Showing preview only (4,530K chars total). Download the full file or copy to clipboard to get everything.
Repository: itcharge/AlgoNote
Branch: main
Commit: 02499d0df8a3
Files: 1514
Total size: 4.0 MB
Directory structure:
gitextract_dhdwtz4s/
├── .github/
│ └── workflows/
│ └── sync.yml
├── .gitignore
├── LICENSE
├── README.md
├── codes/
│ └── python/
│ ├── 01_array/
│ │ ├── array_maxheap.py
│ │ ├── array_sort_bubble_sort.py
│ │ ├── array_sort_bucket_sort.py
│ │ ├── array_sort_counting_sort.py
│ │ ├── array_sort_insertion_sort.py
│ │ ├── array_sort_maxheap_sort.py
│ │ ├── array_sort_merge_sort.py
│ │ ├── array_sort_minheap_sort.py
│ │ ├── array_sort_quick_sort.py
│ │ ├── array_sort_radix_sort.py
│ │ ├── array_sort_selection_sort.py
│ │ └── array_sort_shell_sort.py
│ ├── 02_linked_list/
│ │ ├── linked_list.py
│ │ ├── linked_list_bubble_sort.py
│ │ ├── linked_list_bucket_sort.py
│ │ ├── linked_list_counting_sort.py
│ │ ├── linked_list_insertion_sort.py
│ │ ├── linked_list_merge_sort.py
│ │ ├── linked_list_quick_sort.py
│ │ ├── linked_list_radix_sort.py
│ │ └── linked_list_section_sort.py
│ ├── 03_stack_queue_hash_table/
│ │ ├── queue_circularSequential_queue.py
│ │ ├── queue_deque.py
│ │ ├── queue_link_queue.py
│ │ ├── queue_priority_queue.py
│ │ ├── queue_sequential_queue.py
│ │ ├── stack_link_stack.py
│ │ ├── stack_monotone_stack.py
│ │ └── stack_sequential_stack.py
│ ├── 04_string/
│ │ ├── string_Strcmp.py
│ │ ├── string_boyer_moore.py
│ │ ├── string_brute_force.py
│ │ ├── string_horspool.py
│ │ ├── string_kmp.py
│ │ ├── string_rabin_karp.py
│ │ ├── string_sunday.py
│ │ └── string_trie.py
│ ├── 05_tree/
│ │ ├── tree_binaryindexed_tree.py
│ │ ├── tree_dynamicSegmentTree_update_interval_1.py
│ │ ├── tree_dynamicSegmentTree_update_interval_2.py
│ │ ├── tree_segmentTree_update_interval_1.py
│ │ ├── tree_segmentTree_update_interval_2.py
│ │ ├── tree_segmentTree_update_point.py
│ │ ├── tree_unionFind.py
│ │ ├── tree_unionFind_QuickFind.py
│ │ ├── tree_unionFind_QuickUnion.py
│ │ ├── tree_unionFind_UnoinByRank.py
│ │ └── tree_unionFind_UnoinBySize.py
│ ├── 06_graph/
│ │ ├── Graph-Adjacency-List.py
│ │ ├── Graph-Adjacency-Matrix.py
│ │ ├── Graph-BFS.py
│ │ ├── Graph-Bellman-Ford.py
│ │ ├── Graph-DFS.py
│ │ ├── Graph-Edgeset-Array.py
│ │ ├── Graph-Hash-Table.py
│ │ ├── Graph-Kruskal.py
│ │ ├── Graph-Linked-Forward-Star.py
│ │ ├── Graph-Prim.py
│ │ ├── Graph-Topological-Sorting-DFS.py
│ │ └── Graph-Topological-Sorting-Kahn.py
│ └── 08_dynamic_programming/
│ ├── Digit-DP.py
│ ├── Pack-2DCostPack.py
│ ├── Pack-CompletePack.py
│ ├── Pack-GroupPack.py
│ ├── Pack-MixedPack.py
│ ├── Pack-MultiplePack.py
│ ├── Pack-ProblemVariants.py
│ └── Pack-ZeroOnePack.py
└── docs/
├── 00_preface/
│ ├── 00_01_preface.md
│ ├── 00_02_data_structures_algorithms.md
│ ├── 00_03_algorithm_complexity.md
│ ├── 00_04_leetcode_guide.md
│ ├── 00_05_solutions_list.md
│ ├── 00_06_categories_list.md
│ ├── 00_07_interview_100_list.md
│ ├── 00_08_interview_200_list.md
│ └── index.md
├── 01_array/
│ ├── 01_01_array_basic.md
│ ├── 01_02_array_sort.md
│ ├── 01_03_array_bubble_sort.md
│ ├── 01_04_array_selection_sort.md
│ ├── 01_05_array_insertion_sort.md
│ ├── 01_06_array_shell_sort.md
│ ├── 01_07_array_merge_sort.md
│ ├── 01_08_array_quick_sort.md
│ ├── 01_09_array_heap_sort.md
│ ├── 01_10_array_counting_sort.md
│ ├── 01_11_array_bucket_sort.md
│ ├── 01_12_array_radix_sort.md
│ ├── 01_13_array_binary_search_01.md
│ ├── 01_14_array_binary_search_02.md
│ ├── 01_15_array_two_pointers.md
│ ├── 01_16_array_sliding_window.md
│ └── index.md
├── 02_linked_list/
│ ├── 02_01_linked_list_basic.md
│ ├── 02_02_linked_list_sort.md
│ ├── 02_03_linked_list_bubble_sort.md
│ ├── 02_04_linked_list_selection_sort.md
│ ├── 02_05_linked_list_insertion_sort.md
│ ├── 02_06_linked_list_merge_sort.md
│ ├── 02_07_linked_list_quick_sort.md
│ ├── 02_08_linked_list_counting_sort.md
│ ├── 02_09_linked_list_bucket_sort.md
│ ├── 02_10_linked_list_radix_sort.md
│ ├── 02_11_linked_list_two_pointers.md
│ └── index.md
├── 03_stack_queue_hash_table/
│ ├── 03_01_stack_basic.md
│ ├── 03_02_monotone_stack.md
│ ├── 03_03_queue_basic.md
│ ├── 03_04_priority_queue.md
│ ├── 03_05_bidirectional_queue.md
│ ├── 03_06_hash_table.md
│ └── index.md
├── 04_string/
│ ├── 04_01_string_basic.md
│ ├── 04_02_string_brute_force.md
│ ├── 04_03_string_rabin_karp.md
│ ├── 04_04_string_kmp.md
│ ├── 04_05_string_boyer_moore.md
│ ├── 04_06_string_horspool.md
│ ├── 04_07_string_sunday.md
│ ├── 04_08_trie.md
│ ├── 04_09_ac_automaton.md
│ ├── 04_10_suffix_array.md
│ └── index.md
├── 05_tree/
│ ├── 05_01_tree_basic.md
│ ├── 05_02_binary_tree_traverse.md
│ ├── 05_03_binary_tree_reduction.md
│ ├── 05_04_binary_search_tree.md
│ ├── 05_05_segment_tree_01.md
│ ├── 05_06_segment_tree_02.md
│ ├── 05_07_binary_indexed_tree.md
│ ├── 05_08_union_find.md
│ └── index.md
├── 06_graph/
│ ├── 06_01_graph_basic.md
│ ├── 06_02_graph_structure.md
│ ├── 06_03_graph_dfs.md
│ ├── 06_04_graph_bfs.md
│ ├── 06_05_graph_topological_sorting.md
│ ├── 06_06_graph_minimum_spanning_tree.md
│ ├── 06_07_graph_shortest_path_01.md
│ ├── 06_08_graph_shortest_path_02.md
│ ├── 06_09_graph_multi_source_shortest_path.md
│ ├── 06_10_graph_the_second_shortest_path.md
│ ├── 06_11_graph_bipartite_basic.md
│ ├── 06_12_graph_bipartite_matching.md
│ └── index.md
├── 07_algorithm/
│ ├── 07_01_enumeration_algorithm.md
│ ├── 07_02_recursive_algorithm.md
│ ├── 07_03_divide_and_conquer_algorithm.md
│ ├── 07_04_backtracking_algorithm.md
│ ├── 07_05_greedy_algorithm.md
│ ├── 07_06_bit_operation.md
│ └── index.md
├── 08_dynamic_programming/
│ ├── 08_01_dynamic_programming_basic.md
│ ├── 08_02_memoization_search.md
│ ├── 08_03_linear_dp_01.md
│ ├── 08_04_linear_dp_02.md
│ ├── 08_05_linear_dp_03.md
│ ├── 08_06_knapsack_problem_01.md
│ ├── 08_07_knapsack_problem_02.md
│ ├── 08_08_knapsack_problem_03.md
│ ├── 08_09_knapsack_problem_04.md
│ ├── 08_10_knapsack_problem_05.md
│ ├── 08_11_interval_dp.md
│ ├── 08_12_tree_dp.md
│ ├── 08_13_state_compression_dp.md
│ ├── 08_14_counting_dp.md
│ ├── 08_15_digit_dp.md
│ ├── 08_16_probability_dp.md
│ └── index.md
├── README.md
├── others/
│ ├── index.md
│ ├── todo_list.md
│ └── update_time.md
└── solutions/
├── 0001-0099/
│ ├── 3sum-closest.md
│ ├── 3sum.md
│ ├── 4sum.md
│ ├── add-binary.md
│ ├── add-two-numbers.md
│ ├── binary-tree-inorder-traversal.md
│ ├── climbing-stairs.md
│ ├── combination-sum-ii.md
│ ├── combination-sum.md
│ ├── combinations.md
│ ├── container-with-most-water.md
│ ├── count-and-say.md
│ ├── decode-ways.md
│ ├── divide-two-integers.md
│ ├── edit-distance.md
│ ├── find-first-and-last-position-of-element-in-sorted-array.md
│ ├── find-the-index-of-the-first-occurrence-in-a-string.md
│ ├── first-missing-positive.md
│ ├── generate-parentheses.md
│ ├── gray-code.md
│ ├── group-anagrams.md
│ ├── index.md
│ ├── insert-interval.md
│ ├── integer-to-roman.md
│ ├── interleaving-string.md
│ ├── jump-game-ii.md
│ ├── jump-game.md
│ ├── largest-rectangle-in-histogram.md
│ ├── length-of-last-word.md
│ ├── letter-combinations-of-a-phone-number.md
│ ├── longest-common-prefix.md
│ ├── longest-palindromic-substring.md
│ ├── longest-substring-without-repeating-characters.md
│ ├── longest-valid-parentheses.md
│ ├── maximal-rectangle.md
│ ├── maximum-subarray.md
│ ├── median-of-two-sorted-arrays.md
│ ├── merge-intervals.md
│ ├── merge-k-sorted-lists.md
│ ├── merge-sorted-array.md
│ ├── merge-two-sorted-lists.md
│ ├── minimum-path-sum.md
│ ├── minimum-window-substring.md
│ ├── multiply-strings.md
│ ├── n-queens-ii.md
│ ├── n-queens.md
│ ├── next-permutation.md
│ ├── palindrome-number.md
│ ├── partition-list.md
│ ├── permutation-sequence.md
│ ├── permutations-ii.md
│ ├── permutations.md
│ ├── plus-one.md
│ ├── powx-n.md
│ ├── recover-binary-search-tree.md
│ ├── regular-expression-matching.md
│ ├── remove-duplicates-from-sorted-array-ii.md
│ ├── remove-duplicates-from-sorted-array.md
│ ├── remove-duplicates-from-sorted-list-ii.md
│ ├── remove-duplicates-from-sorted-list.md
│ ├── remove-element.md
│ ├── remove-nth-node-from-end-of-list.md
│ ├── restore-ip-addresses.md
│ ├── reverse-integer.md
│ ├── reverse-linked-list-ii.md
│ ├── reverse-nodes-in-k-group.md
│ ├── roman-to-integer.md
│ ├── rotate-image.md
│ ├── rotate-list.md
│ ├── scramble-string.md
│ ├── search-a-2d-matrix.md
│ ├── search-in-rotated-sorted-array-ii.md
│ ├── search-in-rotated-sorted-array.md
│ ├── search-insert-position.md
│ ├── set-matrix-zeroes.md
│ ├── simplify-path.md
│ ├── sort-colors.md
│ ├── spiral-matrix-ii.md
│ ├── spiral-matrix.md
│ ├── sqrtx.md
│ ├── string-to-integer-atoi.md
│ ├── subsets-ii.md
│ ├── subsets.md
│ ├── substring-with-concatenation-of-all-words.md
│ ├── sudoku-solver.md
│ ├── swap-nodes-in-pairs.md
│ ├── text-justification.md
│ ├── trapping-rain-water.md
│ ├── two-sum.md
│ ├── unique-binary-search-trees-ii.md
│ ├── unique-binary-search-trees.md
│ ├── unique-paths-ii.md
│ ├── unique-paths.md
│ ├── valid-number.md
│ ├── valid-parentheses.md
│ ├── valid-sudoku.md
│ ├── validate-binary-search-tree.md
│ ├── wildcard-matching.md
│ ├── word-search.md
│ └── zigzag-conversion.md
├── 0100-0199/
│ ├── balanced-binary-tree.md
│ ├── best-time-to-buy-and-sell-stock-ii.md
│ ├── best-time-to-buy-and-sell-stock-iii.md
│ ├── best-time-to-buy-and-sell-stock-iv.md
│ ├── best-time-to-buy-and-sell-stock.md
│ ├── binary-search-tree-iterator.md
│ ├── binary-tree-level-order-traversal-ii.md
│ ├── binary-tree-level-order-traversal.md
│ ├── binary-tree-maximum-path-sum.md
│ ├── binary-tree-postorder-traversal.md
│ ├── binary-tree-preorder-traversal.md
│ ├── binary-tree-right-side-view.md
│ ├── binary-tree-upside-down.md
│ ├── binary-tree-zigzag-level-order-traversal.md
│ ├── candy.md
│ ├── clone-graph.md
│ ├── compare-version-numbers.md
│ ├── construct-binary-tree-from-inorder-and-postorder-traversal.md
│ ├── construct-binary-tree-from-preorder-and-inorder-traversal.md
│ ├── convert-sorted-array-to-binary-search-tree.md
│ ├── convert-sorted-list-to-binary-search-tree.md
│ ├── copy-list-with-random-pointer.md
│ ├── distinct-subsequences.md
│ ├── dungeon-game.md
│ ├── evaluate-reverse-polish-notation.md
│ ├── excel-sheet-column-number.md
│ ├── excel-sheet-column-title.md
│ ├── factorial-trailing-zeroes.md
│ ├── find-minimum-in-rotated-sorted-array-ii.md
│ ├── find-minimum-in-rotated-sorted-array.md
│ ├── find-peak-element.md
│ ├── flatten-binary-tree-to-linked-list.md
│ ├── fraction-to-recurring-decimal.md
│ ├── gas-station.md
│ ├── house-robber.md
│ ├── index.md
│ ├── insertion-sort-list.md
│ ├── intersection-of-two-linked-lists.md
│ ├── largest-number.md
│ ├── linked-list-cycle-ii.md
│ ├── linked-list-cycle.md
│ ├── longest-consecutive-sequence.md
│ ├── longest-substring-with-at-most-two-distinct-characters.md
│ ├── lru-cache.md
│ ├── majority-element.md
│ ├── max-points-on-a-line.md
│ ├── maximum-depth-of-binary-tree.md
│ ├── maximum-gap.md
│ ├── maximum-product-subarray.md
│ ├── min-stack.md
│ ├── minimum-depth-of-binary-tree.md
│ ├── missing-ranges.md
│ ├── number-of-1-bits.md
│ ├── one-edit-distance.md
│ ├── palindrome-partitioning-ii.md
│ ├── palindrome-partitioning.md
│ ├── pascals-triangle-ii.md
│ ├── pascals-triangle.md
│ ├── path-sum-ii.md
│ ├── path-sum.md
│ ├── populating-next-right-pointers-in-each-node-ii.md
│ ├── populating-next-right-pointers-in-each-node.md
│ ├── read-n-characters-given-read4-ii-call-multiple-times.md
│ ├── read-n-characters-given-read4.md
│ ├── reorder-list.md
│ ├── repeated-dna-sequences.md
│ ├── reverse-bits.md
│ ├── reverse-words-in-a-string-ii.md
│ ├── reverse-words-in-a-string.md
│ ├── rotate-array.md
│ ├── same-tree.md
│ ├── single-number-ii.md
│ ├── single-number.md
│ ├── sort-list.md
│ ├── sum-root-to-leaf-numbers.md
│ ├── surrounded-regions.md
│ ├── symmetric-tree.md
│ ├── triangle.md
│ ├── two-sum-ii-input-array-is-sorted.md
│ ├── two-sum-iii-data-structure-design.md
│ ├── valid-palindrome.md
│ ├── word-break-ii.md
│ ├── word-break.md
│ ├── word-ladder-ii.md
│ └── word-ladder.md
├── 0200-0299/
│ ├── 3sum-smaller.md
│ ├── add-digits.md
│ ├── alien-dictionary.md
│ ├── basic-calculator-ii.md
│ ├── basic-calculator.md
│ ├── best-meeting-point.md
│ ├── binary-tree-longest-consecutive-sequence.md
│ ├── binary-tree-paths.md
│ ├── bitwise-and-of-numbers-range.md
│ ├── bulls-and-cows.md
│ ├── closest-binary-search-tree-value-ii.md
│ ├── closest-binary-search-tree-value.md
│ ├── combination-sum-iii.md
│ ├── contains-duplicate-ii.md
│ ├── contains-duplicate-iii.md
│ ├── contains-duplicate.md
│ ├── count-complete-tree-nodes.md
│ ├── count-primes.md
│ ├── count-univalue-subtrees.md
│ ├── course-schedule-ii.md
│ ├── course-schedule.md
│ ├── delete-node-in-a-linked-list.md
│ ├── design-add-and-search-words-data-structure.md
│ ├── different-ways-to-add-parentheses.md
│ ├── encode-and-decode-strings.md
│ ├── expression-add-operators.md
│ ├── factor-combinations.md
│ ├── find-median-from-data-stream.md
│ ├── find-the-celebrity.md
│ ├── find-the-duplicate-number.md
│ ├── first-bad-version.md
│ ├── flatten-2d-vector.md
│ ├── flip-game-ii.md
│ ├── flip-game.md
│ ├── game-of-life.md
│ ├── graph-valid-tree.md
│ ├── group-shifted-strings.md
│ ├── h-index-ii.md
│ ├── h-index.md
│ ├── happy-number.md
│ ├── house-robber-ii.md
│ ├── implement-queue-using-stacks.md
│ ├── implement-stack-using-queues.md
│ ├── implement-trie-prefix-tree.md
│ ├── index.md
│ ├── inorder-successor-in-bst.md
│ ├── integer-to-english-words.md
│ ├── invert-binary-tree.md
│ ├── isomorphic-strings.md
│ ├── kth-largest-element-in-an-array.md
│ ├── kth-smallest-element-in-a-bst.md
│ ├── lowest-common-ancestor-of-a-binary-search-tree.md
│ ├── lowest-common-ancestor-of-a-binary-tree.md
│ ├── majority-element-ii.md
│ ├── maximal-square.md
│ ├── meeting-rooms-ii.md
│ ├── meeting-rooms.md
│ ├── minimum-size-subarray-sum.md
│ ├── missing-number.md
│ ├── move-zeroes.md
│ ├── nim-game.md
│ ├── number-of-digit-one.md
│ ├── number-of-islands.md
│ ├── paint-fence.md
│ ├── paint-house-ii.md
│ ├── paint-house.md
│ ├── palindrome-linked-list.md
│ ├── palindrome-permutation-ii.md
│ ├── palindrome-permutation.md
│ ├── peeking-iterator.md
│ ├── perfect-squares.md
│ ├── power-of-two.md
│ ├── product-of-array-except-self.md
│ ├── rectangle-area.md
│ ├── remove-linked-list-elements.md
│ ├── reverse-linked-list.md
│ ├── search-a-2d-matrix-ii.md
│ ├── serialize-and-deserialize-binary-tree.md
│ ├── shortest-palindrome.md
│ ├── shortest-word-distance-ii.md
│ ├── shortest-word-distance-iii.md
│ ├── shortest-word-distance.md
│ ├── single-number-iii.md
│ ├── sliding-window-maximum.md
│ ├── strobogrammatic-number-ii.md
│ ├── strobogrammatic-number-iii.md
│ ├── strobogrammatic-number.md
│ ├── summary-ranges.md
│ ├── the-skyline-problem.md
│ ├── ugly-number-ii.md
│ ├── ugly-number.md
│ ├── unique-word-abbreviation.md
│ ├── valid-anagram.md
│ ├── verify-preorder-sequence-in-binary-search-tree.md
│ ├── walls-and-gates.md
│ ├── wiggle-sort.md
│ ├── word-pattern-ii.md
│ ├── word-pattern.md
│ ├── word-search-ii.md
│ └── zigzag-iterator.md
├── 0300-0399/
│ ├── additive-number.md
│ ├── android-unlock-patterns.md
│ ├── best-time-to-buy-and-sell-stock-with-cooldown.md
│ ├── binary-tree-vertical-order-traversal.md
│ ├── bomb-enemy.md
│ ├── bulb-switcher.md
│ ├── burst-balloons.md
│ ├── coin-change.md
│ ├── combination-sum-iv.md
│ ├── count-numbers-with-unique-digits.md
│ ├── count-of-range-sum.md
│ ├── count-of-smaller-numbers-after-self.md
│ ├── counting-bits.md
│ ├── create-maximum-number.md
│ ├── data-stream-as-disjoint-intervals.md
│ ├── decode-string.md
│ ├── design-hit-counter.md
│ ├── design-phone-directory.md
│ ├── design-snake-game.md
│ ├── design-tic-tac-toe.md
│ ├── design-twitter.md
│ ├── elimination-game.md
│ ├── evaluate-division.md
│ ├── find-k-pairs-with-smallest-sums.md
│ ├── find-leaves-of-binary-tree.md
│ ├── find-the-difference.md
│ ├── first-unique-character-in-a-string.md
│ ├── flatten-nested-list-iterator.md
│ ├── generalized-abbreviation.md
│ ├── guess-number-higher-or-lower-ii.md
│ ├── guess-number-higher-or-lower.md
│ ├── house-robber-iii.md
│ ├── increasing-triplet-subsequence.md
│ ├── index.md
│ ├── insert-delete-getrandom-o1-duplicates-allowed.md
│ ├── insert-delete-getrandom-o1.md
│ ├── integer-break.md
│ ├── integer-replacement.md
│ ├── intersection-of-two-arrays-ii.md
│ ├── intersection-of-two-arrays.md
│ ├── is-subsequence.md
│ ├── kth-smallest-element-in-a-sorted-matrix.md
│ ├── largest-bst-subtree.md
│ ├── largest-divisible-subset.md
│ ├── lexicographical-numbers.md
│ ├── line-reflection.md
│ ├── linked-list-random-node.md
│ ├── logger-rate-limiter.md
│ ├── longest-absolute-file-path.md
│ ├── longest-increasing-path-in-a-matrix.md
│ ├── longest-increasing-subsequence.md
│ ├── longest-substring-with-at-least-k-repeating-characters.md
│ ├── longest-substring-with-at-most-k-distinct-characters.md
│ ├── max-sum-of-rectangle-no-larger-than-k.md
│ ├── maximum-product-of-word-lengths.md
│ ├── maximum-size-subarray-sum-equals-k.md
│ ├── mini-parser.md
│ ├── minimum-height-trees.md
│ ├── moving-average-from-data-stream.md
│ ├── nested-list-weight-sum-ii.md
│ ├── nested-list-weight-sum.md
│ ├── number-of-connected-components-in-an-undirected-graph.md
│ ├── number-of-islands-ii.md
│ ├── odd-even-linked-list.md
│ ├── palindrome-pairs.md
│ ├── patching-array.md
│ ├── perfect-rectangle.md
│ ├── plus-one-linked-list.md
│ ├── power-of-four.md
│ ├── power-of-three.md
│ ├── random-pick-index.md
│ ├── range-addition.md
│ ├── range-sum-query-2d-immutable.md
│ ├── range-sum-query-2d-mutable.md
│ ├── range-sum-query-immutable.md
│ ├── range-sum-query-mutable.md
│ ├── ransom-note.md
│ ├── rearrange-string-k-distance-apart.md
│ ├── reconstruct-itinerary.md
│ ├── remove-duplicate-letters.md
│ ├── remove-invalid-parentheses.md
│ ├── reverse-string.md
│ ├── reverse-vowels-of-a-string.md
│ ├── rotate-function.md
│ ├── russian-doll-envelopes.md
│ ├── self-crossing.md
│ ├── shortest-distance-from-all-buildings.md
│ ├── shuffle-an-array.md
│ ├── smallest-rectangle-enclosing-black-pixels.md
│ ├── sort-transformed-array.md
│ ├── sparse-matrix-multiplication.md
│ ├── sum-of-two-integers.md
│ ├── super-pow.md
│ ├── super-ugly-number.md
│ ├── top-k-frequent-elements.md
│ ├── utf-8-validation.md
│ ├── valid-perfect-square.md
│ ├── verify-preorder-serialization-of-a-binary-tree.md
│ ├── water-and-jug-problem.md
│ ├── wiggle-sort-ii.md
│ └── wiggle-subsequence.md
├── 0400-0499/
│ ├── 132-pattern.md
│ ├── 4sum-ii.md
│ ├── add-strings.md
│ ├── add-two-numbers-ii.md
│ ├── all-oone-data-structure.md
│ ├── arithmetic-slices-ii-subsequence.md
│ ├── arithmetic-slices.md
│ ├── arranging-coins.md
│ ├── assign-cookies.md
│ ├── battleships-in-a-board.md
│ ├── binary-watch.md
│ ├── can-i-win.md
│ ├── circular-array-loop.md
│ ├── concatenated-words.md
│ ├── construct-quad-tree.md
│ ├── construct-the-rectangle.md
│ ├── convert-a-number-to-hexadecimal.md
│ ├── convert-binary-search-tree-to-sorted-doubly-linked-list.md
│ ├── convex-polygon.md
│ ├── count-the-repetitions.md
│ ├── delete-node-in-a-bst.md
│ ├── diagonal-traverse.md
│ ├── encode-n-ary-tree-to-binary-tree.md
│ ├── encode-string-with-shortest-length.md
│ ├── find-all-anagrams-in-a-string.md
│ ├── find-all-duplicates-in-an-array.md
│ ├── find-all-numbers-disappeared-in-an-array.md
│ ├── find-permutation.md
│ ├── find-right-interval.md
│ ├── fizz-buzz.md
│ ├── flatten-a-multilevel-doubly-linked-list.md
│ ├── frog-jump.md
│ ├── generate-random-point-in-a-circle.md
│ ├── hamming-distance.md
│ ├── heaters.md
│ ├── implement-rand10-using-rand7.md
│ ├── index.md
│ ├── island-perimeter.md
│ ├── k-th-smallest-in-lexicographical-order.md
│ ├── largest-palindrome-product.md
│ ├── lfu-cache.md
│ ├── license-key-formatting.md
│ ├── longest-palindrome.md
│ ├── longest-repeating-character-replacement.md
│ ├── magical-string.md
│ ├── matchsticks-to-square.md
│ ├── max-consecutive-ones-ii.md
│ ├── max-consecutive-ones.md
│ ├── maximum-xor-of-two-numbers-in-an-array.md
│ ├── minimum-genetic-mutation.md
│ ├── minimum-moves-to-equal-array-elements-ii.md
│ ├── minimum-moves-to-equal-array-elements.md
│ ├── minimum-number-of-arrows-to-burst-balloons.md
│ ├── minimum-unique-word-abbreviation.md
│ ├── n-ary-tree-level-order-traversal.md
│ ├── next-greater-element-i.md
│ ├── non-decreasing-subsequences.md
│ ├── non-overlapping-intervals.md
│ ├── nth-digit.md
│ ├── number-complement.md
│ ├── number-of-boomerangs.md
│ ├── number-of-segments-in-a-string.md
│ ├── ones-and-zeroes.md
│ ├── optimal-account-balancing.md
│ ├── pacific-atlantic-water-flow.md
│ ├── partition-equal-subset-sum.md
│ ├── path-sum-iii.md
│ ├── poor-pigs.md
│ ├── predict-the-winner.md
│ ├── queue-reconstruction-by-height.md
│ ├── random-point-in-non-overlapping-rectangles.md
│ ├── reconstruct-original-digits-from-english.md
│ ├── remove-k-digits.md
│ ├── repeated-substring-pattern.md
│ ├── reverse-pairs.md
│ ├── robot-room-cleaner.md
│ ├── sentence-screen-fitting.md
│ ├── sequence-reconstruction.md
│ ├── serialize-and-deserialize-bst.md
│ ├── serialize-and-deserialize-n-ary-tree.md
│ ├── sliding-window-median.md
│ ├── smallest-good-base.md
│ ├── sort-characters-by-frequency.md
│ ├── split-array-largest-sum.md
│ ├── string-compression.md
│ ├── strong-password-checker.md
│ ├── sum-of-left-leaves.md
│ ├── target-sum.md
│ ├── teemo-attacking.md
│ ├── ternary-expression-parser.md
│ ├── the-maze-iii.md
│ ├── the-maze.md
│ ├── third-maximum-number.md
│ ├── total-hamming-distance.md
│ ├── trapping-rain-water-ii.md
│ ├── unique-substrings-in-wraparound-string.md
│ ├── valid-word-abbreviation.md
│ ├── valid-word-square.md
│ ├── validate-ip-address.md
│ ├── word-squares.md
│ └── zuma-game.md
├── 0500-0599/
│ ├── 01-matrix.md
│ ├── array-nesting.md
│ ├── array-partition.md
│ ├── base-7.md
│ ├── beautiful-arrangement.md
│ ├── binary-tree-longest-consecutive-sequence-ii.md
│ ├── binary-tree-tilt.md
│ ├── boundary-of-binary-tree.md
│ ├── brick-wall.md
│ ├── coin-change-ii.md
│ ├── complex-number-multiplication.md
│ ├── construct-binary-tree-from-string.md
│ ├── contiguous-array.md
│ ├── continuous-subarray-sum.md
│ ├── convert-bst-to-greater-tree.md
│ ├── delete-operation-for-two-strings.md
│ ├── design-in-memory-file-system.md
│ ├── detect-capital.md
│ ├── diameter-of-binary-tree.md
│ ├── distribute-candies.md
│ ├── encode-and-decode-tinyurl.md
│ ├── erect-the-fence.md
│ ├── fibonacci-number.md
│ ├── find-bottom-left-tree-value.md
│ ├── find-largest-value-in-each-tree-row.md
│ ├── find-mode-in-binary-search-tree.md
│ ├── find-the-closest-palindrome.md
│ ├── fraction-addition-and-subtraction.md
│ ├── freedom-trail.md
│ ├── index.md
│ ├── inorder-successor-in-bst-ii.md
│ ├── ipo.md
│ ├── k-diff-pairs-in-an-array.md
│ ├── keyboard-row.md
│ ├── kill-process.md
│ ├── logical-or-of-two-binary-grids-represented-as-quad-trees.md
│ ├── lonely-pixel-i.md
│ ├── lonely-pixel-ii.md
│ ├── longest-harmonious-subsequence.md
│ ├── longest-line-of-consecutive-one-in-matrix.md
│ ├── longest-palindromic-subsequence.md
│ ├── longest-uncommon-subsequence-i.md
│ ├── longest-uncommon-subsequence-ii.md
│ ├── longest-word-in-dictionary-through-deleting.md
│ ├── maximum-depth-of-n-ary-tree.md
│ ├── maximum-vacation-days.md
│ ├── minesweeper.md
│ ├── minimum-absolute-difference-in-bst.md
│ ├── minimum-index-sum-of-two-lists.md
│ ├── minimum-time-difference.md
│ ├── most-frequent-subtree-sum.md
│ ├── n-ary-tree-postorder-traversal.md
│ ├── n-ary-tree-preorder-traversal.md
│ ├── next-greater-element-ii.md
│ ├── next-greater-element-iii.md
│ ├── number-of-provinces.md
│ ├── optimal-division.md
│ ├── out-of-boundary-paths.md
│ ├── output-contest-matches.md
│ ├── perfect-number.md
│ ├── permutation-in-string.md
│ ├── random-flip-matrix.md
│ ├── random-pick-with-weight.md
│ ├── range-addition-ii.md
│ ├── relative-ranks.md
│ ├── remove-boxes.md
│ ├── reshape-the-matrix.md
│ ├── reverse-string-ii.md
│ ├── reverse-words-in-a-string-iii.md
│ ├── shortest-unsorted-continuous-subarray.md
│ ├── single-element-in-a-sorted-array.md
│ ├── split-array-with-equal-sum.md
│ ├── split-concatenated-strings.md
│ ├── squirrel-simulation.md
│ ├── student-attendance-record-i.md
│ ├── student-attendance-record-ii.md
│ ├── subarray-sum-equals-k.md
│ ├── subtree-of-another-tree.md
│ ├── super-washing-machines.md
│ ├── tag-validator.md
│ ├── the-maze-ii.md
│ ├── valid-square.md
│ └── word-abbreviation.md
├── 0600-0699/
│ ├── 2-keys-keyboard.md
│ ├── 24-game.md
│ ├── 4-keys-keyboard.md
│ ├── add-bold-tag-in-string.md
│ ├── add-one-row-to-tree.md
│ ├── average-of-levels-in-binary-tree.md
│ ├── baseball-game.md
│ ├── beautiful-arrangement-ii.md
│ ├── binary-number-with-alternating-bits.md
│ ├── bulb-switcher-ii.md
│ ├── can-place-flowers.md
│ ├── coin-path.md
│ ├── construct-string-from-binary-tree.md
│ ├── count-binary-substrings.md
│ ├── course-schedule-iii.md
│ ├── cut-off-trees-for-golf-event.md
│ ├── decode-ways-ii.md
│ ├── degree-of-an-array.md
│ ├── design-circular-deque.md
│ ├── design-circular-queue.md
│ ├── design-compressed-string-iterator.md
│ ├── design-excel-sum-formula.md
│ ├── design-log-storage-system.md
│ ├── design-search-autocomplete-system.md
│ ├── dota2-senate.md
│ ├── employee-importance.md
│ ├── equal-tree-partition.md
│ ├── exclusive-time-of-functions.md
│ ├── falling-squares.md
│ ├── find-duplicate-file-in-system.md
│ ├── find-duplicate-subtrees.md
│ ├── find-k-closest-elements.md
│ ├── find-the-derangement-of-an-array.md
│ ├── image-smoother.md
│ ├── implement-magic-dictionary.md
│ ├── index.md
│ ├── k-empty-slots.md
│ ├── k-inverse-pairs-array.md
│ ├── knight-probability-in-chessboard.md
│ ├── longest-continuous-increasing-subsequence.md
│ ├── longest-univalue-path.md
│ ├── map-sum-pairs.md
│ ├── max-area-of-island.md
│ ├── maximum-average-subarray-i.md
│ ├── maximum-average-subarray-ii.md
│ ├── maximum-binary-tree.md
│ ├── maximum-distance-in-arrays.md
│ ├── maximum-length-of-pair-chain.md
│ ├── maximum-product-of-three-numbers.md
│ ├── maximum-sum-of-3-non-overlapping-subarrays.md
│ ├── maximum-swap.md
│ ├── maximum-width-of-binary-tree.md
│ ├── merge-two-binary-trees.md
│ ├── minimum-factorization.md
│ ├── next-closest-time.md
│ ├── non-decreasing-array.md
│ ├── non-negative-integers-without-consecutive-ones.md
│ ├── number-of-distinct-islands.md
│ ├── number-of-longest-increasing-subsequence.md
│ ├── palindromic-substrings.md
│ ├── partition-to-k-equal-sum-subsets.md
│ ├── path-sum-iv.md
│ ├── print-binary-tree.md
│ ├── redundant-connection-ii.md
│ ├── redundant-connection.md
│ ├── remove-9.md
│ ├── repeated-string-match.md
│ ├── replace-words.md
│ ├── robot-return-to-origin.md
│ ├── second-minimum-node-in-a-binary-tree copy.md
│ ├── second-minimum-node-in-a-binary-tree.md
│ ├── set-mismatch.md
│ ├── shopping-offers.md
│ ├── smallest-range-covering-elements-from-k-lists.md
│ ├── solve-the-equation.md
│ ├── split-array-into-consecutive-subsequences.md
│ ├── stickers-to-spell-word.md
│ ├── strange-printer.md
│ ├── sum-of-square-numbers.md
│ ├── task-scheduler.md
│ ├── top-k-frequent-words copy.md
│ ├── top-k-frequent-words.md
│ ├── trim-a-binary-search-tree.md
│ ├── two-sum-iv-input-is-a-bst.md
│ ├── valid-palindrome-ii.md
│ ├── valid-parenthesis-string.md
│ └── valid-triangle-number.md
├── 0700-0799/
│ ├── 1-bit-and-2-bit-characters.md
│ ├── accounts-merge.md
│ ├── all-paths-from-source-to-target.md
│ ├── asteroid-collision.md
│ ├── basic-calculator-iv.md
│ ├── best-time-to-buy-and-sell-stock-with-transaction-fee.md
│ ├── binary-search.md
│ ├── bold-words-in-string.md
│ ├── champagne-tower.md
│ ├── cheapest-flights-within-k-stops.md
│ ├── cherry-pickup.md
│ ├── contain-virus.md
│ ├── count-different-palindromic-subsequences.md
│ ├── couples-holding-hands.md
│ ├── cracking-the-safe.md
│ ├── custom-sort-string.md
│ ├── daily-temperatures.md
│ ├── delete-and-earn.md
│ ├── design-hashmap.md
│ ├── design-hashset.md
│ ├── design-linked-list.md
│ ├── domino-and-tromino-tiling.md
│ ├── escape-the-ghosts.md
│ ├── find-k-th-smallest-pair-distance.md
│ ├── find-pivot-index.md
│ ├── find-smallest-letter-greater-than-target.md
│ ├── flood-fill.md
│ ├── global-and-local-inversions.md
│ ├── index.md
│ ├── insert-into-a-binary-search-tree.md
│ ├── insert-into-a-sorted-circular-linked-list.md
│ ├── is-graph-bipartite.md
│ ├── jewels-and-stones.md
│ ├── k-th-smallest-prime-fraction.md
│ ├── k-th-symbol-in-grammar.md
│ ├── kth-largest-element-in-a-stream.md
│ ├── largest-number-at-least-twice-of-others.md
│ ├── largest-plus-sign.md
│ ├── letter-case-permutation.md
│ ├── longest-word-in-dictionary.md
│ ├── max-chunks-to-make-sorted-ii.md
│ ├── max-chunks-to-make-sorted.md
│ ├── maximum-length-of-repeated-subarray.md
│ ├── min-cost-climbing-stairs.md
│ ├── minimum-ascii-delete-sum-for-two-strings.md
│ ├── minimum-distance-between-bst-nodes.md
│ ├── minimum-window-subsequence.md
│ ├── monotone-increasing-digits.md
│ ├── my-calendar-i.md
│ ├── my-calendar-ii.md
│ ├── my-calendar-iii.md
│ ├── network-delay-time.md
│ ├── number-of-atoms.md
│ ├── number-of-matching-subsequences.md
│ ├── number-of-subarrays-with-bounded-maximum.md
│ ├── open-the-lock.md
│ ├── parse-lisp-expression.md
│ ├── partition-labels.md
│ ├── prefix-and-suffix-search.md
│ ├── preimage-size-of-factorial-zeroes-function.md
│ ├── prime-number-of-set-bits-in-binary-representation.md
│ ├── pyramid-transition-matrix.md
│ ├── rabbits-in-forest.md
│ ├── random-pick-with-blacklist.md
│ ├── range-module.md
│ ├── reach-a-number.md
│ ├── reaching-points.md
│ ├── remove-comments.md
│ ├── reorganize-string.md
│ ├── rotate-string.md
│ ├── rotated-digits.md
│ ├── search-in-a-binary-search-tree.md
│ ├── search-in-a-sorted-array-of-unknown-size.md
│ ├── self-dividing-numbers.md
│ ├── set-intersection-size-at-least-two.md
│ ├── shortest-completing-word.md
│ ├── sliding-puzzle.md
│ ├── smallest-rotation-with-highest-score.md
│ ├── split-linked-list-in-parts.md
│ ├── subarray-product-less-than-k.md
│ ├── swap-adjacent-in-lr-string.md
│ ├── swim-in-rising-water.md
│ ├── to-lower-case.md
│ ├── toeplitz-matrix.md
│ ├── transform-to-chessboard.md
│ └── valid-tic-tac-toe-state.md
├── 0800-0899/
│ ├── advantage-shuffle.md
│ ├── all-nodes-distance-k-in-binary-tree.md
│ ├── all-possible-full-binary-trees.md
│ ├── ambiguous-coordinates.md
│ ├── backspace-string-compare.md
│ ├── binary-gap.md
│ ├── binary-tree-pruning.md
│ ├── binary-trees-with-factors.md
│ ├── bitwise-ors-of-subarrays.md
│ ├── boats-to-save-people.md
│ ├── bricks-falling-when-hit.md
│ ├── buddy-strings.md
│ ├── bus-routes.md
│ ├── car-fleet.md
│ ├── card-flipping-game.md
│ ├── chalkboard-xor-game.md
│ ├── consecutive-numbers-sum.md
│ ├── construct-binary-tree-from-preorder-and-postorder-traversal.md
│ ├── count-unique-characters-of-all-substrings-of-a-given-string.md
│ ├── decoded-string-at-index.md
│ ├── exam-room.md
│ ├── expressive-words.md
│ ├── fair-candy-swap.md
│ ├── find-and-replace-in-string.md
│ ├── find-and-replace-pattern.md
│ ├── find-eventual-safe-states.md
│ ├── flipping-an-image.md
│ ├── friends-of-appropriate-ages.md
│ ├── goat-latin.md
│ ├── groups-of-special-equivalent-strings.md
│ ├── guess-the-word.md
│ ├── hand-of-straights.md
│ ├── image-overlap.md
│ ├── increasing-order-search-tree.md
│ ├── index.md
│ ├── k-similar-strings.md
│ ├── keys-and-rooms.md
│ ├── koko-eating-bananas.md
│ ├── largest-sum-of-averages.md
│ ├── largest-triangle-area.md
│ ├── leaf-similar-trees.md
│ ├── lemonade-change.md
│ ├── length-of-longest-fibonacci-subsequence.md
│ ├── linked-list-components.md
│ ├── longest-mountain-in-array.md
│ ├── loud-and-rich.md
│ ├── magic-squares-in-grid.md
│ ├── making-a-large-island.md
│ ├── masking-personal-information.md
│ ├── max-increase-to-keep-city-skyline.md
│ ├── maximize-distance-to-closest-person.md
│ ├── maximum-frequency-stack.md
│ ├── middle-of-the-linked-list.md
│ ├── minimum-cost-to-hire-k-workers.md
│ ├── minimum-number-of-refueling-stops.md
│ ├── minimum-swaps-to-make-sequences-increasing.md
│ ├── mirror-reflection.md
│ ├── monotonic-array.md
│ ├── most-common-word.md
│ ├── most-profit-assigning-work.md
│ ├── new-21-game.md
│ ├── nth-magical-number.md
│ ├── number-of-lines-to-write-string.md
│ ├── orderly-queue.md
│ ├── peak-index-in-a-mountain-array.md
│ ├── positions-of-large-groups.md
│ ├── possible-bipartition.md
│ ├── prime-palindrome.md
│ ├── profitable-schemes.md
│ ├── projection-area-of-3d-shapes.md
│ ├── push-dominoes.md
│ ├── race-car.md
│ ├── reachable-nodes-in-subdivided-graph.md
│ ├── rectangle-area-ii.md
│ ├── rectangle-overlap.md
│ ├── reordered-power-of-2.md
│ ├── score-after-flipping-matrix.md
│ ├── score-of-parentheses.md
│ ├── shifting-letters copy.md
│ ├── shifting-letters.md
│ ├── short-encoding-of-words.md
│ ├── shortest-distance-to-a-character.md
│ ├── shortest-path-to-get-all-keys.md
│ ├── shortest-path-visiting-all-nodes.md
│ ├── shortest-subarray-with-sum-at-least-k.md
│ ├── similar-rgb-color.md
│ ├── similar-string-groups.md
│ ├── smallest-subtree-with-all-the-deepest-nodes.md
│ ├── soup-servings.md
│ ├── spiral-matrix-iii.md
│ ├── split-array-into-fibonacci-sequence.md
│ ├── split-array-with-same-average.md
│ ├── stone-game.md
│ ├── subdomain-visit-count.md
│ ├── sum-of-distances-in-tree.md
│ ├── sum-of-subsequence-widths.md
│ ├── super-egg-drop.md
│ ├── surface-area-of-3d-shapes.md
│ ├── transpose-matrix.md
│ ├── uncommon-words-from-two-sentences.md
│ ├── unique-morse-code-words.md
│ └── walking-robot-simulation.md
├── 0900-0999/
│ ├── 3sum-with-multiplicity.md
│ ├── add-to-array-form-of-integer.md
│ ├── array-of-doubled-pairs.md
│ ├── available-captures-for-rook.md
│ ├── bag-of-tokens.md
│ ├── beautiful-array.md
│ ├── binary-subarrays-with-sum.md
│ ├── binary-tree-cameras.md
│ ├── broken-calculator.md
│ ├── cat-and-mouse.md
│ ├── check-completeness-of-a-binary-tree.md
│ ├── complete-binary-tree-inserter.md
│ ├── cousins-in-binary-tree.md
│ ├── delete-columns-to-make-sorted-ii.md
│ ├── delete-columns-to-make-sorted-iii.md
│ ├── delete-columns-to-make-sorted.md
│ ├── di-string-match.md
│ ├── distinct-subsequences-ii.md
│ ├── distribute-coins-in-binary-tree.md
│ ├── equal-rational-numbers.md
│ ├── find-the-shortest-superstring.md
│ ├── find-the-town-judge.md
│ ├── flip-binary-tree-to-match-preorder-traversal.md
│ ├── flip-equivalent-binary-trees.md
│ ├── flip-string-to-monotone-increasing.md
│ ├── fruit-into-baskets.md
│ ├── index.md
│ ├── interval-list-intersections.md
│ ├── k-closest-points-to-origin.md
│ ├── knight-dialer.md
│ ├── largest-component-size-by-common-factor.md
│ ├── largest-perimeter-triangle.md
│ ├── largest-time-for-given-digits.md
│ ├── least-operators-to-express-number.md
│ ├── long-pressed-name.md
│ ├── longest-turbulent-subarray.md
│ ├── maximum-binary-tree-ii.md
│ ├── maximum-sum-circular-subarray.md
│ ├── maximum-width-ramp.md
│ ├── minimize-malware-spread-ii.md
│ ├── minimize-malware-spread.md
│ ├── minimum-add-to-make-parentheses-valid.md
│ ├── minimum-area-rectangle-ii.md
│ ├── minimum-area-rectangle.md
│ ├── minimum-cost-for-tickets.md
│ ├── minimum-falling-path-sum.md
│ ├── minimum-increment-to-make-array-unique.md
│ ├── minimum-number-of-k-consecutive-bit-flips.md
│ ├── most-stones-removed-with-same-row-or-column.md
│ ├── n-repeated-element-in-size-2n-array.md
│ ├── number-of-music-playlists.md
│ ├── number-of-recent-calls.md
│ ├── number-of-squareful-arrays.md
│ ├── numbers-at-most-n-given-digit-set.md
│ ├── numbers-with-same-consecutive-differences.md
│ ├── odd-even-jump.md
│ ├── online-election.md
│ ├── online-stock-span.md
│ ├── pancake-sorting.md
│ ├── partition-array-into-disjoint-intervals.md
│ ├── powerful-integers.md
│ ├── prison-cells-after-n-days.md
│ ├── range-sum-of-bst.md
│ ├── regions-cut-by-slashes.md
│ ├── reorder-data-in-log-files.md
│ ├── reveal-cards-in-increasing-order.md
│ ├── reverse-only-letters.md
│ ├── rle-iterator.md
│ ├── rotting-oranges.md
│ ├── satisfiability-of-equality-equations.md
│ ├── shortest-bridge.md
│ ├── smallest-range-i.md
│ ├── smallest-range-ii.md
│ ├── smallest-string-starting-from-leaf.md
│ ├── snakes-and-ladders.md
│ ├── sort-an-array.md
│ ├── sort-array-by-parity-ii.md
│ ├── sort-array-by-parity.md
│ ├── squares-of-a-sorted-array.md
│ ├── stamping-the-sequence.md
│ ├── string-without-aaa-or-bbb.md
│ ├── subarray-sums-divisible-by-k.md
│ ├── subarrays-with-k-different-integers.md
│ ├── sum-of-even-numbers-after-queries.md
│ ├── sum-of-subarray-minimums.md
│ ├── super-palindromes.md
│ ├── tallest-billboard.md
│ ├── three-equal-parts.md
│ ├── time-based-key-value-store.md
│ ├── triples-with-bitwise-and-equal-to-zero.md
│ ├── unique-email-addresses.md
│ ├── unique-paths-iii.md
│ ├── univalued-binary-tree.md
│ ├── valid-mountain-array.md
│ ├── valid-permutations-for-di-sequence.md
│ ├── validate-stack-sequences.md
│ ├── verifying-an-alien-dictionary.md
│ ├── vertical-order-traversal-of-a-binary-tree.md
│ ├── vowel-spellchecker.md
│ ├── word-subsets.md
│ └── x-of-a-kind-in-a-deck-of-cards.md
├── 1000-1099/
│ ├── best-sightseeing-pair.md
│ ├── binary-search-tree-to-greater-sum-tree.md
│ ├── camelcase-matching.md
│ ├── capacity-to-ship-packages-within-d-days.md
│ ├── coloring-a-border.md
│ ├── complement-of-base-10-integer.md
│ ├── construct-binary-search-tree-from-preorder-traversal.md
│ ├── divisor-game.md
│ ├── duplicate-zeros.md
│ ├── find-common-characters.md
│ ├── find-in-mountain-array.md
│ ├── grumpy-bookstore-owner.md
│ ├── height-checker.md
│ ├── index-pairs-of-a-string.md
│ ├── index.md
│ ├── last-stone-weight-ii.md
│ ├── letter-tile-possibilities.md
│ ├── max-consecutive-ones-iii.md
│ ├── maximize-sum-of-array-after-k-negations.md
│ ├── minimum-cost-to-merge-stones.md
│ ├── minimum-score-triangulation-of-polygon.md
│ ├── number-of-enclaves.md
│ ├── numbers-with-repeated-digits.md
│ ├── recover-a-tree-from-preorder-traversal.md
│ ├── remove-all-adjacent-duplicates-in-string.md
│ ├── remove-outermost-parentheses.md
│ ├── robot-bounded-in-circle.md
│ ├── shortest-path-in-binary-matrix.md
│ ├── smallest-subsequence-of-distinct-characters.md
│ ├── stream-of-characters.md
│ ├── two-city-scheduling.md
│ ├── two-sum-less-than-k.md
│ ├── uncrossed-lines.md
│ └── valid-boomerang.md
├── 1100-1199/
│ ├── corporate-flight-bookings.md
│ ├── defanging-an-ip-address.md
│ ├── delete-nodes-and-return-forest.md
│ ├── diet-plan-performance.md
│ ├── distance-between-bus-stops.md
│ ├── distribute-candies-to-people.md
│ ├── find-k-length-substrings-with-no-repeated-characters.md
│ ├── index.md
│ ├── longest-common-subsequence.md
│ ├── maximum-level-sum-of-a-binary-tree.md
│ ├── minimum-swaps-to-group-all-1s-together.md
│ ├── n-th-tribonacci-number.md
│ ├── number-of-dice-rolls-with-target-sum.md
│ ├── parallel-courses.md
│ └── relative-sort-array.md
├── 1200-1299/
│ ├── airplane-seat-assignment-probability.md
│ ├── check-if-it-is-a-straight-line.md
│ ├── count-vowels-permutation.md
│ ├── divide-array-in-sets-of-k-consecutive-numbers.md
│ ├── find-elements-in-a-contaminated-binary-tree.md
│ ├── get-equal-substrings-within-budget.md
│ ├── index.md
│ ├── meeting-scheduler.md
│ ├── minimum-cost-to-move-chips-to-the-same-position.md
│ ├── minimum-swaps-to-make-strings-equal.md
│ ├── minimum-time-visiting-all-points.md
│ ├── number-of-closed-islands.md
│ ├── reconstruct-a-2-row-binary-matrix.md
│ ├── search-suggestions-system.md
│ ├── smallest-string-with-swaps.md
│ ├── subtract-the-product-and-sum-of-digits-of-an-integer.md
│ └── tree-diameter.md
├── 1300-1399/
│ ├── all-elements-in-two-binary-search-trees.md
│ ├── angle-between-hands-of-a-clock.md
│ ├── closest-divisors.md
│ ├── convert-integer-to-the-sum-of-two-no-zero-integers.md
│ ├── decompress-run-length-encoded-list.md
│ ├── design-a-stack-with-increment-operation.md
│ ├── index.md
│ ├── maximum-students-taking-exam.md
│ ├── minimum-number-of-steps-to-make-two-strings-anagram.md
│ ├── number-of-operations-to-make-network-connected.md
│ ├── number-of-sub-arrays-of-size-k-and-average-greater-than-or-equal-to-threshold.md
│ ├── number-of-substrings-containing-all-three-characters.md
│ ├── print-words-vertically.md
│ ├── reduce-array-size-to-the-half.md
│ ├── sum-of-mutated-array-closest-to-target.md
│ └── xor-queries-of-a-subarray.md
├── 1400-1499/
│ ├── average-salary-excluding-the-minimum-and-maximum-salary.md
│ ├── consecutive-characters.md
│ ├── construct-k-palindrome-strings.md
│ ├── form-largest-integer-with-digits-that-add-up-to-target.md
│ ├── index.md
│ ├── longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit.md
│ ├── longest-subarray-of-1s-after-deleting-one-element.md
│ ├── maximum-number-of-vowels-in-a-substring-of-given-length.md
│ ├── maximum-points-you-can-obtain-from-cards.md
│ ├── maximum-score-after-splitting-a-string.md
│ ├── minimum-number-of-days-to-make-m-bouquets.md
│ ├── number-of-students-doing-homework-at-a-given-time.md
│ ├── path-crossing.md
│ ├── rearrange-words-in-a-sentence.md
│ ├── running-sum-of-1d-array.md
│ ├── simplified-fractions.md
│ ├── string-matching-in-an-array.md
│ ├── subrectangle-queries.md
│ └── xor-operation-in-an-array.md
├── 1500-1599/
│ ├── can-make-arithmetic-progression-from-sequence.md
│ ├── count-good-triplets.md
│ ├── count-odd-numbers-in-an-interval-range.md
│ ├── index.md
│ ├── maximum-length-of-subarray-with-positive-product.md
│ ├── maximum-number-of-coins-you-can-get.md
│ ├── min-cost-to-connect-all-points.md
│ ├── minimum-cost-to-connect-two-groups-of-points.md
