Copy disabled (too large)
Download .txt
Showing preview only (11,809K chars total). Download the full file to get everything.
Repository: unmannedlab/RELLIS-3D
Branch: main
Commit: c17a118fcaed
Files: 216
Total size: 11.2 MB
Directory structure:
gitextract_trhdf0kw/
├── .gitignore
├── README.md
├── benchmarks/
│ ├── GSCNN-master/
│ │ ├── .gitignore
│ │ ├── Dockerfile
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── config.py
│ │ ├── datasets/
│ │ │ ├── __init__.py
│ │ │ ├── cityscapes.py
│ │ │ ├── cityscapes_labels.py
│ │ │ ├── edge_utils.py
│ │ │ └── rellis.py
│ │ ├── docs/
│ │ │ ├── index.html
│ │ │ └── resources/
│ │ │ └── bibtex.txt
│ │ ├── gscnn.txt
│ │ ├── loss.py
│ │ ├── my_functionals/
│ │ │ ├── DualTaskLoss.py
│ │ │ ├── GatedSpatialConv.py
│ │ │ ├── __init__.py
│ │ │ └── custom_functional.py
│ │ ├── network/
│ │ │ ├── Resnet.py
│ │ │ ├── SEresnext.py
│ │ │ ├── __init__.py
│ │ │ ├── gscnn.py
│ │ │ ├── mynn.py
│ │ │ └── wider_resnet.py
│ │ ├── optimizer.py
│ │ ├── run_gscnn.sh
│ │ ├── run_gscnn_eval.sh
│ │ ├── train.py
│ │ ├── transforms/
│ │ │ ├── joint_transforms.py
│ │ │ └── transforms.py
│ │ └── utils/
│ │ ├── AttrDict.py
│ │ ├── f_boundary.py
│ │ ├── image_page.py
│ │ └── misc.py
│ ├── HRNet-Semantic-Segmentation-HRNet-OCR/
│ │ ├── .gitignore
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── experiments/
│ │ │ ├── ade20k/
│ │ │ │ ├── seg_hrnet_ocr_w48_520x520_ohem_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml
│ │ │ │ ├── seg_hrnet_w48_520x520_ohem_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml
│ │ │ │ └── seg_hrnet_w48_520x520_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml
│ │ │ ├── cityscapes/
│ │ │ │ ├── seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_ocr_w48_trainval_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_w48_train_ohem_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_w48_trainval_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484x2.yaml
│ │ │ │ └── seg_hrnet_w48_trainval_ohem_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484x2.yaml
│ │ │ ├── cocostuff/
│ │ │ │ ├── seg_hrnet_ocr_w48_520x520_ohem_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml
│ │ │ │ ├── seg_hrnet_w48_520x520_ohem_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml
│ │ │ │ └── seg_hrnet_w48_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml
│ │ │ ├── lip/
│ │ │ │ ├── seg_hrnet_ocr_w48_473x473_sgd_lr7e-3_wd5e-4_bs_40_epoch150.yaml
│ │ │ │ └── seg_hrnet_w48_473x473_sgd_lr7e-3_wd5e-4_bs_40_epoch150.yaml
│ │ │ ├── pascal_ctx/
│ │ │ │ ├── seg_hrnet_ocr_w48_cls59_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml
│ │ │ │ ├── seg_hrnet_ocr_w48_cls60_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml
│ │ │ │ └── seg_hrnet_w48_cls59_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml
│ │ │ └── rellis/
│ │ │ ├── seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ └── seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-3_wd5e-4_bs_12_epoch484.yaml
│ │ ├── hubconf.py
│ │ ├── pretrained_models/
│ │ │ └── .gitignore
│ │ ├── requirements.txt
│ │ ├── run_hrnet.sh
│ │ ├── run_hrnet_test.sh
│ │ └── tools/
│ │ ├── _init_paths.py
│ │ ├── test.py
│ │ └── train.py
│ ├── KPConv-PyTorch-master/
│ │ ├── .gitignore
│ │ ├── INSTALL.md
│ │ ├── README.md
│ │ ├── cpp_wrappers/
│ │ │ ├── compile_wrappers.sh
│ │ │ ├── cpp_neighbors/
│ │ │ │ ├── build.bat
│ │ │ │ ├── neighbors/
│ │ │ │ │ ├── neighbors.cpp
│ │ │ │ │ └── neighbors.h
│ │ │ │ ├── setup.py
│ │ │ │ └── wrapper.cpp
│ │ │ ├── cpp_subsampling/
│ │ │ │ ├── build.bat
│ │ │ │ ├── grid_subsampling/
│ │ │ │ │ ├── grid_subsampling.cpp
│ │ │ │ │ └── grid_subsampling.h
│ │ │ │ ├── setup.py
│ │ │ │ └── wrapper.cpp
│ │ │ └── cpp_utils/
│ │ │ ├── cloud/
│ │ │ │ ├── cloud.cpp
│ │ │ │ └── cloud.h
│ │ │ └── nanoflann/
│ │ │ └── nanoflann.hpp
│ │ ├── datasets/
│ │ │ ├── ModelNet40.py
│ │ │ ├── Rellis.py
│ │ │ ├── S3DIS.py
│ │ │ ├── SemanticKitti.py
│ │ │ └── common.py
│ │ ├── doc/
│ │ │ ├── object_classification_guide.md
│ │ │ ├── pretrained_models_guide.md
│ │ │ ├── scene_segmentation_guide.md
│ │ │ ├── slam_segmentation_guide.md
│ │ │ └── visualization_guide.md
│ │ ├── kernels/
│ │ │ ├── dispositions/
│ │ │ │ └── k_015_center_3D.ply
│ │ │ └── kernel_points.py
│ │ ├── models/
│ │ │ ├── architectures.py
│ │ │ └── blocks.py
│ │ ├── plot_convergence.py
│ │ ├── run_kpconv.sh
│ │ ├── test_models.py
│ │ ├── train_ModelNet40.py
│ │ ├── train_Rellis.py
│ │ ├── train_S3DIS.py
│ │ ├── train_SemanticKitti.py
│ │ ├── utils/
│ │ │ ├── config.py
│ │ │ ├── mayavi_visu.py
│ │ │ ├── metrics.py
│ │ │ ├── ply.py
│ │ │ ├── tester.py
│ │ │ ├── trainer.py
│ │ │ └── visualizer.py
│ │ └── visualize_deformations.py
│ ├── README.md
│ ├── SalsaNext/
│ │ ├── .gitignore
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── eval.sh
│ │ ├── run_salsanext.sh
│ │ ├── run_salsanext_eval.sh
│ │ ├── salsanext.yml
│ │ ├── salsanext_cuda09.yml
│ │ ├── salsanext_cuda10.yml
│ │ ├── train/
│ │ │ ├── __init__.py
│ │ │ ├── common/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── avgmeter.py
│ │ │ │ ├── laserscan.py
│ │ │ │ ├── laserscanvis.py
│ │ │ │ ├── logger.py
│ │ │ │ ├── summary.py
│ │ │ │ ├── sync_batchnorm/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── batchnorm.py
│ │ │ │ │ ├── comm.py
│ │ │ │ │ └── replicate.py
│ │ │ │ └── warmupLR.py
│ │ │ └── tasks/
│ │ │ ├── __init__.py
│ │ │ └── semantic/
│ │ │ ├── __init__.py
│ │ │ ├── config/
│ │ │ │ ├── arch/
│ │ │ │ │ └── salsanext_ouster.yml
│ │ │ │ └── labels/
│ │ │ │ ├── rellis.yaml
│ │ │ │ ├── semantic-kitti-all.yaml
│ │ │ │ └── semantic-kitti.yaml
│ │ │ ├── dataset/
│ │ │ │ ├── kitti/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── parser.py
│ │ │ │ └── rellis/
│ │ │ │ ├── __init__.py
│ │ │ │ └── parser.py
│ │ │ ├── evaluate_iou.py
│ │ │ ├── infer.py
│ │ │ ├── infer2.py
│ │ │ ├── modules/
│ │ │ │ ├── Lovasz_Softmax.py
│ │ │ │ ├── SalsaNext.py
│ │ │ │ ├── SalsaNextAdf.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── adf.py
│ │ │ │ ├── ioueval.py
│ │ │ │ ├── trainer.py
│ │ │ │ ├── user.py
│ │ │ │ └── user2.py
│ │ │ ├── postproc/
│ │ │ │ ├── KNN.py
│ │ │ │ └── __init__.py
│ │ │ ├── train.py
│ │ │ └── visualize.py
│ │ └── train.sh
│ ├── __init__.py
│ ├── gscnn_requirement.txt
│ └── requirement.txt
├── catkin_ws/
│ ├── .catkin_workspace
│ ├── .gitignore
│ └── src/
│ └── platform_description/
│ ├── CMakeLists.txt
│ ├── launch/
│ │ └── description.launch
│ ├── meshes/
│ │ ├── arm-mount-plate.stl
│ │ ├── bulkhead-collision.stl
│ │ ├── bulkhead.stl
│ │ ├── chassis-collision.stl
│ │ ├── chassis.stl
│ │ ├── diff-link.stl
│ │ ├── e-stop.stl
│ │ ├── fenders.stl
│ │ ├── light.stl
│ │ ├── novatel-smart6.stl
│ │ ├── rocker.stl
│ │ ├── susp-link.stl
│ │ ├── tracks.dae
│ │ ├── tracks_collision.stl
│ │ └── wheel.stl
│ ├── package.xml
│ ├── scripts/
│ │ └── env_run
│ └── urdf/
│ ├── accessories/
│ │ ├── novatel_smart6.urdf.xacro
│ │ ├── warthog_arm_mount.urdf.xacro
│ │ └── warthog_bulkhead.urdf.xacro
│ ├── accessories.urdf.xacro
│ ├── configs/
│ │ ├── arm_mount
│ │ ├── base
│ │ ├── bulkhead
│ │ └── empty
│ ├── empty.urdf
│ ├── warthog.gazebo
│ ├── warthog.urdf
│ └── warthog.urdf.xacro
├── images/
│ ├── data_example.eps
│ └── sensor_setup.eps
└── utils/
├── .gitignore
├── Evaluate_img.ipynb
├── Evaluate_pt.ipynb
├── __init__.py
├── convert_ply2bin.py
├── example/
│ ├── 000104.label
│ ├── camera_info.txt
│ ├── frame000104-1581624663_170.ply
│ ├── transforms.yaml
│ └── vel2os1.yaml
├── label2color.ipynb
├── label_convert.py
├── lidar2img.ipynb
├── nerian_camera_info.yaml
├── plyreader.py
└── stereo_camerainfo_pub.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintainted in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
.vscode/*
./utils/.ipynb_checkpoints/*
InputArray.desktop
================================================
FILE: README.md
================================================
<h1>RELLIS-3D: A Multi-modal Dataset for Off-Road Robotics</h1>
<p align="center">
<a href="https://www.tamu.edu/"><img src="images/tamu_logo.png" alt="Texas A&M University" height="90px" width="450px"></a>    <a href="https://www.arl.army.mil/"><img src="images/arl_logo.png" alt="The DEVCOM Army Research Laboratory" height="90px" width="270px"></a></p>
<p align="center">
Peng Jiang<sup>1</sup>, Philip Osteen<sup>2</sup>, Maggie Wigness<sup>2</sup> and Srikanth Saripalli<sup>1</sup><br>
1. <a href="https://www.tamu.edu/">Texas A&M University; </a> 2. <a href="https://www.arl.army.mil/">CCDC Army Research Laboratory</a><br>
<a href="https://unmannedlab.github.io/research/RELLIS-3D">[Website]</a> <a href="https://arxiv.org/abs/2011.12954">[Paper]</a> <a href="https://github.com/unmannedlab/RELLIS-3D">[Github]</a>
</p>
## Updates
* 11/26/2020 v1.0 release
* 02/25/2021 improve camera and lidar calibration parameter
* 03/04/2021 update ROS bag with new tf (v1.1 release)
* 06/14/2021 fix missing labels of point cloud and fix wrong poses
* 01/24/2022 add Velodyne point clouds in kitti format and labels transfered from Ouster
## Overview
Semantic scene understanding is crucial for robust and safe autonomous navigation, particularly so in off-road environments. Recent deep learning advances for 3D semantic segmentation rely heavily on large sets of training data; however, existing autonomy datasets represent urban environments or lack multimodal off-road data. We fill this gap with RELLIS-3D, a multimodal dataset collected in an off-road environment containing annotations for **13,556 LiDAR scans** and **6,235 images**. The data was collected on the Rellis Campus of Texas A\&M University and presents challenges to existing algorithms related to class imbalance and environmental topography. Additionally, we evaluate the current state of the art deep learning semantic segmentation models on this dataset. Experimental results show that RELLIS-3D presents challenges for algorithms designed for segmentation in urban environments. Except for the annotated data, the dataset also provides full-stack sensor data in ROS bag format, including **RGB camera images**, **LiDAR point clouds**, **a pair of stereo images**, **high-precision GPS measurement**, and **IMU data**. This novel dataset provides the resources needed by researchers to develop more advanced algorithms and investigate new research directions to enhance autonomous navigation in off-road environments.

### Recording Platform
* [Clearpath Robobtics Warthog](https://clearpathrobotics.com/warthog-unmanned-ground-vehicle-robot/)
### Sensor Setup
* 64 channels Lidar: [Ouster OS1](https://ouster.com/products/os1-lidar-sensor)
* 32 Channels Lidar: [Velodyne Ultra Puck](https://velodynelidar.com/vlp-32c.html)
* 3D Stereo Camera: [Nerian Karmin2](https://nerian.com/products/karmin2-3d-stereo-camera/) + [Nerian SceneScan](https://nerian.com/products/scenescan-stereo-vision/) [(Sensor Configuration)](https://nerian.com/support/calculator/?1,10,0,6,2,1600,1200,1,1,1,800,592,1,6,2,0,61.4,0,0,1,1,0,5,0,0,0,0.66,0,1,25,1,0,1,256,0.25,256,4.0,5.0,0,1.5,1,#results)
* RGB Camera: [Basler acA1920-50gc](https://www.baslerweb.com/en/products/cameras/area-scan-cameras/ace/aca1920-50gc/) + [Edmund Optics 16mm/F1.8 86-571](https://www.edmundoptics.com/p/16mm-focal-length-hp-series-fixed-focal-length-lens/28990/)
* Inertial Navigation System (GPS/IMU): [Vectornav VN-300 Dual Antenna GNSS/INS](https://www.vectornav.com/products/vn-300)

## Folder structure
<pre>
Rellis-3D
├── pt_test.lst
├── pt_val.lst
├── pt_train.lst
├── pt_test.lst
├── pt_train.lst
├── pt_val.lst
├── 00000
├── os1_cloud_node_kitti_bin/ -- directory containing ".bin" files with Ouster 64-Channels point clouds.
├── os1_cloud_node_semantickitti_label_id/ -- containing, ".label" files for Ouster Lidar point cloud with manually labelled semantics label
├── vel_cloud_node_kitti_bin/ -- directory containing ".bin" files with Velodyne 32-Channels point clouds.
├── vel_cloud_node_semantickitti_label_id/ -- containing, ".label" files for Velodyne Lidar point cloud transfered from Ouster point cloud.
├── pylon_camera_node/ -- directory containing ".png" files from the color camera.
├── pylon_camera_node_label_color -- color image lable
├── pylon_camera_node_label_id -- id image lable
├── calib.txt -- calibration of velodyne vs. camera. needed for projection of point cloud into camera.
└── poses.txt -- file containing the poses of every scan.
</pre>
## Download Link on BaiDu Pan:
链接: https://pan.baidu.com/s/1akqSm7mpIMyUJhn_qwg3-w?pwd=4gk3 提取码: 4gk3 复制这段内容后打开百度网盘手机App,操作更方便哦
## Annotated Data:
### Ontology:
With the goal of providing multi-modal data to enhance autonomous off-road navigation, we defined an ontology of object and terrain classes, which largely derives from [the RUGD dataset](http://rugd.vision/) but also includes unique terrain and object classes not present in RUGD. Specifically, sequences from this dataset includes classes such as mud, man-made barriers, and rubble piles. Additionally, this dataset provides a finer-grained class structure for water sources, i.e., puddle and deep water, as these two classes present different traversability scenarios for most robotic platforms. Overall, 20 classes (including void class) are present in the data.
**Ontology Definition** ([Download 18KB](https://drive.google.com/file/d/1K8Zf0ju_xI5lnx3NTDLJpVTs59wmGPI6/view?usp=sharing))
### Images Statics:

<span style="color:red"> Note: Due to the limitation of Google Drive, the downloads might be constrained. Please wait for 24h and try again. If you still can't access the file, please email maskjp@tamu.edu with the title "RELLIS-3D Access Request".</span>.
### Image Download:
**Image with Annotation Examples** ([Download 3MB](https://drive.google.com/file/d/1wIig-LCie571DnK72p2zNAYYWeclEz1D/view?usp=sharing))
**Full Images** ([Download 11GB](https://drive.google.com/file/d/1F3Leu0H_m6aPVpZITragfreO_SGtL2yV/view?usp=sharing))
**Full Image Annotations Color Format** ([Download 119MB](https://drive.google.com/file/d/1HJl8Fi5nAjOr41DPUFmkeKWtDXhCZDke/view?usp=sharing))
**Full Image Annotations ID Format** ([Download 94MB](https://drive.google.com/file/d/16URBUQn_VOGvUqfms-0I8HHKMtjPHsu5/view?usp=sharing))
**Image Split File** ([44KB](https://drive.google.com/file/d/1zHmnVaItcYJAWat3Yti1W_5Nfux194WQ/view?usp=sharing))
### LiDAR Scans Statics:

### LiDAR Download:
**Ouster LiDAR with Annotation Examples** ([Download 24MB](https://drive.google.com/file/d/1QikPnpmxneyCuwefr6m50fBOSB2ny4LC/view?usp=sharing))
**Ouster LiDAR with Color Annotation PLY Format** ([Download 26GB](https://drive.google.com/file/d/1BZWrPOeLhbVItdN0xhzolfsABr6ymsRr/view?usp=sharing))
The header of the PLY file is described as followed:
```
element vertex
property float x
property float y
property float z
property float intensity
property uint t
property ushort reflectivity
property uchar ring
property ushort noise
property uint range
property uchar label
property uchar red
property uchar green
property uchar blue
```
To visualize the color of the ply file, please use [CloudCompare](https://www.danielgm.net/cc/) or [Open3D](http://www.open3d.org/). Meshlab has problem to visualize the color.
**Ouster LiDAR SemanticKITTI Format** ([Download 14GB](https://drive.google.com/file/d/1lDSVRf_kZrD0zHHMsKJ0V1GN9QATR4wH/view?usp=sharing))
To visualize the datasets using the SemanticKITTI tools, please use this fork: [https://github.com/unmannedlab/point_labeler](https://github.com/unmannedlab/point_labeler)
**Ouster LiDAR Annotation SemanticKITTI Format** ([Download 174MB](https://drive.google.com/file/d/12bsblHXtob60KrjV7lGXUQTdC5PhV8Er/view?usp=sharing))
**Ouster LiDAR Scan Poses files** ([Download 174MB](https://drive.google.com/file/d/1V3PT_NJhA41N7TBLp5AbW31d0ztQDQOX/view?usp=sharing))
**Ouster LiDAR Split File** ([75KB](https://drive.google.com/file/d/1raQJPySyqDaHpc53KPnJVl3Bln6HlcVS/view?usp=sharing))
**Velodyne LiDAR SemanticKITTI Format** ([Download 5.58GB](https://drive.google.com/file/d/1PiQgPQtJJZIpXumuHSig5Y6kxhAzz1cz/view?usp=sharing))
**Velodyne LiDAR Annotation SemanticKITTI Format** ([Download 143.6MB](https://drive.google.com/file/d/1n-9FkpiH4QUP7n0PnQBp-s7nzbSzmxp8/view?usp=sharing))
### Calibration Download:
**Camera Instrinsic** ([Download 2KB](https://drive.google.com/file/d/1NAigZTJYocRSOTfgFBddZYnDsI_CSpwK/view?usp=sharing))
**Basler Camera to Ouster LiDAR** ([Download 3KB](https://drive.google.com/file/d/19EOqWS9fDUFp4nsBrMCa69xs9LgIlS2e/view?usp=sharing))
**Velodyne LiDAR to Ouster LiDAR** ([Download 3KB](https://drive.google.com/file/d/1T6yPwcdzJoU-ifFRelLtDLPuPQswIQwf/view?usp=sharing))
**Stereo Calibration** ([Download 3KB](https://drive.google.com/file/d/1cP5-l_nYt3kZ4hZhEAHEdpt2fzToar0R/view?usp=sharing))
**Calibration Raw Data** ([Download 774MB](https://drive.google.com/drive/folders/1VAb-98lh6HWEe_EKLhUC1Xle0jkpp2Fl?usp=sharing
))
## Benchmarks
### Image Semantic Segmenation
models | sky | grass |tr ee | bush | concrete | mud | person | puddle | rubble | barrier | log | fence | vehicle | object | pole | water | asphalt | building | mean
-------| ----| ------|------|------|----------|-----| -------| -------|--------|---------|-----|-------| --------| -------|------|-------|---------|----------| ----
[HRNet+OCR](https://github.com/HRNet/HRNet-Semantic-Segmentation/tree/HRNet-OCR) | 96.94 | 90.20 | 80.53 | 76.76 | 84.22 | 43.29 | 89.48 | 73.94 | 62.03 | 54.86 | 0.00 | 39.52 | 41.54 | 46.44 | 9.51 | 0.72 | 33.25 | 4.60 | 48.83
[GSCNN](https://github.com/nv-tlabs/GSCNN) | 97.02 | 84.95 | 78.52 | 70.33 | 83.82 | 45.52 | 90.31 | 71.49 | 66.03 | 55.12 | 2.92 | 41.86 | 46.51 | 54.64 | 6.90 | 0.94 | 44.18 | 11.47 | 50.13
[](https://www.youtube.com/watch?v=vr3g6lCTKRM)
### LiDAR Semantic Segmenation
models | sky | grass |tr ee | bush | concrete | mud | person | puddle | rubble | barrier | log | fence | vehicle | object | pole | water | asphalt | building | mean
-------| ----| ------|------|------|----------|-----| -------| -------|--------|---------|-----|-------| --------| -------|------|-------|---------|----------| ----
[SalsaNext](https://github.com/Halmstad-University/SalsaNext) | - | 64.74 | 79.04 | 72.90 | 75.27 | 9.58 | 83.17 | 23.20 | 5.01 | 75.89 | 18.76 | 16.13| 23.12 | - | 56.26 | 0.00 | - | - | 40.20
[KPConv](https://github.com/HuguesTHOMAS/KPConv) | - | 56.41 | 49.25 | 58.45 | 33.91 | 0.00 | 81.20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.40 | 0.00 | - | 0.00 | 0.00 | - | - | 18.64
[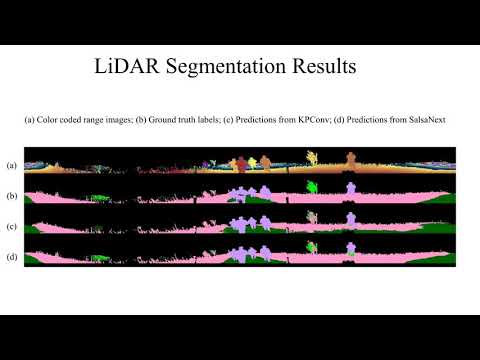](https://www.youtube.com/watch?v=wkm8UiVNGao)
### Benchmark Reproduction
To reproduce the results, please refer to [here](./benchmarks/README.md)
## ROS Bag Raw Data
Data included in raw ROS bagfiles:
Topic Name | Message Tpye | Message Descriptison
------------ | ------------- | ---------------------------------
/img_node/intensity_image | sensor_msgs/Image | Intensity image generated by ouster Lidar
/img_node/noise_image | sensor_msgs/Image | Noise image generated by ouster Lidar
/img_node/range_image | sensor_msgs/Image | Range image generated by ouster Lidar
/imu/data | sensor_msgs/Imu | Filtered imu data from embeded imu of Warthog
/imu/data_raw | sensor_msgs/Imu | Raw imu data from embeded imu of Warthog
/imu/mag | sensor_msgs/MagneticField | Raw magnetic field data from embeded imu of Warthog
/left_drive/status/battery_current | std_msgs/Float64 |
/left_drive/status/battery_voltage | std_msgs/Float64 |
/mcu/status | warthog_msgs/Status |
/nerian/left/camera_info | sensor_msgs/CameraInfo |
/nerian/left/image_raw | sensor_msgs/Image | Left image from Nerian Karmin2
/nerian/right/camera_info | sensor_msgs/CameraInfo |
/nerian/right/image_raw | sensor_msgs/Image | Right image from Nerian Karmin2
/odometry/filtered | nav_msgs/Odometry | A filtered local-ization estimate based on wheel odometry (en-coders) and integrated IMU from Warthog
/os1_cloud_node/imu | sensor_msgs/Imu | Raw imu data from embeded imu of Ouster Lidar
/os1_cloud_node/points | sensor_msgs/PointCloud2 | Point cloud data from Ouster Lidar
/os1_node/imu_packets | ouster_ros/PacketMsg | Raw imu data from Ouster Lidar
/os1_node/lidar_packets | ouster_ros/PacketMsg | Raw lidar data from Ouster Lidar
/pylon_camera_node/camera_info | sensor_msgs/CameraInfo |
/pylon_camera_node/image_raw | sensor_msgs/Image |
/right_drive/status/battery_current | std_msgs/Float64 |
/right_drive/status/battery_voltage | std_msgs/Float64 |
/tf | tf2_msgs/TFMessage |
/tf_static | tf2_msgs/TFMessage
/vectornav/GPS | sensor_msgs/NavSatFix | INS data from VectorNav-VN300
/vectornav/IMU | sensor_msgs/Imu | Imu data from VectorNav-VN300
/vectornav/Mag | sensor_msgs/MagneticField | Raw magnetic field data from VectorNav-VN300
/vectornav/Odom | nav_msgs/Odometry | Odometry from VectorNav-VN300
/vectornav/Pres | sensor_msgs/FluidPressure |
/vectornav/Temp | sensor_msgs/Temperature |
/velodyne_points | sensor_msgs/PointCloud2 | PointCloud produced by the Velodyne Lidar
/warthog_velocity_controller/cmd_vel | geometry_msgs/Twist |
/warthog_velocity_controller/odom | nav_msgs/Odometry |
### ROS Bag Download
The following are the links for the ROS Bag files.
* Synced data (60 seconds example [2 GB](https://drive.google.com/file/d/13EHwiJtU0aAWBQn-ZJhTJwC1Yx2zDVUv/view?usp=sharing)): includes synced */os1_cloud_node/points*, */pylon_camera_node/camera_info* and */pylon_camera_node/image_raw*
* Full-stack Merged data:(60 seconds example [4.2 GB](https://drive.google.com/file/d/1qSeOoY6xbQGjcrZycgPM8Ty37eKDjpJL/view?usp=sharing)): includes all data in above table and extrinsic calibration info data embedded in the tf tree.
* Full-stack Split Raw data:(60 seconds example [4.3 GB](https://drive.google.com/file/d/1-TDpelP4wKTWUDTIn0dNuZIT3JkBoZ_R/view?usp=sharing)): is orignal data recorded by ```rosbag record``` command.
**Sequence 00000**: Synced data: ([12GB](https://drive.google.com/file/d/1bIb-6fWbaiI9Q8Pq9paANQwXWn7GJDtl/view?usp=sharing)) Full-stack Merged data: ([23GB](https://drive.google.com/file/d/1grcYRvtAijiA0Kzu-AV_9K4k2C1Kc3Tn/view?usp=sharing)) Full-stack Split Raw data: ([29GB](https://drive.google.com/drive/folders/1IZ-Tn_kzkp82mNbOL_4sNAniunD7tsYU?usp=sharing))
[](https://www.youtube.com/watch?v=Qc7IepWGKr8)
**Sequence 00001**: Synced data: ([8GB](https://drive.google.com/file/d/1xNjAFE3cv6X8n046irm8Bo5QMerNbwP1/view?usp=sharing)) Full-stack Merged data: ([16GB](https://drive.google.com/file/d/1geoU45pPavnabQ0arm4ILeHSsG3cU6ti/view?usp=sharing)) Full-stack Split Raw data: ([22GB](https://drive.google.com/drive/folders/1hf-vF5zyTKcCLqIiddIGdemzKT742T1t?usp=sharing))
[](https://www.youtube.com/watch?v=nO5JADjDWQ0)
**Sequence 00002**: Synced data: ([14GB](https://drive.google.com/file/d/1gy0ehP9Buj-VkpfvU9Qwyz1euqXXQ_mj/view?usp=sharing)) Full-stack Merged data: ([28GB](https://drive.google.com/file/d/1h0CVg62jTXiJ91LnR6md-WrUBDxT543n/view?usp=sharing)) Full-stack Split Raw data: ([37GB](https://drive.google.com/drive/folders/1R8jP5Qo7Z6uKPoG9XUvFCStwJu6rtliu?usp=sharing))
[](https://www.youtube.com/watch?v=aXaOmzjHmNE)
**Sequence 00003**:Synced data: ([8GB](https://drive.google.com/file/d/1vCeZusijzyn1ZrZbg4JaHKYSc2th7GEt/view?usp=sharing)) Full-stack Merged data: ([15GB](https://drive.google.com/file/d/1glJzgnTYLIB_ar3CgHpc_MBp5AafQpy9/view?usp=sharing)) Full-stack Split Raw data: ([19GB](https://drive.google.com/drive/folders/1iP0k6dbmPdAH9kkxs6ugi6-JbrkGhm5o?usp=sharing))
[](https://www.youtube.com/watch?v=Kjo3tGDSbtU)
**Sequence 00004**:Synced data: ([7GB](https://drive.google.com/file/d/1gxODhAd8CBM5AGvsoyuqN7yGpWazzmVy/view?usp=sharing)) Full-stack Merged data: ([14GB](https://drive.google.com/file/d/1AuEjX0do3jGZhGKPszSEUNoj85YswNya/view?usp=sharing)) Full-stack Split Raw data: ([17GB](https://drive.google.com/drive/folders/1WV9pecF2beESyM7N29W-nhi-JaoKvEqc?usp=sharing))
[](https://www.youtube.com/watch?v=lLLYTI4TCD4)
### ROS Environment Installment
The ROS workspace includes a plaftform description package which can provide rough tf tree for running the rosbag.
To run cartographer on RELLIS-3D please refer to [here](https://github.com/unmannedlab/cartographer)

## Full Data Download:
[Access Link](https://drive.google.com/drive/folders/1aZ1tJ3YYcWuL3oWKnrTIC5gq46zx1bMc?usp=sharing)
## Citation
```
@misc{jiang2020rellis3d,
title={RELLIS-3D Dataset: Data, Benchmarks and Analysis},
author={Peng Jiang and Philip Osteen and Maggie Wigness and Srikanth Saripalli},
year={2020},
eprint={2011.12954},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Collaborator
<a href="https://www.arl.army.mil/"><img src="images/arl_logo.png" alt="The DEVCOM Army Research Laboratory" height="90px" width="270px"></a>
## License
All datasets and code on this page are copyright by us and published under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 License.
## Related Work
[SemanticUSL: A Dataset for Semantic Segmentation Domain Adatpation](https://unmannedlab.github.io/research/SemanticUSL)
[LiDARNet: A Boundary-Aware Domain Adaptation Model for Lidar Point Cloud Semantic Segmentation](https://unmannedlab.github.io/research/LiDARNet)
[A RUGD Dataset for Autonomous Navigation and Visual Perception inUnstructured Outdoor Environments](http://rugd.vision/)
================================================
FILE: benchmarks/GSCNN-master/.gitignore
================================================
logs/
network/pretrained_models/
__pycache__/
================================================
FILE: benchmarks/GSCNN-master/Dockerfile
================================================
FROM pytorch/pytorch:1.0-cuda10.0-cudnn7-devel
RUN apt-get -y update
RUN apt-get -y upgrade
RUN apt-get update \
&& apt-get install -y software-properties-common wget \
&& add-apt-repository -y ppa:ubuntu-toolchain-r/test \
&& apt-get update \
&& apt-get install -y make git curl vim vim-gnome
# Install apt-get
RUN apt-get install -y python3-pip python3-dev vim htop python3-tk pkg-config
RUN pip3 install --upgrade pip==9.0.1
# Install from pip
RUN pip3 install pyyaml \
scipy==1.1.0 \
numpy \
tensorflow \
scikit-learn \
scikit-image \
matplotlib \
opencv-python \
torch==1.0.0 \
torchvision==0.2.0 \
torch-encoding==1.0.1 \
tensorboardX \
tqdm
================================================
FILE: benchmarks/GSCNN-master/LICENSE
================================================
Copyright (C) 2019 NVIDIA Corporation. Towaki Takikawa, David Acuna, Varun Jampani, Sanja Fidler
All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
Permission to use, copy, modify, and distribute this software and its documentation
for any non-commercial purpose is hereby granted without fee, provided that the above
copyright notice appear in all copies and that both that copyright notice and this
permission notice appear in supporting documentation, and that the name of the author
not be used in advertising or publicity pertaining to distribution of the software
without specific, written prior permission.
THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE, INCLUDING ALL
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR ANY PARTICULAR PURPOSE.
IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL
DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING
OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
================================================
FILE: benchmarks/GSCNN-master/README.md
================================================
# GSCNN
This is the official code for:
#### Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
[Towaki Takikawa](https://tovacinni.github.io), [David Acuna](http://www.cs.toronto.edu/~davidj/), [Varun Jampani](https://varunjampani.github.io), [Sanja Fidler](http://www.cs.toronto.edu/~fidler/)
ICCV 2019
**[[Paper](https://arxiv.org/abs/1907.05740)] [[Project Page](https://nv-tlabs.github.io/GSCNN/)]**

Based on based on https://github.com/NVIDIA/semantic-segmentation.
## License
```
Copyright (C) 2019 NVIDIA Corporation. Towaki Takikawa, David Acuna, Varun Jampani, Sanja Fidler
All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
Permission to use, copy, modify, and distribute this software and its documentation
for any non-commercial purpose is hereby granted without fee, provided that the above
copyright notice appear in all copies and that both that copyright notice and this
permission notice appear in supporting documentation, and that the name of the author
not be used in advertising or publicity pertaining to distribution of the software
without specific, written prior permission.
THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE, INCLUDING ALL
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR ANY PARTICULAR PURPOSE.
IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL
DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING
OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
~
```
## Usage
##### Clone this repo
```bash
git clone https://github.com/nv-tlabs/GSCNN
cd GSCNN
```
#### Python requirements
Currently, the code supports Python 3
* numpy
* PyTorch (>=1.1.0)
* torchvision
* scipy
* scikit-image
* tensorboardX
* tqdm
* torch-encoding
* opencv
* PyYAML
#### Download pretrained models
Download the pretrained model from the [Google Drive Folder](https://drive.google.com/file/d/1wlhAXg-PfoUM-rFy2cksk43Ng3PpsK2c/view), and save it in 'checkpoints/'
#### Download inferred images
Download (if needed) the inferred images from the [Google Drive Folder](https://drive.google.com/file/d/105WYnpSagdlf5-ZlSKWkRVeq-MyKLYOV/view)
#### Evaluation (Cityscapes)
```bash
python train.py --evaluate --snapshot checkpoints/best_cityscapes_checkpoint.pth
```
#### Training
A note on training- we train on 8 NVIDIA GPUs, and as such, training will be an issue with WiderResNet38 if you try to train on a single GPU.
If you use this code, please cite:
```
@article{takikawa2019gated,
title={Gated-SCNN: Gated Shape CNNs for Semantic Segmentation},
author={Takikawa, Towaki and Acuna, David and Jampani, Varun and Fidler, Sanja},
journal={ICCV},
year={2019}
}
```
================================================
FILE: benchmarks/GSCNN-master/config.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code adapted from:
# https://github.com/facebookresearch/Detectron/blob/master/detectron/core/config.py
Source License
# Copyright (c) 2017-present, Facebook, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##############################################################################
#
# Based on:
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import copy
import six
import os.path as osp
from ast import literal_eval
import numpy as np
import yaml
import torch
import torch.nn as nn
from torch.nn import init
from utils.AttrDict import AttrDict
__C = AttrDict()
# Consumers can get config by:
# from fast_rcnn_config import cfg
cfg = __C
__C.EPOCH = 0
__C.CLASS_UNIFORM_PCT=0.0
__C.BATCH_WEIGHTING=False
__C.BORDER_WINDOW=1
__C.REDUCE_BORDER_EPOCH= -1
__C.STRICTBORDERCLASS= None
__C.DATASET =AttrDict()
__C.DATASET.CITYSCAPES_DIR='/home/usl/Datasets/cityscapes/'
__C.DATASET.RELLIS_DIR='/path/to/RELLIS-3D/'
__C.DATASET.CV_SPLITS=3
__C.MODEL = AttrDict()
__C.MODEL.BN = 'regularnorm'
__C.MODEL.BNFUNC = torch.nn.BatchNorm2d
__C.MODEL.BIGMEMORY = False
def assert_and_infer_cfg(args, make_immutable=True):
"""Call this function in your script after you have finished setting all cfg
values that are necessary (e.g., merging a config from a file, merging
command line config options, etc.). By default, this function will also
mark the global cfg as immutable to prevent changing the global cfg settings
during script execution (which can lead to hard to debug errors or code
that's harder to understand than is necessary).
"""
if args.batch_weighting:
__C.BATCH_WEIGHTING=True
if args.syncbn:
import encoding
__C.MODEL.BN = 'syncnorm'
__C.MODEL.BNFUNC = encoding.nn.BatchNorm2d
else:
__C.MODEL.BNFUNC = torch.nn.BatchNorm2d
print('Using regular batch norm')
if make_immutable:
cfg.immutable(True)
================================================
FILE: benchmarks/GSCNN-master/datasets/__init__.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
from datasets import cityscapes, rellis
import torchvision.transforms as standard_transforms
import torchvision.utils as vutils
import transforms.joint_transforms as joint_transforms
import transforms.transforms as extended_transforms
from torch.utils.data import DataLoader
def setup_loaders(args):
'''
input: argument passed by the user
return: training data loader, validation data loader loader, train_set
'''
if args.dataset == 'cityscapes':
args.dataset_cls = cityscapes
args.train_batch_size = args.bs_mult * args.ngpu
if args.bs_mult_val > 0:
args.val_batch_size = args.bs_mult_val * args.ngpu
else:
args.val_batch_size = args.bs_mult * args.ngpu
mean_std = ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
elif args.dataset == "rellis":
args.dataset_cls = rellis
args.train_batch_size = args.bs_mult * args.ngpu
if args.bs_mult_val > 0:
args.val_batch_size = args.bs_mult_val * args.ngpu
else:
args.val_batch_size = args.bs_mult * args.ngpu
mean_std = ([0.496588, 0.59493099, 0.53358843], [0.496588, 0.59493099, 0.53358843])
else:
raise
args.num_workers = 4 * args.ngpu
if args.test_mode:
args.num_workers = 0 #1
# Geometric image transformations
train_joint_transform_list = [
joint_transforms.RandomSizeAndCrop(args.crop_size,
False,
pre_size=args.pre_size,
scale_min=args.scale_min,
scale_max=args.scale_max,
ignore_index=args.dataset_cls.ignore_label),
joint_transforms.Resize(args.crop_size),
joint_transforms.RandomHorizontallyFlip()]
#if args.rotate:
# train_joint_transform_list += [joint_transforms.RandomRotate(args.rotate)]
train_joint_transform = joint_transforms.Compose(train_joint_transform_list)
# Image appearance transformations
train_input_transform = []
if args.color_aug:
train_input_transform += [extended_transforms.ColorJitter(
brightness=args.color_aug,
contrast=args.color_aug,
saturation=args.color_aug,
hue=args.color_aug)]
if args.bblur:
train_input_transform += [extended_transforms.RandomBilateralBlur()]
elif args.gblur:
train_input_transform += [extended_transforms.RandomGaussianBlur()]
else:
pass
train_input_transform += [standard_transforms.ToTensor(),
standard_transforms.Normalize(*mean_std)]
train_input_transform = standard_transforms.Compose(train_input_transform)
val_input_transform = standard_transforms.Compose([
standard_transforms.ToTensor(),
standard_transforms.Normalize(*mean_std)
])
target_transform = extended_transforms.MaskToTensor()
target_train_transform = extended_transforms.MaskToTensor()
if args.dataset == 'cityscapes':
city_mode = 'train' ## Can be trainval
city_quality = 'fine'
train_set = args.dataset_cls.CityScapes(
city_quality, city_mode, 0,
joint_transform=train_joint_transform,
transform=train_input_transform,
target_transform=target_train_transform,
dump_images=args.dump_augmentation_images,
cv_split=args.cv)
val_set = args.dataset_cls.CityScapes('fine', 'val', 0,
transform=val_input_transform,
target_transform=target_transform,
cv_split=args.cv)
elif args.dataset == 'rellis':
if args.mode != "test":
city_mode = 'train'
train_set = args.dataset_cls.Rellis(
city_mode,
joint_transform=train_joint_transform,
transform=train_input_transform,
target_transform=target_train_transform,
dump_images=args.dump_augmentation_images,
cv_split=args.cv)
val_set = args.dataset_cls.Rellis('val',
transform=val_input_transform,
target_transform=target_transform,
cv_split=args.cv)
else:
city_mode = 'test'
train_set = args.dataset_cls.Rellis('test',
transform=val_input_transform,
target_transform=target_transform,
cv_split=args.cv)
val_set = args.dataset_cls.Rellis('test',
transform=val_input_transform,
target_transform=target_transform,
cv_split=args.cv)
else:
raise
train_sampler = None
val_sampler = None
train_loader = DataLoader(train_set, batch_size=args.train_batch_size,
num_workers=args.num_workers, shuffle=(train_sampler is None), drop_last=True, sampler = train_sampler)
val_loader = DataLoader(val_set, batch_size=args.val_batch_size,
num_workers=args.num_workers // 2 , shuffle=False, drop_last=False, sampler = val_sampler)
return train_loader, val_loader, train_set
================================================
FILE: benchmarks/GSCNN-master/datasets/cityscapes.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import os
import numpy as np
import torch
from PIL import Image
from torch.utils import data
from collections import defaultdict
import math
import logging
import datasets.cityscapes_labels as cityscapes_labels
import json
from config import cfg
import torchvision.transforms as transforms
import datasets.edge_utils as edge_utils
trainid_to_name = cityscapes_labels.trainId2name
id_to_trainid = cityscapes_labels.label2trainid
num_classes = 19
ignore_label = 255
root = cfg.DATASET.CITYSCAPES_DIR
palette = [128, 64, 128, 244, 35, 232, 70, 70, 70, 102, 102, 156, 190, 153, 153,
153, 153, 153, 250, 170, 30,
220, 220, 0, 107, 142, 35, 152, 251, 152, 70, 130, 180, 220, 20, 60,
255, 0, 0, 0, 0, 142, 0, 0, 70,
0, 60, 100, 0, 80, 100, 0, 0, 230, 119, 11, 32]
zero_pad = 256 * 3 - len(palette)
for i in range(zero_pad):
palette.append(0)
def colorize_mask(mask):
# mask: numpy array of the mask
new_mask = Image.fromarray(mask.astype(np.uint8)).convert('P')
new_mask.putpalette(palette)
return new_mask
def add_items(items, aug_items, cities, img_path, mask_path, mask_postfix, mode, maxSkip):
for c in cities:
c_items = [name.split('_leftImg8bit.png')[0] for name in
os.listdir(os.path.join(img_path, c))]
for it in c_items:
item = (os.path.join(img_path, c, it + '_leftImg8bit.png'),
os.path.join(mask_path, c, it + mask_postfix))
items.append(item)
def make_cv_splits(img_dir_name):
'''
Create splits of train/val data.
A split is a lists of cities.
split0 is aligned with the default Cityscapes train/val.
'''
trn_path = os.path.join(root, img_dir_name, 'leftImg8bit', 'train')
val_path = os.path.join(root, img_dir_name, 'leftImg8bit', 'val')
trn_cities = ['train/' + c for c in os.listdir(trn_path)]
val_cities = ['val/' + c for c in os.listdir(val_path)]
# want reproducible randomly shuffled
trn_cities = sorted(trn_cities)
all_cities = val_cities + trn_cities
num_val_cities = len(val_cities)
num_cities = len(all_cities)
cv_splits = []
for split_idx in range(cfg.DATASET.CV_SPLITS):
split = {}
split['train'] = []
split['val'] = []
offset = split_idx * num_cities // cfg.DATASET.CV_SPLITS
for j in range(num_cities):
if j >= offset and j < (offset + num_val_cities):
split['val'].append(all_cities[j])
else:
split['train'].append(all_cities[j])
cv_splits.append(split)
return cv_splits
def make_split_coarse(img_path):
'''
Create a train/val split for coarse
return: city split in train
'''
all_cities = os.listdir(img_path)
all_cities = sorted(all_cities) # needs to always be the same
val_cities = [] # Can manually set cities to not be included into train split
split = {}
split['val'] = val_cities
split['train'] = [c for c in all_cities if c not in val_cities]
return split
def make_test_split(img_dir_name):
test_path = os.path.join(root, img_dir_name, 'leftImg8bit', 'test')
test_cities = ['test/' + c for c in os.listdir(test_path)]
return test_cities
def make_dataset(quality, mode, maxSkip=0, fine_coarse_mult=6, cv_split=0):
'''
Assemble list of images + mask files
fine - modes: train/val/test/trainval cv:0,1,2
coarse - modes: train/val cv:na
path examples:
leftImg8bit_trainextra/leftImg8bit/train_extra/augsburg
gtCoarse/gtCoarse/train_extra/augsburg
'''
items = []
aug_items = []
if quality == 'fine':
assert mode in ['train', 'val', 'test', 'trainval']
img_dir_name = 'leftImg8bit_trainvaltest'
img_path = os.path.join(root, img_dir_name, 'leftImg8bit')
mask_path = os.path.join(root, 'gtFine_trainvaltest', 'gtFine')
mask_postfix = '_gtFine_labelIds.png'
cv_splits = make_cv_splits(img_dir_name)
if mode == 'trainval':
modes = ['train', 'val']
else:
modes = [mode]
for mode in modes:
if mode == 'test':
cv_splits = make_test_split(img_dir_name)
add_items(items, cv_splits, img_path, mask_path,
mask_postfix)
else:
logging.info('{} fine cities: '.format(mode) + str(cv_splits[cv_split][mode]))
add_items(items, aug_items, cv_splits[cv_split][mode], img_path, mask_path,
mask_postfix, mode, maxSkip)
else:
raise 'unknown cityscapes quality {}'.format(quality)
logging.info('Cityscapes-{}: {} images'.format(mode, len(items)+len(aug_items)))
return items, aug_items
class CityScapes(data.Dataset):
def __init__(self, quality, mode, maxSkip=0, joint_transform=None, sliding_crop=None,
transform=None, target_transform=None, dump_images=False,
cv_split=None, eval_mode=False,
eval_scales=None, eval_flip=False):
self.quality = quality
self.mode = mode
self.maxSkip = maxSkip
self.joint_transform = joint_transform
self.sliding_crop = sliding_crop
self.transform = transform
self.target_transform = target_transform
self.dump_images = dump_images
self.eval_mode = eval_mode
self.eval_flip = eval_flip
self.eval_scales = None
if eval_scales != None:
self.eval_scales = [float(scale) for scale in eval_scales.split(",")]
if cv_split:
self.cv_split = cv_split
assert cv_split < cfg.DATASET.CV_SPLITS, \
'expected cv_split {} to be < CV_SPLITS {}'.format(
cv_split, cfg.DATASET.CV_SPLITS)
else:
self.cv_split = 0
self.imgs, _ = make_dataset(quality, mode, self.maxSkip, cv_split=self.cv_split)
if len(self.imgs) == 0:
raise RuntimeError('Found 0 images, please check the data set')
self.mean_std = ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
def _eval_get_item(self, img, mask, scales, flip_bool):
return_imgs = []
for flip in range(int(flip_bool)+1):
imgs = []
if flip :
img = img.transpose(Image.FLIP_LEFT_RIGHT)
for scale in scales:
w,h = img.size
target_w, target_h = int(w * scale), int(h * scale)
resize_img =img.resize((target_w, target_h))
tensor_img = transforms.ToTensor()(resize_img)
final_tensor = transforms.Normalize(*self.mean_std)(tensor_img)
imgs.append(tensor_img)
return_imgs.append(imgs)
return return_imgs, mask
def __getitem__(self, index):
img_path, mask_path = self.imgs[index]
img, mask = Image.open(img_path).convert('RGB'), Image.open(mask_path)
img_name = os.path.splitext(os.path.basename(img_path))[0]
mask = np.array(mask)
mask_copy = mask.copy()
for k, v in id_to_trainid.items():
mask_copy[mask == k] = v
if self.eval_mode:
return self._eval_get_item(img, mask_copy, self.eval_scales, self.eval_flip), img_name
mask = Image.fromarray(mask_copy.astype(np.uint8))
# Image Transformations
if self.joint_transform is not None:
img, mask = self.joint_transform(img, mask)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
mask = self.target_transform(mask)
_edgemap = mask.numpy()
_edgemap = edge_utils.mask_to_onehot(_edgemap, num_classes)
_edgemap = edge_utils.onehot_to_binary_edges(_edgemap, 2, num_classes)
edgemap = torch.from_numpy(_edgemap).float()
# Debug
if self.dump_images:
outdir = '../../dump_imgs_{}'.format(self.mode)
os.makedirs(outdir, exist_ok=True)
out_img_fn = os.path.join(outdir, img_name + '.png')
out_msk_fn = os.path.join(outdir, img_name + '_mask.png')
mask_img = colorize_mask(np.array(mask))
img.save(out_img_fn)
mask_img.save(out_msk_fn)
return img, mask, edgemap, img_name
def __len__(self):
return len(self.imgs)
def make_dataset_video():
img_dir_name = 'leftImg8bit_demoVideo'
img_path = os.path.join(root, img_dir_name, 'leftImg8bit/demoVideo')
items = []
categories = os.listdir(img_path)
for c in categories[1:]:
c_items = [name.split('_leftImg8bit.png')[0] for name in
os.listdir(os.path.join(img_path, c))]
for it in c_items:
item = os.path.join(img_path, c, it + '_leftImg8bit.png')
items.append(item)
return items
class CityScapesVideo(data.Dataset):
def __init__(self, transform=None):
self.imgs = make_dataset_video()
if len(self.imgs) == 0:
raise RuntimeError('Found 0 images, please check the data set')
self.transform = transform
def __getitem__(self, index):
img_path = self.imgs[index]
img = Image.open(img_path).convert('RGB')
img_name = os.path.splitext(os.path.basename(img_path))[0]
if self.transform is not None:
img = self.transform(img)
return img, img_name
def __len__(self):
return len(self.imgs)
================================================
FILE: benchmarks/GSCNN-master/datasets/cityscapes_labels.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# File taken from https://github.com/mcordts/cityscapesScripts/
# License File Available at:
# https://github.com/mcordts/cityscapesScripts/blob/master/license.txt
# ----------------------
# The Cityscapes Dataset
# ----------------------
#
#
# License agreement
# -----------------
#
# This dataset is made freely available to academic and non-academic entities for non-commercial purposes such as academic research, teaching, scientific publications, or personal experimentation. Permission is granted to use the data given that you agree:
#
# 1. That the dataset comes "AS IS", without express or implied warranty. Although every effort has been made to ensure accuracy, we (Daimler AG, MPI Informatics, TU Darmstadt) do not accept any responsibility for errors or omissions.
# 2. That you include a reference to the Cityscapes Dataset in any work that makes use of the dataset. For research papers, cite our preferred publication as listed on our website; for other media cite our preferred publication as listed on our website or link to the Cityscapes website.
# 3. That you do not distribute this dataset or modified versions. It is permissible to distribute derivative works in as far as they are abstract representations of this dataset (such as models trained on it or additional annotations that do not directly include any of our data) and do not allow to recover the dataset or something similar in character.
# 4. That you may not use the dataset or any derivative work for commercial purposes as, for example, licensing or selling the data, or using the data with a purpose to procure a commercial gain.
# 5. That all rights not expressly granted to you are reserved by us (Daimler AG, MPI Informatics, TU Darmstadt).
#
#
# Contact
# -------
#
# Marius Cordts, Mohamed Omran
# www.cityscapes-dataset.net
"""
from collections import namedtuple
#--------------------------------------------------------------------------------
# Definitions
#--------------------------------------------------------------------------------
# a label and all meta information
Label = namedtuple( 'Label' , [
'name' , # The identifier of this label, e.g. 'car', 'person', ... .
# We use them to uniquely name a class
'id' , # An integer ID that is associated with this label.
# The IDs are used to represent the label in ground truth images
# An ID of -1 means that this label does not have an ID and thus
# is ignored when creating ground truth images (e.g. license plate).
# Do not modify these IDs, since exactly these IDs are expected by the
# evaluation server.
'trainId' , # Feel free to modify these IDs as suitable for your method. Then create
# ground truth images with train IDs, using the tools provided in the
# 'preparation' folder. However, make sure to validate or submit results
# to our evaluation server using the regular IDs above!
# For trainIds, multiple labels might have the same ID. Then, these labels
# are mapped to the same class in the ground truth images. For the inverse
# mapping, we use the label that is defined first in the list below.
# For example, mapping all void-type classes to the same ID in training,
# might make sense for some approaches.
# Max value is 255!
'category' , # The name of the category that this label belongs to
'categoryId' , # The ID of this category. Used to create ground truth images
# on category level.
'hasInstances', # Whether this label distinguishes between single instances or not
'ignoreInEval', # Whether pixels having this class as ground truth label are ignored
# during evaluations or not
'color' , # The color of this label
] )
#--------------------------------------------------------------------------------
# A list of all labels
#--------------------------------------------------------------------------------
# Please adapt the train IDs as appropriate for you approach.
# Note that you might want to ignore labels with ID 255 during training.
# Further note that the current train IDs are only a suggestion. You can use whatever you like.
# Make sure to provide your results using the original IDs and not the training IDs.
# Note that many IDs are ignored in evaluation and thus you never need to predict these!
labels = [
# name id trainId category catId hasInstances ignoreInEval color
Label( 'unlabeled' , 0 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'ego vehicle' , 1 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'rectification border' , 2 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'out of roi' , 3 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'static' , 4 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'dynamic' , 5 , 255 , 'void' , 0 , False , True , (111, 74, 0) ),
Label( 'ground' , 6 , 255 , 'void' , 0 , False , True , ( 81, 0, 81) ),
Label( 'road' , 7 , 0 , 'flat' , 1 , False , False , (128, 64,128) ),
Label( 'sidewalk' , 8 , 1 , 'flat' , 1 , False , False , (244, 35,232) ),
Label( 'parking' , 9 , 255 , 'flat' , 1 , False , True , (250,170,160) ),
Label( 'rail track' , 10 , 255 , 'flat' , 1 , False , True , (230,150,140) ),
Label( 'building' , 11 , 2 , 'construction' , 2 , False , False , ( 70, 70, 70) ),
Label( 'wall' , 12 , 3 , 'construction' , 2 , False , False , (102,102,156) ),
Label( 'fence' , 13 , 4 , 'construction' , 2 , False , False , (190,153,153) ),
Label( 'guard rail' , 14 , 255 , 'construction' , 2 , False , True , (180,165,180) ),
Label( 'bridge' , 15 , 255 , 'construction' , 2 , False , True , (150,100,100) ),
Label( 'tunnel' , 16 , 255 , 'construction' , 2 , False , True , (150,120, 90) ),
Label( 'pole' , 17 , 5 , 'object' , 3 , False , False , (153,153,153) ),
Label( 'polegroup' , 18 , 255 , 'object' , 3 , False , True , (153,153,153) ),
Label( 'traffic light' , 19 , 6 , 'object' , 3 , False , False , (250,170, 30) ),
Label( 'traffic sign' , 20 , 7 , 'object' , 3 , False , False , (220,220, 0) ),
Label( 'vegetation' , 21 , 8 , 'nature' , 4 , False , False , (107,142, 35) ),
Label( 'terrain' , 22 , 9 , 'nature' , 4 , False , False , (152,251,152) ),
Label( 'sky' , 23 , 10 , 'sky' , 5 , False , False , ( 70,130,180) ),
Label( 'person' , 24 , 11 , 'human' , 6 , True , False , (220, 20, 60) ),
Label( 'rider' , 25 , 12 , 'human' , 6 , True , False , (255, 0, 0) ),
Label( 'car' , 26 , 13 , 'vehicle' , 7 , True , False , ( 0, 0,142) ),
Label( 'truck' , 27 , 14 , 'vehicle' , 7 , True , False , ( 0, 0, 70) ),
Label( 'bus' , 28 , 15 , 'vehicle' , 7 , True , False , ( 0, 60,100) ),
Label( 'caravan' , 29 , 255 , 'vehicle' , 7 , True , True , ( 0, 0, 90) ),
Label( 'trailer' , 30 , 255 , 'vehicle' , 7 , True , True , ( 0, 0,110) ),
Label( 'train' , 31 , 16 , 'vehicle' , 7 , True , False , ( 0, 80,100) ),
Label( 'motorcycle' , 32 , 17 , 'vehicle' , 7 , True , False , ( 0, 0,230) ),
Label( 'bicycle' , 33 , 18 , 'vehicle' , 7 , True , False , (119, 11, 32) ),
Label( 'license plate' , -1 , -1 , 'vehicle' , 7 , False , True , ( 0, 0,142) ),
Label( 'license plate' , 34 , 255 , 'vehicle' , 7 , False , True , ( 0, 0,142) ),
]
#--------------------------------------------------------------------------------
# Create dictionaries for a fast lookup
#--------------------------------------------------------------------------------
# Please refer to the main method below for example usages!
# name to label object
name2label = { label.name : label for label in labels }
# id to label object
id2label = { label.id : label for label in labels }
# trainId to label object
trainId2label = { label.trainId : label for label in reversed(labels) }
# label2trainid
label2trainid = { label.id : label.trainId for label in labels }
# trainId to label object
trainId2name = { label.trainId : label.name for label in labels }
trainId2color = { label.trainId : label.color for label in labels }
# category to list of label objects
category2labels = {}
for label in labels:
category = label.category
if category in category2labels:
category2labels[category].append(label)
else:
category2labels[category] = [label]
#--------------------------------------------------------------------------------
# Assure single instance name
#--------------------------------------------------------------------------------
# returns the label name that describes a single instance (if possible)
# e.g. input | output
# ----------------------
# car | car
# cargroup | car
# foo | None
# foogroup | None
# skygroup | None
def assureSingleInstanceName( name ):
# if the name is known, it is not a group
if name in name2label:
return name
# test if the name actually denotes a group
if not name.endswith("group"):
return None
# remove group
name = name[:-len("group")]
# test if the new name exists
if not name in name2label:
return None
# test if the new name denotes a label that actually has instances
if not name2label[name].hasInstances:
return None
# all good then
return name
#--------------------------------------------------------------------------------
# Main for testing
#--------------------------------------------------------------------------------
# just a dummy main
if __name__ == "__main__":
# Print all the labels
print("List of cityscapes labels:")
print("")
print((" {:>21} | {:>3} | {:>7} | {:>14} | {:>10} | {:>12} | {:>12}".format( 'name', 'id', 'trainId', 'category', 'categoryId', 'hasInstances', 'ignoreInEval' )))
print((" " + ('-' * 98)))
for label in labels:
print((" {:>21} | {:>3} | {:>7} | {:>14} | {:>10} | {:>12} | {:>12}".format( label.name, label.id, label.trainId, label.category, label.categoryId, label.hasInstances, label.ignoreInEval )))
print("")
print("Example usages:")
# Map from name to label
name = 'car'
id = name2label[name].id
print(("ID of label '{name}': {id}".format( name=name, id=id )))
# Map from ID to label
category = id2label[id].category
print(("Category of label with ID '{id}': {category}".format( id=id, category=category )))
# Map from trainID to label
trainId = 0
name = trainId2label[trainId].name
print(("Name of label with trainID '{id}': {name}".format( id=trainId, name=name )))
================================================
FILE: benchmarks/GSCNN-master/datasets/edge_utils.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import os
import numpy as np
from PIL import Image
from scipy.ndimage.morphology import distance_transform_edt
def mask_to_onehot(mask, num_classes):
"""
Converts a segmentation mask (H,W) to (K,H,W) where the last dim is a one
hot encoding vector
"""
_mask = [mask == (i + 1) for i in range(num_classes)]
return np.array(_mask).astype(np.uint8)
def onehot_to_mask(mask):
"""
Converts a mask (K,H,W) to (H,W)
"""
_mask = np.argmax(mask, axis=0)
_mask[_mask != 0] += 1
return _mask
def onehot_to_multiclass_edges(mask, radius, num_classes):
"""
Converts a segmentation mask (K,H,W) to an edgemap (K,H,W)
"""
if radius < 0:
return mask
# We need to pad the borders for boundary conditions
mask_pad = np.pad(mask, ((0, 0), (1, 1), (1, 1)), mode='constant', constant_values=0)
channels = []
for i in range(num_classes):
dist = distance_transform_edt(mask_pad[i, :])+distance_transform_edt(1.0-mask_pad[i, :])
dist = dist[1:-1, 1:-1]
dist[dist > radius] = 0
dist = (dist > 0).astype(np.uint8)
channels.append(dist)
return np.array(channels)
def onehot_to_binary_edges(mask, radius, num_classes):
"""
Converts a segmentation mask (K,H,W) to a binary edgemap (H,W)
"""
if radius < 0:
return mask
# We need to pad the borders for boundary conditions
mask_pad = np.pad(mask, ((0, 0), (1, 1), (1, 1)), mode='constant', constant_values=0)
edgemap = np.zeros(mask.shape[1:])
for i in range(num_classes):
dist = distance_transform_edt(mask_pad[i, :])+distance_transform_edt(1.0-mask_pad[i, :])
dist = dist[1:-1, 1:-1]
dist[dist > radius] = 0
edgemap += dist
edgemap = np.expand_dims(edgemap, axis=0)
edgemap = (edgemap > 0).astype(np.uint8)
return edgemap
================================================
FILE: benchmarks/GSCNN-master/datasets/rellis.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import os
import numpy as np
import torch
from PIL import Image
from torch.utils import data
from collections import defaultdict
import math
import logging
import datasets.cityscapes_labels as cityscapes_labels
import json
from config import cfg
import torchvision.transforms as transforms
import datasets.edge_utils as edge_utils
trainid_to_name = cityscapes_labels.trainId2name
id_to_trainid = cityscapes_labels.label2trainid
num_classes = 19
ignore_label = 0
root = cfg.DATASET.RELLIS_DIR
list_paths = {'train':'train.lst','val':"val.lst",'test':'test.lst'}
palette = [128, 64, 128, 244, 35, 232, 70, 70, 70, 102, 102, 156, 190, 153, 153,
153, 153, 153, 250, 170, 30,
220, 220, 0, 107, 142, 35, 152, 251, 152, 70, 130, 180, 220, 20, 60,
255, 0, 0, 0, 0, 142, 0, 0, 70,
0, 60, 100, 0, 80, 100, 0, 0, 230, 119, 11, 32]
zero_pad = 256 * 3 - len(palette)
for i in range(zero_pad):
palette.append(0)
def colorize_mask(mask):
# mask: numpy array of the mask
new_mask = Image.fromarray(mask.astype(np.uint8)).convert('P')
new_mask.putpalette(palette)
return new_mask
class Rellis(data.Dataset):
def __init__(self, mode, joint_transform=None, sliding_crop=None,
transform=None, target_transform=None, dump_images=False,
cv_split=None, eval_mode=False,
eval_scales=None, eval_flip=False):
self.mode = mode
self.joint_transform = joint_transform
self.sliding_crop = sliding_crop
self.transform = transform
self.target_transform = target_transform
self.dump_images = dump_images
self.eval_mode = eval_mode
self.eval_flip = eval_flip
self.eval_scales = None
self.root = root
if eval_scales != None:
self.eval_scales = [float(scale) for scale in eval_scales.split(",")]
self.list_path = list_paths[mode]
self.img_list = [line.strip().split() for line in open(root+self.list_path)]
self.files = self.read_files()
if len(self.files) == 0:
raise RuntimeError('Found 0 images, please check the data set')
self.mean_std = ([0.54218053, 0.64250553, 0.56620195], [0.54218052, 0.64250552, 0.56620194])
self.label_mapping = {0: 0,
1: 0,
3: 1,
4: 2,
5: 3,
6: 4,
7: 5,
8: 6,
9: 7,
10: 8,
12: 9,
15: 10,
17: 11,
18: 12,
19: 13,
23: 14,
27: 15,
29: 1,
30: 1,
31: 16,
32: 4,
33: 17,
34: 18}
def _eval_get_item(self, img, mask, scales, flip_bool):
return_imgs = []
for flip in range(int(flip_bool)+1):
imgs = []
if flip :
img = img.transpose(Image.FLIP_LEFT_RIGHT)
for scale in scales:
w,h = img.size
target_w, target_h = int(w * scale), int(h * scale)
resize_img =img.resize((target_w, target_h))
tensor_img = transforms.ToTensor()(resize_img)
final_tensor = transforms.Normalize(*self.mean_std)(tensor_img)
imgs.append(tensor_img)
return_imgs.append(imgs)
return return_imgs, mask
def read_files(self):
files = []
# if 'test' in self.mode:
# for item in self.img_list:
# image_path = item
# name = os.path.splitext(os.path.basename(image_path[0]))[0]
# files.append({
# "img": image_path[0],
# "name": name,
# })
# else:
for item in self.img_list:
image_path, label_path = item
name = os.path.splitext(os.path.basename(label_path))[0]
files.append({
"img": image_path,
"label": label_path,
"name": name,
"weight": 1
})
return files
def convert_label(self, label, inverse=False):
temp = label.copy()
if inverse:
for v, k in self.label_mapping.items():
label[temp == k] = v
else:
for k, v in self.label_mapping.items():
label[temp == k] = v
return label
def __getitem__(self, index):
item = self.files[index]
img_name = item["name"]
img_path = self.root + item['img']
label_path = self.root + item["label"]
img = Image.open(img_path).convert('RGB')
mask = np.array(Image.open(label_path))
mask = mask[:, :]
mask_copy = self.convert_label(mask)
if self.eval_mode:
return self._eval_get_item(img, mask_copy, self.eval_scales, self.eval_flip), img_name
mask = Image.fromarray(mask_copy.astype(np.uint8))
# Image Transformations
if self.joint_transform is not None:
img, mask = self.joint_transform(img, mask)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
mask = self.target_transform(mask)
if self.mode == 'test':
return img, mask, img_name, item['img']
_edgemap = mask.numpy()
_edgemap = edge_utils.mask_to_onehot(_edgemap, num_classes)
_edgemap = edge_utils.onehot_to_binary_edges(_edgemap, 2, num_classes)
edgemap = torch.from_numpy(_edgemap).float()
# Debug
if self.dump_images:
outdir = '../../dump_imgs_{}'.format(self.mode)
os.makedirs(outdir, exist_ok=True)
out_img_fn = os.path.join(outdir, img_name + '.png')
out_msk_fn = os.path.join(outdir, img_name + '_mask.png')
mask_img = colorize_mask(np.array(mask))
img.save(out_img_fn)
mask_img.save(out_msk_fn)
return img, mask, edgemap, img_name
def __len__(self):
return len(self.files)
def make_dataset_video():
img_dir_name = 'leftImg8bit_demoVideo'
img_path = os.path.join(root, img_dir_name, 'leftImg8bit/demoVideo')
items = []
categories = os.listdir(img_path)
for c in categories[1:]:
c_items = [name.split('_leftImg8bit.png')[0] for name in
os.listdir(os.path.join(img_path, c))]
for it in c_items:
item = os.path.join(img_path, c, it + '_leftImg8bit.png')
items.append(item)
return items
class CityScapesVideo(data.Dataset):
def __init__(self, transform=None):
self.imgs = make_dataset_video()
if len(self.imgs) == 0:
raise RuntimeError('Found 0 images, please check the data set')
self.transform = transform
def __getitem__(self, index):
img_path = self.imgs[index]
img = Image.open(img_path).convert('RGB')
img_name = os.path.splitext(os.path.basename(img_path))[0]
if self.transform is not None:
img = self.transform(img)
return img, img_name
def __len__(self):
return len(self.imgs)
================================================
FILE: benchmarks/GSCNN-master/docs/index.html
================================================
<head>
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-137506474-1"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-137506474-1');
</script>
<script src="http://www.google.com/jsapi" type="text/javascript"></script>
<script type="text/javascript">google.load("jquery", "1.3.2");</script>
</head>
<style type="text/css">
body {
font-family: "HelveticaNeue-Light", "Helvetica Neue Light", "Helvetica Neue", Helvetica, Arial, "Lucida Grande", sans-serif;
font-weight:300;
font-size:18px;
margin-left: auto;
margin-right: auto;
width: 1100px;
}
h1 {
font-weight:300;
margin: 0.4em;
}
p {
margin: 0.2em;
}
.disclaimerbox {
background-color: #eee;
border: 1px solid #eeeeee;
border-radius: 10px ;
-moz-border-radius: 10px ;
-webkit-border-radius: 10px ;
padding: 20px;
}
video.header-vid {
height: 140px;
border: 1px solid black;
border-radius: 10px ;
-moz-border-radius: 10px ;
-webkit-border-radius: 10px ;
}
img.header-img {
height: 140px;
border: 1px solid black;
border-radius: 10px ;
-moz-border-radius: 10px ;
-webkit-border-radius: 10px ;
}
img.rounded {
border: 1px solid #eeeeee;
border-radius: 10px ;
-moz-border-radius: 10px ;
-webkit-border-radius: 10px ;
}
a:link,a:visited
{
color: #1367a7;
text-decoration: none;
}
a:hover {
color: #208799;
}
td.dl-link {
height: 160px;
text-align: center;
font-size: 22px;
}
.layered-paper-big { /* modified from: http://css-tricks.com/snippets/css/layered-paper/ */
box-shadow:
0px 0px 1px 1px rgba(0,0,0,0.35), /* The top layer shadow */
5px 5px 0 0px #fff, /* The second layer */
5px 5px 1px 1px rgba(0,0,0,0.35), /* The second layer shadow */
10px 10px 0 0px #fff, /* The third layer */
10px 10px 1px 1px rgba(0,0,0,0.35), /* The third layer shadow */
15px 15px 0 0px #fff, /* The fourth layer */
15px 15px 1px 1px rgba(0,0,0,0.35), /* The fourth layer shadow */
20px 20px 0 0px #fff, /* The fifth layer */
20px 20px 1px 1px rgba(0,0,0,0.35), /* The fifth layer shadow */
25px 25px 0 0px #fff, /* The fifth layer */
25px 25px 1px 1px rgba(0,0,0,0.35); /* The fifth layer shadow */
margin-left: 10px;
margin-right: 45px;
}
.layered-paper { /* modified from: http://css-tricks.com/snippets/css/layered-paper/ */
box-shadow:
0px 0px 1px 1px rgba(0,0,0,0.35), /* The top layer shadow */
5px 5px 0 0px #fff, /* The second layer */
5px 5px 1px 1px rgba(0,0,0,0.35), /* The second layer shadow */
10px 10px 0 0px #fff, /* The third layer */
10px 10px 1px 1px rgba(0,0,0,0.35); /* The third layer shadow */
margin-top: 5px;
margin-left: 10px;
margin-right: 30px;
margin-bottom: 5px;
}
.vert-cent {
position: relative;
top: 50%;
transform: translateY(-50%);
}
hr
{
margin: 0;
border: 0;
height: 1.5px;
background-image: linear-gradient(to right, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.75), rgba(0, 0, 0, 0));
}
</style>
<html>
<head>
<title>Gated Shape CNN</title>
<meta property="og:title" content="gscnn" />
</head>
<body>
<br>
<center>
<span style="font-size:42px">Gated-SCNN</span>
<br>
<span style="font-size:36px">Gated Shape CNNs for Semantic Segmentation</span>
</center>
<br>
<table align=center width=700px>
<tr>
<td align=center width=100px>
<center>
<span style="font-size:20px"><a href="https://tovacinni.github.io">Towaki Takikawa</a><sup>*1,2</sup></span>
</center>
</td>
<td align=center width=100px>
<center>
<span style="font-size:20px"><a href="http://www.cs.toronto.edu/~davidj/">David Acuna</a><sup>*1,3,4</sup></span>
</center>
</td>
<td align=center width=100px>
<center>
<span style="font-size:20px"><a href="https://varunjampani.github.io/">Varun Jampani</a><sup>1</sup></span>
</center>
</td>
<td align=center width=100px>
<center>
<span style="font-size:20px"><a href="http://www.cs.toronto.edu/~fidler/">Sanja Fidler</a><sup>1,3,4</sup></span>
</center>
</td>
</tr>
</table>
<br>
<table align=center width=700px>
<tr>
<td align=center width=100px>
<center>
<span style="font-size:20px"><sup>1</sup>NVIDIA</span>
</center>
</td>
<td align=center width=100px>
<center>
<span style="font-size:20px"><sup>2</sup>University of Waterloo</span>
</center>
</td>
<td align=center width=100px>
<center>
<span style="font-size:20px"><sup>3</sup>University of Toronto</span>
</center>
</td>
<td align=center width=100px>
<center>
<span style="font-size:20px"><sup>4</sup>Vector Institute</span>
</center>
</td>
</tr>
</table>
<table align=center width=700px>
<tr>
<td align=center width=100px>
<center>
<span style="font-size:20px;color:red">ICCV, 2019</span>
</center>
</td>
</tr>
</table>
<br>
<table align=center width=900px>
<tr>
<td width=450px>
<center>
<a href="./resources/GSCNN.mp4"><img src = "./resources/gscnn.gif" width="450px" height="250px"></img>
</center>
</td>
<td width=450px>
<center>
<a href="./resources/GSCNN.mp4"><img src = "./resources/intro.jpg" width="450px" height="250px"></img></href></a><br>
</center>
</td>
<!-- -->
</tr>
</table>
<table align=center width=900px></table>
<tr>
<td width=600px>
<br>
<center>
<!-- -->
</center>
</td>
</tr>
<tr>
<td width=600px>
<br>
<p align="justify" style="font-size: 18px">
Current state-of-the-art methods for image segmentation form a dense image representation where the color, shape and texture information are all processed together inside a deep CNN. This however may not be ideal as they contain very different type of information relevant for recognition. We propose a new architecture that adds a shape stream to the classical CNN architecture. The two streams process the image in parallel, and their information gets fused in the very top layers. Key to this architecture is a new type of gates that connect the intermediate layers of the two streams. Specifically, we use the higher-level activations in the classical stream to gate the lower-level activations in the shape stream, effectively removing noise and helping the shape stream to only focus on processing the relevant boundary-related information. This enables us to use a very shallow architecture for the shape stream that operates on the image-level resolution. Our experiments show that this leads to a highly effective architecture that produces sharper predictions around object boundaries and significantly boosts performance on thinner and smaller objects. Our method achieves state-of-the-art performance on the Cityscapes benchmark, in terms of both mask (mIoU) and boundary (F-score) quality, improving by 2% and 4% over strong baselines.
