Showing preview only (609K chars total). Download the full file or copy to clipboard to get everything.
Repository: InterviewMap/CS-Interview-Knowledge-Map
Branch: master
Commit: 1de2dc983ea0
Files: 33
Total size: 589.8 KB
Directory structure:
gitextract_zczg9o2q/
├── .gitignore
├── Algorithm/
│ ├── algorithm-ch.md
│ └── algorithm-en.md
├── Browser/
│ ├── browser-ch.md
│ └── browser-en.md
├── Career/
│ └── How-to-use-your-time-correctly.md
├── DataStruct/
│ ├── dataStruct-en.md
│ └── dataStruct-zh.md
├── Framework/
│ ├── framework-br.md
│ ├── framework-en.md
│ ├── framework-zh.md
│ ├── react-br.md
│ ├── react-en.md
│ ├── react-zh.md
│ ├── vue-br.md
│ ├── vue-en.md
│ └── vue-zh.md
├── Git/
│ ├── git-en.md
│ └── git-zh.md
├── JS/
│ ├── JS-br.md
│ ├── JS-ch.md
│ └── JS-en.md
├── LICENSE
├── MP/
│ └── mp-ch.md
├── Network/
│ ├── Network-zh.md
│ └── Network_en.md
├── Performance/
│ ├── performance-ch.md
│ └── performance-en.md
├── README-EN.md
├── README.md
├── Safety/
│ ├── safety-cn.md
│ └── safety-en.md
└── log-zh.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.idea
test.js
.vscode/
================================================
FILE: Algorithm/algorithm-ch.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [时间复杂度](#%E6%97%B6%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6)
- [位运算](#%E4%BD%8D%E8%BF%90%E7%AE%97)
- [左移 <<](#%E5%B7%A6%E7%A7%BB-)
- [算数右移 >>](#%E7%AE%97%E6%95%B0%E5%8F%B3%E7%A7%BB-)
- [按位操作](#%E6%8C%89%E4%BD%8D%E6%93%8D%E4%BD%9C)
- [排序](#%E6%8E%92%E5%BA%8F)
- [冒泡排序](#%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F)
- [插入排序](#%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F)
- [选择排序](#%E9%80%89%E6%8B%A9%E6%8E%92%E5%BA%8F)
- [归并排序](#%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F)
- [快排](#%E5%BF%AB%E6%8E%92)
- [面试题](#%E9%9D%A2%E8%AF%95%E9%A2%98)
- [堆排序](#%E5%A0%86%E6%8E%92%E5%BA%8F)
- [系统自带排序实现](#%E7%B3%BB%E7%BB%9F%E8%87%AA%E5%B8%A6%E6%8E%92%E5%BA%8F%E5%AE%9E%E7%8E%B0)
- [链表](#%E9%93%BE%E8%A1%A8)
- [反转单向链表](#%E5%8F%8D%E8%BD%AC%E5%8D%95%E5%90%91%E9%93%BE%E8%A1%A8)
- [树](#%E6%A0%91)
- [二叉树的先序,中序,后序遍历](#%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E5%85%88%E5%BA%8F%E4%B8%AD%E5%BA%8F%E5%90%8E%E5%BA%8F%E9%81%8D%E5%8E%86)
- [递归实现](#%E9%80%92%E5%BD%92%E5%AE%9E%E7%8E%B0)
- [非递归实现](#%E9%9D%9E%E9%80%92%E5%BD%92%E5%AE%9E%E7%8E%B0)
- [中序遍历的前驱后继节点](#%E4%B8%AD%E5%BA%8F%E9%81%8D%E5%8E%86%E7%9A%84%E5%89%8D%E9%A9%B1%E5%90%8E%E7%BB%A7%E8%8A%82%E7%82%B9)
- [前驱节点](#%E5%89%8D%E9%A9%B1%E8%8A%82%E7%82%B9)
- [后继节点](#%E5%90%8E%E7%BB%A7%E8%8A%82%E7%82%B9)
- [树的深度](#%E6%A0%91%E7%9A%84%E6%B7%B1%E5%BA%A6)
- [动态规划](#%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92)
- [斐波那契数列](#%E6%96%90%E6%B3%A2%E9%82%A3%E5%A5%91%E6%95%B0%E5%88%97)
- [0 - 1背包问题](#0---1%E8%83%8C%E5%8C%85%E9%97%AE%E9%A2%98)
- [最长递增子序列](#%E6%9C%80%E9%95%BF%E9%80%92%E5%A2%9E%E5%AD%90%E5%BA%8F%E5%88%97)
- [字符串相关](#%E5%AD%97%E7%AC%A6%E4%B8%B2%E7%9B%B8%E5%85%B3)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# 时间复杂度
通常使用最差的时间复杂度来衡量一个算法的好坏。
常数时间 O(1) 代表这个操作和数据量没关系,是一个固定时间的操作,比如说四则运算。
对于一个算法来说,可能会计算出如下操作次数 `aN + 1`,`N` 代表数据量。那么该算法的时间复杂度就是 O(N)。因为我们在计算时间复杂度的时候,数据量通常是非常大的,这时候低阶项和常数项可以忽略不计。
当然可能会出现两个算法都是 O(N) 的时间复杂度,那么对比两个算法的好坏就要通过对比低阶项和常数项了。
# 位运算
位运算在算法中很有用,速度可以比四则运算快很多。
在学习位运算之前应该知道十进制如何转二进制,二进制如何转十进制。这里说明下简单的计算方式
- 十进制 `33` 可以看成是 `32 + 1` ,并且 `33` 应该是六位二进制的(因为 `33` 近似 `32`,而 `32` 是 2 的五次方,所以是六位),那么 十进制 `33` 就是 `100001` ,只要是 2 的次方,那么就是 1否则都为 0
- 那么二进制 `100001` 同理,首位是 `2^5` ,末位是 `2^0` ,相加得出 33
## 左移 <<
```js
10 << 1 // -> 20
```
左移就是将二进制全部往左移动,`10` 在二进制中表示为 `1010` ,左移一位后变成 `10100` ,转换为十进制也就是 20,所以基本可以把左移看成以下公式 `a * (2 ^ b)`
## 算数右移 >>
```js
10 >> 1 // -> 5
```
算数右移就是将二进制全部往右移动并去除多余的右边,`10` 在二进制中表示为 `1010` ,右移一位后变成 `101` ,转换为十进制也就是 5,所以基本可以把右移看成以下公式 `int v = a / (2 ^ b)`
右移很好用,比如可以用在二分算法中取中间值
```js
13 >> 1 // -> 6
```
## 按位操作
**按位与**
每一位都为 1,结果才为 1
```js
8 & 7 // -> 0
// 1000 & 0111 -> 0000 -> 0
```
**按位或**
其中一位为 1,结果就是 1
```js
8 | 7 // -> 15
// 1000 | 0111 -> 1111 -> 15
```
**按位异或**
每一位都不同,结果才为 1
```js
8 ^ 7 // -> 15
8 ^ 8 // -> 0
// 1000 ^ 0111 -> 1111 -> 15
// 1000 ^ 1000 -> 0000 -> 0
```
从以上代码中可以发现按位异或就是不进位加法
**面试题**:两个数不使用四则运算得出和
这道题中可以按位异或,因为按位异或就是不进位加法,`8 ^ 8 = 0` 如果进位了,就是 16 了,所以我们只需要将两个数进行异或操作,然后进位。那么也就是说两个二进制都是 1 的位置,左边应该有一个进位 1,所以可以得出以下公式 `a + b = (a ^ b) + ((a & b) << 1)` ,然后通过迭代的方式模拟加法
```js
function sum(a, b) {
if (a == 0) return b
if (b == 0) return a
let newA = a ^ b
let newB = (a & b) << 1
return sum(newA, newB)
}
```
# 排序
以下两个函数是排序中会用到的通用函数,就不一一写了
```js
function checkArray(array) {
if (!array || array.length <= 2) return
}
function swap(array, left, right) {
let rightValue = array[right]
array[right] = array[left]
array[left] = rightValue
}
```
## 冒泡排序
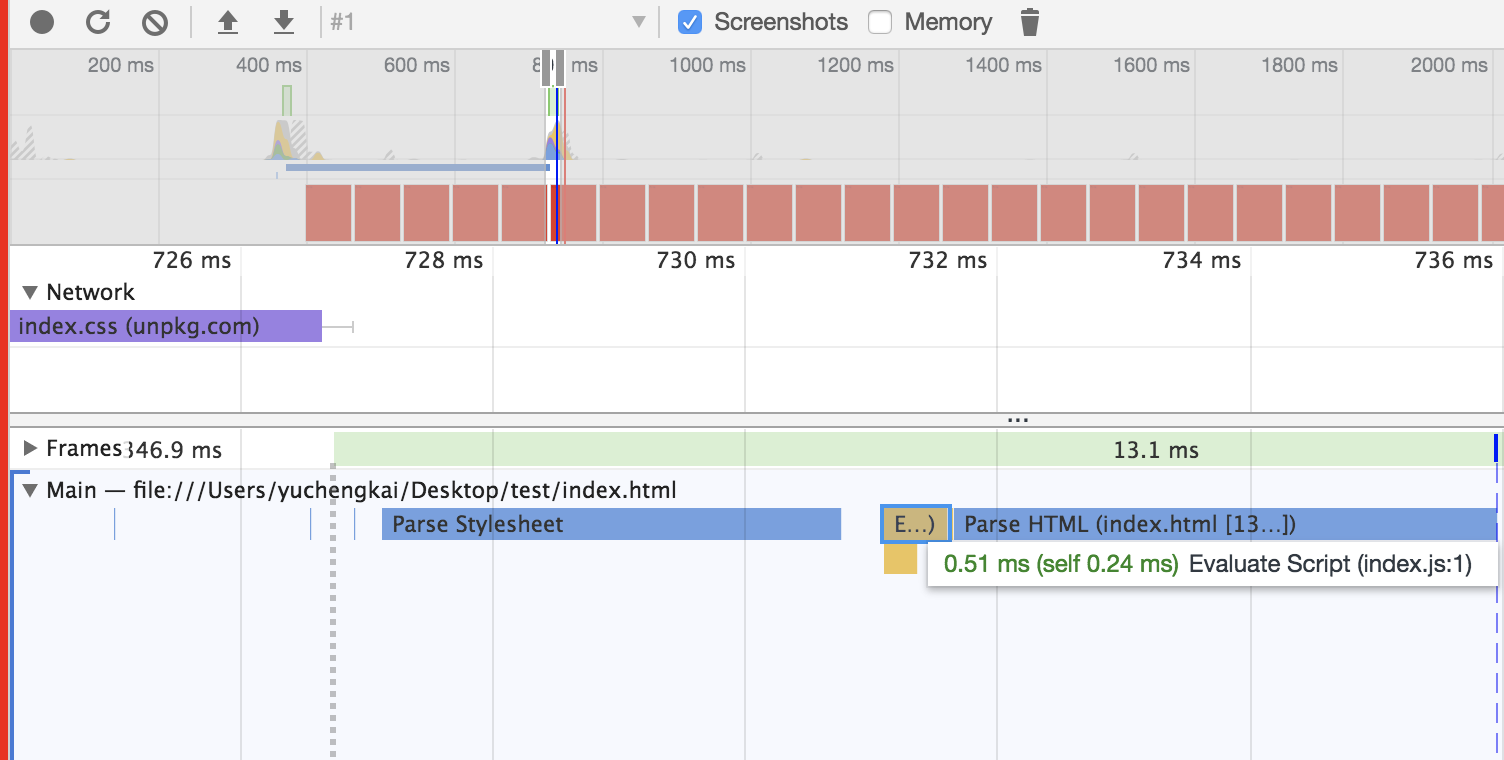
冒泡排序的原理如下,从第一个元素开始,把当前元素和下一个索引元素进行比较。如果当前元素大,那么就交换位置,重复操作直到比较到最后一个元素,那么此时最后一个元素就是该数组中最大的数。下一轮重复以上操作,但是此时最后一个元素已经是最大数了,所以不需要再比较最后一个元素,只需要比较到 `length - 1` 的位置。
<div align="center">
<img src="https://user-gold-cdn.xitu.io/2018/4/12/162b895b452b306c?w=670&h=508&f=gif&s=282307" width="500" />
</div>
以下是实现该算法的代码
```js
function bubble(array) {
checkArray(array);
for (let i = array.length - 1; i > 0; i--) {
// 从 0 到 `length - 1` 遍历
for (let j = 0; j < i; j++) {
if (array[j] > array[j + 1]) swap(array, j, j + 1)
}
}
return array;
}
```
该算法的操作次数是一个等差数列 `n + (n - 1) + (n - 2) + 1` ,去掉常数项以后得出时间复杂度是 O(n * n)
## 插入排序
插入排序的原理如下。第一个元素默认是已排序元素,取出下一个元素和当前元素比较,如果当前元素大就交换位置。那么此时第一个元素就是当前的最小数,所以下次取出操作从第三个元素开始,向前对比,重复之前的操作。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/12/162b895c7e59dcd1?w=670&h=508&f=gif&s=609549" width="500" style="display:block;margin: 0 auto" /></div>
以下是实现该算法的代码
```js
function insertion(array) {
checkArray(array);
for (let i = 1; i < array.length; i++) {
for (let j = i - 1; j >= 0 && array[j] > array[j + 1]; j--)
swap(array, j, j + 1);
}
return array;
}
```
该算法的操作次数是一个等差数列 `n + (n - 1) + (n - 2) + 1` ,去掉常数项以后得出时间复杂度是 O(n * n)
## 选择排序
选择排序的原理如下。遍历数组,设置最小值的索引为 0,如果取出的值比当前最小值小,就替换最小值索引,遍历完成后,将第一个元素和最小值索引上的值交换。如上操作后,第一个元素就是数组中的最小值,下次遍历就可以从索引 1 开始重复上述操作。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/13/162bc8ea14567e2e?w=670&h=508&f=gif&s=965636" width="500" style="display:block;margin: 0 auto" /></div>
以下是实现该算法的代码
```js
function selection(array) {
checkArray(array);
for (let i = 0; i < array.length - 1; i++) {
let minIndex = i;
for (let j = i + 1; j < array.length; j++) {
minIndex = array[j] < array[minIndex] ? j : minIndex;
}
swap(array, i, minIndex);
}
return array;
}
```
该算法的操作次数是一个等差数列 `n + (n - 1) + (n - 2) + 1` ,去掉常数项以后得出时间复杂度是 O(n * n)
## 归并排序
归并排序的原理如下。递归的将数组两两分开直到最多包含两个元素,然后将数组排序合并,最终合并为排序好的数组。假设我有一组数组 `[3, 1, 2, 8, 9, 7, 6]`,中间数索引是 3,先排序数组 `[3, 1, 2, 8]` 。在这个左边数组上,继续拆分直到变成数组包含两个元素(如果数组长度是奇数的话,会有一个拆分数组只包含一个元素)。然后排序数组 `[3, 1]` 和 `[2, 8]` ,然后再排序数组 `[1, 3, 2, 8]` ,这样左边数组就排序完成,然后按照以上思路排序右边数组,最后将数组 `[1, 2, 3, 8]` 和 `[6, 7, 9]` 排序。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/13/162be13c7e30bd86?w=896&h=1008&f=gif&s=937952" width=500 /></div>
以下是实现该算法的代码
```js
function sort(array) {
checkArray(array);
mergeSort(array, 0, array.length - 1);
return array;
}
function mergeSort(array, left, right) {
// 左右索引相同说明已经只有一个数
if (left === right) return;
// 等同于 `left + (right - left) / 2`
// 相比 `(left + right) / 2` 来说更加安全,不会溢出
// 使用位运算是因为位运算比四则运算快
let mid = parseInt(left + ((right - left) >> 1));
mergeSort(array, left, mid);
mergeSort(array, mid + 1, right);
let help = [];
let i = 0;
let p1 = left;
let p2 = mid + 1;
while (p1 <= mid && p2 <= right) {
help[i++] = array[p1] < array[p2] ? array[p1++] : array[p2++];
}
while (p1 <= mid) {
help[i++] = array[p1++];
}
while (p2 <= right) {
help[i++] = array[p2++];
}
for (let i = 0; i < help.length; i++) {
array[left + i] = help[i];
}
return array;
}
```
以上算法使用了递归的思想。递归的本质就是压栈,每递归执行一次函数,就将该函数的信息(比如参数,内部的变量,执行到的行数)压栈,直到遇到终止条件,然后出栈并继续执行函数。对于以上递归函数的调用轨迹如下
```js
mergeSort(data, 0, 6) // mid = 3
mergeSort(data, 0, 3) // mid = 1
mergeSort(data, 0, 1) // mid = 0
mergeSort(data, 0, 0) // 遇到终止,回退到上一步
mergeSort(data, 1, 1) // 遇到终止,回退到上一步
// 排序 p1 = 0, p2 = mid + 1 = 1
// 回退到 `mergeSort(data, 0, 3)` 执行下一个递归
mergeSort(2, 3) // mid = 2
mergeSort(3, 3) // 遇到终止,回退到上一步
// 排序 p1 = 2, p2 = mid + 1 = 3
// 回退到 `mergeSort(data, 0, 3)` 执行合并逻辑
// 排序 p1 = 0, p2 = mid + 1 = 2
// 执行完毕回退
// 左边数组排序完毕,右边也是如上轨迹
```
该算法的操作次数是可以这样计算:递归了两次,每次数据量是数组的一半,并且最后把整个数组迭代了一次,所以得出表达式 `2T(N / 2) + T(N)` (T 代表时间,N 代表数据量)。根据该表达式可以套用 [该公式](https://www.wikiwand.com/zh-hans/%E4%B8%BB%E5%AE%9A%E7%90%86) 得出时间复杂度为 `O(N * logN)`
## 快排
快排的原理如下。随机选取一个数组中的值作为基准值,从左至右取值与基准值对比大小。比基准值小的放数组左边,大的放右边,对比完成后将基准值和第一个比基准值大的值交换位置。然后将数组以基准值的位置分为两部分,继续递归以上操作。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/16/162cd23e69ca9ea3?w=824&h=506&f=gif&s=867744" width=500 /></div>
以下是实现该算法的代码
```js
function sort(array) {
checkArray(array);
quickSort(array, 0, array.length - 1);
return array;
}
function quickSort(array, left, right) {
if (left < right) {
swap(array, , right)
// 随机取值,然后和末尾交换,这样做比固定取一个位置的复杂度略低
let indexs = part(array, parseInt(Math.random() * (right - left + 1)) + left, right);
quickSort(array, left, indexs[0]);
quickSort(array, indexs[1] + 1, right);
}
}
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
// 当前值比基准值小,`less` 和 `left` 都加一
++less;
++left;
} else if (array[left] > array[right]) {
// 当前值比基准值大,将当前值和右边的值交换
// 并且不改变 `left`,因为当前换过来的值还没有判断过大小
swap(array, --more, left);
} else {
// 和基准值相同,只移动下标
left++;
}
}
// 将基准值和比基准值大的第一个值交换位置
// 这样数组就变成 `[比基准值小, 基准值, 比基准值大]`
swap(array, right, more);
return [less, more];
}
```
该算法的复杂度和归并排序是相同的,但是额外空间复杂度比归并排序少,只需 O(logN),并且相比归并排序来说,所需的常数时间也更少。
### 面试题
**Sort Colors**:该题目来自 [LeetCode](https://leetcode.com/problems/sort-colors/description/),题目需要我们将 `[2,0,2,1,1,0]` 排序成 `[0,0,1,1,2,2]` ,这个问题就可以使用三路快排的思想。
以下是代码实现
```js
var sortColors = function(nums) {
let left = -1;
let right = nums.length;
let i = 0;
// 下标如果遇到 right,说明已经排序完成
while (i < right) {
if (nums[i] == 0) {
swap(nums, i++, ++left);
} else if (nums[i] == 1) {
i++;
} else {
swap(nums, i, --right);
}
}
};
```
**Kth Largest Element in an Array**:该题目来自 [LeetCode](https://leetcode.com/problems/kth-largest-element-in-an-array/description/),题目需要找出数组中第 K 大的元素,这问题也可以使用快排的思路。并且因为是找出第 K 大元素,所以在分离数组的过程中,可以找出需要的元素在哪边,然后只需要排序相应的一边数组就好。
以下是代码实现
```js
var findKthLargest = function(nums, k) {
let l = 0
let r = nums.length - 1
// 得出第 K 大元素的索引位置
k = nums.length - k
while (l < r) {
// 分离数组后获得比基准树大的第一个元素索引
let index = part(nums, l, r)
// 判断该索引和 k 的大小
if (index < k) {
l = index + 1
} else if (index > k) {
r = index - 1
} else {
break
}
}
return nums[k]
};
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
++less;
++left;
} else if (array[left] > array[right]) {
swap(array, --more, left);
} else {
left++;
}
}
swap(array, right, more);
return more;
}
```
## 堆排序
堆排序利用了二叉堆的特性来做,二叉堆通常用数组表示,并且二叉堆是一颗完全二叉树(所有叶节点(最底层的节点)都是从左往右顺序排序,并且其他层的节点都是满的)。二叉堆又分为大根堆与小根堆。
- 大根堆是某个节点的所有子节点的值都比他小
- 小根堆是某个节点的所有子节点的值都比他大
堆排序的原理就是组成一个大根堆或者小根堆。以小根堆为例,某个节点的左边子节点索引是 `i * 2 + 1`,右边是 `i * 2 + 2`,父节点是 `(i - 1) /2`。
1. 首先遍历数组,判断该节点的父节点是否比他小,如果小就交换位置并继续判断,直到他的父节点比他大
2. 重新以上操作 1,直到数组首位是最大值
3. 然后将首位和末尾交换位置并将数组长度减一,表示数组末尾已是最大值,不需要再比较大小
4. 对比左右节点哪个大,然后记住大的节点的索引并且和父节点对比大小,如果子节点大就交换位置
5. 重复以上操作 3 - 4 直到整个数组都是大根堆。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/17/162d2a9ff258dfe1?w=1372&h=394&f=gif&s=1018181" width=500 /></div>
以下是实现该算法的代码
```js
function heap(array) {
checkArray(array);
// 将最大值交换到首位
for (let i = 0; i < array.length; i++) {
heapInsert(array, i);
}
let size = array.length;
// 交换首位和末尾
swap(array, 0, --size);
while (size > 0) {
heapify(array, 0, size);
swap(array, 0, --size);
}
return array;
}
function heapInsert(array, index) {
// 如果当前节点比父节点大,就交换
while (array[index] > array[parseInt((index - 1) / 2)]) {
swap(array, index, parseInt((index - 1) / 2));
// 将索引变成父节点
index = parseInt((index - 1) / 2);
}
}
function heapify(array, index, size) {
let left = index * 2 + 1;
while (left < size) {
// 判断左右节点大小
let largest =
left + 1 < size && array[left] < array[left + 1] ? left + 1 : left;
// 判断子节点和父节点大小
largest = array[index] < array[largest] ? largest : index;
if (largest === index) break;
swap(array, index, largest);
index = largest;
left = index * 2 + 1;
}
}
```
以上代码实现了小根堆,如果需要实现大根堆,只需要把节点对比反一下就好。
该算法的复杂度是 O(logN)
## 系统自带排序实现
每个语言的排序内部实现都是不同的。
对于 JS 来说,数组长度大于 10 会采用快排,否则使用插入排序 [源码实现](https://github.com/v8/v8/blob/ad82a40509c5b5b4680d4299c8f08d6c6d31af3c/src/js/array.js#L760:7) 。选择插入排序是因为虽然时间复杂度很差,但是在数据量很小的情况下和 `O(N * logN) `相差无几,然而插入排序需要的常数时间很小,所以相对别的排序来说更快。
对于 Java 来说,还会考虑内部的元素的类型。对于存储对象的数组来说,会采用稳定性好的算法。稳定性的意思就是对于相同值来说,相对顺序不能改变。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/18/162d7df247dcda00?w=440&h=727&f=png&s=38002" height=500 /></div>
# 链表
## 反转单向链表
该题目来自 [LeetCode](https://leetcode.com/problems/reverse-linked-list/description/),题目需要将一个单向链表反转。思路很简单,使用三个变量分别表示当前节点和当前节点的前后节点,虽然这题很简单,但是却是一道面试常考题
以下是实现该算法的代码
```js
var reverseList = function(head) {
// 判断下变量边界问题
if (!head || !head.next) return head
// 初始设置为空,因为第一个节点反转后就是尾部,尾部节点指向 null
let pre = null
let current = head
let next
// 判断当前节点是否为空
// 不为空就先获取当前节点的下一节点
// 然后把当前节点的 next 设为上一个节点
// 然后把 current 设为下一个节点,pre 设为当前节点
while(current) {
next = current.next
current.next = pre
pre = current
current = next
}
return pre
};
```
# 树
## 二叉树的先序,中序,后序遍历
先序遍历表示先访问根节点,然后访问左节点,最后访问右节点。
中序遍历表示先访问左节点,然后访问根节点,最后访问右节点。
后序遍历表示先访问左节点,然后访问右节点,最后访问根节点。
### 递归实现
递归实现相当简单,代码如下
```js
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
var traversal = function(root) {
if (root) {
// 先序
console.log(root);
traversal(root.left);
// 中序
// console.log(root);
traversal(root.right);
// 后序
// console.log(root);
}
};
```
对于递归的实现来说,只需要理解每个节点都会被访问三次就明白为什么这样实现了。
### 非递归实现
非递归实现使用了栈的结构,通过栈的先进后出模拟递归实现。
以下是先序遍历代码实现
```js
function pre(root) {
if (root) {
let stack = [];
// 先将根节点 push
stack.push(root);
// 判断栈中是否为空
while (stack.length > 0) {
// 弹出栈顶元素
root = stack.pop();
console.log(root);
// 因为先序遍历是先左后右,栈是先进后出结构
// 所以先 push 右边再 push 左边
if (root.right) {
stack.push(root.right);
}
if (root.left) {
stack.push(root.left);
}
}
}
}
```
以下是中序遍历代码实现
```js
function mid(root) {
if (root) {
let stack = [];
// 中序遍历是先左再根最后右
// 所以首先应该先把最左边节点遍历到底依次 push 进栈
// 当左边没有节点时,就打印栈顶元素,然后寻找右节点
// 对于最左边的叶节点来说,可以把它看成是两个 null 节点的父节点
// 左边打印不出东西就把父节点拿出来打印,然后再看右节点
while (stack.length > 0 || root) {
if (root) {
stack.push(root);
root = root.left;
} else {
root = stack.pop();
console.log(root);
root = root.right;
}
}
}
}
```
以下是后序遍历代码实现,该代码使用了两个栈来实现遍历,相比一个栈的遍历来说要容易理解很多
```js
function pos(root) {
if (root) {
let stack1 = [];
let stack2 = [];
// 后序遍历是先左再右最后根
// 所以对于一个栈来说,应该先 push 根节点
// 然后 push 右节点,最后 push 左节点
stack1.push(root);
while (stack1.length > 0) {
root = stack1.pop();
stack2.push(root);
if (root.left) {
stack1.push(root.left);
}
if (root.right) {
stack1.push(root.right);
}
}
while (stack2.length > 0) {
console.log(s2.pop());
}
}
}
```
## 中序遍历的前驱后继节点
实现这个算法的前提是节点有一个 `parent` 的指针指向父节点,根节点指向 `null` 。
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/24/162f61ad8e8588b7?w=682&h=486&f=png&s=41027" width=400 /></div>
如图所示,该树的中序遍历结果是 `4, 2, 5, 1, 6, 3, 7`
### 前驱节点
对于节点 `2` 来说,他的前驱节点就是 `4` ,按照中序遍历原则,可以得出以下结论
1. 如果选取的节点的左节点不为空,就找该左节点最右的节点。对于节点 `1` 来说,他有左节点 `2` ,那么节点 `2` 的最右节点就是 `5`
2. 如果左节点为空,且目标节点是父节点的右节点,那么前驱节点为父节点。对于节点 `5` 来说,没有左节点,且是节点 `2` 的右节点,所以节点 `2` 是前驱节点
3. 如果左节点为空,且目标节点是父节点的左节点,向上寻找到第一个是父节点的右节点的节点。对于节点 `6` 来说,没有左节点,且是节点 `3` 的左节点,所以向上寻找到节点 `1` ,发现节点 `3` 是节点 `1` 的右节点,所以节点 `1` 是节点 `6` 的前驱节点
以下是算法实现
```js
function predecessor(node) {
if (!node) return
// 结论 1
if (node.left) {
return getRight(node.left)
} else {
let parent = node.parent
// 结论 2 3 的判断
while(parent && parent.right === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getRight(node) {
if (!node) return
node = node.right
while(node) node = node.right
return node
}
```
### 后继节点
对于节点 `2` 来说,他的后继节点就是 `5` ,按照中序遍历原则,可以得出以下结论
1. 如果有右节点,就找到该右节点的最左节点。对于节点 `1` 来说,他有右节点 `3` ,那么节点 `3` 的最左节点就是 `6`
2. 如果没有右节点,就向上遍历直到找到一个节点是父节点的左节点。对于节点 `5` 来说,没有右节点,就向上寻找到节点 `2` ,该节点是父节点 `1` 的左节点,所以节点 `1` 是后继节点
以下是算法实现
```js
function successor(node) {
if (!node) return
// 结论 1
if (node.right) {
return getLeft(node.right)
} else {
// 结论 2
let parent = node.parent
// 判断 parent 为空
while(parent && parent.left === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getLeft(node) {
if (!node) return
node = node.left
while(node) node = node.left
return node
}
```
## 树的深度
**树的最大深度**:该题目来自 [Leetcode](https://leetcode.com/problems/maximum-depth-of-binary-tree/description/),题目需要求出一颗二叉树的最大深度
以下是算法实现
```js
var maxDepth = function(root) {
if (!root) return 0
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1
};
```
对于该递归函数可以这样理解:一旦没有找到节点就会返回 0,每弹出一次递归函数就会加一,树有三层就会得到3。
# 动态规划
动态规划背后的基本思想非常简单。就是将一个问题拆分为子问题,一般来说这些子问题都是非常相似的,那么我们可以通过只解决一次每个子问题来达到减少计算量的目的。
一旦得出每个子问题的解,就存储该结果以便下次使用。
## 斐波那契数列
斐波那契数列就是从 0 和 1 开始,后面的数都是前两个数之和
0,1,1,2,3,5,8,13,21,34,55,89....
