Showing preview only (5,375K chars total). Download the full file or copy to clipboard to get everything.
Repository: kakao/recoteam
Branch: master
Commit: 65fc78e25cd1
Files: 119
Total size: 5.0 MB
Directory structure:
gitextract_mz78veiu/
├── README.md
├── docs/
│ └── arena/
│ ├── brunch.html
│ ├── common.css
│ ├── index.html
│ ├── melon-en.html
│ └── melon.html
├── onboarding/
│ └── README.md
├── paper_review/
│ ├── README.md
│ ├── recsys/
│ │ └── recsys2021/
│ │ ├── "Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface.md
│ │ ├── Accordion- a Trainable Simulator for Long-Term Interactive Systems.md
│ │ ├── Burst-induced Multi-Armed Bandit for Learning Recommendation.md
│ │ ├── Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders.md
│ │ ├── Debiased Explainable Pairwise Ranking from Implicit Feedback.md
│ │ ├── Evaluating Off-Policy Evaluation- Sensitivity and Robustness.md
│ │ ├── Follow the guides- disentangling human and algorithmic curation in online music consumption.md
│ │ ├── I want to break free! Recommending friends from outside the echo chamber.md
│ │ ├── Local Factor Models for Large-Scale Inductive Recommendation.md
│ │ ├── Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All.md
│ │ ├── Mitigating Confounding Bias in Recommendation via Information Bottleneck.md
│ │ ├── Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher.md
│ │ ├── Next-item Recommendations in Short Sessions.md
│ │ ├── ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation.md
│ │ ├── RecSys2021.md
│ │ ├── Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?.md
│ │ ├── Semi-Supervised Visual Representation Learning for Fashion Compatibility.md
│ │ ├── Shared Neural Item Representation for Completely Cold Start Problem.md
│ │ ├── Sparse Feature Factorization for Recommender Systems with Knowledge Graphs.md
│ │ ├── The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender.md
│ │ ├── Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations.md
│ │ ├── Top-K Contextual Bandits with Equity of Exposure.md
│ │ ├── Toward Unified Metrics for Accuracy and Diversity for Recommender Systems.md
│ │ ├── Towards Source-Aligned Variational Models for Cross-Domain Recommendation.md
│ │ ├── Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation.md
│ │ └── Values of Exploration in Recommender Systems.md
│ └── topics/
│ ├── Algorithmic Advances.md
│ ├── Applications-Driven Advances.md
│ ├── Bandits and Reinforcement Learning.md
│ ├── Echo Chambers and Filter Bubbles.md
│ ├── Interactive Recommendation.md
│ ├── Language and Knowledge.md
│ ├── Metrics and Evaluation.md
│ ├── Practical Issues.md
│ ├── Privacy, Fairness, Bias.md
│ ├── Real-World Concerns.md
│ ├── Scalable Performance.md
│ ├── Theory and Practice.md
│ └── Users in Focus.md
├── presentations/
│ └── README.md
├── programming_assignments/
│ ├── beale_ciphers/
│ │ ├── README.md
│ │ ├── interview.md
│ │ ├── solution/
│ │ │ ├── solve.cpp
│ │ │ ├── solve.java
│ │ │ └── solve.py
│ │ └── testcase/
│ │ ├── README.md
│ │ ├── large/
│ │ │ ├── test1.in
│ │ │ ├── test1.out
│ │ │ ├── test3.in
│ │ │ ├── test3.out
│ │ │ ├── test5.in
│ │ │ ├── test5.out
│ │ │ ├── test7.in
│ │ │ ├── test7.out
│ │ │ ├── test9.in
│ │ │ └── test9.out
│ │ └── small/
│ │ ├── sample.in
│ │ ├── sample.out
│ │ ├── test0.in
│ │ ├── test0.out
│ │ ├── test10.in
│ │ ├── test10.out
│ │ ├── test11.in
│ │ ├── test11.out
│ │ ├── test12.in
│ │ ├── test12.out
│ │ ├── test13.in
│ │ ├── test13.out
│ │ ├── test14.in
│ │ ├── test14.out
│ │ ├── test2.in
│ │ ├── test2.out
│ │ ├── test4.in
│ │ ├── test4.out
│ │ ├── test6.in
│ │ ├── test6.out
│ │ ├── test8.in
│ │ └── test8.out
│ ├── jukebox/
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── listen_count.txt
│ │ └── solution/
│ │ ├── 1. 데이터 전처리.ipynb
│ │ ├── 2-1. Shallow AutoEncoder.ipynb
│ │ ├── 2-2. EASE^R.ipynb
│ │ ├── 3. (optional) Implicit을 이용한 Jukebox 풀이.ipynb
│ │ ├── README.md
│ │ └── code_using_ease/
│ │ ├── evaluate.py
│ │ ├── evaluation/
│ │ │ ├── Evaluate.py
│ │ │ ├── user_id.txt
│ │ │ └── validation_data.txt
│ │ ├── recommend_with_ease.py
│ │ └── recommend_with_sgd.py
│ └── mini_reco/
│ ├── README.md
│ ├── evaluation.py
│ ├── interview.md
│ ├── solution/
│ │ └── solution.py
│ └── testcase/
│ ├── input/
│ │ ├── input000.txt
│ │ ├── input001.txt
│ │ ├── input002.txt
│ │ ├── input003.txt
│ │ ├── input004.txt
│ │ ├── input005.txt
│ │ └── input006.txt
│ └── output/
│ ├── output000.txt
│ ├── output001.txt
│ ├── output002.txt
│ ├── output003.txt
│ ├── output004.txt
│ ├── output005.txt
│ └── output006.txt
└── publications/
└── sigir2023-update-period/
└── README.md
================================================
FILE CONTENTS
================================================
================================================
FILE: README.md
================================================
# 카카오 추천팀
## 소개
카카오 추천팀은 카카오의 다양한 서비스에 추천 기술을 제공하고 있습니다.
추천팀에서는 아래와 같은 업무를 하고 있습니다.
- 추천 기술 고도화 (방향: 사용자의 장기적인 서비스 만족도 증가)
- 추천/ML SaaS 플랫폼 개발 (방향: 높은 품질의 추천 기술을 쉽게 가져다 사용할 수 있는 플랫폼)
- 대규모 추천 서비스를 지탱할 수 있는 안정적이고 효율적인 플랫폼 구축
저희에게 궁금한 점이나 하고 싶은 이야기가 있다면 [Discussions](https://github.com/kakao/recoteam/discussions)를 이용해주세요.
## 영입 지원 링크
(현재는 진행 중인 영입 공고가 없습니다.)
## 영입 기출 문제
추천팀 영입 과정에서 실제로 사용했던 기출 문제입니다.
- [Mini Reco](programming_assignments/mini_reco)
- [Jukebox](programming_assignments/jukebox)
- [Beale Ciphers](programming_assignments/beale_ciphers)
## 오픈소스
추천팀에서 공개한 오픈소스 소프트웨어입니다.
- [TOROS Buffalo](https://github.com/kakao/buffalo) - A fast and scalable production-ready open source project for recommender systems
- [TOROS N2](https://github.com/kakao/n2) - lightweight approximate Nearest Neighbor library which runs fast even with large datasets
- [python-ssdb](https://github.com/kakao/python-ssdb) - Python client for [SSDB](https://github.com/ideawu/ssdb)
## 지식 저장소 (논문 리뷰)
추천 관련 학회의 논문들을 읽고 정리한 것을 공개/공유하는 저장소입니다.
- [카카오 추천팀 지식 저장소](paper_review/README.md)
## 발행 문서, 발표 영상 자료 모음
공개적으로 발행한 문서나, 발표 영상을 아래에 모아놓았습니다.
### 테크 블로그 / AI 리포트
#### 추천팀 소개
- `2022-06-17` [‘AI 추천 기술’을 선도하는 카카오 추천팀을 소개합니다.](https://tech.kakao.com/2022/06/16/data-recommendation-system/)
- `2021-11-02` [charlie의 추천팀 인턴 생활기](https://tech.kakao.com/2021/11/02/charlie-internship/)
- `2021-03-11` [카카오 AI 추천을 소개합니다.](https://tech.kakao.com/2021/03/11/kakao-ai/)
- `2020-06-23` [데이터를 기반으로 새로운 경험을 선사하는 추천팀 이야기](https://tech.kakao.com/2020/06/23/recruit-algorithm-ml/)
#### 추천 시스템
- `2023-03-02` [파이썬과 러스트](https://tech.kakao.com/2023/03/02/python-and-rust/)
- `2022-12-12` [추천팀의 DDD 도입기](https://tech.kakao.com/2022/12/12/ddd-of-recommender-team/)
- `2021-12-27` [카카오 AI추천 : 카카오의 콘텐츠 기반 필터링 (Content-based Filtering in Kakao)](https://tech.kakao.com/2021/12/27/content-based-filtering-in-kakao/)
- `2021-10-18` [카카오 AI추천 : 협업 필터링 모델 선택 시의 기준에 대하여](https://tech.kakao.com/2021/10/18/collaborative-filtering/)
- `2021-06-25` [카카오 AI추천 : 토픽 모델링과 MAB를 이용한 카카오 개인화 추천](https://tech.kakao.com/2021/06/25/kakao-ai-recommendation-01/)
- `2021-05-20` [카카오 AI추천 : 카카오페이지와 멜론으로 살펴보는 카카오 연관 추천](https://tech.kakao.com/2021/05/20/kakao-ai-recommendation/)
- `2018-01-31` [카카오내비 예측의 정확성 그리고 AI](https://brunch.co.kr/@kakao-it/193)
- `2017-10-31` [카카오I 추천 엔진의 진화](https://brunch.co.kr/@kakao-it/136)
- `2017-06-23` [내 손안의 AI 비서, 추천 알고리듬 - 카카오의 AI 추천 플랫폼, ‘토로스(TOROS)’](https://brunch.co.kr/@kakao-it/72)
### 논문
- [How Important is Periodic Model Update in Recommender Systems?](https://doi.org/10.1145/3539618.3591934) (SIGIR '23)
- [Predicting Query-Item Relationship using Adversarial Training and Robust Modeling Techniques](https://amazonkddcup.github.io/papers/0620.pdf) (KDD Cup '22)
- [Simple and Efficient Recommendation Strategy for Warm/Cold Sessions for RecSys Challenge 2022](https://dl.acm.org/doi/10.1145/3556702.3556851) (Recsys'22 Challenge)
- [An Efficient Combinatorial Optimization Model Using Learning-to-Rank Distillation](https://www.aaai.org/AAAI22Papers/AAAI-4140.WooH.pdf) (AAAI '22)
- [A Global DAG Task Scheduler Using Deep Reinforcement Learning and Graph Convolution Network](https://ieeexplore.ieee.org/abstract/document/9626004) (IEEE Access)
- [Melon Playlist Dataset: a public dataset for audio-based playlist generation and music tagging](https://arxiv.org/abs/2102.00201) (ICASSP '21)
- [How Low Can You Go? Reducing Frequency and Time Resolution in Current CNN Architectures for Music Auto-tagging](https://arxiv.org/abs/1911.04824) (EUSIPCO '20)
- [FlexGraph: Flexible partitioning and storage for scalable graph mining](https://journals.plos.org/plosone/article/metrics?id=10.1371/journal.pone.0227032) (PLoS ONE)
- [Artist and style exposure bias in collaborative filtering based music recommendations](https://arxiv.org/abs/1911.04827) (ISMIR '19 Workshop)
- [Enhancing VAEs for Collaborative Filtering: Flexible Priors & Gating Mechanisms](https://arxiv.org/abs/1911.00936) (RecSys '19)
- [Sequential and Diverse Recommendation with Long Tail](https://www.ijcai.org/proceedings/2019/380) (IJCAI '19)
- [Automatic playlist continuation using a hybrid recommender system combining features from text and audio](https://arxiv.org/abs/1901.00450) (RecSys '18 Challenge)
- [A study on intelligent personalized push notification with user history](https://ieeexplore.ieee.org/document/8258081) (BigData '17)
### if(kakao)
#### if(kakao)25
> <https://if.kakao.com/2025>
- `2025-09-23` [커뮤니티로 진화한 오픈채팅, AI로 슬기롭게 연결하다 (추천시스템 파트)](https://if.kakao.com/2025/session?sessionId=11)
#### if(kakao)dev2022
> <https://if.kakao.com/2022>
- `2022-12-08` [실험을 잘한다는 것은 무엇일까?](https://if.kakao.com/2022/session/4)
- `2022-12-08` [Sequential Recommendation System 카카오 서비스 적용기](https://if.kakao.com/2022/session/8)
- `2022-12-08` [Explainable Recommender System in 카카오웹툰](https://if.kakao.com/2022/session/9)
#### if(kakao)2021
> <https://if.kakao.com/2021>
- `2021-11-17` [ML로 기프트권 받을 유저 정하기](https://if.kakao.com/2021/session/26)
- `2021-11-17` [BERT보다 10배 빠른 BERT 모델 구축](https://if.kakao.com/2021/session/27)
- `2021-11-17` [TensorFlow Serving보다 10배 빠르게 서빙하기](https://if.kakao.com/2021/session/28)
- `2021-11-17` [추천 시스템 airflow 2.0 도입기](https://if.kakao.com/2021/session/29)
#### if(kakao)2020
> <https://if.kakao.com/2020>
- `2020-11-18` [개인화 콘텐츠 푸시 고도화 후기](https://if.kakao.com/2020/session/93)
- `2020-11-18` [추천 시스템, 써보지 않겠는가? 맥락과 취향 사이 줄타기](https://if.kakao.com/2020/session/125)
#### if(kakao)dev2019
> <https://if.kakao.com/2019>
- `2019-08-30` [둥꿍둥꿍 느낌 아는 음악 바텐더](https://if.kakao.com/2019/program?sessionId=1bfc0d56-3946-4e40-9ab1-523f16d8594a) - [발표 자료](https://mk.kakaocdn.net/dn/if-kakao/conf2019/%EB%B0%9C%ED%91%9C%EC%9E%90%EB%A3%8C_2019/T08-S01.pdf) / [발표 영상](https://mk-v1.kakaocdn.net/dn/if-kakao/conf2019/conf_video_2019/2_103_01_m1.mp4)
- `2019-08-30` [Buffalo: Open Source Project for Recommender System](https://if.kakao.com/2019/program?sessionId=c59d4061-6914-4a65-8fb5-f0a0c6c65b93) - [발표 자료](https://mk.kakaocdn.net/dn/if-kakao/conf2019/%EB%B0%9C%ED%91%9C%EC%9E%90%EB%A3%8C_2019/T08-S02-Buffalo.pdf) / [발표 영상](https://mk-v1.kakaocdn.net/dn/if-kakao/conf2019/conf_video_2019/2_103_02_m1.mp4)
- `2019-08-30` [상품 카탈로그 자동 생성 ML 모델 소개](https://if.kakao.com/2019/program?sessionId=dce0dd84-d054-4b80-8013-b3d58f61bbe8) - [발표 자료](https://mk.kakaocdn.net/dn/if-kakao/conf2019/%EB%B0%9C%ED%91%9C%EC%9E%90%EB%A3%8C_2019/T08-S04.pdf) / [발표 영상](https://mk-v1.kakaocdn.net/dn/if-kakao/conf2019/conf_video_2019/2_103_04_m1.mp4)
#### if(kakao)dev2018
> <https://if.kakao.com/2018>
- `2018-09-04` [눈으로 듣는 음악 추천 시스템](https://if.kakao.com/2018/program?sessionId=959a3047-0a08-4a42-99ce-35a9210ab49a) - [발표 자료](https://mk.kakaocdn.net/dn/if-kakao/conf2018/%E1%84%82%E1%85%AE%E1%86%AB%E1%84%8B%E1%85%B3%E1%84%85%E1%85%A9%20%E1%84%83%E1%85%B3%E1%86%AE%E1%84%82%E1%85%B3%E1%86%AB%20%E1%84%8B%E1%85%B3%E1%86%B7%E1%84%8B%E1%85%A1%E1%86%A8%20%E1%84%8E%E1%85%AE%E1%84%8E%E1%85%A5%E1%86%AB%20%E1%84%89%E1%85%B5%E1%84%89%E1%85%B3%E1%84%90%E1%85%A6%E1%86%B7.pdf) / [발표 영상](http://tv.kakao.com/v/391418802)
- `2018-10-01` [눈으로 듣는 음악 추천 시스템](https://brunch.co.kr/@kakao-it/282)
- `2018-09-04` [TOROS N2 - lightweight approximate Nearest Neighbor library](https://if.kakao.com/2018/program?sessionId=ad6ea793-70e6-495c-b154-c765e6339793) - [발표 자료](https://mk.kakaocdn.net/dn/if-kakao/conf2018/TOROS%20N2%20-%20lightweight%20approximate%20Nearest%20Neighbor%20library.pdf) / [발표 영상](http://tv.kakao.com/v/391419278)
- `2018-11-21` [TOROS N2](https://brunch.co.kr/@kakao-it/300)
### 카카오 아레나
> [카카오 아레나 서비스 종료 및 데이터셋 다운로드 안내](https://github.com/kakao/recoteam/discussions/9)
- `2018-12-31` [문제 해결을 위한 머신러닝 오픈 플랫폼, 카카오 아레나](https://brunch.co.kr/@kakao-it/321)
#### 3회 대회 (Melon Playlist Continuation)
- `2022-05-27` [카카오 AI추천 : 카카오 음악 추천을 경험해보고 싶다면? Melon Playlist Dataset (feats. Kakao Arena)](https://tech.kakao.com/2022/05/27/melon-playlist-dataset/)
- `2020-04-28` [멜론 플레이리스트 데이터 탐색 - _카카오 아레나 3회 대회 (Part.2)_](https://brunch.co.kr/@kakao-it/343)
- `2020-04-22` [멜론에서 음악 추천을 어떻게 할까? - _카카오 아레나 3회 대회 (Part.1)_](https://brunch.co.kr/@kakao-it/342)
#### 2회 대회 (브런치 사용자를 위한 글 추천 대회)
- `2019-07-04` [브런치 추천의 힘에 대한 6가지 기술(記述) - _카카오 아레나 2회 대회 (Part. 2)_](https://brunch.co.kr/@kakao-it/333)
- `2019-06-24` [브런치 데이터의 탐색과 시각화 - _카카오 아레나 2회 대회 (Part.1)_](https://brunch.co.kr/@kakao-it/332)
### 외부 발표
- `2022-12-22` [Machine Learning Engineer 여행 가이드](/presentations/ksc2022/KSC2022_ML_Engineer_%EC%97%AC%ED%96%89%EA%B0%80%EC%9D%B4%EB%93%9C_%EC%B9%B4%EC%B9%B4%EC%98%A4_%EC%B6%94%EC%B2%9C%ED%8C%80_%EA%B9%80%EC%84%B1%EC%A7%84.pdf) @ KSC 2022
- `2021-12-15` [우리 생활 속 추천 시스템, 어떻게 발전해왔고 어떻게 발전해나가고 있는가?](https://www.youtube.com/watch?v=jJfXHo7nNe8) @ 데이터 그랜드 컨퍼런스 2021
- `2021-05-21` [추천 기술이 마주하고 있는 현실적인 문제들](https://www.youtube.com/watch?v=UUY8YEesIVY) - [발표 자료](/presentations/ai_frontier2021/AIFrontier2021_Recommender_system_in_real_world_nick.pdf) @ AI Frontiers Summit 2021
- `2020-11-25` [유저가 좋은 작품(웹툰)를 만났을 때 (유저의 탐색, 발견 그리고 만족도에 대하여 탐색적 분석하기)](https://deview.kr/2020/sessions/332) @ DEVIEW 2020
- `2019-08-18` [추천시스템, 이제는 돈이 되어야 한다.](https://archive.pycon.kr/2019/program/talk-detail/?id=136) @ PyCon Korea 2019
- `2018-08-19` [추천 시스템을 위한 어플리케이션 서버 개발 후기](https://archive.pycon.kr/2018/program/33) @ PyCon Korea 2018
- `2016-08-13` [TOROS: Python Framework for Recommender](https://archive.pycon.kr/2016apac/program/50) @ PyCon Korea 2016
================================================
FILE: docs/arena/brunch.html
================================================
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="utf-8" />
<title>kakao dataset</title>
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="preconnect" href="https://fonts.googleapis.com" /
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin />
<link
href="https://fonts.googleapis.com/css2?family=Noto+Sans+KR:wght@100;300;400;500;700;900&display=swap"
rel="stylesheet"
/>
<link href="./app.min.css" rel="stylesheet" />
</head>
<body>
<header>
<p>브런치 데이터셋</p>
</header>
<main>
<p class="title">브런치 데이터셋 다운로드 동의서</p>
<section>
<p style="font-weight: 500; color: black">
브런치 데이터셋 다운로드 및 이용에 따른 주의사항
</p>
<br />
<hr />
<br />
<p>
본 데이터셋 다운로드 및 이용을 위해서는 반드시 아래 주의사항을
확인하여야 합니다.
</p>
<div class="border-box">
<ul>
<li>
카카오는 데이터셋에 대한 소유자로 정당한 권리를 가지고 있습니다.
본 데이터셋은 비영리 연구 목적으로 공증된 관행에 합치되는
방법으로만 이용할 수 있습니다. 연구, 논문에 데이터를 이용/인용할
경우 ' Kakao (https://www.kakaocorp.com) ’와 같이 반드시 출처를
포함하여 표기하여야 하며 제공되는 데이터셋의 무단전재 및 재배포를
금지합니다.
</li>
<li>
카카오는 데이터셋을 다른 목적으로 사용함에 따른 정확성, 적합성,
유효성을 보증하지 않습니다. 데이터셋 사용에 따른 책임은 전적으로
이용자에게 있으며, 카카오는 그 사용에 따른 책임으로 면책됩니다. 본
데이터셋 다운로드 및 이용에 따른 주의사항을 위반하거나 데이터셋의
다운로드 및 이용 과정에서 카카오에게 손해가 발생할 경우,
카카오에게 해당 손해를 배상할 책임이 있습니다.
</li>
<li>
본 주의사항을 읽고 이에 동의를 한 경우에만 데이터셋 다운로드 및
이용이 가능합니다.
</li>
</ul>
</div>
<div class="checkbox">
<label for="agree">
<input
type="checkbox"
id="agree"
onchange="document.getElementsByName('download').forEach((el) => el.disabled = !this.checked);"
/>
위 주의사항을 확인하였으며, 모든 내용에 동의합니다.
</label>
</div>
<br />
<hr />
<br />
<p>데이터셋 설명</p>
<div class="border-box">
<p>
이 데이터셋이 제공하는 정보는 2018년 10월 1일부터 2019년 3월
14일까지 브런치 서비스에서 수집된 정보의 일부분입니다.
</p>
<ul>
<li>
read 디렉토리: 본 글 정보
<ul>
<li>
read.tar은 <b>2018년 10월 1일부터 2019년 3월 1일까지</b> 일부
브런치 독자들이 본 글의 정보가 총 3,625개의 파일로 구성되어
있습니다.
</li>
<li>
파일의 이름은 <code>시작일_종료일</code> 형태입니다. 예를 들어
<code>2018110708_2018110709</code> 파일은 2018년 11월 7일 오전
8시부터 2018년 11월 7일 오전 9시 전까지 본 글입니다.
</li>
<li>
파일은 여러 줄로 이뤄져 있으며 하나의 줄은 브런치의 독자가
파일의 시간 동안 본 글을 시간 순으로 기록한 것입니다. 한 줄의
정보는 공백으로 구분되어 있으며 첫번 째가 독자의 암호화된
식별자이고 그 뒤로는 해당 독자가 본 글의 정보입니다.
</li>
<li>
예를 들어 <code>read/2019022823_2019030100</code> 파일에
기록된 아래 정보는
<code>#8a706ac921a11004bab941d22323efab</code> 라는 독자가
2019년 2월 28일 23시에서 2019년 3월 1일 0시 사이에
<code
>@bakchacruz_34 @wo-motivator_133 @wo-motivator_133</code
>
를 순서대로 보았다는 뜻입니다.
<code>@wo-motivator_133</code> 글이 두 번 나타난 것은 이 글을
보기 위해 두 번 방문했다는 뜻입니다.
</li>
<ul>
<li>
<code>
#8a706ac921a11004bab941d22323efab @bakchacruz_34
@wo-motivator_133 @wo-motivator_133</code
>
</li>
</ul>
<li>
글을 보았다는 의미는 특정 글에 모바일, PC, 앱을 통해
접근했다는 뜻입니다. 머문 시간에 대한 정보가 제공되지 않기
때문에 실제로 글을 읽지 않고 이탈하는 등의 가능성도 있습니다.
</li>
</ul>
</li>
<li>
metadata.json: 글의 메타데이터
<ul>
<li>643,104 줄로 구성된 글의 메타데이터입니다.</li>
<li>
이 메타데이터에는
<b>2018년 10월 1일부터 2019년 3월 14일까지</b>
독자들이 본 글에 대한 정보입니다.
</li>
<li>
작가가 비공개로 전환하였거나 삭제 등의 이유로 학습 데이터로
제공된 2018년 10월 1일부터 2019년 3월 1일 전까지의 본 글
정보에는 이 메타데이터에 없는 글이 있을 수 있습니다.
<ul>
<li>
<b
>개발 데이터와 평가 데이터에 포함된 글의 메타데이터도
포함되어 있습니다. 즉, 평가 대상자들이 2019년 3월
1일부터 2019년 3월 14일 사이에 본 모든 글에 대한 정보가
포함되어 있습니다.</b
>
</li>
</ul>
</li>
<li>
필드 설명
<ul>
<li>
magazine_id: 이 글의 브런치 매거진 아이디 (없을 시는 0)
</li>
<li>
reg_ts: 이 글이 등록된 시간(<a
href="https://ko.wikipedia.org/wiki/유닉스_시간"
>유닉스 시간</a
>, 밀리초)
</li>
<li>user_id: 작가 아이디</li>
<li>article_id: 글 번호</li>
<li>id: 글 식별자</li>
<li>title: 제목</li>
<li>sub_title: 부제목</li>
<li>display_url: 웹 주소</li>
<li>keyword_list: 작가가 부여한 글의 태그 정보</li>
</ul>
</li>
<li>
메타데이터의 모든 정보는 작가의 비공개 여부 전환, 글 삭제,
수정 등으로 유효하지 않거나 변동될 수 있습니다.
</li>
</ul>
</li>
<li>contents 디렉토리: 글 본문 정보</li>
<ul>
<li>
저작권을 보호하고자 본문에서 형태소 분석을 통해 추출된 정보를
암호화하여 제공합니다. 총 7개의 파일로 나뉘어있습니다.
</li>
<li>
형태소 분석기는 카카오에서 공개한
<a href="https://github.com/kakao/khaiii">khaiii</a> 의 기본
옵션을 사용했습니다. 형태소 분석 결과의 어휘 정보는 임의의
숫자로 1:1 변환되었습니다. 동일 어휘의 경우, 품사와 관계없이
같은 숫자로 변환됩니다.
</li>
<li>
형태소 분석에 대한 설명과 품사의 의미에 대해서는 별도 제공하지
않습니다.
</li>
<li>
형태소 추출 전에 텍스트를 제외한 HTML과 같은 내용과 관계없는
정보는 제거 했으나 일부 정보가 남았을 수 있습니다.
</li>
<li>
필드 설명
<ul>
<li>id: 글 식별자</li>
<li>
morphs: 형태소 분석 결과
<ul>
<li>
리스트의 리스트로 구성되며, 리스트의 첫 번째 요소는 첫
어절의 분석 결과입니다.
</li>
<li>어휘와 품사는 / 구분자로 구분됩니다.</li>
<li>
예를 들어 "안녕하세요 브런치입니다"라는 문장은 khaiii
형태소분석기에서 "안녕/NNG + 하/XSA + 시/EP + 어요/EF",
"브런치/NNP + 이/VCP + ㅂ니다/EC" 라고 분석되는데, 이
결과는 morphs에서 다음처럼 나타날 수 있습니다.
[["8/NNG", "13/XSA", "81/EP", "888/EF"], ["0/NNP",
"12913/VCP", "29/EC"]]
</li>
<li>
여러 줄에 걸친 결과는 개행 구분 없이 리스트에 연속적으로
등장합니다. 예를 들어 "안녕하세요
브런치입니다\n안녕하세요"의 결과는 다음과 같습니다.
[["8/NNG", "13/XSA", "81/EP", "888/EF"], ["0/NNP",
"12913/VCP", "29/EC"], ["8/NNG", "13/XSA", "81/EP",
"888/EF"]]
</li>
</ul>
</li>
<li>
chars: 형태소 분석 결과
<ul>
<li>
형태소 분석 결과에서 어휘 부분을 문자 단위로 암호화환
결과입니다.
</li>
<li>
한 어휘의 문자는 + 구분자로 결합합니다. 예를 들어 위
예의 "브런치입니다"는 chars 필드에서 다음처럼 나타날 수
있습니다. "0+1+2/NNP", "4/VCP", "9+29+33/EC"
</li>
</ul>
</li>
</ul>
</li>
<li>
<strong
>metadata.json과 마찬가지로 개발 데이터와 평가 데이터의 글
본문도 포함되어 있습니다.</strong
>
</li>
<li>
contents 정보는 본문이 없는 글의 경우 제공되지 않을 수 있습니다.
</li>
</ul>
<li>
users.json: 사용자 정보
<ul>
<li>가입한 사용자(작가 혹은 독자)의 정보입니다.</li>
<li>
필드 설명
<ul>
<li>
keyword_list: 최근 며칠간 작가 글로 유입되었던 검색 키워드
</li>
<li>following_list: 구독 중인 작가 리스트</li>
<li>id: 사용자 식별자</li>
</ul>
</li>
<li>
총 310,758명의 정보가 있습니다. 탈퇴 등의 이유로 사용자 정보가
없을 수 있습니다.
</li>
</ul>
</li>
<li>
magazine.json: 매거진 정보
<ul>
<li>총 27,967개의 브런치 매거진 정보입니다.</li>
<li>
필드 설명
<ul>
<li>id: 매거진 식별자</li>
<li>
<code>magazine_tag_list</code>: 작가가 부여한 매거진의
태그 정보
</li>
</ul>
</li>
</ul>
</li>
<li>
predict 디렉토리: 예측할 사용자 정보
<ul>
<li>
dev.users: 개발 데이터입니다. 대회 기간에 예측한 성능을
평가하기 위해 제공한 사용자 3,000명 리스트입니다.
</li>
<li>
test.users: 평가 데이터입니다. 대회 종료 후 최종 순위를
결정하기 위해 제공한 사용자 5,000명의 리스트입니다.
</li>
<li>
일부 사용자는 2018년 10월 1일부터 2019년 3월 1일까지 본 글이
없을 수도 있습니다.
</li>
</ul>
</li>
<li>
식별자에 대해서
<ul>
<li>
사용자 식별자와 콘텐츠 식별자는 식별자 값에 '_' 존재 여부로
나뉩니다.
</li>
</ul>
</li>
</ul>
</div>
<div style="display: flex; place-content: center">
<a
href="https://drive.google.com/drive/folders/10BTayTV3mFwzAokyTt-20-g79rpUlFVz?usp=sharing"
>
<button name="download" id="download" disabled>Download</button>
</a>
</div>
</section>
</main>
</body>
</html>
================================================
FILE: docs/arena/common.css
================================================
@charset "utf-8";
/* 웹폰트 */
@import url('https://fonts.googleapis.com/css?family=Noto+Sans+KR:400,500&subset=korean');
@font-face {
font-family: 'Noto Sans';
src:url(../font/NotoSansCJKkr-Regular.eot?#iefix) format('embedded-opentype');
font-weight: normal;
font-style: normal;
}
@font-face {
font-family: 'Noto Sans';
src:url(../font/NotoSansCJKkr-Medium.eot?#iefix) format('embedded-opentype');
font-weight: 500;
font-style: normal;
}
@font-face {
font-family: 'Noto Sans';
src:url(../font/NotoSansCJKkr-Bold.eot?#iefix) format('embedded-opentype');
font-weight: bold;
font-style: normal;
}
/* reset */
body,div,dl,dt,dd,ul,ol,li,h1,h2,h3,h4,h5,h6,pre,code,form,fieldset,legend,textarea,p,blockquote,th,td,input,select,button{margin:0;padding:0}
fieldset,img{border:0 none}
dl,ul,ol,menu,li{list-style:none}
blockquote, q{quotes:none}
blockquote:before, blockquote:after,q:before, q:after{content:'';content:none}
input,select,textarea,button{vertical-align:middle;font-size:100%}
button{border:0 none;background-color:transparent;cursor:pointer}
table{border-collapse:collapse;border-spacing:0}
body{-webkit-text-size-adjust:none}
input:checked[type='checkbox']{background-color:#666; -webkit-appearance:checkbox}
input[type='text'],input[type='password'],input[type='submit'],input[type='search'],input[type='tel'],input[type='email'],html input[type='button'],input[type='reset']{-webkit-appearance:none;border-radius:0}
input[type='search']::-webkit-search-cancel-button{-webkit-appearance:none}
body{background:#fff}
body,th,td,input,select,textarea,button{font-size:13px;line-height:1.5;font-family: 'Noto Sans CJK Kr', 'Noto Sans KR', 'Noto Sans', sans-serif;color:#222}
a{color:#222;text-decoration:none}
a:active, a:hover{text-decoration:none}
address,caption,cite,code,dfn,em,var{font-style:normal;font-weight:normal}
/* global */
#kakaoIndex{overflow:hidden;position:absolute;left:-9999px;width:0;height:1px;margin:0;padding:0}
.ir_pm{display:block;overflow:hidden;font-size:1px;line-height:0;color:transparent}
.ir_wa{display:block;overflow:hidden;position:relative;z-index:-1;width:100%;height:100%}
.ir_caption{overflow:hidden;width:1px;font-size:1px;line-height:0;text-indent:-9999px}
.screen_out{overflow:hidden;position:absolute;width:0;height:0;line-height:0;text-indent:-9999px}
.show{display:block}
.hide{display:none}
.comm_layer{display:none;flex-direction:column;overflow:auto;position:fixed;top:0%;left:0%;z-index:1000;width:100%;height:100%;background:rgba(0,0,0,0.4);}
.comm_layer .inner_layer{position:absolute;top:50%;left:50%;background-color:var(--color-white);border:1px solid #cecece;text-align:center;transform:translate(-50%,-50%);}
.info_layer .inner_layer{top:139px;transform:translate(-50%, 0);width:498px;height:396px;box-sizing:border-box;}
.info_layer .layer_head{display:flex;justify-content:center;align-items:center;height:80px;background-color:#fee500;}
.info_layer .layer_head .tit_info{display: inline-block;font-size:21px;line-height:31px;letter-spacing:-1.05px;color:#1E1E1E;}
.info_layer .layer_head .tit_info .logo_kakaoarena{display:inline-block;width:129px;}
.info_layer .layer_body{padding:40px 60px 35px;background-color:#fff;}
.info_layer .layer_body .txt_info{font-size:15px;line-height: 22px;color:#000000;}
.info_layer .layer_body .txt_info .tit_item{display:block;margin-bottom:22px;font-size:16px;font-weight:bold;line-height:22px;}
.info_layer .layer_body .link_detail{display:block;margin:30px auto 0;width:175px;height:50px;background-color:#fee500;font-size:15px;font-weight:500;line-height:50px;text-align:center;color:#1E1E1E;}
.info_layer .layer_foot{display:flex;justify-content:space-between;}
.info_layer .layer_foot .btn_alert{flex:1;width:50%;height:50px;background-color:#f5f5f5;border-top:1px solid #cecece;font-size:14px;font-weight:500;line-height:50px;text-align:center;color:#1E1E1E;}
.info_layer .layer_foot .btn_alert ~ .btn_alert {border-left:1px solid #cecece;}
.comm_layer.show{display:flex;}
.notice_type{padding: 11px 0 80px;}
.notice_type .doc-header .inner-header{max-width:1058px;margin:0 auto;}
.notice_type .logo_kakaoarena{display:inline-block;width:148px;vertical-align:middle;}
.notice_type .inner_main{max-width:1058px;margin:69px auto 0;}
.notice_type .tit_notice{font-size:56px;font-weight:bold;line-height:83px;letter-spacing:-2.33px;color:#1E1E1E;}
.notice_type .txt_notice{margin:28px 0 60px;font-size:18px;font-weight:500;line-height:32px;letter-spacing:-1px;color:#000000;}
.notice_type .tbl_notice{margin-bottom:33px;border-top:1px solid #979797;border-bottom:1px solid #979797;}
.notice_type .tbl_notice th,td{padding:0 42px 0;background-color:#fafafa;border-bottom:1px solid #dadbdc;font-size:14px;font-weight:normal;line-height:70px;color:#000000;text-align:left;vertical-align: middle;}
.notice_type .tbl_notice .tit_item{font-size:15px;font-weight:500;}
.notice_type .list_notice{margin-left:14px;}
.notice_type .list_notice > li{position:relative;padding-left:10px;font-size:13px;line-height:25px;letter-spacing:-0.41px;color:#3C3C3C;}
.notice_type .list_notice > li:before{content:'';position:absolute;top:50%;left:0;width:3px;height:3px;transform: translateY(-50%);background-color:#3C3C3C;border-radius: 100%;}
.notice_type .link_notice{display:block;width:391px;height:70px;margin:60px auto 0;background-color: #FEE500;line-height:70px;font-size:18px;font-weight:500;color:#1E1E1E;text-align: center;}
.tbl_comm{width:100%;border:0;border-spacing:0;table-layout:fixed;border-collapse:collapse;}
================================================
FILE: docs/arena/index.html
================================================
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>kakao arena</title>
<meta name="viewport" content="width=device-width,initial-scale=1,minimum-scale=1,maximum-scale=1,user-scalable=no">
<link rel="icon" type="image/x-icon" href="./favicon.ico">
<link rel="stylesheet" type="text/css" href="./common.css">
</head>
<body>
<div class="container-doc notice_type">
<header class="doc-header">
<div class="inner-header">
<h1 class="doc-title"> <a href="#none"> <img src="./kakao-arena.svg" width="148" height="23" class="logo_kakaoarena" alt="kakao arena"> </a> </h1>
</div>
</header>
<main class="doc-main">
<div class="inner_main">
<article class="content-article">
<h2 class="tit_notice">카카오 아레나가 종료되었습니다.</h2>
<p class="txt_notice">그동안 카카오 아레나 서비스를 이용해 주셔서 진심으로 감사드립니다. 아쉽게도 카카오 아레나 서비스가 2023년 7월 3일 종료되었음을 알려드립니다.<br> 작성하신 게시글과 제출하신 자료에 대해 백업을 원하신다면 고객센터로 요청 바랍니다.<br> 데이터 백업 기간이 종료되면 게시글과 자료는 모두 안전하게 파기될 예정입니다.</p>
<table class="tbl_comm tbl_notice">
<caption class="ir_caption">백업 기간, 백업 대상, 백업 방법으로 구성된 백업 정보</caption>
<colgroup>
<col style="width:18%;">
<col>
</colgroup>
<tbody>
<tr>
<th> <strong class="tit_item">백업 기간</strong> </th>
<td> <strong class="tit_item">2023년 7월 3일(월) ~ 2023년 10월 4일(수)</strong> </td>
</tr>
<tr>
<th>백업 대상</th>
<td>본인이 작성한 글(글에 첨부된 이미지/파일), 대회 제출 소스 코드와 결과 파일</td>
</tr>
<tr>
<th>백업 방법</th>
<td>고객센터로 신청 시 이메일로 전달 (고객센터 로그인 필요)</td>
</tr>
</tbody>
</table> <strong class="screen_out">유의사항</strong>
<ul class="list_notice">
<li>백업 기간 이후에는 백업 신청 및 백업이 불가능합니다. 꼭 기간 내에 백업 신청을 완료해 주세요.</li>
<li>고객센터 백업 신청은 로그인 후 신청이 가능합니다. </li>
</ul> <a href="https://cs.kakao.com/requests?service=220&locale=ko" target="_blank" class="link_notice">백업 신청 고객센터 바로가기</a>
</article>
</div>
</main>
</div>
</body>
</html>
================================================
FILE: docs/arena/melon-en.html
================================================
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="utf-8" />
<title>kakao dataset</title>
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="preconnect" href="https://fonts.googleapis.com" />
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin />
<link
href="https://fonts.googleapis.com/css2?family=Noto+Sans+KR:wght@100;300;400;500;700;900&display=swap"
rel="stylesheet"
/>
<link
rel="stylesheet"
href="node_modules/modern-normalize/modern-normalize.css"
/>
<link href="./app.min.css" rel="stylesheet" />
</head>
<body>
<header>
<p>Melon Dataset</p>
</header>
<main>
<p class="title">Melon Dataset Download Consent Form</p>
<section>
<p style="font-weight: 500; color: black">
Precautions Regarding the Download and Use of the Melon Dataset
</p>
<br />
<hr />
<br />
<p>
Before proceeding with the download and utilization of this dataset,
it is crucial to review and comply with the following precautions
carefully
</p>
<div class="border-box">
<ul>
<li>
Kakao Entertainment is the lawful owner of the dataset and
possesses all the necessary rights. The dataset is intended solely
for non-profit research purposes and should be utilized in
accordance with established industry practices. When utilizing or
referencing the data for research or scholarly papers, it is
mandatory to include the appropriate attribution as follows:
"Kakao Entertainment, melon (www.melon.com)." Unauthorized
reproduction or redistribution of the dataset is strictly
prohibited.
</li>
<li>
Please be aware that Kakao Entertainment does not guarantee the
accuracy, suitability, or validity of the dataset for purposes
other than those specified. The user assumes full responsibility
for the usage of the dataset, and Kakao Entertainment shall not be
held accountable for any consequences or liabilities arising from
its use. In case of any violation of the precautions regarding the
download and use of this dataset, or if any damages occur to Kakao
Entertainment during the process, the user shall be held
responsible for compensating Kakao Entertainment for such damages.
</li>
<li>
By confirming your understanding and agreement to the above
precautions, you may proceed with downloading and utilizing the
dataset.
</li>
</ul>
</div>
<div class="checkbox">
<label for="agree">
<input
type="checkbox"
id="agree"
onchange="document.getElementsByName('download').forEach((el) => el.disabled = !this.checked);"
/>
I have carefully read and fully agree to all the above terms and
conditions.
</label>
</div>
<br />
<hr />
<br />
<p>Dataset Description</p>
<div class="border-box">
<div class="border-content">
<h5>Melon Playlist Dataset</h5>
<p>
This dataset contains 148,826 playlists composed of 649,091 unique
songs and mel-spectrogram data for each song. The included
playlists are the listed item in the Melon DJ Playlist service
provided by Melon. In addition, Melon DJ Playlist consists of
playlists both made by experts contracting with us in advance for
quality assurance and filtered by the company’s quality standard
among those submitted by Melon users who want to put on the Melon
DJ Playlist. Each playlist contains songs and multiple sets of
tags (included in the 30,652 unique tags) assigned by the playlist
creator, along with its title.
</p>
</div>
<div class="border-content">
<h5>Playlist Included</h5>
<p>
For setting contest questions, we will provide the entire playlist
data separately as <code>train.json</code> composed of 115,071
playlists, <code>val.json</code> composed of 23,015 playlists, and
<code>test.json</code> composed of 10,740 playlists. Unlike
<code>train.json</code>, <code>test.json</code> and
<code>train.json</code> have some of the songs and tags in their
playlists masked for the submission of answers.
</p>
<h6 class="mt-2">Field Description</h6>
<ul>
<li>id: Playlist ID</li>
<li>plylst_title: Playlist title</li>
<li>tags: tag list</li>
<li>songs: song list</li>
<li>like_cnt: like count</li>
<li>updt_date: update date</li>
</ul>
</div>
<div class="border-content">
<h5>Mel-Spectrogram Included</h5>
<p>
Mel-spectrogram data are saved as a ‘<code>{songID}.npy</code>’
file name with the file extension npy. A number from 0 to 707988
is assigned as song ID, and each file is allocated to and stored
in the <code>{floor(ID / 1000)}/</code> directory. For example,
the song with ID 415263 is saved as 415/415263.npy. The
2.1b.dev677 version of Essentia library was used to extract each
mel-spectrogram. mel-spectrogram was calculated in the use of
segments of a song’s 20~50 second-interval to reduce the 16Khz
sample size rate, 512 frame size, 256 hop size, Hann window
function, and data size and employed 48 mel-bands resolution so
that Melon Playlist Dataset can contain about 240GB data.
</p>
</div>
<div class="border-content">
<h5>Meta-Data Included</h5>
<p>
Melon Playlist Dataset provides <code>song_meta.json</code>, the
song metadata saved in a separate json file format, and
<code>genre_gn_all.json</code>, the mapping table for genre
included in the song metadata. <code>song_meta.json</code> has
metadata for a total of 707,989 songs, including all songs in
<code>train.json</code>, <code>val.json</code>, and
<code>test.json</code>. The field description included is as
follows.
</p>
<h6 style="margin-top: 0.5rem">Field Description</h6>
<ul>
<li>_id: song ID</li>
<li>album_id: album ID</li>
<li>artist_id_basket: artist ID list</li>
<li>artist_name_basket: artist list</li>
<li>song_name: song title</li>
<li>song_gn_gnr_basket: song genre list</li>
<li>song_gn_dtl_gnr_basket: song detailed genre list</li>
<li>issue_date: issue date</li>
</ul>
</div>
<div class="border-content">
<small>
* All information in the metadata may be invalid or subject to
change due to the copyright holder’s privacy conversion, song
deletion, metadata modification, and the like.
</small>
</div>
<div class="border-content">
<p>
<code>genre_gn_all.json</code> contains a total of 254 genre
codes, including genre information for 30 major category genre
codes (included in <code>song_gn_gnr_basket</code>) and 224
detailed category genre codes (included in
<code>song_gn_gnr_basket</code>).
</p>
</div>
</div>
<div style="display: flex; place-content: center">
<a
href="https://drive.google.com/drive/folders/1h3allMBZAG20wYlt1bLFvZrsTQYB_1VU?usp=sharing"
>
<button name="download" id="download" disabled>Download</button>
</a>
</div>
</section>
</main>
</body>
</html>
================================================
FILE: docs/arena/melon.html
================================================
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="utf-8" />
<title>kakao dataset</title>
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="preconnect" href="https://fonts.googleapis.com" />
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin />
<link
href="https://fonts.googleapis.com/css2?family=Noto+Sans+KR:wght@100;300;400;500;700;900&display=swap"
rel="stylesheet"
/>
<link
rel="stylesheet"
href="node_modules/modern-normalize/modern-normalize.css"
/>
<link href="./app.min.css" rel="stylesheet" />
</head>
<body>
<header>
<p>멜론 데이터셋</p>
</header>
<main>
<p class="title">멜론 데이터셋 다운로드 동의서</p>
<section>
<p style="font-weight: 500; color: black">
멜론 데이터셋 다운로드 및 이용에 따른 주의사항
</p>
<br />
<hr />
<br />
<p>
본 데이터셋 다운로드 및 이용을 위해서는 반드시 아래 주의사항을
확인하여야 합니다.
