Showing preview only (258K chars total). Download the full file or copy to clipboard to get everything.
Repository: zihaosheng/VLM-RL
Branch: main
Commit: 48dbb27cadaf
Files: 38
Total size: 246.0 KB
Directory structure:
gitextract_wbtls8qs/
├── LICENSE
├── README.md
├── carla_env/
│ ├── __init__.py
│ ├── envs/
│ │ ├── Town01.h5
│ │ ├── Town02.h5
│ │ ├── Town03.h5
│ │ ├── Town04.h5
│ │ ├── Town05.h5
│ │ ├── Town06.h5
│ │ └── carla_route_env.py
│ ├── navigation/
│ │ ├── __init__.py
│ │ ├── agent.py
│ │ ├── basic_agent.py
│ │ ├── controller.py
│ │ ├── global_route_planner.py
│ │ ├── global_route_planner_dao.py
│ │ ├── local_planner.py
│ │ ├── planner.py
│ │ └── roaming_agent.py
│ ├── rewards.py
│ ├── state_commons.py
│ ├── tools/
│ │ ├── __init__.py
│ │ ├── hud.py
│ │ └── misc.py
│ └── wrappers.py
├── clip/
│ ├── __init__.py
│ ├── clip_buffer.py
│ ├── clip_reward_model.py
│ ├── clip_rewarded_ppo.py
│ ├── clip_rewarded_sac.py
│ └── transform.py
├── config.py
├── eval.py
├── eval_plots.py
├── requirements.txt
├── run_eval.py
├── train.py
└── utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2024 szh
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
<div id="top" align="center">
<p align="center">
<strong>
<h2 align="center">VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving</h2>
<h3 align="center"><a href="https://www.huang-zilin.com/VLM-RL-website/">Website</a> | <a href="https://arxiv.org/abs/2412.15544">Paper</a> | <a href="https://www.youtube.com/embed/oXBih9r2DdI?si=XRUEthPoni_zNTR6">Video</a> | <a href="https://huggingface.co/zihaosheng/VLM-RL">Hugging Face</a> </h3>
</strong>
</p>
</div>
<br/>
> **[VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving](https://arxiv.org/abs/2412.15544)**
>
> [Zilin Huang](https://scholar.google.com/citations?user=RgO7ppoAAAAJ&hl=en)<sup>1,\*</sup>,
> [Zihao Sheng](https://scholar.google.com/citations?user=3T-SILsAAAAJ&hl=en)<sup>1,\*</sup>,
> [Yansong Qu](https://scholar.google.com/citations?view_op=list_works&hl=zh-CN&user=hIt7KnUAAAAJ)<sup>2,†</sup>,
> [Junwei You](https://scholar.google.com/citations?user=wIGL3SQAAAAJ&hl=en)<sup>1</sup>,
> [Sikai Chen](https://scholar.google.com/citations?user=DPN2wc4AAAAJ&hl=en)<sup>1,✉</sup><br>
>
> <sup>1</sup>University of Wisconsin-Madison, <sup>2</sup>Purdue University
>
> <sup>\*</sup>Equally Contributing First Authors,
> <sup>✉</sup>Corresponding Author
> <br/>
## 📢 News
- **2025.09**: 🔥🔥 The model weights are now available on [🤗 Hugging Face](https://huggingface.co/zihaosheng/VLM-RL). Feel free to try them out!
- **2025.08**: 🔥🔥 **VLM-RL** has been accepted to *Transportation Research Part C: Emerging Technologies*!
## 💡 Highlights <a name="highlight"></a>
🔥 To the best of our knowledge, **VLM-RL** is the first work in the autonomous driving field to unify VLMs with RL for
end-to-end driving policy learning in the CARLA simulator.
🏁 **VLM-RL** outperforms state-of-the-art baselines, achieving a 10.5% reduction in collision rate, a 104.6% increase in
route completion rate, and robust generalization to unseen driving scenarios.
| Route 1 | Route 2 | Route 3 | Route 4 | Route 5 |
|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|
|  |  |  |  |  |
| Route 6 | Route 7 | Route 8 | Route 9 | Route 10 |
|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------:|
|  | 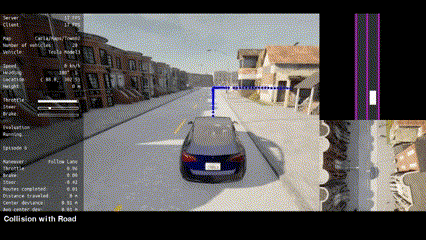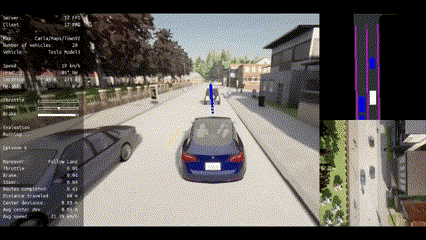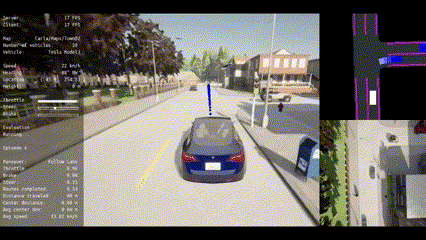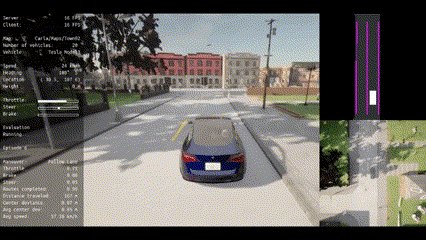 |  |  |  |
## 📋 Table of Contents
1. [Highlights](#highlight)
2. [Getting Started](#setup)
3. [Training](#training)
4. [Evaluation](#evaluation)
5. [Contributors](#contributors)
6. [Citation](#citation)
7. [Other Resources](#resources)
## 🛠️ Getting Started <a name="setup"></a>
1. Download and install `CARLA 0.9.13` from the [official release page](https://github.com/carla-simulator/carla/releases/tag/0.9.13).
2. Create a conda env and install the requirements:
```shell
# Clone the repo
git clone https://github.com/zihaosheng/VLM-RL.git
cd VLM-RL
# Create a conda env
conda create -y -n vlm-rl python=3.8
conda activate vlm-rl
# Install PyTorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
# Install the requirements
pip install -r requirements.txt
```
3. Start a Carla server with the following command. You can ignore this if `start_carla=True`
```shell
./CARLA_0.9.13/CarlaUE4.sh -quality_level=Low -benchmark -fps=15 -RenderOffScreen -prefernvidia -carla-world-port=2000
```
If `start_carla=True`, revise the `CARLA_ROOT` in `carla_env/envs/carla_route_env.py` to the path of your CARLA installation.
<p align="right">(<a href="#top">back to top</a>)</p>
## 🚋 Training <a name="training"></a>
### Training VLM-RL
To reproduce the results in the paper, we provide the following training scripts:
```shell
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
```
**Note:** On the first run, the script will automatically download the required OpenCLIP pre-trained model, which may take a few minutes. Please wait for the download to complete before the training begins.
#### To accelerate the training process, you can set up multiple CARLA servers running in parallel.
<details>
<summary>For example, to train the VLM-RL model with 3 CARLA servers on different GPUs, run the following commands in three separate terminals:
</summary>
#### Terminal 1:
```shell
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
```
#### Terminal 2:
```shell
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2005 --device=cuda:1
```
#### Terminal 3:
```shell
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2010 --device=cuda:2
```
</details>
To train the VLM-RL model with PPO, run:
```shell
python train.py --config=vlm_rl_ppo --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
```
### Training Baselines
To train baseline models, simply change the `--config` argument to the desired model. For example, to train the TIRL-SAC model, run:
```shell
python train.py --config=tirl_sac --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
```
More baseline models can be found in the `CONFIGS` dictionary of `config.py`.
<p align="right">(<a href="#top">back to top</a>)</p>
## 📊 Evaluation <a name="evaluation"></a>
To evaluate trained model checkpoints, run:
```shell
python run_eval.py
```
**Note:** that this command will first **KILL** all the existing CARLA servers and then start a new one.
Try to avoid running this command while training is in progress.
<p align="right">(<a href="#top">back to top</a>)</p>
## 👥 Contributors <a name="contributors"></a>
Special thanks to the following contributors who have helped with this project:
<!-- readme: contributors -start -->
<table>
<tbody>
<tr>
<td align="center">
<a href="https://github.com/zihaosheng">
<img src="https://scholar.googleusercontent.com/citations?view_op=view_photo&user=3T-SILsAAAAJ&citpid=7" width="100;" alt="zihaosheng"/>
<br />
<sub><b>Zihao Sheng</b></sub>
</a>
</td>
<td align="center">
<a href="https://github.com/zilin-huang">
<img src="https://avatars.githubusercontent.com/u/59532565?v=4" width="100;" alt="zilinhuang"/>
<br />
<sub><b>Zilin Huang</b></sub>
</a>
</td>
<td align="center">
<a href="https://scholar.google.com/citations?user=hIt7KnUAAAAJ&hl=en&oi=sra">
<img src="https://scholar.googleusercontent.com/citations?view_op=view_photo&user=hIt7KnUAAAAJ&citpid=2" width="100;" alt="yansongqu"/>
<br />
<sub><b>Yansong Qu</b></sub>
</a>
</td>
<td align="center">
<a href="https://scholar.google.com/citations?user=wIGL3SQAAAAJ&hl=en">
<img src="https://scholar.google.com/citations/images/avatar_scholar_128.png" width="100;" alt="junweiyou"/>
<br />
<sub><b>Junwei You</b></sub>
</a>
</td>
</tr>
<tbody>
</table>
<!-- readme: contributors -end -->
<p align="right">(<a href="#top">back to top</a>)</p>
## 🎯 Citation <a name="citation"></a>
If you find VLM-RL useful for your research, please consider giving us a star 🌟 and citing our paper:
```BibTeX
@article{huang2024vlmrl,
title={VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving},
author={Huang, Zilin and Sheng, Zihao and Qu, Yansong and You, Junwei and Chen, Sikai},
journal={arXiv preprint arXiv:2412.15544},
year={2024}
}
```
<p align="right">(<a href="#top">back to top</a>)</p>
## 📚 Other Resources <a name="resources"></a>
Our team is actively working on research projects in the field of AI and autonomous driving. Here are a few of them you might find interesting:
- **[Human as AI mentor](https://zilin-huang.github.io/HAIM-DRL-website/)**
- **[Physics-enhanced RLHF](https://zilin-huang.github.io/PE-RLHF-website/)**
- **[Traffic expertise meets residual RL](https://github.com/zihaosheng/traffic-expertise-RL)**
<p align="right">(<a href="#top">back to top</a>)</p>
================================================
FILE: carla_env/__init__.py
================================================
import os, sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from carla import *
================================================
FILE: carla_env/envs/carla_route_env.py
================================================
import os
import subprocess
import time
import gym
import h5py
import pygame
import cv2
from pygame.locals import *
import random
from config import CONFIG
from carla_env.tools.hud import HUD
from carla_env.navigation.planner import RoadOption, compute_route_waypoints
from carla_env.wrappers import *
import carla
from collections import deque
import itertools
intersection_routes = itertools.cycle(
[(57, 81), (70, 11), (70, 12), (78, 68), (74, 41), (42, 73), (71, 62), (74, 40), (71, 77), (6, 12), (65, 52),
(63, 80)])
eval_routes = itertools.cycle(
[(48, 21), (0, 72), (28, 83), (61, 39), (27, 14), (6, 67), (61, 49), (37, 64), (33, 80), (12, 30), ])
COLOR_BLACK = (0, 0, 0)
COLOR_RED = (255, 0, 0)
COLOR_GREEN = (0, 255, 0)
COLOR_BLUE = (0, 0, 255)
COLOR_CYAN = (0, 255, 255)
COLOR_MAGENTA = (255, 0, 255)
COLOR_MAGENTA_2 = (255, 140, 255)
COLOR_YELLOW = (255, 255, 0)
COLOR_YELLOW_2 = (160, 160, 0)
COLOR_WHITE = (255, 255, 255)
COLOR_ALUMINIUM_0 = (238, 238, 236)
COLOR_ALUMINIUM_3 = (136, 138, 133)
COLOR_ALUMINIUM_5 = (46, 52, 54)
def tint(color, factor):
r, g, b = color
r = int(r + (255 - r) * factor)
g = int(g + (255 - g) * factor)
b = int(b + (255 - b) * factor)
r = min(r, 255)
g = min(g, 255)
b = min(b, 255)
return (r, g, b)
discrete_actions = {
0: [-1.0, 0.0],
1: [0.7, -0.5],
2: [0.7, -0.3],
3: [0.7, -0.2],
4: [0.7, -0.1],
5: [0.7, 0.0],
6: [0.7, 0.1],
7: [0.7, 0.2],
8: [0.7, 0.3],
9: [0.7, 0.5],
10: [0.3, -0.7],
11: [0.3, -0.5],
12: [0.3, -0.3],
13: [0.3, -0.2],
14: [0.3, -0.1],
15: [0.3, 0.0],
16: [0.3, 0.1],
17: [0.3, 0.2],
18: [0.3, 0.3],
19: [0.3, 0.5],
20: [0.3, 0.7],
21: [0.0, -1.0],
22: [0.0, -0.6],
23: [0.0, -0.3],
24: [0.0, -0.1],
25: [0.0, 0.0],
26: [0.0, 0.1],
27: [0.0, 0.3],
28: [0.0, 0.6],
29: [0.0, 1.0],
}
class_blueprint = {
'car': ['vehicle.tesla.model3',
'vehicle.audi.tt',
'vehicle.chevrolet.impala', ]
}
def random_choice_from_blueprint(blueprint):
all_elements = [item for sublist in blueprint.values() for item in sublist]
return random.choice(all_elements)
class CarlaRouteEnv(gym.Env):
metadata = {
"render.modes": ["human", "rgb_array", "rgb_array_no_hud", "state_pixels"]
}
def __init__(self, host="127.0.0.1", port=2000,
viewer_res=(1120, 560), obs_res=(80, 120),
reward_fn=None,
observation_space=None,
encode_state_fn=None,
fps=15, action_smoothing=0.0,
action_space_type="continuous",
activate_spectator=True,
activate_bev=False,
start_carla=False,
eval=False,
activate_render=True,
activate_traffic_flow=False,
activate_seg_bev=False,
tf_num=20,
town='Town02'):
self.carla_process = None
if start_carla:
CARLA_ROOT = "/home/sky-lab/CARLA_0.9.13"
carla_path = os.path.join(CARLA_ROOT, "CarlaUE4.sh")
launch_command = [carla_path]
launch_command += ['-quality_level=Low']
launch_command += ['-benchmark']
launch_command += ["-fps=%i" % fps]
launch_command += ['-RenderOffScreen']
launch_command += ['-prefernvidia']
launch_command += [f'-carla-world-port={port}']
print("Running command:")
print(" ".join(launch_command))
self.carla_process = subprocess.Popen(launch_command, stdout=subprocess.DEVNULL, stderr=subprocess.STDOUT)
print("Waiting for CARLA to initialize\n")
time.sleep(5)
width, height = viewer_res
if obs_res is None:
out_width, out_height = width, height
else:
out_width, out_height = obs_res
self.activate_render = activate_render
self.num_envs = 1
# Setup gym environment
self.action_space_type = action_space_type
if self.action_space_type == "continuous":
self.action_space = gym.spaces.Box(np.array([-1, -1]), np.array([1, 1]),
dtype=np.float32) # steer, throttle
elif self.action_space_type == "discrete":
self.action_space = gym.spaces.Discrete(len(discrete_actions))
self.observation_space = observation_space
self.fps = fps
self.action_smoothing = action_smoothing
self.episode_idx = -2
self.encode_state_fn = (lambda x: x) if not callable(encode_state_fn) else encode_state_fn
self.reward_fn = (lambda x: 0) if not callable(reward_fn) else reward_fn
self.max_distance = 3000 # m
self.activate_spectator = activate_spectator
self.activate_bev = activate_bev
self.eval = eval
self.activate_traffic_flow = activate_traffic_flow
self.traffic_flow_vehicles = []
self.low_speed_timer = 0.0
self.collision_num = 0
self.cps = 0 # average collision per timestep
self.cpm = 0 # average collision per kilometer
self.collision_speed = 0.0
self.collision_interval = 0
self.last_collision_step = 0
self.collision_deque = deque(maxlen=100)
self.total_steps = 0
# bev parameters
self.use_seg_bev = True if activate_seg_bev else False
self._width = 192
self._pixels_per_meter = 5.0
self._distance_threshold = np.ceil(self._width / self._pixels_per_meter)
self._scale_bbox = True
self._history_queue = deque(maxlen=20)
self._pixels_ev_to_bottom = 40
self._history_idx = [-16, -11, -6, -1]
self._scale_mask_col = 1.0
maps_h5_path = './carla_env/envs/{}.h5'.format(town)
with h5py.File(maps_h5_path, 'r', libver='latest', swmr=True) as hf:
self._road = np.array(hf['road'], dtype=np.uint8)
self._lane_marking_all = np.array(hf['lane_marking_all'], dtype=np.uint8)
self._lane_marking_white_broken = np.array(hf['lane_marking_white_broken'], dtype=np.uint8)
self._world_offset = np.array(hf.attrs['world_offset_in_meters'], dtype=np.float32)
assert np.isclose(self._pixels_per_meter, float(hf.attrs['pixels_per_meter']))
self.world = None
try:
self.client = carla.Client(host, port)
self.client.set_timeout(5.0)
self.world = World(self.client, town=town)
settings = self.world.get_settings()
settings.fixed_delta_seconds = 1 / self.fps
settings.synchronous_mode = True
self.world.apply_settings(settings)
self.client.reload_world(False)
if not self.eval:
self.world.set_weather(
carla.WeatherParameters(cloudiness=100.0, precipitation=0.0, sun_altitude_angle=45.0, )
)
self.vehicle = Vehicle(self.world, self.world.map.get_spawn_points()[0],
on_collision_fn=lambda e: self._on_collision(e),
on_invasion_fn=lambda e: self._on_invasion(e),
is_ego=True)
if self.activate_render:
pygame.init()
pygame.font.init()
self.display = pygame.display.set_mode((width, height), pygame.HWSURFACE | pygame.DOUBLEBUF)
self.clock = pygame.time.Clock()
self.hud = HUD(width, height)
self.hud.set_vehicle(self.vehicle)
self.world.on_tick(self.hud.on_world_tick)
seg_settings = {}
if "seg_camera" in self.observation_space.spaces:
seg_settings.update({
'camera_type': "sensor.camera.semantic_segmentation",
'custom_palette': True
})
if not self.use_seg_bev:
self.dashcam = Camera(self.world, out_width, out_height,
transform=sensor_transforms["dashboard"],
attach_to=self.vehicle, on_recv_image=lambda e: self._set_observation_image(e),
**seg_settings)
if self.activate_spectator:
self.camera = Camera(self.world, width, height,
transform=sensor_transforms["spectator"],
attach_to=self.vehicle, on_recv_image=lambda e: self._set_viewer_image(e))
self.bev_spectator = Camera(self.world, height // 2, height // 2,
transform=sensor_transforms["birdview0"],
attach_to=self.vehicle,
on_recv_image=lambda e: self._set_bev_spectator_data(e))
if self.activate_bev:
self.bev = Camera(self.world, 517, 517,
transform=sensor_transforms["birdview1"],
attach_to=self.vehicle, on_recv_image=lambda e: self._set_bev_data(e))
if self.activate_traffic_flow:
self.tf_num = tf_num
self.traffic_manager = self.client.get_trafficmanager(port + 6000)
self.traffic_manager.set_global_distance_to_leading_vehicle(2.5)
self.traffic_manager.set_synchronous_mode(True)
self.traffic_manager.set_hybrid_physics_mode(True)
self.traffic_manager.set_hybrid_physics_radius(50.0)
except Exception as e:
self.close()
raise e
# Reset env to set initial state
self.reset()
def reset(self, is_training=False):
# Create new route
self.num_routes_completed = -1
self.episode_idx += 1
self.new_route()
self.terminal_state = False # Set to True when we want to end episode
self.success_state = False # Set to True when we want to end episode.
self.collision_state = False
self._history_queue.clear()
self.world.world = None
self.world.world = self.client.get_world()
self.closed = False # Set to True when ESC is pressed
self.extra_info = [] # List of extra info shown on the HUD
self.observation = self.observation_buffer = None # Last received observation
self.viewer_image = self.viewer_image_buffer = None # Last received image to show in the viewer
self.bev_spectator_data = self.bev_spectator_data_buffer = None
self.bev_data = self.bev_data_buffer = None
self.step_count = 0
self.total_reward = 0.0
self.previous_location = self.vehicle.get_transform().location
self.distance_traveled = 0.0
self.center_lane_deviation = 0.0
self.speed_accum = 0.0
self.routes_completed = 0.0
self.low_speed_timer = 0.0
self.collision = False
self.action_list = []
self.world.tick()
time.sleep(0.2)
obs = self.step(None)[0]
time.sleep(0.2)
return obs
def new_route(self):
if self.activate_traffic_flow:
for bg_veh in list(self.traffic_flow_vehicles):
if bg_veh.is_alive:
bg_veh.destroy()
self.traffic_flow_vehicles.remove(bg_veh)
self.vehicle.control.steer = float(0.0)
self.vehicle.control.throttle = float(0.0)
self.vehicle.set_simulate_physics(False)
if not self.eval:
if self.episode_idx % 2 == 0 and self.num_routes_completed == -1:
spawn_points_list = [self.world.map.get_spawn_points()[index] for index in next(intersection_routes)]
else:
spawn_points_list = np.random.choice(self.world.map.get_spawn_points(), 2, replace=False)
else:
spawn_points_list = [self.world.map.get_spawn_points()[index] for index in next(eval_routes)]
route_length = 1
while route_length <= 1:
self.start_wp, self.end_wp = [self.world.map.get_waypoint(spawn.location) for spawn in
spawn_points_list]
self.route_waypoints = compute_route_waypoints(self.world.map, self.start_wp, self.end_wp, resolution=1.0)
route_length = len(self.route_waypoints)
if route_length <= 1:
spawn_points_list = np.random.choice(self.world.map.get_spawn_points(), 2, replace=False)
self.distance_from_center_history = deque(maxlen=30)
self.current_waypoint_index = 0
self.num_routes_completed += 1
self.vehicle.set_transform(self.start_wp.transform)
time.sleep(0.2)
self.vehicle.set_simulate_physics(True)
if self.activate_traffic_flow:
spawn_points = self.world.get_map().get_spawn_points()
number_of_vehicles = min(len(spawn_points), self.tf_num) # Adjust the number of vehicles as needed
for _ in range(number_of_vehicles):
blueprint = random_choice_from_blueprint(class_blueprint)
blueprint = self.world.get_blueprint_library().find(blueprint)
spawn_point = random.choice(spawn_points)
bg_veh = self.world.try_spawn_actor(blueprint, spawn_point)
if bg_veh:
bg_veh.set_autopilot(True, self.traffic_manager.get_port())
self.traffic_flow_vehicles.append(bg_veh)
def close(self):
if self.carla_process:
self.carla_process.terminate()
pygame.quit()
if self.world is not None:
self.world.destroy()
self.closed = True
if self.world is not None:
actors = self.world.get_actors().filter('vehicle.*')
for actor in actors:
actor.destroy()
def render(self, mode="human"):
if mode == "rgb_array_no_hud":
return self.viewer_image
elif mode == "rgb_array":
return np.array(pygame.surfarray.array3d(self.display), dtype=np.uint8).transpose([1, 0, 2])
elif mode == "state_pixels":
return self.observation_render
self.clock.tick()
self.hud.tick(self.world, self.clock)
if self.current_road_maneuver == RoadOption.LANEFOLLOW:
maneuver = "Follow Lane"
elif self.current_road_maneuver == RoadOption.LEFT:
maneuver = "Left"
elif self.current_road_maneuver == RoadOption.RIGHT:
maneuver = "Right"
elif self.current_road_maneuver == RoadOption.STRAIGHT:
maneuver = "Straight"
elif self.current_road_maneuver == RoadOption.CHANGELANELEFT:
maneuver = "Change Lane Left"
elif self.current_road_maneuver == RoadOption.CHANGELANERIGHT:
maneuver = "Change Lane Right"
else:
maneuver = "INVALID"
self.extra_info.extend([
"Episode {}".format(self.episode_idx),
"",
"Maneuver: % 17s" % maneuver,
"Throttle: %7.2f" % self.vehicle.control.throttle,
"Brake: %7.2f" % self.vehicle.control.brake,
"Steer: %7.2f" % self.vehicle.control.steer,
"Routes completed: % 7.2f" % self.routes_completed,
"Distance traveled: % 7d m" % self.distance_traveled,
"Center deviance: % 7.2f m" % self.distance_from_center,
"Avg center dev: % 7.2f m" % (self.center_lane_deviation / self.step_count),
"Avg speed: % 7.2f km/h" % (self.speed_accum / self.step_count),
])
if self.activate_spectator:
self.viewer_image = self._draw_path(self.camera, self.viewer_image)
self.display.blit(pygame.surfarray.make_surface(self.viewer_image.swapaxes(0, 1)), (0, 0))
new_size = (self.display.get_size()[1] // 2, self.display.get_size()[1] // 2)
pos_bev = (self.display.get_size()[0] - self.display.get_size()[1] // 2, self.display.get_size()[1] // 2)
bev_surface = pygame.surfarray.make_surface(self.bev_spectator_data.swapaxes(0, 1))
scaled_surface = pygame.transform.scale(bev_surface, new_size)
self.display.blit(scaled_surface, pos_bev)
pos_obs = (self.display.get_size()[0] - self.display.get_size()[1] // 2, 0)
obs_surface = pygame.surfarray.make_surface(self.observation_render.swapaxes(0, 1))
scaled_surface = pygame.transform.scale(obs_surface, new_size)
self.display.blit(scaled_surface, pos_obs)
self.hud.render(self.display, extra_info=self.extra_info)
self.extra_info = []
pygame.display.flip()
def step(self, action):
if self.closed:
raise Exception("CarlaEnv.step() called after the environment was closed." +
"Check for info[\"closed\"] == True in the learning loop.")