</p>
</td>
</tr>
<tr>
</tr>
</table>
<br>
<hr>
<table align=center width=700>
<center><h1>News</h1></center>
<tr>
<ul>
<li>[August 2019] Code released on <a href="https://github.com/nv-tlabs/gscnn">GitHub</a></li>
<li>[July 2019] Paper accepted at ICCV 2019!</li>
<li>[July 2019] Paper released on <a href="http://arxiv.org/abs/1907.05740">arXiv</a></li>
</ul>
</tr>
</table>
<br>
<hr>
<table align=center width=700>
<center><h1>Paper</h1></center>
<tr>
<td><a href="./"><img style="height:180px; border: solid; border-radius:30px;" src="./resources/top.jpg"/></a></td>
<td><span style="font-size:18px">Towaki Takikawa* , David Acuna* , Varun Jampani , Sanja Fidler<br>
<small>(* denotes equal contribution)</small><br><br>
Gated-SCNN: Gated Shape CNNs for Semantic Segmentation<br><br>
ICCV, 2019. (to appear)<br>
</td>
</tr>
</table>
<br>
<table align=center width=700px>
<tr>
<td>
<span style="font-size:18px"><center>
<a href="http://arxiv.org/abs/1907.05740">[Preprint]</a>
</center></td>
<td><span style="font-size:18px"><center>
<a href="./resources/bibtex.txt">[Bibtex]</a>
</center></td>
<td><span style="font-size:18px"><center>
<a href="./resources/GSCNN.mp4">[Video]</a>
</center></td>
</tr>
<tr>
</tr>
</table>
<br>
<hr>
<center><h1>GSCNN in a nutshell</h1></center>
<table align=center width=1000px>
<tr>
<center>
<a href=''><img class="round" style="height:300" src="./resources/architecture.jpg"/></a>
</center>
</tr>
</table>
<br>
<hr>
<center><h1> Results</h1></center> <br>
<table align=center width=900px>
<tr>
<td width=100px>
<center>
<a href="./resources/seg.jpg"><img src = "./resources/seg.jpg" width="900px"></img></a><br>
</center>
</td>
<tr>
<td>
<center>
<span style="font-size:14px">
Qualitative Segmentation Results
</span>
</center>
</td>
</tr>
<tr>
<td colspan='2'>
<center>
<a href="./resources/edges.jpg"><img src = "./resources/edges.jpg" width="900px"></img></a><br>
</center>
</td>
</tr>
<tr>
<td colspan='2'>
<center>
<span style="font-size:14px">
Qualitative Semantic Boundary Results
</span>
</center>
</td>
</tr>
<tr>
<td colspan='2'>
<center>
<a href="./resources/table.png"><img src = "./resources/table.png" width="900px"></img></a><br>
</center>
</td>
</tr>
<tr>
<td colspan='2'>
<center>
<span style="font-size:14px">
Quantitative Results
</span>
</center>
</td>
</tr>
<tr>
<td colspan='2'>
<center>
<a href="./resources/crop.jpg"><img src = "./resources/crop.jpg" width="600px"></img></a><br>
</center>
</td>
</tr>
<tr>
<td colspan='2'>
<center>
<span style="font-size:14px">
Evaluation at different distances, measured by crop factor.
</span>
</center>
</td>
</tr>
</table>
<hr>
<br>
<table style="font-size:14px">
<tr>
<!-- -->
</table>
</body>
</html>
================================================
FILE: benchmarks/GSCNN-master/docs/resources/bibtex.txt
================================================
@inproceedings{Takikawa2019GatedSCNNGS,
title={Gated-SCNN: Gated Shape CNNs for Semantic Segmentation},
author={Towaki Takikawa and David Acuna and Varun Jampani and Sanja Fidler},
year={2019}
}
================================================
FILE: benchmarks/GSCNN-master/gscnn.txt
================================================
absl-py==0.10.0
aiohttp==3.6.2
astor==0.8.1
astunparse==1.6.3
async-timeout==3.0.1
attrs==20.2.0
cachetools==4.1.1
certifi==2020.6.20
chardet==3.0.4
cycler==0.10.0
decorator==4.4.2
future==0.18.2
gast==0.2.2
google-auth==1.22.0
google-auth-oauthlib==0.4.1
google-pasta==0.2.0
grpcio==1.32.0
h5py==2.10.0
idna==2.10
idna-ssl==1.1.0
imageio==2.9.0
imageio-ffmpeg==0.4.2
importlib-metadata==2.0.0
joblib==0.16.0
Keras-Applications==1.0.8
Keras-Preprocessing==1.1.2
kiwisolver==1.2.0
Markdown==3.2.2
matplotlib==3.3.2
multidict==4.7.6
networkx==2.5
ninja==1.10.0.post2
nose==1.3.7
numpy==1.18.5
oauthlib==3.1.0
opencv-python==4.4.0.44
opt-einsum==3.3.0
Pillow==7.2.0
portalocker==2.0.0
protobuf==3.13.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pyparsing==2.4.7
python-dateutil==2.8.1
PyWavelets==1.1.1
PyYAML==5.3.1
requests==2.24.0
requests-oauthlib==1.3.0
rsa==4.6
scikit-image==0.17.2
scikit-learn==0.23.2
scipy==1.5.2
six==1.15.0
tensorboard==1.15.0
tensorboard-plugin-wit==1.7.0
tensorboardX==2.1
tensorflow-estimator==1.15.1
tensorflow-gpu==1.15.0
termcolor==1.1.0
threadpoolctl==2.1.0
tifffile==2020.9.3
torch==1.4.0
torch-encoding @ git+https://github.com/zhanghang1989/PyTorch-Encoding/@ced288d6fa10d4780fa5205a2f239c84022e71a3
torchvision==0.5.0
tqdm==4.49.0
typing-extensions==3.7.4.3
urllib3==1.25.10
Werkzeug==1.0.1
wrapt==1.12.1
yacs==0.1.8
yarl==1.6.0
zipp==3.2.0
================================================
FILE: benchmarks/GSCNN-master/loss.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import logging
import numpy as np
from config import cfg
from my_functionals.DualTaskLoss import DualTaskLoss
def get_loss(args):
'''
Get the criterion based on the loss function
args:
return: criterion
'''
if args.img_wt_loss:
criterion = ImageBasedCrossEntropyLoss2d(
classes=args.dataset_cls.num_classes, size_average=True,
ignore_index=args.dataset_cls.ignore_label,
upper_bound=args.wt_bound).cuda()
elif args.joint_edgeseg_loss:
criterion = JointEdgeSegLoss(classes=args.dataset_cls.num_classes,
ignore_index=args.dataset_cls.ignore_label, upper_bound=args.wt_bound,
edge_weight=args.edge_weight, seg_weight=args.seg_weight, att_weight=args.att_weight, dual_weight=args.dual_weight).cuda()
else:
criterion = CrossEntropyLoss2d(size_average=True,
ignore_index=args.dataset_cls.ignore_label).cuda()
criterion_val = JointEdgeSegLoss(classes=args.dataset_cls.num_classes, mode='val',
ignore_index=args.dataset_cls.ignore_label, upper_bound=args.wt_bound,
edge_weight=args.edge_weight, seg_weight=args.seg_weight).cuda()
return criterion, criterion_val
class JointEdgeSegLoss(nn.Module):
def __init__(self, classes, weight=None, reduction='mean', ignore_index=255,
norm=False, upper_bound=1.0, mode='train',
edge_weight=1, seg_weight=1, att_weight=1, dual_weight=1, edge='none'):
super(JointEdgeSegLoss, self).__init__()
self.num_classes = classes
if mode == 'train':
self.seg_loss = ImageBasedCrossEntropyLoss2d(
classes=classes, ignore_index=ignore_index, upper_bound=upper_bound).cuda()
elif mode == 'val':
self.seg_loss = CrossEntropyLoss2d(size_average=True,
ignore_index=ignore_index).cuda()
self.ignore_index = ignore_index
self.edge_weight = edge_weight
self.seg_weight = seg_weight
self.att_weight = att_weight
self.dual_weight = dual_weight
self.dual_task = DualTaskLoss()
def bce2d(self, input, target):
n, c, h, w = input.size()
log_p = input.transpose(1, 2).transpose(2, 3).contiguous().view(1, -1)
target_t = target.transpose(1, 2).transpose(2, 3).contiguous().view(1, -1)
target_trans = target_t.clone()
pos_index = (target_t ==1)
neg_index = (target_t ==0)
ignore_index=(target_t >1)
target_trans[pos_index] = 1
target_trans[neg_index] = 0
pos_index = pos_index.data.cpu().numpy().astype(bool)
neg_index = neg_index.data.cpu().numpy().astype(bool)
ignore_index=ignore_index.data.cpu().numpy().astype(bool)
weight = torch.Tensor(log_p.size()).fill_(0)
weight = weight.numpy()
pos_num = pos_index.sum()
neg_num = neg_index.sum()
sum_num = pos_num + neg_num
weight[pos_index] = neg_num*1.0 / sum_num
weight[neg_index] = pos_num*1.0 / sum_num
weight[ignore_index] = 0
weight = torch.from_numpy(weight)
weight = weight.cuda()
loss = F.binary_cross_entropy_with_logits(log_p, target_t, weight, size_average=True)
return loss
def edge_attention(self, input, target, edge):
n, c, h, w = input.size()
filler = torch.ones_like(target) * self.ignore_index
return self.seg_loss(input,
torch.where(edge.max(1)[0] > 0.8, target, filler))
def forward(self, inputs, targets):
segin, edgein = inputs
segmask, edgemask = targets
losses = {}
losses['seg_loss'] = self.seg_weight * self.seg_loss(segin, segmask)
losses['edge_loss'] = self.edge_weight * 20 * self.bce2d(edgein, edgemask)
losses['att_loss'] = self.att_weight * self.edge_attention(segin, segmask, edgein)
losses['dual_loss'] = self.dual_weight * self.dual_task(segin, segmask,ignore_pixel=self.ignore_index)
return losses
#Img Weighted Loss
class ImageBasedCrossEntropyLoss2d(nn.Module):
def __init__(self, classes, weight=None, size_average=True, ignore_index=255,
norm=False, upper_bound=1.0):
super(ImageBasedCrossEntropyLoss2d, self).__init__()
logging.info("Using Per Image based weighted loss")
self.num_classes = classes
self.nll_loss = nn.NLLLoss2d(weight, size_average, ignore_index)
self.norm = norm
self.upper_bound = upper_bound
self.batch_weights = cfg.BATCH_WEIGHTING
def calculateWeights(self, target):
hist = np.histogram(target.flatten(), range(
self.num_classes + 1), normed=True)[0]
if self.norm:
hist = ((hist != 0) * self.upper_bound * (1 / hist)) + 1
else:
hist = ((hist != 0) * self.upper_bound * (1 - hist)) + 1
return hist
def forward(self, inputs, targets):
target_cpu = targets.data.cpu().numpy()
#print("loss",np.unique(target_cpu))
if self.batch_weights:
weights = self.calculateWeights(target_cpu)
self.nll_loss.weight = torch.Tensor(weights).cuda()
loss = 0.0
for i in range(0, inputs.shape[0]):
if not self.batch_weights:
weights = self.calculateWeights(target_cpu[i])
self.nll_loss.weight = torch.Tensor(weights).cuda()
loss += self.nll_loss(F.log_softmax(inputs[i].unsqueeze(0)),
targets[i].unsqueeze(0))
return loss
#Cross Entroply NLL Loss
class CrossEntropyLoss2d(nn.Module):
def __init__(self, weight=None, size_average=True, ignore_index=255):
super(CrossEntropyLoss2d, self).__init__()
logging.info("Using Cross Entropy Loss")
self.nll_loss = nn.NLLLoss2d(weight, size_average, ignore_index)
def forward(self, inputs, targets):
return self.nll_loss(F.log_softmax(inputs), targets)
================================================
FILE: benchmarks/GSCNN-master/my_functionals/DualTaskLoss.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code adapted from:
# https://github.com/ericjang/gumbel-softmax/blob/3c8584924603869e90ca74ac20a6a03d99a91ef9/Categorical%20VAE.ipynb
#
# MIT License
#
# Copyright (c) 2016 Eric Jang
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from my_functionals.custom_functional import compute_grad_mag
def perturbate_input_(input, n_elements=200):
N, C, H, W = input.shape
assert N == 1
c_ = np.random.random_integers(0, C - 1, n_elements)
h_ = np.random.random_integers(0, H - 1, n_elements)
w_ = np.random.random_integers(0, W - 1, n_elements)
for c_idx in c_:
for h_idx in h_:
for w_idx in w_:
input[0, c_idx, h_idx, w_idx] = 1
return input
def _sample_gumbel(shape, eps=1e-10):
"""
Sample from Gumbel(0, 1)
based on
https://github.com/ericjang/gumbel-softmax/blob/3c8584924603869e90ca74ac20a6a03d99a91ef9/Categorical%20VAE.ipynb ,
(MIT license)
"""
U = torch.rand(shape).cuda()
return - torch.log(eps - torch.log(U + eps))
def _gumbel_softmax_sample(logits, tau=1, eps=1e-10):
"""
Draw a sample from the Gumbel-Softmax distribution
based on
https://github.com/ericjang/gumbel-softmax/blob/3c8584924603869e90ca74ac20a6a03d99a91ef9/Categorical%20VAE.ipynb
(MIT license)
"""
assert logits.dim() == 3
gumbel_noise = _sample_gumbel(logits.size(), eps=eps)
y = logits + gumbel_noise
return F.softmax(y / tau, 1)
def _one_hot_embedding(labels, num_classes):
"""Embedding labels to one-hot form.
Args:
labels: (LongTensor) class labels, sized [N,].
num_classes: (int) number of classes.
Returns:
(tensor) encoded labels, sized [N, #classes].
"""
y = torch.eye(num_classes).cuda()
return y[labels].permute(0,3,1,2)
class DualTaskLoss(nn.Module):
def __init__(self, cuda=False):
super(DualTaskLoss, self).__init__()
self._cuda = cuda
return
def forward(self, input_logits, gts, ignore_pixel=255):
"""
:param input_logits: NxCxHxW
:param gt_semantic_masks: NxCxHxW
:return: final loss
"""
N, C, H, W = input_logits.shape
th = 1e-8 # 1e-10
eps = 1e-10
ignore_mask = (gts == ignore_pixel).detach()
input_logits = torch.where(ignore_mask.view(N, 1, H, W).expand(N, C, H, W),
torch.zeros(N,C,H,W).cuda(),
input_logits)
gt_semantic_masks = gts.detach()
gt_semantic_masks = torch.where(ignore_mask, torch.zeros(N,H,W).long().cuda(), gt_semantic_masks)
gt_semantic_masks = _one_hot_embedding(gt_semantic_masks, C).detach()
g = _gumbel_softmax_sample(input_logits.view(N, C, -1), tau=0.5)
g = g.reshape((N, C, H, W))
g = compute_grad_mag(g, cuda=self._cuda)
g_hat = compute_grad_mag(gt_semantic_masks, cuda=self._cuda)
g = g.view(N, -1)
#g_hat = g_hat.view(N, -1)
g_hat = g_hat.reshape(N, -1)
loss_ewise = F.l1_loss(g, g_hat, reduction='none', reduce=False)
p_plus_g_mask = (g >= th).detach().float()
loss_p_plus_g = torch.sum(loss_ewise * p_plus_g_mask) / (torch.sum(p_plus_g_mask) + eps)
p_plus_g_hat_mask = (g_hat >= th).detach().float()
loss_p_plus_g_hat = torch.sum(loss_ewise * p_plus_g_hat_mask) / (torch.sum(p_plus_g_hat_mask) + eps)
total_loss = 0.5 * loss_p_plus_g + 0.5 * loss_p_plus_g_hat
return total_loss
================================================
FILE: benchmarks/GSCNN-master/my_functionals/GatedSpatialConv.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import torch.nn as nn
import torch
import torch.nn.functional as F
from torch.nn.modules.conv import _ConvNd
from torch.nn.modules.utils import _pair
import numpy as np
import math
import network.mynn as mynn
import my_functionals.custom_functional as myF
class GatedSpatialConv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
padding=0, dilation=1, groups=1, bias=False):
"""
:param in_channels:
:param out_channels:
:param kernel_size:
:param stride:
:param padding:
:param dilation:
:param groups:
:param bias:
"""
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(GatedSpatialConv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, 'zeros')
self._gate_conv = nn.Sequential(
mynn.Norm2d(in_channels+1),
nn.Conv2d(in_channels+1, in_channels+1, 1),
nn.ReLU(),
nn.Conv2d(in_channels+1, 1, 1),
mynn.Norm2d(1),
nn.Sigmoid()
)
def forward(self, input_features, gating_features):
"""
:param input_features: [NxCxHxW] featuers comming from the shape branch (canny branch).
:param gating_features: [Nx1xHxW] features comming from the texture branch (resnet). Only one channel feature map.
:return:
"""
alphas = self._gate_conv(torch.cat([input_features, gating_features], dim=1))
input_features = (input_features * (alphas + 1))
return F.conv2d(input_features, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
def reset_parameters(self):
nn.init.xavier_normal_(self.weight)
if self.bias is not None:
nn.init.zeros_(self.bias)
class Conv2dPad(nn.Conv2d):
def forward(self, input):
return myF.conv2d_same(input,self.weight,self.groups)
class HighFrequencyGatedSpatialConv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
padding=0, dilation=1, groups=1, bias=False):
"""
:param in_channels:
:param out_channels:
:param kernel_size:
:param stride:
:param padding:
:param dilation:
:param groups:
:param bias:
"""
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(HighFrequencyGatedSpatialConv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias)
self._gate_conv = nn.Sequential(
mynn.Norm2d(in_channels+1),
nn.Conv2d(in_channels+1, in_channels+1, 1),
nn.ReLU(),
nn.Conv2d(in_channels+1, 1, 1),
mynn.Norm2d(1),
nn.Sigmoid()
)
kernel_size = 7
sigma = 3
x_cord = torch.arange(kernel_size).float()
x_grid = x_cord.repeat(kernel_size).view(kernel_size, kernel_size).float()
y_grid = x_grid.t().float()
xy_grid = torch.stack([x_grid, y_grid], dim=-1).float()
mean = (kernel_size - 1)/2.
variance = sigma**2.
gaussian_kernel = (1./(2.*math.pi*variance)) *\
torch.exp(
-torch.sum((xy_grid - mean)**2., dim=-1) /\
(2*variance)
)
gaussian_kernel = gaussian_kernel / torch.sum(gaussian_kernel)
gaussian_kernel = gaussian_kernel.view(1, 1, kernel_size, kernel_size)
gaussian_kernel = gaussian_kernel.repeat(in_channels, 1, 1, 1)
self.gaussian_filter = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, padding=3,
kernel_size=kernel_size, groups=in_channels, bias=False)
self.gaussian_filter.weight.data = gaussian_kernel
self.gaussian_filter.weight.requires_grad = False
self.cw = nn.Conv2d(in_channels * 2, in_channels, 1)
self.procdog = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
mynn.Norm2d(in_channels),
nn.Sigmoid()
)
def forward(self, input_features, gating_features):
"""
:param input_features: [NxCxHxW] featuers comming from the shape branch (canny branch).
:param gating_features: [Nx1xHxW] features comming from the texture branch (resnet). Only one channel feature map.
:return:
"""
n, c, h, w = input_features.size()
smooth_features = self.gaussian_filter(input_features)
dog_features = input_features - smooth_features
dog_features = self.cw(torch.cat((dog_features, input_features), dim=1))
alphas = self._gate_conv(torch.cat([input_features, gating_features], dim=1))
dog_features = dog_features * (alphas + 1)
return F.conv2d(dog_features, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
def reset_parameters(self):
nn.init.xavier_normal_(self.weight)
if self.bias is not None:
nn.init.zeros_(self.bias)
def t():
import matplotlib.pyplot as plt
canny_map_filters_in = 8
canny_map = np.random.normal(size=(1, canny_map_filters_in, 10, 10)) # NxCxHxW
resnet_map = np.random.normal(size=(1, 1, 10, 10)) # NxCxHxW
plt.imshow(canny_map[0, 0])
plt.show()
canny_map = torch.from_numpy(canny_map).float()
resnet_map = torch.from_numpy(resnet_map).float()
gconv = GatedSpatialConv2d(canny_map_filters_in, canny_map_filters_in,
kernel_size=3, stride=1, padding=1)
output_map = gconv(canny_map, resnet_map)
print('done')
if __name__ == "__main__":
t()
================================================
FILE: benchmarks/GSCNN-master/my_functionals/__init__.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
================================================
FILE: benchmarks/GSCNN-master/my_functionals/custom_functional.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import torch
import torch.nn.functional as F
from torchvision.transforms.functional import pad
import numpy as np
def calc_pad_same(in_siz, out_siz, stride, ksize):
"""Calculate same padding width.
Args:
ksize: kernel size [I, J].
Returns:
pad_: Actual padding width.
"""
return (out_siz - 1) * stride + ksize - in_siz
def conv2d_same(input, kernel, groups,bias=None,stride=1,padding=0,dilation=1):
n, c, h, w = input.shape
kout, ki_c_g, kh, kw = kernel.shape
pw = calc_pad_same(w, w, 1, kw)
ph = calc_pad_same(h, h, 1, kh)
pw_l = pw // 2
pw_r = pw - pw_l
ph_t = ph // 2
ph_b = ph - ph_t
input_ = F.pad(input, (pw_l, pw_r, ph_t, ph_b))
result = F.conv2d(input_, kernel, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
assert result.shape == input.shape
return result
def gradient_central_diff(input, cuda):
return input, input
kernel = [[1, 0, -1]]
kernel_t = 0.5 * torch.Tensor(kernel) * -1. # pytorch implements correlation instead of conv
if type(cuda) is int:
if cuda != -1:
kernel_t = kernel_t.cuda(device=cuda)
else:
if cuda is True:
kernel_t = kernel_t.cuda()
n, c, h, w = input.shape
x = conv2d_same(input, kernel_t.unsqueeze(0).unsqueeze(0).repeat([c, 1, 1, 1]), c)
y = conv2d_same(input, kernel_t.t().unsqueeze(0).unsqueeze(0).repeat([c, 1, 1, 1]), c)
return x, y
def compute_single_sided_diferences(o_x, o_y, input):
# n,c,h,w
#input = input.clone()
o_y[:, :, 0, :] = input[:, :, 1, :].clone() - input[:, :, 0, :].clone()
o_x[:, :, :, 0] = input[:, :, :, 1].clone() - input[:, :, :, 0].clone()
# --
o_y[:, :, -1, :] = input[:, :, -1, :].clone() - input[:, :, -2, :].clone()
o_x[:, :, :, -1] = input[:, :, :, -1].clone() - input[:, :, :, -2].clone()
return o_x, o_y
def numerical_gradients_2d(input, cuda=False):
"""
numerical gradients implementation over batches using torch group conv operator.
the single sided differences are re-computed later.
it matches np.gradient(image) with the difference than here output=x,y for an image while there output=y,x
:param input: N,C,H,W
:param cuda: whether or not use cuda
:return: X,Y
"""
n, c, h, w = input.shape
assert h > 1 and w > 1
x, y = gradient_central_diff(input, cuda)
return x, y
def convTri(input, r, cuda=False):
"""
Convolves an image by a 2D triangle filter (the 1D triangle filter f is
[1:r r+1 r:-1:1]/(r+1)^2, the 2D version is simply conv2(f,f'))
:param input:
:param r: integer filter radius
:param cuda: move the kernel to gpu
:return:
"""
if (r <= 1):
raise ValueError()
n, c, h, w = input.shape
return input
f = list(range(1, r + 1)) + [r + 1] + list(reversed(range(1, r + 1)))
kernel = torch.Tensor([f]) / (r + 1) ** 2
if type(cuda) is int:
if cuda != -1:
kernel = kernel.cuda(device=cuda)
else:
if cuda is True:
kernel = kernel.cuda()
# padding w
input_ = F.pad(input, (1, 1, 0, 0), mode='replicate')
input_ = F.pad(input_, (r, r, 0, 0), mode='reflect')
input_ = [input_[:, :, :, :r], input, input_[:, :, :, -r:]]
input_ = torch.cat(input_, 3)
t = input_
# padding h
input_ = F.pad(input_, (0, 0, 1, 1), mode='replicate')
input_ = F.pad(input_, (0, 0, r, r), mode='reflect')
input_ = [input_[:, :, :r, :], t, input_[:, :, -r:, :]]
input_ = torch.cat(input_, 2)
output = F.conv2d(input_,
kernel.unsqueeze(0).unsqueeze(0).repeat([c, 1, 1, 1]),
padding=0, groups=c)
output = F.conv2d(output,
kernel.t().unsqueeze(0).unsqueeze(0).repeat([c, 1, 1, 1]),
padding=0, groups=c)
return output
def compute_normal(E, cuda=False):
if torch.sum(torch.isnan(E)) != 0:
print('nans found here')
import ipdb;
ipdb.set_trace()
E_ = convTri(E, 4, cuda)
Ox, Oy = numerical_gradients_2d(E_, cuda)
Oxx, _ = numerical_gradients_2d(Ox, cuda)
Oxy, Oyy = numerical_gradients_2d(Oy, cuda)
aa = Oyy * torch.sign(-(Oxy + 1e-5)) / (Oxx + 1e-5)
t = torch.atan(aa)
O = torch.remainder(t, np.pi)
if torch.sum(torch.isnan(O)) != 0:
print('nans found here')
import ipdb;
ipdb.set_trace()
return O
def compute_normal_2(E, cuda=False):
if torch.sum(torch.isnan(E)) != 0:
print('nans found here')
import ipdb;
ipdb.set_trace()
E_ = convTri(E, 4, cuda)
Ox, Oy = numerical_gradients_2d(E_, cuda)
Oxx, _ = numerical_gradients_2d(Ox, cuda)
Oxy, Oyy = numerical_gradients_2d(Oy, cuda)
aa = Oyy * torch.sign(-(Oxy + 1e-5)) / (Oxx + 1e-5)
t = torch.atan(aa)
O = torch.remainder(t, np.pi)
if torch.sum(torch.isnan(O)) != 0:
print('nans found here')
import ipdb;
ipdb.set_trace()
return O, (Oyy, Oxx)
def compute_grad_mag(E, cuda=False):
E_ = convTri(E, 4, cuda)
Ox, Oy = numerical_gradients_2d(E_, cuda)
mag = torch.sqrt(torch.mul(Ox,Ox) + torch.mul(Oy,Oy) + 1e-6)
mag = mag / mag.max()
return mag
================================================
FILE: benchmarks/GSCNN-master/network/Resnet.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code Adapted from:
# https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
#
# BSD 3-Clause License
#
# Copyright (c) 2017,
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice, this
# list of conditions and the following disclaimer.
#
# * Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
#
# * Neither the name of the copyright holder nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
import network.mynn as mynn
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = mynn.Norm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = mynn.Norm2d(planes)
self.downsample = downsample
self.stride = stride
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = mynn.Norm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = mynn.Norm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = mynn.Norm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = mynn.Norm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
mynn.Norm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet18(pretrained=True, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=True, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=True, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=True, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=True, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
================================================
FILE: benchmarks/GSCNN-master/network/SEresnext.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code adapted from:
# https://github.com/Cadene/pretrained-models.pytorch
#
# BSD 3-Clause License
#
# Copyright (c) 2017, Remi Cadene
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice, this
# list of conditions and the following disclaimer.
#
# * Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
#
# * Neither the name of the copyright holder nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
from collections import OrderedDict
import math
import network.mynn as mynn
import torch.nn as nn
from torch.utils import model_zoo
__all__ = ['SENet', 'senet154', 'se_resnet50', 'se_resnet101', 'se_resnet152',
'se_resnext50_32x4d', 'se_resnext101_32x4d']
pretrained_settings = {
'se_resnext50_32x4d': {
'imagenet': {
'url': 'http://data.lip6.fr/cadene/pretrainedmodels/se_resnext50_32x4d-a260b3a4.pth',
'input_space': 'RGB',
'input_size': [3, 224, 224],
'input_range': [0, 1],
'mean': [0.485, 0.456, 0.406],
'std': [0.229, 0.224, 0.225],
'num_classes': 1000
}
},
'se_resnext101_32x4d': {
'imagenet': {
'url': 'http://data.lip6.fr/cadene/pretrainedmodels/se_resnext101_32x4d-3b2fe3d8.pth',
'input_space': 'RGB',
'input_size': [3, 224, 224],
'input_range': [0, 1],
'mean': [0.485, 0.456, 0.406],
'std': [0.229, 0.224, 0.225],
'num_classes': 1000
}
},
}
class SEModule(nn.Module):
def __init__(self, channels, reduction):
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1,
padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1,
padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
module_input = x
x = self.avg_pool(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return module_input * x
class Bottleneck(nn.Module):
"""
Base class for bottlenecks that implements `forward()` method.
"""
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = self.se_module(out) + residual
out = self.relu(out)
return out
class SEBottleneck(Bottleneck):
"""
Bottleneck for SENet154.