│ ├── minimum-cost-to-cut-a-stick.md
│ ├── minimum-operations-to-make-array-equal.md
│ ├── reformat-date.md
│ ├── special-positions-in-a-binary-matrix.md
│ ├── split-a-string-into-the-max-number-of-unique-substrings.md
│ └── thousand-separator.md
├── 1600-1699/
│ ├── count-sorted-vowel-strings.md
│ ├── count-subtrees-with-max-distance-between-cities.md
│ ├── design-parking-system.md
│ ├── determine-if-two-strings-are-close.md
│ ├── find-valid-matrix-given-row-and-column-sums.md
│ ├── get-maximum-in-generated-array.md
│ ├── index.md
│ ├── maximum-erasure-value.md
│ ├── maximum-nesting-depth-of-the-parentheses.md
│ ├── minimum-deletions-to-make-character-frequencies-unique.md
│ ├── minimum-operations-to-reduce-x-to-zero.md
│ ├── number-of-distinct-substrings-in-a-string.md
│ ├── path-with-minimum-effort.md
│ └── richest-customer-wealth.md
├── 1700-1799/
│ ├── calculate-money-in-leetcode-bank.md
│ ├── check-if-one-string-swap-can-make-strings-equal.md
│ ├── decode-xored-array.md
│ ├── find-center-of-star-graph.md
│ ├── find-nearest-point-that-has-the-same-x-or-y-coordinate.md
│ ├── index.md
│ ├── latest-time-by-replacing-hidden-digits.md
│ ├── longest-nice-substring.md
│ ├── maximum-absolute-sum-of-any-subarray.md
│ ├── maximum-number-of-balls-in-a-box.md
│ ├── maximum-units-on-a-truck.md
│ └── tuple-with-same-product.md
├── 1800-1899/
│ ├── check-if-all-the-integers-in-a-range-are-covered.md
│ ├── index.md
│ ├── longest-word-with-all-prefixes.md
│ ├── maximum-ice-cream-bars.md
│ ├── minimize-maximum-pair-sum-in-array.md
│ ├── minimum-operations-to-make-the-array-increasing.md
│ ├── minimum-xor-sum-of-two-arrays.md
│ ├── redistribute-characters-to-make-all-strings-equal.md
│ ├── replace-all-digits-with-characters.md
│ ├── sign-of-the-product-of-an-array.md
│ ├── sorting-the-sentence.md
│ └── substrings-of-size-three-with-distinct-characters.md
├── 1900-1999/
│ ├── add-minimum-number-of-rungs.md
│ ├── check-if-all-characters-have-equal-number-of-occurrences.md
│ ├── concatenation-of-array.md
│ ├── count-square-sum-triples.md
│ ├── eliminate-maximum-number-of-monsters.md
│ ├── find-the-middle-index-in-array.md
│ ├── index.md
│ ├── largest-odd-number-in-string.md
│ ├── maximum-compatibility-score-sum.md
│ ├── minimum-difference-between-highest-and-lowest-of-k-scores.md
│ ├── minimum-number-of-work-sessions-to-finish-the-tasks.md
│ ├── the-number-of-good-subsets.md
│ └── unique-length-3-palindromic-subsequences.md
├── 2000-2099/
│ ├── final-value-of-variable-after-performing-operations.md
│ ├── index.md
│ ├── number-of-pairs-of-strings-with-concatenation-equal-to-target.md
│ └── parallel-courses-iii.md
├── 2100-2199/
│ ├── find-substring-with-given-hash-value.md
│ ├── index.md
│ └── maximum-and-sum-of-array.md
├── 2200-2299/
│ ├── add-two-integers.md
│ ├── count-integers-in-intervals.md
│ ├── count-lattice-points-inside-a-circle.md
│ ├── index.md
│ └── longest-path-with-different-adjacent-characters.md
├── 2300-2399/
│ ├── count-special-integers.md
│ └── index.md
├── 2400-2499/
│ ├── index.md
│ └── number-of-common-factors.md
├── 2500-2599/
│ ├── difference-between-maximum-and-minimum-price-sum.md
│ ├── index.md
│ └── number-of-ways-to-earn-points.md
├── 2700-2799/
│ ├── count-of-integers.md
│ └── index.md
├── LCR/
│ ├── 0H97ZC.md
│ ├── 0on3uN.md
│ ├── 0ynMMM.md
│ ├── 1fGaJU.md
│ ├── 21dk04.md
│ ├── 2AoeFn.md
│ ├── 2VG8Kg.md
│ ├── 2bCMpM.md
│ ├── 3Etpl5.md
│ ├── 3u1WK4.md
│ ├── 4sjJUc.md
│ ├── 4ueAj6.md
│ ├── 569nqc.md
│ ├── 6eUYwP.md
│ ├── 7LpjUW.md
│ ├── 7WHec2.md
│ ├── 7WqeDu.md
│ ├── 7p8L0Z.md
│ ├── 8Zf90G.md
│ ├── A1NYOS.md
│ ├── D0F0SV.md
│ ├── FortPu.md
│ ├── Gu0c2T.md
│ ├── GzCJIP.md
│ ├── H8086Q.md
│ ├── IDBivT.md
│ ├── JFETK5.md
│ ├── LGjMqU.md
│ ├── LwUNpT.md
│ ├── M1oyTv.md
│ ├── M99OJA.md
│ ├── N6YdxV.md
│ ├── NUPfPr.md
│ ├── NYBBNL.md
│ ├── NaqhDT.md
│ ├── O4NDxx.md
│ ├── OrIXps.md
│ ├── P5rCT8.md
│ ├── PzWKhm.md
│ ├── Q91FMA.md
│ ├── QA2IGt.md
│ ├── QC3q1f.md
│ ├── QTMn0o.md
│ ├── Qv1Da2.md
│ ├── RQku0D.md
│ ├── SLwz0R.md
│ ├── SsGoHC.md
│ ├── TVdhkn.md
│ ├── UHnkqh.md
│ ├── US1pGT.md
│ ├── UhWRSj.md
│ ├── VvJkup.md
│ ├── WGki4K.md
│ ├── WNC0Lk.md
│ ├── WhsWhI.md
│ ├── XagZNi.md
│ ├── XltzEq.md
│ ├── YaVDxD.md
│ ├── Ygoe9J.md
│ ├── ZL6zAn.md
│ ├── ZVAVXX.md
│ ├── a7VOhD.md
│ ├── aMhZSa.md
│ ├── aseY1I.md
│ ├── bLyHh0.md
│ ├── ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof.md
│ ├── ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof.md
│ ├── ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof.md
│ ├── bao-han-minhan-shu-de-zhan-lcof.md
│ ├── bu-ke-pai-zhong-de-shun-zi-lcof.md
│ ├── bu-yong-jia-jian-cheng-chu-zuo-jia-fa-lcof.md
│ ├── c32eOV.md
│ ├── chou-shu-lcof.md
│ ├── cong-shang-dao-xia-da-yin-er-cha-shu-ii-lcof.md
│ ├── cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof.md
│ ├── cong-shang-dao-xia-da-yin-er-cha-shu-lcof.md
│ ├── cong-wei-dao-tou-da-yin-lian-biao-lcof.md
│ ├── dKk3P7.md
│ ├── da-yin-cong-1dao-zui-da-de-nwei-shu-lcof.md
│ ├── di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof.md
│ ├── diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof.md
│ ├── dui-cheng-de-er-cha-shu-lcof.md
│ ├── dui-lie-de-zui-da-zhi-lcof.md
│ ├── er-cha-shu-de-jing-xiang-lcof.md
│ ├── er-cha-shu-de-shen-du-lcof.md
│ ├── er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof.md
│ ├── er-cha-shu-zhong-he-wei-mou-yi-zhi-de-lu-jing-lcof.md
│ ├── er-cha-sou-suo-shu-de-di-kda-jie-dian-lcof.md
│ ├── er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof.md
│ ├── er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof.md
│ ├── er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof.md
│ ├── er-jin-zhi-zhong-1de-ge-shu-lcof.md
│ ├── er-wei-shu-zu-zhong-de-cha-zhao-lcof.md
│ ├── fan-zhuan-dan-ci-shun-xu-lcof.md
│ ├── fan-zhuan-lian-biao-lcof.md
│ ├── fei-bo-na-qi-shu-lie-lcof.md
│ ├── fpTFWP.md
│ ├── fu-za-lian-biao-de-fu-zhi-lcof.md
│ ├── g5c51o.md
│ ├── gaM7Ch.md
│ ├── gou-jian-cheng-ji-shu-zu-lcof.md
│ ├── gu-piao-de-zui-da-li-run-lcof.md
│ ├── h54YBf.md
│ ├── hPov7L.md
│ ├── he-bing-liang-ge-pai-xu-de-lian-biao-lcof.md
│ ├── he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof.md
│ ├── he-wei-sde-liang-ge-shu-zi-lcof.md
│ ├── hua-dong-chuang-kou-de-zui-da-zhi-lcof.md
│ ├── iIQa4I.md
│ ├── iSwD2y.md
│ ├── index.md
│ ├── jBjn9C.md
│ ├── jC7MId.md
│ ├── jJ0w9p.md
│ ├── ji-qi-ren-de-yun-dong-fan-wei-lcof.md
│ ├── jian-sheng-zi-lcof.md
│ ├── ju-zhen-zhong-de-lu-jing-lcof.md
│ ├── kLl5u1.md
│ ├── kTOapQ.md
│ ├── lMSNwu.md
│ ├── li-wu-de-zui-da-jie-zhi-lcof.md
│ ├── lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof.md
│ ├── lian-xu-zi-shu-zu-de-zui-da-he-lcof.md
│ ├── liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof.md
│ ├── lwyVBB.md
│ ├── ms70jA.md
│ ├── nZZqjQ.md
│ ├── om3reC.md
│ ├── opLdQZ.md
│ ├── pOCWxh.md
│ ├── ping-heng-er-cha-shu-lcof.md
│ ├── qIsx9U.md
│ ├── qJnOS7.md
│ ├── qing-wa-tiao-tai-jie-wen-ti-lcof.md
│ ├── qiu-12n-lcof.md
│ ├── que-shi-de-shu-zi-lcof.md
│ ├── sfvd7V.md
│ ├── shan-chu-lian-biao-de-jie-dian-lcof.md
│ ├── shu-de-zi-jie-gou-lcof.md
│ ├── shu-ju-liu-zhong-de-zhong-wei-shu-lcof.md
│ ├── shu-zhi-de-zheng-shu-ci-fang-lcof.md
│ ├── shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof.md
│ ├── shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof.md
│ ├── shu-zu-zhong-de-ni-xu-dui-lcof.md
│ ├── shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof.md
│ ├── shu-zu-zhong-zhong-fu-de-shu-zi-lcof.md
│ ├── shun-shi-zhen-da-yin-ju-zhen-lcof.md
│ ├── ti-huan-kong-ge-lcof.md
│ ├── tvdfij.md
│ ├── uUsW3B.md
│ ├── vEAB3K.md
│ ├── vlzXQL.md
│ ├── vvXgSW.md
│ ├── w3tCBm.md
│ ├── w6cpku.md
│ ├── wtcaE1.md
│ ├── xoh6Oh.md
│ ├── xu-lie-hua-er-cha-shu-lcof.md
│ ├── xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof.md
│ ├── xx4gT2.md
│ ├── yong-liang-ge-zhan-shi-xian-dui-lie-lcof.md
│ ├── yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof.md
│ ├── z1R5dt.md
│ ├── zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof.md
│ ├── zhan-de-ya-ru-dan-chu-xu-lie-lcof.md
│ ├── zhong-jian-er-cha-shu-lcof.md
│ ├── zi-fu-chuan-de-pai-lie-lcof.md
│ ├── zlDJc7.md
│ ├── zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof.md
│ ├── zui-xiao-de-kge-shu-lcof.md
│ └── zuo-xuan-zhuan-zi-fu-chuan-lcof.md
├── index.md
└── interviews/
├── bracket-lcci.md
├── calculator-lcci.md
├── color-fill-lcci.md
├── eight-queens-lcci.md
├── factorial-zeros-lcci.md
├── first-common-ancestor-lcci.md
├── group-anagrams-lcci.md
├── implement-queue-using-stacks-lcci.md
├── index.md
├── intersection-of-two-linked-lists-lcci.md
├── kth-node-from-end-of-list-lcci.md
├── legal-binary-search-tree-lcci.md
├── linked-list-cycle-lcci.md
├── longest-word-lcci.md
├── min-stack-lcci.md
├── minimum-height-tree-lcci.md
├── multi-search-lcci.md
├── number-of-2s-in-range-lcci.md
├── palindrome-linked-list-lcci.md
├── paths-with-sum-lcci.md
├── permutation-i-lcci.md
├── permutation-ii-lcci.md
├── power-set-lcci.md
├── rotate-matrix-lcci.md
├── smallest-k-lcci.md
├── sorted-matrix-search-lcci.md
├── sorted-merge-lcci.md
├── successor-lcci.md
├── sum-lists-lcci.md
├── words-frequency-lcci.md
└── zero-matrix-lcci.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/sync.yml
================================================
name: Mirror to Gitee Repo
on: [ push ]
# Ensures that only one mirror task will run at a time.
concurrency:
group: git-mirror
jobs:
git-mirror:
runs-on: ubuntu-latest
steps:
- uses: wearerequired/git-mirror-action@v1
env:
SSH_PRIVATE_KEY: ${{ secrets.SYNC_GITEE_PRI_KEY }}
with:
source-repo: "git@github.com:itcharge/AlgoNote.git"
destination-repo: "git@gitee.com:itcharge/AlgoNote.git"
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# Custom
Temp
.idea
.DS_Store
================================================
FILE: LICENSE
================================================
Creative Commons Attribution-NonCommercial-NoDerivatives 4.0
International
Creative Commons Corporation ("Creative Commons") is not a law firm and
does not provide legal services or legal advice. Distribution of
Creative Commons public licenses does not create a lawyer-client or
other relationship. Creative Commons makes its licenses and related
information available on an "as-is" basis. Creative Commons gives no
warranties regarding its licenses, any material licensed under their
terms and conditions, or any related information. Creative Commons
disclaims all liability for damages resulting from their use to the
fullest extent possible.
Using Creative Commons Public Licenses
Creative Commons public licenses provide a standard set of terms and
conditions that creators and other rights holders may use to share
original works of authorship and other material subject to copyright and
certain other rights specified in the public license below. The
following considerations are for informational purposes only, are not
exhaustive, and do not form part of our licenses.
Considerations for licensors: Our public licenses are intended for use
by those authorized to give the public permission to use material in
ways otherwise restricted by copyright and certain other rights. Our
licenses are irrevocable. Licensors should read and understand the terms
and conditions of the license they choose before applying it. Licensors
should also secure all rights necessary before applying our licenses so
that the public can reuse the material as expected. Licensors should
clearly mark any material not subject to the license. This includes
other CC-licensed material, or material used under an exception or
limitation to copyright. More considerations for licensors :
wiki.creativecommons.org/Considerations_for_licensors
Considerations for the public: By using one of our public licenses, a
licensor grants the public permission to use the licensed material under
specified terms and conditions. If the licensor's permission is not
necessary for any reason–for example, because of any applicable
exception or limitation to copyright–then that use is not regulated by
the license. Our licenses grant only permissions under copyright and
certain other rights that a licensor has authority to grant. Use of the
licensed material may still be restricted for other reasons, including
because others have copyright or other rights in the material. A
licensor may make special requests, such as asking that all changes be
marked or described. Although not required by our licenses, you are
encouraged to respect those requests where reasonable. More
considerations for the public :
wiki.creativecommons.org/Considerations_for_licensees
Creative Commons Attribution-NonCommercial-NoDerivatives 4.0
International Public License
By exercising the Licensed Rights (defined below), You accept and agree
to be bound by the terms and conditions of this Creative Commons
Attribution-NonCommercial-NoDerivatives 4.0 International Public License
("Public License"). To the extent this Public License may be interpreted
as a contract, You are granted the Licensed Rights in consideration of
Your acceptance of these terms and conditions, and the Licensor grants
You such rights in consideration of benefits the Licensor receives from
making the Licensed Material available under these terms and conditions.
- Section 1 – Definitions.
- a. Adapted Material means material subject to Copyright and
Similar Rights that is derived from or based upon the Licensed
Material and in which the Licensed Material is translated,
altered, arranged, transformed, or otherwise modified in a
manner requiring permission under the Copyright and Similar
Rights held by the Licensor. For purposes of this Public
License, where the Licensed Material is a musical work,
performance, or sound recording, Adapted Material is always
produced where the Licensed Material is synched in timed
relation with a moving image.
- b. Copyright and Similar Rights means copyright and/or similar
rights closely related to copyright including, without
limitation, performance, broadcast, sound recording, and Sui
Generis Database Rights, without regard to how the rights are
labeled or categorized. For purposes of this Public License, the
rights specified in Section 2(b)(1)-(2) are not Copyright and
Similar Rights.
- c. Effective Technological Measures means those measures that,
in the absence of proper authority, may not be circumvented
under laws fulfilling obligations under Article 11 of the WIPO
Copyright Treaty adopted on December 20, 1996, and/or similar
international agreements.
- d. Exceptions and Limitations means fair use, fair dealing,
and/or any other exception or limitation to Copyright and
Similar Rights that applies to Your use of the Licensed
Material.
- e. Licensed Material means the artistic or literary work,
database, or other material to which the Licensor applied this
Public License.
- f. Licensed Rights means the rights granted to You subject to
the terms and conditions of this Public License, which are
limited to all Copyright and Similar Rights that apply to Your
use of the Licensed Material and that the Licensor has authority
to license.
- g. Licensor means the individual(s) or entity(ies) granting
rights under this Public License.
- h. NonCommercial means not primarily intended for or directed
towards commercial advantage or monetary compensation. For
purposes of this Public License, the exchange of the Licensed
Material for other material subject to Copyright and Similar
Rights by digital file-sharing or similar means is NonCommercial
provided there is no payment of monetary compensation in
connection with the exchange.
- i. Share means to provide material to the public by any means or
process that requires permission under the Licensed Rights, such
as reproduction, public display, public performance,
distribution, dissemination, communication, or importation, and
to make material available to the public including in ways that
members of the public may access the material from a place and
at a time individually chosen by them.
- j. Sui Generis Database Rights means rights other than copyright
resulting from Directive 96/9/EC of the European Parliament and
of the Council of 11 March 1996 on the legal protection of
databases, as amended and/or succeeded, as well as other
essentially equivalent rights anywhere in the world.
- k. You means the individual or entity exercising the Licensed
Rights under this Public License. Your has a corresponding
meaning.
- Section 2 – Scope.
- a. License grant.
- 1. Subject to the terms and conditions of this Public
License, the Licensor hereby grants You a worldwide,
royalty-free, non-sublicensable, non-exclusive, irrevocable
license to exercise the Licensed Rights in the Licensed
Material to:
- A. reproduce and Share the Licensed Material, in whole
or in part, for NonCommercial purposes only; and
- B. produce and reproduce, but not Share, Adapted
Material for NonCommercial purposes only.
- 2. Exceptions and Limitations. For the avoidance of doubt,
where Exceptions and Limitations apply to Your use, this
Public License does not apply, and You do not need to comply
with its terms and conditions.
- 3. Term. The term of this Public License is specified in
Section 6(a).
- 4. Media and formats; technical modifications allowed. The
Licensor authorizes You to exercise the Licensed Rights in
all media and formats whether now known or hereafter
created, and to make technical modifications necessary to do
so. The Licensor waives and/or agrees not to assert any
right or authority to forbid You from making technical
modifications necessary to exercise the Licensed Rights,
including technical modifications necessary to circumvent
Effective Technological Measures. For purposes of this
Public License, simply making modifications authorized by
this Section 2(a)(4) never produces Adapted Material.
- 5. Downstream recipients.
- A. Offer from the Licensor – Licensed Material. Every
recipient of the Licensed Material automatically
receives an offer from the Licensor to exercise the
Licensed Rights under the terms and conditions of this
Public License.
- B. No downstream restrictions. You may not offer or
impose any additional or different terms or conditions
on, or apply any Effective Technological Measures to,
the Licensed Material if doing so restricts exercise of
the Licensed Rights by any recipient of the Licensed
Material.
- 6. No endorsement. Nothing in this Public License
constitutes or may be construed as permission to assert or
imply that You are, or that Your use of the Licensed
Material is, connected with, or sponsored, endorsed, or
granted official status by, the Licensor or others
designated to receive attribution as provided in Section
3(a)(1)(A)(i).
- b. Other rights.
- 1. Moral rights, such as the right of integrity, are not
licensed under this Public License, nor are publicity,
privacy, and/or other similar personality rights; however,
to the extent possible, the Licensor waives and/or agrees
not to assert any such rights held by the Licensor to the
limited extent necessary to allow You to exercise the
Licensed Rights, but not otherwise.
- 2. Patent and trademark rights are not licensed under this
Public License.
- 3. To the extent possible, the Licensor waives any right to
collect royalties from You for the exercise of the Licensed
Rights, whether directly or through a collecting society
under any voluntary or waivable statutory or compulsory
licensing scheme. In all other cases the Licensor expressly
reserves any right to collect such royalties, including when
the Licensed Material is used other than for NonCommercial
purposes.
- Section 3 – License Conditions.
Your exercise of the Licensed Rights is expressly made subject to
the following conditions.
- a. Attribution.
- 1. If You Share the Licensed Material, You must:
- A. retain the following if it is supplied by the
Licensor with the Licensed Material:
- i. identification of the creator(s) of the Licensed
Material and any others designated to receive
attribution, in any reasonable manner requested by
the Licensor (including by pseudonym if designated);
- ii. a copyright notice;
- iii. a notice that refers to this Public License;
- iv. a notice that refers to the disclaimer of
warranties;
- v. a URI or hyperlink to the Licensed Material to
the extent reasonably practicable;
- B. indicate if You modified the Licensed Material and
retain an indication of any previous modifications; and
- C. indicate the Licensed Material is licensed under this
Public License, and include the text of, or the URI or
hyperlink to, this Public License.
For the avoidance of doubt, You do not have permission under
this Public License to Share Adapted Material.
- 2. You may satisfy the conditions in Section 3(a)(1) in any
reasonable manner based on the medium, means, and context in
which You Share the Licensed Material. For example, it may
be reasonable to satisfy the conditions by providing a URI
or hyperlink to a resource that includes the required
information.
- 3. If requested by the Licensor, You must remove any of the
information required by Section 3(a)(1)(A) to the extent
reasonably practicable.
- Section 4 – Sui Generis Database Rights.
Where the Licensed Rights include Sui Generis Database Rights that
apply to Your use of the Licensed Material:
- a. for the avoidance of doubt, Section 2(a)(1) grants You the
right to extract, reuse, reproduce, and Share all or a
substantial portion of the contents of the database for
NonCommercial purposes only and provided You do not Share
Adapted Material;
- b. if You include all or a substantial portion of the database
contents in a database in which You have Sui Generis Database
Rights, then the database in which You have Sui Generis Database
Rights (but not its individual contents) is Adapted Material;
and
- c. You must comply with the conditions in Section 3(a) if You
Share all or a substantial portion of the contents of the
database.
For the avoidance of doubt, this Section 4 supplements and does not
replace Your obligations under this Public License where the
Licensed Rights include other Copyright and Similar Rights.
- Section 5 – Disclaimer of Warranties and Limitation of Liability.
- a. Unless otherwise separately undertaken by the Licensor, to
the extent possible, the Licensor offers the Licensed Material
as-is and as-available, and makes no representations or
warranties of any kind concerning the Licensed Material, whether
express, implied, statutory, or other. This includes, without
limitation, warranties of title, merchantability, fitness for a
particular purpose, non-infringement, absence of latent or other
defects, accuracy, or the presence or absence of errors, whether
or not known or discoverable. Where disclaimers of warranties
are not allowed in full or in part, this disclaimer may not
apply to You.
- b. To the extent possible, in no event will the Licensor be
liable to You on any legal theory (including, without
limitation, negligence) or otherwise for any direct, special,
indirect, incidental, consequential, punitive, exemplary, or
other losses, costs, expenses, or damages arising out of this
Public License or use of the Licensed Material, even if the
Licensor has been advised of the possibility of such losses,
costs, expenses, or damages. Where a limitation of liability is
not allowed in full or in part, this limitation may not apply to
You.
- c. The disclaimer of warranties and limitation of liability
provided above shall be interpreted in a manner that, to the
extent possible, most closely approximates an absolute
disclaimer and waiver of all liability.
- Section 6 – Term and Termination.
- a. This Public License applies for the term of the Copyright and
Similar Rights licensed here. However, if You fail to comply
with this Public License, then Your rights under this Public
License terminate automatically.
- b. Where Your right to use the Licensed Material has terminated
under Section 6(a), it reinstates:
- 1. automatically as of the date the violation is cured,
provided it is cured within 30 days of Your discovery of the
violation; or
- 2. upon express reinstatement by the Licensor.
For the avoidance of doubt, this Section 6(b) does not affect
any right the Licensor may have to seek remedies for Your
violations of this Public License.
- c. For the avoidance of doubt, the Licensor may also offer the
Licensed Material under separate terms or conditions or stop
distributing the Licensed Material at any time; however, doing
so will not terminate this Public License.
- d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
License.
- Section 7 – Other Terms and Conditions.
- a. The Licensor shall not be bound by any additional or
different terms or conditions communicated by You unless
expressly agreed.
- b. Any arrangements, understandings, or agreements regarding the
Licensed Material not stated herein are separate from and
independent of the terms and conditions of this Public License.
- Section 8 – Interpretation.
- a. For the avoidance of doubt, this Public License does not, and
shall not be interpreted to, reduce, limit, restrict, or impose
conditions on any use of the Licensed Material that could
lawfully be made without permission under this Public License.
- b. To the extent possible, if any provision of this Public
License is deemed unenforceable, it shall be automatically
reformed to the minimum extent necessary to make it enforceable.
If the provision cannot be reformed, it shall be severed from
this Public License without affecting the enforceability of the
remaining terms and conditions.
- c. No term or condition of this Public License will be waived
and no failure to comply consented to unless expressly agreed to
by the Licensor.
- d. Nothing in this Public License constitutes or may be
interpreted as a limitation upon, or waiver of, any privileges
and immunities that apply to the Licensor or You, including from
the legal processes of any jurisdiction or authority.
Creative Commons is not a party to its public licenses. Notwithstanding,
Creative Commons may elect to apply one of its public licenses to
material it publishes and in those instances will be considered the
"Licensor." The text of the Creative Commons public licenses is
dedicated to the public domain under the CC0 Public Domain Dedication.
Except for the limited purpose of indicating that material is shared
under a Creative Commons public license or as otherwise permitted by the
Creative Commons policies published at creativecommons.org/policies,
Creative Commons does not authorize the use of the trademark "Creative
Commons" or any other trademark or logo of Creative Commons without its
prior written consent including, without limitation, in connection with
any unauthorized modifications to any of its public licenses or any
other arrangements, understandings, or agreements concerning use of
licensed material. For the avoidance of doubt, this paragraph does not
form part of the public licenses.
Creative Commons may be contacted at creativecommons.org.
================================================
FILE: README.md
================================================
<div align='center'>
<img src="https://qcdn.itcharge.cn/images/20250925092713.png" alt="alt text" width="100%"/>
<h1>算法通关手册</h1>
</div>
<div align="center">
<img src="https://img.shields.io/github/stars/ITCharge/AlgoNote?style=flat&logo=github" alt="GitHub stars"/>
<img src="https://img.shields.io/github/forks/ITCharge/AlgoNote?style=flat&logo=github" alt="GitHub forks"/>
<img src="https://img.shields.io/badge/language-Chinese%20%7C%20Python-brightgreen?style=flat" alt="Language"/>
<a href="https://github.com/ITCharge/AlgoNote"><img src="https://img.shields.io/badge/GitHub-Project-blue?style=flat&logo=github" alt="GitHub Project"/></a>
<p></p>
<h3>📚 从零开始的「算法与数据结构」学习教程</h3>
<p><em>一本系统讲解算法与数据结构、涵盖 LeetCode 题解的中文学习手册</em></p>
</div>
<div align="center">
<a href="https://algo.itcharge.cn/">
<img src="https://qcdn.itcharge.cn/images/btn_read_online.svg" width="145" alt="在线阅读"></a>
<a href="https://github.com/itcharge/AlgoNote/releases">
<img src="https://qcdn.itcharge.cn/images/btn_download_pdf.svg" width="145" alt="PDF 下载"></a>
</div>
如果觉得本项目对你有帮助,欢迎点亮 🌟 Star,支持一下!
## 1. 本书简介
本书不仅仅只是一本算法题解书,更是一本算法与数据结构基础知识的讲解书。
- 超详细的 **「算法与数据结构」** 基础讲解教程,**「LeetCode 1000+ 道」** 经典题目详细解析。
- 本项目易于理解,没有大跨度的思维跳跃,项目中使用大量图示、例子来帮助理解。
- 本项目先从基础的数据结构和算法开始讲解,再针对不同分类的数据结构和算法,进行具体题目的讲解分析。让读者可以通过「算法基础理论学习」和「编程实战学习」相结合的方式,彻底的掌握算法知识。
- 本项目从各大知名互联网公司面试算法题中整理汇总了 **「LeetCode 200 道高频面试题」**,帮助面试者更有针对性的准备面试。
### 1.1 目标读者
- 拥有 Python 编程基础或其他编程语言基础的编程爱好者
- 对 LeetCode 刷题感兴趣或准备算法面试的面试人员
- 对算法感兴趣的计算机专业学生或程序员
- 想要提升编程思维和问题解决能力的开发者
### 1.2 内容结构
本书采用算法与数据结构相结合的方法,把内容分为如下几个主要部分:
- **0. 序言**:介绍数据结构与算法的基础知识、算法复杂度、LeetCode 的入门和攻略,为后面的学习打好基础。
- **1. 数组**:讲解数组的基本概念、数组的基本操作。
- **2. 链表**:讲解链表的基本概念、操作和应用,包括单链表、双向链表、循环链表等。
- **3. 栈、队列、哈希表**:详细介绍栈、队列、哈希表这三种数据结构,包括它们的基本概念、实现方式、应用场景以及相关的经典算法题。
- **4. 字符串**:讲解字符串的基本操作、单字符串匹配算法、多字符串匹配算法,以及字符串相关的经典算法题。
- **5. 树结构**:介绍树的基本概念、二叉树、二叉搜索树、线段树、树状数组、并查集等数据结构。
- **6. 图论**:讲解图的基本概念、表示方法、遍历算法和经典应用。
- **7. 基础算法**:介绍基本的算法思想。包括枚举、递归、分治、回溯、贪心以及位运算。
- **8. 动态规划**:介绍动态规划的基础知识、各种动态规划题型的解法。
- **9. 附加内容**:作为全书的扩展模块。
- **10. 题目解析**:讲解 LeetCode 上刷过的所有题目,可按照对应题号进行检索和学习。
### 1.3 使用说明
- 本电子书左侧提供了完整的章节目录导航,可直接点击跳转至相应内容。
- 本电子书右上角配有搜索栏,便于快速查找所需章节和题解文章。
- 本电子书集成了 giscus 评论系统,欢迎在页面底部评论区留言(需 GitHub 账号登录)。
- 建议按章节顺序系统学习,逐步掌握各知识点;也可根据兴趣自由选择章节阅读。
- 每篇内容末尾设有练习题,建议及时完成以加深理解、巩固所学。
## 2. 相关说明
### 2.1 关于作者
我是一名 iOS / macOS 的开发程序员,研究生毕业于北航软件学院。曾在大学期间学习过算法知识,并参加过 3 年的 ACM 比赛, 但水平有限,未能取得理想成绩。但是这 3 年的 ACM 经历,给我最大的收获是锻炼了自己的逻辑思维和解决实际问题的能力,这种能力为我今后的工作、学习打下了坚实的基础。
我从 2021 年 03 月 30 日开始每日在 LeetCode 刷题,到目前为止日已经刷了 1800+ 道题目,并且完成了 1000+ 道题解。努力向着 1500+、2000+ 道题解前进。
### 2.2 互助与勘误
限于本人的水平和经验,书中一定不乏纰漏和谬误之处。恳切希望读者给予批评指正。这将有利于我改进和提高,以帮助更多的读者。如果您对本书有任何评论和建议,或者遇到问题需要帮助,可在每页评论区留言,或者致信作者邮箱 [i@itcharge.cn](mailto:i@itcharge.cn),我将不胜感激。
### 2.3 版权说明
- 本书采用 [知识署名—非商业性使用—禁止演绎(BY-NC-ND)4.0 协议国际许可协议](https://creativecommons.org/licenses/by-nc-nd/4.0/legalcode.zh-Hans) 进行许可。
- 本书题解中的所有题目版权均归 [LeetCode](https://leetcode.com/) 和 [力扣中国](https://leetcode.cn/) 所有。
### 2.4 致谢
在本书构思与写作阶段,很多朋友给我提出了有益的意见和建议。这些意见和建议令我受益匪浅。感谢在本书著作准备过程中,帮助过我的朋友,以及一起陪我刷题打卡的朋友,还有提供宝贵意见的读者。谢谢诸位。
================================================
FILE: codes/python/01_array/array_maxheap.py
================================================
class MaxHeap:
def __init__(self):
self.max_heap = []
def peek(self) -> int:
# 大顶堆为空
if not self.max_heap:
return None
# 返回堆顶元素
return self.max_heap[0]
def push(self, val: int):
# 将新元素添加到堆的末尾
self.max_heap.append(val)
size = len(self.max_heap)
# 从新插入的元素节点开始,进行上移调整
self.__shift_up(size - 1)
def __shift_up(self, i: int):
while (i - 1) // 2 >= 0 and self.max_heap[i] > self.max_heap[(i - 1) // 2]:
self.max_heap[i], self.max_heap[(i - 1) // 2] = self.max_heap[(i - 1) // 2], self.max_heap[i]
i = (i - 1) // 2
def pop(self) -> int:
# 堆为空
if not self.max_heap:
raise IndexError("堆为空")
size = len(self.max_heap)
self.max_heap[0], self.max_heap[size - 1] = self.max_heap[size - 1], self.max_heap[0]
# 删除堆顶元素
val = self.max_heap.pop()
# 节点数减 1
size -= 1
self.__shift_down(0, size)
# 返回堆顶元素
return val
def __shift_down(self, i: int, n: int):
while 2 * i + 1 < n:
# 左右子节点编号
left, right = 2 * i + 1, 2 * i + 2
# 找出左右子节点中的较大值节点编号
if 2 * i + 2 >= n:
# 右子节点编号超出范围(只有左子节点
larger = left
else:
# 左子节点、右子节点都存在
if self.max_heap[left] >= self.max_heap[right]:
larger = left
else:
larger = right
# 将当前节点值与其较大的子节点进行比较
if self.max_heap[i] < self.max_heap[larger]:
# 如果当前节点值小于其较大的子节点,则将它们交换
self.max_heap[i], self.max_heap[larger] = self.max_heap[larger], self.max_heap[i]
i = larger
else:
# 如果当前节点值大于等于于其较大的子节点,此时结束
break
class Solution:
def maxHeapOperations(self):
max_heap = MaxHeap()
max_heap.push(3)
print(max_heap.peek())
max_heap.push(2)
print(max_heap.peek())
max_heap.push(4)
print(max_heap.peek())
max_heap.pop()
print(max_heap.peek())
print(Solution().maxHeapOperations())
================================================
FILE: codes/python/01_array/array_sort_bubble_sort.py
================================================
class Solution:
def bubbleSort(self, nums: [int]) -> [int]:
# 第 i 趟「冒泡」
for i in range(len(nums) - 1):
flag = False # 是否发生交换的标志位
# 对数组未排序区间 [0, n - i - 1] 的元素执行「冒泡」
for j in range(len(nums) - i - 1):
# 相邻两个元素进行比较,如果前者大于后者,则交换位置
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
flag = True
if not flag: # 此趟遍历未交换任何元素,直接跳出
break
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.bubbleSort(nums)
print(Solution().sortArray([5, 2, 3, 6, 1, 4]))
================================================
FILE: codes/python/01_array/array_sort_bucket_sort.py
================================================
class Solution:
def insertionSort(self, nums: [int]) -> [int]:
# 遍历无序区间
for i in range(1, len(nums)):
temp = nums[i]
j = i
# 从右至左遍历有序区间
while j > 0 and nums[j - 1] > temp:
# 将有序区间中插入位置右侧的元素依次右移一位
nums[j] = nums[j - 1]
j -= 1
# 将该元素插入到适当位置
nums[j] = temp
return nums
def bucketSort(self, nums: [int], bucket_size=5) -> [int]:
# 计算待排序序列中最大值元素 nums_max、最小值元素 nums_min
nums_min, nums_max = min(nums), max(nums)
# 定义桶的个数为 (最大值元素 - 最小值元素) // 每个桶的大小 + 1
bucket_count = (nums_max - nums_min) // bucket_size + 1
# 定义桶数组 buckets
buckets = [[] for _ in range(bucket_count)]
# 遍历待排序数组元素,将每个元素根据大小分配到对应的桶中
for num in nums:
buckets[(num - nums_min) // bucket_size].append(num)
# 对每个非空桶内的元素单独排序,排序之后,按照区间顺序依次合并到 res 数组中
res = []
for bucket in buckets:
self.insertionSort(bucket)
res.extend(bucket)
# 返回结果数组
return res
def sortArray(self, nums: [int]) -> [int]:
return self.bucketSort(nums)
print(Solution().sortArray([39, 49, 8, 13, 22, 15, 10, 30, 5, 44]))
================================================
FILE: codes/python/01_array/array_sort_counting_sort.py
================================================
class Solution:
def countingSort(self, nums: [int]) -> [int]:
# 计算待排序数组中最大值元素 nums_max 和最小值元素 nums_min
nums_min, nums_max = min(nums), max(nums)
# 定义计数数组 counts,大小为 最大值元素 - 最小值元素 + 1
size = nums_max - nums_min + 1
counts = [0 for _ in range(size)]
# 统计值为 num 的元素出现的次数
for num in nums:
counts[num - nums_min] += 1
# 生成累积计数数组
for i in range(1, size):
counts[i] += counts[i - 1]
# 反向填充目标数组
res = [0 for _ in range(len(nums))]
for i in range(len(nums) - 1, -1, -1):
num = nums[i]
# 根据累积计数数组,将 num 放在数组对应位置
res[counts[num - nums_min] - 1] = num
# 将 num 的对应放置位置减 1,从而得到下个元素 num 的放置位置
counts[nums[i] - nums_min] -= 1
return res
def sortArray(self, nums: [int]) -> [int]:
return self.countingSort(nums)
print(Solution().sortArray([3, 0, 4, 2, 5, 1, 3, 1, 4, 5]))
================================================
FILE: codes/python/01_array/array_sort_insertion_sort.py
================================================
class Solution:
def insertionSort(self, nums: [int]) -> [int]:
# 遍历无序区间
for i in range(1, len(nums)):
temp = nums[i]
j = i
# 从右至左遍历有序区间
while j > 0 and nums[j - 1] > temp:
# 将有序区间中插入位置右侧的所有元素依次右移一位
nums[j] = nums[j - 1]
j -= 1
# 将该元素插入到适当位置
nums[j] = temp
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.insertionSort(nums)
print(Solution().sortArray([5, 2, 3, 6, 1, 4]))
================================================
FILE: codes/python/01_array/array_sort_maxheap_sort.py
================================================
class MaxHeap:
def __init__(self):
self.max_heap = []
def peek(self) -> int:
# 大顶堆为空
if not self.max_heap:
return None
# 返回堆顶元素
return self.max_heap[0]
def push(self, val: int):
# 将新元素添加到堆的末尾
self.max_heap.append(val)
size = len(self.max_heap)
# 从新插入的元素节点开始,进行上移调整
self.__shift_up(size - 1)
def __shift_up(self, i: int):
while (i - 1) // 2 >= 0 and self.max_heap[i] > self.max_heap[(i - 1) // 2]:
self.max_heap[i], self.max_heap[(i - 1) // 2] = self.max_heap[(i - 1) // 2], self.max_heap[i]
i = (i - 1) // 2
def pop(self) -> int:
# 堆为空
if not self.max_heap:
raise IndexError("堆为空")
size = len(self.max_heap)
self.max_heap[0], self.max_heap[size - 1] = self.max_heap[size - 1], self.max_heap[0]
# 删除堆顶元素
val = self.max_heap.pop()
# 节点数减 1
size -= 1
self.__shift_down(0, size)
# 返回堆顶元素
return val
def __shift_down(self, i: int, n: int):
while 2 * i + 1 < n:
# 左右子节点编号
left, right = 2 * i + 1, 2 * i + 2
# 找出左右子节点中的较大值节点编号
if 2 * i + 2 >= n:
# 右子节点编号超出范围(只有左子节点
larger = left
else:
# 左子节点、右子节点都存在
if self.max_heap[left] >= self.max_heap[right]:
larger = left
else:
larger = right
# 将当前节点值与其较大的子节点进行比较
if self.max_heap[i] < self.max_heap[larger]:
# 如果当前节点值小于其较大的子节点,则将它们交换
self.max_heap[i], self.max_heap[larger] = self.max_heap[larger], self.max_heap[i]
i = larger
else:
# 如果当前节点值大于等于于其较大的子节点,此时结束
break
def __buildMaxHeap(self, nums: [int]):
size = len(nums)
# 先将数组 nums 的元素按顺序添加到 max_heap 中
for i in range(size):
self.max_heap.append(nums[i])
# 从最后一个非叶子节点开始,进行下移调整
for i in range((size - 2) // 2, -1, -1):
self.__shift_down(i, size)
def maxHeapSort(self, nums: [int]) -> [int]:
# 根据数组 nums 建立初始堆
self.__buildMaxHeap(nums)
size = len(self.max_heap)
for i in range(size - 1, -1, -1):
# 交换根节点与当前堆的最后一个节点
self.max_heap[0], self.max_heap[i] = self.max_heap[i], self.max_heap[0]
# 从根节点开始,对当前堆进行下移调整
self.__shift_down(0, i)
# 返回排序后的数组
return self.max_heap
class Solution:
def maxHeapSort(self, nums: [int]) -> [int]:
return MaxHeap().maxHeapSort(nums)
def sortArray(self, nums: [int]) -> [int]:
return self.maxHeapSort(nums)
print(Solution().sortArray([10, 25, 6, 8, 7, 1, 20, 23, 16, 19, 17, 3, 18, 14]))
================================================
FILE: codes/python/01_array/array_sort_merge_sort.py
================================================
class Solution:
# 合并过程
def merge(self, left_nums: [int], right_nums: [int]):
nums = []
left_i, right_i = 0, 0
while left_i < len(left_nums) and right_i < len(right_nums):
# 将两个有序子数组中较小元素依次插入到结果数组中
if left_nums[left_i] < right_nums[right_i]:
nums.append(left_nums[left_i])
left_i += 1
else:
nums.append(right_nums[right_i])
right_i += 1
# 如果左子数组有剩余元素,则将其插入到结果数组中
while left_i < len(left_nums):
nums.append(left_nums[left_i])
left_i += 1
# 如果右子数组有剩余元素,则将其插入到结果数组中
while right_i < len(right_nums):
nums.append(right_nums[right_i])
right_i += 1
# 返回合并后的结果数组
return nums
# 分解过程
def mergeSort(self, nums: [int]) -> [int]:
# 数组元素个数小于等于 1 时,直接返回原数组
if len(nums) <= 1:
return nums
mid = len(nums) // 2 # 将数组从中间位置分为左右两个数组
left_nums = self.mergeSort(nums[0: mid]) # 递归将左子数组进行分解和排序
right_nums = self.mergeSort(nums[mid:]) # 递归将右子数组进行分解和排序
return self.merge(left_nums, right_nums) # 把当前数组组中有序子数组逐层向上,进行两两合并
def sortArray(self, nums: [int]) -> [int]:
return self.mergeSort(nums)
print(Solution().sortArray([0, 5, 7, 3, 1, 6, 8, 4]))
================================================
FILE: codes/python/01_array/array_sort_minheap_sort.py
================================================
class MinHeap:
def __init__(self):
self.min_heap = []
def peek(self) -> int:
# 大顶堆为空
if not self.min_heap:
return None
# 返回堆顶元素
return self.min_heap[0]
def push(self, val: int):
# 将新元素添加到堆的末尾
self.min_heap.append(val)
size = len(self.min_heap)
# 从新插入的元素节点开始,进行上移调整
self.__shift_up(size - 1)
def __shift_up(self, i: int):
while (i - 1) // 2 >= 0 and self.min_heap[i] < self.min_heap[(i - 1) // 2]:
self.min_heap[i], self.min_heap[(i - 1) // 2] = self.min_heap[(i - 1) // 2], self.min_heap[i]
i = (i - 1) // 2
def pop(self) -> int:
# 堆为空
if not self.min_heap:
raise IndexError("堆为空")
size = len(self.min_heap)
self.min_heap[0], self.min_heap[size - 1] = self.min_heap[size - 1], self.min_heap[0]
# 删除堆顶元素
val = self.min_heap.pop()
# 节点数减 1
size -= 1
self.__shift_down(0, size)
# 返回堆顶元素
return val
def __shift_down(self, i: int, n: int):
while 2 * i + 1 < n:
# 左右子节点编号
left, right = 2 * i + 1, 2 * i + 2
# 找出左右子节点中的较大值节点编号
if 2 * i + 2 >= n:
# 右子节点编号超出范围(只有左子节点
larger = left
else:
# 左子节点、右子节点都存在
if self.min_heap[left] <= self.min_heap[right]:
larger = left
else:
larger = right
# 将当前节点值与其较小的子节点进行比较
if self.min_heap[i] > self.min_heap[larger]:
# 如果当前节点值小于其较大的子节点,则将它们交换
self.min_heap[i], self.min_heap[larger] = self.min_heap[larger], self.min_heap[i]
i = larger
else:
# 如果当前节点值大于等于于其较大的子节点,此时结束
break
def __buildMinHeap(self, nums: [int]):
size = len(nums)
# 先将数组 nums 的元素按顺序添加到 min_heap 中
for i in range(size):
self.min_heap.append(nums[i])
# 从最后一个非叶子节点开始,进行下移调整
for i in range((size - 2) // 2, -1, -1):
self.__shift_down(i, size)
def minHeapSort(self, nums: [int]) -> [int]:
# 根据数组 nums 建立初始堆
self.__buildMinHeap(nums)
size = len(self.min_heap)
for i in range(size - 1, -1, -1):
# 交换根节点与当前堆的最后一个节点
self.min_heap[0], self.min_heap[i] = self.min_heap[i], self.min_heap[0]
# 从根节点开始,对当前堆进行下移调整
self.__shift_down(0, i)
# 返回排序后的数组
return self.min_heap
class Solution:
def minHeapSort(self, nums: [int]) -> [int]:
return MinHeap().minHeapSort(nums)
def sortArray(self, nums: [int]) -> [int]:
return self.minHeapSort(nums)
print(Solution().sortArray([10, 25, 6, 8, 7, 1, 20, 23, 16, 19, 17, 3, 18, 14]))
================================================
FILE: codes/python/01_array/array_sort_quick_sort.py
================================================
import random
class Solution:
# 随机哨兵划分:从 nums[low: high + 1] 中随机挑选一个基准数,并进行移位排序
def randomPartition(self, nums: [int], low: int, high: int) -> int:
# 随机挑选一个基准数
i = random.randint(low, high)
# 将基准数与最低位互换
nums[i], nums[low] = nums[low], nums[i]
# 以最低位为基准数,然后将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上
return self.partition(nums, low, high)
# 哨兵划分:以第 1 位元素 nums[low] 为基准数,然后将比基准数小的元素移动到基准数左侧,将比基准数大的元素移动到基准数右侧,最后将基准数放到正确位置上
def partition(self, nums: [int], low: int, high: int) -> int:
# 以第 1 位元素为基准数
pivot = nums[low]
i, j = low, high
while i < j:
# 从右向左找到第 1 个小于基准数的元素
while i < j and nums[j] >= pivot:
j -= 1