那么显然易见,我们可以通过递归的方式来完成求解斐波那契数列
```js
function fib(n) {
if (n < 2 && n >= 0) return n
return fib(n - 1) + fib(n - 2)
}
fib(10)
```
以上代码已经可以完美的解决问题。但是以上解法却存在很严重的性能问题,当 n 越大的时候,需要的时间是指数增长的,这时候就可以通过动态规划来解决这个问题。
动态规划的本质其实就是两点
1. 自底向上分解子问题
2. 通过变量存储已经计算过的解
根据上面两点,我们的斐波那契数列的动态规划思路也就出来了
1. 斐波那契数列从 0 和 1 开始,那么这就是这个子问题的最底层
2. 通过数组来存储每一位所对应的斐波那契数列的值
```js
function fib(n) {
let array = new Array(n + 1).fill(null)
array[0] = 0
array[1] = 1
for (let i = 2; i <= n; i++) {
array[i] = array[i - 1] + array[i - 2]
}
return array[n]
}
fib(10)
```
## 0 - 1背包问题
该问题可以描述为:给定一组物品,每种物品都有自己的重量和价格,在限定的总重量内,我们如何选择,才能使得物品的总价格最高。每个问题只能放入至多一次。
假设我们有以下物品
| 物品 ID / 重量 | 价值 |
| :------------: | :--: |
| 1 | 3 |
| 2 | 7 |
| 3 | 12 |
对于一个总容量为 5 的背包来说,我们可以放入重量 2 和 3 的物品来达到背包内的物品总价值最高。
对于这个问题来说,子问题就两个,分别是放物品和不放物品,可以通过以下表格来理解子问题
| 物品 ID / 剩余容量 | 0 | 1 | 2 | 3 | 4 | 5 |
| :----------------: | :--: | :--: | :--: | :--: | :--: | :--: |
| 1 | 0 | 3 | 3 | 3 | 3 | 3 |
| 2 | 0 | 3 | 7 | 10 | 10 | 10 |
| 3 | 0 | 3 | 7 | 12 | 15 | 19 |
直接来分析能放三种物品的情况,也就是最后一行
- 当容量少于 3 时,只取上一行对应的数据,因为当前容量不能容纳物品 3
- 当容量 为 3 时,考虑两种情况,分别为放入物品 3 和不放物品 3
- 不放物品 3 的情况下,总价值为 10
- 放入物品 3 的情况下,总价值为 12,所以应该放入物品 3
- 当容量 为 4 时,考虑两种情况,分别为放入物品 3 和不放物品 3
- 不放物品 3 的情况下,总价值为 10
- 放入物品 3 的情况下,和放入物品 1 的价值相加,得出总价值为 15,所以应该放入物品 3
- 当容量 为 5 时,考虑两种情况,分别为放入物品 3 和不放物品 3
- 不放物品 3 的情况下,总价值为 10
- 放入物品 3 的情况下,和放入物品 2 的价值相加,得出总价值为 19,所以应该放入物品 3
以下代码对照上表更容易理解
```js
/**
* @param {*} w 物品重量
* @param {*} v 物品价值
* @param {*} C 总容量
* @returns
*/
function knapsack(w, v, C) {
let length = w.length
if (length === 0) return 0
// 对照表格,生成的二维数组,第一维代表物品,第二维代表背包剩余容量
// 第二维中的元素代表背包物品总价值
let array = new Array(length).fill(new Array(C + 1).fill(null))
// 完成底部子问题的解
for (let i = 0; i <= C; i++) {
// 对照表格第一行, array[0] 代表物品 1
// i 代表剩余总容量
// 当剩余总容量大于物品 1 的重量时,记录下背包物品总价值,否则价值为 0
array[0][i] = i >= w[0] ? v[0] : 0
}
// 自底向上开始解决子问题,从物品 2 开始
for (let i = 1; i < length; i++) {
for (let j = 0; j <= C; j++) {
// 这里求解子问题,分别为不放当前物品和放当前物品
// 先求不放当前物品的背包总价值,这里的值也就是对应表格中上一行对应的值
array[i][j] = array[i - 1][j]
// 判断当前剩余容量是否可以放入当前物品
if (j >= w[i]) {
// 可以放入的话,就比大小
// 放入当前物品和不放入当前物品,哪个背包总价值大
array[i][j] = Math.max(array[i][j], v[i] + array[i - 1][j - w[i]])
}
}
}
return array[length - 1][C]
}
```
## 最长递增子序列
最长递增子序列意思是在一组数字中,找出最长一串递增的数字,比如
0, 3, 4, 17, 2, 8, 6, 10
对于以上这串数字来说,最长递增子序列就是 0, 3, 4, 8, 10,可以通过以下表格更清晰的理解
| 数字 | 0 | 3 | 4 | 17 | 2 | 8 | 6 | 10 |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| 长度 | 1 | 2 | 3 | 4 | 2 | 4 | 4 | 5 |
通过以上表格可以很清晰的发现一个规律,找出刚好比当前数字小的数,并且在小的数组成的长度基础上加一。
这个问题的动态思路解法很简单,直接上代码
```js
function lis(n) {
if (n.length === 0) return 0
// 创建一个和参数相同大小的数组,并填充值为 1
let array = new Array(n.length).fill(1)
// 从索引 1 开始遍历,因为数组已经所有都填充为 1 了
for (let i = 1; i < n.length; i++) {
// 从索引 0 遍历到 i
// 判断索引 i 上的值是否大于之前的值
for (let j = 0; j < i; j++) {
if (n[i] > n[j]) {
array[i] = Math.max(array[i], 1 + array[j])
}
}
}
let res = 1
for (let i = 0; i < array.length; i++) {
res = Math.max(res, array[i])
}
return res
}
```
# 字符串相关
在字符串相关算法中,Trie 树可以解决解决很多问题,同时具备良好的空间和时间复杂度,比如以下问题
- 词频统计
- 前缀匹配
如果你对于 Trie 树还不怎么了解,可以前往 [这里](../DataStruct/dataStruct-zh.md#trie) 阅读
================================================
FILE: Algorithm/algorithm-en.md
================================================
# Time Complexity
The worst time complexity is often used to measure the quality of an algorithm.
The constant time O(1) means that this operation has nothing to do with the amount of data. It is a fixed-time operation, such as arithmetic operation.
For an algorithm, it is possible to calculate the operation numbers of `aN + 1`, N represents the amount of data. Then the time complexity of the algorithm is O(N). Because when we calculate the time complexity, the amount of data is usually very large, when low-order terms and constant terms are negligible.
Of course, it may happen that both algorithms are O(N) time complexity, then comparing the low-order terms and the constant terms of the two algorithms.
# Bit Operation
Bit operation is useful in algorithms and can be much faster than arithmetic operations.
Before learning bit operation, you should know how decimal converts to binary and how binary turns to decimal. Here is a simple calculation method.
- Decimal `33` can be seen as `32 + 1` and `33` should be six-bit binary (Because 33 is approximately 32, and 32 is the fifth power of 2, so it is six bit), so the decimal `33` is `100001`, as long as it is the power of 2, then it is 1 otherwise it is 0.
- Then binary `100001` is the same, the first is `2^5`, the last is `2^0`, and the sum is 33
## Shift Arithmetic Left <<
```js
10 << 1 // -> 20
```
Shift arithmetic left is to move all the binary to the left, `10` is represented as `1010` in binary, after shifting one bit to the left becomes `10100`, and converted to decimal is 20, so the left shift can be basically regarded as the following formula `a << b => a * (2 ^ b)`.
## Shift Arithmetic Right >>
```js
10 >> 1 // -> 5
```
The bitwise right shift moves all the binary digits to the right and remove the extra left digit. `10` is represented as `1010` in binary, and becomes `101` after shifting one bit to the right, and becomes 5 in decimal value, so the right shift is basically the following formula: `a >> b => a / (2 ^ b)`.
Right shift is very useful, for example, you can calculate the intermediate value in the binary algorithm.
```js
13 >> 1 // -> 6
```
## Bitwise Operation
**Bitwise And**
Each bit is 1, and the result is 1
```js
8 & 7 // -> 0
// 1000 & 0111 -> 0000 -> 0
```
**Bitwise Or**
One of bit is 1, and the result is 1
```js
8 | 7 // -> 15
// 1000 | 0111 -> 1111 -> 15
```
**Bitwise XOR**
Each bit is different, and the result is 1
```js
8 ^ 7 // -> 15
8 ^ 8 // -> 0
// 1000 ^ 0111 -> 1111 -> 15
// 1000 ^ 1000 -> 0000 -> 0
```
From the above code, we can find that the bitwise XOR is the not carry addition.
**Interview Question**:Not using arithmetic operation to get the sum of two numbers
This question can use bitwise XOR, because bitwise XOR is not carry addition, `8 ^ 8 = 0`, but if carry it will be 16 , so we only need to XOR the two numbers and then carry. So, if both bit is 1, and there should be a carry 1 on the left, so the following formula can be obtained `a + b = a ^ b + (a & b) << 1` , then simulate addition by recursive.
```js
function sum(a, b) {
if (a == 0) return b
if (b == 0) return a
let newA = a ^ b
let newB = (a & b) << 1
return sum(newA, newB)
}
```
# Sort
The following two functions will be used in sorting commonly, so I don't write them one by one.
```js
function checkArray(array) {
if (!array || array.length <= 2) return
}
function swap(array, left, right) {
let rightValue = array[right]
array[right] = array[left]
array[left] = rightValue
}
```
## Bubble Sort
The principle of bubble sort is as follows, starting with the first element, and comparing the current element with the next index element. If the current element is larger, then swap them and repeat until the last element is compared, then the last element at this time is the largest number in the array. The above operation is repeated in the next round, but the last element is already the maximum number, so there is no need to compare the last element, only the position of `length - 1` is needed.
<div align="center">
<img src="https://user-gold-cdn.xitu.io/2018/4/12/162b895b452b306c?w=670&h=508&f=gif&s=282307" width="500" />
</div>
The following code is implement of the algorithm.
```js
function bubble(array) {
checkArray(array);
for (let i = array.length - 1; i > 0; i--) {
// Traversing from 0 to `length - 1`
for (let j = 0; j < i; j++) {
if (array[j] > array[j + 1]) swap(array, j, j + 1)
}
}
return array;
}
```
The operation numbers of the algorithm is an arithmetic progression `n + (n - 1) + (n - 2) + 1` . After removing the constant part, the time complexity is `O(n * n)`.
## Insert Sort
The principle of insert sort is as follows. The first element is default as the sorted element, taking the next element and comparing it to the current element, swapping them if the current element is larger. Then the first element is the minimum number at this time, so the next operation starts from the third element, and repeats the previous operation.
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/12/162b895c7e59dcd1?w=670&h=508&f=gif&s=609549" width="500" style="display:block;margin: 0 auto" /></div>
The following code is implement of the algorithm.
```js
function insertion(array) {
checkArray(array);
for (let i = 1; i < array.length; i++) {
for (let j = i - 1; j >= 0 && array[j] > array[j + 1]; j--)
swap(array, j, j + 1);
}
return array;
}
```
The operation numbers of the algorithm is an arithmetic progression `n + (n - 1) + (n - 2) + 1` . After removing the constant part, the time complexity is `O(n * n)`.
## Select Sort
The principle of select sort is as follows. Traverse the array, set the index of minimum to 0. If the extracted value is smaller than the current minimum, replace the minimum index. After the traversal is completed, the value on the first element and the minimum index are exchanged. After the above operation, the first element is the minimum value in the array, and the next operation starts from index 1 and repeats the previous opration.
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/13/162bc8ea14567e2e?w=670&h=508&f=gif&s=965636" width="500" style="display:block;margin: 0 auto" /></div>
The following code is implement of the algorithm.
```js
function selection(array) {
checkArray(array);
for (let i = 0; i < array.length - 1; i++) {
let minIndex = i;
for (let j = i + 1; j < array.length; j++) {
minIndex = array[j] < array[minIndex] ? j : minIndex;
}
swap(array, i, minIndex);
}
return array;
}
```
The operation numbers of the algorithm is an arithmetic progression `n + (n - 1) + (n - 2) + 1` . After removing the constant part, the time complexity is `O(n * n)`.
## Merge Sort
The principle of merge sort is as follows. Divide the array into two parts by recursion until one array contains at most two elements, then sort the array and merge them into a sorted array. Suppose I have a set of array `[3, 1, 2, 8, 9, 7, 6]`, the intermediate index is 3, and the array `[3, 1, 2, 8]` is sorted first. On this left array, continue splitting until the array becomes two elements (if the array length is odd, there will be a array containing only one element). Then sort the array `[3, 1]` and `[2, 8]`, and then sort the array `[1, 3, 2, 8]`, this time the left array is sorted, then sort the right array according to the above method, and finally sort the array `[1, 2, 3, 8]` and `[6, 7, 9]`.
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/13/162be13c7e30bd86?w=896&h=1008&f=gif&s=937952" width=500 /></div>
The following code is implement of the algorithm.
```js
function sort(array) {
checkArray(array);
mergeSort(array, 0, array.length - 1);
return array;
}
function mergeSort(array, left, right) {
// The left and right indexes are the same.
// means there is only one element.
if (left === right) return;
// Equivalent to `left + (right - left) / 2`
// More secure than `(left + right) / 2`,
// and the index will not out of bounds
// Bit operations are used because bit operations
// are faster than arithmetic operation
let mid = parseInt(left + ((right - left) >> 1));
mergeSort(array, left, mid);
mergeSort(array, mid + 1, right);
let help = [];
let i = 0;
let p1 = left;
let p2 = mid + 1;
while (p1 <= mid && p2 <= right) {
help[i++] = array[p1] < array[p2] ? array[p1++] : array[p2++];
}
while (p1 <= mid) {
help[i++] = array[p1++];
}
while (p2 <= right) {
help[i++] = array[p2++];
}
for (let i = 0; i < help.length; i++) {
array[left + i] = help[i];
}
return array;
}
```
The above algorithm uses the idea of recursion. The essence of recursion is pushed into stack. Whenever a function is executed recursively, the information of the function (such as parameters, internal variables, the number of rows has executed) is pushed into stack until a termination condition is encountered, then pop stack and continue execute the function. The call trajectory for the above recursive function is as follows.
```js
mergeSort(data, 0, 6) // mid = 3
mergeSort(data, 0, 3) // mid = 1
mergeSort(data, 0, 1) // mid = 0
mergeSort(data, 0, 0) // return to the previous step
mergeSort(data, 1, 1) // return to the previous step
// Sort p1 = 0, p2 = mid + 1 = 1
// Fall back to `mergeSort(data, 0, 3)`
// and perform the next recursion
mergeSort(2, 3) // mid = 2
mergeSort(3, 3) // return to the previous step
// Sort p1 = 2, p2 = mid + 1 = 3
// Fall back to `mergeSort(data, 0, 3)` and execution merge logic
// Sort p1 = 0, p2 = mid + 1 = 2
// Execution completed
// The array on the left is sorted,
// and the right side is also sorted like this
```
The operation numbers of the algorithm can be calculated as follows: recursively twice and each time the amount of data is half of the array, and finally the entire array is iterated once, so the expression `2T(N / 2) + T(N) `( T represent time and N represent data amount). According to the expression, the [formula](https://www.wikiwand.com/en/Master_theorem_(analysis_of_algorithms)) can be applied to get a time complexity of `O(N * logN)`.
## Quick Sort
The principle of quick sort is as follows. Randomly select a value in the array as the reference value, and compare the value with the reference value from left to right.Move the value to the left of the array if it is smaller than the reference value, and the larger one move to the right. The reference value is exchanged with the value which first larger than the reference value after the comparison completed. Then divide the array into two parts through the position of the reference value and continue the recursive operation.
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/16/162cd23e69ca9ea3?w=824&h=506&f=gif&s=867744" width=500 /></div>
The following code is implement of the algorithm.
```js
function sort(array) {
checkArray(array);
quickSort(array, 0, array.length - 1);
return array;
}
function quickSort(array, left, right) {
if (left < right) {
swap(array, , right)
// Randomly take values and then swap it with the end,
// which is slightly less complex than take a fixed position
let indexs = part(array, parseInt(Math.random() * (right - left + 1)) + left, right);
quickSort(array, left, indexs[0]);
quickSort(array, indexs[1] + 1, right);
}
}
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
// The current value is smaller than the reference value,
// and both `less` and `left` are added one.
++less;
++left;
} else if (array[left] > array[right]) {
// The current value is larger than the reference value,
// and the current value is exchanged with
// the value on the right.
// And don't change `left`, because the current value
// has not been judged yet.
swap(array, --more, left);
} else {
// Same as the reference value, only move the index
left++;
}
}
// Exchange the reference value with the value
// which is first larger than the reference value.
// Thus the array becomes `[less than the reference value,
// the reference value, larger than the reference value]`.
swap(array, right, more);
return [less, more];
}
```
The time complexity is same as merge sort, but the extra space complexity is less than the merge sort, only `O(logN)` is needed, and the constant time also smaller than the merge sort.
### Interview Question
**Sort Colors**:The topic is from [LeetCode](https://leetcode.com/problems/sort-colors/description/),The problem requires us to sort `[2,0,2,1,1,0]` into `[0,0,1,1,2,2]`, and this problem can use the idea of three-way quicksort.
The following code is implement of the algorithm.
```js
var sortColors = function(nums) {
let left = -1;
let right = nums.length;
let i = 0;
// If the index encounters right,
// it indicates that the sort has been completed.
while (i < right) {
if (nums[i] == 0) {
swap(nums, i++, ++left);
} else if (nums[i] == 1) {
i++;
} else {
swap(nums, i, --right);
}
}
};
```
**Kth Largest Element in an Array**:The topic is from [LeetCode](https://leetcode.com/problems/kth-largest-element-in-an-array/description/),The problem needs to find the Kth largest element in the array. This problem can also use the idea of quicksort. And because it is to find out the Kth element, in the process of separating the array, you can find out which side of the element you need, and then just sort the corresponding side array.
The following code is implement of the algorithm.
```js
var findKthLargest = function(nums, k) {
let l = 0
let r = nums.length - 1
// Get the index of the Kth largest element
k = nums.length - k
while (l < r) {
// After separating the array, get the element
// which first larger than the reference element
let index = part(nums, l, r)
// Compare the index with the k
if (index < k) {
l = index + 1
} else if (index > k) {
r = index - 1
} else {
break
}
}
return nums[k]
};
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
++less;
++left;
} else if (array[left] > array[right]) {
swap(array, --more, left);
} else {
left++;
}
}
swap(array, right, more);
return more;
}
```
## Heap Sort
Heap sort takes advantage of the characteristics with the binary heap, which is usually represented by an array, and the binary heap is a complete binary tree (all leaf nodes (the lowest node) are sorted from left to right, and others nodes are all full). The binary heap is divided into max-head and min-heap.
- A max-heap is all child nodes value smaller than the node value.
- A min-heap is all child nodes value larger than the node value.
The principle of heap sort is to compose a max-heap or a min-heap. Taking a min-heap as an example, the index of the left child node is `i * 2 + 1`, and the right node is `i * 2 + 2`, and the parent node is `(i - 1) / 2`.
1. First at all traverse the array to determine if the parent node is smaller than current node. If true, swap the position and continue to judge until his parent node is larger than him.
2. Repeat the above operation 1, until the first position of the array is the maximum.
3. Then swap the first and last position and minus 1with the length of the array, indicating that the end of the array is the maximum, it is no need to compare with it.
4. Compare with the left and right nodes, then remember the index of the larger node and compare it with the parent node. If the child node is larger, then swap them.
5. Repeat the above steps 3 - 4 until the whole array is a max-heap.
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/17/162d2a9ff258dfe1?w=1372&h=394&f=gif&s=1018181" width=500 /></div>
The following code is implement of the algorithm.
```js
function heap(array) {
checkArray(array);
// Exchange the maximum value to the first position
for (let i = 0; i < array.length; i++) {
heapInsert(array, i);
}
let size = array.length;
// Exchange first and last position
swap(array, 0, --size);
while (size > 0) {
heapify(array, 0, size);
swap(array, 0, --size);
}
return array;
}
function heapInsert(array, index) {
// Exchange them if current node larger than parent node
while (array[index] > array[parseInt((index - 1) / 2)]) {
swap(array, index, parseInt((index - 1) / 2));
// Change the index to the parent node
index = parseInt((index - 1) / 2);
}
}
function heapify(array, index, size) {
let left = index * 2 + 1;
while (left < size) {
// Judge the size of the left and right node
let largest =
left + 1 < size && array[left] < array[left + 1] ? left + 1 : left;
// Judge the size of the child and parent node
largest = array[index] < array[largest] ? largest : index;
if (largest === index) break;
swap(array, index, largest);
index = largest;
left = index * 2 + 1;
}
}
```
The above code implements a min-heap. If you need to implement a max-heap, you only need to reverse the comparison.
The time complexity of the algorithm is `O(logN)`.
## System Comes With Sorting Implementation
The internal implementation of sorting for each language is different.
For JS, it will use quick sort if array length greater than 10, otherwise will use insert sort [Source implementation](https://github.com/v8/v8/blob/ad82a40509c5b5b4680d4299c8f08d6c6d31af3c/src/js/array.js#L760:7) . The insert sort is chosen because although the time complexity is very poor, it is almost the same as `O(N * logN)` when the amount of data is small, but the constant time required for insert sort is small, so it is faster than other sorts.
For Java, the type of elements inside is also considered. For arrays that store objects, a stable algorithm is used. Stability means that the relative order cannot be changed for the same value.
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/18/162d7df247dcda00?w=440&h=727&f=png&s=38002" height=500 /></div>
# Linked List
## Reverse Singly Linked List
The topic is from [LeetCode](https://leetcode.com/problems/reverse-linked-list/description/),The problem needs to reverse a singly linked list. The idea is very simple. Use three variables to represent the current node and the previous and next nodes of current node. Although this question is very simple, it is an regular interview question.
The following code is implement of the algorithm.
```js
var reverseList = function(head) {
// Judge the problem of variable boundary
if (!head || !head.next) return head
// The initial setting is empty because the first node is the tail when it is inverted, and the tail node points to null
let pre = null
let current = head
let next
// Judge if the current node is empty
// Get the next node of the current node if it is not empty
// Then set the next node of current to the previous node.