"""
expansion = 4
def __init__(self, inplanes, planes, groups, reduction, stride=1,
downsample=None):
super(SEBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes * 2, kernel_size=1, bias=False)
self.bn1 = mynn.Norm2d(planes * 2)
self.conv2 = nn.Conv2d(planes * 2, planes * 4, kernel_size=3,
stride=stride, padding=1, groups=groups,
bias=False)
self.bn2 = mynn.Norm2d(planes * 4)
self.conv3 = nn.Conv2d(planes * 4, planes * 4, kernel_size=1,
bias=False)
self.bn3 = mynn.Norm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se_module = SEModule(planes * 4, reduction=reduction)
self.downsample = downsample
self.stride = stride
class SEResNetBottleneck(Bottleneck):
"""
ResNet bottleneck with a Squeeze-and-Excitation module. It follows Caffe
implementation and uses `stride=stride` in `conv1` and not in `conv2`
(the latter is used in the torchvision implementation of ResNet).
"""
expansion = 4
def __init__(self, inplanes, planes, groups, reduction, stride=1,
downsample=None):
super(SEResNetBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False,
stride=stride)
self.bn1 = mynn.Norm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1,
groups=groups, bias=False)
self.bn2 = mynn.Norm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = mynn.Norm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se_module = SEModule(planes * 4, reduction=reduction)
self.downsample = downsample
self.stride = stride
class SEResNeXtBottleneck(Bottleneck):
"""
ResNeXt bottleneck type C with a Squeeze-and-Excitation module.
"""
expansion = 4
def __init__(self, inplanes, planes, groups, reduction, stride=1,
downsample=None, base_width=4):
super(SEResNeXtBottleneck, self).__init__()
width = math.floor(planes * (base_width / 64)) * groups
self.conv1 = nn.Conv2d(inplanes, width, kernel_size=1, bias=False,
stride=1)
self.bn1 = mynn.Norm2d(width)
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride,
padding=1, groups=groups, bias=False)
self.bn2 = mynn.Norm2d(width)
self.conv3 = nn.Conv2d(width, planes * 4, kernel_size=1, bias=False)
self.bn3 = mynn.Norm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se_module = SEModule(planes * 4, reduction=reduction)
self.downsample = downsample
self.stride = stride
class SENet(nn.Module):
def __init__(self, block, layers, groups, reduction, dropout_p=0.2,
inplanes=128, input_3x3=True, downsample_kernel_size=3,
downsample_padding=1, num_classes=1000):
"""
Parameters
----------
block (nn.Module): Bottleneck class.
- For SENet154: SEBottleneck
- For SE-ResNet models: SEResNetBottleneck
- For SE-ResNeXt models: SEResNeXtBottleneck
layers (list of ints): Number of residual blocks for 4 layers of the
network (layer1...layer4).
groups (int): Number of groups for the 3x3 convolution in each
bottleneck block.
- For SENet154: 64
- For SE-ResNet models: 1
- For SE-ResNeXt models: 32
reduction (int): Reduction ratio for Squeeze-and-Excitation modules.
- For all models: 16
dropout_p (float or None): Drop probability for the Dropout layer.
If `None` the Dropout layer is not used.
- For SENet154: 0.2
- For SE-ResNet models: None
- For SE-ResNeXt models: None
inplanes (int): Number of input channels for layer1.
- For SENet154: 128
- For SE-ResNet models: 64
- For SE-ResNeXt models: 64
input_3x3 (bool): If `True`, use three 3x3 convolutions instead of
a single 7x7 convolution in layer0.
- For SENet154: True
- For SE-ResNet models: False
- For SE-ResNeXt models: False
downsample_kernel_size (int): Kernel size for downsampling convolutions
in layer2, layer3 and layer4.
- For SENet154: 3
- For SE-ResNet models: 1
- For SE-ResNeXt models: 1
downsample_padding (int): Padding for downsampling convolutions in
layer2, layer3 and layer4.
- For SENet154: 1
- For SE-ResNet models: 0
- For SE-ResNeXt models: 0
num_classes (int): Number of outputs in `last_linear` layer.
- For all models: 1000
"""
super(SENet, self).__init__()
self.inplanes = inplanes
if input_3x3:
layer0_modules = [
('conv1', nn.Conv2d(3, 64, 3, stride=2, padding=1,
bias=False)),
('bn1', mynn.Norm2d(64)),
('relu1', nn.ReLU(inplace=True)),
('conv2', nn.Conv2d(64, 64, 3, stride=1, padding=1,
bias=False)),
('bn2', mynn.Norm2d(64)),
('relu2', nn.ReLU(inplace=True)),
('conv3', nn.Conv2d(64, inplanes, 3, stride=1, padding=1,
bias=False)),
('bn3', mynn.Norm2d(inplanes)),
('relu3', nn.ReLU(inplace=True)),
]
else:
layer0_modules = [
('conv1', nn.Conv2d(3, inplanes, kernel_size=7, stride=2,
padding=3, bias=False)),
('bn1', mynn.Norm2d(inplanes)),
('relu1', nn.ReLU(inplace=True)),
]
# To preserve compatibility with Caffe weights `ceil_mode=True`
# is used instead of `padding=1`.
layer0_modules.append(('pool', nn.MaxPool2d(3, stride=2,
ceil_mode=True)))
self.layer0 = nn.Sequential(OrderedDict(layer0_modules))
self.layer1 = self._make_layer(
block,
planes=64,
blocks=layers[0],
groups=groups,
reduction=reduction,
downsample_kernel_size=1,
downsample_padding=0
)
self.layer2 = self._make_layer(
block,
planes=128,
blocks=layers[1],
stride=2,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.layer3 = self._make_layer(
block,
planes=256,
blocks=layers[2],
stride=1,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.layer4 = self._make_layer(
block,
planes=512,
blocks=layers[3],
stride=1,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.avg_pool = nn.AvgPool2d(7, stride=1)
self.dropout = nn.Dropout(dropout_p) if dropout_p is not None else None
self.last_linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, blocks, groups, reduction, stride=1,
downsample_kernel_size=1, downsample_padding=0):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=downsample_kernel_size, stride=stride,
padding=downsample_padding, bias=False),
mynn.Norm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, groups, reduction, stride,
downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, groups, reduction))
return nn.Sequential(*layers)
def features(self, x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
def logits(self, x):
x = self.avg_pool(x)
if self.dropout is not None:
x = self.dropout(x)
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x
def forward(self, x):
x = self.features(x)
x = self.logits(x)
return x
def initialize_pretrained_model(model, num_classes, settings):
assert num_classes == settings['num_classes'], \
'num_classes should be {}, but is {}'.format(
settings['num_classes'], num_classes)
weights = model_zoo.load_url(settings['url'])
model.load_state_dict(weights)
model.input_space = settings['input_space']
model.input_size = settings['input_size']
model.input_range = settings['input_range']
model.mean = settings['mean']
model.std = settings['std']
def se_resnext50_32x4d(num_classes=1000):
model = SENet(SEResNeXtBottleneck, [3, 4, 6, 3], groups=32, reduction=16,
dropout_p=None, inplanes=64, input_3x3=False,
downsample_kernel_size=1, downsample_padding=0,
num_classes=num_classes)
settings = pretrained_settings['se_resnext50_32x4d']['imagenet']
initialize_pretrained_model(model, num_classes, settings)
return model
def se_resnext101_32x4d(num_classes=1000):
model = SENet(SEResNeXtBottleneck, [3, 4, 23, 3], groups=32, reduction=16,
dropout_p=None, inplanes=64, input_3x3=False,
downsample_kernel_size=1, downsample_padding=0,
num_classes=num_classes)
settings = pretrained_settings['se_resnext101_32x4d']['imagenet']
initialize_pretrained_model(model, num_classes, settings)
return model
================================================
FILE: benchmarks/GSCNN-master/network/__init__.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import importlib
import torch
import logging
def get_net(args, criterion):
net = get_model(network=args.arch, num_classes=args.dataset_cls.num_classes,
criterion=criterion, trunk=args.trunk)
num_params = sum([param.nelement() for param in net.parameters()])
logging.info('Model params = {:2.1f}M'.format(num_params / 1000000))
#net = net
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = torch.nn.DataParallel(net).to(device)
if args.checkpoint_path:
print(f"Loading state_dict from {args.checkpoint_path}")
net.load_state_dict(torch.load(args.checkpoint_path)["state_dict"])
return net
def get_model(network, num_classes, criterion, trunk):
module = network[:network.rfind('.')]
model = network[network.rfind('.')+1:]
mod = importlib.import_module(module)
net_func = getattr(mod, model)
net = net_func(num_classes=num_classes, trunk=trunk, criterion=criterion)
return net
================================================
FILE: benchmarks/GSCNN-master/network/gscnn.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code Adapted from:
# https://github.com/sthalles/deeplab_v3
#
# MIT License
#
# Copyright (c) 2018 Thalles Santos Silva
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
"""
import torch
import torch.nn.functional as F
from torch import nn
from network import SEresnext
from network import Resnet
from network.wider_resnet import wider_resnet38_a2
from config import cfg
from network.mynn import initialize_weights, Norm2d
from torch.autograd import Variable
from my_functionals import GatedSpatialConv as gsc
import cv2
import numpy as np
class Crop(nn.Module):
def __init__(self, axis, offset):
super(Crop, self).__init__()
self.axis = axis
self.offset = offset
def forward(self, x, ref):
"""
:param x: input layer
:param ref: reference usually data in
:return:
"""
for axis in range(self.axis, x.dim()):
ref_size = ref.size(axis)
indices = torch.arange(self.offset, self.offset + ref_size).long()
indices = x.data.new().resize_(indices.size()).copy_(indices).long()
x = x.index_select(axis, Variable(indices))
return x
class MyIdentity(nn.Module):
def __init__(self, axis, offset):
super(MyIdentity, self).__init__()
self.axis = axis
self.offset = offset
def forward(self, x, ref):
"""
:param x: input layer
:param ref: reference usually data in
:return:
"""
return x
class SideOutputCrop(nn.Module):
"""
This is the original implementation ConvTranspose2d (fixed) and crops
"""
def __init__(self, num_output, kernel_sz=None, stride=None, upconv_pad=0, do_crops=True):
super(SideOutputCrop, self).__init__()
self._do_crops = do_crops
self.conv = nn.Conv2d(num_output, out_channels=1, kernel_size=1, stride=1, padding=0, bias=True)
if kernel_sz is not None:
self.upsample = True
self.upsampled = nn.ConvTranspose2d(1, out_channels=1, kernel_size=kernel_sz, stride=stride,
padding=upconv_pad,
bias=False)
##doing crops
if self._do_crops:
self.crops = Crop(2, offset=kernel_sz // 4)
else:
self.crops = MyIdentity(None, None)
else:
self.upsample = False
def forward(self, res, reference=None):
side_output = self.conv(res)
if self.upsample:
side_output = self.upsampled(side_output)
side_output = self.crops(side_output, reference)
return side_output
class _AtrousSpatialPyramidPoolingModule(nn.Module):
'''
operations performed:
1x1 x depth
3x3 x depth dilation 6
3x3 x depth dilation 12
3x3 x depth dilation 18
image pooling
concatenate all together
Final 1x1 conv
'''
def __init__(self, in_dim, reduction_dim=256, output_stride=16, rates=[6, 12, 18]):
super(_AtrousSpatialPyramidPoolingModule, self).__init__()
# Check if we are using distributed BN and use the nn from encoding.nn
# library rather than using standard pytorch.nn
if output_stride == 8:
rates = [2 * r for r in rates]
elif output_stride == 16:
pass
else:
raise 'output stride of {} not supported'.format(output_stride)
self.features = []
# 1x1
self.features.append(
nn.Sequential(nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
Norm2d(reduction_dim), nn.ReLU(inplace=True)))
# other rates
for r in rates:
self.features.append(nn.Sequential(
nn.Conv2d(in_dim, reduction_dim, kernel_size=3,
dilation=r, padding=r, bias=False),
Norm2d(reduction_dim),
nn.ReLU(inplace=True)
))
self.features = torch.nn.ModuleList(self.features)
# img level features
self.img_pooling = nn.AdaptiveAvgPool2d(1)
self.img_conv = nn.Sequential(
nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
Norm2d(reduction_dim), nn.ReLU(inplace=True))
self.edge_conv = nn.Sequential(
nn.Conv2d(1, reduction_dim, kernel_size=1, bias=False),
Norm2d(reduction_dim), nn.ReLU(inplace=True))
def forward(self, x, edge):
x_size = x.size()
img_features = self.img_pooling(x)
img_features = self.img_conv(img_features)
img_features = F.interpolate(img_features, x_size[2:],
mode='bilinear',align_corners=True)
out = img_features
edge_features = F.interpolate(edge, x_size[2:],
mode='bilinear',align_corners=True)
edge_features = self.edge_conv(edge_features)
out = torch.cat((out, edge_features), 1)
for f in self.features:
y = f(x)
out = torch.cat((out, y), 1)
return out
class GSCNN(nn.Module):
'''
Wide_resnet version of DeepLabV3
mod1
pool2
mod2 str2
pool3
mod3-7
structure: [3, 3, 6, 3, 1, 1]
channels = [(128, 128), (256, 256), (512, 512), (512, 1024), (512, 1024, 2048),
(1024, 2048, 4096)]
'''
def __init__(self, num_classes, trunk=None, criterion=None):
super(GSCNN, self).__init__()
self.criterion = criterion
self.num_classes = num_classes
wide_resnet = wider_resnet38_a2(classes=1000, dilation=True)
wide_resnet = torch.nn.DataParallel(wide_resnet)
try:
checkpoint = torch.load('./network/pretrained_models/wider_resnet38.pth.tar', map_location='cpu')
wide_resnet.load_state_dict(checkpoint['state_dict'])
del checkpoint
except:
print("Please download the ImageNet weights of WideResNet38 in our repo to ./pretrained_models/wider_resnet38.pth.tar.")
raise RuntimeError("=====================Could not load ImageNet weights of WideResNet38 network.=======================")
wide_resnet = wide_resnet.module
self.mod1 = wide_resnet.mod1
self.mod2 = wide_resnet.mod2
self.mod3 = wide_resnet.mod3
self.mod4 = wide_resnet.mod4
self.mod5 = wide_resnet.mod5
self.mod6 = wide_resnet.mod6
self.mod7 = wide_resnet.mod7
self.pool2 = wide_resnet.pool2
self.pool3 = wide_resnet.pool3
self.interpolate = F.interpolate
del wide_resnet
self.dsn1 = nn.Conv2d(64, 1, 1)
self.dsn3 = nn.Conv2d(256, 1, 1)
self.dsn4 = nn.Conv2d(512, 1, 1)
self.dsn7 = nn.Conv2d(4096, 1, 1)
self.res1 = Resnet.BasicBlock(64, 64, stride=1, downsample=None)
self.d1 = nn.Conv2d(64, 32, 1)
self.res2 = Resnet.BasicBlock(32, 32, stride=1, downsample=None)
self.d2 = nn.Conv2d(32, 16, 1)
self.res3 = Resnet.BasicBlock(16, 16, stride=1, downsample=None)
self.d3 = nn.Conv2d(16, 8, 1)
self.fuse = nn.Conv2d(8, 1, kernel_size=1, padding=0, bias=False)
self.cw = nn.Conv2d(2, 1, kernel_size=1, padding=0, bias=False)
self.gate1 = gsc.GatedSpatialConv2d(32, 32)
self.gate2 = gsc.GatedSpatialConv2d(16, 16)
self.gate3 = gsc.GatedSpatialConv2d(8, 8)
self.aspp = _AtrousSpatialPyramidPoolingModule(4096, 256,
output_stride=8)
self.bot_fine = nn.Conv2d(128, 48, kernel_size=1, bias=False)
self.bot_aspp = nn.Conv2d(1280 + 256, 256, kernel_size=1, bias=False)
self.final_seg = nn.Sequential(
nn.Conv2d(256 + 48, 256, kernel_size=3, padding=1, bias=False),
Norm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1, bias=False),
Norm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, kernel_size=1, bias=False))
self.sigmoid = nn.Sigmoid()
initialize_weights(self.final_seg)
def forward(self, inp, gts=None):
x_size = inp.size()
# res 1
m1 = self.mod1(inp)
# res 2
m2 = self.mod2(self.pool2(m1))
# res 3
m3 = self.mod3(self.pool3(m2))
# res 4-7
m4 = self.mod4(m3)
m5 = self.mod5(m4)
m6 = self.mod6(m5)
m7 = self.mod7(m6)
s3 = F.interpolate(self.dsn3(m3), x_size[2:],
mode='bilinear', align_corners=True)
s4 = F.interpolate(self.dsn4(m4), x_size[2:],
mode='bilinear', align_corners=True)
s7 = F.interpolate(self.dsn7(m7), x_size[2:],
mode='bilinear', align_corners=True)
m1f = F.interpolate(m1, x_size[2:], mode='bilinear', align_corners=True)
im_arr = inp.cpu().numpy().transpose((0,2,3,1)).astype(np.uint8)
canny = np.zeros((x_size[0], 1, x_size[2], x_size[3]))
for i in range(x_size[0]):
canny[i] = cv2.Canny(im_arr[i],10,100)
canny = torch.from_numpy(canny).cuda().float()
cs = self.res1(m1f)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
cs = self.d1(cs)
cs = self.gate1(cs, s3)
cs = self.res2(cs)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
cs = self.d2(cs)
cs = self.gate2(cs, s4)
cs = self.res3(cs)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
cs = self.d3(cs)
cs = self.gate3(cs, s7)
cs = self.fuse(cs)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
edge_out = self.sigmoid(cs)
cat = torch.cat((edge_out, canny), dim=1)
acts = self.cw(cat)
acts = self.sigmoid(acts)
# aspp
x = self.aspp(m7, acts)
dec0_up = self.bot_aspp(x)
dec0_fine = self.bot_fine(m2)
dec0_up = self.interpolate(dec0_up, m2.size()[2:], mode='bilinear',align_corners=True)
dec0 = [dec0_fine, dec0_up]
dec0 = torch.cat(dec0, 1)
dec1 = self.final_seg(dec0)
seg_out = self.interpolate(dec1, x_size[2:], mode='bilinear')
if self.training:
return self.criterion((seg_out, edge_out), gts)
else:
return seg_out, edge_out
================================================
FILE: benchmarks/GSCNN-master/network/mynn.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
from config import cfg
import torch.nn as nn
from math import sqrt
import torch
from torch.autograd.function import InplaceFunction
from itertools import repeat
from torch.nn.modules import Module
from torch.utils.checkpoint import checkpoint
def Norm2d(in_channels):
"""
Custom Norm Function to allow flexible switching
"""
layer = getattr(cfg.MODEL,'BNFUNC')
normalizationLayer = layer(in_channels)
return normalizationLayer
def initialize_weights(*models):
for model in models:
for module in model.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
nn.init.kaiming_normal(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
================================================
FILE: benchmarks/GSCNN-master/network/wider_resnet.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code adapted from:
# https://github.com/mapillary/inplace_abn/
#
# BSD 3-Clause License
#
# Copyright (c) 2017, mapillary
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice, this
# list of conditions and the following disclaimer.
#
# * Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
#
# * Neither the name of the copyright holder nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
import sys
from collections import OrderedDict
from functools import partial
import torch.nn as nn
import torch
import network.mynn as mynn
def bnrelu(channels):
return nn.Sequential(mynn.Norm2d(channels),
nn.ReLU(inplace=True))
class GlobalAvgPool2d(nn.Module):
def __init__(self):
"""Global average pooling over the input's spatial dimensions"""
super(GlobalAvgPool2d, self).__init__()
def forward(self, inputs):
in_size = inputs.size()
return inputs.view((in_size[0], in_size[1], -1)).mean(dim=2)
class IdentityResidualBlock(nn.Module):
def __init__(self,
in_channels,
channels,
stride=1,
dilation=1,
groups=1,
norm_act=bnrelu,
dropout=None,
dist_bn=False
):
"""Configurable identity-mapping residual block
Parameters
----------
in_channels : int
Number of input channels.
channels : list of int
Number of channels in the internal feature maps.
Can either have two or three elements: if three construct
a residual block with two `3 x 3` convolutions,
otherwise construct a bottleneck block with `1 x 1`, then
`3 x 3` then `1 x 1` convolutions.
stride : int
Stride of the first `3 x 3` convolution
dilation : int
Dilation to apply to the `3 x 3` convolutions.
groups : int
Number of convolution groups.
This is used to create ResNeXt-style blocks and is only compatible with
bottleneck blocks.
norm_act : callable
Function to create normalization / activation Module.
dropout: callable
Function to create Dropout Module.
dist_bn: Boolean
A variable to enable or disable use of distributed BN
"""
super(IdentityResidualBlock, self).__init__()
self.dist_bn = dist_bn
# Check if we are using distributed BN and use the nn from encoding.nn
# library rather than using standard pytorch.nn
# Check parameters for inconsistencies
if len(channels) != 2 and len(channels) != 3:
raise ValueError("channels must contain either two or three values")
if len(channels) == 2 and groups != 1:
raise ValueError("groups > 1 are only valid if len(channels) == 3")
is_bottleneck = len(channels) == 3
need_proj_conv = stride != 1 or in_channels != channels[-1]
self.bn1 = norm_act(in_channels)
if not is_bottleneck:
layers = [
("conv1", nn.Conv2d(in_channels,
channels[0],
3,
stride=stride,
padding=dilation,
bias=False,
dilation=dilation)),
("bn2", norm_act(channels[0])),
("conv2", nn.Conv2d(channels[0], channels[1],
3,
stride=1,
padding=dilation,
bias=False,
dilation=dilation))
]
if dropout is not None:
layers = layers[0:2] + [("dropout", dropout())] + layers[2:]
else:
layers = [
("conv1",
nn.Conv2d(in_channels,
channels[0],
1,
stride=stride,
padding=0,
bias=False)),
("bn2", norm_act(channels[0])),
("conv2", nn.Conv2d(channels[0],
channels[1],
3, stride=1,
padding=dilation, bias=False,
groups=groups,
dilation=dilation)),
("bn3", norm_act(channels[1])),
("conv3", nn.Conv2d(channels[1], channels[2],
1, stride=1, padding=0, bias=False))
]
if dropout is not None:
layers = layers[0:4] + [("dropout", dropout())] + layers[4:]
self.convs = nn.Sequential(OrderedDict(layers))
if need_proj_conv:
self.proj_conv = nn.Conv2d(
in_channels, channels[-1], 1, stride=stride, padding=0, bias=False)
def forward(self, x):
"""
This is the standard forward function for non-distributed batch norm
"""
if hasattr(self, "proj_conv"):
bn1 = self.bn1(x)
shortcut = self.proj_conv(bn1)
else:
shortcut = x.clone()
bn1 = self.bn1(x)
out = self.convs(bn1)
out.add_(shortcut)
return out
class WiderResNet(nn.Module):
def __init__(self,
structure,
norm_act=bnrelu,
classes=0
):
"""Wider ResNet with pre-activation (identity mapping) blocks
Parameters
----------
structure : list of int
Number of residual blocks in each of the six modules of the network.
norm_act : callable
Function to create normalization / activation Module.
classes : int
If not `0` also include global average pooling and \
a fully-connected layer with `classes` outputs at the end
of the network.
"""
super(WiderResNet, self).__init__()
self.structure = structure
if len(structure) != 6:
raise ValueError("Expected a structure with six values")
# Initial layers
self.mod1 = nn.Sequential(OrderedDict([
("conv1", nn.Conv2d(3, 64, 3, stride=1, padding=1, bias=False))
]))
# Groups of residual blocks
in_channels = 64
channels = [(128, 128), (256, 256), (512, 512), (512, 1024),
(512, 1024, 2048), (1024, 2048, 4096)]
for mod_id, num in enumerate(structure):
# Create blocks for module
blocks = []
for block_id in range(num):
blocks.append((
"block%d" % (block_id + 1),
IdentityResidualBlock(in_channels, channels[mod_id],
norm_act=norm_act)
))
# Update channels and p_keep
in_channels = channels[mod_id][-1]
# Create module
if mod_id <= 4:
self.add_module("pool%d" %
(mod_id + 2), nn.MaxPool2d(3, stride=2, padding=1))
self.add_module("mod%d" % (mod_id + 2), nn.Sequential(OrderedDict(blocks)))
# Pooling and predictor
self.bn_out = norm_act(in_channels)
if classes != 0:
self.classifier = nn.Sequential(OrderedDict([
("avg_pool", GlobalAvgPool2d()),
("fc", nn.Linear(in_channels, classes))
]))
def forward(self, img):
out = self.mod1(img)
out = self.mod2(self.pool2(out))
out = self.mod3(self.pool3(out))
out = self.mod4(self.pool4(out))
out = self.mod5(self.pool5(out))
out = self.mod6(self.pool6(out))
out = self.mod7(out)
out = self.bn_out(out)
if hasattr(self, "classifier"):
out = self.classifier(out)
return out
class WiderResNetA2(nn.Module):
def __init__(self,
structure,
norm_act=bnrelu,
classes=0,
dilation=False,
dist_bn=False
):
"""Wider ResNet with pre-activation (identity mapping) blocks
This variant uses down-sampling by max-pooling in the first two blocks and \
by strided convolution in the others.
Parameters
----------
structure : list of int
Number of residual blocks in each of the six modules of the network.
norm_act : callable
Function to create normalization / activation Module.
classes : int
If not `0` also include global average pooling and a fully-connected layer
\with `classes` outputs at the end
of the network.
dilation : bool
If `True` apply dilation to the last three modules and change the
\down-sampling factor from 32 to 8.
"""
super(WiderResNetA2, self).__init__()
self.dist_bn = dist_bn
# If using distributed batch norm, use the encoding.nn as oppose to torch.nn
nn.Dropout = nn.Dropout2d
norm_act = bnrelu
self.structure = structure
self.dilation = dilation
if len(structure) != 6:
raise ValueError("Expected a structure with six values")
# Initial layers
self.mod1 = torch.nn.Sequential(OrderedDict([
("conv1", nn.Conv2d(3, 64, 3, stride=1, padding=1, bias=False))
]))
# Groups of residual blocks
in_channels = 64
channels = [(128, 128), (256, 256), (512, 512), (512, 1024), (512, 1024, 2048),
(1024, 2048, 4096)]
for mod_id, num in enumerate(structure):
# Create blocks for module
blocks = []
for block_id in range(num):
if not dilation:
dil = 1
stride = 2 if block_id == 0 and 2 <= mod_id <= 4 else 1
else:
if mod_id == 3:
dil = 2
elif mod_id > 3:
dil = 4
else:
dil = 1
stride = 2 if block_id == 0 and mod_id == 2 else 1
if mod_id == 4:
drop = partial(nn.Dropout, p=0.3)
elif mod_id == 5:
drop = partial(nn.Dropout, p=0.5)
else:
drop = None
blocks.append((
"block%d" % (block_id + 1),
IdentityResidualBlock(in_channels,
channels[mod_id], norm_act=norm_act,
stride=stride, dilation=dil,
dropout=drop, dist_bn=self.dist_bn)
))
# Update channels and p_keep
in_channels = channels[mod_id][-1]
# Create module
if mod_id < 2:
self.add_module("pool%d" %
(mod_id + 2), nn.MaxPool2d(3, stride=2, padding=1))
self.add_module("mod%d" % (mod_id + 2), nn.Sequential(OrderedDict(blocks)))
# Pooling and predictor
self.bn_out = norm_act(in_channels)
if classes != 0:
self.classifier = nn.Sequential(OrderedDict([
("avg_pool", GlobalAvgPool2d()),
("fc", nn.Linear(in_channels, classes))
]))
def forward(self, img):
out = self.mod1(img)
out = self.mod2(self.pool2(out))
out = self.mod3(self.pool3(out))
out = self.mod4(out)
out = self.mod5(out)
out = self.mod6(out)
out = self.mod7(out)
out = self.bn_out(out)
if hasattr(self, "classifier"):
return self.classifier(out)
else:
return out
_NETS = {
"16": {"structure": [1, 1, 1, 1, 1, 1]},
"20": {"structure": [1, 1, 1, 3, 1, 1]},
"38": {"structure": [3, 3, 6, 3, 1, 1]},
}
__all__ = []
for name, params in _NETS.items():
net_name = "wider_resnet" + name
setattr(sys.modules[__name__], net_name, partial(WiderResNet, **params))
__all__.append(net_name)
for name, params in _NETS.items():
net_name = "wider_resnet" + name + "_a2"
setattr(sys.modules[__name__], net_name, partial(WiderResNetA2, **params))
__all__.append(net_name)
================================================
FILE: benchmarks/GSCNN-master/optimizer.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
import torch
from torch import optim
import math
import logging
from config import cfg
def get_optimizer(args, net):
param_groups = net.parameters()
if args.sgd:
optimizer = optim.SGD(param_groups,
lr=args.lr,
weight_decay=args.weight_decay,
momentum=args.momentum,
nesterov=False)
elif args.adam:
amsgrad=False
if args.amsgrad:
amsgrad=True
optimizer = optim.Adam(param_groups,
lr=args.lr,
weight_decay=args.weight_decay,
amsgrad=amsgrad
)
else:
raise ('Not a valid optimizer')
if args.lr_schedule == 'poly':
lambda1 = lambda epoch: math.pow(1 - epoch / args.max_epoch, args.poly_exp)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
else:
raise ValueError('unknown lr schedule {}'.format(args.lr_schedule))
if args.snapshot:
logging.info('Loading weights from model {}'.format(args.snapshot))
net, optimizer = restore_snapshot(args, net, optimizer, args.snapshot)
else:
logging.info('Loaded weights from IMGNET classifier')
return optimizer, scheduler
def restore_snapshot(args, net, optimizer, snapshot):
checkpoint = torch.load(snapshot, map_location=torch.device('cpu'))
logging.info("Load Compelete")
if args.sgd_finetuned:
print('skipping load optimizer')
else:
if 'optimizer' in checkpoint and args.restore_optimizer:
optimizer.load_state_dict(checkpoint['optimizer'])
if 'state_dict' in checkpoint:
net = forgiving_state_restore(net, checkpoint['state_dict'])
else:
net = forgiving_state_restore(net, checkpoint)
return net, optimizer
def forgiving_state_restore(net, loaded_dict):
# Handle partial loading when some tensors don't match up in size.
# Because we want to use models that were trained off a different
# number of classes.
net_state_dict = net.state_dict()
new_loaded_dict = {}
for k in net_state_dict:
if k in loaded_dict and net_state_dict[k].size() == loaded_dict[k].size():
new_loaded_dict[k] = loaded_dict[k]
else:
logging.info('Skipped loading parameter {}'.format(k))
net_state_dict.update(new_loaded_dict)
net.load_state_dict(net_state_dict)
return net
================================================
FILE: benchmarks/GSCNN-master/run_gscnn.sh
================================================
#!/bin/bash
export PYTHONPATH=/home/usl/Code/Peng/data_collection/benchmarks/GSCNN-master/:$PYTHONPATH
echo $PYTHONPATH
python train.py --dataset rellis --bs_mult 3 --lr 0.001 --exp final
================================================
FILE: benchmarks/GSCNN-master/run_gscnn_eval.sh
================================================
#!/bin/bash
export PYTHONPATH=/home/usl/Code/PengJiang/RELLIS-3D/benchmarks/GSCNN-master/:$PYTHONPATH
echo $PYTHONPATH
python train.py --dataset rellis --bs_mult 3 --lr 0.001 --exp final \
--checkpoint_path /home/usl/Downloads/best_epoch_84_mean-iu_0.46839.pth \
--mode test \
--viz \
--data-cfg /home/usl/Code/Peng/data_collection/benchmarks/SalsaNext/train/tasks/semantic/config/labels/rellis.yaml \
--test_sv_path /home/usl/Datasets/prediction
================================================
FILE: benchmarks/GSCNN-master/train.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
"""
from __future__ import absolute_import
from __future__ import division
import argparse
from functools import partial
from config import cfg, assert_and_infer_cfg
import logging
import math
import os
import sys
import torch
import numpy as np
import yaml
from utils.misc import AverageMeter, prep_experiment, evaluate_eval, fast_hist
from utils.f_boundary import eval_mask_boundary
import datasets
import loss
import network
import optimizer
from tqdm import tqdm
from PIL import Image
# Argument Parser
parser = argparse.ArgumentParser(description='GSCNN')
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--arch', type=str, default='network.gscnn.GSCNN')
parser.add_argument('--dataset', type=str, default='cityscapes')
parser.add_argument('--cv', type=int, default=0,
help='cross validation split')
parser.add_argument('--joint_edgeseg_loss', action='store_true', default=True,
help='joint loss')
parser.add_argument('--img_wt_loss', action='store_true', default=False,
help='per-image class-weighted loss')
parser.add_argument('--batch_weighting', action='store_true', default=False,
help='Batch weighting for class')
parser.add_argument('--eval_thresholds', type=str, default='0.0005,0.001875,0.00375,0.005',
help='Thresholds for boundary evaluation')
parser.add_argument('--rescale', type=float, default=1.0,
help='Rescaled LR Rate')
parser.add_argument('--repoly', type=float, default=1.5,
help='Rescaled Poly')
parser.add_argument('--edge_weight', type=float, default=1.0,
help='Edge loss weight for joint loss')
parser.add_argument('--seg_weight', type=float, default=1.0,
help='Segmentation loss weight for joint loss')
parser.add_argument('--att_weight', type=float, default=1.0,
help='Attention loss weight for joint loss')
parser.add_argument('--dual_weight', type=float, default=1.0,
help='Dual loss weight for joint loss')
parser.add_argument('--evaluate', action='store_true', default=False)
parser.add_argument("--local_rank", default=0, type=int)
parser.add_argument('--sgd', action='store_true', default=True)
parser.add_argument('--sgd_finetuned',action='store_true',default=False)
parser.add_argument('--adam', action='store_true', default=False)
parser.add_argument('--amsgrad', action='store_true', default=False)
parser.add_argument('--trunk', type=str, default='resnet101',
help='trunk model, can be: resnet101 (default), resnet50')
parser.add_argument('--max_epoch', type=int, default=175)
parser.add_argument('--start_epoch', type=int, default=0)
parser.add_argument('--color_aug', type=float,
default=0.25, help='level of color augmentation')
parser.add_argument('--rotate', type=float,
default=0, help='rotation')
parser.add_argument('--gblur', action='store_true', default=True)
parser.add_argument('--bblur', action='store_true', default=False)
parser.add_argument('--lr_schedule', type=str, default='poly',
help='name of lr schedule: poly')
parser.add_argument('--poly_exp', type=float, default=1.0,
help='polynomial LR exponent')
parser.add_argument('--bs_mult', type=int, default=1)
parser.add_argument('--bs_mult_val', type=int, default=2)
parser.add_argument('--crop_size', type=int, default=720,
help='training crop size')
parser.add_argument('--pre_size', type=int, default=None,
help='resize image shorter edge to this before augmentation')
parser.add_argument('--scale_min', type=float, default=0.5,
help='dynamically scale training images down to this size')
parser.add_argument('--scale_max', type=float, default=2.0,
help='dynamically scale training images up to this size')
parser.add_argument('--weight_decay', type=float, default=1e-4)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--snapshot', type=str, default=None)
parser.add_argument('--restore_optimizer', action='store_true', default=False)
parser.add_argument('--exp', type=str, default='default',
help='experiment directory name')
parser.add_argument('--tb_tag', type=str, default='',
help='add tag to tb dir')
parser.add_argument('--ckpt', type=str, default='logs/ckpt')
parser.add_argument('--tb_path', type=str, default='logs/tb')
parser.add_argument('--syncbn', action='store_true', default=True,
help='Synchronized BN')
parser.add_argument('--dump_augmentation_images', action='store_true', default=False,
help='Synchronized BN')
parser.add_argument('--test_mode', action='store_true', default=False,
help='minimum testing (1 epoch run ) to verify nothing failed')
parser.add_argument('--mode',type=str,default="train")
parser.add_argument('--test_sv_path', type=str, default="")
parser.add_argument('--checkpoint_path',type=str,default="")
parser.add_argument('-wb', '--wt_bound', type=float, default=1.0)
parser.add_argument('--maxSkip', type=int, default=0)
parser.add_argument('--data-cfg', help='data config (kitti format)',
default='config/rellis.yaml',
type=str)
parser.add_argument('--viz', dest='viz',
help="Save color predictions to disk",
action='store_true')
args = parser.parse_args()
args.best_record = {'epoch': -1, 'iter': 0, 'val_loss': 1e10, 'acc': 0,
'acc_cls': 0, 'mean_iu': 0, 'fwavacc': 0}
def convert_label(label, inverse=False):
label_mapping = {0: 0,
1: 0,
3: 1,
4: 2,
5: 3,
6: 4,
7: 5,
8: 6,
9: 7,
10: 8,
12: 9,
15: 10,
17: 11,
18: 12,
19: 13,
23: 14,
27: 15,
# 29: 1,
# 30: 1,
31: 16,
# 32: 4,
33: 17,
34: 18}
temp = label.copy()
if inverse:
for v,k in label_mapping.items():
temp[label == k] = v
else:
for k, v in label_mapping.items():
temp[label == k] = v
return temp
def convert_color(label, color_map):
temp = np.zeros(label.shape + (3,)).astype(np.uint8)
for k,v in color_map.items():
temp[label == k] = v
return temp
#Enable CUDNN Benchmarking optimization
torch.backends.cudnn.benchmark = True
args.world_size = 1
#Test Mode run two epochs with a few iterations of training and val
if args.test_mode:
args.max_epoch = 2
if 'WORLD_SIZE' in os.environ:
args.world_size = int(os.environ['WORLD_SIZE'])
print("Total world size: ", int(os.environ['WORLD_SIZE']))
def main():
'''
Main Function
'''
#Set up the Arguments, Tensorboard Writer, Dataloader, Loss Fn, Optimizer
assert_and_infer_cfg(args)
writer = prep_experiment(args,parser)
train_loader, val_loader, train_obj = datasets.setup_loaders(args)
criterion, criterion_val = loss.get_loss(args)
net = network.get_net(args, criterion)
optim, scheduler = optimizer.get_optimizer(args, net)
torch.cuda.empty_cache()
if args.mode=="test":
test_sv_path = args.test_sv_path
print(f"Saving prediction {test_sv_path}")
net.eval()
try:
print("Opening config file %s" % args.data_cfg)
CFG = yaml.safe_load(open(args.data_cfg, 'r'))
except Exception as e:
print(e)
print("Error opening yaml file.")
