Showing preview only (8,838K chars total). Download the full file or copy to clipboard to get everything.
Repository: ludwig-ai/ludwig
Branch: main
Commit: e083d20cd4f0
Files: 893
Total size: 20.6 MB
Directory structure:
gitextract_l1ifb68j/
├── .actrc
├── .deepsource.toml
├── .devcontainer/
│ ├── Dockerfile
│ └── devcontainer.json
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.md
│ │ └── feature_request.md
│ ├── pull_request_template.md
│ └── workflows/
│ ├── docker.yml
│ ├── pytest.yml
│ ├── pytest_slow.yml
│ ├── schema.yml
│ ├── test-results.yml
│ └── upload-pypi.yml
├── .gitignore
├── .nojekyll
├── .pre-commit-config.yaml
├── .protolint.yaml
├── .vscode/
│ └── settings.json
├── CODEOWNERS
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── NOTICE
├── README.md
├── README_KR.md
├── RELEASES.md
├── docker/
│ ├── README.md
│ ├── ludwig/
│ │ └── Dockerfile
│ ├── ludwig-gpu/
│ │ └── Dockerfile
│ ├── ludwig-ray/
│ │ └── Dockerfile
│ └── ludwig-ray-gpu/
│ └── Dockerfile
├── examples/
│ ├── README.md
│ ├── calibration/
│ │ ├── README.md
│ │ ├── train_forest_cover_calibrated.py
│ │ └── train_mushroom_edibility_calibrated.py
│ ├── class_imbalance/
│ │ ├── README.md
│ │ ├── balanced_model_config.yaml
│ │ ├── model_training.py
│ │ ├── model_training_results.ipynb
│ │ └── standard_model_config.yaml
│ ├── forecasting/
│ │ ├── README.md
│ │ └── config.yaml
│ ├── getting_started/
│ │ ├── rotten_tomatoes.yaml
│ │ └── run.sh
│ ├── hyperopt/
│ │ ├── README.md
│ │ └── model_hyperopt_example.ipynb
│ ├── insurance_lite/
│ │ ├── config.yaml
│ │ └── train.py
│ ├── kfold_cv/
│ │ ├── README.md
│ │ ├── display_kfold_cv_results.py
│ │ ├── k-fold_cv_classification.sh
│ │ ├── prepare_classification_data_set.py
│ │ └── regression_example.ipynb
│ ├── lbfgs/
│ │ ├── config.yaml
│ │ └── model.py
│ ├── llama2_7b_finetuning_4bit/
│ │ ├── README.md
│ │ ├── llama2_7b_4bit.yaml
│ │ ├── run_train.sh
│ │ └── train_alpaca.py
│ ├── llm_base_model_dequantization/
│ │ ├── README.md
│ │ └── phi_2_dequantization.py
│ ├── llm_few_shot_learning/
│ │ └── simple_model_training.py
│ ├── llm_finetuning/
│ │ ├── README.md
│ │ ├── imdb_deepspeed_zero3.yaml
│ │ ├── imdb_deepspeed_zero3_ray.yaml
│ │ ├── run_train_dsz3.sh
│ │ ├── run_train_dsz3_ray.sh
│ │ └── train_imdb_ray.py
│ ├── llm_instruction_tuning/
│ │ └── train_alpaca_ray.py
│ ├── llm_text_generation/
│ │ └── simple_model_training.py
│ ├── llm_zero_shot_learning/
│ │ └── simple_model_training.py
│ ├── mnist/
│ │ ├── README.md
│ │ ├── advanced_model_training.py
│ │ ├── assess_model_performance.py
│ │ ├── config.yaml
│ │ ├── simple_model_training.py
│ │ └── visualize_model_test_results.ipynb
│ ├── ray/
│ │ └── kubernetes/
│ │ ├── README.md
│ │ ├── clusters/
│ │ │ ├── ludwig-ray-cpu-cluster.yaml
│ │ │ └── ludwig-ray-gpu-cluster.yaml
│ │ └── utils/
│ │ ├── attach.sh
│ │ ├── dashboard.sh
│ │ ├── krsync.sh
│ │ ├── ray_down.sh
│ │ ├── ray_up.sh
│ │ ├── rsync_up.sh
│ │ ├── submit.sh
│ │ └── upload.sh
│ ├── regex_freezing/
│ │ ├── ecd_freezing_with_regex_training.py
│ │ └── llm_freezing_with_regex_training.py
│ ├── semantic_segmentation/
│ │ ├── camseq.py
│ │ └── config_camseq.yaml
│ ├── serve/
│ │ ├── README.md
│ │ └── client_program.py
│ ├── synthetic/
│ │ └── train.py
│ ├── tabnet/
│ │ └── higgs/
│ │ ├── medium_config.yaml
│ │ ├── small_config.yaml
│ │ ├── train_higgs_medium.py
│ │ └── train_higgs_small.py
│ ├── titanic/
│ │ ├── README.md
│ │ ├── model1_config.yaml
│ │ ├── model2_config.yaml
│ │ ├── model_training_results.ipynb
│ │ ├── multiple_model_training.py
│ │ └── simple_model_training.py
│ ├── twitter_bots/
│ │ ├── README.md
│ │ ├── train_twitter_bots.py
│ │ └── train_twitter_bots_text_only.py
│ ├── wine_quality/
│ │ ├── README.md
│ │ └── model_defaults_example.ipynb
│ └── wmt15/
│ ├── config_large.yaml
│ ├── config_small.yaml
│ └── train_nmt.py
├── ludwig/
│ ├── __init__.py
│ ├── accounting/
│ │ ├── __init__.py
│ │ └── used_tokens.py
│ ├── api.py
│ ├── api_annotations.py
│ ├── automl/
│ │ ├── __init__.py
│ │ ├── auto_tune_config.py
│ │ ├── automl.py
│ │ ├── base_config.py
│ │ └── defaults/
│ │ ├── base_automl_config.yaml
│ │ ├── combiner/
│ │ │ ├── concat_config.yaml
│ │ │ ├── tabnet_config.yaml
│ │ │ └── transformer_config.yaml
│ │ ├── reference_configs.yaml
│ │ └── text/
│ │ └── bert_config.yaml
│ ├── backend/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── datasource.py
│ │ ├── deepspeed.py
│ │ ├── ray.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ └── storage.py
│ ├── benchmarking/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── artifacts.py
│ │ ├── benchmark.py
│ │ ├── examples/
│ │ │ ├── benchmarking_config.yaml
│ │ │ └── process_config.py
│ │ ├── profiler.py
│ │ ├── profiler_callbacks.py
│ │ ├── profiler_dataclasses.py
│ │ ├── reporting.py
│ │ ├── summarize.py
│ │ ├── summary_dataclasses.py
│ │ └── utils.py
│ ├── callbacks.py
│ ├── check.py
│ ├── cli.py
│ ├── collect.py
│ ├── combiners/
│ │ ├── __init__.py
│ │ └── combiners.py
│ ├── config_sampling/
│ │ ├── __init__.py
│ │ ├── explore_schema.py
│ │ └── parameter_sampling.py
│ ├── config_validation/
│ │ ├── __init__.py
│ │ ├── checks.py
│ │ ├── preprocessing.py
│ │ └── validation.py
│ ├── constants.py
│ ├── contrib.py
│ ├── contribs/
│ │ ├── __init__.py
│ │ ├── aim.py
│ │ ├── comet.py
│ │ ├── mlflow/
│ │ │ ├── __init__.py
│ │ │ └── model.py
│ │ └── wandb.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── batcher/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── bucketed.py
│ │ │ ├── iterable.py
│ │ │ ├── random_access.py
│ │ │ └── test_batcher.py
│ │ ├── cache/
│ │ │ ├── __init__.py
│ │ │ ├── manager.py
│ │ │ ├── types.py
│ │ │ └── util.py
│ │ ├── concatenate_datasets.py
│ │ ├── dataframe/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── dask.py
│ │ │ ├── modin.py
│ │ │ └── pandas.py
│ │ ├── dataset/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── pandas.py
│ │ │ └── ray.py
│ │ ├── dataset_synthesizer.py
│ │ ├── negative_sampling.py
│ │ ├── postprocessing.py
│ │ ├── preprocessing.py
│ │ ├── prompt.py
│ │ ├── sampler.py
│ │ ├── split.py
│ │ ├── split_dataset.py
│ │ └── utils.py
│ ├── datasets/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── archives.py
│ │ ├── configs/
│ │ │ ├── __init__.py
│ │ │ ├── adult_census_income.yaml
│ │ │ ├── ae_price_prediction.yaml
│ │ │ ├── agnews.yaml
│ │ │ ├── allstate_claims_severity.yaml
│ │ │ ├── alpaca.yaml
│ │ │ ├── amazon_employee_access_challenge.yaml
│ │ │ ├── amazon_review_polarity.yaml
│ │ │ ├── amazon_reviews.yaml
│ │ │ ├── ames_housing.yaml
│ │ │ ├── bbcnews.yaml
│ │ │ ├── bnp_claims_management.yaml
│ │ │ ├── bookprice_prediction.yaml
│ │ │ ├── california_house_price.yaml
│ │ │ ├── camseq.yaml
│ │ │ ├── code_alpaca.yaml
│ │ │ ├── connect4.yaml
│ │ │ ├── consumer_complaints.yaml
│ │ │ ├── consumer_complaints_generation.yaml
│ │ │ ├── creditcard_fraud.yaml
│ │ │ ├── customer_churn_prediction.yaml
│ │ │ ├── data_scientist_salary.yaml
│ │ │ ├── dbpedia.yaml
│ │ │ ├── electricity.yaml
│ │ │ ├── ethos_binary.yaml
│ │ │ ├── fake_job_postings2.yaml
│ │ │ ├── fever.yaml
│ │ │ ├── flickr8k.yaml
│ │ │ ├── forest_cover.yaml
│ │ │ ├── goemotions.yaml
│ │ │ ├── goodbooks_books.yaml
│ │ │ ├── google_qa_answer_type_reason_explanation.yaml
│ │ │ ├── google_qa_question_type_reason_explanation.yaml
│ │ │ ├── google_quest_qa.yaml
│ │ │ ├── higgs.yaml
│ │ │ ├── hugging_face.yaml
│ │ │ ├── ieee_fraud.yaml
│ │ │ ├── imbalanced_insurance.yaml
│ │ │ ├── imdb.yaml
│ │ │ ├── imdb_genre_prediction.yaml
│ │ │ ├── insurance_lite.yaml
│ │ │ ├── iris.yaml
│ │ │ ├── irony.yaml
│ │ │ ├── jc_penney_products.yaml
│ │ │ ├── jigsaw_unintended_bias.yaml
│ │ │ ├── jigsaw_unintended_bias100k.yaml
│ │ │ ├── kdd_appetency.yaml
│ │ │ ├── kdd_churn.yaml
│ │ │ ├── kdd_upselling.yaml
│ │ │ ├── kick_starter_funding.yaml
│ │ │ ├── melbourne_airbnb.yaml
│ │ │ ├── mercari_price_suggestion.yaml
│ │ │ ├── mercari_price_suggestion100K.yaml
│ │ │ ├── mercedes_benz_greener.yaml
│ │ │ ├── mnist.yaml
│ │ │ ├── mushroom_edibility.yaml
│ │ │ ├── naval.yaml
│ │ │ ├── news_channel.yaml
│ │ │ ├── news_popularity2.yaml
│ │ │ ├── noshow_appointments.yaml
│ │ │ ├── numerai28pt6.yaml
│ │ │ ├── ohsumed_7400.yaml
│ │ │ ├── ohsumed_cmu.yaml
│ │ │ ├── otto_group_product.yaml
│ │ │ ├── poker_hand.yaml
│ │ │ ├── porto_seguro_safe_driver.yaml
│ │ │ ├── product_sentiment_machine_hack.yaml
│ │ │ ├── protein.yaml
│ │ │ ├── reuters_cmu.yaml
│ │ │ ├── reuters_r8.yaml
│ │ │ ├── rossman_store_sales.yaml
│ │ │ ├── santander_customer_satisfaction.yaml
│ │ │ ├── santander_customer_transaction.yaml
│ │ │ ├── santander_value_prediction.yaml
│ │ │ ├── sarcastic_headlines.yaml
│ │ │ ├── sarcos.yaml
│ │ │ ├── sst2.yaml
│ │ │ ├── sst3.yaml
│ │ │ ├── sst5.yaml
│ │ │ ├── synthetic_fraud.yaml
│ │ │ ├── talkingdata_adtrack_fraud.yaml
│ │ │ ├── telco_customer_churn.yaml
│ │ │ ├── temperature.yaml
│ │ │ ├── titanic.yaml
│ │ │ ├── twitter_bots.yaml
│ │ │ ├── walmart_recruiting.yaml
│ │ │ ├── wine_reviews.yaml
│ │ │ ├── wmt15.yaml
│ │ │ ├── women_clothing_review.yaml
│ │ │ ├── yahoo_answers.yaml
│ │ │ ├── yelp_review_polarity.yaml
│ │ │ ├── yelp_reviews.yaml
│ │ │ └── yosemite.yaml
│ │ ├── dataset_config.py
│ │ ├── kaggle.py
│ │ ├── loaders/
│ │ │ ├── __init__.py
│ │ │ ├── adult_census_income.py
│ │ │ ├── agnews.py
│ │ │ ├── allstate_claims_severity.py
│ │ │ ├── camseq.py
│ │ │ ├── code_alpaca_loader.py
│ │ │ ├── consumer_complaints_loader.py
│ │ │ ├── creditcard_fraud.py
│ │ │ ├── dataset_loader.py
│ │ │ ├── ethos_binary.py
│ │ │ ├── flickr8k.py
│ │ │ ├── forest_cover.py
│ │ │ ├── goemotions.py
│ │ │ ├── higgs.py
│ │ │ ├── hugging_face.py
│ │ │ ├── ieee_fraud.py
│ │ │ ├── insurance_lite.py
│ │ │ ├── kdd_loader.py
│ │ │ ├── mnist.py
│ │ │ ├── naval.py
│ │ │ ├── rossman_store_sales.py
│ │ │ ├── santander_value_prediction.py
│ │ │ ├── sarcastic_headlines.py
│ │ │ ├── sarcos.py
│ │ │ ├── split_loaders.py
│ │ │ └── sst.py
│ │ ├── model_configs/
│ │ │ ├── __init__.py
│ │ │ ├── adult_census_income_default.yaml
│ │ │ ├── allstate_claims_severity_default.yaml
│ │ │ ├── ames_housing_default.yaml
│ │ │ ├── bnp_claims_management_default.yaml
│ │ │ ├── forest_cover_default.yaml
│ │ │ ├── higgs_best.yaml
│ │ │ ├── higgs_default.yaml
│ │ │ ├── ieee_fraud_default.yaml
│ │ │ ├── mercedes_benz_greener_default.yaml
│ │ │ ├── mnist_default.yaml
│ │ │ ├── mushroom_edibility_default.yaml
│ │ │ ├── otto_group_product_default.yaml
│ │ │ ├── poker_hand_default.yaml
│ │ │ ├── porto_seguro_safe_driver_default.yaml
│ │ │ ├── synthetic_fraud_default.yaml
│ │ │ └── titanic_default.yaml
│ │ └── utils.py
│ ├── decoders/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── generic_decoders.py
│ │ ├── image_decoders.py
│ │ ├── llm_decoders.py
│ │ ├── registry.py
│ │ ├── sequence_decoder_utils.py
│ │ ├── sequence_decoders.py
│ │ ├── sequence_tagger.py
│ │ └── utils.py
│ ├── distributed/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── ddp.py
│ │ ├── deepspeed.py
│ │ └── fsdp.py
│ ├── encoders/
│ │ ├── __init__.py
│ │ ├── bag_encoders.py
│ │ ├── base.py
│ │ ├── category_encoders.py
│ │ ├── date_encoders.py
│ │ ├── generic_encoders.py
│ │ ├── h3_encoders.py
│ │ ├── image/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── timm.py
│ │ │ └── torchvision.py
│ │ ├── registry.py
│ │ ├── sequence_encoders.py
│ │ ├── set_encoders.py
│ │ ├── text_encoders.py
│ │ └── types.py
│ ├── error.py
│ ├── evaluate.py
│ ├── experiment.py
│ ├── explain/
│ │ ├── __init__.py
│ │ ├── captum.py
│ │ ├── captum_ray.py
│ │ ├── explainer.py
│ │ ├── explanation.py
│ │ └── util.py
│ ├── export.py
│ ├── features/
│ │ ├── __init__.py
│ │ ├── audio_feature.py
│ │ ├── bag_feature.py
│ │ ├── base_feature.py
│ │ ├── binary_feature.py
│ │ ├── category_feature.py
│ │ ├── date_feature.py
│ │ ├── feature_registries.py
│ │ ├── feature_utils.py
│ │ ├── h3_feature.py
│ │ ├── image_feature.py
│ │ ├── number_feature.py
│ │ ├── sequence_feature.py
│ │ ├── set_feature.py
│ │ ├── text_feature.py
│ │ ├── timeseries_feature.py
│ │ └── vector_feature.py
│ ├── forecast.py
│ ├── globals.py
│ ├── hyperopt/
│ │ ├── __init__.py
│ │ ├── execution.py
│ │ ├── results.py
│ │ ├── run.py
│ │ ├── search_algos.py
│ │ └── utils.py
│ ├── hyperopt_cli.py
│ ├── model_export/
│ │ ├── base_model_exporter.py
│ │ └── onnx_exporter.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── calibrator.py
│ │ ├── ecd.py
│ │ ├── embedder.py
│ │ ├── inference.py
│ │ ├── llm.py
│ │ ├── predictor.py
│ │ ├── registry.py
│ │ └── retrieval.py
│ ├── modules/
│ │ ├── __init__.py
│ │ ├── attention_modules.py
│ │ ├── convolutional_modules.py
│ │ ├── embedding_modules.py
│ │ ├── fully_connected_modules.py
│ │ ├── initializer_modules.py
│ │ ├── loss_implementations/
│ │ │ ├── __init__.py
│ │ │ └── corn.py
│ │ ├── loss_modules.py
│ │ ├── lr_scheduler.py
│ │ ├── metric_modules.py
│ │ ├── metric_registry.py
│ │ ├── mlp_mixer_modules.py
│ │ ├── normalization_modules.py
│ │ ├── optimization_modules.py
│ │ ├── recurrent_modules.py
│ │ ├── reduction_modules.py
│ │ ├── tabnet_modules.py
│ │ └── training_hooks.py
│ ├── predict.py
│ ├── preprocess.py
│ ├── progress_bar.py
│ ├── schema/
│ │ ├── __init__.py
│ │ ├── combiners/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── common_transformer_options.py
│ │ │ ├── comparator.py
│ │ │ ├── concat.py
│ │ │ ├── project_aggregate.py
│ │ │ ├── sequence.py
│ │ │ ├── sequence_concat.py
│ │ │ ├── tab_transformer.py
│ │ │ ├── tabnet.py
│ │ │ ├── transformer.py
│ │ │ └── utils.py
│ │ ├── common_fields.py
│ │ ├── decoders/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── image_decoders.py
│ │ │ ├── llm_decoders.py
│ │ │ ├── sequence_decoders.py
│ │ │ └── utils.py
│ │ ├── defaults/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── ecd.py
│ │ │ ├── llm.py
│ │ │ └── utils.py
│ │ ├── encoders/
│ │ │ ├── __init__.py
│ │ │ ├── bag_encoders.py
│ │ │ ├── base.py
│ │ │ ├── category_encoders.py
│ │ │ ├── date_encoders.py
│ │ │ ├── h3_encoders.py
│ │ │ ├── image/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── timm.py
│ │ │ │ └── torchvision.py
│ │ │ ├── sequence_encoders.py
│ │ │ ├── set_encoders.py
│ │ │ ├── text/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── encoders.py
│ │ │ │ └── hf_model_params.py
│ │ │ ├── text_encoders.py
│ │ │ └── utils.py
│ │ ├── export_schema.py
│ │ ├── features/
│ │ │ ├── __init__.py
│ │ │ ├── audio_feature.py
│ │ │ ├── augmentation/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── image.py
│ │ │ │ └── utils.py
│ │ │ ├── bag_feature.py
│ │ │ ├── base.py
│ │ │ ├── binary_feature.py
│ │ │ ├── category_feature.py
│ │ │ ├── date_feature.py
│ │ │ ├── h3_feature.py
│ │ │ ├── image_feature.py
│ │ │ ├── loss/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── loss.py
│ │ │ │ └── utils.py
│ │ │ ├── number_feature.py
│ │ │ ├── preprocessing/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── audio.py
│ │ │ │ ├── bag.py
│ │ │ │ ├── base.py
│ │ │ │ ├── binary.py
│ │ │ │ ├── category.py
│ │ │ │ ├── date.py
│ │ │ │ ├── h3.py
│ │ │ │ ├── image.py
│ │ │ │ ├── number.py
│ │ │ │ ├── sequence.py
│ │ │ │ ├── set.py
│ │ │ │ ├── text.py
│ │ │ │ ├── timeseries.py
│ │ │ │ ├── utils.py
│ │ │ │ └── vector.py
│ │ │ ├── sequence_feature.py
│ │ │ ├── set_feature.py
│ │ │ ├── text_feature.py
│ │ │ ├── timeseries_feature.py
│ │ │ ├── utils.py
│ │ │ └── vector_feature.py
│ │ ├── hyperopt/
│ │ │ ├── __init__.py
│ │ │ ├── executor.py
│ │ │ ├── parameter.py
│ │ │ ├── scheduler.py
│ │ │ ├── search_algorithm.py
│ │ │ └── utils.py
│ │ ├── jsonschema.py
│ │ ├── llms/
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── generation.py
│ │ │ ├── model_parameters.py
│ │ │ ├── peft.py
│ │ │ ├── prompt.py
│ │ │ └── quantization.py
│ │ ├── lr_scheduler.py
│ │ ├── metadata/
│ │ │ ├── __init__.py
│ │ │ ├── configs/
│ │ │ │ ├── combiners.yaml
│ │ │ │ ├── common.yaml
│ │ │ │ ├── decoders.yaml
│ │ │ │ ├── encoders.yaml
│ │ │ │ ├── features.yaml
│ │ │ │ ├── llm.yaml
│ │ │ │ ├── loss.yaml
│ │ │ │ ├── optimizers.yaml
│ │ │ │ ├── preprocessing.yaml
│ │ │ │ └── trainer.yaml
│ │ │ ├── feature_metadata.py
│ │ │ └── parameter_metadata.py
│ │ ├── model_config.py
│ │ ├── model_types/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── ecd.py
│ │ │ ├── llm.py
│ │ │ └── utils.py
│ │ ├── optimizers.py
│ │ ├── preprocessing.py
│ │ ├── profiler.py
│ │ ├── split.py
│ │ ├── trainer.py
│ │ └── utils.py
│ ├── serve.py
│ ├── train.py
│ ├── trainers/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── registry.py
│ │ ├── trainer.py
│ │ └── trainer_llm.py
│ ├── types.py
│ ├── upload.py
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── algorithms_utils.py
│ │ ├── audio_utils.py
│ │ ├── augmentation_utils.py
│ │ ├── automl/
│ │ │ ├── __init__.py
│ │ │ ├── data_source.py
│ │ │ ├── field_info.py
│ │ │ ├── ray_utils.py
│ │ │ ├── type_inference.py
│ │ │ └── utils.py
│ │ ├── backward_compatibility.py
│ │ ├── batch_size_tuner.py
│ │ ├── calibration.py
│ │ ├── carton_utils.py
│ │ ├── checkpoint_utils.py
│ │ ├── config_utils.py
│ │ ├── data_utils.py
│ │ ├── dataframe_utils.py
│ │ ├── dataset_utils.py
│ │ ├── date_utils.py
│ │ ├── defaults.py
│ │ ├── entmax/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── activations.py
│ │ │ ├── losses.py
│ │ │ └── root_finding.py
│ │ ├── error_handling_utils.py
│ │ ├── eval_utils.py
│ │ ├── fs_utils.py
│ │ ├── h3_util.py
│ │ ├── heuristics.py
│ │ ├── hf_utils.py
│ │ ├── html_utils.py
│ │ ├── image_utils.py
│ │ ├── inference_utils.py
│ │ ├── llm_quantization_utils.py
│ │ ├── llm_utils.py
│ │ ├── logging_utils.py
│ │ ├── loss_utils.py
│ │ ├── math_utils.py
│ │ ├── metric_utils.py
│ │ ├── metrics_printed_table.py
│ │ ├── misc_utils.py
│ │ ├── model_utils.py
│ │ ├── nlp_utils.py
│ │ ├── numerical_test_utils.py
│ │ ├── output_feature_utils.py
│ │ ├── package_utils.py
│ │ ├── print_utils.py
│ │ ├── registry.py
│ │ ├── server_utils.py
│ │ ├── state_dict_backward_compatibility.py
│ │ ├── strings_utils.py
│ │ ├── structural_warning.py
│ │ ├── system_utils.py
│ │ ├── time_utils.py
│ │ ├── tokenizers.py
│ │ ├── torch_utils.py
│ │ ├── trainer_utils.py
│ │ ├── triton_utils.py
│ │ ├── types.py
│ │ ├── upload_utils.py
│ │ ├── version_transformation.py
│ │ └── visualization_utils.py
│ ├── vector_index/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ └── faiss.py
│ └── visualize.py
├── pyproject.toml
├── pytest.ini
├── requirements.txt
├── requirements_benchmarking.txt
├── requirements_distributed.txt
├── requirements_explain.txt
├── requirements_extra.txt
├── requirements_hyperopt.txt
├── requirements_llm.txt
├── requirements_serve.txt
├── requirements_test.txt
├── requirements_viz.txt
├── schemastore/
│ ├── README.md
│ ├── catalog-entry.json
│ └── test/
│ ├── ludwig.yaml
│ └── ludwig_config.yaml
├── setup.cfg
├── setup.py
└── tests/
├── README.md
├── __init__.py
├── conftest.py
├── docker-compose.yml
├── integration_tests/
│ ├── __init__.py
│ ├── parameter_update_utils.py
│ ├── scripts/
│ │ ├── run_train_aim.py
│ │ ├── run_train_comet.py
│ │ └── run_train_wandb.py
│ ├── synthetic_test_data.py
│ ├── test_api.py
│ ├── test_audio_feature.py
│ ├── test_automl.py
│ ├── test_cache_manager.py
│ ├── test_cached_preprocessing.py
│ ├── test_carton.py
│ ├── test_class_imbalance_feature.py
│ ├── test_cli.py
│ ├── test_collect.py
│ ├── test_config_global_defaults.py
│ ├── test_contrib_aim.py
│ ├── test_contrib_comet.py
│ ├── test_contrib_wandb.py
│ ├── test_custom_components.py
│ ├── test_date_feature.py
│ ├── test_dependencies.py
│ ├── test_experiment.py
│ ├── test_explain.py
│ ├── test_graph_execution.py
│ ├── test_hyperopt.py
│ ├── test_hyperopt_ray.py
│ ├── test_input_feature_tied.py
│ ├── test_kfold_cv.py
│ ├── test_llm.py
│ ├── test_missing_value_strategy.py
│ ├── test_mlflow.py
│ ├── test_model_save_and_load.py
│ ├── test_model_training_options.py
│ ├── test_number_feature.py
│ ├── test_peft.py
│ ├── test_postprocessing.py
│ ├── test_preprocessing.py
│ ├── test_ray.py
│ ├── test_reducers.py
│ ├── test_regularizers.py
│ ├── test_remote.py
│ ├── test_reproducibility.py
│ ├── test_sequence_decoders.py
│ ├── test_sequence_encoders.py
│ ├── test_sequence_features.py
│ ├── test_server.py
│ ├── test_simple_features.py
│ ├── test_timeseries_feature.py
│ ├── test_torchscript.py
│ ├── test_trainer.py
│ ├── test_triton.py
│ ├── test_triton_configs/
│ │ └── transformer_combiner_with_attention_reduce.yaml
│ ├── test_visualization.py
│ ├── test_visualization_api.py
│ └── utils.py
├── ludwig/
│ ├── __init__.py
│ ├── accounting/
│ │ └── test_used_tokens.py
│ ├── augmentation/
│ │ ├── test_augmentation_pipeline.py
│ │ ├── test_auto_augmentation.py
│ │ └── test_image_augmentation.py
│ ├── automl/
│ │ ├── __init__.py
│ │ ├── test_base_config.py
│ │ ├── test_data_source.py
│ │ ├── test_tune_config.py
│ │ └── test_utils.py
│ ├── backend/
│ │ └── test_ray.py
│ ├── benchmarking/
│ │ ├── example_files/
│ │ │ ├── invalid/
│ │ │ │ ├── benchmarking_config_1.yaml
│ │ │ │ ├── benchmarking_config_2.yaml
│ │ │ │ └── benchmarking_config_3.yaml
│ │ │ ├── process_config.py
│ │ │ └── valid/
│ │ │ ├── benchmarking_config_1.yaml
│ │ │ ├── benchmarking_config_2.yaml
│ │ │ └── benchmarking_config_3.yaml
│ │ ├── test_benchmarking.py
│ │ └── test_profiler.py
│ ├── combiners/
│ │ └── test_combiners.py
│ ├── config_sampling/
│ │ ├── static_schema.json
│ │ └── test_config_sampling.py
│ ├── config_validation/
│ │ ├── test_checks.py
│ │ ├── test_validate_config_combiner.py
│ │ ├── test_validate_config_encoder.py
│ │ ├── test_validate_config_features.py
│ │ ├── test_validate_config_hyperopt.py
│ │ ├── test_validate_config_misc.py
│ │ ├── test_validate_config_preprocessing.py
│ │ └── test_validate_config_trainer.py
│ ├── contrib/
│ │ └── test_contrib.py
│ ├── data/
│ │ ├── dataframe/
│ │ │ └── test_dask.py
│ │ ├── test_cache_util.py
│ │ ├── test_dataset_synthesizer.py
│ │ ├── test_negative_sampling.py
│ │ ├── test_postprocessing.py
│ │ ├── test_preprocessing.py
│ │ ├── test_ray_data.py
│ │ └── test_split.py
│ ├── datasets/
│ │ ├── __init__.py
│ │ ├── download_all_datasets.py
│ │ ├── mnist/
│ │ │ └── test_mnist_workflow.py
│ │ ├── model_configs/
│ │ │ └── train_all_model_configs.py
│ │ ├── test_dataset_configs.py
│ │ ├── test_dataset_links.py
│ │ ├── test_datasets.py
│ │ ├── test_model_configs.py
│ │ └── titanic/
│ │ └── test_titanic_workflow.py
│ ├── decoders/
│ │ ├── test_image_decoder.py
│ │ ├── test_llm_decoders.py
│ │ ├── test_sequence_decoder.py
│ │ ├── test_sequence_decoder_utils.py
│ │ └── test_sequence_tagger.py
│ ├── encoders/
│ │ ├── __init__.py
│ │ ├── test_bag_encoders.py
│ │ ├── test_category_encoders.py
│ │ ├── test_date_encoders.py
│ │ ├── test_generic_encoders.py
│ │ ├── test_h3_encoders.py
│ │ ├── test_image_encoders.py
│ │ ├── test_llm_encoders.py
│ │ ├── test_sequence_encoders.py
│ │ ├── test_set_encoders.py
│ │ ├── test_text_encoders.py
│ │ └── test_timm_encoder.py
│ ├── evaluation/
│ │ └── test_evaluation.py
│ ├── explain/
│ │ ├── test_captum.py
│ │ └── test_util.py
│ ├── features/
│ │ ├── __init__.py
│ │ ├── test_audio_feature.py
│ │ ├── test_bag_feature.py
│ │ ├── test_binary_feature.py
│ │ ├── test_category_feature.py
│ │ ├── test_date_feature.py
│ │ ├── test_feature_utils.py
│ │ ├── test_h3_feature.py
│ │ ├── test_image_feature.py
│ │ ├── test_number_feature.py
│ │ ├── test_sequence_features.py
│ │ ├── test_set_feature.py
│ │ ├── test_text_feature.py
│ │ └── test_timeseries_feature.py
│ ├── hyperopt/
│ │ └── test_hyperopt.py
│ ├── model_export/
│ │ └── test_onnx_exporter.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── test_trainable_image_layers.py
│ │ ├── test_training_determinism.py
│ │ └── test_training_success.py
│ ├── modules/
│ │ ├── __init__.py
│ │ ├── test_attention.py
│ │ ├── test_convolutional_modules.py
│ │ ├── test_embedding_modules.py
│ │ ├── test_encoder.py
│ │ ├── test_fully_connected_modules.py
│ │ ├── test_initializer_modules.py
│ │ ├── test_loss_modules.py
│ │ ├── test_lr_scheduler.py
│ │ ├── test_metric_modules.py
│ │ ├── test_mlp_mixer_modules.py
│ │ ├── test_normalization_modules.py
│ │ ├── test_recurrent_modules.py
│ │ ├── test_reduction_modules.py
│ │ ├── test_regex_freezing.py
│ │ ├── test_tabnet_modules.py
│ │ └── test_utils.py
│ ├── schema/
│ │ ├── hyperopt/
│ │ │ ├── test_scheduler.py
│ │ │ └── test_search_algorithm.py
│ │ ├── test_model_config.py
│ │ └── test_schema_utils.py
│ ├── schema_fields/
│ │ ├── test_fields_misc.py
│ │ ├── test_fields_optimization.py
│ │ ├── test_fields_preprocessing.py
│ │ └── test_marshmallow_misc.py
│ └── utils/
│ ├── __init__.py
│ ├── automl/
│ │ ├── test_type_inference.py
│ │ └── test_utils.py
│ ├── entmax/
│ │ ├── test_losses.py
│ │ ├── test_mask.py
│ │ ├── test_root_finding.py
│ │ └── test_topk.py
│ ├── test_algorithm_utils.py
│ ├── test_audio_utils.py
│ ├── test_backward_compatibility.py
│ ├── test_calibration.py
│ ├── test_class_balancing.py
│ ├── test_config_utils.py
│ ├── test_data_utils.py
│ ├── test_dataframe_utils.py
│ ├── test_dataset_utils.py
│ ├── test_date_utils.py
│ ├── test_defaults.py
│ ├── test_error_handling_utils.py
│ ├── test_errors.py
│ ├── test_fs_utils.py
│ ├── test_heuristics.py
│ ├── test_hf_utils.py
│ ├── test_hyperopt_ray_utils.py
│ ├── test_image_utils.py
│ ├── test_llm_utils.py
│ ├── test_metric_utils.py
│ ├── test_model_utils.py
│ ├── test_normalization.py
│ ├── test_numerical_test_utils.py
│ ├── test_output_feature_utils.py
│ ├── test_server_utils.py
│ ├── test_state_dict_backward_compatibility.py
│ ├── test_strings_utils.py
│ ├── test_tokenizers.py
│ ├── test_torch_utils.py
│ ├── test_trainer_utils.py
│ ├── test_upload_utils.py
│ └── test_version_transformation.py
├── regression_tests/
│ ├── automl/
│ │ ├── golden/
│ │ │ ├── adult_census_income.types.json
│ │ │ └── mnist.types.json
│ │ ├── scripts/
│ │ │ └── update_golden_types.py
│ │ ├── test_auto_type_inference.py
│ │ └── utils.py
│ ├── benchmark/
│ │ ├── configs/
│ │ │ ├── adult_census_income.ecd.yaml
│ │ │ ├── ames_housing.ecd.yaml
│ │ │ ├── mercedes_benz_greener.ecd.yaml
│ │ │ └── sarcos.ecd.yaml
│ │ ├── expected_metric.py
│ │ ├── expected_metrics/
│ │ │ ├── adult_census_income.ecd.yaml
│ │ │ ├── ames_housing.ecd.yaml
│ │ │ ├── mercedes_benz_greener.ecd.yaml
│ │ │ └── sarcos.ecd.yaml
│ │ └── test_model_performance.py
│ └── model/
│ └── test_old_models.py
└── training_success/
├── __init__.py
├── configs.py
└── test_training_success.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .actrc
================================================
-P ubuntu-latest=ludwigai/ludwig-ray
================================================
FILE: .deepsource.toml
================================================
version = 1
test_patterns = [
"tests/**"
]
[[analyzers]]
name = "python"
enabled = true
runtime_version = "3.x.x"
================================================
FILE: .devcontainer/Dockerfile
================================================
FROM python:3.12-slim
RUN apt-get update && export DEBIAN_FRONTEND=noninteractive \
&& apt-get install -y --no-install-recommends \
git \
build-essential \
curl \
libsndfile1 \
ffmpeg \
sox \
&& apt-get clean && rm -rf /var/lib/apt/lists/*
# Create non-root user
ARG USERNAME=vscode
ARG USER_UID=1000
ARG USER_GID=$USER_UID
RUN groupadd --gid $USER_GID $USERNAME \
&& useradd --uid $USER_UID --gid $USER_GID -m $USERNAME
USER $USERNAME
ENV PATH="/home/$USERNAME/.local/bin:$PATH"
# Pre-install pip tools so editable install is fast
RUN pip install --user --no-cache-dir --upgrade pip setuptools wheel
================================================
FILE: .devcontainer/devcontainer.json
================================================
{
"name": "Ludwig Dev",
"build": {
"dockerfile": "Dockerfile",
"context": ".."
},
"customizations": {
"vscode": {
"settings": {
"python.defaultInterpreterPath": "/usr/local/bin/python"
},
"extensions": [
"ms-python.python",
"ms-python.vscode-pylance",
"charliermarsh.ruff"
]
}
},
"postCreateCommand": "pip install --user -e '.[test]'",
"remoteUser": "vscode",
"features": {
"ghcr.io/devcontainers/features/git:1": {}
}
}
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.md
================================================
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: ''
assignees: ''
---
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
1. Click on '....'
1. Scroll down to '....'
1. See error
Please provide code, yaml config file and a sample of data in order to entirely reproduce the issue.
Issues that are not reproducible will be ignored.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment (please complete the following information):**
- OS: [e.g. iOS]
- Version [e.g. 22]
- Python version
- Ludwig version
**Additional context**
Add any other context about the problem here.
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.md
================================================
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: ''
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the use case**
A clear and concise description of what the use case for this feature is.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
================================================
FILE: .github/pull_request_template.md
================================================
# Code Pull Requests
Please provide the following:
- a clear explanation of what your code does
- if applicable, a reference to an issue
- a reproducible test for your PR (code, config and data sample)
# Documentation Pull Requests
Note that the documentation HTML files are in `docs/` while the Markdown sources are in `mkdocs/docs`.
If you are proposing a modification to the documentation you should change only the Markdown files.
`api.md` is automatically generated from the docstrings in the code, so if you want to change something in that file, first modify `ludwig/api.py` docstring, then run `mkdocs/code_docs_autogen.py`, which will create `mkdocs/docs/api.md` .
================================================
FILE: .github/workflows/docker.yml
================================================
name: docker
on:
schedule:
- cron: "0 10 * * *" # everyday at 10am
push:
branches: ["main", "release-*"]
tags: ["v*.*.*"]
jobs:
start-runner:
name: Start self-hosted EC2 runner
if: >
github.event_name == 'schedule' && github.repository == 'ludwig-ai/ludwig' ||
github.event_name == 'push' && github.repository == 'ludwig-ai/ludwig' ||
github.event_name == 'pull_request' && github.event.pull_request.base.repo.full_name == 'ludwig-ai/ludwig' && !github.event.pull_request.head.repo.fork
runs-on: ubuntu-latest
outputs:
label: ${{ steps.start-ec2-runner.outputs.label }}
ec2-instance-id: ${{ steps.start-ec2-runner.outputs.ec2-instance-id }}
steps:
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Start EC2 runner
id: start-ec2-runner
uses: machulav/ec2-github-runner@v2.3.2
with:
mode: start
github-token: ${{ secrets.GH_PERSONAL_ACCESS_TOKEN }}
ec2-image-id: ami-0759580dedc953d1f
ec2-instance-type: r5.large
subnet-id: subnet-0983be43
security-group-id: sg-4cba0d08
aws-resource-tags: >
[
{"Key": "Name", "Value": "ludwig-github-${{ github.head_ref || github.sha }}"},
{"Key": "GitHubRepository", "Value": "${{ github.repository }}"},
{"Key": "GitHubHeadRef", "Value": "${{ github.head_ref }}"},
{"Key": "GitHubSHA", "Value": "${{ github.sha }}"}
]
docker:
name: Build docker image ${{ matrix.docker-image }} (push=${{ github.event_name != 'pull_request' }})
if: needs.start-runner.result != 'skipped'
needs: start-runner # required to start the main job when the runner is ready
runs-on: ${{ needs.start-runner.outputs.label }} # run the job on the newly created runners
# we want an ongoing run of this workflow to be canceled by a later commit
# so that there is only one concurrent run of this workflow for each branch
concurrency:
group: docker-${{ matrix.docker-image }}-${{ github.head_ref || github.sha }}
cancel-in-progress: true
strategy:
fail-fast: false
matrix:
docker-image:
- ludwig
- ludwig-gpu
- ludwig-ray
- ludwig-ray-gpu
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Docker meta
id: meta
uses: docker/metadata-action@v5
with:
# list of Docker images to use as base name for tags
images: |
ludwigai/${{ matrix.docker-image }}
# generate Docker tags based on the following events/attributes
tags: |
type=schedule
type=ref,event=branch
type=ref,event=pr
type=semver,pattern={{version}}
type=semver,pattern={{major}}.{{minor}}
type=semver,pattern={{major}}
type=sha
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to DockerHub
if: github.event_name != 'pull_request'
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
file: ./docker/${{ matrix.docker-image }}/Dockerfile
push: ${{ github.event_name != 'pull_request' }}
tags: ${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}
stop-runner:
name: Stop self-hosted EC2 runner
# required to stop the runner even if the error happened in the previous job
if: always() && needs.start-runner.result != 'skipped'
needs:
- start-runner # required to get output from the start-runner job
- docker # required to wait when the main job is done
runs-on: ubuntu-latest
steps:
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Stop EC2 runner
uses: machulav/ec2-github-runner@v2.3.2
with:
mode: stop
github-token: ${{ secrets.GH_PERSONAL_ACCESS_TOKEN }}
label: ${{ needs.start-runner.outputs.label }}
ec2-instance-id: ${{ needs.start-runner.outputs.ec2-instance-id }}
================================================
FILE: .github/workflows/pytest.yml
================================================
name: pytest
on:
push:
branches: ["main", "release-*"]
pull_request:
branches: ["main", "release-*"]
concurrency:
group: pytest-${{ github.head_ref || github.sha }}
cancel-in-progress: true
jobs:
unit-tests:
runs-on: ubuntu-latest
env:
AWS_ACCESS_KEY_ID: ${{ secrets.LUDWIG_TESTS_AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.LUDWIG_TESTS_AWS_SECRET_ACCESS_KEY }}
KAGGLE_USERNAME: ${{ secrets.KAGGLE_USERNAME }}
KAGGLE_KEY: ${{ secrets.KAGGLE_KEY }}
IS_NOT_FORK: ${{ !(github.event.pull_request.base.repo.full_name == 'ludwig-ai/ludwig' && github.event.pull_request.head.repo.fork) }}
name: Unit Tests
timeout-minutes: 60
steps:
- uses: actions/checkout@v4
- name: Set up Python 3.12
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Setup Linux
run: |
sudo apt-get update && sudo apt-get install -y cmake libsndfile1 libsox-dev
- name: pip cache
uses: actions/cache@v4
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-unit-${{ hashFiles('requirements*.txt', '.github/workflows/pytest.yml') }}
- name: Install dependencies
run: |
python -m pip install -U pip setuptools
pip install torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install '.[test]' --extra-index-url https://download.pytorch.org/whl/cpu
pip list
- name: Unit Tests
run: |
RUN_PRIVATE=$IS_NOT_FORK LUDWIG_TEST_SUITE_TIMEOUT_S=5400 pytest -v --timeout 300 --durations 100 -m "not distributed and not slow and not combinatorial and not llm" --junitxml pytest.xml tests/ludwig
- name: Regression Tests
run: |
RUN_PRIVATE=$IS_NOT_FORK LUDWIG_TEST_SUITE_TIMEOUT_S=5400 pytest -v --timeout 300 --durations 100 -m "not distributed and not slow and not combinatorial and not llm" --junitxml pytest-regression.xml tests/regression_tests
- name: Upload Test Results
if: always()
uses: actions/upload-artifact@v4
with:
name: Unit Test Results
path: pytest*.xml
integration-tests:
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
test-markers:
- "integration_tests_a"
- "integration_tests_b"
- "integration_tests_c"
- "integration_tests_d"
- "integration_tests_e"
- "integration_tests_f"
env:
AWS_ACCESS_KEY_ID: ${{ secrets.LUDWIG_TESTS_AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.LUDWIG_TESTS_AWS_SECRET_ACCESS_KEY }}
KAGGLE_USERNAME: ${{ secrets.KAGGLE_USERNAME }}
KAGGLE_KEY: ${{ secrets.KAGGLE_KEY }}
IS_NOT_FORK: ${{ !(github.event.pull_request.base.repo.full_name == 'ludwig-ai/ludwig' && github.event.pull_request.head.repo.fork) }}
MARKERS: ${{ matrix.test-markers }}
name: Integration (${{ matrix.test-markers }})
services:
minio:
image: fclairamb/minio-github-actions
env:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio123
ports:
- 9000:9000
timeout-minutes: 90
steps:
- uses: actions/checkout@v4
- name: Set up Python 3.12
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Setup Linux
run: |
sudo apt-get update && sudo apt-get install -y cmake libsndfile1 libsox-dev
- name: pip cache
uses: actions/cache@v4
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-integration-${{ hashFiles('requirements*.txt', '.github/workflows/pytest.yml') }}
- name: Install dependencies
run: |
python -m pip install -U pip setuptools
pip install torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install '.[test]' --extra-index-url https://download.pytorch.org/whl/cpu
pip list
- name: Free Disk Space
uses: jlumbroso/free-disk-space@main
with:
tool-cache: false
android: true
dotnet: true
haskell: true
large-packages: false
docker-images: true
swap-storage: true
- name: Integration Tests
run: |
RUN_PRIVATE=$IS_NOT_FORK LUDWIG_TEST_SUITE_TIMEOUT_S=7200 pytest -v --timeout 300 --durations 100 -m "not slow and not combinatorial and not llm and $MARKERS" --junitxml pytest.xml tests/integration_tests
- name: Upload Test Results
if: always()
uses: actions/upload-artifact@v4
with:
name: Integration Test Results (${{ matrix.test-markers }})
path: pytest.xml
distributed-tests:
runs-on: ubuntu-latest
env:
AWS_ACCESS_KEY_ID: ${{ secrets.LUDWIG_TESTS_AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.LUDWIG_TESTS_AWS_SECRET_ACCESS_KEY }}
KAGGLE_USERNAME: ${{ secrets.KAGGLE_USERNAME }}
KAGGLE_KEY: ${{ secrets.KAGGLE_KEY }}
IS_NOT_FORK: ${{ !(github.event.pull_request.base.repo.full_name == 'ludwig-ai/ludwig' && github.event.pull_request.head.repo.fork) }}
name: Distributed Tests
services:
minio:
image: fclairamb/minio-github-actions
env:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio123
ports:
- 9000:9000
timeout-minutes: 120
steps:
- uses: actions/checkout@v4
- name: Set up Python 3.12
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Setup Linux
run: |
sudo apt-get update && sudo apt-get install -y cmake libsndfile1 libsox-dev
- name: pip cache
uses: actions/cache@v4
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-distributed-${{ hashFiles('requirements*.txt', '.github/workflows/pytest.yml') }}
- name: Install dependencies
run: |
python -m pip install -U pip setuptools
pip install torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install '.[test]' --extra-index-url https://download.pytorch.org/whl/cpu
pip list
- name: Free Disk Space
uses: jlumbroso/free-disk-space@main
with:
tool-cache: false
android: true
dotnet: true
haskell: true
large-packages: false
docker-images: true
swap-storage: true
- name: Distributed Unit Tests
run: |
RUN_PRIVATE=$IS_NOT_FORK LUDWIG_TEST_SUITE_TIMEOUT_S=5400 pytest -v --timeout 300 --durations 100 -m "distributed and not slow and not combinatorial and not llm" --junitxml pytest-unit.xml tests/ludwig
- name: Distributed Integration Tests
run: |
RUN_PRIVATE=$IS_NOT_FORK LUDWIG_TEST_SUITE_TIMEOUT_S=7200 pytest -v --timeout 300 --durations 100 -m "distributed and not slow and not combinatorial and not llm" --junitxml pytest-integration.xml tests/integration_tests
- name: Upload Test Results
if: always()
uses: actions/upload-artifact@v4
with:
name: Distributed Test Results
path: pytest*.xml
test-minimal-install:
name: Minimal Install
runs-on: ubuntu-latest
timeout-minutes: 15
steps:
- uses: actions/checkout@v4
- name: Set up Python 3.12
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Setup Linux
run: |
sudo apt-get update && sudo apt-get install -y cmake libsndfile1
- name: Install dependencies
run: |
python -m pip install -U pip setuptools
pip install torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install '.' --extra-index-url https://download.pytorch.org/whl/cpu
pip list
- name: Check Install
run: |
ludwig check_install
event_file:
name: "Event File"
runs-on: ubuntu-latest
steps:
- name: Upload
uses: actions/upload-artifact@v4
with:
name: Event File
path: ${{ github.event_path }}
================================================
FILE: .github/workflows/pytest_slow.yml
================================================
# This workflow will install Python dependencies and run all tests marked as `slow` on a single Python version.
name: pytest (slow)
on:
push:
branches: ["main", "release-*"]
jobs:
slow-pytest:
name: py-slow
runs-on: ubuntu-latest
env:
# Use Minio credentials for all S3 operations in tests.
# PyArrow/Ray S3 clients use these env vars directly, so they must point to Minio.
AWS_ACCESS_KEY_ID: minio
AWS_SECRET_ACCESS_KEY: minio123
AWS_ENDPOINT_URL: http://localhost:9000
KAGGLE_USERNAME: ${{ secrets.KAGGLE_USERNAME }}
KAGGLE_KEY: ${{ secrets.KAGGLE_KEY }}
IS_NOT_FORK: ${{ !(github.event.pull_request.base.repo.full_name == 'ludwig-ai/ludwig' && github.event.pull_request.head.repo.fork) }}
services:
minio:
image: fclairamb/minio-github-actions
env:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio123
ports:
- 9000:9000
timeout-minutes: 150
steps:
- uses: actions/checkout@v4
- name: Set up Python 3.12
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Setup Linux
if: runner.os == 'linux'
run: |
sudo apt-get update && sudo apt-get install -y cmake libsndfile1 libsox-dev
- name: Install dependencies
run: |
python --version
pip --version
python -m pip install -U pip
pip install torch==2.6.0 torchvision torchaudio
pip install '.[test]'
pip list
shell: bash
- name: Create Minio test bucket
run: |
python -c "
import boto3
s3 = boto3.client('s3', endpoint_url='http://localhost:9000',
aws_access_key_id='minio', aws_secret_access_key='minio123')
try:
s3.create_bucket(Bucket='ludwig-tests')
except s3.exceptions.BucketAlreadyOwnedByYou:
pass
"
shell: bash
- name: Tests
run: |
RUN_PRIVATE=$IS_NOT_FORK LUDWIG_TEST_SUITE_TIMEOUT_S=7200 pytest -v --timeout 600 --durations 100 -m "slow" --junitxml pytest.xml tests/integration_tests/
================================================
FILE: .github/workflows/schema.yml
================================================
name: Publish JSON Schema
on:
push:
branches: [main]
paths:
- "ludwig/schema/**"
- "ludwig/config_validation/**"
- "ludwig/constants.py"
release:
types: [published]
workflow_dispatch:
permissions:
contents: read
jobs:
publish-schema:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Install Ludwig
run: pip install -e ".[test]"
- name: Export schemas
run: |
mkdir -p schema-out
ludwig export_schema --model-type combined -o schema-out/ludwig-config.json
ludwig export_schema --model-type ecd -o schema-out/ludwig-config-ecd.json
ludwig export_schema --model-type llm -o schema-out/ludwig-config-llm.json
- name: Generate index.html
run: |
cat > schema-out/index.html << 'HTMLEOF'
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Ludwig JSON Schema</title>
<style>body{font-family:system-ui,sans-serif;max-width:640px;margin:2rem auto;padding:0 1rem}a{color:#0066cc}</style>
</head>
<body>
<h1>Ludwig JSON Schema</h1>
<p>JSON Schema files for <a href="https://github.com/ludwig-ai/ludwig">Ludwig</a> config validation and IDE auto-complete.</p>
<ul>
<li><a href="ludwig-config.json">ludwig-config.json</a> — Combined (ECD + LLM)</li>
<li><a href="ludwig-config-ecd.json">ludwig-config-ecd.json</a> — ECD only</li>
<li><a href="ludwig-config-llm.json">ludwig-config-llm.json</a> — LLM only</li>
</ul>
<h2>Usage</h2>
<p>Add to your Ludwig YAML config:</p>
<pre># yaml-language-server: $schema=https://ludwig-ai.github.io/schema/ludwig-config.json</pre>
<p>Or see <a href="https://www.schemastore.org/json/">SchemaStore</a> for automatic IDE integration.</p>
</body>
</html>
HTMLEOF
- name: Publish to ludwig-ai/schema
uses: cpina/github-action-push-to-another-repository@v1.7.2
env:
SSH_DEPLOY_KEY: ${{ secrets.SCHEMA_REPO_DEPLOY_KEY }}
with:
source-directory: schema-out
destination-github-username: ludwig-ai
destination-repository-name: schema
target-branch: main
commit-message: "Update Ludwig JSON schema from ${{ github.sha }}"
================================================
FILE: .github/workflows/test-results.yml
================================================
name: test results
on:
workflow_run:
workflows: ["pytest"]
types:
- completed
jobs:
test-results:
name: Test Results
runs-on: ubuntu-latest
if: github.event.workflow_run.conclusion != 'skipped'
steps:
- name: Download and Extract Artifacts
env:
GITHUB_TOKEN: ${{secrets.GITHUB_TOKEN}}
run: |
mkdir -p artifacts && cd artifacts
artifacts_url=${{ github.event.workflow_run.artifacts_url }}
gh api "$artifacts_url" -q '.artifacts[] | [.name, .archive_download_url] | @tsv' | while read artifact
do
IFS=$'\t' read name url <<< "$artifact"
gh api $url > "$name.zip"
unzip -d "$name" "$name.zip"
done
- name: Publish Unit Test Results
uses: EnricoMi/publish-unit-test-result-action@v2
with:
commit: ${{ github.event.workflow_run.head_sha }}
event_file: artifacts/Event File/event.json
event_name: ${{ github.event.workflow_run.event }}
files: "artifacts/**/*.xml"
================================================
FILE: .github/workflows/upload-pypi.yml
================================================
name: Upload to PyPI
on:
# Triggers the workflow when a release or draft of a release is published,
# or a pre-release is changed to a release
release:
types: [released]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
pypi-publish:
name: upload release to PyPI
runs-on: ubuntu-latest
# Specifying a GitHub environment is optional, but strongly encouraged
environment: release
permissions:
# IMPORTANT: this permission is mandatory for trusted publishing
id-token: write
steps:
- name: Checkout
uses: actions/checkout@v4
with:
submodules: "recursive"
- uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Build source distribution
run: |
pip install setuptools
python setup.py sdist
- name: Publish package distributions to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
================================================
FILE: .gitignore
================================================
###################
# ludwig specific #
###################
*.lock_preprocessing
results/
ludwig/results/
results_*/
ludwig_arm64/
# ailabs-utils
ailabs_util
docker_assets
# data
mnist_data/
profile_images/
./profile_images/
###########
# General #
###########
# Mac stuff
.DS_Store
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
env/
env*
build/
develop-eggs/
dist/
downloads/
./downloads/
./dataset/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*,cover
.hypothesis/
# Data
*.csv
*.hdf5
*.meta.json
*.parquet
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# dotenv
.env
# virtualenv
.venv
venv*
ENV/
# Spyder project settings
.spyderproject
# Rope project settings
.ropeproject
# PyCharm
.idea
# ctags
tags
# examples
examples/*/data/
examples/*/visualizations/
# benchmarking configs
ludwig/benchmarking/configs/
# Aim tracking
.aim/
# Comet
.comet.config
# Test-generated artifacts (image/audio features)
*.png
*.wav
generated_audio/
generated_images/
================================================
FILE: .nojekyll
================================================
================================================
FILE: .pre-commit-config.yaml
================================================
# Apply to all files without committing:
# pre-commit run --all-files
# Apply to changed files:
# pre-commit run
# Update this file:
# pre-commit autoupdate
# Run a specific hook:
# pre-commit run <hook id>
ci:
autofix_prs: true
autoupdate_commit_msg: "[pre-commit.ci] pre-commit suggestions"
autoupdate_schedule: weekly
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v6.0.0
hooks:
- id: check-ast
- id: fix-byte-order-marker
- id: check-case-conflict
- id: check-executables-have-shebangs
- id: check-json
- id: check-toml
- id: check-yaml
- id: debug-statements
- id: detect-private-key
- id: end-of-file-fixer
- id: trailing-whitespace
- id: mixed-line-ending
- repo: https://github.com/asottile/pyupgrade
rev: v3.21.2
hooks:
- id: pyupgrade
args: [--py312-plus]
- repo: https://github.com/PyCQA/docformatter
rev: v1.7.7
hooks:
- id: docformatter
args: [--in-place, --wrap-summaries=115, --wrap-descriptions=120]
- repo: https://github.com/PyCQA/isort
rev: 8.0.0
hooks:
- id: isort
name: Format imports
- repo: https://github.com/pycqa/flake8
rev: 7.3.0
hooks:
- id: flake8
- repo: https://github.com/psf/black
rev: 26.1.0
hooks:
- id: black
name: Format code
- repo: https://github.com/asottile/blacken-docs
rev: 1.20.0
hooks:
- id: blacken-docs
args: [--line-length=120]
- repo: https://github.com/hukkin/mdformat
rev: 1.0.0
hooks:
- id: mdformat
additional_dependencies:
- mdformat-gfm==1.0.0
- mdformat_frontmatter==2.0.10
exclude: CHANGELOG.md
- repo: https://github.com/yoheimuta/protolint
rev: v0.56.4
hooks:
- id: protolint
================================================
FILE: .protolint.yaml
================================================
# Adapted from
# https://github.com/yoheimuta/protolint/blob/master/_example/config/.protolint.yaml
---
# Lint directives.
lint:
# Linter files to walk.
files:
# The specific files to exclude.
exclude:
# NOTE: UNIX paths will be properly accepted by both UNIX and Windows.
- ../proto/invalidFileName.proto
# Linter rules.
# Run `protolint list` to see all available rules.
rules:
# Set the default to all linters. This option works the other way around as no_default does.
# If you want to enable this option, delete the comment out below and no_default.
# all_default: true
# The specific linters to add.
add:
- FIELD_NAMES_LOWER_SNAKE_CASE
- MESSAGE_NAMES_UPPER_CAMEL_CASE
- MAX_LINE_LENGTH
- INDENT
- FIELD_NAMES_EXCLUDE_PREPOSITIONS
- FILE_NAMES_LOWER_SNAKE_CASE
- IMPORTS_SORTED
- PACKAGE_NAME_LOWER_CASE
- ORDER
- PROTO3_FIELDS_AVOID_REQUIRED
- PROTO3_GROUPS_AVOID
- REPEATED_FIELD_NAMES_PLURALIZED
- QUOTE_CONSISTENT
# Linter rules option.
rules_option:
# MAX_LINE_LENGTH rule option.
max_line_length:
# Enforces a maximum line length
max_chars: 120
# Specifies the character count for tab characters
tab_chars: 2
# FILE_NAMES_LOWER_SNAKE_CASE rule option.
file_names_lower_snake_case:
excludes:
- ../proto/invalidFileName.proto
# QUOTE_CONSISTENT rule option.
quote_consistent:
# Available quote are "double" or "single".
quote: double
================================================
FILE: .vscode/settings.json
================================================
{
"editor.rulers": [
120
],
"editor.formatOnSave": true,
"[python]": {
"editor.defaultFormatter": "ms-python.black-formatter",
"editor.formatOnSave": true
},
"black-formatter.args": [
"--line-length",
"120"
],
"flake8.args": [
"--config=setup.cfg"
],
"python.testing.unittestEnabled": false,
"python.testing.pytestEnabled": false,
"python.envFile": "${workspaceFolder}/.env"
}
================================================
FILE: CODEOWNERS
================================================
# Default code owners for the entire repository
* @w4nderlust @tgaddair @justinxzhao @arnavgarg1 @geoffreyangus @jeffkinnison @Infernaught @alexsherstinsky
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Code of conduct
Ludwig adopts the [Linux Foundation code of conduct](https://lfprojects.org/policies/code-of-conduct/).
================================================
FILE: CONTRIBUTING.md
================================================
# Contributing
Everyone is welcome to contribute, and we value everybody’s contribution. Code is thus not the only
way to help the community. Answering questions, helping others, reaching out and improving the
documentation are immensely valuable contributions as well.
It also helps us if you spread the word: reference the library from blog posts on the awesome
projects it made possible, shout out on X every time it has helped you, or simply star the
repo to say "thank you".
Check out the official [ludwig docs](https://ludwig-ai.github.io/ludwig-docs/) to get oriented
around the codebase, and join the community!
## Open Issues
Issues are listed at: <https://github.com/ludwig-ai/ludwig/issues>
If you would like to work on any of them, make sure it is not already assigned to someone else.
You can self-assign it by commenting on the Issue page with one of the keywords: `#take` or
`#self-assign`.
Work on your self-assigned issue and eventually create a Pull Request.
## Creating Pull Requests
1. Fork the [repository](https://github.com/ludwig-ai/ludwig) by clicking on the "Fork" button on
the repository's page. This creates a copy of the code under your GitHub user account.
1. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone git@github.com:<your Github handle>/ludwig.git
cd ludwig
git remote add upstream https://github.com/ludwig-ai/ludwig.git
```
1. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
*Do not*\* work on the `master` branch.
1. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e .
```
The above command will install only the packages in "requirements.txt" in the developer mode. If you would like to
be able to potentially make changes to the overall Ludwig codebase, then use the following command:
```bash
pip install -e .[full]
```
Please note that in certain Shell environments (e.g., the `Z shell`), the dependencies in brackets have to be quoted:
```bash
pip install -e ."[full]"
```
If you do not need access to the entire Ludwig codebase, but just want to be able to run `pytest` on the essential
functionality, then you would replace the above command with:
```bash
pip install -e .[test]
```
(Please use `pip install -e ."[test]"` where your Shell environment requires quotes around the square brackets.)
For the full list of the optional dependencies available in Ludwig, please see
[Installation Guide](https://ludwig.ai/latest/getting_started/installation/) and "setup.py" in the root of the Ludwig
repository.
1. On MacOS with Apple Silicon, if this installation approach runs into errors, you may need to install the following
prerequisites:
```bash
brew install cmake libomp
```
This step requires `homebrew` to be installed on your development machine.
1. Install and run `pre-commit`:
```bash
pip install pre-commit
pre-commit install
```
1. Develop features on your branch.
1. Format your code by running pre-commits so that your newly added files look nice:
```bash
pre-commit run
```
Pre-commits also run automatically when committing.
1. Once you're happy with your changes, make a commit to record your changes locally:
```bash
git add .
git commit
```
It is a good idea to sync your copy of the code with the original repository regularly. This
way you can quickly account for changes:
```bash
git fetch upstream
git rebase upstream/master
```
Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
1. Once you are satisfied, go the webpage of your fork on GitHub. Click on "Pull request" to send
your contribution to the project maintainers for review.
## Other tips
- Add unit tests for any new code you write.
- Make sure tests pass. See the [Developer Guide](https://ludwig-ai.github.io/ludwig-docs/latest/developer_guide/style_guidelines_and_tests/) for more details.
## Attribution
This contributing guideline is adapted from `huggingface`, available at <https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md>.
## Code of Conduct
Please be mindful of and adhere to the Linux Foundation's
[Code of Conduct](https://lfprojects.org/policies/code-of-conduct) when contributing to Ludwig.
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--------------------------------------------------------------------------
Code in ludwig/api_annotations.py adapted from
https://github.com/ray-project/ray (Apache-2.0 License)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--------------------------------------------------------------------------
Code in ludwig/utils/structural_warnings.py adapted from
https://github.com/ray-project/ray (Apache-2.0 License)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--------------------------------------------------------------------------
Code in ludwig/utils/logging_utils.py adapted from
https://github.com/ray-project/ray (Apache-2.0 License)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: MANIFEST.in
================================================
include *.txt
recursive-include ludwig/datasets *.yaml
recursive-include ludwig/automl/defaults *.yaml
recursive-include ludwig/schema/metadata/configs *.yaml
================================================
FILE: NOTICE
================================================
Ludwig includes derived work from TensorFlow(https://github.com/tensorflow/tensorflow) under the Apache License 2.0:
Copyright 2016 The prometheus-operator Authors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
The derived work can be found in the files: ludwig/models/modules/convolutional_modules.py
------
Ludwig includes derived work from Keras(https://github.com/keras-team/keras) under the MIT License:
COPYRIGHT
All contributions by François Chollet:
Copyright (c) 2015 - 2018, François Chollet.
All rights reserved.
All contributions by Google:
Copyright (c) 2015 - 2018, Google, Inc.
All rights reserved.
All contributions by Microsoft:
Copyright (c) 2017 - 2018, Microsoft, Inc.
All rights reserved.
All other contributions:
Copyright (c) 2015 - 2018, the respective contributors.
All rights reserved.
Each contributor holds copyright over their respective contributions.
The project versioning (Git) records all such contribution source information.
LICENSE
The MIT License (MIT)
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
The derived work can be found in the files: mkdocs/code_docs_autogen.py
================================================
FILE: README.md
================================================
<p align="center">
<a href="https://ludwig.ai">
<img src="https://github.com/ludwig-ai/ludwig-docs/raw/main/docs/images/ludwig_hero_smaller.jpg" height="150">
</a>
</p>
<div align="center">
_Declarative deep learning framework built for scale and efficiency._
[](https://badge.fury.io/py/ludwig)
[](https://discord.gg/CBgdrGnZjy)
[](https://hub.docker.com/r/ludwigai)
[](https://pepy.tech/project/ludwig)
[](https://github.com/ludwig-ai/ludwig/blob/main/LICENSE)
[](https://twitter.com/ludwig_ai)
</div>
# 📖 What is Ludwig?
Ludwig is a **low-code** framework for building **custom** AI models like **LLMs** and other deep neural networks.
Key features:
- 🛠 **Build custom models with ease:** a declarative YAML configuration file is all you need to train a state-of-the-art LLM on your data. Support for multi-task and multi-modality learning. Comprehensive config validation detects invalid parameter combinations and prevents runtime failures.
- ⚡ **Optimized for scale and efficiency:** automatic batch size selection, distributed training ([DDP](https://pytorch.org/tutorials/beginner/ddp_series_theory.html), [DeepSpeed](https://github.com/microsoft/DeepSpeed)), parameter efficient fine-tuning ([PEFT](https://github.com/huggingface/peft)), 4-bit quantization (QLoRA), paged and 8-bit optimizers, and larger-than-memory datasets.
- 📐 **Expert level control:** retain full control of your models down to the activation functions. Support for hyperparameter optimization, explainability, and rich metric visualizations.
- 🧱 **Modular and extensible:** experiment with different model architectures, tasks, features, and modalities with just a few parameter changes in the config. Think building blocks for deep learning.
- 🚢 **Engineered for production:** prebuilt [Docker](https://hub.docker.com/u/ludwigai) containers, native support for running with [Ray](https://www.ray.io/) on [Kubernetes](https://github.com/ray-project/kuberay), export models to [Torchscript](https://pytorch.org/docs/stable/jit.html) and [Triton](https://developer.nvidia.com/triton-inference-server), upload to [HuggingFace](https://huggingface.co/models) with one command.
Ludwig is hosted by the
[Linux Foundation AI & Data](https://lfaidata.foundation/).
**Tech stack:** Python 3.12 | PyTorch 2.6 | Pydantic 2 | Transformers 5 | Ray 2.54
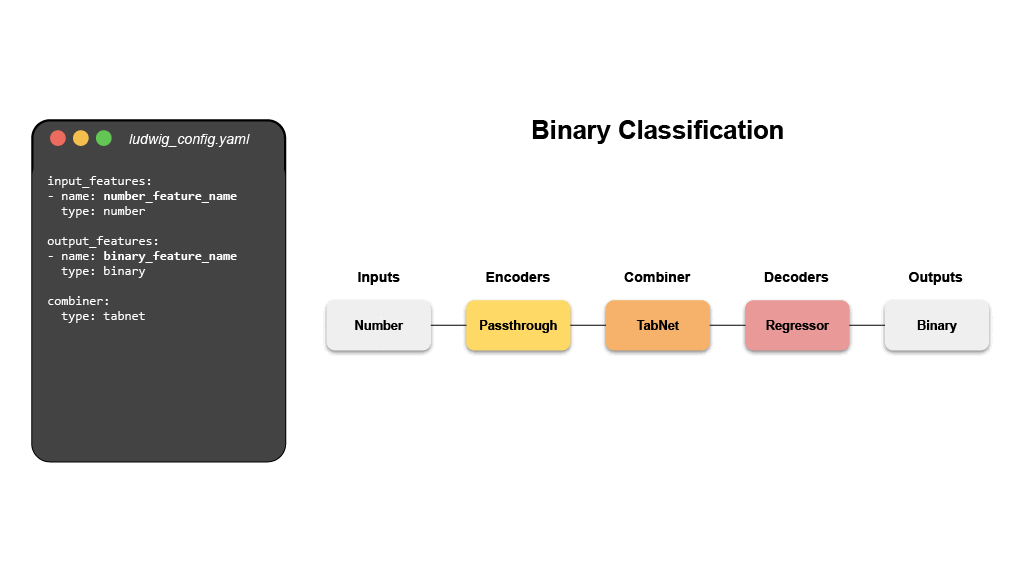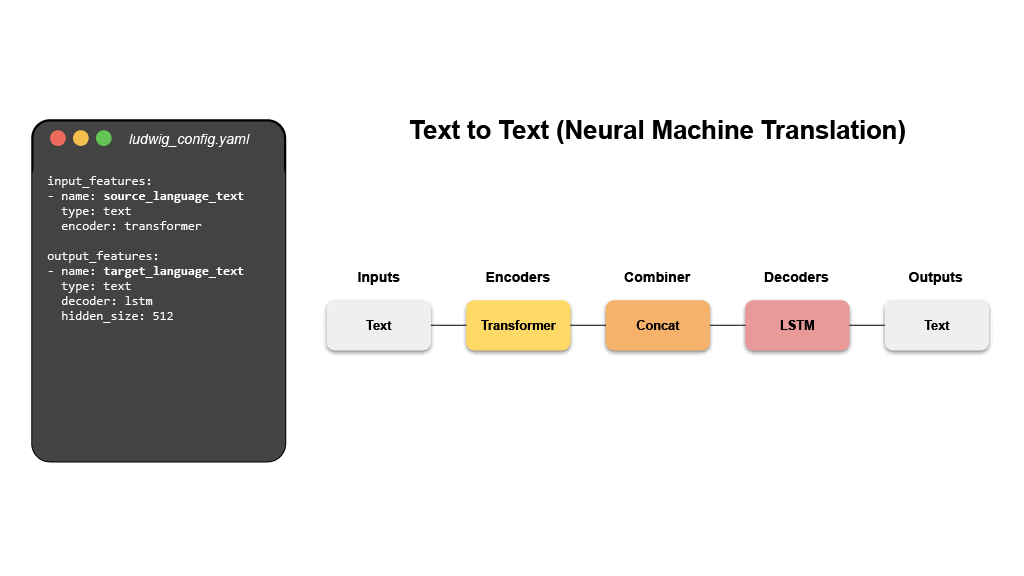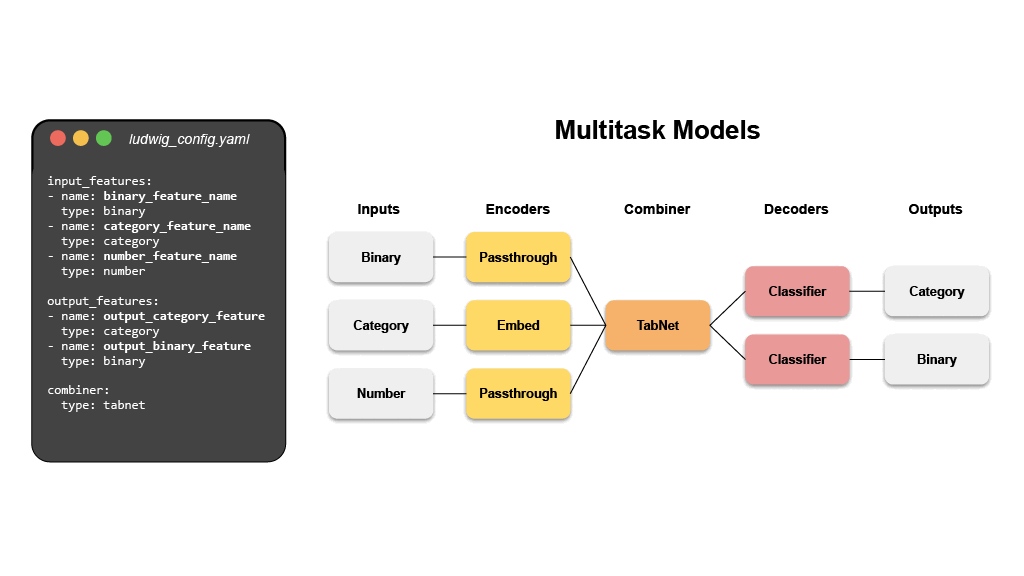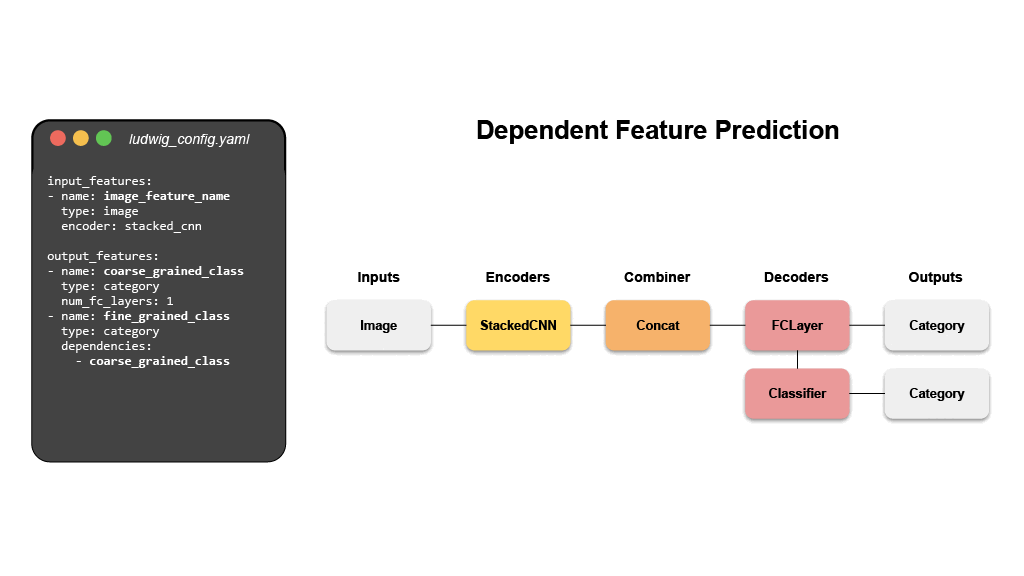
# 💾 Installation
Install from PyPI. Be aware that Ludwig requires Python 3.12+.
