Showing preview only (5,025K chars total). Download the full file or copy to clipboard to get everything.
Repository: h2pl/JavaTutorial
Branch: master
Commit: f7dc65e3b5d8
Files: 358
Total size: 4.7 MB
Directory structure:
gitextract_jwwe335b/
├── .gitignore
├── ReadMe.md
├── docs/
│ ├── Java/
│ │ ├── JVM/
│ │ │ ├── JVM总结.md
│ │ │ ├── 深入理解JVM虚拟机:GC调优思路与常用工具.md
│ │ │ ├── 深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md
│ │ │ ├── 深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md
│ │ │ ├── 深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md
│ │ │ ├── 深入理解JVM虚拟机:JVM常用参数以及调优实践.md
│ │ │ ├── 深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md
│ │ │ ├── 深入理解JVM虚拟机:JVM监控工具与诊断实践.md
│ │ │ ├── 深入理解JVM虚拟机:Java内存异常原理与实践.md
│ │ │ ├── 深入理解JVM虚拟机:Java字节码介绍与解析实践.md
│ │ │ ├── 深入理解JVM虚拟机:Java的编译期优化与运行期优化.md
│ │ │ ├── 深入理解JVM虚拟机:再谈四种引用及GC实践.md
│ │ │ ├── 深入理解JVM虚拟机:垃圾回收器详解.md
│ │ │ ├── 深入理解JVM虚拟机:深入理解JVM类加载机制.md
│ │ │ └── 深入理解JVM虚拟机:虚拟机字节码执行引擎.md
│ │ ├── basic/
│ │ │ ├── Java8新特性终极指南.md
│ │ │ ├── JavaIO流.md
│ │ │ ├── Java中的Class类和Object类.md
│ │ │ ├── Java基本数据类型.md
│ │ │ ├── Java异常.md
│ │ │ ├── Java注解和最佳实践.md
│ │ │ ├── Java类和包.md
│ │ │ ├── Java自动拆箱装箱里隐藏的秘密.md
│ │ │ ├── Java集合框架梳理.md
│ │ │ ├── final关键字特性.md
│ │ │ ├── javac和javap.md
│ │ │ ├── string和包装类.md
│ │ │ ├── 代码块和代码执行顺序.md
│ │ │ ├── 反射.md
│ │ │ ├── 多线程.md
│ │ │ ├── 序列化和反序列化.md
│ │ │ ├── 抽象类和接口.md
│ │ │ ├── 枚举类.md
│ │ │ ├── 泛型.md
│ │ │ ├── 深入理解内部类.md
│ │ │ ├── 继承、封装、多态的实现原理.md
│ │ │ ├── 解读Java中的回调.md
│ │ │ └── 面向对象基础.md
│ │ ├── collection/
│ │ │ ├── Java集合类总结.md
│ │ │ ├── Java集合详解:HashMap和HashTable.md
│ │ │ ├── Java集合详解:HashSet,TreeSet与LinkedHashSet.md
│ │ │ ├── Java集合详解:Iterator,fail-fast机制与比较器.md
│ │ │ ├── Java集合详解:Java集合类细节精讲.md
│ │ │ ├── Java集合详解:Queue和LinkedList.md
│ │ │ ├── Java集合详解:TreeMap和红黑树.md
│ │ │ ├── Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md
│ │ │ └── Java集合详解:深入理解LinkedHashMap和LRU缓存.md
│ │ ├── concurrency/
│ │ │ ├── Java并发指南:AQS中的公平锁与非公平锁,Condtion.md
│ │ │ ├── Java并发指南:AQS共享模式与并发工具类的实现.md
│ │ │ ├── Java并发指南:ForkJoin并发框架与工作窃取算法剖析.md
│ │ │ ├── Java并发指南:JMM中的final关键字解析.md
│ │ │ ├── Java并发指南:JUC中常用的Unsafe和Locksupport.md
│ │ │ ├── Java并发指南:JUC的核心类AQS详解.md
│ │ │ ├── Java并发指南:Java中的HashMap和ConcurrentHashMap全解析.md
│ │ │ ├── Java并发指南:Java中的锁Lock和synchronized.md
│ │ │ ├── Java并发指南:Java内存模型JMM总结.md
│ │ │ ├── Java并发指南:Java读写锁ReentrantReadWriteLock源码分析.md
│ │ │ ├── Java并发指南:并发三大问题与volatile关键字,CAS操作.md
│ │ │ ├── Java并发指南:并发基础与Java多线程.md
│ │ │ ├── Java并发指南:深入理解Java内存模型JMM.md
│ │ │ ├── Java并发指南:深度解读Java线程池设计思想及源码实现.md
│ │ │ ├── Java并发指南:解读Java阻塞队列BlockingQueue.md
│ │ │ └── Java并发编程学习总结.md
│ │ ├── design-parttern/
│ │ │ ├── 初探Java设计模式:JDK中的设计模式.md
│ │ │ ├── 初探Java设计模式:Spring涉及到的种设计模式.md
│ │ │ ├── 初探Java设计模式:创建型模式(工厂,单例等).md
│ │ │ ├── 初探Java设计模式:结构型模式(代理模式,适配器模式等).md
│ │ │ ├── 初探Java设计模式:行为型模式(策略,观察者等).md
│ │ │ └── 设计模式学习总结.md
│ │ └── network/
│ │ ├── Java网络与NIO总结.md
│ │ ├── Java网络编程与NIO详解:IO模型与Java网络编程模型.md
│ │ ├── Java网络编程与NIO详解:JAVA中原生的socket通信机制.md
│ │ ├── Java网络编程与NIO详解:JavaNIO一步步构建IO多路复用的请求模型.md
│ │ ├── Java网络编程与NIO详解:Java非阻塞IO和异步IO.md
│ │ ├── Java网络编程与NIO详解:LinuxEpoll实现原理详解.md
│ │ ├── Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO).md
│ │ ├── Java网络编程与NIO详解:基于NIO的网络编程框架Netty.md
│ │ ├── Java网络编程与NIO详解:浅析NIO包中的Buffer、Channel和Selector.md
│ │ ├── Java网络编程与NIO详解:浅析mmap和DirectBuffer.md
│ │ ├── Java网络编程与NIO详解:浅谈Linux中Selector的实现原理.md
│ │ └── Java网络编程与NIO详解:深度解读Tomcat中的NIO模型.md
│ ├── JavaWeb/
│ │ ├── JavaWeb技术总结.md
│ │ ├── 走进JavaWeb技术世界:Hibernate入门经典与注解式开发.md
│ │ ├── 走进JavaWeb技术世界:JDBC的进化与连接池技术.md
│ │ ├── 走进JavaWeb技术世界:JSP与Servlet的曾经与现在.md
│ │ ├── 走进JavaWeb技术世界:JavaWeb的由来和基础知识.md
│ │ ├── 走进JavaWeb技术世界:Java日志系统的诞生与发展.md
│ │ ├── 走进JavaWeb技术世界:Mybatis入门.md
│ │ ├── 走进JavaWeb技术世界:Servlet工作原理详解.md
│ │ ├── 走进JavaWeb技术世界:Tomcat5总体架构剖析.md
│ │ ├── 走进JavaWeb技术世界:Tomcat和其他WEB容器的区别.md
│ │ ├── 走进JavaWeb技术世界:从JavaBean讲到Spring.md
│ │ ├── 走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven.md
│ │ ├── 走进JavaWeb技术世界:初探Tomcat9的HTTP请求过程.md
│ │ ├── 走进JavaWeb技术世界:单元测试框架Junit.md
│ │ ├── 走进JavaWeb技术世界:极简配置的SpringBoot.md
│ │ ├── 走进JavaWeb技术世界:浅析Tomcat请求处理流程与启动部署过程.md
│ │ └── 走进JavaWeb技术世界:深入浅出Mybatis基本原理.md
│ ├── Spring全家桶/
│ │ ├── Spring/
│ │ │ ├── SpringAOP的概念与作用.md
│ │ │ ├── SpringBean的定义与管理(核心).md
│ │ │ ├── Spring中对于数据库的访问.md
│ │ │ ├── Spring中对于校验功能的支持.md
│ │ │ ├── Spring中的Environment环境变量.md
│ │ │ ├── Spring中的事件处理机制.md
│ │ │ ├── Spring中的资源管理.md
│ │ │ ├── Spring中的配置元数据(管理配置的基本数据).md
│ │ │ ├── Spring事务基本用法.md
│ │ │ ├── Spring合集.md
│ │ │ ├── Spring容器与IOC.md
│ │ │ ├── Spring常见注解.md
│ │ │ ├── Spring概述.md
│ │ │ └── 第一个Spring应用.md
│ │ ├── SpringBoot/
│ │ │ ├── SpringBoot中的任务调度与@Async.md
│ │ │ ├── SpringBoot中的日志管理.md
│ │ │ ├── SpringBoot常见注解.md
│ │ │ ├── SpringBoot应用也可以部署到外部Tomcat.md
│ │ │ ├── SpringBoot打包与启动.md
│ │ │ ├── SpringBoot生产环境工具Actuator.md
│ │ │ ├── SpringBoot的Starter机制.md
│ │ │ ├── SpringBoot的前世今生.md
│ │ │ ├── SpringBoot的基本使用.md
│ │ │ ├── SpringBoot的配置文件管理.md
│ │ │ ├── SpringBoot自带的热部署工具.md
│ │ │ ├── SpringBoot集成Swagger实现API文档自动生成.md
│ │ │ ├── Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot).md
│ │ │ ├── 基于SpringBoot中的开源监控工具SpringBootAdmin.md
│ │ │ └── 给你一份SpringBoot知识清单.md
│ │ ├── SpringBoot源码解析/
│ │ │ ├── @SpringBootApplication注解.md
│ │ │ ├── SpringBootWeb应用(一):servlet组件的注册流程.md
│ │ │ ├── SpringBootWeb应用(二):WebMvc装配过程.md
│ │ │ ├── SpringBoot启动流程(一):准备SpringApplication.md
│ │ │ ├── SpringBoot启动流程(三):准备IOC容器.md
│ │ │ ├── SpringBoot启动流程(二):准备运行环境.md
│ │ │ ├── SpringBoot启动流程(五):完成启动.md
│ │ │ ├── SpringBoot启动流程(六):启动流程总结.md
│ │ │ ├── SpringBoot启动流程(四):启动IOC容器.md
│ │ │ ├── SpringBoot自动装配(一):加载自动装配类.md
│ │ │ ├── SpringBoot自动装配(三):自动装配顺序.md
│ │ │ └── SpringBoot自动装配(二):条件注解.md
│ │ ├── SpringCloud/
│ │ │ ├── SpringCloudConfig.md
│ │ │ ├── SpringCloudConsul.md
│ │ │ ├── SpringCloudEureka.md
│ │ │ ├── SpringCloudGateway.md
│ │ │ ├── SpringCloudHystrix.md
│ │ │ ├── SpringCloudLoadBalancer.md
│ │ │ ├── SpringCloudOpenFeign.md
│ │ │ ├── SpringCloudRibbon.md
│ │ │ ├── SpringCloudSleuth.md
│ │ │ ├── SpringCloudZuul.md
│ │ │ └── SpringCloud概述.md
│ │ ├── SpringCloudAlibaba/
│ │ │ ├── SpringCloudAlibabaNacos.md
│ │ │ ├── SpringCloudAlibabaRocketMQ.md
│ │ │ ├── SpringCloudAlibabaSeata.md
│ │ │ ├── SpringCloudAlibabaSentinel.md
│ │ │ ├── SpringCloudAlibabaSkywalking.md
│ │ │ └── SpringCloudAlibaba概览.md
│ │ ├── SpringCloudAlibaba源码分析/
│ │ │ ├── SpringCloudAlibabaNacos源码分析:服务发现.md
│ │ │ ├── SpringCloudAlibabaNacos源码分析:服务注册.md
│ │ │ ├── SpringCloudAlibabaNacos源码分析:概览.md
│ │ │ ├── SpringCloudAlibabaNacos源码分析:配置中心.md
│ │ │ ├── SpringCloudRocketMQ源码分析.md
│ │ │ ├── SpringCloudSeata源码分析.md
│ │ │ └── SpringCloudSentinel源码分析.md
│ │ ├── SpringCloud源码分析/
│ │ │ ├── SpringCloudConfig源码分析.md
│ │ │ ├── SpringCloudEureka源码分析.md
│ │ │ ├── SpringCloudGateway源码分析.md
│ │ │ ├── SpringCloudHystrix源码分析.md
│ │ │ ├── SpringCloudLoadBalancer源码分析.md
│ │ │ ├── SpringCloudOpenFeign源码分析.md
│ │ │ └── SpringCloudRibbon源码分析.md
│ │ ├── SpringMVC/
│ │ │ ├── SpringMVC中的国际化功能.md
│ │ │ ├── SpringMVC中的常用功能.md
│ │ │ ├── SpringMVC中的异常处理器.md
│ │ │ ├── SpringMVC中的拦截器.md
│ │ │ ├── SpringMVC中的视图解析器.md
│ │ │ ├── SpringMVC中的过滤器Filter.md
│ │ │ ├── SpringMVC基本介绍与快速入门.md
│ │ │ ├── SpringMVC如何实现文件上传.md
│ │ │ └── SpringMVC常见注解.md
│ │ ├── SpringMVC源码分析/
│ │ │ ├── DispatcherServlet初始化流程.md
│ │ │ ├── RequestMapping初始化流程.md
│ │ │ ├── SpringMVC整体源码结构总结.md
│ │ │ ├── SpringMVC源码分析:DispatcherServlet如何找到正确的Controller.md
│ │ │ ├── SpringMVC源码分析:DispatcherServlet的初始化与请求转发.md
│ │ │ ├── SpringMVC源码分析:SpringMVC概述.md
│ │ │ ├── SpringMVC源码分析:SpringMVC的视图解析原理.md
│ │ │ ├── SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet.md
│ │ │ ├── SpringMVC源码分析:消息转换器HttpMessageConverter与@ResponseBody注解.md
│ │ │ ├── SpringMVC的Demo与@EnableWebMvc注解.md
│ │ │ ├── Spring容器启动Tomcat.md
│ │ │ ├── 请求执行流程(一)之获取Handler.md
│ │ │ └── 请求执行流程(二)之执行Handler方法.md
│ │ └── Spring源码分析/
│ │ ├── SpringAOP/
│ │ │ ├── AOP示例demo及@EnableAspectJAutoProxy.md
│ │ │ ├── AnnotationAwareAspectJAutoProxyCreator分析(上).md
│ │ │ ├── AnnotationAwareAspectJAutoProxyCreator分析(下).md
│ │ │ ├── SpringAop(五):cglib代理.md
│ │ │ ├── SpringAop(六):aop总结.md
│ │ │ └── SpringAop(四):jdk动态代理.md
│ │ ├── Spring事务/
│ │ │ ├── Spring事务(一):认识事务组件.md
│ │ │ ├── Spring事务(三):事务的隔离级别与传播方式的处理01.md
│ │ │ ├── Spring事务(二):事务的执行流程.md
│ │ │ ├── Spring事务(五):事务的隔离级别与传播方式的处理03.md
│ │ │ ├── Spring事务(六):事务的隔离级别与传播方式的处理04.md
│ │ │ └── Spring事务(四):事务的隔离级别与传播方式的处理02.md
│ │ ├── Spring启动流程/
│ │ │ ├── Spring启动流程(一):启动流程概览.md
│ │ │ ├── Spring启动流程(七):国际化与事件处理.md
│ │ │ ├── Spring启动流程(三):包的扫描流程.md
│ │ │ ├── Spring启动流程(九):单例bean的创建.md
│ │ │ ├── Spring启动流程(二):ApplicationContext的创建.md
│ │ │ ├── Spring启动流程(五):执行BeanFactoryPostProcessor.md
│ │ │ ├── Spring启动流程(八):完成BeanFactory的初始化.md
│ │ │ ├── Spring启动流程(六):注册BeanPostProcessor.md
│ │ │ ├── Spring启动流程(十一):启动流程总结.md
│ │ │ ├── Spring启动流程(十):启动完成的处理.md
│ │ │ └── Spring启动流程(四):启动前的准备工作.md
│ │ ├── Spring源码剖析:AOP实现原理详解.md
│ │ ├── Spring源码剖析:JDK和cglib动态代理原理详解.md
│ │ ├── Spring源码剖析:SpringAOP概述.md
│ │ ├── Spring源码剖析:SpringIOC容器的加载过程.md
│ │ ├── Spring源码剖析:Spring事务概述.md
│ │ ├── Spring源码剖析:Spring事务源码剖析.md
│ │ ├── Spring源码剖析:初探SpringIOC核心流程.md
│ │ ├── Spring源码剖析:懒加载的单例Bean获取过程分析.md
│ │ ├── Spring组件分析/
│ │ │ ├── Spring组件之ApplicationContext.md
│ │ │ ├── Spring组件之BeanDefinition.md
│ │ │ ├── Spring组件之BeanFactory.md
│ │ │ ├── Spring组件之BeanFactoryPostProcessor.md
│ │ │ └── Spring组件之BeanPostProcessor.md
│ │ └── Spring重要机制探秘/
│ │ ├── ConfigurationClassPostProcessor(一):处理@ComponentScan注解.md
│ │ ├── ConfigurationClassPostProcessor(三):处理@Import注解.md
│ │ ├── ConfigurationClassPostProcessor(二):处理@Bean注解.md
│ │ ├── ConfigurationClassPostProcessor(四):处理@Conditional注解.md
│ │ ├── Spring探秘之AOP的执行顺序.md
│ │ ├── Spring探秘之Spring事件机制.md
│ │ ├── Spring探秘之循环依赖的解决(一):理论基石.md
│ │ ├── Spring探秘之循环依赖的解决(二):源码分析.md
│ │ ├── Spring探秘之监听器注解EventListener.md
│ │ └── Spring探秘之组合注解的处理.md
│ ├── backend/
│ │ ├── Hadoop生态总结.md
│ │ ├── 后端技术杂谈开篇:云计算,大数据与AI的故事.md
│ │ ├── 后端技术杂谈:Docker 核心技术与实现原理.md
│ │ ├── 后端技术杂谈:Elasticsearch与solr入门实践.md
│ │ ├── 后端技术杂谈:Lucene基础原理与实践.md
│ │ ├── 后端技术杂谈:OpenStack架构设计.md
│ │ ├── 后端技术杂谈:OpenStack的基石KVM.md
│ │ ├── 后端技术杂谈:云计算的前世今生.md
│ │ ├── 后端技术杂谈:先搞懂Docker核心概念吧.md
│ │ ├── 后端技术杂谈:十分钟理解Kubernetes核心概念.md
│ │ ├── 后端技术杂谈:捋一捋大数据研发的基本概念.md
│ │ ├── 后端技术杂谈:搜索引擎基础倒排索引.md
│ │ ├── 后端技术杂谈:搜索引擎工作原理.md
│ │ └── 后端技术杂谈:白话虚拟化技术.md
│ ├── cache/
│ │ ├── Redis原理与实践总结.md
│ │ ├── 探索Redis设计与实现开篇:什么是Redis.md
│ │ ├── 探索Redis设计与实现:Redis 的基础数据结构概览.md
│ │ ├── 探索Redis设计与实现:Redis事务浅析与ACID特性介绍.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——dict.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——intset.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——quicklist.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——sds.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——skiplist.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——ziplist.md
│ │ ├── 探索Redis设计与实现:Redis分布式锁进化史.md
│ │ ├── 探索Redis设计与实现:Redis的事件驱动模型与命令执行过程.md
│ │ ├── 探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例.md
│ │ ├── 探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中.md
│ │ ├── 探索Redis设计与实现:数据库redisDb与键过期删除策略.md
│ │ ├── 探索Redis设计与实现:浅析Redis主从复制.md
│ │ └── 探索Redis设计与实现:连接底层与表面的数据结构robj.md
│ ├── cs/
│ │ ├── algorithms/
│ │ │ └── 剑指offer.md
│ │ ├── network/
│ │ │ └── 计算机网络学习总结.md
│ │ └── operating-system/
│ │ ├── Linux内核与基础命令学习总结.md
│ │ └── 操作系统学习总结.md
│ ├── database/
│ │ ├── Mysql原理与实践总结.md
│ │ ├── 重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系.md
│ │ ├── 重新学习MySQL数据库:MySQL的事务隔离级别实战.md
│ │ ├── 重新学习MySQL数据库:MySQL里的那些日志们.md
│ │ ├── 重新学习MySQL数据库:Mysql主从复制,读写分离,分表分库策略与实践.md
│ │ ├── 重新学习MySQL数据库:Mysql存储引擎与数据存储原理.md
│ │ ├── 重新学习MySQL数据库:Mysql索引实现原理和相关数据结构算法.md
│ │ ├── 重新学习MySQL数据库:『浅入浅出』MySQL和InnoDB.md
│ │ ├── 重新学习MySQL数据库:从实践sql语句优化开始.md
│ │ ├── 重新学习MySQL数据库:以Java的视角来聊聊SQL注入.md
│ │ ├── 重新学习MySQL数据库:无废话MySQL入门.md
│ │ ├── 重新学习MySQL数据库:根据MySQL索引原理进行分析与优化.md
│ │ ├── 重新学习MySQL数据库:浅谈MySQL的中事务与锁.md
│ │ └── 重新学习MySQL数据库:详解MyIsam与InnoDB引擎的锁实现.md
│ ├── distributed/
│ │ ├── basic/
│ │ │ ├── 分布式系统理论基础 :CAP.md
│ │ │ ├── 分布式系统理论基础: 一致性、PC和PC.md
│ │ │ ├── 分布式系统理论基础: 时间、时钟和事件顺序.md
│ │ │ ├── 分布式系统理论基础:Paxos.md
│ │ │ ├── 分布式系统理论基础:Raft、Zab.md
│ │ │ ├── 分布式系统理论基础:zookeeper分布式协调服务.md
│ │ │ ├── 分布式系统理论基础:选举、多数派和租约.md
│ │ │ └── 分布式系统理论进阶:Paxos变种和优化.md
│ │ ├── practice/
│ │ │ ├── 搞懂分布式技术:LVS实现负载均衡的原理与实践.md
│ │ │ ├── 搞懂分布式技术:SpringBoot使用注解集成Redis缓存.md
│ │ │ ├── 搞懂分布式技术:ZAB协议概述与选主流程详解.md
│ │ │ ├── 搞懂分布式技术:Zookeeper典型应用场景及实践.md
│ │ │ ├── 搞懂分布式技术:Zookeeper的配置与集群管理实战.md
│ │ │ ├── 搞懂分布式技术:使用RocketMQ事务消息解决分布式事务.md
│ │ │ ├── 搞懂分布式技术:分布式ID生成方案.md
│ │ │ ├── 搞懂分布式技术:分布式session解决方案与一致性hash.md
│ │ │ ├── 搞懂分布式技术:分布式一致性协议与Paxos,Raft算法.md
│ │ │ ├── 搞懂分布式技术:分布式事务常用解决方案.md
│ │ │ ├── 搞懂分布式技术:分布式系统的一些基本概念.md
│ │ │ ├── 搞懂分布式技术:初探分布式协调服务zookeeper.md
│ │ │ ├── 搞懂分布式技术:浅析分布式事务.md
│ │ │ ├── 搞懂分布式技术:浅谈分布式消息技术Kafka.md
│ │ │ ├── 搞懂分布式技术:浅谈分布式锁的几种方案.md
│ │ │ ├── 搞懂分布式技术:消息队列因何而生.md
│ │ │ ├── 搞懂分布式技术:缓存更新的套路.md
│ │ │ └── 搞懂分布式技术:缓存的那些事.md
│ │ ├── 分布式技术实践总结.md
│ │ └── 分布式理论总结.md
│ ├── hxx/
│ │ ├── java/
│ │ │ ├── Java后端工程师必备书单(从Java基础到分布式).md
│ │ │ ├── Java工程师修炼之路(校招总结).md
│ │ │ ├── 为什么我会选择走 Java 这条路?.md
│ │ │ ├── 你不可错过的Java学习资源清单.md
│ │ │ ├── 想了解Java后端学习路线?你只需要这一张图!.md
│ │ │ └── 我的Java秋招面经大合集.md
│ │ ├── think/
│ │ │ └── copy.md
│ │ └── 电子书.md
│ ├── interview/
│ │ ├── BATJ-Experience/
│ │ │ ├── alipay-pinduoduo-toutiao.md
│ │ │ ├── 蚂蚁金服实习生面经总结(已拿口头offer).md
│ │ │ └── 面阿里,终获offer.md
│ │ ├── InterviewQuestions/
│ │ │ └── Java核心技术总结.md
│ │ └── PreparingForInterview/
│ │ ├── JavaInterviewLibrary.md
│ │ ├── JavaProgrammerNeedKnow.md
│ │ ├── interviewPrepare.md
│ │ ├── 如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md
│ │ ├── 程序员的简历之道.md
│ │ └── 美团面试常见问题总结.md
│ ├── monitor/
│ │ ├── Spring Actuator.md
│ │ └── SpringBoot Admin.md
│ └── mq/
│ ├── RocketMQ/
│ │ ├── RocketMQ系列:事务消息(最终一致性).md
│ │ ├── RocketMQ系列:基本概念.md
│ │ ├── RocketMQ系列:广播与延迟消息.md
│ │ ├── RocketMQ系列:批量发送与过滤.md
│ │ ├── RocketMQ系列:消息的生产与消费.md
│ │ ├── RocketMQ系列:环境搭建.md
│ │ └── RocketMQ系列:顺序消费.md
│ └── kafka/
│ ├── 消息队列kafka详解:Kafka 快速上手(Java版).md
│ ├── 消息队列kafka详解:Kafka一条消息存到broker的过程.md
│ ├── 消息队列kafka详解:Kafka介绍.md
│ ├── 消息队列kafka详解:Kafka原理分析总结篇.md
│ ├── 消息队列kafka详解:Kafka常见命令及配置总结.md
│ ├── 消息队列kafka详解:Kafka架构介绍.md
│ ├── 消息队列kafka详解:Kafka的集群工作原理.md
│ ├── 消息队列kafka详解:Kafka重要知识点+面试题大全.md
│ ├── 消息队列kafka详解:如何实现延迟队列.md
│ └── 消息队列kafka详解:如何实现死信队列.md
├── pom.xml
└── src/
└── main/
└── java/
├── Test.java
└── md/
├── codeFormat.java
└── mdToc.java
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Created by .ignore support plugin (hsz.mobi)
### Example user template template
### Example user template
# IntelliJ project files
.idea
*.iml
out
gen
/target/
================================================
FILE: ReadMe.md
================================================
<div align="center">
<a href="https://github.com/h2pl/Java-Tutorial">
<img src="https://java-tutorial.oss-cn-shanghai.aliyuncs.com/Javatutorial-v1.png" width="300" height="300"/>
</a>
</div>
<p>
<div align="center">
<a href="https://github.com/h2pl/Java-Tutorial"><img src="https://img.shields.io/github/stars/h2pl/JavaTutorial.svg"></a>
<a href="https://github.com/h2pl/Java-Tutorial"><img src="https://img.shields.io/github/forks/h2pl/JavaTutorial.svg"></a>
<a href="https://github.com/h2pl/Java-Tutorial"><img src="https://img.shields.io/github/issues/h2pl/JavaTutorial.svg"></a>
<a href="https://github.com/h2pl/Java-Tutorial"><img src="https://img.shields.io/github/license/h2pl/JavaTutorial.svg"></a>
<a href="https://github.com/h2pl/Java-Tutorial"><img src="https://img.shields.io/github/last-commit/h2pl/JavaTutorial.svg"></a>
<a href="https://github.com/h2pl/Java-Tutorial"><img src="https://img.shields.io/github/release/h2pl/JavaTutorial.svg"></a>
</div>
</p>
力求打造最完整最实用的Java工程师学习指南!
这些文章和总结都是我近几年学习Java总结和整理出来的,非常实用,对于学习Java后端的朋友来说应该是最全面最完整的技术仓库。
我靠着这些内容进行复习,拿到了BAT等大厂的offer,这个仓库也已经帮助了很多的Java学习者,如果对你有用,希望能给个star支持我,谢谢!
为了更好地讲清楚每个知识模块,我们也参考了很多网上的优质博文,力求不漏掉每一个知识点,所有参考博文都将声明转载来源,如有侵权,请联系我。
点击关注[微信公众号](#微信公众号)及时获取笔主最新更新文章,并可免费领取Java工程师必备学习资源
<p align="center">
<a href="https://github.com/h2pl/Java-Tutorial" target="_blank">
<img src="https://java-tutorial.oss-cn-shanghai.aliyuncs.com/Javatutorial.jpeg" width="900" height="300"/>
</a>
</p>
<p>
# Java基础
## 基础知识
* [面向对象基础](docs/Java/basic/面向对象基础.md)
* [Java基本数据类型](docs/Java/basic/Java基本数据类型.md)
* [string和包装类](docs/Java/basic/string和包装类.md)
* [final关键字特性](docs/Java/basic/final关键字特性.md)
* [Java类和包](docs/Java/basic/Java类和包.md)
* [抽象类和接口](docs/Java/basic/抽象类和接口.md)
* [代码块和代码执行顺序](docs/Java/basic/代码块和代码执行顺序.md)
* [Java自动拆箱装箱里隐藏的秘密](docs/Java/basic/Java自动拆箱装箱里隐藏的秘密.md)
* [Java中的Class类和Object类](docs/Java/basic/Java中的Class类和Object类.md)
* [Java异常](docs/Java/basic/Java异常.md)
* [解读Java中的回调](docs/Java/basic/解读Java中的回调.md)
* [反射](docs/Java/basic/反射.md)
* [泛型](docs/Java/basic/泛型.md)
* [枚举类](docs/Java/basic/枚举类.md)
* [Java注解和最佳实践](docs/Java/basic/Java注解和最佳实践.md)
* [JavaIO流](docs/Java/basic/JavaIO流.md)
* [多线程](docs/Java/basic/多线程.md)
* [深入理解内部类](docs/Java/basic/深入理解内部类.md)
* [javac和javap](docs/Java/basic/javac和javap.md)
* [Java8新特性终极指南](docs/Java/basic/Java8新特性终极指南.md)
* [序列化和反序列化](docs/Java/basic/序列化和反序列化.md)
* [继承封装多态的实现原理](docs/Java/basic/继承封装多态的实现原理.md)
## 集合类
* [Java集合类总结](docs/Java/collection/Java集合类总结.md)
* [Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理](docs/Java/collection/Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md)
* [Java集合详解:Queue和LinkedList](docs/Java/collection/Java集合详解:Queue和LinkedList.md)
* [Java集合详解:Iterator,fail-fast机制与比较器](docs/Java/collection/Java集合详解:Iterator,fail-fast机制与比较器.md)
* [Java集合详解:HashMap和HashTable](docs/Java/collection/Java集合详解:HashMap和HashTable.md)
* [Java集合详解:深入理解LinkedHashMap和LRU缓存](docs/Java/collection/Java集合详解:深入理解LinkedHashMap和LRU缓存.md)
* [Java集合详解:TreeMap和红黑树](docs/Java/collection/Java集合详解:TreeMap和红黑树.md)
* [Java集合详解:HashSet,TreeSet与LinkedHashSet](docs/Java/collection/Java集合详解:HashSet,TreeSet与LinkedHashSet.md)
* [Java集合详解:Java集合类细节精讲](docs/Java/collection/Java集合详解:Java集合类细节精讲.md)
# JavaWeb
* [走进JavaWeb技术世界:JavaWeb的由来和基础知识](docs/JavaWeb/走进JavaWeb技术世界:JavaWeb的由来和基础知识.md)
* [走进JavaWeb技术世界:JSP与Servlet的曾经与现在](docs/JavaWeb/走进JavaWeb技术世界:JSP与Servlet的曾经与现在.md)
* [走进JavaWeb技术世界:JDBC的进化与连接池技术](docs/JavaWeb/走进JavaWeb技术世界:JDBC的进化与连接池技术.md)
* [走进JavaWeb技术世界:Servlet工作原理详解](docs/JavaWeb/走进JavaWeb技术世界:Servlet工作原理详解.md)
* [走进JavaWeb技术世界:初探Tomcat的HTTP请求过程](docs/JavaWeb/走进JavaWeb技术世界:初探Tomcat的HTTP请求过程.md)
* [走进JavaWeb技术世界:Tomcat5总体架构剖析](docs/JavaWeb/走进JavaWeb技术世界:Tomcat5总体架构剖析.md)
* [走进JavaWeb技术世界:Tomcat和其他WEB容器的区别](docs/JavaWeb/走进JavaWeb技术世界:Tomcat和其他WEB容器的区别.md)
* [走进JavaWeb技术世界:浅析Tomcat9请求处理流程与启动部署过程](docs/JavaWeb/走进JavaWeb技术世界:浅析Tomcat9请求处理流程与启动部署过程.md)
* [走进JavaWeb技术世界:Java日志系统的诞生与发展](docs/JavaWeb/走进JavaWeb技术世界:Java日志系统的诞生与发展.md)
* [走进JavaWeb技术世界:从JavaBean讲到Spring](docs/JavaWeb/走进JavaWeb技术世界:从JavaBean讲到Spring.md)
* [走进JavaWeb技术世界:单元测试框架Junit](docs/JavaWeb/走进JavaWeb技术世界:单元测试框架Junit.md)
* [走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven](docs/JavaWeb/走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven.md)
* [走进JavaWeb技术世界:Hibernate入门经典与注解式开发](docs/JavaWeb/走进JavaWeb技术世界:Hibernate入门经典与注解式开发.md)
* [走进JavaWeb技术世界:Mybatis入门](docs/JavaWeb/走进JavaWeb技术世界:Mybatis入门.md)
* [走进JavaWeb技术世界:深入浅出Mybatis基本原理](docs/JavaWeb/走进JavaWeb技术世界:深入浅出Mybatis基本原理.md)
* [走进JavaWeb技术世界:极简配置的SpringBoot](docs/JavaWeb/走进JavaWeb技术世界:极简配置的SpringBoot.md)
# Java进阶
## 并发编程
* [Java并发指南:并发基础与Java多线程](docs/Java/concurrency/Java并发指南:并发基础与Java多线程.md)
* [Java并发指南:深入理解Java内存模型JMM](docs/Java/concurrency/Java并发指南:深入理解Java内存模型JMM.md)
* [Java并发指南:并发三大问题与volatile关键字,CAS操作](docs/Java/concurrency/Java并发指南:并发三大问题与volatile关键字,CAS操作.md)
* [Java并发指南:Java中的锁Lock和synchronized](docs/Java/concurrency/Java并发指南:Java中的锁Lock和synchronized.md)
* [Java并发指南:JMM中的final关键字解析](docs/Java/concurrency/Java并发指南:JMM中的final关键字解析.md)
* [Java并发指南:Java内存模型JMM总结](docs/Java/concurrency/Java并发指南:Java内存模型JMM总结.md)
* [Java并发指南:JUC的核心类AQS详解](docs/Java/concurrency/Java并发指南:JUC的核心类AQS详解.md)
* [Java并发指南:AQS中的公平锁与非公平锁,Condtion](docs/Java/concurrency/Java并发指南:AQS中的公平锁与非公平锁,Condtion.md)
* [Java并发指南:AQS共享模式与并发工具类的实现](docs/Java/concurrency/Java并发指南:AQS共享模式与并发工具类的实现.md)
* [Java并发指南:Java读写锁ReentrantReadWriteLock源码分析](docs/Java/concurrency/Java并发指南:Java读写锁ReentrantReadWriteLock源码分析.md)
* [Java并发指南:解读Java阻塞队列BlockingQueue](docs/Java/concurrency/Java并发指南:解读Java阻塞队列BlockingQueue.md)
* [Java并发指南:深度解读java线程池设计思想及源码实现](docs/Java/concurrency/Java并发指南:深度解读Java线程池设计思想及源码实现.md)
* [Java并发指南:Java中的HashMap和ConcurrentHashMap全解析](docs/Java/concurrency/Java并发指南:Java中的HashMap和ConcurrentHashMap全解析.md)
* [Java并发指南:JUC中常用的Unsafe和Locksupport](docs/Java/concurrency/Java并发指南:JUC中常用的Unsafe和Locksupport.md)
* [Java并发指南:ForkJoin并发框架与工作窃取算法剖析](docs/Java/concurrency/Java并发指南:ForkJoin并发框架与工作窃取算法剖析.md)
* [Java并发编程学习总结](docs/Java/concurrency/Java并发编程学习总结.md)
## JVM
* [JVM总结](docs/Java/JVM/JVM总结.md)
* [深入理解JVM虚拟机:JVM内存的结构与消失的永久代](docs/Java/JVM/深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md)
* [深入理解JVM虚拟机:JVM垃圾回收基本原理和算法](docs/Java/JVM/深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md)
* [深入理解JVM虚拟机:垃圾回收器详解](docs/Java/JVM/深入理解JVM虚拟机:垃圾回收器详解.md)
* [深入理解JVM虚拟机:Javaclass介绍与解析实践](docs/Java/JVM/深入理解JVM虚拟机:Java字节码介绍与解析实践.md)
* [深入理解JVM虚拟机:虚拟机字节码执行引擎](docs/Java/JVM/深入理解JVM虚拟机:虚拟机字节码执行引擎.md)
* [深入理解JVM虚拟机:深入理解JVM类加载机制](docs/Java/JVM/深入理解JVM虚拟机:深入理解JVM类加载机制.md)
* [深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现](docs/Java/JVM/深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md)
* [深入了解JVM虚拟机:Java的编译期优化与运行期优化](docs/Java/JVM/深入理解JVM虚拟机:Java的编译期优化与运行期优化.md)
* [深入理解JVM虚拟机:JVM监控工具与诊断实践](docs/Java/JVM/深入理解JVM虚拟机:JVM监控工具与诊断实践.md)
* [深入理解JVM虚拟机:JVM常用参数以及调优实践](docs/Java/JVM/深入理解JVM虚拟机:JVM常用参数以及调优实践.md)
* [深入理解JVM虚拟机:Java内存异常原理与实践](docs/Java/JVM/深入理解JVM虚拟机:Java内存异常原理与实践.md)
* [深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战](docs/Java/JVM/深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md)
* [深入理解JVM虚拟机:再谈四种引用及GC实践](docs/Java/JVM/深入理解JVM虚拟机:再谈四种引用及GC实践.md)
* [深入理解JVM虚拟机:GC调优思路与常用工具](docs/Java/JVM/深入理解JVM虚拟机:GC调优思路与常用工具.md)
## Java网络编程
* [Java网络编程和NIO详解:JAVA 中原生的 socket 通信机制](docs/Java/network/Java网络编程与NIO详解:JAVA中原生的socket通信机制.md)
* [Java网络编程与NIO详解:JAVA NIO 一步步构建IO多路复用的请求模型](docs/Java/network/Java网络编程与NIO详解:JavaNIO一步步构建IO多路复用的请求模型.md)
* [Java网络编程和NIO详解:IO模型与Java网络编程模型](docs/Java/network/Java网络编程与NIO详解:IO模型与Java网络编程模型.md)
* [Java网络编程与NIO详解:浅析NIO包中的BufferChannel和Selector](docs/Java/network/Java网络编程与NIO详解:浅析NIO包中的BufferChannel和Selector.md)
* [Java网络编程和NIO详解:Java非阻塞IO和异步IO](docs/Java/network/Java网络编程与NIO详解:Java非阻塞IO和异步IO.md)
* [Java网络编程与NIO详解:LinuxEpoll实现原理详解](docs/Java/network/Java网络编程与NIO详解:LinuxEpoll实现原理详解.md.md)
* [Java网络编程与NIO详解:浅谈Linux中Selector的实现原理](docs/Java/network/Java网络编程与NIO详解:浅谈Linux中Selector的实现原理.md)
* [Java网络编程与NIO详解:浅析mmap和DirectBuffer](docs/Java/network/Java网络编程与NIO详解:浅析mmap和DirectBuffer.md)
* [Java网络编程与NIO详解:基于NIO的网络编程框架Netty](docs/Java/network/Java网络编程与NIO详解:基于NIO的网络编程框架Netty.md)
* [Java网络编程与NIO详解:Java网络编程与NIO详解](docs/Java/network/Java网络编程与NIO详解:深度解读Tomcat中的NIO模型.md)
* [Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO)](docs/Java/network/Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO).md)
# Spring全家桶
## Spring
* [SpringAOP的概念与作用](docs/Spring全家桶/Spring/Spring常见注解.md)
* [SpringBean的定义与管理(核心)](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring中对于数据库的访问](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring中对于校验功能的支持](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring中的Environment环境变量](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring中的事件处理机制](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring中的资源管理](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring中的配置元数据(管理配置的基本数据)](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring事务基本用法](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring合集](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring容器与IOC](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring常见注解](docs/Spring全家桶/Spring/Spring常见注解.md)
* [Spring概述](docs/Spring全家桶/Spring/Spring常见注解.md)
* [第一个Spring应用](docs/Spring全家桶/Spring/Spring常见注解.md)
## Spring源码分析
### 综合
* [Spring源码剖析:初探SpringIOC核心流程](docs/Spring全家桶/Spring源码分析/Spring源码剖析:初探SpringIOC核心流程.md)
* [Spring源码剖析:SpringIOC容器的加载过程 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:SpringIOC容器的加载过程.md)
* [Spring源码剖析:懒加载的单例Bean获取过程分析](docs/Spring全家桶/Spring源码分析/Spring源码剖析:懒加载的单例Bean获取过程分析.md)
* [Spring源码剖析:JDK和cglib动态代理原理详解 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:JDK和cglib动态代理原理详解.md)
* [Spring源码剖析:SpringAOP概述](docs/Spring全家桶/Spring源码分析/Spring源码剖析:SpringAOP概述.md)
* [Spring源码剖析:AOP实现原理详解 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:AOP实现原理详解.md)
* [Spring源码剖析:Spring事务概述](docs/Spring全家桶/Spring源码分析/Spring源码剖析:Spring事务概述.md)
* [Spring源码剖析:Spring事务源码剖析](docs/Spring全家桶/Spring源码分析/Spring源码剖析:Spring事务源码剖析.md)
### AOP
* [AnnotationAwareAspectJAutoProxyCreator 分析(上)](docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(上).md)
* [AnnotationAwareAspectJAutoProxyCreator 分析(下)](docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(下).md)
* [AOP示例demo及@EnableAspectJAutoProxy](docs/Spring全家桶/Spring源码分析/SpringAOP/AOP示例demo及@EnableAspectJAutoProxy.md)
* [SpringAop(四):jdk 动态代理](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(四):jdk动态代理.md)
* [SpringAop(五):cglib 代理](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(五):cglib代理.md)
* [SpringAop(六):aop 总结](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(六):aop总结.md)
### 事务
* [spring 事务(一):认识事务组件](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(一):认识事务组件.md)
* [spring 事务(二):事务的执行流程](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(二):事务的执行流程.md)
* [spring 事务(三):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(三):事务的隔离级别与传播方式的处理01.md)
* [spring 事务(四):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(四):事务的隔离级别与传播方式的处理02.md)
* [spring 事务(五):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(五):事务的隔离级别与传播方式的处理03.md)
* [spring 事务(六):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(六):事务的隔离级别与传播方式的处理04.md)
### 启动流程
* [spring启动流程(一):启动流程概览](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(一):启动流程概览.md)
* [spring启动流程(二):ApplicationContext 的创建](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(二):ApplicationContext的创建.md)
* [spring启动流程(三):包的扫描流程](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(三):包的扫描流程.md)
* [spring启动流程(四):启动前的准备工作](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(四):启动前的准备工作.md)
* [spring启动流程(五):执行 BeanFactoryPostProcessor](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(五):执行BeanFactoryPostProcessor.md)
* [spring启动流程(六):注册 BeanPostProcessor](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(六):注册BeanPostProcessor.md)
* [spring启动流程(七):国际化与事件处理](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(七):国际化与事件处理.md)
* [spring启动流程(八):完成 BeanFactory 的初始化](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(八):完成BeanFactory的初始化.md)
* [spring启动流程(九):单例 bean 的创建](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(九):单例bean的创建.md)
* [spring启动流程(十):启动完成的处理](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(十):启动完成的处理.md)
* [spring启动流程(十一):启动流程总结](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(十一):启动流程总结.md)
### 组件分析
* [spring 组件之 ApplicationContext](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之ApplicationContext.md)
* [spring 组件之 BeanDefinition](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanDefinition.md)
* [Spring 组件之 BeanFactory](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanFactory.md)
* [spring 组件之 BeanFactoryPostProcessor](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanFactoryPostProcessor.md)
* [spring 组件之 BeanPostProcessor](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanPostProcessor.md)
### 重要机制探秘
* [ConfigurationClassPostProcessor(一):处理 @ComponentScan 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(一):处理@ComponentScan注解.md)
* [ConfigurationClassPostProcessor(三):处理 @Import 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(三):处理@Import注解.md)
* [ConfigurationClassPostProcessor(二):处理 @Bean 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(二):处理@Bean注解.md)
* [ConfigurationClassPostProcessor(四):处理 @Conditional 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(四):处理@Conditional注解.md)
* [Spring 探秘之 AOP 的执行顺序](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之AOP的执行顺序.md)
* [Spring 探秘之 Spring 事件机制](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之Spring事件机制.md)
* [spring 探秘之循环依赖的解决(一):理论基石](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之循环依赖的解决(一):理论基石.md)
* [spring 探秘之循环依赖的解决(二):源码分析](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之循环依赖的解决(二):源码分析.md)
* [spring 探秘之监听器注解 @EventListener](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/spring探秘之监听器注解@EventListener.md)
* [spring 探秘之组合注解的处理](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之组合注解的处理.md)
## SpringMVC
* [SpringMVC中的国际化功能](docs/Spring全家桶/SpringMVC/SpringMVC中的国际化功能.md)
* [SpringMVC中的异常处理器](docs/Spring全家桶/SpringMVC/SpringMVC中的异常处理器.md)
* [SpringMVC中的拦截器](docs/Spring全家桶/SpringMVC/SpringMVC中的拦截器.md)
* [SpringMVC中的视图解析器](docs/Spring全家桶/SpringMVC/SpringMVC中的视图解析器.md)
* [SpringMVC中的过滤器Filter](docs/Spring全家桶/SpringMVC/SpringMVC中的过滤器Filter.md)
* [SpringMVC基本介绍与快速入门](docs/Spring全家桶/SpringMVC/SpringMVC基本介绍与快速入门.md)
* [SpringMVC如何实现文件上传](docs/Spring全家桶/SpringMVC/SpringMVC如何实现文件上传.md)
* [SpringMVC中的常用功能](docs/Spring全家桶/SpringMVC/SpringMVC中的常用功能.md)
## SpringMVC源码分析
* [SpringMVC源码分析:SpringMVC概述](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC概述.md)
* [SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet.md)
* [SpringMVC源码分析:DispatcherServlet的初始化与请求转发 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet的初始化与请求转发.md)
* [SpringMVC源码分析:DispatcherServlet如何找到正确的Controller ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet如何找到正确的Controller.md)
* [SpringMVC源码剖析:消息转换器HttpMessageConverter与@ResponseBody注解](docs/Spring全家桶/SpringMVC/SpringMVC源码剖析:消息转换器HttpMessageConverter与@ResponseBody注解.md)
* [DispatcherServlet 初始化流程 ](docs/Spring全家桶/SpringMVC源码分析/DispatcherServlet初始化流程.md)
* [RequestMapping 初始化流程 ](docs/Spring全家桶/SpringMVC源码分析/RequestMapping初始化流程.md)
* [Spring 容器启动 Tomcat ](docs/Spring全家桶/SpringMVC源码分析/Spring容器启动Tomcat.md)
* [SpringMVC demo 与@EnableWebMvc 注解 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC的Demo与@EnableWebMvc注解.md)
* [SpringMVC 整体源码结构总结 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC整体源码结构总结.md)
* [请求执行流程(一)之获取 Handler ](docs/Spring全家桶/SpringMVC源码分析/请求执行流程(一)之获取Handler.md)
* [请求执行流程(二)之执行 Handler 方法 ](docs/Spring全家桶/SpringMVC源码分析/请求执行流程(二)之执行Handler方法.md)
## SpringBoot
* [SpringBoot系列:SpringBoot的前世今生](docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md)
* [给你一份SpringBoot知识清单.md](docs/Spring全家桶/SpringBoot/给你一份SpringBoot知识清单.md)
* [Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot)](docs/Spring全家桶/SpringBoot/Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot).md)
* [SpringBoot中的日志管理](docs/Spring全家桶/SpringBoot/SpringBoot中的日志管理.md)
* [SpringBoot常见注解](docs/Spring全家桶/SpringBoot/SpringBoot常见注解.md)
* [SpringBoot应用也可以部署到外部Tomcat](docs/Spring全家桶/SpringBoot/SpringBoot应用也可以部署到外部Tomcat.md)
* [SpringBoot生产环境工具Actuator](docs/Spring全家桶/SpringBoot/SpringBoot生产环境工具Actuator.md)
* [SpringBoot的Starter机制](docs/Spring全家桶/SpringBoot/SpringBoot的Starter机制.md)
* [SpringBoot的前世今生](docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md)
* [SpringBoot的基本使用](docs/Spring全家桶/SpringBoot/SpringBoot的基本使用.md)
* [SpringBoot的配置文件管理](docs/Spring全家桶/SpringBoot/SpringBoot的配置文件管理.md)
* [SpringBoot自带的热部署工具](docs/Spring全家桶/SpringBoot/SpringBoot自带的热部署工具.md)
* [SpringBoot中的任务调度与@Async](docs/Spring全家桶/SpringBoot/SpringBoot中的任务调度与@Async.md)
* [基于SpringBoot中的开源监控工具SpringBootAdmin](docs/Spring全家桶/SpringBoot/基于SpringBoot中的开源监控工具SpringBootAdmin.md)
## SpringBoot源码分析
* [@SpringBootApplication 注解](docs/Spring全家桶/SpringBoot源码解析/@SpringBootApplication注解.md)
* [springboot web应用(一):servlet 组件的注册流程](docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(一):servlet组件的注册流程.md)
* [springboot web应用(二):WebMvc 装配过程](docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(二):WebMvc装配过程.md)
* [SpringBoot 启动流程(一):准备 SpringApplication](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(一):准备SpringApplication.md)
* [SpringBoot 启动流程(二):准备运行环境](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(二):准备运行环境.md)
* [SpringBoot 启动流程(三):准备IOC容器](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(三):准备IOC容器.md)
* [springboot 启动流程(四):启动IOC容器](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(四):启动IOC容器.md)
* [springboot 启动流程(五):完成启动](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(五):完成启动.md)
* [springboot 启动流程(六):启动流程总结](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(六):启动流程总结.md)
* [springboot 自动装配(一):加载自动装配类](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(一):加载自动装配类.md)
* [springboot 自动装配(二):条件注解](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(二):条件注解.md)
* [springboot 自动装配(三):自动装配顺序](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(三):自动装配顺序.md)
## SpringCloud
* [SpringCloud概述](docs/Spring全家桶/SpringCloud/SpringCloud概述.md)
* [Spring Cloud Config](docs/Spring全家桶/SpringCloud/SpringCloudConfig.md)
* [Spring Cloud Consul](docs/Spring全家桶/SpringCloud/SpringCloudConsul.md)
* [Spring Cloud Eureka](docs/Spring全家桶/SpringCloud/SpringCloudEureka.md)
* [Spring Cloud Gateway](docs/Spring全家桶/SpringCloud/SpringCloudGateway.md)
* [Spring Cloud Hystrix](docs/Spring全家桶/SpringCloud/SpringCloudHystrix.md)
* [Spring Cloud LoadBalancer](docs/Spring全家桶/SpringCloud/SpringCloudLoadBalancer.md)
* [Spring Cloud OpenFeign](docs/Spring全家桶/SpringCloud/SpringCloudOpenFeign.md)
* [Spring Cloud Ribbon](docs/Spring全家桶/SpringCloud/SpringCloudRibbon.md)
* [Spring Cloud Sleuth](docs/Spring全家桶/SpringCloud/SpringCloudSleuth.md)
* [Spring Cloud Zuul](docs/Spring全家桶/SpringCloud/SpringCloudZuul.md)
## SpringCloud 源码分析
* [Spring Cloud Config源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudConfig源码分析.md)
* [Spring Cloud Eureka源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudEureka源码分析.md)
* [Spring Cloud Gateway源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudGateway源码分析.md)
* [Spring Cloud Hystrix源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudHystrix源码分析.md)
* [Spring Cloud LoadBalancer源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudLoadBalancer源码分析.md)
* [Spring Cloud OpenFeign源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudOpenFeign源码分析.md)
* [Spring Cloud Ribbon源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudRibbon源码分析.md)
## SpringCloud Alibaba
* [SpringCloud Alibaba概览](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibaba概览.md)
* [SpringCloud Alibaba nacos](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaNacos.md)
* [SpringCloud Alibaba RocketMQ](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaRocketMQ.md)
* [SpringCloud Alibaba sentinel](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSentinel.md)
* [SpringCloud Alibaba skywalking](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSkywalking.md)
* [SpringCloud Alibaba seata](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSeata.md)
## SpringCloud Alibaba源码分析
* [Spring Cloud Seata源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSeata源码分析.md)
* [Spring Cloud Sentinel源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSentinel源码分析.md)
* [SpringCloudAlibaba nacos源码分析:概览](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:概览.md)
* [SpringCloudAlibaba nacos源码分析:服务发现](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务发现.md)
* [SpringCloudAlibaba nacos源码分析:服务注册](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务注册.md)
* [SpringCloudAlibaba nacos源码分析:配置中心](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:配置中心.md)
* [Spring Cloud RocketMQ源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudRocketMQ源码分析.md)
# 设计模式
* [设计模式学习总结](docs/Java/design-parttern/设计模式学习总结.md)
* [初探Java设计模式:创建型模式(工厂,单例等).md](docs/Java/design-parttern/初探Java设计模式:创建型模式(工厂,单例等).md)
* [初探Java设计模式:结构型模式(代理模式,适配器模式等).md](docs/Java/design-parttern/初探Java设计模式:结构型模式(代理模式,适配器模式等).md)
* [初探Java设计模式:行为型模式(策略,观察者等).md](docs/Java/design-parttern/初探Java设计模式:行为型模式(策略,观察者等).md)
* [初探Java设计模式:JDK中的设计模式.md](docs/Java/design-parttern/初探Java设计模式:JDK中的设计模式.md)
* [初探Java设计模式:Spring涉及到的种设计模式.md](docs/Java/design-parttern/初探Java设计模式:Spring涉及到的种设计模式.md)
# 计算机基础
## 计算机网络
todo
## 操作系统
todo
## Linux相关
todo
## 数据结构与算法
todo
## 数据结构
todo
## 算法
todo
# 数据库
todo
## MySQL
* [Mysql原理与实践总结](docs/database/Mysql原理与实践总结.md)
* [重新学习Mysql数据库:无废话MySQL入门](docs/database/重新学习MySQL数据库:无废话MySQL入门.md)
* [重新学习Mysql数据库:『浅入浅出』MySQL和InnoDB](docs/database/重新学习MySQL数据库:『浅入浅出』MySQL和InnoDB.md)
* [重新学习Mysql数据库:Mysql存储引擎与数据存储原理](docs/database/重新学习MySQL数据库:Mysql存储引擎与数据存储原理.md)
* [重新学习Mysql数据库:Mysql索引实现原理和相关数据结构算法](docs/database/重新学习MySQL数据库:Mysql索引实现原理和相关数据结构算法.md)
* [重新学习Mysql数据库:根据MySQL索引原理进行分析与优化](docs/database/重新学习MySQL数据库:根据MySQL索引原理进行分析与优化.md)
* [重新学习MySQL数据库:浅谈MySQL的中事务与锁](docs/database/重新学习MySQL数据库:浅谈MySQL的中事务与锁.md)
* [重新学习Mysql数据库:详解MyIsam与InnoDB引擎的锁实现](docs/database/重新学习MySQL数据库:详解MyIsam与InnoDB引擎的锁实现.md)
* [重新学习Mysql数据库:MySQL的事务隔离级别实战](docs/database/重新学习MySQL数据库:MySQL的事务隔离级别实战.md)
* [重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系](docs/database/重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系.md)
* [重新学习MySQL数据库:MySQL里的那些日志们](docs/database/重新学习MySQL数据库:MySQL里的那些日志们.md)
* [重新学习MySQL数据库:以Java的视角来聊聊SQL注入](docs/database/重新学习MySQL数据库:以Java的视角来聊聊SQL注入.md)
* [重新学习MySQL数据库:从实践sql语句优化开始](docs/database/重新学习MySQL数据库:从实践sql语句优化开始.md)
* [重新学习Mysql数据库:Mysql主从复制,读写分离,分表分库策略与实践](docs/database/重新学习MySQL数据库:Mysql主从复制,读写分离,分表分库策略与实践.md)
# 缓存
## Redis
* [Redis原理与实践总结](docs/cache/Redis原理与实践总结.md)
* [探索Redis设计与实现开篇:什么是Redis](docs/cache/探索Redis设计与实现开篇:什么是Redis.md)
* [探索Redis设计与实现:Redis的基础数据结构概览](docs/cache/探索Redis设计与实现:Redis的基础数据结构概览.md)
* [探索Redis设计与实现:Redis内部数据结构详解——dict](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——dict.md)
* [探索Redis设计与实现:Redis内部数据结构详解——sds](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——sds.md)
* [探索Redis设计与实现:Redis内部数据结构详解——ziplist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——ziplist.md)
* [探索Redis设计与实现:Redis内部数据结构详解——quicklist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——quicklist.md)
* [探索Redis设计与实现:Redis内部数据结构详解——skiplist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——skiplist.md)
* [探索Redis设计与实现:Redis内部数据结构详解——intset](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——intset.md)
* [探索Redis设计与实现:连接底层与表面的数据结构robj](docs/cache/探索Redis设计与实现:连接底层与表面的数据结构robj.md)
* [探索Redis设计与实现:数据库redisDb与键过期删除策略](docs/cache/探索Redis设计与实现:数据库redisDb与键过期删除策略.md)
* [探索Redis设计与实现:Redis的事件驱动模型与命令执行过程](docs/cache/探索Redis设计与实现:Redis的事件驱动模型与命令执行过程.md)
* [探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中](docs/cache/探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中.md)
* [探索Redis设计与实现:浅析Redis主从复制](docs/cache/探索Redis设计与实现:浅析Redis主从复制.md)
* [探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例](docs/cache/探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例.md)
* [探索Redis设计与实现:Redis事务浅析与ACID特性介绍](docs/cache/探索Redis设计与实现:Redis事务浅析与ACID特性介绍.md)
* [探索Redis设计与实现:Redis分布式锁进化史 ](docs/cache/探索Redis设计与实现:Redis分布式锁进化史.md )
# 消息队列
## Kafka
* [消息队列kafka详解:Kafka快速上手(Java版)](docs/mq/kafka/消息队列kafka详解:Kafka快速上手(Java版).md)
* [消息队列kafka详解:Kafka一条消息存到broker的过程](docs/mq/kafka/消息队列kafka详解:Kafka一条消息存到broker的过程.md)
* [消息队列kafka详解:消息队列kafka详解:Kafka介绍](docs/mq/kafka/消息队列kafka详解:Kafka介绍.md)
* [消息队列kafka详解:Kafka原理分析总结篇](docs/mq/kafka/消息队列kafka详解:Kafka原理分析总结篇.md)
* [消息队列kafka详解:Kafka常见命令及配置总结](docs/mq/kafka/消息队列kafka详解:Kafka常见命令及配置总结.md)
* [消息队列kafka详解:Kafka架构介绍](docs/mq/kafka/消息队列kafka详解:Kafka架构介绍.md)
* [消息队列kafka详解:Kafka的集群工作原理](docs/mq/kafka/消息队列kafka详解:Kafka的集群工作原理.md)
* [消息队列kafka详解:Kafka重要知识点+面试题大全](docs/mq/kafka/消息队列kafka详解:Kafka重要知识点+面试题大全.md)
* [消息队列kafka详解:如何实现延迟队列](docs/mq/kafka/消息队列kafka详解:如何实现延迟队列.md)
* [消息队列kafka详解:如何实现死信队列](docs/mq/kafka/消息队列kafka详解:如何实现死信队列.md)
## RocketMQ
* [RocketMQ系列:事务消息(最终一致性)](docs/mq/RocketMQ/RocketMQ系列:事务消息(最终一致性).md)
* [RocketMQ系列:基本概念](docs/mq/RocketMQ/RocketMQ系列:基本概念.md)
* [RocketMQ系列:广播与延迟消息](docs/mq/RocketMQ/RocketMQ系列:广播与延迟消息.md)
* [RocketMQ系列:批量发送与过滤](docs/mq/RocketMQ/RocketMQ系列:批量发送与过滤.md)
* [RocketMQ系列:消息的生产与消费](docs/mq/RocketMQ/RocketMQ系列:消息的生产与消费.md)
* [RocketMQ系列:环境搭建](docs/mq/RocketMQ/RocketMQ系列:环境搭建.md)
* [RocketMQ系列:顺序消费](docs/mq/RocketMQ/RocketMQ系列:顺序消费.md)
# 大后端
* [后端技术杂谈开篇:云计算,大数据与AI的故事](docs/backend/后端技术杂谈开篇:云计算,大数据与AI的故事.md)
* [后端技术杂谈:搜索引擎基础倒排索引](docs/backend/后端技术杂谈:搜索引擎基础倒排索引.md)
* [后端技术杂谈:搜索引擎工作原理](docs/backend/后端技术杂谈:搜索引擎工作原理.md)
* [后端技术杂谈:Lucene基础原理与实践](docs/backend/后端技术杂谈:Lucene基础原理与实践.md)
* [后端技术杂谈:Elasticsearch与solr入门实践](docs/backend/后端技术杂谈:Elasticsearch与solr入门实践.md)
* [后端技术杂谈:云计算的前世今生](docs/backend/后端技术杂谈:云计算的前世今生.md)
* [后端技术杂谈:白话虚拟化技术](docs/backend/后端技术杂谈:白话虚拟化技术.md )
* [后端技术杂谈:OpenStack的基石KVM](docs/backend/后端技术杂谈:OpenStack的基石KVM.md)
* [后端技术杂谈:OpenStack架构设计](docs/backend/后端技术杂谈:OpenStack架构设计.md)
* [后端技术杂谈:先搞懂Docker核心概念吧](docs/backend/后端技术杂谈:先搞懂Docker核心概念吧.md)
* [后端技术杂谈:Docker 核心技术与实现原理](docs/backend/后端技术杂谈:Docker%核心技术与实现原理.md)
* [后端技术杂谈:十分钟理解Kubernetes核心概念](docs/backend/后端技术杂谈:十分钟理解Kubernetes核心概念.md)
* [后端技术杂谈:捋一捋大数据研发的基本概念](docs/backend/后端技术杂谈:捋一捋大数据研发的基本概念.md)
# 分布式
## 分布式理论
* [分布式系统理论基础:一致性PC和PC ](docs/distributed/basic/分布式系统理论基础:一致性PC和PC.md)
* [分布式系统理论基础:CAP ](docs/distributed/basic/分布式系统理论基础:CAP.md)
* [分布式系统理论基础:时间时钟和事件顺序](docs/distributed/basic/分布式系统理论基础:时间时钟和事件顺序.md)
* [分布式系统理论基础:Paxos](docs/distributed/basic/分布式系统理论基础:Paxos.md)
* [分布式系统理论基础:选举多数派和租约](docs/distributed/basic/分布式系统理论基础:选举多数派和租约.md)
* [分布式系统理论基础:RaftZab ](docs/distributed/basic/分布式系统理论基础:RaftZab.md)
* [分布式系统理论进阶:Paxos变种和优化 ](docs/distributed/basic/分布式系统理论进阶:Paxos变种和优化.md)
* [分布式系统理论基础:zookeeper分布式协调服务 ](docs/distributed/basic/分布式系统理论基础:zookeeper分布式协调服务.md)
* [分布式理论总结](docs/distributed/分布式技术实践总结.md)
## 分布式技术
* [搞懂分布式技术:分布式系统的一些基本概念](docs/distributed/practice/搞懂分布式技术:分布式系统的一些基本概念.md )
* [搞懂分布式技术:分布式一致性协议与Paxos,Raft算法](docs/distributed/practice/搞懂分布式技术:分布式一致性协议与Paxos,Raft算法.md)
* [搞懂分布式技术:初探分布式协调服务zookeeper](docs/distributed/practice/搞懂分布式技术:初探分布式协调服务zookeeper.md )
* [搞懂分布式技术:ZAB协议概述与选主流程详解](docs/distributed/practice/搞懂分布式技术:ZAB协议概述与选主流程详解.md )
* [搞懂分布式技术:Zookeeper的配置与集群管理实战](docs/distributed/practice/搞懂分布式技术:Zookeeper的配置与集群管理实战.md)
* [搞懂分布式技术:Zookeeper典型应用场景及实践](docs/distributed/practice/搞懂分布式技术:Zookeeper典型应用场景及实践.md )
* [搞懂分布式技术:LVS实现负载均衡的原理与实践 ](docs/distributed/practice/搞懂分布式技术:LVS实现负载均衡的原理与实践.md )
* [搞懂分布式技术:分布式session解决方案与一致性hash](docs/distributed/practice/搞懂分布式技术:分布式session解决方案与一致性hash.md)
* [搞懂分布式技术:分布式ID生成方案 ](docs/distributed/practice/搞懂分布式技术:分布式ID生成方案.md )
* [搞懂分布式技术:缓存的那些事](docs/distributed/practice/搞懂分布式技术:缓存的那些事.md)
* [搞懂分布式技术:SpringBoot使用注解集成Redis缓存](docs/distributed/practice/搞懂分布式技术:SpringBoot使用注解集成Redis缓存.md)
* [搞懂分布式技术:缓存更新的套路 ](docs/distributed/practice/搞懂分布式技术:缓存更新的套路.md )
* [搞懂分布式技术:浅谈分布式锁的几种方案 ](docs/distributed/practice/搞懂分布式技术:浅谈分布式锁的几种方案.md )
* [搞懂分布式技术:浅析分布式事务](docs/distributed/practice/搞懂分布式技术:浅析分布式事务.md )
* [搞懂分布式技术:分布式事务常用解决方案 ](docs/distributed/practice/搞懂分布式技术:分布式事务常用解决方案.md )
* [搞懂分布式技术:使用RocketMQ事务消息解决分布式事务 ](docs/distributed/practice/搞懂分布式技术:使用RocketMQ事务消息解决分布式事务.md )
* [搞懂分布式技术:消息队列因何而生](docs/distributed/practice/搞懂分布式技术:消息队列因何而生.md)
* [搞懂分布式技术:浅谈分布式消息技术Kafka](docs/distributed/practice/搞懂分布式技术:浅谈分布式消息技术Kafka.md )
* [分布式技术实践总结](docs/distributed/分布式理论总结.md)
# 面试指南
todo
## 校招指南
todo
## 面经
todo
# 工具
todo
# 资料
todo
## 书单
todo
# 待办
springboot和springcloud
# 微信公众号
## Java技术江湖
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】

