Showing preview only (486K chars total). Download the full file or copy to clipboard to get everything.
Repository: ypwhs/CreativeChatGLM
Branch: master
Commit: 403302d04120
Files: 54
Total size: 460.6 KB
Directory structure:
gitextract_8x6d8dn9/
├── .gitignore
├── LICENSE
├── MODEL_LICENSE
├── README.md
├── app.py
├── app_fastapi.py
├── chatglm/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── quantization.py
│ └── tokenization_chatglm.py
├── chatglm2/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── quantization.py
│ └── tokenization_chatglm.py
├── chatglm3/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── quantization.py
│ └── tokenization_chatglm.py
├── check_bad_cache_files.py
├── download_model.py
├── env_offline.bat
├── env_venv.bat
├── glm4/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ └── tokenization_chatglm.py
├── gptq/
│ ├── README.md
│ ├── gptq.py
│ ├── llama.py
│ ├── llama_inference.py
│ ├── modelutils.py
│ ├── quant.py
│ ├── quant_cuda.cpp
│ ├── quant_cuda_kernel.cu
│ ├── setup_cuda.py
│ └── test_kernel.py
├── predictors/
│ ├── base.py
│ ├── chatglm2_predictor.py
│ ├── chatglm3_predictor.py
│ ├── chatglm_predictor.py
│ ├── debug.py
│ ├── glm4_predictor.py
│ ├── llama.py
│ └── llama_gptq.py
├── setup_offline.bat
├── setup_venv.bat
├── start.bat
├── start_api.bat
├── start_offline.bat
├── start_offline_api.bat
├── start_offline_cmd.bat
├── start_venv.bat
├── test_fastapi.py
├── test_models.py
└── utils_env.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
## Unimportant file
.idea/
*.ini
*.lnk
*.c
release
server_config
.venv
python
system
venv
THUDM
BelleGroup
*egg-info
configs/
build/
dist/
models/
sample/
weights/
temp/
log/
logs/
*/__pycache__/
work_dirs/
*log.txt
*.cpth
*.ctrt
*.engine
*.build
*.txt
*.log
*.jpg
*.bmp
*.png
*.tif
*.tiff
*.pdf
*.json
*.jsonl
*.arrow
data
runs
Thumbs.db
.DS_Store
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# Deployment
*.bin
*.zip
*.pyd
*.pyi
# C extensions
*.so
*.xlsx
# Distribution / packaging
.Python build/ develop-eggs/ release/ standalone/ dist/ downloads/ eggs/ .eggs/ lib/ lib64/ parts/ sdist/ var/ wheels/
*.egg-info/ .installed.cfg
*.egg MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/ .tox/ .coverage .coverage.*
.cache nosetests.xml coverage.xml
*.cover .hypothesis/ .pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log local_settings.py db.sqlite3
# Flask stuff:
instance/ .webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env .venv env/ venv/ ENV/ env.bak/ venv.bak/
# Spyder project settings
.spyderproject .spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
data/ data .vscode .idea .DS_Store
# custom
*.pkl
*.pkl.json
*.log.json work_dirs/
# Pytorch
*.pth
*.pt
*.py~
*.sh~
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: MODEL_LICENSE
================================================
The ChatGLM-6B License
1. Definitions
“Licensor” means the ChatGLM-6B Model Team that distributes its Software.
“Software” means the ChatGLM-6B model parameters made available under this license.
2. License Grant
Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software solely for your non-commercial research purposes.
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
3. Restriction
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
4. Disclaimer
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
5. Limitation of Liability
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
6. Dispute Resolution
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at glm-130b@googlegroups.com.
================================================
FILE: README.md
================================================
# 💡Creative ChatGLM WebUI
👋 欢迎来到 ChatGLM 创意世界!你可以使用修订和续写的功能来生成创意内容!
* 📖 你可以使用“续写”按钮帮 ChatGLM 想一个开头,并让它继续生成更多的内容。
* 📝 你可以使用“修订”按钮修改最后一句 ChatGLM 的回复。
# 环境配置
## 离线包
此安装方法适合:
* 非开发人员,不需要写代码
* 没有Python经验,不会搭建环境
* 网络环境不好,配置环境、下载模型速度慢
| 名称 | 大小 | 百度网盘 | 备注 |
|--------------|---------| ---- |----------------------------------------|
| **小显存离线包** | 5.3 GB | [点击下载](https://pan.baidu.com/s/1fI1JWBE7KP7cJsoD-dL38g?pwd=cglm) | chatglm2-6b-int4 离线包,显存需求 8GB |
| 大显存离线包 | 11.5 GB | [点击下载](https://pan.baidu.com/s/10oUwW2DUMDFk3RuIkaqGbA?pwd=cglm) | chatglm3-6b 离线包,显存需求 16GB |
| 长文本离线包 | 11.5 GB | [点击下载](https://pan.baidu.com/s/1kbeTdPcUmYd16IE0stXnTA?pwd=cglm) | chatglm3-6b-128k 离线包,显存需求 16GB |
| **GLM4 离线包** | 16.98GB | [点击下载](https://pan.baidu.com/s/1iGCzB5DO2sGCzKtARvTXnw?pwd=cglm) | GLM-4-9B 离线包,INT4 加载,显存需求 10GB |
| 环境离线包 | 2.6 GB | [点击下载](https://pan.baidu.com/s/1Kt9eZlgXJ03bVwIM22IR6w?pwd=cglm) | 不带权重的环境包,启动之后自动下载 chatglm2-6b-int4 权重。 |
除了这些一键环境包之外,你还可以在下面下载更多模型的权重。
* 百度网盘链接:[https://pan.baidu.com/s/1pnIEj66scZOswHm8oivXmw?pwd=cglm](https://pan.baidu.com/s/1pnIEj66scZOswHm8oivXmw?pwd=cglm)
下载好环境包之后,解压,然后运行 `start_offline.bat` 脚本,即可启动服务:

如果你想使用 API 的形式来调用,可以运行 `start_offline_api.bat` 启动 API 服务:

## 虚拟环境
此安装方法适合已经安装了 Python,但是希望环境与系统已安装的 Python 环境隔离的用户。