</p>
<div class="border-box">
<ul>
<li>
카카오 엔터테인먼트는 데이터셋에 대한 소유자로 정당한 권리를
가지고 있습니다. 본 데이터셋은 비영리 연구 목적으로 공증된 관행에
합치되는 방법으로만 이용할 수 있습니다. 연구, 논문에 데이터를
이용/인용할 경우 'Kakao Entertainment, melon (www.melon.com) ’와
같이 반드시 출처를 포함하여 표기하여야 하며 제공되는 데이터셋의
무단전재 및 재배포를 금지합니다.
</li>
<li>
카카오 엔터테인먼트는 데이터셋을 다른 목적으로 사용함에 따른
정확성, 적합성, 유효성을 보증하지 않습니다. 데이터셋 사용에 따른
책임은 전적으로 이용자에게 있으며, 카카오 엔터테인먼트는 그 사용에
따른 책임으로 면책됩니다. 본 데이터셋 다운로드 및 이용에 따른
주의사항을 위반하거나 데이터셋의 다운로드 및 이용 과정에서 카카오
엔터테인먼트에게 손해가 발생할 경우, 카카오 엔터테인먼트에게 해당
손해를 배상할 책임이 있습니다.
</li>
<li>
본 주의사항을 읽고 이에 동의를 한 경우에만 데이터셋 다운로드 및
이용이 가능합니다.
</li>
</ul>
</div>
<div class="checkbox">
<label for="agree">
<input
type="checkbox"
id="agree"
onchange="document.getElementsByName('download').forEach((el) => el.disabled = !this.checked);"
/>
위 주의사항을 확인하였으며, 모든 내용에 동의합니다.
</label>
</div>
<br />
<hr />
<br />
<p>데이터셋 설명</p>
<div class="border-box">
<div class="border-content">
<p>
이 데이터셋에는 649,091개의 고유 곡으로 구성된 148,826개의
플레이리스트와 각 곡에 대한 멜 스펙트로그램 데이터가 포함되어
있습니다. 포함된 플레이리스트는 멜론에서 제공하는 멜론 DJ
플레이리스트 서비스에 등재된 항목입니다. 또한, 멜론 DJ
플레이리스트는 당사와 사전 계약을 맺은 전문가가 품질 보증을 위해
만든 플레이리스트와 멜론 이용자가 멜론 DJ 플레이리스트에 올리고
싶은 플레이리스트 중 당사의 품질 기준에 의해 필터링된
플레이리스트로 구성됩니다. 각 재생목록에는 제목과 함께 재생목록
제작자가 지정한 노래와 여러 개의 태그(30,652개의 고유 태그에
포함)가 포함되어 있습니다.
</p>
<ul>
<li>
song_meta.json: 곡 메타데이터
<ul>
<li>
총 707,989개의 곡에 대한 메타데이터가 수록되어 있습니다.
</li>
<li>
<b
>개발 데이터와 평가 데이터에 수록된 모든 곡에 대한
메타데이터가 포함되어 있습니다.</b
>
</li>
<li>
필드 설명
<ul>
<li>_id: 곡 ID</li>
<li>album_id: 앨범 ID</li>
<li>artist_id_basket: 아티스트 ID 리스트</li>
<li>artist_name_basket: 아티스트 리스트</li>
<li>song_name: 곡 제목</li>
<li>song_gn_gnr_basket: 곡 장르 리스트</li>
<li>song_gn_dtl_gnr_basket: 곡 세부 장르 리스트</li>
<li>issue_date: 발매일</li>
</ul>
</li>
<li>
메타데이터의 모든 정보는 저작권자의 비공개 여부 전환, 곡
삭제, 메타데이터 수정 등으로 유효하지 않거나 변동될 수
있습니다.
</li>
</ul>
</li>
<li>
genre_gn_all.json:
<ul>
<li>
곡 메타데이터에 수록된 장르에 대한 정보입니다. 위
song_meta.json 에서 song_gn_gnr_basket 과
song_gn_dtl_gnr_basket 에 들어가는 정보들에 대한
메타데이터입니다.
</li>
</ul>
</li>
<li>
train.json:
<ul>
<li>
모델 학습용 파일로, 115,071개 플레이리스트의 원본 데이터가
수록되어 있습니다.
</li>
<li>
필드 설명
<ul>
<li>id: 플레이리스트 ID</li>
<li>plylst_title: 플레이리스트 제목</li>
<li>tags: 태그 리스트</li>
<li>songs: 곡 리스트</li>
<li>like_cnt: 좋아요 개수</li>
<li>updt_date: 수정 날짜</li>
</ul>
</li>
</ul>
</li>
<li>
val.json:
<ul>
<li>
공개 리더보드용 문제 파일로, 23,015개 플레이리스트에 대한
문제가 수록되어 있습니다. 모든 데이터가 수록되어있는 train
파일과는 다르게, 곡과 태그의 일부가 수록되어 있습니다.
</li>
<li>
필드 설명
<ul>
<li>id: 플레이리스트 ID</li>
<li>plylst_title: 플레이리스트 제목</li>
<li>tags: 태그 리스트</li>
<li>songs: 곡 리스트</li>
<li>like_cnt: 좋아요 개수</li>
<li>updt_date: 수정 날짜</li>
</ul>
</li>
</ul>
</li>
<li>
test.json:
<ul>
<li>
파이널 리더보드용 문제 파일로, 10,740개 플레이리스트에 대한
문제가 수록되어 있습니다. 모든 데이터가 수록되어있는 train
파일과는 다르게, 곡과 태그의 일부가 수록되어 있습니다.
</li>
<li>
필드 설명
<ul>
<li>id: 플레이리스트 ID</li>
<li>plylst_title: 플레이리스트 제목</li>
<li>tags: 태그 리스트</li>
<li>songs: 곡 리스트</li>
<li>like_cnt: 좋아요 개수</li>
<li>updt_date: 수정 날짜</li>
</ul>
</li>
</ul>
</li>
<li>
arena_mel_{0~39}.tar
<ul>
<li>
곡에 대한 mel-spectrogram 데이터를 담고있는 파일입니다. 위에
있는 파일들에서 등장하는 각 곡 ID마다 npy 파일 1개가
배정되어있습니다. numpy로 다음과 같이 로드할 수 있습니다.
<pre><code>import numpy as np
mel = np.load("0.npy")</code></pre>
</li>
<li>
곡 ID는 0~707988 까지 배정되어 있으며,
<code>곡ID.npy</code> 의 파일 이름을 가지고 있습니다. 파일의
갯수가 많기 때문에, 각 npy 파일은 각각
<code>{floor(ID / 1000)}/</code> 폴더 아래에 들어가있습니다.
예를 들어 곡 ID가 415263인 파일의 경우
<code>415/415263.npy</code> 로, 곡 ID가 53712인 경우
<code>53/53712.npy</code> 에 존재합니다.
</li>
</ul>
</li>
</ul>
</div>
</div>
<div style="display: flex; place-content: center">
<a
href="https://drive.google.com/drive/folders/1h3allMBZAG20wYlt1bLFvZrsTQYB_1VU?usp=sharing"
>
<button name="download" id="download" disabled>Download</button>
</a>
</div>
</section>
</main>
</body>
</html>
================================================
FILE: onboarding/README.md
================================================
# 추천팀 온보딩
카카오 추천팀에 입사하기 전에 미리 보시면 좋을 내용들을 정리해놓은 문서입니다.
## 추천 기술 관련 자료
해당 내용에 링크된 자료는 방대하므로(특히 수학/ML 기초) 필요한 부분들 위주로 보시기 바랍니다.
### 수학/ML 기초
추천 시스템은 머신러닝의 응용 분야로서 머신러닝에 대한 기초지식을 탄탄히 다지는 것은 큰 도움이 됩니다. 기본적인 Linear Algebra, Statistical Inference, Convex Optimization에 대해 익숙하지 않다면 이에 대한 학습이 필요할 수 있습니다.
대표적인 ML 교재 최소 1개 이상을 정독해본 경험을 가지는 것을 추천해 드립니다.
- [Introduction to Statistical Learning (ISLR)](https://www.statlearning.com/)
- [Elements of Statistical Learning (ESL)](https://hastie.su.domains/Papers/ESLII.pdf)
- [Machine Learning: A Probabilistic Perspective (Murphey 책)](https://probml.github.io/pml-book/)
- [Pattern Recognition an Machine Learning (Bishop 책)](https://www.microsoft.com/en-us/research/uploads/prod/2006/01/Bishop-Pattern-Recognition-and-Machine-Learning-2006.pdf)
- ... etc.
딥러닝 교재, 최신 추천시스템은 뉴럴넷을 활용하는 경우도 많고 자연어, 이미지 등의 데이터를 활용하는 경우도 있습니다.
- [Deep Learning Book](https://www.deeplearningbook.org/)
- ... etc.
### 추천 알고리즘
대표적인 올드 스쿨 알고리즘입니다. 해당 알고리즘들은 논문이 발표된지 오래되었지만, 아직도 대중적으로 많이 활용되고 있습니다.
- iALS ([Collaborative Filtering for Implicit Feedback Datasets](http://yifanhu.net/PUB/cf.pdf))
- BPR ([BPR: Bayesian Personalized Ranking from Implicit Feedback](https://arxiv.org/pdf/1205.2618.pdf))
- LinUCB ([A Contextual-Bandit Approach to Personalized News Article Recommendation](https://arxiv.org/pdf/1003.0146.pdf))
그 외, 벤치마크로 자주 등장하는 전통 알고리즘은 다음과 같습니다.
- WARP ([Improving Pairwise Learning for Item Recommendation from Implicit Feedback](http://webia.lip6.fr/~gallinar/gallinari/uploads/Teaching/WSDM2014-rendle.pdf))
- SLIM ([SLIM: Sparse Linear Methods for Top-N Recommender Systems](https://ieeexplore.ieee.org/abstract/document/6137254))
카카오 테크 블로그에 카카오 추천시스템에 대하여 주제별로 설명한 글들입니다.
- [테크 블로그: 추천 시스템](/README.md/#%EC%B6%94%EC%B2%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C)
추천 관련 최신 논문들을 서칭해보고 abstract와 related works를 읽어보면 최신 연구 방향과 그 기반이 되는 주요 논문들을 알 수 있습니다
- 추천 관련 대표 학회들: RecSys, WWW, SIGIR, KDD, WSDM, CIKM, AAAI, IJCAI, ICML, NeurIPS, ... etc.
(좋은 논문인지와 별개로) 대표적으로 유명한 추천 알고리즘 논문들은 아래와 같습니다.
- [BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, CIKM'19](https://arxiv.org/abs/1904.06690)
- [Variational Autoencoders for Collaborative Filtering, WWW'18](https://dl.acm.org/doi/10.1145/3178876.3186150)
- [Neural Collaborative Filtering, WWW'17](https://dl.acm.org/doi/10.1145/3038912.3052569)
- [Recommending What Video to Watch Next: A Multitask Ranking System, RecSys'19](https://daiwk.github.io/assets/youtube-multitask.pdf)
- [Collaborative Metric Learning, WWW'17](https://vision.cornell.edu/se3/wp-content/uploads/2017/03/WWW-fp0554-hsiehA.pdf)
- [Convolutional Matrix Factorization for Document Context-Aware Recommendation, RecSys'16](http://uclab.khu.ac.kr/resources/publication/C_351.pdf)
- ... etc.
### 그 외
#### 강화학습
실시간 추천시스템은 사용자와 상호작용하며 사용자들의 취향을 파악하고 추천해주는 시스템으로서 강화학습 framework이 잘 어울린다는 평가가 많습니다, 특히 Multi-Armed Bandit, Contextual-Bandit 등은 팀 내에서도 매우 많이 사용되고 있습니다
- [강화학습 대표 교재 (Reinforcement Learning: An Introduction)](http://incompleteideas.net/book/the-book.html)
- [David Silver 강의](https://www.davidsilver.uk/teaching/)
## 머신러닝플랫폼 관련 자료
아래의 키워드는 모두 머신러닝플랫폼에서 중요한 것들이지만 업무에 필수는 아닙니다.
학습 비용이 만만치 않기 때문에 천천히 기반 다지는 것을 추천합니다.
### 방법론, 가이드
- [Domain Driven Design (DDD)](https://martinfowler.com/bliki/DomainDrivenDesign.html)
- [Microservices (MSA)](https://learn.microsoft.com/en-us/azure/architecture/guide/architecture-styles/microservices)
- [Event Driven Architecture (EDA)](https://learn.microsoft.com/en-us/azure/architecture/guide/architecture-styles/event-driven)
- [Cloud Native](https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/definition)
- [CI/CD](https://en.wikipedia.org/wiki/CI/CD)
- [Test Driven Development (TDD)](https://martinfowler.com/bliki/TestDrivenDevelopment.html)
### 개발 자원
머신러닝플랫폼은 대부분 파이썬 3.10을 사용하고 있습니다.
아래는 개발할 때 많이 사용하는 라이브러리를 간추렸습니다.
- [poetry](https://python-poetry.org/)
- [pydantic](https://pydantic-docs.helpmanual.io/)
- [pytest](https://pytest.org)
- [mypy](https://mypy.readthedocs.io/)
## 팀 개발환경 및 플랫폼
### 기본 개발환경
팀의 메인 개발언어는 Python, C++입니다.
코드 Editor로는 주로 Vim을 사용하고 있으나, 제약은 없으며 VSCode, PyCharm등 개발자 본인에게 가장 편한 editor를 사용할 수 있습니다. (단, 서버 내에서 작업하는 경우도 많기에, Vim에 대한 기본적인 사용법을 익혀두시면 유용합니다.)
- [Vim](https://www.vim.org/)
- [Vim adventures](https://vim-adventures.com/): Vim을 간단한 게임형태로 배워볼 수 있는 페이지입니다.
코드의 버전관리는 Git / GitHub를 사용하고 있습니다.
- [git](https://git-scm.com/)
- [Git/GitHub 안내서](https://subicura.com/git/guide/)
팀 내 대부분의 서비스는 docker 및 kubernetes를 기반으로 동작합니다.
- [docker](https://www.docker.com/)
- [초보를 위한 도커 안내서](https://subicura.com/2017/01/19/docker-guide-for-beginners-1.html)
- [kubernetes](https://kubernetes.io/)
- [쿠버네티스 안내서](https://subicura.com/k8s/guide/#%E1%84%80%E1%85%A1%E1%84%8B%E1%85%B5%E1%84%83%E1%85%B3)
### 플랫폼
#### Kafka
추천 시스템에서는 각 유저가 어떤 아이템을 소비했는지, 또 소비한 아이템에 대해 어떠한 반응을 보였는지에 대한 정보가 중요하게 사용됩니다. 이러한 정보는 서비스단에서 실시간으로 수집되어 [Kafka](https://kafka.apache.org/)를 통해 추천팀에서 받아볼 수 있는 형태로 전달되고 있습니다. 따라서 Kafka의 기본구조 및 동작 방식에 대해 미리 알아두시면 팀에서 실제 업무를 하실 때 많은 도움이 됩니다.
- [Youtube강의-아파치 카프카](https://www.youtube.com/playlist?list=PL3Re5Ri5rZmkY46j6WcJXQYRlDRZSUQ1j)
#### MongoDB
[MongoDB](https://www.mongodb.com/)는 팀에서 가장 많이 사용하는 key-value storage 중 하나이며, 주 사용처는 다음과 같습니다.
- 개별 유저에 대한 추천 결과 저장(캐시 용도)
- Feature storage
- 유저들의 아이템 소비 로그, 피드백 로그 저장
MongoDB 참고 자료 (팀 내에서 직접 관리를 하는 것은 아니기에 깊이 보실 필요는 없습니다. 아래에서는 3, 4, 5를 위주로 보셔도 괜찮습니다.)
- [1편: 소개, 설치 및 데이터 모델링](https://velopert.com/436)
- [2편: Database/Collection/Document 생성, 제거](https://velopert.com/457)
- [3편: Document Query(조회) - find() 메소드](https://velopert.com/479)
- [4편: find() 메소드 활용 - sort(), limit(), skip()](https://velopert.com/516)
- [5편: Document 수정 - update() 메소드](https://velopert.com/545)
- [pymongo docs](https://pymongo.readthedocs.io/en/stable/)
- pymongo는 MongoDB의 python client로써, 팀에서 MongoDB를 다룰 때 주로 사용하고 있습니다.
#### Hadoop
[Hadoop](https://hadoop.apache.org/)을 구성하는 여러 가지 요소가 있지만, 팀에서는 주로 HDFS, Hive(Presto, Spark)를 많이 사용합니다. Hadoop의 개별 요소를 세세히 설명하기엔 양이 너무 방대하기에, 간단한 개념 위주로 링크를 정리했습니다.
- HDFS: 유저 x 아이템 interaction 데이터 저장, 학습된 추천 모델 저장 등
- [hdfs 기본개념](https://kadensungbincho.tistory.com/30)
- [hdfs 명령어 모음](https://blog.voidmainvoid.net/175)
- Hive(Presto, Spark): 데이터 분석, 전처리 등에 사용
- [Hive, Presto, Spark 기본 설명](https://seoyoungh.github.io/data-science/distribute-system-1/)
================================================
FILE: paper_review/README.md
================================================
<p align="center">
<img height="150" src="https://user-images.githubusercontent.com/38134957/165143510-067f6b0f-4e0e-40c4-b224-729c57dc8afa.png"/><br>
<b>📝 카카오 추천팀 지식 저장소</b>
</p>
카카오 추천팀에서 추천 관련 학회의 논문들을 읽고 정리하는 저장소입니다. 정리는 크게 4가지 방식으로 구성되어 있습니다.
- Summary : 3줄 내외로 논문 내용을 요약합니다.
- Approach : 논문에서 쓰인 접근법들을 정리합니다.
- Results : 실험 결과에 대한 내용을 정리합니다.
- Conclusion : 논문에 대한 본인의 생각을 정리합니다.
발표 자료를 학회별, 주제별로 정리한 링크는 다음과 같습니다.
### Conferences
- [RecSys2021](recsys/recsys2021/RecSys2021.md)
### Topics
- [Algorithmic Advances](topics/Algorithmic%20Advances.md)
- [Applications-Driven Advances](topics/Applications-Driven%20Advances.md)
- [Bandits and Reinforcement Learning](topics/Bandits%20and%20Reinforcement%20Learning.md)
- [Echo Chambers and Filter Bubbles](topics/Echo%20Chambers%20and%20Filter%20Bubbles.md)
- [Interactive Recommendation](topics/Interactive%20Recommendation.md)
- [Language and Knowledge](topics/Language%20and%20Knowledge.md)
- [Metrics and Evaluation](topics/Metrics%20and%20Evaluation.md)
- [Practical Issues](topics/Practical%20Issues.md)
- [Privacy, Fairness, Bias](topics/Privacy,%20Fairness,%20Bias.md)
- [Real-World Concerns](topics/Real-World%20Concerns.md)
- [Scalable Performance](topics/Scalable%20Performance.md)
- [Theory and Practice](topics/Theory%20and%20Practice.md)
- [Users in Focus](topics/Users%20in%20Focus.md)
================================================
FILE: paper_review/recsys/recsys2021/"Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface.md
================================================
# "Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface
- Paper : <https://doi.org/10.1145/3460231.3474232>
- Authors : Alain Starke, Edis Asotic, Christoph Trattner
- Reviewer : bell.park, marv.20
- Topics
- [#Users_in_Focus](../../topics/Users%20in%20Focus.md)
- #Diversity
- [#RecSys2021](RecSys2021.md)
## Summary
- 음식 추천 시스템에서, 유저의 다양한 목적을 만족시키기 위해 어떻게 노출시키면 좋을지(인터페이스)에 대해서 연구한 논문입니다.
- 추천 결과를 single-list와 multi-list 각각의 방법으로 노출했을 때 어떠한 차이가 있는지 유저 스터디로 비교 분석하였습니다.
- 리스트 간의 순서를 정하는 모델이나 로직이 없다는 것은 아쉽지만, 현실적인 접근이라고 생각됩니다.
## Approach
- 기본적으로 현재 보고있는 레시피와 유사한 레시피를 추천하는 연관 추천 환경입니다.
- 저자들이 직접 레시피 데이터를 긁어와서 5가지 추천 리스트를 구성하였습니다.
- Similar recipies - 레시피 이름 TF-IDF indexing후 top-5 similarity
- Fewer Calories - top-40 similarity 후 칼로리 작은 순서대로 top-5
- Fewer Carbohydrates - top-40 similarity 후 탄수화물 작은 순서대로 top-5
- Less Fat - top-40 similarity 후 지방 작은 순서대로 top-5
- More Fiber - top-40 similarity 후 섬유질 큰 순서대로 top-5
- 366명의 실험 참가자를 모집해서 실험을 진행하였습니다.
- 실험 참가자 마다 5번의 실험을 진행
- 참가자가 레시피를 검색해서 들어가면 아래 2가지 중 하나의 화면이 노출
- 미리 준비된 5개의 리스트 중 하나를 골라 노출
- 5개의 리스트를 전부 노출
- 설명은 붙이는 경우도 있고 안붙이는 경우(Similar recipies)도 있음
- 참가자는 레시피를 하나 고르고 레시피와 추천에 대해 만족도를 리포트
## Results
- 참가자의 피드백을 Structural Equation Modeling (SEM) 기법으로 분석하였습니다.
- 주목할 만한 결론은 다음과 같습니다.
- Multi-list로 노출하면 설명 여부와 상관 없이 참가자들이 더 다양하게 추천된다고 느낍니다. (higher **perceived** diversity)
- 실제로 다양하게 노출하는 것과는 다르고, 참가자들이 그렇게 느꼈다는 부분이 중요하다고 합니다.
- 참가자들이 다양하게 추천된다고 느끼면, 아래 두 가지 현상이 나타납니다.
- 하나의 아이템을 고르는데는 어려움을 느낍니다. (higher level of diversity, higher level of choice difficulty)
- 추천의 만족도가 증가합니다. (perceived diversity was also positively related to choice satisfaction)
- 참가자들이 추천이 나온 이유를 이해하면, 추천이 더 다양하다고 느낍니다.
- Single-list 노출 시에는 추천에 대한 설명을 붙여주었을 때 참가자 만족도가 올라가지만, Multi-list 노출 시에는 설명이 있을 때 만족도가 소폭 하락하였습니다.
================================================
FILE: paper_review/recsys/recsys2021/Accordion- a Trainable Simulator for Long-Term Interactive Systems.md
================================================
# Accordion- a Trainable Simulator for Long-Term Interactive Systems
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474259>
- Authors : James McInerney, Ehtsham Elahi, Justin Basilico, Yves Raimond, Tony Jebara
- Reviewer : hee.yoon
- Topics
- [#Metrics_and_Evaluation](../../topics/Metrics%20and%20Evaluation.md)
- [#RecSys2021](RecSys2021.md)
## Summary
- 유저와 인터렉션이 있는 시스템 기반의 트레인 가능한 시뮬레이터를 개발하였습니다.
- 구성은 다음과 같습니다.
- 유저가 visit 할지 여부를 결정하는 visit model
- 유저에게 해당 시점에 어떤 아이템이 추천될지 결정하는 recommedation imitator
- 유저가 추천된 아이템을 클릭할지 결정하는 user selection model
- 컨트리뷰션
- 이 중에서 visit model 를 inhomogeneous Poisson process 로 구현한 부분이 중요한 컨트리뷰션이라고 볼 수 있습니다.
- (비교 시뮬레이터가 Norm IPS인데) 왜 Norm IPS 에 비해, sim2real gap 을 더 줄일 수 있는가?
- 추천 퀄리티에 따라 impression수 자체가 차이가 날 수 있는 부분을 시뮬레이션에 녹여 모델링함
- code: <https://github.com/jamesmcinerney/accordion>
## Approach
- Simulator Data Generation Algorithm:
<img width="425" src="https://user-images.githubusercontent.com/38134957/165451689-0a84e898-1dfa-4458-a6cc-ad480e4bf16e.png">
- 구조도
<img width="878" src="https://user-images.githubusercontent.com/38134957/165451706-633cdcef-7bb8-49e8-81bf-77ac802ec50b.png">
- Visit Model
- Global Intensity + State-based intensity + Recent Activity intensity using Hawkes
- user_state, time 이 주어졌을 때 유저의 intensity를 리턴
- Recommender Imitator (= Impression Model?)
- user_state 가 주어졌을 때, item 을 리턴
- 컨트롤 폴리시 목적으로는 imitator 를 학습하여 사용할 수도 있고,
- 타겟 폴리시 목적으로는 실험하고자 하는 모델로 대체하여 사용할 수 있는 것으로 추정. (Non negative Matrix Factorization 으로 Hyperparameter Fitting 시뮬레이션 Section 4.2 참고)
- User Selection Model
- user_state, item 이 주어졌을때 reward 를 리턴
### Visit Model
- <img width="415" src="https://user-images.githubusercontent.com/38134957/165452520-c166ff03-b5e7-48f1-a7e2-9dcaaa73d1e8.png">
- <img width="893" src="https://user-images.githubusercontent.com/38134957/165452527-ee2d5d8d-53aa-435f-9122-daa1a5e12142.png">
- Inhomogeneous Poisson Process:
<img width="458" src="https://user-images.githubusercontent.com/38134957/165452534-fa7bd82a-a3ed-43d7-bfae-6a3730794050.png">
- Hawkes Intensity:
- 과거 추천 아이템에 유저가 긍정적으로 반응했을 경우 더 커짐
- <img width="416" src="https://user-images.githubusercontent.com/38134957/165452540-4820adcc-83a3-4e22-ae11-139ce0c8a46d.png">
### Marking Distribution = Recommendation Imitator (Impression Model) * User Selection Model
<img width="414" src="https://user-images.githubusercontent.com/38134957/165452547-33921795-2807-418f-b456-03c339e401d3.png">
- Both the impression model and user selection model use as
- input: a bag of words representation of previous user interactions with items
- and map these though a dense network
- output: to a multinomial distribution over items.
## Results
AB 테스트 결과를 얼마나 재현 가능한가? 를 평가하였습니다.
<img width="883" src="https://user-images.githubusercontent.com/38134957/165452683-9f9c01cf-f11a-4480-9134-258f926a3651.png">
================================================
FILE: paper_review/recsys/recsys2021/Burst-induced Multi-Armed Bandit for Learning Recommendation.md
================================================
# Burst-induced Multi-Armed Bandit for Learning Recommendation
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474250>
- Authors : Rodrigo Alves, Antoine Ledent, Marius Kloft
- Reviewer : charlie.cs
- Topics
- [#Algorithmic_Advances](../../topics/Algorithmic%20Advances.md)
- [#Bandits_and_Reinforcement_Learning](../../topics/Bandits%20and%20Reinforcement%20Learning.md)
- [#RecSys2021](RecSys2021.md)
## Summary
- non-stationary & context-free MAB 상황에서 Cold-start recommendation (CSR) 을 위한 방법인 BMAB (Burst-induced MAB)을 제시하였습니다.
- 기존 non-stationary MAB(EXP3, Discounted-UCB etc.)의 방식과 비교되는 특징은 다음과 같습니다.
1. context-free: feature vector가 필요하지 않습니다.
2. reward 분포의 변화를 확인하는 대신, 시스템의 temporal dynamics를 활용합니다.
## Approach
### Intuition
- 추천 환경에는 크게 두가지 상태가 있다고 가정: loyal (stable) state 그리고 curious (unstable) state
- 전체 time horizon은 일정 구간으로 나뉘어져서, 두 state 중 하나가 발생한다고 가정함
- loyal state는 구간에 상관없이, curious state는 구간마다 stationary payoff distribution를 가진다고 주장
<img src="https://user-images.githubusercontent.com/38134957/165448255-7e73d749-683e-44a5-9b29-c66dd37ef158.png " width=65%>
- state 마다 MAB 모델을 세우고, 특정 state 상황에 해당하는 모델을 이용하여 추천을 진행
### Burst-induced MAB (BMAB)
- Algorithm
1. 두 state (loyal, curious)마다 각각 K개의 beta parameter를 두고, orcale이 timestamp마다 어떤 state인지 알려줌
2. state를 확인하면, 해당 state의 beta parameter를 통해 일반적인 Thompson Sampling 추천을 진행
3. 만약 curious (s = 1) 에서 loyal (s = 0) 상태로 넘어가는 경우, curious state에 해당하는 beta parameter를 decay
<img src="https://tva1.sinaimg.cn/large/008i3skNgy1gwg5vya71xj30ou0j6gno.jpg" width=75%>
### State Detector
- 매 timestamp 마다 어떤 state인지 파악하는 orcale을 구성하기 위해서는 homoheneous Poisson process에 대한 intensity (`lambda_L`)가 알려져 있다는 가정이 요구됨
- intensity (function)는 쉽게 말하면 특정 구간에서 발생한 이벤트의 rate
- 이 가정의 존재 이유는 문제 초기 정의 시, time series 가 두가지 stochastic point process의 mixture에 의해 생성된다는 가정이 있었기 때문
- loyal: a homogeneous Possion process (HPP) with intensity `lambda_L`
- curious: a piece-wise homogeneous Poisson process (PW-HPP) with intensity `lambda_C(t)`
- 해당 intensity를 몰라도 쉽게 유추할 수 있다고 주장
- 예시 (HPP with `lambda_L=3`, PW-HPP with `lambda_C in (0.15, 15)`)

- Algorithm
- state를 추정할 timestep 구간을 사이즈가 `Delta` 인 window로 나누고, 해당 구간이 intensity 가 `lambda_L` 인 Possion process에서 생성되었는지 검증
- 즉, window 내 분포는 shape가 `Delta-1` 이고 scale이 `lambda_L` 인 Gamma distribution을 따르는지 확인
- 해당 분포를 따른다면 loyal (`0`) 그렇지 않다면 curious (`1`)
<img src="https://tva1.sinaimg.cn/large/008i3skNgy1gwg60ntwk5j30p40go0u5.jpg" alt="image-20211115224032770" width="65%" />
- `q` 는 Gamma 분포의 quantile function
- quantile function의 shape값이 `lambda-1` 인 이유는 `t_{i-\Delta+1}` 부터 event counting이 진행되기 때문
- hypothesis testing의 목적은 burst period를 확인하기 위한 목적 (calm period는 loyal 에게 dominated)
- 만약 `delta=0.95`라면 test는 다음과 같이 해석될 수 있음
: scale이 `lambda_L`인 event가 `Delta-1`번 발생할때까지 걸리는 time interval 분포 중, interval `Delta_i`가 분포의 quntaile 5% 내에 존재하는가?
- 쉽게 말하면, 기존에 이벤트가 `N` 번 발생하는데 `X` 만큼 걸렸는데, `Y`는 그보다 더 짧은가?
- 해당 intensity를 몰라도 쉽게 유추할 수 있다고 주장
- solve with EM - Burstiness scale: A parsimonious model for characterizing random series of events. In Proceedings of the 22nd ACM SIGKDD
## Results
- 합성 데이터, 실제 데이터 모두를 사용해서 제안한 방법을 평가하였습니다.
- 제안한 방법들: BMAB-O (oracle), BMAB-R (detector)
- 실제 데이터의 경우, 전체 timeseries에서 일정 구간은 `lambda_L` 을 추정하는 구간으로 사용하고 나머지는 평가에 사용하였습니다.
- metric: average of the observed reward (`R(T)/N`), and its standard deviation
- the user liked (Behance, MovieLens), searched (Google trends) or clicked on (Outbrain)
- baseline은 크게 세가지로 나뉩니다.
- stationary: TS
- non-stationary: EXP3
- piece-wise stationary: EXP3DD, DUCB, MUCB, WMD
<img src="https://user-images.githubusercontent.com/38134957/165448414-504e4e05-29a3-4e7e-b473-32e85fc13f80.png" alt="image-20211115222133822" style="zoom:50%;" />
- `K` : the number of arms, `N`: the number of events, `T`: the observed time
- 제안한 BMAB-R이 모든 dataset에서 reward가 우세하였습니다.
- MovieLens의 경우 제안한 방법이 TS과 거의 차이가 없었는데 이는 가장 인기있는 다섯개의 아이템이 stationary 하기 때문이라고 주장하였습니다.
================================================
FILE: paper_review/recsys/recsys2021/Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders.md
================================================
# Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
- Paper : <https://arxiv.org/abs/2108.01053>
- Authors : Guillaume Salha-Galvan, Romain Hennequin, Benjamin Chapus, Viet-Anh Tran, Michalis Vazirgiannis
- Reviewer : tony.yoo
- Topics
- [#Real-World_Concerns](../../topics/Real-World%20Concerns.md)
- #Cold_Start
- #Graph
- [#RecSys2021](RecSys2021.md)
## Summary
- Directed graph로 정의된 item network에 대해 link prediction task을 수행한 논문입니다.
- Directed 기반의 similarity를 구하기 위해 gravity 기반의 매커니즘을 도입하여 단 방향 선호도를 예측 가능하게 만들었습니다.
- Cold item (노드 피쳐는 있으나 adjacent 정보가 isolated 된 상황)에 대해 masking과 VAE기반의 구조로 접근하여 성능 향상을 내었습니다.
## Approach
### Gravity-Inspired similiarity
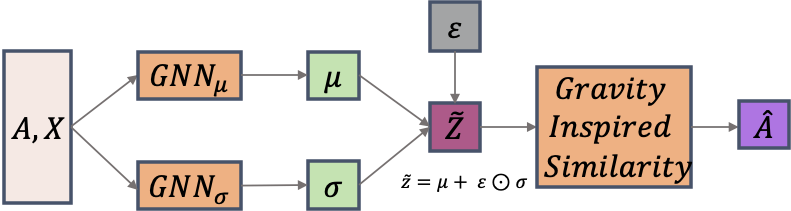
$$
\begin{aligned}
\hat{A}_{ij} &= \sigma \left( \log \frac{Gm_j}{\Vert z_i - z_j \Vert_2^2} \right)\\
&= \sigma \left( \underbrace{\log Gm_j}_{\text{denoted}~\tilde{m}_j} - \log\Vert z_i - z_j \Vert_2^2 \right)
\end{aligned}
$$
즉, VAE기반의 GNN를 태워 얻은 $\tilde{Z} = [Z; \tilde{M}], Z\in \mathbb{R}^{n \times d}, \tilde{M}\in \mathbb{R}^{n }$ 로 similiarity score $\hat{A}_{ij}$를 예측합니다.
### Loss
- VAE 기반의 encoding 모델로 GNN을 사용하였습니다.
$$
q(\tilde{Z} \vert A, X) = \Pi_{i=1}^n q(\tilde{z}_i\vert A, X)
$$
$$
q(\tilde{z}_i \vert A, X) = \mathcal{N}\left( \tilde{z}_i \vert \mu_i, \text{diag}(\sigma_{i}^2)\right)
$$
$$
\begin{cases}
\mu = GNN_{\mu}(A, X) \\
\sigma = GNN_{\sigma}(A, X)
\end{cases}
$$
- $P(A)$ 를 최대화하려면 다음의 ELBO를 최대화 하면 됩니다. (jensen's inequality로 증명 가능).
$$
\mathcal{L} = \underbrace{E_{q(Z |A,X)} \left[ \log p(A|Z) \right]}_{\text{Reconstruction Loss}} − \underbrace{D_{KL}(q(Z|A,X) \Vert p(Z))}_{\text{Regularization Loss}},
$$
- Reconstruction Loss
- $q$ 에 대한 평균을 구하기 어렵기 때문에 $A$ 가 bernoulli distribution을 따른다는 가정 하에 몬테카를로 근사를 이용해서 cross entropy 를 계산합니다.
$$
\mathcal{L}_{Reconstruction} = BCE(A, \hat{A})
$$
- Regularization Loss
- 둘 사이의 KL divergence를 구해야하는데 $p(z)$ 를 normal distribution이라 가정하면 다음과 같이 계산됩니다.
$$
\mathcal{L}_{Regularization} = \frac{1}{2} \sum_d\sum_i^k exp(\sigma_{ii, b}^2) + \mu_{i, b} - \sigma_{ii, b} - 1
$$
### Cold Start Similiar Items Ranking
warm item 수를 $n$, cold item 의 갯수를 $m$ 이라 하면, adjacent matrix $A \in \mathbb{R}^{(n + m) \times (n +m)}$ 에서 cold item의 row는 zero vector로 masking 됩니다.
$A$ 를 GNN 기반의 VAE 모델을 통해 다음과 같이 예측할 수 있습니다. 여기서 $\lambda$ 는 influence 와 proxmity사이의 trade off를 튜닝하는 데 사용되며 이는 popularity bias를 control하는 걸 의미합니다. 이렇게 예측된 similairity로 부터 top $k$ 개를 추천하게 됩니다.
$$
\hat{A}_{ij} = \sigma \left( \underbrace{\tilde{m}_j}_{\text{influence of j}} -\lambda \underbrace{\log \Vert z_i - z_j\Vert_2^2}_{\text{proximity of i and j}} \right)
$$
### Other Methods
- [VGAE](https://arxiv.org/abs/1611.07308):
- Undirected graph 에 대해 $\hat{A} = \sigma \left(z_i^{T}z_j\right)$ 를 통해 예측합니다. 다만, 이렇게 계산하면 symmetric 하다는 단점이 존재합니다.
- Sour-Targ GVAE:
- Directed graph 에 대해 $\hat{A} = \sigma\left( z_i^{(s)T}z_j^{(t)}\right)$, $z^{(s)} = z[:d/2]$, $z^{(t)}=z[d/2:]$. 단, $d$는 짝수이고, 이렇게 계산하면 non-symmetric이 됩니다.
## Results
### Dataset
- [Deezer](https://www.deezer.com/soon) 의 24,270 수의 artist 들로 구성 된 directed graph입니다.
- Node feature는 56 dimension을 가지며 다음 component들로 구성되어 있습니다.
- Genre vector (32-dim)
- Country vector (20-dim)
- Mood vector (4-dim)
- Train, valid, test 는 8:1:1 로 split. Valid와 test의 경우엔 cold 노드들로 구성되어 있기 때문에 neigbor edge는 masking 되어있습니다.
### Metric
- Recall, MAP, NDCG를 사용하였습니다.
### Performance
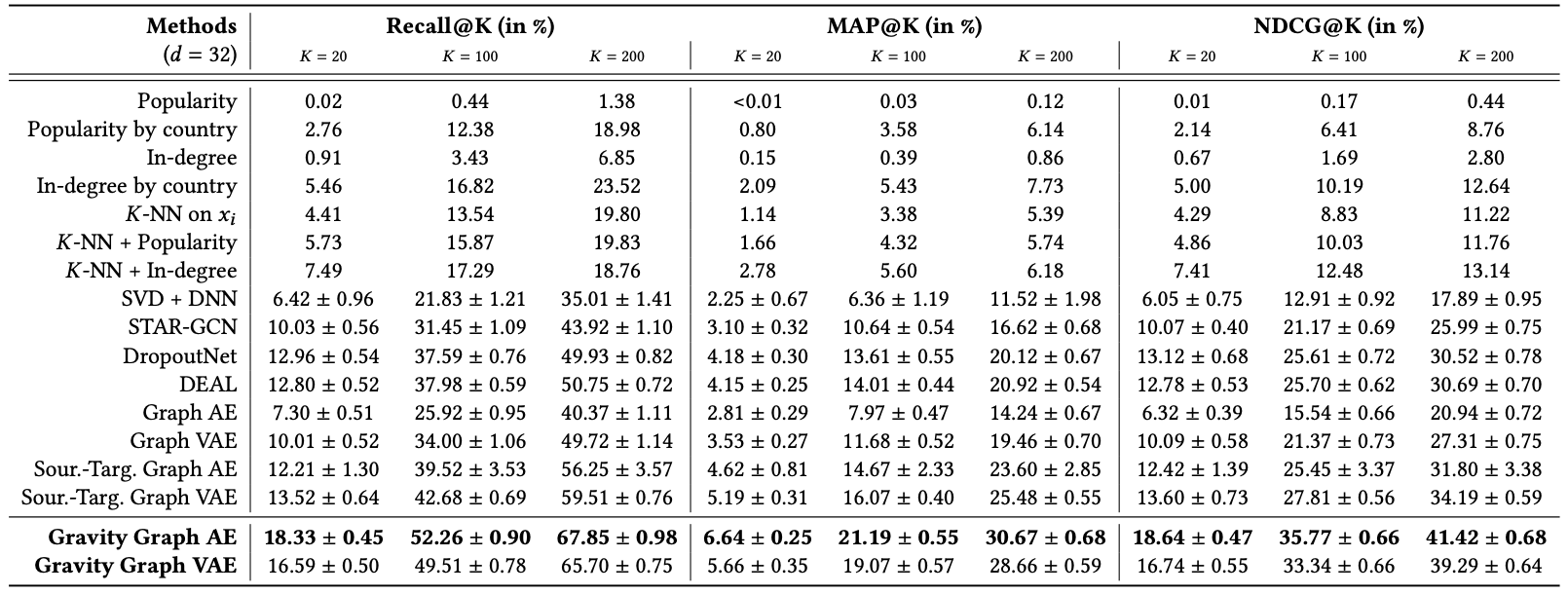
- Gravity 매커니즘이 큰 폭으로 outperform하였습니다.
- Source.-Targ. 버전이 최근 연구에 대해 약간 우위를 보입니다. Non-symmetric 성질을 띈다는 점에 주목할 수 있습니다. Symmetric인 GAE, GVAE는 더 낮은 걸 보았을때 Non-symmetric 방법이 우수함을 의미합니다.
- Source.-Targ. 에서 VAE 가 AE보다 좋은 결과를 보였지만, Gravity 버전에서는 반대의 결과를 보였습니다. 상황에 따라 VAE vs AE의 성능이 달라지게 됩니다.
#### Mass parameter
- 정성적 분석: 왼쪽은 artist별 mass의 크기와 링크 사이를 visualization 한 결과입니다. 빨간색 노드들이 레게 아티스트들 이고, mass가 큰 것 중에 하나를 예로 들은게 레게의 유명한 아티스트 Bob Marley입니다.
- 정량적 분석: 오른쪽은 mass (아티스트들) 사이의 여러 measure (popularity, in-degree, page rank) 로 상관관계 분석을 해보았습니다. 결과를 보았을 때, mass가 높다고 measure 값들이 꼭 높은 것은 아니지만 어느정도 상관관계가 있다는것을 보여주었습니다.
<figure style="text-align: center;">
<img src="https://user-images.githubusercontent.com/38134957/165449149-afb80cd5-74a6-4e5a-beb3-604a4f499811.png" style="zoom:50%;" />
</figure>
#### Impact of attributes
- Node feature를 많이 쓸수록 성능이 향상되었습니다.
<img src="https://user-images.githubusercontent.com/38134957/165449230-747517bf-faaa-49ab-aa64-0380478432e1.png" style="zoom:60%;" />
#### Popularity-diversity trade off
- $\lambda$ 를 높힐 수록 popular한 item의 rank 빈도가 많아지고, 줄이면 distance에 의한 계산만 하기 때문에 줄어들게 됩니다.
<img src="https://user-images.githubusercontent.com/38134957/165449251-63848fd0-1148-43b5-9d42-16472a022176.png" style="zoom:50%;" />
## Conclusion
- 그래프 방법론을 이용하여 similar item 추천을 non-symetric한 상황에서 다루어 성능을 향상시킨 논문입니다.
- Cold-start 상황에서 masking, VAE 방법론등의 이점을 적용하였습니다.
### Critical view of points
- Cold 아이템의 경우 adjacent 정보를 masking (0으로 패딩)하면 모두 동일한 피쳐로 간주되게 됩니다.
- Cold start 상황에 대해서만 평가를 진행해보았을 때의 우위 비교가 없어 아쉬웠습니다.
- 실험에 사용된 benchmark 모델들은 비교적 최근 논문이 적어서(STAR-GCN, DEAL 빼곤 옛날 논문이라) 아쉬웠습니다.
| Model 이름 | 학회 년도 | 인용수 |
| ------------------------------------------------------------ | ---------- | ------ |
| [DropoutNet](https://www.cs.toronto.edu/~mvolkovs/nips2017_deepcf.pdf) | NIPS 2017 | 104 |
| [Graph VAE](https://arxiv.org/abs/1609.02907) | ICLR 2017 | 1,267 |
| [STAR-GCN](https://arxiv.org/abs/1905.13129) | IJCAI 2019 | 72 |
| [DEAL](https://arxiv.org/abs/2007.08053) | IJCAI 2020 | 11 |
================================================
FILE: paper_review/recsys/recsys2021/Debiased Explainable Pairwise Ranking from Implicit Feedback.md
================================================
# Debiased Explainable Pairwise Ranking from Implicit Feedback
- Paper : <https://arxiv.org/pdf/2107.14768.pdf>
- Authors : Khalil Damak, Sami Khenissi, Olfa Nasraoui
- Reviewer : hee.yoon
- Topics
- [#Privacy_Fairness_Bias](../../topics/Privacy,%20Fairness,%20Bias.md)
- #Matrix_Factorization
- #Explainable_Recommendation
- [#RecSys2021](RecSys2021.md)
## Summary
- 기존 Bayesian Personalized Ranking(BPR) 대비하여 explainability를 늘리고 exposure bias를 잡은 논문입니다.
- 기존 BPR 모델은 설명 불가능한 블랙박스 모델이었습니다. -> a novel explainable loss function and a corresponding Matrix Factorization-based model called Explainable Bayesian Personalized Ranking (EBPR) that generates recommendations along with item-based explanations.
- 기존 BPR 모델은 Missing Not At Random (MNAR) 데이터 특성 때문에 exposure bias에 취약했었습니다. -> an unbiased estimator for the ideal EBPR loss.
## Approach
### BPR
- objective function:
<img width="403" src="https://user-images.githubusercontent.com/38134957/165450622-feaf8ae5-a197-4091-b3a9-e862857ca90d.png">
### Explainable BPR
- objective function:
<img width="412" src="https://user-images.githubusercontent.com/38134957/165450632-6b932ca6-71e3-4ca3-a561-b84e2253f4a3.png">
- E_ui+ (1 - E_ui-) 부분은 (u, i+, i-) 인스턴스의 컨트리뷰션의 비중을 정하는 역할을 합니다. Positive 아이템의 설명력이 높을수록, negative 아이템의 설명력이 낮을수록 학습 기여도가 높습니다. 결과적으로 생성된 추천결과의 상위 아이템들은 더 높은 설명력을 가질 것이라고 기대할 수 있습니다.
- For instance, in the extreme case where either the positive item is not explainable at all or the negative item is completely explainable, the update equation is zeroed out. Hence, no contribution will come from the corresponding instance to the learning. This is reasonable and desirable since the aforementioned case depicts a non explainable preference, where either the positive item is not explainable or the negative item is explainable. Either case undermines the explainability of the preference. (설명가능하지 않은 아이템을 소비한 것은 학습에 포함이 안됩니다. 아래 E_ui 정의를 참고하면, 유저가 소비한 아이템의 이웃 아이템을 유저가 소비한 이력이 없으면 학습에 포함이 안됩니다.)