================================================
FILE: docs/Java/JVM/JVM总结.md
================================================
# 目录
* [JVM介绍和源码](#jvm介绍和源码)
* [JVM内存模型](#jvm内存模型)
* [JVM OOM和内存泄漏](#jvm-oom和内存泄漏)
* [常见调试工具](#常见调试工具)
* [class文件结构](#class文件结构)
* [JVM的类加载机制](#jvm的类加载机制)
* [defineclass findclass和loadclass](#defineclass-findclass和loadclass)
* [JVM虚拟机字节码执行引擎](#jvm虚拟机字节码执行引擎)
* [编译期优化和运行期优化](#编译期优化和运行期优化)
* [JVM的垃圾回收](#jvm的垃圾回收)
* [JVM的锁优化](#jvm的锁优化)
---
title: JVM原理学习总结
date: 2018-07-08 22:09:47
tags:
- JVM
categories:
- 后端
- 技术总结
---
这篇总结主要是基于我之前JVM系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
更多详细内容可以查看我的专栏文章:深入理解JVM虚拟机
https://blog.csdn.net/column/details/21960.html
<!-- more -->
## JVM介绍和源码
首先JVM是一个虚拟机,当你安装了jre,它就包含了jvm环境。JVM有自己的内存结构,字节码执行引擎,因此class字节码才能在jvm上运行,除了Java以外,Scala,groovy等语言也可以编译成字节码而后在jvm中运行。JVM是用c开发的。
## JVM内存模型
内存模型老生常谈了,主要就是线程共享的堆区,方法区,本地方法栈。还有线程私有的虚拟机栈和程序计数器。
堆区存放所有对象,每个对象有一个地址,Java类jvm初始化时加载到方法区,而后会在堆区中生成一个Class对象,来负责这个类所有实例的实例化。
栈区存放的是栈帧结构,栈帧是一段内存空间,包括参数列表,返回地址,局部变量表等,局部变量表由一堆slot组成,slot的大小固定,根据变量的数据类型决定需要用到几个slot。
方法区存放类的元数据,将原来的字面量转换成引用,当然,方法区也提供常量池,常量池存放-128到127的数字类型的包装类。
字符串常量池则会存放使用intern的字符串变量。
## JVM OOM和内存泄漏
这里指的是oom和内存泄漏这类错误。
oom一般分为三种,堆区内存溢出,栈区内存溢出以及方法区内存溢出。
堆内存溢出主要原因是创建了太多对象,比如一个集合类死循环添加一个数,此时设置jvm参数使堆内存最大值为10m,一会就会报oom异常。
栈内存溢出主要与栈空间和线程有关,因为栈是线程私有的,如果创建太多线程,内存值超过栈空间上限,也会报oom。
方法区内存溢出主要是由于动态加载类的数量太多,或者是不断创建一个动态代理,用不了多久方法区内存也会溢出,会报oom,这里在1.7之前会报permgem oom,1.8则会报meta space oom,这是因为1.8中删除了堆中的永久代,转而使用元数据区。
内存泄漏一般是因为对象被引用无法回收,比如一个集合中存着很多对象,可能你在外部代码把对象的引用置空了,但是由于对象还被集合给引用着,所以无法被回收,导致内存泄漏。测试也很简单,就在集合里添加对象,添加完以后把引用置空,循环操作,一会就会出现oom异常,原因是内存泄漏太多了,导致没有空间分配新的对象。
## 常见调试工具
命令行工具有jstack jstat jmap 等,jstack可以跟踪线程的调用堆栈,以便追踪错误原因。
jstat可以检查jvm的内存使用情况,gc情况以及线程状态等。
jmap用于把堆栈快照转储到文件系统,然后可以用其他工具去排查。
visualvm是一款很不错的gui调试工具,可以远程登录主机以便访问其jvm的状态并进行监控。
## class文件结构
class文件结构比较复杂,首先jvm定义了一个class文件的规则,并且让jvm按照这个规则去验证与读取。
开头是一串魔数,然后接下来会有各种不同长度的数据,通过class的规则去读取这些数据,jvm就可以识别其内容,最后将其加载到方法区。
## JVM的类加载机制
jvm的类加载顺序是bootstrap类加载器,extclassloader加载器,最后是appclassloader用户加载器,分别加载的是jdk/bin ,jdk/ext以及用户定义的类目录下的类(一般通过ide指定),一般核心类都由bootstrap和ext加载器来加载,appclassloader用于加载自己写的类。
双亲委派模型,加载一个类时,首先获取当前类加载器,先找到最高层的类加载器bootstrap让他尝试加载,他如果加载不了再让ext加载器去加载,如果他也加载不了再让appclassloader去加载。这样的话,确保一个类型只会被加载一次,并且以高层类加载器为准,防止某些类与核心类重复,产生错误。
## defineclass findclass和loadclass
类加载classloader中有两个方法loadclass和findclass,loadclass遵从双亲委派模型,先调用父类加载的loadclass,如果父类和自己都无法加载该类,则会去调用findclass方法,而findclass默认实现为空,如果要自定义类加载方式,则可以重写findclass方法。
常见使用defineclass的情况是从网络或者文件读取字节码,然后通过defineclass将其定义成一个类,并且返回一个Class对象,说明此时类已经加载到方法区了。当然1.8以前实现方法区的是永久代,1.8以后则是元空间了。
## JVM虚拟机字节码执行引擎
jvm通过字节码执行引擎来执行class代码,他是一个栈式执行引擎。这部分内容比较高深,在这里就不献丑了。
## 编译期优化和运行期优化
编译期优化主要有几种
1 泛型的擦除,使得泛型在编译时变成了实际类型,也叫伪泛型。
2 自动拆箱装箱,foreach循环自动变成迭代器实现的for循环。
3 条件编译,比如if(true)直接可得。
运行期优化主要有几种
1 JIT即时编译
Java既是编译语言也是解释语言,因为需要编译代码生成字节码,而后通过解释器解释执行。
但是,有些代码由于经常被使用而成为热点代码,每次都编译太过费时费力,干脆直接把他编译成本地代码,这种方式叫做JIT即时编译处理,所以这部分代码可以直接在本地运行而不需要通过jvm的执行引擎。
2 公共表达式擦除,就是一个式子在后面如果没有被修改,在后面调用时就会被直接替换成数值。
3 数组边界擦除,方法内联,比较偏,意义不大。
4 逃逸分析,用于分析一个对象的作用范围,如果只局限在方法中被访问,则说明不会逃逸出方法,这样的话他就是线程安全的,不需要进行并发加锁。
1
## JVM的垃圾回收
1 GC算法:停止复制,存活对象少时适用,缺点是需要两倍空间。标记清除,存活对象多时适用,但是容易产生随便。标记整理,存活对象少时适用,需要移动对象较多。
2 GC分区,一般GC发生在堆区,堆区可分为年轻代,老年代,以前有永久代,现在没有了。
年轻代分为eden和survior,新对象分配在eden,当年轻代满时触发minor gc,存活对象移至survivor区,然后两个区互换,等待下一场gc,
当对象存活的阈值达到设定值时进入老年代,大对象也会直接进入老年代。
老年代空间较大,当老年代空间不足以存放年轻代过来的对象时,开始进行full gc。同时整理年轻代和老年代。
一般年轻代使用停止复制,老年代使用标记清除。
3 垃圾收集器
serial串行
parallel并行
它们都有年轻代与老年代的不同实现。
然后是scanvage收集器,注重吞吐量,可以自己设置,不过不注重延迟。
cms垃圾收集器,注重延迟的缩短和控制,并且收集线程和系统线程可以并发。
cms收集步骤主要是,初次标记gc root,然后停顿进行并发标记,而后处理改变后的标记,最后停顿进行并发清除。
g1收集器和cms的收集方式类似,但是g1将堆内存划分成了大小相同的小块区域,并且将垃圾集中到一个区域,存活对象集中到另一个区域,然后进行收集,防止产生碎片,同时使分配方式更灵活,它还支持根据对象变化预测停顿时间,从而更好地帮用户解决延迟等问题。
## JVM的锁优化
在Java并发中讲述了synchronized重量级锁以及锁优化的方法,包括轻量级锁,偏向锁,自旋锁等。详细内容可以参考我的专栏:Java并发技术指南
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:GC调优思路与常用工具.md
================================================
# 目录
* [核心概念(Core Concepts)](#核心概念core-concepts)
* [Latency(延迟)](#latency延迟)
* [Throughput(吞吐量)](#throughput吞吐量)
* [Capacity(系统容量)](#capacity系统容量)
* [相关示例](#相关示例)
* [Tuning for Latency(调优延迟指标)](#tuning-for-latency调优延迟指标)
* [Tuning for Throughput(吞吐量调优)](#tuning-for-throughput吞吐量调优)
* [Tuning for Capacity(调优系统容量)](#tuning-for-capacity调优系统容量)
* [6\. GC 调优(工具篇) - GC参考手册](#6-gc-调优工具篇---gc参考手册)
* [JMX API](#jmx-api)
* [JVisualVM](#jvisualvm)
* [jstat](#jstat)
* [GC日志(GC logs)](#gc日志gc-logs)
* [GCViewer](#gcviewer)
* [分析器(Profilers)](#分析器profilers)
* [hprof](#hprof)
* [Java VisualVM](#java-visualvm)
* [AProf](#aprof)
* [参考文章](#参考文章)
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章首发于我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
> **说明**:
>
> **Capacity**: 性能,能力,系统容量; 文中翻译为”**系统容量**“; 意为硬件配置。
您应该已经阅读了前面的章节:
1. 垃圾收集简介 - GC参考手册
2. Java中的垃圾收集 - GC参考手册
3. GC 算法(基础篇) - GC参考手册
4. GC 算法(实现篇) - GC参考手册
GC调优(Tuning Garbage Collection)和其他性能调优是同样的原理。初学者可能会被 200 多个 GC参数弄得一头雾水, 然后随便调整几个来试试结果,又或者修改几行代码来测试。其实只要参照下面的步骤,就能保证你的调优方向正确:
1. 列出性能调优指标(State your performance goals)
2. 执行测试(Run tests)
3. 检查结果(Measure the results)
4. 与目标进行对比(Compare the results with the goals)
5. 如果达不到指标, 修改配置参数, 然后继续测试(go back to running tests)
第一步, 我们需要做的事情就是: 制定明确的GC性能指标。对所有性能监控和管理来说, 有三个维度是通用的:
* Latency(延迟)
* Throughput(吞吐量)
* Capacity(系统容量)
我们先讲解基本概念,然后再演示如何使用这些指标。如果您对 延迟、吞吐量和系统容量等概念很熟悉, 可以跳过这一小节。
### 核心概念(Core Concepts)
我们先来看一家工厂的装配流水线。工人在流水线将现成的组件按顺序拼接,组装成自行车。通过实地观测, 我们发现从组件进入生产线,到另一端组装成自行车需要4小时。
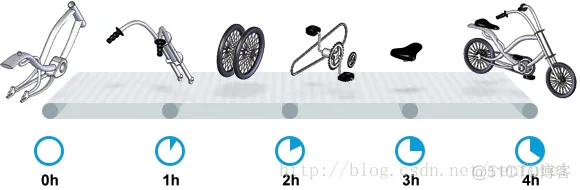
继续观察,我们还发现,此后每分钟就有1辆自行车完成组装, 每天24小时,一直如此。将这个模型简化, 并忽略维护窗口期后得出结论:**这条流水线每小时可以组装60辆自行车**。
> **说明**: 时间窗口/窗口期,请类比车站卖票的窗口,是一段规定/限定做某件事的时间段。
通过这两种测量方法, 就知道了生产线的相关性能信息:**延迟**与**吞吐量**:
* 生产线的延迟:**4小时**
* 生产线的吞吐量:**60辆/小时**
请注意, 衡量延迟的时间单位根据具体需要而确定 —— 从纳秒(nanosecond)到几千年(millennia)都有可能。系统的吞吐量是每个单位时间内完成的操作。操作(Operations)一般是特定系统相关的东西。在本例中,选择的时间单位是小时, 操作就是对自行车的组装。
掌握了延迟和吞吐量两个概念之后, 让我们对这个工厂来进行实际的调优。自行车的需求在一段时间内都很稳定, 生产线组装自行车有四个小时延迟, 而吞吐量在几个月以来都很稳定: 60辆/小时。假设某个销售团队突然业绩暴涨, 对自行车的需求增加了1倍。客户每天需要的自行车不再是 60 * 24 = 1440辆, 而是 2*1440 = 2880辆/天。老板对工厂的产能不满意,想要做些调整以提升产能。
看起来总经理很容易得出正确的判断, 系统的延迟没法子进行处理 —— 他关注的是每天的自行车生产总量。得出这个结论以后, 假若工厂资金充足, 那么应该立即采取措施, 改善吞吐量以增加产能。
我们很快会看到, 这家工厂有两条相同的生产线。每条生产线一分钟可以组装一辆成品自行车。 可以想象,每天生产的自行车数量会增加一倍。达到 2880辆/天。要注意的是, 不需要减少自行车的装配时间 —— 从开始到结束依然需要 4 小时。
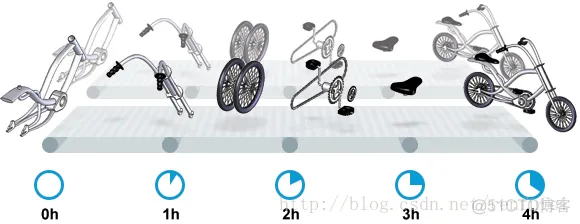
巧合的是,这样进行的性能优化,同时增加了吞吐量和产能。一般来说,我们会先测量当前的系统性能, 再设定新目标, 只优化系统的某个方面来满足性能指标。
在这里做了一个很重要的决定 —— 要增加吞吐量,而不是减小延迟。在增加吞吐量的同时, 也需要增加系统容量。比起原来的情况, 现在需要两条流水线来生产出所需的自行车。在这种情况下, 增加系统的吞吐量并不是免费的, 需要水平扩展, 以满足增加的吞吐量需求。
在处理性能问题时, 应该考虑到还有另一种看似不相关的解决办法。假如生产线的延迟从1分钟降低为30秒,那么吞吐量同样可以增长 1 倍。
或者是降低延迟, 或者是客户非常有钱。软件工程里有一种相似的说法 —— 每个性能问题背后,总有两种不同的解决办法。 可以用更多的机器, 或者是花精力来改善性能低下的代码。
#### Latency(延迟)
GC的延迟指标由一般的延迟需求决定。延迟指标通常如下所述:
* 所有交易必须在10秒内得到响应
* 90%的订单付款操作必须在3秒以内处理完成
* 推荐商品必须在 100 ms 内展示到用户面前
面对这类性能指标时, 需要确保在交易过程中, GC暂停不能占用太多时间,否则就满足不了指标。“不能占用太多” 的意思需要视具体情况而定, 还要考虑到其他因素, 比如外部数据源的交互时间(round-trips), 锁竞争(lock contention), 以及其他的安全点等等。
假设性能需求为:`90%`的交易要在`1000ms`以内完成, 每次交易最长不能超过`10秒`。 根据经验, 假设GC暂停时间比例不能超过10%。 也就是说, 90%的GC暂停必须在`100ms`内结束, 也不能有超过`1000ms`的GC暂停。为简单起见, 我们忽略在同一次交易过程中发生多次GC停顿的可能性。
有了正式的需求,下一步就是检查暂停时间。有许多工具可以使用, 在接下来的6\. GC 调优(工具篇)
```
2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
[PSYoungGen: 93677K->70109K(254976K)]
[ParOldGen: 499597K->511230K(761856K)]
593275K->581339K(1016832K),
[Metaspace: 2936K->2936K(1056768K)]
, 0.0713174 secs]
[Times: user=0.21 sys=0.02, real=0.07 secs
```
这表示一次GC暂停, 在`2015-06-04T13:34:16`这个时刻触发. 对应于JVM启动之后的`2,578 ms`。
此事件将应用线程暂停了`0.0713174`秒。虽然花费的总时间为 210 ms, 但因为是多核CPU机器, 所以最重要的数字是应用线程被暂停的总时间, 这里使用的是并行GC, 所以暂停时间大约为`70ms`。 这次GC的暂停时间小于`100ms`的阈值,满足需求。
继续分析, 从所有GC日志中提取出暂停相关的数据, 汇总之后就可以得知是否满足需求。
#### Throughput(吞吐量)
吞吐量和延迟指标有很大区别。当然两者都是根据一般吞吐量需求而得出的。一般吞吐量需求(Generic requirements for throughput) 类似这样:
* 解决方案每天必须处理 100万个订单
* 解决方案必须支持1000个登录用户,同时在5-10秒内执行某个操作: A、B或C
* 每周对所有客户进行统计, 时间不能超过6小时,时间窗口为每周日晚12点到次日6点之间。
可以看出,吞吐量需求不是针对单个操作的, 而是在给定的时间内, 系统必须完成多少个操作。和延迟需求类似, GC调优也需要确定GC行为所消耗的总时间。每个系统能接受的时间不同, 一般来说, GC占用的总时间比不能超过`10%`。
现在假设需求为: 每分钟处理 1000 笔交易。同时, 每分钟GC暂停的总时间不能超过6秒(即10%)。
有了正式的需求, 下一步就是获取相关的信息。依然是从GC日志中提取数据, 可以看到类似这样的信息:
```
2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
[PSYoungGen: 93677K->70109K(254976K)]
[ParOldGen: 499597K->511230K(761856K)]
593275K->581339K(1016832K),
[Metaspace: 2936K->2936K(1056768K)],
0.0713174 secs]
[Times: user=0.21 sys=0.02, real=0.07 secs
```
此时我们对 用户耗时(user)和系统耗时(sys)感兴趣, 而不关心实际耗时(real)。在这里, 我们关心的时间为`0.23s`(user + sys = 0.21 + 0.02 s), 这段时间内, GC暂停占用了 cpu 资源。 重要的是, 系统运行在多核机器上, 转换为实际的停顿时间(stop-the-world)为`0.0713174秒`, 下面的计算会用到这个数字。
提取出有用的信息后, 剩下要做的就是统计每分钟内GC暂停的总时间。看看是否满足需求: 每分钟内总的暂停时间不得超过6000毫秒(6秒)。
#### Capacity(系统容量)
系统容量(Capacity)需求,是在达成吞吐量和延迟指标的情况下,对硬件环境的额外约束。这类需求大多是来源于计算资源或者预算方面的原因。例如:
* 系统必须能部署到小于512 MB内存的Android设备上
* 系统必须部署在Amazon**EC2**实例上, 配置不得超过**c3.xlarge(4核8GB)**。
* 每月的 Amazon EC2 账单不得超过`$12,000`
因此, 在满足延迟和吞吐量需求的基础上必须考虑系统容量。可以说, 假若有无限的计算资源可供挥霍, 那么任何 延迟和吞吐量指标 都不成问题, 但现实情况是, 预算(budget)和其他约束限制了可用的资源。
### 相关示例
介绍完性能调优的三个维度后, 我们来进行实际的操作以达成GC性能指标。
请看下面的代码:
```
//imports skipped for brevity
public class Producer implements Runnable {
private static ScheduledExecutorService executorService
= Executors.newScheduledThreadPool(2);
private Deque<byte[]> deque;
private int objectSize;
private int queueSize;
public Producer(int objectSize, int ttl) {
this.deque = new ArrayDeque<byte[]>();
this.objectSize = objectSize;
this.queueSize = ttl * 1000;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
deque.add(new byte[objectSize]);
if (deque.size() > queueSize) {
deque.poll();
}
}
}
public static void main(String[] args)
throws InterruptedException {
executorService.scheduleAtFixedRate(
new Producer(200 * 1024 * 1024 / 1000, 5),
0, 100, TimeUnit.MILLISECONDS
);
executorService.scheduleAtFixedRate(
new Producer(50 * 1024 * 1024 / 1000, 120),
0, 100, TimeUnit.MILLISECONDS);
TimeUnit.MINUTES.sleep(10);
executorService.shutdownNow();
}
}
```
这段程序代码, 每 100毫秒 提交两个作业(job)来。每个作业都模拟特定的生命周期: 创建对象, 然后在预定的时间释放, 接着就不管了, 由GC来自动回收占用的内存。
在运行这个示例程序时,通过以下JVM参数打开GC日志记录:
```
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
```
还应该加上JVM参数`-Xloggc`以指定GC日志的存储位置,类似这样:
```
-Xloggc:C:\\Producer_gc.log
```
* 1
* 2
在日志文件中可以看到GC的行为, 类似下面这样:
```
2015-06-04T13:34:16.119-0200: 1.723: [GC (Allocation Failure)
[PSYoungGen: 114016K->73191K(234496K)]
421540K->421269K(745984K),
0.0858176 secs]
[Times: user=0.04 sys=0.06, real=0.09 secs]
2015-06-04T13:34:16.738-0200: 2.342: [GC (Allocation Failure)
[PSYoungGen: 234462K->93677K(254976K)]
582540K->593275K(766464K),
0.2357086 secs]
[Times: user=0.11 sys=0.14, real=0.24 secs]
2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
[PSYoungGen: 93677K->70109K(254976K)]
[ParOldGen: 499597K->511230K(761856K)]
593275K->581339K(1016832K),
[Metaspace: 2936K->2936K(1056768K)],
0.0713174 secs]
[Times: user=0.21 sys=0.02, real=0.07 secs]
```
基于日志中的信息, 可以通过三个优化目标来提升性能:
1. 确保最坏情况下,GC暂停时间不超过预定阀值
2. 确保线程暂停的总时间不超过预定阀值
3. 在确保达到延迟和吞吐量指标的情况下, 降低硬件配置以及成本。
为此, 用三种不同的配置, 将代码运行10分钟, 得到了三种不同的结果, 汇总如下:
<colgroup data-id="c7104f7d-gSmaHJLh"><col data-id="cdf32f61-8J2cfg0C" span="1" width="239"><col data-id="cdf32f61-AWERG8eA" span="1" width="239"><col data-id="cdf32f61-NaGTMlPG" span="1" width="239"><col data-id="cdf32f61-dRpWPkiD" span="1" width="239"></colgroup>
| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | **560 ms** |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
使用不同的GC算法,和不同的内存配置,运行相同的代码, 以测量GC暂停时间与 延迟、吞吐量的关系。实验的细节和结果在后面章节详细介绍。
注意, 为了尽量简单, 示例中只改变了很少的输入参数, 此实验也没有在不同CPU数量或者不同的堆布局下进行测试。
#### Tuning for Latency(调优延迟指标)
假设有一个需求,**每次作业必须在 1000ms 内处理完成**。我们知道, 实际的作业处理只需要100 ms,简化后, 两者相减就可以算出对 GC暂停的延迟要求。现在需求变成:**GC暂停不能超过900ms**。这个问题很容易找到答案, 只需要解析GC日志文件, 并找出GC暂停中最大的那个暂停时间即可。
再来看测试所用的三个配置:
<colgroup data-id="c7104f7d-odLOoE9j"><col data-id="cdf32f61-NXanPMa5" span="1" width="239"><col data-id="cdf32f61-agXUo5B7" span="1" width="239"><col data-id="cdf32f61-1a1qqOLf" span="1" width="239"><col data-id="cdf32f61-k2joL2XZ" span="1" width="239"></colgroup>
| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | **560 ms** |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
可以看到,其中有一个配置达到了要求。运行的参数为:
```
java -Xmx12g -XX:+UseConcMarkSweepGC Producer
```
对应的GC日志中,暂停时间最大为`560 ms`, 这达到了延迟指标`900 ms`的要求。如果还满足吞吐量和系统容量需求的话,就可以说成功达成了GC调优目标, 调优结束。
#### Tuning for Throughput(吞吐量调优)
假定吞吐量指标为:**每小时完成 1300万次操作处理**。同样是上面的配置, 其中有一种配置满足了需求:
<colgroup data-id="c7104f7d-XWFk01FQ"><col data-id="cdf32f61-bRSQkdW2" span="1" width="239"><col data-id="cdf32f61-AX9oFR9r" span="1" width="239"><col data-id="cdf32f61-6dlMCOOR" span="1" width="239"><col data-id="cdf32f61-rnF2Ml61" span="1" width="239"></colgroup>
| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
| -Xmx12g | -XX:+UseParallelGC | **91.5%** | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
此配置对应的命令行参数为:
```
java -Xmx12g -XX:+UseParallelGC Producer
```
* 可以看到,GC占用了 8.5%的CPU时间,剩下的`91.5%`是有效的计算时间。为简单起见, 忽略示例中的其他安全点。现在需要考虑:
1. 每个CPU核心处理一次作业需要耗时`100ms`
2. 因此, 一分钟内每个核心可以执行 60,000 次操作(**每个job完成100次操作**)
3. 一小时内, 一个核心可以执行 360万次操作
4. 有四个CPU内核, 则每小时可以执行: 4 x 3.6M = 1440万次操作
理论上,通过简单的计算就可以得出结论, 每小时可以执行的操作数为:`14.4 M * 91.5% = 13,176,000`次, 满足需求。
值得一提的是, 假若还要满足延迟指标, 那就有问题了, 最坏情况下, GC暂停时间为`1,104 ms`, 最大延迟时间是前一种配置的两倍。
#### Tuning for Capacity(调优系统容量)
假设需要将软件部署到服务器上(commodity-class hardware), 配置为`4核10G`。这样的话, 系统容量的要求就变成: 最大的堆内存空间不能超过`8GB`。有了这个需求, 我们需要调整为第三套配置进行测试:
<colgroup data-id="c7104f7d-CM3OYb8V"><col data-id="cdf32f61-2q4eRIn9" span="1" width="239"><col data-id="cdf32f61-e9evDkSA" span="1" width="239"><col data-id="cdf32f61-32S42uAd" span="1" width="239"><col data-id="cdf32f61-VjMFsW5B" span="1" width="239"></colgroup>
| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| **-Xmx8g** | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
程序可以通过如下参数执行:
```
java -Xmx8g -XX:+UseConcMarkSweepGC Producer
```
* 测试结果是延迟大幅增长, 吞吐量同样大幅降低:
* 现在,GC占用了更多的CPU资源, 这个配置只有`66.3%`的有效CPU时间。因此,这个配置让吞吐量从最好的情况**13,176,000 操作/小时**下降到**不足 9,547,200次操作/小时**.
* 最坏情况下的延迟变成了**1,610 ms**, 而不再是**560ms**。
通过对这三个维度的介绍, 你应该了解, 不是简单的进行“性能(performance)”优化, 而是需要从三种不同的维度来进行考虑, 测量, 并调优延迟和吞吐量, 此外还需要考虑系统容量的约束。
请继续阅读下一章:6\. GC 调优(工具篇) - GC参考手册
原文链接:[GC Tuning: Basics](https://plumbr.eu/handbook/gc-tuning)
翻译时间: 2016年02月06日
## 6\. GC 调优(工具篇) - GC参考手册
2017年02月23日 18:56:02
阅读数:6469
进行GC性能调优时, 需要明确了解, 当前的GC行为对系统和用户有多大的影响。有多种监控GC的工具和方法, 本章将逐一介绍常用的工具。
您应该已经阅读了前面的章节:
1. 垃圾收集简介 - GC参考手册
2. Java中的垃圾收集 - GC参考手册
3. GC 算法(基础篇) - GC参考手册
4. GC 算法(实现篇) - GC参考手册
5. GC 调优(基础篇) - GC参考手册
JVM 在程序执行的过程中, 提供了GC行为的原生数据。那么, 我们就可以利用这些原生数据来生成各种报告。原生数据(_raw data_) 包括:
* 各个内存池的当前使用情况,
* 各个内存池的总容量,
* 每次GC暂停的持续时间,
* GC暂停在各个阶段的持续时间。
可以通过这些数据算出各种指标, 例如: 程序的内存分配率, 提升率等等。本章主要介绍如何获取原生数据。 后续的章节将对重要的派生指标(derived metrics)展开讨论, 并引入GC性能相关的话题。
## JMX API
从 JVM 运行时获取GC行为数据, 最简单的办法是使用标准[JMX API 接口](https://docs.oracle.com/javase/tutorial/jmx/index.html). JMX是获取 JVM内部运行时状态信息 的标准API. 可以编写程序代码, 通过 JMX API 来访问本程序所在的JVM,也可以通过JMX客户端执行(远程)访问。
最常见的 JMX客户端是[JConsole](http://docs.oracle.com/javase/7/docs/technotes/guides/management/jconsole.html)和[JVisualVM](http://docs.oracle.com/javase/7/docs/technotes/tools/share/jvisualvm.html)(可以安装各种插件,十分强大)。两个工具都是标准JDK的一部分, 而且很容易使用. 如果使用的是 JDK 7u40 及更高版本, 还可以使用另一个工具:[Java Mission Control](http://www.oracle.com/technetwork/java/javaseproducts/mission-control/java-mission-control-1998576.html)( 大致翻译为 Java控制中心,`jmc.exe`)。
> JVisualVM安装MBeans插件的步骤: 通过 工具(T) – 插件(G) – 可用插件 – 勾选VisualVM-MBeans – 安装 – 下一步 – 等待安装完成…… 其他插件的安装过程基本一致。
所有 JMX客户端都是独立的程序,可以连接到目标JVM上。目标JVM可以在本机, 也可能是远端JVM. 如果要连接远端JVM, 则目标JVM启动时必须指定特定的环境变量,以开启远程JMX连接/以及端口号。 示例如下:
```
java -Dcom.sun.management.jmxremote.port=5432 com.yourcompany.YourApp
```
在此处, JVM 打开端口`5432`以支持JMX连接。
通过 JVisualVM 连接到某个JVM以后, 切换到 MBeans 标签, 展开 “java.lang/GarbageCollector” . 就可以看到GC行为信息, 下图是 JVisualVM 中的截图:
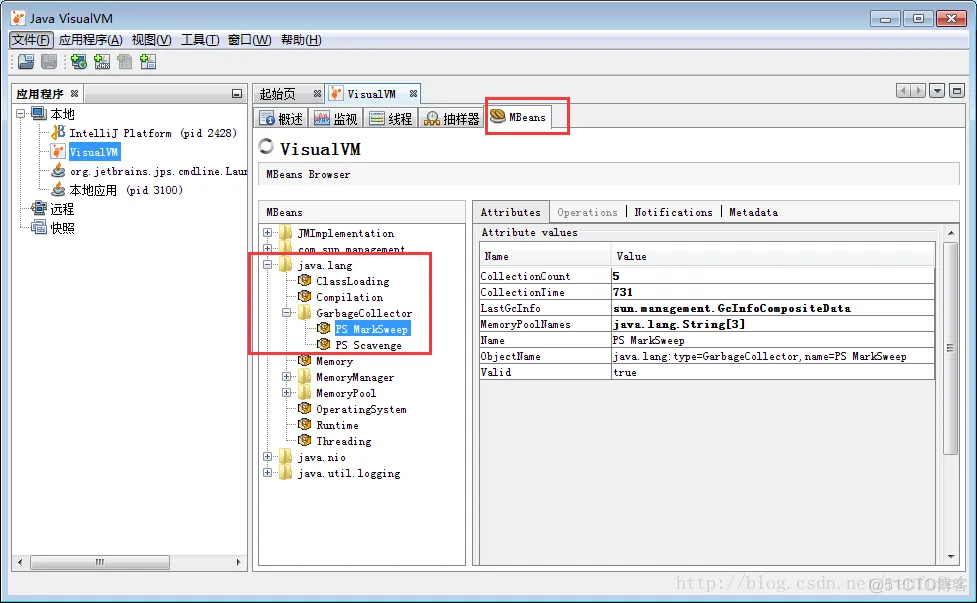
下图是Java Mission Control 中的截图:
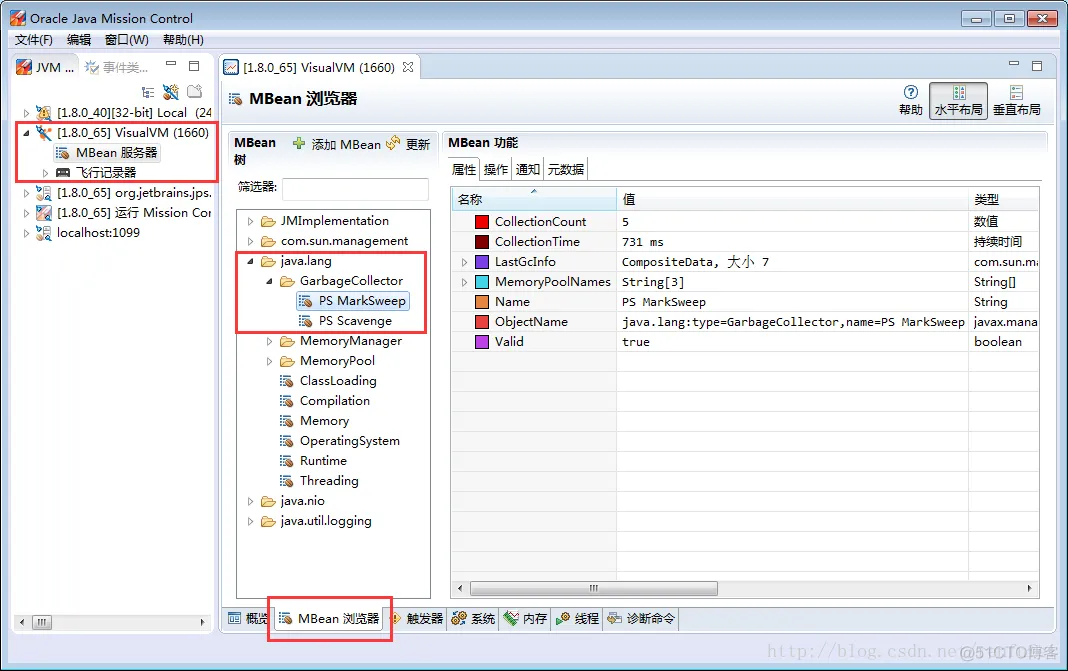
从以上截图中可以看到两款垃圾收集器。其中一款负责清理年轻代(**PS Scavenge**),另一款负责清理老年代(**PS MarkSweep**); 列表中显示的就是垃圾收集器的名称。可以看到 , jmc 的功能和展示数据的方式更强大。
对所有的垃圾收集器, 通过 JMX API 获取的信息包括:
* **CollectionCount**: 垃圾收集器执行的GC总次数,
* **CollectionTime**: 收集器运行时间的累计。这个值等于所有GC事件持续时间的总和,
* **LastGcInfo**: 最近一次GC事件的详细信息。包括 GC事件的持续时间(duration), 开始时间(startTime) 和 结束时间(endTime), 以及各个内存池在最近一次GC之前和之后的使用情况,
* **MemoryPoolNames**: 各个内存池的名称,
* **Name**: 垃圾收集器的名称
* **ObjectName**: 由JMX规范定义的 MBean的名字,,
* **Valid**: 此收集器是否有效。本人只见过 “`true`“的情况 (^_^)
根据经验, 这些信息对GC的性能来说,不能得出什么结论. 只有编写程序, 获取GC相关的 JMX 信息来进行统计和分析。 在下文可以看到, 一般也不怎么关注 MBean , 但 MBean 对于理解GC的原理倒是挺有用的。
## JVisualVM
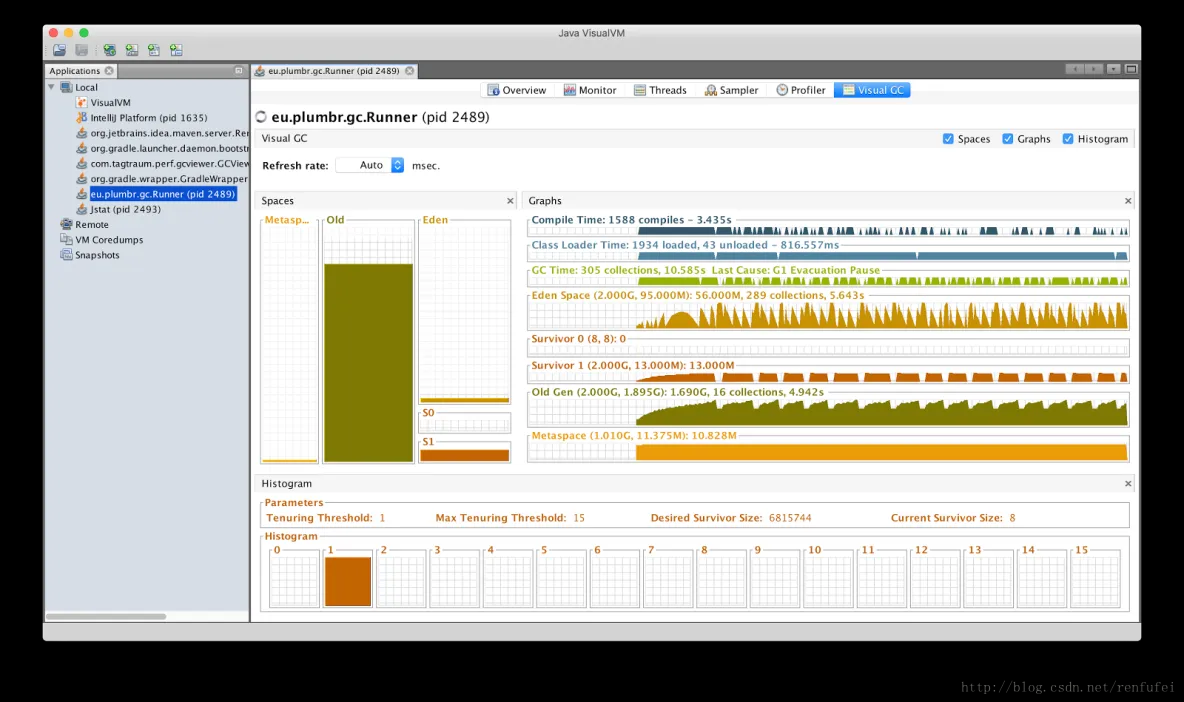
Visual GC 插件常用来监控本机运行的Java程序, 比如开发者和性能调优专家经常会使用此插件, 以快速获取程序运行时的GC信息。

