage-v2.txt",
"chars": 25502,
"preview": " _ _ _ \u001b[38;2;0;204;0m_\u001b[0m\u001b[38;2;0;204;0m_\u001b[0m\u001b[38;2;0;204;0m \u001b[0m\u001b[38;2;0;204;0m \u001b[0m\u001b["
},
{
"path": "share/fish.txt",
"chars": 326,
"preview": "# add it to your ~/.config/fish/config.fish\n\n# retrieve command cheat sheets from cheat.sh\n# fish version by @tobiasreis"
},
{
"path": "share/help.txt",
"chars": 2508,
"preview": "Usage:\n\n $ curl cheat.sh/TOPIC show cheat sheet on the TOPIC\n $ curl cheat.sh/TOPIC/SUB show cheat sheet o"
},
{
"path": "share/intro.txt",
"chars": 7071,
"preview": "## curl cht.sh\n\nTo access a cheat sheet you can simply issue a plain HTTP or HTTPS request\nspecifying the topic name in "
},
{
"path": "share/post.txt",
"chars": 1276,
"preview": "You can add a new entry to a cheat sheet or create a new cheat sheet\nin one of the following ways (your cheat sheet will"
},
{
"path": "share/scripts/cacheCleanup.go",
"chars": 897,
"preview": "package main\n\n// Remove invalid cache entries.\n// Cache entry is invalid, if it contains a special substring.\n\nimport (\n"
},
{
"path": "share/scripts/remove-from-cache.sh",
"chars": 255,
"preview": "#!/usr/bin/env bash\n\nremove_by_name()\n{\n local query; query=\"$1\"\n local q\n\n redis-cli KEYS \"$query\" | while read -r q"
},
{
"path": "share/static/1.html",
"chars": 665,
"preview": "<!doctype html>\n<html>\n <head>\n <link rel=\"stylesheet\" href=\"bower_components/xterm.js/dist/xterm.css\" />\n "
},
{
"path": "share/static/malformed-response.html",
"chars": 2658,
"preview": "<html>\n<title>cheat.sh</title>\n<head>\n<script async src=\"https://platform.twitter.com/widgets.js\" charset=\"utf-8\"></scri"
},
{
"path": "share/static/opensearch.xml",
"chars": 709,
"preview": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<OpenSearchDescription xmlns=\"http://a9.com/-/spec/opensearch/1.1/\" xmlns:moz=\"ht"
},
{
"path": "share/static/style.css",
"chars": 625,
"preview": "body {\n background: black;\n color: #bbbbbb;\n}\n.pre,\npre {\n/* font-family: source_code_proregular; */\n\n/*\nfont-f"
},
{
"path": "share/styles-demo.txt",
"chars": 11119,
"preview": "--------\nabap\n--------\n\u001b[38;5;102m# basic loop\u001b[39m\n\u001b[38;5;21mfor\u001b[39m i in \u001b[38;5;75m1\u001b[39m \u001b[38;5;75m2\u001b[39m \u001b[38;5;75m"
},
{
"path": "share/vim/.vimrc",
"chars": 237,
"preview": "filetype plugin on\n\nset expandtab\nset sts=4\nset ts=4\nset sw=4\nset smartindent\nsyn on\ncolorscheme desert\nmap ds :.,/^--/-"
},
{
"path": "share/vim.txt",
"chars": 777,
"preview": "\" To use cheat.sh from your vim, install the cheat.sh-vim plugin from David Beniamine\n\" located at https://github.com/db"
},
{
"path": "share/zsh.txt",
"chars": 518,
"preview": "#compdef cht.sh\n\n__CHTSH_LANGS=($(curl -s cheat.sh/:list))\n_arguments -C \\\n '--help[show this help message and exit]: :"
},
{
"path": "tests/README.md",
"chars": 101,
"preview": "To run unit tests.\n\n python3 -m pytest -v ../lib/\n\nTo run input/output tests.\n\n ./run-tests.sh\n"
},
{
"path": "tests/results/1",
"chars": 253,
"preview": "1_Inheritance\n1line\n2_Multiple_Inheritance\n:learn\n:list\nAdvanced\nClasses\nComments\nControl_Flow_and_Iterables\nFunctions\nM"
},
{
"path": "tests/results/10",
"chars": 1073,
"preview": "\u001b[38;5;246;03m# How do I copy a file in Python?\u001b[39;00m\n\u001b[38;5;246;03m# \u001b[39;00m\n\u001b[38;5;246;03m# shutil (http://docs."