```shell
pip install ludwig
```
Or install with all optional dependencies:
```shell
pip install ludwig[full]
```
Please see [contributing](https://github.com/ludwig-ai/ludwig/blob/main/CONTRIBUTING.md) for more detailed installation instructions.
# 🚂 Getting Started
Want to take a quick peek at some of Ludwig's features? Check out this Colab Notebook 🚀 [](https://colab.research.google.com/drive/1lB4ALmEyvcMycE3Mlnsd7I3bc0zxvk39)
Looking to fine-tune LLMs? Check out these notebooks:
1. Fine-Tune Llama-2-7b: [](https://colab.research.google.com/drive/1r4oSEwRJpYKBPM0M0RSh0pBEYK_gBKbe)
1. Fine-Tune Llama-2-13b: [](https://colab.research.google.com/drive/1zmSEzqZ7v4twBrXagj1TE_C--RNyVAyu)
1. Fine-Tune Mistral-7b: [](https://colab.research.google.com/drive/1i_8A1n__b7ljRWHzIsAdhO7u7r49vUm4)
For a full tutorial, check out the official [getting started guide](https://ludwig.ai/latest/getting_started/), or take a look at end-to-end [Examples](https://ludwig.ai/latest/examples).
## Large Language Model Fine-Tuning
[](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)
Let's fine-tune a pretrained LLM to follow instructions like a chatbot ("instruction tuning").
### Prerequisites
- [HuggingFace API Token](https://huggingface.co/docs/hub/security-tokens)
- Access approval to your chosen base model (e.g., [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B))
- GPU with at least 12 GiB of VRAM (in our tests, we used an Nvidia T4)
### Running
We'll use the [Stanford Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) dataset, which will be formatted as a table-like file that looks like this:
| instruction | input | output |
| :-----------------------------------------------: | :--------------: | :-----------------------------------------------: |
| Give three tips for staying healthy. | | 1.Eat a balanced diet and make sure to include... |
| Arrange the items given below in the order to ... | cake, me, eating | I eating cake. |
| Write an introductory paragraph about a famous... | Michelle Obama | Michelle Obama is an inspirational woman who r... |
| ... | ... | ... |
Create a YAML config file named `model.yaml` with the following:
```yaml
model_type: llm
base_model: meta-llama/Llama-3.1-8B
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
Below is an instruction that describes a task, paired with an input that may provide further context.
Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
decay: cosine
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
backend:
type: local
```
And now let's train the model:
```bash
export HUGGING_FACE_HUB_TOKEN = "<api_token>"
ludwig train --config model.yaml --dataset "ludwig://alpaca"
```
## Supervised ML
Let's build a neural network that predicts whether a given movie critic's review on [Rotten Tomatoes](https://www.kaggle.com/stefanoleone992/rotten-tomatoes-movies-and-critic-reviews-dataset) was positive or negative.
Our dataset will be a CSV file that looks like this:
| movie_title | content_rating | genres | runtime | top_critic | review_content | recommended |
| :------------------: | :------------: | :------------------------------: | :-----: | ---------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------- |
| Deliver Us from Evil | R | Action & Adventure, Horror | 117.0 | TRUE | Director Scott Derrickson and his co-writer, Paul Harris Boardman, deliver a routine procedural with unremarkable frights. | 0 |
| Barbara | PG-13 | Art House & International, Drama | 105.0 | FALSE | Somehow, in this stirring narrative, Barbara manages to keep hold of her principles, and her humanity and courage, and battles to save a dissident teenage girl whose life the Communists are trying to destroy. | 1 |
| Horrible Bosses | R | Comedy | 98.0 | FALSE | These bosses cannot justify either murder or lasting comic memories, fatally compromising a farce that could have been great but ends up merely mediocre. | 0 |
| ... | ... | ... | ... | ... | ... | ... |
Download a sample of the dataset from [here](https://ludwig.ai/latest/data/rotten_tomatoes.csv).
```bash
wget https://ludwig.ai/latest/data/rotten_tomatoes.csv
```
Next create a YAML config file named `model.yaml` with the following:
```yaml
input_features:
- name: genres
type: set
preprocessing:
tokenizer: comma
- name: content_rating
type: category
- name: top_critic
type: binary
- name: runtime
type: number
- name: review_content
type: text
encoder:
type: embed
output_features:
- name: recommended
type: binary
```
That's it! Now let's train the model:
```bash
ludwig train --config model.yaml --dataset rotten_tomatoes.csv
```
**Happy modeling**
Try applying Ludwig to your data. [Reach out on Discord](https://discord.gg/CBgdrGnZjy)
if you have any questions.
# ❓ Why you should use Ludwig
- **Minimal machine learning boilerplate**
Ludwig takes care of the engineering complexity of machine learning out of
the box, enabling research scientists to focus on building models at the
highest level of abstraction. Data preprocessing, hyperparameter
optimization, device management, and distributed training for
`torch.nn.Module` models come completely free.
- **Easily build your benchmarks**
Creating a state-of-the-art baseline and comparing it with a new model is a
simple config change.
- **Easily apply new architectures to multiple problems and datasets**
Apply new models across the extensive set of tasks and datasets that Ludwig
supports. Ludwig includes a
[full benchmarking toolkit](https://arxiv.org/abs/2111.04260) accessible to
any user, for running experiments with multiple models across multiple
datasets with just a simple configuration.
- **Highly configurable data preprocessing, modeling, and metrics**
Any and all aspects of the model architecture, training loop, hyperparameter
search, and backend infrastructure can be modified as additional fields in
the declarative configuration to customize the pipeline to meet your
requirements. For details on what can be configured, check out
[Ludwig Configuration](https://ludwig.ai/latest/configuration/)
docs.
- **Multi-modal, multi-task learning out-of-the-box**
Mix and match tabular data, text, images, and even audio into complex model
configurations without writing code.
- **Rich model exporting and tracking**
Automatically track all trials and metrics with tools like Tensorboard,
Comet ML, Weights & Biases, MLFlow, and Aim Stack.
- **Automatically scale training to multi-GPU, multi-node clusters**
Go from training on your local machine to the cloud without code changes.
- **Low-code interface for state-of-the-art models, including pre-trained Huggingface Transformers**
Ludwig also natively integrates with pre-trained models, such as the ones
available in [Huggingface Transformers](https://huggingface.co/docs/transformers/index).
Users can choose from a vast collection of state-of-the-art pre-trained
PyTorch models to use without needing to write any code at all. For example,
training a BERT-based sentiment analysis model with Ludwig is as simple as:
```shell
ludwig train --dataset sst5 --config_str "{input_features: [{name: sentence, type: text, encoder: bert}], output_features: [{name: label, type: category}]}"
```
- **Low-code interface for AutoML**
[Ludwig AutoML](https://ludwig.ai/latest/user_guide/automl/)
allows users to obtain trained models by providing just a dataset, the
target column, and a time budget.
```python
auto_train_results = ludwig.automl.auto_train(dataset=my_dataset_df, target=target_column_name, time_limit_s=7200)
```
- **Easy productionisation**
Ludwig makes it easy to serve deep learning models, including on GPUs.
Launch a REST API for your trained Ludwig model.
```shell
ludwig serve --model_path=/path/to/model
```
Ludwig supports exporting models to efficient Torchscript bundles.
```shell
ludwig export_torchscript -–model_path=/path/to/model
```
# 📚 Tutorials
- [Text Classification](https://ludwig.ai/latest/examples/text_classification)
- [Tabular Data Classification](https://ludwig.ai/latest/examples/adult_census_income)
- [Image Classification](https://ludwig.ai/latest/examples/mnist)
- [Multimodal Classification](https://ludwig.ai/latest/examples/multimodal_classification)
# 🔬 Example Use Cases
- [Named Entity Recognition Tagging](https://ludwig.ai/latest/examples/ner_tagging)
- [Natural Language Understanding](https://ludwig.ai/latest/examples/nlu)
- [Machine Translation](https://ludwig.ai/latest/examples/machine_translation)
- [Chit-Chat Dialogue Modeling through seq2seq](https://ludwig.ai/latest/examples/seq2seq)
- [Sentiment Analysis](https://ludwig.ai/latest/examples/sentiment_analysis)
- [One-shot Learning with Siamese Networks](https://ludwig.ai/latest/examples/oneshot)
- [Visual Question Answering](https://ludwig.ai/latest/examples/visual_qa)
- [Spoken Digit Speech Recognition](https://ludwig.ai/latest/examples/speech_recognition)
- [Speaker Verification](https://ludwig.ai/latest/examples/speaker_verification)
- [Binary Classification (Titanic)](https://ludwig.ai/latest/examples/titanic)
- [Timeseries forecasting](https://ludwig.ai/latest/examples/forecasting)
- [Timeseries forecasting (Weather)](https://ludwig.ai/latest/examples/weather)
- [Movie rating prediction](https://ludwig.ai/latest/examples/movie_ratings)
- [Multi-label classification](https://ludwig.ai/latest/examples/multi_label)
- [Multi-Task Learning](https://ludwig.ai/latest/examples/multi_task)
- [Simple Regression: Fuel Efficiency Prediction](https://ludwig.ai/latest/examples/fuel_efficiency)
- [Fraud Detection](https://ludwig.ai/latest/examples/fraud)
# 💡 More Information
Read our publications on [Ludwig](https://arxiv.org/pdf/1909.07930.pdf), [declarative ML](https://arxiv.org/pdf/2107.08148.pdf), and [Ludwig’s SoTA benchmarks](https://openreview.net/pdf?id=hwjnu6qW7E4).
Learn more about [how Ludwig works](https://ludwig.ai/latest/user_guide/how_ludwig_works/), [how to get started](https://ludwig.ai/latest/getting_started/), and work through more [examples](https://ludwig.ai/latest/examples).
If you are interested in [contributing](https://github.com/ludwig-ai/ludwig/blob/main/CONTRIBUTING.md), have questions, comments, or thoughts to share, or if you just want to be in the
know, please consider [joining our Community Discord](https://discord.gg/CBgdrGnZjy) and follow us on [X](https://twitter.com/ludwig_ai)!
# 🤝 Join the community to build Ludwig with us
Ludwig is an actively managed open-source project that relies on contributions from folks just like
you. Consider joining the active group of Ludwig contributors to make Ludwig an even
more accessible and feature rich framework for everyone to use!
<a href="https://github.com/ludwig-ai/ludwig/graphs/contributors">
<img src="https://contrib.rocks/image?repo=ludwig-ai/ludwig" />
</a><br/>
## Star History
[](https://star-history.com/#ludwig-ai/ludwig&Date)
# 👋 Getting Involved
- [Discord](https://discord.gg/CBgdrGnZjy)
- [X (Twitter)](https://twitter.com/ludwig_ai)
- [Medium](https://medium.com/ludwig-ai)
- [GitHub Issues](https://github.com/ludwig-ai/ludwig/issues)
================================================
FILE: README_KR.md
================================================
<p align="center">
<a href="https://ludwig.ai">
<img src="https://github.com/ludwig-ai/ludwig-docs/raw/main/docs/images/ludwig_hero_smaller.jpg" height="150">
</a>
</p>
<div align="center">
_확장성과 효율성을 위해 설계된 선언적 딥러닝 프레임워크_
[](https://badge.fury.io/py/ludwig)
[](https://discord.gg/CBgdrGnZjy)
[](https://hub.docker.com/r/ludwigai)
[](https://pepy.tech/project/ludwig)
[](https://github.com/ludwig-ai/ludwig/blob/main/LICENSE)
[](https://twitter.com/ludwig_ai)
</div>
# 📖 Ludwig란?
Ludwig는 **LLM** 및 기타 심층 신경망과 같은 **맞춤형** AI 모델을 구축하기 위한 **로우코드** 프레임워크입니다.
주요 기능:
- 🛠 **손쉬운 맞춤형 모델 구축:** 선언적 YAML 설정 파일만으로 최신 LLM을 데이터에 맞춰 학습시킬 수 있습니다. 멀티태스크 및 멀티모달 학습을 지원합니다. 포괄적인 설정 검증으로 잘못된 매개변수 조합을 감지하고 런타임 오류를 방지합니다.
- ⚡ **확장성과 효율성 최적화:** 자동 배치 크기 선택, 분산 학습([DDP](https://pytorch.org/tutorials/beginner/ddp_series_theory.html), [DeepSpeed](https://github.com/microsoft/DeepSpeed)), 매개변수 효율적 미세 조정([PEFT](https://github.com/huggingface/peft)), 4비트 양자화(QLoRA), 페이지 및 8비트 옵티마이저, 메모리 초과 데이터셋 지원.
- 📐 **전문가 수준의 제어:** 활성화 함수까지 모델을 완전히 제어할 수 있습니다. 하이퍼파라미터 최적화, 설명 가능성, 풍부한 메트릭 시각화를 지원합니다.
- 🧱 **모듈식 및 확장 가능:** 설정에서 몇 가지 매개변수만 변경하여 다양한 모델 아키텍처, 태스크, 피처, 모달리티를 실험할 수 있습니다. 딥러닝을 위한 빌딩 블록이라고 생각하세요.
- 🚢 **프로덕션을 위한 설계:** 사전 빌드된 [Docker](https://hub.docker.com/u/ludwigai) 컨테이너, [Kubernetes](https://github.com/ray-project/kuberay)에서 [Ray](https://www.ray.io/) 실행 네이티브 지원, [Torchscript](https://pytorch.org/docs/stable/jit.html) 및 [Triton](https://developer.nvidia.com/triton-inference-server)으로 모델 내보내기, 한 번의 명령으로 [HuggingFace](https://huggingface.co/models)에 업로드.
Ludwig는 [Linux Foundation AI & Data](https://lfaidata.foundation/)에서 호스팅합니다.
**기술 스택:** Python 3.12 | PyTorch 2.6 | Pydantic 2 | Transformers 5 | Ray 2.54
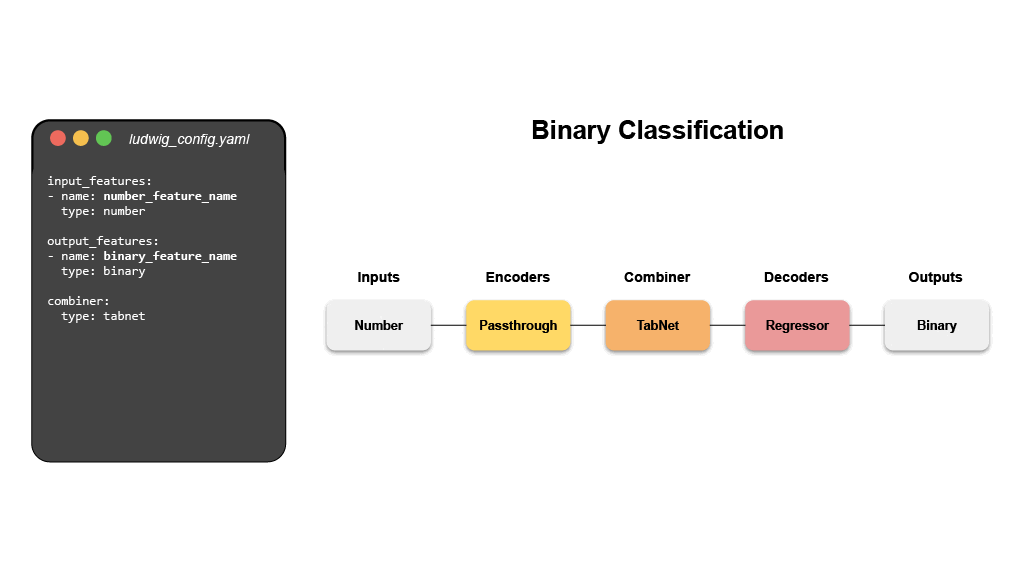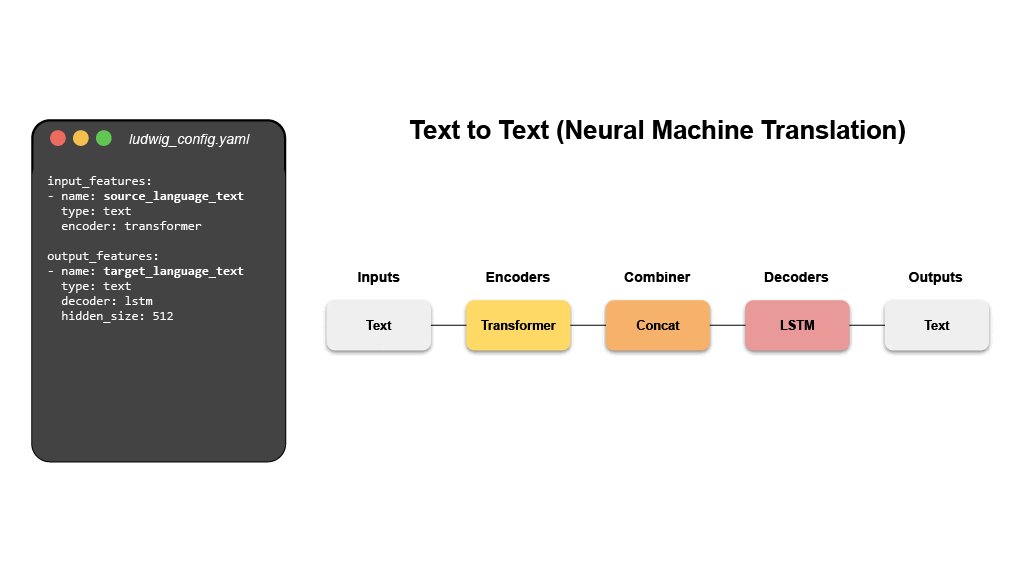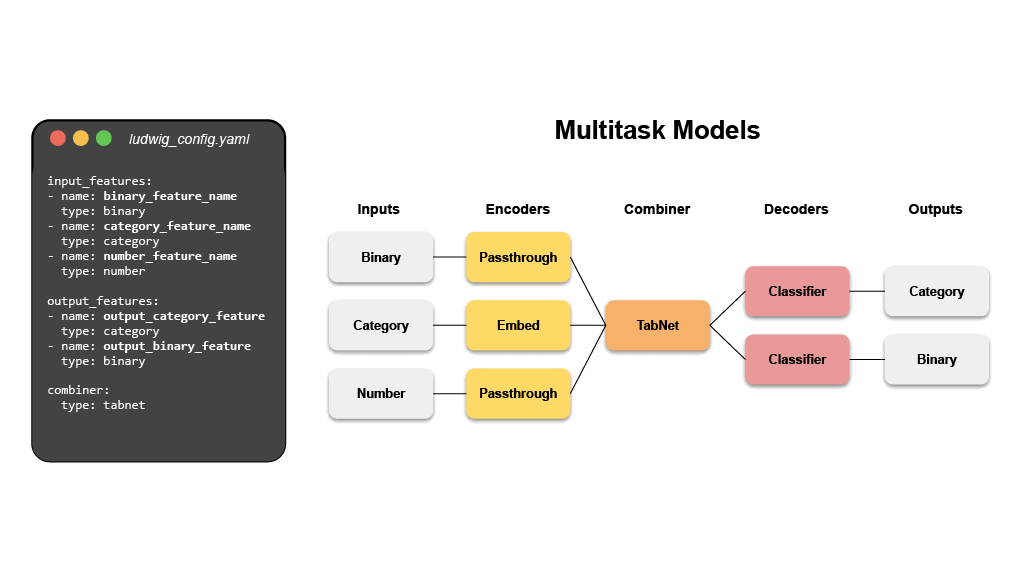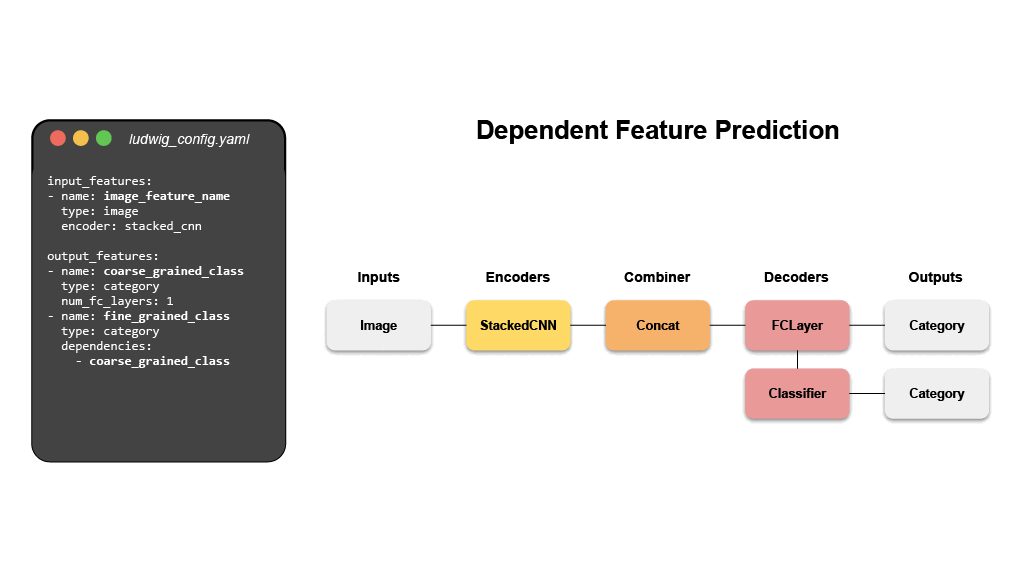
# 💾 설치
PyPI에서 설치합니다. Ludwig는 Python 3.12 이상을 요구합니다.
```shell
pip install ludwig
```
모든 선택적 의존성을 포함하여 설치:
```shell
pip install ludwig[full]
```
더 자세한 설치 방법은 [기여 가이드](https://github.com/ludwig-ai/ludwig/blob/main/CONTRIBUTING.md)를 참조하세요.
# 🚂 시작하기
Ludwig의 기능을 빠르게 살펴보고 싶으시다면 이 Colab 노트북을 확인하세요 🚀 [](https://colab.research.google.com/drive/1lB4ALmEyvcMycE3Mlnsd7I3bc0zxvk39)
LLM 미세 조정을 원하시나요? 다음 노트북을 확인하세요:
1. Fine-Tune Llama-2-7b: [](https://colab.research.google.com/drive/1r4oSEwRJpYKBPM0M0RSh0pBEYK_gBKbe)
1. Fine-Tune Llama-2-13b: [](https://colab.research.google.com/drive/1zmSEzqZ7v4twBrXagj1TE_C--RNyVAyu)
1. Fine-Tune Mistral-7b: [](https://colab.research.google.com/drive/1i_8A1n__b7ljRWHzIsAdhO7u7r49vUm4)
전체 튜토리얼은 공식 [시작 가이드](https://ludwig.ai/latest/getting_started/)를 확인하시거나, 엔드투엔드 [예제](https://ludwig.ai/latest/examples)를 살펴보세요.
## 대규모 언어 모델 미세 조정
[](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)
사전 학습된 LLM을 챗봇처럼 지시를 따르도록 미세 조정("인스트럭션 튜닝")해 봅시다.
### 사전 요구 사항
- [HuggingFace API 토큰](https://huggingface.co/docs/hub/security-tokens)
- 선택한 베이스 모델에 대한 접근 승인 (예: [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B))
- 최소 12 GiB VRAM의 GPU (테스트에서는 Nvidia T4를 사용했습니다)
### 실행
[Stanford Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) 데이터셋을 사용합니다. 다음과 같은 테이블 형식의 파일로 구성됩니다:
| instruction | input | output |
| :-----------------------------------------------: | :--------------: | :-----------------------------------------------: |
| Give three tips for staying healthy. | | 1.Eat a balanced diet and make sure to include... |
| Arrange the items given below in the order to ... | cake, me, eating | I eating cake. |
| Write an introductory paragraph about a famous... | Michelle Obama | Michelle Obama is an inspirational woman who r... |
| ... | ... | ... |
`model.yaml`이라는 YAML 설정 파일을 다음 내용으로 생성하세요:
```yaml
model_type: llm
base_model: meta-llama/Llama-3.1-8B
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
Below is an instruction that describes a task, paired with an input that may provide further context.
Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
decay: cosine
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
backend:
type: local
```
이제 모델을 학습시켜 봅시다:
```bash
export HUGGING_FACE_HUB_TOKEN = "<api_token>"
ludwig train --config model.yaml --dataset "ludwig://alpaca"
```
## 지도 학습 ML
[Rotten Tomatoes](https://www.kaggle.com/stefanoleone992/rotten-tomatoes-movies-and-critic-reviews-dataset) 영화 평론가의 리뷰가 긍정적인지 부정적인지 예측하는 신경망을 만들어 봅시다.
데이터셋은 다음과 같은 CSV 파일입니다:
| movie_title | content_rating | genres | runtime | top_critic | review_content | recommended |
| :------------------: | :------------: | :------------------------------: | :-----: | ---------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------- |
| Deliver Us from Evil | R | Action & Adventure, Horror | 117.0 | TRUE | Director Scott Derrickson and his co-writer, Paul Harris Boardman, deliver a routine procedural with unremarkable frights. | 0 |
| Barbara | PG-13 | Art House & International, Drama | 105.0 | FALSE | Somehow, in this stirring narrative, Barbara manages to keep hold of her principles, and her humanity and courage, and battles to save a dissident teenage girl whose life the Communists are trying to destroy. | 1 |
| Horrible Bosses | R | Comedy | 98.0 | FALSE | These bosses cannot justify either murder or lasting comic memories, fatally compromising a farce that could have been great but ends up merely mediocre. | 0 |
| ... | ... | ... | ... | ... | ... | ... |
[여기](https://ludwig.ai/latest/data/rotten_tomatoes.csv)에서 데이터셋 샘플을 다운로드하세요.
```bash
wget https://ludwig.ai/latest/data/rotten_tomatoes.csv
```
다음으로 `model.yaml`이라는 YAML 설정 파일을 생성하세요:
```yaml
input_features:
- name: genres
type: set
preprocessing:
tokenizer: comma
- name: content_rating
type: category
- name: top_critic
type: binary
- name: runtime
type: number
- name: review_content
type: text
encoder:
type: embed
output_features:
- name: recommended
type: binary
```
이게 전부입니다! 이제 모델을 학습시켜 봅시다:
```bash
ludwig train --config model.yaml --dataset rotten_tomatoes.csv
```
**즐거운 모델링 되세요**
Ludwig를 여러분의 데이터에 적용해 보세요. 질문이 있으시면 [Discord에서 문의](https://discord.gg/CBgdrGnZjy)해 주세요.
# ❓ Ludwig를 사용해야 하는 이유
- **최소한의 머신러닝 보일러플레이트**
Ludwig는 머신러닝의 엔지니어링 복잡성을 기본으로 처리하여, 연구자들이 가장 높은 수준의 추상화에서 모델 구축에 집중할 수 있게 합니다. `torch.nn.Module` 모델에 대한 데이터 전처리, 하이퍼파라미터 최적화, 디바이스 관리, 분산 학습이 완전히 무료로 제공됩니다.
- **손쉬운 벤치마크 구축**
최신 기준 모델을 만들고 새 모델과 비교하는 것이 간단한 설정 변경만으로 가능합니다.
- **새로운 아키텍처를 여러 문제와 데이터셋에 쉽게 적용**
Ludwig가 지원하는 광범위한 태스크 및 데이터셋 세트에 새 모델을 적용하세요. Ludwig에는 간단한 설정만으로 여러 데이터셋에서 여러 모델 실험을 실행할 수 있는 [전체 벤치마킹 도구](https://arxiv.org/abs/2111.04260)가 모든 사용자에게 제공됩니다.
- **데이터 전처리, 모델링, 메트릭의 높은 설정 가능성**
모델 아키텍처, 학습 루프, 하이퍼파라미터 검색, 백엔드 인프라의 모든 측면을 선언적 설정에서 추가 필드로 수정하여 파이프라인을 요구 사항에 맞게 커스터마이즈할 수 있습니다. 설정 가능한 항목에 대한 자세한 내용은 [Ludwig 설정](https://ludwig.ai/latest/configuration/) 문서를 확인하세요.
- **멀티모달, 멀티태스크 학습 기본 지원**
코드 작성 없이 테이블 데이터, 텍스트, 이미지, 오디오까지 복잡한 모델 설정으로 혼합하여 사용할 수 있습니다.
- **풍부한 모델 내보내기 및 추적**
Tensorboard, Comet ML, Weights & Biases, MLFlow, Aim Stack 등의 도구로 모든 시도와 메트릭을 자동으로 추적합니다.
- **멀티 GPU, 멀티 노드 클러스터로 학습 자동 확장**
로컬 머신에서 클라우드로 코드 변경 없이 전환할 수 있습니다.
- **사전 학습된 Huggingface Transformers를 포함한 최신 모델의 로우코드 인터페이스**
Ludwig는 [Huggingface Transformers](https://huggingface.co/docs/transformers/index)에서 제공하는 사전 학습된 모델과 네이티브로 통합됩니다. 사용자는 코드를 전혀 작성하지 않고도 방대한 최신 사전 학습 PyTorch 모델을 사용할 수 있습니다. 예를 들어, Ludwig로 BERT 기반 감성 분석 모델을 학습시키는 것은 다음과 같이 간단합니다:
```shell
ludwig train --dataset sst5 --config_str "{input_features: [{name: sentence, type: text, encoder: bert}], output_features: [{name: label, type: category}]}"
```
- **AutoML을 위한 로우코드 인터페이스**
[Ludwig AutoML](https://ludwig.ai/latest/user_guide/automl/)을 사용하면 데이터셋, 대상 컬럼, 시간 예산만 제공하여 학습된 모델을 얻을 수 있습니다.
```python
auto_train_results = ludwig.automl.auto_train(dataset=my_dataset_df, target=target_column_name, time_limit_s=7200)
```
- **손쉬운 프로덕션화**
Ludwig는 GPU를 포함한 딥러닝 모델 서빙을 쉽게 만들어 줍니다. 학습된 Ludwig 모델에 대한 REST API를 실행하세요.
```shell
ludwig serve --model_path=/path/to/model
```
Ludwig는 효율적인 Torchscript 번들로 모델 내보내기를 지원합니다.
```shell
ludwig export_torchscript --model_path=/path/to/model
```
# 📚 튜토리얼
- [텍스트 분류](https://ludwig.ai/latest/examples/text_classification)
- [테이블 데이터 분류](https://ludwig.ai/latest/examples/adult_census_income)
- [이미지 분류](https://ludwig.ai/latest/examples/mnist)
- [멀티모달 분류](https://ludwig.ai/latest/examples/multimodal_classification)
# 🔬 예제 사용 사례
- [개체명 인식 태깅](https://ludwig.ai/latest/examples/ner_tagging)
- [자연어 이해](https://ludwig.ai/latest/examples/nlu)
- [기계 번역](https://ludwig.ai/latest/examples/machine_translation)
- [seq2seq를 통한 대화 모델링](https://ludwig.ai/latest/examples/seq2seq)
- [감성 분석](https://ludwig.ai/latest/examples/sentiment_analysis)
- [시아미즈 네트워크를 이용한 원샷 학습](https://ludwig.ai/latest/examples/oneshot)
- [시각적 질의응답](https://ludwig.ai/latest/examples/visual_qa)
- [음성 숫자 인식](https://ludwig.ai/latest/examples/speech_recognition)
- [화자 인증](https://ludwig.ai/latest/examples/speaker_verification)
- [이진 분류 (타이타닉)](https://ludwig.ai/latest/examples/titanic)
- [시계열 예측](https://ludwig.ai/latest/examples/forecasting)
- [시계열 예측 (날씨)](https://ludwig.ai/latest/examples/weather)
- [영화 평점 예측](https://ludwig.ai/latest/examples/movie_ratings)
- [다중 레이블 분류](https://ludwig.ai/latest/examples/multi_label)
- [멀티태스크 학습](https://ludwig.ai/latest/examples/multi_task)
- [단순 회귀: 연비 예측](https://ludwig.ai/latest/examples/fuel_efficiency)
- [사기 탐지](https://ludwig.ai/latest/examples/fraud)
# 💡 추가 정보
[Ludwig](https://arxiv.org/pdf/1909.07930.pdf), [선언적 ML](https://arxiv.org/pdf/2107.08148.pdf), [Ludwig의 SoTA 벤치마크](https://openreview.net/pdf?id=hwjnu6qW7E4)에 대한 논문을 읽어보세요.
[Ludwig의 작동 방식](https://ludwig.ai/latest/user_guide/how_ludwig_works/), [시작 가이드](https://ludwig.ai/latest/getting_started/), 더 많은 [예제](https://ludwig.ai/latest/examples)를 확인하세요.
[기여](https://github.com/ludwig-ai/ludwig/blob/main/CONTRIBUTING.md)에 관심이 있으시거나, 질문, 의견, 공유하고 싶은 생각이 있으시거나, 최신 정보를 받고 싶으시다면 [Discord 커뮤니티에 참여](https://discord.gg/CBgdrGnZjy)하시고 [X](https://twitter.com/ludwig_ai)에서 팔로우해 주세요!
# 🤝 함께 Ludwig를 만들어 갈 커뮤니티에 참여하세요
Ludwig는 여러분과 같은 분들의 기여에 의존하는 활발하게 관리되는 오픈소스 프로젝트입니다. Ludwig를 모든 사람이 사용할 수 있는 더 접근 가능하고 기능이 풍부한 프레임워크로 만들기 위해 활발한 Ludwig 기여자 그룹에 참여하는 것을 고려해 주세요!
<a href="https://github.com/ludwig-ai/ludwig/graphs/contributors">
<img src="https://contrib.rocks/image?repo=ludwig-ai/ludwig" />
</a><br/>
## Star History
[](https://star-history.com/#ludwig-ai/ludwig&Date)
# 👋 참여하기
- [Discord](https://discord.gg/CBgdrGnZjy)
- [X (Twitter)](https://twitter.com/ludwig_ai)
- [Medium](https://medium.com/ludwig-ai)
- [GitHub Issues](https://github.com/ludwig-ai/ludwig/issues)
================================================
FILE: RELEASES.md
================================================
# Releasing
## Release procedure
1. Update version number in `ludwig/globals.py`
1. Update version number in `setup.py`
1. Commit
1. Tag the commit with the version number `vX.Y.Z` with a meaningful message
1. Push with `--tags`
1. If a non-patch release, edit the release notes
1. Create a release for Pypi: `python setup.py sdist`
1. Release on Pypi: `twine upaload --repository pypi dist/ludwig-X.Y.Z.tar.gz`
## Release policy
Ludwig follows [Semantic Versioning](https://semver.org).
In general, for major and minor releases, maintainers should all agree on the release.
For patches, in particular time sensitive ones, a single maintainer can release without a full consensus, but this practice should be reserved for critical situations.
================================================
FILE: docker/README.md
================================================
# Ludwig Docker Images
These images provide Ludwig, a toolbox to train and evaluate deep learning models
without the need to write code. Ludwig Docker images contain the full set of pre-requisite
packages to support these capabilities
- text features
- image features
- audio features
- visualizations
- hyperparameter optimization
- distributed training
- model serving
## Repositories
These four repositories contain a version of Ludwig with full features built
from the project's `master` branch.
- `ludwigai/ludwig` Ludwig packaged with PyTorch
- `ludwigai/ludwig-gpu` Ludwig packaged with gpu-enabled version of PyTorch
- `ludwigai/ludwig-ray` Ludwig packaged with PyTorch
and Ray 2.3.1 (https://github.com/ray-project/ray)
- `ludwigai/ludwig-ray-gpu` Ludwig packaged with gpu-enabled versions of PyTorch
and Ray 2.3.1 (https://github.com/ray-project/ray)
## Image Tags
- `master` - built from Ludwig's `master` branch
- `nightly` - nightly build of Ludwig's software.
- `sha-<commit point>` - version of Ludwig software at designated git sha1
7-character commit point.
## Running Containers
Examples of using the `ludwigai/ludwig:master` image to:
- run the `ludwig cli` command or
- run Python program containing Ludwig api or
- view Ludwig results with Tensorboard
For purposes of the examples assume this host directory structure
```
/top/level/directory/path/
data/
train.csv
src/
config.yaml
ludwig_api_program.py
```
### Run Ludwig CLI
```
# set shell variable to parent directory
parent_path=/top/level/directory/path
# invoke docker run command to execute the ludwig cli
# map host directory ${parent_path}/data to container /data directory
# map host directory ${parent_path}/src to container /src directory
docker run -v ${parent_path}/data:/data \
-v ${parent_path}/src:/src \
ludwigai/ludwig:master \
experiment --config /src/config.yaml \
--dataset /data/train.csv \
--output_directory /src/results
```
Experiment results can be found in host directory `/top/level/directory/path/src/results`
### Run Python program using Ludwig APIs
```
# set shell variable to parent directory
parent_path=/top/level/directory/path
# invoke docker run command to execute Python interpreter
# map host directory ${parent_path}/data to container /data directory
# map host directory ${parent_path}/src to container /src directory
# set current working directory to container /src directory
# change default entrypoint from ludwig to python
docker run -v ${parent_path}/data:/data \
-v ${parent_path}/src:/src \
-w /src \
--entrypoint python \
ludwigai/ludwig:master /src/ludwig_api_program.py
```
Ludwig results can be found in host
directory `/top/level/directory/path/src/results`
### View Ludwig Tensorboard results
```
# set shell variable to parent directory
parent_path=/top/level/directory/path
# invoke docker run command to execute Tensorboard
# map host directory ${parent_path}/src to container /src directory
# set up mapping from localhost port 6006 to container port 6006
# change default entrypoint from ludwig to tensorboard
# --logdir container location of tenorboard logs /src/results/<experiment_name>_<model_name>/model/logs
# --bind_all Tensorboard serves on all public container interfaces
docker run -v ${parent_path}/src:/src \
-p 6006:6006 \
--entrypoint tensorboard \
ludwigai/ludwig:master \
--logdir /src/results/experiment_run/model/logs \
--bind_all
```
Point browser to `http://localhost:6006` to see Tensorboard dashboard.
### Devcontainer
If you want to contribute to Ludwig, you can setup a Docker container with all the dependencies
installed as a full featured development environment. This can be done using devcontainers with VS Code:
https://code.visualstudio.com/docs/devcontainers/containers
You can find the `devcontainer.json` file within the top level `.devcontainer` folder.
================================================
FILE: docker/ludwig/Dockerfile
================================================
#
# Ludwig Docker image with full set of pre-requiste packages to support these capabilities
# text features
# image features
# audio features
# visualizations
# hyperparameter optimization
# distributed training
# model serving
#
FROM python:3.12-slim
RUN apt-get -y update && apt-get -y install \
git \
libsndfile1 \
build-essential \
g++ \
cmake \
ffmpeg \
sox \
libsox-dev
RUN pip install -U pip
WORKDIR /ludwig
RUN pip install --no-cache-dir torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
COPY . .
RUN pip install --no-cache-dir '.[full]'
WORKDIR /data
ENTRYPOINT ["ludwig"]
================================================
FILE: docker/ludwig-gpu/Dockerfile
================================================
#
# Ludwig Docker image with full set of pre-requiste packages to support these capabilities
# text features
# image features
# audio features
# visualizations
# hyperparameter optimization
# distributed training
# model serving
#
FROM pytorch/pytorch:2.6.0-cuda12.4-cudnn9-devel
RUN apt-get -y update && DEBIAN_FRONTEND="noninteractive" apt-get -y install \
git \
libsndfile1 \
cmake \
ffmpeg \
sox \
libsox-dev
RUN pip install -U pip
WORKDIR /ludwig
COPY . .
RUN pip install --no-cache-dir '.[full]'
WORKDIR /data
ENTRYPOINT ["ludwig"]
================================================
FILE: docker/ludwig-ray/Dockerfile
================================================
#
# Ludwig Docker image with Ray support and full dependencies including:
# text features
# image features
# audio features
# visualizations
# hyperparameter optimization
# distributed training
# model serving
#
FROM rayproject/ray:2.44.1-py312
RUN sudo apt-get update && DEBIAN_FRONTEND="noninteractive" sudo apt-get install -y \
build-essential \
wget \
git \
curl \
libsndfile1 \
cmake \
tzdata \
rsync \
vim \
ffmpeg \
sox \
libsox-dev
RUN pip install -U pip
WORKDIR /ludwig
RUN pip install --no-cache-dir torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
COPY . .
RUN pip install --no-cache-dir '.[full]' --extra-index-url https://download.pytorch.org/whl/cpu
================================================
FILE: docker/ludwig-ray-gpu/Dockerfile
================================================
#
# Ludwig Docker image with Ray support and full dependencies including:
# text features
# image features
# audio features
# visualizations
# hyperparameter optimization
# distributed training
# model serving
#
FROM rayproject/ray:2.44.1-py312-cu124
RUN sudo apt-get update && \
DEBIAN_FRONTEND="noninteractive" sudo apt-get install -y \
build-essential \
wget \
git \
curl \
libsndfile1 \
cmake \
tzdata \
rsync \
vim \
ffmpeg \
sox \
libsox-dev
RUN pip install -U pip
WORKDIR /ludwig
RUN pip install --no-cache-dir torch==2.6.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
COPY . .
RUN pip install --no-cache-dir '.[full]'
================================================
FILE: examples/README.md
================================================
# Examples
This directory contains example programs demonstrating Ludwig's Python APIs.
| Directory | Examples Provided |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| hyperopt | Demonstrates Ludwig's to hyper-parameter optimization capability. |
| kfold_cv | Provides two examples for performing a k-fold cross validation analysis. One example uses the `ludwig experiment` cli. The other example uses the `ludwig.experiment.kfold_cross_validate()` api function. |
| mnist | Creates a model config data structure from a yaml file and trains a model. Programmatically modify the model config data structure to evaluate several different neural network architectures. Jupyter notebook demonstrates using a hold-out test data set to visualize model performance for alternative model architectures. |
| titanic | Trains a simple model with model config contained in a yaml file. Trains multiple models from yaml files and generate visualizations to compare training results. Jupyter notebook demonstrating how to programmatically create visualizations. |
| serve | Demonstrates running Ludwig http model server. A sample Python program illustrates how to invoke the REST API to get predictions from input features. |
| class_imbalance | Demonstrates using our class balancing feature to over-sample an imbalanced dataset. |
================================================
FILE: examples/calibration/README.md
================================================
# Calibration Examples
Drawing on the methods in
On Calibration of Modern Neural Networks (Chuan Guo, Geoff Pleiss, Yu Sun, Kilian Q. Weinberger), Ludwig supports
temperature scaling for binary and category output features. Temperature scaling brings a model’s output probabilities
closer to the true likelihood while preserving the same accuracy and top k predictions.
To enable calibration, add calibration: True to any binary or category feature:
```
output_features:
- name: Cover_Type
type: category
calibration: True
```
With calibration enabled, Ludwig will attempt to find a scale factor (temperature) which will bring the probabilities
closer to the true likelihoods using the validation set. This calibration phase is run after training is complete. If
no validation set is provided, the training set is used for calibration.
To visualize the effects of calibration in Ludwig, you can use Calibration Plots, which bin the data based on model
probability and plot the model probability (X) versus the observed rate (Y) for each bin.
================================================
FILE: examples/calibration/train_forest_cover_calibrated.py
================================================
#!/usr/bin/env python
import copy
import logging
import shutil
import numpy as np
import yaml
import ludwig.visualize
from ludwig.api import LudwigModel
from ludwig.datasets import forest_cover
# clean out prior results
shutil.rmtree("./results_forest_cover", ignore_errors=True)
shutil.rmtree("./visualizations_forest_cover", ignore_errors=True)
# Download and prepare the dataset
dataset = forest_cover.load()
config_yaml = """
input_features:
- name: Elevation
type: number
- name: Aspect
type: number
- name: Slope
type: number
- name: Horizontal_Distance_To_Hydrology
type: number
- name: Vertical_Distance_To_Hydrology
type: number
- name: Horizontal_Distance_To_Roadways
type: number
- name: Hillshade_9am
type: number
- name: Hillshade_Noon
type: number
- name: Hillshade_3pm
type: number
- name: Horizontal_Distance_To_Fire_Points
type: number
- name: Wilderness_Area
type: category
- name: Soil_Type
type: category
output_features:
- name: Cover_Type
type: category
combiner:
type: transformer
trainer:
batch_size: 256
learning_rate: .001
epochs: 1
"""
uncalibrated_config = yaml.safe_load(config_yaml)
scaled_config = copy.deepcopy(uncalibrated_config)
scaled_config["output_features"][0]["calibration"] = True
uncalibrated_model = LudwigModel(config=uncalibrated_config, logging_level=logging.INFO)
uncalibrated_model.train(
dataset,
model_name="uncalibrated",
experiment_name="forest_cover_calibration",
output_directory="results_forest_cover",
)
scaled_model = LudwigModel(config=scaled_config, logging_level=logging.INFO)
scaled_model.train(
dataset, model_name="scaled", experiment_name="forest_cover_calibration", output_directory="results_forest_cover"
)
# Generates predictions and performance statistics for the test set.
uncalibrated_test_stats, uncalibrated_test_predictions, _ = uncalibrated_model.evaluate(
dataset, collect_predictions=True, collect_overall_stats=True
)
scaled_test_stats, scaled_test_predictions, _ = scaled_model.evaluate(
dataset, collect_predictions=True, collect_overall_stats=True
)
uncalibrated_probs = np.stack(uncalibrated_test_predictions["Cover_Type_probabilities"], axis=0)
scaled_probs = np.stack(scaled_test_predictions["Cover_Type_probabilities"], axis=0)
ludwig.visualize.calibration_1_vs_all(
probabilities_per_model=[uncalibrated_probs, scaled_probs],
model_names=["Uncalibrated", "Calibrated"],
ground_truth=dataset["Cover_Type"],
metadata=uncalibrated_model.training_set_metadata,
output_feature_name="Cover_Type",
top_n_classes=[7, 7],
labels_limit=7,
output_directory="visualizations_forest_cover",
file_format="png",
)
================================================
FILE: examples/calibration/train_mushroom_edibility_calibrated.py
================================================
#!/usr/bin/env python
import copy
import logging
import shutil
import numpy as np
import yaml
import ludwig.visualize
from ludwig.api import LudwigModel
from ludwig.datasets import mushroom_edibility
# clean out prior results
shutil.rmtree("./results_mushroom_edibility", ignore_errors=True)
shutil.rmtree("./visualizations_mushroom_edibility", ignore_errors=True)
# Download and prepare the dataset
dataset = mushroom_edibility.load()
# This dataset has no split, so add a split column
dataset.split = np.random.choice(3, len(dataset), p=(0.7, 0.1, 0.2))
config_yaml = """
input_features:
- name: cap-shape
type: category
- name: cap-surface
type: category
- name: cap-color
type: category
- name: bruises?
type: category
- name: odor
type: category
- name: gill-attachment
type: category
- name: gill-spacing
type: category
- name: gill-size
type: category
- name: gill-color
type: category
- name: stalk-shape
type: category
- name: stalk-root
type: category
- name: stalk-surface-above-ring
type: category
- name: stalk-surface-below-ring
type: category
- name: stalk-color-above-ring
type: category
- name: stalk-color-below-ring
type: category
- name: veil-type
type: category
- name: veil-color
type: category
- name: ring-number
type: category
- name: ring-type
type: category
- name: spore-print-color
type: category
- name: population
type: category
- name: habitat
type: category
output_features:
- name: class
type: category
combiner:
type: concat
trainer:
batch_size: 256
learning_rate: .0001
epochs: 10
"""
uncalibrated_config = yaml.safe_load(config_yaml)
scaled_config = copy.deepcopy(uncalibrated_config)
scaled_config["output_features"][0]["calibration"] = True
uncalibrated_model = LudwigModel(config=uncalibrated_config, logging_level=logging.INFO)
uncalibrated_model.train(
dataset,
model_name="uncalibrated",
experiment_name="mushroom_edibility_calibration",
output_directory="results_mushroom_edibility",
)
scaled_model = LudwigModel(config=scaled_config, logging_level=logging.INFO)
scaled_model.train(
dataset,
model_name="scaled",
experiment_name="mushroom_edibility_calibration",
output_directory="results_mushroom_edibility",
)
# Generates predictions and performance statistics for the test set.
uncalibrated_test_stats, uncalibrated_test_predictions, _ = uncalibrated_model.evaluate(
dataset, collect_predictions=True, collect_overall_stats=True
)
scaled_test_stats, scaled_test_predictions, _ = scaled_model.evaluate(
dataset, collect_predictions=True, collect_overall_stats=True
)
uncalibrated_probs = np.stack(uncalibrated_test_predictions["class_probabilities"], axis=0)
scaled_probs = np.stack(scaled_test_predictions["class_probabilities"], axis=0)
ludwig.visualize.calibration_1_vs_all(
probabilities_per_model=[uncalibrated_probs, scaled_probs],
model_names=["Uncalibrated", "Calibrated"],
ground_truth=dataset["class"],
metadata=uncalibrated_model.training_set_metadata,
output_feature_name="class",
top_n_classes=[3, 3],
labels_limit=3,
output_directory="visualizations_mushroom_edibility",
file_format="png",
)
================================================
FILE: examples/class_imbalance/README.md
================================================
# Credit Card Fraud Detection Example
This API example is based on Kaggle's [Imbalanced Insurance](https://www.kaggle.com/arashnic/imbalanced-data-practice) dataset for detecting whether customers will buy vehicle insurance.
### Preparatory Steps
Create and download your [Kaggle API Credentials](https://github.com/Kaggle/kaggle-api#api-credentials).
The Imbalanced Insurance dataset is hosted by Kaggle, and as such Ludwig will need to authenticate you through the Kaggle API to download the dataset.
### Examples
| File | Description |
| ---------------------------- | -------------------------------------------------------------------------------------------------------------- |
| model_training.py | Demonstrates the use of oversampling by training two different models: one with no oversampling, and one with. |
| model_training_results.ipynb | Example for extracting training statistics and generating visualizations. |
Enter `python model_training.py` will train a standard model with no class balancing and a balanced model with class balancing applied. Results of model training will be stored in this location.
```
./results/
balance_example_standard_model/
balance_example_balanced_model/
```
The only difference between these two models is that the balanced model uses a small amount of oversampling in addition to the other configuration parameters.
The way this is done is by specifying the ratio that you want the minority class to have in relation to the majority class.
For instance, if you specify 0.5 for the `oversample_minority` preprocessing parameter, the minority class will be oversampled until it makes up 50% of the majority class.
In this example, we had an imbalance where the minority class was 19% of the majority class in size. We decided that we wanted to increase that to 26%.
Though this doesn't seem like much, it is enough to get some small performance improvements without experiencing performance degradation due to over-fitting.
Here are the performance differences in the two models followed by some plots showing different metrics over training:
| Metric | Standard Model | Balanced Model |
| :------: | :------------: | :------------: |
| Loss | 0.3649 | 0.2758 |
| Accuracy | 0.7732 | 0.8237 |
| ROC AUC | 0.8533 | 0.8660 |
Here are the learning curve plots from both models:


Here is the comparison of model performances on ROC_AUC and Accuracy:

The creation of the learning curves is demonstrated in the Jupyter notebook `model_training_results.ipynb`. The comparison plot was generated using the ludwig visualize [compare performance](https://ludwig-ai.github.io/ludwig-docs/0.4/user_guide/visualizations/#compare-performance) command.