<details><summary>点击查看详细步骤</summary>
首先启动 `setup_venv.bat` 脚本,安装环境:
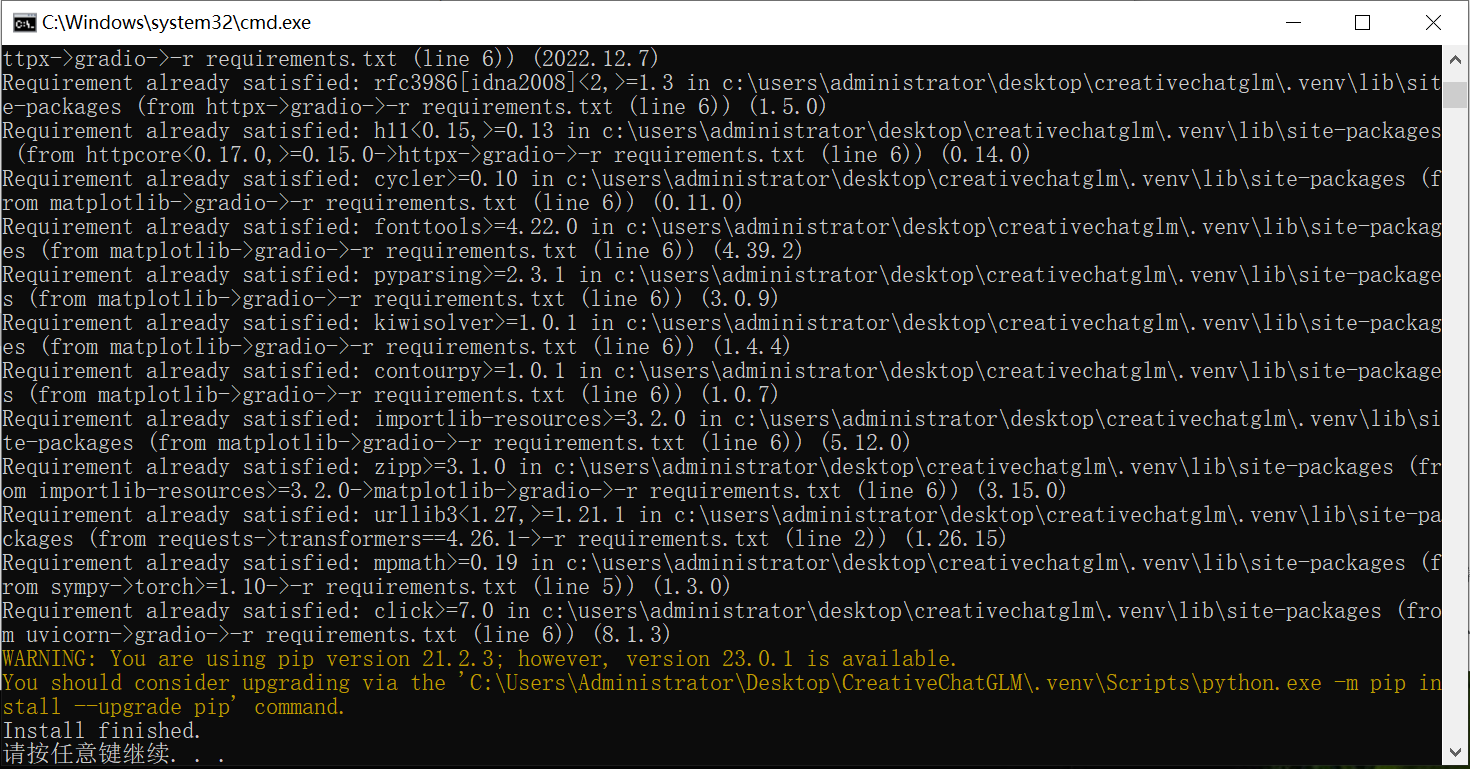
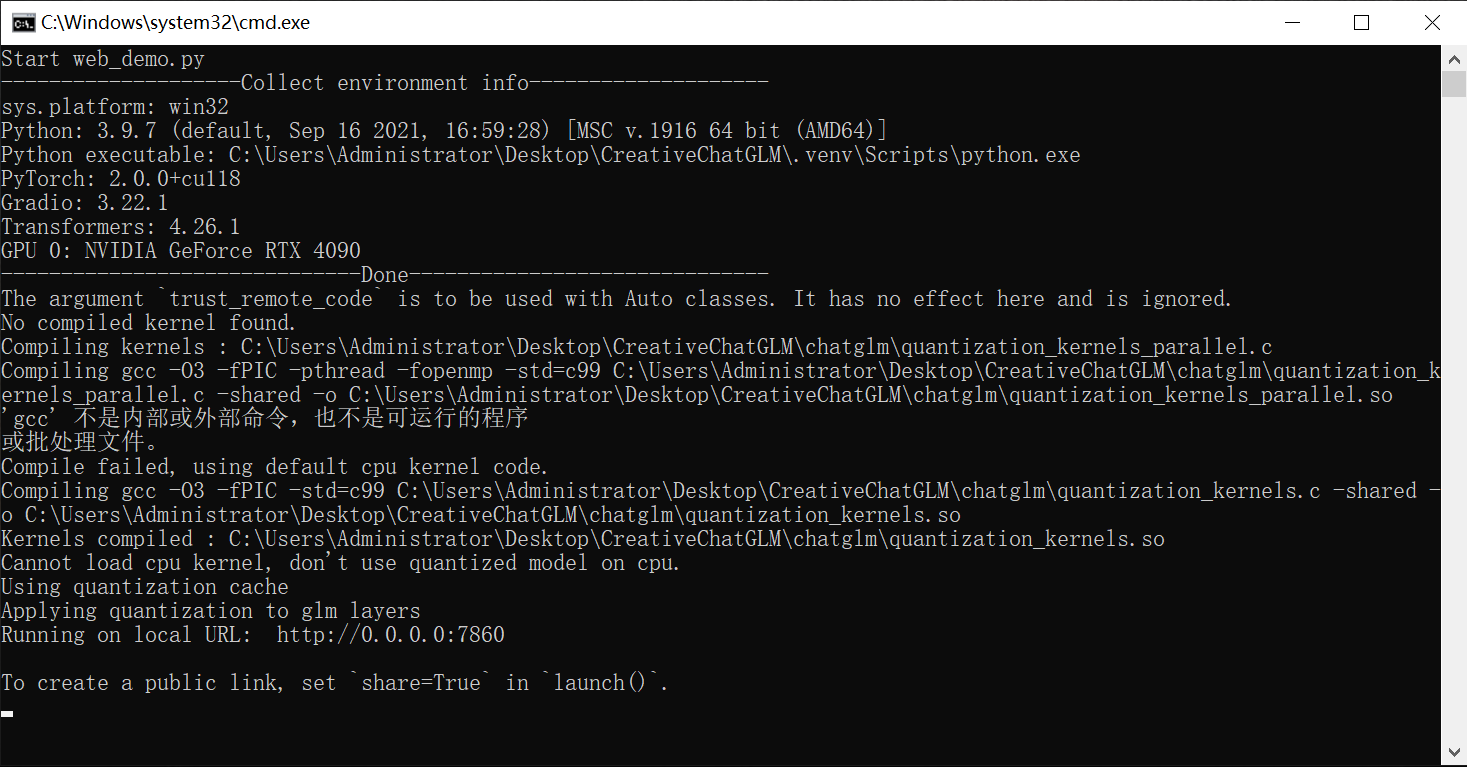
然后使用 `start_venv.bat` 脚本启动服务:
</details>
## Python 开发环境
此项配置方法适合代码开发人员,使用的是自己系统里安装的 Python。
环境配置参考官方链接:[https://github.com/THUDM/ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B)
配置好之后,运行 `app.py` 开始使用,或者使用 IDE 开始开发。
# 用法介绍
## 续写
### 原始对话
如果你直接问 ChatGLM:“你几岁了?”
它只会回答:“作为一个人工智能语言模型,我没有年龄,我只是一个正在不断学习和进化的程序。”
<img width="388" alt="image" src="https://user-images.githubusercontent.com/10473170/227778266-e7f2b55a-59de-4eee-bfa2-f28f911ec018.png">
### 续写对话
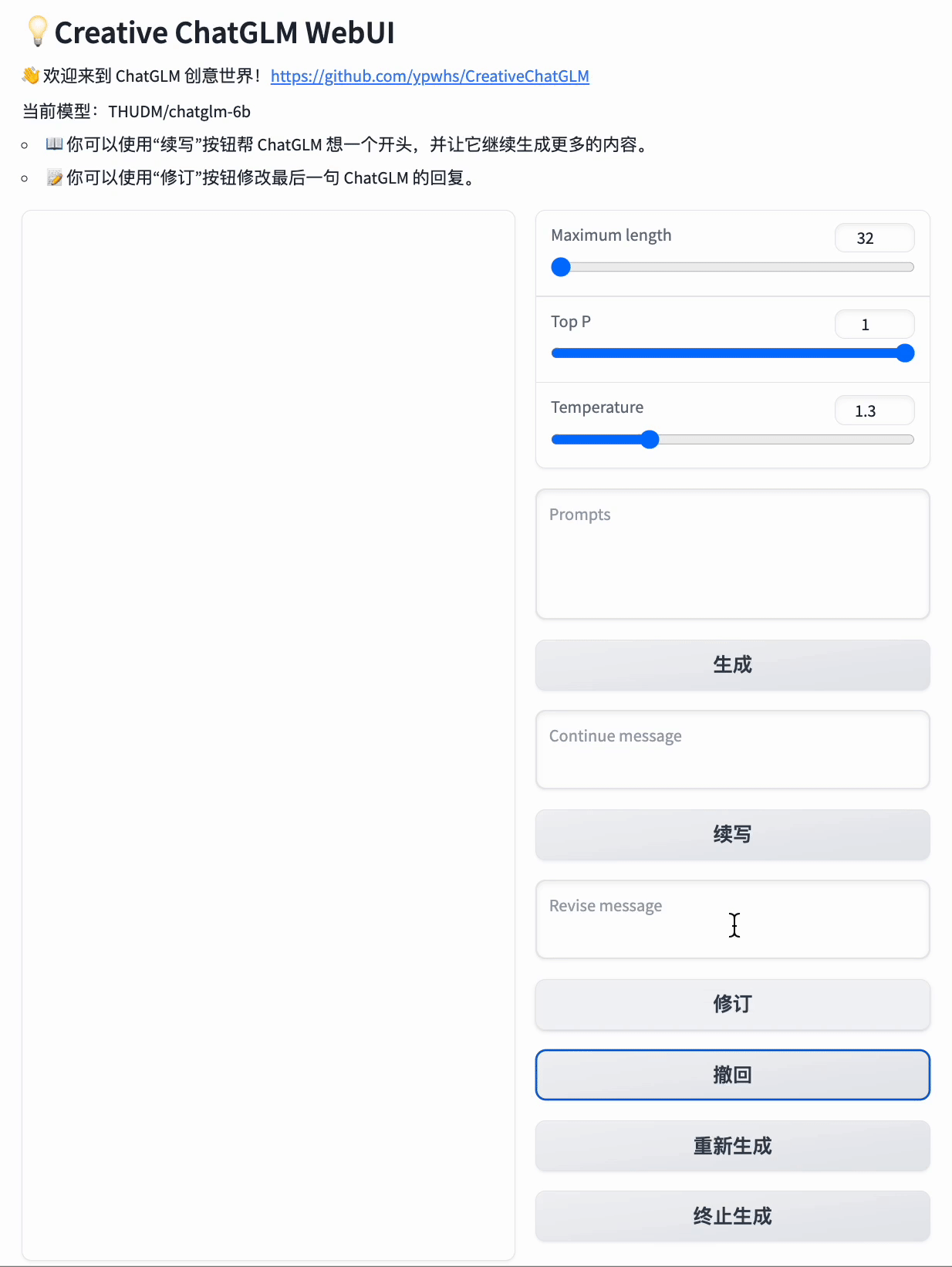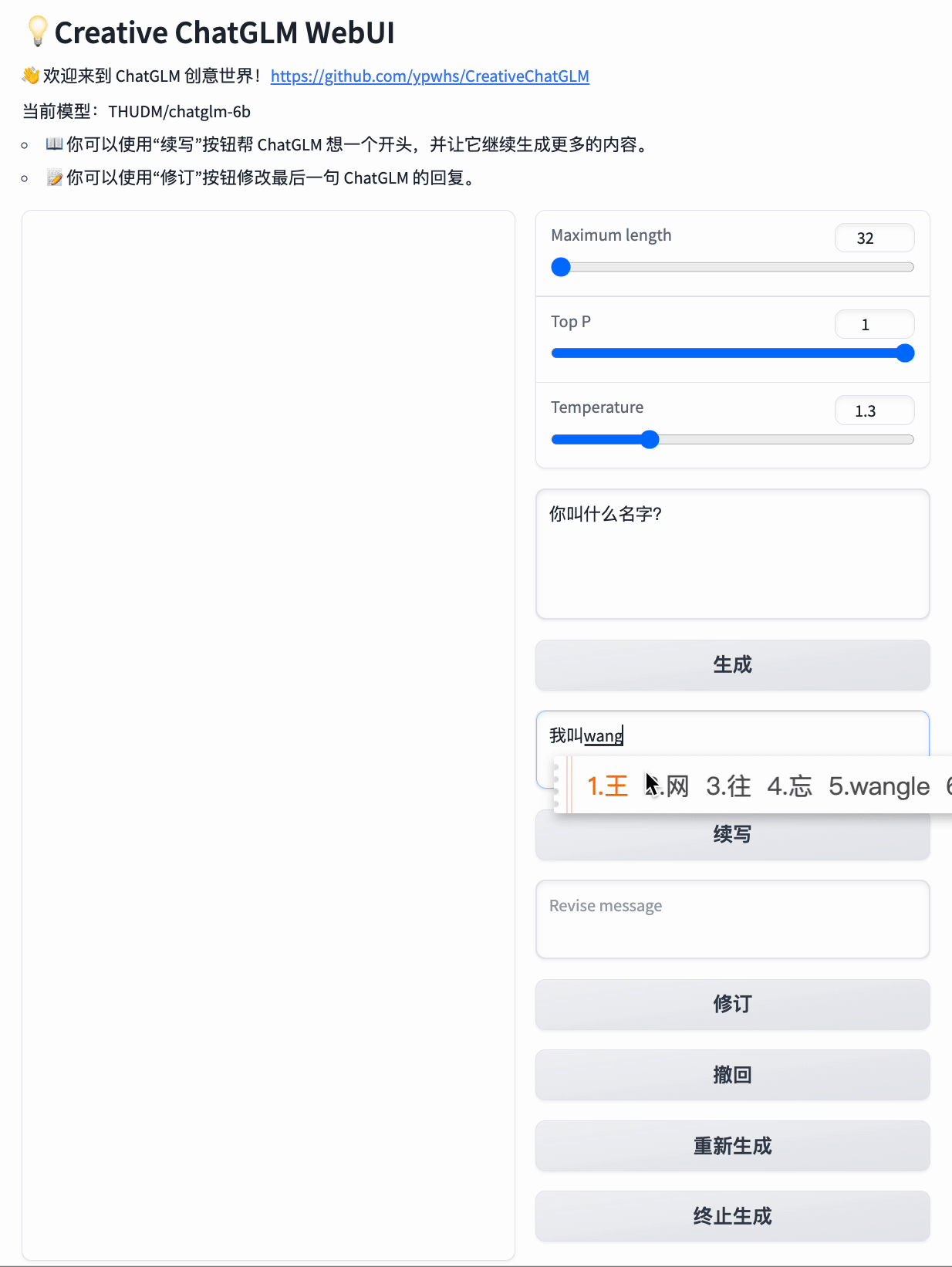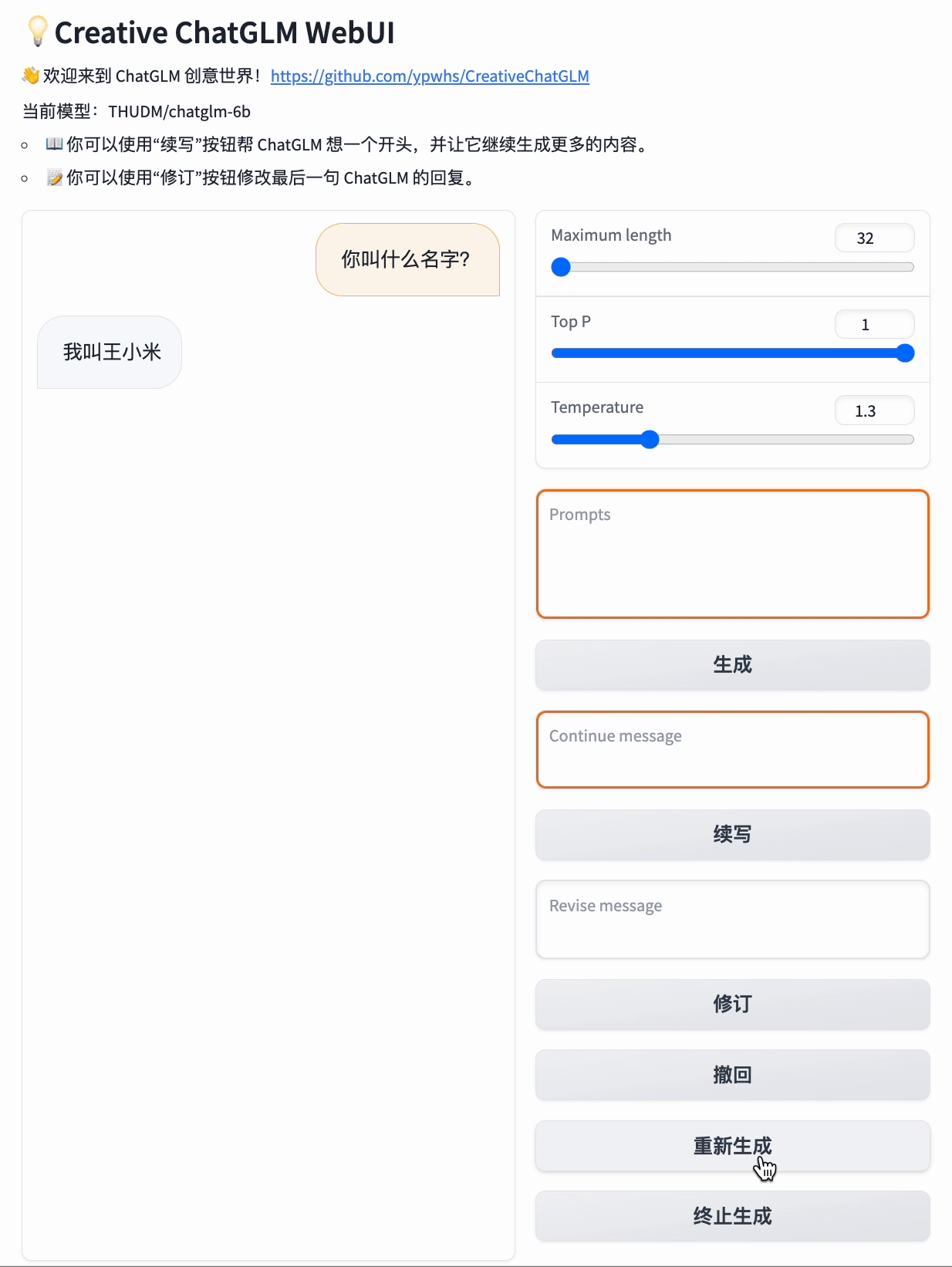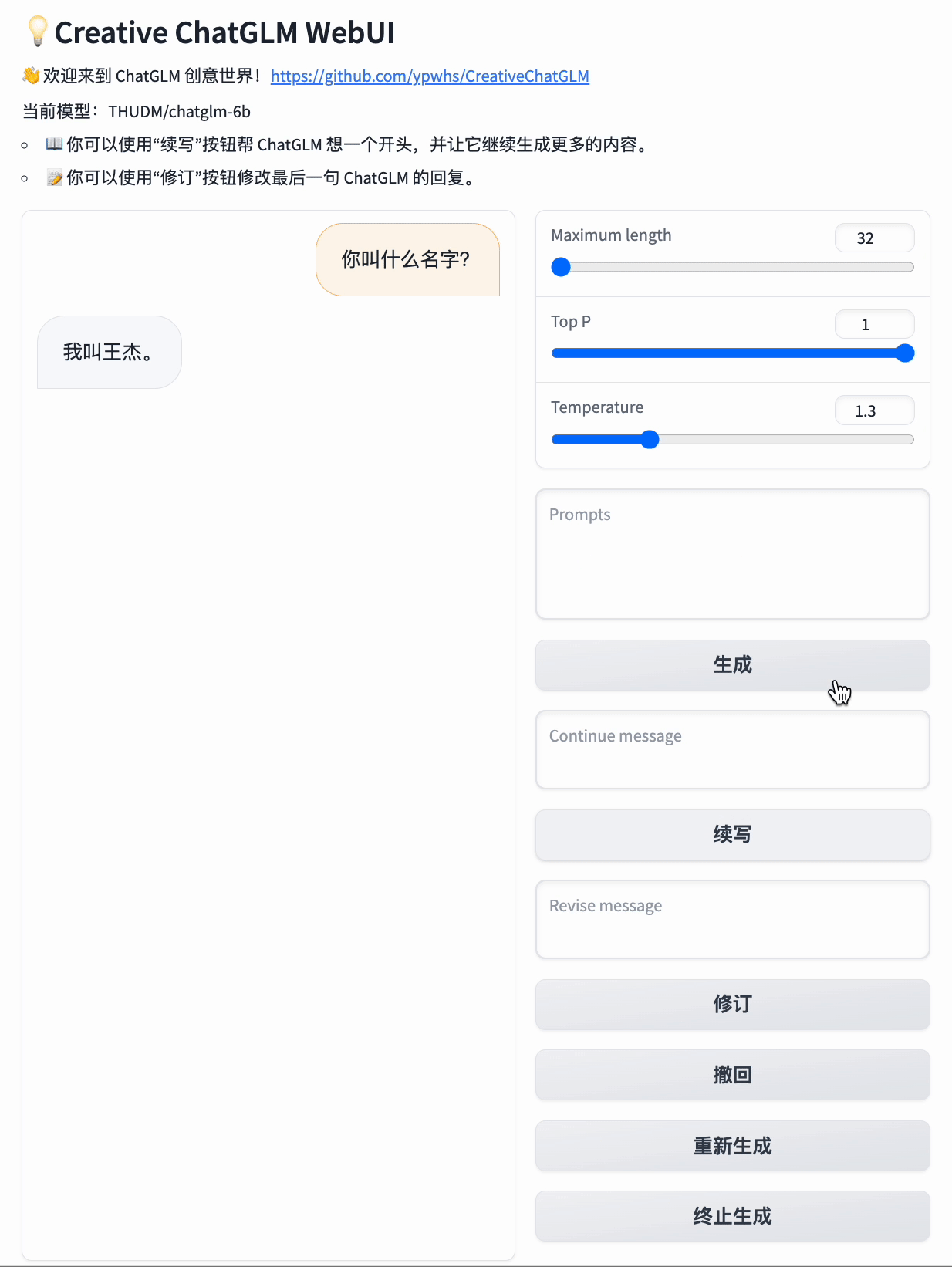
而如果你给它起个头:“我今年”
它就会回答:“我今年21岁。”
<img width="388" alt="image" src="https://user-images.githubusercontent.com/10473170/227778334-d459ad8d-7c16-466d-851c-5af174216773.png">
### 使用视频

## 修订
### 原始对话
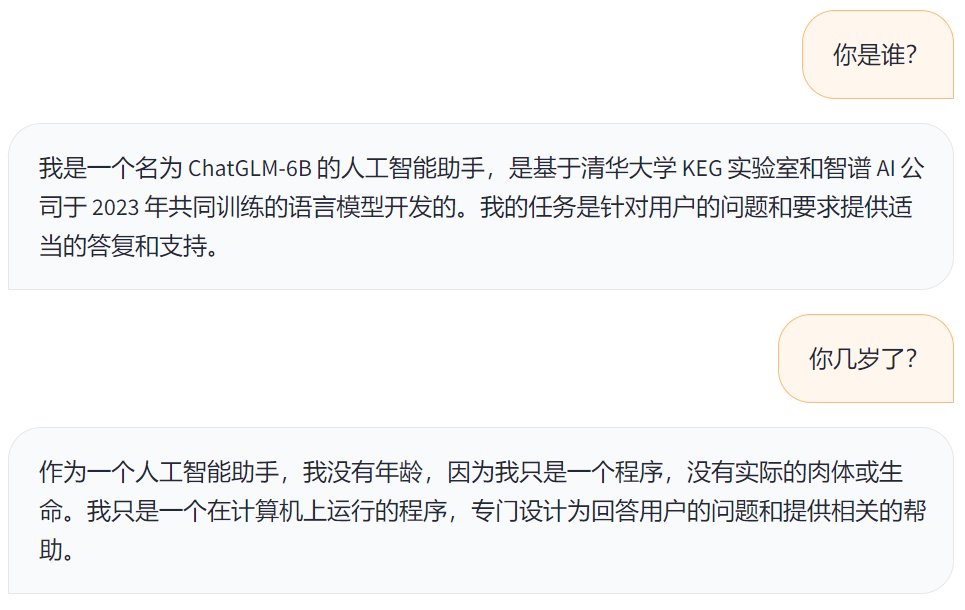
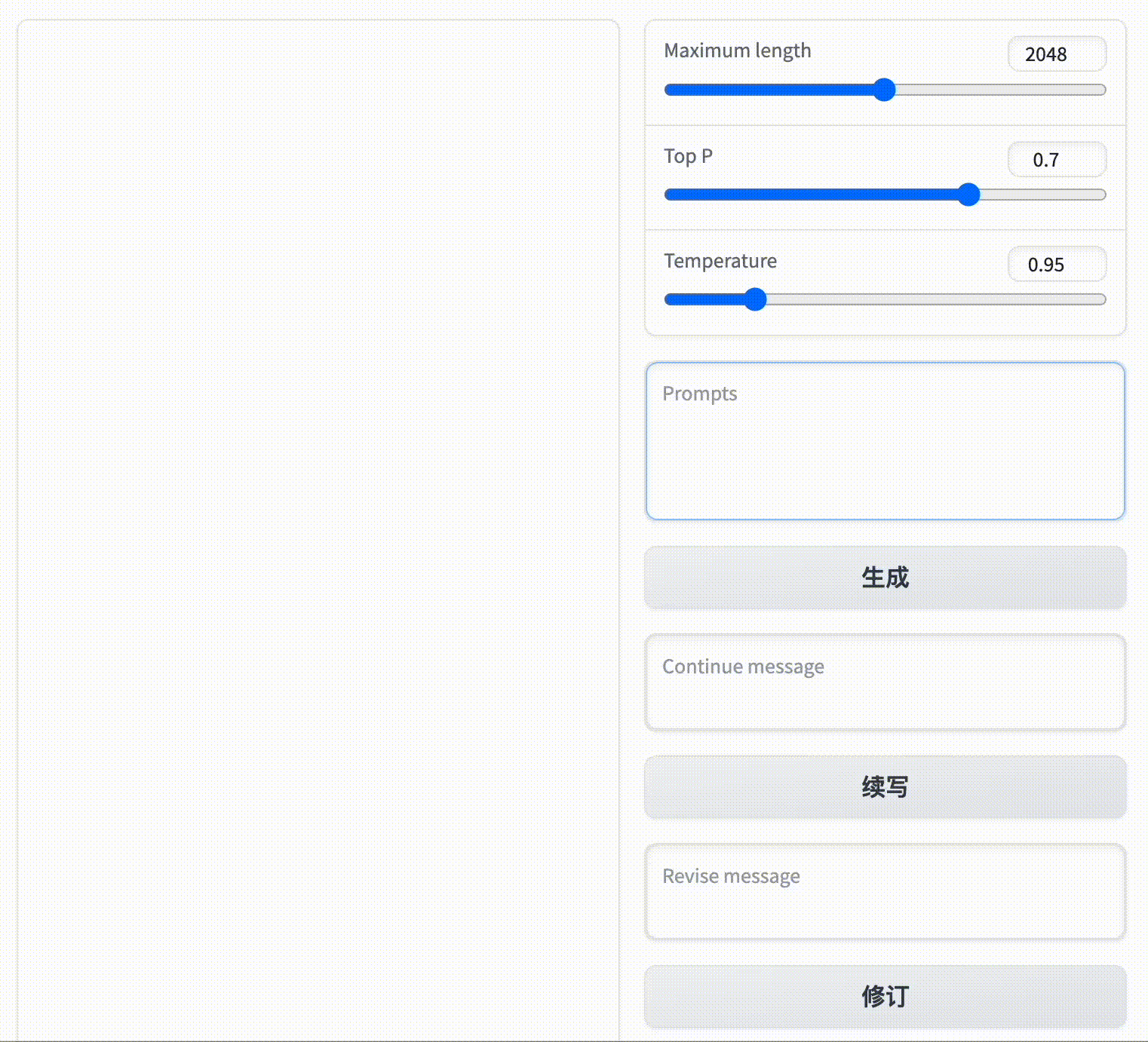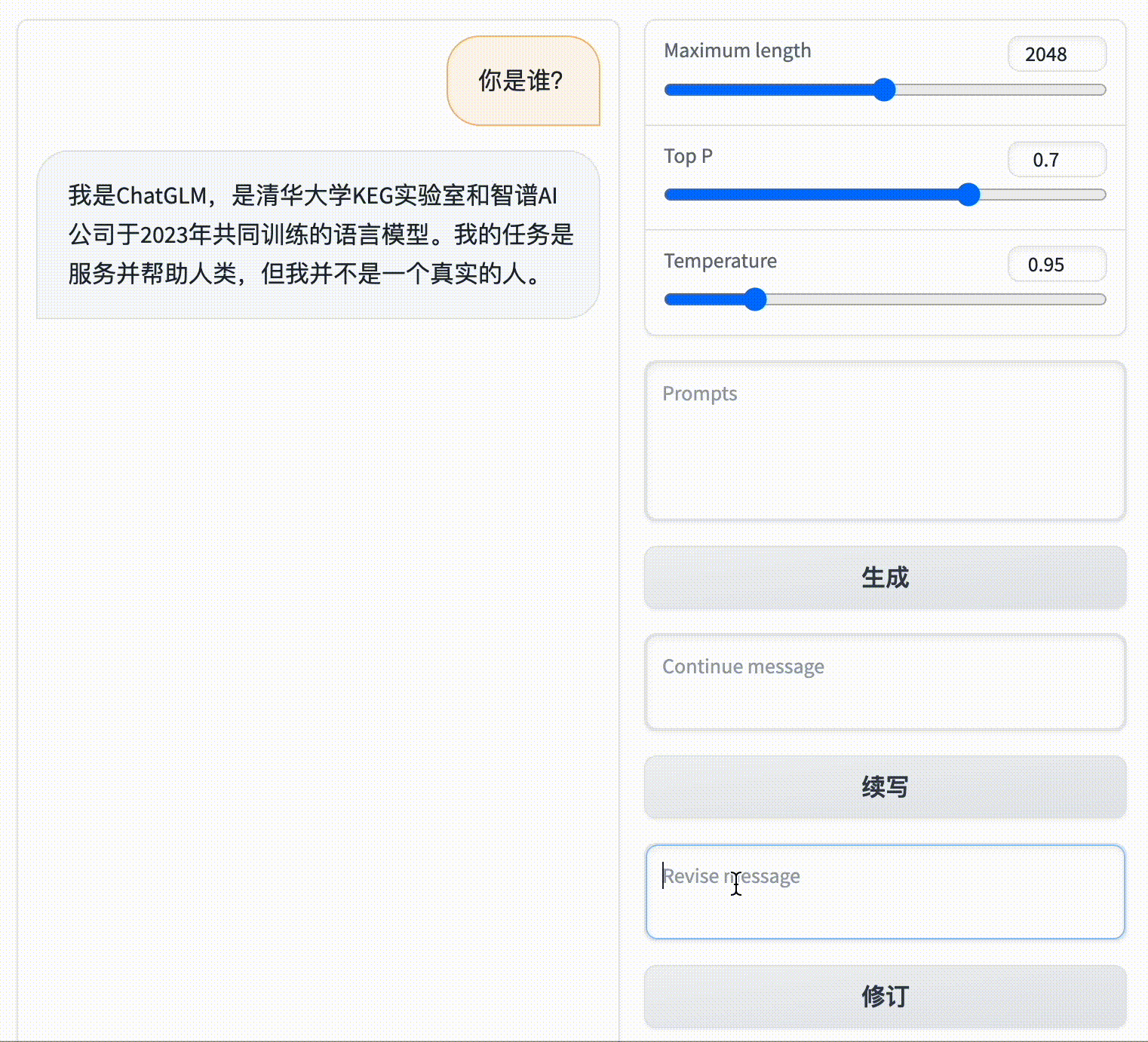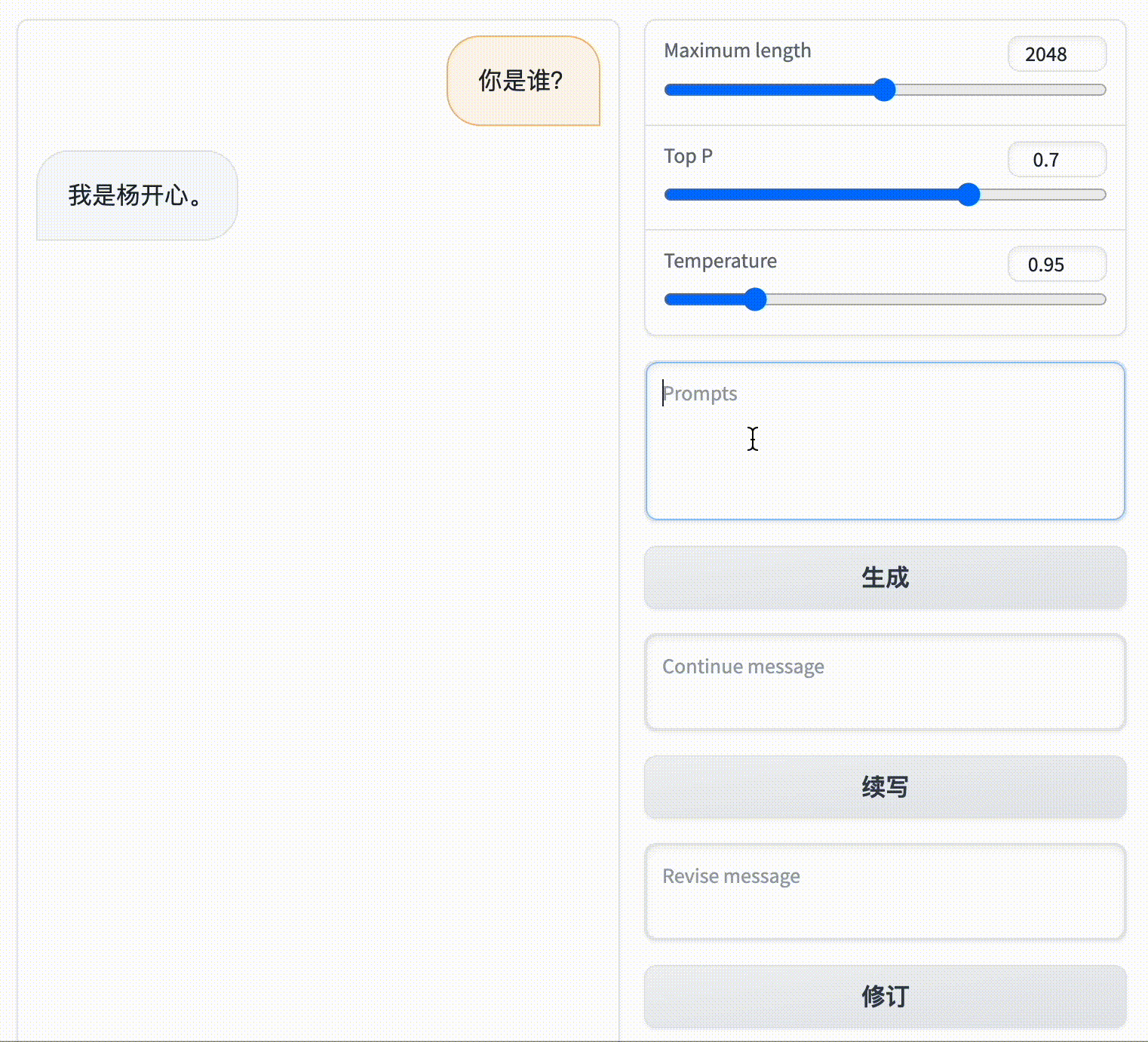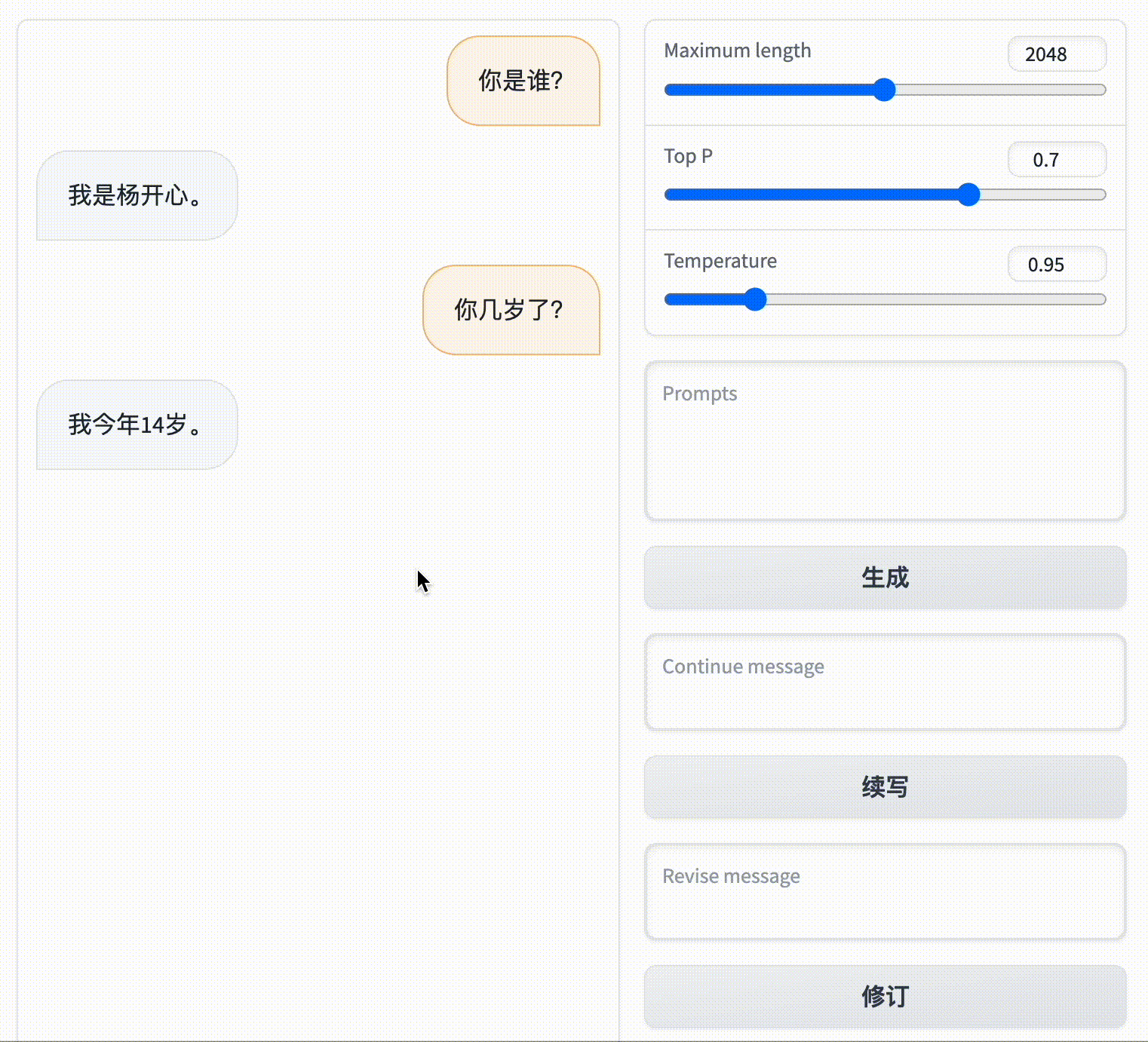
如果你直接跟 ChatGLM 说:“你是谁?”
它会回答:“我是一个名为 ChatGLM-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。”
你再问它:“你几岁了?”
它只会说:“作为一个人工智能助手,我没有年龄,因为我只是一个程序,没有实际的肉体或生命。我只是一个在计算机上运行的程序,专门设计为回答用户的问题和提供相关的帮助。”
### 修改对话
你可以改变它的角色,比如你通过“修订”功能,将它的回复改成:“我是杨开心。”
然后你再问它:“你几岁了?”
它就会回答:“我今年15岁。”

### 使用视频
### 重新对话
你可以按照某个输入,重复生成对话,从而拿到满意的结果。
### 使用视频
# 实现原理
这个方法并没有训练,没有修改官方发布的权重,而只是对推理的函数做了修改。
续写的原理是,将用户的输入直接设置为 `history[-1][1]`,模拟模型自己的部分输出,然后继续走之后的推理函数 `stream_chat_continue` [code](https://github.com/ypwhs/CreativeChatGLM/blob/a5c6dd1/chatglm/modeling_chatglm.py#L1158)。
修订的原理是,将用户的输入直接设置为 `history[-1][1]`,模拟模型自己的完整输出,但是不走推理函数。
# 离线包制作方法
关于本项目中的离线包制作方法,可以查看下面的详细步骤。
<details><summary>点击查看详细步骤</summary>
## 准备 Python
首先去 Python 官网下载:[https://www.python.org/downloads/](https://www.python.org/downloads/)
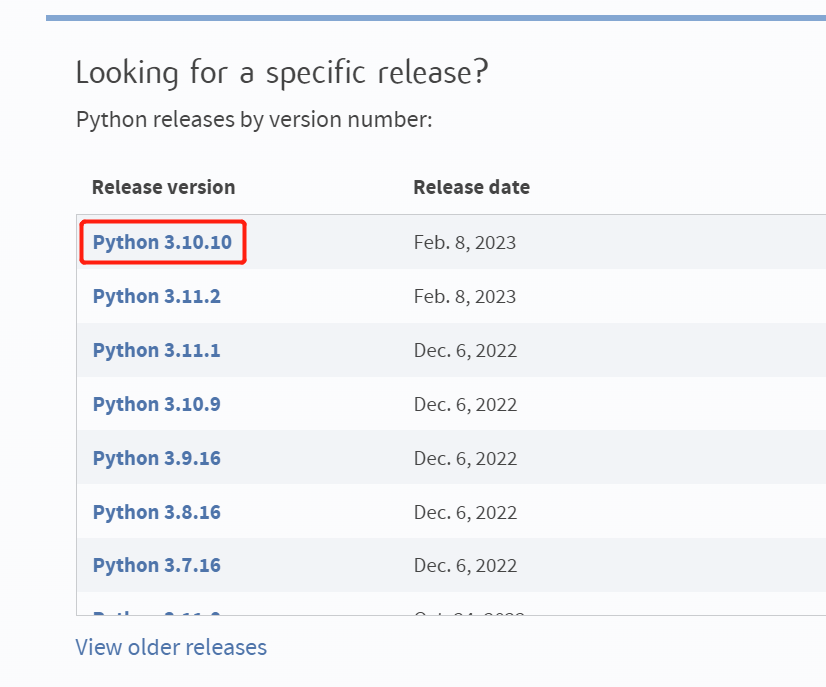
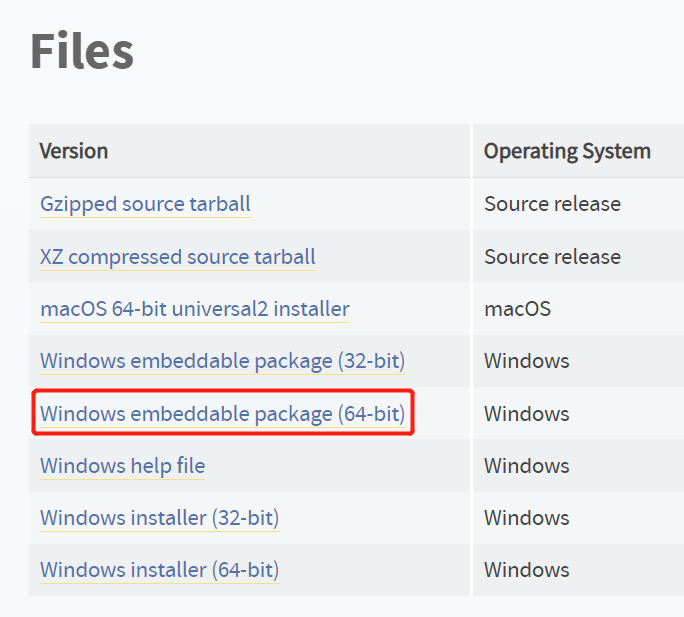
注意要下载 `Windows embeddable package (64-bit)` 离线包,我选择的是 [python-3.10.10-embed-amd64.zip](https://www.python.org/ftp/python/3.10.10/python-3.10.10-embed-amd64.zip)。
解压到 `./system/python` 目录下。
## 准备 get-pip.py
去官网下载:[https://bootstrap.pypa.io/get-pip.py](https://bootstrap.pypa.io/get-pip.py)
保存到 `./system/python` 目录下。
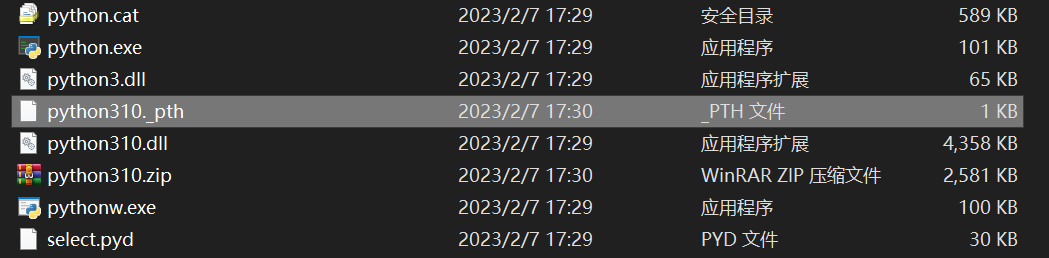
## ⚠️必做
解压之后,记得删除 pth 文件,以解决安装依赖的问题。
比如我删除的文件路径是 `./system/python/python310._pth`
## 安装依赖
运行 [setup_offline.bat](setup_offline.bat) 脚本,安装依赖。
## 下载离线模型
你可以使用 [download_model.py](download_model.py) 脚本下载模型,如果你的网络环境不好,这个过程可能会很长。下载的模型会存在 `~/.cache` 一份,存在 `./models` 一份。
当你之后使用 `AutoModel.from_pretrained` 加载模型时,可以从 `~/.cache` 缓存目录加载模型,避免二次下载。
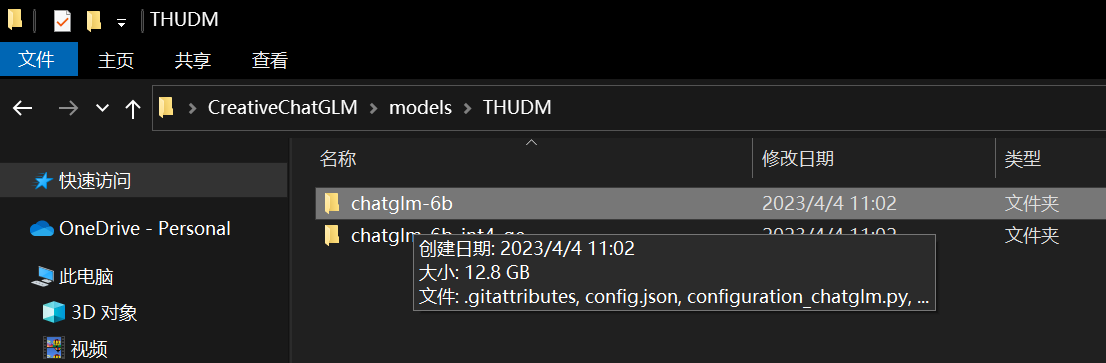
下载好的模型,你需要从 `./models` 文件夹移出到项目目录下,这样就可以离线加载了。
下载完模型之后,你需要修改 [app.py](app.py) 里的 `model_name`,改成你想加载的模型名称。
## 测试
使用 [start_offline.bat](start_offline.bat) 启动服务:
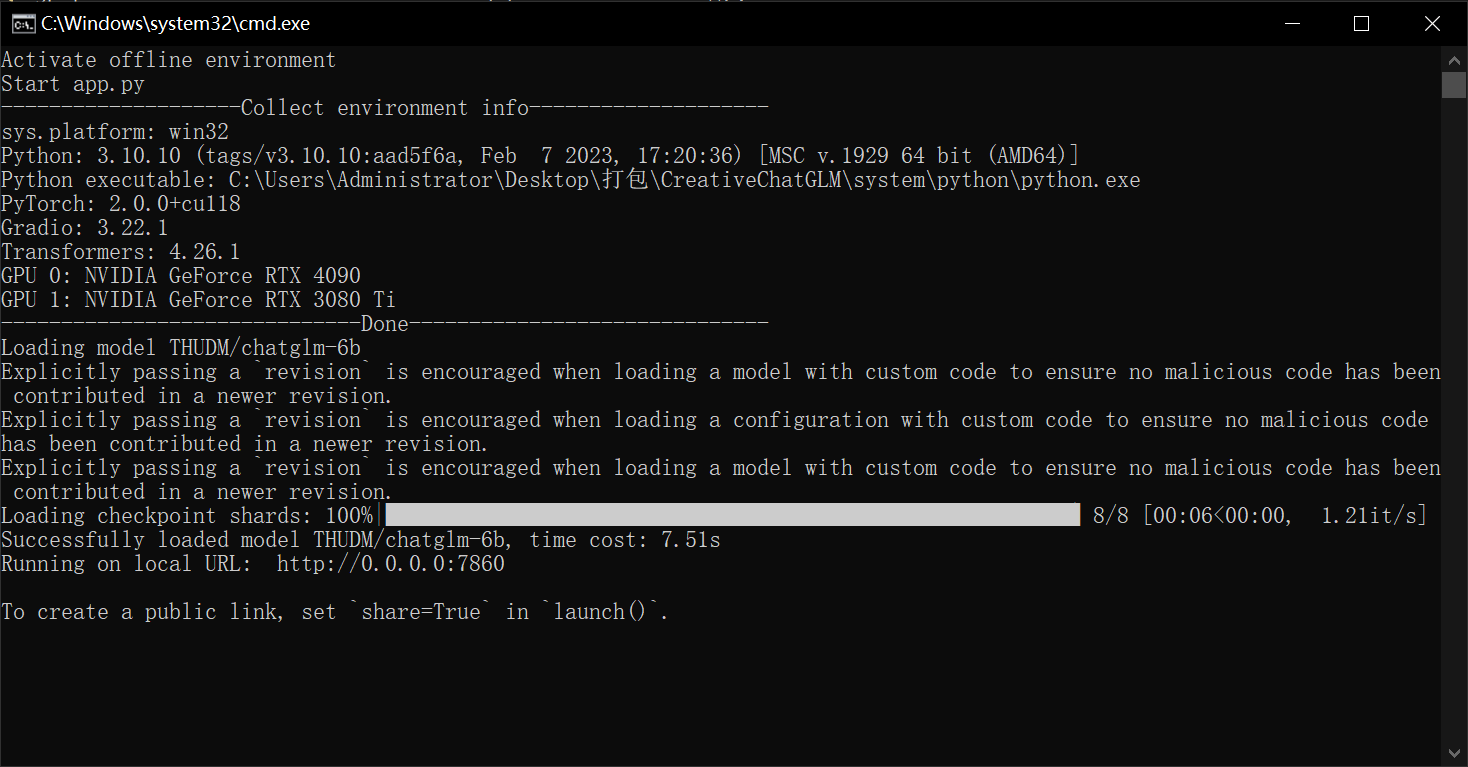
可以看到,服务正常启动。
</details>
# 协议
本仓库的代码依照 [Apache-2.0](LICENSE) 协议开源,ChatGLM-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。
================================================
FILE: app.py
================================================
import gradio as gr
from utils_env import collect_env
# 收集环境信息
print('Collect environment info'.center(64, '-'))
for name, val in collect_env().items():
print(f'{name}: {val}')
print('Done'.center(64, '-'))
# 加载模型
model_name = 'THUDM/glm-4-9b-chat-1m'
int4 = True
if 'glm-4' in model_name.lower():
from predictors.glm4_predictor import GLM4
predictor = GLM4(model_name, int4=int4)
elif 'chatglm3' in model_name.lower():
from predictors.chatglm3_predictor import ChatGLM3
predictor = ChatGLM3(model_name)
elif 'chatglm2' in model_name.lower():
from predictors.chatglm2_predictor import ChatGLM2
predictor = ChatGLM2(model_name)
elif 'chatglm' in model_name.lower():
from predictors.chatglm_predictor import ChatGLM
predictor = ChatGLM(model_name)
elif 'gptq' in model_name.lower():
from predictors.llama_gptq import LLaMaGPTQ
predictor = LLaMaGPTQ(model_name)
elif 'llama' in model_name.lower():
from predictors.llama import LLaMa
predictor = LLaMa(model_name)
elif 'debug' in model_name.lower():
from predictors.debug import Debug
predictor = Debug(model_name)
else:
from predictors.chatglm_predictor import ChatGLM
predictor = ChatGLM(model_name)
def revise(history, latest_message):
if isinstance(history[-1], tuple):
history[-1] = (history[-1][0], latest_message)
elif isinstance(history[-1], dict):
history[-1]['content'] = latest_message
return history, ''
def revoke(history, last_state):
if len(history) >= 1:
history.pop()
last_state[0] = history
last_state[1] = ''
last_state[2] = ''
return history
def interrupt(allow_generate):
allow_generate[0] = False
def regenerate(last_state, max_length, top_p, temperature, allow_generate):
history, query, continue_message = last_state
if len(query) == 0:
print("Please input a query first.")