// Then set current to the next node and pre to the current node
while(current) {
next = current.next
current.next = pre
pre = current
current = next
}
return pre
};
```
# Tree
## Preorder, Inorder, Postorder Traversal of Binary Tree
Preorder traversal means that the root node is accessed first, then the left node is accessed, and the right node is accessed last.
Inorder traversal means that the left node is accessed first, then the root node is accessed, and the right node is accessed last.
Postorder traversal means that the left node is accessed first, then the right node is accessed, and the root node is accessed last.
### Recursive Implementation
Recursive implementation is quite simple, the code is as follows.
```js
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
var traversal = function(root) {
if (root) {
// Preorder
console.log(root);
traversal(root.left);
// Inorder
// console.log(root);
traversal(root.right);
// Postorder
// console.log(root);
}
};
```
For recursive implementation, you only need to understand that each node will be accessed three times so you will understand why this is done.
### Non-Recursive Implementation
The non-recursive implementation uses the structure of the stack, realize the recursive implementation by implementing the FILO of the stack.
The following code is implementation of the preorder traversal.
```js
function pre(root) {
if (root) {
let stack = [];
// Push the root node first
stack.push(root);
// Determine if the stack is empty
while (stack.length > 0) {
// Pop the top element
root = stack.pop();
console.log(root);
// Because the preorder traversal is first left and then right,
// the stack is a structure of FILO.
// So push the right node and then push the left node.
if (root.right) {
stack.push(root.right);
}
if (root.left) {
stack.push(root.left);
}
}
}
}
```
The following code is implementation of the inorder traversal.
```js
function mid(root) {
if (root) {
let stack = [];
// The inorder traversal is first left, then root and last right node
// So first should traverse the left node and push it to the stack.
// When there is no node on the left,
// the top node is printed and then find the right node.
// For the leftmost leaf node,
// you can think of it as the parent of two null nodes.
// If you can't print anything on the left,
// take the parent node out and print it, then look at the right node.
while (stack.length > 0 || root) {
if (root) {
stack.push(root);
root = root.left;
} else {
root = stack.pop();
console.log(root);
root = root.right;
}
}
}
}
```
The following code is the postorder traversal implementation that uses two stacks to implement traversal, which is easier to understand than a stack traversal.
```js
function pos(root) {
if (root) {
let stack1 = [];
let stack2 = [];
// Postorder traversal is first left, then right and last root node
// So for a stack, you should first push the root node
// Then push the right node, and finally push the left node
stack1.push(root);
while (stack1.length > 0) {
root = stack1.pop();
stack2.push(root);
if (root.left) {
stack1.push(root.left);
}
if (root.right) {
stack1.push(root.right);
}
}
while (stack2.length > 0) {
console.log(s2.pop());
}
}
}
```
## Predecessor and Successor Nodes of the Inorder Traversal
The premise of implementing this algorithm is that the node has a `parent` pointer to the parent node and a root node to `null` .
<div align="center"><img src="https://user-gold-cdn.xitu.io/2018/4/24/162f61ad8e8588b7?w=682&h=486&f=png&s=41027" width=400 /></div>
As shown, the tree's inorder traversal result is `4, 2, 5, 1, 6, 3, 7`
### Predecessor Node
For node `2`, his predecessor node is`4 `. According to the principle of inorder traversal, the following conclusions can be drawn.
1. If the left node of the selected node is not empty, look for the rightmost node of the left node. For node `1`, he has left node `2`, then the rightmost node of node `2` is `5`
2. If the left node is empty and the target node is the right node of the parent node, then the predecessor node is the parent node. For node `5`, there is no left node and it is the right node of node `2`, so node `2` is the precursor node.
3. If the left node is empty and the target node is the left node of the parent node, look up the first node that is the right node of the parent node. For node `6`, there is no left node, and it is the left node of node `3`. So look up to node `1` and find that node `3` is the right node of node `1`, so node `1` is the predecessor of node `6`.
The following code is implement of the algorithm.
```js
function predecessor(node) {
if (!node) return
// Conclusion 1
if (node.left) {
return getRight(node.left)
} else {
let parent = node.parent
// Conclusion 2 3 judgment
while(parent && parent.right === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getRight(node) {
if (!node) return
node = node.right
while(node) node = node.right
return node
}
```
### Successor Node
For node `2`, his successor is `5`, according to the principle of inorder traversal, you can draw the following conclusions.
1. If there is a right node, the leftmost node of the right node will be found. For node `1`, he has a right node `3`, then the leftmost node of node `3` is `6`.
2. If there is no right node, it traverses up until it finds a node that is the left node of the parent node. For node `5`, if there is no right node, it will look up to node `2`, which is the left node of parent node `1`, so node `1` is the successor node.
The following code is implement of the algorithm.
```js
function successor(node) {
if (!node) return
// Conclusion 1
if (node.right) {
return getLeft(node.right)
} else {
// Conclusion 2
let parent = node.parent
// Judge parent if it is empty
while(parent && parent.left === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getLeft(node) {
if (!node) return
node = node.left
while(node) node = node.left
return node
}
```
## Depth of the Tree
**Maximum Depth of the Tree**:The topic comes from [Leetcode](https://leetcode.com/problems/maximum-depth-of-binary-tree/description/),The problem needs to find the maximum depth of a binary tree.
The following code is implement of the algorithm.
```js
var maxDepth = function(root) {
if (!root) return 0
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1
};
```
For this recursive function, you can understand that if you don't find the node, it will return 0. Each time you pop up, the recursive function will add one. If you have three layers, you will get 3.
# Dynamic Programming
The basic principle behind dynamic programming is very simple. It split a problem into sub-problems. Generally speaking, these sub-problems are very similar. Then we can reduce the amount of calculation by solving only one sub-problem once.
Once the solution for each sub-problem is derived, the result is stored for next use.
## Fibonacci Sequence
The Fibonacci sequence starts with 0 and 1, and the following numbers are the sum of the first two numbers.
0,1,1,2,3,5,8,13,21,34,55,89....
So obviously easy to see, we can complete the Fibonacci sequence by recursively.
```js
function fib(n) {
if (n < 2 && n >= 0) return n
return fib(n - 1) + fib(n - 2)
}
fib(10)
```
The above code has been able to solve the problem perfectly. However, the above solution has serious performance problems. When n is larger, the time required is exponentially increasing. At this time, dynamic programming can solve this problem.
The essence of dynamic programming is actually two points.
1. Bottom-up decomposition problem
2. Store the already calculated solution by variable
According to the above two points, the dynamic programming of our Fibonacci sequence is coming out.
1. The Fibonacci sequence starts with 0 and 1, then this is the bottom of the sub-problem
2. Store the value of the corresponding Fibonacci sequence for each bit through an array
```js
function fib(n) {
let array = new Array(n + 1).fill(null)
array[0] = 0
array[1] = 1
for (let i = 2; i <= n; i++) {
array[i] = array[i - 1] + array[i - 2]
}
return array[n]
}
fib(10)
```
## 0 - 1 Backpack Problem
The problem can be described as: given a group of goods, each good has its own weight and price, How can we choose to make the highest total price of the good within a limited total weight. Each question can only be placed at most once.
Suppose we have the following goods.
| Goods ID / Weight | Value |
| :---------------: | :---: |
| 1 | 3 |
| 2 | 7 |
| 3 | 12 |
For a backpack with a total capacity of 5, we can put goods with weight 2 and 3 to achieve the highest total value of the goods in the backpack.
For this problem, there are two sub-problems, one is placing goods and another is not. You can use the following table to understand sub-questions.
| Goods ID / The remaining capacity | 0 | 1 | 2 | 3 | 4 | 5 |
| :-------------------------------: | :--: | :--: | :--: | :--: | :--: | :--: |
| 1 | 0 | 3 | 3 | 3 | 3 | 3 |
| 2 | 0 | 3 | 7 | 10 | 10 | 10 |
| 3 | 0 | 3 | 7 | 12 | 15 | 19 |
Directly analyze the situation where three goods can be placed, that is the last line.
- When the capacity is less than 3, only the data corresponding to the previous row is taken because the current capacity cannot accommodate the good 3
- When the capacity is 3, consider two cases, placing the good 3 and another is not placing the good 3
- In the case of not placing good 3, the total value is 10
- In the case of placing good 3, the total value is 12, so goods should be placed 3
- When the capacity is 4, consider two cases, placing goods 3 and another is not placing goods 3
- In the case of not placing good 3, the total value is 10
- In the case of placing good 3, add the value of good 1 to get the total value of 15, so it should be placed in good 3
- When the capacity is 5, consider two cases, placing the good 3 and not placing the good 3
- In the case of not placing good 3, the total value is 10
- In the case of placing good 3, add the value of good 2 to get the total value of 19, so it should be placed in good 3
It is easier to understand the following code with the above table.
```js
/**
* @param {*} w Good weight
* @param {*} v Good value
* @param {*} C Total capacity
* @returns
*/
function knapsack(w, v, C) {
let length = w.length
if (length === 0) return 0
// Compare to the table, the generated two-dimensional array,
// the first dimension represents the good,
// and the second dimension represents the remaining capacity of the backpack.
// The elements in the second dimension represent the total value of the backpack good
let array = new Array(length).fill(new Array(C + 1).fill(null))
// Complete the solution of the bottom sub-problem
for (let i = 0; i <= C; i++) {
// Compare to the first line of the table, array[0] represents the good 1
// i represents the total remaining capacity
// When the remaining total capacity is greater than the weight of the good 1,
// record the total value of the backpack good, otherwise the value is 0.
array[0][i] = i >= w[0] ? v[0] : 0
}
// Solve sub-problems from bottom to up, starting with good 2
for (let i = 1; i < length; i++) {
for (let j = 0; j <= C; j++) {
// Solve the sub-problems here,
// divided into not to put the current good and put the current good
// First solve the total value of the backpack with not putting the current good.
// The value here is the value corresponding to the previous line in the corresponding table.
array[i][j] = array[i - 1][j]
// Determine whether the current remaining capacity can be placed in the current good.
if (j >= w[i]) {
// If you can put it, and then compare it.
// Put the current item and not put the current item,
// which backpack has a max total value
array[i][j] = Math.max(array[i][j], v[i] + array[i - 1][j - w[i]])
}
}
}
return array[length - 1][C]
}
```
## Longest Increasing Subsequence
The longest incrementing subsequence means finding out the longest incremental numbers in a set of numbers, such as
0, 3, 4, 17, 2, 8, 6, 10
For the above numbers, the longest increment subsequence is 0, 3, 4, 8, 10, which can be understood more clearly by the following table.
| Number | 0 | 3 | 4 | 17 | 2 | 8 | 6 | 10 |
| :----: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| Length | 1 | 2 | 3 | 4 | 2 | 4 | 4 | 5 |
Through the above table, you can clearly find a rule, find out the number just smaller than the current number, and add one based on the length of the small number.
The dynamic solution to this problem is very simple, directly on the code.
```js
function lis(n) {
if (n.length === 0) return 0
// Create an array of the same size as the parameter and fill it with a value of 1
let array = new Array(n.length).fill(1)
// Traversing from index 1, because the array has all been filled with 1
for (let i = 1; i < n.length; i++) {
// Traversing from index 0 to i
// Determine if the value on index i is greater than the previous value
for (let j = 0; j < i; j++) {
if (n[i] > n[j]) {
array[i] = Math.max(array[i], 1 + array[j])
}
}
}
let res = 1
for (let i = 0; i < array.length; i++) {
res = Math.max(res, array[i])
}
return res
}
```
# String Related
In the string correlation algorithm, Trie tree can solve many problems, and has good space and time complexity, such as the following problems.
- Word frequency statistics
- Prefix matching
If you don't know much about the Trie tree, you can go [here](../DataStruct/dataStruct-zh.md#trie) to read
================================================
FILE: Browser/browser-ch.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [事件机制](#%E4%BA%8B%E4%BB%B6%E6%9C%BA%E5%88%B6)
- [事件触发三阶段](#%E4%BA%8B%E4%BB%B6%E8%A7%A6%E5%8F%91%E4%B8%89%E9%98%B6%E6%AE%B5)
- [注册事件](#%E6%B3%A8%E5%86%8C%E4%BA%8B%E4%BB%B6)
- [事件代理](#%E4%BA%8B%E4%BB%B6%E4%BB%A3%E7%90%86)
- [跨域](#%E8%B7%A8%E5%9F%9F)
- [JSONP](#jsonp)
- [CORS](#cors)
- [document.domain](#documentdomain)
- [postMessage](#postmessage)
- [Event loop](#event-loop)
- [Node 中的 Event loop](#node-%E4%B8%AD%E7%9A%84-event-loop)
- [timer](#timer)
- [I/O](#io)
- [idle, prepare](#idle-prepare)
- [poll](#poll)
- [check](#check)
- [close callbacks](#close-callbacks)
- [存储](#%E5%AD%98%E5%82%A8)
- [cookie,localStorage,sessionStorage,indexDB](#cookielocalstoragesessionstorageindexdb)
- [Service Worker](#service-worker)
- [渲染机制](#%E6%B8%B2%E6%9F%93%E6%9C%BA%E5%88%B6)
- [Load 和 DOMContentLoaded 区别](#load-%E5%92%8C-domcontentloaded-%E5%8C%BA%E5%88%AB)
- [图层](#%E5%9B%BE%E5%B1%82)
- [重绘(Repaint)和回流(Reflow)](#%E9%87%8D%E7%BB%98repaint%E5%92%8C%E5%9B%9E%E6%B5%81reflow)
- [减少重绘和回流](#%E5%87%8F%E5%B0%91%E9%87%8D%E7%BB%98%E5%92%8C%E5%9B%9E%E6%B5%81)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# 事件机制
## 事件触发三阶段
事件触发有三个阶段
- `window` 往事件触发处传播,遇到注册的捕获事件会触发
- 传播到事件触发处时触发注册的事件
- 从事件触发处往 `window` 传播,遇到注册的冒泡事件会触发
事件触发一般来说会按照上面的顺序进行,但是也有特例,如果给一个目标节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行。
```js
// 以下会先打印冒泡然后是捕获
node.addEventListener('click',(event) =>{
console.log('冒泡')
},false);
node.addEventListener('click',(event) =>{
console.log('捕获 ')
},true)
```
## 注册事件
通常我们使用 `addEventListener` 注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值 `useCapture` 参数来说,该参数默认值为 `false` 。`useCapture` 决定了注册的事件是捕获事件还是冒泡事件。对于对象参数来说,可以使用以下几个属性
- `capture`,布尔值,和 `useCapture` 作用一样
- `once`,布尔值,值为 `true` 表示该回调只会调用一次,调用后会移除监听
- `passive`,布尔值,表示永远不会调用 `preventDefault`
一般来说,我们只希望事件只触发在目标上,这时候可以使用 `stopPropagation` 来阻止事件的进一步传播。通常我们认为 `stopPropagation` 是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。`stopImmediatePropagation` 同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件。
```js
node.addEventListener('click',(event) =>{
event.stopImmediatePropagation()
console.log('冒泡')
},false);
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener('click',(event) => {
console.log('捕获 ')
},true)
```
## 事件代理
如果一个节点中的子节点是动态生成的,那么子节点需要注册事件的话应该注册在父节点上
```html
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
<script>
let ul = document.querySelector('#ul')
ul.addEventListener('click', (event) => {
console.log(event.target);
})
</script>
```
事件代理的方式相对于直接给目标注册事件来说,有以下优点
- 节省内存
- 不需要给子节点注销事件
# 跨域
因为浏览器出于安全考虑,有同源策略。也就是说,如果协议、域名或者端口有一个不同就是跨域,Ajax 请求会失败。
我们可以通过以下几种常用方法解决跨域的问题
## JSONP
JSONP 的原理很简单,就是利用 `<script>` 标签没有跨域限制的漏洞。通过 `<script>` 标签指向一个需要访问的地址并提供一个回调函数来接收数据当需要通讯时。
```js
<script src="http://domain/api?param1=a¶m2=b&callback=jsonp"></script>
<script>
function jsonp(data) {
console.log(data)
}
</script>
```
JSONP 使用简单且兼容性不错,但是只限于 `get` 请求。
在开发中可能会遇到多个 JSONP 请求的回调函数名是相同的,这时候就需要自己封装一个 JSONP,以下是简单实现
```js
function jsonp(url, jsonpCallback, success) {
let script = document.createElement("script");
script.src = url;
script.async = true;
script.type = "text/javascript";
window[jsonpCallback] = function(data) {
success && success(data);
};
document.body.appendChild(script);
}
jsonp(
"http://xxx",
"callback",
function(value) {
console.log(value);
}
);
```
## CORS
CORS需要浏览器和后端同时支持。IE 8 和 9 需要通过 `XDomainRequest` 来实现。
浏览器会自动进行 CORS 通信,实现CORS通信的关键是后端。只要后端实现了 CORS,就实现了跨域。
服务端设置 `Access-Control-Allow-Origin` 就可以开启 CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源。
## document.domain
该方式只能用于二级域名相同的情况下,比如 `a.test.com` 和 `b.test.com` 适用于该方式。
只需要给页面添加 `document.domain = 'test.com'` 表示二级域名都相同就可以实现跨域
## postMessage
这种方式通常用于获取嵌入页面中的第三方页面数据。一个页面发送消息,另一个页面判断来源并接收消息
```js
// 发送消息端
window.parent.postMessage('message', 'http://test.com');
// 接收消息端
var mc = new MessageChannel();
mc.addEventListener('message', (event) => {
var origin = event.origin || event.originalEvent.origin;
if (origin === 'http://test.com') {
console.log('验证通过')
}
});
```
# Event loop
众所周知 JS 是门非阻塞单线程语言,因为在最初 JS 就是为了和浏览器交互而诞生的。如果 JS 是门多线程的语言话,我们在多个线程中处理 DOM 就可能会发生问题(一个线程中新加节点,另一个线程中删除节点),当然可以引入读写锁解决这个问题。
JS 在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到 Task(有多种 task) 队列中。一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说 JS 中的异步还是同步行为。
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
```
以上代码虽然 `setTimeout` 延时为 0,其实还是异步。这是因为 HTML5 标准规定这个函数第二个参数不得小于 4 毫秒,不足会自动增加。所以 `setTimeout` 还是会在 `script end` 之后打印。
不同的任务源会被分配到不同的 Task 队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在 ES6 规范中,microtask 称为 `jobs`,macrotask 称为 `task`。
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
```
以上代码虽然 `setTimeout` 写在 `Promise` 之前,但是因为 `Promise` 属于微任务而 `setTimeout` 属于宏任务,所以会有以上的打印。
微任务包括 `process.nextTick` ,`promise` ,`Object.observe` ,`MutationObserver`
宏任务包括 `script` , `setTimeout` ,`setInterval` ,`setImmediate` ,`I/O` ,`UI rendering`
很多人有个误区,认为微任务快于宏任务,其实是错误的。因为宏任务中包括了 `script` ,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务。
所以正确的一次 Event loop 顺序是这样的
1. 执行同步代码,这属于宏任务
2. 执行栈为空,查询是否有微任务需要执行
3. 执行所有微任务
4. 必要的话渲染 UI
5. 然后开始下一轮 Event loop,执行宏任务中的异步代码
通过上述的 Event loop 顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的 界面响应,我们可以把操作 DOM 放入微任务中。
## Node 中的 Event loop
Node 中的 Event loop 和浏览器中的不相同。
Node 的 Event loop 分为6个阶段,它们会按照顺序反复运行
```
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
```
### timer
timers 阶段会执行 `setTimeout` 和 `setInterval`
一个 `timer` 指定的时间并不是准确时间,而是在达到这个时间后尽快执行回调,可能会因为系统正在执行别的事务而延迟。
下限的时间有一个范围:`[1, 2147483647]` ,如果设定的时间不在这个范围,将被设置为1。
### I/O
I/O 阶段会执行除了 close 事件,定时器和 `setImmediate` 的回调
### idle, prepare
idle, prepare 阶段内部实现
### poll
poll 阶段很重要,这一阶段中,系统会做两件事情
1. 执行到点的定时器
2. 执行 poll 队列中的事件
并且当 poll 中没有定时器的情况下,会发现以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者系统限制
- 如果 poll 队列为空,会有两件事发生
- 如果有 `setImmediate` 需要执行,poll 阶段会停止并且进入到 check 阶段执行 `setImmediate`
- 如果没有 `setImmediate` 需要执行,会等待回调被加入到队列中并立即执行回调
如果有别的定时器需要被执行,会回到 timer 阶段执行回调。
### check
check 阶段执行 `setImmediate`
### close callbacks
close callbacks 阶段执行 close 事件
并且在 Node 中,有些情况下的定时器执行顺序是随机的
```js
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 这里可能会输出 setTimeout,setImmediate
// 可能也会相反的输出,这取决于性能
// 因为可能进入 event loop 用了不到 1 毫秒,这时候会执行 setImmediate
// 否则会执行 setTimeout
```
当然在这种情况下,执行顺序是相同的
```js
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// 因为 readFile 的回调在 poll 中执行
// 发现有 setImmediate ,所以会立即跳到 check 阶段执行回调
// 再去 timer 阶段执行 setTimeout
// 所以以上输出一定是 setImmediate,setTimeout
```
上面介绍的都是 macrotask 的执行情况,microtask 会在以上每个阶段完成后立即执行。
```js
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// 以上代码在浏览器和 node 中打印情况是不同的
// 浏览器中一定打印 timer1, promise1, timer2, promise2
// node 中可能打印 timer1, timer2, promise1, promise2
// 也可能打印 timer1, promise1, timer2, promise2
```
Node 中的 `process.nextTick` 会先于其他 microtask 执行。
```js
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
process.nextTick(() => {
console.log("nextTick");
});
// nextTick, timer1, promise1
```
# 存储
## cookie,localStorage,sessionStorage,indexDB
| 特性 | cookie | localStorage | sessionStorage | indexDB |
| :----------: | :----------------------------------------: | :----------------------: | :------------: | :----------------------: |
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在 header 中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,`cookie` 已经不建议用于存储。如果没有大量数据存储需求的话,可以使用 `localStorage` 和 `sessionStorage` 。对于不怎么改变的数据尽量使用 `localStorage` 存储,否则可以用 `sessionStorage` 存储。
对于 `cookie`,我们还需要注意安全性。
| 属性 | 作用 |
| :-------: | :----------------------------------------------------------: |
| value | 如果用于保存用户登录态,应该将该值加密,不能使用明文的用户标识 |
| http-only | 不能通过 JS 访问 Cookie,减少 XSS 攻击 |
| secure | 只能在协议为 HTTPS 的请求中携带 |
| same-site | 规定浏览器不能在跨域请求中携带 Cookie,减少 CSRF 攻击 |
## Service Worker
> Service workers 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API。
目前该技术通常用来做缓存文件,提高首屏速度,可以试着来实现这个功能。
```js
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register("sw.js")
.then(function(registration) {
console.log("service worker 注册成功");
})
.catch(function(err) {
console.log("servcie worker 注册失败");
});
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener("install", e => {
e.waitUntil(
caches.open("my-cache").then(function(cache) {
return cache.addAll(["./index.html", "./index.js"]);
})
);
});
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener("fetch", e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response;
}
console.log("fetch source");
})
);
});
```
打开页面,可以在开发者工具中的 `Application` 看到 Service Worker 已经启动了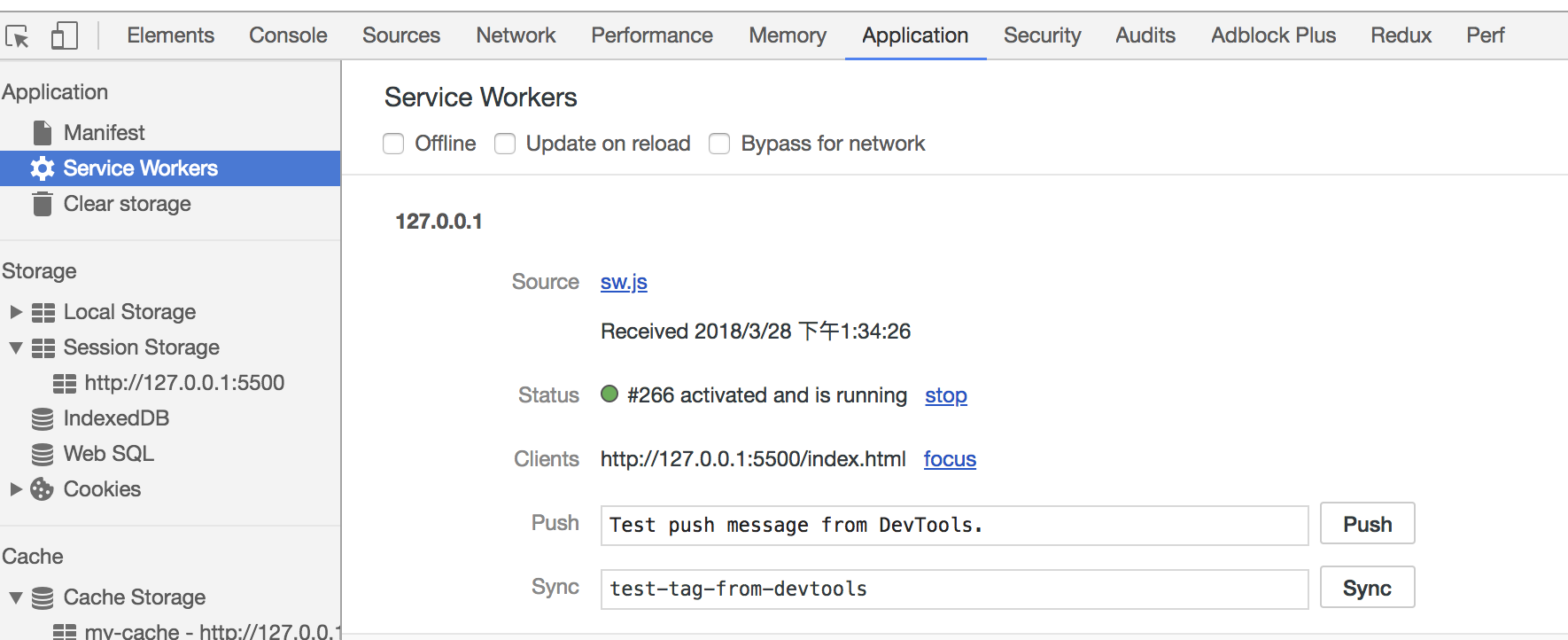
在 Cache 中也可以发现我们所需的文件已被缓存
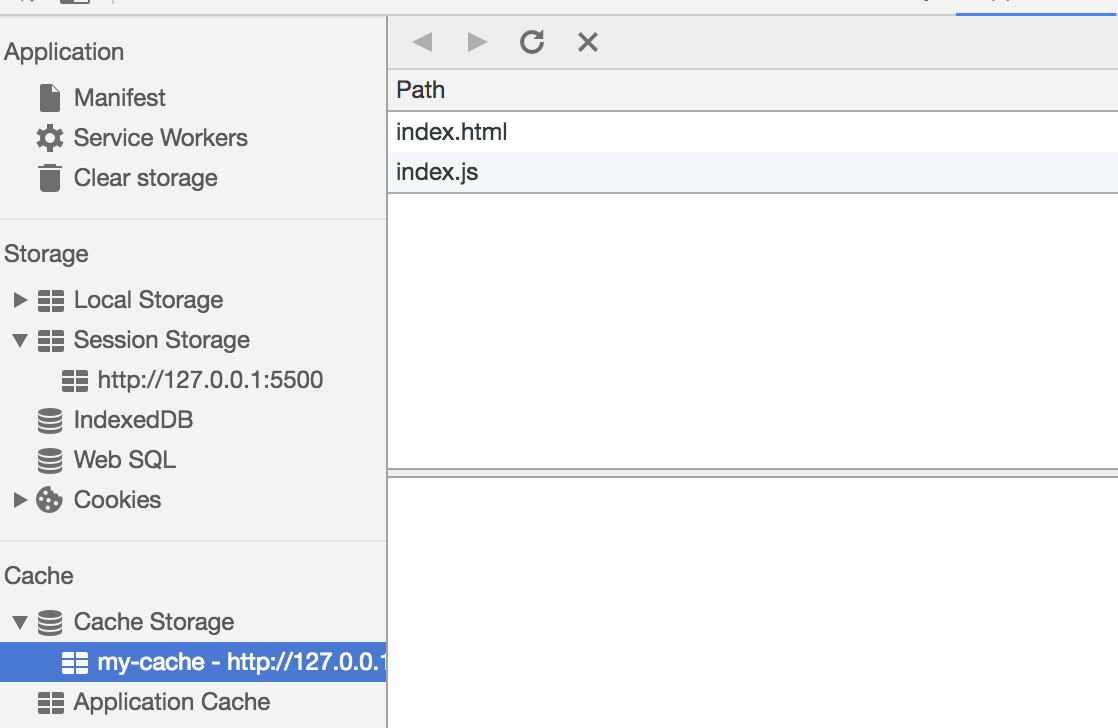
当我们重新刷新页面可以发现我们缓存的数据是从 Service Worker 中读取的

# 渲染机制
浏览器的渲染机制一般分为以下几个步骤
1. 处理 HTML 并构建 DOM 树。
2. 处理 CSS 构建 CSSOM 树。
3. 将 DOM 与 CSSOM 合并成一个渲染树。
4. 根据渲染树来布局,计算每个节点的位置。
5. 调用 GPU 绘制,合成图层,显示在屏幕上。
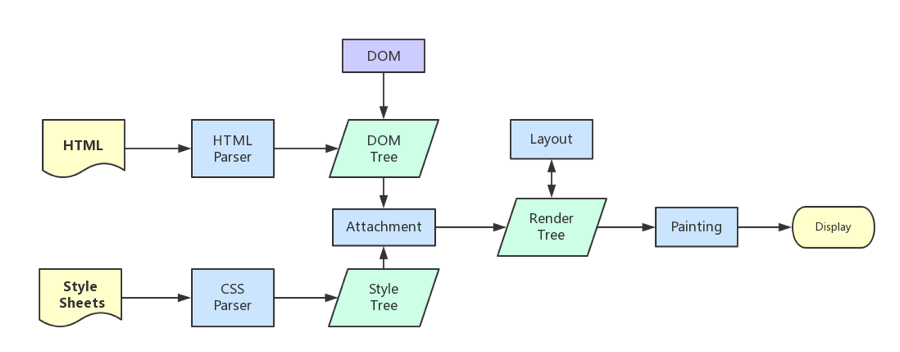
在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM 树构建完成。并且构建 CSSOM 树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的 CSS 选择器,执行速度越慢。
当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM。
## Load 和 DOMContentLoaded 区别
Load 事件触发代表页面中的 DOM,CSS,JS,图片已经全部加载完毕。
DOMContentLoaded 事件触发代表初始的 HTML 被完全加载和解析,不需要等待 CSS,JS,图片加载。
## 图层
一般来说,可以把普通文档流看成一个图层。特定的属性可以生成一个新的图层。**不同的图层渲染互不影响**,所以对于某些频繁需要渲染的建议单独生成一个新图层,提高性能。**但也不能生成过多的图层,会引起反作用。**
通过以下几个常用属性可以生成新图层
- 3D 变换:`translate3d`、`translateZ`
- `will-change`