================================================
FILE: examples/class_imbalance/balanced_model_config.yaml
================================================
input_features:
- name: Gender
type: category
- name: Age
type: number
- name: Driving_License
type: binary
- name: Region_Code
type: number
- name: Previously_Insured
type: binary
- name: Vehicle_Age
type: category
- name: Vehicle_Damage
type: category
- name: Annual_Premium
type: number
- name: Policy_Sales_Channel
type: number
- name: Vintage
type: number
output_features:
- name: Response
type: binary
preprocessing:
oversample_minority: 0.26
trainer:
learning_rate: 0.0001
learning_rate_scheduler:
decay: exponential
decay_rate: 0.9
decay_steps: 30000
staircase: True
epochs: 50
================================================
FILE: examples/class_imbalance/model_training.py
================================================
#!/usr/bin/env python
# # Class Imbalance Model Training Example
#
# This example trains a model utilizing a standard config, and then a config using oversampling
import logging
import shutil
# Import required libraries
from ludwig.api import LudwigModel
from ludwig.datasets import imbalanced_insurance
from ludwig.visualize import compare_performance
# clean out old results
shutil.rmtree("./results", ignore_errors=True)
shutil.rmtree("./visualizations", ignore_errors=True)
# list models to train
list_of_model_ids = ["standard_model", "balanced_model"]
list_of_eval_stats = []
training_set, val_set, test_set = imbalanced_insurance.load()
# Train models
for model_id in list_of_model_ids:
print(">>>> training: ", model_id)
# Define Ludwig model object that drive model training
model = LudwigModel(config=model_id + "_config.yaml", logging_level=logging.WARN)
# initiate model training
train_stats, _, _ = model.train(
training_set=training_set,
validation_set=val_set,
test_set=test_set,
experiment_name="balance_example",
model_name=model_id,
skip_save_model=True,
)
# evaluate model on test_set
eval_stats, _, _ = model.evaluate(test_set)
# save eval stats for later use
list_of_eval_stats.append(eval_stats)
print(">>>>>>> completed: ", model_id, "\n")
compare_performance(
list_of_eval_stats,
"Response",
model_names=list_of_model_ids,
output_directory="./visualizations",
file_format="png",
)
================================================
FILE: examples/class_imbalance/model_training_results.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "8c1e31e4-d8d4-4e83-8f4c-f868365d14d7",
"metadata": {},
"source": [
"# Model Analysis\n",
"\n",
"This notebook will analyze the training results of the standard and balanced model on the [imbalanced insurance](https://www.kaggle.com/arashnic/imbalanced-data-practice) dataset. In order for the cells in this notebook to run, you must first run the following command to train the models:\n",
"```\n",
"python model_training.py\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "a3b3b6c1-5d11-4a03-9dfa-b070e45b2adb",
"metadata": {},
"source": [
"## Import required libraries"
]
},
{
"cell_type": "code",
"execution_count": 226,
"id": "6a6bbd43-1333-4a0e-b895-c3e393d5ee07",
"metadata": {},
"outputs": [],
"source": [
"from ludwig.utils.data_utils import load_json\n",
"from ludwig.visualize import learning_curves\n",
"import pandas as pd\n",
"import numpy as np\n",
"import os.path\n",
"import matplotlib.pyplot as plt\n",
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"id": "b5e4d240-7607-4036-9573-6b452523c18f",
"metadata": {},
"source": [
"## Learning Curves"
]
},
{
"cell_type": "markdown",
"id": "725dde7d-f7a5-4836-8cf1-a3f50acafd30",
"metadata": {},
"source": [
"### Create Plotting Data Function "
]
},
{
"cell_type": "code",
"execution_count": 227,
"id": "d8c35325-cfab-4ead-8699-1e98e55a8c7b",
"metadata": {},
"outputs": [],
"source": [
"def create_plot_ready_data(list_of_train_stats, model_names, metric, target):\n",
" # List of splits to evaluate statistics for\n",
" list_of_splits = ['training', 'validation', 'test'] \n",
" \n",
" # Empty list to fill with dfs for each models' stats\n",
" list_of_train_stats_df = []\n",
" \n",
" # For each models' stats, create a df with columns of stats for each split listed above\n",
" for name, stats in zip(model_names, list_of_train_stats):\n",
" list_of_dfs = []\n",
" for split in list_of_splits:\n",
" df = pd.DataFrame(stats[split][target])\n",
" df.columns = [split + '_' + c for c in df.columns]\n",
" list_of_dfs.append(df)\n",
" \n",
" combined_df = pd.concat(list_of_dfs, axis=1)\n",
" combined_df.name = name\n",
" combined_df['epoch'] = combined_df.index + 1\n",
" list_of_train_stats_df.append(combined_df)\n",
" \n",
" # holding ready for plot ready data\n",
" plot_ready_list = []\n",
" \n",
" # consolidate the multiple training statistics dataframes\n",
" for df in list_of_train_stats_df:\n",
" for col in ['training', 'validation']:\n",
" df2 = df[['epoch', col + '_{}'.format(metric)]].copy()\n",
" df2.columns = ['epoch', '{}'.format(metric)]\n",
" df2['split'] = col\n",
" df2['model'] = df.name\n",
" plot_ready_list.append(df2)\n",
"\n",
" return pd.concat(plot_ready_list, axis=0, ignore_index=True)"
]
},
{
"cell_type": "markdown",
"id": "722f5f48-7026-427e-9bb7-388fec15a24f",
"metadata": {
"tags": []
},
"source": [
"### Create Plotting Data"
]
},
{
"cell_type": "code",
"execution_count": 228,
"id": "6b48aef8-11a8-4bba-8d52-114adb9cb2f2",
"metadata": {},
"outputs": [],
"source": [
"standard_stats = load_json(os.path.join('results/balance_example_standard_model','training_statistics.json'))\n",
"balanced_stats = load_json(os.path.join('results/balance_example_balanced_model','training_statistics.json'))\n",
"\n",
"accuracy_learning_curves = create_plot_ready_data([standard_stats, balanced_stats], ['standard_model', 'balanced_model'], 'accuracy', 'Response')\n",
"roc_auc_learning_curves = create_plot_ready_data([standard_stats, balanced_stats], ['standard_model', 'balanced_model'], 'roc_auc', 'Response')\n",
"loss_learning_curves = create_plot_ready_data([standard_stats, balanced_stats], ['standard_model', 'balanced_model'], 'loss', 'Response')"
]
},
{
"cell_type": "code",
"execution_count": 229,
"id": "a06aaa41-e692-4348-aab5-6bd78711f6f1",
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAmkAAAGICAYAAAAagXdoAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAACwC0lEQVR4nOzddXhb5/nw8e85OkJLMtuJw3jCaaCctiljSiutTNu6des6eLeO6TeGjte1a7uuzExpm2KKYT5hTswk1oH3jyM7dmKQSbLj53NdvhLr0K1j2br1wP1IlmUhCIIgCIIg9C9ytgMQBEEQBEEQDiWSNEEQBEEQhH5IJGmCIAiCIAj9kEjSBEEQBEEQ+iGRpAmCIAiCIPRDIkkTBEEQBEHoh5RsByAIQs+pqroCmAkcpWnaZ1kOJ2tUVf0p8G1N0/zZjqU9qqq+A4Q0TTsvQ9c7Cfg6cAyQC2wHHgH+rGlaOBMxCILQPaIlTRAGOFVVpwMzgHXAzVkOR+jcV4BvZeJCqqp+F3gbkIDbgAXAA6nrL1RVNScTcQiC0D2iJU0QBr7rgJXA/4Cfqar6TdFC0n9pmrYuE9dJtaD9GviNpmnfb7Fpkaqq7wOLgW8Cv8hEPIIgdJ1I0gRhAFNV1QFcid068jjwB+Ay4P4W+4wCfg+cBljAO8A3NE3b2dl2VVWvT52rWNO0qtT+eUAtcIOmaf9NdTGeB7wP3ACs1TTteFVVhwK/BM4CioFK4Angu5qmxVPn8gI/Bz4P5AGrUtvfV1X1aUDVNG3aQc9ZA17UNO3bPbhvnwe+D0wA9mB3/f2txfYgdvJyITAUqAdeAb6uaVpdah8L+AFwFTAE+FLqPvhT9+KbQAnwMfAVTdPWp457h1R3p6qq87Fbuk4EfgPMAfYCv9I07T8t4pkJ3AkcDZQDPwZ+CjykadpP23ma38a+5z8/eIOmaR+pqvpjYGvq/E1xHKlp2pIW161L3Zufpl4LfwB+C3wXqMb+cDBT0zT1oPu7BFinadq1qe9vA74GjAQ2Az/XNO3xFvufk4pzChACXsLutq5p57kJwqAgujsFYWA7HTuJeFjTtL3AW7To8kwlGx9gd4d+BbgemAS8qqqqo7PtXYhjJnAk8DngV6qqysBrwGzgVuBM4EHssVFfbHHcY6nvf4edEJWnrj0eu2Vwaqo7t+n5HAlMTJ2rW1RVvQ57TNa7wPnYCe6dqqr+vxa7PQJcANwBnIGdnFwJ/Oig0/0U+DtwC3ZiBnaye13quV6NnQj+t5OwHgWeBs4BlgP3qKo6JRVvKXYC5QWuwE6S/gqM6OA5StivjUWapsXa2kfTtP/TNO2RTuI6WB52In4VdoL6H2CiqqozWlx7DHay+Wjq+58Af8T+WS8A3gAeVVX10tT2UcAz2C1752B3xS4A/tHF2AThsCNa0gRhYLsWWK5p2prU9/8DHlRVdXKq5eYG7FaeiZqmbQNQVXUX8Cx2MnZaJ9vTpQC3N7XCqKo6Aru17TZN01al9lmkqupZwEnA31KtQ+cD12qa9mDquPewk5TjsROlSuzk6Hupc1wFrNE0bWUXYmuWSh5/hZ3UfjX18MJUq9iPVFX9J2AALuAWTdNeS+3zjqqqx6Vib2mhpmn/anF+gABwrqZp+1KPDQP+oqpqoaZp1e2E9ldN0/6U2n8ZcBFwNvY4w9uwP1Cf3aIVrwp4qoOnWgS4gR0d3Y9ucAA/1jTt9VQcDuzE+lLsVlCAy4Eq4I1Uq+sdwG81TWtKcBeqqhrAbjl8EjgqFetvWtyzEDCql2MXhAFHJGmCMECl3uguAH6dejMEWAREsFvTvgUch939uK3pOE3TVgBjUuf4cSfbj+xCSOtbnGMXMF9VVVlV1QnYrV8zgVJgZ2q341L/vtjiuAQwtcVzfAy79eh7qYTgCuxWme6aCJQBL6uq2vLv36vY3W1HaZr2NnbrGaqqjk4dMw27K+7gVqm2xpftaEo2Unan/s3B7iJsy8dN/9E0rS6VpDQN6p8PvNOUoKU8B+jtnAvsRBP6prek+TlrmmaoqvoEdpLWlIRdBjypaZququoxgIe27/eNqVa3pUAc+DT1834ZeEHTNANBGOREd6cgDFyXAj7ssVO1qa89qceuVVXVBRQAFR2co7Pt6QofPFlBVdWbsMdXbQTuwe4OjWLPNGy6dvKg5ONgDwCjVVU9FrvVrxi7ha27ClP/PgIkW3w1lS0Zmor9fFVVtwDbgIexuw4jLWJv0ta9ixz0vZn6t6O/t20d07R/EXaLYrNUAlPV3slSY7lC2GPA2qSqaomqqs4OYmrPwc/5Eft06nRVVccBs0h1dXLgfn9I6/v9ZOrxoZqmbQVOxR7f9jXsrt3dqqpe1I3YBOGwIlrSBGHguhb4FHsQd0tTscdJXYA94H3cwQeqqno2sCyN7VbqoZYJRqc1yFIzC+/BTiD/rmlaZerxT1vsVg84VVXN1TStvsWxxwK1mqZt0DRtqaqqa4FLsLsRF2matqez63eg6Tq3Yt+7g21Ltfw9iZ0gnqRp2u5UXE9gt6Zl2l7s5LRZqtu2sO3dm70BnKyqqivVQnmw++1TqRNo4+ecGtfWaYkOTdM+VlV1K/Z4xDiwC3ucIxy43xdxoEWx1eGpcywGzlNV1YedsH0HeFJV1ZGpsZaCMCiJljRBGIBUVR2JPSPwQU3T3mn5BdwF7Mfu8vwQmJYanN107GTsmYoz09jekHq4rMXlT0gjxGOw3/j/r0WCVgZM50Br1Iepf5uLuqZa/57ATkCbPIidcJ5LDyYMpGzA7nIcrmnakqYv7ITnF9jFXmdjj0n7TYsELQeYx6EtaZnwHnbXcbDFY2cDnbWC/Rl7dunBkx2aZnOeCTyiaZpF2z/nY0j/g/xj2D+fi4HHUucE+AS75azkoPs9DXuGqqSq6s2qqm5VVdWpaVpE07QXgR9ij38blub1BeGwJFrSBGFguhY7CXr64A2pcUKPY3cdfRH4BvBSqlSGgZ2MfIo9fu3TTrb7scdh/UVV1f/D7j77EXaLSUc+w/4Q+GdVVZ9MHfcD7AHivlScy1RVfQl7EkEQuzTDLditN/9uca6HsAf7x7BnAXbGqarq7W08vkrTtEWp5/mn1CD/t7DH3/0a2ITdvamk7sNvVVX9F3Z347exJ1h09rz7wl+xf5Yvq6r6W+xWtV+ltpntHaRp2nuqqv4e+KGqqpOwuyVD2En2N4GPsEukgD3ofw/wC1VVk0AQe4xe/SEnbtvDHJjc0Tx7V9O0SlVV/wr8UVXVfOzX1RGp6z6vaVpDarLI37Bbzv6JnSD/EPtnsSLN6wvCYUm0pAnCwHQ1sPigAeotPYz9+30jdovbZuwyEP/BfuNboGmanhoP1tn2y7ATg5ewuwmvwX6zb5emaYuwE4HzsAeJ/wh7NuLPgVmqqrpTu16O3Tr2E+wZpQXAqZqm7Whxrj3YScSzmqZ1eN0UF3ZNsYO/Lkudr6lkxvnYLYY/x+7ePFfTNEvTtI3YSfCM1PbfAUuwS5SMTLUIZkxqRujp2D/Pp7Dv5TdSmzv7OXwHe7JFEXbi+xx21+P/AWc21atLjXG7jAOJ8E+wuxw3pxnjOmA1sFHTtOUHbf4OduL/BeyyLF/HbuW7PnXsRuySGyWp5/cI9ozR0zVNS6ZzfUE4XEmWZXW+lyAIQpaodlHcXcBZmqa9me14Mi01Rs+nadpbLR6biD2e6wJN017IWnCCIPQp0d0pCEK/lJopeDV2kdv12F2Tg9E44D5VVb+H3Y1cit11vBFYmM3ABEHoW6K7UxCE/koCbseutH91i8Hog4qmaQ9hdxneDLyOXYl/DXBye6sJCIJweBDdnYIgCIIgCP2QaEkTBEEQBEHohzI2Ji1VfPGf2LWX4sDNmqZtbrH9KuxlbAzgvqb18FRVXc6BaeDbNE27IVMxC4IgCIIgZEsmJw5cCHg0TTs2tZ7bH7ELVDb5A3al9BCwLrWGWxRA07T56V7ENE3LMDruwjVNu7SQLIuGxM6Ie5UecZ/SJ+5V+sS9So+4T+kT9yo9mbxPTqejioNWFWmSySRtHnaNnKZlROYetH0VdrVvHXvAsIXd6uZTVXVhKtbva5r2MR1IJg3276/pMJBo1F4mz+v1df1ZDDLiXqVH3Kf0iXuVPnGv0iPuU/rEvUpPJu/TqFGlO9rblslUOkjr6tWGqqotk8Q1wFJgLfBSqohmBLuF7Uzs4pMPH3SMIAiCIAjCYSmTCU8D9gLJTWRN03QAVVVnYK/7Nga7u/MhVVUvBV4ANqem3m9UVbUaaCps2SZZlvH50st8091PEPcqXeI+pU/cq/SJe5UecZ/SJ+5VerJ9nzLZkrYYOAcgNSZtdYtt9djjz6Kp5UkqgHzsJW3+mDqmDLs1rr1lcARBEARBEA4bmWxJexY4XVXVD7HHnN2gquqVgF/TtLtVVf038IGqqglgC/Y6ggD/VVX1A+wxajc2tb4JgiAIgiAczjKWpGmaZmKPK2tpQ4vtdwF3tXHolX0ZlyAIgiAIQn8k5uAKgiAIgiD0QyJJEwRBEARB6IdEkiYIgiAIgtAPiSRNEARBEAShHxJJmiAIgiAIQj8kkjRBEARBEIR+SCyx1A2RaJS2lnB3OJxIsoyh61iWcch2SXLgcTuRJanvgxQEQRD6DcO0CCd0IgmDIUEPAJsrwzgdEoU5LnJcDiTx3iAcRCRpXfTy2nKOWnQxU+RD10M9J/4r1lmj+bHyP25UXjtk+8+T17Bu+JX87ZLpmQhVOMzsb4jxwdYaNlWG2VEboaIxTm00idvhoDToJp402FEbPeQ4WYJcrxPDtGiI6ZiW/RHDskCSQJYkCnxOctwKsaRJ0jBxOiRcDhmXIuNRZEbl+yjL9RDXDWqiSXxOB4osEddNYrqJz+mgyO+iIaazdl8DScMiYdjnSpoWsiRRFvQQN0y2VoUxTAunIuOUJZwOGZdDYvaIXHK9LvbVx2iM6bidMl6nA2/q35lluYwu9FHRGGNjZRjdsNDNpi+TYr+b8UU5NMSSfLStFt2yMEz7SzdN3A6Z2SPyiOsmizZVEYrrdnyGRdK0/51SGsC0LLZUhamJJDEtC9MC07JwyjLTygLMHZGH1+kgrhtMLg0wssBLid+N09G7HRO6adEY1zFNC11KIskSMiDLEhJ2dW8rFZtlgYUdKxaYqf+bpoXR4j6Ylp0sND2mp553Qjeb/6+bFrkeJ7OG5+JSRGdLE8uyiCQNTAsaYzpaRYglO+uoiyZJGCYJ3SRhmBTkuDh6ZD4Jw+CBT3cT0w2iSZO4bgLgdcr86rzJyJLE797azJ76GAAuh0y+z0lhjosfnDGB8UU5LNlZx576GIU5LgpzXBTluCjwOXv9tSb0X5JltdUmNHAlk4ZVVxfpcJ9IxN7enTW5KhrjfPri3/Emqg/ZtnvkRVg5pfj2vE9hw9pDtr9nTOOT5Fheu+WYLl83W3pyrwaT3rhP++pjLN1dx8aKMNtrIuxviFMTSRD0OIkmDarCCQAkTKZL25ghb2WWYxsjlVpqPSPY5RjBvZH5GLJCy8/jbkXmiGG5yDIs31VP3DCxsJf9MFJJzqzhQSxLYn15I5WhRHNy0sQhgdHNPxWyBE6HzITiHFwOmc1VIZLGgYShKclwKzJx3WyzlbovSRxIVocE3PhcDhpiOjHdQJFlFFlCkSXCCbt1vDaabPM8XqfMkSPyuWx2GbkehRW76xkS9FAScGNZdsLldTqYURakLprkrsXbqYkkqY0kaYzrhOI6cd1k2tAg1eEEm6vC6Gb2/j4X+JycOrGI648eSYnf3afX2lDeyOPL93LdkcMZXZjDok1VvLK2nKBHIehxkutVyPUoTB4SYHJpgLhuUpv63fA6ZaJR+8NJy98/07KTz5huJ0j2l8GEYj8AK/fUUx1OENNNokmDxphOY9zgwhlDcEgSTyzfw9ubqgglDKJJg2TqF6ApQc4ESbIT8YONzPMwJOihPpZkd10MWZJwyKT+lRgadDNlSBDdMFm+ux6HLKE47A9FMhaXzizl9CllGXoW3ZSMoNRuQg6XI8XriY87F5yZex/K5HtfcXFgKTC3rW0iScugpx76M2Nr3mH2bc9l9Lo9IZK09HT3Phmmycvrynng093sqj20G93rMDk+WMXJ/l0UKAmWDbmcycUeLnxrHrIRw/QWYviH4ajfBkD1zetAkgi+eA1yMoyePwGjYAJ6wUSM/AmYOUPsv/xpanqjc8gSkiRRHY6zuy6WaoWy8Lkc+FwOCn1OSgMeHDIkDAunw05uunqvLMsiljQIJQwaYkkaYwahuE5jQkdGwrDsLqNo0kCRZJwOCcUhocgyPpeDgNtOUBOGidNhb7f/td+gmloGPU4HbsWOMZ0uJt+nf0QvmkZi7JlEkwabK8Os2lvPxsowO1IJdV1Ux+jk76nLYV+vqVWlre1jCnwU+d1EEjoyFg5ZQnY4aPpbrZb4CXqc7KyNsKc+1vwmbqZa0yYU5TC2KIeqUJwlu+pRZKn5TVyRJUoCbo4bXQASvLWxCkUGRZaRJcm+n7LE7BF5PLF8L5/sqAVg6pAAt88fwxHD8jq9V+nSDbtF85Gle1i7vxE5lZB4nHYsCcPEssBIJfEAE4pzmDsij8a4zktrywH7A4TX6cClyIzI83Ll3OEkdIMfvaK1ed0vHTcS3YSX1pZT3hg/ZLsMHPzT8SoyQY9Cns/JxBI/M8uC5HkcHLHhdyiBUqpn3orX6bA/+Fj269iwLEzTjt885P/2h5SE0TKBtJPIuG4SS7W8hVO/Bw0xnca4TjhhEEno+N0KiixTH01QfVCLr2XZP2eHLJE0TAxDp4Q6hkrVyJgssSaR61F489bjeu1nmTYr1dQryThqN6PsX4YjvB85XI4c3o8c3k9s8uXEpl2Lc9d75L1wYMGhxhN/SWz6dRkLtb8kaaK7M4MK9X2c6VjCjlgcn6dvP5kK/d/+hhg3PrKCynCCqUMCXDhjCH63wrR8i/n77yO/fg3O6rVI0RhEwQiMYO6x3wFJosH7AEZwFGZgWPPHbSlW25yAGQUTkcpX4N7yMvK6uuZrVl/1PmbeGNza08iRKpJDj0QfMrvdGGVJwuN0NH9fGvBQGvB0+Ly8PeiJkSQJr0vB61Io7uPWm3Q5qjeQ89md6HnjSIw9E6/TwfSyINPLgq32syyLylCCHbURtldH2FgZZktVmH0NMRSHTL7XSZHfxcg8H4U5Tgp8Tor8brsby+ci6FUOGa/a128U88cXtXwCuHYswrPmARpH/IPjRk/lg3de4IENsGY/fOGxVZT4Xdx0zEjOnz603SQ8He9vqeYnr2o0xg8sxTw818sJ4wqxsAgnDKIJg0jSIJKwE/VQwqA+FGbZmh1oCTvu2xzPMFfWGMN+vEacZZUT+OTlyTxjzAOCbV773x/uBECRwa1IKJKM1+VgWNBNWZ6HobleyoJuhgY9lOV6KA3YXdlyeD+uHYtQypcTmvY7kCTyVm7EufMxgtPOxcif0u370W2WiRypRA7tRQ7txcwZgj5kDo7azQQWfct+PFyOZNlpZ7xoGl9w/o6PdtQRSxqtfrf7lJEk7/nLUCrXUH/2PSRHzse1bSH+j34FgOnOw8wpxfQPwXLaLZ168XTqz74X0z+E3JeuRalclZlY+xmRpGWQmXrxVdXWMnLokCxHI2TTwg0V/PhVDcO0uHREmP9z/wvLzKPxxH+BkaTwk+cxCiYQnXo1evEM9NIjMHJHNydhyeHHtz6hJGF5C5q/DR//I/s/loUUrUap3YijZiNmcCQA7i2v4N72OgDR6dcTOu4HoHj7/HkPRJ71TwBQd/EzHe4nSXYrVUnAzZEj8zMRWu8wddybX8K37B8o1esx/ENx1G3DKp7OxXt/x6XspGbITB6KHM1/G2bz6zcT3P/JLi6ZOZQLZwwl1+tM6zIrdtfx4bZadtRG+WBrNQnDIt+rcN60IZw1qYQJxTl2q6ZlgiSDZeFddS+Oum046rfjqN+GnNgNDqj4+iZipkL+Gw/jaIAGzxyikpMT6lZyRngpCy6+CTMwnJKtT+BMNhAfegxGyXQUxYnikHFIpNWCqlSswrX0DVzb38KZShKMwHCkaDWWr4j68/5HwYPHkvPZnTScfU+Pfgxd4VvyFzzrHkMO70cyD3S/RydfQWjIHCzFh+XwkBw+D8NfhukfiukvwwiO5IvrlnP+7mdZsnMK88YVdXCV3qNUrcG57zNi4xfYrflAbPLlxMedi5lT0ubfHsuTT2LsmQDoxdNQKtdkJNb+RiRpmeS2k7S6epGkDVamZfGzVzVeWV+BLMEdp4zmps1fxlG5ndjUa+ydHE6qb1plv1H1lCRh+YpI+opIDjvQvdFwzr1I0Rp8S/+Gb+U9OPd8RMMZ/8AonNTzax5OjASejU8TH3s2lrcQ19bX8Kx/goaz7wZ54P/5dO54m8B7P8TRsAM9fzwNp/yJ+MQLweECoO7CJ3Fveo6g9gy3Je7ma16F7XnHcIfj2/z9g+3844PtHDUqj9tPGsf44pxDzh9N6Pzn4528sGY/dVG71Szfq3DRjKGcMamEGXlJnFWrce58CWXpKpSq9ZiuAHWXvwaShG/p38FIYOSNIVk6C2PiRRh5Y5Cxu9rj5/4bgESqxTHk8xEJ72dYKhEIlr/X/GHEdOagD51LouxYYpMvx/IVH3pDEmFc+z4hMfJkkCT879yBUrUGfcgcQsfcQWL0aRgFavOHJcuTR3TGjeQs+QuOqnUYRZlpTYuplyI37MTyFqaSMPvLCAy3n2ugjPoLH2/z2ImuRcxzvMc173/KvHHnZCRe5/6lgP3h0fTbY+EsbyGWtzCt4yMzv4CkHzopajAY+H9lBhCH225+DzXWZjkSIRuqwglufXIVW6sjBN0Kd18xg2l7HsNZsZKG0/9uvzk26Y0ErROWt4DwvJ+QGHEiwbe+Qc5Hv6LhvP/1+XUHEteOt5Cj1cQmXwGAlAzh3r6QnA9/SXjeT7IcXfdIiUakaDVm7mgslx/Tk0fo+B+SGHPmIa87MzCM6Oxbic6+FUfVOjwbn6Wsfjt/P3sujyzZRc7Hv+a9XZO5+n/VDMvzc8vxozllYhHLd9fz1/e2sqE8ZE9SkeCYUvjy+HqmD8nBGD0eObyfwvsPDMPRc8eQLJmBUXgg0am56j0sV6Br4yhzDnwAbjjnXuRwOc69n+Dc+zHOPR/j//g3xCecjwV41j6EHK3GdAVw71iEc89HSEacmivfxcgfR+Mpf8DMGdKqlfpg0Zk34111HzlL/kLDWf9OO85uMxKYgTJCp/yxW4c3DW/Ir12FbpyFkoGZosr+Zc3JZHckR87v3YAGEJGkZZDTZydp0VBddgMRMu7DbTX87DWNUFznmNH5/P78Kfii+8j5+HfER55MfMIFWYstOepkaq54o3nciqN6PaavtMM3psFCjlSh508gMfIkAOLqJUTKV+JbeQ96yQziEy/q8xiUhh3gHA3OnnVHS9FqvCvvxbvmAfTCSdRf9DT60COpu+SltJIgo2gK4RYtRVdPUshf/i43Sy9QTR7Ph47hsVeO5yevjSNpQDH1fMP7AacF9zDR3IJSvwuWQrJ4BnWjT8H0lRKa9zP0wknoxdOx3IeOIWvrsa4yc0qJTzif+ITzm++D5bFf287dH+LZ/AJgJ4nRadeRGH0qRmpYQDotY5Ynn8hR38JKddF2JaHsKueu9wks+hb15z2IUah26xzJ/InEJTez5E28tqGC86b2fa+Oc/9SkkPmdP8Epo5bexojbyz60CN7L7ABQMzuzKBVm7fy8IsvcOr8szljVvd+wTJNzO5MT3v3KWmY/GrhJl5aV86oAi+/O38KYwvtbiHvirvJ+eQP1Hx+EWZweMZjbpNlkv/oKUjxRhpP+zPJESf0+iUG3Gvq4DdeI0nu81fgrFxJ7cXPYxRP7bNLR8JhRjw8BzkZwvAPxcgdY3/ljSU6/TpQPAfGcLVDbtiNb8VdeNY/BnqcxLizicz6CnrpET0P0Ijbkw20Z3BufxPZTLIoeDF75v6Q4wvCjH3qBIzgKJIlM9CLp9vjK4unYXnyen7tFnrympJitUiJxubxmv2WZZH31HnIkSpqrnrX/tl3QyQSIfeFK9leWcNPi//KPVcc0btxtkEO7UXSYxh5Y7t3Asui8N5pxMcvIDT/N70bXHvWPElgw0OEzrkXy9e3Y/fE7M5+orB4KIvM2cxz5mY7FCEDdtZGue3p1eypj+FWZH50xsTmBA0gesQXiY87DzPQj+oVSTINZ/yT4MJbyXvh80Rm3UL46O80j1EaTBzV6zEDI7Bc/oM2OGk46y7ynzib4BtfpfaKN0HuxVlypk7O4p8Tm/J58Iyg+rhf4IvtxVG3FUfdNtxbX0FKhInOvBmA3Oc/j6NxVyp5G92cyCXLjsZSvOQ9exFypIqYejHRWV/GyB/fe7E63CTGnk1i7NlI8XrcW17hqGg10cklYFlU3bQay9O/J1FYnvxeiVGK1eJb8ldik6/oditXR1xbX7GHRpzyp24naE2kstlMrbqXreU1vRRdx7rbzdlMktCLpqFUru6dgNLgLl+Cq3pD1l+/IknLIK8V5WbHy4R2hmHa2dkOR+hDL63dzy8XbkI3LUbkefjXZTMpDdglJaRoDc69H5EYe07/StBSjKIp1F76Cv7FP8e3/C6cuz+k8Yy/d/9T8EBkWQRfuwUzMIz68x85dLOvmIaz/2N/05sJWjJC8PVbcO9YhBkYDhOvJjL2XDiohUiKNzRfNzH6NJSKFXYCpy1DTjQCUHPFmxiFk2g85U6MvLF9/lqz3Ll2YtkcpJT1N7hM86x7BDlcTuOZ/+zdE5s6OR//Dj1/InH1cz0+XWjC5/jznvFE9sLGihATS/ydH9RN3pX3Ijfu7vEYTr14Gt5V94ORBEd6M4p7wl21ikTRtN79/e4GkaRlkF+BHzof5r4KHyCStMNROKHzmzc28dqGSgBOV4v56Vlqq+V1/It/jnvTc9Rc9V7/7WJxegnN/zWJkScRWPRtHDXaoErSlP1LUeq20DD7K+3u09xdaOq4dr5LYvSpPbqmFK1O1YNaTeNJvyE27WqItD10o+VYregRX2ixwS654qjfhpE3BoDkiHk9iktIj+XJJzb9BrzL/kHkyNsxCib22rk9G55EqdtC/dn/6ZWkQc8dwzHzhnH/E6vYUN63SZp784u9ch69ZAaSmcBRu6nvZ9FaFsm8CSTye+9n2F1iAbAMcqUmDih6OMuRCH1hQ0WYqx9cxkKtkjnDc/l/p4zjl+dOapWgOXe+i0d7isisr/TfBK2FxNizqLnmQxJj7Q8VnjX/Q4rXZzmqvudZ/xiW4iM+7rxO9/Wu/i+5L1+Ha/NL3b6eXL+DvKcvQKneQMNZ99gJWnekSq7oQ48ER/8oBjyYRI74IihefEv+0qvnNQIjiE663J6B20uObXyVb/pe4/2thy5x2GuMOErFqp5NGkjRi+01r50VGShqK0lUn/AbGqfd2PfX6oRI0jJJVohYblxGKNuRCL3sox11fPmZ9TTEdP592Uzuunwml80a1rpgZjJC4N3voeeNJTL3tuwF20VNrTaOmk343/8x+Y+dgbL30yxH1YcSYdybXyQ2YQG4Dq39dbDotGtIls4m+NY3cVS3vRRRZ5zly5Dj9dRd8HhzAU9h4LG8BURnXI970ws4ajb12nmTI+YROvWPvTpz1LV7MVfzMu9urqI20vZ6tD2lVK5BMhMkO1jVJF1G7mgis29FL5rcC5F1TA7ttYcU9AMiScuwEF5cxuAsyne42lwV5kevb8G0YFS+lxnD2i4bkPPpH3E07CQ0/7c9HvibDUbBBOoufhZkhbznLiHwxtfwv/1dlNQnW+eu9wi88TUCC28l8NotBF/7IsFXbsKz9iEA5IZd5L5wJSWvXUdw9b3ZfCodcm95GTkZbq6N1imHm4az78Zy5hB89eYutTTK9dsBiE+8iJqr3kcf2uYEL2EAiRzxJSxnDs7dH/T4XFK8gcAbX8NRt7UXImstOWQOBWY1Q6nm8eV7ev38AM79ywDQe6ElDUkmfOz30Etm9vxcncj56NeUPdd5K3omiCQtwyJ48Vqiu/NwURtJ8LUnV5E0LKYN8XPXZTMPWX8RaC5VEJ1yJclhx2Y+0F6il86i9vLXiU26FNeu93FtfwM5bC90LUcqcO5fhlKxCqVmA47aLTgadiBHU8WbLRMpEcIRqSB/yW9x7l6cxWfSPiN/PJEZN6IPST9hMnOGUH/Wv3E07iLw5tftshidcG94ioJH5uPe+BxAr5elELLD8hZSc+1HxGbc0ONzeVf8G8/GZ5GSvf+e0VTUdpa8mbc2VvX6+cEe22kEhrcqMNwTcmgfbu0pMPXOd+4BpXw5iaLpfXqNdImJAxn2iutMKsxg2wVRhAEloZvc/swaqiJJinOc/Prs8a3Gn7XicFN72atIffzHJRMsl5/QKX/k4E77uHoJcfWSdo8zc0dRd8kLRBtqGPrsOfjf+wG1ly/sd+U99CGzO1x0vt3jyo4idPxPcG9biJSMHFq6o4ll4V32D/wf/4bEsONJjDqlhxEL/Y3lyQfLRClf0a3XEoAUqcS34h5i489vHo/Vm/TCKViKh+OlLbxaewyGaeKQe7fdJnz8j5HD+3rtfM49iwm+eTs1xTN6dWJGS1KsFqV+O43jez6LtjeIlrQMW152FYtcJ2c7DKGHLMvi129sZF15CLci84cFEwl62v7M49r8EnL9DlA87b9xDyKW4qHmmB+j1G7Gu/q/2Q6nFbf2NK5tC7t9fGz69dQveMj+ObfVmmYa+N//Ef6Pf0NswgXUL3iwV6rqC/2Pd/m/yHvmwm53VeYs+QsYcSJHf7uXI0txOEkWz+Q411ZMC97Qer81zQyU9U5XZ4qeat1SKvtu8oBSvgKAeHHfd6umQyRpGVas72NIZEO2wxB66OGle3hpXQWfmzGEP144ldH5bS/ZI9dtI/jm18n5+LcZjrB/i42YT8OpdxKdclW2QznA1Mn56Fd41j7c/XNIEsgOlMo15D962iFv0DmLf4539X+JHPElGk//W79rRRR6T2zSZeBwdWump1y/A8/ah4lN+Xyflr6JHPVNIsf/EICFGyp69dzOXR/gf/cHSLG6XjunkT8OS/GgVK7ptXMezFmxAguJROG0PrtGV4gkLcNOrbifP1h/ynYYQg+8v6Wav7y7lfnjC/nOaRM4elQ7BTsti8A7d2A5XISP/1FmgxwA4pMuBVcOUrTGXnopy1w738URLic2+fIen8t05yFHqwi+chNS4kDHcGz6dTSe+H/266GDpZyEgc/yFROdei3ujc92uTVNqVqD5QoQOfL2vgkuJTn8eIonn8SE4hzqY707FMO14y27lI2zF5d/kxX0oql9uvKA5XCTHHkSyA4Cax/o8/FvnRF/JTIsqeTgl6JE4gN/bNJgtLkqzB0vrgNgYrG/7UkCKe4NT+Das5jwsd/H9A/NVIgDiqNyLQUPHodry8vZDgXPhscxPQUkRp/W43OZweE0nPkvHHVb7Nmub30TklGMvLHEpl/f82D7MSlcgdy4Fzm0DzlcjhSuQIpUIUVr7HUyY3VI8QY7eU1GIBkFPQZGIq0JFwNJZNYtdmva0r916bjEuHOpvu7TdgfcO6rW4dz1Hug9rBRgmXiX/5ubizewam8D1aFEz87XgnP/EnsmZi+3FuvF01Aq1/bZayU6+yvUL3iInM3PU/DpL5HDvdvC2FVi4kCGGUoOfqJsbowxxi3GJw0ktZEEX3tqFQnDYkqpn+uOGtHuvlKkEv/in5McehSxqf2oS6+fMQpVjNxR+D/4CbUj52dtzJ4Urca17Q2i06/vtTeV5PDjCR/7A/wf/gLTFUCZcUPXBoBbFkr9duRkGMXjBqzmx9v8f/P32I/JTvt6GVrWRopW43/vh3h6UGHecrhJlh1NYuR8EiNOsgeH92JtsEMvaNllUBzuPlk2y8opITr1Gryr7iM85zbM1CoQHXFveoH46NOgnRYoz7pH8b9zB5Jl2Pdr2LEH7lf++K7dL0nGu/p+TvBPAa7nb+9v46dn98K6o3oMpXIN0Zk3NT+0dFcdk0r95Lh6lnYkRp2KJTvtxL43W+kAklEkS8dyBfDsXYyeMzTrH7BFkpZhliuASzKobggxpkgkaQNFQjf5xrNrqAonKfQ5ufPiae3P5CRVH8iyaDz5d6JbqyOyQuikX5P39AX4Pv0D4Xk/zUoYno3PIZnJXunqbCl6xBex3AGSpXPSW3Tb1HHu/QTX9jdwb1uIo2Fnj66fLJlJ6MRfHljCqo+4Nr9E4N3vIyUaicz+KkbuKLuloymJtEy7BItlpr4/8BjY+0mWhRStxLXrffyLfw6A4R9KYsSJJEaeTHL4vJ6XKTHiKBWrce5fgnPfZzj3L0WOVmHJLurPvY/kyPk9O38bIrO+jF44yV6LtRPKvs8ILvwKoeN/TPSIL7beaFn4Pv0DOUv+QmLkSUSn34Bz1/u4dr6D/4Of2k/PP4zEyJNIjDzJvl/u3E6vmRwyh9K9nyJL8MmO3llw3S5imySZKmOzdn8jtzyxis/PHsY3Tx7Xo3MnRp3SZzOi3dsXElj4VWovX4hn38dER53etx8S0iCStAyT3AEA6hvqgN6pHSP0Lcuy+OXCjazdH8LpkPjr56ZT4Ou4tSUx9kxqhn+C5QpkKMqBSx8ym9jUq/Guuo+4egl6ceYH7EanXoWROxqjcFLvnliSiE25suNdEiGcO9/BvW0hrh1vIcfrsRxuEsPnUTf1ZgxfMW63G5BavGG0eOOQJKyDt0kSjsY9+D75A3lPLSA25UrCx97R6wueS5FKAu/9APeWV0iWzKTxlD/2+B6GAblxD65d7+La+Q7uLa/iXf84liSjlxyRSkLmo5cc0WkroRSpshOy/Utw7luCUrEKybS79PTc0SRGzic5ZC6etQ+S+8pN1J/3P5LDj+9R/AezckqINyX/ltX+m75l4f/o1xi+UqJTr2m9zUgQeOe7eDY8SXTy5YRO+g04nCRGn2bfr4ZduHa+i2vXO7g3v4h33SNYkgN9yOzmVja9ZEabHxj10ll4Nj3P3LwIn9b6aIwlCXh6toC5c/9SgObloP69eDsAT6/cy1dPGNPhB9x0OOq22sMHiqf26DwHU8qXg8OFlAzhSNQTLTuuV8/frZiyHcBgI+UNZ8nuiSSTvdf3L/Sth5fu4ZX1FYwu8PKVeWM6XIxYSoTwrHmQ6MwbRYLWBeFjvot766v43/8RdRc9k/lPr4qnxwukd4UcLse17Q1c217HtXsxkpnAdOeRGH068TFnkBhxErhyiKQWWJd8Xe/WSQLx8efh+/ROvKvuxb31FcLHfs9eSaGnrbuWhXvT8/jf/xFSIkzomDuIzroF5N55SzEDw4hNudJOcE0dpXwFrp3v4Nr5Dr7P/kzOZ3diunNJDD+B5MiTiBcfjeErwVGt4dxvt5Ap+z5DSa3oYMku9JIZRGfcQHLokSSHzMHyFTdfLz7uHPKeu5Tcl6+nbsHD6GVH9crzaMn/3g/B1AnN/02b2107FuHc9ymNJ/0anAdmi0uJRoKvfhHX7vcJH/UtInNvP+T3wwyOIDbtanvNVyOJs3wZzp12kpvzye/J+eT3mJ58EiNORCo9lsiYswH7NdWUSF1Rup9Pa8fyxPK93HTsqB491/jECzByR2L5ivl0Ry0fba/F53QQSRo8snQ31x/ds3WLA298DcsVoP6Cx3p0noM5y1egl8zAtecjAGJlx5HttWEkqx/MqupNyaRh1dVFOtyn6Q+frxt/+HpqY0WIqx5cxm/Pn8IpE4oyfv2uyua96g/e31LNN59by6kTi/jluZPaLfbYdJ9KlvwKz+oHqLvkxT7vYhqo2ntNOXe+g+krwSiaktF4chb/AikZbvfNs1dYFo6ajXZr2bbXcVasAMAIjrKTsjFnkBx65CFJTm/9/jmqN+B/7we49n5CsnQWoZN+1e0CqVK4gsC738O97XWSpbPs1rM+Kiza5vVjtbh2vW8nIbvewZFa8cJUfMi6fb9MbyHJIXPtr6Fz7efayVJsUqSSvGcvQQ6XU3/+I90uQtuenPd/jHf1A9Rc9R5m7kFJkGWS//iZSMkINVe+Aw67JUsO7SX3petw1G6i8eTf2zOiu0iKVuPa9V4qyX0POVpJaNyFRM/6u72DkaDonsnUT76aI5acyrhCH49d33vl1i++91N21cW486KpfOPZtRT7XbzypWN6dE7/29/FveUlqm9a03sf6IwkRfdMIjrtOpTKVVixBvZf8FxG3vuKiwNLoe0a96IlLcP8bgWwaIyKlrT+zp7JuR6HBFfPGd5pNW5XxXI8qx8gOv16kaB1Q/N4IFNH0mOZmUSgR/Gse7TvWtH0GL6lf8Oz8TkcDTsAe5xY+OjvEB9zBkaBmpFWQ6NwEvUXPoV74zP4F/8feU+cQ2zatYSP/n/pj/OyLNwbn7Vbz/QYoeN+SHTmFzI2MaE5DE8+8QnnE59wfir53YC0+U0cod0wbC76kDkYuWO6fF8tXzH1FzxG3rOXkPvi1dRf+HivVvqPzv4K3rUP41v6N0Kn/KHVNufuD1Cq19Nw+t+bEzRH1TpyX7oWKRGyu2FHnNit61reQuITLyI+8SJ7Nucb38C37VWiyajdYudw0XjSr7EKVQrXRdhTH8OyLKRuvi7l0D58y/5BdMaNfFSfz666GOMKfcwbW8jE4hw2VobZXBlifHH3f7/14ul41z2M3LgbM9j+BK6uUGo2IBlx9MLJeFffT8OU63vlvD0lRjRnmLt6DRvd1xJa92q2QxE6UBtJcNtTq0gaJmOLchhfnNPxAUaCwsU/wPQPJXLMdzMT5OHINMh75mL8734/I5dzb30NOdGQ/mLqXSDXbyfv6QvJWfIXjLzRNJ70a6qvX0LdpS8TmXubPXYrk926kkRc/Rw1V71DdMYNeNY+SMEjJ+Fe/0Sn5Qzk8H6Cr9xI8M3bMPLHU3v566nuzcwmaIeQJIzCyTRMv4naY39CfNKldvHXbt5X0z+Uugsex3IFyH3hShzV63stVDNnCLEpn8ejPYXcsKvVtuSIE6m9+Fk78QScu94n71l7WaK6i5/pdoJ2CEkmPPZ8ZD2Ca8dbzQ/HJ1+GXjKTG44eSUw32VHT/dIezn2f4l39X6RkmF+/uQmAH5xht7TenOpG/fv723rwJGget9qbKw9I0RqMwHCwDHsS0bDsj0cDkaRlXF4gF5dkICUasx2K0I6kYfLNZ9dQGU6S61X480XT8DjbfzOSYrUMefVqXHWbCZ3068Gz9FNfDJWQHSRGnIBn4zMZWYDds/5xjMCIXl/03rX1NfKfOAdH4y7qz/0v9QseJjbtml5baLonLHcu4RN+Tu1lr2HkjiG46JvkPfs5HFXr2tjZwr3hSfIfPRXXrvcIHf9j6i56xi71cJgyg8Opu/BxLIebvOc/j6N2c6+dOzL7VkBuVTdNStXh0oceCZKMe8NT5L50Daa/jLpLXuj17v/YkKMwvEV4Nr9wIIZoDd4Vd3N6SQMAb26s7Pb5lf1LsRQvH4ZK2V0XY3yRj+ll9tJn88cX4nXKfLqzDt3ofp0zvXASlqz06soDyZEnUXPtxyg1G7AcbmIl/WOFbZGkZZjis6dEy8lwliMR2mJZFr98fSNr9odQZIk/XzSNkoC742NcQXRfCZUn/zWjg8+zRQ7tI/fFqyj612gK75tF/mOnkfv85wks/Co5H/wU79K/41n3GK7tb6KUL7dbDbpQdDMy56sYwVH43/0eGPG+ex4Nu3Dt/oDY5Mt6r0yKkSRn8S/IffVmjLwx1F72Wq8Ux+0LRtEU6i5+hoZT/oSjbiv5T5xFzvs/Rorbb9RyaB/Bl68j+NY3MApUaq94wy4Lke3Wswwwc0dTf8HjgETuc5cj1/Ws5af5vP6hRKdfB7LT/pCTCFPw+JnkfPhLu8TGkr8QfOt2kmXHUHfxs5j+3q/dhuwgPOpMXNvfal4NQzLi+Bf/nGHVi/G7Hfzvs93dPr1z/1KSJTP539JynLLEj848UHpGkiS+MX8cScPig609KPeheIhPvKh370/S/hvl2vU+ybKjQen4736miDFpGdbUyqLoIknrjx5euoeX11cgAT85S2Xq0HYWv7YsvMvvIll2FPqQOVSdYg/CPdynV7g3vYj/3TuQjATR6dch6THkaDVypBJnw06kaFW7H0BMZw6Wt4igO5/Y0KNJHHdH8/ibVhQvjSf+H3kvXYNv+V1E5n69T56LUrESS/ESU7s+GLstcmgvwYW34tz3GdFp1xGa92Nw9I8/9O2SZOKTLyMx5gxyPvk93lX349n0IrHJl+FZ8yCSmSA072dEZ9ww6Or9GfnjqLvgMfKeu5S856+g7qKnMYOd1zrrTPj4Hzd3x/pW3YscrSQ+6lT873wH77pHiamX2PUV+3Bd18iYcwhueBjX9jdSyc5QDP9QlPLlqMVHsnR3PVuqwowr6mSYx8H0KErVWnZPuIFPVtbypeNGMWVI61nuC6YN4Z6PdvDsqn3M78HkucZT7+z2sQeTEo0U3jud8FHfQqnRCKmX9Nq5eypjSZqqqjLwT2AmEAdu1jRtc4vtVwHfAgzgPk3T/tXZMQOS4sWwJNyGSNKyqS6aZFt1hK3VYbZWRdhaE2FrVZiaSJJTJhTx1RNGMyK/7ZRLSjQSeOubuLe+SmT6DeipKeyHMyneYFeT3/gMyZIjaDz9r+0v/JyM2olbtMr+ilTZyVvqMRr2kLvq3ySqV9Fw5r+xvAWHnmLUycTGnYdvyV+JTfxcr7w5Hiwx/jyqRp3SK1XLnbveI7jwq0h6jIYz/kF8wgW9EGHmWJ48Qif9ktjky/G/9wN8y/5BouxoGk/+Q1pV8g9XRqFK3fmPkvf8ZeQ9fzl1Fz3Z89YbSQIjiXflf8j55HfER51CzrK/49r5DuG5Xydy1Lf7fKxivHQORs4Q3JtetCcUAMnSOTj3L+XCI4ewdHc9jy7dww/P7NqsXaViNZKpc9e2YjyKzBWzhx26jywxrtDHh9tr2VEbYVQ7f2c7lVotwvSVgKuLyeQhca9CMvXmxeATvTUGsBdksiXtQsCjadqxqqoeA/wRaPmX7A/AVCAErFNV9THg5E6OGXgkiRA+3FbHZUKE3lEfTbI1lYxtqQqzpSrC9poINZFk8z6yBE6HjGlaHDUyj5+eNRFvO0uXOGo2Enz1Czjqt9tVwWd+IVNPJWucez8m8MbXkcP7CR/5DSJzbmu7Baz5AC+mc3i7iVUkEiFny/MULv4h+U+dR/0597VZADV8wk9JjpzfJ8v1SJEqLHeg5wmaaeBb8hd8n92JUTCRhrP+PaDHa+klM6j73PMoVWvRi6YOutazthjFU6lf8DC5z19B7vNXUHfhU1g5JT06pxypxP/RL+3/1+9Aqd9O48m/67Twca+RZOLjz8O7+n9I8Xosdy76kDl4trzEmcNNfiLBh9u73h1pFExgycxf8+InhYwq8aaqGRxqwfQhfLyjjr+9u40/XNi9grRK+TLyn76A+nPuIzHmjG6d48C5lgPgaNyN6S3EKJoM0ViPztlbMpmkzQNeA9A07WNVVQ8elbcKyAV07HLaVhrHHMI0zebaQu2JRrObIN1W/CDVUZjXSZz9QbbvVVcZpsV9n+3hk5317KqLE9NbD04t8bs4emQQCXhlQzV+l4PSgIsSv4tSv4thuW5isRiWfuibk3f76+S9/10sxUv5WQ8QH3IURO1xDAPtPqXFSJC37C8E1/wHPTCCinMeJVFyBMST2KVSuycajRAtO53k2aMpfutW8p66gKoTf0901EFjt6QgjD4fojGkZAjL2XsTMore/RGuqtXsvfj1brdayLEait79Ft69iwmNu4CaY3+G5fRBL/5eZ+11lTOu37xJpaPP71NgIvHT76Fk4U0En7uM8rMfwvQc2gKcNikH56QrydnyIo7QPipOu4vY8JN69bXTnqZ7VT/8DHwr/wMbXiQy4WL0vCn4AXZ/wvDcMnbWxaisbSCnnUSrbW6+tm4CDST400kj230vPn54Dh5F5sNtNTSGwjjkrv8OSt5R5Eky1t5lRErndfn4lnL2LiEZHI1z7ydEhx5LJBrL8O9e+4XPM5mkBYH6Ft8bqqoqmqbpqe/XAEuxVwV5RtO0OlVVOztmQPJ6fEQaRXdnX9hUFeGhZfvJ9ygkDJNcj0JRjpPhuR5G5ns4ZmQu04b4SRgmt80bibeDWZuHkBUSBZOomv9njH4wS68vOWs3UfTet3HVrKdx4mXUHvU9LGfPuhQOliieyf4FT1G86FZKFn2F2tnfoGHGLYckTcHV9xJY91/2XvRqr8ycleP1+Ha8TuOES7udoLnLl1L0zu044rVUH/cLQhMvy/oaf0LfipfOoeK0f1Pyxs2Uvn495Wf9D9Odl9axcrwed8Uy3BXLcVcsw1W5CtmIoXuLqTjtbhJFvbu8UToSxTPR/cPI2fYK4QkXkyicSt2s20nmTWD+OBf/W7qPxTvqOWNiYXontCwib/+SoaGxBIqOYEIH49kkSeLEsXks3FjDi+squXBa11smLaePZO5YXNVru3xs6xNZuCpXkSicgm/3O0TLepbw9bZMJmkNtE4X5aZkS1XVGcC5wBjs7s6HVFW9tKNj2iPLctoVgrNVRf/8qruoj8Tw+f6Tlet3x0BZcWD5fnvq+F2Xz2RMoa/dgozpPhspXIFHe4rorC/DpAU0qufi7qALaKDcp3ZZJt5V95HzkV1KpKkrwdv5kV3m8/nAN5aGzz1DYNH/I3/ZnXgbttB4yh9bLYvD6BNwLPkdRav/TviEn/f4up6tTyEZCYwZV3f952VZeFfeQ85Hv8L0D6PuvBcwi6f1+YSRAf+6ypA+v0/jTqbBeR+5L9/AkDe/QP35j2K5D5pclBor1byI+74lKLUb7U2SA714GrGpV9nLUw0/HsWTn5UZfD6fj8SEBfbYODmO5csnedy3cQE3FCR5ZPl+dtQn076ncsNORu34H1PkGzj3nM93etzt8yewcOMnPLmqgiuPGt2t52CWzMC9Z3GPfu5SrA7J4cDhtCf5SONObXW+bP/uZfK1sRhYADyRGl+2usW2eiAKRDVNM1RVrQDyOzlmwBqu72C01JDtMA5LizZWATAiz9PtitlNlH2fEXztFuREPYmxZ6WKZB6+Y3Tk0D4Ci76Fa9d7xEedSuMpf2i1vmGfUbw0nv439KLJ5Hz0Gxz122g4+97msWh66RHEpl2Ld/V/iU+6tMdV4D3rH0cvnIJe1LWF3KV4PYFF38K99TXiY86k8dQ/YblzexSLMPAkR55Ew9l3E3z1ZnJfuob6c/+Lo25rKiGz1w2Vo/bfIdOdS7J0NvGJF5IcOpdkyRG9MlGlt8THn49v+V24t75KbMqVyA07cW9bCNOuY86IXN7eWMltJ45J629pxYYPKATq8md2XvwbKA64GV+Uw5aqMNXhBIU5XZ/NqhdPx7PxGaRwRbfHCVqePGqu+4zcF65Ez5+A6R/arfP0lUwmac8Cp6uq+iH2mLMbVFW9EvBrmna3qqr/Bj5QVTUBbAH+iz0+rdUxGYy3zyQcOeRRTiRh4HMd/jWHMmlPfQyvU8ap9OC+WpbdmvThLzACw6ld8GD7MxkPE67NLxF457tIRpzGk35NbOrVGa+GH519K0aBSmDhV8l/8lzqz/lP88zZ8DHfwb3lFfzv3EHd517odq0uR9U6nBUrCc37WZeen1K52k7YQ3sOTBgR3ZuDVmL0aTSc8U+Cr3+ZonsPfGgwgqNIjJxvJ2RD5tprmvbjD3Z68XSM4Cjcm14kNuVKnOUr8X/wU5JDj6TE7+GTHXW8t6WGk8Z33uW5d/0HjLLcfPmCsw/daCQIvHEbyA704hnoxdPQi6fzq/Mmc9l/l/DKunKuObLryzslS2eRLJ2FHKvF6O5kDssEI4Fz36dEMzVxowsylqRpmmYCtxz08IYW2+8C7mrj0IOPGfB0xY9firIrFGd0Qf/5VDXQJQ2TcMJgXGEP7mkyQuDt7+DZ9Bzx0WfQeNqd/a+1xIjjqN+Bo24rjrotyJFKLFcAy52L6cnDcudhunMP/OvJbbdelxRvwP/+j/FoT5EsmUnj6X/LakKaGH0adZe8QO7LN5D37KU0zv8N8cmXYblzCc37CcE3vopz78ckhx8PRrLjWaZtkCyT+KhTiaXKDnTGUbcV32d/xr3pOUxfCXUXPmlXhhcGvcS4c6g/7wFcez4kWXIEySFzezzrM+MkidiE8/Et+wdSpIpkalF5Zf8yPjfzc7y4tpxnVu7tNEn7aFsNYxpWURGcSkneoa1oHu1pPFtewvQW49n0fPPjebmjeTAwnOWfjUYZci5G8TQsT37a4etD51J3yYtp79+W3BfsxEzSY723/FYvEsVsu0gpX4Fv2d+7vSROcthxmE4/OcSoaBRJWm9attueY6KW9mxwuaN2E6Fj7iA6+yvZ+xRsWcjhfTjqtuGo22InZLVbUOq2IjfuQmqx1qKl+JD0jmciWYo3lbgdSOQsdy7OPR8hh/YQnnu7XTS2i0lPXzAKJlJ76UsEX/8ywUXfJFK9gfBx3yc+4QJi298gOdSe5B189SaUag29aErqayp60RTM4Mh2f2568TQaznug0xgcdVvxLfkL7o3PgsNFdOYXiMy+tc2absLglRw5n+TI+dkOo0fi4xeQs/RvuLe+QmzqNRg5pTj3L2XqjBtwKzIr93Y+NOdPC1fzprSTmtFttKKZBt5l/yRZPJ26S19BilajVK7GWbkGpXIVk0PLOMH6AF54CAAjOBK9eBrJ4hnoxdPRi6d3/HtnWUjxui4ldy1jc+5fhp4/DktWSJYd0/Vz9DGRpHWRlGhEbtjd6k0yXXJor70grO9MAlKUqtDAmeI+ECxOLTNy9Khu/LI2cfrsT2Z9WO37EHoM97bXcdRsSrWObUWp29oq8bIUL3reWJIlMzEmXoiRNw4jbyxG3lh74LKp26/NWC1SvB4pXo8cq7P/jdfbg2Pj9cjxOqR4HY6GHan6SHnUXfxsvyvIa3nyqT/vQXIW/xzfyrtRajUazvgnjWf8o3mfxOgzsFwBlKr1uHa81fw7WXvJi+ils3Btfws5Um6PPytUUao3ICUj9jqd7SRxbSZns27JzNg8QcgCo3Ayev543JteIDbtWvQhc3CWLwNgcqmfFXsa2FkbYWQ7RWff2VzF/lCCPxfczo1Tz8I4aLt7yyso9duoP/MukCQsXxHJUSeTHHUyAPsbYpx2z1ucGtzLz+YkUCpW46xcjXvLKwdiDI6i4ax/Ny+s3pJ/0bdx7VlMzbUfd/m5O2o3IukRpFgdydI5/XLdZZGkdVFyxAnUXf5at47N+eCneNY9Rmz2pVy6ayRXuMV4tN5U3hhHlmDe2DSnjLdkWQQWfoX4+AUkxp3T+8G1QwpXkPvqTTjLl2NJMmZgBEbeGKJlR6eSsHEY+WPthbk7atWTFSxPPkZ3Pk32Vw4n4RN/gVE4Cf97PyTvqQU0nHM/Rv44AGLTriY27Wp7Xz2KUrPRLsJaYBfGdW94Es+WlwCwJBlL8WK5AtRc+4k9wrXlpeq24lvyV9wbnxHJmTC4SBLx8QvwffZn5PB+kqWzcW95BSlSyflTh7BiTwOPLN3DHadNaPPwPyzaQgw3J51/C8bBQ00sC++yv6PnjSMxto1WNmBI0EMgr5in6wLcOOEoSmZ77LBidShVa1EqV+Nb9g98n/6JhnPvO+R4I388jg2PI8Vqu9ya5ixfAYCjcRfxyZd36dhMEUlaBlmuAHIyRLBkNJ9Z9VxiioHHvak+lmRyaYCgp+sva6V8GZ7NL5IccUIfRNY2R9U6cl++HjlWS8MZ/yQ+5gxQPBm7/kARm3oVRv54gq9+gbynFhA+5jvopbPQCyaCkirVoXjRS2ail8xsPq7xzH8SbrgDpWqd/ce+egPxcee2mnQg120jZ+lfcWvPgMNJdMbNdnI20MYWCUIPxMefT85nd+Le/DKJkScT1mOAxNlTSvjVm5vYXNl2Xc+3N1VR3hjnWwUfMSFkkCw8udV25853cFatpeGUP3Y42efao0bwy4Wb+Pv72/n5OfaHLMuTR3L48SSHH4+UaMS35K/I9Tswc0e1OrZptrdSubrLY8qU8uVYihdJj5LI4N/+rhBJWgY1DUD3163hG8qT7N1zHUwUn9R7g2VZrNvfyJmTuvfm6ln3KJbiIz7+/F6OrG2ubQsJLvwqpifX7m5soxlfOCBZdjS1l75C8NWbCbz3Q8BuHTPyxtnj0QonY6TGppm+UnvmpSRj5o4mkTv6kNbRVsmZrBCdcZNIzoRByyiYgF44CffmF4nOvIlIoQrYCcLpajEfbqvBMK1DVgb449tbAItbjIcxNu9v7sJs4lv6dwz/0Ob1QdtzwbQh/P6tzby9qQrLsg4p+RGbdg2+Zf/Au/oBwvN+3GqbXmwXAu5OkuZo2IXpzkWSna0+4PUnIknLINNlFz0MNm7l68qz/KJyPtDpSldCGtaXh4gmTepjXV+uSEqE8Gx6gdiE8/t+TIJl4V3+L3I++jV6yQwazrkPM6e0b695mDCDw6m77BV7rcPqdakWsvU49y9tNWPM9BSkErcpBxK4ggngcCHXbydnyV9xa0+nkrMbicz6skjOhEEvPv58cj75HXLjXqREI47aTSTGn8cJ4wp5dX0F726u4pQWjQqbq8KUN8b5/Jgkzn01xEpbj2tV9n6Ka98ndrmbTsb4SpLE+dOG8NTKfazd18C0stYz6s2cIcTHnYtn/WOEj/pWqwXVLU8+RnAkSuWaLj/n+gUPU/DgMSSHHwdy/0yH+mdUhynLbS+eEEithWYlGrMZzmHlgy3VAMwZkdflY92bX0DSI8SmfL6XozqIESfwzvfwbHiC2PgFNJ76pwPddUJ6JBkzbwyJvDEkxp174OF4PUr1ehxVqeStej3eNQ8gGXEALFnByB2Lo25LKjm7gcisr4jkTBBSYuMXkPPJ73BvfhE5tAfvukeoGnsWs4fbCdN9n+xqlaTd8+F2clwOvj6hBvZBcmjrJM237O+YnoK0a4/desIYXlpbznNryg9J0gCiM27Es+l5PNpTxKZf12pbsnQ2ktH1iXiOhu04QnuJzPlql4/NFJGkZZCVaklzOuymXCkRymY4h5Xle+3yG/PHF3X5WOeu99ELVPTS2b0dVjMpWkPw1S/g2vcJ4SO/QeTIb4piqL3IcueSLDum9RR6U8dRty3V6rYeR80GEiPnE531JdF6KQgHMfPGkCyejnvzC0SP+CLSqvtQqtdTWDydPI/Clqpwc1fkG1olizZVs2BqKbk1r2A6/Rj5E5vP5ahci3vHIsJHf6f1Em8d8LsVjhqVx0tr9vOVeaMo8LWu7aiXziZZMhPv6vuJTbum1USqxtP/1uW/p96V/8G7/N8AJIb3z/FoAP23FPJhqHmNN9OepKzoIknrLduroyiyRGmg7aKtHWk845/Unf9onyVNjpqN5D91Hs6KFTSc8Q8iR31LJGiZICsYBROIT7iA8LF30HDufwnP+7FI0AShHfHxC3BWrMTw2b8jyn67FMfckXnopsWH2+0yR396ewsANx0zEmX/EvTSWa0mBviW/QPT6Sd6UItXZ44elY9hwT/e337oRkkiOuMmlNrNOHe9d8g2LAvMDpf2bkXZtwQ5XocRGIGZO7pLcWaSSNIyqGlMmmTZLySn0faMGaHraiMJCnK6XohVijfYtXv6qNvLueNt8p6+ACkZpe7CJ4lPuKBPriMIgtBT8fELAHDu+wzDV4Jz/1IALp89DICnV+zj9fUVVIUTzB6ey7A8L9EjvkR0xo3N53DUbcW95SVi06/t8motl8wcilOWeFOraie+8zB8JXhXtS7FISVCFN4/65DHO+KsWA5m0p7V2Y8/NIskLYOaWtIkPc59jsvY7p6U5YgODxWNMQwLJpUEunagHqPgoePxLflr7wdlWXhX3kvuy9dhBkZQe+nL6EP6rjtVEAShp8zgCJKls3BveQm9dBZKqqjtEcNycTkklu+p58537Va0n5xpzwCNqxeTGHN68zm8y/8FspPIjJu7fH1Zljl2TAGRpMHbmyoP3cHhIjb1atw7FuGo29r8sOXyYzmcKBWr0rqOFKnE0bgHydRJ9MOloFoSSVoGWS47iZD0MG+V3MgW1+QsR3R42FRpV+a/au6wLh3n3voqcqyWZG9X2zeS+N/9Pv4PfkJi9OnUXvwsZqCsd68hCILQB+Ljz8dZtZbE8OOJq5+zFyAHZg7LJRQ3qA4nmTMil7I8D85d7+Pa8nLzsXJoH54NTxGbfHm3eye+duIYAP7z0c42t0enXYMlO/Gsur/V43rRdJSq9GZ4NhWxtcBeB7gfE0laJsmKvc5ivJHxiXXkNW7MdkSHhZWpSQMTi7tWPsOz7lGM4Ch7maBeIsXqyH3pGrxrHyQy+1Yazr6n1XRxQRCE/iw+3p41LccbiBz5jeYB+jcdM9J+XDrQiuZd+R9yPvl987HeFXeDZRKZdUu3rz+6wMeQgJtNlWEiiUPHmFm+YuITzsez4QmkFhUS9JLpOGq3QKLzYURK9Tos7EK43VrzM4NEkpZhpjuIlKjnCzW/44rkM9kO57Dw2voKHJI9Oyhdct02XHs+JDb5il5bRF2p30be0+fj3PsJDafeSfjY72VvgXZBEIRuMP1lJIcehXvziyiVa1BS49JmlgUZGnRz87GjGJrrAcvCWb6MZKo+mhSrxbv2YeITLsAMjuxRDF8/aSwW8M7m6ja3R2fciJwM41n/ePNjevF0JCyU6nWdnj86/UaQHCRHnNSjODNBvINkmOUKIicaiUk+cohmO5zDQlU4Qa63a5MGvOsfx5IcxCZf2isxeHe+xZCXLkOO1VF3wePEJ/XOeQVBEDItNn4BSo1G4I3byPn4twAoDpnnbj6Km1Mtao76bcix2uaxtt5V9yHpESKzb+3x9U+ZWMTwPA/PrNzX5na9ZCbJIXPxrrq/uTtWL56GJSs4GtruJm3JufdjJMvot0tBtSSStAyz3EGkeANxRw4BKUokYWQ7pAGtJhwnaViMzO9aUVjTHSQ26VJ74fKeSEbwv3MHJW99GcNfRu0lL6KXHdWzcwqCIGRRfNy5WJKM5fTa47dSpS1kSWpesqmphS05ZC5SIoR31X3Ex5yJkVpSqidkSeKIYUFW7m1g8db2W9McDTtw7XgbANNXStUXNtjj6DrgqNuK/+1vYzlcJIf2/xV/RJKWYaYrgJRoJOHIwU+UilA82yENaO9tsev2zCgLdum46OyvEDrlDz26tlKxivwnzsKz9mHqp32Bfec9ecjiv4IgCAONlVNCsuwY5NBeJD2Co+bQ8dPO/UsxXUGMggl41j6MHK/vlVa0JlfNHQHAvz/c0eb2+NizMXKG4F11r/2AJIHi6fS8yv5lOKLV6MUzwNH1upqZJpK0DLNb0uoxnH5yiFHZKJK0nvh0Zx0AJ4wrTPsY19ZXkaI13b+oaeBd+nfynj4fSY9Sf8Fj1B35/zpdn04QBGGgiI8/H0fELoPRVC+tpcSoU4kc9U0wk3hX3E1i2PG9WmZofFEOxX4XG8pDhOJtFKl1OIlNuw7Xrveak0i39hQFDxwNevtDiVy7FwMQH3tWr8Xal0SSlmGWOxc50Uhj3iRWWuOIJkV3Z0/srosiSzB9aHotaXJoH8HXvoRvxd3dup7cuIfc5y/D//FviI85i9rL3+j3U7gFQRC6Kj7uHCxkLMWLM1UvraXEmNOJzrwZz4YncUTKicz5Wq/HcMnMMizg34u3t7k9OvVKLIcb7+r/AmA5c3CE9qBUb2j3nM69HwOQGNn/Jw2ASNIyznIFkOIN6LNu4evJr+JWHJ0fJLQrppscNzofh5xexWjPhieRLJPo5Mu7fC33pufJf+x0lMo1NJx6J41n/gvLk9fl8wiCIPR3lreA5IgT7LFbJTNbbXPUbrHroyVC+Jb9i2TJzD75sHrNkcNxSPDyuop2YiwkNuFC++96rA69aDoASmU79dL0GHLjbkzFh1EwMIrJiyQtw0x3EMlMEnAk8RCnLiK6O7srmtDZXh1hUmmaKw1YJp71j5EYdhxm3pi0ryPFGwi8cRvBhbdiFEyg9vLX7dmb/XgpEUEQhJ6Kj1+AHK9HLzmi1ePuzS+S+9qXcG96AUfDDiJzvtonfw+dDpkjR+bRGNfZWRtpc5/ojBuR9Cie9Y9jBoZhevJRKle3ua9StRYJC714+oD5+y2StAyzUut3Fqy/jw2eG1i7vfPpwkLbPtxWa1eMNsy09nfuXoyjYSexKVemfQ1l76fkP34G7k3PEz7ym9Rd9HS/XoxXEASht8THnoUlKXhW3Y/csKv5cWX/UvT8ifhW34eeP4HEmDP7LIYfnDGREr+Lhljbi6cbxVNJlB1td3laJnrx9HaTNEu2JwrEJl7cV+H2OpGkZVjT+p0+t13XS482drS70IGPttcCMHNYeuPRPOsexXTnpjdg1Eji++T35D13CUgO6i5+xh4kK6dfMFcQBGEgszx5JIbPw7PxaTzrHk09aOIsX4bpH4JSvcGe0dmHRbuHBD28+MWjmdbBuOPojBtxNO7Ctf0N9OJpKLWbwEgesp9r9/sAJMec2mfx9jaRpGVY0/qdfpedpJnxhmyGM6CtK7cT3CNHpresR3TmzYRO/GWn07Tlum3kPXMROUv+Qly9hNrLX0fv7fU9BUEQBoC4eiES4Nr5DmDXGZPj9cj1OzACw4lPuKDPY5A76ZpMjDkTwz8M76r7iMz6MlU3rgbHoQXOfSv+jZFT2vP6mBkkkrQMM925ACiO1IsuEcpiNAPb3voYXqeMx5ne5At9yGziEy/scB/3+scpePxMHPXbqD/zLhpP/ROWq2trggqCIBwuEmPOxJJke7kl08C5bwkASsMOe43ONpKhjJMVotOvw7XnQ+TQPnAeWtxcCu1DjlZhBHq2ZFWmiSQtw5pa0pqWsnAkRZLWHbphEk4YDA12XrwQyyLw1jdwpipTt8e56wOCi75FsvQIaq94g8T483opWkEQhIHJcgXQC6cimTqO6g3o+eMw/GWYnkJi3Zgl31diUz6PpXjwrr6fwJu34/ukdbFyj/YUYNd3G0hEkpZhTWPSJFMnYTlwmGJ2Z3es2mt3E08q6byVSylfZtfyCbe9DlwT78p7ML3F1C94ENNf1itxCoIgDHSxSfZAe8/Gp8HhxhHaS+SIL4DSteX4+pLlySc28XN4tGdw1G/HtevdVttd2xdhAbHJl2UnwG4SSVqGmanZnZbDzWVFz7Mp/+QsRzQw7a6PAXD1kcM73dez7hEsxUd8/Pnt7uOo24p7x1tEp109IJYKEQRByJTYpM/bXZ6Va/G/90NMp5/YtGuzHdYhojNuQDLiWJKEUrWuec1RAKV6PZbixcopyWKEXSeStExTvFiygpxoxO9WCMXFigPdsbEihNcpM64op8P9pEQjnk0vEJtwfodjyzyr/4slO4lOvaa3QxUEQRjY3H7iY89BKV+Gs3wZ8dGnNvcK9SdG4SQSw45HqdmEZMRx1G4CQIpUISdDGPnjsxxh14kkLdMkqXnVgTv2387xtc9kO6IB6Q2tErfi6HTWj3vT80h6tMPaaFKiEc/6J4iPXzDgPmUJgiBkQnzcOcipNTEjR/2/LEfTvujMm5DjdcCBlQdcuz8AsIvuDjAiScsCyxVESjQw2tzJMGt/tsMZcEzLojaSxO/qfFana9sb6AUqeumsdvfxrH8cORkiOvOm3gxTEAThsNGyJ8LMG529QDqRGHUqRmBEqnvWLmrr3P0+pjuXxJiBsah6SyJJywLTnYuUaCQq+fATxbKsbIc0oGwob8QCJpR03NUJ0HDOvdSf+9/2lwAxDbyr7ic5ZC76QevTCYIgCLbk0KMB0HPHZjmSTsgOe2yaZRIfdx5YFu4tr2J6C0EeeGtliyQtCyxXADnRQEz24peiRBJiXFpXvL+lBoC5I/I63lGPgqxgBke0u4tr59s4GnYQnXFjL0YoCIJwmHHlULfgYeoveiLbkXQqNvlyLMWHd/2jdvHdRAOY6S0f2N+IJC0LLHcQKd5AwpGDnyiV4US2QxpQVuypB+DEcYXt76RHKfzfsXhX3NPhubwr78XIGUJ87Nm9GaIgCMJhJznypAFRrd9y5xIffRruDU/hWfkfAJLDjslyVN0jkrQsMFNj0pJKDn4pSmVI1Errih01URyyxJAOCtm6t7yKHK1CL5rS7j6Oag3X7veJTr++f1TNFgRBEHpFfMIFSFh41z4EQHLEiVmOqHtEkpYFdktaIxunf49vJ2/BJXc8Q1E4wLIs4rrBqROKOtzPs/5RjOAoksOObXcf76r7sBzuDmd+CoIgCANPYvSpWJKMhD3mO9nB5LH+TCRpWWC5AsjJEL4hE9lqlRHVB2ZfeTaUN8ZpiBscMTy33X0cdVtx7fmI2OQrQGr7JS7FavFsfJrYxIuwvAV9Fa4gCIKQDbKCkTsaANMVwAx0Xvi8PxJJWhY0FQHM3/k6dyiPsLEinOWIBo5Fm6oAyOmg/IZn/WNYkoPY5Evb32fdo0h6TJTdEARBOEwlhx0PQMNZd7c/w7+fE0laFjQtDVVYu4wvOl5mZ41I0tL12c46ANQO1uy0ZCfxCRe0P8DV1PGu/i+JYcdhFE7ugygFQRCEbNNLpgNgdDDDv79TMnUhVVVl4J/ATCAO3Kxp2ubUtiHAYy12PwK4Q9O0u1RVXQ7Upx7fpmnaDZmKua80taR5XS5kySIWDWU5ooFjS1UYWYKxhb5294kc3XE1bNe213GE9hI64ee9HZ4gCILQTyRGnUrdhU8MiBmp7clYkgZcCHg0TTtWVdVjgD8CFwBomrYfmA+gquqxwC+Be1RV9aS2z0/3IqZpEolEOtwnGu14e18zLBe5gDM1YSAZqes05mzJ9r06WGUoQdCjEI1G29zuiJRjOdyY7rx2zxFYfg9J/3DqSo6HXrrv/e0+9WfiXqVP3Kv0iPuUvkF1r6QA5B8BCRMSXXvemb1PgXa3ZLK7cx7wGoCmaR8Dcw/eQVVVCfgb8GVN0wzsVjefqqoLVVVdlEruBrym7k5HKkmTEqIlLR3V4QS6aTEyr/3SG7nL/0rZ02dAO6s4OKvX4SlfQuPkqwdk9WlBEARh8MhkS1qQA92WAIaqqoqmaXqLxxYAazVN01LfR4A/AP8BJgCvqqqqHnRMK7Is4/O13xXWUrr79TY5WQyA02knCQ4jkrVY0tUf4lu42X75HDE8r914PDXrMYqn48tpe8mowEcPYyk+zJnX4HP3/nPqD/dpoBD3Kn3iXqVH3Kf0iXuVnmzfp0y2pDXQuk1PbiPZuhq4u8X3G4GHNE2zNE3bCFQDQ/s2zL7XNCbNcvq5U76OpLc0yxENDLXRJAAXTG9nfIERR6nRmgeLHkyKVOHe+DyxSZdiudsv4SEIgiAI/UEmk7TFwDkAqW7L1W3sMwf4sMX3N2KPXUNV1TLs1rh9fRtm37NcqVxVdvBe/qU0OjsuzCrYNlWGKQu6GZnf9icbpXoDkpkkWTyjze3etQ8hmQmxTqcgCIIwIGQySXsWiKmq+iFwJ/ANVVWvVFX1iwCqqhYDjZqmtRxMdC+Qp6rqB8DjwI0ddXUOGLKC6cxBitYwJ/4xcv2ObEc0IHyyvZYcd/s99EqlnffrxW20pBkJPGv+R2LkfIz8cX0VoiAIgiD0moyNSdM0zQRuOejhDS22V2KX3mh5TAI4LNfssdxBpFgtPwzdz8/064Hzsx1SvxaKJ2mI6wyT2580ABLJ4hmYwZGHbHFvfglHpILQjD/0XZCCIAiC0IsyOXFAaMFyBZF1e4qvzxpEU6K76ZPtdQBMHdL+VOXY1KuITb2qzW3eVfeh540lMXJ+H0QnCIIgCL1PrDiQJZY7iJSMkETBL0Wx2ikZIdg+3F4LwHFj8tvewdSR4g1tblL2L8VZscIei9bOWp6CIAiC0N+Id6wsMV0BpHgDUcmHnyjRpJHtkPq19eWNAMwdkdfmdqVqHUX/mYJr+5uHbPOuug/TFSCmtr+WpyAIgiD0NyJJyxLLFURKNBCTc/BLUSpD8WyH1K/trY/hdcp4XW330CuVqwDQ88e3elwO7cO95WVik68AV9u10wRBEAShPxJJWpZY7iByvIFteceyzhxFY0y0pLUnoZtEkwYnjS9sdx+lYjWmOxczOKrV4541D4JpEJ1+fR9HKQiCIAi9SyRpWWK3pDWy76ifcI9xHkjZjqj/2lIdxrRg/vj268kplavRi6aB1OJG6jG8ax8iMeYMzNxR7R4rCIIgCP2RSNKyxHQHkMwkAbOBfBqoiSSyHVK/9c6mKgCGBNxt72AkUKo3HLLSgGfjc8ixGlG8VhAEQRiQRJKWJZbLXpZowtIf8YzrJ6zc0/bMRAE+3VkHwLDctmukyeFyTP8Q9OKZBx60LLvsRoFKcthxGYhSEARBEHqXqJOWJZbbrveluNx4pSj1qXUphUPtqo3ickjk+VxtbjeDI6i55kNoUcbEufdjlOp1NJ78u9ZdoIIgCIIwQIiWtCwxXfYi626nCz8x6mMDf7WrvmCYFg0xnZL2ujoBzNS9a5GMeVfdi+nOIzbxoj6OUBAEQRD6hkjSssRyNyVpCl4pQSQWy3JE/ZNW0YgFTChqv3xG3jMXE3jz9ubv5YZduLYttFcfULx9H6QgCIIg9AGRpGWJlWpJczjsH4EVD2UznH7rvS3VAMwZmdf2DkYSpWotpvdAeQ7v6v8CEtFp1/V5fIIgCILQV0SSliVNLWlIDqqtIA5DtKS1pSaSRJElTpnQdvkNR81GJCOOXpya2ZmM4ln/GPFx52AGyjIYqSAIgiD0LjFxIEuaxqQZ+eO4IvggZcG2Zy4Odjtro6glfor9bY9JczatNFAyw/6+YgVyvJ64eknGYhQEQRCEviBa0rJF8WDJTuR4I363QighJg4czLIs1uxrpNjf9qxOsIvYmk4/Ru5o+/vy5QAkS2dlIkRBEARB6DMiScsWScJyBZAbdvCnqi8RrPg42xH1OztqI8R1k5hutruPHNqHXjwNJPul7KxYgREcheUtyFSYgiAIgtAnRHdnFpnuIFIizBh2EzDqsx1Ov/PBlhoAjhiW2+4+DefeD/qB8XxK+XKSQ4/q89gEQRAEoa+JlrQsslxBSE0Y8FnRLEfT/yzdXQfAieM6aRVT7PF8cng/jtA+dNHVKQiCIBwGRJKWRZY7iKzbyVkOEawWFfMF2FwVQZJgXDs10tzaU+Q/eipSxF7bUylfAYjxaIIgCMLhQSRpWWS5AkiJMAABKUo0aWQ5ov6lKpQgz+tEbmdZJ2f5cuTGPc3jz5zlK7BkBb1oSibDFARBEIQ+IZK0LDLdQaRkIzHJi58olaFEtkPqN6pCcXTT4pjR+e3uo1SsRi+e2jxpQKlYgV44RawyIAiCIBwWRJKWRZYriBRv4MU5/+Mf+gXopujubKJV2C2MF04f0vYOpo5SvQ692K6PhmWiVKxELz0iMwEKgiAIQh8TszuzyHIHkZNhXEXjqCVJJCG6O5t8tN2e2TmmwNfmdkftJiQ91rzSgKN2C3KiUYxHEwRBEA4boiUtiyxXAIBRG+/hC46X2Fwl1u9s8tH2WgD87rY/RyjVG4ADKw00FbHVS47o++AEQRAEIQNES1oWmW67/ldZ9WLOdMR4sS6e5Yj6j/LGOH63gtPR9ueI+MSLqB52HKavGLCL2JquAEb+uEyGKQiCIAh9RrSkZVFTS5pD8eAnSm00meWI+of6aIK4bjI8t+P1TM2c0gOTBsqXo5fMbP5eEARBEAY68Y6WRZbbXmRdcbrwS1EaYyJJA/hwm93VOWNYoO0dTJ28pxbg3vS8/b0eRaleL8ajCYIgCIcVkaRlkemyuzudTid+ojTGxSLrAO9vrQZg/viiNrc7ajfjLF8Opn2/lMq1SKYuxqMJgiAIhxWRpGWR5U51d8oyfqKEYiJJg6bxaA5mlrW9ZqdSuRqgeWans2KF/b0ovyEIgiAcRsTEgSyyXHZ3p5E3ll9JEyjKET8Oy7LYVRtj/vgiXErbnyGUilVYig8jz54koJQvx/CX2WPUBEEQBOEwIVrSsqhp4oDlCvBh4Gxkh0jSdtfFqI0mGV/Udn00AGdlaqUB2WF/X75CtKIJgiAIhx2RpGWT7MB0+pFD+zglvoj62spsR5R172y2F0uPJs22dzANlKq1JFNdnVK0GkfDDpIlYtKAIAiCcHgRTTdZZrkDyA27+F7iUT4X/VW2w8m6T3bYMztPmdD2pAEkmZor323+1lm+AhDj0QRBEITDT1otaaqqLlBV1dHXwQxGliuIZNoLq3vNSJajyb5NlWEcEowubKe7U5IwA2WYgTLAXlTdkmSSTWt4CoIgCMJhIt3uzkeBPaqq/klVVfFu2IssdxBJt1ca8DG4kzTdMKmNJCn2u5Elqc19vCv/Q84HP23+3lm+HKNgIrhyMhSlIAiCIGRGut2dpcAlwNXAMlVVVwMPAA9rmiYGUvWA6Qoix3cDkGNFsSwLqZ0E5XC3bn8IC5hU6m93H/eWV8BKjVezLJTyFcTHnZ2ZAAVBEAQhg9JqSdM0Laxp2gOapp0OjAIeBi4Fdqqq+pyqqheI7tDusVwB5EQYgBwpRiRhZDmi7Fmxpw7oYDyaaaBUrmmeNCDXb0eO14kitoIgCMJhqTuzOxuBaqAm9f1Y4F/AJlVVj+2twAYLy52LlAyxLHgqu6wS6gfx0lA7aqPkeZ2cNbmkze2Ouq1IegS9xO5xbypiK5aDEgRBEA5HaXV3qqqqAOdid3eei52oPQL8SNO0Fantd6UeG9POOWTgn8BMIA7crGna5tS2IcBjLXY/ArgDuLu9Yw4XliuAlAyx/vjf8e4rGl/R2yk9MQgs21WPWpzTbnevUrkKOLDSgFK+HEvx2mPSBEEQBOEwk25LWjnwBOAErgSGaZr2DU3TVgBomqYDrwGeDs5xIeDRNO1Y7ATsj00bNE3br2nafE3T5gPfA5YB93R0zOHCdAeRTJ28+D6KqKc6PDhb0sIJnd31MSrCiXb3USpXYykejPzxgF1+I1kyA2RRSUYQBEE4/KT77vYL4CFN06o62OcF4OkOts/DTuTQNO1jVVXnHryDqqoS8DfgKk3TDFVVOz3mYKZpEol0PEsyGu0/syhlyYMfOOHTG/mecyJr90xlapEr22E1y9S9em+r3Xs+pdjX7s8vrl6Lc8gJxGIJMEIUVa2hYfI1nf68M6E/vab6O3Gv0ifuVXrEfUqfuFfpyex9CrS7Jd2WtL8BX1dV9ctND6iqukRV1Z+kEis0TUtommZ1cI4gUN/ieyPVTdrSAmCtpmlaF44Z0Eyn/cMxHR4CRKmLDs5F1j/cbv+Y543Ja3cfI2cIsTJ72KOrVkMyEiSKREUYQRAE4fCUbsLzK+Aa4OYWj90N/ASQgJ+mcY4GWqeLcqqbtKWrgb908ZhWZFnG52t/3ceW0t2vLzmDxQDILg854RghvX/EdbC+jml9hf2p5bjxpfhch04Ulht24lt+F9GZN2PkjcVTv95+fOQx/ep+9adY+jtxr9In7lV6xH1Kn7hX6cn2fUq3Je0q4EpN015pekDTtLuB64Eb0jzHYuAcAFVVjwFWt7HPHODDLh4zoDUtsu5QXPilKA3RwTkmbV9DjIBbaTNBA3DuW4J3zf9Aj9nfl6/A9BZj+ssyGaYgCIIgZEy6LWl5wP42Ht8JFKd5jmeB01VV/RC79e0GVVWvBPyapt2tqmox0HhQl+khx6R5rQHDcucCqSSNahrjg6+7s6IxTsKwmD28/X55pXI1lsPdPJNTqVhhl94YpIV/BUEQhMNfuknap8Dtqqp++aAk6qvYMzE7pWmaCdxy0MMbWmyvxC690dkxh5WmljTJlUMtAYyORvUdptbubwTgi8eNancfpXIVetEUkBWkeD1K7WbiEy/OVIiCIAiCkHHpJml3AIuAU1VVXZp6bDYwBDirLwIbLEx3EIDkiHncVnkkMwPuLEeUeZ/trMMhwcSSdpaDskyUyrXE1c8BoFTY9dJEEVtBEAThcJbuslCfAtOBp4AcwAU8CUzSNO3Djo4VOuHwYMlO5HgDfpeD0CDs7nx3cxUWoMhtd1066rcjJ0PNRWyd5csBmlceEARBEITDUdrlLDRN24ZdaFboTZKE5Q6ilC/noYZH+FzjncC0bEeVMYZpURVOUOBz4WgnSTO9RTSc8S+SQ+cAoJSvQM8f3zyeTxAEQRAOR+kuC+UBvojdmtY0/U4C3MBcTdPEujw9YLoCSMkIJVItTiOU7XAyanNlCNOCCcU57e5juYPEJyxIfWPhLF9OYuRJGYpQEARBELIj3Za0fwCfx55AMA94DxgHDOcwXKop0yx3Lph26Q23ObiqQb+9uRqAY0fnt7uPd+V/MHLHkBh9KnJoL3K0UoxHEwRBEA576dZJWwBcl1pbcytwKzAWexmodkZ7C+myXAEkw16z0msNriRtyc46AE4cX9j2DpaJ79M/4trxFmAvqg6glx6RgegEQRAEIXvSTdJygU9S/18LzNE0zQB+TarYrNB9ljvYXKTVTxTLGjx1OPY1xMlxOSgLetrc7qjfjpxobDVpwHK40QsnZzJMQRAEQci4dJO0fcCw1P83Ak3T6upJv5it0A7TFUTS7RY0P1HCicExwzOWNKgOx7l8VhlSO0VplUp7kYlksf2SU8pXoBdNBUf/WYReEARBEPpCuknaM8B/VVU9FngTuE5V1QuAHwFb+iq4wcJyBZETEe6f/QJvmbMJxY1sh5QRa/c1YFgwdWiw3X2UilUHVhowdZyVq0iKrk5BEARhEEh34sD3ACcwRtO0R1RVfQF7PFojcFlfBTdYWO4gkhHFkzeUOCHCicGRpC3UqgAwO+jeVSpXoxdOAocTR9U6JD2KLiYNCIIgCINAukna9cAvNE2rANA07Quqqn4DiGmaNjj65vpQ09JQc1bewXnyFLZXT2ZcUfslKQ4Xq/Y2ADB7ePv1zqIzbgDTTlqbitgmS47o89gEQRAEIdvSTdJ+A7wNVDQ9oGna4Cro1YfMVFHWMbUfMEP2sD8Uz3JEBzywZC9jC7ycOc3X6+feXRfF53QQ9Djb3Scx9uzm/ysVKzDdeZi5o3s9FkEQBEHob9Idk7YcOL0vAxnMmlrSDIcXPxHqIoksR3TAfZ/t5Yevb+nWjFPX1tdQ9i1pc1t1OE5MNxmR3/asTgClcg1u7enmma/O8uV26Y12JhkIgiAIwuEk3Za0CuCvqqp+H7tOWrTlRk3TzujtwAYTK7XIuuVwE5Ci1EWTWY7IFmkxNm5XbZSRBem3pknRanJfvZnkkDnUfe75Q7Z/tL0WgFnD2u/qdG96Du/K+4iPXwCJMI6ajcRbtKwJgiAIwuEs3Za0KPA/YCGwGdhz0JfQA6bLTtIkxY2fKPXR/jHMb2t1uPn/z68p79Kxrh1vAxA+6tsAeNY9RuCNryHX7wBg2a56AOZPKGr3HEpF06QBF87KVUiWiS7GowmCIAiDRFotaZqm3dDXgQxmTS1pssNJjhSjMd4/krRt1XbtNpdD4rFlu7n+qOEEOhg/1pJr+5sYvhKSw48HQIrX4d7yCu7NLxKbehWJhjOYUOxvf9KAZaFUrSE+7jzAro8GiOWgBEEQhEEj3QXWr+xou6Zpj/ROOINT05g0ffhx/LtmJEU5/aNQa1O366xhAT7Z2cC/Fu/gO6eO7/xAI4lr17vEx50Dkt1YG511C/GJF+L77C941jzEneZjfFBwCZI5DRzuQ04hN+xAjtejl6RWGqhYjhEcheUt6L0nKAiCIAj9WLrdnQ+18/Uf4Kd9Etkg0pSkWb5iNvjm9JuB8X63ncPfPm8kDlnitfXpdXk693+GnGgkMfq0Vo+bOUMIzf81q855lTfN2UwIfQpyqmXObN166KywVxrQW6w0IIrYCoIgCINJWkmapmlyyy/swrZTgU+Bn/RlgIOC7MB0+nHUbuY8/XV21PSPRdYrUqVAivwu5ozIpTFu8ElqwH9HkkOOpO7CJ0gMP7HN7QvL/dyW/BrPTLsbJBlH1ToKHjwOz9qHm5M1I280kRk3oReqyOFyHKG9ooitIAiCMKik25LWiqZphqZp64FvAr/o3ZAGJ8sdRKnZyLf1/7C3Ptr5ARnwplaJLIHLIfO1E8YAcNfi7Z0f6HCSHHYcuNouyPvpzjoA5k0ssx+wLEx/GYF3vkv+Iyfj3vQietFUwif8DBzuA+PRxKQBQRAEYRDpVpLWgg6U9UYgg53lCoBl4JQMMPpHMduGmI4i212vk0oDFPqcrCtvJKG3v2yV3LCT4EvX4qha1+4+myvDOCQYXWiX9DCKp1J38bPUn3M/OFwEF36ZggeOQg7vB+z6aJasoBdP7cVnJwiCIAj9W08mDgSBLwKf9GpEg5TlzkWKVALgNvpHd2ckYeB1Hsjjv3riGH722kbe21LDaWpxm8e4tr+Je8ciQvN+1ub2hG5SG00yNOhGbjn2TpJIjDmdxKhTcG96Fu+q+3HUbMTMGYJSsQK9cDIo3l59foIgCILQn6VbzPahNh5LAh8BX+m9cAYv0x3EEdoLgM/qH0lawjAp9B2YeXn25FLu/nAHT63c226S5t7xFnreOMy8MW1u31DeCMDkUn/bF5UdxNVLiKuX2N9bJkrFSuITL+r+ExEEQRCEASjdOmk97RYVOmG5Aki63c2ZQwzTslq3NGVY0jAxLcjzHniJOGSJ6WVBFm6oZOWeemYevFpAIoxz90dEp1/f7nk3VNhLvn7txLaTuIM5arcgJxrFeDRBEARh0Ek7+VJV9SZVVa9o8f0zqqpe1zdhDT6WO4hkxHkveD71+FotyZQNu2vtyQvFB9Vsu2TmUAD+8cH2Q45x7f4AyUyQGH1qu+dds6+BohwXw3LT67pUKlYAiJmdgiAIwqCTVpKmquq3gT/TuuVtHfB3VVVv7YO4Bh3TFURKhtFm/JDdVgmhLK86YKTWU583Jq/V47OG55HrUVi5p/6QCQSuXe9iOv0khx7Z7nnf3VKDaVlIabYSOsuXY7oCGPnjuhS/IAiCIAx06bakfQW4WtO05rFpmqb9ELgeuL33wxp8LFcQyTIoDm8gnwZqsrzIelXY7not8R+6+sF5U0sxLXjg092tHg/N+yl1n3sOHG2vmNAQSxJJGOR701taCuwitnrJzOaVCwRBEARhsEj3na8UWNvG4yuA4b0WzSBmue1VBy5cfi3nOD5lZ5YL2r63pRoAt3Joi9cXjh2FBDy9am/rDQ4XRuGkds/5yQ67EO6MsmB6QehRlOp1YlF1QRAEYVBKN0lbDVzdxuNXABt6L5zBy3IdGITvJ0p1OLstaTtq7DFpZcFD19XMcStMHRqgOpxsTia9K+4m+MpNhyzv1NL7qcTvpPGFacWgVK1DMnWxHJQgCIIwKKVbguNnwIuqqp6IvRQUwFzgJODivghssDFTLWkmMn4pSlUku0ladSQBQNDTdtfkbxdM5vx7PuX5Nfv52oljcW9+CSwT5PZfUmv22eU3Zg3PSysGZ/lyQEwaEARBEAandNfufBU4AdgPnAucAZQDR2ma9mLfhTd4WC67C9B0ePATpT6W3SStPqrjdLQ/uL8k4OH4sQU8s3IfRqgSpXx5h7M6LcuivDFOwK3gcznSikEpX47hH4qZU9rl+AVBEARhoEu3JQ3sFrTbNU2rAFBV9ThgTZ9ENQhZbjtJsxQ3gUSU+lh2Z3dGEjoepeNkqjTgJpQwWP7+M5yNRWJU+0navoY4CcPiK/NGpB2Ds3yFaEUTBEEQBq10S3BMBDYB/6/Fw88Cq1VVTa8qqdAhs6klzVdKlRXEsqysxhPXTQLujpO0m48ZBYBz25sYvhL04mmttud89CtyPvgZzp3vsGGPveTV7BF5aV1fitbgaNghitgKgiAIg1a6LWl/BZYBv27x2ATgfuz6aRf0bliDT9PszqR6IXfVzeHUnLbLWGQkFsvCIUvMHpHb4X4FOS4mFHqYGtKoLj0FqUWZDEfdVnzL/gmAb+U9XISTMuckxm09B4dyGkbBJOigVpoYjyYIgiAMdukmaccBczRNq2l6QNO0BlVVf4C9fqfQUw4PluxCTjTgdztozOKYtHDCIGFYjC3M6XTf648ZzUkv38lpETctl1R3bX0dgJor30Fu3M3LLz3GXGkFZct+C8t+i+ErJTnyRBIj7C/L23rGp1KxAkuSSRbP6M2nJgiCIAgDRrpJWgQow+7ybKkIyO76RYcLScJyB3FtW8hd0Ve5cc/vsxbK+tQi6On0uJ42sYhfvO5m4S6LHxomTofdmube9jrJomkY+eOJ547jh1GZIv/1vHbVSJy73se1811c297As+FJAJLF00mOOJHEyJNIDpmLUr4Co2AiuDpPFAVBEAThcJRukvY08C9VVb8EfJZ6bC7wL+D5vghsMDJdATASFNNIXDezFsf6cnsRdKWD2Z1NCp5ewD/K5nLTzlN5Z3M1p6vFSJFKlP1LiRz5DQC08kYsYGKxH9NfRnzy5cQnXw6mgVK5Gteu93DufBfvin/jW/YPLMUHpk5MFdVdBEEQhMEr3STtu8CTwLtAU/uKBDwHfKP3wxqcLHcQKVqNX4qSMLKXpO2pswvZji7wdbifXL8DZ8VKjjz+IobWuXl21T5OV4txb38DCYv42LMAeGezXcT22DH5B53AgV56BHrpETD3NqREI849H+Ha+S7K/iXEJ5zf689NEARBEAaKtJI0TdNCwNmqqqrANCCJXTPtaOADoNOBQ6qqysA/gZlAHLhZ07TNLbYfCfwJO/nbj71WaExV1eVAfWq3bZqm3ZDmcxtwLFcQOVxBDjEMI3u9yPsb7XU7xxf5gPaTRdeOtwBIjj6VE6oNnlixl+3VEWZsW4gRGIFROBmAZbvrADhhbEGH17VcARJjziAx5oyePwlBEARBGOC6tGq1pmkasA97lYG3gb+Q/pi0CwGPpmnHAncAf2zaoKqqBNwD3KBp2jzgNWCUqqqe1HXnp74O2wQNUrXSTHvCgMeMZi2OpiWpiv2HLgnVknv7W+h54zDzxjC+2G51u//9dbh2vU98zBnNszdDcZ05w3MZGvT0beCCIAiCcBhJqyVNVdVc4Frgi8CU1MMLgd9pmvZ2mtdqSr7QNO1jVVXnttg2EagGbldVdTrwsqZpmqqqRwM+VVUXpmL9vqZpH3d0EdM0iUQ6Xpw8Gs3u4uXt8cheFMNuxfIRJRQOI3dQpqKv1EbiOGSIRqPt3ispGaZoz4c0Tr6aSCTCKWOC/E6WkLe/g+SM01A2n3gkQiRhsK06yklz84lGs5d49rX++prqj8S9Sp+4V+kR9yl94l6lJ7P3KdDulg5b0lRVPV5V1QeAvditZnHge9h9YN/qQoIGEORAtyWAoapqU5JYhF3m45/AacCpqqqeij2r9A/AmcAtwMMtjjnsmK4gkqHzx+mvsp8CosnsjEsLuBWGdNKK5qzdhCUrRIfPt793yBw7KpeT5SXElCDx0jkArNjbgEWHJdEEQRAEQWhDuwmPqqprgMnAcuCXwBNNY8hUVf1lN67VQOt0UdY0rWnto2pgs6Zp61Lnfw2Yg50YbtY0zQI2qqpaDQwFdrV3EVmW8fk6HvDeJN39MkXJKUA2ouTl5gG1GLITny/zXYSmJTGxNNDq/hxyr0YfR/VNq5FlBV9qUfVbjx/BpCeX87Z5JHP99goKH+/aDcCE0tx+d7/7wmB4jr1F3Kv0iXuVHnGf0ifuVXqyfZ86akmbhF0X7SXgvZaD/LtpMXAOgKqqxwCrW2zbCvhVVR2f+v4EYC1wI6mxa6qqlmG3xu3rYRz9lplav/PEFV9nhrSFvfXxjMdgWRb7GmK4HR28NCwLjAQoHpAP5PmTkuvIk8I8FzuCXbV21+bqfQ0AHDkyry/DFgRBEITDTkdJ2jDgP8DngHdVVd2rqupfVVU9kQNlOLriWSCmquqHwJ3AN1RVvVJV1S9qmpYAbgIeUVX1M2CXpmkvA/cCeaqqfgA8DtzYovXtsGOl1u+cEPqUYVIVFY2xjMdQFU4Q003qO1jxQKlaS+G9M3DuXtzqcde21zFkNx+YM3hutZ1L766L4nM6yPU6+zRuQRAEQTjctNvdqWlaOfZ4sD+kymNcD1wJ3Jra5RZVVX+vaVq7XY8Hnc/EHlfW0oYW2xcBRx10TCJ1zUHBSrWkAfilKNWRRMZj2FIVBqA00P6YNNeOt5CTIfSCiQcetCzc2xaijzyBI/VhvLB6PxfPGErCsBhX5O3rsAVBEAThsJNWCQ5N0z7TNO1W7PFgVwCvAl8Gtqqq+kwfxjeoWK4DQ/b8RKmNZL7RcHuNPaNlWF77Y+Fc298kWXIElq+4+TFH1TocjbtJjDmT0QU+6mI6v19k95DPGt7xQu2CIAiCIByqq3XSkpqmPalp2nnAcOD7wIQ+iWwQMt0Hkhk/UeqimV9kfU+d3cU6Kr/twZJStBqlfAWJ0ae2ety97XUsJOKjT+e4MXbR2sXbanFIcOWc4X0btCAIgiAchrpdziLVHfr71JfQC5pa0kzZSY4Uo6GDcWF9ZV9qtYFxhW0naa4dbyNhkRjVOklzbXsdfehcLF8RR3gt8rxO6qJJJpb4O+w6FQRBEAShbV1qSRP6VtOYtMiEz/G0eVKnFf/7gkOy1+Vqr7tTDu/HCI5CL5524LGG3Tir1hIfcyYAkiRxycyhAFldKF4QBEEQBjKRpPUjliuAhYQUHEqVezSG1Z1JtD2T41Io8rtwyG2/NKJzvkrNVe+BdGC7e9vrAK3W3Lx0VhkAhT5XH0YrCIIgCIevw7Z6/4AkyVguP0r5cs6wTDZWnZ7xEHbXRclvp1yGFG/AUrzgaL3dte119PyJGHljmx8r8Ll46OrZDAmKrk5BEARB6A7RktbPWK4gStVaPme+zp76zNdJW7O/kZpI22PhfEv+QuEDR4JxYLsUq8W595NWrWhN1FK/qI8mCIIgCN0kkrR+xnLbkwf8Uiwr47mShkXQ03YDq2vHW+hFU1q1pLl2vIVkGcTHnpmpEAVBEARhUBBJWj9junLBsghIURJGZpO0xrhdl63Qd2jrl1y/HaV2M4lRp7R63L1tIYavFL1kZkZiFARBEITBQiRp/YzlDoBl4idK0sjsxIEtlfZqAyVtlMxwb38LgHjL0ht6DNeOd+yuTkm8lARBEAShN4l31n7GcgWRTJ0cIhhmZpO0banVBspyDy2/4dqxCD1vLGbemAOP7V6MpEeItzEeTRAEQRCEnhFJWj9jt6QZvBG8BDAxM1iGoya1Vujo/IPW2rQsLMVDYuw5rR52bXsN0+knOfy4TIUoCIIgCIOGKMHRz5iuXCQ9xqZJX8eq2EYkYeB3Z+bHlJ+qaTZj2EFrbUoSDefce1CgBu5tb9hj1ByizIYgCIIg9DbRktbPWK4AkmUwvP4zvMSoiyYydu2qkL0kVGFO6wK0SsNOMFsv9q6UL0eOVrVZekMQBEEQhJ4TSVo/07Q01CXabYyR9rO/IZ6xay/UKnFIEk5Hi5eFZVH66pUEFn2r1b7uba9jyc5DZnsKgiAIgtA7RJLWz1iuYPP//USpCmdukfX6aBLFIbV6zFmzHiVSQWLY8QcetCxcW18jOezY5qRSEARBEITeJZK0fsZskfTkSDGqw5nr7owmTXxOR6vHfLvexkIiMerk5scctZtR6rc1L6guCIIgCELvE0laP9OyZSpAlNoMjklL6OYhqw14d79Domg6lq+4+TFX84LqmV9bVBAEQRAGC5Gk9TOtujulKPVRvYO9e09cN7CA/JarDSTCuKrWECs7vtW+7m2vkyyZiekvy0hsgiAIgjAYiSStn2nq7oznDKPeyslYnbSmQrYl/gPlNORYLbGhxxIbesyBx8LlOMuXi1mdgiAIgtDHRJLWz1gue4H15PRrWCgdS57X1ckRvUPGnjAwb2xB82NmcDgVZ95HrOzY5sdc294AEOPRBEEQBKGPiSStv1E8WA43cqKBHKdMQywzszurUhMUWi4J5ajbekh9NNe21zGCozAK1IzEJQiCIAiDlUjS+iHLFcCz5kG+r/+T5bvrM3LN97dUA+Btmt1p6uQ9cTb5n/6qeR8pEcK1e7HdiiZJbZ1GEARBEIReIpK0fqhpXFpQjhJNGhm55sGLqyvVG5CTYeLFs5r3ce58B8lMkBgrujoFQRAEoa+JJK0fsselSfil/9/enYdHUaQPHP/2nLkmByGQACFcUiAIiqCiiIp4i8p6rLuuoiCgP1A8uQRRREUEF1ZlBUVBRREXj0XRRV3FRUS5BA3QXOFOIAnknsyR6d8fk4RADgbIMUnez/PwPElXV3dNpSEv1VX1FlLo9dXKPY/ke9CgNE+oJXUNAK7m55eeY9/1Nb6QJnjie9ZKm4QQQojGTIK0IGTY/QnOHZoTT1HtBGk5hR6sZbINWFPXUBSRQFHJNhtFHmx7/ourzVVgMldyFSGEEEJUFwnSgpBhc4Dhw4ETT1HtbMGR7yk6Nh/NMLCm/oon4YLScuvB1ZjcObL1hhBCCFFLJEgLQj57JBhewrXCWtsnze31lb7qxOukqElHPK0uLS23p3yNYQnBndi3VtojhBBCNHaWk58iapthi0Qz4M1uS/D9coAin4HZVHOrKQ3Df/1zW/pfs2INI/umD/xfFxT4E6qnLMedeBlYQ2usHUIIIYQ4RkbSgpBhj0QrKiTK7n/9WOCu2RWeea4iPEUGHeLCATDlHTxufzRbZjLmvFTZwFYIIYSoRRKkBSFfcf7OGzcNI5TCGk+yvjktF4CSdQNRX9xD5FdDS8tD936HoZlwt+lfo+0QQgghxDESpAUhw+5PDdW2cDMOnBzOddXo/ZLTcgAwmzQ0VzbmTB1vs+6l5WF7v8WT0AsjtElllxBCCCFENZMgLQgZtqjSrx1aARn5NZsa6kB2IQBtm4RhTVuHhoEnoRcAlty92I7quNteW6NtEEIIIcTxJEgLQiUjaQAROMnMr9nXnSUjde3jwrGkrsXQzHia+zMNhO79DgCXbL0hhBBC1CoJ0oJQyZw0gAjNWeNz0jIL/CN1MaFWrKm/4o3rCtYwAML2foc7RuGLSqrRNgghhBDieBKkBSGjbJCGkyynt4qzz1y204PFpKEV39udeJm/wJ2P/dB6nK0uq9H7CyGEEKI82SctCBnFCdazO93Fr7914k/hthq9X7jdjM1sAk0j54a3S49bU39FM7wUJvSWaF4IIYSoZfK7NwgZtggMNCwRceSbo2o8f6fPB6p5BJrzyPH7ox34CcNkxdW8R43eXwghhBDl1dpImlLKBMwGugMu4H5d13eUKe8FvAJoQBrwN8BdVZ0GSzNhWCOw7vuRS0zhbE+PrrFbGYZBWq6Lc1o4cPwwGnP2Ho7e+Q0A1gM/44rrjmGRLANCCCFEbavNkbRbgBBd13sDY4EZJQVKKQ14E7hP1/U+wNdAUlV1GjrDHon18G9caGziYPEWGTXhUK4Ll9fH0XwP1tS1eJt2AUBzZWNJ/53ChItq7N5CCCGEqFxtzkkrCb7QdX21UqpnmbKOQCbwiFLqHOBLXdd1pdTwKupUyOfzUVBQUOU5TmfV5cEgyhqBSTPj0JwUuL0n/UynK/lAFgCdrWmYnBnkx3ajoKCA0L0/ohk+spucWy/6q65JHwVO+ipw0leBkX4KnPRVYGq3nxyVltTmSFokkF3m+yKlVEmQ2BS4GP+rzf7AlUqpK09Sp0Hz2RwYmgmHVojLW3Nz0vZm+UfpztO2AeBqdj4AIamr8ZntFMZ2q7F7CyGEEKJytRnw5HB8uGjSdb1klnomsEPX9c0ASqmvgfNPUqdCJpOJsLCwgBoU6Hl1QQuNQUMj0uTEXWTUWFsP5/uTt3fxbcVnj8La4hysmomwQ7/iTehFSEQ0ENx9FUyknwInfRU46avANKZ+KirycvRoOl7vqe2j6fMZAHg8+TXRrAajJvrJYrERExOH2Rx46FWbQdpPwABgsVLqIuD3MmW7gAilVIfihQGXAvOAnVXUadAMmwMwcODEW2TU2H3SirMNOEKs/v3RNBOaMxNL5hbyLxxTY/cVQghx+o4eTSckJIzw8Hg0TQu4XlGR/z/mZrO5pprWIFR3PxmGQX5+DkePptO0aULA9WozSPsUuEoptQr/Cs77lFJ/BSJ0XZ+rlBoCfFC8iGCVrutfFq8IPa5OLba3Thn2SAzNzLro6zCl19x9Sv5qe6+eQW7xX3TrgZ8BcLe6uOZuLIQQ4rR5ve5TDtBE3dE0jfDwSPLysk6pXq0Fabqu+4AHTji8tUz5f4ELAqjTKPjsUWhFhWS0GYg7bS9FPgOzqfr/MkaGWmkTXoTJ8IHm/x+D7cAqfNZwvHHdwFWzyd2FEEKcHgnQ6pfT+XnJZrZByrA50AwfSUf+B0C+u2ZSQ6VlFzLC/Amx75xXupGt9cAqPAkXgNlaI/cUQghR/7hcLm67bUCl5evXr2XSpHG12KKGT4K0IFWSGur2vU8DcLSgZka0Nh3MQbmTKYpuByYLpvw0LEd34Gl1SY3cTwghhBCBaRTbWdRHvuIk6zY8WPCSnuciqUn1rlwyDAOTz0VnduFJuB8A6/5VAHhaynw0IYRoSJYtW8rKlStwuVwcOZLJ7bf/hf/9bwUpKTsZMWIUTqeTxYs/xGq1kpjYmtGjn8LtdjN58gRyc3Np2bJV6bV27tzBzJkvYxgGUVFRjBs3qQ4/WcMlQVqQKhlJAwinkIz8U1tmHYhsp4du2i6seClI8E8HtB5Yhc8eVZp5QAghRMNRUFDAjBmv8v333/LRRx8wd+58NmxYx6JFC9mzJ4V33llIWFg4//jHDD7/fAkAbdu2Z/jwESQn/8H69WsBeOmlKYwb9zRt27bjiy8+Y+HCBfTqdWFdfrQGSYK0IOXfgsPPoTk5UgOvO3dk5NPT5N/E1hPvT+ZgO7AKT4uLwCTLs4UQoqE56ywFQESEgzZt2qJpGg6HA5erkLZt2xEWFg5A9+49WLNmNQAXXtgbgC5dumKx+MOGPXtSmDFjKuDfsy0xMam2P0qjIEFakDLsUaVfR+CskTlpu48UEKEVkBamMIc2wZSzD3POXpzdhlT7vYQQQtS9ylcYauzenYLT6SQ0NJTffltPYmJrNM3EH3/8zqWXXs62bVvxev0LzFq3TmLChMnEx8ezadNvZGZm1N6HaEQkSAtSvuKRtPyIdnhcZnxG9W9om5HvZp73TmIv7sSV+F91Arhl0YAQQjQqZrOZwYOH8/DDw9E0E61aJfLAAyMxm828+OKzPPjgEJKS2mC1+lf9P/74OKZMeRqfz5+2cOzYiWRk1OCmno2UZtTAL/+65PEUGVlZVSdGLUlWHtQpRLyFxM3pQM4Fo+n247k8eEkbBl/Uulpv8emG3Uz9726+GN6buAg7jm9HYdv7A5n3/QbF/9uqF30VBKSfAid9FTjpq8A0xn5KS9tDfPypv2KUjAOBqal+qujnFhfnWAf0rOh82YIjWFlCMMx2zK4sws1FHCmo/oUDLfd+zm/2ocQaR8AwsO7/CXfLi0sDNCGEEELUHQnSgphhDSd841wGsIJNB3Oq/fqW1DW4sWKKiMecnYI5P0223hBCCCGChARpQcxXvA2HAycF7qJqv/7ZRVtYbyjQtGP7o8l8NCGEECIoSJAWxAybf4VnpMmJ01O9QZop/xCJHOJ3c2fAv2igKLw5RVFtq/U+QgghhDg9EqQFMSMkGkMz4dAKKfT6qvXaltQ1AOy0dQHD8O+P1vISmY8mhBBCBAkJ0oKYfxsOE5GmQtxF1RukeXPSOGJEkBmhMB/ZhsmZIfPRhBBCiCAiQVoQ86eGMggx+fD5qnerlI0Jd9DT9QZNIiOwHvgJkP3RhBBCiGAiQVoQM2wOMFlY2flZzKZqfA3pK8JiGPgwcVGbGGwHVlHkSMQXmVh99xBCCNGoLFny0RlfY9iwe0lNPXjK9fbs2c3IkcPO+P4nc9NN11Ralpp6kGHD7q3W+0nGgSBm2KPQilxEWg2cHh9en4GlGoI168HV9P7yfrppo2kV1Q3rgZ9xtbu2GloshBCitn2ZfIh//5EW0LklG9hXnh7K76au8dzQpfkptWPBgre59dY/n1IdUTUJ0oJYSWqoa7aM4Q1Gke/yEhVqPePrWlPXYPbmsduIp7lzOyZXtsxHE0IIEbC9e/fwwgvPYrFYMJvN9OjRk5ycbKZPn8qDD45k6tQp5OXlkp2dxYABAxk48DZGjhzGWWcpdu3aSUFBHs899xLx8QnMmfM6v/zyM82bNyc7OwuAw4cPMX36VNxuFzk52dx771D69r2cu+++g8TEJKxWKw899BiTJ0/AMAyaNImtsr3r16/l/ffnY7VaOXz4EDfffCvr169lx45t3H77Xxg48DbWrFnN3Ln/xG6343BEMmbMBBwOB9OmPU9Kyi5atmyF2+3fWP7QoTSmTXsBt9uFzWZn9OjxNdLPEqQFMaN4n7Q2nh0AZBW6qy1I22tOIodwWmavBZAgTQgh6qkbujQPeNSrutIdrVnzC0p14qGHHmPjxg3ExMSwZMlinnhiLLq+lf79r+ayy/qRkZHOyJHDGDjwNgA6d+7CqFGPM2fO63zzzX+45JI+bNy4gbfeehens4A77/wT4H99eeedd9GjR09+/30j8+bNoW/fy3E6ndx77xA6duzEa6/NpH//a7jppoF8991yPv30X1W2+fDhw8yf/wFbt27h6afH8tFHn5Gefpjx45/klltuZdq0F5g9+y3i4prx0UcLee+9t+nRoxdut5u5c+eTlpbGDz98B8Drr8/ittv+TO/el7B27a+88cZrDBv2f2fUpxWRIC2IGTZ/kBZq+PPSped5SIo5w4v6irCkreM3+qABYamr8Ua3wxeRcIYXFkII0VjceOPNLFy4gMcff4jw8AiGDx9RWhYbG8vixR+wYsX3hIWF4/V6S8s6dlQANG/enMzMTFJSdtGpU2dMJhPh4RG0a9eh+BpNWbBgHl9++TmgHXeN1q3bAJCSsotrrrkegHPO6X7SIK1du/ZYLBYcDgctWrTEarXicETidrvIysoiLCycuLhmAHTrdh5vvvlPYmKa0LlzFwDi4+Np1swfDO/atYP33nuHhQsXAGCx1Ew4JQsHgljJSJrNKAQMMvJcZ3xNc+ZWTJ48fi3qSIjZwHrwF//+aEIIIUSAVq5cQffu5zFr1j+54oorWbhwQel8tw8/fI+uXbvx9NPP0a9f/9LjUH4uXOvWSWzZkozP58PpdLJ79y4A3nrrDa699gYmTnyOHj2Ozz1eco2kpCSSkzcBsGXL5pO2uappeNHR0RQU5JORkQHAxo3rSUxMJCmpTek9MjLSSU9PL253Gx588CFee20uTz45nssvv/Kk9z8dMpIWxErmpJkwCMXFkXzPGV/TnLMbw2xntesszrfuxuTJk1edQgghTkmnTmczefJEzGYzJpOJhx56jNTUg0yePJEbb7yZ6dNfZPnyr4iKisJsNpfO5TrRWWcprriiP/fffw9Nm8YRE9MEgCuuuJJZs6bz3nvv0KxZc7KyssrVvf/+B5k0aRzffrucFi1antHn0TSN0aOf4qmnnsRk0oiIcDB27NPExsayadNGhg4dRHx8AtHR0QCMGDGKGTOm4na7cbkKGTXqiTO6f6XtKhvhNgQeT5GRlVVQ5TkFBf7ysLCw2mjSaTPlHiD23QsB6FU4mxsuOIcRl1ZD2qYiNxfO+pkx4V8x3Ps+Gff9hhHWtMJT60tf1TXpp8BJXwVO+iowjbGf0tL2EB+fdMr1qmtOWkNXU/1U0c8tLs6xDuhZ0fkykhbEjOKRtPRO95H1WwTRIdXw4zJ8GCYrmqbR17IZb6SqNEATQggh6pN33nmTdevWlDs+fvykMx5tqwsSpAUxwxaBgUZIeCQeLBSeYWooU+4BYj66mkN9pmH2hdDBnYy7413V1FohhBCibt1331Duu29oXTej2sjCgWCmmTCs4dh3f8tZpgPoh/PO6HLW1DWYXNlsd0VzrrYDq88l89GEEEKIICVBWpAzrGHYMpNpy0HScs5sdac1dQ0+azg/5cfT27QZAw1Pi4uqqaVCCCGEqE4SpAW5kr3SIiikwF10Rteypq7B27wHB3K8XGxOJieqM0ZIdDW0UgghhBDVTYK0IOcr3ist0lSI03P6QZrmysGcuQVPQi+OZmdzrrYDX2vZH00IIYQIVhKkBTnD7k8xEGlykncGI2nmozvAbMOTcAEt8n7HrnkxJV1aXc0UQgjRyCxbtpR//vPVk563fv1aJk0aVwst8rvppmtq/B6TJo1j/fq1lZbfdtsAXK4z34BeVncGOSMkCgNoYnFTUFDEzox82jcNP+XreON7kDF0M2Cis2sxXsOEJ+GCam+vEEKI2mXf+i9CtiwK7OSSrVGr2H0foLDznbg63XZG7RJnToK0IOezR2GYQ2jW7Xq0n+EbPf20gjQMA8x2AC7gD7aYziLeFlHNrRVCCNGYJCf/zqhRD5Kfn8/gwcNwuQr55JOPS1NBTZky7bjzlyz5iBUrvsfr9RIREcHzz7/MN998zc8//4TLVciBA/u5665BXH/9AJKT/2DWrOkYhkFcXDMmTXqO/fv3M3PmyxiGQVRUFOPGTSI0NJRp054nJWUXLVu2qjS7QYk///kWunbtxv79++jRoyf5+Xls2ZJM69ZJTJz4HKmpB3nxxcl4vV5MJhOjRj3BWWd1ZMmSxXzxxWfExjbl6NGjAHi9Xl5++QX279+Hz+dj6NAHy6WxOhMSpAU5wx6J5nPTq/c19DzwO9/o6Qy/OKlc/rMqFXlo8v7FFJw/ClfHW+hk7OA/kX8mvuaaLYQQopa4Ot0W8KhXde+kHxISwssvzyIr6yjDht3LgAG38PLLswgJCWHatOf59defado0DgCfz0d2djYzZ87GZDLx2GMj2bIlGYD8/DxeeeU19u3by5gxj3L99QOYNu15nn32Bdq0acsnn3zM7t27mTFjKuPGPU3btu344ovPWLhwAV27dsPtdjN37nzS0tL44YfvqmxzWloqs2a9QdOmTbnuun7MnTufRx8dzR133Exubi6vvz6TW2+9gz59LmPXrh1Mnfocs2b9k48/XsS77y7CZDIxZMjfAFi69DOioqIZN+5psrOzGDFiGO+/v7ha+hYkSAt6hi0SzfBh3buCuPB41uzNYtvhfFTzwEfBLBnJmPNSMexRmA78ggUfux3nIy87hRBCnIlu3c5F0zRiYpoQHh6BxWJhypRJhIWFsWfPbrp27VZ6rslkwmq18swzTxEaGsrhw4fxer0AdOjQEYBmzZqXjoQdPXqENm38qRD/9KfbAdizJ4UZM6YCUFTkJTExiZSUnXTu3AWA+Ph4mjVrXmWbIyOjiI/3D1OEhobStm07AMLDI3C7XezevZvu3c8D/LlFDx8+xJ49u2nbth02mw2g9H47d+5g06YNbN78R2mbsrOzTrc7y5EgLcgZdn9qqPC1M8nSngPg662HTilIs6b6U2R4Enri/fUNXIaFDUZH7qj+5gohhGhEtmzZDEBmZgb5+XksXvwhS5Z8AcCjj46gbH7wHTu28+OPP/DmmwsoLCwsHY0CKnw71LRpU/bt20tiYmvef38+iYlJtG6dxIQJk4mPj2fTpt/IzMzAYrHw7bf/Af5CRkY66enpVbb5ZG+i2rRpw6ZNv3HJJX3Zvl2nSZNYWrRoye7du3C5CrFYrGzbpnP11deRlNSGZs2acc89g3G5Clmw4G0cjshAu++kJEgLcr7ifdI0dw43nx/PqpSjfJl8mIf7tgv4laf14GqKHIn4IhKwHVjFBuMsYqOq7yESQgjROLlcLh5++AGczgLGjJnA559/wuDBfyM0NBSHw0FGRjoJCS0AaNUqkdDQUIYMuRubzUpsbFMyMioPqJ58cjwvvjgZk8lEbGwsd9zxV5o3j2fKlKfx+fxpEseOnUjr1kls2rSRoUMHER+fQHR09Bl9phEjHmHq1CksWrSQoqIixo2bSExMDPff/wAPPDCY6OgYQkNDAbj55j/x0ktTGDlyGPn5eQwceDsmU/VtnKGVjXIbAo+nyMjKKqjynIICf3lYWFhtNOmMWPf9SPS//0pRRAvS7lrNla+votDrY95fzqVbi5MHWvbtS4lc/iAF3YdS0HMUsfPOYabnT1guHc2d55882Wx96qu6JP0UOOmrwElfBaYx9lNa2h7i45NOuV51z0lrqGqqnyr6ucXFOdYBFa42kJG0IFeScUDz5GOzmLhKxbE0+RBfJqcFFKRp7hzcLXuT33sstj3fo2GwyteFu2NDa7rpQgghRJ1YuXIFixYtLHf89tv/wmWXXVEHLTo9EqQFOcNeEqQ5Abj5nHiWJh9iuZ7O6CvPwmyq5JWntxAsIRR2uYvCs/8CmgnrgVW4sLPRaM8zp7ONhxBCCFEP9OlzGX36XFbXzThjtRakKaVMwGygO+AC7td1fUeZ8seAIUDJC+rhuq7rSqkNQHbxsRRd1++rrTYHg5I5ad4mHcEw6NYikuEXJzFn1R427M+mZ+vocnU0dy7RnwykUN2G87wHQPO/H7ft/4nNtrPxFFqJC7fV5scQQgghxCmqzZG0W4AQXdd7K6UuAmYAN5cp7wHco+v6upIDSqkQAF3XL6/FdgaVktWd7vY3gKahAX/r2Yp31+xj+dbD5YM0n5fI/zyI+ch2vE27lB7WCjKwHNFJiRlMc8N+avusCSGEEKLW1WaQ1gf4GkDX9dVKqRMnyZ0PjFNKxQNf6rr+Iv5RtzCl1PLito7XdX11VTfx+Xylk0gr43RWXR5sfCYbRdkHKMjLBpMVd5GPUIuJr7YcZmTvFljMx1aSxKyejG3vD2RePJm82POhZEJtyg8ArCzqTEyI+aR9VKK+9VVdkX4KnPRV4KSvAtMY+8nnM0ont58Kw/CvijyNqo1KTfWTz2dU8PvXUen5tZlgPZJjry0BipRSZYPERcADQD+gj1LqRqAAmA5cU1y28IQ6jYJhCSFy6/tYs1MAsJlNRNgtFHp9rN2fU3qeY/N7RG55n+wug8lTdx53jZDUX/BZw/k8I55Mp7dW2y+EEKJ+GDXqQfbs2c1XX33BTz/9CMAnn3xcx61qvGoz4Mnh+HDRpOu6F0AppQEzdV3PLv7+S+A84Btgh67rBrBNKZUJJAD7KruJyWQKeBl2vVmubQ0Hdw6hJi/W4jb/uUdLXv7vTpZuPUK/zi3A4yRq8zu42lyNu+8kwkzHLxsOPfQLnhYX4dbNRIdaT/mz15u+qmPST4GTvgqc9FVgGlM/5eRop7U9RMnIUFV1zWYzN954bDbSe++9w+2331np+Q1RIP10Okwm7ZSe09oM0n4CBgCLi+ek/V6mLBL4QynVGcjHP5r2NjAYOAf4P6VUi+LzUmuxzUHBsDkgPxXNnVt67NrOzZjx/U5W7z6Ky+vDbg0l69bP8FkdcEKAZspLxZK1i4z2fwYdmkbIogEhhGhM9u7dwwsvPIvZbC4NwpYtW4rJZCIzM5ObbhrIrbcey0Mzb94cYmNjyc7OJicnm+nTp/LEE2Pr8BM0TrX5uvNToFAptQr4O/CoUuqvSqlhxSNo44Hvgf8BybquLwPmAdFKqZXAR8DgktG3xqRkGw6TO6/0WGSIlW4tIon2ZeH5/EG0wix84fFgK7+1hvXAKgD00HMBiHfYa77RQgghgsaaNb+gVCdeeeU17r77PnJzc8jISGfq1FeYO/cdFi/+gKNHj5SrN2jQECIjoyRAqyO1NpKm67oP/7yysraWKX8PeO+EOm7grzXfuuBWZI/CCmievOOO/+3cprRPf4SEQ/tw5u7HGxJdYX3r/lX47FFs8rQGUmgZJRvZCiFEY3LjjTezcOECnnxyFOHhEVx44UV07dqtNGF4u3btOXBgfx23UpyoNkfSxGkyQmIw0KB4tYn/oI8bdk+hu2knj3tHkhvducK6tp3LCNm2BHdSPw7lewBIaiJBmhBCNCYrV66ge/fz+PvfX+fyy/uxcOG7bN++jaKiIgoLC0lJ2UWrVq0rrNvQ0kfWJxKk1QNGWFOw2CnsclfpsbBfZxC68wu2nf0oX3rO57tt5ZPU2rf/m8j/PIi32bnk9X2eFlEhAJwdX/lyXyGEEA1Pp05nM3fubEaOHMa///0pt956B16vlyeeeJj/+7/7GTRoSKWJydu0acvkyRNrt8ECkLRQ9YJhi0TzFkKRG8w2rPt+JHztLJyd7yS323BYv45F6w9wY5f40jp2fQmO7x7FE9+LnBsXYNgiyMg/gkmDJmGycEAIIRqTli1bMWfOO6V7q23cuIEtW5J59tkXjzvvtdfmAjBkyPDSY6++Oqf2GiqOIyNp9YCveOFA+KopAHhaXkJu3ynkXfYCSU3CcNgtbDucT57Lv6bCvmUxjm8fwdPiIrIHvIdhiwDg+20ZWEymyvN9CiGEECJoSJBWDxg2/+tJ24HVWNLWgclM4Tn3gtmGpmn0V00xgM9+TyUkeSGO/z6OJ/FSsm9YANZj+7Fk5rsxy09cCCEavR49epYbRRPBR35l1wOGPQoAS+ZmIr8eDkWu48oH9UoEwLfubRw/jMGddAXZ178N1uMXCDi9RYTb5A23EEIIUR/Ib+x6wGfzv+40NDO5V78G5uP3OWsZHcrDYd/wmPcd8hL747xuTrlzDMPAU2QQFSI/ciGEEKI+kJG0esCw+1935vcchafFReXKQze8wWO+d/iqqBcLWj5TLkADyC30z1drEi6LBoQQQoj6QIK0esCw+V93GhEJ5crC1r5KxKopFHYYwMvho/l+Z3a5cwB2ZeYD0FyyDQghhBD1ggRp9UDJSFrZ3J0YBmG/vkL4Ly9R2HEguVe9St+OzVm7L5vUbGe5a1iKV3T2SoyujSYLIYRowFwuF0uXfhbQucuWLWXlyhWVlr/33nw2b/6jmlrWsEiQVg8Y1nAMzYTmKh4lMwzCfnmZ8DWvUNjpDnKvnAkmC/EO/2a1837ZV+4aR53+152tJduAEEKIM3TkSGbAQdr11w+gT5/LKi2/++57OfvsrtXUsoZFZpHXB5oJw+ZAc+WAYRD+8/OEbXgD59l/Je/yqaD5Y+2bz4nn5f/u4PvtGUy4uuNxl/h5tz9xriwcEEKIhuXbb//D8uVfBXRuSYonTat6v8yrr76O/v2vqbT83XffZvfuFC69tBc9e16A0+lk7NiJfP31l2zdupmCggLatGnL+PGTmDdvDrGxsbRu3YaFC9/FarWQmnqQfv2uYtCgITz//DNceeXVHDmSyc8//4TLVciBA/u5665BXH/9ADZv/oNXXplGWFgYMTEx2Gx2nnrqmYD7pz6T39j1hGGLxOTOIfynZwnb+BbOroPI6/tcaYAGYDGb6JLgYNPBXLYdzqNjs4jSMv2wzEkTQghRPe65ZzA7d+7gwgt7k5ubyyOPPEF+fh4Oh4OZM2fj8/m4++47SE8/fFy9Q4dSmT//QzweD7fcci2DBg05rjw/P49XXnmNffv2MmbMo1x//QCmT3+RCRMm065de+bMeZ2MjPJpEBsqCdLqCcPmwL7jC7QiFwXdhpDf5xmo4H9C9/RK5InPN/PWz3uYdnOX0uNHC9xoGtgs5lpstRBCiJrWv/81VY56lVWSFspsrr7fBa1bJwFgt4dw9OhRJk0aT1hYGE6nE6/Xe9y57dp1wGKxYLFYsNtDyl2rQwf/W6BmzZrjdrsByMjIoF279gB0734e3323vNraHuxkTlo94bNH+gO0c4dXGqAB9G0fi91iYvWeo8cdzy30Ypd0A0IIIaqBppkwDB8ApuKFaatX/8Thw4d49tkXGDZsBC5XYenr1WP1Tnbd8ic0a9aclJRdACQn/14Nra8/ZCStnijsOgh3u2txdhtS5VOuaRpXqziWJh9iz5ECkpr400IVeHyE22UUTQghxJmLiYnB4/Hich3LgNO5cxfmz5/HsGH3YrPZaNGiZbW8mnz88TG8+OJkQkPDsFotxMU1O+Nr1hfaiVFufefxFBlZWQVVnlNQ4C8PCwur8rz66nCuixvn/sKwi5O4v7d/GPqCGT/SOiaUfw3udUrXauh9VV2knwInfRU46avANMZ+SkvbQ3x80inXq4nXnTVtyZLF9Ot3FTExMcydOxur1cp99w2t0XvWVD9V9HOLi3OsA3pWdL6MpDVAzRx2OsSF88G6Awy+0J/XU9Pg7HhHHbdMCCGEODVNmjThscdGEBoaRkRERKNZ2QkSpDVYHZqGsz09n6+3pnNxmyb4DOgsQZoQQoh65oor+nPFFf3ruhl1QmaSN1DDLvYPp36wbj9bD+UBEGKRH7cQQghRX8hv7QaqVXQosWFWtqXns3aff6Wn+WTLaoQQQggRNCRIa8Cu7tQMw4Cvtvg3E2wb23gm1QohhBD1nQRpDdh9xYsGDuf5NwRs11SCNCGEEKK+kCCtAYsJs3Fey0gANCDcJutEhBBC1J6RI4exZ89uli1bysqVK8qV33RT1ZkSVqz4noyMdDIzM5g+fWpNNTNoSZDWwA3sngCA1Szz0YQQQtSN668fQJ8+l51yvY8//pD8/HxiY5vyxBNja6BlwU2GVhq4vu1jMWkQaq0/GxcKIYQ4NaNHP1Lh8WnTZgLwxhuvsWvXjtI0TSXpl4YPH0n79h345puv+eabr8vVq8z48U9y++13ct5557NlSzKzZ/+D6OgY8vJyyc7OYsCAgQwceFvp+fPmzSE2NpYBAwYybdrzpKTsomXLVqX5OXft2sGrr/4dn88gL8+fsD03N5cdO7YxZcrTTJz4HFOmTGLu3PmsWbOauXP/id1uJzIyinHjnmb7dp2FC9/FarWQmnqQfv2uKpe8vT6SIK2BC7dZeLhvO2LDbXXdFCGEEA3EgAG38NVXX3DeeeezbNkX9OjRk3bt2nPZZf3IyEhn5MhhxwVpJVavXoXb7Wbu3PmkpaXxww/fAZCSsouRIx+lffsOLF/+NcuWLWXMmAl06NCRJ58cj9VqBcAwDKZNe4HZs98iLq4Zixd/yIIF87j44j4cOpTK/Pkf4vF4uOWWayVIE/XDXT1b1XUThBBC1KCTjXw98MBIoPJ0R1dddS1XXXVtwPe78MLezJ49i5ycbDZt2sD06f/gjTdeY8WK7wkLC8fr9VZYLyVlJ507dwEgPj6eZs2aA9C0aTPmz38Lu91OQUEB4eHhFdbPysoiLCy8NH/nueeex5w5s7n44j60a9cBi8WCxWLBbg8J+LMEM5mTJoQQQohTYjKZuOKK/kyfPpVLL72cRYvep2vXbjz99HP069efyvKCJyW1ITl5EwAZGemkp/sTsM+a9TJDhgxnwoRnad++Q2l9k8mEz+crrR8dHU1BQT4ZGRkA/PbbehITWwP+9IcNjYykCSGEEOKU3XDDTdxxx80sWvQpqakHmT79RZYv/4qoqCjMZnPpfLOyLr30cjZt2sjQoYOIj08gOjoagKuvvo6xYx+nSZMmxMU1Izs7C4CuXbsxZcokRo9+CvDPpRs9+imeeupJTCYNhyOS8eOfYdeuHbX1sWuVVlm0W195PEVGVlZBlecUFPjLw8Jk37CTkb4KjPRT4KSvAid9FZjG2E9paXuIj0865XqVve4Ux6upfqro5xYX51gH9KzofHndKYQQQggRhCRIE0IIIYQIQhKkCSGEEEIEIQnShBBCiHqooc0pb+hO5+clQZoQQghRz1gsNvLzcyRQqycMwyA/PweL5dQ2lpctOIQQQoh6JiYmjqNH08nLyzqlej5fyf5jDXBTsWpUE/1ksdiIiYk7tTrVdnchhBBC1Aqz2ULTpgmnXK8xbldyOoKln2otSFNKmYDZQHfABdyv6/qOMuWPAUOA9OJDw4HtVdURQgghhGioanNO2i1AiK7rvYGxwIwTynsA9+i6fnnxHz2AOkIIIYQQDVJtvu7sA3wNoOv6aqXUibvrng+MU0rFA1/quv5iAHXK8fl8pcOUlXE6qy4Xx0hfBUb6KXDSV4GTvgqM9FPgpK8CU7v95Ki0pDaDtEggu8z3RUopi67r3uLvFwGvAznAp0qpGwOoU47dbs1ISmq+p5rbLoQQQghREyrN71WbQVoOx4eLppJgSymlATN1Xc8u/v5L4Lyq6lTh1JZOCCGEEEIEodqck/YTcD2AUuoi4PcyZZHAH0qpiOKArR+w7iR1hBBCCCEaLK22NsIrs7qzG6AB9+FfLBCh6/pcpdTdwMP4V3F+p+v6pIrq6Lq+tVYaLIQQQghRh2otSBNCCCGEEIGTtFBCCCGEEEFIgjQhhBBCiCDU6NJCnSzzgThGKbWBY1ugpOi6fl9dticYKaUuBF7Sdf1ypVQHYD5gAH8AI3Rd99Vl+4LJCX3VA1iKP6sIwD91Xf+o7lpX95RSVuBtoA1gB6YAm5FnqpxK+mo/8kyVo5QyA28CCijCPx9cQ56r41TST1HU8TPV6II0ymQxKF4xOgO4uW6bFHyUUiEAuq5fXsdNCVpKqdHA3UB+8aFXgAm6rv+glHoD/3P1aV21L5hU0Fc9gFd0XZcsIsf8DcjUdf1upVQssAH4DXmmKlJRX01GnqmKDADQdf0SpdTl+P+d0pDn6kQV9dNS6viZaoyvO4/LYgCcNItBI9UdCFNKLVdK/bc4oBXH2wn8qcz35wMrir/+Cuhf6y0KXhX11Q1KqR+VUvOUUpVvud14fAxMLPO9F3mmKlNZX8kzdQJd1z8DhhV/mwQcQp6rcqropzp9phpjkFZhFoO6akwQKwCmA9cADwALpZ+Op+v6EsBT5pCm63rJculc/EPlggr76lfgSV3X+wK7gEl10rAgout6nq7rucW/CP4FTECeqQpV0lfyTFVC13WvUmoB8Cr+/pLnqgIV9FOdP1ONMUg7nSwGjdE24H1d1w1d17cBmUBCHbcp2JWd0+EAsuqoHfXBp7quryv5Gn+GkUZPKZUIfA+8p+v6B8gzVakK+kqeqSrouj4I6Ih/3lVomSJ5rso4oZ+W1/Uz1RiDNMliEJjB+OfroZRqgX8EMrVOWxT8NhTPZQC4DvhfHbYl2P1HKXVB8ddX4s8w0qgppZoDy4Exuq6/XXxYnqkKVNJX8kxVQCl1t1JqXPG3BfgD/7XyXB2vkn76pK6fqcb4+upT4Cql1CqOZT4Q5c0D5iulVuJfATRYRhxP6nHgTaWUDdiCf7hcVOxB4DWllBtI49hckMZsPBADTFRKlcy3GgX8Q56pcirqq8eAmfJMlfMJ8I5S6kfACjyC/1mSf6uOV1E/7aOO/52SjANCCCGEEEGoMb7uFEIIIYQIehKkCSGEEEIEIQnShBBCCCGCkARpQgghhBBBSII0IYQQQogg1Bi34BBCNAJKqd3407tUJFnX9a610AYDuFvX9fdr+l5CiIZHgjQhREP2EjCzguOeCo4JIURQkSBNCNGQ5em6nlbXjRBCiNMhQZoQolFSSrUBUoC7gIn4X43+Cjyk6/rvxedY8O9kPxRIBLYDz+m6vrjMda4DngHOAQ4Dr+u6/nKZW52tlPoBuAj/ruWTy6QyEkKISsnCASFEY/cKMAHohT/R9LdKqagyZU8C44BuwIfAIqXUrQBKqd7AF/jzSJ4LPApMUkoNLXP9EcBs4Gzg3/jT8bSt2Y8khGgIJC2UEKJBKl44kEDF888ewx9YpQAP67r+anGdKGA/8AT+gCwTGKHr+twy1/0IaKfrei+l1IdAgq7rl5cpvwfw6rr+QfHCgRd0XX+quCwGOALcquv6J9X8kYUQDYy87hRCNGSv4x/FOlE6/gTdACtKDuq6nq2U2oL/1eUG/P9G/nRC3R+Bm4q/PgdYVrZQ1/V3Tzh/W5myo0opgNBT+hRCiEZJgjQhREN2RNf1HRUVFI9qQfmRNjPgAworuaa5TJ1AVokWVXBMC6CeEKKRkzlpQojG7vySL4oDN4V/FG074Ab6nHB+H2Bz8ddbgJ5lC5VSU5RSn9VUY4UQjYeMpAkhGrIIpVR8JWUlo1kvKqUOAweBqUAGsFjXdadS6hVgilIqE9gI/Am4FbizuO50YI1SagKwCOgOPAI8XBMfRgjRuMhImhCiIRsDpFbyJ7b4nLn45679gj9wu0LX9fzisonAHPwb4v6OPzi7U9f1jwF0XV+PP3C7HUgGpgHjZYsNIUR1kNWdQohGqcw+aZfqur6yjpsjhBDlyEiaEEIIIUQQkiBNCCGEECIIyetOIYQQQoggJCNpQgghhBBBSII0IYQQQoggJEGaEEIIIUQQkiBNCCGEECIISZAmhBBCCBGEJEgTQgghhAhC/w/XDYCl8UM8UgAAAABJRU5ErkJggg==\n",
"text/plain": [
"<Figure size 720x432 with 1 Axes>"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"fig = plt.figure(figsize=(10,6))\n",
"sns.set_style(style='dark')\n",
"ax = sns.lineplot(x='epoch', y='accuracy',\n",
" style='split',\n",
" hue='model',\n",
" data=accuracy_learning_curves)\n",
"ax.set_title('Accuracy Learning Curves', fontdict={'fontsize': 16})\n",
"ax.grid(visible=True, which='major', color='black', linewidth=0.075)\n",
"ax.grid(visible=True, which='minor', color='black', linewidth=0.075)\n",
"ax.set_xlabel(\"Epoch\", fontsize = 15)\n",
"ax.set_ylabel(\"Accuracy\", fontsize = 15);"
]
},
{
"cell_type": "code",
"execution_count": 230,
"id": "b6ef7fce-b49e-49a6-a4b0-436d078f72ed",
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAmMAAAGICAYAAAANo+ehAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAB3l0lEQVR4nO3dd3gUxRvA8e9eSy69J9RAAoTeBBGkFwsIwk/sYkMRFQuKBbuAiogI9oaKigKioKCIogiKiNI7CIQSIL1ecrm2+/vj4DQmgQDJXcr7eR4ekp0t704W7s3M7IyiaZqGEEIIIYTwCZ2vAxBCCCGEqMskGRNCCCGE8CFJxoQQQgghfEiSMSGEEEIIH5JkTAghhBDChyQZE0IIIYTwIUnGhKhmRo0aRVJSUok/rVu35oILLuDOO+9k//79pY7Jzc1l+vTpXHzxxbRr146ePXsyduxY1q5dW+51VqxYwejRo+nevTudOnVi+PDhzJ07F4fDUaE4n3vuOZKSknj//ffLLO/fvz+TJk0q99pJSUmkpKSU2H748GGeffZZBgwYQPv27RkwYABPPvkkx44dO2UsX331FUlJSWRnZ1codl949NFHueyyy7x2vV27dvHwww/Tt29f2rdvz8UXX8yLL75YretIiLrK4OsAhBClde7cmUceecTzvd1uZ/fu3bzxxhuMHj2a5cuX4+fnB8DBgwe55ZZbcDqd3HLLLbRp04bc3FwWL17MzTffzLhx47jnnntKnP/ZZ59l3rx5DB8+nGuvvZaAgAD+/PNPXnzxRf744w9mzpyJXq8vNz6n08m3335L8+bNWbhwIbfddts53/Pvv//OPffcQ6NGjbjzzjtp2LAhR48e5f3332fkyJF8+umnJCQknPN1fOWuu+6iqKjIK9f6+uuvefzxx+nUqRMPPPAAMTEx7N+/n3fffZeff/6ZuXPnEhUV5ZVYhBAVoAkhqpUbbrhBGzNmTJll8+fP11q0aKH98ssvmqZpmtPp1C677DJt0KBBWlZWVqn9Z86cqbVo0UL76aefPNsWLVqktWjRQps3b16p/b/99lutRYsW2qJFi04Z488//6y1bNlS+/3337UWLVpof/31V6l9+vXrpz377LNlHv/jjz9qLVq00I4cOaJpmqZlZWVpF1xwgXbDDTdoNputxL7Z2dlar169tBtvvLHceL788kutRYsWZdZBXbN//36tXbt22oMPPqipqlqi7NChQ1rHjh21iRMn+ig6IURZpJtSiBokKCioxPcrV65k7969TJgwgYiIiFL7jxs3jsaNG/P22297ts2ePZukpCSuvvrqUvsPHjyYW2+9lfDw8FPGsXjxYtq3b0/37t1JSEjgiy++OMs7+ud82dnZTJw4EZPJVKIsPDycRx55hO7du+N0Os/pOmvWrOHKK6+kffv29O7dm1mzZuFyuTzlDoeDV199lYsvvpi2bdvStWtXxo0bx/Hjxz379O/fn+nTp3PVVVfRpUsXPvroI1577TX+97//sXTpUk9X8RVXXMHGjRs9x/27mzIlJYWkpCR+/vlnRo8eTYcOHejVqxdvvfVWiXhTUlK488476dy5Mz179mT27NncfPPNPProo+Xe49y5c1FVlUcffRRFUUqUNW7cmAkTJtCqVasScXz//fcl9rv88ss911i3bh1JSUnMmzePnj170qdPHx599FE6d+6M3W4vcdy9997L9ddf7/l+6dKlDB06lHbt2jFw4EA++eSTEvtv2bKF66+/nk6dOnH++edz7733cvTo0XLvTYjaSpIxIaohTdNwOp2eP4WFhaxbt45XXnmF+vXr06VLF8CdXOh0Onr27FnmefR6PQMGDGDLli1kZ2eTnp7O3r176dOnT7nXfuSRR05ZXlBQwMqVKxk6dCjg/uD+/vvvKSgoOOv7XbNmDdHR0bRu3brM8iFDhjB27FgMhrMfWbF27Vpuv/12GjZsyOuvv87o0aP58MMPmTJlimefF154gU8//ZTbb7+dDz74gPvvv5+1a9fy/PPPlzjXhx9+SO/evXnppZfo3bs34O4ufvXVVxk3bhyvvfYaNpuN++6775QJ5MSJE+nQoQNvv/02/fr1Y+bMmaxatQoAm83GzTffTHJyMi+88AIPP/wwH3/8MRs2bDjlff7222+0adOm3G7I66+/nlGjRlWozv7tzTffZNKkSYwfP5477riDwsJCfv31V095UVERq1evZsiQIQAsWrSIBx98kK5du/LWW28xfPhwXnjhBc8YQ6vVypgxY4iNjeXNN99k8uTJ7Ny5kwceeOCMYxOippMxY0JUQ6tWraJNmzYltvn7+9O9e3cmTpxIYGAgAEePHiU8PJyAgIByz9WwYUMAjh8/7mkFql+//lnH9t1336GqKoMHDwbcydjMmTNZsmQJ11133VmdMzU19ZxiqoiZM2fSoUMHXnnlFQB69+5NaGgoEydOZPTo0TRs2JDs7GwefvhhRo4cCcD5559PcnIyS5YsKXGupk2bMm7cuBLbCgsL+eijj2jfvj0ALpeLu+66i927d9O2bdsyY7r00ku59957AejWrRvLly9n9erV9OnTh6+//ppjx46xbNky4uPjAUhISOCKK6445X2mpaWVm9Sei5tuuon+/ft7vm/Tpg3ff/89AwYMANyttA6Hg0suuQRVVZkxYwZDhw7lqaeeAqBnz54oisKbb77Jddddx759+8jNzWXUqFF06tQJcLeC/vHHH6iqik4nbQWi7pBkTIhq6LzzzmPixIkA/P3337z44ot0796dadOmlejG0zTtlAPtgRLlJ79WVfWsY1u8eDHdunXDYDCQn59PYGAgnTp1YuHChWecjJ3sRtPpdOcU0+lYrVa2bt3K+PHjS7RU9e7dG1VVWbduHQ0bNmTmzJmAO6E5cOAABw4cYOPGjaW64xITE0tdw2AwlEi64uLiPNcuT8eOHT1f63Q6YmJiPIP8161bR/PmzT2JGEDbtm09yXV5qqoumzVrVuL7oUOH8vrrr2O32zGZTCxbtowePXoQERHB/v37SU9Pp2/fvqXq+9VXX2Xr1q20bduWsLAwxo4dy5AhQ+jTpw/du3fn/PPPr/TYhajuJBkTohoKDg6mXbt2ALRr14569epxyy23YDKZmDZtmme/Bg0asHbtWmw2m+ftyv86OQanXr16nm3/HgP1X+np6URFRZXZMnHkyBHPOKiuXbuWKt+5c6enVcZsNpdKYk46ud1sNnvuY9u2beXGZLFY0DSN4ODgcvc5lfz8fFRV5eWXX+bll18uVZ6RkQHAxo0beeaZZ9izZw/BwcG0atWqzHqNjIwstc1kMpWos5Nfnyox8vf3L/G9TqdD0zTAPV1JWeMAT/cWZIMGDU75883NzcXPz89T9xX131gGDx7MtGnT+O233+jWrRu//vorzz77rOcaAA8++CAPPvhgqXNlZGQQFBTEp59+yhtvvMGiRYuYO3cuISEhjB8//qxbWIWoqSQZE6IG6N69OyNHjuSLL77gkksu8XQX9evXj88//5yVK1dyySWXlDpO0zR+/vln2rVr5/kwbd26Nb/++isTJkwo81q33HILUVFRzJkzp1TZ4sWL8ff35+233y6ReLhcLsaOHcsXX3zB008/DbgTlszMzDKvkZaWhtFoJCQkBIAePXqwcuVKdu3a5Rlc/m/z5s3jlVde4fvvv6dRo0anqqoynezWvfPOOz3dav8WExNDQUEBY8eOpXPnzrz22mueFqlp06axe/fuM77muYqJiWHnzp2ltmdnZ9O0adNyj+vRoweffvop2dnZZSZzs2bN4ptvvmH16tWelsn/JowVmYIjNjaWLl268MMPP3j2HzhwIIAnaX7qqac83bb/drJ1r3nz5sycORO73c6GDRuYM2cOzz77LG3atKFDhw6njUGI2kI65YWoIR544AGCg4OZOnWqp2WpZ8+etGvXjmnTpnlad/7tnXfeYf/+/YwZM8az7aabbmL37t1lvgH59ddfs2/fPs/g/P/65ptvPN1J3bp18/zp0aMHffv2ZenSpRQXFwPulrP169eXOcnoihUr6NSpk2dA/uWXX05YWBgvvvhiqda0zMxM5syZQ8eOHc8qEQP3W6gtW7bkyJEjtGvXzvPHaDQyY8YMUlNTOXDgAHl5edx0002eRExVVX7//XdPa5U3denShb///psjR454tu3du7fE92W57rrrUBSFF198sVTc+/fvZ/HixQwYMIDAwEDP27np6emefdLS0kpNxlueoUOHsnr1apYvX07fvn0950tISCAsLIy0tLQS9Z2bm8usWbOwWCysXr2a7t27k52djclkonv37jz55JMAp53kV4jaRlrGhKghIiIiuOOOO5g+fTqffPIJo0ePRq/XM2PGDEaPHs2IESO47bbbaN26Nfn5+SxdupRly5YxduxYLrroIs95Lr/8cn755Reeeuoptm7dyoABA1AUhd9++43PP/+cSy+9tMxB4uvXr+fw4cOMHz++zPiGDRvG8uXL+f777xk+fDg33HAD8+fPZ9SoUdx22200aNCA9PR0Fi1axNatW/nwww89x4aGhvLcc89x//33c80113DDDTdQv3599u/fz/vvv4/L5WLq1KmnraP58+eX6n5r2LAhAwcO5N577+Xuu+8mKCiIQYMGkZOTw8yZM9HpdLRo0QKn00lgYCBvvvkmqqpSXFzMZ599xu7du1EUBU3TSk0VUZWGDRvG22+/zdixY7n33ntxuVy88sorKIpyyjji4+OZOHEikydPJi0tjSuvvJKIiAh27NjB+++/T2xsLI899hjgrvcOHTrwwQcfUK9ePfR6Pa+//rqnxfJ0Lr74YiZNmsRPP/3ErFmzPNsNBgP33HOP52fWvXt3UlJSePnll2nSpAkNGzYkODgYTdMYN24ct99+O0ajkTlz5hASEkK3bt3OoeaEqHkkGROiBrnpppv4/PPPeeuttxgxYgQRERE0btyYhQsX8vHHH/PFF1+QkpJCYGAg7du358MPP6RHjx4lzqEoCjNmzGDBggV89dVX/PDDD9jtdpo2bcoTTzzByJEjy/yw/+abb/D39y932ouTbycuXLiQ4cOHEx4ezsKFC3nttdeYNWsWmZmZhISE0L59e+bOnVuq+2rgwIF89tlnzJ49m1mzZpGdnU1sbCy9evXi7rvvJjY29rT1c3IA/r/17NmTgQMHMmDAAN58803eeOMNvvrqK4KCgujRowcTJkzwJHCvvfYa06ZN48477yQ8PJwuXbowa9Ys7r33XrZs2VJiwH1VMxqNzJ49m2effZaHH36Y4OBgxowZw0cffeTpdi3P9ddfT5MmTZgzZw4vvPAC+fn51K9fn5EjR3L77bcTGhrq2feFF17gmWeeYcKECURHRzNmzBh+//33CsUYGhpKr169+Ouvv0o9FzfccAP+/v589NFHfPDBB4SFhXHJJZcwfvx4FEUhLCyM999/n5dffpmHH34Yh8PheWbL6l4VojZTNF+0vwshhDilPXv2kJKSUmKMm8VioXv37jz00EPceOONPoxOCFGZpGVMCCGqoYKCAu666y7Gjh1Ljx49sFgsnlaxkxOrCiFqB2kZE0KIauqbb77hgw8+4ODBgxiNRrp06cKECRPKnOdMCFFzSTImhBBCCOFDMrWFEEIIIYQPSTImhBBCCOFDNXYAv6qquFyn72E9ObO0LDp7alJPFSd1VTFSTxUndVVxUlcVI/VUcd6qK6Ox/HWEa2wy5nJp5OaefsmOk8t0BAQEVHVINZrUU8VJXVWM1FPFSV1VnNRVxUg9VZy36io6uvy1dSVlFkIIIYTwIUnGhBBCCCF8SJIxIYQQQggfqrFjxsricjnJycnA6bR7tqmqe5B/fr73FvitiXxVTwaDifDwaPT6WvUoCiGEEBVWqz4Bc3Iy8PcPIDAwzrPQscvlAkCvL/8tBuGbetI0jcLCfHJyMoiKque16wohhBDVSa3qpnQ67QQGhngSMVG9KYpCYGBIiZZMIYQQoq6pVckYIIlYDSM/LyGEEHVdrUvGvM1mszFy5NByyzduXM/TT0/0YkRCCCGEqEkkGRNCCCGE8KFaNYD/bHz33RLWrFmNzWYjKyuTK6+8ll9/XUVy8n7uvvs+rFYrCxZ8jtFopFGjxjz88OPY7XYmTXqCgoICGjRo6DnX/v37mDnzJTRNIzQ0lIkTn/bhnQkhhBCiJqjzyRi4l0J45ZU3WLFiOfPnf8a7737Epk0bmDdvLocOJfPhh3MJCAjk1Vdf5uuvvwSgadNE7rjjbnbs2M7GjesBePHFKUyc+BRNmyawdOli5s6dQ9eu3Xx5a0IIIYSo5iQZA5o3TwIgKCiYJk2aoigKwcHB2GzFNG2aQEBAIAAdOnTmr7/+AKBbt+4AtGnTFoPBXY2HDiXz8stTAfecZ40axXv7VoQQQlQjWYV2UgtstI4NOvcXljT1xB8XqCqK5vrne00F1YWCCqqKvsiCagoBWZvytBR7AZreD/BdXUkyxqne6FM4eDAZq9WK2Wxm8+aNNGrUGEXRsX37Nnr16svevbtxOp0ANG4czxNPTCIuLo6tWzeTlZXpvZsQQghv0zRQ7SjOYhRnMZz4W3HZ3F+7ikuWuWzur102UPRoBj/Qm9D0/qD3QzP4uT8UT/zt/tofTWc6sa8fuFTQGX195+XKKbKz8UgOB/bvIe/YLoIsyTRS0rEFQodYf8JMGorLfqKO7CiqDZw2FNUBqhPFYQWXDcVlB82B4nKCprqTrDOk6QwUnXcvRZ3vBIO5Cu62hnPZCdj0FlF/vkJO14dwdb3bZ6FIMnYKer2eW2+9g3vvvQNF0dGwYSPGjh2HXq/nhRee5c47RxMf3wSj0f0fw4MPTmTKlKdQVfc/mkcffZLMzAxf3oIQwls0DRxFKE4rirMIxWE98bUVxVEETuuJxOTfZUXgsOJfXICiOt2t7J5fDt1/ayf+xvM748nv/7Wf3oRmDDzxJ6Ccv//5WjUEkGvTSC+w42/U0SBYj9Geh86Wi1Kce+LvHHTFuSi2XHTFOe7txTnu7dZsFHue+x68VL0nRQEqYMOEAz8cigmn3h+Xzg+X3h/N4P6DwR+d0YzO6I/OFIDBZMboF4g+KBLVHIVmjkA1R7m/9g8D5SzeZ3NaKUrdy7Hk7ViO7cSQs48GjoP8T0nFpLgn0sYITk1HdnEotoMG9LocDLjLFDTPqWyN+qD5hWJM24S+MKvUpYqbXowrui2GjG34Jf9Qqtwedx62pJEo1iyC/pzuPr/qJPCvGfjvmoelz/PYmww883s8Azanync709CAYW3jMOiq79RFhrTNBK+cgCFrN6oxkMKmQ/D3YTyKpmna6XerfhwOF7m5RSW2paYeIi6uZNegzMBfMb6sp7J+btVZUZH7uQuQ5v9TqvX15CjCmL4ZQ+pGjEfXYUzbgM6ef0an0HQmNJ0BxWkFlBN51okkzGBG8wsB1YWuOPvEEf8kZpqiQzOFAho6Wx64HGfUemLX9BTihxGVIKW4/BgVPZopGMVecKKF5p+PDNUvDGvHO9AM/gT8NQOdvaDU8dMjprCpIJiri+fRQ7eDYs2EDSNGRcUfG6+o13DA3J7hyi9ca1tQ6vjfXG1ZF9iPNuYcLsn5tFR5vhbAb3TErDg4T9uOARcaiieV1aFhw4A/TvwUR5n3qKJgM4bj9I+EgCh0QdEoAZFoAVGo5hPJmzEQff4hXBl/Y03dSUDeXoKdWZ4pCVRNIVMfRYz6zy/gNkxk+TXkaFB7tEEvsnRHOlGbXyGIYlrWj6BNgygMRj80vZHiNtejmYIxHPsTveUoms7obi3UuRN0V2RL1MA4dJbj6HP2/5OMKwqgoAbG4gpLAKcVQ8Z2bMU2/I/9RujWd9wtbmjYmgzC0utZ1JDG5f68z0axw8VXW4/z0boj5Fjdddw6NpjnLmtJw7Bq1iLnKCLwj2mYt85GDYylsPtjqJl7yG93B+aQiCq9dHR0cLllkowJQJKxM1Hrk4xKUqvqSdPQ5yVjSNuI4eif6I+uw1Rw0D1mpxwfBtzGEV19+thW0s65DRsmijFRjB9Fmh+fcBk/a+fRWtvHMG0lKjr8dC78dComRWW3Poll5suIVvJ5sGgGRsWFERdGxYUBF1Z9CB81eRmTQcfNe8cSYT+KXrVj1BwYcaJTNG63PYBFMTNOv5gL9TtKxfi7qzVpAc1J8suldf4qwN2KY8FMgRbAd2o33jKMol24i7GuzzAFhuEfHEFISCQhYZEU6sPYZurI35mFFKZs42BOMftynBS4jBRjxIYJ9CZ6NI2iZWwQq/ZnsTO1gHohfoSZjRh0Oox6hfv6JNA6Nohf9h7ntz1HCdA5CFDsmBUHTmMQrZolcWEDI0X7VrPxwDFwWtG5bGj2QvI0M/saXsk9vRMIWPkIf+zch1Etxg8bARQTgI3h9smMG9ieftsfokXuqlL1sNR1PvlaEB11+2ihpKABOkVDT+mPR1Vzp8T/Ht2yxtWaDd3e5NrzEyla9x7JWj0aN2tPcFTjEjuqmsaw9/4k02LHpWlEB5m4v08Cg5KiK30C7JP//oKc2QSteRbVHIn/nq9AdVJ03jiKOt8FhnNrCyq0O1m4+Thz16eQY3WgAM10xzDiZJfaGKNeYUL/ZgxvF1ctJvg2HvmV4J/Goy9MRdP7kX3dKtSQhl77v0qSMSQZOx1JxiquViUZVaim1ZOmaRTaXeRaHWTlZMOxjfhnbKJ+zjrqWfdg1opP7Ofe/03XUP5SW9JR2Y8NE1u0RPar9bDihxU/HOhpEGamUZiZ/GIHO1Mtpa4ZF+xH3+ZROB0OFm5LB9wf9DrFPZZVr1PoUD8Eu0vlQFYRNoeKhoZ2Ig5Nc38daDJg1CsUFDtxqBqgYcCFEz23dY/ntg4hbD+UwmfrkokyK0T5a0T5gxbWlAYNGtMl1kBKWjr3fnuYw4UK/+oTJdTfQEJkAAezrZ5WD3BPUvnvdrgwsxG7U6XI4SpxbPPoQJ69tCUxwX6kF9gI8jMQYDr7/2cq+lw5XCoWm5NCu4tCu4ukmCAAlm87xNG0NArzsrAVZuEozOXXosY8NKwHDfM3krtlMVZLNuFKEeGKhXAKWK11ZIXWhUYRIQy2fsNfRdEcUOtjD00kqnFL2sXXo3PDUMLMpx/LdjC7iDd/O8jKvzPR6xRcqka7esE82L8ZbeLK/7A+U2XVk67gKGFfDEFvzcQVWA9L36nYmww443MXFDuZt+koc9enUGh3MayhjXHRmwlJXkpc8X4AdpPAR47+fOPqQeeE+jx+UQuiAk2Vc3NnSCnOIejXp/Hf+5X7344xiMKez1Dc6ipQdJKMnQtJxiqXJGMVV9OSDF+pzHpSNQ1V1XBp7q9dqoamgUvTyixzujQKbE7ybU4sxSf+tjnJL3ZSYHNSUOwkr9hBkd1FfrETi9VKa+dOBuv+oK9uCw2UTE4Od3FqOgyKSrFmZJfWmD/U1mxWm/GL2oH7B7Sid2IUW47ls/FILiFmIydTGUWBbvHhdGgQypEcKz/sSUdB+ad3CWgYZmZgUjT5BRbmb0kDvQGHS8Xu1HCeGHs6oX8zAGatOsDB7CIcLhWHS/P8/ezgJBIiA/lhdzrrj+QSFWgiKtBEZKAfUUEmGoX5E+Jf8QHvNqfKsbxijuRaScm1YtTruLJjfZwulT6vrcHuKvmRoVNg8W3nExfsx9wNR9EpkBgZSGJ0IJEBxipr8anMf38Ol4ruRPK7MSWXLUfzSSuwkZpvI7WgmNR8Gw/1b8aQNrEcyi7iQFYRnRqEEhZw9i8SbDmax6urk9l6LB+jXsHh0hjSOoa7ejYlJtjvnO+pzHrSVPy3f0zg2hdQHIUogK1RPyx9n6tQ12VukYPPNqbw+YajhDizuEz/B5cb1tJB2ec+vd4fxXXilxa9H4rLhl1n5gtnL75SBnHNxYPo2zzqnO+twjQN0/5vCV75iHuMI2BNGknhhU+hmf/pkpRk7BxIMla5JBmrOEnGcI9BKTHQOwfFmo2uMA295Ri47KjF+eitWej0Cqo5GjUwDldIA7SAWFRzBJp/BKp/BKo5vNSbXou3HmfmqgMUO1y4KvF/KM+QLA1ijEXcGLGXPvaVNCvajL/iQNPcSZRD0/OI7iFuu+pK6lv/5pdUPYd1DYkJ9ic6yI+YIHfCY9BXziImNeWZcqka6RYbKblWjuUVE+JvJDEqkIZh/ui81A3lq7pSNa3S71HTNFbty8KgU9h0NJ/PNhxBpyjc0q0xN3RpiL+xaloQFWs2gX+8iP/OzwANFANFXe+nqNPYMrsuMwvtfPpXCis272IAfzJU9zvddLvQKeD0j6S40x3Y4vsT/PtkbE0GAQr+u+ZhzNiGM7QJ5B/DoNnZoDZje8z/6HPZrQQGBp31vVWEznKcoFWP43fwB5xhiaA6sQx4GUf9C0rtK8nYOZBkrHJJMlZxNeWD85xpGsZjf+C34zMMBUdQirPR2fLBXoDOZTvloaoxGGdADIrTirHw2OkvpTOgGYNQ/ULJ1oLZkOuP1dwAU3QzVmSGsSYvkgxC+Xf32ZDWMbSMDWZzSh4//V16GpkeTSMYfUFjimxOXv01mVB/I80NaVxg/50uhauoV7wfnWewt0ZRQENy4wfjanoRfg07oBi9N/C4zjxTlaA219VDX+/gl33uNykjA4080DexQuPJXOo/LaV2l4rDpZJvKUIDIkODCDLp8TPoSp1Hn7GD4F8eAZcNY9YuXMGNsfSZgj2+PwCp+cV8sW4PxTuXMkT5jZ76HehRUdGhQ0XTmyhuPgLLgJfLjEufuRMM/lh0waQtmkDHgpUYFZV8zGQnjCTkgtG4wpude8X9m6biv/0TAtdMQlEdFF4wEWvH291vy5bzxqwkY+dAkrHKJclYxdXmDwMANBXTge8J2PgmxvTNZe5S1PZmXOGJGI//hT7vIGpANGpgLGpwA1yB9XE0uACLIRKdLY8gRzq6okx0hanoClLQFxzFGdoEV1RrDBlbCdj0jnvOpX+xaQZ0eiNG1erZ5tL74wisjy2sBdbItuijW6KPbkGhuQFFLgXdibcRFcCgVwgw6lE0FUPqBvz3LsKU/D36IvebbhpgbX87tuaXoTiLcYUloAbVq6IKPb1a/0xVotpcV0V2F3PXpzDnryPYnO5u6gah/oT4G7C7VKwOFYfThf1EV7zDpeJ0aRV6h1avQIBJj79RT5DJQLCfniB/A4FGPcEmhbaObVyT8gwBrnxSwi5gpV8/4o4tp49uCybFhS2gHqaiNDSDP/amF2FLvBR7o75gCqzQvRmPrsX220yiM9e4xxtq7i5uW73zsbW7CVvCJe555M6BPvcAwcvvwpi5HQB7/QvIH/IhmunUY/EkGTsHkoxVLknGKq7Wfhi4bPjvmEvA+lnorVm4QuJxhsbjjG6LK6otakCUu7sxIArNL/S08zKdUT05rexNPsj0pWuJIpfL2jWkx4Ar0eUlE7r0RvSWY+5JMMugKXpUcxSu0CY4o9vijG4HOiOmwysxHfoJXXGOZ1/VLwx7kwEUNx+Oo+GFoPfNgOL/qrXPVBWoC3WVWWjnvd8PsWjbcfz0Ojo3CsWk1/F7cg52V+nU6/rzGhBmNrJibwZ70gtLlV/SMpr6of5sPprPxpQ8z3ZFcb+IYTLo0DQYoy3kXsNX6FFRFPdLIjbFxMrOb9HlgoswpG/BGdX6nP7dWDIOsWn5e3TLXUoDJZNsQokgD9U/guKWV+Fo0N29ooDLjqI6QXW4J8R1/ftvJ6h293AJpw00F4o1G/99X4OmoplCKOg3DXvikJKvvZZDkrFzUJOSsS+/nM8VV1x9TucYM+Zmnn32eerVq39Gxx06dJCXXnqe119/95T7nWs9DRt2Md98s7zMsuPHj/H004/x7rsflVkuyZhvKbZ8zOtnYt7+CTqnuyWqqONYCrtPBF3Vv/UGcCCzkBs+2YhD1RjTvTG392hScgdNQ1eUjj73APrcA+gsx7HH90efu5+g355xz7P1H6op1P2mmKbiCkvAljgEV0SLCv3n7G217ZmqSnWprg5mF7ExJY//tXe32v64JwOXqmHSK5gMOox6HX56Ha3jgjEZdGQW2nG6VIx6HS67eyC9qjcR7G8g0GTgcI6V7cfzKSh2YrE7KSh2YbE56dwolMGtY/k7w8LLi37mXvv7tFCOkFl/IPW6XoHW4PyzmxT3FLILi0nb8QsP/uVPa/s2Xg+cTZAj84wmEdYAdAY0g9k9B56jkOJW11LY86nTtob9W3VIxmrtDPzf7kjjm+2pnMw1K+ONnmFt4xjSJvaMj5sz54NzTsaEqGy6wjQCf5+C39/foGjusVP2hr0ovOARnLEd0TSNA5mFHMgqomdCBOZzGEx8Kqn5xdwxfwsOVeOazg1KJ2IAintSSzUw1v2b8wnOuM7YWoxAV3DUnajl7MOYvhXFno+l9+RKn9xSCG9qEhFAk4h/EoRBSdGn3P/fU0cUKe5l+gIC/hmQ3zjcTOPw8sdCNo8O4u0xw4BhAMRBGTOtVY6IQH8izr+Ey2zJfPinjklF/2OM/0801WeiGPxPLInlj+XCJ3FFJGE68B2mlDVohgA0oxnNGAAGM7b4ATjrn48uPwXFno8rqnUVRVy1am0y5iuHDx/i+eefxWAwoNfr6dy5C/n5eUyfPpU77xzH1KlTsFgKyMvLZejQEYwYMZJx48bQvHkSBw7sp6jIwuTJLxIXV4933nmDdevWEhsbS15eLgDp6WlMnz4Vu91Gfn4eN998O71792XUqKto1Cgeo9HIPfc8wKRJT6BpGhERkaeMd+PG9Xz66UcYDEbS09MYPvwKNm5cz759e7nyymsZMWIkf/31B++++xZ+fn6EhIQyceJTBAQEMG3acyQnH6BBg4bY7e4upLS0VKZNex673YbJ5MfDDz9W1VUuzpAhbQvmLe/gt/97UB2gN2FteR2F5z9IjhLK7weyWPbrVranFmCxuVtMw81Gpl3eio4Nwio1ltwiB/d8uQ2HqvHMJUkMbh1z5ifRGVBD41FD43HE96P8ueSFENXNnT2bUC/Un+k/K3xR2Je+zSJ56fI2pfYr7nAbxR1uK/c8akjDqgyzytXaZGxIm1iGtIn1ejflX3+tIympJffc8wBbtmwiPDycL79cwIQJj7Jnz24GDryIPn36k5mZwbhxYxgxYiQArVq14b77HuSdd97gxx+Xc+GFPdmyZRPvv/8xVmsR11zzP8Dd7XjNNdfTuXMXtm3bwuzZ79C7d1+sVis33zyaFi1a8vrrMxk48GKGDRvBTz/9wKJFC08Zc3p6OrNnf8KePbt45pnHmT9/MRkZ6Tz22EMMH34F06Y9z5tvvk90dAwLFnzOnDmz6dTpPOx2O++++xGpqan88stPALzxxixGjrya7t0vZP36P3n77dcZM+auqq10USGmvYsJWvciuvwjgI7itjdQ0OYWthSF89O+XFbN3c/x/H8G0ut1Co8MSMTqUHl1dTK3z9vKVR3r8WD/ZpXyin+R3cV1n2wgu9DOG1e257xGYed8TiFEzaIoCiPa1+P8+DA+/vMIYy9s4uuQfKLWJmO+ctlllzN37hwefPAeAgODuOOOf1aBj4yMZMGCz1i1aiUBAYE4nU5PWYsWSQDExsaSlZVFcvIBWrZshU6nIzAwiISEZifOEcWcObP59tuvAaXEORo3bgJAcvIBLr54MADt2nU4bTKWkJCIwWAgKCiY+vUbYDQaCQ4OwW63kZubS0BAINHR7haLjh078c47bxIWFkarVu7fXuLi4oiJcXffHjiwj08++ZC5c+cAuBc+FudMn7ED85bZ6KzpKKoTTWcCgwkcxehsOaA6QXWhaO6/NYMZNSgOXE4M2btQHIXoHO5X3a1hSfxQbxyfpiWwa2s6hfbjnusEmvR0bRzGkNaxdGsS7umajA8389i3u1mw+Ti/Hcjmnas7EBdy9kup2J0qoz7dQIbFTpdGoXRuGHquVSSEqMEahJqZOKiFr8PwGfmkrGS//baKDh06ceutY/jxx++ZO3eOZ9za559/Qtu27RkxYiQbN65n7drfPMf9d0xb48bxLFw4D1VVsdlsHDx4AID333+boUOH0737hXz77TcsW7a01Dni4+PZsWMrzZu3YNeunaeN+VSNHGFhYRQVFZKZmUlUVBSbN2+kUaPGxMc3YcWK5cC1ZGZmkJGRcSLuJlx77Q20a9eBQ4cOsmnThgrVmyibIXUDAWtfxO/Y72j8M8uWyxyFZo5EcRSiL0gpdZxqCgadAdBQbPm40LPLfD4PW29kR2oEpALkMaxtLD0TIrE5VBKjA2gWFVjm+MrezaJYdkc37vtqO9uOFzD8/T95/KIWDG0bd8b35FI1Rn++mcM5xbSKDeK1ke2rxbp1QgjhK5KMVbKWLVszadKT6PV6dDod99zzAMePH2PSpCe57LLLmT79BX74YRmhoaHo9XrPWKv/at48iX79BnLbbTcSFRVNeLh76YZ+/QYwa9Z0PvnkQ2JiYsnNzS117G233cnTT09kxYofqF+/wTndj6IoPPzw4zz++EPodArBwSE89tgzhIWFsXXrFm6//Sbi4uoRFhYGwN1338fLL0/FbrdjsxVz330Tzun6dZKmYUxZQ8CGVzEddSdhmqKnOGkkjvrngyEAZ1RrXOGJKHYLuoIUNGMAmsGMZgigWDOyJbWQdYdy2HAkj91FBagacOKNd7NRR9fGYQxKiqZf82j8DBV7SyrY38gH13Xisw0pvLPmEJOW72VHagH390mo8EzhmqZxz5fb2J1uoUmEmdnXdsSgk0RMCFG3ydQWApB5xs5Elb0GrWmYDq4gYN2LGLN24wqIxdruJnTWTKyd7ix3UlKnS2VnmoV1h7JZtS+LvzMK3ckX0K5eMN3iwzmSayU22I/eiZG0rReC/hwTIJvDxdu/H+LT9SkEmPS8fHlrujQOL7FPWfX0+uoDzPkrhdhgPxbe0uWclnupTerSdA3nSuqqYqSeKk6mthBe8+GH77Fhw1+ltj/22NPn3HomzpHqwm//twSsewlDXjIauJcFun4VmEqv36ZqGvsyCvnrcA7rj+SxKSWPQrurxD71Qvzo0TSCsT2anNNixuXxM+q5r08CRp3Ch38e4c4vtnF5uzgeH9S83C7H+RuPMuevFPo1i+SpS1pIIiaEECdIy5gApGXsTFTab1EuO/57vsL81wwMFvf6jZrej6IOt2HteAeaOcKzq6ZpLN+dztId6Ww9lofV4Z6Fu2GYP93iw0krsBFuNtKjaQTnNQolPMB7M8tvSsll/KIdFNpdxASZeOfqDjQMM5eop3fWHOT9Pw7Ts2kELw1vI12T/yGtGBUndVUxUk8VJy1jQtRFTiv+O+cRsOlt9JajqMYgNEMARZ3uwNp+NJp/WKlDFm4+xrSf93u+Dzcb6RofxoP9EonwYuJVlk4Nw1g+9gIe/HoH6w7lMvKDv3jp8jacV889ueTnG1J4/4/D+Bl0PDKwuSRiQgjxH5KMCeEtmoZ562wC/nwFnT0PZ0QL8i77GGd4czT/sHKX70grsPHKqgMowKODmtO9STj1zmFaiargZ9Tz+sj2LN2eyju/H+KBxTsY3iaaxEgzM1YfxqhT+OSGTsSFnNtCwEIIURtJMiaEN7jsBP9wD/4HvgXcY8KKutyPPb7/KQ/TNI3Jy/egA6YObUX/FqdeDsXXLmsbx6CWMbz+azLzNh4FQK/Ae9d0oGlkoI+jE0KI6kmSMSGqmGLLJ2TpKEypG9AUA4U9Hsfa9gYwlL9G3ElvrznEukO5PDqwWbVPxE7yM+h4sF8iBs3F0l2ZTLmsJW3qhfg6LCGEqLYqdxl2wXffLeGtt1477X4bN67n6acneiEit2HDLq7yazz99EQ2blxfbvnIkUOx2WzlltdGOstxwr76H8bUDaiGAHJHLMTa8fYKJWL7Mix8uO4wJr3C0LNYoN7Xbr+gIV/f0pFu8RGn31kIIeqwWtsy5rd7If675v2z5HwljBkubnUNtpYjz/1Eok7QZ+0mdMkNKHYLBX1ewNmgB67wxAod61Q17vlyOxrwyMBmmAzyNrAQQtRWtTYZ86UdO7Zx3313UlhYyK23jsFmK+arr77wLIs0Zcq0Evt/+eV8Vq1aidPpJCgoiOeee4kff/yetWvXYLMVc/RoCtdffxODBw9lx47tzJo1HU3TiI6O4emnJ5OSksLMmS+haRqhoaFMnPg0ZrOZadOeIzn5AA0aNCx3pv+TrrvuCtq0acfRoyl07tyFwkILu3btoHHjeJ58cjLHjx9j6tTJOJ1OFEXhvvsm0Lx5C778cgFLly4mMjKKnJwcAJxOJy+99DwpKUdQVZXbb7+Tzp27VE1lV1PGo78TsuRGFE0lZ8RXuOI6ntHxU3/cS2ahe93GYW3LnuxVCCFE7VBrkzFby5HYWo70yfxZ/v7+vPTSLHJzcxgz5maGDh3OSy/Nwt/fn2nTnuPPP9cSFeUe/6OqKnl5ecyc+SY6nY4HHhjHrl07ACgstDBjxuscOXKYRx4Zz+DBQ5k27TmeffZ5mjRpyldffcHBgwd5+eWpTJz4FE2bJrB06WLmzp1D27btsdvtvPvuR6SmpvLLLz+dMubU1OO88sobxMTEcuml/Xn33Y8YP/5hrrrqcgoKCnjjjZmMHHk1vXr15e+/9zB16mRmzXqLL76Yx8cfz0On0zF69A0ALFmymNDQMCZOfIq8vFzuvnsMn366oGorvRrx27OI4BX3oaBib9ADV+SZLX674UguX29Pw2zU8fLwtlUUpRBCiOqi1iZjvtS+fUcURSE8PILAwCAMBgNTpjxNQEAAhw4dpG3b9p59dTodRqORZ555HLPZTHp6Ok6nE4Bmzdwf4jExsZ6WrZycbJo0aQrA//53JQCHDiXz8stTAXC5nDRqFE9y8n5atWoDQFxcHDExpx5zFBISQmxsHHq9HrPZTNOmCQAEBgZht9s4ePAgHTp0BtzrZqanp3Ho0EGaNk3AZHLPc3Xyevv372Pr1k3s3LndE1NeXu451GgNoWmYN7xB0Dr3z6I4aSQF/aefWLC7YoodLp5dtgcFeHFoawJM0j0phBC1nSRjVWDXrp0AZGVlUlhoYcGCz/nyy6UAjB9/N/9e9GDfvr9ZvfoX3ntvDsXFxZ7WJaDMZWWioqI4cuQwjRo15tNPP6JRo3gaN47niScmERcXx9atm8nKysRgMLBixXLgWjIzM8jIyDhlzOUtYXNSkyZN2Lp1Ez179uHvv/cQERFJ/foNOHjwADZbMQaDkb1793DRRZcSH9+EmJgYbrzxVmy2YubM+YDg4Fr+Np3qInDV4wTs/BSAwq7jKer6AJymXv/rrTUHOV5g46VhrejeVAa+CyFEXSDJWBWw2Wzce+9YrNYiHnnkCb7++ituvfUGzGYzwcHBZGZmUK9efQAaNmyE2Wxm9OhRmExGIiOjyMwsP3F66KHHeOGFSeh0OiIjI7nqquuIjY1jypSnUFX3EjmPPvokjRvHs3XrFm6//Sbi4uoRFhZ2Tvd099338+KLU/j8809xOp1MnPgk4eHh3HbbWMaOvZWwsHDMZvcbgpdf/j9efHEK48aNobDQwogRV6LT1eIXd51WQn68B78D3+MMiaeoy73YWl19xqdZsSeDzzYcZXi7OPo2rxnTWAghhDh3sjalAGRtyjPx73XMFGs2oV9fgyFrJ4U9n8HafvQZt4YB5Bc7uPTtP3C4NObe2Jnm0aUXCK9pZG28ipO6qjipq4qReqo4WZtSeNVvv61i3ry5pbZfeeW19OzZ2wcR1Wy6vEOELh6J3nIcNbjRWSdiAPd8uQ27S+Omro1qRSImhBCi4iQZq0N69uxDz559yiw72TImKsaUuY3w729GcRSgBjUgd/iCs07E5m1IYWeqhcbhZu7u1aRyAxVCCFHtSTImxBnyP/IL0T/fjU514IhuR96wz9D8w8/qXKkFxcxcdQC9ovDmle1O+yKFEEKI2keSMSHOgGIvIPqXe1FUB7b4geRf8jYY/M/qXJqmMfXHfWjAg/0SiA0+u/MIIYSo2SQZE+IM+O3+Ap2zmKzuk1A73QzK2b8lumR7KmuSs7m/TwJXdWpQeUEKIYSoUWrxfAOVa9y4MRw6dJDvvlvCb7+tAtzLGIk6RFMxb34XW1QHLC2vOadEbG+6hed+/JtmUQFce54kYkIIUZdJMnaGBg8e6hkEP2fOBz6ORniT8eBPGApS0M6yW/IkVdMYt3AbqgZjL2yCTsaJCSFEnVbnuykPHz7E888/i8FgQK/XM2TIML77bgk6nY6srCyGDRvBFVdc5dl/9ux3iIyMJC8vj/z8PKZPn8qECY/68A6EtwT+OR2AvHZjzuk8Ty/bQ47VQd9mkfRpFlUZoQkhhKjB6nwy9tdf60hKask99zzAli2bOHjwAJmZGXzwwVw0TeXGG6+hf/+BpY676abRfPnlAknE6ghd3iEMmTtQ/cMpbtDzrM+z7mAO3+9KJ8TPwPOXtarECIUQQtRUdb6b8rLLLic0NIwHH7yHL79cgF6vp23b9phMJvz8/ElISOTo0RRfhyl8LODPl1HgnGbY/2ZbKo8sca9bOuuKthj1df6fnxBCCKRljN9+W0WHDp249dYx/Pjj97z77puEhITicrlwOBwkJx+gYcPGZR5bQ1eSEmfKYcV/3xI0RY+1/S1Qwflxi+wulmxP5YvNx0jJteLSICLAyFWd6tO2Xi1fOF0IIUSF1flkrGXL1kya9CR6vR6dTscVV1zFsmXfMmHCveTl5XHTTaPLXWS7SZOmTJr0JE89Ndm7QQuv8t/7FYrqoKjtTWh+oVBUVO6+NqfKqn2ZfL7hKDvSCjiZr3dsEMr4vgm0ig2SiV2FEEKUIAuF/8fGjev5+usvefbZFyon0BpCFgovh6YRPv8iQCHn6uWgKKUWlXW6VP48nMsPezL4aU8GxU7VXW7UM6BFFLde0JiGYWZf3YHPyELFFSd1VXFSVxUj9VRxslC4ENWc8dgfGLJ2Udh1fImxYi5VY8ORXJZsT+WnvZkUO1WC/PT0bRZJVpGDUV0b0i0+XKatEEIIcVpeS8ZUVeWZZ55hz549mEwmpkyZQnz8P60h33zzDR9++OGJrsIruO6667wVWgmdO3ehc+cuPrm2qH4C1rmns3AF/TMx67zNx/l0YyoFtn8Gj7WKDeL9azpiMsigfCGEEGfGa8nYihUrsNvtzJ8/n82bNzN16lTeeustT/m0adNYunQpAQEBDBkyhCFDhhAaGuqt8IQoRWc5jvH4OjSDP7YWwwFIzS/mrbVHAQg06bmsTSwj2tcjMSrQh5EKIYSoybyWjG3YsIFevXoB0LFjR7Zv316iPCkpiYKCAgwGA5qmnXaQs6qqnn7ef7ZpnrFPJ2mae/yOq4JvwNVVvqwnVdVK/Syrg7A/XwPAkjicIrsK9iK+3nIMgKvaRnJHj3gMJ6anqI7x+5rVKnVSUVJXFSd1VTFSTxXnvbqqBmPGLBYLQUFBnu/1ej1OpxODwR1C8+bNueKKKzCbzQwaNIiQEHn1X/iQy07w3i8AyG93O+CeyuSnv7NpFW3m1i6xnkRMCCGEOBdeS8aCgoIoLCz0fK+qqicR2717N7/88gs//fQTAQEBPPTQQyxbtoxLL7203PPpdLpSbz7k5yul3gY82dLji7cEaxJf1pNOp1S7N378dn+HzmXFEdsJU2wSJmDH8QKSc4oZ3bU+ZnNAtYu5upJ6qjipq4qTuqoYqaeK82Vdee1X+86dO7N69WoANm/eTIsWLTxlwcHB+Pv74+fnh16vJyIigvz8fG+FVmlsNhtLliyu0L7ffbeE335bVW75J598xM6d28stF1XLvH0OzpAm5A+c5dn24Z+HAYgL8fNVWEIIIWohr7WMDRo0iDVr1nDNNdegaRrPP/88S5YsoaioiKuvvpqrr76a6667DqPRSOPGjRkxYoS3Qqs02dlZLFmymKFDh59238GDh56yfNSomysnKHHGDGmbMaZtoqDXZNSwBACcqsba5GwMOoV+ieE+jlAIIURt4rVkTKfTMWnSpBLbEhMTPV9fe+21XHvttZV2vRUrlvPDD8s8SxZVxqznF110KQMHXlxu+ccff8DBg8n06tWVLl3Ox2q18uijT/L999+ye/dOioqKaNKkKY899jSzZ79DZGQkjRs3Ye7cjzEaDRw/foz+/Qdx002jee65Zxgw4CKys7NYu3YNNlsxR4+mcP31NzF48FB27tzOjBnTCAgIIDw8HJPJj8cff+ac71FAwPpZaIAr9J+pV37dn4ndpdEtPlzWlBRCCFGpZNLXSnTjjbeyf/8+unXrTkFBAfffP4HCQgvBwcHMnPkmqqoyatRVZGSklzguLe04H330OQ6Hg+HDL+Gmm0aXKC8stDBjxuscOXKYRx4Zz+DBQ5k+/QWeeGISCQmJvPPOG2RmZnjzVmstpSgT08GfQNHhjOno2f7JX+7F4m/s2tBHkQkhhKitam0yNnDgxQwceLHPlvlp3NjdquLn509OTg5PP/0YAQEBWK1WnE5niX0TEpphMBgwGAz4+fmXOlezZu7xdTExsdjtdgAyMzNJSHC3LHbo0ImffvqhKm+nzjBv+wgFFVuTi9HMEQAU2p1sTy0gwKinS+Mwiq1WH0cphBCiNpH+lkqkKDrPfF06nbtb9I8/1pCensazzz7PmDF3Y7MV89/lQE/Xg1pWF2tMTCzJyQcA2LFjWyVEL1CdmLd9AEBR57s9m3/em4mmwR094mV5IyGEEJWu1raM+UJ4eDgOhxObzebZ1qpVGz76aDZjxtyMyWSifv0GldKl+OCDj/DCC5MwmwMwGg1ER8ec8znrOtOB79HZ8nGGxOOM7eTZ/t2udBqG+XPteQ1OcbQQQghxdhTtv800NYTD4SI3t+Ssuamph4iLiy+xzVfdlFXtyy8X0L//IMLDw3n33TcxGo3ccsvtZ30+X9ZTWT83Xwj9cjjGjG0U9J6CrbX7ZZK0AhuXvbuOfs0jmTasDfDPbPsyf8+pST1VnNRVxUldVYzUU8V5q66io6vBDPyickVERPDAA3djNgcQFBQkb1KeI33WLkyp67F0fxxbq2s82+dtdK9D2SjM7KvQhBBC1HKSjNVQ/foNpF+/gb4Oo9Ywb3wbTWekuNXVnkF8mqaxdEcaAFd3ki5KIYQQVUMG8Is6TynOxX/f1yiqA8WW59m+O62AXKuDxuFmYoJl1n0hhBBVQ5IxUef575qHojpxxHZCDWvq2f7pencX5ZUd6vkqNCGEEHWAJGOibtNUzJveAUpOZ+FUNVbvz0IBhrSJ81FwQggh6gJJxkSdZjq0Er01A9UvHHuTf8bgrTuUQ7FTZUL/RIL9ZWilEEKIqiPJmA+MGzeGQ4cO8t13S/jtt1WlyocNK3/9S4BVq1aSmZlBVlYm06dPraow6wTzxjcAsLa/BXT/JF3f7UglxN/A8HbSRSmEEKJqSTLmQ4MHD6Vnzz5nfNwXX3xOYWEhkZFRTJjwaBVEVjfocw9gOv4ntviBWNvc4NlusTlZsTeTQJMek0H+iQghhKhatbr/5eGH7/csPfTvJYWmTZsJwNtvv86BA/tKHXfHHeNITGzGjz9+z48/fl/quPI89thDXHnlNXTqdB67du3gzTdfJSwsHIulgLy8XIYOHcGIESM9+8+e/Q6RkZEMHTqCadOeIzn5AA0aNPSsP3ngwD5ee+0VVFXDYnEvPF5QUMC+fXuZMuUpnnxyMlOmPM27737EX3/9wbvvvoWfnx8hIaFMnPgUf/+9h7lzP8ZoNHD8+DH69x9UahHyusx/2xw0nZGCftPQAv9ZweD7XemoGjSLDvRhdEIIIeqKWp2MedvQocNZtmwpnTqdx3ffLaVz5y4kJCTSp09/MjMzGDduTIlk7KQ//vgdu93Ou+9+RGpqKr/88hMAyckHGDduPImJzfjhh+/57rslPPLIEzRr1oKHHnoMo9EIuOfDmjbted58832io2NYsOBz5syZTY8ePUlLO85HH32Ow+Fg+PBLJBk7yV6I/465uEIao/mVnBV5wSb3W5TXdZa5xYQQQlS9Wp2MTZs285TL/IwdO+6Uxw8adAmDBl1S4et169adN9+cRX5+Hlu3bmL69Fd5++3XWbVqJQEBgTidzjKPS07eT6tW7qV24uLiiImJBSAqKoaPPnofPz8/ioqKCAwsu6UmNzeXgIBAz/qUHTt24p133qRHj54kJDTDYDBgMBjw8/Ov8L3Udv57FqJzFaOpDtD/Uy+p+cUkZ1sJNOnp3CjMdwEKIYSoM2RATCXS6XT06zeQ6dOn0qtXX+bN+5S2bdvz1FOT6d9/IOUtAxof34QdO7YCkJmZQUaGeyHxWbNeYvToO3jiiWdJTGzmOV6n06Gqquf4sLAwiooKyczMBGDz5o00atQY8EwmL/5N0zBvPjGdRccxJSpp0dbjAAxKikYnlSeEEMILanXLmC8MGTKMq666nHnzFnH8+DGmT3+BH35YRmhoKHq93jMe7N969erL1q1buP32m4iLq0dYWBgAF110KY8++iARERFER8eQl5cLQNu27Zky5WkefvhxwD0e7uGHH+fxxx9Cp1MIDg7hsceeKXM8nADj8T8x5B9G0/thS7rCs13TNJbtSseoU7iyY30fRiiEEKIuUbTymmuqOYfDRW5uUYltqamHiIuLL7HtVN2U4h++rKeyfm5VKXjZGPwOfEdxq2ux9H/Js313WgGjPt3EIwMSuaJD/RIvffxbUZH7uQsICPBKvDWV1FPFSV1VnNRVxUg9VZy36io6OrjcMummFHWKYs3CL/kHQMHa7uYSZYu2pmLQwaCkmHITMSGEEKKySTIm6hT/XQtQNCe5w7/AFd3Gs92paizblYZLBbVmNhYLIYSooSQZE3WHpmLe/jH2eufjbHBBiaI/krOxOlSaRAQQHmDyUYBCCCHqolo3gF/TNOliqkG8OWTRmPIb+oIjoKmgaSXeopx/Ym6xKzvK8kdCCCG8q1a1jBkMJgoL8736AS/OnqZpFBbmYzB4pyXKvOUDNMDeuG+JRMxic/LX4VwUBS5qGVPu8UIIIURVqFUtY+Hh0eTkZGCx5Hq2qerJubmktexUfFVPBoOJ8PDoKr+OznIc06GfUABr2xtLlK3Ym4FLg44NQgg1G6s8FiGEEOLfalUyptcbiIoq2c0kr/dWTG2vJ/+dn6Og4YhsXWLgPsC3O9IINOkZ1bWhj6ITQghRl9WqbkohyqQ68d8+B4Di9reUKErNL2bL0Xyu79KQ3olRvohOCCFEHSfJmKj1TId+Rm/NwhnZkuJmw0qULdmeigb0TozwTXBCCCHqvFrVTSlEWfy3f4IrMJacq74H3T+PvKZpLN6WCkCutexF3IUQQoiqJi1jolbT5R/GdHgl9vgBJRIxgN3pFtItdoJMero0CvNNgEIIIeo8ScZErWbePhcAY9rmUmWLtrpbxS5pFYNe3rYVQgjhI5KMidrLZcd/x6fu6Sz+M3DfqWos350OwOXt4nwQnBBCCOEmyZiotfwOfI/Onodm8C81cH/dwRyK7C5igkwkxQT5KEIhhBBCkjFRi/lv+xANheKkkWAKLFH23c40Aow6HuyXKMtnCSGE8Cl5m1LUSvqcfZiO/wWAtc2oEmUOl8pvB7K5qGUM/VtU/ez/QgghxKlIMiZqJf8dn6IpBiw9Hi814/7WY/kUOVzEBvn5KDohhBDiH9JNKWofpxX/3V9gazaE4o63lypesScTAE2RBeWFEEL4niRjotbx27cUnS0PzVj2wPxfD7iTsT6y/JEQQohqQJIxUeuYt7oH7lPGwPwMi420AjsBRj3NowPLOFoIIYTwLhkzJmoVfcYOjBlbgdID9wHWJGcDcF6jUHmLUgghRLUgyZioVczbP0ZDwRnVptTAfYAfdmUAcFFLeYtSCCFE9SDdlKLWUOwW/PZ8iYJGcbsbS5U7VY3d6QWc3ziMHk0jfBChEEIIUZokY6LW8Nu7CJ2rGM1gprjZ5aXKdxzPp8DmYnj7eoT4G30QoRBCCFGaJGOidtA0zNs/wRHVlqxRa0vNuA/wy74sAMLN0jsvhBCi+pBkTNQKhrSNGLJ2UtzmerSAsqes+GWfe0oLvU4eeyGEENWHfCqJWsG8/RM0dBhT1pRZnlNkJyW3GKNeoV29YC9HJ4QQQpRPkjFR4ynFOfj9/TUKKo7GvcvcZ+1B95QW7euHYNDLYy+EEKL6kE8lUeP57/kSRXWgGQLKHLgP/yyBNDBJprQQQghRvUgyJmo2TcN/60doKBQnXVHmwH1V01h/JBeAHk1kSgshhBDVi7xWJmo049HfMeQfBKC4zfVl7rMn3YLVoTKqS0Pqh/p7MTohhBDi9CQZEzWa/45PUQ1m7E0G4oxuW+Y+v59YAumGrg29GZoQQghRIdJNKWospSgDvwPLKG5zAwUXv1Xufj/uziDE34Cqal6MTgghhKgYaRkTNZb/rvkoqhN7o77l7pNf7GB/VhF6BYL85HEXQghR/UjLmKix/PYtRUPBL3lZufv8dTgXgBYxQfgb9V6KTAghhKg4ScZEzaRp6LP3uhcFb3NDubv9tCcDkCkthBBCVF+SjIkaSVeUhk614wqsV+7AfU3TWHsoB4AeTWVKCyGEENWTJGOiRtLn7AfAGdW63H32ZxZhsbkI9jOQGBngrdCEEEKIMyLJmKiRDOlbAHBGty93n5NLID03pCWKonglLiGEEOJMSTImaiR9XjKqzoQt8dJy9/k9OZtmUYF0ly5KIYQQ1ZgkY6JG0uen4IpqhaucbspCu5ONKXmomoaqyfxiQgghqi+vTbykqirPPPMMe/bswWQyMWXKFOLj4wHIyMjggQce8Oy7a9cuHnzwQa699lpvhSdqGH3WTlyR5Y8XW384D1UDVQOddFEKIYSoxryWjK1YsQK73c78+fPZvHkzU6dO5a233LOmR0dH88knnwCwadMmXnnlFa666ipvhSZqGMVuQW/Nguw95e6zal8mAP2bR3orLCGEEOKsnDYZ27p1K0lJSfj5+Xm2/fDDD0RFRdG5c+cKX2jDhg306tULgI4dO7J9+/ZS+2iaxuTJk5k+fTp6/akn6FRVlaKiotNe12o9/T6iZtWTKXMHAI6ghmU+A5qmsXq/Oxk7r35ghZ6TM1GT6sqXpJ4qTuqq4qSuKkbqqeK8V1fB5ZaccszY008/zdVXX82mTZtKbP/yyy+5/vrree655yocgsViISgoyPO9Xq/H6XSW2Ofnn3+mefPmJCQkVPi8ou4x5rhbxOwRLcssP5JrI6/YhZ9BoWVMoDdDE0IIIc5YuS1j8+bNY+nSpcyYMYNu3bqVKHv77bdZunQpTz31FK1ateJ///vfaS8UFBREYWGh53tVVTEYSl7+m2++4cYbb6xQ4DqdjoCAis8ddSb71mU1oZ4Cst0tYzTsVma8m3a7J3o9r1EYIUFVl4zVhLqqDqSeKk7qquKkripG6qnifFlX5baMzZ8/n0cffZRLL7201BxNiqIwdOhQ7rnnHubOnVuhC3Xu3JnVq1cDsHnzZlq0aFFqnx07dpxR16eom4xZOwFwltMytjY5m0ah/jw6sLk3wxJCCCHOSrnJ2MGDB7ngggtOeXDfvn05ePBghS40aNAgTCYT11xzDS+88AITJ05kyZIlzJ8/H4Ds7GwCAwNlck5xWkphBq7AOFxhTUuVFTtcbEzJ48LESOqF+PsgOiGEEOLMlNtNaTabS3QrlsXpdGI0Git0IZ1Ox6RJk0psS0xM9HwdERHB119/XaFziTpMdaIvSsPa8XYwlm5S3piSh82pklNk90FwQgghxJkrt2Wsffv2fP/996c8+Ntvv6V5c+kKEt6jzz+MojpwBtYrs/zXA1kAhPh7bdYWIYQQ4pyUm4zddNNNvP/++8ybNw+tjBnMP/vsM2bPnl3hAfdCVAZ99j4ATMf/LLN89T53MtYrUeYXE0IIUTOU23zQvXt3xo8fz+TJk3n99ddp27YtISEh5OXlsW3bNvLz87n77rsZNGiQN+MVdZwhbSMAzthOpcqO5llJt9jR6xQ6NQj1dmhCCCHEWTllX87o0aPp3r07X3zxBTt37uTgwYOEh4dz+eWX87///U+6KIXXGTK2AeCMbluqbG2ye0qLtnHB+BtPPWmwEEIIUV2cdmBN69atefrpp70RixCnZcg9AIAzrFmpslUnuij7NY/yakxCCCHEuSg3GUtLSytzu9FoJCQkpNSErUJUOU1DV5iGpjOiBUSXKHK4VLYcy2No21iGtY3zUYBCCCHEmSs3o+rTp0+5c34pikJSUhJ33XWXjBkTXqNYM1FUO46otvCfZ3Pz0TysDpU+iVEEy5uUQgghapByP7U+/vjjMrerqkp+fj7r16/noYceYtasWfTp06fKAhTiJEOO+03Kwu4TS5Wt2Z8NQEahzasxCSGEEOeq3GTs/PPPP+WBF110EVFRUbz77ruSjAmv0GfvBcAVXnq82C/73ePFws0Vm4RYCCGEqC7KnWesIvr06cPevXsrKxYhTsl4Ym4xQ9auEtvTC2wczStGAc5vHO6DyIQQQoizd07JWGBgIE6ns7JiEeKUDNl7A
gitextract_l1ifb68j/
├── .actrc
├── .deepsource.toml
├── .devcontainer/
│ ├── Dockerfile
│ └── devcontainer.json
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.md
│ │ └── feature_request.md
│ ├── pull_request_template.md
│ └── workflows/
│ ├── docker.yml
│ ├── pytest.yml
│ ├── pytest_slow.yml
│ ├── schema.yml
│ ├── test-results.yml
│ └── upload-pypi.yml
├── .gitignore
├── .nojekyll
├── .pre-commit-config.yaml
├── .protolint.yaml
├── .vscode/
│ └── settings.json
├── CODEOWNERS
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── NOTICE
├── README.md
├── README_KR.md
├── RELEASES.md
├── docker/
│ ├── README.md
│ ├── ludwig/
│ │ └── Dockerfile
│ ├── ludwig-gpu/
│ │ └── Dockerfile
│ ├── ludwig-ray/
│ │ └── Dockerfile
│ └── ludwig-ray-gpu/
│ └── Dockerfile
├── examples/
│ ├── README.md
│ ├── calibration/
│ │ ├── README.md
│ │ ├── train_forest_cover_calibrated.py
│ │ └── train_mushroom_edibility_calibrated.py
│ ├── class_imbalance/
│ │ ├── README.md
│ │ ├── balanced_model_config.yaml
│ │ ├── model_training.py
│ │ ├── model_training_results.ipynb
│ │ └── standard_model_config.yaml
│ ├── forecasting/
│ │ ├── README.md
│ │ └── config.yaml
│ ├── getting_started/
│ │ ├── rotten_tomatoes.yaml
│ │ └── run.sh
│ ├── hyperopt/
│ │ ├── README.md
│ │ └── model_hyperopt_example.ipynb
│ ├── insurance_lite/
│ │ ├── config.yaml
│ │ └── train.py
│ ├── kfold_cv/
│ │ ├── README.md
│ │ ├── display_kfold_cv_results.py
│ │ ├── k-fold_cv_classification.sh
│ │ ├── prepare_classification_data_set.py
│ │ └── regression_example.ipynb
│ ├── lbfgs/
│ │ ├── config.yaml
│ │ └── model.py
│ ├── llama2_7b_finetuning_4bit/
│ │ ├── README.md
│ │ ├── llama2_7b_4bit.yaml
│ │ ├── run_train.sh
│ │ └── train_alpaca.py
│ ├── llm_base_model_dequantization/
│ │ ├── README.md
│ │ └── phi_2_dequantization.py
│ ├── llm_few_shot_learning/
│ │ └── simple_model_training.py
│ ├── llm_finetuning/
│ │ ├── README.md
│ │ ├── imdb_deepspeed_zero3.yaml
│ │ ├── imdb_deepspeed_zero3_ray.yaml
│ │ ├── run_train_dsz3.sh
│ │ ├── run_train_dsz3_ray.sh
│ │ └── train_imdb_ray.py
│ ├── llm_instruction_tuning/
│ │ └── train_alpaca_ray.py
│ ├── llm_text_generation/
│ │ └── simple_model_training.py
│ ├── llm_zero_shot_learning/
│ │ └── simple_model_training.py
│ ├── mnist/
│ │ ├── README.md
│ │ ├── advanced_model_training.py
│ │ ├── assess_model_performance.py
│ │ ├── config.yaml
│ │ ├── simple_model_training.py
│ │ └── visualize_model_test_results.ipynb
│ ├── ray/
│ │ └── kubernetes/
│ │ ├── README.md
│ │ ├── clusters/
│ │ │ ├── ludwig-ray-cpu-cluster.yaml
│ │ │ └── ludwig-ray-gpu-cluster.yaml
│ │ └── utils/
│ │ ├── attach.sh
│ │ ├── dashboard.sh
│ │ ├── krsync.sh
│ │ ├── ray_down.sh
│ │ ├── ray_up.sh
│ │ ├── rsync_up.sh
│ │ ├── submit.sh
│ │ └── upload.sh
│ ├── regex_freezing/
│ │ ├── ecd_freezing_with_regex_training.py
│ │ └── llm_freezing_with_regex_training.py
│ ├── semantic_segmentation/
│ │ ├── camseq.py
│ │ └── config_camseq.yaml
│ ├── serve/
│ │ ├── README.md
│ │ └── client_program.py
│ ├── synthetic/
│ │ └── train.py
│ ├── tabnet/
│ │ └── higgs/
│ │ ├── medium_config.yaml
│ │ ├── small_config.yaml
│ │ ├── train_higgs_medium.py
│ │ └── train_higgs_small.py
│ ├── titanic/
│ │ ├── README.md
│ │ ├── model1_config.yaml
│ │ ├── model2_config.yaml
│ │ ├── model_training_results.ipynb
│ │ ├── multiple_model_training.py
│ │ └── simple_model_training.py
│ ├── twitter_bots/
│ │ ├── README.md
│ │ ├── train_twitter_bots.py
│ │ └── train_twitter_bots_text_only.py
│ ├── wine_quality/
│ │ ├── README.md
│ │ └── model_defaults_example.ipynb
│ └── wmt15/
│ ├── config_large.yaml
│ ├── config_small.yaml
│ └── train_nmt.py
├── ludwig/
│ ├── __init__.py
│ ├── accounting/
│ │ ├── __init__.py
│ │ └── used_tokens.py
│ ├── api.py
│ ├── api_annotations.py
│ ├── automl/
│ │ ├── __init__.py
│ │ ├── auto_tune_config.py
│ │ ├── automl.py
│ │ ├── base_config.py
│ │ └── defaults/
│ │ ├── base_automl_config.yaml
│ │ ├── combiner/
│ │ │ ├── concat_config.yaml
│ │ │ ├── tabnet_config.yaml
│ │ │ └── transformer_config.yaml
│ │ ├── reference_configs.yaml
│ │ └── text/
│ │ └── bert_config.yaml
│ ├── backend/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── datasource.py
│ │ ├── deepspeed.py
│ │ ├── ray.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ └── storage.py
│ ├── benchmarking/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── artifacts.py
│ │ ├── benchmark.py
│ │ ├── examples/
│ │ │ ├── benchmarking_config.yaml
│ │ │ └── process_config.py
│ │ ├── profiler.py
│ │ ├── profiler_callbacks.py
│ │ ├── profiler_dataclasses.py
│ │ ├── reporting.py
│ │ ├── summarize.py
│ │ ├── summary_dataclasses.py
│ │ └── utils.py
│ ├── callbacks.py
│ ├── check.py
│ ├── cli.py
│ ├── collect.py
│ ├── combiners/
│ │ ├── __init__.py
│ │ └── combiners.py
│ ├── config_sampling/
│ │ ├── __init__.py
│ │ ├── explore_schema.py
│ │ └── parameter_sampling.py
│ ├── config_validation/
│ │ ├── __init__.py
│ │ ├── checks.py
│ │ ├── preprocessing.py
│ │ └── validation.py
│ ├── constants.py
│ ├── contrib.py
│ ├── contribs/
│ │ ├── __init__.py
│ │ ├── aim.py
│ │ ├── comet.py
│ │ ├── mlflow/
│ │ │ ├── __init__.py
│ │ │ └── model.py
│ │ └── wandb.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── batcher/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── bucketed.py
│ │ │ ├── iterable.py
│ │ │ ├── random_access.py
│ │ │ └── test_batcher.py
│ │ ├── cache/
│ │ │ ├── __init__.py
│ │ │ ├── manager.py
│ │ │ ├── types.py
│ │ │ └── util.py
│ │ ├── concatenate_datasets.py
│ │ ├── dataframe/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── dask.py
│ │ │ ├── modin.py
│ │ │ └── pandas.py
│ │ ├── dataset/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── pandas.py
│ │ │ └── ray.py
│ │ ├── dataset_synthesizer.py
│ │ ├── negative_sampling.py
│ │ ├── postprocessing.py
│ │ ├── preprocessing.py
│ │ ├── prompt.py
│ │ ├── sampler.py
│ │ ├── split.py
│ │ ├── split_dataset.py
│ │ └── utils.py
│ ├── datasets/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── archives.py
│ │ ├── configs/
│ │ │ ├── __init__.py
│ │ │ ├── adult_census_income.yaml
│ │ │ ├── ae_price_prediction.yaml
│ │ │ ├── agnews.yaml
│ │ │ ├── allstate_claims_severity.yaml
│ │ │ ├── alpaca.yaml
│ │ │ ├── amazon_employee_access_challenge.yaml
│ │ │ ├── amazon_review_polarity.yaml
│ │ │ ├── amazon_reviews.yaml
│ │ │ ├── ames_housing.yaml
│ │ │ ├── bbcnews.yaml
│ │ │ ├── bnp_claims_management.yaml
│ │ │ ├── bookprice_prediction.yaml
│ │ │ ├── california_house_price.yaml
│ │ │ ├── camseq.yaml
│ │ │ ├── code_alpaca.yaml
│ │ │ ├── connect4.yaml
│ │ │ ├── consumer_complaints.yaml
│ │ │ ├── consumer_complaints_generation.yaml
│ │ │ ├── creditcard_fraud.yaml
│ │ │ ├── customer_churn_prediction.yaml
│ │ │ ├── data_scientist_salary.yaml
│ │ │ ├── dbpedia.yaml
│ │ │ ├── electricity.yaml
│ │ │ ├── ethos_binary.yaml
│ │ │ ├── fake_job_postings2.yaml
│ │ │ ├── fever.yaml
│ │ │ ├── flickr8k.yaml
│ │ │ ├── forest_cover.yaml
│ │ │ ├── goemotions.yaml
│ │ │ ├── goodbooks_books.yaml
│ │ │ ├── google_qa_answer_type_reason_explanation.yaml
│ │ │ ├── google_qa_question_type_reason_explanation.yaml
│ │ │ ├── google_quest_qa.yaml
│ │ │ ├── higgs.yaml
│ │ │ ├── hugging_face.yaml
│ │ │ ├── ieee_fraud.yaml
│ │ │ ├── imbalanced_insurance.yaml
│ │ │ ├── imdb.yaml
│ │ │ ├── imdb_genre_prediction.yaml
│ │ │ ├── insurance_lite.yaml
│ │ │ ├── iris.yaml
│ │ │ ├── irony.yaml
│ │ │ ├── jc_penney_products.yaml
│ │ │ ├── jigsaw_unintended_bias.yaml
│ │ │ ├── jigsaw_unintended_bias100k.yaml
│ │ │ ├── kdd_appetency.yaml
│ │ │ ├── kdd_churn.yaml
│ │ │ ├── kdd_upselling.yaml
│ │ │ ├── kick_starter_funding.yaml
│ │ │ ├── melbourne_airbnb.yaml
│ │ │ ├── mercari_price_suggestion.yaml
│ │ │ ├── mercari_price_suggestion100K.yaml
│ │ │ ├── mercedes_benz_greener.yaml
│ │ │ ├── mnist.yaml
│ │ │ ├── mushroom_edibility.yaml
│ │ │ ├── naval.yaml
│ │ │ ├── news_channel.yaml
│ │ │ ├── news_popularity2.yaml
│ │ │ ├── noshow_appointments.yaml
│ │ │ ├── numerai28pt6.yaml
│ │ │ ├── ohsumed_7400.yaml
│ │ │ ├── ohsumed_cmu.yaml
│ │ │ ├── otto_group_product.yaml
│ │ │ ├── poker_hand.yaml
│ │ │ ├── porto_seguro_safe_driver.yaml
│ │ │ ├── product_sentiment_machine_hack.yaml
│ │ │ ├── protein.yaml
│ │ │ ├── reuters_cmu.yaml
│ │ │ ├── reuters_r8.yaml
│ │ │ ├── rossman_store_sales.yaml
│ │ │ ├── santander_customer_satisfaction.yaml
│ │ │ ├── santander_customer_transaction.yaml
│ │ │ ├── santander_value_prediction.yaml
│ │ │ ├── sarcastic_headlines.yaml
│ │ │ ├── sarcos.yaml
│ │ │ ├── sst2.yaml
│ │ │ ├── sst3.yaml
│ │ │ ├── sst5.yaml
│ │ │ ├── synthetic_fraud.yaml
│ │ │ ├── talkingdata_adtrack_fraud.yaml
│ │ │ ├── telco_customer_churn.yaml
│ │ │ ├── temperature.yaml
│ │ │ ├── titanic.yaml
│ │ │ ├── twitter_bots.yaml
│ │ │ ├── walmart_recruiting.yaml
│ │ │ ├── wine_reviews.yaml
│ │ │ ├── wmt15.yaml
│ │ │ ├── women_clothing_review.yaml
│ │ │ ├── yahoo_answers.yaml
│ │ │ ├── yelp_review_polarity.yaml
│ │ │ ├── yelp_reviews.yaml
│ │ │ └── yosemite.yaml
│ │ ├── dataset_config.py
│ │ ├── kaggle.py
│ │ ├── loaders/
│ │ │ ├── __init__.py
│ │ │ ├── adult_census_income.py
│ │ │ ├── agnews.py
│ │ │ ├── allstate_claims_severity.py
│ │ │ ├── camseq.py
│ │ │ ├── code_alpaca_loader.py
│ │ │ ├── consumer_complaints_loader.py
│ │ │ ├── creditcard_fraud.py
│ │ │ ├── dataset_loader.py
│ │ │ ├── ethos_binary.py
│ │ │ ├── flickr8k.py
│ │ │ ├── forest_cover.py
│ │ │ ├── goemotions.py
│ │ │ ├── higgs.py
│ │ │ ├── hugging_face.py
│ │ │ ├── ieee_fraud.py
│ │ │ ├── insurance_lite.py
│ │ │ ├── kdd_loader.py
│ │ │ ├── mnist.py
│ │ │ ├── naval.py
│ │ │ ├── rossman_store_sales.py
│ │ │ ├── santander_value_prediction.py
│ │ │ ├── sarcastic_headlines.py
│ │ │ ├── sarcos.py
│ │ │ ├── split_loaders.py
│ │ │ └── sst.py
│ │ ├── model_configs/
│ │ │ ├── __init__.py
│ │ │ ├── adult_census_income_default.yaml
│ │ │ ├── allstate_claims_severity_default.yaml
│ │ │ ├── ames_housing_default.yaml
│ │ │ ├── bnp_claims_management_default.yaml
│ │ │ ├── forest_cover_default.yaml
│ │ │ ├── higgs_best.yaml
│ │ │ ├── higgs_default.yaml
│ │ │ ├── ieee_fraud_default.yaml
│ │ │ ├── mercedes_benz_greener_default.yaml
│ │ │ ├── mnist_default.yaml
│ │ │ ├── mushroom_edibility_default.yaml
│ │ │ ├── otto_group_product_default.yaml
│ │ │ ├── poker_hand_default.yaml
│ │ │ ├── porto_seguro_safe_driver_default.yaml
│ │ │ ├── synthetic_fraud_default.yaml
│ │ │ └── titanic_default.yaml
│ │ └── utils.py
│ ├── decoders/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── generic_decoders.py
│ │ ├── image_decoders.py
│ │ ├── llm_decoders.py
│ │ ├── registry.py
│ │ ├── sequence_decoder_utils.py
│ │ ├── sequence_decoders.py
│ │ ├── sequence_tagger.py
│ │ └── utils.py
│ ├── distributed/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── ddp.py
│ │ ├── deepspeed.py
│ │ └── fsdp.py
│ ├── encoders/
│ │ ├── __init__.py
│ │ ├── bag_encoders.py
│ │ ├── base.py
│ │ ├── category_encoders.py
│ │ ├── date_encoders.py
│ │ ├── generic_encoders.py
│ │ ├── h3_encoders.py
│ │ ├── image/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── timm.py
│ │ │ └── torchvision.py
│ │ ├── registry.py
│ │ ├── sequence_encoders.py
│ │ ├── set_encoders.py
│ │ ├── text_encoders.py
│ │ └── types.py
│ ├── error.py
│ ├── evaluate.py
│ ├── experiment.py
│ ├── explain/
│ │ ├── __init__.py
│ │ ├── captum.py
│ │ ├── captum_ray.py
│ │ ├── explainer.py
│ │ ├── explanation.py
│ │ └── util.py
│ ├── export.py
│ ├── features/
│ │ ├── __init__.py
│ │ ├── audio_feature.py
│ │ ├── bag_feature.py
│ │ ├── base_feature.py
│ │ ├── binary_feature.py
│ │ ├── category_feature.py
│ │ ├── date_feature.py
│ │ ├── feature_registries.py
│ │ ├── feature_utils.py
│ │ ├── h3_feature.py
│ │ ├── image_feature.py
│ │ ├── number_feature.py
│ │ ├── sequence_feature.py
│ │ ├── set_feature.py
│ │ ├── text_feature.py
│ │ ├── timeseries_feature.py
│ │ └── vector_feature.py
│ ├── forecast.py
│ ├── globals.py
│ ├── hyperopt/
│ │ ├── __init__.py
│ │ ├── execution.py
│ │ ├── results.py
│ │ ├── run.py
│ │ ├── search_algos.py
│ │ └── utils.py
│ ├── hyperopt_cli.py
│ ├── model_export/
│ │ ├── base_model_exporter.py
│ │ └── onnx_exporter.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── calibrator.py
│ │ ├── ecd.py
│ │ ├── embedder.py
│ │ ├── inference.py
│ │ ├── llm.py
│ │ ├── predictor.py
│ │ ├── registry.py
│ │ └── retrieval.py
│ ├── modules/
│ │ ├── __init__.py
│ │ ├── attention_modules.py
│ │ ├── convolutional_modules.py
│ │ ├── embedding_modules.py
│ │ ├── fully_connected_modules.py
│ │ ├── initializer_modules.py
│ │ ├── loss_implementations/
│ │ │ ├── __init__.py
│ │ │ └── corn.py
│ │ ├── loss_modules.py
│ │ ├── lr_scheduler.py
│ │ ├── metric_modules.py
│ │ ├── metric_registry.py
│ │ ├── mlp_mixer_modules.py
│ │ ├── normalization_modules.py
│ │ ├── optimization_modules.py
│ │ ├── recurrent_modules.py
│ │ ├── reduction_modules.py
│ │ ├── tabnet_modules.py
│ │ └── training_hooks.py
│ ├── predict.py
│ ├── preprocess.py
│ ├── progress_bar.py
│ ├── schema/
│ │ ├── __init__.py
│ │ ├── combiners/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── common_transformer_options.py
│ │ │ ├── comparator.py
│ │ │ ├── concat.py
│ │ │ ├── project_aggregate.py
│ │ │ ├── sequence.py
│ │ │ ├── sequence_concat.py
│ │ │ ├── tab_transformer.py
│ │ │ ├── tabnet.py
│ │ │ ├── transformer.py
│ │ │ └── utils.py
│ │ ├── common_fields.py
│ │ ├── decoders/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── image_decoders.py
│ │ │ ├── llm_decoders.py
│ │ │ ├── sequence_decoders.py
│ │ │ └── utils.py
│ │ ├── defaults/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── ecd.py
│ │ │ ├── llm.py
│ │ │ └── utils.py
│ │ ├── encoders/
│ │ │ ├── __init__.py
│ │ │ ├── bag_encoders.py
│ │ │ ├── base.py
│ │ │ ├── category_encoders.py
│ │ │ ├── date_encoders.py
│ │ │ ├── h3_encoders.py
│ │ │ ├── image/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── timm.py
│ │ │ │ └── torchvision.py
│ │ │ ├── sequence_encoders.py
│ │ │ ├── set_encoders.py
│ │ │ ├── text/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── encoders.py
│ │ │ │ └── hf_model_params.py
│ │ │ ├── text_encoders.py
│ │ │ └── utils.py
│ │ ├── export_schema.py
│ │ ├── features/
│ │ │ ├── __init__.py
│ │ │ ├── audio_feature.py
│ │ │ ├── augmentation/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── image.py
│ │ │ │ └── utils.py
│ │ │ ├── bag_feature.py
│ │ │ ├── base.py
│ │ │ ├── binary_feature.py
│ │ │ ├── category_feature.py
│ │ │ ├── date_feature.py
│ │ │ ├── h3_feature.py
│ │ │ ├── image_feature.py
│ │ │ ├── loss/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── loss.py
│ │ │ │ └── utils.py
│ │ │ ├── number_feature.py
│ │ │ ├── preprocessing/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── audio.py
│ │ │ │ ├── bag.py
│ │ │ │ ├── base.py
│ │ │ │ ├── binary.py
│ │ │ │ ├── category.py
│ │ │ │ ├── date.py
│ │ │ │ ├── h3.py
│ │ │ │ ├── image.py
│ │ │ │ ├── number.py
│ │ │ │ ├── sequence.py
│ │ │ │ ├── set.py
│ │ │ │ ├── text.py
│ │ │ │ ├── timeseries.py
│ │ │ │ ├── utils.py
│ │ │ │ └── vector.py
│ │ │ ├── sequence_feature.py
│ │ │ ├── set_feature.py
│ │ │ ├── text_feature.py
│ │ │ ├── timeseries_feature.py
│ │ │ ├── utils.py
│ │ │ └── vector_feature.py
│ │ ├── hyperopt/
│ │ │ ├── __init__.py
│ │ │ ├── executor.py
│ │ │ ├── parameter.py
│ │ │ ├── scheduler.py
│ │ │ ├── search_algorithm.py
│ │ │ └── utils.py
│ │ ├── jsonschema.py
│ │ ├── llms/
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── generation.py
│ │ │ ├── model_parameters.py
│ │ │ ├── peft.py
│ │ │ ├── prompt.py
│ │ │ └── quantization.py
│ │ ├── lr_scheduler.py
│ │ ├── metadata/
│ │ │ ├── __init__.py
│ │ │ ├── configs/
│ │ │ │ ├── combiners.yaml
│ │ │ │ ├── common.yaml
│ │ │ │ ├── decoders.yaml
│ │ │ │ ├── encoders.yaml
│ │ │ │ ├── features.yaml
│ │ │ │ ├── llm.yaml
│ │ │ │ ├── loss.yaml
│ │ │ │ ├── optimizers.yaml
│ │ │ │ ├── preprocessing.yaml
│ │ │ │ └── trainer.yaml
│ │ │ ├── feature_metadata.py
│ │ │ └── parameter_metadata.py
│ │ ├── model_config.py
│ │ ├── model_types/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── ecd.py
│ │ │ ├── llm.py
│ │ │ └── utils.py
│ │ ├── optimizers.py
│ │ ├── preprocessing.py
│ │ ├── profiler.py
│ │ ├── split.py
│ │ ├── trainer.py
│ │ └── utils.py
│ ├── serve.py
│ ├── train.py
│ ├── trainers/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── registry.py
│ │ ├── trainer.py
│ │ └── trainer_llm.py
│ ├── types.py
│ ├── upload.py
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── algorithms_utils.py
│ │ ├── audio_utils.py
│ │ ├── augmentation_utils.py
│ │ ├── automl/
│ │ │ ├── __init__.py
│ │ │ ├── data_source.py
│ │ │ ├── field_info.py
│ │ │ ├── ray_utils.py
│ │ │ ├── type_inference.py
│ │ │ └── utils.py
│ │ ├── backward_compatibility.py
│ │ ├── batch_size_tuner.py
│ │ ├── calibration.py
│ │ ├── carton_utils.py
│ │ ├── checkpoint_utils.py
│ │ ├── config_utils.py
│ │ ├── data_utils.py
│ │ ├── dataframe_utils.py
│ │ ├── dataset_utils.py
│ │ ├── date_utils.py
│ │ ├── defaults.py
│ │ ├── entmax/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── activations.py
│ │ │ ├── losses.py
│ │ │ └── root_finding.py
│ │ ├── error_handling_utils.py
│ │ ├── eval_utils.py
│ │ ├── fs_utils.py
│ │ ├── h3_util.py
│ │ ├── heuristics.py
│ │ ├── hf_utils.py
│ │ ├── html_utils.py
│ │ ├── image_utils.py
│ │ ├── inference_utils.py
│ │ ├── llm_quantization_utils.py
│ │ ├── llm_utils.py
│ │ ├── logging_utils.py
│ │ ├── loss_utils.py
│ │ ├── math_utils.py
│ │ ├── metric_utils.py
│ │ ├── metrics_printed_table.py
│ │ ├── misc_utils.py
│ │ ├── model_utils.py
│ │ ├── nlp_utils.py
│ │ ├── numerical_test_utils.py
│ │ ├── output_feature_utils.py
│ │ ├── package_utils.py
│ │ ├── print_utils.py
│ │ ├── registry.py
│ │ ├── server_utils.py
│ │ ├── state_dict_backward_compatibility.py
│ │ ├── strings_utils.py
│ │ ├── structural_warning.py
│ │ ├── system_utils.py
│ │ ├── time_utils.py
│ │ ├── tokenizers.py
│ │ ├── torch_utils.py
│ │ ├── trainer_utils.py
│ │ ├── triton_utils.py
│ │ ├── types.py
│ │ ├── upload_utils.py
│ │ ├── version_transformation.py
│ │ └── visualization_utils.py
│ ├── vector_index/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ └── faiss.py
│ └── visualize.py
├── pyproject.toml
├── pytest.ini
├── requirements.txt
├── requirements_benchmarking.txt
├── requirements_distributed.txt
├── requirements_explain.txt
├── requirements_extra.txt
├── requirements_hyperopt.txt
├── requirements_llm.txt
├── requirements_serve.txt
├── requirements_test.txt
├── requirements_viz.txt
├── schemastore/
│ ├── README.md
│ ├── catalog-entry.json
│ └── test/
│ ├── ludwig.yaml
│ └── ludwig_config.yaml
├── setup.cfg
├── setup.py
└── tests/
├── README.md
├── __init__.py
├── conftest.py
├── docker-compose.yml
├── integration_tests/
│ ├── __init__.py
│ ├── parameter_update_utils.py
│ ├── scripts/
│ │ ├── run_train_aim.py
│ │ ├── run_train_comet.py
│ │ └── run_train_wandb.py
│ ├── synthetic_test_data.py
│ ├── test_api.py
│ ├── test_audio_feature.py
│ ├── test_automl.py
│ ├── test_cache_manager.py
│ ├── test_cached_preprocessing.py
│ ├── test_carton.py
│ ├── test_class_imbalance_feature.py
│ ├── test_cli.py
│ ├── test_collect.py
│ ├── test_config_global_defaults.py
│ ├── test_contrib_aim.py
│ ├── test_contrib_comet.py
│ ├── test_contrib_wandb.py
│ ├── test_custom_components.py
│ ├── test_date_feature.py
│ ├── test_dependencies.py
│ ├── test_experiment.py
│ ├── test_explain.py
│ ├── test_graph_execution.py
│ ├── test_hyperopt.py
│ ├── test_hyperopt_ray.py
│ ├── test_input_feature_tied.py
│ ├── test_kfold_cv.py
│ ├── test_llm.py
│ ├── test_missing_value_strategy.py
│ ├── test_mlflow.py
│ ├── test_model_save_and_load.py
│ ├── test_model_training_options.py
│ ├── test_number_feature.py
│ ├── test_peft.py
│ ├── test_postprocessing.py
│ ├── test_preprocessing.py
│ ├── test_ray.py
│ ├── test_reducers.py
│ ├── test_regularizers.py
│ ├── test_remote.py
│ ├── test_reproducibility.py
│ ├── test_sequence_decoders.py
│ ├── test_sequence_encoders.py
│ ├── test_sequence_features.py
│ ├── test_server.py
│ ├── test_simple_features.py
│ ├── test_timeseries_feature.py
│ ├── test_torchscript.py
│ ├── test_trainer.py
│ ├── test_triton.py
│ ├── test_triton_configs/
│ │ └── transformer_combiner_with_attention_reduce.yaml
│ ├── test_visualization.py
│ ├── test_visualization_api.py
│ └── utils.py
├── ludwig/
│ ├── __init__.py
│ ├── accounting/
│ │ └── test_used_tokens.py
│ ├── augmentation/
│ │ ├── test_augmentation_pipeline.py
│ │ ├── test_auto_augmentation.py
│ │ └── test_image_augmentation.py
│ ├── automl/
│ │ ├── __init__.py
│ │ ├── test_base_config.py
│ │ ├── test_data_source.py
│ │ ├── test_tune_config.py
│ │ └── test_utils.py
│ ├── backend/
│ │ └── test_ray.py
│ ├── benchmarking/
│ │ ├── example_files/
│ │ │ ├── invalid/
│ │ │ │ ├── benchmarking_config_1.yaml
│ │ │ │ ├── benchmarking_config_2.yaml
│ │ │ │ └── benchmarking_config_3.yaml
│ │ │ ├── process_config.py
│ │ │ └── valid/
│ │ │ ├── benchmarking_config_1.yaml
│ │ │ ├── benchmarking_config_2.yaml
│ │ │ └── benchmarking_config_3.yaml
│ │ ├── test_benchmarking.py
│ │ └── test_profiler.py
│ ├── combiners/
│ │ └── test_combiners.py
│ ├── config_sampling/
│ │ ├── static_schema.json
│ │ └── test_config_sampling.py
│ ├── config_validation/
│ │ ├── test_checks.py
│ │ ├── test_validate_config_combiner.py
│ │ ├── test_validate_config_encoder.py
│ │ ├── test_validate_config_features.py
│ │ ├── test_validate_config_hyperopt.py
│ │ ├── test_validate_config_misc.py
│ │ ├── test_validate_config_preprocessing.py
│ │ └── test_validate_config_trainer.py
│ ├── contrib/
│ │ └── test_contrib.py
│ ├── data/
│ │ ├── dataframe/
│ │ │ └── test_dask.py
│ │ ├── test_cache_util.py
│ │ ├── test_dataset_synthesizer.py
│ │ ├── test_negative_sampling.py
│ │ ├── test_postprocessing.py
│ │ ├── test_preprocessing.py
│ │ ├── test_ray_data.py
│ │ └── test_split.py
│ ├── datasets/
│ │ ├── __init__.py
│ │ ├── download_all_datasets.py
│ │ ├── mnist/
│ │ │ └── test_mnist_workflow.py
│ │ ├── model_configs/
│ │ │ └── train_all_model_configs.py
│ │ ├── test_dataset_configs.py
│ │ ├── test_dataset_links.py
│ │ ├── test_datasets.py
│ │ ├── test_model_configs.py
│ │ └── titanic/
│ │ └── test_titanic_workflow.py
│ ├── decoders/
│ │ ├── test_image_decoder.py
│ │ ├── test_llm_decoders.py
│ │ ├── test_sequence_decoder.py
│ │ ├── test_sequence_decoder_utils.py
│ │ └── test_sequence_tagger.py
│ ├── encoders/
│ │ ├── __init__.py
│ │ ├── test_bag_encoders.py
│ │ ├── test_category_encoders.py
│ │ ├── test_date_encoders.py
│ │ ├── test_generic_encoders.py
│ │ ├── test_h3_encoders.py
│ │ ├── test_image_encoders.py
│ │ ├── test_llm_encoders.py
│ │ ├── test_sequence_encoders.py
│ │ ├── test_set_encoders.py
│ │ ├── test_text_encoders.py
│ │ └── test_timm_encoder.py
│ ├── evaluation/
│ │ └── test_evaluation.py
│ ├── explain/
│ │ ├── test_captum.py
│ │ └── test_util.py
│ ├── features/
│ │ ├── __init__.py
│ │ ├── test_audio_feature.py
│ │ ├── test_bag_feature.py
│ │ ├── test_binary_feature.py
│ │ ├── test_category_feature.py
│ │ ├── test_date_feature.py
│ │ ├── test_feature_utils.py
│ │ ├── test_h3_feature.py
│ │ ├── test_image_feature.py
│ │ ├── test_number_feature.py
│ │ ├── test_sequence_features.py
│ │ ├── test_set_feature.py
│ │ ├── test_text_feature.py
│ │ └── test_timeseries_feature.py
│ ├── hyperopt/
│ │ └── test_hyperopt.py
│ ├── model_export/
│ │ └── test_onnx_exporter.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── test_trainable_image_layers.py
│ │ ├── test_training_determinism.py
│ │ └── test_training_success.py
│ ├── modules/
│ │ ├── __init__.py
│ │ ├── test_attention.py
│ │ ├── test_convolutional_modules.py
│ │ ├── test_embedding_modules.py
│ │ ├── test_encoder.py
│ │ ├── test_fully_connected_modules.py
│ │ ├── test_initializer_modules.py
│ │ ├── test_loss_modules.py
│ │ ├── test_lr_scheduler.py
│ │ ├── test_metric_modules.py
│ │ ├── test_mlp_mixer_modules.py
│ │ ├── test_normalization_modules.py
│ │ ├── test_recurrent_modules.py
│ │ ├── test_reduction_modules.py
│ │ ├── test_regex_freezing.py
│ │ ├── test_tabnet_modules.py
│ │ └── test_utils.py
│ ├── schema/
│ │ ├── hyperopt/
│ │ │ ├── test_scheduler.py
│ │ │ └── test_search_algorithm.py
│ │ ├── test_model_config.py
│ │ └── test_schema_utils.py
│ ├── schema_fields/
│ │ ├── test_fields_misc.py
│ │ ├── test_fields_optimization.py
│ │ ├── test_fields_preprocessing.py
│ │ └── test_marshmallow_misc.py
│ └── utils/
│ ├── __init__.py
│ ├── automl/
│ │ ├── test_type_inference.py
│ │ └── test_utils.py
│ ├── entmax/
│ │ ├── test_losses.py
│ │ ├── test_mask.py
│ │ ├── test_root_finding.py
│ │ └── test_topk.py
│ ├── test_algorithm_utils.py
│ ├── test_audio_utils.py
│ ├── test_backward_compatibility.py
│ ├── test_calibration.py
│ ├── test_class_balancing.py
│ ├── test_config_utils.py
│ ├── test_data_utils.py
│ ├── test_dataframe_utils.py
│ ├── test_dataset_utils.py
│ ├── test_date_utils.py
│ ├── test_defaults.py
│ ├── test_error_handling_utils.py
│ ├── test_errors.py
│ ├── test_fs_utils.py
│ ├── test_heuristics.py
│ ├── test_hf_utils.py
│ ├── test_hyperopt_ray_utils.py
│ ├── test_image_utils.py
│ ├── test_llm_utils.py
│ ├── test_metric_utils.py
│ ├── test_model_utils.py
│ ├── test_normalization.py
│ ├── test_numerical_test_utils.py
│ ├── test_output_feature_utils.py
│ ├── test_server_utils.py
│ ├── test_state_dict_backward_compatibility.py
│ ├── test_strings_utils.py
│ ├── test_tokenizers.py
│ ├── test_torch_utils.py
│ ├── test_trainer_utils.py
│ ├── test_upload_utils.py
│ └── test_version_transformation.py
├── regression_tests/
│ ├── automl/
│ │ ├── golden/
│ │ │ ├── adult_census_income.types.json
│ │ │ └── mnist.types.json
│ │ ├── scripts/
│ │ │ └── update_golden_types.py
│ │ ├── test_auto_type_inference.py
│ │ └── utils.py
│ ├── benchmark/
│ │ ├── configs/
│ │ │ ├── adult_census_income.ecd.yaml
│ │ │ ├── ames_housing.ecd.yaml
│ │ │ ├── mercedes_benz_greener.ecd.yaml
│ │ │ └── sarcos.ecd.yaml
│ │ ├── expected_metric.py
│ │ ├── expected_metrics/
│ │ │ ├── adult_census_income.ecd.yaml
│ │ │ ├── ames_housing.ecd.yaml
│ │ │ ├── mercedes_benz_greener.ecd.yaml
│ │ │ └── sarcos.ecd.yaml
│ │ └── test_model_performance.py
│ └── model/
│ └── test_old_models.py
└── training_success/
├── __init__.py
├── configs.py
└── test_training_success.py
Showing preview only (579K chars total). Download the full file or copy to clipboard to get everything.