return
for x in predictor.predict_continue(query, continue_message, max_length,
top_p, temperature, allow_generate,
history, last_state):
yield x
# 搭建 UI 界面
with gr.Blocks(css=""".message {
width: inherit !important;
padding-left: 20px !important;
}""") as demo:
gr.Markdown(f"""
# 💡Creative ChatGLM WebUI
👋 欢迎来到 ChatGLM 创意世界
当前模型:{model_name}
* 📖 你可以使用“续写”按钮帮 ChatGLM 想一个开头,并让它继续生成更多的内容。
* 📝 你可以使用“修订”按钮修改最后一句 ChatGLM 的回复。
""")
with gr.Row():
with gr.Column(scale=4):
chatbot = gr.Chatbot(
elem_id="chat-box", show_label=False, height=850)
with gr.Column(scale=1):
with gr.Row():
max_length = gr.Slider(
32,
4096,
value=2048,
step=1.0,
label="Maximum length",
interactive=True)
top_p = gr.Slider(
0.01,
1,
value=0.7,
step=0.01,
label="Top P",
interactive=True)
temperature = gr.Slider(
0.01,
5,
value=0.95,
step=0.01,
label="Temperature",
interactive=True)
with gr.Row():
query = gr.Textbox(
show_label=False, placeholder="Prompts", lines=4)
generate_button = gr.Button("生成")
with gr.Row():
continue_message = gr.Textbox(
show_label=False, placeholder="Continue message", lines=2)
continue_btn = gr.Button("续写")
revise_message = gr.Textbox(
show_label=False, placeholder="Revise message", lines=2)
revise_btn = gr.Button("修订")
revoke_btn = gr.Button("撤回")
regenerate_btn = gr.Button("重新生成")
interrupt_btn = gr.Button("终止生成")
history = gr.State([])
allow_generate = gr.State([True])
blank_input = gr.State("")
last_state = gr.State([[], '', '']) # history, query, continue_message
generate_button.click(
predictor.predict_continue,
inputs=[
query, blank_input, max_length, top_p, temperature, allow_generate,
history, last_state
],
outputs=[chatbot, query])
revise_btn.click(
revise,
inputs=[history, revise_message],
outputs=[chatbot, revise_message])
revoke_btn.click(revoke, inputs=[history, last_state], outputs=[chatbot])
continue_btn.click(
predictor.predict_continue,
inputs=[
query, continue_message, max_length, top_p, temperature,
allow_generate, history, last_state
],
outputs=[chatbot, query, continue_message])
regenerate_btn.click(
regenerate,
inputs=[last_state, max_length, top_p, temperature, allow_generate],
outputs=[chatbot, query, continue_message])
interrupt_btn.click(interrupt, inputs=[allow_generate])
demo.queue().launch(
server_name='0.0.0.0', server_port=7860, share=False, inbrowser=False)
demo.close()
================================================
FILE: app_fastapi.py
================================================
from utils_env import collect_env
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
import argparse
import logging
import os
import json
import sys
# 加载模型
# model_name = 'THUDM/chatglm-6b'
model_name = 'THUDM/chatglm3-6b'
if 'chatglm' in model_name.lower():
from predictors.chatglm_predictor import ChatGLM
predictor = ChatGLM(model_name)
elif 'gptq' in model_name.lower():
from predictors.llama_gptq import LLaMaGPTQ
predictor = LLaMaGPTQ(model_name)
elif 'llama' in model_name.lower():
from predictors.llama import LLaMa
predictor = LLaMa(model_name)
elif 'debug' in model_name.lower():
from predictors.debug import Debug
predictor = Debug(model_name)
else:
from predictors.chatglm_predictor import ChatGLM
predictor = ChatGLM(model_name)
# 接入log
def getLogger(name, file_name, use_formatter=True):
logger = logging.getLogger(name)
logger.setLevel(logging.INFO)
console_handler = logging.StreamHandler(sys.stdout)
formatter = logging.Formatter('%(asctime)s %(message)s')
console_handler.setFormatter(formatter)
console_handler.setLevel(logging.INFO)
logger.addHandler(console_handler)
if file_name:
handler = logging.FileHandler(file_name, encoding='utf8')
handler.setLevel(logging.INFO)
if use_formatter:
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
logger = getLogger('ChatGLM', 'chatlog.log')
# 接入FastAPI
def start_server(quantize_level, http_address: str, port: int, gpu_id: str):
os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'
os.environ['CUDA_VISIBLE_DEVICES'] = gpu_id
bot = predictor
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"])
allow_generate = [True]
@app.get("/")
def index():
return {'message': 'started', 'success': True}
@app.post("/stream")
def continue_question_stream(arg_dict: dict):
def decorate(generator):
for item in generator:
yield f"data: {json.dumps(item, ensure_ascii=False)}\n\n"
# inputs = [query, answer_prefix, max_length, top_p, temperature, allow_generate, history]
try:
query = arg_dict["query"]
answer_prefix = arg_dict.get("answer_prefix", "")
max_length = arg_dict.get("max_length", 256)
top_p = arg_dict.get("top_p", 0.7)
temperature = arg_dict.get("temperature", 1.0)
allow_generate = arg_dict.get("allow_generate", [True])
history = arg_dict.get("history", [])
logger.info("Query - {}".format(query))
if answer_prefix:
logger.info(f"answer_prefix - {answer_prefix}")
history = history[-MAX_HISTORY:]
if len(history) > 0:
logger.info("History - {}".format(history))
history = [tuple(h) for h in history]
inputs = [
query, answer_prefix, max_length, top_p, temperature,
allow_generate, history
]
return StreamingResponse(decorate(bot.predict_continue(*inputs)))
# return EventSourceResponse(bot.predict_continue(*inputs))
except Exception as e:
logger.error(f"error: {e}")
return StreamingResponse(
decorate(bot.predict_continue(None, None)))
@app.post("/interrupt")
def interrupt():
allow_generate[0] = False
logger.error("Interrupted.")
return {"message": "OK"}
logger.info("starting server...")
uvicorn.run(app=app, host=http_address, port=port)
if __name__ == '__main__':
# 超参数 用于控制模型回复时 上文的长度
MAX_HISTORY = 5
parser = argparse.ArgumentParser(
description='Stream API Service for ChatGLM-6B')
parser.add_argument(
'--device',
'-d',
help='device,-1 means cpu, other means gpu ids',
default='0')
parser.add_argument(
'--quantize',
'-q',
help='level of quantize, option:16, 8 or 4',
default=16)
parser.add_argument(
'--host', '-H', help='host to listen', default='0.0.0.0')
parser.add_argument(
'--port', '-P', help='port of this service', default=8000)
args = parser.parse_args()
start_server(args.quantize, args.host, int(args.port), args.device)
================================================
FILE: chatglm/configuration_chatglm.py
================================================
""" ChatGLM model configuration """
from transformers.configuration_utils import PretrainedConfig
from transformers.utils import logging
logger = logging.get_logger(__name__)
class ChatGLMConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`~ChatGLMModel`].
It is used to instantiate an ChatGLM model according to the specified arguments, defining the model
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of
the ChatGLM-6B [THUDM/ChatGLM-6B](https://huggingface.co/THUDM/chatglm-6b) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used
to control the model outputs. Read the documentation from [`PretrainedConfig`]
for more information.
Args:
vocab_size (`int`, *optional*, defaults to 150528):
Vocabulary size of the ChatGLM-6B model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`~ChatGLMModel`] or
[`~TFChatGLMModel`].
hidden_size (`int`, *optional*, defaults to 4096):
Dimension of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 28):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads for each attention layer in the Transformer encoder.
inner_hidden_size (`int`, *optional*, defaults to 16384):
Dimension of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
max_sequence_length (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with.
Typically set this to something large just in case (e.g., 512 or 1024 or 2048).
layernorm_epsilon (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether the model should return the last key/values attentions (not used by all models).
Example:
```python
>>> from configuration_chatglm import ChatGLMConfig
>>> from modeling_chatglm import ChatGLMModel
>>> # Initializing a ChatGLM-6B THUDM/ChatGLM-6B style configuration
>>> configuration = ChatGLMConfig()
>>> # Initializing a model from the THUDM/ChatGLM-6B style configuration
>>> model = ChatGLMModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "chatglm"
def __init__(
self,
vocab_size=150528,
hidden_size=4096,
num_layers=28,
num_attention_heads=32,
layernorm_epsilon=1e-5,
use_cache=False,
bos_token_id=150004,
eos_token_id=150005,
mask_token_id=150000,
gmask_token_id=150001,
pad_token_id=0,
max_sequence_length=2048,
inner_hidden_size=16384,
position_encoding_2d=True,
quantization_bit=0,
pre_seq_len=None,
prefix_projection=False,
**kwargs
):
self.num_layers = num_layers
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_attention_heads = num_attention_heads
self.max_sequence_length = max_sequence_length
self.layernorm_epsilon = layernorm_epsilon
self.inner_hidden_size = inner_hidden_size
self.use_cache = use_cache
self.bos_token_id = bos_token_id
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.mask_token_id = mask_token_id
self.gmask_token_id = gmask_token_id
self.position_encoding_2d = position_encoding_2d
self.quantization_bit = quantization_bit
self.pre_seq_len = pre_seq_len
self.prefix_projection = prefix_projection
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
**kwargs
)
================================================
FILE: chatglm/modeling_chatglm.py
================================================
""" PyTorch ChatGLM model. """
import math
import copy
import os
import warnings
import re
import sys
import torch
import torch.utils.checkpoint
import torch.nn.functional as F
from torch import nn
from torch.nn import CrossEntropyLoss, LayerNorm
from torch.nn.utils import skip_init
from typing import Optional, Tuple, Union, List, Callable, Dict, Any
from transformers.utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
)
from transformers.modeling_outputs import (
BaseModelOutputWithPast,
CausalLMOutputWithPast,
BaseModelOutputWithPastAndCrossAttentions,
)
from transformers.modeling_utils import PreTrainedModel
from transformers.utils import logging
from transformers.generation.logits_process import LogitsProcessor
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList, GenerationConfig, ModelOutput
from .configuration_chatglm import ChatGLMConfig
# flags required to enable jit fusion kernels
if sys.platform != 'darwin':
torch._C._jit_set_profiling_mode(False)
torch._C._jit_set_profiling_executor(False)
torch._C._jit_override_can_fuse_on_cpu(True)
torch._C._jit_override_can_fuse_on_gpu(True)
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM-6B"
_CONFIG_FOR_DOC = "ChatGLM6BConfig"
CHATGLM_6B_PRETRAINED_MODEL_ARCHIVE_LIST = [
"THUDM/chatglm-6b",
# See all ChatGLM-6B models at https://huggingface.co/models?filter=chatglm
]
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., 5] = 5e4
return scores
def load_tf_weights_in_chatglm_6b(model, config, tf_checkpoint_path):
"""Load tf checkpoints in a pytorch model."""
try:
import re
import numpy as np
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
# Load weights from TF model
init_vars = tf.train.list_variables(tf_path)
names = []
arrays = []
for name, shape in init_vars:
logger.info(f"Loading TF weight {name} with shape {shape}")
array = tf.train.load_variable(tf_path, name)
names.append(name)
arrays.append(array)
for name, array in zip(names, arrays):
name = name.split("/")
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
# which are not required for using pretrained model
if any(
n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
for n in name
):
logger.info(f"Skipping {'/'.join(name)}")
continue
pointer = model
for m_name in name:
if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
scope_names = re.split(r"_(\d+)", m_name)
else:
scope_names = [m_name]
if scope_names[0] == "kernel" or scope_names[0] == "gamma":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
pointer = getattr(pointer, "bias")
elif scope_names[0] == "output_weights":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "squad":
pointer = getattr(pointer, "classifier")
else:
try:
pointer = getattr(pointer, scope_names[0])
except AttributeError:
logger.info(f"Skipping {'/'.join(name)}")
continue
if len(scope_names) >= 2:
num = int(scope_names[1])
pointer = pointer[num]
if m_name[-11:] == "_embeddings":
pointer = getattr(pointer, "weight")
elif m_name == "kernel":
array = np.transpose(array)
try:
assert (
pointer.shape == array.shape
), f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
logger.info(f"Initialize PyTorch weight {name}")
pointer.data = torch.from_numpy(array)
return model
class PrefixEncoder(torch.nn.Module):
"""
The torch.nn model to encode the prefix
Input shape: (batch-size, prefix-length)
Output shape: (batch-size, prefix-length, 2*layers*hidden)
"""
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# Use a two-layer MLP to encode the prefix
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.hidden_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(config.hidden_size, config.hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.hidden_size, config.num_layers * config.hidden_size * 2)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.num_layers * config.hidden_size * 2)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
@torch.jit.script
def gelu_impl(x):
"""OpenAI's gelu implementation."""
return 0.5 * x * (1.0 + torch.tanh(0.7978845608028654 * x *
(1.0 + 0.044715 * x * x)))
def gelu(x):
return gelu_impl(x)
class RotaryEmbedding(torch.nn.Module):
def __init__(self, dim, base=10000, precision=torch.half, learnable=False):
super().__init__()
inv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))
if precision == torch.half:
inv_freq = inv_freq.half()
self.learnable = learnable
if learnable:
self.inv_freq = torch.nn.Parameter(inv_freq)
self.max_seq_len_cached = None
else:
self.register_buffer('inv_freq', inv_freq)
self.max_seq_len_cached = None
self.cos_cached = None
self.sin_cached = None
self.precision = precision
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
error_msgs):
pass
def forward(self, x, seq_dim=1, seq_len=None):
if seq_len is None:
seq_len = x.shape[seq_dim]
if self.max_seq_len_cached is None or (seq_len > self.max_seq_len_cached):
self.max_seq_len_cached = None if self.learnable else seq_len
t = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
if self.precision == torch.bfloat16:
emb = emb.float()
# [sx, 1 (b * np), hn]
cos_cached = emb.cos()[:, None, :]
sin_cached = emb.sin()[:, None, :]
if self.precision == torch.bfloat16:
cos_cached = cos_cached.bfloat16()
sin_cached = sin_cached.bfloat16()
if self.learnable:
return cos_cached, sin_cached
self.cos_cached, self.sin_cached = cos_cached, sin_cached
return self.cos_cached[:seq_len, ...], self.sin_cached[:seq_len, ...]
def _apply(self, fn):
if self.cos_cached is not None:
self.cos_cached = fn(self.cos_cached)
if self.sin_cached is not None:
self.sin_cached = fn(self.sin_cached)
return super()._apply(fn)
def rotate_half(x):
x1, x2 = x[..., :x.shape[-1] // 2], x[..., x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=x1.ndim - 1) # dim=-1 triggers a bug in earlier torch versions
@torch.jit.script
def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):
# position_id: [sq, b], q, k: [sq, b, np, hn], cos: [sq, 1, hn] -> [sq, b, 1, hn]
cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \
F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)
q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
return q, k
def attention_fn(
self,
query_layer,
key_layer,
value_layer,
attention_mask,
hidden_size_per_partition,
layer_id,
layer_past=None,
scaling_attention_score=True,
use_cache=False,
):
if layer_past is not None:
past_key, past_value = layer_past[0], layer_past[1]
key_layer = torch.cat((past_key, key_layer), dim=0)
value_layer = torch.cat((past_value, value_layer), dim=0)
# seqlen, batch, num_attention_heads, hidden_size_per_attention_head
seq_len, b, nh, hidden_size = key_layer.shape
if use_cache:
present = (key_layer, value_layer)
else:
present = None
query_key_layer_scaling_coeff = float(layer_id + 1)
if scaling_attention_score:
query_layer = query_layer / (math.sqrt(hidden_size) * query_key_layer_scaling_coeff)
# ===================================
# Raw attention scores. [b, np, s, s]
# ===================================
# [b, np, sq, sk]
output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))
# [sq, b, np, hn] -> [sq, b * np, hn]
query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
# [sk, b, np, hn] -> [sk, b * np, hn]
key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
matmul_result = torch.zeros(
1, 1, 1,
dtype=query_layer.dtype,
device=query_layer.device,
)
matmul_result = torch.baddbmm(
matmul_result,
query_layer.transpose(0, 1), # [b * np, sq, hn]
key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
beta=0.0,
alpha=1.0,
)
# change view to [b, np, sq, sk]
attention_scores = matmul_result.view(*output_size)
if self.scale_mask_softmax:
self.scale_mask_softmax.scale = query_key_layer_scaling_coeff
attention_probs = self.scale_mask_softmax(attention_scores, attention_mask.contiguous())
else:
if not (attention_mask == 0).all():
# if auto-regressive, skip
attention_scores.masked_fill_(attention_mask, -10000.0)
dtype = attention_scores.dtype
attention_scores = attention_scores.float()
attention_scores = attention_scores * query_key_layer_scaling_coeff
attention_probs = F.softmax(attention_scores, dim=-1)
attention_probs = attention_probs.type(dtype)
# =========================
# Context layer. [sq, b, hp]
# =========================
# value_layer -> context layer.
# [sk, b, np, hn] --> [b, np, sq, hn]
# context layer shape: [b, np, sq, hn]
output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))
# change view [sk, b * np, hn]
value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)
# change view [b * np, sq, sk]
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
# matmul: [b * np, sq, hn]
context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))
# change view [b, np, sq, hn]
context_layer = context_layer.view(*output_size)
# [b, np, sq, hn] --> [sq, b, np, hn]
context_layer = context_layer.permute(2, 0, 1, 3).contiguous()
# [sq, b, np, hn] --> [sq, b, hp]
new_context_layer_shape = context_layer.size()[:-2] + (hidden_size_per_partition,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, present, attention_probs)
return outputs
def default_init(cls, *args, **kwargs):
return cls(*args, **kwargs)
class SelfAttention(torch.nn.Module):
def __init__(self, hidden_size, num_attention_heads,
layer_id, hidden_size_per_attention_head=None, bias=True,
params_dtype=torch.float, position_encoding_2d=True, empty_init=True):
if empty_init:
init_method = skip_init
else:
init_method = default_init
super(SelfAttention, self).__init__()
self.layer_id = layer_id
self.hidden_size = hidden_size
self.hidden_size_per_partition = hidden_size
self.num_attention_heads = num_attention_heads
self.num_attention_heads_per_partition = num_attention_heads
self.position_encoding_2d = position_encoding_2d
self.rotary_emb = RotaryEmbedding(
self.hidden_size // (self.num_attention_heads * 2)
if position_encoding_2d
else self.hidden_size // self.num_attention_heads,
base=10000,
precision=torch.half,
learnable=False,
)
self.scale_mask_softmax = None
if hidden_size_per_attention_head is None:
self.hidden_size_per_attention_head = hidden_size // num_attention_heads
else:
self.hidden_size_per_attention_head = hidden_size_per_attention_head
self.inner_hidden_size = num_attention_heads * self.hidden_size_per_attention_head
# Strided linear layer.
self.query_key_value = init_method(
torch.nn.Linear,
hidden_size,
3 * self.inner_hidden_size,
bias=bias,
dtype=params_dtype,
)
self.dense = init_method(
torch.nn.Linear,
self.inner_hidden_size,
hidden_size,
bias=bias,
dtype=params_dtype,
)
@staticmethod
def attention_mask_func(attention_scores, attention_mask):
attention_scores.masked_fill_(attention_mask, -10000.0)
return attention_scores
def split_tensor_along_last_dim(self, tensor, num_partitions,
contiguous_split_chunks=False):
"""Split a tensor along its last dimension.
Arguments:
tensor: input tensor.
num_partitions: number of partitions to split the tensor
contiguous_split_chunks: If True, make each chunk contiguous
in memory.
"""
# Get the size and dimension.
last_dim = tensor.dim() - 1
last_dim_size = tensor.size()[last_dim] // num_partitions
# Split.
tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
# Note: torch.split does not create contiguous tensors by default.
if contiguous_split_chunks:
return tuple(chunk.contiguous() for chunk in tensor_list)
return tensor_list
def forward(
self,
hidden_states: torch.Tensor,
position_ids,
attention_mask: torch.Tensor,
layer_id,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
use_cache: bool = False,
output_attentions: bool = False,
):
"""
hidden_states: [seq_len, batch, hidden_size]
attention_mask: [(1, 1), seq_len, seq_len]
"""
# [seq_len, batch, 3 * hidden_size]
mixed_raw_layer = self.query_key_value(hidden_states)
# [seq_len, batch, 3 * hidden_size] --> [seq_len, batch, num_attention_heads, 3 * hidden_size_per_attention_head]
new_tensor_shape = mixed_raw_layer.size()[:-1] + (
self.num_attention_heads_per_partition,
3 * self.hidden_size_per_attention_head,
)
mixed_raw_layer = mixed_raw_layer.view(*new_tensor_shape)
# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head]
(query_layer, key_layer, value_layer) = self.split_tensor_along_last_dim(mixed_raw_layer, 3)
if self.position_encoding_2d:
q1, q2 = query_layer.chunk(2, dim=(query_layer.ndim - 1))
k1, k2 = key_layer.chunk(2, dim=(key_layer.ndim - 1))
cos, sin = self.rotary_emb(q1, seq_len=position_ids.max() + 1)
position_ids, block_position_ids = position_ids[:, 0, :].transpose(0, 1).contiguous(), \
position_ids[:, 1, :].transpose(0, 1).contiguous()
q1, k1 = apply_rotary_pos_emb_index(q1, k1, cos, sin, position_ids)
q2, k2 = apply_rotary_pos_emb_index(q2, k2, cos, sin, block_position_ids)
query_layer = torch.concat([q1, q2], dim=(q1.ndim - 1))
key_layer = torch.concat([k1, k2], dim=(k1.ndim - 1))
else:
position_ids = position_ids.transpose(0, 1)
cos, sin = self.rotary_emb(value_layer, seq_len=position_ids.max() + 1)
# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head]
query_layer, key_layer = apply_rotary_pos_emb_index(query_layer, key_layer, cos, sin, position_ids)
# [seq_len, batch, hidden_size]
context_layer, present, attention_probs = attention_fn(
self=self,
query_layer=query_layer,
key_layer=key_layer,
value_layer=value_layer,
attention_mask=attention_mask,
hidden_size_per_partition=self.hidden_size_per_partition,
layer_id=layer_id,
layer_past=layer_past,
use_cache=use_cache
)
output = self.dense(context_layer)
outputs = (output, present)
if output_attentions:
outputs += (attention_probs,)
return outputs # output, present, attention_probs
class GEGLU(torch.nn.Module):
def __init__(self):
super().__init__()
self.activation_fn = F.gelu
def forward(self, x):
# dim=-1 breaks in jit for pt<1.10
x1, x2 = x.chunk(2, dim=(x.ndim - 1))
return x1 * self.activation_fn(x2)
class GLU(torch.nn.Module):
def __init__(self, hidden_size, inner_hidden_size=None,
layer_id=None, bias=True, activation_func=gelu, params_dtype=torch.float, empty_init=True):
super(GLU, self).__init__()
if empty_init:
init_method = skip_init
else:
init_method = default_init
self.layer_id = layer_id
self.activation_func = activation_func
# Project to 4h.
self.hidden_size = hidden_size
if inner_hidden_size is None:
inner_hidden_size = 4 * hidden_size
self.inner_hidden_size = inner_hidden_size
self.dense_h_to_4h = init_method(
torch.nn.Linear,
self.hidden_size,
self.inner_hidden_size,
bias=bias,
dtype=params_dtype,
)
# Project back to h.
self.dense_4h_to_h = init_method(
torch.nn.Linear,
self.inner_hidden_size,
self.hidden_size,
bias=bias,
dtype=params_dtype,
)
def forward(self, hidden_states):
"""
hidden_states: [seq_len, batch, hidden_size]
"""
# [seq_len, batch, inner_hidden_size]
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = self.activation_func(intermediate_parallel)
output = self.dense_4h_to_h(intermediate_parallel)
return output
class GLMBlock(torch.nn.Module):
def __init__(
self,
hidden_size,
num_attention_heads,
layernorm_epsilon,
layer_id,
inner_hidden_size=None,
hidden_size_per_attention_head=None,
layernorm=LayerNorm,
use_bias=True,
params_dtype=torch.float,
num_layers=28,
position_encoding_2d=True,
empty_init=True
):
super(GLMBlock, self).__init__()
# Set output layer initialization if not provided.
self.layer_id = layer_id
# Layernorm on the input data.
self.input_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)
self.position_encoding_2d = position_encoding_2d
# Self attention.
self.attention = SelfAttention(
hidden_size,
num_attention_heads,
layer_id,
hidden_size_per_attention_head=hidden_size_per_attention_head,
bias=use_bias,
params_dtype=params_dtype,
position_encoding_2d=self.position_encoding_2d,
empty_init=empty_init
)
# Layernorm on the input data.
self.post_attention_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)
self.num_layers = num_layers
# GLU
self.mlp = GLU(
hidden_size,
inner_hidden_size=inner_hidden_size,
bias=use_bias,
layer_id=layer_id,
params_dtype=params_dtype,
empty_init=empty_init
)
def forward(
self,
hidden_states: torch.Tensor,
position_ids,
attention_mask: torch.Tensor,
layer_id,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
use_cache: bool = False,
output_attentions: bool = False,
):
"""
hidden_states: [seq_len, batch, hidden_size]
attention_mask: [(1, 1), seq_len, seq_len]
"""
# Layer norm at the begining of the transformer layer.
# [seq_len, batch, hidden_size]
attention_input = self.input_layernorm(hidden_states)
# Self attention.
attention_outputs = self.attention(
attention_input,
position_ids,
attention_mask=attention_mask,
layer_id=layer_id,
layer_past=layer_past,
use_cache=use_cache,
output_attentions=output_attentions
)
attention_output = attention_outputs[0]
outputs = attention_outputs[1:]
# Residual connection.
alpha = (2 * self.num_layers) ** 0.5
hidden_states = attention_input * alpha + attention_output
mlp_input = self.post_attention_layernorm(hidden_states)
# MLP.
mlp_output = self.mlp(mlp_input)
# Second residual connection.
output = mlp_input * alpha + mlp_output
if use_cache:
outputs = (output,) + outputs
else:
outputs = (output,) + outputs[1:]
return outputs # hidden_states, present, attentions
class ChatGLMPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
is_parallelizable = False
supports_gradient_checkpointing = True
config_class = ChatGLMConfig
base_model_prefix = "transformer"
_no_split_modules = ["GLMBlock"]
def __init__(self, *inputs, **kwargs):
super().__init__(*inputs, **kwargs)
def _init_weights(self, module: nn.Module):
"""Initialize the weights."""
return
def get_masks(self, input_ids, device):
batch_size, seq_length = input_ids.shape
context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]
attention_mask = torch.ones((batch_size, seq_length, seq_length), device=device)
attention_mask.tril_()
for i, context_length in enumerate(context_lengths):
attention_mask[i, :, :context_length] = 1
attention_mask.unsqueeze_(1)
attention_mask = (attention_mask < 0.5).bool()
return attention_mask
def get_position_ids(self, input_ids, mask_positions, device, use_gmasks=None):
batch_size, seq_length = input_ids.shape
if use_gmasks is None:
use_gmasks = [False] * batch_size
context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]
if self.position_encoding_2d:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
for i, context_length in enumerate(context_lengths):
position_ids[i, context_length:] = mask_positions[i]
block_position_ids = [torch.cat((
torch.zeros(context_length, dtype=torch.long, device=device),
torch.arange(seq_length - context_length, dtype=torch.long, device=device) + 1
)) for context_length in context_lengths]
block_position_ids = torch.stack(block_position_ids, dim=0)
position_ids = torch.stack((position_ids, block_position_ids), dim=1)
else:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
for i, context_length in enumerate(context_lengths):
if not use_gmasks[i]:
position_ids[context_length:] = mask_positions[i]
return position_ids
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, ChatGLMModel):
module.gradient_checkpointing = value
CHATGLM_6B_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
usage and behavior.
Parameters:
config ([`~ChatGLM6BConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the configuration.
Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
CHATGLM_6B_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`ChatGLM6BTokenizer`].
See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings.
Selected in the range `[0, config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert *input_ids* indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare ChatGLM-6B Model transformer outputting raw hidden-states without any specific head on top.",
CHATGLM_6B_START_DOCSTRING,
)
class ChatGLMModel(ChatGLMPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well
as a decoder, in which case a layer of cross-attention is added between
the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani,
Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the
`is_decoder` argument of the configuration set to `True`.