- `video`、`iframe` 标签
- 通过动画实现的 `opacity` 动画转换
- `position: fixed`
## 重绘(Repaint)和回流(Reflow)
重绘和回流是渲染步骤中的一小节,但是这两个步骤对于性能影响很大。
- 重绘是当节点需要更改外观而不会影响布局的,比如改变 `color` 就叫称为重绘
- 回流是布局或者几何属性需要改变就称为回流。
回流必定会发生重绘,重绘不一定会引发回流。回流所需的成本比重绘高的多,改变深层次的节点很可能导致父节点的一系列回流。
所以以下几个动作可能会导致性能问题:
- 改变 window 大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
很多人不知道的是,重绘和回流其实和 Event loop 有关。
1. 当 Event loop 执行完 Microtasks 后,会判断 document 是否需要更新。因为浏览器是 60Hz 的刷新率,每 16ms 才会更新一次。
2. 然后判断是否有 `resize` 或者 `scroll` ,有的话会去触发事件,所以 `resize` 和 `scroll` 事件也是至少 16ms 才会触发一次,并且自带节流功能。
3. 判断是否触发了 media query
4. 更新动画并且发送事件
5. 判断是否有全屏操作事件
6. 执行 `requestAnimationFrame` 回调
7. 执行 `IntersectionObserver` 回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好
8. 更新界面
9. 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行 `requestIdleCallback` 回调。
以上内容来自于 [HTML 文档](https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model)
## 减少重绘和回流
- 使用 `translate` 替代 `top`
```html
<div class="test"></div>
<style>
.test {
position: absolute;
top: 10px;
width: 100px;
height: 100px;
background: red;
}
</style>
<script>
setTimeout(() => {
// 引起回流
document.querySelector('.test').style.top = '100px'
}, 1000)
</script>
```
- 使用 `visibility` 替换 `display: none` ,因为前者只会引起重绘,后者会引发回流(改变了布局)
- 把 DOM 离线后修改,比如:先把 DOM 给 `display:none` (有一次 Reflow),然后你修改100次,然后再把它显示出来
- 不要把 DOM 结点的属性值放在一个循环里当成循环里的变量
```js
for(let i = 0; i < 1000; i++) {
// 获取 offsetTop 会导致回流,因为需要去获取正确的值
console.log(document.querySelector('.test').style.offsetTop)
}
```
- 不要使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局
- 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用 `requestAnimationFrame`
- CSS 选择符从右往左匹配查找,避免 DOM 深度过深
- 将频繁运行的动画变为图层,图层能够阻止该节点回流影响别的元素。比如对于 `video` 标签,浏览器会自动将该节点变为图层。
================================================
FILE: Browser/browser-en.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Event mechanism](#event-mechanism)
- [The three phases of event propagation](#the-three-phases-of-event-propagation)
- [Event Registration](#event-registration)
- [Event Delegation](#event-delegation)
- [Cross Domain](#cross-domain)
- [JSONP](#jsonp)
- [CORS](#cors)
- [document.domain](#documentdomain)
- [postMessage](#postmessage)
- [Event Loop](#event-loop)
- [Event Loop in Node](#event-loop-in-node)
- [timer](#timer)
- [pending callbacks](#pending-callbacks)
- [idle, prepare](#idle-prepare)
- [poll](#poll)
- [check](#check)
- [close callbacks](#close-callbacks)
- [Storage](#storage)
- [cookie,localStorage,sessionStorage,indexDB](#cookielocalstoragesessionstorageindexdb)
- [Service Worker](#service-worker)
- [Rendering mechanism](#rendering-mechanism)
- [Difference between Load & DOMContentLoaded](#difference-between-load--domcontentloaded)
- [Layers](#layers)
- [Repaint & Reflow](#repaint--reflow)
- [Minimize Repaint & Reflow](#minimize-repaint--reflow)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# Event mechanism
## The three phases of event propagation
Event propagation has three phases:
- The event object propagates from the Window to the target’s parent. Capturing events will trigger.
- The event object arrives at the event object’s event target. Events registered to target will trigger.
- The event object propagates from the target's parent up to the Window. Bubbling events will trigger.
Event propagation generally follows the above sequence, but there are exceptions. If a target node is registered for both bubbling and capturing events, events are invoked in the order they were registered.
```js
// The following code will print bubbling first and then trigger capture events
node.addEventListener('click',(event) =>{
console.log('bubble')
},false);
node.addEventListener('click',(event) =>{
console.log('capture')
},true)
```
## Event Registration
Usually, we use `addEventListener` to register an event, and the `useCapture` is a function parameter, which receives a Boolean value, the default value is `false`. `useCapture` determines whether the registered event is a capturing event or a bubbling event. For the object parameter, you can use the following properties:
- `capture`, Boolean value, same as `useCapture`
- `once`, Boolean value, `true` indicating that the callback should be called at most once, after invoked the listener will be removed
- `passive`, Boolean, means it will never call `preventDefault`
Generally speaking, we only want the event to trigger on the target. To achieve this we can use `stopPropagation` to prevent the propagation of the event. Usually, we would think that `stopPropagation` is used to stop the event bubbling, but this function can also prevent the event capturing. `stopImmediatePropagation` can achieve the same effects, and it can also prevent other listeners of the same event from being called.
```js
node.addEventListener('click',(event) =>{
event.stopImmediatePropagation()
console.log('bubbling')
},false);
// Clicking node will only execute the above function, this function will not execute
node.addEventListener('click',(event) => {
console.log('capture ')
},true)
```
## Event Delegation
If a child node inside a parent node is dynamically generated, events on the child node should be added to parent node:
```html
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
<script>
let ul = document.querySelector('#ul')
ul.addEventListener('click', (event) => {
console.log(event.target);
})
</script>
```
Event delegation has the following advantages over adding events straight to child nodes:
- Save memory
- No need remove event listeners on child nodes
# Cross Domain
Browsers have the same-origin policy for security reasons. In other words, if the protocol, domain name or port has one difference, that would be cross-domain, and the Ajax request will fail.
We can solve the cross-domain issues through following methods:
## JSONP
The principle of JSONP is very simple, that is to make use of the `<script>` tag not subject to same-origin policy. Use the `src` attribute of `<script>` tag and provide a callback function to receive data:
```js
<script src="http://domain/api?param1=a¶m2=b&callback=jsonp"></script>
<script>
function jsonp(data) {
console.log(data)
}
</script>
```
JSONP is simple to use and has good compatibility, but is limited to `get` requests.
You may encounter the situation where you have the same callback names in multiple JSONP requests. In this situation you need to encapsulate JSONP. The following is a simple implementation:
```js
function jsonp(url, jsonpCallback, success) {
let script = document.createElement("script");
script.src = url;
script.async = true;
script.type = "text/javascript";
window[jsonpCallback] = function(data) {
success && success(data);
};
document.body.appendChild(script);
}
jsonp(
"http://xxx",
"callback",
function(value) {
console.log(value);
}
);
```
## CORS
CORS requires browser and backend support at the same time. Internet Explorer 8 and 9 expose CORS via the XDomainRequest object.
The browser will automatically perform CORS. The key to implementing CORS is the backend. As long as the backend implements CORS, it enables cross-domain.
The server sets `Access-Control-Allow-Origin` to enable CORS. This property specifies which domains can access the resource. If set to wildcard, all websites can access the resource.
## document.domain
This can only be used for the same second-level domain, for example, `a.test.com` and `b.test.com` are suitable for this case.
Set `document.domain = 'test.com'` would enable CORS within the same second-level domain.
## postMessage
This method is usually used to get data from embedded third-party page. One page sends a message, the other page checks the source and receives the message:
```js
// send of page
window.parent.postMessage('message', 'http://test.com');
// receive of page
var mc = new MessageChannel();
mc.addEventListener('message', (event) => {
var origin = event.origin || event.originalEvent.origin;
if (origin === 'http://test.com') {
console.log('success')
}
});
```
# Event Loop
As we all know, JS is a non-blocking and single-threaded language, because JS was born to interact with the browser in the beginning. If JS was a multi-threaded language, we might have problems handling DOM in multiple threads (imagine adding nodes in a thread and deleting nodes in another thread at the same time), however we could introduce a read-write lock to solve this problem.
Execution context, generated during JS execution, will be pushed into call stack sequentially. Asynchronous codes will hang up and get pushed into the task queues (there are multiple kinds of tasks). Once the call stack is empty, the Event Loop will process the next message in the task queues and push it into the call stack for execution, thus essentially the asynchronous operation in JS is actually synchronous.
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
```
The above code is asynchronous, even though the `setTimeout` delay is 0. That’s because the HTML5 standard stipulates that the second parameter of the function `setTimeout` must not be less than 4 milliseconds, otherwise it will automatically . So `setTimeout` is still logged after `script end`.
Different tasks are assigned to different Task queues. Tasks can be divided into `microtasks` and `macrotasks`. In the ES6 specification, a `microtask` is called a `job` and a `macrotask` is called a `task`.
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
```
Although `setTimeout` is set before `Promise`, the above printing still occurs because `Promise` belongs to microtask and `setTimeout` belongs to macrotask.
Microtasks include `process.nextTick`, `promise`, `Object.observe` and `MutationObserver`.
Macrotasks include `script`, `setTimeout`, `setInterval`, `setImmediate`, `I/O` and `UI rendering`.
Many people have the misunderstanding that microtasks always get executed before macrotasks and this is incorrect. Because the macrotask includes `script`, the browser will perform this macrotask first, followed by any microtasks in asynchronous codes.
So the correct sequence of an event loop looks like this:
1. Execute synchronous codes, which belongs to macrotask
2. Once call stack is empty, query if any microtasks need to be executed
3. Execute all the microtasks
4. If necessary, render the UI
5. Then start the next round of the Event loop, and execute the asynchronous operations in the macrotask
According to the above sequence of the event loop, if the asynchronous codes in the macrotask have a large number of calculations and need to operate on DOM, we can put DOM operation into microtask for faster interface response.
## Event Loop in Node
The event loop in Node is not the same as in the browser.
The event loop in Node is divided into 6 phases, and they will be executed in order repeatedly:
```
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ pending callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──---| connections │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
```
### timer
The `timer` phase executes the callbacks of `setTimeout` and `setInterval`.
`Timer` specifies the time that callbacks will run as early as they can be scheduled, after the specified amount of time has passed rather than the exact time a person wants it to be executed.
The lower bound time has a range: `[1, 2147483647]`. If the set time is not in this range, it will be set to 1.
### pending callbacks
This phase executes I/O callbacks deferred to the next loop iteration.
### idle, prepare
The `idle, prepare` phase is for internal implementation.
### poll
This phase retrieves new I/O events; execute I/O related callbacks (almost all with the exception of close callbacks, the ones scheduled by timers, and setImmediate()); node will block here when appropriate.
The `poll` phase has two main functions:
1. Calculating how long it should block and poll for I/O, then
2. Processing events in the poll queue.
When the event loop enters the `poll` phase and there are no timers scheduled, one of two things will happen:
- If the `poll` queue is not empty, the event loop will iterate through its queue of callbacks executing them synchronously until either the queue has been exhausted, or the system-dependent hard limit is reached.
- If the `poll` queue is empty, one of two more things will happen:
1. If scripts have been scheduled by `setImmediate`. the event loop will end the `poll` phase and continue to the check phase to execute those scheduled scripts.
2. If scripts have not been scheduled by `setImmediate`, the event loop will wait for callbacks to be added to the queue, then execute them immediately.
Once the `poll` queue is empty the event loop will check for timers whose time thresholds have been reached. If one or more timers are ready, the event loop will wrap back to the timers phase to execute those timers' callbacks.
### check
The `check` phase executes the callbacks of `setImmediate`.
### close callbacks
The `close` event will be emitted in this phase.
And in Node, the order of execution of timers is random in some cases:
```js
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// Here, it may log setTimeout => setImmediate
// It is also possible to log the opposite result, which depends on performance
// Because it may take less than 1 millisecond to enter the event loop, `setImmediate` would be executed at this time.
// Otherwise it will execute `setTimeout`
```
Certainly, in this case, the execution order is the same:
```js
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// Because the callback of `readFile` was executed in `poll` phase
// Founding `setImmediate`,it immediately jumps to the `check` phase to execute the callback
// and then goes to the `timer` phase to execute `setTimeout`
// so the above output must be `setImmediate` => `setTimeout`
```
The above is the implementation of the macrotask. The microtask will be executed immediately after each phase is completed.
```js
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// The log result is different, when the above code is executed in browser and node
// In browser, it will log: timer1 => promise1 => timer2 => promise2
// In node, it may log: timer1 => timer2 => promise1 => promise2
// or timer1, promise1, timer2, promise2
```
`process.nextTick` in Node will be executed before other microtasks.
```js
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
process.nextTick(() => {
console.log("nextTick");
});
// nextTick => timer1 => promise1
```
# Storage
## cookie,localStorage,sessionStorage,indexDB
| features | cookie | localStorage | sessionStorage | indexDB |
| :---------------------: | :----------------------------------------------------------: | :---------------------------------------: | :----------------------------------------------------------: | :---------------------------------------: |
| Life cycle of data | generally generated by the server, but you can set the expiration time | unless cleared manually, it always exists | once the browser tab is closed, it will be cleaned up immediately | unless cleared manually, it always exists |
| Storage size of data | 4K | 5M | 5M | unlimited |
| Communication with server | it is carried in the header everytime, and has a performance impact on the request | doesn't participate | doesn't participate | doesn't participate |
As we can see from the above table, `cookies` are no longer recommended for storage. We can use `localStorage` and `sessionStorage` if we don't have much data to store. Use `localStorage` to store data that doesn't change much, otherwise `sessionStorage` can be used.
For `cookies`, we also need pay attention to security issue.
| attribute | effect |
| :-------: | :----------------------------------------------------------: |
| value | the value should be encrypted if used to save the login state, and the cleartext user ID shouldn't be used |
| http-only | cookies cannot be accessed through JS, for reducing XSS attack |
| secure | cookies can only be carried in requests with HTTPS protocol |
| same-site | browsers cannot pass cookies in cross-origin requests, for reducing CSRF attacks |
## Service Worker
> Service workers essentially act as proxy servers that sit between web applications, the browser and the network (when available). They are intended, among other things, to enable the creation of effective offline experiences, intercept network requests and take appropriate action based on whether the network is available, and update assets residing on the server. They will also allow access to push notifications and background sync APIs.
At present, this technology is usually used to cache files and increase the render speed of the first screen. We can try to implement this function:
```js
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register("sw.js")
.then(function(registration) {
console.log("service worker register success");
})
.catch(function(err) {
console.log("servcie worker register error");
});
}
// sw.js
// Listen for the `install` event, and cache the required files in the callback
self.addEventListener("install", e => {
e.waitUntil(
caches.open("my-cache").then(function(cache) {
return cache.addAll(["./index.html", "./index.js"]);
})
);
});
// intercept all the request events
// use the cache directly if the requested data already existed in the cache; otherwise, send requests for data
self.addEventListener("fetch", e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response;
}
console.log("fetch source");
})
);
});
```
Open the page, we can see that the Service Worker has started in the `Application` pane of devTools:
In the Cache pane, we can also find that the files we need have been cached:

Refreshing the page, we can see that our cached data is read from the Service Worker:

# Rendering mechanism
The mechanism of the browser engine usually has the following steps:
1. Parse HTML to construct the DOM tree.
2. Parse CSS to construct the CSSOM tree.
3. Create the render tree by combining the DOM & CSSOM.
4. Run layout based on the render tree, then calculate each node's exact coordinates on the screen.
5. Paint elements by GPU, composite layers and display on the screen.
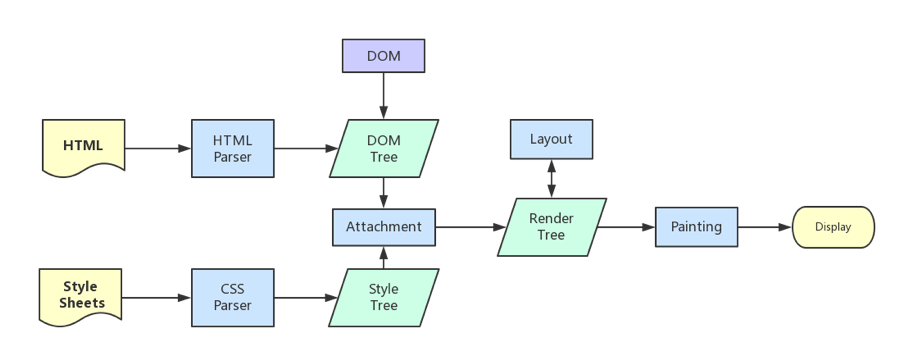
When building the CSSOM tree, the rendering is blocked until the CSSOM tree is built. And building the CSSOM tree is a very cost-intensive process, so you should try to ensure that the level is flat and reduce excessive cascading. The more specific the CSS selector is, the slower the execution.
When the HTML is parsing the script tag, the DOM is paused and will restart from the paused position. In other words, the faster you want to render the first screen, the less you should load the JS file on the first screen. And CSS will also affect the execution of JS. JS will only be executed when the stylesheet is parsed. Therefore, it can be considered that CSS will also suspend the DOM in this case.
## Difference between Load & DOMContentLoaded
**Load** event occurs when all the resources (e.g. DOM、CSS、JS、pictures) have been loaded.
**DOMContentLoaded** event occurs as soon as the HTML of the pages has been loaded, no matter whether the other resources have been loaded.
## Layers
Generally,we can treat the document flow as a single layer. Some special attributes also could create a new layer. **Different Layers are independent**. So, it is recommended to create a new layer to render some elements which changes frequently. **But it is also a bad idea to create too many layers.**
The following attributes usually can create a new layer:
- 3Dtranslate: `translate3d`, `translateZ`
- `will-change`
- tags like: `video`, `iframe`
- animation achieved by `opacity`
- `position: fixed`
## Repaint & Reflow
Repaint and Reflow is a small step in the main rendering flow, but they have a great impact on the performance.
- Repaint occurs when the node changes but doesn't affect the layout, e.g. `color`.
- Reflow occurs when the node changes caused by layout or the geometry attributes.
Reflow will trigger a Repaint, but the opposite is not necessarily true. Reflow is much more expensive than Repaint. The changes in deep level node's attributes may cause a series of changes of its ancestral nodes.
Actions like the following may cause performance problems:
- change the window's size
- change font-family
- add or delete styles
- change texts
- change position & float
- change box model
You may not know that Repaint and Reflow has something to do with the **Event Loop**.
- In a event loop, when a microtask finishes, the engine will check whether the document needs update. As the refresh rate of the browse is 60Hz, this means it will update every 16ms.
- Then browser would check whether there are events like `resize` or `scroll` and if true, trigger the handlers. So the handlers of resize and scroll will be invoked every 16ms, which means automatic throttling.
- Evaluate media queries and report changes.
- Update animations and send events.
- Check whether this is a full-screen event.
- Execute `requestAnimationFrame` callback.
- Execute `IntersectionObserver` callback, which is used to determine whether an element should be displaying, usually in lazy-load, but has poor compatibility.
- Update the screen.
- The above events may occur in every frame. If there is idle time, the `requestIdleCallback` callback will be called.
All of the above are from [HTML Documents](https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model).
## Minimize Repaint & Reflow
- Use `translate` instead of `top`:
```html
<div class="test"></div>
<style>
.test {
position: absolute;
top: 10px;
width: 100px;
height: 100px;
background: red;
}
</style>
<script>
setTimeout(() => {
// occurs reflow
document.querySelector('.test').style.top = '100px'
}, 1000)
</script>
```
- Use `visibility` instead of `display: none`, because the former will only cause Repaint while the latter will cause Reflow, which changes the layout.
- Change the DOM when it is offline, e.g. change the DOM 100 times after set it `display: none` and then show it on screen. During this process there is only one Reflow.
- Do not put an attribute of a node inside a loop:
```js
for(let i = 0; i < 1000; i++) {
// it will cause the reflow to get offsetTop, because it need to calculate the right value
console.log(document.querySelector('.test').style.offsetTop)
}
```
- Do not use table to construct the layout, because even a little change will cause the re-construct.
- Animation speed matters: the faster it goes, the more Reflow. You can also utilize `requestAnimationFrame`.
- The css selector will search to match from right to left, so you'd better avoid deep level DOM node.
- As we know that the layer will prevent the changed node from affecting others, so it is good practice to create a new layer for animations with high frequency.
================================================
FILE: Career/How-to-use-your-time-correctly.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [花时间补基础,读文档](#%E8%8A%B1%E6%97%B6%E9%97%B4%E8%A1%A5%E5%9F%BA%E7%A1%80%E8%AF%BB%E6%96%87%E6%A1%A3)
- [学会搜索](#%E5%AD%A6%E4%BC%9A%E6%90%9C%E7%B4%A2)
- [学点英语](#%E5%AD%A6%E7%82%B9%E8%8B%B1%E8%AF%AD)
- [画个图,想一想再做](#%E7%94%BB%E4%B8%AA%E5%9B%BE%E6%83%B3%E4%B8%80%E6%83%B3%E5%86%8D%E5%81%9A)
- [利用好下班时间学习](#%E5%88%A9%E7%94%A8%E5%A5%BD%E4%B8%8B%E7%8F%AD%E6%97%B6%E9%97%B4%E5%AD%A6%E4%B9%A0)
- [列好 ToDo](#%E5%88%97%E5%A5%BD-todo)
- [反思和整理](#%E5%8F%8D%E6%80%9D%E5%92%8C%E6%95%B4%E7%90%86)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
你是否时常会焦虑时间过的很快,没时间学习,本文将会分享一些个人的见解。
### 花时间补基础,读文档
在工作中我们时常会花很多时间去 debug,但是你是否发现很多问题最终只是你基础不扎实或者文档没有仔细看。
基础是你技术的基石,一定要花时间打好基础,而不是追各种新的技术。一旦你的基础扎实,学习各种新的技术也肯定不在话下,因为新的技术,究其根本都是相通的。
文档同样也是一门技术的基础。一个优秀的库,开发人员肯定已经把如何使用这个库都写在文档中了,仔细阅读文档一定会是少写 bug 的最省事路子。
### 学会搜索
如果你还在使用百度搜索编程问题,请尽快抛弃这个垃圾搜索引擎。同样一个关键字,使用百度和谷歌,谷歌基本完胜的。即使你使用中文在谷歌中搜索,得到的结果也往往是谷歌占优,所以如果你想迅速的通过搜索引擎来解决问题,那一定是谷歌。
### 学点英语
说到英语,一定是大家所最不想听的。其实我一直认为程序员学习英语是简单的,因为我们工作中是一直接触着英语,并且看懂技术文章,文档所需要的单词量是极少的。我时常在群里看到大家发出一个问题的截图问什么原因,其实在截图中英语已经很明白的说明了问题的所在,如果你的英语过关,完全不需要浪费时间来提问和搜索。所以我认为学点英语也是节省时间中很重要的一点。
那么如何去学习呢,chrome 装个翻译插件,直接拿英文文档或文章读,不会的就直接划词翻译,然后记录下这个单词并背诵。每天花半小时看点英文文档和文章,坚持两个月,你的英语水平不说别的,看文档和文章绝对不会有难题了。这一定是一个很划算的个人时间投资,花点时间学习英语,能为你将来的技术之路铺平很多坎。
### 画个图,想一想再做
你是否遇到过这种问题,需求一下来,看一眼,然后马上就按照设计稿开始做了,可能中间出个问题导致你需要返工。
如果你存在这样的问题,我很推荐在看到设计稿和需求的时候花点时间想一想,画一画。考虑一下设计稿中是否可以找到可以拆分出来的复用组件,是否存在之前写过的组件。该如何组织这个界面,数据的流转是怎么样的。然后画一下这个页面的需求,最后再动手做。
### 利用好下班时间学习
说到下班时间,那可能就有人说了公司很迟下班,这其实是国内很普遍的情况。但是我认为正常的加班是可以的,但是强制的加班就是在损耗你的身体和前途。
可以这么说,大部分的 996 公司,加班的这些时间并不会增加你的技术,无非就是在写一些重复的业务逻辑。也许你可以拿到更多的钱,但是代价是身体还有前途。程序员是靠技术吃饭的,如果你长久呆在一个长时间加班的公司,不能增长你的技术还要吞噬你的下班学习时间,那么你一定会废掉的。如果你遇到了这种情况,只能推荐尽快跳槽到非 996 的公司。
那么如果你有足够的下班时间,一定要花上 1, 2 小时去学习,上班大家基本都一样,技术的精进就是看下班以后的那几个小时了。如果你能利用好下班时间来学习,坚持下去,时间一定会给你很好的答复。
### 列好 ToDo
我喜欢规划好一段时间内要做的事情,并且要把事情拆分为小点。给 ToDo 列好优先级,紧急的优先级最高。相同优先级的我喜欢先做简单的,因为这样一旦完成就能划掉一个,提高成就感。
### 反思和整理
每周末都会花上点时间整理下本周记录的笔记和看到的不错文章。然后考虑下本周完成的工作和下周准备要完成的工作。
================================================
FILE: DataStruct/dataStruct-en.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Stack](#stack)
- [Conception](#conception)
- [Implementation](#implementation)
- [Application](#application)
- [Queues](#queues)
- [concept](#concept)
- [implementation](#implementation)
- [Singly-linked Queue](#singly-linked-queue)
- [Circular Queue](#circular-queue)
- [Linked List](#linked-list)
- [Concept](#concept)
- [Implementation](#implementation-1)
- [Tree](#tree)
- [Binary Tree](#binary-tree)
- [Binary Search Tree](#binary-search-tree)
- [Implementation](#implementation-2)
- [AVL Tree](#avl-tree)
- [Concept](#concept-1)
- [Implementation](#implementation-3)
- [Trie](#trie)
- [Concept](#concept-2)
- [Implementation](#implementation-4)
- [Disjoint Set](#disjoint-set)
- [Concept](#concept-3)
- [Implementation](#implementation-5)
- [Heap](#heap)
- [Concept](#concept-4)
- [Implementation of Max Binary Heap](#implementation-of-max-binary-heap)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# Stack
## Conception
A stack is the basic data structure that can be logically thought of as a linear structure.
Insertion and deletion of items at the top of the stack and the operation should obey the rules LIFO(Last In First Out).

## Implementation
Each data structure can be implemented by the different method. We can treat stack as a subclass of Array. So we take the array for example here.
```js
class Stack {
constructor() {
this.stack = []
}
push(item) {
this.stack.push(item)
}
pop() {
this.stack.pop()
}
peek() {
return this.stack[this.getCount() - 1]
}
getCount() {
return this.stack.length
}
isEmpty() {
return this.getCount() === 0
}
}
```
## Application
We choose [the NO.20 topic in LeetCode](https://leetcode.com/problems/valid-parentheses/submissions/1)
Our goal is to match the brackets. We can use the features of the stack to implement it.
```js
var isValid = function (s) {
let map = {
'(': -1,
')': 1,
'[': -2,
']': 2,
'{': -3,
'}': 3
}
let stack = []
for (let i = 0; i < s.length; i++) {
if (map[s[i]] < 0) {
stack.push(s[i])
} else {
let last = stack.pop()
if (map[last] + map[s[i]] != 0) return false
}
}
if (stack.length > 0) return false
return true
};
```
# Queues
## concept
A queue is a linear data structure. The insertion takes place at one end while the deletion occurs the other one. And the operation should obey the rules FIFO(First In First Out).

## implementation
Here, we'll talk two implementations of the queue: Singly-linked Queue and Circular Queue.
### Singly-linked Queue
```js
class Queue {
constructor() {
this.queue = []
}
enQueue(item) {
this.queue.push(item)
}
deQueue() {
return this.queue.shift()
}
getHeader() {
return this.queue[0]
}
getLength() {
return this.queue.length
}
isEmpty() {
return this.getLength() === 0
}
}
```
It is an O(n) operation to enqueue in a Singly-linked Queue, while it is an average O(1) in a Circular Queue. So here comes the Circular Queue.
### Circular Queue
```js
class SqQueue {
constructor(length) {
this.queue = new Array(length + 1)
// head of the queue
this.first = 0
// tail of the queue
this.last = 0
// size of the queue
this.size = 0
}
enQueue(item) {
// the array need to expand if last + 1 is the head
// `% this.queue.length` is to avoid index out of bounds
if (this.first === (this.last + 1) % this.queue.length) {
this.resize(this.getLength() * 2 + 1)
}
this.queue[this.last] = item
this.size++
this.last = (this.last + 1) % this.queue.length
}
deQueue() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
let r = this.queue[this.first]
this.queue[this.first] = null
this.first = (this.first + 1) % this.queue.length
this.size--
// if the size of queue is too small
// reduce the size half when the real size is quarter of the length and the length is not 2
if (this.size === this.getLength() / 4 && this.getLength() / 2 !== 0) {
this.resize(this.getLength() / 2)
}
return r
}
getHeader() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
return this.queue[this.first]
}
getLength() {
return this.queue.length - 1
}
isEmpty() {
return this.first === this.last
}
resize(length) {
let q = new Array(length)
for (let i = 0; i < length; i++) {
q[i] = this.queue[(i + this.first) % this.queue.length]
}
this.queue = q
this.first = 0
this.last = this.size
}
}
```
# Linked List
## Concept
The linked list is a linear data structure and born to be recursive structure. It can fully use the memory of the computer and manage the memory dynamically and flexibly. But Nodes in the linked list must be read in order from the beginning which can be random in the array, and it uses more memory than the array because of the storage used by their pointers.

## Implementation
Singly-linked list
```javascript
class Node {
constructor(v, next) {
this.value = v
this.next = next
}
}
class LinkList {
constructor() {
// size
this.size = 0
// virtual head
this.dummyNode = new Node(null, null)
}
find(header, index, currentIndex) {
if (index === currentIndex) return header
return this.find(header.next, index, currentIndex + 1)
}
addNode(v, index) {
this.checkIndex(index)
// the next of the node inserted should be previous node'next
// and the previous node's next should point to the node insert,
// except inserted to tail which next is null
let prev = this.find(this.dummyNode, index, 0)
prev.next = new Node(v, prev.next)
this.size++
return prev.next
}
insertNode(v, index) {
return this.addNode(v, index)
}
addToFirst(v) {
return this.addNode(v, 0)
}
addToLast(v) {
return this.addNode(v, this.size)
}
removeNode(index, isLast) {
this.checkIndex(index)
index = isLast ? index - 1 : index
let prev = this.find(this.dummyNode, index, 0)
let node = prev.next
prev.next = node.next
node.next = null
this.size--
return node
}
removeFirstNode() {
return this.removeNode(0)
}
removeLastNode() {
return this.removeNode(this.size, true)
}
checkIndex(index) {
if (index < 0 || index > this.size) throw Error('Index error')
}
getNode(index) {
this.checkIndex(index)
if (this.isEmpty()) return
return this.find(this.dummyNode, index, 0).next
}
isEmpty() {
return this.size === 0
}
getSize() {
return this.size
}
}
```
# Tree
## Binary Tree
Binary Tree is a common one of the many structures of the tree. And it is born to be recursive.
Binary tree start at a root node and each node consists of two child-nodes at most: left node and right node. The nodes in the bottom are usually called leaf nodes, and when the leaf nodes is full, we call the Full Binary Tree.
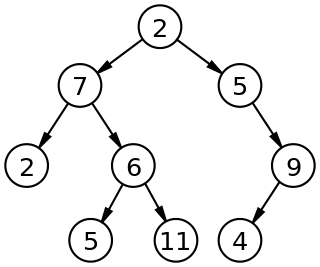
## Binary Search Tree
Binary Search Tree (BST) is one of the binary trees, so it has all the features of the binary tree. But different with the binary tree, the value in any node is larger than the values in all nodes in that node's left subtree and smaller than the values in all nodes in that node's right subtree.
This storage method is very suitable for data search. As shown below, when you need to find 6, because the value you need to find is larger than the value of the root node, you only need to find it in the right subtree of the root node, which greatly improves the search efficiency.
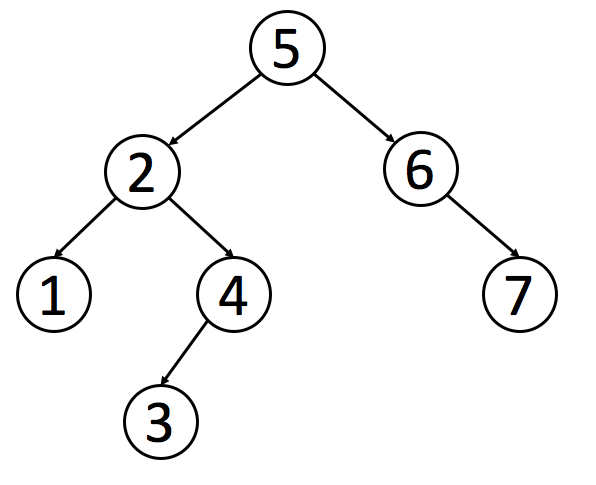
### Implementation
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BST {
constructor() {
this.root = null
this.size = 0
}
getSize() {
return this.size
}
isEmpty() {
return this.size === 0
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
// make comparison to the value of the node when insertion
_addChild(node, v) {
if (!node) {
this.size++
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
}
return node
}
}
```
Above is the basic implementation of BST, the implementation of traversing tree are as follows.
There are three ways for traversing trees: Preorder Traversal, In order Traversal, PostOrder Traversal. The difference of these ways is the time when to visit the root node. In the process of traversing the tree, each node traverses three times, traversing itself, traversing the left subtree and traversing the right subtree. If you need to implement pre-order traversal, you only need to operate the first time when traversing to the node.
Following are the implementation by recursive, if you want to find the non-recursive, [click here](../Algorithm/algorithm-ch.md#%E9%9D%9E%E9%80%92%E5%BD%92%E5%AE%9E%E7%8E%B0)
```js
// Preorder traversal can be used to print the structure of the tree
// first root then left, and the right is last
traversal() {
this._pre(this.root)
}
_pre(node) {
if (node) {
console.log(node.value)
this._pre(node.left)
this._pre(node.right)
}
}
// Inorder traversal can be used to order
// you can sort the value of BST only by one time of Inorder traversal
// first left , then root and right is last
midTraversal() {
this._mid(this.root)
}
_mid(node) {
if (node) {
this._mid(node.left)
console.log(node.value)
this._mid(node.right)
}
}
// Postorder traversal can be used in the case that you want to
// operate the child node first and then the parent node
// first left, then right and the root is last
backTraversal() {
this._back(this.root)
}
_back(node) {
if (node) {
this._back(node.left)
this._back(node.right)
console.log(node.value)
}
}
```
These three ways belong to Deep First Search. Meanwhile, there is Breadth First Search, which traverse the node layer by layer. We can implement it in the queue.
```js
breadthTraversal() {
if (!this.root) return null
let q = new Queue()
// enqueue the root node
q.enQueue(this.root)
// whether the queue is empty, if true, the traverse is finished.
while (!q.isEmpty()) {
// dequeue the head, and whether it has child-node,
// if true, enqueue th left and the right
let n = q.deQueue()
if (n.left) q.enQueue(n.left)
if (n.right) q.enQueue(n.right)
}
}
```
We will introduce how to find the smallest and the biggest in the tree. Because of the feature of the BST, the smallest must be on the left while the biggest is on the right.
```js
getMin() {
return this._getMin(this.root).value
}
_getMin(node) {
if (!node.left) return node
return this._getMin(node.left)
}
getMax() {
return this._getMax(this.root).value
}
_getMax(node) {
if (!node.right) return node
return this._getMin(node.right)
}
```
**Round up and Round down** Since these two operations are opposite, the code is similar, here we'll talk about round down. According to the feature of the BST, the target must be on the left. We only need to traverse the left nodes until the current node is no bigger than the target. And then adjudge if there have right nodes, if do, continue the judgment recursively.
```js
floor(v) {
let node = this._floor(this.root, v)
return node ? node.value : null
}
_floor(node, v) {
if (!node) return null
if (node.value === v) return v
// if the current node is bigger than the target, continue
if (node.value > v) {
return this._floor(node.left, v)
}
// whether the current node has the right subtree
let right = this._floor(node.right, v)
if (right) return right
return node
}
```
**Rank** get the rank of the given value or get the value of the given rank, and these two operations are also similar. We as usual only introduce the operation of the latter. We should retrofit the code to add a property `size` to each node which indicates how many subnodes a node has, include itself.
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
// add code
this.size = 1
}
}
// add code
_getSize(node) {
return node ? node.size : 0
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
// edit code
node.size++
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
// edit code
node.size++
node.right = this._addChild(node.right, v)
}
return node
}
select(k) {
let node = this._select(this.root, k)
return node ? node.value : null
}
_select(node, k) {
if (!node) return null
// get the size of the node in the left subtree
let size = node.left ? node.left.size : 0
// if size is bigger than k, the target is in the left side
if (size > k) return this._select(node.left, k)
// if the size is smaller than k, the target is in the right side
// there is need to recalculate the k
if (size < k) return this._select(node.right, k - size - 1)
return node
}
```
Here come the most difficult parts in BST: delete nodes, include the following cases:
- the target node has no subtree
- the target node has only one subtree
- the target node has two subtrees
The first and the second is easy to resolve, while the last is a little difficult.
So let us implement the simple operation at first: delete the minimum node. It could not appear in the third case, and the operation delete the largest node is opposite, so there is no need to talk.
```js
delectMin() {
this.root = this._delectMin(this.root)
console.log(this.root)
}
_delectMin(node) {
// rescursive the left subtree
// if the left subtree is null, check if the right is exist
// if true, take the right subtree in place of the delect node
if ((node != null) & !node.left) return node.right
node.left = this._delectMin(node.left)
// update the size at last
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
The last, how to delete a random node. T.Hibbard put forward the solution in 1962 which can be used to solve the third case.
In this situation, we should get the descendant node of the current node which is the smallest node in the current node's right subtree and replace the target node by it. And then assign the descendant node with the subtree of the target, and give the right subtree without decent node to the left subtree.
Since the root node is bigger than all the nodes in left subtree, while less than all the nodes in the right subtree. When you want to delete a root node, you need to pick a suitable node to take place, which should bigger than the root node that means it must come from the right subtree. Then the smallest node would be picked with the limit that all the nodes in the right subtree should bigger than the root node.
```js
delect(v) {
this.root = this._delect(this.root, v)
}
_delect(node, v) {
if (!node) return null
// if the target is less than the current node, serach in the left subtree
if (node.value < v) {
node.right = this._delect(node.right, v)
} else if (node.value > v) {
// if the target is bigger than the current node, serach in the right subtree
node.left = this._delect(node.left, v)
} else {
// in this case, the target has been found
// check if the node has subtree
// if true, return the subtree, same operation with `_delectMin`
if (!node.left) return node.right
if (!node.right) return node.left
// in this case, the node has both subtree
// get the decendent node of the current node,
// which is the smallest node in the right subtree
let min = this._getMin(node.right)
// delete the smallest after got it
// Then assign the subtree after deleting the node to the smallest node
min.right = this._delectMin(node.right)
// subtree is the same
min.left = node.left
node = min
}
// update size
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
## AVL Tree
### Concept
BST is limited in the production because it is not the strict O(log N) and sometimes it will degenerate to a linked list, e.g., insertion of an ascending order number list.
AVL tree improved the BST, the difference between the left subtree height and the right subtree height in each node is less than 1, which can ensure that the time complexity is strict O(log N). Based on this, the insertion and deletion may need to rotate the tree to balance the height.
### Implementation
Since improved from the BST, some codes in AVL are repeated, which we will not analysis again.
Four cases are in the node insertion of AVL tree.

As for l-l(left-left), the new node T1 is in the left side of the node X. The tree cannot keep balance by now, so there need to rotate. After rotating, the tree should still obey the rules the mid is bigger than the left and less than the right according to the features of the BST.
before rotating: T1 < X < T2 < Y < T3 < Z < T4, after rotating, the node Y is the root, so we need to add the right subtree of Y to the left of the Z and update the height of the nodes.
The same situation to the r-r, opposite to the l-l, we do not talk more.
As for the l-r, the new node is on the right side of the node X, and we need to rotate twice.
First, rotate the left node to the left, after that the case change to l-l, we can handle it like l-l.
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
this.height = 1
}
}
class AVL {
constructor() {
this.root = null
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
} else {
node.value = v
}
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
let factor = this._getBalanceFactor(node)
// when need right-rotate, the height of the left subtree must higher than right
if (factor > 1 && this._getBalanceFactor(node.left) >= 0) {
return this._rightRotate(node)
}
// when need left-rotate, the height of the left subtree must lower than right
if (factor < -1 && this._getBalanceFactor(node.right) <= 0) {
return this._leftRotate(node)
}
// l-r
// left subtree is higher than right,
// and the right subtree of the left subtree of the node
// is higher than the left subtree of the left subtree of the node
if (factor > 1 && this._getBalanceFactor(node.left) < 0) {
node.left = this._leftRotate(node.left)
return this._rightRotate(node)
}
// r-l
// left subtree is lower than right,
// and the right subtree of the right subtree of the node
// is lower than the left subtree of the right subtree of the node
if (factor < -1 && this._getBalanceFactor(node.right) > 0) {
node.right = this._rightRotate(node.right)
return this._leftRotate(node)
}
return node
}
_getHeight(node) {
if (!node) return 0
return node.height
}
_getBalanceFactor(node) {
return this._getHeight(node.left) - this._getHeight(node.right)
}
// right-rotate
// 5 2
// / \ / \
// 2 6 ==> 1 5
// / \ / / \
// 1 3 new 3 6
// /
// new
_rightRotate(node) {
// new root after rotate
let newRoot = node.left
// node need to be moved
let moveNode = newRoot.right
// right node of the node 2 change to node 5
newRoot.right = node
// left node of node 5 change to node 3
node.left = moveNode
// update the height
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
// left-rotate
// 4 6
// / \ / \
// 2 6 ==> 4 7
// / \ / \ \
// 5 7 2 5 new
// \
// new
_leftRotate(node) {
// new root after rotate
let newRoot = node.right
// node need to be moved
let moveNode = newRoot.left
// left node of the node 6 change to node 4
newRoot.left = node
// right node of the node 4 change to node 5
node.right = moveNode
// update the height
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
}
```
# Trie
## Concept
In computer science, a trie, also called digital tree and sometimes radix tree or prefix tree (as prefixes can search them), is a kind of search tree—an ordered tree data structure that is used to store a dynamic set or associative array where the keys are usually strings.
Simply, this data structure is used to search string easily, with the following features:
- the root is on behalf of the empty string, and each node has N links (N is 26 in searching English character), each link represents a character.
- all nodes do not store a character, and only the path store, this is different from other tree structures.
- the character in the path from the root to the random node can combine to the strings corresponding to the node
## Implementation
Generally, the implementation of the trie is much more simple than others, let's take the English character searching for example.
```js
class TrieNode {
constructor() {
// the times of each character travels through the node
this.path = 0
// the amount of the string to the node
this.end = 0
// links
this.next = new Array(26).fill(null)
}
}
class Trie {
constructor() {
// root node, empty string
this.root = new TrieNode()
}
// insert string
insert(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
// get the index of the character
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// create if without the index
if (!node.next[index]) {
node.next[index] = new TrieNode()
}
node.path += 1
node = node.next[index]
}
node.end += 1
}
// The number of times the search string appears
search(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// if the index does node exists, there is no string to be search
if (!node.next[index]) {
return 0
}
node = node.next[index]
}
return node.end
}
// delete the string
delete(str) {
if (!this.search(str)) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// if the path is 0, this means no string pass
// delete it
if (--node.next[index].path == 0) {
node.next[index] = null
return
}
node = node.next[index]
}
node.end -= 1
}
}
```
# Disjoint Set
## Concept
Disjoint Set is a special data structure of the tree. Each node in this structure has a parent node, if there is only the current node, then the pointer of the parent node points to itself.
Two important operations are in this structure,
- Find: find the member of the set to which the element belongs, and it can be used to determine whether the two elements belong to the same set
- Union: combine two sets to a new set
## Implementation
```js
class DisjointSet {
// init sample
constructor(count) {
// each node's parenet node is iteself when initialization
this.parent = new Array(count)
// record the deepth of the tree to optimize the complexity of query
this.rank = new Array(count)
for (let i = 0; i < count; i++) {
this.parent[i] = i
this.rank[i] = 1
}
}
find(p) {
// check whether the parent node of the current node is itself, if false, means has not found yet
// uglify the path for optimization
// assume the parent node of the current node is A
// mount the current node to the parent node of A to deeply optimize
while (p != this.parent[p]) {
this.parent[p] = this.parent[this.parent[p]]
p = this.parent[p]
}
return p
}
isConnected(p, q) {
return this.find(p) === this.find(q)
}
// combine
union(p, q) {
// find the parent node of the two number
let i = this.find(p)
let j = this.find(q)
if (i === j) return
// compare the deepth of the two trees
// if the deepth is equal, add as you wish
if (this.rank[i] < this.rank[j]) {
this.parent[i] = j
} else if (this.rank[i] > this.rank[j]) {
this.parent[j] = i
} else {
this.parent[i] = j
this.rank[j] += 1
}
}
}
```
# Heap
## Concept
Heap is usually treated as a tree-based array list.
It is implemented by constructure binary heap, one of the BST. Features are as follows:
- each node either larger or less than all its child-nodes
- heap is always a full-tree
We call the heap **Max Binary Heap** that its root value is the largest, while the heap with the smallest root value is called **Min Binary Heap**.
Priority Queue also can be implemented by the heap, with the same operation.
## Implementation of Max Binary Heap
The index of the left-child of each node is `i * 2 + 1`, while the right's is `i * 2 + 2`, and the parent's is `(i - 1) / 2`
There are two central operations in the heap, `shiftUp` and `shiftDown`. The former is used for insertion, and the latter is to delete the root node.
The key of `shiftUp` is to compare with the parent node bubbly and exchange the position if it is larger than the parent.
As for `shiftDown`, first exchange root and the tail node, and then delete the tail. After that, Compare with the parent node and both child-nodes circularly, if the child-node is larger, assign the parent node with the larger node.