左侧的图表展示了各个内存池的使用情况: Metaspace/永久代, 老年代, Eden区以及两个存活区。
在右边, 顶部的两个图表与 GC无关, 显示的是 JIT编译时间 和 类加载时间。下面的6个图显示的是内存池的历史记录, 每个内存池的GC次数,GC总时间, 以及最大值,峰值, 当前使用情况。
再下面是 HistoGram, 显示了年轻代对象的年龄分布。至于对象的年龄监控(objects tenuring monitoring), 本章不进行讲解。
与纯粹的JMX工具相比, VisualGC 插件提供了更友好的界面, 如果没有其他趁手的工具, 请选择VisualGC. 本章接下来会介绍其他工具, 这些工具可以提供更多的信息, 以及更好的视角. 当然, 在“Profilers(分析器)”一节中,也会介绍 JVisualVM 的适用场景 —— 如: 分配分析(allocation profiling), 所以我们绝不会贬低哪一款工具, 关键还得看实际情况。
## jstat
[jstat](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html)也是标准JDK提供的一款监控工具(Java Virtual Machine statistics monitoring tool),可以统计各种指标。既可以连接到本地JVM,也可以连到远程JVM. 查看支持的指标和对应选项可以执行 “`jstat -options`” 。例如:
```
+-----------------+---------------------------------------------------------------+
| Option | Displays... |
+-----------------+---------------------------------------------------------------+
|class | Statistics on the behavior of the class loader |
|compiler | Statistics on the behavior of the HotSpot Just-In-Time com- |
| | piler |
|gc | Statistics on the behavior of the garbage collected heap |
|gccapacity | Statistics of the capacities of the generations and their |
| | corresponding spaces. |
|gccause | Summary of garbage collection statistics (same as -gcutil), |
| | with the cause of the last and current (if applicable) |
| | garbage collection events. |
|gcnew | Statistics of the behavior of the new generation. |
|gcnewcapacity | Statistics of the sizes of the new generations and its corre- |
| | sponding spaces. |
|gcold | Statistics of the behavior of the old and permanent genera- |
| | tions. |
|gcoldcapacity | Statistics of the sizes of the old generation. |
|gcpermcapacity | Statistics of the sizes of the permanent generation. |
|gcutil | Summary of garbage collection statistics. |
|printcompilation | Summary of garbage collection statistics. |
+-----------------+---------------------------------------------------------------+
```
* jstat 对于快速确定GC行为是否健康非常有用。启动方式为: “`jstat -gc -t PID 1s`” , 其中,PID 就是要监视的Java进程ID。可以通过`jps`命令查看正在运行的Java进程列表。
```
jps
jstat -gc -t 2428 1s
```
以上命令的结果, 是 jstat 每秒向标准输出输出一行新内容, 比如:
```
Timestamp S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
200.0 8448.0 8448.0 8448.0 0.0 67712.0 67712.0 169344.0 169344.0 21248.0 20534.3 3072.0 2807.7 34 0.720 658 133.684 134.404
201.0 8448.0 8448.0 8448.0 0.0 67712.0 67712.0 169344.0 169343.2 21248.0 20534.3 3072.0 2807.7 34 0.720 662 134.712 135.432
202.0 8448.0 8448.0 8102.5 0.0 67712.0 67598.5 169344.0 169343.6 21248.0 20534.3 3072.0 2807.7 34 0.720 667 135.840 136.559
203.0 8448.0 8448.0 8126.3 0.0 67712.0 67702.2 169344.0 169343.6 21248.0 20547.2 3072.0 2807.7 34 0.720 669 136.178 136.898
204.0 8448.0 8448.0 8126.3 0.0 67712.0 67702.2 169344.0 169343.6 21248.0 20547.2 3072.0 2807.7 34 0.720 669 136.178 136.898
205.0 8448.0 8448.0 8134.6 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 671 136.234 136.954
206.0 8448.0 8448.0 8134.6 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 671 136.234 136.954
207.0 8448.0 8448.0 8154.8 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 673 136.289 137.009
208.0 8448.0 8448.0 8154.8 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 673 136.289 137.009
```
稍微解释一下上面的内容。参考[jstat manpage](http://www.manpagez.com/man/1/jstat/), 我们可以知道:
* jstat 连接到 JVM 的时间, 是JVM启动后的 200秒。此信息从第一行的 “**Timestamp**” 列得知。继续看下一行, jstat 每秒钟从JVM 接收一次信息, 也就是命令行参数中 “`1s`” 的含义。
* 从第一行的 “**YGC**” 列得知年轻代共执行了34次GC, 由 “**FGC**” 列得知整个堆内存已经执行了 658次 full GC。
* 年轻代的GC耗时总共为`0.720 秒`, 显示在“**YGCT**” 这一列。
* Full GC 的总计耗时为`133.684 秒`, 由“**FGCT**”列得知。 这立马就吸引了我们的目光, 总的JVM 运行时间只有 200 秒,**但其中有 66% 的部分被 Full GC 消耗了**。
再看下一行, 问题就更明显了。
* 在接下来的一秒内共执行了 4 次 Full GC。参见 “**FGC**” 列.
* 这4次 Full GC 暂停占用了差不多 1秒的时间(根据**FGCT**列的差得知)。与第一行相比, Full GC 耗费了`928 毫秒`, 即`92.8%`的时间。
* 根据 “**OC**和 “**OU**” 列得知,**整个老年代的空间**为`169,344.0 KB`(“OC“), 在 4 次 Full GC 后依然占用了`169,344.2 KB`(“OU“)。用了`928ms`的时间却只释放了 800 字节的内存, 怎么看都觉得很不正常。
只看这两行的内容, 就知道程序出了很严重的问题。继续分析下一行, 可以确定问题依然存在,而且变得更糟。
JVM几乎完全卡住了(stalled), 因为GC占用了90%以上的计算资源。GC之后, 所有的老代空间仍然还在占用。事实上, 程序在一分钟以后就挂了, 抛出了 “[java.lang.OutOfMemoryError: GC overhead limit exceeded](https://plumbr.eu/outofmemoryerror/gc-overhead-limit-exceeded)” 错误。
可以看到, 通过 jstat 能很快发现对JVM健康极为不利的GC行为。一般来说, 只看 jstat 的输出就能快速发现以下问题:
* 最后一列 “**GCT**”, 与JVM的总运行时间 “**Timestamp**” 的比值, 就是GC 的开销。如果每一秒内, “**GCT**” 的值都会明显增大, 与总运行时间相比, 就暴露出GC开销过大的问题. 不同系统对GC开销有不同的容忍度, 由性能需求决定, 一般来讲, 超过`10%`的GC开销都是有问题的。
* “**YGC**” 和 “**FGC**” 列的快速变化往往也是有问题的征兆。频繁的GC暂停会累积,并导致更多的线程停顿(stop-the-world pauses), 进而影响吞吐量。
* 如果看到 “**OU**” 列中,老年代的使用量约等于老年代的最大容量(**OC**), 并且不降低的话, 就表示虽然执行了老年代GC, 但基本上属于无效GC。
## GC日志(GC logs)
通过日志内容也可以得到GC相关的信息。因为GC日志模块内置于JVM中, 所以日志中包含了对GC活动最全面的描述。 这就是事实上的标准, 可作为GC性能评估和优化的最真实数据来源。
GC日志一般输出到文件之中, 是纯 text 格式的, 当然也可以打印到控制台。有多个可以控制GC日志的JVM参数。例如,可以打印每次GC的持续时间, 以及程序暂停时间(`-XX:+PrintGCApplicationStoppedTime`), 还有GC清理了多少引用类型(`-XX:+PrintReferenceGC`)。
要打印GC日志, 需要在启动脚本中指定以下参数:
```
-XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:<filename>
```
以上参数指示JVM: 将所有GC事件打印到日志文件中, 输出每次GC的日期和时间戳。不同GC算法输出的内容略有不同. ParallelGC 输出的日志类似这样:
```
199.879: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1473386 secs] [Times: user=0.43 sys=0.01, real=0.15 secs]
200.027: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1567794 secs] [Times: user=0.41 sys=0.00, real=0.16 secs]
200.184: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1621946 secs] [Times: user=0.43 sys=0.00, real=0.16 secs]
200.346: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1547695 secs] [Times: user=0.41 sys=0.00, real=0.15 secs]
200.502: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1563071 secs] [Times: user=0.42 sys=0.01, real=0.16 secs]
200.659: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1538778 secs] [Times: user=0.42 sys=0.00, real=0.16 secs]
```
在 “04\. GC算法:实现篇” 中详细介绍了这些格式, 如果对此不了解, 可以先阅读该章节。
分析以上日志内容, 可以得知:
* 这部分日志截取自JVM启动后200秒左右。
* 日志片段中显示, 在`780毫秒`以内, 因为垃圾回收 导致了5次 Full GC 暂停(去掉第六次暂停,这样更精确一些)。
* 这些暂停事件的总持续时间是`777毫秒`, 占总运行时间的**99.6%**。
* 在GC完成之后, 几乎所有的老年代空间(`169,472 KB`)依然被占用(`169,318 KB`)。
通过日志信息可以确定, 该应用的GC情况非常糟糕。JVM几乎完全停滞, 因为GC占用了超过`99%`的CPU时间。 而GC的结果是, 老年代空间仍然被占满, 这进一步肯定了我们的结论。 示例程序和jstat 小节中的是同一个, 几分钟之后系统就挂了, 抛出 “[java.lang.OutOfMemoryError: GC overhead limit exceeded](https://plumbr.eu/outofmemoryerror/gc-overhead-limit-exceeded)” 错误, 不用说, 问题是很严重的.
从此示例可以看出, GC日志对监控GC行为和JVM是否处于健康状态非常有用。一般情况下, 查看 GC 日志就可以快速确定以下症状:
* GC开销太大。如果GC暂停的总时间很长, 就会损害系统的吞吐量。不同的系统允许不同比例的GC开销, 但一般认为, 正常范围在`10%`以内。
* 极个别的GC事件暂停时间过长。当某次GC暂停时间太长, 就会影响系统的延迟指标. 如果延迟指标规定交易必须在`1,000 ms`内完成, 那就不能容忍任何超过`1000毫秒`的GC暂停。
* 老年代的使用量超过限制。如果老年代空间在 Full GC 之后仍然接近全满, 那么GC就成为了性能瓶颈, 可能是内存太小, 也可能是存在内存泄漏。这种症状会让GC的开销暴增。
可以看到,GC日志中的信息非常详细。但除了这些简单的小程序, 生产系统一般都会生成大量的GC日志, 纯靠人工是很难阅读和进行解析的。
## GCViewer
我们可以自己编写解析器, 来将庞大的GC日志解析为直观易读的图形信息。 但很多时候自己写程序也不是个好办法, 因为各种GC算法的复杂性, 导致日志信息格式互相之间不太兼容。那么神器来了:[GCViewer](https://github.com/chewiebug/GCViewer)。
[GCViewer](https://github.com/chewiebug/GCViewer)是一款开源的GC日志分析工具。项目的 GitHub 主页对各项指标进行了完整的描述. 下面我们介绍最常用的一些指标。
第一步是获取GC日志文件。这些日志文件要能够反映系统在性能调优时的具体场景. 假若运营部门(operational department)反馈: 每周五下午,系统就运行缓慢, 不管GC是不是主要原因, 分析周一早晨的日志是没有多少意义的。
获取到日志文件之后, 就可以用 GCViewer 进行分析, 大致会看到类似下面的图形界面:
使用的命令行大致如下:
```
java -jar gcviewer_1.3.4.jar gc.log
```
当然, 如果不想打开程序界面,也可以在后面加上其他参数,直接将分析结果输出到文件。
命令大致如下:
```
java -jar gcviewer_1.3.4.jar gc.log summary.csv chart.png
```
以上命令将信息汇总到当前目录下的 Excel 文件`summary.csv`之中, 将图形信息保存为`chart.png`文件。
点击下载:gcviewer的jar包及使用示例
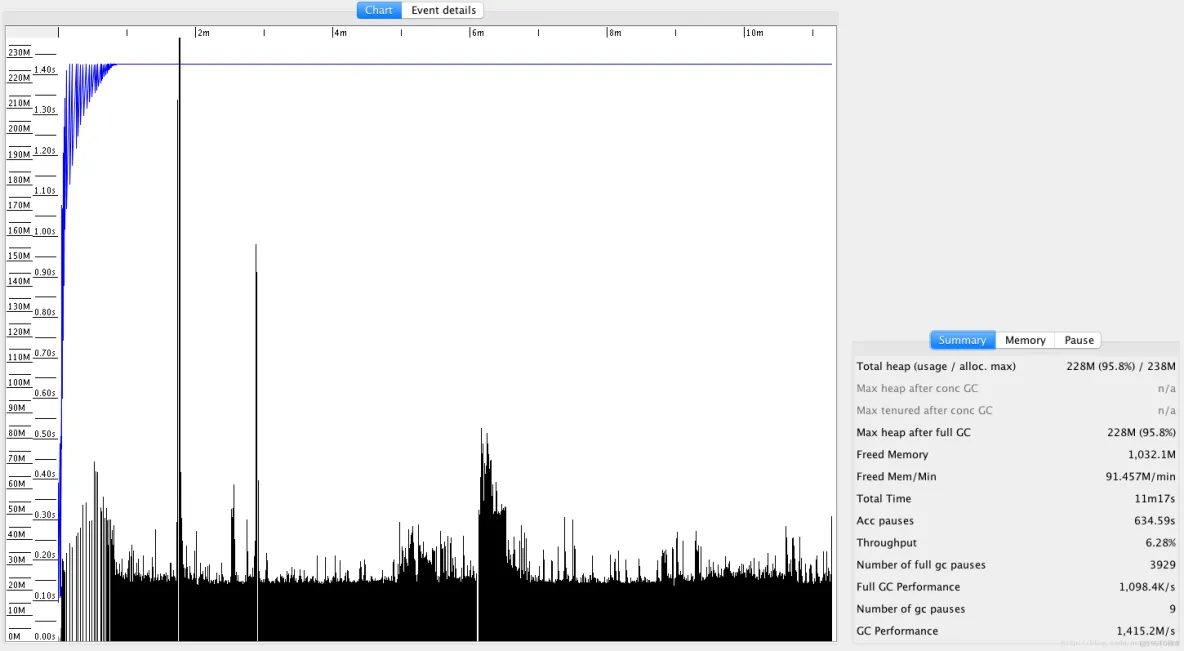
上图中, Chart 区域是对GC事件的图形化展示。包括各个内存池的大小和GC事件。上图中, 只有两个可视化指标: 蓝色线条表示堆内存的使用情况, 黑色的Bar则表示每次GC暂停时间的长短。
从图中可以看到, 内存使用量增长很快。一分钟左右就达到了堆内存的最大值. 堆内存几乎全部被消耗, 不能顺利分配新对象, 并引发频繁的 Full GC 事件. 这说明程序可能存在内存泄露, 或者启动时指定的内存空间不足。
从图中还可以看到 GC暂停的频率和持续时间。`30秒`之后, GC几乎不间断地运行,最长的暂停时间超过`1.4秒`。
在右边有三个选项卡。“`**Summary**`(摘要)” 中比较有用的是 “`Throughput`”(吞吐量百分比) 和 “`Number of GC pauses`”(GC暂停的次数), 以及“`Number of full GC pauses`”(Full GC 暂停的次数). 吞吐量显示了有效工作的时间比例, 剩下的部分就是GC的消耗。
以上示例中的吞吐量为`**6.28%**`。这意味着有`**93.72%**`
下一个有意思的地方是“**Pause**”(暂停)选项卡:
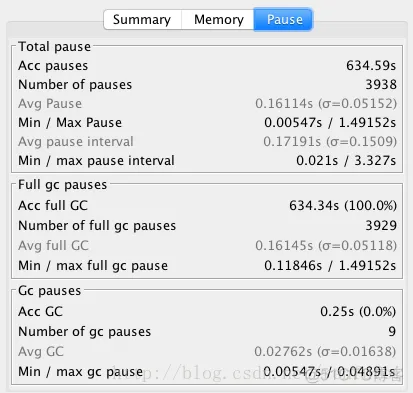
“`Pause`” 展示了GC暂停的总时间,平均值,最小值和最大值, 并且将 total 与minor/major 暂停分开统计。如果要优化程序的延迟指标, 这些统计可以很快判断出暂停时间是否过长。另外, 我们可以得出明确的信息: 累计暂停时间为`634.59 秒`, GC暂停的总次数为`3,938 次`, 这在`11分钟/660秒`的总运行时间里那不是一般的高。
更详细的GC暂停汇总信息, 请查看主界面中的 “**Event details**” 标签:
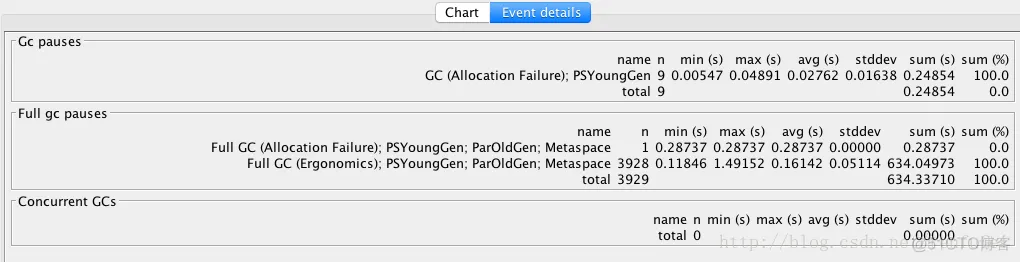
从“**Event details**” 标签中, 可以看到日志中所有重要的GC事件汇总:`普通GC停顿`和`Full GC 停顿次数`, 以及`并发执行数`,`非 stop-the-world 事件`等。此示例中, 可以看到一个明显的地方, Full GC 暂停严重影响了吞吐量和延迟, 依据是:`3,928 次 Full GC`, 暂停了`634秒`。
可以看到, GCViewer 能用图形界面快速展现异常的GC行为。一般来说, 图像化信息能迅速揭示以下症状:
* 低吞吐量。当应用的吞吐量下降到不能容忍的地步时, 有用工作的总时间就大量减少. 具体有多大的 “容忍度”(tolerable) 取决于具体场景。按照经验, 低于 90% 的有效时间就值得警惕了, 可能需要好好优化下GC。
* 单次GC的暂停时间过长。只要有一次GC停顿时间过长,就会影响程序的延迟指标. 例如, 延迟需求规定必须在 1000 ms以内完成交易, 那就不能容忍任何一次GC暂停超过1000毫秒。
* 堆内存使用率过高。如果老年代空间在 Full GC 之后仍然接近全满, 程序性能就会大幅降低, 可能是资源不足或者内存泄漏。这种症状会对吞吐量产生严重影响。
业界良心 —— 图形化展示的GC日志信息绝对是我们重磅推荐的。不用去阅读冗长而又复杂的GC日志,通过容易理解的图形, 也可以得到同样的信息。
## 分析器(Profilers)
下面介绍分析器([profilers](http://zeroturnaround.com/rebellabs/developer-productivity-report-2015-java-performance-survey-results/3/), Oracle官方翻译是:`抽样器`)。相对于前面的工具, 分析器只关心GC中的一部分领域. 本节我们也只关注分析器相关的GC功能。
首先警告 —— 不要认为分析器适用于所有的场景。分析器有时确实作用很大, 比如检测代码中的CPU热点时。但某些情况使用分析器不一定是个好方案。
对GC调优来说也是一样的。要检测是否因为GC而引起延迟或吞吐量问题时, 不需要使用分析器. 前面提到的工具(`jstat`或 原生/可视化GC日志)就能更好更快地检测出是否存在GC问题. 特别是从生产环境中收集性能数据时, 最好不要使用分析器, 因为性能开销非常大。
如果确实需要对GC进行优化, 那么分析器就可以派上用场了, 可以对 Object 的创建信息一目了然. 换个角度看, 如果GC暂停的原因不在某个内存池中, 那就只会是因为创建对象太多了。 所有分析器都能够跟踪对象分配(via allocation profiling), 根据内存分配的轨迹, 让你知道**实际驻留在内存中的是哪些对象**。
分配分析能定位到在哪个地方创建了大量的对象. 使用分析器辅助进行GC调优的好处是, 能确定哪种类型的对象最占用内存, 以及哪些线程创建了最多的对象。
下面我们通过实例介绍3种分配分析器:`**hprof**`,`**JVisualV**`**M**和`**AProf**`。实际上还有很多分析器可供选择, 有商业产品,也有免费工具, 但其功能和应用基本上都是类似的。
### hprof
[hprof 分析器](http://docs.oracle.com/javase/8/docs/technotes/samples/hprof.html)内置于JDK之中。 在各种环境下都可以使用, 一般优先使用这款工具。
要让`hprof`和程序一起运行, 需要修改启动脚本, 类似这样:
```
java -agentlib:hprof=heap=sites com.yourcompany.YourApplication
```
在程序退出时,会将分配信息dump(转储)到工作目录下的`java.hprof.txt`文件中。使用文本编辑器打开, 并搜索 “**SITES BEGIN**” 关键字, 可以看到:
```
SITES BEGIN (ordered by live bytes) Tue Dec 8 11:16:15 2015
percent live alloc'ed stack class
rank self accum bytes objs bytes objs trace name
1 64.43% 4.43% 8370336 20121 27513408 66138 302116 int[]
2 3.26% 88.49% 482976 20124 1587696 66154 302104 java.util.ArrayList
3 1.76% 88.74% 241704 20121 1587312 66138 302115 eu.plumbr.demo.largeheap.ClonableClass0006
... 部分省略 ...
SITES END
```
从以上片段可以看到, allocations 是根据每次创建的对象数量来排序的。第一行显示所有对象中有`**64.43%**`的对象是整型数组(`int[]`), 在标识为`302116`的位置创建。搜索 “**TRACE 302116**” 可以看到:
```
TRACE 302116:
eu.plumbr.demo.largeheap.ClonableClass0006.<init>(GeneratorClass.java:11)
sun.reflect.GeneratedConstructorAccessor7.newInstance(<Unknown Source>:Unknown line)
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
java.lang.reflect.Constructor.newInstance(Constructor.java:422)
```
现在, 知道有`64.43%`的对象是整数数组, 在`ClonableClass0006`类的构造函数中, 第11行的位置, 接下来就可以优化代码, 以减少GC的压力。
### Java VisualVM
本章前面的第一部分, 在监控 JVM 的GC行为工具时介绍了 JVisualVM , 本节介绍其在分配分析上的应用。
JVisualVM 通过GUI的方式连接到正在运行的JVM。 连接上目标JVM之后 :
1. 打开 “工具” –> “选项” 菜单, 点击**性能分析(Profiler)**标签, 新增配置, 选择 Profiler 内存, 确保勾选了 “Record allocations stack traces”(记录分配栈跟踪)。
2. 勾选 “Settings”(设置) 复选框, 在内存设置标签下,修改预设配置。
3. 点击 “Memory”(内存) 按钮开始进行内存分析。
4. 让程序运行一段时间,以收集关于对象分配的足够信息。
5. 单击下方的 “Snapshot”(快照) 按钮。可以获取收集到的快照信息。
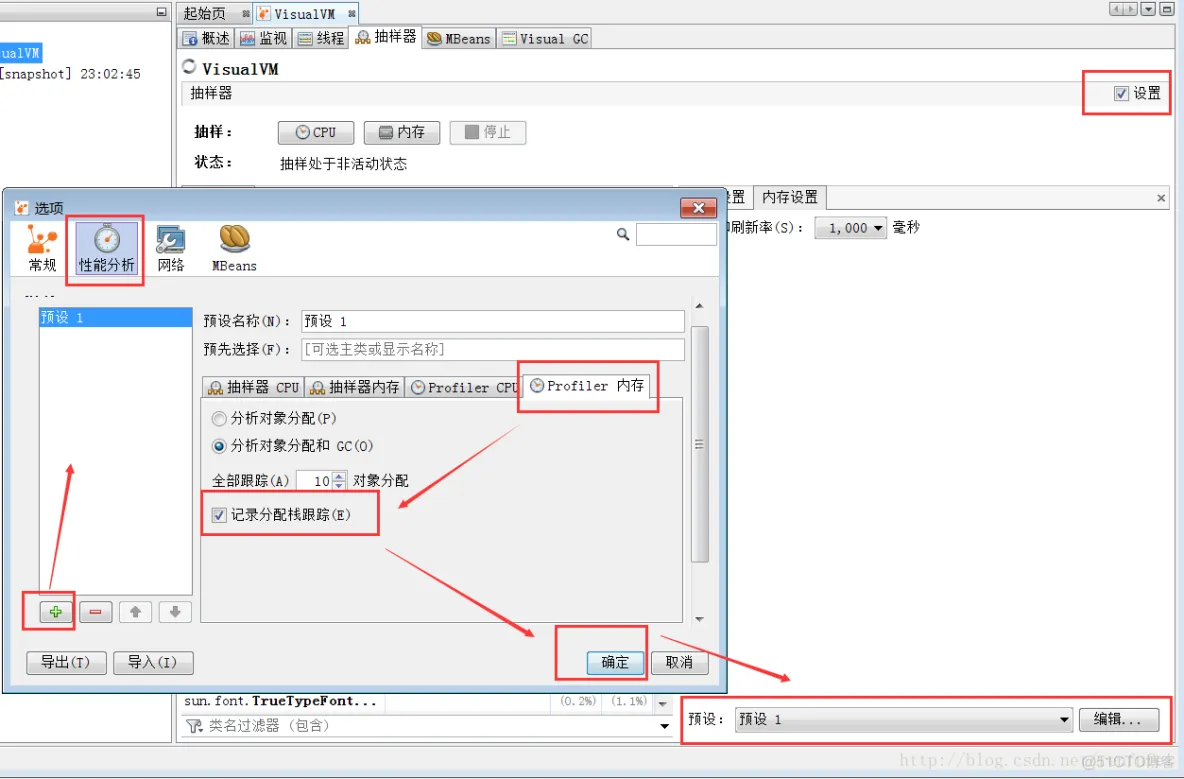
完成上面的步骤后, 可以得到类似这样的信息:
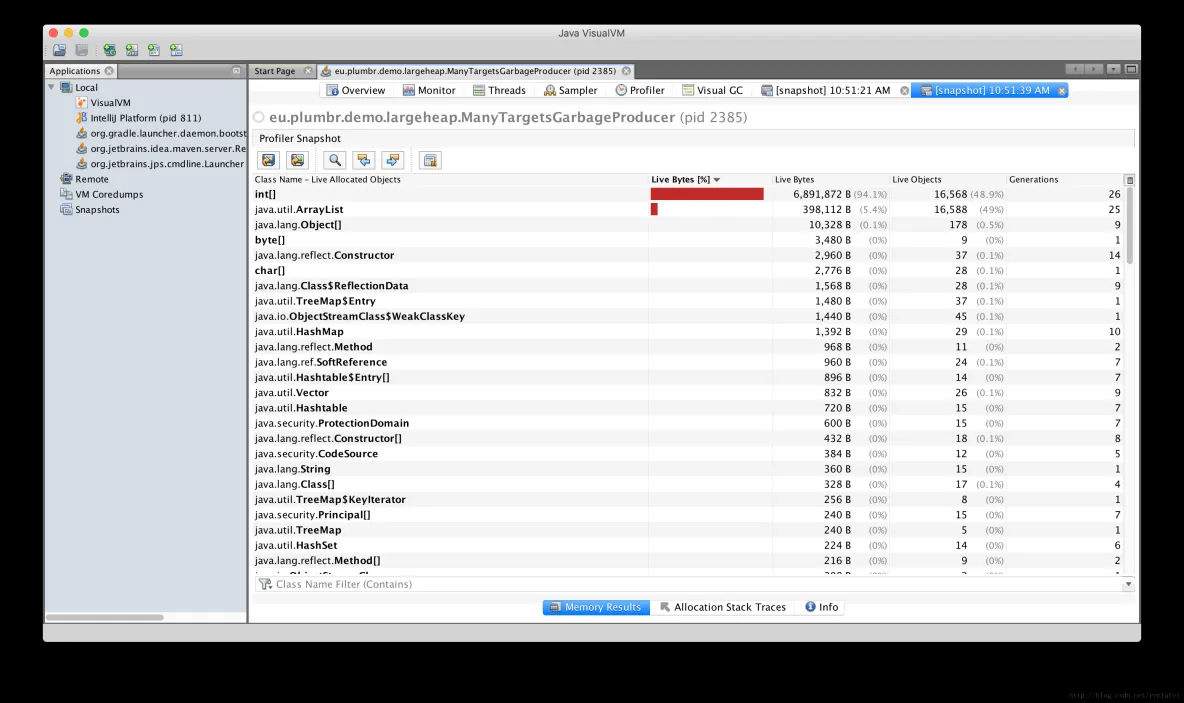
上图按照每个类被创建的对象数量多少来排序。看第一行可以知道, 创建的最多的对象是`int[]`数组. 鼠标右键单击这行, 就可以看到这些对象都在哪些地方创建的:
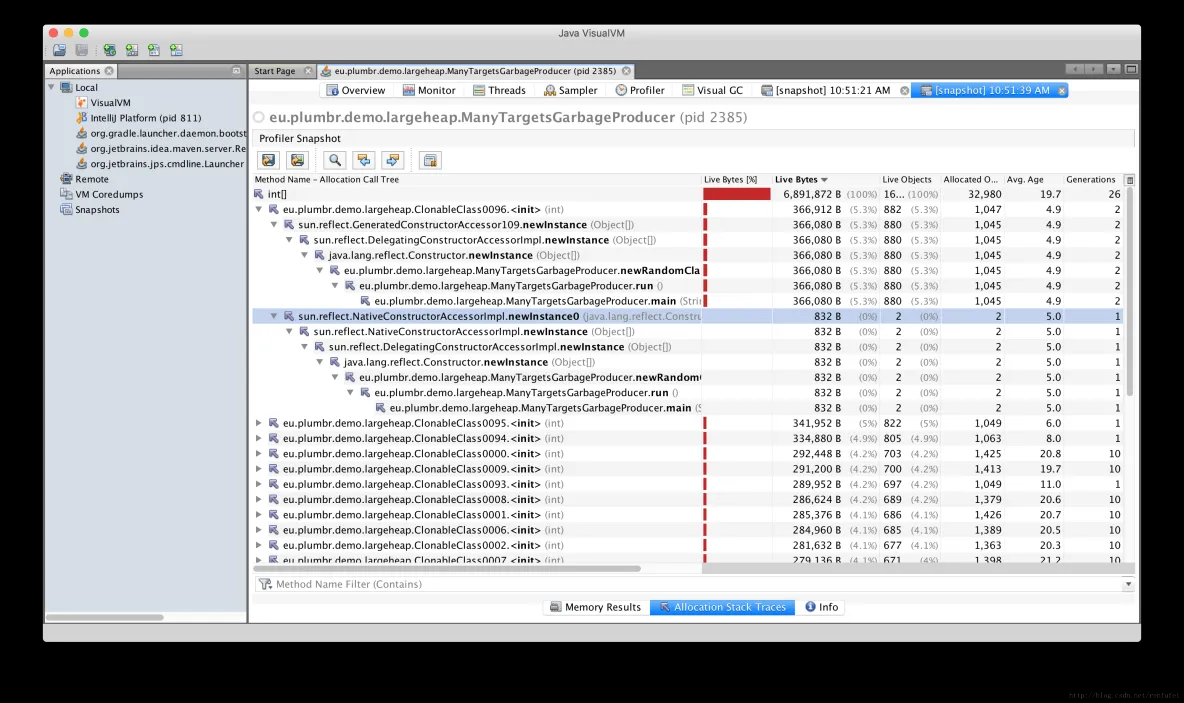
与`hprof`相比, JVisualVM 更加容易使用 —— 比如上面的截图中, 在一个地方就可以看到所有`int[]`的分配信息, 所以多次在同一处代码进行分配的情况就很容易发现。
### AProf
最重要的一款分析器,是由 Devexperts 开发的[**AProf**](https://code.devexperts.com/display/AProf/About+Aprof)。 内存分配分析器 AProf 也被打包为 Java agent 的形式。
用 AProf 分析应用程序, 需要修改 JVM 启动脚本,类似这样:
```
java -javaagent:/path-to/aprof.jar com.yourcompany.YourApplication
```
重启应用之后, 工作目录下会生成一个`aprof.txt`文件。此文件每分钟更新一次, 包含这样的信息:
```
========================================================================================================================
TOTAL allocation dump for 91,289 ms (0h01m31s)
Allocated 1,769,670,584 bytes in 24,868,088 objects of 425 classes in 2,127 locations
========================================================================================================================
Top allocation-inducing locations with the data types allocated from them
------------------------------------------------------------------------------------------------------------------------
eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 1,423,675,776 (80.44%) bytes in 17,113,721 (68.81%) objects (avg size 83 bytes)
int[]: 711,322,976 (40.19%) bytes in 1,709,911 (6.87%) objects (avg size 416 bytes)
char[]: 369,550,816 (20.88%) bytes in 5,132,759 (20.63%) objects (avg size 72 bytes)
java.lang.reflect.Constructor: 136,800,000 (7.73%) bytes in 1,710,000 (6.87%) objects (avg size 80 bytes)
java.lang.Object[]: 41,079,872 (2.32%) bytes in 1,710,712 (6.87%) objects (avg size 24 bytes)
java.lang.String: 41,063,496 (2.32%) bytes in 1,710,979 (6.88%) objects (avg size 24 bytes)
java.util.ArrayList: 41,050,680 (2.31%) bytes in 1,710,445 (6.87%) objects (avg size 24 bytes)
... cut for brevity ...
```
上面的输出是按照`size`进行排序的。可以看出,`80.44%`的 bytes 和`68.81%`的 objects 是在`ManyTargetsGarbageProducer.newRandomClassObject()`方法中分配的。 其中,**int[]**数组占用了`40.19%`的内存, 是最大的一个。
继续往下看, 会发现`allocation traces`(分配痕迹)相关的内容, 也是以 allocation size 排序的:
```
Top allocated data types with reverse location traces
------------------------------------------------------------------------------------------------------------------------
int[]: 725,306,304 (40.98%) bytes in 1,954,234 (7.85%) objects (avg size 371 bytes)
eu.plumbr.demo.largeheap.ClonableClass0006.: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)
java.lang.reflect.Constructor.newInstance: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)
eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 38,357,280 (2.16%) bytes in 92,205 (0.37%) objects (avg size 416 bytes)
java.lang.reflect.Constructor.newInstance: 416 (0.00%) bytes in 1 (0.00%) objects (avg size 416 bytes)
... cut for brevity ...
```
可以看到,`int[]`数组的分配, 在`ClonableClass0006`构造函数中继续增大。
和其他工具一样,`AProf`揭露了 分配的大小以及位置信息(`allocation size and locations`), 从而能够快速找到最耗内存的部分。在我们看来,**AProf**是最有用的分配分析器, 因为它只专注于内存分配, 所以做得最好。 当然, 这款工具是开源免费的, 资源开销也最小。
请继续阅读下一章:7\. GC 调优(实战篇) - GC参考手册
原文链接:[GC Tuning: Tooling](https://plumbr.eu/handbook/gc-tuning-measuring)
翻译时间: 2016年02月06日
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md
================================================
# 目录
* [打破双亲委派模型](#打破双亲委派模型)
* [JNDI](#jndi)
* [JNDI 的理解](#[jndi-的理解])
* [OSGI](#osgi)
* [1.如何正确的理解和认识OSGI技术?](#1如何正确的理解和认识osgi技术?)
* [Tomcat类加载器以及应用间class隔离与共享](#tomcat类加载器以及应用间class隔离与共享)
* [类加载器](#类加载器)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 打破双亲委派模型
### JNDI
### JNDI 的理解
JNDI是 Java 命名与文件夹接口(Java Naming and Directory Interface),在J2EE规范中是重要的规范之中的一个,不少专家觉得,没有透彻理解JNDI的意义和作用,就没有真正掌握J2EE特别是EJB的知识。
那么,JNDI究竟起什么作用?//带着问题看文章是最有效的
要了解JNDI的作用,我们能够从“假设不用JNDI我们如何做?用了JNDI后我们又将如何做?”这个问题来探讨。
没有JNDI的做法:
程序猿开发时,知道要开发訪问MySQL数据库的应用,于是将一个对 MySQL JDBC 驱动程序类的引用进行了编码,并通过使用适当的 JDBC URL 连接到数据库。
就像以下代码这样:
````
1. Connectionconn=null;
2. try{
3. Class.forName("com.mysql.jdbc.Driver",
4. true,Thread.currentThread().getContextClassLoader());
5. conn=DriverManager.
6. getConnection("jdbc:mysql://MyDBServer?user=qingfeng&password=mingyue");
7. ......
8. conn.close();
9. }catch(Exceptione){
10. e.printStackTrace();
11. }finally{
12. if(conn!=null){
13. try{
14. conn.close();
15. }catch(SQLExceptione){}
16. }
17. }
````
这是传统的做法,也是曾经非Java程序猿(如Delphi、VB等)常见的做法。
这种做法一般在小规模的开发过程中不会产生问题,仅仅要程序猿熟悉Java语言、了解JDBC技术和MySQL,能够非常快开发出对应的应用程序。
没有JNDI的做法存在的问题:
1、数据库server名称MyDBServer 、username和口令都可能须要改变,由此引发JDBC URL须要改动;
2、数据库可能改用别的产品,如改用DB2或者Oracle,引发JDBC驱动程序包和类名须要改动;
3、随着实际使用终端的添加,原配置的连接池參数可能须要调整;
4、......
解决的方法:
程序猿应该不须要关心“详细的数据库后台是什么?JDBC驱动程序是什么?JDBC URL格式是什么?訪问数据库的username和口令是什么?”等等这些问题。
程序猿编写的程序应该没有对 JDBC驱动程序的引用,没有server名称,没实username称或口令 —— 甚至没有数据库池或连接管理。
而是把这些问题交给J2EE容器(比方weblogic)来配置和管理,程序猿仅仅须要对这些配置和管理进行引用就可以。
由此,就有了JNDI。
//看的出来。是为了一个最最核心的问题:是为了解耦,是为了开发出更加可维护、可扩展//的系统
用了JNDI之后的做法:
首先。在在J2EE容器中配置JNDI參数,定义一个数据源。也就是JDBC引用參数,给这个数据源设置一个名称;然后,在程序中,通过数据源名称引用数据源从而訪问后台数据库。
//红色的字能够看出。JNDI是由j2ee容器提供的功能
详细操作例如以下(以JBoss为例):
1、配置数据源
在JBoss 的 D:\jboss420GA\docs\examples\jca 文件夹以下。有非常多不同数据库引用的数据源定义模板。
将当中的 mysql-ds.xml 文件Copy到你使用的server下,如 D:\jboss420GA\server\default\deploy。
改动 mysql-ds.xml 文件的内容,使之能通过JDBC正确訪问你的MySQL数据库。例如以下:
````
<?xmlversion="1.0"encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>MySqlDS</jndi-name>
<connection-url>jdbc:mysql://localhost:3306/lw</connection-url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<user-name>root</user-name>
<password>rootpassword</password>
<exception-sorter-class-name>
org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter
</exception-sorter-class-name>
<metadata>
<type-mapping>mySQL</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>
````
这里,定义了一个名为MySqlDS的数据源。其參数包含JDBC的URL。驱动类名,username及密码等。
2、在程序中引用数据源:
````
1. Connectionconn=null;
2. try{
3. Contextctx=newInitialContext();
4. ObjectdatasourceRef=ctx.lookup("java:MySqlDS");//引用数据源
5. DataSourceds=(Datasource)datasourceRef;
6. conn=ds.getConnection();
7. ......
8. c.close();
9. }catch(Exceptione){
10. e.printStackTrace();
11. }finally{
12. if(conn!=null){
13. try{
14. conn.close();
15. }catch(SQLExceptione){}
16. }
17. }
````
直接使用JDBC或者通过JNDI引用数据源的编程代码量相差无几,可是如今的程序能够不用关心详细JDBC參数了。
//解藕了。可扩展了
在系统部署后。假设数据库的相关參数变更。仅仅须要又一次配置 mysql-ds.xml 改动当中的JDBC參数,仅仅要保证数据源的名称不变,那么程序源码就无需改动。
由此可见。JNDI避免了程序与数据库之间的紧耦合,使应用更加易于配置、易于部署。
JNDI的扩展:
JNDI在满足了数据源配置的要求的基础上。还进一步扩充了作用:全部与系统外部的资源的引用,都能够通过JNDI定义和引用。
//注意什么叫资源
所以,在J2EE规范中,J2EE 中的资源并不局限于 JDBC 数据源。
引用的类型有非常多,当中包含资源引用(已经讨论过)、环境实体和 EJB 引用。
特别是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一项关键角色:查找其它应用程序组件。
EJB 的 JNDI 引用非常相似于 JDBC 资源的引用。在服务趋于转换的环境中,这是一种非常有效的方法。能够对应用程序架构中所得到的全部组件进行这类配置管理,从 EJB 组件到 JMS 队列和主题。再到简单配置字符串或其它对象。这能够降低随时间的推移服务变更所产生的维护成本,同一时候还能够简化部署,降低集成工作。外部资源”。
总结:
J2EE 规范要求全部 J2EE 容器都要提供 JNDI 规范的实现。//sun 果然喜欢制定规范JNDI 在 J2EE 中的角色就是“交换机” —— J2EE 组件在执行时间接地查找其它组件、资源或服务的通用机制。在多数情况下,提供 JNDI 供应者的容器能够充当有限的数据存储。这样管理员就能够设置应用程序的执行属性,并让其它应用程序引用这些属性(Java 管理扩展(Java Management Extensions,JMX)也能够用作这个目的)。JNDI 在 J2EE 应用程序中的主要角色就是提供间接层,这样组件就能够发现所须要的资源,而不用了解这些间接性。
在 J2EE 中,JNDI 是把 J2EE 应用程序合在一起的粘合剂。JNDI 提供的间接寻址同意跨企业交付可伸缩的、功能强大且非常灵活的应用程序。
这是 J2EE 的承诺,并且经过一些计划和预先考虑。这个承诺是全然能够实现的。
从上面的文章中能够看出:
1、JNDI 提出的目的是为了解藕,是为了开发更加easy维护,easy扩展。easy部署的应用。
2、JNDI 是一个sun提出的一个规范(相似于jdbc),详细的实现是各个j2ee容器提供商。sun 仅仅是要求,j2ee容器必须有JNDI这种功能。
3、JNDI 在j2ee系统中的角色是“交换机”,是J2EE组件在执行时间接地查找其它组件、资源或服务的通用机制。
4、JNDI 是通过资源的名字来查找的,资源的名字在整个j2ee应用中(j2ee容器中)是唯一的。
上文提到过双亲委派模型并不是一个强制性的约束模型,而是Java设计者推荐给开发者的类加载器实现方式。在Java的世界中大部分的类加载器都遵循这个模型,但也有例外。
双亲委派模型的一次“被破坏”是由这个模型自身的缺陷所导致的,双亲委派很好地解决了各个类加载器的基础类的统一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API,但世事往往没有绝对的完美,如果基础类又要调用回用户的代码,那该怎么办?
这并非是不可能的事情,一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK 1.3时放进去的rt.jar),但JNDI的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI,Service Provider Interface)的代码,但启动类加载器不可能“认识”这些代码,因为启动类加载器的搜索范围中找不到用户应用程序类,那该怎么办?
为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器(Application ClassLoader)。
有了线程上下文类加载器,就可以做一些“舞弊”的事情了,JNDI服务使用这个线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。
## OSGI
目前,业内关于OSGI技术的学习资源或者技术文档还是很少的。我在某宝网搜索了一下“OSGI”的书籍,结果倒是有,但是种类少的可怜,而且几乎没有人购买。
因为工作的原因我需要学习OSGI,所以我不得不想尽办法来主动学习OSGI。我将用文字记录学习OSGI的整个过程,通过整理书籍和视频教程,来让我更加了解这门技术,同时也让需要学习这门技术的同志们有一个清晰的学习路线。
我们需要解决一下几问题:
### 1.如何正确的理解和认识OSGI技术?
我们从外文资料上或者从翻译过来的资料上看到OSGi解释和定义,都是直译过来的,但是OSGI的真实意义未必是中文直译过来的意思。OSGI的解释就是Open Service Gateway Initiative,直译过来就是“开放的服务入口(网关)的初始化”,听起来非常费解,什么是服务入口初始化?
所以我们不去直译这个OSGI,我们换一种说法来描述OSGI技术。
我们来回到我们以前的某些开发场景中去,假设我们使用SSH(struts+spring+hibernate)框架来开发我们的Web项目,我们做产品设计和开发的时候都是分模块的,我们分模块的目的就是实现模块之间的“解耦”,更进一步的目的是方便对一个项目的控制和管理。
我们对一个项目进行模块化分解之后,我们就可以把不同模块交给不同的开发人员来完成开发,然后项目经理把大家完成的模块集中在一起,然后拼装成一个最终的产品。一般我们开发都是这样的基本情况。
那么我们开发的时候预计的是系统的功能,根据系统的功能来进行模块的划分,也就是说,这个产品的功能或客户的需求是划分的重要依据。
但是我们在开发过程中,我们模块之间还要彼此保持联系,比如A模块要从B模块拿到一些数据,而B模块可能要调用C模块中的一些方法(除了公共底层的工具类之外)。所以这些模块只是一种逻辑意义上的划分。
最重要的一点是,我们把最终的项目要去部署到tomcat或者jBoss的服务器中去部署。那么我们启动服务器的时候,能不能关闭项目的某个模块或功能呢?很明显是做不到的,一旦服务器启动,所有模块就要一起启动,都要占用服务器资源,所以关闭不了模块,假设能强制拿掉,就会影响其它的功能。
以上就是我们传统模块式开发的一些局限性。
我们做软件开发一直在追求一个境界,就是模块之间的真正“解耦”、“分离”,这样我们在软件的管理和开发上面就会更加的灵活,甚至包括给客户部署项目的时候都可以做到更加的灵活可控。但是我们以前使用SSH框架等架构模式进行产品开发的时候我们是达不到这种要求的。
所以我们“架构师”或顶尖的技术高手都在为模块化开发努力的摸索和尝试,然后我们的OSGI的技术规范就应运而生。
现在我们的OSGI技术就可以满足我们之前所说的境界:在不同的模块中做到彻底的分离,而不是逻辑意义上的分离,是物理上的分离,也就是说在运行部署之后都可以在不停止服务器的时候直接把某些模块拿下来,其他模块的功能也不受影响。
由此,OSGI技术将来会变得非常的重要,因为它在实现模块化解耦的路上,走得比现在大家经常所用的SSH框架走的更远。这个技术在未来大规模、高访问、高并发的Java模块化开发领域,或者是项目规范化管理中,会大大超过SSH等框架的地位。
现在主流的一些应用服务器,Oracle的weblogic服务器,IBM的WebSphere,JBoss,还有Sun公司的glassfish服务器,都对OSGI提供了强大的支持,都是在OSGI的技术基础上实现的。有那么多的大型厂商支持OSGI这门技术,我们既可以看到OSGI技术的重要性。所以将来OSGI是将来非常重要的技术。
但是OSGI仍然脱离不了框架的支持,因为OSGI本身也使用了很多spring等框架的基本控件(因为要实现AOP依赖注入等功能),但是哪个项目又不去依赖第三方jar呢?
双亲委派模型的另一次“被破坏”是由于用户对程序动态性的追求而导致的,这里所说的“动态性”指的是当前一些非常“热门”的名词:代码热替换(HotSwap)、模块热部署(HotDeployment)等,说白了就是希望应用程序能像我们的计算机外设那样,接上鼠标、U盘,不用重启机器就能立即使用,鼠标有问题或要升级就换个鼠标,不用停机也不用重启。
对于个人计算机来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是企业级软件开发者具有很大的吸引力。Sun公司所提出的JSR-294、JSR-277规范在与JCP组织的模块化规范之争中落败给JSR-291(即OSGi R4.2),虽然Sun不甘失去Java模块化的主导权,独立在发展Jigsaw项目,但目前OSGi已经成为了业界“事实上”的Java模块化标准,而OSGi实现模块化热部署的关键则是它自定义的类加载器机制的实现。
每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。
在OSGi环境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:
1)将以java.*开头的类委派给父类加载器加载。
2)否则,将委派列表名单内的类委派给父类加载器加载。
3)否则,将Import列表中的类委派给Export这个类的Bundle的类加载器加载。
4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。
5)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。
6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。
7)否则,类查找失败。
上面的查找顺序中只有开头两点仍然符合双亲委派规则,其余的类查找都是在平级的类加载器中进行的。
只要有足够意义和理由,突破已有的原则就可认为是一种创新。正如OSGi中的类加载器并不符合传统的双亲委派的类加载器,并且业界对其为了实现热部署而带来的额外的高复杂度还存在不少争议,但在Java程序员中基本有一个共识:OSGi中对类加载器的使用是很值得学习的,弄懂了OSGi的实现,就可以算是掌握了类加载器的精髓。
## Tomcat类加载器以及应用间class隔离与共享
Tomcat的用户一定都使用过其应用部署功能,无论是直接拷贝文件到webapps目录,还是修改server.xml以目录的形式部署,或者是增加虚拟主机,指定新的appBase等等。
但部署应用时,不知道你是否曾注意过这几点:
1. 如果在一个Tomcat内部署多个应用,甚至多个应用内使用了某个类似的几个不同版本,但它们之间却互不影响。这是如何做到的。
2. 如果多个应用都用到了某类似的相同版本,是否可以统一提供,不在各个应用内分别提供,占用内存呢。
3. 还有时候,在开发Web应用时,在pom.xml中添加了servlet-api的依赖,那实际应用的class加载时,会加载你的servlet-api 这个jar吗
以上提到的这几点,在Tomcat以及各类的应用服务器中,都是通过类加载器(ClasssLoader)来实现的。通过本文,你可以了解到Tomcat内部提供的各种类加载器,Web应用的class和资源等加载的方式,以及其内部的实现原理。在遇到类似问题时,更胸有成竹。
### 类加载器
Java语言本身,以及现在其它的一些基于JVM之上的语言(Groovy,Jython, Scala...),都是在将代码编译生成class文件,以实现跨多平台,write once, run anywhere。最终的这些class文件,在应用中,又被加载到JVM虚拟机中,开始工作。而把class文件加载到JVM的组件,就是我们所说的类加载器。而对于类加载器的抽象,能面对更多的class数据提供形式,例如网络、文件系统等。
Java中常见的那个ClassNotFoundException和NoClassDefFoundError就是类加载器告诉我们的。
Servlet规范指出,容器用于加载Web应用内Servlet的class loader, 允许加载位于Web应用内的资源。但不允许重写java.*, javax.*以及容器实现的类。同时
每个应用内使用Thread.currentThread.getContextClassLoader()获得的类加载器,都是该应用区别于其它应用的类加载器等等。
根据Servlet规范,各个应用服务器厂商自行实现。所以像其他的一些应用服务器一样, Tomcat也提供了多种的类加载器,以便应用服务器内的class以及部署的Web应用类文件运行在容器中时,可以使用不同的class repositories。
在Java中,类加载器是以一种父子关系树来组织的。除Bootstrap外,都会包含一个parent 类加载器。(这里写parent 类加载器,而不是父类加载器,不是为了装X,是为了避免和Java里的父类混淆)一般以类加载器需要加载一个class或者资源文件的时候,他会先委托给他的parent类加载器,让parent类加载器先来加载,如果没有,才再在自己的路径上加载。这就是人们常说的双亲委托,即把类加载的请求委托给parent。
但是...,这里需要注意一下
> 对于Web应用的类加载,和上面的双亲委托是有区别的。
主流的Java Web服务器(也就是Web容器),如Tomcat、Jetty、WebLogic、WebSphere或其他笔者没有列举的服务器,都实现了自己定义的类加载器(一般都不止一个)。因为一个功能健全的Web容器,要解决如下几个问题:
1)部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以实现相互隔离。这是最基本的需求,两个不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求一个类库在一个服务器中只有一份,服务器应当保证两个应用程序的类库可以互相独立使用。
2)部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以互相共享。这个需求也很常见,例如,用户可能有10个使用[spring](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Fjavaee "Java EE知识库")组织的应用程序部署在同一台服务器上,如果把10份Spring分别存放在各个应用程序的隔离目录中,将会是很大的资源浪费——这主要倒不是浪费磁盘空间的问题,而是指类库在使用时都要被加载到Web容器的内存,如果类库不能共享,虚拟机的方法区就会很容易出现过度膨胀的风险。
3)Web容器需要尽可能地保证自身的安全不受部署的Web应用程序影响。目前,有许多主流的Java Web容器自身也是使用Java语言来实现的。因此,Web容器本身也有类库依赖的问题,一般来说,基于安全考虑,容器所使用的类库应该与应用程序的类库互相独立。
4)支持JSP应用的Web容器,大多数都需要支持HotSwap功能。我们知道,JSP文件最终要编译成Java Class才能由虚拟机执行,但JSP文件由于其纯文本存储的特性,运行时修改的概率远远大于第三方类库或程序自身的Class文件。而且ASP、[PHP](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Fphp "PHP知识库")和JSP这些网页应用也把修改后无须重启作为一个很大的“优势”来看待,因此“主流”的Web容器都会支持JSP生成类的热替换,当然也有“非主流”的,如运行在生产模式(Production Mode)下的WebLogic服务器默认就不会处理JSP文件的变化。
由于存在上述问题,在部署Web应用时,单独的一个Class Path就无法满足需求了,所以各种Web容都“不约而同”地提供了好几个Class Path路径供用户存放第三方类库,这些路径一般都以“lib”或“classes”命名。被放置到不同路径中的类库,具备不同的访问范围和服务对象,通常,每一个目录都会有一个相应的自定义类加载器去加载放置在里面的Java类库。现在,就以Tomcat容器为例,看一看Tomcat具体是如何规划用户类库结构和类加载器的。
在Tomcat目录结构中,有3组目录(“/common/*”、“/server/*”和“/shared/*”)可以存放Java类库,另外还可以加上Web应用程序自身的目录“/WEB-INF/*”,一共4组,把Java类库放置在这些目录中的含义分别如下:
①放置在/common目录中:类库可被Tomcat和所有的Web应用程序共同使用。
②放置在/server目录中:类库可被Tomcat使用,对所有的Web应用程序都不可见。
③放置在/shared目录中:类库可被所有的Web应用程序共同使用,但对Tomcat自己不可见。
④放置在/WebApp/WEB-INF目录中:类库仅仅可以被此Web应用程序使用,对Tomcat和其他Web应用程序都不可见。
为了支持这套目录结构,并对目录里面的类库进行加载和隔离,Tomcat自定义了多个类加载器,这些类加载器按照经典的双亲委派模型来实现,其关系如下图所示。
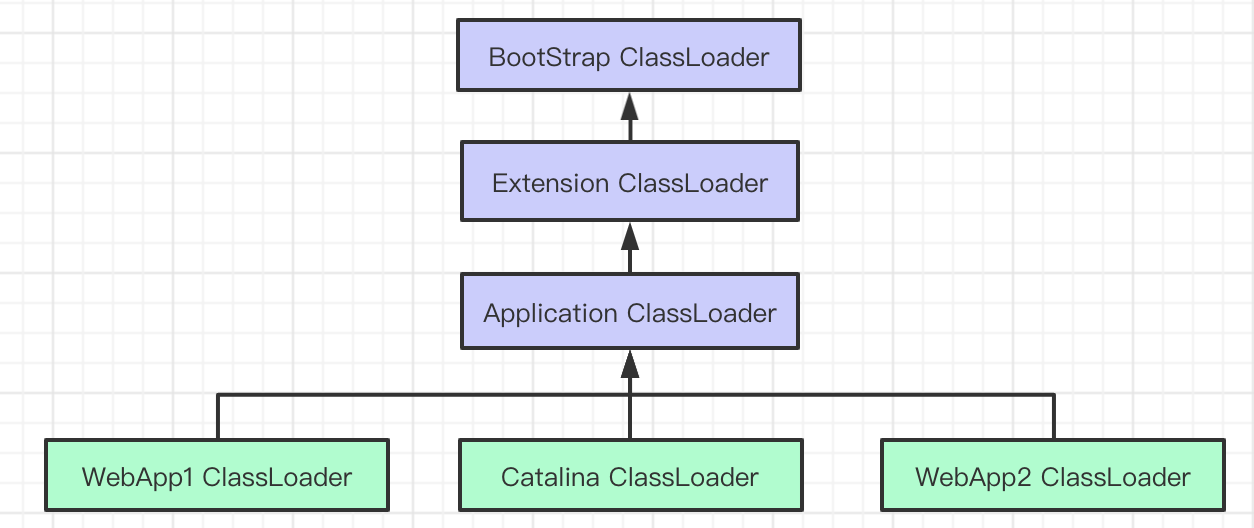
上图中灰色背景的3个类加载器是JDK默认提供的类加载器,这3个加载器的作用已经介绍过了。而CommonClassLoader、CatalinaClassLoader、SharedClassLoader和WebappClassLoader则是Tomcat自己定义的类加载器,它们分别加载/common/*、/server/*、/shared/*和/WebApp/WEB-INF/*中的Java类库。其中WebApp类加载器和Jsp类加载器通常会存在多个实例,每一个Web应用程序对应一个WebApp类加载器,每一个JSP文件对应一个Jsp类加载器。
从图中的委派关系中可以看出,CommonClassLoader能加载的类都可以被CatalinaClassLoader和SharedClassLoader使用,而CatalinaClassLoader和SharedClassLoader自己能加载的类则与对方相互隔离。WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离。
而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能。
对于Tomcat的6.x版本,只有指定了tomcat/conf/catalina.properties配置文件的server.loader和share.loader项后才会真正建立CatalinaClassLoader和Shared ClassLoader的实例,否则在用到这两个类加载器的地方都会用Common ClassLoader的实例代替,而默认的配置文件中没有设置这两个loader项,所以Tomcat 6.x顺理成章地把/common、/server和/shared三个目录默认合并到一起变成一个/lib目录,这个目录里的类库相当于以前/common目录中类库的作用。
这是Tomcat设计团队为了简化大多数的部署场景所做的一项改进,如果默认设置不能满足需要,用户可以通过修改配置文件指定server.loader和share.loader的方式重新启用Tomcat 5.x的加载器[架构](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Farchitecture "大型网站架构知识库")。
Tomcat加载器的实现清晰易懂,并且采用了官方推荐的“正统”的使用类加载器的方式。如果读者阅读完上面的案例后,能完全理解Tomcat设计团队这样布置加载器架构的用意,那说明已经大致掌握了类加载器“主流”的使用方式,那么笔者不妨再提一个问题让读者思考一下:前面曾经提到过一个场景,如果有10个Web应用程序都是用Spring来进行组织和管理的话,可以把Spring放到Common或Shared目录下让这些程序共享。
Spring要对用户程序的类进行管理,自然要能访问到用户程序的类,而用户的程序显然是放在/WebApp/WEB-INF目录中的,那么被CommonClassLoader或SharedClassLoader加载的Spring如何访问并不在其加载范围内的用户程序呢?如果研究过虚拟机类加载器机制中的双亲委派模型,相信读者可以很容易地回答这个问题。
分析:如果按主流的双亲委派机制,显然无法做到让父类加载器加载的类去访问子类加载器加载的类,上面在类加载器一节中提到过通过线程上下文方式传播类加载器。
答案是使用线程上下文类加载器来实现的,使用线程上下文加载器,可以让父类加载器请求子类加载器去完成类加载的动作。
看spring源码发现,spring加载类所用的Classloader是通过Thread.currentThread().getContextClassLoader()来获取的,而当线程创建时会默认setContextClassLoader(AppClassLoader),即线程上下文类加载器被设置为AppClassLoader,spring中始终可以获取到这个AppClassLoader(在Tomcat里就是WebAppClassLoader)子类加载器来加载bean,以后任何一个线程都可以通过getContextClassLoader()获取到WebAppClassLoader来getbean了。
本篇博文内容取材自《深入理解Java虚拟机:JVM高级特性与最佳实践》
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md
================================================
# 目录
* [前言](#前言)
* [Java堆(Heap)](#java堆(heap))
* [方法区(Method Area)](#方法区(method-area))
* [程序计数器(Program Counter Register)](#程序计数器(program-counter-register))
* [JVM栈(JVM Stacks)](#jvm栈(jvm-stacks))
* [本地方法栈(Native Method Stacks)](#本地方法栈(native-method-stacks))
* [哪儿的OutOfMemoryError](#哪儿的outofmemoryerror)
* [一、背景](#一、背景)
* [1.1 永久代(PermGen)在哪里?](#11-永久代(permgen)在哪里?)
* [1.2 JDK8永久代的废弃](#12-jdk8永久代的废弃)
* [二、为什么废弃永久代(PermGen)](#二、为什么废弃永久代(permgen))
* [2.1 官方说明](#21-官方说明)
* [Motivation](#motivation)
* [2.2 现实使用中易出问题](#22-现实使用中易出问题)
* [三、深入理解元空间(Metaspace)](#三、深入理解元空间(metaspace))
* [3.1元空间的内存大小](#31元空间的内存大小)
* [3.2常用配置参数](#32常用配置参数)
* [3.3测试并追踪元空间大小](#33测试并追踪元空间大小)
* [3.3.1.测试字符串常量](#331测试字符串常量)
* [3.3.2.测试元空间溢出](#332测试元空间溢出)
* [四、总结](#四、总结)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 前言
所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemoryError的异常到底涉及到运行时数据的哪块区域?该怎么解决呢?
其实如果你经常解决服务器性能问题,那么这些问题就会变的非常常见,了解JVM内存也是为了服务器出现性能问题的时候可以快速的了解那块的内存区域出现问题,以便于快速的解决生产故障。
先看一张图,这张图能很清晰的说明JVM内存结构布局。
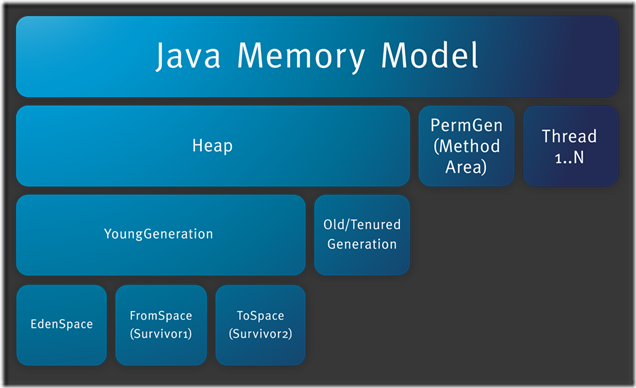
JVM内存结构主要有三大块:堆内存、方法区和栈。堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor空间、To Survivor空间,默认情况下年轻代按照8:1:1的比例来分配;
方法区存储类信息、常量、静态变量等数据,是线程共享的区域,为与Java堆区分,方法区还有一个别名Non-Heap(非堆);栈又分为java虚拟机栈和本地方法栈主要用于方法的执行。
在通过一张图来了解如何通过参数来控制各区域的内存大小