if action is not None:
if self.current_waypoint_index >= len(self.route_waypoints) - 1:
if not self.eval:
self.new_route()
else:
self.success_state = True
if self.action_space_type == "continuous":
steer, throttle = [float(a) for a in action]
elif self.action_space_type == "discrete":
throttle, steer = discrete_actions[int(action)]
self.vehicle.control.steer = smooth_action(self.vehicle.control.steer, steer, self.action_smoothing)
if throttle >= 0:
self.vehicle.control.throttle = throttle
self.vehicle.control.brake = 0
else:
self.vehicle.control.throttle = 0
self.vehicle.control.brake = -throttle
self.action_list.append(self.vehicle.control.steer)
self.world.tick()
if self.use_seg_bev:
self.observation_render = self._get_observation_seg_bev()['rendered']
self.observation = self._get_observation_seg_bev()['masks']
else:
self.observation = self._get_observation()
self.observation_render = self._get_observation_seg_bev()['rendered']
if self.activate_spectator:
self.viewer_image = self._get_viewer_image()
self.bev_spectator_data = self._get_bev_spectator_data()
if self.activate_bev:
self.bev_data = self._get_bev_data()
transform = self.vehicle.get_transform()
self.prev_waypoint_index = self.current_waypoint_index
waypoint_index = self.current_waypoint_index
for _ in range(len(self.route_waypoints)):
next_waypoint_index = waypoint_index + 1
wp, _ = self.route_waypoints[next_waypoint_index % len(self.route_waypoints)]
dot = np.dot(vector(wp.transform.get_forward_vector())[:2],
vector(transform.location - wp.transform.location)[:2])
if dot > 0.0:
waypoint_index += 1
else:
break
self.current_waypoint_index = waypoint_index
if self.current_waypoint_index < len(self.route_waypoints) - 1:
self.next_waypoint, self.next_road_maneuver = self.route_waypoints[
(self.current_waypoint_index + 1) % len(self.route_waypoints)]
self.current_waypoint, self.current_road_maneuver = self.route_waypoints[
self.current_waypoint_index % len(self.route_waypoints)]
self.routes_completed = self.num_routes_completed + (self.current_waypoint_index + 1) / len(
self.route_waypoints)
self.distance_from_center = distance_to_line(vector(self.current_waypoint.transform.location),
vector(self.next_waypoint.transform.location),
vector(transform.location))
self.center_lane_deviation += self.distance_from_center
if action is not None:
self.distance_traveled += self.previous_location.distance(transform.location)
self.previous_location = transform.location
self.speed_accum += self.vehicle.get_speed()
if self.distance_traveled >= self.max_distance and not self.eval:
self.success_state = True
self.distance_from_center_history.append(self.distance_from_center)
self.last_reward = self.reward_fn(self)
self.total_reward += self.last_reward
encoded_state = self.encode_state_fn(self)
self.step_count += 1
self.total_steps += 1
if self.activate_render:
pygame.event.pump()
if pygame.key.get_pressed()[K_ESCAPE]:
self.close()
self.terminal_state = True
self.render()
max_distance = CONFIG.reward_params.max_distance
max_std_center_lane = CONFIG.reward_params.max_std_center_lane
max_angle_center_lane = CONFIG.reward_params.max_angle_center_lane
centering_factor = max(1.0 - self.distance_from_center / max_distance, 0.0)
angle = self.vehicle.get_angle(self.current_waypoint)
angle_factor = max(1.0 - abs(angle / np.deg2rad(max_angle_center_lane)), 0.0)
std = np.std(self.distance_from_center_history)
distance_std_factor = max(1.0 - abs(std / max_std_center_lane), 0.0)
if self.terminal_state or self.success_state:
if self.collision_state:
self.collision_num += 1
self.collision_deque.append(1)
self.cps = 1 / self.step_count
self.cpm = 1 / self.distance_traveled * 1000
self.collision_interval = self.total_steps - self.last_collision_step
self.last_collision_step = self.total_steps
self.collision_speed = self.vehicle.get_speed()
else:
self.collision_deque.append(0)
info = {
"closed": self.closed,
'total_reward': self.total_reward,
'routes_completed': self.routes_completed,
'total_distance': self.distance_traveled,
'avg_center_dev': (self.center_lane_deviation / self.step_count),
'avg_speed': (self.speed_accum / self.step_count),
'mean_reward': (self.total_reward / self.step_count),
'render_array': self.bev_data,
"centering_factor": centering_factor,
"angle_factor": angle_factor,
"distance_std_factor": distance_std_factor,
"speed": self.vehicle.get_speed(),
"collision_num": self.collision_num,
"collision_rate": sum(self.collision_deque) / len(self.collision_deque) if self.collision_deque else 0.0,
"episode_length": self.step_count,
"collision_state": self.collision_state,
}
if self.terminal_state or self.success_state:
if self.collision_state:
info.update({"CPS": self.cps,
"CPM": self.cpm,
"collision_interval": self.collision_interval,
"collision_speed": self.collision_speed,
})
return encoded_state, self.last_reward, self.terminal_state or self.success_state, info
def _draw_path_server(self, life_time=60.0, skip=0):
"""
Draw a connected path from start of route to end.
Green node = start
Red node = point along path
Blue node = destination
"""
for i in range(0, len(self.route_waypoints) - 1, skip + 1):
z = 30.25
w0 = self.route_waypoints[i][0]
w1 = self.route_waypoints[i + 1][0]
self.world.debug.draw_line(
w0.transform.location + carla.Location(z=z),
w1.transform.location + carla.Location(z=z),
thickness=0.1, color=carla.Color(255, 0, 0),
life_time=life_time, persistent_lines=False)
self.world.debug.draw_point(
w0.transform.location + carla.Location(z=z), 0.1,
carla.Color(0, 255, 0) if i == 0 else carla.Color(255, 0, 0),
life_time, False)
self.world.debug.draw_point(
self.route_waypoints[-1][0].transform.location + carla.Location(z=z), 0.1,
carla.Color(0, 0, 255),
life_time, False)
def _draw_path(self, camera, image):
"""
Draw a connected path from start of route to end using homography.
"""
vehicle_vector = vector(self.vehicle.get_transform().location)
# Get the world to camera matrix
world_2_camera = np.array(camera.get_transform().get_inverse_matrix())
# Get the attributes from the camera
image_w = int(camera.actor.attributes['image_size_x'])
image_h = int(camera.actor.attributes['image_size_y'])
fov = float(camera.actor.attributes['fov'])
for i in range(self.current_waypoint_index, len(self.route_waypoints)):
waypoint_location = self.route_waypoints[i][0].transform.location + carla.Location(z=1.25)
waypoint_vector = vector(waypoint_location)
if not (2 < abs(np.linalg.norm(vehicle_vector - waypoint_vector)) < 50):
continue
# Calculate the camera projection matrix to project from 3D -> 2D
K = build_projection_matrix(image_w, image_h, fov)
x, y = get_image_point(waypoint_location, K, world_2_camera)
if i == len(self.route_waypoints) - 1:
color = (255, 0, 0)
else:
color = (0, 0, 255)
image = cv2.circle(image, (x, y), radius=3, color=color, thickness=-1)
return image
def _get_observation(self):
while self.observation_buffer is None:
pass
obs = self.observation_buffer.copy()
self.observation_buffer = None
return obs
def _get_viewer_image(self):
while self.viewer_image_buffer is None:
pass
image = self.viewer_image_buffer.copy()
self.viewer_image_buffer = None
return image
def _get_bev_spectator_data(self):
while self.bev_spectator_data_buffer is None:
pass
image = self.bev_spectator_data_buffer.copy()
self.bev_spectator_data_buffer = None
return image
def _get_bev_data(self):
while self.bev_data_buffer is None:
pass
image = self.bev_data_buffer.copy()
self.bev_data_buffer = None
return image
def _on_collision(self, event):
if get_actor_display_name(event.other_actor) != "Road":
self.terminal_state = True
self.collision_state = True
print("0| Terminal: Collision with {}".format(event.other_actor.type_id))
if self.activate_render:
self.hud.notification("Collision with {}".format(get_actor_display_name(event.other_actor)))
def _on_invasion(self, event):
lane_types = set(x.type for x in event.crossed_lane_markings)
text = ["%r" % str(x).split()[-1] for x in lane_types]
if self.activate_render:
self.hud.notification("Crossed line %s" % " and ".join(text))
def _set_observation_image(self, image):
self.observation_buffer = image
def _set_viewer_image(self, image):
self.viewer_image_buffer = image
def _set_bev_spectator_data(self, image):
self.bev_spectator_data_buffer = image
def _set_bev_data(self, image):
self.bev_data_buffer = image
def _get_observation_seg_bev(self):
ev_transform = self.vehicle.get_transform()
ev_loc = ev_transform.location
ev_rot = ev_transform.rotation
ev_bbox = self.vehicle.bounding_box
def is_within_distance(w):
c_distance = abs(ev_loc.x - w.location.x) < self._distance_threshold \
and abs(ev_loc.y - w.location.y) < self._distance_threshold \
and abs(ev_loc.z - w.location.z) < 8.0
c_ev = abs(ev_loc.x - w.location.x) < 1.0 and abs(ev_loc.y - w.location.y) < 1.0
return c_distance and (not c_ev)
vehicle_bbox_list = self.world.get_level_bbs(carla.CityObjectLabel.Vehicles)
walker_bbox_list = self.world.get_level_bbs(carla.CityObjectLabel.Pedestrians)
if self._scale_bbox:
vehicles = self._get_surrounding_actors(vehicle_bbox_list, is_within_distance, 1.0)
walkers = self._get_surrounding_actors(walker_bbox_list, is_within_distance, 2.0)
else:
vehicles = self._get_surrounding_actors(vehicle_bbox_list, is_within_distance)
walkers = self._get_surrounding_actors(walker_bbox_list, is_within_distance)
self._history_queue.append((vehicles, walkers))
M_warp = self._get_warp_transform(ev_loc, ev_rot)
# objects with history
vehicle_masks, walker_masks = self._get_history_masks(M_warp)
# road_mask, lane_mask
road_mask = cv2.warpAffine(self._road, M_warp, (self._width, self._width)).astype(bool)
lane_mask_all = cv2.warpAffine(self._lane_marking_all, M_warp, (self._width, self._width)).astype(bool)
lane_mask_broken = cv2.warpAffine(self._lane_marking_white_broken, M_warp,
(self._width, self._width)).astype(bool)
# ev_mask
ev_mask = self._get_mask_from_actor_list([(ev_transform, ev_bbox.location, ev_bbox.extent)], M_warp)
# render
image = np.zeros([self._width, self._width, 3], dtype=np.uint8)
image[road_mask] = COLOR_ALUMINIUM_5
# image[route_mask] = COLOR_ALUMINIUM_3
image[lane_mask_all] = COLOR_MAGENTA
image[lane_mask_broken] = COLOR_MAGENTA_2
h_len = len(self._history_idx) - 1
for i, mask in enumerate(vehicle_masks):
image[mask] = tint(COLOR_BLUE, (h_len - i) * 0.2)
for i, mask in enumerate(walker_masks):
image[mask] = tint(COLOR_CYAN, (h_len - i) * 0.2)
image[ev_mask] = COLOR_WHITE
# masks
c_road = road_mask * 255
c_lane = lane_mask_all * 255
c_lane[lane_mask_broken] = 120
# masks with history
c_vehicle_history = [m * 255 for m in vehicle_masks]
masks = np.stack((c_road, c_lane, *c_vehicle_history), axis=2)
obs_dict = {'rendered': image, 'masks': masks}
return obs_dict
@staticmethod
def _get_surrounding_actors(bbox_list, criterium, scale=None):
actors = []
for bbox in bbox_list:
is_within_distance = criterium(bbox)
if is_within_distance:
bb_loc = carla.Location()
bb_ext = carla.Vector3D(bbox.extent)
if scale is not None:
bb_ext = bb_ext * scale
bb_ext.x = max(bb_ext.x, 0.8)
bb_ext.y = max(bb_ext.y, 0.8)
actors.append((carla.Transform(bbox.location, bbox.rotation), bb_loc, bb_ext))
return actors
def _get_warp_transform(self, ev_loc, ev_rot):
ev_loc_in_px = self._world_to_pixel(ev_loc)
yaw = np.deg2rad(ev_rot.yaw)
forward_vec = np.array([np.cos(yaw), np.sin(yaw)])
right_vec = np.array([np.cos(yaw + 0.5 * np.pi), np.sin(yaw + 0.5 * np.pi)])
bottom_left = ev_loc_in_px - self._pixels_ev_to_bottom * forward_vec - (0.5 * self._width) * right_vec
top_left = ev_loc_in_px + (self._width - self._pixels_ev_to_bottom) * forward_vec - (
0.5 * self._width) * right_vec
top_right = ev_loc_in_px + (self._width - self._pixels_ev_to_bottom) * forward_vec + (
0.5 * self._width) * right_vec
src_pts = np.stack((bottom_left, top_left, top_right), axis=0).astype(np.float32)
dst_pts = np.array([[0, self._width - 1],
[0, 0],
[self._width - 1, 0]], dtype=np.float32)
return cv2.getAffineTransform(src_pts, dst_pts)
def _world_to_pixel(self, location, projective=False):
"""Converts the world coordinates to pixel coordinates"""
x = self._pixels_per_meter * (location.x - self._world_offset[0])
y = self._pixels_per_meter * (location.y - self._world_offset[1])
if projective:
p = np.array([x, y, 1], dtype=np.float32)
else:
p = np.array([x, y], dtype=np.float32)
return p
def _get_history_masks(self, M_warp):
qsize = len(self._history_queue)
vehicle_masks, walker_masks, tl_green_masks, tl_yellow_masks, tl_red_masks, stop_masks = [], [], [], [], [], []
for idx in self._history_idx:
idx = max(idx, -1 * qsize)
vehicles, walkers = self._history_queue[idx]
vehicle_masks.append(self._get_mask_from_actor_list(vehicles, M_warp))
walker_masks.append(self._get_mask_from_actor_list(walkers, M_warp))
return vehicle_masks, walker_masks
def _get_mask_from_actor_list(self, actor_list, M_warp):
mask = np.zeros([self._width, self._width], dtype=np.uint8)
# for actor_transform, bb_loc, bb_ext in actor_list:
for data in actor_list:
if len(data) == 12:
loc_x, loc_y, loc_z, pitch, yaw, roll, bb_loc_x, bb_loc_y, bb_loc_z, bb_ext_x, bb_ext_y, bb_ext_z = data
actor_transform = carla.Transform(
carla.Location(x=loc_x, y=loc_y, z=loc_z),
carla.Rotation(pitch=pitch, yaw=yaw, roll=roll)
)
bb_loc = carla.Location(x=bb_loc_x, y=bb_loc_y, z=bb_loc_z)
bb_ext = carla.Vector3D(x=bb_ext_x, y=bb_ext_y, z=bb_ext_z)
else:
actor_transform, bb_loc, bb_ext = data
corners = [carla.Location(x=-bb_ext.x, y=-bb_ext.y),
carla.Location(x=bb_ext.x, y=-bb_ext.y),
carla.Location(x=bb_ext.x, y=0),
carla.Location(x=bb_ext.x, y=bb_ext.y),
carla.Location(x=-bb_ext.x, y=bb_ext.y)]
corners = [bb_loc + corner for corner in corners]
corners = [actor_transform.transform(corner) for corner in corners]
corners_in_pixel = np.array([[self._world_to_pixel(corner)] for corner in corners])
corners_warped = cv2.transform(corners_in_pixel, M_warp)
cv2.fillConvexPoly(mask, np.round(corners_warped).astype(np.int32), 1)
return mask.astype(bool)
if __name__ == "__main__":
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
================================================
FILE: carla_env/navigation/__init__.py
================================================
================================================
FILE: carla_env/navigation/agent.py
================================================
#!/usr/bin/env python
# Copyright (c) 2018 Intel Labs.
# authors: German Ros (german.ros@intel.com)
#
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
""" This module implements an agent that roams around a track following random
waypoints and avoiding other vehicles.
The agent also responds to traffic lights. """
from enum import Enum
import carla
from agents.tools.misc import is_within_distance_ahead, compute_magnitude_angle
class AgentState(Enum):
"""
AGENT_STATE represents the possible states of a roaming agent
"""
NAVIGATING = 1
BLOCKED_BY_VEHICLE = 2
BLOCKED_RED_LIGHT = 3
class Agent(object):
"""
Base class to define agents in CARLA
"""
def __init__(self, vehicle):
"""
:param vehicle: actor to apply to local planner logic onto
"""
self._vehicle = vehicle
self._proximity_threshold = 10.0 # meters
self._local_planner = None
self._world = self._vehicle.get_world()
self._map = self._vehicle.get_world().get_map()
self._last_traffic_light = None
def run_step(self, debug=False):
"""
Execute one step of navigation.
:return: control
"""
control = carla.VehicleControl()
if debug:
control.steer = 0.0
control.throttle = 0.0
control.brake = 0.0
control.hand_brake = False
control.manual_gear_shift = False
return control
def _is_light_red(self, lights_list):
"""
Method to check if there is a red light affecting us. This version of
the method is compatible with both European and US style traffic lights.
:param lights_list: list containing TrafficLight objects
:return: a tuple given by (bool_flag, traffic_light), where
- bool_flag is True if there is a traffic light in RED
affecting us and False otherwise
- traffic_light is the object itself or None if there is no
red traffic light affecting us
"""
if self._map.name == 'Town01' or self._map.name == 'Town02':
return self._is_light_red_europe_style(lights_list)
else:
return self._is_light_red_us_style(lights_list)
def _is_light_red_europe_style(self, lights_list):
"""
This method is specialized to check European style traffic lights.
:param lights_list: list containing TrafficLight objects
:return: a tuple given by (bool_flag, traffic_light), where
- bool_flag is True if there is a traffic light in RED
affecting us and False otherwise
- traffic_light is the object itself or None if there is no
red traffic light affecting us
"""
ego_vehicle_location = self._vehicle.get_location()
ego_vehicle_waypoint = self._map.get_waypoint(ego_vehicle_location)
for traffic_light in lights_list:
object_waypoint = self._map.get_waypoint(traffic_light.get_location())
if object_waypoint.road_id != ego_vehicle_waypoint.road_id or \
object_waypoint.lane_id != ego_vehicle_waypoint.lane_id:
continue
loc = traffic_light.get_location()
if is_within_distance_ahead(loc, ego_vehicle_location,
self._vehicle.get_transform().rotation.yaw,
self._proximity_threshold):
if traffic_light.state == carla.TrafficLightState.Red:
return (True, traffic_light)
return (False, None)
def _is_light_red_us_style(self, lights_list, debug=False):
"""
This method is specialized to check US style traffic lights.
:param lights_list: list containing TrafficLight objects
:return: a tuple given by (bool_flag, traffic_light), where
- bool_flag is True if there is a traffic light in RED
affecting us and False otherwise
- traffic_light is the object itself or None if there is no
red traffic light affecting us
"""
ego_vehicle_location = self._vehicle.get_location()
ego_vehicle_waypoint = self._map.get_waypoint(ego_vehicle_location)
if ego_vehicle_waypoint.is_intersection:
# It is too late. Do not block the intersection! Keep going!
return (False, None)
if self._local_planner.target_waypoint is not None:
if self._local_planner.target_waypoint.is_intersection:
min_angle = 180.0
sel_magnitude = 0.0
sel_traffic_light = None
for traffic_light in lights_list:
loc = traffic_light.get_location()
magnitude, angle = compute_magnitude_angle(loc,
ego_vehicle_location,
self._vehicle.get_transform().rotation.yaw)
if magnitude < 60.0 and angle < min(25.0, min_angle):
sel_magnitude = magnitude
sel_traffic_light = traffic_light
min_angle = angle
if sel_traffic_light is not None:
if debug:
print('=== Magnitude = {} | Angle = {} | ID = {}'.format(
sel_magnitude, min_angle, sel_traffic_light.id))
if self._last_traffic_light is None:
self._last_traffic_light = sel_traffic_light
if self._last_traffic_light.state == carla.TrafficLightState.Red:
return (True, self._last_traffic_light)
else:
self._last_traffic_light = None
return (False, None)
def _is_vehicle_hazard(self, vehicle_list):
"""
Check if a given vehicle is an obstacle in our way. To this end we take
into account the road and lane the target vehicle is on and run a
geometry test to check if the target vehicle is under a certain distance
in front of our ego vehicle.
WARNING: This method is an approximation that could fail for very large
vehicles, which center is actually on a different lane but their
extension falls within the ego vehicle lane.
:param vehicle_list: list of potential obstacle to check
:return: a tuple given by (bool_flag, vehicle), where
- bool_flag is True if there is a vehicle ahead blocking us
and False otherwise
- vehicle is the blocker object itself
"""
ego_vehicle_location = self._vehicle.get_location()
ego_vehicle_waypoint = self._map.get_waypoint(ego_vehicle_location)
for target_vehicle in vehicle_list:
# do not account for the ego vehicle
if target_vehicle.id == self._vehicle.id:
continue
# if the object is not in our lane it's not an obstacle
target_vehicle_waypoint = self._map.get_waypoint(target_vehicle.get_location())
if target_vehicle_waypoint.road_id != ego_vehicle_waypoint.road_id or \
target_vehicle_waypoint.lane_id != ego_vehicle_waypoint.lane_id:
continue
loc = target_vehicle.get_location()
if is_within_distance_ahead(loc, ego_vehicle_location,
self._vehicle.get_transform().rotation.yaw,
self._proximity_threshold):
return (True, target_vehicle)
return (False, None)
def emergency_stop(self):
"""
Send an emergency stop command to the vehicle
:return:
"""
control = carla.VehicleControl()
control.steer = 0.0
control.throttle = 0.0
control.brake = 1.0
control.hand_brake = False
return control
================================================
FILE: carla_env/navigation/basic_agent.py
================================================
#!/usr/bin/env python
# Copyright (c) 2018 Intel Labs.
# authors: German Ros (german.ros@intel.com)
#
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
""" This module implements an agent that roams around a track following random
waypoints and avoiding other vehicles.