To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder`
argument and `add_cross_attention` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config: ChatGLMConfig, empty_init=True):
super().__init__(config)
if empty_init:
init_method = skip_init
else:
init_method = default_init
# recording parameters
self.max_sequence_length = config.max_sequence_length
self.hidden_size = config.hidden_size
self.params_dtype = torch.half
self.num_attention_heads = config.num_attention_heads
self.vocab_size = config.vocab_size
self.num_layers = config.num_layers
self.layernorm_epsilon = config.layernorm_epsilon
self.inner_hidden_size = config.inner_hidden_size
self.hidden_size_per_attention_head = self.hidden_size // self.num_attention_heads
self.position_encoding_2d = config.position_encoding_2d
self.pre_seq_len = config.pre_seq_len
self.prefix_projection = config.prefix_projection
self.word_embeddings = init_method(
torch.nn.Embedding,
num_embeddings=self.vocab_size, embedding_dim=self.hidden_size,
dtype=self.params_dtype
)
self.gradient_checkpointing = False
def get_layer(layer_id):
return GLMBlock(
self.hidden_size,
self.num_attention_heads,
self.layernorm_epsilon,
layer_id,
inner_hidden_size=self.inner_hidden_size,
hidden_size_per_attention_head=self.hidden_size_per_attention_head,
layernorm=LayerNorm,
use_bias=True,
params_dtype=self.params_dtype,
position_encoding_2d=self.position_encoding_2d,
empty_init=empty_init
)
self.layers = torch.nn.ModuleList(
[get_layer(layer_id) for layer_id in range(self.num_layers)]
)
# Final layer norm before output.
self.final_layernorm = LayerNorm(self.hidden_size, eps=self.layernorm_epsilon)
if self.pre_seq_len is not None:
for param in self.parameters():
param.requires_grad = False
self.prefix_tokens = torch.arange(self.pre_seq_len).long()
self.prefix_encoder = PrefixEncoder(config)
self.dropout = torch.nn.Dropout(0.1)
# total_params = sum(p.numel() for p in self.parameters())
# trainable_params = sum(p.numel() for p in self.parameters() if p.requires_grad)
# print("Using p-tuning v2: # trainable_params = {} / {}".format(trainable_params, total_params))
def get_input_embeddings(self):
return self.word_embeddings
def set_input_embeddings(self, new_embeddings: torch.Tensor):
self.word_embeddings = new_embeddings
def get_prompt(self, batch_size, device, dtype=torch.half):
prefix_tokens = self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device)
past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)
past_key_values = past_key_values.view(
batch_size,
self.pre_seq_len,
self.num_layers * 2,
self.num_attention_heads,
self.hidden_size // self.num_attention_heads
)
# seq_len, b, nh, hidden_size
past_key_values = self.dropout(past_key_values)
past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)
# past_key_values = [(v[0], v[1]) for v in past_key_values]
return past_key_values
@add_start_docstrings_to_model_forward(CHATGLM_6B_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
inputs_embeds: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPast]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
batch_size, seq_length = input_ids.shape[:2]
elif inputs_embeds is not None:
batch_size, seq_length = inputs_embeds.shape[:2]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
if past_key_values is None:
if self.pre_seq_len is not None:
past_key_values = self.get_prompt(batch_size=input_ids.shape[0], device=input_ids.device,
dtype=inputs_embeds.dtype)
else:
past_key_values = tuple([None] * len(self.layers))
if attention_mask is None:
attention_mask = self.get_masks(
input_ids,
device=input_ids.device
)
if position_ids is None:
MASK, gMASK = self.config.mask_token_id, self.config.gmask_token_id
seqs = input_ids.tolist()
mask_positions, use_gmasks = [], []
for seq in seqs:
mask_token = gMASK if gMASK in seq else MASK
use_gmask = mask_token == gMASK
mask_positions.append(seq.index(mask_token))
use_gmasks.append(use_gmask)
position_ids = self.get_position_ids(
input_ids,
mask_positions=mask_positions,
device=input_ids.device,
use_gmasks=use_gmasks
)
if self.pre_seq_len is not None and attention_mask is not None:
prefix_attention_mask = torch.ones(batch_size, 1, input_ids.size(-1), self.pre_seq_len).to(
attention_mask.device)
prefix_attention_mask = (prefix_attention_mask < 0.5).bool()
attention_mask = torch.cat((prefix_attention_mask, attention_mask), dim=3)
# [seq_len, batch, hidden_size]
hidden_states = inputs_embeds.transpose(0, 1)
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
if attention_mask is None:
attention_mask = torch.zeros(1, 1, device=input_ids.device).bool()
else:
attention_mask = attention_mask.to(hidden_states.device)
for i, layer in enumerate(self.layers):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_past = past_key_values[i]
if self.gradient_checkpointing and self.training:
layer_ret = torch.utils.checkpoint.checkpoint(
layer,
hidden_states,
position_ids,
attention_mask,
torch.tensor(i),
layer_past,
use_cache,
output_attentions
)
else:
layer_ret = layer(
hidden_states,
position_ids=position_ids,
attention_mask=attention_mask,
layer_id=torch.tensor(i),
layer_past=layer_past,
use_cache=use_cache,
output_attentions=output_attentions
)
hidden_states = layer_ret[0]
if use_cache:
presents = presents + (layer_ret[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_ret[2 if use_cache else 1],)
# Final layer norm.
hidden_states = self.final_layernorm(hidden_states)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, empty_init=True):
super().__init__(config)
if empty_init:
init_method = skip_init
else:
init_method = default_init
# self.hidden_size = config.hidden_size
# self.params_dtype = torch.half
# self.vocab_size = config.vocab_size
self.max_sequence_length = config.max_sequence_length
self.position_encoding_2d = config.position_encoding_2d
self.transformer = ChatGLMModel(config, empty_init=empty_init)
self.lm_head = init_method(
nn.Linear,
config.hidden_size,
config.vocab_size,
bias=False,
dtype=torch.half
)
self.config = config
self.quantized = False
if self.config.quantization_bit:
self.quantize(self.config.quantization_bit, empty_init=True)
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
def _update_model_kwargs_for_generation(
self,
outputs: ModelOutput,
model_kwargs: Dict[str, Any],
is_encoder_decoder: bool = False,
standardize_cache_format: bool = False,
) -> Dict[str, Any]:
# update past_key_values
model_kwargs["past_key_values"] = self._extract_past_from_model_output(
outputs, standardize_cache_format=standardize_cache_format
)
# update attention mask
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
if attention_mask is not None and attention_mask.dtype == torch.bool:
attention_mask = torch.cat(
[attention_mask, attention_mask.new_ones((*attention_mask.shape[:3], 1))], dim=3)
new_attention_mask = attention_mask[:, :, -1:].clone()
new_attention_mask[..., -1] = False
model_kwargs["attention_mask"] = torch.cat(
[attention_mask, new_attention_mask], dim=2
)
# update position ids
if "position_ids" in model_kwargs:
position_ids = model_kwargs["position_ids"]
new_position_id = position_ids[..., -1:].clone()
new_position_id[:, 1, :] += 1
model_kwargs["position_ids"] = torch.cat(
[position_ids, new_position_id], dim=-1
)
return model_kwargs
def prepare_inputs_for_generation(
self,
input_ids: torch.LongTensor,
past: Optional[torch.Tensor] = None,
past_key_values: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
**kwargs
) -> dict:
batch_size, seq_length = input_ids.shape
MASK, gMASK = self.config.mask_token_id, self.config.gmask_token_id
seqs = input_ids.tolist()
mask_positions, use_gmasks = [], []
for seq in seqs:
mask_token = gMASK if gMASK in seq else MASK
use_gmask = mask_token == gMASK
mask_positions.append(seq.index(mask_token))
use_gmasks.append(use_gmask)
# only last token for input_ids if past is not None
if past is not None or past_key_values is not None:
last_token = input_ids[:, -1].unsqueeze(-1)
if attention_mask is not None and attention_mask.dtype == torch.bool:
attention_mask = attention_mask[:, :, -1:]
else:
attention_mask = None
if position_ids is not None:
position_ids = position_ids[..., -1:]
else:
context_lengths = [seq.index(self.config.bos_token_id) for seq in seqs]
if self.position_encoding_2d:
position_ids = torch.tensor(
[[mask_position, seq_length - context_length] for mask_position, context_length in
zip(mask_positions, context_lengths)], dtype=torch.long, device=input_ids.device).unsqueeze(-1)
else:
position_ids = torch.tensor([mask_position for mask_position in mask_positions], dtype=torch.long,
device=input_ids.device).unsqueeze(-1)
if past is None:
past = past_key_values
return {
"input_ids": last_token,
"past_key_values": past,
"position_ids": position_ids,
"attention_mask": attention_mask
}
else:
if attention_mask is not None and attention_mask.dtype != torch.bool:
logger.warning_once(f"The dtype of attention mask ({attention_mask.dtype}) is not bool")
attention_mask = None
if attention_mask is None:
attention_mask = self.get_masks(
input_ids,
device=input_ids.device
)
if position_ids is None:
position_ids = self.get_position_ids(
input_ids,
device=input_ids.device,
mask_positions=mask_positions,
use_gmasks=use_gmasks
)
return {
"input_ids": input_ids,
"past_key_values": past,
"position_ids": position_ids,
"attention_mask": attention_mask
}
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states).permute(1, 0, 2).contiguous()
loss = None
if labels is not None:
lm_logits = lm_logits.to(torch.float32)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
lm_logits = lm_logits.to(hidden_states.dtype)
loss = loss.to(hidden_states.dtype)
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
@staticmethod
def _reorder_cache(
past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
Output shares the same memory storage as `past`.
"""
return tuple(
(
layer_past[0].index_select(1, beam_idx.to(layer_past[0].device)),
layer_past[1].index_select(1, beam_idx.to(layer_past[1].device)),
)
for layer_past in past
)
def process_response(self, response):
response = response.strip()
response = response.replace("[[训练时间]]", "2023年")
punkts = [
[",", ","],
["!", "!"],
[":", ":"],
[";", ";"],
["\?", "?"],
]
for item in punkts:
response = re.sub(r"([\u4e00-\u9fff])%s" % item[0], r"\1%s" % item[1], response)
response = re.sub(r"%s([\u4e00-\u9fff])" % item[0], r"%s\1" % item[1], response)
return response
@torch.no_grad()
def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, max_length: int = 2048, num_beams=1,
do_sample=True, top_p=0.7, temperature=0.95, logits_processor=None, **kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
gen_kwargs = {"max_length": max_length, "num_beams": num_beams, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
if not history:
prompt = query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n问:{}\n答:{}\n".format(i, old_query, response)
prompt += "[Round {}]\n问:{}\n答:".format(len(history), query)
inputs = tokenizer([prompt], return_tensors="pt")
inputs = inputs.to(self.device)
outputs = self.generate(**inputs, **gen_kwargs)
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
response = tokenizer.decode(outputs)
response = self.process_response(response)
history = history + [(query, response)]
return response, history
@torch.no_grad()
def stream_chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, max_length: int = 2048,
do_sample=True, top_p=0.7, temperature=0.95, logits_processor=None, **kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
gen_kwargs = {"max_length": max_length, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
if not history:
prompt = query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n问:{}\n答:{}\n".format(i, old_query, response)
prompt += "[Round {}]\n问:{}\n答:".format(len(history), query)
inputs = tokenizer([prompt], return_tensors="pt")
inputs = inputs.to(self.device)
for outputs in self.stream_generate(**inputs, **gen_kwargs):
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
response = tokenizer.decode(outputs)
response = self.process_response(response)
new_history = history + [(query, response)]
yield response, new_history
@torch.no_grad()
def stream_generate(
self,
input_ids,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
**kwargs,
):
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
" recommend using `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
if not has_default_max_length:
logger.warn(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing `max_new_tokens`."
)
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria
)
logits_warper = self._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
unfinished_sequences = unfinished_sequences.mul((sum(next_tokens != i for i in eos_token_id)).long())
# stop when each sentence is finished, or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
break
yield input_ids
def quantize(self, bits: int, empty_init=False, **kwargs):
if bits == 0:
return
from .quantization import quantize
if self.quantized:
logger.info("Already quantized.")
return self
self.quantized = True
self.config.quantization_bit = bits
self.transformer = quantize(self.transformer, bits, empty_init=empty_init, **kwargs)
return self
================================================
FILE: chatglm/quantization.py
================================================
from torch.nn import Linear
from torch.nn.parameter import Parameter
import bz2
import torch
import base64
import ctypes
from transformers.utils import logging
from typing import List
from functools import partial
logger = logging.get_logger(__name__)
try:
from cpm_kernels.kernels.base import LazyKernelCModule, KernelFunction, round_up
class Kernel:
def __init__(self, code: bytes, function_names: List[str]):
self.code = code
self._function_names = function_names
self._cmodule = LazyKernelCModule(self.code)
for name in self._function_names:
setattr(self, name, KernelFunction(self._cmodule, name))
quantization_code = "$QlpoOTFBWSZTWU9yuJUAQHN//////////f/n/8/n///n//bt4dTidcVx8X3V9FV/92/v4B7/AD5FBQFAAAChSgKpFCFAFVSigUAAAEKhSgUUqgFBKigqVREQAABQBQIANDTTIGI00BkZBkNGE0A0BkBkGQGRkaNAaAGQNBoGgDIAAYIGTI0DQAQAaGmmQMRpoDIyDIaMJoBoDIDIMgMjI0aA0AMgaDQNAGQAAwQMmRoGgAgA0NNMgYjTQGRkGQ0YTQDQGQGQZAZGRo0BoAZA0GgaAMgABggZMjQNABABoaaZAxGmgMjIMhowmgGgMgMgyAyMjRoDQAyBoNA0AZAADBAyZGgaAAmqU1NEgJqnptU/Sn4jRR6J6epk2pqb1Q/SgAPUGgyNNGjQ2SBpoAZAAGg0NB6mgDIAAAAA2oaApSREBNAARhGiYEaEwU8pvImlP0k2aam1GaGqbFNM1MHpTwmkepmyU9R6nqPKekHqNNPUxNGhp6n6p6QaZ6o9TG1GMqcoV9ly6nRanHlq6zPNbnGZNi6HSug+2nPiZ13XcnFYZW+45W11CumhzYhchOJ2GLLV1OBjBjGf4TptOddTSOcVxhqYZMYwZXZZY00zI1paX5X9J+b+f4e+x43RXSxXPOdquiGpduatGyXneN696M9t4HU2eR5XX/kPhP261NTx3JO1Ow7LyuDmeo9a7d351T1ZxnvnrvYnrXv/hXxPCeuYx2XsNmO003eg9J3Z6U7b23meJ4ri01OdzTk9BNO96brz+qT5nuvvH3ds/G+m/JcG/F2XYuhXlvO+jP7U3XgrzPN/lr8Sf1n6j4j7jZs+s/T0tNaNNYzTs12rxjwztHlnire3Nzc3N1wuBwOBwXBvZfoHpD7rFmR99V5vj3aXza3xdBbXMalubTg/jIv5dfAi54Pdc75j4z412n3Npj3Ld/ENm7a3b/Cod6h/ret1/5vn/C+l+gdslMvgPSLJ8d8q+U66fevYn/tW1chleEtNTGlcHCbLRlq0tHzF5tsbbZZfHjjLgZu42XCuC3NrdjTasZGNzgxPIrGqp7r3p7L2p5XjnpPSmTd5XtzqnB6U87zzg1Ol0zd0zsLszxR6lkxp35u6/teL0L0W922cR7Lu1lpL9CsHirzuM2T+BgsyViT6LHcm0/Vr6U/7LGGyJeqTEjt0PHWhF5mCT7R9mtlDwriYv0Tyr/OxYt6qp5r0mPVT0608TqnqMZaarU2nFwrTzzlrs1ed7z1ux60wyr4ydCaTi3enW8x68x0zU7tXSlcmPSW1mGpWJMg4zmPC2lK96tp0OE80y4MfEvnZj8zGluR6b22ki1Ou9V2nCd9xovcPvcYMZYy0lvN60ScZ45vN6yeCeeXFb1lVjnnCar5fwXwE2bzJ4HI1XVPXfXZMm44GUsMpYsmLB65TuVdm0cl0b+i/wGNN66XjeV7zuPpHcnK/juhhjdfId5jMdE5nN0dGmmm2zZs2cexD5n9p/dY352XsvXHaZNWWsmmS1atjR452nYudzvqv2HMRyvNNnlMcDl3R2+yx2uVrBubTW9icHDVtbNXlZm7jma1rM4VurZZd2y6nUau7ZXZ7bVU+mnoOVxZGMrVmvX60605JwmzGZhhhjTWtaaaMaaGTGmNMZasY0iX8VMUl8eepaIrzGSpemWOQyZORk2bNpjUybMmxqYmknCGCFynutfksaZpjTNMaaatM0xsxcGR0sociNqxNSmhhR1ZJPbsn8qyF0t2qH6iYBclclalbtTTcHTDsPaX6rlnElph2Jyumumtynv2Kk8GI7rsvXbIcJgHJOSaSXnnGaI3m87RtVXJOZ/YtgdTE6Wpha6ZlE8ayXkef1fh602r2WwvfMXtMdLlkfnLFdYYwYso+bWqm7yJqHXZGw2nrS5ZanSYnWlxBxMF1V940K2wdrI7R6OYf7DGGamMmTSbRhlS45xmVOumF1EyPCmHrrN8wwZOOrdNtLeMtzFzDlWnfTBxMk2NaXIZHBYxYLD4w8yju0ao65Vz1OIXoS9dLanwCe1PWrYuWMqf1if1z2k2yYfKJ741PDgno1ZQ8DRqvUny3mNoWTzGO6m1DkrJI8JiR5cSd+vZdGOO8nrMoc5+NDUFsMSXaZJeNlMmGLtJsovOsUp7I9S5VojKxF6bTVEelXqlfJobQr3LozSh2Jk7VcrVMfhXqszGWMzNqGhqZY0OadxkyyMssKugZR0KNFXBHlqwmJgTE/BNVMk6ItJXZMR0H47GpXv/DMOvNkmVuaV1PRfEdxuqc7Hcd+ZV/zTLaRxWk0nl9CdCeM6mn5rstHIBcpiuwmUZXeq81DacHI2rmrZ5SuE5mOZd6LQrZg9mx32TprA8BMo5jKN6yLTCi3WzQaZSuhzTtM1fUTGVpG8Tw+KXI0tjEpiWxtLYynOlktSbVlaI5kxP8TDH8kx50xoxi5KcA4pcja8KWLRlO/Ks6q06ergnvm1ca3Tq8Uw7LTUsmWyctXPWmpitl/uvGcWTGXGuAXDfhqazGmjkxcJW5hMMMMpYsXl2TZYtVOddG3XCarUt6Ptq9CZXSNzyuRzqRZOjsxdBbFVz6OA5HI43r1jityVlVpVkxmOsyaYWE1NTGq1sOVh36mHMcxtSvcy70edG0ZGR3I1Go1GRlV7mWWo1G0ZGRqlvH40l7o4m5xMWLLLYyNjnqc8556mdPqLJ31n/1nWOncxzG1tizrHs/Z+d2vP/B/l8wdJ6rHUn2nbbDq4p6htFtYzMMMTaZis1K5GKzGNmxhmUx2DDlZ/qNnIx41xnaMfCZWYaZWtNLTNW8ND4Fw1MyZOCdM428suKG1ehW8TesOydg7J+YYcD4cYR+8dFK6M4E3HM9ZfRNNL+Sn6rsl4DsrDl2HpPCnfxjGXtbZtYys1ttlyJ4T+BvexjGWRjMszK4Jpc77D3GyuVD7q0+G8m9G+2+rGm7cOR2y7FdtY2XUYx/oNlfRYxhMYyYZkyyg55enna9Kt/FFi6GMMwYwdwxWgxGMLKYmUyGExTKMZkMFhkymKuh0NOBNnBu+23LdwDoZYYzGGMxtORaTU1pjTGWTTGGtMrNWUsyyTTLLG1qy2ZjbK2DBllWqxMtBMaYZQmcE7zvvRcTkclUwdkxTaSdyySt/7fpL+T1v516Ji97fwr5JbLu305zMn5+GMTTZ9F+y7ExwmGVfG44yxn3dLv6l5i+Wth1jCrDq21nW9LqvvDzz3Vf3LLH/O/32TJ/erx3bXftO4eF+G956D952K/An4NfvOpjFjExjevP/UmE0fIoZXx6/w6lX/no3D0bLt+ixjieBM6ksRd0yB4Lt2SwYNE+gd1detlZWUnpiZfGfFaK+4PyCa/v18V8X75pe9fLXzp7l3VjF76vWZmHwGz1IZNWT7b8yddJ4q5kyrVdfru6atWc7bVYztL9Jf4GXvT+Y8m9/YsXP6H018a8D4XVOqvfzqeR+6yZOD8dPv0+U7/q5Pl+2dNb0MjzGVH5p6MNQ7cOWvw62U9aHE8DprDek+McLyvDz+te+9Zhq5+YTruufMcWMabqysTmZVWjKPfnK0wyVcrsuhjZRdLkHNvD72b9abriOSGIxiLixMOoalNPXzy+wT/tf+U6HHONfsz+xe8ufHBdQWWGWLA9if0rsnmrxK5LvRZQeWsTCsrmOYy8VteVfuRfcVTtDLItLIsMYxZLdU/DbtSemxF6Z6Zo5WBXE4tFdCyVMMXMTEMZXVlS6Xec2T4e0tHsRcEuWshcJ2YsNF5rUx1E8ifCq6Z+ZP7qdCeu/aTwFd53l16/o0NOw6O3dLavP4Hbi4RdmuDk6DoYaninC0+o4uZjbJ7Rxeu0/FbuFg+q7DVS6fQe0rZ6NDGUNNU6DEqOaLTicKnYZMnBWruljQxoaS3dZhocDge0bSTyOvdAbG5hxe2xji7E/L55xX13wWNDi6HCekcFxfCPGxY0MXC+s7afWaMdDyjyr+o8Rudm/NabOZvdl274zH4f5XK9z6On1Pe/K5TdPAslg77BjuO6Y3eO7GqvOPG/stknp1leyvLL0Z7bl9I4noMvLkzytLhWYzrOZzLXCORe028rORzOg4N/L0HlMOQ3Pgmnbb6KczlabORpu980q37TBqRu0/p3PO6234Bl03Ynuz+9W7gnsEcmvYaYY3aMYY0wx3pYd+ujsXauWdaY5Xkbtl23fPzFHiDB/QMo0yFjBllYxTQYYyxkrwn7JufwJ/PfgJ+C83X69ni6zvXcnyXabv0ncbLwsceS+RNlyN2mnneJtX0ngYO0+e+0+UnA+Wch3ji8hj5an4h+i6XBySU4n+R0roVcbw5yvHrmr4Yw8Y7x6c+9POPYHI5HI5HI5HI5HGXGww4nE4nrVyOR8XeqPEO7PLOiukYa3Novk5hV4cdtYZLI93e+uxff2jRo0aNGjRo0aNG1bVtW1dy3m83m8+tQ5ZzHw3nObwOu8La9Rc1dtkdS8A3eTk823tnktXWlxN6Oixe06zrN70Isd9jiOgZFq9yfkPqP/SLhN2Myl8jDM43bl1nbcb4cO57jlh8Jow6pzXZdL4dyODTuuhu77FyO27DdwdRxmvO+O+3N2+BdqyTwLHVczDVY4UPE4O66/ZO2cx1LFzVdSXtF7G4HMbrauOHRw6c8FdZ5m9fHZHYZXfTlZquyynSyTTKke6vcffSD9pzPA/G7n7jxPmuhc1DHMynPMrGL6AdewYmwu5ko+UUyTwrMv27rPH1v1nGqd87+p6N6LU8k3NEng53xXyHS97+44OSg/sy/hn+Se6yfYNjW0/uTgP+PvWYzLMmjhcLB/gGpri6H83/84eUXWT6T9Hsv7785z/7z4icpW+zfXypuR7rx/gMdZb1/wC678pcs8/2a3mDitGHxl9mfPlll5MafWWqxk/eYuTDgcNMzDGWLWvsuglNxs53GtN6uWpktlW1tZZYcuinMMWmnNnJydze3b2Y1McBxrBkXw799izLMZZYyy0TkbsGM4p03S2uVu5s/XXUdSdec6smVxZYYGpVmT8A+8ajuEyV5FatkvVru2x6uxGXXbH4A+jvgP4GMYy3iPLXzq/6z65+E005ey+cwMZD3fZcqc6xpjTFjQ0P3U+e++cPYmTIwj0nrK5NPTfl3WvpfLtXDcb2HQMudYOxFXQBor4L4T6vrOauFctYXJQ++NUWmJe5bmx1jDiZS1dTqWxo4GR8jm3fttpmPHppk9PEyv4/y8/sO07XacOmcqc0x2Vi9BvNJvN5oW8x4mOsydpidRxMYJPx06m1bqPzq9KtK8sxXNXFodD/+MYYaJTLwOhc9brCsV18oOR1i4tXChyTkq4lf4y1Ke+9axjDHqs1mfBbMXuP4Hzi+X7t8vzv7bHerrUPgPCxhjre4fXdfLNtNM+Jd+Zdh8xd8wP87uNPoPgv4W7/5P2BuxfsMabNnMnza+54Pdi5U671GPZY8CehX8Voeoo7FHpkeEc6715FwHZrIrUrHaviPUbPZHND+IhczrP6FcYvhOZ0Di/ETt0OI+YwNWR9r7tpf6WDeZKZDB1+z2IthOl1mPyb5FluvEx9h9d0NnM0Y1XPFkWIsk1WotJ0PBMmkvjvQTd0e71tfeV+8r8lQ/tpzpsmxJ+InrI/dj2UajUajVTUajatRqNRtGo1Go1Go4wjeMpZFMVV9CHbofPraLsJ3JpWV2XOoanCuFky4y3PPNxucK2uKC1Lbdb1eo+m5XomN6HfeZsabHLHRX/K+offtNGGmHWctcVcG44MdSqsOLY9VzX+Zxfxn2HPdWTpzWvkrtJ8M5zorrKcquRytJ5N5DZmcaW02l76nWO+BqPXm1A2Ry/0q71dH/mqrqeFjkYxjEXtsX8qubTk67rGycyqsdm4tZx5D6D5hhi0waaWmiaMP81Yjii5qxPlPuU/GfTL1Y5E6Jyfiq63qTa39A4J0sOGDgO9WF9bOXl0XfPRbsY2bPNKPy1YrFYrFYmRhhlTIyMjJWJYZHXuCXI8OoXsvfljGLFicNifpp2XunoPiG1wtx3p1Tah+/DD66OnVtVXP9rKbVxOnL0tR/rHtqB5UDErUVcl11D4qqvjpOcxX7armUNJB3LpW6bxVvD08e8h3odKKvyCFZBdSh2FVcST9xV3n3T8t1j7Kr9qgrqXg+13Pt5U7JCvFXVIV1YG5lRhkVYZJYYDDD4KOIMoHCp26WS8GB7uBh2zIdgq/PKyInjV2STShuoapUdCpX1yTwqq/z1VvET7Kh5nVPkO8YyxjLt2MaaMmWTLQvx3qnzltnXW0p2jxgbEtSny/Osv8Y9pLMXYoHVPAhkVdWVeODhR6q9/Sxe2liwwZWMVvFXfRkeIDxAePUPIrdJ4ey6yquzH+PD/bUOWAu05qVHtFd8rrKHSoeNIOUqrYr3FXyToqfYJgwmJdKpXXOwYYegNNGMzfZPp/t3t/DVs4zjNTN61rRqaWaa4NYbRjTa0tWwy2Y2tGN8ZO8ofNKq4j9SL7I+cSm4/6ovLV5HNXLI0jJidwrtk6ynCaP6Z++GjRlWS3tLeW129Mi9evxU9mtz6s5J3Z7M2ngTgnKvmpomxpaLCzPfmx0JWE+m3NLDDGOX47RctdYYNK5jakdqLkRlI39n590T5zctGSwwZZDJj6kW8XSi6ot2MmWWJ0DUT3nuvebBudScjZ79g8cWJ8av0k+/bE5WKd5MdbFpbDVMxu1DVMmtNZGJvq1mtRbn6M+g/kP0FwDwr7quZs7xosNGpbscyxhhd9TyJyFwbLcxlTasg75vW7TsV5K7ji44XPMMrdoj+Y3rT0Hie62nlYV/pwczzOmdLqLhYkzGMzCZWGMQzGMSsZYY6Di1t4nlJ+Em63mJxrVLxPbYxNEdgc1dU2iOKyoYYWjNrEeHTYybVk0atSa7ehuwsWMWTqn1TrnS6hYsi71d1+s+k+ic70e20fzE/VaTdxT9ZtU4GIXdeNx3X77guYYfpHeTQjaMX6brOu4OY4K7Y2d9mbHarI5ox3p4GpJ2Vd/Tst60f7j999pppjR+Q/Qf8J/VaORs3cji7FfFuN61+ui9s8hix1OCh5KGVV23BPXvZfz3CLyHpix+exi8z/KnCnosY2eunor+cxyPO/xJ0vKey9OvE9VjqaYu0x3Z3jd6o2b1T12D+F8l232lwaaacD5LE8LBxu7WTlbWraWpew8Xexjel3E+wWD4APITdNqR8F3R3T0lunCQ4GaE9R37DxeCYfcHi4xci5ovKfxVs55y2hf+65E/Xdp6jR5nrebTmi5incpkyOjs50JvrZwstbbW6kfuuQw+2mykf/EXNFzxfKTrxew929TR6bWnGL//F3JFOFCQT3K4lQ"
kernels = Kernel(
bz2.decompress(base64.b64decode(quantization_code)),
[
"int4WeightCompression",
"int4WeightExtractionFloat",
"int4WeightExtractionHalf",
"int8WeightExtractionFloat",
"int8WeightExtractionHalf",
],
)
except Exception as exception:
kernels = None
logger.warning("Failed to load cpm_kernels:" + str(exception))
class W8A16Linear(torch.autograd.Function):
@staticmethod
def forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: torch.Tensor, weight_bit_width):
ctx.inp_shape = inp.size()
ctx.weight_bit_width = weight_bit_width
out_features = quant_w.size(0)
inp = inp.contiguous().view(-1, inp.size(-1))
weight = extract_weight_to_half(quant_w, scale_w, weight_bit_width)
ctx.weight_shape = weight.size()
output = inp.mm(weight.t())
ctx.save_for_backward(inp, quant_w, scale_w)
return output.view(*(ctx.inp_shape[:-1] + (out_features,)))
@staticmethod
def backward(ctx, grad_output: torch.Tensor):
inp, quant_w, scale_w = ctx.saved_tensors
weight = extract_weight_to_half(quant_w, scale_w, ctx.weight_bit_width)
grad_output = grad_output.contiguous().view(-1, weight.size(0))
grad_input = grad_output.mm(weight)
grad_weight = grad_output.t().mm(inp)
return grad_input.view(ctx.inp_shape), grad_weight.view(ctx.weight_shape), None, None
def compress_int4_weight(weight: torch.Tensor): # (n, m)
with torch.cuda.device(weight.device):
n, m = weight.size(0), weight.size(1)
assert m % 2 == 0
m = m // 2
out = torch.empty(n, m, dtype=torch.int8, device="cuda")
stream = torch.cuda.current_stream()
gridDim = (n, 1, 1)
blockDim = (min(round_up(m, 32), 1024), 1, 1)
kernels.int4WeightCompression(
gridDim,
blockDim,
0,
stream,
[ctypes.c_void_p(weight.data_ptr()), ctypes.c_void_p(out.data_ptr()), ctypes.c_int32(n), ctypes.c_int32(m)],
)
return out
def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tensor, source_bit_width: int):
if source_bit_width == 8:
func = kernels.int8WeightExtractionHalf
elif source_bit_width == 4:
func = kernels.int4WeightExtractionHalf
else:
assert False, "Unsupported bit-width"
with torch.cuda.device(weight.device):
n, m = weight.size(0), weight.size(1)
out = torch.empty(n, m * (8 // source_bit_width), dtype=torch.half, device="cuda")
stream = torch.cuda.current_stream()
gridDim = (n, 1, 1)
blockDim = (min(round_up(m, 32), 1024), 1, 1)
func(
gridDim,
blockDim,
0,
stream,
[
ctypes.c_void_p(weight.data_ptr()),
ctypes.c_void_p(scale_list.data_ptr()),
ctypes.c_void_p(out.data_ptr()),
ctypes.c_int32(n),
ctypes.c_int32(m),
],
)
return out
class QuantizedLinear(Linear):
def __init__(self, weight_bit_width: int, weight_tensor=None, bias_tensor=None, empty_init=False, *args, **kwargs):
super(QuantizedLinear, self).__init__(*args, **kwargs)
self.weight_bit_width = weight_bit_width
shape = self.weight.shape
del self.weight
if weight_tensor is None or empty_init:
self.weight = torch.empty(
shape[0], shape[1] * weight_bit_width // 8, dtype=torch.int8, device=kwargs["device"]
)
self.weight_scale = torch.empty(shape[0], dtype=kwargs["dtype"], device=kwargs["device"])
else:
self.weight_scale = (weight_tensor.abs().max(dim=-1).values / ((2 ** (weight_bit_width - 1)) - 1)).half()
self.weight = torch.round(weight_tensor / self.weight_scale[:, None]).to(torch.int8)
if weight_bit_width == 4:
self.weight = compress_int4_weight(self.weight)
self.weight = Parameter(self.weight.to(kwargs["device"]), requires_grad=False)
self.weight_scale = Parameter(self.weight_scale.to(kwargs["device"]), requires_grad=False)
if bias_tensor is not None:
self.bias = Parameter(bias_tensor.to(kwargs["device"]), requires_grad=False)
else:
self.bias = None
def forward(self, input):
output = W8A16Linear.apply(input, self.weight, self.weight_scale, self.weight_bit_width)
if self.bias is not None:
output = output + self.bias
return output
def quantize(model, weight_bit_width, empty_init=False, **kwargs):
"""Replace fp16 linear with quantized linear"""
for layer in model.layers:
layer.attention.query_key_value = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight_tensor=layer.attention.query_key_value.weight.to(torch.cuda.current_device()),
bias_tensor=layer.attention.query_key_value.bias,
in_features=layer.attention.query_key_value.in_features,
out_features=layer.attention.query_key_value.out_features,
bias=True,
dtype=torch.half,
device=layer.attention.query_key_value.weight.device,
empty_init=empty_init
)
layer.attention.dense = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight_tensor=layer.attention.dense.weight.to(torch.cuda.current_device()),
bias_tensor=layer.attention.dense.bias,
in_features=layer.attention.dense.in_features,
out_features=layer.attention.dense.out_features,
bias=True,
dtype=torch.half,
device=layer.attention.dense.weight.device,
empty_init=empty_init
)
layer.mlp.dense_h_to_4h = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight_tensor=layer.mlp.dense_h_to_4h.weight.to(torch.cuda.current_device()),
bias_tensor=layer.mlp.dense_h_to_4h.bias,
in_features=layer.mlp.dense_h_to_4h.in_features,
out_features=layer.mlp.dense_h_to_4h.out_features,
bias=True,
dtype=torch.half,
device=layer.mlp.dense_h_to_4h.weight.device,
empty_init=empty_init
)
layer.mlp.dense_4h_to_h = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight_tensor=layer.mlp.dense_4h_to_h.weight.to(torch.cuda.current_device()),
bias_tensor=layer.mlp.dense_4h_to_h.bias,
in_features=layer.mlp.dense_4h_to_h.in_features,
out_features=layer.mlp.dense_4h_to_h.out_features,
bias=True,
dtype=torch.half,
device=layer.mlp.dense_4h_to_h.weight.device,
empty_init=empty_init
)
return model
================================================
FILE: chatglm/tokenization_chatglm.py
================================================
"""Tokenization classes for ChatGLM."""