# 从左向右找到第 1 个大于基准数的元素
while i < j and nums[i] <= pivot:
i += 1
# 交换元素
nums[i], nums[j] = nums[j], nums[i]
# 将基准数放到正确位置上
nums[j], nums[low] = nums[low], nums[j]
return j
def quickSort(self, nums: [int], low: int, high: int) -> [int]:
if low < high:
# 按照基准数的位置,将数组划分为左右两个子数组
pivot_i = self.partition(nums, low, high)
# 对左右两个子数组分别进行递归快速排序
self.quickSort(nums, low, pivot_i - 1)
self.quickSort(nums, pivot_i + 1, high)
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.quickSort(nums, 0, len(nums) - 1)
print(Solution().sortArray([4, 7, 5, 2, 6, 1, 3]))
================================================
FILE: codes/python/01_array/array_sort_radix_sort.py
================================================
class Solution:
def radixSort(self, nums: [int]) -> [int]:
# 桶的大小为所有元素的最大位数
size = len(str(max(nums)))
# 从最低位(个位)开始,逐位遍历每一位
for i in range(size):
# 定义长度为 10 的桶数组 buckets,每个桶分别代表 0 ~ 9 中的 1 个数字。
buckets = [[] for _ in range(10)]
# 遍历数组元素,按照每个元素当前位上的数字,将元素放入对应数字的桶中。
for num in nums:
buckets[num // (10 ** i) % 10].append(num)
# 清空原始数组
nums.clear()
# 按照桶的顺序依次取出对应元素,重新加入到原始数组中。
for bucket in buckets:
for num in bucket:
nums.append(num)
# 完成排序,返回结果数组
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.radixSort(nums)
print(Solution().sortArray([692, 924, 969, 503, 871, 704, 542, 436]))
================================================
FILE: codes/python/01_array/array_sort_selection_sort.py
================================================
class Solution:
def selectionSort(self, nums: [int]) -> [int]:
for i in range(len(nums) - 1):
# 记录未排序区间中最小值的位置
min_i = i
for j in range(i + 1, len(nums)):
if nums[j] < nums[min_i]:
min_i = j
# 如果找到最小值的位置,将 i 位置上元素与最小值位置上的元素进行交换
if i != min_i:
nums[i], nums[min_i] = nums[min_i], nums[i]
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.selectionSort(nums)
print(Solution().sortArray([5, 2, 3, 6, 1, 4]))
================================================
FILE: codes/python/01_array/array_sort_shell_sort.py
================================================
class Solution:
def shellSort(self, nums: [int]) -> [int]:
size = len(nums)
gap = size // 2
# 按照 gap 分组
while gap > 0:
# 对每组元素进行插入排序
for i in range(gap, size):
# temp 为每组中无序数组第 1 个元素
temp = nums[i]
j = i
# 从右至左遍历每组中的有序数组元素
while j >= gap and nums[j - gap] > temp:
# 将每组有序数组中插入位置右侧的元素依次在组中右移一位
nums[j] = nums[j - gap]
j -= gap
# 将该元素插入到适当位置
nums[j] = temp
# 缩小 gap 间隔
gap = gap // 2
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.shellSort(nums)
print(Solution().sortArray([7, 2, 6, 8, 0, 4, 1, 5, 9, 3]))
================================================
FILE: codes/python/02_linked_list/linked_list.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class LinkedList:
def __init__(self):
self.head = None
# 根据 data 初始化一个新链表
def create(self, data):
if not data:
return
self.head = ListNode(data[0])
cur = self.head
for i in range(1, len(data)):
node = ListNode(data[i])
cur.next = node
cur = cur.next
# 获取线性链表长度
def length(self):
count = 0
cur = self.head
while cur:
count += 1
cur = cur.next
return count
# 查找元素:在链表中查找值为 val 的元素
def find(self, val):
cur = self.head
while cur:
if val == cur.val:
return cur
cur = cur.next
return None
# 链表头部插入元素
def insertFront(self, val):
node = ListNode(val)
node.next = self.head
self.head = node
# 链表尾部插入元素
def insertRear(self, val):
node = ListNode(val)
cur = self.head
while cur.next:
cur = cur.next
cur.next = node
# 链表中间插入元素
def insertInside(self, index, val):
count = 0
cur = self.head
while cur and count < index - 1:
count += 1
cur = cur.next
if not cur:
return 'Error'
node = ListNode(val)
node.next = cur.next
cur.next = node
# 改变元素:将链表中第 i 个元素值改为 val
def change(self, index, val):
count = 0
cur = self.head
while cur and count < index:
count += 1
cur = cur.next
if not cur:
return 'Error'
cur.val = val
# 链表头部删除元素
def removeFront(self):
if self.head:
self.head = self.head.next
# 链表尾部删除元素
def removeRear(self):
if not self.head or not self.head.next:
return 'Error'
cur = self.head
while cur.next.next:
cur = cur.next
cur.next = None
# 链表中间删除元素
def removeInside(self, index):
count = 0
cur = self.head
while cur.next and count < index - 1:
count += 1
cur = cur.next
if not cur:
return 'Error'
del_node = cur.next
cur.next = del_node.next
================================================
FILE: codes/python/02_linked_list/linked_list_bubble_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def bubbleSort(self, head: ListNode):
node_i = head
tail = None
# 外层循环次数为 链表长度 次
while node_i:
node_j = head
while node_j and node_j.next != tail:
if node_j.val > node_j.next.val:
# 交换两个节点的值
node_j.val, node_j.next.val = node_j.next.val, node_j.val
node_j = node_j.next
# 尾指针向前移动 1 位,此时尾指针右侧为排好序的链表
tail = node_j
node_i = node_i.next
return head
def sortLinkedList(self, head: ListNode):
return self.bubbleSort(head)
================================================
FILE: codes/python/02_linked_list/linked_list_bucket_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
# 将链表节点值 val 添加到对应桶 buckets[index] 中
def insertion(self, buckets, index, val):
if not buckets[index]:
buckets[index] = ListNode(val)
return
node = ListNode(val)
node.next = buckets[index]
buckets[index] = node
# 归并环节
def merge(self, left, right):
dummy_head = ListNode(-1)
cur = dummy_head
while left and right:
if left.val <= right.val:
cur.next = left
left = left.next
else:
cur.next = right
right = right.next
cur = cur.next
if left:
cur.next = left
elif right:
cur.next = right
return dummy_head.next
# 归并排序
def mergeSort(self, head: ListNode):
# 分割环节
if not head or not head.next:
return head
# 快慢指针找到中心链节点
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# 断开左右链节点
left_head, right_head = head, slow.next
slow.next = None
# 归并操作
return self.merge(self.mergeSort(left_head), self.mergeSort(right_head))
def bucketSort(self, head: ListNode, bucket_size=5):
if not head:
return head
# 找出链表中最大值 list_max 和最小值 list_min
list_min, list_max = float('inf'), float('-inf')
cur = head
while cur:
if cur.val < list_min:
list_min = cur.val
if cur.val > list_max:
list_max = cur.val
cur = cur.next
# 计算桶的个数,并定义桶
bucket_count = (list_max - list_min) // bucket_size + 1
buckets = [None for _ in range(bucket_count)]
# 将链表节点值依次添加到对应桶中
cur = head
while cur:
index = (cur.val - list_min) // bucket_size
self.insertion(buckets, index, cur.val)
cur = cur.next
dummy_head = ListNode(-1)
cur = dummy_head
# 将元素依次出桶,并拼接成有序链表
for bucket_head in buckets:
bucket_cur = self.mergeSort(bucket_head)
while bucket_cur:
cur.next = bucket_cur
cur = cur.next
bucket_cur = bucket_cur.next
return dummy_head.next
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.bucketSort(head)
================================================
FILE: codes/python/02_linked_list/linked_list_counting_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def countingSort(self, head: ListNode):
if not head:
return head
list_min, list_max = float('inf'), float('-inf')
cur = head
while cur:
if cur.val < list_min:
list_min = cur.val
if cur.val > list_max:
list_max = cur.val
cur = cur.next
size = list_max - list_min + 1
counts = [0 for _ in range(size)]
cur = head
while cur:
counts[cur.val - list_min] += 1
cur = cur.next
dummy_head = ListNode(-1)
cur = dummy_head
for i in range(size):
while counts[i]:
cur.next = ListNode(i + list_min)
counts[i] -= 1
cur = cur.next
return dummy_head.next
def sortLinkedList(self, head: ListNode):
return self.countingSort(head, None)
================================================
FILE: codes/python/02_linked_list/linked_list_insertion_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def insertionSort(self, head: ListNode):
if not head and not head.next:
return head
dummy_head = ListNode(-1)
dummy_head.next = head
sorted_list = head
cur = head.next
while cur:
if sorted_list.val <= cur.val:
# 将 cur 插入到 sorted_list 之后
sorted_list = sorted_list.next
else:
prev = dummy_head
while prev.next.val <= cur.val:
prev = prev.next
# 将 cur 到链表中间
sorted_list.next = cur.next
cur.next = prev.next
prev.next = curr
cur = sorted_list.next
return dummy_head.next
def sortLinkedList(self, head: ListNode):
return self.insertionSort(head)
================================================
FILE: codes/python/02_linked_list/linked_list_merge_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def merge(self, left, right):
# 归并环节
dummy_head = ListNode(-1)
cur = dummy_head
while left and right:
if left.val <= right.val:
cur.next = left
left = left.next
else:
cur.next = right
right = right.next
cur = cur.next
if left:
cur.next = left
elif right:
cur.next = right
return dummy_head.next
def mergeSort(self, head: ListNode):
# 分割环节
if not head or not head.next:
return head
# 快慢指针找到中心链节点
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# 断开左右链节点
left_head, right_head = head, slow.next
slow.next = None
# 归并操作
return self.merge(self.mergeSort(left_head), self.mergeSort(right_head))
def sortLinkedList(self, head: ListNode):
return self.mergeSort(head)
================================================
FILE: codes/python/02_linked_list/linked_list_quick_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def partition(self, left: ListNode, right: ListNode):
# 左闭右开,区间没有元素或者只有一个元素,直接返回第一个节点
if left == right or left.next == right:
return left
# 选择头节点为基准节点
pivot = left.val
# 使用 node_i, node_j 双指针,保证 node_i 之前的节点值都小于基准节点值,node_i 与 node_j 之间的节点值都大于等于基准节点值
node_i, node_j = left, left.next
while node_j != right:
# 发现一个小与基准值的元素
if node_j.val < pivot:
# node_i 之前节点都小于基准值,所以 node_i 向右移动一位(此时 node_i 节点值大于等于基准节点值)
node_i = node_i.next
# 将小于基准值的元素与当前 node_i 换位,换位后可以保证 node_i 之前的节点都小于基准节点值
node_i.val, node_j.val = node_j.val, node_i.val
node_j = node_j.next
# 将基准节点放到正确位置上
node_i.val, left.val = left.val, node_i.val
return node_i
def quickSort(self, left: ListNode, right: ListNode):
if left == right or left.next == right:
return left
pi = self.partition(left, right)
self.quickSort(left, pi)
self.quickSort(pi.next, right)
return left
def sortLinkedList(self, head: ListNode):
if not head or not head.next:
return head
return self.quickSort(head, None)
================================================
FILE: codes/python/02_linked_list/linked_list_radix_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def radixSort(self, head: ListNode):
# 计算位数最长的位数
size = 0
cur = head
while cur:
val_len = len(str(cur.val))
if val_len > size:
size = val_len
cur = cur.next
# 从个位到高位遍历位数
for i in range(size):
buckets = [[] for _ in range(10)]
cur = head
while cur:
# 以每个节点对应位数上的数字为索引,将节点值放入到对应桶中
buckets[cur.val // (10 ** i) % 10].append(cur.val)
cur = cur.next
# 生成新的链表
dummy_head = ListNode(-1)
cur = dummy_head
for bucket in buckets:
for num in bucket:
cur.next = ListNode(num)
cur = cur.next
head = dummy_head.next
return head
def sortLinkedList(self, head: ListNode):
return self.radixSort(head)
================================================
FILE: codes/python/02_linked_list/linked_list_section_sort.py
================================================
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def sectionSort(self, head: ListNode):
node_i = head
# node_i 为当前未排序链表的第一个链节点
while node_i and node_i.next:
# min_node 为未排序链表中的值最小节点
min_node = node_i
node_j = node_i.next
while node_j:
if node_j.val < min_node.val:
min_node = node_j
node_j = node_j.next
# 交换值最小节点与未排序链表中第一个节点的值
if node_i != min_node:
node_i.val, min_node.val = min_node.val, node_i.val
node_i = node_i.next
return head
def sortLinkedList(self, head: ListNode):
return self.sectionSort(head)
================================================
FILE: codes/python/03_stack_queue_hash_table/queue_circularSequential_queue.py
================================================
class Queue:
# 初始化空队列
def __init__(self, size=100):
self.size = size + 1
self.queue = [None for _ in range(size + 1)]
self.front = 0
self.rear = 0
# 判断队列是否为空
def is_empty(self):
return self.front == self.rear
# 判断队列是否已满
def is_full(self):
return (self.rear + 1) % self.size == self.front
# 入队操作
def enqueue(self, value):
if self.is_full():
raise Exception('Queue is full')
else:
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = value
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
self.queue[self.front] = None
self.front = (self.front + 1) % self.size
return self.queue[self.front]
# 获取队头元素
def front_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
value = self.queue[(self.front + 1) % self.size]
return value
# 获取队尾元素
def rear_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
value = self.queue[self.rear]
return value
queue = Queue(size=2)
queue.enqueue(1)
#print(queue.front_value())
#print(queue.rear_value())
#queue.dequeue()
queue.enqueue(2)
queue.enqueue(3)
#queue.dequeue()
print(queue.front_value())
print(queue.rear_value())
#queue.dequeue()
#print(queue.front_value())
#print(queue.rear_value())
================================================
FILE: codes/python/03_stack_queue_hash_table/queue_deque.py
================================================
class Node:
"""双向链表节点"""
def __init__(self, value):
self.value = value # 节点值
self.prev = None # 指向前一个节点的指针
self.next = None # 指向后一个节点的指针
class Deque:
"""双向队列实现 - 链式存储"""
def __init__(self):
"""初始化空双向队列"""
# 创建哨兵节点
self.head = Node(0) # 头哨兵节点
self.tail = Node(0) # 尾哨兵节点
self.head.next = self.tail
self.tail.prev = self.head
self.size = 0 # 队列大小
def is_empty(self):
"""判断队列是否为空"""
return self.size == 0
def get_size(self):
"""获取队列大小"""
return self.size
def push_front(self, value):
"""队头入队"""
new_node = Node(value)
# 在头哨兵节点后插入新节点
new_node.next = self.head.next
new_node.prev = self.head
self.head.next.prev = new_node
self.head.next = new_node
self.size += 1
def push_back(self, value):
"""队尾入队"""
new_node = Node(value)
# 在尾哨兵节点前插入新节点
new_node.prev = self.tail.prev
new_node.next = self.tail
self.tail.prev.next = new_node
self.tail.prev = new_node
self.size += 1
def pop_front(self):
"""队头出队"""
if self.is_empty():
raise Exception('Deque is empty')
# 删除头哨兵节点后的第一个节点
node = self.head.next
self.head.next = node.next
node.next.prev = self.head
self.size -= 1
return node.value
def pop_back(self):
"""队尾出队"""
if self.is_empty():
raise Exception('Deque is empty')
# 删除尾哨兵节点前的第一个节点
node = self.tail.prev
self.tail.prev = node.prev
node.prev.next = self.tail
self.size -= 1
return node.value
def peek_front(self):
"""查看队头元素"""
if self.is_empty():
raise Exception('Deque is empty')
return self.head.next.value
def peek_back(self):
"""查看队尾元素"""
if self.is_empty():
raise Exception('Deque is empty')
return self.tail.prev.value
class ArrayDeque:
"""双向队列实现 - 顺序存储"""
def __init__(self, capacity=100):
"""初始化双向队列"""
self.capacity = capacity
self.queue = [None] * capacity
self.front = 0 # 队头指针
self.rear = 0 # 队尾指针
self.size = 0 # 队列大小
def is_empty(self):
"""判断队列是否为空"""
return self.size == 0
def is_full(self):
"""判断队列是否已满"""
return self.size == self.capacity
def get_size(self):
"""获取队列大小"""
return self.size
def push_front(self, value):
"""队头入队"""
if self.is_full():
raise Exception('Deque is full')
# 队头指针向前移动
self.front = (self.front - 1) % self.capacity
self.queue[self.front] = value
self.size += 1
def push_back(self, value):
"""队尾入队"""
if self.is_full():
raise Exception('Deque is full')
self.queue[self.rear] = value
# 队尾指针向后移动
self.rear = (self.rear + 1) % self.capacity
self.size += 1
def pop_front(self):
"""队头出队"""
if self.is_empty():
raise Exception('Deque is empty')
value = self.queue[self.front]
# 队头指针向后移动
self.front = (self.front + 1) % self.capacity
self.size -= 1
return value
def pop_back(self):
"""队尾出队"""
if self.is_empty():
raise Exception('Deque is empty')
# 队尾指针向前移动
self.rear = (self.rear - 1) % self.capacity
value = self.queue[self.rear]
self.size -= 1
return value
def peek_front(self):
"""查看队头元素"""
if self.is_empty():
raise Exception('Deque is empty')
return self.queue[self.front]
def peek_back(self):
"""查看队尾元素"""
if self.is_empty():
raise Exception('Deque is empty')
return self.queue[(self.rear - 1) % self.capacity]
# 测试代码
if __name__ == "__main__":
print("=== 链式存储双向队列测试 ===")
deque = Deque()
# 测试队尾入队
deque.push_back(1)
deque.push_back(2)
deque.push_back(3)
print(f"队尾入队后,队列大小: {deque.get_size()}")
print(f"队头元素: {deque.peek_front()}")
print(f"队尾元素: {deque.peek_back()}")
# 测试队头入队
deque.push_front(0)
print(f"队头入队后,队列大小: {deque.get_size()}")
print(f"队头元素: {deque.peek_front()}")
print(f"队尾元素: {deque.peek_back()}")
# 测试出队操作
print(f"队头出队: {deque.pop_front()}")
print(f"队尾出队: {deque.pop_back()}")
print(f"出队后,队列大小: {deque.get_size()}")
print("\n=== 顺序存储双向队列测试 ===")
array_deque = ArrayDeque(capacity=5)
# 测试队尾入队
array_deque.push_back(1)
array_deque.push_back(2)
array_deque.push_back(3)
print(f"队尾入队后,队列大小: {array_deque.get_size()}")
print(f"队头元素: {array_deque.peek_front()}")
print(f"队尾元素: {array_deque.peek_back()}")
# 测试队头入队
array_deque.push_front(0)
print(f"队头入队后,队列大小: {array_deque.get_size()}")
print(f"队头元素: {array_deque.peek_front()}")
print(f"队尾元素: {array_deque.peek_back()}")
# 测试出队操作
print(f"队头出队: {array_deque.pop_front()}")
print(f"队尾出队: {array_deque.pop_back()}")
print(f"出队后,队列大小: {array_deque.get_size()}")
# 测试循环队列特性
print("\n=== 循环队列特性测试 ===")
array_deque.push_back(4)
array_deque.push_back(5)
array_deque.push_front(6)
print(f"队列大小: {array_deque.get_size()}")
print(f"是否已满: {array_deque.is_full()}")
# 清空队列
while not array_deque.is_empty():
print(f"出队: {array_deque.pop_front()}")
print(f"队列是否为空: {array_deque.is_empty()}")
================================================
FILE: codes/python/03_stack_queue_hash_table/queue_link_queue.py
================================================
class Node:
def __init__(self, value):
self.value = value
self.next = None
class Queue:
# 初始化空队列
def __init__(self):
head = Node(0)
self.front = head
self.rear = head
# 判断队列是否为空
def is_empty(self):
return self.front == self.rear
# 入队操作
def enqueue(self, value):
node = Node(value)
self.rear.next = node
self.rear = node
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
node = self.front.next
self.front.next = node.next
if self.rear == node:
self.rear = self.front
value = node.value
del node
return value
# 获取队头元素
def front_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.front.next.value
# 获取队尾元素
def rear_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.rear.value
queue = Queue()
queue.enqueue(1)
print(queue.front_value())
print(queue.rear_value())
queue.dequeue()
queue.enqueue(2)
queue.enqueue(3)
queue.dequeue()
print(queue.front_value())
print(queue.rear_value())
queue.dequeue()
print(queue.front_value())
print(queue.rear_value())
================================================
FILE: codes/python/03_stack_queue_hash_table/queue_priority_queue.py
================================================
class Heapq:
# 堆调整方法:调整为大顶堆
def heapAdjust(self, nums: [int], index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子结点
max_index = index
if nums[left] > nums[max_index]:
max_index = left
if right <= end and nums[right] > nums[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 将数组构建为二叉堆
def heapify(self, nums: [int]):
size = len(nums)
# (size - 2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
# 调用调整堆函数
self.heapAdjust(nums, i, size - 1)
# 入队操作
def heappush(self, nums: list, value):
nums.append(value)
size = len(nums)
i = size - 1
# 寻找插入位置
while (i - 1) // 2 >= 0:
cur_root = (i - 1) // 2
# value 小于当前根节点,则插入到当前位置
if nums[cur_root] > value:
break
# 继续向上查找
nums[i] = nums[cur_root]
i = cur_root
# 找到插入位置或者到达根位置,将其插入
nums[i] = value
# 出队操作
def heappop(self, nums: list) -> int:
size = len(nums)
nums[0], nums[-1] = nums[-1], nums[0]
# 得到最大值(堆顶元素)然后调整堆
top = nums.pop()
if size > 0:
self.heapAdjust(nums, 0, size - 2)
return top
# 升序堆排序
def heapSort(self, nums: [int]):
self.heapify(nums)
size = len(nums)
for i in range(size):
nums[0], nums[size - i - 1] = nums[size - i - 1], nums[0]
self.heapAdjust(nums, 0, size - i - 2)
return nums
nums = [49, 38, 65, 97, 76, 13, 27, 49]
heap = Heapq()
# 1. 创建堆,并进行堆排序
heap.heapSort(nums)
heap.heapify(nums)
# 2. 测试 heappop()
rst = heap.heappop(nums)
print(rst)
rst = heap.heappop(nums)
print(rst)
rst = heap.heappop(nums)
print(rst)
rst = heap.heappop(nums)
print(rst)
rst = heap.heappop(nums)
print(rst)
rst = heap.heappop(nums)
print(rst)
# 3. 测试 heappush()
nums = [49, 38, 65, 97, 76, 13, 27, 49]
heapList = []
for num in nums:
heap.heappush(heapList, num)
print(heapList)
# 4. 堆排序
rst = heap.heapSort(heapList)
print(heapList)
================================================
FILE: codes/python/03_stack_queue_hash_table/queue_sequential_queue.py
================================================
class Queue:
# 初始化空队列
def __init__(self, size=100):
self.size = size
self.queue = [None for _ in range(size)]
self.front = -1
self.rear = -1
# 判断队列是否为空
def is_empty(self):
return self.front == self.rear
# 判断队列是否已满
def is_full(self):
return self.rear + 1 == self.size
# 入队操作
def enqueue(self, value):
if self.is_full():
raise Exception('Queue is full')
else:
self.rear += 1
self.queue[self.rear] = value
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
self.queue[self.front] = None
self.front += 1
return self.queue[self.front]
# 获取队头元素
def front_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.queue[self.front + 1]
# 获取队尾元素
def rear_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.queue[self.rear]
queue = Queue(size=2)
queue.enqueue(1)
print(queue.front_value())
print(queue.rear_value())
#queue.dequeue()
queue.enqueue(2)
queue.enqueue(3)
#queue.dequeue()
print(queue.front_value())
print(queue.rear_value())
#queue.dequeue()
#print(queue.front_value())
#print(queue.rear_value())
================================================
FILE: codes/python/03_stack_queue_hash_table/stack_link_stack.py
================================================
class Node:
def __init__(self, value):
self.value = value
self.next = None
class Stack:
# 初始化空栈
def __init__(self):
self.top = None
# 判断栈是否为空
def is_empty(self):
return self.top == None
# 入栈操作
def push(self, value):
cur = Node(value)
cur.next = self.top
self.top = cur
# 出栈操作
def pop(self):
if self.is_empty():
raise Exception('Stack is empty')
else:
cur = self.top
self.top = self.top.next
del cur
# 获取栈顶元素
def peek(self):
if self.is_empty():
raise Exception('Stack is empty')
else:
return self.top.value
stack = Stack()
for i in range(5):
stack.push(i)
for i in range(3):
stack.pop()
print(stack.peek())
================================================
FILE: codes/python/03_stack_queue_hash_table/stack_monotone_stack.py
================================================
import random
def monotoneStack(nums):
print(str(nums))
stack = []
for num in nums:
while stack and num <= stack[-1]:
top = stack[-1]
stack.pop()
print(str(top) + " 出栈 " + str(stack))
stack.append(num)
print(str(num) + " 入栈 " + str(stack))
def monotoneIncreasingStack(nums):
stack = []
for num in nums:
while stack and num >= stack[-1]:
top = stack[-1]
stack.pop()
print(str(top) + " 出栈 " + str(stack))
stack.append(num)
print(str(num) + " 入栈 " + str(stack))
def monotoneDecreasingStack(nums):
stack = []
for num in nums:
while stack and num <= stack[-1]:
top = stack[-1]
stack.pop()
print(str(top) + " 出栈 " + str(stack))
stack.append(num)
print(str(num) + " 入栈 " + str(stack))
nums = []
for i in range(8):
nums.append(random.randint(1, 9))
print(nums)
#nums = [4, 3, 2, 5, 7, 4, 6, 8]
monotoneIncreasingStack(nums)
================================================
FILE: codes/python/03_stack_queue_hash_table/stack_sequential_stack.py
================================================
#!/usr/bin/env python3
class Stack:
# 初始化空栈
def __init__(self, size=100):
self.stack = []
self.size = size
self.top = -1
# 判断栈是否为空
def is_empty(self):
return self.top == -1
# 判断栈是否已满
def is_full(self):
return self.top + 1 == self.size
# 入栈操作
def push(self, value):
if self.is_full():
raise Exception('Stack is full')
else:
self.stack.append(value)
self.top += 1
# 出栈操作
def pop(self):
if self.is_empty():
raise Exception('Stack is empty')
else:
self.top -= 1
self.stack.pop()
# 获取栈顶元素
def peek(self):
if self.is_empty():
raise Exception('Stack is empty')
else:
return self.stack[self.top]
S = Stack(10)
for i in range(5):
S.push(i)
for i in range(3):
S.pop()
print(S.peek())
================================================
FILE: codes/python/04_string/string_Strcmp.py
================================================
def strcmp(str1, str2):
index1, index2 = 0, 0
while index1 < len(str1) and index2 < len(str2):
if ord(str1[index1]) == ord(str2[index2]):
index1 += 1
index2 += 1
elif ord(str1[index1]) < ord(str2[index2]):
return -1
else:
return 1
if len(str1) < len(str2):
return -1
elif len(str1) > len(str2):
return 1
else:
return 0
print(strcmp("123", "123"))
print(strcmp("123", "124"))
print(strcmp("123", "1235"))
print(strcmp("223", "123"))
print(strcmp("13", "123"))
print(strcmp("132", "123"))
print(strcmp("1322", "1325"))
================================================
FILE: codes/python/04_string/string_boyer_moore.py
================================================
# BM 匹配算法
def boyerMoore(T: str, p: str) -> int:
n, m = len(T), len(p)
bc_table = generateBadCharTable(p) # 生成坏字符位置表
gs_list = generageGoodSuffixList(p) # 生成好后缀规则后移位数表
i = 0
while i <= n - m:
j = m - 1
while j > -1 and T[i + j] == p[j]: # 进行后缀匹配,跳出循环说明出现坏字符
j -= 1
if j < 0:
return i # 匹配完成,返回模式串 p 在文本串 T 中的位置
bad_move = j - bc_table.get(T[i + j], -1) # 坏字符规则下的后移位数
good_move = gs_list[j] # 好后缀规则下的后移位数
i += max(bad_move, good_move) # 取两种规则下后移位数的最大值进行移动
return -1
# 生成坏字符位置表
# bc_table[bad_char] 表示坏字符在模式串中最后一次出现的位置
def generateBadCharTable(p: str):
bc_table = dict()
for i in range(len(p)):
bc_table[p[i]] = i # 更新坏字符在模式串中最后一次出现的位置
return bc_table
# 生成好后缀规则后移位数表
# gs_list[j] 表示在 j 下标处遇到坏字符时,可根据好规则向右移动的距离
def generageGoodSuffixList(p: str):
# 好后缀规则后移位数表
# 情况 1: 模式串中有子串匹配上好后缀
# 情况 2: 模式串中无子串匹配上好后缀,但有最长前缀匹配好后缀的后缀
# 情况 3: 模式串中无子串匹配上好后缀,也找不到前缀匹配
m = len(p)
gs_list = [m for _ in range(m)] # 情况 3:初始化时假设全部为情况 3
suffix = generageSuffixArray(p) # 生成 suffix 数组
j = 0 # j 为好后缀前的坏字符位置
for i in range(m - 1, -1, -1): # 情况 2:从最长的前缀开始检索
if suffix[i] == i + 1: # 匹配到前缀,即 p[0...i] == p[m-1-i...m-1]
while j < m - 1 - i:
if gs_list[j] == m:
gs_list[j] = m - 1 - i # 更新在 j 处遇到坏字符可向后移动位数
j += 1
for i in range(m - 1): # 情况 1:匹配到子串 p[i-s...i] == p[m-1-s, m-1]
gs_list[m - 1 - suffix[i]] = m - 1 - i # 更新在好后缀的左端点处遇到坏字符可向后移动位数
return gs_list
# 生成 suffix 数组
# suffix[i] 表示为以下标 i 为结尾的子串与模式串后缀匹配的最大长度
def generageSuffixArray(p: str):
m = len(p)
suffix = [m for _ in range(m)] # 初始化时假设匹配的最大长度为 m
for i in range(m - 2, -1, -1): # 子串末尾从 m - 2 开始
start = i # start 为子串开始位置
while start >= 0 and p[start] == p[m - 1 - i + start]:
start -= 1 # 进行后缀匹配,start 为匹配到的子串开始位置
suffix[i] = i - start # 更新以下标 i 为结尾的子串与模式串后缀匹配的最大长度
return suffix
print(boyerMoore("abbcfdddbddcaddebc", "aaaaa"))
print(boyerMoore("", ""))
================================================
FILE: codes/python/04_string/string_brute_force.py
================================================
def bruteForce(T: str, p: str) -> int:
n, m = len(T), len(p)
i, j = 0, 0 # i 表示文本串 T 的当前位置,j 表示模式串 p 的当前位置
while i < n and j < m: # i 或 j 其中一个到达尾部时停止搜索
if T[i] == p[j]: # 如果相等,则继续进行下一个字符匹配
i += 1
j += 1
else:
i = i - (j - 1) # 如果匹配失败则将 i 移动到上次匹配开始位置的下一个位置
j = 0 # 匹配失败 j 回退到模式串开始位置
if j == m:
return i - j # 匹配成功,返回匹配的开始位置
else:
return -1 # 匹配失败,返回 -1
print(bruteForce("abcdeabc", "bcd"))
================================================
FILE: codes/python/04_string/string_horspool.py
================================================
# horspool 算法,T 为文本串,p 为模式串
def horspool(T: str, p: str) -> int:
n, m = len(T), len(p)
bc_table = generateBadCharTable(p) # 生成后移位数表
i = 0
while i <= n - m:
j = m - 1
while j > -1 and T[i + j] == p[j]: # 进行后缀匹配,跳出循环说明出现坏字符
j -= 1
if j < 0:
return i # 匹配完成,返回模式串 p 在文本串 T 中的位置
i += bc_table.get(T[i + m - 1], m) # 通过后移位数表,向右进行进行快速移动
return -1 # 匹配失败
# 生成后移位数表
# bc_table[bad_char] 表示遇到坏字符可以向右移动的距离
def generateBadCharTable(p: str):
m = len(p)
bc_table = dict()
for i in range(m - 1): # 迭代到 m - 2
bc_table[p[i]] = m - 1 - i # 更新遇到坏字符可向右移动的距离
return bc_table
print(horspool("abbcfdddbddcaddebc", "aaaaa"))
print(horspool("abbcfdddbddcaddebc", "bcf"))
print(horspool("aaaaa", "bba"))
print(horspool("mississippi", "issi"))
print(horspool("ababbbbaaabbbaaa", "bbbb"))
================================================
FILE: codes/python/04_string/string_kmp.py
================================================
# KMP 匹配算法,T 为文本串,p 为模式串
def kmp(T: str, p: str) -> int:
n, m = len(T), len(p)
next = generateNext(p) # 生成 next 数组
j = 0 # j 为模式串中当前匹配的位置
for i in range(n): # i 为文本串中当前匹配的位置
while j > 0 and T[i] != p[j]: # 如果模式串匹配不成功, 将模式串进行回退, j == 0 时停止回退
j = next[j - 1]
if T[i] == p[j]: # 当前模式串前缀匹配成功,令 j += 1,继续匹配
j += 1
if j == m: # 当前模式串完全匹配成功,返回匹配开始位置
return i - j + 1
return -1 # 匹配失败,返回 -1
# 生成 next 数组
# next[j] 表示下标 j 之前的模式串 p 中,最长相等前后缀的长度
def generateNext(p: str):
m = len(p)
next = [0 for _ in range(m)] # 初始化数组元素全部为 0
left = 0 # left 表示前缀串开始所在的下标位置
for right in range(1, m): # right 表示后缀串开始所在的下标位置
while left > 0 and p[left] != p[right]: # 匹配不成功, left 进行回退, left == 0 时停止回退
left = next[left - 1] # left 进行回退操作
if p[left] == p[right]: # 匹配成功,找到相同的前后缀,先让 left += 1,此时 left 为前缀长度
left += 1
next[right] = left # 记录前缀长度,更新 next[right], 结束本次循环, right += 1
return next
print(kmp("abbcfdddbddcaddebc", "ABCABCD"))
print(kmp("abbcfdddbddcaddebc", "bcf"))
print(kmp("aaaaa", "bba"))
print(kmp("mississippi", "issi"))
print(kmp("ababbbbaaabbbaaa", "bbbb"))
================================================
FILE: codes/python/04_string/string_rabin_karp.py
================================================
# T 为文本串,p 为模式串,d 为字符集的字符种类数,q 为质数
def rabinKarp(T: str, p: str, d, q) -> int:
n, m = len(T), len(p)
if n < m:
return -1
hash_p, hash_t = 0, 0
for i in range(m):
hash_p = (hash_p * d + ord(p[i])) % q # 计算模式串 p 的哈希值
hash_t = (hash_t * d + ord(T[i])) % q # 计算文本串 T 中第一个子串的哈希值
power = pow(d, m - 1) % q # power 用于移除字符哈希时
for i in range(n - m + 1):
if hash_p == hash_t: # 检查模式串 p 的哈希值和子串的哈希值
match = True # 如果哈希值相等,验证模式串和子串每个字符是否完全相同(避免哈希冲突)
for j in range(m):
if T[i + j] != p[j]:
match = False # 模式串和子串某个字符不相等,验证失败,跳出循环
break
if match: # 如果模式串和子串每个字符是否完全相同,返回匹配开始位置
return i
if i < n - m: # 计算下一个相邻子串的哈希值
hash_t = (hash_t - power * ord(T[i])) % q # 移除字符 T[i]
hash_t = (hash_t * d + ord(T[i + m])) % q # 增加字符 T[i + m]
hash_t = (hash_t + q) % q # 确保 hash_t >= 0
return -1
print(rabinKarp("aaaaa", "bba", 256, 101))
================================================
FILE: codes/python/04_string/string_sunday.py
================================================
# sunday 算法,T 为文本串,p 为模式串
def sunday(T: str, p: str) -> int:
n, m = len(T), len(p)
bc_table = generateBadCharTable(p) # 生成后移位数表
i = 0
while i <= n - m:
j = 0
if T[i: i + m] == p:
return i # 匹配完成,返回模式串 p 在文本串 T 的位置
if i + m >= n:
return -1
i += bc_table.get(T[i + m], m + 1) # 通过后移位数表,向右进行进行快速移动
return -1 # 匹配失败
# 生成后移位数表
# bc_table[bad_char] 表示遇到坏字符可以向右移动的距离
def generateBadCharTable(p: str):
m = len(p)
bc_table = dict()
for i in range(m): # 迭代到最后一个位置 m - 1
bc_table[p[i]] = m - i # 更新遇到坏字符可向右移动的距离
return bc_table
print(sunday("abbcfdddbddcaddebc", "aaaaa"))
print(sunday("abbcfdddbddcaddebc", "bcf"))
print(sunday("aaaaa", "bba"))
print(sunday("mississippi", "issi"))
print(sunday("ababbbbaaabbbaaa", "bbbb"))
================================================
FILE: codes/python/04_string/string_trie.py
================================================
class Node: # 字符节点
def __init__(self): # 初始化字符节点
self.children = dict() # 初始化子节点
self.isEnd = False # isEnd 用于标记单词结束
class Trie: # 字典树
# 初始化字典树
def __init__(self): # 初始化字典树
self.root = Node() # 初始化根节点(根节点不保存字符)
# 向字典树中插入一个单词
def insert(self, word: str) -> None:
cur = self.root
for ch in word: # 遍历单词中的字符
if ch not in cur.children: # 如果当前节点的子节点中,不存在键为 ch 的节点
cur.children[ch] = Node() # 建立一个节点,并将其保存到当前节点的子节点
cur = cur.children[ch] # 令当前节点指向新建立的节点,继续处理下一个字符
cur.isEnd = True # 单词处理完成时,将当前节点标记为单词结束
# 查找字典树中是否存在一个单词
def search(self, word: str) -> bool:
cur = self.root
for ch in word: # 遍历单词中的字符
if ch not in cur.children: # 如果当前节点的子节点中,不存在键为 ch 的节点
return False # 直接返回 False
cur = cur.children[ch] # 令当前节点指向新建立的节点,然后继续查找下一个字符
return cur is not None and cur.isEnd # 判断当前节点是否为空,并且是否有单词结束标记
# 查找字典树中是否存在一个前缀
def startsWith(self, prefix: str) -> bool:
cur = self.root
for ch in prefix: # 遍历前缀中的字符
if ch not in cur.children: # 如果当前节点的子节点中,不存在键为 ch 的节点
return False # 直接返回 False
cur = cur.children[ch] # 令当前节点指向新建立的节点,然后继续查找下一个字符
return cur is not None # 判断当前节点是否为空,不为空则查找成功
================================================
FILE: codes/python/05_tree/tree_binaryindexed_tree.py
================================================
class BinaryIndexTree:
def __init__(self, n):
self.size = n
self.tree = [0 for _ in range(n + 1)]
def lowbit(self, index):
return index & (-index)
def update(self, index, delta):
while index <= self.size:
self.tree[index] += delta
index += self.lowbit(index)
def query(self, index):
res = 0
while index > 0:
res += self.tree[index]
index -= self.lowbit(index)
return res
================================================
FILE: codes/python/05_tree/tree_dynamicSegmentTree_update_interval_1.py
================================================
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, val=False, lazy_tag=None, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, function):
self.tree = SegTreeNode(0, int(1e9))
self.function = function # function 是一个函数,左右区间的聚合方法
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.__update_point(i, val, self.tree)
# 区间更新接口:将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self, length):
nums = [0 for _ in range(length)]
for i in range(length):
nums[i] = self.query_interval(i, i)
return nums
# 以下为内部实现方法
# 单点更新实现方法:将 nums[i] 更改为 val。node 节点的区间为 [node.left, node.right]
def __update_point(self, i, val, node):
if node.left == node.right:
node.val = val # 叶子节点,节点值修改为 val
return
if i <= node.mid: # 在左子树中更新节点值
self.__update_point(i, val, node.leftNode)
else: # 在右子树中更新节点值
self.__update_point(i, val, node.rightNode)
self.__pushup(node) # 向上更新节点的区间值
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
node.lazy_tag = val # 将当前节点的延迟标记增加 val
interval_size = (node.right - node.left + 1) # 当前节点所在区间大小
node.val = val * interval_size # 当前节点所在区间每个元素值改为 val
return
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询实现方法:在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, node.rightNode)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新 node 节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = self.function(node.leftNode.val, node.rightNode.val)
# 向下更新实现方法:更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
lazy_tag = node.lazy_tag
if node.lazy_tag is None:
return
node.leftNode.lazy_tag = lazy_tag # 更新左子节点懒惰标记
left_size = (node.leftNode.right - node.leftNode.left + 1)
node.leftNode.val = lazy_tag * left_size # 更新左子节点值
node.rightNode.lazy_tag = lazy_tag # 更新右子节点懒惰标记
right_size = (node.rightNode.right - node.rightNode.left + 1)
node.rightNode.val = lazy_tag * right_size # 更新右子节点值
node.lazy_tag = None # 更新当前节点的懒惰标记
# 线段树使用方法
class Solution:
# 初始化线段树
def __init__(self):
self.STree = SegmentTree(lambda x, y: x + y)
# 将区间 [left, right] 上的元素值全部修改为 val
def update(self, left: int, right: int, val) -> None:
self.STree.update_interval(left, right, val)
# 查询区间 [left, right] 的区间值
def sumRange(self, left: int, right: int) -> int:
return self.STree.query_interval(left, right)
================================================
FILE: codes/python/05_tree/tree_dynamicSegmentTree_update_interval_2.py
================================================
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, function):
self.tree = SegTreeNode(0, int(1e9))
self.function = function # function 是一个函数,左右区间的聚合方法
# 单点更新,将 nums[i] 更改为 val
def update_point(self, i, val):
self.__update_point(i, val, self.tree)
# 区间更新,将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询,查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self, length):
nums = [0 for _ in range(length)]
for i in range(length):
nums[i] = self.query_interval(i, i)
return nums
# 以下为内部实现方法
# 单点更新,将 nums[i] 更改为 val。node 节点的区间为 [node.left, node.right]
def __update_point(self, i, val, node):
if node.left == node.right:
node.val = val # 叶子节点,节点值修改为 val
return
if i <= node.mid: # 在左子树中更新节点值
self.__update_point(i, val, node.leftNode)
else: # 在右子树中更新节点值
self.__update_point(i, val, node.rightNode)
self.__pushup(node) # 向上更新节点的区间值
# 区间更新
def __update_interval(self, q_left, q_right, val, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if node.lazy_tag is not None:
node.lazy_tag += val # 将当前节点的延迟标记增加 val
else:
node.lazy_tag = val # 将当前节点的延迟标记增加 val
interval_size = (node.right - node.left + 1) # 当前节点所在区间大小
node.val += val * interval_size # 当前节点所在区间每个元素值增加 val
return
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询,在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, node.rightNode)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新 node 节点区间值,节点的区间值等于该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = self.function(node.leftNode.val, node.rightNode.val)
# 向下更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
lazy_tag = node.lazy_tag
if node.lazy_tag is None:
return
if node.leftNode.lazy_tag is not None:
node.leftNode.lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
node.leftNode.lazy_tag = lazy_tag # 更新左子节点懒惰标记
left_size = (node.leftNode.right - node.leftNode.left + 1)
node.leftNode.val += lazy_tag * left_size # 左子节点每个元素值增加 lazy_tag
if node.rightNode.lazy_tag is not None:
node.rightNode.lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
node.rightNode.lazy_tag = lazy_tag # 更新右子节点懒惰标记
right_size = (node.rightNode.right - node.rightNode.left + 1)
node.rightNode.val += lazy_tag * right_size # 右子节点每个元素值增加 lazy_tag
node.lazy_tag = None # 更新当前节点的懒惰标记
# 线段树使用方法
class Solution:
# 初始化线段树
def __init__(self):
self.STree = SegmentTree(lambda x, y: x + y)
# 将区间 [left, right] 上的元素值全部修改为 val
def update(self, left: int, right: int, val) -> None:
self.STree.update_interval(left, right, val)
# 查询区间 [left, right] 的区间值
def sumRange(self, left: int, right: int) -> int:
return self.STree.query_interval(left, right)
================================================
FILE: codes/python/05_tree/tree_segmentTree_update_interval_1.py
================================================
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=0):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
self.lazy_tag = None # 区间和问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, nums, function):
self.size = len(nums)
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
self.nums = nums # 原始数据
self.function = function # function 是一个函数,左右区间的聚合方法
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.nums[i] = val
self.__update_point(i, val, 0)
# 区间更新接口:将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self):
for i in range(self.size):
self.nums[i] = self.query_interval(i, i)
return self.nums
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = self.nums[left]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.__pushup(index) # 向上更新节点的区间值
# 单点更新实现方法:将 nums[i] 更改为 val,节点的存储下标为 index
def __update_point(self, i, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left == right:
self.tree[index].val = val # 叶子节点,节点值修改为 val
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if i <= mid: # 在左子树中更新节点值
self.__update_point(i, val, left_index)
else: # 在右子树中更新节点值
self.__update_point(i, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, index):
left = self.tree[index].left
right = self.tree[index].right
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
self.tree[index].lazy_tag = val # 将当前节点的延迟标记为区间值
interval_size = (right - left + 1) # 当前节点所在区间大小
self.tree[index].val = interval_size * val # 当前节点所在区间每个元素值改为 val
return
self.__pushdown(index) # 向下更新节点的区间值
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if q_left <= mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, left_index)
if q_right > mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间查询实现方法:在线段树中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(index)
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新下标为 index 的节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, index):
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[index].val = self.function(self.tree[left_index].val, self.tree[right_index].val)
# 向下更新实现方法:更新下标为 index 的节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, index):
lazy_tag = self.tree[index].lazy_tag
if lazy_tag is None:
return
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[left_index].lazy_tag = lazy_tag # 更新左子节点懒惰标记
left_size = (self.tree[left_index].right - self.tree[left_index].left + 1)
self.tree[left_index].val = lazy_tag * left_size # 更新左子节点值
self.tree[right_index].lazy_tag = lazy_tag # 更新右子节点懒惰标记
right_size = (self.tree[right_index].right - self.tree[right_index].left + 1)
self.tree[right_index].val = lazy_tag * right_size # 更新右子节点值
self.tree[index].lazy_tag = None # 更新当前节点的懒惰标记
class Solution:
# 根据原始数组 nums 初始化线段树
def __init__(self, nums: List[int]):
self.STree = SegmentTree(nums, lambda x, y: x + y)
# 将数组 nums 将区间为 [left, right] 上的元素值全部修改为 val
def update(self, left: int, right: int, val) -> None:
self.STree.update_interval(left, right, val)
# 查询区间为 [left, right] 的区间值
def sumRange(self, left: int, right: int) -> int:
return self.STree.query_interval(left, right)
================================================
FILE: codes/python/05_tree/tree_segmentTree_update_interval_2.py
================================================
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=0):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
self.lazy_tag = None # 区间和问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, nums, function):