```js
class MaxHeap {
constructor() {
this.heap = []
}
size() {
return this.heap.length
}
empty() {
return this.size() == 0
}
add(item) {
this.heap.push(item)
this._shiftUp(this.size() - 1)
}
removeMax() {
this._shiftDown(0)
}
getParentIndex(k) {
return parseInt((k - 1) / 2)
}
getLeftIndex(k) {
return k * 2 + 1
}
_shiftUp(k) {
// exchange if the current node is bigger than the parent node
while (this.heap[k] > this.heap[this.getParentIndex(k)]) {
this._swap(k, this.getParentIndex(k))
// update the index to the parent node's
k = this.getParentIndex(k)
}
}
_shiftDown(k) {
// exchange the head and tail, then delete the tail
this._swap(k, this.size() - 1)
this.heap.splice(this.size() - 1, 1)
// check whether the node has left child-node,
// the right must exist because of full-tree
while (this.getLeftIndex(k) < this.size()) {
let j = this.getLeftIndex(k)
// check whether the right child exits, and whether it is largger than the left
if (j + 1 < this.size() && this.heap[j + 1] > this.heap[j]) j++
// check whether the parenet node is largger than both child-nodes
if (this.heap[k] >= this.heap[j]) break
this._swap(k, j)
k = j
}
}
_swap(left, right) {
let rightValue = this.heap[right]
this.heap[right] = this.heap[left]
this.heap[left] = rightValue
}
}
```
```js
class MaxHeap {
constructor() {
this.heap = []
}
size() {
return this.heap.length
}
empty() {
return this.size() == 0
}
add(item) {
this.heap.push(item)
this._shiftUp(this.size() - 1)
}
removeMax() {
this._shiftDown(0)
}
getParentIndex(k) {
return parseInt((k - 1) / 2)
}
getLeftIndex(k) {
return k * 2 + 1
}
_shiftUp(k) {
// exchange if the current node is bigger than the parent node
while (this.heap[k] > this.heap[this.getParentIndex(k)]) {
this._swap(k, this.getParentIndex(k))
// update the index to the parent node's
k = this.getParentIndex(k)
}
}
_shiftDown(k) {
// exchange the head and delete the tail
this._swap(k, this.size() - 1)
this.heap.splice(this.size() - 1, 1)
// check if the node has left child-node, the right must exist if true according to the binary heap
while (this.getLeftIndex(k) < this.size()) {
let j = this.getLeftIndex(k)
// check if the right child exits, and whether it is largger than the left
if (j + 1 < this.size() && this.heap[j + 1] > this.heap[j]) j++
// check if the parenet node is largger than both child-nodes
if (this.heap[k] >= this.heap[j]) break
this._swap(k, j)
k = j
}
}
_swap(left, right) {
let rightValue = this.heap[right]
this.heap[right] = this.heap[left]
this.heap[left] = rightValue
}
}
```
================================================
FILE: DataStruct/dataStruct-zh.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [栈](#%E6%A0%88)
- [概念](#%E6%A6%82%E5%BF%B5)
- [实现](#%E5%AE%9E%E7%8E%B0)
- [应用](#%E5%BA%94%E7%94%A8)
- [队列](#%E9%98%9F%E5%88%97)
- [概念](#%E6%A6%82%E5%BF%B5-1)
- [实现](#%E5%AE%9E%E7%8E%B0-1)
- [单链队列](#%E5%8D%95%E9%93%BE%E9%98%9F%E5%88%97)
- [循环队列](#%E5%BE%AA%E7%8E%AF%E9%98%9F%E5%88%97)
- [链表](#%E9%93%BE%E8%A1%A8)
- [概念](#%E6%A6%82%E5%BF%B5-2)
- [实现](#%E5%AE%9E%E7%8E%B0-2)
- [树](#%E6%A0%91)
- [二叉树](#%E4%BA%8C%E5%8F%89%E6%A0%91)
- [二分搜索树](#%E4%BA%8C%E5%88%86%E6%90%9C%E7%B4%A2%E6%A0%91)
- [实现](#%E5%AE%9E%E7%8E%B0-3)
- [AVL 树](#avl-%E6%A0%91)
- [概念](#%E6%A6%82%E5%BF%B5-3)
- [实现](#%E5%AE%9E%E7%8E%B0-4)
- [Trie](#trie)
- [概念](#%E6%A6%82%E5%BF%B5-4)
- [实现](#%E5%AE%9E%E7%8E%B0-5)
- [并查集](#%E5%B9%B6%E6%9F%A5%E9%9B%86)
- [概念](#%E6%A6%82%E5%BF%B5-5)
- [实现](#%E5%AE%9E%E7%8E%B0-6)
- [堆](#%E5%A0%86)
- [概念](#%E6%A6%82%E5%BF%B5-6)
- [实现大根堆](#%E5%AE%9E%E7%8E%B0%E5%A4%A7%E6%A0%B9%E5%A0%86)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# 栈
## 概念
栈是一个线性结构,在计算机中是一个相当常见的数据结构。
栈的特点是只能在某一端添加或删除数据,遵循先进后出的原则

## 实现
每种数据结构都可以用很多种方式来实现,其实可以把栈看成是数组的一个子集,所以这里使用数组来实现
```js
class Stack {
constructor() {
this.stack = []
}
push(item) {
this.stack.push(item)
}
pop() {
this.stack.pop()
}
peek() {
return this.stack[this.getCount() - 1]
}
getCount() {
return this.stack.length
}
isEmpty() {
return this.getCount() === 0
}
}
```
## 应用
选取了 [LeetCode 上序号为 20 的题目](https://leetcode.com/problems/valid-parentheses/submissions/1)
题意是匹配括号,可以通过栈的特性来完成这道题目
```js
var isValid = function (s) {
let map = {
'(': -1,
')': 1,
'[': -2,
']': 2,
'{': -3,
'}': 3
}
let stack = []
for (let i = 0; i < s.length; i++) {
if (map[s[i]] < 0) {
stack.push(s[i])
} else {
let last = stack.pop()
if (map[last] + map[s[i]] != 0) return false
}
}
if (stack.length > 0) return false
return true
};
```
# 队列
## 概念
队列一个线性结构,特点是在某一端添加数据,在另一端删除数据,遵循先进先出的原则。

## 实现
这里会讲解两种实现队列的方式,分别是单链队列和循环队列。
### 单链队列
```js
class Queue {
constructor() {
this.queue = []
}
enQueue(item) {
this.queue.push(item)
}
deQueue() {
return this.queue.shift()
}
getHeader() {
return this.queue[0]
}
getLength() {
return this.queue.length
}
isEmpty() {
return this.getLength() === 0
}
}
```
因为单链队列在出队操作的时候需要 O(n) 的时间复杂度,所以引入了循环队列。循环队列的出队操作平均是 O(1) 的时间复杂度。
## 循环队列
```js
class SqQueue {
constructor(length) {
this.queue = new Array(length + 1)
// 队头
this.first = 0
// 队尾
this.last = 0
// 当前队列大小
this.size = 0
}
enQueue(item) {
// 判断队尾 + 1 是否为队头
// 如果是就代表需要扩容数组
// % this.queue.length 是为了防止数组越界
if (this.first === (this.last + 1) % this.queue.length) {
this.resize(this.getLength() * 2 + 1)
}
this.queue[this.last] = item
this.size++
this.last = (this.last + 1) % this.queue.length
}
deQueue() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
let r = this.queue[this.first]
this.queue[this.first] = null
this.first = (this.first + 1) % this.queue.length
this.size--
// 判断当前队列大小是否过小
// 为了保证不浪费空间,在队列空间等于总长度四分之一时
// 且不为 2 时缩小总长度为当前的一半
if (this.size === this.getLength() / 4 && this.getLength() / 2 !== 0) {
this.resize(this.getLength() / 2)
}
return r
}
getHeader() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
return this.queue[this.first]
}
getLength() {
return this.queue.length - 1
}
isEmpty() {
return this.first === this.last
}
resize(length) {
let q = new Array(length)
for (let i = 0; i < length; i++) {
q[i] = this.queue[(i + this.first) % this.queue.length]
}
this.queue = q
this.first = 0
this.last = this.size
}
}
```
# 链表
## 概念
链表是一个线性结构,同时也是一个天然的递归结构。链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。

## 实现
单向链表
```javascript
class Node {
constructor(v, next) {
this.value = v
this.next = next
}
}
class LinkList {
constructor() {
// 链表长度
this.size = 0
// 虚拟头部
this.dummyNode = new Node(null, null)
}
find(header, index, currentIndex) {
if (index === currentIndex) return header
return this.find(header.next, index, currentIndex + 1)
}
addNode(v, index) {
this.checkIndex(index)
// 当往链表末尾插入时,prev.next 为空
// 其他情况时,因为要插入节点,所以插入的节点
// 的 next 应该是 prev.next
// 然后设置 prev.next 为插入的节点
let prev = this.find(this.dummyNode, index, 0)
prev.next = new Node(v, prev.next)
this.size++
return prev.next
}
insertNode(v, index) {
return this.addNode(v, index)
}
addToFirst(v) {
return this.addNode(v, 0)
}
addToLast(v) {
return this.addNode(v, this.size)
}
removeNode(index, isLast) {
this.checkIndex(index)
index = isLast ? index - 1 : index
let prev = this.find(this.dummyNode, index, 0)
let node = prev.next
prev.next = node.next
node.next = null
this.size--
return node
}
removeFirstNode() {
return this.removeNode(0)
}
removeLastNode() {
return this.removeNode(this.size, true)
}
checkIndex(index) {
if (index < 0 || index > this.size) throw Error('Index error')
}
getNode(index) {
this.checkIndex(index)
if (this.isEmpty()) return
return this.find(this.dummyNode, index, 0).next
}
isEmpty() {
return this.size === 0
}
getSize() {
return this.size
}
}
```
# 树
## 二叉树
树拥有很多种结构,二叉树是树中最常用的结构,同时也是一个天然的递归结构。
二叉树拥有一个根节点,每个节点至多拥有两个子节点,分别为:左节点和右节点。树的最底部节点称之为叶节点,当一颗树的叶数量数量为满时,该树可以称之为满二叉树。

## 二分搜索树
二分搜索树也是二叉树,拥有二叉树的特性。但是区别在于二分搜索树每个节点的值都比他的左子树的值大,比右子树的值小。
这种存储方式很适合于数据搜索。如下图所示,当需要查找 6 的时候,因为需要查找的值比根节点的值大,所以只需要在根节点的右子树上寻找,大大提高了搜索效率。
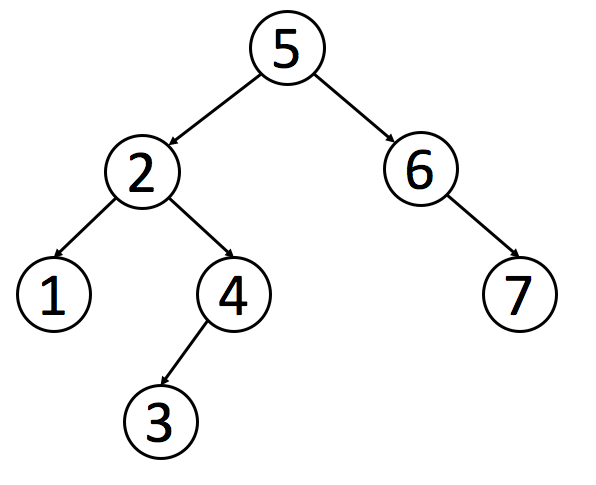
### 实现
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BST {
constructor() {
this.root = null
this.size = 0
}
getSize() {
return this.size
}
isEmpty() {
return this.size === 0
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
// 添加节点时,需要比较添加的节点值和当前
// 节点值的大小
_addChild(node, v) {
if (!node) {
this.size++
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
}
return node
}
}
```
以上是最基本的二分搜索树实现,接下来实现树的遍历。
对于树的遍历来说,有三种遍历方法,分别是先序遍历、中序遍历、后序遍历。三种遍历的区别在于何时访问节点。在遍历树的过程中,每个节点都会遍历三次,分别是遍历到自己,遍历左子树和遍历右子树。如果需要实现先序遍历,那么只需要第一次遍历到节点时进行操作即可。
以下都是递归实现,如果你想学习非递归实现,可以 [点击这里阅读](../Algorithm/algorithm-ch.md#%E9%9D%9E%E9%80%92%E5%BD%92%E5%AE%9E%E7%8E%B0)
```js
// 先序遍历可用于打印树的结构
// 先序遍历先访问根节点,然后访问左节点,最后访问右节点。
preTraversal() {
this._pre(this.root)
}
_pre(node) {
if (node) {
console.log(node.value)
this._pre(node.left)
this._pre(node.right)
}
}
// 中序遍历可用于排序
// 对于 BST 来说,中序遍历可以实现一次遍历就
// 得到有序的值
// 中序遍历表示先访问左节点,然后访问根节点,最后访问右节点。
midTraversal() {
this._mid(this.root)
}
_mid(node) {
if (node) {
this._mid(node.left)
console.log(node.value)
this._mid(node.right)
}
}
// 后序遍历可用于先操作子节点
// 再操作父节点的场景
// 后序遍历表示先访问左节点,然后访问右节点,最后访问根节点。
backTraversal() {
this._back(this.root)
}
_back(node) {
if (node) {
this._back(node.left)
this._back(node.right)
console.log(node.value)
}
}
```
以上的这几种遍历都可以称之为深度遍历,对应的还有种遍历叫做广度遍历,也就是一层层地遍历树。对于广度遍历来说,我们需要利用之前讲过的队列结构来完成。
```js
breadthTraversal() {
if (!this.root) return null
let q = new Queue()
// 将根节点入队
q.enQueue(this.root)
// 循环判断队列是否为空,为空
// 代表树遍历完毕
while (!q.isEmpty()) {
// 将队首出队,判断是否有左右子树
// 有的话,就先左后右入队
let n = q.deQueue()
console.log(n.value)
if (n.left) q.enQueue(n.left)
if (n.right) q.enQueue(n.right)
}
}
```
接下来先介绍如何在树中寻找最小值或最大数。因为二分搜索树的特性,所以最小值一定在根节点的最左边,最大值相反
```js
getMin() {
return this._getMin(this.root).value
}
_getMin(node) {
if (!node.left) return node
return this._getMin(node.left)
}
getMax() {
return this._getMax(this.root).value
}
_getMax(node) {
if (!node.right) return node
return this._getMin(node.right)
}
```
**向上取整和向下取整**,这两个操作是相反的,所以代码也是类似的,这里只介绍如何向下取整。既然是向下取整,那么根据二分搜索树的特性,值一定在根节点的左侧。只需要一直遍历左子树直到当前节点的值不再大于等于需要的值,然后判断节点是否还拥有右子树。如果有的话,继续上面的递归判断。
```js
floor(v) {
let node = this._floor(this.root, v)
return node ? node.value : null
}
_floor(node, v) {
if (!node) return null
if (node.value === v) return v
// 如果当前节点值还比需要的值大,就继续递归
if (node.value > v) {
return this._floor(node.left, v)
}
// 判断当前节点是否拥有右子树
let right = this._floor(node.right, v)
if (right) return right
return node
}
```
**排名**,这是用于获取给定值的排名或者排名第几的节点的值,这两个操作也是相反的,所以这个只介绍如何获取排名第几的节点的值。对于这个操作而言,我们需要略微的改造点代码,让每个节点拥有一个 `size` 属性。该属性表示该节点下有多少子节点(包含自身)。
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
// 修改代码
this.size = 1
}
}
// 新增代码
_getSize(node) {
return node ? node.size : 0
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
// 修改代码
node.size++
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
// 修改代码
node.size++
node.right = this._addChild(node.right, v)
}
return node
}
select(k) {
let node = this._select(this.root, k)
return node ? node.value : null
}
_select(node, k) {
if (!node) return null
// 先获取左子树下有几个节点
let size = node.left ? node.left.size : 0
// 判断 size 是否大于 k
// 如果大于 k,代表所需要的节点在左节点
if (size > k) return this._select(node.left, k)
// 如果小于 k,代表所需要的节点在右节点
// 注意这里需要重新计算 k,减去根节点除了右子树的节点数量
if (size < k) return this._select(node.right, k - size - 1)
return node
}
```
接下来讲解的是二分搜索树中最难实现的部分:删除节点。因为对于删除节点来说,会存在以下几种情况
- 需要删除的节点没有子树
- 需要删除的节点只有一条子树
- 需要删除的节点有左右两条树
对于前两种情况很好解决,但是第三种情况就有难度了,所以先来实现相对简单的操作:删除最小节点,对于删除最小节点来说,是不存在第三种情况的,删除最大节点操作是和删除最小节点相反的,所以这里也就不再赘述。
```js
delectMin() {
this.root = this._delectMin(this.root)
console.log(this.root)
}
_delectMin(node) {
// 一直递归左子树
// 如果左子树为空,就判断节点是否拥有右子树
// 有右子树的话就把需要删除的节点替换为右子树
if ((node != null) & !node.left) return node.right
node.left = this._delectMin(node.left)
// 最后需要重新维护下节点的 `size`
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
最后讲解的就是如何删除任意节点了。对于这个操作,T.Hibbard 在 1962 年提出了解决这个难题的办法,也就是如何解决第三种情况。
当遇到这种情况时,需要取出当前节点的后继节点(也就是当前节点右子树的最小节点)来替换需要删除的节点。然后将需要删除节点的左子树赋值给后继结点,右子树删除后继结点后赋值给他。
你如果对于这个解决办法有疑问的话,可以这样考虑。因为二分搜索树的特性,父节点一定比所有左子节点大,比所有右子节点小。那么当需要删除父节点时,势必需要拿出一个比父节点大的节点来替换父节点。这个节点肯定不存在于左子树,必然存在于右子树。然后又需要保持父节点都是比右子节点小的,那么就可以取出右子树中最小的那个节点来替换父节点。
```js
delect(v) {
this.root = this._delect(this.root, v)
}
_delect(node, v) {
if (!node) return null
// 寻找的节点比当前节点小,去左子树找
if (node.value < v) {
node.right = this._delect(node.right, v)
} else if (node.value > v) {
// 寻找的节点比当前节点大,去右子树找
node.left = this._delect(node.left, v)
} else {
// 进入这个条件说明已经找到节点
// 先判断节点是否拥有拥有左右子树中的一个
// 是的话,将子树返回出去,这里和 `_delectMin` 的操作一样
if (!node.left) return node.right
if (!node.right) return node.left
// 进入这里,代表节点拥有左右子树
// 先取出当前节点的后继结点,也就是取当前节点右子树的最小值
let min = this._getMin(node.right)
// 取出最小值后,删除最小值
// 然后把删除节点后的子树赋值给最小值节点
min.right = this._delectMin(node.right)
// 左子树不动
min.left = node.left
node = min
}
// 维护 size
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
## AVL 树
### 概念
二分搜索树实际在业务中是受到限制的,因为并不是严格的 O(logN),在极端情况下会退化成链表,比如加入一组升序的数字就会造成这种情况。
AVL 树改进了二分搜索树,在 AVL 树中任意节点的左右子树的高度差都不大于 1,这样保证了时间复杂度是严格的 O(logN)。基于此,对 AVL 树增加或删除节点时可能需要旋转树来达到高度的平衡。
### 实现
因为 AVL 树是改进了二分搜索树,所以部分代码是于二分搜索树重复的,对于重复内容不作再次解析。
对于 AVL 树来说,添加节点会有四种情况
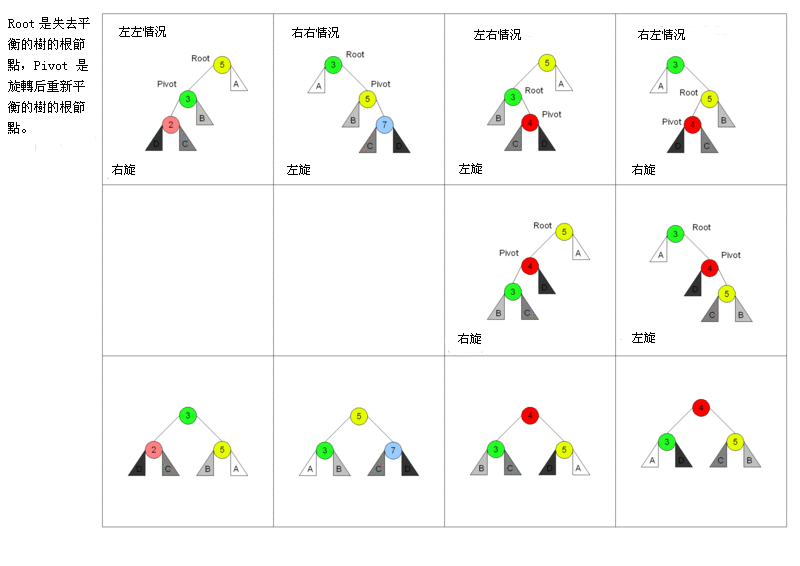
对于左左情况来说,新增加的节点位于节点 2 的左侧,这时树已经不平衡,需要旋转。因为搜索树的特性,节点比左节点大,比右节点小,所以旋转以后也要实现这个特性。
旋转之前:new < 2 < C < 3 < B < 5 < A,右旋之后节点 3 为根节点,这时候需要将节点 3 的右节点加到节点 5 的左边,最后还需要更新节点的高度。
对于右右情况来说,相反于左左情况,所以不再赘述。
对于左右情况来说,新增加的节点位于节点 4 的右侧。对于这种情况,需要通过两次旋转来达到目的。
首先对节点的左节点左旋,这时树满足左左的情况,再对节点进行一次右旋就可以达到目的。
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
this.height = 1
}
}
class AVL {
constructor() {
this.root = null
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
} else {
node.value = v
}
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
let factor = this._getBalanceFactor(node)
// 当需要右旋时,根节点的左树一定比右树高度高
if (factor > 1 && this._getBalanceFactor(node.left) >= 0) {
return this._rightRotate(node)
}
// 当需要左旋时,根节点的左树一定比右树高度矮
if (factor < -1 && this._getBalanceFactor(node.right) <= 0) {
return this._leftRotate(node)
}
// 左右情况
// 节点的左树比右树高,且节点的左树的右树比节点的左树的左树高
if (factor > 1 && this._getBalanceFactor(node.left) < 0) {
node.left = this._leftRotate(node.left)
return this._rightRotate(node)
}
// 右左情况
// 节点的左树比右树矮,且节点的右树的右树比节点的右树的左树矮
if (factor < -1 && this._getBalanceFactor(node.right) > 0) {
node.right = this._rightRotate(node.right)
return this._leftRotate(node)
}
return node
}
_getHeight(node) {
if (!node) return 0
return node.height
}
_getBalanceFactor(node) {
return this._getHeight(node.left) - this._getHeight(node.right)
}
// 节点右旋
// 5 2
// / \ / \
// 2 6 ==> 1 5
// / \ / / \
// 1 3 new 3 6
// /
// new
_rightRotate(node) {
// 旋转后新根节点
let newRoot = node.left
// 需要移动的节点
let moveNode = newRoot.right
// 节点 2 的右节点改为节点 5
newRoot.right = node
// 节点 5 左节点改为节点 3
node.left = moveNode
// 更新树的高度
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
// 节点左旋
// 4 6
// / \ / \
// 2 6 ==> 4 7
// / \ / \ \
// 5 7 2 5 new
// \
// new
_leftRotate(node) {
// 旋转后新根节点
let newRoot = node.right
// 需要移动的节点
let moveNode = newRoot.left
// 节点 6 的左节点改为节点 4
newRoot.left = node
// 节点 4 右节点改为节点 5
node.right = moveNode
// 更新树的高度
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
}
```
# Trie
## 概念
在计算机科学,**trie**,又称**前缀树**或**字典树**,是一种有序树,用于保存关联数组,其中的键通常是字符串。
简单点来说,这个结构的作用大多是为了方便搜索字符串,该树有以下几个特点
- 根节点代表空字符串,每个节点都有 N(假如搜索英文字符,就有 26 条) 条链接,每条链接代表一个字符
- 节点不存储字符,只有路径才存储,这点和其他的树结构不同
- 从根节点开始到任意一个节点,将沿途经过的字符连接起来就是该节点对应的字符串
、
## 实现
总得来说 Trie 的实现相比别的树结构来说简单的很多,实现就以搜索英文字符为例。
```js
class TrieNode {
constructor() {
// 代表每个字符经过节点的次数
this.path = 0
// 代表到该节点的字符串有几个
this.end = 0
// 链接
this.next = new Array(26).fill(null)
}
}
class Trie {
constructor() {
// 根节点,代表空字符
this.root = new TrieNode()
}
// 插入字符串
insert(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
// 获得字符先对应的索引
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// 如果索引对应没有值,就创建
if (!node.next[index]) {
node.next[index] = new TrieNode()
}
node.path += 1
node = node.next[index]
}
node.end += 1
}
// 搜索字符串出现的次数
search(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// 如果索引对应没有值,代表没有需要搜素的字符串
if (!node.next[index]) {
return 0
}
node = node.next[index]
}
return node.end
}
// 删除字符串
delete(str) {
if (!this.search(str)) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// 如果索引对应的节点的 Path 为 0,代表经过该节点的字符串
// 已经一个,直接删除即可
if (--node.next[index].path == 0) {
node.next[index] = null
return
}
node = node.next[index]
}
node.end -= 1
}
}
```
# 并查集
## 概念
并查集是一种特殊的树结构,用于处理一些不交集的合并及查询问题。该结构中每个节点都有一个父节点,如果只有当前一个节点,那么该节点的父节点指向自己。
这个结构中有两个重要的操作,分别是:
- Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- Union:将两个子集合并成同一个集合。

## 实现
```js
class DisjointSet {
// 初始化样本
constructor(count) {
// 初始化时,每个节点的父节点都是自己
this.parent = new Array(count)
// 用于记录树的深度,优化搜索复杂度
this.rank = new Array(count)
for (let i = 0; i < count; i++) {
this.parent[i] = i
this.rank[i] = 1
}
}
find(p) {
// 寻找当前节点的父节点是否为自己,不是的话表示还没找到
// 开始进行路径压缩优化
// 假设当前节点父节点为 A
// 将当前节点挂载到 A 节点的父节点上,达到压缩深度的目的
while (p != this.parent[p]) {
this.parent[p] = this.parent[this.parent[p]]
p = this.parent[p]
}
return p
}
isConnected(p, q) {
return this.find(p) === this.find(q)
}
// 合并
union(p, q) {
// 找到两个数字的父节点
let i = this.find(p)
let j = this.find(q)
if (i === j) return
// 判断两棵树的深度,深度小的加到深度大的树下面
// 如果两棵树深度相等,那就无所谓怎么加
if (this.rank[i] < this.rank[j]) {
this.parent[i] = j
} else if (this.rank[i] > this.rank[j]) {
this.parent[j] = i
} else {
this.parent[i] = j
this.rank[j] += 1
}
}
}
```
# 堆
## 概念
堆通常是一个可以被看做一棵树的数组对象。
堆的实现通过构造**二叉堆**,实为二叉树的一种。这种数据结构具有以下性质。
- 任意节点小于(或大于)它的所有子节点
- 堆总是一棵完全树。即除了最底层,其他层的节点都被元素填满,且最底层从左到右填入。
将根节点最大的堆叫做**最大堆**或**大根堆**,根节点最小的堆叫做**最小堆**或**小根堆**。
优先队列也完全可以用堆来实现,操作是一模一样的。
## 实现大根堆
堆的每个节点的左边子节点索引是 `i * 2 + 1`,右边是 `i * 2 + 2`,父节点是 `(i - 1) /2`。
堆有两个核心的操作,分别是 `shiftUp` 和 `shiftDown` 。前者用于添加元素,后者用于删除根节点。
`shiftUp` 的核心思路是一路将节点与父节点对比大小,如果比父节点大,就和父节点交换位置。
`shiftDown` 的核心思路是先将根节点和末尾交换位置,然后移除末尾元素。接下来循环判断父节点和两个子节点的大小,如果子节点大,就把最大的子节点和父节点交换。
```js
class MaxHeap {
constructor() {
this.heap = []
}
size() {
return this.heap.length
}
empty() {
return this.size() == 0
}
add(item) {
this.heap.push(item)
this._shiftUp(this.size() - 1)
}
removeMax() {
this._shiftDown(0)
}
getParentIndex(k) {
return parseInt((k - 1) / 2)
}
getLeftIndex(k) {
return k * 2 + 1
}
_shiftUp(k) {
// 如果当前节点比父节点大,就交换
while (this.heap[k] > this.heap[this.getParentIndex(k)]) {
this._swap(k, this.getParentIndex(k))
// 将索引变成父节点
k = this.getParentIndex(k)
}
}
_shiftDown(k) {
// 交换首位并删除末尾
this._swap(k, this.size() - 1)
this.heap.splice(this.size() - 1, 1)
// 判断节点是否有左孩子,因为二叉堆的特性,有右必有左
while (this.getLeftIndex(k) < this.size()) {
let j = this.getLeftIndex(k)
// 判断是否有右孩子,并且右孩子是否大于左孩子
if (j + 1 < this.size() && this.heap[j + 1] > this.heap[j]) j++
// 判断父节点是否已经比子节点都大
if (this.heap[k] >= this.heap[j]) break
this._swap(k, j)
k = j
}
}
_swap(left, right) {
let rightValue = this.heap[right]
this.heap[right] = this.heap[left]
this.heap[left] = rightValue
}
}
```
================================================
FILE: Framework/framework-br.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [MVVM](#mvvm)
- [Verificação suja](#dirty-checking)
- [Sequestro de dados](#data-hijacking)
- [Proxy vs. Obeject.defineProperty](#proxy-vs-obejectdefineproperty)
- [Princípios de rota](#routing-principle)
- [Virtual Dom](#virtual-dom)
- [Por que Virtual Dom é preciso](#why-virtual-dom-is-needed)
- [Intrudução ao algoritmo do Virtual Dom](#virtual-dom-algorithm-introduction)
- [Implementação do algoritimo do Virtual Dom](#virtual-dom-algorithm-implementation)
- [recursão da árvore](#recursion-of-the-tree)
- [varificando mudança de propriedades](#checking-property-changes)
- [Implementação do algoritimo para detectar mudanças de lista](#algorithm-implementation-for-detecting-list-changes)
- [Iterando e marcando elementos filhos](#iterating-and-marking-child-elements)
- [Diferença de renderização](#rendering-difference)
- [Fim](#the-end)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# MVVM
MVVM consiste dos três seguintes conceitos
* View: Interface
* Model:Modelo de dados
* ViewModel:Como uma ponte responsável pela comunicação entre a View e o Model
Na época do JQuery, se você precisar atualizar a UI, você precisar obter o DOM correspondente e então atualizar a UI, então os dados e as regras de negócio estão fortemente acoplados com a página.