- explainability matrix:
- E_ui = items the user interacted from the neighboring items / len(neighboring items)
- 이웃한 아이템 중에서 해당 유저와의 인터랙션이 발생한 아이템의 비중입니다.
- similarity의 계산: 별도의 데이터가 아닌, rating 메트릭스 기반으로 cosine similarity를 계산합니다.
- for a specific item, the more neighboring items a given user has interacted with, the higher the explainability of that item will be to this user.
- 학습 시작 전, 미리 계산하는 방식입니다.
- <img width="411" src="https://user-images.githubusercontent.com/38134957/165450706-8c030819-c642-48a2-95e8-a5750254812d.png">
- <img width="405" src="https://user-images.githubusercontent.com/38134957/165450714-805f92ba-7bad-4dc8-9b31-a7513126faca.png">
- neighborhood size
- <img width="820" src="https://user-images.githubusercontent.com/38134957/165450725-593fe1e4-88d2-421d-b8a4-6d674286b0a3.png">
- 추천 결과 서빙시 explainability 기반으로 해석된 결과를 제공 가능합니다. (참조 논문에서 언급한 방식)
- 참조 논문(Using Explainability for Constrained Matrix Factorization): <https://uknowledge.uky.edu/cgi/viewcontent.cgi?article=1017&context=ccs2>
- item 기반 explainability 사용시:
- <img width="335" src="https://user-images.githubusercontent.com/38134957/165450845-b2fdc4ab-3fc6-4aef-8d54-e2ff856df60a.png">
- user 기반 explainability 사용시:
- <img width="262" src="https://user-images.githubusercontent.com/38134957/165450849-6a219ded-aeb6-44a5-9748-c7d0951250c8.png">
### Unbiased Explainable BPR (UEBPR)
- objective function:
- <img width="403" src="https://user-images.githubusercontent.com/38134957/165450866-14ebe685-15c8-4b7d-a037-a82e9c3b447a.png">
- 가정
- <img width="80" src="https://user-images.githubusercontent.com/38134957/165450996-03f03a0a-dcbf-4cf8-a4f9-8d07f9c141a7.png">
- Y_u,i: user 가 item 과 인터렉션을 했는지 여부 (예: 클릭 여부) = 노출이 되고, 관련성도 있다
- O_u,i: user 에게 item 이 노출됐는지 여부
- <img width="237" src="https://user-images.githubusercontent.com/38134957/165451006-800761c4-3242-4313-9852-ada592cb3c61.png">
- R_u,i: user 에게 item 이 관련성이 있는지 여부
- <img width="96" src="https://user-images.githubusercontent.com/38134957/165451017-9b05f8d7-64c6-41d4-bda4-54ddbaf219f9.png">
- <img width="137" src="https://user-images.githubusercontent.com/38134957/165451021-f977c481-a9d7-4b7c-a321-c66e1f2409a8.png">
#### Unbiased BPR Loss (UBPR)
- objective function:
<img width="413" src="https://user-images.githubusercontent.com/38134957/165451226-1757c3d5-18f7-4f59-aa1e-fd3069474ade.png">
#### Ideal Explainable BPR
- objective function:
<img width="403" src="https://user-images.githubusercontent.com/38134957/165451231-7247f495-40f1-4227-aca3-4e2cf6ccf78b.png">
<img width="425" src="https://user-images.githubusercontent.com/38134957/165451234-6b09a4e0-09fd-4bda-a95c-a8e53b130320.png">
#### Partially Unbiased Explainable BPR (pUEBPR)
- objective function:
<img width="396" src="https://user-images.githubusercontent.com/38134957/165451247-65014171-77dc-46e2-8a9c-83919065f26e.png">
## Results
<img width="815" src="https://user-images.githubusercontent.com/38134957/165451256-5957ea77-ef9f-4b02-8e96-5045c50368ea.png">
<img width="816" src="https://user-images.githubusercontent.com/38134957/165451259-f01fdf91-f6d6-4460-9a6a-36ed018bad14.png">
================================================
FILE: paper_review/recsys/recsys2021/Evaluating Off-Policy Evaluation- Sensitivity and Robustness.md
================================================
# Evaluating Off-Policy Evaluation- Sensitivity and Robustness
- Paper : <https://arxiv.org/abs/2108.13703>
- Authors : Yuta Saito, Takuma Udagawa, Haruka Kiyohara, Kazuki Mogi, Yusuke Narita, Kei Tateno
- Reviewer : iggy.ll
- Topics
- [#Metrics_and_Evaluation](../../topics/Metrics%20and%20Evaluation.md)
- [#RecSys2021](RecSys2021.md)
## Summary
- 이 논문의 목표는 online에 올려보지 않고 모델을 평가하는 것입니다.
- 모델: 유저가 페이지에 접속했을 때, 유저의 정보, 시간 정보 등을 활용해 A안/B안/C안 중 어떤게 나을 지 확률적으로 결정합니다. e.g., [0.4, 0.3, 0,3]
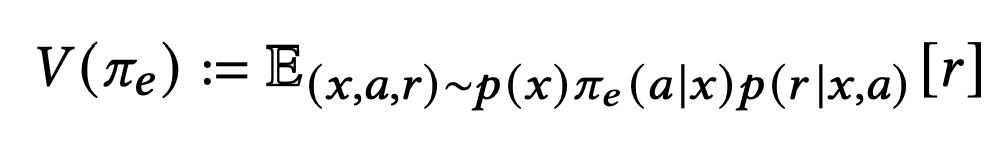
- context x: 유저가 접속한 시간, 유저 정보 등.
- action: 보여준 페이지 레이아웃
- reward:유저가 클릭했거나 안 했거나, 우리가 보여준 레이아웃에 따른 유저의 행동 결과(숫자)
여기서 문제는 $p(r_i...)$를 알 수가 없다는 점과, 모델이 아이템을 선택해서 보여주어야 그에 대한 결과를 만들 수 있다는 점이 있습니다.
## Approach
Off Policy Evaluation은 두 가지 분류로 나눌 수 있습니다.
1. Direct Method (DM): mean reward 자체를 estimate하는 방법
2. Inverse Propensity Weight (IPW), SNIPW: logging policy, or base policy의 log를 요구하는 방법
그리고 저 두 가지 방법을 함께 사용하는 방법들도 있습니다.: DR, SNDR, Switch-DR, DRos
DM은 모델을 하나 더 만들어야 하기 때문에, 이 모델에 관한 하이퍼패러미터를 또 신경써주어야 합니다.
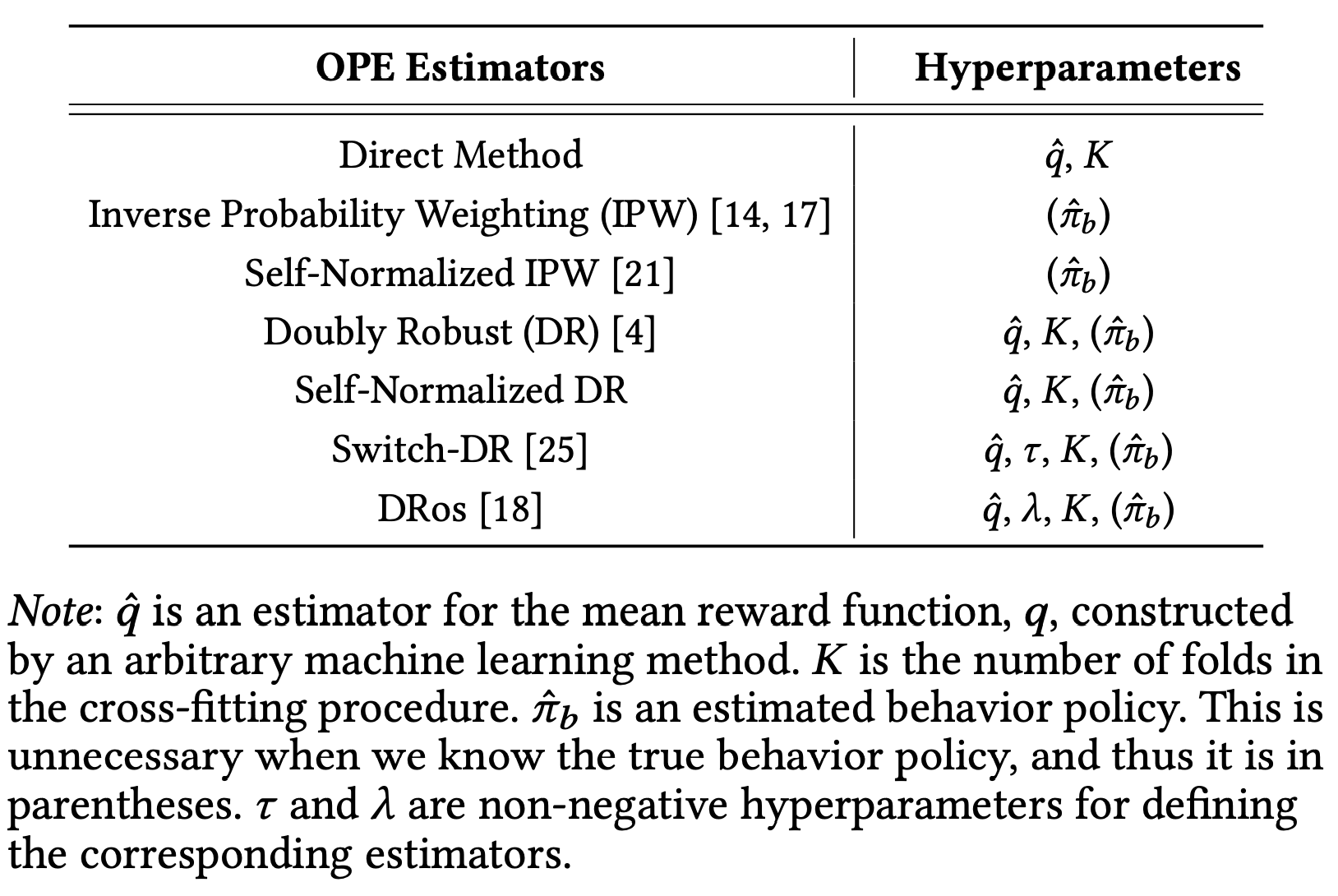
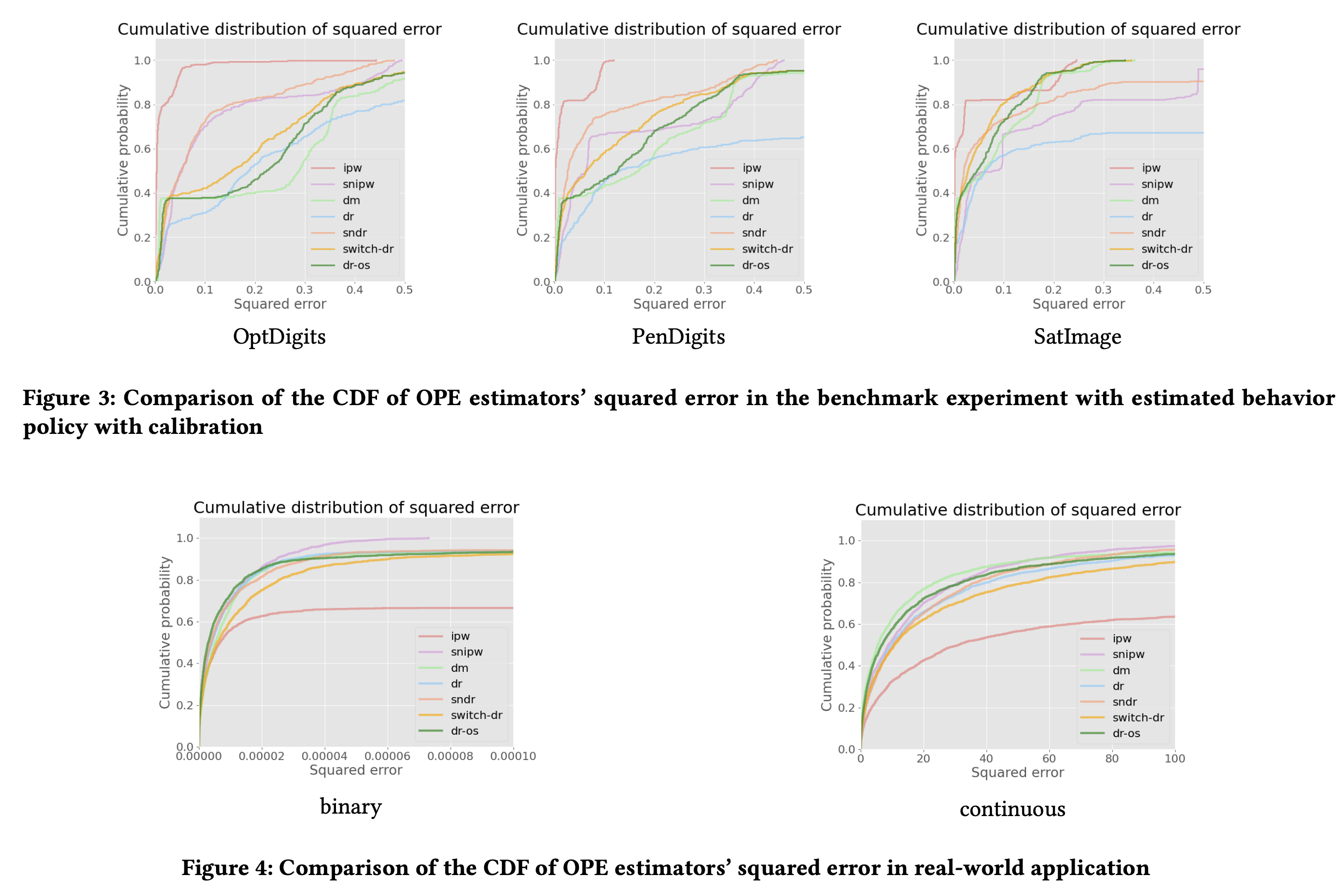
## Conclusion
- mean reward를 estimate하기 어렵기 때문에 계열의 방법은 사용하지 않는게 좋을 것 같습니다.
- SNIPW가 일반적으로 가장 괜찮았습니다. (적절히 Calibration해줄 수 있다면 IPW를 써도 괜찮을 것 같습니다.)
- 적절히 Calibration해줄 수 있다면 logging policy를 estimate한 값으로 (logging policy를 따라하도록 다른 모델을 학습해서) 사용해도 나쁘지 않아 보입니다.
- 이건 조금 이상한게, logging policy를 이미 갖고 있으면 이를 사용하지 왜 다른 estimator를 더 만들어야 하는지는 잘 모르겠습니다.
================================================
FILE: paper_review/recsys/recsys2021/Follow the guides- disentangling human and algorithmic curation in online music consumption.md
================================================
# Follow the guides- disentangling human and algorithmic curation in online music consumption
- Paper : <https://arxiv.org/abs/2109.03915>
- Authors : Quentin Villermet, Jérémie Poiroux, Manuel Moussallam, Thomas Louail, Camille Roth
- Reviewer : jinny.kk
- Topics
- [#Applications-Driven_Advances](../../topics/Applications-Driven%20Advances.md)
- #Music_Recommendation
- [#RecSys2021](RecSys2021.md)
## Summary
- Contribution
1. algorithmic guidance에 대한 유저의 태도에 따라 유저군을 선분류하고 각 유저군별로 나눠서 콘텐츠 소비 방식을 분석하였습니다.
- “추천”이라는 개입이 유저의 소비 컨텐츠 다양성에 어떤 영향을 끼치는가는 논란이 많은 뜨거운 감자였다. 기존 연구들의 대부분은 유저들을 뭉뚱그려서 혹은 binary category (성별, 나이)로 나누어서 결과를 분석했는데 이 논문의 저자들은 유저가 플랫폼을 사용하는 타입별로 그 영향이 다르게 나타나므로 유저들의 그룹을 access mode에 따라 구분해서 영향을 분석하였습니다.
2. platform recommendation을 algorithmic 과 editorial로 나눠서 살펴보았습니다.
3. platform recommendation과 offline radio recommendation 간의 관계를 살펴보았습니다.
- Key Observations
- 음악 플랫폼에서 유저들이 음악을 주로 소비하는 경로 access mode (organic, algorithmic, editorial)에 따라 네 가지 유저그룹으로 (a, e, o, o+) 나누고, 유저들이 소비하는 음악의 다양성 (두 가지 디멘션: dispersion & artist popularity)을 유저 그룹별로 복합적으로 분석한 논문입니다. (그래서 정리하면서 좀 헷갈림...)
- 소비의 diversity를 두 가지 디멘션에서 보았는데, 유저가 총 소비한 곡들 중 unique 곡들의 비중 측면 (dispersion)과 유저가 소비하는 음악의 아티스트의 인기도 측면 (popularity)입니다.
- dispersion 측면에선
- very organic users 보다 어떤 형태로든지 추천을 사용하는 유저들의 dispersion 값이 높았고,
- 각각의 유저 클래스에서 각자의 main access mode를 통한 소비의 dispersion이 낮았습니다 (=그쪽에서 exploitation이 일어나는 것을 관찰하였습니다.)
- (오프라인 vs 플랫폼) 라디오 프로그램들의 플레이리스트 dispersion < 온라인 플랫폼 내 대부분 유저들의 소비 dispersion
- artist popularity 측면에선
- algorithmic user들은 인기 있는 곡을 under-consume했고 editorial user들은 인기 있는 곡을 over consume하는 모습을 보였으며,
- 모든 유저 클래스에 대해서 공통적으로 대체로 algorithmic access mode를 통해서는 덜 인기있는 곡들이, editorial access mode를 통해서는 인기 있는 곡들이 소비되는 경향이 보였습니다.
- (오프라인 vs 플랫폼) 라디오 플레이리스트나 온라인 플랫폼 유저들이나 곡들의 평균 popularity는 비슷비슷했습니다.
- 그리고 dispersion과 artist popularity간에 mild correlation도 관찰되었습니다.
## Results
### Dataset
- Deezer (프랑스 음악 스트리밍 플랫폼) 2019년 1년동안 8639명의 구독자들의 play history (총 51m 개) (어떤 유저가 어떤 가수의 어떤 노래를 몇 분간 들었는지) + 노래에 접근한 경로 (access mode) (직접 검색, 추천 등)
- 동일 기간동안 프랑스의 라디오 방송국 39곳의 플레이리스트 히스토리를 사용하였습니다.
### User Practices
#### Modes of access and user behavior classes
- Three types of content access mode
- organic (self-selected)
- algorithmic (suggested by recommendation engine)
- editorial (human curation)
- 유저의 플레이 히스토리에서 각각의 access mode의 비율 (Pa (algorithmic), Pe (editorial), Po (organic))에 따라 유저 클래스를 4가지로 분류함.
- `fig 1` 에 나타나듯 대부분의 유저가 organic mode 에 많이 의존하고 있긴 한데
- 그럼에도 불구하고 구분이 가능하긴 하고 k means를 통해 `user class`을 4가지로 나누었습니다.
- a (989명), e (655명), o (1614명), o+ (5381명)
- 각 유저 클래스별로 number of plays의 분포는 비슷했습니다 (= 모든 클래스에는 active한 유저 덜 active한 유저가 모두 있습니다. 평균 activity는 e 유저 클래스에서 다소 낮긴 했습니다) (`fig 1 - right`)
#### Two dimensions of diversity
- dispersion: (functional diversity - denoting the lack of redundancy in the listening history)
- 정의 = S (number of unique songs) / P (number of plays)
- `fig 2 - left`
- 각 유저 클래스별로 linear model을 fit해서 경향성을 보았더니 모든 유저 클래스에서 activity (P) 와 dispersion은 inverse relationship을 보였습니다.
- 하지만 동일 P에 대해선, o+ 인 유저들이 가장 낮은 dispersion을 보였습니다. 즉, algorithmic이든 editorial이든 어떤 형태로든 플랫폼의 추천 모드를 활용하는 유저군들에서 dispersion 값이 더 높게 나타났습니다.
- o+ 유저들은 플랫폼을 “digital librarian”이 아니라 “digital library”로 사용하는 것이라고 표현하였습니다.
- “even a moderate use of some form of recommendation is generally associated with a higher level of exploration.”라고 해석하였습니다.
- `fig 3`
- 각 유저 클래스에서 각 access mode 별로 dispersion 값들을 확인했는데 모든 유저 클래스에 대해 각 클래스가 중점적으로 사용하는 access mode에서의 dispersion 값이 낮았다. 예를 들어 algorithmic 유저 클래스에선 alogrithmic access mode에서 dispersion이 낮고 이랬다.
- “Users tend to prioritize exploitation in their preferred mode of access, and favor exploration in the others, in terms of more dispersed plays.”
- artist popularity (semantic diversity - denoting the tilt toward songs by more popular artists.)
- 정의 = 그 아티스트의 곡들의 재생 횟수를 바탕으로 아티스트들을 4개의 인기도 구간으로 나눔 (각 인기도 구간의 재생 횟수 합이 비슷하게 되도록)
- 인기도 구간: (높은 인기도) v1 - v2 - v3 - v4 (낮은 인기도)
- `Table 2`
- 곡들은 아티스트의 인기도에 상관없이 대부분 organic access mode를 통해 소비되는 비중이 가장 높았다.
- algorithmic access mode는 중간 인기도의 곡들을 주로 소비하는 통로가 됨을 알 수 있고, editorial access mode는 높은 인기도의 곡들의 비중이 많음. organic은 제일 인기 있거나 제일 인기 낮은 곡들의 비중이 많음.
- `fig 4 -left`
- artist popularity와 dispersion이 서로 연관이 되어 있다. 인기도 낮은 아티스트 곡 소비하는 (x축 우측) 유저들의 dispersion 값이 더 높더라 (y축).
#### User types and access mode biases
- user type, access mode, diversity가 어떻게 상호 작용을 하는지 “disentangle”한 그래프가 `fig 5.` 그래프의 y축이 완전히 이해 가는 것은 아님.
- 각 유저 타입별로 소비하는 곡들의 인기도 경향성이 어떻게 되는지를 보여준 건데, access mode에 따라 세분화한 게 밑에 있는 그림.
- `fig 5 - top` : algorithmic users under-consume popular artists, editorial users over-consume popular artists, organic users favor less popular artists in monotonous manner, and very organic users 는 인기도 양 극단에서의 소비가 “약간 더” 많다. (그림에서 잘 보이지 않기는 하는 듯..)
- `fig 5 - bottom` : 유저 타입 구분 없이 모두 전반적으로, algorithmic access로 덜 유명한 아티스트 곡 소비가 되고 editorial access는 인기 있는 아티스트 곡 소비로 치우치고 organic은 그 사이 어디쯤을 보여주는 것으로 해석함.
### The diversity of human-assisted guidance
- 바로 위에서 관찰한 것 중에서, algorithm으로는 덜 유명한 곡 소비를, editor들은 유명한 곡 소비를 이끌어내는 경향성이 보인다는 점이 있는데, 이를 좀더 확인하기 위해 전통적인 오프라인의 editorial 추천이라고 볼 수 있는 라디오 프로그램 플레이리스트를 분석했다.
- `fig 6 - left`
- 대부분의 user type이 라디오 프로그램들보다 높은 dispersion을 보여줬다. 즉 라디오 프로그램은 보다 제한적인 카탈로그에서의 exploitation으로 기울어져 있다는 이야기.
- 그리고 색깔 그라데이션 보면 알 수 있듯, dispersion과 popularity의 mild correlation도 볼 수 있다.
- `fig 6 - right`: 대부분의 user type이 중간 부근에 있다. 즉 해석하면 “while online music listening practices seem to foster functional diversity (dispersion), in terms of semantic diversity (popularity) they seem, on average, to be neither significantly above nor significantly below the mass of the radios we focus on.”
### Concluding Remarks
- future work로 언급하는 것들
- “the chronology of access modes to a song probably carries valuable information.” (특정 곡이 어떤 access mode를 통해 최초 발견되었는가.)
- “user trajectories and transitions between classes”
## Conclusion
- 우리의 경우도 비즈니스 로직이 항상 끼어 들어가서 human curation에 의한 것과 알고리즘에 의한 것이 복합적으로 섞여 있는 경우가 많은 것 같아서 공감이 되었다. 몇 가지 디테일들은 잘 이해 못 한 것도 있는데, 나름 흥미로운 논문이었다.
- (diversity를 functional diversity (number of unique songs played / total number of plays) 와 semantic diversity (popularity) 로 나누고, semantic diversity를 보기 위해 왜 embedding space를 사용한 diversity가 아니라 인기도를 보았는지를 기술했는데, 그 이유가 잘 이해가 안 갔다.)
- primary access mode 별로 유저들을 분류하고, 각 access mode 별로 소비하는 음악의 다양성이 어떻게 달라지는지 분석하고, 알고리즘이든 사람이든 큐레이션을 이용하는 유저집단이 좀더 다양한 소비를 한다는 분석 내용이 인상적이었다.
- 기존의 filter bubble 효과를 주장한 논문들과는 달리 이 논문에선 오히려 추천 알고리즘을 이용하는 유저군에서 다양성 수치가 높게 나왔다는 점이 의외였고 추천 알고리즘에 의해 filter bubble에 갇힌다가 myth일 수도 있겠다는 생각이 들었다. 문제는 이 논문이 사용한 데이터셋인 Deezer 음악 플랫폼이 사용하는 추천 알고리즘이 무엇인지에 대한 설명이 없다는 점이다. 추천 알고리즘과 filter bubble에 대해 상반된 결론을 내리는 논문들을 다 모아놓고 리뷰해보면 어떨지.
================================================
FILE: paper_review/recsys/recsys2021/I want to break free! Recommending friends from outside the echo chamber.md
================================================
# I want to break free! Recommending friends from outside the echo chamber
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474270>
- Authors : Antonela Tommasel, Juan Manuel Rodriguez, Daniela Godoy
- Reviewer : iggy.ll
- Topics
- [#Echo_Chambers_and_Filter_Bubbles](../../topics/Echo%20Chambers%20and%20Filter%20Bubbles.md)
- [#RecSys2021](RecSys2021.md)
## Summary
- 논문에서 제안하는 GNN 모델에서는 사실 별로 특별히 느끼는 점이 없었습니다.
- Echo chamber로 인해 나타날 것이라 생각이 드는 현상이나 가설을 실험으로 잘 재현한다음 풀어내는데, 이게 정말 잘 된 것 같아서 공유합니다.
## Approach
### 친구 추천
유저 집합 U, 아이템 집합 I가 존재한다고 가정하자. 기존의 추천이 다루는 것은 다음과 같습니다.
1. p(r_{ui}\vert u \in U, i \in I) (연관추천)
2. \text{sim}(i \in I, j \in I) (아이템추천)
친구 추천은 p(r_{uv}|u \in U, v \in U)을 푸는 것이 목표입니다.
기존의 데이터는 주로
- 유저-아이템 인터랙션 (u, i, c) where u \in U and i \in I, and c is context w.r.t. user-item relationship.
이런 형태의 데이터가 주어지는데, 친구 추천에서는 다음과 같은 데이터가 새롭게 주어집니다.
- 유저-유저 인터랙션 (u, v, c) where u, v \in U, and c is context user-user relationship
그리고 기존의 (u, i, c)가 존재하지 않을 수도 있고, 추천 팀이 담당하는 서비스 중에서는 `mm에서의 친구 추천`이 친구 추천을 요구하는 영역 중 하나입니다. `친구 추천`을 다루는 추천 영역이 지금은 많지 않지만, 지금까지는 이런 문제에 그리 큰 관심이 없었던가, 기존 연관 추천/아이템 추천 문제로 캐스팅해서 풀고 있었던 것 같습니다. 친구 추천이 가진 특성을 활용해서, 연관/아이템 추천을 방법보다 더 좋은 성과를 낼 수 있다면 팀 내에서, 그리고 회사 내의 서비스에 적용할 만한 요소는 많을 것 같습니다.
### (가정) Relevancy보다 Diversity가 더 중요하다.
논문 내에서 암묵적으로 가정하고 있는 것들을 정리해보면 이렇습니다. 친구 관계 그래프에서는 일반적으로 유저들은 작은 그룹(클러스터)로 묶일 수 있고, 유저-유저 인터랙션은 대부분 이 클러스터 안에서 이뤄지고, 또한 한 클러스터 내의 유저들의 아이템 소비 패턴도 유사합니다. 이를 고려하지 않는 추천 시스템이 일반적으로 이 커뮤니티 내부에서만 추천을 만드는 경향이 있습니다. 이를테면, MF 모델을 사용한다면 (클러스터가 완벽히 분리된다고 가정한다면) 큰 interaction matrix M은 사실 다음과 같이 분해될 수 있습니다.
$$
M \simeq \begin{bmatrix}M_1 & 0 & 0 \\0 & M_2& 0 \\ 0 & 0 & M_3 \end{bmatrix}
$$
이러한 matrix에 대해 MF 모델은 사실 많은 MF 모델 여러 개를 만드는 것과 유사한 효과를 만듭니다. 또한, 클러스터 밖의 추천/유사도 비교를 힘들게 만듭니다. 따라서, 모델은 클러스터 내부의 유저와 그 유저들이 소비하는 아이템 이외의 추천을 생성하지 않으며, 이 효과는 추천 시스템이 deploy될 수록 고착화된다고 볼 수 있고, 이는 서비스/지표에 해롭습니다. 따라서 Diversity나 Novelty를 고려한 평가가 이뤄져야 한다는 것이 이 논문의 주장인 것 같습니다. 이 가정이 설득력이 있다는 생각은 들긴 하는데, 논문에서 자세한 근거를 제시하지는 않았습니다.
================================================
FILE: paper_review/recsys/recsys2021/Local Factor Models for Large-Scale Inductive Recommendation.md
================================================
# Local Factor Models for Large-Scale Inductive Recommendation
- Paper : <https://ylongqi.com/assets/pdf/yang2021local.pdf>
- Authors : Longqi Yang, Tobias Schnabel, Paul N. Bennett, Susan Dumais
- Reviewer : bell.park
- Topics
- [#Scalable_Performance](../../topics/Scalable%20Performance.md)
- #Local_Model
- [#RecSys2021](RecSys2021.md)
## Summary
- User-Item co-clustering을 사용해서 Local Model의 개수를 늘릴 수 있도록 추천 모델을 디자인한 논문입니다.
- User 기준 inductive 상황에서도 모델이 추천 결과를 계산할 수 있도록, item에 대해서만 embedding 을 학습하였습니다.
- 추천 성능도 기존 local model, global model 모두에 대해서 개선이 되었습니다.
- 그런데, 이걸 local model이라고 부를 수 있는 구조인지 의문이 들었습니다.
## Approach
### 문제 인식
- Local Model은 user subgroup에 대해서만 추천을 하는 모델을 여러개 만들어, subgroup 마다 다른 모델로 추천을 하는 방식입니다.
- User subgroup마다 소비 취향이 다를 것이다라는 가정이 있고, 여러 선행 연구에서 괜찮은 접근임이 이미 검증되었습니다.
- User subgroup마다 모델을 만들어야 해서, 모델이 무겁다면 subgroup 개수에 제한이 생깁니다.
- 선행 연구에서는 대부분 40-50개 수준이고 100개 정도 쓰는 모델(rGLSVD)은 파라미터가 10억개나 됩니다.
- Subgroup을 나누는 단계와 Subgroup의 추천을 계산하는 단계가 나뉘어 있고 이로 인해 inductive 상황에서 추천이 어렵습니다.
- Subgroup을 나누는 것도 학습이 필요한데, 선행 연구 대부분이 이걸 inductive 상황에서 못하는 모델입니다. (factorization)
### 제안 모델
- 이 논문에서는 User representation을 소비한 item의 embedding으로 표현하였습니다. (Fig1에서 (b))
- item embedding을 N-head self-attention을 돌려서 N 차원 벡터로 표현하였습니다.
- Differentiable Latent Co-Clustering에 User representation, Item representation을 넣어서 학습하였습니다. (Fig1에서 (c))
- 이름이 거창하긴 하지만 실제로는 ReLU activation 이후, Min-Sum pooling이 전부입니다.
- ReLU 가 negative score를 제거, 클러스터 멤버십 기능을 하게 됩니다.
- 학습은 선행 연구(VAE-CF) 따라서 Softmax loss로 학습하였습니다.
- 클러스터 개수는 512개에서 2048개까지 늘려보았다고 합니다.
## Results
- 기존 모델들 대비 성능이 소폭 좋긴한데, 큰 차이는 아닙니다.
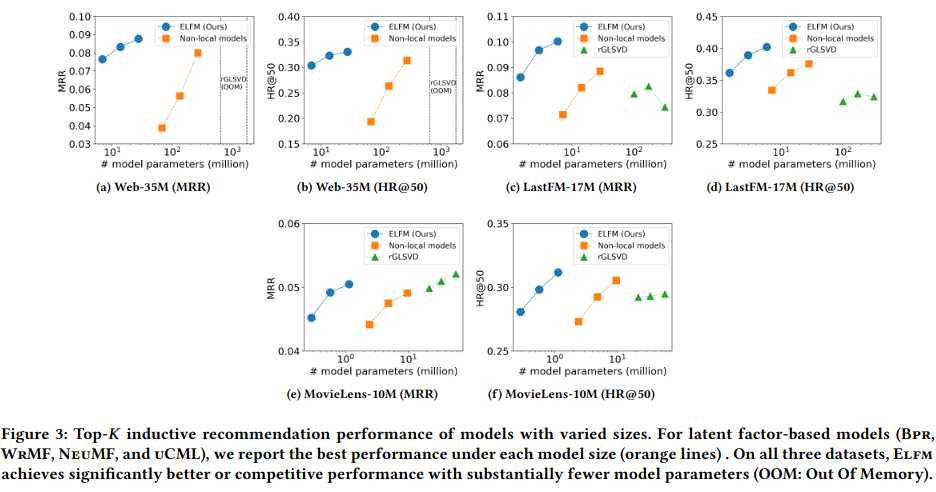
- 같은 성능을 더 적은 파라미터로 만들었다는데에 의의가 있습니다.
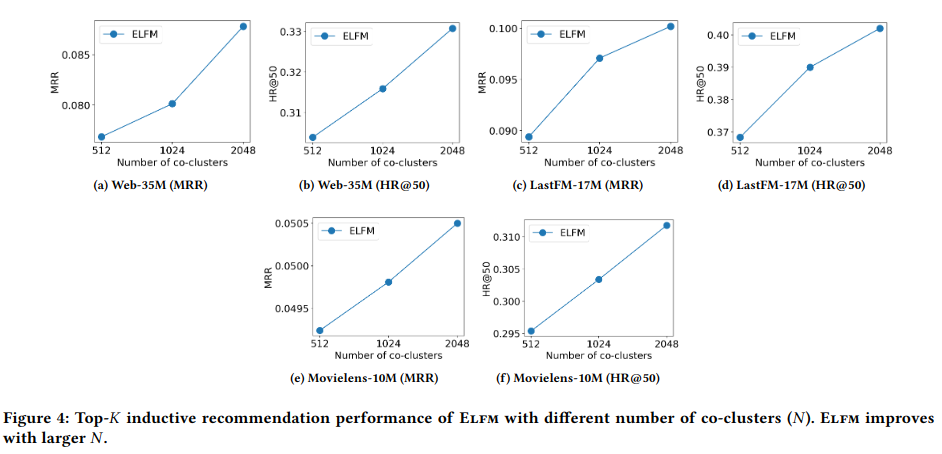
- 클러스터 개수를 늘리면 당연하게도 성능이 추천 증가하게 됩니다.
================================================
FILE: paper_review/recsys/recsys2021/Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All.md
================================================
# Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All
- Paper : <https://dl.acm.org/doi/abs/10.1145/3460231.3474266>
- Authors : Florian Wilhelm
- Reviewer : tony.yoo
- Topics
- [#Theory_and_Practice](../../topics/Theory%20and%20Practice.md)
- #Matrix_Factorization
- [#RecSys2021](RecSys2021.md)
## Summary
- Matrix Factorization 문제를 Latent Dirichlet Allocation 으로 접근하여 interpretability를 향상시켰습니다.
- 추천시트템에 맞게 Bias term을 추가(기존 단점 개선)한 LDA4Rec 을 제안하여 Classic LDA 대비 성능 향상이 있었습니다.
- LDA4Rec의 rating 예측으로 MF, NMF(Non-negative MF), SNMF(Semi-NMP)의 personalized ranking 처럼 사용 할 수 있다는 걸 증명하였습니다. (증명 관점에서는 다루지 않겠습니다.)
## Approach
### Matrix Factorization
User, item 에 대한 latent vector 에 item에 대한 bias 가 있는 MF를 벤치마킹하였습니다.
$$
\hat{x} = < \mathbf{x}_u , \mathbf{h}_i > + b_i
$$
### LDA Approach
아래의 [Probabilistic Graph Model, PGM](https://en.wikipedia.org/wiki/Graphical_model) 을 보면, 관측되는 $i_{us}$ 를 이용하여 다른 변수들을 [EM algorithm](https://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm) 을 통해 unsupervised 방법으로 학습해나가게 됩니다. (기존 모델은 [smoothed LDA](https://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf))
| 기존 | 변형 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| <img src="/Users/kakao/Library/Application Support/typora-user-images/image-20220111110340092.png" alt="image-20220111110340092" style="zoom:50%;" /> | <img src="https://user-images.githubusercontent.com/38134957/165449976-f47ac226-be39-4389-a89a-50ecd9be470c.png" alt="LDA4Rec" style="zoom:50%;" /> |
Notation: $\boldsymbol{\varphi}_k \in \mathbb{R}^{\vert \mathcal{I} \vert}$, $\boldsymbol{\theta}_u \in \mathbb{R}^{\mathcal{\vert K \vert}}$ (보충: $\mathbf{c} \in \mathbb{R}^{\vert \mathcal{I} \vert}$)
$$
\begin{align}
\delta_i &\sim LogNormal(\mu_\delta, \sigma_\delta) \\
z_{us} &\sim Categorical(\boldsymbol{\theta}_u) \\
i_{us} &\sim p(i_{us} \vert \boldsymbol{\varphi}_{z_{us}}, \delta_i, \lambda_i) \\
p(i_{us} &\vert \boldsymbol{\varphi}_{z_{us}}, \delta_i, \lambda_i) := Categorical(\Vert \mathbf{c} \Vert_1^{-1}\mathbf{c}) \\
\mathbf{c} &= \boldsymbol{\varphi}_{z_{us}} + \lambda_u \cdot \boldsymbol{\delta}
\end{align}
$$
## Results
### Datasets
- Split: train(90%), valid(5%), test(5%)
- The explicit feedback of these datasets was treated as implicit.
| Movielens-1M, MoiveLens-100K | Goodbooks |
| - | - |
| 1 million movie ratings across 6,040 users and 3,706 movies<br />100 thousand interactions across 610 users and 9,724 movies | 6 million interactions across 53,425 users and 10,001 books |
**Note**: LDA4Rec의 evaluation 과정에서 rating 예측을 item 하나씩 해야하기 때문에 유저당 10000개씩만 샘플링 하여 측정하였습니다.
> The bottleneck of LDA4Rec is the prediction of the personalized rankings for which we need a high number of samples per user to compute a stable ranking. Thus for each user 10,000 items were sampled.
### Performance
- MoiveLens-100K 에서 성능 향상이 있었습니다.
<img src="https://user-images.githubusercontent.com/38134957/165450153-ca5300b3-4845-448d-a49a-6fa142dff3b4.png" alt="ex1" style="zoom:67%;" />
아쉽게도 Goodbooks에서 LDA4Rec 비교가 빠져 있지만, MF가 SNMF 보다 성능 면에서는 우수했습니다.
<img src="https://user-images.githubusercontent.com/38134957/165450159-23e829f6-3b95-4950-8b02-e47a9a34c49b.png" alt="ex2" style="zoom:60%;" />
## Conclusion
- Traditional LDA 를 the popularity of items 과 conformity of user를 통합하여 성능 향상을 이끌어 내었습니다.
- MF의 personalized ranking과 NMF, SNMF, LDA4Rec의 personalized ranking으로 transformable하다는 걸 증명하였습니다.
- (MF대비) accuracy의 큰 손실 없이 interpretability를 높혔습니다.
### Question & View
- Q. Item에 대한 user의 bias로 접근하였는데, 굳이 종속적인 방법으로 할 필요가 있을까?
- Evalutaion 이 느리다는 단점 때문에 실용면에서 떨어집니다.
- Q. Latent representation의 most_similar 값으로 추천을 하면 성능이 어떨까?
- Accuracy 손실이 적다고 했는데, 데이터 셋 향샹을 보인건 겨우 movielen-100K 뿐입니다.
- Q. MRR과 recall은 높지만, precision이 좀 떨어지는 걸로 봐서 implicit nDCG 측정이 있었다면 어땠을까?
================================================
FILE: paper_review/recsys/recsys2021/Mitigating Confounding Bias in Recommendation via Information Bottleneck.md
================================================
# Mitigating Confounding Bias in Recommendation via Information Bottleneck
- Paper : <https://dl.acm.org/doi/pdf/10.1145/3460231.3474263>
- Authors : Dugang Liu, Pengxiang Cheng, Hong Zhu, Zhenhua Dong, Xiuqiang He, Weike Pan, Zhong Ming
- Reviewer : charlie.cs
- Topics
- [#Privacy_Fairness_Bias](../../topics/Privacy,%20Fairness,%20Bias.md)
- #Bias
- [#RecSys2021](RecSys2021.md)
## Summary
- 추천 시스템에서 수집한 feedback 데이터의 bias를 효율적으로 완화(alleviate)할 수 있는 debiased information bottleneck (DIB) objective function을 제시하였습니다.
- 제시된 DIB objective function은 intractable 한데, 이를 information theory에 기반하여 tractable 한 solution으로 derive할 수 있었습니다.
- 기존 추천 시스템에서 debiased를 위한 대부분의 방법들은 bias generation process를 고려하지 않았기 때문에 특정 bias 가 발생하는 현상에서만 적용할 수 있는 문제가 있었습니다.
- Related works: (1) heuristic-based (2) inverse propensity score-based (3) unbiased data augmentation (4) some theoretical tools-based
- 해당 논문에서는 confounding bias 라는 포괄적 형태의 bias를 정의하고, 이 bias를 완화하는 것에 초점을 두었습니다.
## Approach
### Confounding Bias

- 일반적인 추천 시스템의 feedback event 생성 process는 Figure 1.(a)와 같습니다.
- variable (the feature vector) `x`는 다음과 같은 세개의 변수로 구성되어 있다고 가정
- Instrumental variables `I`, Confounder variables `C`, Adjustment variables `A`
- 세 변수 중 `I`와 `C`는 treatment `T` 를 결정하고, 이는 outcome `y`에 간접적으로 영향을 미침
- `T`는 시스템이 추천할 아이템을 선택하거나 아이템들을 rank 하는 과정을 의미하고, `y`는 추천 결과 (e.g. click)
- 이 부분에서 position bias, popularity bias와 같은 다양한 bias가 feedback에 영향을 줌
- `C` 와 `A`는 직접적으로 `y` 에 영향을 미침
- unbiased feedback이 생성됨
- 세 변수에 대한 구체적인 정의는 없지만, site된 논문(*Learning disentangled representations for counterfactual regression, ICLR 2020*)에서 예시를 통해 어느정도 이해할 수 있었음
- 어떤 환자에 대한 context `x`를 기반으로 치료 방법 `T`를 정하고, 치료에 따른 결과 `y`가 있다고 가정
- `I`는 환자의 재정 상태를 나타낼 수 있음: 부자면 높은 수준의 치료를 받거나 가난하면 저렴한 치료를 받아야 한다. 다만, 이것이 직접적으로 치료 결과에 영향을 미치진 않음
- `C` 는 환자의 나이를 나타낼 수 있음: 나이에 따라 어떤 치료를 받는지도 결정되고, 나이가 치료 결과에 직접적인 영향을 미침
- `A`는 환자의 유전적 정보를 나타낼 수 있음: 유전적 정보를 가지고 어떤 치료를 받을지는 일반적으로 고려하진 않지만, 이것이 치료 결과에 직접적인 영향을 미침
- Confounding bias는 특정 bias들의 collection을 나타내며, 추천 시스템에서 간접적인 영향으로 인해 발생하는 the confusion of the observed feedback을 의미하게 됩니다.
- 쉽게 말하면 Figure 1.(a) 와 1.(b)의 차이가 confounding bias
- Figure 1.(b)는 `x`를 고려하지 않은 추천이므로, uniform random 추천을 생각할 수 있습니다.
### The proposed method: DIB objective function

- 이 논문에서는 위에서 언급한 confounding bias가 embedding representation에 반영된다고 가정하고, embedding vector에 포함된 biased component `r`과 unbiased component `z`를 각각 학습 후, 실제 추천을 진행할 때는 `z`로만 구성된 feature vector로 treatment `T`를 선택하는 방향을 제시하였습니다.
- `r`과 `z`를 제대로 학습하기 위해서는 다음과 같은 조건들을 만족해야 합니다.
1. biased된 변수의 영향을 줄이기 위해서 `z` 가 `x`에 대해 overfit 되면 안됩니다.
2. `z`는 label `y`를 정확하게 예측할 수 있도록 학습합니다. (direct effect 최대화)
3. `r`과 `z` 는 가능한 독립이어야 합니다. (to get a better distinction)
4. `r` 도 (`z` 정도 까지는 아니지만) `y` 를 예측할 수 있도록 학습합니다. (indirect effect)
- 위와 같은 네 가지 조건을 만족하기 위해 다음과 같은 DIB objective function을 최소화 하는 방향으로 학습합니다.

- `I(z;x)` 는 `x`와 `z`의 mutual information을 나타냅니다.
- 이 함수는 최적화 하기에는 intractable 하므로, information theory에 기반하여 다음과 같이 conditional entropy 형태로 표현할 수 있습니다.

- (a)는 `y`와 `y_z`간 cross entropy, (b)는 `y` 와 `y_r` 간 cross entropy, (c)는 `y`와 `y_{z,r}` 간 cross entropy
- 여기서 `y_z`는 unbiased component `z`를 사용해서 생성된 label 이고, `y_r` 과 `y_{z,r}` 도 비슷한 맥락으로 생성된 label
- (d)는 embedding representation의 robustness를 추가하기 위한 regularization term
- variational approximation을 활용하여 `z`는 Gaussian 분포를 따른다고 가정했습니다.
### Complement optimization process of DIB

## Results
- 기존의 추천 모델 Matrix Factorization (MF)과 neural collaborative filtering (NCF)에 DIB를 적용하여 학습했을 때, 상대적으로 어느정도의 성능 향상이 있는지 실험하였습니다.
- 측정 metrics: AUC, precision (P@K), recall (R@K), 그리고 nDCG(@50)
- 두 개의 dataset을 사용: Yahoo! R3, Product
- Yahoo! R3: 15,400 명 사용자의 1,000개 곡에 대한 ratings
- Product: 300,000 명 사용자의 122개 광고에 대한 click records
- test를 위해 unbiased 데이터를 확보해야 하는데, 이를 위해 일정 유저 군에게 랜덤 추천을 진행했다고 합니다.