SYMBOL INDEX (6370 symbols across 552 files)
FILE: ludwig/accounting/used_tokens.py
function get_used_tokens_for_ecd (line 4) | def get_used_tokens_for_ecd(inputs: dict[str, torch.Tensor], targets: di...
function get_used_tokens_for_llm (line 25) | def get_used_tokens_for_llm(model_inputs: torch.Tensor, tokenizer) -> int:
FILE: ludwig/api.py
class EvaluationFrequency (line 123) | class EvaluationFrequency: # noqa F821
class TrainingStats (line 142) | class TrainingStats: # noqa F821
method __iter__ (line 154) | def __iter__(self):
method __contains__ (line 157) | def __contains__(self, key):
method __getitem__ (line 164) | def __getitem__(self, key):
class PreprocessedDataset (line 171) | class PreprocessedDataset: # noqa F821
method __iter__ (line 178) | def __iter__(self):
method __getitem__ (line 181) | def __getitem__(self, index):
class TrainingResults (line 187) | class TrainingResults: # noqa F821
method __iter__ (line 192) | def __iter__(self):
method __getitem__ (line 199) | def __getitem__(self, index):
class LudwigModel (line 208) | class LudwigModel:
method __init__ (line 277) | def __init__(
method _initialize_llm (line 353) | def _initialize_llm(self, random_seed: int = default_random_seed):
method train (line 364) | def train(
method train_online (line 786) | def train_online(
method _tune_batch_size (line 858) | def _tune_batch_size(self, trainer, dataset, random_seed: int = defaul...
method save_dequantized_base_model (line 920) | def save_dequantized_base_model(self, save_path: str) -> None:
method generate (line 968) | def generate(
method _generate_streaming_outputs (line 1019) | def _generate_streaming_outputs(
method _generate_non_streaming_outputs (line 1055) | def _generate_non_streaming_outputs(
method predict (line 1082) | def predict(
method evaluate (line 1187) | def evaluate(
method forecast (line 1344) | def forecast(
method experiment (line 1411) | def experiment(
method collect_weights (line 1604) | def collect_weights(self, tensor_names: list[str] = None, **kwargs) ->...
method collect_activations (line 1618) | def collect_activations(
method preprocess (line 1673) | def preprocess(
method load (line 1765) | def load(
method load_weights (line 1863) | def load_weights(
method save (line 1900) | def save(self, save_path: str) -> None:
method upload_to_hf_hub (line 1933) | def upload_to_hf_hub(
method save_config (line 1994) | def save_config(self, save_path: str) -> None:
method to_torchscript (line 2009) | def to_torchscript(
method save_torchscript (line 2039) | def save_torchscript(
method _check_initialization (line 2071) | def _check_initialization(self):
method free_gpu_memory (line 2075) | def free_gpu_memory(self):
method create_model (line 2085) | def create_model(config_obj: ModelConfig | dict, random_seed: int = de...
method set_logging_level (line 2100) | def set_logging_level(logging_level: int) -> None:
method config (line 2119) | def config(self) -> ModelConfigDict:
method config (line 2124) | def config(self, user_config: ModelConfigDict):
method is_merge_and_unload_set (line 2132) | def is_merge_and_unload_set(self) -> bool:
function kfold_cross_validate (line 2144) | def kfold_cross_validate(
function _get_compute_description (line 2372) | def _get_compute_description(backend) -> dict:
function get_experiment_description (line 2398) | def get_experiment_description(
FILE: ludwig/api_annotations.py
function PublicAPI (line 1) | def PublicAPI(*args, **kwargs):
function DeveloperAPI (line 46) | def DeveloperAPI(*args, **kwargs):
function Deprecated (line 68) | def Deprecated(*args, **kwargs):
function _append_doc (line 104) | def _append_doc(obj, message: str, directive: str | None = None) -> str:
function _mark_annotated (line 127) | def _mark_annotated(obj) -> None:
function _is_annotated (line 133) | def _is_annotated(obj) -> bool:
function _get_indent (line 138) | def _get_indent(docstring: str) -> int:
FILE: ludwig/automl/auto_tune_config.py
function get_trainingset_metadata (line 76) | def get_trainingset_metadata(config, dataset, backend):
function _get_machine_memory (line 84) | def _get_machine_memory():
function _get_text_feature_max_length (line 92) | def _get_text_feature_max_length(config, training_set_metadata) -> int:
function _get_text_model_memory_usage (line 113) | def _get_text_model_memory_usage(config, training_set_metadata, memory_u...
function compute_memory_usage (line 119) | def compute_memory_usage(config_obj, training_set_metadata, model_catego...
function sub_new_params (line 134) | def sub_new_params(config: dict, new_param_vals: dict):
function get_new_params (line 143) | def get_new_params(current_param_values, hyperparam_search_space, params...
function _update_text_encoder (line 153) | def _update_text_encoder(input_features: list, old_text_encoder: str, ne...
function _get_text_feature_min_usable_length (line 159) | def _get_text_feature_min_usable_length(input_features: list, training_s...
function reduce_text_feature_max_length (line 170) | def reduce_text_feature_max_length(config, training_set_metadata) -> bool:
function _update_num_samples (line 190) | def _update_num_samples(num_samples, hyperparam_search_space):
function memory_tune_config (line 203) | def memory_tune_config(config, dataset, model_category, row_count, backe...
FILE: ludwig/automl/automl.py
class AutoTrainResults (line 80) | class AutoTrainResults:
method __init__ (line 81) | def __init__(self, experiment_analysis: ExperimentAnalysis, creds: dic...
method experiment_analysis (line 86) | def experiment_analysis(self):
method best_trial_id (line 90) | def best_trial_id(self) -> str:
method best_model (line 94) | def best_model(self) -> LudwigModel | None:
function auto_train (line 117) | def auto_train(
function create_auto_config (line 167) | def create_auto_config(
function create_automl_config_for_features (line 225) | def create_automl_config_for_features(
function create_features_config (line 249) | def create_features_config(
function train_with_config (line 257) | def train_with_config(
function _model_select (line 308) | def _model_select(
function _train (line 397) | def _train(
function init_config (line 417) | def init_config(
function cli_init_config (line 458) | def cli_init_config(sys_argv):
FILE: ludwig/automl/base_config.py
class DatasetInfo (line 73) | class DatasetInfo:
function allocate_experiment_resources (line 79) | def allocate_experiment_resources(resources: Resources) -> dict:
function get_resource_aware_hyperopt_config (line 103) | def get_resource_aware_hyperopt_config(
function _get_stratify_split_config (line 123) | def _get_stratify_split_config(field_meta: FieldMetadata) -> dict:
function get_default_automl_hyperopt (line 134) | def get_default_automl_hyperopt() -> dict[str, Any]:
function create_default_config (line 159) | def create_default_config(
function get_reference_configs (line 250) | def get_reference_configs() -> dict:
function get_dataset_info (line 255) | def get_dataset_info(df: pd.DataFrame | dd.DataFrame) -> DatasetInfo:
function is_field_boolean (line 267) | def is_field_boolean(source: DataSource, field: str) -> bool:
function get_dataset_info_from_source (line 290) | def get_dataset_info_from_source(source: DataSource) -> DatasetInfo:
function get_features_config (line 341) | def get_features_config(
function convert_targets (line 360) | def convert_targets(target_name: str | list[str] = None) -> set[str]:
function get_config_from_metadata (line 369) | def get_config_from_metadata(metadata: list[FieldMetadata], targets: set...
function get_field_metadata (line 392) | def get_field_metadata(fields: list[FieldInfo], row_count: int, targets:...
function infer_mode (line 425) | def infer_mode(field: FieldInfo, targets: set[str] = None) -> str:
FILE: ludwig/backend/__init__.py
function _has_ray (line 39) | def _has_ray():
function get_local_backend (line 60) | def get_local_backend(**kwargs):
function create_deepspeed_backend (line 64) | def create_deepspeed_backend(**kwargs):
function create_ray_backend (line 70) | def create_ray_backend(**kwargs):
function create_backend (line 85) | def create_backend(type, **kwargs):
function initialize_backend (line 96) | def initialize_backend(backend):
function provision_preprocessing_workers (line 106) | def provision_preprocessing_workers(backend):
FILE: ludwig/backend/base.py
class Backend (line 59) | class Backend(ABC):
method __init__ (line 60) | def __init__(
method storage (line 72) | def storage(self) -> StorageManager:
method cache (line 76) | def cache(self) -> CacheManager:
method dataset_manager (line 80) | def dataset_manager(self) -> DatasetManager:
method initialize (line 84) | def initialize(self):
method initialize_pytorch (line 88) | def initialize_pytorch(self, *args, **kwargs):
method create_trainer (line 93) | def create_trainer(self, config: BaseTrainerConfig, model: BaseModel, ...
method sync_model (line 97) | def sync_model(self, model):
method broadcast_return (line 101) | def broadcast_return(self, fn):
method is_coordinator (line 105) | def is_coordinator(self):
method df_engine (line 110) | def df_engine(self) -> DataFrameEngine:
method supports_multiprocessing (line 115) | def supports_multiprocessing(self):
method read_binary_files (line 119) | def read_binary_files(self, column: Series, map_fn: Callable | None = ...
method num_nodes (line 124) | def num_nodes(self) -> int:
method num_training_workers (line 129) | def num_training_workers(self) -> int:
method get_available_resources (line 133) | def get_available_resources(self) -> Resources:
method max_concurrent_trials (line 137) | def max_concurrent_trials(self, hyperopt_config: HyperoptConfigDict) -...
method tune_batch_size (line 141) | def tune_batch_size(self, evaluator_cls: type[BatchSizeEvaluator], dat...
method batch_transform (line 150) | def batch_transform(
method supports_batch_size_tuning (line 156) | def supports_batch_size_tuning(self) -> bool:
class LocalPreprocessingMixin (line 160) | class LocalPreprocessingMixin:
method df_engine (line 162) | def df_engine(self):
method supports_multiprocessing (line 166) | def supports_multiprocessing(self):
method read_binary_files (line 170) | def read_binary_files(column: pd.Series, map_fn: Callable | None = Non...
method batch_transform (line 194) | def batch_transform(df: DataFrame, batch_size: int, transform_fn: Call...
class LocalTrainingMixin (line 203) | class LocalTrainingMixin:
method initialize (line 205) | def initialize():
method initialize_pytorch (line 209) | def initialize_pytorch(*args, **kwargs):
method create_predictor (line 213) | def create_predictor(model: BaseModel, **kwargs):
method sync_model (line 218) | def sync_model(self, model):
method broadcast_return (line 222) | def broadcast_return(fn):
method is_coordinator (line 226) | def is_coordinator() -> bool:
method tune_batch_size (line 230) | def tune_batch_size(evaluator_cls: type[BatchSizeEvaluator], dataset_l...
class RemoteTrainingMixin (line 235) | class RemoteTrainingMixin:
method sync_model (line 236) | def sync_model(self, model):
method broadcast_return (line 240) | def broadcast_return(fn):
method is_coordinator (line 244) | def is_coordinator() -> bool:
class LocalBackend (line 249) | class LocalBackend(LocalPreprocessingMixin, LocalTrainingMixin, Backend):
method shared_instance (line 255) | def shared_instance(cls) -> LocalBackend:
method __init__ (line 261) | def __init__(self, **kwargs) -> None:
method num_nodes (line 265) | def num_nodes(self) -> int:
method num_training_workers (line 269) | def num_training_workers(self) -> int:
method get_available_resources (line 272) | def get_available_resources(self) -> Resources:
method max_concurrent_trials (line 275) | def max_concurrent_trials(self, hyperopt_config: HyperoptConfigDict) -...
method create_trainer (line 280) | def create_trainer(
class DataParallelBackend (line 298) | class DataParallelBackend(LocalPreprocessingMixin, Backend, ABC):
method __init__ (line 301) | def __init__(self, **kwargs):
method initialize (line 306) | def initialize(self):
method initialize_pytorch (line 309) | def initialize_pytorch(self, *args, **kwargs):
method create_trainer (line 314) | def create_trainer(
method create_predictor (line 324) | def create_predictor(self, model: BaseModel, **kwargs):
method sync_model (line 329) | def sync_model(self, model):
method broadcast_return (line 334) | def broadcast_return(self, fn):
method is_coordinator (line 346) | def is_coordinator(self):
method num_nodes (line 350) | def num_nodes(self) -> int:
method num_training_workers (line 354) | def num_training_workers(self) -> int:
method get_available_resources (line 357) | def get_available_resources(self) -> Resources:
method max_concurrent_trials (line 367) | def max_concurrent_trials(self, hyperopt_config: HyperoptConfigDict) -...
method tune_batch_size (line 371) | def tune_batch_size(self, evaluator_cls: type[BatchSizeEvaluator], dat...
FILE: ludwig/backend/datasource.py
function read_binary_files_with_index (line 18) | def read_binary_files_with_index(
FILE: ludwig/backend/deepspeed.py
class DeepSpeedBackend (line 11) | class DeepSpeedBackend(DataParallelBackend):
method __init__ (line 14) | def __init__(
method initialize (line 28) | def initialize(self):
method supports_batch_size_tuning (line 40) | def supports_batch_size_tuning(self) -> bool:
method tune_batch_size (line 44) | def tune_batch_size(self, evaluator_cls: type[BatchSizeEvaluator], dat...
FILE: ludwig/backend/ray.py
function _num_nodes (line 78) | def _num_nodes() -> int:
function get_trainer_kwargs (line 83) | def get_trainer_kwargs(**kwargs) -> dict[str, Any]:
function _create_dask_engine (line 110) | def _create_dask_engine(**kwargs):
function _create_modin_engine (line 116) | def _create_modin_engine(**kwargs):
function _create_pandas_engine (line 122) | def _create_pandas_engine(**kwargs):
function _get_df_engine (line 135) | def _get_df_engine(processor):
function _make_picklable (line 150) | def _make_picklable(obj):
function train_fn (line 168) | def train_fn(
function tune_batch_size_fn (line 247) | def tune_batch_size_fn(
function tune_learning_rate_fn (line 278) | def tune_learning_rate_fn(
class TqdmCallback (line 308) | class TqdmCallback(rt.UserCallback):
method __init__ (line 311) | def __init__(self) -> None:
method after_report (line 316) | def after_report(self, run_context, metrics: list[dict], checkpoint=No...
function spread_env (line 344) | def spread_env(use_gpu: bool = False, num_workers: int = 1, **kwargs):
function _build_scaling_config (line 361) | def _build_scaling_config(trainer_kwargs: dict[str, Any]) -> ScalingConfig:
function run_train_remote (line 370) | def run_train_remote(train_loop, trainer_kwargs: dict[str, Any], callbac...
class RayTrainerV2 (line 395) | class RayTrainerV2(BaseTrainer):
method __init__ (line 396) | def __init__(
method get_schema_cls (line 412) | def get_schema_cls():
method train (line 415) | def train(
method train_online (line 461) | def train_online(self, *args, **kwargs):
method tune_batch_size (line 466) | def tune_batch_size(
method tune_learning_rate (line 485) | def tune_learning_rate(self, config, training_set: RayDataset, **kwarg...
method validation_field (line 500) | def validation_field(self):
method validation_metric (line 504) | def validation_metric(self):
method config (line 508) | def config(self) -> ECDTrainerConfig:
method batch_size (line 512) | def batch_size(self) -> int:
method batch_size (line 516) | def batch_size(self, value: int):
method eval_batch_size (line 520) | def eval_batch_size(self) -> int:
method eval_batch_size (line 524) | def eval_batch_size(self, value: int):
method resources_per_worker (line 528) | def resources_per_worker(self) -> dict[str, Any]:
method num_cpus (line 533) | def num_cpus(self) -> int:
method num_gpus (line 537) | def num_gpus(self) -> int:
method set_base_learning_rate (line 540) | def set_base_learning_rate(self, learning_rate: float):
method shutdown (line 543) | def shutdown(self):
function eval_fn (line 547) | def eval_fn(
class RayPredictor (line 595) | class RayPredictor(BasePredictor):
method __init__ (line 596) | def __init__(
method get_trainer_kwargs (line 607) | def get_trainer_kwargs(self) -> dict[str, Any]:
method get_resources_per_worker (line 610) | def get_resources_per_worker(self) -> tuple[int, int]:
method batch_predict (line 617) | def batch_predict(self, dataset: RayDataset, *args, collect_logits: bo...
method predict_single (line 655) | def predict_single(self, batch):
method batch_evaluation (line 658) | def batch_evaluation(
method batch_collect_activations (line 704) | def batch_collect_activations(self, model, *args, **kwargs):
method _check_dataset (line 707) | def _check_dataset(self, dataset):
method shutdown (line 711) | def shutdown(self):
method get_batch_infer_model (line 716) | def get_batch_infer_model(
class RayBackend (line 776) | class RayBackend(RemoteTrainingMixin, Backend):
method __init__ (line 779) | def __init__(self, processor=None, trainer=None, loader=None, preproce...
method initialize (line 788) | def initialize(self):
method generate_bundles (line 798) | def generate_bundles(self, num_cpu):
method provision_preprocessing_workers (line 805) | def provision_preprocessing_workers(self):
method _release_preprocessing_workers (line 832) | def _release_preprocessing_workers(self):
method initialize_pytorch (line 837) | def initialize_pytorch(self, **kwargs):
method create_trainer (line 842) | def create_trainer(self, model: BaseModel, **kwargs) -> "BaseTrainer":...
method create_predictor (line 863) | def create_predictor(self, model: BaseModel, **kwargs):
method set_distributed_kwargs (line 873) | def set_distributed_kwargs(self, **kwargs):
method df_engine (line 877) | def df_engine(self):
method supports_multiprocessing (line 881) | def supports_multiprocessing(self):
method check_lazy_load_supported (line 884) | def check_lazy_load_supported(self, feature):
method read_binary_files (line 891) | def read_binary_files(self, column: Series, map_fn: Callable | None = ...
method num_nodes (line 943) | def num_nodes(self) -> int:
method num_training_workers (line 949) | def num_training_workers(self) -> int:
method max_concurrent_trials (line 952) | def max_concurrent_trials(self, hyperopt_config) -> int | None:
method tune_batch_size (line 963) | def tune_batch_size(self, evaluator_cls, dataset_len: int) -> int:
method batch_transform (line 967) | def batch_transform(self, df, batch_size: int, transform_fn, name: str...
method get_available_resources (line 984) | def get_available_resources(self) -> Resources:
function initialize_ray (line 989) | def initialize_ray():
function init_ray_local (line 997) | def init_ray_local():
FILE: ludwig/backend/utils/storage.py
class Storage (line 15) | class Storage:
method __init__ (line 16) | def __init__(self, creds: dict[str, Any] | None):
method use_credentials (line 20) | def use_credentials(self):
method credentials (line 25) | def credentials(self) -> dict[str, Any] | None:
class StorageManager (line 29) | class StorageManager:
method __init__ (line 30) | def __init__(
method defaults (line 48) | def defaults(self) -> Storage:
method artifacts (line 52) | def artifacts(self) -> Storage:
method datasets (line 57) | def datasets(self) -> Storage:
method cache (line 62) | def cache(self) -> Storage:
function load_creds (line 66) | def load_creds(cred: CredInputs) -> dict[str, Any]:
FILE: ludwig/benchmarking/artifacts.py
class BenchmarkingResult (line 11) | class BenchmarkingResult:
function build_benchmarking_result (line 43) | def build_benchmarking_result(benchmarking_config: dict, experiment_idx:...
FILE: ludwig/benchmarking/benchmark.py
function setup_experiment (line 30) | def setup_experiment(experiment: dict[str, str]) -> dict[Any, Any]:
function benchmark_one (line 57) | def benchmark_one(experiment: dict[str, str | dict[str, str]]) -> None:
function benchmark (line 113) | def benchmark(benchmarking_config: dict[str, Any] | str) -> dict[str, tu...
function cli (line 144) | def cli(sys_argv):
FILE: ludwig/benchmarking/examples/process_config.py
function process_config (line 5) | def process_config(ludwig_config: dict, experiment_dict: dict) -> dict:
FILE: ludwig/benchmarking/profiler.py
function get_gpu_info (line 29) | def get_gpu_info():
function monitor (line 57) | def monitor(queue: Queue, info: dict[str, Any], logging_interval: int, c...
class LudwigProfiler (line 111) | class LudwigProfiler(contextlib.ContextDecorator):
method __init__ (line 125) | def __init__(self, tag: str, use_torch_profiler: bool, output_dir: str...
method _init_tracker_info (line 139) | def _init_tracker_info(self):
method _populate_static_information (line 150) | def _populate_static_information(self) -> None:
method __enter__ (line 177) | def __enter__(self):
method __exit__ (line 218) | def __exit__(self, exc_type, exc_val, exc_tb) -> None:
method _export_system_usage_metrics (line 239) | def _export_system_usage_metrics(self):
method _reformat_torch_usage_metrics_tags (line 248) | def _reformat_torch_usage_metrics_tags(
method _export_torch_metrics (line 258) | def _export_torch_metrics(self):
FILE: ludwig/benchmarking/profiler_callbacks.py
class LudwigProfilerCallback (line 11) | class LudwigProfilerCallback(Callback):
method __init__ (line 14) | def __init__(self, experiment: dict[str, Any]):
method on_preprocess_start (line 22) | def on_preprocess_start(self, *args, **kwargs):
method on_preprocess_end (line 31) | def on_preprocess_end(self, *args, **kwargs):
method on_train_start (line 35) | def on_train_start(self, *args, **kwargs):
method on_train_end (line 44) | def on_train_end(self, *args, **kwargs):
method on_evaluation_start (line 48) | def on_evaluation_start(self):
method on_evaluation_end (line 57) | def on_evaluation_end(self):
FILE: ludwig/benchmarking/profiler_dataclasses.py
class DeviceUsageMetrics (line 8) | class DeviceUsageMetrics:
class SystemResourceMetrics (line 17) | class SystemResourceMetrics:
class TorchProfilerMetrics (line 71) | class TorchProfilerMetrics:
function profiler_dataclass_to_flat_dict (line 85) | def profiler_dataclass_to_flat_dict(data: SystemResourceMetrics | TorchP...
FILE: ludwig/benchmarking/reporting.py
function initialize_stats_dict (line 13) | def initialize_stats_dict(main_function_events: list[profiler_util.Funct...
function get_memory_details (line 24) | def get_memory_details(kineto_event: _KinetoEvent) -> tuple[str, int]:
function get_device_memory_usage (line 37) | def get_device_memory_usage(
function get_torch_op_time (line 70) | def get_torch_op_time(events: list[profiler_util.FunctionEvent], attr: s...
function get_device_run_durations (line 90) | def get_device_run_durations(function_event: profiler_util.FunctionEvent...
function get_num_oom_events (line 100) | def get_num_oom_events(kineto_event: _KinetoEvent, out_of_memory_events:...
function get_resource_usage_report (line 108) | def get_resource_usage_report(
function get_all_events (line 144) | def get_all_events(kineto_events: list[_KinetoEvent], function_events: p...
function get_metrics_from_torch_profiler (line 166) | def get_metrics_from_torch_profiler(profile: torch.profiler.profiler.pro...
function get_metrics_from_system_usage_profiler (line 197) | def get_metrics_from_system_usage_profiler(system_usage_info: dict) -> S...
FILE: ludwig/benchmarking/summarize.py
function summarize_metrics (line 19) | def summarize_metrics(
function export_and_print (line 53) | def export_and_print(
FILE: ludwig/benchmarking/summary_dataclasses.py
class MetricDiff (line 18) | class MetricDiff:
method __post_init__ (line 36) | def __post_init__(self):
function build_diff (line 53) | def build_diff(name: str, base_value: float, experimental_value: float) ...
class MetricsSummary (line 78) | class MetricsSummary:
class MetricsDiff (line 101) | class MetricsDiff:
method to_string (line 125) | def to_string(self):
function export_metrics_diff_to_csv (line 160) | def export_metrics_diff_to_csv(metrics_diff: MetricsDiff, path: str):
function build_metrics_summary (line 204) | def build_metrics_summary(experiment_local_directory: str) -> MetricsSum...
function build_metrics_diff (line 233) | def build_metrics_diff(
class ResourceUsageSummary (line 274) | class ResourceUsageSummary:
class ResourceUsageDiff (line 288) | class ResourceUsageDiff:
method to_string (line 303) | def to_string(self):
function export_resource_usage_diff_to_csv (line 331) | def export_resource_usage_diff_to_csv(resource_usage_diff: ResourceUsage...
function average_runs (line 368) | def average_runs(path_to_runs_dir: str) -> dict[str, int | float]:
function summarize_resource_usage (line 387) | def summarize_resource_usage(path: str, tags: list[str] | None = None) -...
function build_resource_usage_diff (line 426) | def build_resource_usage_diff(
FILE: ludwig/benchmarking/utils.py
function load_from_module (line 36) | def load_from_module(
function export_artifacts (line 60) | def export_artifacts(experiment: dict[str, str], experiment_output_direc...
function download_artifacts (line 92) | def download_artifacts(
function download_one (line 130) | async def download_one(
function validate_benchmarking_config (line 162) | def validate_benchmarking_config(benchmarking_config: dict[str, Any]) ->...
function populate_benchmarking_config_with_defaults (line 188) | def populate_benchmarking_config_with_defaults(benchmarking_config: dict...
function propagate_global_parameters (line 203) | def propagate_global_parameters(benchmarking_config: dict[str, Any]) -> ...
function create_default_config (line 223) | def create_default_config(experiment: dict[str, Any]) -> str:
function delete_model_checkpoints (line 244) | def delete_model_checkpoints(output_directory: str):
function delete_hyperopt_outputs (line 255) | def delete_hyperopt_outputs(output_directory: str):
function save_yaml (line 268) | def save_yaml(filename, dictionary):
function format_time (line 273) | def format_time(time_us):
function format_memory (line 287) | def format_memory(nbytes):
FILE: ludwig/callbacks.py
class Callback (line 26) | class Callback(ABC):
method on_cmdline (line 27) | def on_cmdline(self, cmd: str, *args: list[str]):
method on_preprocess_start (line 34) | def on_preprocess_start(self, config: ModelConfigDict, **kwargs):
method on_preprocess_end (line 40) | def on_preprocess_end(
method on_hyperopt_init (line 60) | def on_hyperopt_init(self, experiment_name: str, **kwargs):
method on_hyperopt_preprocessing_start (line 66) | def on_hyperopt_preprocessing_start(self, experiment_name: str, **kwar...
method on_hyperopt_preprocessing_end (line 72) | def on_hyperopt_preprocessing_end(self, experiment_name: str, **kwargs):
method on_hyperopt_start (line 78) | def on_hyperopt_start(self, experiment_name: str, **kwargs):
method on_hyperopt_end (line 84) | def on_hyperopt_end(self, experiment_name: str, **kwargs):
method on_hyperopt_finish (line 90) | def on_hyperopt_finish(self, experiment_name: str, **kwargs):
method on_hyperopt_trial_start (line 97) | def on_hyperopt_trial_start(self, parameters: HyperoptConfigDict, **kw...
method on_hyperopt_trial_end (line 103) | def on_hyperopt_trial_end(self, parameters: HyperoptConfigDict, **kwar...
method should_stop_hyperopt (line 109) | def should_stop_hyperopt(self):
method on_resume_training (line 116) | def on_resume_training(self, is_coordinator: bool, **kwargs):
method on_train_init (line 119) | def on_train_init(
method on_train_start (line 139) | def on_train_start(
method on_train_end (line 154) | def on_train_end(self, output_directory: str, **kwargs):
method on_trainer_train_setup (line 160) | def on_trainer_train_setup(self, trainer, save_path: str, is_coordinat...
method on_trainer_train_teardown (line 169) | def on_trainer_train_teardown(self, trainer, progress_tracker, save_pa...
method on_batch_start (line 180) | def on_batch_start(self, trainer, progress_tracker, save_path: str, **...
method on_batch_end (line 190) | def on_batch_end(self, trainer, progress_tracker, save_path: str, sync...
method on_eval_start (line 201) | def on_eval_start(self, trainer, progress_tracker, save_path: str, **k...
method on_eval_end (line 211) | def on_eval_end(self, trainer, progress_tracker, save_path: str, **kwa...
method on_epoch_start (line 221) | def on_epoch_start(self, trainer, progress_tracker, save_path: str, **...
method on_epoch_end (line 231) | def on_epoch_end(self, trainer, progress_tracker, save_path: str, **kw...
method on_validation_start (line 241) | def on_validation_start(self, trainer, progress_tracker, save_path: st...
method on_validation_end (line 251) | def on_validation_end(self, trainer, progress_tracker, save_path: str,...
method on_test_start (line 261) | def on_test_start(self, trainer, progress_tracker, save_path: str, **k...
method on_test_end (line 271) | def on_test_end(self, trainer, progress_tracker, save_path: str, **kwa...
method should_early_stop (line 281) | def should_early_stop(self, trainer, progress_tracker, is_coordinator,...
method on_checkpoint (line 285) | def on_checkpoint(self, trainer, progress_tracker, **kwargs):
method on_save_best_checkpoint (line 289) | def on_save_best_checkpoint(self, trainer, progress_tracker, save_path...
method on_build_metadata_start (line 292) | def on_build_metadata_start(self, df, mode: str, **kwargs):
method on_build_metadata_end (line 300) | def on_build_metadata_end(self, df, mode, **kwargs):
method on_build_data_start (line 308) | def on_build_data_start(self, df, mode, **kwargs):
method on_build_data_end (line 317) | def on_build_data_end(self, df, mode, **kwargs):
method on_evaluation_start (line 325) | def on_evaluation_start(self, **kwargs):
method on_evaluation_end (line 328) | def on_evaluation_end(self, **kwargs):
method on_visualize_figure (line 331) | def on_visualize_figure(self, fig, **kwargs):
method on_ludwig_end (line 338) | def on_ludwig_end(self, **kwargs):
method prepare_ray_tune (line 344) | def prepare_ray_tune(
FILE: ludwig/check.py
function check_install (line 16) | def check_install(logging_level: int = logging.INFO, **kwargs):
function cli (line 40) | def cli(sys_argv):
FILE: ludwig/cli.py
class CLI (line 24) | class CLI:
method __init__ (line 30) | def __init__(self):
method train (line 73) | def train(self):
method predict (line 78) | def predict(self):
method evaluate (line 83) | def evaluate(self):
method forecast (line 88) | def forecast(self):
method experiment (line 93) | def experiment(self):
method hyperopt (line 98) | def hyperopt(self):
method benchmark (line 103) | def benchmark(self):
method serve (line 108) | def serve(self):
method visualize (line 113) | def visualize(self):
method collect_summary (line 118) | def collect_summary(self):
method collect_weights (line 123) | def collect_weights(self):
method collect_activations (line 128) | def collect_activations(self):
method export_torchscript (line 133) | def export_torchscript(self):
method export_triton (line 138) | def export_triton(self):
method export_mlflow (line 143) | def export_mlflow(self):
method export_schema (line 148) | def export_schema(self):
method preprocess (line 153) | def preprocess(self):
method synthesize_dataset (line 158) | def synthesize_dataset(self):
method init_config (line 163) | def init_config(self):
method render_config (line 168) | def render_config(self):
method check_install (line 173) | def check_install(self):
method datasets (line 178) | def datasets(self):
method upload (line 183) | def upload(self):
function main (line 189) | def main():
FILE: ludwig/collect.py
function collect_activations (line 38) | def collect_activations(
function collect_weights (line 123) | def collect_weights(model_path: str, tensors: list[str], output_director...
function save_tensors (line 156) | def save_tensors(collected_tensors, output_directory):
function print_model_summary (line 167) | def print_model_summary(model_path: str, **kwargs) -> None:
function pretrained_summary (line 190) | def pretrained_summary(pretrained_model: str, **kwargs) -> None:
function cli_collect_activations (line 235) | def cli_collect_activations(sys_argv):
function cli_collect_weights (line 363) | def cli_collect_weights(sys_argv):
function cli_collect_summary (line 419) | def cli_collect_summary(sys_argv):
FILE: ludwig/combiners/combiners.py
class Handle (line 51) | class Handle:
class Combiner (line 63) | class Combiner(LudwigModule, ABC):
method __init__ (line 71) | def __init__(self, input_features: dict[str, "InputFeature"]):
method concatenated_shape (line 76) | def concatenated_shape(self) -> torch.Size:
method input_shape (line 86) | def input_shape(self) -> dict:
method output_shape (line 94) | def output_shape(self) -> torch.Size:
function register_combiner (line 109) | def register_combiner(config_cls: type[BaseCombinerConfig]):
function create_combiner (line 117) | def create_combiner(config: BaseCombinerConfig, **kwargs) -> Combiner:
class ConcatCombiner (line 122) | class ConcatCombiner(Combiner):
method __init__ (line 123) | def __init__(self, input_features: dict[str, "InputFeature"] = None, c...
method forward (line 158) | def forward(self, inputs: dict) -> dict: # encoder outputs
class SequenceConcatCombiner (line 190) | class SequenceConcatCombiner(Combiner):
method __init__ (line 191) | def __init__(
method concatenated_shape (line 209) | def concatenated_shape(self) -> torch.Size:
method forward (line 229) | def forward(self, inputs: dict) -> dict: # encoder outputs
class SequenceCombiner (line 331) | class SequenceCombiner(Combiner):
method __init__ (line 332) | def __init__(self, input_features: dict[str, "InputFeature"], config: ...
method concatenated_shape (line 358) | def concatenated_shape(self) -> torch.Size:
method forward (line 378) | def forward(self, inputs: dict) -> dict: # encoder outputs
class TabNetCombiner (line 394) | class TabNetCombiner(Combiner):
method __init__ (line 395) | def __init__(
method concatenated_shape (line 424) | def concatenated_shape(self) -> torch.Size:
method forward (line 433) | def forward(
method output_shape (line 468) | def output_shape(self) -> torch.Size:
class TransformerCombiner (line 473) | class TransformerCombiner(Combiner):
method __init__ (line 474) | def __init__(
method forward (line 534) | def forward(
class TabTransformerCombiner (line 570) | class TabTransformerCombiner(Combiner):
method __init__ (line 571) | def __init__(
method get_flatten_size (line 690) | def get_flatten_size(output_shape: torch.Size) -> torch.Size:
method output_shape (line 695) | def output_shape(self) -> torch.Size:
method forward (line 698) | def forward(
class ComparatorCombiner (line 776) | class ComparatorCombiner(Combiner):
method __init__ (line 777) | def __init__(
method get_entity_shape (line 838) | def get_entity_shape(self, entity: list) -> torch.Size:
method output_shape (line 843) | def output_shape(self) -> torch.Size:
method forward (line 846) | def forward(
class ProjectAggregateCombiner (line 917) | class ProjectAggregateCombiner(Combiner):
method __init__ (line 918) | def __init__(
method forward (line 968) | def forward(self, inputs: dict) -> dict: # encoder outputs
FILE: ludwig/config_sampling/explore_schema.py
function explore_properties (line 21) | def explore_properties(
function get_samples (line 103) | def get_samples(jsonschema_property: dict[str, Any]) -> list[ParameterBa...
function merge_dq (line 118) | def merge_dq(config_options: dict[str, Any], child_config_options_dq: De...
function explore_from_all_of (line 128) | def explore_from_all_of(config_options: dict[str, Any], item: dict[str, ...
function get_potential_values (line 139) | def get_potential_values(item: dict[str, Any]) -> list[ParameterBaseType...
function generate_possible_configs (line 172) | def generate_possible_configs(config_options: dict[str, Any]):
function create_nested_dict (line 206) | def create_nested_dict(flat_dict: dict[str, float | str]) -> ModelConfig...
function combine_configs (line 237) | def combine_configs(
function combine_configs_for_comparator_combiner (line 259) | def combine_configs_for_comparator_combiner(
function combine_configs_for_sequence_combiner (line 290) | def combine_configs_for_sequence_combiner(
FILE: ludwig/config_sampling/parameter_sampling.py
function handle_property_type (line 10) | def handle_property_type(
function explore_array (line 48) | def explore_array(item: dict[str, Any]) -> list[list[ParameterBaseTypes]]:
function explore_number (line 80) | def explore_number(item: dict[str, Any]) -> list[ParameterBaseTypes]:
function explore_integer (line 102) | def explore_integer(item: dict[str, Any]) -> list[ParameterBaseTypes]:
function explore_string (line 126) | def explore_string(item: dict[str, Any]) -> list[ParameterBaseTypes]:
function explore_boolean (line 138) | def explore_boolean() -> list[bool]:
function explore_null (line 143) | def explore_null() -> list[None]:
FILE: ludwig/config_validation/checks.py
class ConfigCheckRegistry (line 36) | class ConfigCheckRegistry:
method __init__ (line 39) | def __init__(self):
method register (line 42) | def register(self, check_fn):
method check_config (line 45) | def check_config(self, config: "ModelConfig") -> None: # noqa: F821
function get_config_check_registry (line 53) | def get_config_check_registry():
function register_config_check (line 59) | def register_config_check(fn) -> Callable:
class ConfigCheck (line 64) | class ConfigCheck(ABC):
method check (line 69) | def check(config: "ModelConfig") -> None: # noqa: F821
function check_feature_names_unique (line 75) | def check_feature_names_unique(config: "ModelConfig") -> None: # noqa: ...
function check_tied_features_valid (line 88) | def check_tied_features_valid(config: "ModelConfig") -> None: # noqa: F821
function check_training_runway (line 102) | def check_training_runway(config: "ModelConfig") -> None: # noqa: F821
function check_ray_backend_in_memory_preprocessing (line 114) | def check_ray_backend_in_memory_preprocessing(config: "ModelConfig") -> ...
function check_sequence_concat_combiner_requirements (line 136) | def check_sequence_concat_combiner_requirements(config: "ModelConfig") -...
function check_comparator_combiner_requirements (line 154) | def check_comparator_combiner_requirements(config: "ModelConfig") -> Non...
function check_class_balance_preprocessing (line 178) | def check_class_balance_preprocessing(config: "ModelConfig") -> None: #...
function check_sampling_exclusivity (line 188) | def check_sampling_exclusivity(config: "ModelConfig") -> None: # noqa: ...
function check_validation_metric_exists (line 197) | def check_validation_metric_exists(config: "ModelConfig") -> None: # no...
function check_splitter (line 215) | def check_splitter(config: "ModelConfig") -> None: # noqa: F821
function check_hf_tokenizer_requirements (line 224) | def check_hf_tokenizer_requirements(config: "ModelConfig") -> None: # n...
function check_hf_encoder_requirements (line 237) | def check_hf_encoder_requirements(config: "ModelConfig") -> None: # noq...
function check_stacked_transformer_requirements (line 250) | def check_stacked_transformer_requirements(config: "ModelConfig") -> Non...
function check_hyperopt_search_algorithm_dependencies_installed (line 274) | def check_hyperopt_search_algorithm_dependencies_installed(config: "Mode...
function check_hyperopt_scheduler_dependencies_installed (line 286) | def check_hyperopt_scheduler_dependencies_installed(config: "ModelConfig...
function check_tagger_decoder_requirements (line 298) | def check_tagger_decoder_requirements(config: "ModelConfig") -> None: #...
function check_hyperopt_parameter_dicts (line 329) | def check_hyperopt_parameter_dicts(config: "ModelConfig") -> None: # no...
function check_concat_combiner_requirements (line 372) | def check_concat_combiner_requirements(config: "ModelConfig") -> None: ...
function check_hyperopt_nested_parameter_dicts (line 403) | def check_hyperopt_nested_parameter_dicts(config: "ModelConfig") -> None...
function check_llm_exactly_one_input_text_feature (line 439) | def check_llm_exactly_one_input_text_feature(config: "ModelConfig"): # ...
function check_llm_finetuning_output_feature_config (line 450) | def check_llm_finetuning_output_feature_config(config: "ModelConfig"): ...
function check_llm_finetuning_trainer_config (line 466) | def check_llm_finetuning_trainer_config(config: "ModelConfig"): # noqa:...
function check_llm_finetuning_backend_config (line 484) | def check_llm_finetuning_backend_config(config: "ModelConfig"): # noqa:...
function check_llm_finetuning_adalora_config (line 515) | def check_llm_finetuning_adalora_config(config: "ModelConfig"):
function check_llm_finetuning_adaption_prompt_parameters (line 543) | def check_llm_finetuning_adaption_prompt_parameters(config: "ModelConfig"):
function _get_llm_model_config (line 568) | def _get_llm_model_config(model_name: str) -> AutoConfig:
function check_llm_quantization_backend_incompatibility (line 575) | def check_llm_quantization_backend_incompatibility(config: "ModelConfig"...
function check_llm_text_encoder_is_not_used_with_ecd (line 608) | def check_llm_text_encoder_is_not_used_with_ecd(config: "ModelConfig") -...
function check_qlora_requirements (line 627) | def check_qlora_requirements(config: "ModelConfig") -> None: # noqa: F821
function check_qlora_merge_and_unload_compatibility (line 637) | def check_qlora_merge_and_unload_compatibility(config: "ModelConfig") ->...
function check_prompt_requirements (line 662) | def check_prompt_requirements(config: "ModelConfig") -> None: # noqa: F821
function check_sample_ratio_and_size_compatible (line 724) | def check_sample_ratio_and_size_compatible(config: "ModelConfig") -> None:
FILE: ludwig/config_validation/preprocessing.py
function check_global_max_sequence_length_fits_prompt_template (line 1) | def check_global_max_sequence_length_fits_prompt_template(metadata, glob...
FILE: ludwig/config_validation/validation.py
function get_schema (line 24) | def get_schema(model_type: str = MODEL_ECD):
function get_validator (line 48) | def get_validator():
function check_schema (line 60) | def check_schema(updated_config):
FILE: ludwig/contrib.py
function create_load_action (line 22) | def create_load_action(contrib_loader: ContribLoader) -> argparse.Action:
function add_contrib_callback_args (line 32) | def add_contrib_callback_args(parser: argparse.ArgumentParser):
function preload (line 42) | def preload(argv):
FILE: ludwig/contribs/__init__.py
class ContribLoader (line 25) | class ContribLoader(ABC):
method load (line 27) | def load(self) -> Callback:
method preload (line 30) | def preload(self):
class AimLoader (line 42) | class AimLoader(ContribLoader):
method load (line 43) | def load(self) -> Callback:
method preload (line 48) | def preload(self):
class CometLoader (line 52) | class CometLoader(ContribLoader):
method load (line 53) | def load(self) -> Callback:
method preload (line 58) | def preload(self):
class WandbLoader (line 62) | class WandbLoader(ContribLoader):
method load (line 63) | def load(self) -> Callback:
method preload (line 68) | def preload(self):
class MlflowLoader (line 72) | class MlflowLoader(ContribLoader):
method load (line 73) | def load(self) -> Callback:
FILE: ludwig/contribs/aim.py
class AimCallback (line 15) | class AimCallback(Callback):
method __init__ (line 18) | def __init__(self, repo=None):
method on_train_init (line 21) | def on_train_init(
method aim_track (line 51) | def aim_track(self, progress_tracker):
method on_trainer_train_teardown (line 67) | def on_trainer_train_teardown(self, trainer, progress_tracker, save_pa...
method on_train_start (line 70) | def on_train_start(self, model, config, *args, **kwargs):
method on_train_end (line 79) | def on_train_end(self, output_directory, *args, **kwargs):
method on_eval_end (line 82) | def on_eval_end(self, trainer, progress_tracker, save_path):
method on_ludwig_end (line 93) | def on_ludwig_end(self):
method on_visualize_figure (line 97) | def on_visualize_figure(self, fig):
method normalize_config (line 103) | def normalize_config(config):
FILE: ludwig/contribs/comet.py
class CometCallback (line 29) | class CometCallback(Callback):
method __init__ (line 32) | def __init__(self):
method on_train_init (line 35) | def on_train_init(
method on_train_start (line 60) | def on_train_start(self, model, config, config_fp, *args, **kwargs):
method on_train_end (line 79) | def on_train_end(self, output_directory, *args, **kwargs):
method on_eval_end (line 83) | def on_eval_end(self, trainer, progress_tracker, save_path):
method on_epoch_end (line 89) | def on_epoch_end(self, trainer, progress_tracker, save_path):
method on_visualize_figure (line 95) | def on_visualize_figure(self, fig):
method on_cmdline (line 99) | def on_cmdline(self, cmd, *args):
method _save_config (line 126) | def _save_config(self, config, directory="."):
method _log_html (line 131) | def _log_html(self, text):
method _make_command_line (line 137) | def _make_command_line(self, cmd, args):
FILE: ludwig/contribs/mlflow/__init__.py
function _get_runs (line 19) | def _get_runs(experiment_id: str):
function get_or_create_experiment_id (line 24) | def get_or_create_experiment_id(experiment_name, artifact_uri: str = None):
class MlflowCallback (line 38) | class MlflowCallback(Callback):
method __init__ (line 39) | def __init__(self, tracking_uri=None, log_artifacts: bool = True):
method get_experiment_id (line 68) | def get_experiment_id(self, experiment_name):
method on_preprocess_end (line 71) | def on_preprocess_end(
method on_hyperopt_init (line 80) | def on_hyperopt_init(self, experiment_name):
method on_hyperopt_trial_start (line 84) | def on_hyperopt_trial_start(self, parameters):
method on_train_init (line 96) | def on_train_init(self, base_config, experiment_name, output_directory...
method log_config (line 123) | def log_config(self, config):
method on_train_start (line 127) | def on_train_start(self, config, **kwargs):
method on_train_end (line 131) | def on_train_end(self, output_directory):
method on_trainer_train_setup (line 139) | def on_trainer_train_setup(self, trainer, save_path, is_coordinator):
method on_eval_end (line 161) | def on_eval_end(self, trainer, progress_tracker, save_path):
method on_trainer_train_teardown (line 168) | def on_trainer_train_teardown(self, trainer, progress_tracker, save_pa...
method on_visualize_figure (line 185) | def on_visualize_figure(self, fig):
method prepare_ray_tune (line 190) | def prepare_ray_tune(self, train_fn, tune_config, tune_callbacks):
method _log_params (line 210) | def _log_params(self, params):
method __setstate__ (line 215) | def __setstate__(self, d):
function _log_mlflow_loop (line 226) | def _log_mlflow_loop(q: queue.Queue, log_artifacts: bool = True):
function _log_mlflow (line 251) | def _log_mlflow(log_metrics, steps, save_path, should_continue, log_arti...
function _log_artifacts (line 266) | def _log_artifacts(output_directory):
function _log_model (line 280) | def _log_model(lpath):
FILE: ludwig/contribs/mlflow/model.py
function get_default_conda_env (line 28) | def get_default_conda_env():
function save_model (line 43) | def save_model(
function log_model (line 150) | def log_model(
function _load_model (line 184) | def _load_model(path):
function _load_pyfunc (line 190) | def _load_pyfunc(path):
function load_model (line 198) | def load_model(model_uri):
class _LudwigModelWrapper (line 220) | class _LudwigModelWrapper:
method __init__ (line 221) | def __init__(self, ludwig_model):
method predict (line 224) | def predict(self, dataframe):
function export_model (line 229) | def export_model(model_path, output_path, registered_model_name=None):
function log_saved_model (line 255) | def log_saved_model(lpath):
class _CopyModel (line 266) | class _CopyModel:
method __init__ (line 269) | def __init__(self, lpath):
method save (line 272) | def save(self, path):
method config (line 276) | def config(self):
FILE: ludwig/contribs/wandb.py
class WandbCallback (line 28) | class WandbCallback(Callback):
method on_train_init (line 31) | def on_train_init(
method on_train_start (line 49) | def on_train_start(self, model, config, *args, **kwargs):
method on_eval_end (line 56) | def on_eval_end(self, trainer, progress_tracker, save_path):
method on_epoch_end (line 61) | def on_epoch_end(self, trainer, progress_tracker, save_path):
method on_visualize_figure (line 66) | def on_visualize_figure(self, fig):
method on_train_end (line 71) | def on_train_end(self, output_directory):
FILE: ludwig/data/batcher/base.py
class Batcher (line 22) | class Batcher(ABC):
method next_batch (line 24) | def next_batch(self) -> dict[str, np.ndarray]:
method last_batch (line 28) | def last_batch(self) -> bool:
method set_epoch (line 32) | def set_epoch(self, epoch: int, batch_size: int):
FILE: ludwig/data/batcher/bucketed.py
class BucketedBatcher (line 21) | class BucketedBatcher(Batcher):
method __init__ (line 22) | def __init__(
method shuffle (line 63) | def shuffle(self, buckets_idcs):
method next_batch (line 67) | def next_batch(self):
method last_batch (line 101) | def last_batch(self):
method set_epoch (line 106) | def set_epoch(self, epoch, batch_size):
method _compute_steps_per_epoch (line 113) | def _compute_steps_per_epoch(self) -> int:
FILE: ludwig/data/batcher/iterable.py
class IterableBatcher (line 19) | class IterableBatcher(Batcher):
method __init__ (line 20) | def __init__(self, dataset, data, steps_per_epoch, ignore_last=False):
method next_batch (line 29) | def next_batch(self):
method last_batch (line 41) | def last_batch(self):
method set_epoch (line 44) | def set_epoch(self, epoch, batch_size):
FILE: ludwig/data/batcher/random_access.py
class RandomAccessBatcher (line 28) | class RandomAccessBatcher(Batcher):
method __init__ (line 29) | def __init__(self, dataset, sampler, batch_size=128, ignore_last=False...
method next_batch (line 43) | def next_batch(self):
method last_batch (line 65) | def last_batch(self):
method set_epoch (line 85) | def set_epoch(self, epoch, batch_size):
method _compute_steps_per_epoch (line 93) | def _compute_steps_per_epoch(self):
FILE: ludwig/data/batcher/test_batcher.py
function test_pandas_size (line 10) | def test_pandas_size():
function test_pandas_batcher_use_all_samples (line 48) | def test_pandas_batcher_use_all_samples():
FILE: ludwig/data/cache/manager.py
class DatasetCache (line 14) | class DatasetCache:
method __init__ (line 15) | def __init__(self, config, checksum, cache_map, dataset_manager):
method get (line 21) | def get(self):
method put (line 48) | def put(self, training_set, test_set, validation_set, training_set_met...
method delete (line 83) | def delete(self):
method get_cached_obj_path (line 89) | def get_cached_obj_path(self, cached_obj_name: str) -> str:
class CacheManager (line 93) | class CacheManager:
method __init__ (line 94) | def __init__(
method get_dataset_cache (line 102) | def get_dataset_cache(
method get_cache_key (line 129) | def get_cache_key(self, dataset: CacheableDataset, config: dict) -> str:
method get_cache_path (line 132) | def get_cache_path(self, dataset: CacheableDataset | None, key: str, t...
method get_cache_directory (line 145) | def get_cache_directory(self, dataset: CacheableDataset | None) -> str:
method can_cache (line 152) | def can_cache(self, skip_save_processed_input: bool) -> bool:
method data_format (line 156) | def data_format(self) -> str:
FILE: ludwig/data/cache/types.py
function alphanum (line 30) | def alphanum(v):
class CacheableDataset (line 36) | class CacheableDataset(ABC):
method get_cache_path (line 41) | def get_cache_path(self) -> str:
method get_cache_directory (line 45) | def get_cache_directory(self) -> str:
method unwrap (line 49) | def unwrap(self) -> str | DataFrame:
class CacheableDataframe (line 55) | class CacheableDataframe(CacheableDataset):
method get_cache_path (line 60) | def get_cache_path(self) -> str:
method get_cache_directory (line 63) | def get_cache_directory(self) -> str:
method unwrap (line 66) | def unwrap(self) -> str | DataFrame:
class CacheablePath (line 72) | class CacheablePath(CacheableDataset):
method name (line 76) | def name(self) -> str:
method checksum (line 80) | def checksum(self) -> str:
method get_cache_path (line 83) | def get_cache_path(self) -> str:
method get_cache_directory (line 86) | def get_cache_directory(self) -> str:
method unwrap (line 89) | def unwrap(self) -> str | DataFrame:
function wrap (line 96) | def wrap(dataset: CacheInput | None) -> CacheableDataset:
FILE: ludwig/data/cache/util.py
function calculate_checksum (line 8) | def calculate_checksum(original_dataset: CacheableDataset, config: Model...
FILE: ludwig/data/concatenate_datasets.py
function concatenate_csv (line 28) | def concatenate_csv(train_csv, vali_csv, test_csv, output_csv):
function concatenate_files (line 36) | def concatenate_files(train_fname, vali_fname, test_fname, read_fn, back...
function concatenate_df (line 58) | def concatenate_df(train_df, vali_df, test_df, backend):
function concatenate_splits (line 77) | def concatenate_splits(train_df, vali_df, test_df, backend):
FILE: ludwig/data/dataframe/base.py
class DataFrameEngine (line 22) | class DataFrameEngine(ABC):
method df_like (line 24) | def df_like(self, df, proc_cols):
method parallelize (line 28) | def parallelize(self, data):
method persist (line 32) | def persist(self, data):
method compute (line 36) | def compute(self, data):
method from_pandas (line 40) | def from_pandas(self, df):
method map_objects (line 44) | def map_objects(self, series, map_fn, meta=None):
method map_partitions (line 48) | def map_partitions(self, series, map_fn, meta=None):
method map_batches (line 52) | def map_batches(self, df, map_fn, enable_tensor_extension_casting=True):
method apply_objects (line 56) | def apply_objects(self, series, map_fn, meta=None):
method reduce_objects (line 60) | def reduce_objects(self, series, reduce_fn):
method split (line 64) | def split(self, df, probabilities):
method to_parquet (line 69) | def to_parquet(self, df, path, index=False):
method write_predictions (line 77) | def write_predictions(self, df: DataFrame, path: str):
method read_predictions (line 81) | def read_predictions(self, path: str) -> DataFrame:
method to_ray_dataset (line 85) | def to_ray_dataset(self, df):
method array_lib (line 90) | def array_lib(self):
method df_lib (line 95) | def df_lib(self):
method partitioned (line 100) | def partitioned(self):
method set_parallelism (line 104) | def set_parallelism(self, parallelism):
FILE: ludwig/data/dataframe/dask.py
function set_scheduler (line 48) | def set_scheduler(scheduler):
function reset_index_across_all_partitions (line 53) | def reset_index_across_all_partitions(df):
class DaskEngine (line 72) | class DaskEngine(DataFrameEngine):
method __init__ (line 73) | def __init__(self, parallelism=None, persist=True, _use_ray=True, **kw...
method set_parallelism (line 81) | def set_parallelism(self, parallelism):
method df_like (line 84) | def df_like(self, df: dd.DataFrame, proc_cols: dict[str, dd.Series]):
method parallelize (line 127) | def parallelize(self, data):
method persist (line 132) | def persist(self, data):
method concat (line 137) | def concat(self, dfs):
method compute (line 140) | def compute(self, data):
method from_pandas (line 143) | def from_pandas(self, df):
method map_objects (line 147) | def map_objects(self, series, map_fn, meta=None):
method map_partitions (line 151) | def map_partitions(self, series, map_fn, meta=None):
method map_batches (line 155) | def map_batches(self, series, map_fn, enable_tensor_extension_casting=...
method apply_objects (line 172) | def apply_objects(self, df, apply_fn, meta=None):
method reduce_objects (line 176) | def reduce_objects(self, series, reduce_fn):
method split (line 184) | def split(self, df, probabilities):
method remove_empty_partitions (line 201) | def remove_empty_partitions(self, df):
method to_parquet (line 221) | def to_parquet(self, df, path, index=False):
method write_predictions (line 232) | def write_predictions(self, df: dd.DataFrame, path: str):
method read_predictions (line 241) | def read_predictions(self, path: str) -> dd.DataFrame:
method to_ray_dataset (line 246) | def to_ray_dataset(self, df) -> Dataset:
method from_ray_dataset (line 251) | def from_ray_dataset(self, dataset) -> dd.DataFrame:
method reset_index (line 262) | def reset_index(self, df):
method array_lib (line 266) | def array_lib(self):
method df_lib (line 270) | def df_lib(self):
method parallelism (line 274) | def parallelism(self):
method partitioned (line 278) | def partitioned(self):
function tensor_extension_casting (line 283) | def tensor_extension_casting(enforced: bool):
FILE: ludwig/data/dataframe/modin.py
class ModinEngine (line 28) | class ModinEngine(DataFrameEngine):
method __init__ (line 29) | def __init__(self, **kwargs):
method df_like (line 32) | def df_like(self, df, proc_cols):
method parallelize (line 36) | def parallelize(self, data):
method persist (line 39) | def persist(self, data):
method compute (line 42) | def compute(self, data):
method from_pandas (line 45) | def from_pandas(self, df):
method map_objects (line 48) | def map_objects(self, series, map_fn, meta=None):
method map_batches (line 51) | def map_batches(self, df, map_fn, enable_tensor_extension_casting=True):
method map_partitions (line 54) | def map_partitions(self, series, map_fn, meta=None):
method apply_objects (line 57) | def apply_objects(self, df, apply_fn, meta=None):
method reduce_objects (line 60) | def reduce_objects(self, series, reduce_fn):
method split (line 63) | def split(self, df, probabilities):
method remove_empty_partitions (line 66) | def remove_empty_partitions(self, df):
method to_parquet (line 69) | def to_parquet(self, df, path, index=False):
method write_predictions (line 78) | def write_predictions(self, df: pd.DataFrame, path: str):
method read_predictions (line 83) | def read_predictions(self, path: str) -> pd.DataFrame:
method to_ray_dataset (line 88) | def to_ray_dataset(self, df):
method from_ray_dataset (line 93) | def from_ray_dataset(self, dataset) -> pd.DataFrame:
method reset_index (line 96) | def reset_index(self, df):
method array_lib (line 100) | def array_lib(self):
method df_lib (line 104) | def df_lib(self):
method partitioned (line 108) | def partitioned(self):
method set_parallelism (line 111) | def set_parallelism(self, parallelism):
FILE: ludwig/data/dataframe/pandas.py
class PandasEngine (line 27) | class PandasEngine(DataFrameEngine):
method __init__ (line 28) | def __init__(self, **kwargs):
method df_like (line 31) | def df_like(self, df, proc_cols):
method parallelize (line 35) | def parallelize(self, data):
method persist (line 38) | def persist(self, data):
method compute (line 41) | def compute(self, data):
method concat (line 45) | def concat(dfs) -> pd.DataFrame:
method from_pandas (line 48) | def from_pandas(self, df):
method map_objects (line 51) | def map_objects(self, series, map_fn, meta=None):
method map_batches (line 54) | def map_batches(self, df, map_fn, enable_tensor_extension_casting=True):
method map_partitions (line 57) | def map_partitions(self, series, map_fn, meta=None):
method apply_objects (line 60) | def apply_objects(self, df, apply_fn, meta=None):
method reduce_objects (line 63) | def reduce_objects(self, series, reduce_fn):
method split (line 66) | def split(self, df, probabilities):
method remove_empty_partitions (line 70) | def remove_empty_partitions(df: pd.DataFrame) -> pd.DataFrame:
method to_parquet (line 73) | def to_parquet(self, df, path, index=False):
method write_predictions (line 76) | def write_predictions(self, df: pd.DataFrame, path: str):
method read_predictions (line 81) | def read_predictions(self, path: str) -> pd.DataFrame:
method to_ray_dataset (line 86) | def to_ray_dataset(self, df):
method from_ray_dataset (line 92) | def from_ray_dataset(dataset) -> pd.DataFrame:
method reset_index (line 96) | def reset_index(df) -> pd.DataFrame:
method array_lib (line 100) | def array_lib(self):
method df_lib (line 104) | def df_lib(self):
method partitioned (line 108) | def partitioned(self):
method set_parallelism (line 111) | def set_parallelism(self, parallelism):
FILE: ludwig/data/dataset/__init__.py
function get_pandas_dataset_manager (line 18) | def get_pandas_dataset_manager(**kwargs):
function get_ray_dataset_manager (line 24) | def get_ray_dataset_manager(**kwargs):
function create_dataset_manager (line 37) | def create_dataset_manager(backend, cache_format, **kwargs):
FILE: ludwig/data/dataset/base.py
class Dataset (line 30) | class Dataset(ABC):
method __len__ (line 32) | def __len__(self) -> int:
method initialize_batcher (line 37) | def initialize_batcher(
method to_df (line 48) | def to_df(self, features: Iterable[BaseFeature] | None = None) -> Data...
method to_scalar_df (line 52) | def to_scalar_df(self, features: Iterable[BaseFeature] | None = None) ...
method in_memory_size_bytes (line 56) | def in_memory_size_bytes(self) -> int:
class DatasetManager (line 60) | class DatasetManager(ABC):
method create (line 62) | def create(self, dataset, config, training_set_metadata) -> Dataset:
method save (line 66) | def save(self, cache_path, dataset, config, training_set_metadata, tag...
method can_cache (line 70) | def can_cache(self, skip_save_processed_input) -> bool:
method data_format (line 75) | def data_format(self) -> str:
FILE: ludwig/data/dataset/pandas.py
class PandasDataset (line 43) | class PandasDataset(Dataset):
method __init__ (line 44) | def __init__(self, dataset, features, data_hdf5_fp):
method to_df (line 53) | def to_df(self, features: Iterable[BaseFeature] | None = None) -> Data...
method to_scalar_df (line 59) | def to_scalar_df(self, features: Iterable[BaseFeature] | None = None) ...
method get (line 62) | def get(self, proc_column, idx=None):
method get_dataset (line 87) | def get_dataset(self) -> dict[str, np.ndarray]:
method __len__ (line 90) | def __len__(self):
method processed_data_fp (line 94) | def processed_data_fp(self) -> str | None:
method in_memory_size_bytes (line 98) | def in_memory_size_bytes(self) -> int:
method initialize_batcher (line 103) | def initialize_batcher(
class PandasDatasetManager (line 125) | class PandasDatasetManager(DatasetManager):
method __init__ (line 126) | def __init__(self, backend: Backend):
method create (line 129) | def create(self, dataset, config, training_set_metadata) -> Dataset:
method save (line 132) | def save(self, cache_path, dataset, config, training_set_metadata, tag...
method can_cache (line 138) | def can_cache(self, skip_save_processed_input) -> bool:
method data_format (line 142) | def data_format(self) -> str:
FILE: ludwig/data/dataset/ray.py
function cast_as_tensor_dtype (line 43) | def cast_as_tensor_dtype(series: Series) -> Series:
function read_remote_parquet (line 47) | def read_remote_parquet(path: str):
class RayDataset (line 52) | class RayDataset(Dataset):
method __init__ (line 55) | def __init__(
method to_ray_dataset (line 69) | def to_ray_dataset(
method initialize_batcher (line 85) | def initialize_batcher(self, batch_size=128, should_shuffle=True, rand...
method __len__ (line 97) | def __len__(self):
method size (line 101) | def size(self):
method in_memory_size_bytes (line 105) | def in_memory_size_bytes(self):
method to_df (line 108) | def to_df(self, features=None):
method to_scalar_df (line 111) | def to_scalar_df(self, features=None):
class RayDatasetManager (line 117) | class RayDatasetManager(DatasetManager):
method __init__ (line 118) | def __init__(self, backend):
method create (line 121) | def create(self, dataset: str | DataFrame, config: dict[str, Any], tra...
method save (line 124) | def save(
method can_cache (line 135) | def can_cache(self, skip_save_processed_input):
method data_format (line 139) | def data_format(self):
class RayDatasetShard (line 143) | class RayDatasetShard(Dataset):
method __init__ (line 146) | def __init__(
method initialize_batcher (line 157) | def initialize_batcher(self, batch_size=128, should_shuffle=True, rand...
method __len__ (line 167) | def __len__(self):
method size (line 176) | def size(self):
method to_df (line 179) | def to_df(self, features=None):
method to_scalar_df (line 182) | def to_scalar_df(self, features=None):
class _BaseBatcher (line 186) | class _BaseBatcher(Batcher):
method __init__ (line 189) | def __init__(
method next_batch (line 213) | def next_batch(self):
method last_batch (line 222) | def last_batch(self):
method set_epoch (line 225) | def set_epoch(self, epoch, batch_size):
method step (line 232) | def step(self):
method steps_per_epoch (line 236) | def steps_per_epoch(self):
method _fetch_next_batch (line 239) | def _fetch_next_batch(self):
method _fetch_next_epoch (line 250) | def _fetch_next_epoch(self):
method _to_tensors_fn (line 253) | def _to_tensors_fn(self):
method _prepare_batch (line 268) | def _prepare_batch(self, batch: pd.DataFrame) -> dict[str, np.ndarray]:
class RayDatasetBatcher (line 283) | class RayDatasetBatcher(_BaseBatcher):
method __init__ (line 286) | def __init__(
method _fetch_next_epoch (line 298) | def _fetch_next_epoch(self):
method _create_async_reader (line 304) | def _create_async_reader(self, dataset: RayNativeDataset):
class RayDatasetShardBatcher (line 330) | class RayDatasetShardBatcher(_BaseBatcher):
method __init__ (line 333) | def __init__(
method _fetch_next_epoch (line 345) | def _fetch_next_epoch(self):
method _create_async_reader (line 351) | def _create_async_reader(self):
FILE: ludwig/data/dataset_synthesizer.py
function _get_feature_encoder_or_decoder (line 105) | def _get_feature_encoder_or_decoder(feature):
function generate_string (line 119) | def generate_string(length):
function build_vocab (line 126) | def build_vocab(size):
function return_none (line 133) | def return_none(feature):
function assign_vocab (line 137) | def assign_vocab(feature):
function build_feature_parameters (line 143) | def build_feature_parameters(features):
function build_synthetic_dataset_df (line 170) | def build_synthetic_dataset_df(dataset_size: int, config: ModelConfigDic...
function build_synthetic_dataset (line 181) | def build_synthetic_dataset(dataset_size: int, features: list[dict], out...
function generate_datapoint (line 228) | def generate_datapoint(features: list[dict], outdir: str) -> str | int |...
function generate_category (line 245) | def generate_category(feature, outdir: str | None = None) -> str:
function generate_number (line 254) | def generate_number(feature, outdir: str | None = None) -> int:
function generate_binary (line 262) | def generate_binary(feature, outdir: str | None = None) -> bool:
function generate_sequence (line 272) | def generate_sequence(feature, outdir: str | None = None) -> str:
function generate_set (line 288) | def generate_set(feature, outdir: str | None = None) -> str:
function generate_bag (line 300) | def generate_bag(feature, outdir: str | None = None) -> str:
function generate_text (line 312) | def generate_text(feature, outdir: str | None = None) -> str:
function generate_timeseries (line 325) | def generate_timeseries(feature, max_len=10, outdir: str | None = None) ...
function generate_audio (line 339) | def generate_audio(feature, outdir: str) -> str:
function generate_image (line 370) | def generate_image(feature, outdir: str, save_as_numpy: bool = False) ->...
function generate_datetime (line 425) | def generate_datetime(feature, outdir: str | None = None) -> str:
function generate_h3 (line 448) | def generate_h3(feature, outdir: str | None = None) -> str:
function generate_vector (line 466) | def generate_vector(feature, outdir: str | None = None) -> str:
function generate_category_distribution (line 479) | def generate_category_distribution(feature, outdir: str | None = None) -...
function cycle_category (line 512) | def cycle_category(feature):
function cycle_binary (line 525) | def cycle_binary(feature):
function cli_synthesize_dataset (line 538) | def cli_synthesize_dataset(dataset_size: int, features: list[dict], outp...
function cli (line 583) | def cli(sys_argv):
FILE: ludwig/data/negative_sampling.py
function _negative_sample_user (line 12) | def _negative_sample_user(interaction_row: np.array, neg_pos_ratio: int,...
function negative_sample (line 39) | def negative_sample(
FILE: ludwig/data/postprocessing.py
function postprocess (line 33) | def postprocess(
function _save_as_numpy (line 69) | def _save_as_numpy(predictions, output_directory, saved_keys, backend):
function convert_dict_to_df (line 84) | def convert_dict_to_df(predictions: dict[str, dict[str, list[Any] | torc...