self.size = len(nums)
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
self.nums = nums # 原始数据
self.function = function # function 是一个函数,左右区间的聚合方法
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.nums[i] = val
self.__update_point(i, val, 0)
# 区间更新接口:将区间为 [q_left, q_right] 上的所有元素值加上 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self):
for i in range(self.size):
self.nums[i] = self.query_interval(i, i)
return self.nums
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = self.nums[left]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.__pushup(index) # 向上更新节点的区间值
# 单点更新实现方法:将 nums[i] 更改为 val,节点的存储下标为 index
def __update_point(self, i, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left == right:
self.tree[index].val = val # 叶子节点,节点值修改为 val
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if i <= mid: # 在左子树中更新节点值
self.__update_point(i, val, left_index)
else: # 在右子树中更新节点值
self.__update_point(i, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if self.tree[index].lazy_tag is not None:
self.tree[index].lazy_tag += val # 将当前节点的延迟标记增加 val
else:
self.tree[index].lazy_tag = val # 将当前节点的延迟标记增加 val
interval_size = (right - left + 1) # 当前节点所在区间大小
self.tree[index].val += val * interval_size # 当前节点所在区间每个元素值增加 val
return
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
self.__pushdown(index) # 向下更新节点的区间值
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if q_left <= mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, left_index)
if q_right > mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间查询实现方法:在线段树中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(index)
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新下标为 index 的节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, index):
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[index].val = self.function(self.tree[left_index].val, self.tree[right_index].val)
# 向下更新实现方法:更新下标为 index 的节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, index):
lazy_tag = self.tree[index].lazy_tag
if lazy_tag is None:
return
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if self.tree[left_index].lazy_tag is not None:
self.tree[left_index].lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
self.tree[left_index].lazy_tag = lazy_tag
left_size = (self.tree[left_index].right - self.tree[left_index].left + 1)
self.tree[left_index].val += lazy_tag * left_size # 左子节点每个元素值增加 lazy_tag
if self.tree[right_index].lazy_tag is not None:
self.tree[right_index].lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
self.tree[right_index].lazy_tag = lazy_tag
right_size = (self.tree[right_index].right - self.tree[right_index].left + 1)
self.tree[right_index].val += lazy_tag * right_size # 右子节点每个元素值增加 lazy_tag
self.tree[index].lazy_tag = None # 更新当前节点的懒惰标记
class Solution:
# 根据原始数组 nums 初始化线段树
def __init__(self, nums: List[int]):
self.STree = SegmentTree(nums, lambda x, y: x + y)
# 将数组 nums 将区间为 [left, right] 上每个元素值增加 val
def addVal(self, left: int, right: int, val) -> None:
self.STree.update_interval(left, right, val)
# 查询区间为 [left, right] 的区间值
def sumRange(self, left: int, right: int) -> int:
return self.STree.query_interval(left, right)
================================================
FILE: codes/python/05_tree/tree_segmentTree_update_point.py
================================================
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=0):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, nums, function):
self.size = len(nums)
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
self.nums = nums # 原始数据
self.function = function # function 是一个函数,左右区间的聚合方法
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.nums[i] = val
self.__update_point(i, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self):
for i in range(self.size):
self.nums[i] = self.query_interval(i, i)
return self.nums
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = self.nums[left]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.__pushup(index) # 向上更新节点的区间值
# 单点更新实现方法:将 nums[i] 更改为 val。节点的存储下标为 index,节点的区间为 [left, right]
def __update_point(self, i, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left == right:
self.tree[index].val = val # 叶子节点,节点值修改为 val
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if i <= mid: # 在左子树中更新节点值
self.__update_point(i, val, left_index)
else: # 在右子树中更新节点值
self.__update_point(i, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间查询实现方法:在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:下标为 index 的节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, index):
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[index].val = self.function(self.tree[left_index].val, self.tree[right_index].val)
# 线段树使用方法
class Solution:
# 根据原始数组 nums 初始化线段树
def __init__(self, nums: List[int]):
self.STree = SegmentTree(nums, lambda x, y: x + y)
# 将 nums[index] 更改为 val
def update(self, index: int, val: int) -> None:
self.STree.update_point(index, val)
# 查询区间为 [left, right] 的区间值
def sumRange(self, left: int, right: int) -> int:
return self.STree.query_interval(left, right)
================================================
FILE: codes/python/05_tree/tree_unionFind.py
================================================
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)
================================================
FILE: codes/python/05_tree/tree_unionFind_QuickFind.py
================================================
class UnionFind:
def __init__(self, n): # 初始化:将每个元素的集合编号初始化为数组下标索引
self.ids = [i for i in range(n)]
def find(self, x): # 查找元素所属集合编号内部实现方法
return self.ids[x]
def union(self, x, y): # 合并操作:将集合 x 和集合 y 合并成一个集合
x_id = self.find(x)
y_id = self.find(y)
if x_id == y_id: # x 和 y 已经同属于一个集合
return False
for i in range(len(self.ids)): # 将两个集合的集合编号改为一致
if self.ids[i] == y_id:
self.ids[i] = x_id
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)
================================================
FILE: codes/python/05_tree/tree_unionFind_QuickUnion.py
================================================
class UnionFind:
def __init__(self, n): # 初始化:将每个元素的集合编号初始化为数组 fa 的下标索引
self.fa = [i for i in range(n)]
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while x != self.fa[x]: # 递归查找元素的父节点,直到根节点
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)
================================================
FILE: codes/python/05_tree/tree_unionFind_UnoinByRank.py
================================================
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
self.rank = [1 for i in range(n)] # 每个元素的深度初始化为 1
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
if self.rank[root_x] < self.rank[root_y]: # x 的根节点对应的树的深度 小于 y 的根节点对应的树的深度
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
elif self.rank[root_y] > self.rank[root_y]: # x 的根节点对应的树的深度 大于 y 的根节点对应的树的深度
self.fa[root_y] = root_x # y 的根节点连接到 x 的根节点上,成为 x 的根节点的子节点
else: # x 的根节点对应的树的深度 等于 y 的根节点对应的树的深度
self.fa[root_x] = root_y # 向任意一方合并即可
self.rank[root_y] += 1 # 因为层数相同,被合并的树必然层数会 +1
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)
================================================
FILE: codes/python/05_tree/tree_unionFind_UnoinBySize.py
================================================
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
self.size = [1 for i in range(n)] # 每个元素的集合个数初始化为 1
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
if self.size[root_x] < self.size[root_y]: # x 对应的集合元素个数 小于 y 对应的集合元素个数
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
self.size[root_y] += self.size[root_x] # y 的根节点对应的集合元素个数 累加上 x 的根节点对应的集合元素个数
elif self.size[root_x] > self.size[root_y]: # x 对应的集合元素个数 大于 y 对应的集合元素个数
self.fa[root_y] = root_x # y 的根节点连接到 x 的根节点上,成为 x 的根节点的子节点
self.size[root_x] += self.size[root_y] # x 的根节点对应的集合元素个数 累加上 y 的根节点对应的集合元素个数
else: # x 对应的集合元素个数 小于 y 对应的集合元素个数
self.fa[root_x] = root_y # 向任意一方合并即可
self.size[root_y] += self.size[root_x]
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)
================================================
FILE: codes/python/06_graph/Graph-Adjacency-List.py
================================================
class EdgeNode: # 边信息类
def __init__(self, vj, val):
self.vj = vj # 边的终点
self.val = val # 边的权值
self.next = None # 下一条边
class VertexNode: # 顶点信息类
def __init__(self, vi):
self.vi = vi # 边的起点
self.head = None # 下一个邻接点
class Graph:
def __init__(self, ver_count):
self.ver_count = ver_count
self.vertices = []
for vi in range(ver_count):
vertex = VertexNode(vi)
self.vertices.append(vertex)
# 判断顶点 v 是否有效
def __valid(self, v):
return 0 <= v <= self.ver_count
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图的邻接表中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
vertex = self.vertices[vi]
edge = EdgeNode(vj, val)
edge.next = vertex.head
vertex.head = edge
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
vertex = self.vertices[vi]
cur_edge = vertex.head
while cur_edge:
if cur_edge.vj == vj:
return cur_edge.val
cur_edge = cur_edge.next
return None
# 根据邻接表打印图的边
def printGraph(self):
for vertex in self.vertices:
cur_edge = vertex.head
while cur_edge:
print(str(vertex.vi) + ' - ' + str(cur_edge.vj) + ' : ' + str(cur_edge.val))
cur_edge = cur_edge.next
graph = Graph(7)
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()
================================================
FILE: codes/python/06_graph/Graph-Adjacency-Matrix.py
================================================
class Graph: # 基本图类,采用邻接矩阵表示
# 图的初始化操作,ver_count 为顶点个数
def __init__(self, ver_count):
self.ver_count = ver_count # 顶点个数
self.adj_matrix = [[None for _ in range(ver_count)] for _ in range(ver_count)] # 邻接矩阵
# 判断顶点 v 是否有效
def __valid(self, v):
return 0 <= v <= self.ver_count
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图的邻接矩阵中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
self.adj_matrix[vi][vj] = val
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
return self.adj_matrix[vi][vj]
# 根据邻接矩阵打印图的边
def printGraph(self):
for vi in range(self.ver_count):
for vj in range(self.ver_count):
val = self.get_edge(vi, vj)
if val:
print(str(vi) + ' - ' + str(vj) + ' : ' + str(val))
graph = Graph(5)
edges = [[1, 2, 5],[2, 1, 5],[1, 3, 30],[3, 1, 30],[2, 3, 14],[3, 2, 14],[2, 4, 26], [4, 2, 26]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()
================================================
FILE: codes/python/06_graph/Graph-BFS.py
================================================
import collections
class Solution:
def bfs(self, graph, u):
visited = set() # 使用 visited 标记访问过的节点
queue = collections.deque([]) # 使用 queue 存放临时节点
visited.add(u) # 将起始节点 u 标记为已访问
queue.append(u) # 将起始节点 u 加入队列中
while queue: # 队列不为空
u = queue.popleft() # 取出队头节点 u
print(u) # 访问节点 u
for v in graph[u]: # 遍历节点 u 的所有未访问邻接节点 v
if v not in visited: # 节点 v 未被访问
visited.add(v) # 将节点 v 标记为已访问
queue.append(v) # 将节点 v 加入队列中
graph = {
"0": ["1", "2"],
"1": ["0", "2", "3"],
"2": ["0", "1", "3", "4"],
"3": ["1", "2", "4", "5"],
"4": ["2", "3"],
"5": ["3", "6"],
"6": []
}
# 基于队列实现的广度优先搜索
Solution().bfs(graph, "0")
================================================
FILE: codes/python/06_graph/Graph-Bellman-Ford.py
================================================
class Solution:
def bellmanFord(self, graph, source):
size = len(graph)
dist = dict()
for vi in graph:
dist[vi] = float('inf')
dist[source] = 0
for i in range(size - 1):
for vi in graph:
for vj in graph[vi]:
if dist[vj] > graph[vi][vj] + dist[vi]:
dist[vj] = graph[vi][vj] + dist[vi]
for vi in graph:
for vj in graph[vi]:
if dist[vj] > dist[vi] + graph[vi][vj]:
return None
return dist
graph = {
'a': {'b': -1, 'c': 4},
'b': {'c': 2, 'd': 3, 'e': 2},
'c': {},
'd': {'b': 3, 'c': 5},
'e': {'d': -3}
}
dist = Solution().bellmanFord(graph, 'a')
print(dist)
================================================
FILE: codes/python/06_graph/Graph-DFS.py
================================================
class Solution:
def dfs_recursive(self, graph, u, visited):
print(u) # 访问节点
visited.add(u) # 节点 u 标记其已访问
for v in graph[u]:
if v not in visited: # 节点 v 未访问过
# 深度优先搜索遍历节点
self.dfs_recursive(graph, v, visited)
def dfs_stack(self, graph, u):
print(u) # 访问节点 u
visited, stack = set(), [] # 使用 visited 标记访问过的节点, 使用栈 stack 存放临时节点
stack.append([u, 0]) # 将起始节点 u 以及节点 u 的下一个邻接节点下标放入栈中,下一次将遍历 graph[u][0]
visited.add(u) # 将起始节点 u 标记为已访问
while stack:
u, i = stack.pop() # 取出节点 u,以及节点 u 下一个将要访问的邻接节点下标 i
if i < len(graph[u]):
v = graph[u][i] # 取出邻接节点 v
stack.append([u, i + 1])# 将节点 u 以及节点 u 的下一个邻接节点下标 i + 1 放入栈中,下一次将遍历 graph[u][i + 1]
if v not in visited: # 节点 v 未访问过
print(v) # 访问节点 v
stack.append([v, 0])# 将节点 v 以及节点 v 的下一个邻接节点下标 0 放入栈中,下一次将遍历 graph[v][0]
visited.add(v) # 将节点 v 标记为已访问
graph = {
"A": ["B", "C"],
"B": ["A", "C", "D"],
"C": ["A", "B", "D", "E"],
"D": ["B", "C", "E", "F"],
"E": ["C", "D"],
"F": ["D", "G"],
"G": []
}
# 基于递归实现的深度优先搜索
visited = set()
Solution().dfs_recursive(graph, "A", visited)
# 基于堆栈实现的深度优先搜索
Solution().dfs_stack(graph, "A")
================================================
FILE: codes/python/06_graph/Graph-Edgeset-Array.py
================================================
class EdgeNode: # 边信息类
def __init__(self, vi, vj, val):
self.vi = vi # 边的起点
self.vj = vj # 边的终点
self.val = val # 边的权值
class Graph: # 基本图类,采用边集数组表示
def __init__(self):
self.edges = [] # 边数组
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图的边数组中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
edge = EdgeNode(vi, vj, val) # 创建边节点
self.edges.append(edge) # 将边节点添加到边数组中
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
for edge in self.edges:
if vi == edge.vi and vj == edge.vj:
val = edge.val
return val
return None
# 根据边数组打印图
def printGraph(self):
for edge in self.edges:
print(str(edge.vi) + ' - ' + str(edge.vj) + ' : ' + str(edge.val))
graph = Graph()
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()
================================================
FILE: codes/python/06_graph/Graph-Hash-Table.py
================================================
class VertexNode: # 顶点信息类
def __init__(self, vi):
self.vi = vi # 顶点
self.adj_edges = dict() # 顶点的邻接边
class Graph:
def __init__(self):
self.vertices = dict() # 顶点
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图中添加节点
def add_vertex(self, vi):
vertex = VertexNode(vi)
self.vertices[vi] = vertex
# 向图的邻接表中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
if vi not in self.vertices:
self.add_vertex(vi)
if vj not in self.vertices:
self.add_vertex(vj)
self.vertices[vi].adj_edges[vj] = val
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if vi in self.vertices and vj in self.vertices[vi].adj_edges:
return self.vertices[vi].adj_edges[vj]
return None
# 根据邻接表打印图的边
def printGraph(self):
for vi in self.vertices:
for vj in self.vertices[vi].adj_edges:
print(str(vi) + ' - ' + str(vj) + ' : ' + str(self.vertices[vi].adj_edges[vj]))
graph = Graph()
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()
================================================
FILE: codes/python/06_graph/Graph-Kruskal.py
================================================
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def Kruskal(self, edges, size):
union_find = UnionFind(size)
edges.sort(key=lambda x: x[2])
res, cnt = 0, 1
for x, y, dist in edges:
if union_find.is_connected(x, y):
continue
ans += dist
cnt += 1
union_find.union(x, y)
if cnt == size - 1:
return ans
return ans
def minCostConnectPoints(self, points: List[List[int]]) -> int:
size = len(points)
edges = []
for i in range(size):
xi, yi = points[i]
for j in range(i + 1, size):
xj, yj = points[j]
dist = abs(xi - xj) + abs(yi - yj)
edges.append([i, j, dist])
ans = Solution().Kruskal(edges, size)
return ans
================================================
FILE: codes/python/06_graph/Graph-Linked-Forward-Star.py
================================================
class EdgeNode: # 边信息类
def __init__(self, vj, val):
self.vj = vj # 边的终点
self.val = val # 边的权值
self.next = None # 下一条边
class Graph:
def __init__(self, ver_count, edge_count):
self.ver_count = ver_count # 顶点个数
self.edge_count = edge_count # 边个数
self.head = [-1 for _ in range(ver_count)] # 头节点数组
self.edges = [] # 边集数组
# 判断顶点 v 是否有效
def __valid(self, v):
return 0 <= v <= self.ver_count
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for i in range(len(edges)):
vi, vj, val = edges[i]
self.add_edge(i, vi, vj, val)
# 向图的边集数组中添加边:vi - vj,权值为 val
def add_edge(self, index, vi, vj, val):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
edge = EdgeNode(vj, val) # 构造边节点
edge.next = self.head[vi] # 边节点的 next 指向原来首指针
self.edges.append(edge) # 边集数组添加该边
self.head[vi] = index # 首指针指向新加边所在边集数组的下标
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
index = self.head[vi] # 得到顶点 vi 相连的第一条边在边集数组的下标
while index != -1: # index == -1 时说明 vi 相连的边遍历完了
if vj == self.edges[index].vj: # 找到了 vi - vj 边
return self.edges[index].val # 返回 vi - vj 边的权值
index = self.edges[index].next # 取顶点 vi 相连的下一条边在边集数组的下标
return None # 没有找到 vi - vj 边
# 根据链式前向星打印图的边
def printGraph(self):
for vi in range(self.ver_count): # 遍历顶点 vi
index = self.head[vi] # 得到顶点 vi 相连的第一条边在边集数组的下标
while index != -1: # index == -1 时说明 vi 相连的边遍历完了
print(str(vi) + ' - ' + str(self.edges[index].vj) + ' : ' + str(self.edges[index].val))
index = self.edges[index].next # 取顶点 vi 相连的下一条边在边集数组的下标
graph = Graph(7, 7)
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(4, 3))
print(graph.get_edge(4, 5))
graph.printGraph()
================================================
FILE: codes/python/06_graph/Graph-Prim.py
================================================
class Solution:
# graph 为图的邻接矩阵,start 为起始顶点
def Prim(self, graph, start):
size = len(graph)
vis = set()
dist = [float('inf') for _ in range(size)]
ans = 0 # 最小生成树的边权和
dist[start] = 0 # 初始化起始顶点到起始顶点的边权值为 0
for i in range(1, size): # 初始化起始顶点到其他顶点的边权值
dist[i] = graph[start][i]
vis.add(start) # 将 start 顶点标记为已访问
for _ in range(size - 1):
min_dis = float('inf')
min_dis_pos = -1
for i in range(size):
if i not in vis and dist[i] < min_dis:
min_dis = dist[i]
min_dis_pos = i
if min_dis_pos == -1: # 没有顶点可以加入 MST,图 G 不连通
return -1
ans += min_dis # 将顶点加入 MST,并将边权值加入到答案中
vis.add(min_dis_pos)
for i in range(size):
if i not in vis and dist[i] > graph[min_dis_pos][i]:
dist[i] = graph[min_dis_pos][i]
return ans
points = [[0,0]]
graph = dict()
size = len(points)
for i in range(size):
x1, y1 = points[i]
for j in range(size):
x2, y2 = points[j]
dist = abs(x2 - x1) + abs(y2 - y1)
if i not in graph:
graph[i] = dict()
if j not in graph:
graph[j] = dict()
graph[i][j] = dist
graph[j][i] = dist
print(Solution().Prim(graph))
================================================
FILE: codes/python/06_graph/Graph-Topological-Sorting-DFS.py
================================================
import collections
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingDFS(self, graph: dict):
visited = set() # 记录当前顶点是否被访问过
onStack = set() # 记录同一次深搜时,当前顶点是否被访问过
order = [] # 用于存储拓扑序列
hasCycle = False # 用于判断是否存在环
def dfs(u):
nonlocal hasCycle
if u in onStack: # 同一次深度优先搜索时,当前顶点被访问过,说明存在环
hasCycle = True
if u in visited or hasCycle: # 当前节点被访问或者有环时直接返回
return
visited.add(u) # 标记节点被访问
onStack.add(u) # 标记本次深搜时,当前顶点被访问
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
dfs(v) # 递归访问节点 v
order.append(u) # 后序遍历顺序访问节点 u
onStack.remove(u) # 取消本次深搜时的 顶点访问标记
for u in graph:
if u not in visited:
dfs(u) # 递归遍历未访问节点 u
if hasCycle: # 判断是否存在环
return [] # 存在环,无法构成拓扑序列
order.reverse() # 将后序遍历转为拓扑排序顺序
return order # 返回拓扑序列
def findOrder(self, n: int, edges):
# 构建图
graph = dict()
for i in range(n):
graph[i] = []
for v, u in edges:
graph[u].append(v)
return self.topologicalSortingDFS(graph)
print(Solution().findOrder(2, [[1,0]]))
print(Solution().findOrder(4, [[1,0],[2,0],[3,1],[3,2]]))
print(Solution().findOrder(1, []))
================================================
FILE: codes/python/06_graph/Graph-Topological-Sorting-Kahn.py
================================================
import collections
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingKahn(self, graph: dict):
indegrees = {u: 0 for u in graph} # indegrees 用于记录所有节点入度
for u in graph:
for v in graph[u]:
indegrees[v] += 1 # 统计所有节点入度
# 将入度为 0 的顶点存入集合 S 中
S = collections.deque([u for u in indegrees if indegrees[u] == 0])
order = [] # order 用于存储拓扑序列
while S:
u = S.pop() # 从集合中选择一个没有前驱的顶点 0
order.append(u) # 将其输出到拓扑序列 order 中
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
indegrees[v] -= 1 # 删除从顶点 u 出发的有向边
if indegrees[v] == 0: # 如果删除该边后顶点 v 的入度变为 0
S.append(v) # 将其放入集合 S 中
if len(indegrees) != len(order): # 还有顶点未遍历(存在环),无法构成拓扑序列
return []
return order # 返回拓扑序列
def findOrder(self, n: int, edges):
# 构建图
graph = dict()
for i in range(n):
graph[i] = []
for u, v in edges:
graph[u].append(v)
return self.topologicalSortingKahn(graph)
print(Solution().findOrder(2, [[1,0]]))
print(Solution().findOrder(4, [[1,0],[2,0],[3,1],[3,2]]))
print(Solution().findOrder(1, []))
================================================
FILE: codes/python/08_dynamic_programming/Digit-DP.py
================================================
class Solution:
def digitDP(self, n: int) -> int:
s = str(n)
@cache
# pos: 第 pos 个数位
# state: 之前选过的数字集合。
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
# isNum: 表示 pos 前面的数位是否填了数字。
# 如果为真,则当前位不可跳过;如果为假,则当前位可跳过。
def dfs(pos, state, isLimit, isNum):
if pos == len(s):
# isNum 为 True,则表示当前方案符合要求
return int(isNum)
ans = 0
if not isNum:
# 如果 isNumb 为 False,则可以跳过当前数位
ans = dfs(pos + 1, state, False, False)
# 如果前一位没有填写数字,则最小可选择数字为 0,否则最少为 1(不能含有前导 0)。
minX = 0 if isNum else 1
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = int(s[pos]) if isLimit else 9
# 枚举可选择的数字
for x in range(minX, maxX + 1):
# x 不在选择的数字集合中,即之前没有选择过 x
if (state >> x) & 1 == 0:
ans += dfs(pos + 1, state | (1 << x), isLimit and x == maxX, True)
return ans
return dfs(0, 0, True, False)
================================================
FILE: codes/python/08_dynamic_programming/Pack-2DCostPack.py
================================================
class Solution:
# 思路 1:动态规划 + 三维基本思路
def twoDCostPackMethod1(self, weight: [int], volume: [int], value: [int], W: int, V: int):
size = len(weight)
dp = [[[0 for _ in range(V + 1)] for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 组物品
for i in range(1, N + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 枚举背包装载容量
for v in range(V + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1] or v < volume[i - 1]:
# dp[i][w][v] 取「前 i - 1 件物品装入装载重量为 w、装载容量为 v 的背包中的最大价值」
dp[i][w][v] = dp[i - 1][w][v]
else:
# dp[i][w][v] 取所有 dp[w - weight[i - 1]][v - volume[i - 1]] + value[i - 1] 中最大值
dp[i][w][v] = max(dp[i - 1][w][v], dp[i - 1][w - weight[i - 1]][v - volume[i - 1]] + value[i - 1])
return dp[size][W][V]
# 思路 2:动态规划 + 滚动数组优化
def twoDCostPackMethod2(self, weight: [int], volume: [int], value: [int], W: int, V: int):
size = len(weight)
dp = [[0 for _ in range(V + 1)] for _ in range(W + 1)]
# 枚举前 i 组物品
for i in range(1, N + 1):
# 逆序枚举背包装载重量
for w in range(W, weight[i - 1] - 1, -1):
# 逆序枚举背包装载容量
for v in range(V, volume[i - 1] - 1, -1):
# dp[w][v] 取所有 dp[w - weight[i - 1]][v - volume[i - 1]] + value[i - 1] 中最大值
dp[w][v] = max(dp[w][v], dp[w - weight[i - 1]][v - volume[i - 1]] + value[i - 1])
return dp[W][V]
================================================
FILE: codes/python/08_dynamic_programming/Pack-CompletePack.py
================================================
class Solution:
# 思路 1:动态规划 + 二维基本思路
def completePackMethod1(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 枚举第 i - 1 种物品能取个数
for k in range(w // weight[i - 1] + 1):
# dp[i][w] 取所有 dp[i - 1][w - k * weight[i - 1] + k * value[i - 1] 中最大值
dp[i][w] = max(dp[i][w], dp[i - 1][w - k * weight[i - 1]] + k * value[i - 1])
return dp[size][W]
# 思路 2:动态规划 + 状态转移方程优化
def completePackMethod2(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1]:
# dp[i][w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」
dp[i][w] = dp[i - 1][w]
else:
# dp[i][w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」与「前 i 种物品装入载重为 w - weight[i - 1] 的背包中,再装入 1 件第 i - 1 种物品所得的最大价值」两者中的最大值
dp[i][w] = max(dp[i - 1][w], dp[i][w - weight[i - 1]] + value[i - 1])
return dp[size][W]
# 思路 3:动态规划 + 滚动数组优化
def completePackMethod3(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 正序枚举背包装载重量
for w in range(weight[i - 1], W + 1):
# dp[w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」与「前 i 种物品装入载重为 w - weight[i - 1] 的背包中,再装入 1 件第 i - 1 种物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight[i - 1]] + value[i - 1])
return dp[W]
================================================
FILE: codes/python/08_dynamic_programming/Pack-GroupPack.py
================================================
class Solution:
# 思路 1:动态规划 + 二维基本思路
def groupPackMethod1(self, group_count: [int], weight: [[int]], value: [[int]], W: int):
size = len(group_count)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 组物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 枚举第 i - 1 组物品能取个数
dp[i][w] = dp[i - 1][w]
for k in range(group_count[i - 1]):
if w >= weight[i - 1][k]:
# dp[i][w] 取所有 dp[i - 1][w - weight[i - 1][k]] + value[i - 1][k] 中最大值
dp[i][w] = max(dp[i][w], dp[i - 1][w - weight[i - 1][k]] + value[i - 1][k])
return dp[size][W]
# 思路 2:动态规划 + 滚动数组优化
def groupPackMethod2(self, group_count: [int], weight: [[int]], value: [[int]], W: int):
size = len(group_count)
dp = [0 for _ in range(W + 1)]
# 枚举前 i 组物品
for i in range(1, size + 1):
# 逆序枚举背包装载重量
for w in range(W, -1, -1):
# 枚举第 i - 1 组物品能取个数
for k in range(group_count[i - 1]):
if w >= weight[i - 1][k]:
# dp[w] 取所有 dp[w - weight[i - 1][k]] + value[i - 1][k] 中最大值
dp[w] = max(dp[w], dp[w - weight[i - 1][k]] + value[i - 1][k])
return dp[W]
================================================
FILE: codes/python/08_dynamic_programming/Pack-MixedPack.py
================================================
class Solution:
def mixedPackMethod1(self, weight: [int], value: [int], count: [int], W: int):
weight_new, value_new, count_new = [], [], []
# 二进制优化
for i in range(len(weight)):
cnt = count[i]
# 多重背包问题,转为 0-1 背包问题
if cnt > 0:
k = 1
while k <= cnt:
cnt -= k
weight_new.append(weight[i] * k)
value_new.append(value[i] * k)
count_new.append(1)
k *= 2
if cnt > 0:
weight_new.append(weight[i] * cnt)
value_new.append(value[i] * cnt)
count_new.append(1)
# 0-1 背包问题,直接添加
elif cnt == -1:
weight_new.append(weight[i])
value_new.append(value[i])
count_new.append(1)
# 完全背包问题,标记并添加
else:
weight_new.append(weight[i])
value_new.append(value[i])
count_new.append(0)
dp = [0 for _ in range(W + 1)]
size = len(weight_new)
# 枚举前 i 种物品
for i in range(1, size + 1):
# 0-1 背包问题
if count_new[i - 1] == 1:
# 逆序枚举背包装载重量(避免状态值错误)
for w in range(W, weight_new[i - 1] - 1, -1):
# dp[w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」与「前 i - 1 件物品装入载重为 w - weight_new[i - 1] 的背包中,再装入第 i - 1 物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight_new[i - 1]] + value_new[i - 1])
# 完全背包问题
else:
# 正序枚举背包装载重量
for w in range(weight_new[i - 1], W + 1):
# dp[w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」与「前 i 种物品装入载重为 w - weight[i - 1] 的背包中,再装入 1 件第 i - 1 种物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight_new[i - 1]] + value_new[i - 1])
return dp[W]
================================================
FILE: codes/python/08_dynamic_programming/Pack-MultiplePack.py
================================================
class Solution:
# 思路 1:动态规划 + 二维基本思路
def multiplePackMethod1(self, weight: [int], value: [int], count: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 枚举第 i - 1 种物品能取个数
for k in range(min(count[i - 1], w // weight[i - 1]) + 1):
# dp[i][w] 取所有 dp[i - 1][w - k * weight[i - 1] + k * value[i - 1] 中最大值
dp[i][w] = max(dp[i][w], dp[i - 1][w - k * weight[i - 1]] + k * value[i - 1])
return dp[size][W]
# 思路 2:动态规划 + 滚动数组优化
def multiplePackMethod2(self, weight: [int], value: [int], count: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 逆序枚举背包装载重量(避免状态值错误)
for w in range(W, weight[i - 1] - 1, -1):
# 枚举第 i - 1 种物品能取个数
for k in range(min(count[i - 1], w // weight[i - 1]) + 1):
# dp[w] 取所有 dp[w - k * weight[i - 1]] + k * value[i - 1] 中最大值
dp[w] = max(dp[w], dp[w - k * weight[i - 1]] + k * value[i - 1])
return dp[W]
# 思路 3:动态规划 + 二进制优化
def multiplePackMethod3(self, weight: [int], value: [int], count: [int], W: int):
weight_new, value_new = [], []
# 二进制优化
for i in range(len(weight)):
cnt = count[i]
k = 1
while k <= cnt:
cnt -= k
weight_new.append(weight[i] * k)
value_new.append(value[i] * k)
k *= 2
if cnt > 0:
weight_new.append(weight[i] * cnt)
value_new.append(value[i] * cnt)
dp = [0 for _ in range(W + 1)]
size = len(weight_new)
# 枚举前 i 种物品
for i in range(1, size + 1):
# 逆序枚举背包装载重量(避免状态值错误)
for w in range(W, weight_new[i - 1] - 1, -1):
# dp[w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」与「前 i - 1 件物品装入载重为 w - weight_new[i - 1] 的背包中,再装入第 i - 1 物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight_new[i - 1]] + value_new[i - 1])
return dp[W]
================================================
FILE: codes/python/08_dynamic_programming/Pack-ProblemVariants.py
================================================
class Solution:
# 1. 求恰好装满背包的最大价值
# 0-1 背包问题 求恰好装满背包的最大价值
def zeroOnePackJustFillUp(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [float('-inf') for _ in range(W + 1)]
dp[0] = 0
# 枚举前 i 种物品
for i in range(1, size + 1):
# 逆序枚举背包装载重量(避免状态值错误)
for w in range(W, weight[i - 1] - 1, -1):
# dp[w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」与「前 i - 1 件物品装入载重为 w - weight[i - 1] 的背包中,再装入第 i - 1 物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight[i - 1]] + value[i - 1])
if dp[W] == float('-inf'):
return -1
return dp[W]
# 完全背包问题 求恰好装满背包的最大价值
def completePackJustFillUp(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [float('-inf') for _ in range(W + 1)]
dp[0] = 0
# 枚举前 i 种物品
for i in range(1, size + 1):
# 正序枚举背包装载重量
for w in range(weight[i - 1], W + 1):
# dp[w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」与「前 i - 1 件物品装入载重为 w - weight[i - 1] 的背包中,再装入第 i - 1 物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight[i - 1]] + value[i - 1])
if dp[W] == float('-inf'):
return -1
return dp[W]
# 2. 求方案总数
# 0-1 背包问题 求方案总数
def zeroOnePackNumbers(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
dp[0] = 1
# 枚举前 i 种物品
for i in range(1, size + 1):
# 逆序枚举背包装载重量
for w in range(W, weight[i - 1] - 1, -1):
# dp[w] = 前 i - 1 件物品装入载重为 w 的背包中的方案数 + 前 i 件物品装入载重为 w - weight[i - 1] 的背包中,再装入第 i - 1 件物品的方案数
dp[w] = dp[w] + dp[w - weight[i - 1]]
return dp[W]
# 完全背包问题求方案总数
def completePackNumbers(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
dp[0] = 1
# 枚举前 i 种物品
for i in range(1, size + 1):
# 正序枚举背包装载重量
for w in range(weight[i - 1], W + 1):
# dp[w] = 前 i - 1 种物品装入载重为 w 的背包中的方案数 + 前 i 种物品装入载重为 w - weight[i - 1] 的背包中,再装入 1 件第 i - 1 种物品的方案数
dp[w] = dp[w] + dp[w - weight[i - 1]]
return dp[W]
# 3. 求最优方案数
# 0-1 背包问题 求最优方案数 思路 1
def zeroOnePackMaxProfitNumbers1(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
op = [[1 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1]:
# dp[i][w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」
dp[i][w] = dp[i - 1][w]
op[i][w] = op[i - 1][w]
else:
# 选择第 i - 1 件物品获得价值更高
if dp[i - 1][w] < dp[i - 1][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w - weight[i - 1]] + value[i - 1]
# 在之前方案基础上添加了第 i - 1 件物品,因此方案数量不变
op[i][w] = op[i - 1][w - weight[i - 1]]
# 两种方式获得价格相等
elif dp[i - 1][w] == dp[i - 1][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w]
# 方案数 = 不使用第 i - 1 件物品的方案数 + 使用第 i - 1 件物品的方案数
op[i][w] = op[i - 1][w] + op[i - 1][w - weight[i - 1]]
# 不选择第 i - 1 件物品获得价值最高
else:
dp[i][w] = dp[i - 1][w]
# 不选择第 i - 1 件物品,与之前方案数相等
op[i][w] = op[i - 1][w]
return op[size][W]
# 0-1 背包问题求最优方案数 思路 2
def zeroOnePackMaxProfitNumbers2(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
op = [1 for _ in range(W + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W, weight[i - 1] - 1, -1):
# 选择第 i - 1 件物品获得价值更高
if dp[w] < dp[w - weight[i - 1]] + value[i - 1]:
dp[w] = dp[w - weight[i - 1]] + value[i - 1]
# 在之前方案基础上添加了第 i - 1 件物品,因此方案数量不变
op[w] = op[w - weight[i - 1]]
# 两种方式获得价格相等
elif dp[w] == dp[w - weight[i - 1]] + value[i - 1]:
# 方案数 = 不使用第 i - 1 件物品的方案数 + 使用第 i - 1 件物品的方案数
op[w] = op[w] + op[w - weight[i - 1]]
return op[W]
# 完全背包问题求最优方案数 思路 1
def completePackMaxProfitNumbers1(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
op = [[1 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1]:
# dp[i][w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」
dp[i][w] = dp[i - 1][w]
op[i][w] = op[i - 1][w]
else:
# 选择第 i - 1 件物品获得价值更高
if dp[i - 1][w] < dp[i][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i][w - weight[i - 1]] + value[i - 1]
# 在之前方案基础上添加了 1 件第 i - 1 种物品,因此方案数量不变
op[i][w] = op[i][w - weight[i - 1]]
# 两种方式获得价格相等
elif dp[i - 1][w] == dp[i][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w]
# 方案数 = 不使用第 i - 1 种物品的方案数 + 使用 1 件第 i - 1 种物品的方案数
op[i][w] = op[i - 1][w] + op[i][w - weight[i - 1]]
# 不选择第 i - 1 件物品获得价值最高
else:
dp[i][w] = dp[i - 1][w]
# 不选择第 i - 1 种物品,与之前方案数相等
op[i][w] = op[i - 1][w]
return dp[size][W]
# 完全背包问题求最优方案数 思路 2
def completePackMaxProfitNumbers2(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
op = [1 for _ in range(W + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(weight[i - 1], W + 1):
# 选择第 i - 1 件物品获得价值更高
if dp[w] < dp[w - weight[i - 1]] + value[i - 1]:
dp[w] = dp[w - weight[i - 1]] + value[i - 1]
# 在之前方案基础上添加了 1 件第 i - 1 种物品,因此方案数量不变
op[w] = op[w - weight[i - 1]]
# 两种方式获得价格相等
elif dp[w] == dp[w - weight[i - 1]] + value[i - 1]:
# 方案数 = 不使用第 i - 1 种物品的方案数 + 使用 1 件第 i - 1 种物品的方案数
op[w] = op[w] + op[w - weight[i - 1]]
return dp[size][W]
# 4. 求具体方案
# 0-1 背包问题求具体方案
def zeroOnePackPrintPath(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
path = [[False for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1]:
# dp[i][w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」
dp[i][w] = dp[i - 1][w]
path[i][w] = False
else:
# 选择第 i - 1 件物品获得价值更高
if dp[i - 1][w] < dp[i - 1][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w - weight[i - 1]] + value[i - 1]
# 取状态转移式第二项:在之前方案基础上添加了第 i - 1 件物品
path[i][w] = True
# 两种方式获得价格相等
elif dp[i - 1][w] == dp[i - 1][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w]
# 取状态转移式第二项:尽量使用第 i - 1 件物品
path[i][w] = True
# 不选择第 i - 1 件物品获得价值最高
else:
dp[i][w] = dp[i - 1][w]
# 取状态转移式第一项:不选择第 i - 1 件物品
path[i][w] = False
res = []
i, w = size, W
while i >= 1 and w >= 0:
if path[i][w]:
res.append(str(i - 1))
w -= weight[i - 1]
i -= 1
return " ".join(res[::-1])
# 0-1 背包问题求具体方案,要求最小序输出
def zeroOnePackPrintPathMinOrder(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
path = [[False for _ in range(W + 1)] for _ in range(size + 1)]
weight.reverse()
value.reverse()
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1]:
# dp[i][w] 取「前 i - 1 种物品装入载重为 w 的背包中的最大价值」
dp[i][w] = dp[i - 1][w]
path[i][w] = False
else:
# 选择第 i - 1 件物品获得价值更高
if dp[i - 1][w] < dp[i - 1][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w - weight[i - 1]] + value[i - 1]
# 取状态转移式第二项:在之前方案基础上添加了第 i - 1 件物品
path[i][w] = True
# 两种方式获得价格相等
elif dp[i - 1][w] == dp[i - 1][w - weight[i - 1]] + value[i - 1]:
dp[i][w] = dp[i - 1][w]
# 取状态转移式第二项:尽量使用第 i - 1 件物品
path[i][w] = True
# 不选择第 i - 1 件物品获得价值最高
else:
dp[i][w] = dp[i - 1][w]
# 取状态转移式第一项:不选择第 i - 1 件物品
path[i][w] = False
res = []
i, w = size, W
while i >= 1 and w >= 0:
if path[i][w]:
res.append(str(size - i))
w -= weight[i - 1]
i -= 1
return " ".join(res)
================================================
FILE: codes/python/08_dynamic_programming/Pack-ZeroOnePack.py
================================================
class Solution:
# 思路 1:动态规划 + 二维基本思路
def zeroOnePackMethod1(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [[0 for _ in range(W + 1)] for _ in range(size + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(W + 1):
# 第 i - 1 件物品装不下
if w < weight[i - 1]:
# dp[i][w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」
dp[i][w] = dp[i - 1][w]
else:
# dp[i][w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」与「前 i - 1 件物品装入载重为 w - weight[i - 1] 的背包中,再装入第 i - 1 物品所得的最大价值」两者中的最大值
dp[i][w] = max(dp[i - 1][w], dp[i - 1][w - weight[i - 1]] + value[i - 1])
return dp[size][W]
# 思路 2:动态规划 + 滚动数组优化
def zeroOnePackMethod2(self, weight: [int], value: [int], W: int):
size = len(weight)
dp = [0 for _ in range(W + 1)]
# 枚举前 i 种物品
for i in range(1, size + 1):
# 逆序枚举背包装载重量(避免状态值错误)
for w in range(W, weight[i - 1] - 1, -1):
# dp[w] 取「前 i - 1 件物品装入载重为 w 的背包中的最大价值」与「前 i - 1 件物品装入载重为 w - weight[i - 1] 的背包中,再装入第 i - 1 物品所得的最大价值」两者中的最大值
dp[w] = max(dp[w], dp[w - weight[i - 1]] + value[i - 1])
return dp[W]
================================================
FILE: docs/00_preface/00_01_preface.md
================================================
## 1. 创作历程
### 1.1 创作起因
写一本通俗易懂的算法书一直是我的心愿,这个想法已经在我心中埋藏了七年之久。至今我仍记得大学时立下的 flag:**要把所学的算法知识系统整理,编写成书,署上自己的名字,并分享给所有热爱算法的朋友们。**
然而,毕业后由于工作繁忙,这个计划被一再搁置。直到 2021 年 3 月,在朋友的建议下,我们组建了一个算法学习群,并制定了为期三个月(2021 年 4 月 ~ 6 月)的刷题打卡计划,规定连续两天不刷题就会被移出群。
最初有 39 人参与,不过最终坚持下来的只有 13 人。虽然计划未能全部完成,但这三个月的坚持让我重新找回了学习算法的乐趣,也养成了刷题的习惯。工作之余,我总会习惯性地打开 LeetCode 刷题、写题解,收获满满。
后来,我们又重新组建了算法交流群。群里的伙伴越来越多,大家每天刷题、写题解、讨论思路、交流心得,甚至还一起参加周赛、双周赛,赛后还会分享做题心得。
### 1.2 输出是最好的学习方法
在刷题和撰写题解的过程中,我逐步整理了算法与数据结构的基础知识,最终汇聚成了这个开源项目。随后,我又学习搭建了电子书网站,方便大家随时在线阅读。
在这个过程中,我深刻体会到一个重要秘诀:**「输出」是最有效的学习方式**,这正是费曼学习法的真实写照。
只有真正理解了某个概念,才能用简明易懂的语言表达出来,让他人也能明白。如果自己尚未吃透,就很难讲清楚。为此,我广泛阅读了各类算法书籍和高质量博客,不断思考和总结,力求把复杂的知识用更简单通俗的方式表达出来。
刷题过程中,我与许多朋友和群里的小伙伴们积极探讨算法知识,大家互相交流、分享见解,也会帮助我发现不足并提出改进建议。这些宝贵反馈如同专业老师批改作业,不仅不断推动内容的完善,也让我对算法有了更加深入的理解。
就这样,从 2021 年 7 月到 2022 年 7 月,经过一年的坚持,我在 LeetCode 上完成了 1000 多道题目,然后系统总结了算法与数据结构知识,最终完成了这本 **「算法通关手册」**。
## 2. 为什么要学习算法和数据结构
### 2.1 算法是程序员的底层能力
**算法和数据结构** 是计算机程序设计的核心理论基础,但在实际开发中,许多程序员往往忽视了它们的重要性。日常工作中,我们更多依赖成熟的框架和封装良好的接口来完成 CRUD 操作,极少需要自己从零实现底层的数据结构和算法。
此外,编程语言和开发框架的迭代速度极快。以前端为例,React 还没完全掌握,Vue 又流行起来了;刚研究完 Vue 2.0,Vue 3.0 又已发布。新技术层出不穷,学习都来不及,很难专门抽出时间去深入研究算法。
不可否认,语言、技术和框架固然重要,但它们背后的计算机算法与理论才是根本。无论技术如何更迭,始终不变的是底层的算法和理论基础,比如:**数据结构**、**算法**、**编译原理**、**计算机网络**、**计算机体系结构** 等。掌握这些核心理论,才能灵活应对各种技术变化,深入理解系统设计原理和框架思想,快速上手新技术,并有效提升工作效率。
**学习数据结构与算法的关键,在于领悟其思想和精髓,掌握解决实际问题的方法。**
### 2.2 算法是技术面试的必考内容
在互联网行业的技术面试中,**算法与数据结构** 几乎是所有公司必考的核心内容。许多知名互联网公司倾向于以 LeetCode 等平台上的算法题作为考察标准,要求面试者不仅要分析问题、阐述解题思路,还需要评估算法的时间复杂度和空间复杂度。通过这些题目的考察,面试官能够有效判断候选人解决实际问题的能力和思维深度。
LeetCode 等平台的算法题已成为行业通用标准,许多公司会直接选用或稍作改编作为面试题。系统地练习这些题目,不仅能提升解决实际问题的能力,也能让你在面试中遇到类似问题时更加自信、从容。
学习算法应当循序渐进,从基础数据结构入手,逐步掌握常见的算法思想。每当学习一个新概念,都要通过实际题目加以巩固,长期积累下来,才能建立起完善的算法知识体系。
本书「算法通关手册」旨在帮助读者系统学习算法知识,既包含基础理论讲解,也有大量实战题目分析。通过理论与实践相结合,读者能够真正掌握算法精髓,提升解决问题的能力。无论是备战面试,还是提升编程能力,这本书都将为你带来切实的帮助。
================================================
FILE: docs/00_preface/00_02_data_structures_algorithms.md
================================================

> 数据结构是程序的骨架,而算法则是程序的灵魂。
**《算法 + 数据结构 = 程序》** 是 Pascal 语言之父 [Niklaus Emil Wirth](https://zh.wikipedia.org/wiki/尼克劳斯·维尔特) 所著的经典著作,其书名也成为计算机科学领域广为流传的名言。这句话深刻揭示了算法与数据结构在程序设计中的密切关系。
在正式学习之前,我们首先要搞清楚:什么是算法?什么是数据结构?为什么要学习它们?
简而言之,**「算法」是解决问题的方法或步骤**。如果把问题看作一个函数,算法就是将输入转化为输出的过程。**「数据结构」则是数据在计算机中的组织方式及其相关操作**。**「程序」就是算法和数据结构的具体实现**。
如果把「程序设计」比作烹饪,「数据结构」就像是食材和调料,「算法」则是不同的烹饪方法或菜谱。不同的食材、调料和烹饪方式可以组合出千变万化的菜肴。同样的原料,不同的人做出来,味道也会大不相同。
为什么要学习算法和数据结构呢?
还是以做菜为例。做菜讲究「色香味俱全」,而程序设计则追求为问题选择最合适的「数据结构」,并采用更高效、占用资源更少的「算法」。
学习算法和数据结构,能够帮助我们在编程时从时间复杂度和空间复杂度等角度优化解决方案,提升逻辑思维能力,写出高质量的代码,从而增强编程能力,获得更好的职业发展。
当然,正如掌握了食材和烹饪方法并不代表就能做出美味佳肴,学会了算法和数据结构也不意味着就能写出优秀的程序。这需要不断实践、思考和持续学习,才能真正成长为一名优秀的 ~~厨师~~(程序员)。
## 1. 数据结构
> **数据结构(Data Structure)**:具有特定结构特征的数据元素的集合。
简而言之,「数据结构」 就是数据的组织结构,用来组织、存储数据。
进一步来说,数据结构关注的是数据的逻辑结构、物理结构及其相互关系,并针对这些结构定义相应的操作和算法,确保经过操作后数据依然保持原有的结构特性。
数据结构的核心作用在于提升计算机资源的利用效率。例如,操作系统想要查找硬盘中「Microsoft Word」的存储位置,如果采用全盘扫描,则效率极低;而通过「B+ 树」索引,可以迅速定位到 `Microsoft Word`,进而快速获取其文件信息和磁盘位置。
学习数据结构,能够帮助我们理解和掌握数据在计算机中的组织与存储方式,从而为高效编程打下坚实基础。
---
通常,我们可以从 **「逻辑结构」** 和 **「物理结构」** 两个维度对数据结构进行分类。
### 1.1 数据的逻辑结构
> **逻辑结构(Logical Structure)**:指数据元素之间的相互关系。
根据数据元素之间的关系,数据的逻辑结构通常分为以下四类:
1. 集合结构
2. 线性结构
3. 树形结构
4. 图形结构
#### 1.1.1 集合结构
> **集合结构**:数据元素属于同一个集合,彼此之间没有其他关系。
集合结构中的数据元素是无序且互不相同的,每个元素在集合中只出现一次。这种结构与数学中的「集合」概念非常相似。

#### 1.1.2 线性结构
> **线性结构**:数据元素之间存在严格的「一对一」关系。
在线性结构中,除第一个元素和最后一个元素外,每个数据元素都仅与前后各一个元素相邻。常见的线性结构有:数组、链表,以及基于它们实现的栈、队列等。此外,哈希表在底层实现时也常依赖数组或链表等线性结构。

#### 1.1.3 树形结构
> **树形结构**:数据元素之间存在「一对多」的层次关系。
树形结构最典型的例子是二叉树,其基本形式包括根节点、左子树和右子树,而每个子树又可以递归地包含自己的子树。除了二叉树之外,树形结构还包括多叉树、字典树等多种类型,广泛用于表达具有层级关系的数据。
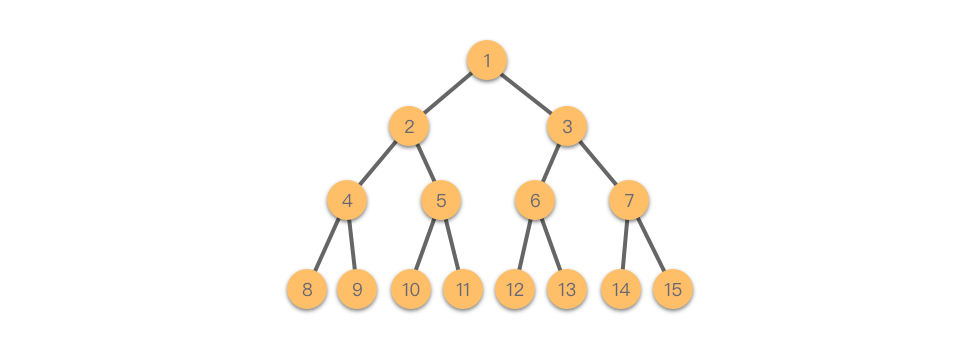
#### 1.1.4 图形结构
> **图形结构**:数据元素之间存在「多对多」的关系。
图形结构是一种比树形结构更为复杂的非线性结构,常用于描述对象之间任意的关联关系。在图结构中,数据元素被称为 **「顶点」**(或 **「结点」**),顶点之间通过 **「边」**(可以是直线或曲线)相连,形成复杂的网络。
与树形结构不同,图形结构允许任意两个顶点之间建立连接,顶点之间的邻接关系没有限制。常见的图结构类型包括:无向图、有向图、连通图等。
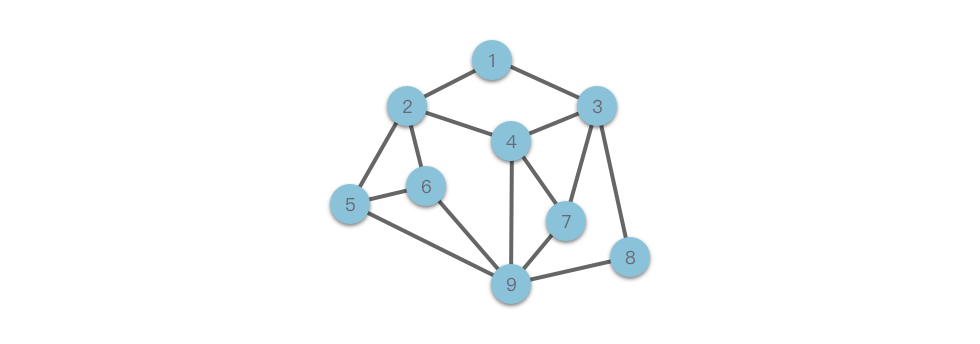
### 1.2 数据的物理结构
> **物理结构(Physical Structure)**:指数据的逻辑结构在计算机中的具体存储方式。
在计算机中,常见的物理存储结构主要有两种:**顺序存储结构** 和 **链式存储结构**,它们被广泛应用于各类数据结构的实现。
#### 1.2.1 顺序存储结构
> **顺序存储结构(Sequential Storage Structure)**:指将所有数据元素依次存放在一块地址连续的存储空间中,元素之间的逻辑关系通过它们在物理存储上的相对位置来体现。

在顺序存储结构中,逻辑上相邻的数据元素在物理地址上也紧密相邻。
顺序存储结构的优点在于:结构简单、易于理解,并且能够高效利用存储空间。其缺点主要包括:必须预先分配一块连续的存储空间,灵活性较差;在插入、删除等需要移动大量元素的操作时,时间效率较低。
#### 2. 链式存储结构
> **链式存储结构(Linked Storage Structure)**:指将数据元素存放在内存中的任意存储单元,这些单元可以是连续的,也可以是不连续的。

在链式存储结构中,逻辑上相邻的数据元素在物理地址上不要求相邻,实际存储位置是随机的。通常,每个数据元素及其相关信息被组合成一个「链结点」。每个链结点除了存放数据本身外,还包含一个「指针(或引用)」,用于指向下一个逻辑上相邻的链结点。也就是说,数据元素之间的逻辑关系是通过指针来连接和体现的。
链式存储结构的主要优点在于:无需预先分配一整块连续的存储空间,能够根据需要动态申请和释放内存,避免空间浪费;在插入、删除等操作时,通常只需修改指针,效率较高。其缺点是:每个链结点除了存储数据外,还需额外存储指针信息,因此整体空间开销相较于顺序存储结构更大。
## 2. 算法
> **算法(Algorithm)**:解决特定问题求解步骤的准确而完整的描述,在计算机中表现为一系列指令的集合,算法代表着用系统的方法描述解决问题的策略机制。
简而言之,**「算法」** 就是解决问题的具体方法和步骤。
进一步来说,算法是一系列有序的运算步骤,能够为某一类计算问题提供通用的解决方案。对于任意合法输入,算法都能按照既定步骤逐步执行,最终得到正确的输出。算法本身与具体的编程语言无关,可以用 **自然语言、编程语言(如 Python、C、C++、Java 等)**,也可以用 **伪代码或流程图** 等多种方式进行描述。
下面通过几个例子来直观理解什么是算法。
- 示例 1:
> **问题描述**:
>
> - 如何从上海前往北京?