quit()
id_color_map = CFG["color_map"]
for vi, data in enumerate(tqdm(val_loader)):
input, mask, img_name, img_path = data
assert len(input.size()) == 4 and len(mask.size()) == 3
assert input.size()[2:] == mask.size()[1:]
b, h, w = mask.size()
batch_pixel_size = input.size(0) * input.size(2) * input.size(3)
input, mask_cuda = input.cuda(), mask.cuda()
with torch.no_grad():
seg_out, edge_out = net(input) # output = (1, 19, 713, 713)
seg_predictions = seg_out.data.cpu().numpy()
edge_predictions = edge_out.cpu().numpy()
for i in range(b):
_,file_name = os.path.split(img_path[i])
file_name = file_name.replace("jpg","png")
seq = img_path[i][:5]
seg_path = os.path.join(test_sv_path,"gscnn","labels",seq)
if not os.path.exists(seg_path):
os.makedirs(seg_path)
seg_arg = np.argmax(seg_predictions[i],axis=0).astype(np.uint8)
seg_arg = convert_label(seg_arg,True)
seg_img = np.stack((seg_arg,seg_arg,seg_arg),axis=2)
seg_img = Image.fromarray(seg_img)
seg_img.save(os.path.join(seg_path,file_name))
if args.viz:
edge_arg = np.argmax(edge_predictions[i],axis=0).astype(np.uint8)
edge_img = np.stack((edge_arg,edge_arg,edge_arg),axis=2)
edge_path = os.path.join(test_sv_path,"gscnn","edge",seq)
#edgenp_path = os.path.join(test_sv_path,"gscnn","edgenp",seq)
if not os.path.exists(edge_path):
os.makedirs(edge_path)
#os.makedirs(edgenp_path)
edge_img = Image.fromarray(edge_img)
edge_img.save(os.path.join(edge_path,file_name))
color_label = convert_color(seg_arg,id_color_map)
color_path = os.path.join(test_sv_path,"gscnn","color",seq)
if not os.path.exists(color_path):
os.makedirs(color_path)
color_label = convert_color(seg_arg,id_color_map)
color_label = Image.fromarray(color_label)
color_label.save(os.path.join(color_path,file_name))
return
if args.evaluate:
# Early evaluation for benchmarking
default_eval_epoch = 1
validate(val_loader, net, criterion_val,
optim, default_eval_epoch, writer)
evaluate(val_loader, net)
return
#Main Loop
for epoch in range(args.start_epoch, args.max_epoch):
# Update EPOCH CTR
cfg.immutable(False)
cfg.EPOCH = epoch
cfg.immutable(True)
scheduler.step()
train(train_loader, net, criterion, optim, epoch, writer)
validate(val_loader, net, criterion_val,
optim, epoch, writer)
def train(train_loader, net, criterion, optimizer, curr_epoch, writer):
'''
Runs the training loop per epoch
train_loader: Data loader for train
net: thet network
criterion: loss fn
optimizer: optimizer
curr_epoch: current epoch
writer: tensorboard writer
return: val_avg for step function if required
'''
net.train()
train_main_loss = AverageMeter()
train_edge_loss = AverageMeter()
train_seg_loss = AverageMeter()
train_att_loss = AverageMeter()
train_dual_loss = AverageMeter()
curr_iter = curr_epoch * len(train_loader)
for i, data in enumerate(train_loader):
if i==0:
print('running....')
inputs, mask, edge, _img_name = data
if torch.sum(torch.isnan(inputs)) > 0:
import pdb; pdb.set_trace()
batch_pixel_size = inputs.size(0) * inputs.size(2) * inputs.size(3)
inputs, mask, edge = inputs.cuda(), mask.cuda(), edge.cuda()
if i==0:
print('forward done')
optimizer.zero_grad()
main_loss = None
loss_dict = None
if args.joint_edgeseg_loss:
loss_dict = net(inputs, gts=(mask, edge))
if args.seg_weight > 0:
log_seg_loss = loss_dict['seg_loss'].mean().clone().detach_()
train_seg_loss.update(log_seg_loss.item(), batch_pixel_size)
main_loss = loss_dict['seg_loss']
if args.edge_weight > 0:
log_edge_loss = loss_dict['edge_loss'].mean().clone().detach_()
train_edge_loss.update(log_edge_loss.item(), batch_pixel_size)
if main_loss is not None:
main_loss += loss_dict['edge_loss']
else:
main_loss = loss_dict['edge_loss']
if args.att_weight > 0:
log_att_loss = loss_dict['att_loss'].mean().clone().detach_()
train_att_loss.update(log_att_loss.item(), batch_pixel_size)
if main_loss is not None:
main_loss += loss_dict['att_loss']
else:
main_loss = loss_dict['att_loss']
if args.dual_weight > 0:
log_dual_loss = loss_dict['dual_loss'].mean().clone().detach_()
train_dual_loss.update(log_dual_loss.item(), batch_pixel_size)
if main_loss is not None:
main_loss += loss_dict['dual_loss']
else:
main_loss = loss_dict['dual_loss']
else:
main_loss = net(inputs, gts=mask)
main_loss = main_loss.mean()
log_main_loss = main_loss.clone().detach_()
train_main_loss.update(log_main_loss.item(), batch_pixel_size)
main_loss.backward()
optimizer.step()
if i==0:
print('step 1 done')
curr_iter += 1
if args.local_rank == 0:
msg = '[epoch {}], [iter {} / {}], [train main loss {:0.6f}], [seg loss {:0.6f}], [edge loss {:0.6f}], [lr {:0.6f}]'.format(
curr_epoch, i + 1, len(train_loader), train_main_loss.avg, train_seg_loss.avg, train_edge_loss.avg, optimizer.param_groups[-1]['lr'] )
logging.info(msg)
# Log tensorboard metrics for each iteration of the training phase
writer.add_scalar('training/loss', (train_main_loss.val),
curr_iter)
writer.add_scalar('training/lr', optimizer.param_groups[-1]['lr'],
curr_iter)
if args.joint_edgeseg_loss:
writer.add_scalar('training/seg_loss', (train_seg_loss.val),
curr_iter)
writer.add_scalar('training/edge_loss', (train_edge_loss.val),
curr_iter)
writer.add_scalar('training/att_loss', (train_att_loss.val),
curr_iter)
writer.add_scalar('training/dual_loss', (train_dual_loss.val),
curr_iter)
if i > 5 and args.test_mode:
return
def validate(val_loader, net, criterion, optimizer, curr_epoch, writer):
'''
Runs the validation loop after each training epoch
val_loader: Data loader for validation
net: thet network
criterion: loss fn
optimizer: optimizer
curr_epoch: current epoch
writer: tensorboard writer
return:
'''
net.eval()
val_loss = AverageMeter()
mf_score = AverageMeter()
IOU_acc = 0
dump_images = []
heatmap_images = []
for vi, data in enumerate(val_loader):
input, mask, edge, img_names = data
assert len(input.size()) == 4 and len(mask.size()) == 3
assert input.size()[2:] == mask.size()[1:]
h, w = mask.size()[1:]
batch_pixel_size = input.size(0) * input.size(2) * input.size(3)
input, mask_cuda, edge_cuda = input.cuda(), mask.cuda(), edge.cuda()
with torch.no_grad():
seg_out, edge_out = net(input) # output = (1, 19, 713, 713)
if args.joint_edgeseg_loss:
loss_dict = criterion((seg_out, edge_out), (mask_cuda, edge_cuda))
val_loss.update(sum(loss_dict.values()).item(), batch_pixel_size)
else:
val_loss.update(criterion(seg_out, mask_cuda).item(), batch_pixel_size)
# Collect data from different GPU to a single GPU since
# encoding.parallel.criterionparallel function calculates distributed loss
# functions
seg_predictions = seg_out.data.max(1)[1].cpu()
edge_predictions = edge_out.max(1)[0].cpu()
#Logging
if vi % 20 == 0:
if args.local_rank == 0:
logging.info('validating: %d / %d' % (vi + 1, len(val_loader)))
if vi > 10 and args.test_mode:
break
_edge = edge.max(1)[0]
#Image Dumps
if vi < 10:
dump_images.append([mask, seg_predictions, img_names])
heatmap_images.append([_edge, edge_predictions, img_names])
IOU_acc += fast_hist(seg_predictions.numpy().flatten(), mask.numpy().flatten(),
args.dataset_cls.num_classes)
del seg_out, edge_out, vi, data
if args.local_rank == 0:
evaluate_eval(args, net, optimizer, val_loss, mf_score, IOU_acc, dump_images, heatmap_images,
writer, curr_epoch, args.dataset_cls)
return val_loss.avg
def evaluate(val_loader, net):
'''
Runs the evaluation loop and prints F score
val_loader: Data loader for validation
net: thet network
return:
'''
net.eval()
for thresh in args.eval_thresholds.split(','):
mf_score1 = AverageMeter()
mf_pc_score1 = AverageMeter()
ap_score1 = AverageMeter()
ap_pc_score1 = AverageMeter()
Fpc = np.zeros((args.dataset_cls.num_classes))
Fc = np.zeros((args.dataset_cls.num_classes))
for vi, data in enumerate(val_loader):
input, mask, edge, img_names = data
assert len(input.size()) == 4 and len(mask.size()) == 3
assert input.size()[2:] == mask.size()[1:]
h, w = mask.size()[1:]
batch_pixel_size = input.size(0) * input.size(2) * input.size(3)
input, mask_cuda, edge_cuda = input.cuda(), mask.cuda(), edge.cuda()
with torch.no_grad():
seg_out, edge_out = net(input)
seg_predictions = seg_out.data.max(1)[1].cpu()
edge_predictions = edge_out.max(1)[0].cpu()
logging.info('evaluating: %d / %d' % (vi + 1, len(val_loader)))
_Fpc, _Fc = eval_mask_boundary(seg_predictions.numpy(), mask.numpy(), args.dataset_cls.num_classes, bound_th=float(thresh))
Fc += _Fc
Fpc += _Fpc
del seg_out, edge_out, vi, data
logging.info('Threshold: ' + thresh)
logging.info('F_Score: ' + str(np.sum(Fpc/Fc)/args.dataset_cls.num_classes))
logging.info('F_Score (Classwise): ' + str(Fpc/Fc))
if __name__ == '__main__':
main()
================================================
FILE: benchmarks/GSCNN-master/transforms/joint_transforms.py
================================================
"""
Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
# Code borrowded from:
# https://github.com/zijundeng/pytorch-semantic-segmentation/blob/master/utils/joint_transforms.py
#
#
# MIT License
#
# Copyright (c) 2017 ZijunDeng
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
"""
import math
import numbers
import random
from PIL import Image, ImageOps
import numpy as np
import random
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img, mask):
assert img.size == mask.size
for t in self.transforms:
img, mask = t(img, mask)
return img, mask
class RandomCrop(object):
'''
Take a random crop from the image.
First the image or crop size may need to be adjusted if the incoming image
is too small...
If the image is smaller than the crop, then:
the image is padded up to the size of the crop
unless 'nopad', in which case the crop size is shrunk to fit the image
A random crop is taken such that the crop fits within the image.
If a centroid is passed in, the crop must intersect the centroid.
'''
def __init__(self, size, ignore_index=0, nopad=True):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
self.ignore_index = ignore_index
self.nopad = nopad
self.pad_color = (0, 0, 0)
def __call__(self, img, mask, centroid=None):
assert img.size == mask.size
w, h = img.size
# ASSUME H, W
th, tw = self.size
if w == tw and h == th:
return img, mask
if self.nopad:
if th > h or tw > w:
# Instead of padding, adjust crop size to the shorter edge of image.
shorter_side = min(w, h)
th, tw = shorter_side, shorter_side
else:
# Check if we need to pad img to fit for crop_size.
if th > h:
pad_h = (th - h) // 2 + 1
else:
pad_h = 0
if tw > w:
pad_w = (tw - w) // 2 + 1
else:
pad_w = 0
border = (pad_w, pad_h, pad_w, pad_h)
if pad_h or pad_w:
img = ImageOps.expand(img, border=border, fill=self.pad_color)
mask = ImageOps.expand(mask, border=border, fill=self.ignore_index)
w, h = img.size
if centroid is not None:
# Need to insure that centroid is covered by crop and that crop
# sits fully within the image
c_x, c_y = centroid
max_x = w - tw
max_y = h - th
x1 = random.randint(c_x - tw, c_x)
x1 = min(max_x, max(0, x1))
y1 = random.randint(c_y - th, c_y)
y1 = min(max_y, max(0, y1))
else:
if w == tw:
x1 = 0
else:
x1 = random.randint(0, w - tw)
if h == th:
y1 = 0
else:
y1 = random.randint(0, h - th)
return img.crop((x1, y1, x1 + tw, y1 + th)), mask.crop((x1, y1, x1 + tw, y1 + th))
class ResizeHeight(object):
def __init__(self, size, interpolation=Image.BICUBIC):
self.target_h = size
self.interpolation = interpolation
def __call__(self, img, mask):
w, h = img.size
target_w = int(w / h * self.target_h)
return (img.resize((target_w, self.target_h), self.interpolation),
mask.resize((target_w, self.target_h), Image.NEAREST))
class CenterCrop(object):
def __init__(self, size):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
th, tw = self.size
x1 = int(round((w - tw) / 2.))
y1 = int(round((h - th) / 2.))
return img.crop((x1, y1, x1 + tw, y1 + th)), mask.crop((x1, y1, x1 + tw, y1 + th))
class CenterCropPad(object):
def __init__(self, size, ignore_index=0):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
self.ignore_index = ignore_index
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
if isinstance(self.size, tuple):
tw, th = self.size[0], self.size[1]
else:
th, tw = self.size, self.size
if w < tw:
pad_x = tw - w
else:
pad_x = 0
if h < th:
pad_y = th - h
else:
pad_y = 0
if pad_x or pad_y:
# left, top, right, bottom
img = ImageOps.expand(img, border=(pad_x, pad_y, pad_x, pad_y), fill=0)
mask = ImageOps.expand(mask, border=(pad_x, pad_y, pad_x, pad_y),
fill=self.ignore_index)
x1 = int(round((w - tw) / 2.))
y1 = int(round((h - th) / 2.))
return img.crop((x1, y1, x1 + tw, y1 + th)), mask.crop((x1, y1, x1 + tw, y1 + th))
class PadImage(object):
def __init__(self, size, ignore_index):
self.size = size
self.ignore_index = ignore_index
def __call__(self, img, mask):
assert img.size == mask.size
th, tw = self.size, self.size
w, h = img.size
if w > tw or h > th :
wpercent = (tw/float(w))
target_h = int((float(img.size[1])*float(wpercent)))
img, mask = img.resize((tw, target_h), Image.BICUBIC), mask.resize((tw, target_h), Image.NEAREST)
w, h = img.size
##Pad
img = ImageOps.expand(img, border=(0,0,tw-w, th-h), fill=0)
mask = ImageOps.expand(mask, border=(0,0,tw-w, th-h), fill=self.ignore_index)
return img, mask
class RandomHorizontallyFlip(object):
def __call__(self, img, mask):
if random.random() < 0.5:
return img.transpose(Image.FLIP_LEFT_RIGHT), mask.transpose(
Image.FLIP_LEFT_RIGHT)
return img, mask
class FreeScale(object):
def __init__(self, size):
self.size = tuple(reversed(size)) # size: (h, w)
def __call__(self, img, mask):
assert img.size == mask.size
return img.resize(self.size, Image.BICUBIC), mask.resize(self.size, Image.NEAREST)
class Scale(object):
'''
Scale image such that longer side is == size
'''
def __init__(self, size):
self.size = size
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
if (w >= h and w == self.size) or (h >= w and h == self.size):
return img, mask
if w > h:
ow = self.size
oh = int(self.size * h / w)
return img.resize((ow, oh), Image.BICUBIC), mask.resize(
(ow, oh), Image.NEAREST)
else:
oh = self.size
ow = int(self.size * w / h)
return img.resize((ow, oh), Image.BICUBIC), mask.resize(
(ow, oh), Image.NEAREST)
class ScaleMin(object):
'''
Scale image such that shorter side is == size
'''
def __init__(self, size):
self.size = size
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
if (w <= h and w == self.size) or (h <= w and h == self.size):
return img, mask
if w < h:
ow = self.size
oh = int(self.size * h / w)
return img.resize((ow, oh), Image.BICUBIC), mask.resize(
(ow, oh), Image.NEAREST)
else:
oh = self.size
ow = int(self.size * w / h)
return img.resize((ow, oh), Image.BICUBIC), mask.resize(
(ow, oh), Image.NEAREST)
class Resize(object):
'''
Resize image to exact size of crop
'''
def __init__(self, size):
self.size = (size, size)
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
if (w == h and w == self.size):
return img, mask
return (img.resize(self.size, Image.BICUBIC),
mask.resize(self.size, Image.NEAREST))
class RandomSizedCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, img, mask):
assert img.size == mask.size
for attempt in range(10):
area = img.size[0] * img.size[1]
target_area = random.uniform(0.45, 1.0) * area
aspect_ratio = random.uniform(0.5, 2)
w = int(round(math.sqrt(target_area * aspect_ratio)))
h = int(round(math.sqrt(target_area / aspect_ratio)))
if random.random() < 0.5:
w, h = h, w
if w <= img.size[0] and h <= img.size[1]:
x1 = random.randint(0, img.size[0] - w)
y1 = random.randint(0, img.size[1] - h)
img = img.crop((x1, y1, x1 + w, y1 + h))
mask = mask.crop((x1, y1, x1 + w, y1 + h))
assert (img.size == (w, h))
return img.resize((self.size, self.size), Image.BICUBIC),\
mask.resize((self.size, self.size), Image.NEAREST)
# Fallback
scale = Scale(self.size)
crop = CenterCrop(self.size)
return crop(*scale(img, mask))
class RandomRotate(object):
def __init__(self, degree):
self.degree = degree
def __call__(self, img, mask):
rotate_degree = random.random() * 2 * self.degree - self.degree
return img.rotate(rotate_degree, Image.BICUBIC), mask.rotate(
rotate_degree, Image.NEAREST)
class RandomSizeAndCrop(object):
def __init__(self, size, crop_nopad,
scale_min=0.5, scale_max=2.0, ignore_index=0, pre_size=None):
self.size = size
self.crop = RandomCrop(self.size, ignore_index=ignore_index, nopad=crop_nopad)
self.scale_min = scale_min
self.scale_max = scale_max
self.pre_size = pre_size
def __call__(self, img, mask, centroid=None):
assert img.size == mask.size
# first, resize such that shorter edge is pre_size
if self.pre_size is None:
scale_amt = 1.
elif img.size[1] < img.size[0]:
scale_amt = self.pre_size / img.size[1]
else:
scale_amt = self.pre_size / img.size[0]
scale_amt *= random.uniform(self.scale_min, self.scale_max)
w, h = [int(i * scale_amt) for i in img.size]
if centroid is not None:
centroid = [int(c * scale_amt) for c in centroid]
img, mask = img.resize((w, h), Image.BICUBIC), mask.resize((w, h), Image.NEAREST)
return self.crop(img, mask, centroid)
class SlidingCropOld(object):
def __init__(self, crop_size, stride_rate, ignore_label):
self.crop_size = crop_size
self.stride_rate = stride_rate
self.ignore_label = ignore_label
def _pad(self, img, mask):
h, w = img.shape[: 2]
pad_h = max(self.crop_size - h, 0)
pad_w = max(self.crop_size - w, 0)
img = np.pad(img, ((0, pad_h), (0, pad_w), (0, 0)), 'constant')
mask = np.pad(mask, ((0, pad_h), (0, pad_w)), 'constant',
constant_values=self.ignore_label)
return img, mask
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
long_size = max(h, w)
img = np.array(img)
mask = np.array(mask)
if long_size > self.crop_size:
stride = int(math.ceil(self.crop_size * self.stride_rate))
h_step_num = int(math.ceil((h - self.crop_size) / float(stride))) + 1
w_step_num = int(math.ceil((w - self.crop_size) / float(stride))) + 1
img_sublist, mask_sublist = [], []
for yy in range(h_step_num):
for xx in range(w_step_num):
sy, sx = yy * stride, xx * stride
ey, ex = sy + self.crop_size, sx + self.crop_size
img_sub = img[sy: ey, sx: ex, :]
mask_sub = mask[sy: ey, sx: ex]
img_sub, mask_sub = self._pad(img_sub, mask_sub)
img_sublist.append(
Image.fromarray(
img_sub.astype(
np.uint8)).convert('RGB'))
mask_sublist.append(
Image.fromarray(
mask_sub.astype(
np.uint8)).convert('P'))
return img_sublist, mask_sublist
else:
img, mask = self._pad(img, mask)
img = Image.fromarray(img.astype(np.uint8)).convert('RGB')
mask = Image.fromarray(mask.astype(np.uint8)).convert('P')
return img, mask
class SlidingCrop(object):
def __init__(self, crop_size, stride_rate, ignore_label):
self.crop_size = crop_size
self.stride_rate = stride_rate
self.ignore_label = ignore_label
def _pad(self, img, mask):
h, w = img.shape[: 2]
pad_h = max(self.crop_size - h, 0)
pad_w = max(self.crop_size - w, 0)
img = np.pad(img, ((0, pad_h), (0, pad_w), (0, 0)), 'constant')
mask = np.pad(mask, ((0, pad_h), (0, pad_w)), 'constant',
constant_values=self.ignore_label)
return img, mask, h, w
def __call__(self, img, m
gitextract_trhdf0kw/
├── .gitignore
├── README.md
├── benchmarks/
│ ├── GSCNN-master/
│ │ ├── .gitignore
│ │ ├── Dockerfile
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── config.py
│ │ ├── datasets/
│ │ │ ├── __init__.py
│ │ │ ├── cityscapes.py
│ │ │ ├── cityscapes_labels.py
│ │ │ ├── edge_utils.py
│ │ │ └── rellis.py
│ │ ├── docs/
│ │ │ ├── index.html
│ │ │ └── resources/
│ │ │ └── bibtex.txt
│ │ ├── gscnn.txt
│ │ ├── loss.py
│ │ ├── my_functionals/
│ │ │ ├── DualTaskLoss.py
│ │ │ ├── GatedSpatialConv.py
│ │ │ ├── __init__.py
│ │ │ └── custom_functional.py
│ │ ├── network/
│ │ │ ├── Resnet.py
│ │ │ ├── SEresnext.py
│ │ │ ├── __init__.py
│ │ │ ├── gscnn.py
│ │ │ ├── mynn.py
│ │ │ └── wider_resnet.py
│ │ ├── optimizer.py
│ │ ├── run_gscnn.sh
│ │ ├── run_gscnn_eval.sh
│ │ ├── train.py
│ │ ├── transforms/
│ │ │ ├── joint_transforms.py
│ │ │ └── transforms.py
│ │ └── utils/
│ │ ├── AttrDict.py
│ │ ├── f_boundary.py
│ │ ├── image_page.py
│ │ └── misc.py
│ ├── HRNet-Semantic-Segmentation-HRNet-OCR/
│ │ ├── .gitignore
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── experiments/
│ │ │ ├── ade20k/
│ │ │ │ ├── seg_hrnet_ocr_w48_520x520_ohem_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml
│ │ │ │ ├── seg_hrnet_w48_520x520_ohem_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml
│ │ │ │ └── seg_hrnet_w48_520x520_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml
│ │ │ ├── cityscapes/
│ │ │ │ ├── seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_ocr_w48_trainval_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_w48_train_ohem_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ │ ├── seg_hrnet_w48_trainval_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484x2.yaml
│ │ │ │ └── seg_hrnet_w48_trainval_ohem_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484x2.yaml
│ │ │ ├── cocostuff/
│ │ │ │ ├── seg_hrnet_ocr_w48_520x520_ohem_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml
│ │ │ │ ├── seg_hrnet_w48_520x520_ohem_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml
│ │ │ │ └── seg_hrnet_w48_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml
│ │ │ ├── lip/
│ │ │ │ ├── seg_hrnet_ocr_w48_473x473_sgd_lr7e-3_wd5e-4_bs_40_epoch150.yaml
│ │ │ │ └── seg_hrnet_w48_473x473_sgd_lr7e-3_wd5e-4_bs_40_epoch150.yaml
│ │ │ ├── pascal_ctx/
│ │ │ │ ├── seg_hrnet_ocr_w48_cls59_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml
│ │ │ │ ├── seg_hrnet_ocr_w48_cls60_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml
│ │ │ │ └── seg_hrnet_w48_cls59_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml
│ │ │ └── rellis/
│ │ │ ├── seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
│ │ │ └── seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-3_wd5e-4_bs_12_epoch484.yaml
│ │ ├── hubconf.py
│ │ ├── pretrained_models/
│ │ │ └── .gitignore
│ │ ├── requirements.txt
│ │ ├── run_hrnet.sh
│ │ ├── run_hrnet_test.sh
│ │ └── tools/
│ │ ├── _init_paths.py
│ │ ├── test.py
│ │ └── train.py
│ ├── KPConv-PyTorch-master/
│ │ ├── .gitignore
│ │ ├── INSTALL.md
│ │ ├── README.md
│ │ ├── cpp_wrappers/
│ │ │ ├── compile_wrappers.sh
│ │ │ ├── cpp_neighbors/
│ │ │ │ ├── build.bat
│ │ │ │ ├── neighbors/
│ │ │ │ │ ├── neighbors.cpp
│ │ │ │ │ └── neighbors.h
│ │ │ │ ├── setup.py
│ │ │ │ └── wrapper.cpp
│ │ │ ├── cpp_subsampling/
│ │ │ │ ├── build.bat
│ │ │ │ ├── grid_subsampling/
│ │ │ │ │ ├── grid_subsampling.cpp
│ │ │ │ │ └── grid_subsampling.h
│ │ │ │ ├── setup.py
│ │ │ │ └── wrapper.cpp
│ │ │ └── cpp_utils/
│ │ │ ├── cloud/
│ │ │ │ ├── cloud.cpp
│ │ │ │ └── cloud.h
│ │ │ └── nanoflann/
│ │ │ └── nanoflann.hpp
│ │ ├── datasets/
│ │ │ ├── ModelNet40.py
│ │ │ ├── Rellis.py
│ │ │ ├── S3DIS.py
│ │ │ ├── SemanticKitti.py
│ │ │ └── common.py
│ │ ├── doc/
│ │ │ ├── object_classification_guide.md
│ │ │ ├── pretrained_models_guide.md
│ │ │ ├── scene_segmentation_guide.md
│ │ │ ├── slam_segmentation_guide.md
│ │ │ └── visualization_guide.md
│ │ ├── kernels/
│ │ │ ├── dispositions/
│ │ │ │ └── k_015_center_3D.ply
│ │ │ └── kernel_points.py
│ │ ├── models/
│ │ │ ├── architectures.py
│ │ │ └── blocks.py
│ │ ├── plot_convergence.py
│ │ ├── run_kpconv.sh
│ │ ├── test_models.py
│ │ ├── train_ModelNet40.py
│ │ ├── train_Rellis.py
│ │ ├── train_S3DIS.py
│ │ ├── train_SemanticKitti.py
│ │ ├── utils/
│ │ │ ├── config.py
│ │ │ ├── mayavi_visu.py
│ │ │ ├── metrics.py
│ │ │ ├── ply.py
│ │ │ ├── tester.py
│ │ │ ├── trainer.py
│ │ │ └── visualizer.py
│ │ └── visualize_deformations.py
│ ├── README.md
│ ├── SalsaNext/
│ │ ├── .gitignore
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── eval.sh
│ │ ├── run_salsanext.sh
│ │ ├── run_salsanext_eval.sh
│ │ ├── salsanext.yml
│ │ ├── salsanext_cuda09.yml
│ │ ├── salsanext_cuda10.yml
│ │ ├── train/
│ │ │ ├── __init__.py
│ │ │ ├── common/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── avgmeter.py
│ │ │ │ ├── laserscan.py
│ │ │ │ ├── laserscanvis.py
│ │ │ │ ├── logger.py
│ │ │ │ ├── summary.py
│ │ │ │ ├── sync_batchnorm/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── batchnorm.py
│ │ │ │ │ ├── comm.py
│ │ │ │ │ └── replicate.py
│ │ │ │ └── warmupLR.py
│ │ │ └── tasks/
│ │ │ ├── __init__.py
│ │ │ └── semantic/
│ │ │ ├── __init__.py
│ │ │ ├── config/
│ │ │ │ ├── arch/
│ │ │ │ │ └── salsanext_ouster.yml
│ │ │ │ └── labels/
│ │ │ │ ├── rellis.yaml
│ │ │ │ ├── semantic-kitti-all.yaml
│ │ │ │ └── semantic-kitti.yaml
│ │ │ ├── dataset/
│ │ │ │ ├── kitti/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── parser.py
│ │ │ │ └── rellis/
│ │ │ │ ├── __init__.py
│ │ │ │ └── parser.py
│ │ │ ├── evaluate_iou.py
│ │ │ ├── infer.py
│ │ │ ├── infer2.py
│ │ │ ├── modules/
│ │ │ │ ├── Lovasz_Softmax.py
│ │ │ │ ├── SalsaNext.py
│ │ │ │ ├── SalsaNextAdf.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── adf.py
│ │ │ │ ├── ioueval.py
│ │ │ │ ├── trainer.py
│ │ │ │ ├── user.py
│ │ │ │ └── user2.py
│ │ │ ├── postproc/
│ │ │ │ ├── KNN.py
│ │ │ │ └── __init__.py
│ │ │ ├── train.py
│ │ │ └── visualize.py
│ │ └── train.sh
│ ├── __init__.py
│ ├── gscnn_requirement.txt
│ └── requirement.txt
├── catkin_ws/
│ ├── .catkin_workspace
│ ├── .gitignore
│ └── src/
│ └── platform_description/
│ ├── CMakeLists.txt
│ ├── launch/
│ │ └── description.launch
│ ├── meshes/
│ │ ├── arm-mount-plate.stl
│ │ ├── bulkhead-collision.stl
│ │ ├── bulkhead.stl
│ │ ├── chassis-collision.stl
│ │ ├── chassis.stl
│ │ ├── diff-link.stl
│ │ ├── e-stop.stl
│ │ ├── fenders.stl
│ │ ├── light.stl
│ │ ├── novatel-smart6.stl
│ │ ├── rocker.stl
│ │ ├── susp-link.stl
│ │ ├── tracks.dae
│ │ ├── tracks_collision.stl
│ │ └── wheel.stl
│ ├── package.xml
│ ├── scripts/
│ │ └── env_run
│ └── urdf/
│ ├── accessories/
│ │ ├── novatel_smart6.urdf.xacro
│ │ ├── warthog_arm_mount.urdf.xacro
│ │ └── warthog_bulkhead.urdf.xacro
│ ├── accessories.urdf.xacro
│ ├── configs/
│ │ ├── arm_mount
│ │ ├── base
│ │ ├── bulkhead
│ │ └── empty
│ ├── empty.urdf
│ ├── warthog.gazebo
│ ├── warthog.urdf
│ └── warthog.urdf.xacro
├── images/
│ ├── data_example.eps
│ └── sensor_setup.eps
└── utils/
├── .gitignore
├── Evaluate_img.ipynb
├── Evaluate_pt.ipynb
├── __init__.py
├── convert_ply2bin.py
├── example/
│ ├── 000104.label
│ ├── camera_info.txt
│ ├── frame000104-1581624663_170.ply
│ ├── transforms.yaml
│ └── vel2os1.yaml
├── label2color.ipynb
├── label_convert.py
├── lidar2img.ipynb
├── nerian_camera_info.yaml
├── plyreader.py
└── stereo_camerainfo_pub.py
SYMBOL INDEX (930 symbols across 86 files)
FILE: benchmarks/GSCNN-master/config.py
function assert_and_infer_cfg (line 74) | def assert_and_infer_cfg(args, make_immutable=True):
FILE: benchmarks/GSCNN-master/datasets/__init__.py
function setup_loaders (line 13) | def setup_loaders(args):
FILE: benchmarks/GSCNN-master/datasets/cityscapes.py
function colorize_mask (line 36) | def colorize_mask(mask):
function add_items (line 43) | def add_items(items, aug_items, cities, img_path, mask_path, mask_postfi...