The agent also responds to traffic lights. """
import carla
from agents.navigation.agent import Agent, AgentState
from agents.navigation.local_planner import LocalPlanner
from agents.navigation.global_route_planner import GlobalRoutePlanner
from agents.navigation.global_route_planner_dao import GlobalRoutePlannerDAO
class BasicAgent(Agent):
"""
BasicAgent implements a basic agent that navigates scenes to reach a given
target destination. This agent respects traffic lights and other vehicles.
"""
def __init__(self, vehicle, target_speed=20):
"""
:param vehicle: actor to apply to local planner logic onto
"""
super(BasicAgent, self).__init__(vehicle)
self._proximity_threshold = 10.0 # meters
self._state = AgentState.NAVIGATING
args_lateral_dict = {
'K_P': 1,
'K_D': 0.02,
'K_I': 0,
'dt': 1.0/20.0}
self._local_planner = LocalPlanner(
self._vehicle, opt_dict={'target_speed' : target_speed,
'lateral_control_dict':args_lateral_dict})
self._hop_resolution = 2.0
self._path_seperation_hop = 2
self._path_seperation_threshold = 0.5
self._target_speed = target_speed
self._grp = None
def set_destination(self, location):
"""
This method creates a list of waypoints from agent's position to destination location
based on the route returned by the global router
"""
start_waypoint = self._map.get_waypoint(self._vehicle.get_location())
end_waypoint = self._map.get_waypoint(
carla.Location(location[0], location[1], location[2]))
route_trace = self._trace_route(start_waypoint, end_waypoint)
assert route_trace
self._local_planner.set_global_plan(route_trace)
def _trace_route(self, start_waypoint, end_waypoint):
"""
This method sets up a global router and returns the optimal route
from start_waypoint to end_waypoint
"""
# Setting up global router
if self._grp is None:
dao = GlobalRoutePlannerDAO(self._vehicle.get_world().get_map(), self._hop_resolution)
grp = GlobalRoutePlanner(dao)
grp.setup()
self._grp = grp
# Obtain route plan
route = self._grp.trace_route(
start_waypoint.transform.location,
end_waypoint.transform.location)
return route
def run_step(self, debug=False):
"""
Execute one step of navigation.
:return: carla.VehicleControl
"""
# is there an obstacle in front of us?
hazard_detected = False
# retrieve relevant elements for safe navigation, i.e.: traffic lights
# and other vehicles
actor_list = self._world.get_actors()
vehicle_list = actor_list.filter("*vehicle*")
lights_list = actor_list.filter("*traffic_light*")
# check possible obstacles
vehicle_state, vehicle = self._is_vehicle_hazard(vehicle_list)
if vehicle_state:
if debug:
print('!!! VEHICLE BLOCKING AHEAD [{}])'.format(vehicle.id))
self._state = AgentState.BLOCKED_BY_VEHICLE
hazard_detected = True
# check for the state of the traffic lights
light_state, traffic_light = self._is_light_red(lights_list)
if light_state:
if debug:
print('=== RED LIGHT AHEAD [{}])'.format(traffic_light.id))
self._state = AgentState.BLOCKED_RED_LIGHT
hazard_detected = True
if hazard_detected:
control = self.emergency_stop()
else:
self._state = AgentState.NAVIGATING
# standard local planner behavior
control = self._local_planner.run_step()
return control
================================================
FILE: carla_env/navigation/controller.py
================================================
#!/usr/bin/env python
# Copyright (c) 2018 Intel Labs.
# authors: German Ros (german.ros@intel.com)
#
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
""" This module contains PID controllers to perform lateral and longitudinal control. """
from collections import deque
import math
import numpy as np
import carla
from carla_env.tools.misc import get_speed
class VehiclePIDController():
"""
VehiclePIDController is the combination of two PID controllers (lateral and longitudinal) to perform the
low level control a vehicle from client side
"""
def __init__(self, vehicle, args_lateral=None, args_longitudinal=None):
"""
:param vehicle: actor to apply to local planner logic onto
:param args_lateral: dictionary of arguments to set the lateral PID controller using the following semantics:
K_P -- Proportional term
K_D -- Differential term
K_I -- Integral term
:param args_longitudinal: dictionary of arguments to set the longitudinal PID controller using the following
semantics:
K_P -- Proportional term
K_D -- Differential term
K_I -- Integral term
"""
if not args_lateral:
args_lateral = {'K_P': 1.0, 'K_D': 0.0, 'K_I': 0.0}
if not args_longitudinal:
args_longitudinal = {'K_P': 1.0, 'K_D': 0.0, 'K_I': 0.0}
self._vehicle = vehicle
self._world = self._vehicle.get_world()
self._lon_controller = PIDLongitudinalController(self._vehicle, **args_longitudinal)
self._lat_controller = PIDLateralController(self._vehicle, **args_lateral)
def run_step(self, target_speed, waypoint):
"""
Execute one step of control invoking both lateral and longitudinal PID controllers to reach a target waypoint
at a given target_speed.
:param target_speed: desired vehicle speed
:param waypoint: target location encoded as a waypoint
:return: distance (in meters) to the waypoint
"""
throttle = self._lon_controller.run_step(target_speed)
steering = self._lat_controller.run_step(waypoint)
control = carla.VehicleControl()
control.steer = steering
control.throttle = throttle
control.brake = 0.0
control.hand_brake = False
control.manual_gear_shift = False
return control
class PIDLongitudinalController():
"""
PIDLongitudinalController implements longitudinal control using a PID.
"""
def __init__(self, vehicle, K_P=1.0, K_D=0.0, K_I=0.0, dt=0.03):
"""
:param vehicle: actor to apply to local planner logic onto
:param K_P: Proportional term
:param K_D: Differential term
:param K_I: Integral term
:param dt: time differential in seconds
"""
self._vehicle = vehicle
self._K_P = K_P
self._K_D = K_D
self._K_I = K_I
self._dt = dt
self._e_buffer = deque(maxlen=30)
def run_step(self, target_speed, debug=False):
"""
Execute one step of longitudinal control to reach a given target speed.
:param target_speed: target speed in Km/h
:return: throttle control in the range [0, 1]
"""
current_speed = get_speed(self._vehicle)
if debug:
print('Current speed = {}'.format(current_speed))
return self._pid_control(target_speed, current_speed)
def _pid_control(self, target_speed, current_speed):
"""
Estimate the throttle of the vehicle based on the PID equations
:param target_speed: target speed in Km/h
:param current_speed: current speed of the vehicle in Km/h
:return: throttle control in the range [0, 1]
"""
_e = (target_speed - current_speed)
self._e_buffer.append(_e)
if len(self._e_buffer) >= 2:
_de = (self._e_buffer[-1] - self._e_buffer[-2]) / self._dt
_ie = sum(self._e_buffer) * self._dt
else:
_de = 0.0
_ie = 0.0
return np.clip((self._K_P * _e) + (self._K_D * _de / self._dt) + (self._K_I * _ie * self._dt), 0.0, 1.0)
class PIDLateralController():
"""
PIDLateralController implements lateral control using a PID.
"""
def __init__(self, vehicle, K_P=1.0, K_D=0.0, K_I=0.0, dt=0.03):
"""
:param vehicle: actor to apply to local planner logic onto
:param K_P: Proportional term
:param K_D: Differential term
:param K_I: Integral term
:param dt: time differential in seconds
"""
self._vehicle = vehicle
self._K_P = K_P
self._K_D = K_D
self._K_I = K_I
self._dt = dt
self._e_buffer = deque(maxlen=10)
def run_step(self, waypoint):
"""
Execute one step of lateral control to steer the vehicle towards a certain waypoin.
:param waypoint: target waypoint
:return: steering control in the range [-1, 1] where:
-1 represent maximum steering to left
+1 maximum steering to right
"""
return self._pid_control(waypoint, self._vehicle.get_transform())
def _pid_control(self, waypoint, vehicle_transform):
"""
Estimate the steering angle of the vehicle based on the PID equations
:param waypoint: target waypoint
:param vehicle_transform: current transform of the vehicle
:return: steering control in the range [-1, 1]
"""
v_begin = vehicle_transform.location
v_end = v_begin + carla.Location(x=math.cos(math.radians(vehicle_transform.rotation.yaw)),
y=math.sin(math.radians(vehicle_transform.rotation.yaw)))
v_vec = np.array([v_end.x - v_begin.x, v_end.y - v_begin.y, 0.0])
w_vec = np.array([waypoint.transform.location.x -
v_begin.x, waypoint.transform.location.y -
v_begin.y, 0.0])
_dot = math.acos(np.clip(np.dot(w_vec, v_vec) /
(np.linalg.norm(w_vec) * np.linalg.norm(v_vec)), -1.0, 1.0))
_cross = np.cross(v_vec, w_vec)
if _cross[2] < 0:
_dot *= -1.0
self._e_buffer.append(_dot)
if len(self._e_buffer) >= 2:
_de = (self._e_buffer[-1] - self._e_buffer[-2]) / self._dt
_ie = sum(self._e_buffer) * self._dt
else:
_de = 0.0
_ie = 0.0
return np.clip((self._K_P * _dot) + (self._K_D * _de /
self._dt) + (self._K_I * _ie * self._dt), -1.0, 1.0)
================================================
FILE: carla_env/navigation/global_route_planner.py
================================================
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
"""
This module provides GlobalRoutePlanner implementation.
"""
import math
import numpy as np
import networkx as nx
import carla
from carla_env.navigation.local_planner import RoadOption
from carla_env.tools.misc import vector
class GlobalRoutePlanner(object):
"""
This class provides a very high level route plan.
Instantiate the class by passing a reference to
A GlobalRoutePlannerDAO object.
"""
def __init__(self, dao):
"""
Constructor
"""
self._dao = dao
self._topology = None
self._graph = None
self._id_map = None
self._road_id_to_edge = None
self._intersection_end_node = -1
self._previous_decision = RoadOption.VOID
def setup(self):
"""
Performs initial server data lookup for detailed topology
and builds graph representation of the world map.
"""
self._topology = self._dao.get_topology()
self._graph, self._id_map, self._road_id_to_edge = self._build_graph()
self._find_loose_ends()
self._lane_change_link()
def _build_graph(self):
"""
This function builds a networkx graph representation of topology.
The topology is read from self._topology.
graph node properties:
vertex - (x,y,z) position in world map
graph edge properties:
entry_vector - unit vector along tangent at entry point
exit_vector - unit vector along tangent at exit point
net_vector - unit vector of the chord from entry to exit
intersection - boolean indicating if the edge belongs to an
intersection
return : graph -> networkx graph representing the world map,
id_map-> mapping from (x,y,z) to node id
road_id_to_edge-> map from road id to edge in the graph
"""
graph = nx.DiGraph()
id_map = dict() # Map with structure {(x,y,z): id, ... }
road_id_to_edge = dict() # Map with structure {road_id: {lane_id: edge, ... }, ... }
for segment in self._topology:
entry_xyz, exit_xyz = segment['entryxyz'], segment['exitxyz']
path = segment['path']
entry_wp, exit_wp = segment['entry'], segment['exit']
intersection = entry_wp.is_intersection
road_id, section_id, lane_id = entry_wp.road_id, entry_wp.section_id, entry_wp.lane_id
for vertex in entry_xyz, exit_xyz:
# Adding unique nodes and populating id_map
if vertex not in id_map:
new_id = len(id_map)
id_map[vertex] = new_id
graph.add_node(new_id, vertex=vertex)
n1 = id_map[entry_xyz]
n2 = id_map[exit_xyz]
if road_id not in road_id_to_edge:
road_id_to_edge[road_id] = dict()
if section_id not in road_id_to_edge[road_id]:
road_id_to_edge[road_id][section_id] = dict()
road_id_to_edge[road_id][section_id][lane_id] = (n1, n2)
entry_carla_vector = entry_wp.transform.rotation.get_forward_vector()
exit_carla_vector = exit_wp.transform.rotation.get_forward_vector()
# Adding edge with attributes
graph.add_edge(
n1, n2,
length=len(path) + 1, path=path,
entry_waypoint=entry_wp, exit_waypoint=exit_wp,
entry_vector=np.array(
[entry_carla_vector.x, entry_carla_vector.y, entry_carla_vector.z]),
exit_vector=np.array(
[exit_carla_vector.x, exit_carla_vector.y, exit_carla_vector.z]),
net_vector=vector(entry_wp.transform.location, exit_wp.transform.location),
intersection=intersection, type=RoadOption.LANEFOLLOW)
return graph, id_map, road_id_to_edge
def _find_loose_ends(self):
"""
This method finds road segments that have an unconnected end and
adds them to the internal graph representation
"""
count_loose_ends = 0
hop_resolution = self._dao.get_resolution()
for segment in self._topology:
end_wp = segment['exit']
exit_xyz = segment['exitxyz']
road_id, section_id, lane_id = end_wp.road_id, end_wp.section_id, end_wp.lane_id
if road_id in self._road_id_to_edge and \
section_id in self._road_id_to_edge[road_id] and \
lane_id in self._road_id_to_edge[road_id][section_id]:
pass
else:
count_loose_ends += 1
if road_id not in self._road_id_to_edge:
self._road_id_to_edge[road_id] = dict()
if section_id not in self._road_id_to_edge[road_id]:
self._road_id_to_edge[road_id][section_id] = dict()
n1 = self._id_map[exit_xyz]
n2 = -1*count_loose_ends
self._road_id_to_edge[road_id][section_id][lane_id] = (n1, n2)
next_wp = end_wp.next(hop_resolution)
path = []
while next_wp is not None and next_wp and \
next_wp[0].road_id == road_id and \
next_wp[0].section_id == section_id and \
next_wp[0].lane_id == lane_id:
path.append(next_wp[0])
next_wp = next_wp[0].next(hop_resolution)
if path:
n2_xyz = (path[-1].transform.location.x,
path[-1].transform.location.y,
path[-1].transform.location.z)
self._graph.add_node(n2, vertex=n2_xyz)
self._graph.add_edge(
n1, n2,
length=len(path) + 1, path=path,
entry_waypoint=end_wp, exit_waypoint=path[-1],
entry_vector=None, exit_vector=None, net_vector=None,
intersection=end_wp.is_intersection, type=RoadOption.LANEFOLLOW)
def _localize(self, location):
"""
This function finds the road segment closest to given location
location : carla.Location to be localized in the graph
return : pair node ids representing an edge in the graph
"""
waypoint = self._dao.get_waypoint(location)
edge = None
try:
edge = self._road_id_to_edge[waypoint.road_id][waypoint.section_id][waypoint.lane_id]
except KeyError:
print(
"Failed to localize! : ",
"Road id : ", waypoint.road_id,
"Section id : ", waypoint.section_id,
"Lane id : ", waypoint.lane_id,
"Location : ", waypoint.transform.location.x,
waypoint.transform.location.y)
return edge
def _lane_change_link(self):
"""
This method places zero cost links in the topology graph
representing availability of lane changes.
"""
for segment in self._topology:
left_found, right_found = False, False
for waypoint in segment['path']:
if not segment['entry'].is_intersection:
next_waypoint, next_road_option, next_segment = None, None, None
if bool(waypoint.lane_change & carla.LaneChange.Right) and not right_found:
next_waypoint = waypoint.get_right_lane()
if next_waypoint is not None and \
next_waypoint.lane_type == carla.LaneType.Driving and \
waypoint.road_id == next_waypoint.road_id:
next_road_option = RoadOption.CHANGELANERIGHT
next_segment = self._localize(next_waypoint.transform.location)
if next_segment is not None:
self._graph.add_edge(
self._id_map[segment['entryxyz']], next_segment[0], entry_waypoint=segment['entry'],
exit_waypoint=self._graph.edges[next_segment[0], next_segment[1]]['entry_waypoint'],
path=[], length=0, type=next_road_option, change_waypoint = waypoint)
right_found = True
if bool(waypoint.lane_change & carla.LaneChange.Left) and not left_found:
next_waypoint = waypoint.get_left_lane()
if next_waypoint is not None and next_waypoint.lane_type == carla.LaneType.Driving and \
waypoint.road_id == next_waypoint.road_id:
next_road_option = RoadOption.CHANGELANELEFT
next_segment = self._localize(next_waypoint.transform.location)
if next_segment is not None:
self._graph.add_edge(
self._id_map[segment['entryxyz']], next_segment[0], entry_waypoint=segment['entry'],
exit_waypoint=self._graph.edges[next_segment[0], next_segment[1]]['entry_waypoint'],
path=[], length=0, type=next_road_option, change_waypoint = waypoint)
left_found = True
if left_found and right_found:
break
def _distance_heuristic(self, n1, n2):
"""
Distance heuristic calculator for path searching
in self._graph
"""
l1 = np.array(self._graph.nodes[n1]['vertex'])
l2 = np.array(self._graph.nodes[n2]['vertex'])
return np.linalg.norm(l1-l2)
def _path_search(self, origin, destination):
"""
This function finds the shortest path connecting origin and destination
using A* search with distance heuristic.
origin : carla.Location object of start position
destination : carla.Location object of of end position
return : path as list of node ids (as int) of the graph self._graph
connecting origin and destination
"""
start, end = self._localize(origin), self._localize(destination)
route = nx.astar_path(
self._graph, source=start[0], target=end[0],
heuristic=self._distance_heuristic, weight='length')
route.append(end[1])
return route
def _successive_last_intersection_edge(self, index, route):
"""
This method returns the last successive intersection edge
from a starting index on the route.
This helps moving past tiny intersection edges to calculate
proper turn decisions.
"""
last_intersection_edge = None
last_node = None
for node1, node2 in [(route[i], route[i+1]) for i in range(index, len(route)-1)]:
candidate_edge = self._graph.edges[node1, node2]
if node1 == route[index]:
last_intersection_edge = candidate_edge
if candidate_edge['type'] == RoadOption.LANEFOLLOW and \
candidate_edge['intersection']:
last_intersection_edge = candidate_edge
last_node = node2
else:
break
return last_node, last_intersection_edge
def _turn_decision(self, index, route, threshold=math.radians(5)):
"""
This method returns the turn decision (RoadOption) for pair of edges
around current index of route list
"""
decision = None
previous_node = route[index-1]
current_node = route[index]
next_node = route[index+1]
next_edge = self._graph.edges[current_node, next_node]
if index > 0:
if self._previous_decision != RoadOption.VOID and \
self._intersection_end_node > 0 and \
self._intersection_end_node != previous_node and \
next_edge['type'] == RoadOption.LANEFOLLOW and \
next_edge['intersection']:
decision = self._previous_decision
else:
self._intersection_end_node = -1
current_edge = self._graph.edges[previous_node, current_node]
calculate_turn = current_edge['type'].value == RoadOption.LANEFOLLOW.value and \
not current_edge['intersection'] and \
next_edge['type'].value == RoadOption.LANEFOLLOW.value and \
next_edge['intersection']
if calculate_turn:
last_node, tail_edge = self._successive_last_intersection_edge(index, route)
self._intersection_end_node = last_node
if tail_edge is not None:
next_edge = tail_edge
cv, nv = current_edge['exit_vector'], next_edge['net_vector']
cross_list = []
for neighbor in self._graph.successors(current_node):
select_edge = self._graph.edges[current_node, neighbor]
if select_edge['type'].value == RoadOption.LANEFOLLOW.value:
if neighbor != route[index+1]:
sv = select_edge['net_vector']
cross_list.append(np.cross(cv, sv)[2])
next_cross = np.cross(cv, nv)[2]
deviation = math.acos(np.clip(
np.dot(cv, nv)/(np.linalg.norm(cv)*np.linalg.norm(nv)), -1.0, 1.0))
if not cross_list:
cross_list.append(0)
if deviation < threshold:
decision = RoadOption.STRAIGHT
elif cross_list and next_cross < min(cross_list):
decision = RoadOption.LEFT
elif cross_list and next_cross > max(cross_list):
decision = RoadOption.RIGHT
elif next_cross < 0:
decision = RoadOption.LEFT
elif next_cross > 0:
decision = RoadOption.RIGHT
else:
decision = next_edge['type']
else:
decision = next_edge['type']
self._previous_decision = decision
return decision
def abstract_route_plan(self, origin, destination):
"""
The following function generates the route plan based on
origin : carla.Location object of the route's start position
destination : carla.Location object of the route's end position
return : list of turn by turn navigation decisions as
agents.navigation.local_planner.RoadOption elements
Possible values are STRAIGHT, LEFT, RIGHT, LANEFOLLOW, VOID
CHANGELANELEFT, CHANGELANERIGHT
"""
route = self._path_search(origin, destination)
plan = []
for i in range(len(route) - 1):
road_option = self._turn_decision(i, route)
plan.append(road_option)
return plan
def _find_closest_in_list(self, current_waypoint, waypoint_list):
min_distance = float('inf')
closest_index = -1
for i, waypoint in enumerate(waypoint_list):
distance = waypoint.transform.location.distance(
current_waypoint.transform.location)
if distance < min_distance:
min_distance = distance
closest_index = i
return closest_index
def trace_route(self, origin, destination):
"""
This method returns list of (carla.Waypoint, RoadOption)
from origin (carla.Location) to destination (carla.Location)
"""
route_trace = []
route = self._path_search(origin, destination)
current_waypoint = self._dao.get_waypoint(origin)
destination_waypoint = self._dao.get_waypoint(destination)
resolution = self._dao.get_resolution()
for i in range(len(route) - 1):
road_option = self._turn_decision(i, route)
edge = self._graph.edges[route[i], route[i+1]]
path = []
if edge['type'].value != RoadOption.LANEFOLLOW.value and \
edge['type'].value != RoadOption.VOID.value:
route_trace.append((current_waypoint, road_option))
exit_wp = edge['exit_waypoint']
n1, n2 = self._road_id_to_edge[exit_wp.road_id][exit_wp.section_id][exit_wp.lane_id]
next_edge = self._graph.edges[n1, n2]
if next_edge['path']:
closest_index = self._find_closest_in_list(current_waypoint, next_edge['path'])
closest_index = min(len(next_edge['path'])-1, closest_index+5)
current_waypoint = next_edge['path'][closest_index]
else:
current_waypoint = next_edge['exit_waypoint']
route_trace.append((current_waypoint, road_option))
else:
path = path + [edge['entry_waypoint']] + edge['path'] + [edge['exit_waypoint']]
closest_index = self._find_closest_in_list(current_waypoint, path)
for waypoint in path[closest_index:]:
current_waypoint = waypoint
route_trace.append((current_waypoint, road_option))
if len(route)-i <= 2 and \
waypoint.transform.location.distance(destination) < 2*resolution:
break
elif len(route)-i <= 2 and \
current_waypoint.road_id == destination_waypoint.road_id and \
current_waypoint.section_id == destination_waypoint.section_id and \
current_waypoint.lane_id == destination_waypoint.lane_id:
destination_index = self._find_closest_in_list(destination_waypoint, path)
if closest_index > destination_index:
break
return route_trace
================================================
FILE: carla_env/navigation/global_route_planner_dao.py
================================================
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
"""
This module provides implementation for GlobalRoutePlannerDAO
"""
import numpy as np
class GlobalRoutePlannerDAO(object):
"""
This class is the data access layer for fetching data
from the carla server instance for GlobalRoutePlanner
"""
def __init__(self, wmap, sampling_resolution=1):
"""get_topology
Constructor
wmap : carl world map object
"""
self._sampling_resolution = sampling_resolution
self._wmap = wmap
def get_topology(self):
"""
Accessor for topology.