function convert_predictions (line 118) | def convert_predictions(
function convert_to_df (line 125) | def convert_to_df(
FILE: ludwig/data/preprocessing.py
class DataFormatPreprocessor (line 131) | class DataFormatPreprocessor(ABC):
method preprocess_for_training (line 134) | def preprocess_for_training(
method preprocess_for_prediction (line 152) | def preprocess_for_prediction(
method prepare_processed_data (line 159) | def prepare_processed_data(
class DictPreprocessor (line 174) | class DictPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 176) | def preprocess_for_training(
method preprocess_for_prediction (line 218) | def preprocess_for_prediction(
class DataFramePreprocessor (line 234) | class DataFramePreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 236) | def preprocess_for_training(
method preprocess_for_prediction (line 272) | def preprocess_for_prediction(
class CSVPreprocessor (line 291) | class CSVPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 293) | def preprocess_for_training(
method preprocess_for_prediction (line 324) | def preprocess_for_prediction(
class TSVPreprocessor (line 342) | class TSVPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 344) | def preprocess_for_training(
method preprocess_for_prediction (line 375) | def preprocess_for_prediction(
class JSONPreprocessor (line 393) | class JSONPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 395) | def preprocess_for_training(
method preprocess_for_prediction (line 426) | def preprocess_for_prediction(
class JSONLPreprocessor (line 444) | class JSONLPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 446) | def preprocess_for_training(
method preprocess_for_prediction (line 477) | def preprocess_for_prediction(
class ExcelPreprocessor (line 495) | class ExcelPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 497) | def preprocess_for_training(
method preprocess_for_prediction (line 528) | def preprocess_for_prediction(
class ParquetPreprocessor (line 546) | class ParquetPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 548) | def preprocess_for_training(
method preprocess_for_prediction (line 579) | def preprocess_for_prediction(
method prepare_processed_data (line 597) | def prepare_processed_data(
class PicklePreprocessor (line 626) | class PicklePreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 628) | def preprocess_for_training(
method preprocess_for_prediction (line 659) | def preprocess_for_prediction(
class FatherPreprocessor (line 677) | class FatherPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 679) | def preprocess_for_training(
method preprocess_for_prediction (line 710) | def preprocess_for_prediction(
class FWFPreprocessor (line 728) | class FWFPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 730) | def preprocess_for_training(
method preprocess_for_prediction (line 761) | def preprocess_for_prediction(
class HTMLPreprocessor (line 779) | class HTMLPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 781) | def preprocess_for_training(
method preprocess_for_prediction (line 812) | def preprocess_for_prediction(
class ORCPreprocessor (line 830) | class ORCPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 832) | def preprocess_for_training(
method preprocess_for_prediction (line 863) | def preprocess_for_prediction(
class SASPreprocessor (line 881) | class SASPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 883) | def preprocess_for_training(
method preprocess_for_prediction (line 914) | def preprocess_for_prediction(
class SPSSPreprocessor (line 932) | class SPSSPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 934) | def preprocess_for_training(
method preprocess_for_prediction (line 965) | def preprocess_for_prediction(
class StataPreprocessor (line 983) | class StataPreprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 985) | def preprocess_for_training(
method preprocess_for_prediction (line 1016) | def preprocess_for_prediction(
class HDF5Preprocessor (line 1034) | class HDF5Preprocessor(DataFormatPreprocessor):
method preprocess_for_training (line 1036) | def preprocess_for_training(
method preprocess_for_prediction (line 1064) | def preprocess_for_prediction(
method prepare_processed_data (line 1072) | def prepare_processed_data(
function build_dataset (line 1147) | def build_dataset(
function embed_fixed_features (line 1376) | def embed_fixed_features(
function _get_sampled_dataset_df (line 1402) | def _get_sampled_dataset_df(dataset_df, df_engine, sample_ratio, sample_...
function get_features_with_cacheable_fixed_embeddings (line 1425) | def get_features_with_cacheable_fixed_embeddings(
function cast_columns (line 1454) | def cast_columns(dataset_cols, features, backend) -> None:
function merge_preprocessing (line 1470) | def merge_preprocessing(
function build_preprocessing_parameters (line 1479) | def build_preprocessing_parameters(
function is_input_feature (line 1525) | def is_input_feature(feature_config: FeatureConfigDict) -> bool:
function build_metadata (line 1531) | def build_metadata(
function build_data (line 1556) | def build_data(
function balance_data (line 1603) | def balance_data(
function precompute_fill_value (line 1645) | def precompute_fill_value(
function handle_missing_values (line 1705) | def handle_missing_values(dataset_cols, feature, preprocessing_parameter...
function handle_outliers (line 1712) | def handle_outliers(dataset_cols, feature, preprocessing_parameters: Pre...
function _handle_missing_values (line 1729) | def _handle_missing_values(
function handle_features_with_prompt_config (line 1772) | def handle_features_with_prompt_config(
function _get_prompt_config (line 1841) | def _get_prompt_config(config: ModelConfigDict, input_feature_config: di...
function _has_prompt_section (line 1856) | def _has_prompt_section(config: dict) -> bool:
function load_hdf5 (line 1860) | def load_hdf5(hdf5_file_path, preprocessing_params, backend, split_data=...
function load_metadata (line 1881) | def load_metadata(metadata_file_path: str) -> TrainingSetMetadataDict:
function drop_extra_cols (line 1890) | def drop_extra_cols(features, dfs):
function preprocess_for_training (line 1895) | def preprocess_for_training(
function _preprocess_file_for_training (line 2077) | def _preprocess_file_for_training(
function _preprocess_df_for_training (line 2182) | def _preprocess_df_for_training(
function preprocess_for_prediction (line 2237) | def preprocess_for_prediction(
function _get_cache_hit_message (line 2378) | def _get_cache_hit_message(cache: DatasetCache) -> str:
FILE: ludwig/data/prompt.py
function index_column (line 46) | def index_column(
function format_input_with_prompt (line 121) | def format_input_with_prompt(
function _validate_prompt_template (line 206) | def _validate_prompt_template(
function _get_template_fields (line 228) | def _get_template_fields(template: str) -> tuple[set[str], dict[str, typ...
function _get_dtype (line 236) | def _get_dtype(format_spec: str) -> type:
FILE: ludwig/data/sampler.py
class DistributedSampler (line 25) | class DistributedSampler:
method __init__ (line 28) | def __init__(
method __iter__ (line 44) | def __iter__(self):
method __len__ (line 61) | def __len__(self):
method set_epoch (line 64) | def set_epoch(self, epoch):
FILE: ludwig/data/split.py
class Splitter (line 51) | class Splitter(ABC):
method split (line 53) | def split(
method validate (line 58) | def validate(self, config: ModelConfigDict):
method has_split (line 61) | def has_split(self, split_index: int) -> bool:
method required_columns (line 65) | def required_columns(self) -> list[str]:
function _make_divisions_ensure_minimum_rows (line 70) | def _make_divisions_ensure_minimum_rows(
function _split_divisions_with_min_rows (line 89) | def _split_divisions_with_min_rows(n_rows: int, probabilities: list[floa...
class RandomSplitter (line 106) | class RandomSplitter(Splitter):
method __init__ (line 107) | def __init__(self, probabilities: list[float] = DEFAULT_PROBABILITIES,...
method split (line 110) | def split(
method has_split (line 127) | def has_split(self, split_index: int) -> bool:
method get_schema_cls (line 131) | def get_schema_cls():
class FixedSplitter (line 136) | class FixedSplitter(Splitter):
method __init__ (line 137) | def __init__(self, column: str = SPLIT, **kwargs):
method split (line 140) | def split(
method required_columns (line 149) | def required_columns(self) -> list[str]:
method get_schema_cls (line 153) | def get_schema_cls():
function stratify_split_dataframe (line 157) | def stratify_split_dataframe(
class StratifySplitter (line 193) | class StratifySplitter(Splitter):
method __init__ (line 194) | def __init__(self, column: str, probabilities: list[float] = DEFAULT_P...
method split (line 198) | def split(
method validate (line 229) | def validate(self, config: "ModelConfig"): # noqa: F821
method has_split (line 240) | def has_split(self, split_index: int) -> bool:
method required_columns (line 244) | def required_columns(self) -> list[str]:
method get_schema_cls (line 248) | def get_schema_cls():
class DatetimeSplitter (line 253) | class DatetimeSplitter(Splitter):
method __init__ (line 254) | def __init__(
method split (line 267) | def split(
method validate (line 298) | def validate(self, config: "ModelConfig"): # noqa: F821
method has_split (line 309) | def has_split(self, split_index: int) -> bool:
method required_columns (line 313) | def required_columns(self) -> list[str]:
method get_schema_cls (line 317) | def get_schema_cls():
class HashSplitter (line 322) | class HashSplitter(Splitter):
method __init__ (line 323) | def __init__(
method split (line 332) | def split(
method has_split (line 354) | def has_split(self, split_index: int) -> bool:
method required_columns (line 358) | def required_columns(self) -> list[str]:
method get_schema_cls (line 362) | def get_schema_cls():
function get_splitter (line 367) | def get_splitter(type: str | None = None, **kwargs) -> Splitter:
function split_dataset (line 375) | def split_dataset(
FILE: ludwig/data/split_dataset.py
function split (line 20) | def split(input_path, output1, output2, split):
FILE: ludwig/data/utils.py
function convert_to_dict (line 11) | def convert_to_dict(
function set_fixed_split (line 37) | def set_fixed_split(preprocessing_params: PreprocessingConfigDict) -> Pr...
function get_input_and_output_features (line 52) | def get_input_and_output_features(feature_configs):
FILE: ludwig/datasets/__init__.py
function _load_dataset_config (line 31) | def _load_dataset_config(config_filename: str):
function _get_dataset_configs (line 39) | def _get_dataset_configs() -> dict[str, DatasetConfig]:
function _get_dataset_config (line 48) | def _get_dataset_config(dataset_name) -> DatasetConfig:
function get_dataset (line 57) | def get_dataset(dataset_name, cache_dir=None) -> DatasetLoader:
function load_dataset_uris (line 70) | def load_dataset_uris(
function _is_hf (line 129) | def _is_hf(dataset, training_set):
function _load_hf_datasets (line 137) | def _load_hf_datasets(
function _load_cacheable_hf_dataset (line 201) | def _load_cacheable_hf_dataset(
function _load_cacheable_dataset (line 217) | def _load_cacheable_dataset(dataset: str, backend: Backend) -> Cacheable...
function list_datasets (line 226) | def list_datasets() -> list[str]:
function get_datasets_output_features (line 232) | def get_datasets_output_features(
function describe_dataset (line 291) | def describe_dataset(dataset_name: str) -> str:
function download_dataset (line 297) | def download_dataset(dataset_name: str, output_dir: str = "."):
function get_buffer (line 305) | def get_buffer(dataset_name: str, kaggle_username: str = None, kaggle_ke...
function _get_hf_dataset_and_subsample (line 319) | def _get_hf_dataset_and_subsample(dataset_name: str) -> tuple[str, str |...
function cli (line 334) | def cli(sys_argv):
function __getattr__ (line 373) | def __getattr__(name: str) -> Any:
FILE: ludwig/datasets/archives.py
class ArchiveType (line 29) | class ArchiveType(str, Enum):
function infer_archive_type (line 41) | def infer_archive_type(archive_path):
function is_archive (line 62) | def is_archive(path):
function list_archive (line 67) | def list_archive(archive_path, archive_type: ArchiveType | None = None) ...
function extract_archive (line 90) | def extract_archive(archive_path: str, archive_type: ArchiveType | None ...
FILE: ludwig/datasets/dataset_config.py
class DatasetFallbackMirror (line 22) | class DatasetFallbackMirror:
class DatasetConfig (line 33) | class DatasetConfig:
FILE: ludwig/datasets/kaggle.py
function create_kaggle_client (line 7) | def create_kaggle_client():
function update_env (line 15) | def update_env(**kwargs):
function download_kaggle_dataset (line 25) | def download_kaggle_dataset(
FILE: ludwig/datasets/loaders/adult_census_income.py
class AdultCensusIncomeLoader (line 20) | class AdultCensusIncomeLoader(DatasetLoader):
method load_file_to_dataframe (line 21) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
method transform_dataframe (line 27) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/agnews.py
class AGNewsLoader (line 20) | class AGNewsLoader(DatasetLoader):
method transform_dataframe (line 21) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/allstate_claims_severity.py
class AllstateClaimsSeverityLoader (line 22) | class AllstateClaimsSeverityLoader(DatasetLoader):
method load_file_to_dataframe (line 23) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/camseq.py
class CamseqLoader (line 23) | class CamseqLoader(DatasetLoader):
method transform_files (line 24) | def transform_files(self, file_paths: list[str]) -> list[str]:
method load_unprocessed_dataframe (line 49) | def load_unprocessed_dataframe(self, file_paths: list[str]) -> pd.Data...
FILE: ludwig/datasets/loaders/code_alpaca_loader.py
class CodeAlpacaLoader (line 21) | class CodeAlpacaLoader(DatasetLoader):
method load_file_to_dataframe (line 24) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/consumer_complaints_loader.py
class ConsumerComplaintsLoader (line 19) | class ConsumerComplaintsLoader(DatasetLoader):
method load_file_to_dataframe (line 22) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
function preprocess_df (line 31) | def preprocess_df(df):
FILE: ludwig/datasets/loaders/creditcard_fraud.py
class CreditCardFraudLoader (line 20) | class CreditCardFraudLoader(DatasetLoader):
method transform_dataframe (line 21) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/dataset_loader.py
class TqdmUpTo (line 42) | class TqdmUpTo(tqdm):
method update_to (line 48) | def update_to(self, b=1, bsize=1, tsize=None):
function _list_of_strings (line 62) | def _list_of_strings(list_or_string: str | list[str]) -> list[str]:
function _glob_multiple (line 67) | def _glob_multiple(pathnames: list[str], root_dir: str = None, recursive...
function _sha256_digest (line 77) | def _sha256_digest(file_path) -> str:
class DatasetState (line 89) | class DatasetState(int, Enum):
class DatasetLoader (line 99) | class DatasetLoader:
method __init__ (line 121) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None):
method name (line 127) | def name(self):
method version (line 132) | def version(self):
method is_kaggle_dataset (line 137) | def is_kaggle_dataset(self) -> bool:
method download_dir (line 141) | def download_dir(self) -> str:
method raw_dataset_dir (line 146) | def raw_dataset_dir(self) -> str:
method processed_dataset_dir (line 151) | def processed_dataset_dir(self) -> str:
method processed_dataset_filename (line 156) | def processed_dataset_filename(self) -> str:
method processed_dataset_path (line 161) | def processed_dataset_path(self) -> str:
method processed_temp_dir (line 166) | def processed_temp_dir(self) -> str:
method state (line 171) | def state(self) -> DatasetState:
method download_urls (line 191) | def download_urls(self) -> list[str]:
method download_filenames (line 195) | def download_filenames(self) -> list[str]:
method get_mirror_download_paths (line 202) | def get_mirror_download_paths(mirror: DatasetFallbackMirror):
method get_mirror_download_filenames (line 206) | def get_mirror_download_filenames(self, mirror: DatasetFallbackMirror):
method description (line 212) | def description(self) -> str:
method model_configs (line 217) | def model_configs(self) -> dict[str, dict]:
method best_model_config (line 222) | def best_model_config(self) -> dict | None:
method default_model_config (line 227) | def default_model_config(self) -> dict | None:
method _get_preserved_paths (line 234) | def _get_preserved_paths(self, root_dir=None):
method export (line 243) | def export(self, output_directory: str) -> None:
method _download_and_process (line 257) | def _download_and_process(self, kaggle_username: str | None = None, ka...
method load (line 288) | def load(
method download (line 309) | def download(self, kaggle_username: str | None = None, kaggle_key: str...
method download_from_fallback_mirrors (line 326) | def download_from_fallback_mirrors(self):
method verify (line 341) | def verify(self) -> None:
method extract (line 356) | def extract(self) -> list[str]:
method transform (line 373) | def transform(self) -> None:
method transform_files (line 382) | def transform_files(self, file_paths: list[str]) -> list[str]:
method load_file_to_dataframe (line 399) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
method load_files_to_dataframe (line 418) | def load_files_to_dataframe(self, file_paths: list[str], root_dir=None...
method load_unprocessed_dataframe (line 448) | def load_unprocessed_dataframe(self, file_paths: list[str]) -> pd.Data...
method _get_dataframe_with_fixed_splits_from_hf (line 468) | def _get_dataframe_with_fixed_splits_from_hf(self):
method _get_dataframe_with_fixed_splits (line 482) | def _get_dataframe_with_fixed_splits(self, train_paths, validation_pat...
method transform_dataframe (line 504) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
method save_processed (line 513) | def save_processed(self, dataframe: pd.DataFrame) -> None:
method load_transformed_dataset (line 519) | def load_transformed_dataset(self) -> pd.DataFrame:
method get_mtime (line 523) | def get_mtime(self) -> float:
method split (line 528) | def split(dataset: pd.DataFrame) -> tuple[pd.DataFrame, pd.DataFrame, ...
FILE: ludwig/datasets/loaders/ethos_binary.py
class EthosBinaryLoader (line 20) | class EthosBinaryLoader(DatasetLoader):
method load_file_to_dataframe (line 21) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
method transform_dataframe (line 25) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/flickr8k.py
class Flickr8kLoader (line 22) | class Flickr8kLoader(DatasetLoader):
method transform_files (line 23) | def transform_files(self, file_paths: list[str]) -> list[str]:
FILE: ludwig/datasets/loaders/forest_cover.py
class ForestCoverLoader (line 23) | class ForestCoverLoader(DatasetLoader):
method __init__ (line 24) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None...
method transform_dataframe (line 28) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/goemotions.py
class GoEmotionsLoader (line 20) | class GoEmotionsLoader(DatasetLoader):
method transform_dataframe (line 21) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/higgs.py
class HiggsLoader (line 22) | class HiggsLoader(DatasetLoader):
method __init__ (line 23) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None...
method load_file_to_dataframe (line 27) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
method transform_dataframe (line 31) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/hugging_face.py
class HFLoader (line 29) | class HFLoader(DatasetLoader):
method load_hf_to_dict (line 38) | def load_hf_to_dict(hf_id: str | None = None, hf_subsample: str | None...
method load (line 52) | def load(
FILE: ludwig/datasets/loaders/ieee_fraud.py
class IEEEFraudLoader (line 22) | class IEEEFraudLoader(DatasetLoader):
method load_unprocessed_dataframe (line 25) | def load_unprocessed_dataframe(self, file_paths: list[str]) -> pd.Data...
FILE: ludwig/datasets/loaders/insurance_lite.py
class InsuranceLiteLoader (line 22) | class InsuranceLiteLoader(DatasetLoader):
method transform_dataframe (line 26) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/kdd_loader.py
class KDDCup2009Loader (line 23) | class KDDCup2009Loader(DatasetLoader):
method __init__ (line 24) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None...
method load_file_to_dataframe (line 29) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
method transform_dataframe (line 33) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
function process_categorical_features (line 73) | def process_categorical_features(df, categorical_features):
function process_number_features (line 79) | def process_number_features(df, categorical_features):
class KDDAppetencyLoader (line 128) | class KDDAppetencyLoader(KDDCup2009Loader):
method __init__ (line 134) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None...
class KDDChurnLoader (line 140) | class KDDChurnLoader(KDDCup2009Loader):
method __init__ (line 146) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None...
class KDDUpsellingLoader (line 150) | class KDDUpsellingLoader(KDDCup2009Loader):
method __init__ (line 156) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None...
FILE: ludwig/datasets/loaders/mnist.py
class MNISTLoader (line 32) | class MNISTLoader(DatasetLoader):
method __init__ (line 33) | def __init__(self, config: DatasetConfig, cache_dir: str | None = None):
method transform_files (line 47) | def transform_files(self, file_paths: list[str]) -> list[str]:
method load_unprocessed_dataframe (line 53) | def load_unprocessed_dataframe(self, file_paths: list[str]) -> pd.Data...
method read_source_dataset (line 57) | def read_source_dataset(self, dataset="training", path="."):
method write_output_dataset (line 83) | def write_output_dataset(self, labels, images, output_dir):
method output_training_and_test_data (line 109) | def output_training_and_test_data(self):
FILE: ludwig/datasets/loaders/naval.py
class NavalLoader (line 20) | class NavalLoader(DatasetLoader):
method load_file_to_dataframe (line 21) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/rossman_store_sales.py
class RossmanStoreSalesLoader (line 24) | class RossmanStoreSalesLoader(DatasetLoader):
method load_unprocessed_dataframe (line 27) | def load_unprocessed_dataframe(self, file_paths: list[str]) -> pd.Data...
function preprocess_dates (line 42) | def preprocess_dates(df):
function preprocess_stores (line 56) | def preprocess_stores(df, stores_df):
function preprocess_df (line 92) | def preprocess_df(df, stores_df):
FILE: ludwig/datasets/loaders/santander_value_prediction.py
class SantanderValuePredictionLoader (line 20) | class SantanderValuePredictionLoader(DatasetLoader):
method transform_dataframe (line 26) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/sarcastic_headlines.py
class SarcasticHeadlinesLoader (line 21) | class SarcasticHeadlinesLoader(DatasetLoader):
method load_file_to_dataframe (line 22) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/sarcos.py
class SarcosLoader (line 24) | class SarcosLoader(DatasetLoader):
method load_file_to_dataframe (line 44) | def load_file_to_dataframe(self, file_path: str) -> pd.DataFrame:
method transform_dataframe (line 51) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/split_loaders.py
class RandomSplitLoader (line 22) | class RandomSplitLoader(DatasetLoader):
method transform_dataframe (line 31) | def transform_dataframe(self, dataframe: pd.DataFrame) -> pd.DataFrame:
FILE: ludwig/datasets/loaders/sst.py
class SSTLoader (line 23) | class SSTLoader(DatasetLoader):
method __init__ (line 35) | def __init__(
method get_sentiment_label (line 51) | def get_sentiment_label(id2sent, phrase_id):
method transform_files (line 54) | def transform_files(self, file_paths: list[str]) -> list[str]:
class SST2Loader (line 160) | class SST2Loader(SSTLoader):
method __init__ (line 177) | def __init__(
method get_sentiment_label (line 194) | def get_sentiment_label(self, id2sent, phrase_id):
class SST3Loader (line 203) | class SST3Loader(SSTLoader):
method __init__ (line 219) | def __init__(
method get_sentiment_label (line 235) | def get_sentiment_label(self, id2sent, phrase_id):
class SST5Loader (line 246) | class SST5Loader(SSTLoader):
method __init__ (line 262) | def __init__(
method get_sentiment_label (line 278) | def get_sentiment_label(self, id2sent, phrase_id):
function format_text (line 293) | def format_text(text: str):
function convert_parentheses (line 298) | def convert_parentheses(text: str):
function convert_parentheses_back (line 303) | def convert_parentheses_back(text: str):
function get_sentence_idcs_in_split (line 308) | def get_sentence_idcs_in_split(datasplit: pd.DataFrame, split_id: int):
function get_sentences_with_idcs (line 314) | def get_sentences_with_idcs(sentences: pd.DataFrame, sentences_idcs: set...
function sentence_subtrees (line 320) | def sentence_subtrees(sentence_idx, trees_pointers, trees_phrases):
function visit_postorder (line 327) | def visit_postorder(node, visit_list):
class SSTTree (line 334) | class SSTTree:
class Node (line 335) | class Node:
method __init__ (line 336) | def __init__(self, key, val=None):
method create_node (line 342) | def create_node(self, parent, i):
method create_tree (line 364) | def create_tree(self, parents, tree_phrases):
method __init__ (line 376) | def __init__(self, tree_pointers, tree_phrases):
method subtrees (line 379) | def subtrees(self):
FILE: ludwig/datasets/utils.py
function model_configs_for_dataset (line 11) | def model_configs_for_dataset(dataset_name: str) -> dict[str, dict]:
function _get_model_configs (line 20) | def _get_model_configs(dataset_name: str) -> dict[str, dict]:
function _load_model_config (line 40) | def _load_model_config(model_config_filename: str):
FILE: ludwig/decoders/base.py
class Decoder (line 24) | class Decoder(LudwigModule, ABC):
method forward (line 26) | def forward(self, inputs, mask=None):
method name (line 30) | def name(self):
FILE: ludwig/decoders/generic_decoders.py
class PassthroughDecoder (line 34) | class PassthroughDecoder(Decoder):
method __init__ (line 35) | def __init__(self, input_size: int = 1, num_classes: int = None, decod...
method forward (line 43) | def forward(self, inputs, **kwargs):
method get_schema_cls (line 47) | def get_schema_cls():
method input_shape (line 51) | def input_shape(self) -> torch.Size:
method output_shape (line 55) | def output_shape(self) -> torch.Size:
class Regressor (line 61) | class Regressor(Decoder):
method __init__ (line 62) | def __init__(
method get_schema_cls (line 87) | def get_schema_cls():
method input_shape (line 91) | def input_shape(self):
method forward (line 94) | def forward(self, inputs, **kwargs):
class Projector (line 100) | class Projector(Decoder):
method __init__ (line 101) | def __init__(
method get_schema_cls (line 143) | def get_schema_cls():
method input_shape (line 147) | def input_shape(self):
method forward (line 150) | def forward(self, inputs, **kwargs):
class Classifier (line 159) | class Classifier(Decoder):
method __init__ (line 160) | def __init__(
method get_schema_cls (line 190) | def get_schema_cls():
method input_shape (line 194) | def input_shape(self):
method forward (line 197) | def forward(self, inputs, **kwargs):
FILE: ludwig/decoders/image_decoders.py
class UNetDecoder (line 32) | class UNetDecoder(Decoder):
method __init__ (line 33) | def __init__(
method forward (line 65) | def forward(self, combiner_outputs: dict[str, torch.Tensor], target: t...
method get_prediction_set (line 77) | def get_prediction_set(self):
method get_schema_cls (line 81) | def get_schema_cls() -> type[ImageDecoderConfig]:
method output_shape (line 85) | def output_shape(self) -> torch.Size:
method input_shape (line 89) | def input_shape(self) -> torch.Size:
FILE: ludwig/decoders/llm_decoders.py
class Matcher (line 19) | class Matcher:
method __init__ (line 20) | def __init__(self, match: dict[str, dict[str, Any]]):
method contains (line 23) | def contains(self, decoded_input: str, value: str) -> bool:
method regex (line 26) | def regex(self, decoded_input: str, regex_pattern: str) -> bool:
method __call__ (line 48) | def __call__(self, decoded_input: str) -> str | None:
class TextExtractorDecoder (line 71) | class TextExtractorDecoder(Decoder):
method __init__ (line 72) | def __init__(
method get_schema_cls (line 103) | def get_schema_cls():
method input_shape (line 107) | def input_shape(self):
method get_prediction_set (line 110) | def get_prediction_set(self):
method forward (line 113) | def forward(self, inputs: list[torch.Tensor], input_lengths: list[int]...
class CategoryExtractorDecoder (line 144) | class CategoryExtractorDecoder(Decoder):
method __init__ (line 145) | def __init__(
method get_schema_cls (line 171) | def get_schema_cls():
method input_shape (line 175) | def input_shape(self):
method get_prediction_set (line 178) | def get_prediction_set(self):
method forward (line 181) | def forward(self, inputs: list[torch.Tensor], input_lengths: list[int]...
FILE: ludwig/decoders/registry.py
function get_decoder_registry (line 9) | def get_decoder_registry() -> Registry:
function register_decoder (line 14) | def register_decoder(name: str, features: str | list[str]):
function get_decoder_cls (line 29) | def get_decoder_cls(feature: str, name: str) -> type[Decoder]:
function get_decoder_classes (line 34) | def get_decoder_classes(feature: str) -> dict[str, type[Decoder]]:
FILE: ludwig/decoders/sequence_decoder_utils.py
function repeat_2D_tensor (line 9) | def repeat_2D_tensor(tensor, k):
function get_rnn_init_state (line 21) | def get_rnn_init_state(
function get_lstm_init_state (line 64) | def get_lstm_init_state(
FILE: ludwig/decoders/sequence_decoders.py
class RNNDecoder (line 33) | class RNNDecoder(nn.Module):
method __init__ (line 36) | def __init__(self, hidden_size: int, vocab_size: int, cell_type: str, ...
method forward (line 52) | def forward(self, input: torch.Tensor, hidden: torch.Tensor) -> tuple[...
class LSTMDecoder (line 75) | class LSTMDecoder(nn.Module):
method __init__ (line 78) | def __init__(self, hidden_size: int, vocab_size: int, num_layers: int ...
method forward (line 91) | def forward(
class SequenceRNNDecoder (line 118) | class SequenceRNNDecoder(nn.Module):
method __init__ (line 121) | def __init__(
method forward (line 141) | def forward(self, combiner_outputs: dict[str, torch.Tensor], target: t...
class SequenceLSTMDecoder (line 189) | class SequenceLSTMDecoder(nn.Module):
method __init__ (line 192) | def __init__(
method forward (line 211) | def forward(self, combiner_outputs: dict[str, torch.Tensor], target: t...
class SequenceGeneratorDecoder (line 260) | class SequenceGeneratorDecoder(Decoder):
method __init__ (line 263) | def __init__(
method forward (line 307) | def forward(
method get_prediction_set (line 322) | def get_prediction_set(self):
method get_schema_cls (line 326) | def get_schema_cls():
method input_shape (line 330) | def input_shape(self):
method output_shape (line 335) | def output_shape(self):
FILE: ludwig/decoders/sequence_tagger.py
class SequenceTaggerDecoder (line 18) | class SequenceTaggerDecoder(Decoder):
method __init__ (line 19) | def __init__(
method forward (line 47) | def forward(self, inputs: dict[str, torch.Tensor], target: torch.Tenso...
method get_prediction_set (line 78) | def get_prediction_set(self):
method get_schema_cls (line 82) | def get_schema_cls():
method input_shape (line 86) | def input_shape(self):
method output_shape (line 91) | def output_shape(self):
FILE: ludwig/decoders/utils.py
function extract_generated_tokens (line 5) | def extract_generated_tokens(
FILE: ludwig/distributed/__init__.py
function load_ddp (line 6) | def load_ddp():
function load_fsdp (line 12) | def load_fsdp():
function load_deepspeed (line 18) | def load_deepspeed():
function load_local (line 24) | def load_local():
function init_dist_strategy (line 39) | def init_dist_strategy(strategy: str | dict[str, Any], **kwargs) -> Dist...
function get_current_dist_strategy (line 50) | def get_current_dist_strategy() -> DistributedStrategy:
function get_dist_strategy (line 56) | def get_dist_strategy(strategy: str | dict[str, Any]) -> type[Distribute...
function get_default_strategy_name (line 63) | def get_default_strategy_name() -> str:
FILE: ludwig/distributed/base.py
class DistributedStrategy (line 25) | class DistributedStrategy(ABC):
method prepare (line 34) | def prepare(
method prepare_for_inference (line 51) | def prepare_for_inference(self, model: nn.Module) -> nn.Module:
method to_device (line 54) | def to_device(self, model: BaseModel, device: torch.device | None = No...
method backward (line 57) | def backward(self, loss: torch.Tensor, model: nn.Module):
method step (line 60) | def step(self, optimizer: Optimizer, *args, **kwargs):
method zero_grad (line 63) | def zero_grad(self, optimizer: Optimizer):
method set_batch_size (line 66) | def set_batch_size(self, model: nn.Module, batch_size: int):
method size (line 70) | def size(self) -> int:
method rank (line 74) | def rank(self) -> int:
method local_size (line 78) | def local_size(self) -> int:
method local_rank (line 82) | def local_rank(self) -> int:
method is_coordinator (line 85) | def is_coordinator(self) -> bool:
method barrier (line 89) | def barrier(self):
method allreduce (line 93) | def allreduce(self, t: torch.Tensor) -> torch.Tensor:
method broadcast (line 97) | def broadcast(self, t: torch.Tensor) -> torch.Tensor:
method sync_model (line 101) | def sync_model(self, model: nn.Module):
method sync_optimizer (line 105) | def sync_optimizer(self, optimizer: Optimizer):
method broadcast_object (line 109) | def broadcast_object(self, v: Any, name: str | None = None) -> Any:
method wait_optimizer_synced (line 113) | def wait_optimizer_synced(self, optimizer: Optimizer):
method prepare_model_update (line 118) | def prepare_model_update(self, model: nn.Module, should_step: bool):
method prepare_optimizer_update (line 123) | def prepare_optimizer_update(self, optimizer: Optimizer):
method is_available (line 128) | def is_available(cls) -> bool:
method gather_all_tensors_fn (line 133) | def gather_all_tensors_fn(cls) -> Callable | None:
method get_ray_trainer_backend (line 138) | def get_ray_trainer_backend(cls, **kwargs) -> Any | None:
method get_trainer_cls (line 143) | def get_trainer_cls(cls, backend_config: BackendConfig) -> tuple[type[...
method shutdown (line 147) | def shutdown(self):
method return_first (line 150) | def return_first(self, fn: Callable) -> Callable:
method allow_gradient_accumulation (line 162) | def allow_gradient_accumulation(self) -> bool:
method allow_mixed_precision (line 165) | def allow_mixed_precision(self) -> bool:
method allow_clip_gradients (line 168) | def allow_clip_gradients(self) -> bool:
method prepare_before_load (line 171) | def prepare_before_load(self) -> bool:
method is_model_parallel (line 176) | def is_model_parallel(cls) -> bool:
method create_checkpoint_handle (line 179) | def create_checkpoint_handle(
method extract_model_for_serialization (line 191) | def extract_model_for_serialization(cls, model: nn.Module) -> nn.Modul...
method replace_model_from_serialization (line 195) | def replace_model_from_serialization(cls, state: nn.Module | tuple[nn....
class LocalStrategy (line 200) | class LocalStrategy(DistributedStrategy):
method prepare (line 201) | def prepare(
method size (line 209) | def size(self) -> int:
method rank (line 212) | def rank(self) -> int:
method local_size (line 215) | def local_size(self) -> int:
method local_rank (line 218) | def local_rank(self) -> int:
method barrier (line 221) | def barrier(self):
method allreduce (line 224) | def allreduce(self, t: torch.Tensor) -> torch.Tensor:
method broadcast (line 227) | def broadcast(self, t: torch.Tensor) -> torch.Tensor:
method sync_model (line 230) | def sync_model(self, model: nn.Module):
method sync_optimizer (line 233) | def sync_optimizer(self, optimizer: Optimizer):
method broadcast_object (line 236) | def broadcast_object(self, v: Any, name: str | None = None) -> Any:
method wait_optimizer_synced (line 239) | def wait_optimizer_synced(self, optimizer: Optimizer):
method prepare_model_update (line 243) | def prepare_model_update(self, model: nn.Module, should_step: bool):
method prepare_optimizer_update (line 247) | def prepare_optimizer_update(self, optimizer: Optimizer):
method is_available (line 251) | def is_available(cls) -> bool:
method gather_all_tensors_fn (line 257) | def gather_all_tensors_fn(cls) -> Callable | None:
method get_ray_trainer_backend (line 261) | def get_ray_trainer_backend(cls, **kwargs) -> Any | None:
method get_trainer_cls (line 265) | def get_trainer_cls(cls, backend_config: BackendConfig) -> tuple[type[...
method shutdown (line 268) | def shutdown(self):
FILE: ludwig/distributed/ddp.py
class DDPStrategy (line 29) | class DDPStrategy(DistributedStrategy):
method __init__ (line 30) | def __init__(self):
method _log_on_init (line 34) | def _log_on_init(self):
method prepare (line 37) | def prepare(
method size (line 45) | def size(self) -> int:
method rank (line 48) | def rank(self) -> int:
method local_size (line 51) | def local_size(self) -> int:
method local_rank (line 54) | def local_rank(self) -> int:
method barrier (line 57) | def barrier(self):
method allreduce (line 60) | def allreduce(self, t: torch.Tensor) -> torch.Tensor:
method broadcast (line 64) | def broadcast(self, t: torch.Tensor) -> torch.Tensor:
method sync_model (line 68) | def sync_model(self, model: nn.Module):
method sync_optimizer (line 72) | def sync_optimizer(self, optimizer: Optimizer):
method broadcast_object (line 76) | def broadcast_object(self, v: Any, name: str | None = None) -> Any:
method wait_optimizer_synced (line 81) | def wait_optimizer_synced(self, optimizer: Optimizer):
method prepare_model_update (line 85) | def prepare_model_update(self, model: nn.Module, should_step: bool):
method prepare_optimizer_update (line 94) | def prepare_optimizer_update(self, optimizer: Optimizer):
method is_available (line 98) | def is_available(cls) -> bool:
method gather_all_tensors_fn (line 102) | def gather_all_tensors_fn(cls) -> Callable | None:
method get_ray_trainer_backend (line 106) | def get_ray_trainer_backend(cls, **kwargs) -> Any | None:
method get_trainer_cls (line 112) | def get_trainer_cls(cls, backend_config: BackendConfig) -> tuple[type[...
method shutdown (line 115) | def shutdown(self):
method create_checkpoint_handle (line 123) | def create_checkpoint_handle(
method to_device (line 134) | def to_device(self, model: Union["BaseModel", DDP], device: torch.devi...
function local_rank_and_size (line 142) | def local_rank_and_size() -> tuple[int, int]:
FILE: ludwig/distributed/deepspeed.py
class DeepSpeedStrategy (line 44) | class DeepSpeedStrategy(DDPStrategy):
method __init__ (line 45) | def __init__(
method _log_on_init (line 72) | def _log_on_init(self):
method prepare (line 75) | def prepare(
method prepare_for_inference (line 125) | def prepare_for_inference(self, model: nn.Module) -> nn.Module:
method to_device (line 130) | def to_device(self, model: nn.Module, device: torch.device | None = No...
method backward (line 133) | def backward(self, loss: torch.Tensor, model: nn.Module):
method step (line 150) | def step(self, optimizer: Optimizer, *args, **kwargs):
method zero_grad (line 154) | def zero_grad(self, optimizer: Optimizer):
method set_batch_size (line 158) | def set_batch_size(self, model: nn.Module, batch_size: int):
method barrier (line 164) | def barrier(self):
method allow_gradient_accumulation (line 167) | def allow_gradient_accumulation(self) -> bool:
method allow_mixed_precision (line 171) | def allow_mixed_precision(self) -> bool:
method allow_clip_gradients (line 175) | def allow_clip_gradients(self) -> bool:
method prepare_before_load (line 179) | def prepare_before_load(self) -> bool:
method is_model_parallel (line 187) | def is_model_parallel(cls) -> bool:
method create_checkpoint_handle (line 190) | def create_checkpoint_handle(
method extract_model_for_serialization (line 200) | def extract_model_for_serialization(cls, model: nn.Module) -> nn.Modul...
method replace_model_from_serialization (line 204) | def replace_model_from_serialization(cls, state: nn.Module | tuple[nn....
class DeepSpeedCheckpoint (line 211) | class DeepSpeedCheckpoint(Checkpoint):
method prepare (line 212) | def prepare(self, directory: str):
method load (line 217) | def load(self, save_path: str, device: torch.device | None = None) -> ...
method save (line 238) | def save(self, save_path: str, global_step: int):
method get_state_for_inference (line 251) | def get_state_for_inference(self, save_path: str, device: torch.device...
FILE: ludwig/distributed/fsdp.py
class FSDPStrategy (line 16) | class FSDPStrategy(DDPStrategy):
method _log_on_init (line 17) | def _log_on_init(self):
method prepare (line 20) | def prepare(
method to_device (line 28) | def to_device(self, model: nn.Module, device: torch.device | None = No...
method is_model_parallel (line 32) | def is_model_parallel(cls) -> bool:
FILE: ludwig/encoders/bag_encoders.py
class BagEmbedWeightedEncoder (line 36) | class BagEmbedWeightedEncoder(Encoder):
method __init__ (line 37) | def __init__(
method get_schema_cls (line 92) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 96) | def input_shape(self) -> torch.Size:
method output_shape (line 100) | def output_shape(self) -> torch.Size:
method forward (line 103) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
FILE: ludwig/encoders/base.py
class Encoder (line 26) | class Encoder(LudwigModule, ABC):
method forward (line 28) | def forward(self, inputs, training=None, mask=None):
method get_embedding_layer (line 31) | def get_embedding_layer(self) -> nn.Module:
method name (line 40) | def name(self) -> str:
FILE: ludwig/encoders/category_encoders.py
class CategoricalPassthroughEncoder (line 40) | class CategoricalPassthroughEncoder(Encoder):
method __init__ (line 41) | def __init__(self, input_size=1, encoder_config=None, **kwargs):
method forward (line 49) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 57) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 61) | def input_shape(self) -> torch.Size:
method output_shape (line 65) | def output_shape(self) -> torch.Size:
method get_embedding_layer (line 68) | def get_embedding_layer(self) -> nn.Module:
class CategoricalEmbedEncoder (line 74) | class CategoricalEmbedEncoder(Encoder):
method __init__ (line 75) | def __init__(
method forward (line 105) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 116) | def get_schema_cls() -> type[BaseEncoderConfig]:
method output_shape (line 120) | def output_shape(self) -> torch.Size:
method input_shape (line 124) | def input_shape(self) -> torch.Size:
class CategoricalSparseEncoder (line 130) | class CategoricalSparseEncoder(Encoder):
method __init__ (line 131) | def __init__(
method forward (line 160) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 171) | def get_schema_cls() -> type[BaseEncoderConfig]:
method output_shape (line 175) | def output_shape(self) -> torch.Size:
method input_shape (line 179) | def input_shape(self) -> torch.Size:
class CategoricalOneHotEncoder (line 185) | class CategoricalOneHotEncoder(Encoder):
method __init__ (line 186) | def __init__(
method forward (line 199) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 211) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 215) | def input_shape(self) -> torch.Size:
method output_shape (line 219) | def output_shape(self) -> torch.Size:
method get_embedding_layer (line 222) | def get_embedding_layer(self) -> nn.Module:
FILE: ludwig/encoders/date_encoders.py
class DateEmbed (line 40) | class DateEmbed(Encoder):
method __init__ (line 41) | def __init__(
method forward (line 228) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 269) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 273) | def input_shape(self) -> torch.Size:
method output_shape (line 277) | def output_shape(self) -> torch.Size:
class DateWave (line 283) | class DateWave(Encoder):
method __init__ (line 284) | def __init__(
method forward (line 362) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 402) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 406) | def input_shape(self) -> torch.Size:
method output_shape (line 410) | def output_shape(self) -> torch.Size:
FILE: ludwig/encoders/generic_encoders.py
class PassthroughEncoder (line 33) | class PassthroughEncoder(Encoder):
method __init__ (line 34) | def __init__(self, input_size=1, encoder_config=None, **kwargs):
method forward (line 41) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 49) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 53) | def input_shape(self) -> torch.Size:
method output_shape (line 57) | def output_shape(self) -> torch.Size:
class DenseEncoder (line 63) | class DenseEncoder(Encoder):
method __init__ (line 64) | def __init__(
method forward (line 101) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 109) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 113) | def input_shape(self) -> torch.Size:
method output_shape (line 117) | def output_shape(self) -> torch.Size:
FILE: ludwig/encoders/h3_encoders.py
class H3Embed (line 42) | class H3Embed(Encoder):
method __init__ (line 43) | def __init__(
method forward (line 171) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 208) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 212) | def input_shape(self) -> torch.Size:
method output_shape (line 216) | def output_shape(self) -> torch.Size:
class H3WeightedSum (line 222) | class H3WeightedSum(Encoder):
method __init__ (line 223) | def __init__(
method forward (line 297) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 322) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 326) | def input_shape(self) -> torch.Size:
method output_shape (line 330) | def output_shape(self) -> torch.Size:
class H3RNN (line 336) | class H3RNN(Encoder):
method __init__ (line 337) | def __init__(
method forward (line 442) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 458) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 462) | def input_shape(self) -> torch.Size:
method output_shape (line 466) | def output_shape(self) -> torch.Size:
FILE: ludwig/encoders/image/base.py
class ImageEncoder (line 43) | class ImageEncoder(Encoder):
class Stacked2DCNN (line 49) | class Stacked2DCNN(ImageEncoder):
method __init__ (line 50) | def __init__(
method forward (line 147) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 160) | def get_schema_cls() -> type[ImageEncoderConfig]:
method output_shape (line 164) | def output_shape(self) -> torch.Size:
method input_shape (line 168) | def input_shape(self) -> torch.Size:
class ResNetEncoder (line 174) | class ResNetEncoder(ImageEncoder):
method __init__ (line 175) | def __init__(
method forward (line 243) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 251) | def get_schema_cls() -> type[ImageEncoderConfig]:
method output_shape (line 255) | def output_shape(self) -> torch.Size:
method input_shape (line 259) | def input_shape(self) -> torch.Size:
class MLPMixerEncoder (line 265) | class MLPMixerEncoder(ImageEncoder):
method __init__ (line 266) | def __init__(
method forward (line 311) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 316) | def get_schema_cls() -> type[ImageEncoderConfig]:
method input_shape (line 320) | def input_shape(self) -> torch.Size:
method output_shape (line 324) | def output_shape(self) -> torch.Size:
class ViTEncoder (line 330) | class ViTEncoder(ImageEncoder):
method __init__ (line 331) | def __init__(
method forward (line 413) | def forward(self, inputs: torch.Tensor, head_mask: torch.Tensor | None...
method get_schema_cls (line 418) | def get_schema_cls() -> type[ImageEncoderConfig]:
method input_shape (line 422) | def input_shape(self) -> torch.Size:
method output_shape (line 426) | def output_shape(self) -> torch.Size:
class UNetEncoder (line 432) | class UNetEncoder(ImageEncoder):
method __init__ (line 433) | def __init__(
method forward (line 456) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 461) | def get_schema_cls() -> type[ImageEncoderConfig]:
method output_shape (line 465) | def output_shape(self) -> torch.Size:
method input_shape (line 469) | def input_shape(self) -> torch.Size:
FILE: ludwig/encoders/image/timm.py
function _get_timm (line 21) | def _get_timm():
class TimmEncoder (line 31) | class TimmEncoder(ImageEncoder):
method __init__ (line 45) | def __init__(
method forward (line 83) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 87) | def get_schema_cls() -> type[BaseEncoderConfig]:
method output_shape (line 91) | def output_shape(self) -> torch.Size:
method input_shape (line 95) | def input_shape(self) -> torch.Size:
class TimmCAFormerEncoder (line 101) | class TimmCAFormerEncoder(TimmEncoder):
method __init__ (line 107) | def __init__(self, model_name: str = "caformer_s18", **kwargs):
method get_schema_cls (line 111) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TimmConvFormerEncoder (line 117) | class TimmConvFormerEncoder(TimmEncoder):
method __init__ (line 120) | def __init__(self, model_name: str = "convformer_s18", **kwargs):
method get_schema_cls (line 124) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TimmPoolFormerEncoder (line 130) | class TimmPoolFormerEncoder(TimmEncoder):
method __init__ (line 133) | def __init__(self, model_name: str = "poolformerv2_s12", **kwargs):
method get_schema_cls (line 137) | def get_schema_cls() -> type[BaseEncoderConfig]:
FILE: ludwig/encoders/image/torchvision.py
class TVBaseEncoder (line 41) | class TVBaseEncoder(ImageEncoder):
method __init__ (line 42) | def __init__(
method forward (line 118) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method _remove_softmax_layer (line 122) | def _remove_softmax_layer(self):
method output_shape (line 133) | def output_shape(self) -> torch.Size:
method input_shape (line 140) | def input_shape(self) -> torch.Size:
class TVAlexNetEncoder (line 155) | class TVAlexNetEncoder(TVBaseEncoder):
method __init__ (line 159) | def __init__(
method _remove_softmax_layer (line 171) | def _remove_softmax_layer(self):
method get_schema_cls (line 175) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVConvNeXtEncoder (line 197) | class TVConvNeXtEncoder(TVBaseEncoder):
method __init__ (line 201) | def __init__(
method _remove_softmax_layer (line 208) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 212) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVDenseNetEncoder (line 226) | class TVDenseNetEncoder(TVBaseEncoder):
method __init__ (line 230) | def __init__(
method _remove_softmax_layer (line 237) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 241) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVEfficientNetEncoder (line 262) | class TVEfficientNetEncoder(TVBaseEncoder):
method __init__ (line 266) | def __init__(
method _remove_softmax_layer (line 273) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 277) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVGoogLeNetEncoder (line 288) | class TVGoogLeNetEncoder(TVBaseEncoder):
method __init__ (line 292) | def __init__(
method _remove_softmax_layer (line 307) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 311) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVInceptionV3Encoder (line 322) | class TVInceptionV3Encoder(TVBaseEncoder):
method __init__ (line 326) | def __init__(
method _remove_softmax_layer (line 340) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 344) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVMaxVitEncoder (line 355) | class TVMaxVitEncoder(TVBaseEncoder):
method __init__ (line 359) | def __init__(
method _remove_softmax_layer (line 366) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 370) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVMNASNetEncoder (line 384) | class TVMNASNetEncoder(TVBaseEncoder):
method __init__ (line 388) | def __init__(
method _remove_softmax_layer (line 395) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 399) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVMobileNetV2Encoder (line 410) | class TVMobileNetV2Encoder(TVBaseEncoder):
method __init__ (line 414) | def __init__(
method _remove_softmax_layer (line 421) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 425) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVMobileNetV3Encoder (line 437) | class TVMobileNetV3Encoder(TVBaseEncoder):
method __init__ (line 441) | def __init__(
method _remove_softmax_layer (line 448) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 452) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVRegNetEncoder (line 477) | class TVRegNetEncoder(TVBaseEncoder):
method __init__ (line 481) | def __init__(
method _remove_softmax_layer (line 488) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 492) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVResNetEncoder (line 507) | class TVResNetEncoder(TVBaseEncoder):
method __init__ (line 511) | def __init__(
method _remove_softmax_layer (line 518) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 522) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVResNeXtEncoder (line 535) | class TVResNeXtEncoder(TVBaseEncoder):
method __init__ (line 539) | def __init__(
method _remove_softmax_layer (line 546) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 550) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVShuffleNetV2Encoder (line 564) | class TVShuffleNetV2Encoder(TVBaseEncoder):
method __init__ (line 568) | def __init__(
method _remove_softmax_layer (line 575) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 579) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVSqueezeNetEncoder (line 591) | class TVSqueezeNetEncoder(TVBaseEncoder):
method __init__ (line 595) | def __init__(
method _remove_softmax_layer (line 602) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 609) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVSwinTransformerEncoder (line 622) | class TVSwinTransformerEncoder(TVBaseEncoder):
method __init__ (line 626) | def __init__(
method _remove_softmax_layer (line 633) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 637) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVVGGEncoder (line 655) | class TVVGGEncoder(TVBaseEncoder):
method __init__ (line 659) | def __init__(
method _remove_softmax_layer (line 666) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 670) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVViTEncoder (line 685) | class TVViTEncoder(TVBaseEncoder):
method __init__ (line 689) | def __init__(
method _remove_softmax_layer (line 708) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 712) | def get_schema_cls() -> type[BaseEncoderConfig]:
class TVWideResNetEncoder (line 724) | class TVWideResNetEncoder(TVBaseEncoder):
method __init__ (line 728) | def __init__(
method _remove_softmax_layer (line 735) | def _remove_softmax_layer(self) -> None:
method get_schema_cls (line 739) | def get_schema_cls() -> type[BaseEncoderConfig]:
FILE: ludwig/encoders/registry.py
function get_encoder_registry (line 10) | def get_encoder_registry() -> Registry:
function get_sequence_encoder_registry (line 15) | def get_sequence_encoder_registry() -> Registry:
function register_sequence_encoder (line 19) | def register_sequence_encoder(name: str):
function register_encoder (line 27) | def register_encoder(name: str, features: str | list[str]):
function get_encoder_cls (line 44) | def get_encoder_cls(feature: str, name: str) -> type[Encoder]:
function get_encoder_classes (line 48) | def get_encoder_classes(feature: str) -> dict[str, type[Encoder]]:
FILE: ludwig/encoders/sequence_encoders.py
class SequenceEncoder (line 47) | class SequenceEncoder(Encoder):
class SequencePassthroughEncoder (line 53) | class SequencePassthroughEncoder(SequenceEncoder):
method __init__ (line 54) | def __init__(
method forward (line 86) | def forward(self, input_sequence: torch.Tensor, mask: torch.Tensor | N...
method get_schema_cls (line 104) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 108) | def input_shape(self) -> torch.Size:
method output_shape (line 112) | def output_shape(self) -> torch.Size:
class SequenceEmbedEncoder (line 118) | class SequenceEmbedEncoder(SequenceEncoder):
method __init__ (line 119) | def __init__(
method forward (line 231) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 242) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 246) | def input_shape(self) -> torch.Size:
method output_shape (line 250) | def output_shape(self) -> torch.Size:
class ParallelCNN (line 257) | class ParallelCNN(SequenceEncoder):
method __init__ (line 258) | def __init__(
method forward (line 510) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 541) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 545) | def input_shape(self) -> torch.Size:
method output_shape (line 549) | def output_shape(self) -> torch.Size:
class StackedCNN (line 558) | class StackedCNN(SequenceEncoder):
method __init__ (line 559) | def __init__(
method get_schema_cls (line 848) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 852) | def input_shape(self) -> torch.Size:
method output_shape (line 856) | def output_shape(self) -> torch.Size:
method forward (line 861) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
class StackedParallelCNN (line 896) | class StackedParallelCNN(SequenceEncoder):
method __init__ (line 897) | def __init__(
method get_schema_cls (line 1161) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 1165) | def input_shape(self) -> torch.Size:
method output_shape (line 1169) | def output_shape(self) -> torch.Size:
method forward (line 1174) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
class StackedRNN (line 1209) | class StackedRNN(SequenceEncoder):
method __init__ (line 1210) | def __init__(
method get_schema_cls (line 1431) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 1435) | def input_shape(self) -> torch.Size:
method output_shape (line 1439) | def output_shape(self) -> torch.Size:
method input_dtype (line 1444) | def input_dtype(self):
method forward (line 1447) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
class StackedCNNRNN (line 1480) | class StackedCNNRNN(SequenceEncoder):
method __init__ (line 1481) | def __init__(
method get_schema_cls (line 1714) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 1718) | def input_shape(self) -> torch.Size:
method output_shape (line 1722) | def output_shape(self) -> torch.Size:
method forward (line 1727) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
class StackedTransformer (line 1767) | class StackedTransformer(SequenceEncoder):
method __init__ (line 1768) | def __init__(
method get_schema_cls (line 1986) | def get_schema_cls() -> type[SequenceEncoderConfig]:
method input_shape (line 1990) | def input_shape(self) -> torch.Size:
method output_shape (line 1994) | def output_shape(self) -> torch.Size:
method forward (line 1999) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
FILE: ludwig/encoders/set_encoders.py
class SetSparseEncoder (line 36) | class SetSparseEncoder(Encoder):
method __init__ (line 37) | def __init__(
method forward (line 93) | def forward(self, inputs: torch.Tensor) -> EncoderOutputDict:
method get_schema_cls (line 108) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 112) | def input_shape(self) -> torch.Size:
method output_shape (line 116) | def output_shape(self) -> torch.Size:
FILE: ludwig/encoders/text_encoders.py
function _cls_pooled_error_message (line 72) | def _cls_pooled_error_message(encoder: str):
class HFTextEncoder (line 78) | class HFTextEncoder(Encoder):
method _init_config (line 79) | def _init_config(self, transformer, schema_keys: list[str], encoder_co...
method _init_transformer_from_scratch (line 101) | def _init_transformer_from_scratch(
method _maybe_resize_token_embeddings (line 120) | def _maybe_resize_token_embeddings(self, transformer, vocab_size: int)...
method _wrap_transformer (line 140) | def _wrap_transformer(
method get_embedding_layer (line 158) | def get_embedding_layer(self) -> nn.Module:
class HFTextEncoderImpl (line 167) | class HFTextEncoderImpl(HFTextEncoder):
method __init__ (line 168) | def __init__(
method forward (line 208) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method input_shape (line 224) | def input_shape(self) -> torch.Size:
method output_shape (line 228) | def output_shape(self) -> torch.Size:
method input_dtype (line 243) | def input_dtype(self) -> torch.dtype:
class ALBERTEncoder (line 249) | class ALBERTEncoder(HFTextEncoder):
method __init__ (line 252) | def __init__(
method forward (line 331) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 348) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 352) | def input_shape(self) -> torch.Size:
method output_shape (line 356) | def output_shape(self) -> torch.Size:
method input_dtype (line 371) | def input_dtype(self) -> torch.dtype:
class MT5Encoder (line 377) | class MT5Encoder(HFTextEncoder):
method __init__ (line 380) | def __init__(
method forward (line 458) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 470) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 474) | def input_shape(self) -> torch.Size:
method output_shape (line 478) | def output_shape(self) -> torch.Size:
method input_dtype (line 493) | def input_dtype(self) -> torch.dtype:
class XLMRoBERTaEncoder (line 499) | class XLMRoBERTaEncoder(HFTextEncoder):
method __init__ (line 502) | def __init__(
method forward (line 555) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 572) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 576) | def input_shape(self) -> torch.Size:
method output_shape (line 580) | def output_shape(self) -> torch.Size:
method input_dtype (line 595) | def input_dtype(self) -> torch.dtype:
class BERTEncoder (line 601) | class BERTEncoder(HFTextEncoder):
method __init__ (line 604) | def __init__(
method forward (line 677) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 694) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 698) | def input_shape(self) -> torch.Size:
method output_shape (line 703) | def output_shape(self) -> torch.Size:
method input_dtype (line 718) | def input_dtype(self) -> torch.dtype:
class XLMEncoder (line 724) | class XLMEncoder(HFTextEncoder):
method __init__ (line 727) | def __init__(
method forward (line 820) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 833) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 837) | def input_shape(self) -> torch.Size:
method output_shape (line 842) | def output_shape(self) -> torch.Size:
method input_dtype (line 857) | def input_dtype(self) -> torch.dtype:
class GPTEncoder (line 863) | class GPTEncoder(HFTextEncoder):
method __init__ (line 866) | def __init__(
method forward (line 932) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 945) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 949) | def input_shape(self) -> torch.Size:
method output_shape (line 953) | def output_shape(self) -> torch.Size:
method input_dtype (line 961) | def input_dtype(self) -> torch.dtype:
class GPT2Encoder (line 967) | class GPT2Encoder(HFTextEncoder):
method __init__ (line 970) | def __init__(
method forward (line 1037) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1050) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1054) | def input_shape(self) -> torch.Size:
method output_shape (line 1058) | def output_shape(self) -> torch.Size:
method input_dtype (line 1066) | def input_dtype(self) -> torch.dtype:
class DeBERTaEncoder (line 1072) | class DeBERTaEncoder(HFTextEncoderImpl):
method __init__ (line 1073) | def __init__(self, *args, **kwargs):
method get_schema_cls (line 1080) | def get_schema_cls() -> type[BaseEncoderConfig]:
class RoBERTaEncoder (line 1086) | class RoBERTaEncoder(HFTextEncoder):
method __init__ (line 1089) | def __init__(
method forward (line 1139) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1155) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1159) | def input_shape(self) -> torch.Size:
method output_shape (line 1163) | def output_shape(self) -> torch.Size:
method input_dtype (line 1172) | def input_dtype(self) -> torch.dtype:
class TransformerXLEncoder (line 1178) | class TransformerXLEncoder(HFTextEncoder):
method __init__ (line 1181) | def __init__(
method forward (line 1274) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1281) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1285) | def input_shape(self) -> torch.Size:
method output_shape (line 1289) | def output_shape(self) -> torch.Size:
method input_dtype (line 1298) | def input_dtype(self) -> torch.dtype:
class XLNetEncoder (line 1304) | class XLNetEncoder(HFTextEncoder):
method __init__ (line 1307) | def __init__(
method forward (line 1401) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1414) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1418) | def input_shape(self) -> torch.Size:
method output_shape (line 1422) | def output_shape(self) -> torch.Size:
method input_dtype (line 1430) | def input_dtype(self) -> torch.dtype:
class DistilBERTEncoder (line 1436) | class DistilBERTEncoder(HFTextEncoder):
method __init__ (line 1439) | def __init__(
method forward (line 1509) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1524) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1528) | def input_shape(self) -> torch.Size:
method output_shape (line 1532) | def output_shape(self) -> torch.Size:
method input_dtype (line 1542) | def input_dtype(self) -> torch.dtype:
class CTRLEncoder (line 1548) | class CTRLEncoder(HFTextEncoder):
method __init__ (line 1551) | def __init__(
method forward (line 1617) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1630) | def get_schema_cls():
method input_shape (line 1634) | def input_shape(self) -> torch.Size:
method output_shape (line 1638) | def output_shape(self) -> torch.Size:
method input_dtype (line 1647) | def input_dtype(self) -> torch.dtype:
class CamemBERTEncoder (line 1653) | class CamemBERTEncoder(HFTextEncoder):
method __init__ (line 1656) | def __init__(
method forward (line 1729) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1746) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1750) | def input_shape(self) -> torch.Size:
method output_shape (line 1754) | def output_shape(self) -> torch.Size:
method input_dtype (line 1769) | def input_dtype(self) -> torch.dtype:
class T5Encoder (line 1775) | class T5Encoder(HFTextEncoder):
method __init__ (line 1778) | def __init__(
method forward (line 1842) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1855) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1859) | def input_shape(self) -> torch.Size:
method output_shape (line 1863) | def output_shape(self) -> torch.Size:
method input_dtype (line 1878) | def input_dtype(self) -> torch.dtype:
class FlauBERTEncoder (line 1884) | class FlauBERTEncoder(HFTextEncoder):
method __init__ (line 1887) | def __init__(
method forward (line 1981) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 1994) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 1998) | def input_shape(self) -> torch.Size:
method output_shape (line 2002) | def output_shape(self) -> torch.Size:
method input_dtype (line 2017) | def input_dtype(self) -> torch.dtype:
class ELECTRAEncoder (line 2023) | class ELECTRAEncoder(HFTextEncoder):
method __init__ (line 2026) | def __init__(
method forward (line 2096) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 2109) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 2113) | def input_shape(self) -> torch.Size:
method output_shape (line 2117) | def output_shape(self) -> torch.Size:
method input_dtype (line 2132) | def input_dtype(self) -> torch.dtype:
class LongformerEncoder (line 2138) | class LongformerEncoder(HFTextEncoder):
method __init__ (line 2141) | def __init__(
method forward (line 2190) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 2206) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 2210) | def input_shape(self) -> torch.Size:
method output_shape (line 2214) | def output_shape(self) -> torch.Size:
method input_dtype (line 2229) | def input_dtype(self) -> torch.dtype:
class AutoTransformerEncoder (line 2235) | class AutoTransformerEncoder(HFTextEncoder):
method __init__ (line 2238) | def __init__(
method _maybe_resize_token_embeddings (line 2274) | def _maybe_resize_token_embeddings(self, transformer, vocab_size: int ...
method forward (line 2282) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method get_schema_cls (line 2307) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 2311) | def input_shape(self) -> torch.Size:
method output_shape (line 2315) | def output_shape(self) -> torch.Size:
method input_dtype (line 2331) | def input_dtype(self) -> torch.dtype:
class TfIdfEncoder (line 2337) | class TfIdfEncoder(Encoder):
method __init__ (line 2338) | def __init__(
method forward (line 2360) | def forward(self, t: torch.Tensor, mask: torch.Tensor | None = None) -...
method get_schema_cls (line 2373) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 2377) | def input_shape(self) -> torch.Size:
method output_shape (line 2381) | def output_shape(self) -> torch.Size:
method get_embedding_layer (line 2384) | def get_embedding_layer(self) -> nn.Module:
class LLMEncoder (line 2390) | class LLMEncoder(Encoder):
method __init__ (line 2399) | def __init__(self, encoder_config: LLMEncoderConfig = None, **kwargs):
method get_schema_cls (line 2444) | def get_schema_cls() -> type[BaseEncoderConfig]:
method input_shape (line 2448) | def input_shape(self) -> torch.Size:
method output_shape (line 2452) | def output_shape(self) -> torch.Size:
method get_embedding_layer (line 2455) | def get_embedding_layer(self) -> nn.Module:
method initialize_adapter (line 2458) | def initialize_adapter(self):
method prepare_for_training (line 2471) | def prepare_for_training(self):
method prepare_for_quantized_training (line 2477) | def prepare_for_quantized_training(self):
method forward (line 2482) | def forward(self, inputs: torch.Tensor, mask: torch.Tensor | None = No...
method _save_to_state_dict (line 2488) | def _save_to_state_dict(self, destination: dict, prefix: str, keep_var...
method state_dict (line 2504) | def state_dict(self, *args, destination=None, prefix="", keep_vars=Fal...
method _load_from_state_dict (line 2516) | def _load_from_state_dict(
method remove_missing_non_adapter_keys (line 2537) | def remove_missing_non_adapter_keys(self, module, incompatible_keys):
FILE: ludwig/encoders/types.py
class EncoderOutputDict (line 6) | class EncoderOutputDict(TypedDict, total=False):
FILE: ludwig/error.py
class LudwigError (line 20) | class LudwigError(Exception):
method __reduce__ (line 23) | def __reduce__(self):
class InputDataError (line 32) | class InputDataError(LudwigError, ValueError):
method __init__ (line 44) | def __init__(self, column_name: str, feature_type: str, message: str):
method __str__ (line 50) | def __str__(self):
method __reduce__ (line 53) | def __reduce__(self):
class ConfigValidationError (line 58) | class ConfigValidationError(LudwigError, ValueError):
method __init__ (line 67) | def __init__(self, message: str):
method __reduce__ (line 71) | def __reduce__(self):
FILE: ludwig/evaluate.py
function evaluate_cli (line 33) | def evaluate_cli(
function cli (line 129) | def cli(sys_argv):
FILE: ludwig/experiment.py
function experiment_cli (line 36) | def experiment_cli(
function kfold_cross_validate_cli (line 245) | def kfold_cross_validate_cli(
function cli (line 285) | def cli(sys_argv):
FILE: ludwig/explain/captum.py
class ExplanationRunConfig (line 49) | class ExplanationRunConfig:
function retry_with_halved_batch_size (line 59) | def retry_with_halved_batch_size(run_config: ExplanationRunConfig):
class WrapperModule (line 96) | class WrapperModule(torch.nn.Module):
method __init__ (line 105) | def __init__(self, model: ECD, target: str):
method forward (line 118) | def forward(self, *args):
class IntegratedGradientsExplainer (line 155) | class IntegratedGradientsExplainer(Explainer):
method explain (line 156) | def explain(self) -> ExplanationsResult:
function get_input_tensors (line 269) | def get_input_tensors(
function get_baseline (line 345) | def get_baseline(model: LudwigModel, sample_encoded: list[Variable]) -> ...
function get_total_attribution (line 373) | def get_total_attribution(
function get_token_attributions (line 494) | def get_token_attributions(
FILE: ludwig/explain/captum_ray.py
class RayIntegratedGradientsExplainer (line 26) | class RayIntegratedGradientsExplainer(IntegratedGradientsExplainer):
method __init__ (line 27) | def __init__(self, *args, resources_per_task: dict[str, Any] = None, n...
method explain (line 32) | def explain(self) -> ExplanationsResult:
function get_input_tensors_task (line 164) | def get_input_tensors_task(
function get_total_attribution_task (line 177) | def get_total_attribution_task(
function split_list (line 206) | def split_list(v, n):
FILE: ludwig/explain/explainer.py
class Explainer (line 13) | class Explainer(metaclass=ABCMeta):
method __init__ (line 14) | def __init__(
method is_binary_target (line 46) | def is_binary_target(self) -> bool:
method is_category_target (line 51) | def is_category_target(self) -> bool:
method vocab_size (line 56) | def vocab_size(self) -> int:
method explain (line 68) | def explain(self) -> ExplanationsResult:
FILE: ludwig/explain/explanation.py
class FeatureAttribution (line 11) | class FeatureAttribution:
class LabelExplanation (line 26) | class LabelExplanation:
method add (line 32) | def add(self, feature_name: str, attribution: float, token_attribution...
method to_array (line 36) | def to_array(self) -> npt.NDArray[np.float64]:
class Explanation (line 43) | class Explanation:
method add (line 54) | def add(
method to_array (line 81) | def to_array(self) -> npt.NDArray[np.float64]:
class ExplanationsResult (line 88) | class ExplanationsResult:
FILE: ludwig/explain/util.py
function filter_cols (line 12) | def filter_cols(df, cols):
function prepare_data (line 18) | def prepare_data(model: LudwigModel, inputs_df: pd.DataFrame, sample_df:...
function get_pred_col (line 34) | def get_pred_col(preds, target):
function get_feature_name (line 45) | def get_feature_name(model: LudwigModel, target: str) -> str:
function get_absolute_module_key_from_submodule (line 53) | def get_absolute_module_key_from_submodule(module: torch.nn.Module, subm...
function replace_layer_with_copy (line 72) | def replace_layer_with_copy(feat: BaseFeature, target_layer: torch.nn.Mo...