控制参数
* -Xms设置堆的最小空间大小。
* -Xmx设置堆的最大空间大小。
* -XX:NewSize设置新生代最小空间大小。
* -XX:MaxNewSize设置新生代最大空间大小。
* -XX:PermSize设置永久代最小空间大小。
* -XX:MaxPermSize设置永久代最大空间大小。
* -Xss设置每个线程的堆栈大小。
没有直接设置老年代的参数,但是可以设置堆空间大小和新生代空间大小两个参数来间接控制。
> 老年代空间大小=堆空间大小-年轻代大空间大小
从更高的一个维度再次来看JVM和系统调用之间的关系

方法区和对是所有线程共享的内存区域;而java栈、本地方法栈和程序员计数器是运行是线程私有的内存区域。
下面我们详细介绍每个区域的作用
## Java堆(Heap)
对于大多数应用来说,Java堆(Java Heap)是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms控制)。
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
## 方法区(Method Area)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
对于习惯在HotSpot虚拟机上开发和部署程序的开发者来说,很多人愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。
Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,还可以选择不实现垃圾收集。相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入了方法区就如永久代的名字一样“永久”存在了。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说这个区域的回收“成绩”比较难以令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分区域的回收确实是有必要的。
根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
方法区有时被称为持久代(PermGen)。

所有的对象在实例化后的整个运行周期内,都被存放在堆内存中。堆内存又被划分成不同的部分:伊甸区(Eden),幸存者区域(Survivor Sapce),老年代(Old Generation Space)。
方法的执行都是伴随着线程的。原始类型的本地变量以及引用都存放在线程栈中。而引用关联的对象比如String,都存在在堆中。为了更好的理解上面这段话,我们可以看一个例子:
````
import java.text.SimpleDateFormat;import java.util.Date;import org.apache.log4j.Logger;
public class HelloWorld {
private static Logger LOGGER = Logger.getLogger(HelloWorld.class.getName());
public void sayHello(String message) {
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.YYYY");
String today = formatter.format(new Date());
LOGGER.info(today + ": " + message);
}}
````
这段程序的数据在内存中的存放如下:
通过JConsole工具可以查看运行中的Java程序(比如Eclipse)的一些信息:堆内存的分配,线程的数量以及加载的类的个数;
## 程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie方法,这个计数器值则为空(Undefined)。
此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
## JVM栈(JVM Stacks)
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,根据不同的虚拟机实现,它可能是一个指向对象起始地址的引用指针,也可能指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
其中64位长度的long和double类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在Java虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
## 本地方法栈(Native Method Stacks)
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
## 哪儿的OutOfMemoryError
对内存结构清晰的认识同样可以帮助理解不同OutOfMemoryErrors:
Exception in thread “main”: java.lang.OutOfMemoryError: Java heap space
原因:对象不能被分配到堆内存中
Exception in thread “main”: java.lang.OutOfMemoryError: PermGen space
原因:类或者方法不能被加载到持久代。它可能出现在一个程序加载很多类的时候,比如引用了很多第三方的库;
Exception in thread “main”: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
原因:创建的数组大于堆内存的空间
Exception in thread “main”: java.lang.OutOfMemoryError: request <size> bytes for <reason>. Out of swap space?
原因:分配本地分配失败。JNI、本地库或者Java虚拟机都会从本地堆中分配内存空间。
Exception in thread “main”: java.lang.OutOfMemoryError: <reason> <stack trace>(Native method)
原因:同样是本地方法内存分配失败,只不过是JNI或者本地方法或者Java虚拟机发现
关于永久代的废弃可以参考这篇文章
JDK8-废弃永久代(PermGen)迎来元空间(Metaspace)
(https://www.cnblogs.com/yulei126/p/6777323.html)
1.背景
2.为什么废弃永久代(PermGen)
3.深入理解元空间(Metaspace)
4.总结
========正文分割线=====
## 一、背景
### 1.1 永久代(PermGen)在哪里?
根据,hotspot jvm结构如下(虚拟机栈和本地方法栈合一起了):

上图引自网络,但有个问题:方法区和heap堆都是线程共享的内存区域。
关于方法区和永久代:
在HotSpot JVM中,这次讨论的永久代,就是上图的方法区(JVM规范中称为方法区)。《Java虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。在其他JVM上不存在永久代。
### 1.2 JDK8永久代的废弃
JDK8 永久代变化如下图:
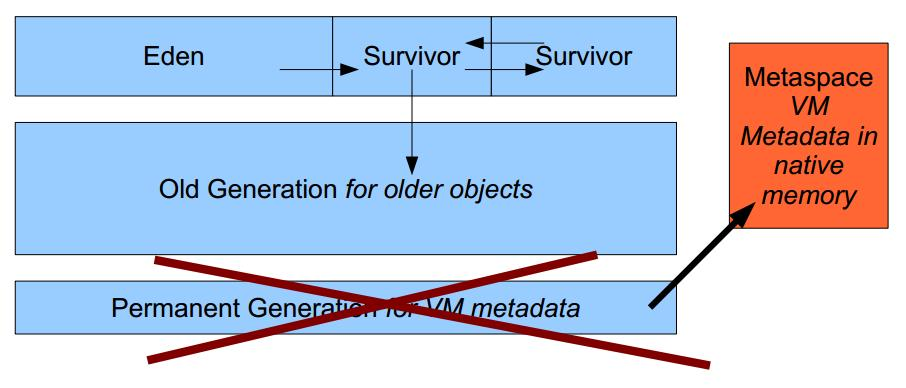
1.新生代:Eden+From Survivor+To Survivor
2.老年代:OldGen
3.永久代(方法区的实现) : PermGen----->替换为Metaspace(本地内存中)
## 二、为什么废弃永久代(PermGen)
### 2.1 官方说明
参照JEP122:http://openjdk.java.net/jeps/122,原文截取:
## Motivation
This is part of the JRockit and Hotspot convergence effort. JRockit customers do not need to configure the permanent generation (since JRockit does not have a permanent generation) and are accustomed to not configuring the permanent generation.
即:移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。
### 2.2 现实使用中易出问题
由于永久代内存经常不够用或发生内存泄露,爆出异常java.lang.OutOfMemoryError: PermGen
其实在JDK7时就已经逐步把永久代的内容移动到其他区域了,比如移动到native区,移动到堆区等,而JDK8则是则是废除了永久代,改用元数据。
## 三、深入理解元空间(Metaspace)
### 3.1元空间的内存大小
元空间是方法区的在HotSpot jvm 中的实现,方法区主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。,理论上取决于32位/64位系统可虚拟的内存大小。可见也不是无限制的,需要配置参数。
### 3.2常用配置参数
1.MetaspaceSize
初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用[Java](http://lib.csdn.net/base/javase "Java SE知识库")-XX:+PrintFlagsInitial命令查看本机的初始化参数
2.MaxMetaspaceSize
限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
3.MinMetaspaceFreeRatio
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数(即实际非空闲占比过大,内存不够用),那么虚拟机将增长Metaspace的大小。默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。
4.MaxMetasaceFreeRatio
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。默认值为70,也就是70%。
5.MaxMetaspaceExpansion
Metaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。
6.MinMetaspaceExpansion
Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)。
### 3.3测试并追踪元空间大小
#### 3.3.1.测试字符串常量
````
public class StringOomMock {
static String base = "string";
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (int i=0;i< Integer.MAX_VALUE;i++){
String str = base + base;
base = str;
list.add(str.intern());
}
}
}
````
在eclipse中选中类--》run configuration-->java application--》new 参数如下:
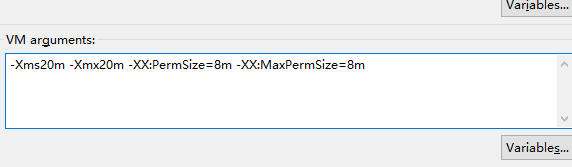
由于设定了最大内存20M,很快就溢出,如下图:
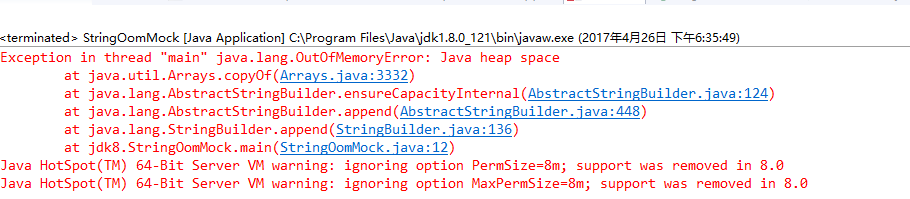
可见在jdk8中:
1.字符串常量由永久代转移到堆中。
2.持久代已不存在,PermSize MaxPermSize参数已移除。(看图中最后两行)
#### 3.3.2.测试元空间溢出
根据定义,我们以加载类来测试元空间溢出,代码如下:
````
package jdk8;
import java.io.File;
import java.lang.management.ClassLoadingMXBean;
import java.lang.management.ManagementFactory;
import java.net.URL;
import java.net.URLClassLoader;
import java.util.ArrayList;
import java.util.List;
/**
*
* @ClassName:OOMTest
* @Description:模拟类加载溢出(元空间oom)
* @author diandian.zhang
* @date 2017年4月27日上午9:45:40
*/
public class OOMTest {
public static void main(String[] args) {
try {
//准备url
URL url = new File("D:/58workplace/11study/src/main/java/jdk8").toURI().toURL();
URL[] urls = {url};
//获取有关类型加载的JMX接口
ClassLoadingMXBean loadingBean = ManagementFactory.getClassLoadingMXBean();
//用于缓存类加载器
List<ClassLoader> classLoaders = new ArrayList<ClassLoader>();
while (true) {
//加载类型并缓存类加载器实例
ClassLoader classLoader = new URLClassLoader(urls);
classLoaders.add(classLoader);
classLoader.loadClass("ClassA");
//显示数量信息(共加载过的类型数目,当前还有效的类型数目,已经被卸载的类型数目)
System.out.println("total: " + loadingBean.getTotalLoadedClassCount());
System.out.println("active: " + loadingBean.getLoadedClassCount());
System.out.println("unloaded: " + loadingBean.getUnloadedClassCount());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
````
为了快速溢出,设置参数:-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=80m,运行结果如下:
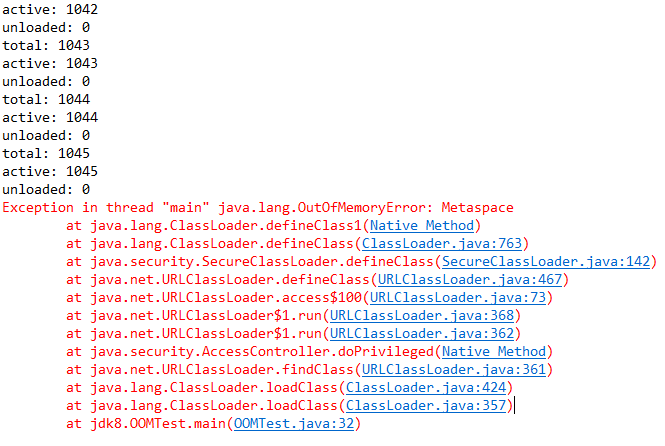
上图证实了,我们的JDK8中类加载(方法区的功能)已经不在永久代PerGem中了,而是Metaspace中。可以配合JVisualVM来看,更直观一些。
## 四、总结
本文讲解了元空间(Metaspace)的由来和本质,常用配置,以及监控测试。元空间的大小是动态变更的,但不是无限大的,最好也时常关注一下大小,以免影响服务器内存。
## 参考文章
https://segmentfault.com/a/1190000009707894
https://www.cnblogs.com/hysum/p/7100874.html
http://c.biancheng.net/view/939.html
https://www.runoob.com
https://blog.csdn.net/android_hl/article/details/53228348
## 微信公众号
### Java技术江湖
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。

### 个人公众号:黄小斜
作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。

================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md
================================================
# 目录
* [JVM GC基本原理与GC算法](#jvm-gc基本原理与gc算法)
* [Java关键术语](#java关键术语)
* [Java HotSpot 虚拟机](#java-hotspot-虚拟机)
* [Java堆内存](#java堆内存)
* [启动Java垃圾回收](#启动java垃圾回收)
* [各种GC的触发时机(When)](#各种gc的触发时机when)
* [GC类型](#gc类型)
* [触发时机](#触发时机)
* [FULL GC触发条件详解](#full-gc触发条件详解)
* [总结](#总结)
* [什么是Stop the world](#什么是stop-the-world)
* [Java垃圾回收过程](#java垃圾回收过程)
* [垃圾回收中实例的终结](#垃圾回收中实例的终结)
* [对象什么时候符合垃圾回收的条件?](#对象什么时候符合垃圾回收的条件?)
* [GC Scope 示例程序](#gc-scope-示例程序)
* [JVM GC算法](#JVM GC算法)
* [JVM垃圾判定算法](#jvm垃圾判定算法)
* [引用计数算法(Reference Counting)](#引用计数算法reference-counting)
* [可达性分析算法(根搜索算法)](#可达性分析算法(根搜索算法))
* [四种引用](#四种引用)
* [JVM垃圾回收算法](#jvm垃圾回收算法)
* [标记—清除算法(Mark-Sweep)](#标记清除算法(mark-sweep))
* [复制算法(Copying)](#复制算法(copying))
* [标记—整理算法(Mark-Compact)](#标记整理算法(mark-compact))
* [分代收集算法(Generational Collection)](#分代收集算法generational-collection)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## JVM GC基本原理与GC算法
Java的内存分配与回收全部由JVM垃圾回收进程自动完成。与C语言不同,Java开发者不需要自己编写代码实现垃圾回收。这是Java深受大家欢迎的众多特性之一,能够帮助程序员更好地编写Java程序。
下面四篇教程是了解Java 垃圾回收(GC)的基础:
1. [垃圾回收简介](http://www.importnew.com/13504.html)
2. [圾回收是如何工作的?](http://www.importnew.com/13493.html)
3. [垃圾回收的类别](http://www.importnew.com/13827.html)
这篇教程是系列第一部分。首先会解释基本的术语,比如JDK、JVM、JRE和HotSpotVM。接着会介绍JVM结构和Java 堆内存结构。理解这些基础对于理解后面的垃圾回收知识很重要。
## Java关键术语
* JavaAPI:一系列帮助开发者创建Java应用程序的封装好的库。
* Java 开发工具包 (JDK):一系列工具帮助开发者创建Java应用程序。JDK包含工具编译、运行、打包、分发和监视Java应用程序。
* Java 虚拟机(JVM):JVM是一个抽象的计算机结构。Java程序根据JVM的特性编写。JVM针对特定于操作系统并且可以将Java指令翻译成底层系统的指令并执行。JVM确保了Java的平台无关性。
* Java 运行环境(JRE):JRE包含JVM实现和Java API。
## Java HotSpot 虚拟机
每种JVM实现可能采用不同的方法实现垃圾回收机制。在收购SUN之前,Oracle使用的是JRockit JVM,收购之后使用HotSpot JVM。目前Oracle拥有两种JVM实现并且一段时间后两个JVM实现会合二为一。
HotSpot JVM是目前Oracle SE平台标准核心组件的一部分。在这篇垃圾回收教程中,我们将会了解基于HotSpot虚拟机的垃圾回收原则。
## Java堆内存
我们有必要了解堆内存在JVM内存模型的角色。在运行时,Java的实例被存放在堆内存区域。当一个对象不再被引用时,满足条件就会从堆内存移除。在垃圾回收进程中,这些对象将会从堆内存移除并且内存空间被回收。堆内存以下三个主要区域:
1. 新生代(Young Generation)
* Eden空间(Eden space,任何实例都通过Eden空间进入运行时内存区域)
* S0 Survivor空间(S0 Survivor space,存在时间长的实例将会从Eden空间移动到S0 Survivor空间)
* S1 Survivor空间 (存在时间更长的实例将会从S0 Survivor空间移动到S1 Survivor空间)
2. 老年代(Old Generation)实例将从S1提升到Tenured(终身代)
3. 永久代(Permanent Generation)包含类、方法等细节的元信息
永久代空间[在Java SE8特性](http://javapapers.com/java/java-8-features/)中已经被移除。
Java 垃圾回收是一项自动化的过程,用来管理程序所使用的运行时内存。通过这一自动化过程,JVM 解除了程序员在程序中分配和释放内存资源的开销。
## 启动Java垃圾回收
作为一个自动的过程,程序员不需要在代码中显示地启动垃圾回收过程。`System.gc()`和`Runtime.gc()`用来请求JVM启动垃圾回收。
虽然这个请求机制提供给程序员一个启动 GC 过程的机会,但是启动由 JVM负责。JVM可以拒绝这个请求,所以并不保证这些调用都将执行垃圾回收。启动时机的选择由JVM决定,并且取决于堆内存中Eden区是否可用。JVM将这个选择留给了Java规范的实现,不同实现具体使用的算法不尽相同。
毋庸置疑,我们知道垃圾回收过程是不能被强制执行的。我刚刚发现了一个调用`System.gc()`有意义的场景。通过这篇文章了解一下[适合调用System.gc()](http://javapapers.com/core-java/system-gc-invocation-a-suitable-scenario/)这种极端情况。
## 各种GC的触发时机(When)
### GC类型
说到GC类型,就更有意思了,为什么呢,因为业界没有统一的严格意义上的界限,也没有严格意义上的GC类型,都是左边一个教授一套名字,右边一个作者一套名字。为什么会有这个情况呢,因为GC类型是和收集器有关的,不同的收集器会有自己独特的一些收集类型。所以作者在这里引用**R大**关于GC类型的介绍,作者觉得还是比较妥当准确的。如下:
* Partial GC:并不收集整个GC堆的模式
* Young GC(Minor GC):只收集young gen的GC
* Old GC:只收集old gen的GC。只有CMS的concurrent collection是这个模式
* Mixed GC:收集整个young gen以及部分old gen的GC。只有G1有这个模式
* Full GC(Major GC):收集整个堆,包括young gen、old gen、perm gen(如果存在的话)等所有部分的模式。
### 触发时机
上面大家也看到了,GC类型分分类是和收集器有关的,那么当然了,对于不同的收集器,GC触发时机也是不一样的,作者就针对默认的serial GC来说:
* young GC:当young gen中的eden区分配满的时候触发。注意young GC中有部分存活对象会晋升到old gen,所以young GC后old gen的占用量通常会有所升高。
* full GC:当准备要触发一次young GC时,如果发现统计数据说之前young GC的平均晋升大小比目前old gen剩余的空间大,则不会触发young GC而是转为触发full GC(因为HotSpot VM的GC里,除了CMS的concurrent collection之外,其它能收集old gen的GC都会同时收集整个GC堆,包括young gen,所以不需要事先触发一次单独的young GC);或者,如果有perm gen的话,要在perm gen分配空间但已经没有足够空间时,也要触发一次full GC;或者System.gc()、heap dump带GC,默认也是触发full GC。
### FULL GC触发条件详解
除直接调用System.gc外,触发Full GC执行的情况有如下四种。
1.旧生代空间不足
旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
java.lang.OutOfMemoryError:Javaheapspace
为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
2\. Permanet Generation空间满
Permanet Generation中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
java.lang.OutOfMemoryError:PermGenspace
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
3\. CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行旧生代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。
promotion failed是在进行Minor GC时,survivor space放不下、对象只能放入旧生代,而此时旧生代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的。
应对措施为:增大survivor space、旧生代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX: CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。
4.统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间
这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。
例如程序第一次触发Minor GC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。
当新生代采用PS GC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。
除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java -Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
### 总结
**Minor GC ,Full GC 触发条件**
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法去空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
### 什么是Stop the world
Java中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(除了垃圾收集帮助器之外)。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于gc引起。
GC时的Stop the World(STW)是大家最大的敌人。但可能很多人还不清楚,除了GC,JVM下还会发生停顿现象。
JVM里有一条特殊的线程--VM Threads,专门用来执行一些特殊的VM Operation,比如分派GC,thread dump等,这些任务,都需要整个Heap,以及所有线程的状态是静止的,一致的才能进行。所以JVM引入了安全点(Safe Point)的概念,想办法在需要进行VM Operation时,通知所有的线程进入一个静止的安全点。
除了GC,其他触发安全点的VM Operation包括:
1\. JIT相关,比如Code deoptimization, Flushing code cache ;
2\. Class redefinition (e.g. javaagent,AOP代码植入的产生的instrumentation) ;
3\. Biased lock revocation 取消偏向锁 ;
4\. Various debug operation (e.g. thread dump or deadlock check);
## Java垃圾回收过程
垃圾回收是一种回收无用内存空间并使其对未来实例可用的过程。
Eden 区:当一个实例被创建了,首先会被存储在堆内存年轻代的 Eden 区中。
注意:如果你不能理解这些词汇,我建议你阅读这篇[垃圾回收介绍](http://javapapers.com/java/java-garbage-collection-introduction/),这篇教程详细地介绍了内存模型、JVM 架构以及这些术语。
Survivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分,存活的对象(仍然被引用的)从 Eden 区被移动到 Survivor 区的 S0 中。类似的,垃圾回收器会扫描 S0 然后将存活的实例移动到 S1 中。
(译注:此处不应该是Eden和S0中存活的都移到S1么,为什么会先移到S0再从S0移到S1?)
死亡的实例(不再被引用)被标记为垃圾回收。根据垃圾回收器(有四种常用的垃圾回收器,将在下一教程中介绍它们)选择的不同,要么被标记的实例都会不停地从内存中移除,要么回收过程会在一个单独的进程中完成。
老年代:老年代(Old or tenured generation)是堆内存中的第二块逻辑区。当垃圾回收器执行 Minor GC 周期时,在 S1 Survivor 区中的存活实例将会被晋升到老年代,而未被引用的对象被标记为回收。
老年代 GC(Major GC):相对于 Java 垃圾回收过程,老年代是实例生命周期的最后阶段。Major GC 扫描老年代的垃圾回收过程。如果实例不再被引用,那么它们会被标记为回收,否则它们会继续留在老年代中。
内存碎片:一旦实例从堆内存中被删除,其位置就会变空并且可用于未来实例的分配。这些空出的空间将会使整个内存区域碎片化。为了实例的快速分配,需要进行碎片整理。基于垃圾回收器的不同选择,回收的内存区域要么被不停地被整理,要么在一个单独的GC进程中完成。
## 垃圾回收中实例的终结
在释放一个实例和回收内存空间之前,Java 垃圾回收器会调用实例各自的`finalize()`方法,从而该实例有机会释放所持有的资源。虽然可以保证`finalize()`会在回收内存空间之前被调用,但是没有指定的顺序和时间。多个实例间的顺序是无法被预知,甚至可能会并行发生。程序不应该预先调整实例之间的顺序并使用`finalize()`方法回收资源。
* 任何在 finalize过程中未被捕获的异常会自动被忽略,然后该实例的 finalize 过程被取消。
* JVM 规范中并没有讨论关于弱引用的垃圾回收机制,也没有很明确的要求。具体的实现都由实现方决定。
* 垃圾回收是由一个守护线程完成的。
## 对象什么时候符合垃圾回收的条件?
* 所有实例都没有活动线程访问。
* 没有被其他任何实例访问的循环引用实例。
[Java 中有不同的引用类型](http://javapapers.com/core-java/java-weak-reference/)。判断实例是否符合垃圾收集的条件都依赖于它的引用类型。
| 引用类型 | 垃圾收集 |
| --- | --- |
| 强引用(Strong Reference) | 不符合垃圾收集 |
| 软引用(Soft Reference) | 垃圾收集可能会执行,但会作为最后的选择 |
| 弱引用(Weak Reference) | 符合垃圾收集 |
| 虚引用(Phantom Reference) | 符合垃圾收集 |
在编译过程中作为一种优化技术,Java 编译器能选择给实例赋`null`值,从而标记实例为可回收。
````
class Animal {
public static void main(String[] args) {
Animal lion = new Animal();
System.out.println("Main is completed.");
}
protected void finalize() {
System.out.println("Rest in Peace!");
}
}
````
在上面的类中,`lion`对象在实例化行后从未被使用过。因此 Java 编译器作为一种优化措施可以直接在实例化行后赋值`lion = null`。因此,即使在 SOP 输出之前, finalize 函数也能够打印出`'Rest in Peace!'`。我们不能证明这确定会发生,因为它依赖JVM的实现方式和运行时使用的内存。然而,我们还能学习到一点:如果编译器看到该实例在未来再也不会被引用,能够选择并提早释放实例空间。
* 关于对象什么时候符合垃圾回收有一个更好的例子。实例的所有属性能被存储在寄存器中,随后寄存器将被访问并读取内容。无一例外,这些值将被写回到实例中。虽然这些值在将来能被使用,这个实例仍然能被标记为符合垃圾回收。这是一个很经典的例子,不是吗?
* 当被赋值为null时,这是很简单的一个符合垃圾回收的示例。当然,复杂的情况可以像上面的几点。这是由 JVM 实现者所做的选择。目的是留下尽可能小的内存占用,加快响应速度,提高吞吐量。为了实现这一目标, JVM 的实现者可以选择一个更好的方案或算法在垃圾回收过程中回收内存空间。
* 当`finalize()`方法被调用时,JVM 会释放该线程上的所有同步锁。
### GC Scope 示例程序
````
Class GCScope {
GCScope t;
static int i = 1;
public static void main(String args[]) {
GCScope t1 = new GCScope();
GCScope t2 = new GCScope();
GCScope t3 = new GCScope();
// No Object Is Eligible for GC
t1.t = t2; // No Object Is Eligible for GC
t2.t = t3; // No Object Is Eligible for GC
t3.t = t1; // No Object Is Eligible for GC
t1 = null;
// No Object Is Eligible for GC (t3.t still has a reference to t1)
t2 = null;
// No Object Is Eligible for GC (t3.t.t still has a reference to t2)
t3 = null;
// All the 3 Object Is Eligible for GC (None of them have a reference.
// only the variable t of the objects are referring each other in a
// rounded fashion forming the Island of objects with out any external
// reference)
}
protected void finalize() {
System.out.println("Garbage collected from object" + i);
i++;
}
class GCScope {
GCScope t;
static int i = 1;
public static void main(String args[]) {
GCScope t1 = new GCScope();
GCScope t2 = new GCScope();
GCScope t3 = new GCScope();
// 没有对象符合GC
t1.t = t2; // 没有对象符合GC
t2.t = t3; // 没有对象符合GC
t3.t = t1; // 没有对象符合GC
t1 = null;
// 没有对象符合GC (t3.t 仍然有一个到 t1 的引用)
t2 = null;
// 没有对象符合GC (t3.t.t 仍然有一个到 t2 的引用)
t3 = null;
// 所有三个对象都符合GC (它们中没有一个拥有引用。
// 只有各对象的变量 t 还指向了彼此,
// 形成了一个由对象组成的环形的岛,而没有任何外部的引用。)
}
protected void finalize() {
System.out.println("Garbage collected from object" + i);
i++;
}
}
````
## JVM GC算法
在判断哪些内存需要回收和什么时候回收用到GC 算法,本文主要对GC 算法进行讲解。
## JVM垃圾判定算法
常见的JVM垃圾判定算法包括:引用计数算法、可达性分析算法。
### 引用计数算法(Reference Counting)
引用计数算法是通过判断对象的引用数量来决定对象是否可以被回收。
给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。
优点:简单,高效,现在的objective-c用的就是这种算法。
缺点:很难处理循环引用,相互引用的两个对象则无法释放。因此目前主流的Java虚拟机都摒弃掉了这种算法。
举个简单的例子,对象objA和objB都有字段instance,赋值令objA.instance=objB及objB.instance=objA,除此之外,这两个对象没有任何引用,实际上这两个对象已经不可能再被访问,但是因为互相引用,导致它们的引用计数都不为0,因此引用计数算法无法通知GC收集器回收它们。
```
public class ReferenceCountingGC {
public Object instance = null;
public static void main(String[] args) {
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
System.gc();//GC
}
}
```
运行结果
```
[GC (System.gc()) [PSYoungGen: 3329K->744K(38400K)] 3329K->752K(125952K), 0.0341414 secs] [Times: user=0.00 sys=0.00, real=0.06 secs]
[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->628K(87552K)] 752K->628K(125952K), [Metaspace: 3450K->3450K(1056768K)], 0.0060728 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 38400K, used 998K [0x00000000d5c00000, 0x00000000d8680000, 0x0000000100000000)
eden space 33280K, 3% used [0x00000000d5c00000,0x00000000d5cf9b20,0x00000000d7c80000)
from space 5120K, 0% used [0x00000000d7c80000,0x00000000d7c80000,0x00000000d8180000)
to space 5120K, 0% used [0x00000000d8180000,0x00000000d8180000,0x00000000d8680000)
ParOldGen total 87552K, used 628K [0x0000000081400000, 0x0000000086980000, 0x00000000d5c00000)
object space 87552K, 0% used [0x0000000081400000,0x000000008149d2c8,0x0000000086980000)
Metaspace used 3469K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 381K, capacity 388K, committed 512K, reserved 1048576K
Process finished with exit code 0
```
从运行结果看,GC日志中包含“3329K->744K”,意味着虚拟机并没有因为这两个对象互相引用就不回收它们,说明虚拟机不是通过引用技术算法来判断对象是否存活的。
### 可达性分析算法(根搜索算法)
可达性分析算法是通过判断对象的引用链是否可达来决定对象是否可以被回收。
从GC Roots(每种具体实现对GC Roots有不同的定义)作为起点,向下搜索它们引用的对象,可以生成一棵引用树,树的节点视为可达对象,反之视为不可达。

在Java语言中,可以作为GC Roots的对象包括下面几种:
* 虚拟机栈(栈帧中的本地变量表)中的引用对象。
* 方法区中的类静态属性引用的对象。
* 方法区中的常量引用的对象。
* 本地方法栈中JNI(Native方法)的引用对象
真正标记以为对象为可回收状态至少要标记两次。
## 四种引用
强引用就是指在程序代码之中普遍存在的,类似"Object obj = new Object()"这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
```
Object obj = new Object();
```
软引用是用来描述一些还有用但并非必需的对象,对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在JDK1.2之后,提供了SoftReference类来实现软引用。
```
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
```
弱引用也是用来描述非必需对象的,但是它的强度比软引用更弱一些,被弱引用关联的对象,只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。
```
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
```
虚引用也成为幽灵引用或者幻影引用,它是最弱的一中引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。在JDK1.2之后,提供给了PhantomReference类来实现虚引用。
```
Object obj = new Object();
PhantomReference<Object> pf = new PhantomReference<Object>(obj);
```
## JVM垃圾回收算法
常见的垃圾回收算法包括:标记-清除算法,复制算法,标记-整理算法,分代收集算法。
在介绍JVM垃圾回收算法前,先介绍一个概念。
Stop-the-World
Stop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,并且这种情形会在任何一种GC算法中发生。当Stop-the-world发生时,除了GC所需的线程以外,所有线程都处于等待状态直到GC任务完成。事实上,GC优化很多时候就是指减少Stop-the-world发生的时间,从而使系统具有高吞吐 、低停顿的特点。
## 标记—清除算法(Mark-Sweep)
之所以说标记/清除算法是几种GC算法中最基础的算法,是因为后续的收集算法都是基于这种思路并对其不足进行改进而得到的。标记/清除算法的基本思想就跟它的名字一样,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
标记阶段:标记的过程其实就是前面介绍的可达性分析算法的过程,遍历所有的GC Roots对象,对从GC Roots对象可达的对象都打上一个标识,一般是在对象的header中,将其记录为可达对象;
清除阶段:清除的过程是对堆内存进行遍历,如果发现某个对象没有被标记为可达对象(通过读取对象header信息),则将其回收。
不足:
* 标记和清除过程效率都不高
* 会产生大量碎片,内存碎片过多可能导致无法给大对象分配内存。

## 复制算法(Copying)
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
现在的商业虚拟机都采用这种收集算法来回收新生代,但是并不是将内存划分为大小相等的两块,而是分为一块较大的 Eden 空间和两块较小的 Survior 空间,每次使用 Eden 空间和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象一次性复制到另一块 Survivor 空间上,最后清理 Eden 和 使用过的那一块 Survivor。HotSpot 虚拟机的 Eden 和 Survivor 的大小比例默认为 8:1,保证了内存的利用率达到 90 %。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 空间就不够用了,此时需要依赖于老年代进行分配担保,也就是借用老年代的空间。
不足:
* 将内存缩小为原来的一半,浪费了一半的内存空间,代价太高;如果不想浪费一半的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
* 复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。

## 标记—整理算法(Mark-Compact)
标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存,因此其不会产生内存碎片。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
不足:
效率不高,不仅要标记存活对象,还要整理所有存活对象的引用地址,在效率上不如复制算法。

## 分代收集算法(Generational Collection)
分代回收算法实际上是把复制算法和标记整理法的结合,并不是真正一个新的算法,一般分为:老年代(Old Generation)和新生代(Young Generation),老年代就是很少垃圾需要进行回收的,新生代就是有很多的内存空间需要回收,所以不同代就采用不同的回收算法,以此来达到高效的回收算法。
新生代:由于新生代产生很多临时对象,大量对象需要进行回收,所以采用复制算法是最高效的。
老年代:回收的对象很少,都是经过几次标记后都不是可回收的状态转移到老年代的,所以仅有少量对象需要回收,故采用标记清除或者标记整理算法。
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:JVM常用参数以及调优实践.md
================================================
# 目录
* [JVM优化的必要性](#jvm优化的必要性)
* [JVM调优原则](#jvm调优原则)
* [JVM运行参数设置](#jvm运行参数设置)
* [JVM性能调优工具](#jvm性能调优工具)
* [常用调优策略](#常用调优策略)
* [六、JVM调优实例](#六、jvm调优实例)
* [七、一个具体的实战案例分析](#七、一个具体的实战案例分析)
* [参考资料](#参考资料)
* [参考文章](#参考文章)
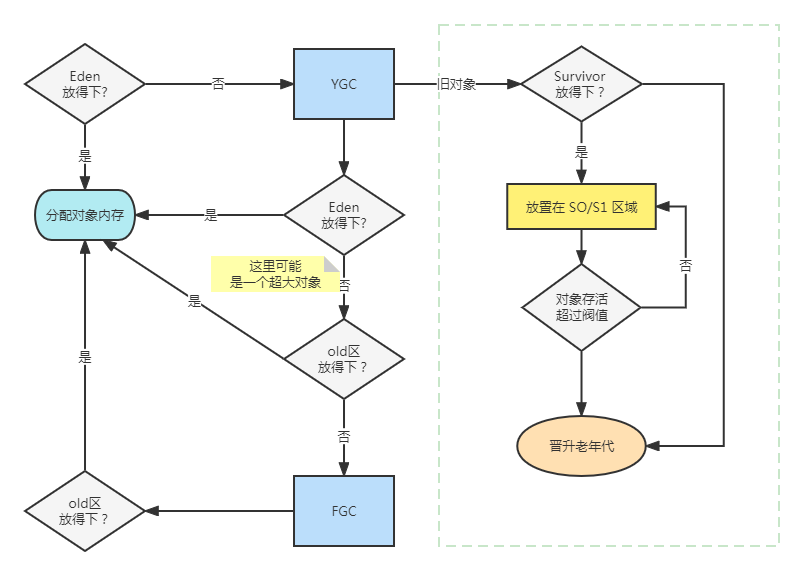
## JVM优化的必要性
**1.1: 项目上线后,什么原因使得我们需要进行jvm调优**
1)、垃圾太多(java线程,对象占满内存),内存占满了,程序跑不动了!!
2)、垃圾回收线程太多,频繁地回收垃圾(垃圾回收线程本身也会占用资源: 占用内存,cpu资源),导致程序性能下降
3)、回收垃圾频繁导致STW
因此基于以上的原因,程序上线后,必须进行调优,否则程序性能就无法提升;也就是程序上线后,必须设置合理的垃圾回收策略;
**1.2: jvm调优的本质是什么??**
答案: 回收垃圾,及时回收没有用垃圾对象,及时释放掉内存空间
**1.3: 基于服务器环境,jvm堆内存到底应用设置多少内存?**
1、32位的操作系统 --- 寻址能力 2^32 = 4GB ,最大的能支持4gb; jvm可以分配 2g+
2、64位的操作系统 --- 寻址能力 2^64 = 16384PB , 高性能计算机(IBM Z unix 128G 200+)

Jvm堆内存不能设置太大,否则会导致寻址垃圾的时间过长,也就是导致整个程序STW, 也不能设置太小,否则会导致回收垃圾过于频繁;
**1.4:总结**
如果你遇到以下情况,就需要考虑进行JVM调优了:
* Heap内存(老年代)持续上涨达到设置的最大内存值;
* Full GC 次数频繁;
* GC 停顿时间过长(超过1秒);
* 应用出现OutOfMemory 等内存异常;
* 应用中有使用本地缓存且占用大量内存空间;
* 系统吞吐量与响应性能不高或下降。
## JVM调优原则
JVM调优是一个手段,但并不一定所有问题都可以通过JVM进行调优解决,因此,在进行JVM调优时,我们要遵循一些原则:
* 大多数的Java应用不需要进行JVM优化;
* 大多数导致GC问题的原因是代码层面的问题导致的(代码层面);
* 上线之前,应先考虑将机器的JVM参数设置到最优;
* 减少创建对象的数量(代码层面);
* 减少使用全局变量和大对象(代码层面);
* 优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
* 分析GC情况优化代码比优化JVM参数更好(代码层面);
通过以上原则,我们发现,其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
**2.1 JVM调优目标**
调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。jvm调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量。
* 延迟:GC低停顿和GC低频率;
* 低内存占用;
* 高吞吐量;
其中,任何一个属性性能的提高,几乎都是以牺牲其他属性性能的损为代价的,不可兼得。具体根据在业务中的重要性确定。
**2.2 JVM调优量化目标**
下面展示了一些JVM调优的量化目标参考实例:
* Heap 内存使用率 <= 70%;
* Old generation内存使用率<= 70%;
* avgpause <= 1秒;
* Full gc 次数0 或 avg pause interval >= 24小时 ;
注意:不同应用的JVM调优量化目标是不一样的。
**2.3 JVM调优的步骤**
一般情况下,JVM调优可通过以下步骤进行:
* 分析GC日志及dump文件,判断是否需要优化,确定瓶颈问题点;
* 确定JVM调优量化目标;
* 确定JVM调优参数(根据历史JVM参数来调整);
* 依次调优内存、延迟、吞吐量等指标;
* 对比观察调优前后的差异;
* 不断的分析和调整,直到找到合适的JVM参数配置;
* 找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪。
以上操作步骤中,某些步骤是需要多次不断迭代完成的。一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。
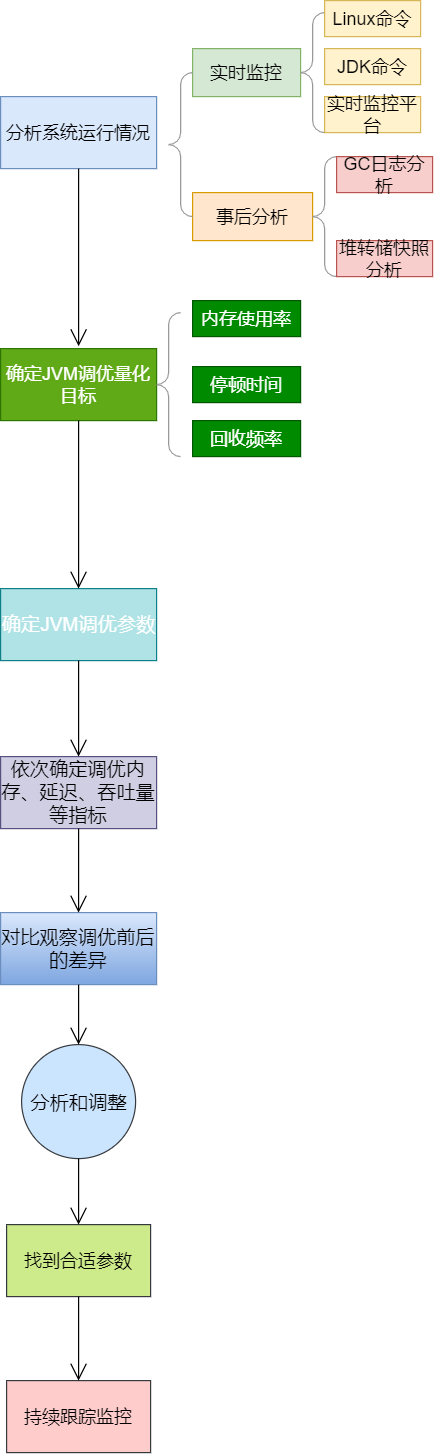
**调优原则总结**
JVM的自动内存管理本来就是为了将开发人员从内存管理的泥潭里拉出来。JVM调优不是常规手段,性能问题一般第一选择是优化程序,最后的选择才是进行JVM调优。
即使不得不进行JVM调优,也绝对不能拍脑门就去调整参数,一定要全面监控,详细分析性能数据。
**附录:系统性能优化指导**
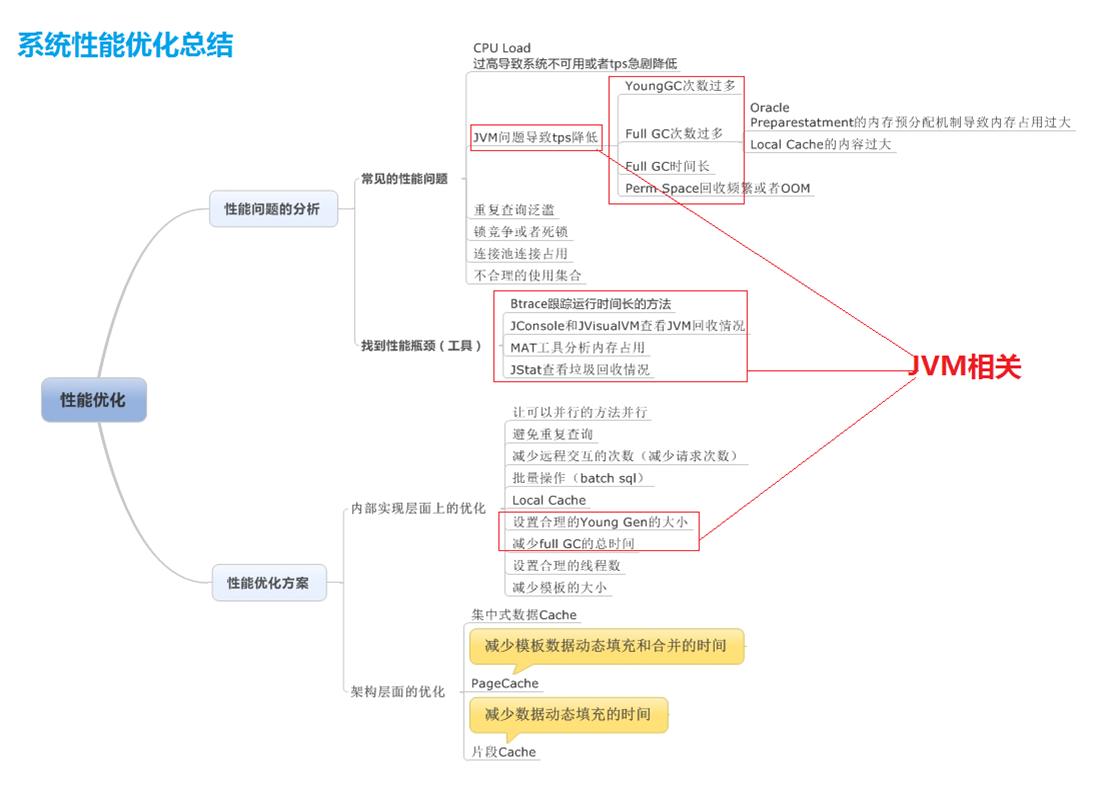
### JVM运行参数设置
**3.1、堆参数设置**
**-XX:+PrintGC**使用这个参数,虚拟机启动后,只要遇到GC就会打印日志
**-XX:+UseSerialGC**配置串行回收器
**-XX:+PrintGCDetails**可以查看详细信息,包括各个区的情况
**-Xms**设置Java程序启动时初始化堆大小
**-Xmx**设置Java程序能获得最大的堆大小
**-Xmx20m -Xms5m -XX:+PrintCommandLineFlags**可以将隐式或者显示传给虚拟机的参数输出
**3.2、新生代参数配置**
**-Xmn**可以设置新生代的大小,设置一个比较大的新生代会减少老年代的大小,这个参数对系统性能以及GC行为有很大的影响,新生代大小一般会设置整个堆空间的1/3到1/4左右
**-XX:SurvivorRatio**用来设置新生代中eden空间和from/to空间的比例。含义:-XX:SurvivorRatio=eden/from**/**eden/to
不同的堆分布情况,对系统执行会产生一定的影响,在实际工作中,应该根据系统的特点做出合理的配置,基本策略:尽可能将对象预留在新生代,减少老年代的GC次数
除了可以设置新生代的绝对大小(-Xmn),还可以使用(-XX:NewRatio)设置新生代和老年代的比例:-XX:NewRatio=老年代/新生代
**配置运行时参数:**
-Xms20m -Xmx20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
**3.3、堆溢出参数配置**
在Java程序在运行过程中,如果对空间不足,则会抛出内存溢出的错误(Out Of Memory)OOM,一旦这类问题发生在生产环境,则可能引起严重的业务中断,Java虚拟机提供了**-XX:+
HeapDumpOnOutOfMemoryError**,使用该参数可以在内存溢出时导出整个堆信息,与之配合使用的还有参数**-XX:HeapDumpPath**,可以设置导出堆的存放路径
内存分析工具:Memory Analyzer
**配置运行时参数**-Xms1m -Xmx1m -XX:+
HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/Demo3.dump
**3.4、栈参数配置**
Java虚拟机提供了参数**-Xss**来指定线程的最大栈空间,整个参数也直接决定了函数可调用的最大深度。
**配置运行时参数:**-Xss1m
3.5、方法区参数配置
和Java堆一样,方法区是一块所有线程共享的内存区域,它用于保存系统的类信息,方法区(永久区)可以保存多少信息可以对其进行配置,在默认情况下,**-XX:MaxPermSize**为64M,如果系统运行时生产大量的类,就需要设置一个相对合适的方法区,以免出现永久区内存溢出的问题
-XX:PermSize=64M -XX:MaxPermSize=64M
**3.6、直接内存参数配置**
直接内存也是Java程序中非常重要的组成部分,特别是广泛用在NIO中,直接内存跳过了Java堆,使用Java程序可以直接访问原生堆空间,因此在一定程度上加快了内存空间的访问速度
但是说直接内存一定就可以提高内存访问速度也不见得,具体情况具体分析
**相关配置参数:-XX:MaxDirectMemorySize**,如果不设置,默认值为最大堆空间,即-Xmx。直接内存使用达到上限时,就会触发垃圾回收,如果不能有效的释放空间,就会引起系统的OOM
**3.7、对象进入老年代的参数配置**
一般而言,对象首次创建会被放置在新生代的eden区,如果没有GC介入,则对象不会离开eden区,那么eden区的对象如何进入老年代呢?
通常情况下,只要对象的年龄达到一定的大小,就会自动离开年轻代进入老年代,对象年龄是由对象经历数次GC决定的,在新生代每次GC之后如果对象没有被回收,则年龄加1
虚拟机提供了一个参数来控制新生代对象的最大年龄,当超过这个年龄范围就会晋升老年代
**-XX:MaxTenuringThreshold**,默认情况下为15
**配置运行时参数:**-Xmx64M -Xms64M -XX:+PrintGCDetails
**结论**:对象首次创建会被放置在新生代的eden区,因此输出结果中from和to区都为0%
根据设置MaxTenuringThreshold参数,可以指定新生代对象经过多少次回收后进入老年代。另外,大对象新生代eden区无法装入时,也会直接进入老年代。
JVM里有个参数可以设置对象的大小超过在指定的大小之后,直接晋升老年代 **-XX:PretenureSizeThreshold=15**
参数:-Xmx1024M -Xms1024M -XX:+UseSerialGC -XX:MaxTenuringThreshold=15 -XX:+PrintGCDetails
使用PretenureSizeThreshold可以进行指定进入老年代的对象大小,但是要注意TLAB区域优先分配空间。虚拟机对于体积不大的对象 会优先把数据分配到TLAB区域中,因此就失去了在老年代分配的机会
参数:-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails
-XX:PretenureSizeThreshold=1000 -XX:-UseTLAB
**3.8、TLAB参数配置**
TLAB全称是Thread Local Allocation Buffer,即线程本地分配缓存,从名字上看是一个线程专用的内存分配区域,是为了加速对象分配对象而生的。每一个线程都会产生一个TLAB,该线程独享的工作区域,Java虚拟机使用这种TLAB区来避免多线程冲突问题,提高了对象分配的效率
TLAB空间一般不会太大,当大对象无法在TLAB分配时,则会直接分配到堆上
**-XX:+UseTLAB**使用TLAB
**-XX:+TLABSize**设置TLAB大小
**-XX:TLABRefillWasteFraction**设置维护进入TLAB空间的单个对象大小,它是一个比例值,默认为64,即如果对象大于整个空间的1/64,则在堆创建对象
**-XX:+PrintTLAB**查看TLAB信息
**-XX:ResizeTLAB**自调整TLABRefillWasteFraction阈值
参数:-XX:+UseTLAB -XX:+PrintTLAB -XX:+PrintGC -XX:TLABSize=102400 -XX:-ResizeTLAB
-XX:TLABRefillWasteFraction=100 -XX:-DoEscapeAnalysis -server
内存参数