>
> **解决方法**:
>
> 1. 选择乘坐飞机,速度最快但费用最高。
> 2. 选择长途汽车,费用最低但耗时最长。
> 3. 选择高铁或火车,时间和费用都较为适中。
- 示例 2:
> **问题描述**:
>
> - 如何计算 $1 + 2 + 3 + \dots + 100$ 的和?
>
> **解决方法**:
>
> 1. 依次用计算器从 $1$ 加到 $100$,最终得到 $5050$。
> 2. 利用高斯求和公式:**和 = (首项 + 末项) × 项数 ÷ 2**,直接计算得 $\frac{(1+100) \times 100}{2} = 5050$。
- 示例 3:
> **问题描述**:
>
> - 如何将一个包含 $n$ 个整数的数组按升序排列?
>
> **解决方法**:
>
> 1. 使用冒泡排序对数组进行升序排序。
> 2. 也可以选择插入排序、归并排序、快速排序等其他排序算法实现升序排列。
上述三个示例中的解决方法都属于算法。从上海到北京的出行方案是一种算法,对 $1$ 到 $100$ 求和的方法是一种算法,对数组排序的方法同样是一种算法。可以看出,对于同一个问题,往往存在多种不同的算法可供选择。
### 2.1 算法的基本特性
算法本质上是一组有序的运算步骤,用于解决特定的问题。除此之外,**算法** 还必须具备以下五个基本特性:
1. **输入**:算法需要接收外部提供的信息作为处理对象,这些信息称为输入。一个算法可以有零个、一个或多个输入。例如,示例 $1$ 的输入是出发地和目的地(如上海、北京),示例 $3$ 的输入是由 $n$ 个整数构成的数组,而示例 $2$ 针对的是固定问题,可以视为没有输入。
2. **输出**:算法的执行结果必须有明确的输出,即至少有一个输出结果。比如,示例 $1$ 的输出是最终选择的交通方式,示例 $2$ 的输出是求和的结果,示例 $3$ 的输出是排好序的数组。
3. **有穷性**:算法必须在有限的步骤内终止,并且能够在合理的时间内完成。如果算法无法在有限时间内结束,就不能称为有效的算法。例如,如果五一假期从上海到北京旅游,三天都没决定交通方式,计划就无法实现,这样的「算法」显然不合理。
4. **确定性**:算法中的每一步操作都必须有明确、唯一的含义,不能存在歧义。也就是说,任何人在相同输入下执行算法,得到的中间过程和最终结果都应一致。
5. **可行性**:算法的每一步都必须是可执行的,即在现有条件下能够通过有限次数的操作实现,并且可以被计算机程序实现并运行,最终得到正确的结果。
### 2.2 算法追求的目标
研究算法的核心目的,是让我们以更高效的方式解决问题。对于同一个问题,往往存在多种算法可选,而不同算法的「代价」也各不相同。一般来说,优秀的算法应当重点追求以下两个目标:
1. **更少的运行时间(更低的时间复杂度)**
2. **更小的内存占用(更低的空间复杂度)**
举例来说,假设计算机执行一条指令需要 $1$ 纳秒。如果某算法需 $100$ 纳秒,另一算法只需 $3$ 纳秒,在不考虑内存消耗的前提下,显然后者更优。再比如,如果某算法只需 $3$ 字节内存,另一算法需 $100$ 字节,在不考虑运行时间的情况下,前者更优。
实际应用中,算法设计往往需要在运行时间和空间占用之间权衡。理想情况下,算法既快又省空间,但现实中常常需要根据具体需求做出取舍。例如,当程序运行速度要求较高时,可以适当增加空间消耗以换取更快的执行速度;反之,如果设备内存有限且对速度要求不高,则可以选择更节省空间的算法,即使牺牲一些运行时间。
除了运行时间和空间占用,优秀的算法还应具备以下基本特性:
1. **正确性**:算法能准确满足问题需求,程序运行无语法错误,能通过典型测试,达到预期目标。
2. **可读性**:算法结构清晰,命名规范,注释恰当,便于理解、维护和后续修改。
3. **健壮性**:算法能合理应对非法输入或异常操作,具备良好的容错能力。
这三点是算法的基本要求,所有算法都必须满足。而我们评价一个算法是否优秀,通常最看重的还是其运行时间和空间占用两个方面。
## 3. 总结
### 3.1 数据结构
数据结构通常分为 **逻辑结构** 和 **物理结构** 两大类。
- **逻辑结构**:描述数据元素之间的关系,主要包括:**集合结构**、**线性结构**、**树形结构** 和 **图形结构**。
- **物理结构**:指数据在计算机中的实际存储方式,主要有:**顺序存储结构** 和 **链式存储结构**。
逻辑结构强调数据元素之间的相互关系,而物理结构则关注这些关系在计算机内的具体实现。例如,线性表中的「栈」在逻辑上属于线性结构,元素之间是一对一的关系(除首尾元素外,每个元素有唯一前驱和后继)。在物理实现上,栈可以采用顺序存储(即 **顺序栈**,元素在内存中连续存放),也可以采用链式存储(即 **链式栈**,元素在内存中不一定连续,通过指针连接)。
### 3.2 算法
**算法** 是解决特定问题的有序操作步骤的集合。
一个算法应具备以下五个基本特性:**输入**、**输出**、**有穷性**、**确定性**、**可行性**。
优秀的算法通常追求以下目标:**正确性**、**可读性**、**健壮性**、**更低的时间复杂度(运行时间更短)** 和 **更低的空间复杂度(占用内存更小)**。
## 参考资料
- 【文章】[数据结构与算法 · 看云](https://www.kancloud.cn/zxliu/algorithm/2088786)
- 【书籍】大话数据结构——程杰 著
- 【书籍】趣学算法——陈小玉 著
- 【书籍】计算机程序设计艺术(第一卷)基本算法(第三版)——苏运霖 译
- 【书籍】算法艺术与信息学竞赛——刘汝佳、黄亮 著
================================================
FILE: docs/00_preface/00_03_algorithm_complexity.md
================================================
## 1. 算法复杂度简介
> **算法复杂度(Algorithm complexity)**:用于衡量算法在输入规模为 $n$ 时所需的时间和空间资源。
这里的 **问题规模 $n$**,指的是算法输入的数据量。不同类型的算法,$n$ 的具体含义也有所不同:
- 排序算法中,$n$ 表示待排序元素的数量;
- 查找算法中,$n$ 表示查找范围的大小(如数组长度、字符串长度等);
- 图论算法中,$n$ 可以指节点数或边数,具体视问题而定;
- 二进制相关算法中,$n$ 通常指二进制的位数。
一般来说,输入规模越大,算法的计算成本也会随之增加;而当输入规模相近时,计算成本也会比较接近。
「算法分析」的核心目标是优化算法,使其 **运行时间更短**、**内存占用更小**。分析算法时,主要从运行时间和空间使用两个方面入手。常见的分析方法有两种:
- **事后统计**:将不同算法分别实现并运行,通过实际测量运行时间和内存占用来比较优劣。
- **预先估算**:在算法设计阶段,根据算法的步骤,理论上估算其运行时间和空间消耗,并进行比较。
实际应用中,我们更倾向于采用预先估算的方法,因为事后统计不仅工作量大,而且同一算法在不同编程语言和硬件环境下的表现差异较大。
采用预先估算时,我们通常不考虑编程语言、计算机运行速度等外部因素,关注的是算法随问题规模增长时的资源消耗趋势。
## 2. 时间复杂度
### 2.1 时间复杂度简介
> **时间复杂度(Time Complexity)**:用于衡量算法在输入规模为 $n$ 时的运行时间,通常记作 $T(n)$。
时间复杂度的本质,是统计算法中 **基本操作** 的执行次数。也就是说,时间复杂度与算法中基本操作的数量成正比。
- **基本操作**:指的是在常数时间内可以完成的语句,其执行时间与操作数的大小无关。
举例来说,两个小整数相加,所需时间不会因为数字位数的不同而变化,因此属于基本操作。但如果操作数非常大,运算时间会随位数增加而增长,这时整体加法就不再是基本操作,应将每一位的加法视为基本操作。
下面通过一个具体例子来演示时间复杂度的计算方法。
```python
def find_max(arr):
max_val = arr[0] # 1 次操作
for i in range(len(arr)): # n 次循环
if arr[i] > max_val: # n 次比较
max_val = arr[i] # 最多 n 次赋值
return max_val # 1 次操作
```
在上述例子中,基本操作总共执行了 $1 + n + n + n + 1 = 3 \times n + 2$ 次,因此可以用 $f(n) = 3 \times n + 2$ 表示其操作次数。
时间复杂度分析如下:
- 当 $n$ 足够大时,$3n$ 是主要影响项,常数 $2$ 可以忽略不计。
- 由于我们关注的是随规模增长的趋势,常数系数 $3$ 也可以省略。
- 因此,该算法的时间复杂度为 $O(n)$。这里的 $O$ 表示渐近符号,强调 $f(n)$ 与 $n$ 成正比。
所谓「算法执行时间的增长趋势」,实际上就是用类似 $O$ 这样的渐近符号,来简洁地描述算法随输入规模变化时的资源消耗情况。
### 2.2 渐近符号
时间复杂度通常记作 $T(n) = O(f(n))$,称为 **渐近时间复杂度(Asymptotic Time Complexity)**,用于描述当问题规模 $n$ 趋近于无穷大时,算法运行时间的增长趋势。我们常用渐近符号(如 $O$、$\Omega$、$\Theta$ 等)来表达这种增长关系。渐近时间复杂度只关注主导项,忽略常数和低阶项,从而简洁地反映算法的本质效率。
> **渐近符号(Asymptotic Symbol)**:一类数学符号,用于描述函数(如算法运行时间或空间)随输入规模增长时的变化速度。在算法分析中,常用的渐近符号有大 $O$(上界)、大 $\Omega$(下界)、大 $\Theta$(紧确界),它们帮助我们以统一的方式比较不同算法的效率。
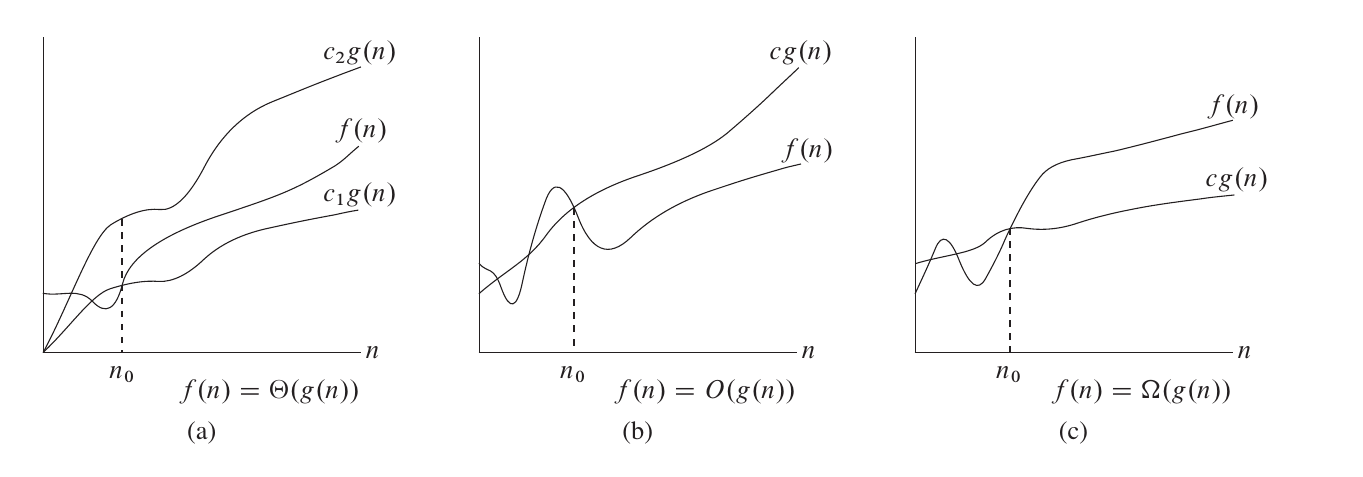
#### 2.2.1 渐近上界符号 $O$
> **渐近上界符号 $O$**:用于描述算法运行时间的上限,通常反映算法在最坏情况下的性能。
**数学定义**:设 $T(n)$ 和 $f(n)$ 为两个函数,如果存在正常数 $c$ 和 $n_0$,使得对所有 $n \geq n_0$,都有 $T(n) \leq c \cdot f(n)$,则称 $T(n) = O(f(n))$。
**直观理解**:$T(n) = O(f(n))$ 表示「算法的运行时间至多为 $f(n)$ 的某个常数倍」,即不会比 $f(n)$ 增长得更快。
> **示例**:
>
> - 如果 $T(n) = 3 \times n^2 + 2 \times n + 1$,则 $T(n) = O(n^2)$。
> - 如果 $T(n) = 2 \times n + 5$,则 $T(n) = O(n)$。
> - 如果 $T(n) = 100$,则 $T(n) = O(1)$。
#### 2.2.2 渐近下界符号 $\Omega$
> **渐近下界符号 $\Omega$**:用于描述算法运行时间的下界,通常反映算法在最优情况下的性能。
**数学定义**:设 $T(n)$ 和 $f(n)$ 为两个函数,如果存在正常数 $c > 0$ 和 $n_0$,使得对所有 $n \geq n_0$,都有 $T(n) \geq c \cdot f(n)$,则称 $T(n) = \Omega(f(n))$。
**直观理解**:$T(n) = \Omega(f(n))$ 表示「算法的运行时间至少不会低于 $f(n)$ 的某个常数倍」,即增长速度不慢于 $f(n)$。
> **示例**:
>
> - 如果 $T(n) = 3 \times n^2 + 2 \times n + 1$,则 $T(n) = \Omega(n^2)$。
> - 如果 $T(n) = 2 \times n + 5$,则 $T(n) = \Omega(n)$。
> - 如果 $T(n) = n^3$,则 $T(n) = \Omega(n^2)$。
#### 2.2.3 渐近紧确界符号 $\Theta$
> **渐近紧确界符号 $\Theta$**:用于描述算法运行时间的精确数量级,即算法在最好和最坏情况下的增长速度都与 $f(n)$ 保持一致。
**数学定义**:设 $T(n)$ 和 $f(n)$ 为两个函数,如果存在正常数 $c_1, c_2 > 0$ 及 $n_0$,使得对所有 $n \geq n_0$,都有 $c_1 \cdot f(n) \leq T(n) \leq c_2 \cdot f(n)$,则称 $T(n) = \Theta(f(n))$。
**直观理解**:$T(n) = \Theta(f(n))$ 表示「算法运行时间与 $f(n)$ 同阶」,即上下界都为 $f(n)$ 的常数倍。
> **示例**:
>
> - 如果 $T(n) = 3 \times n^2 + 2 \times n + 1$,则 $T(n) = \Theta(n^2)$。
> - 如果 $T(n) = 2 \times n + 5$,则 $T(n) = \Theta(n)$。
> - 如果 $T(n) = n \log n + n$,则 $T(n) = \Theta(n \log n)$。
### 2.3 时间复杂度计算
渐近符号用于描述函数的上界、下界,以及算法执行时间随问题规模增长的趋势。
在分析时间复杂度时,我们通常使用 $O$ 符号来表示算法的上界,因为实际应用中更关注算法在最坏情况下的表现。
那么,如何具体计算时间复杂度呢?
一般来说,计算时间复杂度可以分为以下几个步骤:
1. **确定基本操作**:找出算法中执行次数最多的语句,通常是最内层循环的核心操作。
2. **估算执行次数**:只关注基本操作的最高阶项,忽略常数系数和低阶项。
3. **用大 O 符号表示**:将上一步得到的数量级用 $O$ 符号表示出来。
在计算时间复杂度时,还需注意以下两条常用原则:
> **加法原则**:多个代码块顺序执行时,总时间复杂度等于其中最大的那一个。
即如果 $T_1(n) = O(f_1(n))$,$T_2(n) = O(f_2(n))$,$T(n) = T_1(n) + T_2(n)$,则 $T(n) = O(\max(f_1(n), f_2(n)))$。
> **乘法原则**:循环嵌套时,总时间复杂度等于各层复杂度的乘积。
即如果 $T_1(n) = O(f_1(n))$,$T_2(n) = O(f_2(n))$,$T(n) = T_1(n) \times T_2(n)$,则 $T(n) = O(f_1(n) \times f_2(n))$。
下面通过具体实例来说明各种常见时间复杂度的计算方法。
#### 2.3.1 常数时间 $O(1)$
没有循环和递归的算法,时间复杂度通常为 $O(1)$。
```python
def get_first_element(arr):
return arr[0] # 直接返回第一个元素
def add_two_numbers(a, b):
return a + b # 简单的加法运算
```
上述代码中,每个函数都只执行常数次操作,时间复杂度为 $O(1)$。
#### 2.3.2 线性时间 $O(n)$
单层循环遍历 $n$ 个元素的算法,时间复杂度为 $O(n)$。
```python
def find_max(arr):
max_val = arr[0]
for num in arr: # 遍历数组中的每个元素
if num > max_val:
max_val = num
return max_val
def sum_array(arr):
total = 0
for num in arr: # 遍历数组中的每个元素
total += num
return total
```
上述代码中,每个函数都只遍历数组一次,时间复杂度为 $O(n)$。
#### 2.3.3 平方时间 $O(n^2)$
两层嵌套循环,每层执行 $n$ 次操作的算法,时间复杂度为 $O(n^2)$。
```python
def bubble_sort(arr):
n = len(arr)
for i in range(n): # 外层循环
for j in range(n - 1): # 内层循环
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
def find_all_pairs(arr):
pairs = []
for i in range(len(arr)): # 外层循环
for j in range(len(arr)): # 内层循环
pairs.append((arr[i], arr[j]))
return pairs
```
上述代码中,每个函数都包含两层嵌套循环,总操作次数为 $n^2$,时间复杂度为 $O(n^2)$。
#### 2.3.4 对数时间 $O(\log n)$
每次操作将问题规模缩小一半的算法,如「二分查找」和「分治算法」,时间复杂度为 $O(\log n)$。
```python
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
def power_of_two(n):
count = 0
while n > 1:
n = n // 2 # 每次除以2
count += 1
return count
```
上述代码中,每次将问题规模缩小一半,循环次数为 $\log_2 n$,时间复杂度为 $O(\log n)$。
#### 2.3.5 线性对数时间 $O(n \log n)$
线性对数一般出现在排序算法中,例如「快速排序」、「归并排序」、「堆排序」等,时间复杂度为 $O(n \log n)$。
```python
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid]) # 递归处理左半部分
right = merge_sort(arr[mid:]) # 递归处理右半部分
return merge(left, right) # 合并两个有序数组
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
```
上述代码中,`merge_sort` 函数采用了分治思想,每次递归将数组一分为二,递归深度为 $\log_2 n$ 层,每层处理 $n$ 个元素,整体的时间复杂度为 $O(n \log n)$。
#### 2.3.6 指数时间 $O(2^n)$
指数时间复杂度 $O(2^n)$ 通常出现在每一步都存在两种选择、递归分支成倍增长的算法中,如递归斐波那契、子集枚举等,时间复杂度为 $O(2^n)$。
```python
def fibonacci_recursive(n):
if n <= 1:
return n
return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
def generate_subsets(arr):
def backtrack(start, current):
result.append(current[:])
for i in range(start, len(arr)):
current.append(arr[i])
backtrack(i + 1, current)
current.pop()
result = []
backtrack(0, [])
return result
```
上述代码中,`fibonacci_recursive` 函数每次递归都会分裂成两个子问题,递归树的节点总数为 $2^n$,因此时间复杂度为 $O(2^n)$。`generate_subsets` 函数通过回溯法枚举所有子集,每个元素有选或不选两种选择,子集总数为 $2^n$,所以整体时间复杂度也是 $O(2^n)$。
#### 2.3.7 阶乘时间 $O(n!)$
阶乘时间 $O(n!)$ 通常出现在需要枚举所有排列或组合的算法中,如全排列、旅行商问题暴力解法等。随着输入规模 $n$ 的增加,算法的执行次数以阶乘级别增长,计算量极大,几乎
无法处理较大的输入规模。
```python
def generate_permutations(arr):
def backtrack(start):
if start == len(arr):
result.append(arr[:])
return
for i in range(start, len(arr)):
arr[start], arr[i] = arr[i], arr[start] # 交换
backtrack(start + 1) # 递归
arr[start], arr[i] = arr[i], arr[start] # 恢复
result = []
backtrack(0)
return result
```
上述代码中,`generate_permutations` 函数通过回溯法枚举所有排列。每一层递归会将当前位置与后续每个元素交换,递归深度为 $n$ 层。第 1 层有 $n$ 种选择,第 2 层有 $n - 1$ 种选择,依此类推,总共 $n!$ 种排列,因此时间复杂度为 $O(n!)$。
#### 2.3.8 时间复杂度对比
常见时间复杂度从小到大排序:$O(1)$ < $O(\log n)$ < $O(n)$ < $O(n \log n)$ < $O(n^2)$ < $O(n^3)$ < $O(2^n)$ < $O(n!)$ < $O(n^n)$
| 时间复杂度 | 输入规模 $n=10$ | $n=100$ | $n=1000$ | 实际应用 |
|------------|---------------|-------|--------|----------|
| $O(1)$ | $1$ | $1$ | $1$ | 数组访问、哈希表查找 |
| $O(\log n)$| $3$ | $7$ | $10$ | 二分查找、平衡树操作 |
| $O(n)$ | $10$ | $100$ | $1000$ | 线性搜索、数组遍历 |
| $O(n \log n)$ | $33$ | $664$ | $9966$ | 快速排序、归并排序 |
| $O(n^2)$ | $100$ | $10000$ | $1000000$ | 冒泡排序、选择排序 |
| $O(2^n)$ | $1024$ | $1.3 \times 10^{30}$ | $1.1 \times 10^{301}$ | 递归斐波那契 |
| $O(n!)$ | $3628800$ | $9.3 \times 10^{157}$ | $4.0 \times 10^{2567}$ | 全排列 |
### 2.4 最佳、最坏、平均时间复杂度
由于同一算法在不同输入下的表现可能差异很大,我们通常从三个角度分析时间复杂度:
- **最佳时间复杂度**:最理想输入下的时间复杂度
- **最坏时间复杂度**:最差输入下的时间复杂度
- **平均时间复杂度**:随机输入下的期望时间复杂度
**示例**:在数组中查找目标值
```python
def find(nums, val):
for i in range(len(nums)):
if nums[i] == val:
return i
return -1
```
- **最佳情况**:目标值在数组开头,时间复杂度 $O(1)$
- **最坏情况**:目标值不存在,需要遍历整个数组,时间复杂度 $O(n)$
- **平均情况**:假设目标值等概率出现在任意位置,平均时间复杂度 $O(n)$
> **实际应用**:通常使用 **最坏时间复杂度** 作为算法性能的衡量标准,因为它能保证算法在任何输入下的性能上限。只有在不同情况下的时间复杂度存在量级差异时,才需要区分三种情况。
## 3. 空间复杂度
### 3.1 空间复杂度简介
> **空间复杂度(Space Complexity)**:在问题的输入规模为 $n$ 的条件下,算法所占用的空间大小,可以记作为 $S(n)$。一般将 **算法的辅助空间** 作为衡量空间复杂度的标准。
空间复杂度的渐近符号表示方法与时间复杂度相同,可以表示为 $S(n) = O(f(n))$,表示算法空间占用随问题规模 $n$ 的增长趋势。
相对于算法的时间复杂度计算来说,算法的空间复杂度更容易计算。空间复杂度的计算主要包括局部变量占用的存储空间和递归栈空间两个部分。
### 3.2 空间复杂度计算
空间复杂度的计算主要考虑算法运行过程中额外占用的空间,包括局部变量和递归栈空间。
#### 3.2.1 常数空间 $O(1)$
```python
def algorithm(n):
a = 1
b = 2
res = a * b + n
return res
```
上述代码中,只使用了固定数量的变量,因此空间复杂度为 $O(1)$。
#### 3.2.2 线性空间 $O(n)$
```python
def algorithm(n):
if n <= 0:
return 1
return n * algorithm(n - 1)
```
上述代码中,递归深度为 $n$,需要 $O(n)$ 的栈空间。
#### 3.2.3 常见空间复杂度
常见空间复杂度从小到大排序:$O(1)$ < $O(\log n)$ < $O(n)$ < $O(n^2)$ < $O(2^n)$
## 4. 总结
**「算法复杂度」** 包括 **「时间复杂度」** 和 **「空间复杂度」**,用于衡量算法在输入规模 $n$ 增大时的资源消耗情况。通常使用**渐近符号**(如 $O$ 符号)来描述算法复杂度的增长趋势。
常见的时间复杂度有:$O(1)$、$O(\log n)$、$O(n)$、$O(n \log n)$、$O(n^2)$、$O(n^3)$、$O(2^n)$、$O(n!)$。
常见的空间复杂度有:$O(1)$、$O(\log n)$、$O(n)$、$O(n^2)$。
## 参考资料
- 【书籍】数据结构(C++ 语言版)- 邓俊辉 著
- 【书籍】算法导论 第三版(中文版)- 殷建平等 译
- 【书籍】算法艺术与信息学竞赛 - 刘汝佳、黄亮 著
- 【书籍】数据结构(C 语言版)- 严蔚敏 著
- 【书籍】趣学算法 - 陈小玉 著
- 【文章】[复杂度分析 - 数据结构与算法之美 王争](https://time.geekbang.org/column/intro/126)
- 【文章】[算法复杂度(时间复杂度+空间复杂度)](https://www.biancheng.net/algorithm/complexity.html)
- 【文章】[算法基础 - 复杂度 - OI Wiki](https://oi-wiki.org/basic/complexity/)
- 【文章】[图解算法数据结构 - 算法复杂度 - LeetBook - 力扣](https://leetcode.cn/leetbook/read/illustration-of-algorithm/r84gmi/)
================================================
FILE: docs/00_preface/00_04_leetcode_guide.md
================================================
## 1. LeetCode 是什么
**「LeetCode」** 是一个在线编程评测平台,主要包含算法、数据库、Shell、多线程等题目,其中以算法题目为主。LeetCode 上有 $3000+$ 道编程问题,支持 $16+$ 种编程语言,还有一个活跃的社区用于技术交流。我们可以通过解决 LeetCode 题库中的问题来练习编程技能,以及提高算法能力。
许多知名互联网公司在面试时会考察 LeetCode 题目,要求面试者分析问题、编写代码,并分析算法的时间复杂度和空间复杂度。通过 LeetCode 刷题,充分准备算法知识,对获得好的工作机会很有帮助。
## 2. LeetCode 新手入门
### 2.1 LeetCode 注册
1. 打开 LeetCode 中文主页,链接:[力扣(LeetCode)官网](https://leetcode.cn/)。
2. 输入手机号,获取验证码。
3. 输入验证码之后,点击「登录 / 注册」,就注册好了。
### 2.2 LeetCode 题库
「[题库](https://leetcode.cn/problemset/algorithms/)」是 LeetCode 上最直接的练习入口,在这里可以根据题目的标签、难度、状态进行刷题。也可以按照随机一题开始刷题。
#### 2.2.1 题目标签
LeetCode 的题目涉及了许多算法和数据结构。有贪心,搜索,动态规划,链表,二叉树,哈希表等等,可以通过选择对应标签进行专项刷题,同时也可以看到对应专题的完成度情况。

#### 2.2.2 题目列表
LeetCode 提供了题目的搜索过滤功能。可以筛选相关题单、不同难易程度、题目完成状态、不同标签的题目。还可以根据题目编号、题解数目、通过率、难度、出现频率等进行排序。
#### 2.2.3 当前进度
当前进度提供了一个直观的进度展示。在这里可以看到自己的练习概况。进度会自动展现当前的做题情况。也可以点击「[进度设置](https://leetcode.cn/session/)」创建新的进度,在这里还可以修改、删除相关的进度。
#### 2.2.4 题目详情
从题目列表点击进入,就可以看到这道题目的内容描述和代码编辑器。在这里还可以查看相关的题解和自己的提交记录。
### 2.3 LeetCode 刷题语言
面试时考察的是算法基本功,对于语言的选择没有限制。建议使用熟悉的语言或语法简洁的语言刷题。
相对于 Python 而言,C、C++ 语法比较复杂,在做题的时候除了要思考思路,还得考虑语法,不太利于刷题。Python 等语言更简洁,能让你专注于算法思路本身,提高刷题效率。当然,算法竞赛选手通常使用 C++,已经成为传统了。
> 人生苦短,我用 Python。
### 2.4 LeetCode 刷题流程
在「2.2.1 题目标签」中我们介绍了题目的相关情况。

可以看到左侧区域为题目内容描述区域,还可以看到题目的内容描述和一些示例数据。而右侧是代码编辑区域,代码编辑区域里边默认显示了待实现的方法。
我们需要在代码编辑器中根据方法给定的参数实现对应的算法,并返回题目要求的结果。然后还要经过「执行代码」测试结果,点击「提交」后,显示执行结果为「**通过**」时,才算完成一道题目。
总结一下我们的刷题流程为:
1. 在 LeetCode 题库中选择一道自己想要解决的题目。
2. 查看题目左侧的题目描述,理解题目要求。
3. 思考解决思路,并在右侧代码编辑区域实现对应的方法,并返回题目要求的结果。
4. 如果实在想不出解决思路,可以查看题目相关的题解,努力理解他人的解题思路和代码。
5. 点击「执行代码」按钮测试结果。
- 如果输出结果与预期结果不符,则回到第 3 步重新思考解决思路,并改写代码。
6. 如果输出结果与预期符合,则点击「提交」按钮。
- 如果执行结果显示「编译出错」、「解答错误」、「执行出错」、「超出时间限制」、「超出内存限制」等情况,则需要回到第 3 步重新思考解决思路,或者思考特殊数据,并改写代码。
7. 如果执行结果显示「通过」,恭喜你通过了这道题目。
接下来我们将通过「[2235. 两整数相加 - 力扣(LeetCode)](https://leetcode.cn/problems/add-two-integers/)」这道题目来讲解如何在 LeetCode 上刷题。
### 2.5 LeetCode 第一题
#### 2.5.1 题目链接
- [2235. 两整数相加 - 力扣(LeetCode)](https://leetcode.cn/problems/add-two-integers/)
#### 2.5.2 题目大意
**描述**:给定两个整数 $num1$ 和 $num2$。
**要求**:返回这两个整数的和。
**说明**:
- $-100 \le num1, num2 \le 100$。
**示例**:
- 示例 1:
```python
输入:num1 = 12, num2 = 5
输出:17
解释:num1 是 12,num2 是 5,它们的和是 12 + 5 = 17,因此返回 17。
```
- 示例 2:
```python
输入:num1 = -10, num2 = 4
输出:-6
解释:num1 + num2 = -6,因此返回 -6。
```
#### 2.5.3 解题思路
##### 思路 1:直接计算
1. 直接计算整数 $num1$ 与 $num2$ 的和,返回 $num1 + num2$ 即可。
##### 思路 1:代码
```python
class Solution:
def sum(self, num1: int, num2: int) -> int:
return num1 + num2
```
##### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
理解了上面这道题的题意,就可以试着自己编写代码,并尝试提交通过。如果提交结果显示「通过」,那么恭喜你完成了 LeetCode 上的第一题。虽然只是一道题,但这意味着刷题计划的开始!希望你能坚持下去,得到应有的收获。
## 3. LeetCode 刷题攻略
### 3.1 LeetCode 前期准备
如果你是算法和数据结构的新手,建议在刷 LeetCode 之前先学习一下基础知识,这样刷题时会更顺利。
基础知识包括:
- **数据结构**:数组、字符串、链表、树(如二叉树)等。
- **算法**:分治、贪心、回溯、动态规划等。
这个阶段推荐看一些经典的算法基础书来进行学习。这里推荐一下我看过的感觉不错的算法书:
- 【书籍】[算法(第 4 版)- 谢路云 译](https://book.douban.com/subject/19952400/)
- 【书籍】[大话数据结构 - 程杰 著](https://book.douban.com/subject/6424904/)
- 【书籍】[趣学算法 - 陈小玉 著](https://book.douban.com/subject/27109832/)
- 【书籍】[算法图解 - 袁国忠 译](https://book.douban.com/subject/26979890/)
- 【书籍】[算法竞赛入门经典(第 2 版) - 刘汝佳 著](https://book.douban.com/subject/25902102/)
- 【书籍】[数据结构与算法分析 - 冯舜玺 译](https://book.douban.com/subject/1139426/)
- 【书籍】[算法导论(原书第 3 版) - 殷建平 / 徐云 / 王刚 / 刘晓光 / 苏明 / 邹恒明 / 王宏志 译](https://book.douban.com/subject/20432061/)
当然,也可以直接看我写的「算法通关手册」,欢迎指正和提出建议,万分感谢。
- 「算法通关手册」GitHub 地址:[https://github.com/ITCharge/AlgoNote](https://github.com/ITCharge/AlgoNote)
- 「算法通关手册」电子书网站地址:[https://algo.itcharge.cn](https://algo.itcharge.cn)
### 3.2 LeetCode 刷题顺序
讲个笑话,从前有个人以为 LeetCode 的题目是按照难易程度排序的,所以他从 [1. 两数之和](https://leetcode.cn/problems/two-sum) 开始刷题,结果他卡在了 [4. 寻找两个正序数组的中位数](https://leetcode.cn/problems/median-of-two-sorted-arrays) 这道困难题上。
LeetCode 的题目序号并不是按难易程度排序的,不建议按序号顺序刷题。新手建议从「简单」难度开始,熟练后再刷中等难度题目,最后考虑面试题或难题。
其实 LeetCode 官方网站上就有整理好的题目不错的刷题清单。链接为:[https://leetcode.cn/leetbook/](https://leetcode.cn/leetbook/)。可以先刷这里边的题目卡片。我这里也做了一个整理。
推荐刷题顺序和目录如下:
[1. 初级算法](https://leetcode.cn/leetbook/detail/top-interview-questions-easy/)、[2. 数组类算法](https://leetcode.cn/leetbook/detail/all-about-array/)、[3. 数组和字符串](https://leetcode.cn/leetbook/detail/array-and-string/)、[4. 链表类算法](https://leetcode.cn/leetbook/detail/linked-list/)、[5. 哈希表](https://leetcode.cn/leetbook/detail/hash-table/)、[6. 队列 & 栈](https://leetcode.cn/leetbook/detail/queue-stack/)、[7. 递归](https://leetcode.cn/leetbook/detail/recursion/)、[8. 二分查找](https://leetcode.cn/leetbook/detail/binary-search/)、[9. 二叉树](https://leetcode.cn/leetbook/detail/data-structure-binary-tree/)、[10. 中级算法](https://leetcode.cn/leetbook/detail/top-interview-questions-medium/)、[11. 高级算法](https://leetcode.cn/leetbook/detail/top-interview-questions-hard/)、[12. 算法面试题汇总](https://leetcode.cn/leetbook/detail/top-interview-questions/)。
当然还可以通过官方推出的「[学习计划 - 力扣](https://leetcode.cn/study-plan/)」按计划每天刷题。
或者直接按照我整理的分类刷题列表进行刷题:
- LeetCode 分类刷题列表:[点击打开「LeetCode 分类刷题列表」](https://github.com/ITCharge/AlgoNote/tree/main/docs/00_preface/00_06_categories_list.md)
正在准备面试、没有太多时间刷题的小伙伴,可以按照我总结的「LeetCode 面试最常考 100 题」、「LeetCode 面试最常考 200 题」进行刷题。
> **说明**:「LeetCode 面试最常考 100 题」、「LeetCode 面试最常考 200 题」是笔者根据「[CodeTop 企业题库](https://codetop.cc/home)」按频度从高到低进行筛选,并且去除了一部分 LeetCode 上没有的题目和重复题目后得到的题目清单。
- [LeetCode 面试最常考 100 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/00_preface/00_07_interview_100_list.md)
- [LeetCode 面试最常考 200 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/00_preface/00_08_interview_200_list.md)
### 3.3 LeetCode 刷题技巧
下面分享一下我在刷题过程中用到的刷题技巧。简单来说,可以分为 $5$ 条:
> 1. 五分钟思考法
> 2. 重复刷题
> 3. 按专题分类刷题
> 4. 写解题报告
> 5. 坚持刷题
#### 3.3.1 五分钟思考法
> **五分钟思考法**:如果一道题如果 $5$ 分钟之内有思路,就立即动手写代码解题。如果 $5$ 分钟之后还没有思路,就直接去看题解。然后根据题解的思路,自己去实现代码。如果发现自己看了题解也无法实现代码,就认真阅读题解的代码,并理解代码的逻辑。
其实,刷算法题的过程和背英语单词很相似。
刚开始学英语时,先从最基础的字母学起,不必纠结每个字母的由来。接着学习简单的单词,也不用深究单词的含义,先记住再说。掌握了基础词汇后,再逐步学习词组、短句、长句,最后阅读文章。
背单词不是看一遍就能记住,而是需要不断重复练习、反复记忆来加深印象。
刷算法题也是如此。零基础时,不要纠结为什么自己想不出解法,或者为什么没想到更高效的方法。遇到没有思路的题目时,直接去看题解区的高赞解答,尽快积累经验,帮助自己快速入门。
#### 3.3.2 重复刷题
> **重复刷题**:遇见不会的题,多刷几遍,不断加深理解。
刷算法题经常是做完一遍后,隔一段时间就忘记了,看到之前做过的题目也未必能立刻想起解题思路。所以,刷题并不是做完一遍就结束了,还需要定期回顾和复习。
此外,一道题往往有多种解法和不同的优化思路。第一次做时可能只想到一种方法,等到第二遍、第三遍时,可能会发现新的解法或更优的实现。
因此,建议对不会的题目多刷几遍,通过反复练习不断加深理解和记忆。
#### 3.3.3 按专题分类刷题
> **按专题分类刷题**:按照不同专题分类刷题,既可以巩固刚学完的算法知识,还可以提高刷题效率。
按专题分类刷题有两个好处:
1. **巩固知识**:刚学完某个算法时,可能对里边的相关知识理解的不够透彻,或者说可能会遗漏一些关键知识点,这时候可以通过刷对应题目的方式来帮助我们巩固刚学完的算法知识。
2. **提高效率**:同类题目所用到的算法知识其实是相同或者相似的,同一种解题思路可以运用到多道题目中。通过不断求解同一类算法专题下的题目,可以大大的提升我们的刷题速度。
#### 3.3.4 写解题报告
> **写解题报告**:如果能够用简洁清晰的语言让别人听懂这道题目的思路,那就说明你真正理解了这道题的解法。
写解题报告是很有用的技巧。如果你能用通俗易懂的语言写出解题思路,说明你真正理解了这道题。这相当于「费曼学习法」,也能减少重复刷题的时间。
#### 3.3.5 坚持刷题
> **坚持刷题**:算法刷题没有捷径,只有不断的刷题、总结,再刷题,再总结。
千万不要相信「3天精通数据结构」这类速成学习宣传。学习算法需要不断积累,反复理解算法思想,并通过刷题来应用知识。
根据我的个人经验,能坚持每天刷题并掌握基础算法知识的人总是少数。但如果你选择了学习算法,希望在达成目标前能坚持下去,通过「刻意练习」把刷题变成兴趣。
## 4. 总结
LeetCode 是一个在线编程练习平台,主要用于提升算法和编程能力。新手可以从简单题目开始,逐步学习数据结构和算法。
刷题技巧包括:五分钟思考法、重复刷题、按专题分类刷题、写解题报告、坚持刷题。最重要的是坚持,通过不断练习和总结来掌握算法知识。
## 练习题目
- [2235. 两整数相加](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2200-2299/add-two-integers.md)
- [1929. 数组串联](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/concatenation-of-array.md)
## 参考资料
- 【文章】[What is LeetCode? - Quora](https://www.quora.com/What-is-Leetcode)
- 【文章】[LeetCode 帮助中心 - 力扣(LeetCode)](https://support.leetcode-cn.com/hc/)
- 【回答】[刷 leetcode 使用 python 还是 c++? - 知乎](https://www.zhihu.com/question/319448129)
- 【回答】[刷完 LeetCode 是什么水平?能拿到什么水平的 offer? - 知乎](https://www.zhihu.com/question/32019460)
================================================
FILE: docs/00_preface/00_05_solutions_list.md
================================================
# LeetCode 题解(已完成 1303 道)
### 第 1 ~ 99 题
| 标题 | 题解 | 标签 | 难度 |
| :--- | :--- | :--- | :--- |
| [0001. 两数之和](https://leetcode.cn/problems/two-sum/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/two-sum.md) | 数组、哈希表 | 简单 |
| [0002. 两数相加](https://leetcode.cn/problems/add-two-numbers/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/add-two-numbers.md) | 递归、链表、数学 | 中等 |
| [0003. 无重复字符的最长子串](https://leetcode.cn/problems/longest-substring-without-repeating-characters/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/longest-substring-without-repeating-characters.md) | 哈希表、字符串、滑动窗口 | 中等 |
| [0004. 寻找两个正序数组的中位数](https://leetcode.cn/problems/median-of-two-sorted-arrays/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/median-of-two-sorted-arrays.md) | 数组、二分查找、分治 | 困难 |
| [0005. 最长回文子串](https://leetcode.cn/problems/longest-palindromic-substring/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/longest-palindromic-substring.md) | 双指针、字符串、动态规划 | 中等 |
| [0006. Z 字形变换](https://leetcode.cn/problems/zigzag-conversion/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/zigzag-conversion.md) | 字符串 | 中等 |
| [0007. 整数反转](https://leetcode.cn/problems/reverse-integer/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/reverse-integer.md) | 数学 | 中等 |
| [0008. 字符串转换整数 (atoi)](https://leetcode.cn/problems/string-to-integer-atoi/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/string-to-integer-atoi.md) | 字符串 | 中等 |
| [0009. 回文数](https://leetcode.cn/problems/palindrome-number/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/palindrome-number.md) | 数学 | 简单 |
| [0010. 正则表达式匹配](https://leetcode.cn/problems/regular-expression-matching/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/regular-expression-matching.md) | 递归、字符串、动态规划 | 困难 |
| [0011. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/container-with-most-water.md) | 贪心、数组、双指针 | 中等 |
| [0012. 整数转罗马数字](https://leetcode.cn/problems/integer-to-roman/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/integer-to-roman.md) | 哈希表、数学、字符串 | 中等 |
| [0013. 罗马数字转整数](https://leetcode.cn/problems/roman-to-integer/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/roman-to-integer.md) | 哈希表、数学、字符串 | 简单 |
| [0014. 最长公共前缀](https://leetcode.cn/problems/longest-common-prefix/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/longest-common-prefix.md) | 字典树、数组、字符串 | 简单 |
| [0015. 三数之和](https://leetcode.cn/problems/3sum/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/3sum.md) | 数组、双指针、排序 | 中等 |
| [0016. 最接近的三数之和](https://leetcode.cn/problems/3sum-closest/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/3sum-closest.md) | 数组、双指针、排序 | 中等 |
| [0017. 电话号码的字母组合](https://leetcode.cn/problems/letter-combinations-of-a-phone-number/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/letter-combinations-of-a-phone-number.md) | 哈希表、字符串、回溯 | 中等 |
| [0018. 四数之和](https://leetcode.cn/problems/4sum/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/4sum.md) | 数组、双指针、排序 | 中等 |
| [0019. 删除链表的倒数第 N 个结点](https://leetcode.cn/problems/remove-nth-node-from-end-of-list/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/remove-nth-node-from-end-of-list.md) | 链表、双指针 | 中等 |
| [0020. 有效的括号](https://leetcode.cn/problems/valid-parentheses/) | [题解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/va
gitextract_dhdwtz4s/
├── .github/
│ └── workflows/
│ └── sync.yml
├── .gitignore
├── LICENSE
├── README.md
├── codes/
│ └── python/
│ ├── 01_array/
│ │ ├── array_maxheap.py
│ │ ├── array_sort_bubble_sort.py
│ │ ├── array_sort_bucket_sort.py
│ │ ├── array_sort_counting_sort.py
│ │ ├── array_sort_insertion_sort.py
│ │ ├── array_sort_maxheap_sort.py
│ │ ├── array_sort_merge_sort.py
│ │ ├── array_sort_minheap_sort.py
│ │ ├── array_sort_quick_sort.py
│ │ ├── array_sort_radix_sort.py
│ │ ├── array_sort_selection_sort.py
│ │ └── array_sort_shell_sort.py
│ ├── 02_linked_list/
│ │ ├── linked_list.py
│ │ ├── linked_list_bubble_sort.py
│ │ ├── linked_list_bucket_sort.py
│ │ ├── linked_list_counting_sort.py
│ │ ├── linked_list_insertion_sort.py
│ │ ├── linked_list_merge_sort.py
│ │ ├── linked_list_quick_sort.py
│ │ ├── linked_list_radix_sort.py
│ │ └── linked_list_section_sort.py
│ ├── 03_stack_queue_hash_table/
│ │ ├── queue_circularSequential_queue.py
│ │ ├── queue_deque.py
│ │ ├── queue_link_queue.py
│ │ ├── queue_priority_queue.py
│ │ ├── queue_sequential_queue.py
│ │ ├── stack_link_stack.py
│ │ ├── stack_monotone_stack.py
│ │ └── stack_sequential_stack.py
│ ├── 04_string/
│ │ ├── string_Strcmp.py
│ │ ├── string_boyer_moore.py
│ │ ├── string_brute_force.py
│ │ ├── string_horspool.py
│ │ ├── string_kmp.py
│ │ ├── string_rabin_karp.py
│ │ ├── string_sunday.py
│ │ └── string_trie.py
│ ├── 05_tree/
│ │ ├── tree_binaryindexed_tree.py
│ │ ├── tree_dynamicSegmentTree_update_interval_1.py
│ │ ├── tree_dynamicSegmentTree_update_interval_2.py
│ │ ├── tree_segmentTree_update_interval_1.py
│ │ ├── tree_segmentTree_update_interval_2.py
│ │ ├── tree_segmentTree_update_point.py
│ │ ├── tree_unionFind.py
│ │ ├── tree_unionFind_QuickFind.py
│ │ ├── tree_unionFind_QuickUnion.py
│ │ ├── tree_unionFind_UnoinByRank.py
│ │ └── tree_unionFind_UnoinBySize.py
│ ├── 06_graph/
│ │ ├── Graph-Adjacency-List.py
│ │ ├── Graph-Adjacency-Matrix.py
│ │ ├── Graph-BFS.py
│ │ ├── Graph-Bellman-Ford.py
│ │ ├── Graph-DFS.py
│ │ ├── Graph-Edgeset-Array.py
│ │ ├── Graph-Hash-Table.py
│ │ ├── Graph-Kruskal.py
│ │ ├── Graph-Linked-Forward-Star.py
│ │ ├── Graph-Prim.py
│ │ ├── Graph-Topological-Sorting-DFS.py
│ │ └── Graph-Topological-Sorting-Kahn.py
│ └── 08_dynamic_programming/
│ ├── Digit-DP.py
│ ├── Pack-2DCostPack.py
│ ├── Pack-CompletePack.py
│ ├── Pack-GroupPack.py
│ ├── Pack-MixedPack.py
│ ├── Pack-MultiplePack.py
│ ├── Pack-ProblemVariants.py
│ └── Pack-ZeroOnePack.py
└── docs/
├── 00_preface/
│ ├── 00_01_preface.md
│ ├── 00_02_data_structures_algorithms.md
│ ├── 00_03_algorithm_complexity.md
│ ├── 00_04_leetcode_guide.md
│ ├── 00_05_solutions_list.md
│ ├── 00_06_categories_list.md
│ ├── 00_07_interview_100_list.md
│ ├── 00_08_interview_200_list.md
│ └── index.md
├── 01_array/
│ ├── 01_01_array_basic.md
│ ├── 01_02_array_sort.md
│ ├── 01_03_array_bubble_sort.md
│ ├── 01_04_array_selection_sort.md
│ ├── 01_05_array_insertion_sort.md
│ ├── 01_06_array_shell_sort.md
│ ├── 01_07_array_merge_sort.md
│ ├── 01_08_array_quick_sort.md
│ ├── 01_09_array_heap_sort.md
│ ├── 01_10_array_counting_sort.md
│ ├── 01_11_array_bucket_sort.md
│ ├── 01_12_array_radix_sort.md
│ ├── 01_13_array_binary_search_01.md
│ ├── 01_14_array_binary_search_02.md
│ ├── 01_15_array_two_pointers.md
│ ├── 01_16_array_sliding_window.md
│ └── index.md
├── 02_linked_list/
│ ├── 02_01_linked_list_basic.md
│ ├── 02_02_linked_list_sort.md
│ ├── 02_03_linked_list_bubble_sort.md
│ ├── 02_04_linked_list_selection_sort.md
│ ├── 02_05_linked_list_insertion_sort.md
│ ├── 02_06_linked_list_merge_sort.md
│ ├── 02_07_linked_list_quick_sort.md
│ ├── 02_08_linked_list_counting_sort.md
│ ├── 02_09_linked_list_bucket_sort.md
│ ├── 02_10_linked_list_radix_sort.md
│ ├── 02_11_linked_list_two_pointers.md
│ └── index.md
├── 03_stack_queue_hash_table/
│ ├── 03_01_stack_basic.md
│ ├── 03_02_monotone_stack.md
│ ├── 03_03_queue_basic.md
│ ├── 03_04_priority_queue.md
│ ├── 03_05_bidirectional_queue.md
│ ├── 03_06_hash_table.md
│ └── index.md
├── 04_string/
│ ├── 04_01_string_basic.md
│ ├── 04_02_string_brute_force.md
│ ├── 04_03_string_rabin_karp.md
│ ├── 04_04_string_kmp.md
│ ├── 04_05_string_boyer_moore.md
│ ├── 04_06_string_horspool.md
│ ├── 04_07_string_sunday.md
│ ├── 04_08_trie.md
│ ├── 04_09_ac_automaton.md
│ ├── 04_10_suffix_array.md
│ └── index.md
├── 05_tree/
│ ├── 05_01_tree_basic.md
│ ├── 05_02_binary_tree_traverse.md
│ ├── 05_03_binary_tree_reduction.md
│ ├── 05_04_binary_search_tree.md
│ ├── 05_05_segment_tree_01.md
│ ├── 05_06_segment_tree_02.md
│ ├── 05_07_binary_indexed_tree.md
│ ├── 05_08_union_find.md
│ └── index.md
├── 06_graph/
│ ├── 06_01_graph_basic.md
│ ├── 06_02_graph_structure.md
│ ├── 06_03_graph_dfs.md
│ ├── 06_04_graph_bfs.md
│ ├── 06_05_graph_topological_sorting.md
│ ├── 06_06_graph_minimum_spanning_tree.md
│ ├── 06_07_graph_shortest_path_01.md
│ ├── 06_08_graph_shortest_path_02.md
│ ├── 06_09_graph_multi_source_shortest_path.md
│ ├── 06_10_graph_the_second_shortest_path.md
│ ├── 06_11_graph_bipartite_basic.md
│ ├── 06_12_graph_bipartite_matching.md
│ └── index.md
├── 07_algorithm/
│ ├── 07_01_enumeration_algorithm.md
│ ├── 07_02_recursive_algorithm.md
│ ├── 07_03_divide_and_conquer_algorithm.md
│ ├── 07_04_backtracking_algorithm.md
│ ├── 07_05_greedy_algorithm.md
│ ├── 07_06_bit_operation.md
│ └── index.md
├── 08_dynamic_programming/
│ ├── 08_01_dynamic_programming_basic.md
│ ├── 08_02_memoization_search.md
│ ├── 08_03_linear_dp_01.md
│ ├── 08_04_linear_dp_02.md
│ ├── 08_05_linear_dp_03.md
│ ├── 08_06_knapsack_problem_01.md
│ ├── 08_07_knapsack_problem_02.md
│ ├── 08_08_knapsack_problem_03.md
│ ├── 08_09_knapsack_problem_04.md
│ ├── 08_10_knapsack_problem_05.md
│ ├── 08_11_interval_dp.md
│ ├── 08_12_tree_dp.md
│ ├── 08_13_state_compression_dp.md
│ ├── 08_14_counting_dp.md
│ ├── 08_15_digit_dp.md
│ ├── 08_16_probability_dp.md
│ └── index.md
├── README.md
├── others/
│ ├── index.md
│ ├── todo_list.md
│ └── update_time.md
└── solutions/
├── 0001-0099/
│ ├── 3sum-closest.md
│ ├── 3sum.md
│ ├── 4sum.md
│ ├── add-binary.md
│ ├── add-two-numbers.md
│ ├── binary-tree-inorder-traversal.md
│ ├── climbing-stairs.md
│ ├── combination-sum-ii.md
│ ├── combination-sum.md
│ ├── combinations.md
│ ├── container-with-most-water.md
│ ├── count-and-say.md
│ ├── decode-ways.md
│ ├── divide-two-integers.md
│ ├── edit-distance.md
│ ├── find-first-and-last-position-of-element-in-sorted-array.md
│ ├── find-the-index-of-the-first-occurrence-in-a-string.md
│ ├── first-missing-positive.md
│ ├── generate-parentheses.md
│ ├── gray-code.md
│ ├── group-anagrams.md
│ ├── index.md
│ ├── insert-interval.md
│ ├── integer-to-roman.md
│ ├── interleaving-string.md
│ ├── jump-game-ii.md
│ ├── jump-game.md
│ ├── largest-rectangle-in-histogram.md
│ ├── length-of-last-word.md
│ ├── letter-combinations-of-a-phone-number.md
│ ├── longest-common-prefix.md
│ ├── longest-palindromic-substring.md
│ ├── longest-substring-without-repeating-characters.md
│ ├── longest-valid-parentheses.md
│ ├── maximal-rectangle.md
│ ├── maximum-subarray.md
│ ├── median-of-two-sorted-arrays.md
│ ├── merge-intervals.md
│ ├── merge-k-sorted-lists.md
│ ├── merge-sorted-array.md
│ ├── merge-two-sorted-lists.md
│ ├── minimum-path-sum.md
│ ├── minimum-window-substring.md
│ ├── multiply-strings.md
│ ├── n-queens-ii.md
│ ├── n-queens.md
│ ├── next-permutation.md
│ ├── palindrome-number.md
│ ├── partition-list.md
│ ├── permutation-sequence.md
│ ├── permutations-ii.md
│ ├── permutations.md
│ ├── plus-one.md
│ ├── powx-n.md
│ ├── recover-binary-search-tree.md
│ ├── regular-expression-matching.md
│ ├── remove-duplicates-from-sorted-array-ii.md
│ ├── remove-duplicates-from-sorted-array.md
│ ├── remove-duplicates-from-sorted-list-ii.md
│ ├── remove-duplicates-from-sorted-list.md
│ ├── remove-element.md
│ ├── remove-nth-node-from-end-of-list.md
│ ├── restore-ip-addresses.md
│ ├── reverse-integer.md
│ ├── reverse-linked-list-ii.md
│ ├── reverse-nodes-in-k-group.md
│ ├── roman-to-integer.md
│ ├── rotate-image.md
│ ├── rotate-list.md
│ ├── scramble-string.md
│ ├── search-a-2d-matrix.md
│ ├── search-in-rotated-sorted-array-ii.md
│ ├── search-in-rotated-sorted-array.md
│ ├── search-insert-position.md
│ ├── set-matrix-zeroes.md
│ ├── simplify-path.md
│ ├── sort-colors.md
│ ├── spiral-matrix-ii.md
│ ├── spiral-matrix.md
│ ├── sqrtx.md
│ ├── string-to-integer-atoi.md
│ ├── subsets-ii.md
│ ├── subsets.md
│ ├── substring-with-concatenation-of-all-words.md
│ ├── sudoku-solver.md
│ ├── swap-nodes-in-pairs.md
│ ├── text-justification.md
│ ├── trapping-rain-water.md
│ ├── two-sum.md
│ ├── unique-binary-search-trees-ii.md
│ ├── unique-binary-search-trees.md
│ ├── unique-paths-ii.md
│ ├── unique-paths.md
│ ├── valid-number.md
│ ├── valid-parentheses.md
│ ├── valid-sudoku.md
│ ├── validate-binary-search-tree.md
│ ├── wildcard-matching.md
│ ├── word-search.md
│ └── zigzag-conversion.md
├── 0100-0199/
│ ├── balanced-binary-tree.md
│ ├── best-time-to-buy-and-sell-stock-ii.md
│ ├── best-time-to-buy-and-sell-stock-iii.md
│ ├── best-time-to-buy-and-sell-stock-iv.md
│ ├── best-time-to-buy-and-sell-stock.md
│ ├── binary-search-tree-iterator.md
│ ├── binary-tree-level-order-traversal-ii.md
│ ├── binary-tree-level-order-traversal.md
│ ├── binary-tree-maximum-path-sum.md
│ ├── binary-tree-postorder-traversal.md
│ ├── binary-tree-preorder-traversal.md
│ ├── binary-tree-right-side-view.md
│ ├── binary-tree-upside-down.md
│ ├── binary-tree-zigzag-level-order-traversal.md
│ ├── candy.md
│ ├── clone-graph.md
│ ├── compare-version-numbers.md
│ ├── construct-binary-tree-from-inorder-and-postorder-traversal.md
│ ├── construct-binary-tree-from-preorder-and-inorder-traversal.md
│ ├── convert-sorted-array-to-binary-search-tree.md
│ ├── convert-sorted-list-to-binary-search-tree.md
│ ├── copy-list-with-random-pointer.md
│ ├── distinct-subsequences.md
│ ├── dungeon-game.md
│ ├── evaluate-reverse-polish-notation.md
│ ├── excel-sheet-column-number.md
│ ├── excel-sheet-column-title.md
│ ├── factorial-trailing-zeroes.md
│ ├── find-minimum-in-rotated-sorted-array-ii.md
│ ├── find-minimum-in-rotated-sorted-array.md
│ ├── find-peak-element.md
│ ├── flatten-binary-tree-to-linked-list.md
│ ├── fraction-to-recurring-decimal.md
│ ├── gas-station.md
│ ├── house-robber.md
│ ├── index.md
│ ├── insertion-sort-list.md
│ ├── intersection-of-two-linked-lists.md
│ ├── largest-number.md
│ ├── linked-list-cycle-ii.md
│ ├── linked-list-cycle.md
│ ├── longest-consecutive-sequence.md
│ ├── longest-substring-with-at-most-two-distinct-characters.md
│ ├── lru-cache.md
│ ├── majority-element.md
│ ├── max-points-on-a-line.md
│ ├── maximum-depth-of-binary-tree.md
│ ├── maximum-gap.md
│ ├── maximum-product-subarray.md
│ ├── min-stack.md
│ ├── minimum-depth-of-binary-tree.md
│ ├── missing-ranges.md
│ ├── number-of-1-bits.md
│ ├── one-edit-distance.md
│ ├── palindrome-partitioning-ii.md
│ ├── palindrome-partitioning.md
│ ├── pascals-triangle-ii.md
│ ├── pascals-triangle.md
│ ├── path-sum-ii.md
│ ├── path-sum.md
│ ├── populating-next-right-pointers-in-each-node-ii.md
│ ├── populating-next-right-pointers-in-each-node.md
│ ├── read-n-characters-given-read4-ii-call-multiple-times.md
│ ├── read-n-characters-given-read4.md
│ ├── reorder-list.md
│ ├── repeated-dna-sequences.md
│ ├── reverse-bits.md
│ ├── reverse-words-in-a-string-ii.md
│ ├── reverse-words-in-a-string.md
│ ├── rotate-array.md
│ ├── same-tree.md
│ ├── single-number-ii.md
│ ├── single-number.md
│ ├── sort-list.md
│ ├── sum-root-to-leaf-numbers.md
│ ├── surrounded-regions.md
│ ├── symmetric-tree.md
│ ├── triangle.md
│ ├── two-sum-ii-input-array-is-sorted.md
│ ├── two-sum-iii-data-structure-design.md
│ ├── valid-palindrome.md
│ ├── word-break-ii.md
│ ├── word-break.md
│ ├── word-ladder-ii.md
│ └── word-ladder.md
├── 0200-0299/
│ ├── 3sum-smaller.md
│ ├── add-digits.md
│ ├── alien-dictionary.md
│ ├── basic-calculator-ii.md
│ ├── basic-calculator.md
│ ├── best-meeting-point.md
│ ├── binary-tree-longest-consecutive-sequence.md
│ ├── binary-tree-paths.md
│ ├── bitwise-and-of-numbers-range.md
│ ├── bulls-and-cows.md
│ ├── closest-binary-search-tree-value-ii.md
│ ├── closest-binary-search-tree-value.md
│ ├── combination-sum-iii.md
│ ├── contains-duplicate-ii.md
│ ├── contains-duplicate-iii.md
│ ├── contains-duplicate.md
│ ├── count-complete-tree-nodes.md
│ ├── count-primes.md
│ ├── count-univalue-subtrees.md
│ ├── course-schedule-ii.md
│ ├── course-schedule.md
│ ├── delete-node-in-a-linked-list.md
│ ├── design-add-and-search-words-data-structure.md
│ ├── different-ways-to-add-parentheses.md
│ ├── encode-and-decode-strings.md
│ ├── expression-add-operators.md
│ ├── factor-combinations.md
│ ├── find-median-from-data-stream.md
│ ├── find-the-celebrity.md
│ ├── find-the-duplicate-number.md
│ ├── first-bad-version.md
│ ├── flatten-2d-vector.md
│ ├── flip-game-ii.md
│ ├── flip-game.md
│ ├── game-of-life.md
│ ├── graph-valid-tree.md
│ ├── group-shifted-strings.md
│ ├── h-index-ii.md
│ ├── h-index.md
│ ├── happy-number.md
│ ├── house-robber-ii.md
│ ├── implement-queue-using-stacks.md
│ ├── implement-stack-using-queues.md
│ ├── implement-trie-prefix-tree.md
│ ├── index.md
│ ├── inorder-successor-in-bst.md
│ ├── integer-to-english-words.md
│ ├── invert-binary-tree.md
│ ├── isomorphic-strings.md
│ ├── kth-largest-element-in-an-array.md
│ ├── kth-smallest-element-in-a-bst.md