function make_cv_splits (line 53) | def make_cv_splits(img_dir_name):
function make_split_coarse (line 88) | def make_split_coarse(img_path):
function make_test_split (line 102) | def make_test_split(img_dir_name):
function make_dataset (line 109) | def make_dataset(quality, mode, maxSkip=0, fine_coarse_mult=6, cv_split=0):
class CityScapes (line 150) | class CityScapes(data.Dataset):
method __init__ (line 152) | def __init__(self, quality, mode, maxSkip=0, joint_transform=None, sli...
method _eval_get_item (line 183) | def _eval_get_item(self, img, mask, scales, flip_bool):
method __getitem__ (line 201) | def __getitem__(self, index):
method __len__ (line 245) | def __len__(self):
function make_dataset_video (line 249) | def make_dataset_video():
class CityScapesVideo (line 263) | class CityScapesVideo(data.Dataset):
method __init__ (line 265) | def __init__(self, transform=None):
method __getitem__ (line 271) | def __getitem__(self, index):
method __len__ (line 280) | def __len__(self):
FILE: benchmarks/GSCNN-master/datasets/cityscapes_labels.py
function assureSingleInstanceName (line 168) | def assureSingleInstanceName( name ):
FILE: benchmarks/GSCNN-master/datasets/edge_utils.py
function mask_to_onehot (line 11) | def mask_to_onehot(mask, num_classes):
function onehot_to_mask (line 20) | def onehot_to_mask(mask):
function onehot_to_multiclass_edges (line 28) | def onehot_to_multiclass_edges(mask, radius, num_classes):
function onehot_to_binary_edges (line 49) | def onehot_to_binary_edges(mask, radius, num_classes):
FILE: benchmarks/GSCNN-master/datasets/rellis.py
function colorize_mask (line 38) | def colorize_mask(mask):
class Rellis (line 45) | class Rellis(data.Dataset):
method __init__ (line 47) | def __init__(self, mode, joint_transform=None, sliding_crop=None,
method _eval_get_item (line 94) | def _eval_get_item(self, img, mask, scales, flip_bool):
method read_files (line 110) | def read_files(self):
method convert_label (line 132) | def convert_label(self, label, inverse=False):
method __getitem__ (line 143) | def __getitem__(self, index):
method __len__ (line 190) | def __len__(self):
function make_dataset_video (line 194) | def make_dataset_video():
class CityScapesVideo (line 208) | class CityScapesVideo(data.Dataset):
method __init__ (line 210) | def __init__(self, transform=None):
method __getitem__ (line 216) | def __getitem__(self, index):
method __len__ (line 225) | def __len__(self):
FILE: benchmarks/GSCNN-master/loss.py
function get_loss (line 14) | def get_loss(args):
class JointEdgeSegLoss (line 41) | class JointEdgeSegLoss(nn.Module):
method __init__ (line 42) | def __init__(self, classes, weight=None, reduction='mean', ignore_inde...
method bce2d (line 62) | def bce2d(self, input, target):
method edge_attention (line 95) | def edge_attention(self, input, target, edge):
method forward (line 101) | def forward(self, inputs, targets):
class ImageBasedCrossEntropyLoss2d (line 114) | class ImageBasedCrossEntropyLoss2d(nn.Module):
method __init__ (line 116) | def __init__(self, classes, weight=None, size_average=True, ignore_ind...
method calculateWeights (line 126) | def calculateWeights(self, target):
method forward (line 135) | def forward(self, inputs, targets):
class CrossEntropyLoss2d (line 153) | class CrossEntropyLoss2d(nn.Module):
method __init__ (line 154) | def __init__(self, weight=None, size_average=True, ignore_index=255):
method forward (line 159) | def forward(self, inputs, targets):
FILE: benchmarks/GSCNN-master/my_functionals/DualTaskLoss.py
function perturbate_input_ (line 38) | def perturbate_input_(input, n_elements=200):
function _sample_gumbel (line 50) | def _sample_gumbel(shape, eps=1e-10):
function _gumbel_softmax_sample (line 62) | def _gumbel_softmax_sample(logits, tau=1, eps=1e-10):
function _one_hot_embedding (line 76) | def _one_hot_embedding(labels, num_classes):
class DualTaskLoss (line 90) | class DualTaskLoss(nn.Module):
method __init__ (line 91) | def __init__(self, cuda=False):
method forward (line 96) | def forward(self, input_logits, gts, ignore_pixel=255):
FILE: benchmarks/GSCNN-master/my_functionals/GatedSpatialConv.py
class GatedSpatialConv2d (line 15) | class GatedSpatialConv2d(_ConvNd):
method __init__ (line 16) | def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
method forward (line 47) | def forward(self, input_features, gating_features):
method reset_parameters (line 60) | def reset_parameters(self):
class Conv2dPad (line 66) | class Conv2dPad(nn.Conv2d):
method forward (line 67) | def forward(self, input):
class HighFrequencyGatedSpatialConv2d (line 70) | class HighFrequencyGatedSpatialConv2d(_ConvNd):
method __init__ (line 71) | def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
method forward (line 137) | def forward(self, input_features, gating_features):
method reset_parameters (line 156) | def reset_parameters(self):
function t (line 161) | def t():
FILE: benchmarks/GSCNN-master/my_functionals/custom_functional.py
function calc_pad_same (line 12) | def calc_pad_same(in_siz, out_siz, stride, ksize):
function conv2d_same (line 22) | def conv2d_same(input, kernel, groups,bias=None,stride=1,padding=0,dilat...
function gradient_central_diff (line 38) | def gradient_central_diff(input, cuda):
function compute_single_sided_diferences (line 55) | def compute_single_sided_diferences(o_x, o_y, input):
function numerical_gradients_2d (line 66) | def numerical_gradients_2d(input, cuda=False):
function convTri (line 81) | def convTri(input, r, cuda=False):
function compute_normal (line 125) | def compute_normal(E, cuda=False):
function compute_normal_2 (line 147) | def compute_normal_2(E, cuda=False):
function compute_grad_mag (line 169) | def compute_grad_mag(E, cuda=False):
FILE: benchmarks/GSCNN-master/network/Resnet.py
function conv3x3 (line 57) | def conv3x3(in_planes, out_planes, stride=1):
class BasicBlock (line 63) | class BasicBlock(nn.Module):
method __init__ (line 66) | def __init__(self, inplanes, planes, stride=1, downsample=None):
method forward (line 82) | def forward(self, x):
class Bottleneck (line 101) | class Bottleneck(nn.Module):
method __init__ (line 104) | def __init__(self, inplanes, planes, stride=1, downsample=None):
method forward (line 117) | def forward(self, x):
class ResNet (line 140) | class ResNet(nn.Module):
method __init__ (line 142) | def __init__(self, block, layers, num_classes=1000):
method _make_layer (line 164) | def _make_layer(self, block, planes, blocks, stride=1):
method forward (line 181) | def forward(self, x):
function resnet18 (line 199) | def resnet18(pretrained=True, **kwargs):
function resnet34 (line 211) | def resnet34(pretrained=True, **kwargs):
function resnet50 (line 223) | def resnet50(pretrained=True, **kwargs):
function resnet101 (line 235) | def resnet101(pretrained=True, **kwargs):
function resnet152 (line 247) | def resnet152(pretrained=True, **kwargs):
FILE: benchmarks/GSCNN-master/network/SEresnext.py
class SEModule (line 75) | class SEModule(nn.Module):
method __init__ (line 77) | def __init__(self, channels, reduction):
method forward (line 87) | def forward(self, x):
class Bottleneck (line 97) | class Bottleneck(nn.Module):
method forward (line 101) | def forward(self, x):
class SEBottleneck (line 124) | class SEBottleneck(Bottleneck):
method __init__ (line 130) | def __init__(self, inplanes, planes, groups, reduction, stride=1,
class SEResNetBottleneck (line 148) | class SEResNetBottleneck(Bottleneck):
method __init__ (line 156) | def __init__(self, inplanes, planes, groups, reduction, stride=1,
class SEResNeXtBottleneck (line 173) | class SEResNeXtBottleneck(Bottleneck):
method __init__ (line 179) | def __init__(self, inplanes, planes, groups, reduction, stride=1,
class SENet (line 197) | class SENet(nn.Module):
method __init__ (line 199) | def __init__(self, block, layers, groups, reduction, dropout_p=0.2,
method _make_layer (line 318) | def _make_layer(self, block, planes, blocks, groups, reduction, stride=1,
method features (line 338) | def features(self, x):
method logits (line 346) | def logits(self, x):
method forward (line 354) | def forward(self, x):
function initialize_pretrained_model (line 360) | def initialize_pretrained_model(model, num_classes, settings):
function se_resnext50_32x4d (line 374) | def se_resnext50_32x4d(num_classes=1000):
function se_resnext101_32x4d (line 384) | def se_resnext101_32x4d(num_classes=1000):
FILE: benchmarks/GSCNN-master/network/__init__.py
function get_net (line 10) | def get_net(args, criterion):
function get_model (line 25) | def get_model(network, num_classes, criterion, trunk):
FILE: benchmarks/GSCNN-master/network/gscnn.py
class Crop (line 45) | class Crop(nn.Module):
method __init__ (line 46) | def __init__(self, axis, offset):
method forward (line 51) | def forward(self, x, ref):
class MyIdentity (line 66) | class MyIdentity(nn.Module):
method __init__ (line 67) | def __init__(self, axis, offset):
method forward (line 72) | def forward(self, x, ref):
class SideOutputCrop (line 81) | class SideOutputCrop(nn.Module):
method __init__ (line 86) | def __init__(self, num_output, kernel_sz=None, stride=None, upconv_pad...
method forward (line 104) | def forward(self, res, reference=None):
class _AtrousSpatialPyramidPoolingModule (line 113) | class _AtrousSpatialPyramidPoolingModule(nn.Module):
method __init__ (line 125) | def __init__(self, in_dim, reduction_dim=256, output_stride=16, rates=...
method forward (line 163) | def forward(self, x, edge):
class GSCNN (line 182) | class GSCNN(nn.Module):
method __init__ (line 196) | def __init__(self, num_classes, trunk=None, criterion=None):
method forward (line 263) | def forward(self, inp, gts=None):
FILE: benchmarks/GSCNN-master/network/mynn.py
function Norm2d (line 16) | def Norm2d(in_channels):
function initialize_weights (line 25) | def initialize_weights(*models):
FILE: benchmarks/GSCNN-master/network/wider_resnet.py
function bnrelu (line 46) | def bnrelu(channels):
class GlobalAvgPool2d (line 50) | class GlobalAvgPool2d(nn.Module):
method __init__ (line 52) | def __init__(self):
method forward (line 56) | def forward(self, inputs):
class IdentityResidualBlock (line 61) | class IdentityResidualBlock(nn.Module):
method __init__ (line 63) | def __init__(self,
method forward (line 164) | def forward(self, x):
class WiderResNet (line 182) | class WiderResNet(nn.Module):
method __init__ (line 184) | def __init__(self,
method forward (line 244) | def forward(self, img):
class WiderResNetA2 (line 260) | class WiderResNetA2(nn.Module):
method __init__ (line 262) | def __init__(self,
method forward (line 359) | def forward(self, img):
FILE: benchmarks/GSCNN-master/optimizer.py
function get_optimizer (line 12) | def get_optimizer(args, net):
function restore_snapshot (line 48) | def restore_snapshot(args, net, optimizer, snapshot):
function forgiving_state_restore (line 64) | def forgiving_state_restore(net, loaded_dict):
FILE: benchmarks/GSCNN-master/train.py
function convert_label (line 123) | def convert_label(label, inverse=False):
function convert_color (line 156) | def convert_color(label, color_map):
function main (line 173) | def main():
function train (line 279) | def train(train_loader, net, criterion, optimizer, curr_epoch, writer):
function validate (line 393) | def validate(val_loader, net, criterion, optimizer, curr_epoch, writer):
function evaluate (line 459) | def evaluate(val_loader, net):
FILE: benchmarks/GSCNN-master/transforms/joint_transforms.py
class Compose (line 40) | class Compose(object):
method __init__ (line 41) | def __init__(self, transforms):
method __call__ (line 44) | def __call__(self, img, mask):
class RandomCrop (line 51) | class RandomCrop(object):
method __init__ (line 65) | def __init__(self, size, ignore_index=0, nopad=True):
method __call__ (line 74) | def __call__(self, img, mask, centroid=None):
class ResizeHeight (line 125) | class ResizeHeight(object):
method __init__ (line 126) | def __init__(self, size, interpolation=Image.BICUBIC):
method __call__ (line 130) | def __call__(self, img, mask):
class CenterCrop (line 137) | class CenterCrop(object):
method __init__ (line 138) | def __init__(self, size):
method __call__ (line 144) | def __call__(self, img, mask):
class CenterCropPad (line 153) | class CenterCropPad(object):
method __init__ (line 154) | def __init__(self, size, ignore_index=0):
method __call__ (line 161) | def __call__(self, img, mask):
class PadImage (line 192) | class PadImage(object):
method __init__ (line 193) | def __init__(self, size, ignore_index):
method __call__ (line 198) | def __call__(self, img, mask):
class RandomHorizontallyFlip (line 217) | class RandomHorizontallyFlip(object):
method __call__ (line 218) | def __call__(self, img, mask):
class FreeScale (line 225) | class FreeScale(object):
method __init__ (line 226) | def __init__(self, size):
method __call__ (line 229) | def __call__(self, img, mask):
class Scale (line 234) | class Scale(object):
method __init__ (line 239) | def __init__(self, size):
method __call__ (line 242) | def __call__(self, img, mask):
class ScaleMin (line 259) | class ScaleMin(object):
method __init__ (line 264) | def __init__(self, size):
method __call__ (line 267) | def __call__(self, img, mask):
class Resize (line 284) | class Resize(object):
method __init__ (line 289) | def __init__(self, size):
method __call__ (line 292) | def __call__(self, img, mask):
class RandomSizedCrop (line 301) | class RandomSizedCrop(object):
method __init__ (line 302) | def __init__(self, size):
method __call__ (line 305) | def __call__(self, img, mask):
class RandomRotate (line 335) | class RandomRotate(object):
method __init__ (line 336) | def __init__(self, degree):
method __call__ (line 339) | def __call__(self, img, mask):
class RandomSizeAndCrop (line 345) | class RandomSizeAndCrop(object):
method __init__ (line 346) | def __init__(self, size, crop_nopad,
method __call__ (line 354) | def __call__(self, img, mask, centroid=None):
class SlidingCropOld (line 375) | class SlidingCropOld(object):
method __init__ (line 376) | def __init__(self, crop_size, stride_rate, ignore_label):
method _pad (line 381) | def _pad(self, img, mask):
method __call__ (line 390) | def __call__(self, img, mask):
class SlidingCrop (line 427) | class SlidingCrop(object):
method __init__ (line 428) | def __init__(self, crop_size, stride_rate, ignore_label):
method _pad (line 433) | def _pad(self, img, mask):
method __call__ (line 442) | def __call__(self, img, mask):
class ClassUniform (line 480) | class ClassUniform(object):
method __init__ (line 481) | def __init__(self, size, crop_nopad, scale_min=0.5, scale_max=2.0, ign...
method detect_peaks (line 500) | def detect_peaks(self, image):
method __call__ (line 536) | def __call__(self, img, mask):
FILE: benchmarks/GSCNN-master/transforms/transforms.py
class RandomVerticalFlip (line 46) | class RandomVerticalFlip(object):
method __call__ (line 47) | def __call__(self, img):
class DeNormalize (line 53) | class DeNormalize(object):
method __init__ (line 54) | def __init__(self, mean, std):
method __call__ (line 58) | def __call__(self, tensor):
class MaskToTensor (line 64) | class MaskToTensor(object):
method __call__ (line 65) | def __call__(self, img):
class RelaxedBoundaryLossToTensor (line 68) | class RelaxedBoundaryLossToTensor(object):
method __init__ (line 69) | def __init__(self,ignore_id, num_classes):
method new_one_hot_converter (line 74) | def new_one_hot_converter(self,a):
method __call__ (line 81) | def __call__(self,img):
class ResizeHeight (line 124) | class ResizeHeight(object):
method __init__ (line 125) | def __init__(self, size, interpolation=Image.BILINEAR):
method __call__ (line 129) | def __call__(self, img):
class FreeScale (line 135) | class FreeScale(object):
method __init__ (line 136) | def __init__(self, size, interpolation=Image.BILINEAR):
method __call__ (line 140) | def __call__(self, img):
class FlipChannels (line 144) | class FlipChannels(object):
method __call__ (line 145) | def __call__(self, img):
class RandomGaussianBlur (line 149) | class RandomGaussianBlur(object):
method __call__ (line 150) | def __call__(self, img):
class RandomBilateralBlur (line 157) | class RandomBilateralBlur(object):
method __call__ (line 158) | def __call__(self, img):
function _is_pil_image (line 170) | def _is_pil_image(img):
function adjust_brightness (line 177) | def adjust_brightness(img, brightness_factor):
function adjust_contrast (line 197) | def adjust_contrast(img, contrast_factor):
function adjust_saturation (line 217) | def adjust_saturation(img, saturation_factor):
function adjust_hue (line 237) | def adjust_hue(img, hue_factor):
class ColorJitter (line 282) | class ColorJitter(object):
method __init__ (line 295) | def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
method get_params (line 302) | def get_params(brightness, contrast, saturation, hue):
method __call__ (line 337) | def __call__(self, img):
FILE: benchmarks/GSCNN-master/utils/AttrDict.py
class AttrDict (line 34) | class AttrDict(dict):
method __init__ (line 38) | def __init__(self, *args, **kwargs):
method __getattr__ (line 42) | def __getattr__(self, name):
method __setattr__ (line 50) | def __setattr__(self, name, value):
method immutable (line 62) | def immutable(self, is_immutable):
method is_immutable (line 75) | def is_immutable(self):
FILE: benchmarks/GSCNN-master/utils/f_boundary.py
function eval_mask_boundary (line 59) | def eval_mask_boundary(seg_mask,gt_mask,num_classes,num_proc=10,bound_th...
function db_eval_boundary_wrapper (line 104) | def db_eval_boundary_wrapper(args):
function db_eval_boundary (line 108) | def db_eval_boundary(foreground_mask,gt_mask, ignore_mask,bound_th=0.008):
function seg2bmap (line 173) | def seg2bmap(seg,width=None,height=None):
FILE: benchmarks/GSCNN-master/utils/image_page.py
class ImagePage (line 9) | class ImagePage(object):
method __init__ (line 22) | def __init__(self, experiment_name, html_filename):
method _print_header (line 28) | def _print_header(self):
method _print_footer (line 37) | def _print_footer(self):
method _print_table_header (line 41) | def _print_table_header(self, table_name):
method _print_table_footer (line 47) | def _print_table_footer(self):
method _print_table_guts (line 52) | def _print_table_guts(self, img_fn, descr):
method add_table (line 63) | def add_table(self, img_label_pairs):
method _write_table (line 66) | def _write_table(self, table):
method write_page (line 73) | def write_page(self):
function main (line 82) | def main():
FILE: benchmarks/GSCNN-master/utils/misc.py
function make_exp_name (line 23) | def make_exp_name(args, parser):
function save_log (line 60) | def save_log(prefix, output_dir, date_str):
function save_code (line 74) | def save_code(exp_path, date_str):
function prep_experiment (line 85) | def prep_experiment(args, parser):
class AverageMeter (line 109) | class AverageMeter(object):
method __init__ (line 111) | def __init__(self):
method reset (line 114) | def reset(self):
method update (line 120) | def update(self, val, n=1):
function evaluate_eval (line 128) | def evaluate_eval(args, net, optimizer, val_loss, mf_score, hist, dump_i...
function fast_hist (line 274) | def fast_hist(label_pred, label_true, num_classes):
function print_evaluate_results (line 283) | def print_evaluate_results(hist, iu, writer=None, epoch=0, dataset=None):
FILE: benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/hubconf.py
function hrnet_w48_cityscapes (line 16) | def hrnet_w48_cityscapes(pretrained=False, **kwargs):
FILE: benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/tools/_init_paths.py
function add_path (line 15) | def add_path(path):
FILE: benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/tools/test.py
function parse_args (line 34) | def parse_args():
function main (line 56) | def main():
FILE: benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/tools/train.py
function parse_args (line 36) | def parse_args():
function get_sampler (line 55) | def get_sampler(dataset):
function main (line 63) | def main():
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/neighbors/neighbors.cpp
function brute_neighbors (line 5) | void brute_neighbors(vector<PointXYZ>& queries, vector<PointXYZ>& suppor...
function ordered_neighbors (line 58) | void ordered_neighbors(vector<PointXYZ>& queries,
function batch_ordered_neighbors (line 125) | void batch_ordered_neighbors(vector<PointXYZ>& queries,
function batch_nanoflann_neighbors (line 211) | void batch_nanoflann_neighbors(vector<PointXYZ>& queries,
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/wrapper.cpp
type PyModuleDef (line 35) | struct PyModuleDef
function PyMODINIT_FUNC (line 48) | PyMODINIT_FUNC PyInit_radius_neighbors(void)
function PyObject (line 58) | static PyObject* batch_neighbors(PyObject* self, PyObject* args, PyObjec...
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/grid_subsampling/grid_subsampling.cpp
function grid_subsampling (line 5) | void grid_subsampling(vector<PointXYZ>& original_points,
function batch_grid_subsampling (line 109) | void batch_grid_subsampling(vector<PointXYZ>& original_points,
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/grid_subsampling/grid_subsampling.h
function class (line 10) | class SampledData
function update_all (line 42) | void update_all(const PointXYZ p, vector<float>::iterator f_begin, vecto...
function update_features (line 55) | void update_features(const PointXYZ p, vector<float>::iterator f_begin)
function update_classes (line 62) | void update_classes(const PointXYZ p, vector<int>::iterator l_begin)
function update_points (line 74) | void update_points(const PointXYZ p)
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/wrapper.cpp
type PyModuleDef (line 39) | struct PyModuleDef
function PyMODINIT_FUNC (line 52) | PyMODINIT_FUNC PyInit_grid_subsampling(void)
function PyObject (line 62) | static PyObject* batch_subsampling(PyObject* self, PyObject* args, PyObj...
function PyObject (line 338) | static PyObject* cloud_subsampling(PyObject* self, PyObject* args, PyObj...
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_utils/cloud/cloud.cpp
function PointXYZ (line 27) | PointXYZ max_point(std::vector<PointXYZ> points)
function PointXYZ (line 48) | PointXYZ min_point(std::vector<PointXYZ> points)
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_utils/cloud/cloud.h
function class (line 40) | class PointXYZ
function const (line 58) | float operator [] (int i) const
function dot (line 66) | float dot(const PointXYZ P) const
function sq_norm (line 71) | float sq_norm()
function PointXYZ (line 76) | PointXYZ cross(const PointXYZ P) const
function PointXYZ (line 110) | inline PointXYZ operator + (const PointXYZ A, const PointXYZ B)
function PointXYZ (line 115) | inline PointXYZ operator - (const PointXYZ A, const PointXYZ B)
function PointXYZ (line 120) | inline PointXYZ operator * (const PointXYZ P, const float a)
function PointXYZ (line 125) | inline PointXYZ operator * (const float a, const PointXYZ P)
function operator (line 135) | inline bool operator == (const PointXYZ A, const PointXYZ B)
function PointXYZ (line 140) | inline PointXYZ floor(const PointXYZ P)
function kdtree_get_pt (line 150) | struct PointCloud
FILE: benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_utils/nanoflann/nanoflann.hpp
function T (line 79) | T pi_const() {
type has_resize (line 87) | struct has_resize : std::false_type {}
type has_resize<T, decltype((void)std::declval<T>().resize(1), 0)> (line 90) | struct has_resize<T, decltype((void)std::declval<T>().resize(1), 0)>
type has_assign (line 93) | struct has_assign : std::false_type {}
type has_assign<T, decltype((void)std::declval<T>().assign(1, 0), 0)> (line 96) | struct has_assign<T, decltype((void)std::declval<T>().assign(1, 0), 0)>
function resize (line 103) | inline typename std::enable_if<has_resize<Container>::value, void>::type
function resize (line 113) | inline typename std::enable_if<!has_resize<Container>::value, void>::type
function assign (line 123) | inline typename std::enable_if<has_assign<Container>::value, void>::type
function assign (line 132) | inline typename std::enable_if<!has_assign<Container>::value, void>::type
class KNNResultSet (line 142) | class KNNResultSet {
method KNNResultSet (line 155) | inline KNNResultSet(CountType capacity_)
method init (line 158) | inline void init(IndexType *indices_, DistanceType *dists_) {
method CountType (line 166) | inline CountType size() const { return count; }
method full (line 168) | inline bool full() const { return count == capacity; }
method addPoint (line 175) | inline bool addPoint(DistanceType dist, IndexType index) {
type IndexDist_Sorter (line 208) | struct IndexDist_Sorter {
class RadiusResultSet (line 220) | class RadiusResultSet {
method RadiusResultSet (line 230) | inline RadiusResultSet(
method init (line 237) | inline void init() { clear(); }
method clear (line 238) | inline void clear() { m_indices_dists.clear(); }
method size (line 240) | inline size_t size() const { return m_indices_dists.size(); }
method full (line 242) | inline bool full() const { return true; }
method addPoint (line 249) | inline bool addPoint(DistanceType dist, IndexType index) {
method DistanceType (line 255) | inline DistanceType worstDist() const { return radius; }
method worst_item (line 261) | std::pair<IndexType, DistanceType> worst_item() const {
method save_value (line 279) | void save_value(FILE *stream, const T &value, size_t count = 1) {
method save_value (line 284) | void save_value(FILE *stream, const std::vector<T> &value) {
method load_value (line 291) | void load_value(FILE *stream, T &value, size_t count = 1) {
method load_value (line 298) | void load_value(FILE *stream, std::vector<T> &value) {
type Metric (line 315) | struct Metric {}
type L1_Adaptor (line 324) | struct L1_Adaptor {
method L1_Adaptor (line 330) | L1_Adaptor(const DataSource &_data_source) : data_source(_data_sourc...
method DistanceType (line 332) | inline DistanceType evalMetric(const T *a, const size_t b_idx, size_...
method DistanceType (line 363) | inline DistanceType accum_dist(const U a, const V b, const size_t) c...
type L2_Adaptor (line 375) | struct L2_Adaptor {
method L2_Adaptor (line 381) | L2_Adaptor(const DataSource &_data_source) : data_source(_data_sourc...
method DistanceType (line 383) | inline DistanceType evalMetric(const T *a, const size_t b_idx, size_...
method DistanceType (line 411) | inline DistanceType accum_dist(const U a, const V b, const size_t) c...
type L2_Simple_Adaptor (line 423) | struct L2_Simple_Adaptor {
method L2_Simple_Adaptor (line 429) | L2_Simple_Adaptor(const DataSource &_data_source)
method DistanceType (line 432) | inline DistanceType evalMetric(const T *a, const size_t b_idx,
method DistanceType (line 443) | inline DistanceType accum_dist(const U a, const V b, const size_t) c...
type SO2_Adaptor (line 455) | struct SO2_Adaptor {
method SO2_Adaptor (line 461) | SO2_Adaptor(const DataSource &_data_source) : data_source(_data_sour...
method DistanceType (line 463) | inline DistanceType evalMetric(const T *a, const size_t b_idx,
method DistanceType (line 471) | inline DistanceType accum_dist(const U a, const V b, const size_t) c...
type SO3_Adaptor (line 489) | struct SO3_Adaptor {
method SO3_Adaptor (line 495) | SO3_Adaptor(const DataSource &_data_source)
method DistanceType (line 498) | inline DistanceType evalMetric(const T *a, const size_t b_idx,
method DistanceType (line 504) | inline DistanceType accum_dist(const U a, const V b, const size_t id...
type metric_L1 (line 510) | struct metric_L1 : public Metric {
type traits (line 511) | struct traits {
type metric_L2 (line 516) | struct metric_L2 : public Metric {
type traits (line 517) | struct traits {
type metric_L2_Simple (line 522) | struct metric_L2_Simple : public Metric {
type traits (line 523) | struct traits {
type metric_SO2 (line 528) | struct metric_SO2 : public Metric {
type traits (line 529) | struct traits {
type metric_SO3 (line 534) | struct metric_SO3 : public Metric {
type traits (line 535) | struct traits {
type KDTreeSingleIndexAdaptorParams (line 546) | struct KDTreeSingleIndexAdaptorParams {
method KDTreeSingleIndexAdaptorParams (line 547) | KDTreeSingleIndexAdaptorParams(size_t _leaf_max_size = 10)
type SearchParams (line 554) | struct SearchParams {
method SearchParams (line 557) | SearchParams(int checks_IGNORED_ = 32, float eps_ = 0, bool sorted_ ...
method T (line 578) | inline T *allocate(size_t count = 1) {
class PooledAllocator (line 601) | class PooledAllocator {
method internal_init (line 612) | void internal_init() {
method PooledAllocator (line 626) | PooledAllocator() { internal_init(); }
method free_all (line 634) | void free_all() {
method T (line 702) | T *allocate(const size_t count = 1) {
type array_or_vector_selector (line 715) | struct array_or_vector_selector {
type array_or_vector_selector<-1, T> (line 719) | struct array_or_vector_selector<-1, T> {
class KDTreeBaseClass (line 739) | class KDTreeBaseClass {
method freeIndex (line 744) | void freeIndex(Derived &obj) {
type Node (line 754) | struct Node {
type leaf (line 758) | struct leaf {
type nonleaf (line 761) | struct nonleaf {
type Interval (line 771) | struct Interval {
method size (line 813) | size_t size(const Derived &obj) const { return obj.m_size; }
method veclen (line 816) | size_t veclen(const Derived &obj) {
method ElementType (line 821) | inline ElementType dataset_get(const Derived &obj, size_t idx,
method usedMemory (line 830) | size_t usedMemory(Derived &obj) {
method computeMinMax (line 836) | void computeMinMax(const Derived &obj, IndexType *ind, IndexType count,
method NodePtr (line 857) | NodePtr divideTree(Derived &obj, const IndexType left, const IndexTy...
method middleSplit_ (line 909) | void middleSplit_(Derived &obj, IndexType *ind, IndexType count,
method planeSplit (line 967) | void planeSplit(Derived &obj, IndexType *ind, const IndexType count,
method DistanceType (line 1005) | DistanceType computeInitialDistances(const Derived &obj,
method save_tree (line 1024) | void save_tree(Derived &obj, FILE *stream, NodePtr tree) {
method load_tree (line 1034) | void load_tree(Derived &obj, FILE *stream, NodePtr &tree) {
method saveIndex_ (line 1050) | void saveIndex_(Derived &obj, FILE *stream) {
method loadIndex_ (line 1064) | void loadIndex_(Derived &obj, FILE *stream) {
class KDTreeSingleIndexAdaptor (line 1116) | class KDTreeSingleIndexAdaptor
method KDTreeSingleIndexAdaptor (line 1122) | KDTreeSingleIndexAdaptor(
method KDTreeSingleIndexAdaptor (line 1170) | KDTreeSingleIndexAdaptor(const int dimensionality,
method buildIndex (line 1190) | void buildIndex() {
method findNeighbors (line 1221) | bool findNeighbors(RESULTSET &result, const ElementType *vec,
method knnSearch (line 1254) | size_t knnSearch(const ElementType *query_point, const size_t num_cl...
method radiusSearch (line 1279) | size_t
method radiusSearchCustomCallback (line 1297) | size_t radiusSearchCustomCallback(
method init_vind (line 1309) | void init_vind() {
method computeBoundingBox (line 1318) | void computeBoundingBox(BoundingBox &bbox) {
method searchLevel (line 1348) | bool searchLevel(RESULTSET &result_set, const ElementType *vec,
method saveIndex (line 1419) | void saveIndex(FILE *stream) { this->saveIndex_(*this, stream); }
method loadIndex (line 1426) | void loadIndex(FILE *stream) { this->loadIndex_(*this, stream); }
class KDTreeSingleIndexDynamicAdaptor_ (line 1468) | class KDTreeSingleIndexDynamicAdaptor_
method KDTreeSingleIndexDynamicAdaptor_ (line 1519) | KDTreeSingleIndexDynamicAdaptor_(
method KDTreeSingleIndexDynamicAdaptor_ (line 1536) | KDTreeSingleIndexDynamicAdaptor_
method buildIndex (line 1555) | void buildIndex() {
method findNeighbors (line 1584) | bool findNeighbors(RESULTSET &result, const ElementType *vec,
method knnSearch (line 1616) | size_t knnSearch(const ElementType *query_point, const size_t num_cl...
method radiusSearch (line 1641) | size_t
method radiusSearchCustomCallback (line 1659) | size_t radiusSearchCustomCallback(
method computeBoundingBox (line 1669) | void computeBoundingBox(BoundingBox &bbox) {
method searchLevel (line 1699) | void searchLevel(RESULTSET &result_set, const ElementType *vec,
method saveIndex (line 1765) | void saveIndex(FILE *stream) { this->saveIndex_(*this, stream); }
method loadIndex (line 1772) | void loadIndex(FILE *stream) { this->loadIndex_(*this, stream); }
class KDTreeSingleIndexDynamicAdaptor (line 1791) | class KDTreeSingleIndexDynamicAdaptor {
method First0Bit (line 1825) | int First0Bit(IndexType num) {
method init (line 1835) | void init() {
method KDTreeSingleIndexDynamicAdaptor (line 1860) | KDTreeSingleIndexDynamicAdaptor(const int dimensionality,
method KDTreeSingleIndexDynamicAdaptor (line 1881) | KDTreeSingleIndexDynamicAdaptor(
method addPoints (line 1886) | void addPoints(IndexType start, IndexType end) {
method removePoint (line 1909) | void removePoint(size_t idx) {
method findNeighbors (line 1929) | bool findNeighbors(RESULTSET &result, const ElementType *vec,
type KDTreeEigenMatrixAdaptor (line 1957) | struct KDTreeEigenMatrixAdaptor {
method KDTreeEigenMatrixAdaptor (line 1971) | KDTreeEigenMatrixAdaptor(const size_t dimensionality,
method KDTreeEigenMatrixAdaptor (line 1990) | KDTreeEigenMatrixAdaptor(const self_t &) = delete;
method query (line 2002) | inline void query(const num_t *query_point, const size_t num_closest,
method self_t (line 2013) | const self_t &derived() const { return *this; }
method self_t (line 2014) | self_t &derived() { return *this; }
method kdtree_get_point_count (line 2017) | inline size_t kdtree_get_point_count() const {
method num_t (line 2022) | inline num_t kdtree_get_pt(const IndexType idx, size_t dim) const {
method kdtree_get_bbox (line 2031) | bool kdtree_get_bbox(BBOX & /*bb*/) const {
FILE: benchmarks/KPConv-PyTorch-master/datasets/ModelNet40.py
class ModelNet40Dataset (line 51) | class ModelNet40Dataset(PointCloudDataset):
method __init__ (line 54) | def __init__(self, config, train=True, orient_correction=True):
method __len__ (line 150) | def __len__(self):
method __getitem__ (line 156) | def __getitem__(self, idx_list):
method load_subsampled_clouds (line 232) | def load_subsampled_clouds(self, orient_correction):
class ModelNet40Sampler (line 322) | class ModelNet40Sampler(Sampler):
method __init__ (line 325) | def __init__(self, dataset: ModelNet40Dataset, use_potential=True, bal...