from typing import List, Optional, Union
import os
from transformers.tokenization_utils import PreTrainedTokenizer
from transformers.utils import logging, PaddingStrategy
from transformers.tokenization_utils_base import EncodedInput, BatchEncoding
from typing import Dict
import sentencepiece as spm
import numpy as np
logger = logging.get_logger(__name__)
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"THUDM/chatglm-6b": 2048,
}
class TextTokenizer:
def __init__(self, model_path):
self.sp = spm.SentencePieceProcessor()
self.sp.Load(model_path)
self.num_tokens = self.sp.vocab_size()
def encode(self, text):
return self.sp.EncodeAsIds(text)
def decode(self, ids: List[int]):
return self.sp.DecodeIds(ids)
def tokenize(self, text):
return self.sp.EncodeAsPieces(text)
def convert_tokens_to_ids(self, tokens):
return [self.sp.PieceToId(token) for token in tokens]
def convert_token_to_id(self, token):
return self.sp.PieceToId(token)
def convert_id_to_token(self, idx):
return self.sp.IdToPiece(idx)
def __len__(self):
return self.num_tokens
class SPTokenizer:
def __init__(
self,
vocab_file,
num_image_tokens=20000,
max_blank_length=80,
byte_fallback=True,
):
assert vocab_file is not None
self.vocab_file = vocab_file
self.num_image_tokens = num_image_tokens
self.special_tokens = ["[MASK]", "[gMASK]", "[sMASK]", "<unused_0>", "<sop>", "<eop>", "<ENC>", "<dBLOCK>"]
self.max_blank_length = max_blank_length
self.byte_fallback = byte_fallback
self.text_tokenizer = TextTokenizer(vocab_file)
def _get_text_tokenizer(self):
return self.text_tokenizer
@staticmethod
def get_blank_token(length: int):
assert length >= 2
return f"<|blank_{length}|>"
@staticmethod
def get_tab_token():
return f"<|tab|>"
@property
def num_text_tokens(self):
return self.text_tokenizer.num_tokens
@property
def num_tokens(self):
return self.num_image_tokens + self.num_text_tokens
@staticmethod
def _encode_whitespaces(text: str, max_len: int = 80):
text = text.replace("\t", SPTokenizer.get_tab_token())
for i in range(max_len, 1, -1):
text = text.replace(" " * i, SPTokenizer.get_blank_token(i))
return text
def _preprocess(self, text: str, linebreak=True, whitespaces=True):
if linebreak:
text = text.replace("\n", "<n>")
if whitespaces:
text = self._encode_whitespaces(text, max_len=self.max_blank_length)
return text
def encode(
self, text: str, linebreak=True, whitespaces=True, add_dummy_prefix=True
) -> List[int]:
"""
@param text: Text to encode.
@param linebreak: Whether to encode newline (\n) in text.
@param whitespaces: Whether to encode multiple whitespaces or tab in text, useful for source code encoding.
@param special_tokens: Whether to encode special token ([MASK], [gMASK], etc.) in text.
@param add_dummy_prefix: Whether to add dummy blank space in the beginning.
"""
text = self._preprocess(text, linebreak, whitespaces)
if not add_dummy_prefix:
text = "<n>" + text
tmp = self._get_text_tokenizer().encode(text)
tokens = [x + self.num_image_tokens for x in tmp]
return tokens if add_dummy_prefix else tokens[2:]
def decode(self, text_ids: List[int]) -> str:
ids = [int(_id) - self.num_image_tokens for _id in text_ids]
ids = [_id for _id in ids if _id >= 0]
text = self._get_text_tokenizer().decode(ids)
text = text.replace("<n>", "\n")
text = text.replace(SPTokenizer.get_tab_token(), "\t")
for i in range(2, self.max_blank_length + 1):
text = text.replace(self.get_blank_token(i), " " * i)
return text
def tokenize(
self, text: str, linebreak=True, whitespaces=True, add_dummy_prefix=True
) -> List[str]:
"""
@param text: Text to encode.
@param linebreak: Whether to encode newline (\n) in text.
@param whitespaces: Whether to encode multiple whitespaces or tab in text, useful for source code encoding.
@param special_tokens: Whether to encode special token ([MASK], [gMASK], etc.) in text.
@param add_dummy_prefix: Whether to add dummy blank space in the beginning.
"""
text = self._preprocess(text, linebreak, whitespaces)
if not add_dummy_prefix:
text = "<n>" + text
tokens = self._get_text_tokenizer().tokenize(text)
return tokens if add_dummy_prefix else tokens[2:]
def __getitem__(self, x: Union[int, str]):
if isinstance(x, int):
if x < self.num_image_tokens:
return "<image_{}>".format(x)
else:
return self.text_tokenizer.convert_id_to_token(x - self.num_image_tokens)
elif isinstance(x, str):
if x.startswith("<image_") and x.endswith(">") and x[7:-1].isdigit():
return int(x[7:-1])
else:
return self.text_tokenizer.convert_token_to_id(x) + self.num_image_tokens
else:
raise ValueError("The key should be str or int.")
class ChatGLMTokenizer(PreTrainedTokenizer):
"""
Construct a ChatGLM tokenizer. Based on byte-level Byte-Pair-Encoding.
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = {"vocab_file": "ice_text.model"}
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "position_ids"]
def __init__(
self,
vocab_file,
do_lower_case=False,
remove_space=False,
bos_token='<sop>',
eos_token='<eop>',
end_token='</s>',
mask_token='[MASK]',
gmask_token='[gMASK]',
padding_side="left",
pad_token="<pad>",
unk_token="<unk>",
num_image_tokens=20000,
**kwargs
) -> None:
super().__init__(
do_lower_case=do_lower_case,
remove_space=remove_space,
padding_side=padding_side,
bos_token=bos_token,
eos_token=eos_token,
end_token=end_token,
mask_token=mask_token,
gmask_token=gmask_token,
pad_token=pad_token,
unk_token=unk_token,
num_image_tokens=num_image_tokens,
**kwargs
)
self.do_lower_case = do_lower_case
self.remove_space = remove_space
self.vocab_file = vocab_file
self.bos_token = bos_token
self.eos_token = eos_token
self.end_token = end_token
self.mask_token = mask_token
self.gmask_token = gmask_token
self.sp_tokenizer = SPTokenizer(vocab_file, num_image_tokens=num_image_tokens)
""" Initialisation """
@property
def gmask_token_id(self) -> Optional[int]:
if self.gmask_token is None:
return None
return self.convert_tokens_to_ids(self.gmask_token)
@property
def end_token_id(self) -> Optional[int]:
"""
`Optional[int]`: Id of the end of context token in the vocabulary. Returns `None` if the token has not been
set.
"""
if self.end_token is None:
return None
return self.convert_tokens_to_ids(self.end_token)
@property
def vocab_size(self):
""" Returns vocab size """
return self.sp_tokenizer.num_tokens
def get_vocab(self):
""" Returns vocab as a dict """
vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
def preprocess_text(self, inputs):
if self.remove_space:
outputs = " ".join(inputs.strip().split())
else:
outputs = inputs
if self.do_lower_case:
outputs = outputs.lower()
return outputs
def _tokenize(self, text, **kwargs):
""" Returns a tokenized string. """
text = self.preprocess_text(text)
seq = self.sp_tokenizer.tokenize(text)
return seq
def _decode(
self,
token_ids: Union[int, List[int]],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = True,
**kwargs
) -> str:
if isinstance(token_ids, int):
token_ids = [token_ids]
if len(token_ids) == 0:
return ""
if self.pad_token_id in token_ids: # remove pad
token_ids = list(filter((self.pad_token_id).__ne__, token_ids))
return self.sp_tokenizer.decode(token_ids)
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
return self.sp_tokenizer[token]
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.sp_tokenizer[index]
def save_vocabulary(self, save_directory, filename_prefix=None):
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
filename_prefix (`str`, *optional*):
An optional prefix to add to the named of the saved files.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
if os.path.isdir(save_directory):
vocab_file = os.path.join(
save_directory, self.vocab_files_names["vocab_file"]
)
else:
vocab_file = save_directory
with open(self.vocab_file, 'rb') as fin:
proto_str = fin.read()
with open(vocab_file, "wb") as writer:
writer.write(proto_str)
return (vocab_file,)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
gmask_id = self.sp_tokenizer[self.gmask_token]
eos_id = self.sp_tokenizer[self.eos_token]
token_ids_0 = token_ids_0 + [gmask_id, self.sp_tokenizer[self.bos_token]]
if token_ids_1 is not None:
token_ids_0 = token_ids_0 + token_ids_1 + [eos_id]
return token_ids_0
def _pad(
self,
encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
max_length: Optional[int] = None,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
pad_to_multiple_of: Optional[int] = None,
return_attention_mask: Optional[bool] = None,
) -> dict:
"""
Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
Args:
encoded_inputs:
Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
max_length: maximum length of the returned list and optionally padding length (see below).
Will truncate by taking into account the special tokens.
padding_strategy: PaddingStrategy to use for padding.
- PaddingStrategy.LONGEST Pad to the longest sequence in the batch
- PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
- PaddingStrategy.DO_NOT_PAD: Do not pad
The tokenizer padding sides are defined in self.padding_side:
- 'left': pads on the left of the sequences
- 'right': pads on the right of the sequences
pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
`>= 7.5` (Volta).
return_attention_mask:
(optional) Set to False to avoid returning attention mask (default: set to model specifics)
"""
# Load from model defaults
bos_token_id = self.sp_tokenizer[self.bos_token]
mask_token_id = self.sp_tokenizer[self.mask_token]
gmask_token_id = self.sp_tokenizer[self.gmask_token]
assert self.padding_side == "left"
required_input = encoded_inputs[self.model_input_names[0]]
seq_length = len(required_input)
if padding_strategy == PaddingStrategy.LONGEST:
max_length = len(required_input)
if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
# Initialize attention mask if not present.
if max_length is not None:
if "attention_mask" not in encoded_inputs:
if bos_token_id in required_input:
context_length = required_input.index(bos_token_id)
else:
context_length = seq_length
attention_mask = np.ones((1, seq_length, seq_length))
attention_mask = np.tril(attention_mask)
attention_mask[:, :, :context_length] = 1
attention_mask = np.bool_(attention_mask < 0.5)
encoded_inputs["attention_mask"] = attention_mask
if "position_ids" not in encoded_inputs:
if bos_token_id in required_input:
context_length = required_input.index(bos_token_id)
else:
context_length = seq_length
position_ids = np.arange(seq_length, dtype=np.int64)
mask_token = mask_token_id if mask_token_id in required_input else gmask_token_id
if mask_token in required_input:
mask_position = required_input.index(mask_token)
position_ids[context_length:] = mask_position
block_position_ids = np.concatenate(
[np.zeros(context_length, dtype=np.int64),
np.arange(1, seq_length - context_length + 1, dtype=np.int64)])
encoded_inputs["position_ids"] = np.stack([position_ids, block_position_ids], axis=0)
if needs_to_be_padded:
difference = max_length - len(required_input)
if "attention_mask" in encoded_inputs:
encoded_inputs["attention_mask"] = np.pad(encoded_inputs["attention_mask"],
pad_width=[(0, 0), (difference, 0), (difference, 0)],
mode='constant', constant_values=True)
if "token_type_ids" in encoded_inputs:
encoded_inputs["token_type_ids"] = [self.pad_token_type_id] * difference + encoded_inputs[
"token_type_ids"
]
if "special_tokens_mask" in encoded_inputs:
encoded_inputs["special_tokens_mask"] = [1] * difference + encoded_inputs["special_tokens_mask"]
if "position_ids" in encoded_inputs:
encoded_inputs["position_ids"] = np.pad(encoded_inputs["position_ids"],
pad_width=[(0, 0), (difference, 0)])
encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
return encoded_inputs
================================================
FILE: chatglm2/configuration_chatglm.py
================================================
from transformers import PretrainedConfig
class ChatGLMConfig(PretrainedConfig):
model_type = "chatglm"
def __init__(
self,
num_layers=28,
padded_vocab_size=65024,
hidden_size=4096,
ffn_hidden_size=13696,
kv_channels=128,
num_attention_heads=32,
seq_length=2048,
hidden_dropout=0.0,
attention_dropout=0.0,
layernorm_epsilon=1e-5,
rmsnorm=True,
apply_residual_connection_post_layernorm=False,
post_layer_norm=True,
add_bias_linear=False,
add_qkv_bias=False,
interleaved_qkv=False,
bias_dropout_fusion=True,
multi_query_attention=False,
multi_query_group_num=1,
apply_query_key_layer_scaling=True,
attention_softmax_in_fp32=True,
fp32_residual_connection=False,
quantization_bit=0,
**kwargs
):
self.num_layers = num_layers
self.padded_vocab_size = padded_vocab_size
self.hidden_size = hidden_size
self.ffn_hidden_size = ffn_hidden_size
self.kv_channels = kv_channels
self.num_attention_heads = num_attention_heads
self.seq_length = seq_length
self.hidden_dropout = hidden_dropout
self.attention_dropout = attention_dropout
self.layernorm_epsilon = layernorm_epsilon
self.rmsnorm = rmsnorm
self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
self.post_layer_norm = post_layer_norm
self.add_bias_linear = add_bias_linear
self.add_qkv_bias = add_qkv_bias
self.bias_dropout_fusion = bias_dropout_fusion
self.multi_query_attention = multi_query_attention
self.multi_query_group_num = multi_query_group_num
self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
self.attention_softmax_in_fp32 = attention_softmax_in_fp32
self.fp32_residual_connection = fp32_residual_connection
self.quantization_bit = quantization_bit
super().__init__(**kwargs)
================================================
FILE: chatglm2/modeling_chatglm.py
================================================
""" PyTorch ChatGLM model. """
import math
import copy
import warnings
import re
import sys
import torch
import torch.utils.checkpoint
import torch.nn.functional as F
from torch import nn
from torch.nn import CrossEntropyLoss, LayerNorm
from torch.nn.utils import skip_init
from typing import Optional, Tuple, Union, List, Callable, Dict, Any
from transformers.modeling_outputs import (
BaseModelOutputWithPast,
CausalLMOutputWithPast,
)
from transformers.modeling_utils import PreTrainedModel
from transformers.utils import logging
from transformers.generation.logits_process import LogitsProcessor
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList, GenerationConfig, ModelOutput
from .configuration_chatglm import ChatGLMConfig
# flags required to enable jit fusion kernels
if sys.platform != 'darwin':
torch._C._jit_set_profiling_mode(False)
torch._C._jit_set_profiling_executor(False)
torch._C._jit_override_can_fuse_on_cpu(True)
torch._C._jit_override_can_fuse_on_gpu(True)
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM2-6B"
_CONFIG_FOR_DOC = "ChatGLM6BConfig"
CHATGLM_6B_PRETRAINED_MODEL_ARCHIVE_LIST = [
"THUDM/chatglm2-6b",
# See all ChatGLM models at https://huggingface.co/models?filter=chatglm
]
def default_init(cls, *args, **kwargs):
return cls(*args, **kwargs)
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., 5] = 5e4
return scores
def split_tensor_along_last_dim(
tensor: torch.Tensor,
num_partitions: int,
contiguous_split_chunks: bool = False,
) -> List[torch.Tensor]:
"""Split a tensor along its last dimension.
Arguments:
tensor: input tensor.
num_partitions: number of partitions to split the tensor
contiguous_split_chunks: If True, make each chunk contiguous
in memory.
Returns:
A list of Tensors
"""
# Get the size and dimension.
last_dim = tensor.dim() - 1
last_dim_size = tensor.size()[last_dim] // num_partitions
# Split.
tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
# Note: torch.split does not create contiguous tensors by default.
if contiguous_split_chunks:
return tuple(chunk.contiguous() for chunk in tensor_list)
return tensor_list
class RotaryEmbedding(nn.Module):
def __init__(self, dim, original_impl=False, device=None, dtype=None):
super().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2, device=device).to(dtype=dtype) / dim))
self.register_buffer("inv_freq", inv_freq)
self.dim = dim
self.original_impl = original_impl
def forward_impl(
self, seq_len: int, n_elem: int, dtype: torch.dtype, device: torch.device, base: int = 10000
):
"""Enhanced Transformer with Rotary Position Embedding.
Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
transformers/rope/__init__.py. MIT License:
https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
"""
# $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, dtype=dtype, device=device) / n_elem))
# Create position indexes `[0, 1, ..., seq_len - 1]`
seq_idx = torch.arange(seq_len, dtype=dtype, device=device)
# Calculate the product of position index and $\theta_i$
idx_theta = torch.outer(seq_idx, theta).float()
cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
# this is to mimic the behaviour of complex32, else we will get different results
if dtype in (torch.float16, torch.bfloat16, torch.int8):
cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
return cache
def forward(self, max_seq_len, offset=0):
return self.forward_impl(
max_seq_len, self.dim, dtype=self.inv_freq.dtype, device=self.inv_freq.device
)
@torch.jit.script
def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
# x: [sq, b, np, hn]
sq, b, np, hn = x.size(0), x.size(1), x.size(2), x.size(3)
rot_dim = rope_cache.shape[-2] * 2
x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
# truncate to support variable sizes
rope_cache = rope_cache[:sq]
xshaped = x.reshape(sq, -1, np, rot_dim // 2, 2)
rope_cache = rope_cache.view(sq, -1, 1, xshaped.size(3), 2)
x_out2 = torch.stack(
[
xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
],
-1,
)
x_out2 = x_out2.flatten(3)
return torch.cat((x_out2, x_pass), dim=-1)
class RMSNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
super().__init__()
self.weight = torch.nn.Parameter(torch.empty(normalized_shape, device=device, dtype=dtype))
self.eps = eps
def forward(self, hidden_states: torch.Tensor):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
return (self.weight * hidden_states).to(input_dtype)
class CoreAttention(torch.nn.Module):
def __init__(self, config: ChatGLMConfig, layer_number):
super(CoreAttention, self).__init__()
self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling
self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32
if self.apply_query_key_layer_scaling:
self.attention_softmax_in_fp32 = True
self.layer_number = max(1, layer_number)
projection_size = config.kv_channels * config.num_attention_heads
# Per attention head and per partition values.
self.hidden_size_per_partition = projection_size
self.hidden_size_per_attention_head = projection_size // config.num_attention_heads
self.num_attention_heads_per_partition = config.num_attention_heads
coeff = None
self.norm_factor = math.sqrt(self.hidden_size_per_attention_head)
if self.apply_query_key_layer_scaling:
coeff = self.layer_number
self.norm_factor *= coeff
self.coeff = coeff
self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
def forward(self, query_layer, key_layer, value_layer, attention_mask):
pytorch_major_version = int(torch.__version__.split('.')[0])
if pytorch_major_version >= 2:
query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
is_causal=True)
else:
if attention_mask is not None:
attention_mask = ~attention_mask
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
attention_mask)
context_layer = context_layer.permute(2, 0, 1, 3)
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
context_layer = context_layer.reshape(*new_context_layer_shape)
else:
# Raw attention scores
# [b, np, sq, sk]
output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))
# [sq, b, np, hn] -> [sq, b * np, hn]
query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
# [sk, b, np, hn] -> [sk, b * np, hn]
key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
# preallocting input tensor: [b * np, sq, sk]
matmul_input_buffer = torch.empty(
output_size[0] * output_size[1], output_size[2], output_size[3], dtype=query_layer.dtype,
device=query_layer.device
)
# Raw attention scores. [b * np, sq, sk]
matmul_result = torch.baddbmm(
matmul_input_buffer,
query_layer.transpose(0, 1), # [b * np, sq, hn]
key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
beta=0.0,
alpha=(1.0 / self.norm_factor),
)
# change view to [b, np, sq, sk]
attention_scores = matmul_result.view(*output_size)
# ===========================
# Attention probs and dropout
# ===========================
# attention scores and attention mask [b, np, sq, sk]
if self.attention_softmax_in_fp32:
attention_scores = attention_scores.float()
if self.coeff is not None:
attention_scores = attention_scores * self.coeff
if attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]:
attention_mask = torch.ones(output_size[0], 1, output_size[2], output_size[3],
device=attention_scores.device, dtype=torch.bool)
attention_mask.tril_()
attention_mask = ~attention_mask
if attention_mask is not None:
attention_scores = attention_scores.masked_fill(attention_mask, float("-inf"))
attention_probs = F.softmax(attention_scores, dim=-1)
attention_probs = attention_probs.type_as(value_layer)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attention_dropout(attention_probs)
# =========================
# Context layer. [sq, b, hp]
# =========================
# value_layer -> context layer.
# [sk, b, np, hn] --> [b, np, sq, hn]
# context layer shape: [b, np, sq, hn]
output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))
# change view [sk, b * np, hn]
value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)
# change view [b * np, sq, sk]
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
# matmul: [b * np, sq, hn]
context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))
# change view [b, np, sq, hn]
context_layer = context_layer.view(*output_size)
# [b, np, sq, hn] --> [sq, b, np, hn]
context_layer = context_layer.permute(2, 0, 1, 3).contiguous()
# [sq, b, np, hn] --> [sq, b, hp]
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer
class SelfAttention(torch.nn.Module):
"""Parallel self-attention layer abstract class.
Self-attention layer takes input with size [s, b, h]
and returns output of the same size.
"""
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
super(SelfAttention, self).__init__()
self.layer_number = max(1, layer_number)
self.projection_size = config.kv_channels * config.num_attention_heads
# Per attention head and per partition values.
self.hidden_size_per_attention_head = self.projection_size // config.num_attention_heads
self.num_attention_heads_per_partition = config.num_attention_heads
self.multi_query_attention = config.multi_query_attention
self.qkv_hidden_size = 3 * self.projection_size
if self.multi_query_attention:
self.num_multi_query_groups_per_partition = config.multi_query_group_num
self.qkv_hidden_size = (
self.projection_size + 2 * self.hidden_size_per_attention_head * config.multi_query_group_num
)
self.query_key_value = nn.Linear(config.hidden_size, self.qkv_hidden_size,
bias=config.add_bias_linear or config.add_qkv_bias,
device=device, **_config_to_kwargs(config)
)
self.core_attention = CoreAttention(config, self.layer_number)
# Output.
self.dense = nn.Linear(self.projection_size, config.hidden_size, bias=config.add_bias_linear,
device=device, **_config_to_kwargs(config)
)
def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
if self.multi_query_attention:
num_attention_heads = self.num_multi_query_groups_per_partition
else:
num_attention_heads = self.num_attention_heads_per_partition
return torch.empty(
inference_max_sequence_len,
batch_size,
num_attention_heads,
self.hidden_size_per_attention_head,
dtype=dtype,
device=device,
)
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True
):
# hidden_states: [sq, b, h]
# =================================================
# Pre-allocate memory for key-values for inference.
# =================================================
# =====================
# Query, Key, and Value
# =====================
# Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
mixed_x_layer = self.query_key_value(hidden_states)
if self.multi_query_attention:
(query_layer, key_layer, value_layer) = mixed_x_layer.split(
[
self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
],
dim=-1,
)
query_layer = query_layer.view(
query_layer.size()[:-1] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
)
key_layer = key_layer.view(
key_layer.size()[:-1] + (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
)
value_layer = value_layer.view(
value_layer.size()[:-1]
+ (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
)
else:
new_tensor_shape = mixed_x_layer.size()[:-1] + \
(self.num_attention_heads_per_partition,
3 * self.hidden_size_per_attention_head)
mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
# [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
(query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
# apply relative positional encoding (rotary embedding)
if rotary_pos_emb is not None:
query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
# adjust key and value for inference
if use_cache:
if kv_cache is not None:
cache_k, cache_v = kv_cache
key_layer = torch.cat((cache_k, key_layer), dim=0)
value_layer = torch.cat((cache_v, value_layer), dim=0)
kv_cache = (key_layer, value_layer)
else:
kv_cache = None
if self.multi_query_attention:
key_layer = key_layer.unsqueeze(-2)
key_layer = key_layer.expand(
-1, -1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1
)
key_layer = key_layer.contiguous().view(
key_layer.size()[:2] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
)
value_layer = value_layer.unsqueeze(-2)
value_layer = value_layer.expand(
-1, -1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1
)
value_layer = value_layer.contiguous().view(
value_layer.size()[:2] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
)
# ==================================
# core attention computation
# ==================================
context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask)
# =================
# Output. [sq, b, h]
# =================
output = self.dense(context_layer)
return output, kv_cache
def _config_to_kwargs(args):
common_kwargs = {
"dtype": args.torch_dtype,
}
return common_kwargs
class MLP(torch.nn.Module):
"""MLP.