- Baselines
- MF, NCF (classic reco models) / IPS, SNIPS (IPS-based) / AT, Rel, CVIB (theoretical tools-based)
### MF

- 제안한 DIB-MF가 가장 높은 성능을 보였습니다.
- dataset 사이즈가 커질수록 상대적으로 높은 성능을 보였습니다.
### NCF

- metric@K 가 높을수록 좋은 성능을 보였습니다.
================================================
FILE: paper_review/recsys/recsys2021/Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher.md
================================================
# Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher
- Paper : <https://dl.acm.org/doi/pdf/10.1145/3460231.3474273>
- Authors : Harald Steck, Dawen Liang
- Reviewer : marv.20
- Topics
- [#Theory_and_Practice](../../topics/Theory%20and%20Practice.md)
- #Netflix
- #High-Order_Interactions
- [#RecSys2021](RecSys2021.md)
## Summary
- Collaborative Filtering 모델에서 higher-order interaction을 어떻게 할 것인지에 대한 방법론을 새롭게 제안하고 있습니다.
- Linear full-rank model을 통해 higher-order interaction을 넣을 수 있게 하였고, 그 결과 큰 데이터셋에서 딥러닝 기반 방법론들보다 좋은 성능을 보였습니다.
## Approach
이 논문이 다루는 모델은 SLIM -> EASE(Embarrassingly Shallow AutoEncoder) -> Pair(this paper) 순으로 발전시켰습니다. EASE와 이 논문에서 제안한 Pair만 보면 다음과 같습니다.
### EASE
- <https://arxiv.org/abs/1905.03375>
- hidden layer가 없는 autoencoder 모델입니다. 파라미터는 item-item weight matrix $B$입니다. objective는 다음과 같습니다. 이 때 X는 interaction matrix, F는 Frobenius norm을 의미합니다.
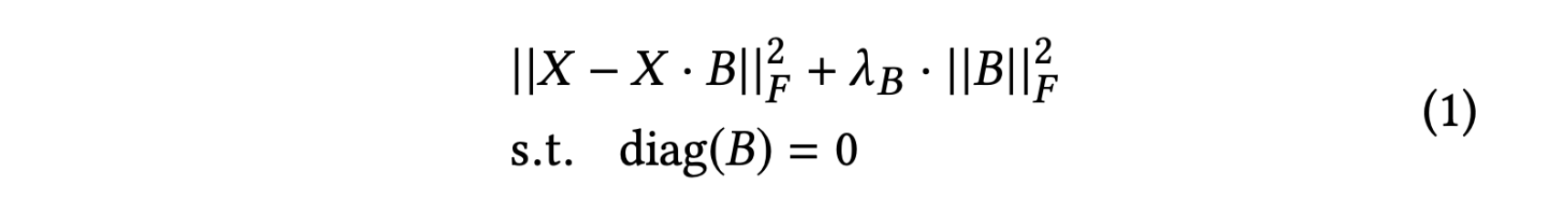
- solution은 다음과 같습니다.
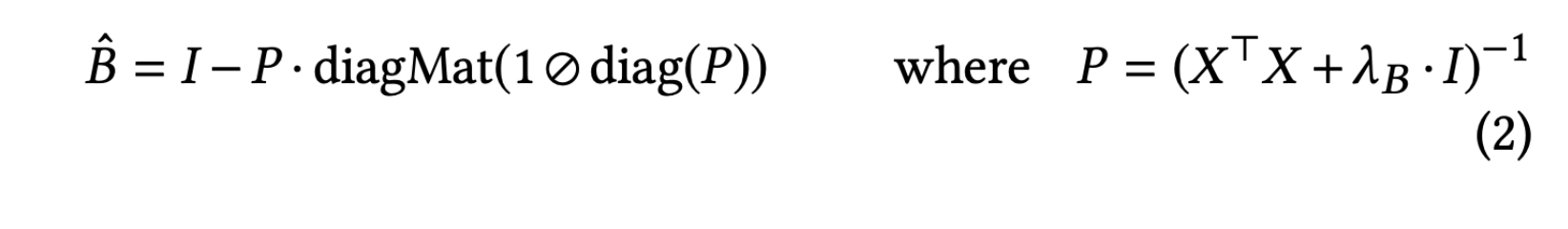
### Pair (this paper)
- Relation의 용어에 대한 설명은 다음과 같습니다.
- pairwise($B_{ij}$ ) : 유저가 item i를 소비하였을 때, item j 의 선호 예측값을 의미합니다. 따라서 유저가 i랑 k를 소비 한다면, item j에 대한 선호도 예측값은 가 됩니다.
- triplet : $(i, k, j)$는 위 정보를 바로 반영합니다. 유저가 i, k를 소비하였을 때 item j에 대한 선호도 예측값을 의미합 니다.
- EASE 구조에 higher-order matrix를 추가한 간단한 extension입니다. EASE에서 학습하는 파라미터 은 각각의 의 미가 item i와 item j의 pairwise한 관계를 캡쳐한다고 볼수 있습니다. 따라서 유저가 i와 k 2개의 아이템을 볼 경우 이를 모델은 $B_{ij} + B_{kj}$를 통해 점수를 내게 됩니다. 이를 직접적으로 넣기 위해서, triplet relation (i, k, j)와 같은 higher order interaction을 뽑아서 넣어주었습니다. 이 때 넣을 수 있는 relation이 매우 커지는 데, 이는 등장 횟수로 잘라주었습니다.
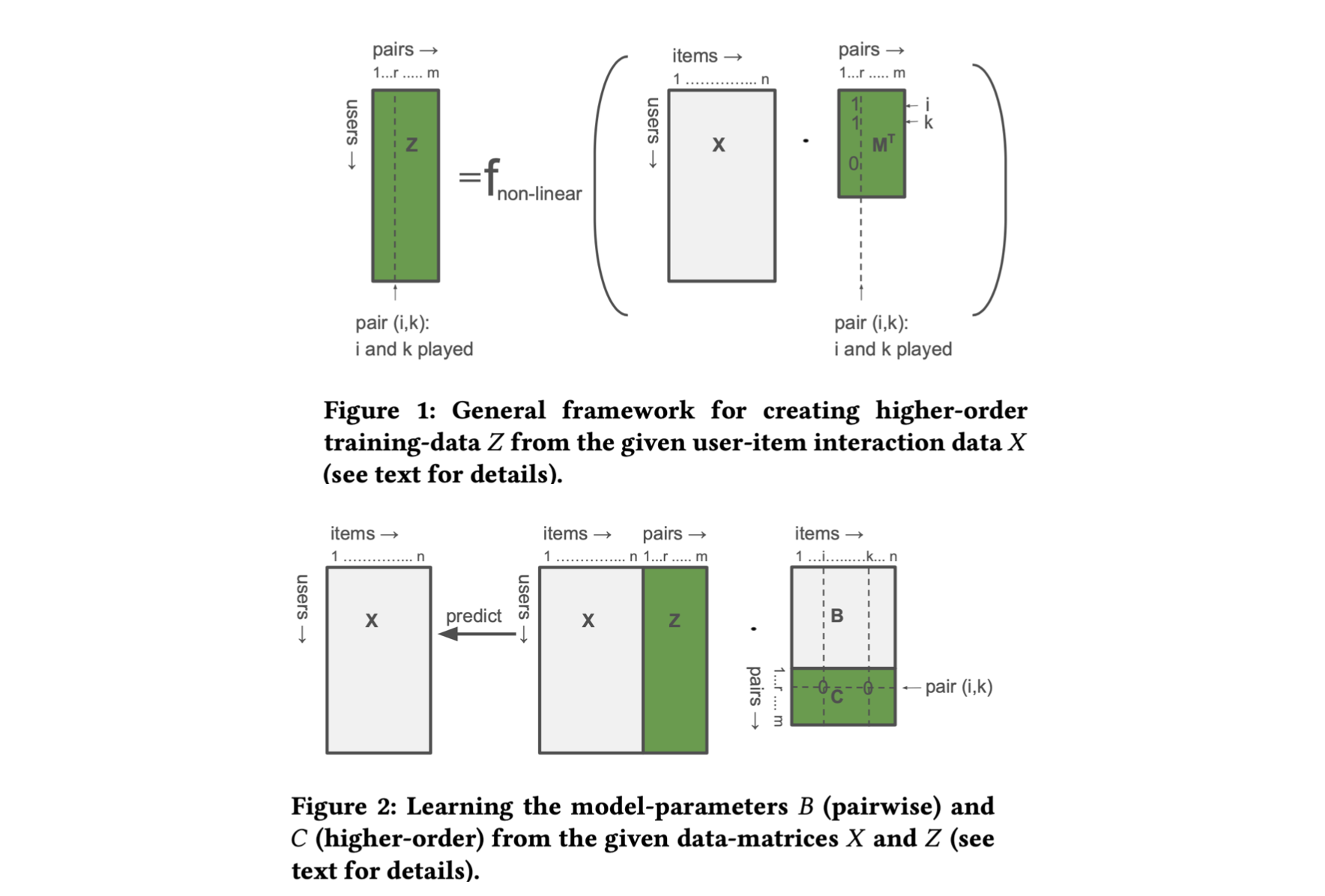
- EASE 구조를 이해한다면, 옆에다가 간단한 triplet relation matrix만 추가되었다고 보시면 됩니다.
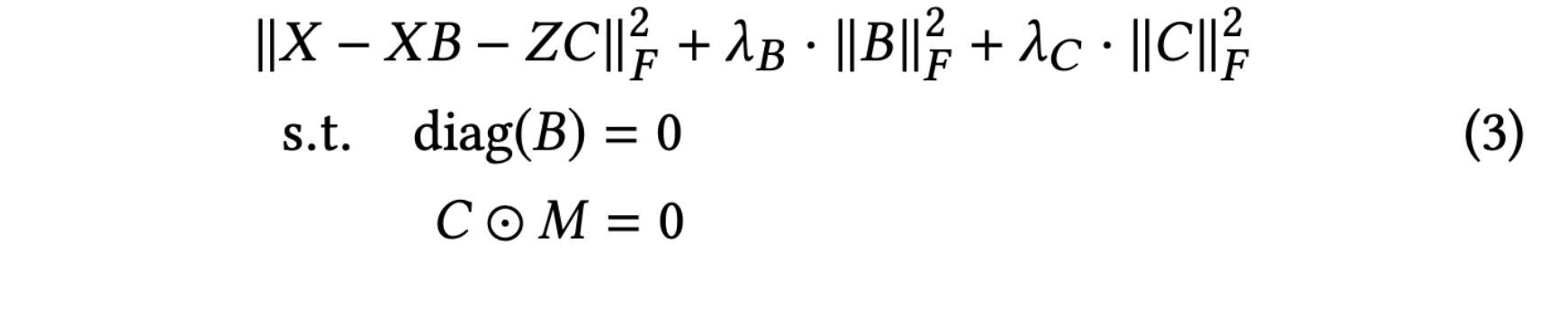
## Results
- triplet ralation을 추가함에 따라, VAE관련 모델들과 유사하거나 특정 데이터셋에서는 더 좋은 성능을 보여주었습니다.
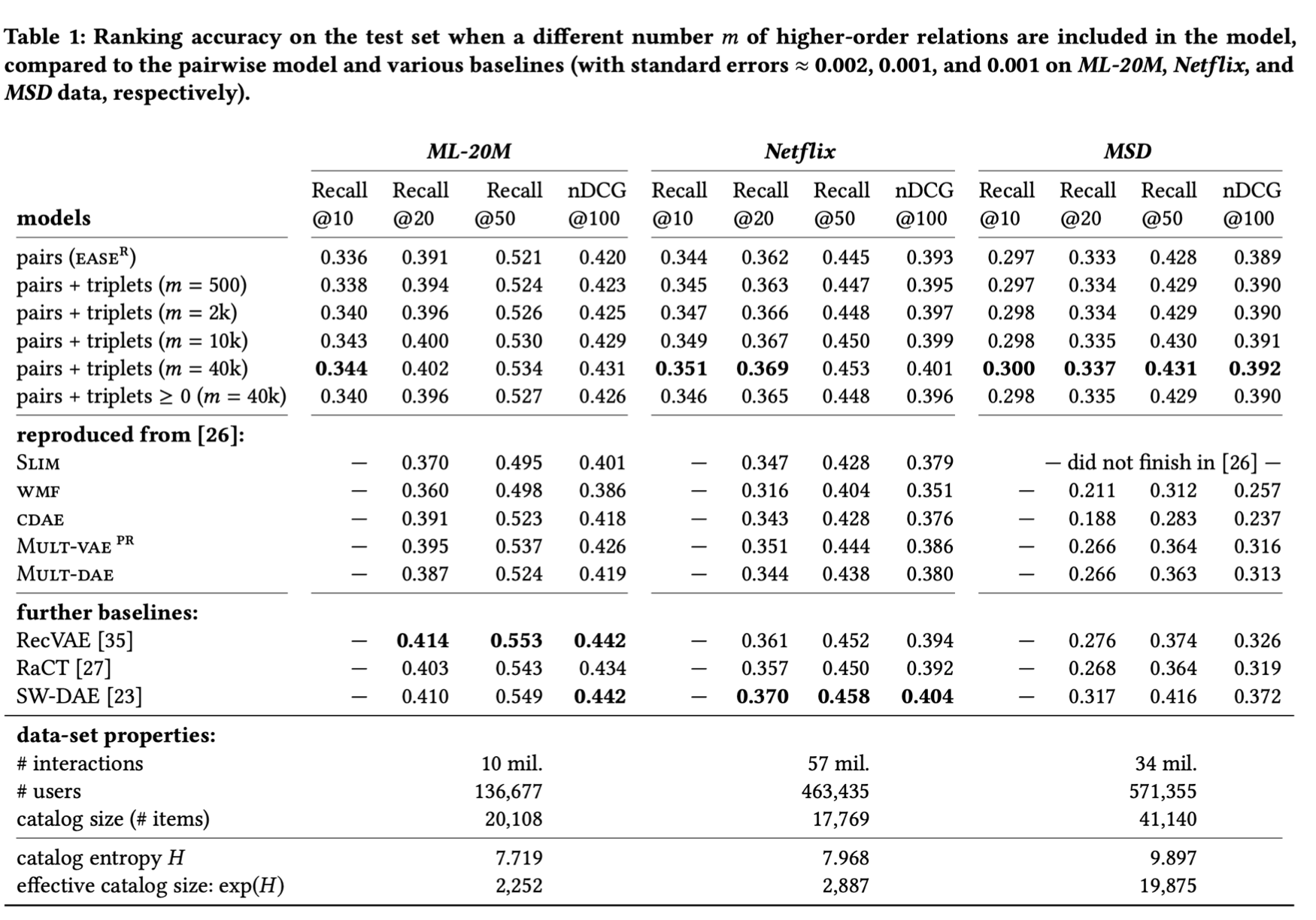
- 이 그림은 higher order interaction이 score에 어떤 역할을 하는지를 보여주는 겁니다. pairwise relation은 positive value에 치중되어 있고, triplet relation은 negative value에 치중되어 영향을 줍니다.
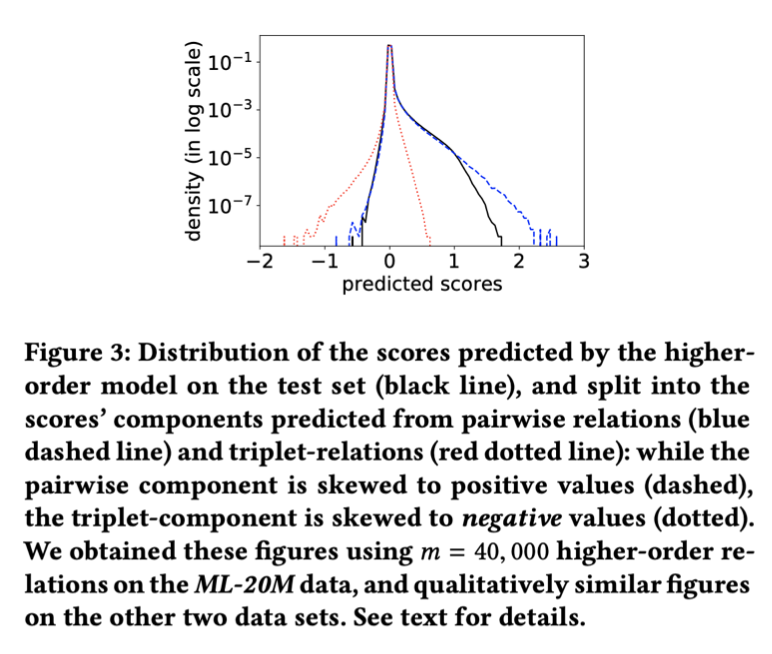
## Conclusion
- 아직까지도 단순한 user-item interaction feature를 가지고도 발전할 여지가 많습니다. 위 구조는, 기존 EASE에다가 정 말 단순하게 많이 등장하는 triplet을 넣어서 학습한 구조이기 때문에 확장이 매우 쉽습니다. 그럼에도 기존 다양한 딥러닝 기반 방식들보다 성능이 비슷하거나 더 좋다는 것은, 온라인 실험상에서의 이점까지 고려할 때 좋은 모델인 것 같습니다. 식 이 쉬운것도 좋은 것 같습니다.
- 다만 이 high-order interaction을 단순히 등장 횟수로만 자르는 건 cf의 약점인 cold-start item들에 대해 더 취약해질 것 같습니다.
================================================
FILE: paper_review/recsys/recsys2021/Next-item Recommendations in Short Sessions.md
================================================
# Next-item Recommendations in Short Sessions
- Paper : <https://arxiv.org/abs/2107.07453>
- Authors : Wenzhuo Song, Shoujin Wang, Yan Wang, Shengsheng Wang
- Reviewer : marv.20
- Topics
- [#Algorithmic_Advances](../../topics/Algorithmic%20Advances.md)
- #Sequential_Recommendation
- #Cold_Start
- #Few-Shot_Learning
- [#RecSys2021](RecSys2021.md)
## Summary
- 짧은 길이의 세션에 대해, 유사한 유저들의 세션을 가져온 다음(global module), 유저의 현재 세션과 결합(local module)한 뒤 Few-Shot Learning을 통해 추천(prediction module)하는 모델을 제안하였습니다.
- Delicious, Reddit 데이터셋에서 기존 single / multi session 기반 모델들보다 좋은 성능을 보여주었습니다. 세션길이가 짧을 때 더 우수한 상대 지표를 보여주었습니다.
## Approach
### 1. 문제 정의
- 실제 환경에서의 세션 기반 추천에서 대부분은 매우 짧은 세션입니다. 짧은 세션에서는 문맥에 대한 정보가 매우 제한적이고, 유사한 유저의 정보를 효율적으로 사용하지 못하며, 관련 있는 세션들을 어떻게 결합할 지에 대한 연구도 잘 이뤄지지 못했습니다.
- 이 논문에서는 현재 세션과 유사한 세션을 찾고, 이를 현재 세션의 정보와 결합하여 추천을 내보내는 INSERT 모델을 제안하였습니다.
### 2. 모델 구조
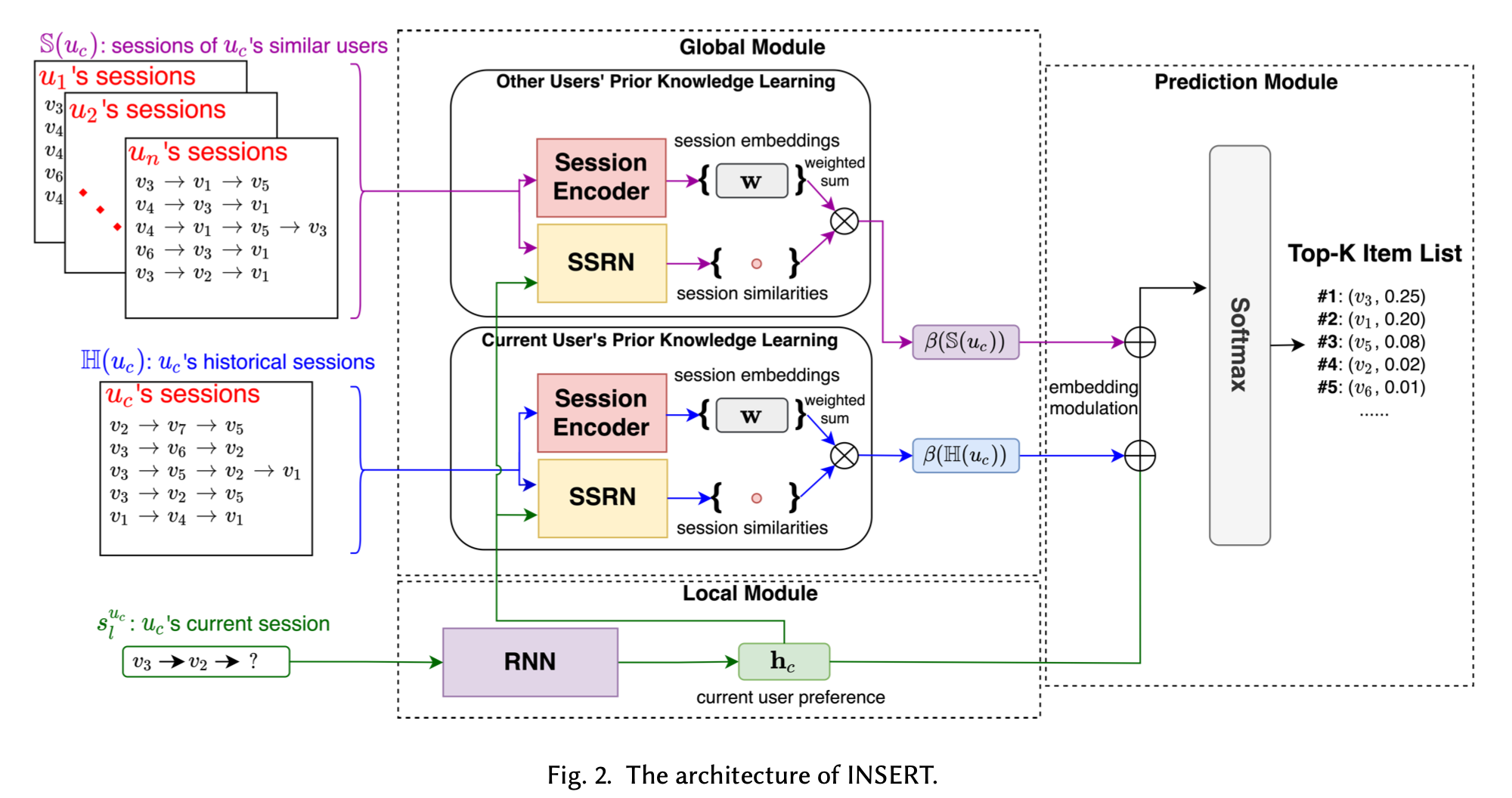
- Global Module : 유사한 유저들의 세션 정보를 활용하는 모듈입니다.
- Candidate Similar Session Sets : 같은 아이템을 얼마나 interact하는 지의 여부로 판단됩니다.
<img width="150" src="https://user-images.githubusercontent.com/38134957/165445886-572fdec6-1811-46e2-8d62-f153383c89d9.png">
- Session Encoder : weighted sum of item embedding입니다.
- SSRN : candidate에서 item embedding 각각에 대해 RNN을 구한 다음 similarity의 max pool을 취하게 됩니다.
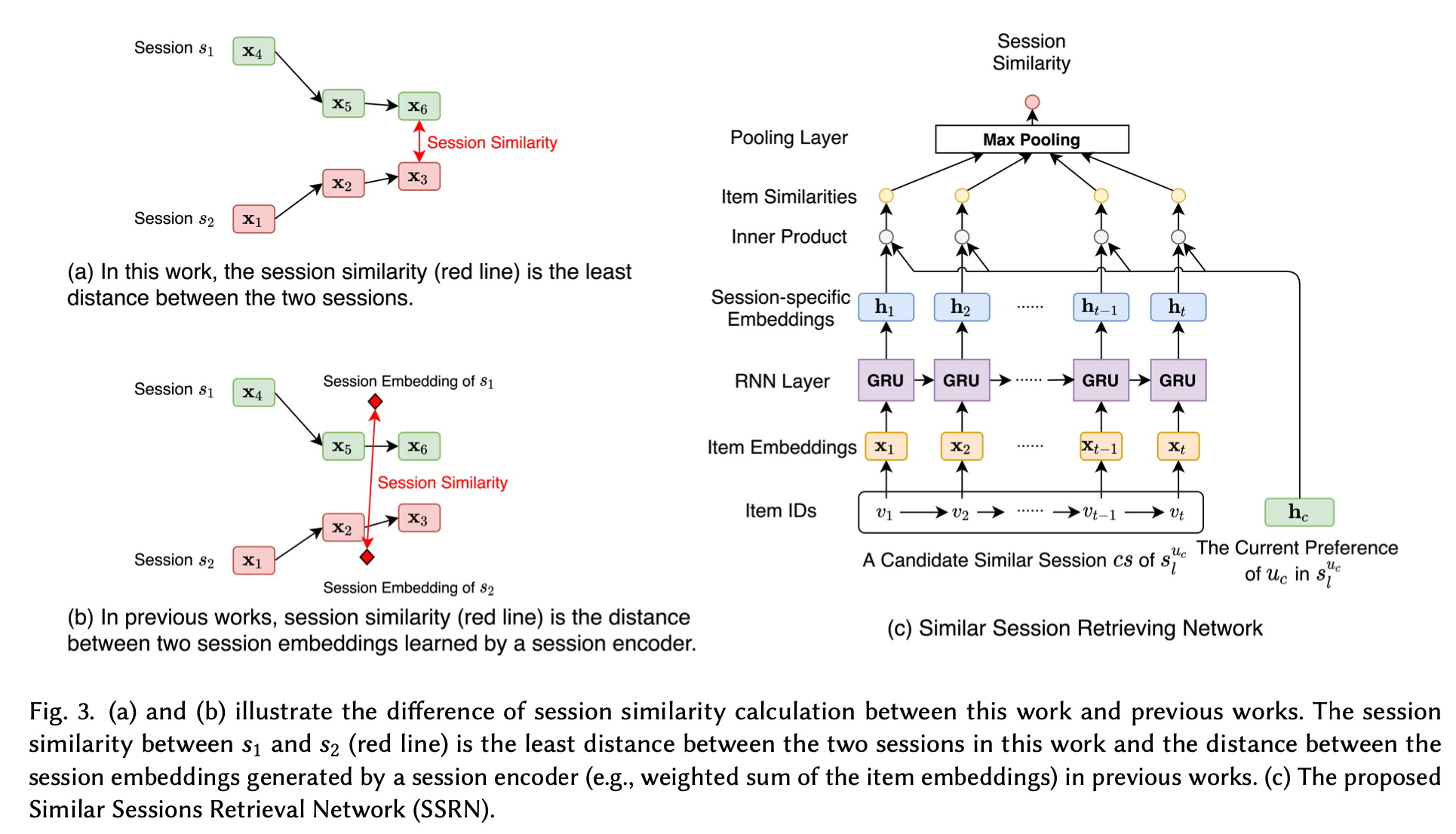
- Local Module : item sequence -> GRU
- Prediction Module : MLP + softmax
## Results
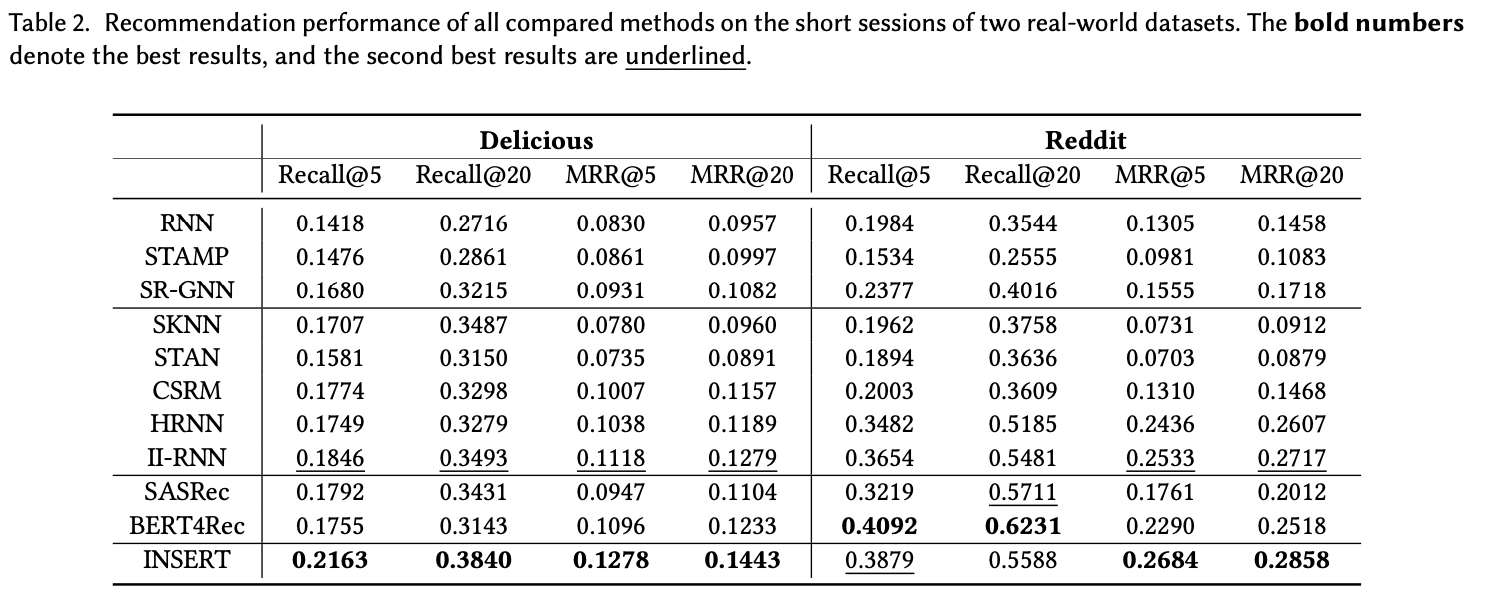
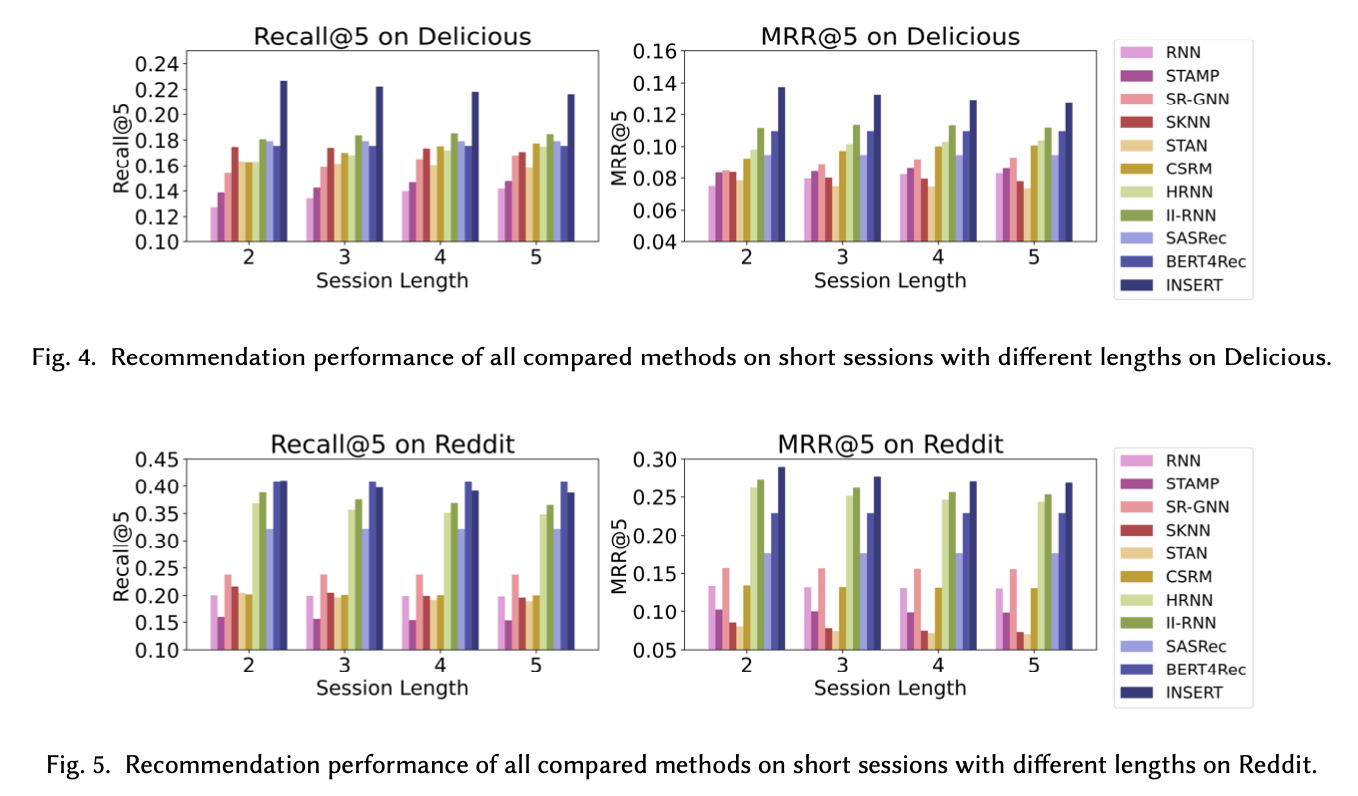
- Delicious, Reddit에서 짧은 세션들을 뽑아 평가하였습니다.
- 논문에서 제안된 모델이 기존 session-based 모델들보다 짧은 세션에서 더 좋은 성능을 보였습니다.
## Conclusion
- FSL이라고 하지만 FSL의 장점인 in-context learning이 잘 발휘되어 보이지는 않았습니다.
- 세션 기반 추천에서 유사 유저의 세션을 넣는 방법은 참고할 만한 부분인 것 같습니다.
================================================
FILE: paper_review/recsys/recsys2021/ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation.md
================================================
# ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474268>
- Authors : Aravind Sankar, Junting Wang, Adit Krishnan, Hari Sundaram
- Reviewer : matthew.g
- Topics
- [#Language_and_Knowledge](../../topics/Language%20and%20Knowledge.md)
- #Few-Shot_Learning
- [#RecSys2021](RecSys2021.md)
## Summary
- Long-tail item (interaction 갯수가 작은 대다수의 아이템) 에 대해서 성능을 떨어지는 문제를 개선하고자 한 논문입니다.
- Item side information 없이 neural base recommender의 capability 만을 이용한 것이 특징입니다.
### Contribution
- Few-shot Item Recommendation
- 피드백이 풍부한 head item으로 base recommender를 학습한 뒤, 이를 기반으로 fine-tuning하는 컨셉입니다.
- Tail item의 단점인 head item과의 distribution mismatch 를 극복하고자 하였습니다.
- 피드백이 풍부한 head item 데이터를 Meta Learning set up (support set & query set) 으로 변경하였습니다.
- Data-rich head item에 대한 interaction으로부터 데이터를 sub-sampling하여 tail item의 피드백과 비슷한 distribution을 모사하였습니다.
- Discriminative Prototype Learning
- Tail item이 sparse interaction을 가진다는 단점을 보완하고자 하였습니다.
- 특정 그룹을 대표하는 벡터들을 이용하여 Base Recommender를 teacher로 삼고 Knowledge Distilation을 진행하였습니다.
- Architecture-agnostic Knowledge Transfer
- Base recommender로 아무 NN 모델 (CF, GNN, AE 등)이나 사용 가능하다는 장점이 있습니다.
## Approach
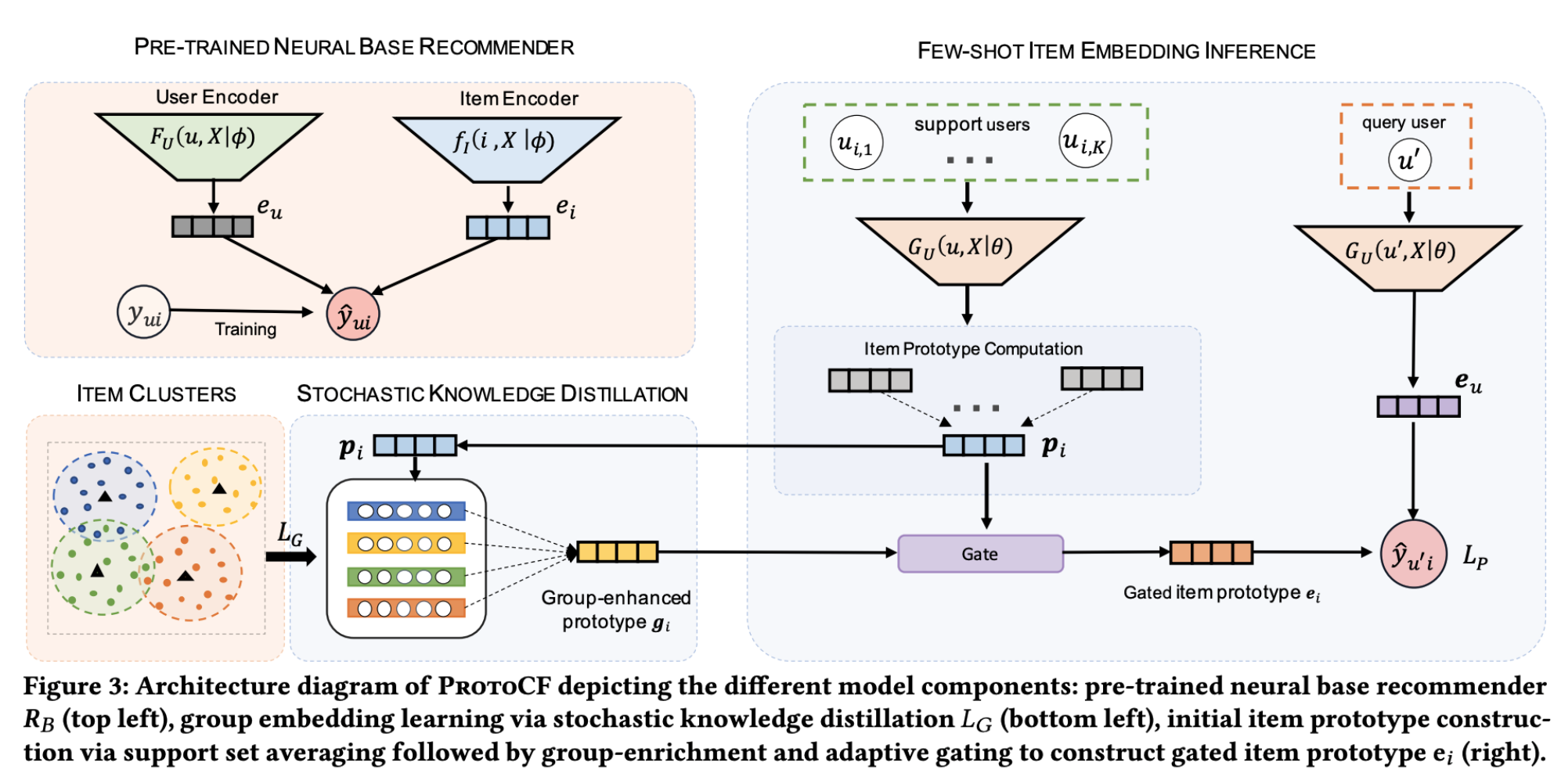
- ProtoCF Framework
- head item으로 Neural Recommender를 pre-train합니다.
- tail item을 head item의 특징을 이용하여 분류할 수 있도록 Meta Learning (1) / Knowledge Distillation (2) 을 적용합니다.
- (1) 과 (2)를 gate algorithm으로 섞어서 각 아이템을 나타내는 $e_i$를 구합니다.
### Preliminaries
- user/item encoder의 자세한 구조는 이해하지 않아도 됩니다.
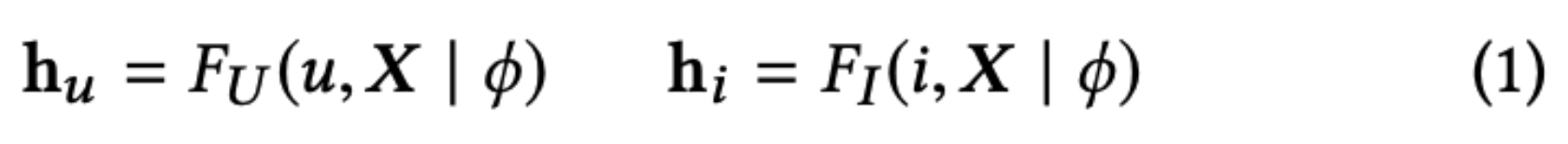
- user/item latent feature 간의 dot product와 실제 feedback으로 손실함수를 생성합니다.
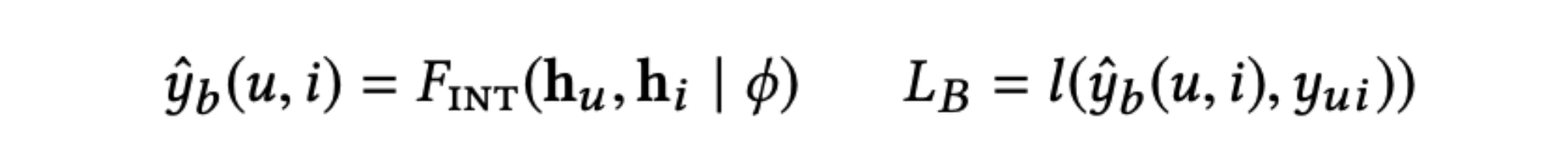
- 아이템 간의 proximity (유사도) 를 구해내서 이를 knowledge distillation 단에서 사용합니다.
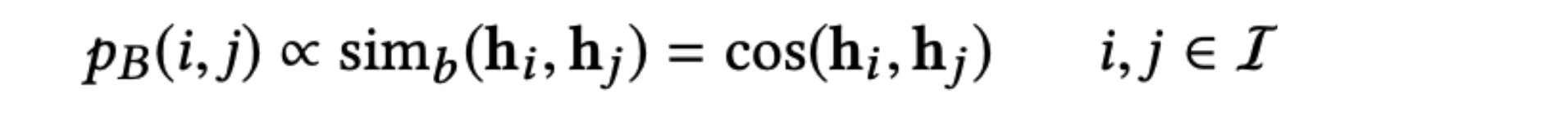
### Pre-trained Neural Based Recommender
- head item 만을 이용하여 user/item encoder를 생성합니다.
- 다양한 종류의 모델을 아무거나 사용할 수 있습니다. (논문에서는 BPR, VAE, CDAE를 사용함.)
- 대신, NN 모델이여야 합니다.
- tail item에 대해서도 embedding을 뽑아낼 수 있도록, 또한 이후에 knowledge distillation을 이용하여 학습시킬 수 있도록 위함입니다.
### Few-Shot Item Recommendation
meta learning 방식으로 데이터 셋을 쪼개서 학습을 진행하였습니다.
#### Task Formulation
- head item 데이터를 sub-sampling하여 tail item 과 비슷한 상황을 가진 데이터 형태로 모사하였습니다.
- 전체 head item 중 개의 아이템만 샘플링하였습니다.
- head item i에 대해서 support set, query set으로 나누어서 meta learning방식으로 학습을 진행하였습니다.
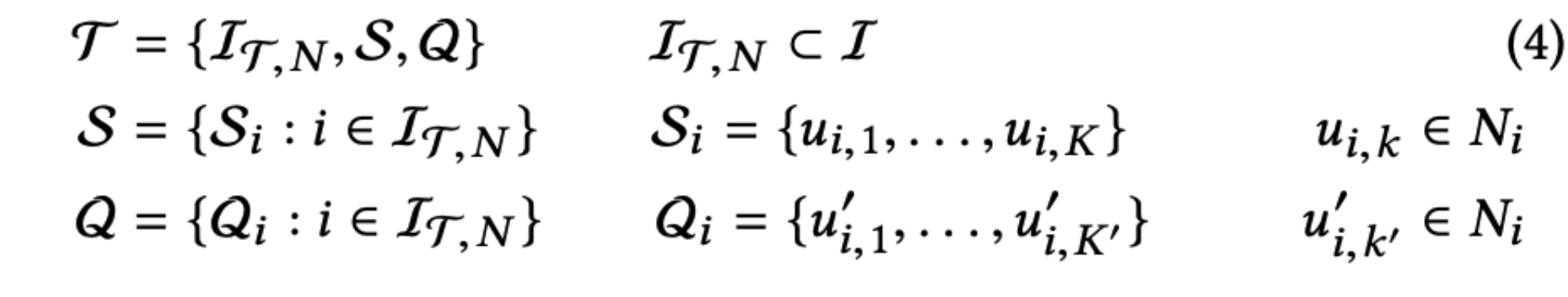
#### Item Prototype & Knowledge Distillation
- item 에 대한 representation을 mean vector of the embedded support user set S_i 로 표현하였습니다.
- 논문에서는 아이템을 소비한 유저들을 중심으로 한 clustering의 결과로 해석하였습니다.
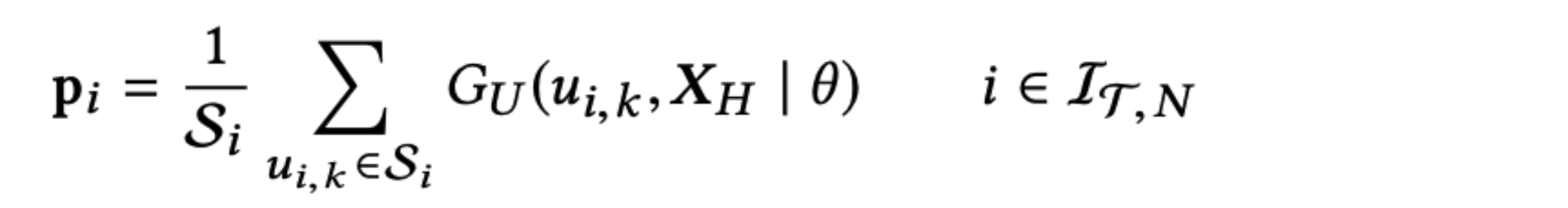
- 그러나 해당 prototype만으로는 문제가 있는데,
- 데이터가 매우 sparse해서 tail item에 대해서는 해당 값이 매우 noisy할 수 있습니다.
- tail item에 대해서는 데이터의 분별력이 떨어지므로, 아이템 별로 거의 비슷한 값이 나올 수 있습니다.
- 추가적으로 분별 가능한 inductive bias 역할을 하는 새로운 term이 필요합니다!
#### Group Embedding
- tail item을 좀 더 분별력 있게 설명하려면 head item과의 item - item proximity를 이용할 수 있습니다.
- 그러나 아이템의 갯수가 많아지게 되면 pairwise proximity 를 직접 저장하고 불러오는 데에 한계가 생깁니다.
- 따라서, Group Embedding 을 이용하여 item - item proximity를 저차원으로 묘사합니다.