This function retrieves topology from the server as a list of
road segments as pairs of waypoint objects, and processes the
topology into a list of dictionary objects.
return: list of dictionary objects with the following attributes
entry - waypoint of entry point of road segment
entryxyz- (x,y,z) of entry point of road segment
exit - waypoint of exit point of road segment
exitxyz - (x,y,z) of exit point of road segment
path - list of waypoints separated by 1m from entry
to exit
"""
topology = []
# Retrieving waypoints to construct a detailed topology
for segment in self._wmap.get_topology():
wp1, wp2 = segment[0], segment[1]
l1, l2 = wp1.transform.location, wp2.transform.location
# Rounding off to avoid floating point imprecision
x1, y1, z1, x2, y2, z2 = np.round([l1.x, l1.y, l1.z, l2.x, l2.y, l2.z], 0)
wp1.transform.location, wp2.transform.location = l1, l2
seg_dict = dict()
seg_dict['entry'], seg_dict['exit'] = wp1, wp2
seg_dict['entryxyz'], seg_dict['exitxyz'] = (x1, y1, z1), (x2, y2, z2)
seg_dict['path'] = []
endloc = wp2.transform.location
if wp1.transform.location.distance(endloc) > self._sampling_resolution:
w = wp1.next(self._sampling_resolution)[0]
while w.transform.location.distance(endloc) > self._sampling_resolution:
seg_dict['path'].append(w)
w = w.next(self._sampling_resolution)[0]
else:
seg_dict['path'].append(wp1.next(self._sampling_resolution/2.0)[0])
topology.append(seg_dict)
return topology
def get_waypoint(self, location):
"""
The method returns waypoint at given location
"""
waypoint = self._wmap.get_waypoint(location)
return waypoint
def get_resolution(self):
""" Accessor for self._sampling_resolution """
return self._sampling_resolution
================================================
FILE: carla_env/navigation/local_planner.py
================================================
#!/usr/bin/env python
# Copyright (c) 2018 Intel Labs.
# authors: German Ros (german.ros@intel.com)
#
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
""" This module contains a local planner to perform low-level waypoint following based on PID controllers. """
from enum import Enum
from collections import deque
import random
import carla
from carla_env.navigation.controller import VehiclePIDController
from carla_env.tools.misc import distance_vehicle, draw_waypoints
class RoadOption(Enum):
"""
RoadOption represents the possible topological configurations when moving from a segment of lane to other.
"""
LANEFOLLOW = 0
LEFT = 1
RIGHT = 2
STRAIGHT = 3
VOID = -1
CHANGELANELEFT = 5
CHANGELANERIGHT = 6
def __eq__(self, other):
return self.value == other.value
class LocalPlanner(object):
"""
LocalPlanner implements the basic behavior of following a trajectory of waypoints that is generated on-the-fly.
The low-level motion of the vehicle is computed by using two PID controllers, one is used for the lateral control
and the other for the longitudinal control (cruise speed).
When multiple paths are available (intersections) this local planner makes a random choice.
"""
# minimum distance to target waypoint as a percentage (e.g. within 90% of
# total distance)
MIN_DISTANCE_PERCENTAGE = 0.9
def __init__(self, vehicle, opt_dict=None):
"""
:param vehicle: actor to apply to local planner logic onto
:param opt_dict: dictionary of arguments with the following semantics:
dt -- time difference between physics control in seconds. This is typically fixed from server side
using the arguments -benchmark -fps=F . In this case dt = 1/F
target_speed -- desired cruise speed in Km/h
sampling_radius -- search radius for next waypoints in seconds: e.g. 0.5 seconds ahead
lateral_control_dict -- dictionary of arguments to setup the lateral PID controller
{'K_P':, 'K_D':, 'K_I':, 'dt'}
longitudinal_control_dict -- dictionary of arguments to setup the longitudinal PID controller
{'K_P':, 'K_D':, 'K_I':, 'dt'}
"""
self._vehicle = vehicle
self._map = self._vehicle.get_world().get_map()
self._dt = None
self._target_speed = None
self._sampling_radius = None
self._min_distance = None
self._current_waypoint = None
self._target_road_option = None
self._next_waypoints = None
self.target_waypoint = None
self._vehicle_controller = None
self._global_plan = None
# queue with tuples of (waypoint, RoadOption)
self._waypoints_queue = deque(maxlen=20000)
self._buffer_size = 5
self._waypoint_buffer = deque(maxlen=self._buffer_size)
# initializing controller
self._init_controller(opt_dict)
def __del__(self):
if self._vehicle:
self._vehicle.destroy()
print("Destroying ego-vehicle!")
def reset_vehicle(self):
self._vehicle = None
print("Resetting ego-vehicle!")
def _init_controller(self, opt_dict):
"""
Controller initialization.
:param opt_dict: dictionary of arguments.
:return:
"""
# default params
self._dt = 1.0 / 20.0
self._target_speed = 20.0 # Km/h
self._sampling_radius = self._target_speed * 1 / 3.6 # 1 seconds horizon
self._min_distance = self._sampling_radius * self.MIN_DISTANCE_PERCENTAGE
args_lateral_dict = {
'K_P': 1.95,
'K_D': 0.01,
'K_I': 1.4,
'dt': self._dt}
args_longitudinal_dict = {
'K_P': 1.0,
'K_D': 0,
'K_I': 1,
'dt': self._dt}
# parameters overload
if opt_dict:
if 'dt' in opt_dict:
self._dt = opt_dict['dt']
if 'target_speed' in opt_dict:
self._target_speed = opt_dict['target_speed']
if 'sampling_radius' in opt_dict:
self._sampling_radius = self._target_speed * \
opt_dict['sampling_radius'] / 3.6
if 'lateral_control_dict' in opt_dict:
args_lateral_dict = opt_dict['lateral_control_dict']
if 'longitudinal_control_dict' in opt_dict:
args_longitudinal_dict = opt_dict['longitudinal_control_dict']
self._current_waypoint = self._map.get_waypoint(self._vehicle.get_location())
self._vehicle_controller = VehiclePIDController(self._vehicle,
args_lateral=args_lateral_dict,
args_longitudinal=args_longitudinal_dict)
self._global_plan = False
# compute initial waypoints
self._waypoints_queue.append((self._current_waypoint.next(self._sampling_radius)[0], RoadOption.LANEFOLLOW))
self._target_road_option = RoadOption.LANEFOLLOW
# fill waypoint trajectory queue
self._compute_next_waypoints(k=200)
def set_speed(self, speed):
"""
Request new target speed.
:param speed: new target speed in Km/h
:return:
"""
self._target_speed = speed
def _compute_next_waypoints(self, k=1):
"""
Add new waypoints to the trajectory queue.
:param k: how many waypoints to compute
:return:
"""
# check we do not overflow the queue
available_entries = self._waypoints_queue.maxlen - len(self._waypoints_queue)
k = min(available_entries, k)
for _ in range(k):
last_waypoint = self._waypoints_queue[-1][0]
next_waypoints = list(last_waypoint.next(self._sampling_radius))
if len(next_waypoints) == 1:
# only one option available ==> lanefollowing
next_waypoint = next_waypoints[0]
road_option = RoadOption.LANEFOLLOW
else:
# random choice between the possible options
road_options_list = _retrieve_options(
next_waypoints, last_waypoint)
road_option = random.choice(road_options_list)
next_waypoint = next_waypoints[road_options_list.index(
road_option)]
self._waypoints_queue.append((next_waypoint, road_option))
def set_global_plan(self, current_plan):
self._waypoints_queue.clear()
for elem in current_plan:
self._waypoints_queue.append(elem)
self._target_road_option = RoadOption.LANEFOLLOW
self._global_plan = True
def run_step(self, debug=True):
"""
Execute one step of local planning which involves running the longitudinal and lateral PID controllers to
follow the waypoints trajectory.
:param debug: boolean flag to activate waypoints debugging
:return:
"""
# not enough waypoints in the horizon? => add more!
if not self._global_plan and len(self._waypoints_queue) < int(self._waypoints_queue.maxlen * 0.5):
self._compute_next_waypoints(k=100)
if len(self._waypoints_queue) == 0:
control = carla.VehicleControl()
control.steer = 0.0
control.throttle = 0.0
control.brake = 1.0
control.hand_brake = False
control.manual_gear_shift = False
return control
# Buffering the waypoints
if not self._waypoint_buffer:
for i in range(self._buffer_size):
if self._waypoints_queue:
self._waypoint_buffer.append(
self._waypoints_queue.popleft())
else:
break
# current vehicle waypoint
self._current_waypoint = self._map.get_waypoint(self._vehicle.get_location())
# target waypoint
self.target_waypoint, self._target_road_option = self._waypoint_buffer[0]
# move using PID controllers
control = self._vehicle_controller.run_step(self._target_speed, self.target_waypoint)
# purge the queue of obsolete waypoints
vehicle_transform = self._vehicle.get_transform()
max_index = -1
for i, (waypoint, _) in enumerate(self._waypoint_buffer):
if distance_vehicle(
waypoint, vehicle_transform) < self._min_distance:
max_index = i
if max_index >= 0:
for i in range(max_index + 1):
self._waypoint_buffer.popleft()
if debug:
draw_waypoints(self._vehicle.get_world(), [self.target_waypoint], self._vehicle.get_location().z + 1.0)
return control
def _retrieve_options(list_waypoints, current_waypoint):
"""
Compute the type of connection between the current active waypoint and the multiple waypoints present in
list_waypoints. The result is encoded as a list of RoadOption enums.
:param list_waypoints: list with the possible target waypoints in case of multiple options
:param current_waypoint: current active waypoint
:return: list of RoadOption enums representing the type of connection from the active waypoint to each
candidate in list_waypoints
"""
options = []
for next_waypoint in list_waypoints:
# this is needed because something we are linking to
# the beggining of an intersection, therefore the
# variation in angle is small
next_next_waypoint = next_waypoint.next(3.0)[0]
link = _compute_connection(current_waypoint, next_next_waypoint)
options.append(link)
return options
def _compute_connection(current_waypoint, next_waypoint):
"""
Compute the type of topological connection between an active waypoint (current_waypoint) and a target waypoint
(next_waypoint).
:param current_waypoint: active waypoint
:param next_waypoint: target waypoint
:return: the type of topological connection encoded as a RoadOption enum:
RoadOption.STRAIGHT
RoadOption.LEFT
RoadOption.RIGHT
"""
n = next_waypoint.transform.rotation.yaw
n = n % 360.0
c = current_waypoint.transform.rotation.yaw
c = c % 360.0
diff_angle = (n - c) % 180.0
if diff_angle < 1.0:
return RoadOption.STRAIGHT
elif diff_angle > 90.0:
return RoadOption.LEFT
else:
return RoadOption.RIGHT
================================================
FILE: carla_env/navigation/planner.py
================================================
import numpy as np
# ==============================================================================
# -- import route planning (copied and modified from CARLA 0.9.4's PythonAPI) --
# ==============================================================================
import carla
from carla_env.navigation.local_planner import RoadOption
from carla_env.navigation.global_route_planner import GlobalRoutePlanner
from carla_env.navigation.global_route_planner_dao import GlobalRoutePlannerDAO
from carla_env.tools.misc import vector
def compute_route_waypoints(world_map, start_waypoint, end_waypoint, resolution=1.0, plan=None):
"""
Returns a list of (waypoint, RoadOption)-tuples that describes a route
starting at start_waypoint, ending at end_waypoint.
start_waypoint (carla.Waypoint):
Starting waypoint of the route
end_waypoint (carla.Waypoint):
Destination waypoint of the route
resolution (float):
Resolution, or lenght, of the steps between waypoints
(in meters)
plan (list(RoadOption) or None):
If plan is not None, generate a route that takes every option as provided
in the list for every intersections, in the given order.
(E.g. set plan=[RoadOption.STRAIGHT, RoadOption.LEFT, RoadOption.RIGHT]
to make the route go straight, then left, then right.)
If plan is None, we use the GlobalRoutePlanner to find a path between
start_waypoint and end_waypoint.
"""
if plan is None:
# Setting up global router
dao = GlobalRoutePlannerDAO(world_map, resolution)
grp = GlobalRoutePlanner(dao)
grp.setup()
# Obtain route plan
route = grp.trace_route(
start_waypoint.transform.location,
end_waypoint.transform.location)
else:
# Compute route waypoints
route = []
current_waypoint = start_waypoint
for i, action in enumerate(plan):
# Generate waypoints to next junction
wp_choice = [current_waypoint]
while len(wp_choice) == 1:
current_waypoint = wp_choice[0]
route.append((current_waypoint, RoadOption.LANEFOLLOW))
wp_choice = current_waypoint.next(resolution)
# Stop at destination
if i > 0 and current_waypoint.transform.location.distance(end_waypoint.transform.location) < resolution:
break
if action == RoadOption.VOID:
break
# Make sure that next intersection waypoints are far enough
# from each other so we choose the correct path
step = resolution
while len(wp_choice) > 1:
wp_choice = current_waypoint.next(step)
wp0, wp1 = wp_choice[:2]
if wp0.transform.location.distance(wp1.transform.location) < resolution:
step += resolution
else:
break
# Select appropriate path at the junction
if len(wp_choice) > 1:
# Current heading vector
current_transform = current_waypoint.transform
current_location = current_transform.location
projected_location = current_location + \
carla.Location(
x=np.cos(np.radians(current_transform.rotation.yaw)),
y=np.sin(np.radians(current_transform.rotation.yaw)))
v_current = vector(current_location, projected_location)
direction = 0
if action == RoadOption.LEFT:
direction = 1
elif action == RoadOption.RIGHT:
direction = -1
elif action == RoadOption.STRAIGHT:
direction = 0
select_criteria = float("inf")
# Choose correct path
for wp_select in wp_choice:
v_select = vector(
current_location, wp_select.transform.location)
cross = float("inf")
if direction == 0:
cross = abs(np.cross(v_current, v_select)[-1])
else:
cross = direction * np.cross(v_current, v_select)[-1]
if cross < select_criteria:
select_criteria = cross
current_waypoint = wp_select
# Generate all waypoints within the junction
# along selected path
route.append((current_waypoint, action))
current_waypoint = current_waypoint.next(resolution)[0]
while current_waypoint.is_intersection:
route.append((current_waypoint, action))
current_waypoint = current_waypoint.next(resolution)[0]
assert route
# Change action 5 wp before intersection
num_wp_to_extend_actions_with = 5
action = route[0][1]
for i in range(1, len(route)):
next_action = route[i][1]
if next_action != action:
if next_action != RoadOption.LANEFOLLOW:
for j in range(num_wp_to_extend_actions_with):
route[i-j-1] = (route[i-j-1][0], route[i][1])
action = next_action
return route
================================================
FILE: carla_env/navigation/roaming_agent.py
================================================
#!/usr/bin/env python
# Copyright (c) 2018 Intel Labs.
# authors: German Ros (german.ros@intel.com)
#
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
""" This module implements an agent that roams around a track following random waypoints and avoiding other vehicles.
The agent also responds to traffic lights. """
from agents.navigation.agent import Agent, AgentState
from agents.navigation.local_planner import LocalPlanner
class RoamingAgent(Agent):
"""
RoamingAgent implements a basic agent that navigates scenes making random
choices when facing an intersection.
This agent respects traffic lights and other vehicles.
"""
def __init__(self, vehicle):
"""
:param vehicle: actor to apply to local planner logic onto
"""
super(RoamingAgent, self).__init__(vehicle)
self._proximity_threshold = 10.0 # meters
self._state = AgentState.NAVIGATING
self._local_planner = LocalPlanner(self._vehicle)
def run_step(self, debug=False):
"""
Execute one step of navigation.
:return: carla.VehicleControl
"""
# is there an obstacle in front of us?
hazard_detected = False
# retrieve relevant elements for safe navigation, i.e.: traffic lights
# and other vehicles
actor_list = self._world.get_actors()
vehicle_list = actor_list.filter("*vehicle*")
lights_list = actor_list.filter("*traffic_light*")
# check possible obstacles
vehicle_state, vehicle = self._is_vehicle_hazard(vehicle_list)
if vehicle_state:
if debug:
print('!!! VEHICLE BLOCKING AHEAD [{}])'.format(vehicle.id))
self._state = AgentState.BLOCKED_BY_VEHICLE
hazard_detected = True
# check for the state of the traffic lights
light_state, traffic_light = self._is_light_red(lights_list)
if light_state:
if debug:
print('=== RED LIGHT AHEAD [{}])'.format(traffic_light.id))
self._state = AgentState.BLOCKED_RED_LIGHT
hazard_detected = True
if hazard_detected:
control = self.emergency_stop()
else:
self._state = AgentState.NAVIGATING
# standard local planner behavior
control = self._local_planner.run_step()
return control
================================================
FILE: carla_env/rewards.py
================================================
import math
import numpy as np
from config import CONFIG
min_speed = CONFIG.reward_params.min_speed
max_speed = CONFIG.reward_params.max_speed
target_speed = CONFIG.reward_params.target_speed
max_distance = CONFIG.reward_params.max_distance
max_std_center_lane = CONFIG.reward_params.max_std_center_lane
max_angle_center_lane = CONFIG.reward_params.max_angle_center_lane
penalty_reward = CONFIG.reward_params.penalty_reward
early_stop = CONFIG.reward_params.early_stop
reward_functions = {}
def create_reward_fn(reward_fn):
def func(env):
terminal_reason = "Running..."
if early_stop:
speed = env.vehicle.get_speed()
if speed < 1.0:
env.low_speed_timer += 1
else:
env.low_speed_timer = 0.0 # Reset timer if speed goes above threshold
# Check if speed is low for 90 consecutive second
if env.low_speed_timer >= 90 * env.fps:
env.terminal_state = True
terminal_reason = "Vehicle stopped"
# Stop if distance from center > max distance
if env.distance_from_center > max_distance and not env.eval:
env.terminal_state = True
terminal_reason = "Off-track"
# Stop if speed is too high
if max_speed > 0 and speed > max_speed and not env.eval:
env.terminal_state = True
terminal_reason = "Too fast"
# Calculate reward
reward = 0
if not env.terminal_state:
reward += reward_fn(env)
else:
env.low_speed_timer = 0.0
if reward_fn in {reward_fn5}:
reward += penalty_reward
print(f"{env.episode_idx}| Terminal: ", terminal_reason)
if env.success_state:
print(f"{env.episode_idx}| Success")
env.extra_info.extend([
terminal_reason,
""
])
return reward
return func
def reward_fn_revolve(env):
"""
Revolve reward function
https://arxiv.org/pdf/2406.01309
:return: reward value and reward_components
"""
# Parameters to tweak the importance of different reward components
collision_penalty = -100
inactivity_penalty = -10
speed_reward_weight = 2.0
position_reward_weight = 1.0
smoothness_reward_weight = 0.5
# Adjusted temperature parameters for score transformation
speed_temp = 0.5 # Increased temperature for speed_reward
position_temp = 0.1
smoothness_temp = 0.1
reward_components = {
"collision_penalty": 0,
"inactivity_penalty": 0,
"speed_reward": 0,
"position_reward": 0,
"smoothness_reward": 0
}
collision = env.collision_state
speed = env.vehicle.get_speed() / 3.6 # unit: m/s
action_list = env.action_list ### record the historical actions by setting self.steering_list = []
min_pos = env.distance_from_center
# Penalize for collision
if collision:
reward_components["collision_penalty"] = collision_penalty
# Penalize for inactivity (speed too close to zero)
if speed < 1.5: # Adjusted threshold for inactivity
reward_components["inactivity_penalty"] = inactivity_penalty
# Reward for maintaining an optimal speed range
if 4.0 <= speed <= 6.0:
# Centering and normalizing around the average of optima speed range
speed_score = 1 - np.abs(speed - 5) / 1.75
else:
speed_score = -1
# Use a sigmoid function to smoothly transform the speed score and constrain it
reward_components["speed_reward"] = speed_reward_weight * (1 / (1 + np.exp(
-speed_score / speed_temp)))
# Reward for being close to the center of the road
position_score = np.exp(-min_pos / position_temp)
reward_components["position_reward"] = position_reward_weight * position_score
# Reward for smooth driving (small variations in consecutive steering actions)
steering_smoothness = -np.std(action_list)
reward_components["smoothness_reward"] = smoothness_reward_weight * np.exp(
steering_smoothness / smoothness_temp)
# Calculate total reward, giving precedence to penalties
total_reward = 0
if reward_components["collision_penalty"] < 0:
total_reward = reward_components["collision_penalty"]
elif reward_components["inactivity_penalty"] < 0:
total_reward = reward_components["inactivity_penalty"]
else:
total_reward = sum(reward_components.values())
# Ensure the total reward is within a reasonable range
total_reward = np.clip(total_reward, -1, 1)
return total_reward
reward_functions["reward_fn_revolve"] = create_reward_fn(reward_fn_revolve)
def reward_fn_revolve_auto(env):
"""
An variant of revolve reward function, with an automatic feedback mechanism originally proposed in Eureka
:return: reward value
"""
def calculate_distance(point1, point2):
return math.sqrt((point1.x - point2.x) ** 2 + (point1.y - point2.y) ** 2 + (point1.z - point2.z) ** 2)
def get_distance_to_nearest_obstacle(vehicle, max_distance_view=20):
vehicle_transform = vehicle.get_transform()
start_location = vehicle_transform.location
forward_vector = vehicle_transform.get_forward_vector()
end_location = start_location + forward_vector * max_distance_view
world = vehicle.get_world()
hit_result = world.cast_ray(start_location, end_location)
if hit_result:
min_distance = 9999
for hit_res in hit_result:
distance = calculate_distance(start_location, hit_res.location)
if distance < min_distance:
min_distance = distance
# distance = start_location.distance(hit_result.location)
return min_distance
else:
return max_distance_view
# Define temperature parameters for reward transformations
temp_collision = 5.0
temp_inactivity = 10.0
temp_centering = 2.0
temp_speed = 2.0
temp_smoothness = 1.0
temp_proximity = 2.0
# Initialize the total reward and reward components dictionary
reward_components = {
'collision_penalty': 0,
'inactivity_penalty': 0,
'lane_centering_bonus': 0,
'speed_regulation_bonus': 0,
'smooth_driving_bonus': 0,
'front_distance_bonus': 0
}
collision = env.collision_state
speed = env.vehicle.get_speed() / 3.6 # unit: m/s
action_list = env.action_list ### record the historical actions by setting self.steering_list = []
min_pos = env.distance_from_center
# Penalty for collisions
reward_components['collision_penalty'] = np.exp(-temp_collision) if collision else 0
# Penalty for inactivity
inactivity_threshold = 1.5
if speed < inactivity_threshold and not collision:
reward_components['inactivity_penalty'] = np.exp(-temp_inactivity * (
inactivity_threshold - speed))
# Lane centering bonus
max_distance_from_center = 2.0 # adaptable based on road width
reward_components['lane_centering_bonus'] = np.exp(-temp_centering * min_pos)
# Speed regulation bonus
ideal_speed = (4.0 + 6.0) / 2
speed_range = 6.0 - 4.0
reward_components['speed_regulation_bonus'] = np.exp(-temp_speed * (abs(speed - ideal_speed) / speed_range))
# Smooth driving bonus
max_steering_variance = 0.1 # configured to the acceptable steering variance for full bonus
smoothness_factor = np.std(action_list)
reward_components['smooth_driving_bonus'] = np.exp(-temp_smoothness * (
smoothness_factor / max_steering_variance))
# Front distance bonus
max_distance_view = 20
distance = get_distance_to_nearest_obstacle(env.vehicle, max_distance_view)
reward_components['front_distance_bonus'] = np.clip(distance / max_distance_view, 0, 1)
# Sum the individual rewards for the total reward
total_reward = sum(reward_components.values())
# Ensure penalties take precedence
if collision or speed < inactivity_threshold:
total_reward = -1 # Apply max negative reward for collision or inactivity
# Normalize the total reward to lie between-1 and 1
total_reward = np.clip(total_reward, -1, 1)
return total_reward
reward_functions["reward_fn_revolve_auto"] = create_reward_fn(reward_fn_revolve_auto)
def reward_fn_chatscene(env):
out_lane_thres = 4
desired_speed = 5.5
def get_lane_dis(waypoints, x, y):
"""
Calculate distance from (x, y) to waypoints.
:param waypoints: a list of list storing waypoints like [[x0, y0], [x1, y1], ...]