│ ├── lowest-common-ancestor-of-a-binary-search-tree.md
│ ├── lowest-common-ancestor-of-a-binary-tree.md
│ ├── majority-element-ii.md
│ ├── maximal-square.md
│ ├── meeting-rooms-ii.md
│ ├── meeting-rooms.md
│ ├── minimum-size-subarray-sum.md
│ ├── missing-number.md
│ ├── move-zeroes.md
│ ├── nim-game.md
│ ├── number-of-digit-one.md
│ ├── number-of-islands.md
│ ├── paint-fence.md
│ ├── paint-house-ii.md
│ ├── paint-house.md
│ ├── palindrome-linked-list.md
│ ├── palindrome-permutation-ii.md
│ ├── palindrome-permutation.md
│ ├── peeking-iterator.md
│ ├── perfect-squares.md
│ ├── power-of-two.md
│ ├── product-of-array-except-self.md
│ ├── rectangle-area.md
│ ├── remove-linked-list-elements.md
│ ├── reverse-linked-list.md
│ ├── search-a-2d-matrix-ii.md
│ ├── serialize-and-deserialize-binary-tree.md
│ ├── shortest-palindrome.md
│ ├── shortest-word-distance-ii.md
│ ├── shortest-word-distance-iii.md
│ ├── shortest-word-distance.md
│ ├── single-number-iii.md
│ ├── sliding-window-maximum.md
│ ├── strobogrammatic-number-ii.md
│ ├── strobogrammatic-number-iii.md
│ ├── strobogrammatic-number.md
│ ├── summary-ranges.md
│ ├── the-skyline-problem.md
│ ├── ugly-number-ii.md
│ ├── ugly-number.md
│ ├── unique-word-abbreviation.md
│ ├── valid-anagram.md
│ ├── verify-preorder-sequence-in-binary-search-tree.md
│ ├── walls-and-gates.md
│ ├── wiggle-sort.md
│ ├── word-pattern-ii.md
│ ├── word-pattern.md
│ ├── word-search-ii.md
│ └── zigzag-iterator.md
├── 0300-0399/
│ ├── additive-number.md
│ ├── android-unlock-patterns.md
│ ├── best-time-to-buy-and-sell-stock-with-cooldown.md
│ ├── binary-tree-vertical-order-traversal.md
│ ├── bomb-enemy.md
│ ├── bulb-switcher.md
│ ├── burst-balloons.md
│ ├── coin-change.md
│ ├── combination-sum-iv.md
│ ├── count-numbers-with-unique-digits.md
│ ├── count-of-range-sum.md
│ ├── count-of-smaller-numbers-after-self.md
│ ├── counting-bits.md
│ ├── create-maximum-number.md
│ ├── data-stream-as-disjoint-intervals.md
│ ├── decode-string.md
│ ├── design-hit-counter.md
│ ├── design-phone-directory.md
│ ├── design-snake-game.md
│ ├── design-tic-tac-toe.md
│ ├── design-twitter.md
│ ├── elimination-game.md
│ ├── evaluate-division.md
│ ├── find-k-pairs-with-smallest-sums.md
│ ├── find-leaves-of-binary-tree.md
│ ├── find-the-difference.md
│ ├── first-unique-character-in-a-string.md
│ ├── flatten-nested-list-iterator.md
│ ├── generalized-abbreviation.md
│ ├── guess-number-higher-or-lower-ii.md
│ ├── guess-number-higher-or-lower.md
│ ├── house-robber-iii.md
│ ├── increasing-triplet-subsequence.md
│ ├── index.md
│ ├── insert-delete-getrandom-o1-duplicates-allowed.md
│ ├── insert-delete-getrandom-o1.md
│ ├── integer-break.md
│ ├── integer-replacement.md
│ ├── intersection-of-two-arrays-ii.md
│ ├── intersection-of-two-arrays.md
│ ├── is-subsequence.md
│ ├── kth-smallest-element-in-a-sorted-matrix.md
│ ├── largest-bst-subtree.md
│ ├── largest-divisible-subset.md
│ ├── lexicographical-numbers.md
│ ├── line-reflection.md
│ ├── linked-list-random-node.md
│ ├── logger-rate-limiter.md
│ ├── longest-absolute-file-path.md
│ ├── longest-increasing-path-in-a-matrix.md
│ ├── longest-increasing-subsequence.md
│ ├── longest-substring-with-at-least-k-repeating-characters.md
│ ├── longest-substring-with-at-most-k-distinct-characters.md
│ ├── max-sum-of-rectangle-no-larger-than-k.md
│ ├── maximum-product-of-word-lengths.md
│ ├── maximum-size-subarray-sum-equals-k.md
│ ├── mini-parser.md
│ ├── minimum-height-trees.md
│ ├── moving-average-from-data-stream.md
│ ├── nested-list-weight-sum-ii.md
│ ├── nested-list-weight-sum.md
│ ├── number-of-connected-components-in-an-undirected-graph.md
│ ├── number-of-islands-ii.md
│ ├── odd-even-linked-list.md
│ ├── palindrome-pairs.md
│ ├── patching-array.md
│ ├── perfect-rectangle.md
│ ├── plus-one-linked-list.md
│ ├── power-of-four.md
│ ├── power-of-three.md
│ ├── random-pick-index.md
│ ├── range-addition.md
│ ├── range-sum-query-2d-immutable.md
│ ├── range-sum-query-2d-mutable.md
│ ├── range-sum-query-immutable.md
│ ├── range-sum-query-mutable.md
│ ├── ransom-note.md
│ ├── rearrange-string-k-distance-apart.md
│ ├── reconstruct-itinerary.md
│ ├── remove-duplicate-letters.md
│ ├── remove-invalid-parentheses.md
│ ├── reverse-string.md
│ ├── reverse-vowels-of-a-string.md
│ ├── rotate-function.md
│ ├── russian-doll-envelopes.md
│ ├── self-crossing.md
│ ├── shortest-distance-from-all-buildings.md
│ ├── shuffle-an-array.md
│ ├── smallest-rectangle-enclosing-black-pixels.md
│ ├── sort-transformed-array.md
│ ├── sparse-matrix-multiplication.md
│ ├── sum-of-two-integers.md
│ ├── super-pow.md
│ ├── super-ugly-number.md
│ ├── top-k-frequent-elements.md
│ ├── utf-8-validation.md
│ ├── valid-perfect-square.md
│ ├── verify-preorder-serialization-of-a-binary-tree.md
│ ├── water-and-jug-problem.md
│ ├── wiggle-sort-ii.md
│ └── wiggle-subsequence.md
├── 0400-0499/
│ ├── 132-pattern.md
│ ├── 4sum-ii.md
│ ├── add-strings.md
│ ├── add-two-numbers-ii.md
│ ├── all-oone-data-structure.md
│ ├── arithmetic-slices-ii-subsequence.md
│ ├── arithmetic-slices.md
│ ├── arranging-coins.md
│ ├── assign-cookies.md
│ ├── battleships-in-a-board.md
│ ├── binary-watch.md
│ ├── can-i-win.md
│ ├── circular-array-loop.md
│ ├── concatenated-words.md
│ ├── construct-quad-tree.md
│ ├── construct-the-rectangle.md
│ ├── convert-a-number-to-hexadecimal.md
│ ├── convert-binary-search-tree-to-sorted-doubly-linked-list.md
│ ├── convex-polygon.md
│ ├── count-the-repetitions.md
│ ├── delete-node-in-a-bst.md
│ ├── diagonal-traverse.md
│ ├── encode-n-ary-tree-to-binary-tree.md
│ ├── encode-string-with-shortest-length.md
│ ├── find-all-anagrams-in-a-string.md
│ ├── find-all-duplicates-in-an-array.md
│ ├── find-all-numbers-disappeared-in-an-array.md
│ ├── find-permutation.md
│ ├── find-right-interval.md
│ ├── fizz-buzz.md
│ ├── flatten-a-multilevel-doubly-linked-list.md
│ ├── frog-jump.md
│ ├── generate-random-point-in-a-circle.md
│ ├── hamming-distance.md
│ ├── heaters.md
│ ├── implement-rand10-using-rand7.md
│ ├── index.md
│ ├── island-perimeter.md
│ ├── k-th-smallest-in-lexicographical-order.md
│ ├── largest-palindrome-product.md
│ ├── lfu-cache.md
│ ├── license-key-formatting.md
│ ├── longest-palindrome.md
│ ├── longest-repeating-character-replacement.md
│ ├── magical-string.md
│ ├── matchsticks-to-square.md
│ ├── max-consecutive-ones-ii.md
│ ├── max-consecutive-ones.md
│ ├── maximum-xor-of-two-numbers-in-an-array.md
│ ├── minimum-genetic-mutation.md
│ ├── minimum-moves-to-equal-array-elements-ii.md
│ ├── minimum-moves-to-equal-array-elements.md
│ ├── minimum-number-of-arrows-to-burst-balloons.md
│ ├── minimum-unique-word-abbreviation.md
│ ├── n-ary-tree-level-order-traversal.md
│ ├── next-greater-element-i.md
│ ├── non-decreasing-subsequences.md
│ ├── non-overlapping-intervals.md
│ ├── nth-digit.md
│ ├── number-complement.md
│ ├── number-of-boomerangs.md
│ ├── number-of-segments-in-a-string.md
│ ├── ones-and-zeroes.md
│ ├── optimal-account-balancing.md
│ ├── pacific-atlantic-water-flow.md
│ ├── partition-equal-subset-sum.md
│ ├── path-sum-iii.md
│ ├── poor-pigs.md
│ ├── predict-the-winner.md
│ ├── queue-reconstruction-by-height.md
│ ├── random-point-in-non-overlapping-rectangles.md
│ ├── reconstruct-original-digits-from-english.md
│ ├── remove-k-digits.md
│ ├── repeated-substring-pattern.md
│ ├── reverse-pairs.md
│ ├── robot-room-cleaner.md
│ ├── sentence-screen-fitting.md
│ ├── sequence-reconstruction.md
│ ├── serialize-and-deserialize-bst.md
│ ├── serialize-and-deserialize-n-ary-tree.md
│ ├── sliding-window-median.md
│ ├── smallest-good-base.md
│ ├── sort-characters-by-frequency.md
│ ├── split-array-largest-sum.md
│ ├── string-compression.md
│ ├── strong-password-checker.md
│ ├── sum-of-left-leaves.md
│ ├── target-sum.md
│ ├── teemo-attacking.md
│ ├── ternary-expression-parser.md
│ ├── the-maze-iii.md
│ ├── the-maze.md
│ ├── third-maximum-number.md
│ ├── total-hamming-distance.md
│ ├── trapping-rain-water-ii.md
│ ├── unique-substrings-in-wraparound-string.md
│ ├── valid-word-abbreviation.md
│ ├── valid-word-square.md
│ ├── validate-ip-address.md
│ ├── word-squares.md
│ └── zuma-game.md
├── 0500-0599/
│ ├── 01-matrix.md
│ ├── array-nesting.md
│ ├── array-partition.md
│ ├── base-7.md
│ ├── beautiful-arrangement.md
│ ├── binary-tree-longest-consecutive-sequence-ii.md
│ ├── binary-tree-tilt.md
│ ├── boundary-of-binary-tree.md
│ ├── brick-wall.md
│ ├── coin-change-ii.md
│ ├── complex-number-multiplication.md
│ ├── construct-binary-tree-from-string.md
│ ├── contiguous-array.md
│ ├── continuous-subarray-sum.md
│ ├── convert-bst-to-greater-tree.md
│ ├── delete-operation-for-two-strings.md
│ ├── design-in-memory-file-system.md
│ ├── detect-capital.md
│ ├── diameter-of-binary-tree.md
│ ├── distribute-candies.md
│ ├── encode-and-decode-tinyurl.md
│ ├── erect-the-fence.md
│ ├── fibonacci-number.md
│ ├── find-bottom-left-tree-value.md
│ ├── find-largest-value-in-each-tree-row.md
│ ├── find-mode-in-binary-search-tree.md
│ ├── find-the-closest-palindrome.md
│ ├── fraction-addition-and-subtraction.md
│ ├── freedom-trail.md
│ ├── index.md
│ ├── inorder-successor-in-bst-ii.md
│ ├── ipo.md
│ ├── k-diff-pairs-in-an-array.md
│ ├── keyboard-row.md
│ ├── kill-process.md
│ ├── logical-or-of-two-binary-grids-represented-as-quad-trees.md
│ ├── lonely-pixel-i.md
│ ├── lonely-pixel-ii.md
│ ├── longest-harmonious-subsequence.md
│ ├── longest-line-of-consecutive-one-in-matrix.md
│ ├── longest-palindromic-subsequence.md
│ ├── longest-uncommon-subsequence-i.md
│ ├── longest-uncommon-subsequence-ii.md
│ ├── longest-word-in-dictionary-through-deleting.md
│ ├── maximum-depth-of-n-ary-tree.md
│ ├── maximum-vacation-days.md
│ ├── minesweeper.md
│ ├── minimum-absolute-difference-in-bst.md
│ ├── minimum-index-sum-of-two-lists.md
│ ├── minimum-time-difference.md
│ ├── most-frequent-subtree-sum.md
│ ├── n-ary-tree-postorder-traversal.md
│ ├── n-ary-tree-preorder-traversal.md
│ ├── next-greater-element-ii.md
│ ├── next-greater-element-iii.md
│ ├── number-of-provinces.md
│ ├── optimal-division.md
│ ├── out-of-boundary-paths.md
│ ├── output-contest-matches.md
│ ├── perfect-number.md
│ ├── permutation-in-string.md
│ ├── random-flip-matrix.md
│ ├── random-pick-with-weight.md
│ ├── range-addition-ii.md
│ ├── relative-ranks.md
│ ├── remove-boxes.md
│ ├── reshape-the-matrix.md
│ ├── reverse-string-ii.md
│ ├── reverse-words-in-a-string-iii.md
│ ├── shortest-unsorted-continuous-subarray.md
│ ├── single-element-in-a-sorted-array.md
│ ├── split-array-with-equal-sum.md
│ ├── split-concatenated-strings.md
│ ├── squirrel-simulation.md
│ ├── student-attendance-record-i.md
│ ├── student-attendance-record-ii.md
│ ├── subarray-sum-equals-k.md
│ ├── subtree-of-another-tree.md
│ ├── super-washing-machines.md
│ ├── tag-validator.md
│ ├── the-maze-ii.md
│ ├── valid-square.md
│ └── word-abbreviation.md
├── 0600-0699/
│ ├── 2-keys-keyboard.md
│ ├── 24-game.md
│ ├── 4-keys-keyboard.md
│ ├── add-bold-tag-in-string.md
│ ├── add-one-row-to-tree.md
│ ├── average-of-levels-in-binary-tree.md
│ ├── baseball-game.md
│ ├── beautiful-arrangement-ii.md
│ ├── binary-number-with-alternating-bits.md
│ ├── bulb-switcher-ii.md
│ ├── can-place-flowers.md
│ ├── coin-path.md
│ ├── construct-string-from-binary-tree.md
│ ├── count-binary-substrings.md
│ ├── course-schedule-iii.md
│ ├── cut-off-trees-for-golf-event.md
│ ├── decode-ways-ii.md
│ ├── degree-of-an-array.md
│ ├── design-circular-deque.md
│ ├── design-circular-queue.md
│ ├── design-compressed-string-iterator.md
│ ├── design-excel-sum-formula.md
│ ├── design-log-storage-system.md
│ ├── design-search-autocomplete-system.md
│ ├── dota2-senate.md
│ ├── employee-importance.md
│ ├── equal-tree-partition.md
│ ├── exclusive-time-of-functions.md
│ ├── falling-squares.md
│ ├── find-duplicate-file-in-system.md
│ ├── find-duplicate-subtrees.md
│ ├── find-k-closest-elements.md
│ ├── find-the-derangement-of-an-array.md
│ ├── image-smoother.md
│ ├── implement-magic-dictionary.md
│ ├── index.md
│ ├── k-empty-slots.md
│ ├── k-inverse-pairs-array.md
│ ├── knight-probability-in-chessboard.md
│ ├── longest-continuous-increasing-subsequence.md
│ ├── longest-univalue-path.md
│ ├── map-sum-pairs.md
│ ├── max-area-of-island.md
│ ├── maximum-average-subarray-i.md
│ ├── maximum-average-subarray-ii.md
│ ├── maximum-binary-tree.md
│ ├── maximum-distance-in-arrays.md
│ ├── maximum-length-of-pair-chain.md
│ ├── maximum-product-of-three-numbers.md
│ ├── maximum-sum-of-3-non-overlapping-subarrays.md
│ ├── maximum-swap.md
│ ├── maximum-width-of-binary-tree.md
│ ├── merge-two-binary-trees.md
│ ├── minimum-factorization.md
│ ├── next-closest-time.md
│ ├── non-decreasing-array.md
│ ├── non-negative-integers-without-consecutive-ones.md
│ ├── number-of-distinct-islands.md
│ ├── number-of-longest-increasing-subsequence.md
│ ├── palindromic-substrings.md
│ ├── partition-to-k-equal-sum-subsets.md
│ ├── path-sum-iv.md
│ ├── print-binary-tree.md
│ ├── redundant-connection-ii.md
│ ├── redundant-connection.md
│ ├── remove-9.md
│ ├── repeated-string-match.md
│ ├── replace-words.md
│ ├── robot-return-to-origin.md
│ ├── second-minimum-node-in-a-binary-tree copy.md
│ ├── second-minimum-node-in-a-binary-tree.md
│ ├── set-mismatch.md
│ ├── shopping-offers.md
│ ├── smallest-range-covering-elements-from-k-lists.md
│ ├── solve-the-equation.md
│ ├── split-array-into-consecutive-subsequences.md
│ ├── stickers-to-spell-word.md
│ ├── strange-printer.md
│ ├── sum-of-square-numbers.md
│ ├── task-scheduler.md
│ ├── top-k-frequent-words copy.md
│ ├── top-k-frequent-words.md
│ ├── trim-a-binary-search-tree.md
│ ├── two-sum-iv-input-is-a-bst.md
│ ├── valid-palindrome-ii.md
│ ├── valid-parenthesis-string.md
│ └── valid-triangle-number.md
├── 0700-0799/
│ ├── 1-bit-and-2-bit-characters.md
│ ├── accounts-merge.md
│ ├── all-paths-from-source-to-target.md
│ ├── asteroid-collision.md
│ ├── basic-calculator-iv.md
│ ├── best-time-to-buy-and-sell-stock-with-transaction-fee.md
│ ├── binary-search.md
│ ├── bold-words-in-string.md
│ ├── champagne-tower.md
│ ├── cheapest-flights-within-k-stops.md
│ ├── cherry-pickup.md
│ ├── contain-virus.md
│ ├── count-different-palindromic-subsequences.md
│ ├── couples-holding-hands.md
│ ├── cracking-the-safe.md
│ ├── custom-sort-string.md
│ ├── daily-temperatures.md
│ ├── delete-and-earn.md
│ ├── design-hashmap.md
│ ├── design-hashset.md
│ ├── design-linked-list.md
│ ├── domino-and-tromino-tiling.md
│ ├── escape-the-ghosts.md
│ ├── find-k-th-smallest-pair-distance.md
│ ├── find-pivot-index.md
│ ├── find-smallest-letter-greater-than-target.md
│ ├── flood-fill.md
│ ├── global-and-local-inversions.md
│ ├── index.md
│ ├── insert-into-a-binary-search-tree.md
│ ├── insert-into-a-sorted-circular-linked-list.md
│ ├── is-graph-bipartite.md
│ ├── jewels-and-stones.md
│ ├── k-th-smallest-prime-fraction.md
│ ├── k-th-symbol-in-grammar.md
│ ├── kth-largest-element-in-a-stream.md
│ ├── largest-number-at-least-twice-of-others.md
│ ├── largest-plus-sign.md
│ ├── letter-case-permutation.md
│ ├── longest-word-in-dictionary.md
│ ├── max-chunks-to-make-sorted-ii.md
│ ├── max-chunks-to-make-sorted.md
│ ├── maximum-length-of-repeated-subarray.md
│ ├── min-cost-climbing-stairs.md
│ ├── minimum-ascii-delete-sum-for-two-strings.md
│ ├── minimum-distance-between-bst-nodes.md
│ ├── minimum-window-subsequence.md
│ ├── monotone-increasing-digits.md
│ ├── my-calendar-i.md
│ ├── my-calendar-ii.md
│ ├── my-calendar-iii.md
│ ├── network-delay-time.md
│ ├── number-of-atoms.md
│ ├── number-of-matching-subsequences.md
│ ├── number-of-subarrays-with-bounded-maximum.md
│ ├── open-the-lock.md
│ ├── parse-lisp-expression.md
│ ├── partition-labels.md
│ ├── prefix-and-suffix-search.md
│ ├── preimage-size-of-factorial-zeroes-function.md
│ ├── prime-number-of-set-bits-in-binary-representation.md
│ ├── pyramid-transition-matrix.md
│ ├── rabbits-in-forest.md
│ ├── random-pick-with-blacklist.md
│ ├── range-module.md
│ ├── reach-a-number.md
│ ├── reaching-points.md
│ ├── remove-comments.md
│ ├── reorganize-string.md
│ ├── rotate-string.md
│ ├── rotated-digits.md
│ ├── search-in-a-binary-search-tree.md
│ ├── search-in-a-sorted-array-of-unknown-size.md
│ ├── self-dividing-numbers.md
│ ├── set-intersection-size-at-least-two.md
│ ├── shortest-completing-word.md
│ ├── sliding-puzzle.md
│ ├── smallest-rotation-with-highest-score.md
│ ├── split-linked-list-in-parts.md
│ ├── subarray-product-less-than-k.md
│ ├── swap-adjacent-in-lr-string.md
│ ├── swim-in-rising-water.md
│ ├── to-lower-case.md
│ ├── toeplitz-matrix.md
│ ├── transform-to-chessboard.md
│ └── valid-tic-tac-toe-state.md
├── 0800-0899/
│ ├── advantage-shuffle.md
│ ├── all-nodes-distance-k-in-binary-tree.md
│ ├── all-possible-full-binary-trees.md
│ ├── ambiguous-coordinates.md
│ ├── backspace-string-compare.md
│ ├── binary-gap.md
│ ├── binary-tree-pruning.md
│ ├── binary-trees-with-factors.md
│ ├── bitwise-ors-of-subarrays.md
│ ├── boats-to-save-people.md
│ ├── bricks-falling-when-hit.md
│ ├── buddy-strings.md
│ ├── bus-routes.md
│ ├── car-fleet.md
│ ├── card-flipping-game.md
│ ├── chalkboard-xor-game.md
│ ├── consecutive-numbers-sum.md
│ ├── construct-binary-tree-from-preorder-and-postorder-traversal.md
│ ├── count-unique-characters-of-all-substrings-of-a-given-string.md
│ ├── decoded-string-at-index.md
│ ├── exam-room.md
│ ├── expressive-words.md
│ ├── fair-candy-swap.md
│ ├── find-and-replace-in-string.md
│ ├── find-and-replace-pattern.md
│ ├── find-eventual-safe-states.md
│ ├── flipping-an-image.md
│ ├── friends-of-appropriate-ages.md
│ ├── goat-latin.md
│ ├── groups-of-special-equivalent-strings.md
│ ├── guess-the-word.md
│ ├── hand-of-straights.md
│ ├── image-overlap.md
│ ├── increasing-order-search-tree.md
│ ├── index.md
│ ├── k-similar-strings.md
│ ├── keys-and-rooms.md
│ ├── koko-eating-bananas.md
│ ├── largest-sum-of-averages.md
│ ├── largest-triangle-area.md
│ ├── leaf-similar-trees.md
│ ├── lemonade-change.md
│ ├── length-of-longest-fibonacci-subsequence.md
│ ├── linked-list-components.md
│ ├── longest-mountain-in-array.md
│ ├── loud-and-rich.md
│ ├── magic-squares-in-grid.md
│ ├── making-a-large-island.md
│ ├── masking-personal-information.md
│ ├── max-increase-to-keep-city-skyline.md
│ ├── maximize-distance-to-closest-person.md
│ ├── maximum-frequency-stack.md
│ ├── middle-of-the-linked-list.md
│ ├── minimum-cost-to-hire-k-workers.md
│ ├── minimum-number-of-refueling-stops.md
│ ├── minimum-swaps-to-make-sequences-increasing.md
│ ├── mirror-reflection.md
│ ├── monotonic-array.md
│ ├── most-common-word.md
│ ├── most-profit-assigning-work.md
│ ├── new-21-game.md
│ ├── nth-magical-number.md
│ ├── number-of-lines-to-write-string.md
│ ├── orderly-queue.md
│ ├── peak-index-in-a-mountain-array.md
│ ├── positions-of-large-groups.md
│ ├── possible-bipartition.md
│ ├── prime-palindrome.md
│ ├── profitable-schemes.md
│ ├── projection-area-of-3d-shapes.md
│ ├── push-dominoes.md
│ ├── race-car.md
│ ├── reachable-nodes-in-subdivided-graph.md
│ ├── rectangle-area-ii.md
│ ├── rectangle-overlap.md
│ ├── reordered-power-of-2.md
│ ├── score-after-flipping-matrix.md
│ ├── score-of-parentheses.md
│ ├── shifting-letters copy.md
│ ├── shifting-letters.md
│ ├── short-encoding-of-words.md
│ ├── shortest-distance-to-a-character.md
│ ├── shortest-path-to-get-all-keys.md
│ ├── shortest-path-visiting-all-nodes.md
│ ├── shortest-subarray-with-sum-at-least-k.md
│ ├── similar-rgb-color.md
│ ├── similar-string-groups.md
│ ├── smallest-subtree-with-all-the-deepest-nodes.md
│ ├── soup-servings.md
│ ├── spiral-matrix-iii.md
│ ├── split-array-into-fibonacci-sequence.md
│ ├── split-array-with-same-average.md
│ ├── stone-game.md
│ ├── subdomain-visit-count.md
│ ├── sum-of-distances-in-tree.md
│ ├── sum-of-subsequence-widths.md
│ ├── super-egg-drop.md
│ ├── surface-area-of-3d-shapes.md
│ ├── transpose-matrix.md
│ ├── uncommon-words-from-two-sentences.md
│ ├── unique-morse-code-words.md
│ └── walking-robot-simulation.md
├── 0900-0999/
│ ├── 3sum-with-multiplicity.md
│ ├── add-to-array-form-of-integer.md
│ ├── array-of-doubled-pairs.md
│ ├── available-captures-for-rook.md
│ ├── bag-of-tokens.md
│ ├── beautiful-array.md
│ ├── binary-subarrays-with-sum.md
│ ├── binary-tree-cameras.md
│ ├── broken-calculator.md
│ ├── cat-and-mouse.md
│ ├── check-completeness-of-a-binary-tree.md
│ ├── complete-binary-tree-inserter.md
│ ├── cousins-in-binary-tree.md
│ ├── delete-columns-to-make-sorted-ii.md
│ ├── delete-columns-to-make-sorted-iii.md
│ ├── delete-columns-to-make-sorted.md
│ ├── di-string-match.md
│ ├── distinct-subsequences-ii.md
│ ├── distribute-coins-in-binary-tree.md
│ ├── equal-rational-numbers.md
│ ├── find-the-shortest-superstring.md
│ ├── find-the-town-judge.md
│ ├── flip-binary-tree-to-match-preorder-traversal.md
│ ├── flip-equivalent-binary-trees.md
│ ├── flip-string-to-monotone-increasing.md
│ ├── fruit-into-baskets.md
│ ├── index.md
│ ├── interval-list-intersections.md
│ ├── k-closest-points-to-origin.md
│ ├── knight-dialer.md
│ ├── largest-component-size-by-common-factor.md
│ ├── largest-perimeter-triangle.md
│ ├── largest-time-for-given-digits.md
│ ├── least-operators-to-express-number.md
│ ├── long-pressed-name.md
│ ├── longest-turbulent-subarray.md
│ ├── maximum-binary-tree-ii.md
│ ├── maximum-sum-circular-subarray.md
│ ├── maximum-width-ramp.md
│ ├── minimize-malware-spread-ii.md
│ ├── minimize-malware-spread.md
│ ├── minimum-add-to-make-parentheses-valid.md
│ ├── minimum-area-rectangle-ii.md
│ ├── minimum-area-rectangle.md
│ ├── minimum-cost-for-tickets.md
│ ├── minimum-falling-path-sum.md
│ ├── minimum-increment-to-make-array-unique.md
│ ├── minimum-number-of-k-consecutive-bit-flips.md
│ ├── most-stones-removed-with-same-row-or-column.md
│ ├── n-repeated-element-in-size-2n-array.md
│ ├── number-of-music-playlists.md
│ ├── number-of-recent-calls.md
│ ├── number-of-squareful-arrays.md
│ ├── numbers-at-most-n-given-digit-set.md
│ ├── numbers-with-same-consecutive-differences.md
│ ├── odd-even-jump.md
│ ├── online-election.md
│ ├── online-stock-span.md
│ ├── pancake-sorting.md
│ ├── partition-array-into-disjoint-intervals.md
│ ├── powerful-integers.md
│ ├── prison-cells-after-n-days.md
│ ├── range-sum-of-bst.md
│ ├── regions-cut-by-slashes.md
│ ├── reorder-data-in-log-files.md
│ ├── reveal-cards-in-increasing-order.md
│ ├── reverse-only-letters.md
│ ├── rle-iterator.md
│ ├── rotting-oranges.md
│ ├── satisfiability-of-equality-equations.md
│ ├── shortest-bridge.md
│ ├── smallest-range-i.md
│ ├── smallest-range-ii.md
│ ├── smallest-string-starting-from-leaf.md
│ ├── snakes-and-ladders.md
│ ├── sort-an-array.md
│ ├── sort-array-by-parity-ii.md
│ ├── sort-array-by-parity.md
│ ├── squares-of-a-sorted-array.md
│ ├── stamping-the-sequence.md
│ ├── string-without-aaa-or-bbb.md
│ ├── subarray-sums-divisible-by-k.md
│ ├── subarrays-with-k-different-integers.md
│ ├── sum-of-even-numbers-after-queries.md
│ ├── sum-of-subarray-minimums.md
│ ├── super-palindromes.md
│ ├── tallest-billboard.md
│ ├── three-equal-parts.md
│ ├── time-based-key-value-store.md
│ ├── triples-with-bitwise-and-equal-to-zero.md
│ ├── unique-email-addresses.md
│ ├── unique-paths-iii.md
│ ├── univalued-binary-tree.md
│ ├── valid-mountain-array.md
│ ├── valid-permutations-for-di-sequence.md
│ ├── validate-stack-sequences.md
│ ├── verifying-an-alien-dictionary.md
│ ├── vertical-order-traversal-of-a-binary-tree.md
│ ├── vowel-spellchecker.md
│ ├── word-subsets.md
│ └── x-of-a-kind-in-a-deck-of-cards.md
├── 1000-1099/
│ ├── best-sightseeing-pair.md
│ ├── binary-search-tree-to-greater-sum-tree.md
│ ├── camelcase-matching.md
│ ├── capacity-to-ship-packages-within-d-days.md
│ ├── coloring-a-border.md
│ ├── complement-of-base-10-integer.md
│ ├── construct-binary-search-tree-from-preorder-traversal.md
│ ├── divisor-game.md
│ ├── duplicate-zeros.md
│ ├── find-common-characters.md
│ ├── find-in-mountain-array.md
│ ├── grumpy-bookstore-owner.md
│ ├── height-checker.md
│ ├── index-pairs-of-a-string.md
│ ├── index.md
│ ├── last-stone-weight-ii.md
│ ├── letter-tile-possibilities.md
│ ├── max-consecutive-ones-iii.md
│ ├── maximize-sum-of-array-after-k-negations.md
│ ├── minimum-cost-to-merge-stones.md
│ ├── minimum-score-triangulation-of-polygon.md
│ ├── number-of-enclaves.md
│ ├── numbers-with-repeated-digits.md
│ ├── recover-a-tree-from-preorder-traversal.md
│ ├── remove-all-adjacent-duplicates-in-string.md
│ ├── remove-outermost-parentheses.md
│ ├── robot-bounded-in-circle.md
│ ├── shortest-path-in-binary-matrix.md
│ ├── smallest-subsequence-of-distinct-characters.md
│ ├── stream-of-characters.md
│ ├── two-city-scheduling.md
│ ├── two-sum-less-than-k.md
│ ├── uncrossed-lines.md
│ └── valid-boomerang.md
├── 1100-1199/
│ ├── corporate-flight-bookings.md
│ ├── defanging-an-ip-address.md
│ ├── delete-nodes-and-return-forest.md
│ ├── diet-plan-performance.md
│ ├── distance-between-bus-stops.md
│ ├── distribute-candies-to-people.md
│ ├── find-k-length-substrings-with-no-repeated-characters.md
│ ├── index.md
│ ├── longest-common-subsequence.md
│ ├── maximum-level-sum-of-a-binary-tree.md
│ ├── minimum-swaps-to-group-all-1s-together.md
│ ├── n-th-tribonacci-number.md
│ ├── number-of-dice-rolls-with-target-sum.md
│ ├── parallel-courses.md
│ └── relative-sort-array.md
├── 1200-1299/
│ ├── airplane-seat-assignment-probability.md
│ ├── check-if-it-is-a-straight-line.md
│ ├── count-vowels-permutation.md
│ ├── divide-array-in-sets-of-k-consecutive-numbers.md
│ ├── find-elements-in-a-contaminated-binary-tree.md
│ ├── get-equal-substrings-within-budget.md
│ ├── index.md
│ ├── meeting-scheduler.md
│ ├── minimum-cost-to-move-chips-to-the-same-position.md
│ ├── minimum-swaps-to-make-strings-equal.md
│ ├── minimum-time-visiting-all-points.md
│ ├── number-of-closed-islands.md
│ ├── reconstruct-a-2-row-binary-matrix.md
│ ├── search-suggestions-system.md
│ ├── smallest-string-with-swaps.md
│ ├── subtract-the-product-and-sum-of-digits-of-an-integer.md
│ └── tree-diameter.md
├── 1300-1399/
│ ├── all-elements-in-two-binary-search-trees.md
│ ├── angle-between-hands-of-a-clock.md
│ ├── closest-divisors.md
│ ├── convert-integer-to-the-sum-of-two-no-zero-integers.md
│ ├── decompress-run-length-encoded-list.md
│ ├── design-a-stack-with-increment-operation.md
│ ├── index.md
│ ├── maximum-students-taking-exam.md
│ ├── minimum-number-of-steps-to-make-two-strings-anagram.md
│ ├── number-of-operations-to-make-network-connected.md
│ ├── number-of-sub-arrays-of-size-k-and-average-greater-than-or-equal-to-threshold.md
│ ├── number-of-substrings-containing-all-three-characters.md
│ ├── print-words-vertically.md
│ ├── reduce-array-size-to-the-half.md
│ ├── sum-of-mutated-array-closest-to-target.md
│ └── xor-queries-of-a-subarray.md
├── 1400-1499/
│ ├── average-salary-excluding-the-minimum-and-maximum-salary.md
│ ├── consecutive-characters.md
│ ├── construct-k-palindrome-strings.md
│ ├── form-largest-integer-with-digits-that-add-up-to-target.md
│ ├── index.md
│ ├── longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit.md
│ ├── longest-subarray-of-1s-after-deleting-one-element.md
│ ├── maximum-number-of-vowels-in-a-substring-of-given-length.md
│ ├── maximum-points-you-can-obtain-from-cards.md
│ ├── maximum-score-after-splitting-a-string.md
│ ├── minimum-number-of-days-to-make-m-bouquets.md
│ ├── number-of-students-doing-homework-at-a-given-time.md
│ ├── path-crossing.md
│ ├── rearrange-words-in-a-sentence.md
│ ├── running-sum-of-1d-array.md
│ ├── simplified-fractions.md
│ ├── string-matching-in-an-array.md
│ ├── subrectangle-queries.md
│ └── xor-operation-in-an-array.md
├── 1500-1599/
│ ├── can-make-arithmetic-progression-from-sequence.md
│ ├── count-good-triplets.md
│ ├── count-odd-numbers-in-an-interval-range.md
│ ├── index.md
│ ├── maximum-length-of-subarray-with-positive-product.md
│ ├── maximum-number-of-coins-you-can-get.md
│ ├── min-cost-to-connect-all-points.md
│ ├── minimum-cost-to-connect-two-groups-of-points.md
│ ├── minimum-cost-to-cut-a-stick.md
│ ├── minimum-operations-to-make-array-equal.md
│ ├── reformat-date.md
│ ├── special-positions-in-a-binary-matrix.md
│ ├── split-a-string-into-the-max-number-of-unique-substrings.md
│ └── thousand-separator.md
├── 1600-1699/
│ ├── count-sorted-vowel-strings.md
│ ├── count-subtrees-with-max-distance-between-cities.md
│ ├── design-parking-system.md
│ ├── determine-if-two-strings-are-close.md
│ ├── find-valid-matrix-given-row-and-column-sums.md
│ ├── get-maximum-in-generated-array.md
│ ├── index.md
│ ├── maximum-erasure-value.md
│ ├── maximum-nesting-depth-of-the-parentheses.md
│ ├── minimum-deletions-to-make-character-frequencies-unique.md
│ ├── minimum-operations-to-reduce-x-to-zero.md
│ ├── number-of-distinct-substrings-in-a-string.md
│ ├── path-with-minimum-effort.md
│ └── richest-customer-wealth.md
├── 1700-1799/
│ ├── calculate-money-in-leetcode-bank.md
│ ├── check-if-one-string-swap-can-make-strings-equal.md
│ ├── decode-xored-array.md
│ ├── find-center-of-star-graph.md
│ ├── find-nearest-point-that-has-the-same-x-or-y-coordinate.md
│ ├── index.md
│ ├── latest-time-by-replacing-hidden-digits.md
│ ├── longest-nice-substring.md
│ ├── maximum-absolute-sum-of-any-subarray.md
│ ├── maximum-number-of-balls-in-a-box.md
│ ├── maximum-units-on-a-truck.md
│ └── tuple-with-same-product.md
├── 1800-1899/
│ ├── check-if-all-the-integers-in-a-range-are-covered.md
│ ├── index.md
│ ├── longest-word-with-all-prefixes.md
│ ├── maximum-ice-cream-bars.md
│ ├── minimize-maximum-pair-sum-in-array.md
│ ├── minimum-operations-to-make-the-array-increasing.md
│ ├── minimum-xor-sum-of-two-arrays.md
│ ├── redistribute-characters-to-make-all-strings-equal.md
│ ├── replace-all-digits-with-characters.md
│ ├── sign-of-the-product-of-an-array.md
│ ├── sorting-the-sentence.md
│ └── substrings-of-size-three-with-distinct-characters.md
├── 1900-1999/
│ ├── add-minimum-number-of-rungs.md
│ ├── check-if-all-characters-have-equal-number-of-occurrences.md
│ ├── concatenation-of-array.md
│ ├── count-square-sum-triples.md
│ ├── eliminate-maximum-number-of-monsters.md
│ ├── find-the-middle-index-in-array.md
│ ├── index.md
│ ├── largest-odd-number-in-string.md
│ ├── maximum-compatibility-score-sum.md
│ ├── minimum-difference-between-highest-and-lowest-of-k-scores.md
│ ├── minimum-number-of-work-sessions-to-finish-the-tasks.md
│ ├── the-number-of-good-subsets.md
│ └── unique-length-3-palindromic-subsequences.md
├── 2000-2099/
│ ├── final-value-of-variable-after-performing-operations.md
│ ├── index.md
│ ├── number-of-pairs-of-strings-with-concatenation-equal-to-target.md
│ └── parallel-courses-iii.md
├── 2100-2199/
│ ├── find-substring-with-given-hash-value.md
│ ├── index.md
│ └── maximum-and-sum-of-array.md
├── 2200-2299/
│ ├── add-two-integers.md
│ ├── count-integers-in-intervals.md
│ ├── count-lattice-points-inside-a-circle.md
│ ├── index.md
│ └── longest-path-with-different-adjacent-characters.md
├── 2300-2399/
│ ├── count-special-integers.md
│ └── index.md
├── 2400-2499/
│ ├── index.md
│ └── number-of-common-factors.md
├── 2500-2599/
│ ├── difference-between-maximum-and-minimum-price-sum.md
│ ├── index.md
│ └── number-of-ways-to-earn-points.md
├── 2700-2799/
│ ├── count-of-integers.md
│ └── index.md
├── LCR/
│ ├── 0H97ZC.md
│ ├── 0on3uN.md
│ ├── 0ynMMM.md
│ ├── 1fGaJU.md
│ ├── 21dk04.md
│ ├── 2AoeFn.md
│ ├── 2VG8Kg.md
│ ├── 2bCMpM.md
│ ├── 3Etpl5.md
│ ├── 3u1WK4.md
│ ├── 4sjJUc.md
│ ├── 4ueAj6.md
│ ├── 569nqc.md
│ ├── 6eUYwP.md
│ ├── 7LpjUW.md
│ ├── 7WHec2.md
│ ├── 7WqeDu.md
│ ├── 7p8L0Z.md
│ ├── 8Zf90G.md
│ ├── A1NYOS.md
│ ├── D0F0SV.md
│ ├── FortPu.md
│ ├── Gu0c2T.md
│ ├── GzCJIP.md
│ ├── H8086Q.md
│ ├── IDBivT.md
│ ├── JFETK5.md
│ ├── LGjMqU.md
│ ├── LwUNpT.md
│ ├── M1oyTv.md
│ ├── M99OJA.md
│ ├── N6YdxV.md
│ ├── NUPfPr.md
│ ├── NYBBNL.md
│ ├── NaqhDT.md
│ ├── O4NDxx.md
│ ├── OrIXps.md
│ ├── P5rCT8.md
│ ├── PzWKhm.md
│ ├── Q91FMA.md
│ ├── QA2IGt.md
│ ├── QC3q1f.md
│ ├── QTMn0o.md
│ ├── Qv1Da2.md
│ ├── RQku0D.md
│ ├── SLwz0R.md
│ ├── SsGoHC.md
│ ├── TVdhkn.md
│ ├── UHnkqh.md
│ ├── US1pGT.md
│ ├── UhWRSj.md
│ ├── VvJkup.md
│ ├── WGki4K.md
│ ├── WNC0Lk.md
│ ├── WhsWhI.md
│ ├── XagZNi.md
│ ├── XltzEq.md
│ ├── YaVDxD.md
│ ├── Ygoe9J.md
│ ├── ZL6zAn.md
│ ├── ZVAVXX.md
│ ├── a7VOhD.md
│ ├── aMhZSa.md
│ ├── aseY1I.md
│ ├── bLyHh0.md
│ ├── ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof.md
│ ├── ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof.md
│ ├── ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof.md
│ ├── bao-han-minhan-shu-de-zhan-lcof.md
│ ├── bu-ke-pai-zhong-de-shun-zi-lcof.md
│ ├── bu-yong-jia-jian-cheng-chu-zuo-jia-fa-lcof.md
│ ├── c32eOV.md
│ ├── chou-shu-lcof.md
│ ├── cong-shang-dao-xia-da-yin-er-cha-shu-ii-lcof.md
│ ├── cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof.md
│ ├── cong-shang-dao-xia-da-yin-er-cha-shu-lcof.md
│ ├── cong-wei-dao-tou-da-yin-lian-biao-lcof.md
│ ├── dKk3P7.md
│ ├── da-yin-cong-1dao-zui-da-de-nwei-shu-lcof.md
│ ├── di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof.md
│ ├── diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof.md
│ ├── dui-cheng-de-er-cha-shu-lcof.md
│ ├── dui-lie-de-zui-da-zhi-lcof.md
│ ├── er-cha-shu-de-jing-xiang-lcof.md
│ ├── er-cha-shu-de-shen-du-lcof.md
│ ├── er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof.md
│ ├── er-cha-shu-zhong-he-wei-mou-yi-zhi-de-lu-jing-lcof.md
│ ├── er-cha-sou-suo-shu-de-di-kda-jie-dian-lcof.md
│ ├── er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof.md
│ ├── er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof.md
│ ├── er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof.md
│ ├── er-jin-zhi-zhong-1de-ge-shu-lcof.md
│ ├── er-wei-shu-zu-zhong-de-cha-zhao-lcof.md
│ ├── fan-zhuan-dan-ci-shun-xu-lcof.md
│ ├── fan-zhuan-lian-biao-lcof.md
│ ├── fei-bo-na-qi-shu-lie-lcof.md
│ ├── fpTFWP.md
│ ├── fu-za-lian-biao-de-fu-zhi-lcof.md
│ ├── g5c51o.md
│ ├── gaM7Ch.md
│ ├── gou-jian-cheng-ji-shu-zu-lcof.md
│ ├── gu-piao-de-zui-da-li-run-lcof.md
│ ├── h54YBf.md
│ ├── hPov7L.md
│ ├── he-bing-liang-ge-pai-xu-de-lian-biao-lcof.md
│ ├── he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof.md
│ ├── he-wei-sde-liang-ge-shu-zi-lcof.md
│ ├── hua-dong-chuang-kou-de-zui-da-zhi-lcof.md
│ ├── iIQa4I.md
│ ├── iSwD2y.md
│ ├── index.md
│ ├── jBjn9C.md
│ ├── jC7MId.md
│ ├── jJ0w9p.md
│ ├── ji-qi-ren-de-yun-dong-fan-wei-lcof.md
│ ├── jian-sheng-zi-lcof.md
│ ├── ju-zhen-zhong-de-lu-jing-lcof.md
│ ├── kLl5u1.md
│ ├── kTOapQ.md
│ ├── lMSNwu.md
│ ├── li-wu-de-zui-da-jie-zhi-lcof.md
│ ├── lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof.md
│ ├── lian-xu-zi-shu-zu-de-zui-da-he-lcof.md
│ ├── liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof.md
│ ├── lwyVBB.md
│ ├── ms70jA.md
│ ├── nZZqjQ.md
│ ├── om3reC.md
│ ├── opLdQZ.md
│ ├── pOCWxh.md
│ ├── ping-heng-er-cha-shu-lcof.md
│ ├── qIsx9U.md
│ ├── qJnOS7.md
│ ├── qing-wa-tiao-tai-jie-wen-ti-lcof.md
│ ├── qiu-12n-lcof.md
│ ├── que-shi-de-shu-zi-lcof.md
│ ├── sfvd7V.md
│ ├── shan-chu-lian-biao-de-jie-dian-lcof.md
│ ├── shu-de-zi-jie-gou-lcof.md
│ ├── shu-ju-liu-zhong-de-zhong-wei-shu-lcof.md
│ ├── shu-zhi-de-zheng-shu-ci-fang-lcof.md
│ ├── shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof.md
│ ├── shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof.md
│ ├── shu-zu-zhong-de-ni-xu-dui-lcof.md
│ ├── shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof.md
│ ├── shu-zu-zhong-zhong-fu-de-shu-zi-lcof.md
│ ├── shun-shi-zhen-da-yin-ju-zhen-lcof.md
│ ├── ti-huan-kong-ge-lcof.md
│ ├── tvdfij.md
│ ├── uUsW3B.md
│ ├── vEAB3K.md
│ ├── vlzXQL.md
│ ├── vvXgSW.md
│ ├── w3tCBm.md
│ ├── w6cpku.md
│ ├── wtcaE1.md
│ ├── xoh6Oh.md
│ ├── xu-lie-hua-er-cha-shu-lcof.md
│ ├── xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof.md
│ ├── xx4gT2.md
│ ├── yong-liang-ge-zhan-shi-xian-dui-lie-lcof.md
│ ├── yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof.md
│ ├── z1R5dt.md
│ ├── zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof.md
│ ├── zhan-de-ya-ru-dan-chu-xu-lie-lcof.md
│ ├── zhong-jian-er-cha-shu-lcof.md
│ ├── zi-fu-chuan-de-pai-lie-lcof.md
│ ├── zlDJc7.md
│ ├── zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof.md
│ ├── zui-xiao-de-kge-shu-lcof.md