## JVM性能调优工具
这个篇幅在这里就不过多介绍了,可以参照:
深入理解JVM虚拟机——Java虚拟机的监控及诊断工具大全
## 常用调优策略
这里还是要提一下,及时确定要进行JVM调优,也不要陷入“知见障”,进行分析之后,发现可以通过优化程序提升性能,仍然首选优化程序。
**5.1、选择合适的垃圾回收器**
CPU单核,那么毫无疑问Serial 垃圾收集器是你唯一的选择。
CPU多核,关注吞吐量 ,那么选择PS+PO组合。
CPU多核,关注用户停顿时间,JDK版本1.6或者1.7,那么选择CMS。
CPU多核,关注用户停顿时间,JDK1.8及以上,JVM可用内存6G以上,那么选择G1。
参数配置:
> //设置Serial垃圾收集器(新生代)
>
> 开启:-XX:+UseSerialGC
>
> //设置PS+PO,新生代使用功能Parallel Scavenge 老年代将会使用Parallel Old收集器
>
> 开启 -XX:+UseParallelOldGC
>
> //CMS垃圾收集器(老年代)
>
> 开启 -XX:+UseConcMarkSweepGC
>
> //设置G1垃圾收集器
>
> 开启 -XX:+UseG1GC
**5.2、调整内存大小**
现象:垃圾收集频率非常频繁。
原因:如果内存太小,就会导致频繁的需要进行垃圾收集才能释放出足够的空间来创建新的对象,所以增加堆内存大小的效果是非常显而易见的。
注意:如果垃圾收集次数非常频繁,但是每次能回收的对象非常少,那么这个时候并非内存太小,而可能是内存泄露导致对象无法回收,从而造成频繁GC。
参数配置:
> //设置堆初始值
>
> 指令1:-Xms2g
>
> 指令2:-XX:InitialHeapSize=2048m
>
> //设置堆区最大值
>
> 指令1:`-Xmx2g`
>
> 指令2: -XX:MaxHeapSize=2048m
>
> //新生代内存配置
>
> 指令1:-Xmn512m
>
> 指令2:-XX:MaxNewSize=512m
**5.3、设置符合预期的停顿时间**
**现象**:程序间接性的卡顿
**原因**:如果没有确切的停顿时间设定,垃圾收集器以吞吐量为主,那么垃圾收集时间就会不稳定。
**注意**:不要设置不切实际的停顿时间,单次时间越短也意味着需要更多的GC次数才能回收完原有数量的垃圾.
**参数配置**:
> //GC停顿时间,垃圾收集器会尝试用各种手段达到这个时间
>
> -XX:MaxGCPauseMillis
**5.4、调整内存区域大小比率**
现象:某一个区域的GC频繁,其他都正常。
原因:如果对应区域空间不足,导致需要频繁GC来释放空间,在JVM堆内存无法增加的情况下,可以调整对应区域的大小比率。
注意:也许并非空间不足,而是因为内存泄造成内存无法回收。从而导致GC频繁。
参数配置:
> //survivor区和Eden区大小比率
>
> 指令:-XX:SurvivorRatio=6 //S区和Eden区占新生代比率为1:6,两个S区2:6
>
> //新生代和老年代的占比
>
> -XX:NewRatio=4 //表示新生代:老年代 = 1:4 即老年代占整个堆的4/5;默认值=2
**5.5、调整对象升老年代的年龄**
**现象**:老年代频繁GC,每次回收的对象很多。
**原因**:如果升代年龄小,新生代的对象很快就进入老年代了,导致老年代对象变多,而这些对象其实在随后的很短时间内就可以回收,这时候可以调整对象的升级代年龄,让对象不那么容易进入老年代解决老年代空间不足频繁GC问题。
**注意**:增加了年龄之后,这些对象在新生代的时间会变长可能导致新生代的GC频率增加,并且频繁复制这些对象新生的GC时间也可能变长。
配置参数:
> //进入老年代最小的GC年龄,年轻代对象转换为老年代对象最小年龄值,默认值7
>
> -XX:InitialTenuringThreshol=7
**5.6、调整大对象的标准**
**现象**:老年代频繁GC,每次回收的对象很多,而且单个对象的体积都比较大。
**原因**:如果大量的大对象直接分配到老年代,导致老年代容易被填满而造成频繁GC,可设置对象直接进入老年代的标准。
**注意**:这些大对象进入新生代后可能会使新生代的GC频率和时间增加。
配置参数:
> //新生代可容纳的最大对象,大于则直接会分配到老年代,0代表没有限制。
>
> -XX:PretenureSizeThreshold=1000000
**5.7、调整GC的触发时机**
**现象**:CMS,G1 经常 Full GC,程序卡顿严重。
**原因**:G1和CMS 部分GC阶段是并发进行的,业务线程和垃圾收集线程一起工作,也就说明垃圾收集的过程中业务线程会生成新的对象,所以在GC的时候需要预留一部分内存空间来容纳新产生的对象,如果这个时候内存空间不足以容纳新产生的对象,那么JVM就会停止并发收集暂停所有业务线程(STW)来保证垃圾收集的正常运行。这个时候可以调整GC触发的时机(比如在老年代占用60%就触发GC),这样就可以预留足够的空间来让业务线程创建的对象有足够的空间分配。
**注意**:提早触发GC会增加老年代GC的频率。
配置参数:
> //使用多少比例的老年代后开始CMS收集,默认是68%,如果频繁发生SerialOld卡顿,应该调小
>
> -XX:CMSInitiatingOccupancyFraction
>
> //G1混合垃圾回收周期中要包括的旧区域设置占用率阈值。默认占用率为 65%
>
> -XX:G1MixedGCLiveThresholdPercent=65
5.8、调整 JVM本地内存大小
**现象**:GC的次数、时间和回收的对象都正常,堆内存空间充足,但是报OOM
**原因**: JVM除了堆内存之外还有一块堆外内存,这片内存也叫本地内存,可是这块内存区域不足了并不会主动触发GC,只有在堆内存区域触发的时候顺带会把本地内存回收了,而一旦本地内存分配不足就会直接报OOM异常。
**注意**: 本地内存异常的时候除了上面的现象之外,异常信息可能是OutOfMemoryError:Direct buffer memory。 解决方式除了调整本地内存大小之外,也可以在出现此异常时进行捕获,手动触发GC(System.gc())。
配置参数:
> XX:MaxDirectMemorySize
## 六、JVM调优实例
整理的一些JVM调优实例:
**6.1、网站流量浏览量暴增后,网站反应页面响很慢**
> 1、问题推测:在测试环境测速度比较快,但是一到生产就变慢,所以推测可能是因为垃圾收集导致的业务线程停顿。
>
> 2、定位:为了确认推测的正确性,在线上通过jstat -gc 指令 看到JVM进行GC 次数频率非常高,GC所占用的时间非常长,所以基本推断就是因为GC频率非常高,所以导致业务线程经常停顿,从而造成网页反应很慢。
>
> 3、解决方案:因为网页访问量很高,所以对象创建速度非常快,导致堆内存容易填满从而频繁GC,所以这里问题在于新生代内存太小,所以这里可以增加JVM内存就行了,所以初步从原来的2G内存增加到16G内存。
>
> 4、第二个问题:增加内存后的确平常的请求比较快了,但是又出现了另外一个问题,就是不定期的会间断性的卡顿,而且单次卡顿的时间要比之前要长很多。
>
> 5、问题推测:练习到是之前的优化加大了内存,所以推测可能是因为内存加大了,从而导致单次GC的时间变长从而导致间接性的卡顿。
>
> 6、定位:还是通过jstat -gc 指令 查看到 的确FGC次数并不是很高,但是花费在FGC上的时间是非常高的,根据GC日志 查看到单次FGC的时间有达到几十秒的。
>
> 7、解决方案: 因为JVM默认使用的是PS+PO的组合,PS+PO垃圾标记和收集阶段都是STW,所以内存加大了之后,需要进行垃圾回收的时间就变长了,所以这里要想避免单次GC时间过长,所以需要更换并发类的收集器,因为当前的JDK版本为1.7,所以最后选择CMS垃圾收集器,根据之前垃圾收集情况设置了一个预期的停顿的时间,上线后网站再也没有了卡顿问题。
**6.2、后台导出数据引发的OOM**
**问题描述:**公司的后台系统,偶发性的引发OOM异常,堆内存溢出。
> 1、因为是偶发性的,所以第一次简单的认为就是堆内存不足导致,所以单方面的加大了堆内存从4G调整到8G。
>
> 2、但是问题依然没有解决,只能从堆内存信息下手,通过开启了-XX:+
> HeapDumpOnOutOfMemoryError参数 获得堆内存的dump文件。
>
> 3、VisualVM 对 堆dump文件进行分析,通过VisualVM查看到占用内存最大的对象是String对象,本来想跟踪着String对象找到其引用的地方,但dump文件太大,跟踪进去的时候总是卡死,而String对象占用比较多也比较正常,最开始也没有认定就是这里的问题,于是就从线程信息里面找突破点。
>
> 4、通过线程进行分析,先找到了几个正在运行的业务线程,然后逐一跟进业务线程看了下代码,发现有个引起我注意的方法,导出订单信息。
>
> 5、因为订单信息导出这个方法可能会有几万的数据量,首先要从数据库里面查询出来订单信息,然后把订单信息生成excel,这个过程会产生大量的String对象。
>
> 6、为了验证自己的猜想,于是准备登录后台去测试下,结果在测试的过程中发现到处订单的按钮前端居然没有做点击后按钮置灰交互事件,结果按钮可以一直点,因为导出订单数据本来就非常慢,使用的人员可能发现点击后很久后页面都没反应,结果就一直点,结果就大量的请求进入到后台,堆内存产生了大量的订单对象和EXCEL对象,而且方法执行非常慢,导致这一段时间内这些对象都无法被回收,所以最终导致内存溢出。
>
> 7、知道了问题就容易解决了,最终没有调整任何JVM参数,只是在前端的导出订单按钮上加上了置灰状态,等后端响应之后按钮才可以进行点击,然后减少了查询订单信息的非必要字段来减少生成对象的体积,然后问题就解决了。
**6.3、单个缓存数据过大导致的系统CPU飚高**
> 1、系统发布后发现CPU一直飚高到600%,发现这个问题后首先要做的是定位到是哪个应用占用CPU高,通过top 找到了对应的一个java应用占用CPU资源600%。
>
> 2、如果是应用的CPU飚高,那么基本上可以定位可能是锁资源竞争,或者是频繁GC造成的。
>
> 3、所以准备首先从GC的情况排查,如果GC正常的话再从线程的角度排查,首先使用jstat -gc PID 指令打印出GC的信息,结果得到得到的GC 统计信息有明显的异常,应用在运行了才几分钟的情况下GC的时间就占用了482秒,那么问这很明显就是频繁GC导致的CPU飚高。
>
> 4、定位到了是GC的问题,那么下一步就是找到频繁GC的原因了,所以可以从两方面定位了,可能是哪个地方频繁创建对象,或者就是有内存泄露导致内存回收不掉。
>
> 5、根据这个思路决定把堆内存信息dump下来看一下,使用jmap -dump 指令把堆内存信息dump下来(堆内存空间大的慎用这个指令否则容易导致会影响应用,因为我们的堆内存空间才2G所以也就没考虑这个问题了)。
>
> 6、把堆内存信息dump下来后,就使用visualVM进行离线分析了,首先从占用内存最多的对象中查找,结果排名第三看到一个业务VO占用堆内存约10%的空间,很明显这个对象是有问题的。
>
> 7、通过业务对象找到了对应的业务代码,通过代码的分析找到了一个可疑之处,这个业务对象是查看新闻资讯信息生成的对象,由于想提升查询的效率,所以把新闻资讯保存到了redis缓存里面,每次调用资讯接口都是从缓存里面获取。
>
> 8、把新闻保存到redis缓存里面这个方式是没有问题的,有问题的是新闻的50000多条数据都是保存在一个key里面,这样就导致每次调用查询新闻接口都会从redis里面把50000多条数据都拿出来,再做筛选分页拿出10条返回给前端。50000多条数据也就意味着会产生50000多个对象,每个对象280个字节左右,50000个对象就有13.3M,这就意味着只要查看一次新闻信息就会产生至少13.3M的对象,那么并发请求量只要到10,那么每秒钟都会产生133M的对象,而这种大对象会被直接分配到老年代,这样的话一个2G大小的老年代内存,只需要几秒就会塞满,从而触发GC。
>
> 9、知道了问题所在后那么就容易解决了,问题是因为单个缓存过大造成的,那么只需要把缓存减小就行了,这里只需要把缓存以页的粒度进行缓存就行了,每个key缓存10条作为返回给前端1页的数据,这样的话每次查询新闻信息只会从缓存拿出10条数据,就避免了此问题的 产生。
**6.4、CPU经常100% 问题定位**
问题分析:CPU高一定是某个程序长期占用了CPU资源。
1、所以先需要找出那个进行占用CPU高。
> top 列出系统各个进程的资源占用情况。
2、然后根据找到对应进行里哪个线程占用CPU高。
> top -Hp 进程ID 列出对应进程里面的线程占用资源情况
3、找到对应线程ID后,再打印出对应线程的堆栈信息
> printf "%x\n" PID 把线程ID转换为16进制。
>
> jstack PID 打印出进程的所有线程信息,从打印出来的线程信息中找到上一步转换为16进制的线程ID对应的线程信息。
4、最后根据线程的堆栈信息定位到具体业务方法,从代码逻辑中找到问题所在。
> 查看是否有线程长时间的watting 或blocked
>
> 如果线程长期处于watting状态下, 关注watting on xxxxxx,说明线程在等待这把锁,然后根据锁的地址找到持有锁的线程。
**6.5、内存飚高问题定位**
分析: 内存飚高如果是发生在java进程上,一般是因为创建了大量对象所导致,持续飚高说明垃圾回收跟不上对象创建的速度,或者内存泄露导致对象无法回收。
1、先观察垃圾回收的情况
> jstat -gcPID 1000查看GC次数,时间等信息,每隔一秒打印一次。
>
> jmap -histo PID | head -20 查看堆内存占用空间最大的前20个对象类型,可初步查看是哪个对象占用了内存。
如果每次GC次数频繁,而且每次回收的内存空间也正常,那说明是因为对象创建速度快导致内存一直占用很高;如果每次回收的内存非常少,那么很可能是因为内存泄露导致内存一直无法被回收。
2、导出堆内存文件快照
> jmap -dump:live,format=b,file=/home/myheapdump.hprof PID dump堆内存信息到文件。
3、使用visualVM对dump文件进行离线分析,找到占用内存高的对象,再找到创建该对象的业务代码位置,从代码和业务场景中定位具体问题。
**6.6、数据分析平台系统频繁 Full GC**
平台主要对用户在 App 中行为进行定时分析统计,并支持报表导出,使用 CMS GC 算法。
数据分析师在使用中发现系统页面打开经常卡顿,通过 jstat 命令发现系统每次 Young GC 后大约有 10% 的存活对象进入老年代。
原来是因为 Survivor 区空间设置过小,每次 Young GC 后存活对象在 Survivor 区域放不下,提前进入老年代。
通过调大 Survivor 区,使得 Survivor 区可以容纳 Young GC 后存活对象,对象在 Survivor 区经历多次 Young GC 达到年龄阈值才进入老年代。
调整之后每次 Young GC 后进入老年代的存活对象稳定运行时仅几百 Kb,Full GC 频率大大降低。
**6.7、业务对接网关 OOM**
网关主要消费 Kafka 数据,进行数据处理计算然后转发到另外的 Kafka 队列,系统运行几个小时候出现 OOM,重启系统几个小时之后又 OOM。
通过 jmap 导出堆内存,在 eclipse MAT 工具分析才找出原因:代码中将某个业务 Kafka 的 topic 数据进行日志异步打印,该业务数据量较大,大量对象堆积在内存中等待被打印,导致 OOM。
**6.8、鉴权系统频繁长时间 Full GC**
系统对外提供各种账号鉴权服务,使用时发现系统经常服务不可用,通过 Zabbix 的监控平台监控发现系统频繁发生长时间 Full GC,且触发时老年代的堆内存通常并没有占满,发现原来是业务代码中调用了
## 七、一个具体的实战案例分析
**7.1 典型调优参数设置**
> 服务器配置: 4cpu,8GB内存 ---- jvm调优实际上是设置一个合理大小的jvm堆内存(既不能太大,也不能太小)
> -Xmx3550m 设置jvm堆内存最大值 (经验值设置: 根据压力测试,根据线上程序运行效果情况)
>
> -Xms3550m 设置jvm堆内存初始化大小,一般情况下必须设置此值和最大的最大的堆内存空间保持一致,防止内存抖动,消耗性能
>
> -Xmn2g 设置年轻代占用的空间大小
>
> -Xss256k 设置线程堆栈的大小;jdk5.0以后默认线程堆栈大小为1MB; 在相同的内存情况下,减小堆栈大小,可以使得操作系统创建更多的业务线程;
jvm堆内存设置:
> nohup java -Xmx3550m -Xms3550m -Xmn2g -Xss256k -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
TPS性能曲线:
**7.2 分析gc日志**
如果需要分析gc日志,就必须使得服务gc输入gc详情到log日志文件中,然后使用相应gc日志分析工具来对日志进行分析即可;
把gc详情输出到一个gc.log日志文件中,便于gc分析
> -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log
Throughput: 业务线程执行时间 / (gc时间+业务线程时间)
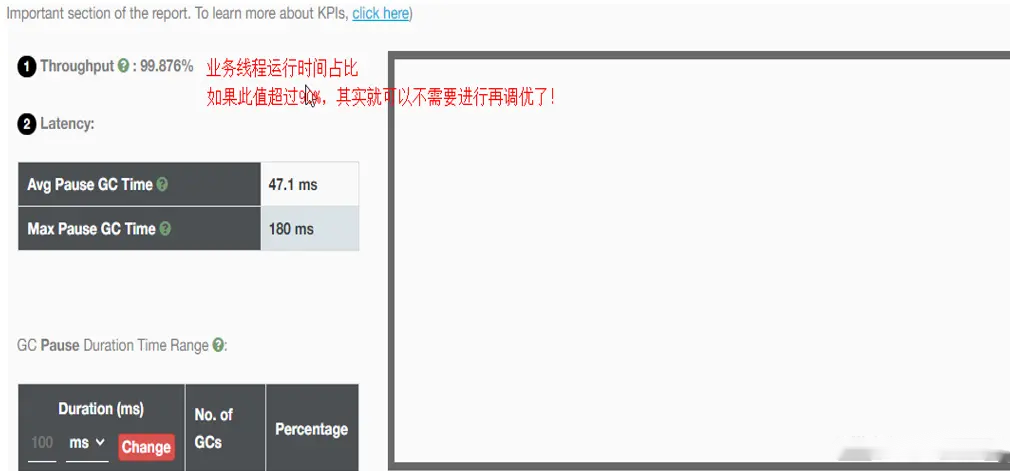
分析gc日志,发现,一开始就发生了3次fullgc,很明显jvm优化参数的设置是有问题的;
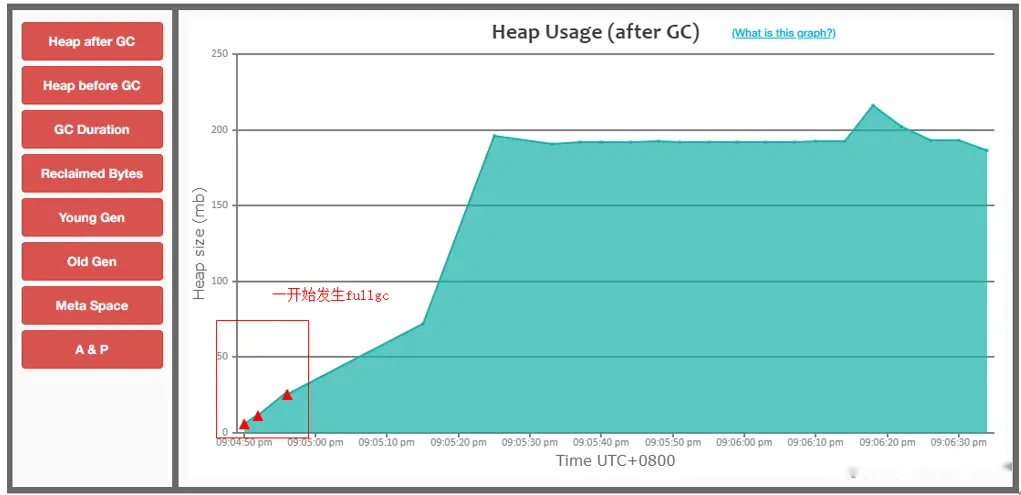
查看fullgc发生问题原因: jstat -gcutil pid

Metaspace持久代: 初始化分配大小20m , 当metaspace被占满后,必须对持久代进行扩容,如果metaspace每进行一次扩容,fullgc就需要执行一次;(fullgc回收整个堆空间,非常占用时间)
调整gc配置: 修改永久代空间初始化大小:
> nohup java -Xmx3550m -Xms3550m -Xmn2g -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
经过调优后,fullgc现象已经消失了:

**7.3 Young&Old比例**
年轻代和老年代比例:1:2 参数:-XX:NewRetio = 4 , 表示年轻代(eden,s0,s1)和老年代所占比值为1:4
1) -XX:NewRetio = 4
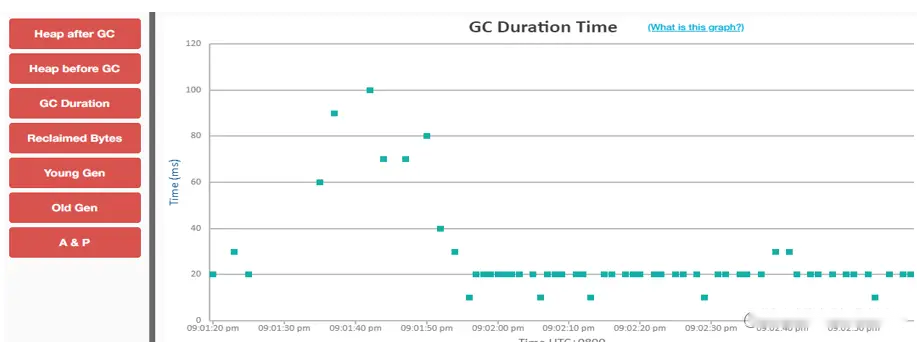
年轻代分配的内存大小变小了,这样YGC次数变多了,虽然fullgc不发生了,但是YGC花费的时间更多了!
2) -XX:NewRetio = 2 YGC发生的次数必然会减少;因为eden区域的大小变大了,因此YGC就会变少;
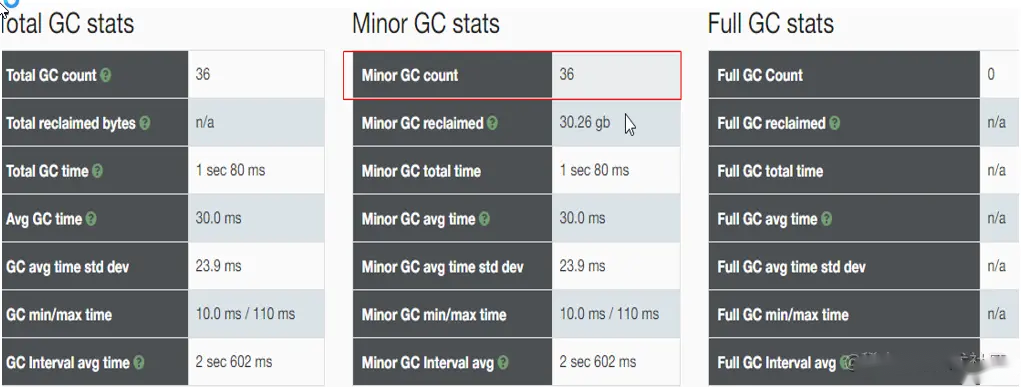
7.4 Eden&S0S1
为了进一步减少YGC, 可以设置 enden ,s 区域的比值大小; 设置方式: -XX:SurvivorRatio=8
1) 设置比值:8:1:1
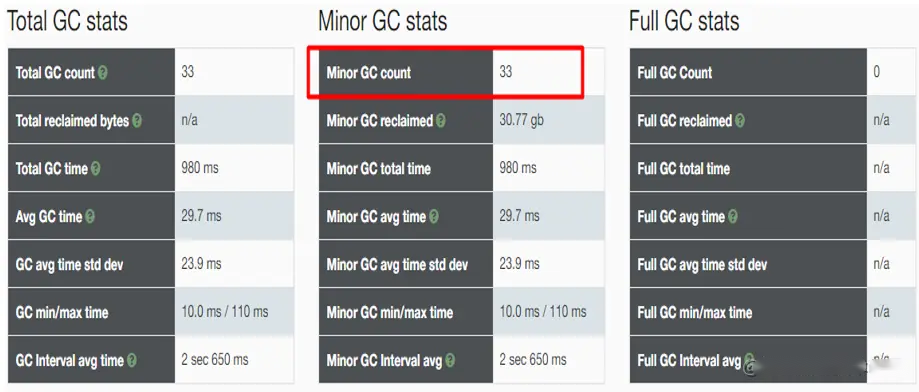
2) Xmn2g 8:1:1
nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
根据gc调优,垃圾回收次数,时间,吞吐量都是一个比较优的一个配置;
**7.5 吞吐量优先**
使用并行的垃圾回收器,可以充分利用多核心cpu来帮助进行垃圾回收;这样的gc方式,就叫做吞吐量优先的调优方式
垃圾回收器组合: ps(parallel scavenge) + po (parallel old) 此垃圾回收器是Jdk1.8 默认的垃圾回收器组合;
> nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:+UseParallelGC -XX:UseParallelOldGC -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
**7.6 响应时间优先**
使用cms垃圾回收器,就是一个响应时间优先的组合; cms垃圾回收器(垃圾回收和业务线程交叉执行,不会让业务线程进行停顿stw)尽可能的减少stw的时间,因此使用cms垃圾回收器组合,是响应时间优先组合
> nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:+UseParNewGC -XX:UseConcMarkSweepGC -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
可以发现,cms垃圾回收器时间变长;
**7.7 g1**
配置方式如下所示:
> nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:+UseG1GC -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
## 参考资料
* [Java HotSpot™ Virtual Machine Performance Enhancements](http://docs.oracle.com/javase/8/docs/technotes/guides/vm/performance-enhancements-7.html)
* [Java HotSpot Virtual Machine Garbage Collection Tuning Guide](http://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html)
* [[HotSpot VM] JVM调优的”标准参数”的各种陷阱](http://hllvm.group.iteye.com/group/topic/27945)
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md
================================================
# 目录
* [一、VisualVM是什么?](#一、visualvm是什么?)
* [二、如何获取VisualVM?](#二、如何获取visualvm?)
* [三、获取那个版本?](#三、获取那个版本?)
* [四、VisualVM能做什么?](#四、visualvm能做什么?)
* [监控远程主机上的JAVA应用程序](#监控远程主机上的java应用程序)
* [排查JAVA应用程序内存泄漏](#排查java应用程序内存泄漏)
* [查找JAVA应用程序耗时的方法函数](#查找java应用程序耗时的方法函数)
* [排查JAVA应用程序线程锁](#排查java应用程序线程锁)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 一、VisualVM是什么?
VisualVM是一款免费的JAVA虚拟机图形化监控分析工具。
1. 拥有图形化的监控界面。
2. 提供本地、远程的JVM监控分析功能。
3. 是一款免费的JAVA工具。
4. VisualVM拥有丰富的插件支持。
## 二、如何获取VisualVM?
VisualVM官方网站:http://visualvm.java.net/
VisualVM各版本下载页面: http://visualvm.java.net/releases.html
下载VisualVM时也应该注意,不同的JDK版本对应不同版本的VisualVM,具体根据安装的JDK版本来下载第一的VisualVM。
## 三、获取那个版本?
下载版本参考:Java虚拟机性能管理神器 - VisualVM(4) - JDK版本与VisualVM版本对应关系
备注:下列表中显示1.3.6版本只适合JDK7和JDK8,可是我用1.3.6版还是可以监控JDK1.6_45的版本。
## 四、VisualVM能做什么?
1. 显示JAVA应用程序配置和运行时环境。
显示JAVA应用程序JVM参数,系统属性,JVM的信息和运行环境。
2. 显示本地和远程JAVA应用程序运行状态。
可以连接到远程服务器上运行的JAVA应用程序,监控应用程序的运行状态。
3. 监控应用程序的性能消耗。
可以监控到应用程序热点方法的执行单次时间、总耗时、耗时占比。
4. 显示应用程序内存分配,显示分析堆信息。
显示应用程序在运行时的编译时间、加载时间、垃圾回收时间、内存区域的回收状态等。
5. 监控应用程序线程状态和生命周期。
监控应用程序线程的运行、休眠、等待、锁定状态。
6. 显示、分析线程堆信息。
显示线程当前运行状态和关联类信息。
7. 支持第三方插件来分析JAVA应用程序。
另外还提供更多更强大、方便的第三方插件。
### 监控远程主机上的JAVA应用程序
使用VisualVM监控远程主机上JAVA应用程序时,需要开启远程主机上的远程监控访问,或者在远程JAVA应用程序启动时,开启远程监控选项,两种方法,选择其中一种就可以开启远程监控功能,配置完成后就可以在本地对远程主机上的JAVA应用程序进行监控。
1.远程服务器、应用程序配置
1.1配合jstatd工具提供监控数据
1.1.1创建安全访问文件
在JAVA_HOME/bin目录中,创建名称为jstatdAllPolicy文件(这个文件名称也可以顺便起,不过要与jstatd启动时指定名称相同),将以下内容拷贝到文件中。并保证文件的权限和用户都正确。
grant codebase"file:${java.home}/../lib/tools.jar"{ permission java.security.AllPermission; };
1.1.2启动jstatd服务
在JAVA_HOME/bin目录中,执行以下命令:
./jstatd -J-Djava.security.policy=jstatdAllPolicy-p 1099 -J-Djava.rmi.server.hostname=192.168.xxx.xxx
jstatd命令描述以及参数说明:
jstatd是一个基于RMI(Remove Method Invocation)的服务程序,它用于监控基于HotSpot的JVM中资源的创建及销毁,并且提供了一个远程接口允许远程的监控工具连接到本地的JVM执行命令。
-J-Djava.security.policy=jstatdAllPolicy 指定安全策略文件名称
-p 1099 指定启动端口
-J-Djava.rmi.server.hostname=192.168.xxx.xxx 指定本机IP地址,在hosts文件配置不正常时使用,最好加上。
1.2JVM启动时配置远程监控选项
在需要远程监控的JVM启动时,开启远程监控选项
-Dcom.sun.management.jmxremote.port=1099
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=192.168.xxx.xxx
2.本地VisualVM配置
在本地VisualVM的应用程序窗口,右键单击【远程】》【添加远程主机】》【主机名】中输入远程主机的IP地址,点击【高级设置】输入远程主机开启的监控端口,点击【确定】完成配置。
如果一切正常,就可以看到远程主机上的JAVA应用程序了。
## 排查JAVA应用程序内存泄漏
1. 发现问题
线上应用部署完成后,运行1~2天左右就会出现假死,或者某天早上8~10点高峰期间突然不处理数据了。由于在测试环境的压力测试没有做完全,也没有遇到相关问题。情况出现后对客户的使用造成很大影响,领导要求赶紧排查出问题原因!
2. 排查原因
排查原因前,与运维沟通,了解线上服务器的运行状态,通过ganglila观察网络、CPU、内存、磁盘的运行历史状态,发现程序故障前,都有一波很高的负载,排查线上日志,负载来源在8~9点平台接入数据量成倍增加,通过与产品和市场人员分析,此时段是用户集中上班、接入平台的高峰时段,访问日志也显示,业务场景正常,无网络攻击和安全问题。属于产品业务正常的场景。
排除了网络安全因素后,就从程序的运行内部进行排查,首先想到的获取JVM的dmp文件。获取JVM的dmp文件有两中方式:
1. JVM启动时增加两个参数,出现 OOME 时生成堆 dump:
-XX:+HeapDumpOnOutOfMemoryError
生成堆文件地址:
-XX:HeapDumpPath=/home/test/jvmlogs/
2. 发现程序异常前通过执行指令,直接生成当前JVM的dmp文件,15434是指JVM的进程号
jmap -dump:format=b,file=serviceDump.dat 15434
由于第一种方式是一种事后方式,需要等待当前JVM出现问题后才能生成dmp文件,实时性不高,第二种方式在执行时,JVM是暂停服务的,所以对线上的运行会产生影响。所以建议第一种方式。
3. 解决方案
获取到dmp文件后,就开始进行分析。将服务器上的dmp文件拷贝到本地,然后启动本地的VisualVM,点击菜单栏【文件】选项,装入dmp文件
打开dmp文件后,查看类标签,就能看到占用内存的一个排行。
然后通过检查中查找最大的对象,排查到具体线程和对象。
上列中的com.ctfo.trackservice.handler.TrackHandleThread#4就是重点排查对象。
通过代码的比对,在此线程中,有调用DAO接口,负责将数据存储到数据库中。而存储到数据库中时,由于存储速度较慢,导致此线程中的数据队列满了,数据积压,无法回收导致了队列锁定,结果就是程序假死,不处理数据。
通过进一步分析,发现数据库存储时有瓶颈,虽然当前是批量提交,速度也不快。平均8000/秒的存储速度。而数据库有一个DG(备份)节点,采用的是同步备份方式,即主库事务要等DG的事务也完成后才能返回成功,这样就会因为网络因素、DG性能因素等原因导致性能下降。通过与DBA、产品、沟通,将同步备份改为异步备份,实时同步改为异步(异步可能会导致主备有10分钟以内的数据延迟)。速度达到30000/秒。问题解决。
至此,通过VisualVM分析java程序内存泄漏到此结束。不过还有几个问题:1. 如果dmp文件较大,VisualVM分析时间可能很久;另外,VisualVM对堆的分析显示功能还不算全面。如果需要更全面的显示,就可以使用另外一个专业的dmp文件分析工具【Memory Analyzer (MAT)】,此工具可以作为eclipse的插件进行安装,也可以单独下载使用。如果有感兴趣的朋友,我个人建议还是单独下载使用。下载地址:http://www.eclipse.org/mat/
## 查找JAVA应用程序耗时的方法函数
1.为什么要监控?
JAVA程序在开发前,根据设计文档的性能需求,是要对程序的性能指标进行测试的。比如接口每秒响应次数要求1000次/秒,就需要平均每次请求处理的时间在1ms以内,如果需要满足这个指标,就需要在开发阶段对接口执行函数进行监控,也可以通过打印日志进行监控,从而统计对应的性能指标,然后可以根据性能指标的要求进行相应优化。
2. 那些方法函数需要监控?
根据具体业务的场景和需求,主要集中在IO通讯、文件读写、数据库操作、业务逻辑处理上,这些都是制约性能的重要因素,所以需要重点关注。
3. 如何排查
在研发环境,大部分会使用syso的方式或者日志方式打印性能损耗,如果代码没有加在运行时才想起来,或者想关注突然想起的函数,换做以前,是需要重启服务的,如果有VisualVM就可以直接查看耗时以及调用次数等情况。而不用打印、输出日志来查看性能损耗。
4. 如何处理
对于性能损耗的函数,根据业务逻辑可以进行相应的优化,例如字符串处理、文件读写方式、SQL语句优化、多线程处理等等方式。
由于性能优化涉及的内容很多,这里就不深入了。主要是告诉大家通过VisualVM来排查问题的具体位置。
## 排查JAVA应用程序线程锁
1. JAVA应用程序线程锁原因
JAVA线程锁的例子和原因网上一大堆,我也不在这里深入说明,这里主要是否讲如何使用VisualVM进行排查。至于例子可以看这里:http://blog.csdn.net/fengzhe0411/article/details/6953370
这个例子比较极端,一般情况下,出现锁竞争激烈是比较常见的。
2. 排查JAVA应用程序线程锁
启动 VisualVM,在应用程序窗口,选择对应的JAVA应用,在详情窗口》线程标签(勾选线程可视化),查看线程生命周期状态,主要留意线程生命周期中红色部分。
(1)绿色:代表运行状态。一般属于正常情况。如果是多线程环境,生产者消费者模式下,消费者一直处于运行状态,说明消费者处理性能低,跟不上生产者的节奏,需要优化对应的代码,如果不处理,就可能导致消费者队列阻塞的现象。对应线程的【RUNNABLE】状态。
(2)蓝色:代表线程休眠。线程中调用Thread.sleep()函数的线程状态时,就是蓝色。对应线程的【TIMED_WAITING】状态。
(3)黄色:代表线程等待。调用线程的wait()函数就会出现黄色状态。对应线程的【WAITING】状态。
(4)红色:代码线程锁定。对应线程的【BLOCKED】状态。
3. 分析解决JAVA应用程序线程锁
发生线程锁的原因有很多,我所遇到比较多的情况是多线程同时访问同一资源,且此资源使用synchronized关键字,导致一个线程要等另外一个线程使用完资源后才能运行。例如再没有连接池的情况下,同时访问数据库接口。这种情况会导致性能的极具下降,解决的方案是增加连接池,或者修改访问方式。或者将资源粒度细化,类似ConCurrentHashMap中的处理方式,将资源分为多个更小粒度的资源,在更小粒度资源上来处理锁,就可以解决资源竞争激烈的问题。]
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:JVM监控工具与诊断实践.md
================================================
# 目录
* [一、jvm常见监控工具&指令](#一、jvm常见监控工具指令)
* [1、 jps:jvm进程状况工具](#1、-jpsjvm进程状况工具)
* [2、jstat: jvm统计信息监控工具](#2、jstat-jvm统计信息监控工具)
* [3、jinfo: java配置信息](#3、jinfo:-java配置信息)
* [4、jmap: java 内存映射工具](#4、jmap-java-内存映射工具)
* [5、jhat:jvm堆快照分析工具](#5、jhatjvm堆快照分析工具)
* [6、jstack:java堆栈跟踪工具](#6、jstackjava堆栈跟踪工具)
* [二、可视化工具](#二、可视化工具)
* [三、应用](#三、应用)
* [1、cpu飙升](#1、cpu飙升)
* [2、线程死锁](#2、线程死锁)
* [2.查看java进程的线程快照信息](#2查看java进程的线程快照信息)
* [3、OOM内存泄露](#3、oom内存泄露)
* [参考文章](#参考文章)
本文转自:https://juejin.im/post/59e6c1f26fb9a0451c397a8c
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
在常见的线上问题时候,我们多数会遇到以下问题:
> * 内存泄露
> * 某个进程突然cpu飙升
> * 线程死锁
> * 响应变慢...等等其他问题。
如果遇到了以上这种问题,在线下可以有各种本地工具支持查看,但到线上了,就没有这么多的本地调试工具支持,我们该如何基于监控工具来进行定位问题?
我们一般会基于数据收集来定位,而数据的收集离不开监控工具的处理,比如:运行日志、异常堆栈、GC日志、线程快照、堆快照等。经常使用恰当的分析和监控工具可以加快我们的分析数据、定位解决问题的速度。以下我们将会详细介绍。
## 一、jvm常见监控工具&指令
### 1、 jps:jvm进程状况工具
```
jps [options] [hostid]
```
如果不指定hostid就默认为当前主机或服务器。
命令行参数选项说明如下:
```
-q 不输出类名、Jar名和传入main方法的参数
- l 输出main类或Jar的全限名
-m 输出传入main方法的参数
- v 输出传入JVM的参数复制代码
```
### 2、jstat: jvm统计信息监控工具
jstat 是用于见识虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、jit编译等运行数据,它是线上定位jvm性能的首选工具。
命令格式:
```
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
generalOption - 单个的常用的命令行选项,如-help, -options, 或 -version。
outputOptions -一个或多个输出选项,由单个的statOption选项组成,可以和-t, -h, and -J等选项配合使用。复制代码
```

参数选项:
| Option | Displays | Ex |
| --- | --- | --- |
| [class](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#class_option) | 用于查看类加载情况的统计 | jstat -class pid:显示加载class的数量,及所占空间等信息。 |
| [compiler](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#compiler_option) | 查看HotSpot中即时编译器编译情况的统计 | jstat -compiler pid:显示VM实时编译的数量等信息。 |
| [gc](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gc_option) | 查看JVM中堆的垃圾收集情况的统计 | jstat -gc pid:可以显示gc的信息,查看gc的次数,及时间。其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。 |
| [gccapacity](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gccapacity_option) | 查看新生代、老生代及持久代的存储容量情况 | jstat -gccapacity:可以显示,VM内存中三代(young,old,perm)对象的使用和占用大小 |
| [gccause](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gccause_option) | 查看垃圾收集的统计情况(这个和-gcutil选项一样),如果有发生垃圾收集,它还会显示最后一次及当前正在发生垃圾收集的原因。 | jstat -gccause:显示gc原因 |
| [gcnew](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gcnew_option) | 查看新生代垃圾收集的情况 | jstat -gcnew pid:new对象的信息 |
| [gcnewcapacity](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gcnewcapacity_option) | 用于查看新生代的存储容量情况 | jstat -gcnewcapacity pid:new对象的信息及其占用量 |
| [gcold](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gcold_option) | 用于查看老生代及持久代发生GC的情况 | jstat -gcold pid:old对象的信息 |
| [gcoldcapacity](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gcoldcapacity_option) | 用于查看老生代的容量 | jstat -gcoldcapacity pid:old对象的信息及其占用量 |
| [gcpermcapacity](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gcpermcapacity_option) | 用于查看持久代的容量 | jstat -gcpermcapacity pid: perm对象的信息及其占用量 |
| [gcutil](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#gcutil_option) | 查看新生代、老生代及持代垃圾收集的情况 | jstat -util pid:统计gc信息统计 |
| [printcompilation](http://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html#printcompilation_option) | HotSpot编译方法的统计 | jstat -printcompilation pid:当前VM执行的信息 |
**例如**:
查看gc 情况执行:jstat-gcutil 27777
### 3、jinfo: java配置信息
命令格式:
```
jinfo[option] pid复制代码
```