},
{
"path": "tests/results/11",
"chars": 287,
"preview": "\u001b[38;5;70;01mfrom\u001b[39;00m\u001b[38;5;252m \u001b[39m\u001b[38;5;68;04mshutil\u001b[39;00m\u001b[38;5;252m \u001b[39m\u001b[38;5;70;01mimport\u001b[39;00m\u001b[38;5;"
},
{
"path": "tests/results/12",
"chars": 48,
"preview": "from shutil import copyfile\n\ncopyfile(src, dst)\n"
},
{
"path": "tests/results/13",
"chars": 25502,
"preview": " _ _ _ \u001b[38;2;0;204;0m_\u001b[0m\u001b[38;2;0;204;0m_\u001b[0m\u001b[38;2;0;204;0m \u001b[0m\u001b[38;2;0;204;0m \u001b[0m\u001b["
},
{
"path": "tests/results/14",
"chars": 25502,
"preview": " _ _ _ \u001b[38;2;0;204;0m_\u001b[0m\u001b[38;2;0;204;0m_\u001b[0m\u001b[38;2;0;204;0m \u001b[0m\u001b[38;2;0;204;0m \u001b[0m\u001b["
},
{
"path": "tests/results/15",
"chars": 106294,
"preview": "\u001b[38;5;246;03m# Single line comments start with a number symbol.\u001b[39;00m\n\n\u001b[38;5;214m\"\"\" Multiline strings can be writte"
},
{
"path": "tests/results/16",
"chars": 4580,
"preview": "\u001b[38;5;242m# Latency numbers every programmer should know \u001b[m\n\n1ns Main memory reference: "
},
{
"path": "tests/results/17",
"chars": 13043,
"preview": "\u001b[48;5;8m\u001b[24m cheat.sheets:az \u001b[24m\u001b[0m\n\u001b[38;5;246;03m# Microsoft Azure CLI 2.0\u001b[39;00m\n\u001b[38;5;246;03m# Command-line to"
},
{
"path": "tests/results/18",
"chars": 3128,
"preview": "\u001b[38;5;252m>>\u001b[39m\u001b[38;5;252m>\u001b[39m\u001b[38;5;252m \u001b[39m\u001b[38;5;252ms\u001b[39m\u001b[38;5;252m \u001b[39m\u001b[38;5;252m=\u001b[39m\u001b[38;5;252m \u001b[39m"
},
{
"path": "tests/results/19",
"chars": 560,
"preview": ">>> s = 'abcdefgh'\n>>> n, m, char, chars = 2, 3, 'd', 'cd'\n>>> # starting from n=2 characters in and m=3 in length;\n>>> "
},
{
"path": "tests/results/2",
"chars": 2504,
"preview": "\u001b[48;5;8m\u001b[24m cheat:ls \u001b[24m\u001b[0m\n\u001b[38;5;246;03m# To display everything in <dir>, excluding hidden files:\u001b[39;00m\n\u001b[38;5"
},
{
"path": "tests/results/20",
"chars": 15541,
"preview": "00DESCRIPTION\n100-doors\n24-game\n24-game-Solve\n9-billion-names-of-God-the-integer\n99-Bottles-of-Beer\nA+B\nABC-Problem\nAKS-"
},
{
"path": "tests/results/21",
"chars": 58758,
"preview": "\u001b[38;5;246;03m// Single-line comments start with two slashes.\u001b[39;00m\n\u001b[38;5;246;03m/* Multiline comments start with sla"
},
{
"path": "tests/results/22",
"chars": 58758,
"preview": "\u001b[38;5;246;03m// Single-line comments start with two slashes.\u001b[39;00m\n\u001b[38;5;246;03m/* Multiline comments start with sla"
},
{
"path": "tests/results/23",
"chars": 185,
"preview": ":learn\n:list\nArrays\nAxioms\nChannels\nDeclarations\nEmbedding\nErrors\nInterfaces\nMaps\nOperators\nPointers\nStructs\nfor\nfunc\ngo"
},
{
"path": "tests/results/24",
"chars": 117,
"preview": "Unknown topic.\nDo you mean one of these topics maybe?\n\n * mkfs.fat 84\n * mkfs.vfat 80\n * mkfs.exfat 76\n \n"
},
{
"path": "tests/results/25",
"chars": 4581,
"preview": "\u001b[38;5;242m# Latency numbers every programmer should know \u001b[m\n\n1ns Main memory reference: "
},
{
"path": "tests/results/3",
"chars": 1029,
"preview": "#[cheat:ls]\n# To display everything in <dir>, excluding hidden files:\nls <dir>\n\n# To display everything in <dir>, includ"
},
{
"path": "tests/results/4",
"chars": 5726,
"preview": "\u001b[48;5;8m\u001b[24m cheat.sheets:btrfs \u001b[24m\u001b[0m\n\u001b[38;5;246;03m# Create a btrfs file system on /dev/sdb, /dev/sdc, and /dev/s"
},
{
"path": "tests/results/5",
"chars": 4493,
"preview": "\u001b[48;5;8m\u001b[24m cheat.sheets:btrfs \u001b[24m\u001b[0m\n\u001b[38;5;246;03m# create the subvolume /mnt/sv1 in the /mnt volume\u001b[39;00m\n\u001b[3"
},
{
"path": "tests/results/6",
"chars": 7987,
"preview": "\u001b[38;5;172m## curl cht.sh\u001b[0m\n\nTo access a cheat sheet you can simply issue a plain HTTP or HTTPS request\nspecifying the"
},
{
"path": "tests/results/7",
"chars": 2508,
"preview": "Usage:\n\n $ curl cheat.sh/TOPIC show cheat sheet on the TOPIC\n $ curl cheat.sh/TOPIC/SUB show cheat sheet o"
},
{
"path": "tests/results/8",
"chars": 22888,
"preview": "#!/bin/bash\n# shellcheck disable=SC1117,SC2001\n#\n# [X] open section\n# [X] one shot mode\n# [X] usage info\n# [X] dependenc"
},
{
"path": "tests/results/9",
"chars": 1073,
"preview": "\u001b[38;5;246;03m# How do I copy a file in Python?\u001b[39;00m\n\u001b[38;5;246;03m# \u001b[39;00m\n\u001b[38;5;246;03m# shutil (http://docs."
},
{
"path": "tests/run-tests.sh",
"chars": 3179,
"preview": "#!/bin/bash\n\n# 1) start server:\n# without caching:\n# CHEATSH_CACHE_TYPE=none CHEATSH_PORT=50000 python bin/srv.p"
},
{
"path": "tests/tests.txt",
"chars": 697,
"preview": "python/:list\nls\nls?T\nbtrfs\nbtrfs~volume # search on page\n:intro\n:help\n:cht.sh\ncht.sh python copy file "
}
]
About this extraction
This page contains the full source code of the chubin/cheat.sh GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 112 files (747.8 KB), approximately 346.7k tokens, and a symbol index with 338 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.