│ └── zuo-xuan-zhuan-zi-fu-chuan-lcof.md
├── index.md
└── interviews/
├── bracket-lcci.md
├── calculator-lcci.md
├── color-fill-lcci.md
├── eight-queens-lcci.md
├── factorial-zeros-lcci.md
├── first-common-ancestor-lcci.md
├── group-anagrams-lcci.md
├── implement-queue-using-stacks-lcci.md
├── index.md
├── intersection-of-two-linked-lists-lcci.md
├── kth-node-from-end-of-list-lcci.md
├── legal-binary-search-tree-lcci.md
├── linked-list-cycle-lcci.md
├── longest-word-lcci.md
├── min-stack-lcci.md
├── minimum-height-tree-lcci.md
├── multi-search-lcci.md
├── number-of-2s-in-range-lcci.md
├── palindrome-linked-list-lcci.md
├── paths-with-sum-lcci.md
├── permutation-i-lcci.md
├── permutation-ii-lcci.md
├── power-set-lcci.md
├── rotate-matrix-lcci.md
├── smallest-k-lcci.md
├── sorted-matrix-search-lcci.md
├── sorted-merge-lcci.md
├── successor-lcci.md
├── sum-lists-lcci.md
├── words-frequency-lcci.md
└── zero-matrix-lcci.md
SYMBOL INDEX (429 symbols across 68 files)
FILE: codes/python/01_array/array_maxheap.py
class MaxHeap (line 1) | class MaxHeap:
method __init__ (line 2) | def __init__(self):
method peek (line 5) | def peek(self) -> int:
method push (line 12) | def push(self, val: int):
method __shift_up (line 20) | def __shift_up(self, i: int):
method pop (line 25) | def pop(self) -> int:
method __shift_down (line 43) | def __shift_down(self, i: int, n: int):
class Solution (line 69) | class Solution:
method maxHeapOperations (line 70) | def maxHeapOperations(self):
FILE: codes/python/01_array/array_sort_bubble_sort.py
class Solution (line 1) | class Solution:
method bubbleSort (line 2) | def bubbleSort(self, nums: [int]) -> [int]:
method sortArray (line 17) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_bucket_sort.py
class Solution (line 1) | class Solution:
method insertionSort (line 2) | def insertionSort(self, nums: [int]) -> [int]:
method bucketSort (line 17) | def bucketSort(self, nums: [int], bucket_size=5) -> [int]:
method sortArray (line 38) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_counting_sort.py
class Solution (line 1) | class Solution:
method countingSort (line 2) | def countingSort(self, nums: [int]) -> [int]:
method sortArray (line 28) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_insertion_sort.py
class Solution (line 1) | class Solution:
method insertionSort (line 2) | def insertionSort(self, nums: [int]) -> [int]:
method sortArray (line 17) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_maxheap_sort.py
class MaxHeap (line 1) | class MaxHeap:
method __init__ (line 2) | def __init__(self):
method peek (line 5) | def peek(self) -> int:
method push (line 12) | def push(self, val: int):
method __shift_up (line 20) | def __shift_up(self, i: int):
method pop (line 25) | def pop(self) -> int:
method __shift_down (line 43) | def __shift_down(self, i: int, n: int):
method __buildMaxHeap (line 68) | def __buildMaxHeap(self, nums: [int]):
method maxHeapSort (line 78) | def maxHeapSort(self, nums: [int]) -> [int]:
class Solution (line 92) | class Solution:
method maxHeapSort (line 93) | def maxHeapSort(self, nums: [int]) -> [int]:
method sortArray (line 96) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_merge_sort.py
class Solution (line 1) | class Solution:
method merge (line 3) | def merge(self, left_nums: [int], right_nums: [int]):
method mergeSort (line 29) | def mergeSort(self, nums: [int]) -> [int]:
method sortArray (line 39) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_minheap_sort.py
class MinHeap (line 1) | class MinHeap:
method __init__ (line 2) | def __init__(self):
method peek (line 5) | def peek(self) -> int:
method push (line 12) | def push(self, val: int):
method __shift_up (line 20) | def __shift_up(self, i: int):
method pop (line 25) | def pop(self) -> int:
method __shift_down (line 43) | def __shift_down(self, i: int, n: int):
method __buildMinHeap (line 68) | def __buildMinHeap(self, nums: [int]):
method minHeapSort (line 78) | def minHeapSort(self, nums: [int]) -> [int]:
class Solution (line 92) | class Solution:
method minHeapSort (line 93) | def minHeapSort(self, nums: [int]) -> [int]:
method sortArray (line 96) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_quick_sort.py
class Solution (line 3) | class Solution:
method randomPartition (line 5) | def randomPartition(self, nums: [int], low: int, high: int) -> int:
method partition (line 14) | def partition(self, nums: [int], low: int, high: int) -> int:
method quickSort (line 33) | def quickSort(self, nums: [int], low: int, high: int) -> [int]:
method sortArray (line 43) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_radix_sort.py
class Solution (line 1) | class Solution:
method radixSort (line 2) | def radixSort(self, nums: [int]) -> [int]:
method sortArray (line 23) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_selection_sort.py
class Solution (line 1) | class Solution:
method selectionSort (line 2) | def selectionSort(self, nums: [int]) -> [int]:
method sortArray (line 14) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/01_array/array_sort_shell_sort.py
class Solution (line 1) | class Solution:
method shellSort (line 2) | def shellSort(self, nums: [int]) -> [int]:
method sortArray (line 23) | def sortArray(self, nums: [int]) -> [int]:
FILE: codes/python/02_linked_list/linked_list.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class LinkedList (line 6) | class LinkedList:
method __init__ (line 7) | def __init__(self):
method create (line 11) | def create(self, data):
method length (line 22) | def length(self):
method find (line 31) | def find(self, val):
method insertFront (line 41) | def insertFront(self, val):
method insertRear (line 47) | def insertRear(self, val):
method insertInside (line 56) | def insertInside(self, index, val):
method change (line 71) | def change(self, index, val):
method removeFront (line 84) | def removeFront(self):
method removeRear (line 89) | def removeRear(self):
method removeInside (line 99) | def removeInside(self, index):
FILE: codes/python/02_linked_list/linked_list_bubble_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method bubbleSort (line 7) | def bubbleSort(self, head: ListNode):
method sortLinkedList (line 24) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/02_linked_list/linked_list_bucket_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method insertion (line 8) | def insertion(self, buckets, index, val):
method merge (line 18) | def merge(self, left, right):
method mergeSort (line 39) | def mergeSort(self, head: ListNode):
method bucketSort (line 57) | def bucketSort(self, head: ListNode, bucket_size=5):
method sortList (line 94) | def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
FILE: codes/python/02_linked_list/linked_list_counting_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method countingSort (line 7) | def countingSort(self, head: ListNode):
method sortLinkedList (line 37) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/02_linked_list/linked_list_insertion_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method insertionSort (line 7) | def insertionSort(self, head: ListNode):
method sortLinkedList (line 32) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/02_linked_list/linked_list_merge_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method merge (line 7) | def merge(self, left, right):
method mergeSort (line 27) | def mergeSort(self, head: ListNode):
method sortLinkedList (line 46) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/02_linked_list/linked_list_quick_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method partition (line 7) | def partition(self, left: ListNode, right: ListNode):
method quickSort (line 29) | def quickSort(self, left: ListNode, right: ListNode):
method sortLinkedList (line 37) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/02_linked_list/linked_list_radix_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method radixSort (line 7) | def radixSort(self, head: ListNode):
method sortLinkedList (line 37) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/02_linked_list/linked_list_section_sort.py
class ListNode (line 1) | class ListNode:
method __init__ (line 2) | def __init__(self, val=0, next=None):
class Solution (line 6) | class Solution:
method sectionSort (line 7) | def sectionSort(self, head: ListNode):
method sortLinkedList (line 25) | def sortLinkedList(self, head: ListNode):
FILE: codes/python/03_stack_queue_hash_table/queue_circularSequential_queue.py
class Queue (line 1) | class Queue:
method __init__ (line 3) | def __init__(self, size=100):
method is_empty (line 10) | def is_empty(self):
method is_full (line 14) | def is_full(self):
method enqueue (line 18) | def enqueue(self, value):
method dequeue (line 26) | def dequeue(self):
method front_value (line 35) | def front_value(self):
method rear_value (line 43) | def rear_value(self):
FILE: codes/python/03_stack_queue_hash_table/queue_deque.py
class Node (line 1) | class Node:
method __init__ (line 3) | def __init__(self, value):
class Deque (line 8) | class Deque:
method __init__ (line 10) | def __init__(self):
method is_empty (line 19) | def is_empty(self):
method get_size (line 23) | def get_size(self):
method push_front (line 27) | def push_front(self, value):
method push_back (line 37) | def push_back(self, value):
method pop_front (line 47) | def pop_front(self):
method pop_back (line 59) | def pop_back(self):
method peek_front (line 71) | def peek_front(self):
method peek_back (line 77) | def peek_back(self):
class ArrayDeque (line 83) | class ArrayDeque:
method __init__ (line 85) | def __init__(self, capacity=100):
method is_empty (line 93) | def is_empty(self):
method is_full (line 97) | def is_full(self):
method get_size (line 101) | def get_size(self):
method push_front (line 105) | def push_front(self, value):
method push_back (line 115) | def push_back(self, value):
method pop_front (line 125) | def pop_front(self):
method pop_back (line 136) | def pop_back(self):
method peek_front (line 147) | def peek_front(self):
method peek_back (line 153) | def peek_back(self):
FILE: codes/python/03_stack_queue_hash_table/queue_link_queue.py
class Node (line 1) | class Node:
method __init__ (line 2) | def __init__(self, value):
class Queue (line 6) | class Queue:
method __init__ (line 8) | def __init__(self):
method is_empty (line 14) | def is_empty(self):
method enqueue (line 18) | def enqueue(self, value):
method dequeue (line 24) | def dequeue(self):
method front_value (line 37) | def front_value(self):
method rear_value (line 44) | def rear_value(self):
FILE: codes/python/03_stack_queue_hash_table/queue_priority_queue.py
class Heapq (line 1) | class Heapq:
method heapAdjust (line 3) | def heapAdjust(self, nums: [int], index: int, end: int):
method heapify (line 23) | def heapify(self, nums: [int]):
method heappush (line 31) | def heappush(self, nums: list, value):
method heappop (line 48) | def heappop(self, nums: list) -> int:
method heapSort (line 59) | def heapSort(self, nums: [int]):
FILE: codes/python/03_stack_queue_hash_table/queue_sequential_queue.py
class Queue (line 1) | class Queue:
method __init__ (line 3) | def __init__(self, size=100):
method is_empty (line 10) | def is_empty(self):
method is_full (line 14) | def is_full(self):
method enqueue (line 18) | def enqueue(self, value):
method dequeue (line 26) | def dequeue(self):
method front_value (line 35) | def front_value(self):
method rear_value (line 42) | def rear_value(self):
FILE: codes/python/03_stack_queue_hash_table/stack_link_stack.py
class Node (line 1) | class Node:
method __init__ (line 2) | def __init__(self, value):
class Stack (line 6) | class Stack:
method __init__ (line 8) | def __init__(self):
method is_empty (line 12) | def is_empty(self):
method push (line 16) | def push(self, value):
method pop (line 22) | def pop(self):
method peek (line 31) | def peek(self):
FILE: codes/python/03_stack_queue_hash_table/stack_monotone_stack.py
function monotoneStack (line 3) | def monotoneStack(nums):
function monotoneIncreasingStack (line 14) | def monotoneIncreasingStack(nums):
function monotoneDecreasingStack (line 24) | def monotoneDecreasingStack(nums):
FILE: codes/python/03_stack_queue_hash_table/stack_sequential_stack.py
class Stack (line 3) | class Stack:
method __init__ (line 5) | def __init__(self, size=100):
method is_empty (line 11) | def is_empty(self):
method is_full (line 15) | def is_full(self):
method push (line 19) | def push(self, value):
method pop (line 27) | def pop(self):
method peek (line 35) | def peek(self):
FILE: codes/python/04_string/string_Strcmp.py
function strcmp (line 1) | def strcmp(str1, str2):
FILE: codes/python/04_string/string_boyer_moore.py
function boyerMoore (line 2) | def boyerMoore(T: str, p: str) -> int:
function generateBadCharTable (line 23) | def generateBadCharTable(p: str):
function generageGoodSuffixList (line 32) | def generageGoodSuffixList(p: str):
function generageSuffixArray (line 56) | def generageSuffixArray(p: str):
FILE: codes/python/04_string/string_brute_force.py
function bruteForce (line 1) | def bruteForce(T: str, p: str) -> int:
FILE: codes/python/04_string/string_horspool.py
function horspool (line 2) | def horspool(T: str, p: str) -> int:
function generateBadCharTable (line 19) | def generateBadCharTable(p: str):
FILE: codes/python/04_string/string_kmp.py
function kmp (line 2) | def kmp(T: str, p: str) -> int:
function generateNext (line 20) | def generateNext(p: str):
FILE: codes/python/04_string/string_rabin_karp.py
function rabinKarp (line 2) | def rabinKarp(T: str, p: str, d, q) -> int:
FILE: codes/python/04_string/string_sunday.py
function sunday (line 2) | def sunday(T: str, p: str) -> int:
function generateBadCharTable (line 19) | def generateBadCharTable(p: str):
FILE: codes/python/04_string/string_trie.py
class Node (line 1) | class Node: # 字符节点
method __init__ (line 2) | def __init__(self): # 初始化字符节点
class Trie (line 7) | class Trie: # 字典树
method __init__ (line 10) | def __init__(self): # 初始化字典树
method insert (line 14) | def insert(self, word: str) -> None:
method search (line 23) | def search(self, word: str) -> bool:
method startsWith (line 33) | def startsWith(self, prefix: str) -> bool:
FILE: codes/python/05_tree/tree_binaryindexed_tree.py
class BinaryIndexTree (line 1) | class BinaryIndexTree:
method __init__ (line 3) | def __init__(self, n):
method lowbit (line 7) | def lowbit(self, index):
method update (line 10) | def update(self, index, delta):
method query (line 15) | def query(self, index):
FILE: codes/python/05_tree/tree_dynamicSegmentTree_update_interval_1.py
class SegTreeNode (line 2) | class SegTreeNode:
method __init__ (line 3) | def __init__(self, left=-1, right=-1, val=False, lazy_tag=None, leftNo...
class SegmentTree (line 14) | class SegmentTree:
method __init__ (line 16) | def __init__(self, function):
method update_point (line 21) | def update_point(self, i, val):
method update_interval (line 25) | def update_interval(self, q_left, q_right, val):
method query_interval (line 29) | def query_interval(self, q_left, q_right):
method get_nums (line 33) | def get_nums(self, length):
method __update_point (line 43) | def __update_point(self, i, val, node):
method __update_interval (line 55) | def __update_interval(self, q_left, q_right, val, node):
method __query_interval (line 74) | def __query_interval(self, q_left, q_right, node):
method __pushup (line 91) | def __pushup(self, node):
method __pushdown (line 96) | def __pushdown(self, node):
class Solution (line 117) | class Solution:
method __init__ (line 119) | def __init__(self):
method update (line 123) | def update(self, left: int, right: int, val) -> None:
method sumRange (line 127) | def sumRange(self, left: int, right: int) -> int:
FILE: codes/python/05_tree/tree_dynamicSegmentTree_update_interval_2.py
class SegTreeNode (line 2) | class SegTreeNode:
method __init__ (line 3) | def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=N...
class SegmentTree (line 14) | class SegmentTree:
method __init__ (line 16) | def __init__(self, function):
method update_point (line 21) | def update_point(self, i, val):
method update_interval (line 25) | def update_interval(self, q_left, q_right, val):
method query_interval (line 29) | def query_interval(self, q_left, q_right):
method get_nums (line 33) | def get_nums(self, length):
method __update_point (line 43) | def __update_point(self, i, val, node):
method __update_interval (line 55) | def __update_interval(self, q_left, q_right, val, node):
method __query_interval (line 77) | def __query_interval(self, q_left, q_right, node):
method __pushup (line 94) | def __pushup(self, node):
method __pushdown (line 99) | def __pushdown(self, node):
class Solution (line 126) | class Solution:
method __init__ (line 128) | def __init__(self):
method update (line 132) | def update(self, left: int, right: int, val) -> None:
method sumRange (line 136) | def sumRange(self, left: int, right: int) -> int:
FILE: codes/python/05_tree/tree_segmentTree_update_interval_1.py
class SegTreeNode (line 2) | class SegTreeNode:
method __init__ (line 3) | def __init__(self, val=0):
class SegmentTree (line 11) | class SegmentTree:
method __init__ (line 13) | def __init__(self, nums, function):
method update_point (line 22) | def update_point(self, i, val):
method update_interval (line 27) | def update_interval(self, q_left, q_right, val):
method query_interval (line 31) | def query_interval(self, q_left, q_right):
method get_nums (line 35) | def get_nums(self):
method __build (line 44) | def __build(self, index, left, right):
method __update_point (line 59) | def __update_point(self, i, val, index):
method __update_interval (line 78) | def __update_interval(self, q_left, q_right, val, index):
method __query_interval (line 108) | def __query_interval(self, q_left, q_right, index):
method __pushup (line 132) | def __pushup(self, index):
method __pushdown (line 138) | def __pushdown(self, index):
class Solution (line 157) | class Solution:
method __init__ (line 159) | def __init__(self, nums: List[int]):
method update (line 163) | def update(self, left: int, right: int, val) -> None:
method sumRange (line 167) | def sumRange(self, left: int, right: int) -> int:
FILE: codes/python/05_tree/tree_segmentTree_update_interval_2.py
class SegTreeNode (line 2) | class SegTreeNode:
method __init__ (line 3) | def __init__(self, val=0):
class SegmentTree (line 11) | class SegmentTree:
method __init__ (line 13) | def __init__(self, nums, function):
method update_point (line 22) | def update_point(self, i, val):
method update_interval (line 27) | def update_interval(self, q_left, q_right, val):
method query_interval (line 31) | def query_interval(self, q_left, q_right):
method get_nums (line 35) | def get_nums(self):
method __build (line 44) | def __build(self, index, left, right):
method __update_point (line 59) | def __update_point(self, i, val, index):
method __update_interval (line 78) | def __update_interval(self, q_left, q_right, val, index):
method __query_interval (line 107) | def __query_interval(self, q_left, q_right, index):
method __pushup (line 131) | def __pushup(self, index):
method __pushdown (line 137) | def __pushdown(self, index):
class Solution (line 162) | class Solution:
method __init__ (line 164) | def __init__(self, nums: List[int]):
method addVal (line 168) | def addVal(self, left: int, right: int, val) -> None:
method sumRange (line 172) | def sumRange(self, left: int, right: int) -> int:
FILE: codes/python/05_tree/tree_segmentTree_update_point.py
class SegTreeNode (line 2) | class SegTreeNode:
method __init__ (line 3) | def __init__(self, val=0):
class SegmentTree (line 10) | class SegmentTree:
method __init__ (line 12) | def __init__(self, nums, function):
method update_point (line 21) | def update_point(self, i, val):
method query_interval (line 26) | def query_interval(self, q_left, q_right):
method get_nums (line 30) | def get_nums(self):
method __build (line 39) | def __build(self, index, left, right):
method __update_point (line 55) | def __update_point(self, i, val, index):
method __query_interval (line 75) | def __query_interval(self, q_left, q_right, index):
method __pushup (line 97) | def __pushup(self, index):
class Solution (line 104) | class Solution:
method __init__ (line 106) | def __init__(self, nums: List[int]):
method update (line 110) | def update(self, index: int, val: int) -> None:
method sumRange (line 114) | def sumRange(self, left: int, right: int) -> int:
FILE: codes/python/05_tree/tree_unionFind.py
class UnionFind (line 1) | class UnionFind:
method __init__ (line 2) | def __init__(self, n): # 初始化
method find (line 5) | def find(self, x): # 查找元素根节点的集合编号内部实现方法
method union (line 11) | def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另...
method is_connected (line 19) | def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
FILE: codes/python/05_tree/tree_unionFind_QuickFind.py
class UnionFind (line 1) | class UnionFind:
method __init__ (line 2) | def __init__(self, n): # 初始化:将每个元素的集合编号初始化为数组...
method find (line 5) | def find(self, x): # 查找元素所属集合编号内部实现方法
method union (line 8) | def union(self, x, y): # 合并操作:将集合 x 和集合 y 合并成...
method is_connected (line 20) | def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
FILE: codes/python/05_tree/tree_unionFind_QuickUnion.py
class UnionFind (line 1) | class UnionFind:
method __init__ (line 2) | def __init__(self, n): # 初始化:将每个元素的集合编号初始化为数组...
method find (line 5) | def find(self, x): # 查找元素根节点的集合编号内部实现方法
method union (line 10) | def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另...
method is_connected (line 18) | def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
FILE: codes/python/05_tree/tree_unionFind_UnoinByRank.py
class UnionFind (line 1) | class UnionFind:
method __init__ (line 2) | def __init__(self, n): # 初始化
method find (line 6) | def find(self, x): # 查找元素根节点的集合编号内部实现方法
method union (line 12) | def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另...
method is_connected (line 27) | def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
FILE: codes/python/05_tree/tree_unionFind_UnoinBySize.py
class UnionFind (line 1) | class UnionFind:
method __init__ (line 2) | def __init__(self, n): # 初始化
method find (line 6) | def find(self, x): # 查找元素根节点的集合编号内部实现方法
method union (line 12) | def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另...
method is_connected (line 30) | def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
FILE: codes/python/06_graph/Graph-Adjacency-List.py
class EdgeNode (line 1) | class EdgeNode: # 边信息类
method __init__ (line 2) | def __init__(self, vj, val):
class VertexNode (line 7) | class VertexNode: # 顶点信息类
method __init__ (line 8) | def __init__(self, vi):
class Graph (line 12) | class Graph:
method __init__ (line 13) | def __init__(self, ver_count):
method __valid (line 21) | def __valid(self, v):
method creatGraph (line 25) | def creatGraph(self, edges=[]):
method add_edge (line 30) | def add_edge(self, vi, vj, val):
method get_edge (line 40) | def get_edge(self, vi, vj):
method printGraph (line 53) | def printGraph(self):
FILE: codes/python/06_graph/Graph-Adjacency-Matrix.py
class Graph (line 1) | class Graph: # 基本图类,采用邻接矩阵表示
method __init__ (line 3) | def __init__(self, ver_count):
method __valid (line 8) | def __valid(self, v):
method creatGraph (line 12) | def creatGraph(self, edges=[]):
method add_edge (line 17) | def add_edge(self, vi, vj, val):
method get_edge (line 24) | def get_edge(self, vi, vj):
method printGraph (line 31) | def printGraph(self):
FILE: codes/python/06_graph/Graph-BFS.py
class Solution (line 3) | class Solution:
method bfs (line 4) | def bfs(self, graph, u):
FILE: codes/python/06_graph/Graph-Bellman-Ford.py
class Solution (line 1) | class Solution:
method bellmanFord (line 2) | def bellmanFord(self, graph, source):
FILE: codes/python/06_graph/Graph-DFS.py
class Solution (line 1) | class Solution:
method dfs_recursive (line 2) | def dfs_recursive(self, graph, u, visited):
method dfs_stack (line 11) | def dfs_stack(self, graph, u):
FILE: codes/python/06_graph/Graph-Edgeset-Array.py
class EdgeNode (line 1) | class EdgeNode: # 边信息类
method __init__ (line 2) | def __init__(self, vi, vj, val):
class Graph (line 7) | class Graph: # 基本图类,采用边集数组表示
method __init__ (line 8) | def __init__(self):
method creatGraph (line 12) | def creatGraph(self, edges=[]):
method add_edge (line 17) | def add_edge(self, vi, vj, val):
method get_edge (line 22) | def get_edge(self, vi, vj):
method printGraph (line 30) | def printGraph(self):
FILE: codes/python/06_graph/Graph-Hash-Table.py
class VertexNode (line 1) | class VertexNode: # 顶点信息类
method __init__ (line 2) | def __init__(self, vi):
class Graph (line 6) | class Graph:
method __init__ (line 7) | def __init__(self):
method creatGraph (line 11) | def creatGraph(self, edges=[]):
method add_vertex (line 16) | def add_vertex(self, vi):
method add_edge (line 21) | def add_edge(self, vi, vj, val):
method get_edge (line 30) | def get_edge(self, vi, vj):
method printGraph (line 36) | def printGraph(self):
FILE: codes/python/06_graph/Graph-Kruskal.py
class UnionFind (line 1) | class UnionFind:
method __init__ (line 3) | def __init__(self, n):
method find (line 7) | def find(self, x):
method union (line 13) | def union(self, x, y):
method is_connected (line 22) | def is_connected(self, x, y):
class Solution (line 26) | class Solution:
method Kruskal (line 27) | def Kruskal(self, edges, size):
method minCostConnectPoints (line 43) | def minCostConnectPoints(self, points: List[List[int]]) -> int:
FILE: codes/python/06_graph/Graph-Linked-Forward-Star.py
class EdgeNode (line 1) | class EdgeNode: # 边信息类
method __init__ (line 2) | def __init__(self, vj, val):
class Graph (line 7) | class Graph:
method __init__ (line 8) | def __init__(self, ver_count, edge_count):
method __valid (line 15) | def __valid(self, v):
method creatGraph (line 19) | def creatGraph(self, edges=[]):
method add_edge (line 25) | def add_edge(self, index, vi, vj, val):
method get_edge (line 35) | def get_edge(self, vi, vj):
method printGraph (line 47) | def printGraph(self):
FILE: codes/python/06_graph/Graph-Prim.py
class Solution (line 1) | class Solution:
method Prim (line 3) | def Prim(self, graph, start):
FILE: codes/python/06_graph/Graph-Topological-Sorting-DFS.py
class Solution (line 3) | class Solution:
method topologicalSortingDFS (line 5) | def topologicalSortingDFS(self, graph: dict):
method findOrder (line 36) | def findOrder(self, n: int, edges):
FILE: codes/python/06_graph/Graph-Topological-Sorting-Kahn.py
class Solution (line 3) | class Solution:
method topologicalSortingKahn (line 5) | def topologicalSortingKahn(self, graph: dict):
method findOrder (line 28) | def findOrder(self, n: int, edges):
FILE: codes/python/08_dynamic_programming/Digit-DP.py
class Solution (line 1) | class Solution:
method digitDP (line 2) | def digitDP(self, n: int) -> int:
FILE: codes/python/08_dynamic_programming/Pack-2DCostPack.py
class Solution (line 1) | class Solution:
method twoDCostPackMethod1 (line 3) | def twoDCostPackMethod1(self, weight: [int], volume: [int], value: [in...
method twoDCostPackMethod2 (line 24) | def twoDCostPackMethod2(self, weight: [int], volume: [int], value: [in...
FILE: codes/python/08_dynamic_programming/Pack-CompletePack.py
class Solution (line 1) | class Solution:
method completePackMethod1 (line 3) | def completePackMethod1(self, weight: [int], value: [int], W: int):
method completePackMethod2 (line 19) | def completePackMethod2(self, weight: [int], value: [int], W: int):
method completePackMethod3 (line 38) | def completePackMethod3(self, weight: [int], value: [int], W: int):
FILE: codes/python/08_dynamic_programming/Pack-GroupPack.py
class Solution (line 1) | class Solution:
method groupPackMethod1 (line 3) | def groupPackMethod1(self, group_count: [int], weight: [[int]], value:...
method groupPackMethod2 (line 21) | def groupPackMethod2(self, group_count: [int], weight: [[int]], value:...
FILE: codes/python/08_dynamic_programming/Pack-MixedPack.py
class Solution (line 1) | class Solution:
method mixedPackMethod1 (line 2) | def mixedPackMethod1(self, weight: [int], value: [int], count: [int], ...
FILE: codes/python/08_dynamic_programming/Pack-MultiplePack.py
class Solution (line 1) | class Solution:
method multiplePackMethod1 (line 3) | def multiplePackMethod1(self, weight: [int], value: [int], count: [int...
method multiplePackMethod2 (line 19) | def multiplePackMethod2(self, weight: [int], value: [int], count: [int...
method multiplePackMethod3 (line 35) | def multiplePackMethod3(self, weight: [int], value: [int], count: [int...
FILE: codes/python/08_dynamic_programming/Pack-ProblemVariants.py
class Solution (line 1) | class Solution:
method zeroOnePackJustFillUp (line 5) | def zeroOnePackJustFillUp(self, weight: [int], value: [int], W: int):
method completePackJustFillUp (line 22) | def completePackJustFillUp(self, weight: [int], value: [int], W: int):
method zeroOnePackNumbers (line 42) | def zeroOnePackNumbers(self, weight: [int], value: [int], W: int):
method completePackNumbers (line 57) | def completePackNumbers(self, weight: [int], value: [int], W: int):
method zeroOnePackMaxProfitNumbers1 (line 75) | def zeroOnePackMaxProfitNumbers1(self, weight: [int], value: [int], W:...
method zeroOnePackMaxProfitNumbers2 (line 109) | def zeroOnePackMaxProfitNumbers2(self, weight: [int], value: [int], W:...
method completePackMaxProfitNumbers1 (line 131) | def completePackMaxProfitNumbers1(self, weight: [int], value: [int], W...
method completePackMaxProfitNumbers2 (line 165) | def completePackMaxProfitNumbers2(self, weight: [int], value: [int], W...
method zeroOnePackPrintPath (line 190) | def zeroOnePackPrintPath(self, weight: [int], value: [int], W: int):
method zeroOnePackPrintPathMinOrder (line 232) | def zeroOnePackPrintPathMinOrder(self, weight: [int], value: [int], W:...
FILE: codes/python/08_dynamic_programming/Pack-ZeroOnePack.py
class Solution (line 1) | class Solution:
method zeroOnePackMethod1 (line 3) | def zeroOnePackMethod1(self, weight: [int], value: [int], W: int):
method zeroOnePackMethod2 (line 22) | def zeroOnePackMethod2(self, weight: [int], value: [int], W: int):
Condensed preview — 1514 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (4,523K chars).
[
{
"path": ".github/workflows/sync.yml",
"chars": 455,
"preview": "name: Mirror to Gitee Repo\n\non: [ push ]\n\n# Ensures that only one mirror task will run at a time.\nconcurrency:\n group: "
},
{
"path": ".gitignore",
"chars": 1830,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": "LICENSE",
"chars": 19554,
"preview": "Creative Commons Attribution-NonCommercial-NoDerivatives 4.0\nInternational\n\nCreative Commons Corporation (\"Creative Comm"
},
{
"path": "README.md",
"chars": 3100,
"preview": "<div align='center'>\n <img src=\"https://qcdn.itcharge.cn/images/20250925092713.png\" alt=\"alt text\" width=\"100%\"/>\n "
},
{
"path": "codes/python/01_array/array_maxheap.py",
"chars": 2340,
"preview": "class MaxHeap:\n def __init__(self):\n self.max_heap = []\n \n def peek(self) -> int:\n # 大顶堆为空\n "
},
{
"path": "codes/python/01_array/array_sort_bubble_sort.py",
"chars": 685,
"preview": "class Solution:\n def bubbleSort(self, nums: [int]) -> [int]:\n # 第 i 趟「冒泡」\n for i in range(len(nums) - 1"
},
{
"path": "codes/python/01_array/array_sort_bucket_sort.py",
"chars": 1278,
"preview": "class Solution:\n def insertionSort(self, nums: [int]) -> [int]:\n # 遍历无序区间\n for i in range(1, len(nums))"
},
{
"path": "codes/python/01_array/array_sort_counting_sort.py",
"chars": 984,
"preview": "class Solution:\n def countingSort(self, nums: [int]) -> [int]:\n # 计算待排序数组中最大值元素 nums_max 和最小值元素 nums_min\n "
},
{
"path": "codes/python/01_array/array_sort_insertion_sort.py",
"chars": 557,
"preview": "class Solution:\n def insertionSort(self, nums: [int]) -> [int]:\n # 遍历无序区间\n for i in range(1, len(nums))"
},
{
"path": "codes/python/01_array/array_sort_maxheap_sort.py",
"chars": 2998,
"preview": "class MaxHeap:\n def __init__(self):\n self.max_heap = []\n \n def peek(self) -> int:\n # 大顶堆为空\n "
},
{
"path": "codes/python/01_array/array_sort_merge_sort.py",
"chars": 1402,
"preview": "class Solution:\n # 合并过程\n def merge(self, left_nums: [int], right_nums: [int]):\n nums = []\n left_i, r"
},
{
"path": "codes/python/01_array/array_sort_minheap_sort.py",
"chars": 2998,
"preview": "class MinHeap:\n def __init__(self):\n self.min_heap = []\n \n def peek(self) -> int:\n # 大顶堆为空\n "
},
{
"path": "codes/python/01_array/array_sort_quick_sort.py",
"chars": 1538,
"preview": "import random\n\nclass Solution:\n # 随机哨兵划分:从 nums[low: high + 1] 中随机挑选一个基准数,并进行移位排序\n def randomPartition(self, nums:"
},
{
"path": "codes/python/01_array/array_sort_radix_sort.py",
"chars": 853,
"preview": "class Solution:\n def radixSort(self, nums: [int]) -> [int]:\n # 桶的大小为所有元素的最大位数\n size = len(str(max(nums)"
},
{
"path": "codes/python/01_array/array_sort_selection_sort.py",
"chars": 571,
"preview": "class Solution:\n def selectionSort(self, nums: [int]) -> [int]:\n for i in range(len(nums) - 1):\n # "
},
{
"path": "codes/python/01_array/array_sort_shell_sort.py",
"chars": 806,
"preview": "class Solution:\n def shellSort(self, nums: [int]) -> [int]:\n size = len(nums)\n gap = size // 2\n "
},
{
"path": "codes/python/02_linked_list/linked_list.py",
"chars": 2482,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass LinkedL"
},
{
"path": "codes/python/02_linked_list/linked_list_bubble_sort.py",
"chars": 745,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_bucket_sort.py",
"chars": 2718,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_counting_sort.py",
"chars": 1072,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_insertion_sort.py",
"chars": 966,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_merge_sort.py",
"chars": 1215,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_quick_sort.py",
"chars": 1377,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_radix_sort.py",
"chars": 1082,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/02_linked_list/linked_list_section_sort.py",
"chars": 795,
"preview": "class ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solutio"
},
{
"path": "codes/python/03_stack_queue_hash_table/queue_circularSequential_queue.py",
"chars": 1613,
"preview": "class Queue:\n # 初始化空队列\n def __init__(self, size=100):\n self.size = size + 1\n self.queue = [None for "
},
{
"path": "codes/python/03_stack_queue_hash_table/queue_deque.py",
"chars": 5791,
"preview": "class Node:\n \"\"\"双向链表节点\"\"\"\n def __init__(self, value):\n self.value = value # 节点值\n self.prev = Non"
},
{
"path": "codes/python/03_stack_queue_hash_table/queue_link_queue.py",
"chars": 1433,
"preview": "class Node:\n def __init__(self, value):\n self.value = value\n self.next = None\n \nclass Queue:\n "
},
{
"path": "codes/python/03_stack_queue_hash_table/queue_priority_queue.py",
"chars": 2518,
"preview": "class Heapq:\n # 堆调整方法:调整为大顶堆\n def heapAdjust(self, nums: [int], index: int, end: int):\n left = index * 2 + "
},
{
"path": "codes/python/03_stack_queue_hash_table/queue_sequential_queue.py",
"chars": 1483,
"preview": "class Queue:\n # 初始化空队列\n def __init__(self, size=100):\n self.size = size\n self.queue = [None for _ in"
},
{
"path": "codes/python/03_stack_queue_hash_table/stack_link_stack.py",
"chars": 871,
"preview": "class Node:\n def __init__(self, value):\n self.value = value\n self.next = None\n \nclass Stack:\n "
},
{
"path": "codes/python/03_stack_queue_hash_table/stack_monotone_stack.py",
"chars": 1056,
"preview": "import random\n\ndef monotoneStack(nums):\n print(str(nums))\n stack = []\n for num in nums:\n while stack and"
},
{
"path": "codes/python/03_stack_queue_hash_table/stack_sequential_stack.py",
"chars": 970,
"preview": "#!/usr/bin/env python3\n\nclass Stack:\n # 初始化空栈\n def __init__(self, size=100):\n self.stack = []\n self."