:param x: x position of vehicle
:param y: y position of vehicle
:return: a tuple of the distance and the closest waypoint orientation
"""
eps = 1e-5
dis_min = 99999
waypt = waypoints[0]
for pt in waypoints:
pt_loc = pt.transform.location
d = np.sqrt((x - pt_loc.x) ** 2 + (y - pt_loc.y) ** 2)
if d < dis_min:
dis_min = d
waypt = pt
vec = np.array([x - waypt.transform.location.x, y - waypt.transform.location.y])
lv = np.linalg.norm(np.array(vec)) + eps
w = np.array([np.cos(waypt.transform.rotation.yaw / 180 * np.pi),
np.sin(waypt.transform.rotation.yaw / 180 * np.pi)])
cross = np.cross(w, vec / lv)
dis = - lv * cross
return dis, w
collision = env.collision_state ### self.collision in env
waypoints = [i[0] for i in env.route_waypoints[env.current_waypoint_index % len(env.route_waypoints): ]]
r_collision = -1 if collision else 0
# reward for steering:
r_steer = -env.vehicle.get_control().steer ** 2
# reward for out of lane
trans = env.vehicle.get_transform()
ego_x = trans.location.x
ego_y = trans.location.y
dis, w = get_lane_dis(waypoints, ego_x, ego_y)
r_out = -1 if abs(dis) > out_lane_thres else 0
# reward for speed tracking
v = env.vehicle.get_velocity()
# cost for too fast
lspeed = np.array([v.x, v.y])
lspeed_lon = np.dot(lspeed, w)
r_fast = -1 if lspeed_lon > desired_speed else 0
# cost for lateral acceleration
r_lat = -abs(env.vehicle.get_control().steer) * lspeed_lon ** 2
# combine all rewards
total_reward = 1 * r_collision + 1 * lspeed_lon + 10 * r_fast + 1 * r_out + r_steer * 5 + 0.2 * r_lat
return total_reward
reward_functions["reward_fn_chatscene"] = create_reward_fn(reward_fn_chatscene)
def reward_fn_simple(env):
"""
Trustworthy safety improvement for autonomous driving using reinforcement learning, 2022
When getting collisions, the reward is -1, else it is 0.
"""
collision = env.collision_state ### self.collision in env
if collision:
return -1
else:
return 0
reward_functions["reward_fn_simple"] = create_reward_fn(reward_fn_simple)
def reward_fn5(env):
"""
reward = Positive speed reward for being close to target speed,
however, quick decline in reward beyond target speed
* centering factor (1 when centered, 0 when not)
* angle factor (1 when aligned with the road, 0 when more than max_angle_center_lane degress off)
* distance_std_factor (1 when std from center lane is low, 0 when not)
"""
angle = env.vehicle.get_angle(env.current_waypoint)
speed_kmh = env.vehicle.get_speed()
if speed_kmh < min_speed: # When speed is in [0, min_speed] range
speed_reward = speed_kmh / min_speed # Linearly interpolate [0, 1] over [0, min_speed]
elif speed_kmh > target_speed: # When speed is in [target_speed, inf]
# Interpolate from [1, 0, -inf] over [target_speed, max_speed, inf]
speed_reward = 1.0 - (speed_kmh - target_speed) / (max_speed - target_speed)
else: # Otherwise
speed_reward = 1.0 # Return 1 for speeds in range [min_speed, target_speed]
# Interpolated from 1 when centered to 0 when 3 m from center
centering_factor = max(1.0 - env.distance_from_center / max_distance, 0.0)
# Interpolated from 1 when aligned with the road to 0 when +/- 20 degress of road
angle_factor = max(1.0 - abs(angle / np.deg2rad(max_angle_center_lane)), 0.0)
std = np.std(env.distance_from_center_history)
distance_std_factor = max(1.0 - abs(std / max_std_center_lane), 0.0)
# Final reward
reward = speed_reward * centering_factor * angle_factor * distance_std_factor
return reward
reward_functions["reward_fn5"] = create_reward_fn(reward_fn5)
def reward_fn_Chen(env):
"""
A reward function that combines multiple factors:
r = 200*r_collision + v_lon + 10*r_fast + r_out - 5*α^2 + 0.2*r_lat - 0.1
where:
- r_collision: -1 if collision occurs, 0 otherwise
- v_lon: longitudinal speed of the ego vehicle
- r_fast: -1 if speed exceeds threshold (8 m/s), 0 otherwise
- r_out: -1 if vehicle leaves the lane, 0 otherwise
- α: steering angle in radians, penalized quadratically
- r_lat: lateral acceleration term, calculated as r_lat = -|α|*v_lon^2
- -0.1: constant term to discourage the vehicle from remaining stationary
"""
# Get vehicle state
collision = env.collision_state
speed = env.vehicle.get_speed() / 3.6 # Convert from km/h to m/s
steering = env.vehicle.get_control().steer # Steering angle in radians
# Calculate individual reward components
r_collision = -1 if collision else 0
v_lon = speed # Longitudinal speed
r_fast = -1 if speed > 8 else 0 # Penalty for exceeding 8 m/s
r_out = -1 if env.distance_from_center > 4 else 0 # Penalty for leaving lane (assuming 4m threshold)
alpha_squared = -5 * (steering ** 2) # Quadratic steering penalty
r_lat = -abs(steering) * (speed ** 2) # Lateral acceleration penalty
constant_term = -0.1 # Constant penalty
# Combine all components according to the formula
total_reward = (200 * r_collision +
v_lon +
10 * r_fast +
r_out +
alpha_squared +
0.2 * r_lat +
constant_term)
return total_reward
reward_functions["reward_fn_Chen"] = create_reward_fn(reward_fn_Chen)
def reward_fn_ASAP(env):
"""
ASAP (Approximate Safe Action Policy) reward function that combines multiple factors:
r_t = R_progress + R_destination + R_crash + R_overtaking
where:
- R_progress: 1 reward for every 10 meters of distance completed
- R_destination: 1 reward if the agent successfully reaches its destination
- R_crash: -5 penalty if the agent collides with another vehicle or road curbs
- R_overtaking: 0.1 reward each time the agent overtakes another vehicle
"""
# Get vehicle state
collision = env.collision_state
# Calculate progress reward (1 reward per 10 meters)
distance_traveled = env.distance_traveled # Total distance traveled in meters
r_progress = distance_traveled / 10.0 # 1 reward per 10 meters
# Calculate destination reward
r_destination = 1.0 if env.success_state else 0.0
# Calculate crash penalty
r_crash = -5.0 if collision else 0.0
# Calculate overtaking reward
# Note: This requires tracking overtaken vehicles, which might need to be implemented in the environment
# For now, we'll use a placeholder based on nearby vehicles
r_overtaking = 0.0 # This should be implemented based on environment's vehicle tracking
# Combine all components according to the formula
total_reward = (r_progress +
r_destination +
r_crash +
r_overtaking)
return total_reward
reward_functions["reward_fn_ASAP"] = create_reward_fn(reward_fn_ASAP)
================================================
FILE: carla_env/state_commons.py
================================================
import torch
from torchvision import transforms
import numpy as np
import gym
from carla_env.wrappers import vector, get_displacement_vector
torch.cuda.empty_cache()
def preprocess_frame(frame):
preprocess = transforms.Compose([
transforms.ToTensor(),
])
frame = preprocess(frame).unsqueeze(0)
return frame
def create_encode_state_fn(measurements_to_include, CONFIG, vae=None):
"""
Returns a function that encodes the current state of
the environment into some feature vector.
"""
measure_flags = ["steer" in measurements_to_include,
"throttle" in measurements_to_include,
"speed" in measurements_to_include,
"angle_next_waypoint" in measurements_to_include,
"maneuver" in measurements_to_include,
"waypoints" in measurements_to_include,
"rgb_camera" in measurements_to_include,
"seg_camera" in measurements_to_include,
"end_wp_vector" in measurements_to_include,
"end_wp_fixed" in measurements_to_include,
"distance_goal" in measurements_to_include]
def create_observation_space():
observation_space = {}
low, high = [], []
if measure_flags[0]: low.append(-1), high.append(1)
if measure_flags[1]: low.append(0), high.append(1)
if measure_flags[2]: low.append(0), high.append(120)
if measure_flags[3]: low.append(-3.14), high.append(3.14)
observation_space['vehicle_measures'] = gym.spaces.Box(low=np.array(low), high=np.array(high), dtype=np.float32)
if measure_flags[4]: observation_space['maneuver'] = gym.spaces.Discrete(4)
if measure_flags[5]: observation_space['waypoints'] = gym.spaces.Box(low=-50, high=50, shape=(15, 2),
dtype=np.float32)
if measure_flags[6]: observation_space['rgb_camera'] = gym.spaces.Box(low=0, high=255, shape=(CONFIG['obs_res'][1], CONFIG['obs_res'][0], 3), dtype=np.uint8)
if measure_flags[7]: observation_space['seg_camera'] = gym.spaces.Box(low=0, high=255, shape=(CONFIG['obs_res'][1], CONFIG['obs_res'][0], 3), dtype=np.uint8)
if measure_flags[8]: observation_space['end_wp_vector'] = gym.spaces.Box(low=-50, high=50, shape=(1, 2), dtype=np.float32)
if measure_flags[9]: observation_space['end_wp_fixed'] = gym.spaces.Box(low=-50, high=50, shape=(1, 2), dtype=np.float32)
if measure_flags[10]: observation_space['distance_goal'] = gym.spaces.Box(low=0, high=1500, shape=(1, 1), dtype=np.float32)
if CONFIG.use_seg_bev: observation_space['seg_camera'] = gym.spaces.Box(low=0, high=255, shape=(192, 192, 6), dtype=np.uint8)
return gym.spaces.Dict(observation_space)
def encode_state(env):
encoded_state = {}
vehicle_measures = []
if measure_flags[0]: vehicle_measures.append(env.vehicle.control.steer)
if measure_flags[1]: vehicle_measures.append(env.vehicle.control.throttle)
if measure_flags[2]: vehicle_measures.append(env.vehicle.get_speed())
if measure_flags[3]: vehicle_measures.append(env.vehicle.get_angle(env.current_waypoint))
encoded_state['vehicle_measures'] = vehicle_measures
if measure_flags[4]: encoded_state['maneuver'] = env.current_road_maneuver.value
if measure_flags[5]:
next_waypoints_state = env.route_waypoints[env.current_waypoint_index: env.current_waypoint_index + 15]
waypoints = [vector(way[0].transform.location) for way in next_waypoints_state]
vehicle_location = vector(env.vehicle.get_location())
theta = np.deg2rad(env.vehicle.get_transform().rotation.yaw)
relative_waypoints = np.zeros((15, 2))
for i, w_location in enumerate(waypoints):
relative_waypoints[i] = get_displacement_vector(vehicle_location, w_location, theta)[:2]
if len(waypoints) < 15:
start_index = len(waypoints)
reference_vector = relative_waypoints[start_index-1] - relative_waypoints[start_index-2]
for i in range(start_index, 15):
relative_waypoints[i] = relative_waypoints[i-1] + reference_vector
encoded_state['waypoints'] = relative_waypoints
if measure_flags[6]: encoded_state['rgb_camera'] = env.observation
if measure_flags[7] : encoded_state['seg_camera'] = env.observation
if measure_flags[8]:
vehicle_location = vector(env.vehicle.get_location())
theta = np.deg2rad(env.vehicle.get_transform().rotation.yaw)
end_wp_location = vector(env.end_wp.transform.location)
encoded_state['end_wp_vector'] = get_displacement_vector(vehicle_location, end_wp_location, theta)[:2]
if measure_flags[9]:
vehicle_location = vector(env.start_wp.transform.location)
theta = np.deg2rad(env.start_wp.transform.rotation.yaw)
end_wp_location = vector(env.end_wp.transform.location)
encoded_state['end_wp_fixed'] = get_displacement_vector(vehicle_location, end_wp_location, theta)[:2]
if measure_flags[10]:
encoded_state['distance_goal'] = [[len(env.route_waypoints) - env.current_waypoint_index]]
return encoded_state
return create_observation_space(), encode_state
================================================
FILE: carla_env/tools/__init__.py
================================================
================================================
FILE: carla_env/tools/hud.py
================================================
"""
Welcome to CARLA manual control.
Use ARROWS or WASD keys for control.
W : throttle
S : brake
AD : steer
Q : toggle reverse
Space : hand-brake
M : toggle manual transmission
,/. : gear up/down
TAB : change sensor position
` : next sensor
[1-9] : change to sensor [1-9]
C : change weather (Shift+C reverse)
Backspace : change vehicle
R : toggle recording images to disk
F1 : toggle HUD
H/? : toggle help
ESC : quit
"""
import pygame
import math
from carla_env.wrappers import get_actor_display_name
#===============================================================================
# HUD
#===============================================================================
class HUD(object):
"""
HUD class for displaying on-screen information
"""
def __init__(self, width, height):
self.dim = (width, height)
# Select a monospace font for the info panel
fonts = [x for x in pygame.font.get_fonts() if "mono" in x]
default_font = "ubuntumono"
mono = default_font if default_font in fonts else fonts[0]
mono = pygame.font.match_font(mono)
self.font_mono = pygame.font.Font(mono, 14)
# Use default font for everything else
font = pygame.font.Font(pygame.font.get_default_font(), 20)
self.notifications = FadingText(font, (width, 40), (0, height - 40))
self.help = HelpText(pygame.font.Font(mono, 24), width, height)
self.server_fps = 0
self.frame_number = 0
self.simulation_time = 0
self.show_info = True
self.info_text = []
self.server_clock = pygame.time.Clock()
self.vehicle = None
def set_vehicle(self, vehicle):
self.vehicle = vehicle
def tick(self, world, clock):
if self.show_info:
# Get all world vehicles
vehicles = world.get_actors().filter("vehicle.*")
# General simulation info
self.info_text = [
"Server: % 16d FPS" % self.server_fps,
"Client: % 16d FPS" % clock.get_fps(),
"",
"Map: % 20s" % world.map.name,
#"Simulation time: % 12s" % datetime.timedelta(seconds=int(self.simulation_time)),
"Number of vehicles: % 8d" % len(vehicles)
]
# Show info of attached vehicle
if self.vehicle is not None:
# Get transform, velocity and heading
t = self.vehicle.get_transform()
v = self.vehicle.get_velocity()
c = self.vehicle.get_control()
heading = "N" if abs(t.rotation.yaw) < 89.5 else ""
heading += "S" if abs(t.rotation.yaw) > 90.5 else ""
heading += "E" if 179.5 > t.rotation.yaw > 0.5 else ""
heading += "W" if -0.5 > t.rotation.yaw > -179.5 else ""
self.info_text.extend([
"Vehicle: % 20s" % get_actor_display_name(self.vehicle, truncate=20),
"",
"Speed: % 15.0f km/h" % (3.6 * math.sqrt(v.x**2 + v.y**2 + v.z**2)),
u"Heading:% 16.0f\N{DEGREE SIGN} % 2s" % (t.rotation.yaw, heading),
"Location:% 20s" % ("(% 5.1f, % 5.1f)" % (t.location.x, t.location.y)),
"Height: % 18.0f m" % t.location.z,
"",
("Throttle:", c.throttle, 0.0, 1.0),
("Steer:", c.steer, -1.0, 1.0),
("Brake:", c.brake, 0.0, 1.0)
])
else:
self.info_text.append("Vehicle: % 20s" % "None")
# Tick notifications
self.notifications.tick(world, clock)
def render(self, display, extra_info=[]):
if self.show_info:
info_surface = pygame.Surface((220, self.dim[1]))
info_surface.set_alpha(100)
display.blit(info_surface, (0, 0))
v_offset = 4
bar_h_offset = 100
bar_width = 106
self.info_text.append("")
self.info_text.extend(extra_info)
for item in self.info_text:
if v_offset + 18 > self.dim[1]:
break
if isinstance(item, list):
if len(item) > 1:
points = [(x + 8, v_offset + 8 + (1.0 - y) * 30) for x, y in enumerate(item)]
pygame.draw.lines(display, (255, 136, 0), False, points, 2)
item = None
v_offset += 18
elif isinstance(item, tuple):
if isinstance(item[1], bool):
rect = pygame.Rect((bar_h_offset, v_offset + 8), (6, 6))
pygame.draw.rect(display, (255, 255, 255), rect, 0 if item[1] else 1)
else:
rect_border = pygame.Rect((bar_h_offset, v_offset + 8), (bar_width, 6))
pygame.draw.rect(display, (255, 255, 255), rect_border, 1)
f = (item[1] - item[2]) / (item[3] - item[2])
if item[2] < 0.0:
rect = pygame.Rect((bar_h_offset + f * (bar_width - 6), v_offset + 8), (6, 6))
else:
rect = pygame.Rect((bar_h_offset, v_offset + 8), (f * bar_width, 6))
pygame.draw.rect(display, (255, 255, 255), rect)
item = item[0]
if item: # At this point has to be a str.
surface = self.font_mono.render(item, True, (255, 255, 255))
display.blit(surface, (8, v_offset))
v_offset += 18
self.notifications.render(display)
self.help.render(display)
def on_world_tick(self, timestamp):
# Store info when server ticks
self.server_clock.tick()
self.server_fps = self.server_clock.get_fps()
self.frame_number = timestamp.frame_count
self.simulation_time = timestamp.elapsed_seconds
def toggle_info(self):
self.show_info = not self.show_info
def notification(self, text, seconds=2.0):
self.notifications.set_text(text, seconds=seconds)
def error(self, text):
self.notifications.set_text("Error: %s" % text, (255, 0, 0))
#===============================================================================
# FadingText
#===============================================================================
class FadingText(object):
def __init__(self, font, dim, pos):
self.font = font
self.dim = dim
self.pos = pos
self.seconds_left = 0
self.surface = pygame.Surface(self.dim)
def set_text(self, text, color=(255, 255, 255), seconds=2.0):
text_texture = self.font.render(text, True, color)
self.surface = pygame.Surface(self.dim)
self.seconds_left = seconds
self.surface.fill((0, 0, 0, 0))
self.surface.blit(text_texture, (10, 11))
def tick(self, _, clock):
delta_seconds = 1e-3 * clock.get_time()
self.seconds_left = max(0.0, self.seconds_left - delta_seconds)
self.surface.set_alpha(500.0 * self.seconds_left)
def render(self, display):
display.blit(self.surface, self.pos)
#===============================================================================
# HelpText
#===============================================================================
class HelpText(object):
def __init__(self, font, width, height):
lines = __doc__.split("\n")
self.font = font
self.dim = (680, len(lines) * 22 + 12)
self.pos = (0.5 * width - 0.5 * self.dim[0], 0.5 * height - 0.5 * self.dim[1])
self.seconds_left = 0
self.surface = pygame.Surface(self.dim)
self.surface.fill((0, 0, 0, 0))
for n, line in enumerate(lines):
text_texture = self.font.render(line, True, (255, 255, 255))
self.surface.blit(text_texture, (22, n * 22))
self._render = False
self.surface.set_alpha(220)
def toggle(self):
self._render = not self._render
def render(self, display):
if self._render:
display.blit(self.surface, self.pos)
================================================
FILE: carla_env/tools/misc.py
================================================
#!/usr/bin/env python
# Copyright (c) 2018 Intel Labs.
# authors: German Ros (german.ros@intel.com)
#
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
""" Module with auxiliary functions. """
import math
import numpy as np
import carla
def draw_waypoints(world, waypoints, z=0.5):
"""
Draw a list of waypoints at a certain height given in z.
:param world: carla.world object
:param waypoints: list or iterable container with the waypoints to draw
:param z: height in meters
:return:
"""
for w in waypoints:
t = w.transform
begin = t.location + carla.Location(z=z)
angle = math.radians(t.rotation.yaw)
end = begin + carla.Location(x=math.cos(angle), y=math.sin(angle))
world.debug.draw_arrow(begin, end, arrow_size=0.3, life_time=1.0)
def get_speed(vehicle):
"""
Compute speed of a vehicle in Kmh
:param vehicle: the vehicle for which speed is calculated
:return: speed as a float in Kmh
"""
vel = vehicle.get_velocity()
return 3.6 * math.sqrt(vel.x ** 2 + vel.y ** 2 + vel.z ** 2)
def is_within_distance_ahead(target_location, current_location, orientation, max_distance):
"""
Check if a target object is within a certain distance in front of a reference object.
:param target_location: location of the target object
:param current_location: location of the reference object
:param orientation: orientation of the reference object
:param max_distance: maximum allowed distance
:return: True if target object is within max_distance ahead of the reference object
"""
target_vector = np.array([target_location.x - current_location.x, target_location.y - current_location.y])
norm_target = np.linalg.norm(target_vector)
# If the vector is too short, we can simply stop here
if norm_target < 0.001:
return True
if norm_target > max_distance:
return False
forward_vector = np.array(
[math.cos(math.radians(orientation)), math.sin(math.radians(orientation))])
d_angle = math.degrees(math.acos(np.dot(forward_vector, target_vector) / norm_target))
return d_angle < 90.0
def compute_magnitude_angle(target_location, current_location, orientation):
"""
Compute relative angle and distance between a target_location and a current_location
:param target_location: location of the target object
:param current_location: location of the reference object
:param orientation: orientation of the reference object
:return: a tuple composed by the distance to the object and the angle between both objects
"""
target_vector = np.array([target_location.x - current_location.x, target_location.y - current_location.y])
norm_target = np.linalg.norm(target_vector)
forward_vector = np.array([math.cos(math.radians(orientation)), math.sin(math.radians(orientation))])
d_angle = math.degrees(math.acos(np.dot(forward_vector, target_vector) / norm_target))
return (norm_target, d_angle)
def distance_vehicle(waypoint, vehicle_transform):
loc = vehicle_transform.location
dx = waypoint.transform.location.x - loc.x
dy = waypoint.transform.location.y - loc.y
return math.sqrt(dx * dx + dy * dy)
def vector(location_1, location_2):
"""
Returns the unit vector from location_1 to location_2
location_1, location_2: carla.Location objects
"""
x = location_2.x - location_1.x
y = location_2.y - location_1.y
z = location_2.z - location_1.z
norm = np.linalg.norm([x, y, z]) + np.finfo(float).eps
return [x / norm, y / norm, z / norm]
================================================
FILE: carla_env/wrappers.py
================================================
import carla
import numpy as np
import weakref
def get_actor_display_name(actor, truncate=250):
name = " ".join(actor.type_id.replace("_", ".").title().split(".")[1:])
return (name[:truncate - 1] + u"\u2026") if len(name) > truncate else name
def get_displacement_vector(car_pos, waypoint_pos, theta):
"""
Calculates the displacement vector from the car to a waypoint, taking into account the orientation of the car.
Parameters:
car_pos (numpy.ndarray): 1D numpy array of shape (3,) representing the x, y, z coordinates of the car.
waypoint_pos (numpy.ndarray): 1D numpy array of shape (3,) representing the x, y, z coordinates of the waypoint.
theta (float): Angle in radians representing the orientation of the car.
Returns:
numpy.ndarray: 1D numpy array of shape (3,) representing the displacement vector from the car to the waypoint,
with the car as the origin and the y-axis pointing in the direction of the car's orientation.
"""
# Calculate the relative position of the waypoint with respect to the car
relative_pos = waypoint_pos - car_pos
theta = theta
# Construct the rotation transformation matrix
R = np.array([[np.cos(theta), np.sin(theta), 0],
[-np.sin(theta), np.cos(theta), 0],
[0, 0, 1]])
T = np.array([[0, 1, 0],
[1, 0, 0],
[0, 0, 1]])
# Apply the rotation matrix to the relative position vector
waypoint_car = R @ relative_pos
waypoint_car = T @ waypoint_car
# Set values very close to zero to exactly zero
waypoint_car[np.abs(waypoint_car) < 10e-10] = 0
return waypoint_car
def angle_diff(v0, v1):
"""
Calculates the signed angle difference between 2D vectors v0 and v1.
It returns the angle difference in radians between v0 and v1.