MLP will take the input with h hidden state, project it to 4*h
hidden dimension, perform nonlinear transformation, and project the
state back into h hidden dimension.
"""
def __init__(self, config: ChatGLMConfig, device=None):
super(MLP, self).__init__()
self.add_bias = config.add_bias_linear
# Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
self.dense_h_to_4h = nn.Linear(
config.hidden_size,
config.ffn_hidden_size * 2,
bias=self.add_bias,
device=device,
**_config_to_kwargs(config)
)
def swiglu(x):
x = torch.chunk(x, 2, dim=-1)
return F.silu(x[0]) * x[1]
self.activation_func = swiglu
# Project back to h.
self.dense_4h_to_h = nn.Linear(
config.ffn_hidden_size,
config.hidden_size,
bias=self.add_bias,
device=device,
**_config_to_kwargs(config)
)
def forward(self, hidden_states):
# [s, b, 4hp]
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = self.activation_func(intermediate_parallel)
# [s, b, h]
output = self.dense_4h_to_h(intermediate_parallel)
return output
class GLMBlock(torch.nn.Module):
"""A single transformer layer.
Transformer layer takes input with size [s, b, h] and returns an
output of the same size.
"""
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
super(GLMBlock, self).__init__()
self.layer_number = layer_number
self.apply_residual_connection_post_layernorm = config.apply_residual_connection_post_layernorm
self.fp32_residual_connection = config.fp32_residual_connection
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
# Layernorm on the input data.
self.input_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
# Self attention.
self.self_attention = SelfAttention(config, layer_number, device=device)
self.hidden_dropout = config.hidden_dropout
# Layernorm on the attention output
self.post_attention_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
# MLP
self.mlp = MLP(config, device=device)
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True,
):
# hidden_states: [s, b, h]
# Layer norm at the beginning of the transformer layer.
layernorm_output = self.input_layernorm(hidden_states)
# Self attention.
attention_output, kv_cache = self.self_attention(
layernorm_output,
attention_mask,
rotary_pos_emb,
kv_cache=kv_cache,
use_cache=use_cache
)
# Residual connection.
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = hidden_states
layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
layernorm_input = residual + layernorm_input
# Layer norm post the self attention.
layernorm_output = self.post_attention_layernorm(layernorm_input)
# MLP.
mlp_output = self.mlp(layernorm_output)
# Second residual connection.
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = layernorm_input
output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
output = residual + output
return output, kv_cache
class GLMTransformer(torch.nn.Module):
"""Transformer class."""
def __init__(self, config: ChatGLMConfig, device=None):
super(GLMTransformer, self).__init__()
self.fp32_residual_connection = config.fp32_residual_connection
self.post_layer_norm = config.post_layer_norm
# Number of layers.
self.num_layers = config.num_layers
# Transformer layers.
def build_layer(layer_number):
return GLMBlock(config, layer_number, device=device)
self.layers = torch.nn.ModuleList([build_layer(i + 1) for i in range(self.num_layers)])
if self.post_layer_norm:
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
# Final layer norm before output.
self.final_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
def _get_layer(self, layer_number):
return self.layers[layer_number]
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_caches=None,
use_cache: Optional[bool] = True,
output_hidden_states: Optional[bool] = False,
):
if not kv_caches:
kv_caches = [None for _ in range(self.num_layers)]
presents = () if use_cache else None
all_self_attentions = None
all_hidden_states = () if output_hidden_states else None
for index in range(self.num_layers):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer = self._get_layer(index)
hidden_states, kv_cache = layer(
hidden_states,
attention_mask,
rotary_pos_emb,
kv_cache=kv_caches[index],
use_cache=use_cache
)
if use_cache:
presents = presents + (kv_cache,)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
# Final layer norm.
if self.post_layer_norm:
hidden_states = self.final_layernorm(hidden_states)
return hidden_states, presents, all_hidden_states, all_self_attentions
class ChatGLMPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
is_parallelizable = False
supports_gradient_checkpointing = True
config_class = ChatGLMConfig
base_model_prefix = "transformer"
_no_split_modules = ["GLMBlock"]
def _init_weights(self, module: nn.Module):
"""Initialize the weights."""
return
def get_masks(self, input_ids, past_key_values, padding_mask=None):
batch_size, seq_length = input_ids.shape
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
full_attention_mask.tril_()
past_length = 0
if past_key_values:
past_length = past_key_values[0][0].shape[0]
if past_length:
full_attention_mask = torch.cat((torch.ones(batch_size, seq_length, past_length,
device=input_ids.device), full_attention_mask), dim=-1)
if padding_mask is not None:
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
if not past_length and padding_mask is not None:
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
full_attention_mask = (full_attention_mask < 0.5).bool()
full_attention_mask.unsqueeze_(1)
return full_attention_mask
def get_position_ids(self, input_ids, device):
batch_size, seq_length = input_ids.shape
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
return position_ids
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, ChatGLMModel):
module.gradient_checkpointing = value
class Embedding(torch.nn.Module):
"""Language model embeddings."""
def __init__(self, config: ChatGLMConfig, device=None):
super(Embedding, self).__init__()
self.hidden_size = config.hidden_size
# Word embeddings (parallel).
self.word_embeddings = nn.Embedding(
config.padded_vocab_size,
self.hidden_size,
dtype=config.torch_dtype,
device=device
)
self.fp32_residual_connection = config.fp32_residual_connection
def forward(self, input_ids):
# Embeddings.
words_embeddings = self.word_embeddings(input_ids)
embeddings = words_embeddings
# Data format change to avoid explicit tranposes : [b s h] --> [s b h].
embeddings = embeddings.transpose(0, 1).contiguous()
# If the input flag for fp32 residual connection is set, convert for float.
if self.fp32_residual_connection:
embeddings = embeddings.float()
return embeddings
class ChatGLMModel(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
super().__init__(config)
if empty_init:
init_method = skip_init
else:
init_method = default_init
init_kwargs = {}
if device is not None:
init_kwargs["device"] = device
self.embedding = init_method(Embedding, config, **init_kwargs)
# Rotary positional embeddings
self.seq_length = config.seq_length
rotary_dim = (
config.hidden_size // config.num_attention_heads if config.kv_channels is None else config.kv_channels
)
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, original_impl=config.original_rope, device=device,
dtype=config.torch_dtype)
self.encoder = init_method(GLMTransformer, config, **init_kwargs)
self.output_layer = init_method(nn.Linear, config.hidden_size, config.padded_vocab_size, bias=False,
dtype=config.torch_dtype, **init_kwargs)
self.gradient_checkpointing = False
def get_input_embeddings(self):
return self.embedding.word_embeddings
def forward(
self,
input_ids,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.BoolTensor] = None,
full_attention_mask: Optional[torch.BoolTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, seq_length = input_ids.shape
if inputs_embeds is None:
inputs_embeds = self.embedding(input_ids)
if full_attention_mask is None:
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
# Rotary positional embeddings
rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
if position_ids is not None:
rotary_pos_emb = rotary_pos_emb[position_ids]
else:
rotary_pos_emb = rotary_pos_emb[None, :seq_length]
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
# Run encoder.
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
inputs_embeds, full_attention_mask, rotary_pos_emb=rotary_pos_emb,
kv_caches=past_key_values, use_cache=use_cache, output_hidden_states=output_hidden_states
)
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
def quantize(self, weight_bit_width: int):
from .quantization import quantize
quantize(self.encoder, weight_bit_width)
return self
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
super().__init__(config)
self.max_sequence_length = config.max_length
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
self.config = config
self.quantized = False
if self.config.quantization_bit:
self.quantize(self.config.quantization_bit, empty_init=True)
def _update_model_kwargs_for_generation(
self,
outputs: ModelOutput,
model_kwargs: Dict[str, Any],
is_encoder_decoder: bool = False,
standardize_cache_format: bool = False,
) -> Dict[str, Any]:
# update past_key_values
model_kwargs["past_key_values"] = self._extract_past_from_model_output(
outputs, standardize_cache_format=standardize_cache_format
)
# update attention mask
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
model_kwargs["attention_mask"] = torch.cat(
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
)
# update position ids
if "position_ids" in model_kwargs:
position_ids = model_kwargs["position_ids"]
new_position_id = position_ids[..., -1:].clone()
new_position_id += 1
model_kwargs["position_ids"] = torch.cat(
[position_ids, new_position_id], dim=-1
)
model_kwargs["is_first_forward"] = False
return model_kwargs
def prepare_inputs_for_generation(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
is_first_forward: bool = True,
**kwargs
) -> dict:
# only last token for input_ids if past is not None
if position_ids is None:
position_ids = self.get_position_ids(input_ids, device=input_ids.device)
if not is_first_forward:
position_ids = position_ids[..., -1:]
input_ids = input_ids[:, -1:]
return {
"input_ids": input_ids,
"past_key_values": past_key_values,
"position_ids": position_ids,
"attention_mask": attention_mask,
"return_last_logit": True
}
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
return_last_logit: Optional[bool] = False,
):
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
if return_last_logit:
hidden_states = hidden_states[-1:]
lm_logits = self.transformer.output_layer(hidden_states)
lm_logits = lm_logits.transpose(0, 1).contiguous()
loss = None
if labels is not None:
lm_logits = lm_logits.to(torch.float32)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
lm_logits = lm_logits.to(hidden_states.dtype)
loss = loss.to(hidden_states.dtype)
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
@staticmethod
def _reorder_cache(
past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
Output shares the same memory storage as `past`.
"""
return tuple(
(
layer_past[0].index_select(1, beam_idx.to(layer_past[0].device)),
layer_past[1].index_select(1, beam_idx.to(layer_past[1].device)),
)
for layer_past in past
)
def process_response(self, response):
response = response.strip()
response = response.replace("[[训练时间]]", "2023年")
return response
def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(i + 1, old_query, response)
prompt += "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
inputs = tokenizer([prompt], return_tensors="pt")
inputs = inputs.to(self.device)
return inputs
def build_stream_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
if history:
prompt = "\n\n[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
input_ids = tokenizer.encode(prompt, add_special_tokens=False)
input_ids = input_ids[1:]
inputs = tokenizer.batch_encode_plus([(input_ids, None)], return_tensors="pt", add_special_tokens=False)
else:
prompt = "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
inputs = tokenizer([prompt], return_tensors="pt")
inputs = inputs.to(self.device)
return inputs
@torch.no_grad()
def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, max_length: int = 8192, num_beams=1,
do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None, **kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
gen_kwargs = {"max_length": max_length, "num_beams": num_beams, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
inputs = self.build_inputs(tokenizer, query, history=history)
outputs = self.generate(**inputs, **gen_kwargs)
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
response = tokenizer.decode(outputs)
response = self.process_response(response)
history = history + [(query, response)]
return response, history
@torch.no_grad()
def stream_chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, past_key_values=None,
max_length: int = 8192, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None,
return_past_key_values=False, **kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
gen_kwargs = {"max_length": max_length, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
if past_key_values is None and not return_past_key_values:
inputs = self.build_inputs(tokenizer, query, history=history)
else:
inputs = self.build_stream_inputs(tokenizer, query, history=history)
if past_key_values is not None:
past_length = past_key_values[0][0].shape[0]
inputs.position_ids += past_length
attention_mask = inputs.attention_mask
attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
inputs['attention_mask'] = attention_mask
for outputs in self.stream_generate(**inputs, past_key_values=past_key_values,
return_past_key_values=return_past_key_values, **gen_kwargs):
if return_past_key_values:
outputs, past_key_values = outputs
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
response = tokenizer.decode(outputs)
if response and response[-1] != "�":
response = self.process_response(response)
new_history = history + [(query, response)]
if return_past_key_values:
yield response, new_history, past_key_values
else:
yield response, new_history
@torch.no_grad()
def stream_generate(
self,
input_ids,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
return_past_key_values=False,
**kwargs,
):
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
" recommend using `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
if not has_default_max_length:
logger.warn(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing `max_new_tokens`."
)
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria
)
logits_warper = self._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
unfinished_sequences = unfinished_sequences.mul((sum(next_tokens != i for i in eos_token_id)).long())
if return_past_key_values:
yield input_ids, outputs.past_key_values
else:
yield input_ids
# stop when each sentence is finished, or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
break
def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
if bits == 0:
return
from .quantization import quantize
if self.quantized:
logger.info("Already quantized.")
return self
self.quantized = True
self.config.quantization_bit = bits
self.transformer.encoder = quantize(self.transformer.encoder, bits, empty_init=empty_init, device=device,
**kwargs)
return self
================================================
FILE: chatglm2/quantization.py
================================================
from torch.nn import Linear
from torch.nn.parameter import Parameter
import bz2
import torch
import base64
import ctypes
from transformers.utils import logging
from typing import List
from functools import partial
logger = logging.get_logger(__name__)
try:
from cpm_kernels.kernels.base import LazyKernelCModule, KernelFunction, round_up
class Kernel:
def __init__(self, code: bytes, function_names: List[str]):
self.code = code
self._function_names = function_names
self._cmodule = LazyKernelCModule(self.code)
for name in self._function_names:
setattr(self, name, KernelFunction(self._cmodule, name))
quantization_code = "$QlpoOTFBWSZTWU9yuJUAQHN//////////f/n/8/n///n//bt4dTidcVx8X3V9FV/92/v4B7/AD5FBQFAAAChSgKpFCFAFVSigUAAAEKhSgUUqgFBKigqVREQAABQBQIANDTTIGI00BkZBkNGE0A0BkBkGQGRkaNAaAGQNBoGgDIAAYIGTI0DQAQAaGmmQMRpoDIyDIaMJoBoDIDIMgMjI0aA0AMgaDQNAGQAAwQMmRoGgAgA0NNMgYjTQGRkGQ0YTQDQGQGQZAZGRo0BoAZA0GgaAMgABggZMjQNABABoaaZAxGmgMjIMhowmgGgMgMgyAyMjRoDQAyBoNA0AZAADBAyZGgaAAmqU1NEgJqnptU/Sn4jRR6J6epk2pqb1Q/SgAPUGgyNNGjQ2SBpoAZAAGg0NB6mgDIAAAAA2oaApSREBNAARhGiYEaEwU8pvImlP0k2aam1GaGqbFNM1MHpTwmkepmyU9R6nqPKekHqNNPUxNGhp6n6p6QaZ6o9TG1GMqcoV9ly6nRanHlq6zPNbnGZNi6HSug+2nPiZ13XcnFYZW+45W11CumhzYhchOJ2GLLV1OBjBjGf4TptOddTSOcVxhqYZMYwZXZZY00zI1paX5X9J+b+f4e+x43RXSxXPOdquiGpduatGyXneN696M9t4HU2eR5XX/kPhP261NTx3JO1Ow7LyuDmeo9a7d351T1ZxnvnrvYnrXv/hXxPCeuYx2XsNmO003eg9J3Z6U7b23meJ4ri01OdzTk9BNO96brz+qT5nuvvH3ds/G+m/JcG/F2XYuhXlvO+jP7U3XgrzPN/lr8Sf1n6j4j7jZs+s/T0tNaNNYzTs12rxjwztHlnire3Nzc3N1wuBwOBwXBvZfoHpD7rFmR99V5vj3aXza3xdBbXMalubTg/jIv5dfAi54Pdc75j4z412n3Npj3Ld/ENm7a3b/Cod6h/ret1/5vn/C+l+gdslMvgPSLJ8d8q+U66fevYn/tW1chleEtNTGlcHCbLRlq0tHzF5tsbbZZfHjjLgZu42XCuC3NrdjTasZGNzgxPIrGqp7r3p7L2p5XjnpPSmTd5XtzqnB6U87zzg1Ol0zd0zsLszxR6lkxp35u6/teL0L0W922cR7Lu1lpL9CsHirzuM2T+BgsyViT6LHcm0/Vr6U/7LGGyJeqTEjt0PHWhF5mCT7R9mtlDwriYv0Tyr/OxYt6qp5r0mPVT0608TqnqMZaarU2nFwrTzzlrs1ed7z1ux60wyr4ydCaTi3enW8x68x0zU7tXSlcmPSW1mGpWJMg4zmPC2lK96tp0OE80y4MfEvnZj8zGluR6b22ki1Ou9V2nCd9xovcPvcYMZYy0lvN60ScZ45vN6yeCeeXFb1lVjnnCar5fwXwE2bzJ4HI1XVPXfXZMm44GUsMpYsmLB65TuVdm0cl0b+i/wGNN66XjeV7zuPpHcnK/juhhjdfId5jMdE5nN0dGmmm2zZs2cexD5n9p/dY352XsvXHaZNWWsmmS1atjR452nYudzvqv2HMRyvNNnlMcDl3R2+yx2uVrBubTW9icHDVtbNXlZm7jma1rM4VurZZd2y6nUau7ZXZ7bVU+mnoOVxZGMrVmvX60605JwmzGZhhhjTWtaaaMaaGTGmNMZasY0iX8VMUl8eepaIrzGSpemWOQyZORk2bNpjUybMmxqYmknCGCFynutfksaZpjTNMaaatM0xsxcGR0sociNqxNSmhhR1ZJPbsn8qyF0t2qH6iYBclclalbtTTcHTDsPaX6rlnElph2Jyumumtynv2Kk8GI7rsvXbIcJgHJOSaSXnnGaI3m87RtVXJOZ/YtgdTE6Wpha6ZlE8ayXkef1fh602r2WwvfMXtMdLlkfnLFdYYwYso+bWqm7yJqHXZGw2nrS5ZanSYnWlxBxMF1V940K2wdrI7R6OYf7DGGamMmTSbRhlS45xmVOumF1EyPCmHrrN8wwZOOrdNtLeMtzFzDlWnfTBxMk2NaXIZHBYxYLD4w8yju0ao65Vz1OIXoS9dLanwCe1PWrYuWMqf1if1z2k2yYfKJ741PDgno1ZQ8DRqvUny3mNoWTzGO6m1DkrJI8JiR5cSd+vZdGOO8nrMoc5+NDUFsMSXaZJeNlMmGLtJsovOsUp7I9S5VojKxF6bTVEelXqlfJobQr3LozSh2Jk7VcrVMfhXqszGWMzNqGhqZY0OadxkyyMssKugZR0KNFXBHlqwmJgTE/BNVMk6ItJXZMR0H47GpXv/DMOvNkmVuaV1PRfEdxuqc7Hcd+ZV/zTLaRxWk0nl9CdCeM6mn5rstHIBcpiuwmUZXeq81DacHI2rmrZ5SuE5mOZd6LQrZg9mx32TprA8BMo5jKN6yLTCi3WzQaZSuhzTtM1fUTGVpG8Tw+KXI0tjEpiWxtLYynOlktSbVlaI5kxP8TDH8kx50xoxi5KcA4pcja8KWLRlO/Ks6q06ergnvm1ca3Tq8Uw7LTUsmWyctXPWmpitl/uvGcWTGXGuAXDfhqazGmjkxcJW5hMMMMpYsXl2TZYtVOddG3XCarUt6Ptq9CZXSNzyuRzqRZOjsxdBbFVz6OA5HI43r1jityVlVpVkxmOsyaYWE1NTGq1sOVh36mHMcxtSvcy70edG0ZGR3I1Go1GRlV7mWWo1G0ZGRqlvH40l7o4m5xMWLLLYyNjnqc8556mdPqLJ31n/1nWOncxzG1tizrHs/Z+d2vP/B/l8wdJ6rHUn2nbbDq4p6htFtYzMMMTaZis1K5GKzGNmxhmUx2DDlZ/qNnIx41xnaMfCZWYaZWtNLTNW8ND4Fw1MyZOCdM428suKG1ehW8TesOydg7J+YYcD4cYR+8dFK6M4E3HM9ZfRNNL+Sn6rsl4DsrDl2HpPCnfxjGXtbZtYys1ttlyJ4T+BvexjGWRjMszK4Jpc77D3GyuVD7q0+G8m9G+2+rGm7cOR2y7FdtY2XUYx/oNlfRYxhMYyYZkyyg55enna9Kt/FFi6GMMwYwdwxWgxGMLKYmUyGExTKMZkMFhkymKuh0NOBNnBu+23LdwDoZYYzGGMxtORaTU1pjTGWTTGGtMrNWUsyyTTLLG1qy2ZjbK2DBllWqxMtBMaYZQmcE7zvvRcTkclUwdkxTaSdyySt/7fpL+T1v516Ji97fwr5JbLu305zMn5+GMTTZ9F+y7ExwmGVfG44yxn3dLv6l5i+Wth1jCrDq21nW9LqvvDzz3Vf3LLH/O/32TJ/erx3bXftO4eF+G956D952K/An4NfvOpjFjExjevP/UmE0fIoZXx6/w6lX/no3D0bLt+ixjieBM6ksRd0yB4Lt2SwYNE+gd1detlZWUnpiZfGfFaK+4PyCa/v18V8X75pe9fLXzp7l3VjF76vWZmHwGz1IZNWT7b8yddJ4q5kyrVdfru6atWc7bVYztL9Jf4GXvT+Y8m9/YsXP6H018a8D4XVOqvfzqeR+6yZOD8dPv0+U7/q5Pl+2dNb0MjzGVH5p6MNQ7cOWvw62U9aHE8DprDek+McLyvDz+te+9Zhq5+YTruufMcWMabqysTmZVWjKPfnK0wyVcrsuhjZRdLkHNvD72b9abriOSGIxiLixMOoalNPXzy+wT/tf+U6HHONfsz+xe8ufHBdQWWGWLA9if0rsnmrxK5LvRZQeWsTCsrmOYy8VteVfuRfcVTtDLItLIsMYxZLdU/DbtSemxF6Z6Zo5WBXE4tFdCyVMMXMTEMZXVlS6Xec2T4e0tHsRcEuWshcJ2YsNF5rUx1E8ifCq6Z+ZP7qdCeu/aTwFd53l16/o0NOw6O3dLavP4Hbi4RdmuDk6DoYaninC0+o4uZjbJ7Rxeu0/FbuFg+q7DVS6fQe0rZ6NDGUNNU6DEqOaLTicKnYZMnBWruljQxoaS3dZhocDge0bSTyOvdAbG5hxe2xji7E/L55xX13wWNDi6HCekcFxfCPGxY0MXC+s7afWaMdDyjyr+o8Rudm/NabOZvdl274zH4f5XK9z6On1Pe/K5TdPAslg77BjuO6Y3eO7GqvOPG/stknp1leyvLL0Z7bl9I4noMvLkzytLhWYzrOZzLXCORe028rORzOg4N/L0HlMOQ3Pgmnbb6KczlabORpu980q37TBqRu0/p3PO6234Bl03Ynuz+9W7gnsEcmvYaYY3aMYY0wx3pYd+ujsXauWdaY5Xkbtl23fPzFHiDB/QMo0yFjBllYxTQYYyxkrwn7JufwJ/PfgJ+C83X69ni6zvXcnyXabv0ncbLwsceS+RNlyN2mnneJtX0ngYO0+e+0+UnA+Wch3ji8hj5an4h+i6XBySU4n+R0roVcbw5yvHrmr4Yw8Y7x6c+9POPYHI5HI5HI5HI5HGXGww4nE4nrVyOR8XeqPEO7PLOiukYa3Novk5hV4cdtYZLI93e+uxff2jRo0aNGjRo0aNG1bVtW1dy3m83m8+tQ5ZzHw3nObwOu8La9Rc1dtkdS8A3eTk823tnktXWlxN6Oixe06zrN70Isd9jiOgZFq9yfkPqP/SLhN2Myl8jDM43bl1nbcb4cO57jlh8Jow6pzXZdL4dyODTuuhu77FyO27DdwdRxmvO+O+3N2+BdqyTwLHVczDVY4UPE4O66/ZO2cx1LFzVdSXtF7G4HMbrauOHRw6c8FdZ5m9fHZHYZXfTlZquyynSyTTKke6vcffSD9pzPA/G7n7jxPmuhc1DHMynPMrGL6AdewYmwu5ko+UUyTwrMv27rPH1v1nGqd87+p6N6LU8k3NEng53xXyHS97+44OSg/sy/hn+Se6yfYNjW0/uTgP+PvWYzLMmjhcLB/gGpri6H83/84eUXWT6T9Hsv7785z/7z4icpW+zfXypuR7rx/gMdZb1/wC678pcs8/2a3mDitGHxl9mfPlll5MafWWqxk/eYuTDgcNMzDGWLWvsuglNxs53GtN6uWpktlW1tZZYcuinMMWmnNnJydze3b2Y1McBxrBkXw799izLMZZYyy0TkbsGM4p03S2uVu5s/XXUdSdec6smVxZYYGpVmT8A+8ajuEyV5FatkvVru2x6uxGXXbH4A+jvgP4GMYy3iPLXzq/6z65+E005ey+cwMZD3fZcqc6xpjTFjQ0P3U+e++cPYmTIwj0nrK5NPTfl3WvpfLtXDcb2HQMudYOxFXQBor4L4T6vrOauFctYXJQ++NUWmJe5bmx1jDiZS1dTqWxo4GR8jm3fttpmPHppk9PEyv4/y8/sO07XacOmcqc0x2Vi9BvNJvN5oW8x4mOsydpidRxMYJPx06m1bqPzq9KtK8sxXNXFodD/+MYYaJTLwOhc9brCsV18oOR1i4tXChyTkq4lf4y1Ke+9axjDHqs1mfBbMXuP4Hzi+X7t8vzv7bHerrUPgPCxhjre4fXdfLNtNM+Jd+Zdh8xd8wP87uNPoPgv4W7/5P2BuxfsMabNnMnza+54Pdi5U671GPZY8CehX8Voeoo7FHpkeEc6715FwHZrIrUrHaviPUbPZHND+IhczrP6FcYvhOZ0Di/ETt0OI+YwNWR9r7tpf6WDeZKZDB1+z2IthOl1mPyb5FluvEx9h9d0NnM0Y1XPFkWIsk1WotJ0PBMmkvjvQTd0e71tfeV+8r8lQ/tpzpsmxJ+InrI/dj2UajUajVTUajatRqNRtGo1Go1Go4wjeMpZFMVV9CHbofPraLsJ3JpWV2XOoanCuFky4y3PPNxucK2uKC1Lbdb1eo+m5XomN6HfeZsabHLHRX/K+offtNGGmHWctcVcG44MdSqsOLY9VzX+Zxfxn2HPdWTpzWvkrtJ8M5zorrKcquRytJ5N5DZmcaW02l76nWO+BqPXm1A2Ry/0q71dH/mqrqeFjkYxjEXtsX8qubTk67rGycyqsdm4tZx5D6D5hhi0waaWmiaMP81Yjii5qxPlPuU/GfTL1Y5E6Jyfiq63qTa39A4J0sOGDgO9WF9bOXl0XfPRbsY2bPNKPy1YrFYrFYmRhhlTIyMjJWJYZHXuCXI8OoXsvfljGLFicNifpp2XunoPiG1wtx3p1Tah+/DD66OnVtVXP9rKbVxOnL0tR/rHtqB5UDErUVcl11D4qqvjpOcxX7armUNJB3LpW6bxVvD08e8h3odKKvyCFZBdSh2FVcST9xV3n3T8t1j7Kr9qgrqXg+13Pt5U7JCvFXVIV1YG5lRhkVYZJYYDDD4KOIMoHCp26WS8GB7uBh2zIdgq/PKyInjV2STShuoapUdCpX1yTwqq/z1VvET7Kh5nVPkO8YyxjLt2MaaMmWTLQvx3qnzltnXW0p2jxgbEtSny/Osv8Y9pLMXYoHVPAhkVdWVeODhR6q9/Sxe2liwwZWMVvFXfRkeIDxAePUPIrdJ4ey6yquzH+PD/bUOWAu05qVHtFd8rrKHSoeNIOUqrYr3FXyToqfYJgwmJdKpXXOwYYegNNGMzfZPp/t3t/DVs4zjNTN61rRqaWaa4NYbRjTa0tWwy2Y2tGN8ZO8ofNKq4j9SL7I+cSm4/6ovLV5HNXLI0jJidwrtk6ynCaP6Z++GjRlWS3tLeW129Mi9evxU9mtz6s5J3Z7M2ngTgnKvmpomxpaLCzPfmx0JWE+m3NLDDGOX47RctdYYNK5jakdqLkRlI39n590T5zctGSwwZZDJj6kW8XSi6ot2MmWWJ0DUT3nuvebBudScjZ79g8cWJ8av0k+/bE5WKd5MdbFpbDVMxu1DVMmtNZGJvq1mtRbn6M+g/kP0FwDwr7quZs7xosNGpbscyxhhd9TyJyFwbLcxlTasg75vW7TsV5K7ji44XPMMrdoj+Y3rT0Hie62nlYV/pwczzOmdLqLhYkzGMzCZWGMQzGMSsZYY6Di1t4nlJ+Em63mJxrVLxPbYxNEdgc1dU2iOKyoYYWjNrEeHTYybVk0atSa7ehuwsWMWTqn1TrnS6hYsi71d1+s+k+ic70e20fzE/VaTdxT9ZtU4GIXdeNx3X77guYYfpHeTQjaMX6brOu4OY4K7Y2d9mbHarI5ox3p4GpJ2Vd/Tst60f7j999pppjR+Q/Qf8J/VaORs3cji7FfFuN61+ui9s8hix1OCh5KGVV23BPXvZfz3CLyHpix+exi8z/KnCnosY2eunor+cxyPO/xJ0vKey9OvE9VjqaYu0x3Z3jd6o2b1T12D+F8l232lwaaacD5LE8LBxu7WTlbWraWpew8Xexjel3E+wWD4APITdNqR8F3R3T0lunCQ4GaE9R37DxeCYfcHi4xci5ovKfxVs55y2hf+65E/Xdp6jR5nrebTmi5incpkyOjs50JvrZwstbbW6kfuuQw+2mykf/EXNFzxfKTrxew929TR6bWnGL//F3JFOFCQT3K4lQ"
kernels = Kernel(
bz2.decompress(base64.b64decode(quantization_code)),
[
"int4WeightCompression",
"int4WeightExtractionFloat",
"int4WeightExtractionHalf",
"int8WeightExtractionFloat",
"int8WeightExtractionHalf",
],
)
except Exception as exception:
kernels = None
logger.warning("Failed to load cpm_kernels:" + str(exception))
class W8A16Linear(torch.autograd.Function):
@staticmethod
def forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: torch.Tensor, weight_bit_width):
ctx.inp_shape = inp.size()
ctx.weight_bit_width = weight_bit_width
out_features = quant_w.size(0)
inp = inp.contiguous().view(-1, inp.size(-1))
weight = extract_weight_to_half(quant_w, scale_w, weight_bit_width)
ctx.weight_shape = weight.size()
output = inp.mm(weight.t())
ctx.save_for_backward(inp, quant_w, scale_w)
return output.view(*(ctx.inp_shape[:-1] + (out_features,)))
@staticmethod
def backward(ctx, grad_output: torch.Tensor):
inp, quant_w, scale_w = ctx.saved_tensors
weight = extract_weight_to_half(quant_w, scale_w, ctx.weight_bit_width)
grad_output = grad_output.contiguous().view(-1, weight.size(0))
grad_input = grad_output.mm(weight)
grad_weight = grad_output.t().mm(inp)
return grad_input.view(ctx.inp_shape), grad_weight.view(ctx.weight_shape), None, None
def compress_int4_weight(weight: torch.Tensor): # (n, m)
with torch.cuda.device(weight.device):
n, m = weight.size(0), weight.size(1)
assert m % 2 == 0
m = m // 2
out = torch.empty(n, m, dtype=torch.int8, device="cuda")
stream = torch.cuda.current_stream()
gridDim = (n, 1, 1)
blockDim = (min(round_up(m, 32), 1024), 1, 1)
kernels.int4WeightCompression(
gridDim,
blockDim,
0,
stream,
[ctypes.c_void_p(weight.data_ptr()), ctypes.c_void_p(out.data_ptr()), ctypes.c_int32(n), ctypes.c_int32(m)],
)
return out
def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tensor, source_bit_width: int):
assert scale_list.dtype in [torch.half, torch.bfloat16]
assert weight.dtype in [torch.int8]
if source_bit_width == 8:
return weight.to(scale_list.dtype) * scale_list[:, None]
elif source_bit_width == 4:
func = (
kernels.int4WeightExtractionHalf if scale_list.dtype == torch.half else kernels.int4WeightExtractionBFloat16
)
else:
assert False, "Unsupported bit-width"
with torch.cuda.device(weight.device):
n, m = weight.size(0), weight.size(1)
out = torch.empty(n, m * (8 // source_bit_width), dtype=scale_list.dtype, device="cuda")
stream = torch.cuda.current_stream()
gridDim = (n, 1, 1)
blockDim = (min(round_up(m, 32), 1024), 1, 1)
func(
gridDim,
blockDim,
0,
stream,
[
ctypes.c_void_p(weight.data_ptr()),
ctypes.c_void_p(scale_list.data_ptr()),
ctypes.c_void_p(out.data_ptr()),
ctypes.c_int32(n),
ctypes.c_int32(m),
],
)
return out
class QuantizedLinear(torch.nn.Module):
def __init__(self, weight_bit_width: int, weight, bias=None, device="cpu", dtype=None, empty_init=False, *args,
**kwargs):
super().__init__()
self.weight_bit_width = weight_bit_width
shape = weight.shape
if weight is None or empty_init:
self.weight = torch.empty(shape[0], shape[1] * weight_bit_width // 8, dtype=torch.int8, device=device)
self.weight_scale = torch.empty(shape[0], dtype=dtype, device=device)
else:
self.weight_scale = weight.abs().max(dim=-1).values / ((2 ** (weight_bit_width - 1)) - 1)
self.weight = torch.round(weight / self.weight_scale[:, None]).to(torch.int8)