No MVVM, o UI é condizudo pelos dados. Uma vez que o dado mudou, a UI correspondente será atualizada. Se a UI mudar, o dado correspondente também ira mudar. Dessas forma, nos preocupamos apenas com o fluxo de dados no processamento do negócio sem lidar com a página diretamente. ViewModel apenas se preocupa com o processamento de dados e regras de negócio e não se preocupa como a View manipula os dados. Nesse caso, nós podemos separar a View da Model. Se qualquer uma das partes mudarem, isso não necessariamente precisa mudar na outra parte, e qualquer lógica reusável pode ser colocado na ViewModel, permitindo multiplas View reusarem esse ViewModel.
No MVVM, o núcleo é two-way binding de dados, tal como a verificação suja do Angular e sequestro de dados no Vue.
## Verificação Suja
Quando o evento especificado é disparado, ele irá entrar na verificação suja e chamar o laço `$digest` caminhando através de todos os dados observados para determinar se o valor atual é diferente do valor anterior. Se a mudança é detectada, irá chamar a função `$watch`, e então chamar o laço `$digest` novamente até que nenhuma mudança seja encontrada. O ciclo vai de pelo menos de duas vezes até dez vezes.
Embora a verificação suja ser ineficiente, ele consegue completar a tarefa sem se preocupar sobre como o dado mudou, mas o two-way binding no `Vue` é problemático. E a verificação suja consegue alcançar detecção de lotes de valores atualizados, e então unificar atualizações na UI, com grandeza reduzindo o número de operações no DOM. Assim sendo, ineficiência é relativa, e é assim que o benevolente vê o sábio e a sabedoria.
## Sequesto de dados
Vue internamente usa `Obeject.defineProperty()` para implementar o two-way binding, do qual permite você escutar por eventos de `set` e `get`.
```js
var data = { name: 'yck' }
observe(data)
let name = data.name // -> ontém o valor
data.name = 'yyy' // -> muda o valor
function observe(obj) {
// juiz do tipo
if (!obj || typeof obj !== 'object') {
return
}
Object.keys(obj).forEach(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, key, val) {
// recurse as propriedades dos filhos
observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
}
})
}
```
O código acima é uma simples implementação de como escutar os eventos `set` e `get` dos dados, mas isso não é o suficiente. Você também precisa adicionar um Publish/Subscribe para as propriedades quando apropriado.
```html
<div>
{{name}}
</div>
```
::: v-pre
Nesse processo, análisando o código do modelo, como acima, quando encontrando `{{name}}`, adicione um publish/subscribe para a propriedade `name`
:::
```js
// dissociar por Dep
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
// Sub é uma instância do observador
this.subs.push(sub)
}
notify() {
this.subs.forEach(sub => {
sub.update()
})
}
}
// Propriedade global, configura o observador com essa propriedade
Dep.target = null
function update(value) {
document.querySelector('div').innerText = value
}
class Watcher {
constructor(obj, key, cb) {
// Aponte Dep.target para se mesmo
// Então dispare o getter para a propriedade adicionar o ouvinte
// Finalmente, set Dep.target como null
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
update() {
// obtenha o novo valor
this.value = this.obj[this.key]
// update Dom with the update method
// atualize o DOM com o método de atualizar
this.cb(this.value)
}
}
var data = { name: 'yck' }
observe(data)
// Simulando a ação disparada analisando o `{{name}}`
new Watcher(data, 'name', update)
// atualiza o DOM innerText
data.name = 'yyy'
```
Next, improve on the `defineReactive` function.
```js
function defineReactive(obj, key, val) {
// recurse as propriedades do filho
observe(val)
let dp = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
// Adiciona o Watcher para inscrição
if (Dep.target) {
dp.addSub(Dep.target)
}
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
// Execute o método de atualização do Watcher
dp.notify()
}
})
}
```
A implementação acima é um simples two-way binding. A idéia central é manualmente disparar o getter das propriedades para adicionar o Publish/Subscribe.
## Proxy vs. Obeject.defineProperty
Apesar do `Obeject.defineProperty` ser capaz de implementar o two-way binding, ele ainda é falho.
* Ele consegue implementar apenas o sequestro de dados nas propriedades,
* ele não consegue escutar a mudança de dados para arrays
Apesar de Vue conseguir detectar mudanças em um array de dados, é na verdade um hack e é falho.
```js
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
// hack as seguintes funções
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// obter a função nativa
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
// chama a função nativa
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// dispara uma atualização
ob.dep.notify()
return result
})
})
```
Por outro lado, `Proxy` não tem o problema acima. Ele suporta nativamente a escuta para mudança no array e consegue interceptar o objeto completo diretamente, então Vue irá também substituir `Obeject.defineProperty` por `Proxy` na próxima grande versão.
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // vincula `value` para `2`
p.a // -> obtém 'a' = 2
```
# Princípio de rotas
As rotas no front-end é atualmente simples de implementar. A essência é escutar as mudanças na URL, então coincidir com as regras de roteamento, exibindo a página correspondente, e não precisa atualizar. Atualmente, existe apenas duas implementações de rotas usados pela página única.
- modo hash
- modo history
`www.test.com/#/` é a hash URL. Quando o valor depois do hash `#` muda, nenhuma request será enviada ao servidor. Você pode escutar as mudanças na URL através do evento `hashchange`, e então pular para a página correspondente.
O modo history é uma nova funcionalidade do HTML5, do qual é muito mais lindo que o Hash URL.
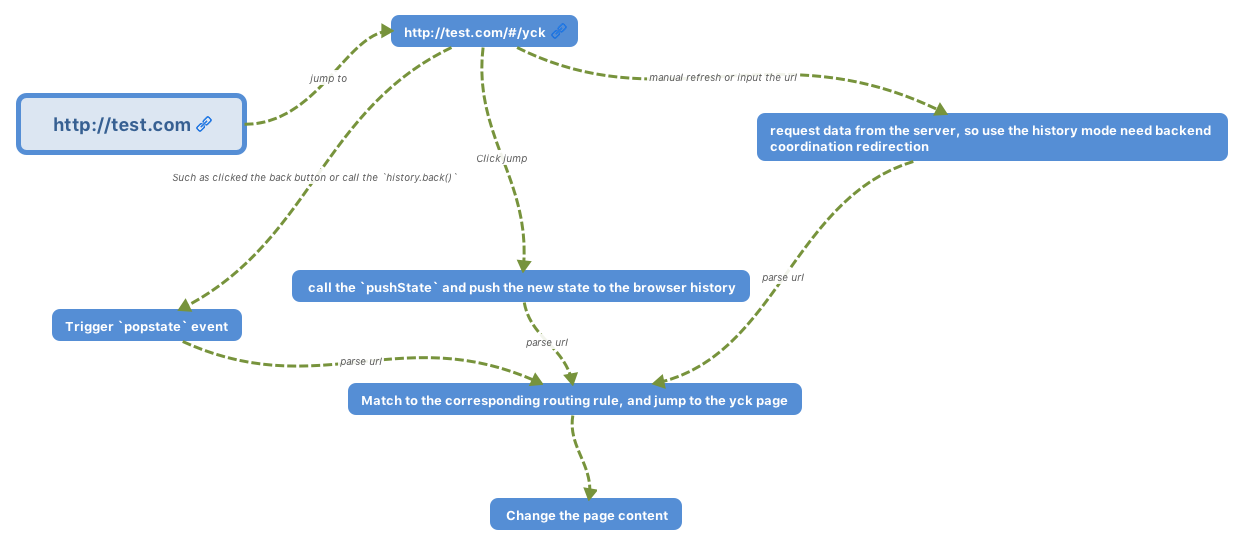
# Virtual Dom
[source code](https://github.com/KieSun/My-wheels/tree/master/Virtual%20Dom)
## Por que Virtual Dom é preciso
Como nós sabemos, modificar o DOM é uma tarefa custosa. Poderiamos considerar usar objetos JS para simular objetos DOM, desde de que operando em objetos JS é economizado muito mais tempo que operar no DOM.
Por exemplo
```js
// Vamos assumir que esse array simula um ul do qual cotém 5 li's.
[1, 2, 3, 4, 5]
// usando esse para substituir a ul acima.
[1, 2, 5, 4]
```
A partir do exemplo acima, é aparente que a terceira li foi removida, e a quarta e quinta mudaram suas posições
Se a operação anterior for aplicada no DOM, nós temos o seguinte código:
```js
// removendo a terceira li
ul.childNodes[2].remove()
// trocando internamente as posições do quarto e quinto elemento
let fromNode = ul.childNodes[4]
let toNode = node.childNodes[3]
let cloneFromNode = fromNode.cloneNode(true)
let cloenToNode = toNode.cloneNode(true)
ul.replaceChild(cloneFromNode, toNode)
ul.replaceChild(cloenToNode, fromNode)
```
De fato, nas operações atuais, nós precisamos de um identificador para cada nó, como um index para verificar se os dois nós são idênticos. Esse é o motivo de ambos Vue e React sugerirem na documentação oficial usar identificadores `key` para os nós em uma lista para garantir eficiência.
Elementos do DOM não só podem ser simulados, mas eles também podem ser renderizados por objetos JS.
Abaixo está uma simples implementação de um objeto JS simulando um elemento DOM.
```js
export default class Element {
/**
* @param {String} tag 'div'
* @param {Object} props { class: 'item' }
* @param {Array} children [ Element1, 'text']
* @param {String} key option
*/
constructor(tag, props, children, key) {
this.tag = tag
this.props = props
if (Array.isArray(children)) {
this.children = children
} else if (isString(children)) {
this.key = children
this.children = null
}
if (key) this.key = key
}
// renderização
render() {
let root = this._createElement(
this.tag,
this.props,
this.children,
this.key
)
document.body.appendChild(root)
return root
}
create() {
return this._createElement(this.tag, this.props, this.children, this.key)
}
// criando um elemento
_createElement(tag, props, child, key) {
// criando um elemento com tag
let el = document.createElement(tag)
// definindo propriedades em um elemento
for (const key in props) {
if (props.hasOwnProperty(key)) {
const value = props[key]
el.setAttribute(key, value)
}
}
if (key) {
el.setAttribute('key', key)
}
// adicionando nós filhos recursivamente
if (child) {
child.forEach(element => {
let child
if (element instanceof Element) {
child = this._createElement(
element.tag,
element.props,
element.children,
element.key
)
} else {
child = document.createTextNode(element)
}
el.appendChild(child)
})
}
return el
}
}
```
## Introdução ao algoritmo de Virtual Dom
O próximo passo depois de usar JS para implementar elementos DOM é detectar mudanças no objeto.
DOM é uma árvore de multi-ramifacações. Se nós compararmos a antiga e a nova árvore completamente, o tempo de complexidade seria O(n ^ 3), o que é simplesmente inaceitável. Assim sendo, o time do React otimizou esse algoritimo para alcançar uma complexidade O(n) para detectar as mudanças.
A chave para alcançar O(n) é apenas comparar os
nós no mesmo nível em vez de através dos níveis. Isso funciona porque no uso atual nós raramente movemos elementos DOM através dos níveis.
Nós então temos dois passos do algoritmo.
- Do topo para fundo, da esquerda para direita itera o objeto, primeira pesquisa de profundidade. Nesse passo adicionamos um índice para cada nó, renderizando as diferenças depois.
- sempre que um nó tiver um elemento filho, nós verificamos se o elemento filho mudou.
## Implementação do algoritmo do Virtual Dom
### recursão da árvore
Primeiro vamos implementar o algoritmo de recursão da árvore. Antes de fazer isso, vamos considerar os diferentes casos de comparar dois nós.
1. novos nós `tagName` ou `key` são diferentes do antigo. Isso significa que o nó antigo é substituido, e nós não temos que recorrer no nó mais porque a subárvore foi completamente removida.
2. novos nós `tagName` e `key` (talvez inexistente) são a mesma do antigo. Nós começamos a recursar na subárvore.
3. não aparece novo nó. Não é preciso uma operação.
```js
import { StateEnums, isString, move } from './util'
import Element from './element'
export default function diff(oldDomTree, newDomTree) {
// para gravar mudanças
let pathchs = {}
// o índice começa no 0
dfs(oldDomTree, newDomTree, 0, pathchs)
return pathchs
}
function dfs(oldNode, newNode, index, patches) {
// para salvar as mudanças na subárvore
let curPatches = []
// três casos
// 1. não é novo nó, não faça nada
// 2. novos nós tagName e `key` são diferentes dos antigos, substitua
// 3. novos nós tagName e key são o mesmo do antigo, comece a recursão
if (!newNode) {
} else if (newNode.tag === oldNode.tag && newNode.key === oldNode.key) {
// verifique se as propriedades mudaram
let props = diffProps(oldNode.props, newNode.props)
if (props.length) curPatches.push({ type: StateEnums.ChangeProps, props })
// recurse a subárvore
diffChildren(oldNode.children, newNode.children, index, patches)
} else {
// diferentes nós, substitua
curPatches.push({ type: StateEnums.Replace, node: newNode })
}
if (curPatches.length) {
if (patches[index]) {
patches[index] = patches[index].concat(curPatches)
} else {
patches[index] = curPatches
}
}
}
```
### verificando mudança das propriedades
Nós temos também três passos para verificar por mudanças nas propriedades
1. itere a lista de propriedades antiga, verifique se a propriedade ainda existe na nova lista de propriedade.
2. itere a nova lista de propriedades, verifique se existe mudanças para propriedades existente nas duas listas.
3. no segundo passo, também verifique se a propriedade não existe na lista de propriedades antiga.
```js
function diffProps(oldProps, newProps) {
// três passos para checar as props
// itere oldProps para remover propriedades
// itere newProps para mudar os valores das propriedades
// por último verifique se novas propriedades foram adicionadas
let change = []
for (const key in oldProps) {
if (oldProps.hasOwnProperty(key) && !newProps[key]) {
change.push({
prop: key
})
}
}
for (const key in newProps) {
if (newProps.hasOwnProperty(key)) {
const prop = newProps[key]
if (oldProps[key] && oldProps[key] !== newProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
} else if (!oldProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
}
}
}
return change
}
```
### Implementação do Algoritmo de detecção de mudanças na lista
Esse algoritmo é o núcle do Virtual Dom. Vamos descer a lista.
O passo principal é similar a verificação de mudanças nas propriedades. Também existe três passos.
1. itere a antiga lista de nós, verifique se ao nó ainda existe na nova lista.
2. itere a nova lista de nós, verifiquen se existe algum novo nó.
3. para o seguindo passo, também verifique se o nó moveu.
PS: esse algoritmo apenas manipula nós com `key`s.
```js
function listDiff(oldList, newList, index, patches) {
// para fazer a iteração mais conveniente, primeiro pegue todas as chaves de ambas as listas
let oldKeys = getKeys(oldList)
let newKeys = getKeys(newList)
let changes = []
// para salvar o dado do nó depois das mudanças
// existe varia vantagem de usar esse array para salvar
// 1. nós conseguimos obter corretamente o index de nós deletados
// 2. precisamos apenas opera no DOM uma vez para interexchanged os nós
// 3. precisamos apenas iterar para verificar na função `diffChildren`
// nós não precisamos verificar de novo para nós existente nas duas listas
let list = []
oldList &&
oldList.forEach(item => {
let key = item.key
if (isString(item)) {
key = item
}
// verificando se o novo filho tem o nó atual
// se não, então delete
let index = newKeys.indexOf(key)
if (index === -1) {
list.push(null)
} else list.push(key)
})
// array depois de alterações iterativas
let length = list.length
// uma vez deletando um array de elementos, o índice muda
// removemos de trás para ter certeza que os índices permanecem o mesmo
for (let i = length - 1; i >= 0; i--) {
// verifica se o elemento atual é null, se sim então significa que precisamos remover ele
if (!list[i]) {
list.splice(i, 1)
changes.push({
type: StateEnums.Remove,
index: i
})
}
}
// itere a nova lista, verificando se um nó é adicionado ou movido
// também adicione ou mova nós para `list`
newList &&
newList.forEach((item, i) => {
let key = item.key
if (isString(item)) {
key = item
}
// verifique se o filho antigo tem o nó atual
let index = list.indexOf(key)
// se não então precisamos inserir
if (index === -1 || key == null) {
changes.push({
type: StateEnums.Insert,
node: item,
index: i
})
list.splice(i, 0, key)
} else {
// encontrado o nó, precisamos verificar se ele precisar ser movido.
if (index !== i) {
changes.push({
type: StateEnums.Move,
from: index,
to: i
})
move(list, index, i)
}
}
})
return { changes, list }
}
function getKeys(list) {
let keys = []
let text
list &&
list.forEach(item => {
let key
if (isString(item)) {
key = [item]
} else if (item instanceof Element) {
key = item.key
}
keys.push(key)
})
return keys
}
```
### Iterando e marcando elementos filho
Para essa função, existe duas principais funcionalidades.
1. verificando diferenças entre duas listas
2. marcando nós
No geral, a implementação das funcionalidades são simples.
```js
function diffChildren(oldChild, newChild, index, patches) {
let { changes, list } = listDiff(oldChild, newChild, index, patches)
if (changes.length) {
if (patches[index]) {
patches[index] = patches[index].concat(changes)
} else {
patches[index] = changes
}
}
// marcando o ultimo nó iterado
let last = null
oldChild &&
oldChild.forEach((item, i) => {
let child = item && item.children
if (child) {
index =
last && last.children ? index + last.children.length + 1 : index + 1
let keyIndex = list.indexOf(item.key)
let node = newChild[keyIndex]
// só itera nós existentes em ambas as listas
// não precisamos visitar os adicionados ou removidos
if (node) {
dfs(item, node, index, patches)
}
} else index += 1
last = item
})
}
```
### Renderizando diferenças
A partir dos algoritmos anteriores, nós já obtemos as diferenças entre duas árvores. Depois de saber as diferenças, precisamos atualizar o DOM localmente. Vamos dar uma olhada no último passo do algoritmo do Virtual Dom.
Há duas funcionalidades principais para isso
1. Busca profunda na árvore e extrair os nós que precisam ser modificados.
2. Atualize o DOM local
Esse pedaço de código é bastante fácil de entender como um todo.
```js
let index = 0
export default function patch(node, patchs) {
let changes = patchs[index]
let childNodes = node && node.childNodes
// essa busca profunda é a mesma do algoritmo de diff
if (!childNodes) index += 1
if (changes && changes.length && patchs[index]) {
changeDom(node, changes)
}
let last = null
if (childNodes && childNodes.length) {
childNodes.forEach((item, i) => {
index =
last && last.children ? index + last.children.length + 1 : index + 1
patch(item, patchs)
last = item
})
}
}
function changeDom(node, changes, noChild) {
changes &&
changes.forEach(change => {
let { type } = change
switch (type) {
case StateEnums.ChangeProps:
let { props } = change
props.forEach(item => {
if (item.value) {
node.setAttribute(item.prop, item.value)
} else {
node.removeAttribute(item.prop)
}
})
break
case StateEnums.Remove:
node.childNodes[change.index].remove()
break
case StateEnums.Insert:
let dom
if (isString(change.node)) {
dom = document.createTextNode(change.node)
} else if (change.node instanceof Element) {
dom = change.node.create()
}
node.insertBefore(dom, node.childNodes[change.index])
break
case StateEnums.Replace:
node.parentNode.replaceChild(change.node.create(), node)
break
case StateEnums.Move:
let fromNode = node.childNodes[change.from]
let toNode = node.childNodes[change.to]
let cloneFromNode = fromNode.cloneNode(true)
let cloenToNode = toNode.cloneNode(true)
node.replaceChild(cloneFromNode, toNode)
node.replaceChild(cloenToNode, fromNode)
break
default:
break
}
})
}
```
## Fim
A implementação dos algoritimos do Virtual Dom contém os três seguintes passos:
1. Simular a criação de objetos DOM através do JS
2. Verifica a diferança entre dois objetos
2. Renderiza a diferença
```js
let test4 = new Element('div', { class: 'my-div' }, ['test4'])
let test5 = new Element('ul', { class: 'my-div' }, ['test5'])
let test1 = new Element('div', { class: 'my-div' }, [test4])
let test2 = new Element('div', { id: '11' }, [test5, test4])
let root = test1.render()
let pathchs = diff(test1, test2)
console.log(pathchs)
setTimeout(() => {
console.log('start updating')
patch(root, pathchs)
console.log('end updating')
}, 1000)
```
Embora a implementação atual seja simples, isso não é definitivamente o suficiente para ententer os algoritmos do Virtual Dom.
================================================
FILE: Framework/framework-en.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [MVVM](#mvvm)
- [Dirty Checking](#dirty-checking)
- [Data hijacking](#data-hijacking)
- [Proxy vs. Object.defineProperty](#proxy-vs-objectdefineproperty)
- [Routing principle](#routing-principle)
- [Virtual Dom](#virtual-dom)
- [Why Virtual Dom is needed](#why-virtual-dom-is-needed)
- [Virtual Dom algorithm introduction](#virtual-dom-algorithm-introduction)
- [Virtual Dom algorithm implementation](#virtual-dom-algorithm-implementation)
- [recursion of the tree](#recursion-of-the-tree)
- [checking property changes](#checking-property-changes)
- [Algorithm Implementation for Detecting List Changes](#algorithm-implementation-for-detecting-list-changes)
- [Iterating and Marking Child Elements](#iterating-and-marking-child-elements)
- [Rendering Difference](#rendering-difference)
- [The End](#the-end)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# MVVM
MVVM consists of the following three contents
* View: interface
* Model:Data model
* ViewModel:As a bridge responsible for communicating View and Model
In the JQuery period, if you need to refresh the UI, you need to get the corresponding DOM and then update the UI, so the data and business logic are strongly-coupled with the page.
In MVVM, the UI is driven by data. Once the data is changed, the corresponding UI will be refreshed. If the UI changes, the corresponding data will also be changed. In this way, we can only care about the data flow in business processing without dealing with the page directly. ViewModel only cares about the processing of data and business and does not care how View handles data. In this case, we can separate the View from the Model. If either party changes, it does not necessarily need to change the other party, and some reusable logic can be placed in a ViewModel, allowing multiple Views to reuse this ViewModel.
In MVVM, the core is the two-way binding of data, such as dirty checking by Angular and data hijacking in Vue.
## Dirty Checking
When the specified event is triggered, it will enter the dirty checking and call the `$digest` loop to walk through all the data observers to determine whether the current value is different from the previous value. If a change is detected, it will call the `$watch` function, and then call the `$digest` loop again until no changes are found. The cycle is at least two times, up to ten times.
Although dirty checking has inefficiencies, it can complete the task without caring about how the data is changed, but the two-way binding in `Vue` is problematic. And dirty checking can achieve batch detection of updated values, and then unified update UI, greatly reducing the number of operating DOM. Therefore, inefficiency is also relative, and this is what the benevolent sees the wise and sees wisdom.
## Data hijacking
Vue internally uses `Object.defineProperty()` to implement two-way binding, which allows you to listen for events of `set` and `get`.
```js
var data = { name: 'yck' }
observe(data)
let name = data.name // -> get value
data.name = 'yyy' // -> change value
function observe(obj) {
// judge the type
if (!obj || typeof obj !== 'object') {
return
}
Object.keys(obj).forEach(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, key, val) {
// recurse the properties of child
observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
}
})
}
```
The above code simply implements how to listen for the `set` and `get` events of the data, but that's not enough. You also need to add a Publish/Subscribe to the property when appropriate.