},
{
"path": "codes/python/04_string/string_Strcmp.py",
"chars": 648,
"preview": "def strcmp(str1, str2):\n index1, index2 = 0, 0\n while index1 < len(str1) and index2 < len(str2):\n if ord(st"
},
{
"path": "codes/python/04_string/string_boyer_moore.py",
"chars": 2527,
"preview": "# BM 匹配算法\ndef boyerMoore(T: str, p: str) -> int:\n n, m = len(T), len(p)\n \n bc_table = generateBadCharTable(p) "
},
{
"path": "codes/python/04_string/string_brute_force.py",
"chars": 602,
"preview": "def bruteForce(T: str, p: str) -> int:\n n, m = len(T), len(p)\n \n i, j = 0, 0 # i 表示文本串 T 的当"
},
{
"path": "codes/python/04_string/string_horspool.py",
"chars": 992,
"preview": "# horspool 算法,T 为文本串,p 为模式串\ndef horspool(T: str, p: str) -> int:\n n, m = len(T), len(p)\n \n bc_table = generateB"
},
{
"path": "codes/python/04_string/string_kmp.py",
"chars": 1525,
"preview": "# KMP 匹配算法,T 为文本串,p 为模式串\ndef kmp(T: str, p: str) -> int:\n n, m = len(T), len(p)\n \n next = generateNext(p) "
},
{
"path": "codes/python/04_string/string_rabin_karp.py",
"chars": 1268,
"preview": "# T 为文本串,p 为模式串,d 为字符集的字符种类数,q 为质数\ndef rabinKarp(T: str, p: str, d, q) -> int:\n n, m = len(T), len(p)\n if n < m:\n "
},
{
"path": "codes/python/04_string/string_sunday.py",
"chars": 939,
"preview": "# sunday 算法,T 为文本串,p 为模式串\ndef sunday(T: str, p: str) -> int:\n n, m = len(T), len(p)\n \n bc_table = generateBadCh"
},
{
"path": "codes/python/04_string/string_trie.py",
"chars": 1749,
"preview": "class Node: # 字符节点\n def __init__(self): # 初始化字符节点\n "
},
{
"path": "codes/python/05_tree/tree_binaryindexed_tree.py",
"chars": 494,
"preview": "class BinaryIndexTree:\n\n def __init__(self, n):\n self.size = n\n self.tree = [0 for _ in range(n + 1)]\n\n"
},
{
"path": "codes/python/05_tree/tree_dynamicSegmentTree_update_interval_1.py",
"chars": 5423,
"preview": "# 线段树的节点类\nclass SegTreeNode:\n def __init__(self, left=-1, right=-1, val=False, lazy_tag=None, leftNode=None, rightNod"
},
{
"path": "codes/python/05_tree/tree_dynamicSegmentTree_update_interval_2.py",
"chars": 5792,
"preview": "# 线段树的节点类\nclass SegTreeNode:\n def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=None, rightNode=No"
},
{
"path": "codes/python/05_tree/tree_segmentTree_update_interval_1.py",
"chars": 6923,
"preview": "# 线段树的节点类\nclass SegTreeNode:\n def __init__(self, val=0):\n self.left = -1 # 区间左边界\n"
},
{
"path": "codes/python/05_tree/tree_segmentTree_update_interval_2.py",
"chars": 7320,
"preview": "# 线段树的节点类\nclass SegTreeNode:\n def __init__(self, val=0):\n self.left = -1 # 区间左边界\n"
},
{
"path": "codes/python/05_tree/tree_segmentTree_update_point.py",
"chars": 4605,
"preview": "# 线段树的节点类\nclass SegTreeNode:\n def __init__(self, val=0):\n self.left = -1 # 区间左边界\n"
},
{
"path": "codes/python/05_tree/tree_unionFind.py",
"chars": 946,
"preview": "class UnionFind:\n def __init__(self, n): # 初始化\n self.fa = [i for i in range(n)] "
},
{
"path": "codes/python/05_tree/tree_unionFind_QuickFind.py",
"chars": 767,
"preview": "class UnionFind:\n def __init__(self, n): # 初始化:将每个元素的集合编号初始化为数组下标索引\n self.ids = [i fo"
},
{
"path": "codes/python/05_tree/tree_unionFind_QuickUnion.py",
"chars": 868,
"preview": "class UnionFind:\n def __init__(self, n): # 初始化:将每个元素的集合编号初始化为数组 fa 的下标索引\n self.fa = ["
},
{
"path": "codes/python/05_tree/tree_unionFind_UnoinByRank.py",
"chars": 1503,
"preview": "class UnionFind:\n def __init__(self, n): # 初始化\n self.fa = [i for i in range(n)] "
},
{
"path": "codes/python/05_tree/tree_unionFind_UnoinBySize.py",
"chars": 1662,
"preview": "class UnionFind:\n def __init__(self, n): # 初始化\n self.fa = [i for i in range(n)] "
},
{
"path": "codes/python/06_graph/Graph-Adjacency-List.py",
"chars": 2159,
"preview": "class EdgeNode: # 边信息类\n def __init__(self, vj, val):\n self.vj = vj "
},
{
"path": "codes/python/06_graph/Graph-Adjacency-Matrix.py",
"chars": 1477,
"preview": "class Graph: # 基本图类,采用邻接矩阵表示\n # 图的初始化操作,ver_count 为顶点个数\n def __init__(self, ver"
},
{
"path": "codes/python/06_graph/Graph-BFS.py",
"chars": 967,
"preview": "import collections\n\nclass Solution:\n def bfs(self, graph, u):\n visited = set() # 使用 visite"
},
{
"path": "codes/python/06_graph/Graph-Bellman-Ford.py",
"chars": 858,
"preview": "class Solution:\n def bellmanFord(self, graph, source):\n size = len(graph)\n dist = dict()\n \n "
},
{
"path": "codes/python/06_graph/Graph-DFS.py",
"chars": 1518,
"preview": "class Solution:\n def dfs_recursive(self, graph, u, visited):\n print(u) # 访问节点\n v"
},
{
"path": "codes/python/06_graph/Graph-Edgeset-Array.py",
"chars": 1308,
"preview": "class EdgeNode: # 边信息类\n def __init__(self, vi, vj, val):\n self.vi = vi "
},
{
"path": "codes/python/06_graph/Graph-Hash-Table.py",
"chars": 1422,
"preview": "class VertexNode: # 顶点信息类\n def __init__(self, vi):\n self.vi = vi "
},
{
"path": "codes/python/06_graph/Graph-Kruskal.py",
"chars": 1435,
"preview": "class UnionFind:\n\n def __init__(self, n):\n self.parent = [i for i in range(n)]\n self.count = n\n\n def"
},
{
"path": "codes/python/06_graph/Graph-Linked-Forward-Star.py",
"chars": 2601,
"preview": "class EdgeNode: # 边信息类\n def __init__(self, vj, val):\n self.vj = vj "
},
{
"path": "codes/python/06_graph/Graph-Prim.py",
"chars": 1509,
"preview": "class Solution:\n # graph 为图的邻接矩阵,start 为起始顶点\n def Prim(self, graph, start):\n size = len(graph)\n vis "
},
{
"path": "codes/python/06_graph/Graph-Topological-Sorting-DFS.py",
"chars": 1749,
"preview": "import collections\n\nclass Solution:\n # 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)\n def topologicalSortingDFS(self, graph: di"
},
{
"path": "codes/python/06_graph/Graph-Topological-Sorting-Kahn.py",
"chars": 1439,
"preview": "import collections\n\nclass Solution:\n # 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)\n def topologicalSortingKahn(self, graph: d"
},
{
"path": "codes/python/08_dynamic_programming/Digit-DP.py",
"chars": 1137,
"preview": "class Solution:\n def digitDP(self, n: int) -> int:\n s = str(n)\n \n @cache\n # pos: 第 pos 个数"
},
{
"path": "codes/python/08_dynamic_programming/Pack-2DCostPack.py",
"chars": 1667,
"preview": "class Solution:\n # 思路 1:动态规划 + 三维基本思路\n def twoDCostPackMethod1(self, weight: [int], volume: [int], value: [int], W"
},
{
"path": "codes/python/08_dynamic_programming/Pack-CompletePack.py",
"chars": 1986,
"preview": "class Solution:\n # 思路 1:动态规划 + 二维基本思路\n def completePackMethod1(self, weight: [int], value: [int], W: int):\n "
},
{
"path": "codes/python/08_dynamic_programming/Pack-GroupPack.py",
"chars": 1476,
"preview": "class Solution:\n # 思路 1:动态规划 + 二维基本思路\n def groupPackMethod1(self, group_count: [int], weight: [[int]], value: [[in"
},
{
"path": "codes/python/08_dynamic_programming/Pack-MixedPack.py",
"chars": 1990,
"preview": "class Solution:\n def mixedPackMethod1(self, weight: [int], value: [int], count: [int], W: int):\n weight_new, v"
},
{
"path": "codes/python/08_dynamic_programming/Pack-MultiplePack.py",
"chars": 2390,
"preview": "class Solution:\n # 思路 1:动态规划 + 二维基本思路\n def multiplePackMethod1(self, weight: [int], value: [int], count: [int], W:"
},
{
"path": "codes/python/08_dynamic_programming/Pack-ProblemVariants.py",
"chars": 10738,
"preview": "class Solution:\n # 1. 求恰好装满背包的最大价值\n \n # 0-1 背包问题 求恰好装满背包的最大价值\n def zeroOnePackJustFillUp(self, weight: [int]"
},
{
"path": "codes/python/08_dynamic_programming/Pack-ZeroOnePack.py",
"chars": 1362,
"preview": "class Solution:\n # 思路 1:动态规划 + 二维基本思路\n def zeroOnePackMethod1(self, weight: [int], value: [int], W: int):\n "
},
{
"path": "docs/00_preface/00_01_preface.md",
"chars": 1835,
"preview": "## 1. 创作历程\n\n### 1.1 创作起因\n\n写一本通俗易懂的算法书一直是我的心愿,这个想法已经在我心中埋藏了七年之久。至今我仍记得大学时立下的 flag:**要把所学的算法知识系统整理,编写成书,署上自己的名字,并分享给所有热爱算法"
},
{
"path": "docs/00_preface/00_02_data_structures_algorithms.md",
"chars": 5858,
"preview": "\n\n> 数据结构是程序的骨架,而算法则是程序的灵魂。\n\n**《算法 + 数据结构 = 程序》** 是 Pas"
},
{
"path": "docs/00_preface/00_03_algorithm_complexity.md",
"chars": 10529,
"preview": "## 1. 算法复杂度简介\n\n> **算法复杂度(Algorithm complexity)**:用于衡量算法在输入规模为 $n$ 时所需的时间和空间资源。\n\n这里的 **问题规模 $n$**,指的是算法输入的数据量。不同类型的算法,$n$"
},
{
"path": "docs/00_preface/00_04_leetcode_guide.md",
"chars": 8109,
"preview": "## 1. LeetCode 是什么\n\n**「LeetCode」** 是一个在线编程评测平台,主要包含算法、数据库、Shell、多线程等题目,其中以算法题目为主。LeetCode 上有 $3000+$ 道编程问题,支持 $16+$ 种编程语"
},
{
"path": "docs/00_preface/00_05_solutions_list.md",
"chars": 265985,
"preview": "# LeetCode 题解(已完成 1303 道)\n\n### 第 1 ~ 99 题\n\n| 标题 | 题解 | 标签 | 难度 |\n| :--- | :--- | :--- | :--- |\n| [0001. 两数之和](https://le"
},
{
"path": "docs/00_preface/00_06_categories_list.md",
"chars": 144852,
"preview": "# LeetCode 题解(按分类排序,推荐刷题列表 ★★★)\n\n## 第 1 章 数组\n\n### 数组基础题目\n\n#### 数组操作题目\n\n| 标题 | 题解 | 标签 | 难度 |\n| :--- | :--- | :--- | :--"
},
{
"path": "docs/00_preface/00_07_interview_100_list.md",
"chars": 29266,
"preview": "# LeetCode 面试最常考 100 题(按分类排序)\n\n## 第 1 章 数组\n\n### 数组基础题目\n\n| 标题 | 题解 | 标签 | 难度 |\n| :--- | :--- | :--- | :--- |\n| [0054. 螺旋"
},
{
"path": "docs/00_preface/00_08_interview_200_list.md",
"chars": 53726,
"preview": "# LeetCode 面试最常考 200 题(按分类排序)\n\n## 第 1 章 数组\n\n### 数组基础题目\n\n| 标题 | 题解 | 标签 | 难度 |\n| :--- | :--- | :--- | :--- |\n| [0189. 轮转"
},
{
"path": "docs/00_preface/index.md",
"chars": 1079,
"preview": "\n\n::: tip 引 言\n\n数据结构如同星辰,算法宛若清风,星光与微风交织,点亮智慧的夜空。\n\n愿本书与你同行,助你轻装前行,"
},
{
"path": "docs/01_array/01_01_array_basic.md",
"chars": 6739,
"preview": "## 1. 数组简介\n\n### 1.1 数组定义\n\n> **数组(Array)**:一种线性表数据结构,利用一段连续的内存空间,存储一组相同类型的数据。\n\n简而言之,**「数组」** 是线性表顺序存储结构的典型代表。\n\n以整数数组为例,其存"
},
{
"path": "docs/01_array/01_02_array_sort.md",
"chars": 1707,
"preview": "数组排序是计算机科学中最基本的问题之一。排序算法有很多种,每种算法都有其特点和适用场景。\n\n## 1. 排序算法的分类\n\n排序算法可以按照不同的标准进行分类:\n\n1. 按照时间复杂度分类\n - **简单排序算法**:时间复杂度为 $O("
},
{
"path": "docs/01_array/01_03_array_bubble_sort.md",
"chars": 3095,
"preview": "## 1. 冒泡排序算法思想\n\n> **冒泡排序(Bubble Sort)基本思想**:\n>\n> 通过相邻元素的比较与交换,将较大的元素逐步「冒泡」到数组末尾,较小的元素自然「下沉」到数组开头。\n\n冒泡排序的名字来源于这个过程:就像水中的气"
},
{
"path": "docs/01_array/01_04_array_selection_sort.md",
"chars": 2288,
"preview": "## 1. 选择排序算法思想\n\n> **选择排序(Selection Sort)基本思想**:\n>\n> 将数组分为两个区间:左侧为已排序区间,右侧为未排序区间。每趟从未排序区间中选择最小的元素,放到已排序区间的末尾。\n\n选择排序是一种简单直"
},
{
"path": "docs/01_array/01_05_array_insertion_sort.md",
"chars": 1728,
"preview": "## 1. 插入排序算法思想\n\n> **插入排序(Insertion Sort)基本思想**:\n>\n> 将数组分为有序区间和无序区间,每次从无序区间取出一个元素插入到有序区间的正确位置。\n\n插入排序通过逐步构建有序序列来实现排序,每次插入后"
},
{
"path": "docs/01_array/01_06_array_shell_sort.md",
"chars": 2763,
"preview": "## 1. 希尔排序算法思想\n\n> **希尔排序(Shell Sort)基本思想**:\n>\n> 通过设定不同的间隔(gap),将数组分组进行插入排序,然后逐步缩小间隔直至为 $1$,最终完成整个数组的排序。\n\n## 2. 希尔排序算法步骤\n"
},
{
"path": "docs/01_array/01_07_array_merge_sort.md",
"chars": 3575,
"preview": "## 1. 归并排序算法思想\n\n> **归并排序(Merge Sort)基本思想**:\n>\n> 利用分治法,将数组递归地一分为二,直至每个子数组只包含一个元素。随后,将这些有序子数组两两合并,最终得到一个整体有序的数组。\n\n## 2. 归并"
},
{
"path": "docs/01_array/01_08_array_quick_sort.md",
"chars": 3738,
"preview": "## 1. 快速排序算法思想\n\n> **快速排序(Quick Sort)基本思想**:\n>\n> 采用分治策略,选择一个基准元素,将数组分为两部分:小于基准的元素放在左侧,大于基准的元素放在右侧。然后递归地对左右两部分进行排序,最终得到有序数"
},
{
"path": "docs/01_array/01_09_array_heap_sort.md",
"chars": 9590,
"preview": "\n\n## 1. 堆结构\n\n「堆排序(Heap sort)」是一种基于「堆结构」实现的高效排序算法。在介绍堆排序之前,我们先来了解什么是堆结构。\n\n### 1.1 堆的定义\n\n> **堆(Heap)**:一种特殊的完全二叉树,具有以下性质之一"
},
{
"path": "docs/01_array/01_10_array_counting_sort.md",
"chars": 2126,
"preview": "## 1. 计数排序算法思想\n\n> **计数排序(Counting Sort)基本思想**:\n>\n> 统计数组中每个元素出现的次数,然后根据统计信息将元素按顺序放置到正确位置,实现排序。\n\n## 2. 计数排序算法步骤\n\n1. **确定数值"
},
{
"path": "docs/01_array/01_11_array_bucket_sort.md",
"chars": 2462,
"preview": "## 1. 桶排序算法思想\n\n> **桶排序(Bucket Sort)**:\n> \n> 将待排序元素分散到多个桶中,对每个桶单独排序后合并。\n\n## 2. 桶排序算法步骤\n\n1. **确定桶的数量**:根据待排序数组的数值范围,将其划分为 "
},
{
"path": "docs/01_array/01_12_array_radix_sort.md",
"chars": 2240,
"preview": "## 1. 基数排序算法思想\n\n> **基数排序(Radix Sort)基本思想**:\n>\n> 按照数字的每一位进行排序,从最低位到最高位,逐位比较。\n\n## 2. 基数排序算法步骤\n\n基数排序算法可以采用「最低位优先法(Least Sig"
},
{
"path": "docs/01_array/01_13_array_binary_search_01.md",
"chars": 4964,
"preview": "## 1. 二分查找算法介绍\n\n### 1.1 算法简介\n\n> **二分查找算法(Binary Search Algorithm)**,又称折半查找或对数查找,是一种在有序数组中高效定位目标元素的方法。其核心思想是每次将查找区间缩小一半,从"
},
{
"path": "docs/01_array/01_14_array_binary_search_02.md",
"chars": 8756,
"preview": "## 1. 二分查找细节\n\n在上一节中,我们已经掌握了二分查找的基本思路和实现代码。然而,在实际解题过程中,二分查找还涉及许多关键细节,常见的有以下几个方面:\n\n1. **区间的开闭选择**:查找区间应采用左闭右闭 $[left, righ"
},
{
"path": "docs/01_array/01_15_array_two_pointers.md",
"chars": 10036,
"preview": "## 1. 双指针简介\n\n> **双指针(Two Pointers)**:在遍历序列时,同时用两个指针协同访问元素,以高效解决问题。常见类型有三种:同序列相向移动的「对撞指针」、同序列同向移动的「快慢指针」、以及分别指向不同序列的「分离双指"
},
{
"path": "docs/01_array/01_16_array_sliding_window.md",
"chars": 7175,
"preview": "## 1. 滑动窗口算法简介\n\n在计算机网络中,滑动窗口协议(Sliding Window Protocol)是传输层进行流控的一种措施,接收方通过通告发送方自己的窗口大小,从而控制发送方的发送速度,从而达到防止发送方发送速度过快而导致自己"
},
{
"path": "docs/01_array/index.md",
"chars": 1808,
"preview": "\n\n::: tip 引 言\n\n数组如同连续砖块砌成的墙。\n\n每一块砖石紧密相依,井然有序,宛如时光的流转,悄然记录着数据的点滴。"
},
{
"path": "docs/02_linked_list/02_01_linked_list_basic.md",
"chars": 8490,
"preview": "## 1. 链表简介\n\n### 1.1 链表定义\n\n> **链表(Linked List)**:一种线性表数据结构,通过一组任意(可连续或不连续)的存储单元,存储同类型数据。\n\n简而言之,**链表** 是线性表的链式存储实现。\n\n以单链表为"
},
{
"path": "docs/02_linked_list/02_02_linked_list_sort.md",
"chars": 2108,
"preview": "## 1. 链表排序简介\n\n链表排序相比数组排序具有独特的挑战性。由于链表 **不支持随机访问**,只能通过 $next$ 指针顺序遍历,这使得某些排序算法在链表上的实现更加复杂。\n\n### 1.1 算法适用性分析\n\n| 适用性 | 排序算"
},
{
"path": "docs/02_linked_list/02_03_linked_list_bubble_sort.md",
"chars": 2083,
"preview": "## 1. 链表冒泡排序算法思想\n\n> **链表冒泡排序基本思想**:\n> \n> **通过相邻节点比较和交换,将最大值逐步「冒泡」到链表末尾**。\n\n与数组冒泡排序类似,但需要处理链表的指针操作。\n\n## 2. 链表冒泡排序算法步骤\n\n链表"
},
{
"path": "docs/02_linked_list/02_04_linked_list_selection_sort.md",
"chars": 2099,
"preview": "## 1. 链表选择排序算法思想\n\n> **链表选择排序基本思想**:\n> \n> 在未排序部分中找到最小元素,然后将其放到已排序部分的末尾。\n\n## 2. 链表选择排序算法步骤\n\n1. **初始化**:使用两个指针 `node_i` 和 `"
},
{
"path": "docs/02_linked_list/02_05_linked_list_insertion_sort.md",
"chars": 3071,
"preview": "\n\n## 1. 链表插入排序基本思想\n\n> **链表插入排序基本思想**:\n> \n> 将链表分为已排序部分和未排序部分,逐个将未排序部分的节点插入到已排序部分的正确位置**。\n\n链表插入排序的算法步骤如下:\n\n1. **初始化**:\n "
},
{
"path": "docs/02_linked_list/02_06_linked_list_merge_sort.md",
"chars": 2883,
"preview": "## 1. 链表归并算法基本思想\n\n> **链表归并排序基本思想**:\n> \n> **采用分治策略,将链表递归分割为更小的子链表,然后两两归并得到有序链表**。\n\n链表归并排序的算法步骤如下:\n\n\n1. **分割阶段**:找到链表的中间节点"
},
{
"path": "docs/02_linked_list/02_07_linked_list_quick_sort.md",
"chars": 2821,
"preview": "## 1. 链表快速排序基本思想\n\n> **链表快速排序基本思想**:\n> \n> 通过选择基准值(pivot)将链表分割为两部分,使得左部分所有节点的值都小于基准值,右部分所有节点的值都大于等于基准值,然后递归地对左右两部分进行排序,最终实"
},
{
"path": "docs/02_linked_list/02_08_linked_list_counting_sort.md",
"chars": 2914,
"preview": "## 1. 链表计数排序基本思想\n\n> **计数排序(Counting Sort)基本思想**:\n> \n> 统计每个元素在序列中出现的次数,然后根据统计结果将元素放回正确的位置。\n\n对于链表结构,计数排序的基本思想是:\n1. **统计阶段*"
},
{
"path": "docs/02_linked_list/02_09_linked_list_bucket_sort.md",
"chars": 4609,
"preview": "## 1. 链表桶排序算法思想\n\n> **桶排序基本思想**:\n> \n> 将数据分散到若干个有序的桶中,每个桶内再单独排序,最后按顺序合并所有桶。\n\n\n## 2. 链表桶排序算法步骤\n\n1. **确定数据范围**:遍历链表找出最大值和最小值"
},
{
"path": "docs/02_linked_list/02_10_linked_list_radix_sort.md",
"chars": 1994,
"preview": "## 1. 链表基数排序算法思想\n\n> **基数排序算法思想**:\n> \n> 从最低位(个位)开始,按照每一位的数字将节点分配到对应的桶中,然后按顺序重新连接\n\n\n## 2. 链表基数排序算法步骤\n\n1. **确定最大位数**:遍历链表找出"
},
{
"path": "docs/02_linked_list/02_11_linked_list_two_pointers.md",
"chars": 7227,
"preview": "## 1. 双指针简介\n\n双指针是链表问题中非常常用且高效的技巧,通过两个指针的配合移动,能够巧妙地解决许多复杂问题。\n\n> **双指针(Two Pointers)**:指在遍历链表时同时使用两个指针,根据移动方式主要分为以下两类:\n> \n"
},
{
"path": "docs/02_linked_list/index.md",
"chars": 1392,
"preview": "\n\n::: tip 引 言\n\n链表如同夜空中串联的星星。\n\n节点相连,如繁星串珠,静静铺展成一条灵动的数据长河。\n:::\n\n##"
},
{
"path": "docs/03_stack_queue_hash_table/03_01_stack_basic.md",
"chars": 9202,
"preview": "## 1. 栈简介\n\n> **栈(Stack)**:也叫做「堆栈」,一种线性表数据结构,只允许在表的一端进行插入和删除操作。\n\n### 1.1 基本概念\n\n我们可以把栈想象成一摞叠放的盘子:\n\n- **栈顶(top)**:可以插入和删除元素"
},
{
"path": "docs/03_stack_queue_hash_table/03_02_monotone_stack.md",
"chars": 8042,
"preview": "## 1. 单调栈简介\n\n> **单调栈(Monotone Stack)**:在栈「先进后出」规则的基础上,要求从 **栈顶** 到 **栈底** 的元素单调递增或单调递减。\n> \n> - **单调递增栈**:从栈顶到栈底元素单调递增\n> "
},
{
"path": "docs/03_stack_queue_hash_table/03_03_queue_basic.md",
"chars": 10582,
"preview": "## 1. 队列简介\n\n> **队列(Queue)**:一种线性表数据结构,遵循「先进先出(FIFO)」原则,只允许在一端插入元素(队尾),在另一端删除元素(队头)。\n\n### 1.1 基本概念\n\n- **队尾(rear)**:允许插入元素"
},
{
"path": "docs/03_stack_queue_hash_table/03_04_priority_queue.md",
"chars": 8232,
"preview": "## 1. 优先队列简介\n\n> **优先队列(Priority Queue)**:是一种为每个元素分配优先级的特殊队列结构。每次访问或移除元素时,总是优先处理优先级最高的元素。\n\n优先队列与普通队列的核心区别在于 **出队顺序**:\n\n- "
},
{
"path": "docs/03_stack_queue_hash_table/03_05_bidirectional_queue.md",
"chars": 9420,
"preview": "## 1. 双向队列简介\n\n> **双向队列(Deque,Double-Ended Queue)**:一种线性表数据结构,允许在队列的两端进行插入和删除操作,既可以从队头入队/出队,也可以从队尾入队/出队。\n\n### 1.1 基本概念\n\n双"
},
{
"path": "docs/03_stack_queue_hash_table/03_06_hash_table.md",
"chars": 6651,
"preview": "## 1. 哈希表简介\n\n> **哈希表(Hash Table)**,又称散列表,是一种能通过关键码(Key)直接访问数据的结构。\n>\n> 哈希表利用「键 $key$」和「哈希函数 $Hash(key)$」将关键码映射到表中的某个位置,从而"
},
{
"path": "docs/03_stack_queue_hash_table/index.md",
"chars": 851,
"preview": "\n\n::: tip 引 言\n\n栈如杯中叠盘,盘盘相扣,取放皆自上,后进先出。\n\n队列如河中行舟,前舟先行,后舟继发,川流不息。\n"
},
{
"path": "docs/04_string/04_01_string_basic.md",
"chars": 9316,
"preview": "## 1. 字符串简介\n\n> **字符串(String)**:简称为串,由零个或多个字符组成的有限序列,常记为 $s = a_1a_2…a_n(0 \\le n \\lneqq\t \\infty)$。\n\n### 1.1 字符串常见概念\n\n- **"
},
{
"path": "docs/04_string/04_02_string_brute_force.md",
"chars": 2972,
"preview": "## 1. Brute Force 算法介绍\n\n> **Brute Force 算法**:简称为 BF 算法,也可以叫做「朴素匹配算法」。\n> \n> - **Brute Force 算法核心思想**:将模式串 $p$ 依次与文本串 $T$ "
},
{
"path": "docs/04_string/04_03_string_rabin_karp.md",
"chars": 5001,
"preview": "## 1. Rabin Karp 算法介绍\n\n> **Rabin Karp(RK)算法**:由 Michael Oser Rabin 与 Richard Manning Karp 于 1987 年提出,是一种利用哈希快速筛查匹配起点的单模式"
},
{
"path": "docs/04_string/04_04_string_kmp.md",
"chars": 7707,
"preview": "## 1. KMP 算法介绍\n\n> **KMP 算法**(全称 **Knuth-Morris-Pratt 算法**):由 Donald Knuth、James H. Morris 和 Vaughan Pratt 三位学者于 1977 年联合"
},
{
"path": "docs/04_string/04_05_string_boyer_moore.md",
"chars": 13089,
"preview": "## 1. Boyer Moore 算法介绍\n\n> **Boyer Moore 算法(BM 算法)**:由 Robert S. Boyer 和 J Strother Moore 于 1977 年提出,是一种高效的字符串搜索算法,实际应用中通"
},
{
"path": "docs/04_string/04_06_string_horspool.md",
"chars": 5171,
"preview": "## 1. Horspool 算法介绍\n\n> **Horspool 算法**:由 Nigel Horspool 教授于 1980 年提出,是对 Boyer Moore 算法的简化版,用于在字符串中查找子串。\n>\n> - **Horspool"
},
{
"path": "docs/04_string/04_07_string_sunday.md",
"chars": 5801,
"preview": "## 1. Sunday 算法介绍\n\n> **Sunday 算法**:Sunday 算法是一种高效的字符串查找算法,由 Daniel M. Sunday 于 1990 年提出,专门用于在主串中查找子串的位置。\n>\n> - **核心思想**:"
},
{
"path": "docs/04_string/04_08_trie.md",
"chars": 9152,
"preview": "## 1. 字典树介绍\n\n> **字典树(Trie)**,又称前缀树,是一种高效存储和查找字符串集合的树形结构。可以把它想象成一本「分层字典」:每个单词从根节点出发,按字母顺序一层层分支,直到单词结尾。具有相同前缀的单词会在树上共用同一条路"
},
{
"path": "docs/04_string/04_09_ac_automaton.md",
"chars": 7615,
"preview": "## 1. AC 自动机简介\n\n> **AC 自动机(Aho-Corasick Automaton)**:由 Alfred V. Aho 和 Margaret J. Corasick 于 1975 年在贝尔实验室提出,是最著名的多模式匹配算"
},
{
"path": "docs/04_string/04_10_suffix_array.md",
"chars": 2505,
"preview": "## 1. 后缀数组简介\n\n> **后缀数组(Suffix Array)**:是一种高效处理字符串后缀相关问题的数据结构。它将字符串的所有后缀按字典序排序,并记录每个后缀在原串中的起始位置,便于实现高效的子串查找、最长重复子串、最长公共子串"
},
{
"path": "docs/04_string/index.md",
"chars": 1158,
"preview": "\n\n::: tip 引 言\n\n字符串如同夜色中流淌的音符。\n\n如清风拂过琴弦,谱写数据的旋律与梦想。\n:::\n\n## 本章内容\n"
},
{
"path": "docs/05_tree/05_01_tree_basic.md",
"chars": 6539,
"preview": "## 1. 树\n\n### 1.1 树的定义\n\n> **树(Tree)**:由 $n \\ge 0$ 个节点及其相互之间的关系组成的有限集合。当 $n = 0$ 时称为空树,$n > 0$ 时称为非空树。\n\n之所以称为「树」,是因为这种数据结构"
},
{
"path": "docs/05_tree/05_02_binary_tree_traverse.md",
"chars": 11492,
"preview": "## 1. 二叉树的遍历简介\n\n> **二叉树的遍历**:是指从根节点出发,按照特定顺序依次访问二叉树中的所有节点,确保每个节点被且仅被访问一次。\n\n在实际应用中,常常需要按照一定的顺序访问二叉树的每个节点,以便查找特定节点或处理全部节点。"
},
{
"path": "docs/05_tree/05_03_binary_tree_reduction.md",
"chars": 7363,
"preview": "## 1. 二叉树的还原简介\n\n> **二叉树的还原**:指通过已知的二叉树遍历序列,重建出原始的二叉树结构。\n\n我们知道,对于一棵非空二叉树,其前序、中序、后序遍历序列都是唯一的。但反过来,如果只给出某一种遍历序列,是否能唯一确定这棵二叉"
},
{
"path": "docs/05_tree/05_04_binary_search_tree.md",
"chars": 8499,
"preview": "## 1. 二叉搜索树简介\n\n> **二叉搜索树(Binary Search Tree, BST)**,又称二叉查找树、有序二叉树或排序二叉树,是一种特殊的二叉树结构,满足以下性质:\n>\n> - 对于任意节点,如果其左子树非空,则左子树所有"
},
{
"path": "docs/05_tree/05_05_segment_tree_01.md",
"chars": 13665,
"preview": "## 1. 线段树简介\n\n### 1.1 线段树的定义\n\n> **线段树(Segment Tree)**:一种用于高效处理区间查询和区间修改的二叉树结构。它将一个区间不断二分,每个节点管理一个区间,叶子节点对应单个元素,内部节点则代表其子区"
},
{
"path": "docs/05_tree/05_06_segment_tree_02.md",
"chars": 7646,
"preview": "## 1. 线段树常见题型\n\n线段树是一种高效的数据结构,常用于处理区间相关的查询与修改。以下是线段树常见的几类题型及其简要说明:\n\n### 1.1 区间最大 / 最小值查询(RMQ)\n\n> **RMQ(Range Maximum / Mi"
},
{
"path": "docs/05_tree/05_07_binary_indexed_tree.md",
"chars": 5059,
"preview": "## 1. 树状数组简介\n\n### 1.1 树状数组的定义\n\n> **树状数组(Binary Indexed Tree)**:也因其发明者命名为 Fenwick 树,最早 Peter M. Fenwick 于 1994 年以 A New D"
},
{
"path": "docs/05_tree/05_08_union_find.md",
"chars": 18445,
"preview": "## 1. 并查集简介\n\n### 1.1 并查集的定义\n\n> **并查集(Union Find)**:一种高效的数据结构,常用于处理若干不相交集合(Disjoint Sets)的合并与查询操作。不相交集合指的是元素互不重叠的集合族。\n>\n>"
},
{
"path": "docs/05_tree/index.md",
"chars": 938,
"preview": "\n\n::: tip 引 言\n\n树如同大地上拔节生长的脉络。\n\n枝叶纵横,层层递进,信息在脉络间流转,万物由此相连。\n:::\n\n#"
},
{
"path": "docs/06_graph/06_01_graph_basic.md",
"chars": 4809,
"preview": "## 1. 图的定义\n\n> **图(Graph)**:由顶点集合 $V$ 和边集合 $E$(即顶点之间的连接关系)组成的数据结构,通常记作 $G = (V, E)$。\n\n- **顶点(Vertex)**:图的基本单元,表示对象或节点。顶点集"
},
{
"path": "docs/06_graph/06_02_graph_structure.md",
"chars": 16233,
"preview": "## 1. 图的存储结构\n\n图是一种由顶点和边构成的复杂数据结构,通常包含若干(有限个)顶点,任意两个顶点之间都可能通过边相连。在实现图的存储时,关键在于如何高效地表示顶点与边之间的关系。\n\n常见的图存储方式主要分为「顺序存储结构」和「链式"
},
{
"path": "docs/06_graph/06_03_graph_dfs.md",
"chars": 9810,
"preview": "## 1. 深度优先搜索简介\n\n> **深度优先搜索算法(Depth First Search,简称 DFS)**:是一种用于遍历或搜索树、图等结构的经典算法。其核心思想是「沿一条路径尽可能深入」,遇到无法继续的节点时再回溯到上一个分叉点,"
},
{
"path": "docs/06_graph/06_04_graph_bfs.md",
"chars": 7798,
"preview": "## 1. 广度优先搜索简介\n\n> **广度优先搜索算法(Breadth First Search,简称 BFS)**:是一种用于遍历或搜索树、图等结构的经典算法。BFS 从起始节点出发,按照层级逐步向外扩展,优先访问距离起点较近的节点,再"
},
{
"path": "docs/06_graph/06_05_graph_topological_sorting.md",
"chars": 7977,
"preview": "## 1. 拓扑排序简介\n\n> **拓扑排序(Topological Sorting)**:是一种针对有向无环图(DAG)的排序方法。它将图中的所有顶点排成一个线性序列,使得对于任意一条有向边 $<u, v>$,顶点 $u$ 都排在顶点 $"
},
{
"path": "docs/06_graph/06_06_graph_minimum_spanning_tree.md",
"chars": 6492,
"preview": "## 1. 最小生成树的定义\n\n在介绍「最小生成树」之前,先来理解什么是「生成树」。\n\n> **生成树(Spanning Tree)**:对于一个无向连通图 $G$,如果它的一个子图既包含 $G$ 的所有顶点,又是一棵树(即连通且无环),那"
},
{
"path": "docs/06_graph/06_07_graph_shortest_path_01.md",
"chars": 6084,
"preview": "## 1. 单源最短路径简介\n\n> **单源最短路径(Single Source Shortest Path)**:在一个带权图 $G = (V, E)$ 中,给定一个起点(源点)$v$,找到从这个源点出发,到图中其他所有顶点的最短路径长度"
},
{
"path": "docs/06_graph/06_08_graph_shortest_path_02.md",
"chars": 5279,
"preview": "## 1. Bellman-Ford 算法\n\n### 1.1 Bellman-Ford 算法的核心思想\n\n> **Bellman-Ford 算法**:一种可以处理带有负权边的单源最短路径算法,还能检测图中是否存在负权环。\n\nBellman-"
},
{
"path": "docs/06_graph/06_09_graph_multi_source_shortest_path.md",
"chars": 6034,
"preview": "## 1. 多源最短路径简介\n\n> **多源最短路径(All-Pairs Shortest Paths)**:指的是在一个带权图 $G = (V, E)$ 中,计算任意两个顶点之间的最短路径长度。\n\n多源最短路径问题的本质,就是要找出图中每"
},
{
"path": "docs/06_graph/06_10_graph_the_second_shortest_path.md",
"chars": 3951,
"preview": "## 1. 次短路径简介\n\n> **次短路径(Second Shortest Path)**:指从起点到终点的所有简单路径中,路径总权值严格大于最短路径、且在此条件下最小的那条路径。\n\n次短路径的本质,是在所有从起点到终点的路径中,找到一条"
},
{
"path": "docs/06_graph/06_11_graph_bipartite_basic.md",
"chars": 2073,
"preview": "## 1. 二分图简介\n\n> **二分图(Bipartite Graph)**:又称「二部图」,是一类特殊的无向图。其顶点集可以被划分为两个互不重叠的子集,且所有边仅连接这两个子集之间的顶点,同一子集内的顶点之间没有边相连。\n\n直观地说,就"
},
{
"path": "docs/06_graph/06_12_graph_bipartite_matching.md",
"chars": 10835,
"preview": "## 1. 二分图最大匹配简介\n\n> **二分图最大匹配(Maximum Bipartite Matching)**:图论中的一个基础且重要的问题。其目标是在一个二分图中,找到一组两两不相交的边,使得被匹配的点对数量最大。\n\n- **匹配*"
},
{
"path": "docs/06_graph/index.md",
"chars": 1457,
"preview": "\n\n::: tip 引 言\n\n图如同无垠夜空中繁星交织成的瑰丽星网。\n\n点点星光闪烁,彼此相连,交织成一张神秘而浪漫的梦幻之网,"
},
{
"path": "docs/07_algorithm/07_01_enumeration_algorithm.md",
"chars": 5200,
"preview": "## 1. 枚举算法简介\n\n> **枚举算法(Enumeration Algorithm)**,又称穷举算法,是指根据问题的特点,逐一列出所有可能的解,并与目标条件进行比较,找出满足要求的答案。枚举时要确保不遗漏、不重复。\n\n枚举算法的核心"
},
{
"path": "docs/07_algorithm/07_02_recursive_algorithm.md",
"chars": 8339,
"preview": "## 1. 递归简介\n\n> **递归(Recursion)**:是一种将复杂问题分解为与原问题结构相同的子问题,并通过重复求解这些子问题来获得最终解答的方法。在大多数编程语言中,递归通常通过函数自身的调用来实现。\n\n以阶乘为例,数学定义如下"
},
{
"path": "docs/07_algorithm/07_03_divide_and_conquer_algorithm.md",
"chars": 7751,
"preview": "## 1. 分治算法简介\n\n### 1.1 分治算法的定义\n\n> **分治算法(Divide and Conquer)**:即「分而治之」,把一个复杂问题拆分成多个相同或相似的子问题,递归分解,直到子问题足够简单可以直接解决,最后将子问题的"
},
{
"path": "docs/07_algorithm/07_04_backtracking_algorithm.md",
"chars": 13962,
"preview": "## 1. 回溯算法简介\n\n> **回溯算法(Backtracking)**:回溯算法是一种系统地搜索所有可能解的算法,通过递归和试错的方式逐步构建解的过程。当发现当前路径无法满足题目要求或无法得到有效解时,算法会撤销上一步的选择(即「回溯"
},
{
"path": "docs/07_algorithm/07_05_greedy_algorithm.md",
"chars": 7716,
"preview": "## 1. 贪心算法简介\n\n### 1.1 贪心算法的定义\n\n> **贪心算法(Greedy Algorithm)**:每一步都选择当前最优(看起来最好的)方案,期望通过一系列局部最优,最终获得全局最优解。\n\n贪心算法的核心思想是:将问题分"
},
{
"path": "docs/07_algorithm/07_06_bit_operation.md",
"chars": 12715,
"preview": "## 1. 位运算简介\n\n### 1.1 位运算与二进制基础\n\n> **位运算(Bit Operation)**:计算机内部所有数据均以「二进制(Binary)」形式存储。位运算是直接对二进制位进行操作的运算方式,能够极大提升程序的执行效率"
},
{
"path": "docs/07_algorithm/index.md",
"chars": 887,
"preview": "\n\n::: tip 引 言\n\n算法如梦中星河,闪烁着智慧的光芒:\n\n枚举如夜空点点,耐心数尽每一颗星辰;\n\n递归如山谷回音,层层"
},
{
"path": "docs/08_dynamic_programming/08_01_dynamic_programming_basic.md",
"chars": 8092,
"preview": "## 1. 动态规划简介\n\n### 1.1 动态规划的定义\n\n> **动态规划(Dynamic Programming,DP)**:是一种求解多阶段决策过程最优化问题的方法。在动态规划中,通过把原问题分解为相对简单的子问题,先求解子问题,再"
},
{
"path": "docs/08_dynamic_programming/08_02_memoization_search.md",
"chars": 7405,
"preview": "## 1. 记忆化搜索简介\n\n>**记忆化搜索(Memoization Search)**:是一种通过存储已经遍历过的状态信息,从而避免对同一状态重复遍历的搜索算法。\n\n记忆化搜索是动态规划的一种实现方式。在记忆化搜索中,当算法需要计算某个"
},
{
"path": "docs/08_dynamic_programming/08_03_linear_dp_01.md",
"chars": 12057,
"preview": "## 1. 线性动态规划简介\n\n> **线性动态规划(线性 DP)**:指的是将问题的阶段按线性顺序划分,并基于此进行状态转移的动态规划方法。如下图所示:\n\n$」到达「$(i, j)$」的最优解(如最小路径和、最大路径和等)"
},
{
"path": "docs/08_dynamic_programming/08_06_knapsack_problem_01.md",
"chars": 8171,
"preview": "## 1. 背包问题简介\n\n### 1.1 背包问题的定义\n\n> **背包问题**:背包问题是线性 DP 问题中一类经典模型。其基本描述为:给定若干物品,每种物品有各自的重量、价值和数量限制,以及一个最大承重为 $W$ 的背包。要求在不超过"
},
{
"path": "docs/08_dynamic_programming/08_07_knapsack_problem_02.md",
"chars": 8854,
"preview": "## 1. 完全背包问题简介\n\n> **完全背包问题**:给定 $n$ 种物品和一个最大承重为 $W$ 的背包。每种物品的重量为 $weight[i]$,价值为 $value[i]$,且每种物品的数量不限。请问在不超过背包承重上限的前提下,"
},
{
"path": "docs/08_dynamic_programming/08_08_knapsack_problem_03.md",
"chars": 7036,
"preview": "## 1. 多重背包问题简介\n\n> **多重背包问题**:有 $n$ 种物品和一个最多能装重量为 $W$ 的背包,第 $i$ 种物品的重量为 $weight[i]$,价值为 $value[i]$,件数为 $count[i]$。请问在总重量不"
},
{
"path": "docs/08_dynamic_programming/08_09_knapsack_problem_04.md",
"chars": 11749,
"preview": "## 1. 混合背包问题简介\n\n> **混合背包问题**:有 $n$ 种物品和一个最多能装重量为 $W$ 的背包,第 $i$ 种物品的重量为 $weight[i]$,价值为 $value[i]$,件数为 $count[i]$。其中:\n>\n>"
},
{
"path": "docs/08_dynamic_programming/08_10_knapsack_problem_05.md",
"chars": 12354,
"preview": "## 1. 求恰好装满背包的最大价值\n\n> **背包问题求恰好装满背包的最大价值**:在给定背包重量 $W$,每件物品重量 $weight[i]$,物品间相互关系(分组、依赖等)的背包问题中,请问在恰好装满背包的情况下,能装入背包的最大价值"
},
{
"path": "docs/08_dynamic_programming/08_11_interval_dp.md",
"chars": 7398,
"preview": "## 1. 区间动态规划简介\n\n> **区间动态规划(区间 DP)**:是一类以区间为阶段、以区间的左右端点为状态的动态规划方法。它常用于解决「在一段区间内进行某种操作,使得总代价最小或总价值最大」这类问题。区间 DP 的核心思想是:先解决"
},
{
"path": "docs/08_dynamic_programming/08_12_tree_dp.md",
"chars": 11920,
"preview": "## 1. 树形动态规划简介\n\n> **树形动态规划**:简称为「树形 DP」,是一种在树形结构上进行推导的动态规划方法。如下图所示,树形 DP 的求解过程一般以节点从深到浅(子树从小到大)的顺序作为动态规划的「阶段」。在树形 DP 中,第"
},
{
"path": "docs/08_dynamic_programming/08_13_state_compression_dp.md",
"chars": 9063,
"preview": "## 1. 状态压缩动态规划简介\n\n> **状态压缩动态规划(状压 DP)**:是一种适用于「小规模数据」的数组或字符串问题的动态规划方法。它利用二进制的特性,将集合的选取状态压缩为一个整数,通过位运算实现高效的状态表示与转移。\n\n在「位运"
},
{
"path": "docs/08_dynamic_programming/08_14_counting_dp.md",
"chars": 4517,
"preview": "## 1. 计数类 DP 简介\n\n### 1.1 计数问题简介\n\n> **计数问题**:计算满足特定条件下的可行方案数目的问题。\n\n这里的「可行方案数目」指的是某个问题一共有多少种方法。\n\n「计数问题」本身是组合数学中的重要内容,这类问题通"
},
{
"path": "docs/08_dynamic_programming/08_15_digit_dp.md",
"chars": 11017,
"preview": "## 1. 数位 DP 简介\n\n### 1.1 数位 DP 简介\n\n> **数位动态规划**:简称为「数位 DP」,是一种与数位相关的一类计数类动态规划问题,即在数位上进行动态规划。这里的数位指的是个位、十位、百位、千位等。\n\n数位 DP "
},
{
"path": "docs/08_dynamic_programming/08_16_probability_dp.md",
"chars": 2505,
"preview": "## 1. 概率 DP 简介\n\n> **概率 DP**:一类使用动态规划方法来求解概率与期望的问题,也可以分别叫做「概率 DP」、「期望 DP」。由于概率和期望具有线性性质,使得可以在概率和期望之间建立一定的递推关系,从而通过动态规划的方式"
},
{
"path": "docs/08_dynamic_programming/index.md",
"chars": 2081,
"preview": "\n\n::: tip 引 言\n\n动态规划如同在迷雾中铺设星光小径。\n\n循着昨日星辰的余晖,步步生辉,终将抵达最璀璨的彼岸。\n:::"
},
{
"path": "docs/README.md",
"chars": 2562,
"preview": "<div align='center'>\n <img src=\"https://qcdn.itcharge.cn/images/20250925092713.png\" alt=\"alt text\" width=\"100%\"/>\n "
},
{
"path": "docs/others/index.md",
"chars": 176,
"preview": "## 本章内容\n\n- [待办清单](https://github.com/ITCharge/AlgoNote/tree/main/docs/others/todo_list.md)\n- [网站时间线](https://github.com/"
},
{
"path": "docs/others/todo_list.md",
"chars": 421,
"preview": "## 内容优化\n\n- 借助 DeepSeek 优化全书内容(高优先级)\n - 单调栈文章内容优化\n - 双向队列文章内容优化 \n - 后缀数组文章内容优化\n - 树状数组文章内容优化\n - 第 8 章 动态规划章节优化"
},
{
"path": "docs/others/update_time.md",
"chars": 5768,
"preview": "## 2026-01\n\n- 2026-01-16 **完成「第 1 ~ 1000 题」的题目解析**\n- 2026-01-15 补充第 600 ~ 699 题的题目解析(增加 3 道题)\n- 2026-01-12 补充第 600 ~ 699"
},
{
"path": "docs/solutions/0001-0099/3sum-closest.md",
"chars": 1913,
"preview": "# [0016. 最接近的三数之和](https://leetcode.cn/problems/3sum-closest/)\n\n- 标签:数组、双指针、排序\n- 难度:中等\n\n## 题目链接\n\n- [0016. 最接近的三数之和 - 力扣]"
},
{
"path": "docs/solutions/0001-0099/3sum.md",
"chars": 2059,
"preview": "# [0015. 三数之和](https://leetcode.cn/problems/3sum/)\n\n- 标签:数组、双指针、排序\n- 难度:中等\n\n## 题目链接\n\n- [0015. 三数之和 - 力扣](https://leetcod"
},
{
"path": "docs/solutions/0001-0099/4sum.md",
"chars": 2649,
"preview": "# [0018. 四数之和](https://leetcode.cn/problems/4sum/)\n\n- 标签:数组、双指针、排序\n- 难度:中等\n\n## 题目链接\n\n- [0018. 四数之和 - 力扣](https://leetcod"
},
{
"path": "docs/solutions/0001-0099/add-binary.md",
"chars": 835,
"preview": "# [0067. 二进制求和](https://leetcode.cn/problems/add-binary/)\n\n- 标签:位运算、数学、字符串、模拟\n- 难度:简单\n\n## 题目链接\n\n- [0067. 二进制求和 - 力扣](htt"
},
{
"path": "docs/solutions/0001-0099/add-two-numbers.md",
"chars": 1371,
"preview": "# [0002. 两数相加](https://leetcode.cn/problems/add-two-numbers/)\n\n- 标签:递归、链表、数学\n- 难度:中等\n\n## 题目链接\n\n- [0002. 两数相加 - 力扣](https"
},
{
"path": "docs/solutions/0001-0099/binary-tree-inorder-traversal.md",
"chars": 2105,
"preview": "# [0094. 二叉树的中序遍历](https://leetcode.cn/problems/binary-tree-inorder-traversal/)\n\n- 标签:栈、树、深度优先搜索、二叉树\n- 难度:简单\n\n## 题目链接\n\n-"
},
{
"path": "docs/solutions/0001-0099/climbing-stairs.md",
"chars": 2228,
"preview": "# [0070. 爬楼梯](https://leetcode.cn/problems/climbing-stairs/)\n\n- 标签:记忆化搜索、数学、动态规划\n- 难度:简单\n\n## 题目链接\n\n- [0070. 爬楼梯 - 力扣](ht"
},
{
"path": "docs/solutions/0001-0099/combination-sum-ii.md",
"chars": 2002,
"preview": "# [0040. 组合总和 II](https://leetcode.cn/problems/combination-sum-ii/)\n\n- 标签:数组、回溯\n- 难度:中等\n\n## 题目链接\n\n- [0040. 组合总和 II - 力扣]"
},
{
"path": "docs/solutions/0001-0099/combination-sum.md",
"chars": 3217,
"preview": "# [0039. 组合总和](https://leetcode.cn/problems/combination-sum/)\n\n- 标签:数组、回溯\n- 难度:中等\n\n## 题目链接\n\n- [0039. 组合总和 - 力扣](https://"
},
{
"path": "docs/solutions/0001-0099/combinations.md",
"chars": 1086,
"preview": "# [0077. 组合](https://leetcode.cn/problems/combinations/)\n\n- 标签:回溯\n- 难度:中等\n\n## 题目链接\n\n- [0077. 组合 - 力扣](https://leetcode.c"
},
{
"path": "docs/solutions/0001-0099/container-with-most-water.md",
"chars": 1623,
"preview": "# [0011. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/)\n\n- 标签:贪心、数组、双指针\n- 难度:中等\n\n## 题目链接\n\n- [0011. 盛最"
},
{
"path": "docs/solutions/0001-0099/count-and-say.md",
"chars": 916,
"preview": "# [0038. 外观数列](https://leetcode.cn/problems/count-and-say/)\n\n- 标签:字符串\n- 难度:中等\n\n## 题目链接\n\n- [0038. 外观数列 - 力扣](https://leet"
},
{
"path": "docs/solutions/0001-0099/decode-ways.md",
"chars": 1945,
"preview": "# [0091. 解码方法](https://leetcode.cn/problems/decode-ways/)\n\n- 标签:字符串、动态规划\n- 难度:中等\n\n## 题目链接\n\n- [0091. 解码方法 - 力扣](https://l"
},
{
"path": "docs/solutions/0001-0099/divide-two-integers.md",
"chars": 1385,
"preview": "# [0029. 两数相除](https://leetcode.cn/problems/divide-two-integers/)\n\n- 标签:位运算、数学\n- 难度:中等\n\n## 题目链接\n\n- [0029. 两数相除 - 力扣](htt"
},
{
"path": "docs/solutions/0001-0099/edit-distance.md",
"chars": 3157,
"preview": "# [0072. 编辑距离](https://leetcode.cn/problems/edit-distance/)\n\n- 标签:字符串、动态规划\n- 难度:困难\n\n## 题目链接\n\n- [0072. 编辑距离 - 力扣](https:/"
},
{
"path": "docs/solutions/0001-0099/find-first-and-last-position-of-element-in-sorted-array.md",
"chars": 1546,
"preview": "# [0034. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/)\n\n"
},
{
"path": "docs/solutions/0001-0099/find-the-index-of-the-first-occurrence-in-a-string.md",
"chars": 11382,
"preview": "# [0028. 找出字符串中第一个匹配项的下标](https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string/)\n\n- 标签:双指针、字符"
},
{
"path": "docs/solutions/0001-0099/first-missing-positive.md",
"chars": 1456,
"preview": "# [0041. 缺失的第一个正数](https://leetcode.cn/problems/first-missing-positive/)\n\n- 标签:数组、哈希表\n- 难度:困难\n\n## 题目链接\n\n- [0041. 缺失的第一个正"
},
{
"path": "docs/solutions/0001-0099/generate-parentheses.md",
"chars": 2853,
"preview": "# [0022. 括号生成](https://leetcode.cn/problems/generate-parentheses/)\n\n- 标签:字符串、回溯算法\n- 难度:中等\n\n## 题目链接\n\n- [0022. 括号生成 - 力扣]("
},
{
"path": "docs/solutions/0001-0099/gray-code.md",
"chars": 1386,
"preview": "# [0089. 格雷编码](https://leetcode.cn/problems/gray-code/)\n\n- 标签:位运算、数学、回溯\n- 难度:中等\n\n## 题目链接\n\n- [0089. 格雷编码 - 力扣](https://le"
},
{
"path": "docs/solutions/0001-0099/group-anagrams.md",
"chars": 738,
"preview": "# [0049. 字母异位词分组](https://leetcode.cn/problems/group-anagrams/)\n\n- 标签:数组、哈希表、字符串、排序\n- 难度:中等\n\n## 题目链接\n\n- [0049. 字母异位词分组 -"
},
{
"path": "docs/solutions/0001-0099/index.md",
"chars": 11251,
"preview": "## 本章内容\n\n- [0001. 两数之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/two-sum.md)\n- [0002. 两数相"
}
]
// ... and 1314 more files (download for full content)
About this extraction
This page contains the full source code of the itcharge/AlgoNote GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 1514 files (4.0 MB), approximately 1.1M tokens, and a symbol index with 429 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.