method __iter__ (line 348) | def __iter__(self):
method __len__ (line 434) | def __len__(self):
method calibration (line 440) | def calibration(self, dataloader, untouched_ratio=0.9, verbose=False):
class ModelNet40CustomBatch (line 681) | class ModelNet40CustomBatch:
method __init__ (line 684) | def __init__(self, input_list):
method pin_memory (line 714) | def pin_memory(self):
method to (line 731) | def to(self, device):
method unstack_points (line 745) | def unstack_points(self, layer=None):
method unstack_neighbors (line 749) | def unstack_neighbors(self, layer=None):
method unstack_pools (line 753) | def unstack_pools(self, layer=None):
method unstack_elements (line 757) | def unstack_elements(self, element_name, layer=None, to_numpy=True):
function ModelNet40Collate (line 808) | def ModelNet40Collate(batch_data):
function debug_sampling (line 818) | def debug_sampling(dataset, sampler, loader):
function debug_timing (line 837) | def debug_timing(dataset, sampler, loader):
function debug_show_clouds (line 879) | def debug_show_clouds(dataset, sampler, loader):
function debug_batch_and_neighbors_calib (line 934) | def debug_batch_and_neighbors_calib(dataset, sampler, loader):
class ModelNet40WorkerInitDebug (line 971) | class ModelNet40WorkerInitDebug:
method __init__ (line 974) | def __init__(self, dataset):
method __call__ (line 978) | def __call__(self, worker_id):
FILE: benchmarks/KPConv-PyTorch-master/datasets/Rellis.py
class RellisDataset (line 54) | class RellisDataset(PointCloudDataset):
method __init__ (line 57) | def __init__(self, config, set='training', balance_classes=True):
method __len__ (line 210) | def __len__(self):
method __getitem__ (line 216) | def __getitem__(self, batch_i):
method load_calib_poses (line 560) | def load_calib_poses(self):
method parse_calibration (line 746) | def parse_calibration(self, filename):
method parse_poses (line 773) | def parse_poses(self, filename, calibration):
class RellisSampler (line 808) | class RellisSampler(Sampler):
method __init__ (line 811) | def __init__(self, dataset: RellisDataset):
method __iter__ (line 825) | def __iter__(self):
method __len__ (line 926) | def __len__(self):
method calib_max_in (line 932) | def calib_max_in(self, config, dataloader, untouched_ratio=0.8, verbos...
method calibration (line 1049) | def calibration(self, dataloader, untouched_ratio=0.9, verbose=False, ...
class RellisCustomBatch (line 1324) | class RellisCustomBatch:
method __init__ (line 1327) | def __init__(self, input_list):
method pin_memory (line 1367) | def pin_memory(self):
method to (line 1386) | def to(self, device):
method unstack_points (line 1402) | def unstack_points(self, layer=None):
method unstack_neighbors (line 1406) | def unstack_neighbors(self, layer=None):
method unstack_pools (line 1410) | def unstack_pools(self, layer=None):
method unstack_elements (line 1414) | def unstack_elements(self, element_name, layer=None, to_numpy=True):
function RellisCollate (line 1465) | def RellisCollate(batch_data):
function debug_timing (line 1475) | def debug_timing(dataset, loader):
function debug_class_w (line 1520) | def debug_class_w(dataset, loader):
FILE: benchmarks/KPConv-PyTorch-master/datasets/S3DIS.py
class S3DISDataset (line 53) | class S3DISDataset(PointCloudDataset):
method __init__ (line 56) | def __init__(self, config, set='training', use_potentials=True, load_d...
method __len__ (line 225) | def __len__(self):
method __getitem__ (line 231) | def __getitem__(self, batch_i):
method potential_item (line 242) | def potential_item(self, batch_i, debug_workers=False):
method random_item (line 495) | def random_item(self, batch_i):
method prepare_S3DIS_ply (line 620) | def prepare_S3DIS_ply(self):
method load_subsampled_clouds (line 694) | def load_subsampled_clouds(self):
method load_evaluation_points (line 869) | def load_evaluation_points(self, file_path):
class S3DISSampler (line 885) | class S3DISSampler(Sampler):
method __init__ (line 888) | def __init__(self, dataset: S3DISDataset):
method __iter__ (line 902) | def __iter__(self):
method __len__ (line 955) | def __len__(self):
method fast_calib (line 961) | def fast_calib(self):
method calibration (line 1038) | def calibration(self, dataloader, untouched_ratio=0.9, verbose=False, ...
class S3DISCustomBatch (line 1291) | class S3DISCustomBatch:
method __init__ (line 1294) | def __init__(self, input_list):
method pin_memory (line 1330) | def pin_memory(self):
method to (line 1350) | def to(self, device):
method unstack_points (line 1367) | def unstack_points(self, layer=None):
method unstack_neighbors (line 1371) | def unstack_neighbors(self, layer=None):
method unstack_pools (line 1375) | def unstack_pools(self, layer=None):
method unstack_elements (line 1379) | def unstack_elements(self, element_name, layer=None, to_numpy=True):
function S3DISCollate (line 1430) | def S3DISCollate(batch_data):
function debug_upsampling (line 1440) | def debug_upsampling(dataset, loader):
function debug_timing (line 1474) | def debug_timing(dataset, loader):
function debug_show_clouds (line 1519) | def debug_show_clouds(dataset, loader):
function debug_batch_and_neighbors_calib (line 1574) | def debug_batch_and_neighbors_calib(dataset, loader):
FILE: benchmarks/KPConv-PyTorch-master/datasets/SemanticKitti.py
class SemanticKittiDataset (line 54) | class SemanticKittiDataset(PointCloudDataset):
method __init__ (line 57) | def __init__(self, config, set='training', balance_classes=True):
method __len__ (line 194) | def __len__(self):
method __getitem__ (line 200) | def __getitem__(self, batch_i):
method load_calib_poses (line 542) | def load_calib_poses(self):
method parse_calibration (line 661) | def parse_calibration(self, filename):
method parse_poses (line 688) | def parse_poses(self, filename, calibration):
class SemanticKittiSampler (line 723) | class SemanticKittiSampler(Sampler):
method __init__ (line 726) | def __init__(self, dataset: SemanticKittiDataset):
method __iter__ (line 740) | def __iter__(self):
method __len__ (line 831) | def __len__(self):
method calib_max_in (line 837) | def calib_max_in(self, config, dataloader, untouched_ratio=0.8, verbos...
method calibration (line 954) | def calibration(self, dataloader, untouched_ratio=0.9, verbose=False, ...
class SemanticKittiCustomBatch (line 1229) | class SemanticKittiCustomBatch:
method __init__ (line 1232) | def __init__(self, input_list):
method pin_memory (line 1272) | def pin_memory(self):
method to (line 1291) | def to(self, device):
method unstack_points (line 1307) | def unstack_points(self, layer=None):
method unstack_neighbors (line 1311) | def unstack_neighbors(self, layer=None):
method unstack_pools (line 1315) | def unstack_pools(self, layer=None):
method unstack_elements (line 1319) | def unstack_elements(self, element_name, layer=None, to_numpy=True):
function SemanticKittiCollate (line 1370) | def SemanticKittiCollate(batch_data):
function debug_timing (line 1380) | def debug_timing(dataset, loader):
function debug_class_w (line 1425) | def debug_class_w(dataset, loader):
FILE: benchmarks/KPConv-PyTorch-master/datasets/common.py
function grid_subsampling (line 44) | def grid_subsampling(points, features=None, labels=None, sampleDl=0.1, v...
function batch_grid_subsampling (line 77) | def batch_grid_subsampling(points, batches_len, features=None, labels=None,
function batch_neighbors (line 185) | def batch_neighbors(queries, supports, q_batches, s_batches, radius):
class PointCloudDataset (line 205) | class PointCloudDataset(Dataset):
method __init__ (line 208) | def __init__(self, name):
method __len__ (line 226) | def __len__(self):
method __getitem__ (line 232) | def __getitem__(self, idx):
method init_labels (line 239) | def init_labels(self):
method augmentation_transform (line 248) | def augmentation_transform(self, points, normals=None, verbose=False):
method big_neighborhood_filter (line 332) | def big_neighborhood_filter(self, neighbors, layer):
method classification_inputs (line 344) | def classification_inputs(self,
method segmentation_inputs (line 457) | def segmentation_inputs(self,
FILE: benchmarks/KPConv-PyTorch-master/kernels/kernel_points.py
function create_3D_rotations (line 44) | def create_3D_rotations(axis, angle):
function spherical_Lloyd (line 78) | def spherical_Lloyd(radius, num_cells, dimension=3, fixed='center', appr...
function kernel_point_optimization_debug (line 258) | def kernel_point_optimization_debug(radius, num_points, num_kernels=1, d...
function load_kernels (line 400) | def load_kernels(radius, num_kpoints, dimension, fixed, lloyd=False):
FILE: benchmarks/KPConv-PyTorch-master/models/architectures.py
function p2p_fitting_regularizer (line 21) | def p2p_fitting_regularizer(net):
class KPCNN (line 57) | class KPCNN(nn.Module):
method __init__ (line 62) | def __init__(self, config):
method forward (line 136) | def forward(self, batch, config):
method loss (line 151) | def loss(self, outputs, labels):
method accuracy (line 174) | def accuracy(outputs, labels):
class KPFCNN (line 189) | class KPFCNN(nn.Module):
method __init__ (line 194) | def __init__(self, config, lbl_values, ign_lbls):
method forward (line 322) | def forward(self, batch, config):
method loss (line 345) | def loss(self, outputs, labels):
method accuracy (line 377) | def accuracy(self, outputs, labels):
FILE: benchmarks/KPConv-PyTorch-master/models/blocks.py
function gather (line 35) | def gather(x, idx, method=2):
function radius_gaussian (line 69) | def radius_gaussian(sq_r, sig, eps=1e-9):
function closest_pool (line 79) | def closest_pool(x, inds):
function max_pool (line 94) | def max_pool(x, inds):
function global_average (line 113) | def global_average(x, batch_lengths):
class KPConv (line 143) | class KPConv(nn.Module):
method __init__ (line 145) | def __init__(self, kernel_size, p_dim, in_channels, out_channels, KP_e...
method reset_parameters (line 216) | def reset_parameters(self):
method init_KP (line 222) | def init_KP(self):
method forward (line 237) | def forward(self, q_pts, s_pts, neighb_inds, x):
method __repr__ (line 375) | def __repr__(self):
function block_decider (line 386) | def block_decider(block_name,
class BatchNormBlock (line 429) | class BatchNormBlock(nn.Module):
method __init__ (line 431) | def __init__(self, in_dim, use_bn, bn_momentum):
method reset_parameters (line 449) | def reset_parameters(self):
method forward (line 452) | def forward(self, x):
method __repr__ (line 463) | def __repr__(self):
class UnaryBlock (line 469) | class UnaryBlock(nn.Module):
method __init__ (line 471) | def __init__(self, in_dim, out_dim, use_bn, bn_momentum, no_relu=False):
method forward (line 492) | def forward(self, x, batch=None):
method __repr__ (line 499) | def __repr__(self):
class SimpleBlock (line 506) | class SimpleBlock(nn.Module):
method __init__ (line 508) | def __init__(self, block_name, in_dim, out_dim, radius, layer_ind, con...
method forward (line 548) | def forward(self, x, batch):
class ResnetBottleneckBlock (line 563) | class ResnetBottleneckBlock(nn.Module):
method __init__ (line 565) | def __init__(self, block_name, in_dim, out_dim, radius, layer_ind, con...
method forward (line 620) | def forward(self, features, batch):
class GlobalAverageBlock (line 651) | class GlobalAverageBlock(nn.Module):
method __init__ (line 653) | def __init__(self):
method forward (line 660) | def forward(self, x, batch):
class NearestUpsampleBlock (line 664) | class NearestUpsampleBlock(nn.Module):
method __init__ (line 666) | def __init__(self, layer_ind):
method forward (line 674) | def forward(self, x, batch):
method __repr__ (line 677) | def __repr__(self):
class MaxPoolBlock (line 682) | class MaxPoolBlock(nn.Module):
method __init__ (line 684) | def __init__(self, layer_ind):
method forward (line 692) | def forward(self, x, batch):
FILE: benchmarks/KPConv-PyTorch-master/plot_convergence.py
function running_mean (line 51) | def running_mean(signal, n, axis=0, stride=1):
function IoU_class_metrics (line 83) | def IoU_class_metrics(all_IoUs, smooth_n):
function load_confusions (line 97) | def load_confusions(filename, n_class):
function load_training_results (line 110) | def load_training_results(path):
function load_single_IoU (line 137) | def load_single_IoU(filename, n_parts):
function load_snap_clouds (line 149) | def load_snap_clouds(path, dataset, only_last=False):
function compare_trainings (line 199) | def compare_trainings(list_of_paths, list_of_labels=None):
function compare_convergences_segment (line 332) | def compare_convergences_segment(dataset, list_of_paths, list_of_names=N...
function compare_convergences_classif (line 448) | def compare_convergences_classif(list_of_paths, list_of_labels=None):
function compare_convergences_SLAM (line 563) | def compare_convergences_SLAM(dataset, list_of_paths, list_of_names=None):
function experiment_name_1 (line 691) | def experiment_name_1():
function experiment_name_2 (line 720) | def experiment_name_2():
FILE: benchmarks/KPConv-PyTorch-master/test_models.py
function model_choice (line 49) | def model_choice(chosen_log):
FILE: benchmarks/KPConv-PyTorch-master/train_ModelNet40.py
class Modelnet40Config (line 46) | class Modelnet40Config(Config):
FILE: benchmarks/KPConv-PyTorch-master/train_Rellis.py
class RellisConfig (line 46) | class RellisConfig(Config):
FILE: benchmarks/KPConv-PyTorch-master/train_S3DIS.py
class S3DISConfig (line 43) | class S3DISConfig(Config):
FILE: benchmarks/KPConv-PyTorch-master/train_SemanticKitti.py
class SemanticKittiConfig (line 46) | class SemanticKittiConfig(Config):
FILE: benchmarks/KPConv-PyTorch-master/utils/config.py
class bcolors (line 23) | class bcolors:
class Config (line 34) | class Config:
method __init__ (line 190) | def __init__(self):
method load (line 234) | def load(self, path):
method save (line 277) | def save(self):
FILE: benchmarks/KPConv-PyTorch-master/utils/mayavi_visu.py
function show_ModelNet_models (line 42) | def show_ModelNet_models(all_points):
function show_ModelNet_examples (line 106) | def show_ModelNet_examples(clouds, cloud_normals=None, cloud_labels=None):
function show_neighbors (line 191) | def show_neighbors(query, supports, neighbors):
function show_input_batch (line 271) | def show_input_batch(batch):
FILE: benchmarks/KPConv-PyTorch-master/utils/metrics.py
function fast_confusion (line 35) | def fast_confusion(true, pred, label_values=None):
function metrics (line 121) | def metrics(confusions, ignore_unclassified=False):
function smooth_metrics (line 158) | def smooth_metrics(confusions, smooth_n=0, ignore_unclassified=False):
function IoU_from_confusions (line 204) | def IoU_from_confusions(confusions):
FILE: benchmarks/KPConv-PyTorch-master/utils/ply.py
function parse_header (line 62) | def parse_header(plyfile, ext):
function parse_mesh_header (line 82) | def parse_mesh_header(plyfile, ext):
function read_ply (line 116) | def read_ply(filename, triangular_mesh=False):
function header_properties (line 199) | def header_properties(field_list, field_names):
function write_ply (line 217) | def write_ply(filename, field_list, field_names, triangular_faces=None):
function describe_element (line 331) | def describe_element(name, df):
FILE: benchmarks/KPConv-PyTorch-master/utils/tester.py
class ModelTester (line 52) | class ModelTester:
method __init__ (line 57) | def __init__(self, net, chkp_path=None, on_gpu=True):
method classification_test (line 85) | def classification_test(self, net, test_loader, config, num_votes=100,...
method cloud_segmentation_test (line 177) | def cloud_segmentation_test(self, net, test_loader, config, num_votes=...
method slam_segmentation_test (line 467) | def slam_segmentation_test(self, net, test_loader, config, num_votes=1...
method rellis_segmentation_test (line 776) | def rellis_segmentation_test(self, net, test_loader, config, num_votes...
FILE: benchmarks/KPConv-PyTorch-master/utils/trainer.py
class ModelTrainer (line 54) | class ModelTrainer:
method __init__ (line 59) | def __init__(self, net, config, chkp_path=None, finetune=False, on_gpu...
method train (line 125) | def train(self, net, training_loader, val_loader, config):
method validation (line 280) | def validation(self, net, val_loader, config: Config):
method object_classification_validation (line 293) | def object_classification_validation(self, net, val_loader, config):
method cloud_segmentation_validation (line 413) | def cloud_segmentation_validation(self, net, val_loader, config, debug...
method slam_segmentation_validation (line 652) | def slam_segmentation_validation(self, net, val_loader, config, debug=...
FILE: benchmarks/KPConv-PyTorch-master/utils/visualizer.py
class ModelVisualizer (line 51) | class ModelVisualizer:
method __init__ (line 56) | def __init__(self, net, config, chkp_path, on_gpu=True):
method show_deformable_kernels (line 99) | def show_deformable_kernels(self, net, loader, config, deform_idx=0):
function show_ModelNet_models (line 447) | def show_ModelNet_models(all_points):
FILE: benchmarks/KPConv-PyTorch-master/visualize_deformations.py
function model_choice (line 47) | def model_choice(chosen_log):
FILE: benchmarks/SalsaNext/train/common/avgmeter.py
class AverageMeter (line 4) | class AverageMeter(object):
method __init__ (line 7) | def __init__(self):
method reset (line 10) | def reset(self):
method update (line 16) | def update(self, val, n=1):
FILE: benchmarks/SalsaNext/train/common/laserscan.py
class LaserScan (line 10) | class LaserScan:
method __init__ (line 14) | def __init__(self, project=False, H=64, W=1024, fov_up=3.0, fov_down=-...
method reset (line 27) | def reset(self):
method size (line 60) | def size(self):
method __len__ (line 64) | def __len__(self):
method open_scan (line 67) | def open_scan(self, filename):
method set_points (line 96) | def set_points(self, points, remissions=None):
method do_range_projection (line 134) | def do_range_projection(self):
class SemLaserScan (line 198) | class SemLaserScan(LaserScan):
method __init__ (line 202) | def __init__(self, sem_color_dict=None, project=False, H=64, W=1024, f...
method reset (line 233) | def reset(self):
method open_label (line 257) | def open_label(self, filename):
method set_label (line 278) | def set_label(self, label):
method colorize (line 300) | def colorize(self):
method do_label_projection (line 309) | def do_label_projection(self):
FILE: benchmarks/SalsaNext/train/common/laserscanvis.py
class LaserScanVis (line 10) | class LaserScanVis:
method __init__ (line 13) | def __init__(self, scan, scan_names, label_names, offset=0,
method reset (line 29) | def reset(self):
method get_mpl_colormap (line 115) | def get_mpl_colormap(self, cmap_name):
method update_scan (line 126) | def update_scan(self):
method key_press (line 193) | def key_press(self, event):
method draw (line 205) | def draw(self, event):
method destroy (line 211) | def destroy(self):
method run (line 217) | def run(self):
FILE: benchmarks/SalsaNext/train/common/logger.py
class Logger (line 14) | class Logger(object):
method __init__ (line 16) | def __init__(self, log_dir):
method scalar_summary (line 20) | def scalar_summary(self, tag, value, step):
method image_summary (line 27) | def image_summary(self, tag, images, step):
method histo_summary (line 52) | def histo_summary(self, tag, values, step, bins=1000):
FILE: benchmarks/SalsaNext/train/common/summary.py
function summary (line 10) | def summary(model, input_size, batch_size=-1, device="cuda"):
FILE: benchmarks/SalsaNext/train/common/sync_batchnorm/batchnorm.py
function _sum_ft (line 25) | def _sum_ft(tensor):
function _unsqueeze_ft (line 30) | def _unsqueeze_ft(tensor):
class _SynchronizedBatchNorm (line 40) | class _SynchronizedBatchNorm(_BatchNorm):
method __init__ (line 41) | def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True):
method forward (line 51) | def forward(self, input):
method __data_parallel_replicate__ (line 86) | def __data_parallel_replicate__(self, ctx, copy_id):
method _data_parallel_master (line 96) | def _data_parallel_master(self, intermediates):
method _compute_mean_std (line 119) | def _compute_mean_std(self, sum_, ssum, size):
class SynchronizedBatchNorm1d (line 136) | class SynchronizedBatchNorm1d(_SynchronizedBatchNorm):
method _check_input_dim (line 192) | def _check_input_dim(self, input):
class SynchronizedBatchNorm2d (line 199) | class SynchronizedBatchNorm2d(_SynchronizedBatchNorm):
method _check_input_dim (line 255) | def _check_input_dim(self, input):
class SynchronizedBatchNorm3d (line 262) | class SynchronizedBatchNorm3d(_SynchronizedBatchNorm):
method _check_input_dim (line 319) | def _check_input_dim(self, input):
function convert_model (line 326) | def convert_model(module):
FILE: benchmarks/SalsaNext/train/common/sync_batchnorm/comm.py
class FutureResult (line 18) | class FutureResult(object):
method __init__ (line 21) | def __init__(self):
method put (line 26) | def put(self, result):
method get (line 32) | def get(self):
class SlavePipe (line 47) | class SlavePipe(_SlavePipeBase):
method run_slave (line 50) | def run_slave(self, msg):
class SyncMaster (line 57) | class SyncMaster(object):
method __init__ (line 68) | def __init__(self, master_callback):
method __getstate__ (line 79) | def __getstate__(self):
method __setstate__ (line 82) | def __setstate__(self, state):
method register_slave (line 85) | def register_slave(self, identifier):
method run_master (line 103) | def run_master(self, master_msg):
method nr_slaves (line 137) | def nr_slaves(self):
FILE: benchmarks/SalsaNext/train/common/sync_batchnorm/replicate.py
class CallbackContext (line 23) | class CallbackContext(object):
function execute_replication_callbacks (line 27) | def execute_replication_callbacks(modules):
class DataParallelWithCallback (line 50) | class DataParallelWithCallback(DataParallel):
method replicate (line 64) | def replicate(self, module, device_ids):
function patch_replication_callback (line 71) | def patch_replication_callback(data_parallel):
FILE: benchmarks/SalsaNext/train/common/warmupLR.py
class warmupLR (line 6) | class warmupLR(toptim._LRScheduler):
method __init__ (line 13) | def __init__(self, optimizer, lr, warmup_steps, momentum, decay):
method get_lr (line 40) | def get_lr(self):
method step (line 43) | def step(self, epoch=None):
FILE: benchmarks/SalsaNext/train/tasks/semantic/dataset/kitti/parser.py
function is_scan (line 27) | def is_scan(filename):
function is_label (line 31) | def is_label(filename):
function my_collate (line 35) | def my_collate(batch):
class SemanticKitti (line 62) | class SemanticKitti(Dataset):
method __init__ (line 64) | def __init__(self, root, # directory where data is
method __getitem__ (line 155) | def __getitem__(self, index):
method __len__ (line 249) | def __len__(self):
method map (line 253) | def map(label, mapdict):
class Parser (line 279) | class Parser():
method __init__ (line 281) | def __init__(self,
method get_train_batch (line 374) | def get_train_batch(self):
method get_train_set (line 378) | def get_train_set(self):
method get_valid_batch (line 381) | def get_valid_batch(self):
method get_valid_set (line 385) | def get_valid_set(self):
method get_test_batch (line 388) | def get_test_batch(self):
method get_test_set (line 392) | def get_test_set(self):
method get_train_size (line 395) | def get_train_size(self):
method get_valid_size (line 398) | def get_valid_size(self):
method get_test_size (line 401) | def get_test_size(self):
method get_n_classes (line 404) | def get_n_classes(self):
method get_original_class_string (line 407) | def get_original_class_string(self, idx):
method get_xentropy_class_string (line 410) | def get_xentropy_class_string(self, idx):
method to_original (line 413) | def to_original(self, label):
method to_xentropy (line 417) | def to_xentropy(self, label):
method to_color (line 421) | def to_color(self, label):
FILE: benchmarks/SalsaNext/train/tasks/semantic/dataset/rellis/parser.py
function is_scan (line 27) | def is_scan(filename):
function is_label (line 31) | def is_label(filename):
function my_collate (line 35) | def my_collate(batch):
class Rellis (line 67) | class Rellis(Dataset):
method __init__ (line 69) | def __init__(self, root, # directory where data is
method __getitem__ (line 145) | def __getitem__(self, index):
method __len__ (line 242) | def __len__(self):
method map (line 246) | def map(label, mapdict):
class Parser (line 272) | class Parser():
method __init__ (line 274) | def __init__(self,
method get_train_batch (line 368) | def get_train_batch(self):
method get_train_set (line 372) | def get_train_set(self):
method get_valid_batch (line 375) | def get_valid_batch(self):
method get_valid_set (line 379) | def get_valid_set(self):
method get_test_batch (line 382) | def get_test_batch(self):
method get_test_set (line 386) | def get_test_set(self):
method get_train_size (line 389) | def get_train_size(self):
method get_valid_size (line 392) | def get_valid_size(self):
method get_test_size (line 395) | def get_test_size(self):
method get_n_classes (line 398) | def get_n_classes(self):
method get_original_class_string (line 401) | def get_original_class_string(self, idx):
method get_xentropy_class_string (line 404) | def get_xentropy_class_string(self, idx):
method to_original (line 407) | def to_original(self, label):
method to_xentropy (line 411) | def to_xentropy(self, label):
method to_color (line 415) | def to_color(self, label):
FILE: benchmarks/SalsaNext/train/tasks/semantic/evaluate_iou.py
function save_to_log (line 17) | def save_to_log(logdir,logfile,message):
function eval (line 23) | def eval(test_sequences,splits,pred):
FILE: benchmarks/SalsaNext/train/tasks/semantic/infer.py
function str2bool (line 14) | def str2bool(v):
FILE: benchmarks/SalsaNext/train/tasks/semantic/infer2.py
function str2bool (line 14) | def str2bool(v):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/Lovasz_Softmax.py
function isnan (line 31) | def isnan(x):
function mean (line 35) | def mean(l, ignore_nan=False, empty=0):
function lovasz_grad (line 56) | def lovasz_grad(gt_sorted):
function lovasz_softmax (line 71) | def lovasz_softmax(probas, labels, classes='present', per_image=False, i...
function lovasz_softmax_flat (line 89) | def lovasz_softmax_flat(probas, labels, classes='present'):
function flatten_probas (line 120) | def flatten_probas(probas, labels, ignore=None):
class Lovasz_softmax (line 139) | class Lovasz_softmax(nn.Module):
method __init__ (line 140) | def __init__(self, classes='present', per_image=False, ignore=None):
method forward (line 146) | def forward(self, probas, labels):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/SalsaNext.py
class ResContextBlock (line 10) | class ResContextBlock(nn.Module):
method __init__ (line 11) | def __init__(self, in_filters, out_filters):
method forward (line 25) | def forward(self, x):
class ResBlock (line 42) | class ResBlock(nn.Module):
method __init__ (line 43) | def __init__(self, in_filters, out_filters, dropout_rate, kernel_size=...
method forward (line 73) | def forward(self, x):
class UpBlock (line 112) | class UpBlock(nn.Module):
method __init__ (line 113) | def __init__(self, in_filters, out_filters, dropout_rate, drop_out=True):
method forward (line 142) | def forward(self, x, skip):
class SalsaNext (line 173) | class SalsaNext(nn.Module):
method __init__ (line 174) | def __init__(self, nclasses):
method forward (line 195) | def forward(self, x):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/SalsaNextAdf.py
function keep_variance_fn (line 17) | def keep_variance_fn(x):
class ResContextBlock (line 20) | class ResContextBlock(nn.Module):
method __init__ (line 21) | def __init__(self, in_filters, out_filters):
method forward (line 35) | def forward(self, x):
class ResBlock (line 52) | class ResBlock(nn.Module):
method __init__ (line 53) | def __init__(self, in_filters, out_filters, kernel_size=(3, 3), stride=1,
method forward (line 85) | def forward(self, x):
class UpBlock (line 126) | class UpBlock(nn.Module):
method __init__ (line 127) | def __init__(self, in_filters, out_filters,drop_out=True, p=0.2):
method forward (line 155) | def forward(self, x, skip):
class SalsaNextUncertainty (line 198) | class SalsaNextUncertainty(nn.Module):
method __init__ (line 199) | def __init__(self, nclasses,p=0.2):
method forward (line 222) | def forward(self, x):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/adf.py
function resize2D (line 39) | def resize2D(inputs, size_targets, mode="bilinear"):
function resize2D_as (line 53) | def resize2D_as(inputs, output_as, mode="bilinear"):
function normcdf (line 58) | def normcdf(value, mu=0.0, stddev=1.0):
function _normal_log_pdf (line 63) | def _normal_log_pdf(value, mu, stddev):
function normpdf (line 69) | def normpdf(value, mu=0.0, stddev=1.0):
class AvgPool2d (line 73) | class AvgPool2d(nn.Module):
method __init__ (line 74) | def __init__(self, keep_variance_fn=None,kernel_size=2):
method forward (line 79) | def forward(self, inputs_mean, inputs_variance):
class Softmax (line 94) | class Softmax(nn.Module):
method __init__ (line 95) | def __init__(self, dim=1, keep_variance_fn=None):
method forward (line 100) | def forward(self, features_mean, features_variance, eps=1e-5):
class ReLU (line 125) | class ReLU(nn.Module):
method __init__ (line 126) | def __init__(self, keep_variance_fn=None):
method forward (line 130) | def forward(self, features_mean, features_variance):
class LeakyReLU (line 143) | class LeakyReLU(nn.Module):
method __init__ (line 144) | def __init__(self, negative_slope=0.01, keep_variance_fn=None):
method forward (line 149) | def forward(self, features_mean, features_variance):
class Dropout (line 173) | class Dropout(nn.Module):
method __init__ (line 176) | def __init__(self, p: float = 0.5, keep_variance_fn=None, inplace=False):
method forward (line 184) | def forward(self, inputs_mean, inputs_variance):
class MaxPool2d (line 202) | class MaxPool2d(nn.Module):
method __init__ (line 203) | def __init__(self, keep_variance_fn=None):
method _max_pool_internal (line 207) | def _max_pool_internal(self, mu_a, mu_b, var_a, var_b):
method _max_pool_1x2 (line 221) | def _max_pool_1x2(self, inputs_mean, inputs_variance):
method _max_pool_2x1 (line 230) | def _max_pool_2x1(self, inputs_mean, inputs_variance):
method forward (line 239) | def forward(self, inputs_mean, inputs_variance):
class Linear (line 245) | class Linear(nn.Module):
method __init__ (line 246) | def __init__(self, in_features, out_features, bias=True, keep_variance...
method forward (line 257) | def forward(self, inputs_mean, inputs_variance):
class BatchNorm2d (line 265) | class BatchNorm2d(nn.Module):
method __init__ (line 270) | def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
method reset_running_stats (line 295) | def reset_running_stats(self):
method reset_parameters (line 301) | def reset_parameters(self):
method _check_input_dim (line 307) | def _check_input_dim(self, input):
method forward (line 310) | def forward(self, inputs_mean, inputs_variance):
class Conv2d (line 344) | class Conv2d(_ConvNd):
method __init__ (line 345) | def __init__(self, in_channels, out_channels, kernel_size, stride=1,
method forward (line 357) | def forward(self, inputs_mean, inputs_variance):
class ConvTranspose2d (line 367) | class ConvTranspose2d(_ConvTransposeMixin, _ConvNd):
method __init__ (line 368) | def __init__(self, in_channels, out_channels, kernel_size, stride=1,
method forward (line 381) | def forward(self, inputs_mean, inputs_variance, output_size=None):
function concatenate_as (line 394) | def concatenate_as(tensor_list, tensor_as, dim, mode="bilinear"):
class Sequential (line 402) | class Sequential(nn.Module):
method __init__ (line 403) | def __init__(self, *args):
method _get_item_by_idx (line 412) | def _get_item_by_idx(self, iterator, idx):
method __getitem__ (line 421) | def __getitem__(self, idx):
method __setitem__ (line 427) | def __setitem__(self, idx, module):
method __delitem__ (line 431) | def __delitem__(self, idx):
method __len__ (line 439) | def __len__(self):
method __dir__ (line 442) | def __dir__(self):
method forward (line 447) | def forward(self, inputs, inputs_variance):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/ioueval.py
class iouEval (line 9) | class iouEval:
method __init__ (line 10) | def __init__(self, n_classes, device, ignore=None):
method num_classes (line 21) | def num_classes(self):
method reset (line 24) | def reset(self):
method addBatch (line 30) | def addBatch(self, x, y): # x=preds, y=targets
method getStats (line 58) | def getStats(self):
method getIoU (line 70) | def getIoU(self):
method getacc (line 78) | def getacc(self):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/trainer.py
function keep_variance_fn (line 25) | def keep_variance_fn(x):
function one_hot_pred_from_label (line 28) | def one_hot_pred_from_label(y_pred, labels):
class SoftmaxHeteroscedasticLoss (line 37) | class SoftmaxHeteroscedasticLoss(torch.nn.Module):
method __init__ (line 38) | def __init__(self):
method forward (line 42) | def forward(self, outputs, targets, eps=1e-5):
function save_to_log (line 50) | def save_to_log(logdir, logfile, message):
function save_checkpoint (line 57) | def save_checkpoint(to_save, logdir, suffix=""):
class Trainer (line 63) | class Trainer():
method __init__ (line 64) | def __init__(self, ARCH, DATA, datadir, logdir, path=None,uncertainty=...
method calculate_estimate (line 190) | def calculate_estimate(self, epoch, iter):
method get_mpl_colormap (line 199) | def get_mpl_colormap(cmap_name):
method make_log_img (line 208) | def make_log_img(depth, mask, pred, gt, color_fn):
method save_to_log (line 225) | def save_to_log(logdir, logger, info, epoch, w_summary=False, model=No...
method train (line 247) | def train(self):
method train_epoch (line 344) | def train_epoch(self, train_loader, model, criterion, optimizer, epoch...
method validate (line 499) | def validate(self, val_loader, model, criterion, evaluator, class_func...