```html
<div>
{{name}}
</div>
```
::: v-pre
In the process of parsing the template code like above, when encountering `{{name}}`, add a publish/subscribe to the property `name`
:::
```js
// decouple by Dep
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
// Sub is an instance of Watcher
this.subs.push(sub)
}
notify() {
this.subs.forEach(sub => {
sub.update()
})
}
}
// Global property, configure Watcher with this property
Dep.target = null
function update(value) {
document.querySelector('div').innerText = value
}
class Watcher {
constructor(obj, key, cb) {
// Point Dep.target to itself
// Then trigger the getter of the property to add the listener
// Finally, set Dep.target as null
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
update() {
// get the new value
this.value = this.obj[this.key]
// update Dom with the update method
this.cb(this.value)
}
}
var data = { name: 'yck' }
observe(data)
// Simulate the action triggered by parsing the `{{name}}`
new Watcher(data, 'name', update)
// update Dom innerText
data.name = 'yyy'
```
Next, improve on the `defineReactive` function.
```js
function defineReactive(obj, key, val) {
// recurse the properties of child
observe(val)
let dp = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
// Add Watcher to the subscription
if (Dep.target) {
dp.addSub(Dep.target)
}
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
// Execute the update method of Watcher
dp.notify()
}
})
}
```
The above implements a simple two-way binding. The core idea is to manually trigger the getter of the property to add the Publish/Subscribe.
## Proxy vs. Object.defineProperty
Although `Object.defineProperty` has been able to implement two-way binding, it is still flawed.
* It can only implement data hijacking on properties, so it needs deep traversal of the entire object
* it can't listen to changes in data for arrays
Although Vue can detect the changes in array data, it is actually a hack and is flawed.
```js
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
// hack the following functions
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// get the native function
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
// call the native function
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// trigger the update
ob.dep.notify()
return result
})
})
```
On the other hand, `Proxy` doesn't have the above problem. It natively supports listening to array changes and can intercept the entire object directly, so Vue will also replace `Object.defineProperty` with `Proxy` in the next big version.
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
```
# Routing principle
The front-end routing is actually very simple to implement. The essence is to listen to changes in the URL, then match the routing rules, display the corresponding page, and no need to refresh. Currently, there are only two implementations of the route used by a single page.
- hash mode
- history mode
`www.test.com/#/` is the hash URL. When the hash value after `#` changes, no request will be sent to server. You can listen to the URL change through the `hashchange` event, and then jump to the corresponding page.

History mode is a new feature of HTML5, which is more beautiful than Hash URL.
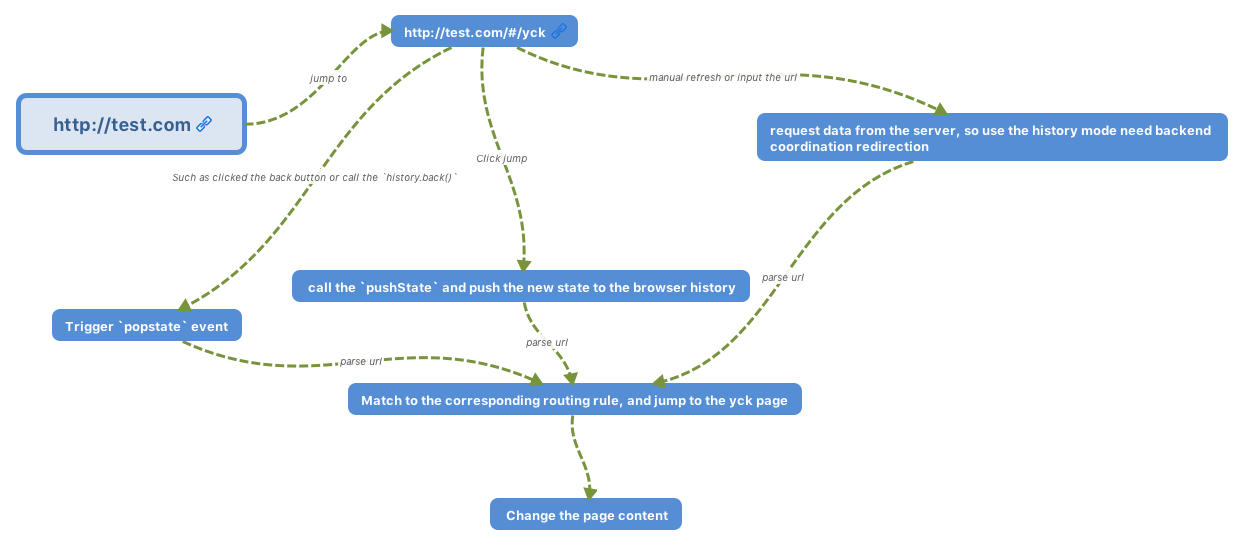
# Virtual Dom
[source code](https://github.com/KieSun/My-wheels/tree/master/Virtual%20Dom)
## Why Virtual Dom is needed
As we know, modifying DOM is a costly task. We could consider using JS objects to simulate DOM objects, since operating on JS objects is much more time saving than operating on DOM.
For example
```js
// Let's assume this array simulates a ul which contains five li's.
[1, 2, 3, 4, 5]
// using this to replace the ul above.
[1, 2, 5, 4]
```
From the above example, it's apparent that the first ul's 3rd li is removed, and the 4th and the 5th are exchanged positions.
If the previous operation is applied to DOM, we have the following code:
```js
// removing the 3rd li
ul.childNodes[2].remove()
// interexchanging positions between the 4th and the 5th
let fromNode = ul.childNodes[4]
let toNode = node.childNodes[3]
let cloneFromNode = fromNode.cloneNode(true)
let cloneToNode = toNode.cloneNode(true)
ul.replaceChild(cloneFromNode, toNode)
ul.replaceChild(cloneToNode, fromNode)
```
Of course, in actual operations, we need an identifier for each node, as an index for checking if two nodes are identical. This is why both Vue and React's official documentation suggests using a unique identifier `key` for nodes in a list to ensure efficiency.
DOM element can not only be simulated, but they can also be rendered by JS objects.
Below is a simple implementation of a JS object simulating a DOM element.
```js
export default class Element {
/**
* @param {String} tag 'div'
* @param {Object} props { class: 'item' }
* @param {Array} children [ Element1, 'text']
* @param {String} key option
*/
constructor(tag, props, children, key) {
this.tag = tag
this.props = props
if (Array.isArray(children)) {
this.children = children
} else if (isString(children)) {
this.key = children
this.children = null
}
if (key) this.key = key
}
// render
render() {
let root = this._createElement(
this.tag,
this.props,
this.children,
this.key
)
document.body.appendChild(root)
return root
}
create() {
return this._createElement(this.tag, this.props, this.children, this.key)
}
// create an element
_createElement(tag, props, child, key) {
// create an element with tag
let el = document.createElement(tag)
// set properties on the element
for (const key in props) {
if (props.hasOwnProperty(key)) {
const value = props[key]
el.setAttribute(key, value)
}
}
if (key) {
el.setAttribute('key', key)
}
// add children nodes recursively
if (child) {
child.forEach(element => {
let child
if (element instanceof Element) {
child = this._createElement(
element.tag,
element.props,
element.children,
element.key
)
} else {
child = document.createTextNode(element)
}
el.appendChild(child)
})
}
return el
}
}
```
## Virtual Dom algorithm introduction
The next step after using JS to implement DOM element is to detect object changes.
DOM is a multi-branching tree. If we were to compare the old and the new trees thoroughly, the time complexity would be O(n ^ 3), which is simply unacceptable. Therefore, the React team optimized their algorithm to achieve an O(n) complexity for detecting changes.
The key to achieving O(n) is to only compare the nodes on the same level rather than across levels. This works because in actual usage we rarely move DOM elements across levels.
We then have two steps of the algorithm.
- from top to bottom, from left to right to iterate the object, aka depth first search. This step adds an index to every node, for rendering the differences later.
- whenever a node has a child element, we check whether the child element changed.
## Virtual Dom algorithm implementation
### recursion of the tree
First let's implement the recursion algorithm of the tree. Before doing that, let's consider the different cases of comparing two nodes.
1. new node's `tagName` or `key` is different from that of the old one. This means the old node is replaced, and we don't have to recurse on the node any more because the whole subtree is removed.
2. new node's `tagName` and `key` (maybe nonexistent) are the same as the old's. We start recursing on the subtree.
3. no new node appears. No operation needed.
```js
import { StateEnums, isString, move } from './util'
import Element from './element'
export default function diff(oldDomTree, newDomTree) {
// for recording changes
let patches = {}
// the index starts at 0
dfs(oldDomTree, newDomTree, 0, patches)
return patches
}
function dfs(oldNode, newNode, index, patches) {
// for saving the subtree changes
let curPatches = []
// three cases
// 1. no new node, do nothing
// 2. new nodes' tagName and `key` are different from the old one's, replace
// 3. new nodes' tagName and key are the same as the old one's, start recursing
if (!newNode) {
} else if (newNode.tag === oldNode.tag && newNode.key === oldNode.key) {
// check whether properties changed
let props = diffProps(oldNode.props, newNode.props)
if (props.length) curPatches.push({ type: StateEnums.ChangeProps, props })
// recurse the subtree
diffChildren(oldNode.children, newNode.children, index, patches)
} else {
// different node, replace
curPatches.push({ type: StateEnums.Replace, node: newNode })
}
if (curPatches.length) {
if (patches[index]) {
patches[index] = patches[index].concat(curPatches)
} else {
patches[index] = curPatches
}
}
}
```
### checking property changes
We also have three steps for checking for property changes
1. iterate the old property list, check if the property still exists in the new property list.
2. iterate the new property list, check if there are changes for properties existing in both lists.
3. for the second step, also check if a property doesn't exist in the old property list.
```js
function diffProps(oldProps, newProps) {
// three steps for checking for props
// iterate oldProps for removed properties
// iterate newProps for changed property values
// lastly check if new properties are added
let change = []
for (const key in oldProps) {
if (oldProps.hasOwnProperty(key) && !newProps[key]) {
change.push({
prop: key
})
}
}
for (const key in newProps) {
if (newProps.hasOwnProperty(key)) {
const prop = newProps[key]
if (oldProps[key] && oldProps[key] !== newProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
} else if (!oldProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
}
}
}
return change
}
```
### Algorithm Implementation for Detecting List Changes
This algorithm is the core of the Virtual Dom. Let's go down the list.
The main steps are similar to checking property changes. There are also three steps.
1. iterate the old node list, check if the node still exists in the new list.
2. iterate the new node list, check if there is any new node.
3. for the second step, also check if a node moved.
PS: this algorithm only handles nodes with `key`s.
```js
function listDiff(oldList, newList, index, patches) {
// to make the iteration more convenient, first take all keys from both lists
let oldKeys = getKeys(oldList)
let newKeys = getKeys(newList)
let changes = []
// for saving the node data after changes
// there are several advantages of using this array to save
// 1. we can correctly obtain the index of the deleted node
// 2. we only need to operate on the DOM once for interexchanged nodes
// 3. we only need to iterate for the checking in the `diffChildren` function
// we don't need to check again for nodes existing in both lists
let list = []
oldList &&
oldList.forEach(item => {
let key = item.key
if (isString(item)) {
key = item
}
// checking if the new children has the current node
// if not then delete
let index = newKeys.indexOf(key)
if (index === -1) {
list.push(null)
} else list.push(key)
})
// array after iterative changes
let length = list.length
// since deleting array elements changes the indices
// we remove from the back to make sure indices stay the same
for (let i = length - 1; i >= 0; i--) {
// check if the current element is null, if so then it means we need to remove it
if (!list[i]) {
list.splice(i, 1)
changes.push({
type: StateEnums.Remove,
index: i
})
}
}
// iterate the new list, check if a node is added or moved
// also add and move nodes for `list`
newList &&
newList.forEach((item, i) => {
let key = item.key
if (isString(item)) {
key = item
}
// check if the old children has the current node
let index = list.indexOf(key)
// if not then we need to insert
if (index === -1 || key == null) {
changes.push({
type: StateEnums.Insert,
node: item,
index: i
})
list.splice(i, 0, key)
} else {
// found the node, need to check if it needs to be moved.
if (index !== i) {
changes.push({
type: StateEnums.Move,
from: index,
to: i
})
move(list, index, i)
}
}
})
return { changes, list }
}
function getKeys(list) {
let keys = []
let text
list &&
list.forEach(item => {
let key
if (isString(item)) {
key = [item]
} else if (item instanceof Element) {
key = item.key
}
keys.push(key)
})
return keys
}
```
### Iterating and Marking Child Elements
For this function, there are two main functionalities.
1. checking differences between two lists
2. marking nodes
In general, the functionalities implemented are simple.
```js
function diffChildren(oldChild, newChild, index, patches) {
let { changes, list } = listDiff(oldChild, newChild, index, patches)
if (changes.length) {
if (patches[index]) {
patches[index] = patches[index].concat(changes)
} else {
patches[index] = changes
}
}
// marking last iterated node
let last = null
oldChild &&
oldChild.forEach((item, i) => {
let child = item && item.children
if (child) {
index =
last && last.children ? index + last.children.length + 1 : index + 1
let keyIndex = list.indexOf(item.key)
let node = newChild[keyIndex]
// only iterate nodes existing in both lists
// no need to visit the added or removed ones
if (node) {
dfs(item, node, index, patches)
}
} else index += 1
last = item
})
}
```
### Rendering Difference
From the earlier algorithms, we can already get the differences between two trees. After knowing the differences, we need to locally update DOM. Let's take a look at the last step of Virtual Dom algorithms.
Two main functionalities for this function
1. Deep search the tree and extract the nodes needing modifications
2. Locally update DOM
This code snippet is pretty easy to understand as a whole.
```js
let index = 0
export default function patch(node, patches) {
let changes = patches[index]
let childNodes = node && node.childNodes
// this deep search is the same as the one in diff algorithm
if (!childNodes) index += 1
if (changes && changes.length && patches[index]) {
changeDom(node, changes)
}
let last = null
if (childNodes && childNodes.length) {
childNodes.forEach((item, i) => {
index =
last && last.children ? index + last.children.length + 1 : index + 1
patch(item, patches)
last = item
})
}
}
function changeDom(node, changes, noChild) {
changes &&
changes.forEach(change => {
let { type } = change
switch (type) {
case StateEnums.ChangeProps:
let { props } = change
props.forEach(item => {
if (item.value) {
node.setAttribute(item.prop, item.value)
} else {
node.removeAttribute(item.prop)
}
})
break
case StateEnums.Remove:
node.childNodes[change.index].remove()
break
case StateEnums.Insert:
let dom
if (isString(change.node)) {
dom = document.createTextNode(change.node)
} else if (change.node instanceof Element) {
dom = change.node.create()
}
node.insertBefore(dom, node.childNodes[change.index])
break
case StateEnums.Replace:
node.parentNode.replaceChild(change.node.create(), node)
break
case StateEnums.Move:
let fromNode = node.childNodes[change.from]
let toNode = node.childNodes[change.to]
let cloneFromNode = fromNode.cloneNode(true)
let cloneToNode = toNode.cloneNode(true)
node.replaceChild(cloneFromNode, toNode)
node.replaceChild(cloneToNode, fromNode)
break
default:
break
}
})
}
```
## The End
The implementation of the Virtual Dom algorithms contains the following three steps:
1. Simulate the creation of DOM objects through JS
2. Check differences between two objects
3. Render the differences
```js
let test4 = new Element('div', { class: 'my-div' }, ['test4'])
let test5 = new Element('ul', { class: 'my-div' }, ['test5'])
let test1 = new Element('div', { class: 'my-div' }, [test4])
let test2 = new Element('div', { id: '11' }, [test5, test4])
let root = test1.render()
let patches = diff(test1, test2)
console.log(patches)
setTimeout(() => {
console.log('start updating')
patch(root, patches)
console.log('end updating')
}, 1000)
```
Although the current implementation is simple, it's definitely enough for understanding Virtual Dom algorithms.
================================================
FILE: Framework/framework-zh.md
================================================
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [MVVM](#mvvm)
- [脏数据检测](#%E8%84%8F%E6%95%B0%E6%8D%AE%E6%A3%80%E6%B5%8B)
- [数据劫持](#%E6%95%B0%E6%8D%AE%E5%8A%AB%E6%8C%81)
- [Proxy 与 Object.defineProperty 对比](#proxy-%E4%B8%8E-objectdefineproperty-%E5%AF%B9%E6%AF%94)
- [路由原理](#%E8%B7%AF%E7%94%B1%E5%8E%9F%E7%90%86)
- [Virtual Dom](#virtual-dom)
- [为什么需要 Virtual Dom](#%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81-virtual-dom)
- [Virtual Dom 算法简述](#virtual-dom-%E7%AE%97%E6%B3%95%E7%AE%80%E8%BF%B0)
- [Virtual Dom 算法实现](#virtual-dom-%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0)
- [树的递归](#%E6%A0%91%E7%9A%84%E9%80%92%E5%BD%92)
- [判断属性的更改](#%E5%88%A4%E6%96%AD%E5%B1%9E%E6%80%A7%E7%9A%84%E6%9B%B4%E6%94%B9)
- [判断列表差异算法实现](#%E5%88%A4%E6%96%AD%E5%88%97%E8%A1%A8%E5%B7%AE%E5%BC%82%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0)
- [遍历子元素打标识](#%E9%81%8D%E5%8E%86%E5%AD%90%E5%85%83%E7%B4%A0%E6%89%93%E6%A0%87%E8%AF%86)
- [渲染差异](#%E6%B8%B2%E6%9F%93%E5%B7%AE%E5%BC%82)
- [最后](#%E6%9C%80%E5%90%8E)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# MVVM
MVVM 由以下三个内容组成
- View:界面
- Model:数据模型
- ViewModel:作为桥梁负责沟通 View 和 Model
在 JQuery 时期,如果需要刷新 UI 时,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和页面有强耦合。
在 MVVM 中,UI 是通过数据驱动的,数据一旦改变就会相应的刷新对应的 UI,UI 如果改变,也会改变对应的数据。这种方式就可以在业务处理中只关心数据的流转,而无需直接和页面打交道。ViewModel 只关心数据和业务的处理,不关心 View 如何处理数据,在这种情况下,View 和 Model 都可以独立出来,任何一方改变了也不一定需要改变另一方,并且可以将一些可复用的逻辑放在一个 ViewModel 中,让多个 View 复用这个 ViewModel。
在 MVVM 中,最核心的也就是数据双向绑定,例如 Angluar 的脏数据检测,Vue 中的数据劫持。
## 脏数据检测
当触发了指定事件后会进入脏数据检测,这时会调用 `$digest` 循环遍历所有的数据观察者,判断当前值是否和先前的值有区别,如果检测到变化的话,会调用 `$watch` 函数,然后再次调用 `$digest` 循环直到发现没有变化。循环至少为二次 ,至多为十次。
脏数据检测虽然存在低效的问题,但是不关心数据是通过什么方式改变的,都可以完成任务,但是这在 Vue 中的双向绑定是存在问题的。并且脏数据检测可以实现批量检测出更新的值,再去统一更新 UI,大大减少了操作 DOM 的次数。所以低效也是相对的,这就仁者见仁智者见智了。
## 数据劫持
Vue 内部使用了 `Object.defineProperty()` 来实现双向绑定,通过这个函数可以监听到 `set` 和 `get` 的事件。
```js
var data = { name: 'yck' }
observe(data)
let name = data.name // -> get value
data.name = 'yyy' // -> change value
function observe(obj) {
// 判断类型
if (!obj || typeof obj !== 'object') {
return
}
Object.keys(obj).forEach(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, key, val) {
// 递归子属性
observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
}
})
}
```
以上代码简单的实现了如何监听数据的 `set` 和 `get` 的事件,但是仅仅如此是不够的,还需要在适当的时候给属性添加发布订阅
```html
<div>
{{name}}
</div>
```
::: v-pre
在解析如上模板代码时,遇到 `{{name}}` 就会给属性 `name` 添加发布订阅。
:::
```js
// 通过 Dep 解耦
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
// sub 是 Watcher 实例
this.subs.push(sub)
}
notify() {
this.subs.forEach(sub => {
sub.update()
})
}
}
// 全局属性,通过该属性配置 Watcher
Dep.target = null
function update(value) {
document.querySelector('div').innerText = value
}
class Watcher {
constructor(obj, key, cb) {
// 将 Dep.target 指向自己
// 然后触发属性的 getter 添加监听
// 最后将 Dep.target 置空
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
update() {
// 获得新值
this.value = this.obj[this.key]
// 调用 update 方法更新 Dom
this.cb(this.value)
}
}
var data = { name: 'yck' }
observe(data)
// 模拟解析到 `{{name}}` 触发的操作
new Watcher(data, 'name', update)
// update Dom innerText
data.name = 'yyy'
```
接下来,对 `defineReactive` 函数进行改造
```js
function defineReactive(obj, key, val) {
// 递归子属性
observe(val)
let dp = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
// 将 Watcher 添加到订阅
if (Dep.target) {
dp.addSub(Dep.target)
}
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
// 执行 watcher 的 update 方法
dp.notify()
}
})
}
```
以上实现了一个简易的双向绑定,核心思路就是手动触发一次属性的 getter 来实现发布订阅的添加。
## Proxy 与 Object.defineProperty 对比
`Object.defineProperty` 虽然已经能够实现双向绑定了,但是他还是有缺陷的。
1. 只能对属性进行数据劫持,所以需要深度遍历整个对象
2. 对于数组不能监听到数据的变化
虽然 Vue 中确实能检测到数组数据的变化,但是其实是使用了 hack 的办法,并且也是有缺陷的。
```js
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
// hack 以下几个函数
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// 获得原生函数
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
// 调用原生函数
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// 触发更新
ob.dep.notify()
return result
})
})
```
反观 Proxy 就没以上的问题,原生支持监听数组变化,并且可以直接对整个对象进行拦截,所以 Vue 也将在下个大版本中使用 Proxy 替换 Object.defineProperty
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${targ
gitextract_zczg9o2q/ ├── .gitignore ├── Algorithm/ │ ├── algorithm-ch.md │ └── algorithm-en.md ├── Browser/ │ ├── browser-ch.md │ └── browser-en.md ├── Career/ │ └── How-to-use-your-time-correctly.md ├── DataStruct/ │ ├── dataStruct-en.md │ └── dataStruct-zh.md ├── Framework/ │ ├── framework-br.md │ ├── framework-en.md │ ├── framework-zh.md │ ├── react-br.md │ ├── react-en.md │ ├── react-zh.md │ ├── vue-br.md │ ├── vue-en.md │ └── vue-zh.md ├── Git/ │ ├── git-en.md │ └── git-zh.md ├── JS/ │ ├── JS-br.md │ ├── JS-ch.md │ └── JS-en.md ├── LICENSE ├── MP/ │ └── mp-ch.md ├── Network/ │ ├── Network-zh.md │ └── Network_en.md ├── Performance/ │ ├── performance-ch.md │ └── performance-en.md ├── README-EN.md ├── README.md ├── Safety/ │ ├── safety-cn.md │ └── safety-en.md └── log-zh.md
Condensed preview — 33 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (626K chars).
[
{
"path": ".gitignore",
"chars": 23,
"preview": ".idea\ntest.js\n.vscode/\n"
},
{
"path": "Algorithm/algorithm-ch.md",
"chars": 20694,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Algorithm/algorithm-en.md",
"chars": 33966,
"preview": "# Time Complexity\n\nThe worst time complexity is often used to measure the quality of an algorithm.\n\nThe constant time O("
},
{
"path": "Browser/browser-ch.md",
"chars": 14007,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Browser/browser-en.md",
"chars": 24118,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Career/How-to-use-your-time-correctly.md",
"chars": 2204,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "DataStruct/dataStruct-en.md",
"chars": 30404,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "DataStruct/dataStruct-zh.md",
"chars": 20384,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/framework-br.md",
"chars": 23815,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/framework-en.md",
"chars": 23062,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/framework-zh.md",
"chars": 16816,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/react-br.md",
"chars": 22680,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/react-en.md",
"chars": 22059,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/react-zh.md",
"chars": 16906,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/vue-br.md",
"chars": 7071,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/vue-en.md",
"chars": 6851,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Framework/vue-zh.md",
"chars": 28558,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Git/git-en.md",
"chars": 2577,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Git/git-zh.md",
"chars": 1752,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "JS/JS-br.md",
"chars": 47730,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "JS/JS-ch.md",
"chars": 34183,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "JS/JS-en.md",
"chars": 47113,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "LICENSE",
"chars": 1067,
"preview": "MIT License\n\nCopyright (c) 2018 YuChengKai\n\nPermission is hereby granted, free of charge, to any person obtaining a copy"
},
{
"path": "MP/mp-ch.md",
"chars": 65489,
"preview": "<!-- TOC -->\n\n- [小程序-登录](#小程序-登录)\n - [unionid和openid](#unionid和openid)\n - [关键Api](#关键api)\n - [登录流程设计](#登录流程设计)\n"
},
{
"path": "Network/Network-zh.md",
"chars": 16179,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Network/Network_en.md",
"chars": 34547,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Performance/performance-ch.md",
"chars": 6874,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Performance/performance-en.md",
"chars": 13626,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "README-EN.md",
"chars": 4553,
"preview": "<img align=\"center\" src='./InterviewMap.png' />\n\n<h1 align=\"center\">\n Interview Map\n</h1>\n\n<h4 align=\"center\">This is a"
},
{
"path": "README.md",
"chars": 2109,
"preview": "<img align=\"center\" src='./InterviewMap.png' />\n\n<h1 align=\"center\">\n Interview Map\n</h1>\n\n<h4 align=\"center\">这是一份能让你更好"
},
{
"path": "Safety/safety-cn.md",
"chars": 4434,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "Safety/safety-en.md",
"chars": 7914,
"preview": "<!-- START doctoc generated TOC please keep comment here to allow auto update -->\n<!-- DON'T EDIT THIS SECTION, INSTEAD "
},
{
"path": "log-zh.md",
"chars": 234,
"preview": "##2018-07-28\n\n- flattenDeep 代码修改\n- 修改 Node eventloop 中对于 node 环境下 setTimeout 的打印描述\n- 增加 VueRouter 源码分析\n\n## 2018-07-23 \n\n"
}
]
About this extraction
This page contains the full source code of the InterviewMap/CS-Interview-Knowledge-Map GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 33 files (589.8 KB), approximately 192.5k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.