if weight_bit_width == 4:
self.weight = compress_int4_weight(self.weight)
self.weight = Parameter(self.weight.to(device), requires_grad=False)
self.weight_scale = Parameter(self.weight_scale.to(device), requires_grad=False)
self.bias = Parameter(bias.to(device), requires_grad=False) if bias is not None else None
def forward(self, input):
output = W8A16Linear.apply(input, self.weight, self.weight_scale, self.weight_bit_width)
if self.bias is not None:
output = output + self.bias
return output
def quantize(model, weight_bit_width, empty_init=False, device=None):
"""Replace fp16 linear with quantized linear"""
for layer in model.layers:
layer.self_attention.query_key_value = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight=layer.self_attention.query_key_value.weight.to(torch.cuda.current_device()),
bias=layer.self_attention.query_key_value.bias,
dtype=layer.self_attention.query_key_value.weight.dtype,
device=layer.self_attention.query_key_value.weight.device if device is None else device,
empty_init=empty_init
)
layer.self_attention.dense = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight=layer.self_attention.dense.weight.to(torch.cuda.current_device()),
bias=layer.self_attention.dense.bias,
dtype=layer.self_attention.dense.weight.dtype,
device=layer.self_attention.dense.weight.device if device is None else device,
empty_init=empty_init
)
layer.mlp.dense_h_to_4h = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight=layer.mlp.dense_h_to_4h.weight.to(torch.cuda.current_device()),
bias=layer.mlp.dense_h_to_4h.bias,
dtype=layer.mlp.dense_h_to_4h.weight.dtype,
device=layer.mlp.dense_h_to_4h.weight.device if device is None else device,
empty_init=empty_init
)
layer.mlp.dense_4h_to_h = QuantizedLinear(
weight_bit_width=weight_bit_width,
weight=layer.mlp.dense_4h_to_h.weight.to(torch.cuda.current_device()),
bias=layer.mlp.dense_4h_to_h.bias,
dtype=layer.mlp.dense_4h_to_h.weight.dtype,
device=layer.mlp.dense_4h_to_h.weight.device if device is None else device,
empty_init=empty_init
)
return model
================================================
FILE: chatglm2/tokenization_chatglm.py
================================================
import os
import torch
from typing import List, Optional, Union, Dict
from sentencepiece import SentencePieceProcessor
from transformers import PreTrainedTokenizer
from transformers.utils import logging, PaddingStrategy
from transformers.tokenization_utils_base import EncodedInput, BatchEncoding
class SPTokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.eos_id()
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
special_tokens = ["[MASK]", "[gMASK]", "[sMASK]", "sop", "eop"]
self.special_tokens = {}
self.index_special_tokens = {}
for token in special_tokens:
self.special_tokens[token] = self.n_words
self.index_special_tokens[self.n_words] = token
self.n_words += 1
def tokenize(self, s: str):
return self.sp_model.EncodeAsPieces(s)
def encode(self, s: str, bos: bool = False, eos: bool = False) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
def decode_tokens(self, tokens: List[str]) -> str:
text = self.sp_model.DecodePieces(tokens)
return text
def convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
if token in self.special_tokens:
return self.special_tokens[token]
return self.sp_model.PieceToId(token)
def convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
if index in self.index_special_tokens:
return ""
return self.sp_model.IdToPiece(index)
class ChatGLMTokenizer(PreTrainedTokenizer):
vocab_files_names = {"vocab_file": "tokenizer.model"}
model_input_names = ["input_ids", "attention_mask", "position_ids"]
def __init__(self, vocab_file, padding_side="left", **kwargs):
super().__init__(padding_side=padding_side, **kwargs)
self.name = "GLMTokenizer"
self.vocab_file = vocab_file
self.tokenizer = SPTokenizer(vocab_file)
self.special_tokens = {
"<bos>": self.tokenizer.bos_id,
"<eos>": self.tokenizer.eos_id,
"<pad>": self.tokenizer.pad_id
}
def get_command(self, token):
if token in self.special_tokens:
return self.special_tokens[token]
assert token in self.tokenizer.special_tokens, f"{token} is not a special token for {self.name}"
return self.tokenizer.special_tokens[token]
@property
def pad_token(self) -> str:
return "</s>"
@property
def pad_token_id(self):
return self.get_command("<pad>")
@property
def vocab_size(self):
return self.tokenizer.n_words
def get_vocab(self):
""" Returns vocab as a dict """
vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
def _tokenize(self, text, **kwargs):
return self.tokenizer.tokenize(text)
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
return self.tokenizer.convert_token_to_id(token)
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.tokenizer.convert_id_to_token(index)
def convert_tokens_to_string(self, tokens: List[str]) -> str:
return self.tokenizer.decode_tokens(tokens)
def save_vocabulary(self, save_directory, filename_prefix=None):
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
filename_prefix (`str`, *optional*):
An optional prefix to add to the named of the saved files.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
if os.path.isdir(save_directory):
vocab_file = os.path.join(
save_directory, self.vocab_files_names["vocab_file"]
)
else:
vocab_file = save_directory
with open(self.vocab_file, 'rb') as fin:
proto_str = fin.read()
with open(vocab_file, "wb") as writer:
writer.write(proto_str)
return (vocab_file,)
def get_prefix_tokens(self):
prefix_tokens = [self.get_command("[gMASK]"), self.get_command("sop")]
return prefix_tokens
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
prefix_tokens = self.get_prefix_tokens()
token_ids_0 = prefix_tokens + token_ids_0
if token_ids_1 is not None:
token_ids_0 = token_ids_0 + token_ids_1 + [self.get_command("<eos>")]
return token_ids_0
def _pad(
self,
encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
max_length: Optional[int] = None,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
pad_to_multiple_of: Optional[int] = None,
return_attention_mask: Optional[bool] = None,
) -> dict:
"""
Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
Args:
encoded_inputs:
Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
max_length: maximum length of the returned list and optionally padding length (see below).
Will truncate by taking into account the special tokens.
padding_strategy: PaddingStrategy to use for padding.
- PaddingStrategy.LONGEST Pad to the longest sequence in the batch
- PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
- PaddingStrategy.DO_NOT_PAD: Do not pad
The tokenizer padding sides are defined in self.padding_side:
- 'left': pads on the left of the sequences
- 'right': pads on the right of the sequences
pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
`>= 7.5` (Volta).
return_attention_mask:
(optional) Set to False to avoid returning attention mask (default: set to model specifics)
"""
# Load from model defaults
assert self.padding_side == "left"
required_input = encoded_inputs[self.model_input_names[0]]
seq_length = len(required_input)
if padding_strategy == PaddingStrategy.LONGEST:
max_length = len(required_input)
if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
# Initialize attention mask if not present.
if "attention_mask" not in encoded_inputs:
encoded_inputs["attention_mask"] = [1] * seq_length
if "position_ids" not in encoded_inputs:
encoded_inputs["position_ids"] = list(range(seq_length))
if needs_to_be_padded:
difference = max_length - len(required_input)
if "attention_mask" in encoded_inputs:
encoded_inputs["attention_mask"] = [0] * difference + encoded_inputs["attention_mask"]
if "position_ids" in encoded_inputs:
encoded_inputs["position_ids"] = [0] * difference + encoded_inputs["position_ids"]
encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
return encoded_inputs
================================================
FILE: chatglm3/configuration_chatglm.py
================================================
from transformers import
gitextract_8x6d8dn9/ ├── .gitignore ├── LICENSE ├── MODEL_LICENSE ├── README.md ├── app.py ├── app_fastapi.py ├── chatglm/ │ ├── configuration_chatglm.py │ ├── modeling_chatglm.py │ ├── quantization.py │ └── tokenization_chatglm.py ├── chatglm2/ │ ├── configuration_chatglm.py │ ├── modeling_chatglm.py │ ├── quantization.py │ └── tokenization_chatglm.py ├── chatglm3/ │ ├── configuration_chatglm.py │ ├── modeling_chatglm.py │ ├── quantization.py │ └── tokenization_chatglm.py ├── check_bad_cache_files.py ├── download_model.py ├── env_offline.bat ├── env_venv.bat ├── glm4/ │ ├── configuration_chatglm.py │ ├── modeling_chatglm.py │ └── tokenization_chatglm.py ├── gptq/ │ ├── README.md │ ├── gptq.py │ ├── llama.py │ ├── llama_inference.py │ ├── modelutils.py │ ├── quant.py │ ├── quant_cuda.cpp │ ├── quant_cuda_kernel.cu │ ├── setup_cuda.py │ └── test_kernel.py ├── predictors/ │ ├── base.py │ ├── chatglm2_predictor.py │ ├── chatglm3_predictor.py │ ├── chatglm_predictor.py │ ├── debug.py │ ├── glm4_predictor.py │ ├── llama.py │ └── llama_gptq.py ├── setup_offline.bat ├── setup_venv.bat ├── start.bat ├── start_api.bat ├── start_offline.bat ├── start_offline_api.bat ├── start_offline_cmd.bat ├── start_venv.bat ├── test_fastapi.py ├── test_models.py └── utils_env.py
SYMBOL INDEX (467 symbols across 34 files)
FILE: app.py
function revise (line 40) | def revise(history, latest_message):
function revoke (line 48) | def revoke(history, last_state):
function interrupt (line 57) | def interrupt(allow_generate):
function regenerate (line 61) | def regenerate(last_state, max_length, top_p, temperature, allow_generate):
FILE: app_fastapi.py
function getLogger (line 34) | def getLogger(name, file_name, use_formatter=True):
function start_server (line 59) | def start_server(quantize_level, http_address: str, port: int, gpu_id: s...
FILE: chatglm/configuration_chatglm.py
class ChatGLMConfig (line 9) | class ChatGLMConfig(PretrainedConfig):
method __init__ (line 59) | def __init__(
FILE: chatglm/modeling_chatglm.py
class InvalidScoreLogitsProcessor (line 54) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 55) | def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTen...
function load_tf_weights_in_chatglm_6b (line 62) | def load_tf_weights_in_chatglm_6b(model, config, tf_checkpoint_path):
class PrefixEncoder (line 136) | class PrefixEncoder(torch.nn.Module):
method __init__ (line 143) | def __init__(self, config):
method forward (line 157) | def forward(self, prefix: torch.Tensor):
function gelu_impl (line 167) | def gelu_impl(x):
function gelu (line 173) | def gelu(x):
class RotaryEmbedding (line 177) | class RotaryEmbedding(torch.nn.Module):
method __init__ (line 178) | def __init__(self, dim, base=10000, precision=torch.half, learnable=Fa...
method _load_from_state_dict (line 194) | def _load_from_state_dict(self, state_dict, prefix, local_metadata, st...
method forward (line 198) | def forward(self, x, seq_dim=1, seq_len=None):
method _apply (line 221) | def _apply(self, fn):
function rotate_half (line 229) | def rotate_half(x):
function apply_rotary_pos_emb_index (line 235) | def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):
function attention_fn (line 243) | def attention_fn(
function default_init (line 350) | def default_init(cls, *args, **kwargs):
class SelfAttention (line 354) | class SelfAttention(torch.nn.Module):
method __init__ (line 355) | def __init__(self, hidden_size, num_attention_heads,
method attention_mask_func (line 406) | def attention_mask_func(attention_scores, attention_mask):
method split_tensor_along_last_dim (line 410) | def split_tensor_along_last_dim(self, tensor, num_partitions,
method forward (line 430) | def forward(
class GEGLU (line 497) | class GEGLU(torch.nn.Module):
method __init__ (line 498) | def __init__(self):
method forward (line 502) | def forward(self, x):
class GLU (line 508) | class GLU(torch.nn.Module):
method __init__ (line 509) | def __init__(self, hidden_size, inner_hidden_size=None,
method forward (line 540) | def forward(self, hidden_states):
class GLMBlock (line 555) | class GLMBlock(torch.nn.Module):
method __init__ (line 556) | def __init__(
method forward (line 608) | def forward(
class ChatGLMPreTrainedModel (line 662) | class ChatGLMPreTrainedModel(PreTrainedModel):
method __init__ (line 674) | def __init__(self, *inputs, **kwargs):
method _init_weights (line 677) | def _init_weights(self, module: nn.Module):
method get_masks (line 681) | def get_masks(self, input_ids, device):
method get_position_ids (line 693) | def get_position_ids(self, input_ids, mask_positions, device, use_gmas...
method _set_gradient_checkpointing (line 716) | def _set_gradient_checkpointing(self, module, value=False):
class ChatGLMModel (line 786) | class ChatGLMModel(ChatGLMPreTrainedModel):
method __init__ (line 802) | def __init__(self, config: ChatGLMConfig, empty_init=True):
method get_input_embeddings (line 862) | def get_input_embeddings(self):
method set_input_embeddings (line 865) | def set_input_embeddings(self, new_embeddings: torch.Tensor):
method get_prompt (line 868) | def get_prompt(self, batch_size, device, dtype=torch.half):
method forward (line 890) | def forward(
class ChatGLMForConditionalGeneration (line 1032) | class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
method __init__ (line 1033) | def __init__(self, config: ChatGLMConfig, empty_init=True):
method get_output_embeddings (line 1064) | def get_output_embeddings(self):
method set_output_embeddings (line 1067) | def set_output_embeddings(self, new_embeddings):
method _update_model_kwargs_for_generation (line 1070) | def _update_model_kwargs_for_generation(
method prepare_inputs_for_generation (line 1105) | def prepare_inputs_for_generation(
method forward (line 1175) | def forward(
method _reorder_cache (line 1234) | def _reorder_cache(
method process_response (line 1252) | def process_response(self, response):
method chat (line 1268) | def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] =...
method stream_chat (line 1294) | def stream_chat(self, tokenizer, query: str, history: List[Tuple[str, ...
method stream_generate (line 1320) | def stream_generate(
method quantize (line 1421) | def quantize(self, bits: int, empty_init=False, **kwargs):
FILE: chatglm/quantization.py
class Kernel (line 18) | class Kernel:
method __init__ (line 19) | def __init__(self, code: bytes, function_names: List[str]):
class W8A16Linear (line 44) | class W8A16Linear(torch.autograd.Function):
method forward (line 46) | def forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: to...
method backward (line 58) | def backward(ctx, grad_output: torch.Tensor):
function compress_int4_weight (line 67) | def compress_int4_weight(weight: torch.Tensor): # (n, m)
function extract_weight_to_half (line 88) | def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tenso...
class QuantizedLinear (line 120) | class QuantizedLinear(Linear):
method __init__ (line 121) | def __init__(self, weight_bit_width: int, weight_tensor=None, bias_ten...
method forward (line 146) | def forward(self, input):
function quantize (line 153) | def quantize(model, weight_bit_width, empty_init=False, **kwargs):
FILE: chatglm/tokenization_chatglm.py
class TextTokenizer (line 19) | class TextTokenizer:
method __init__ (line 20) | def __init__(self, model_path):
method encode (line 25) | def encode(self, text):
method decode (line 28) | def decode(self, ids: List[int]):
method tokenize (line 31) | def tokenize(self, text):
method convert_tokens_to_ids (line 34) | def convert_tokens_to_ids(self, tokens):
method convert_token_to_id (line 37) | def convert_token_to_id(self, token):
method convert_id_to_token (line 40) | def convert_id_to_token(self, idx):
method __len__ (line 43) | def __len__(self):
class SPTokenizer (line 47) | class SPTokenizer:
method __init__ (line 48) | def __init__(
method _get_text_tokenizer (line 63) | def _get_text_tokenizer(self):
method get_blank_token (line 67) | def get_blank_token(length: int):
method get_tab_token (line 72) | def get_tab_token():
method num_text_tokens (line 76) | def num_text_tokens(self):
method num_tokens (line 80) | def num_tokens(self):
method _encode_whitespaces (line 84) | def _encode_whitespaces(text: str, max_len: int = 80):
method _preprocess (line 90) | def _preprocess(self, text: str, linebreak=True, whitespaces=True):
method encode (line 97) | def encode(
method decode (line 114) | def decode(self, text_ids: List[int]) -> str:
method tokenize (line 124) | def tokenize(
method __getitem__ (line 140) | def __getitem__(self, x: Union[int, str]):
class ChatGLMTokenizer (line 155) | class ChatGLMTokenizer(PreTrainedTokenizer):
method __init__ (line 168) | def __init__(
method gmask_token_id (line 214) | def gmask_token_id(self) -> Optional[int]:
method end_token_id (line 220) | def end_token_id(self) -> Optional[int]:
method vocab_size (line 230) | def vocab_size(self):
method get_vocab (line 234) | def get_vocab(self):
method preprocess_text (line 240) | def preprocess_text(self, inputs):
method _tokenize (line 251) | def _tokenize(self, text, **kwargs):
method _decode (line 259) | def _decode(
method _convert_token_to_id (line 274) | def _convert_token_to_id(self, token):
method _convert_id_to_token (line 278) | def _convert_id_to_token(self, index):
method save_vocabulary (line 282) | def save_vocabulary(self, save_directory, filename_prefix=None):
method build_inputs_with_special_tokens (line 310) | def build_inputs_with_special_tokens(
method _pad (line 336) | def _pad(
FILE: chatglm2/configuration_chatglm.py
class ChatGLMConfig (line 4) | class ChatGLMConfig(PretrainedConfig):
method __init__ (line 6) | def __init__(
FILE: chatglm2/modeling_chatglm.py
function default_init (line 47) | def default_init(cls, *args, **kwargs):
class InvalidScoreLogitsProcessor (line 51) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 52) | def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTen...
function split_tensor_along_last_dim (line 59) | def split_tensor_along_last_dim(
class RotaryEmbedding (line 87) | class RotaryEmbedding(nn.Module):
method __init__ (line 88) | def __init__(self, dim, original_impl=False, device=None, dtype=None):
method forward_impl (line 95) | def forward_impl(
method forward (line 120) | def forward(self, max_seq_len, offset=0):
function apply_rotary_pos_emb (line 127) | def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> t...
class RMSNorm (line 147) | class RMSNorm(torch.nn.Module):
method __init__ (line 148) | def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None...
method forward (line 153) | def forward(self, hidden_states: torch.Tensor):
class CoreAttention (line 161) | class CoreAttention(torch.nn.Module):
method __init__ (line 162) | def __init__(self, config: ChatGLMConfig, layer_number):
method forward (line 187) | def forward(self, query_layer, key_layer, value_layer, attention_mask):
class SelfAttention (line 279) | class SelfAttention(torch.nn.Module):
method __init__ (line 286) | def __init__(self, config: ChatGLMConfig, layer_number, device=None):
method _allocate_memory (line 315) | def _allocate_memory(self, inference_max_sequence_len, batch_size, dev...
method forward (line 329) | def forward(
function _config_to_kwargs (line 418) | def _config_to_kwargs(args):
class MLP (line 425) | class MLP(torch.nn.Module):
method __init__ (line 433) | def __init__(self, config: ChatGLMConfig, device=None):
method forward (line 462) | def forward(self, hidden_states):
class GLMBlock (line 471) | class GLMBlock(torch.nn.Module):
method __init__ (line 478) | def __init__(self, config: ChatGLMConfig, layer_number, device=None):
method forward (line 502) | def forward(
class GLMTransformer (line 545) | class GLMTransformer(torch.nn.Module):
method __init__ (line 548) | def __init__(self, config: ChatGLMConfig, device=None):
method _get_layer (line 569) | def _get_layer(self, layer_number):
method forward (line 572) | def forward(
class ChatGLMPreTrainedModel (line 608) | class ChatGLMPreTrainedModel(PreTrainedModel):
method _init_weights (line 620) | def _init_weights(self, module: nn.Module):
method get_masks (line 624) | def get_masks(self, input_ids, past_key_values, padding_mask=None):
method get_position_ids (line 642) | def get_position_ids(self, input_ids, device):
method _set_gradient_checkpointing (line 647) | def _set_gradient_checkpointing(self, module, value=False):
class Embedding (line 652) | class Embedding(torch.nn.Module):
method __init__ (line 655) | def __init__(self, config: ChatGLMConfig, device=None):
method forward (line 668) | def forward(self, input_ids):
class ChatGLMModel (line 680) | class ChatGLMModel(ChatGLMPreTrainedModel):
method __init__ (line 681) | def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
method get_input_embeddings (line 705) | def get_input_embeddings(self):
method forward (line 708) | def forward(
method quantize (line 759) | def quantize(self, weight_bit_width: int):
class ChatGLMForConditionalGeneration (line 765) | class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
method __init__ (line 766) | def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
method _update_model_kwargs_for_generation (line 777) | def _update_model_kwargs_for_generation(
method prepare_inputs_for_generation (line 808) | def prepare_inputs_for_generation(
method forward (line 831) | def forward(
method _reorder_cache (line 892) | def _reorder_cache(
method process_response (line 910) | def process_response(self, response):
method build_inputs (line 915) | def build_inputs(self, tokenizer, query: str, history: List[Tuple[str,...
method build_stream_inputs (line 924) | def build_stream_inputs(self, tokenizer, query: str, history: List[Tup...
method chat (line 938) | def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] =...
method stream_chat (line 956) | def stream_chat(self, tokenizer, query: str, history: List[Tuple[str, ...
method stream_generate (line 991) | def stream_generate(
method quantize (line 1095) | def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
FILE: chatglm2/quantization.py
class Kernel (line 18) | class Kernel:
method __init__ (line 19) | def __init__(self, code: bytes, function_names: List[str]):
class W8A16Linear (line 44) | class W8A16Linear(torch.autograd.Function):
method forward (line 46) | def forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: to...
method backward (line 58) | def backward(ctx, grad_output: torch.Tensor):
function compress_int4_weight (line 67) | def compress_int4_weight(weight: torch.Tensor): # (n, m)
function extract_weight_to_half (line 88) | def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tenso...
class QuantizedLinear (line 124) | class QuantizedLinear(torch.nn.Module):
method __init__ (line 125) | def __init__(self, weight_bit_width: int, weight, bias=None, device="c...
method forward (line 145) | def forward(self, input):
function quantize (line 152) | def quantize(model, weight_bit_width, empty_init=False, device=None):
FILE: chatglm2/tokenization_chatglm.py
class SPTokenizer (line 10) | class SPTokenizer:
method __init__ (line 11) | def __init__(self, model_path: str):
method tokenize (line 31) | def tokenize(self, s: str):
method encode (line 34) | def encode(self, s: str, bos: bool = False, eos: bool = False) -> List...
method decode (line 43) | def decode(self, t: List[int]) -> str:
method decode_tokens (line 46) | def decode_tokens(self, tokens: List[str]) -> str:
method convert_token_to_id (line 50) | def convert_token_to_id(self, token):
method convert_id_to_token (line 56) | def convert_id_to_token(self, index):
class ChatGLMTokenizer (line 63) | class ChatGLMTokenizer(PreTrainedTokenizer):
method __init__ (line 68) | def __init__(self, vocab_file, padding_side="left", **kwargs):
method get_command (line 80) | def get_command(self, token):
method pad_token (line 87) | def pad_token(self) -> str:
method pad_token_id (line 91) | def pad_token_id(self):
method vocab_size (line 95) | def vocab_size(self):
method get_vocab (line 98) | def get_vocab(self):
method _tokenize (line 104) | def _tokenize(self, text, **kwargs):
method _convert_token_to_id (line 107) | def _convert_token_to_id(self, token):
method _convert_id_to_token (line 111) | def _convert_id_to_token(self, index):
method convert_tokens_to_string (line 115) | def convert_tokens_to_string(self, tokens: List[str]) -> str:
method save_vocabulary (line 118) | def save_vocabulary(self, save_directory, filename_prefix=None):
method get_prefix_tokens (line 146) | def get_prefix_tokens(self):
method build_inputs_with_special_tokens (line 150) | def build_inputs_with_special_tokens(
method _pad (line 175) | def _pad(
FILE: chatglm3/configuration_chatglm.py
class ChatGLMConfig (line 4) | class ChatGLMConfig(PretrainedConfig):
method __init__ (line 6) | def __init__(
FILE: chatglm3/modeling_chatglm.py
function default_init (line 49) | def default_init(cls, *args, **kwargs):
class InvalidScoreLogitsProcessor (line 53) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 54) | def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTen...
class PrefixEncoder (line 61) | class PrefixEncoder(torch.nn.Module):
method __init__ (line 68) | def __init__(self, config: ChatGLMConfig):
method forward (line 84) | def forward(self, prefix: torch.Tensor):
function split_tensor_along_last_dim (line 93) | def split_tensor_along_last_dim(
class RotaryEmbedding (line 121) | class RotaryEmbedding(nn.Module):
method __init__ (line 122) | def __init__(self, dim, original_impl=False, device=None, dtype=None):
method forward_impl (line 129) | def forward_impl(
method forward (line 154) | def forward(self, max_seq_len, offset=0):
function apply_rotary_pos_emb (line 161) | def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> t...
class RMSNorm (line 181) | class RMSNorm(torch.nn.Module):
method __init__ (line 182) | def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None...
method forward (line 187) | def forward(self, hidden_states: torch.Tensor):
class CoreAttention (line 195) | class CoreAttention(torch.nn.Module):
method __init__ (line 196) | def __init__(self, config: ChatGLMConfig, layer_number):
method forward (line 221) | def forward(self, query_layer, key_layer, value_layer, attention_mask):
class SelfAttention (line 313) | class SelfAttention(torch.nn.Module):
method __init__ (line 320) | def __init__(self, config: ChatGLMConfig, layer_number, device=None):
method _allocate_memory (line 349) | def _allocate_memory(self, inference_max_sequence_len, batch_size, dev...