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/user.py
class User (line 24) | class User():
method __init__ (line 25) | def __init__(self, ARCH, DATA, datadir, logdir, modeldir,split,uncerta...
method infer (line 88) | def infer(self):
method infer_subset (line 120) | def infer_subset(self, loader, to_orig_fn,cnn,knn):
FILE: benchmarks/SalsaNext/train/tasks/semantic/modules/user2.py
class User (line 24) | class User():
method __init__ (line 25) | def __init__(self, ARCH, DATA, datadir, logdir, modeldir,split,uncerta...
method infer (line 88) | def infer(self):
method infer_subset (line 120) | def infer_subset(self, loader, to_orig_fn,cnn,knn):
FILE: benchmarks/SalsaNext/train/tasks/semantic/postproc/KNN.py
function get_gaussian_kernel (line 11) | def get_gaussian_kernel(kernel_size=3, sigma=2, channels=1):
class KNN (line 36) | class KNN(nn.Module):
method __init__ (line 37) | def __init__(self, params, nclasses):
method forward (line 54) | def forward(self, proj_range, unproj_range, proj_argmax, px, py):
FILE: benchmarks/SalsaNext/train/tasks/semantic/train.py
function remove_exponent (line 20) | def remove_exponent(d):
function millify (line 23) | def millify(n, precision=0, drop_nulls=True, prefixes=[]):
function str2bool (line 37) | def str2bool(v):
FILE: utils/convert_ply2bin.py
function load_from_bin (line 5) | def load_from_bin(bin_path):
function convert_ply2bin (line 9) | def convert_ply2bin(ply_path,bin_path=None):
FILE: utils/label_convert.py
function convert_label (line 11) | def convert_label(label, label_mapping, inverse=False):
function convert_color (line 21) | def convert_color(label, color_map):
function save_output (line 27) | def save_output(label_dir, output_dir, config_path):
FILE: utils/plyreader.py
class PlyObject (line 4) | class PlyObject:
method __init__ (line 5) | def __init__(self,header) -> None:
method __str__ (line 9) | def __str__(self):
method __getitem__ (line 12) | def __getitem__(self, key):
method element_info (line 15) | def element_info(self,key):
class PlyReader (line 18) | class PlyReader:
method __init__ (line 29) | def __init__(self):
method _headerparse (line 32) | def _headerparse(self,f):
method open (line 69) | def open(self,filename):
FILE: utils/stereo_camerainfo_pub.py
class NerianStereoInfoPub (line 6) | class NerianStereoInfoPub():
method __init__ (line 7) | def __init__(self):
method get_infos (line 22) | def get_infos(self, info):
method cb_l (line 44) | def cb_l(self, m):
method cb_r (line 52) | def cb_r(self, m):
Copy disabled (too large)
Download .json
Condensed preview — 216 files, each showing path, character count, and a content snippet. Download the .json file for the full structured content (12,024K chars).
[
{
"path": ".gitignore",
"chars": 2822,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": "README.md",
"chars": 18301,
"preview": "<h1>RELLIS-3D: A Multi-modal Dataset for Off-Road Robotics</h1>\n<p align=\"center\">\n<a href=\"https://www.tamu.edu/\"><img "
},
{
"path": "benchmarks/GSCNN-master/.gitignore",
"chars": 45,
"preview": "logs/\nnetwork/pretrained_models/\n__pycache__/"
},
{
"path": "benchmarks/GSCNN-master/Dockerfile",
"chars": 877,
"preview": "FROM pytorch/pytorch:1.0-cuda10.0-cudnn7-devel\n\nRUN apt-get -y update\nRUN apt-get -y upgrade\n\nRUN apt-get update \\\n &"
},
{
"path": "benchmarks/GSCNN-master/LICENSE",
"chars": 1171,
"preview": "Copyright (C) 2019 NVIDIA Corporation. Towaki Takikawa, David Acuna, Varun Jampani, Sanja Fidler\nAll rights reserved. \nL"
},
{
"path": "benchmarks/GSCNN-master/README.md",
"chars": 2981,
"preview": "# GSCNN\nThis is the official code for:\n\n#### Gated-SCNN: Gated Shape CNNs for Semantic Segmentation\n\n[Towaki Takikawa](h"
},
{
"path": "benchmarks/GSCNN-master/config.py",
"chars": 2946,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/datasets/__init__.py",
"chars": 5858,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/datasets/cityscapes.py",
"chars": 9757,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/datasets/cityscapes_labels.py",
"chars": 12955,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/datasets/edge_utils.py",
"chars": 2082,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/datasets/rellis.py",
"chars": 7828,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/docs/index.html",
"chars": 13416,
"preview": "<head>\n<!-- Global site tag (gtag.js) - Google Analytics -->\n<script async src=\"https://www.googletagmanager.com/gtag/js"
},
{
"path": "benchmarks/GSCNN-master/docs/resources/bibtex.txt",
"chars": 202,
"preview": "@inproceedings{Takikawa2019GatedSCNNGS,\n title={Gated-SCNN: Gated Shape CNNs for Semantic Segmentation},\n author={Towa"
},
{
"path": "benchmarks/GSCNN-master/gscnn.txt",
"chars": 1370,
"preview": "absl-py==0.10.0\naiohttp==3.6.2\nastor==0.8.1\nastunparse==1.6.3\nasync-timeout==3.0.1\nattrs==20.2.0\ncachetools==4.1.1\ncerti"
},
{
"path": "benchmarks/GSCNN-master/loss.py",
"chars": 6380,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/my_functionals/DualTaskLoss.py",
"chars": 4789,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/my_functionals/GatedSpatialConv.py",
"chars": 6289,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/my_functionals/__init__.py",
"chars": 175,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/my_functionals/custom_functional.py",
"chars": 5446,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/network/Resnet.py",
"chars": 8714,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/network/SEresnext.py",
"chars": 14906,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/network/__init__.py",
"chars": 1181,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/network/gscnn.py",
"chars": 11956,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/network/mynn.py",
"chars": 1089,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/network/wider_resnet.py",
"chars": 14165,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/optimizer.py",
"chars": 2720,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/run_gscnn.sh",
"chars": 187,
"preview": "#!/bin/bash\nexport PYTHONPATH=/home/usl/Code/Peng/data_collection/benchmarks/GSCNN-master/:$PYTHONPATH\necho $PYTHONPATH\n"
},
{
"path": "benchmarks/GSCNN-master/run_gscnn_eval.sh",
"chars": 527,
"preview": "#!/bin/bash\nexport PYTHONPATH=/home/usl/Code/PengJiang/RELLIS-3D/benchmarks/GSCNN-master/:$PYTHONPATH\necho $PYTHONPATH\np"
},
{
"path": "benchmarks/GSCNN-master/train.py",
"chars": 19465,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/transforms/joint_transforms.py",
"chars": 22787,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/transforms/transforms.py",
"chars": 12085,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/utils/AttrDict.py",
"chars": 2635,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/utils/f_boundary.py",
"chars": 7242,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/utils/image_page.py",
"chars": 2563,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/GSCNN-master/utils/misc.py",
"chars": 13199,
"preview": "\"\"\"\nCopyright (C) 2019 NVIDIA Corporation. All rights reserved.\nLicensed under the CC BY-NC-SA 4.0 license (https://cre"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/.gitignore",
"chars": 79,
"preview": ".vscode\n__pycache__/\n*.py[co]\ndata/\nlog/\noutput/\nscripts/\ndetail-api/\ndata/list"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/LICENSE",
"chars": 1362,
"preview": "MIT License\n\nCopyright (c) [2019] [Microsoft]\n\nPermission is hereby granted, free of charge, to any person obtaining a c"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/README.md",
"chars": 17163,
"preview": "# High-resolution networks (HRNets) for Semantic Segmentation\n## Branches\n- This is the implementation for HRNet + OCR.\n"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/ade20k/seg_hrnet_ocr_w48_520x520_ohem_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml",
"chars": 1716,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/ade20k/seg_hrnet_w48_520x520_ohem_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml",
"chars": 1685,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/ade20k/seg_hrnet_w48_520x520_sgd_lr2e-2_wd1e-4_bs_16_epoch120.yaml",
"chars": 1685,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cityscapes/seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml",
"chars": 1712,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cityscapes/seg_hrnet_ocr_w48_trainval_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml",
"chars": 1715,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cityscapes/seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml",
"chars": 1689,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cityscapes/seg_hrnet_w48_train_ohem_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml",
"chars": 1688,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cityscapes/seg_hrnet_w48_trainval_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484x2.yaml",
"chars": 1776,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cityscapes/seg_hrnet_w48_trainval_ohem_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484x2.yaml",
"chars": 1775,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cocostuff/seg_hrnet_ocr_w48_520x520_ohem_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml",
"chars": 1795,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cocostuff/seg_hrnet_w48_520x520_ohem_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml",
"chars": 1756,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/cocostuff/seg_hrnet_w48_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch110.yaml",
"chars": 1757,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/lip/seg_hrnet_ocr_w48_473x473_sgd_lr7e-3_wd5e-4_bs_40_epoch150.yaml",
"chars": 1721,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/lip/seg_hrnet_w48_473x473_sgd_lr7e-3_wd5e-4_bs_40_epoch150.yaml",
"chars": 1694,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/pascal_ctx/seg_hrnet_ocr_w48_cls59_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml",
"chars": 1741,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/pascal_ctx/seg_hrnet_ocr_w48_cls60_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml",
"chars": 1741,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/pascal_ctx/seg_hrnet_w48_cls59_520x520_sgd_lr1e-3_wd1e-4_bs_16_epoch200.yaml",
"chars": 1725,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1,2,3)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORK"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/rellis/seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml",
"chars": 1688,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORKERS:"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/experiments/rellis/seg_hrnet_ocr_w48_train_512x1024_sgd_lr1e-3_wd5e-4_bs_12_epoch484.yaml",
"chars": 1741,
"preview": "CUDNN:\n BENCHMARK: true\n DETERMINISTIC: false\n ENABLED: true\nGPUS: (0,1)\nOUTPUT_DIR: 'output'\nLOG_DIR: 'log'\nWORKERS:"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/hubconf.py",
"chars": 861,
"preview": "\"\"\"File for accessing HRNet via PyTorch Hub https://pytorch.org/hub/\n\nUsage:\n import torch\n model = torch.hub.load"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/pretrained_models/.gitignore",
"chars": 5,
"preview": "*.pth"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/requirements.txt",
"chars": 136,
"preview": "EasyDict==1.7\nopencv-python\nshapely==1.6.4\nCython\nscipy\npandas\npyyaml\njson_tricks\nscikit-image\nyacs>=0.1.5\ntensorboardX>"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/run_hrnet.sh",
"chars": 327,
"preview": "#!/bin/bash\nexport PYTHONPATH=/home/usl/Code/Peng/data_collection/benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/:$PYT"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/run_hrnet_test.sh",
"chars": 587,
"preview": "#!/bin/bash\nexport PYTHONPATH=/home/usl/Code/PengJiang/RELLIS-3D/benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/:$PYTH"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/tools/_init_paths.py",
"chars": 591,
"preview": "# ------------------------------------------------------------------------------\n# Copyright (c) Microsoft\n# Licensed un"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/tools/test.py",
"chars": 5620,
"preview": "# ------------------------------------------------------------------------------\n# Copyright (c) Microsoft\n# Licensed un"
},
{
"path": "benchmarks/HRNet-Semantic-Segmentation-HRNet-OCR/tools/train.py",
"chars": 12281,
"preview": "# ------------------------------------------------------------------------------\n# Copyright (c) Microsoft\n# Licensed un"
},
{
"path": "benchmarks/KPConv-PyTorch-master/.gitignore",
"chars": 84,
"preview": "results/\ntest/\n/cpp_wrappers/cpp_neighbors\n/cpp_wrappers/cpp_subsampling\n__pycache__"
},
{
"path": "benchmarks/KPConv-PyTorch-master/INSTALL.md",
"chars": 2004,
"preview": "\n# Installation instructions\n\n## Ubuntu 18.04\n \n* Make sure <a href=\"https://docs.nvidia.com/cuda/cuda-installation-"
},
{
"path": "benchmarks/KPConv-PyTorch-master/README.md",
"chars": 2293,
"preview": "\n\n\nCreated by Hugues THO"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/compile_wrappers.sh",
"chars": 185,
"preview": "#!/bin/bash\n\n# Compile cpp subsampling\ncd cpp_subsampling\npython3 setup.py build_ext --inplace\ncd ..\n\n# Compile cpp neig"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/build.bat",
"chars": 49,
"preview": "@echo off\npy setup.py build_ext --inplace\n\n\npause"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/neighbors/neighbors.cpp",
"chars": 7454,
"preview": "\n#include \"neighbors.h\"\n\n\nvoid brute_neighbors(vector<PointXYZ>& queries, vector<PointXYZ>& supports, vector<int>& neigh"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/neighbors/neighbors.h",
"chars": 1032,
"preview": "\n\n#include \"../../cpp_utils/cloud/cloud.h\"\n#include \"../../cpp_utils/nanoflann/nanoflann.hpp\"\n\n#include <set>\n#include <"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/setup.py",
"chars": 619,
"preview": "from distutils.core import setup, Extension\nimport numpy.distutils.misc_util\n\n# Adding OpenCV to project\n# *************"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_neighbors/wrapper.cpp",
"chars": 7178,
"preview": "#include <Python.h>\n#include <numpy/arrayobject.h>\n#include \"neighbors/neighbors.h\"\n#include <string>\n\n\n\n// docstrings f"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/build.bat",
"chars": 49,
"preview": "@echo off\npy setup.py build_ext --inplace\n\n\npause"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/grid_subsampling/grid_subsampling.cpp",
"chars": 7076,
"preview": "\n#include \"grid_subsampling.h\"\n\n\nvoid grid_subsampling(vector<PointXYZ>& original_points,\n vector<P"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/grid_subsampling/grid_subsampling.h",
"chars": 2464,
"preview": "\n\n#include \"../../cpp_utils/cloud/cloud.h\"\n\n#include <set>\n#include <cstdint>\n\nusing namespace std;\n\nclass SampledData\n{"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/setup.py",
"chars": 633,
"preview": "from distutils.core import setup, Extension\nimport numpy.distutils.misc_util\n\n# Adding OpenCV to project\n# *************"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_subsampling/wrapper.cpp",
"chars": 17331,
"preview": "#include <Python.h>\n#include <numpy/arrayobject.h>\n#include \"grid_subsampling/grid_subsampling.h\"\n#include <string>\n\n\n\n/"
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_utils/cloud/cloud.cpp",
"chars": 962,
"preview": "//\n//\n//\t\t0==========================0\n//\t\t| Local feature test |\n//\t\t0==========================0\n//\n//\t\tversion "
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_utils/cloud/cloud.h",
"chars": 3381,
"preview": "//\n//\n//\t\t0==========================0\n//\t\t| Local feature test |\n//\t\t0==========================0\n//\n//\t\tversion "
},
{
"path": "benchmarks/KPConv-PyTorch-master/cpp_wrappers/cpp_utils/nanoflann/nanoflann.hpp",
"chars": 73133,
"preview": "/***********************************************************************\n * Software License Agreement (BSD License)\n *\n"
},
{
"path": "benchmarks/KPConv-PyTorch-master/datasets/ModelNet40.py",
"chars": 35834,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/datasets/Rellis.py",
"chars": 59892,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/datasets/S3DIS.py",
"chars": 60322,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/datasets/SemanticKitti.py",
"chars": 55628,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/datasets/common.py",
"chars": 22088,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/doc/object_classification_guide.md",
"chars": 1940,
"preview": "\n## Object classification on ModelNet40\n\n### Data\n\nWe consider our experiment folder is located at `XXXX/Experiments/KPC"
},
{
"path": "benchmarks/KPConv-PyTorch-master/doc/pretrained_models_guide.md",
"chars": 36,
"preview": "\n\n## Test a pretrained network\n\nTODO"
},
{
"path": "benchmarks/KPConv-PyTorch-master/doc/scene_segmentation_guide.md",
"chars": 1757,
"preview": "\n## Scene Segmentation on S3DIS\n\n### Data\n\nWe consider our experiment folder is located at `XXXX/Experiments/KPConv-PyTo"
},
{
"path": "benchmarks/KPConv-PyTorch-master/doc/slam_segmentation_guide.md",
"chars": 2435,
"preview": "\n## Scene Segmentation on SemanticKitti\n\n### Data\n\nWe consider our experiment folder is located at `XXXX/Experiments/KPC"
},
{
"path": "benchmarks/KPConv-PyTorch-master/doc/visualization_guide.md",
"chars": 960,
"preview": "\n\n## Visualize kernel deformations\n\n### Intructions\n\nIn order to visualize features you need a dataset and a pretrained "
},
{
"path": "benchmarks/KPConv-PyTorch-master/kernels/kernel_points.py",
"chars": 17505,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/models/architectures.py",
"chars": 13303,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/models/blocks.py",
"chars": 25359,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/plot_convergence.py",
"chars": 24506,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/run_kpconv.sh",
"chars": 32,
"preview": "#!/bin/sh\npython train_Rellis.py"
},
{
"path": "benchmarks/KPConv-PyTorch-master/test_models.py",
"chars": 7467,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/train_ModelNet40.py",
"chars": 8717,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/train_Rellis.py",
"chars": 10295,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/train_S3DIS.py",
"chars": 9594,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/train_SemanticKitti.py",
"chars": 10297,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/config.py",
"chars": 14443,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/mayavi_visu.py",
"chars": 12434,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/metrics.py",
"chars": 8881,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/ply.py",
"chars": 10309,
"preview": "#\n#\n# 0===============================0\n# | PLY files reader/writer |\n# 0=========================="
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/tester.py",
"chars": 48076,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/trainer.py",
"chars": 32714,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/utils/visualizer.py",
"chars": 19972,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/KPConv-PyTorch-master/visualize_deformations.py",
"chars": 6225,
"preview": "#\n#\n# 0=================================0\n# | Kernel Point Convolutions |\n# 0======================"
},
{
"path": "benchmarks/README.md",
"chars": 5401,
"preview": "# RELLIS-3D Benchmarks\n\nThe HRNet, SalsaNext and KPConv can use environment file ```requirement.txt```. GSCNN need use f"
},
{
"path": "benchmarks/SalsaNext/.gitignore",
"chars": 69,
"preview": "*.pyc\n.idea\ntrain/tasks/semantic/logs\ntrain/__pycache__\n__pycache__/*"
},
{
"path": "benchmarks/SalsaNext/LICENSE",
"chars": 1379,
"preview": "The MIT License\n\nCopyright (c) 2019 Tiago Cortinhal (Halmstad University, Sweden), George Tzelepis (Volvo Technology AB,"
},
{
"path": "benchmarks/SalsaNext/README.md",
"chars": 4500,
"preview": "[\n{\n echo \"Options not found\"\n exit 1\n}\n\nget_abs_filename() {\n echo \"$(cd \"$(dirname \"$1\")\" "
},
{
"path": "benchmarks/SalsaNext/run_salsanext.sh",
"chars": 209,
"preview": "#!/bin/sh\nexport CUDA_VISIBLE_DEVICES=\"0,1\"\ncd ./train/tasks/semantic; ./train.py -d /home/usl/Datasets/rellis -ac ./c"
},
{
"path": "benchmarks/SalsaNext/run_salsanext_eval.sh",
"chars": 187,
"preview": "#!/bin/sh\nexport CUDA_VISIBLE_DEVICES=\"1\"\ncd ./train/tasks/semantic\npython infer2.py -d /path/to/Datasets/rellis -l /pat"
},
{
"path": "benchmarks/SalsaNext/salsanext.yml",
"chars": 2205,
"preview": "################################################################################\n# training parameters\n#################"
},
{
"path": "benchmarks/SalsaNext/salsanext_cuda09.yml",
"chars": 1777,
"preview": "name: salsanext\nchannels:\n - pytorch\n - defaults\ndependencies:\n - _libgcc_mutex=0.1=main\n - blas=1.0=mkl\n - ca-cert"
},
{
"path": "benchmarks/SalsaNext/salsanext_cuda10.yml",
"chars": 1958,
"preview": "name: salsanext\nchannels:\n - defaults\ndependencies:\n - _libgcc_mutex=0.1=main\n - _tflow_select=2.3.0=mkl\n - blas=1.0"
},
{
"path": "benchmarks/SalsaNext/train/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/common/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/common/avgmeter.py",
"chars": 465,
"preview": "# This file is covered by the LICENSE file in the root of this project.\n\n\nclass AverageMeter(object):\n \"\"\"Computes an"
},
{
"path": "benchmarks/SalsaNext/train/common/laserscan.py",
"chars": 12869,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\nimport time\n\nimport numpy"
},
{
"path": "benchmarks/SalsaNext/train/common/laserscanvis.py",
"chars": 7621,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport vispy\nfrom vispy."
},
{
"path": "benchmarks/SalsaNext/train/common/logger.py",
"chars": 2599,
"preview": "# Code referenced from https://gist.github.com/gyglim/1f8dfb1b5c82627ae3efcfbbadb9f514\n\nimport numpy as np\nimport scipy."
},
{
"path": "benchmarks/SalsaNext/train/common/summary.py",
"chars": 4574,
"preview": "### https://github.com/sksq96/pytorch-summary/blob/master/torchsummary/torchsummary.py\nimport torch\nimport torch.nn as n"
},
{
"path": "benchmarks/SalsaNext/train/common/sync_batchnorm/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/common/sync_batchnorm/batchnorm.py",
"chars": 14932,
"preview": "# -*- coding: utf-8 -*-\n# File : batchnorm.py\n# Author : Jiayuan Mao\n# Email : maojiayuan@gmail.com\n# Date : 27/01/"
},
{
"path": "benchmarks/SalsaNext/train/common/sync_batchnorm/comm.py",
"chars": 4453,
"preview": "# -*- coding: utf-8 -*-\n# File : comm.py\n# Author : Jiayuan Mao\n# Email : maojiayuan@gmail.com\n# Date : 27/01/2018\n"
},
{
"path": "benchmarks/SalsaNext/train/common/sync_batchnorm/replicate.py",
"chars": 3249,
"preview": "# -*- coding: utf-8 -*-\n# File : replicate.py\n# Author : Jiayuan Mao\n# Email : maojiayuan@gmail.com\n# Date : 27/01/"
},
{
"path": "benchmarks/SalsaNext/train/common/warmupLR.py",
"chars": 1975,
"preview": "# This file is covered by the LICENSE file in the root of this project.\n\nimport torch.optim.lr_scheduler as toptim\n\n\ncla"
},
{
"path": "benchmarks/SalsaNext/train/tasks/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/__init__.py",
"chars": 97,
"preview": "import sys\n\nTRAIN_PATH = \"../../\"\nDEPLOY_PATH = \"../../../deploy\"\nsys.path.insert(0, TRAIN_PATH)\n"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/config/arch/salsanext_ouster.yml",
"chars": 2280,
"preview": "################################################################################\n# training parameters\n#################"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/config/labels/rellis.yaml",
"chars": 2326,
"preview": "# This file is covered by the LICENSE file in the root of this project.\nname: \"rellis\"\nlabels:\n 0: \"void\"\n 1: \"dirt\"\n "
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/config/labels/semantic-kitti-all.yaml",
"chars": 5678,
"preview": "# This file is covered by the LICENSE file in the root of this project.\nname: \"kitti\"\nlabels:\n 0: \"unlabeled\"\n 1: \"out"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/config/labels/semantic-kitti.yaml",
"chars": 5546,
"preview": "# This file is covered by the LICENSE file in the root of this project.\nname: \"kitti\"\nlabels:\n 0: \"unlabeled\"\n 1: \"out"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/dataset/kitti/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/dataset/kitti/parser.py",
"chars": 15884,
"preview": "import os\nimport numpy as np\nimport torch\nfrom torch.utils.data import Dataset\nfrom common.laserscan import LaserScan, S"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/dataset/rellis/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/dataset/rellis/parser.py",
"chars": 16564,
"preview": "import os\nimport numpy as np\nimport torch\nfrom torch.utils.data import Dataset\nfrom common.laserscan import LaserScan, S"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/evaluate_iou.py",
"chars": 8341,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport argparse\nimport o"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/infer.py",
"chars": 4564,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport argparse\nimport s"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/infer2.py",
"chars": 4731,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport argparse\nimport s"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/Lovasz_Softmax.py",
"chars": 4923,
"preview": "\"\"\"\n\nMIT License\n\nCopyright (c) 2018 Maxim Berman\nCopyright (c) 2020 Tiago Cortinhal, George Tzelepis and Eren Erdal Aks"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/SalsaNext.py",
"chars": 6863,
"preview": "# !/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\nimport imp\n\nimport __ini"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/SalsaNextAdf.py",
"chars": 8301,
"preview": "# !/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\nimport imp\n\nimport __ini"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/adf.py",
"chars": 18895,
"preview": "\"\"\"\nMIT License\n\nCopyright (c) 2019 mattiasegu\n\nPermission is hereby granted, free of charge, to any person obtaining a "
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/ioueval.py",
"chars": 2909,
"preview": "#!/usr/bin/env python3\n\n# This file is covered by the LICENSE file in the root of this project.\n\nimport numpy as np\nimpo"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/trainer.py",
"chars": 31141,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\nimport datetime\nimport os"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/user.py",
"chars": 10924,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport torch\nimport torc"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/modules/user2.py",
"chars": 11128,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport torch\nimport torc"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/postproc/KNN.py",
"chars": 5576,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport math\n\nimport torc"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/postproc/__init__.py",
"chars": 91,
"preview": "import sys\n\nTRAIN_PATH = \"../\"\nDEPLOY_PATH = \"../../deploy\"\nsys.path.insert(0, TRAIN_PATH)\n"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/train.py",
"chars": 6112,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport argparse\nimport d"
},
{
"path": "benchmarks/SalsaNext/train/tasks/semantic/visualize.py",
"chars": 5113,
"preview": "#!/usr/bin/env python3\n# This file is covered by the LICENSE file in the root of this project.\n\nimport argparse\nimport o"
},
{
"path": "benchmarks/SalsaNext/train.sh",
"chars": 826,
"preview": "#!/bin/sh\n\nget_abs_filename() {\n echo \"$(cd \"$(dirname \"$1\")\" && pwd)/$(basename \"$1\")\"\n}\n\nhelpFunction()\n{\n echo \"TO"
},
{
"path": "benchmarks/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "benchmarks/gscnn_requirement.txt",
"chars": 1066,
"preview": "absl-py==0.11.0\nastunparse==1.6.3\ncachetools==4.2.0\ncertifi==2020.12.5\nchardet==4.0.0\ncycler==0.10.0\ndecorator==4.4.2\nfl"
},
{
"path": "benchmarks/requirement.txt",
"chars": 2048,
"preview": "absl-py==0.11.0\nastroid==2.4.0\nastunparse==1.6.3\nattrs==19.3.0\nautopep8==1.5.2\nbackcall==0.2.0\nbleach==3.1.5\ncachetools="
},
{
"path": "catkin_ws/.catkin_workspace",
"chars": 98,
"preview": "# This file currently only serves to mark the location of a catkin workspace for tool integration\n"
},
{
"path": "catkin_ws/.gitignore",
"chars": 553,
"preview": "devel/\nlogs/\nbuild/\n.catkin_tools/\nbin/\nlib/\nmsg_gen/\nsrv_gen/\nmsg/*Action.msg\nmsg/*ActionFeedback.msg\nmsg/*ActionGoal.m"
},
{
"path": "catkin_ws/src/platform_description/CMakeLists.txt",
"chars": 365,
"preview": "cmake_minimum_required(VERSION 2.8.3)\nproject(platform_description)\n\nfind_package(catkin REQUIRED COMPONENTS roslaunch)\n"
},
{
"path": "catkin_ws/src/platform_description/launch/description.launch",
"chars": 569,
"preview": "<?xml version=\"1.0\"?>\n<launch>\n <arg name=\"config\" default=\"base\" />\n\n <param name=\"robot_description\"\n comman"
},
{
"path": "catkin_ws/src/platform_description/meshes/tracks.dae",
"chars": 78198,
"preview": "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<COLLADA xmlns=\"http://www.collada.org/2005/11/COLLADASchema\" version=\"1.4.1\">\n "
},
{
"path": "catkin_ws/src/platform_description/package.xml",
"chars": 540,
"preview": "<?xml version=\"1.0\"?>\n<package>\n <name>platform_description</name>\n <version>0.1.1</version>\n <description>URDF robot"
},
{
"path": "catkin_ws/src/platform_description/scripts/env_run",
"chars": 271,
"preview": "#!/bin/bash\n# This simple wrapper allowing us to pass a set of\n# environment variables to be sourced prior to running\n# "
},
{
"path": "catkin_ws/src/platform_description/urdf/accessories/novatel_smart6.urdf.xacro",
"chars": 479,
"preview": "<?xml version=\"1.0\"?>\n<robot xmlns:xacro=\"http://www.ros.org/wiki/xacro\">\n <xacro:macro name=\"novatel_smart6\" params=\"p"
},
{
"path": "catkin_ws/src/platform_description/urdf/accessories/warthog_arm_mount.urdf.xacro",
"chars": 808,
"preview": "<?xml version=\"1.0\"?>\n<robot xmlns:xacro=\"http://ros.org/wiki/xacro\">\n <xacro:macro name=\"warthog_arm_mount\">\n <link"
},
{
"path": "catkin_ws/src/platform_description/urdf/accessories/warthog_bulkhead.urdf.xacro",
"chars": 928,
"preview": "<?xml version=\"1.0\"?>\n<robot xmlns:xacro=\"http://www.ros.org/wiki/xacro\">\n <xacro:macro name=\"warthog_bulkhead\">\n <l"
},
{
"path": "catkin_ws/src/platform_description/urdf/accessories.urdf.xacro",
"chars": 1935,
"preview": "<?xml version=\"1.0\"?>\n<robot xmlns:xacro=\"http://www.ros.org/wiki/xacro\">\n <!--\n As you add to this URDF, please be "
},
{
"path": "catkin_ws/src/platform_description/urdf/configs/arm_mount",
"chars": 102,
"preview": "# This config enables the bulkhead and the arm mounting plate\n\nWARTHOG_BULKHEAD=1\nWARTHOG_ARM_MOUNT=1\n"
},
{
"path": "catkin_ws/src/platform_description/urdf/configs/base",
"chars": 165,
"preview": "# The empty Warthog configuration has no accessories at all,\n# so nothing need be specified here; the defaults as given\n"
},
{
"path": "catkin_ws/src/platform_description/urdf/configs/bulkhead",
"chars": 85,
"preview": "# This config enables the bulkhead for mounting other components\n\nWARTHOG_BULKHEAD=1\n"
},
{
"path": "catkin_ws/src/platform_description/urdf/configs/empty",
"chars": 165,
"preview": "# The empty Warthog configuration has no accessories at all,\n# so nothing need be specified here; the defaults as given\n"
},
{
"path": "catkin_ws/src/platform_description/urdf/empty.urdf",
"chars": 294,
"preview": "<robot>\n <!-- This file is a placeholder which is included by default from\n warthog.urdf.xacro. If a robot is bei"
},
{
"path": "catkin_ws/src/platform_description/urdf/warthog.gazebo",
"chars": 1978,
"preview": "<?xml version=\"1.0\"?>\n<robot>\n <gazebo>\n <plugin name=\"gazebo_ros_control\" filename=\"libgazebo_ros_control.so\">\n "
},
{
"path": "catkin_ws/src/platform_description/urdf/warthog.urdf",
"chars": 15340,
"preview": "<?xml version=\"1.0\" ?>\n<!-- =================================================================================== -->\n<!--"
},
{
"path": "catkin_ws/src/platform_description/urdf/warthog.urdf.xacro",
"chars": 13803,
"preview": "<?xml version='1.0'?>\n\n<robot name=\"warthog\" xmlns:xacro=\"http://www.ros.org/wiki/xacro\">\n\n <xacro:property name=\"PI\" v"
},
{
"path": "images/data_example.eps",
"chars": 3986989,
"preview": "%!PS-Adobe-3.0 EPSF-3.0\n%%Creator: cairo 1.14.6 (http://cairographics.org)\n%%CreationDate: Wed Oct 28 11:58:40 2020\n%%Pa"
},
{
"path": "images/sensor_setup.eps",
"chars": 1313369,
"preview": "%!PS-Adobe-3.0 EPSF-3.0\n%%Creator: cairo 1.14.6 (http://cairographics.org)\n%%CreationDate: Sat Oct 31 16:38:14 2020\n%%Pa"
},
{
"path": "utils/.gitignore",
"chars": 21,
"preview": ".ipynb_checkpoints/*\n"
},
{
"path": "utils/Evaluate_img.ipynb",
"chars": 199118,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n "
},
{
"path": "utils/Evaluate_pt.ipynb",
"chars": 159051,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n"
},
{
"path": "utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "utils/convert_ply2bin.py",
"chars": 673,
"preview": "from json import load\nimport numpy as np\nfrom plyreader import PlyReader\n\ndef load_from_bin(bin_path):\n obj = np.from"
},
{
"path": "utils/example/camera_info.txt",
"chars": 46,
"preview": "2813.643275 2808.326079 969.285772 624.049972\n"
},
{
"path": "utils/example/transforms.yaml",
"chars": 174,
"preview": "os1_cloud_node-pylon_camera_node:\n q:\n w: -0.50507811\n x: 0.51206185\n y: 0.49024953\n z: -0.49228464\n t:\n "
},
{
"path": "utils/example/vel2os1.yaml",
"chars": 220,
"preview": "vel2os1:\n q:\n w: 0.00018954284517174916\n x: 0.00021657374105704352\n y: -0.0001811754269666679\n z: 0.9999999"
},
{
"path": "utils/label2color.ipynb",
"chars": 95315,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {\n \"ExecuteTime\": {\n \"end_time\""
},
{
"path": "utils/label_convert.py",
"chars": 2474,
"preview": "import os\n\nimport cv2\nimport numpy as np\nfrom PIL import Image\nimport yaml\nimport argparse\nfrom tqdm import tqdm\n\n\ndef c"
},
{
"path": "utils/lidar2img.ipynb",
"chars": 4668138,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {\n \"ExecuteTime\": {\n \"end_time\""
},
{
"path": "utils/nerian_camera_info.yaml",
"chars": 1861,
"preview": "M1: [ 6.5446097578519868e+02, 0., 4.0838789584433096e+02, 0.,\n 6.5406762994100598e+02, 2.9848072034310803e+02, 0., 0."
},
{
"path": "utils/plyreader.py",
"chars": 3119,
"preview": "import numpy as np\n\n\nclass PlyObject:\n def __init__(self,header) -> None:\n self.header = header\n self.e"
},
{
"path": "utils/stereo_camerainfo_pub.py",
"chars": 2463,
"preview": "import rospy\nimport yaml\n\nfrom sensor_msgs.msg import CameraInfo\n\nclass NerianStereoInfoPub():\n def __init__(self):\n "
}
]
// ... and 17 more files (download for full content)
About this extraction
This page contains the full source code of the unmannedlab/RELLIS-3D GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 216 files (11.2 MB), approximately 3.0M tokens, and a symbol index with 930 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.