The v0 is the reference for the sign of the angle
"""
v0_xy = v0[:2]
v1_xy = v1[:2]
v0_xy_norm = np.linalg.norm(v0_xy)
v1_xy_norm = np.linalg.norm(v1_xy)
if v0_xy_norm == 0 or v1_xy_norm == 0:
return 0
v0_xy_u = v0_xy / v0_xy_norm
v1_xy_u = v1_xy / v1_xy_norm
dot_product = np.dot(v0_xy_u, v1_xy_u)
angle = np.arccos(dot_product)
# Calculate the sign of the angle using the cross product
cross_product = np.cross(v0_xy_u, v1_xy_u)
if cross_product < 0:
angle = -angle
if abs(angle) >= 2.3:
return 0
return round(angle, 2)
def distance_to_line(A, B, p):
p[2] = 0
num = np.linalg.norm(np.cross(B - A, A - p))
denom = np.linalg.norm(B - A)
if np.isclose(denom, 0):
return np.linalg.norm(p - A)
return num / denom
def vector(v):
""" Turn carla Location/Vector3D/Rotation to np.array """
if isinstance(v, carla.Location) or isinstance(v, carla.Vector3D):
return np.array([v.x, v.y, v.z])
elif isinstance(v, carla.Rotation):
return np.array([v.pitch, v.yaw, v.roll])
def smooth_action(old_value, new_value, smooth_factor):
return old_value * smooth_factor + new_value * (1.0 - smooth_factor)
def build_projection_matrix(w, h, fov):
focal = w / (2.0 * np.tan(fov * np.pi / 360.0))
K = np.identity(3)
K[0, 0] = K[1, 1] = focal
K[0, 2] = w / 2.0
K[1, 2] = h / 2.0
return K
def get_image_point(loc, K, w2c):
# Calculate 2D projection of 3D coordinate
# Format the input coordinate (loc is a carla.Position object)
point = np.array([loc.x, loc.y, loc.z, 1])
# transform to camera coordinates
point_camera = np.dot(w2c, point)
# New we must change from UE4's coordinate system to an "standard"
# (x, y ,z) -> (y, -z, x)
# and we remove the fourth componebonent also
point_camera = [point_camera[1], -point_camera[2], point_camera[0]]
# now project 3D->2D using the camera matrix
point_img = np.dot(K, point_camera)
# normalize
point_img[0] /= point_img[2]
point_img[1] /= point_img[2]
return point_img[0:2].astype(int)
sensor_transforms = {
"spectator": carla.Transform(carla.Location(x=-5.5, z=2.8), carla.Rotation(pitch=-15)),
"lidar": carla.Transform(carla.Location(x=0.0, z=2.4)),
"dashboard": carla.Transform(carla.Location(z=10, x=10), carla.Rotation(pitch=-90)),
"birdview0": carla.Transform(carla.Location(x=0, y=0, z=16), carla.Rotation(pitch=-90)),
"birdview1": carla.Transform(carla.Location(z=6.4, x=5.2, y=-1.6), carla.Rotation(pitch=-90)),
"fpv": carla.Transform(carla.Location(x=0.6, y=-0.5, z=1.2)),
}
# ===============================================================================
# CarlaActorBase
# ===============================================================================
class CarlaActorBase(object):
def __init__(self, world, actor):
self.world = world
self.actor = actor
self.world.actor_list.append(self)
self.destroyed = False
def destroy(self):
if self.destroyed:
raise Exception("Actor already destroyed.")
else:
print("Destroying ", self, "...")
self.actor.destroy()
self.world.actor_list.remove(self)
self.destroyed = True
def get_carla_actor(self):
return self.actor
def tick(self):
pass
def __getattr__(self, name):
"""Relay missing methods to underlying carla actor"""
return getattr(self.actor, name)
# ===============================================================================
# Lidar
# ===============================================================================
class Lidar(CarlaActorBase):
def __init__(self, world, width=120, height=120, transform=carla.Transform(), on_recv_image=None,
attach_to=None):
self._width = width
self._height = height
self.on_recv_image = on_recv_image
self.range = 20
# Setup lidar blueprint
lidar_bp = world.get_blueprint_library().find('sensor.lidar.ray_cast')
lidar_bp.set_attribute('points_per_second', '50000')
lidar_bp.set_attribute('channels', '64')
lidar_bp.set_attribute('range', str(self.range))
lidar_bp.set_attribute('upper_fov', '10')
lidar_bp.set_attribute('horizontal_fov', '110')
lidar_bp.set_attribute('lower_fov', '-20')
lidar_bp.set_attribute('rotation_frequency', '30')
# Create and setup camera actor
weak_self = weakref.ref(self)
actor = world.spawn_actor(lidar_bp, transform, attach_to=attach_to.get_carla_actor())
actor.listen(lambda lidar_data: Lidar.process_lidar_input(weak_self, lidar_data))
print("Spawned actor \"{}\"".format(actor.type_id))
super().__init__(world, actor)
@staticmethod
def process_lidar_input(weak_self, raw):
self = weak_self()
if not self:
return
if callable(self.on_recv_image):
lidar_range = 2.0 * float(self.range)
points = np.frombuffer(raw.raw_data, dtype=np.dtype('f4'))
points = np.reshape(points, (int(points.shape[0] / 4), 4))
lidar_data = np.array(points[:, :2])
lidar_data *= min(self._width, self._height) / lidar_range
lidar_data += (0.5 * self._width, 0.5 * self._height)
lidar_data = np.fabs(lidar_data) # pylint: disable=E1111
lidar_data = lidar_data.astype(np.int32)
lidar_data = np.reshape(lidar_data, (-1, 2))
lidar_img_size = (self._width, self._height, 3)
lidar_img = np.zeros((lidar_img_size), dtype=np.uint8)
lidar_img[tuple(lidar_data.T)] = (255, 255, 255)
self.on_recv_image(lidar_img)
"""
if callable(self.on_recv_image):
lidar_data.convert(self.color_converter)
array = np.frombuffer(lidar_data.raw_data, dtype=np.dtype("uint8"))
array = np.reshape(array, (lidar_data.height, lidar_data.width, 4))
array = array[:, :, :3]
array = array[:, :, ::-1]
self.on_recv_image(array)
"""
# ===============================================================================
# CollisionSensor
# ===============================================================================
class CollisionSensor(CarlaActorBase):
def __init__(self, world, vehicle, on_collision_fn):
self.on_collision_fn = on_collision_fn
# Collision history
self.history = []
# Setup sensor blueprint
bp = world.get_blueprint_library().find("sensor.other.collision")
# Create and setup sensor
weak_self = weakref.ref(self)
actor = world.spawn_actor(bp, carla.Transform(), attach_to=vehicle.get_carla_actor())
actor.listen(lambda event: CollisionSensor.on_collision(weak_self, event))
super().__init__(world, actor)
@staticmethod
def on_collision(weak_self, event):
self = weak_self()
if not self:
return
# Call on_collision_fn
if callable(self.on_collision_fn):
self.on_collision_fn(event)
# ===============================================================================
# LaneInvasionSensor
# ===============================================================================
class LaneInvasionSensor(CarlaActorBase):
def __init__(self, world, vehicle, on_invasion_fn):
self.on_invasion_fn = on_invasion_fn
# Setup sensor blueprint
bp = world.get_blueprint_library().find("sensor.other.lane_invasion")
# Create sensor
weak_self = weakref.ref(self)
actor = world.spawn_actor(bp, carla.Transform(), attach_to=vehicle.get_carla_actor())
actor.listen(lambda event: LaneInvasionSensor.on_invasion(weak_self, event))
super().__init__(world, actor)
@staticmethod
def on_invasion(weak_self, event):
self = weak_self()
if not self:
return
# Call on_invasion_fn
if callable(self.on_invasion_fn):
self.on_invasion_fn(event)
# ===============================================================================
# Camera
# ===============================================================================
class Camera(CarlaActorBase):
def __init__(self, world, width, height, transform=carla.Transform(),
attach_to=None, on_recv_image=None,
camera_type="sensor.camera.rgb", color_converter=carla.ColorConverter.Raw, custom_palette=False):
self.on_recv_image = on_recv_image
self.color_converter = color_converter
self.custom_palette = custom_palette
# Setup camera blueprint
camera_bp = world.get_blueprint_library().find(camera_type)
camera_bp.set_attribute("image_size_x", str(width))
camera_bp.set_attribute("image_size_y", str(height))
camera_bp.set_attribute("fov", f"110")
# camera_bp.set_attribute("sensor_tick", str(sensor_tick))
# Create and setup camera actor
weak_self = weakref.ref(self)
actor = world.spawn_actor(camera_bp, transform, attach_to=attach_to.get_carla_actor())
actor.listen(lambda image: Camera.process_camera_input(weak_self, image))
print("Spawned actor \"{}\"".format(actor.type_id))
super().__init__(world, actor)
@staticmethod
def process_camera_input(weak_self, image):
self = weak_self()
if not self:
return
if callable(self.on_recv_image):
image.convert(self.color_converter)
array = np.frombuffer(image.raw_data, dtype=np.dtype("uint8"))
array = np.reshape(array, (image.height, image.width, 4))
array = array[:, :, :3]
array = array[:, :, ::-1]
if self.custom_palette:
classes = {
0: [0, 0, 0], # None
1: [0, 0, 0], # Buildings
2: [0, 0, 0], # Fences
3: [0, 0, 0], # Other
4: [0, 0, 0], # Pedestrians
5: [0, 0, 0], # Poles
6: [157, 234, 50], # RoadLines
7: [50, 64, 128], # Roads
8: [255, 255, 255], # Sidewalks
9: [0, 0, 0], # Vegetation
10: [255, 0, 0], # Vehicles
11: [0, 0, 0], # Walls
12: [0, 0, 0] # TrafficSigns
}
segimg = np.round((array[:, :, 0])).astype(np.uint8)
array = array.copy()
for j in range(array.shape[0]):
for i in range(array.shape[1]):
r_id = segimg[j, i]
if r_id <= 12:
array[j, i] = classes[segimg[j, i]]
else:
array[j, i] = classes[0]
self.on_recv_image(array)
def destroy(self):
super().destroy()
# ===============================================================================
# Vehicle
# ===============================================================================
class Vehicle(CarlaActorBase):
def __init__(self, world, transform=carla.Transform(),
on_collision_fn=None, on_invasion_fn=None,
vehicle_type="vehicle.tesla.model3", is_ego=False):
# Setup vehicle blueprint
vehicle_bp = world.get_blueprint_library().find(vehicle_type)
if is_ego:
vehicle_bp.set_attribute('role_name', 'hero')
# vehicle_bp.set_attribute('color', '0, 255, 0')
color = vehicle_bp.get_attribute("color").recommended_values[0]
else:
color = vehicle_bp.get_attribute("color").recommended_values[0]
vehicle_bp.set_attribute("color", color)
# Create vehicle actor
actor = world.spawn_actor(vehicle_bp, transform)
print("Spawned actor \"{}\"".format(actor.type_id))
super().__init__(world, actor)
# Maintain vehicle control
self.control = carla.VehicleControl()
if callable(on_collision_fn):
self.collision_sensor = CollisionSensor(world, self, on_collision_fn=on_collision_fn)
if callable(on_invasion_fn):
self.lane_sensor = LaneInvasionSensor(world, self, on_invasion_fn=on_invasion_fn)
def tick(self):
self.actor.apply_control(self.control)
def get_speed(self):
"""
Return current vehicle speed in km/h
"""
velocity = self.get_velocity()
return 3.6 * np.sqrt(velocity.x ** 2 + velocity.y ** 2 + velocity.z ** 2)
def get_angle(self, waypoint):
fwd = vector(self.get_velocity())
wp_fwd = vector(waypoint.transform.rotation.get_forward_vector())
return angle_diff(wp_fwd, fwd)
def get_closest_waypoint(self):
return self.world.map.get_waypoint(self.get_transform().location, project_to_road=True)
def set_autopilot(self, is_true, *args, **kwargs):
self.actor.set_autopilot(is_true, *args, **kwargs)
# ===============================================================================
# World
# ===============================================================================
class World():
def __init__(self, client, town='Town02'):
self.world = client.load_world(town)
self.map = self.get_map()
self.actor_list = []
def tick(self):
for actor in list(self.actor_list):
actor.tick()
self.world.tick()
def destroy(self):
print("Destroying all spawned actors")
for actor in list(self.actor_list):
actor.destroy()
def get_carla_world(self):
return self.world
def __getattr__(self, name):
"""Relay missing methods to underlying carla object"""
return getattr(self.world, name)
================================================
FILE: clip/__init__.py
================================================
import os, sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
================================================
FILE: clip/clip_buffer.py
================================================
import torch as th
from gym import spaces
from typing import Any, Dict, List, Union
import numpy as np
from stable_baselines3.common.buffers import DictReplayBuffer, DictRolloutBuffer
class CLIPReplayBuffer(DictReplayBuffer):
def __init__(
self,
buffer_size: int,
observation_space: spaces.Space,
action_space: spaces.Space,
device: Union[th.device, str] = "auto",
n_envs: int = 1,
optimize_memory_usage: bool = False,
handle_timeout_termination: bool = True,
):
super().__init__(
buffer_size,
observation_space,
action_space,
device,
n_envs,
optimize_memory_usage,
handle_timeout_termination,
)
self.render_arrays: List[np.ndarray] = []
self.base_rewards: List = []
self.centering_factors: List = []
self.angle_factors: List = []
self.speeds: List = []
self.distance_std_factors: List = []
def add(
self,
obs: Dict[str, Any],
next_obs: Dict[str, Any],
action: np.ndarray,
reward: np.ndarray,
done: np.ndarray,
infos: List[Dict[str, Any]],
) -> None:
super().add(
obs,
next_obs,
action,
reward,
done,
infos,
)
assert len(self.render_arrays) < self.buffer_size
self.render_arrays.append(infos[0]["render_array"])
self.base_rewards.append(reward[0])
self.centering_factors.append(infos[0]["centering_factor"])
self.angle_factors.append(infos[0]["angle_factor"])
self.speeds.append(infos[0]["speed"])
self.distance_std_factors.append(infos[0]["distance_std_factor"])
def clear_render_arrays(self) -> None:
self.render_arrays = []
self.base_rewards = []
self.centering_factors = []
self.angle_factors = []
self.speeds = []
self.distance_std_factors = []
class CLIPRolloutBuffer(DictRolloutBuffer):
def __init__(
self,
buffer_size: int,
observation_space: spaces.Space,
action_space: spaces.Space,
device: Union[th.device, str] = "auto",
gae_lambda: float = 1,
gamma: float = 0.99,
n_envs: int = 1,
):
super().__init__(
buffer_size,
observation_space,
action_space,
device,
gae_lambda,
gamma,
n_envs,
)
self.render_arrays: List[np.ndarray] = []
self.base_rewards: List = []
self.centering_factors: List = []
self.angle_factors: List = []
self.speeds: List = []
self.distance_std_factors: List = []
def add(
self,
obs: Dict[str, np.ndarray],
action: np.ndarray,
reward: np.ndarray,
episode_start: np.ndarray,
value: th.Tensor,
log_prob: th.Tensor,
infos: List[Dict[str, Any]],
) -> None:
super().add(
obs,
action,
reward,
episode_start,
value,
log_prob
)
assert len(self.render_arrays) < self.buffer_size
self.render_arrays.append(infos[0]["render_array"])
self.base_rewards.append(reward[0])
self.centering_factors.append(infos[0]["centering_factor"])
self.angle_factors.append(infos[0]["angle_factor"])
self.speeds.append(infos[0]["speed"])
self.distance_std_factors.append(infos[0]["distance_std_factor"])
def clear_render_arrays(self) -> None:
self.render_arrays = []
self.base_rewards = []
self.centering_factors = []
self.angle_factors = []
self.speeds = []
self.distance_std_factors = []
================================================
FILE: clip/clip_reward_model.py
================================================
from typing import List, Tuple
import open_clip
import torch
import torch.nn as nn
from torch import Tensor
from clip.transform import image_transform
class CLIPEmbed(nn.Module):
def __init__(self, clip_model):
super().__init__()
self.clip_model = clip_model
if isinstance(clip_model.visual.image_size, int):
image_size = clip_model.visual.image_size
else:
image_size = clip_model.visual.image_size[0]
self.transform = image_transform(image_size)
@torch.inference_mode()
def forward(self, x):
if x.shape[1] != 3:
x = x.permute(0, 3, 1, 2)
with torch.no_grad(), torch.autocast("cuda", enabled=torch.cuda.is_available()):
x = self.transform(x) # [batch, 3, 244, 244]
x = self.clip_model.encode_image(x, normalize=True) # [batch, 1024]
return x
class CLIPReward(nn.Module):
def __init__(
self,
*,
model: CLIPEmbed,
alpha: float,
target_prompts: torch.Tensor,
baseline_prompts: torch.Tensor,
) -> None:
super().__init__()
self.clip_embed_module = model
targets = self.embed_prompts(target_prompts)
self.register_buffer("targets", targets)
if len(baseline_prompts) > 0:
baselines = self.embed_prompts(baseline_prompts)
direction = targets - baselines # [1, 1024]
# Register them as buffers so they are automatically moved around.
self.register_buffer("baselines", baselines)
self.register_buffer("direction", direction)
self.alpha = alpha
projection = self.compute_projection(alpha, self.direction) # [1024, 1024]
self.register_buffer("projection", projection)
def compute_projection(self, alpha: float, direction) -> torch.Tensor:
projection = direction.T @ direction / torch.norm(direction) ** 2
identity = torch.diag(torch.ones(projection.shape[0])).to(projection.device)
projection = alpha * projection + (1 - alpha) * identity
return projection
@torch.inference_mode()
def forward(self, x: torch.Tensor, vlm_reward_type: str) -> torch.Tensor:
if vlm_reward_type == "VLM-RL":
return self.forward_vlm_rl(x)
elif "LORD" in vlm_reward_type:
return self.forward_lord(x)
elif vlm_reward_type == "VLM-RM":
return self.forward_vlm_rm(x)
elif vlm_reward_type in ["VLM-SR", "RoboCLIP"]:
return self.forward_vlm_sr(x)
else:
raise NotImplementedError
@torch.inference_mode()
def forward_vlm_rl(self, x: torch.Tensor) -> torch.Tensor:
x = x / torch.norm(x, dim=-1, keepdim=True)
y = (x @ self.targets.T)
z = y[:, 0] - y[:, 1]
return z
@torch.inference_mode()
def forward_lord(self, x: torch.Tensor) -> torch.Tensor:
x = x / torch.norm(x, dim=-1, keepdim=True)
y = (x @ self.targets.T)
z = 1 - y
return z.squeeze()
@torch.inference_mode()
def forward_vlm_rm(self, x: torch.Tensor) -> torch.Tensor:
x = x / torch.norm(x, dim=-1, keepdim=True)
y = 1 - (torch.norm((x - self.targets) @ self.projection, dim=-1) ** 2) / 2
return y
@torch.inference_mode()
def forward_vlm_sr(self, x: torch.Tensor) -> torch.Tensor:
x = x / torch.norm(x, dim=-1, keepdim=True)
y = (x @ self.targets.T)
return y.squeeze()
@torch.inference_mode()
def get_pos_neg(self, x: torch.Tensor):
x = x / torch.norm(x, dim=-1, keepdim=True)
y = (x @ self.targets.T)
return y[:, 0], y[:, 1]
@staticmethod
def tokenize_prompts(x: List[str]) -> torch.Tensor:
"""Tokenize a list of prompts."""
return open_clip.tokenize(x)
def embed_prompts(self, x) -> torch.Tensor:
"""Embed a list of prompts."""
with torch.no_grad():
x = self.clip_embed_module.clip_model.encode_text(x).float()
x = x / x.norm(dim=-1, keepdim=True)
return x
def embed_images(self, x):
return self.clip_embed_module.forward(x)
def compute_rewards(
model: CLIPReward,
frames: torch.Tensor,
batch_size: int,
vlm_reward_type: str = "VLM-RL",
) -> Tensor:
assert frames.device == torch.device("cpu")
n_samples = len(frames)
basic_rewards = torch.zeros(n_samples, device=torch.device("cpu"))
model = model.eval()
with torch.no_grad():
for i in range(0, n_samples, batch_size):
frames_batch = frames[i: i + batch_size].to(next(model.parameters()).device)
with torch.no_grad():
embeddings = model.clip_embed_module(frames_batch)
rewards_batch = model(embeddings, vlm_reward_type=vlm_reward_type)
basic_rewards[i: i + batch_size] = rewards_batch
return basic_rewards
================================================
FILE: clip/clip_rewarded_ppo.py
================================================
import pathlib
import sys
import time
import warnings
from collections import deque
from typing import Optional, Tuple, TypeVar, Type, Union, Dict, Any
import numpy as np
import open_clip
from gymnasium import spaces
import torch
import torch as th
from box import Box
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.save_util import recursive_setattr, load_from_zip_file
from stable_baselines3.common.type_aliases import MaybeCallback, RolloutReturn
from stable_baselines3.common.utils import safe_mean, check_for_correct_spaces, obs_as_tensor
from stable_baselines3.common.vec_env import VecEnv
from stable_baselines3.common.vec_env.patch_gym import _convert_space
from clip.clip_buffer import CLIPReplayBuffer, CLIPRolloutBuffer
from clip.clip_reward_model import compute_rewards, CLIPEmbed, CLIPReward
from config import CONFIG
SelfCLIPRewardedPPO = TypeVar("SelfCLIPRewardedPPO", bound="CLIPRewardedPPO")
class CLIPRewardedPPO(PPO):
rollout_buffer: CLIPReplayBuffer
def __init__(
self,
*,
env: VecEnv,
config: Box,
inference_only: bool = False,
):
self.config = config
super().__init__(
env=env,
policy='MultiInputPolicy',
tensorboard_log='tensorboard',
seed=config.seed,
**self.config.algorithm_params,
)
self.ep_clip_info_buffer = None # type: Optional[deque]
self.inference_only = inference_only
if not self.inference_only:
self._setup_model()
self._load_modules()
def _dump_logs(self) -> None:
pass
def _setup_model(self):
super()._setup_model()
self.rollout_buffer = CLIPRolloutBuffer(
self.n_steps,
self.observation_space,
self.action_space,
device=self.device,
gamma=self.gamma,
gae_lambda=self.gae_lambda,
n_envs=self.n_envs,
)
def _load_modules(self):
model_name_prefix, pretrained = self.config.clip_reward_params.pretrained_model.split("/")
clip_model = open_clip.create_model(
model_name=model_name_prefix, pretrained=pretrained # , cache_dir=cache_dir
)
clip_model = CLIPEmbed(clip_model)
target_prompts = CLIPReward.tokenize_prompts(self.config.clip_reward_params.target_prompts)
baseline_prompts = CLIPReward.tokenize_prompts(self.config.clip_reward_params.baseline_prompts)
clip_model = CLIPReward(
model=clip_model,
alpha=self.config.clip_reward_params.alpha,
target_prompts=target_prompts,
baseline_prompts=baseline_prompts,
)
self.reward_model = clip_model.eval().to(self.device)
def _compute_clip_rewards(self) -> None:
assert self.env is not None
assert self.ep_info_buffer is not None
ep_info_buffer_maxlen = self.ep_info_buffer.maxlen
assert ep_info_buffer_maxlen is not None
frames = torch.from_numpy(np.array(self.rollout_buffer.render_arrays)) # [1024, 80, 160, 3]
# only use the right half
width = frames.shape[2]
left = width // 2
frames = frames[:, :, left:, :]
rewards0 = compute_rewards(
model=self.reward_model,
frames=frames,
batch_size=self.config.clip_reward_params.batch_size,
)
rewards0 = rewards0.numpy().reshape(-1, 1)
print("Clip reward ...")
print(list(np.round(rewards0.flatten(), 4)))
base_reward = np.array(self.rollout_buffer.base_rewards).reshape(-1, 1)
speeds = np.array(self.rollout_buffer.speeds)
print("Speed ...")
print(list(np.round(speeds.flatten(), 4)))
thre_min, thre_max = 0.0, 0.03
rewards0 = np.clip(rewards0, a_min=thre_min, a_max=thre_max)
rewards0 = 1 - (rewards0 - thre_min) / (thre_max - thre_min)
centering_factors = np.array(self.rollout_buffer.centering_factors)
angle_factors = np.array(self.rollout_buffer.angle_factors)
distance_std_factors = np.array(self.rollout_buffer.distance_std_factors)
desired_speed = np.clip(rewards0.flatten(), 0.0, 1.0) * CONFIG.reward_params.target_speed
r_speeds = 1.0 - np.abs(speeds - desired_speed) / CONFIG.reward_params.target_speed
rewards = (r_speeds * centering_factors * angle_factors * distance_std_factors).reshape(-1, 1)
rewards = np.where(base_reward < 0, base_reward, rewards)
print("Final reward ...")
print(list(np.round(rewards.flatten(), 4)))
self.rollout_buffer.clear_render_arrays()
self.rollout_buffer.rewards = rewards
def collect_rollouts(
self,
env: VecEnv,
callback: BaseCallback,
rollout_buffer: CLIPRolloutBuffer,
n_rollout_steps: int,
) -> bool:
"""
Collect experiences using the current policy and fill a ``RolloutBuffer``.