FILE: ludwig/export.py
function export_torchscript (line 30) | def export_torchscript(
function export_triton (line 60) | def export_triton(model_path, output_path="model_repository", model_name...
function export_mlflow (line 89) | def export_mlflow(model_path, output_path="mlflow", registered_model_nam...
function cli_export_torchscript (line 115) | def cli_export_torchscript(sys_argv):
function cli_export_triton (line 182) | def cli_export_triton(sys_argv):
function cli_export_mlflow (line 229) | def cli_export_mlflow(sys_argv):
FILE: ludwig/features/audio_feature.py
class _AudioPreprocessing (line 54) | class _AudioPreprocessing(torch.nn.Module):
method __init__ (line 57) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 69) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class AudioFeatureMixin (line 88) | class AudioFeatureMixin(BaseFeatureMixin):
method type (line 90) | def type():
method cast_column (line 94) | def cast_column(column, backend):
method get_feature_meta (line 98) | def get_feature_meta(
method _get_feature_dim (line 121) | def _get_feature_dim(preprocessing_parameters: PreprocessingConfigDict...
method _process_in_memory (line 144) | def _process_in_memory(
method _transform_to_feature (line 224) | def _transform_to_feature(
method _get_stats (line 264) | def _get_stats(audio, sampling_rate_in_hz, max_length_in_s):
method _merge_stats (line 276) | def _merge_stats(merged_stats, audio_stats):
method _get_2D_feature (line 285) | def _get_2D_feature(
method add_feature_data (line 346) | def add_feature_data(
method _get_max_length_feature (line 413) | def _get_max_length_feature(
class AudioInputFeature (line 439) | class AudioInputFeature(AudioFeatureMixin, SequenceInputFeature):
method __init__ (line 440) | def __init__(self, input_feature_config: AudioInputFeatureConfig, enco...
method forward (line 448) | def forward(self, inputs, mask=None):
method input_shape (line 458) | def input_shape(self) -> torch.Size:
method input_dtype (line 462) | def input_dtype(self):
method update_config_with_metadata (line 466) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method create_preproc_module (line 472) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
method get_schema_cls (line 476) | def get_schema_cls():
FILE: ludwig/features/bag_feature.py
class BagFeatureMixin (line 33) | class BagFeatureMixin(BaseFeatureMixin):
method type (line 35) | def type():
method cast_column (line 39) | def cast_column(column, backend):
method get_feature_meta (line 43) | def get_feature_meta(
method feature_data (line 66) | def feature_data(column, metadata, preprocessing_parameters: Preproces...
method add_feature_data (line 77) | def add_feature_data(
class BagInputFeature (line 95) | class BagInputFeature(BagFeatureMixin, InputFeature):
method __init__ (line 96) | def __init__(self, input_feature_config: BagInputFeatureConfig, encode...
method forward (line 104) | def forward(self, inputs):
method input_shape (line 113) | def input_shape(self) -> torch.Size:
method output_shape (line 117) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 121) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 125) | def get_schema_cls():
method create_preproc_module (line 129) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
FILE: ludwig/features/base_feature.py
class BaseFeatureMixin (line 57) | class BaseFeatureMixin(ABC):
method type (line 64) | def type() -> str:
method cast_column (line 69) | def cast_column(column: DataFrame, backend) -> DataFrame:
method get_feature_meta (line 79) | def get_feature_meta(
method add_feature_data (line 97) | def add_feature_data(
class ModuleWrapper (line 121) | class ModuleWrapper:
class PredictModule (line 131) | class PredictModule(torch.nn.Module):
method __init__ (line 138) | def __init__(self):
class BaseFeature (line 145) | class BaseFeature:
method __init__ (line 153) | def __init__(self, feature: BaseFeatureConfig):
class InputFeature (line 167) | class InputFeature(BaseFeature, LudwigModule, ABC):
method create_sample_input (line 170) | def create_sample_input(self, batch_size: int = 2):
method unskip (line 174) | def unskip(self) -> "InputFeature":
method update_config_with_metadata (line 180) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method update_config_after_module_init (line 183) | def update_config_after_module_init(self, feature_config):
method initialize_encoder (line 186) | def initialize_encoder(self, encoder_config):
method get_preproc_input_dtype (line 193) | def get_preproc_input_dtype(cls, metadata: TrainingSetMetadataDict) ->...
method create_preproc_module (line 197) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class OutputFeature (line 201) | class OutputFeature(BaseFeature, LudwigModule, ABC):
method __init__ (line 204) | def __init__(
method create_sample_output (line 260) | def create_sample_output(self, batch_size: int = 2):
method get_prediction_set (line 266) | def get_prediction_set(self):
method get_output_dtype (line 275) | def get_output_dtype(cls):
method initialize_decoder (line 278) | def initialize_decoder(self, decoder_config):
method train_loss (line 286) | def train_loss(self, targets: Tensor, predictions: dict[str, Tensor], ...
method eval_loss (line 291) | def eval_loss(self, targets: Tensor, predictions: dict[str, Tensor]):
method _setup_loss (line 301) | def _setup_loss(self):
method _setup_metrics (line 305) | def _setup_metrics(self):
method create_calibration_module (line 318) | def create_calibration_module(self, feature: BaseOutputFeatureConfig) ...
method eval_loss_metric (line 323) | def eval_loss_metric(self) -> LudwigMetric:
method calibration_module (line 327) | def calibration_module(self) -> torch.nn.Module:
method create_predict_module (line 332) | def create_predict_module(self) -> PredictModule:
method prediction_module (line 340) | def prediction_module(self) -> PredictModule:
method predictions (line 344) | def predictions(self, all_decoder_outputs: dict[str, torch.Tensor], fe...
method logits (line 358) | def logits(self, combiner_outputs: dict[str, torch.Tensor], target=Non...
method metric_kwargs (line 371) | def metric_kwargs(self) -> dict[str, Any]:
method update_metrics (line 375) | def update_metrics(self, targets: Tensor, predictions: dict[str, Tenso...
method get_metrics (line 387) | def get_metrics(self):
method reset_metrics (line 407) | def reset_metrics(self):
method forward (line 412) | def forward(
method postprocess_predictions (line 463) | def postprocess_predictions(
method get_postproc_output_dtype (line 471) | def get_postproc_output_dtype(cls, metadata: TrainingSetMetadataDict) ...
method create_postproc_module (line 475) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
method update_config_with_metadata (line 480) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 485) | def calculate_overall_stats(predictions, targets, train_set_metadata):
method output_specific_fully_connected (line 488) | def output_specific_fully_connected(self, inputs, mask=None):
method prepare_decoder_inputs (line 507) | def prepare_decoder_inputs(
class PassthroughPreprocModule (line 537) | class PassthroughPreprocModule(torch.nn.Module):
method __init__ (line 545) | def __init__(self, preproc: torch.nn.Module, encoder: torch.nn.Module):
method forward (line 549) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
function create_passthrough_input_feature (line 554) | def create_passthrough_input_feature(feature: InputFeature, config: Base...
FILE: ludwig/features/binary_feature.py
class _BinaryPreprocessing (line 46) | class _BinaryPreprocessing(torch.nn.Module):
method __init__ (line 47) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 53) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class _BinaryPostprocessing (line 70) | class _BinaryPostprocessing(torch.nn.Module):
method __init__ (line 71) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 78) | def forward(self, preds: dict[str, torch.Tensor], feature_name: str) -...
class _BinaryPredict (line 94) | class _BinaryPredict(PredictModule):
method __init__ (line 95) | def __init__(self, threshold, calibration_module=None):
method forward (line 100) | def forward(self, inputs: dict[str, torch.Tensor], feature_name: str) ...
class BinaryFeatureMixin (line 116) | class BinaryFeatureMixin(BaseFeatureMixin):
method type (line 118) | def type():
method cast_column (line 122) | def cast_column(column, backend):
method get_feature_meta (line 144) | def get_feature_meta(
method add_feature_data (line 180) | def add_feature_data(
class BinaryInputFeature (line 204) | class BinaryInputFeature(BinaryFeatureMixin, InputFeature):
method __init__ (line 205) | def __init__(self, input_feature_config: BinaryInputFeatureConfig, enc...
method forward (line 214) | def forward(self, inputs):
method input_dtype (line 232) | def input_dtype(self):
method input_shape (line 236) | def input_shape(self) -> torch.Size:
method output_shape (line 240) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 244) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 248) | def get_schema_cls():
method create_sample_input (line 251) | def create_sample_input(self, batch_size: int = 2):
method get_preproc_input_dtype (line 255) | def get_preproc_input_dtype(cls, metadata: TrainingSetMetadataDict) ->...
method create_preproc_module (line 259) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class BinaryOutputFeature (line 263) | class BinaryOutputFeature(BinaryFeatureMixin, OutputFeature):
method __init__ (line 264) | def __init__(
method logits (line 276) | def logits(self, inputs, **kwargs):
method create_calibration_module (line 280) | def create_calibration_module(self, feature: BinaryOutputFeatureConfig...
method create_predict_module (line 291) | def create_predict_module(self) -> PredictModule:
method get_prediction_set (line 297) | def get_prediction_set(self):
method get_output_dtype (line 301) | def get_output_dtype(cls):
method output_shape (line 305) | def output_shape(self) -> torch.Size:
method input_shape (line 309) | def input_shape(self) -> torch.Size:
method update_config_with_metadata (line 313) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 317) | def calculate_overall_stats(predictions, targets, train_set_metadata):
method postprocess_predictions (line 347) | def postprocess_predictions(
method get_schema_cls (line 383) | def get_schema_cls():
method get_postproc_output_dtype (line 387) | def get_postproc_output_dtype(cls, metadata: TrainingSetMetadataDict) ...
method create_postproc_module (line 391) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
method metric_kwargs (line 394) | def metric_kwargs(self) -> dict:
FILE: ludwig/features/category_feature.py
class _CategoryPreprocessing (line 61) | class _CategoryPreprocessing(torch.nn.Module):
method __init__ (line 62) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 72) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class _CategoryPostprocessing (line 80) | class _CategoryPostprocessing(torch.nn.Module):
method __init__ (line 81) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 88) | def forward(self, preds: dict[str, torch.Tensor], feature_name: str) -...
class _CategoryPredict (line 100) | class _CategoryPredict(PredictModule):
method __init__ (line 101) | def __init__(self, calibration_module=None, use_cumulative_probs=False):
method forward (line 110) | def forward(self, inputs: dict[str, torch.Tensor], feature_name: str) ...
class CategoryFeatureMixin (line 138) | class CategoryFeatureMixin(BaseFeatureMixin):
method type (line 140) | def type():
method cast_column (line 144) | def cast_column(column, backend):
method get_feature_meta (line 148) | def get_feature_meta(
method feature_data (line 196) | def feature_data(backend, column, metadata):
method add_feature_data (line 236) | def add_feature_data(
class CategoryDistributionFeatureMixin (line 254) | class CategoryDistributionFeatureMixin(VectorFeatureMixin):
method type (line 256) | def type():
method get_feature_meta (line 260) | def get_feature_meta(
class CategoryInputFeature (line 277) | class CategoryInputFeature(CategoryFeatureMixin, InputFeature):
method __init__ (line 278) | def __init__(self, input_feature_config: CategoryInputFeatureConfig, e...
method forward (line 286) | def forward(self, inputs):
method input_dtype (line 299) | def input_dtype(self):
method input_shape (line 303) | def input_shape(self) -> torch.Size:
method output_shape (line 307) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 311) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 316) | def get_schema_cls():
method create_preproc_module (line 320) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class CategoryOutputFeature (line 324) | class CategoryOutputFeature(CategoryFeatureMixin, OutputFeature):
method __init__ (line 325) | def __init__(
method logits (line 344) | def logits(self, inputs, **kwargs): # hidden
method create_calibration_module (line 352) | def create_calibration_module(self, feature: CategoryOutputFeatureConf...
method create_predict_module (line 363) | def create_predict_module(self) -> PredictModule:
method get_prediction_set (line 368) | def get_prediction_set(self):
method input_shape (line 372) | def input_shape(self) -> torch.Size:
method get_output_dtype (line 376) | def get_output_dtype(cls):
method output_shape (line 380) | def output_shape(self) -> torch.Size:
method metric_kwargs (line 383) | def metric_kwargs(self):
method update_config_with_metadata (line 387) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 480) | def calculate_overall_stats(predictions, targets, train_set_metadata):
method postprocess_predictions (line 489) | def postprocess_predictions(
method get_schema_cls (line 524) | def get_schema_cls():
method create_postproc_module (line 528) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
class CategoryDistributionOutputFeature (line 532) | class CategoryDistributionOutputFeature(CategoryDistributionFeatureMixin...
method input_shape (line 534) | def input_shape(self) -> torch.Size:
method get_output_dtype (line 538) | def get_output_dtype(cls):
method output_shape (line 542) | def output_shape(self) -> torch.Size:
method get_schema_cls (line 546) | def get_schema_cls():
FILE: ludwig/features/date_feature.py
class _DatePreprocessing (line 40) | class _DatePreprocessing(torch.nn.Module):
method __init__ (line 41) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 44) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class DateFeatureMixin (line 54) | class DateFeatureMixin(BaseFeatureMixin):
method type (line 56) | def type():
method cast_column (line 60) | def cast_column(column, backend):
method get_feature_meta (line 64) | def get_feature_meta(
method date_to_list (line 74) | def date_to_list(date_value, datetime_format, preprocessing_parameters):
method add_feature_data (line 106) | def add_feature_data(
class DateInputFeature (line 125) | class DateInputFeature(DateFeatureMixin, InputFeature):
method __init__ (line 126) | def __init__(self, input_feature_config: DateInputFeatureConfig, encod...
method forward (line 134) | def forward(self, inputs):
method input_dtype (line 141) | def input_dtype(self):
method input_shape (line 145) | def input_shape(self) -> torch.Size:
method output_shape (line 149) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 153) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method create_sample_input (line 156) | def create_sample_input(self, batch_size: int = 2):
method get_schema_cls (line 161) | def get_schema_cls():
method create_preproc_module (line 165) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
FILE: ludwig/features/feature_registries.py
function get_base_type_registry (line 61) | def get_base_type_registry() -> dict:
function get_input_type_registry (line 81) | def get_input_type_registry() -> dict:
function get_output_type_registry (line 100) | def get_output_type_registry() -> dict:
function update_config_with_metadata (line 115) | def update_config_with_metadata(config_obj: "ModelConfig", training_set_...
function update_config_with_model (line 127) | def update_config_with_model(config_obj: "ModelConfig", model: "BaseMode...
FILE: ludwig/features/feature_utils.py
function should_regularize (line 30) | def should_regularize(regularize_layers):
function set_str_to_idx (line 39) | def set_str_to_idx(set_string, feature_dict, tokenizer_name):
function compute_token_probabilities (line 50) | def compute_token_probabilities(
function compute_sequence_probability (line 83) | def compute_sequence_probability(
function sanitize (line 106) | def sanitize(name):
function compute_feature_hash (line 111) | def compute_feature_hash(feature: dict) -> str:
function get_input_size_with_dependencies (line 127) | def get_input_size_with_dependencies(
function get_module_dict_key_from_name (line 147) | def get_module_dict_key_from_name(name: str, feature_name_suffix: str = ...
function get_name_from_module_dict_key (line 153) | def get_name_from_module_dict_key(key: str, feature_name_suffix_length: ...
class LudwigFeatureDict (line 159) | class LudwigFeatureDict(torch.nn.Module):
method __init__ (line 173) | def __init__(self):
method get (line 178) | def get(self, key) -> torch.nn.Module:
method set (line 181) | def set(self, key: str, module: torch.nn.Module) -> None:
method __len__ (line 186) | def __len__(self) -> int:
method __next__ (line 189) | def __next__(self) -> None:
method __iter__ (line 192) | def __iter__(self) -> None:
method keys (line 195) | def keys(self) -> list[str]:
method values (line 201) | def values(self) -> list[torch.nn.Module]:
method items (line 204) | def items(self) -> list[tuple[str, torch.nn.Module]]:
method update (line 209) | def update(self, modules: dict[str, torch.nn.Module]) -> None:
FILE: ludwig/features/h3_feature.py
class _H3Preprocessing (line 34) | class _H3Preprocessing(torch.nn.Module):
method __init__ (line 35) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 41) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class H3FeatureMixin (line 67) | class H3FeatureMixin(BaseFeatureMixin):
method type (line 69) | def type():
method cast_column (line 73) | def cast_column(column, backend):
method get_feature_meta (line 81) | def get_feature_meta(
method h3_to_list (line 91) | def h3_to_list(h3_int):
method add_feature_data (line 98) | def add_feature_data(
class H3InputFeature (line 118) | class H3InputFeature(H3FeatureMixin, InputFeature):
method __init__ (line 119) | def __init__(self, input_feature_config: H3InputFeatureConfig, encoder...
method forward (line 127) | def forward(self, inputs):
method input_dtype (line 137) | def input_dtype(self):
method input_shape (line 141) | def input_shape(self) -> torch.Size:
method output_shape (line 145) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 149) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method create_preproc_module (line 153) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
method get_schema_cls (line 157) | def get_schema_cls():
FILE: ludwig/features/image_feature.py
class AutoAugment (line 110) | class AutoAugment(torch.nn.Module):
method __init__ (line 111) | def __init__(self, config: AutoAugmentationConfig):
method get_augmentation_method (line 116) | def get_augmentation_method(self):
method forward (line 125) | def forward(self, imgs: torch.Tensor) -> torch.Tensor:
class RandomVFlip (line 134) | class RandomVFlip(torch.nn.Module):
method __init__ (line 135) | def __init__(
method forward (line 141) | def forward(self, imgs):
class RandomHFlip (line 149) | class RandomHFlip(torch.nn.Module):
method __init__ (line 150) | def __init__(
method forward (line 156) | def forward(self, imgs):
class RandomRotate (line 164) | class RandomRotate(torch.nn.Module):
method __init__ (line 165) | def __init__(self, config: RandomRotateConfig):
method forward (line 169) | def forward(self, imgs):
class RandomContrast (line 179) | class RandomContrast(torch.nn.Module):
method __init__ (line 180) | def __init__(self, config: RandomContrastConfig):
method forward (line 185) | def forward(self, imgs):
class RandomBrightness (line 195) | class RandomBrightness(torch.nn.Module):
method __init__ (line 196) | def __init__(self, config: RandomBrightnessConfig):
method forward (line 201) | def forward(self, imgs):
class RandomBlur (line 211) | class RandomBlur(torch.nn.Module):
method __init__ (line 212) | def __init__(self, config: RandomBlurConfig):
method forward (line 216) | def forward(self, imgs):
class ImageAugmentation (line 223) | class ImageAugmentation(torch.nn.Module):
method __init__ (line 224) | def __init__(
method forward (line 249) | def forward(self, imgs):
method _convert_back_to_uint8 (line 266) | def _convert_back_to_uint8(self, images):
method _renormalize_image (line 277) | def _renormalize_image(self, images):
class ImageTransformMetadata (line 287) | class ImageTransformMetadata:
function _get_torchvision_transform (line 293) | def _get_torchvision_transform(
function _get_torchvision_parameters (line 320) | def _get_torchvision_parameters(model_type: str, model_variant: str) -> ...
function is_torchvision_encoder (line 324) | def is_torchvision_encoder(encoder_obj: Encoder) -> bool:
class _ImagePreprocessing (line 331) | class _ImagePreprocessing(torch.nn.Module):
method __init__ (line 334) | def __init__(
method forward (line 355) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class _ImagePostprocessing (line 416) | class _ImagePostprocessing(torch.nn.Module):
method __init__ (line 417) | def __init__(self):
method forward (line 422) | def forward(self, preds: dict[str, torch.Tensor], feature_name: str) -...
class _ImagePredict (line 429) | class _ImagePredict(PredictModule):
method forward (line 430) | def forward(self, inputs: dict[str, torch.Tensor], feature_name: str) ...
class ImageFeatureMixin (line 437) | class ImageFeatureMixin(BaseFeatureMixin):
method type (line 439) | def type():
method cast_column (line 443) | def cast_column(column, backend):
method get_feature_meta (line 447) | def get_feature_meta(
method _read_image_if_bytes_obj_and_resize (line 457) | def _read_image_if_bytes_obj_and_resize(
method _read_image_with_pretrained_transform (line 559) | def _read_image_with_pretrained_transform(
method _set_image_and_height_equal_for_encoder (line 581) | def _set_image_and_height_equal_for_encoder(
method _infer_image_size (line 611) | def _infer_image_size(
method _infer_number_of_channels (line 647) | def _infer_number_of_channels(image_sample: list[torch.Tensor]):
method _infer_image_num_classes (line 684) | def _infer_image_num_classes(
method _finalize_preprocessing_parameters (line 719) | def _finalize_preprocessing_parameters(
method add_feature_data (line 853) | def add_feature_data(
class ImageInputFeature (line 1002) | class ImageInputFeature(ImageFeatureMixin, InputFeature):
method __init__ (line 1003) | def __init__(self, input_feature_config: ImageInputFeatureConfig, enco...
method forward (line 1034) | def forward(self, inputs: torch.Tensor) -> torch.Tensor:
method input_dtype (line 1043) | def input_dtype(self):
method input_shape (line 1047) | def input_shape(self) -> torch.Size:
method output_shape (line 1051) | def output_shape(self) -> torch.Size:
method update_config_after_module_init (line 1054) | def update_config_after_module_init(self, feature_config):
method update_config_with_metadata (line 1066) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 1072) | def get_schema_cls():
method create_preproc_module (line 1076) | def create_preproc_module(metadata: dict[str, Any]) -> torch.nn.Module:
method get_augmentation_pipeline (line 1094) | def get_augmentation_pipeline(self):
class ImageOutputFeature (line 1098) | class ImageOutputFeature(ImageFeatureMixin, OutputFeature):
method __init__ (line 1099) | def __init__(
method logits (line 1110) | def logits(self, inputs: dict[str, torch.Tensor], target=None, **kwargs):
method metric_kwargs (line 1113) | def metric_kwargs(self):
method create_predict_module (line 1116) | def create_predict_module(self) -> PredictModule:
method get_prediction_set (line 1119) | def get_prediction_set(self):
method get_output_dtype (line 1123) | def get_output_dtype(cls):
method output_shape (line 1127) | def output_shape(self) -> torch.Size:
method input_shape (line 1131) | def input_shape(self) -> torch.Size:
method update_config_with_metadata (line 1135) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 1141) | def calculate_overall_stats(predictions, targets, metadata):
method postprocess_predictions (line 1145) | def postprocess_predictions(
method create_postproc_module (line 1166) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
method get_schema_cls (line 1170) | def get_schema_cls():
FILE: ludwig/features/number_feature.py
class NumberTransformer (line 43) | class NumberTransformer(nn.Module, ABC):
method transform (line 45) | def transform(self, x: np.ndarray) -> np.ndarray:
method inverse_transform (line 49) | def inverse_transform(self, x: np.ndarray) -> np.ndarray:
method transform_inference (line 53) | def transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method inverse_transform_inference (line 57) | def inverse_transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method fit_transform_params (line 62) | def fit_transform_params(column: np.ndarray, backend: Any) -> dict[str...
class ZScoreTransformer (line 66) | class ZScoreTransformer(NumberTransformer):
method __init__ (line 67) | def __init__(self, mean: float = None, std: float = None, **kwargs: di...
method transform (line 80) | def transform(self, x: np.ndarray) -> np.ndarray:
method inverse_transform (line 83) | def inverse_transform(self, x: np.ndarray) -> np.ndarray:
method transform_inference (line 86) | def transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method inverse_transform_inference (line 89) | def inverse_transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method fit_transform_params (line 93) | def fit_transform_params(column: np.ndarray, backend: "Backend") -> di...
class MinMaxTransformer (line 101) | class MinMaxTransformer(NumberTransformer):
method __init__ (line 102) | def __init__(self, min: float = None, max: float = None, **kwargs: dict):
method transform (line 111) | def transform(self, x: np.ndarray) -> np.ndarray:
method inverse_transform (line 114) | def inverse_transform(self, x: np.ndarray) -> np.ndarray:
method transform_inference (line 119) | def transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method inverse_transform_inference (line 122) | def inverse_transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method fit_transform_params (line 128) | def fit_transform_params(column: np.ndarray, backend: "Backend") -> di...
class InterQuartileTransformer (line 136) | class InterQuartileTransformer(NumberTransformer):
method __init__ (line 137) | def __init__(self, q1: float = None, q2: float = None, q3: float = Non...
method transform (line 153) | def transform(self, x: np.ndarray) -> np.ndarray:
method inverse_transform (line 156) | def inverse_transform(self, x: np.ndarray) -> np.ndarray:
method transform_inference (line 159) | def transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method inverse_transform_inference (line 162) | def inverse_transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method fit_transform_params (line 166) | def fit_transform_params(column: np.ndarray, backend: "Backend") -> di...
class Log1pTransformer (line 176) | class Log1pTransformer(NumberTransformer):
method __init__ (line 177) | def __init__(self, **kwargs: dict):
method transform (line 181) | def transform(self, x: np.ndarray) -> np.ndarray:
method inverse_transform (line 189) | def inverse_transform(self, x: np.ndarray) -> np.ndarray:
method transform_inference (line 192) | def transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method inverse_transform_inference (line 195) | def inverse_transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method fit_transform_params (line 199) | def fit_transform_params(column: np.ndarray, backend: "Backend") -> di...
class IdentityTransformer (line 203) | class IdentityTransformer(NumberTransformer):
method __init__ (line 204) | def __init__(self, **kwargs):
method transform (line 207) | def transform(self, x: np.ndarray) -> np.ndarray:
method inverse_transform (line 210) | def inverse_transform(self, x: np.ndarray) -> np.ndarray:
method transform_inference (line 213) | def transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method inverse_transform_inference (line 216) | def inverse_transform_inference(self, x: torch.Tensor) -> torch.Tensor:
method fit_transform_params (line 220) | def fit_transform_params(column: np.ndarray, backend: "Backend") -> di...
function get_transformer (line 233) | def get_transformer(metadata, preprocessing_parameters) -> NumberTransfo...
class _OutlierReplacer (line 240) | class _OutlierReplacer(torch.nn.Module):
method __init__ (line 241) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 247) | def forward(self, v: torch.Tensor) -> torch.Tensor:
class _NumberPreprocessing (line 255) | class _NumberPreprocessing(torch.nn.Module):
method __init__ (line 256) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 266) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class _NumberPostprocessing (line 280) | class _NumberPostprocessing(torch.nn.Module):
method __init__ (line 281) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 286) | def forward(self, preds: dict[str, torch.Tensor], feature_name: str) -...
class _NumberPredict (line 292) | class _NumberPredict(PredictModule):
method __init__ (line 293) | def __init__(self, clip):
method forward (line 297) | def forward(self, inputs: dict[str, torch.Tensor], feature_name: str) ...
class NumberFeatureMixin (line 308) | class NumberFeatureMixin(BaseFeatureMixin):
method type (line 310) | def type():
method cast_column (line 314) | def cast_column(column, backend):
method get_feature_meta (line 318) | def get_feature_meta(
method add_feature_data (line 340) | def add_feature_data(
class NumberInputFeature (line 379) | class NumberInputFeature(NumberFeatureMixin, InputFeature):
method __init__ (line 380) | def __init__(self, input_feature_config: NumberInputFeatureConfig, enc...
method forward (line 389) | def forward(self, inputs):
method input_shape (line 401) | def input_shape(self) -> torch.Size:
method output_shape (line 405) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 409) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 413) | def get_schema_cls():
method create_sample_input (line 416) | def create_sample_input(self, batch_size: int = 2):
method get_preproc_input_dtype (line 420) | def get_preproc_input_dtype(cls, metadata: TrainingSetMetadataDict) ->...
method create_preproc_module (line 424) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class NumberOutputFeature (line 428) | class NumberOutputFeature(NumberFeatureMixin, OutputFeature):
method __init__ (line 429) | def __init__(
method logits (line 441) | def logits(self, inputs, **kwargs): # hidden
method create_predict_module (line 445) | def create_predict_module(self) -> PredictModule:
method get_prediction_set (line 453) | def get_prediction_set(self):
method input_shape (line 457) | def input_shape(self) -> torch.Size:
method get_output_dtype (line 461) | def get_output_dtype(cls):
method output_shape (line 465) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 469) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 473) | def calculate_overall_stats(predictions, targets, metadata):
method postprocess_predictions (line 477) | def postprocess_predictions(
method get_schema_cls (line 496) | def get_schema_cls():
method get_postproc_output_dtype (line 500) | def get_postproc_output_dtype(cls, metadata: TrainingSetMetadataDict) ...
method create_postproc_module (line 504) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
FILE: ludwig/features/sequence_feature.py
class _SequencePreprocessing (line 60) | class _SequencePreprocessing(torch.nn.Module):
method __init__ (line 63) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 82) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
method _process_sequence (line 102) | def _process_sequence(self, sequence: str) -> torch.Tensor:
class _SequencePostprocessing (line 143) | class _SequencePostprocessing(torch.nn.Module):
method __init__ (line 144) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 153) | def forward(self, preds: dict[str, torch.Tensor], feature_name: str) -...
class _SequencePredict (line 179) | class _SequencePredict(PredictModule):
method forward (line 180) | def forward(self, inputs: dict[str, torch.Tensor], feature_name: str) ...
class SequenceFeatureMixin (line 191) | class SequenceFeatureMixin(BaseFeatureMixin):
method type (line 193) | def type():
method cast_column (line 197) | def cast_column(column, backend):
method get_feature_meta (line 201) | def get_feature_meta(
method feature_data (line 255) | def feature_data(column, metadata, preprocessing_parameters: Preproces...
method add_feature_data (line 271) | def add_feature_data(
class SequenceInputFeature (line 290) | class SequenceInputFeature(SequenceFeatureMixin, InputFeature):
method __init__ (line 291) | def __init__(self, input_feature_config: SequenceInputFeatureConfig, e...
method forward (line 299) | def forward(self, inputs: torch.Tensor, mask=None):
method input_dtype (line 311) | def input_dtype(self):
method update_config_with_metadata (line 315) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 321) | def get_schema_cls():
method input_shape (line 325) | def input_shape(self) -> torch.Size:
method output_shape (line 329) | def output_shape(self) -> torch.Size:
method create_preproc_module (line 333) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class SequenceOutputFeature (line 337) | class SequenceOutputFeature(SequenceFeatureMixin, OutputFeature):
method __init__ (line 338) | def __init__(
method logits (line 349) | def logits(self, inputs: dict[str, torch.Tensor], target=None):
method create_predict_module (line 352) | def create_predict_module(self) -> PredictModule:
method get_prediction_set (line 355) | def get_prediction_set(self):
method get_output_dtype (line 359) | def get_output_dtype(cls):
method input_shape (line 363) | def input_shape(self) -> torch.Size:
method output_shape (line 368) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 372) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 456) | def calculate_overall_stats(predictions, targets, train_set_metadata):
method postprocess_predictions (line 461) | def postprocess_predictions(
method create_postproc_module (line 513) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
method get_schema_cls (line 517) | def get_schema_cls():
FILE: ludwig/features/set_feature.py
class _SetPreprocessing (line 41) | class _SetPreprocessing(torch.nn.Module):
method __init__ (line 48) | def __init__(self, metadata: TrainingSetMetadataDict, is_bag: bool = F...
method forward (line 63) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class _SetPostprocessing (line 95) | class _SetPostprocessing(torch.nn.Module):
method __init__ (line 98) | def __init__(self, metadata: TrainingSetMetadataDict):
method forward (line 105) | def forward(self, preds: dict[str, torch.Tensor], feature_name: str) -...
class _SetPredict (line 129) | class _SetPredict(PredictModule):
method __init__ (line 130) | def __init__(self, threshold):
method forward (line 134) | def forward(self, inputs: dict[str, torch.Tensor], feature_name: str) ...
class SetFeatureMixin (line 144) | class SetFeatureMixin(BaseFeatureMixin):
method type (line 146) | def type():
method cast_column (line 150) | def cast_column(column, backend):
method get_feature_meta (line 154) | def get_feature_meta(
method feature_data (line 178) | def feature_data(column, metadata, preprocessing_parameters: Preproces...
method add_feature_data (line 189) | def add_feature_data(
class SetInputFeature (line 207) | class SetInputFeature(SetFeatureMixin, InputFeature):
method __init__ (line 208) | def __init__(self, input_feature_config: SetInputFeatureConfig, encode...
method forward (line 216) | def forward(self, inputs):
method input_dtype (line 225) | def input_dtype(self):
method input_shape (line 229) | def input_shape(self) -> torch.Size:
method update_config_with_metadata (line 233) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 237) | def get_schema_cls():
method output_shape (line 241) | def output_shape(self) -> torch.Size:
method create_preproc_module (line 245) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class SetOutputFeature (line 249) | class SetOutputFeature(SetFeatureMixin, OutputFeature):
method __init__ (line 250) | def __init__(
method logits (line 262) | def logits(self, inputs, **kwargs): # hidden
method metric_kwargs (line 266) | def metric_kwargs(self) -> dict[str, Any]:
method create_predict_module (line 269) | def create_predict_module(self) -> PredictModule:
method get_prediction_set (line 272) | def get_prediction_set(self):
method get_output_dtype (line 276) | def get_output_dtype(cls):
method input_shape (line 280) | def input_shape(self) -> torch.Size:
method output_shape (line 284) | def output_shape(self) -> torch.Size:
method update_config_with_metadata (line 288) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 316) | def calculate_overall_stats(predictions, targets, train_set_metadata):
method postprocess_predictions (line 320) | def postprocess_predictions(
method create_postproc_module (line 345) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
method get_schema_cls (line 349) | def get_schema_cls():
FILE: ludwig/features/text_feature.py
function get_decoded_targets_and_predictions (line 62) | def get_decoded_targets_and_predictions(
function _get_metadata_reconciled_max_sequence_length (line 83) | def _get_metadata_reconciled_max_sequence_length(
class TextFeatureMixin (line 119) | class TextFeatureMixin(BaseFeatureMixin):
method type (line 121) | def type():
method cast_column (line 125) | def cast_column(column, backend):
method get_feature_meta (line 129) | def get_feature_meta(
method feature_data (line 191) | def feature_data(column, metadata, preprocessing_parameters: Preproces...
method add_feature_data (line 230) | def add_feature_data(
class TextInputFeature (line 248) | class TextInputFeature(TextFeatureMixin, SequenceInputFeature):
method __init__ (line 249) | def __init__(self, input_feature_config: TextInputFeatureConfig, encod...
method forward (line 252) | def forward(self, inputs, mask=None):
method input_dtype (line 272) | def input_dtype(self):
method input_shape (line 276) | def input_shape(self):
method update_config_after_module_init (line 279) | def update_config_after_module_init(self, feature_config):
method update_config_with_metadata (line 283) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method get_schema_cls (line 294) | def get_schema_cls():
method output_shape (line 298) | def output_shape(self) -> torch.Size:
method create_preproc_module (line 302) | def create_preproc_module(metadata: TrainingSetMetadataDict) -> torch....
class TextOutputFeature (line 306) | class TextOutputFeature(TextFeatureMixin, SequenceOutputFeature):
method __init__ (line 307) | def __init__(
method get_output_dtype (line 316) | def get_output_dtype(cls):
method output_shape (line 320) | def output_shape(self) -> torch.Size:
method update_metrics (line 323) | def update_metrics(
method update_config_with_metadata (line 368) | def update_config_with_metadata(feature_config, feature_metadata, *arg...
method calculate_overall_stats (line 410) | def calculate_overall_stats(
method postprocess_predictions (line 417) | def postprocess_predictions(
method create_postproc_module (line 509) | def create_postproc_module(metadata: TrainingSetMetadataDict) -> torch...
method get_schema_cls (line 513) | def get_schema_cls():
FILE: ludwig/features/timeseries_feature.py
function create_time_delay_embedding (line 37) | def create_time_delay_embedding(
class _TimeseriesPreprocessing (line 68) | class _TimeseriesPreprocessing(torch.nn.Module):
method __init__ (line 71) | def __init__(self, metadata: TrainingSetMetadataDict):
method _process_str_sequence (line 84) | def _process_str_sequence(self, sequence: list[str], limit: int) -> to...
method _nan_to_fill_value (line 88) | def _nan_to_fill_value(self, v: torch.Tensor) -> torch.Tensor:
method forward_list_of_tensors (line 96) | def forward_list_of_tensors(self, v: list[torch.Tensor]) -> torch.Tensor:
method forward_list_of_strs (line 110) | def forward_list_of_strs(self, v: list[str]) -> torch.Tensor:
method forward (line 129) | def forward(self, v: TorchscriptPreprocessingInput) -> torch.Tensor:
class TimeseriesFeatureMixin (line 138) | class TimeseriesFeatureMixin(BaseFeatureMixin):
method type (line 140) | def type():
method cast_column (line 144) | def cast_column(column, backend):
method get_feature_meta (line 148) | def get_feature_meta(
method build_matrix (line 171) | def build_matrix(timeseries, tokenizer_name, length_limit, padding_val...
method feature_data (line 195) | def feature_data(column, metadata, preprocessing_parameters: Preproces...
method add_feature_data (line 215) | def add_feature_data(
class TimeseriesInputFeature (line 233) | class TimeseriesInputFeature(TimeseriesFeatureMixin,
Condensed preview — 893 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (8,996K chars).
[
{
"path": ".actrc",
"chars": 37,
"preview": "-P ubuntu-latest=ludwigai/ludwig-ray\n"
},
{
"path": ".deepsource.toml",
"chars": 118,
"preview": "version = 1\n\ntest_patterns = [\n \"tests/**\"\n]\n\n[[analyzers]]\nname = \"python\"\nenabled = true\nruntime_version = \"3.x.x\"\n"
},
{
"path": ".devcontainer/Dockerfile",
"chars": 665,
"preview": "FROM python:3.12-slim\n\nRUN apt-get update && export DEBIAN_FRONTEND=noninteractive \\\n && apt-get install -y --no-inst"
},
{
"path": ".devcontainer/devcontainer.json",
"chars": 468,
"preview": "{\n\t\"name\": \"Ludwig Dev\",\n\t\"build\": {\n\t\t\"dockerfile\": \"Dockerfile\",\n\t\t\"context\": \"..\"\n\t},\n\t\"customizations\": {\n\t\t\"vscode\""
},
{
"path": ".github/ISSUE_TEMPLATE/bug_report.md",
"chars": 821,
"preview": "---\nname: Bug report\nabout: Create a report to help us improve\ntitle: ''\nlabels: ''\nassignees: ''\n---\n\n**Describe the bu"
},
{
"path": ".github/ISSUE_TEMPLATE/feature_request.md",
"chars": 695,
"preview": "---\nname: Feature request\nabout: Suggest an idea for this project\ntitle: ''\nlabels: ''\nassignees: ''\n---\n\n**Is your feat"
},
{
"path": ".github/pull_request_template.md",
"chars": 680,
"preview": "# Code Pull Requests\n\nPlease provide the following:\n\n- a clear explanation of what your code does\n- if applicable, a ref"
},
{
"path": ".github/workflows/docker.yml",
"chars": 4883,
"preview": "name: docker\n\non:\n schedule:\n - cron: \"0 10 * * *\" # everyday at 10am\n push:\n branches: [\"main\", \"release-*\"]\n "
},
{
"path": ".github/workflows/pytest.yml",
"chars": 8372,
"preview": "name: pytest\n\non:\n push:\n branches: [\"main\", \"release-*\"]\n pull_request:\n branches: [\"main\", \"release-*\"]\n\nconcu"
},
{
"path": ".github/workflows/pytest_slow.yml",
"chars": 2217,
"preview": "# This workflow will install Python dependencies and run all tests marked as `slow` on a single Python version.\n\nname: p"
},
{
"path": ".github/workflows/schema.yml",
"chars": 2580,
"preview": "name: Publish JSON Schema\n\non:\n push:\n branches: [main]\n paths:\n - \"ludwig/schema/**\"\n - \"ludwig/config"
},
{
"path": ".github/workflows/test-results.yml",
"chars": 1086,
"preview": "name: test results\n\non:\n workflow_run:\n workflows: [\"pytest\"]\n types:\n - completed\n\njobs:\n test-results:\n "
},
{
"path": ".github/workflows/upload-pypi.yml",
"chars": 990,
"preview": "name: Upload to PyPI\n\non:\n # Triggers the workflow when a release or draft of a release is published,\n # or a pre-rele"
},
{
"path": ".gitignore",
"chars": 1738,
"preview": "###################\n# ludwig specific #\n###################\n\n*.lock_preprocessing\nresults/\nludwig/results/\nresults_*/\nlu"
},
{
"path": ".nojekyll",
"chars": 0,
"preview": ""
},
{
"path": ".pre-commit-config.yaml",
"chars": 1857,
"preview": "# Apply to all files without committing:\n# pre-commit run --all-files\n# Apply to changed files:\n# pre-commit run\n# U"
},
{
"path": ".protolint.yaml",
"chars": 1555,
"preview": "# Adapted from\n# https://github.com/yoheimuta/protolint/blob/master/_example/config/.protolint.yaml\n---\n# Lint directive"
},
{
"path": ".vscode/settings.json",
"chars": 473,
"preview": "{\n \"editor.rulers\": [\n 120\n ],\n \"editor.formatOnSave\": true,\n \"[python]\": {\n \"editor.defaultFo"
},
{
"path": "CODEOWNERS",
"chars": 156,
"preview": "# Default code owners for the entire repository\n* @w4nderlust @tgaddair @justinxzhao @arnavgarg1 @geoffreyangus @jeffkin"
},
{
"path": "CODE_OF_CONDUCT.md",
"chars": 123,
"preview": "# Code of conduct\n\nLudwig adopts the [Linux Foundation code of conduct](https://lfprojects.org/policies/code-of-conduct/"
},
{
"path": "CONTRIBUTING.md",
"chars": 4511,
"preview": "# Contributing\n\nEveryone is welcome to contribute, and we value everybody’s contribution. Code is thus not the only\nway "
},
{
"path": "LICENSE",
"chars": 13489,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "MANIFEST.in",
"chars": 159,
"preview": "include *.txt\nrecursive-include ludwig/datasets *.yaml\nrecursive-include ludwig/automl/defaults *.yaml\nrecursive-include"
},
{
"path": "NOTICE",
"chars": 2615,
"preview": "Ludwig includes derived work from TensorFlow(https://github.com/tensorflow/tensorflow) under the Apache License 2.0:\n\nCo"
},
{
"path": "README.md",
"chars": 16317,
"preview": "<p align=\"center\">\n <a href=\"https://ludwig.ai\">\n <img src=\"https://github.com/ludwig-ai/ludwig-docs/raw/main/docs/i"
},
{
"path": "README_KR.md",
"chars": 13131,
"preview": "<p align=\"center\">\n <a href=\"https://ludwig.ai\">\n <img src=\"https://github.com/ludwig-ai/ludwig-docs/raw/main/docs/i"
},
{
"path": "RELEASES.md",
"chars": 747,
"preview": "# Releasing\n\n## Release procedure\n\n1. Update version number in `ludwig/globals.py`\n1. Update version number in `setup.py"
},
{
"path": "docker/README.md",
"chars": 3959,
"preview": "# Ludwig Docker Images\n\nThese images provide Ludwig, a toolbox to train and evaluate deep learning models\nwithout the ne"
},
{
"path": "docker/ludwig/Dockerfile",
"chars": 677,
"preview": "#\n# Ludwig Docker image with full set of pre-requiste packages to support these capabilities\n# text features\n# image"
},
{
"path": "docker/ludwig-gpu/Dockerfile",
"chars": 582,
"preview": "#\n# Ludwig Docker image with full set of pre-requiste packages to support these capabilities\n# text features\n# image"
},
{
"path": "docker/ludwig-ray/Dockerfile",
"chars": 737,
"preview": "#\n# Ludwig Docker image with Ray support and full dependencies including:\n# text features\n# image features\n# audio"
},
{
"path": "docker/ludwig-ray-gpu/Dockerfile",
"chars": 732,
"preview": "#\n# Ludwig Docker image with Ray support and full dependencies including:\n# text features\n# image features\n# audio"
},
{
"path": "examples/README.md",
"chars": 2826,
"preview": "# Examples\n\nThis directory contains example programs demonstrating Ludwig's Python APIs.\n\n| Directory | Examples P"
},
{
"path": "examples/calibration/README.md",
"chars": 1054,
"preview": "# Calibration Examples\n\nDrawing on the methods in\nOn Calibration of Modern Neural Networks (Chuan Guo, Geoff Pleiss, Yu "
},
{
"path": "examples/calibration/train_forest_cover_calibrated.py",
"chars": 2747,
"preview": "#!/usr/bin/env python\n\nimport copy\nimport logging\nimport shutil\n\nimport numpy as np\nimport yaml\n\nimport ludwig.visualize"
},
{
"path": "examples/calibration/train_mushroom_edibility_calibrated.py",
"chars": 3289,
"preview": "#!/usr/bin/env python\n\nimport copy\nimport logging\nimport shutil\n\nimport numpy as np\nimport yaml\n\nimport ludwig.visualize"
},
{
"path": "examples/class_imbalance/README.md",
"chars": 3085,
"preview": "# Credit Card Fraud Detection Example\n\nThis API example is based on Kaggle's [Imbalanced Insurance](https://www.kaggle.c"
},
{
"path": "examples/class_imbalance/balanced_model_config.yaml",
"chars": 676,
"preview": "input_features:\n - name: Gender\n type: category\n - name: Age\n type: number\n - name: Driving_License\n type: b"
},
{
"path": "examples/class_imbalance/model_training.py",
"chars": 1531,
"preview": "#!/usr/bin/env python\n\n# # Class Imbalance Model Training Example\n#\n# This example trains a model utilizing a standard c"
},
{
"path": "examples/class_imbalance/model_training_results.ipynb",
"chars": 138930,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c1e31e4-d8d4-4e83-8f4c-f868365d14d7\",\n \"metadata\": {},\n \"so"
},
{
"path": "examples/class_imbalance/standard_model_config.yaml",
"chars": 633,
"preview": "input_features:\n - name: Gender\n type: category\n - name: Age\n type: number\n - name: Driving_License\n type: b"
},
{
"path": "examples/forecasting/README.md",
"chars": 271,
"preview": "- Download and unpack hourly weather data from https://www.kaggle.com/selfishgene/historical-hourly-weather-data\n- `ludw"
},
{
"path": "examples/forecasting/config.yaml",
"chars": 362,
"preview": "input_features:\n - name: Seattle\n type: timeseries\n preprocessing:\n window_size: 10\n encoder:\n type:"
},
{
"path": "examples/getting_started/rotten_tomatoes.yaml",
"chars": 354,
"preview": "input_features:\n - name: genres\n type: set\n preprocessing:\n tokenizer: comma\n - name: content_rating\n ty"
},
{
"path": "examples/getting_started/run.sh",
"chars": 611,
"preview": "#!/usr/bin/env bash\n\n# Fail fast if an error occurs\nset -e\n\n# Get the directory of this script, which contains the confi"
},
{
"path": "examples/hyperopt/README.md",
"chars": 1009,
"preview": "# Hyperparameter Optimization\n\nDemonstrates hyperparameter optimization using Ludwig's in-built capabilities.\n\n### Prepa"
},
{
"path": "examples/hyperopt/model_hyperopt_example.ipynb",
"chars": 1462587,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# Hyperparameter Optimization In Lu"
},
{
"path": "examples/insurance_lite/config.yaml",
"chars": 1450,
"preview": "input_features:\n - name: image_path\n type: image\n preprocessing:\n height: 224\n width: 224\n in_memo"
},
{
"path": "examples/insurance_lite/train.py",
"chars": 1014,
"preview": "#!/usr/bin/env python\n\n# # Simple Model Training Example on multi-modal data.\n\n# Import required libraries\nimport loggin"
},
{
"path": "examples/kfold_cv/README.md",
"chars": 3746,
"preview": "# K-Ffold Cross Validation Example\n\nThis directory contains two examples of performing a k-fold cross validation analysi"
},
{
"path": "examples/kfold_cv/display_kfold_cv_results.py",
"chars": 936,
"preview": "#!/usr/bin/env python\n\n\nimport argparse\nimport os.path\nimport pprint\nimport sys\n\nfrom ludwig.utils.data_utils import loa"
},
{
"path": "examples/kfold_cv/k-fold_cv_classification.sh",
"chars": 373,
"preview": "#!/bin/bash\n\n#\n# Download and prepare training data\n#\npython prepare_classification_data_set.py\n\n#\n# Run 5-fold cross va"
},
{
"path": "examples/kfold_cv/prepare_classification_data_set.py",
"chars": 2550,
"preview": "#!/usr/bin/env python\n\n\n# Download and prepare training data set\n# Create Ludwig config file\n#\n# Based on the\n# [UCI Wis"
},
{
"path": "examples/kfold_cv/regression_example.ipynb",
"chars": 41942,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n "
},
{
"path": "examples/lbfgs/config.yaml",
"chars": 773,
"preview": "input_features:\n - name: RESOURCE\n type: category\n - name: MGR_ID\n type: category\n - name: ROLE_ROLLUP_1\n ty"
},
{
"path": "examples/lbfgs/model.py",
"chars": 1033,
"preview": "import logging\n\nimport pandas as pd\n\nfrom ludwig.api import LudwigModel\nfrom ludwig.datasets import amazon_employee_acce"
},
{
"path": "examples/llama2_7b_finetuning_4bit/README.md",
"chars": 1345,
"preview": "# Llama2-7b Fine-Tuning 4bit (QLoRA)\n\n[](https"
},
{
"path": "examples/llama2_7b_finetuning_4bit/llama2_7b_4bit.yaml",
"chars": 394,
"preview": "model_type: llm\nbase_model: meta-llama/Llama-2-7b-hf\n\nquantization:\n bits: 4\n\nadapter:\n type: lora\n\ninput_features:\n "
},
{
"path": "examples/llama2_7b_finetuning_4bit/run_train.sh",
"chars": 298,
"preview": "#!/usr/bin/env bash\n\n# Fail fast if an error occurs\nset -e\n\n# Get the directory of this script, which contains the confi"
},
{
"path": "examples/llama2_7b_finetuning_4bit/train_alpaca.py",
"chars": 1161,
"preview": "import logging\nimport os\n\nimport yaml\n\nfrom ludwig.api import LudwigModel\n\nconfig = yaml.safe_load(\"\"\"\nmodel_type: llm\nb"
},
{
"path": "examples/llm_base_model_dequantization/README.md",
"chars": 4998,
"preview": "# Convert quantized base model to fp16\n\nLudwig has utility functions to convert nf4 quantized bitsandbytes base models b"
},
{
"path": "examples/llm_base_model_dequantization/phi_2_dequantization.py",
"chars": 991,
"preview": "import logging\nimport os\n\nimport yaml\nfrom huggingface_hub import whoami\n\nfrom ludwig.api import LudwigModel\nfrom ludwig"
},
{
"path": "examples/llm_few_shot_learning/simple_model_training.py",
"chars": 4148,
"preview": "#!/usr/bin/env python\n\n# # Simple Model Training Example\n#\n# This is a simple example of how to use the LLM model type t"
},
{
"path": "examples/llm_finetuning/README.md",
"chars": 2187,
"preview": "# LLM Fine-tuning\n\nThese examples show you how to fine-tune Large Language Models by taking advantage of model paralleli"
},
{
"path": "examples/llm_finetuning/imdb_deepspeed_zero3.yaml",
"chars": 443,
"preview": "input_features:\n - name: review\n type: text\n encoder:\n type: auto_transformer\n pretrained_model_name_or"
},
{
"path": "examples/llm_finetuning/imdb_deepspeed_zero3_ray.yaml",
"chars": 522,
"preview": "input_features:\n - name: review\n type: text\n encoder:\n type: auto_transformer\n pretrained_model_name_or"
},
{
"path": "examples/llm_finetuning/run_train_dsz3.sh",
"chars": 353,
"preview": "#!/usr/bin/env bash\n\n# Fail fast if an error occurs\nset -e\n\n# Get the directory of this script, which contains the confi"
},
{
"path": "examples/llm_finetuning/run_train_dsz3_ray.sh",
"chars": 306,
"preview": "#!/usr/bin/env bash\n\n# Fail fast if an error occurs\nset -e\n\n# Get the directory of this script, which contains the confi"
},
{
"path": "examples/llm_finetuning/train_imdb_ray.py",
"chars": 1247,
"preview": "import logging\nimport os\n\nimport yaml\n\nfrom ludwig.api import LudwigModel\n\nconfig = yaml.safe_load(\"\"\"\ninput_features:\n "
},
{
"path": "examples/llm_instruction_tuning/train_alpaca_ray.py",
"chars": 1190,
"preview": "import logging\nimport os\n\nimport yaml\n\nfrom ludwig.api import LudwigModel\n\nconfig = yaml.safe_load(\"\"\"\nmodel_type: llm\nb"
},
{
"path": "examples/llm_text_generation/simple_model_training.py",
"chars": 3317,
"preview": "#!/usr/bin/env python\n\n# # Simple Model Training Example\n#\n# This is a simple example of how to use the LLM model type t"
},
{
"path": "examples/llm_zero_shot_learning/simple_model_training.py",
"chars": 3974,
"preview": "#!/usr/bin/env python\n\n# # Simple Model Training Example\n#\n# This is a simple example of how to use the LLM model type t"
},
{
"path": "examples/mnist/README.md",
"chars": 1215,
"preview": "# MNIST Hand-written Digit Classification\n\nThis API example is based on [Ludwig's MNIST Hand-written Digit image classif"
},
{
"path": "examples/mnist/advanced_model_training.py",
"chars": 2588,
"preview": "#!/usr/bin/env python\n\n# # Multiple Model Training Example\n#\n# This example trains multiple models and extracts training"
},
{
"path": "examples/mnist/assess_model_performance.py",
"chars": 1072,
"preview": "#!/usr/bin/env python\n\n#\n# Load a previously saved model and make predictions on the test data set\n#\n\nimport os.path\n\n# "
},
{
"path": "examples/mnist/config.yaml",
"chars": 476,
"preview": "input_features:\n - name: image_path\n type: image\n preprocessing:\n num_processes: 4\n encoder: stacked_cnn\n"
},
{
"path": "examples/mnist/simple_model_training.py",
"chars": 1027,
"preview": "#!/usr/bin/env python\n\n# # Simple Model Training Example\n#\n# This example is the API example for this Ludwig command lin"
},
{
"path": "examples/mnist/visualize_model_test_results.ipynb",
"chars": 529912,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# Ludwig Visualization Demonstratio"
},
{
"path": "examples/ray/kubernetes/README.md",
"chars": 1644,
"preview": "## Running on Kubernetes\n\n### Connect to k8s cluster with a Ray operator\n\nYou should now be pointing to your cluster wit"
},
{
"path": "examples/ray/kubernetes/clusters/ludwig-ray-cpu-cluster.yaml",
"chars": 3826,
"preview": "apiVersion: ray.io/v1alpha1\nkind: RayCluster\nmetadata:\n labels:\n controller-tools.k8s.io: \"1.0\"\n name: ludwig-ray-c"
},
{
"path": "examples/ray/kubernetes/clusters/ludwig-ray-gpu-cluster.yaml",
"chars": 3908,
"preview": "apiVersion: ray.io/v1alpha1\nkind: RayCluster\nmetadata:\n labels:\n controller-tools.k8s.io: \"1.0\"\n name: ludwig-ray-g"
},
{
"path": "examples/ray/kubernetes/utils/attach.sh",
"chars": 159,
"preview": "#!/bin/bash\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\nhead_pod=$(kubectl get pods | grep $cluster_name-head | cut -d' ' -f1)\nk"
},
{
"path": "examples/ray/kubernetes/utils/dashboard.sh",
"chars": 162,
"preview": "#!/bin/bash\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\nhead_pod=$(kubectl get pods | grep $cluster_name-head | cut -d' ' -f1)\nk"
},
{
"path": "examples/ray/kubernetes/utils/krsync.sh",
"chars": 409,
"preview": "#!/bin/bash\n\n# https://serverfault.com/a/887402\n\nif [ -z \"$KRSYNC_STARTED\" ]; then\n export KRSYNC_STARTED=true\n ex"
},
{
"path": "examples/ray/kubernetes/utils/ray_down.sh",
"chars": 94,
"preview": "#!/bin/bash\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\nkubectl delete -f clusters/$cluster_name.yaml\n"
},
{
"path": "examples/ray/kubernetes/utils/ray_up.sh",
"chars": 93,
"preview": "#!/bin/bash\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\nkubectl apply -f clusters/$cluster_name.yaml\n"
},
{
"path": "examples/ray/kubernetes/utils/rsync_up.sh",
"chars": 491,
"preview": "#!/bin/bash\n\n# Example: ./rsync_up.sh cluster-name ~/repos/ludwig\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\nludwig_local_dir=$"
},
{
"path": "examples/ray/kubernetes/utils/submit.sh",
"chars": 264,
"preview": "#!/bin/bash\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\npy_script=$2\n\nhead_pod=$(kubectl get pods | grep $cluster_name-head | cu"
},
{
"path": "examples/ray/kubernetes/utils/upload.sh",
"chars": 229,
"preview": "#!/bin/bash\n\ncluster_name=\"${1:-$CLUSTER_NAME}\"\npy_script=$2\n\nhead_pod=$(kubectl get pods | grep $cluster_name-head | cu"
},
{
"path": "examples/regex_freezing/ecd_freezing_with_regex_training.py",
"chars": 1999,
"preview": "import logging\nimport os\nimport shutil\n\nimport pandas as pd\nimport yaml\nfrom datasets import load_dataset\n\nfrom ludwig.a"
},
{
"path": "examples/regex_freezing/llm_freezing_with_regex_training.py",
"chars": 1219,
"preview": "import logging\n\nimport yaml\n\nfrom ludwig.api import LudwigModel\n\n\"\"\"\nTo inspect model layers in the terminal, type: \"lud"
},
{
"path": "examples/semantic_segmentation/camseq.py",
"chars": 1866,
"preview": "import logging\nimport os\nimport shutil\n\nimport pandas as pd\nimport torch\nimport yaml\nfrom torchvision.utils import save_"
},
{
"path": "examples/semantic_segmentation/config_camseq.yaml",
"chars": 624,
"preview": "input_features:\n - name: image_path\n type: image\n preprocessing:\n num_processes: 6\n infer_image_max_hei"
},
{
"path": "examples/serve/README.md",
"chars": 3252,
"preview": "# Ludwig Model Serve Example\n\nThis example shows Ludwig's http model serving capability, which is able to load a pre-tra"
},
{
"path": "examples/serve/client_program.py",
"chars": 2758,
"preview": "import sys\n\nimport pandas as pd\nimport requests\n\nfrom ludwig.datasets import titanic\n\n# Ludwig model server default valu"
},
{
"path": "examples/synthetic/train.py",
"chars": 559,
"preview": "\"\"\"Train a model from entirely synthetic data.\"\"\"\n\nimport logging\nimport tempfile\n\nimport yaml\n\nfrom ludwig.api import L"
},
{
"path": "examples/tabnet/higgs/medium_config.yaml",
"chars": 1737,
"preview": "input_features:\n - name: lepton_pT\n type: number\n - name: lepton_eta\n type: number\n - name: lepton_phi\n type"
},
{
"path": "examples/tabnet/higgs/small_config.yaml",
"chars": 1739,
"preview": "input_features:\n - name: lepton_pT\n type: number\n - name: lepton_eta\n type: number\n - name: lepton_phi\n type"
},
{
"path": "examples/tabnet/higgs/train_higgs_medium.py",
"chars": 295,
"preview": "import logging\n\nfrom ludwig.api import LudwigModel\nfrom ludwig.datasets import higgs\n\nmodel = LudwigModel(\n config=\"m"
},
{
"path": "examples/tabnet/higgs/train_higgs_small.py",
"chars": 292,
"preview": "import logging\n\nfrom ludwig.api import LudwigModel\nfrom ludwig.datasets import higgs\n\nmodel = LudwigModel(\n config=\"s"
},
{
"path": "examples/titanic/README.md",
"chars": 2022,
"preview": "# Kaggle Titanic Survivor Prediction\n\nThis API example is based on [Ludwig's Kaggle Titanic example](https://ludwig-ai.g"
},
{
"path": "examples/titanic/model1_config.yaml",
"chars": 478,
"preview": "input_features:\n - name: Pclass\n type: category\n - name: Sex\n type: category\n - name: Age\n type:"
},
{
"path": "examples/titanic/model2_config.yaml",
"chars": 711,
"preview": "input_features:\n - name: Pclass\n type: category\n - name: Sex\n type: category\n - name: Age\n type: number\n "
},
{
"path": "examples/titanic/model_training_results.ipynb",
"chars": 109081,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# Custom Analysis of Training Resul"
},
{
"path": "examples/titanic/multiple_model_training.py",
"chars": 1326,
"preview": "#!/usr/bin/env python\n\n# # Multiple Model Training Example\n#\n# This example trains multiple models and extracts training"
},
{
"path": "examples/titanic/simple_model_training.py",
"chars": 1765,
"preview": "#!/usr/bin/env python\n\n# # Simple Model Training Example\n#\n# This example is the API example for this Ludwig command lin"
},
{
"path": "examples/twitter_bots/README.md",
"chars": 1617,
"preview": "# Twitter Bots Example\n\nWe'll be using the twitter human-bots dataset which is composed of 37438 rows each corresponding"
},
{
"path": "examples/twitter_bots/train_twitter_bots.py",
"chars": 2920,
"preview": "#!/usr/bin/env python\n\"\"\"Trains model on Twitter Bots dataset using default settings.\"\"\"\n\nimport logging\nimport os\nimpor"
},
{
"path": "examples/twitter_bots/train_twitter_bots_text_only.py",
"chars": 2802,
"preview": "#!/usr/bin/env python\n\"\"\"Trains twitter bots using tabular and text features only, no images.\"\"\"\n\nimport logging\nimport "
},
{
"path": "examples/wine_quality/README.md",
"chars": 759,
"preview": "# Ludwig Defaults Config Section Example\n\nDemonstrates how to use Ludwig's defaults section introduced in v0.6.\n\n### Pre"
},
{
"path": "examples/wine_quality/model_defaults_example.ipynb",
"chars": 6892,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": "
},
{
"path": "examples/wmt15/config_large.yaml",
"chars": 192,
"preview": "input_features:\n - name: en\n type: text\n encoder: bert\n pretrained_model_name_or_path: bert-base-uncased\n\noutp"
},
{
"path": "examples/wmt15/config_small.yaml",
"chars": 109,
"preview": "input_features:\n - name: en\n type: text\n encoder: embed\n\noutput_features:\n - name: fr\n type: text\n"
},
{
"path": "examples/wmt15/train_nmt.py",
"chars": 835,
"preview": "\"\"\"Sample ludwig training code for training an NMT model (en -> fr) on WMT15 (https://www.statmt.org/wmt15/).\n\nThe datas"
},
{
"path": "ludwig/__init__.py",
"chars": 977,
"preview": "# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (t"
},
{
"path": "ludwig/accounting/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/accounting/used_tokens.py",
"chars": 1383,
"preview": "import torch\n\n\ndef get_used_tokens_for_ecd(inputs: dict[str, torch.Tensor], targets: dict[str, torch.Tensor]) -> int:\n "
},
{
"path": "ludwig/api.py",
"chars": 112220,
"preview": "# !/usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/api_annotations.py",
"chars": 5835,
"preview": "def PublicAPI(*args, **kwargs):\n \"\"\"Annotation for documenting public APIs. Public APIs are classes and methods expos"
},
{
"path": "ludwig/automl/__init__.py",
"chars": 234,
"preview": "from ludwig.automl.automl import auto_train # noqa\nfrom ludwig.automl.automl import cli_init_config # noqa\nfrom ludwig"
},
{
"path": "ludwig/automl/auto_tune_config.py",
"chars": 12262,
"preview": "import copy\nimport logging\nimport math\nfrom collections import OrderedDict\n\nimport psutil\n\ntry:\n import GPUtil\nexcept"
},
{
"path": "ludwig/automl/automl.py",
"chars": 19860,
"preview": "\"\"\"automl.py.\n\nDriver script which:\n\n(1) Builds a base config by performing type inference and populating config\n w/d"
},
{
"path": "ludwig/automl/base_config.py",
"chars": 15843,
"preview": "\"\"\"Uses heuristics to build ludwig configuration file:\n\n(1) infer types based on dataset\n(2) populate with\n - default"
},
{
"path": "ludwig/automl/defaults/base_automl_config.yaml",
"chars": 515,
"preview": "trainer:\n batch_size: auto #256\n learning_rate: auto #.001\n # validation_metric: accuracy\n\nhyperopt:\n search_alg:\n "
},
{
"path": "ludwig/automl/defaults/combiner/concat_config.yaml",
"chars": 678,
"preview": "combiner:\n type: concat\n\nhyperopt:\n # goal: maximize\n parameters:\n combiner.num_fc_layers:\n space: randint\n "
},
{
"path": "ludwig/automl/defaults/combiner/tabnet_config.yaml",
"chars": 1183,
"preview": "combiner:\n type: tabnet\n\ntrainer:\n batch_size: auto\n learning_rate_scaling: sqrt\n learning_rate_scheduler:\n decay"
},
{
"path": "ludwig/automl/defaults/combiner/transformer_config.yaml",
"chars": 710,
"preview": "combiner:\n type: transformer\n\ntrainer:\n batch_size: auto #256\n learning_rate: auto #0.0001\n # validation_metric: acc"
},
{
"path": "ludwig/automl/defaults/reference_configs.yaml",
"chars": 101826,
"preview": "# Record the score and configuration of a reference model trained by Ludwig for specified datasets.\n# This information i"
},
{
"path": "ludwig/automl/defaults/text/bert_config.yaml",
"chars": 821,
"preview": "trainer:\n epochs: 10\n learning_rate_scheduler:\n warmup_fraction: 0.1\n decay: linear\n optimizer:\n type: adamw"
},
{
"path": "ludwig/backend/__init__.py",
"chars": 2821,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/backend/base.py",
"chars": 12784,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/backend/datasource.py",
"chars": 2188,
"preview": "\"\"\"Custom Ray datasource utilities for reading binary files with None handling.\"\"\"\n\nimport logging\nfrom typing import Op"
},
{
"path": "ludwig/backend/deepspeed.py",
"chars": 1602,
"preview": "from typing import Any\n\nimport deepspeed\n\nfrom ludwig.backend.base import DataParallelBackend\nfrom ludwig.constants impo"
},
{
"path": "ludwig/backend/ray.py",
"chars": 37634,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 ("
},
{
"path": "ludwig/backend/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/backend/utils/storage.py",
"chars": 1758,
"preview": "import contextlib\nfrom typing import Any, Optional, Union\n\nfrom ludwig.utils import data_utils\n\nCredInputs = Optional[Un"
},
{
"path": "ludwig/benchmarking/README.md",
"chars": 11433,
"preview": "# Ludwig Benchmarking\n\n### Some use cases\n\n- Regression testing for ML experiments across releases and PRs.\n- Model perf"
},
{
"path": "ludwig/benchmarking/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/benchmarking/artifacts.py",
"chars": 2531,
"preview": "import os\nfrom dataclasses import dataclass\nfrom typing import Any\n\nfrom ludwig.globals import MODEL_FILE_NAME\nfrom ludw"
},
{
"path": "ludwig/benchmarking/benchmark.py",
"chars": 6477,
"preview": "import argparse\nimport importlib\nimport logging\nimport os\nimport shutil\nfrom typing import Any\n\nimport ludwig.datasets\nf"
},
{
"path": "ludwig/benchmarking/examples/benchmarking_config.yaml",
"chars": 2947,
"preview": "experiment_name: example_benchmarking_run\nhyperopt: false\nprocess_config_file_path: /home/ray/process_config.py\nprofiler"
},
{
"path": "ludwig/benchmarking/examples/process_config.py",
"chars": 4150,
"preview": "\"\"\"This function will take in a Ludwig config, strip away all its parameters except input and output featuresand\nadd som"
},
{
"path": "ludwig/benchmarking/profiler.py",
"chars": 12249,
"preview": "import contextlib\nimport glob\nimport logging\nimport os\nimport shutil\nimport threading\nimport time\nfrom queue import Empt"
},
{
"path": "ludwig/benchmarking/profiler_callbacks.py",
"chars": 2211,
"preview": "from typing import Any\n\nfrom ludwig.api_annotations import DeveloperAPI\nfrom ludwig.benchmarking.profiler import LudwigP"
},
{
"path": "ludwig/benchmarking/profiler_dataclasses.py",
"chars": 2575,
"preview": "import dataclasses\nfrom dataclasses import dataclass\n\nfrom ludwig.utils.data_utils import flatten_dict\n\n\n@dataclass\nclas"
},
{
"path": "ludwig/benchmarking/reporting.py",
"chars": 11089,
"preview": "from collections import Counter, defaultdict\nfrom statistics import mean\nfrom typing import Any\n\nimport torch\nfrom torch"
},
{
"path": "ludwig/benchmarking/summarize.py",
"chars": 5301,
"preview": "import argparse\nimport logging\nimport os\nimport shutil\n\nfrom ludwig.benchmarking.summary_dataclasses import (\n build_"
},
{
"path": "ludwig/benchmarking/summary_dataclasses.py",
"chars": 17709,
"preview": "import csv\nimport logging\nimport os\nfrom dataclasses import dataclass\nfrom statistics import mean\n\nimport ludwig.modules"
},
{
"path": "ludwig/benchmarking/utils.py",
"chars": 12102,
"preview": "import asyncio\nimport functools\nimport logging\nimport os\nimport shutil\nimport uuid\nfrom concurrent.futures import Thread"
},
{
"path": "ludwig/callbacks.py",
"chars": 14634,
"preview": "# !/usr/bin/env python\n# Copyright (c) 2021 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 ("
},
{
"path": "ludwig/check.py",
"chars": 1990,
"preview": "import argparse\nimport logging\nimport tempfile\n\nfrom ludwig.api import LudwigModel\nfrom ludwig.api_annotations import De"
},
{
"path": "ludwig/cli.py",
"chars": 6032,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/collect.py",
"chars": 17001,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/combiners/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/combiners/combiners.py",
"chars": 42846,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/config_sampling/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/config_sampling/explore_schema.py",
"chars": 13922,
"preview": "import copy\nimport random\nfrom collections import deque, namedtuple\nfrom typing import Any, Deque\n\nimport pandas as pd\n\n"
},
{
"path": "ludwig/config_sampling/parameter_sampling.py",
"chars": 4910,
"preview": "import random\nfrom typing import Any, Union\n\nfrom ludwig.schema.metadata.parameter_metadata import ExpectedImpact\n\n# bas"
},
{
"path": "ludwig/config_validation/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/config_validation/checks.py",
"chars": 30197,
"preview": "\"\"\"Checks that are not easily covered by marshmallow JSON schema validation like parameter interdependencies.\"\"\"\n\nfrom a"
},
{
"path": "ludwig/config_validation/preprocessing.py",
"chars": 1230,
"preview": "def check_global_max_sequence_length_fits_prompt_template(metadata, global_preprocessing_parameters):\n \"\"\"Checks that"
},
{
"path": "ludwig/config_validation/validation.py",
"chars": 3092,
"preview": "from functools import lru_cache\nfrom threading import Lock\n\nimport jsonschema.exceptions\nfrom jsonschema import Draft7Va"
},
{
"path": "ludwig/constants.py",
"chars": 8688,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/contrib.py",
"chars": 1686,
"preview": "# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (t"
},
{
"path": "ludwig/contribs/__init__.py",
"chars": 2559,
"preview": "# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (t"
},
{
"path": "ludwig/contribs/aim.py",
"chars": 3643,
"preview": "import json\nimport logging\n\nfrom ludwig.api_annotations import PublicAPI\nfrom ludwig.callbacks import Callback\nfrom ludw"
},
{
"path": "ludwig/contribs/comet.py",
"chars": 5379,
"preview": "# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (t"
},
{
"path": "ludwig/contribs/mlflow/__init__.py",
"chars": 11617,
"preview": "import logging\nimport os\nimport queue\nimport threading\n\nfrom ludwig.api_annotations import DeveloperAPI, PublicAPI\nfrom "
},
{
"path": "ludwig/contribs/mlflow/model.py",
"chars": 10289,
"preview": "import logging\nimport os\nimport shutil\nimport tempfile\n\nimport mlflow\nimport yaml\nfrom mlflow import pyfunc\nfrom mlflow."
},
{
"path": "ludwig/contribs/wandb.py",
"chars": 2489,
"preview": "# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (t"
},
{
"path": "ludwig/data/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/data/batcher/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/data/batcher/base.py",
"chars": 1105,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/batcher/bucketed.py",
"chars": 5982,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 ("
},
{
"path": "ludwig/data/batcher/iterable.py",
"chars": 1655,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/batcher/random_access.py",
"chars": 3776,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/batcher/test_batcher.py",
"chars": 3628,
"preview": "import logging\n\nimport pandas as pd\nimport yaml\n\nfrom ludwig.api import LudwigModel\nfrom ludwig.data.dataset.pandas impo"
},
{
"path": "ludwig/data/cache/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "ludwig/data/cache/manager.py",
"chars": 6421,
"preview": "import logging\nimport os\n\nfrom ludwig.constants import CHECKSUM, META, TEST, TRAINING, VALIDATION\nfrom ludwig.data.cache"
},
{
"path": "ludwig/data/cache/types.py",
"chars": 2760,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2022 Predibase, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"Lic"
},
{
"path": "ludwig/data/cache/util.py",
"chars": 1792,
"preview": "import ludwig\nfrom ludwig.constants import DEFAULTS, INPUT_FEATURES, OUTPUT_FEATURES, PREPROCESSING, PROC_COLUMN, TYPE\nf"
},
{
"path": "ludwig/data/concatenate_datasets.py",
"chars": 3484,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataframe/__init__.py",
"chars": 717,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataframe/base.py",
"chars": 2996,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataframe/dask.py",
"chars": 12097,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataframe/modin.py",
"chars": 3337,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2022 Predibase, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"Lic"
},
{
"path": "ludwig/data/dataframe/pandas.py",
"chars": 3420,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataset/__init__.py",
"chars": 1278,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataset/base.py",
"chars": 2448,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataset/pandas.py",
"chars": 5335,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/dataset/ray.py",
"chars": 11983,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 ("
},
{
"path": "ludwig/data/dataset_synthesizer.py",
"chars": 23233,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/negative_sampling.py",
"chars": 4011,
"preview": "import logging\nimport time\nfrom typing import Any\n\nimport numpy as np\nimport pandas as pd\nimport scipy\n\nfrom ludwig.util"
},
{
"path": "ludwig/data/postprocessing.py",
"chars": 5176,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/preprocessing.py",
"chars": 92585,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/prompt.py",
"chars": 11087,
"preview": "import json\nimport logging\nimport os\nimport string\nfrom typing import Any, TYPE_CHECKING\n\nimport pandas as pd\n\nif TYPE_C"
},
{
"path": "ludwig/data/sampler.py",
"chars": 2610,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/split.py",
"chars": 15244,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2022 Predibase, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"Lic"
},
{
"path": "ludwig/data/split_dataset.py",
"chars": 1835,
"preview": "#! /usr/bin/env python\n# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache "
},
{
"path": "ludwig/data/utils.py",
"chars": 2125,
"preview": "from typing import Optional\n\nimport numpy as np\n\nfrom ludwig.constants import DECODER, ENCODER, SPLIT\nfrom ludwig.types "
}
]
// ... and 693 more files (download for full content)
About this extraction
This page contains the full source code of the ludwig-ai/ludwig GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 893 files (20.6 MB), approximately 2.2M tokens, and a symbol index with 6370 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.