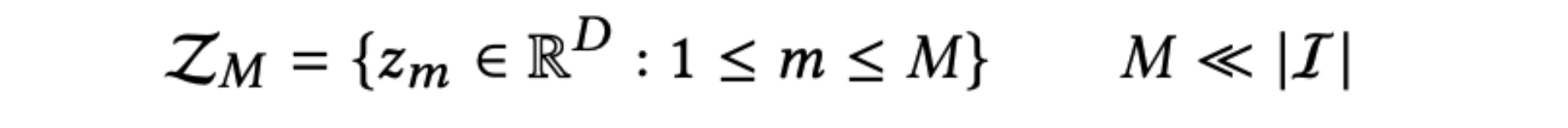
- 직관적으로 생각해서 의 각 벡터가 아이템의 특정한 정보 (국가, 카테고리, 장소, 업종) 등을 표현한다고 생각하면 됩니다. (MMoE랑 비슷한 느낌으로 이해하면 좋을 듯.)
- Group enhanced prototype $g_i$-> $z_i$와 $p_i$를 learnable parameter를 이용하여 attention을 처리하였습니다.
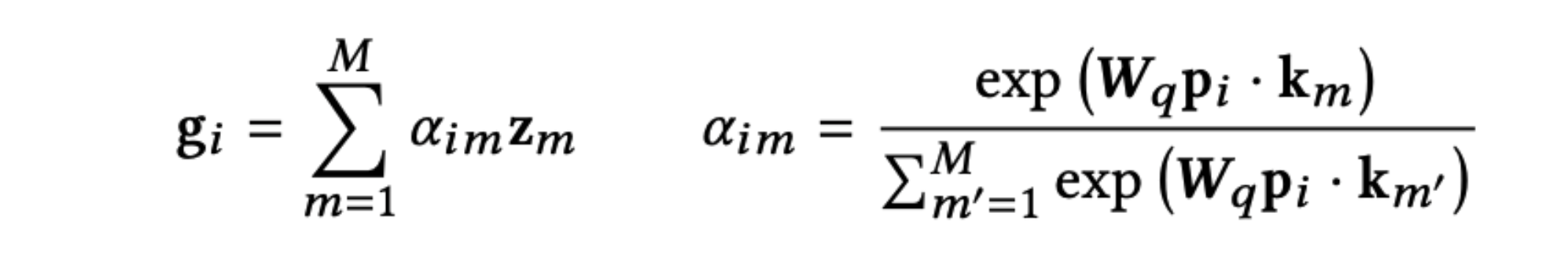
#### Knowledge Distillation
- Base Recommender를 통해 구한 item-item proximity에 대한 정보를 $Z_M$에 심습니다.
- $R_B$을 기준으로 i와 가장 비슷한 아이템 n=10개의 아이템에 대해서
- base recommender / group-enhanced prototype 간의 Cross Entropy를 최소화하고자 하는 것입니다.
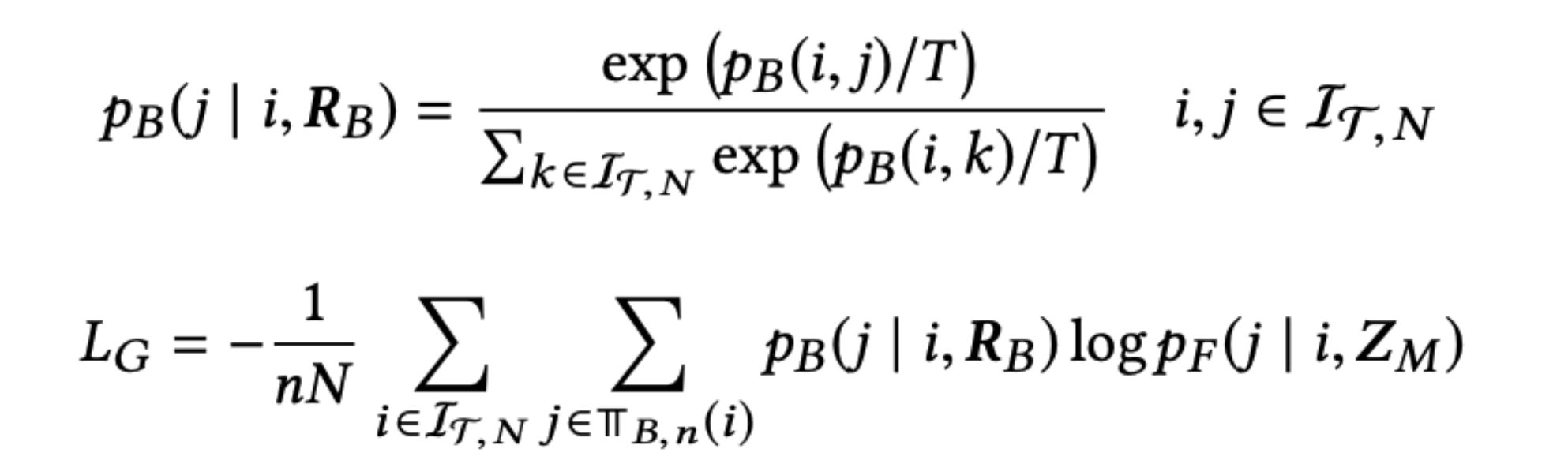
### Final Item Embedding
- $R_B$, $Z_M$로 구한 item embedding의 gated result로 최종 item embedding $e_i$를 구할 수 있습니다.
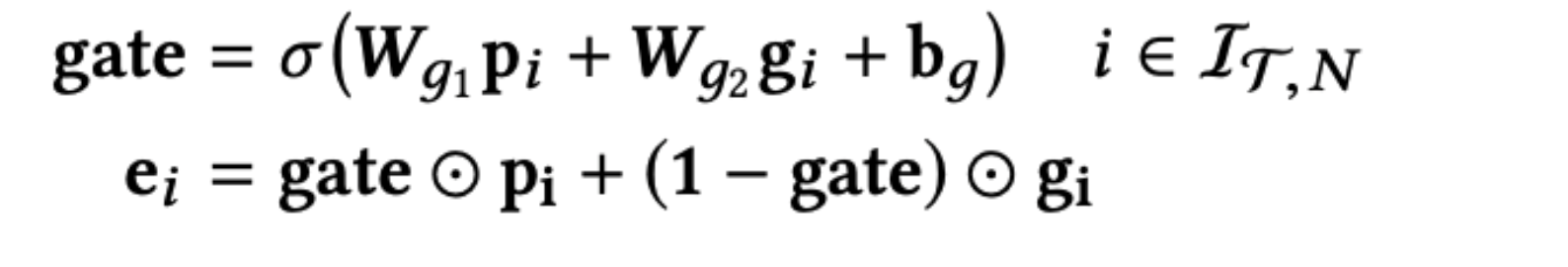
### Few-shot Recommender Training
- query set Q를 이용하여 query set에 속한 user와의 relevance score를 생성합니다. (by cosine similiarity)
- 이 때 pair 는 값이 애초에 1이므로 Negative Cross Entropy를 최소화하는 방향으로 학습 진행하면 됩니다.
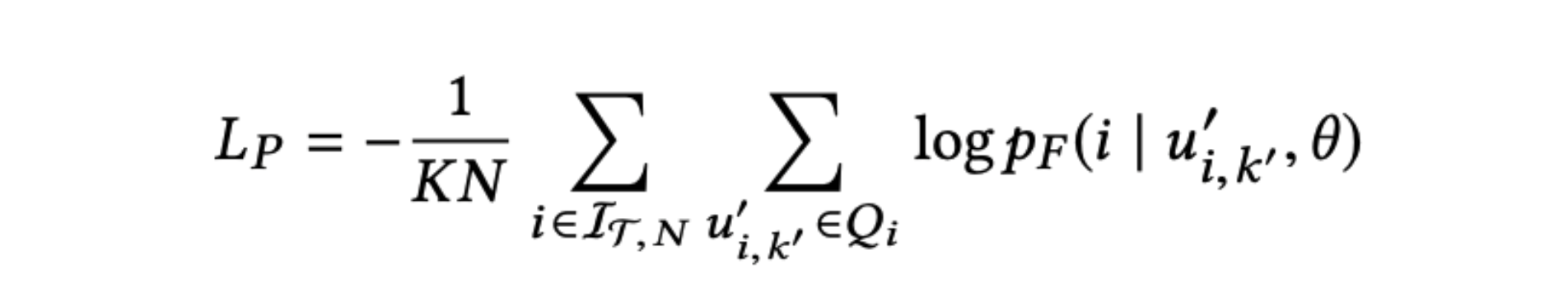
- 이 때 p_F를 구하는 방법으로 두 가지 방식이 있습니다.
- Multimodial Log-Likelihood ( 에 속하는 모든 아이템에 대한 softmax)
- Logistic Log-Likelihood
## Results
### Overall
- Epinions, Yelp, Weeplaces, Gowalla에서 실험을 진행하였습니다.
- NCF Autoencoder > latent-factor models
- ProtoCF는 SOTA를 overall item에서 앞서는 것을 확인할 수 있었습니다.
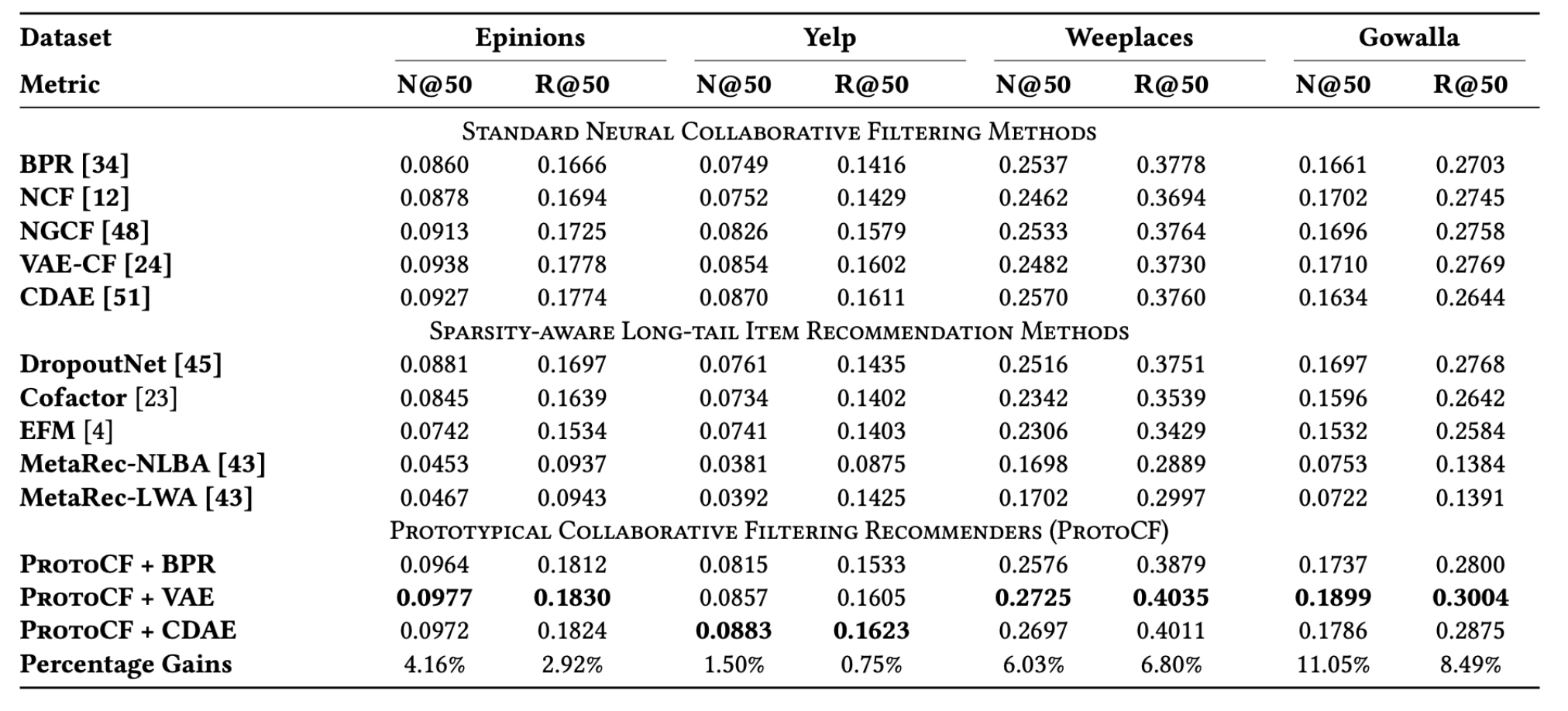
### Few-shot Recommendation Result
- interaction 갯수가 적은 구간일수록 ProtoCF >> baseline 경향이 강해졌습니다.
- 아래 지표는 item들을 popularity 순서대로 그룹화한 것인데, interaction 갯수가 낮은 구간에서 성능 차이가 더 발생하는 것을 확인할 수 있었습니다.
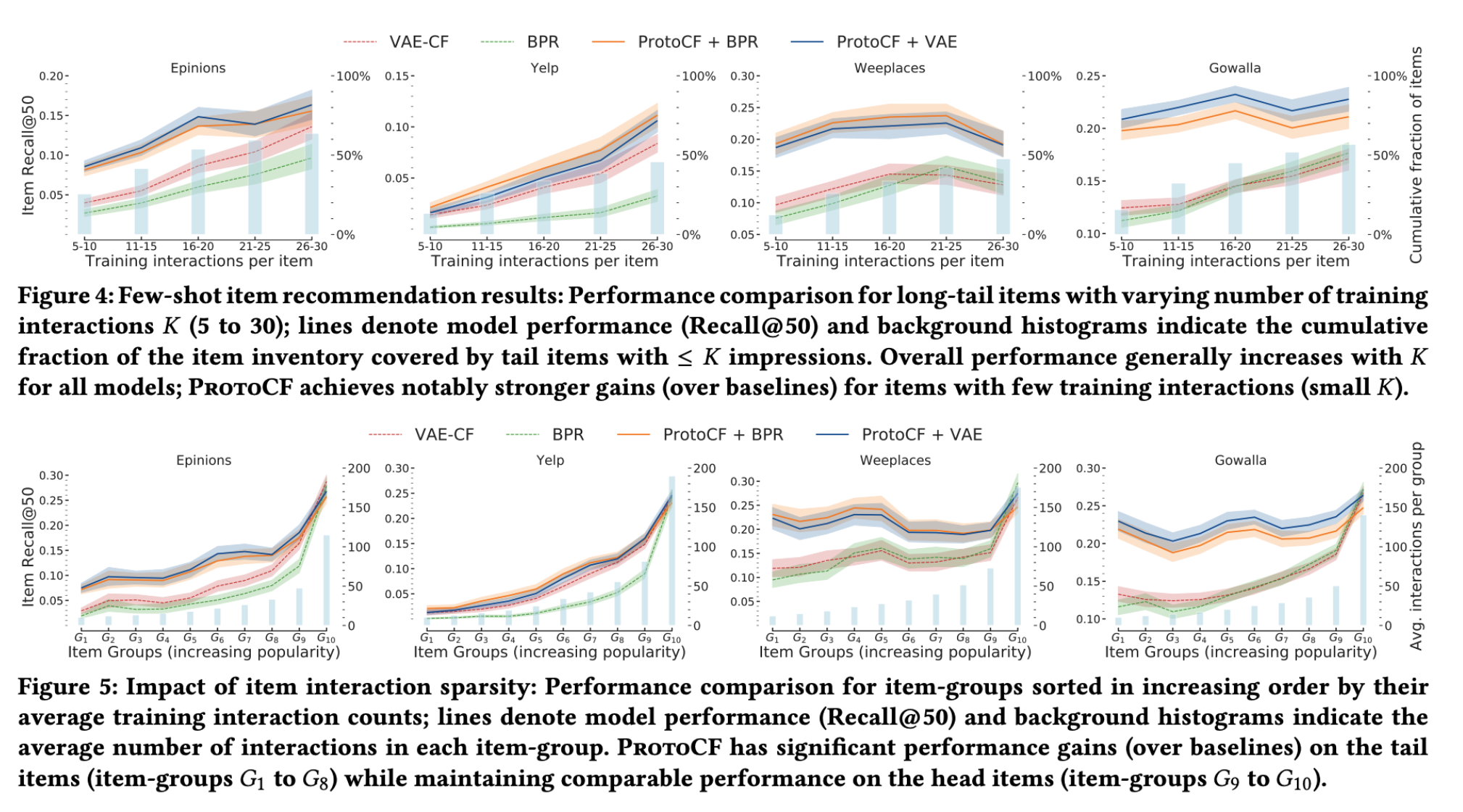
### Ablation Study
- few-shot performance (long tail items with less than 20 interactions) 만을 기재하였습니다.
- 모든 부분이 critical 하게 성능에 영향을 준 것은 아니나 (모델 자체가 와 의 앙상블이므로) 각 모듈이 성능 향상에 영향을 끼쳤습니다.
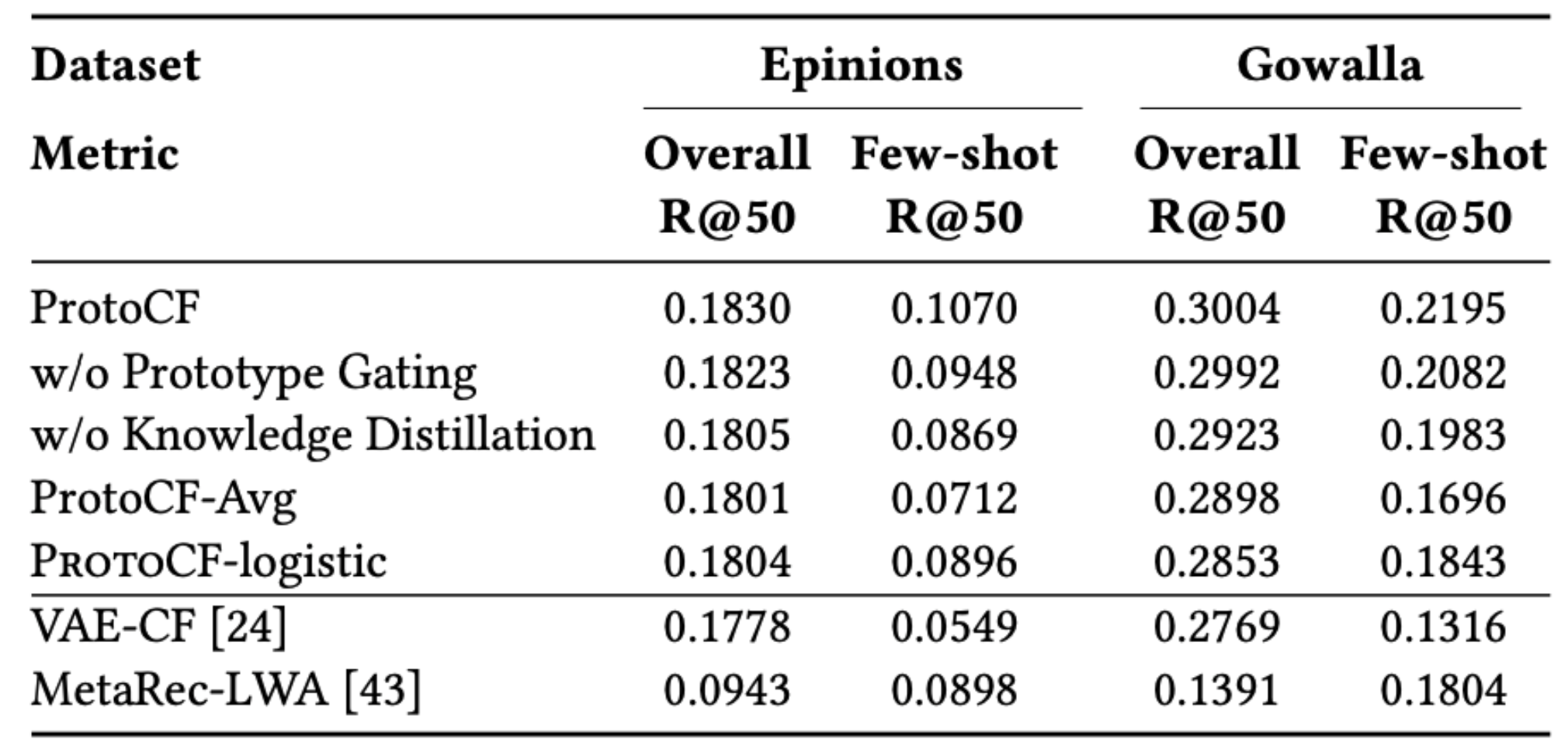
### Parameter Sensitivity
- $\lambda=0.01$ 에서 제일 성능이 좋고, 이후에는 커질수록 성능이 하락하였습니다.
- $N$(task에서의 sample size)는 클수록 성능이 좋아지는 것을 확인할 수 있었습니다.
================================================
FILE: paper_review/recsys/recsys2021/RecSys2021.md
================================================
# RecSys2021
- ["Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface]("Serving%20Each%20User"-%20Supporting%20Different%20Eating%20Goals%20Through%20a%20Multi-List%20Recommender%20Interface.md)
- [Accordion- a Trainable Simulator for Long-Term Interactive Systems](Accordion-%20a%20Trainable%20Simulator%20for%20Long-Term%20Interactive%20Systems.md)
- [Burst-induced Multi-Armed Bandit for Learning Recommendation](Burst-induced%20Multi-Armed%20Bandit%20for%20Learning%20Recommendation.md)
- [Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders](Cold%20Start%20Similar%20Artists%20Ranking%20with%20Gravity-Inspired%20Graph%20Autoencoders.md)
- [Debiased Explainable Pairwise Ranking from Implicit Feedback](Debiased%20Explainable%20Pairwise%20Ranking%20from%20Implicit%20Feedback.md)
- [Evaluating Off-Policy Evaluation- Sensitivity and Robustness](Evaluating%20Off-Policy%20Evaluation-%20Sensitivity%20and%20Robustness.md)
- [Follow the guides- disentangling human and algorithmic curation in online music consumption](Follow%20the%20guides-%20disentangling%20human%20and%20algorithmic%20curation%20in%20online%20music%20consumption.md)
- [I want to break free! Recommending friends from outside the echo chamber](I%20want%20to%20break%20free!%20Recommending%20friends%20from%20outside%20the%20echo%20chamber.md)
- [Local Factor Models for Large-Scale Inductive Recommendation](Local%20Factor%20Models%20for%20Large-Scale%20Inductive%20Recommendation.md)
- [Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All](Matrix%20Factorization%20for%20Collaborative%20Filtering%20Is%20Just%20Solving%20an%20Adjoint%20Latent%20Dirichlet%20Allocation%20Model%20After%20All.md)
- [Mitigating Confounding Bias in Recommendation via Information Bottleneck](Mitigating%20Confounding%20Bias%20in%20Recommendation%20via%20Information%20Bottleneck.md)
- [Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher](Negative%20Interactions%20for%20Improved%20Collaborative%20Filtering-%20Don’t%20go%20Deeper,%20go%20Higher.md)
- [Next-item Recommendations in Short Sessions](Next-item%20Recommendations%20in%20Short%20Sessions.md)
- [ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation](ProtoCF-%20Prototypical%20Collaborative%20Filtering%20for%20Few-shot%20Item%20Recommendation.md)
- [Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?](Reverse%20Maximum%20Inner%20Product%20Search-%20How%20to%20efficiently%20find%20users%20who%20would%20like%20to%20buy%20my%20item%3F.md)
- [Semi-Supervised Visual Representation Learning for Fashion Compatibility](Semi-Supervised%20Visual%20Representation%20Learning%20for%20Fashion%20Compatibility.md)
- [Shared Neural Item Representation for Completely Cold Start Problem](Shared%20Neural%20Item%20Representation%20for%20Completely%20Cold%20Start%20Problem.md)
- [Sparse Feature Factorization for Recommender Systems with Knowledge Graphs](Sparse%20Feature%20Factorization%20for%20Recommender%20Systems%20with%20Knowledge%20Graphs.md)
- [The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender](The%20role%20of%20preference%20consistency%2C%20defaults%20and%20musical%20expertise%20in%20users’%20exploration%20behavior%20in%20a%20genre%20exploration%20recommender.md)
- [Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations](Together%20is%20Better-%20Hybrid%20Recommendations%20Combining%20Graph%20Embeddings%20and%20Contextualized%20Word%20Representations.md)
- [Top-K Contextual Bandits with Equity of Exposure](Top-K%20Contextual%20Bandits%20with%20Equity%20of%20Exposure.md)
- [Towards Source-Aligned Variational Models for Cross-Domain Recommendation](Towards%20Source-Aligned%20Variational%20Models%20for%20Cross-Domain%20Recommendation.md)
- [Toward Unified Metrics for Accuracy and Diversity for Recommender Systems](Toward%20Unified%20Metrics%20for%20Accuracy%20and%20Diversity%20for%20Recommender%20Systems.md)
- [Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation](Transformers4Rec-%20Bridging%20the%20Gap%20between%20NLP%20and%20Sequential%20&%20Session-Based%20Recommendation.md)
- [Values of Exploration in Recommender Systems](Values%20of%20Exploration%20in%20Recommender%20Systems.md)
================================================
FILE: paper_review/recsys/recsys2021/Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?.md
================================================
# Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?
- Paper : <https://arxiv.org/abs/2110.07131>
- Authors : Daichi Amagata, Takahiro Hara
- Reviewer : iggy.ll
- Topics
- [#Scalable_Performance](../../topics/Scalable%20Performance.md)
- #Inner_Product_Search
- [#RecSys2021](RecSys2021.md)
## Summary
## Approach
### Notations
- u_i in Q (User vectors)
- p_j in P (Item vectors)
- <a, b>: dot product between a and b.
### Maximum Inner Product Search (MIPS)
Given a user u_i \in Q, Find \text{Topk}(u_i) = \text{argtopk}_{p_j \in P} <u_i, p_j>
### Reverse Inner Product Search (R-MIPS)
Given an item q \in P, Find a set of users u_i such that q \in \text{TopK}(u_i)
### Main claim
with simple preprocessing, those three questions can be answered in constant time:
1. Given query item q is included in \text{Topk}(u_i) of the user u_i
2. Given query item q is not included in \text{Topk}(u_i) of the user u_i
3. Given query item q is not included in \text{Topk}(u_i) of all users u_i of some (not any) set of users u_i, or block B.
#### Constructing Block B
1. Perform Descending Sort Q, P according to their L2 norm. i.e., \|\|u_i\|\| \geq \|\|u_j\|\| if i < j.
2. appropriately partition user vectors Q. e.g., Q = [u_1, u_2, ...,u_6], then B_1 = [u_1,u_2, u_3], and B_2 = [u_4, u_5, u_6]
3. define L_i (it is easier to write in python here)
`L_i = np.array(sorted(dot(u_i, P[:50, :]), ascending=False))`
`L(B) = np.min([L_i for u_i in B], axis=0)`
L_i is sorted values of dot products between user u_i and item vectors with top-k norms.
Claim 1. Given u_i, q, if <u_i, q> \leq L_i[k], then q \notin \text{TopK}(u_i)
proof: L_i[k] is dot product between u_i and item p such that p is in top-K ranking in norm. Thus p cannot be higher than rank k and dot product with q is lower than dot product with p. Thus q cannot be in \text{TopK}(u_i)
Claim 2. Given u_i, q, if <u_i, q> \geq \|\|u_i\|\| \|\| p_k\|\|, then q \in \text{TopK}(u_i)
proof: Let p to be a true top-k item. \|\|u_i\|\| \|\| p\|\| \geq \|\|u_i\|\| \|\| p_k\|\| \geq <u_i, q> holds. Thus q must be in top-k ranking
Claim 3. Given q, a block B and u_i is a first vector in B, \|\|u_i\|\| \|\|q\|\| \leq L(B)[k], then q \notin \text{TopK}(u_i) for all u_i \in B
proof: \max_{u_i \in B} <u_i, q> \leq \|\|u_i\|\| \|\|q\|\| \leq L(B)[k]. Then by Claim 1, it holds
### Procedure
```text
given item query vector q
ret = {}
for B in Blocks:
if we can skip block B using Claim 3:
continue;
for u in B:
if we can skip u using Claim 1:
continue
if u, q satisfy Claim 2:
ret.add(u)
else:
let TopK(u) using exhaustie search;
if q in TopK(u)
ret.add(u)
return ret
```
Note:
- We can parallelize easily along with Blocks.
- Worst Case bound is equal to Exhaustive Search
- No theoretical bound is given
## Conclusion
- 생각해보면 쓰이는 수학/프로그래밍 테크 기술이 난이도가 고등학교때 기하와 벡터 배웠을 때 딱 그 정도만 쓰는 것 같은데 아이디어가 진짜 좋은 것 같습니다.
- 개선 여지가 많은 것 같다. 특히, Block Construction 부분에서, 블록 내부의 벡터들의 순서나, 블록 사이의 관계 측면에서 뭔가 개선할 여지가 있을 것 같은데 하는 생각이 듭니다. 아이디어를 일부로 약간만 풀고 세부적인 테크닉들은 공개 안 한 것 같습니다.
================================================
FILE: paper_review/recsys/recsys2021/Semi-Supervised Visual Representation Learning for Fashion Compatibility.md
================================================
# Semi-Supervised Visual Representation Learning for Fashion Compatibility
- Paper : <https://arxiv.org/abs/2109.08052>
- Authors : Ambareesh Revanur, Vijay Kuma, Deepthi Sharma
- Reviewer : matthew.g
- Topics
- [#Real-World_Concerns](../../topics/Real-World%20Concerns.md)
- #Semi-Supervised_Learning
- [#RecSys2021](RecSys2021.md)
## Summary
- Semi-Supervised Learning을 사용한 다른 모델들과 다르게, conditional mask를 통해서 color와 pattern 같은 attribute를 학습하는 것이 아니라 color, shape를 직접적으로 변경해주는 self-supervised learning의 방법론을 적용하였습니다.
- pseudo-labeling를 이용하여 unlabeled-image를 이용하여 학습을 진행하였습니다.
- Polyvore, Polyvore-D, newly created Fashion outfit dataset에 대해서, 적은 수의 labeled data를 사용하였고, text 등과 같은 metadata 를 전혀 사용하지 않았음에도 supervised method에 준하는 결과를 만들었습니다.
## Introduction
### Fashion Compatibility
- 이 논문의 main task. 한글로 번역하면 **잘 어울리는 룩 만들기** 정도?로 볼 수 있을 것 같습니다.
> compose matching clothing items that are appealing and complement well.
### Problem & Contribution
- 기존에는 handcraft labeling 을 했었으나 그걸 매번 진행하기에는 번거롭고 cost가 많이 듭니다.
- 이를 해결하고자 **semi-supervised learning** 기법을 적용하였습니다.
- 적은 양의 labeled data, 많은 양의 unlabeled data를 이용하여 supervised training에 준하는 학습 효과를 냄과 동시에, supervised learning의 단점인 overfitting을 해소하고, 일반화 성능을 끌어올리고자 하였습니다.
- 다양한 기법 및 방법론이 존재하는데, 더 자세한 내용은 이 [포스팅](https://sanghyu.tistory.com/177)이 도움이 되었으니 읽어보시면 좋을 것 같습니다.
- 이 논문에서는 다양한 기법 중에 아래와 같은 기법들을 도입하였습니다.
- Proxy-label 기법 (labeled data로 학습한 뒤, unlabeled data를 labeling하고 그걸로 재학습.)
- consistency regularization 기법 (기존 데이터에 대해서 일부 perturbated 된 데이터에 대해서도 예측의 결과는 일관성이 있어야 한다.)
### Main Assumption
- 기존 모델들처럼 각각의 attrbute를 implicit하게 배우는 것이 아니라 (MMoE와 같은 형태로 K개로 표현된 FFN의 모음으로 모델 구성.), explicit하게 attribute를 설정 (color, shape) 하고 해당 부분에 대한 특징을 표현하는 Representation을 찾고자 하였습니다.
## Approach
- 원하는 것은 `visual representation for the task of fashion compatibility`를 학습하는 것입니다.
- Metric Learning을 적용한 목적함수를 설계하여 compatible한 아이템끼리의 embedding은 가깝게 하고자 하였습니다.
- 이를 위해 (Anchor, pseudo-positive, negative) triplet을 만들어 학습을 진행하였습니다.
### Loss
$$
\mathcal{L} = \mathcal{L_l} + \lambda_{ss}\mathcal{L_{ss}} + \lambda_{pseudo}\mathcal{L_{pseudo}}\\
\mathcal{L_l} = \max{(0, d(\phi_A, \phi_P) - d(\phi_A, \phi_N) + m)}\\
\mathcal{L_ss} = \max{(0, d(\hat{\phi_{u}}, \hat{\phi_{[s]}}) - d(\hat{\phi_{u}}, \hat{\phi_{[a]}}) + m)}\\
\mathcal{L_{pseudo}} = \max{(0, d(\hat{\phi_{A}}, \hat{\phi_{P}}) - d(\hat{\phi_{u}}, \hat{\phi_{N}}) + m)}
$$
- Loss on Labeled item
기존에 존재하는 labeled data (A, P, N) 에 대해서는 A와 P는 가깝게, A와 N은 멀어지도록 학습을 진행하였습니다. 추가로 margin loss도 두었습니다.
### Loss on Consistency Regularization
- Self-supervised learning에서 일반적으로 사용되는 접근을 차용하였습니다.
- Consistency Regularization의 가설 중 `perturbation`에 해당하는 전처리 방법을 self-supervised learning 관련 논문에서 영감을 받아 적용하였습니다.
- `fashion compatibility를 위해서는 fashion item을 구분하는 중요한 attribute (color, shape)에 대한 구분 능력이 필요하다`는 전제를 이용하여, 한 아이템에 대해서 color와 shape를 바꾼 negative sample과의 discrepancy를 늘리는 방향으로 학습을 진행하였습니다.
- 이러한 방법론들이 이미지를 돌리거나, color jittering을 하거나, 이미지에 대한 직소 퍼즐 형태의 퀴즈를 풀거나 하는 self-supervised learning에서의 pretext task와 비슷한 경향이 있어서 논문에서 그렇게 언급한 것으로 보입니다.
### Data Augmentation on Pseudo-Labeled Data
- (A, P, N) 에 대해서 embedding space에서의 nearest element (A', P', N')를 on-the-fly로 계산하고 이에 대한 margin loss를 계산하였습니다.
- 계산 상의 속도를 높이고자 mini-batch 내에서만 nearest element를 찾는 방법을 취하였습니다.
### Model Structure
- siamese network와 비슷한 구조를 가지고 있습니다.
- ImageNet pretrained CNN (ResNet18) -> fully-connected layer per category ($W_c$)
- 학습 파라미터는 다음과 같습니다.
- 256 batch size for labeled data, 1024 batch size for unlabeled data
- margin $m$ 을 0.4 for margin loss
- $\lambda_{ss}=0.1\quad\lambda_{pseudo}=1$
- adam optimizer, lr 5e-5, 10 epochs
## Results
- Polyvore (패션 커머스 서비스, ssense에 최근 합병됨) dataset, Polyvore-disjoint (Polyvore 중에서 train/valid/test에 중복된 이미지가 없도록 처리한 것), Fashion outfits (e-commerce platform에서 데이터를 크롤링하고 **같은 세션에서 산 아이템의 경우 compatible하다고 가정**)를 이용하여 학습을 진행하였습니다.
- 5%의 labeled data만을 이용하여 supervised learning에 준하는 학습 결과를 얻을 수 있었으며 100%를 적용하면 supervised model들을 상회하는 성능을 보여주었습니다.
================================================
FILE: paper_review/recsys/recsys2021/Shared Neural Item Representation for Completely Cold Start Problem.md
================================================
# Shared Neural Item Representation for Completely Cold Start Problem
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474228>
- Authors : Ramin Raziperchikolaei, Guannan Liang, Young-joo Chung
- Reviewer : matthew.g
- Topics
- [#Practical_Issues](../../topics/Practical%20Issues.md)
- #Cold_Start
- #Representation_Learning
- [#RecSys2021](RecSys2021.md)
## Summary
- Complete item cold start 환경에서의 새로운 hybrid 모델을 제안하였습니다.
- User Interaction vector가 단순 user one-hot encoding vector보다 학습 과정에서 더 좋은 성능을 낸다는 것을 증명하였습니다.
## Approach
### User Interaction Vector
- User Interaction Vector를 표현하는 방식에는 두 가지가 있습니다.
1. User ID
1. User ID에 상응하는 임베딩을 뽑아냄.
2. embedding matrix $E^u \in \mathbb{R}^{d^u}$ 에서 $z^u_j = I^u_jE^u \in \mathbb{R}^{d^u}$를 뽑아냄.
2. Interaction Vector
1. $z^u_i = g^u(R_{j,:}) = \sigma(...\sigma(R_j, W^u_1)W^u_2)... W^u_L)$
- 이 중에서 (어찌보면 당연히,, ) 2번이 더 나은 결과가 나옵니다.
- 이를 증명하는 방법으로 아래와 같은 방법들을 사용하였습니다.
- training loss / recall이 가장 빠르고 높은 지점에서 수렴된다.
- prob density at initialization 이 가장 normal distribution에 가깝다.
- prob density at convergence 이 가장 normal distribution에 가깝다.
- 이러한 점을 해석해보면 아래와 같이 정리가 가능합니다.
- **$W^u_1 \in \mathbb{R^{n \cross p}}$ 으로부터의 output은 user가 interact했던 아이템들의 임베딩의 합이다.**
### Sharing neural Item rep with the hidden item embeddings
- Item representations from the item model을 user model에서의 hidden item embedding으로 사용하였습니다.
$$
\sum_{j,k\in S^+\bigcup{S^-}}{||(\vb{z}^u_j)^T\vb{z}^i_k - \vb{R}_{ij}||^2} s.t. \\
\vb{z}^u_j = g^u(\vb{R}_{j,:}) = \sigma(...\sigma(\sigma(\vb{R}_{j,:}\vb{W}^u_1)\vb{W}^u_2)...\vb{W}^u_L)\\
\vb{W}^u_1 = g^i(\vb{X}), \quad \vb{z}^i_k = g^i(\vb{X}_k,:)
$$
### Faster training with a simpler formulation
- 각 미니 배치마다 모든 아이템에 대한 $W^u_1$을 계산하는 것은 비효율적이라고 지적하였습니다.
- 그래서 한 번 구해놓은 $W^u_1$을 이용해서 각 유저가 소비한 아이템 ($p \in N_j$) 에 대해서만 $g_i$ 값을 구하는 식으로 처리하였습니다.
$$
\vb{y}_j = \vb{R}_{j,:}\vb{W}^u_1 = R_{j,:}g^i(\vb{X}) = \Sigma_{p\in N_j}g^i(\vb{X}_{p,:})
$$
### Attention mechanism in learning uesr representations
- 유저가 소비한 **모든 아이템이 같은 가중치를 가질 필요는 없다**고 주장하였습니다.
- user의 representation을 구할 때에 k-th item rep와 비슷한 아이템일수록 높은 attention을 주는 구조로 각 아이템 vector에 weight를 부여하였습니다.
$$
\sum_{j,k\in S^+\bigcup{S^-}}{||(\vb{z}^u_j)^T\vb{z}^i_k - \vb{R}_{ij}||^2} s.t. \\
\vb{z}^u_j = g^u(\sigma(\vb{y_j})), \quad \vb{y}_j = \Sigma_{p \in N_j}\alpha_{pk}g^i(\vb{X}_{p, :}), \quad \vb{z}^i_k = g^i(\vb{X}_k,:)
$$
- 이 때 가중치 $\alpha_{pk}$를 주는 방식을 여러 가지로 두고 이에 대한 실험을 진행하였습니다.
- dot product similarity
- cosine similarity
- general (with weight matrix)
- 그리고 나서 attention과 같이 softmax 처리하여 $\alpha_{pk}$를 구하고 이를 weight으로 정하였습니다.
## Results
### Dataset
- CiteULike: 사용자가 인용을 저장하고 학술 논문에 공유 할 수있는 웹 서비스입니다.
- Ichiba 1M, Ichiba 20M: *Rakuten Ichiba* (일본 온라인 전자 상거래 플랫폼) interaction 데이터.
### Result
#### Shared Item Representation
- Sharing item rep이 더 적은 iteration에서 더 나은 recall을 보여주었습니다.
- parameter 수가 많아지는 대규모 데이터셋에서 더 좋은 성능을 보여주었습니다.
#### Attention Mechanism
- Attention mechanism이 성능 향상에 도움이 되었다고 합니다.
- Attention의 경우에도 attention 계산 시에 아래와 같은 두 종류로 모델을 나누었습니다.
- item $i_k$ 그대로 사용하는 경우 (attention)
- $i_k$는 제외하는 경우 (attention_rm_item)
- attention의 경우가 training set recall이 더 높았습니다.
- 그러나 general과 dot similarity의 경우 overfitting에 취약했던 반면, cosine similarity의 경우 Ichiba1M 데이터셋에 대해 overfitting은 적으면서도 (normalization의 효과로 보임), 가장 높은 recall을 기록하였습니다.
#### Shared Item Representation & dataset size
Sharing item rep의 경우, 데이터셋의 크기가 작을 수록 더 모델 성능에 도움을 주는 것으로 확인되었습니다. (데이터셋의 크기가 작을 수록 nonshared와 성능 차이가 더 크다.)
#### Comparison with other models
Cold-start 상황 해결을 다룬 다른 모델 (DropoutNet-WMF, ACCM, DeepMusic, CDL) 대비 CiteULike 데이터셋에서 높은 test recall을 기록하였습니다.
================================================
FILE: paper_review/recsys/recsys2021/Sparse Feature Factorization for Recommender Systems with Knowledge Graphs.md
================================================
# Sparse Feature Factorization for Recommender Systems with Knowledge Graphs
- Paper : <https://arxiv.org/abs/2107.14290>
- Authors : Vito Walter Anelli, Tommaso Di Noia, Eugenio Di Sciascio, Antonio Ferrara, Alberto Carlo Maria Mancino
- Reviewer : bell.park
- Topics
- [#Language_and_Knowledge](../../topics/Language%20and%20Knowledge.md)
- #Knowledge_Graphs
- [#RecSys2021](RecSys2021.md)
## Summary
- 지식그래프(Knowledge Graph)와 엔트로피 기반 feature selection을 결합해서 만든 추천 모델을 제안한 논문입니다.
- 아이템 수에 따라 모델 복잡도(embedding)가 선형적으로 증가하는 기존 모델과 다르게 아이템 수가 늘어나도 모델 복잡도가 크게 증가하지 않습니다.
- nDCG는 나쁘지만(MP보다도 나쁜 케이스도 있음), diversity 측면에서 좋은 부분이 있습니다.
- 그러나 실험 신뢰도가 낮은 편입니다. MP > MF 케이스도 있는데 저는 결과를 납득하기 어려웠습니다.
## Approach
### 문제 인식
- 최근에 DL 기반 추천 모델들이 많이 사용되지만, 이 모델들은 아이템 수가 늘어나면 embedding 개수를 늘려야해서 모델 복잡도가 계속해서 증가하는 단점이 있습니다.
- Content-based와 접목시켜 만든 하이브리드 모델들도 아이템마다 feature를 concatenate하는 전략이 일반적이라 모델이 무거워지게 됩니다.
### 제안 모델
- 이 논문에서는 각 아이템의 특성을 지식 그래프에서 가져오고, 아이템의 추천 점수를 특성의 추천 점수 weighted sum으로 계산하였습니다.
- 예를 들어, 아래 그래프에서 `Rijksmuseum`의 추천 점수는 `<type, Art Museum>`, `<location, Amsterdam`, `<type, Location>`의 추천 점수의 weighted sum이 됩니다.
- 각 특성 점수의 weight는 유저별로 다르게 적용이 되고, 정확하게는 user-feature 조합의 information gain으로 계산하였습니다.
- information gain은 유저가 positive interaction한 아이템의 feature set을 대상으로 특정 feature를 넣었을 때와 제외했을 때의 entropy 차이를 의미합니다.
- 예를 들어, 아래 그래프에서 모든 아이템은 다 `<type, Location>` 특성이 있어서 information gain이 0이 됩니다.
- 대신 Pink가 고른 아이템 중 2개가 `<location, Amsterdam>`를 가지고 있어서 이 경우는 information gain이 0보다 크게 됩니다.
- 각 특성의 점수는 MF 스타일의 간단한 방식으로 계산 (user embedding dot feature embedding + user bias)하였습니다.