比如:获取一些当前进程的jvm运行和启动信息。
### 4、jmap: java 内存映射工具
jmap命令用于生产堆转存快照。打印出某个java进程(使用pid)内存内的,所有‘对象’的情况(如:产生那些对象,及其数量)。
命令格式:
```
jmap [ option ] pid
jmap [ option ] executable core
jmap [ option ] [server-id@]remote-hostname-or-IP复制代码
```
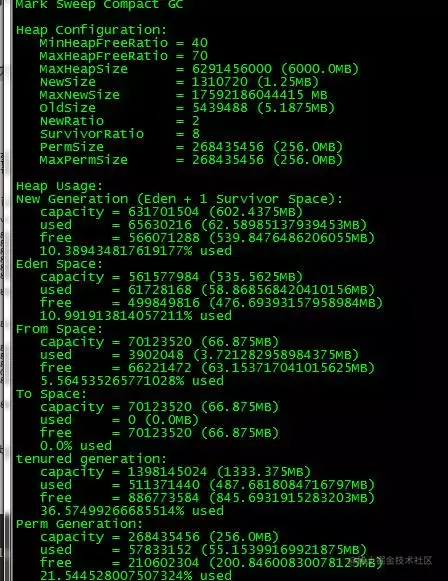
参数选项:
```
-dump:[live,]format=b,file=<filename> 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
-finalizerinfo 打印正等候回收的对象的信息.
-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.
-histo[:live] 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量.
-permstat 打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
-F 强迫.在pid没有相应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
-h | -help 打印辅助信息
-J 传递参数给jmap启动的jvm. 复制代码
```
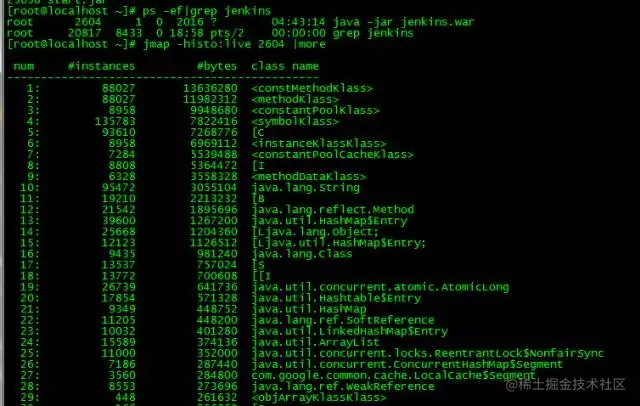
### 5、jhat:jvm堆快照分析工具
jhat 命令与jamp搭配使用,用来分析map生产的堆快存储快照。jhat内置了一个微型http/Html服务器,可以在浏览器找那个查看。不过建议尽量不用,既然有dumpt文件,可以从生产环境拉取下来,然后通过本地可视化工具来分析,这样既减轻了线上服务器压力,有可以分析的足够详尽(比如 MAT/jprofile/visualVm)等。
### 6、jstack:java堆栈跟踪工具
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
命令格式:
```
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [server-id@]remote-hostname-or-IP复制代码
```
参数:
```
-F当’jstack [-l] pid’没有相应的时候强制打印栈信息
-l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
-m打印java和native c/c++框架的所有栈信息.
-h | -help打印帮助信息
pid 需要被打印配置信息的java进程id,可以用jps查询.复制代码
```
后续的查找耗费最高cpu例子会用到。
## 二、可视化工具
对jvm监控的常见可视化工具,除了jdk本身提供的Jconsole和visualVm以外,还有第三方提供的jprofilter,perfino,Yourkit,Perf4j,JProbe,MAT等。这些工具都极大的丰富了我们定位以及优化jvm方式。
这些工具的使用,网上有很多教程提供,这里就不再过多介绍了。对于VisualVm来说,比较推荐使用,它除了对jvm的侵入性比较低以外,还是jdk团队自己开发的,相信以后功能会更加丰富和完善。jprofilter对于第三方监控工具,提供的功能和可视化最为完善,目前多数ide都支持其插件,对于上线前的调试以及性能调优可以配合使用。
另外对于线上dump的heap信息,应该尽量拉去到线下用于可视化工具来分析,这样分析更详细。如果对于一些紧急的问题,必须需要通过线上监控,可以采用 VisualVm的远程功能来进行,这需要使用tool.jar下的MAT功能。
## 三、应用
### 1、cpu飙升
在线上有时候某个时刻,可能会出现应用某个时刻突然cpu飙升的问题。对此我们应该熟悉一些指令,快速排查对应代码。
**_1.找到最耗CPU的进程_**
```
指令:top复制代码
```
**_2.找到该进程下最耗费cpu的线程_**
```
指令:top -Hp pid复制代码
```
**_3.转换进制_**
```
printf “%x\n” 15332 // 转换16进制(转换后为0x3be4) 复制代码
```
**_4.过滤指定线程,打印堆栈信息_**
```
指令:
jstack pid |grep 'threadPid' -C5 --color
jstack 13525 |grep '0x3be4' -C5 --color // 打印进程堆栈 并通过线程id,过滤得到线程堆栈信息。复制代码
```
可以看到是一个上报程序,占用过多cpu了(以上例子只为示例,本身耗费cpu并不高)
### 2、线程死锁
有时候部署场景会有线程死锁的问题发生,但又不常见。此时我们采用jstack查看下一下。比如说我们现在已经有一个线程死锁的程序,导致某些操作waiting中。
**_1.查找java进程id_**
```
指令:top 或者 jps 复制代码
```
### 2.查看java进程的线程快照信息
```
指令:jstack -l pid复制代码
```
从输出信息可以看到,有一个线程死锁发生,并且指出了那行代码出现的。如此可以快速排查问题。
### 3、OOM内存泄露
java堆内的OOM异常是实际应用中常见的内存溢出异常。一般我们都是先通过内存映射分析工具(比如MAT)对dump出来的堆转存快照进行分析,确认内存中对象是否出现问题。
当然了出现OOM的原因有很多,并非是堆中申请资源不足一种情况。还有可能是申请太多资源没有释放,或者是频繁频繁申请,系统资源耗尽。针对这三种情况我需要一一排查。
OOM的三种情况:
> 1.申请资源(内存)过小,不够用。
>
> 2.申请资源太多,没有释放。
>
> 3.申请资源过多,资源耗尽。比如:线程过多,线程内存过大等。
**1.排查申请申请资源问题。**
```
指令:jmap -heap 11869 复制代码
```
查看新生代,老生代堆内存的分配大小以及使用情况,看是否本身分配过小。
从上述排查,发现程序申请的内存没有问题。
**2.排查gc**
特别是fgc情况下,各个分代内存情况。
```
指令:jstat -gcutil 11938 1000 每秒输出一次gc的分代内存分配情况,以及gc时间复制代码
```
**3.查找最费内存的对象**
```
指令: jmap -histo:live 11869 | more复制代码
```
上述输出信息中,最大内存对象才161kb,属于正常范围。如果某个对象占用空间很大,比如超过了100Mb,应该着重分析,为何没有释放。
注意,上述指令:
```
jmap -histo:live 11869 | more
执行之后,会造成jvm强制执行一次fgc,在线上不推荐使用,可以采取dump内存快照,线下采用可视化工具进行分析,更加详尽。
jmap -dump:format=b,file=/tmp/dump.dat 11869
或者采用线上运维工具,自动化处理,方便快速定位,遗失出错时间。复制代码
```
**4.确认资源是否耗尽**
> * pstree 查看进程线程数量
> * netstat 查看网络连接数量
或者采用:
> * ll /proc/${PID}/fd | wc -l // 打开的句柄数
> * ll /proc/${PID}/task | wc -l (效果等同pstree -p | wc -l) //打开的线程数
以上就是一些常见的jvm命令应用。
一种工具的应用并非是万能钥匙,包治百病,问题的解决往往是需要多种工具的结合才能更好的定位问题,无论使用何种分析工具,最重要的是熟悉每种工具的优势和劣势。这样才能取长补短,配合使用。
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:Java内存异常原理与实践.md
================================================
# 目录
* [实战内存溢出异常](#实战内存溢出异常)
* [1 . 对象的创建过程](#1--对象的创建过程)
* [2 . 对象的内存布局](#2--对象的内存布局)
* [3 . 对象的访问定位](#3--对象的访问定位)
* [4 .实战内存异常](#4-实战内存异常)
* [Java堆内存异常](#java堆内存异常)
* [Java栈内存异常](#java栈内存异常)
* [方法区内存异常](#方法区内存异常)
* [方法区与运行时常量池OOM](#方法区与运行时常量池oom)
* [附加-直接内存异常](#附加-直接内存异常)
* [Java内存泄漏](#java内存泄漏)
* [Java是如何管理内存?](#java是如何管理内存?)
* [什么是Java中的内存泄露?](#什么是java中的内存泄露?)
* [其他常见内存泄漏](#其他常见内存泄漏)
* [1、静态集合类引起内存泄露:](#1、静态集合类引起内存泄露:)
* [2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。](#2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。)
* [3、监听器](#3、监听器)
* [4、各种连接](#4、各种连接)
* [5、内部类和外部模块等的引用](#5、内部类和外部模块等的引用)
* [6、单例模式](#6、单例模式)
* [如何检测内存泄漏](#如何检测内存泄漏)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 实战内存溢出异常
大家好,相信大部分Javaer在code时经常会遇到本地代码运行正常,但在生产环境偶尔会莫名其妙的报一些关于内存的异常,StackOverFlowError,OutOfMemoryError异常是最常见的。今天就基于上篇文章JVM系列之Java内存结构详解讲解的各个内存区域重点实战分析下内存溢出的情况。在此之前,我还是想多余累赘一些其他关于对象的问题,具体内容如下:
> 文章结构:
> 对象的创建过程
> 对象的内存布局
> 对象的访问定位
> 实战内存异常
## 1 . 对象的创建过程
关于对象的创建,第一反应是new关键字,那么本文就主要讲解new关键字创建对象的过程。
```
Student stu =new Student("张三","18");
```
就拿上面这句代码来说,虚拟机首先会去检查Student这个类有没有被加载,如果没有,首先去加载这个类到方法区,然后根据加载的Class类对象创建stu实例对象,需要注意的是,stu对象所需的内存大小在Student类加载完成后便可完全确定。内存分配完成后,虚拟机需要将分配到的内存空间的实例数据部分初始化为零值,这也就是为什么我们在编写Java代码时创建一个变量不需要初始化。紧接着,虚拟机会对对象的对象头进行必要的设置,如这个对象属于哪个类,如何找到类的元数据(Class对象),对象的锁信息,GC分代年龄等。设置完对象头信息后,调用类的构造函数。
其实讲实话,虚拟机创建对象的过程远不止这么简单,我这里只是把大致的脉络讲解了一下,方便大家理解。
## 2 . 对象的内存布局
刚刚提到的实例数据,对象头,有些小伙伴也许有点陌生,这一小节就详细讲解一下对象的内存布局,对象创建完成后大致可以分为以下几个部分:
* 对象头
* 实例数据
* 对齐填充
**对象头:**对象头中包含了对象运行时一些必要的信息,如GC分代信息,锁信息,哈希码,指向Class类元信息的指针等,其中对Javaer比较有用的是**锁信息与指向Class对象的指针**,关于锁信息,后期有机会讲解并发编程JUC时再扩展,关于指向Class对象的指针其实很好理解。比如上面那个Student的例子,当我们拿到stu对象时,调用Class stuClass=stu.getClass();的时候,其实就是根据这个指针去拿到了stu对象所属的Student类在方法区存放的Class类对象。虽然说的有点拗口,但这句话我反复琢磨了好几遍,应该是说清楚了。
**实例数据:**实例数据部分是对象真正存储的有效信息,就是程序代码中所定义的各种类型的字段内容。
**对齐填充:**虚拟机规范要求对象大小必须是8字节的整数倍。对齐填充其实就是来补全对象大小的。
## 3 . 对象的访问定位
谈到对象的访问,还拿上面学生的例子来说,当我们拿到stu对象时,直接调用stu.getName();时,其实就完成了对对象的访问。但这里要累赘说一下的是,stu虽然通常被认为是一个对象,其实准确来说是不准确的,stu只是一个变量,变量里存储的是指向对象的指针,(如果干过C或者C++的小伙伴应该比较清楚指针这个概念),当我们调用stu.getName()时,虚拟机会根据指针找到堆里面的对象然后拿到实例数据name.需要注意的是,当我们调用stu.getClass()时,虚拟机会首先根据stu指针定位到堆里面的对象,然后根据对象头里面存储的指向Class类元信息的指针再次到方法区拿到Class对象,进行了两次指针寻找。具体讲解图如下:
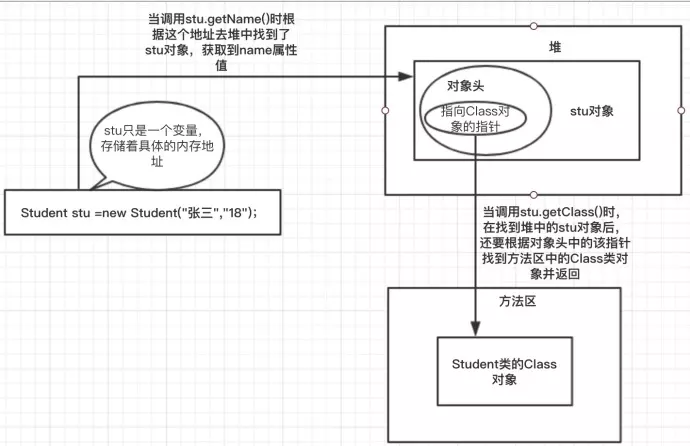
## 4 .实战内存异常
内存异常是我们工作当中经常会遇到问题,但如果仅仅会通过加大内存参数来解决问题显然是不够的,应该通过一定的手段定位问题,到底是因为参数问题,还是程序问题(无限创建,内存泄露)。定位问题后才能采取合适的解决方案,而不是一内存溢出就查找相关参数加大。
> 概念
> 内存泄露:代码中的某个对象本应该被虚拟机回收,但因为拥有GCRoot引用而没有被回收。关于GCRoot概念,下一篇文章讲解。
> 内存溢出: 虚拟机由于堆中拥有太多不可回收对象没有回收,导致无法继续创建新对象。
在分析问题之前先给大家讲一讲排查内存溢出问题的方法,内存溢出时JVM虚拟机会退出,**那么我们怎么知道JVM运行时的各种信息呢,Dump机制会帮助我们,可以通过加上VM参数-XX:+HeapDumpOnOutOfMemoryError让虚拟机在出现内存溢出异常时生成dump文件,然后通过外部工具(作者使用的是VisualVM)来具体分析异常的原因。**
下面从以下几个方面来配合代码实战演示内存溢出及如何定位:
* Java堆内存异常
* Java栈内存异常
* 方法区内存异常
### Java堆内存异常
```
/**
VM Args:
//这两个参数保证了堆中的可分配内存固定为20M
-Xms20m
-Xmx20m
//文件生成的位置,作则生成在桌面的一个目录
-XX:+HeapDumpOnOutOfMemoryError //文件生成的位置,作则生成在桌面的一个目录
//文件生成的位置,作则生成在桌面的一个目录
-XX:HeapDumpPath=/Users/zdy/Desktop/dump/
*/
public class HeapOOM {
//创建一个内部类用于创建对象使用
static class OOMObject {
}
public static void main(String[] args) {
List<OOMObject> list = new ArrayList<OOMObject>();
//无限创建对象,在堆中
while (true) {
list.add(new OOMObject());
}
}
}
```
Run起来代码后爆出异常如下:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to /Users/zdy/Desktop/dump/java_pid1099.hprof …
可以看到生成了dump文件到指定目录。并且爆出了OutOfMemoryError,还告诉了你是哪一片区域出的问题:heap space
打开VisualVM工具导入对应的heapDump文件(如何使用请读者自行查阅相关资料),相应的说明见图:
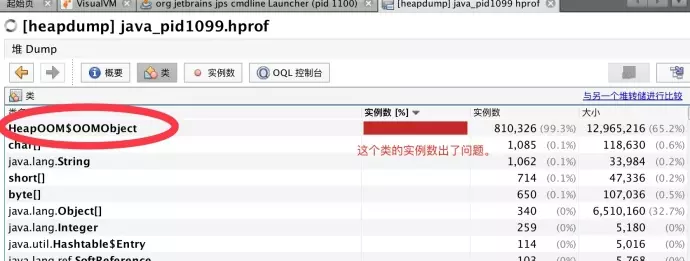
分析dump文件后,我们可以知道,OOMObject这个类创建了810326个实例。所以它能不溢出吗?接下来就在代码里找这个类在哪new的。排查问题。(我们的样例代码就不用排查了,While循环太凶猛了)分析dump文件后,我们可以知道,OOMObject这个类创建了810326个实例。所以它能不溢出吗?接下来就在代码里找这个类在哪new的。排查问题。(我们的样例代码就不用排查了,While循环太凶猛了)
### Java栈内存异常
老实说,在栈中出现异常(StackOverFlowError)的概率小到和去苹果专卖店买手机,买回来后发现是Android系统的概率是一样的。因为作者确实没有在生产环境中遇到过,除了自己作死写样例代码测试。先说一下异常出现的情况,前面讲到过,方法调用的过程就是方法帧进虚拟机栈和出虚拟机栈的过程,那么有两种情况可以导致StackOverFlowError,当一个方法帧(比如需要2M内存)进入到虚拟机栈(比如还剩下1M内存)的时候,就会报出StackOverFlow.这里先说一个概念,栈深度:指目前虚拟机栈中没有出栈的方法帧。虚拟机栈容量通过参数-Xss来控制,下面通过一段代码,把栈容量人为的调小一点,然后通过递归调用触发异常。
```
/**
* VM Args:
//设置栈容量为160K,默认1M
-Xss160k
*/
public class JavaVMStackSOF {
private int stackLength = 1;
public void stackLeak() {
stackLength++;
//递归调用,触发异常
stackLeak();
}
public static void main(String[] args) throws Throwable {
JavaVMStackSOF oom = new JavaVMStackSOF();
try {
oom.stackLeak();
} catch (Throwable e) {
System.out.println("stack length:" + oom.stackLength);
throw e;
}
}
}
```
> 结果如下:
> stack length:751 Exception in thread “main”
> java.lang.StackOverflowError
可以看到,递归调用了751次,栈容量不够用了。
默认的栈容量在正常的方法调用时,栈深度可以达到1000-2000深度,所以,一般的递归是可以承受的住的。如果你的代码出现了StackOverflowError,首先检查代码,而不是改参数。
这里顺带提一下,很多人在做多线程开发时,当创建很多线程时,**容易出现OOM(OutOfMemoryError),**这时可以通过具体情况,减少最大堆容量,或者栈容量来解决问题,这是为什么呢。请看下面的公式:
<font color="red">线程数*(最大栈容量)+最大堆值+其他内存(忽略不计或者一般不改动)=机器最大内存</font>
当线程数比较多时,且无法通过业务上削减线程数,那么再不换机器的情况下,**你只能把最大栈容量设置小一点,或者把最大堆值设置小一点。**
### 方法区内存异常
写到这里时,作者本来想写一个无限创建动态代理对象的例子来演示方法区溢出,避开谈论JDK7与JDK8的内存区域变更的过渡,但细想一想,还是把这一块从始致终的说清楚。在上一篇文章中JVM系列之Java内存结构详解讲到方法区时提到,JDK7环境下方法区包括了(运行时常量池),其实这么说是不准确的。因为从JDK7开始,HotSpot团队就想到开始去"永久代",大家首先明确一个概念,**方法区和"永久代"(PermGen space)是两个概念,方法区是JVM虚拟机规范,任何虚拟机实现(J9等)都不能少这个区间,而"永久代"只是HotSpot对方法区的一个实现。**为了把知识点列清楚,我还是才用列表的形式:
* [ ] JDK7之前(包括JDK7)拥有"永久代"(PermGen space),用来实现方法区。但在JDK7中已经逐渐在实现中把永久代中把很多东西移了出来,比如:符号引用(Symbols)转移到了native heap,运行时常量池(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap.
* [ ] 所以这就是为什么我说上一篇文章中说方法区中包含运行时常量池是不正确的,因为已经移动到了java heap;
**在JDK7之前(包括7)可以通过-XX:PermSize -XX:MaxPermSize来控制永久代的大小.
JDK8正式去除"永久代",换成Metaspace(元空间)作为JVM虚拟机规范中方法区的实现。**
元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但仍可以通过参数控制:-XX:MetaspaceSize与-XX:MaxMetaspaceSize来控制大小。
### 方法区与运行时常量池OOM
Java 永久代是非堆内存的组成部分,用来存放类名、访问修饰符、常量池、字段描述、方法描述等,因运行时常量池是方法区的一部分,所以这里也包含运行时常量池。我们可以通过 jvm 参数 -XX:PermSize=10M -XX:MaxPermSize=10M 来指定该区域的内存大小,-XX:PermSize 默认为物理内存的 1/64 ,-XX:MaxPermSize 默认为物理内存的 1/4 。String.intern() 方法是一个 Native 方法,它的作用是:如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回代表池中这个字符串的 String 对象;否则,将此 String 对象包含的字符串添加到常量池中,并且返回此 String 对象的引用。在 JDK 1.6 及之前的版本中,由于常量池分配在永久代内,我们可以通过 -XX:PermSize 和 -XX:MaxPermSize 限制方法区大小,从而间接限制其中常量池的容量,通过运行 java -XX:PermSize=8M -XX:MaxPermSize=8M RuntimeConstantPoolOom 下面的代码我们可以模仿一个运行时常量池内存溢出的情况:
```
import java.util.ArrayList;
import java.util.List;
public class RuntimeConstantPoolOom {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
int i = 0;
while (true) {
list.add(String.valueOf(i++).intern());
}
}
}
```
运行结果如下:
```
[root@9683817ada51 oom]# ../jdk1.6.0_45/bin/java -XX:PermSize=8m -XX:MaxPermSize=8m RuntimeConstantPoolOom
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
at java.lang.String.intern(Native Method)
at RuntimeConstantPoolOom.main(RuntimeConstantPoolOom.java:9)
```
还有一种情况就是我们可以通过不停的加载class来模拟方法区内存溢出,《深入理解java虚拟机》中借助 CGLIB 这类字节码技术模拟了这个异常,我们这里使用不同的 classloader 来实现(同一个类在不同的 classloader 中是不同的),代码如下
```
import java.io.File;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLClassLoader;
import java.util.HashSet;
import java.util.Set;
public class MethodAreaOom {
public static void main(String[] args) throws MalformedURLException, ClassNotFoundException {
Set<Class<?>> classes = new HashSet<Class<?>>();
URL url = new File("").toURI().toURL();
URL[] urls = new URL[]{url};
while (true) {
ClassLoader loader = new URLClassLoader(urls);
Class<?> loadClass = loader.loadClass(Object.class.getName());
classes.add(loadClass);
}
}
}
```
```
[root@9683817ada51 oom]# ../jdk1.6.0_45/bin/java -XX:PermSize=2m -XX:MaxPermSize=2m MethodAreaOom
Error occurred during initialization of VM
java.lang.OutOfMemoryError: PermGen space
at sun.net.www.ParseUtil.<clinit>(ParseUtil.java:31)
at sun.misc.Launcher.getFileURL(Launcher.java:476)
at sun.misc.Launcher$ExtClassLoader.getExtURLs(Launcher.java:187)
at sun.misc.Launcher$ExtClassLoader.<init>(Launcher.java:158)
at sun.misc.Launcher$ExtClassLoader$1.run(Launcher.java:142)
at java.security.AccessController.doPrivileged(Native Method)
at sun.misc.Launcher$ExtClassLoader.getExtClassLoader(Launcher.java:135)
at sun.misc.Launcher.<init>(Launcher.java:55)
at sun.misc.Launcher.<clinit>(Launcher.java:43)
at java.lang.ClassLoader.initSystemClassLoader(ClassLoader.java:1337)
at java.lang.ClassLoader.getSystemClassLoader(ClassLoader.java:1319)
```
在 jdk1.8 上运行上面的代码将不会出现异常,因为 jdk1.8 已结去掉了永久代,当然 -XX:PermSize=2m -XX:MaxPermSize=2m 也将被忽略,如下
```
[root@9683817ada51 oom]# java -XX:PermSize=2m -XX:MaxPermSize=2m MethodAreaOom
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=2m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=2m; support was removed in 8.0
```
jdk1.8 使用元空间( Metaspace )替代了永久代( PermSize ),因此我们可以在 1.8 中指定 Metaspace 的大小模拟上述情况
```
[root@9683817ada51 oom]# java -XX:MetaspaceSize=2m -XX:MaxMetaspaceSize=2m RuntimeConstantPoolOom
Error occurred during initialization of VM
java.lang.OutOfMemoryError: Metaspace
<<no stack trace available>>
```
在JDK8的环境下将报出异常:
Exception in thread “main” java.lang.OutOfMemoryError: Metaspace
这是因为在调用CGLib的创建代理时会生成动态代理类,即Class对象到Metaspace,所以While一下就出异常了。
**提醒一下:虽然我们日常叫"堆Dump",但是dump技术不仅仅是对于"堆"区域才有效,而是针对OOM的,也就是说不管什么区域,凡是能够报出OOM错误的,都可以使用dump技术生成dump文件来分析。**
在经常动态生成大量Class的应用中,需要特别注意类的回收状况,这类场景除了例子中的CGLib技术,常见的还有,大量JSP,反射,OSGI等。需要特别注意,当出现此类异常,应该知道是哪里出了问题,然后看是调整参数,还是在代码层面优化。
### 附加-直接内存异常
直接内存异常非常少见,而且机制很特殊,因为直接内存不是直接向操作系统分配内存,而且通过计算得到的内存不够而手动抛出异常,所以当你发现你的dump文件很小,而且没有明显异常,只是告诉你OOM,你就可以考虑下你代码里面是不是直接或者间接使用了NIO而导致直接内存溢出。
## Java内存泄漏
Java的一个重要优点就是通过垃圾收集器(Garbage Collection,GC)自动管理内存的回收,程序员不需要通过调用函数来释放内存。因此,很多程序员认为Java不存在内存泄漏问题,或者认为即使有内存泄漏也不是程序的责任,而是GC或JVM的问题。其实,这种想法是不正确的,因为Java也存在内存泄露,但它的表现与C++不同。
随着越来越多的服务器程序采用Java技术,例如JSP,Servlet, EJB等,服务器程序往往长期运行。另外,在很多嵌入式系统中,内存的总量非常有限。内存泄露问题也就变得十分关键,即使每次运行少量泄漏,长期运行之后,系统也是面临崩溃的危险。
## Java是如何管理内存?
为了判断Java中是否有内存泄露,我们首先必须了解Java是如何管理内存的。Java的内存管理就是对象的分配和释放问题。在Java中,程序员需要通过关键字new为每个对象申请内存空间 (基本类型除外),所有的对象都在堆 (Heap)中分配空间。另外,对象的释放是由GC决定和执行的。在Java中,内存的分配是由程序完成的,而内存的释放是有GC完成的,这种收支两条线的方法确实简化了程序员的工作。但同时,它也加重了JVM的工作。这也是Java程序运行速度较慢的原因之一。因为,GC为了能够正确释放对象,GC必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要进行监控。
监视对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再被引用。
为了更好理解GC的工作原理,我们可以将对象考虑为有向图的顶点,将引用关系考虑为图的有向边,有向边从引用者指向被引对象。另外,每个线程对象可以作为一个图的起始顶点,例如大多程序从main进程开始执行,那么该图就是以main进程顶点开始的一棵根树。在这个有向图中,根顶点可达的对象都是有效对象,GC将不回收这些对象。如果某个对象 (连通子图)与这个根顶点不可达(注意,该图为有向图),那么我们认为这个(这些)对象不再被引用,可以被GC回收。
以下,我们举一个例子说明如何用有向图表示内存管理。对于程序的每一个时刻,我们都有一个有向图表示JVM的内存分配情况。以下右图,就是左边程序运行到第6行的示意图。
Java使用有向图的方式进行内存管理,可以消除引用循环的问题,例如有三个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的。这种方式的优点是管理内存的精度很高,但是效率较低。另外一种常用的内存管理技术是使用计数器,例如COM模型采用计数器方式管理构件,它与有向图相比,精度行低(很难处理循环引用的问题),但执行效率很高。
## 什么是Java中的内存泄露?
下面,我们就可以描述什么是内存泄漏。在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。
在C++中,内存泄漏的范围更大一些。有些对象被分配了内存空间,然后却不可达,由于C++中没有GC,这些内存将永远收不回来。在Java中,这些不可达的对象都由GC负责回收,因此程序员不需要考虑这部分的内存泄露。
通过分析,我们得知,对于C++,程序员需要自己管理边和顶点,而对于Java程序员只需要管理边就可以了(不需要管理顶点的释放)。通过这种方式,Java提高了编程的效率。
因此,通过以上分析,我们知道在Java中也有内存泄漏,但范围比C++要小一些。因为Java从语言上保证,任何对象都是可达的,所有的不可达对象都由GC管理。
对于程序员来说,GC基本是透明的,不可见的。虽然,我们只有几个函数可以访问GC,例如运行GC的函数System.gc(),但是根据Java语言规范定义, 该函数不保证JVM的垃圾收集器一定会执行。因为,不同的JVM实现者可能使用不同的算法管理GC。通常,GC的线程的优先级别较低。JVM调用GC的策略也有很多种,有的是内存使用到达一定程度时,GC才开始工作,也有定时执行的,有的是平缓执行GC,有的是中断式执行GC。但通常来说,我们不需要关心这些。除非在一些特定的场合,GC的执行影响应用程序的性能,例如对于基于Web的实时系统,如网络游戏等,用户不希望GC突然中断应用程序执行而进行垃圾回收,那么我们需要调整GC的参数,让GC能够通过平缓的方式释放内存,例如将垃圾回收分解为一系列的小步骤执行,Sun提供的HotSpot JVM就支持这一特性。
下面给出了一个简单的内存泄露的例子。在这个例子中,我们循环申请Object对象,并将所申请的对象放入一个Vector中,如果我们仅仅释放引用本身,那么Vector仍然引用该对象,所以这个对象对GC来说是不可回收的。因此,如果对象加入到Vector后,还必须从Vector中删除,最简单的方法就是将Vector对象设置为null。
```
Vector v=new Vector(10);
for (int i=1;i<100; i++)
{
Object o=new Object();
v.add(o);
o=null;
}
//此时,所有的Object对象都没有被释放,因为变量v引用这些对象
```
### 其他常见内存泄漏
#### 1、静态集合类引起内存泄露:
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
例:
```
Static Vector v = new Vector(10);
for (int i = 1; i<100; i++) {
Object o = new Object();
v.add(o);
o = null;
}//
在这个例子中,循环申请Object 对象,并将所申请的对象放入一个Vector 中,如果仅仅释放引用本身(o=null),那么Vector 仍然引用该对象,所以这个对象对GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从Vector 中删除,最简单的方法就是将Vector对象设置为null。
```
#### 2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。
例:
```
public static void main(String[] args) {
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("唐僧","pwd1",25);
Person p2 = new Person("孙悟空","pwd2",26);
Person p3 = new Person("猪八戒","pwd3",27);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:3 个元素!
p3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变
set.remove(p3); //此时remove不掉,造成内存泄漏
set.add(p3); //重新添加,居然添加成功
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:4 个元素!
for (Person person : set) {
System.out.println(person);
}
}
```
#### 3、监听器
在java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如addXXXListener()等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
#### 4、各种连接
比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close()方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。
#### 5、内部类和外部模块等的引用
内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。此外程序员还要小心外部模块不经意的引用,例如程序员A 负责A 模块,调用了B 模块的一个方法如:
public void registerMsg(Object b);
这种调用就要非常小心了,传入了一个对象,很可能模块B就保持了对该对象的引用,这时候就需要注意模块B 是否提供相应的操作去除引用。
#### 6、单例模式
不正确使用单例模式是引起内存泄露的一个常见问题,单例对象在被初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露,考虑下面的例子:
```
class A{
public A(){
B.getInstance().setA(this);
}
....
}
//B类采用单例模式
class B{
private A a;
private static B instance=new B();
public B(){}
public static B getInstance(){
return instance;
}
public void setA(A a){
this.a=a;
}
//getter...
}
```
**显然B采用singleton模式,它持有一个A对象的引用,而这个A类的对象将不能被回收。想象下如果A是个比较复杂的对象或者集合类型会发生什么情况。**
## 如何检测内存泄漏
最后一个重要的问题,就是如何检测Java的内存泄漏。目前,我们通常使用一些工具来检查Java程序的内存泄漏问题。市场上已有几种专业检查Java内存泄漏的工具,它们的基本工作原理大同小异,都是通过监测Java程序运行时,所有对象的申请、释放等动作,将内存管理的所有信息进行统计、分析、可视化。开发人员将根据这些信息判断程序是否有内存泄漏问题。这些工具包括Optimizeit Profiler,JProbe Profiler,JinSight , Rational 公司的Purify等。
下面,我们将简单介绍Optimizeit的基本功能和工作原理。
Optimizeit Profiler版本4.11支持Application,Applet,Servlet和Romote Application四类应用,并且可以支持大多数类型的JVM,包括SUN JDK系列,IBM的JDK系列,和Jbuilder的JVM等。并且,该软件是由Java编写,因此它支持多种操作系统。Optimizeit系列还包括Thread Debugger和Code Coverage两个工具,分别用于监测运行时的线程状态和代码覆盖面。
当设置好所有的参数了,我们就可以在OptimizeIt环境下运行被测程序,在程序运行过程中,Optimizeit可以监视内存的使用曲线(如下图),包括JVM申请的堆(heap)的大小,和实际使用的内存大小。另外,在运行过程中,我们可以随时暂停程序的运行,甚至强行调用GC,让GC进行内存回收。通过内存使用曲线,我们可以整体了解程序使用内存的情况。这种监测对于长期运行的应用程序非常有必要,也很容易发现内存泄露。
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:Java字节码介绍与解析实践.md
================================================
# 目录
* [前言](#前言)
* [Class文件](#class文件)
* [什么是Class文件?](#什么是class文件?)
* [基本结构](#基本结构)
* [解析](#解析)
* [字段类型](#字段类型)
* [常量池](#常量池)
* [字节码指令](#字节码指令)
* [运行](#运行)
* [总结](#总结)
* [参考:](#参考:)
本文转自:https://juejin.im/post/589834a20ce4630056097a56
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 前言
身为一个java程序员,怎么能不了解JVM呢,倘若想学习JVM,那就又必须要了解Class文件,Class之于虚拟机,就如鱼之于水,虚拟机因为Class而有了生命。《深入理解java虚拟机》中花了一整个章节来讲解Class文件,可是看完后,一直都还是迷迷糊糊,似懂非懂。正好前段时间看见一本书很不错:《自己动手写Java虚拟机》,作者利用go语言实现了一个简单的JVM,虽然没有完整实现JVM的所有功能,但是对于一些对JVM稍感兴趣的人来说,可读性还是很高的。作者讲解的很详细,每个过程都分为了一章,其中一部分就是讲解如何解析Class文件。
这本书不太厚,很快就读完了,读完后,收获颇丰。但是纸上得来终觉浅,绝知此事要躬行,我便尝试着自己解析Class文件。go语言虽然很优秀,但是终究不熟练,尤其是不太习惯其把类型放在变量之后的语法,还是老老实实用java吧。
**话不多说,先贴出项目地址:[github.com/HalfStackDe…](https://github.com/HalfStackDeveloper/ClassReader)**
## Class文件
### 什么是Class文件?
java之所以能够实现跨平台,便在于其编译阶段不是将代码直接编译为平台相关的机器语言,而是先编译成二进制形式的java字节码,放在Class文件之中,虚拟机再加载Class文件,解析出程序运行所需的内容。每个类都会被编译成一个单独的class文件,内部类也会作为一个独立的类,生成自己的class。
### 基本结构
随便找到一个class文件,用Sublime Text打开是这样的:
是不是一脸懵逼,不过java虚拟机规范中给出了class文件的基本格式,只要按照这个格式去解析就可以了:
```
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
```
ClassFile中的字段类型有u1、u2、u4,这是什么类型呢?其实很简单,就是分别表示1个字节,2个字节和4个字节。
开头四个字节为:magic,是用来唯一标识文件格式的,一般被称作magic number(魔数),这样虚拟机才能识别出所加载的文件是否是class格式,class文件的魔数为cafebabe。不只是class文件,基本上大部分文件都有魔数,用来标识自己的格式。
接下来的部分主要是class文件的一些信息,如常量池、类访问标志、父类、接口信息、字段、方法等,具体的信息可参考《Java虚拟机规范》。
## 解析
### 字段类型
上面说到ClassFile中的字段类型有u1、u2、u4,分别表示1个字节,2个字节和4个字节的无符号整数。java中short、int、long分别为2、4、8个字节的有符号整数,去掉符号位,刚好可以用来表示u1、u2、u4。
```
public class U1 {
public static short read(InputStream inputStream) {
byte[] bytes = new byte[1];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
short value = (short) (bytes[0] & 0xFF);
return value;
}
}
public class U2 {
public static int read(InputStream inputStream) {
byte[] bytes = new byte[2];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
int num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}
public class U4 {
public static long read(InputStream inputStream) {
byte[] bytes = new byte[4];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
long num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}
```
### 常量池
定义好字段类型后,我们就可以读取class文件了,首先是读取魔数之类的基本信息,这部分很简单:
```
FileInputStream inputStream = new FileInputStream(file);
ClassFile classFile = new ClassFile();
classFile.magic = U4.read(inputStream);
classFile.minorVersion = U2.read(inputStream);
classFile.majorVersion = U2.read(inputStream);
```
这部分只是热热身,接下来的大头在于常量池。解析常量池之前,我们先来解释一下常量池是什么。
常量池,顾名思义,存放常量的资源池,这里的常量指的是字面量和符号引用。字面量指的是一些字符串资源,而符号引用分为三类:类符号引用、方法符号引用和字段符号引用。通过将资源放在常量池中,其他项就可以直接定义成常量池中的索引了,避免了空间的浪费,不只是class文件,Android可执行文件dex也是同样如此,将字符串资源等放在DexData中,其他项通过索引定位资源。java虚拟机规范给出了常量池中每一项的格式:
```
cp_info {
u1 tag;
u1 info[];
}
```
由于格式太多,文章中只挑选一部分讲解:
这里首先读取常量池的大小,初始化常量池:
```
//解析常量池
int constant_pool_count = U2.read(inputStream);
ConstantPool constantPool = new ConstantPool(constant_pool_count);
constantPool.read(inputStream);
```
接下来再逐个读取每项内容,并存储到数组cpInfo中,这里需要注意的是,cpInfo[]下标从1开始,0无效,且真正的常量池大小为constant_pool_count-1。
```
public class ConstantPool {
public int constant_pool_count;
public ConstantInfo[] cpInfo;
public ConstantPool(int count) {
constant_pool_count = count;
cpInfo = new ConstantInfo[constant_pool_count];
}
public void read(InputStream inputStream) {
for (int i = 1; i < constant_pool_count; i++) {
short tag = U1.read(inputStream);
ConstantInfo constantInfo = ConstantInfo.getConstantInfo(tag);
constantInfo.read(inputStream);
cpInfo[i] = constantInfo;
if (tag == ConstantInfo.CONSTANT_Double || tag == ConstantInfo.CONSTANT_Long) {
i++;
}
}
}
}
```
我们先来看看CONSTANT_Utf8格式,这一项里面存放的是MUTF-8编码的字符串:
```
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
```
那么如何读取这一项呢?
```
public class ConstantUtf8 extends ConstantInfo {
public String value;
@Override
public void read(InputStream inputStream) {
int length = U2.read(inputStream);
byte[] bytes = new byte[length];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
value = readUtf8(bytes);
} catch (UTFDataFormatException e) {
e.printStackTrace();
}
}
private String readUtf8(byte[] bytearr) throws UTFDataFormatException {
//copy from java.io.DataInputStream.readUTF()
}
}
```
很简单,首先读取这一项的字节数组长度,接着调用readUtf8(),将字节数组转化为String字符串。
再来看看CONSTANT_Class这一项,这一项存储的是类或者接口的符号引用:
```
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}
```
注意这里的name_index并不是直接的字符串,而是指向常量池中cpInfo数组的name_index项,且cpInfo[name_index]一定是CONSTANT_Utf8格式。
```
public class ConstantClass extends ConstantInfo {
public int nameIndex;
@Override
public void read(InputStream inputStream) {
nameIndex = U2.read(inputStream);
}
}
```
常量池解析完毕后,就可以供后面的数据使用了,比方说ClassFile中的this_class指向的就是常量池中格式为CONSTANT_Class的某一项,那么我们就可以读取出类名:
```
int classIndex = U2.read(inputStream);
ConstantClass clazz = (ConstantClass) constantPool.cpInfo[classIndex];
ConstantUtf8 className = (ConstantUtf8) constantPool.cpInfo[clazz.nameIndex];
classFile.className = className.value;
System.out.print("classname:" + classFile.className + "\n");
```
### 字节码指令
解析常量池之后还需要接着解析一些类信息,如父类、接口类、字段等,但是相信大家最好奇的还是java指令的存储,大家都知道,我们平时写的java代码会被编译成java字节码,那么这些字节码到底存储在哪呢?别急,讲解指令之前,我们先来了解下ClassFile中的method_info,其格式如下:
```
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
```
method_info里主要是一些方法信息:如访问标志、方法名索引、方法描述符索引及属性数组。这里要强调的是属性数组,因为字节码指令就存储在这个属性数组里。属性有很多种,比如说异常表就是一个属性,而存储字节码指令的属性为CODE属性,看这名字也知道是用来存储代码的了。属性的通用格式为:
```
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
```
根据attribute_name_index可以从常量池中拿到属性名,再根据属性名就可以判断属性种类了。
Code属性的具体格式为:
```
Code_attribute {
u2 attribute_name_index; u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
```
其中code数组里存储就是字节码指令,那么如何解析呢?每条指令在code[]中都是一个字节,我们平时javap命令反编译看到的指令其实是助记符,只是方便阅读字节码使用的,jvm有一张字节码与助记符的对照表,根据对照表,就可以将指令翻译为可读的助记符了。这里我也是在网上随便找了一个对照表,保存到本地txt文件中,并在使用时解析成HashMap。代码很简单,就不贴了,可以参考我代码中InstructionTable.java。
接下来我们就可以解析字节码了:
```
for (int j = 0; j < methodInfo.attributesCount; j++) {
if (methodInfo.attributes[j] instanceof CodeAttribute) {
CodeAttribute codeAttribute = (CodeAttribute) methodInfo.attributes[j];
for (int m = 0; m < codeAttribute.codeLength; m++) {
short code = codeAttribute.code[m];
System.out.print(InstructionTable.getInstruction(code) + "\n");
}
}
}
```
## 运行
整个项目终于写完了,接下来就来看看效果如何,随便找一个class文件解析运行:
哈哈,是不是很赞!
**最后再贴一下项目地址:[github.com/HalfStackDe…](https://github.com/HalfStackDeveloper/ClassReader),欢迎Fork And Star!**
## 总结
Class文件看起来很复杂,其实真正解析起来,也没有那么难,关键是要自己动手试试,才能彻底理解,希望各位看完后也能觉知此事要躬行!
## 参考:
[1\. 周志明《java虚拟机规范(JavaSE7)》](https://book.douban.com/subject/25792515/)
[2\. 张秀宏《自己动手写Java虚拟机》](https://book.douban.com/subject/26802084/)
[3\. 周志明《深入理解Java虚拟机(第2版)》](https://book.douban.com/subject/26802084/)
**(如有错误,欢迎指正!)**
**(转载请标明ID:半栈工程师,个人博客:[halfstackdeveloper.github.io](https://halfstackdeveloper.github.io/))**
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:Java的编译期优化与运行期优化.md
================================================
# 目录
* [java编译期优化](#[java编译期优化])
* [早期(编译期)优化](#早期(编译期)优化)
* [泛型与类型擦除](#泛型与类型擦除)
* [自动装箱、拆箱与遍历循环](#自动装箱、拆箱与遍历循环)
* [条件编译](#条件编译)
* [晚期(运行期)优化](#晚期(运行期)优化)
* [解释器与编译器](#解释器与编译器)
* [分层编译策略](#分层编译策略)
* [热点代码探测](#热点代码探测)
* [编译优化技术](#编译优化技术)
* [java与C/C++编译器对比](#java与cc编译器对比)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## java编译期优化
java语言的编译期其实是一段不确定的操作过程,因为它可以分为三类编译过程:
1.前端编译:把_.java文件转变为_.class文件
2.后端编译:把字节码转变为机器码
3.静态提前编译:直接把*.java文件编译成本地机器代码
从JDK1.3开始,虚拟机设计团队就把对性能的优化集中到了后端的即时编译中,这样可以让那些不是由Javac产生的Class文件(如JRuby、Groovy等语言的Class文件)也能享受到编译期优化所带来的好处
**Java中即时编译在运行期的优化过程对于程序运行来说更重要,而前端编译期在编译期的优化过程对于程序编码来说关系更加密切**
### 早期(编译期)优化
```
早期编译过程主要分为3个部分:1.解析与填充符号表过程:词法、语法分析;填充符号表 2.插入式注解处理器的注解处理过程 3.语义分析与字节码生成过程:标注检查、数据与控制流分析、解语法糖、字节码生成
```
##### 泛型与类型擦除
Java语言中的泛型只在程序源码中存在,在编译后的字节码文件中,就已经替换成原来的原生类型了,并且在相应的地方插入了强制转型代码
```
泛型擦除前的例子
public static void main( String[] args )
{
Map<String,String> map = new HashMap<String, String>();
map.put("hello","你好");
System.out.println(map.get("hello"));
}
泛型擦除后的例子
public static void main( String[] args )
{
Map map = new HashMap();
map.put("hello","你好");
System.out.println((String)map.get("hello"));
}
```
##### 自动装箱、拆箱与遍历循环
自动装箱、拆箱在编译之后会被转化成对应的包装和还原方法,如Integer.valueOf()与Integer.intValue(),而遍历循环则把代码还原成了迭代器的实现,变长参数会变成数组类型的参数。
**然而包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱,以及它们的equals()方法不处理数据转型的关系。**
##### 条件编译
Java语言也可以进行条件编译,方法就是使用条件为常量的if语句,它在编译阶段就会被“运行”:
```
public static void main(String[] args) {
if(true){
System.out.println("block 1");
}
else{
System.out.println("block 2");
}
}
编译后Class文件的反编译结果:
public static void main(String[] args) {
System.out.println("block 1");
}
```
**只能是条件为常量的if语句,这也是Java语言的语法糖,根据布尔常量值的真假,编译器会把分支中不成立的代码块消除掉**
### 晚期(运行期)优化
##### 解释器与编译器
Java程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。**同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。
HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler(C1编译器)和Server Compiler(C2编译器),默认采用解释器与其中一个编译器直接配合的方式工作,使用哪个编译器取决于虚拟机运行的模式,也可以自己去指定。若强制虚拟机运行与“解释模式”,编译器完全不介入工作,若强制虚拟机运行于“编译模式”,则优先采用编译方式执行程序,解释器仍然要在编译无法进行的情况下介入执行过程。
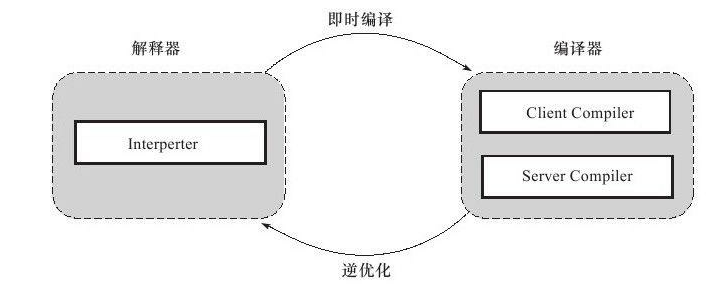
##### 分层编译策略
```
分层编译策略作为默认编译策略在JDK1.7的Server模式虚拟机中被开启,其中包括:
第0层:程序解释执行,解释器不开启性能监控功能,可触发第1层编译;
第1层:C1编译,将字节码编译成本地代码,进行简单可靠的优化,如有必要将加入性能监控的逻辑;
第2层:C2编译,也是将字节码编译成本地代码,但是会启动一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
实施分层编译后,C1和C2将会同时工作,C1获取更高的编译速度,C2获取更好的编译质量,在解释执行的时候也无须再承担性能监控信息的任务。
```
##### 热点代码探测
```
在运行过程中会被即时编译器编译的“热点代码”有两类:
1.被多次调用的方法:由方法调用触发的编译,属于JIT编译方式
2.被多次执行的循环体:也以整个方法作为编译对象,因为编译发生在方法执行过程中,因此成为栈上替换(OSR编译)
热点探测判定方式有两种:
1.基于采样的热点探测:虚拟机周期性的检查各个线程的栈顶,如果某个方法经常出现在栈顶,则判定为“热点方法”。(简单高效,可以获取方法的调用关系,但容易受线程阻塞或别的外界因素影响扰乱热点探测)
2.基于计数的热点探测:虚拟机为每个方法建立一个计数器,统计方法的执行次数,超过一定阈值就是“热点方法”。(需要为每个方法维护计数器,不能直接获取方法的调用关系,但是统计结果精确严谨)
```
HotSpot虚拟机使用的是第二种,它为每个方法准备了两类计数器:方法调用计数器和回边计数器,下图表示方法调用计数器触发即时编译:
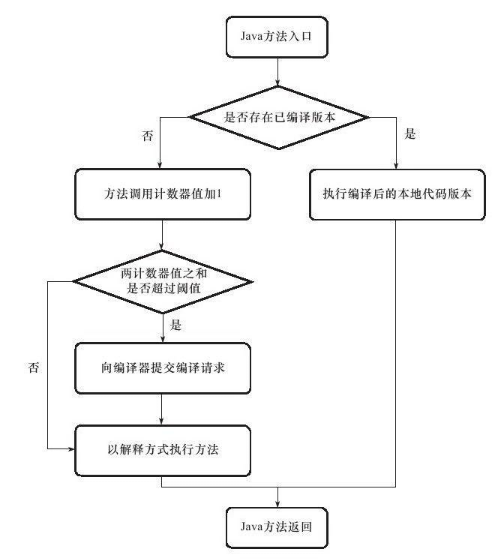
如果不做任何设置,执行引擎会继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成,下次调用才会使用已编译的版本。另外,方法调用计数器的值也不是一个绝对次数,而是一段时间之内被调用的次数,超过这个时间,次数就减半,这称为计数器热度的衰减。
下图表示回边计数器触发即时编译:
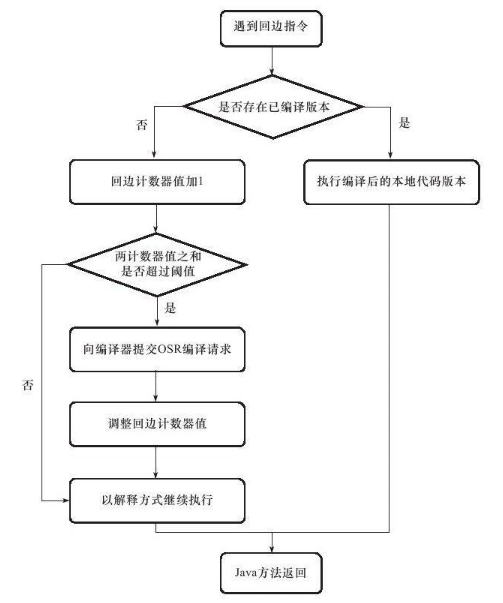
回边计数器没有计数器热度衰减的过程,因此统计的就是绝对次数,并且当计数器溢出时,它还会把方法计数器的值也调整到溢出状态,这样下次进入该方法的时候就会执行标准编译过程。
##### 编译优化技术
虚拟机设计团队几乎把对代码的所有优化措施都集中在了即时编译器之中,那么在编译器编译的过程中,到底做了些什么事情呢?下面将介绍几种最有代表性的优化技术:
**公共子表达式消除**
如果一个表达式E已经计算过了,并且先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就成为了公共表达式,可以直接用之前的结果替换。
例:int d = (c * b) * 12 + a + (a + b * c) => int d = E * 12 + a + (a + E)
**数组边界检查消除**
Java语言中访问数组元素都要进行上下界的范围检查,每次读写都有一次条件判定操作,这无疑是一种负担。编译器只要通过数据流分析就可以判定循环变量的取值范围永远在数组长度以内,那么整个循环中就可以把上下界检查消除,这样可以省很多次的条件判断操作。
另一种方法叫做隐式异常处理,Java中空指针的判断和算术运算中除数为0的检查都采用了这个思路:
```
if(foo != null){
return foo.value;
}else{
throw new NullPointException();
}
使用隐式异常优化以后:
try{
return foo.value;
}catch(segment_fault){
uncommon_trap();
}
当foo极少为空时,隐式异常优化是值得的,但是foo经常为空,这样的优化反而会让程序变慢,而HotSpot虚拟机会根据运行期收集到的Profile信息自动选择最优方案。
```
**方法内联**
方法内联能去除方法调用的成本,同时也为其他优化建立了良好的基础,因此各种编译器一般会把内联优化放在优化序列的最靠前位置,然而由于Java对象的方法默认都是虚方法,因此方法调用都需要在运行时进行多态选择,为了解决虚方法的内联问题,首先引入了“类型继承关系分析(CHA)”的技术。
```
1.在内联时,若是非虚方法,则可以直接内联
2.遇到虚方法,首先根据CHA判断此方法是否有多个目标版本,若只有一个,可以直接内联,但是需要预留一个“逃生门”,称为守护内联,若在程序的后续执行过程中,加载了导致继承关系发生变化的新类,就需要抛弃已经编译的代码,退回到解释状态执行,或者重新编译。
3.若CHA判断此方法有多个目标版本,则编译器会使用“内联缓存”,第一次调用缓存记录下方法接收者的版本信息,并且每次调用都比较版本,若一致则可以一直使用,若不一致则取消内联,查找虚方法表进行方法分派。
```
**逃逸分析**
逃逸分析的基本行为就是分析对象动态作用域,当一个对象被外部方法所引用,称为方法逃逸;当被外部线程访问,称为线程逃逸。若能证明一个对象不会被外部方法或进程引用,则可以为这个变量进行一些优化:
```
1.栈上分配:如果确定一个对象不会逃逸,则可以让它分配在栈上,对象所占用的内存空间就可以随栈帧出栈而销毁。这样可以减小垃圾收集系统的压力。
2.同步消除:线程同步相对耗时,如果确定一个变量不会逃逸出线程,那这个变量的读写不会有竞争,则对这个变量实施的同步措施也就可以消除掉。
3.标量替换:如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆散的话,那么程序真正执行的时候可以不创建这个对象,改为直接创建它的成员变量,这样就可以在栈上分配。
```
**可是目前还不能保证逃逸分析的性能收益必定高于它的消耗,所以这项技术还不是很成熟。**
### java与C/C++编译器对比
```
Java虚拟机的即时编译器与C/C++的静态编译器相比,可能会由于下面的原因导致输出的本地代码有一些劣势:
1.即时编译器运行占用的是用户程序的运行时间,具有很大的时间压力,因此不敢随便引入大规模的优化技术;
2.Java语言是动态的类型安全语言,虚拟器需要频繁的进行动态检查,如空指针,上下界范围,继承关系等;
3.Java中使用虚方法频率远高于C++,则需要进行多态选择的频率远高于C++;
4.Java是可以动态扩展的语言,运行时加载新的类可能改变原有的继承关系,许多全局的优化措施只能以激进优化的方式来完成;
5.Java语言的对象内存都在堆上分配,垃圾回收的压力比C++大
然而,Java语言这些性能上的劣势换取了开发效率上的优势,并且由于C++编译器所有优化都是在编译期完成的,以运行期性能监控为基础的优化措施都无法进行,这也是Java编译器独有的优势。
```
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:再谈四种引用及GC实践.md
================================================
# 目录
* [一、背景](#一、背景)
* [二、简介](#二、简介)
* [1.强引用 StrongReference](#1强引用-strongreference)
* [2.弱引用 WeakReference](#2弱引用-weakreference)
* [3.软引用 SoftReference](#3软引用-softreference)
* [4.虚引用 PhantomReference](#4虚引用-phantomreference)
* [三、小结](#三、小结)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 一、背景
Java的内存回收不需要程序员负责,JVM会在必要时启动Java GC完成垃圾回收。Java以便我们控制对象的生存周期,提供给了我们四种引用方式,引用强度从强到弱分别为:强引用、软引用、弱引用、虚引用。
## 二、简介
### 1.强引用 StrongReference
StrongReference是Java的默认引用形式,使用时不需要显示定义。任何通过强引用所使用的对象不管系统资源有多紧张,Java GC都不会主动回收具有强引用的对象。
````
public class StrongReferenceTest {
public static int M = 1024*1024;
public static void printlnMemory(String tag){
Runtime runtime = Runtime.getRuntime();
int M = StrongReferenceTest.M;
System.out.println("\n"+tag+":");
System.out.println(runtime.freeMemory()/M+"M(free)/" + runtime.totalMemory()/M+"M(total)");
}
public static void main(String[] args){
StrongReferenceTest.printlnMemory("1.原可用内存和总内存");
//实例化10M的数组并与strongReference建立强引用
byte[] strongReference = new byte[10*StrongReferenceTest.M];
StrongReferenceTest.printlnMemory("2.实例化10M的数组,并建立强引用");
System.out.println("strongReference : "+strongReference);
System.gc();
StrongReferenceTest.printlnMemory("3.GC后");
System.out.println("strongReference : "+strongReference);
//strongReference = null;后,强引用断开了
strongReference = null;
StrongReferenceTest.printlnMemory("4.强引用断开后");
System.out.println("strongReference : "+strongReference);
System.gc();
StrongReferenceTest.printlnMemory("5.GC后");
System.out.println("strongReference : "+strongReference);
}
}
````
运行结果:
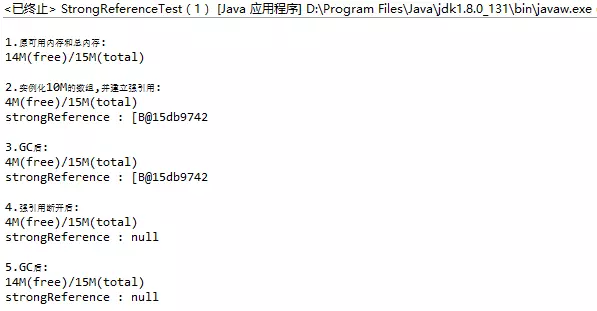
### 2.弱引用 WeakReference
如果一个对象只具有弱引用,无论内存充足与否,Java GC后对象如果只有弱引用将会被自动回收。
````
public class WeakReferenceTest {
public static int M = 1024*1024;
public static void printlnMemory(String tag){
Runtime runtime = Runtime.getRuntime();
int M = WeakReferenceTest.M;
System.out.println("\n"+tag+":");
System.out.println(runtime.freeMemory()/M+"M(free)/" + runtime.totalMemory()/M+"M(total)");
}
public static void main(String[] args){
WeakReferenceTest.printlnMemory("1.原可用内存和总内存");
//创建弱引用
WeakReference<Object> weakRerference = new WeakReference<Object>(new byte[10*WeakReferenceTest.M]);
WeakReferenceTest.printlnMemory("2.实例化10M的数组,并建立弱引用");
System.out.println("weakRerference.get() : "+weakRerference.get());
System.gc();
StrongReferenceTest.printlnMemory("3.GC后");
System.out.println("weakRerference.get() : "+weakRerference.get());
}
}
````
运行结果:
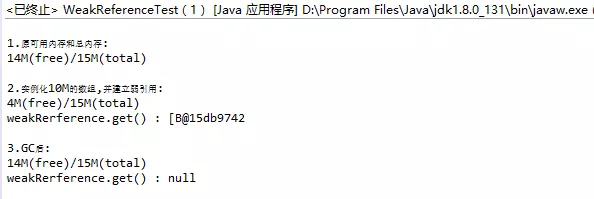
### 3.软引用 SoftReference
软引用和弱引用的特性基本一致, 主要的区别在于软引用在内存不足时才会被回收。如果一个对象只具有软引用,Java GC在内存充足的时候不会回收它,内存不足时才会被回收。
````
public class SoftReferenceTest {
public static int M = 1024*1024;
public static void printlnMemory(String tag){
Runtime runtime = Runtime.getRuntime();
int M = StrongReferenceTest.M;
System.out.println("\n"+tag+":");
System.out.println(runtime.freeMemory()/M+"M(free)/" + runtime.totalMemory()/M+"M(total)");
}
public static void main(String[] args){
SoftReferenceTest.printlnMemory("1.原可用内存和总内存");
//建立软引用
SoftReference<Object> softRerference = new SoftReference<Object>(new byte[10*SoftReferenceTest.M]);
SoftReferenceTest.printlnMemory("2.实例化10M的数组,并建立软引用");
System.out.println("softRerference.get() : "+softRerference.get());
System.gc();
SoftReferenceTest.printlnMemory("3.内存可用容量充足,GC后");
System.out.println("softRerference.get() : "+softRerference.get());
//实例化一个4M的数组,使内存不够用,并建立软引用
//free=10M=4M+10M-4M,证明内存可用量不足时,GC后byte[10*m]被回收
SoftReference<Object> softRerference2 = new SoftReference<Object>(new byte[4*SoftReferenceTest.M]);
SoftReferenceTest.printlnMemory("4.实例化一个4M的数组后");
System.out.println("softRerference.get() : "+softRerference.get());
System.out.println("softRerference2.get() : "+softRerference2.get());
}
}
````
运行结果:
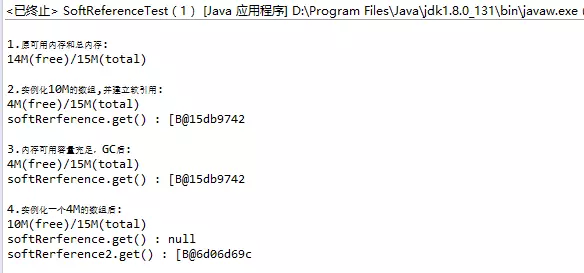
### 4.虚引用 PhantomReference
从PhantomReference类的源代码可以知道,它的get()方法无论何时返回的都只会是null。所以单独使用虚引用时,没有什么意义,需要和引用队列ReferenceQueue类联合使用。当执行Java GC时如果一个对象只有虚引用,就会把这个对象加入到与之关联的ReferenceQueue中。
````
public class PhantomReferenceTest {
public static int M = 1024*1024;
public static void printlnMemory(String tag){
Runtime runtime = Runtime.getRuntime();
int M = PhantomReferenceTest.M;
System.out.println("\n"+tag+":");
System.out.println(runtime.freeMemory()/M+"M(free)/" + runtime.totalMemory()/M+"M(total)");
}
public static void main(String[] args) throws InterruptedException {
PhantomReferenceTest.printlnMemory("1.原可用内存和总内存");
byte[] object = new byte[10*PhantomReferenceTest.M];
PhantomReferenceTest.printlnMemory("2.实例化10M的数组后");
//建立虚引用
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<Object>();
PhantomReference<Object> phantomReference = new PhantomReference<Object>(object,referenceQueue);
PhantomReferenceTest.printlnMemory("3.建立虚引用后");
System.out.println("phantomReference : "+phantomReference);
System.out.println("phantomReference.get() : "+phantomReference.get());
System.out.println("referenceQueue.poll() : "+referenceQueue.poll());
//断开byte[10*PhantomReferenceTest.M]的强引用
object = null;
PhantomReferenceTest.printlnMemory("4.执行object = null;强引用断开后");
System.gc();
PhantomReferenceTest.printlnMemory("5.GC后");
System.out.println("phantomReference : "+phantomReference);
System.out.println("phantomReference.get() : "+phantomReference.get());
System.out.println("referenceQueue.poll() : "+referenceQueue.poll());
//断开虚引用
phantomReference = null;
System.gc();
PhantomReferenceTest.printlnMemory("6.断开虚引用后GC");
System.out.println("phantomReference : "+phantomReference);
System.out.println("referenceQueue.poll() : "+referenceQueue.poll());
}
}
````
运行结果:
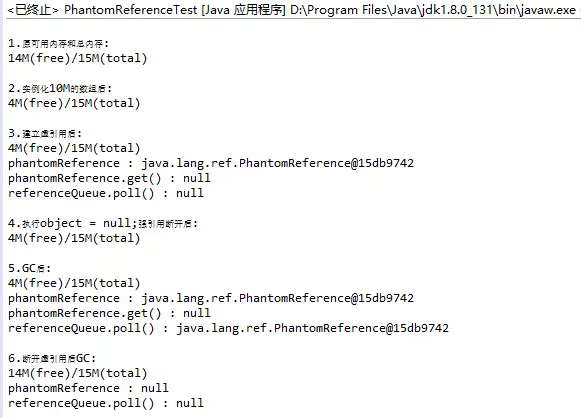
## 三、小结
强引用是 Java 的默认引用形式,使用时不需要显示定义,是我们平时最常使用到的引用方式。不管系统资源有多紧张,Java GC都不会主动回收具有强引用的对象。 弱引用和软引用一般在引用对象为非必需对象的时候使用。它们的区别是被弱引用关联的对象在垃圾回收时总是会被回收,被软引用关联的对象只有在内存不足时才会被回收。 虚引用的get()方法获取的永远是null,无法获取对象实例。Java GC会把虚引用的对象放到引用队列里面。可用来在对象被回收时做额外的一些资源清理或事物回滚等处理。 由于无法从虚引获取到引用对象的实例。它的使用情况比较特别,所以这里不把虚引用放入表格进行对比。这里对强引用、弱引用、软引用进行对比:
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:垃圾回收器详解.md
================================================
# 目录
* [1 概述](#1-概述)
* [2 对象已经死亡?](#2-对象已经死亡?)
* [2.1引用计数法](#21引用计数法)
* [2.2可达性分析算法](#22可达性分析算法)
* [2.3 再谈引用](#23-再谈引用)
* [2.4 生存还是死亡](#24-生存还是死亡)
* [2.5 回收方法区](#25-回收方法区)
* [3 垃圾收集算法](#3-垃圾收集算法)
* [3.1 标记-清除算法](#31-标记-清除算法)
* [3.2 复制算法](#32-复制算法)
* [3.3 标记-整理算法](#33-标记-整理算法)
* [3.4分代收集算法](#34分代收集算法)
* [4 垃圾收集器](#4-垃圾收集器)
* [4.1 Serial收集器](#41-serial收集器)
* [4.2 ParNew收集器](#42-parnew收集器)
* [4.3 Parallel Scavenge收集器](#43-parallel-scavenge收集器)
* [4.4.Serial Old收集器](#44serial-old收集器)
* [4.5 Parallel Old收集器](#45-parallel-old收集器)
* [4.6 CMS收集器](#46-cms收集器)
* [4.7 G1收集器](#47-g1收集器)
* [5 内存分配与回收策略](#5-内存分配与回收策略)
* [5.1对象优先在Eden区分配](#51对象优先在eden区分配)
* [5.2 大对象直接进入老年代](#52-大对象直接进入老年代)
* [5.3长期存活的对象将进入老年代](#53长期存活的对象将进入老年代)
* [5.4 动态对象年龄判定](#54-动态对象年龄判定)
* [总结:](#总结:)
本文转自:https://www.cnblogs.com/snailclimb/p/9086341.html
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
**本节常见面试题(推荐带着问题阅读,问题答案在文中都有提到):**
如何判断对象是否死亡(两种方法)。
简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
垃圾收集有哪些算法,各自的特点?
HotSpot为什么要分为新生代和老年代?
常见的垃圾回收器有那些?
介绍一下CMS,G1收集器。
Minor Gc和Full GC 有什么不同呢?