The term rollout here refers to the model-free notion and should not
be used with the concept of rollout used in model-based RL or planning.
:param env: The training environment
:param callback: Callback that will be called at each step
(and at the beginning and end of the rollout)
:param rollout_buffer: Buffer to fill with rollouts
:param n_rollout_steps: Number of experiences to collect per environment
:return: True if function returned with at least `n_rollout_steps`
collected, False if callback terminated rollout prematurely.
"""
assert self._last_obs is not None, "No previous observation was provided"
# Switch to eval mode (this affects batch norm / dropout)
self.policy.set_training_mode(False)
n_steps = 0
rollout_buffer.reset()
# Sample new weights for the state dependent exploration
if self.use_sde:
self.policy.reset_noise(env.num_envs)
callback.on_rollout_start()
while n_steps < n_rollout_steps:
if self.use_sde and self.sde_sample_freq > 0 and n_steps % self.sde_sample_freq == 0:
# Sample a new noise matrix
self.policy.reset_noise(env.num_envs)
with th.no_grad():
# Convert to pytorch tensor or to TensorDict
obs_tensor = obs_as_tensor(self._last_obs, self.device)
actions, values, log_probs = self.policy(obs_tensor)
actions = actions.cpu().numpy()
# Rescale and perform action
clipped_actions = actions
# Clip the actions to avoid out of bound error
if isinstance(self.action_space, spaces.Box):
clipped_actions = np.clip(actions, self.action_space.low, self.action_space.high)
new_obs, rewards, dones, infos = env.step(clipped_actions)
self.num_timesteps += env.num_envs
# Give access to local variables
callback.update_locals(locals())
if callback.on_step() is False:
return False
self._update_info_buffer(infos)
n_steps += 1
if isinstance(self.action_space, spaces.Discrete):
# Reshape in case of discrete action
actions = actions.reshape(-1, 1)
# Handle timeout by bootstraping with value function
# see GitHub issue #633
for idx, done in enumerate(dones):
if (
done
and infos[idx].get("terminal_observation") is not None
and infos[idx].get("TimeLimit.truncated", False)
):
terminal_obs = self.policy.obs_to_tensor(infos[idx]["terminal_observation"])[0]
with th.no_grad():
terminal_value = self.policy.predict_values(terminal_obs)[0]
rewards[idx] += self.gamma * terminal_value
rollout_buffer.add(self._last_obs, actions, rewards, self._last_episode_starts, values, log_probs, infos)
self._last_obs = new_obs
self._last_episode_starts = dones
with th.no_grad():
# Compute value for the last timestep
values = self.policy.predict_values(obs_as_tensor(new_obs, self.device))
if not self.inference_only:
self._compute_clip_rewards()
rollout_buffer.compute_returns_and_advantage(last_values=values, dones=dones)
callback.on_rollout_end()
return True
def _log(self) -> None:
time_elapsed = max(
(time.time_ns() - self.start_time) / 1e9, sys.float_info.epsilon
)
fps = int((self.num_timesteps - self._num_timesteps_at_start) / time_elapsed)
self.logger.record("time/episodes", self._episode_num, exclude="tensorboard")
if len(self.ep_info_buffer) > 0 and len(self.ep_info_buffer[0]) > 0:
self.logger.record(
"rollout/ep_gt_rew_mean",
safe_mean([ep_info["r"] for ep_info in self.ep_info_buffer]),
)
self.logger.record(
"rollout/ep_len_mean",
safe_mean([ep_info["l"] for ep_info in self.ep_info_buffer]),
)
self.logger.record("time/fps", fps)
self.logger.record(
"time/time_elapsed", int(time_elapsed), exclude="tensorboard"
)
self.logger.record(
"time/total_timesteps", self.num_timesteps, exclude="tensorboard"
)
if self.use_sde:
self.logger.record("train/std", (self.actor.get_std()).mean().item())
if len(self.ep_success_buffer) > 0:
self.logger.record(
"rollout/success_rate", safe_mean(self.ep_success_buffer)
)
# Pass the number of timesteps for tensorboard
self.logger.dump(step=self.num_timesteps)
def train(self) -> None:
self._log()
super().train()
def _setup_learn(
self,
total_timesteps: int,
callback: MaybeCallback = None,
reset_num_timesteps: bool = True,
*args,
) -> Tuple[int, BaseCallback]:
total_timesteps, callback = super()._setup_learn(
total_timesteps,
callback,
reset_num_timesteps,
*args,
)
if self.ep_clip_info_buffer is None or reset_num_timesteps:
self.ep_clip_info_buffer = deque(maxlen=100)
return total_timesteps, callback
def learn(self: SelfCLIPRewardedPPO, *args, **kwargs) -> SelfCLIPRewardedPPO:
assert not self.inference_only
return super().learn(*args, **kwargs)
def save(self, *args, **kwargs) -> None: # type: ignore
super().save(*args, exclude=["reward_model", "worker_frames_tensor"], **kwargs)
@classmethod
def load(
cls: Type[SelfCLIPRewardedPPO],
path: Union[str, pathlib.Path],
*,
env: Optional[VecEnv] = None,
load_clip: bool = True,
device: Union[torch.device, str] = "cuda:0",
custom_objects: Optional[Dict[str, Any]] = None,
force_reset: bool = True,
**kwargs,
) -> SelfCLIPRewardedPPO:
data, params, pytorch_variables = load_from_zip_file(
path,
device=device,
custom_objects=custom_objects,
)
assert data is not None, "No data found in the saved file"
assert params is not None, "No params found in the saved file"
# Remove stored device information and replace with ours
if "policy_kwargs" in data:
if "device" in data["policy_kwargs"]:
del data["policy_kwargs"]["device"]
# backward compatibility, convert to new format
if (
"net_arch" in data["policy_kwargs"]
and len(data["policy_kwargs"]["net_arch"]) > 0
):
saved_net_arch = data["policy_kwargs"]["net_arch"]
if isinstance(saved_net_arch, list) and isinstance(
saved_net_arch[0], dict
):
data["policy_kwargs"]["net_arch"] = saved_net_arch[0]
if (
"policy_kwargs" in kwargs
and kwargs["policy_kwargs"] != data["policy_kwargs"]
):
raise ValueError(
f"The specified policy kwargs do not equal the stored policy kwargs."
f"Stored kwargs: {data['policy_kwargs']}, "
f"specified kwargs: {kwargs['policy_kwargs']}"
)
if "observation_space" not in data or "action_space" not in data:
raise KeyError(
"The observation_space and action_space were not given, can't verify "
"new environments."
)
# Gym -> Gymnasium space conversion
for key in {"observation_space", "action_space"}:
data[key] = _convert_space(
data[key]
) # pytype: disable=unsupported-operands
if env is not None:
# Wrap first if needed
env = cls._wrap_env(env, data["verbose"])
# Check if given env is valid
check_for_correct_spaces(
env, data["observation_space"], data["action_space"]
)
# Discard `_last_obs`, this will force the env to reset before training
# See issue https://github.com/DLR-RM/stable-baselines3/issues/597
if force_reset and data is not None:
data["_last_obs"] = None
# `n_envs` must be updated.
# See issue https://github.com/DLR-RM/stable-baselines3/issues/1018
if data is not None:
data["n_envs"] = env.num_envs
else:
# Use stored env, if one exists. If not, continue as is (can be used for
# predict)
if "env" in data:
env = data["env"]
# Ensure the config has the necessary structure
if "config" not in data:
data["config"] = Box(default_box=True)
if not hasattr(data["config"], "action_noise"):
data["config"].action_noise = None
# pytype: disable=not-instantiable,wrong-keyword-args
# use current device
data["config"].algorithm_params.device = device
model = cls(
env=env,
config=data["config"],
inference_only=not load_clip,
)
# pytype: enable=not-instantiable,wrong-keyword-args
# load parameters
model.__dict__.update(data)
model.__dict__.update(kwargs)
model._setup_model()
try:
# put state_dicts back in place
model.set_parameters(params, exact_match=True, device=device)
except RuntimeError as e:
# Patch to load Policy saved using SB3 < 1.7.0
# the error is probably due to old policy being loaded
# See https://github.com/DLR-RM/stable-baselines3/issues/1233
if "pi_features_extractor" in str(
e
) and "Missing key(s) in state_dict" in str(e):
model.set_parameters(params, exact_match=False, device=device)
warnings.warn(
"You are probably loading a model saved with SB3 < 1.7.0, "
"we deactivated exact_match so you can save the model "
"again to avoid issues in the future "
"(see https://github.com/DLR-RM/stable-baselines3/issues/1233 for "
f"more info). Original error: {e} \n"
"Note: the model should still work fine, this only a warning."
)
else:
raise e
# put other pytorch variables back in place
if pytorch_variables is not None:
for name in pytorch_variables:
# Skip if PyTorch variable was not defined (to ensure backward
# compatibility). This happens when using SAC/TQC.
# SAC has an entropy coefficient which can be fixed or optimized.
# If it is optimized, an additional PyTorch variable `log_ent_coef` is
# defined, otherwise it is initialized to `None`.
if pytorch_variables[name] is None:
continue
# Set the data attribute directly to avoid issue when using optimizers
# See https://github.com/DLR-RM/stable-baselines3/issues/391
recursive_setattr(model, f"{name}.data", pytorch_variables[name].data)
# Sample gSDE exploration matrix, so it uses the right device
# see issue #44
if model.use_sde:
model.policy.reset_noise()
if load_clip:
model._load_modules()
return model
================================================
FILE: clip/clip_rewarded_sac.py
================================================
import pathlib
import sys
import time
import warnings
from collections import deque
from typing import Optional, Tuple, TypeVar, Type, Union, Dict, Any
import numpy as np
import open_clip
import stable_baselines3.common.noise as sb3_noise
import torch
from box import Box
from stable_baselines3 import SAC
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.save_util import recursive_setattr, load_from_zip_file
from stable_baselines3.common.type_aliases import MaybeCallback, RolloutReturn
from stable_baselines3.common.utils import safe_mean, check_for_correct_spaces
from stable_baselines3.common.vec_env import VecEnv
from stable_baselines3.common.vec_env.patch_gym import _convert_space
from clip.clip_buffer import CLIPReplayBuffer
from clip.clip_reward_model import compute_rewards, CLIPEmbed, CLIPReward
from config import CONFIG
SelfCLIPRewardedSAC = TypeVar("SelfCLIPRewardedSAC", bound="CLIPRewardedSAC")
class CLIPRewardedSAC(SAC):
replay_buffer: CLIPReplayBuffer
def __init__(
self,
*,
env: VecEnv,
config: Box,
inference_only: bool = False,
):
self.config = config
if config.action_noise:
mean = config.action_noise.mean * np.ones(env.action_space.shape)
sigma = config.action_noise.sigma * np.ones(env.action_space.shape)
if config.action_noise.name == "NormalActionNoise":
action_noise = sb3_noise.NormalActionNoise(mean=mean, sigma=sigma)
elif config.action_noise.name == "OrnsteinUhlenbeckActionNoise":
action_noise = sb3_noise.OrnsteinUhlenbeckActionNoise(
mean=mean,
sigma=sigma,
theta=config.action_noise.theta,
dt=config.action_noise.dt,
)
else:
raise ValueError(
f"Unknown action noise name: {config.action_noise.name}"
)
else:
action_noise = None
super().__init__(
env=env,
policy='MultiInputPolicy',
replay_buffer_class=CLIPReplayBuffer,
tensorboard_log='tensorboard',
seed=config.seed,
action_noise=action_noise,
**self.config.algorithm_params,
)
self.ep_clip_info_buffer = None # type: Optional[deque]
self.inference_only = inference_only
if not self.inference_only:
self._load_modules()
self.previous_num_timesteps = 0
self.previous_num_episodes = 0
def _dump_logs(self) -> None:
pass
def _load_modules(self):
model_name_prefix, pretrained = self.config.clip_reward_params.pretrained_model.split("/")
clip_model = open_clip.create_model(
model_name=model_name_prefix, pretrained=pretrained # , cache_dir=cache_dir
)
clip_model = CLIPEmbed(clip_model)
target_prompts = CLIPReward.tokenize_prompts(self.config.clip_reward_params.target_prompts)
baseline_prompts = CLIPReward.tokenize_prompts(self.config.clip_reward_params.baseline_prompts)
clip_model = CLIPReward(
model=clip_model,
alpha=self.config.clip_reward_params.alpha,
target_prompts=target_prompts,
baseline_prompts=baseline_prompts,
)
self.reward_model = clip_model.eval().to(self.device)
def _compute_clip_rewards(self):
assert self.env is not None
replay_buffer_pos = self.replay_buffer.pos
total_timesteps = self.num_timesteps - self.previous_num_timesteps
env_episode_timesteps = total_timesteps // self.env.num_envs
frames = torch.from_numpy(np.array(self.replay_buffer.render_arrays)) # [64, height, width, 3]
# only use the right half
width = frames.shape[2]
left = width // 2
frames = frames[:, :, left:, :]
rewards0 = compute_rewards(
model=self.reward_model,
frames=frames,
batch_size=self.config.clip_reward_params.batch_size,
vlm_reward_type=self.config.vlm_reward_type,
)
rewards0 = rewards0.numpy().reshape(-1, 1)
print("Clip reward ...")
print(list(np.round(rewards0.flatten(), 4)))
base_reward = np.array(self.replay_buffer.base_rewards).reshape(-1, 1)
speeds = np.array(self.replay_buffer.speeds)
print("Speed ...")
print(list(np.round(speeds.flatten(), 4)))
if self.config.vlm_reward_type == "VLM-RL":
thre_min, thre_max = 0.0, 0.03
rewards0 = np.clip(rewards0, a_min=thre_min, a_max=thre_max)
rewards0 = 1 - (rewards0 - thre_min) / (thre_max - thre_min)
centering_factors = np.array(self.replay_buffer.centering_factors)
angle_factors = np.array(self.replay_buffer.angle_factors)
distance_std_factors = np.array(self.replay_buffer.distance_std_factors)
desired_speed = np.clip(rewards0.flatten(), 0.0, 1.0) * CONFIG.reward_params.target_speed
r_speeds = 1.0 - np.abs(speeds - desired_speed) / CONFIG.reward_params.target_speed
rewards = (r_speeds * centering_factors * angle_factors * distance_std_factors).reshape(-1, 1)
rewards = np.where(base_reward < 0, base_reward, rewards)
elif self.config.vlm_reward_type == "LORD-Speed":
lord_speed_r = 1.0 - np.abs(speeds - 20.0) / 20.0
rewards = rewards0 + lord_speed_r.reshape(-1, 1)
elif self.config.vlm_reward_type == "VLM-SR":
rewards = np.where(rewards0 > 0.32, 1, -1)
else:
rewards = rewards0
print("Final reward ...")
print(list(np.round(rewards.flatten(), 4)))
self.replay_buffer.clear_render_arrays()
if not self.inference_only:
if replay_buffer_pos - env_episode_timesteps >= 0:
self.replay_buffer.rewards[
replay_buffer_pos - env_episode_timesteps: replay_buffer_pos
] = rewards
else:
self.replay_buffer.rewards[
-(env_episode_timesteps - replay_buffer_pos):
] = rewards[: env_episode_timesteps - replay_buffer_pos]
self.replay_buffer.rewards[:replay_buffer_pos] = rewards[
env_episode_timesteps - replay_buffer_pos:
]
def collect_rollouts(self, *args, **kwargs) -> RolloutReturn:
rollout = super().collect_rollouts(*args, **kwargs)
if not self.inference_only:
self._compute_clip_rewards()
self.previous_num_timesteps = self.num_timesteps
self.previous_num_episodes = self._episode_num
return rollout
def _log(self) -> None:
time_elapsed = max(
(time.time_ns() - self.start_time) / 1e9, sys.float_info.epsilon
)
fps = int((self.num_timesteps - self._num_timesteps_at_start) / time_elapsed)
self.logger.record("time/episodes", self._episode_num, exclude="tensorboard")
if len(self.ep_info_buffer) > 0 and len(self.ep_info_buffer[0]) > 0:
self.logger.record(
"rollout/ep_gt_rew_mean",
safe_mean([ep_info["r"] for ep_info in self.ep_info_buffer]),
)
self.logger.record(
"rollout/ep_len_mean",
safe_mean([ep_info["l"] for ep_info in self.ep_info_buffer]),
)
self.logger.record("time/fps", fps)
self.logger.record(
"time/time_elapsed", int(time_elapsed), exclude="tensorboard"
)
self.logger.record(
"time/total_timesteps", self.num_timesteps, exclude="tensorboard"
)
if self.use_sde:
self.logger.record("train/std", (self.actor.get_std()).mean().item())
if len(self.ep_success_buffer) > 0:
self.logger.record(
"rollout/success_rate", safe_mean(self.ep_success_buffer)
)
# Pass the number of timesteps for tensorboard
self.logger.dump(step=self.num_timesteps)
def train(self, gradient_steps: int, batch_size: int = 100) -> None:
self._log()
super().train(gradient_steps, batch_size)
def _setup_learn(
self,
total_timesteps: int,
callback: MaybeCallback = None,
reset_num_timesteps: bool = True,
*args,
) -> Tuple[int, BaseCallback]:
total_timesteps, callback = super()._setup_learn(
total_timesteps,
callback,
reset_num_timesteps,
*args,
)
if self.ep_clip_info_buffer is None or reset_num_timesteps:
self.ep_clip_info_buffer = deque(maxlen=100)
return total_timesteps, callback
def learn(self: SelfCLIPRewardedSAC, *args, **kwargs) -> SelfCLIPRewardedSAC:
assert not self.inference_only
self.previous_num_timesteps = 0
self.previous_num_episodes = 0
return super().learn(*args, **kwargs)
def save(self, *args, **kwargs) -> None: # type: ignore
super().save(*args, exclude=["reward_model", "worker_frames_tensor"], **kwargs)
@classmethod
def load(
cls: Type[SelfCLIPRewardedSAC],
path: Union[str, pathlib.Path],
*,
env: Optional[VecEnv] = None,
load_clip: bool = True,
device: Union[torch.device, str] = "cuda:0",
custom_objects: Optional[Dict[str, Any]] = None,
force_reset: bool = True,
**kwargs,
) -> SelfCLIPRewardedSAC:
data, params, pytorch_variables = load_from_zip_file(
path,
device=device,
custom_objects=custom_objects,
)
assert data is not None, "No data found in the saved file"
assert params is not None, "No params found in the saved file"
# Remove stored device information and replace with ours
if "policy_kwargs" in data:
if "device" in data["policy_kwargs"]:
del data["policy_kwargs"]["device"]
# backward compatibility, convert to new format
if (
"net_arch" in data["policy_kwargs"]
and len(data["policy_kwargs"]["net_arch"]) > 0
):
saved_net_arch = data["policy_kwargs"]["net_arch"]
if isinstance(saved_net_arch, list) and isinstance(
saved_net_arch[0], dict
):
data["policy_kwargs"]["net_arch"] = saved_net_arch[0]
if (
"policy_kwargs" in kwargs
and kwargs["policy_kwargs"] != data["policy_kwargs"]
):
raise ValueError(
f"The specified policy kwargs do not equal the stored policy kwargs."
f"Stored kwargs: {data['policy_kwargs']}, "
f"specified kwargs: {kwargs['policy_kwargs']}"
)
if "observation_space" not in data or "action_space" not in data:
raise KeyError(
"The observation_space and action_space were not given, can't verify "
"new environments."
)
# Gym -> Gymnasium space conversion
for key in {"observation_space", "action_space"}:
data[key] = _convert_space(
data[key]
) # pytype: disable=unsupported-operands
if env is not None:
# Wrap first if needed
env = cls._wrap_env(env, data["verbose"])
# Check if given env is valid
check_for_correct_spaces(
env, data["observation_space"], data["action_space"]
)
# Discard `_last_obs`, this will force the env to reset before training
# See issue https://github.com/DLR-RM/stable-baselines3/issues/597
if force_reset and data is not None:
data["_last_obs"] = None
# `n_envs` must be updated.
# See issue https://github.com/DLR-RM/stable-baselines3/issues/1018
if data is not None:
data["n_envs"] = env.num_envs
else:
# Use stored env, if one exists. If not, continue as is (can be used for
# predict)
if "env" in data:
env = data["env"]
# Ensure the config has the necessary structure
if "config" not in data:
data["config"] = Box(default_box=True)
if not hasattr(data["config"], "action_noise"):
data["config"].action_noise = None
# pytype: disable=not-instantiable,wrong-keyword-args
# use current device
data["config"].algorithm_params.device = device
model = cls(
env=env,
config=data["config"],
inference_only=not load_clip,
)
# pytype: enable=not-instantiable,wrong-keyword-args
# load parameters
mode
gitextract_wbtls8qs/ ├── LICENSE ├── README.md ├── carla_env/ │ ├── __init__.py │ ├── envs/ │ │ ├── Town01.h5 │ │ ├── Town02.h5 │ │ ├── Town03.h5 │ │ ├── Town04.h5 │ │ ├── Town05.h5 │ │ ├── Town06.h5 │ │ └── carla_route_env.py │ ├── navigation/ │ │ ├── __init__.py │ │ ├── agent.py │ │ ├── basic_agent.py │ │ ├── controller.py │ │ ├── global_route_planner.py │ │ ├── global_route_planner_dao.py │ │ ├── local_planner.py │ │ ├── planner.py │ │ └── roaming_agent.py │ ├── rewards.py │ ├── state_commons.py │ ├── tools/ │ │ ├── __init__.py │ │ ├── hud.py │ │ └── misc.py │ └── wrappers.py ├── clip/ │ ├── __init__.py │ ├── clip_buffer.py │ ├── clip_reward_model.py │ ├── clip_rewarded_ppo.py │ ├── clip_rewarded_sac.py │ └── transform.py ├── config.py ├── eval.py ├── eval_plots.py ├── requirements.txt ├── run_eval.py ├── train.py └── utils.py
SYMBOL INDEX (255 symbols across 24 files)
FILE: carla_env/envs/carla_route_env.py
function tint (line 42) | def tint(color, factor):
function random_choice_from_blueprint (line 93) | def random_choice_from_blueprint(blueprint):
class CarlaRouteEnv (line 98) | class CarlaRouteEnv(gym.Env):
method __init__ (line 103) | def __init__(self, host="127.0.0.1", port=2000,
method reset (line 265) | def reset(self, is_training=False):
method new_route (line 303) | def new_route(self):
method close (line 352) | def close(self):
method render (line 364) | def render(self, mode="human"):
method step (line 424) | def step(self, action):
method _draw_path_server (line 568) | def _draw_path_server(self, life_time=60.0, skip=0):
method _draw_path (line 593) | def _draw_path(self, camera, image):
method _get_observation (line 620) | def _get_observation(self):
method _get_viewer_image (line 627) | def _get_viewer_image(self):
method _get_bev_spectator_data (line 634) | def _get_bev_spectator_data(self):
method _get_bev_data (line 641) | def _get_bev_data(self):
method _on_collision (line 648) | def _on_collision(self, event):
method _on_invasion (line 656) | def _on_invasion(self, event):
method _set_observation_image (line 662) | def _set_observation_image(self, image):
method _set_viewer_image (line 665) | def _set_viewer_image(self, image):
method _set_bev_spectator_data (line 668) | def _set_bev_spectator_data(self, image):
method _set_bev_data (line 671) | def _set_bev_data(self, image):
method _get_observation_seg_bev (line 674) | def _get_observation_seg_bev(self):
method _get_surrounding_actors (line 743) | def _get_surrounding_actors(bbox_list, criterium, scale=None):
method _get_warp_transform (line 758) | def _get_warp_transform(self, ev_loc, ev_rot):
method _world_to_pixel (line 777) | def _world_to_pixel(self, location, projective=False):
method _get_history_masks (line 788) | def _get_history_masks(self, M_warp):
method _get_mask_from_actor_list (line 801) | def _get_mask_from_actor_list(self, actor_list, M_warp):
FILE: carla_env/navigation/agent.py
class AgentState (line 19) | class AgentState(Enum):
class Agent (line 28) | class Agent(object):
method __init__ (line 33) | def __init__(self, vehicle):
method run_step (line 45) | def run_step(self, debug=False):
method _is_light_red (line 61) | def _is_light_red(self, lights_list):
method _is_light_red_europe_style (line 78) | def _is_light_red_europe_style(self, lights_list):
method _is_light_red_us_style (line 107) | def _is_light_red_us_style(self, lights_list, debug=False):
method _is_vehicle_hazard (line 155) | def _is_vehicle_hazard(self, vehicle_list):
method emergency_stop (line 195) | def emergency_stop(self):
FILE: carla_env/navigation/basic_agent.py
class BasicAgent (line 20) | class BasicAgent(Agent):
method __init__ (line 26) | def __init__(self, vehicle, target_speed=20):
method set_destination (line 49) | def set_destination(self, location):
method _trace_route (line 64) | def _trace_route(self, start_waypoint, end_waypoint):
method run_step (line 84) | def run_step(self, debug=False):
FILE: carla_env/navigation/controller.py
class VehiclePIDController (line 20) | class VehiclePIDController():
method __init__ (line 26) | def __init__(self, vehicle, args_lateral=None, args_longitudinal=None):
method run_step (line 49) | def run_step(self, target_speed, waypoint):
class PIDLongitudinalController (line 71) | class PIDLongitudinalController():
method __init__ (line 76) | def __init__(self, vehicle, K_P=1.0, K_D=0.0, K_I=0.0, dt=0.03):
method run_step (line 91) | def run_step(self, target_speed, debug=False):
method _pid_control (line 105) | def _pid_control(self, target_speed, current_speed):
class PIDLateralController (line 126) | class PIDLateralController():
method __init__ (line 131) | def __init__(self, vehicle, K_P=1.0, K_D=0.0, K_I=0.0, dt=0.03):
method run_step (line 146) | def run_step(self, waypoint):
method _pid_control (line 157) | def _pid_control(self, waypoint, vehicle_transform):
FILE: carla_env/navigation/global_route_planner.py
class GlobalRoutePlanner (line 18) | class GlobalRoutePlanner(object):
method __init__ (line 25) | def __init__(self, dao):
method setup (line 37) | def setup(self):
method _build_graph (line 47) | def _build_graph(self):
method _find_loose_ends (line 105) | def _find_loose_ends(self):
method _localize (line 149) | def _localize(self, location):
method _lane_change_link (line 169) | def _lane_change_link(self):
method _distance_heuristic (line 212) | def _distance_heuristic(self, n1, n2):
method _path_search (line 221) | def _path_search(self, origin, destination):
method _successive_last_intersection_edge (line 239) | def _successive_last_intersection_edge(self, index, route):
method _turn_decision (line 263) | def _turn_decision(self, index, route, threshold=math.radians(5)):
method abstract_route_plan (line 324) | def abstract_route_plan(self, origin, destination):
method _find_closest_in_list (line 344) | def _find_closest_in_list(self, current_waypoint, waypoint_list):
method trace_route (line 356) | def trace_route(self, origin, destination):
FILE: carla_env/navigation/global_route_planner_dao.py
class GlobalRoutePlannerDAO (line 11) | class GlobalRoutePlannerDAO(object):
method __init__ (line 17) | def __init__(self, wmap, sampling_resolution=1):
method get_topology (line 26) | def get_topology(self):
method get_waypoint (line 64) | def get_waypoint(self, location):
method get_resolution (line 71) | def get_resolution(self):
FILE: carla_env/navigation/local_planner.py
class RoadOption (line 20) | class RoadOption(Enum):
method __eq__ (line 32) | def __eq__(self, other):
class LocalPlanner (line 36) | class LocalPlanner(object):
method __init__ (line 49) | def __init__(self, vehicle, opt_dict=None):
method __del__ (line 87) | def __del__(self):
method reset_vehicle (line 92) | def reset_vehicle(self):
method _init_controller (line 96) | def _init_controller(self, opt_dict):
method set_speed (line 147) | def set_speed(self, speed):
method _compute_next_waypoints (line 156) | def _compute_next_waypoints(self, k=1):
method set_global_plan (line 185) | def set_global_plan(self, current_plan):
method run_step (line 192) | def run_step(self, debug=True):
function _retrieve_options (line 249) | def _retrieve_options(list_waypoints, current_waypoint):
function _compute_connection (line 271) | def _compute_connection(current_waypoint, next_waypoint):
FILE: carla_env/navigation/planner.py
function compute_route_waypoints (line 12) | def compute_route_waypoints(world_map, start_waypoint, end_waypoint, res...
FILE: carla_env/navigation/roaming_agent.py
class RoamingAgent (line 16) | class RoamingAgent(Agent):
method __init__ (line 24) | def __init__(self, vehicle):
method run_step (line 34) | def run_step(self, debug=False):
FILE: carla_env/rewards.py
function create_reward_fn (line 19) | def create_reward_fn(reward_fn):
function reward_fn_revolve (line 65) | def reward_fn_revolve(env):
function reward_fn_revolve_auto (line 129) | def reward_fn_revolve_auto(env):
function reward_fn_chatscene (line 214) | def reward_fn_chatscene(env):
function reward_fn_simple (line 274) | def reward_fn_simple(env):
function reward_fn5 (line 287) | def reward_fn5(env):
function reward_fn_Chen (line 323) | def reward_fn_Chen(env):
function reward_fn_ASAP (line 366) | def reward_fn_ASAP(env):
FILE: carla_env/state_commons.py
function preprocess_frame (line 12) | def preprocess_frame(frame):
function create_encode_state_fn (line 20) | def create_encode_state_fn(measurements_to_include, CONFIG, vae=None):
FILE: carla_env/tools/hud.py
class HUD (line 34) | class HUD(object):
method __init__ (line 39) | def __init__(self, width, height):
method set_vehicle (line 62) | def set_vehicle(self, vehicle):
method tick (line 65) | def tick(self, world, clock):
method render (line 109) | def render(self, display, extra_info=[]):
method on_world_tick (line 149) | def on_world_tick(self, timestamp):
method toggle_info (line 156) | def toggle_info(self):
method notification (line 159) | def notification(self, text, seconds=2.0):
method error (line 162) | def error(self, text):
class FadingText (line 170) | class FadingText(object):
method __init__ (line 171) | def __init__(self, font, dim, pos):
method set_text (line 178) | def set_text(self, text, color=(255, 255, 255), seconds=2.0):
method tick (line 185) | def tick(self, _, clock):
method render (line 190) | def render(self, display):
class HelpText (line 198) | class HelpText(object):
method __init__ (line 199) | def __init__(self, font, width, height):
method toggle (line 213) | def toggle(self):
method render (line 216) | def render(self, display):
FILE: carla_env/tools/misc.py
function draw_waypoints (line 18) | def draw_waypoints(world, waypoints, z=0.5):
function get_speed (line 35) | def get_speed(vehicle):
function is_within_distance_ahead (line 45) | def is_within_distance_ahead(target_location, current_location, orientat...
function compute_magnitude_angle (line 72) | def compute_magnitude_angle(target_location, current_location, orientati...
function distance_vehicle (line 90) | def distance_vehicle(waypoint, vehicle_transform):
function vector (line 98) | def vector(location_1, location_2):
FILE: carla_env/wrappers.py
function get_actor_display_name (line 6) | def get_actor_display_name(actor, truncate=250):
function get_displacement_vector (line 11) | def get_displacement_vector(car_pos, waypoint_pos, theta):
function angle_diff (line 44) | def angle_diff(v0, v1):
function distance_to_line (line 71) | def distance_to_line(A, B, p):
function vector (line 80) | def vector(v):
function smooth_action (line 88) | def smooth_action(old_value, new_value, smooth_factor):
function build_projection_matrix (line 92) | def build_projection_matrix(w, h, fov):
function get_image_point (line 101) | def get_image_point(loc, K, w2c):
class CarlaActorBase (line 137) | class CarlaActorBase(object):
method __init__ (line 138) | def __init__(self, world, actor):
method destroy (line 144) | def destroy(self):
method get_carla_actor (line 153) | def get_carla_actor(self):
method tick (line 156) | def tick(self):
method __getattr__ (line 159) | def __getattr__(self, name):
class Lidar (line 168) | class Lidar(CarlaActorBase):
method __init__ (line 169) | def __init__(self, world, width=120, height=120, transform=carla.Trans...
method process_lidar_input (line 194) | def process_lidar_input(weak_self, raw):
class CollisionSensor (line 229) | class CollisionSensor(CarlaActorBase):
method __init__ (line 230) | def __init__(self, world, vehicle, on_collision_fn):
method on_collision (line 247) | def on_collision(weak_self, event):
class LaneInvasionSensor (line 261) | class LaneInvasionSensor(CarlaActorBase):
method __init__ (line 262) | def __init__(self, world, vehicle, on_invasion_fn):
method on_invasion (line 276) | def on_invasion(weak_self, event):
class Camera (line 290) | class Camera(CarlaActorBase):
method __init__ (line 291) | def __init__(self, world, width, height, transform=carla.Transform(),
method process_camera_input (line 314) | def process_camera_input(weak_self, image):
method destroy (line 354) | def destroy(self):
class Vehicle (line 362) | class Vehicle(CarlaActorBase):
method __init__ (line 363) | def __init__(self, world, transform=carla.Transform(),
method tick (line 390) | def tick(self):
method get_speed (line 393) | def get_speed(self):
method get_angle (line 400) | def get_angle(self, waypoint):
method get_closest_waypoint (line 405) | def get_closest_waypoint(self):
method set_autopilot (line 408) | def set_autopilot(self, is_true, *args, **kwargs):
class World (line 417) | class World():
method __init__ (line 418) | def __init__(self, client, town='Town02'):
method tick (line 423) | def tick(self):
method destroy (line 429) | def destroy(self):
method get_carla_world (line 434) | def get_carla_world(self):
method __getattr__ (line 437) | def __getattr__(self, name):
FILE: clip/clip_buffer.py
class CLIPReplayBuffer (line 8) | class CLIPReplayBuffer(DictReplayBuffer):
method __init__ (line 9) | def __init__(
method add (line 35) | def add(
method clear_render_arrays (line 60) | def clear_render_arrays(self) -> None:
class CLIPRolloutBuffer (line 69) | class CLIPRolloutBuffer(DictRolloutBuffer):
method __init__ (line 70) | def __init__(
method add (line 96) | def add(
method clear_render_arrays (line 122) | def clear_render_arrays(self) -> None:
FILE: clip/clip_reward_model.py
class CLIPEmbed (line 11) | class CLIPEmbed(nn.Module):
method __init__ (line 12) | def __init__(self, clip_model):
method forward (line 22) | def forward(self, x):
class CLIPReward (line 32) | class CLIPReward(nn.Module):
method __init__ (line 33) | def __init__(
method compute_projection (line 55) | def compute_projection(self, alpha: float, direction) -> torch.Tensor:
method forward (line 62) | def forward(self, x: torch.Tensor, vlm_reward_type: str) -> torch.Tensor:
method forward_vlm_rl (line 75) | def forward_vlm_rl(self, x: torch.Tensor) -> torch.Tensor:
method forward_lord (line 82) | def forward_lord(self, x: torch.Tensor) -> torch.Tensor:
method forward_vlm_rm (line 89) | def forward_vlm_rm(self, x: torch.Tensor) -> torch.Tensor:
method forward_vlm_sr (line 95) | def forward_vlm_sr(self, x: torch.Tensor) -> torch.Tensor:
method get_pos_neg (line 101) | def get_pos_neg(self, x: torch.Tensor):
method tokenize_prompts (line 107) | def tokenize_prompts(x: List[str]) -> torch.Tensor:
method embed_prompts (line 111) | def embed_prompts(self, x) -> torch.Tensor:
method embed_images (line 118) | def embed_images(self, x):
function compute_rewards (line 122) | def compute_rewards(
FILE: clip/clip_rewarded_ppo.py
class CLIPRewardedPPO (line 31) | class CLIPRewardedPPO(PPO):
method __init__ (line 34) | def __init__(
method _dump_logs (line 57) | def _dump_logs(self) -> None:
method _setup_model (line 60) | def _setup_model(self):
method _load_modules (line 72) | def _load_modules(self):
method _compute_clip_rewards (line 89) | def _compute_clip_rewards(self) -> None:
method collect_rollouts (line 135) | def collect_rollouts(
method _log (line 230) | def _log(self) -> None:
method train (line 262) | def train(self) -> None:
method _setup_learn (line 266) | def _setup_learn(
method learn (line 283) | def learn(self: SelfCLIPRewardedPPO, *args, **kwargs) -> SelfCLIPRewar...
method save (line 287) | def save(self, *args, **kwargs) -> None: # type: ignore
method load (line 291) | def load(
FILE: clip/clip_rewarded_sac.py
class CLIPRewardedSAC (line 29) | class CLIPRewardedSAC(SAC):
method __init__ (line 32) | def __init__(
method _dump_logs (line 77) | def _dump_logs(self) -> None:
method _load_modules (line 80) | def _load_modules(self):
method _compute_clip_rewards (line 97) | def _compute_clip_rewards(self):
method collect_rollouts (line 159) | def collect_rollouts(self, *args, **kwargs) -> RolloutReturn:
method _log (line 167) | def _log(self) -> None:
method train (line 199) | def train(self, gradient_steps: int, batch_size: int = 100) -> None:
method _setup_learn (line 203) | def _setup_learn(
method learn (line 220) | def learn(self: SelfCLIPRewardedSAC, *args, **kwargs) -> SelfCLIPRewar...
method save (line 226) | def save(self, *args, **kwargs) -> None: # type: ignore
method load (line 231) | def load(
FILE: clip/transform.py
function image_transform (line 16) | def image_transform(
FILE: config.py
class CustomCNN (line 14) | class CustomCNN(nn.Module):
method __init__ (line 15) | def __init__(self, input_shape, features_dim=1):
method forward (line 54) | def forward(self, x):
class CustomMultiInputExtractor (line 60) | class CustomMultiInputExtractor(BaseFeaturesExtractor):
method __init__ (line 61) | def __init__(self, observation_space: gym.Space, features_dim: int = 2...
method forward (line 81) | def forward(self, observations) -> torch.Tensor:
function set_config (line 515) | def set_config(config_name):
FILE: eval.py
function convert_state (line 40) | def convert_state(state):
function run_eval (line 49) | def run_eval(env, model, model_path=None, record_video=False, eval_suffi...
FILE: eval_plots.py
function plot_eval (line 9) | def plot_eval(eval_csv_paths, output_name=None):
function summary_eval (line 102) | def summary_eval(eval_csv_path):
function eucldist (line 165) | def eucldist(x1, y1, x2, y2):
function main (line 169) | def main():
FILE: run_eval.py
function kill_carla (line 9) | def kill_carla():
FILE: utils.py
function write_json (line 12) | def write_json(data, path):
class VideoRecorder (line 28) | class VideoRecorder():
method __init__ (line 29) | def __init__(self, filename, frame_size, fps=30):
method add_frame (line 33) | def add_frame(self, frame):
method add_frame_with_reward (line 36) | def add_frame_with_reward(self, frame, reward):
method release (line 52) | def release(self):
method __del__ (line 55) | def __del__(self):
class HParamCallback (line 59) | class HParamCallback(BaseCallback):
method __init__ (line 60) | def __init__(self, config):
method _on_training_start (line 67) | def _on_training_start(self) -> None:
method _on_step (line 91) | def _on_step(self) -> bool:
class TensorboardCallback (line 95) | class TensorboardCallback(BaseCallback):
method __init__ (line 100) | def __init__(self, verbose=0):
method _on_step (line 103) | def _on_step(self) -> bool:
class VideoRecorderCallback (line 137) | class VideoRecorderCallback(BaseCallback):
method __init__ (line 138) | def __init__(self, video_path, frame_size, video_length=-1, fps=30, sk...
method _on_step (line 144) | def _on_step(self) -> bool:
method _on_training_end (line 158) | def _on_training_end(self) -> None:
function lr_schedule (line 162) | def lr_schedule(initial_value: float, end_value: float, rate: float):
class HistoryWrapperObsDict (line 191) | class HistoryWrapperObsDict(gym.Wrapper):
method __init__ (line 200) | def __init__(self, env: gym.Env, horizon: int = 2, obs_key: str = 'vae...
method _create_obs_from_history (line 228) | def _create_obs_from_history(self):
method reset (line 231) | def reset(self):
method step (line 243) | def step(self, action):
class FrameSkip (line 259) | class FrameSkip(gym.Wrapper):
method __init__ (line 266) | def __init__(self, env: gym.Env, skip: int = 4):
method step (line 271) | def step(self, action: np.ndarray):
method reset (line 288) | def reset(self):
function parse_wrapper_class (line 292) | def parse_wrapper_class(wrapper_class_str: str):
Condensed preview — 38 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (263K chars).
[
{
"path": "LICENSE",
"chars": 1060,
"preview": "MIT License\n\nCopyright (c) 2024 szh\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof thi"
},
{
"path": "README.md",
"chars": 12014,
"preview": "<div id=\"top\" align=\"center\">\n<p align=\"center\">\n <strong>\n <h2 align=\"center\">VLM-RL: A Unified Vision Language Mod"
},
{
"path": "carla_env/__init__.py",
"chars": 94,
"preview": "import os, sys\nsys.path.append(os.path.dirname(os.path.abspath(__file__)))\nfrom carla import *"
},
{
"path": "carla_env/envs/carla_route_env.py",
"chars": 35129,
"preview": "import os\nimport subprocess\nimport time\nimport gym\nimport h5py\nimport pygame\nimport cv2\nfrom pygame.locals import *\nimpo"
},
{
"path": "carla_env/navigation/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "carla_env/navigation/agent.py",
"chars": 8222,
"preview": "#!/usr/bin/env python\n\n# Copyright (c) 2018 Intel Labs.\n# authors: German Ros (german.ros@intel.com)\n#\n# This work is li"
},
{
"path": "carla_env/navigation/basic_agent.py",
"chars": 4241,
"preview": "#!/usr/bin/env python\n\n# Copyright (c) 2018 Intel Labs.\n# authors: German Ros (german.ros@intel.com)\n#\n# This work is li"
},
{
"path": "carla_env/navigation/controller.py",
"chars": 6875,
"preview": "#!/usr/bin/env python\n\n# Copyright (c) 2018 Intel Labs.\n# authors: German Ros (german.ros@intel.com)\n#\n# This work is li"
},
{
"path": "carla_env/navigation/global_route_planner.py",
"chars": 18570,
"preview": "# This work is licensed under the terms of the MIT license.\n# For a copy, see <https://opensource.org/licenses/MIT>.\n\n\"\""
},
{
"path": "carla_env/navigation/global_route_planner_dao.py",
"chars": 2883,
"preview": "# This work is licensed under the terms of the MIT license.\n# For a copy, see <https://opensource.org/licenses/MIT>.\n\n\"\""
},
{
"path": "carla_env/navigation/local_planner.py",
"chars": 10781,
"preview": "#!/usr/bin/env python\n\n# Copyright (c) 2018 Intel Labs.\n# authors: German Ros (german.ros@intel.com)\n#\n# This work is li"
},
{
"path": "carla_env/navigation/planner.py",
"chars": 5453,
"preview": "import numpy as np\n\n# ==============================================================================\n# -- import route p"
},
{
"path": "carla_env/navigation/roaming_agent.py",
"chars": 2458,
"preview": "#!/usr/bin/env python\n\n# Copyright (c) 2018 Intel Labs.\n# authors: German Ros (german.ros@intel.com)\n#\n# This work is li"
},
{
"path": "carla_env/rewards.py",
"chars": 15959,
"preview": "import math\n\nimport numpy as np\n\nfrom config import CONFIG\n\n\nmin_speed = CONFIG.reward_params.min_speed\nmax_speed = CONF"
},
{
"path": "carla_env/state_commons.py",
"chars": 5502,
"preview": "import torch\nfrom torchvision import transforms\n\nimport numpy as np\nimport gym\n\nfrom carla_env.wrappers import vector, g"
},
{
"path": "carla_env/tools/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "carla_env/tools/hud.py",
"chars": 8536,
"preview": "\"\"\"\nWelcome to CARLA manual control.\n\nUse ARROWS or WASD keys for control.\n\n W : throttle\n S "
},
{
"path": "carla_env/tools/misc.py",
"chars": 3687,
"preview": "#!/usr/bin/env python\n\n# Copyright (c) 2018 Intel Labs.\n# authors: German Ros (german.ros@intel.com)\n#\n# This work is li"
},
{
"path": "carla_env/wrappers.py",
"chars": 15954,
"preview": "import carla\nimport numpy as np\nimport weakref\n\n\ndef get_actor_display_name(actor, truncate=250):\n name = \" \".join(ac"
},
{
"path": "clip/__init__.py",
"chars": 74,
"preview": "import os, sys\nsys.path.append(os.path.dirname(os.path.abspath(__file__)))"
},
{
"path": "clip/clip_buffer.py",
"chars": 3989,
"preview": "import torch as th\nfrom gym import spaces\nfrom typing import Any, Dict, List, Union\nimport numpy as np\nfrom stable_basel"
},
{
"path": "clip/clip_reward_model.py",
"chars": 4989,
"preview": "from typing import List, Tuple\n\nimport open_clip\nimport torch\nimport torch.nn as nn\nfrom torch import Tensor\n\nfrom clip."
},
{
"path": "clip/clip_rewarded_ppo.py",
"chars": 17144,
"preview": "import pathlib\nimport sys\nimport time\nimport warnings\nfrom collections import deque\nfrom typing import Optional, Tuple, "
},
{
"path": "clip/clip_rewarded_sac.py",
"chars": 15461,
"preview": "import pathlib\nimport sys\nimport time\nimport warnings\nfrom collections import deque\nfrom typing import Optional, Tuple, "
},
{
"path": "clip/transform.py",
"chars": 1304,
"preview": "from typing import Optional, Tuple\n\nimport torch\n\nfrom torchvision.transforms import (\n Normalize,\n Compose,\n I"
},
{
"path": "config.py",
"chars": 15463,
"preview": "import torch as th\nfrom box import Box\nfrom stable_baselines3.common.noise import NormalActionNoise\nimport numpy as np\nf"
},
{
"path": "eval.py",
"chars": 9216,
"preview": "import os\nimport argparse\nimport pandas as pd\nimport numpy as np\nimport config\nfrom clip.clip_rewarded_ppo import CLIPRe"
},
{
"path": "eval_plots.py",
"chars": 8889,
"preview": "import os\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport argparse\n\n\ndef plot_eval(eval_c"
},
{
"path": "requirements.txt",
"chars": 209,
"preview": "carla==0.9.13\nnetworkx\npygame\ngym==0.23.0\ngymnasium==0.28.1\nstable-baselines3==2.0.0\nopen_clip_torch==2.20.0\nopencv-pyth"
},
{
"path": "run_eval.py",
"chars": 1878,
"preview": "import glob\nimport subprocess\nimport time\nimport os\n\nfrom tqdm import tqdm\n\n\ndef kill_carla():\n print(\"Killing Carla "
},
{
"path": "train.py",
"chars": 4164,
"preview": "import warnings\nimport os\nfrom datetime import datetime\n\nwarnings.filterwarnings(\"ignore\")\nos.environ['TF_CPP_MIN_LOG_LE"
},
{
"path": "utils.py",
"chars": 11749,
"preview": "import cv2\nimport math\nimport json\n\nimport gym\nimport numpy as np\nimport pygame\nfrom stable_baselines3.common.callbacks "
}
]
// ... and 6 more files (download for full content)
About this extraction
This page contains the full source code of the zihaosheng/VLM-RL GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 38 files (246.0 KB), approximately 59.7k tokens, and a symbol index with 255 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.