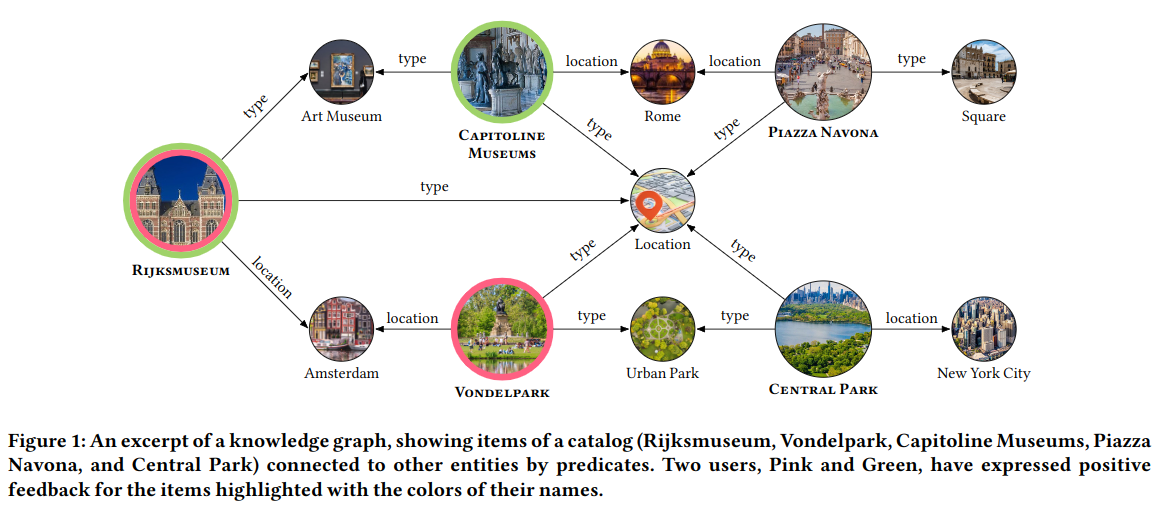
## Results
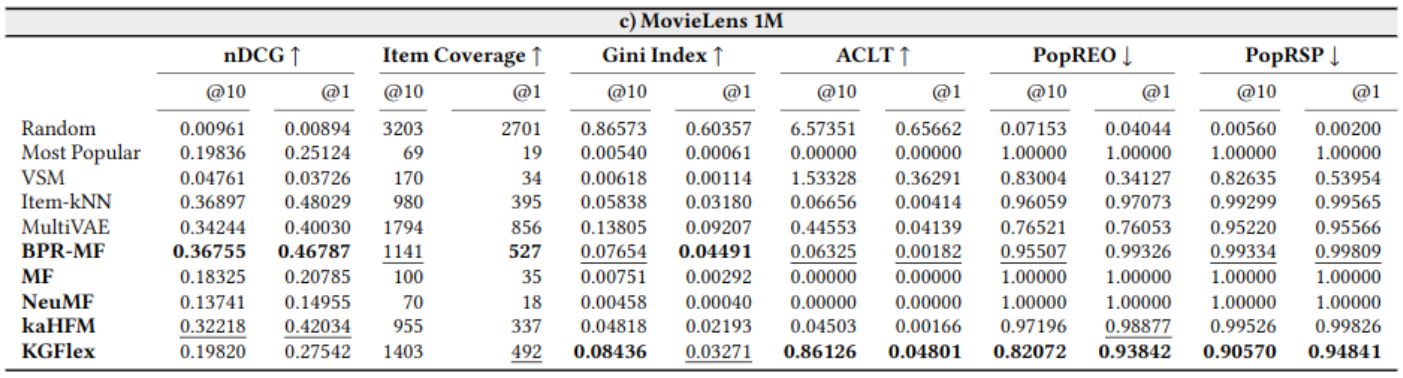
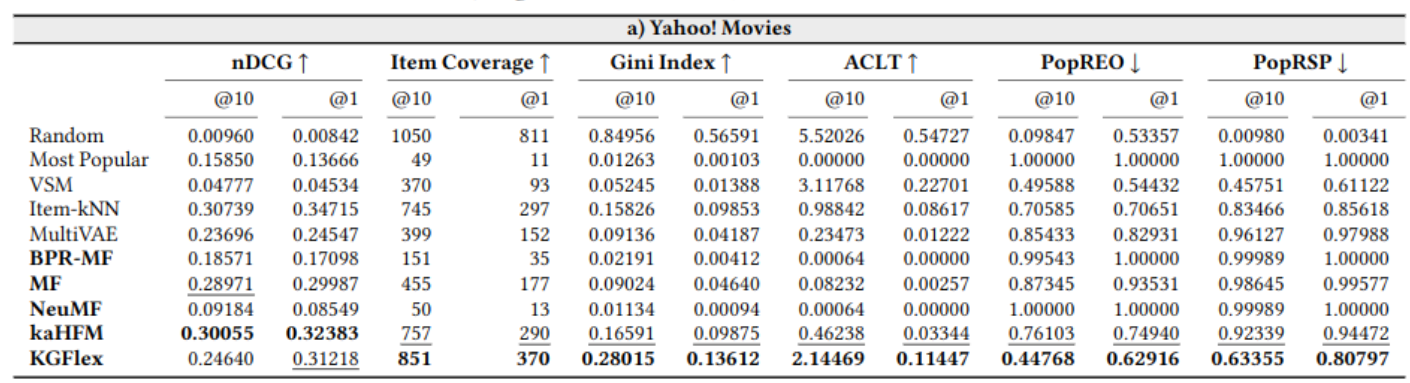
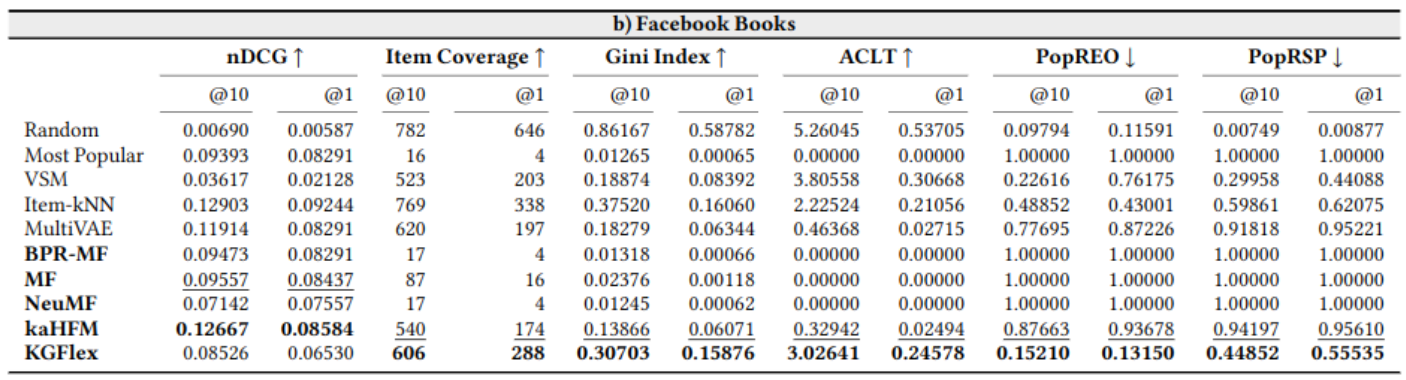
- Movielens-1M, Facebook Books, Yahoo! Movies에서 평가하였습니다.
- 저자들은 괜찮은 수준이라고 얘기하긴 하지만, nDCG 차이가 많이 나는 편입니다. Facebook Books의 경우 다른 메서드도 성능이 안좋긴하지만 MP보다도 결과가 안좋았습니다. nDCG가 추천 퀄리티를 담보하진 않지만 차이가 너무나는데 contribution이라고 보기 어렵다고 생각됩니다.
================================================
FILE: paper_review/recsys/recsys2021/The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender.md
================================================
# The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474253>
- Authors : Yu Liang, Martijn C. Willemsen
- Reviewer : jinny.kk
- Topics
- [#Interactive_Recommendation](../../topics/Interactive%20Recommendation.md)
- #Music_Recommendation
- [#RecSys2021](RecSys2021.md)
## Summary
- 유저의 preference가 시간이 지남에 따라 어떻게 발전하는지는 많이 연구되지 않았다는 문제의식에서 출발하여 음악 도메인에서 유저들의 short-term, long-term preference간의 관계를 이해해보고자 한 논문입니다.
## Approach
### 접근 방법
- 음악 도메인에서 유저들의 short-term, long-term preference간의 관계를 이해해보자.
- 정의: short-term은 session 내에서의 소비, long-term은 whole history에서의 소비를 뜻한다.
- 그걸 이해하면 시간에 따라 유저의 취향이 어떻게 발전하는지 이해할 수 있을 것이고, 유저가 새로운 취향을 탐색할 때 어떻게 행동하는지 이해할 수 있을 것이고, 탐색 툴에서 우리가 유저를 어떻게 서포팅해주면 좋을지도 생각해볼 수 있을 것이기 때문이다.
- 왜냐?
- 유저의 취향이 시간이 지남에 따라 어떻게 발전하는지 취향의 stability가 있는지, 그들간의 관계는 under-explored되었다.
- 이전 연구들이 보인 것들은, 단기 취향 ≠ 장기 취향인 것 같더라, 그리고 음악 도메인에선 유저의 음악적 전문성에 따라 청취 행태 (다양성, 추천 시스템 사용 방식)가 다르더라 정도였다.
- 논문의 도메인: 음악
### Research Questions
- RQ 1: 시간에 따라 유저 취향이 어떻게 변화하는지 이해해보자. (users's preference consistency)
- 스터디 디자인: data는 (다른 스터디에서 수집한) 스포티파이에서 319명의 유저들의 청취 기록을 사용했다. short (최근 4주), medium (최근 6달), long-term (모든 기록) preference는 track-level, artist-level, tag-level로 측정했다.
- 유저의 음악적 전문성이 높을수록 (높은 MSAE 점수) 시간에 따른 더 일관된 (consistent) 취향을 가지더라.
- short-term 과 medium-term 취향의 일관성이나, medium-term과 long-term 취향의 일관성 > short-term과 long-term 취향의 일관성. (어찌 보면 당연하긴 한 듯하지만..)
- RQ 2: 유저는 새로운 취향을 어떤 방식으로 탐색할까?
- (유저의 음악적 전문성에 따라 새로운 음악 장르를 탐색하는 방식이 달라질까?)
- 스터디 디자인: 저자들이 수행한 이전 연구가 이미 있고, 거기에 새로운 분석을 추가한 느낌이다. 어쨌든, 유저들에게 장르 목록을 주고 탐색할 장르를 선택하게 했다.
- 유저들은 현재 취향에 가까운 장르를 탐색하는 경향을 보였다.
- 유저의 음악적 전문성이 낮을수록 (낮은 MSAE 점수) 취향이 less stable 하더라. 그래서 탐색할 때 (well-developed된) long-term 취향의 장르에 가까운 장르를 탐색하더라.
- 유저의 음악적 전문성이 높을수록 (높은 MSAE 점수) 취향이 stable 하더라. 그래서 short, medium, long-term 취향의 것을 비슷비슷한 수준으로 탐색하더라.
- RQ 3: 그렇다면 유저가 현재 취향보다 좀더 멀리 떨어진 취향을 탐색하도록 넛지할 수 있을까?
- 스터디 디자인: 저자들이 고안한 interaction tool을 유저들이 사용하게 하였고, 2 X 3의 default conditions에서 between-subjects로 실험을 진행했다. 설정이 유저가 더 기존 취향으로부터 더 멀리 탐색하도록 넛지할 수 있는지 등을 분석하였다.
- 2 X 3 default conditions
- genre presentation order: 유저 취향에서 가까운 순 - 유저 취향에서 멀리 있는 순
- 장르 내 플레이 리스트의 personalization-level을 컨트롤하는 slider position: fully personalized - middle - fully representative
- RQ 3-1: 시스템의 Default order of genre presentation에 따라 유저가 현재 취향에서 좀더 먼 취향을 탐색하도록 넛지할 수 있을까?
- 넛지할 수 있더라. 하지만 음악적 전문성이 높을수록 이에 영향 받는 정도가 적더라.
- RQ 3-2: 시스템의 slider position의 default 세팅에 따라 유저들이 선택하는 추천의 개인화 정도가 달라질까?
- 유저의 slider interaction 횟수에 따라 유저별로 경향성이 다르게 나타났다. Fig 6 참고.
- low interaction group: final slider position은 default slider position에 강하게 영향 받았다.
- medium interaction group: default slider position의 반대 방향으로 slider를 이동시켰다.
- high interaction group: default에 덜 영향을 받았고, mixed position으로 slider를 이동시켰다.
- 대체로 유저들이 선택한 slider position으로 미루어 볼 때, 최적은 personalization과 representativeness 사이 어딘가에서 형성되더라.
- RQ 3-3: 유저들이 기꺼이 탐색하고자 하는 거리가 유저의 음악적 전문성에 따라 달리 나타날까?
- path model을 구축해서 (Fig 7) default setting이 유저의 (현재 취향으로부터의) 탐색 거리에 영향을 끼칠 수 있다고 분석했다.
## Conclusion
- `Strong Points?`
- 음악적 전문성에 따라 시간에 따른 유저 취향의 일관성 정도가 다르다는 걸 분석했다는 점이 흥미로웠다.
- 유저들이 컨트롤할 수 있는 어떠한 디폴트 세팅이 주어졌을 때 어떤 방식으로 새로운 장르를 탐색하는지 분석한 점이 흥미로웠다.
- `Weak Points?`
- 논문에서는 "취향"을 CB적으로 정의하였고, CF적으로 정의한 것은 아니다.
- 분석 논문인 것 같고, 그래서 이를 추천 시스템이 어떻게 반영해야 하는지의 방향성을 제시하지는 않는 것 같다.
- 음악 도메인이라 유저의 전문성이 하나의 factor가 되었는데, 다른 도메인에선 다른 것이 factor가 될 수 있을 것 같다.
================================================
FILE: paper_review/recsys/recsys2021/Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations.md
================================================
# Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations
- Paper : <https://dl.acm.org/doi/abs/10.1145/3460231.3474272>
- Authors : Marco Polignano, Cataldo Musto, Marco de Gemmis, Pasquale Lops, Giovanni Semeraro
- Reviewer : tony.yoo
- Topics
- [#Language_and_Knowledge](../../topics/Language%20and%20Knowledge.md)
- #Graph
- #Sequence_Modeling
- [#RecSys2021](RecSys2021.md)
## Summary
Main author: [Marco Polignano](https://scholar.google.it/citations?user=sjQSYGQAAAAJ&hl=it) - BERT 기반의 감정 분석 연구를 많이 하신것 같습니다.
- 두 가지 다른 정보(interaction feedback, text information)로 부터 user, item 임베딩을 얻는 hybrid 방법 제시하였습니다.
- 정보를 융합하는 방법은 두 가지 concatenation 방법을 제시하였습니다.
- 기본 architecture: Two-tower 모델과 같습니다.
<img src="https://user-images.githubusercontent.com/38134957/165453439-f3d2480f-69d5-487b-905f-7640927d1085.png" style="zoom:50%;" />
양쪽 방향이 같은 구조를 띄무로 한쪽 방향에 대해서만 표현하였습니다.
| Entity-based | Feature-based |
|--|--|
| <img src="https://user-images.githubusercontent.com/38134957/165453456-d22d9141-eca7-4fe9-b305-d194de75c8b1.png" width="80%"> | <img src="https://user-images.githubusercontent.com/38134957/165453460-f28ad0a6-44a5-4da4-a111-0404affc513b.png" width="80%"> |
|각 entity의 intrinsic charateristic 을 배움 | heterogenous 한 두 entity 사이의 relationship을 배움 |
다음의 두가지 모듈로 구성되있고, Sota 모델로 바꾸는게 쉽게 가능합니다.
- Collaborative Filtering 모듈: graph embedding 방법을 사용합니다.
- Content-based 모듈: contextual word representation 방법을 사용합니다.
## Approach
### Graph Embedding
다음 두개의 모델 사용. (이 외에도 TransR, TransD, ... 많은 모델 존재. [survey paper](https://www.mdpi.com/2073-8994/13/3/485/htm) 참고.)
- [TransE, NIPS'13](https://papers.nips.cc/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html)
- [TransH, AAAI'14](https://ojs.aaai.org/index.php/AAAI/article/view/8870)
이 모델은 본래 Knowledge graph 에서 entity(head)-relation-entity(tail)의 triple 정보를 임베딩에 반영하고자 한 방법. 추천시스템에서 유저, 아이템을 entity, 평점을 relation으로 생각 가능. 다음과 같은 관계로 임베딩.
| - | TransE | TransH |
| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| Architecture | <img src="https://user-images.githubusercontent.com/38134957/165453533-45b48c87-ceff-4e82-b009-3be1322d6f94.png" style="zoom:40%;" /> | <img src="https://user-images.githubusercontent.com/38134957/165453540-f5375f62-a31a-46a5-b700-4a599d34b6b9.png" style="zoom:40%;" /> |
| Score function | $\Vert \textbf{h} + \textbf{d}_r - \textbf{t} \Vert _{2}^2$ | $\Vert \textbf{h}_{\bot} + \textbf{d}*r - \textbf{t}_{\bot} \Vert _{2}^2$ |
> TransE 에서 "동일 entity가 여러 relation에서 구분이 안된다"는 단점을 TransH에서 hyperplane을 도입시킴으로써 해결.
### Contextual Word Reprentation
Text 정보를 임베딩. 둘다 Transformer 기반의 모델. (자세한 설명 생략)
- [BERT, NAACL'19](https://arxiv.org/abs/1810.04805)
- [USE, ICLR'19](https://arxiv.org/abs/1804.07461)
## Results
### Dataset
비교적 적은 데이터셋. 참고할 점은 train, test 셋을 나눌때, positive 비율을 train과 동일하게 나눔.
<img src="https://user-images.githubusercontent.com/38134957/165453586-8ba4b994-2d45-4f58-9594-e3a810679141.png" style="zoom:80%;" />
### Protocol
[TestRating](https://dl.acm.org/doi/10.1145/2043932.2043996) strategy 사용. 각 유저별로 테스트 셋에 있는 rating만 예측. ranking을 구할때는 예측한 평점들을 sorting하여 구함.
<img src="https://user-images.githubusercontent.com/38134957/165453619-20aa2173-20a3-4c76-be9f-634204d3dd5c.png" style="zoom:50%;" />
> **비평:** 이 방법을 사용하면 topk 보다 test 아이템의 수가 적으면 무조껀 ranking안에 포함되고, 순서 맞추기 싸움이 됨. 기본적으로 ndcg가 높음.
>
> <img src="https://user-images.githubusercontent.com/38134957/165453674-e668d165-7bef-43ed-b43b-986877cb9753.png" style="zoom:50%;" />
### Performance
| error-based | ranking-based |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| 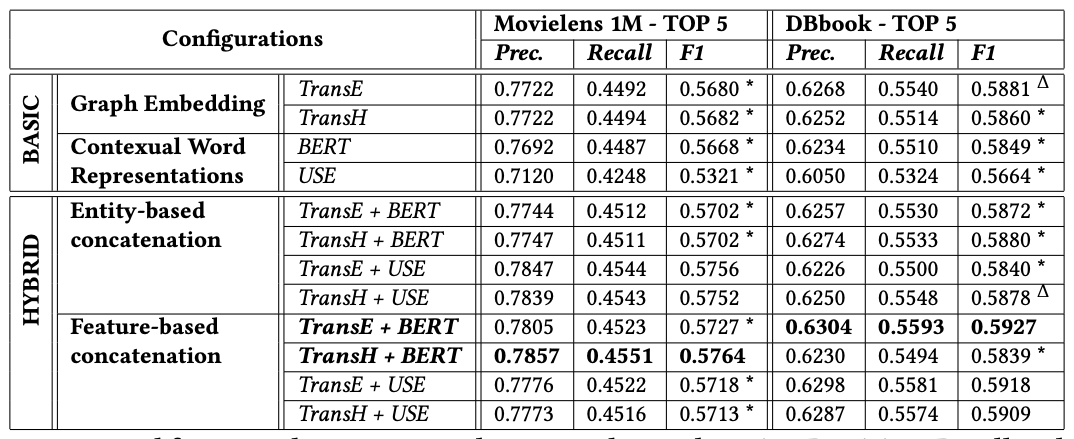 | 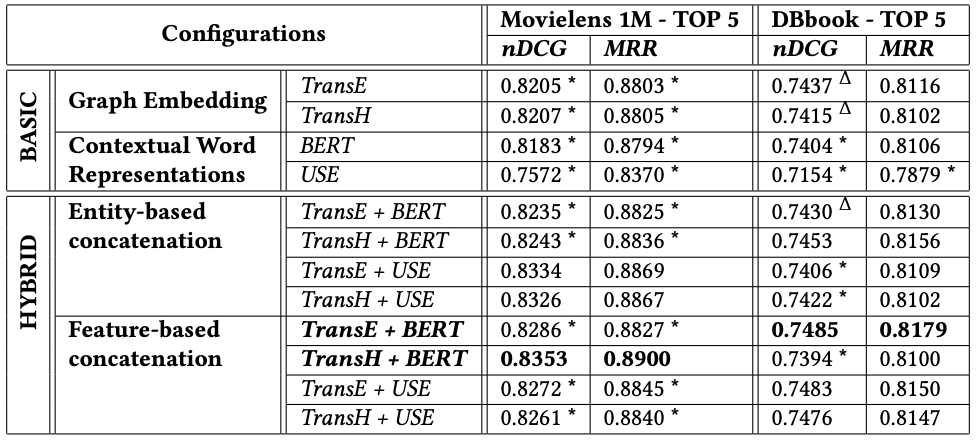 |
|  | 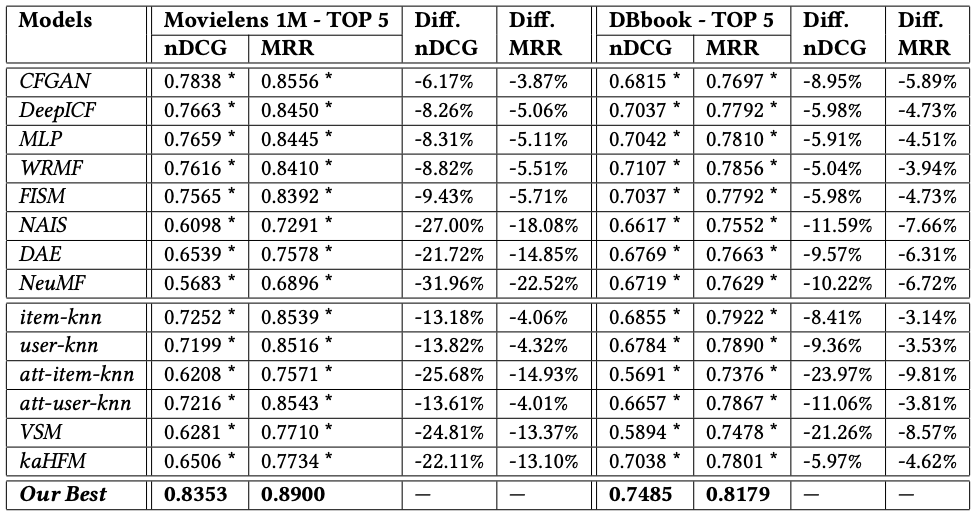 |
- TransE 와 TransH의 우위는 domain 에 따라 다르다.
- 논문 제목에서 강조하듯 Together is better. Collaborative 방법과 content방법의 시너지 효과.
- concatenate 방법은 Feature based 방법이 더 효과적.
[Open benchmark - Movielens 1M](https://paperswithcode.com/sota/collaborative-filtering-on-movielens-1m?metric=nDCG%4010)
<img src="https://user-images.githubusercontent.com/38134957/165454097-c7ce869c-3680-46fb-9697-ce6219b308b4.png" style="zoom:50%;" />
위의 오픈 벤치 마킹 정보에 의한 nDCG@10 Score와는 다른 test evaluation 프로토콜을 사용하였기 때문에 참고 부탁드립니다.
## Conclusion
- user, item 임베딩을 얻는 두가지 hybrid 방법(entity, feature-based)을 제시하였습니다.
- 모델 architecture가 simple하여 sota 모델을 쉽게 적용 가능할 수 있고 성능도 우수합니다.
### Weak points
- CF 기반 모델에서 interaction 정보만 사용할 거면 굳이 graph model을 쓸 필요는 없을 것 같습니다. CF Sota를 넣어도 될 것 같습니다.
> 저자는 이후에 knowledge graph정보를 추가로 넣어 볼 예정이라고하였는데 baseline으로 사용할 big picture?...
>
> attention 매커니즘도 적용해 볼 것이라고 했는데, 왜 안해봤을까.. 분명해봤는데 성능이 안좋은것이었을까?.. 하는 의문이 있었습니다.
- Test protocol로 TestRating 기법을 사용했는데, 이 방법은 ranking 비교에는 좀 맞지 않은 설정입니다. 차라리 leave-one-out 을 사용하는게 좋을것 같습니다.
================================================
FILE: paper_review/recsys/recsys2021/Top-K Contextual Bandits with Equity of Exposure.md
================================================
# Top-K Contextual Bandits with Equity of Exposure
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474248>
- Authors : Olivier Jeunen, Bart Goethals
- Reviewer : charlie.cs
- Topics
- [#Algorithmic_Advances](../../topics/Algorithmic%20Advances.md)
- [#Bandits_and_Reinforcement_Learning](../../topics/Bandits%20and%20Reinforcement%20Learning.md)
- [#RecSys2021](RecSys2021.md)
## Summary
- "equity of exposure" principle 이 어떻게 추천을 위한 top-K contextual bandit의 문제에 적용될 수 있는지 조사(investigate)한 논문입니다.
- equity of exposure: 동일한 relevance를 가진 아이템들은 동일한 노출이 있을 것을 기대하게 됩니다.(_items of equal relevance should receive equal exposure in expectation_)
- 기존 추천 시스템의 사용자 중심 utility(click or relevance)에 대한 최적화 방식은 시스템 내 다른 관계자(stakeholders)들에겐 악영향을 끼칠 수 있습니다.
- 예시) 음악 스트리밍, 음식 배달, e-commerce, 그리고 viewtab
- top-K contextual bandits 추천에서 relevance-fairness trade-off 문제를 다룰 수 있는 EARS (Exposure-Aware aRm Selection) 알고리즘을 제시하였습니다.
- model-agnostic algorithm이라 기존 bandit system에 적용이 가능합니다.
## Approach
### Intuition
- 사용자마다 추천 결과에 적용된 diversify의 반응이 다르며, 랜덤한 추천에 대해서 얼마나 열려(openness)있는지의 정도 또한 다양하다는 것을 관찰한 연구가 있습니다.
- _Investigating Listeners’ Responses to Divergent Recommendations. R. Mehrotra, et al. RecSys' 20_
- 이를 통해 단순히 모든 사용자에게 relevance-fairness의 trade-off 정도를 동일하게 적용하기 보다는 특정 유저 군에 한하여 적용하면 좋을 수 있습니다.
- 예시) good choice for _diverse_ and _average_ users, but worse for _focused_ users.
- 
- x-axis: top-12 items for a given user.
- y-axis: the probability of relevance over these items for that user.
### Exposure-Aware aRm Selection (EARS)
- 아이템이 클릭될 확률 `P(C)` 는 사용자가 이 아이템이 연관 있다고 고려할 확률 `P(R)`과 그 사용자에게 노출될 확률 `P(E)` 로 factorize될 수 있습니다.
- <img src="https://tva1.sinaimg.cn/large/008i3skNgy1gxcz1xaqdkj30gc02y0sq.jpg" width="50%" />
- 그리고 fairness of exposure을 목적하는 알고리즘은 다음과 같은 두 조건부 확률 분포 간 statistical divergence, 즉 disparity를 최소화하는 것으로 볼 수 있습니다.: `D(P(A|R); P(A|C))`
- 본 논문에서는 f-divergences로 Hellinger distance를 사용합니다.
- EARS algorithm Figure
- <img src="https://s2.loli.net/2021/12/14/Tu2U6VRj71MECck.png" width="70%" />
- Default bandit 알고리즘으로 logistic regression thompson sampling을 사용합니다.
- _An Empirical Evaluation of Thompson Sampling. L. Li, et al. NIPS' 11_
- EARS의 목적은 최대 ε 만큼의 expected clicks을 잃으면서 disparity를 최소화하는 것입니다.
- Algorithm 4.(3)의 greedy policy에서 얻을 수 있는 추천 결과에 diversifying(shuffling)을 적용했을 경우(4.(4)의 equity policy), 최대 (1 - ε) * 100 % 만큼의 expected clicks 을 보존하는 선까지 disparity를 최소화합니다.
- In experiments, `ε={0.01, 0.025, 0.05, 0.1}`
- shuffle 방식은 random shuffling
- 위에서 설명한 ε 조건을 만족할 수 있을 때까지 K값을 감소시키면서 shuffle을 진행합니다.
- Why? 상위 추천 결과에서 shuffle을 진행해야 expected clicks 손해가 적고, 그에 따른 disparity 감소가 크기 때문입니다.
## Results ([github](https://github.com/olivierjeunen/EARS-recsys-2021))
- Real-world data from the Deezer music streaming platform
- Relevance information between 862 playlists (items) and 974,960 users.
- Users are represented by a dense 97d feature vector.
- 추천 결과 수: top- `K`=12
- 매 round 마다 사용자를 20,000명 복원 추출하여 추천 결과 제공하고, batch로 parameter를 업데이트합니다.
- EARS algorithm에서 tolerance parameter ε 값을 조절해가며 실험하였습니다.: `{0.01, 0.025, 0.05, 0.1}`
- baseline은 greedy approach
- Carousel-기반의 추천 환경 (_Personalization in Music Streaming Apps with Contextual Bandits. W.Bendada. et al. Recsys' 20_)
- <img src="https://s2.loli.net/2021/12/14/HlxNMSPs6ZYOVnR.png" width="30%" />
- 사용자가 추천 결과를 보다가 중간에 포기할 확률 abandonment parameter `γ(=0.9)` 을 포함합니다.
- EARS에서 사용할 Expected clicks 값 계산
- Greedy approach
- <img src="https://tva1.sinaimg.cn/large/008i3skNgy1gxd09llzwnj30x20cidgw.jpg" width="75%" />
- Shuffling approach
- greedy 와 동일하지만, 추천 결과를 K개까지 shuffling 한 모든 조합에 대해서 expected clicks을 일일이 구해야하므로 `O(K!)` 만큼의 비용이 소모됩니다.
- 논문에서는 이를 효율적으로 계산하기 위한 방법을 제시했고, `O(K*2^(K-1)*(K-1))`까지 복잡도를 줄였다고 합니다.
### 실험 결과

- Figure 4(a): EARS’ Impact on Expected Reward
- `ε=0.01`일 때 greedy 보다 성능이 좋았는데, 이에 대한 이유를 두 가지로 설명합니다.
- (1) EARS의 rank 방식을 통해 positional bias를 완화하여 모델이 `P(R)` 대신 `P(C)`를 학습하게 됩니다.
- (2) top-K list를 랜덤으로 섞으면서 매 라운드마다 배치로 학습할 데이터가 더욱 diverse 해집니다.
- Figure 4(b): EARS’ Impact on Exposure Disparity
- greedy 방식이 가장 큰 disparity를 보였고, ε이 증가할수록 조금씩 감소합니다.
- Figure 4(c): EARS’ Relevance-Fairness Trade-Off
- Rounds 20부터 수렴까지 4(a)와 4(b)의 measurement를 plot
- expected clicks과 expected disparity의 linear한 관계를 확인할 수 있었습니다.
- `ε=0.01`의 경우 greedy 방식에 비교했을 때, expected reward 증가와 disparity 감소를 보입니다.
## Conclusion
- 컨텐츠의 노출에 따라 수익이 발생하는 환경이면 이와 관련된 이슈가 있을 것 같다는 생각이 들었습니다.
- 제안된 EARS 알고리즘은 cost가 높고, 단순 랜덤 셔플 방식이라 실제로 적용하기는 좋아보이지 않았습니다. (K 또한 낮았음)
- 다만, 사용자에 따라 다양화가 적용되는 정도가 달라져야 한다는 insight를 얻을 수 있어서 좋았습니다.
================================================
FILE: paper_review/recsys/recsys2021/Toward Unified Metrics for Accuracy and Diversity for Recommender Systems.md
================================================
# Toward Unified Metrics for Accuracy and Diversity for Recommender Systems
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474234>
- Authors : Javier Parapar, Filip Radlinski
- Reviewer : iggy.ll
- Topics
- [#Metrics_and_Evaluation](../../topics/Metrics%20and%20Evaluation.md)
- #Diversity
- [#RecSys2021](RecSys2021.md)
## Summary
## Approach
### 왜 다양성이 중요한가
추천 시스템을 평가하는 방법은 대부분 Information Retrieval (IR)에서 가져왔다고 생각합니다. NDCG를 비롯한 랭킹 메트릭도 마찬가지인데, 추천 시스템에서 고민하던 요소는 대부분 IR에서 비슷하게 고민했던 것들이지만, 디테일한 부분에서 다른 점이 많이 발생합니다.
### Diversity에 대한 대한 요구
추천 시스템뿐만 아니라, IR에서도 다양성은 중요한 metric 중 하나인데, 이는 주로 Ambiguity 때문입니다. 검색 엔진이 "재규어"라는 입력을 받을 경우 자동차 브랜드와, 고양잇과 동물에 대한 문서를 모두 찾아주어야 하고, 이러한 Ambiguity가 추천 시스템에서는 유저의 취향에 대응됩니다.
유저는 대체로 여러 취향을 가지고, 추천의 결과가 한 가지 종류의 아이템으로만 이루어져 있다면 추천이 불완전하다고 생각할 것입니다. 유저가 로맨스 영화와 호러 영화를 둘 다 좋아한다고 했을 때, 로맨스 영화만 추천하는 추천 모델은 불완전한 모델입니다.
### Novelty에 대한 요구
추천은 대부분 list 형태로 주어지며, 유저는 list를 좌에서 우로, 혹은 위에서 아래로 탐색하는 경우가 일반적입니다. $N$개의 추천 아이템이 주어진 경우, $k \leq N$인 $k$을 유저가 클릭한 경우, 유저가 $1, \dots, k-1$까지 보지 않았던 이유가 분명히 존재할 것이며, 이는 rank가 $k$ 미만인 아이템이 유저가 relevant하지 않았다고 판단했기 때문일 가능성이 높으며, $i_1, i_2, \dots, i_{k-1}$는 서로 닮아 있을 가능성이 높습니다. 이를 대비해서, $k$번째 아이템은 이전의 아이템과 충분히 다른 아이템인 게 더 좋을 수도 있습니다. 즉, Novelty는 추천 시스템이 실패했을 때를 대비한 보험이라 생각할 수 있습니다.
OTT 영화 추천을 예시로 들면, 유저가 로맨스를 좋아할 것이라 판단한 후에 로맨스 영화 5개를 추천했을 때, 추천이 성공적이었다 해도 유저는 랭크 상위의 영화 1-2개 정도밖에 보지 않을 것인데, 추천에 임의로 다른 영화를 한 두개 섞는다고 하면, 이 판단이 틀렸다고 하더라도 한 번의 기회를 더 얻을 수 있을 것입니다.
### Diversity와 Novelty를 고려한 Metric $\alpha\beta$-nDCG
#### Notation
- $\alpha_\phi$: 토픽(취향이나 선호도, 이하 토픽이라 칭함)
- 유저는 topic의 집합을 선호도로 갖고 있으며 $p(\alpha_\phi \vert u)$는 유저가 그 토픽을 선호할 확률을 나타낸다.
- 아이템 또한, topic의 집합을 갖고 있으며, 이 논문에서는 아이템의 토픽은 알려져 있다고 가정한다.
특정 유저 $u$가 rank $S \in \{1, 2, \dots, n\}$에 있는 item $i$를 선호할 확률은
$$
p(R=1 \vert u, i) = 1 - \prod_{\phi} [1 - p(\alpha_\phi \vert u, i) p(\alpha_\phi \vert u, S)]
$$
로 정의된다.
#### Diversity Consideration
$p(\alpha_\phi \vert u, i)$ (Diversity Term)는 Diversity를 고려한 식이다. 기존 ndcg에서 item 단위의 hit을 고려하는 것과는 별개로, topic 단위의 hit을 반영합니다.
$p(\alpha_\phi \vert u, i)$는 그 유저가 유저의 선호도 $\alpha_\phi$를 만족하는 정도를 나타내는데, 이를 별도로 정의하는 이유는 같은 장르이더라도, 유저가 특정 아이템을 선호할 수 있고 선호하지 않을 수 있기 때문입니다. 예를 들어서, *밴드 오브 브라더스*는 좋아하지만 *오! 인천*은 그다지 좋아하지 않는 경우가 있습니다.
$$
p(\alpha_\phi \vert u, i) = \begin{cases}
0 & \text{아이템의 장르가 다름} \\
\alpha & \text{유저가 그 장르를 좋아하는데, 유저가 클릭하지 않은 경우} \\
\beta & \text{유저가 그 장르를 좋아하고, 유저가 그 아이템을 클릭한 경우} \\
\end{cases}
$$
Diversity Term은 유저가 그 아이템을 좋아하거나, 그 장르를 선호하거나에 따라 score에 대해 차등을 주는 식으로 모델링됩니다. 간단히 요약하자면, 기존 nDCG에서는 유저가 실제로 클릭한(relevant) 대해서만 추천을 준다고 가정하는 반면, 유저가 좋아하는 장르에 대한 추천에도 약간이나마 선호도를 부여합니다.
$\alpha, \beta$에 대한 정의는 논문에서 자세히 되어있지 않지만, $p(\alpha \vert u), p(\alpha \vert i)$에 따라 적절히 정의될 수 있을 것 같습니다.
### Novelty Consideration
$p(\alpha_\phi \vert u, S)$ (Novelty Term)는 유저가 특정 위치 $S\in \{1, 2, \dots, n\}$에 존재하는 추천에 대해 얼마나 만족하는지를 나타내는 지표입니다. 이를 별도로 모델링하는 이유는, 유저가 상위 랭크 $1, 2, \dots, S-1$에서 특정 토픽 $\alpha_\phi$를 봤다면, rank $S$에서 같은 토픽 $\alpha_\phi$인 아이템을 보더라도 만족도가 그리 높지 않을 것이라는 가정을 포함하고 있습니다.
$$
p(\alpha_\phi \vert u, S) = p(\alpha_\phi \vert u) \prod_{j = 1}^S [1-p(\alpha_\phi \vert u, i_j)]
$$
유저가 이전에 본 항목에 같은 토픽의 아이템이 많이 들어있을 경우, Novelty Term은 감소한다. 새로운 토픽의 아이템이 추천될 경우, 이 값은 증가한다. 증가폭은 유저가 그 토픽을 선호할 확률 $p(\alpha_\phi \vert u)$에 비례합니다.
### Axioms for Diverse Ranking Evaluation
논문에서 추천 리스트와, 그 추천 리스트에 대한 평가 메트릭에 관한 공리를 정의해놨는데, 논문에서 8가지 공리가 정의되어 있지만, 거칠게 요약하자면 다음과 같습니다.
1. 두 아이템의 토픽이 완전히 같다고 가정하면, 유저는 relevancy가 더 높은 아이템이 추천되는 추천 리스트를 선호한다.
2. 유저가 좋아하는 아이템이 추천 리스트에 포함될 경우, 이 아이템이 더 상위 랭크에 있는 추천 리스트가 더 하위 랭크에 있는 추천 리스트보다 선호된다.
3. 한 추천 리스트에서 같은 토픽이 너무 자주 추천되는 경우, 이 토픽이 유저가 선호하는 토픽이라 할 지라도 유저가 좋아하지 않는 토픽의 아이템을 더 선호할 수 있다.
4. 유저는 본 적 없는 아이템을, 이미 싫어하는 아이템보다 더 선호한다.
## Conclusion
- 구현 후, 오프라인 메트릭은 구현이 제대로 되어 있는 지만 확인 한 이후 온라인 평가가 실전이다 이런 느낌으로 온라인에 배포해던가, 혹은 IPS같은 방법으로 온라인 평가를 오프라인으로 가져오는 방법만 알고 있었는데, 유저 행동에 대한 합리적인 가정과 모델링을 통해 더 좋은 offline metric을 만드는 일도 좋은 방향일 수 있구나 하는 생각이 들었습니다.
- Novelty가 중요하다는 얘기만 들었었는데, 그럴 듯 한 설명을 들은 것은 처음입니다.
================================================
FILE: paper_review/recsys/recsys2021/Towards Source-Aligned Variational Models for Cross-Domain Recommendation.md
================================================
# Towards Source-Aligned Variational Models for Cross-Domain Recommendation
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474265>
- Authors : Aghiles Salah, Thanh Binh Tran, Hady Lauw
- Reviewer : andrew.y
- Topics
- [#Language_and_Knowledge](../../topics/Language%20and%20Knowledge.md)
- #Cross-Domain
- [#RecSys2021](RecSys2021.md)
## Summary
- Cross Domain 추천이란?
- 기존 data sparsity로 힘든 콜드 유저의 추천을 위해 다른 서비스에서 해당 유저의 소비 이력을 쓰는 추천입니다. (예. 유저의 영화 소비 이력으로 유저한테 책 추천)
- 기존에 있던 방법은 아래와 같습니다.
- matrix factorization jointly factorizes rating matrices from various domains with a shared user-latent space
- transfer learning: a mapping between the source and target models or infer user representations that are domain-invariant
- 이 논문에서 제안하는 방법은 다음과 같습니다.
- Variational AutoEncoder (VAE)를 사용하는 기법
- VAE를 source domain에서 학습 시켜서 target domain에 preference modeling을 한다.
## Approach
### VAE?
- [참고 링크](https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73#:~:text=In%20a%20nutshell%2C%20a%20VAE,to%20generate%20some%20new%20data.)
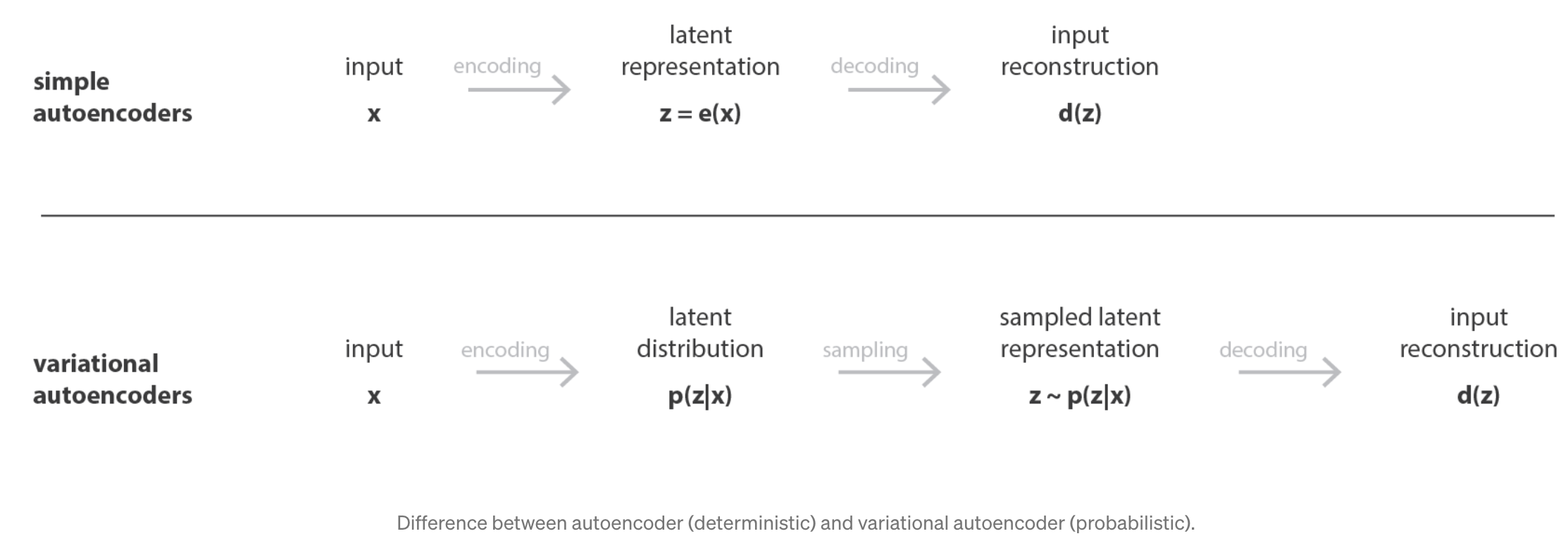
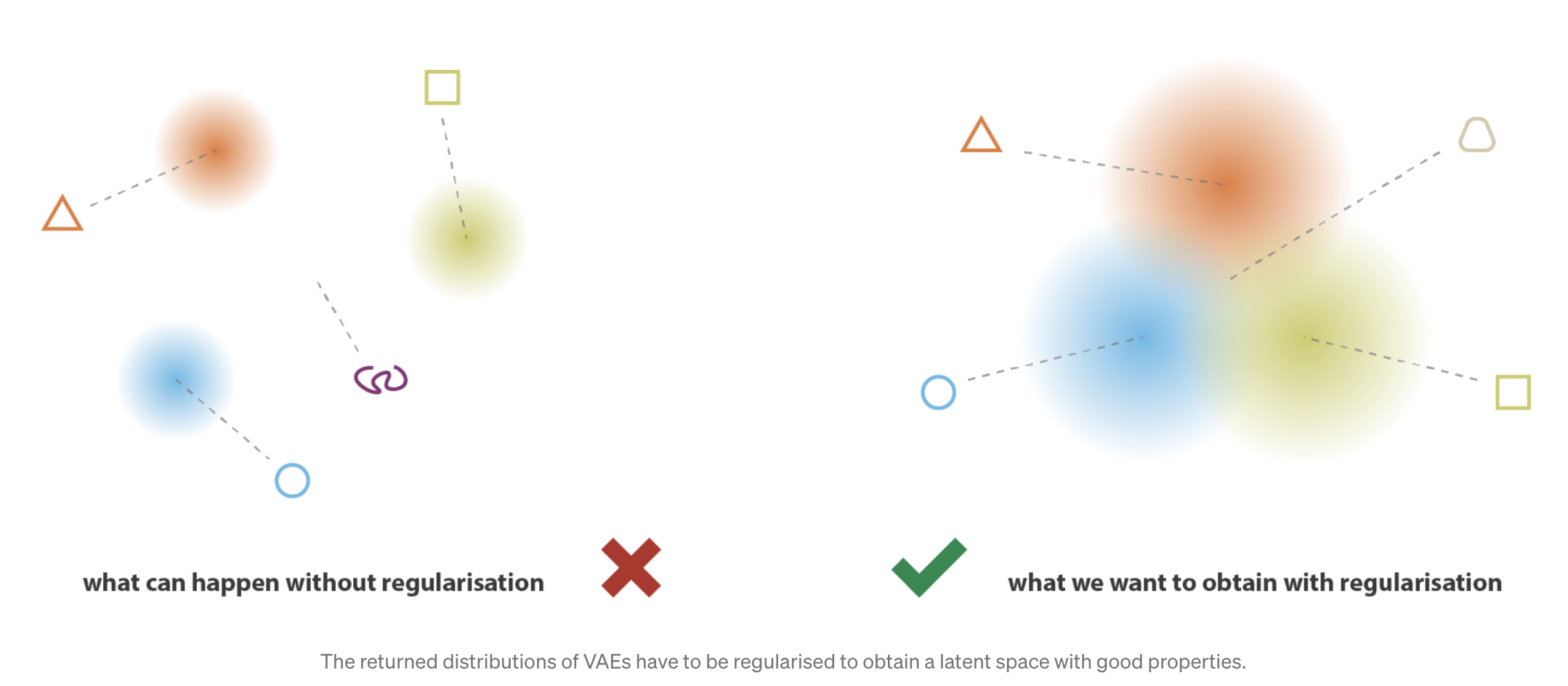
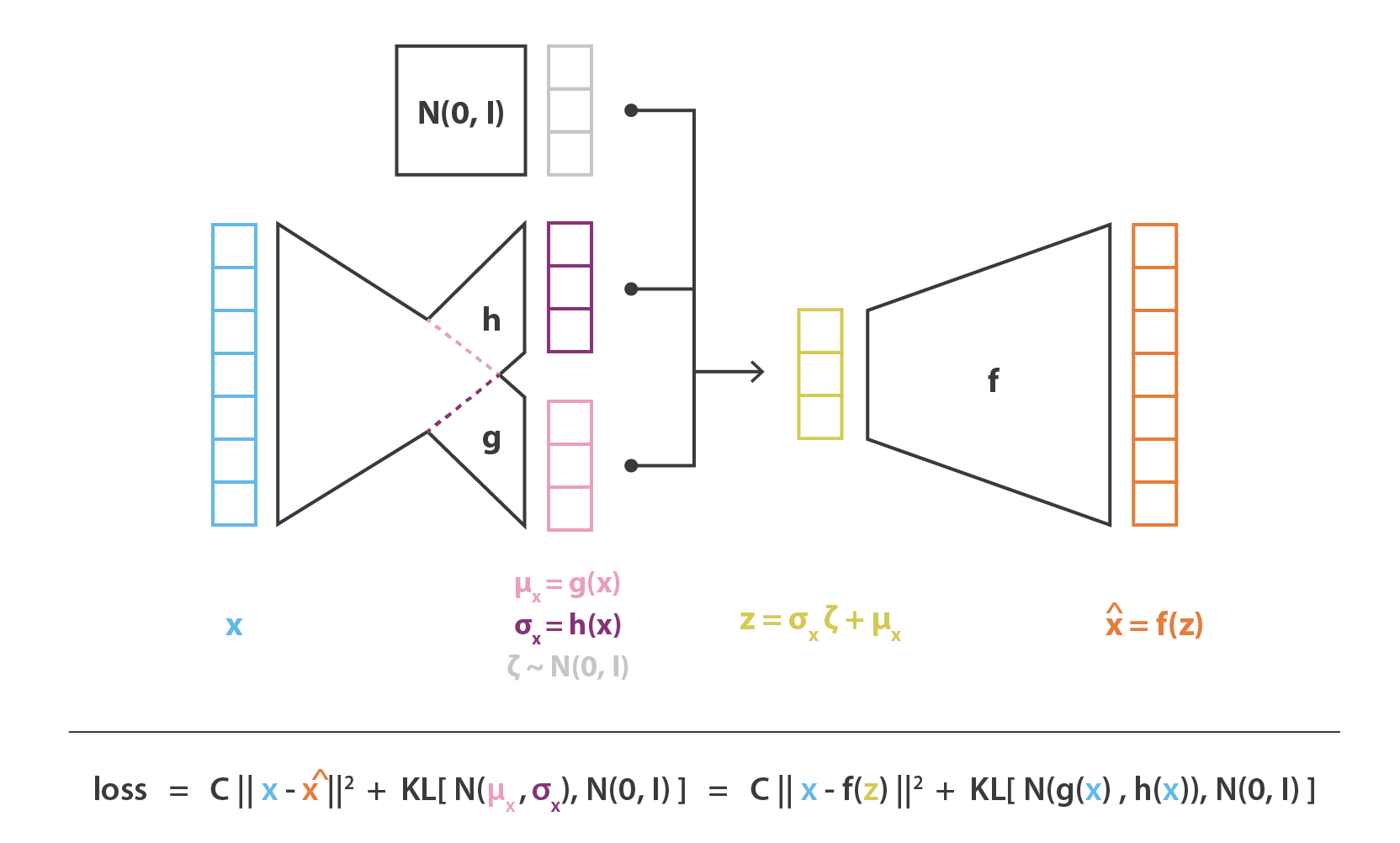
### Why VAE?
- Matrix Factorization의 limitation인 linear nature가 아닌 non-linear recommendation 모델을 써보기 위해 VAE를 사용할 수 있습니다.