## 1 概述
首先所需要考虑:
- 那些垃圾需要回收?
- 什么时候回收?
- 如何回收?
当需要排查各种 内存溢出问题、当垃圾收集称为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
## 2 对象已经死亡?
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断那些对象已经死亡(即不能再被任何途径使用的对象)
### 2.1引用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加1;当引用失效,计数器就减1;任何时候计数器为0的对象就是不可能再被使用的。
这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。
### 2.2可达性分析算法
这个算法的基本思想就是通过一系列的称为**“GC Roots”**的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连的话,则证明此对象是不可用的。
### 2.3 再谈引用
JDK1.2以后,Java对引用的感念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
**1.强引用**
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空 间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
**2.软引用(SoftReference)**
如果一个对象只具有软引用,那就类似于**可有可物的生活用品**。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA虚拟机就会把这个软引用加入到与之关联的引用队列中。
**3.弱引用(WeakReference)**
如果一个对象只具有弱引用,那就类似于**可有可物的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
**4.虚引用(PhantomReference)**
“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
**虚引用主要用来跟踪对象被垃圾回收的活动**。
**虚引用与软引用和弱引用的一个区别在于:**虚引用必须和引用队列(ReferenceQueue)联合使用。当垃 圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是 否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速JVM对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
### 2.4 生存还是死亡
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行finalize方法。当对象没有覆盖finalize方法,或finalize方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
### 2.5 回收方法区
方法区(或Hotspot虚拟中的永久代)的垃圾收集主要回收两部分内容:**废弃常量和无用的类。**
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面3个条件才能算是**“无用的类”**:
- 该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例。
- 加载该类的ClassLoader已经被回收。
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
## 3 垃圾收集算法
### 3.1 标记-清除算法
算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,会带来两个明显的问题;1:效率问题和2:空间问题(标记清除后会产生大量不连续的碎片)
### 3.2 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
### 3.3 标记-整理算法
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一段移动,然后直接清理掉端边界以外的内存。
### 3.4分代收集算法
当前虚拟机的垃圾手机都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的所以我们可以选择“标记-清理”或“标记-整理”算法进行垃圾收集。
**延伸面试问题:**HotSpot为什么要分为新生代和老年代?
根据上面的对分代收集算法的介绍回答。
## 4 垃圾收集器
**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
虽然我们对各个收集器进行比较,但并非了挑选出一个最好的收集器。因为知道现在位置还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的HotSpot虚拟机就不会实现那么多不同的垃圾收集器了。
### 4.1 Serial收集器
Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的**“单线程”**的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程(**“Stop The World”**了解一下),直到它收集结束。
虚拟机的设计者们当然知道Stop The World带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
但是Serial收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial收集器对于运行在Client模式下的虚拟机来说是个不错的选择。
### 4.2 ParNew收集器
**ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和Serial收集器完全一样。**
它是许多运行在Server模式下的虚拟机的首要选择,除了Serial收集器外,只有它能与CMS收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
**并行和并发概念补充:**
* **并行(Parallel)**:指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
* **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个CPU上。
### 4.3 Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的的多线程收集器。。。那么它有什么特别之处呢?
**Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。**Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
### 4.4.Serial Old收集器
**Serial收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在JDK1.5以及以前的版本中与Parallel Scavenge收集器搭配使用,另一种用途是作为CMS收集器的后备方案。
### 4.5 Parallel Old收集器
**Parallel Scavenge收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及CPU资源的场合,都可以优先考虑 Parallel Scavenge收集器和Parallel Old收集器。
### 4.6 CMS收集器
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
从名字中的**Mark Sweep**这两个词可以看出,CMS收集器是一种**“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
* **初始标记:**暂停所有的其他线程,并记录下直接与root相连的对象,速度很快 ;
* **并发标记:**同时开启GC和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以GC线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
* **重新标记:**重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
* **并发清除:**开启用户线程,同时GC线程开始对为标记的区域做清扫。
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
-**对CPU资源敏感;**
-**无法处理浮动垃圾;**
-**它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
### 4.7 G1收集器
上一代的垃圾收集器(串行serial, 并行parallel, 以及CMS)都把堆内存划分为固定大小的三个部分: 年轻代(young generation), 年老代(old generation), 以及持久代(permanent generation).
**G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征.**
被视为JDK1.7中HotSpot虚拟机的一个重要进化特征。它具备一下特点:
-**并行与并发**:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
-**分代收集**:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
-**空间整合**:与CMS的“标记–清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
-**可预测的停顿**:这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内。
**G1收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的Region(这也就是它的名字Garbage-First的由来)**。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了GF收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
G1收集器的运作大致分为以下几个步骤:
-**初始标记**
-**并发标记**
-**最终标记**
-**筛选回收**
上面几个步骤的运作过程和CMS有很多相似之处。初始标记阶段仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS的值,让下一个阶段用户程序并发运行时,能在正确可用的Region中创建新对象,这一阶段需要停顿线程,但是耗时很短,并发标记阶段是从GC Root开始对堆中对象进行可达性分析,找出存活的对象,这阶段时耗时较长,但可与用户程序并发执行。而最终标记阶段则是为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remenbered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这一阶段需要停顿线程,但是可并行执行。最后在筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。
## 5 内存分配与回收策略
### 5.1对象优先在Eden区分配
大多数情况下,对象在新生代中Eden区分配。当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC.
**Minor Gc和Full GC 有什么不同呢?**
**新生代GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC非常频繁,回收速度一般也比较快。
**老年代GC(Major GC/Full GC)**:指发生在老年代的GC,出现了Major GC经常会伴随至少一次的Minor GC(并非绝对),Major GC的速度一般会比Minor GC的慢10倍以上。
### 5.2 大对象直接进入老年代
大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
### 5.3长期存活的对象将进入老年代
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别那些对象应放在新生代,那些对象应放在老年代中。为了做到这一点,虚拟机给每个对象一个对象年龄(Age)计数器。
### 5.4 动态对象年龄判定
为了更好的适应不同程序的内存情况,虚拟机不是永远要求对象年龄必须达到了某个值才能进入老年代,如果Survivor 空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无需达到要求的年龄。
## 总结:
本节介绍了垃圾收集算法,几款JDK1.7中提供的垃圾收集器特点以及运作原理。
内存回收与垃圾收集器在很多时候都是影响系统性能、并发能力的主要因素之一,虚拟机之所以提供多种不同的收集器以及大量调节参数,是因为只有根据实际应用的需求、实现方式选择最优的收集方式才能获取最高的性能。没有固定收集器、参数组合、也没有最优的调优方法,那么必须了解每一个具体收集器的行为、优势和劣势、调节参数。
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:深入理解JVM类加载机制.md
================================================
# 目录
* [一.目标:](#一目标:)
* [二.原理 (类的加载过程及其最终产品):](#二原理-(类的加载过程及其最终产品))
* [三.过程(类的生命周期):](#三过程(类的生命周期):)
* [加载:](#加载:)
* [校验:](#校验:)
* [准备:](#准备:)
* [解析:](#解析:)
* [初始化:](#初始化:)
* [四.类加载器:](#四类加载器:)
* [五.双亲委派机制:](#五双亲委派机制:)
* [参考文章](#参考文章)
本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 一.目标:
1.什么是类的加载?
2.类的生命周期?
3.类加载器是什么?
4.双亲委派机制是什么?
## 二.原理 (类的加载过程及其最终产品):
JVM将class文件字节码文件加载到内存中, 并将这些静态数据转换成方法区中的运行时数据结构,在堆(并不一定在堆中,HotSpot在方法区中)中生成一个代表这个类的java.lang.Class 对象,作为方法区类数据的访问入口。
## 三.过程(类的生命周期):
JVM类加载机制分为五个部分:加载,验证,准备,解析,初始化,下面我们就分别来看一下这五个过程。其中加载、检验、准备、初始化和卸载这个五个阶段的顺序是固定的,而解析则未必。为了支持动态绑定,解析这个过程可以发生在初始化阶段之后。
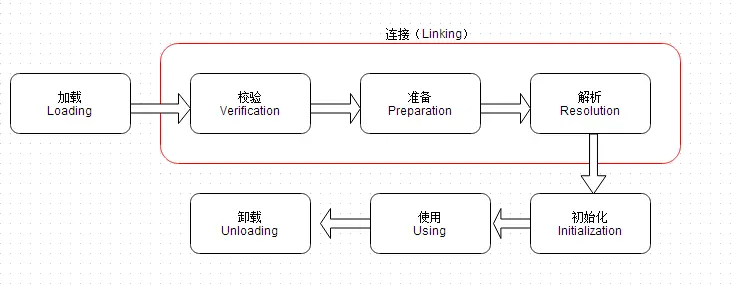
### 加载:
加载过程主要完成三件事情:
1. 通过类的全限定名来获取定义此类的二进制字节流
2. 将这个类字节流代表的静态存储结构转为方法区的运行时数据结构
3. 在堆中生成一个代表此类的java.lang.Class对象,作为访问方法区这些数据结构的入口。
这个过程主要就是类加载器完成。
### 校验:
此阶段主要确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机的自身安全。
1. 文件格式验证:基于字节流验证。
2. 元数据验证:基于**_方法区_**的存储结构验证。
3. 字节码验证:基于方法区的存储结构验证。
4. 符号引用验证:基于方法区的存储结构验证。
### 准备:
为类变量分配内存,并将其初始化为默认值。(此时为默认值,在初始化的时候才会给变量赋值)即在方法区中分配这些变量所使用的内存空间。例如:
```
public static int value = 123;
```
此时在准备阶段过后的初始值为0而不是123;将value赋值为123的putstatic指令是程序被编译后,存放于类构造器<client>方法之中.特例:
```
public static final int value = 123;
```
此时value的值在准备阶段过后就是123。
### 解析:
把类型中的符号引用转换为直接引用。
* 符号引用与虚拟机实现的布局无关,引用的目标并不一定要已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
* 直接引用可以是指向目标的指针,相对偏移量或是一个能间接定位到目标的句柄。如果有了直接引用,那引用的目标必定已经在内存中存在
主要有以下四种:
1. 类或接口的解析
2. 字段解析
3. 类方法解析
4. 接口方法解析
### 初始化:
初始化阶段是执行类构造器<client>方法的过程。<client>方法是由编译器自动收集类中的类变量的赋值操作和静态语句块中的语句合并而成的。虚拟机会保证<client>方法执行之前,父类的<client>方法已经执行完毕。如果一个类中没有对静态变量赋值也没有静态语句块,那么编译器可以不为这个类生成<client>()方法。
java中,对于初始化阶段,有且只有以下五种情况才会对要求类立刻“初始化”(加载,验证,准备,自然需要在此之前开始):
1. 使用new关键字实例化对象、访问或者设置一个类的静态字段(被final修饰、编译器优化时已经放入常量池的例外)、调用类方法,都会初始化该静态字段或者静态方法所在的类。
2. 初始化类的时候,如果其父类没有被初始化过,则要先触发其父类初始化。
3. 使用java.lang.reflect包的方法进行反射调用的时候,如果类没有被初始化,则要先初始化。
4. 虚拟机启动时,用户会先初始化要执行的主类(含有main)
5. jdk 1.7后,如果java.lang.invoke.MethodHandle的实例最后对应的解析结果是 REF_getStatic、REF_putStatic、REF_invokeStatic方法句柄,并且这个方法所在类没有初始化,则先初始化。
## 四.类加载器:
把类加载阶段的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作交给虚拟机之外的类加载器来完成。这样的好处在于,我们可以自行实现类加载器来加载其他格式的类,只要是二进制字节流就行,这就大大增强了加载器灵活性。系统自带的类加载器分为三种:
1. 启动类加载器。
2. 扩展类加载器。
3. 应用程序类加载器。
## 五.双亲委派机制:
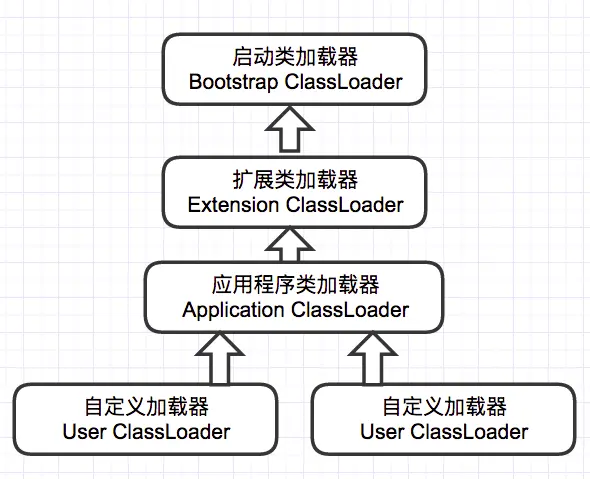
双亲委派机制工作过程:
如果一个类加载器收到了类加载器的请求.它首先不会自己去尝试加载这个类.而是把这个请求委派给父加载器去完成.每个层次的类加载器都是如此.因此所有的加载请求最终都会传送到Bootstrap类加载器(启动类加载器)中.只有父类加载反馈自己无法加载这个请求(它的搜索范围中没有找到所需的类)时.子加载器才会尝试自己去加载。
双亲委派模型的优点:java类随着它的加载器一起具备了一种带有优先级的层次关系.
例如类java.lang.Object,它存放在rt.jart之中.无论哪一个类加载器都要加载这个类.最终都是双亲委派模型最顶端的Bootstrap类加载器去加载.因此Object类在程序的各种类加载器环境中都是同一个类.相反.如果没有使用双亲委派模型.由各个类加载器自行去加载的话.如果用户编写了一个称为“java.lang.Object”的类.并存放在程序的ClassPath中.那系统中将会出现多个不同的Object类.java类型体系中最基础的行为也就无法保证.应用程序也将会一片混乱.
## 参考文章
<https://segmentfault.com/a/1190000009707894>
<https://www.cnblogs.com/hysum/p/7100874.html>
<http://c.biancheng.net/view/939.html>
<https://www.runoob.com/>
https://blog.csdn.net/android_hl/article/details/53228348
================================================
FILE: docs/Java/JVM/深入理解JVM虚拟机:虚拟机字节码执行引擎.md
================================================
# 目录
* [1 概述](#1-概述)
* [2 运行时栈帧结构](#2-运行时栈帧结构)
* [2.1 局部变量表](#21-局部变量表)
* [2.2 操作数栈](#22-操作数栈)
* [2.3 动态连接](#23-动态连接)
* [2.4 方法返回地址](#24-方法返回地址)
* [2.5 附加信息](#25-附加信息)
* [3 方法调用](#3-方法调用)
* [3.1 解析](#31-解析)
* [3.2 分派](#32-分派)
* [3.3 动态类型语言的支持](#33-动态类型语言的支持)
* [4 基于栈的字节码解释执行引擎](#4-基于栈的字节码解释执行引擎)
* [4.1 解释执行](#41-解释执行)
* [4.2 基于栈的指令集和基于寄存器的指令集](#42-基于栈的指令集和基于寄存器的指令集)
* [总结](#总结)
本文转自:https://www.cnblogs.com/snailclimb/p/9086337.html
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
> www.how2playlife.com
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
<!-- more -->
## 1 概述
执行引擎是java虚拟机最核心的组成部件之一。虚拟机的执行引擎由自己实现,所以可以自行定制指令集与执行引擎的结构体系,并且能够执行那些不被硬件直接支持的指令集格式。
所有的Java虚拟机的执行引擎都是一致的:**输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果**。本节将主要从概念模型的角度来讲解**虚拟机的方法调用和字节码执行**。
## 2 运行时栈帧结构
**栈帧(Stack Frame)**是用于支持虚拟机方法调用和方法执行的数据结构,它是虚拟机运行时数据区中**虚拟机栈(Virtual Machine Stack)的栈元素**。
栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法从调用开始至执行完成的过程,都对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。
**栈帧概念结构如下图所示:**
### 2.1 局部变量表
**局部变量表是一组变量值存储空间,用于存放方法参数和方法内定义的局部变量。
局部变量表的容量以变量槽(Variable Slot)为最小单位。** 一个Slot可以存放一个32位以内(boolean、byte、char、short、int、float、reference和returnAddress)的数据类型,reference类型表示一个对象实例的引用,returnAddress已经很少见了,可以忽略。
**对于64位的数据类型(Java语言中明确的64位数据类型只有long和double),虚拟机会以高位对齐的方式为其分配两个连续的Slot空间。**
**虚拟机通过索引定位的方式使用局部变量表**,索引值的范围从0开始至局部变量表最大的Slot数量。访问的是32位数据类型的变量,索引n就代表了使用第n个Slot,如果是64位数据类型,就代表会同时使用n和n+1这两个Slot。
**为了节省栈帧空间,局部变量Slot可以重用**,方法体中定义的变量,其作用域并不一定会覆盖整个方法体。如果当前字节码PC计数器的值超出了某个变量的作用域,那么这个变量的Slot就可以交给其他变量使用。这样的设计会带来一些额外的副作用,比如:在某些情况下,Slot的复用会直接影响到系统的收集行为。
### 2.2 操作数栈
**操作数栈(Operand Stack)**也常称为操作栈,它是一个**后入先出栈**。当一个方法执行开始时,这个方法的操作数栈是空的,在方法执行过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是**出栈/入栈**操作。
在概念模型中,一个活动线程中两个栈帧是相互独立的。但大多数虚拟机实现都会做一些优化处理:让下一个栈帧的部分操作数栈与上一个栈帧的部分局部变量表重叠在一起,这样的好处是方法调用时可以共享一部分数据,而无须进行额外的参数复制传递。
### 2.3 动态连接
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的**动态连接**;
字节码中方法调用指令是以常量池中的指向方法的符号引用为参数的,有一部分符号引用会在类加载阶段或第一次使用的时候转化为直接引用,这种转化称为**静态解析**,另外一部分在每次的运行期间转化为直接引用,这部分称为**动态连接**。
### 2.4 方法返回地址
当一个方法被执行后,有两种方式退出这个方法:
* 第一种是执行引擎遇到任意一个方法返回的字节码指令,这种退出方法的方式称为**正常完成出口(Normal Method Invocation Completion)**。
* 另外一种是在方法执行过程中遇到了异常,并且这个异常没有在方法体内得到处理(即本方法异常处理表中没有匹配的异常处理器),就会导致方法退出,这种退出方式称为**异常完成出口(Abrupt Method Invocation Completion)**。
注意:这种退出方式不会给上层调用者产生任何返回值。
**无论采用何种退出方式,在方法退出后,都需要返回到方法被调用的位置,程序才能继续执行**,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层方法的执行状态。一般来说,方法正常退出时,调用者的PC计数器的值可以作为返回地址,栈帧中很可能会保存这个计数器值。而方法异常退出时,返回地址是通过异常处理器表来确定的,栈帧中一般不会保存这部分信息。
方法退出的过程实际上等同于把当前栈帧出栈,因此退出时可能执行的操作有:恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用者栈帧的操作数栈中,调整PC计数器的值以指向方法调用指令后面的一条指令等。
### 2.5 附加信息
虚拟机规范允许虚拟机实现向栈帧中添加一些自定义的附加信息,例如与调试相关的信息等。
## 3 方法调用
方法调用阶段的目的:**确定被调用方法的版本(哪一个方法),不涉及方法内部的具体运行过程**,在程序运行时,进行方法调用是最普遍、最频繁的操作。
**一切方法调用在Class文件里存储的都只是符号引用,这是需要在类加载期间或者是运行期间,才能确定为方法在实际 运行时内存布局中的入口地址(相当于之前说的直接引用)**。
### 3.1 解析
“编译期可知,运行期不可变”的方法(静态方法和私有方法),在类加载的解析阶段,会将其符号引用转化为直接引用(入口地址)。这类方法的调用称为“**解析(Resolution)**”。
在Java虚拟机中提供了5条方法调用字节码指令:
-**invokestatic**: 调用静态方法
-**invokespecial**:调用实例构造器方法、私有方法、父类方法
-**invokevirtual**:调用所有的虚方法
-**invokeinterface**:调用接口方法,会在运行时在确定一个实现此接口的对象
-**invokedynamic**:先在运行时动态解析出点限定符所引用的方法,然后再执行该方法,在此之前的4条调用命令的分派逻辑是固化在Java虚拟机内部的,而invokedynamic指令的分派逻辑是由用户所设定的引导方法决定的。
### 3.2 分派
**分派调用过程将会揭示多态性特征的一些最基本的体现,如“重载”和“重写”在Java虚拟中是如何实现的。**
**1 静态分派**
所有依赖静态类型来定位方法执行版本的分派动作,都称为静态分派。静态分派发生在编译阶段。
静态分派最典型的应用就是方法重载。
```
package jvm8_3_2;
public class StaticDispatch {
static abstract class Human {
}
static class Man extends Human {
}
static class Woman extends Human {
}
public void sayhello(Human guy) {
System.out.println("Human guy");
}
public void sayhello(Man guy) {
System.out.println("Man guy");
}
public void sayhello(Woman guy) {
System.out.println("Woman guy");
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
StaticDispatch staticDispatch = new StaticDispatch();
staticDispatch.sayhello(man);// Human guy
staticDispatch.sayhello(woman);// Human guy
}
}
```
运行结果:
Human guy
Human guy
**为什么会出现这样的结果呢?**
Human man = new Man();其中的Human称为变量的**静态类型(Static Type)**,Man称为变量的**实际类型(Actual Type)**。
**两者的区别是**:静态类型在编译器可知,而实际类型到运行期才确定下来。
在重载时通过参数的静态类型而不是实际类型作为判定依据,因此,在编译阶段,Javac编译器会根据参数的静态类型决定使用哪个重载版本。所以选择了sayhello(Human)作为调用目标,并把这个方法的符号引用写到main()方法里的两条invokevirtual指令的参数中。
**2 动态分派**
在运行期根据实际类型确定方法执行版本的分派过程称为动态分派。最典型的应用就是方法重写。
```
package jvm8_3_2;
public class DynamicDisptch {
static abstract class Human {
abstract void sayhello();
}
static class Man extends Human {
@Override
void sayhello() {
System.out.println("man");
}
}
static class Woman extends Human {
@Override
void sayhello() {
System.out.println("woman");
}
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
man.sayhello();
woman.sayhello();
man = new Woman();
man.sayhello();
}
}
```
运行结果:
man
woman
woman
**3 单分派和多分派**
方法的接收者、方法的参数都可以称为方法的宗量。根据分批基于多少种宗量,可以将分派划分为单分派和多分派。**单分派是根据一个宗量对目标方法进行选择的,多分派是根据多于一个的宗量对目标方法进行选择的。**
Java在进行静态分派时,选择目标方法要依据两点:一是变量的静态类型是哪个类型,二是方法参数是什么类型。因为要根据两个宗量进行选择,所以Java语言的静态分派属于多分派类型。
运行时阶段的动态分派过程,由于编译器已经确定了目标方法的签名(包括方法参数),运行时虚拟机只需要确定方法的接收者的实际类型,就可以分派。因为是根据一个宗量作为选择依据,所以Java语言的动态分派属于单分派类型。
注:到JDK1.7时,Java语言还是静态多分派、动态单分派的语言,未来有可能支持动态多分派。
**4 虚拟机动态分派的实现**
由于动态分派是非常频繁的动作,而动态分派在方法版本选择过程中又需要在方法元数据中搜索合适的目标方法,虚拟机实现出于性能的考虑,通常不直接进行如此频繁的搜索,而是采用优化方法。
其中一种“稳定优化”手段是:在类的方法区中建立一个**虚方法表**(Virtual Method Table, 也称vtable, 与此对应,也存在接口方法表——Interface Method Table,也称itable)。**使用虚方法表索引来代替元数据查找以提高性能。其原理与C++的虚函数表类似。**
虚方法表中存放的是各个方法的实际入口地址。如果某个方法在子类中没有被重写,那子类的虚方法表里面的地址入口和父类中该方法相同,都指向父类的实现入口。虚方法表一般在类加载的连接阶段进行初始化。
### 3.3 动态类型语言的支持
JDK新增加了invokedynamic指令来是实现“动态类型语言”。
**静态语言和动态语言的区别:**
* **静态语言(强类型语言)**:
静态语言是在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型。
例如:C++、Java、Delphi、C#等。
* **动态语言(弱类型语言)**:
动态语言是在运行时确定数据类型的语言。变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
例如PHP/ASP/Ruby/Python/Perl/ABAP/SQL/JavaScript/Unix Shell等等。
* **强类型定义语言**:
强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
* **弱类型定义语言**:
数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。
## 4 基于栈的字节码解释执行引擎
虚拟机如何调用方法的内容已经讲解完毕,现在我们来探讨虚拟机是如何执行方法中的字节码指令。
### 4.1 解释执行
Java语言经常被人们定位为**“解释执行”语言**,在Java初生的JDK1.0时代,这种定义还比较准确的,但当主流的虚拟机中都包含了即时编译后,Class文件中的代码到底会被解释执行还是编译执行,就成了只有虚拟机自己才能准确判断的事情。再后来,Java也发展出来了直接生成本地代码的编译器[如何GCJ(GNU Compiler for the Java)],而C/C++也出现了通过解释器执行的版本(如CINT),这时候再笼统的说“解释执行”,对于整个Java语言来说就成了几乎没有任何意义的概念,**只有确定了谈论对象是某种具体的Java实现版本和执行引擎运行模式时,谈解释执行还是编译执行才会比较确切**。
Java语言中,javac编译器完成了程序代码经过词法分析、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令流的过程,因为这一部分动作是在Java虚拟机之外进行的,而解释器在虚拟机内部,所以Java程序的编译就是半独立实现的,
### 4.2 基于栈的指令集和基于寄存器的指令集
Java编译器输出的指令流,基本上是一种**基于栈的指令集架构(Instruction Set Architecture,ISA)**,**依赖操作数栈进行工作**。与之相对应的另一套常用的指令集架构是**基于寄存器的指令集**,**依赖寄存器进行工作**。
那么,**基于栈的指令集和基于寄存器的指令集这两者有什么不同呢?**
举个简单例子,分别使用这两种指令计算1+1的结果,**基于栈的指令集会是这个样子:**
iconst_1
iconst_1
iadd
istore_0
两条iconst_1指令连续把两个常量1压入栈后,iadd指令把栈顶的两个值出栈、相加,然后将结果放回栈顶,最后istore_0把栈顶的值放到局部变量表中的第0个Slot中。
**如果基于寄存器的指令集,那程序可能会是这个样子:**
mov eax, 1
add eax, 1
mov指令把EAX寄存器的值设置为1,然后add指令再把这个值加1,将结果就保存在EAX寄存器里面。
**基于栈的指令集主要的优点就是可移植,寄存器是由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免地要受到硬件的约束。**
**栈架构的指令集还有一些其他的优点,如代码相对更加紧凑,编译器实现更加简单等。
栈架构指令集的主要缺点是执行速度相对来说会稍微慢一些。**
## 总结
本节中,我们分析了虚拟机在执行代码时,如何找到正确的方法、如何执行方法内的字节码,以及执行代码时涉及的内存结构。
================================================
FILE: docs/Java/basic/Java8新特性终极指南.md
================================================
# 目录
* [Java语言新特性](#java语言新特性)
* [Lambda表达式](#lambda表达式)
* [函数式接口](#函数式
gitextract_jwwe335b/
├── .gitignore
├── ReadMe.md
├── docs/
│ ├── Java/
│ │ ├── JVM/
│ │ │ ├── JVM总结.md
│ │ │ ├── 深入理解JVM虚拟机:GC调优思路与常用工具.md
│ │ │ ├── 深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md
│ │ │ ├── 深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md
│ │ │ ├── 深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md
│ │ │ ├── 深入理解JVM虚拟机:JVM常用参数以及调优实践.md
│ │ │ ├── 深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md
│ │ │ ├── 深入理解JVM虚拟机:JVM监控工具与诊断实践.md
│ │ │ ├── 深入理解JVM虚拟机:Java内存异常原理与实践.md
│ │ │ ├── 深入理解JVM虚拟机:Java字节码介绍与解析实践.md
│ │ │ ├── 深入理解JVM虚拟机:Java的编译期优化与运行期优化.md
│ │ │ ├── 深入理解JVM虚拟机:再谈四种引用及GC实践.md
│ │ │ ├── 深入理解JVM虚拟机:垃圾回收器详解.md
│ │ │ ├── 深入理解JVM虚拟机:深入理解JVM类加载机制.md
│ │ │ └── 深入理解JVM虚拟机:虚拟机字节码执行引擎.md
│ │ ├── basic/
│ │ │ ├── Java8新特性终极指南.md
│ │ │ ├── JavaIO流.md
│ │ │ ├── Java中的Class类和Object类.md
│ │ │ ├── Java基本数据类型.md
│ │ │ ├── Java异常.md
│ │ │ ├── Java注解和最佳实践.md
│ │ │ ├── Java类和包.md
│ │ │ ├── Java自动拆箱装箱里隐藏的秘密.md
│ │ │ ├── Java集合框架梳理.md
│ │ │ ├── final关键字特性.md
│ │ │ ├── javac和javap.md
│ │ │ ├── string和包装类.md
│ │ │ ├── 代码块和代码执行顺序.md
│ │ │ ├── 反射.md
│ │ │ ├── 多线程.md
│ │ │ ├── 序列化和反序列化.md
│ │ │ ├── 抽象类和接口.md
│ │ │ ├── 枚举类.md
│ │ │ ├── 泛型.md
│ │ │ ├── 深入理解内部类.md
│ │ │ ├── 继承、封装、多态的实现原理.md
│ │ │ ├── 解读Java中的回调.md
│ │ │ └── 面向对象基础.md
│ │ ├── collection/
│ │ │ ├── Java集合类总结.md
│ │ │ ├── Java集合详解:HashMap和HashTable.md
│ │ │ ├── Java集合详解:HashSet,TreeSet与LinkedHashSet.md
│ │ │ ├── Java集合详解:Iterator,fail-fast机制与比较器.md
│ │ │ ├── Java集合详解:Java集合类细节精讲.md
│ │ │ ├── Java集合详解:Queue和LinkedList.md
│ │ │ ├── Java集合详解:TreeMap和红黑树.md
│ │ │ ├── Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md
│ │ │ └── Java集合详解:深入理解LinkedHashMap和LRU缓存.md
│ │ ├── concurrency/
│ │ │ ├── Java并发指南:AQS中的公平锁与非公平锁,Condtion.md
│ │ │ ├── Java并发指南:AQS共享模式与并发工具类的实现.md
│ │ │ ├── Java并发指南:ForkJoin并发框架与工作窃取算法剖析.md
│ │ │ ├── Java并发指南:JMM中的final关键字解析.md
│ │ │ ├── Java并发指南:JUC中常用的Unsafe和Locksupport.md
│ │ │ ├── Java并发指南:JUC的核心类AQS详解.md
│ │ │ ├── Java并发指南:Java中的HashMap和ConcurrentHashMap全解析.md
│ │ │ ├── Java并发指南:Java中的锁Lock和synchronized.md
│ │ │ ├── Java并发指南:Java内存模型JMM总结.md
│ │ │ ├── Java并发指南:Java读写锁ReentrantReadWriteLock源码分析.md
│ │ │ ├── Java并发指南:并发三大问题与volatile关键字,CAS操作.md
│ │ │ ├── Java并发指南:并发基础与Java多线程.md
│ │ │ ├── Java并发指南:深入理解Java内存模型JMM.md
│ │ │ ├── Java并发指南:深度解读Java线程池设计思想及源码实现.md
│ │ │ ├── Java并发指南:解读Java阻塞队列BlockingQueue.md
│ │ │ └── Java并发编程学习总结.md
│ │ ├── design-parttern/
│ │ │ ├── 初探Java设计模式:JDK中的设计模式.md
│ │ │ ├── 初探Java设计模式:Spring涉及到的种设计模式.md
│ │ │ ├── 初探Java设计模式:创建型模式(工厂,单例等).md
│ │ │ ├── 初探Java设计模式:结构型模式(代理模式,适配器模式等).md
│ │ │ ├── 初探Java设计模式:行为型模式(策略,观察者等).md
│ │ │ └── 设计模式学习总结.md
│ │ └── network/
│ │ ├── Java网络与NIO总结.md
│ │ ├── Java网络编程与NIO详解:IO模型与Java网络编程模型.md
│ │ ├── Java网络编程与NIO详解:JAVA中原生的socket通信机制.md
│ │ ├── Java网络编程与NIO详解:JavaNIO一步步构建IO多路复用的请求模型.md
│ │ ├── Java网络编程与NIO详解:Java非阻塞IO和异步IO.md
│ │ ├── Java网络编程与NIO详解:LinuxEpoll实现原理详解.md
│ │ ├── Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO).md
│ │ ├── Java网络编程与NIO详解:基于NIO的网络编程框架Netty.md
│ │ ├── Java网络编程与NIO详解:浅析NIO包中的Buffer、Channel和Selector.md
│ │ ├── Java网络编程与NIO详解:浅析mmap和DirectBuffer.md
│ │ ├── Java网络编程与NIO详解:浅谈Linux中Selector的实现原理.md
│ │ └── Java网络编程与NIO详解:深度解读Tomcat中的NIO模型.md
│ ├── JavaWeb/
│ │ ├── JavaWeb技术总结.md
│ │ ├── 走进JavaWeb技术世界:Hibernate入门经典与注解式开发.md
│ │ ├── 走进JavaWeb技术世界:JDBC的进化与连接池技术.md
│ │ ├── 走进JavaWeb技术世界:JSP与Servlet的曾经与现在.md
│ │ ├── 走进JavaWeb技术世界:JavaWeb的由来和基础知识.md
│ │ ├── 走进JavaWeb技术世界:Java日志系统的诞生与发展.md
│ │ ├── 走进JavaWeb技术世界:Mybatis入门.md
│ │ ├── 走进JavaWeb技术世界:Servlet工作原理详解.md
│ │ ├── 走进JavaWeb技术世界:Tomcat5总体架构剖析.md
│ │ ├── 走进JavaWeb技术世界:Tomcat和其他WEB容器的区别.md
│ │ ├── 走进JavaWeb技术世界:从JavaBean讲到Spring.md
│ │ ├── 走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven.md
│ │ ├── 走进JavaWeb技术世界:初探Tomcat9的HTTP请求过程.md
│ │ ├── 走进JavaWeb技术世界:单元测试框架Junit.md
│ │ ├── 走进JavaWeb技术世界:极简配置的SpringBoot.md
│ │ ├── 走进JavaWeb技术世界:浅析Tomcat请求处理流程与启动部署过程.md
│ │ └── 走进JavaWeb技术世界:深入浅出Mybatis基本原理.md
│ ├── Spring全家桶/
│ │ ├── Spring/
│ │ │ ├── SpringAOP的概念与作用.md
│ │ │ ├── SpringBean的定义与管理(核心).md
│ │ │ ├── Spring中对于数据库的访问.md
│ │ │ ├── Spring中对于校验功能的支持.md
│ │ │ ├── Spring中的Environment环境变量.md
│ │ │ ├── Spring中的事件处理机制.md
│ │ │ ├── Spring中的资源管理.md
│ │ │ ├── Spring中的配置元数据(管理配置的基本数据).md
│ │ │ ├── Spring事务基本用法.md
│ │ │ ├── Spring合集.md
│ │ │ ├── Spring容器与IOC.md
│ │ │ ├── Spring常见注解.md
│ │ │ ├── Spring概述.md
│ │ │ └── 第一个Spring应用.md
│ │ ├── SpringBoot/
│ │ │ ├── SpringBoot中的任务调度与@Async.md
│ │ │ ├── SpringBoot中的日志管理.md
│ │ │ ├── SpringBoot常见注解.md
│ │ │ ├── SpringBoot应用也可以部署到外部Tomcat.md
│ │ │ ├── SpringBoot打包与启动.md
│ │ │ ├── SpringBoot生产环境工具Actuator.md
│ │ │ ├── SpringBoot的Starter机制.md
│ │ │ ├── SpringBoot的前世今生.md
│ │ │ ├── SpringBoot的基本使用.md
│ │ │ ├── SpringBoot的配置文件管理.md
│ │ │ ├── SpringBoot自带的热部署工具.md
│ │ │ ├── SpringBoot集成Swagger实现API文档自动生成.md
│ │ │ ├── Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot).md
│ │ │ ├── 基于SpringBoot中的开源监控工具SpringBootAdmin.md
│ │ │ └── 给你一份SpringBoot知识清单.md
│ │ ├── SpringBoot源码解析/
│ │ │ ├── @SpringBootApplication注解.md
│ │ │ ├── SpringBootWeb应用(一):servlet组件的注册流程.md
│ │ │ ├── SpringBootWeb应用(二):WebMvc装配过程.md
│ │ │ ├── SpringBoot启动流程(一):准备SpringApplication.md
│ │ │ ├── SpringBoot启动流程(三):准备IOC容器.md
│ │ │ ├── SpringBoot启动流程(二):准备运行环境.md
│ │ │ ├── SpringBoot启动流程(五):完成启动.md
│ │ │ ├── SpringBoot启动流程(六):启动流程总结.md
│ │ │ ├── SpringBoot启动流程(四):启动IOC容器.md
│ │ │ ├── SpringBoot自动装配(一):加载自动装配类.md
│ │ │ ├── SpringBoot自动装配(三):自动装配顺序.md
│ │ │ └── SpringBoot自动装配(二):条件注解.md
│ │ ├── SpringCloud/
│ │ │ ├── SpringCloudConfig.md
│ │ │ ├── SpringCloudConsul.md
│ │ │ ├── SpringCloudEureka.md
│ │ │ ├── SpringCloudGateway.md
│ │ │ ├── SpringCloudHystrix.md
│ │ │ ├── SpringCloudLoadBalancer.md
│ │ │ ├── SpringCloudOpenFeign.md
│ │ │ ├── SpringCloudRibbon.md
│ │ │ ├── SpringCloudSleuth.md
│ │ │ ├── SpringCloudZuul.md
│ │ │ └── SpringCloud概述.md
│ │ ├── SpringCloudAlibaba/
│ │ │ ├── SpringCloudAlibabaNacos.md
│ │ │ ├── SpringCloudAlibabaRocketMQ.md
│ │ │ ├── SpringCloudAlibabaSeata.md
│ │ │ ├── SpringCloudAlibabaSentinel.md
│ │ │ ├── SpringCloudAlibabaSkywalking.md
│ │ │ └── SpringCloudAlibaba概览.md
│ │ ├── SpringCloudAlibaba源码分析/
│ │ │ ├── SpringCloudAlibabaNacos源码分析:服务发现.md
│ │ │ ├── SpringCloudAlibabaNacos源码分析:服务注册.md
│ │ │ ├── SpringCloudAlibabaNacos源码分析:概览.md
│ │ │ ├── SpringCloudAlibabaNacos源码分析:配置中心.md
│ │ │ ├── SpringCloudRocketMQ源码分析.md
│ │ │ ├── SpringCloudSeata源码分析.md
│ │ │ └── SpringCloudSentinel源码分析.md
│ │ ├── SpringCloud源码分析/
│ │ │ ├── SpringCloudConfig源码分析.md
│ │ │ ├── SpringCloudEureka源码分析.md
│ │ │ ├── SpringCloudGateway源码分析.md
│ │ │ ├── SpringCloudHystrix源码分析.md
│ │ │ ├── SpringCloudLoadBalancer源码分析.md
│ │ │ ├── SpringCloudOpenFeign源码分析.md
│ │ │ └── SpringCloudRibbon源码分析.md
│ │ ├── SpringMVC/
│ │ │ ├── SpringMVC中的国际化功能.md
│ │ │ ├── SpringMVC中的常用功能.md
│ │ │ ├── SpringMVC中的异常处理器.md
│ │ │ ├── SpringMVC中的拦截器.md
│ │ │ ├── SpringMVC中的视图解析器.md
│ │ │ ├── SpringMVC中的过滤器Filter.md
│ │ │ ├── SpringMVC基本介绍与快速入门.md
│ │ │ ├── SpringMVC如何实现文件上传.md
│ │ │ └── SpringMVC常见注解.md
│ │ ├── SpringMVC源码分析/
│ │ │ ├── DispatcherServlet初始化流程.md
│ │ │ ├── RequestMapping初始化流程.md
│ │ │ ├── SpringMVC整体源码结构总结.md
│ │ │ ├── SpringMVC源码分析:DispatcherServlet如何找到正确的Controller.md
│ │ │ ├── SpringMVC源码分析:DispatcherServlet的初始化与请求转发.md
│ │ │ ├── SpringMVC源码分析:SpringMVC概述.md
│ │ │ ├── SpringMVC源码分析:SpringMVC的视图解析原理.md
│ │ │ ├── SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet.md
│ │ │ ├── SpringMVC源码分析:消息转换器HttpMessageConverter与@ResponseBody注解.md
│ │ │ ├── SpringMVC的Demo与@EnableWebMvc注解.md
│ │ │ ├── Spring容器启动Tomcat.md
│ │ │ ├── 请求执行流程(一)之获取Handler.md
│ │ │ └── 请求执行流程(二)之执行Handler方法.md
│ │ └── Spring源码分析/
│ │ ├── SpringAOP/
│ │ │ ├── AOP示例demo及@EnableAspectJAutoProxy.md
│ │ │ ├── AnnotationAwareAspectJAutoProxyCreator分析(上).md
│ │ │ ├── AnnotationAwareAspectJAutoProxyCreator分析(下).md
│ │ │ ├── SpringAop(五):cglib代理.md
│ │ │ ├── SpringAop(六):aop总结.md
│ │ │ └── SpringAop(四):jdk动态代理.md
│ │ ├── Spring事务/
│ │ │ ├── Spring事务(一):认识事务组件.md
│ │ │ ├── Spring事务(三):事务的隔离级别与传播方式的处理01.md
│ │ │ ├── Spring事务(二):事务的执行流程.md
│ │ │ ├── Spring事务(五):事务的隔离级别与传播方式的处理03.md
│ │ │ ├── Spring事务(六):事务的隔离级别与传播方式的处理04.md
│ │ │ └── Spring事务(四):事务的隔离级别与传播方式的处理02.md
│ │ ├── Spring启动流程/
│ │ │ ├── Spring启动流程(一):启动流程概览.md
│ │ │ ├── Spring启动流程(七):国际化与事件处理.md
│ │ │ ├── Spring启动流程(三):包的扫描流程.md
│ │ │ ├── Spring启动流程(九):单例bean的创建.md
│ │ │ ├── Spring启动流程(二):ApplicationContext的创建.md
│ │ │ ├── Spring启动流程(五):执行BeanFactoryPostProcessor.md
│ │ │ ├── Spring启动流程(八):完成BeanFactory的初始化.md
│ │ │ ├── Spring启动流程(六):注册BeanPostProcessor.md
│ │ │ ├── Spring启动流程(十一):启动流程总结.md
│ │ │ ├── Spring启动流程(十):启动完成的处理.md
│ │ │ └── Spring启动流程(四):启动前的准备工作.md
│ │ ├── Spring源码剖析:AOP实现原理详解.md
│ │ ├── Spring源码剖析:JDK和cglib动态代理原理详解.md
│ │ ├── Spring源码剖析:SpringAOP概述.md
│ │ ├── Spring源码剖析:SpringIOC容器的加载过程.md
│ │ ├── Spring源码剖析:Spring事务概述.md
│ │ ├── Spring源码剖析:Spring事务源码剖析.md
│ │ ├── Spring源码剖析:初探SpringIOC核心流程.md
│ │ ├── Spring源码剖析:懒加载的单例Bean获取过程分析.md
│ │ ├── Spring组件分析/
│ │ │ ├── Spring组件之ApplicationContext.md
│ │ │ ├── Spring组件之BeanDefinition.md
│ │ │ ├── Spring组件之BeanFactory.md
│ │ │ ├── Spring组件之BeanFactoryPostProcessor.md
│ │ │ └── Spring组件之BeanPostProcessor.md
│ │ └── Spring重要机制探秘/
│ │ ├── ConfigurationClassPostProcessor(一):处理@ComponentScan注解.md
│ │ ├── ConfigurationClassPostProcessor(三):处理@Import注解.md
│ │ ├── ConfigurationClassPostProcessor(二):处理@Bean注解.md
│ │ ├── ConfigurationClassPostProcessor(四):处理@Conditional注解.md
│ │ ├── Spring探秘之AOP的执行顺序.md
│ │ ├── Spring探秘之Spring事件机制.md
│ │ ├── Spring探秘之循环依赖的解决(一):理论基石.md
│ │ ├── Spring探秘之循环依赖的解决(二):源码分析.md
│ │ ├── Spring探秘之监听器注解EventListener.md
│ │ └── Spring探秘之组合注解的处理.md
│ ├── backend/
│ │ ├── Hadoop生态总结.md
│ │ ├── 后端技术杂谈开篇:云计算,大数据与AI的故事.md
│ │ ├── 后端技术杂谈:Docker 核心技术与实现原理.md
│ │ ├── 后端技术杂谈:Elasticsearch与solr入门实践.md
│ │ ├── 后端技术杂谈:Lucene基础原理与实践.md
│ │ ├── 后端技术杂谈:OpenStack架构设计.md
│ │ ├── 后端技术杂谈:OpenStack的基石KVM.md
│ │ ├── 后端技术杂谈:云计算的前世今生.md
│ │ ├── 后端技术杂谈:先搞懂Docker核心概念吧.md
│ │ ├── 后端技术杂谈:十分钟理解Kubernetes核心概念.md
│ │ ├── 后端技术杂谈:捋一捋大数据研发的基本概念.md
│ │ ├── 后端技术杂谈:搜索引擎基础倒排索引.md
│ │ ├── 后端技术杂谈:搜索引擎工作原理.md
│ │ └── 后端技术杂谈:白话虚拟化技术.md
│ ├── cache/
│ │ ├── Redis原理与实践总结.md
│ │ ├── 探索Redis设计与实现开篇:什么是Redis.md
│ │ ├── 探索Redis设计与实现:Redis 的基础数据结构概览.md
│ │ ├── 探索Redis设计与实现:Redis事务浅析与ACID特性介绍.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——dict.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——intset.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——quicklist.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——sds.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——skiplist.md
│ │ ├── 探索Redis设计与实现:Redis内部数据结构详解——ziplist.md
│ │ ├── 探索Redis设计与实现:Redis分布式锁进化史.md
│ │ ├── 探索Redis设计与实现:Redis的事件驱动模型与命令执行过程.md
│ │ ├── 探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例.md
│ │ ├── 探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中.md
│ │ ├── 探索Redis设计与实现:数据库redisDb与键过期删除策略.md
│ │ ├── 探索Redis设计与实现:浅析Redis主从复制.md
│ │ └── 探索Redis设计与实现:连接底层与表面的数据结构robj.md
│ ├── cs/
│ │ ├── algorithms/
│ │ │ └── 剑指offer.md
│ │ ├── network/
│ │ │ └── 计算机网络学习总结.md
│ │ └── operating-system/
│ │ ├── Linux内核与基础命令学习总结.md
│ │ └── 操作系统学习总结.md
│ ├── database/
│ │ ├── Mysql原理与实践总结.md
│ │ ├── 重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系.md
│ │ ├── 重新学习MySQL数据库:MySQL的事务隔离级别实战.md
│ │ ├── 重新学习MySQL数据库:MySQL里的那些日志们.md
│ │ ├── 重新学习MySQL数据库:Mysql主从复制,读写分离,分表分库策略与实践.md
│ │ ├── 重新学习MySQL数据库:Mysql存储引擎与数据存储原理.md
│ │ ├── 重新学习MySQL数据库:Mysql索引实现原理和相关数据结构算法.md
│ │ ├── 重新学习MySQL数据库:『浅入浅出』MySQL和InnoDB.md
│ │ ├── 重新学习MySQL数据库:从实践sql语句优化开始.md
│ │ ├── 重新学习MySQL数据库:以Java的视角来聊聊SQL注入.md
│ │ ├── 重新学习MySQL数据库:无废话MySQL入门.md
│ │ ├── 重新学习MySQL数据库:根据MySQL索引原理进行分析与优化.md
│ │ ├── 重新学习MySQL数据库:浅谈MySQL的中事务与锁.md
│ │ └── 重新学习MySQL数据库:详解MyIsam与InnoDB引擎的锁实现.md
│ ├── distributed/
│ │ ├── basic/
│ │ │ ├── 分布式系统理论基础 :CAP.md
│ │ │ ├── 分布式系统理论基础: 一致性、PC和PC.md
│ │ │ ├── 分布式系统理论基础: 时间、时钟和事件顺序.md
│ │ │ ├── 分布式系统理论基础:Paxos.md
│ │ │ ├── 分布式系统理论基础:Raft、Zab.md
│ │ │ ├── 分布式系统理论基础:zookeeper分布式协调服务.md
│ │ │ ├── 分布式系统理论基础:选举、多数派和租约.md
│ │ │ └── 分布式系统理论进阶:Paxos变种和优化.md
│ │ ├── practice/
│ │ │ ├── 搞懂分布式技术:LVS实现负载均衡的原理与实践.md
│ │ │ ├── 搞懂分布式技术:SpringBoot使用注解集成Redis缓存.md
│ │ │ ├── 搞懂分布式技术:ZAB协议概述与选主流程详解.md
│ │ │ ├── 搞懂分布式技术:Zookeeper典型应用场景及实践.md
│ │ │ ├── 搞懂分布式技术:Zookeeper的配置与集群管理实战.md
│ │ │ ├── 搞懂分布式技术:使用RocketMQ事务消息解决分布式事务.md
│ │ │ ├── 搞懂分布式技术:分布式ID生成方案.md
│ │ │ ├── 搞懂分布式技术:分布式session解决方案与一致性hash.md
│ │ │ ├── 搞懂分布式技术:分布式一致性协议与Paxos,Raft算法.md
│ │ │ ├── 搞懂分布式技术:分布式事务常用解决方案.md
│ │ │ ├── 搞懂分布式技术:分布式系统的一些基本概念.md
│ │ │ ├── 搞懂分布式技术:初探分布式协调服务zookeeper.md
│ │ │ ├── 搞懂分布式技术:浅析分布式事务.md
│ │ │ ├── 搞懂分布式技术:浅谈分布式消息技术Kafka.md
│ │ │ ├── 搞懂分布式技术:浅谈分布式锁的几种方案.md
│ │ │ ├── 搞懂分布式技术:消息队列因何而生.md
│ │ │ ├── 搞懂分布式技术:缓存更新的套路.md
│ │ │ └── 搞懂分布式技术:缓存的那些事.md
│ │ ├── 分布式技术实践总结.md
│ │ └── 分布式理论总结.md
│ ├── hxx/
│ │ ├── java/
│ │ │ ├── Java后端工程师必备书单(从Java基础到分布式).md
│ │ │ ├── Java工程师修炼之路(校招总结).md
│ │ │ ├── 为什么我会选择走 Java 这条路?.md
│ │ │ ├── 你不可错过的Java学习资源清单.md
│ │ │ ├── 想了解Java后端学习路线?你只需要这一张图!.md
│ │ │ └── 我的Java秋招面经大合集.md
│ │ ├── think/
│ │ │ └── copy.md
│ │ └── 电子书.md
│ ├── interview/
│ │ ├── BATJ-Experience/
│ │ │ ├── alipay-pinduoduo-toutiao.md
│ │ │ ├── 蚂蚁金服实习生面经总结(已拿口头offer).md
│ │ │ └── 面阿里,终获offer.md
│ │ ├── InterviewQuestions/
│ │ │ └── Java核心技术总结.md
│ │ └── PreparingForInterview/
│ │ ├── JavaInterviewLibrary.md
│ │ ├── JavaProgrammerNeedKnow.md
│ │ ├── interviewPrepare.md
│ │ ├── 如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md
│ │ ├── 程序员的简历之道.md
│ │ └── 美团面试常见问题总结.md
│ ├── monitor/
│ │ ├── Spring Actuator.md
│ │ └── SpringBoot Admin.md
│ └── mq/
│ ├── RocketMQ/
│ │ ├── RocketMQ系列:事务消息(最终一致性).md
│ │ ├── RocketMQ系列:基本概念.md
│ │ ├── RocketMQ系列:广播与延迟消息.md
│ │ ├── RocketMQ系列:批量发送与过滤.md
│ │ ├── RocketMQ系列:消息的生产与消费.md
│ │ ├── RocketMQ系列:环境搭建.md
│ │ └── RocketMQ系列:顺序消费.md
│ └── kafka/
│ ├── 消息队列kafka详解:Kafka 快速上手(Java版).md
│ ├── 消息队列kafka详解:Kafka一条消息存到broker的过程.md
│ ├── 消息队列kafka详解:Kafka介绍.md
│ ├── 消息队列kafka详解:Kafka原理分析总结篇.md
│ ├── 消息队列kafka详解:Kafka常见命令及配置总结.md
│ ├── 消息队列kafka详解:Kafka架构介绍.md
│ ├── 消息队列kafka详解:Kafka的集群工作原理.md
│ ├── 消息队列kafka详解:Kafka重要知识点+面试题大全.md
│ ├── 消息队列kafka详解:如何实现延迟队列.md
│ └── 消息队列kafka详解:如何实现死信队列.md
├── pom.xml
└── src/
└── main/
└── java/
├── Test.java
└── md/
├── codeFormat.java
└── mdToc.java
SYMBOL INDEX (6 symbols across 3 files)
FILE: src/main/java/Test.java
class Test (line 8) | @Service
method main (line 14) | public static void main(String[] args) {
method test (line 19) | public void test(){
FILE: src/main/java/md/codeFormat.java
class codeFormat (line 7) | public class codeFormat {
FILE: src/main/java/md/mdToc.java
class mdToc (line 5) | public class mdToc {
method main (line 6) | public static void main(String[] args) {
Condensed preview — 358 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (5,166K chars).
[
{
"path": ".gitignore",
"chars": 166,
"preview": "# Created by .ignore support plugin (hsz.mobi)\n### Example user template template\n### Example user template\n\n# IntelliJ "
},
{
"path": "ReadMe.md",
"chars": 28156,
"preview": "<div align=\"center\">\n<a href=\"https://github.com/h2pl/Java-Tutorial\">\n <img src=\"https://java-tutorial.oss-cn-shangha"
},
{
"path": "docs/Java/JVM/JVM总结.md",
"chars": 3733,
"preview": "# 目录\n\n * [JVM介绍和源码](#jvm介绍和源码)\n * [JVM内存模型](#jvm内存模型)\n * [JVM OOM和内存泄漏](#jvm-oom和内存泄漏)\n * [常见调试工具](#常见调试工具)\n * [cla"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:GC调优思路与常用工具.md",
"chars": 31575,
"preview": "# 目录\n\n* [核心概念(Core Concepts)](#核心概念core-concepts)\n * [Latency(延迟)](#latency延迟)\n * [Throughput(吞吐量)](#throughput吞吐量)\n "
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md",
"chars": 13947,
"preview": "# 目录\n * [打破双亲委派模型](#打破双亲委派模型)\n * [JNDI](#jndi)\n * [JNDI 的理解](#[jndi-的理解])\n * [OSGI](#osgi)\n * [1.如何正确的理解和认识OS"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md",
"chars": 12238,
"preview": "# 目录\n * [前言](#前言)\n * [Java堆(Heap)](#java堆(heap))\n * [方法区(Method Area)](#方法区(method-area))\n * [程序计数器(Program Counter "
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md",
"chars": 16320,
"preview": "# 目录\n * [JVM GC基本原理与GC算法](#jvm-gc基本原理与gc算法)\n * [Java关键术语](#java关键术语)\n * [Java HotSpot 虚拟机](#java-hotspot-虚拟机)\n * [Ja"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JVM常用参数以及调优实践.md",
"chars": 17306,
"preview": "# 目录\n\n * [JVM优化的必要性](#jvm优化的必要性)\n * [JVM调优原则](#jvm调优原则)\n * [JVM运行参数设置](#jvm运行参数设置)\n * [JVM性能调优工具](#jvm性能调优工具)\n * "
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md",
"chars": 6347,
"preview": "# 目录\n * [一、VisualVM是什么?](#一、visualvm是什么?)\n * [二、如何获取VisualVM?](#二、如何获取visualvm?)\n * [三、获取那个版本?](#三、获取那个版本?)\n * [四、Vi"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JVM监控工具与诊断实践.md",
"chars": 8323,
"preview": "# 目录\n * [一、jvm常见监控工具&指令](#一、jvm常见监控工具指令)\n * [1、 jps:jvm进程状况工具](#1、-jpsjvm进程状况工具)\n * [2、jstat: jvm统计信息监控工具](#2、jst"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:Java内存异常原理与实践.md",
"chars": 16229,
"preview": "# 目录\n * [实战内存溢出异常](#实战内存溢出异常)\n * [1 . 对象的创建过程](#1--对象的创建过程)\n * [2 . 对象的内存布局](#2--对象的内存布局)\n * [3 . 对象的访问定位](#3--对象的访问"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:Java字节码介绍与解析实践.md",
"chars": 9411,
"preview": "# 目录\n * [前言](#前言)\n * [Class文件](#class文件)\n * [什么是Class文件?](#什么是class文件?)\n * [基本结构](#基本结构)\n * [解析](#解析)\n * [字段"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:Java的编译期优化与运行期优化.md",
"chars": 6077,
"preview": "# 目录\n * [java编译期优化](#[java编译期优化])\n * [早期(编译期)优化](#早期(编译期)优化)\n * [泛型与类型擦除](#泛型与类型擦除)\n * [自动装箱、拆箱与遍历循环]("
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:再谈四种引用及GC实践.md",
"chars": 7081,
"preview": "# 目录\n * [一、背景](#一、背景)\n * [二、简介](#二、简介)\n * [1.强引用 StrongReference](#1强引用-strongreference)\n * [2.弱引用 WeakReference"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:垃圾回收器详解.md",
"chars": 8742,
"preview": "# 目录\n * [1 概述](#1-概述)\n * [2 对象已经死亡?](#2-对象已经死亡?)\n * [2.1引用计数法](#21引用计数法)\n * [2.2可达性分析算法](#22可达性分析算法)\n * [2.3 "
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:深入理解JVM类加载机制.md",
"chars": 3582,
"preview": "# 目录\n * [一.目标:](#一目标:)\n * [二.原理 (类的加载过程及其最终产品):](#二原理-(类的加载过程及其最终产品))\n * [三.过程(类的生命周期):](#三过程(类的生命周期):)\n * [加载:](#"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:虚拟机字节码执行引擎.md",
"chars": 8106,
"preview": "# 目录\n * [1 概述](#1-概述)\n * [2 运行时栈帧结构](#2-运行时栈帧结构)\n * [2.1 局部变量表](#21-局部变量表)\n * [2.2 操作数栈](#22-操作数栈)\n * [2.3 动态"
},
{
"path": "docs/Java/basic/Java8新特性终极指南.md",
"chars": 27574,
"preview": "# 目录\n * [Java语言新特性](#java语言新特性)\n * [Lambda表达式](#lambda表达式)\n * [函数式接口](#函数式接口)\n * [方法引用](#方法引用)\n * [接口的默认方法]"
},
{
"path": "docs/Java/basic/JavaIO流.md",
"chars": 14630,
"preview": "# 目录\n * [IO概述](#io概述)\n * [什么是Java IO流](#什么是java-io流)\n * [IO文件](#io文件)\n * [字符流和字节流](#字符流和字节流)\n * [IO管道](#io管"
},
{
"path": "docs/Java/basic/Java中的Class类和Object类.md",
"chars": 24106,
"preview": "# 目录\n\n * [Java中Class类及用法](#java中class类及用法)\n * [Class类原理](#class类原理)\n * [如何获得一个Class类对象](#如何获得一个class类对象)\n * [使"
},
{
"path": "docs/Java/basic/Java基本数据类型.md",
"chars": 12979,
"preview": "\n# 目录\n\n* [Java 基本数据类型](#java-基本数据类型)\n * [Java 的两大数据类型:](#java-的两大数据类型)\n * [内置数据类型](#内置数据类型)\n * [引用类型](#引用类型)\n "
},
{
"path": "docs/Java/basic/Java异常.md",
"chars": 25158,
"preview": "# 目录\n\n * [为什么要使用异常](#为什么要使用异常)\n * [异常基本定义](#异常基本定义)\n * [异常体系](#异常体系)\n * [初识异常](#初识异常)\n * [异常和错误](#异常和错误)\n * [异常的处理"
},
{
"path": "docs/Java/basic/Java注解和最佳实践.md",
"chars": 14839,
"preview": "# 目录\n * [Java注解简介](#java注解简介)\n * [注解如同标签](#注解如同标签)\n * [Java 注解概述](#java-注解概述)\n * [什么是注解?](#什么是注解?)\n * [注解的用处]"
},
{
"path": "docs/Java/basic/Java类和包.md",
"chars": 10760,
"preview": "# 目录\n\n* [Java中的包概念](#java中的包概念)\n * [包的作用](#包的作用)\n * [package 的目录结构](#package-的目录结构)\n * [设置 CLASSPATH 系统变量](#设置-"
},
{
"path": "docs/Java/basic/Java自动拆箱装箱里隐藏的秘密.md",
"chars": 13646,
"preview": "# 目录\n\n* [Java 基本数据类型](#java-基本数据类型)\n * [Java 的两大数据类型:](#java-的两大数据类型)\n * [内置数据类型](#内置数据类型)\n * [引用类型](#引用类型)\n *"
},
{
"path": "docs/Java/basic/Java集合框架梳理.md",
"chars": 17599,
"preview": "# 目录\n * [集合类大图](#集合类大图)\n * [Collection接口](#collection接口)\n * [List接口](#list接口)\n * [Set接口](#set接口)\n * [Map接口](#map接口)"
},
{
"path": "docs/Java/basic/final关键字特性.md",
"chars": 14956,
"preview": "# 目录\n\n * [final使用](#final使用)\n * [final变量](#final变量)\n * [final修饰基本数据类型变量和引用](#final修饰基本数据类型变量和引用)\n * [final类](#"
},
{
"path": "docs/Java/basic/javac和javap.md",
"chars": 23947,