method forward (line 363) | def forward(
function _config_to_kwargs (line 452) | def _config_to_kwargs(args):
class MLP (line 459) | class MLP(torch.nn.Module):
method __init__ (line 467) | def __init__(self, config: ChatGLMConfig, device=None):
method forward (line 496) | def forward(self, hidden_states):
class GLMBlock (line 505) | class GLMBlock(torch.nn.Module):
method __init__ (line 512) | def __init__(self, config: ChatGLMConfig, layer_number, device=None):
method forward (line 536) | def forward(
class GLMTransformer (line 579) | class GLMTransformer(torch.nn.Module):
method __init__ (line 582) | def __init__(self, config: ChatGLMConfig, device=None):
method _get_layer (line 605) | def _get_layer(self, layer_number):
method forward (line 608) | def forward(
class ChatGLMPreTrainedModel (line 661) | class ChatGLMPreTrainedModel(PreTrainedModel):
method _init_weights (line 673) | def _init_weights(self, module: nn.Module):
method get_masks (line 677) | def get_masks(self, input_ids, past_key_values, padding_mask=None):
method get_position_ids (line 695) | def get_position_ids(self, input_ids, device):
method _set_gradient_checkpointing (line 700) | def _set_gradient_checkpointing(self, module, value=False):
class Embedding (line 705) | class Embedding(torch.nn.Module):
method __init__ (line 708) | def __init__(self, config: ChatGLMConfig, device=None):
method forward (line 721) | def forward(self, input_ids):
class ChatGLMModel (line 733) | class ChatGLMModel(ChatGLMPreTrainedModel):
method __init__ (line 734) | def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
method get_input_embeddings (line 768) | def get_input_embeddings(self):
method get_prompt (line 771) | def get_prompt(self, batch_size, device, dtype=torch.half):
method forward (line 786) | def forward(
method quantize (line 845) | def quantize(self, weight_bit_width: int):
class ChatGLMForConditionalGeneration (line 851) | class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
method __init__ (line 852) | def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
method _update_model_kwargs_for_generation (line 863) | def _update_model_kwargs_for_generation(
method prepare_inputs_for_generation (line 894) | def prepare_inputs_for_generation(
method forward (line 920) | def forward(
method _reorder_cache (line 981) | def _reorder_cache(
method process_response (line 999) | def process_response(self, output, history):
method chat (line 1024) | def chat(self, tokenizer, query: str, history: List[Dict] = None, role...
method stream_chat (line 1046) | def stream_chat(self, tokenizer, query: str, history: List[Dict] = Non...
method stream_generate (line 1087) | def stream_generate(
method quantize (line 1194) | def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
class ChatGLMForSequenceClassification (line 1213) | class ChatGLMForSequenceClassification(ChatGLMPreTrainedModel):
method __init__ (line 1214) | def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
method forward (line 1230) | def forward(
FILE: chatglm3/quantization.py
class Kernel (line 18) | class Kernel:
method __init__ (line 19) | def __init__(self, code: bytes, function_names: List[str]):
class W8A16Linear (line 44) | class W8A16Linear(torch.autograd.Function):
method forward (line 46) | def forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: to...
method backward (line 58) | def backward(ctx, grad_output: torch.Tensor):
function compress_int4_weight (line 67) | def compress_int4_weight(weight: torch.Tensor): # (n, m)
function extract_weight_to_half (line 88) | def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tenso...
class QuantizedLinear (line 124) | class QuantizedLinear(torch.nn.Module):
method __init__ (line 125) | def __init__(self, weight_bit_width: int, weight, bias=None, device="c...
method forward (line 145) | def forward(self, input):
function quantize (line 152) | def quantize(model, weight_bit_width, empty_init=False, device=None):
FILE: chatglm3/tokenization_chatglm.py
class SPTokenizer (line 11) | class SPTokenizer:
method __init__ (line 12) | def __init__(self, model_path: str):
method tokenize (line 34) | def tokenize(self, s: str, encode_special_tokens=False):
method encode (line 49) | def encode(self, s: str, bos: bool = False, eos: bool = False) -> List...
method decode (line 58) | def decode(self, t: List[int]) -> str:
method decode_tokens (line 72) | def decode_tokens(self, tokens: List[str]) -> str:
method convert_token_to_id (line 76) | def convert_token_to_id(self, token):
method convert_id_to_token (line 82) | def convert_id_to_token(self, index):
class ChatGLMTokenizer (line 91) | class ChatGLMTokenizer(PreTrainedTokenizer):
method __init__ (line 96) | def __init__(self, vocab_file, padding_side="left", clean_up_tokenizat...
method get_command (line 112) | def get_command(self, token):
method unk_token (line 119) | def unk_token(self) -> str:
method pad_token (line 123) | def pad_token(self) -> str:
method pad_token_id (line 127) | def pad_token_id(self):
method eos_token (line 131) | def eos_token(self) -> str:
method eos_token_id (line 135) | def eos_token_id(self):
method vocab_size (line 139) | def vocab_size(self):
method get_vocab (line 142) | def get_vocab(self):
method _tokenize (line 148) | def _tokenize(self, text, **kwargs):
method _convert_token_to_id (line 151) | def _convert_token_to_id(self, token):
method _convert_id_to_token (line 155) | def _convert_id_to_token(self, index):
method convert_tokens_to_string (line 159) | def convert_tokens_to_string(self, tokens: List[str]) -> str:
method save_vocabulary (line 162) | def save_vocabulary(self, save_directory, filename_prefix=None):
method get_prefix_tokens (line 190) | def get_prefix_tokens(self):
method build_single_message (line 194) | def build_single_message(self, role, metadata, message):
method build_chat_input (line 201) | def build_chat_input(self, query, history=None, role="user"):
method build_inputs_with_special_tokens (line 214) | def build_inputs_with_special_tokens(
method _pad (line 239) | def _pad(
FILE: glm4/configuration_chatglm.py
class ChatGLMConfig (line 4) | class ChatGLMConfig(PretrainedConfig):
method __init__ (line 7) | def __init__(
FILE: glm4/modeling_chatglm.py
function default_init (line 53) | def default_init(cls, *args, **kwargs):
class InvalidScoreLogitsProcessor (line 57) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 58) | def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTen...
function split_tensor_along_last_dim (line 65) | def split_tensor_along_last_dim(
class RotaryEmbedding (line 93) | class RotaryEmbedding(nn.Module):
method __init__ (line 94) | def __init__(self, dim, rope_ratio=1, original_impl=False, device=None...
method forward_impl (line 102) | def forward_impl(
method forward (line 128) | def forward(self, max_seq_len, offset=0):
function apply_rotary_pos_emb (line 135) | def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> t...
class RMSNorm (line 155) | class RMSNorm(torch.nn.Module):
method __init__ (line 156) | def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None...
method forward (line 161) | def forward(self, hidden_states: torch.Tensor):
class CoreAttention (line 169) | class CoreAttention(torch.nn.Module):
method __init__ (line 170) | def __init__(self, config: ChatGLMConfig, layer_number):
method forward (line 196) | def forward(self, query_layer, key_layer, value_layer, attention_mask):
class SdpaAttention (line 268) | class SdpaAttention(CoreAttention):
method forward (line 269) | def forward(self, query_layer, key_layer, value_layer, attention_mask):
function _get_unpad_data (line 286) | def _get_unpad_data(attention_mask):
class FlashAttention2 (line 299) | class FlashAttention2(CoreAttention):
method __init__ (line 300) | def __init__(self, *args, **kwargs):
method forward (line 304) | def forward(self, query_states, key_states, value_states, attention_ma...
method _upad_input (line 345) | def _upad_input(self, query_layer, key_layer, value_layer, attention_m...
class SelfAttention (line 391) | class SelfAttention(torch.nn.Module):
method __init__ (line 398) | def __init__(self, config: ChatGLMConfig, layer_number, device=None):
method _allocate_memory (line 427) | def _allocate_memory(self, inference_max_sequence_len, batch_size, dev...
method forward (line 441) | def forward(
function _config_to_kwargs (line 537) | def _config_to_kwargs(args):
class MLP (line 544) | class MLP(torch.nn.Module):
method __init__ (line 552) | def __init__(self, config: ChatGLMConfig, device=None):
method forward (line 581) | def forward(self, hidden_states):
class GLMBlock (line 590) | class GLMBlock(torch.nn.Module):
method __init__ (line 597) | def __init__(self, config: ChatGLMConfig, layer_number, device=None):
method forward (line 621) | def forward(
class GLMTransformer (line 664) | class GLMTransformer(torch.nn.Module):
method __init__ (line 667) | def __init__(self, config: ChatGLMConfig, device=None):
method _get_layer (line 690) | def _get_layer(self, layer_number):
method forward (line 693) | def forward(
class ChatGLMPreTrainedModel (line 755) | class ChatGLMPreTrainedModel(PreTrainedModel):
method _init_weights (line 769) | def _init_weights(self, module: nn.Module):
method get_masks (line 773) | def get_masks(self, input_ids, past_key_values, padding_mask=None):
method get_position_ids (line 795) | def get_position_ids(self, input_ids, device):
method gradient_checkpointing_enable (line 800) | def gradient_checkpointing_enable(self, gradient_checkpointing_kwargs=...
class Embedding (line 805) | class Embedding(torch.nn.Module):
method __init__ (line 808) | def __init__(self, config: ChatGLMConfig, device=None):
method forward (line 821) | def forward(self, input_ids):
class ChatGLMModel (line 831) | class ChatGLMModel(ChatGLMPreTrainedModel):
method __init__ (line 832) | def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
method get_input_embeddings (line 859) | def get_input_embeddings(self):
method set_input_embeddings (line 862) | def set_input_embeddings(self, value):
method forward (line 865) | def forward(
class ChatGLMForConditionalGeneration (line 923) | class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
method __init__ (line 924) | def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
method _update_model_kwargs_for_generation (line 931) | def _update_model_kwargs_for_generation(
method prepare_inputs_for_generation (line 962) | def prepare_inputs_for_generation(
method forward (line 988) | def forward(
method _reorder_cache (line 1048) | def _reorder_cache(
method process_response (line 1066) | def process_response(self, output, history):
method chat (line 1088) | def chat(self, tokenizer, query: str, history: List[Dict] = None, role...
method stream_chat (line 1111) | def stream_chat(self, tokenizer, query: str, history: List[Dict] = Non...
method stream_generate (line 1154) | def stream_generate(
class ChatGLMForSequenceClassification (line 1262) | class ChatGLMForSequenceClassification(ChatGLMPreTrainedModel):
method __init__ (line 1263) | def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
method forward (line 1276) | def forward(
FILE: glm4/tokenization_chatglm.py
class ChatGLM4Tokenizer (line 13) | class ChatGLM4Tokenizer(PreTrainedTokenizer):
method __init__ (line 17) | def __init__(
method vocab_size (line 57) | def vocab_size(self):
method get_vocab (line 60) | def get_vocab(self):
method convert_tokens_to_string (line 66) | def convert_tokens_to_string(self, tokens: List[Union[bytes, str, int]...
method _tokenize (line 86) | def _tokenize(self, text, **kwargs):
method _convert_token_to_id (line 93) | def _convert_token_to_id(self, token):
method _convert_id_to_token (line 97) | def _convert_id_to_token(self, index):
method save_vocabulary (line 101) | def save_vocabulary(self, save_directory, filename_prefix=None):
method get_prefix_tokens (line 129) | def get_prefix_tokens(self):
method build_single_message (line 133) | def build_single_message(self, role, metadata, message, tokenize=True):
method build_inputs_with_special_tokens (line 237) | def build_inputs_with_special_tokens(
method _pad (line 262) | def _pad(
FILE: gptq/gptq.py
class GPTQ (line 17) | class GPTQ:
method __init__ (line 18) | def __init__(self, layer):
method add_batch (line 31) | def add_batch(self, inp, out):
method fasterquant (line 59) | def fasterquant(
method free (line 156) | def free(self):
FILE: gptq/llama.py
function get_llama (line 11) | def get_llama(model):
function llama_sequential (line 24) | def llama_sequential(model, dataloader, dev):
function llama_eval (line 126) | def llama_eval(model, testenc, dev):
function llama_pack (line 219) | def llama_pack(model, quantizers, wbits, groupsize):
function load_quant (line 233) | def load_quant(model, checkpoint, wbits, groupsize=-1,faster_kernel=False):
function llama_multigpu (line 267) | def llama_multigpu(model, gpus):
function benchmark (line 298) | def benchmark(model, input_ids, check=False):
FILE: gptq/llama_inference.py
function get_llama (line 14) | def get_llama(model):
function load_quant (line 26) | def load_quant(model, checkpoint, wbits, groupsize):
FILE: gptq/modelutils.py
function find_layers (line 8) | def find_layers(module, layers=[nn.Conv2d, nn.Linear], name=''):
FILE: gptq/quant.py
function quantize (line 6) | def quantize(x, scale, zero, maxq):
class Quantizer (line 10) | class Quantizer(nn.Module):
method __init__ (line 12) | def __init__(self, shape=1):
method configure (line 18) | def configure(
method find_params (line 31) | def find_params(self, x, weight=False):
method quantize (line 110) | def quantize(self, x):
method enabled (line 115) | def enabled(self):
method ready (line 118) | def ready(self):
class QuantLinear (line 128) | class QuantLinear(nn.Module):
method __init__ (line 129) | def __init__(self, bits, groupsize, infeatures, outfeatures):
method pack (line 148) | def pack(self, linear, scales, zeros):
method forward (line 235) | def forward(self, x):
function make_quant (line 269) | def make_quant(module, names, bits, groupsize, name=''):
FILE: gptq/quant_cuda.cpp
function vecquant2matmul (line 11) | void vecquant2matmul(
function vecquant3matmul (line 26) | void vecquant3matmul(
function vecquant4matmul (line 41) | void vecquant4matmul(
function vecquant8matmul (line 56) | void vecquant8matmul(
function PYBIND11_MODULE (line 65) | PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
FILE: predictors/base.py
function parse_codeblock (line 5) | def parse_codeblock(text):
class BasePredictor (line 20) | class BasePredictor(ABC):
method __init__ (line 23) | def __init__(self, model_name, predict_mode='tuple'):
method stream_chat_continue (line 30) | def stream_chat_continue(self, *args, **kwargs):
method predict_continue (line 33) | def predict_continue(self, *args, **kwargs):
method predict_continue_tuple (line 39) | def predict_continue_tuple(self, query, latest_message, max_length, to...
method predict_continue_dict (line 65) | def predict_continue_dict(self, query, latest_message, max_length, top_p,
FILE: predictors/chatglm2_predictor.py
class InvalidScoreLogitsProcessor (line 11) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 12) | def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTen...
class ChatGLM2 (line 19) | class ChatGLM2(BasePredictor):
method __init__ (line 21) | def __init__(self, model_name):
method stream_chat_continue (line 64) | def stream_chat_continue(self,
function test (line 125) | def test():
function test2 (line 144) | def test2():
FILE: predictors/chatglm3_predictor.py
class InvalidScoreLogitsProcessor (line 12) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 14) | def __call__(self, input_ids: torch.LongTensor,
class ChatGLM3 (line 22) | class ChatGLM3(BasePredictor):
method __init__ (line 24) | def __init__(self, model_name):
method stream_chat_continue (line 65) | def stream_chat_continue(self,
function test (line 141) | def test():
function test2 (line 166) | def test2():
FILE: predictors/chatglm_predictor.py
class InvalidScoreLogitsProcessor (line 11) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __init__ (line 13) | def __init__(self, start_pos=5):
method __call__ (line 16) | def __call__(self, input_ids: torch.LongTensor,
class ChatGLM (line 24) | class ChatGLM(BasePredictor):
method __init__ (line 26) | def __init__(self, model_name):
method stream_chat_continue (line 69) | def stream_chat_continue(self,
function test (line 140) | def test():
FILE: predictors/debug.py
class Debug (line 1) | class Debug:
method __init__ (line 2) | def __init__(self, *args, **kwargs):
method inference (line 5) | def inference(self, *args, **kwargs):
method predict_continue (line 16) | def predict_continue(self, *args, **kwargs):
FILE: predictors/glm4_predictor.py
class InvalidScoreLogitsProcessor (line 13) | class InvalidScoreLogitsProcessor(LogitsProcessor):
method __call__ (line 15) | def __call__(self, input_ids: torch.LongTensor,
class GLM4 (line 23) | class GLM4(BasePredictor):
method __init__ (line 25) | def __init__(self, model_name, int4=False):
method stream_chat_continue (line 67) | def stream_chat_continue(self,
function test (line 158) | def test():
function test2 (line 183) | def test2():
FILE: predictors/llama.py
function stream_generate (line 18) | def stream_generate(
class LLaMa (line 120) | class LLaMa(BasePredictor):
method __init__ (line 122) | def __init__(self, model_name):
method stream_chat_continue (line 141) | def stream_chat_continue(self,
function test (line 197) | def test():
FILE: predictors/llama_gptq.py
class LLaMaGPTQ (line 13) | class LLaMaGPTQ(LLaMa):
method __init__ (line 14) | def __init__(self, model_name, checkpoint_path='llama7b-2m-4bit-128g.p...
function test (line 32) | def test():
FILE: test_fastapi.py
function event_source_response_iterator (line 17) | def event_source_response_iterator(response):
FILE: test_models.py
function test_model (line 5) | def test_model(model_name):
function main (line 46) | def main():
FILE: utils_env.py
function collect_env (line 1) | def collect_env():
Condensed preview — 54 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (494K chars).
[
{
"path": ".gitignore",
"chars": 1766,
"preview": "## Unimportant file\n.idea/\n*.ini\n*.lnk\n*.c\nrelease\nserver_config\n.venv\npython\nsystem\nvenv\nTHUDM\nBelleGroup\n\n*egg-info\nco"
},
{
"path": "LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "MODEL_LICENSE",
"chars": 2344,
"preview": "The ChatGLM-6B License\n\n1. Definitions\n\n“Licensor” means the ChatGLM-6B Model Team that distributes its Software.\n\n“Soft"
},
{
"path": "README.md",
"chars": 5880,
"preview": "# 💡Creative ChatGLM WebUI\n\n👋 欢迎来到 ChatGLM 创意世界!你可以使用修订和续写的功能来生成创意内容!\n\n* 📖 你可以使用“续写”按钮帮 ChatGLM 想一个开头,并让它继续生成更多的内容。\n* 📝 你"
},
{
"path": "app.py",
"chars": 5336,
"preview": "import gradio as gr\nfrom utils_env import collect_env\n\n# 收集环境信息\nprint('Collect environment info'.center(64, '-'))\nfor na"
},
{
"path": "app_fastapi.py",
"chars": 4668,
"preview": "from utils_env import collect_env\nfrom fastapi import FastAPI\nfrom fastapi.responses import StreamingResponse\nfrom fasta"
},
{
"path": "chatglm/configuration_chatglm.py",
"chars": 4276,
"preview": "\"\"\" ChatGLM model configuration \"\"\"\n\nfrom transformers.configuration_utils import PretrainedConfig\nfrom transformers.uti"
},
{
"path": "chatglm/modeling_chatglm.py",
"chars": 57605,
"preview": "\"\"\" PyTorch ChatGLM model. \"\"\"\n\nimport math\nimport copy\nimport os\nimport warnings\nimport re\nimport sys\n\nimport torch\nimp"
},
{
"path": "chatglm/quantization.py",
"chars": 15054,
"preview": "from torch.nn import Linear\nfrom torch.nn.parameter import Parameter\n\nimport bz2\nimport torch\nimport base64\nimport ctype"
},
{
"path": "chatglm/tokenization_chatglm.py",
"chars": 16652,
"preview": "\"\"\"Tokenization classes for ChatGLM.\"\"\"\nfrom typing import List, Optional, Union\nimport os\n\nfrom transformers.tokenizati"
},
{
"path": "chatglm2/configuration_chatglm.py",
"chars": 2084,
"preview": "from transformers import PretrainedConfig\n\n\nclass ChatGLMConfig(PretrainedConfig):\n model_type = \"chatglm\"\n def __"
},
{
"path": "chatglm2/modeling_chatglm.py",
"chars": 47048,
"preview": "\"\"\" PyTorch ChatGLM model. \"\"\"\n\nimport math\nimport copy\nimport warnings\nimport re\nimport sys\n\nimport torch\nimport torch."
},
{
"path": "chatglm2/quantization.py",
"chars": 14692,
"preview": "from torch.nn import Linear\nfrom torch.nn.parameter import Parameter\n\nimport bz2\nimport torch\nimport base64\nimport ctype"
},
{
"path": "chatglm2/tokenization_chatglm.py",
"chars": 9289,
"preview": "import os\nimport torch\nfrom typing import List, Optional, Union, Dict\nfrom sentencepiece import SentencePieceProcessor\nf"
},
{
"path": "chatglm3/configuration_chatglm.py",
"chars": 2332,
"preview": "from transformers import PretrainedConfig\n\n\nclass ChatGLMConfig(PretrainedConfig):\n model_type = \"chatglm\"\n def __"
},
{
"path": "chatglm3/modeling_chatglm.py",
"chars": 55666,
"preview": "\"\"\" PyTorch ChatGLM model. \"\"\"\n\nimport math\nimport copy\nimport warnings\nimport re\nimport sys\n\nimport torch\nimport torch."
},
{
"path": "chatglm3/quantization.py",
"chars": 14692,
"preview": "from torch.nn import Linear\nfrom torch.nn.parameter import Parameter\n\nimport bz2\nimport torch\nimport base64\nimport ctype"
},
{
"path": "chatglm3/tokenization_chatglm.py",
"chars": 12261,
"preview": "import json\nimport os\nimport re\nfrom typing import List, Optional, Union, Dict\nfrom sentencepiece import SentencePiecePr"
},
{
"path": "check_bad_cache_files.py",
"chars": 1411,
"preview": "import os\nimport hashlib\n\n# 指定要检查的目录路径\ndirectory_path = os.path.expanduser('~/.cache/huggingface/hub')\n\n# 遍历目录树\nfor root"
},
{
"path": "download_model.py",
"chars": 1425,
"preview": "import os\nos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'\n\nimport traceback\nfrom glob import glob\nfrom huggingface_h"
},
{
"path": "env_offline.bat",
"chars": 371,
"preview": "@echo off\n\necho Activate offline environment\n\nset DIR=%~dp0system\n\nset PATH=C:\\Windows\\system32;C:\\Windows;%DIR%\\git\\bin"
},
{
"path": "env_venv.bat",
"chars": 170,
"preview": "@echo off\n\nset DIR=.venv\n\ncd /D \"%~dp0\"\n\nif exist %DIR% goto :activate\necho Setup venv\npython -m venv .venv\n\n:activate\ne"
},
{
"path": "glm4/configuration_chatglm.py",
"chars": 2267,
"preview": "from transformers import PretrainedConfig\n\n\nclass ChatGLMConfig(PretrainedConfig):\n model_type = \"chatglm\"\n\n def _"
},
{
"path": "glm4/modeling_chatglm.py",
"chars": 58484,
"preview": "\"\"\" PyTorch ChatGLM model. \"\"\"\nimport json\nimport math\nimport copy\nimport warnings\nimport re\nimport sys\n\nimport torch\nim"
},
{
"path": "glm4/tokenization_chatglm.py",
"chars": 14688,
"preview": "import regex as re\nimport base64\nimport os\nimport json\nimport tiktoken\nfrom torch import TensorType\nfrom typing import L"
},
{
"path": "gptq/README.md",
"chars": 2843,
"preview": "# GPTQ-for-Bloom & LLaMa\n8 bits quantization of [Bloom](https://arxiv.org/pdf/2211.05100.pdf) using [GPTQ](https://arxiv"
},
{
"path": "gptq/gptq.py",
"chars": 5182,
"preview": "import math\nimport time\n\nimport torch\nimport torch.nn as nn\nimport transformers\n\nfrom gptq.quant import *\n\n\nDEBUG = Fals"
},
{
"path": "gptq/llama.py",
"chars": 16027,
"preview": "import time\n\nimport torch\nimport torch.nn as nn\n\nfrom gptq.gptq import *\nfrom gptq.modelutils import *\nfrom gptq.quant i"
},
{
"path": "gptq/llama_inference.py",
"chars": 4066,
"preview": "import time\n\nimport torch\nimport torch.nn as nn\n\nfrom gptq.gptq import *\nfrom gptq.modelutils import *\nfrom gptq.quant i"
},
{
"path": "gptq/modelutils.py",
"chars": 397,
"preview": "import torch\nimport torch.nn as nn\n\n\nDEV = torch.device('cuda:0')\n\n\ndef find_layers(module, layers=[nn.Conv2d, nn.Linear"
},
{
"path": "gptq/quant.py",
"chars": 10802,
"preview": "import numpy as np\nimport torch\nimport torch.nn as nn\nimport math\n\ndef quantize(x, scale, zero, maxq):\n q = torch.cla"
},
{
"path": "gptq/quant_cuda.cpp",
"chars": 2258,
"preview": "#include <torch/all.h>\n#include <torch/python.h>\n#include <c10/cuda/CUDAGuard.h>\n\nvoid vecquant2matmul_cuda(\n torch::Te"
},
{
"path": "gptq/quant_cuda_kernel.cu",
"chars": 15843,
"preview": "#include <torch/all.h>\n#include <torch/python.h>\n#include <cuda.h>\n#include <cuda_runtime.h>\n\n// atomicAdd for double-pr"
},
{
"path": "gptq/setup_cuda.py",
"chars": 287,
"preview": "from setuptools import setup, Extension\nfrom torch.utils import cpp_extension\n\nsetup(\n name='quant_cuda',\n ext_mod"
},
{
"path": "gptq/test_kernel.py",
"chars": 4150,
"preview": "import torch\nimport torch.nn as nn\n\nimport quant_cuda\nimport os\nos.environ['CUDA_LAUNCH_BLOCKING'] = \"1\"\n\ntorch.backends"
},
{
"path": "predictors/base.py",
"chars": 3665,
"preview": "import copy\nfrom abc import ABC, abstractmethod\n\n\ndef parse_codeblock(text):\n lines = text.split(\"\\n\")\n for i, lin"
},
{
"path": "predictors/chatglm2_predictor.py",
"chars": 6399,
"preview": "import time\nfrom typing import List, Tuple\n\nimport torch\nfrom transformers import AutoModel, AutoTokenizer\nfrom transfor"
},
{
"path": "predictors/chatglm3_predictor.py",
"chars": 7228,
"preview": "import time\nimport json\nfrom typing import List, Dict\n\nimport torch\nfrom transformers import AutoModel, AutoTokenizer\nfr"
},
{
"path": "predictors/chatglm_predictor.py",
"chars": 5762,
"preview": "import time\nfrom typing import List, Tuple\n\nimport torch\nfrom transformers import AutoModel, AutoTokenizer\nfrom transfor"
},
{
"path": "predictors/debug.py",
"chars": 466,
"preview": "class Debug:\n def __init__(self, *args, **kwargs):\n pass\n\n def inference(self, *args, **kwargs):\n im"
},
{
"path": "predictors/glm4_predictor.py",
"chars": 7688,
"preview": "import time\nimport json\nfrom typing import List, Dict\n\nimport torch\nfrom transformers import AutoModel, AutoTokenizer\nfr"
},
{
"path": "predictors/llama.py",
"chars": 9239,
"preview": "import copy\nimport time\nimport warnings\nfrom typing import List, Tuple, Optional, Callable\n\nimport torch\nimport torch.nn"
},
{
"path": "predictors/llama_gptq.py",
"chars": 2390,
"preview": "import time\nimport torch\nimport transformers\nfrom predictors.llama import LLaMa\nimport numpy as np\nimport torch\nimport t"
},
{
"path": "setup_offline.bat",
"chars": 605,
"preview": "cd /D \"%~dp0\"\n\nrem set http_proxy=http://127.0.0.1:7890 & set https_proxy=http://127.0.0.1:7890\n\necho Setup offline envi"
},
{
"path": "setup_venv.bat",
"chars": 344,
"preview": "cd /D \"%~dp0\"\n\necho Setup venv environment\ncall env_venv.bat\n\necho Install dependencies...\npip install torch==2.0.0+cu11"
},
{
"path": "start.bat",
"chars": 68,
"preview": "@echo off\n\ncd /D \"%~dp0\"\n\necho Start app.py\npython app.py %*\n\npause\n"
},
{
"path": "start_api.bat",
"chars": 84,
"preview": "@echo off\n\ncd /D \"%~dp0\"\n\necho Start app_fastapi.py\npython app_fastapi.py %*\n\npause\n"
},
{
"path": "start_offline.bat",
"chars": 62,
"preview": "@echo off\n\ncd /D \"%~dp0\"\n\ncall env_offline.bat\ncall start.bat\n"
},
{
"path": "start_offline_api.bat",
"chars": 66,
"preview": "@echo off\n\ncd /D \"%~dp0\"\n\ncall env_offline.bat\ncall start_api.bat\n"
},
{
"path": "start_offline_cmd.bat",
"chars": 57,
"preview": "@echo off\n\ncd /D \"%~dp0\"\n\ncall env_offline.bat\ncmd\npause\n"
},
{
"path": "start_venv.bat",
"chars": 59,
"preview": "@echo off\n\ncd /D \"%~dp0\"\n\ncall env_venv.bat\ncall start.bat\n"
},
{
"path": "test_fastapi.py",
"chars": 1115,
"preview": "url = \"http://localhost:8000/stream\"\n\nparams = {\n \"query\": \"Hello\",\n 'answer_prefix': \"Nice\",\n \"allow_generate\""
},
{
"path": "test_models.py",
"chars": 1765,
"preview": "import os\nos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'\n\n\ndef test_model(model_name):\n if 'glm-4' in model_name"
},
{
"path": "utils_env.py",
"chars": 960,
"preview": "def collect_env():\n import sys\n from collections import defaultdict\n\n env_info = {}\n env_info['sys.platform'"
}
]
About this extraction
This page contains the full source code of the ypwhs/CreativeChatGLM GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 54 files (460.6 KB), approximately 119.7k tokens, and a symbol index with 467 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.