- non-linear recommendation 모델은 sparse data에 overfitting 하기 쉬운 문제는 있습니다.
- VAE가 다른 논문들에서 성능이 좋은 측면도 있습니다.
### Source Domain
- VAE의 디코더랑 상응하는 부분 (theta 학습)
<img src= "https://user-images.githubusercontent.com/38134957/165147892-55e1404c-fade-47ba-9156-20025239bce7.png" width = "450">
- VAE의 인코더랑 상응하는 부분 (phi 학습)
<img src= "https://user-images.githubusercontent.com/38134957/165147904-3c60a039-d5ce-42f8-9de9-315ef79d3506.png" width = "250">
- Evidence Lower BOund (ELBO) -> maximize:
<img src= "https://user-images.githubusercontent.com/38134957/165147946-3479fa18-9ce9-4af0-be82-de8df93315ae.png" width = "450">
- a given input x, we want to maximise the probability to have x̂ = x when we sample z from the distribution q*_x(z) and then sample x̂ from the distribution p(x|z)
- KL divergence: staying close to the prior distribution ( <img src= "https://user-images.githubusercontent.com/38134957/165147967-c1c13c7a-abdf-456c-b178-5c3c2ac55fa0.png" width = "150"> )
### Target Domain
- Rigidly Aligned VAE (RA-VAE):
<img src= "https://user-images.githubusercontent.com/38134957/165148025-3248eb3e-1d4a-4818-bc07-76bb609f7ac3.png" width = "450">
- source domain data held fixed while training target domain data
- Softly Aligned VAE (SA-VAE):
<img src= "https://user-images.githubusercontent.com/38134957/165148041-e6fc2157-42f9-460d-9ec3-c39e0a083b5c.png" width = "250">
<img src= "https://user-images.githubusercontent.com/38134957/165148047-55caad69-19a5-4183-9d1f-b0c45d63886c.png" width = "450">
### 논문에서 쓰는 모델들 (baseline 포함)
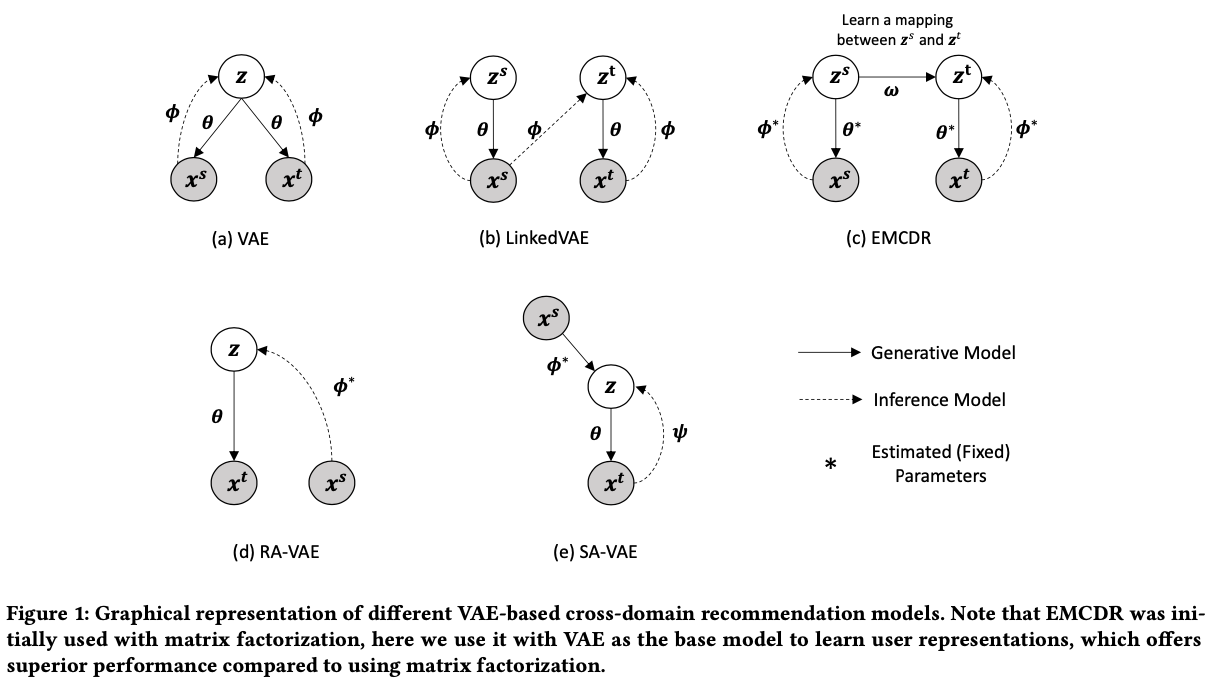
## Results
- Amazon, Douban 데이터셋에서 실험하였습니다.
- 오프라인 실험: 10%, 20%, 30% 랜덤하게 테스트 셋으로 ndcg, recall 계산 (target domain에서 콜드 유저로 인식)
tldr; RA-VAE, SA-VAE가 베이스라인보다 더 성능이 좋음. baseline에서는 EMCDR이 제일 성능이 좋음.
### 모델의 성능이 유저 활동성에 따라 달라지나? (robustness of the model)
테스트 셋은 10%으로.
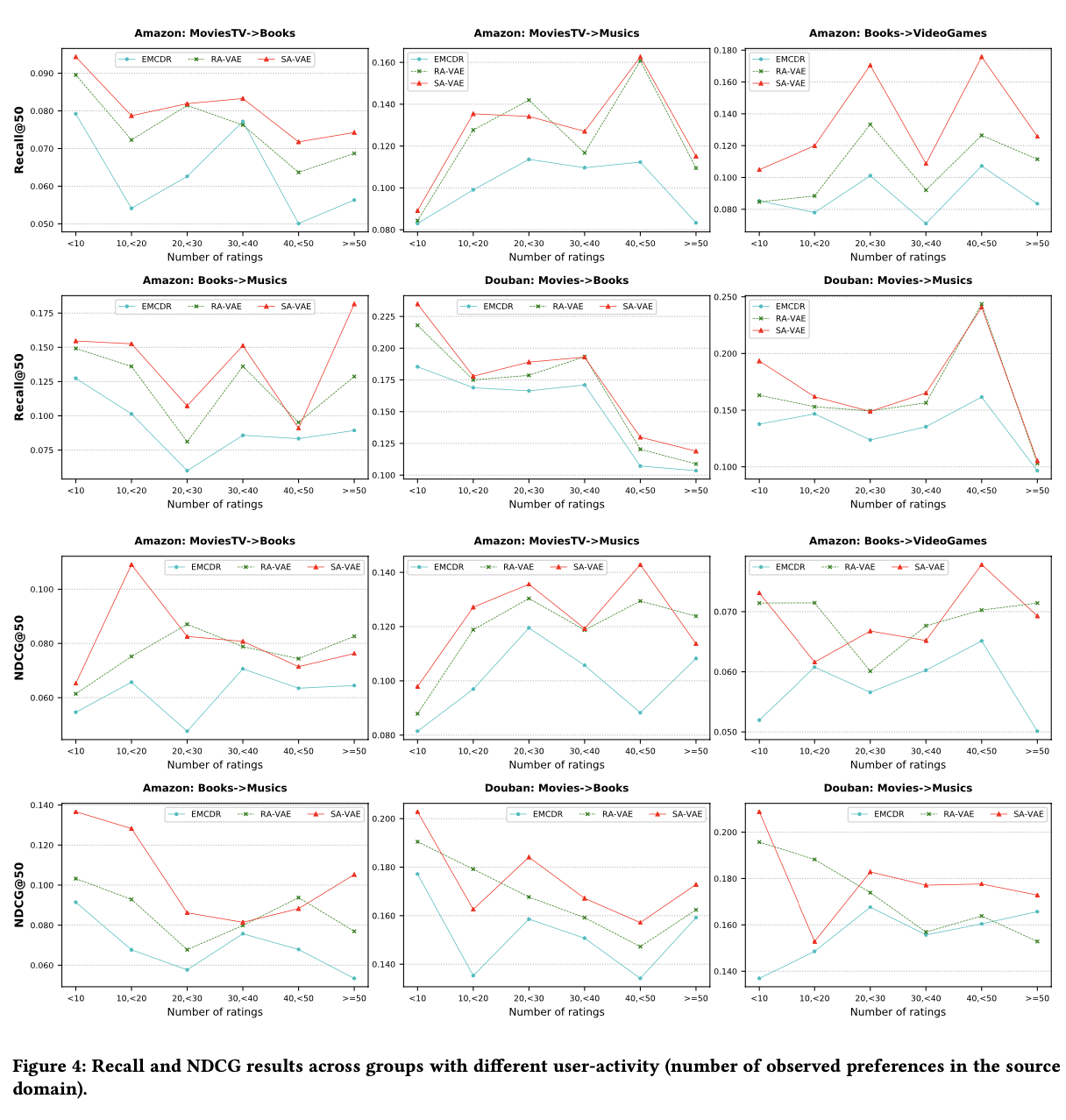
tldr; 모든 그룹에 성능 좋아지고, 30회 이하 유저 그룹들에 베이스라인보다 더 성능이 좋아졌다 한다.
## Conclusion
- VAE 기반 cross-domain 추천을 할때 모델을 어떻게 짜는지가 중요한걸 볼수 있다. (e.g. 모델 architecture에서 sparsity issue를 줄인다던지)
- 기존에 쓰인 deterministic methods과 달리 VAE를 쓴 probabilistic approach도 cross-domain 추천에 잘 쓰일수 있다.
================================================
FILE: paper_review/recsys/recsys2021/Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation.md
================================================
# Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474255>
- Authors : Gabriel de Souza Pereira Moreira, Sara Rabhi, Jeong Min Lee, Ronay Ak, Even Oldridge
- Reviewer : marv.20
- Topics
- [#Language_and_Knowledge](../../topics/Language%20and%20Knowledge.md)
- #Semi-Supervised_Learning
- #Sequential_Recommendation
- [#RecSys2021](RecSys2021.md)
## Summary
- NLP와 sequential / session 기반 추천 방식이 유사한데, 최근 NLP의 수많은 모델 구조들을 바로 추천에 적용할 수 있게끔 huggingface transformers 라이브러리 기반의 transformer4rec 라이브러리를 공개하였습니다. Huggingface의 모델 구조를 적용, 튜닝하는 것으로 2개의 2021 이커머스 챌린지에서 우승할 수 있었습니다.
- casual language modeling에서 자주 쓰였던 학습방법들인 masked LM, permutation LM, replacement token detection 방법론들을 비교하여 보았습니다.
- 사이드 정보를 결합하여 추천해보았습니다.
## Approach
### NLP 모델들과 Sequential / Session 기반 추천의 관계
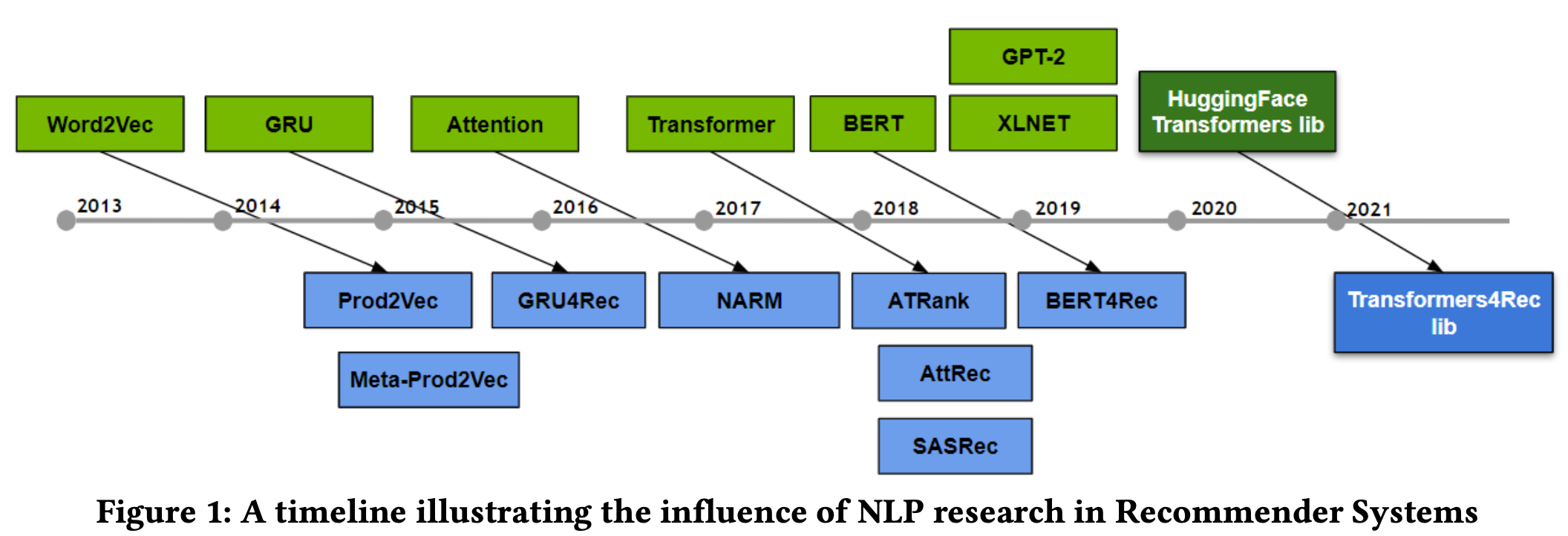
### LM 학습기법들 비교 (CLM, MLM, PLM, RTD)
![The possible transformation of MLM and PLM, where w i and p i represent token and position embeddings. [M ] is the special mask token used in MLM. The left side of MLM (a) can be seen as bidirectional AR streams (in blue and yellow, respectively) at the right side. For MLM (b) and PLM (c), the left sides are in original order, and the right sides are in permuted order, which are regarded as a unified view.](https://www.researchgate.net/profile/Rui-Wang-17/publication/341369190/figure/fig4/AS:890933465849856@1589426499052/The-possible-transformation-of-MLM-and-PLM-where-w-i-and-p-i-represent-token-and.png)
- causal language model (CLM) : next token prediction
- masked language model (MLM) : masked token prediction
- permuation languagem model (PLM) : permutation + next token prediction
### Transformer4Rec 구조
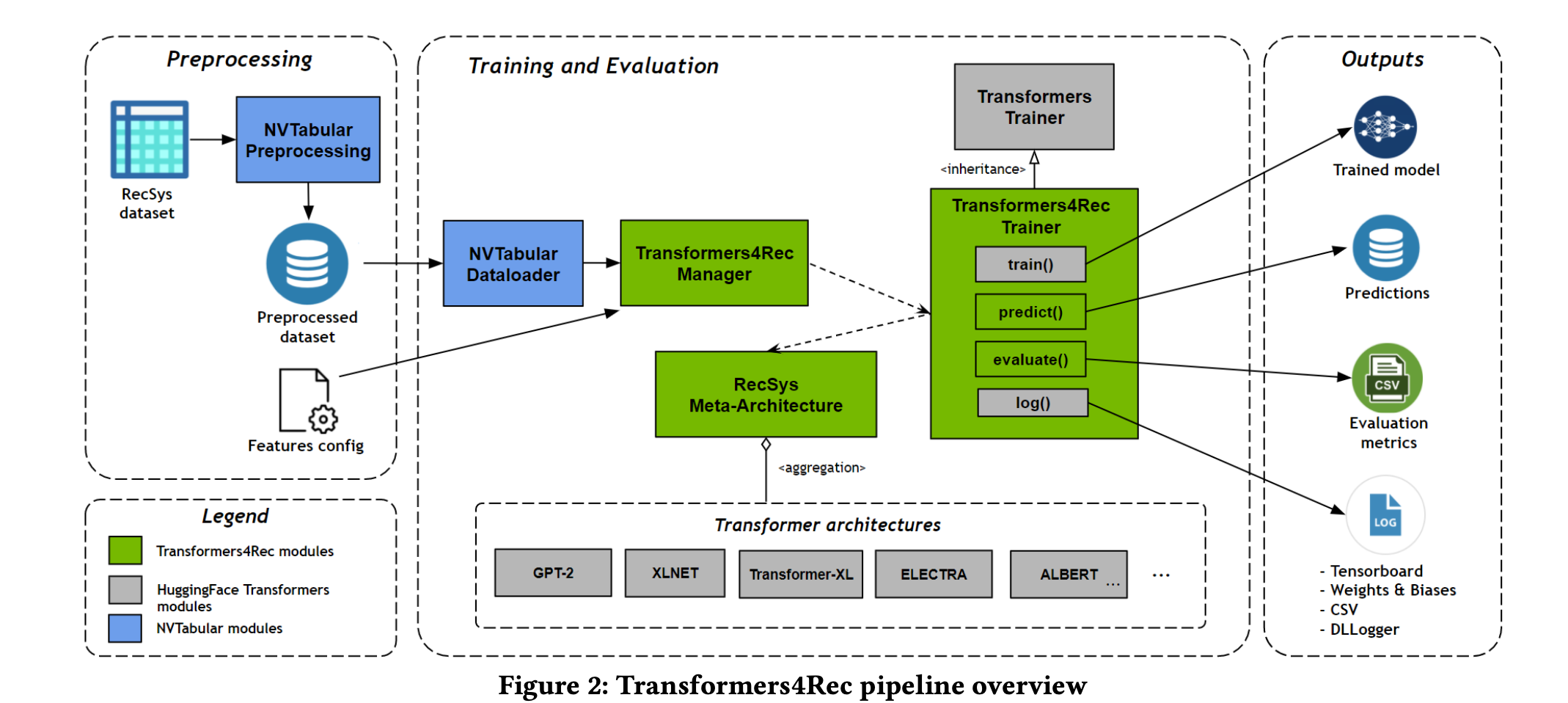
- 데이터 전처리, 피처 엔지니어링 : NVTabular
- sequential reco를 위한 ops : grouping time-sorted interactions, truncating first/last N interactions
- Meta architecture
- feature processing module : sparse categorical, continuous -> normalized and combined
- sequence masking module : CLM, MLM, PLM
- prediction head module : tasks (item prediction, sequence-level prediction)
## Results
- RQ1. 다양한 모델 아키텍쳐 실험 결과
- RQ2. 다양한 학습 방식 실험 결과
- RQ3. item embedding을 다양한 feature들의 결합으로 변형
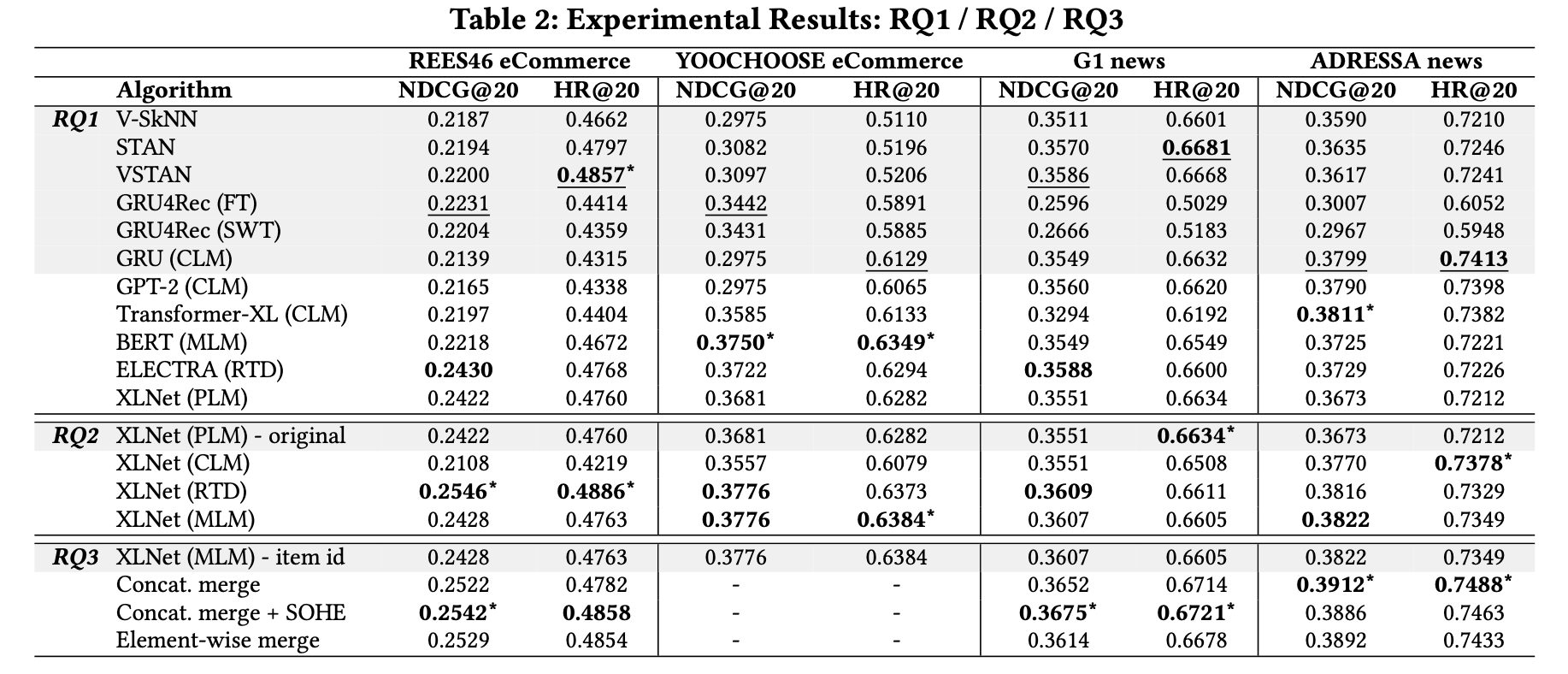
## Conclusion
- sequential recommendation이 NLP의 발전을 따라가기만 하는 형태여서 비판적이었는데 이를 실용적으로 풀어낸 게 인상깊었습니다.
- winning solution은 존재하지 않았습니다. 오히려 그렇기 때문에 데이터셋이나 환경에 따라 다양한 모델을 자유롭게 실험해볼 수 있어야 하고, 그런 의미에서 이 논문의 가치가 있다고 생각합니다.
- 사이드 정보를 넣는 방식이 인상 깊었습니다. 상당히 간단해서 어느 구좌 / 메타이던지 사용해볼 수 있을 것 같습니다.
================================================
FILE: paper_review/recsys/recsys2021/Values of Exploration in Recommender Systems.md
================================================
# Values of Exploration in Recommender Systems
- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474236>
- Authors : Minmin Chen, Yuyan Wang, Can Xu, Ya Le, Mohit Sharma, Lee Richardson, Su-Lin Wu, Ed Chi
- Reviewer : andrew.y
- Topics
- [#Metrics_and_Evaluation](../../topics/Metrics%20and%20Evaluation.md)
- [#RecSys2021](RecSys2021.md)
## Summary
- 강화학습 기반 추천 시스템에서 exploration이 어떤 영향을 미치는지 알아보고 user exploration을 추가하는 methodology를 소개한 논문입니다.
- Accuracy, diversity, novelty, serendipity를 측정하고, 오프라인과 온라인 실험을 통해 exploration의 영향을 분석하였습니다.
## Approach
### 배경
논문은 REINFORCE 추천 시스템을 베이스로 사용합니다. ([참고 논문](https://arxiv.org/abs/1812.02353))
- 용어 정리
<img src= "https://user-images.githubusercontent.com/38134957/165144415-0170f299-f9ae-4722-9469-ce1f0af61ab6.png" width = "300">
- 유저의 히스토리 up to time t, A_t = set of item recommended at time t, a = item user interacted with, r = reward
- u_s_t = RNN_theta(H_t) → latent user state (s_t = user state)
- v_a = embedding of item a
- Softmax Policy over item corpus given the latent user state
<img src= "https://user-images.githubusercontent.com/38134957/165144428-8d2c6ec7-c820-42f3-8430-d8d8e9db1962.png" width = "300">
- 여기서 policy parameters θ가 밑의 수식을 (expected culumative reward) 최대화 하게 학습을 합니다.
<img src= "https://user-images.githubusercontent.com/38134957/165144509-e0c3f37c-7ce9-4661-8ce4-8158b0a8cf61.png" width = "400">
<img src= "https://user-images.githubusercontent.com/38134957/165144527-cbcb50aa-3377-4dc8-81a3-f7b18e5f86b7.png" width = "300">
- 이 학습된 softmax policy를 사용해서 time t에 set of recommendation A_t생성해서 A_t를 유저한테 추천합니다.
### User Exploration 활성화 하는 방법
#### Entropy Regularization
policy π_θ (·|s)를 entropy가 높은 output distribution으로 유도해서 유저 관심사 밖 콘텐츠를 추천하는걸 더 활성화 시킵니다. (user exploration 활성화)
<img src= "https://user-images.githubusercontent.com/38134957/165144584-ed071f3e-f88b-4982-8607-48836a6b9ce8.png" width = "250">
<img src= "https://user-images.githubusercontent.com/38134957/165144623-fcf2ad13-7044-4350-9306-d835117751be.png" width = "300">
- entropy는 negative reverse KL divergence of the conditional distribution π_θ (·|s) to the uniform distribution. (uniform distribution과 얼마나 비슷한지)
- entropy를 높이면 높일수록 학습된 policy는 uniform distribution이 된다. (선호도와 상관 없이 공평하게 추천된다)
#### Intrinsic Motivation and Reward Shaping
<img src= "https://user-images.githubusercontent.com/38134957/165144712-b484ec78-6d0a-420e-9cdb-aa2face9c1c6.png" width = "400">
<img src= "https://user-images.githubusercontent.com/38134957/165144729-a64a4d65-e7ba-47f3-ad85-ec3faaa631a4.png" width = "350">
- 위 policy 수식의 r(s,a) reward function (유저 s에게 a를 추천하는 immediate value)에서 intrinsic reward를 추가합니다.
- 유저가 소비한 아이템의 리스트가 있을때 유저가 막 소비한 아이템이 이전 아이템들이랑 많이 다르면 reward를 높게 합니다.
- multiplication인 이유는 relevance를 유지하기 위해서 (R_t^e (s_t , a_t ) = 0는 계속 0)입니다.
- 유저에게 더 좋은 user experience를 주는 surprising한 (과거 소비 아이템이랑 다른) 아이템에게 reward를 많이 줍니다.
- unknown interest는 아이템의 클러스터가 유저가 이미 소비한 클러스터가 아닌 경우를 의미합니다. (i.e. different topic, different provider)
#### Actionable Representation for Exploration
- 유저가 surprising한 아이템을 소비해서 리워드를 높게 받은 상태면, 다음에는 다르게 interact할수있게 유저 피쳐에 반영을 해야합니다.
- 따라서 유저 피쳐 (유저 히스토리)에 surprise랑 relevance를 추가합니다.
<img src= "https://user-images.githubusercontent.com/38134957/165144855-ba16e911-78d7-4f93-81d5-a0873336e306.png" width = "300">, i_t = 1 if topic/provider cluster different, r_t (reward) > 0 (relevance)
### 측정 방법
#### Accuracy
- mean average precision at K = 50 (밑의 수식에서는 j) ([참고 논문](https://www.cs.cornell.edu/people/tj/publications/yue_etal_07a.pdf))
<img src= "https://user-images.githubusercontent.com/38134957/165144933-887d51f6-961a-4d60-b4b7-2699164e4936.png" width = "450">
#### Diversity
<img src= "https://user-images.githubusercontent.com/38134957/165144961-14ba6d0e-e18c-44d5-b962-dd903ce99089.png" width = "450">
- 직관적인 수식입니다. uniform에서는 sim(i,j)는 1이니까 diversity는 0, sim(i,j)가 낮으면 낮을수록 diversity가 올라가게 됩니다.
#### Novelty
<img src= "https://user-images.githubusercontent.com/38134957/165145030-a712e303-ec3b-4126-b8d2-0640e0ec51b6.png" width = "350">
- I(a)= − log (# users consumed item a) + const
- globally 덜 popular 한 아이템 (모두가 좋아하지 않는 아이템)을 학습해서 추천하면 더 novel하다고 봅니다.
#### Serendipity
<img src= "https://user-images.githubusercontent.com/38134957/165145071-ec69eaa5-bbf0-4033-bd5b-5ebff2a5f469.png" width = "450">
<img src= "https://user-images.githubusercontent.com/38134957/165145088-f66bfd38-e9fe-41ff-8b6d-9e23bba9e0e2.png" width = "450">
- 위에 언급한 surprise + relevance를 둘다 챙기면 1, 아니면 0로 둡니다.
- 유저가 소비하는 주류 아이템이 아닌 관심있는 아이템이 있는지 quanitify 하는 metric입니다.
#### Long Term User Experience
- 결국엔 exploration이 long term user experience에는 도움이 될것인지 알려면 이거에 대한 측정 방법도 있어야 합니다.
- 논문에서는 유저가 다시 서비스를 쓰는지, 그리고 활동량이 적은 유저들이 활동량이 많은 유저로 변하는지를 보고 long term user experience를 판단합니다.
## Results
### 오프라인 실험 결과 및 분석
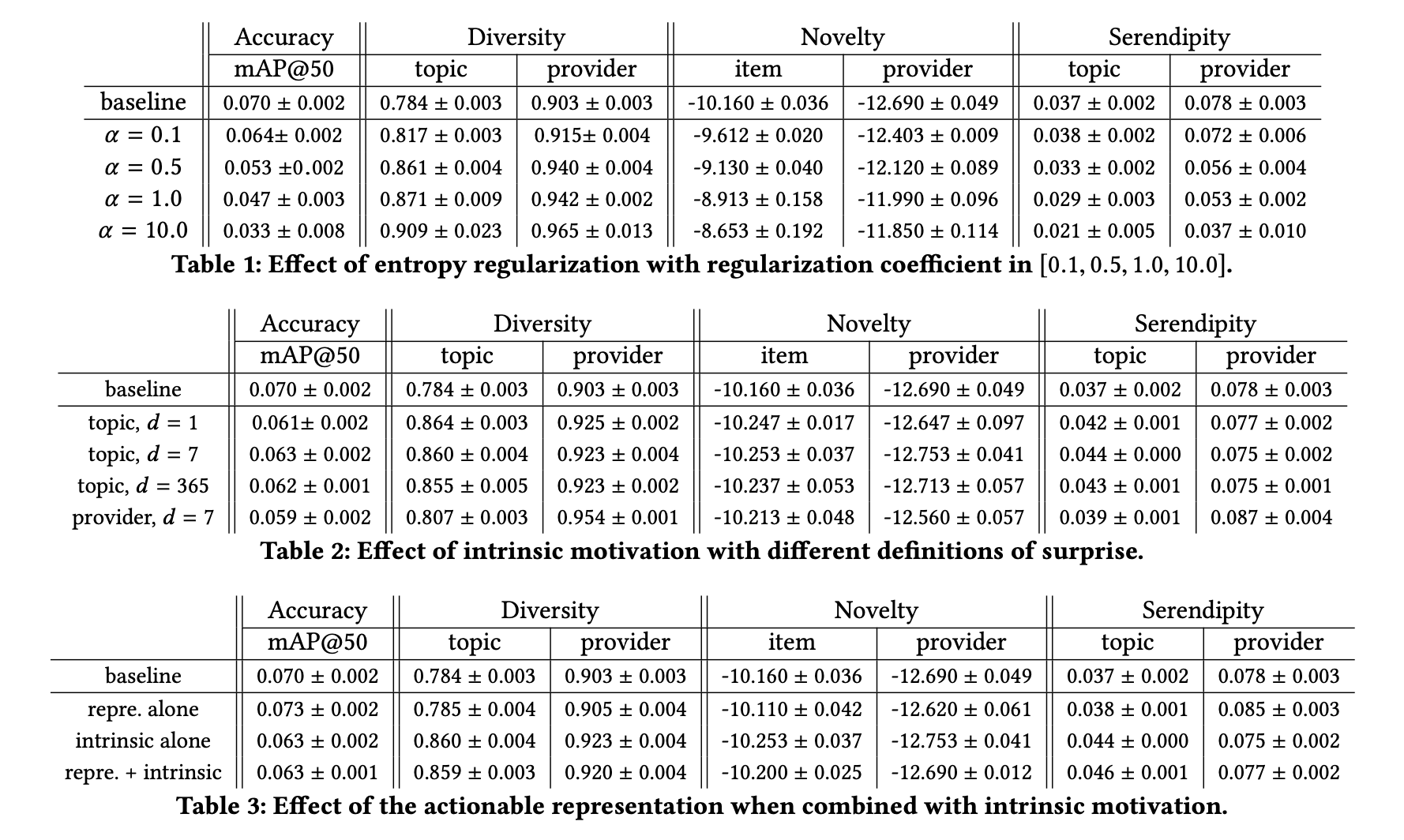
- 무슨 데이터셋을 썼는지 정확히 언급은 하고 있지 않습니다. ("a billion user trajectories from a commercial recommendation platform")
- item space = most popular 10 million items in the past 48 hours on the platform
- 99% training, 1% validation
#### Entropy Regularization
- as α ↑, diversity ↑, novelty ↑ at cost of accuracy ↓ + serendipity ↓ (due to loss of relevance)
#### Intrinsic Motivation
- 위의 c를 조정 가능하지만 이 페이퍼에서는 | I_t | 를 조정하기로 하였습니다.
- baseline 대비 diversity ↑ at cost of accuracy ↓, serendipity ↑, novelty - 의 성능을 보여주었습니다.
- d = 1, 7, 365에서는 큰 차이 없었습니다.
- In the datasets, the percentage is reduced from 36% → 19% → 12% when the window size is extended from 1 → 7 → 365 days. (서프라이징 한 state-action pair %)
#### Actionable Representation
- actionable representation만으로는 baseline과 비슷해서 intrinsic motivation이랑 같이 써야합니다.
- intrinsic motivation 대비 serendipity ↑
- mean input gate activation value차이 → RNN이 surprising event때 더 큰 업데이트를 합니다. → 유의미한 차이가 있습니다.
<img src= "https://user-images.githubusercontent.com/38134957/165145193-c7bfa990-970c-4c2d-b533-ab6fc41b5e55.png" width = "600">
### 온라인 실험 결과 및 분석
- 오프라인 실험과 데이터 크기는 비슷합니다.
- "a industrial recommendation platform serving billions of users", "a corpus of 10 million"
- entropy regularization (red: α = 0.1, blue: α = 0.5)
- intrinsic motivation (d = 7, topic, c = 4)
- user enjoyment improvement 어떻게 측정 했는지 안나와있습니다.
- α = 0.1 → α = 0.5: lower user enjoyment improvement. 따라서 diversity ↑ novelty ↑은 better user experience를 가져오지 못한다고 볼 수 있습니다.
- Figure 3b, 3c에서는 user enjoyment이 improve했고 (baseline 대비) 오프라인 분석과 합쳐서 분석하면 serendipity ↑ 이 user experience를 더 좋게 만든다고 볼 수 있습니다.
<img src= "https://user-images.githubusercontent.com/38134957/165145396-d4ad3847-6f51-4a00-8423-e3522bf7146d.png" width = "300">
- Returning 유저도 더 많아졌습니다.
#### Long Term User Experience
- 시간이 지날수록 exploration의 효과 (유저가 새로운 "interest"를 찾는거)가 있었습니다.
- 실험 시작하기 전과 후를 비교한 a user activity level transition matrix입니다.
- 저 %가 어떻게 계산되는지는 불확실합니다. (개인적으로 이해 못함)
- casual → core conversion이 많았다 주장하고 있습니다.
## Conclusion
- serendipity가 long term user experience에 좋은 영향을 준다는 것을 밝혔습니다. 따라서 long term user experience를 높히기 위해서는 exploration을 해야하고, exploration이 serendipitous recommendation을 잘 해줘야 합니다.
================================================
FILE: paper_review/topics/Algorithmic Advances.md
================================================
# Algorithmic Advances
- [Next-item Recommendations in Short Sessions](../recsys/recsys2021/Next-item%20Recommendations%20in%20Short%20Sessions.md)
- [Burst-induced Multi-Armed Bandit for Learning Recommendation](../recsys/recsys2021/Burst-induced%20Multi-Armed%20Bandit%20for%20Learning%20Recommendation.md)
- [Top-K Contextual Bandits with Equity of Exposure](../recsys/recsys2021/Top-K%20Contextual%20Bandits%20with%20Equity%20of%20Exposure.md)
================================================
FILE: paper_review/topics/Applications-Driven Advances.md
================================================
# Applications-Driven Advances
- [Follow the guides- disentangling human and algorithmic curation in online music consumption](../recsys/recsys2021/Follow%20the%20guides-%20disentangling%20human%20and%20algorithmic%20curation%20in%20online%20music%20consumption.md)
================================================
FILE: paper_review/topics/Bandits and Reinforcement Learning.md
================================================
# Bandits and Reinforcement Learning
- [Burst-induced Multi-Armed Bandit for Learning Recommendation](../recsys/recsys2021/Burst-induced%20Multi-Armed%20Bandit%20for%20Learning%20Recommendation.md)
- [Top-K Contextual Bandits with Equity of Exposure](../recsys/recsys2021/Top-K%20Contextual%20Bandits%20with%20Equity%20of%20Exposure.md)
================================================
FILE: paper_review/topics/Echo Chambers and Filter Bubbles.md
================================================
# Echo Chambers and Filter Bubbles
- [I want to break free! Recommending friends from outside the echo chamber](../recsys/recsys2021/I%20want%20to%20break%20free!%20Recommending%20friends%20from%20outside%20the%20echo%20chamber.md)
================================================
FILE: paper_review/topics/Interactive Recommendation.md
================================================
# Interactive Recommendation
- [The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender](../recsys/recsys2021/The%20role%20of%20preference%20consistency,%20defaults%20and%20musical%20expertise%20in%20users’%20exploration%20behavior%20in%20a%20genre%20exploration%20recommender.md)
================================================
FILE: paper_review/topics/Language and Knowledge.md
================================================
# Language and Knowledge
- [Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation](../recsys/recsys2021/Transformers4Rec-%20Bridging%20the%20Gap%20between%20NLP%20and%20Sequential%20&%20Session-Based%20Recommendation.md)
- [Sparse Feature Factorization for Recommender Systems with Knowledge Graphs](../recsys/recsys2021/Sparse%20Feature%20Factorization%20for%20Recommender%20Systems%20with%20Knowledge%20Graphs.md)
- [ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation](../recsys/recsys2021/ProtoCF-%20Prototypical%20Collaborative%20Filtering%20for%20Few-shot%20Item%20Recommendation.md)
- [Towards Source-Aligned Variational Models for Cross-Domain Recommendation](../recsys/recsys2021/Towards%20Source-Aligned%20Variational%20Models%20for%20Cross-Domain%20Recommendation.md)
- [Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations](../recsys/recsys2021/Together%20is%20Better-%20Hybrid%20Recommendations%20Combining%20Graph%20Embeddings%20and%20Contextualized%20Word%20Representations.md)
================================================
FILE: paper_review/topics/Metrics and Evaluation.md
================================================
# Metrics and Evaluation
- [Toward Unified Metrics for Accuracy and Diversity for Recommender Systems](../recsys/recsys2021/Toward%20Unified%20Metrics%20for%20Accuracy%20and%20Diversity%20for%20Recommender%20Systems.md)
- [Values of Exploration in Recommender Systems](../recsys/recsys2021/Values%20of%20Exploration%20in%20Recommender%20Systems.md)
- [Accordion- a Trainable Simulator for Long-Term Interactive Systems](../recsys/recsys2021/Accordion-%20a%20Trainable%20Simulator%20for%20Long-Term%20Interactive%20Systems.md)
- [Evaluating Off-Policy Evaluation- Sensitivity and Robustness](../recsys/recsys2021/Evaluating%20Off-Policy%20Evaluation-%20Sensitivity%20and%20Robustness.md)
================================================
FILE: paper_review/topics/Practical Issues.md
================================================
# Practical Issues
- [Shared Neural Item Representation for Completely Cold Start Problem](../recsys/recsys2021/Shared%20Neural%20Item%20Representation%20for%20Completely%20Cold%20Start%20Problem.md)
================================================
FILE: paper_review/topics/Privacy, Fairness, Bias.md
================================================
# Privacy, Fairness, Bias
- [Debiased Explainable Pairwise Ranking from Implicit Feedback](../recsys/recsys2021/Debiased%20Explainable%20Pairwise%20Ranking%20from%20Implicit%20Feedback.md)
- [Mitigating Confounding Bias in Recommendation via Information Bottleneck](../recsys/recsys2021/Mitigating%20Confounding%20Bias%20in%20Recommendation%20via%20Information%20Bottleneck.md)
================================================
FILE: paper_review/topics/Real-World Concerns.md
================================================
# Real-World Concerns
- [Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders](../recsys/recsys2021/Cold%20Start%20Similar%20Artists%20Ranking%20with%20Gravity-Inspired%20Graph%20Autoencoders.md)
- [Semi-Supervised Visual Representation Learning for Fashion Compatibility](../recsys/recsys2021/Semi-Supervised%20Visual%20Representation%20Learning%20for%20Fashion%20Compatibility.md)
================================================
FILE: paper_review/topics/Scalable Performance.md
================================================
# Scalable Performance
- [Local Factor Models for Large-Scale Inductive Recommendation](../recsys/recsys2021/Local%20Factor%20Models%20for%20Large-Scale%20Inductive%20Recommendation.md)
- [Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?](../recsys/recsys2021/Reverse%20Maximum%20Inner%20Product%20Search-%20How%20to%20efficiently%20find%20users%20who%20would%20like%20to%20buy%20my%20item%3F.md)
================================================
FILE: paper_review/topics/Theory and Practice.md
================================================
# Theory and Practice
- [Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher](../recsys/recsys2021/Negative%20Interactions%20for%20Improved%20Collaborative%20Filtering-%20Don’t%20go%20Deeper,%20go%20Higher.md)
- [Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All](../recsys/recsys2021/Matrix%20Factorization%20for%20Collaborative%20Filtering%20Is%20Just%20Solving%20an%20Adjoint%20Latent%20Dirichlet%20Allocation%20Model%20After%20All.md)
================================================
FILE: paper_review/topics/Users in Focus.md
================================================
# Users in Focus
- ["Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface](../recsys/recsys2021/"Serving%20Each%20User"-%20Supporting%20Different%20Eating%20Goals%20Through%20a%20Multi-List%20Recommender%20Interface.md)
================================================
FILE: presentations/README.md
================================================
# 발표 자료 모음
================================================
FILE: programming_assignments/beale_ciphers/README.md
================================================
# 빌 암호(Beale Ciphers) 해독
문제 출제 및 검수: 한상덕(leo.han)
> 이 문제로 영입을 진행하며 지원자분에게 드렸던 인터뷰 질문은 [interview.md](interview.md)에 있습니다. 문제를 풀어보시고 이 문서도 확인해보세요.
## 문제
사건은 1885년 한 조그마난 팜플렛이 버지니아에서 발견되면서부터 시작된다. 이 팜플렛에는 빌이라는 이름의 한 남자의 이야기와 세 개의 암호 메세지가 담겨있었다.
이야기의 내용은 1820년 빌이라는 남자가 버지니아 베드포드 카운티 한 비밀의 장소에 보물로 가득 찬 수레 두 대를 묻었다는 것이다.
이 남자는 여관 주인에게 작은 열쇠 상자를 맡기고 마을을 떠난 뒤 다시는 나타나지 않았다. 수 년 뒤 여관 주인은 열쇠 상자를 열었고 세 개의 암호화된 메세지를 발견한다.
그는 평생 암호를 해독하지 못하고 1863년 죽기 전에 친구에게 암호를 준다. 그로부터 20년 후 이 이름 모를 친구는 세 개의 암호 중 첫 번째와 두 번째 암호를 해독하는데 성공한다.
해독된 메세지에는 빌이 묻은 금은보화들의 존재와 위치가 담겨있었다. 마지막 메세지에는 세부 위치와 그 보물들이 누구의 소유인지 밝혀져 있다고 한다.
수십 년간 많은 사람이 암호 해독을 시도해보았고 보물을 찾아 나섰지만 모두 실패했다.

빌의 두번째 암호

빌의 세번째 암호
그러던 중 카카오 추천팀 레오는 빌의 다른 암호문 중에서 세 번째 암호를 해결하기 위한 단서가 첫 번째 암호와 두 번째 암호에 존재한다는 사실을 발견했다.
첫 번째 암호문을 행렬로 표현했을 때 k x k 크기의 정방 블록부분행렬들 중 한 블록부분행렬 X와 X와 같은 크기의 두 번째 암호의 블록부분행렬들 중 한 블록부분행렬 Y가 세 번째 암호를 해독하는데 중요한 역할을 한다는 사실을 발견한 것이다.