"preview": "# 目录\n * [聊聊IDE的实现原理](#聊聊ide的实现原理)\n * [源代码保存](#源代码保存)\n * [编译为class文件](#编译为class文件)\n * [查找class](#查找class)\n *"
},
{
"path": "docs/Java/basic/string和包装类.md",
"chars": 21053,
"preview": "# 目录\n\n * [string基础](#string基础)\n * [Java String 类](#java-string-类)\n * [创建字符串](#创建字符串)\n * [StringDemo.java 文件代码:"
},
{
"path": "docs/Java/basic/代码块和代码执行顺序.md",
"chars": 11568,
"preview": "# 目录\n\n * [Java中的构造方法](#java中的构造方法)\n * [构造方法简介](#构造方法简介)\n * [构造方法实例](#构造方法实例)\n * [例 1](#例-1)\n * [例 2](#例"
},
{
"path": "docs/Java/basic/反射.md",
"chars": 18839,
"preview": "# 目录\n\n * [回顾:什么是反射?](#回顾:什么是反射?)\n * [反射的主要用途](#反射的主要用途)\n * [反射的基础:关于Class类](#反射的基础:关于class类)\n * [Java为什么需要反射?反射要解决什么"
},
{
"path": "docs/Java/basic/多线程.md",
"chars": 19814,
"preview": "# 目录\n * [Java中的线程](#java中的线程)\n * [Java线程状态机](#java线程状态机)\n * [一个线程的生命周期](#一个线程的生命周期)\n * [Java多线程实战](#java多线程实战)\n *"
},
{
"path": "docs/Java/basic/序列化和反序列化.md",
"chars": 16197,
"preview": "# 目录\n * [序列化与反序列化概念](#序列化与反序列化概念)\n * [Java对象的序列化与反序列化](#java对象的序列化与反序列化)\n * [相关接口及类](#相关接口及类)\n * [序列化ID](#序列化id)"
},
{
"path": "docs/Java/basic/抽象类和接口.md",
"chars": 17678,
"preview": "# 目录\n * [抽象类介绍](#抽象类介绍)\n * [为什么要用抽象类](#为什么要用抽象类)\n * [一个抽象类小故事](#一个抽象类小故事)\n * [一个抽象类小游戏](#一个抽象类小游戏)\n * [接口介绍]("
},
{
"path": "docs/Java/basic/枚举类.md",
"chars": 13270,
"preview": "# 目录\n * [初探枚举类](#初探枚举类)\n * [枚举类-语法](#枚举类-语法)\n * [枚举类的具体使用](#枚举类的具体使用)\n * [常量](#常量)\n * [switch](#switch)"
},
{
"path": "docs/Java/basic/泛型.md",
"chars": 15906,
"preview": "# 目录\n * [泛型概述](#泛型概述)\n * [一个栗子](#一个栗子)\n * [特性](#特性)\n * [泛型的使用方式](#泛型的使用方式)\n * [泛型类](#泛型类)\n * [泛型接口](#泛型接口)"
},
{
"path": "docs/Java/basic/深入理解内部类.md",
"chars": 12565,
"preview": "# 目录\n * [内部类初探](#内部类初探)\n * [什么是内部类?](#什么是内部类?)\n * [内部类的共性](#内部类的共性)\n * [使用内部类的好处:](#使用内部类的好处:)\n * [那静态内部类与普"
},
{
"path": "docs/Java/basic/继承、封装、多态的实现原理.md",
"chars": 10097,
"preview": "# 目录\n * [从JVM结构开始谈多态](#从jvm结构开始谈多态)\n * [JVM 的结构](#jvm-的结构)\n * [Java 的方法调用方式](#java-的方法调用方式)\n * [常量池(constant p"
},
{
"path": "docs/Java/basic/解读Java中的回调.md",
"chars": 11855,
"preview": "# 目录\n * [模块间的调用](#模块间的调用)\n * [多线程中的“回调”](#多线程中的回调)\n * [Java回调机制实战](#java回调机制实战)\n * [实例一 : 同步调用](#实例一-:-同步调用)\n *"
},
{
"path": "docs/Java/basic/面向对象基础.md",
"chars": 15699,
"preview": "点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取Java工程师必备学习资源。\n\n* [Java面向对象三大特性(基础篇)](#java面向对象三大特性(基础篇))\n * [对象的概念](#对象的概念)\n * [面向对"
},
{
"path": "docs/Java/collection/Java集合类总结.md",
"chars": 2452,
"preview": "# 目录\n * [Colletion,iterator,comparable](#colletion,iterator,comparable)\n * [List](#list)\n * [Map](#map)\n * [CHM](#ch"
},
{
"path": "docs/Java/collection/Java集合详解:HashMap和HashTable.md",
"chars": 19895,
"preview": "# 目录\n * [HashMap](#hashmap)\n * [定义](#定义)\n * [构造函数](#构造函数)\n * [数据结构](#数据结构)\n * [存储实现:put(key,vlaue)](#存储实现:p"
},
{
"path": "docs/Java/collection/Java集合详解:HashSet,TreeSet与LinkedHashSet.md",
"chars": 17009,
"preview": "# 目录\n * [HashSet](#hashset)\n * [定义](#定义)\n * [方法](#方法)\n * [TreeSet](#treeset)\n * [TreeSet定义](#treeset定义)\n *"
},
{
"path": "docs/Java/collection/Java集合详解:Iterator,fail-fast机制与比较器.md",
"chars": 22204,
"preview": "# 目录\n * [Iterator](#iterator)\n * [java.util.Iterator](#javautiliterator)\n * [各个集合的Iterator的实现](#各个集合的iterator的实现)"
},
{
"path": "docs/Java/collection/Java集合详解:Java集合类细节精讲.md",
"chars": 15453,
"preview": "# 目录\n * [初始容量](#初始容量)\n * [asList的缺陷](#aslist的缺陷)\n * [避免使用基本数据类型数组转换为列表](#避免使用基本数据类型数组转换为列表)\n * [asList产生的列表不可操作]"
},
{
"path": "docs/Java/collection/Java集合详解:Queue和LinkedList.md",
"chars": 16077,
"preview": "# 目录\n * [LinkedList](#linkedlist)\n * [概述](#概述)\n * [源码分析](#源码分析)\n * [定义](#定义)\n * [属性](#属性)\n * [构造方法"
},
{
"path": "docs/Java/collection/Java集合详解:TreeMap和红黑树.md",
"chars": 13440,
"preview": "# 目录\n * [什么是红黑树](#什么是红黑树)\n * [定义](#定义)\n * [实践](#实践)\n * [红黑树操作](#红黑树操作)\n * [插入操作](#插入操作)\n * [删除"
},
{
"path": "docs/Java/collection/Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md",
"chars": 17827,
"preview": "# 目录\n * [ArrayList](#arraylist)\n * [ArrayList概述](#arraylist概述)\n * [ArrayList的继承关系](#arraylist的继承关系)\n * [底层数据结构"
},
{
"path": "docs/Java/collection/Java集合详解:深入理解LinkedHashMap和LRU缓存.md",
"chars": 30458,
"preview": "# 目录\n * [LinkedHashMap 概述](#linkedhashmap-概述)\n * [LinkedHashMap 在 JDK 中的定义](#linkedhashmap-在-jdk-中的定义)\n * [类结构定义](#"
},
{
"path": "docs/Java/concurrency/Java并发指南:AQS中的公平锁与非公平锁,Condtion.md",
"chars": 30737,
"preview": "# 目录\n * [公平锁和非公平锁](#公平锁和非公平锁)\n * [Condition](#condition)\n * [1\\. 将节点加入到条件队列](#1-将节点加入到条件队列)\n * [2\\. 完全释放独占锁](#2-"
},
{
"path": "docs/Java/concurrency/Java并发指南:AQS共享模式与并发工具类的实现.md",
"chars": 27025,
"preview": "# 目录\n * [前言](#前言)\n * [CountDownLatch](#countdownlatch)\n * [使用例子](#使用例子)\n * [源码分析](#源码分析)\n * [CyclicBarrier](#cy"
},
{
"path": "docs/Java/concurrency/Java并发指南:ForkJoin并发框架与工作窃取算法剖析.md",
"chars": 5762,
"preview": "# 目录\n * [Fork/Join框架介绍](#forkjoin框架介绍)\n * [简介](#简介)\n * [工作窃取算法介绍](#工作窃取算法介绍)\n\n本文转自:https://www.imooc.com/article/2482"
},
{
"path": "docs/Java/concurrency/Java并发指南:JMM中的final关键字解析.md",
"chars": 7471,
"preview": "# 目录\n\n * [一、properly constructed / this对象逸出](#一、properly-constructed--this对象逸出)\n * [二、对象的安全发布](#二、对象的安全发布)\n * [三、 fin"
},
{
"path": "docs/Java/concurrency/Java并发指南:JUC中常用的Unsafe和Locksupport.md",
"chars": 12334,
"preview": "# 目录\n * [前言](#前言)\n * [Unsafe类是啥?](#unsafe类是啥?)\n * [为什么叫Unsafe?](#为什么叫unsafe?)\n * [JAVA高并发—LockSupport的学习及简单使用](#java"
},
{
"path": "docs/Java/concurrency/Java并发指南:JUC的核心类AQS详解.md",
"chars": 19172,
"preview": "# 目录\n * [简介](#简介)\n * [AQS 结构](#aqs-结构)\n * [线程抢锁](#线程抢锁)\n * [解锁操作](#解锁操作)\n * [总结](#总结)\n * [示例图解析](#示例图解析)\n\n本文转自:htt"
},
{
"path": "docs/Java/concurrency/Java并发指南:Java中的HashMap和ConcurrentHashMap全解析.md",
"chars": 48029,
"preview": "# 目录\n * [前言](#前言)\n * [Java7 HashMap](#java7-hashmap)\n * [put 过程分析](#put-过程分析)\n * [数组初始化](#数组初始化)\n * [计算具体"
},
{
"path": "docs/Java/concurrency/Java并发指南:Java中的锁Lock和synchronized.md",
"chars": 17429,
"preview": "# 目录\n * [Java中的锁机制及Lock类](#java中的锁机制及lock类)\n * [锁的释放-获取建立的happens before 关系](#锁的释放-获取建立的happens-before-关系)\n * [锁释"
},
{
"path": "docs/Java/concurrency/Java并发指南:Java内存模型JMM总结.md",
"chars": 20686,
"preview": "# 目录\n * [简介](#简介)\n * [一、Java内存区域(JVM内存区域)](#一、java内存区域(jvm内存区域))\n * [二、Java内存模型](#二、java内存模型)\n * [三、as-if-serial"
},
{
"path": "docs/Java/concurrency/Java并发指南:Java读写锁ReentrantReadWriteLock源码分析.md",
"chars": 17509,
"preview": "# 目录\n * [使用示例](#使用示例)\n * [ReentrantReadWriteLock 总览](#reentrantreadwritelock-总览)\n * [源码分析](#源码分析)\n * [读锁获取](#读锁获取)"
},
{
"path": "docs/Java/concurrency/Java并发指南:并发三大问题与volatile关键字,CAS操作.md",
"chars": 21261,
"preview": "# 目录\n * [序言](#序言)\n * [原子性](#原子性)\n * [可见性](#可见性)\n * [有序性](#有序性)\n * [volatile关键字详解:在JMM中volatile的内存语义是锁](#volatile关键字"
},
{
"path": "docs/Java/concurrency/Java并发指南:并发基础与Java多线程.md",
"chars": 3917,
"preview": "# 目录\n * [1多线程的优点](#1多线程的优点)\n * [1.1资源利用率更好案例](#11资源利用率更好案例)\n * [1.2程序响应更快](#12程序响应更快)\n * [2多线程的代价](#2多线程的代价)\n "
},
{
"path": "docs/Java/concurrency/Java并发指南:深入理解Java内存模型JMM.md",
"chars": 7774,
"preview": "# 目录\n * [一:JMM基础与happens-before](#一:jmm基础与happens-before)\n * [并发编程模型的分类](#并发编程模型的分类)\n * [重排序](#重排序)\n * [处理器重排序"
},
{
"path": "docs/Java/concurrency/Java并发指南:深度解读Java线程池设计思想及源码实现.md",
"chars": 45598,
"preview": "# 目录\n * [前言](#前言)\n * [总览](#总览)\n * [Executor 接口](#executor-接口)\n * [ExecutorService](#executorservice)\n * [FutureTask"
},
{
"path": "docs/Java/concurrency/Java并发指南:解读Java阻塞队列BlockingQueue.md",
"chars": 26155,
"preview": "# 目录\n * [前言](#前言)\n * [BlockingQueue](#blockingqueue)\n * [BlockingQueue 实现之 ArrayBlockingQueue](#blockingqueue-实现之-arr"
},
{
"path": "docs/Java/concurrency/Java并发编程学习总结.md",
"chars": 7594,
"preview": "# 目录\n * [线程安全](#线程安全)\n * [互斥和同步](#互斥和同步)\n * [JMM内存模型](#jmm内存模型)\n * [as-if-Serial,happens-before](#as-if-serial,happe"
},
{
"path": "docs/Java/design-parttern/初探Java设计模式:JDK中的设计模式.md",
"chars": 6262,
"preview": "# 目录\n\n * [**一,结构型模式**](#一,结构型模式)\n * [**1,适配器模式**](#1,适配器模式)\n * [**2,桥接模式**](#2,桥接模式)\n * [**3,组合模式**](#3,组合模式)\n"
},
{
"path": "docs/Java/design-parttern/初探Java设计模式:Spring涉及到的种设计模式.md",
"chars": 4916,
"preview": "# 目录\n * [结构型模式](#结构型模式)\n * [代理模式](#代理模式)\n * [适配器模式](#适配器模式)\n * [桥梁模式](#桥梁模式)\n * [装饰模式](#装饰模式)\n * [门面模式]("
},
{
"path": "docs/Java/design-parttern/初探Java设计模式:创建型模式(工厂,单例等).md",
"chars": 11237,
"preview": "# 目录\n * [创建型模式](#创建型模式)\n * [简单工厂模式](#简单工厂模式)\n * [工厂模式](#工厂模式)\n * [抽象工厂模式](#抽象工厂模式)\n * [单例模式](#单例模式)\n * ["
},
{
"path": "docs/Java/design-parttern/初探Java设计模式:结构型模式(代理模式,适配器模式等).md",
"chars": 15464,
"preview": "# 目录\n * [结构型模式](#结构型模式)\n * [代理模式](#代理模式)\n * [适配器模式](#适配器模式)\n * [桥梁模式](#桥梁模式)\n * [装饰模式](#装饰模式)\n * [门面模式]("
},
{
"path": "docs/Java/design-parttern/初探Java设计模式:行为型模式(策略,观察者等).md",
"chars": 25699,
"preview": "# 目录\n * [行为型模式](#行为型模式)\n * [策略模式](#策略模式)\n * [观察者模式](#观察者模式)\n * [责任链模式](#责任链模式)\n * [模板方法模式](#模板方法模式)\n * ["
},
{
"path": "docs/Java/design-parttern/设计模式学习总结.md",
"chars": 4057,
"preview": "# 目录\n* [设计模式](#设计模式)\n* [创建型模式](#创建型模式)\n * [单例](#单例)\n * [工厂模式](#工厂模式)\n * [原型模式](#原型模式)\n * [建造者模式](#建造者模式)\n* [结构型模式](#"
},
{
"path": "docs/Java/network/Java网络与NIO总结.md",
"chars": 7448,
"preview": "# 目录\n\n* [目录](#目录)\n * [Java IO](#java-io)\n * [Socket编程](#socket编程)\n * [客户端,服务端的线程模型](#客户端,服务端的线程模型)\n * [IO模型](#io模型)\n"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:IO模型与Java网络编程模型.md",
"chars": 11058,
"preview": "# 目录\n\n* [目录](#目录)\n * [IO模型介绍](#io模型介绍)\n * [阻塞 I/O(blocking IO)](#阻塞-io(blocking-io))\n * [非阻塞 I/O(nonblocking IO)]"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:JAVA中原生的socket通信机制.md",
"chars": 9740,
"preview": "# 目录\n\n * [当前环境](#当前环境)\n * [处理 socket 输入输出流](#处理-socket-输入输出流)\n * [结果展示](#结果展示)\n * [请求模型优化](#请求模型优化)\n * [补充1:TCP"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:JavaNIO一步步构建IO多路复用的请求模型.md",
"chars": 13877,
"preview": "# 目录\n\n * [当前环境](#当前环境)\n * [代码地址](#代码地址)\n * [知识点](#知识点)\n * [获取 socket 连接](#获取-socket-连接)\n * [完整示例](#完整示例)\n * "
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:Java非阻塞IO和异步IO.md",
"chars": 21081,
"preview": "# 目录\n\n* [目录](#目录)\n * [阻塞模式 IO](#阻塞模式-io)\n * [非阻塞 IO](#非阻塞-io)\n * [NIO.2 异步 IO](#nio2-异步-io)\n * [1、返回 Future 实例](#1"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:LinuxEpoll实现原理详解.md",
"chars": 10223,
"preview": "# 目录\n\n * [为什么要 I/O 多路复用](#为什么要-io-多路复用)\n * [select](#select)\n * [poll](#poll)\n * [epoll](#epoll)\n * [epol"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO).md",
"chars": 25582,
"preview": "# 目录\n\n* [目录](#目录)\n * [前言](#前言)\n * [源码环境准备](#源码环境准备)\n * [endpoint](#endpoint)\n * [init 过程分析](#init-过程分析)\n * [start 过"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:基于NIO的网络编程框架Netty.md",
"chars": 52603,
"preview": "# 目录\n\n* [目录](#目录)\n * [Netty概述](#netty概述)\n * [Netty简介](#netty简介)\n * [Netty都有哪些组件?](#netty都有哪些组件?)\n * [Netty是如何处理连"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:浅析NIO包中的Buffer、Channel和Selector.md",
"chars": 12299,
"preview": "# 目录\n\n* [目录](#目录)\n * [Buffer](#buffer)\n * [position、limit、capacity](#position、limit、capacity)\n * [初始化 Buffer](#初始"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:浅析mmap和DirectBuffer.md",
"chars": 19648,
"preview": "# 目录\n\n* [目录](#目录)\n* [mmap基础概念](#mmap基础概念)\n* [mmap内存映射原理](#mmap内存映射原理)\n* [mmap和常规文件操作的区别](#mmap和常规文件操作的区别)\n* [mmap优点总结](#"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:浅谈Linux中Selector的实现原理.md",
"chars": 19630,
"preview": "# 目录\n\n* [目录](#目录)\n * [概述](#概述)\n * [Selector的中的重要属性](#selector的中的重要属性)\n * [Selector 源码解析](#selector-源码解析)\n * [1、Sel"
},
{
"path": "docs/Java/network/Java网络编程与NIO详解:深度解读Tomcat中的NIO模型.md",
"chars": 6724,
"preview": "# 目录\n\n* [目录](#目录)\n * [一、I/O复用模型解读](#一、io复用模型解读)\n * [二、TOMCAT对IO模型的支持](#二、tomcat对io模型的支持)\n * [三、TOMCAT中NIO的配置与使用](#三、t"
},
{
"path": "docs/JavaWeb/JavaWeb技术总结.md",
"chars": 2584,
"preview": "# 目录\n * [Servlet及相关类](#servlet及相关类)\n * [Jsp和ViewResolver](#jsp和viewresolver)\n * [filter,listener](#filter,listener)\n "
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:Hibernate入门经典与注解式开发.md",
"chars": 24145,
"preview": "# 目录\n* [前言](#前言)\n* [ORM概述](#orm概述)\n* [测试](#测试)\n* [相关类](#相关类)\n* [扩展](#扩展)\n* [参考文章](#参考文章)\n\n\n本文转载自互联网,侵删\n本系列文章将整理到我在GitHub"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:JDBC的进化与连接池技术.md",
"chars": 5864,
"preview": "# 目录\n* [JDBC数据库连接池](#jdbc数据库连接池)\n * [谈谈连接池、线程池技术原理](#谈谈连接池、线程池技术原理)\n* [JDBC 数据库连接池](#jdbc-数据库连接池)\n * [什么情况下使用连接池?](#"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:JSP与Servlet的曾经与现在.md",
"chars": 6876,
"preview": "# 目录\n * [servlet和jsp的区别](#servlet和jsp的区别)\n * [servlet和jsp各自的特点](#servlet和jsp各自的特点)\n * [通过MVC双剑合璧](#通过mvc双剑合璧)\n * [Ja"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:JavaWeb的由来和基础知识.md",
"chars": 5398,
"preview": "# 目录\n * [什么是 Java Web](#什么是-java-web)\n * [Web开发的历史](#web开发的历史)\n * [开源框架时代](#开源框架时代)\n * [Java Web基础知识](#java-web基"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:Java日志系统的诞生与发展.md",
"chars": 7250,
"preview": "# 目录\n * [Java日志系统的演变史](#java日志系统的演变史)\n * [阶段一](#阶段一)\n * [阶段二](#阶段二)\n * [阶段三](#阶段三)\n * [阶段四](#阶段四)\n * [阶段"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:Mybatis入门.md",
"chars": 13191,
"preview": "# 目录\n* [前言](#前言)\n* [Mybatis是什么](#mybatis是什么)\n * [特点](#特点)\n * [核心类介绍](#核心类介绍)\n * [功能架构:我们把Mybatis的功能架构分为三层](#功能架"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:Servlet工作原理详解.md",
"chars": 11803,
"preview": "# 目录\n * [什么是Servlet](#什么是servlet)\n * [Servlet体系结构](#servlet体系结构)\n * [Servlet工作原理](#servlet工作原理)\n * [Servlet生命周期](#se"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:Tomcat5总体架构剖析.md",
"chars": 5176,
"preview": "# 目录\n\n * [连接器(Connector)](#连接器(connector))\n * [容器(Container)](#容器(container))\n\n\n \n本文转载自互联网,侵删\n本系列文章将整理到我在GitHub上的《Java"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:Tomcat和其他WEB容器的区别.md",
"chars": 3690,
"preview": "# 目录\n * [Tomcat和物理服务器的区别](#tomcat和物理服务器的区别)\n * [Tomcat:](#tomcat:)\n * [物理服务器:](#物理服务器:)\n * [详解tomcat 与 nginx,apa"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:从JavaBean讲到Spring.md",
"chars": 5980,
"preview": "# 目录\n * [**Java Bean**](#java-bean)\n * [**JSP + Java Bean**](#jsp--java-bean)\n * [Enterprise Java bean](#enterprise-j"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven.md",
"chars": 12658,
"preview": "# 目录\n * [maven简介](#maven简介)\n * [1.1 Maven是什么](#11-maven是什么)\n * [1.2 Maven发展史](#12-maven发展史)\n * [1.3 为什么要用Maven"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:初探Tomcat9的HTTP请求过程.md",
"chars": 11131,
"preview": "# 目录\n * [初探Tomcat的HTTP请求过程](#初探tomcat的http请求过程)\n * [Tomcat的组织结构](#tomcat的组织结构)\n * [由Server.xml的结构看Tomcat的体系结构](#由se"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:单元测试框架Junit.md",
"chars": 13157,
"preview": "# 目录\n* [简介](#简介)\n* [概述](#概述)\n* [好处](#好处)\n* [Junit单元测试](#junit单元测试)\n * [1 简介](#1-简介)\n * [2 特点](#2-特点)\n * [3 内容]("
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:极简配置的SpringBoot.md",
"chars": 15200,
"preview": "# 目录\n* [Spring Boot 概述](#spring-boot-概述)\n * [什么是 Spring Boot](#什么是-spring-boot)\n * [使用 Spring Boot 有什么好处](#使用-spri"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:浅析Tomcat请求处理流程与启动部署过程.md",
"chars": 6108,
"preview": "# 目录\n * [Overview](#overview)\n * [Connector Init and Start](#connector-init-and-start)\n * [Request Process](#request-"
},
{
"path": "docs/JavaWeb/走进JavaWeb技术世界:深入浅出Mybatis基本原理.md",
"chars": 5111,
"preview": "# 目录\n* [引言](#引言)\n* [工作原理原型图](#工作原理原型图)\n* [工作原理解析](#工作原理解析)\n* [mybatis层次图:](#mybatis层次图:)\n * [MyBatis框架及原理分析](#MyBatis"
},
{
"path": "docs/Spring全家桶/Spring/SpringAOP的概念与作用.md",
"chars": 14080,
"preview": "# Spring ܵ AOP\n\n## Spring ܵ AOP\n\nSpring ܵһؼ**ı**(AOP)ܡıҪѳֽɲͬIJֳΪνĹע㡣һӦóĶĹܱΪ**йע**Щйעڸ϶Ӧóҵиָĺܺõӣ־¼ơʽȫԺͻȡ\n\n OOP УؼԪģ࣬ AO"
},
{
"path": "docs/Spring全家桶/Spring/SpringBean的定义与管理(核心).md",
"chars": 4997,
"preview": "### ע\n\nSpringܵĺĹ\n\n* SpringΪеJavaЩJavaΪBean\n* SpringBean֮ϵSpringʹһֱΪ\"ע\"ķʽBean֮ϵ\n\nʹע룬ΪBeanעֵͨעBeanáעһĽʽBeanļ֯һ𣬶Ӳķʽ"
},
{
"path": "docs/Spring全家桶/Spring/Spring中对于数据库的访问.md",
"chars": 29978,
"preview": "\n## Դ\n\n### Spring Դ\n\nSpring Դжַʽһһо٣\n\n#### [#](https://dunwu.github.io/spring-tutorial/pages/1b774c/#%E4%BD%BF%E7%94%A8-"
},
{
"path": "docs/Spring全家桶/Spring/Spring中对于校验功能的支持.md",
"chars": 19248,
"preview": "# Spring У\n\nJava API 淶(`JSR303`)`Bean`Уı`validation-api`ûṩʵ֡`hibernate validation`Ƕ淶ʵ֣Уע`@Email``@Length`ȡ`Spring Valid"
},
{
"path": "docs/Spring全家桶/Spring/Spring中的Environment环境变量.md",
"chars": 34558,
"preview": "\n\n\n\nڰøٵĴ롢дϵͳ Spring Boot ȻΪ Java Ӧÿʵ Spring Boot ṩڶУ**Զ**ǶһԣSpring Boot һΪԱԶɿ伴á߱ijһܵ Bean£Զõ Bean պҵijЩ£òظǣʱֻҪ͵ Bean ɣΪԶ"
},
{
"path": "docs/Spring全家桶/Spring/Spring中的事件处理机制.md",
"chars": 6938,
"preview": "\n\n\n\n# Spring е¼\n\n\n\n2022-05-16 15:29 \n\n\n\n\n\n\n\n\n\n## Spring е¼\n\nѾ½ Spring ĺ **ApplicationContext** beans ڡ beans ʱApplicatio"
},
{
"path": "docs/Spring全家桶/Spring/Spring中的资源管理.md",
"chars": 9413,
"preview": "## Resource ӿ\n\nԱ URL ʻƣSpring `org.springframework.core.io.Resource` ӿڳ˶ԵײԴķʽӿڣṩһõķʷʽ\n\n\n\n```\npublic interface Resourc"
},
{
"path": "docs/Spring全家桶/Spring/Spring中的配置元数据(管理配置的基本数据).md",
"chars": 11096,
"preview": "\n\n# Spring Ԫ\n\n\n\n## [#](https://dunwu.github.io/spring-tutorial/pages/55f315/#spring-%E9%85%8D%E7%BD%AE%E5%85%83%E4%BF%A1"
},
{
"path": "docs/Spring全家桶/Spring/Spring事务基本用法.md",
"chars": 13234,
"preview": "# SpringĽӿ\n\n[Spring](http://www.voidme.com/spring) ǻ AOP ʵֵģ AOP ԷΪλġSpring ԷֱΪΪ뼶ֻͳʱԣЩṩӦõķԡ\n\n [Java](http://www.voidme.c"
},
{
"path": "docs/Spring全家桶/Spring/Spring合集.md",
"chars": 205,
"preview": "# Spring\n\n\n# SpringԴ\n\n# SpringMVC\n\n# SpringMVC Դ\n\n# SpringBoot\n## springbootǰ\n## springbootĻʹ\n## springbootijע\n## springb"
},
{
"path": "docs/Spring全家桶/Spring/Spring容器与IOC.md",
"chars": 3095,
"preview": "IoC Inversion of Control ļдΪƷתһżһ˼룬һҪ̷ָܹƳϡij\n\nSpring ͨ IoC Java ʵͳʼƶ֮ϵǽ IoC Java Ϊ Spring Beanʹùؼ new Java ûκ\n\nIoC S"
},
{
"path": "docs/Spring全家桶/Spring/Spring常见注解.md",
"chars": 11934,
"preview": "# Springע\n## 1 \n\nǶ֪SpringĵԾIOC+AOPIOCԭʵһSpringSpring Beanʵ\nDIҲע룬ΪҪĵĺĻ⣬עעĸҪȷ֪ġ\nǰϰxmlļһbeanڣǸʹעʹDIĹ\n\n\nǿʹ org.springframewo"
},
{
"path": "docs/Spring全家桶/Spring/Spring概述.md",
"chars": 3935,
"preview": "Spring Java EE һĿԴܣɱΪSpring ֮ Rod Johnson 2002 ĿҪ Java ҵӦóĿѶȺڡ\n\nSpring ԵһֱԱΪ Java ҵӦóѡʱգSpring ٲȻΪ Java EE ʣΪ˹ Java "
},
{
"path": "docs/Spring全家桶/Spring/第一个Spring应用.md",
"chars": 1851,
"preview": "## \nǿȰ Spring Jar Լ Commons-loggin 뵽ĿУӣҪٵ Spring Jar\n\n````\norg.springframework.core-5.3.13.jar\norg.springframework.bea"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot中的任务调度与@Async.md",
"chars": 4812,
"preview": "\n\n<header>\n\n# Spring Boot\n\nݽվѸѧϰʼǡܽоղء֤ȷԣʹöķ뱾վأ\n\n</header>\n\n\n\n<script>( adsbygoogle = window.adsbygoogle || []).push({}"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot中的日志管理.md",
"chars": 15072,
"preview": "## 4\\. ־\n\n\n\n\n\nSpring Bootڲ־ʹ [Commons Logging](https://commons.apache.org/logging) Եײ־ʵֱֿš Ϊ [Java Util Logging](https:/"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot常见注解.md",
"chars": 2662,
"preview": "## 1 \nSpring Boot ͨԶùʹ Spring øס\n\nڱٽ̳Уǽ̽ org.springframework.boot.autoconfigure org.springframework.boot.autoconfigure."
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot应用也可以部署到外部Tomcat.md",
"chars": 6848,
"preview": "\n\n<header>\n\n# Spring Boot Tomcat\n\nݽվѸѧϰʼǡܽоղء֤ȷԣʹöķ뱾վأ\n\n</header>\n\n\n\n<script>( adsbygoogle = window.adsbygoogle || [])."
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot打包与启动.md",
"chars": 60286,
"preview": "在使用`maven`构建`springboot`项目时,`springboot`相关 jar 包可以使用`parent方式`引入(即在`pom.xml`的`parent`节点引入`springboot`的`GAV`:`org.springf"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot生产环境工具Actuator.md",
"chars": 88572,
"preview": "\n\n# \n\n[Back to index](https://springdoc.cn/spring-boot/index.html)\n\n* [1\\. Ĺ](https://springdoc.cn/spring-boot/actuato"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot的Starter机制.md",
"chars": 5623,
"preview": "starterSpringBootеһ·ЧĽĿ̵ĸӳ̶ȣڼŷdzõЧתһƬ£ϸspring boot staterʲôʲô\n\nSpring Boot StarterSpringBootбһָstackoverflowѾ˸starterʲô"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md",
"chars": 6520,
"preview": "# SpringBootǰ\n\nSpring Boot 2.0 Ƴּһѧϰ Spring Boot ȣ͵Ҹ˵IJ͵ķӾͿԸܵҶѧϰ Spring Boot 飬ôôѧϰ Spring Boot ֮ʱԼҲ˼ Spring Boot ıʲôSprin"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot的基本使用.md",
"chars": 3568,
"preview": "# ٹSpringBootӦ\n\n̳springboot㹻ȨҲ㹻\n\n## һ hello world \n\nһġHello WorldκӵĶ˵㡣Ը֣ԸѺõķʽӦ\n\n## Ҫ\n\n1һֵIDE,ѡ IntelliJ IDEASpring Too"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot的配置文件管理.md",
"chars": 41819,
"preview": "## 1.SpringBootùı\n\nΪʵֿٴͿĿSpringbootܴspringbootĿԽĿֱӴjarУԼװTomcatһַݵIJʽ\n\nĿķʽһjar𣬼ļ͵jarͻ\n\nһĿйУҪĶļĻҪ´\n\nĿҪͬһ̨ʱԵjarͬĵĿjar1"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot自带的热部署工具.md",
"chars": 9471,
"preview": "# SpringBoot - Ȳdevtools\n\n> SpringBootУÿдĶҪٵԣܱȽϷʱ䣻SpringBootŶԴṩspring-boot-devtoolsdevtoolsͼԵЧʡ@pdai\n\n* [SpringBoot -"
},
{
"path": "docs/Spring全家桶/SpringBoot/SpringBoot集成Swagger实现API文档自动生成.md",
"chars": 16489,
"preview": "\n\nĿ¼\n\n* [SwaggerĽ](https://www.cnblogs.com/progor/p/13297904.html#swagger%E7%9A%84%E4%BB%8B%E7%BB%8D)\n * [ŵȱ](htt"
},
{
"path": "docs/Spring全家桶/SpringBoot/Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot).md",
"chars": 18146,
"preview": "# Springע\n## 1 \n\nǶ֪SpringĵԾIOC+AOPIOCԭʵһSpringSpring Beanʵ\nDIҲע룬ΪҪĵĺĻ⣬עעĸҪȷ֪ġ\nǰϰxmlļһbeanڣǸʹעʹDIĹ\n\n\nǿʹ org.springframewo"
},
{
"path": "docs/Spring全家桶/SpringBoot/基于SpringBoot中的开源监控工具SpringBootAdmin.md",
"chars": 6815,
"preview": "Spring Boot Admin(SBA)һԴĿڹͼ Spring Boot ӦóӦóͨ http ķʽ Spring Cloud ֻעᵽ SBA УȻͿʵֶ Spring Boot ĿĿӻͲ鿴ˡ\n\nSpring Boot Admin Լ"
},
{
"path": "docs/Spring全家桶/SpringBoot/给你一份SpringBoot知识清单.md",
"chars": 40586,
"preview": "# 目录\n* [一、抛砖引玉:探索Spring IoC容器](#一、抛砖引玉:探索spring-ioc容器)\n * [1.1、Spring IoC容器](#11、spring-ioc容器)\n * [1.2、Spring容器扩展机"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/@SpringBootApplication注解.md",
"chars": 11013,
"preview": "springboot ϻעһע⣺`@SpringBootApplication`˽Դ עá\n\n`@SpringBootApplication` £\n\n```\n@Target(ElementType.TYPE)\n@Retention(Rete"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(一):servlet组件的注册流程.md",
"chars": 18970,
"preview": " springboot УҪע servlet `servlet``filter``listener`ôأspringboot ĵΪṩ 3 ַľ 3 ַԴʵ֡\n\n### 1\\. ע᷽ʽ\n\n#### 1.1 ʹ `XxxRegistratio"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(二):WebMvc装配过程.md",
"chars": 26554,
"preview": "ƽʱУspringboot е web ĿĽ springboot Զ springMvc Ŀ̡\n\n### 1\\. springMvc Զװ\n\nspringMvc ԶװΪ\n\n```\n@Configuration(proxyBeanMetho"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(一):准备SpringApplication.md",
"chars": 9630,
"preview": "̽ springboot ģʹõ demo λ?[gitee/funcy](https://gitee.com/funcy/spring-boot/tree/v2.2.2.RELEASE_learn/spring-boot-project/"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(三):准备IOC容器.md",
"chars": 14254,
"preview": "һƪܽ springboot £\n\n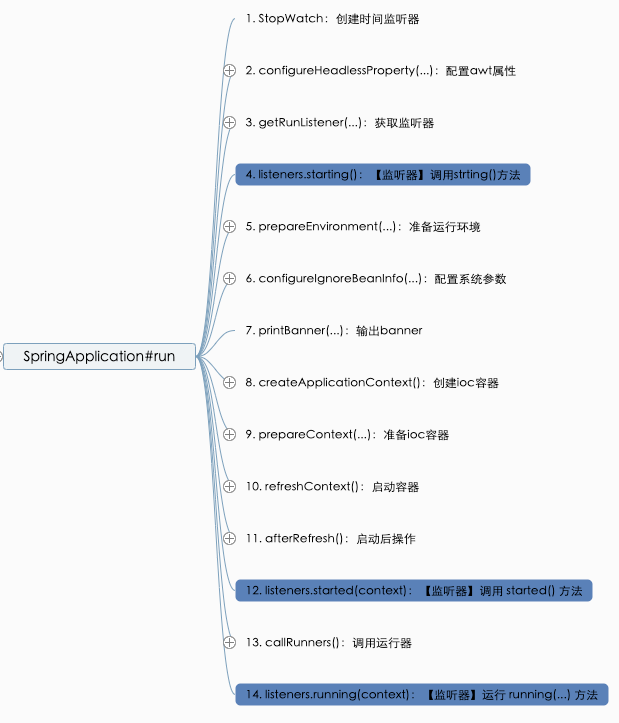\n\nģǼ"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(二):准备运行环境.md",
"chars": 14341,
"preview": "ģǼĽ`SpringApplication#run(String...)`\n\n## 3.`springboot`У`SpringApplication#run(String...)`\n\n£\n\n```\npublic ConfigurableA"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(五):完成启动.md",
"chars": 2616,
"preview": "һƪܽ springboot £\n\n\n"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(六):启动流程总结.md",
"chars": 1240,
"preview": "ǰ漸ƪ· springboot ̣ܽ¡\n\nһʼ `SpringApplication.run(Demo01Application.class, args);` ֣ط\n\n* `SpringApplication#SpringApplica"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(四):启动IOC容器.md",
"chars": 10774,
"preview": "һƪܽ springboot £\n\n\n\nģǼ"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(一):加载自动装配类.md",
"chars": 15028,
"preview": "Զװ springboot ĺ֮һĽ̽ springboot μԶװġ\n\n [@SpringBootApplication ע](https://my.oschina.net/funcy/blog/4870882)һУᵽ springboo"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(三):自动装配顺序.md",
"chars": 18686,
"preview": " [springboot Զװ֮ע⣨һ](https://my.oschina.net/funcy/blog/4918863)һУڷ `@ConditionalOnBean/@ConditionalOnMissingBean` עжʱٷǿҽ"
},
{
"path": "docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(二):条件注解.md",
"chars": 32464,
"preview": "### 1\\. ע⼰ж\n\n [springboot Զװ֮Զװ](https://my.oschina.net/funcy/blog/4870868)һУǷ springboot `META-INF/spring.factories` ļ"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudConfig.md",
"chars": 19785,
"preview": "ڷֲʽϵͳУзж벻ļ֧֣Щļͨɸй properties yml ʽڸ·£ application.properties application.yml ȡ\n\nֽļɢڸеĹʽ⣺\n\n* **Ѷȴ**ļɢڸУԹ\n* **ȫԵ*"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudConsul.md",
"chars": 3872,
"preview": "Spring Cloud Consul Ϊ SpringBoot Ӧṩ Consul֧֣ConsulȿΪעʹãҲΪʹãĽ÷ϸܡ\n\n# Consul \n\nConsulHashiCorp˾ƳĿԴṩϵͳеķġߵȹܡЩеÿһԸҪʹãҲһʹԹȫλķ"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudEureka.md",
"chars": 27449,
"preview": "Eureka һԴڹϣʻ㣬ǡˡ˼Eureka Netflix ˾һԴķע뷢\n\nSpring Cloud Eureka Netflix еԴ RibbonFeign Լ Hystrix ȣһϽ Spring Cloud Netflix"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudGateway.md",
"chars": 12941,
"preview": "ܹУһϵͳɶɣЩܲڲͬͬͬ¡£ͻˣֻߵȣҪֱЩҪ֪ǾĵַϢ IP ַ˿ںŵȡ\n\nֿͻֱķʽ⣺\n\n* ڶʱͻҪάķַڿͻ˵Ƿdzӵġ\n* ijЩ¿ܻڿ⡣\n* ֤ѶȴÿҪ֤\n\nǿͨ API Щ⣬ʲô API ء\n\n## API "
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudHystrix.md",
"chars": 26770,
"preview": "ܹУһӦɶɣЩ֮ϵ۸ӡ\n\nһϵͳд ABCDEF ȶǵϵͼ\n\n\n\nͼ1ϵ\n\nͨ£һûҪϲɡͼ"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudLoadBalancer.md",
"chars": 8639,
"preview": "ǰãҰMall汾ȫ ͨGatewayصʱService Unavailable⡣ŲԭʱΪؾRibbonˣΪNetflixԴһRibbonѽά״̬ƼʹõLoadbalancerǾLoadbalancerʹã\n\n# LoadBalancer"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudOpenFeign.md",
"chars": 13106,
"preview": "Netflix Feign Netflix ˾һʵָؾͷõĿԴSpring Cloud Netflix еԴ EurekaRibbon Լ Hystrix ȣһϽ Spring Cloud Netflix ģУϺȫΪ Spring Cl"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudRibbon.md",
"chars": 17010,
"preview": "Spring Cloud Ribbon һ Netflix Ribbon ʵֵĿͻ˸ؾͷùߡ\n\nNetflix Ribbon Netflix ˾ĿԴҪṩͻ˵ĸؾ㷨ͷáSpring Cloud Netflix еԴ EurekaFeig"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudSleuth.md",
"chars": 4142,
"preview": "> Spring Cloud Sleuth ǷֲʽϵͳиٷõĹߣֱ۵չʾһĵụ̀Ľ÷ϸܡ\n\n## [#](https://www.macrozheng.com/cloud/sleuth.html#spring-cloud-sleuth-%E"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloudZuul.md",
"chars": 6994,
"preview": "Spring Cloud Zuul Spring Cloud Netflix Ŀĺ֮һΪܹеAPIʹãֶ֧̬·˹ܣĽ÷ϸܡ\n\n# Zuul\n\nAPIΪܹеķṩͳһķڣͻͨAPIططAPIصĶģʽеģʽ൱ܹе棬пͻ˵ķʶͨ·ɼˡʵ·ɡؾ"
},
{
"path": "docs/Spring全家桶/SpringCloud/SpringCloud概述.md",
"chars": 4672,
"preview": "Spring Cloud һ Spring Boot ʵֵܡSpring Cloud Դ Spring Ҫ Pivotal Netflix ˾ṩά\n\nĻУ˾̷ܹУԲֵͬĸĽͿԴܡ\n\n* ****ͰͿԴ Dubbo ͵չ Dubb"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaNacos.md",
"chars": 38523,
"preview": "Nacos ӢȫΪ Dynamic Naming and Configuration ServiceһɰͰŶʹ Java ԿĿԴĿ\n\nNacos һڰԭӦõĶ̬֡úͷƽ̨ο [Nacos ](https://nacos.io/zh-cn/i"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaRocketMQ.md",
"chars": 5474,
"preview": "1. RocketMQ \n\nRocketMQ ǰͰͿԴķֲʽϢм֧Ϣ˳ϢϢʱϢϢݵȡмڱϢмĸGroupTopicQueueȡϵͳProducerConsumerBrokerNameServerȡ\n\nRocketMQ ص\n\n- ַ֧/ģ"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSeata.md",
"chars": 20020,
"preview": "## \n\nǶ֪ Seata һֲʽĽǾ˽һʲôǷֲʽ˽һ»֪ʶ˽һĸʲô\n\n### \n\nIJֹɡ ACID\n\n* A(Atomic)ԭԣвҪôȫִгɹҪôȫִʧܣֲֳɹ߲ʧܵ\n* C(Consistency)һԣִǰݿһԼûбƻ磬Сȥ"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSentinel.md",
"chars": 12486,
"preview": "## ժҪ\n\nSpring Cloud Alibaba ṩһվʽSentinel Ϊ֮һ۶һϵзܣĽ÷ϸܡ\n\n## Sentinel\n\nУͷ֮ȶԱԽԽҪ Sentinel Ϊ㣬ơ۶Ͻϵͳرȶάȱȶԡ\n\nSentinel:\n\n* "
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSkywalking.md",
"chars": 13335,
"preview": "# 1\\. SkyWalking \n\n> Skywalking ɹڿԴɣԭ OneAPM ʦĿǰڻΪԴύ Apache IJƷͬʱ Zipkin/Pinpoint/CAT ˼·ַ֧ʽ㡣һڷֲʽٵӦóܼϵͳչһ OpenTracing ּ֯ƽص"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibaba概览.md",
"chars": 6199,
"preview": "Spring Cloud AlibabaṩһվʽSpring CloudֲAlibabaԪ֮IJSpring Cloud AlibabaԿٴܹɼСҵҪҵ̨ͼֻ̨ҵתͣSpring Cloud Alibabaһ\n\n# ʲôSpring"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务发现.md",
"chars": 16624,
"preview": "# һNacosͼ\n\n\n\nԼһ̣ҲԲο[N"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务注册.md",
"chars": 10432,
"preview": "# һ NacosעԴ\n\n\n\n* * *\n\n\n\n## 1.1 Դ뷽ʽ\n\n\n\n* * *\n\n\n\nͻԴӴʽԴ\n\n\n\n\n\n\n\n```<plugin> <groupId>org.apache.maven.plugins</groupId> m"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:概览.md",
"chars": 12448,
"preview": "ڿƪ֮ǰöNACOSع˽⣬Ƽ[Spring Cloud Alibaba Nacosƪ](https://zhuanlan.zhihu.com/p/68700978)\n\nԹܣĿĵȥӦԴ룬һ˽αʵֳġ\n\nһԴĶȺ̫ϸڣҪߴԴ٣ᡣ\n\n## һ\n"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:配置中心.md",
"chars": 7626,
"preview": "# Nacos\n\n## Nacosĵʹ\n\nοٷ[github.com/alibaba/spr](https://link.juejin.cn?target=https%3A%2F%2Fgithub.com%2Falibaba%2Fsprin"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudRocketMQ源码分析.md",
"chars": 20953,
"preview": "### һNameServer\n\nԴڣNamesrvStartup#main\n\n##### 1.NamesrvController controller = createNamesrvController(args);\n\n* в\n* "
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSeata源码分析.md",
"chars": 44148,
"preview": " | һߣJava\nԴ |ͷ\n\n**ѧϰĿ**\n\n* Seata ATģʽԴ\n **1 ATģʽ**\n **1.1 ˼άƵ**\n ѾATģʽĴԭԴУͨREADMEҲܿATģʽʹãDZĽӵײԴȥATģʽԭڷԭ֮ǰͼһĹ˼·"
},
{
"path": "docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSentinel源码分析.md",
"chars": 29240,
"preview": " | һߣJava\nԴ |ͷ\n\n**ѧϰĿ**\n\n* SentinelĹԭ\n **1 ԭ**\n SentinelУеԴӦһԴԼһEntryÿһentryԱʾһSentinelУԵǰڹжʵصĿƣԭͼʾ\n\n![SpringCl"
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudConfig源码分析.md",
"chars": 33250,
"preview": "Ҫ˽spring cloud configǾͱ˽springbootenvironmentļع̡\n\n\n\n```\nSpringApplication.run(AppApiApplication.class, args);\n\npublic st"
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudEureka源码分析.md",
"chars": 54074,
"preview": "EurekaԴ\n\n**1 **\n**1.1 Eurekaʲô**\n\nǶףEurekaעģעҪʵʲôأȷˡ\n\n1. ȻעģҪܱipportϢɣEureka-serverṩĻܡ\n2. ע֮ҪṩһЩ̬֪ߵĹܰɣһߣEureka-server"
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudGateway源码分析.md",
"chars": 10932,
"preview": "**ѧϰĿ**\n\n1. Gatewayԭ\n **1 Bean**\n ǰҲôˣǼ\n spring-cloud-starter-gateway֣һstarter˵ȥspring.factoriesļһЩҪbeanԶװIoC"
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudHystrix源码分析.md",
"chars": 38160,
"preview": "ѧϰĿ\n\n1. дMiniHystrix\n2. RxJava֪ʶ\n3. Hystrixĺ̷\n4. Դ֤\n 1 дMini\n ѾҽܹHystrixĺĹܺʹˣǾṩ۶ϡȹܣ۶ϺĿģǽʹùʵĵע⣺@EnableHystrix@Hystr"
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudLoadBalancer源码分析.md",
"chars": 24465,
"preview": "# Spring Cloud LoadBalancer\n\n## \n\n> Spring Cloud LoadBalancerĿǰSpringٷǷspring-cloud-commonsSpring Cloud°汾Ϊ2021.0.2\n>\n> "
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudOpenFeign源码分析.md",
"chars": 23334,
"preview": " | ľľ\nԴ |ͷ\n\n**ѧϰĿ**\n\n1. ΪʲôһעʵԶ̵̹أƵײʵ̣\n2. OpenFeignôʵRPCĻܵ\n3. ͨԴ֤\n **1 OpenFeignƵ**\n ҪȷOpenFeignǻҪȷĺĿʲô\n\n˵ˣOpen"
},
{
"path": "docs/Spring全家桶/SpringCloud源码分析/SpringCloudRibbon源码分析.md",
"chars": 24172,
"preview": "**ѧϰĿ**\n\n1. ƵRibbonĺ\n2. дһװRibbon\n3. ͨԴ֤Ƶ\n **1 Ƶ**\n ʵRibbonĺ̺ܼʹùǾһspring-cloud-starter-netflix-ribbonjarȻڳʱעһ"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC中的国际化功能.md",
"chars": 6226,
"preview": "#### ʻ\n\n* * *\n\nڿӦóʱֶ֧Եֶ֧ԵĹ֮ܳΪʻӢinternationalizationдΪi18nΪĸiĩĸnм18ĸ\n\nضıػܣӢlocalizationдΪL10nػָݵڵʾȡ\n\nҲаߺϳΪȫӢglobalizati"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC中的常用功能.md",
"chars": 29497,
"preview": "\n\n\n\n# Spring MVC ʹ@Controllerעⶨһ\n\n\n\n2018-07-26 14:02 \n\n\n\n\n\n\n\n<section>\n\n> [Original] The `@Controller` annotation indica"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC中的异常处理器.md",
"chars": 5304,
"preview": "\n\n\n\n# Spring MVC 쳣\n\n\n\n2018-07-26 14:32 \n\n\n\n\n\n\n\nSpringĴ쳣`HandlerExceptionResolver`ӿڵʵִָйгֵ쳣ij̶ֳϽ`HandlerExceptionResolver`"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC中的拦截器.md",
"chars": 2319,
"preview": "\n\n\n\n# Spring MVC ʹHandlerInterceptor\n\n\n\n2018-07-26 14:07 \n\n\n\n\n\n\n\nSpringĴӳư˴ҪΪض͵ӦһЩʱܺã磬ûݵȡ\n\n<section>\n\nӳ䴦õʵ `org.springfr"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC中的视图解析器.md",
"chars": 5674,
"preview": "\n\n\n\n# Spring MVC ʹViewResolverӿڽͼ\n\n\n\n2018-07-26 15:39 \n\n\n\n\n\n\n\n[Spring MVC ʵ](https://www.w3cschool.cn/spring_mvc_documen"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC中的过滤器Filter.md",
"chars": 4177,
"preview": "Filter\n\nSpring MVCУDispatcherServletֻҪ̶õweb.xmlУʣµĹҪרעڱдController\n\nǣServlet淶УǻʹFilterҪSpring MVCʹFilterӦô\n\nеͯЬһڵWebӦпܷˣ"
},
{
"path": "docs/Spring全家桶/SpringMVC/SpringMVC基本介绍与快速入门.md",
"chars": 18343,
"preview": "\n\n\n\n## MVC Ƹ\n\n Java Web ĿУͳһʾ㡢Ʋ㡢ݲIJȫ JSP JavaBean дdz֮Ϊ **Model1**\n\n\n\n\n\nУͨһ demo ɹ springmvc Ӧãṩ demo У֪ tomcat ʱ `MyWebApplicationInitiali"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/RequestMapping初始化流程.md",
"chars": 25684,
"preview": "ǰУǷ `DispatcherServlet` ʼ̣Ľ `RequestMapping` ʼ̡˵ `RequestMapping` ʼֱ̣˵ spring `@RequestMaping` עĹ̡\n\n### 1\\. ̸ `@EnableW"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC整体源码结构总结.md",
"chars": 1737,
"preview": "### 1\\. servlet 3.0 淶\n\nϵһʼȽ `servlet3.0` 淶ͨù淶ʵ web Ŀ `0xml` .\n\n* `servlet3.0` 淶Уservlet ͨ `SPI` ṩһӿڣ`ServletContainerI"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet如何找到正确的Controller.md",
"chars": 8978,
"preview": "# 目录\n* [前言](#前言)\n* [源码分析](#源码分析)\n* [实例](#实例)\n* [资源文件映射](#资源文件映射)\n* [总结](#总结)\n\n\n本文转载自互联网,侵删\n\n本系列文章将整理到我在GitHub上的《Java面试指南"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet的初始化与请求转发.md",
"chars": 15454,
"preview": "# 目录\n * [前言](#前言)\n * [容器上下文的建立](#容器上下文的建立)\n * [初始化SpringMVC默认实现类](#初始化springmvc默认实现类)\n * [总结](#总结)\n\n\n本文转载自互联网,侵删\n\n本系"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC概述.md",
"chars": 22473,
"preview": "# 目录\n\n * [1.1、SpringMVC引言](#11、springmvc引言)\n * [1.2、SpringMVC的优势](#12、springmvc的优势)\n * [二、SpringMVC入门](#二、springmvc入门"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC的视图解析原理.md",
"chars": 12643,
"preview": "# 目录\n* [目录](#目录)\n* [前言](#前言)\n* [重要接口和类介绍](#重要接口和类介绍)\n* [源码分析](#源码分析)\n* [编码自定义的ViewResolver](#编码自定义的viewresolver)\n* [总结]("
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet.md",
"chars": 12357,
"preview": "# 目录\n * [SpringMVC简介](#springmvc简介)\n * [HandlerMapping接口](#handlermapping接口)\n * [DispatcherServlet接受请求并找到对应Handler](#"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:消息转换器HttpMessageConverter与@ResponseBody注解.md",
"chars": 16962,
"preview": "# 目录\n* [前言](#前言)\n* [现象](#现象)\n* [源码分析](#源码分析)\n* [实例讲解](#实例讲解)\n* [关于配置](#关于配置)\n* [总结](#总结)\n* [详解RequestBody和@ResponseBody注"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/SpringMVC的Demo与@EnableWebMvc注解.md",
"chars": 17601,
"preview": "### 1\\. demo \n\nΪ˸õط springmvc Դ룬Ҫһ springmvc demo demo Ƿ `spring-learn` ģ顣\n\n#### 1\\. tomcat \n\n tomcat 8 ֮tomcat ṩ˶аҪ"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/Spring容器启动Tomcat.md",
"chars": 8833,
"preview": "'' [spring mvc ֮ springmvc demo @EnableWebMvc ע](https://my.oschina.net/funcy/blog/4696657)һУṩһʾ demo demo servlet Ȼͨ "
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/请求执行流程(一)之获取Handler.md",
"chars": 24539,
"preview": "һƪǷ `RequestMapping` ʼ̣Ľ spring mvc ִ̡\n\n### 1\\. ִ\n\n [spring mvc ֮ DispatcherServlet ʼ](https://my.oschina.net/funcy/blog"
},
{
"path": "docs/Spring全家桶/SpringMVC源码分析/请求执行流程(二)之执行Handler方法.md",
"chars": 20563,
"preview": " **springmvc ִ**ĵڶƪ£һƪУǷ `DispatcherServlet#doDispatch` ִܽзΪ²裺\n\n1. ȡӦ `HandlerExecutionChain`, ȡ `HandlerExecutionChain"
},
{
"path": "docs/Spring全家桶/Spring源码分析/SpringAOP/AOP示例demo及@EnableAspectJAutoProxy.md",
"chars": 8277,
"preview": "在前面的文章中,我们成功的编译了 spring 源码,也构建了第一个 spring 测试 demo,接下来我们就基于[第一个 spring 源码调试 demo](https://my.oschina.net/funcy/blog/45332"
},
{
"path": "docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(上).md",
"chars": 24706,
"preview": "在[上一篇文章](https://my.oschina.net/funcy/blog/4678093 \"上一篇文章\")的分析中,我们介绍了使用 `@EnableAspectJAutoProxy` 开启用 spring aop 功能,而 `@"
},
{
"path": "docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(下).md",
"chars": 18180,
"preview": "[һƪ](https://my.oschina.net/funcy/blog/4678817 \"һƪ\")Ҫ `AbstractAutoProxyCreator#postProcessAfterInitialization` `Abstra"
},
{
"path": "docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(五):cglib代理.md",
"chars": 13617,
"preview": "\n\n[һƪ](https://my.oschina.net/funcy/blog/4696654 \"һƪ\") spring jdK ̬ spring cglib \n\n### 1\\. cglib \n\njdk Ȼṩ˶̬Ƕ̬һ㣺**ûʵֽӿڣ"
},
{
"path": "docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(六):aop总结.md",
"chars": 972,
"preview": "ǰ漸ƪǷ spring aop ش룬ܽᡣ\n\n### 1\\. spring aop \n\n [spring aopһʾ demo @EnableAspectJAutoProxy](https://my.oschina.net/funcy/b"
},
{
"path": "docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(四):jdk动态代理.md",
"chars": 21823,
"preview": "\n\nһƪµǷ spring ڴ˴дķʽΪ `jdk̬` `cglib`ǽ spring Ķ̬\n\n### 1. jdk ̬\n\n spring Ķ̬ǰ˽ jdk Ķ̬jdk ̬ҪӿڣΪӿڣ\n\n> IJdkDynamicProxy01\n\n```"
}
]
// ... and 158 more files (download for full content)
About this extraction
This page contains the full source code of the h2pl/JavaTutorial GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 358 files (4.7 MB), approximately 1.3M tokens, and a symbol index with 6 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.