레오는 세 번째 암호문의 k x k 크기의 블록부분행렬 집합 Q의 원소 중 의미있는 원소의 집합 S를 다음과 같이 표현하였다.
$$\large S = \\{ Z | XZ = Y, Z \in Q \\}$$
레오는 집합 S의 크기가 클수록 암호를 해독할 가능성이 높아진다고 생각하였지만 모든 경우를 전부 해보는 것은 시간상 힘들기 때문에 X, Y 그리고 세 번째 암호문 n×m 행렬 R이 주어졌을 때 |S|를 구하는 프로그램을 구현하고자 한다.
## 조건
1. 입력제한
- C++, Java : 1 ≤ k ≤ 100, k ≤ n, m ≤ 150
- Python : 1 ≤ k ≤ 40, k ≤ n, m ≤ 60
2. k×k의 두 행렬의 곱 연산은 일반적인 방법으로 O(k^3)에 구현이 가능하고 가장 빠른 방법은 O(k^2.373)에 구하는 방법으로 알려져 있다.
하지만 위 두 가지 방법론으로 위 문제를 해결하기에는 적절하지 않기 때문에 다음 방법론을 이용하여 구현해야 한다.
- 링크: <https://en.wikipedia.org/wiki/Freivalds%27_algorithm>
3. Standard Library만 사용해야 한다. (ex Python 2, Python 3 - numpy 모듈 허용하지 않음)
4. 제한시간 C++ 1.5초, Java 2.5초, Python 5초
5. 표준 입출력 사용
6. matrix 연산 과정은 int 범위 안에서 계산할 수 있습니다.
## 입력
첫 번째 줄에 테스트 케이스 T(1 ≤ T ≤ 10)가 입력으로 주어진다. 두 번째 줄부터 테스트케이스가 시작된다.
각 테스트 케이스의 첫 번째 줄에 공백을 기준으로 n, m, k가 주어진다. 그 다음줄부터 k개의 줄에는 X의 원소가 k개씩 주어진다.
이어서 k개의 줄에는 Y의 원소가 k개씩 주어지고 그 다음에 n개의 줄에 R의 원소가 m개씩 주어진다.
## 출력
각 테스트케이스마다 |S| 를 한 줄에 하나씩 출력한다.
## 예제
|입력 예제|출력 예제|
|:---|:---|
|2<br>1 4 1<br>2<br>6<br>3 4 3 3<br>3 4 2<br>1 0<br>0 1<br>1 1<br>0 1<br>1 1 1 1<br>0 1 0 1<br>1 3 1 -1|3<br>2<br><br><br><br><br><br><br><br><br><br><br><br>|
================================================
FILE: programming_assignments/beale_ciphers/interview.md
================================================
# 빌 암호(Beale Ciphers) 해독 인터뷰 질문
> [▶︎ 빌 암호(Beale Ciphers) 해독 문제로 돌아가기](README.md)
빌 암호(Beale Ciphers) 해독 문제로 영입을 진행하며 지원자분에게 드렸던 인터뷰 질문과 예시 답변을 모아놓았습니다.
## 질문 1
Freivalds 알고리즘의 목적 및 동작에 대해 설명해주세요.
<details>
<summary>예시 답변</summary>
- N x N 행렬 A, B, C에 대해서, AB = C 인지 여부를 빠르게 계산하기 위한 확률 기반 approximate 알고리즘
</details>
## 질문 2
빌 암호 해독 문제를 freivalds 알고리즘을 이용하여 해결 했을 경우 시간 복잡도는? 그리고 시간복잡도 그렇게 되는 이유(증명)를 설명할 수 있겠는가?
<details>
<summary>예시 답변</summary>
- O(kN^2), k는 frealids 알고리즘 반복 횟수
- 간혹 kN^2 이 아니라 반복횟수 k를 상수 취급해서 무시하는 경우가 있는데, 정확하게 집고 넘어가도록 하자.
- 문제를 풀 때 증명을 읽지 않고 문제를 해결할 수 있기 때문에 증명 내용에 대해서는 추가 점수 정도로 조정
</details>
## 질문 3
Freivalds 알고리즘의 오답률은?
<details>
<summary>예시 답변</summary>
≤ 1/(2^k)
</details>
## 질문 4
Freivalds 알고리즘 반복 횟수 k는 문제에서 몇 번 시도하였는가? 왜 그렇게 값을 정하였는가?
만약 K 값을 더 최적화해보라고 한다면, 어떻게 접근하겠는가? 필요한 가정은 직접 추가해도 무방하다.
<details>
<summary>예시 답변</summary>
- 시스템이 요구하는 정확도가 xx 라면 xx 를 초과하도록 k 를 정하겠다.
- 시스템의 수행시간이 허용하는 한도 내에서 가장 높은 k 를 실험적으로 찾겠다.
- 정확도와 수행시간 간에 트레이드오프임을 인지하는지 판단
</details>
================================================
FILE: programming_assignments/beale_ciphers/solution/solve.cpp
================================================
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
const int K = 102;
const int N = 302;
const int M = 302;
int X[K][K], Y[K][K], Q[N][M], _C[K][K];
int v[K], t[K], q[K];
bool freivald(int X[][K], int Y[][K], int Q[][M], int x, int y, int n, int m, int k){
int T = 10;
while(T--){
for(int i=0; i<k; i++)
v[i] = rand() % 2;
for(int i=0; i<k; i++){
t[i] = q[i] = 0;
for(int j=0; j<k; j++){
t[i] += Q[x+i][y+j] * v[j];
q[i] += Y[i][j] * v[j];
}
}
for(int i=0; i<k; i++){
v[i] = 0;
for(int j=0; j<k; j++)
v[i] += X[i][j] * t[j];
}
for(int i=0; i<k; i++)
if(v[i] != q[i])
return 0;
}
return 1;
}
bool back(int X[][K], int Y[][K], int Q[][M], int x, int y, int n, int m ,int k){
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
_C[i][j] = 0;
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
for(int r=0; r<k; r++)
_C[i][j] += X[i][r] * Q[x+r][y+j];
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
if(_C[i][j] != Y[i][j])
return 0;
return 1;
}
void solve(){
int n, m, k;
scanf("%d %d %d", &n, &m, &k);
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
scanf("%d", &X[i][j]);
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
scanf("%d", &Y[i][j]);
for(int i=0; i<n; i++)
for(int j=0; j<m; j++)
scanf("%d", &Q[i][j]);
int ans = 0;
for(int i=0; i<n-k+1; i++)
for(int j=0; j<m-k+1; j++)
if(freivald(X, Y, Q, i, j, n, m, k))
++ans;
printf("%d\n", ans);
}
int main(){
srand(time(NULL));
int T;
scanf("%d", &T);
while( T-- ) solve();
}
================================================
FILE: programming_assignments/beale_ciphers/solution/solve.java
================================================
import java.util.*;
public class Main{
public static void main(String args[]){
Task solver = new Task();
solver.solve();
}
}
class Task{
public void solve(){
Scanner sc = new Scanner(System.in);
int T = sc.nextInt();
for(int R=1; R<=T; R++)
Do(sc);
}
public boolean freivald(int X[][], int Y[][], int Q[][], int x, int y, int n, int m, int k){
int T = 10;
int v[] = new int[k];
int t[] = new int[k];
int q[] = new int[k];
Random rd = new Random();
while( T-- > 0 ) {
for(int i=0; i<k; i++)
v[i] = rd.nextInt(2);
for(int i=0; i<k; i++){
t[i] = q[i] = 0;
for(int j=0; j<k; j++){
t[i] += Q[x+i][y+j] * v[j];
q[i] += Y[i][j] * v[j];
}
}
for(int i=0; i<k; i++){
v[i] = 0;
for(int j=0; j<k; j++)
v[i] += X[i][j] * t[j];
}
for(int i=0; i<k; i++)
if( v[i] != q[i] ) return false;
}
return true;
}
public void Do(Scanner sc){
int n, m, k;
n = sc.nextInt();
m = sc.nextInt();
k = sc.nextInt();
int X[][] = new int[k][k];
int Y[][] = new int[k][k];
int Q[][] = new int[n][m];
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
X[i][j] = sc.nextInt();
for(int i=0; i<k; i++)
for(int j=0; j<k; j++)
Y[i][j] = sc.nextInt();
for(int i=0; i<n; i++)
for(int j=0; j<m; j++)
Q[i][j] = sc.nextInt();
int ans = 0;
for(int i=0; i<n-k+1; i++)
for(int j=0; j<m-k+1; j++)
if(freivald( X, Y, Q, i, j, n, m, k ))
++ans;
System.out.println(ans);
}
}
================================================
FILE: programming_assignments/beale_ciphers/solution/solve.py
================================================
import time
import random
def freivald(X, Y, Q, x, y, n, m, k, v, t, q):
count = 0
while True:
v = [random.randint(0, 1) for i in range(k)]
for i in range(k):
t[i] = 0
q[i] = 0
for j in range(k):
t[i] = t[i] + Q[x + i][y + j] * v[j]
q[i] = q[i] + Y[i][j] * v[j]
for i in range(k):
v[i] = 0
for j in range(k):
v[i] = v[i] + X[i][j] * t[j]
for i in range(k):
if v[i] != q[i]:
return False
if count > 10:
break
count = count + 1
return True
def solve():
n, m, k = map(int, input().split())
X = []
Y = []
Q = []
v = [0 for i in range(k)]
t = [0 for i in range(k)]
q = [0 for i in range(k)]
for i in range(k):
X.append(map(int, input().split()))
for i in range(k):
Y.append(map(int, input().split()))
for i in range(n):
Q.append(map(int, input().split()))
ans = 0
for i in range(n - k + 1):
for j in range(m - k + 1):
if freivald(X, Y, Q, i, j, n, m, k, v, t, q):
ans = ans + 1
print(ans)
def test():
T = map(int, input().split())[0]
for i in range(T):
solve()
if __name__ == '__main__':
test()
================================================
FILE: programming_assignments/beale_ciphers/testcase/README.md
================================================
# 테스트 케이스
- Python2, Python3의 경우 small test case까지만 채점
- C++, Java의 경우 small + large test case로 채점
================================================
FILE: programming_assignments/beale_ciphers/testcase/large/test1.in
================================================
1
150 150 100
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
gitextract_mz78veiu/
├── README.md
├── docs/
│ └── arena/
│ ├── brunch.html
│ ├── common.css
│ ├── index.html
│ ├── melon-en.html
│ └── melon.html
├── onboarding/
│ └── README.md
├── paper_review/
│ ├── README.md
│ ├── recsys/
│ │ └── recsys2021/
│ │ ├── "Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface.md
│ │ ├── Accordion- a Trainable Simulator for Long-Term Interactive Systems.md
│ │ ├── Burst-induced Multi-Armed Bandit for Learning Recommendation.md
│ │ ├── Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders.md
│ │ ├── Debiased Explainable Pairwise Ranking from Implicit Feedback.md
│ │ ├── Evaluating Off-Policy Evaluation- Sensitivity and Robustness.md
│ │ ├── Follow the guides- disentangling human and algorithmic curation in online music consumption.md
│ │ ├── I want to break free! Recommending friends from outside the echo chamber.md
│ │ ├── Local Factor Models for Large-Scale Inductive Recommendation.md
│ │ ├── Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All.md
│ │ ├── Mitigating Confounding Bias in Recommendation via Information Bottleneck.md
│ │ ├── Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher.md
│ │ ├── Next-item Recommendations in Short Sessions.md
│ │ ├── ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation.md
│ │ ├── RecSys2021.md
│ │ ├── Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?.md
│ │ ├── Semi-Supervised Visual Representation Learning for Fashion Compatibility.md
│ │ ├── Shared Neural Item Representation for Completely Cold Start Problem.md
│ │ ├── Sparse Feature Factorization for Recommender Systems with Knowledge Graphs.md
│ │ ├── The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender.md
│ │ ├── Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations.md
│ │ ├── Top-K Contextual Bandits with Equity of Exposure.md
│ │ ├── Toward Unified Metrics for Accuracy and Diversity for Recommender Systems.md
│ │ ├── Towards Source-Aligned Variational Models for Cross-Domain Recommendation.md
│ │ ├── Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation.md
│ │ └── Values of Exploration in Recommender Systems.md
│ └── topics/
│ ├── Algorithmic Advances.md
│ ├── Applications-Driven Advances.md
│ ├── Bandits and Reinforcement Learning.md
│ ├── Echo Chambers and Filter Bubbles.md
│ ├── Interactive Recommendation.md
│ ├── Language and Knowledge.md
│ ├── Metrics and Evaluation.md
│ ├── Practical Issues.md
│ ├── Privacy, Fairness, Bias.md
│ ├── Real-World Concerns.md
│ ├── Scalable Performance.md
│ ├── Theory and Practice.md
│ └── Users in Focus.md
├── presentations/
│ └── README.md
├── programming_assignments/
│ ├── beale_ciphers/
│ │ ├── README.md
│ │ ├── interview.md
│ │ ├── solution/
│ │ │ ├── solve.cpp
│ │ │ ├── solve.java
│ │ │ └── solve.py
│ │ └── testcase/
│ │ ├── README.md
│ │ ├── large/
│ │ │ ├── test1.in
│ │ │ ├── test1.out
│ │ │ ├── test3.in
│ │ │ ├── test3.out
│ │ │ ├── test5.in
│ │ │ ├── test5.out
│ │ │ ├── test7.in
│ │ │ ├── test7.out
│ │ │ ├── test9.in
│ │ │ └── test9.out
│ │ └── small/
│ │ ├── sample.in
│ │ ├── sample.out
│ │ ├── test0.in
│ │ ├── test0.out
│ │ ├── test10.in
│ │ ├── test10.out
│ │ ├── test11.in
│ │ ├── test11.out
│ │ ├── test12.in
│ │ ├── test12.out
│ │ ├── test13.in
│ │ ├── test13.out
│ │ ├── test14.in
│ │ ├── test14.out
│ │ ├── test2.in
│ │ ├── test2.out
│ │ ├── test4.in
│ │ ├── test4.out
│ │ ├── test6.in
│ │ ├── test6.out
│ │ ├── test8.in
│ │ └── test8.out
│ ├── jukebox/
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── listen_count.txt
│ │ └── solution/
│ │ ├── 1. 데이터 전처리.ipynb
│ │ ├── 2-1. Shallow AutoEncoder.ipynb
│ │ ├── 2-2. EASE^R.ipynb
│ │ ├── 3. (optional) Implicit을 이용한 Jukebox 풀이.ipynb
│ │ ├── README.md
│ │ └── code_using_ease/
│ │ ├── evaluate.py
│ │ ├── evaluation/
│ │ │ ├── Evaluate.py
│ │ │ ├── user_id.txt
│ │ │ └── validation_data.txt
│ │ ├── recommend_with_ease.py
│ │ └── recommend_with_sgd.py
│ └── mini_reco/
│ ├── README.md
│ ├── evaluation.py
│ ├── interview.md
│ ├── solution/
│ │ └── solution.py
│ └── testcase/
│ ├── input/
│ │ ├── input000.txt
│ │ ├── input001.txt
│ │ ├── input002.txt
│ │ ├── input003.txt
│ │ ├── input004.txt
│ │ ├── input005.txt
│ │ └── input006.txt
│ └── output/
│ ├── output000.txt
│ ├── output001.txt
│ ├── output002.txt
│ ├── output003.txt
│ ├── output004.txt
│ ├── output005.txt
│ └── output006.txt
└── publications/
└── sigir2023-update-period/
└── README.md
SYMBOL INDEX (30 symbols across 8 files)
FILE: programming_assignments/beale_ciphers/solution/solve.cpp
function freivald (line 13) | bool freivald(int X[][K], int Y[][K], int Q[][M], int x, int y, int n, i...
function back (line 39) | bool back(int X[][K], int Y[][K], int Q[][M], int x, int y, int n, int m...
function solve (line 58) | void solve(){
function main (line 82) | int main(){
FILE: programming_assignments/beale_ciphers/solution/solve.java
class Main (line 3) | public class Main{
method main (line 4) | public static void main(String args[]){
class Task (line 10) | class Task{
method solve (line 11) | public void solve(){
method freivald (line 19) | public boolean freivald(int X[][], int Y[][], int Q[][], int x, int y,...
method Do (line 50) | public void Do(Scanner sc){
FILE: programming_assignments/beale_ciphers/solution/solve.py
function freivald (line 5) | def freivald(X, Y, Q, x, y, n, m, k, v, t, q):
function solve (line 29) | def solve():
function test (line 53) | def test():
FILE: programming_assignments/jukebox/solution/code_using_ease/evaluate.py
function load_res (line 6) | def load_res(fname):
function ndcg (line 16) | def ndcg(recs, gt):
FILE: programming_assignments/jukebox/solution/code_using_ease/evaluation/Evaluate.py
class Metric (line 11) | class Metric:
method mrr (line 13) | def mrr(recs, db):
method map (line 37) | def map(recs, db):
method auc (line 60) | def auc(recs, db, num_total_cand):
method ndcg (line 90) | def ndcg(recs, db):
class Evaluation (line 112) | class Evaluation:
method __init__ (line 113) | def __init__(self):
method load_database (line 129) | def load_database(self, fname_target_users, fname_database, has_header...
method load_test_file (line 165) | def load_test_file(self, fpath, has_header=True):
method load_topk_file (line 180) | def load_topk_file(self, fpath):
method eval_topk (line 194) | def eval_topk(self, topk, td, metrics=[]):
FILE: programming_assignments/jukebox/solution/code_using_ease/recommend_with_ease.py
function gen_top_reco (line 7) | def gen_top_reco(X, lamb=10.0, K=100, target_user_inds=None):
FILE: programming_assignments/jukebox/solution/code_using_ease/recommend_with_sgd.py
function loss_fn (line 38) | def loss_fn(X, P):
function loss_fn_with_reg (line 45) | def loss_fn_with_reg(X, P):
FILE: programming_assignments/mini_reco/evaluation.py
function ndcg (line 4) | def ndcg(gt, rec):
Condensed preview — 119 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (5,743K chars).
[
{
"path": "README.md",
"chars": 9473,
"preview": "# 카카오 추천팀\n\n## 소개\n\n카카오 추천팀은 카카오의 다양한 서비스에 추천 기술을 제공하고 있습니다.\n\n추천팀에서는 아래와 같은 업무를 하고 있습니다.\n\n- 추천 기술 고도화 (방향: 사용자의 장기적인 서비스 만"
},
{
"path": "docs/arena/brunch.html",
"chars": 10954,
"preview": "<!DOCTYPE html>\n<html lang=\"ko\">\n <head>\n <meta charset=\"utf-8\" />\n <title>kakao dataset</title>\n <meta name=\""
},
{
"path": "docs/arena/common.css",
"chars": 5533,
"preview": "@charset \"utf-8\";\n/* 웹폰트 */\n@import url('https://fonts.googleapis.com/css?family=Noto+Sans+KR:400,500&subset=korean');\n@"
},
{
"path": "docs/arena/index.html",
"chars": 2452,
"preview": "<!DOCTYPE html>\n <html lang=\"ko\">\n <head>\n <meta charset=\"utf-8\">\n <meta http-equiv=\"X-UA-Compatible\" cont"
},
{
"path": "docs/arena/melon-en.html",
"chars": 8504,
"preview": "<!DOCTYPE html>\n<html lang=\"ko\">\n <head>\n <meta charset=\"utf-8\" />\n <title>kakao dataset</title>\n <meta name=\""
},
{
"path": "docs/arena/melon.html",
"chars": 7782,
"preview": "<!DOCTYPE html>\n<html lang=\"ko\">\n <head>\n <meta charset=\"utf-8\" />\n <title>kakao dataset</title>\n <meta name=\""
},
{
"path": "onboarding/README.md",
"chars": 6376,
"preview": "# 추천팀 온보딩\n\n카카오 추천팀에 입사하기 전에 미리 보시면 좋을 내용들을 정리해놓은 문서입니다.\n\n## 추천 기술 관련 자료\n\n해당 내용에 링크된 자료는 방대하므로(특히 수학/ML 기초) 필요한 부분들 위주로 보"
},
{
"path": "paper_review/README.md",
"chars": 1367,
"preview": "<p align=\"center\">\n <img height=\"150\" src=\"https://user-images.githubusercontent.com/38134957/165143510-067f6b0f-4e0e"
},
{
"path": "paper_review/recsys/recsys2021/\"Serving Each User\"- Supporting Different Eating Goals Through a Multi-List Recommender Interface.md",
"chars": 1871,
"preview": "# \"Serving Each User\"- Supporting Different Eating Goals Through a Multi-List Recommender Interface\n\n- Paper : <https://"
},
{
"path": "paper_review/recsys/recsys2021/Accordion- a Trainable Simulator for Long-Term Interactive Systems.md",
"chars": 2919,
"preview": "# Accordion- a Trainable Simulator for Long-Term Interactive Systems\n\n- Paper : <https://dl.acm.org/doi/10.1145/3460231."
},
{
"path": "paper_review/recsys/recsys2021/Burst-induced Multi-Armed Bandit for Learning Recommendation.md",
"chars": 4128,
"preview": "# Burst-induced Multi-Armed Bandit for Learning Recommendation\n\n- Paper : <https://dl.acm.org/doi/10.1145/3460231.347425"
},
{
"path": "paper_review/recsys/recsys2021/Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders.md",
"chars": 5666,
"preview": "# Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders\n\n- Paper : <https://arxiv.org/abs/2108.010"
},
{
"path": "paper_review/recsys/recsys2021/Debiased Explainable Pairwise Ranking from Implicit Feedback.md",
"chars": 5172,
"preview": "# Debiased Explainable Pairwise Ranking from Implicit Feedback\n\n- Paper : <https://arxiv.org/pdf/2107.14768.pdf>\n- Autho"
},
{
"path": "paper_review/recsys/recsys2021/Evaluating Off-Policy Evaluation- Sensitivity and Robustness.md",
"chars": 1815,
"preview": "# Evaluating Off-Policy Evaluation- Sensitivity and Robustness\n\n- Paper : <https://arxiv.org/abs/2108.13703>\n- Authors :"
},
{
"path": "paper_review/recsys/recsys2021/Follow the guides- disentangling human and algorithmic curation in online music consumption.md",
"chars": 6835,
"preview": "# Follow the guides- disentangling human and algorithmic curation in online music consumption\n\n- Paper : <https://arxiv."
},
{
"path": "paper_review/recsys/recsys2021/I want to break free! Recommending friends from outside the echo chamber.md",
"chars": 2011,
"preview": "# I want to break free! Recommending friends from outside the echo chamber\n\n- Paper : <https://dl.acm.org/doi/10.1145/34"
},
{
"path": "paper_review/recsys/recsys2021/Local Factor Models for Large-Scale Inductive Recommendation.md",
"chars": 2159,
"preview": "# Local Factor Models for Large-Scale Inductive Recommendation\n\n- Paper : <https://ylongqi.com/assets/pdf/yang2021local."
},
{
"path": "paper_review/recsys/recsys2021/Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All.md",
"chars": 4041,
"preview": "# Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After Al"
},
{
"path": "paper_review/recsys/recsys2021/Mitigating Confounding Bias in Recommendation via Information Bottleneck.md",
"chars": 4548,
"preview": "# Mitigating Confounding Bias in Recommendation via Information Bottleneck\n\n- Paper : <https://dl.acm.org/doi/pdf/10.114"
},
{
"path": "paper_review/recsys/recsys2021/Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher.md",
"chars": 2884,
"preview": "# Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher\n\n- Paper : <https://dl.acm.org/"
},
{
"path": "paper_review/recsys/recsys2021/Next-item Recommendations in Short Sessions.md",
"chars": 2054,
"preview": "# Next-item Recommendations in Short Sessions\n\n- Paper : <https://arxiv.org/abs/2107.07453>\n- Authors : Wenzhuo Song, Sh"
},
{
"path": "paper_review/recsys/recsys2021/ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation.md",
"chars": 6011,
"preview": "# ProtoCF- Prototypical Collaborative Filtering for Few-shot Item Recommendation\n\n- Paper : <https://dl.acm.org/doi/10.1"
},
{
"path": "paper_review/recsys/recsys2021/RecSys2021.md",
"chars": 4540,
"preview": "# RecSys2021\n\n- [\"Serving Each User\"- Supporting Different Eating Goals Through a Multi-List Recommender Interface](\"Ser"
},
{
"path": "paper_review/recsys/recsys2021/Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?.md",
"chars": 3138,
"preview": "# Reverse Maximum Inner Product Search- How to efficiently find users who would like to buy my item?\n\n- Paper : <https:/"
},
{
"path": "paper_review/recsys/recsys2021/Semi-Supervised Visual Representation Learning for Fashion Compatibility.md",
"chars": 4033,
"preview": "# Semi-Supervised Visual Representation Learning for Fashion Compatibility\n\n- Paper : <https://arxiv.org/abs/2109.08052>"
},
{
"path": "paper_review/recsys/recsys2021/Shared Neural Item Representation for Completely Cold Start Problem.md",
"chars": 3706,
"preview": "# Shared Neural Item Representation for Completely Cold Start Problem\n\n- Paper : <https://dl.acm.org/doi/10.1145/3460231"
},
{
"path": "paper_review/recsys/recsys2021/Sparse Feature Factorization for Recommender Systems with Knowledge Graphs.md",
"chars": 2311,
"preview": "# Sparse Feature Factorization for Recommender Systems with Knowledge Graphs\n\n- Paper : <https://arxiv.org/abs/2107.1429"
},
{
"path": "paper_review/recsys/recsys2021/The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre exploration recommender.md",
"chars": 3585,
"preview": "# The role of preference consistency, defaults and musical expertise in users’ exploration behavior in a genre explorati"
},
{
"path": "paper_review/recsys/recsys2021/Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations.md",
"chars": 5292,
"preview": "# Together is Better- Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations\n\n- Paper"
},
{
"path": "paper_review/recsys/recsys2021/Top-K Contextual Bandits with Equity of Exposure.md",
"chars": 4769,
"preview": "# Top-K Contextual Bandits with Equity of Exposure\n\n- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474248>\n- Authors"
},
{
"path": "paper_review/recsys/recsys2021/Toward Unified Metrics for Accuracy and Diversity for Recommender Systems.md",
"chars": 4000,
"preview": "# Toward Unified Metrics for Accuracy and Diversity for Recommender Systems\n\n- Paper : <https://dl.acm.org/doi/10.1145/3"
},
{
"path": "paper_review/recsys/recsys2021/Towards Source-Aligned Variational Models for Cross-Domain Recommendation.md",
"chars": 4196,
"preview": "# Towards Source-Aligned Variational Models for Cross-Domain Recommendation\n\n- Paper : <https://dl.acm.org/doi/10.1145/3"
},
{
"path": "paper_review/recsys/recsys2021/Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation.md",
"chars": 2835,
"preview": "# Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendation\n\n- Paper : <https://dl.ac"
},
{
"path": "paper_review/recsys/recsys2021/Values of Exploration in Recommender Systems.md",
"chars": 7509,
"preview": "# Values of Exploration in Recommender Systems\n\n- Paper : <https://dl.acm.org/doi/10.1145/3460231.3474236>\n- Authors : M"
},
{
"path": "paper_review/topics/Algorithmic Advances.md",
"chars": 449,
"preview": "# Algorithmic Advances\n\n- [Next-item Recommendations in Short Sessions](../recsys/recsys2021/Next-item%20Recommendations"
},
{
"path": "paper_review/topics/Applications-Driven Advances.md",
"chars": 267,
"preview": "# Applications-Driven Advances\n\n- [Follow the guides- disentangling human and algorithmic curation in online music consu"
},
{
"path": "paper_review/topics/Bandits and Reinforcement Learning.md",
"chars": 338,
"preview": "# Bandits and Reinforcement Learning\n\n- [Burst-induced Multi-Armed Bandit for Learning Recommendation](../recsys/recsys2"
},
{
"path": "paper_review/topics/Echo Chambers and Filter Bubbles.md",
"chars": 233,
"preview": "# Echo Chambers and Filter Bubbles\n\n- [I want to break free! Recommending friends from outside the echo chamber](../recs"
},
{
"path": "paper_review/topics/Interactive Recommendation.md",
"chars": 359,
"preview": "# Interactive Recommendation\n\n- [The role of preference consistency, defaults and musical expertise in users’ exploratio"
},
{
"path": "paper_review/topics/Language and Knowledge.md",
"chars": 1117,
"preview": "# Language and Knowledge\n\n- [Transformers4Rec- Bridging the Gap between NLP and Sequential & Session-Based Recommendatio"
},
{
"path": "paper_review/topics/Metrics and Evaluation.md",
"chars": 688,
"preview": "# Metrics and Evaluation\n\n- [Toward Unified Metrics for Accuracy and Diversity for Recommender Systems](../recsys/recsys"
},
{
"path": "paper_review/topics/Practical Issues.md",
"chars": 201,
"preview": "# Practical Issues\n\n- [Shared Neural Item Representation for Completely Cold Start Problem](../recsys/recsys2021/Shared%"
},
{
"path": "paper_review/topics/Privacy, Fairness, Bias.md",
"chars": 379,
"preview": "# Privacy, Fairness, Bias\n\n- [Debiased Explainable Pairwise Ranking from Implicit Feedback](../recsys/recsys2021/Debiase"
},
{
"path": "paper_review/topics/Real-World Concerns.md",
"chars": 407,
"preview": "# Real-World Concerns\n\n- [Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders](../recsys/recsys2"
},
{
"path": "paper_review/topics/Scalable Performance.md",
"chars": 448,
"preview": "# Scalable Performance\n\n- [Local Factor Models for Large-Scale Inductive Recommendation](../recsys/recsys2021/Local%20Fa"
},
{
"path": "paper_review/topics/Theory and Practice.md",
"chars": 545,
"preview": "# Theory and Practice\n\n- [Negative Interactions for Improved Collaborative Filtering- Don’t go Deeper, go Higher](../rec"
},
{
"path": "paper_review/topics/Users in Focus.md",
"chars": 265,
"preview": "# Users in Focus\n\n- [\"Serving Each User\"- Supporting Different Eating Goals Through a Multi-List Recommender Interface]("
},
{
"path": "presentations/README.md",
"chars": 11,
"preview": "# 발표 자료 모음\n"
},
{
"path": "programming_assignments/beale_ciphers/README.md",
"chars": 2333,
"preview": "# 빌 암호(Beale Ciphers) 해독\n\n문제 출제 및 검수: 한상덕(leo.han)\n\n> 이 문제로 영입을 진행하며 지원자분에게 드렸던 인터뷰 질문은 [interview.md](interview.md)에 있습"
},
{
"path": "programming_assignments/beale_ciphers/interview.md",
"chars": 1024,
"preview": "# 빌 암호(Beale Ciphers) 해독 인터뷰 질문\n\n> [▶︎ 빌 암호(Beale Ciphers) 해독 문제로 돌아가기](README.md)\n\n빌 암호(Beale Ciphers) 해독 문제로 영입을 진행하며 "
},
{
"path": "programming_assignments/beale_ciphers/solution/solve.cpp",
"chars": 1893,
"preview": "#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n\nconst int K = 102;\nconst int N = 302;\nconst int M = 302;\n\nint "
},
{
"path": "programming_assignments/beale_ciphers/solution/solve.java",
"chars": 1960,
"preview": "import java.util.*;\n\npublic class Main{\n public static void main(String args[]){\n Task solver = new Task();\n "
},
{
"path": "programming_assignments/beale_ciphers/solution/solve.py",
"chars": 1341,
"preview": "import time\nimport random\n\n\ndef freivald(X, Y, Q, x, y, n, m, k, v, t, q):\n count = 0\n while True:\n v = [ra"
},
{
"path": "programming_assignments/beale_ciphers/testcase/README.md",
"chars": 100,
"preview": "# 테스트 케이스\n\n- Python2, Python3의 경우 small test case까지만 채점\n- C++, Java의 경우 small + large test case로 채점\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test1.in",
"chars": 85014,
"preview": "1\n150 150 100\n1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test1.out",
"chars": 5,
"preview": "2601\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test3.in",
"chars": 85014,
"preview": "1\n150 150 100\n1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test3.out",
"chars": 2,
"preview": "1\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test5.in",
"chars": 48613,
"preview": "1\n150 150 30\n1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0"
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test5.out",
"chars": 2,
"preview": "8\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test7.in",
"chars": 93160,
"preview": "1\n100 100 100\n-8 -4 -9 -1 -9 -6 5 -10 -3 -4 -5 2 4 0 0 -4 -9 -4 -4 7 -1 4 1 4 -4 4 -1 -7 -1 -10 6 -7 -3 -1 2 -10 -5 9 2 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test7.out",
"chars": 2,
"preview": "1\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test9.in",
"chars": 93160,
"preview": "1\n100 100 100\n-8 -4 -9 -1 -9 -6 5 -10 -3 -4 -5 2 4 0 0 -4 -9 -4 -4 7 -1 4 1 4 -4 4 -1 -7 -1 -10 6 -7 -3 -1 2 -10 -5 9 2 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/large/test9.out",
"chars": 2,
"preview": "0\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/sample.in",
"chars": 67,
"preview": "2\n1 4 1\n2\n6\n3 4 3 3\n3 4 2\n1 0\n0 1\n1 1\n0 1\n1 1 1 1\n0 1 0 1\n1 3 1 -1\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/sample.out",
"chars": 5,
"preview": "3\n2\n\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test0.in",
"chars": 629,
"preview": "10\n3 3 3\n1 0 0\n0 0 0\n0 0 1\n-100 -100 -100\n-100 -100 -100 \n-100 -100 -100\n-100 -100 -100\n-100 -100 -100\n-100 -100 -100\n4 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test0.out",
"chars": 20,
"preview": "0\n1\n0\n0\n0\n1\n1\n1\n0\n1\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test10.in",
"chars": 14754,
"preview": "1\n40 40 40\n-7 -4 -9 8 -7 -6 2 -10 3 -2 -2 -9 6 -3 -1 -4 7 -6 1 9 -3 2 2 0 -2 -2 -2 5 -10 8 0 -7 -6 1 3 -3 5 7 9 -9\n8 -3 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test10.out",
"chars": 2,
"preview": "0\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test11.in",
"chars": 11411,
"preview": "1\n50 50 40\n1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n0 1 0 0 0 0 0 0 0 0 0 0 0 0 0"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test11.out",
"chars": 4,
"preview": "121\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test12.in",
"chars": 7611,
"preview": "1\n60 60 10\n1 0 0 0 0 0 0 0 0 0\n0 1 0 0 0 0 0 0 0 0\n0 0 1 0 0 0 0 0 0 0\n0 0 0 1 0 0 0 0 0 0\n0 0 0 0 1 0 0 0 0 0\n0 0 0 0 0"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test12.out",
"chars": 3,
"preview": "11\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test13.in",
"chars": 14671,
"preview": "1\n40 40 40\n-6 9 -3 1 -1 2 -3 -8 -7 9 -5 -2 -6 2 5 9 4 7 -10 -2 -4 -6 -4 -8 -6 -1 -5 9 -7 9 8 -2 8 -5 1 9 7 8 3 2\n-1 1 -9"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test13.out",
"chars": 2,
"preview": "1\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test14.in",
"chars": 14759,
"preview": "1\n40 40 40\n8 -1 -3 9 0 -4 -3 8 -5 -5 -1 0 6 9 -9 -4 -10 7 -2 0 -3 5 1 4 3 -7 2 8 9 -2 -9 7 8 -9 -1 -2 -3 -2 8 3\n-4 -3 -7"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test14.out",
"chars": 2,
"preview": "0\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test2.in",
"chars": 13611,
"preview": "1\n60 60 40\n1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n0 1 0 0 0 0 0 0 0 0 0 0 0 0 0"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test2.out",
"chars": 4,
"preview": "441\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test4.in",
"chars": 13611,
"preview": "1\n60 60 40\n1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n0 1 0 0 0 0 0 0 0 0 0 0 0 0 0"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test4.out",
"chars": 2,
"preview": "1\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test6.in",
"chars": 7611,
"preview": "1\n60 60 10\n1 0 0 0 0 0 0 0 0 0\n0 1 0 0 0 0 0 0 0 0\n0 0 1 0 0 0 0 0 0 0\n0 0 0 1 0 0 0 0 0 0\n0 0 0 0 1 0 0 0 0 0\n0 0 0 0 0"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test6.out",
"chars": 3,
"preview": "10\n"
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test8.in",
"chars": 14754,
"preview": "1\n40 40 40\n-7 -4 -9 8 -7 -6 2 -10 3 -2 -2 -9 6 -3 -1 -4 7 -6 1 9 -3 2 2 0 -2 -2 -2 5 -10 8 0 -7 -6 1 3 -3 5 7 9 -9\n8 -3 "
},
{
"path": "programming_assignments/beale_ciphers/testcase/small/test8.out",
"chars": 2,
"preview": "1\n"
},
{
"path": "programming_assignments/jukebox/.gitignore",
"chars": 1724,
"preview": "*.bundle.*\nlib/\nnode_modules/\n*.egg-info/\n.ipynb_checkpoints\n*.tsbuildinfo\njupyterlab_git/labextension\n\nsrc/version.ts\n\n"
},
{
"path": "programming_assignments/jukebox/README.md",
"chars": 2898,
"preview": "# Jukebox\n\n- 문제 출제 및 검수: lucas.ii\n- 해설 작성자: iggy.ll\n\n> 이 문서에는 Jukebox 문제의 요약과 간단한 설명이 덧붙여져 있습니다. **문제 원문은 [jukebox.pdf]("
},
{
"path": "programming_assignments/jukebox/listen_count.txt",
"chars": 4110398,
"preview": "18091 6716 3\n15722 1251 1\n2716 4394 1\n3759 7857 4\n11755 5000 1\n15712 1776 1\n10826 3374 1\n5074 4635 1\n4068 1755 1\n16290 2"
},
{
"path": "programming_assignments/jukebox/solution/1. 데이터 전처리.ipynb",
"chars": 6236,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c9a6149a\",\n \"metadata\": {},\n \"source\": [\n \"# 데이터 전처리\"\n "
},
{
"path": "programming_assignments/jukebox/solution/2-1. Shallow AutoEncoder.ipynb",
"chars": 14378,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"020c94ee\",\n \"metadata\": {},\n \"source\": [\n \"# Shallow Auto"
},
{
"path": "programming_assignments/jukebox/solution/2-2. EASE^R.ipynb",
"chars": 6086,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"3c0dbaaf\",\n \"metadata\": {},\n \"outputs\""
},
{
"path": "programming_assignments/jukebox/solution/3. (optional) Implicit을 이용한 Jukebox 풀이.ipynb",
"chars": 5863,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4c1dbc84\",\n \"metadata\": {},\n \"source\": [\n \"# Matrix Facto"
},
{
"path": "programming_assignments/jukebox/solution/README.md",
"chars": 2899,
"preview": "# Shallow AutoEncoder를 이용한 Jukebox 풀이\n\n## 데이터 전처리\n\n[`1. 데이터 전처리.ipynb`](1.%20데이터%20전처리.ipynb)를 참조하세요.\n\n## 오토인코더를 이용한 추천 "
},
{
"path": "programming_assignments/jukebox/solution/code_using_ease/evaluate.py",
"chars": 863,
"preview": "#!/Users/ita/opt/anaconda3/bin/python\nimport math\nimport sys\n\n\ndef load_res(fname):\n ret = {}\n with open(fname, 'r"
},
{
"path": "programming_assignments/jukebox/solution/code_using_ease/evaluation/Evaluate.py",
"chars": 7235,
"preview": "#-*- coding: utf8 -*-\nimport re\nimport sys\nimport math\nimport logging\n\n\nNUM_ITEMS = 1078898\n\n\nclass Metric:\n @staticm"
},
{
"path": "programming_assignments/jukebox/solution/code_using_ease/evaluation/user_id.txt",
"chars": 2700,
"preview": "10111\n10139\n1014\n10151\n10153\n102\n1029\n103\n10300\n10349\n10393\n10396\n10450\n10458\n10459\n1047\n10715\n10811\n10828\n1087\n10896\n10"
},
{
"path": "programming_assignments/jukebox/solution/code_using_ease/evaluation/validation_data.txt",
"chars": 34875,
"preview": "1303 103 11\n5618 1249 9\n4193 2352 1\n18215 6150 1\n8848 1734 1\n11929 505 1\n6342 6546 1\n8375 4245 1\n1765 5820 1\n19127 1740 "
},
{
"path": "programming_assignments/jukebox/solution/code_using_ease/recommend_with_ease.py",
"chars": 1745,
"preview": "import pandas as pd\nfrom scipy.sparse import csr_matrix\nimport numpy as np\nimport sys\n\n\ndef gen_top_reco(X, lamb=10.0, K"
},
{
"path": "programming_assignments/jukebox/solution/code_using_ease/recommend_with_sgd.py",
"chars": 2006,
"preview": "import pandas as pd\nfrom scipy.sparse import csr_matrix\nimport numpy as np\nfrom jax import grad, jit\nimport jax.numpy as"
},
{
"path": "programming_assignments/mini_reco/README.md",
"chars": 8532,
"preview": "# Mini Reco <!-- omit in toc -->\n\n문제 출제 및 검수: [김성진(nick.kim)](https://github.com/lancifollia), [양세현(dan.ce)](https://git"
},
{
"path": "programming_assignments/mini_reco/evaluation.py",
"chars": 385,
"preview": "import math\n\n\ndef ndcg(gt, rec):\n idcg = sum([1.0 / math.log(i + 2, 2) for i in range(len(gt))])\n dcg = 0.0\n fo"
},
{
"path": "programming_assignments/mini_reco/interview.md",
"chars": 2049,
"preview": "# Mini Reco 인터뷰 질문\n\n> [▶︎ Mini Reco 문제로 돌아가기](README.md)\n\nMini Reco 문제로 영입을 진행하며 지원자분에게 드렸던 인터뷰 질문과 예시 답변을 모아놓았습니다.\n\n## "
},
{
"path": "programming_assignments/mini_reco/solution/solution.py",
"chars": 3014,
"preview": "import sys\n\n# 데이터 입력\nnum_sim_user_top_N = int(sys.stdin.readline()) # 유사도 top N 사용자에 대하여 예측 평점 계산\nnum_item_rec_top_M = "
},
{
"path": "programming_assignments/mini_reco/testcase/input/input000.txt",
"chars": 138,
"preview": "2\n2\n5\n10\n15\n1 1 1.0\n1 2 2.0\n1 5 1.2\n2 2 1.5\n2 3 3.0\n3 1 2.2\n3 2 6.2\n3 7 1.5\n4 6 1.2\n4 3 1.5\n4 1 3.1\n4 2 4.0\n5 4 8.2\n5 2 "
},
{
"path": "programming_assignments/mini_reco/testcase/input/input001.txt",
"chars": 42459,
"preview": "32\n7\n200\n50\n3454\n1 1 4.989\n1 2 1.000\n1 3 4.989\n1 4 1.000\n1 5 1.000\n1 6 6.338\n1 7 1.000\n1 8 2.543\n1 9 1.000\n1 10 1.000\n1 "
},
{
"path": "programming_assignments/mini_reco/testcase/input/input002.txt",
"chars": 42460,
"preview": "21\n15\n200\n50\n3454\n1 1 4.989\n1 2 1.000\n1 3 4.989\n1 4 1.000\n1 5 1.000\n1 6 6.338\n1 7 1.000\n1 8 2.543\n1 9 1.000\n1 10 1.000\n1"
},
{
"path": "programming_assignments/mini_reco/testcase/input/input003.txt",
"chars": 42460,
"preview": "50\n10\n200\n50\n3454\n1 1 4.989\n1 2 1.000\n1 3 4.989\n1 4 1.000\n1 5 1.000\n1 6 6.338\n1 7 1.000\n1 8 2.543\n1 9 1.000\n1 10 1.000\n1"
},
{
"path": "programming_assignments/mini_reco/testcase/input/input004.txt",
"chars": 80511,
"preview": "35\n10\n300\n70\n6440\n1 1 5.655\n1 2 5.122\n1 3 2.468\n1 4 3.937\n1 5 1.000\n1 6 6.873\n1 7 5.122\n1 8 5.405\n1 9 2.468\n1 10 2.468\n1"
},
{
"path": "programming_assignments/mini_reco/testcase/input/input005.txt",
"chars": 80550,
"preview": "40\n15\n300\n70\n6440\n1 1 5.655\n1 2 5.122\n1 3 2.468\n1 4 3.937\n1 5 1.000\n1 6 6.873\n1 7 5.122\n1 8 5.405\n1 9 2.468\n1 10 2.468\n1"
},
{
"path": "programming_assignments/mini_reco/testcase/input/input006.txt",
"chars": 80550,
"preview": "45\n12\n300\n70\n6440\n1 1 5.655\n1 2 5.122\n1 3 2.468\n1 4 3.937\n1 5 1.000\n1 6 6.873\n1 7 5.122\n1 8 5.405\n1 9 2.468\n1 10 2.468\n1"
},
{
"path": "programming_assignments/mini_reco/testcase/output/output000.txt",
"chars": 8,
"preview": "3 6\n1 6\n"
},
{
"path": "programming_assignments/mini_reco/testcase/output/output001.txt",
"chars": 609,
"preview": "50 49 35 6 48 25 21\n30 15 42 26 41 28 3\n30 42 28 20 3 26 31\n15 30 35 41 19 28 31\n35 40 25 21 29 28 41\n15 30 25 14 41 45 "
},
{
"path": "programming_assignments/mini_reco/testcase/output/output002.txt",
"chars": 1261,
"preview": "25 26 15 8 28 3 38 9 14 24 39 48 16 12 31\n32 26 35 8 1 15 3 38 9 34 24 33 29 16 48\n30 23 19 41 33 26 35 28 11 6 16 42 50"
},
{
"path": "programming_assignments/mini_reco/testcase/output/output003.txt",
"chars": 865,
"preview": "42 30 28 25 15 26 48 14 50 36\n20 35 25 50 14 6 3 29 44 1\n25 45 44 1 46 30 3 41 24 36\n20 35 14 28 3 41 6 40 38 49\n11 3 50"
},
{
"path": "programming_assignments/mini_reco/testcase/output/output004.txt",
"chars": 895,
"preview": "40 24 47 45 66 32 41 69 27 42\n40 46 42 30 49 47 61 63 64 43\n24 70 64 56 63 65 60 66 47 61\n24 48 12 42 50 63 30 64 67 52\n"
},
{
"path": "programming_assignments/mini_reco/testcase/output/output005.txt",
"chars": 1344,
"preview": "55 66 17 40 52 12 48 46 36 70 60 57 53 42 30\n27 40 12 60 42 17 63 70 30 43 24 61 56 69 64\n40 50 57 69 48 30 37 47 64 63 "
},
{
"path": "programming_assignments/mini_reco/testcase/output/output006.txt",
"chars": 1075,
"preview": "48 57 37 66 24 30 42 26 41 13 63 64\n37 66 48 69 24 41 50 30 33 42 5 14\n46 43 39 60 53 69 6 66 26 49 51 13\n70 55 68 56 12"
},
{
"path": "publications/sigir2023-update-period/README.md",
"chars": 5316,
"preview": "## Summary\n\nWe publish these real industry data sets across various domains from one of the largest web services compani"
}
]
About this extraction
This page contains the full source code of the kakao/recoteam GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 119 files (5.0 MB), approximately 1.3M tokens, and a symbol index with 30 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.